
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:FAM213A-IGJ (FusionGDB2 ID:28906) |
Fusion Gene Summary for FAM213A-IGJ |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: FAM213A-IGJ | Fusion gene ID: 28906 | Hgene | Tgene | Gene symbol | FAM213A | IGJ | Gene ID | 84293 | 3512 |
| Gene name | peroxiredoxin like 2A | joining chain of multimeric IgA and IgM | |
| Synonyms | Adrx|C10orf58|FAM213A|PAMM | IGCJ|IGJ|JCH | |
| Cytomap | 10q23.1 | 4q13.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | peroxiredoxin-like 2AAdiporedoxinUPF0765 protein C10orf58family with sequence similarity 213 member Aperoxiredoxin (PRX)-like 2 activated in M-CSF stimulated monocytesperoxiredoxin-like 2 activated in M-CSF stimulated monocytesredox-regulatory prote | immunoglobulin J chainIgJ chainJ chainimmunoglobulin J polypeptide, linker protein for immunoglobulin alpha and mu polypeptides | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000372181, ENST00000372185, ENST00000372187, ENST00000372188, | ENST00000254801, ENST00000543780, | |
| Fusion gene scores | * DoF score | 8 X 9 X 5=360 | 5 X 4 X 3=60 |
| # samples | 9 | 5 | |
| ** MAII score | log2(9/360*10)=-2 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(5/60*10)=-0.263034405833794 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: FAM213A [Title/Abstract] AND IGJ [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | FAM213A(82180401)-IGJ(71527932), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | FAM213A | GO:0045670 | regulation of osteoclast differentiation | 19951071 |
| Hgene | FAM213A | GO:0055114 | oxidation-reduction process | 19951071 |
| Tgene | IGJ | GO:0002250 | adaptive immune response | 21786026 |
| Tgene | IGJ | GO:0019731 | antibacterial humoral response | 23250751 |
| Tgene | IGJ | GO:0045087 | innate immune response | 21786026 |
| Tgene | IGJ | GO:0060267 | positive regulation of respiratory burst | 24145934 |
| Fusion gene breakpoints across FAM213A (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across IGJ (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-AQ-A04L-01B | FAM213A | chr10 | 82180401 | + | IGJ | chr4 | 71527932 | - |
Top |
Fusion Gene ORF analysis for FAM213A-IGJ |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| In-frame | ENST00000372181 | ENST00000254801 | FAM213A | chr10 | 82180401 | + | IGJ | chr4 | 71527932 | - |
| In-frame | ENST00000372181 | ENST00000543780 | FAM213A | chr10 | 82180401 | + | IGJ | chr4 | 71527932 | - |
| In-frame | ENST00000372185 | ENST00000254801 | FAM213A | chr10 | 82180401 | + | IGJ | chr4 | 71527932 | - |
| In-frame | ENST00000372185 | ENST00000543780 | FAM213A | chr10 | 82180401 | + | IGJ | chr4 | 71527932 | - |
| In-frame | ENST00000372187 | ENST00000254801 | FAM213A | chr10 | 82180401 | + | IGJ | chr4 | 71527932 | - |
| In-frame | ENST00000372187 | ENST00000543780 | FAM213A | chr10 | 82180401 | + | IGJ | chr4 | 71527932 | - |
| In-frame | ENST00000372188 | ENST00000254801 | FAM213A | chr10 | 82180401 | + | IGJ | chr4 | 71527932 | - |
| In-frame | ENST00000372188 | ENST00000543780 | FAM213A | chr10 | 82180401 | + | IGJ | chr4 | 71527932 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000372188 | FAM213A | chr10 | 82180401 | + | ENST00000254801 | IGJ | chr4 | 71527932 | - | 1512 | 308 | 130 | 723 | 197 |
| ENST00000372188 | FAM213A | chr10 | 82180401 | + | ENST00000543780 | IGJ | chr4 | 71527932 | - | 724 | 308 | 130 | 723 | 198 |
| ENST00000372187 | FAM213A | chr10 | 82180401 | + | ENST00000254801 | IGJ | chr4 | 71527932 | - | 1535 | 331 | 153 | 746 | 197 |
| ENST00000372187 | FAM213A | chr10 | 82180401 | + | ENST00000543780 | IGJ | chr4 | 71527932 | - | 747 | 331 | 153 | 746 | 197 |
| ENST00000372185 | FAM213A | chr10 | 82180401 | + | ENST00000254801 | IGJ | chr4 | 71527932 | - | 1517 | 313 | 168 | 728 | 186 |
| ENST00000372185 | FAM213A | chr10 | 82180401 | + | ENST00000543780 | IGJ | chr4 | 71527932 | - | 729 | 313 | 168 | 728 | 186 |
| ENST00000372181 | FAM213A | chr10 | 82180401 | + | ENST00000254801 | IGJ | chr4 | 71527932 | - | 1852 | 648 | 470 | 1063 | 197 |
| ENST00000372181 | FAM213A | chr10 | 82180401 | + | ENST00000543780 | IGJ | chr4 | 71527932 | - | 1064 | 648 | 470 | 1063 | 198 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000372188 | ENST00000254801 | FAM213A | chr10 | 82180401 | + | IGJ | chr4 | 71527932 | - | 0.000861665 | 0.99913836 |
| ENST00000372188 | ENST00000543780 | FAM213A | chr10 | 82180401 | + | IGJ | chr4 | 71527932 | - | 0.005033897 | 0.9949661 |
| ENST00000372187 | ENST00000254801 | FAM213A | chr10 | 82180401 | + | IGJ | chr4 | 71527932 | - | 0.000716047 | 0.99928397 |
| ENST00000372187 | ENST00000543780 | FAM213A | chr10 | 82180401 | + | IGJ | chr4 | 71527932 | - | 0.001935993 | 0.998064 |
| ENST00000372185 | ENST00000254801 | FAM213A | chr10 | 82180401 | + | IGJ | chr4 | 71527932 | - | 0.000779421 | 0.9992206 |
| ENST00000372185 | ENST00000543780 | FAM213A | chr10 | 82180401 | + | IGJ | chr4 | 71527932 | - | 0.002100121 | 0.9978999 |
| ENST00000372181 | ENST00000254801 | FAM213A | chr10 | 82180401 | + | IGJ | chr4 | 71527932 | - | 0.001223955 | 0.998776 |
| ENST00000372181 | ENST00000543780 | FAM213A | chr10 | 82180401 | + | IGJ | chr4 | 71527932 | - | 0.004238473 | 0.9957616 |
Top |
Fusion Genomic Features for FAM213A-IGJ |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
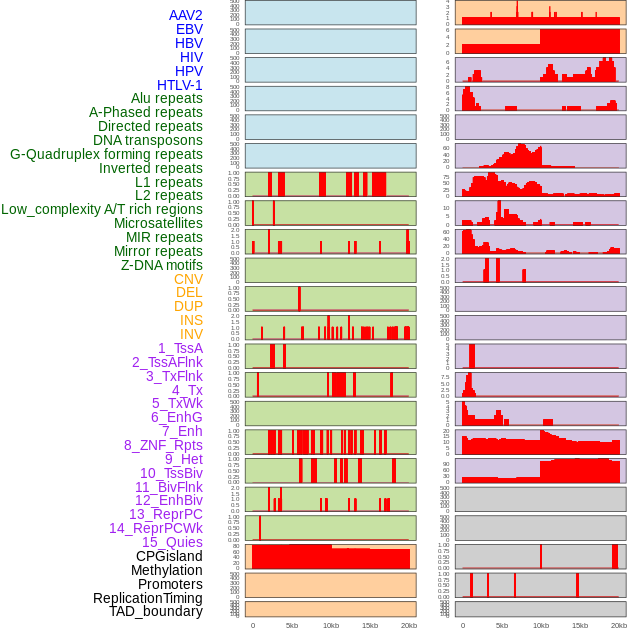 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for FAM213A-IGJ |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr10:82180401/chr4:71527932) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | FAM213A | chr10:82180401 | chr4:71527932 | ENST00000372181 | + | 1 | 5 | 14_112 | 59 | 230.0 | Region | Thioredoxin fold |
| Hgene | FAM213A | chr10:82180401 | chr4:71527932 | ENST00000372185 | + | 2 | 6 | 14_112 | 48 | 219.0 | Region | Thioredoxin fold |
| Hgene | FAM213A | chr10:82180401 | chr4:71527932 | ENST00000372187 | + | 2 | 6 | 14_112 | 59 | 230.0 | Region | Thioredoxin fold |
| Hgene | FAM213A | chr10:82180401 | chr4:71527932 | ENST00000372188 | + | 2 | 6 | 14_112 | 59 | 230.0 | Region | Thioredoxin fold |
Top |
Fusion Gene Sequence for FAM213A-IGJ |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >28906_28906_1_FAM213A-IGJ_FAM213A_chr10_82180401_ENST00000372181_IGJ_chr4_71527932_ENST00000254801_length(transcript)=1852nt_BP=648nt AGTATCCTCTGATCACAGAAGAGAAAGCTGCCCCTACCCAGGGACATGATCCTGAGCCACCTGGATTGTGAGGGAGAATCAGGCATTGAT GAGGAGGGGAATGAGGAAGTAGTCTGCCTACAGGGGACATAGCTCGGCACAGCTCCACAGAGCTAGGGGCTGCAACTTGGGGCATGAGAA GAGAGAGCAGCAAGAGAACCATTTGAGAAGGCTGTCCTTTCTCTGTCATCACTCCTGATGCCCTGGTGAGCTCCACGGTGCAGGAACCTC CATGTGTGTGCTGCATCCCCAAGTTCTGGTGGCAGCAGGTGCTTAGCAGCCCTTGTCCAGTCTCGCCTGTGACACTGCTGCTCCCTTCCC CTGTCCTGACCTCCTGGTTGGCTGTCCTGCCAGAGCCTTGCCTGGAAGATGAAATTCCAGCTACCCTGTGGGAGCAGTAACGCCTTCTTC CTTCTTCTCAATCTCCAGAAATGTCTTTCCTCCAGGACCCAAGTTTCTTCACCATGGGGATGTGGTCCATTGGTGCAGGAGCCCTGGGGG CTGCTGCCTTGGCATTGCTGCTTGCCAACACAGACGTGTTTCTGTCCAAGCCCCAGAAAGCGGCCCTGGAGTACCTGGAGGATATAGACC TGAAAACACTGGAGAAGGCCCAAGAAGATGAAAGGATTGTTCTTGTTGACAACAAATGTAAGTGTGCCCGGATTACTTCCAGGATCATCC GTTCTTCCGAAGATCCTAATGAGGACATTGTGGAGAGAAACATCCGAATTATTGTTCCTCTGAACAACAGGGAGAATATCTCTGATCCCA CCTCACCATTGAGAACCAGATTTGTGTACCATTTGTCTGACCTCTGTAAAAAATGTGATCCTACAGAAGTGGAGCTGGATAATCAGATAG TTACTGCTACCCAGAGCAATATCTGTGATGAAGACAGTGCTACAGAGACCTGCTACACTTATGACAGAAACAAGTGCTACACAGCTGTGG TCCCACTCGTATATGGTGGTGAGACCAAAATGGTGGAAACAGCCTTAACCCCAGATGCCTGCTATCCTGACTAATTTAAGTCATTGCTGA CTGCATAGCTCTTTTTCTTGAGAGGCTCTCCATTTTGATTCAGAAAGTTAGCATATTTATTACCAATGAATTTGAAACCAGGGCTTTTTT TTTTTTTTGGGTGATGTAAAACCAACTCCCTGCCACCAAAATAATTAAAATAGTCACATTGTTATCTTTATTAGGTAATCACTTCTTAAT TATATGTTCATACTCTAAGTATCAAAATCTTCCAATTATCATGCTCACCTGAAAGAGGTATGCTCTCTTAGGAATACAGTTTCTAGCATT AAACAAATAAACAAGGGGAGAAAATAAAACTCAAGGACTGAAAATCAGGAGGTGTAATAAAATGTTCCTCGCATTCCCCCCCGCTTTTTT TTTTTTTTTTGACTTTGCCTTGGAGAGCCAGAGCTTCCGCATTTTCTTTACTATTCTTTTTAAAAAAAGTTTCACTGTGTAGAGAACATA TATGCATAAACATAGGTCAATTATATGTCTCCATTAGAAAAATAATAATTGGAAAACATGTTCTAGAACTAGTTACAAAAATAATTTAAG GTGAAATCTCTAATATTTATAAAAGTAGCAAAATAAATGCATAATTAAAATATATTTGGACATAACAGACTTGGAAGCAGATGATACAGA CTTCTTTTTTTCATAATCAGGTTAGTGTAAGAAATTGCCATTTGAAACAATCCATTTTGTAACTGAACCTTATGAAATATATGTATTTCA >28906_28906_1_FAM213A-IGJ_FAM213A_chr10_82180401_ENST00000372181_IGJ_chr4_71527932_ENST00000254801_length(amino acids)=197AA_BP=59 MSFLQDPSFFTMGMWSIGAGALGAAALALLLANTDVFLSKPQKAALEYLEDIDLKTLEKAQEDERIVLVDNKCKCARITSRIIRSSEDPN EDIVERNIRIIVPLNNRENISDPTSPLRTRFVYHLSDLCKKCDPTEVELDNQIVTATQSNICDEDSATETCYTYDRNKCYTAVVPLVYGG -------------------------------------------------------------- >28906_28906_2_FAM213A-IGJ_FAM213A_chr10_82180401_ENST00000372181_IGJ_chr4_71527932_ENST00000543780_length(transcript)=1064nt_BP=648nt AGTATCCTCTGATCACAGAAGAGAAAGCTGCCCCTACCCAGGGACATGATCCTGAGCCACCTGGATTGTGAGGGAGAATCAGGCATTGAT GAGGAGGGGAATGAGGAAGTAGTCTGCCTACAGGGGACATAGCTCGGCACAGCTCCACAGAGCTAGGGGCTGCAACTTGGGGCATGAGAA GAGAGAGCAGCAAGAGAACCATTTGAGAAGGCTGTCCTTTCTCTGTCATCACTCCTGATGCCCTGGTGAGCTCCACGGTGCAGGAACCTC CATGTGTGTGCTGCATCCCCAAGTTCTGGTGGCAGCAGGTGCTTAGCAGCCCTTGTCCAGTCTCGCCTGTGACACTGCTGCTCCCTTCCC CTGTCCTGACCTCCTGGTTGGCTGTCCTGCCAGAGCCTTGCCTGGAAGATGAAATTCCAGCTACCCTGTGGGAGCAGTAACGCCTTCTTC CTTCTTCTCAATCTCCAGAAATGTCTTTCCTCCAGGACCCAAGTTTCTTCACCATGGGGATGTGGTCCATTGGTGCAGGAGCCCTGGGGG CTGCTGCCTTGGCATTGCTGCTTGCCAACACAGACGTGTTTCTGTCCAAGCCCCAGAAAGCGGCCCTGGAGTACCTGGAGGATATAGACC TGAAAACACTGGAGAAGGCCCAAGAAGATGAAAGGATTGTTCTTGTTGACAACAAATGTAAGTGTGCCCGGATTACTTCCAGGATCATCC GTTCTTCCGAAGATCCTAATGAGGACATTGTGGAGAGAAACATCCGAATTATTGTTCCTCTGAACAACAGGGAGAATATCTCTGATCCCA CCTCACCATTGAGAACCAGATTTGTGTACCATTTGTCTGACCTCTGTAAAAAATGTGATCCTACAGAAGTGGAGCTGGATAATCAGATAG TTACTGCTACCCAGAGCAATATCTGTGATGAAGACAGTGCTACAGAGACCTGCTACACTTATGACAGAAACAAGTGCTACACAGCTGTGG >28906_28906_2_FAM213A-IGJ_FAM213A_chr10_82180401_ENST00000372181_IGJ_chr4_71527932_ENST00000543780_length(amino acids)=198AA_BP=59 MSFLQDPSFFTMGMWSIGAGALGAAALALLLANTDVFLSKPQKAALEYLEDIDLKTLEKAQEDERIVLVDNKCKCARITSRIIRSSEDPN EDIVERNIRIIVPLNNRENISDPTSPLRTRFVYHLSDLCKKCDPTEVELDNQIVTATQSNICDEDSATETCYTYDRNKCYTAVVPLVYGG -------------------------------------------------------------- >28906_28906_3_FAM213A-IGJ_FAM213A_chr10_82180401_ENST00000372185_IGJ_chr4_71527932_ENST00000254801_length(transcript)=1517nt_BP=313nt TGGCGGTGGCGCGGTAGCGCGCGATGCAGCACAGGCTAGAGGCTGCGCAAGCGCGGGGCCCGCCCCTGGGACCCTCCGGGCCGGGCGGTT TGGCCCCTTAGCGCCCGGGCGTCGGGGCGGTAAAAGGCCGGCAGAAGGGAGGCACTTGAGGACCCAAGTTTCTTCACCATGGGGATGTGG TCCATTGGTGCAGGAGCCCTGGGGGCTGCTGCCTTGGCATTGCTGCTTGCCAACACAGACGTGTTTCTGTCCAAGCCCCAGAAAGCGGCC CTGGAGTACCTGGAGGATATAGACCTGAAAACACTGGAGAAGGCCCAAGAAGATGAAAGGATTGTTCTTGTTGACAACAAATGTAAGTGT GCCCGGATTACTTCCAGGATCATCCGTTCTTCCGAAGATCCTAATGAGGACATTGTGGAGAGAAACATCCGAATTATTGTTCCTCTGAAC AACAGGGAGAATATCTCTGATCCCACCTCACCATTGAGAACCAGATTTGTGTACCATTTGTCTGACCTCTGTAAAAAATGTGATCCTACA GAAGTGGAGCTGGATAATCAGATAGTTACTGCTACCCAGAGCAATATCTGTGATGAAGACAGTGCTACAGAGACCTGCTACACTTATGAC AGAAACAAGTGCTACACAGCTGTGGTCCCACTCGTATATGGTGGTGAGACCAAAATGGTGGAAACAGCCTTAACCCCAGATGCCTGCTAT CCTGACTAATTTAAGTCATTGCTGACTGCATAGCTCTTTTTCTTGAGAGGCTCTCCATTTTGATTCAGAAAGTTAGCATATTTATTACCA ATGAATTTGAAACCAGGGCTTTTTTTTTTTTTTGGGTGATGTAAAACCAACTCCCTGCCACCAAAATAATTAAAATAGTCACATTGTTAT CTTTATTAGGTAATCACTTCTTAATTATATGTTCATACTCTAAGTATCAAAATCTTCCAATTATCATGCTCACCTGAAAGAGGTATGCTC TCTTAGGAATACAGTTTCTAGCATTAAACAAATAAACAAGGGGAGAAAATAAAACTCAAGGACTGAAAATCAGGAGGTGTAATAAAATGT TCCTCGCATTCCCCCCCGCTTTTTTTTTTTTTTTTGACTTTGCCTTGGAGAGCCAGAGCTTCCGCATTTTCTTTACTATTCTTTTTAAAA AAAGTTTCACTGTGTAGAGAACATATATGCATAAACATAGGTCAATTATATGTCTCCATTAGAAAAATAATAATTGGAAAACATGTTCTA GAACTAGTTACAAAAATAATTTAAGGTGAAATCTCTAATATTTATAAAAGTAGCAAAATAAATGCATAATTAAAATATATTTGGACATAA CAGACTTGGAAGCAGATGATACAGACTTCTTTTTTTCATAATCAGGTTAGTGTAAGAAATTGCCATTTGAAACAATCCATTTTGTAACTG >28906_28906_3_FAM213A-IGJ_FAM213A_chr10_82180401_ENST00000372185_IGJ_chr4_71527932_ENST00000254801_length(amino acids)=186AA_BP=48 MGMWSIGAGALGAAALALLLANTDVFLSKPQKAALEYLEDIDLKTLEKAQEDERIVLVDNKCKCARITSRIIRSSEDPNEDIVERNIRII VPLNNRENISDPTSPLRTRFVYHLSDLCKKCDPTEVELDNQIVTATQSNICDEDSATETCYTYDRNKCYTAVVPLVYGGETKMVETALTP -------------------------------------------------------------- >28906_28906_4_FAM213A-IGJ_FAM213A_chr10_82180401_ENST00000372185_IGJ_chr4_71527932_ENST00000543780_length(transcript)=729nt_BP=313nt TGGCGGTGGCGCGGTAGCGCGCGATGCAGCACAGGCTAGAGGCTGCGCAAGCGCGGGGCCCGCCCCTGGGACCCTCCGGGCCGGGCGGTT TGGCCCCTTAGCGCCCGGGCGTCGGGGCGGTAAAAGGCCGGCAGAAGGGAGGCACTTGAGGACCCAAGTTTCTTCACCATGGGGATGTGG TCCATTGGTGCAGGAGCCCTGGGGGCTGCTGCCTTGGCATTGCTGCTTGCCAACACAGACGTGTTTCTGTCCAAGCCCCAGAAAGCGGCC CTGGAGTACCTGGAGGATATAGACCTGAAAACACTGGAGAAGGCCCAAGAAGATGAAAGGATTGTTCTTGTTGACAACAAATGTAAGTGT GCCCGGATTACTTCCAGGATCATCCGTTCTTCCGAAGATCCTAATGAGGACATTGTGGAGAGAAACATCCGAATTATTGTTCCTCTGAAC AACAGGGAGAATATCTCTGATCCCACCTCACCATTGAGAACCAGATTTGTGTACCATTTGTCTGACCTCTGTAAAAAATGTGATCCTACA GAAGTGGAGCTGGATAATCAGATAGTTACTGCTACCCAGAGCAATATCTGTGATGAAGACAGTGCTACAGAGACCTGCTACACTTATGAC AGAAACAAGTGCTACACAGCTGTGGTCCCACTCGTATATGGTGGTGAGACCAAAATGGTGGAAACAGCCTTAACCCCAGATGCCTGCTAT >28906_28906_4_FAM213A-IGJ_FAM213A_chr10_82180401_ENST00000372185_IGJ_chr4_71527932_ENST00000543780_length(amino acids)=186AA_BP=48 MGMWSIGAGALGAAALALLLANTDVFLSKPQKAALEYLEDIDLKTLEKAQEDERIVLVDNKCKCARITSRIIRSSEDPNEDIVERNIRII VPLNNRENISDPTSPLRTRFVYHLSDLCKKCDPTEVELDNQIVTATQSNICDEDSATETCYTYDRNKCYTAVVPLVYGGETKMVETALTP -------------------------------------------------------------- >28906_28906_5_FAM213A-IGJ_FAM213A_chr10_82180401_ENST00000372187_IGJ_chr4_71527932_ENST00000254801_length(transcript)=1535nt_BP=331nt ATGGCGGTGGCGCGGTAGCGCGCGATGCAGCACAGGCTAGAGGCTGCGCAAGCGCGGGGCCCGCCCCTGGGACCCTCCGGGCCGGGCGGT TTGGCCCCTTAGCGCCCGGGCGTCGGGGCGGTAAAAGGCCGGCAGAAGGGAGGCACTTGAGAAATGTCTTTCCTCCAGGACCCAAGTTTC TTCACCATGGGGATGTGGTCCATTGGTGCAGGAGCCCTGGGGGCTGCTGCCTTGGCATTGCTGCTTGCCAACACAGACGTGTTTCTGTCC AAGCCCCAGAAAGCGGCCCTGGAGTACCTGGAGGATATAGACCTGAAAACACTGGAGAAGGCCCAAGAAGATGAAAGGATTGTTCTTGTT GACAACAAATGTAAGTGTGCCCGGATTACTTCCAGGATCATCCGTTCTTCCGAAGATCCTAATGAGGACATTGTGGAGAGAAACATCCGA ATTATTGTTCCTCTGAACAACAGGGAGAATATCTCTGATCCCACCTCACCATTGAGAACCAGATTTGTGTACCATTTGTCTGACCTCTGT AAAAAATGTGATCCTACAGAAGTGGAGCTGGATAATCAGATAGTTACTGCTACCCAGAGCAATATCTGTGATGAAGACAGTGCTACAGAG ACCTGCTACACTTATGACAGAAACAAGTGCTACACAGCTGTGGTCCCACTCGTATATGGTGGTGAGACCAAAATGGTGGAAACAGCCTTA ACCCCAGATGCCTGCTATCCTGACTAATTTAAGTCATTGCTGACTGCATAGCTCTTTTTCTTGAGAGGCTCTCCATTTTGATTCAGAAAG TTAGCATATTTATTACCAATGAATTTGAAACCAGGGCTTTTTTTTTTTTTTGGGTGATGTAAAACCAACTCCCTGCCACCAAAATAATTA AAATAGTCACATTGTTATCTTTATTAGGTAATCACTTCTTAATTATATGTTCATACTCTAAGTATCAAAATCTTCCAATTATCATGCTCA CCTGAAAGAGGTATGCTCTCTTAGGAATACAGTTTCTAGCATTAAACAAATAAACAAGGGGAGAAAATAAAACTCAAGGACTGAAAATCA GGAGGTGTAATAAAATGTTCCTCGCATTCCCCCCCGCTTTTTTTTTTTTTTTTGACTTTGCCTTGGAGAGCCAGAGCTTCCGCATTTTCT TTACTATTCTTTTTAAAAAAAGTTTCACTGTGTAGAGAACATATATGCATAAACATAGGTCAATTATATGTCTCCATTAGAAAAATAATA ATTGGAAAACATGTTCTAGAACTAGTTACAAAAATAATTTAAGGTGAAATCTCTAATATTTATAAAAGTAGCAAAATAAATGCATAATTA AAATATATTTGGACATAACAGACTTGGAAGCAGATGATACAGACTTCTTTTTTTCATAATCAGGTTAGTGTAAGAAATTGCCATTTGAAA CAATCCATTTTGTAACTGAACCTTATGAAATATATGTATTTCATGGTACGTATTCTCTAGCACAGTCTGAGCAATTAAATAGATTCATAA >28906_28906_5_FAM213A-IGJ_FAM213A_chr10_82180401_ENST00000372187_IGJ_chr4_71527932_ENST00000254801_length(amino acids)=197AA_BP=59 MSFLQDPSFFTMGMWSIGAGALGAAALALLLANTDVFLSKPQKAALEYLEDIDLKTLEKAQEDERIVLVDNKCKCARITSRIIRSSEDPN EDIVERNIRIIVPLNNRENISDPTSPLRTRFVYHLSDLCKKCDPTEVELDNQIVTATQSNICDEDSATETCYTYDRNKCYTAVVPLVYGG -------------------------------------------------------------- >28906_28906_6_FAM213A-IGJ_FAM213A_chr10_82180401_ENST00000372187_IGJ_chr4_71527932_ENST00000543780_length(transcript)=747nt_BP=331nt ATGGCGGTGGCGCGGTAGCGCGCGATGCAGCACAGGCTAGAGGCTGCGCAAGCGCGGGGCCCGCCCCTGGGACCCTCCGGGCCGGGCGGT TTGGCCCCTTAGCGCCCGGGCGTCGGGGCGGTAAAAGGCCGGCAGAAGGGAGGCACTTGAGAAATGTCTTTCCTCCAGGACCCAAGTTTC TTCACCATGGGGATGTGGTCCATTGGTGCAGGAGCCCTGGGGGCTGCTGCCTTGGCATTGCTGCTTGCCAACACAGACGTGTTTCTGTCC AAGCCCCAGAAAGCGGCCCTGGAGTACCTGGAGGATATAGACCTGAAAACACTGGAGAAGGCCCAAGAAGATGAAAGGATTGTTCTTGTT GACAACAAATGTAAGTGTGCCCGGATTACTTCCAGGATCATCCGTTCTTCCGAAGATCCTAATGAGGACATTGTGGAGAGAAACATCCGA ATTATTGTTCCTCTGAACAACAGGGAGAATATCTCTGATCCCACCTCACCATTGAGAACCAGATTTGTGTACCATTTGTCTGACCTCTGT AAAAAATGTGATCCTACAGAAGTGGAGCTGGATAATCAGATAGTTACTGCTACCCAGAGCAATATCTGTGATGAAGACAGTGCTACAGAG ACCTGCTACACTTATGACAGAAACAAGTGCTACACAGCTGTGGTCCCACTCGTATATGGTGGTGAGACCAAAATGGTGGAAACAGCCTTA >28906_28906_6_FAM213A-IGJ_FAM213A_chr10_82180401_ENST00000372187_IGJ_chr4_71527932_ENST00000543780_length(amino acids)=197AA_BP=59 MSFLQDPSFFTMGMWSIGAGALGAAALALLLANTDVFLSKPQKAALEYLEDIDLKTLEKAQEDERIVLVDNKCKCARITSRIIRSSEDPN EDIVERNIRIIVPLNNRENISDPTSPLRTRFVYHLSDLCKKCDPTEVELDNQIVTATQSNICDEDSATETCYTYDRNKCYTAVVPLVYGG -------------------------------------------------------------- >28906_28906_7_FAM213A-IGJ_FAM213A_chr10_82180401_ENST00000372188_IGJ_chr4_71527932_ENST00000254801_length(transcript)=1512nt_BP=308nt TGCCCAGACTGGTCTTGAACTCCTGGGCTCAAGCGATCCTCCCAAAGCCCTGAGATTACAGGCGTGAGCCAGCGCGCCGGACACAACCTC CTACTTTCATGAAAGAGTGGGCACTTCCAACAGGAGGAAAATGTCTTTCCTCCAGGACCCAAGTTTCTTCACCATGGGGATGTGGTCCAT TGGTGCAGGAGCCCTGGGGGCTGCTGCCTTGGCATTGCTGCTTGCCAACACAGACGTGTTTCTGTCCAAGCCCCAGAAAGCGGCCCTGGA GTACCTGGAGGATATAGACCTGAAAACACTGGAGAAGGCCCAAGAAGATGAAAGGATTGTTCTTGTTGACAACAAATGTAAGTGTGCCCG GATTACTTCCAGGATCATCCGTTCTTCCGAAGATCCTAATGAGGACATTGTGGAGAGAAACATCCGAATTATTGTTCCTCTGAACAACAG GGAGAATATCTCTGATCCCACCTCACCATTGAGAACCAGATTTGTGTACCATTTGTCTGACCTCTGTAAAAAATGTGATCCTACAGAAGT GGAGCTGGATAATCAGATAGTTACTGCTACCCAGAGCAATATCTGTGATGAAGACAGTGCTACAGAGACCTGCTACACTTATGACAGAAA CAAGTGCTACACAGCTGTGGTCCCACTCGTATATGGTGGTGAGACCAAAATGGTGGAAACAGCCTTAACCCCAGATGCCTGCTATCCTGA CTAATTTAAGTCATTGCTGACTGCATAGCTCTTTTTCTTGAGAGGCTCTCCATTTTGATTCAGAAAGTTAGCATATTTATTACCAATGAA TTTGAAACCAGGGCTTTTTTTTTTTTTTGGGTGATGTAAAACCAACTCCCTGCCACCAAAATAATTAAAATAGTCACATTGTTATCTTTA TTAGGTAATCACTTCTTAATTATATGTTCATACTCTAAGTATCAAAATCTTCCAATTATCATGCTCACCTGAAAGAGGTATGCTCTCTTA GGAATACAGTTTCTAGCATTAAACAAATAAACAAGGGGAGAAAATAAAACTCAAGGACTGAAAATCAGGAGGTGTAATAAAATGTTCCTC GCATTCCCCCCCGCTTTTTTTTTTTTTTTTGACTTTGCCTTGGAGAGCCAGAGCTTCCGCATTTTCTTTACTATTCTTTTTAAAAAAAGT TTCACTGTGTAGAGAACATATATGCATAAACATAGGTCAATTATATGTCTCCATTAGAAAAATAATAATTGGAAAACATGTTCTAGAACT AGTTACAAAAATAATTTAAGGTGAAATCTCTAATATTTATAAAAGTAGCAAAATAAATGCATAATTAAAATATATTTGGACATAACAGAC TTGGAAGCAGATGATACAGACTTCTTTTTTTCATAATCAGGTTAGTGTAAGAAATTGCCATTTGAAACAATCCATTTTGTAACTGAACCT >28906_28906_7_FAM213A-IGJ_FAM213A_chr10_82180401_ENST00000372188_IGJ_chr4_71527932_ENST00000254801_length(amino acids)=197AA_BP=59 MSFLQDPSFFTMGMWSIGAGALGAAALALLLANTDVFLSKPQKAALEYLEDIDLKTLEKAQEDERIVLVDNKCKCARITSRIIRSSEDPN EDIVERNIRIIVPLNNRENISDPTSPLRTRFVYHLSDLCKKCDPTEVELDNQIVTATQSNICDEDSATETCYTYDRNKCYTAVVPLVYGG -------------------------------------------------------------- >28906_28906_8_FAM213A-IGJ_FAM213A_chr10_82180401_ENST00000372188_IGJ_chr4_71527932_ENST00000543780_length(transcript)=724nt_BP=308nt TGCCCAGACTGGTCTTGAACTCCTGGGCTCAAGCGATCCTCCCAAAGCCCTGAGATTACAGGCGTGAGCCAGCGCGCCGGACACAACCTC CTACTTTCATGAAAGAGTGGGCACTTCCAACAGGAGGAAAATGTCTTTCCTCCAGGACCCAAGTTTCTTCACCATGGGGATGTGGTCCAT TGGTGCAGGAGCCCTGGGGGCTGCTGCCTTGGCATTGCTGCTTGCCAACACAGACGTGTTTCTGTCCAAGCCCCAGAAAGCGGCCCTGGA GTACCTGGAGGATATAGACCTGAAAACACTGGAGAAGGCCCAAGAAGATGAAAGGATTGTTCTTGTTGACAACAAATGTAAGTGTGCCCG GATTACTTCCAGGATCATCCGTTCTTCCGAAGATCCTAATGAGGACATTGTGGAGAGAAACATCCGAATTATTGTTCCTCTGAACAACAG GGAGAATATCTCTGATCCCACCTCACCATTGAGAACCAGATTTGTGTACCATTTGTCTGACCTCTGTAAAAAATGTGATCCTACAGAAGT GGAGCTGGATAATCAGATAGTTACTGCTACCCAGAGCAATATCTGTGATGAAGACAGTGCTACAGAGACCTGCTACACTTATGACAGAAA CAAGTGCTACACAGCTGTGGTCCCACTCGTATATGGTGGTGAGACCAAAATGGTGGAAACAGCCTTAACCCCAGATGCCTGCTATCCTGA >28906_28906_8_FAM213A-IGJ_FAM213A_chr10_82180401_ENST00000372188_IGJ_chr4_71527932_ENST00000543780_length(amino acids)=198AA_BP=59 MSFLQDPSFFTMGMWSIGAGALGAAALALLLANTDVFLSKPQKAALEYLEDIDLKTLEKAQEDERIVLVDNKCKCARITSRIIRSSEDPN EDIVERNIRIIVPLNNRENISDPTSPLRTRFVYHLSDLCKKCDPTEVELDNQIVTATQSNICDEDSATETCYTYDRNKCYTAVVPLVYGG -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for FAM213A-IGJ |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for FAM213A-IGJ |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for FAM213A-IGJ |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies