
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:EIF4B-ADAP1 (FusionGDB2 ID:25950) |
Fusion Gene Summary for EIF4B-ADAP1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: EIF4B-ADAP1 | Fusion gene ID: 25950 | Hgene | Tgene | Gene symbol | EIF4B | ADAP1 | Gene ID | 1975 | 11033 |
| Gene name | eukaryotic translation initiation factor 4B | ArfGAP with dual PH domains 1 | |
| Synonyms | EIF-4B|PRO1843 | CENTA1|GCS1L|p42IP4 | |
| Cytomap | 12q13.13 | 7p22.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | eukaryotic translation initiation factor 4B | arf-GAP with dual PH domain-containing protein 1centaurin-alphacentaurin-alpha-1cnt-a1putative MAPK-activating protein PM25 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | O75689 | |
| Ensembl transtripts involved in fusion gene | ENST00000262056, ENST00000416762, ENST00000420463, ENST00000551527, | ENST00000463358, ENST00000449296, ENST00000539900, ENST00000265846, | |
| Fusion gene scores | * DoF score | 9 X 8 X 5=360 | 6 X 4 X 4=96 |
| # samples | 9 | 6 | |
| ** MAII score | log2(9/360*10)=-2 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(6/96*10)=-0.678071905112638 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: EIF4B [Title/Abstract] AND ADAP1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | EIF4B(53421972)-ADAP1(975141), # samples:2 ADAP1(994031)-EIF4B(53427589), # samples:1 ADAP1(994032)-EIF4B(53427590), # samples:1 ADAP1(985398)-EIF4B(53427590), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | ADAP1-EIF4B seems lost the major protein functional domain in Tgene partner, which is a cell metabolism gene due to the frame-shifted ORF. ADAP1-EIF4B seems lost the major protein functional domain in Tgene partner, which is a essential gene due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across EIF4B (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
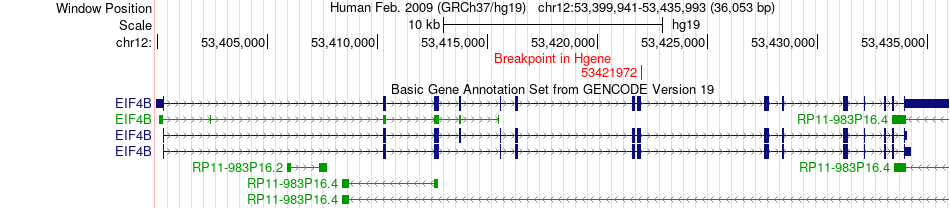 |
| Fusion gene breakpoints across ADAP1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-D7-A4YT-01A | EIF4B | chr12 | 53421972 | + | ADAP1 | chr7 | 975141 | - |
| ChimerDB4 | STAD | TCGA-D7-A4YT | EIF4B | chr12 | 53421972 | + | ADAP1 | chr7 | 975141 | - |
Top |
Fusion Gene ORF analysis for EIF4B-ADAP1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-5UTR | ENST00000262056 | ENST00000463358 | EIF4B | chr12 | 53421972 | + | ADAP1 | chr7 | 975141 | - |
| 5CDS-5UTR | ENST00000416762 | ENST00000463358 | EIF4B | chr12 | 53421972 | + | ADAP1 | chr7 | 975141 | - |
| 5CDS-5UTR | ENST00000420463 | ENST00000463358 | EIF4B | chr12 | 53421972 | + | ADAP1 | chr7 | 975141 | - |
| 5CDS-intron | ENST00000262056 | ENST00000449296 | EIF4B | chr12 | 53421972 | + | ADAP1 | chr7 | 975141 | - |
| 5CDS-intron | ENST00000262056 | ENST00000539900 | EIF4B | chr12 | 53421972 | + | ADAP1 | chr7 | 975141 | - |
| 5CDS-intron | ENST00000416762 | ENST00000449296 | EIF4B | chr12 | 53421972 | + | ADAP1 | chr7 | 975141 | - |
| 5CDS-intron | ENST00000416762 | ENST00000539900 | EIF4B | chr12 | 53421972 | + | ADAP1 | chr7 | 975141 | - |
| 5CDS-intron | ENST00000420463 | ENST00000449296 | EIF4B | chr12 | 53421972 | + | ADAP1 | chr7 | 975141 | - |
| 5CDS-intron | ENST00000420463 | ENST00000539900 | EIF4B | chr12 | 53421972 | + | ADAP1 | chr7 | 975141 | - |
| In-frame | ENST00000262056 | ENST00000265846 | EIF4B | chr12 | 53421972 | + | ADAP1 | chr7 | 975141 | - |
| In-frame | ENST00000416762 | ENST00000265846 | EIF4B | chr12 | 53421972 | + | ADAP1 | chr7 | 975141 | - |
| In-frame | ENST00000420463 | ENST00000265846 | EIF4B | chr12 | 53421972 | + | ADAP1 | chr7 | 975141 | - |
| intron-3CDS | ENST00000551527 | ENST00000265846 | EIF4B | chr12 | 53421972 | + | ADAP1 | chr7 | 975141 | - |
| intron-5UTR | ENST00000551527 | ENST00000463358 | EIF4B | chr12 | 53421972 | + | ADAP1 | chr7 | 975141 | - |
| intron-intron | ENST00000551527 | ENST00000449296 | EIF4B | chr12 | 53421972 | + | ADAP1 | chr7 | 975141 | - |
| intron-intron | ENST00000551527 | ENST00000539900 | EIF4B | chr12 | 53421972 | + | ADAP1 | chr7 | 975141 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000262056 | EIF4B | chr12 | 53421972 | + | ENST00000265846 | ADAP1 | chr7 | 975141 | - | 3366 | 1305 | 326 | 2347 | 673 |
| ENST00000420463 | EIF4B | chr12 | 53421972 | + | ENST00000265846 | ADAP1 | chr7 | 975141 | - | 3068 | 1007 | 28 | 2049 | 673 |
| ENST00000416762 | EIF4B | chr12 | 53421972 | + | ENST00000265846 | ADAP1 | chr7 | 975141 | - | 2950 | 889 | 27 | 1931 | 634 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000262056 | ENST00000265846 | EIF4B | chr12 | 53421972 | + | ADAP1 | chr7 | 975141 | - | 0.004582883 | 0.9954171 |
| ENST00000420463 | ENST00000265846 | EIF4B | chr12 | 53421972 | + | ADAP1 | chr7 | 975141 | - | 0.004334356 | 0.9956657 |
| ENST00000416762 | ENST00000265846 | EIF4B | chr12 | 53421972 | + | ADAP1 | chr7 | 975141 | - | 0.004724132 | 0.99527586 |
Top |
Fusion Genomic Features for EIF4B-ADAP1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
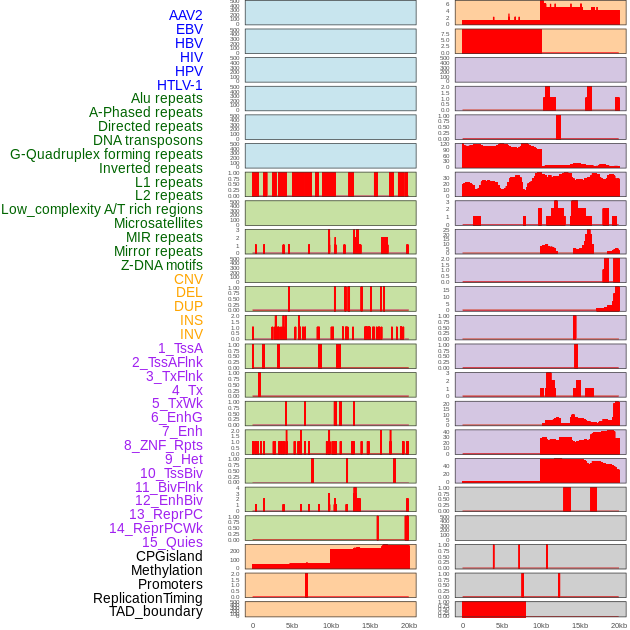 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for EIF4B-ADAP1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr12:53421972/chr7:975141) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | ADAP1 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: GTPase-activating protein for the ADP ribosylation factor family (Probable). Binds phosphatidylinositol 3,4,5-trisphosphate (PtdInsP3) and inositol 1,3,4,5-tetrakisphosphate (InsP4). {ECO:0000269|PubMed:10448098, ECO:0000303|PubMed:10333475, ECO:0000305}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | EIF4B | chr12:53421972 | chr7:975141 | ENST00000262056 | + | 8 | 15 | 169_325 | 326 | 612.0 | Compositional bias | Note=Asp-rich |
| Hgene | EIF4B | chr12:53421972 | chr7:975141 | ENST00000262056 | + | 8 | 15 | 96_173 | 326 | 612.0 | Domain | RRM |
| Tgene | ADAP1 | chr12:53421972 | chr7:975141 | ENST00000265846 | 0 | 11 | 129_230 | 27 | 375.0 | Domain | PH 1 | |
| Tgene | ADAP1 | chr12:53421972 | chr7:975141 | ENST00000265846 | 0 | 11 | 252_356 | 27 | 375.0 | Domain | PH 2 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | EIF4B | chr12:53421972 | chr7:975141 | ENST00000262056 | + | 8 | 15 | 164_331 | 326 | 612.0 | Compositional bias | Note=Arg-rich |
| Tgene | ADAP1 | chr12:53421972 | chr7:975141 | ENST00000265846 | 0 | 11 | 7_126 | 27 | 375.0 | Domain | Arf-GAP | |
| Tgene | ADAP1 | chr12:53421972 | chr7:975141 | ENST00000265846 | 0 | 11 | 21_44 | 27 | 375.0 | Zinc finger | C4-type |
Top |
Fusion Gene Sequence for EIF4B-ADAP1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >25950_25950_1_EIF4B-ADAP1_EIF4B_chr12_53421972_ENST00000262056_ADAP1_chr7_975141_ENST00000265846_length(transcript)=3366nt_BP=1305nt TCTTCCGGCAGGAAGTCTGTGCGTCAGGAGGCCGGCCAGGACTCAGCTCCAGCCCCGCGCTCGCGTGTAGCCCTACGTAAAGCGTGAGGG GTTTCGCGACAACCCAGGCCCCGCCCCTTTGGCCACATGTCGCGCATGTCTTCCCGTCGGACGGCGTGCCACCTCGCCGCGCAGCTTTAC GAACCTAGAGCAGCGCCGCCCCGCCTCCTGTCTCCGTCCTCACCTCCCCGCCCCCTCCCAGCTTCGCGTCTCCTAGCTCGACGCGCCCGC TATAATCACGTGATTGCCTCATCCGGGTCTTTTGCGTTCTCTTTCCCTCTCCCAACATGGCGGCCTCAGCAAAAAAGAAGAATAAGAAGG GGAAGACTATCTCCCTAACAGACTTTCTGGCTGAGGATGGGGGTACTGGTGGAGGAAGCACCTATGTTTCCAAACCAGTCAGCTGGGCTG ATGAAACGGATGACCTGGAAGGAGATGTTTCGACCACTTGGCACAGTAACGATGACGATGTGTATAGGGCGCCTCCAATTGACCGTTCCA TCCTTCCCACTGCTCCACGGGCTGCTCGGGAACCCAATATCGACCGGAGCCGTCTTCCCAAATCGCCACCCTACACTGCTTTTCTAGGAA ACCTACCCTATGATGTTACAGAAGAGTCAATTAAGGAATTCTTTCGAGGATTAAATATCAGTGCAGTGCGTTTACCACGTGAACCCAGCA ATCCAGAGAGGTTGAAAGGTTTTGGTTATGCTGAATTTGAGGACCTGGATTCCCTGCTCAGTGCCCTGAGTCTCAATGAAGAGTCTCTAG GTAACAGGAGAATTCGAGTGGACGTTGCTGATCAAGCACAGGATAAAGACAGGGATGATCGTTCTTTTGGCCGTGATAGAAATCGGGATT CTGACAAAACAGATACAGACTGGAGGGCTCGTCCTGCTACAGACAGCTTTGATGACTACCCACCTAGAAGAGGTGATGATAGCTTTGGAG ACAAGTATCGAGATCGTTATGATTCAGACCGGTATCGGGATGGGTATCGGGATGGGTATCGGGATGGCCCACGCCGGGATATGGATCGAT ATGGTGGCCGGGATCGCTATGATGACCGAGGCAGCAGAGACTATGATAGAGGCTATGATTCCCGGATAGGCAGTGGCAGAAGAGCATTTG GCAGTGGGTATCGCAGGGATGATGACTACAGAGGAGGCGGGGACCGCTATGAAGACCGATATGACAGACGGGATGATCGGTCGTGGAGCT CCAGAGATGATTACTCTCGGGATGATTATAGGCGTGATGATAGAGATCCCGACTGGGCCTCCTACACTCTGGGCGTCTTCATCTGCCTGA GCTGCTCGGGAATCCACCGGAATATCCCCCAGGTCAGCAAGGTGAAGTCCGTCCGCCTGGACGCCTGGGAGGAGGCCCAAGTGGAGTTCA TGGCCTCCCACGGGAACGACGCCGCGAGAGCCAGGTTTGAGTCCAAAGTACCCTCCTTCTACTACCGGCCCACGCCCTCCGACTGCCAGC TCCTTCGAGAGCAGTGGATCCGGGCCAAGTACGAGCGACAGGAGTTCATCTACCCGGAGAAGCAGGAGCCCTACTCGGCAGGGTACCGTG AGGGTTTTCTCTGGAAGCGTGGCCGGGACAACGGGCAGTTTTTGAGCCGGAAGTTTGTGCTGACAGAACGAGAGGGTGCTCTGAAGTATT TCAACAGAAATGATGCCAAGGAGCCCAAGGCCGTGATGAAGATCGAGCACCTGAACGCCACCTTCCAGCCGGCCAAGATCGGCCACCCCC ACGGCCTGCAGGTCACCTACCTGAAGGACAACAGCACCCGTAACATCTTCATCTACCATGAGGACGGGAAGGAGATTGTGGACTGGTTCA ATGCACTCCGAGCTGCTCGCTTCCACTACCTGCAGGTGGCATTCCCAGGGGCCGGCGACGCAGATCTGGTGCCAAAGCTCTCCAGGAACT ACCTGAAGGAAGGCTACATGGAGAAGACGGGGCCCAAGCAAACGGAAGGCTTCCGGAAGCGCTGGTTCACCATGGATGACCGCAGGCTCA TGTACTTCAAAGACCCCCTGGACGCCTTCGCCCGAGGGGAAGTCTTCATTGGCAGCAAGGAGAGTGGCTACACGGTGCTGCATGGGTTCC CGCCGTCCACCCAGGGCCACCACTGGCCACATGGCATCACCATCGTCACGCCCGACCGCAAGTTTCTGTTTGCCTGCGAGACGGAGTCCG ACCAGAGGGAGTGGGTGGCGGCCTTCCAGAAGGCGGTGGACAGGCCCATGCTGCCCCAGGAGTACGCAGTGGAGGCGCACTTCAAGCATA AACCTTAGCGAGTGCGGCTGGAGGACCACGGACATTGGACTCACTGTGGCTGGACGGAGGGGACCCGTGGATGGGGGGGCTCTGGCGTCC TGAGGCCACCTGGCCCCACCTGCTCCTCAGGGCAGCCCGGCGCGGCCAGGTAGGGCCCGAGCTTCAGCTTCCAGGATGCTTCTCTGGAAC CTCAAGGCAGGCAGCCCAGGCCCTGGGCCTGATCTCTAACCCCGTCATGCTGCTGCTGACCACACCCAGCCAACCTGCCCCTCCCTGACC CGGGGCCCCCTTTCCTCCAGGGCCCAGTCTGGCTCCCGAGCTCAGACACAGCCCCCAGGAGCCGCCCACCACGGCTGTGGGAACTTCCAG GCCTCAGCGCAGAGCCCTGCTTGGGGCCAGCACGGTGGGCAGCTGCCGGCCGCTGGGGACTGGGCCCTGCTCGCATGCCGCCCCGCCCTC CCCCCACCTCCACGACTATTTATTGAGCGCCTGTTGTGTGTCACGGGGCTATGAGGGCCGTGGGGTGTTTGGGTGGATTATCCACACAGG TCCCGGCCCCTGCCCGGGCTGGAGTTGCCACAGCCTGTGCTCCTGGTCCTCACCTGGAGGGGCCAGCAGGCTGCCGTCCCACCACACGTG GCCTCTGCGCCCAGCACGGTGCTCGCCGACAGTGGTGTCTGAACCCTTGGGGACGAGGGCCTGGGCCGCGGTGAGGCCACCAGAGGCAGG AGTGGCCCTGGGGGTCCCGGGCACTGTCGCGCTTGCTGCAGGCGGCCCAGCCGTGTATTTATTTTTCACCTATCTCCTTCCTGTCAAGGC AGGCCGGGCTCCAGGGCTCCCCTTGCGTGGGGCATGTAGGTGGGGGAGGCGTCTGCAGGTCACCTGGGGGGCCCAGCCCTCTCCCAGCCT TGCCTGGCTGAGCTGTGTTCCAGGGGAGCCCTGGACAAGCCCTCATAGGCAGGGAGGGGGTTTCCGAGGCCAGGCATCCGCCGCCCCGTG >25950_25950_1_EIF4B-ADAP1_EIF4B_chr12_53421972_ENST00000262056_ADAP1_chr7_975141_ENST00000265846_length(amino acids)=673AA_BP=326 MAASAKKKNKKGKTISLTDFLAEDGGTGGGSTYVSKPVSWADETDDLEGDVSTTWHSNDDDVYRAPPIDRSILPTAPRAAREPNIDRSRL PKSPPYTAFLGNLPYDVTEESIKEFFRGLNISAVRLPREPSNPERLKGFGYAEFEDLDSLLSALSLNEESLGNRRIRVDVADQAQDKDRD DRSFGRDRNRDSDKTDTDWRARPATDSFDDYPPRRGDDSFGDKYRDRYDSDRYRDGYRDGYRDGPRRDMDRYGGRDRYDDRGSRDYDRGY DSRIGSGRRAFGSGYRRDDDYRGGGDRYEDRYDRRDDRSWSSRDDYSRDDYRRDDRDPDWASYTLGVFICLSCSGIHRNIPQVSKVKSVR LDAWEEAQVEFMASHGNDAARARFESKVPSFYYRPTPSDCQLLREQWIRAKYERQEFIYPEKQEPYSAGYREGFLWKRGRDNGQFLSRKF VLTEREGALKYFNRNDAKEPKAVMKIEHLNATFQPAKIGHPHGLQVTYLKDNSTRNIFIYHEDGKEIVDWFNALRAARFHYLQVAFPGAG DADLVPKLSRNYLKEGYMEKTGPKQTEGFRKRWFTMDDRRLMYFKDPLDAFARGEVFIGSKESGYTVLHGFPPSTQGHHWPHGITIVTPD -------------------------------------------------------------- >25950_25950_2_EIF4B-ADAP1_EIF4B_chr12_53421972_ENST00000416762_ADAP1_chr7_975141_ENST00000265846_length(transcript)=2950nt_BP=889nt TTTTGCGTTCTCTTTCCCTCTCCCAACATGGCGGCCTCAGCAAAAAAGAAGAATAAGAAGGGGAAGACTATCTCCCTAACAGACTTTCTG GCTGAGGATGGGGGTACTGGTGGAGGAAGCACCTATGTTTCCAAACCAGTCAGCTGGGCTGATGAAACGGATGACCTGGAAGGAGATGTT TCGACCACTTGGCACAGTAACGATGACGATGTGTATAGGGCGCCTCCAATTGACCGTTCCATCCTTCCCACTGCTCCACGGGCTGCTCGG GAACCCAATATCGACCGGAGCCGTCTTCCCAAATCGCCACCCTACACTGCTTTTCTAGGAAACCTACCCTATGATGTTACAGAAGAGTCA ATTAAGGAATTCTTTCGAGGATTAAATTCTCTAGGTAACAGGAGAATTCGAGTGGACGTTGCTGATCAAGCACAGGATAAAGACAGGGAT GATCGTTCTTTTGGCCGTGATAGAAATCGGGATTCTGACAAAACAGATACAGACTGGAGGGCTCGTCCTGCTACAGACAGCTTTGATGAC TACCCACCTAGAAGAGGTGATGATAGCTTTGGAGACAAGTATCGAGATCGTTATGATTCAGACCGGTATCGGGATGGGTATCGGGATGGG TATCGGGATGGCCCACGCCGGGATATGGATCGATATGGTGGCCGGGATCGCTATGATGACCGAGGCAGCAGAGACTATGATAGAGGCTAT GATTCCCGGATAGGCAGTGGCAGAAGAGCATTTGGCAGTGGGTATCGCAGGGATGATGACTACAGAGGAGGCGGGGACCGCTATGAAGAC CGATATGACAGACGGGATGATCGGTCGTGGAGCTCCAGAGATGATTACTCTCGGGATGATTATAGGCGTGATGATAGAGATCCCGACTGG GCCTCCTACACTCTGGGCGTCTTCATCTGCCTGAGCTGCTCGGGAATCCACCGGAATATCCCCCAGGTCAGCAAGGTGAAGTCCGTCCGC CTGGACGCCTGGGAGGAGGCCCAAGTGGAGTTCATGGCCTCCCACGGGAACGACGCCGCGAGAGCCAGGTTTGAGTCCAAAGTACCCTCC TTCTACTACCGGCCCACGCCCTCCGACTGCCAGCTCCTTCGAGAGCAGTGGATCCGGGCCAAGTACGAGCGACAGGAGTTCATCTACCCG GAGAAGCAGGAGCCCTACTCGGCAGGGTACCGTGAGGGTTTTCTCTGGAAGCGTGGCCGGGACAACGGGCAGTTTTTGAGCCGGAAGTTT GTGCTGACAGAACGAGAGGGTGCTCTGAAGTATTTCAACAGAAATGATGCCAAGGAGCCCAAGGCCGTGATGAAGATCGAGCACCTGAAC GCCACCTTCCAGCCGGCCAAGATCGGCCACCCCCACGGCCTGCAGGTCACCTACCTGAAGGACAACAGCACCCGTAACATCTTCATCTAC CATGAGGACGGGAAGGAGATTGTGGACTGGTTCAATGCACTCCGAGCTGCTCGCTTCCACTACCTGCAGGTGGCATTCCCAGGGGCCGGC GACGCAGATCTGGTGCCAAAGCTCTCCAGGAACTACCTGAAGGAAGGCTACATGGAGAAGACGGGGCCCAAGCAAACGGAAGGCTTCCGG AAGCGCTGGTTCACCATGGATGACCGCAGGCTCATGTACTTCAAAGACCCCCTGGACGCCTTCGCCCGAGGGGAAGTCTTCATTGGCAGC AAGGAGAGTGGCTACACGGTGCTGCATGGGTTCCCGCCGTCCACCCAGGGCCACCACTGGCCACATGGCATCACCATCGTCACGCCCGAC CGCAAGTTTCTGTTTGCCTGCGAGACGGAGTCCGACCAGAGGGAGTGGGTGGCGGCCTTCCAGAAGGCGGTGGACAGGCCCATGCTGCCC CAGGAGTACGCAGTGGAGGCGCACTTCAAGCATAAACCTTAGCGAGTGCGGCTGGAGGACCACGGACATTGGACTCACTGTGGCTGGACG GAGGGGACCCGTGGATGGGGGGGCTCTGGCGTCCTGAGGCCACCTGGCCCCACCTGCTCCTCAGGGCAGCCCGGCGCGGCCAGGTAGGGC CCGAGCTTCAGCTTCCAGGATGCTTCTCTGGAACCTCAAGGCAGGCAGCCCAGGCCCTGGGCCTGATCTCTAACCCCGTCATGCTGCTGC TGACCACACCCAGCCAACCTGCCCCTCCCTGACCCGGGGCCCCCTTTCCTCCAGGGCCCAGTCTGGCTCCCGAGCTCAGACACAGCCCCC AGGAGCCGCCCACCACGGCTGTGGGAACTTCCAGGCCTCAGCGCAGAGCCCTGCTTGGGGCCAGCACGGTGGGCAGCTGCCGGCCGCTGG GGACTGGGCCCTGCTCGCATGCCGCCCCGCCCTCCCCCCACCTCCACGACTATTTATTGAGCGCCTGTTGTGTGTCACGGGGCTATGAGG GCCGTGGGGTGTTTGGGTGGATTATCCACACAGGTCCCGGCCCCTGCCCGGGCTGGAGTTGCCACAGCCTGTGCTCCTGGTCCTCACCTG GAGGGGCCAGCAGGCTGCCGTCCCACCACACGTGGCCTCTGCGCCCAGCACGGTGCTCGCCGACAGTGGTGTCTGAACCCTTGGGGACGA GGGCCTGGGCCGCGGTGAGGCCACCAGAGGCAGGAGTGGCCCTGGGGGTCCCGGGCACTGTCGCGCTTGCTGCAGGCGGCCCAGCCGTGT ATTTATTTTTCACCTATCTCCTTCCTGTCAAGGCAGGCCGGGCTCCAGGGCTCCCCTTGCGTGGGGCATGTAGGTGGGGGAGGCGTCTGC AGGTCACCTGGGGGGCCCAGCCCTCTCCCAGCCTTGCCTGGCTGAGCTGTGTTCCAGGGGAGCCCTGGACAAGCCCTCATAGGCAGGGAG >25950_25950_2_EIF4B-ADAP1_EIF4B_chr12_53421972_ENST00000416762_ADAP1_chr7_975141_ENST00000265846_length(amino acids)=634AA_BP=287 MAASAKKKNKKGKTISLTDFLAEDGGTGGGSTYVSKPVSWADETDDLEGDVSTTWHSNDDDVYRAPPIDRSILPTAPRAAREPNIDRSRL PKSPPYTAFLGNLPYDVTEESIKEFFRGLNSLGNRRIRVDVADQAQDKDRDDRSFGRDRNRDSDKTDTDWRARPATDSFDDYPPRRGDDS FGDKYRDRYDSDRYRDGYRDGYRDGPRRDMDRYGGRDRYDDRGSRDYDRGYDSRIGSGRRAFGSGYRRDDDYRGGGDRYEDRYDRRDDRS WSSRDDYSRDDYRRDDRDPDWASYTLGVFICLSCSGIHRNIPQVSKVKSVRLDAWEEAQVEFMASHGNDAARARFESKVPSFYYRPTPSD CQLLREQWIRAKYERQEFIYPEKQEPYSAGYREGFLWKRGRDNGQFLSRKFVLTEREGALKYFNRNDAKEPKAVMKIEHLNATFQPAKIG HPHGLQVTYLKDNSTRNIFIYHEDGKEIVDWFNALRAARFHYLQVAFPGAGDADLVPKLSRNYLKEGYMEKTGPKQTEGFRKRWFTMDDR RLMYFKDPLDAFARGEVFIGSKESGYTVLHGFPPSTQGHHWPHGITIVTPDRKFLFACETESDQREWVAAFQKAVDRPMLPQEYAVEAHF -------------------------------------------------------------- >25950_25950_3_EIF4B-ADAP1_EIF4B_chr12_53421972_ENST00000420463_ADAP1_chr7_975141_ENST00000265846_length(transcript)=3068nt_BP=1007nt CTTTTGCGTTCTCTTTCCCTCTCCCAACATGGCGGCCTCAGCAAAAAAGAAGAATAAGAAGGGGAAGACTATCTCCCTAACAGACTTTCT GGCTGAGGATGGGGGTACTGGTGGAGGAAGCACCTATGTTTCCAAACCAGTCAGCTGGGCTGATGAAACGGATGACCTGGAAGGAGATGT TTCGACCACTTGGCACAGTAACGATGACGATGTGTATAGGGCGCCTCCAATTGACCGTTCCATCCTTCCCACTGCTCCACGGGCTGCTCG GGAACCCAATATCGACCGGAGCCGTCTTCCCAAATCGCCACCCTACACTGCTTTTCTAGGAAACCTACCCTATGATGTTACAGAAGAGTC AATTAAGGAATTCTTTCGAGGATTAAATATCAGTGCAGTGCGTTTACCACGTGAACCCAGCAATCCAGAGAGGTTGAAAGGTTTTGGTTA TGCTGAATTTGAGGACCTGGATTCCCTGCTCAGTGCCCTGAGTCTCAATGAAGAGTCTCTAGGTAACAGGAGAATTCGAGTGGACGTTGC TGATCAAGCACAGGATAAAGACAGGGATGATCGTTCTTTTGGCCGTGATAGAAATCGGGATTCTGACAAAACAGATACAGACTGGAGGGC TCGTCCTGCTACAGACAGCTTTGATGACTACCCACCTAGAAGAGGTGATGATAGCTTTGGAGACAAGTATCGAGATCGTTATGATTCAGA CCGGTATCGGGATGGGTATCGGGATGGGTATCGGGATGGCCCACGCCGGGATATGGATCGATATGGTGGCCGGGATCGCTATGATGACCG AGGCAGCAGAGACTATGATAGAGGCTATGATTCCCGGATAGGCAGTGGCAGAAGAGCATTTGGCAGTGGGTATCGCAGGGATGATGACTA CAGAGGAGGCGGGGACCGCTATGAAGACCGATATGACAGACGGGATGATCGGTCGTGGAGCTCCAGAGATGATTACTCTCGGGATGATTA TAGGCGTGATGATAGAGATCCCGACTGGGCCTCCTACACTCTGGGCGTCTTCATCTGCCTGAGCTGCTCGGGAATCCACCGGAATATCCC CCAGGTCAGCAAGGTGAAGTCCGTCCGCCTGGACGCCTGGGAGGAGGCCCAAGTGGAGTTCATGGCCTCCCACGGGAACGACGCCGCGAG AGCCAGGTTTGAGTCCAAAGTACCCTCCTTCTACTACCGGCCCACGCCCTCCGACTGCCAGCTCCTTCGAGAGCAGTGGATCCGGGCCAA GTACGAGCGACAGGAGTTCATCTACCCGGAGAAGCAGGAGCCCTACTCGGCAGGGTACCGTGAGGGTTTTCTCTGGAAGCGTGGCCGGGA CAACGGGCAGTTTTTGAGCCGGAAGTTTGTGCTGACAGAACGAGAGGGTGCTCTGAAGTATTTCAACAGAAATGATGCCAAGGAGCCCAA GGCCGTGATGAAGATCGAGCACCTGAACGCCACCTTCCAGCCGGCCAAGATCGGCCACCCCCACGGCCTGCAGGTCACCTACCTGAAGGA CAACAGCACCCGTAACATCTTCATCTACCATGAGGACGGGAAGGAGATTGTGGACTGGTTCAATGCACTCCGAGCTGCTCGCTTCCACTA CCTGCAGGTGGCATTCCCAGGGGCCGGCGACGCAGATCTGGTGCCAAAGCTCTCCAGGAACTACCTGAAGGAAGGCTACATGGAGAAGAC GGGGCCCAAGCAAACGGAAGGCTTCCGGAAGCGCTGGTTCACCATGGATGACCGCAGGCTCATGTACTTCAAAGACCCCCTGGACGCCTT CGCCCGAGGGGAAGTCTTCATTGGCAGCAAGGAGAGTGGCTACACGGTGCTGCATGGGTTCCCGCCGTCCACCCAGGGCCACCACTGGCC ACATGGCATCACCATCGTCACGCCCGACCGCAAGTTTCTGTTTGCCTGCGAGACGGAGTCCGACCAGAGGGAGTGGGTGGCGGCCTTCCA GAAGGCGGTGGACAGGCCCATGCTGCCCCAGGAGTACGCAGTGGAGGCGCACTTCAAGCATAAACCTTAGCGAGTGCGGCTGGAGGACCA CGGACATTGGACTCACTGTGGCTGGACGGAGGGGACCCGTGGATGGGGGGGCTCTGGCGTCCTGAGGCCACCTGGCCCCACCTGCTCCTC AGGGCAGCCCGGCGCGGCCAGGTAGGGCCCGAGCTTCAGCTTCCAGGATGCTTCTCTGGAACCTCAAGGCAGGCAGCCCAGGCCCTGGGC CTGATCTCTAACCCCGTCATGCTGCTGCTGACCACACCCAGCCAACCTGCCCCTCCCTGACCCGGGGCCCCCTTTCCTCCAGGGCCCAGT CTGGCTCCCGAGCTCAGACACAGCCCCCAGGAGCCGCCCACCACGGCTGTGGGAACTTCCAGGCCTCAGCGCAGAGCCCTGCTTGGGGCC AGCACGGTGGGCAGCTGCCGGCCGCTGGGGACTGGGCCCTGCTCGCATGCCGCCCCGCCCTCCCCCCACCTCCACGACTATTTATTGAGC GCCTGTTGTGTGTCACGGGGCTATGAGGGCCGTGGGGTGTTTGGGTGGATTATCCACACAGGTCCCGGCCCCTGCCCGGGCTGGAGTTGC CACAGCCTGTGCTCCTGGTCCTCACCTGGAGGGGCCAGCAGGCTGCCGTCCCACCACACGTGGCCTCTGCGCCCAGCACGGTGCTCGCCG ACAGTGGTGTCTGAACCCTTGGGGACGAGGGCCTGGGCCGCGGTGAGGCCACCAGAGGCAGGAGTGGCCCTGGGGGTCCCGGGCACTGTC GCGCTTGCTGCAGGCGGCCCAGCCGTGTATTTATTTTTCACCTATCTCCTTCCTGTCAAGGCAGGCCGGGCTCCAGGGCTCCCCTTGCGT GGGGCATGTAGGTGGGGGAGGCGTCTGCAGGTCACCTGGGGGGCCCAGCCCTCTCCCAGCCTTGCCTGGCTGAGCTGTGTTCCAGGGGAG CCCTGGACAAGCCCTCATAGGCAGGGAGGGGGTTTCCGAGGCCAGGCATCCGCCGCCCCGTGTCGCATCCTGGAATAAAATGTGGCTCTG >25950_25950_3_EIF4B-ADAP1_EIF4B_chr12_53421972_ENST00000420463_ADAP1_chr7_975141_ENST00000265846_length(amino acids)=673AA_BP=326 MAASAKKKNKKGKTISLTDFLAEDGGTGGGSTYVSKPVSWADETDDLEGDVSTTWHSNDDDVYRAPPIDRSILPTAPRAAREPNIDRSRL PKSPPYTAFLGNLPYDVTEESIKEFFRGLNISAVRLPREPSNPERLKGFGYAEFEDLDSLLSALSLNEESLGNRRIRVDVADQAQDKDRD DRSFGRDRNRDSDKTDTDWRARPATDSFDDYPPRRGDDSFGDKYRDRYDSDRYRDGYRDGYRDGPRRDMDRYGGRDRYDDRGSRDYDRGY DSRIGSGRRAFGSGYRRDDDYRGGGDRYEDRYDRRDDRSWSSRDDYSRDDYRRDDRDPDWASYTLGVFICLSCSGIHRNIPQVSKVKSVR LDAWEEAQVEFMASHGNDAARARFESKVPSFYYRPTPSDCQLLREQWIRAKYERQEFIYPEKQEPYSAGYREGFLWKRGRDNGQFLSRKF VLTEREGALKYFNRNDAKEPKAVMKIEHLNATFQPAKIGHPHGLQVTYLKDNSTRNIFIYHEDGKEIVDWFNALRAARFHYLQVAFPGAG DADLVPKLSRNYLKEGYMEKTGPKQTEGFRKRWFTMDDRRLMYFKDPLDAFARGEVFIGSKESGYTVLHGFPPSTQGHHWPHGITIVTPD -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for EIF4B-ADAP1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for EIF4B-ADAP1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for EIF4B-ADAP1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies