
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:EYA2-SYS1 (FusionGDB2 ID:28053) |
Fusion Gene Summary for EYA2-SYS1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: EYA2-SYS1 | Fusion gene ID: 28053 | Hgene | Tgene | Gene symbol | EYA2 | SYS1 | Gene ID | 2139 | 90196 |
| Gene name | EYA transcriptional coactivator and phosphatase 2 | SYS1 golgi trafficking protein | |
| Synonyms | EAB1 | C20orf169|dJ453C12.4|dJ453C12.4.1 | |
| Cytomap | 20q13.12 | 20q13.12 | |
| Type of gene | protein-coding | protein-coding | |
| Description | eyes absent homolog 2 | protein SYS1 homologSYS1 Golgi-localized integral membrane protein homolog | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | O00167 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000317304, ENST00000327619, ENST00000357410, ENST00000497428, | ENST00000479779, ENST00000243918, ENST00000372727, ENST00000414310, ENST00000426004, | |
| Fusion gene scores | * DoF score | 7 X 5 X 6=210 | 1 X 1 X 1=1 |
| # samples | 10 | 1 | |
| ** MAII score | log2(10/210*10)=-1.0703893278914 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(1/1*10)=3.32192809488736 | |
| Context | PubMed: EYA2 [Title/Abstract] AND SYS1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | EYA2(45725807)-SYS1(43994259), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | EYA2 | GO:0016576 | histone dephosphorylation | 19351884 |
| Fusion gene breakpoints across EYA2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across SYS1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | PRAD | TCGA-KK-A5A1-01A | EYA2 | chr20 | 45725807 | - | SYS1 | chr20 | 43994259 | + |
| ChimerDB4 | PRAD | TCGA-KK-A5A1-01A | EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994259 | + |
| ChimerDB4 | PRAD | TCGA-KK-A5A1 | EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994259 | + |
Top |
Fusion Gene ORF analysis for EYA2-SYS1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-3UTR | ENST00000317304 | ENST00000479779 | EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994259 | + |
| 5CDS-3UTR | ENST00000327619 | ENST00000479779 | EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994259 | + |
| 5CDS-3UTR | ENST00000357410 | ENST00000479779 | EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994259 | + |
| In-frame | ENST00000317304 | ENST00000243918 | EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994259 | + |
| In-frame | ENST00000317304 | ENST00000372727 | EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994259 | + |
| In-frame | ENST00000317304 | ENST00000414310 | EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994259 | + |
| In-frame | ENST00000317304 | ENST00000426004 | EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994259 | + |
| In-frame | ENST00000327619 | ENST00000243918 | EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994259 | + |
| In-frame | ENST00000327619 | ENST00000372727 | EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994259 | + |
| In-frame | ENST00000327619 | ENST00000414310 | EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994259 | + |
| In-frame | ENST00000327619 | ENST00000426004 | EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994259 | + |
| In-frame | ENST00000357410 | ENST00000243918 | EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994259 | + |
| In-frame | ENST00000357410 | ENST00000372727 | EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994259 | + |
| In-frame | ENST00000357410 | ENST00000414310 | EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994259 | + |
| In-frame | ENST00000357410 | ENST00000426004 | EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994259 | + |
| intron-3CDS | ENST00000497428 | ENST00000243918 | EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994259 | + |
| intron-3CDS | ENST00000497428 | ENST00000372727 | EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994259 | + |
| intron-3CDS | ENST00000497428 | ENST00000414310 | EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994259 | + |
| intron-3CDS | ENST00000497428 | ENST00000426004 | EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994259 | + |
| intron-3UTR | ENST00000497428 | ENST00000479779 | EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994259 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000357410 | EYA2 | chr20 | 45725807 | + | ENST00000372727 | SYS1 | chr20 | 43994259 | + | 1670 | 1262 | 68 | 1570 | 500 |
| ENST00000357410 | EYA2 | chr20 | 45725807 | + | ENST00000414310 | SYS1 | chr20 | 43994259 | + | 1681 | 1262 | 68 | 1570 | 500 |
| ENST00000357410 | EYA2 | chr20 | 45725807 | + | ENST00000243918 | SYS1 | chr20 | 43994259 | + | 3671 | 1262 | 68 | 1570 | 500 |
| ENST00000357410 | EYA2 | chr20 | 45725807 | + | ENST00000426004 | SYS1 | chr20 | 43994259 | + | 3835 | 1262 | 68 | 1330 | 420 |
| ENST00000327619 | EYA2 | chr20 | 45725807 | + | ENST00000372727 | SYS1 | chr20 | 43994259 | + | 1670 | 1262 | 68 | 1570 | 500 |
| ENST00000327619 | EYA2 | chr20 | 45725807 | + | ENST00000414310 | SYS1 | chr20 | 43994259 | + | 1681 | 1262 | 68 | 1570 | 500 |
| ENST00000327619 | EYA2 | chr20 | 45725807 | + | ENST00000243918 | SYS1 | chr20 | 43994259 | + | 3671 | 1262 | 68 | 1570 | 500 |
| ENST00000327619 | EYA2 | chr20 | 45725807 | + | ENST00000426004 | SYS1 | chr20 | 43994259 | + | 3835 | 1262 | 68 | 1330 | 420 |
| ENST00000317304 | EYA2 | chr20 | 45725807 | + | ENST00000372727 | SYS1 | chr20 | 43994259 | + | 1306 | 898 | 10 | 1206 | 398 |
| ENST00000317304 | EYA2 | chr20 | 45725807 | + | ENST00000414310 | SYS1 | chr20 | 43994259 | + | 1317 | 898 | 10 | 1206 | 398 |
| ENST00000317304 | EYA2 | chr20 | 45725807 | + | ENST00000243918 | SYS1 | chr20 | 43994259 | + | 3307 | 898 | 10 | 1206 | 398 |
| ENST00000317304 | EYA2 | chr20 | 45725807 | + | ENST00000426004 | SYS1 | chr20 | 43994259 | + | 3471 | 898 | 10 | 966 | 318 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000357410 | ENST00000372727 | EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994259 | + | 0.04362884 | 0.9563712 |
| ENST00000357410 | ENST00000414310 | EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994259 | + | 0.04174056 | 0.95825946 |
| ENST00000357410 | ENST00000243918 | EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994259 | + | 0.013665169 | 0.9863348 |
| ENST00000357410 | ENST00000426004 | EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994259 | + | 0.008157167 | 0.99184287 |
| ENST00000327619 | ENST00000372727 | EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994259 | + | 0.04362884 | 0.9563712 |
| ENST00000327619 | ENST00000414310 | EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994259 | + | 0.04174056 | 0.95825946 |
| ENST00000327619 | ENST00000243918 | EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994259 | + | 0.013665169 | 0.9863348 |
| ENST00000327619 | ENST00000426004 | EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994259 | + | 0.008157167 | 0.99184287 |
| ENST00000317304 | ENST00000372727 | EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994259 | + | 0.041327514 | 0.9586725 |
| ENST00000317304 | ENST00000414310 | EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994259 | + | 0.03853881 | 0.96146125 |
| ENST00000317304 | ENST00000243918 | EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994259 | + | 0.010659961 | 0.98934 |
| ENST00000317304 | ENST00000426004 | EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994259 | + | 0.007190853 | 0.9928092 |
Top |
Fusion Genomic Features for EYA2-SYS1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994258 | + | 0.01592812 | 0.9840719 |
| EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994258 | + | 0.01592812 | 0.9840719 |
| EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994258 | + | 0.01592812 | 0.9840719 |
| EYA2 | chr20 | 45725807 | + | SYS1 | chr20 | 43994258 | + | 0.01592812 | 0.9840719 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
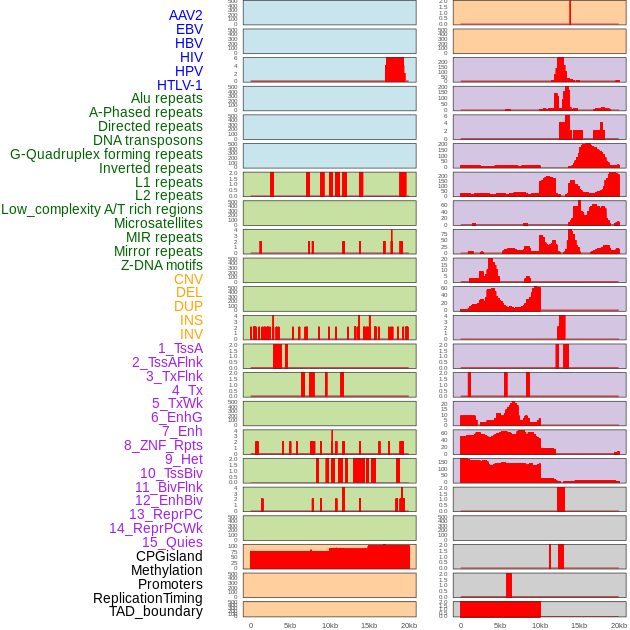 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
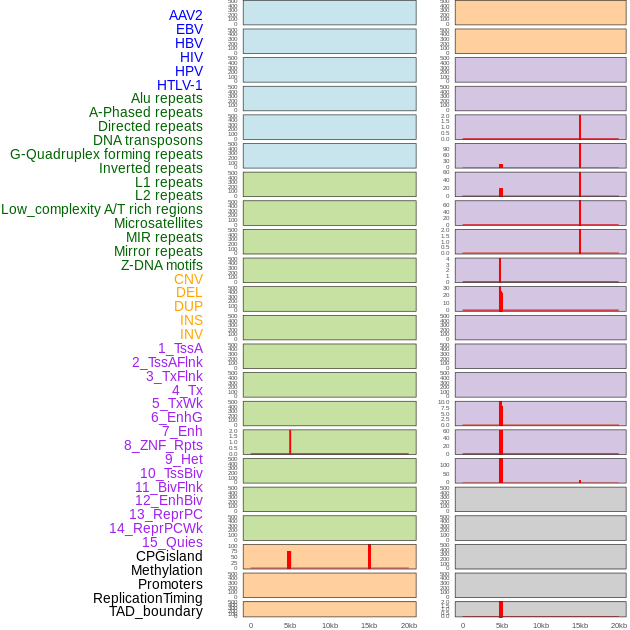 |
Top |
Fusion Protein Features for EYA2-SYS1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr20:45725807/chr20:43994259) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| EYA2 | . |
| FUNCTION: Functions both as protein phosphatase and as transcriptional coactivator for SIX1, and probably also for SIX2, SIX4 and SIX5 (PubMed:12500905, PubMed:23435380). Tyrosine phosphatase that dephosphorylates 'Tyr-142' of histone H2AX (H2AXY142ph) and promotes efficient DNA repair via the recruitment of DNA repair complexes containing MDC1. 'Tyr-142' phosphorylation of histone H2AX plays a central role in DNA repair and acts as a mark that distinguishes between apoptotic and repair responses to genotoxic stress (PubMed:19351884). Its function as histone phosphatase may contribute to its function in transcription regulation during organogenesis. Plays an important role in hypaxial muscle development together with SIX1 and DACH2; in this it is functionally redundant with EYA1 (PubMed:12500905). {ECO:0000269|PubMed:12500905, ECO:0000269|PubMed:19351884, ECO:0000269|PubMed:21706047, ECO:0000269|PubMed:23435380}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | SYS1 | chr20:45725807 | chr20:43994259 | ENST00000243918 | 1 | 4 | 113_133 | 54 | 157.0 | Transmembrane | Helical | |
| Tgene | SYS1 | chr20:45725807 | chr20:43994259 | ENST00000243918 | 1 | 4 | 65_85 | 54 | 157.0 | Transmembrane | Helical | |
| Tgene | SYS1 | chr20:45725807 | chr20:43994259 | ENST00000243918 | 1 | 4 | 91_111 | 54 | 157.0 | Transmembrane | Helical | |
| Tgene | SYS1 | chr20:45725807 | chr20:43994259 | ENST00000372727 | 2 | 5 | 113_133 | 54 | 157.0 | Transmembrane | Helical | |
| Tgene | SYS1 | chr20:45725807 | chr20:43994259 | ENST00000372727 | 2 | 5 | 65_85 | 54 | 157.0 | Transmembrane | Helical | |
| Tgene | SYS1 | chr20:45725807 | chr20:43994259 | ENST00000372727 | 2 | 5 | 91_111 | 54 | 157.0 | Transmembrane | Helical | |
| Tgene | SYS1 | chr20:45725807 | chr20:43994259 | ENST00000426004 | 1 | 4 | 113_133 | 54 | 77.0 | Transmembrane | Helical | |
| Tgene | SYS1 | chr20:45725807 | chr20:43994259 | ENST00000426004 | 1 | 4 | 65_85 | 54 | 77.0 | Transmembrane | Helical | |
| Tgene | SYS1 | chr20:45725807 | chr20:43994259 | ENST00000426004 | 1 | 4 | 91_111 | 54 | 77.0 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | SYS1 | chr20:45725807 | chr20:43994259 | ENST00000243918 | 1 | 4 | 13_33 | 54 | 157.0 | Transmembrane | Helical | |
| Tgene | SYS1 | chr20:45725807 | chr20:43994259 | ENST00000372727 | 2 | 5 | 13_33 | 54 | 157.0 | Transmembrane | Helical | |
| Tgene | SYS1 | chr20:45725807 | chr20:43994259 | ENST00000426004 | 1 | 4 | 13_33 | 54 | 77.0 | Transmembrane | Helical |
Top |
Fusion Gene Sequence for EYA2-SYS1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >28053_28053_1_EYA2-SYS1_EYA2_chr20_45725807_ENST00000317304_SYS1_chr20_43994259_ENST00000243918_length(transcript)=3307nt_BP=898nt GTACAAGGAAATGGTAGAACTAGTGATCTCACCCAGCCTCACTGTAAACAGCGATTGTCTGGATAAACTGAAGTTTAACCGTGCTGACGC TGCTGTGTGGACTCTGAGTGACAGACAAGGCATCACCAAATCGGCCCCCCTGAGAGTGTCCCAGCTCTTCTCCAGATCTTGCCCACGTGT CCTCCCCCGCCAGCCTTCCACAGCCATGGCAGCCTACGGCCAGACGCAGTACAGTGCGGGGATCCAGCAGGCTACCCCCTATACAGCTTA CCCACCTCCAGCACAAGCCTATGGAATCCCTTCCTACAGCATCAAGACAGAAGACAGCTTGAACCATTCCCCTGGCCAGAGTGGATTCCT CAGCTATGGCTCCAGCTTCAGCACCTCACCCACTGGACAGAGCCCATACACCTACCAGATGCACGGCACAACAGGGTTCTATCAAGGAGG AAATGGACTGGGCAACGCAGCCGGTTTCGGGAGTGTGCACCAGGACTATCCTTCCTACCCCGGCTTCCCCCAGAGCCAGTACCCCCAGTA TTACGGCTCATCCTACAACCCTCCCTACGTCCCGGCCAGCAGCATCTGCCCTTCGCCCCTCTCCACGTCCACCTACGTCCTCCAGGAGGC ATCTCACAACGTCCCCAACCAGAGTTCCGAGTCACTTGCTGGTGAATACAACACACACAATGGACCTTCCACACCAGCGAAAGAGGGAGA CACAGACAGGCCGCACCGGGCCTCCGACGGGAAGCTCCGAGGCCGGTCTAAGAGGAGCAGTGACCCGTCCCCGGCAGGGGACAATGAGAT TGAGCGTGTGTTCGTGTGGGACTTGGATGAGACAATAATTATTTTTCACTCCTTACTCACGGGGACATTTGCATCCAGATACGGGAAGAT CCTGGGCTTTTCCACCCCTCCAGGCCGGCTCTCCATGATGTCCTTCATCCTCAACGCCCTCACCTGTGCCCTGGGCTTGCTGTACTTCAT CCGGCGAGGAAAGCAGTGTCTGGATTTCACTGTCACTGTCCATTTCTTTCACCTCCTGGGCTGCTGGTTCTACAGCTCCCGTTTCCCCTC GGCGCTGACCTGGTGGCTGGTCCAAGCCGTGTGCATTGCACTCATGGCTGTCATCGGGGAGTACCTGTGCATGCGGACGGAGCTCAAGGA GATACCCCTCAACTCAGCCCCTAAATCCAATGTCTAGAATCAGGCCCTTTGGACATCCTGCTGACACTTGGGCCCCTTAACACCTTGGGC TGCTCAGACCCTCCAGATGAGGTCCAGCCCAGATCTGAGAGGAACCCTGGAAATGTGAAGTCTCTGTTGGTTTGGGAGAGATAGTGAGGG CCTGTCAAAGAAGGCAGGTAGCAGTCAGCATGACAGCTGCAAGAATGACCTCTGTCTGTTGAAGCCTTGGTATCTGAGAGGTCAGGAAGG GGACCTCTTTGAGGGTAATAACAGAATTGGAACCATGCCACTCTTGAGCCACAATACCTGTCACCAGCCTGTTGTTTTAAGAGAGAAAAA AAATCAAGGATATCTGATTGGAGCAAACCACTTCTTTAGTCATCTGTCTTACCCCCCTGGGACAGCTGTTACCTTTGCAGTGTTGCCGAA TCACAGCAGTTACCTTTGCAGTGTTGCCGAATCACAGCAGTTCTGTTGGAGAAACGCTTGGTTTCCGGATCCAGAGCCACAGAAAGAAAT GTAGGTGTGAAGTATTAGGCTGCTGTCAGGGAGAGGATGGCAGATGGAGGCATCAAGCACAAGGAAAATGCACAACCTGTGCCCTGTTAT ACACACGTTCATGTGCACCCAAGAACCTATGACTTTCTTCCAGTTCCTTCTACCAGGTCCCCATCCTGCTGCCAGCTCTCAACATAGCAG GCCATAGGACCCAGAGAAGAATCCCAGCGTTGCTCAAAGTCTAACCATCATAAAGACACTGCCTGTCTTCTAGGAATGACCAGGCACCCA GCTCCCACTGGACTCCAATTTTTTTTCCTGCCTTATTTAGAATTCTTTGGCGGGAAGGGTATGATGGGTTCCCAGAGACAAGAAGCCCAA CCTTCTGGCCTGGGCTGTGCTGATAGTGCTGAGGGAGATAGGAATTTGCTGCTAAGATTTTTCTTTGGGGTGGAGTTTCCTCTGTGAGGG GCTTGCAGCTATCCTTCCTGTGTATACAAATACAGTATTTTCCATGGTTCTGCCTGCACTTACTTTGTAATGCCACGGTTGAGATTGAGA GAGATCAGCGCAGCCAGGCAAGGGAACTTTAAAGAATTATTAGGCCACCTTCTCCCTTTCCTGGACCCCAGAGTCATTCCTCCATTTGGT TAAAATACTCAGTGCAGGGAACTCTTACATCCTGTCTCCTTCACTTGCAGCGTCCCCTGCTATGCCTCAGGTGAACCACATAATTCTTGG GTTTCCGTTCCTACTTGCTAGTGATTTCTGAACATGTTCAATGGAGCGGCACACAGTCTAGACCCACTTCCGCATTGAAACCTTCACTGT TCCTCTTTGGTTTCTTCAGAGCTTTCCCAAGAGAGCTGTCAGTTTTCAGCTGTCAGTAACACAAATGAGTTTATGGTAACACAAATGAGT TTTGCTATCTCTCTGAGAAGCTCATCTGACCTCCTGACTCTCAGCCCTACAGAGTAGGGAGTTGATGCTGACAGGATGAAGATTTAGGAA TAAATATGCCTGGGAAGAGACTGGGAAGGTTCTAGGGTGAGGCACCTCAGTAACTCATGGTACCTTGGCCAAGTTGGAAGGAAGCAGTTT GTTAATGAGGCACAGTAATCCTGGCTGCAGGGTCTAGGAGGTAAGACCAGCTGGGATGACCTTCCCTGGGTTAATCAATTTCCCTCTAGA CAACACAAACTGCAGGCATGTGACTAACTTTGAAAGAACACCCATCATGTGGCTGCTGTCACCCTTGACCAGCCGTGGTGGTGGTTACTC CATCTGTGGTTGGAGCGCCTCTTTGGGATTCACTTCAAGGTCTTGTGCCTATTTTTCTGCATATCTTCTGTGATGACAAATCTCTGTCCC CTGAGTGTTAATTTGATTTTTAGAAATGGCCAAAAGTCACGTGATCCAAACTTTTTTTCAGTAATATGGAGACTGAGCTGCATGGTAGTT GGGGATCAAAAATATGTGACCTTAATGAGATTTTTATGATTTCTAAAGTAACAATAAAAGCAGTTTTTAGAGTTGAGTTCCAGAGAGGGC >28053_28053_1_EYA2-SYS1_EYA2_chr20_45725807_ENST00000317304_SYS1_chr20_43994259_ENST00000243918_length(amino acids)=398AA_BP=296 MVELVISPSLTVNSDCLDKLKFNRADAAVWTLSDRQGITKSAPLRVSQLFSRSCPRVLPRQPSTAMAAYGQTQYSAGIQQATPYTAYPPP AQAYGIPSYSIKTEDSLNHSPGQSGFLSYGSSFSTSPTGQSPYTYQMHGTTGFYQGGNGLGNAAGFGSVHQDYPSYPGFPQSQYPQYYGS SYNPPYVPASSICPSPLSTSTYVLQEASHNVPNQSSESLAGEYNTHNGPSTPAKEGDTDRPHRASDGKLRGRSKRSSDPSPAGDNEIERV FVWDLDETIIIFHSLLTGTFASRYGKILGFSTPPGRLSMMSFILNALTCALGLLYFIRRGKQCLDFTVTVHFFHLLGCWFYSSRFPSALT -------------------------------------------------------------- >28053_28053_2_EYA2-SYS1_EYA2_chr20_45725807_ENST00000317304_SYS1_chr20_43994259_ENST00000372727_length(transcript)=1306nt_BP=898nt GTACAAGGAAATGGTAGAACTAGTGATCTCACCCAGCCTCACTGTAAACAGCGATTGTCTGGATAAACTGAAGTTTAACCGTGCTGACGC TGCTGTGTGGACTCTGAGTGACAGACAAGGCATCACCAAATCGGCCCCCCTGAGAGTGTCCCAGCTCTTCTCCAGATCTTGCCCACGTGT CCTCCCCCGCCAGCCTTCCACAGCCATGGCAGCCTACGGCCAGACGCAGTACAGTGCGGGGATCCAGCAGGCTACCCCCTATACAGCTTA CCCACCTCCAGCACAAGCCTATGGAATCCCTTCCTACAGCATCAAGACAGAAGACAGCTTGAACCATTCCCCTGGCCAGAGTGGATTCCT CAGCTATGGCTCCAGCTTCAGCACCTCACCCACTGGACAGAGCCCATACACCTACCAGATGCACGGCACAACAGGGTTCTATCAAGGAGG AAATGGACTGGGCAACGCAGCCGGTTTCGGGAGTGTGCACCAGGACTATCCTTCCTACCCCGGCTTCCCCCAGAGCCAGTACCCCCAGTA TTACGGCTCATCCTACAACCCTCCCTACGTCCCGGCCAGCAGCATCTGCCCTTCGCCCCTCTCCACGTCCACCTACGTCCTCCAGGAGGC ATCTCACAACGTCCCCAACCAGAGTTCCGAGTCACTTGCTGGTGAATACAACACACACAATGGACCTTCCACACCAGCGAAAGAGGGAGA CACAGACAGGCCGCACCGGGCCTCCGACGGGAAGCTCCGAGGCCGGTCTAAGAGGAGCAGTGACCCGTCCCCGGCAGGGGACAATGAGAT TGAGCGTGTGTTCGTGTGGGACTTGGATGAGACAATAATTATTTTTCACTCCTTACTCACGGGGACATTTGCATCCAGATACGGGAAGAT CCTGGGCTTTTCCACCCCTCCAGGCCGGCTCTCCATGATGTCCTTCATCCTCAACGCCCTCACCTGTGCCCTGGGCTTGCTGTACTTCAT CCGGCGAGGAAAGCAGTGTCTGGATTTCACTGTCACTGTCCATTTCTTTCACCTCCTGGGCTGCTGGTTCTACAGCTCCCGTTTCCCCTC GGCGCTGACCTGGTGGCTGGTCCAAGCCGTGTGCATTGCACTCATGGCTGTCATCGGGGAGTACCTGTGCATGCGGACGGAGCTCAAGGA GATACCCCTCAACTCAGCCCCTAAATCCAATGTCTAGAATCAGGCCCTTTGGACATCCTGCTGACACTTGGGCCCCTTAACACCTTGGGC >28053_28053_2_EYA2-SYS1_EYA2_chr20_45725807_ENST00000317304_SYS1_chr20_43994259_ENST00000372727_length(amino acids)=398AA_BP=296 MVELVISPSLTVNSDCLDKLKFNRADAAVWTLSDRQGITKSAPLRVSQLFSRSCPRVLPRQPSTAMAAYGQTQYSAGIQQATPYTAYPPP AQAYGIPSYSIKTEDSLNHSPGQSGFLSYGSSFSTSPTGQSPYTYQMHGTTGFYQGGNGLGNAAGFGSVHQDYPSYPGFPQSQYPQYYGS SYNPPYVPASSICPSPLSTSTYVLQEASHNVPNQSSESLAGEYNTHNGPSTPAKEGDTDRPHRASDGKLRGRSKRSSDPSPAGDNEIERV FVWDLDETIIIFHSLLTGTFASRYGKILGFSTPPGRLSMMSFILNALTCALGLLYFIRRGKQCLDFTVTVHFFHLLGCWFYSSRFPSALT -------------------------------------------------------------- >28053_28053_3_EYA2-SYS1_EYA2_chr20_45725807_ENST00000317304_SYS1_chr20_43994259_ENST00000414310_length(transcript)=1317nt_BP=898nt GTACAAGGAAATGGTAGAACTAGTGATCTCACCCAGCCTCACTGTAAACAGCGATTGTCTGGATAAACTGAAGTTTAACCGTGCTGACGC TGCTGTGTGGACTCTGAGTGACAGACAAGGCATCACCAAATCGGCCCCCCTGAGAGTGTCCCAGCTCTTCTCCAGATCTTGCCCACGTGT CCTCCCCCGCCAGCCTTCCACAGCCATGGCAGCCTACGGCCAGACGCAGTACAGTGCGGGGATCCAGCAGGCTACCCCCTATACAGCTTA CCCACCTCCAGCACAAGCCTATGGAATCCCTTCCTACAGCATCAAGACAGAAGACAGCTTGAACCATTCCCCTGGCCAGAGTGGATTCCT CAGCTATGGCTCCAGCTTCAGCACCTCACCCACTGGACAGAGCCCATACACCTACCAGATGCACGGCACAACAGGGTTCTATCAAGGAGG AAATGGACTGGGCAACGCAGCCGGTTTCGGGAGTGTGCACCAGGACTATCCTTCCTACCCCGGCTTCCCCCAGAGCCAGTACCCCCAGTA TTACGGCTCATCCTACAACCCTCCCTACGTCCCGGCCAGCAGCATCTGCCCTTCGCCCCTCTCCACGTCCACCTACGTCCTCCAGGAGGC ATCTCACAACGTCCCCAACCAGAGTTCCGAGTCACTTGCTGGTGAATACAACACACACAATGGACCTTCCACACCAGCGAAAGAGGGAGA CACAGACAGGCCGCACCGGGCCTCCGACGGGAAGCTCCGAGGCCGGTCTAAGAGGAGCAGTGACCCGTCCCCGGCAGGGGACAATGAGAT TGAGCGTGTGTTCGTGTGGGACTTGGATGAGACAATAATTATTTTTCACTCCTTACTCACGGGGACATTTGCATCCAGATACGGGAAGAT CCTGGGCTTTTCCACCCCTCCAGGCCGGCTCTCCATGATGTCCTTCATCCTCAACGCCCTCACCTGTGCCCTGGGCTTGCTGTACTTCAT CCGGCGAGGAAAGCAGTGTCTGGATTTCACTGTCACTGTCCATTTCTTTCACCTCCTGGGCTGCTGGTTCTACAGCTCCCGTTTCCCCTC GGCGCTGACCTGGTGGCTGGTCCAAGCCGTGTGCATTGCACTCATGGCTGTCATCGGGGAGTACCTGTGCATGCGGACGGAGCTCAAGGA GATACCCCTCAACTCAGCCCCTAAATCCAATGTCTAGAATCAGGCCCTTTGGACATCCTGCTGACACTTGGGCCCCTTAACACCTTGGGC >28053_28053_3_EYA2-SYS1_EYA2_chr20_45725807_ENST00000317304_SYS1_chr20_43994259_ENST00000414310_length(amino acids)=398AA_BP=296 MVELVISPSLTVNSDCLDKLKFNRADAAVWTLSDRQGITKSAPLRVSQLFSRSCPRVLPRQPSTAMAAYGQTQYSAGIQQATPYTAYPPP AQAYGIPSYSIKTEDSLNHSPGQSGFLSYGSSFSTSPTGQSPYTYQMHGTTGFYQGGNGLGNAAGFGSVHQDYPSYPGFPQSQYPQYYGS SYNPPYVPASSICPSPLSTSTYVLQEASHNVPNQSSESLAGEYNTHNGPSTPAKEGDTDRPHRASDGKLRGRSKRSSDPSPAGDNEIERV FVWDLDETIIIFHSLLTGTFASRYGKILGFSTPPGRLSMMSFILNALTCALGLLYFIRRGKQCLDFTVTVHFFHLLGCWFYSSRFPSALT -------------------------------------------------------------- >28053_28053_4_EYA2-SYS1_EYA2_chr20_45725807_ENST00000317304_SYS1_chr20_43994259_ENST00000426004_length(transcript)=3471nt_BP=898nt GTACAAGGAAATGGTAGAACTAGTGATCTCACCCAGCCTCACTGTAAACAGCGATTGTCTGGATAAACTGAAGTTTAACCGTGCTGACGC TGCTGTGTGGACTCTGAGTGACAGACAAGGCATCACCAAATCGGCCCCCCTGAGAGTGTCCCAGCTCTTCTCCAGATCTTGCCCACGTGT CCTCCCCCGCCAGCCTTCCACAGCCATGGCAGCCTACGGCCAGACGCAGTACAGTGCGGGGATCCAGCAGGCTACCCCCTATACAGCTTA CCCACCTCCAGCACAAGCCTATGGAATCCCTTCCTACAGCATCAAGACAGAAGACAGCTTGAACCATTCCCCTGGCCAGAGTGGATTCCT CAGCTATGGCTCCAGCTTCAGCACCTCACCCACTGGACAGAGCCCATACACCTACCAGATGCACGGCACAACAGGGTTCTATCAAGGAGG AAATGGACTGGGCAACGCAGCCGGTTTCGGGAGTGTGCACCAGGACTATCCTTCCTACCCCGGCTTCCCCCAGAGCCAGTACCCCCAGTA TTACGGCTCATCCTACAACCCTCCCTACGTCCCGGCCAGCAGCATCTGCCCTTCGCCCCTCTCCACGTCCACCTACGTCCTCCAGGAGGC ATCTCACAACGTCCCCAACCAGAGTTCCGAGTCACTTGCTGGTGAATACAACACACACAATGGACCTTCCACACCAGCGAAAGAGGGAGA CACAGACAGGCCGCACCGGGCCTCCGACGGGAAGCTCCGAGGCCGGTCTAAGAGGAGCAGTGACCCGTCCCCGGCAGGGGACAATGAGAT TGAGCGTGTGTTCGTGTGGGACTTGGATGAGACAATAATTATTTTTCACTCCTTACTCACGGGGACATTTGCATCCAGATACGGGAAGAT CCTGGGCTTTTCCACCCCTCCAGGCCGGCTCTCCATGATGTCCTTCATCCTCAACGCCCTCACCTGACAGGGTCTTGCTCTCTTGCCCAG GCTGGAGTGCAGTGGCGAAGTCACAGCTCACTGCAGCCTCGACTCCTGGGCTTAAGCGATCCTCCGACCTCAGCCTCCTGAGTAGCTGAT ACTACAAGCGCAAGGCACCACATCTGGCTAATTTTTAAATTTTTTGTAGAGACAGTGTCTCATTATGTTGCCCAGGATGGTCTTGAACTC CTGGCCTCAAGCAGTCTTCCTGCCTCGACCTCCCAAGGTGCTGGGATTACAGGCGTGAGCCACCATGCCTAGCCTGTTCAGAGTAAATCT TATTTGAGGCATGAATCAATCAAACATAAATAGAGAGTTGAATTGATCTTAGAGGGAATGGGATGCAGCAAAGCCCTACTTGACCATCTC CCCCCTCCCACATTTGGAAATCCTTAAACCCACTTATGTAGGCCTCTGACTGTGAGATTCAGAGCCACAGCAGTTTCCACCTCTGCTAAG GCCTTCAGGCAGTGAGATGGCTCACTTCAGTGCCCCTCCTTCCACACATCTCCTAGCTGTATCCTGAGACGCCTCAACCTAGTCACTACC CTTCTGTATGATGTTGGTCTAAGGCTTCCCCCTCTCTGGACATGAAGGCGGAGCCTCCCAGCACTACCAGCCACACACCACTCAAGACTC CAGATCCTGAACCCTGACTCTGGGGCCCAGCTCTGGGCCTGGCTTGGGGCTTGCATCTCACCTAGCCTGGCAGTGTTGTTGTCACACCCA CCTTGTATGGATGCCACATAGGCATTTCAAGTGATGCGGAGCAGAAGCGGGTGCAGCGGCGCTTGACCCAACGCAGGGTGGAGGATCTGC ACATCACCCTGGGCGCCGGGAGGTGGATTCGTGTGGGCAGCCCCTCAAACCAGATCCACTGGTCGGCTACATCCAGCTGCTTCATGTGCC CCATGGGAGTTCTATTGCGGTAGGGCTTAATGAAGATGACTCGGGGGCCCTCGGTGAGTGGTTGCCTCCCCTGGACTCCAGGGTTCAAGC TATCATCCCTCGATGTCCTTGGAACCTCAGGCTCTATATGCTTTTCTTTCCGTGGCATTGCCGCCAATGACGTTTTCTCCTTGTTCCTCA TCCCTGACTGCACCTGGGACTTCCACTCCTTGTACTCTTTTTTCTTAGGGTCCCCTGTGGACTCTAATTTCTTGGACTTGAGTTCCTTCT CGGAGCACCCGATCTCCTGGAACTCTTCATTATTTTGTTTTGTTTTATTGCAGGCACTGTTTTCCCTGGCAGGGAGAGGAAAGGCAGTCA GCACAGCAGGACCGAGGCCCTGGTTCCCGAGACAGTTGCTATGTAGCCAGCTCAGGGGAGCCTGTTAAGAAAGGCTAGAGGGGCCTGCAA AGAAACTTCTCTACTGCCCAGAGGCCTTGTGCTGGTGTGAGGAGGTGTGATGAGCACTAGCAGAGGGATGTGAGAGATTGGGAAGGTGAA AGCCATGACTAGTAGTTAAGGCCCCTAAGAATGAATATTGTCTACATCATCTGCCACTAGATTAGGGTTCTGTCTCTCTGGACTTCAGCT GGGAGGGTGAACAGTCCAGTAGTTTTTCTAAATTGTGCTCCAAGAACCTTAGGGTTCTGAGGAGGTGTCTCAATGTCACCTCCCCTGACC CACTGGGGCAGGATACCTCTCCCCAGCTCATAACAACACAATTGGGGCTTGGAAATAGATATTTGAACAGAGGTTTCACTGCTTTAATAA AGTTGGAAAACTGTTCAAGACCAGCCTGGGCAACATGGTGAGACTCTGTCTCCATACAAAAAAAAAATTTTTAAGTTGGAAAATGATGGG GCTAGATGATCCTGATCCTTCTAGCTCTATGTTTCCTGATTGCCTGCGACTAGAGGCCAAATCAGAAAGAGGAGCCCAGAAAGGTGGCCT TGACAGAAATATTAAATGCTGAGACTTTCCCAAAGGGTGTCTGTAACAGACTGGGCCCCCTGCAAACCCCCAGTGGCAACACCATCCTAG CCAAGGGCGTGGAGAGAGATGAGGCCTTGGGCTGCAGATAATGGCAATACTGTGATGATAATAATGGCTCCCGCTGATTGAGTCCTCGCT CTATGCCAGACTCGGGACCCTTACAACTTGGGATCCTTACTATTTCTGTGAAGTAGAAGGCAGTGAAACAGAGTGGCTTACAGAGCACAG GTGTTGGATTCAGACAAACGGGCTCAGATTCTGCTTCTGCCTCTTACCACCTGTGTGATTTGGGCAAGATATTTAACCTCTCAGAGCCTT AGCTTCCTTATCTGTAAAACTAGGATAATTCTGTCTACCTAACAGGATTGTTGTGAAGAATAAACTAAATGGGAAAATTCTTAAGTGCTT AACACTGTAGGATGGTACTTAGCAGGCACCAATCAATGTTAGCTTTCTTAATACTGTCATGTGACTTATGAGGAAACGGTTTGAACTTGT >28053_28053_4_EYA2-SYS1_EYA2_chr20_45725807_ENST00000317304_SYS1_chr20_43994259_ENST00000426004_length(amino acids)=318AA_BP=296 MVELVISPSLTVNSDCLDKLKFNRADAAVWTLSDRQGITKSAPLRVSQLFSRSCPRVLPRQPSTAMAAYGQTQYSAGIQQATPYTAYPPP AQAYGIPSYSIKTEDSLNHSPGQSGFLSYGSSFSTSPTGQSPYTYQMHGTTGFYQGGNGLGNAAGFGSVHQDYPSYPGFPQSQYPQYYGS SYNPPYVPASSICPSPLSTSTYVLQEASHNVPNQSSESLAGEYNTHNGPSTPAKEGDTDRPHRASDGKLRGRSKRSSDPSPAGDNEIERV -------------------------------------------------------------- >28053_28053_5_EYA2-SYS1_EYA2_chr20_45725807_ENST00000327619_SYS1_chr20_43994259_ENST00000243918_length(transcript)=3671nt_BP=1262nt GCGCGCTCTGCTCGGCTGCAGGCTCAGGAAGCGGCGCGGCGGCACGTGCTGGGCCAGAGCCCCGCGCCCTGCGTCCAGCCGCCGGGTGTG TGCGCCCGCGTAGCCCAGCGTCGCGCCTCGGCGCCCCCACGCGCCCACGCAGCGGCGCGGGGACCCGGGCGGGGGCAGAGGGAGGGCCCG GCCCAGGGAGGAGAAGGGGCCGGTCCTCCCGGCGCAGGCAGCAGCCGCGGCAGCCCAGGAGGCGGAGGCAGCGGCAACGGCAGAGACAGC AACGTGCCCGCCGCAGTCAGCCCGGCCTCGTCGGACCCGCACCGGCCCGCCCGCCCGCCCGCACCGCGTCGGGGCGCCCTCTCCACTGCG CGCGGTACAAGGAAATGGTAGAACTAGTGATCTCACCCAGCCTCACTGTAAACAGCGATTGTCTGGATAAACTGAAGTTTAACCGTGCTG ACGCTGCTGTGTGGACTCTGAGTGACAGACAAGGCATCACCAAATCGGCCCCCCTGAGAGTGTCCCAGCTCTTCTCCAGATCTTGCCCAC GTGTCCTCCCCCGCCAGCCTTCCACAGCCATGGCAGCCTACGGCCAGACGCAGTACAGTGCGGGGATCCAGCAGGCTACCCCCTATACAG CTTACCCACCTCCAGCACAAGCCTATGGAATCCCTTCCTACAGCATCAAGACAGAAGACAGCTTGAACCATTCCCCTGGCCAGAGTGGAT TCCTCAGCTATGGCTCCAGCTTCAGCACCTCACCCACTGGACAGAGCCCATACACCTACCAGATGCACGGCACAACAGGGTTCTATCAAG GAGGAAATGGACTGGGCAACGCAGCCGGTTTCGGGAGTGTGCACCAGGACTATCCTTCCTACCCCGGCTTCCCCCAGAGCCAGTACCCCC AGTATTACGGCTCATCCTACAACCCTCCCTACGTCCCGGCCAGCAGCATCTGCCCTTCGCCCCTCTCCACGTCCACCTACGTCCTCCAGG AGGCATCTCACAACGTCCCCAACCAGAGTTCCGAGTCACTTGCTGGTGAATACAACACACACAATGGACCTTCCACACCAGCGAAAGAGG GAGACACAGACAGGCCGCACCGGGCCTCCGACGGGAAGCTCCGAGGCCGGTCTAAGAGGAGCAGTGACCCGTCCCCGGCAGGGGACAATG AGATTGAGCGTGTGTTCGTGTGGGACTTGGATGAGACAATAATTATTTTTCACTCCTTACTCACGGGGACATTTGCATCCAGATACGGGA AGATCCTGGGCTTTTCCACCCCTCCAGGCCGGCTCTCCATGATGTCCTTCATCCTCAACGCCCTCACCTGTGCCCTGGGCTTGCTGTACT TCATCCGGCGAGGAAAGCAGTGTCTGGATTTCACTGTCACTGTCCATTTCTTTCACCTCCTGGGCTGCTGGTTCTACAGCTCCCGTTTCC CCTCGGCGCTGACCTGGTGGCTGGTCCAAGCCGTGTGCATTGCACTCATGGCTGTCATCGGGGAGTACCTGTGCATGCGGACGGAGCTCA AGGAGATACCCCTCAACTCAGCCCCTAAATCCAATGTCTAGAATCAGGCCCTTTGGACATCCTGCTGACACTTGGGCCCCTTAACACCTT GGGCTGCTCAGACCCTCCAGATGAGGTCCAGCCCAGATCTGAGAGGAACCCTGGAAATGTGAAGTCTCTGTTGGTTTGGGAGAGATAGTG AGGGCCTGTCAAAGAAGGCAGGTAGCAGTCAGCATGACAGCTGCAAGAATGACCTCTGTCTGTTGAAGCCTTGGTATCTGAGAGGTCAGG AAGGGGACCTCTTTGAGGGTAATAACAGAATTGGAACCATGCCACTCTTGAGCCACAATACCTGTCACCAGCCTGTTGTTTTAAGAGAGA AAAAAAATCAAGGATATCTGATTGGAGCAAACCACTTCTTTAGTCATCTGTCTTACCCCCCTGGGACAGCTGTTACCTTTGCAGTGTTGC CGAATCACAGCAGTTACCTTTGCAGTGTTGCCGAATCACAGCAGTTCTGTTGGAGAAACGCTTGGTTTCCGGATCCAGAGCCACAGAAAG AAATGTAGGTGTGAAGTATTAGGCTGCTGTCAGGGAGAGGATGGCAGATGGAGGCATCAAGCACAAGGAAAATGCACAACCTGTGCCCTG TTATACACACGTTCATGTGCACCCAAGAACCTATGACTTTCTTCCAGTTCCTTCTACCAGGTCCCCATCCTGCTGCCAGCTCTCAACATA GCAGGCCATAGGACCCAGAGAAGAATCCCAGCGTTGCTCAAAGTCTAACCATCATAAAGACACTGCCTGTCTTCTAGGAATGACCAGGCA CCCAGCTCCCACTGGACTCCAATTTTTTTTCCTGCCTTATTTAGAATTCTTTGGCGGGAAGGGTATGATGGGTTCCCAGAGACAAGAAGC CCAACCTTCTGGCCTGGGCTGTGCTGATAGTGCTGAGGGAGATAGGAATTTGCTGCTAAGATTTTTCTTTGGGGTGGAGTTTCCTCTGTG AGGGGCTTGCAGCTATCCTTCCTGTGTATACAAATACAGTATTTTCCATGGTTCTGCCTGCACTTACTTTGTAATGCCACGGTTGAGATT GAGAGAGATCAGCGCAGCCAGGCAAGGGAACTTTAAAGAATTATTAGGCCACCTTCTCCCTTTCCTGGACCCCAGAGTCATTCCTCCATT TGGTTAAAATACTCAGTGCAGGGAACTCTTACATCCTGTCTCCTTCACTTGCAGCGTCCCCTGCTATGCCTCAGGTGAACCACATAATTC TTGGGTTTCCGTTCCTACTTGCTAGTGATTTCTGAACATGTTCAATGGAGCGGCACACAGTCTAGACCCACTTCCGCATTGAAACCTTCA CTGTTCCTCTTTGGTTTCTTCAGAGCTTTCCCAAGAGAGCTGTCAGTTTTCAGCTGTCAGTAACACAAATGAGTTTATGGTAACACAAAT GAGTTTTGCTATCTCTCTGAGAAGCTCATCTGACCTCCTGACTCTCAGCCCTACAGAGTAGGGAGTTGATGCTGACAGGATGAAGATTTA GGAATAAATATGCCTGGGAAGAGACTGGGAAGGTTCTAGGGTGAGGCACCTCAGTAACTCATGGTACCTTGGCCAAGTTGGAAGGAAGCA GTTTGTTAATGAGGCACAGTAATCCTGGCTGCAGGGTCTAGGAGGTAAGACCAGCTGGGATGACCTTCCCTGGGTTAATCAATTTCCCTC TAGACAACACAAACTGCAGGCATGTGACTAACTTTGAAAGAACACCCATCATGTGGCTGCTGTCACCCTTGACCAGCCGTGGTGGTGGTT ACTCCATCTGTGGTTGGAGCGCCTCTTTGGGATTCACTTCAAGGTCTTGTGCCTATTTTTCTGCATATCTTCTGTGATGACAAATCTCTG TCCCCTGAGTGTTAATTTGATTTTTAGAAATGGCCAAAAGTCACGTGATCCAAACTTTTTTTCAGTAATATGGAGACTGAGCTGCATGGT AGTTGGGGATCAAAAATATGTGACCTTAATGAGATTTTTATGATTTCTAAAGTAACAATAAAAGCAGTTTTTAGAGTTGAGTTCCAGAGA >28053_28053_5_EYA2-SYS1_EYA2_chr20_45725807_ENST00000327619_SYS1_chr20_43994259_ENST00000243918_length(amino acids)=500AA_BP=398 MRPAAGCVRPRSPASRLGAPTRPRSGAGTRAGAEGGPGPGRRRGRSSRRRQQPRQPRRRRQRQRQRQQRARRSQPGLVGPAPARPPARTA SGRPLHCARYKEMVELVISPSLTVNSDCLDKLKFNRADAAVWTLSDRQGITKSAPLRVSQLFSRSCPRVLPRQPSTAMAAYGQTQYSAGI QQATPYTAYPPPAQAYGIPSYSIKTEDSLNHSPGQSGFLSYGSSFSTSPTGQSPYTYQMHGTTGFYQGGNGLGNAAGFGSVHQDYPSYPG FPQSQYPQYYGSSYNPPYVPASSICPSPLSTSTYVLQEASHNVPNQSSESLAGEYNTHNGPSTPAKEGDTDRPHRASDGKLRGRSKRSSD PSPAGDNEIERVFVWDLDETIIIFHSLLTGTFASRYGKILGFSTPPGRLSMMSFILNALTCALGLLYFIRRGKQCLDFTVTVHFFHLLGC -------------------------------------------------------------- >28053_28053_6_EYA2-SYS1_EYA2_chr20_45725807_ENST00000327619_SYS1_chr20_43994259_ENST00000372727_length(transcript)=1670nt_BP=1262nt GCGCGCTCTGCTCGGCTGCAGGCTCAGGAAGCGGCGCGGCGGCACGTGCTGGGCCAGAGCCCCGCGCCCTGCGTCCAGCCGCCGGGTGTG TGCGCCCGCGTAGCCCAGCGTCGCGCCTCGGCGCCCCCACGCGCCCACGCAGCGGCGCGGGGACCCGGGCGGGGGCAGAGGGAGGGCCCG GCCCAGGGAGGAGAAGGGGCCGGTCCTCCCGGCGCAGGCAGCAGCCGCGGCAGCCCAGGAGGCGGAGGCAGCGGCAACGGCAGAGACAGC AACGTGCCCGCCGCAGTCAGCCCGGCCTCGTCGGACCCGCACCGGCCCGCCCGCCCGCCCGCACCGCGTCGGGGCGCCCTCTCCACTGCG CGCGGTACAAGGAAATGGTAGAACTAGTGATCTCACCCAGCCTCACTGTAAACAGCGATTGTCTGGATAAACTGAAGTTTAACCGTGCTG ACGCTGCTGTGTGGACTCTGAGTGACAGACAAGGCATCACCAAATCGGCCCCCCTGAGAGTGTCCCAGCTCTTCTCCAGATCTTGCCCAC GTGTCCTCCCCCGCCAGCCTTCCACAGCCATGGCAGCCTACGGCCAGACGCAGTACAGTGCGGGGATCCAGCAGGCTACCCCCTATACAG CTTACCCACCTCCAGCACAAGCCTATGGAATCCCTTCCTACAGCATCAAGACAGAAGACAGCTTGAACCATTCCCCTGGCCAGAGTGGAT TCCTCAGCTATGGCTCCAGCTTCAGCACCTCACCCACTGGACAGAGCCCATACACCTACCAGATGCACGGCACAACAGGGTTCTATCAAG GAGGAAATGGACTGGGCAACGCAGCCGGTTTCGGGAGTGTGCACCAGGACTATCCTTCCTACCCCGGCTTCCCCCAGAGCCAGTACCCCC AGTATTACGGCTCATCCTACAACCCTCCCTACGTCCCGGCCAGCAGCATCTGCCCTTCGCCCCTCTCCACGTCCACCTACGTCCTCCAGG AGGCATCTCACAACGTCCCCAACCAGAGTTCCGAGTCACTTGCTGGTGAATACAACACACACAATGGACCTTCCACACCAGCGAAAGAGG GAGACACAGACAGGCCGCACCGGGCCTCCGACGGGAAGCTCCGAGGCCGGTCTAAGAGGAGCAGTGACCCGTCCCCGGCAGGGGACAATG AGATTGAGCGTGTGTTCGTGTGGGACTTGGATGAGACAATAATTATTTTTCACTCCTTACTCACGGGGACATTTGCATCCAGATACGGGA AGATCCTGGGCTTTTCCACCCCTCCAGGCCGGCTCTCCATGATGTCCTTCATCCTCAACGCCCTCACCTGTGCCCTGGGCTTGCTGTACT TCATCCGGCGAGGAAAGCAGTGTCTGGATTTCACTGTCACTGTCCATTTCTTTCACCTCCTGGGCTGCTGGTTCTACAGCTCCCGTTTCC CCTCGGCGCTGACCTGGTGGCTGGTCCAAGCCGTGTGCATTGCACTCATGGCTGTCATCGGGGAGTACCTGTGCATGCGGACGGAGCTCA AGGAGATACCCCTCAACTCAGCCCCTAAATCCAATGTCTAGAATCAGGCCCTTTGGACATCCTGCTGACACTTGGGCCCCTTAACACCTT >28053_28053_6_EYA2-SYS1_EYA2_chr20_45725807_ENST00000327619_SYS1_chr20_43994259_ENST00000372727_length(amino acids)=500AA_BP=398 MRPAAGCVRPRSPASRLGAPTRPRSGAGTRAGAEGGPGPGRRRGRSSRRRQQPRQPRRRRQRQRQRQQRARRSQPGLVGPAPARPPARTA SGRPLHCARYKEMVELVISPSLTVNSDCLDKLKFNRADAAVWTLSDRQGITKSAPLRVSQLFSRSCPRVLPRQPSTAMAAYGQTQYSAGI QQATPYTAYPPPAQAYGIPSYSIKTEDSLNHSPGQSGFLSYGSSFSTSPTGQSPYTYQMHGTTGFYQGGNGLGNAAGFGSVHQDYPSYPG FPQSQYPQYYGSSYNPPYVPASSICPSPLSTSTYVLQEASHNVPNQSSESLAGEYNTHNGPSTPAKEGDTDRPHRASDGKLRGRSKRSSD PSPAGDNEIERVFVWDLDETIIIFHSLLTGTFASRYGKILGFSTPPGRLSMMSFILNALTCALGLLYFIRRGKQCLDFTVTVHFFHLLGC -------------------------------------------------------------- >28053_28053_7_EYA2-SYS1_EYA2_chr20_45725807_ENST00000327619_SYS1_chr20_43994259_ENST00000414310_length(transcript)=1681nt_BP=1262nt GCGCGCTCTGCTCGGCTGCAGGCTCAGGAAGCGGCGCGGCGGCACGTGCTGGGCCAGAGCCCCGCGCCCTGCGTCCAGCCGCCGGGTGTG TGCGCCCGCGTAGCCCAGCGTCGCGCCTCGGCGCCCCCACGCGCCCACGCAGCGGCGCGGGGACCCGGGCGGGGGCAGAGGGAGGGCCCG GCCCAGGGAGGAGAAGGGGCCGGTCCTCCCGGCGCAGGCAGCAGCCGCGGCAGCCCAGGAGGCGGAGGCAGCGGCAACGGCAGAGACAGC AACGTGCCCGCCGCAGTCAGCCCGGCCTCGTCGGACCCGCACCGGCCCGCCCGCCCGCCCGCACCGCGTCGGGGCGCCCTCTCCACTGCG CGCGGTACAAGGAAATGGTAGAACTAGTGATCTCACCCAGCCTCACTGTAAACAGCGATTGTCTGGATAAACTGAAGTTTAACCGTGCTG ACGCTGCTGTGTGGACTCTGAGTGACAGACAAGGCATCACCAAATCGGCCCCCCTGAGAGTGTCCCAGCTCTTCTCCAGATCTTGCCCAC GTGTCCTCCCCCGCCAGCCTTCCACAGCCATGGCAGCCTACGGCCAGACGCAGTACAGTGCGGGGATCCAGCAGGCTACCCCCTATACAG CTTACCCACCTCCAGCACAAGCCTATGGAATCCCTTCCTACAGCATCAAGACAGAAGACAGCTTGAACCATTCCCCTGGCCAGAGTGGAT TCCTCAGCTATGGCTCCAGCTTCAGCACCTCACCCACTGGACAGAGCCCATACACCTACCAGATGCACGGCACAACAGGGTTCTATCAAG GAGGAAATGGACTGGGCAACGCAGCCGGTTTCGGGAGTGTGCACCAGGACTATCCTTCCTACCCCGGCTTCCCCCAGAGCCAGTACCCCC AGTATTACGGCTCATCCTACAACCCTCCCTACGTCCCGGCCAGCAGCATCTGCCCTTCGCCCCTCTCCACGTCCACCTACGTCCTCCAGG AGGCATCTCACAACGTCCCCAACCAGAGTTCCGAGTCACTTGCTGGTGAATACAACACACACAATGGACCTTCCACACCAGCGAAAGAGG GAGACACAGACAGGCCGCACCGGGCCTCCGACGGGAAGCTCCGAGGCCGGTCTAAGAGGAGCAGTGACCCGTCCCCGGCAGGGGACAATG AGATTGAGCGTGTGTTCGTGTGGGACTTGGATGAGACAATAATTATTTTTCACTCCTTACTCACGGGGACATTTGCATCCAGATACGGGA AGATCCTGGGCTTTTCCACCCCTCCAGGCCGGCTCTCCATGATGTCCTTCATCCTCAACGCCCTCACCTGTGCCCTGGGCTTGCTGTACT TCATCCGGCGAGGAAAGCAGTGTCTGGATTTCACTGTCACTGTCCATTTCTTTCACCTCCTGGGCTGCTGGTTCTACAGCTCCCGTTTCC CCTCGGCGCTGACCTGGTGGCTGGTCCAAGCCGTGTGCATTGCACTCATGGCTGTCATCGGGGAGTACCTGTGCATGCGGACGGAGCTCA AGGAGATACCCCTCAACTCAGCCCCTAAATCCAATGTCTAGAATCAGGCCCTTTGGACATCCTGCTGACACTTGGGCCCCTTAACACCTT >28053_28053_7_EYA2-SYS1_EYA2_chr20_45725807_ENST00000327619_SYS1_chr20_43994259_ENST00000414310_length(amino acids)=500AA_BP=398 MRPAAGCVRPRSPASRLGAPTRPRSGAGTRAGAEGGPGPGRRRGRSSRRRQQPRQPRRRRQRQRQRQQRARRSQPGLVGPAPARPPARTA SGRPLHCARYKEMVELVISPSLTVNSDCLDKLKFNRADAAVWTLSDRQGITKSAPLRVSQLFSRSCPRVLPRQPSTAMAAYGQTQYSAGI QQATPYTAYPPPAQAYGIPSYSIKTEDSLNHSPGQSGFLSYGSSFSTSPTGQSPYTYQMHGTTGFYQGGNGLGNAAGFGSVHQDYPSYPG FPQSQYPQYYGSSYNPPYVPASSICPSPLSTSTYVLQEASHNVPNQSSESLAGEYNTHNGPSTPAKEGDTDRPHRASDGKLRGRSKRSSD PSPAGDNEIERVFVWDLDETIIIFHSLLTGTFASRYGKILGFSTPPGRLSMMSFILNALTCALGLLYFIRRGKQCLDFTVTVHFFHLLGC -------------------------------------------------------------- >28053_28053_8_EYA2-SYS1_EYA2_chr20_45725807_ENST00000327619_SYS1_chr20_43994259_ENST00000426004_length(transcript)=3835nt_BP=1262nt GCGCGCTCTGCTCGGCTGCAGGCTCAGGAAGCGGCGCGGCGGCACGTGCTGGGCCAGAGCCCCGCGCCCTGCGTCCAGCCGCCGGGTGTG TGCGCCCGCGTAGCCCAGCGTCGCGCCTCGGCGCCCCCACGCGCCCACGCAGCGGCGCGGGGACCCGGGCGGGGGCAGAGGGAGGGCCCG GCCCAGGGAGGAGAAGGGGCCGGTCCTCCCGGCGCAGGCAGCAGCCGCGGCAGCCCAGGAGGCGGAGGCAGCGGCAACGGCAGAGACAGC AACGTGCCCGCCGCAGTCAGCCCGGCCTCGTCGGACCCGCACCGGCCCGCCCGCCCGCCCGCACCGCGTCGGGGCGCCCTCTCCACTGCG CGCGGTACAAGGAAATGGTAGAACTAGTGATCTCACCCAGCCTCACTGTAAACAGCGATTGTCTGGATAAACTGAAGTTTAACCGTGCTG ACGCTGCTGTGTGGACTCTGAGTGACAGACAAGGCATCACCAAATCGGCCCCCCTGAGAGTGTCCCAGCTCTTCTCCAGATCTTGCCCAC GTGTCCTCCCCCGCCAGCCTTCCACAGCCATGGCAGCCTACGGCCAGACGCAGTACAGTGCGGGGATCCAGCAGGCTACCCCCTATACAG CTTACCCACCTCCAGCACAAGCCTATGGAATCCCTTCCTACAGCATCAAGACAGAAGACAGCTTGAACCATTCCCCTGGCCAGAGTGGAT TCCTCAGCTATGGCTCCAGCTTCAGCACCTCACCCACTGGACAGAGCCCATACACCTACCAGATGCACGGCACAACAGGGTTCTATCAAG GAGGAAATGGACTGGGCAACGCAGCCGGTTTCGGGAGTGTGCACCAGGACTATCCTTCCTACCCCGGCTTCCCCCAGAGCCAGTACCCCC AGTATTACGGCTCATCCTACAACCCTCCCTACGTCCCGGCCAGCAGCATCTGCCCTTCGCCCCTCTCCACGTCCACCTACGTCCTCCAGG AGGCATCTCACAACGTCCCCAACCAGAGTTCCGAGTCACTTGCTGGTGAATACAACACACACAATGGACCTTCCACACCAGCGAAAGAGG GAGACACAGACAGGCCGCACCGGGCCTCCGACGGGAAGCTCCGAGGCCGGTCTAAGAGGAGCAGTGACCCGTCCCCGGCAGGGGACAATG AGATTGAGCGTGTGTTCGTGTGGGACTTGGATGAGACAATAATTATTTTTCACTCCTTACTCACGGGGACATTTGCATCCAGATACGGGA AGATCCTGGGCTTTTCCACCCCTCCAGGCCGGCTCTCCATGATGTCCTTCATCCTCAACGCCCTCACCTGACAGGGTCTTGCTCTCTTGC CCAGGCTGGAGTGCAGTGGCGAAGTCACAGCTCACTGCAGCCTCGACTCCTGGGCTTAAGCGATCCTCCGACCTCAGCCTCCTGAGTAGC TGATACTACAAGCGCAAGGCACCACATCTGGCTAATTTTTAAATTTTTTGTAGAGACAGTGTCTCATTATGTTGCCCAGGATGGTCTTGA ACTCCTGGCCTCAAGCAGTCTTCCTGCCTCGACCTCCCAAGGTGCTGGGATTACAGGCGTGAGCCACCATGCCTAGCCTGTTCAGAGTAA ATCTTATTTGAGGCATGAATCAATCAAACATAAATAGAGAGTTGAATTGATCTTAGAGGGAATGGGATGCAGCAAAGCCCTACTTGACCA TCTCCCCCCTCCCACATTTGGAAATCCTTAAACCCACTTATGTAGGCCTCTGACTGTGAGATTCAGAGCCACAGCAGTTTCCACCTCTGC TAAGGCCTTCAGGCAGTGAGATGGCTCACTTCAGTGCCCCTCCTTCCACACATCTCCTAGCTGTATCCTGAGACGCCTCAACCTAGTCAC TACCCTTCTGTATGATGTTGGTCTAAGGCTTCCCCCTCTCTGGACATGAAGGCGGAGCCTCCCAGCACTACCAGCCACACACCACTCAAG ACTCCAGATCCTGAACCCTGACTCTGGGGCCCAGCTCTGGGCCTGGCTTGGGGCTTGCATCTCACCTAGCCTGGCAGTGTTGTTGTCACA CCCACCTTGTATGGATGCCACATAGGCATTTCAAGTGATGCGGAGCAGAAGCGGGTGCAGCGGCGCTTGACCCAACGCAGGGTGGAGGAT CTGCACATCACCCTGGGCGCCGGGAGGTGGATTCGTGTGGGCAGCCCCTCAAACCAGATCCACTGGTCGGCTACATCCAGCTGCTTCATG TGCCCCATGGGAGTTCTATTGCGGTAGGGCTTAATGAAGATGACTCGGGGGCCCTCGGTGAGTGGTTGCCTCCCCTGGACTCCAGGGTTC AAGCTATCATCCCTCGATGTCCTTGGAACCTCAGGCTCTATATGCTTTTCTTTCCGTGGCATTGCCGCCAATGACGTTTTCTCCTTGTTC CTCATCCCTGACTGCACCTGGGACTTCCACTCCTTGTACTCTTTTTTCTTAGGGTCCCCTGTGGACTCTAATTTCTTGGACTTGAGTTCC TTCTCGGAGCACCCGATCTCCTGGAACTCTTCATTATTTTGTTTTGTTTTATTGCAGGCACTGTTTTCCCTGGCAGGGAGAGGAAAGGCA GTCAGCACAGCAGGACCGAGGCCCTGGTTCCCGAGACAGTTGCTATGTAGCCAGCTCAGGGGAGCCTGTTAAGAAAGGCTAGAGGGGCCT GCAAAGAAACTTCTCTACTGCCCAGAGGCCTTGTGCTGGTGTGAGGAGGTGTGATGAGCACTAGCAGAGGGATGTGAGAGATTGGGAAGG TGAAAGCCATGACTAGTAGTTAAGGCCCCTAAGAATGAATATTGTCTACATCATCTGCCACTAGATTAGGGTTCTGTCTCTCTGGACTTC AGCTGGGAGGGTGAACAGTCCAGTAGTTTTTCTAAATTGTGCTCCAAGAACCTTAGGGTTCTGAGGAGGTGTCTCAATGTCACCTCCCCT GACCCACTGGGGCAGGATACCTCTCCCCAGCTCATAACAACACAATTGGGGCTTGGAAATAGATATTTGAACAGAGGTTTCACTGCTTTA ATAAAGTTGGAAAACTGTTCAAGACCAGCCTGGGCAACATGGTGAGACTCTGTCTCCATACAAAAAAAAAATTTTTAAGTTGGAAAATGA TGGGGCTAGATGATCCTGATCCTTCTAGCTCTATGTTTCCTGATTGCCTGCGACTAGAGGCCAAATCAGAAAGAGGAGCCCAGAAAGGTG GCCTTGACAGAAATATTAAATGCTGAGACTTTCCCAAAGGGTGTCTGTAACAGACTGGGCCCCCTGCAAACCCCCAGTGGCAACACCATC CTAGCCAAGGGCGTGGAGAGAGATGAGGCCTTGGGCTGCAGATAATGGCAATACTGTGATGATAATAATGGCTCCCGCTGATTGAGTCCT CGCTCTATGCCAGACTCGGGACCCTTACAACTTGGGATCCTTACTATTTCTGTGAAGTAGAAGGCAGTGAAACAGAGTGGCTTACAGAGC ACAGGTGTTGGATTCAGACAAACGGGCTCAGATTCTGCTTCTGCCTCTTACCACCTGTGTGATTTGGGCAAGATATTTAACCTCTCAGAG CCTTAGCTTCCTTATCTGTAAAACTAGGATAATTCTGTCTACCTAACAGGATTGTTGTGAAGAATAAACTAAATGGGAAAATTCTTAAGT GCTTAACACTGTAGGATGGTACTTAGCAGGCACCAATCAATGTTAGCTTTCTTAATACTGTCATGTGACTTATGAGGAAACGGTTTGAAC >28053_28053_8_EYA2-SYS1_EYA2_chr20_45725807_ENST00000327619_SYS1_chr20_43994259_ENST00000426004_length(amino acids)=420AA_BP=398 MRPAAGCVRPRSPASRLGAPTRPRSGAGTRAGAEGGPGPGRRRGRSSRRRQQPRQPRRRRQRQRQRQQRARRSQPGLVGPAPARPPARTA SGRPLHCARYKEMVELVISPSLTVNSDCLDKLKFNRADAAVWTLSDRQGITKSAPLRVSQLFSRSCPRVLPRQPSTAMAAYGQTQYSAGI QQATPYTAYPPPAQAYGIPSYSIKTEDSLNHSPGQSGFLSYGSSFSTSPTGQSPYTYQMHGTTGFYQGGNGLGNAAGFGSVHQDYPSYPG FPQSQYPQYYGSSYNPPYVPASSICPSPLSTSTYVLQEASHNVPNQSSESLAGEYNTHNGPSTPAKEGDTDRPHRASDGKLRGRSKRSSD -------------------------------------------------------------- >28053_28053_9_EYA2-SYS1_EYA2_chr20_45725807_ENST00000357410_SYS1_chr20_43994259_ENST00000243918_length(transcript)=3671nt_BP=1262nt GCGCGCTCTGCTCGGCTGCAGGCTCAGGAAGCGGCGCGGCGGCACGTGCTGGGCCAGAGCCCCGCGCCCTGCGTCCAGCCGCCGGGTGTG TGCGCCCGCGTAGCCCAGCGTCGCGCCTCGGCGCCCCCACGCGCCCACGCAGCGGCGCGGGGACCCGGGCGGGGGCAGAGGGAGGGCCCG GCCCAGGGAGGAGAAGGGGCCGGTCCTCCCGGCGCAGGCAGCAGCCGCGGCAGCCCAGGAGGCGGAGGCAGCGGCAACGGCAGAGACAGC AACGTGCCCGCCGCAGTCAGCCCGGCCTCGTCGGACCCGCACCGGCCCGCCCGCCCGCCCGCACCGCGTCGGGGCGCCCTCTCCACTGCG CGCGGTACAAGGAAATGGTAGAACTAGTGATCTCACCCAGCCTCACTGTAAACAGCGATTGTCTGGATAAACTGAAGTTTAACCGTGCTG ACGCTGCTGTGTGGACTCTGAGTGACAGACAAGGCATCACCAAATCGGCCCCCCTGAGAGTGTCCCAGCTCTTCTCCAGATCTTGCCCAC GTGTCCTCCCCCGCCAGCCTTCCACAGCCATGGCAGCCTACGGCCAGACGCAGTACAGTGCGGGGATCCAGCAGGCTACCCCCTATACAG CTTACCCACCTCCAGCACAAGCCTATGGAATCCCTTCCTACAGCATCAAGACAGAAGACAGCTTGAACCATTCCCCTGGCCAGAGTGGAT TCCTCAGCTATGGCTCCAGCTTCAGCACCTCACCCACTGGACAGAGCCCATACACCTACCAGATGCACGGCACAACAGGGTTCTATCAAG GAGGAAATGGACTGGGCAACGCAGCCGGTTTCGGGAGTGTGCACCAGGACTATCCTTCCTACCCCGGCTTCCCCCAGAGCCAGTACCCCC AGTATTACGGCTCATCCTACAACCCTCCCTACGTCCCGGCCAGCAGCATCTGCCCTTCGCCCCTCTCCACGTCCACCTACGTCCTCCAGG AGGCATCTCACAACGTCCCCAACCAGAGTTCCGAGTCACTTGCTGGTGAATACAACACACACAATGGACCTTCCACACCAGCGAAAGAGG GAGACACAGACAGGCCGCACCGGGCCTCCGACGGGAAGCTCCGAGGCCGGTCTAAGAGGAGCAGTGACCCGTCCCCGGCAGGGGACAATG AGATTGAGCGTGTGTTCGTGTGGGACTTGGATGAGACAATAATTATTTTTCACTCCTTACTCACGGGGACATTTGCATCCAGATACGGGA AGATCCTGGGCTTTTCCACCCCTCCAGGCCGGCTCTCCATGATGTCCTTCATCCTCAACGCCCTCACCTGTGCCCTGGGCTTGCTGTACT TCATCCGGCGAGGAAAGCAGTGTCTGGATTTCACTGTCACTGTCCATTTCTTTCACCTCCTGGGCTGCTGGTTCTACAGCTCCCGTTTCC CCTCGGCGCTGACCTGGTGGCTGGTCCAAGCCGTGTGCATTGCACTCATGGCTGTCATCGGGGAGTACCTGTGCATGCGGACGGAGCTCA AGGAGATACCCCTCAACTCAGCCCCTAAATCCAATGTCTAGAATCAGGCCCTTTGGACATCCTGCTGACACTTGGGCCCCTTAACACCTT GGGCTGCTCAGACCCTCCAGATGAGGTCCAGCCCAGATCTGAGAGGAACCCTGGAAATGTGAAGTCTCTGTTGGTTTGGGAGAGATAGTG AGGGCCTGTCAAAGAAGGCAGGTAGCAGTCAGCATGACAGCTGCAAGAATGACCTCTGTCTGTTGAAGCCTTGGTATCTGAGAGGTCAGG AAGGGGACCTCTTTGAGGGTAATAACAGAATTGGAACCATGCCACTCTTGAGCCACAATACCTGTCACCAGCCTGTTGTTTTAAGAGAGA AAAAAAATCAAGGATATCTGATTGGAGCAAACCACTTCTTTAGTCATCTGTCTTACCCCCCTGGGACAGCTGTTACCTTTGCAGTGTTGC CGAATCACAGCAGTTACCTTTGCAGTGTTGCCGAATCACAGCAGTTCTGTTGGAGAAACGCTTGGTTTCCGGATCCAGAGCCACAGAAAG AAATGTAGGTGTGAAGTATTAGGCTGCTGTCAGGGAGAGGATGGCAGATGGAGGCATCAAGCACAAGGAAAATGCACAACCTGTGCCCTG TTATACACACGTTCATGTGCACCCAAGAACCTATGACTTTCTTCCAGTTCCTTCTACCAGGTCCCCATCCTGCTGCCAGCTCTCAACATA GCAGGCCATAGGACCCAGAGAAGAATCCCAGCGTTGCTCAAAGTCTAACCATCATAAAGACACTGCCTGTCTTCTAGGAATGACCAGGCA CCCAGCTCCCACTGGACTCCAATTTTTTTTCCTGCCTTATTTAGAATTCTTTGGCGGGAAGGGTATGATGGGTTCCCAGAGACAAGAAGC CCAACCTTCTGGCCTGGGCTGTGCTGATAGTGCTGAGGGAGATAGGAATTTGCTGCTAAGATTTTTCTTTGGGGTGGAGTTTCCTCTGTG AGGGGCTTGCAGCTATCCTTCCTGTGTATACAAATACAGTATTTTCCATGGTTCTGCCTGCACTTACTTTGTAATGCCACGGTTGAGATT GAGAGAGATCAGCGCAGCCAGGCAAGGGAACTTTAAAGAATTATTAGGCCACCTTCTCCCTTTCCTGGACCCCAGAGTCATTCCTCCATT TGGTTAAAATACTCAGTGCAGGGAACTCTTACATCCTGTCTCCTTCACTTGCAGCGTCCCCTGCTATGCCTCAGGTGAACCACATAATTC TTGGGTTTCCGTTCCTACTTGCTAGTGATTTCTGAACATGTTCAATGGAGCGGCACACAGTCTAGACCCACTTCCGCATTGAAACCTTCA CTGTTCCTCTTTGGTTTCTTCAGAGCTTTCCCAAGAGAGCTGTCAGTTTTCAGCTGTCAGTAACACAAATGAGTTTATGGTAACACAAAT GAGTTTTGCTATCTCTCTGAGAAGCTCATCTGACCTCCTGACTCTCAGCCCTACAGAGTAGGGAGTTGATGCTGACAGGATGAAGATTTA GGAATAAATATGCCTGGGAAGAGACTGGGAAGGTTCTAGGGTGAGGCACCTCAGTAACTCATGGTACCTTGGCCAAGTTGGAAGGAAGCA GTTTGTTAATGAGGCACAGTAATCCTGGCTGCAGGGTCTAGGAGGTAAGACCAGCTGGGATGACCTTCCCTGGGTTAATCAATTTCCCTC TAGACAACACAAACTGCAGGCATGTGACTAACTTTGAAAGAACACCCATCATGTGGCTGCTGTCACCCTTGACCAGCCGTGGTGGTGGTT ACTCCATCTGTGGTTGGAGCGCCTCTTTGGGATTCACTTCAAGGTCTTGTGCCTATTTTTCTGCATATCTTCTGTGATGACAAATCTCTG TCCCCTGAGTGTTAATTTGATTTTTAGAAATGGCCAAAAGTCACGTGATCCAAACTTTTTTTCAGTAATATGGAGACTGAGCTGCATGGT AGTTGGGGATCAAAAATATGTGACCTTAATGAGATTTTTATGATTTCTAAAGTAACAATAAAAGCAGTTTTTAGAGTTGAGTTCCAGAGA >28053_28053_9_EYA2-SYS1_EYA2_chr20_45725807_ENST00000357410_SYS1_chr20_43994259_ENST00000243918_length(amino acids)=500AA_BP=398 MRPAAGCVRPRSPASRLGAPTRPRSGAGTRAGAEGGPGPGRRRGRSSRRRQQPRQPRRRRQRQRQRQQRARRSQPGLVGPAPARPPARTA SGRPLHCARYKEMVELVISPSLTVNSDCLDKLKFNRADAAVWTLSDRQGITKSAPLRVSQLFSRSCPRVLPRQPSTAMAAYGQTQYSAGI QQATPYTAYPPPAQAYGIPSYSIKTEDSLNHSPGQSGFLSYGSSFSTSPTGQSPYTYQMHGTTGFYQGGNGLGNAAGFGSVHQDYPSYPG FPQSQYPQYYGSSYNPPYVPASSICPSPLSTSTYVLQEASHNVPNQSSESLAGEYNTHNGPSTPAKEGDTDRPHRASDGKLRGRSKRSSD PSPAGDNEIERVFVWDLDETIIIFHSLLTGTFASRYGKILGFSTPPGRLSMMSFILNALTCALGLLYFIRRGKQCLDFTVTVHFFHLLGC -------------------------------------------------------------- >28053_28053_10_EYA2-SYS1_EYA2_chr20_45725807_ENST00000357410_SYS1_chr20_43994259_ENST00000372727_length(transcript)=1670nt_BP=1262nt GCGCGCTCTGCTCGGCTGCAGGCTCAGGAAGCGGCGCGGCGGCACGTGCTGGGCCAGAGCCCCGCGCCCTGCGTCCAGCCGCCGGGTGTG TGCGCCCGCGTAGCCCAGCGTCGCGCCTCGGCGCCCCCACGCGCCCACGCAGCGGCGCGGGGACCCGGGCGGGGGCAGAGGGAGGGCCCG GCCCAGGGAGGAGAAGGGGCCGGTCCTCCCGGCGCAGGCAGCAGCCGCGGCAGCCCAGGAGGCGGAGGCAGCGGCAACGGCAGAGACAGC AACGTGCCCGCCGCAGTCAGCCCGGCCTCGTCGGACCCGCACCGGCCCGCCCGCCCGCCCGCACCGCGTCGGGGCGCCCTCTCCACTGCG CGCGGTACAAGGAAATGGTAGAACTAGTGATCTCACCCAGCCTCACTGTAAACAGCGATTGTCTGGATAAACTGAAGTTTAACCGTGCTG ACGCTGCTGTGTGGACTCTGAGTGACAGACAAGGCATCACCAAATCGGCCCCCCTGAGAGTGTCCCAGCTCTTCTCCAGATCTTGCCCAC GTGTCCTCCCCCGCCAGCCTTCCACAGCCATGGCAGCCTACGGCCAGACGCAGTACAGTGCGGGGATCCAGCAGGCTACCCCCTATACAG CTTACCCACCTCCAGCACAAGCCTATGGAATCCCTTCCTACAGCATCAAGACAGAAGACAGCTTGAACCATTCCCCTGGCCAGAGTGGAT TCCTCAGCTATGGCTCCAGCTTCAGCACCTCACCCACTGGACAGAGCCCATACACCTACCAGATGCACGGCACAACAGGGTTCTATCAAG GAGGAAATGGACTGGGCAACGCAGCCGGTTTCGGGAGTGTGCACCAGGACTATCCTTCCTACCCCGGCTTCCCCCAGAGCCAGTACCCCC AGTATTACGGCTCATCCTACAACCCTCCCTACGTCCCGGCCAGCAGCATCTGCCCTTCGCCCCTCTCCACGTCCACCTACGTCCTCCAGG AGGCATCTCACAACGTCCCCAACCAGAGTTCCGAGTCACTTGCTGGTGAATACAACACACACAATGGACCTTCCACACCAGCGAAAGAGG GAGACACAGACAGGCCGCACCGGGCCTCCGACGGGAAGCTCCGAGGCCGGTCTAAGAGGAGCAGTGACCCGTCCCCGGCAGGGGACAATG AGATTGAGCGTGTGTTCGTGTGGGACTTGGATGAGACAATAATTATTTTTCACTCCTTACTCACGGGGACATTTGCATCCAGATACGGGA AGATCCTGGGCTTTTCCACCCCTCCAGGCCGGCTCTCCATGATGTCCTTCATCCTCAACGCCCTCACCTGTGCCCTGGGCTTGCTGTACT TCATCCGGCGAGGAAAGCAGTGTCTGGATTTCACTGTCACTGTCCATTTCTTTCACCTCCTGGGCTGCTGGTTCTACAGCTCCCGTTTCC CCTCGGCGCTGACCTGGTGGCTGGTCCAAGCCGTGTGCATTGCACTCATGGCTGTCATCGGGGAGTACCTGTGCATGCGGACGGAGCTCA AGGAGATACCCCTCAACTCAGCCCCTAAATCCAATGTCTAGAATCAGGCCCTTTGGACATCCTGCTGACACTTGGGCCCCTTAACACCTT >28053_28053_10_EYA2-SYS1_EYA2_chr20_45725807_ENST00000357410_SYS1_chr20_43994259_ENST00000372727_length(amino acids)=500AA_BP=398 MRPAAGCVRPRSPASRLGAPTRPRSGAGTRAGAEGGPGPGRRRGRSSRRRQQPRQPRRRRQRQRQRQQRARRSQPGLVGPAPARPPARTA SGRPLHCARYKEMVELVISPSLTVNSDCLDKLKFNRADAAVWTLSDRQGITKSAPLRVSQLFSRSCPRVLPRQPSTAMAAYGQTQYSAGI QQATPYTAYPPPAQAYGIPSYSIKTEDSLNHSPGQSGFLSYGSSFSTSPTGQSPYTYQMHGTTGFYQGGNGLGNAAGFGSVHQDYPSYPG FPQSQYPQYYGSSYNPPYVPASSICPSPLSTSTYVLQEASHNVPNQSSESLAGEYNTHNGPSTPAKEGDTDRPHRASDGKLRGRSKRSSD PSPAGDNEIERVFVWDLDETIIIFHSLLTGTFASRYGKILGFSTPPGRLSMMSFILNALTCALGLLYFIRRGKQCLDFTVTVHFFHLLGC -------------------------------------------------------------- >28053_28053_11_EYA2-SYS1_EYA2_chr20_45725807_ENST00000357410_SYS1_chr20_43994259_ENST00000414310_length(transcript)=1681nt_BP=1262nt GCGCGCTCTGCTCGGCTGCAGGCTCAGGAAGCGGCGCGGCGGCACGTGCTGGGCCAGAGCCCCGCGCCCTGCGTCCAGCCGCCGGGTGTG TGCGCCCGCGTAGCCCAGCGTCGCGCCTCGGCGCCCCCACGCGCCCACGCAGCGGCGCGGGGACCCGGGCGGGGGCAGAGGGAGGGCCCG GCCCAGGGAGGAGAAGGGGCCGGTCCTCCCGGCGCAGGCAGCAGCCGCGGCAGCCCAGGAGGCGGAGGCAGCGGCAACGGCAGAGACAGC AACGTGCCCGCCGCAGTCAGCCCGGCCTCGTCGGACCCGCACCGGCCCGCCCGCCCGCCCGCACCGCGTCGGGGCGCCCTCTCCACTGCG CGCGGTACAAGGAAATGGTAGAACTAGTGATCTCACCCAGCCTCACTGTAAACAGCGATTGTCTGGATAAACTGAAGTTTAACCGTGCTG ACGCTGCTGTGTGGACTCTGAGTGACAGACAAGGCATCACCAAATCGGCCCCCCTGAGAGTGTCCCAGCTCTTCTCCAGATCTTGCCCAC GTGTCCTCCCCCGCCAGCCTTCCACAGCCATGGCAGCCTACGGCCAGACGCAGTACAGTGCGGGGATCCAGCAGGCTACCCCCTATACAG CTTACCCACCTCCAGCACAAGCCTATGGAATCCCTTCCTACAGCATCAAGACAGAAGACAGCTTGAACCATTCCCCTGGCCAGAGTGGAT TCCTCAGCTATGGCTCCAGCTTCAGCACCTCACCCACTGGACAGAGCCCATACACCTACCAGATGCACGGCACAACAGGGTTCTATCAAG GAGGAAATGGACTGGGCAACGCAGCCGGTTTCGGGAGTGTGCACCAGGACTATCCTTCCTACCCCGGCTTCCCCCAGAGCCAGTACCCCC AGTATTACGGCTCATCCTACAACCCTCCCTACGTCCCGGCCAGCAGCATCTGCCCTTCGCCCCTCTCCACGTCCACCTACGTCCTCCAGG AGGCATCTCACAACGTCCCCAACCAGAGTTCCGAGTCACTTGCTGGTGAATACAACACACACAATGGACCTTCCACACCAGCGAAAGAGG GAGACACAGACAGGCCGCACCGGGCCTCCGACGGGAAGCTCCGAGGCCGGTCTAAGAGGAGCAGTGACCCGTCCCCGGCAGGGGACAATG AGATTGAGCGTGTGTTCGTGTGGGACTTGGATGAGACAATAATTATTTTTCACTCCTTACTCACGGGGACATTTGCATCCAGATACGGGA AGATCCTGGGCTTTTCCACCCCTCCAGGCCGGCTCTCCATGATGTCCTTCATCCTCAACGCCCTCACCTGTGCCCTGGGCTTGCTGTACT TCATCCGGCGAGGAAAGCAGTGTCTGGATTTCACTGTCACTGTCCATTTCTTTCACCTCCTGGGCTGCTGGTTCTACAGCTCCCGTTTCC CCTCGGCGCTGACCTGGTGGCTGGTCCAAGCCGTGTGCATTGCACTCATGGCTGTCATCGGGGAGTACCTGTGCATGCGGACGGAGCTCA AGGAGATACCCCTCAACTCAGCCCCTAAATCCAATGTCTAGAATCAGGCCCTTTGGACATCCTGCTGACACTTGGGCCCCTTAACACCTT >28053_28053_11_EYA2-SYS1_EYA2_chr20_45725807_ENST00000357410_SYS1_chr20_43994259_ENST00000414310_length(amino acids)=500AA_BP=398 MRPAAGCVRPRSPASRLGAPTRPRSGAGTRAGAEGGPGPGRRRGRSSRRRQQPRQPRRRRQRQRQRQQRARRSQPGLVGPAPARPPARTA SGRPLHCARYKEMVELVISPSLTVNSDCLDKLKFNRADAAVWTLSDRQGITKSAPLRVSQLFSRSCPRVLPRQPSTAMAAYGQTQYSAGI QQATPYTAYPPPAQAYGIPSYSIKTEDSLNHSPGQSGFLSYGSSFSTSPTGQSPYTYQMHGTTGFYQGGNGLGNAAGFGSVHQDYPSYPG FPQSQYPQYYGSSYNPPYVPASSICPSPLSTSTYVLQEASHNVPNQSSESLAGEYNTHNGPSTPAKEGDTDRPHRASDGKLRGRSKRSSD PSPAGDNEIERVFVWDLDETIIIFHSLLTGTFASRYGKILGFSTPPGRLSMMSFILNALTCALGLLYFIRRGKQCLDFTVTVHFFHLLGC -------------------------------------------------------------- >28053_28053_12_EYA2-SYS1_EYA2_chr20_45725807_ENST00000357410_SYS1_chr20_43994259_ENST00000426004_length(transcript)=3835nt_BP=1262nt GCGCGCTCTGCTCGGCTGCAGGCTCAGGAAGCGGCGCGGCGGCACGTGCTGGGCCAGAGCCCCGCGCCCTGCGTCCAGCCGCCGGGTGTG TGCGCCCGCGTAGCCCAGCGTCGCGCCTCGGCGCCCCCACGCGCCCACGCAGCGGCGCGGGGACCCGGGCGGGGGCAGAGGGAGGGCCCG GCCCAGGGAGGAGAAGGGGCCGGTCCTCCCGGCGCAGGCAGCAGCCGCGGCAGCCCAGGAGGCGGAGGCAGCGGCAACGGCAGAGACAGC AACGTGCCCGCCGCAGTCAGCCCGGCCTCGTCGGACCCGCACCGGCCCGCCCGCCCGCCCGCACCGCGTCGGGGCGCCCTCTCCACTGCG CGCGGTACAAGGAAATGGTAGAACTAGTGATCTCACCCAGCCTCACTGTAAACAGCGATTGTCTGGATAAACTGAAGTTTAACCGTGCTG ACGCTGCTGTGTGGACTCTGAGTGACAGACAAGGCATCACCAAATCGGCCCCCCTGAGAGTGTCCCAGCTCTTCTCCAGATCTTGCCCAC GTGTCCTCCCCCGCCAGCCTTCCACAGCCATGGCAGCCTACGGCCAGACGCAGTACAGTGCGGGGATCCAGCAGGCTACCCCCTATACAG CTTACCCACCTCCAGCACAAGCCTATGGAATCCCTTCCTACAGCATCAAGACAGAAGACAGCTTGAACCATTCCCCTGGCCAGAGTGGAT TCCTCAGCTATGGCTCCAGCTTCAGCACCTCACCCACTGGACAGAGCCCATACACCTACCAGATGCACGGCACAACAGGGTTCTATCAAG GAGGAAATGGACTGGGCAACGCAGCCGGTTTCGGGAGTGTGCACCAGGACTATCCTTCCTACCCCGGCTTCCCCCAGAGCCAGTACCCCC AGTATTACGGCTCATCCTACAACCCTCCCTACGTCCCGGCCAGCAGCATCTGCCCTTCGCCCCTCTCCACGTCCACCTACGTCCTCCAGG AGGCATCTCACAACGTCCCCAACCAGAGTTCCGAGTCACTTGCTGGTGAATACAACACACACAATGGACCTTCCACACCAGCGAAAGAGG GAGACACAGACAGGCCGCACCGGGCCTCCGACGGGAAGCTCCGAGGCCGGTCTAAGAGGAGCAGTGACCCGTCCCCGGCAGGGGACAATG AGATTGAGCGTGTGTTCGTGTGGGACTTGGATGAGACAATAATTATTTTTCACTCCTTACTCACGGGGACATTTGCATCCAGATACGGGA AGATCCTGGGCTTTTCCACCCCTCCAGGCCGGCTCTCCATGATGTCCTTCATCCTCAACGCCCTCACCTGACAGGGTCTTGCTCTCTTGC CCAGGCTGGAGTGCAGTGGCGAAGTCACAGCTCACTGCAGCCTCGACTCCTGGGCTTAAGCGATCCTCCGACCTCAGCCTCCTGAGTAGC TGATACTACAAGCGCAAGGCACCACATCTGGCTAATTTTTAAATTTTTTGTAGAGACAGTGTCTCATTATGTTGCCCAGGATGGTCTTGA ACTCCTGGCCTCAAGCAGTCTTCCTGCCTCGACCTCCCAAGGTGCTGGGATTACAGGCGTGAGCCACCATGCCTAGCCTGTTCAGAGTAA ATCTTATTTGAGGCATGAATCAATCAAACATAAATAGAGAGTTGAATTGATCTTAGAGGGAATGGGATGCAGCAAAGCCCTACTTGACCA TCTCCCCCCTCCCACATTTGGAAATCCTTAAACCCACTTATGTAGGCCTCTGACTGTGAGATTCAGAGCCACAGCAGTTTCCACCTCTGC TAAGGCCTTCAGGCAGTGAGATGGCTCACTTCAGTGCCCCTCCTTCCACACATCTCCTAGCTGTATCCTGAGACGCCTCAACCTAGTCAC TACCCTTCTGTATGATGTTGGTCTAAGGCTTCCCCCTCTCTGGACATGAAGGCGGAGCCTCCCAGCACTACCAGCCACACACCACTCAAG ACTCCAGATCCTGAACCCTGACTCTGGGGCCCAGCTCTGGGCCTGGCTTGGGGCTTGCATCTCACCTAGCCTGGCAGTGTTGTTGTCACA CCCACCTTGTATGGATGCCACATAGGCATTTCAAGTGATGCGGAGCAGAAGCGGGTGCAGCGGCGCTTGACCCAACGCAGGGTGGAGGAT CTGCACATCACCCTGGGCGCCGGGAGGTGGATTCGTGTGGGCAGCCCCTCAAACCAGATCCACTGGTCGGCTACATCCAGCTGCTTCATG TGCCCCATGGGAGTTCTATTGCGGTAGGGCTTAATGAAGATGACTCGGGGGCCCTCGGTGAGTGGTTGCCTCCCCTGGACTCCAGGGTTC AAGCTATCATCCCTCGATGTCCTTGGAACCTCAGGCTCTATATGCTTTTCTTTCCGTGGCATTGCCGCCAATGACGTTTTCTCCTTGTTC CTCATCCCTGACTGCACCTGGGACTTCCACTCCTTGTACTCTTTTTTCTTAGGGTCCCCTGTGGACTCTAATTTCTTGGACTTGAGTTCC TTCTCGGAGCACCCGATCTCCTGGAACTCTTCATTATTTTGTTTTGTTTTATTGCAGGCACTGTTTTCCCTGGCAGGGAGAGGAAAGGCA GTCAGCACAGCAGGACCGAGGCCCTGGTTCCCGAGACAGTTGCTATGTAGCCAGCTCAGGGGAGCCTGTTAAGAAAGGCTAGAGGGGCCT GCAAAGAAACTTCTCTACTGCCCAGAGGCCTTGTGCTGGTGTGAGGAGGTGTGATGAGCACTAGCAGAGGGATGTGAGAGATTGGGAAGG TGAAAGCCATGACTAGTAGTTAAGGCCCCTAAGAATGAATATTGTCTACATCATCTGCCACTAGATTAGGGTTCTGTCTCTCTGGACTTC AGCTGGGAGGGTGAACAGTCCAGTAGTTTTTCTAAATTGTGCTCCAAGAACCTTAGGGTTCTGAGGAGGTGTCTCAATGTCACCTCCCCT GACCCACTGGGGCAGGATACCTCTCCCCAGCTCATAACAACACAATTGGGGCTTGGAAATAGATATTTGAACAGAGGTTTCACTGCTTTA ATAAAGTTGGAAAACTGTTCAAGACCAGCCTGGGCAACATGGTGAGACTCTGTCTCCATACAAAAAAAAAATTTTTAAGTTGGAAAATGA TGGGGCTAGATGATCCTGATCCTTCTAGCTCTATGTTTCCTGATTGCCTGCGACTAGAGGCCAAATCAGAAAGAGGAGCCCAGAAAGGTG GCCTTGACAGAAATATTAAATGCTGAGACTTTCCCAAAGGGTGTCTGTAACAGACTGGGCCCCCTGCAAACCCCCAGTGGCAACACCATC CTAGCCAAGGGCGTGGAGAGAGATGAGGCCTTGGGCTGCAGATAATGGCAATACTGTGATGATAATAATGGCTCCCGCTGATTGAGTCCT CGCTCTATGCCAGACTCGGGACCCTTACAACTTGGGATCCTTACTATTTCTGTGAAGTAGAAGGCAGTGAAACAGAGTGGCTTACAGAGC ACAGGTGTTGGATTCAGACAAACGGGCTCAGATTCTGCTTCTGCCTCTTACCACCTGTGTGATTTGGGCAAGATATTTAACCTCTCAGAG CCTTAGCTTCCTTATCTGTAAAACTAGGATAATTCTGTCTACCTAACAGGATTGTTGTGAAGAATAAACTAAATGGGAAAATTCTTAAGT GCTTAACACTGTAGGATGGTACTTAGCAGGCACCAATCAATGTTAGCTTTCTTAATACTGTCATGTGACTTATGAGGAAACGGTTTGAAC >28053_28053_12_EYA2-SYS1_EYA2_chr20_45725807_ENST00000357410_SYS1_chr20_43994259_ENST00000426004_length(amino acids)=420AA_BP=398 MRPAAGCVRPRSPASRLGAPTRPRSGAGTRAGAEGGPGPGRRRGRSSRRRQQPRQPRRRRQRQRQRQQRARRSQPGLVGPAPARPPARTA SGRPLHCARYKEMVELVISPSLTVNSDCLDKLKFNRADAAVWTLSDRQGITKSAPLRVSQLFSRSCPRVLPRQPSTAMAAYGQTQYSAGI QQATPYTAYPPPAQAYGIPSYSIKTEDSLNHSPGQSGFLSYGSSFSTSPTGQSPYTYQMHGTTGFYQGGNGLGNAAGFGSVHQDYPSYPG FPQSQYPQYYGSSYNPPYVPASSICPSPLSTSTYVLQEASHNVPNQSSESLAGEYNTHNGPSTPAKEGDTDRPHRASDGKLRGRSKRSSD -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for EYA2-SYS1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for EYA2-SYS1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for EYA2-SYS1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies