
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ENY2-NSF (FusionGDB2 ID:26728) |
Fusion Gene Summary for ENY2-NSF |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ENY2-NSF | Fusion gene ID: 26728 | Hgene | Tgene | Gene symbol | ENY2 | NSF | Gene ID | 56943 | 4905 |
| Gene name | ENY2 transcription and export complex 2 subunit | N-ethylmaleimide sensitive factor, vesicle fusing ATPase | |
| Synonyms | DC6|Sus1|e(y)2 | SEC18|SKD2 | |
| Cytomap | 8q23.1 | 17q21.31 | |
| Type of gene | protein-coding | protein-coding | |
| Description | transcription and mRNA export factor ENY2enhancer of yellow 2 homologenhancer of yellow 2 transcription factor homolog | vesicle-fusing ATPaseN-ethylmaleimide-sensitive factor-like proteinN-ethylmaleimide-sensitive fusion proteinNEM-sensitive fusion proteinepididymis secretory sperm binding proteinvesicular-fusion protein NSF | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q9NPA8 | NSFL1C | |
| Ensembl transtripts involved in fusion gene | ENST00000522407, ENST00000520147, ENST00000521662, ENST00000521688, | ENST00000225282, ENST00000398238, ENST00000575068, | |
| Fusion gene scores | * DoF score | 7 X 5 X 3=105 | 11 X 8 X 6=528 |
| # samples | 7 | 12 | |
| ** MAII score | log2(7/105*10)=-0.584962500721156 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(12/528*10)=-2.13750352374993 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: ENY2 [Title/Abstract] AND NSF [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ENY2(110352792)-NSF(44751780), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | ENY2 | GO:0016578 | histone deubiquitination | 18206972 |
| Hgene | ENY2 | GO:0045893 | positive regulation of transcription, DNA-templated | 18206972 |
| Tgene | NSF | GO:0001921 | positive regulation of receptor recycling | 15613468 |
| Fusion gene breakpoints across ENY2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across NSF (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | PRAD | TCGA-YL-A9WL-01A | ENY2 | chr8 | 110352792 | + | NSF | chr17 | 44751780 | + |
| ChimerDB4 | PRAD | TCGA-YL-A9WL | ENY2 | chr8 | 110352792 | + | NSF | chr17 | 44751780 | + |
Top |
Fusion Gene ORF analysis for ENY2-NSF |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000522407 | ENST00000225282 | ENY2 | chr8 | 110352792 | + | NSF | chr17 | 44751780 | + |
| 3UTR-3CDS | ENST00000522407 | ENST00000398238 | ENY2 | chr8 | 110352792 | + | NSF | chr17 | 44751780 | + |
| 3UTR-3CDS | ENST00000522407 | ENST00000575068 | ENY2 | chr8 | 110352792 | + | NSF | chr17 | 44751780 | + |
| In-frame | ENST00000520147 | ENST00000225282 | ENY2 | chr8 | 110352792 | + | NSF | chr17 | 44751780 | + |
| In-frame | ENST00000520147 | ENST00000398238 | ENY2 | chr8 | 110352792 | + | NSF | chr17 | 44751780 | + |
| In-frame | ENST00000520147 | ENST00000575068 | ENY2 | chr8 | 110352792 | + | NSF | chr17 | 44751780 | + |
| In-frame | ENST00000521662 | ENST00000225282 | ENY2 | chr8 | 110352792 | + | NSF | chr17 | 44751780 | + |
| In-frame | ENST00000521662 | ENST00000398238 | ENY2 | chr8 | 110352792 | + | NSF | chr17 | 44751780 | + |
| In-frame | ENST00000521662 | ENST00000575068 | ENY2 | chr8 | 110352792 | + | NSF | chr17 | 44751780 | + |
| In-frame | ENST00000521688 | ENST00000225282 | ENY2 | chr8 | 110352792 | + | NSF | chr17 | 44751780 | + |
| In-frame | ENST00000521688 | ENST00000398238 | ENY2 | chr8 | 110352792 | + | NSF | chr17 | 44751780 | + |
| In-frame | ENST00000521688 | ENST00000575068 | ENY2 | chr8 | 110352792 | + | NSF | chr17 | 44751780 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000521662 | ENY2 | chr8 | 110352792 | + | ENST00000398238 | NSF | chr17 | 44751780 | + | 3433 | 302 | 88 | 1791 | 567 |
| ENST00000521662 | ENY2 | chr8 | 110352792 | + | ENST00000225282 | NSF | chr17 | 44751780 | + | 2293 | 302 | 88 | 1773 | 561 |
| ENST00000521662 | ENY2 | chr8 | 110352792 | + | ENST00000575068 | NSF | chr17 | 44751780 | + | 2028 | 302 | 88 | 1791 | 567 |
| ENST00000521688 | ENY2 | chr8 | 110352792 | + | ENST00000398238 | NSF | chr17 | 44751780 | + | 3505 | 374 | 145 | 1863 | 572 |
| ENST00000521688 | ENY2 | chr8 | 110352792 | + | ENST00000225282 | NSF | chr17 | 44751780 | + | 2365 | 374 | 145 | 1845 | 566 |
| ENST00000521688 | ENY2 | chr8 | 110352792 | + | ENST00000575068 | NSF | chr17 | 44751780 | + | 2100 | 374 | 145 | 1863 | 572 |
| ENST00000520147 | ENY2 | chr8 | 110352792 | + | ENST00000398238 | NSF | chr17 | 44751780 | + | 3417 | 286 | 72 | 1775 | 567 |
| ENST00000520147 | ENY2 | chr8 | 110352792 | + | ENST00000225282 | NSF | chr17 | 44751780 | + | 2277 | 286 | 72 | 1757 | 561 |
| ENST00000520147 | ENY2 | chr8 | 110352792 | + | ENST00000575068 | NSF | chr17 | 44751780 | + | 2012 | 286 | 72 | 1775 | 567 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000521662 | ENST00000398238 | ENY2 | chr8 | 110352792 | + | NSF | chr17 | 44751780 | + | 0.00031917 | 0.9996809 |
| ENST00000521662 | ENST00000225282 | ENY2 | chr8 | 110352792 | + | NSF | chr17 | 44751780 | + | 0.001023102 | 0.99897695 |
| ENST00000521662 | ENST00000575068 | ENY2 | chr8 | 110352792 | + | NSF | chr17 | 44751780 | + | 0.001085814 | 0.99891424 |
| ENST00000521688 | ENST00000398238 | ENY2 | chr8 | 110352792 | + | NSF | chr17 | 44751780 | + | 0.000401968 | 0.9995981 |
| ENST00000521688 | ENST00000225282 | ENY2 | chr8 | 110352792 | + | NSF | chr17 | 44751780 | + | 0.001223874 | 0.99877614 |
| ENST00000521688 | ENST00000575068 | ENY2 | chr8 | 110352792 | + | NSF | chr17 | 44751780 | + | 0.001339293 | 0.9986607 |
| ENST00000520147 | ENST00000398238 | ENY2 | chr8 | 110352792 | + | NSF | chr17 | 44751780 | + | 0.000317216 | 0.9996828 |
| ENST00000520147 | ENST00000225282 | ENY2 | chr8 | 110352792 | + | NSF | chr17 | 44751780 | + | 0.001035052 | 0.9989649 |
| ENST00000520147 | ENST00000575068 | ENY2 | chr8 | 110352792 | + | NSF | chr17 | 44751780 | + | 0.001109492 | 0.9988906 |
Top |
Fusion Genomic Features for ENY2-NSF |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| ENY2 | chr8 | 110352792 | + | NSF | chr17 | 44751779 | + | 3.25E-06 | 0.9999968 |
| ENY2 | chr8 | 110352792 | + | NSF | chr17 | 44751779 | + | 3.25E-06 | 0.9999968 |
| ENY2 | chr8 | 110352792 | + | NSF | chr17 | 44751779 | + | 3.25E-06 | 0.9999968 |
| ENY2 | chr8 | 110352792 | + | NSF | chr17 | 44751779 | + | 3.25E-06 | 0.9999968 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
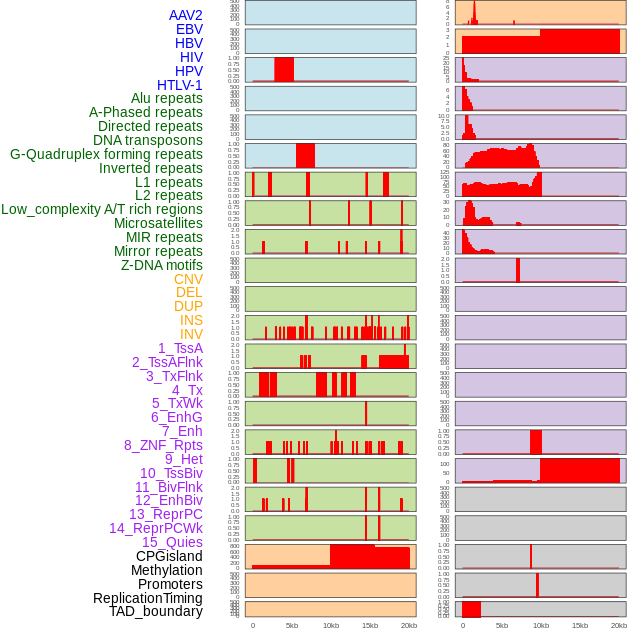 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
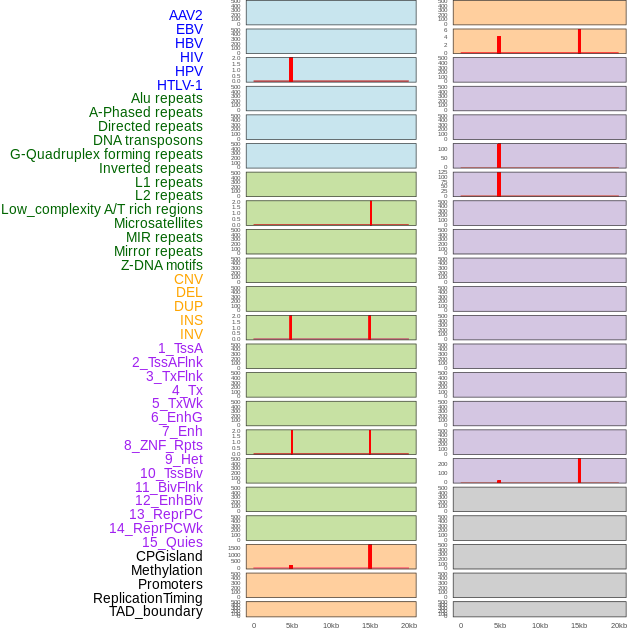 |
Top |
Fusion Protein Features for ENY2-NSF |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr8:110352792/chr17:44751780) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| ENY2 | NSF |
| FUNCTION: Involved in mRNA export coupled transcription activation by association with both the TREX-2 and the SAGA complexes. The transcription regulatory histone acetylation (HAT) complex SAGA is a multiprotein complex that activates transcription by remodeling chromatin and mediating histone acetylation and deubiquitination. Within the SAGA complex, participates in a subcomplex that specifically deubiquitinates both histones H2A and H2B. The SAGA complex is recruited to specific gene promoters by activators such as MYC, where it is required for transcription. Required for nuclear receptor-mediated transactivation (PubMed:18206972, PubMed:21746879). As a component of the TREX-2 complex, involved in the export of mRNAs to the cytoplasm through the nuclear pores (PubMed:23591820). {ECO:0000269|PubMed:18206972, ECO:0000269|PubMed:21746879, ECO:0000269|PubMed:23591820}. | 370 |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | NSF | chr8:110352792 | chr17:44751780 | ENST00000398238 | 7 | 21 | 505_510 | 248 | 745.0 | Nucleotide binding | ATP | |
| Tgene | NSF | chr8:110352792 | chr17:44751780 | ENST00000398238 | 7 | 21 | 545_552 | 248 | 745.0 | Nucleotide binding | ATP |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
Top |
Fusion Gene Sequence for ENY2-NSF |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >26728_26728_1_ENY2-NSF_ENY2_chr8_110352792_ENST00000520147_NSF_chr17_44751780_ENST00000225282_length(transcript)=2277nt_BP=286nt TCTGTGTGCTTAGGTGCCCGAGCTACTGAGGGTCTAAGTCCGGGCAGCCGAAGAGTGTGGTAGGTTAGCAAGATGAACAAAGATGCGCAG ATGAGAGCAGCGATTAACCAAAAGTTGATAGAAACTGGAGAAAGAGAACGCCTCAAAGAGTTGCTGAGAGCTAAATTAATTGAATGTGGC TGGAAGGATCAGTTGAAGGCACACTGTAAAGAGGTAATTAAAGAAAAAGGACTAGAACACGTTACTGTTGATGACTTGGTGGCTGAAATC ACTCCAAAAGGCAGAGGTTGTAAACATGTTAAAGGCATCCTGTTATATGGACCCCCAGGTTGTGGTAAGACTCTCTTGGCTCGACAGATT GGCAAGATGTTGAATGCAAGAGAGCCCAAAGTGGTCAATGGGCCAGAAATCCTTAACAAATATGTGGGAGAATCAGAGGCTAACATTCGC AAACTTTTTGCTGATGCTGAAGAGGAGCAAAGGAGGCTTGGTGCTAACAGTGGTTTGCACATCATCATCTTTGATGAAATTGATGCCATC TGCAAGCAGAGAGGGAGCATGGCTGGTAGCACGGGAGTTCATGACACTGTTGTCAACCAGTTGCTGTCCAAAATTGATGGCGTGGAGCAG CTAAACAACATCCTAGTCATTGGAATGACCAATAGACCAGATCTGATAGATGAGGCTCTTCTTAGACCTGGAAGACTGGAAGTTAAAATG GAGATAGGCTTGCCAGATGAGAAAGGCCGACTACAGATTCTTCACATCCACACAGCAAGAATGAGAGGGCATCAGTTACTCTCTGCTGAT GTAGACATTAAAGAACTGGCCGTGGAGACCAAGAATTTCAGTGGTGCTGAATTGGAGGGTCTGGTGCGAGCAGCCCAGTCCACTGCTATG AATAGACACATAAAGGCCAGTACTAAAGTGGAAGTGGACATGGAGAAAGCAGAAAGCCTGCAAGTGACGAGAGGAGACTTCCTTGCTTCT TTGGAGAATGATATCAAACCAGCCTTTGGCACAAACCAAGAAGATTATGCAAGTTACATTATGAACGGTATCATCAAATGGGGTGACCCA GTTACTCGAGTTCTAGATGATGGGGAGCTGCTGGTGCAGCAGACTAAGAACAGTGACCGCACACCATTGGTCAGCGTGCTTCTGGAAGGC CCTCCTCACAGTGGGAAGACTGCTTTAGCTGCAAAAATTGCAGAGGAATCCAACTTCCCGTTCATCAAGATCTGTTCTCCTGATAAAATG ATTGGCTTTTCTGAAACAGCCAAATGTCAGGCCATGAAGAAGATCTTTGATGATGCGTACAAATCCCAGCTCAGTTGTGTGGTTGTGGAT GACATTGAGAGATTGCTTGATTACGTCCCTATTGGCCCTCGATTTTCAAATCTTGTATTACAGGCTCTTCTCGTTTTACTGAAAAAGGCA CCTCCTCAGGGCCGCAAGCTTCTTATCATTGGGACCACTAGCCGCAAAGATGTCCTTCAGGAGATGGAAATGCTTAACGCTTTCAGCACC ACCATCCACGTGCCCAACATTGCCACAGGAGAGCAGCTGTTGGAAGCTTTGGAGCTTTTGGGCAACTTCAAGGATAAGGAACGCACCACA ATTGCACAGCAAGTCAAAGGGAAGAAGGTCTGGATAGGAATCAAGAAGTTACTAATGCTGATCGAGATGTCCCTACAGATGGATCCTGAA TACCGTGTGAGAAAATTCTTGGCCCTCTTAAGAGAAGAAGGAGCGTAATAGCCCCCTTGATTTTGATTGAAAATGAACTATTTGAAACAC ACAGTGACCAAGGGAAGTGACCAAGGTGAAGATGGCCTAGGATCTTCACTGTCTTACTCAAGATACTGGACTAAGTGGAACGTTCTCTAC CTTCAACATGTGCTCGCTCTGCATGATTAGTGCAATAAAACTCCCTTCCTTATGCATACTGAGATAGCTTAGTGTCTCGTGGAAGGTGTC AATTTGGTTTAGAATGCTGCGCTTACCTTCCCATGCAGGCTAAAGTGATTCCTTCTTGCTCAGTCCCTCTGGGTGGGAACCATCCAGTAC TTGTGGACACTACACGTTTCAACCTCTCTACTAGCACCATCACCCTTGAAAACTCTCAGTCAGTGTCATGAATGTTGCATGACAACAGTT GGCCGATTAGAAGGCAGACTTTCTACATGCAAATCTGGCTTAGTAAATCGAGGTGTGGGCCAGAGATCCTCTGACAGCTGTCCTGAGCTA >26728_26728_1_ENY2-NSF_ENY2_chr8_110352792_ENST00000520147_NSF_chr17_44751780_ENST00000225282_length(amino acids)=561AA_BP=71 MNKDAQMRAAINQKLIETGERERLKELLRAKLIECGWKDQLKAHCKEVIKEKGLEHVTVDDLVAEITPKGRGCKHVKGILLYGPPGCGKT LLARQIGKMLNAREPKVVNGPEILNKYVGESEANIRKLFADAEEEQRRLGANSGLHIIIFDEIDAICKQRGSMAGSTGVHDTVVNQLLSK IDGVEQLNNILVIGMTNRPDLIDEALLRPGRLEVKMEIGLPDEKGRLQILHIHTARMRGHQLLSADVDIKELAVETKNFSGAELEGLVRA AQSTAMNRHIKASTKVEVDMEKAESLQVTRGDFLASLENDIKPAFGTNQEDYASYIMNGIIKWGDPVTRVLDDGELLVQQTKNSDRTPLV SVLLEGPPHSGKTALAAKIAEESNFPFIKICSPDKMIGFSETAKCQAMKKIFDDAYKSQLSCVVVDDIERLLDYVPIGPRFSNLVLQALL VLLKKAPPQGRKLLIIGTTSRKDVLQEMEMLNAFSTTIHVPNIATGEQLLEALELLGNFKDKERTTIAQQVKGKKVWIGIKKLLMLIEMS -------------------------------------------------------------- >26728_26728_2_ENY2-NSF_ENY2_chr8_110352792_ENST00000520147_NSF_chr17_44751780_ENST00000398238_length(transcript)=3417nt_BP=286nt TCTGTGTGCTTAGGTGCCCGAGCTACTGAGGGTCTAAGTCCGGGCAGCCGAAGAGTGTGGTAGGTTAGCAAGATGAACAAAGATGCGCAG ATGAGAGCAGCGATTAACCAAAAGTTGATAGAAACTGGAGAAAGAGAACGCCTCAAAGAGTTGCTGAGAGCTAAATTAATTGAATGTGGC TGGAAGGATCAGTTGAAGGCACACTGTAAAGAGGTAATTAAAGAAAAAGGACTAGAACACGTTACTGTTGATGACTTGGTGGCTGAAATC ACTCCAAAAGGCAGAGGTTGTAAACATGTTAAAGGCATCCTGTTATATGGACCCCCAGGTTGTGGTAAGACTCTCTTGGCTCGACAGATT GGCAAGATGTTGAATGCAAGAGAGCCCAAAGTGGTCAATGGGCCAGAAATCCTTAACAAATATGTGGGAGAATCAGAGGCTAACATTCGC AAACTTTTTGCTGATGCTGAAGAGGAGCAAAGGAGGCTTGGTGCTAACAGTGGTTTGCACATCATCATCTTTGATGAAATTGATGCCATC TGCAAGCAGAGAGGGAGCATGGCTGGTAGCACGGGAGTTCATGACACTGTTGTCAACCAGTTGCTGTCCAAAATTGATGGCGTGGAGCAG CTAAACAACATCCTAGTCATTGGAATGACCAATAGACCAGATCTGATAGATGAGGCTCTTCTTAGACCTGGAAGACTGGAAGTTAAAATG GAGATAGGCTTGCCAGATGAGAAAGGCCGACTACAGATTCTTCACATCCACACAGCAAGAATGAGAGGGCATCAGTTACTCTCTGCTGAT GTAGACATTAAAGAACTGGCCGTGGAGACCAAGAATTTCAGTGGTGCTGAATTGGAGGGTCTGGTGCGAGCAGCCCAGTCCACTGCTATG AATAGACACATAAAGGCCAGTACTAAAGTGGAAGTGGACATGGAGAAAGCAGAAAGCCTGCAAGTGACGAGAGGAGACTTCCTTGCTTCT TTGGAGAATGATATCAAACCAGCCTTTGGCACAAACCAAGAAGATTATGCAAGTTACATTATGAACGGTATCATCAAATGGGGTGACCCA GTTACTCGAGTTCTAGATGATGGGGAGCTGCTGGTGCAGCAGACTAAGAACAGTGACCGCACACCATTGGTCAGCGTGCTTCTGGAAGGC CCTCCTCACAGTGGGAAGACTGCTTTAGCTGCAAAAATTGCAGAGGAATCCAACTTCCCGTTCATCAAGATCTGTTCTCCTGATAAAATG ATTGGCTTTTCTGAAACAGCCAAATGTCAGGCCATGAAGAAGATCTTTGATGATGCGTACAAATCCCAGCTCAGTTGTGTGGTTGTGGAT GACATTGAGAGATTGCTTGATTACGTCCCTATTGGCCCTCGATTTTCAAATCTTGTATTACAGGCTCTTCTCGTTTTACTGAAAAAGGCA CCTCCTCAGGGCCGCAAGCTTCTTATCATTGGGACCACTAGCCGCAAAGATGTCCTTCAGGAGATGGAAATGCTTAACGCTTTCAGCACC ACCATCCACGTGCCCAACATTGCCACAGGAGAGCAGCTGTTGGAAGCTTTGGAGCTTTTGGGCAACTTCAAGGATAAGGAACGCACCACA ATTGCACAGCAAGTCAAAGGGAAGAAGGTCTGGATAGGAATCAAGAAGTTACTAATGCTGATCGAGATGTCCCTACAGATGGATCCTGAA TACCGTGTGAGAAAATTCTTGGCCCTCTTAAGAGAAGAAGGAGCTAGCCCCCTTGATTTTGATTGAAAATGAACTATTTGAAACACACAG TGACCAAGGGAAGTGACCAAGGTGAAGATGGCCTAGGATCTTCACTGTCTTACTCAAGATACTGGACTAAGTGGAACGTTCTCTACCTTC AACATGTGCTCGCTCTGCATGATTAGTGCAATAAAACTCCCTTCCTTATGCATACTGAGATAGCTTAGTGTCTCGTGGAAGGTGTCAATT TGGTTTAGAATGCTGCGCTTACCTTCCCATGCAGGCTAAAGTGATTCCTTCTTGCTCAGTCCCTCTGGGTGGGAACCATCCAGTACTTGT GGACACTACACGTTTCAACCTCTCTACTAGCACCATCACCCTTGAAAACTCTCAGTCAGTGTCATGAATGTTGCATGACAACAGTTGGCC GATTAGAAGGCAGACTTTCTACATGCAAATCTGGCTTAGTAAATCGAGGTGTGGGCCAGAGATCCTCTGACAGCTGTCCTGAGCTAACAC TAAAAGTCACTGGGTATTTGGTTAAAGGTCTCCCACAAGACTGGTATTCTCTTTGCCTGAAGAAACAAGGCATTGAATCTCTAAAATGCT GTTCTCAATCATTGTCAGAGATGTTTTCAAGTTGCAGTCAGAAGATCTTTCTTAATAGAAAGTCAGATGACTACCGTGTTGGTTGTGACT TCCCCTTAAGTATAACTAATTTGCTCTGTGGTAAGAGATATGCTCATTATTACCACTTAGAAGATGTTGTTAAAAACATGTGAAAGATAG GTATGGAAAAAGCATACACCCCCAAACAGAAAGGAGTTATTAAAGTAATTTACAAACCTCTCAGCACTAATTAGTGTCCAACTCCAAGTG GGTCAATTCCTTAGTATAATATTAAGGCTTACTAGTATCACTGCTTTTTCCTTAGCTTAATGACTTACTTAGAATTTATCCTTTATTTTA AATGATCTGTACTATCTAGTGTCTAAAACACTATTCTCCAGAAAAATCAATCATTTTCTAGCCCTCTCCCTCAGTCCTTTATTGTCCATT CCAATACATTGAACACATTTCCTTTACCCTCCACACACTTCTTCCAAAAGGAAGCACCCGTTGAGTCCTTTTGAGGGTGATTTGTCTTAC AACTGACTGACTTAGCAGGAATTTAATTAGGTCATATTTGGTGATGAGACTTATGGAGTGTGCCTCTCTCTCCCAACTGCTGCTTAAAAT GCAAGGACAAGCAATTAGAAGCCATCCTAAGGTGCTTACCTCACACGCCACCCATGAGGCTTGTGGCCACAGTGGCACTTGGGTGTGGCT CCTCTGTTATTTGTCCTCATGTGAGAAAGCAGATCATCTCCAAATCTTGCCATTTGTATACTTTTGGTGGAGACTTGGATGTCATATCTT CTTTGTTTTGGGTTTTCTTCCCTAGCTTATTTTGTGGCTTTTAAAGAAGTGGATTGTATTGTGAGATCCTGTGATTCCTGGTGGCCAGTA TCCTGGATTCCTCTAAGATCTTGCCTCTTTCCTCCTCATGAAAGCAGCACACATTGTGTTAACTTATGTCTCTTGTTAAATGAGCTTAAT >26728_26728_2_ENY2-NSF_ENY2_chr8_110352792_ENST00000520147_NSF_chr17_44751780_ENST00000398238_length(amino acids)=567AA_BP=71 MNKDAQMRAAINQKLIETGERERLKELLRAKLIECGWKDQLKAHCKEVIKEKGLEHVTVDDLVAEITPKGRGCKHVKGILLYGPPGCGKT LLARQIGKMLNAREPKVVNGPEILNKYVGESEANIRKLFADAEEEQRRLGANSGLHIIIFDEIDAICKQRGSMAGSTGVHDTVVNQLLSK IDGVEQLNNILVIGMTNRPDLIDEALLRPGRLEVKMEIGLPDEKGRLQILHIHTARMRGHQLLSADVDIKELAVETKNFSGAELEGLVRA AQSTAMNRHIKASTKVEVDMEKAESLQVTRGDFLASLENDIKPAFGTNQEDYASYIMNGIIKWGDPVTRVLDDGELLVQQTKNSDRTPLV SVLLEGPPHSGKTALAAKIAEESNFPFIKICSPDKMIGFSETAKCQAMKKIFDDAYKSQLSCVVVDDIERLLDYVPIGPRFSNLVLQALL VLLKKAPPQGRKLLIIGTTSRKDVLQEMEMLNAFSTTIHVPNIATGEQLLEALELLGNFKDKERTTIAQQVKGKKVWIGIKKLLMLIEMS -------------------------------------------------------------- >26728_26728_3_ENY2-NSF_ENY2_chr8_110352792_ENST00000520147_NSF_chr17_44751780_ENST00000575068_length(transcript)=2012nt_BP=286nt TCTGTGTGCTTAGGTGCCCGAGCTACTGAGGGTCTAAGTCCGGGCAGCCGAAGAGTGTGGTAGGTTAGCAAGATGAACAAAGATGCGCAG ATGAGAGCAGCGATTAACCAAAAGTTGATAGAAACTGGAGAAAGAGAACGCCTCAAAGAGTTGCTGAGAGCTAAATTAATTGAATGTGGC TGGAAGGATCAGTTGAAGGCACACTGTAAAGAGGTAATTAAAGAAAAAGGACTAGAACACGTTACTGTTGATGACTTGGTGGCTGAAATC ACTCCAAAAGGCAGAGGTTGTAAACATGTTAAAGGCATCCTGTTATATGGACCCCCAGGTTGTGGTAAGACTCTCTTGGCTCGACAGATT GGCAAGATGTTGAATGCAAGAGAGCCCAAAGTGGTCAATGGGCCAGAAATCCTTAACAAATATGTGGGAGAATCAGAGGCTAACATTCGC AAACTTTTTGCTGATGCTGAAGAGGAGCAAAGGAGGCTTGGTGCTAACAGTGGTTTGCACATCATCATCTTTGATGAAATTGATGCCATC TGCAAGCAGAGAGGGAGCATGGCTGGTAGCACGGGAGTTCATGACACTGTTGTCAACCAGTTGCTGTCCAAAATTGATGGCGTGGAGCAG CTAAACAACATCCTAGTCATTGGAATGACCAATAGACCAGATCTGATAGATGAGGCTCTTCTTAGACCTGGAAGACTGGAAGTTAAAATG GAGATAGGCTTGCCAGATGAGAAAGGCCGACTACAGATTCTTCACATCCACACAGCAAGAATGAGAGGGCATCAGTTACTCTCTGCTGAT GTAGACATTAAAGAACTGGCCGTGGAGACCAAGAATTTCAGTGGTGCTGAATTGGAGGGTCTGGTGCGAGCAGCCCAGTCCACTGCTATG AATAGACACATAAAGGCCAGTACTAAAGTGGAAGTGGACATGGAGAAAGCAGAAAGCCTGCAAGTGACGAGAGGAGACTTCCTTGCTTCT TTGGAGAATGATATCAAACCAGCCTTTGGCACAAACCAAGAAGATTATGCAAGTTACATTATGAACGGTATCATCAAATGGGGTGACCCA GTTACTCGAGTTCTAGATGATGGGGAGCTGCTGGTGCAGCAGACTAAGAACAGTGACCGCACACCATTGGTCAGCGTGCTTCTGGAAGGC CCTCCTCACAGTGGGAAGACTGCTTTAGCTGCAAAAATTGCAGAGGAATCCAACTTCCCGTTCATCAAGATCTGTTCTCCTGATAAAATG ATTGGCTTTTCTGAAACAGCCAAATGTCAGGCCATGAAGAAGATCTTTGATGATGCGTACAAATCCCAGCTCAGTTGTGTGGTTGTGGAT GACATTGAGAGATTGCTTGATTACGTCCCTATTGGCCCTCGATTTTCAAATCTTGTATTACAGGCTCTTCTCGTTTTACTGAAAAAGGCA CCTCCTCAGGGCCGCAAGCTTCTTATCATTGGGACCACTAGCCGCAAAGATGTCCTTCAGGAGATGGAAATGCTTAACGCTTTCAGCACC ACCATCCACGTGCCCAACATTGCCACAGGAGAGCAGCTGTTGGAAGCTTTGGAGCTTTTGGGCAACTTCAAGGATAAGGAACGCACCACA ATTGCACAGCAAGTCAAAGGGAAGAAGGTCTGGATAGGAATCAAGAAGTTACTAATGCTGATCGAGATGTCCCTACAGATGGATCCTGAA TACCGTGTGAGAAAATTCTTGGCCCTCTTAAGAGAAGAAGGAGCTAGCCCCCTTGATTTTGATTGAAAATGAACTATTTGAAACACACAG TGACCAAGGGAAGTGACCAAGGTGAAGATGGCCTAGGATCTTCACTGTCTTACTCAAGATACTGGACTAAGTGGAACGTTCTCTACCTTC AACATGTGCTCGCTCTGCATGATTAGTGCAATAAAACTCCCTTCCTTATGCATACTGAGATAGCTTAGTGTCTCGTGGAAGGTGTCAATT >26728_26728_3_ENY2-NSF_ENY2_chr8_110352792_ENST00000520147_NSF_chr17_44751780_ENST00000575068_length(amino acids)=567AA_BP=71 MNKDAQMRAAINQKLIETGERERLKELLRAKLIECGWKDQLKAHCKEVIKEKGLEHVTVDDLVAEITPKGRGCKHVKGILLYGPPGCGKT LLARQIGKMLNAREPKVVNGPEILNKYVGESEANIRKLFADAEEEQRRLGANSGLHIIIFDEIDAICKQRGSMAGSTGVHDTVVNQLLSK IDGVEQLNNILVIGMTNRPDLIDEALLRPGRLEVKMEIGLPDEKGRLQILHIHTARMRGHQLLSADVDIKELAVETKNFSGAELEGLVRA AQSTAMNRHIKASTKVEVDMEKAESLQVTRGDFLASLENDIKPAFGTNQEDYASYIMNGIIKWGDPVTRVLDDGELLVQQTKNSDRTPLV SVLLEGPPHSGKTALAAKIAEESNFPFIKICSPDKMIGFSETAKCQAMKKIFDDAYKSQLSCVVVDDIERLLDYVPIGPRFSNLVLQALL VLLKKAPPQGRKLLIIGTTSRKDVLQEMEMLNAFSTTIHVPNIATGEQLLEALELLGNFKDKERTTIAQQVKGKKVWIGIKKLLMLIEMS -------------------------------------------------------------- >26728_26728_4_ENY2-NSF_ENY2_chr8_110352792_ENST00000521662_NSF_chr17_44751780_ENST00000225282_length(transcript)=2293nt_BP=302nt GGAAATGCGTGTTCTAGCTTTCTGTGTGCTTAGGTGCCCGAGCTACTGAGGGTCTAAGTCCGGGCAGCCGAAGAGTGTGGTTAGCAAGAT GAACAAAGATGCGCAGATGAGAGCAGCGATTAACCAAAAGTTGATAGAAACTGGAGAAAGAGAACGCCTCAAAGAGTTGCTGAGAGCTAA ATTAATTGAATGTGGCTGGAAGGATCAGTTGAAGGCACACTGTAAAGAGGTAATTAAAGAAAAAGGACTAGAACACGTTACTGTTGATGA CTTGGTGGCTGAAATCACTCCAAAAGGCAGAGGTTGTAAACATGTTAAAGGCATCCTGTTATATGGACCCCCAGGTTGTGGTAAGACTCT CTTGGCTCGACAGATTGGCAAGATGTTGAATGCAAGAGAGCCCAAAGTGGTCAATGGGCCAGAAATCCTTAACAAATATGTGGGAGAATC AGAGGCTAACATTCGCAAACTTTTTGCTGATGCTGAAGAGGAGCAAAGGAGGCTTGGTGCTAACAGTGGTTTGCACATCATCATCTTTGA TGAAATTGATGCCATCTGCAAGCAGAGAGGGAGCATGGCTGGTAGCACGGGAGTTCATGACACTGTTGTCAACCAGTTGCTGTCCAAAAT TGATGGCGTGGAGCAGCTAAACAACATCCTAGTCATTGGAATGACCAATAGACCAGATCTGATAGATGAGGCTCTTCTTAGACCTGGAAG ACTGGAAGTTAAAATGGAGATAGGCTTGCCAGATGAGAAAGGCCGACTACAGATTCTTCACATCCACACAGCAAGAATGAGAGGGCATCA GTTACTCTCTGCTGATGTAGACATTAAAGAACTGGCCGTGGAGACCAAGAATTTCAGTGGTGCTGAATTGGAGGGTCTGGTGCGAGCAGC CCAGTCCACTGCTATGAATAGACACATAAAGGCCAGTACTAAAGTGGAAGTGGACATGGAGAAAGCAGAAAGCCTGCAAGTGACGAGAGG AGACTTCCTTGCTTCTTTGGAGAATGATATCAAACCAGCCTTTGGCACAAACCAAGAAGATTATGCAAGTTACATTATGAACGGTATCAT CAAATGGGGTGACCCAGTTACTCGAGTTCTAGATGATGGGGAGCTGCTGGTGCAGCAGACTAAGAACAGTGACCGCACACCATTGGTCAG CGTGCTTCTGGAAGGCCCTCCTCACAGTGGGAAGACTGCTTTAGCTGCAAAAATTGCAGAGGAATCCAACTTCCCGTTCATCAAGATCTG TTCTCCTGATAAAATGATTGGCTTTTCTGAAACAGCCAAATGTCAGGCCATGAAGAAGATCTTTGATGATGCGTACAAATCCCAGCTCAG TTGTGTGGTTGTGGATGACATTGAGAGATTGCTTGATTACGTCCCTATTGGCCCTCGATTTTCAAATCTTGTATTACAGGCTCTTCTCGT TTTACTGAAAAAGGCACCTCCTCAGGGCCGCAAGCTTCTTATCATTGGGACCACTAGCCGCAAAGATGTCCTTCAGGAGATGGAAATGCT TAACGCTTTCAGCACCACCATCCACGTGCCCAACATTGCCACAGGAGAGCAGCTGTTGGAAGCTTTGGAGCTTTTGGGCAACTTCAAGGA TAAGGAACGCACCACAATTGCACAGCAAGTCAAAGGGAAGAAGGTCTGGATAGGAATCAAGAAGTTACTAATGCTGATCGAGATGTCCCT ACAGATGGATCCTGAATACCGTGTGAGAAAATTCTTGGCCCTCTTAAGAGAAGAAGGAGCGTAATAGCCCCCTTGATTTTGATTGAAAAT GAACTATTTGAAACACACAGTGACCAAGGGAAGTGACCAAGGTGAAGATGGCCTAGGATCTTCACTGTCTTACTCAAGATACTGGACTAA GTGGAACGTTCTCTACCTTCAACATGTGCTCGCTCTGCATGATTAGTGCAATAAAACTCCCTTCCTTATGCATACTGAGATAGCTTAGTG TCTCGTGGAAGGTGTCAATTTGGTTTAGAATGCTGCGCTTACCTTCCCATGCAGGCTAAAGTGATTCCTTCTTGCTCAGTCCCTCTGGGT GGGAACCATCCAGTACTTGTGGACACTACACGTTTCAACCTCTCTACTAGCACCATCACCCTTGAAAACTCTCAGTCAGTGTCATGAATG TTGCATGACAACAGTTGGCCGATTAGAAGGCAGACTTTCTACATGCAAATCTGGCTTAGTAAATCGAGGTGTGGGCCAGAGATCCTCTGA >26728_26728_4_ENY2-NSF_ENY2_chr8_110352792_ENST00000521662_NSF_chr17_44751780_ENST00000225282_length(amino acids)=561AA_BP=71 MNKDAQMRAAINQKLIETGERERLKELLRAKLIECGWKDQLKAHCKEVIKEKGLEHVTVDDLVAEITPKGRGCKHVKGILLYGPPGCGKT LLARQIGKMLNAREPKVVNGPEILNKYVGESEANIRKLFADAEEEQRRLGANSGLHIIIFDEIDAICKQRGSMAGSTGVHDTVVNQLLSK IDGVEQLNNILVIGMTNRPDLIDEALLRPGRLEVKMEIGLPDEKGRLQILHIHTARMRGHQLLSADVDIKELAVETKNFSGAELEGLVRA AQSTAMNRHIKASTKVEVDMEKAESLQVTRGDFLASLENDIKPAFGTNQEDYASYIMNGIIKWGDPVTRVLDDGELLVQQTKNSDRTPLV SVLLEGPPHSGKTALAAKIAEESNFPFIKICSPDKMIGFSETAKCQAMKKIFDDAYKSQLSCVVVDDIERLLDYVPIGPRFSNLVLQALL VLLKKAPPQGRKLLIIGTTSRKDVLQEMEMLNAFSTTIHVPNIATGEQLLEALELLGNFKDKERTTIAQQVKGKKVWIGIKKLLMLIEMS -------------------------------------------------------------- >26728_26728_5_ENY2-NSF_ENY2_chr8_110352792_ENST00000521662_NSF_chr17_44751780_ENST00000398238_length(transcript)=3433nt_BP=302nt GGAAATGCGTGTTCTAGCTTTCTGTGTGCTTAGGTGCCCGAGCTACTGAGGGTCTAAGTCCGGGCAGCCGAAGAGTGTGGTTAGCAAGAT GAACAAAGATGCGCAGATGAGAGCAGCGATTAACCAAAAGTTGATAGAAACTGGAGAAAGAGAACGCCTCAAAGAGTTGCTGAGAGCTAA ATTAATTGAATGTGGCTGGAAGGATCAGTTGAAGGCACACTGTAAAGAGGTAATTAAAGAAAAAGGACTAGAACACGTTACTGTTGATGA CTTGGTGGCTGAAATCACTCCAAAAGGCAGAGGTTGTAAACATGTTAAAGGCATCCTGTTATATGGACCCCCAGGTTGTGGTAAGACTCT CTTGGCTCGACAGATTGGCAAGATGTTGAATGCAAGAGAGCCCAAAGTGGTCAATGGGCCAGAAATCCTTAACAAATATGTGGGAGAATC AGAGGCTAACATTCGCAAACTTTTTGCTGATGCTGAAGAGGAGCAAAGGAGGCTTGGTGCTAACAGTGGTTTGCACATCATCATCTTTGA TGAAATTGATGCCATCTGCAAGCAGAGAGGGAGCATGGCTGGTAGCACGGGAGTTCATGACACTGTTGTCAACCAGTTGCTGTCCAAAAT TGATGGCGTGGAGCAGCTAAACAACATCCTAGTCATTGGAATGACCAATAGACCAGATCTGATAGATGAGGCTCTTCTTAGACCTGGAAG ACTGGAAGTTAAAATGGAGATAGGCTTGCCAGATGAGAAAGGCCGACTACAGATTCTTCACATCCACACAGCAAGAATGAGAGGGCATCA GTTACTCTCTGCTGATGTAGACATTAAAGAACTGGCCGTGGAGACCAAGAATTTCAGTGGTGCTGAATTGGAGGGTCTGGTGCGAGCAGC CCAGTCCACTGCTATGAATAGACACATAAAGGCCAGTACTAAAGTGGAAGTGGACATGGAGAAAGCAGAAAGCCTGCAAGTGACGAGAGG AGACTTCCTTGCTTCTTTGGAGAATGATATCAAACCAGCCTTTGGCACAAACCAAGAAGATTATGCAAGTTACATTATGAACGGTATCAT CAAATGGGGTGACCCAGTTACTCGAGTTCTAGATGATGGGGAGCTGCTGGTGCAGCAGACTAAGAACAGTGACCGCACACCATTGGTCAG CGTGCTTCTGGAAGGCCCTCCTCACAGTGGGAAGACTGCTTTAGCTGCAAAAATTGCAGAGGAATCCAACTTCCCGTTCATCAAGATCTG TTCTCCTGATAAAATGATTGGCTTTTCTGAAACAGCCAAATGTCAGGCCATGAAGAAGATCTTTGATGATGCGTACAAATCCCAGCTCAG TTGTGTGGTTGTGGATGACATTGAGAGATTGCTTGATTACGTCCCTATTGGCCCTCGATTTTCAAATCTTGTATTACAGGCTCTTCTCGT TTTACTGAAAAAGGCACCTCCTCAGGGCCGCAAGCTTCTTATCATTGGGACCACTAGCCGCAAAGATGTCCTTCAGGAGATGGAAATGCT TAACGCTTTCAGCACCACCATCCACGTGCCCAACATTGCCACAGGAGAGCAGCTGTTGGAAGCTTTGGAGCTTTTGGGCAACTTCAAGGA TAAGGAACGCACCACAATTGCACAGCAAGTCAAAGGGAAGAAGGTCTGGATAGGAATCAAGAAGTTACTAATGCTGATCGAGATGTCCCT ACAGATGGATCCTGAATACCGTGTGAGAAAATTCTTGGCCCTCTTAAGAGAAGAAGGAGCTAGCCCCCTTGATTTTGATTGAAAATGAAC TATTTGAAACACACAGTGACCAAGGGAAGTGACCAAGGTGAAGATGGCCTAGGATCTTCACTGTCTTACTCAAGATACTGGACTAAGTGG AACGTTCTCTACCTTCAACATGTGCTCGCTCTGCATGATTAGTGCAATAAAACTCCCTTCCTTATGCATACTGAGATAGCTTAGTGTCTC GTGGAAGGTGTCAATTTGGTTTAGAATGCTGCGCTTACCTTCCCATGCAGGCTAAAGTGATTCCTTCTTGCTCAGTCCCTCTGGGTGGGA ACCATCCAGTACTTGTGGACACTACACGTTTCAACCTCTCTACTAGCACCATCACCCTTGAAAACTCTCAGTCAGTGTCATGAATGTTGC ATGACAACAGTTGGCCGATTAGAAGGCAGACTTTCTACATGCAAATCTGGCTTAGTAAATCGAGGTGTGGGCCAGAGATCCTCTGACAGC TGTCCTGAGCTAACACTAAAAGTCACTGGGTATTTGGTTAAAGGTCTCCCACAAGACTGGTATTCTCTTTGCCTGAAGAAACAAGGCATT GAATCTCTAAAATGCTGTTCTCAATCATTGTCAGAGATGTTTTCAAGTTGCAGTCAGAAGATCTTTCTTAATAGAAAGTCAGATGACTAC CGTGTTGGTTGTGACTTCCCCTTAAGTATAACTAATTTGCTCTGTGGTAAGAGATATGCTCATTATTACCACTTAGAAGATGTTGTTAAA AACATGTGAAAGATAGGTATGGAAAAAGCATACACCCCCAAACAGAAAGGAGTTATTAAAGTAATTTACAAACCTCTCAGCACTAATTAG TGTCCAACTCCAAGTGGGTCAATTCCTTAGTATAATATTAAGGCTTACTAGTATCACTGCTTTTTCCTTAGCTTAATGACTTACTTAGAA TTTATCCTTTATTTTAAATGATCTGTACTATCTAGTGTCTAAAACACTATTCTCCAGAAAAATCAATCATTTTCTAGCCCTCTCCCTCAG TCCTTTATTGTCCATTCCAATACATTGAACACATTTCCTTTACCCTCCACACACTTCTTCCAAAAGGAAGCACCCGTTGAGTCCTTTTGA GGGTGATTTGTCTTACAACTGACTGACTTAGCAGGAATTTAATTAGGTCATATTTGGTGATGAGACTTATGGAGTGTGCCTCTCTCTCCC AACTGCTGCTTAAAATGCAAGGACAAGCAATTAGAAGCCATCCTAAGGTGCTTACCTCACACGCCACCCATGAGGCTTGTGGCCACAGTG GCACTTGGGTGTGGCTCCTCTGTTATTTGTCCTCATGTGAGAAAGCAGATCATCTCCAAATCTTGCCATTTGTATACTTTTGGTGGAGAC TTGGATGTCATATCTTCTTTGTTTTGGGTTTTCTTCCCTAGCTTATTTTGTGGCTTTTAAAGAAGTGGATTGTATTGTGAGATCCTGTGA TTCCTGGTGGCCAGTATCCTGGATTCCTCTAAGATCTTGCCTCTTTCCTCCTCATGAAAGCAGCACACATTGTGTTAACTTATGTCTCTT GTTAAATGAGCTTAATGTCTTTGTGTTTTGTCCAAAACTGTATTGAAAAAATATTGTTTAATGCAAATGAAGGAATGCAATAAAGAGTAA >26728_26728_5_ENY2-NSF_ENY2_chr8_110352792_ENST00000521662_NSF_chr17_44751780_ENST00000398238_length(amino acids)=567AA_BP=71 MNKDAQMRAAINQKLIETGERERLKELLRAKLIECGWKDQLKAHCKEVIKEKGLEHVTVDDLVAEITPKGRGCKHVKGILLYGPPGCGKT LLARQIGKMLNAREPKVVNGPEILNKYVGESEANIRKLFADAEEEQRRLGANSGLHIIIFDEIDAICKQRGSMAGSTGVHDTVVNQLLSK IDGVEQLNNILVIGMTNRPDLIDEALLRPGRLEVKMEIGLPDEKGRLQILHIHTARMRGHQLLSADVDIKELAVETKNFSGAELEGLVRA AQSTAMNRHIKASTKVEVDMEKAESLQVTRGDFLASLENDIKPAFGTNQEDYASYIMNGIIKWGDPVTRVLDDGELLVQQTKNSDRTPLV SVLLEGPPHSGKTALAAKIAEESNFPFIKICSPDKMIGFSETAKCQAMKKIFDDAYKSQLSCVVVDDIERLLDYVPIGPRFSNLVLQALL VLLKKAPPQGRKLLIIGTTSRKDVLQEMEMLNAFSTTIHVPNIATGEQLLEALELLGNFKDKERTTIAQQVKGKKVWIGIKKLLMLIEMS -------------------------------------------------------------- >26728_26728_6_ENY2-NSF_ENY2_chr8_110352792_ENST00000521662_NSF_chr17_44751780_ENST00000575068_length(transcript)=2028nt_BP=302nt GGAAATGCGTGTTCTAGCTTTCTGTGTGCTTAGGTGCCCGAGCTACTGAGGGTCTAAGTCCGGGCAGCCGAAGAGTGTGGTTAGCAAGAT GAACAAAGATGCGCAGATGAGAGCAGCGATTAACCAAAAGTTGATAGAAACTGGAGAAAGAGAACGCCTCAAAGAGTTGCTGAGAGCTAA ATTAATTGAATGTGGCTGGAAGGATCAGTTGAAGGCACACTGTAAAGAGGTAATTAAAGAAAAAGGACTAGAACACGTTACTGTTGATGA CTTGGTGGCTGAAATCACTCCAAAAGGCAGAGGTTGTAAACATGTTAAAGGCATCCTGTTATATGGACCCCCAGGTTGTGGTAAGACTCT CTTGGCTCGACAGATTGGCAAGATGTTGAATGCAAGAGAGCCCAAAGTGGTCAATGGGCCAGAAATCCTTAACAAATATGTGGGAGAATC AGAGGCTAACATTCGCAAACTTTTTGCTGATGCTGAAGAGGAGCAAAGGAGGCTTGGTGCTAACAGTGGTTTGCACATCATCATCTTTGA TGAAATTGATGCCATCTGCAAGCAGAGAGGGAGCATGGCTGGTAGCACGGGAGTTCATGACACTGTTGTCAACCAGTTGCTGTCCAAAAT TGATGGCGTGGAGCAGCTAAACAACATCCTAGTCATTGGAATGACCAATAGACCAGATCTGATAGATGAGGCTCTTCTTAGACCTGGAAG ACTGGAAGTTAAAATGGAGATAGGCTTGCCAGATGAGAAAGGCCGACTACAGATTCTTCACATCCACACAGCAAGAATGAGAGGGCATCA GTTACTCTCTGCTGATGTAGACATTAAAGAACTGGCCGTGGAGACCAAGAATTTCAGTGGTGCTGAATTGGAGGGTCTGGTGCGAGCAGC CCAGTCCACTGCTATGAATAGACACATAAAGGCCAGTACTAAAGTGGAAGTGGACATGGAGAAAGCAGAAAGCCTGCAAGTGACGAGAGG AGACTTCCTTGCTTCTTTGGAGAATGATATCAAACCAGCCTTTGGCACAAACCAAGAAGATTATGCAAGTTACATTATGAACGGTATCAT CAAATGGGGTGACCCAGTTACTCGAGTTCTAGATGATGGGGAGCTGCTGGTGCAGCAGACTAAGAACAGTGACCGCACACCATTGGTCAG CGTGCTTCTGGAAGGCCCTCCTCACAGTGGGAAGACTGCTTTAGCTGCAAAAATTGCAGAGGAATCCAACTTCCCGTTCATCAAGATCTG TTCTCCTGATAAAATGATTGGCTTTTCTGAAACAGCCAAATGTCAGGCCATGAAGAAGATCTTTGATGATGCGTACAAATCCCAGCTCAG TTGTGTGGTTGTGGATGACATTGAGAGATTGCTTGATTACGTCCCTATTGGCCCTCGATTTTCAAATCTTGTATTACAGGCTCTTCTCGT TTTACTGAAAAAGGCACCTCCTCAGGGCCGCAAGCTTCTTATCATTGGGACCACTAGCCGCAAAGATGTCCTTCAGGAGATGGAAATGCT TAACGCTTTCAGCACCACCATCCACGTGCCCAACATTGCCACAGGAGAGCAGCTGTTGGAAGCTTTGGAGCTTTTGGGCAACTTCAAGGA TAAGGAACGCACCACAATTGCACAGCAAGTCAAAGGGAAGAAGGTCTGGATAGGAATCAAGAAGTTACTAATGCTGATCGAGATGTCCCT ACAGATGGATCCTGAATACCGTGTGAGAAAATTCTTGGCCCTCTTAAGAGAAGAAGGAGCTAGCCCCCTTGATTTTGATTGAAAATGAAC TATTTGAAACACACAGTGACCAAGGGAAGTGACCAAGGTGAAGATGGCCTAGGATCTTCACTGTCTTACTCAAGATACTGGACTAAGTGG AACGTTCTCTACCTTCAACATGTGCTCGCTCTGCATGATTAGTGCAATAAAACTCCCTTCCTTATGCATACTGAGATAGCTTAGTGTCTC >26728_26728_6_ENY2-NSF_ENY2_chr8_110352792_ENST00000521662_NSF_chr17_44751780_ENST00000575068_length(amino acids)=567AA_BP=71 MNKDAQMRAAINQKLIETGERERLKELLRAKLIECGWKDQLKAHCKEVIKEKGLEHVTVDDLVAEITPKGRGCKHVKGILLYGPPGCGKT LLARQIGKMLNAREPKVVNGPEILNKYVGESEANIRKLFADAEEEQRRLGANSGLHIIIFDEIDAICKQRGSMAGSTGVHDTVVNQLLSK IDGVEQLNNILVIGMTNRPDLIDEALLRPGRLEVKMEIGLPDEKGRLQILHIHTARMRGHQLLSADVDIKELAVETKNFSGAELEGLVRA AQSTAMNRHIKASTKVEVDMEKAESLQVTRGDFLASLENDIKPAFGTNQEDYASYIMNGIIKWGDPVTRVLDDGELLVQQTKNSDRTPLV SVLLEGPPHSGKTALAAKIAEESNFPFIKICSPDKMIGFSETAKCQAMKKIFDDAYKSQLSCVVVDDIERLLDYVPIGPRFSNLVLQALL VLLKKAPPQGRKLLIIGTTSRKDVLQEMEMLNAFSTTIHVPNIATGEQLLEALELLGNFKDKERTTIAQQVKGKKVWIGIKKLLMLIEMS -------------------------------------------------------------- >26728_26728_7_ENY2-NSF_ENY2_chr8_110352792_ENST00000521688_NSF_chr17_44751780_ENST00000225282_length(transcript)=2365nt_BP=374nt GGAAATGCGTGTTCTAGCTTTCTGTGTGCTTAGGTGCCCGAGCTACTGAGGGTCTAAGTCCGGGCAGCCGAAGAGTGTGGTAGGTAACGG TCCTCAGCGCAAGGGTCATTTCGTCGCTGGGAAGGGACGGCCCTCGCCCGCGGTGATGGTGGTTAGCAAGATGAACAAAGATGCGCAGAT GAGAGCAGCGATTAACCAAAAGTTGATAGAAACTGGAGAAAGAGAACGCCTCAAAGAGTTGCTGAGAGCTAAATTAATTGAATGTGGCTG GAAGGATCAGTTGAAGGCACACTGTAAAGAGGTAATTAAAGAAAAAGGACTAGAACACGTTACTGTTGATGACTTGGTGGCTGAAATCAC TCCAAAAGGCAGAGGTTGTAAACATGTTAAAGGCATCCTGTTATATGGACCCCCAGGTTGTGGTAAGACTCTCTTGGCTCGACAGATTGG CAAGATGTTGAATGCAAGAGAGCCCAAAGTGGTCAATGGGCCAGAAATCCTTAACAAATATGTGGGAGAATCAGAGGCTAACATTCGCAA ACTTTTTGCTGATGCTGAAGAGGAGCAAAGGAGGCTTGGTGCTAACAGTGGTTTGCACATCATCATCTTTGATGAAATTGATGCCATCTG CAAGCAGAGAGGGAGCATGGCTGGTAGCACGGGAGTTCATGACACTGTTGTCAACCAGTTGCTGTCCAAAATTGATGGCGTGGAGCAGCT AAACAACATCCTAGTCATTGGAATGACCAATAGACCAGATCTGATAGATGAGGCTCTTCTTAGACCTGGAAGACTGGAAGTTAAAATGGA GATAGGCTTGCCAGATGAGAAAGGCCGACTACAGATTCTTCACATCCACACAGCAAGAATGAGAGGGCATCAGTTACTCTCTGCTGATGT AGACATTAAAGAACTGGCCGTGGAGACCAAGAATTTCAGTGGTGCTGAATTGGAGGGTCTGGTGCGAGCAGCCCAGTCCACTGCTATGAA TAGACACATAAAGGCCAGTACTAAAGTGGAAGTGGACATGGAGAAAGCAGAAAGCCTGCAAGTGACGAGAGGAGACTTCCTTGCTTCTTT GGAGAATGATATCAAACCAGCCTTTGGCACAAACCAAGAAGATTATGCAAGTTACATTATGAACGGTATCATCAAATGGGGTGACCCAGT TACTCGAGTTCTAGATGATGGGGAGCTGCTGGTGCAGCAGACTAAGAACAGTGACCGCACACCATTGGTCAGCGTGCTTCTGGAAGGCCC TCCTCACAGTGGGAAGACTGCTTTAGCTGCAAAAATTGCAGAGGAATCCAACTTCCCGTTCATCAAGATCTGTTCTCCTGATAAAATGAT TGGCTTTTCTGAAACAGCCAAATGTCAGGCCATGAAGAAGATCTTTGATGATGCGTACAAATCCCAGCTCAGTTGTGTGGTTGTGGATGA CATTGAGAGATTGCTTGATTACGTCCCTATTGGCCCTCGATTTTCAAATCTTGTATTACAGGCTCTTCTCGTTTTACTGAAAAAGGCACC TCCTCAGGGCCGCAAGCTTCTTATCATTGGGACCACTAGCCGCAAAGATGTCCTTCAGGAGATGGAAATGCTTAACGCTTTCAGCACCAC CATCCACGTGCCCAACATTGCCACAGGAGAGCAGCTGTTGGAAGCTTTGGAGCTTTTGGGCAACTTCAAGGATAAGGAACGCACCACAAT TGCACAGCAAGTCAAAGGGAAGAAGGTCTGGATAGGAATCAAGAAGTTACTAATGCTGATCGAGATGTCCCTACAGATGGATCCTGAATA CCGTGTGAGAAAATTCTTGGCCCTCTTAAGAGAAGAAGGAGCGTAATAGCCCCCTTGATTTTGATTGAAAATGAACTATTTGAAACACAC AGTGACCAAGGGAAGTGACCAAGGTGAAGATGGCCTAGGATCTTCACTGTCTTACTCAAGATACTGGACTAAGTGGAACGTTCTCTACCT TCAACATGTGCTCGCTCTGCATGATTAGTGCAATAAAACTCCCTTCCTTATGCATACTGAGATAGCTTAGTGTCTCGTGGAAGGTGTCAA TTTGGTTTAGAATGCTGCGCTTACCTTCCCATGCAGGCTAAAGTGATTCCTTCTTGCTCAGTCCCTCTGGGTGGGAACCATCCAGTACTT GTGGACACTACACGTTTCAACCTCTCTACTAGCACCATCACCCTTGAAAACTCTCAGTCAGTGTCATGAATGTTGCATGACAACAGTTGG CCGATTAGAAGGCAGACTTTCTACATGCAAATCTGGCTTAGTAAATCGAGGTGTGGGCCAGAGATCCTCTGACAGCTGTCCTGAGCTAAC >26728_26728_7_ENY2-NSF_ENY2_chr8_110352792_ENST00000521688_NSF_chr17_44751780_ENST00000225282_length(amino acids)=566AA_BP=76 MVVSKMNKDAQMRAAINQKLIETGERERLKELLRAKLIECGWKDQLKAHCKEVIKEKGLEHVTVDDLVAEITPKGRGCKHVKGILLYGPP GCGKTLLARQIGKMLNAREPKVVNGPEILNKYVGESEANIRKLFADAEEEQRRLGANSGLHIIIFDEIDAICKQRGSMAGSTGVHDTVVN QLLSKIDGVEQLNNILVIGMTNRPDLIDEALLRPGRLEVKMEIGLPDEKGRLQILHIHTARMRGHQLLSADVDIKELAVETKNFSGAELE GLVRAAQSTAMNRHIKASTKVEVDMEKAESLQVTRGDFLASLENDIKPAFGTNQEDYASYIMNGIIKWGDPVTRVLDDGELLVQQTKNSD RTPLVSVLLEGPPHSGKTALAAKIAEESNFPFIKICSPDKMIGFSETAKCQAMKKIFDDAYKSQLSCVVVDDIERLLDYVPIGPRFSNLV LQALLVLLKKAPPQGRKLLIIGTTSRKDVLQEMEMLNAFSTTIHVPNIATGEQLLEALELLGNFKDKERTTIAQQVKGKKVWIGIKKLLM -------------------------------------------------------------- >26728_26728_8_ENY2-NSF_ENY2_chr8_110352792_ENST00000521688_NSF_chr17_44751780_ENST00000398238_length(transcript)=3505nt_BP=374nt GGAAATGCGTGTTCTAGCTTTCTGTGTGCTTAGGTGCCCGAGCTACTGAGGGTCTAAGTCCGGGCAGCCGAAGAGTGTGGTAGGTAACGG TCCTCAGCGCAAGGGTCATTTCGTCGCTGGGAAGGGACGGCCCTCGCCCGCGGTGATGGTGGTTAGCAAGATGAACAAAGATGCGCAGAT GAGAGCAGCGATTAACCAAAAGTTGATAGAAACTGGAGAAAGAGAACGCCTCAAAGAGTTGCTGAGAGCTAAATTAATTGAATGTGGCTG GAAGGATCAGTTGAAGGCACACTGTAAAGAGGTAATTAAAGAAAAAGGACTAGAACACGTTACTGTTGATGACTTGGTGGCTGAAATCAC TCCAAAAGGCAGAGGTTGTAAACATGTTAAAGGCATCCTGTTATATGGACCCCCAGGTTGTGGTAAGACTCTCTTGGCTCGACAGATTGG CAAGATGTTGAATGCAAGAGAGCCCAAAGTGGTCAATGGGCCAGAAATCCTTAACAAATATGTGGGAGAATCAGAGGCTAACATTCGCAA ACTTTTTGCTGATGCTGAAGAGGAGCAAAGGAGGCTTGGTGCTAACAGTGGTTTGCACATCATCATCTTTGATGAAATTGATGCCATCTG CAAGCAGAGAGGGAGCATGGCTGGTAGCACGGGAGTTCATGACACTGTTGTCAACCAGTTGCTGTCCAAAATTGATGGCGTGGAGCAGCT AAACAACATCCTAGTCATTGGAATGACCAATAGACCAGATCTGATAGATGAGGCTCTTCTTAGACCTGGAAGACTGGAAGTTAAAATGGA GATAGGCTTGCCAGATGAGAAAGGCCGACTACAGATTCTTCACATCCACACAGCAAGAATGAGAGGGCATCAGTTACTCTCTGCTGATGT AGACATTAAAGAACTGGCCGTGGAGACCAAGAATTTCAGTGGTGCTGAATTGGAGGGTCTGGTGCGAGCAGCCCAGTCCACTGCTATGAA TAGACACATAAAGGCCAGTACTAAAGTGGAAGTGGACATGGAGAAAGCAGAAAGCCTGCAAGTGACGAGAGGAGACTTCCTTGCTTCTTT GGAGAATGATATCAAACCAGCCTTTGGCACAAACCAAGAAGATTATGCAAGTTACATTATGAACGGTATCATCAAATGGGGTGACCCAGT TACTCGAGTTCTAGATGATGGGGAGCTGCTGGTGCAGCAGACTAAGAACAGTGACCGCACACCATTGGTCAGCGTGCTTCTGGAAGGCCC TCCTCACAGTGGGAAGACTGCTTTAGCTGCAAAAATTGCAGAGGAATCCAACTTCCCGTTCATCAAGATCTGTTCTCCTGATAAAATGAT TGGCTTTTCTGAAACAGCCAAATGTCAGGCCATGAAGAAGATCTTTGATGATGCGTACAAATCCCAGCTCAGTTGTGTGGTTGTGGATGA CATTGAGAGATTGCTTGATTACGTCCCTATTGGCCCTCGATTTTCAAATCTTGTATTACAGGCTCTTCTCGTTTTACTGAAAAAGGCACC TCCTCAGGGCCGCAAGCTTCTTATCATTGGGACCACTAGCCGCAAAGATGTCCTTCAGGAGATGGAAATGCTTAACGCTTTCAGCACCAC CATCCACGTGCCCAACATTGCCACAGGAGAGCAGCTGTTGGAAGCTTTGGAGCTTTTGGGCAACTTCAAGGATAAGGAACGCACCACAAT TGCACAGCAAGTCAAAGGGAAGAAGGTCTGGATAGGAATCAAGAAGTTACTAATGCTGATCGAGATGTCCCTACAGATGGATCCTGAATA CCGTGTGAGAAAATTCTTGGCCCTCTTAAGAGAAGAAGGAGCTAGCCCCCTTGATTTTGATTGAAAATGAACTATTTGAAACACACAGTG ACCAAGGGAAGTGACCAAGGTGAAGATGGCCTAGGATCTTCACTGTCTTACTCAAGATACTGGACTAAGTGGAACGTTCTCTACCTTCAA CATGTGCTCGCTCTGCATGATTAGTGCAATAAAACTCCCTTCCTTATGCATACTGAGATAGCTTAGTGTCTCGTGGAAGGTGTCAATTTG GTTTAGAATGCTGCGCTTACCTTCCCATGCAGGCTAAAGTGATTCCTTCTTGCTCAGTCCCTCTGGGTGGGAACCATCCAGTACTTGTGG ACACTACACGTTTCAACCTCTCTACTAGCACCATCACCCTTGAAAACTCTCAGTCAGTGTCATGAATGTTGCATGACAACAGTTGGCCGA TTAGAAGGCAGACTTTCTACATGCAAATCTGGCTTAGTAAATCGAGGTGTGGGCCAGAGATCCTCTGACAGCTGTCCTGAGCTAACACTA AAAGTCACTGGGTATTTGGTTAAAGGTCTCCCACAAGACTGGTATTCTCTTTGCCTGAAGAAACAAGGCATTGAATCTCTAAAATGCTGT TCTCAATCATTGTCAGAGATGTTTTCAAGTTGCAGTCAGAAGATCTTTCTTAATAGAAAGTCAGATGACTACCGTGTTGGTTGTGACTTC CCCTTAAGTATAACTAATTTGCTCTGTGGTAAGAGATATGCTCATTATTACCACTTAGAAGATGTTGTTAAAAACATGTGAAAGATAGGT ATGGAAAAAGCATACACCCCCAAACAGAAAGGAGTTATTAAAGTAATTTACAAACCTCTCAGCACTAATTAGTGTCCAACTCCAAGTGGG TCAATTCCTTAGTATAATATTAAGGCTTACTAGTATCACTGCTTTTTCCTTAGCTTAATGACTTACTTAGAATTTATCCTTTATTTTAAA TGATCTGTACTATCTAGTGTCTAAAACACTATTCTCCAGAAAAATCAATCATTTTCTAGCCCTCTCCCTCAGTCCTTTATTGTCCATTCC AATACATTGAACACATTTCCTTTACCCTCCACACACTTCTTCCAAAAGGAAGCACCCGTTGAGTCCTTTTGAGGGTGATTTGTCTTACAA CTGACTGACTTAGCAGGAATTTAATTAGGTCATATTTGGTGATGAGACTTATGGAGTGTGCCTCTCTCTCCCAACTGCTGCTTAAAATGC AAGGACAAGCAATTAGAAGCCATCCTAAGGTGCTTACCTCACACGCCACCCATGAGGCTTGTGGCCACAGTGGCACTTGGGTGTGGCTCC TCTGTTATTTGTCCTCATGTGAGAAAGCAGATCATCTCCAAATCTTGCCATTTGTATACTTTTGGTGGAGACTTGGATGTCATATCTTCT TTGTTTTGGGTTTTCTTCCCTAGCTTATTTTGTGGCTTTTAAAGAAGTGGATTGTATTGTGAGATCCTGTGATTCCTGGTGGCCAGTATC CTGGATTCCTCTAAGATCTTGCCTCTTTCCTCCTCATGAAAGCAGCACACATTGTGTTAACTTATGTCTCTTGTTAAATGAGCTTAATGT >26728_26728_8_ENY2-NSF_ENY2_chr8_110352792_ENST00000521688_NSF_chr17_44751780_ENST00000398238_length(amino acids)=572AA_BP=76 MVVSKMNKDAQMRAAINQKLIETGERERLKELLRAKLIECGWKDQLKAHCKEVIKEKGLEHVTVDDLVAEITPKGRGCKHVKGILLYGPP GCGKTLLARQIGKMLNAREPKVVNGPEILNKYVGESEANIRKLFADAEEEQRRLGANSGLHIIIFDEIDAICKQRGSMAGSTGVHDTVVN QLLSKIDGVEQLNNILVIGMTNRPDLIDEALLRPGRLEVKMEIGLPDEKGRLQILHIHTARMRGHQLLSADVDIKELAVETKNFSGAELE GLVRAAQSTAMNRHIKASTKVEVDMEKAESLQVTRGDFLASLENDIKPAFGTNQEDYASYIMNGIIKWGDPVTRVLDDGELLVQQTKNSD RTPLVSVLLEGPPHSGKTALAAKIAEESNFPFIKICSPDKMIGFSETAKCQAMKKIFDDAYKSQLSCVVVDDIERLLDYVPIGPRFSNLV LQALLVLLKKAPPQGRKLLIIGTTSRKDVLQEMEMLNAFSTTIHVPNIATGEQLLEALELLGNFKDKERTTIAQQVKGKKVWIGIKKLLM -------------------------------------------------------------- >26728_26728_9_ENY2-NSF_ENY2_chr8_110352792_ENST00000521688_NSF_chr17_44751780_ENST00000575068_length(transcript)=2100nt_BP=374nt GGAAATGCGTGTTCTAGCTTTCTGTGTGCTTAGGTGCCCGAGCTACTGAGGGTCTAAGTCCGGGCAGCCGAAGAGTGTGGTAGGTAACGG TCCTCAGCGCAAGGGTCATTTCGTCGCTGGGAAGGGACGGCCCTCGCCCGCGGTGATGGTGGTTAGCAAGATGAACAAAGATGCGCAGAT GAGAGCAGCGATTAACCAAAAGTTGATAGAAACTGGAGAAAGAGAACGCCTCAAAGAGTTGCTGAGAGCTAAATTAATTGAATGTGGCTG GAAGGATCAGTTGAAGGCACACTGTAAAGAGGTAATTAAAGAAAAAGGACTAGAACACGTTACTGTTGATGACTTGGTGGCTGAAATCAC TCCAAAAGGCAGAGGTTGTAAACATGTTAAAGGCATCCTGTTATATGGACCCCCAGGTTGTGGTAAGACTCTCTTGGCTCGACAGATTGG CAAGATGTTGAATGCAAGAGAGCCCAAAGTGGTCAATGGGCCAGAAATCCTTAACAAATATGTGGGAGAATCAGAGGCTAACATTCGCAA ACTTTTTGCTGATGCTGAAGAGGAGCAAAGGAGGCTTGGTGCTAACAGTGGTTTGCACATCATCATCTTTGATGAAATTGATGCCATCTG CAAGCAGAGAGGGAGCATGGCTGGTAGCACGGGAGTTCATGACACTGTTGTCAACCAGTTGCTGTCCAAAATTGATGGCGTGGAGCAGCT AAACAACATCCTAGTCATTGGAATGACCAATAGACCAGATCTGATAGATGAGGCTCTTCTTAGACCTGGAAGACTGGAAGTTAAAATGGA GATAGGCTTGCCAGATGAGAAAGGCCGACTACAGATTCTTCACATCCACACAGCAAGAATGAGAGGGCATCAGTTACTCTCTGCTGATGT AGACATTAAAGAACTGGCCGTGGAGACCAAGAATTTCAGTGGTGCTGAATTGGAGGGTCTGGTGCGAGCAGCCCAGTCCACTGCTATGAA TAGACACATAAAGGCCAGTACTAAAGTGGAAGTGGACATGGAGAAAGCAGAAAGCCTGCAAGTGACGAGAGGAGACTTCCTTGCTTCTTT GGAGAATGATATCAAACCAGCCTTTGGCACAAACCAAGAAGATTATGCAAGTTACATTATGAACGGTATCATCAAATGGGGTGACCCAGT TACTCGAGTTCTAGATGATGGGGAGCTGCTGGTGCAGCAGACTAAGAACAGTGACCGCACACCATTGGTCAGCGTGCTTCTGGAAGGCCC TCCTCACAGTGGGAAGACTGCTTTAGCTGCAAAAATTGCAGAGGAATCCAACTTCCCGTTCATCAAGATCTGTTCTCCTGATAAAATGAT TGGCTTTTCTGAAACAGCCAAATGTCAGGCCATGAAGAAGATCTTTGATGATGCGTACAAATCCCAGCTCAGTTGTGTGGTTGTGGATGA CATTGAGAGATTGCTTGATTACGTCCCTATTGGCCCTCGATTTTCAAATCTTGTATTACAGGCTCTTCTCGTTTTACTGAAAAAGGCACC TCCTCAGGGCCGCAAGCTTCTTATCATTGGGACCACTAGCCGCAAAGATGTCCTTCAGGAGATGGAAATGCTTAACGCTTTCAGCACCAC CATCCACGTGCCCAACATTGCCACAGGAGAGCAGCTGTTGGAAGCTTTGGAGCTTTTGGGCAACTTCAAGGATAAGGAACGCACCACAAT TGCACAGCAAGTCAAAGGGAAGAAGGTCTGGATAGGAATCAAGAAGTTACTAATGCTGATCGAGATGTCCCTACAGATGGATCCTGAATA CCGTGTGAGAAAATTCTTGGCCCTCTTAAGAGAAGAAGGAGCTAGCCCCCTTGATTTTGATTGAAAATGAACTATTTGAAACACACAGTG ACCAAGGGAAGTGACCAAGGTGAAGATGGCCTAGGATCTTCACTGTCTTACTCAAGATACTGGACTAAGTGGAACGTTCTCTACCTTCAA CATGTGCTCGCTCTGCATGATTAGTGCAATAAAACTCCCTTCCTTATGCATACTGAGATAGCTTAGTGTCTCGTGGAAGGTGTCAATTTG >26728_26728_9_ENY2-NSF_ENY2_chr8_110352792_ENST00000521688_NSF_chr17_44751780_ENST00000575068_length(amino acids)=572AA_BP=76 MVVSKMNKDAQMRAAINQKLIETGERERLKELLRAKLIECGWKDQLKAHCKEVIKEKGLEHVTVDDLVAEITPKGRGCKHVKGILLYGPP GCGKTLLARQIGKMLNAREPKVVNGPEILNKYVGESEANIRKLFADAEEEQRRLGANSGLHIIIFDEIDAICKQRGSMAGSTGVHDTVVN QLLSKIDGVEQLNNILVIGMTNRPDLIDEALLRPGRLEVKMEIGLPDEKGRLQILHIHTARMRGHQLLSADVDIKELAVETKNFSGAELE GLVRAAQSTAMNRHIKASTKVEVDMEKAESLQVTRGDFLASLENDIKPAFGTNQEDYASYIMNGIIKWGDPVTRVLDDGELLVQQTKNSD RTPLVSVLLEGPPHSGKTALAAKIAEESNFPFIKICSPDKMIGFSETAKCQAMKKIFDDAYKSQLSCVVVDDIERLLDYVPIGPRFSNLV LQALLVLLKKAPPQGRKLLIIGTTSRKDVLQEMEMLNAFSTTIHVPNIATGEQLLEALELLGNFKDKERTTIAQQVKGKKVWIGIKKLLM -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ENY2-NSF |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ENY2-NSF |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ENY2-NSF |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies