
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:AGRN-NOC4L (FusionGDB2 ID:3003) |
Fusion Gene Summary for AGRN-NOC4L |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: AGRN-NOC4L | Fusion gene ID: 3003 | Hgene | Tgene | Gene symbol | AGRN | NOC4L | Gene ID | 375790 | 79050 |
| Gene name | agrin | nucleolar complex associated 4 homolog | |
| Synonyms | AGRIN|CMS8|CMSPPD | NET49|NOC4|UTP19 | |
| Cytomap | 1p36.33 | 12q24.33 | |
| Type of gene | protein-coding | protein-coding | |
| Description | agrinagrin proteoglycan | nucleolar complex protein 4 homologNOC4 protein homologNOC4-like proteinnucleolar complex-associated protein 4-like protein | |
| Modification date | 20200315 | 20200313 | |
| UniProtAcc | O00468 | Q9BVI4 | |
| Ensembl transtripts involved in fusion gene | ENST00000477585, ENST00000379370, | ENST00000330579, ENST00000538784, ENST00000535343, | |
| Fusion gene scores | * DoF score | 14 X 7 X 10=980 | 36 X 4 X 20=2880 |
| # samples | 18 | 41 | |
| ** MAII score | log2(18/980*10)=-2.4447848426729 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(41/2880*10)=-2.81237299682423 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: AGRN [Title/Abstract] AND NOC4L [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | AGRN(970704)-NOC4L(132635526), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | AGRN | GO:0043113 | receptor clustering | 15340048 |
| Fusion gene breakpoints across AGRN (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across NOC4L (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-BH-A0DK-01A | AGRN | chr1 | 970704 | - | NOC4L | chr12 | 132635526 | + |
| ChimerDB4 | KIRC | TCGA-B8-A54I-01A | AGRN | chr1 | 957842 | + | NOC4L | chr12 | 132635526 | + |
| ChimerDB4 | LUSC | TCGA-39-5029-01A | AGRN | chr1 | 970704 | - | NOC4L | chr12 | 132635526 | + |
| ChimerDB4 | STAD | TCGA-CG-5723 | AGRN | chr1 | 970704 | + | NOC4L | chr12 | 132635525 | + |
Top |
Fusion Gene ORF analysis for AGRN-NOC4L |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000477585 | ENST00000330579 | AGRN | chr1 | 970704 | - | NOC4L | chr12 | 132635526 | + |
| 3UTR-3CDS | ENST00000477585 | ENST00000330579 | AGRN | chr1 | 970704 | + | NOC4L | chr12 | 132635525 | + |
| 3UTR-5UTR | ENST00000477585 | ENST00000538784 | AGRN | chr1 | 970704 | - | NOC4L | chr12 | 132635526 | + |
| 3UTR-5UTR | ENST00000477585 | ENST00000538784 | AGRN | chr1 | 970704 | + | NOC4L | chr12 | 132635525 | + |
| 3UTR-intron | ENST00000477585 | ENST00000535343 | AGRN | chr1 | 970704 | - | NOC4L | chr12 | 132635526 | + |
| 3UTR-intron | ENST00000477585 | ENST00000535343 | AGRN | chr1 | 970704 | + | NOC4L | chr12 | 132635525 | + |
| 5CDS-5UTR | ENST00000379370 | ENST00000538784 | AGRN | chr1 | 957842 | + | NOC4L | chr12 | 132635526 | + |
| 5CDS-5UTR | ENST00000379370 | ENST00000538784 | AGRN | chr1 | 970704 | - | NOC4L | chr12 | 132635526 | + |
| 5CDS-5UTR | ENST00000379370 | ENST00000538784 | AGRN | chr1 | 970704 | + | NOC4L | chr12 | 132635525 | + |
| 5CDS-intron | ENST00000379370 | ENST00000535343 | AGRN | chr1 | 957842 | + | NOC4L | chr12 | 132635526 | + |
| 5CDS-intron | ENST00000379370 | ENST00000535343 | AGRN | chr1 | 970704 | - | NOC4L | chr12 | 132635526 | + |
| 5CDS-intron | ENST00000379370 | ENST00000535343 | AGRN | chr1 | 970704 | + | NOC4L | chr12 | 132635525 | + |
| In-frame | ENST00000379370 | ENST00000330579 | AGRN | chr1 | 957842 | + | NOC4L | chr12 | 132635526 | + |
| In-frame | ENST00000379370 | ENST00000330579 | AGRN | chr1 | 970704 | - | NOC4L | chr12 | 132635526 | + |
| In-frame | ENST00000379370 | ENST00000330579 | AGRN | chr1 | 970704 | + | NOC4L | chr12 | 132635525 | + |
| intron-3CDS | ENST00000477585 | ENST00000330579 | AGRN | chr1 | 957842 | + | NOC4L | chr12 | 132635526 | + |
| intron-5UTR | ENST00000477585 | ENST00000538784 | AGRN | chr1 | 957842 | + | NOC4L | chr12 | 132635526 | + |
| intron-intron | ENST00000477585 | ENST00000535343 | AGRN | chr1 | 957842 | + | NOC4L | chr12 | 132635526 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000379370 | AGRN | chr1 | 970704 | + | ENST00000330579 | NOC4L | chr12 | 132635525 | + | 1251 | 561 | 1192 | 2 | 397 |
| ENST00000379370 | AGRN | chr1 | 957842 | + | ENST00000330579 | NOC4L | chr12 | 132635526 | + | 1203 | 513 | 1144 | 2 | 381 |
| ENST00000379370 | AGRN | chr1 | 970704 | - | ENST00000330579 | NOC4L | chr12 | 132635526 | + | 1251 | 561 | 1192 | 2 | 397 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000379370 | ENST00000330579 | AGRN | chr1 | 970704 | + | NOC4L | chr12 | 132635525 | + | 0.01224119 | 0.9877588 |
| ENST00000379370 | ENST00000330579 | AGRN | chr1 | 957842 | + | NOC4L | chr12 | 132635526 | + | 0.008579757 | 0.99142027 |
| ENST00000379370 | ENST00000330579 | AGRN | chr1 | 970704 | - | NOC4L | chr12 | 132635526 | + | 0.01224119 | 0.9877588 |
Top |
Fusion Genomic Features for AGRN-NOC4L |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| AGRN | chr1 | 970704 | + | NOC4L | chr12 | 132635525 | + | 0.000739436 | 0.9992606 |
| AGRN | chr1 | 957842 | + | NOC4L | chr12 | 132635525 | + | 8.00E-06 | 0.999992 |
| AGRN | chr1 | 970704 | + | NOC4L | chr12 | 132635525 | + | 0.000739436 | 0.9992606 |
| AGRN | chr1 | 957842 | + | NOC4L | chr12 | 132635525 | + | 8.00E-06 | 0.999992 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
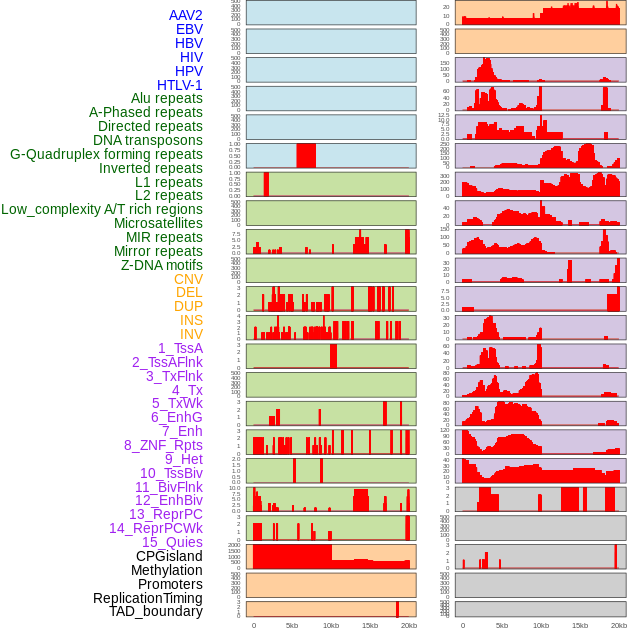 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
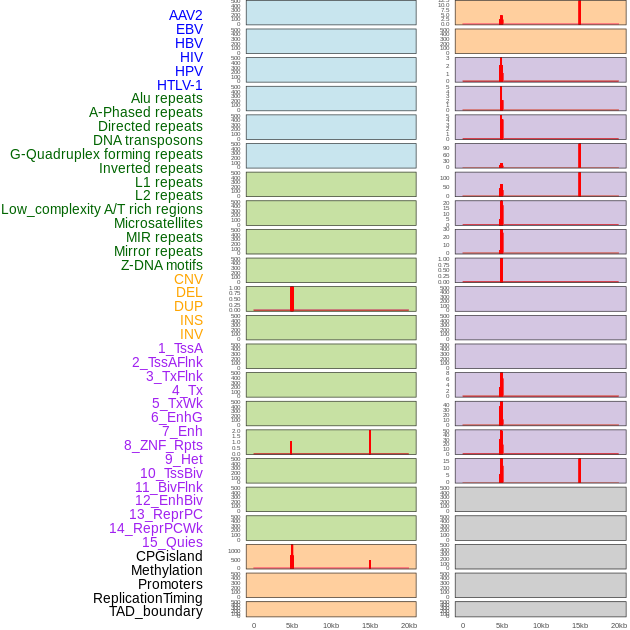 |
Top |
Fusion Protein Features for AGRN-NOC4L |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr1:970704/chr12:132635526) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| AGRN | NOC4L |
| FUNCTION: [Isoform 1]: heparan sulfate basal lamina glycoprotein that plays a central role in the formation and the maintenance of the neuromuscular junction (NMJ) and directs key events in postsynaptic differentiation. Component of the AGRN-LRP4 receptor complex that induces the phosphorylation and activation of MUSK. The activation of MUSK in myotubes induces the formation of NMJ by regulating different processes including the transcription of specific genes and the clustering of AChR in the postsynaptic membrane. Calcium ions are required for maximal AChR clustering. AGRN function in neurons is highly regulated by alternative splicing, glycan binding and proteolytic processing. Modulates calcium ion homeostasis in neurons, specifically by inducing an increase in cytoplasmic calcium ions. Functions differentially in the central nervous system (CNS) by inhibiting the alpha(3)-subtype of Na+/K+-ATPase and evoking depolarization at CNS synapses. This secreted isoform forms a bridge, after release from motor neurons, to basal lamina through binding laminin via the NtA domain.; FUNCTION: [Isoform 2]: transmembrane form that is the predominate form in neurons of the brain, induces dendritic filopodia and synapse formation in mature hippocampal neurons in large part due to the attached glycosaminoglycan chains and the action of Rho-family GTPases.; FUNCTION: Isoform 1, isoform 4 and isoform 5: neuron-specific (z+) isoforms that contain C-terminal insertions of 8-19 AA are potent activators of AChR clustering. Isoform 5, agrin (z+8), containing the 8-AA insert, forms a receptor complex in myotubules containing the neuronal AGRN, the muscle-specific kinase MUSK and LRP4, a member of the LDL receptor family. The splicing factors, NOVA1 and NOVA2, regulate AGRN splicing and production of the 'z' isoforms.; FUNCTION: Isoform 3 and isoform 6: lack any 'z' insert, are muscle-specific and may be involved in endothelial cell differentiation.; FUNCTION: [Agrin N-terminal 110 kDa subunit]: is involved in regulation of neurite outgrowth probably due to the presence of the glycosaminoglcan (GAG) side chains of heparan and chondroitin sulfate attached to the Ser/Thr- and Gly/Ser-rich regions. Also involved in modulation of growth factor signaling (By similarity). {ECO:0000250, ECO:0000269|PubMed:19631309, ECO:0000269|PubMed:21969364}.; FUNCTION: [Agrin C-terminal 22 kDa fragment]: this released fragment is important for agrin signaling and to exert a maximal dendritic filopodia-inducing effect. All 'z' splice variants (z+) of this fragment also show an increase in the number of filopodia. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | AGRN | chr1:957842 | chr12:132635526 | ENST00000379370 | + | 2 | 36 | 30_157 | 154 | 2046.0 | Domain | NtA |
| Hgene | AGRN | chr1:970704 | chr12:132635525 | ENST00000379370 | + | 3 | 36 | 30_157 | 170 | 2046.0 | Domain | NtA |
| Hgene | AGRN | chr1:970704 | chr12:132635526 | ENST00000379370 | - | 3 | 36 | 30_157 | 170 | 2046.0 | Domain | NtA |
| Tgene | NOC4L | chr1:957842 | chr12:132635526 | ENST00000330579 | 8 | 15 | 347_367 | 300 | 517.0 | Transmembrane | Helical | |
| Tgene | NOC4L | chr1:957842 | chr12:132635526 | ENST00000330579 | 8 | 15 | 375_395 | 300 | 517.0 | Transmembrane | Helical | |
| Tgene | NOC4L | chr1:970704 | chr12:132635525 | ENST00000330579 | 8 | 15 | 347_367 | 300 | 517.0 | Transmembrane | Helical | |
| Tgene | NOC4L | chr1:970704 | chr12:132635525 | ENST00000330579 | 8 | 15 | 375_395 | 300 | 517.0 | Transmembrane | Helical | |
| Tgene | NOC4L | chr1:970704 | chr12:132635526 | ENST00000330579 | 8 | 15 | 347_367 | 300 | 517.0 | Transmembrane | Helical | |
| Tgene | NOC4L | chr1:970704 | chr12:132635526 | ENST00000330579 | 8 | 15 | 375_395 | 300 | 517.0 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | AGRN | chr1:957842 | chr12:132635526 | ENST00000379370 | + | 2 | 36 | 1941_2009 | 154 | 2046.0 | Calcium binding | Ontology_term=ECO:0000250 |
| Hgene | AGRN | chr1:970704 | chr12:132635525 | ENST00000379370 | + | 3 | 36 | 1941_2009 | 170 | 2046.0 | Calcium binding | Ontology_term=ECO:0000250 |
| Hgene | AGRN | chr1:970704 | chr12:132635526 | ENST00000379370 | - | 3 | 36 | 1941_2009 | 170 | 2046.0 | Calcium binding | Ontology_term=ECO:0000250 |
| Hgene | AGRN | chr1:957842 | chr12:132635526 | ENST00000379370 | + | 2 | 36 | 1058_1097 | 154 | 2046.0 | Compositional bias | Note=Gly/Ser-rich |
| Hgene | AGRN | chr1:957842 | chr12:132635526 | ENST00000379370 | + | 2 | 36 | 1254_1324 | 154 | 2046.0 | Compositional bias | Note=Ser/Thr-rich |
| Hgene | AGRN | chr1:957842 | chr12:132635526 | ENST00000379370 | + | 2 | 36 | 671_677 | 154 | 2046.0 | Compositional bias | Note=Gly/Ser-rich |
| Hgene | AGRN | chr1:957842 | chr12:132635526 | ENST00000379370 | + | 2 | 36 | 974_1099 | 154 | 2046.0 | Compositional bias | Note=Ser/Thr-rich |
| Hgene | AGRN | chr1:970704 | chr12:132635525 | ENST00000379370 | + | 3 | 36 | 1058_1097 | 170 | 2046.0 | Compositional bias | Note=Gly/Ser-rich |
| Hgene | AGRN | chr1:970704 | chr12:132635525 | ENST00000379370 | + | 3 | 36 | 1254_1324 | 170 | 2046.0 | Compositional bias | Note=Ser/Thr-rich |
| Hgene | AGRN | chr1:970704 | chr12:132635525 | ENST00000379370 | + | 3 | 36 | 671_677 | 170 | 2046.0 | Compositional bias | Note=Gly/Ser-rich |
| Hgene | AGRN | chr1:970704 | chr12:132635525 | ENST00000379370 | + | 3 | 36 | 974_1099 | 170 | 2046.0 | Compositional bias | Note=Ser/Thr-rich |
| Hgene | AGRN | chr1:970704 | chr12:132635526 | ENST00000379370 | - | 3 | 36 | 1058_1097 | 170 | 2046.0 | Compositional bias | Note=Gly/Ser-rich |
| Hgene | AGRN | chr1:970704 | chr12:132635526 | ENST00000379370 | - | 3 | 36 | 1254_1324 | 170 | 2046.0 | Compositional bias | Note=Ser/Thr-rich |
| Hgene | AGRN | chr1:970704 | chr12:132635526 | ENST00000379370 | - | 3 | 36 | 671_677 | 170 | 2046.0 | Compositional bias | Note=Gly/Ser-rich |
| Hgene | AGRN | chr1:970704 | chr12:132635526 | ENST00000379370 | - | 3 | 36 | 974_1099 | 170 | 2046.0 | Compositional bias | Note=Ser/Thr-rich |
| Hgene | AGRN | chr1:957842 | chr12:132635526 | ENST00000379370 | + | 2 | 36 | 1130_1252 | 154 | 2046.0 | Domain | SEA |
| Hgene | AGRN | chr1:957842 | chr12:132635526 | ENST00000379370 | + | 2 | 36 | 1329_1367 | 154 | 2046.0 | Domain | EGF-like 1 |
| Hgene | AGRN | chr1:957842 | chr12:132635526 | ENST00000379370 | + | 2 | 36 | 1372_1548 | 154 | 2046.0 | Domain | Laminin G-like 1 |
| Hgene | AGRN | chr1:957842 | chr12:132635526 | ENST00000379370 | + | 2 | 36 | 1549_1586 | 154 | 2046.0 | Domain | EGF-like 2 |
| Hgene | AGRN | chr1:957842 | chr12:132635526 | ENST00000379370 | + | 2 | 36 | 1588_1625 | 154 | 2046.0 | Domain | EGF-like 3 |
| Hgene | AGRN | chr1:957842 | chr12:132635526 | ENST00000379370 | + | 2 | 36 | 1635_1822 | 154 | 2046.0 | Domain | Laminin G-like 2 |
| Hgene | AGRN | chr1:957842 | chr12:132635526 | ENST00000379370 | + | 2 | 36 | 1818_1857 | 154 | 2046.0 | Domain | EGF-like 4 |
| Hgene | AGRN | chr1:957842 | chr12:132635526 | ENST00000379370 | + | 2 | 36 | 1868_2065 | 154 | 2046.0 | Domain | Laminin G-like 3 |
| Hgene | AGRN | chr1:957842 | chr12:132635526 | ENST00000379370 | + | 2 | 36 | 191_244 | 154 | 2046.0 | Domain | Kazal-like 1 |
| Hgene | AGRN | chr1:957842 | chr12:132635526 | ENST00000379370 | + | 2 | 36 | 264_319 | 154 | 2046.0 | Domain | Kazal-like 2 |
| Hgene | AGRN | chr1:957842 | chr12:132635526 | ENST00000379370 | + | 2 | 36 | 337_391 | 154 | 2046.0 | Domain | Kazal-like 3 |
| Hgene | AGRN | chr1:957842 | chr12:132635526 | ENST00000379370 | + | 2 | 36 | 408_463 | 154 | 2046.0 | Domain | Kazal-like 4 |
| Hgene | AGRN | chr1:957842 | chr12:132635526 | ENST00000379370 | + | 2 | 36 | 484_536 | 154 | 2046.0 | Domain | Kazal-like 5 |
| Hgene | AGRN | chr1:957842 | chr12:132635526 | ENST00000379370 | + | 2 | 36 | 540_601 | 154 | 2046.0 | Domain | Kazal-like 6 |
| Hgene | AGRN | chr1:957842 | chr12:132635526 | ENST00000379370 | + | 2 | 36 | 607_666 | 154 | 2046.0 | Domain | Kazal-like 7 |
| Hgene | AGRN | chr1:957842 | chr12:132635526 | ENST00000379370 | + | 2 | 36 | 699_752 | 154 | 2046.0 | Domain | Kazal-like 8 |
| Hgene | AGRN | chr1:957842 | chr12:132635526 | ENST00000379370 | + | 2 | 36 | 793_846 | 154 | 2046.0 | Domain | Laminin EGF-like 1 |
| Hgene | AGRN | chr1:957842 | chr12:132635526 | ENST00000379370 | + | 2 | 36 | 847_893 | 154 | 2046.0 | Domain | Laminin EGF-like 2 |
| Hgene | AGRN | chr1:957842 | chr12:132635526 | ENST00000379370 | + | 2 | 36 | 917_971 | 154 | 2046.0 | Domain | Kazal-like 9 |
| Hgene | AGRN | chr1:970704 | chr12:132635525 | ENST00000379370 | + | 3 | 36 | 1130_1252 | 170 | 2046.0 | Domain | SEA |
| Hgene | AGRN | chr1:970704 | chr12:132635525 | ENST00000379370 | + | 3 | 36 | 1329_1367 | 170 | 2046.0 | Domain | EGF-like 1 |
| Hgene | AGRN | chr1:970704 | chr12:132635525 | ENST00000379370 | + | 3 | 36 | 1372_1548 | 170 | 2046.0 | Domain | Laminin G-like 1 |
| Hgene | AGRN | chr1:970704 | chr12:132635525 | ENST00000379370 | + | 3 | 36 | 1549_1586 | 170 | 2046.0 | Domain | EGF-like 2 |
| Hgene | AGRN | chr1:970704 | chr12:132635525 | ENST00000379370 | + | 3 | 36 | 1588_1625 | 170 | 2046.0 | Domain | EGF-like 3 |
| Hgene | AGRN | chr1:970704 | chr12:132635525 | ENST00000379370 | + | 3 | 36 | 1635_1822 | 170 | 2046.0 | Domain | Laminin G-like 2 |
| Hgene | AGRN | chr1:970704 | chr12:132635525 | ENST00000379370 | + | 3 | 36 | 1818_1857 | 170 | 2046.0 | Domain | EGF-like 4 |
| Hgene | AGRN | chr1:970704 | chr12:132635525 | ENST00000379370 | + | 3 | 36 | 1868_2065 | 170 | 2046.0 | Domain | Laminin G-like 3 |
| Hgene | AGRN | chr1:970704 | chr12:132635525 | ENST00000379370 | + | 3 | 36 | 191_244 | 170 | 2046.0 | Domain | Kazal-like 1 |
| Hgene | AGRN | chr1:970704 | chr12:132635525 | ENST00000379370 | + | 3 | 36 | 264_319 | 170 | 2046.0 | Domain | Kazal-like 2 |
| Hgene | AGRN | chr1:970704 | chr12:132635525 | ENST00000379370 | + | 3 | 36 | 337_391 | 170 | 2046.0 | Domain | Kazal-like 3 |
| Hgene | AGRN | chr1:970704 | chr12:132635525 | ENST00000379370 | + | 3 | 36 | 408_463 | 170 | 2046.0 | Domain | Kazal-like 4 |
| Hgene | AGRN | chr1:970704 | chr12:132635525 | ENST00000379370 | + | 3 | 36 | 484_536 | 170 | 2046.0 | Domain | Kazal-like 5 |
| Hgene | AGRN | chr1:970704 | chr12:132635525 | ENST00000379370 | + | 3 | 36 | 540_601 | 170 | 2046.0 | Domain | Kazal-like 6 |
| Hgene | AGRN | chr1:970704 | chr12:132635525 | ENST00000379370 | + | 3 | 36 | 607_666 | 170 | 2046.0 | Domain | Kazal-like 7 |
| Hgene | AGRN | chr1:970704 | chr12:132635525 | ENST00000379370 | + | 3 | 36 | 699_752 | 170 | 2046.0 | Domain | Kazal-like 8 |
| Hgene | AGRN | chr1:970704 | chr12:132635525 | ENST00000379370 | + | 3 | 36 | 793_846 | 170 | 2046.0 | Domain | Laminin EGF-like 1 |
| Hgene | AGRN | chr1:970704 | chr12:132635525 | ENST00000379370 | + | 3 | 36 | 847_893 | 170 | 2046.0 | Domain | Laminin EGF-like 2 |
| Hgene | AGRN | chr1:970704 | chr12:132635525 | ENST00000379370 | + | 3 | 36 | 917_971 | 170 | 2046.0 | Domain | Kazal-like 9 |
| Hgene | AGRN | chr1:970704 | chr12:132635526 | ENST00000379370 | - | 3 | 36 | 1130_1252 | 170 | 2046.0 | Domain | SEA |
| Hgene | AGRN | chr1:970704 | chr12:132635526 | ENST00000379370 | - | 3 | 36 | 1329_1367 | 170 | 2046.0 | Domain | EGF-like 1 |
| Hgene | AGRN | chr1:970704 | chr12:132635526 | ENST00000379370 | - | 3 | 36 | 1372_1548 | 170 | 2046.0 | Domain | Laminin G-like 1 |
| Hgene | AGRN | chr1:970704 | chr12:132635526 | ENST00000379370 | - | 3 | 36 | 1549_1586 | 170 | 2046.0 | Domain | EGF-like 2 |
| Hgene | AGRN | chr1:970704 | chr12:132635526 | ENST00000379370 | - | 3 | 36 | 1588_1625 | 170 | 2046.0 | Domain | EGF-like 3 |
| Hgene | AGRN | chr1:970704 | chr12:132635526 | ENST00000379370 | - | 3 | 36 | 1635_1822 | 170 | 2046.0 | Domain | Laminin G-like 2 |
| Hgene | AGRN | chr1:970704 | chr12:132635526 | ENST00000379370 | - | 3 | 36 | 1818_1857 | 170 | 2046.0 | Domain | EGF-like 4 |
| Hgene | AGRN | chr1:970704 | chr12:132635526 | ENST00000379370 | - | 3 | 36 | 1868_2065 | 170 | 2046.0 | Domain | Laminin G-like 3 |
| Hgene | AGRN | chr1:970704 | chr12:132635526 | ENST00000379370 | - | 3 | 36 | 191_244 | 170 | 2046.0 | Domain | Kazal-like 1 |
| Hgene | AGRN | chr1:970704 | chr12:132635526 | ENST00000379370 | - | 3 | 36 | 264_319 | 170 | 2046.0 | Domain | Kazal-like 2 |
| Hgene | AGRN | chr1:970704 | chr12:132635526 | ENST00000379370 | - | 3 | 36 | 337_391 | 170 | 2046.0 | Domain | Kazal-like 3 |
| Hgene | AGRN | chr1:970704 | chr12:132635526 | ENST00000379370 | - | 3 | 36 | 408_463 | 170 | 2046.0 | Domain | Kazal-like 4 |
| Hgene | AGRN | chr1:970704 | chr12:132635526 | ENST00000379370 | - | 3 | 36 | 484_536 | 170 | 2046.0 | Domain | Kazal-like 5 |
| Hgene | AGRN | chr1:970704 | chr12:132635526 | ENST00000379370 | - | 3 | 36 | 540_601 | 170 | 2046.0 | Domain | Kazal-like 6 |
| Hgene | AGRN | chr1:970704 | chr12:132635526 | ENST00000379370 | - | 3 | 36 | 607_666 | 170 | 2046.0 | Domain | Kazal-like 7 |
| Hgene | AGRN | chr1:970704 | chr12:132635526 | ENST00000379370 | - | 3 | 36 | 699_752 | 170 | 2046.0 | Domain | Kazal-like 8 |
| Hgene | AGRN | chr1:970704 | chr12:132635526 | ENST00000379370 | - | 3 | 36 | 793_846 | 170 | 2046.0 | Domain | Laminin EGF-like 1 |
| Hgene | AGRN | chr1:970704 | chr12:132635526 | ENST00000379370 | - | 3 | 36 | 847_893 | 170 | 2046.0 | Domain | Laminin EGF-like 2 |
| Hgene | AGRN | chr1:970704 | chr12:132635526 | ENST00000379370 | - | 3 | 36 | 917_971 | 170 | 2046.0 | Domain | Kazal-like 9 |
| Tgene | NOC4L | chr1:957842 | chr12:132635526 | ENST00000330579 | 8 | 15 | 297_317 | 300 | 517.0 | Transmembrane | Helical | |
| Tgene | NOC4L | chr1:970704 | chr12:132635525 | ENST00000330579 | 8 | 15 | 297_317 | 300 | 517.0 | Transmembrane | Helical | |
| Tgene | NOC4L | chr1:970704 | chr12:132635526 | ENST00000330579 | 8 | 15 | 297_317 | 300 | 517.0 | Transmembrane | Helical |
Top |
Fusion Gene Sequence for AGRN-NOC4L |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >3003_3003_1_AGRN-NOC4L_AGRN_chr1_957842_ENST00000379370_NOC4L_chr12_132635526_ENST00000330579_length(transcript)=1203nt_BP=513nt CCCGTCCCCGGCGCGGCCCGCGCGCTCCTCCGCCGCCTCTCGCCTGCGCCATGGCCGGCCGGTCCCACCCGGGCCCGCTGCGGCCGCTGC TGCCGCTCCTTGTGGTGGCCGCGTGCGTCCTGCCCGGAGCCGGCGGGACATGCCCGGAGCGCGCGCTGGAGCGGCGCGAGGAGGAGGCGA ACGTGGTGCTCACCGGGACGGTGGAGGAGATCCTCAACGTGGACCCGGTGCAGCACACGTACTCCTGCAAGGTTCGGGTCTGGCGGTACT TGAAGGGCAAAGACCTGGTGGCCCGGGAGAGCCTGCTGGACGGCGGCAACAAGGTGGTGATCAGCGGCTTTGGAGACCCCCTCATCTGTG ACAACCAGGTGTCCACTGGGGACACCAGGATCTTCTTTGTGAACCCTGCACCCCCATACCTGTGGCCAGCCCACAAGAACGAGCTGATGC TCAACTCCAGCCTCATGCGGATCACCCTGCGGAACCTGGAGGAGGTGGAGTTCTGTGTGGAAGGGGGGGCCCTCAGCCTCTTGGCCTTGA ACGGGCTGTTCATCTTGATTCACAAACACAACCTGGAGTACCCTGACTTCTACCGGAAGCTCTACGGCCTCTTGGACCCCTCTGTCTTTC ACGTCAAGTACCGCGCCCGCTTCTTCCACCTGGCTGACCTCTTCCTGTCCTCCTCCCACCTCCCCGCCTACCTGGTGGCCGCCTTCGCCA AGCGGCTGGCCCGCCTGGCCCTGACGGCTCCCCCTGAGGCCCTGCTCATGGTCCTGCCTTTCATCTGTAACCTGCTGCGCCGGCACCCTG CCTGCCGGGTCCTCGTGCACCGTCCACACGGCCCTGAGTTGGACGCCGACCCCTACGACCCTGGAGAGGAGGACCCAGCCCAGAGCCGGG CCTTGGAGAGCTCCCTGTGGGAGCTTCAGGCCCTCCAGCGCCACTACCACCCTGAGGTGTCCAAAGCCGCCAGCGTCATCAACCAGGCCC TGTCCATGCCTGAGGTCAGCATCGCGCCACTGCTGGAGCTCACGGCCTACGAGATCTTTGAGCGGGACCTGAAGAAGAAGGGGCCCGAGC CGGTGCCACTGGAGTTTATCCCAGCCCAGGGCCTGCTGGGACGGCCGGGTGAACTCTGTGCCCAGCACTTCACGCTCAGCTGACCCTGGC >3003_3003_1_AGRN-NOC4L_AGRN_chr1_957842_ENST00000379370_NOC4L_chr12_132635526_ENST00000330579_length(amino acids)=381AA_BP=1 MGTEFTRPSQQALGWDKLQWHRLGPLLLQVPLKDLVGRELQQWRDADLRHGQGLVDDAGGFGHLRVVVALEGLKLPQGALQGPALGWVLL SRVVGVGVQLRAVWTVHEDPAGRVPAQQVTDERQDHEQGLRGSRQGQAGQPLGEGGHQVGGEVGGGQEEVSQVEEAGAVLDVKDRGVQEA VELPVEVRVLQVVFVNQDEQPVQGQEAEGPPFHTELHLLQVPQGDPHEAGVEHQLVLVGWPQVWGCRVHKEDPGVPSGHLVVTDEGVSKA ADHHLVAAVQQALPGHQVFALQVPPDPNLAGVRVLHRVHVEDLLHRPGEHHVRLLLAPLQRALRACPAGSGQDARGHHKERQQRPQRARV -------------------------------------------------------------- >3003_3003_2_AGRN-NOC4L_AGRN_chr1_970704_ENST00000379370_NOC4L_chr12_132635525_ENST00000330579_length(transcript)=1251nt_BP=561nt CCCGTCCCCGGCGCGGCCCGCGCGCTCCTCCGCCGCCTCTCGCCTGCGCCATGGCCGGCCGGTCCCACCCGGGCCCGCTGCGGCCGCTGC TGCCGCTCCTTGTGGTGGCCGCGTGCGTCCTGCCCGGAGCCGGCGGGACATGCCCGGAGCGCGCGCTGGAGCGGCGCGAGGAGGAGGCGA ACGTGGTGCTCACCGGGACGGTGGAGGAGATCCTCAACGTGGACCCGGTGCAGCACACGTACTCCTGCAAGGTTCGGGTCTGGCGGTACT TGAAGGGCAAAGACCTGGTGGCCCGGGAGAGCCTGCTGGACGGCGGCAACAAGGTGGTGATCAGCGGCTTTGGAGACCCCCTCATCTGTG ACAACCAGGTGTCCACTGGGGACACCAGGATCTTCTTTGTGAACCCTGCACCCCCATACCTGTGGCCAGCCCACAAGAACGAGCTGATGC TCAACTCCAGCCTCATGCGGATCACCCTGCGGAACCTGGAGGAGGTGGAGTTCTGTGTGGAAGATAAACCCGGGACCCACTTCACTCCAG TGCCTCCGACGCCTCCTGATGGGGGGGCCCTCAGCCTCTTGGCCTTGAACGGGCTGTTCATCTTGATTCACAAACACAACCTGGAGTACC CTGACTTCTACCGGAAGCTCTACGGCCTCTTGGACCCCTCTGTCTTTCACGTCAAGTACCGCGCCCGCTTCTTCCACCTGGCTGACCTCT TCCTGTCCTCCTCCCACCTCCCCGCCTACCTGGTGGCCGCCTTCGCCAAGCGGCTGGCCCGCCTGGCCCTGACGGCTCCCCCTGAGGCCC TGCTCATGGTCCTGCCTTTCATCTGTAACCTGCTGCGCCGGCACCCTGCCTGCCGGGTCCTCGTGCACCGTCCACACGGCCCTGAGTTGG ACGCCGACCCCTACGACCCTGGAGAGGAGGACCCAGCCCAGAGCCGGGCCTTGGAGAGCTCCCTGTGGGAGCTTCAGGCCCTCCAGCGCC ACTACCACCCTGAGGTGTCCAAAGCCGCCAGCGTCATCAACCAGGCCCTGTCCATGCCTGAGGTCAGCATCGCGCCACTGCTGGAGCTCA CGGCCTACGAGATCTTTGAGCGGGACCTGAAGAAGAAGGGGCCCGAGCCGGTGCCACTGGAGTTTATCCCAGCCCAGGGCCTGCTGGGAC >3003_3003_2_AGRN-NOC4L_AGRN_chr1_970704_ENST00000379370_NOC4L_chr12_132635525_ENST00000330579_length(amino acids)=397AA_BP=1 MGTEFTRPSQQALGWDKLQWHRLGPLLLQVPLKDLVGRELQQWRDADLRHGQGLVDDAGGFGHLRVVVALEGLKLPQGALQGPALGWVLL SRVVGVGVQLRAVWTVHEDPAGRVPAQQVTDERQDHEQGLRGSRQGQAGQPLGEGGHQVGGEVGGGQEEVSQVEEAGAVLDVKDRGVQEA VELPVEVRVLQVVFVNQDEQPVQGQEAEGPPIRRRRRHWSEVGPGFIFHTELHLLQVPQGDPHEAGVEHQLVLVGWPQVWGCRVHKEDPG VPSGHLVVTDEGVSKAADHHLVAAVQQALPGHQVFALQVPPDPNLAGVRVLHRVHVEDLLHRPGEHHVRLLLAPLQRALRACPAGSGQDA -------------------------------------------------------------- >3003_3003_3_AGRN-NOC4L_AGRN_chr1_970704_ENST00000379370_NOC4L_chr12_132635526_ENST00000330579_length(transcript)=1251nt_BP=561nt CCCGTCCCCGGCGCGGCCCGCGCGCTCCTCCGCCGCCTCTCGCCTGCGCCATGGCCGGCCGGTCCCACCCGGGCCCGCTGCGGCCGCTGC TGCCGCTCCTTGTGGTGGCCGCGTGCGTCCTGCCCGGAGCCGGCGGGACATGCCCGGAGCGCGCGCTGGAGCGGCGCGAGGAGGAGGCGA ACGTGGTGCTCACCGGGACGGTGGAGGAGATCCTCAACGTGGACCCGGTGCAGCACACGTACTCCTGCAAGGTTCGGGTCTGGCGGTACT TGAAGGGCAAAGACCTGGTGGCCCGGGAGAGCCTGCTGGACGGCGGCAACAAGGTGGTGATCAGCGGCTTTGGAGACCCCCTCATCTGTG ACAACCAGGTGTCCACTGGGGACACCAGGATCTTCTTTGTGAACCCTGCACCCCCATACCTGTGGCCAGCCCACAAGAACGAGCTGATGC TCAACTCCAGCCTCATGCGGATCACCCTGCGGAACCTGGAGGAGGTGGAGTTCTGTGTGGAAGATAAACCCGGGACCCACTTCACTCCAG TGCCTCCGACGCCTCCTGATGGGGGGGCCCTCAGCCTCTTGGCCTTGAACGGGCTGTTCATCTTGATTCACAAACACAACCTGGAGTACC CTGACTTCTACCGGAAGCTCTACGGCCTCTTGGACCCCTCTGTCTTTCACGTCAAGTACCGCGCCCGCTTCTTCCACCTGGCTGACCTCT TCCTGTCCTCCTCCCACCTCCCCGCCTACCTGGTGGCCGCCTTCGCCAAGCGGCTGGCCCGCCTGGCCCTGACGGCTCCCCCTGAGGCCC TGCTCATGGTCCTGCCTTTCATCTGTAACCTGCTGCGCCGGCACCCTGCCTGCCGGGTCCTCGTGCACCGTCCACACGGCCCTGAGTTGG ACGCCGACCCCTACGACCCTGGAGAGGAGGACCCAGCCCAGAGCCGGGCCTTGGAGAGCTCCCTGTGGGAGCTTCAGGCCCTCCAGCGCC ACTACCACCCTGAGGTGTCCAAAGCCGCCAGCGTCATCAACCAGGCCCTGTCCATGCCTGAGGTCAGCATCGCGCCACTGCTGGAGCTCA CGGCCTACGAGATCTTTGAGCGGGACCTGAAGAAGAAGGGGCCCGAGCCGGTGCCACTGGAGTTTATCCCAGCCCAGGGCCTGCTGGGAC >3003_3003_3_AGRN-NOC4L_AGRN_chr1_970704_ENST00000379370_NOC4L_chr12_132635526_ENST00000330579_length(amino acids)=397AA_BP=1 MGTEFTRPSQQALGWDKLQWHRLGPLLLQVPLKDLVGRELQQWRDADLRHGQGLVDDAGGFGHLRVVVALEGLKLPQGALQGPALGWVLL SRVVGVGVQLRAVWTVHEDPAGRVPAQQVTDERQDHEQGLRGSRQGQAGQPLGEGGHQVGGEVGGGQEEVSQVEEAGAVLDVKDRGVQEA VELPVEVRVLQVVFVNQDEQPVQGQEAEGPPIRRRRRHWSEVGPGFIFHTELHLLQVPQGDPHEAGVEHQLVLVGWPQVWGCRVHKEDPG VPSGHLVVTDEGVSKAADHHLVAAVQQALPGHQVFALQVPPDPNLAGVRVLHRVHVEDLLHRPGEHHVRLLLAPLQRALRACPAGSGQDA -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for AGRN-NOC4L |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for AGRN-NOC4L |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for AGRN-NOC4L |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies