
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ERP44-CCNB1IP1 (FusionGDB2 ID:27479) |
Fusion Gene Summary for ERP44-CCNB1IP1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ERP44-CCNB1IP1 | Fusion gene ID: 27479 | Hgene | Tgene | Gene symbol | ERP44 | CCNB1IP1 | Gene ID | 23071 | 57820 |
| Gene name | endoplasmic reticulum protein 44 | cyclin B1 interacting protein 1 | |
| Synonyms | PDIA10|TXNDC4 | C14orf18|HEI10 | |
| Cytomap | 9q31.1 | 14q11.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | endoplasmic reticulum resident protein 44ER protein 44endoplasmic reticulum resident protein 44 kDaepididymis secretory sperm binding proteinprotein disulfide isomerase family A, member 10thioredoxin domain containing 4 (endoplasmic reticulum)thiore | E3 ubiquitin-protein ligase CCNB1IP1RING-type E3 ubiquitin transferase CCNB1IP1cyclin B1 interacting protein 1, E3 ubiquitin protein ligaseepididymis secretory sperm binding proteinhuman enhancer of invasion 10 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q9BS26 | Q9NPC3 | |
| Ensembl transtripts involved in fusion gene | ENST00000262455, | ENST00000557114, ENST00000353689, ENST00000358932, ENST00000398160, ENST00000398163, ENST00000398169, ENST00000437553, | |
| Fusion gene scores | * DoF score | 6 X 5 X 3=90 | 6 X 5 X 6=180 |
| # samples | 7 | 6 | |
| ** MAII score | log2(7/90*10)=-0.362570079384708 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(6/180*10)=-1.58496250072116 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: ERP44 [Title/Abstract] AND CCNB1IP1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ERP44(102778604)-CCNB1IP1(20781960), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | ERP44 | GO:0006457 | protein folding | 11847130 |
| Hgene | ERP44 | GO:0006986 | response to unfolded protein | 11847130 |
| Hgene | ERP44 | GO:0009100 | glycoprotein metabolic process | 11847130 |
| Hgene | ERP44 | GO:0034976 | response to endoplasmic reticulum stress | 11847130 |
| Fusion gene breakpoints across ERP44 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across CCNB1IP1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
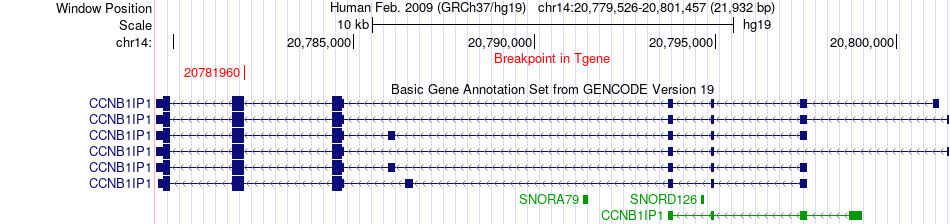 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-CD-A4MH-01A | ERP44 | chr9 | 102778604 | - | CCNB1IP1 | chr14 | 20781960 | - |
Top |
Fusion Gene ORF analysis for ERP44-CCNB1IP1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000262455 | ENST00000557114 | ERP44 | chr9 | 102778604 | - | CCNB1IP1 | chr14 | 20781960 | - |
| In-frame | ENST00000262455 | ENST00000353689 | ERP44 | chr9 | 102778604 | - | CCNB1IP1 | chr14 | 20781960 | - |
| In-frame | ENST00000262455 | ENST00000358932 | ERP44 | chr9 | 102778604 | - | CCNB1IP1 | chr14 | 20781960 | - |
| In-frame | ENST00000262455 | ENST00000398160 | ERP44 | chr9 | 102778604 | - | CCNB1IP1 | chr14 | 20781960 | - |
| In-frame | ENST00000262455 | ENST00000398163 | ERP44 | chr9 | 102778604 | - | CCNB1IP1 | chr14 | 20781960 | - |
| In-frame | ENST00000262455 | ENST00000398169 | ERP44 | chr9 | 102778604 | - | CCNB1IP1 | chr14 | 20781960 | - |
| In-frame | ENST00000262455 | ENST00000437553 | ERP44 | chr9 | 102778604 | - | CCNB1IP1 | chr14 | 20781960 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000262455 | ERP44 | chr9 | 102778604 | - | ENST00000398160 | CCNB1IP1 | chr14 | 20781960 | - | 1681 | 962 | 50 | 1498 | 482 |
| ENST00000262455 | ERP44 | chr9 | 102778604 | - | ENST00000398169 | CCNB1IP1 | chr14 | 20781960 | - | 1679 | 962 | 50 | 1498 | 482 |
| ENST00000262455 | ERP44 | chr9 | 102778604 | - | ENST00000358932 | CCNB1IP1 | chr14 | 20781960 | - | 1679 | 962 | 50 | 1498 | 482 |
| ENST00000262455 | ERP44 | chr9 | 102778604 | - | ENST00000437553 | CCNB1IP1 | chr14 | 20781960 | - | 1678 | 962 | 50 | 1498 | 482 |
| ENST00000262455 | ERP44 | chr9 | 102778604 | - | ENST00000353689 | CCNB1IP1 | chr14 | 20781960 | - | 1678 | 962 | 50 | 1498 | 482 |
| ENST00000262455 | ERP44 | chr9 | 102778604 | - | ENST00000398163 | CCNB1IP1 | chr14 | 20781960 | - | 1620 | 962 | 50 | 1498 | 482 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000262455 | ENST00000398160 | ERP44 | chr9 | 102778604 | - | CCNB1IP1 | chr14 | 20781960 | - | 0.000175849 | 0.9998242 |
| ENST00000262455 | ENST00000398169 | ERP44 | chr9 | 102778604 | - | CCNB1IP1 | chr14 | 20781960 | - | 0.000176184 | 0.99982387 |
| ENST00000262455 | ENST00000358932 | ERP44 | chr9 | 102778604 | - | CCNB1IP1 | chr14 | 20781960 | - | 0.000176184 | 0.99982387 |
| ENST00000262455 | ENST00000437553 | ERP44 | chr9 | 102778604 | - | CCNB1IP1 | chr14 | 20781960 | - | 0.000178948 | 0.9998211 |
| ENST00000262455 | ENST00000353689 | ERP44 | chr9 | 102778604 | - | CCNB1IP1 | chr14 | 20781960 | - | 0.000178948 | 0.9998211 |
| ENST00000262455 | ENST00000398163 | ERP44 | chr9 | 102778604 | - | CCNB1IP1 | chr14 | 20781960 | - | 0.000202986 | 0.99979705 |
Top |
Fusion Genomic Features for ERP44-CCNB1IP1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
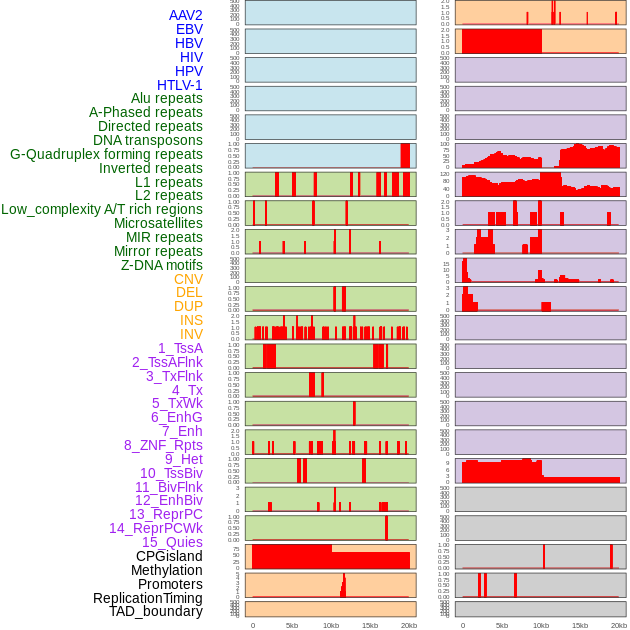 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for ERP44-CCNB1IP1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr9:102778604/chr14:20781960) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| ERP44 | CCNB1IP1 |
| FUNCTION: Mediates thiol-dependent retention in the early secretory pathway, forming mixed disulfides with substrate proteins through its conserved CRFS motif. Inhibits the calcium channel activity of ITPR1. May have a role in the control of oxidative protein folding in the endoplasmic reticulum. Required to retain ERO1A and ERO1B in the endoplasmic reticulum. {ECO:0000269|PubMed:11847130, ECO:0000269|PubMed:14517240}. | FUNCTION: Ubiquitin E3 ligase that acts as a limiting factor for crossing-over during meiosis: required during zygonema to limit the colocalization of RNF212 with MutS-gamma-associated recombination sites and thereby establish early differentiation of crossover and non-crossover sites. Later, it is directed by MutL-gamma to stably accumulate at designated crossover sites. Probably promotes the dissociation of RNF212 and MutS-gamma to allow the progression of recombination and the implementation of the final steps of crossing over (By similarity). Modulates cyclin-B levels and participates in the regulation of cell cycle progression through the G2 phase. Overexpression causes delayed entry into mitosis. {ECO:0000250, ECO:0000269|PubMed:12612082, ECO:0000269|PubMed:17297447}.; FUNCTION: E3 ubiquitin-protein ligase. Modulates cyclin B levels and participates in the regulation of cell cycle progression through the G2 phase. Overexpression causes delayed entry into mitosis. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ERP44 | chr9:102778604 | chr14:20781960 | ENST00000262455 | - | 8 | 12 | 30_138 | 254 | 407.0 | Domain | Thioredoxin |
| Tgene | CCNB1IP1 | chr9:102778604 | chr14:20781960 | ENST00000353689 | 3 | 6 | 127_182 | 99 | 278.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CCNB1IP1 | chr9:102778604 | chr14:20781960 | ENST00000358932 | 4 | 7 | 127_182 | 99 | 278.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CCNB1IP1 | chr9:102778604 | chr14:20781960 | ENST00000398160 | 4 | 7 | 127_182 | 99 | 278.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CCNB1IP1 | chr9:102778604 | chr14:20781960 | ENST00000398163 | 4 | 7 | 127_182 | 99 | 278.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CCNB1IP1 | chr9:102778604 | chr14:20781960 | ENST00000398169 | 4 | 7 | 127_182 | 99 | 278.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CCNB1IP1 | chr9:102778604 | chr14:20781960 | ENST00000437553 | 4 | 7 | 127_182 | 99 | 278.0 | Coiled coil | Ontology_term=ECO:0000255 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ERP44 | chr9:102778604 | chr14:20781960 | ENST00000262455 | - | 8 | 12 | 403_406 | 254 | 407.0 | Motif | Prevents secretion from ER |
| Tgene | CCNB1IP1 | chr9:102778604 | chr14:20781960 | ENST00000353689 | 3 | 6 | 4_51 | 99 | 278.0 | Zinc finger | Note=RING-type%3B atypical | |
| Tgene | CCNB1IP1 | chr9:102778604 | chr14:20781960 | ENST00000358932 | 4 | 7 | 4_51 | 99 | 278.0 | Zinc finger | Note=RING-type%3B atypical | |
| Tgene | CCNB1IP1 | chr9:102778604 | chr14:20781960 | ENST00000398160 | 4 | 7 | 4_51 | 99 | 278.0 | Zinc finger | Note=RING-type%3B atypical | |
| Tgene | CCNB1IP1 | chr9:102778604 | chr14:20781960 | ENST00000398163 | 4 | 7 | 4_51 | 99 | 278.0 | Zinc finger | Note=RING-type%3B atypical | |
| Tgene | CCNB1IP1 | chr9:102778604 | chr14:20781960 | ENST00000398169 | 4 | 7 | 4_51 | 99 | 278.0 | Zinc finger | Note=RING-type%3B atypical | |
| Tgene | CCNB1IP1 | chr9:102778604 | chr14:20781960 | ENST00000437553 | 4 | 7 | 4_51 | 99 | 278.0 | Zinc finger | Note=RING-type%3B atypical |
Top |
Fusion Gene Sequence for ERP44-CCNB1IP1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >27479_27479_1_ERP44-CCNB1IP1_ERP44_chr9_102778604_ENST00000262455_CCNB1IP1_chr14_20781960_ENST00000353689_length(transcript)=1678nt_BP=962nt GAAGTGAGGGTGTGAGAGGCCTCTCTGGAAGTTGTCCCGGGTGTTCGCCGCTGGAGCCCGGGTCGAGAGGACGAGGTGCCGCTGCCTGGA GAATCCTCCGCTGCCGTCGGCTCCCGGAGCCCAGCCCTTTCCTAACCCAACCCAACCTAGCCCAGTCCCAGCCGCCAGCGCCTGTCCCTG TCACGGACCCCAGCGTTACCATGCATCCTGCCGTCTTCCTATCCTTACCCGACCTCAGATGCTCCCTTCTGCTCCTGGTAACTTGGGTTT TTACTCCTGTAACAACTGAAATAACAAGTCTTGATACAGAGAATATAGATGAAATTTTAAACAATGCTGATGTTGCTTTAGTAAATTTTT ATGCTGACTGGTGTCGTTTCAGTCAGATGTTGCATCCAATTTTTGAGGAAGCTTCCGATGTCATTAAGGAAGAATTTCCAAATGAAAATC AAGTAGTGTTTGCCAGAGTTGATTGTGATCAGCACTCTGACATAGCCCAGAGATACAGGATAAGCAAATACCCAACCCTCAAATTGTTTC GTAATGGGATGATGATGAAGAGAGAATACAGGGGTCAGCGATCAGTGAAAGCATTGGCAGATTACATCAGGCAACAAAAAAGTGACCCCA TTCAAGAAATTCGGGACTTAGCAGAAATCACCACTCTTGATCGCAGCAAAAGAAATATCATTGGATATTTTGAGCAAAAGGACTCGGACA ACTATAGAGTTTTTGAACGAGTAGCGAATATTTTGCATGATGACTGTGCCTTTCTTTCTGCATTTGGGGATGTTTCAAAACCGGAAAGAT ATAGTGGCGACAACATAATCTACAAACCACCAGGGCATTCTGCTCCGGATATGGTGTACTTGGGAGCTATGACAAATTTTGATGTGACTT ACAATTGGATTCAAGATAAATGTGTTCCTCTTGTCCGAGAAATAACATTTGAAAATGGAGAGGTACATCAGGAACGTCTCTATCAAGAAT ACAATTTCAGCAAGGCTGAGGGCCATCTGAAACAGATGGAGAAGATATATACTCAGCAAATACAAAGCAAGGATGTAGAATTGACCTCTA TGAAAGGGGAGGTTACCTCCATGAAGAAAGTACTAGAAGAATACAAGAAAAAGTTCAGTGACATCTCTGAGAAACTTATGGAGCGCAATC GTCAGTATCAAAAGCTCCAAGGCCTCTATGATAGCCTTAGGCTACGAAACATCACTATTGCTAACCATGAAGGCACCCTTGAACCATCCA TGATTGCACAGTCTGGTGTTCTTGGCTTCCCATTAGGTAACAACTCCAAGTTTCCTTTGGATAATACACCTGTTCGAAATCGGGGCGATG GAGATGGAGATTTTCAGTTCAGACCATTTTTTGCGGGTTCTCCCACAGCACCTGAACCCAGCAACAGCTTTTTTAGTTTTGTCTCTCCAA GTCGTGAATTAGAGCAGCAGCAAGTTTCTAGCAGGGCCTTCAAAGTAAAAAGAATTTGAGCCACGCATAGTGTCACGCACCTGTGATCCC AGCTACTTAGGAGGTTGAGGCTGGGAGGATCACTTGAGCCCAGGAGTCTGAGGCTTTAGTGATCTAAGATCATGCCACTGCACTCCAGCC >27479_27479_1_ERP44-CCNB1IP1_ERP44_chr9_102778604_ENST00000262455_CCNB1IP1_chr14_20781960_ENST00000353689_length(amino acids)=482AA_BP=304 MEPGSRGRGAAAWRILRCRRLPEPSPFLTQPNLAQSQPPAPVPVTDPSVTMHPAVFLSLPDLRCSLLLLVTWVFTPVTTEITSLDTENID EILNNADVALVNFYADWCRFSQMLHPIFEEASDVIKEEFPNENQVVFARVDCDQHSDIAQRYRISKYPTLKLFRNGMMMKREYRGQRSVK ALADYIRQQKSDPIQEIRDLAEITTLDRSKRNIIGYFEQKDSDNYRVFERVANILHDDCAFLSAFGDVSKPERYSGDNIIYKPPGHSAPD MVYLGAMTNFDVTYNWIQDKCVPLVREITFENGEVHQERLYQEYNFSKAEGHLKQMEKIYTQQIQSKDVELTSMKGEVTSMKKVLEEYKK KFSDISEKLMERNRQYQKLQGLYDSLRLRNITIANHEGTLEPSMIAQSGVLGFPLGNNSKFPLDNTPVRNRGDGDGDFQFRPFFAGSPTA -------------------------------------------------------------- >27479_27479_2_ERP44-CCNB1IP1_ERP44_chr9_102778604_ENST00000262455_CCNB1IP1_chr14_20781960_ENST00000358932_length(transcript)=1679nt_BP=962nt GAAGTGAGGGTGTGAGAGGCCTCTCTGGAAGTTGTCCCGGGTGTTCGCCGCTGGAGCCCGGGTCGAGAGGACGAGGTGCCGCTGCCTGGA GAATCCTCCGCTGCCGTCGGCTCCCGGAGCCCAGCCCTTTCCTAACCCAACCCAACCTAGCCCAGTCCCAGCCGCCAGCGCCTGTCCCTG TCACGGACCCCAGCGTTACCATGCATCCTGCCGTCTTCCTATCCTTACCCGACCTCAGATGCTCCCTTCTGCTCCTGGTAACTTGGGTTT TTACTCCTGTAACAACTGAAATAACAAGTCTTGATACAGAGAATATAGATGAAATTTTAAACAATGCTGATGTTGCTTTAGTAAATTTTT ATGCTGACTGGTGTCGTTTCAGTCAGATGTTGCATCCAATTTTTGAGGAAGCTTCCGATGTCATTAAGGAAGAATTTCCAAATGAAAATC AAGTAGTGTTTGCCAGAGTTGATTGTGATCAGCACTCTGACATAGCCCAGAGATACAGGATAAGCAAATACCCAACCCTCAAATTGTTTC GTAATGGGATGATGATGAAGAGAGAATACAGGGGTCAGCGATCAGTGAAAGCATTGGCAGATTACATCAGGCAACAAAAAAGTGACCCCA TTCAAGAAATTCGGGACTTAGCAGAAATCACCACTCTTGATCGCAGCAAAAGAAATATCATTGGATATTTTGAGCAAAAGGACTCGGACA ACTATAGAGTTTTTGAACGAGTAGCGAATATTTTGCATGATGACTGTGCCTTTCTTTCTGCATTTGGGGATGTTTCAAAACCGGAAAGAT ATAGTGGCGACAACATAATCTACAAACCACCAGGGCATTCTGCTCCGGATATGGTGTACTTGGGAGCTATGACAAATTTTGATGTGACTT ACAATTGGATTCAAGATAAATGTGTTCCTCTTGTCCGAGAAATAACATTTGAAAATGGAGAGGTACATCAGGAACGTCTCTATCAAGAAT ACAATTTCAGCAAGGCTGAGGGCCATCTGAAACAGATGGAGAAGATATATACTCAGCAAATACAAAGCAAGGATGTAGAATTGACCTCTA TGAAAGGGGAGGTTACCTCCATGAAGAAAGTACTAGAAGAATACAAGAAAAAGTTCAGTGACATCTCTGAGAAACTTATGGAGCGCAATC GTCAGTATCAAAAGCTCCAAGGCCTCTATGATAGCCTTAGGCTACGAAACATCACTATTGCTAACCATGAAGGCACCCTTGAACCATCCA TGATTGCACAGTCTGGTGTTCTTGGCTTCCCATTAGGTAACAACTCCAAGTTTCCTTTGGATAATACACCTGTTCGAAATCGGGGCGATG GAGATGGAGATTTTCAGTTCAGACCATTTTTTGCGGGTTCTCCCACAGCACCTGAACCCAGCAACAGCTTTTTTAGTTTTGTCTCTCCAA GTCGTGAATTAGAGCAGCAGCAAGTTTCTAGCAGGGCCTTCAAAGTAAAAAGAATTTGAGCCACGCATAGTGTCACGCACCTGTGATCCC AGCTACTTAGGAGGTTGAGGCTGGGAGGATCACTTGAGCCCAGGAGTCTGAGGCTTTAGTGATCTAAGATCATGCCACTGCACTCCAGCC >27479_27479_2_ERP44-CCNB1IP1_ERP44_chr9_102778604_ENST00000262455_CCNB1IP1_chr14_20781960_ENST00000358932_length(amino acids)=482AA_BP=304 MEPGSRGRGAAAWRILRCRRLPEPSPFLTQPNLAQSQPPAPVPVTDPSVTMHPAVFLSLPDLRCSLLLLVTWVFTPVTTEITSLDTENID EILNNADVALVNFYADWCRFSQMLHPIFEEASDVIKEEFPNENQVVFARVDCDQHSDIAQRYRISKYPTLKLFRNGMMMKREYRGQRSVK ALADYIRQQKSDPIQEIRDLAEITTLDRSKRNIIGYFEQKDSDNYRVFERVANILHDDCAFLSAFGDVSKPERYSGDNIIYKPPGHSAPD MVYLGAMTNFDVTYNWIQDKCVPLVREITFENGEVHQERLYQEYNFSKAEGHLKQMEKIYTQQIQSKDVELTSMKGEVTSMKKVLEEYKK KFSDISEKLMERNRQYQKLQGLYDSLRLRNITIANHEGTLEPSMIAQSGVLGFPLGNNSKFPLDNTPVRNRGDGDGDFQFRPFFAGSPTA -------------------------------------------------------------- >27479_27479_3_ERP44-CCNB1IP1_ERP44_chr9_102778604_ENST00000262455_CCNB1IP1_chr14_20781960_ENST00000398160_length(transcript)=1681nt_BP=962nt GAAGTGAGGGTGTGAGAGGCCTCTCTGGAAGTTGTCCCGGGTGTTCGCCGCTGGAGCCCGGGTCGAGAGGACGAGGTGCCGCTGCCTGGA GAATCCTCCGCTGCCGTCGGCTCCCGGAGCCCAGCCCTTTCCTAACCCAACCCAACCTAGCCCAGTCCCAGCCGCCAGCGCCTGTCCCTG TCACGGACCCCAGCGTTACCATGCATCCTGCCGTCTTCCTATCCTTACCCGACCTCAGATGCTCCCTTCTGCTCCTGGTAACTTGGGTTT TTACTCCTGTAACAACTGAAATAACAAGTCTTGATACAGAGAATATAGATGAAATTTTAAACAATGCTGATGTTGCTTTAGTAAATTTTT ATGCTGACTGGTGTCGTTTCAGTCAGATGTTGCATCCAATTTTTGAGGAAGCTTCCGATGTCATTAAGGAAGAATTTCCAAATGAAAATC AAGTAGTGTTTGCCAGAGTTGATTGTGATCAGCACTCTGACATAGCCCAGAGATACAGGATAAGCAAATACCCAACCCTCAAATTGTTTC GTAATGGGATGATGATGAAGAGAGAATACAGGGGTCAGCGATCAGTGAAAGCATTGGCAGATTACATCAGGCAACAAAAAAGTGACCCCA TTCAAGAAATTCGGGACTTAGCAGAAATCACCACTCTTGATCGCAGCAAAAGAAATATCATTGGATATTTTGAGCAAAAGGACTCGGACA ACTATAGAGTTTTTGAACGAGTAGCGAATATTTTGCATGATGACTGTGCCTTTCTTTCTGCATTTGGGGATGTTTCAAAACCGGAAAGAT ATAGTGGCGACAACATAATCTACAAACCACCAGGGCATTCTGCTCCGGATATGGTGTACTTGGGAGCTATGACAAATTTTGATGTGACTT ACAATTGGATTCAAGATAAATGTGTTCCTCTTGTCCGAGAAATAACATTTGAAAATGGAGAGGTACATCAGGAACGTCTCTATCAAGAAT ACAATTTCAGCAAGGCTGAGGGCCATCTGAAACAGATGGAGAAGATATATACTCAGCAAATACAAAGCAAGGATGTAGAATTGACCTCTA TGAAAGGGGAGGTTACCTCCATGAAGAAAGTACTAGAAGAATACAAGAAAAAGTTCAGTGACATCTCTGAGAAACTTATGGAGCGCAATC GTCAGTATCAAAAGCTCCAAGGCCTCTATGATAGCCTTAGGCTACGAAACATCACTATTGCTAACCATGAAGGCACCCTTGAACCATCCA TGATTGCACAGTCTGGTGTTCTTGGCTTCCCATTAGGTAACAACTCCAAGTTTCCTTTGGATAATACACCTGTTCGAAATCGGGGCGATG GAGATGGAGATTTTCAGTTCAGACCATTTTTTGCGGGTTCTCCCACAGCACCTGAACCCAGCAACAGCTTTTTTAGTTTTGTCTCTCCAA GTCGTGAATTAGAGCAGCAGCAAGTTTCTAGCAGGGCCTTCAAAGTAAAAAGAATTTGAGCCACGCATAGTGTCACGCACCTGTGATCCC AGCTACTTAGGAGGTTGAGGCTGGGAGGATCACTTGAGCCCAGGAGTCTGAGGCTTTAGTGATCTAAGATCATGCCACTGCACTCCAGCC >27479_27479_3_ERP44-CCNB1IP1_ERP44_chr9_102778604_ENST00000262455_CCNB1IP1_chr14_20781960_ENST00000398160_length(amino acids)=482AA_BP=304 MEPGSRGRGAAAWRILRCRRLPEPSPFLTQPNLAQSQPPAPVPVTDPSVTMHPAVFLSLPDLRCSLLLLVTWVFTPVTTEITSLDTENID EILNNADVALVNFYADWCRFSQMLHPIFEEASDVIKEEFPNENQVVFARVDCDQHSDIAQRYRISKYPTLKLFRNGMMMKREYRGQRSVK ALADYIRQQKSDPIQEIRDLAEITTLDRSKRNIIGYFEQKDSDNYRVFERVANILHDDCAFLSAFGDVSKPERYSGDNIIYKPPGHSAPD MVYLGAMTNFDVTYNWIQDKCVPLVREITFENGEVHQERLYQEYNFSKAEGHLKQMEKIYTQQIQSKDVELTSMKGEVTSMKKVLEEYKK KFSDISEKLMERNRQYQKLQGLYDSLRLRNITIANHEGTLEPSMIAQSGVLGFPLGNNSKFPLDNTPVRNRGDGDGDFQFRPFFAGSPTA -------------------------------------------------------------- >27479_27479_4_ERP44-CCNB1IP1_ERP44_chr9_102778604_ENST00000262455_CCNB1IP1_chr14_20781960_ENST00000398163_length(transcript)=1620nt_BP=962nt GAAGTGAGGGTGTGAGAGGCCTCTCTGGAAGTTGTCCCGGGTGTTCGCCGCTGGAGCCCGGGTCGAGAGGACGAGGTGCCGCTGCCTGGA GAATCCTCCGCTGCCGTCGGCTCCCGGAGCCCAGCCCTTTCCTAACCCAACCCAACCTAGCCCAGTCCCAGCCGCCAGCGCCTGTCCCTG TCACGGACCCCAGCGTTACCATGCATCCTGCCGTCTTCCTATCCTTACCCGACCTCAGATGCTCCCTTCTGCTCCTGGTAACTTGGGTTT TTACTCCTGTAACAACTGAAATAACAAGTCTTGATACAGAGAATATAGATGAAATTTTAAACAATGCTGATGTTGCTTTAGTAAATTTTT ATGCTGACTGGTGTCGTTTCAGTCAGATGTTGCATCCAATTTTTGAGGAAGCTTCCGATGTCATTAAGGAAGAATTTCCAAATGAAAATC AAGTAGTGTTTGCCAGAGTTGATTGTGATCAGCACTCTGACATAGCCCAGAGATACAGGATAAGCAAATACCCAACCCTCAAATTGTTTC GTAATGGGATGATGATGAAGAGAGAATACAGGGGTCAGCGATCAGTGAAAGCATTGGCAGATTACATCAGGCAACAAAAAAGTGACCCCA TTCAAGAAATTCGGGACTTAGCAGAAATCACCACTCTTGATCGCAGCAAAAGAAATATCATTGGATATTTTGAGCAAAAGGACTCGGACA ACTATAGAGTTTTTGAACGAGTAGCGAATATTTTGCATGATGACTGTGCCTTTCTTTCTGCATTTGGGGATGTTTCAAAACCGGAAAGAT ATAGTGGCGACAACATAATCTACAAACCACCAGGGCATTCTGCTCCGGATATGGTGTACTTGGGAGCTATGACAAATTTTGATGTGACTT ACAATTGGATTCAAGATAAATGTGTTCCTCTTGTCCGAGAAATAACATTTGAAAATGGAGAGGTACATCAGGAACGTCTCTATCAAGAAT ACAATTTCAGCAAGGCTGAGGGCCATCTGAAACAGATGGAGAAGATATATACTCAGCAAATACAAAGCAAGGATGTAGAATTGACCTCTA TGAAAGGGGAGGTTACCTCCATGAAGAAAGTACTAGAAGAATACAAGAAAAAGTTCAGTGACATCTCTGAGAAACTTATGGAGCGCAATC GTCAGTATCAAAAGCTCCAAGGCCTCTATGATAGCCTTAGGCTACGAAACATCACTATTGCTAACCATGAAGGCACCCTTGAACCATCCA TGATTGCACAGTCTGGTGTTCTTGGCTTCCCATTAGGTAACAACTCCAAGTTTCCTTTGGATAATACACCTGTTCGAAATCGGGGCGATG GAGATGGAGATTTTCAGTTCAGACCATTTTTTGCGGGTTCTCCCACAGCACCTGAACCCAGCAACAGCTTTTTTAGTTTTGTCTCTCCAA GTCGTGAATTAGAGCAGCAGCAAGTTTCTAGCAGGGCCTTCAAAGTAAAAAGAATTTGAGCCACGCATAGTGTCACGCACCTGTGATCCC AGCTACTTAGGAGGTTGAGGCTGGGAGGATCACTTGAGCCCAGGAGTCTGAGGCTTTAGTGATCTAAGATCATGCCACTGCACTCCAGCC >27479_27479_4_ERP44-CCNB1IP1_ERP44_chr9_102778604_ENST00000262455_CCNB1IP1_chr14_20781960_ENST00000398163_length(amino acids)=482AA_BP=304 MEPGSRGRGAAAWRILRCRRLPEPSPFLTQPNLAQSQPPAPVPVTDPSVTMHPAVFLSLPDLRCSLLLLVTWVFTPVTTEITSLDTENID EILNNADVALVNFYADWCRFSQMLHPIFEEASDVIKEEFPNENQVVFARVDCDQHSDIAQRYRISKYPTLKLFRNGMMMKREYRGQRSVK ALADYIRQQKSDPIQEIRDLAEITTLDRSKRNIIGYFEQKDSDNYRVFERVANILHDDCAFLSAFGDVSKPERYSGDNIIYKPPGHSAPD MVYLGAMTNFDVTYNWIQDKCVPLVREITFENGEVHQERLYQEYNFSKAEGHLKQMEKIYTQQIQSKDVELTSMKGEVTSMKKVLEEYKK KFSDISEKLMERNRQYQKLQGLYDSLRLRNITIANHEGTLEPSMIAQSGVLGFPLGNNSKFPLDNTPVRNRGDGDGDFQFRPFFAGSPTA -------------------------------------------------------------- >27479_27479_5_ERP44-CCNB1IP1_ERP44_chr9_102778604_ENST00000262455_CCNB1IP1_chr14_20781960_ENST00000398169_length(transcript)=1679nt_BP=962nt GAAGTGAGGGTGTGAGAGGCCTCTCTGGAAGTTGTCCCGGGTGTTCGCCGCTGGAGCCCGGGTCGAGAGGACGAGGTGCCGCTGCCTGGA GAATCCTCCGCTGCCGTCGGCTCCCGGAGCCCAGCCCTTTCCTAACCCAACCCAACCTAGCCCAGTCCCAGCCGCCAGCGCCTGTCCCTG TCACGGACCCCAGCGTTACCATGCATCCTGCCGTCTTCCTATCCTTACCCGACCTCAGATGCTCCCTTCTGCTCCTGGTAACTTGGGTTT TTACTCCTGTAACAACTGAAATAACAAGTCTTGATACAGAGAATATAGATGAAATTTTAAACAATGCTGATGTTGCTTTAGTAAATTTTT ATGCTGACTGGTGTCGTTTCAGTCAGATGTTGCATCCAATTTTTGAGGAAGCTTCCGATGTCATTAAGGAAGAATTTCCAAATGAAAATC AAGTAGTGTTTGCCAGAGTTGATTGTGATCAGCACTCTGACATAGCCCAGAGATACAGGATAAGCAAATACCCAACCCTCAAATTGTTTC GTAATGGGATGATGATGAAGAGAGAATACAGGGGTCAGCGATCAGTGAAAGCATTGGCAGATTACATCAGGCAACAAAAAAGTGACCCCA TTCAAGAAATTCGGGACTTAGCAGAAATCACCACTCTTGATCGCAGCAAAAGAAATATCATTGGATATTTTGAGCAAAAGGACTCGGACA ACTATAGAGTTTTTGAACGAGTAGCGAATATTTTGCATGATGACTGTGCCTTTCTTTCTGCATTTGGGGATGTTTCAAAACCGGAAAGAT ATAGTGGCGACAACATAATCTACAAACCACCAGGGCATTCTGCTCCGGATATGGTGTACTTGGGAGCTATGACAAATTTTGATGTGACTT ACAATTGGATTCAAGATAAATGTGTTCCTCTTGTCCGAGAAATAACATTTGAAAATGGAGAGGTACATCAGGAACGTCTCTATCAAGAAT ACAATTTCAGCAAGGCTGAGGGCCATCTGAAACAGATGGAGAAGATATATACTCAGCAAATACAAAGCAAGGATGTAGAATTGACCTCTA TGAAAGGGGAGGTTACCTCCATGAAGAAAGTACTAGAAGAATACAAGAAAAAGTTCAGTGACATCTCTGAGAAACTTATGGAGCGCAATC GTCAGTATCAAAAGCTCCAAGGCCTCTATGATAGCCTTAGGCTACGAAACATCACTATTGCTAACCATGAAGGCACCCTTGAACCATCCA TGATTGCACAGTCTGGTGTTCTTGGCTTCCCATTAGGTAACAACTCCAAGTTTCCTTTGGATAATACACCTGTTCGAAATCGGGGCGATG GAGATGGAGATTTTCAGTTCAGACCATTTTTTGCGGGTTCTCCCACAGCACCTGAACCCAGCAACAGCTTTTTTAGTTTTGTCTCTCCAA GTCGTGAATTAGAGCAGCAGCAAGTTTCTAGCAGGGCCTTCAAAGTAAAAAGAATTTGAGCCACGCATAGTGTCACGCACCTGTGATCCC AGCTACTTAGGAGGTTGAGGCTGGGAGGATCACTTGAGCCCAGGAGTCTGAGGCTTTAGTGATCTAAGATCATGCCACTGCACTCCAGCC >27479_27479_5_ERP44-CCNB1IP1_ERP44_chr9_102778604_ENST00000262455_CCNB1IP1_chr14_20781960_ENST00000398169_length(amino acids)=482AA_BP=304 MEPGSRGRGAAAWRILRCRRLPEPSPFLTQPNLAQSQPPAPVPVTDPSVTMHPAVFLSLPDLRCSLLLLVTWVFTPVTTEITSLDTENID EILNNADVALVNFYADWCRFSQMLHPIFEEASDVIKEEFPNENQVVFARVDCDQHSDIAQRYRISKYPTLKLFRNGMMMKREYRGQRSVK ALADYIRQQKSDPIQEIRDLAEITTLDRSKRNIIGYFEQKDSDNYRVFERVANILHDDCAFLSAFGDVSKPERYSGDNIIYKPPGHSAPD MVYLGAMTNFDVTYNWIQDKCVPLVREITFENGEVHQERLYQEYNFSKAEGHLKQMEKIYTQQIQSKDVELTSMKGEVTSMKKVLEEYKK KFSDISEKLMERNRQYQKLQGLYDSLRLRNITIANHEGTLEPSMIAQSGVLGFPLGNNSKFPLDNTPVRNRGDGDGDFQFRPFFAGSPTA -------------------------------------------------------------- >27479_27479_6_ERP44-CCNB1IP1_ERP44_chr9_102778604_ENST00000262455_CCNB1IP1_chr14_20781960_ENST00000437553_length(transcript)=1678nt_BP=962nt GAAGTGAGGGTGTGAGAGGCCTCTCTGGAAGTTGTCCCGGGTGTTCGCCGCTGGAGCCCGGGTCGAGAGGACGAGGTGCCGCTGCCTGGA GAATCCTCCGCTGCCGTCGGCTCCCGGAGCCCAGCCCTTTCCTAACCCAACCCAACCTAGCCCAGTCCCAGCCGCCAGCGCCTGTCCCTG TCACGGACCCCAGCGTTACCATGCATCCTGCCGTCTTCCTATCCTTACCCGACCTCAGATGCTCCCTTCTGCTCCTGGTAACTTGGGTTT TTACTCCTGTAACAACTGAAATAACAAGTCTTGATACAGAGAATATAGATGAAATTTTAAACAATGCTGATGTTGCTTTAGTAAATTTTT ATGCTGACTGGTGTCGTTTCAGTCAGATGTTGCATCCAATTTTTGAGGAAGCTTCCGATGTCATTAAGGAAGAATTTCCAAATGAAAATC AAGTAGTGTTTGCCAGAGTTGATTGTGATCAGCACTCTGACATAGCCCAGAGATACAGGATAAGCAAATACCCAACCCTCAAATTGTTTC GTAATGGGATGATGATGAAGAGAGAATACAGGGGTCAGCGATCAGTGAAAGCATTGGCAGATTACATCAGGCAACAAAAAAGTGACCCCA TTCAAGAAATTCGGGACTTAGCAGAAATCACCACTCTTGATCGCAGCAAAAGAAATATCATTGGATATTTTGAGCAAAAGGACTCGGACA ACTATAGAGTTTTTGAACGAGTAGCGAATATTTTGCATGATGACTGTGCCTTTCTTTCTGCATTTGGGGATGTTTCAAAACCGGAAAGAT ATAGTGGCGACAACATAATCTACAAACCACCAGGGCATTCTGCTCCGGATATGGTGTACTTGGGAGCTATGACAAATTTTGATGTGACTT ACAATTGGATTCAAGATAAATGTGTTCCTCTTGTCCGAGAAATAACATTTGAAAATGGAGAGGTACATCAGGAACGTCTCTATCAAGAAT ACAATTTCAGCAAGGCTGAGGGCCATCTGAAACAGATGGAGAAGATATATACTCAGCAAATACAAAGCAAGGATGTAGAATTGACCTCTA TGAAAGGGGAGGTTACCTCCATGAAGAAAGTACTAGAAGAATACAAGAAAAAGTTCAGTGACATCTCTGAGAAACTTATGGAGCGCAATC GTCAGTATCAAAAGCTCCAAGGCCTCTATGATAGCCTTAGGCTACGAAACATCACTATTGCTAACCATGAAGGCACCCTTGAACCATCCA TGATTGCACAGTCTGGTGTTCTTGGCTTCCCATTAGGTAACAACTCCAAGTTTCCTTTGGATAATACACCTGTTCGAAATCGGGGCGATG GAGATGGAGATTTTCAGTTCAGACCATTTTTTGCGGGTTCTCCCACAGCACCTGAACCCAGCAACAGCTTTTTTAGTTTTGTCTCTCCAA GTCGTGAATTAGAGCAGCAGCAAGTTTCTAGCAGGGCCTTCAAAGTAAAAAGAATTTGAGCCACGCATAGTGTCACGCACCTGTGATCCC AGCTACTTAGGAGGTTGAGGCTGGGAGGATCACTTGAGCCCAGGAGTCTGAGGCTTTAGTGATCTAAGATCATGCCACTGCACTCCAGCC >27479_27479_6_ERP44-CCNB1IP1_ERP44_chr9_102778604_ENST00000262455_CCNB1IP1_chr14_20781960_ENST00000437553_length(amino acids)=482AA_BP=304 MEPGSRGRGAAAWRILRCRRLPEPSPFLTQPNLAQSQPPAPVPVTDPSVTMHPAVFLSLPDLRCSLLLLVTWVFTPVTTEITSLDTENID EILNNADVALVNFYADWCRFSQMLHPIFEEASDVIKEEFPNENQVVFARVDCDQHSDIAQRYRISKYPTLKLFRNGMMMKREYRGQRSVK ALADYIRQQKSDPIQEIRDLAEITTLDRSKRNIIGYFEQKDSDNYRVFERVANILHDDCAFLSAFGDVSKPERYSGDNIIYKPPGHSAPD MVYLGAMTNFDVTYNWIQDKCVPLVREITFENGEVHQERLYQEYNFSKAEGHLKQMEKIYTQQIQSKDVELTSMKGEVTSMKKVLEEYKK KFSDISEKLMERNRQYQKLQGLYDSLRLRNITIANHEGTLEPSMIAQSGVLGFPLGNNSKFPLDNTPVRNRGDGDGDFQFRPFFAGSPTA -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ERP44-CCNB1IP1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Hgene | ERP44 | chr9:102778604 | chr14:20781960 | ENST00000262455 | - | 8 | 12 | 236_285 | 254.0 | 407.0 | ITPR1 |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ERP44-CCNB1IP1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ERP44-CCNB1IP1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies