
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:FDFT1-DEFB135 (FusionGDB2 ID:30043) |
Fusion Gene Summary for FDFT1-DEFB135 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: FDFT1-DEFB135 | Fusion gene ID: 30043 | Hgene | Tgene | Gene symbol | FDFT1 | DEFB135 | Gene ID | 2222 | 613209 |
| Gene name | farnesyl-diphosphate farnesyltransferase 1 | defensin beta 135 | |
| Synonyms | DGPT|ERG9|SQS|SQSD|SS | DEFB136 | |
| Cytomap | 8p23.1 | 8p23.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | squalene synthaseFPP:FPP farnesyltransferasepresqualene-di-diphosphate synthasesqualene synthetase | beta-defensin 135beta-defensin 136 | |
| Modification date | 20200320 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000446331, ENST00000220584, ENST00000525777, ENST00000525900, ENST00000528643, ENST00000538689, ENST00000443614, ENST00000528812, ENST00000530664, | ENST00000382208, | |
| Fusion gene scores | * DoF score | 16 X 12 X 9=1728 | 5 X 2 X 6=60 |
| # samples | 20 | 8 | |
| ** MAII score | log2(20/1728*10)=-3.11103131238874 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(8/60*10)=0.415037499278844 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | |
| Context | PubMed: FDFT1 [Title/Abstract] AND DEFB135 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | FDFT1(11696082)-DEFB135(11841930), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | FDFT1-DEFB135 seems lost the major protein functional domain in Hgene partner, which is a cell metabolism gene due to the frame-shifted ORF. FDFT1-DEFB135 seems lost the major protein functional domain in Hgene partner, which is a IUPHAR drug target due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across FDFT1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
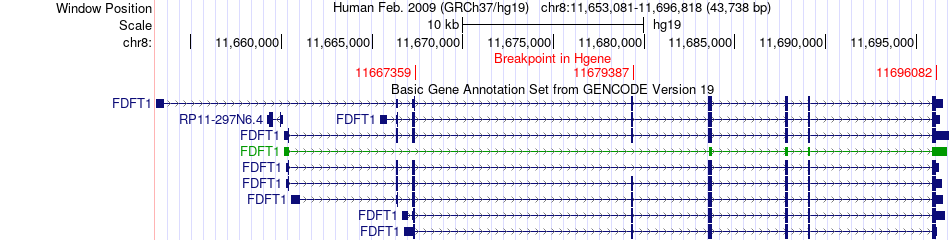 |
| Fusion gene breakpoints across DEFB135 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | LUAD | TCGA-35-5375-01A | FDFT1 | chr8 | 11679387 | + | DEFB135 | chr8 | 11841930 | + |
| ChimerDB4 | OV | TCGA-30-1860-01A | FDFT1 | chr8 | 11696082 | + | DEFB135 | chr8 | 11841930 | + |
| ChimerDB4 | UCEC | TCGA-DI-A1NO-01A | FDFT1 | chr8 | 11667359 | + | DEFB135 | chr8 | 11841930 | + |
Top |
Fusion Gene ORF analysis for FDFT1-DEFB135 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000446331 | ENST00000382208 | FDFT1 | chr8 | 11696082 | + | DEFB135 | chr8 | 11841930 | + |
| Frame-shift | ENST00000220584 | ENST00000382208 | FDFT1 | chr8 | 11696082 | + | DEFB135 | chr8 | 11841930 | + |
| Frame-shift | ENST00000525777 | ENST00000382208 | FDFT1 | chr8 | 11696082 | + | DEFB135 | chr8 | 11841930 | + |
| Frame-shift | ENST00000525900 | ENST00000382208 | FDFT1 | chr8 | 11696082 | + | DEFB135 | chr8 | 11841930 | + |
| Frame-shift | ENST00000528643 | ENST00000382208 | FDFT1 | chr8 | 11696082 | + | DEFB135 | chr8 | 11841930 | + |
| Frame-shift | ENST00000538689 | ENST00000382208 | FDFT1 | chr8 | 11696082 | + | DEFB135 | chr8 | 11841930 | + |
| In-frame | ENST00000220584 | ENST00000382208 | FDFT1 | chr8 | 11679387 | + | DEFB135 | chr8 | 11841930 | + |
| In-frame | ENST00000220584 | ENST00000382208 | FDFT1 | chr8 | 11667359 | + | DEFB135 | chr8 | 11841930 | + |
| In-frame | ENST00000443614 | ENST00000382208 | FDFT1 | chr8 | 11696082 | + | DEFB135 | chr8 | 11841930 | + |
| In-frame | ENST00000443614 | ENST00000382208 | FDFT1 | chr8 | 11667359 | + | DEFB135 | chr8 | 11841930 | + |
| In-frame | ENST00000525777 | ENST00000382208 | FDFT1 | chr8 | 11679387 | + | DEFB135 | chr8 | 11841930 | + |
| In-frame | ENST00000525777 | ENST00000382208 | FDFT1 | chr8 | 11667359 | + | DEFB135 | chr8 | 11841930 | + |
| In-frame | ENST00000525900 | ENST00000382208 | FDFT1 | chr8 | 11679387 | + | DEFB135 | chr8 | 11841930 | + |
| In-frame | ENST00000525900 | ENST00000382208 | FDFT1 | chr8 | 11667359 | + | DEFB135 | chr8 | 11841930 | + |
| In-frame | ENST00000528643 | ENST00000382208 | FDFT1 | chr8 | 11679387 | + | DEFB135 | chr8 | 11841930 | + |
| In-frame | ENST00000528643 | ENST00000382208 | FDFT1 | chr8 | 11667359 | + | DEFB135 | chr8 | 11841930 | + |
| In-frame | ENST00000528812 | ENST00000382208 | FDFT1 | chr8 | 11679387 | + | DEFB135 | chr8 | 11841930 | + |
| In-frame | ENST00000528812 | ENST00000382208 | FDFT1 | chr8 | 11696082 | + | DEFB135 | chr8 | 11841930 | + |
| In-frame | ENST00000528812 | ENST00000382208 | FDFT1 | chr8 | 11667359 | + | DEFB135 | chr8 | 11841930 | + |
| In-frame | ENST00000530664 | ENST00000382208 | FDFT1 | chr8 | 11679387 | + | DEFB135 | chr8 | 11841930 | + |
| In-frame | ENST00000530664 | ENST00000382208 | FDFT1 | chr8 | 11696082 | + | DEFB135 | chr8 | 11841930 | + |
| In-frame | ENST00000530664 | ENST00000382208 | FDFT1 | chr8 | 11667359 | + | DEFB135 | chr8 | 11841930 | + |
| In-frame | ENST00000538689 | ENST00000382208 | FDFT1 | chr8 | 11679387 | + | DEFB135 | chr8 | 11841930 | + |
| In-frame | ENST00000538689 | ENST00000382208 | FDFT1 | chr8 | 11667359 | + | DEFB135 | chr8 | 11841930 | + |
| intron-3CDS | ENST00000443614 | ENST00000382208 | FDFT1 | chr8 | 11679387 | + | DEFB135 | chr8 | 11841930 | + |
| intron-3CDS | ENST00000446331 | ENST00000382208 | FDFT1 | chr8 | 11679387 | + | DEFB135 | chr8 | 11841930 | + |
| intron-3CDS | ENST00000446331 | ENST00000382208 | FDFT1 | chr8 | 11667359 | + | DEFB135 | chr8 | 11841930 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000538689 | FDFT1 | chr8 | 11679387 | + | ENST00000382208 | DEFB135 | chr8 | 11841930 | + | 1020 | 850 | 376 | 933 | 185 |
| ENST00000220584 | FDFT1 | chr8 | 11679387 | + | ENST00000382208 | DEFB135 | chr8 | 11841930 | + | 902 | 732 | 222 | 815 | 197 |
| ENST00000525900 | FDFT1 | chr8 | 11679387 | + | ENST00000382208 | DEFB135 | chr8 | 11841930 | + | 726 | 556 | 67 | 639 | 190 |
| ENST00000528812 | FDFT1 | chr8 | 11679387 | + | ENST00000382208 | DEFB135 | chr8 | 11841930 | + | 1088 | 918 | 525 | 1001 | 158 |
| ENST00000530664 | FDFT1 | chr8 | 11679387 | + | ENST00000382208 | DEFB135 | chr8 | 11841930 | + | 956 | 786 | 345 | 869 | 174 |
| ENST00000528643 | FDFT1 | chr8 | 11679387 | + | ENST00000382208 | DEFB135 | chr8 | 11841930 | + | 830 | 660 | 369 | 743 | 124 |
| ENST00000525777 | FDFT1 | chr8 | 11679387 | + | ENST00000382208 | DEFB135 | chr8 | 11841930 | + | 894 | 724 | 433 | 807 | 124 |
| ENST00000443614 | FDFT1 | chr8 | 11696082 | + | ENST00000382208 | DEFB135 | chr8 | 11841930 | + | 1377 | 1207 | 94 | 1032 | 312 |
| ENST00000528812 | FDFT1 | chr8 | 11696082 | + | ENST00000382208 | DEFB135 | chr8 | 11841930 | + | 1997 | 1827 | 525 | 1475 | 316 |
| ENST00000530664 | FDFT1 | chr8 | 11696082 | + | ENST00000382208 | DEFB135 | chr8 | 11841930 | + | 1745 | 1575 | 345 | 1343 | 332 |
| ENST00000538689 | FDFT1 | chr8 | 11667359 | + | ENST00000382208 | DEFB135 | chr8 | 11841930 | + | 891 | 721 | 376 | 804 | 142 |
| ENST00000220584 | FDFT1 | chr8 | 11667359 | + | ENST00000382208 | DEFB135 | chr8 | 11841930 | + | 773 | 603 | 222 | 686 | 154 |
| ENST00000443614 | FDFT1 | chr8 | 11667359 | + | ENST00000382208 | DEFB135 | chr8 | 11841930 | + | 645 | 475 | 94 | 558 | 154 |
| ENST00000525900 | FDFT1 | chr8 | 11667359 | + | ENST00000382208 | DEFB135 | chr8 | 11841930 | + | 597 | 427 | 67 | 510 | 147 |
| ENST00000528812 | FDFT1 | chr8 | 11667359 | + | ENST00000382208 | DEFB135 | chr8 | 11841930 | + | 959 | 789 | 525 | 872 | 115 |
| ENST00000530664 | FDFT1 | chr8 | 11667359 | + | ENST00000382208 | DEFB135 | chr8 | 11841930 | + | 827 | 657 | 345 | 740 | 131 |
| ENST00000528643 | FDFT1 | chr8 | 11667359 | + | ENST00000382208 | DEFB135 | chr8 | 11841930 | + | 701 | 531 | 369 | 614 | 81 |
| ENST00000525777 | FDFT1 | chr8 | 11667359 | + | ENST00000382208 | DEFB135 | chr8 | 11841930 | + | 765 | 595 | 433 | 678 | 81 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000538689 | ENST00000382208 | FDFT1 | chr8 | 11679387 | + | DEFB135 | chr8 | 11841930 | + | 0.004440818 | 0.9955592 |
| ENST00000220584 | ENST00000382208 | FDFT1 | chr8 | 11679387 | + | DEFB135 | chr8 | 11841930 | + | 0.004799319 | 0.99520063 |
| ENST00000525900 | ENST00000382208 | FDFT1 | chr8 | 11679387 | + | DEFB135 | chr8 | 11841930 | + | 0.001739018 | 0.99826103 |
| ENST00000528812 | ENST00000382208 | FDFT1 | chr8 | 11679387 | + | DEFB135 | chr8 | 11841930 | + | 0.0053615 | 0.9946385 |
| ENST00000530664 | ENST00000382208 | FDFT1 | chr8 | 11679387 | + | DEFB135 | chr8 | 11841930 | + | 0.00501212 | 0.99498785 |
| ENST00000528643 | ENST00000382208 | FDFT1 | chr8 | 11679387 | + | DEFB135 | chr8 | 11841930 | + | 0.00996956 | 0.9900304 |
| ENST00000525777 | ENST00000382208 | FDFT1 | chr8 | 11679387 | + | DEFB135 | chr8 | 11841930 | + | 0.01595922 | 0.98404074 |
| ENST00000443614 | ENST00000382208 | FDFT1 | chr8 | 11696082 | + | DEFB135 | chr8 | 11841930 | + | 0.001281144 | 0.99871886 |
| ENST00000528812 | ENST00000382208 | FDFT1 | chr8 | 11696082 | + | DEFB135 | chr8 | 11841930 | + | 0.000323406 | 0.9996766 |
| ENST00000530664 | ENST00000382208 | FDFT1 | chr8 | 11696082 | + | DEFB135 | chr8 | 11841930 | + | 0.000394596 | 0.9996055 |
| ENST00000538689 | ENST00000382208 | FDFT1 | chr8 | 11667359 | + | DEFB135 | chr8 | 11841930 | + | 0.020664234 | 0.9793357 |
| ENST00000220584 | ENST00000382208 | FDFT1 | chr8 | 11667359 | + | DEFB135 | chr8 | 11841930 | + | 0.010395994 | 0.989604 |
| ENST00000443614 | ENST00000382208 | FDFT1 | chr8 | 11667359 | + | DEFB135 | chr8 | 11841930 | + | 0.008735449 | 0.9912646 |
| ENST00000525900 | ENST00000382208 | FDFT1 | chr8 | 11667359 | + | DEFB135 | chr8 | 11841930 | + | 0.004622113 | 0.9953779 |
| ENST00000528812 | ENST00000382208 | FDFT1 | chr8 | 11667359 | + | DEFB135 | chr8 | 11841930 | + | 0.027476922 | 0.9725231 |
| ENST00000530664 | ENST00000382208 | FDFT1 | chr8 | 11667359 | + | DEFB135 | chr8 | 11841930 | + | 0.027397243 | 0.9726027 |
| ENST00000528643 | ENST00000382208 | FDFT1 | chr8 | 11667359 | + | DEFB135 | chr8 | 11841930 | + | 0.070015855 | 0.9299842 |
| ENST00000525777 | ENST00000382208 | FDFT1 | chr8 | 11667359 | + | DEFB135 | chr8 | 11841930 | + | 0.27296746 | 0.7270326 |
Top |
Fusion Genomic Features for FDFT1-DEFB135 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| FDFT1 | chr8 | 11679387 | + | DEFB135 | chr8 | 11841929 | + | 0.088493414 | 0.9115066 |
| FDFT1 | chr8 | 11667359 | + | DEFB135 | chr8 | 11841929 | + | 2.15E-05 | 0.99997854 |
| FDFT1 | chr8 | 11679387 | + | DEFB135 | chr8 | 11841929 | + | 0.088493414 | 0.9115066 |
| FDFT1 | chr8 | 11667359 | + | DEFB135 | chr8 | 11841929 | + | 2.15E-05 | 0.99997854 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
 |
Top |
Fusion Protein Features for FDFT1-DEFB135 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr8:11696082/chr8:11841930) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | FDFT1 | chr8:11667359 | chr8:11841930 | ENST00000220584 | + | 3 | 8 | 284_304 | 127 | 418.0 | Transmembrane | Helical |
| Hgene | FDFT1 | chr8:11667359 | chr8:11841930 | ENST00000220584 | + | 3 | 8 | 384_404 | 127 | 418.0 | Transmembrane | Helical |
| Hgene | FDFT1 | chr8:11679387 | chr8:11841930 | ENST00000220584 | + | 4 | 8 | 284_304 | 170 | 418.0 | Transmembrane | Helical |
| Hgene | FDFT1 | chr8:11679387 | chr8:11841930 | ENST00000220584 | + | 4 | 8 | 384_404 | 170 | 418.0 | Transmembrane | Helical |
| Hgene | FDFT1 | chr8:11696082 | chr8:11841930 | ENST00000220584 | + | 1 | 8 | 284_304 | 0 | 418.0 | Transmembrane | Helical |
| Hgene | FDFT1 | chr8:11696082 | chr8:11841930 | ENST00000220584 | + | 1 | 8 | 384_404 | 0 | 418.0 | Transmembrane | Helical |
Top |
Fusion Gene Sequence for FDFT1-DEFB135 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >30043_30043_1_FDFT1-DEFB135_FDFT1_chr8_11667359_ENST00000220584_DEFB135_chr8_11841930_ENST00000382208_length(transcript)=773nt_BP=603nt AATCAGCGCCCGTCAGCCCACCCCACGAGGCCGCAGCTAGCCCCGCTGGCGGCCGAGGCCGGTTGAAGTGGGCGGAGCGGCGGGCGGGGC GTCGCCGTACTAGGCCTGCCCCCTGTCCGGCCAGCCCCTCGAAGCACCTACTCCACAGGTCCAGCCGGCCGGTGAGCGCCTGGGGACCGC AGAGGTGAGAGTCGCGCCCGGGAGTCCGCCGCCTGCGCCAGGATGGAGTTCGTGAAATGCCTTGGCCACCCCGAAGAGTTCTACAACCTG GTGCGCTTCCGGATCGGGGGCAAGCGGAAGGTGATGCCCAAGATGGACCAGGACTCGCTCAGCAGCAGCCTGAAAACTTGCTACAAGTAT CTCAATCAGACCAGTCGCAGTTTCGCAGCTGTTATCCAGGCGCTGGATGGGGAAATGCGCAACGCAGTGTGCATATTTTATCTGGTTCTC CGAGCTCTGGACACACTGGAAGATGACATGACCATCAGTGTGGAAAAGAAGGTCCCGCTGTTACACAACTTTCACTCTTTCCTTTACCAA CCAGACTGGCGGTTCATGGAGAGCAAGGAGAAGGATCGCCAGGTGCTGGAGGACTTCCCAACGGTAGAAGTGGACCCAATGTCTACATAC AAAAAATCTTTGCTTCATGTTGGCGACTGCAAGGTACTTGCCGGCCAAAATGTCTAAAAAACGAACAATATCGTATTTTGTGTGATACTA >30043_30043_1_FDFT1-DEFB135_FDFT1_chr8_11667359_ENST00000220584_DEFB135_chr8_11841930_ENST00000382208_length(amino acids)=154AA_BP=0 MEFVKCLGHPEEFYNLVRFRIGGKRKVMPKMDQDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISV -------------------------------------------------------------- >30043_30043_2_FDFT1-DEFB135_FDFT1_chr8_11667359_ENST00000443614_DEFB135_chr8_11841930_ENST00000382208_length(transcript)=645nt_BP=475nt TCGAAGCACCTACTCCACAGGTCCAGCCGGCCGGTGAGCGCCTGGGGACCGCAGAGGTGAGAGTCGCGCCCGGGAGTCCGCCGCCTGCGC CAGGATGGAGTTCGTGAAATGCCTTGGCCACCCCGAAGAGTTCTACAACCTGGTGCGCTTCCGGATCGGGGGCAAGCGGAAGGTGATGCC CAAGATGGACCAGGACTCGCTCAGCAGCAGCCTGAAAACTTGCTACAAGTATCTCAATCAGACCAGTCGCAGTTTCGCAGCTGTTATCCA GGCGCTGGATGGGGAAATGCGCAACGCAGTGTGCATATTTTATCTGGTTCTCCGAGCTCTGGACACACTGGAAGATGACATGACCATCAG TGTGGAAAAGAAGGTCCCGCTGTTACACAACTTTCACTCTTTCCTTTACCAACCAGACTGGCGGTTCATGGAGAGCAAGGAGAAGGATCG CCAGGTGCTGGAGGACTTCCCAACGGTAGAAGTGGACCCAATGTCTACATACAAAAAATCTTTGCTTCATGTTGGCGACTGCAAGGTACT TGCCGGCCAAAATGTCTAAAAAACGAACAATATCGTATTTTGTGTGATACTATACATTTGTGCTGTGTAAACCCAAAATATTTACCTATA >30043_30043_2_FDFT1-DEFB135_FDFT1_chr8_11667359_ENST00000443614_DEFB135_chr8_11841930_ENST00000382208_length(amino acids)=154AA_BP=0 MEFVKCLGHPEEFYNLVRFRIGGKRKVMPKMDQDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISV -------------------------------------------------------------- >30043_30043_3_FDFT1-DEFB135_FDFT1_chr8_11667359_ENST00000525777_DEFB135_chr8_11841930_ENST00000382208_length(transcript)=765nt_BP=595nt GCACATTACACCCATGAACTTAGACCAGTTGCCTTTATGTATGATCGTATTTATACTGAGAAGTTACTGTGTTTTTTGACTTTCTTTTCT ATTTGCTACATATTAGTTCGGTCTAAACGTTTGGTCTTCTGGTCTCCATAGTTCTACATTGGTTAAATGCAACTCACTTCTGGGAGTAGT GGTGACATTCAACTAGTAGGCTTTTTAATAAACTACAGAAGTTCATTACTCTCATGTAAGGAAGGAAAACTAATGTAACTTTCGTTAAGT ATGAAAAGCGTTGGATATCCTTATAGTTCTTTAGAGTTAAGGGTGAGATGGGTTTAGAAAGTGGCCAGGCACAAGTTATTTTAAAATAAA AAATCTTTGGCTGTTTGTTCCAATATATTAATAGTTTTCCCTTTTTTACAGCAACGCAGTGTGCATATTTTATCTGGTTCTCCGAGCTCT GGACACACTGGAAGATGACATGACCATCAGTGTGGAAAAGAAGGTCCCGCTGTTACACAACTTTCACTCTTTCCTTTACCAACCAGACTG GCGGTTCATGGAGAGCAAGGAGAAGGATCGCCAGGTGCTGGAGGACTTCCCAACGGTAGAAGTGGACCCAATGTCTACATACAAAAAATC TTTGCTTCATGTTGGCGACTGCAAGGTACTTGCCGGCCAAAATGTCTAAAAAACGAACAATATCGTATTTTGTGTGATACTATACATTTG >30043_30043_3_FDFT1-DEFB135_FDFT1_chr8_11667359_ENST00000525777_DEFB135_chr8_11841930_ENST00000382208_length(amino acids)=81AA_BP=1 -------------------------------------------------------------- >30043_30043_4_FDFT1-DEFB135_FDFT1_chr8_11667359_ENST00000525900_DEFB135_chr8_11841930_ENST00000382208_length(transcript)=597nt_BP=427nt CGGCCGGTGAGCGCCTGGGGACCGCAGAGGTGAGAGTCGCGCCCGGGAGTCCGCCGCCTGCGCCAGGATGGAGTTCGTGAAATGCCTTGG CCACCCCGAAGAGTTCTACAACCTGGTGCGCTTCCGGATCGGGGGCAAGCGGAAGGACTCGCTCAGCAGCAGCCTGAAAACTTGCTACAA GTATCTCAATCAGACCAGTCGCAGTTTCGCAGCTGTTATCCAGGCGCTGGATGGGGAAATGCGCAACGCAGTGTGCATATTTTATCTGGT TCTCCGAGCTCTGGACACACTGGAAGATGACATGACCATCAGTGTGGAAAAGAAGGTCCCGCTGTTACACAACTTTCACTCTTTCCTTTA CCAACCAGACTGGCGGTTCATGGAGAGCAAGGAGAAGGATCGCCAGGTGCTGGAGGACTTCCCAACGGTAGAAGTGGACCCAATGTCTAC ATACAAAAAATCTTTGCTTCATGTTGGCGACTGCAAGGTACTTGCCGGCCAAAATGTCTAAAAAACGAACAATATCGTATTTTGTGTGAT >30043_30043_4_FDFT1-DEFB135_FDFT1_chr8_11667359_ENST00000525900_DEFB135_chr8_11841930_ENST00000382208_length(amino acids)=147AA_BP=0 MEFVKCLGHPEEFYNLVRFRIGGKRKDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLL -------------------------------------------------------------- >30043_30043_5_FDFT1-DEFB135_FDFT1_chr8_11667359_ENST00000528643_DEFB135_chr8_11841930_ENST00000382208_length(transcript)=701nt_BP=531nt CTTGGCAGCTGAACCTGCCTGTGAGCAGGTCGTGTATTTCTCGGCTTCCCTTATCCAACTTTGCATTTCTATTTCTAGCATATTGGGTTG ATTCTTTTGAAGCTGCCTCTGTGCACATTACACCCATGAACTTAGACCAGTTGCCTTTATGTATGATCGTATTTATACTGAGAAGTTACT GTGTTTTTTGACTTTCTTTTCTATTTGCTACATATTAGTTCGGTCTAAACGTTTGGTCTTCTGGTCTCCATAGTTCTACATTGGTTAAAT GCAACTCACTTCTGGGAGTAGTGGTGACATTCAACTAGTAGGCTTTTTAATAAACTACAGAAGTTCATTACTCTCATCAACGCAGTGTGC ATATTTTATCTGGTTCTCCGAGCTCTGGACACACTGGAAGATGACATGACCATCAGTGTGGAAAAGAAGGTCCCGCTGTTACACAACTTT CACTCTTTCCTTTACCAACCAGACTGGCGGTTCATGGAGAGCAAGGAGAAGGATCGCCAGGTGCTGGAGGACTTCCCAACGGTAGAAGTG GACCCAATGTCTACATACAAAAAATCTTTGCTTCATGTTGGCGACTGCAAGGTACTTGCCGGCCAAAATGTCTAAAAAACGAACAATATC >30043_30043_5_FDFT1-DEFB135_FDFT1_chr8_11667359_ENST00000528643_DEFB135_chr8_11841930_ENST00000382208_length(amino acids)=81AA_BP=1 -------------------------------------------------------------- >30043_30043_6_FDFT1-DEFB135_FDFT1_chr8_11667359_ENST00000528812_DEFB135_chr8_11841930_ENST00000382208_length(transcript)=959nt_BP=789nt ATCTGGGGCAAGGGGCGCGGCGAGCAGGGCCGACGCCTGGGTGTTCCCGTCCCCCTTTCCTCGAGCCTTCCCCCTGTAGGGCCCGGGTGG ACGCGGCCGTCCTGGCTGACCTGTCCCTGCCCCCGCAAGCCGCCCTGGGCATGAGCGACTTTTGCGTGGTTCCCGGTGGTTGCGCTCCCC GTTTCGTCCCCTCCGTGAGCATCGGCGCTTACCGGTATTTTAACCCGAGGGTTACACATCTGAGGCAATGTGGGTGGGTTACGCGGGAGA GGACGAGTGAGTTTTTTGGTAAGCGGAATGAACTATGCAGATAACATCACATGAAGGCCGTTTCTGGAATGAAGTCTGACTCCTCCAGTT TCACCACCTCTTCCGGAGCTCTCCCCGCCTTGCTGCCTTCCATCGCTTCATCCTCGGTGCTTCCTGAGTTTTAAAATCGCCTATCTACGC TTCCAAGTTCCAATGAGTTATCTAACGTCTATGGATTAGCTAGGTGGTTGGTGGAAGGACTCGCTCAGCAGCAGCCTGAAAACTTGCTAC AAGTATCTCAATCAGACCAGTCGCAGTTTCGCAGCTGTTATCCAGGCGCTGGATGGGGAAATGCGCAACGCAGTGTGCATATTTTATCTG GTTCTCCGAGCTCTGGACACACTGGAAGATGACATGACCATCAGTGTGGAAAAGAAGGTCCCGCTGTTACACAACTTTCACTCTTTCCTT TACCAACCAGACTGGCGGTTCATGGAGAGCAAGGAGAAGGATCGCCAGGTGCTGGAGGACTTCCCAACGGTAGAAGTGGACCCAATGTCT ACATACAAAAAATCTTTGCTTCATGTTGGCGACTGCAAGGTACTTGCCGGCCAAAATGTCTAAAAAACGAACAATATCGTATTTTGTGTG >30043_30043_6_FDFT1-DEFB135_FDFT1_chr8_11667359_ENST00000528812_DEFB135_chr8_11841930_ENST00000382208_length(amino acids)=115AA_BP=1 MKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLLHNFHSFLYQPDWRFMESKEKDRQVLEDFPTVE -------------------------------------------------------------- >30043_30043_7_FDFT1-DEFB135_FDFT1_chr8_11667359_ENST00000530664_DEFB135_chr8_11841930_ENST00000382208_length(transcript)=827nt_BP=657nt AATTGATGGCGGGGGAGCCGGATGTCAGTGGATGGAAAATTATTACGAGGAAACACAGGGGTGTGCATTCTTGCTGAAGGCAGGCCAGAG TTATCAGACATCACCTGAGGGATGGAGGGGGATGTGGAACCTAATCGGCTGTCTAGGGTGATCAGATACTGAAGTTGGGGGATTCTGGTC AAATCAATTTAGCAGGATTCTTGGTAAAACTGGGCGATGCAAAGACAGATGCGTTGAGTACAAAGTCCAGGCCTTATTGGGAAGAGGATT TCAGCGGAGCCCGAGTAGAGTTTGGTCTAGGGAGACTCTGTCACTGGGAGGACGAGCGAGCCGCTCGGAAGTGCGCTGGGTTCCCTTAGC GGCCAGTGGGTTCTGGACTCGCTCAGCAGCAGCCTGAAAACTTGCTACAAGTATCTCAATCAGACCAGTCGCAGTTTCGCAGCTGTTATC CAGGCGCTGGATGGGGAAATGCGCAACGCAGTGTGCATATTTTATCTGGTTCTCCGAGCTCTGGACACACTGGAAGATGACATGACCATC AGTGTGGAAAAGAAGGTCCCGCTGTTACACAACTTTCACTCTTTCCTTTACCAACCAGACTGGCGGTTCATGGAGAGCAAGGAGAAGGAT CGCCAGGTGCTGGAGGACTTCCCAACGGTAGAAGTGGACCCAATGTCTACATACAAAAAATCTTTGCTTCATGTTGGCGACTGCAAGGTA CTTGCCGGCCAAAATGTCTAAAAAACGAACAATATCGTATTTTGTGTGATACTATACATTTGTGCTGTGTAAACCCAAAATATTTACCTA >30043_30043_7_FDFT1-DEFB135_FDFT1_chr8_11667359_ENST00000530664_DEFB135_chr8_11841930_ENST00000382208_length(amino acids)=131AA_BP=1 MGSLSGQWVLDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLLHNFHSFLYQPDWRFME -------------------------------------------------------------- >30043_30043_8_FDFT1-DEFB135_FDFT1_chr8_11667359_ENST00000538689_DEFB135_chr8_11841930_ENST00000382208_length(transcript)=891nt_BP=721nt AAAAACGGTGGCAACACGCTGGGTTTGCTTTACAACGCTTGGGAAGCTTTGTTGTTTGCAATAAATTTTAATACTTGTCTGTTTCGGTCT GCACTGCCTTTATGAGCTGTAACACTCACAGGGTAGGTTTGCAGCTTCACTCCTGAAGCCAGTAAGACAACGAACCCACTGGGAGAAACA AACAACTCCAGACGCGCCGACTTAAGAGCTGTAATACTCGCTGTGACGGTCTGCAGCTTCACTCCTGAGCCAGCGAGACCACGAACCCAC CAGAAGGAAGAAACTCCGAACACATCTGAACATCAGAAGGAACAGACTCCGGACACGCCGCCTTTAAGAACTGTAACACTCACCGCGAGG GTGGGCGGTTTCATTCCTGAAGTCAGTGAGACCAAGAACCAACCAATTCCGGACACACTTGGACTCGACAGACTCTAAGGACTCGCTCAG CAGCAGCCTGAAAACTTGCTACAAGTATCTCAATCAGACCAGTCGCAGTTTCGCAGCTGTTATCCAGGCGCTGGATGGGGAAATGCGCAA CGCAGTGTGCATATTTTATCTGGTTCTCCGAGCTCTGGACACACTGGAAGATGACATGACCATCAGTGTGGAAAAGAAGGTCCCGCTGTT ACACAACTTTCACTCTTTCCTTTACCAACCAGACTGGCGGTTCATGGAGAGCAAGGAGAAGGATCGCCAGGTGCTGGAGGACTTCCCAAC GGTAGAAGTGGACCCAATGTCTACATACAAAAAATCTTTGCTTCATGTTGGCGACTGCAAGGTACTTGCCGGCCAAAATGTCTAAAAAAC >30043_30043_8_FDFT1-DEFB135_FDFT1_chr8_11667359_ENST00000538689_DEFB135_chr8_11841930_ENST00000382208_length(amino acids)=142AA_BP=1 MKSVRPRTNQFRTHLDSTDSKDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLLHNFHS -------------------------------------------------------------- >30043_30043_9_FDFT1-DEFB135_FDFT1_chr8_11679387_ENST00000220584_DEFB135_chr8_11841930_ENST00000382208_length(transcript)=902nt_BP=732nt AATCAGCGCCCGTCAGCCCACCCCACGAGGCCGCAGCTAGCCCCGCTGGCGGCCGAGGCCGGTTGAAGTGGGCGGAGCGGCGGGCGGGGC GTCGCCGTACTAGGCCTGCCCCCTGTCCGGCCAGCCCCTCGAAGCACCTACTCCACAGGTCCAGCCGGCCGGTGAGCGCCTGGGGACCGC AGAGGTGAGAGTCGCGCCCGGGAGTCCGCCGCCTGCGCCAGGATGGAGTTCGTGAAATGCCTTGGCCACCCCGAAGAGTTCTACAACCTG GTGCGCTTCCGGATCGGGGGCAAGCGGAAGGTGATGCCCAAGATGGACCAGGACTCGCTCAGCAGCAGCCTGAAAACTTGCTACAAGTAT CTCAATCAGACCAGTCGCAGTTTCGCAGCTGTTATCCAGGCGCTGGATGGGGAAATGCGCAACGCAGTGTGCATATTTTATCTGGTTCTC CGAGCTCTGGACACACTGGAAGATGACATGACCATCAGTGTGGAAAAGAAGGTCCCGCTGTTACACAACTTTCACTCTTTCCTTTACCAA CCAGACTGGCGGTTCATGGAGAGCAAGGAGAAGGATCGCCAGGTGCTGGAGGACTTCCCAACGATCTCCCTTGAGTTTAGAAATCTGGCT GAGAAATACCAAACAGTGATTGCCGACATTTGCCGGAGAATGGGCATTGGGATGGCAGAGTTTTTGGATAAGCATGTGACCTCTGAACAG GAGTGGGACAAGGTAGAAGTGGACCCAATGTCTACATACAAAAAATCTTTGCTTCATGTTGGCGACTGCAAGGTACTTGCCGGCCAAAAT GTCTAAAAAACGAACAATATCGTATTTTGTGTGATACTATACATTTGTGCTGTGTAAACCCAAAATATTTACCTATACTGACTGGGAAAT >30043_30043_9_FDFT1-DEFB135_FDFT1_chr8_11679387_ENST00000220584_DEFB135_chr8_11841930_ENST00000382208_length(amino acids)=197AA_BP=0 MEFVKCLGHPEEFYNLVRFRIGGKRKVMPKMDQDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISV EKKVPLLHNFHSFLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKVEVDPMSTYK -------------------------------------------------------------- >30043_30043_10_FDFT1-DEFB135_FDFT1_chr8_11679387_ENST00000525777_DEFB135_chr8_11841930_ENST00000382208_length(transcript)=894nt_BP=724nt GCACATTACACCCATGAACTTAGACCAGTTGCCTTTATGTATGATCGTATTTATACTGAGAAGTTACTGTGTTTTTTGACTTTCTTTTCT ATTTGCTACATATTAGTTCGGTCTAAACGTTTGGTCTTCTGGTCTCCATAGTTCTACATTGGTTAAATGCAACTCACTTCTGGGAGTAGT GGTGACATTCAACTAGTAGGCTTTTTAATAAACTACAGAAGTTCATTACTCTCATGTAAGGAAGGAAAACTAATGTAACTTTCGTTAAGT ATGAAAAGCGTTGGATATCCTTATAGTTCTTTAGAGTTAAGGGTGAGATGGGTTTAGAAAGTGGCCAGGCACAAGTTATTTTAAAATAAA AAATCTTTGGCTGTTTGTTCCAATATATTAATAGTTTTCCCTTTTTTACAGCAACGCAGTGTGCATATTTTATCTGGTTCTCCGAGCTCT GGACACACTGGAAGATGACATGACCATCAGTGTGGAAAAGAAGGTCCCGCTGTTACACAACTTTCACTCTTTCCTTTACCAACCAGACTG GCGGTTCATGGAGAGCAAGGAGAAGGATCGCCAGGTGCTGGAGGACTTCCCAACGATCTCCCTTGAGTTTAGAAATCTGGCTGAGAAATA CCAAACAGTGATTGCCGACATTTGCCGGAGAATGGGCATTGGGATGGCAGAGTTTTTGGATAAGCATGTGACCTCTGAACAGGAGTGGGA CAAGGTAGAAGTGGACCCAATGTCTACATACAAAAAATCTTTGCTTCATGTTGGCGACTGCAAGGTACTTGCCGGCCAAAATGTCTAAAA >30043_30043_10_FDFT1-DEFB135_FDFT1_chr8_11679387_ENST00000525777_DEFB135_chr8_11841930_ENST00000382208_length(amino acids)=124AA_BP=1 MVLRALDTLEDDMTISVEKKVPLLHNFHSFLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVT -------------------------------------------------------------- >30043_30043_11_FDFT1-DEFB135_FDFT1_chr8_11679387_ENST00000525900_DEFB135_chr8_11841930_ENST00000382208_length(transcript)=726nt_BP=556nt CGGCCGGTGAGCGCCTGGGGACCGCAGAGGTGAGAGTCGCGCCCGGGAGTCCGCCGCCTGCGCCAGGATGGAGTTCGTGAAATGCCTTGG CCACCCCGAAGAGTTCTACAACCTGGTGCGCTTCCGGATCGGGGGCAAGCGGAAGGACTCGCTCAGCAGCAGCCTGAAAACTTGCTACAA GTATCTCAATCAGACCAGTCGCAGTTTCGCAGCTGTTATCCAGGCGCTGGATGGGGAAATGCGCAACGCAGTGTGCATATTTTATCTGGT TCTCCGAGCTCTGGACACACTGGAAGATGACATGACCATCAGTGTGGAAAAGAAGGTCCCGCTGTTACACAACTTTCACTCTTTCCTTTA CCAACCAGACTGGCGGTTCATGGAGAGCAAGGAGAAGGATCGCCAGGTGCTGGAGGACTTCCCAACGATCTCCCTTGAGTTTAGAAATCT GGCTGAGAAATACCAAACAGTGATTGCCGACATTTGCCGGAGAATGGGCATTGGGATGGCAGAGTTTTTGGATAAGCATGTGACCTCTGA ACAGGAGTGGGACAAGGTAGAAGTGGACCCAATGTCTACATACAAAAAATCTTTGCTTCATGTTGGCGACTGCAAGGTACTTGCCGGCCA AAATGTCTAAAAAACGAACAATATCGTATTTTGTGTGATACTATACATTTGTGCTGTGTAAACCCAAAATATTTACCTATACTGACTGGG >30043_30043_11_FDFT1-DEFB135_FDFT1_chr8_11679387_ENST00000525900_DEFB135_chr8_11841930_ENST00000382208_length(amino acids)=190AA_BP=0 MEFVKCLGHPEEFYNLVRFRIGGKRKDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLL HNFHSFLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKVEVDPMSTYKKSLLHVG -------------------------------------------------------------- >30043_30043_12_FDFT1-DEFB135_FDFT1_chr8_11679387_ENST00000528643_DEFB135_chr8_11841930_ENST00000382208_length(transcript)=830nt_BP=660nt CTTGGCAGCTGAACCTGCCTGTGAGCAGGTCGTGTATTTCTCGGCTTCCCTTATCCAACTTTGCATTTCTATTTCTAGCATATTGGGTTG ATTCTTTTGAAGCTGCCTCTGTGCACATTACACCCATGAACTTAGACCAGTTGCCTTTATGTATGATCGTATTTATACTGAGAAGTTACT GTGTTTTTTGACTTTCTTTTCTATTTGCTACATATTAGTTCGGTCTAAACGTTTGGTCTTCTGGTCTCCATAGTTCTACATTGGTTAAAT GCAACTCACTTCTGGGAGTAGTGGTGACATTCAACTAGTAGGCTTTTTAATAAACTACAGAAGTTCATTACTCTCATCAACGCAGTGTGC ATATTTTATCTGGTTCTCCGAGCTCTGGACACACTGGAAGATGACATGACCATCAGTGTGGAAAAGAAGGTCCCGCTGTTACACAACTTT CACTCTTTCCTTTACCAACCAGACTGGCGGTTCATGGAGAGCAAGGAGAAGGATCGCCAGGTGCTGGAGGACTTCCCAACGATCTCCCTT GAGTTTAGAAATCTGGCTGAGAAATACCAAACAGTGATTGCCGACATTTGCCGGAGAATGGGCATTGGGATGGCAGAGTTTTTGGATAAG CATGTGACCTCTGAACAGGAGTGGGACAAGGTAGAAGTGGACCCAATGTCTACATACAAAAAATCTTTGCTTCATGTTGGCGACTGCAAG GTACTTGCCGGCCAAAATGTCTAAAAAACGAACAATATCGTATTTTGTGTGATACTATACATTTGTGCTGTGTAAACCCAAAATATTTAC >30043_30043_12_FDFT1-DEFB135_FDFT1_chr8_11679387_ENST00000528643_DEFB135_chr8_11841930_ENST00000382208_length(amino acids)=124AA_BP=1 MVLRALDTLEDDMTISVEKKVPLLHNFHSFLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVT -------------------------------------------------------------- >30043_30043_13_FDFT1-DEFB135_FDFT1_chr8_11679387_ENST00000528812_DEFB135_chr8_11841930_ENST00000382208_length(transcript)=1088nt_BP=918nt ATCTGGGGCAAGGGGCGCGGCGAGCAGGGCCGACGCCTGGGTGTTCCCGTCCCCCTTTCCTCGAGCCTTCCCCCTGTAGGGCCCGGGTGG ACGCGGCCGTCCTGGCTGACCTGTCCCTGCCCCCGCAAGCCGCCCTGGGCATGAGCGACTTTTGCGTGGTTCCCGGTGGTTGCGCTCCCC GTTTCGTCCCCTCCGTGAGCATCGGCGCTTACCGGTATTTTAACCCGAGGGTTACACATCTGAGGCAATGTGGGTGGGTTACGCGGGAGA GGACGAGTGAGTTTTTTGGTAAGCGGAATGAACTATGCAGATAACATCACATGAAGGCCGTTTCTGGAATGAAGTCTGACTCCTCCAGTT TCACCACCTCTTCCGGAGCTCTCCCCGCCTTGCTGCCTTCCATCGCTTCATCCTCGGTGCTTCCTGAGTTTTAAAATCGCCTATCTACGC TTCCAAGTTCCAATGAGTTATCTAACGTCTATGGATTAGCTAGGTGGTTGGTGGAAGGACTCGCTCAGCAGCAGCCTGAAAACTTGCTAC AAGTATCTCAATCAGACCAGTCGCAGTTTCGCAGCTGTTATCCAGGCGCTGGATGGGGAAATGCGCAACGCAGTGTGCATATTTTATCTG GTTCTCCGAGCTCTGGACACACTGGAAGATGACATGACCATCAGTGTGGAAAAGAAGGTCCCGCTGTTACACAACTTTCACTCTTTCCTT TACCAACCAGACTGGCGGTTCATGGAGAGCAAGGAGAAGGATCGCCAGGTGCTGGAGGACTTCCCAACGATCTCCCTTGAGTTTAGAAAT CTGGCTGAGAAATACCAAACAGTGATTGCCGACATTTGCCGGAGAATGGGCATTGGGATGGCAGAGTTTTTGGATAAGCATGTGACCTCT GAACAGGAGTGGGACAAGGTAGAAGTGGACCCAATGTCTACATACAAAAAATCTTTGCTTCATGTTGGCGACTGCAAGGTACTTGCCGGC CAAAATGTCTAAAAAACGAACAATATCGTATTTTGTGTGATACTATACATTTGTGCTGTGTAAACCCAAAATATTTACCTATACTGACTG >30043_30043_13_FDFT1-DEFB135_FDFT1_chr8_11679387_ENST00000528812_DEFB135_chr8_11841930_ENST00000382208_length(amino acids)=158AA_BP=1 MKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLLHNFHSFLYQPDWRFMESKEKDRQVLEDFPTIS -------------------------------------------------------------- >30043_30043_14_FDFT1-DEFB135_FDFT1_chr8_11679387_ENST00000530664_DEFB135_chr8_11841930_ENST00000382208_length(transcript)=956nt_BP=786nt AATTGATGGCGGGGGAGCCGGATGTCAGTGGATGGAAAATTATTACGAGGAAACACAGGGGTGTGCATTCTTGCTGAAGGCAGGCCAGAG TTATCAGACATCACCTGAGGGATGGAGGGGGATGTGGAACCTAATCGGCTGTCTAGGGTGATCAGATACTGAAGTTGGGGGATTCTGGTC AAATCAATTTAGCAGGATTCTTGGTAAAACTGGGCGATGCAAAGACAGATGCGTTGAGTACAAAGTCCAGGCCTTATTGGGAAGAGGATT TCAGCGGAGCCCGAGTAGAGTTTGGTCTAGGGAGACTCTGTCACTGGGAGGACGAGCGAGCCGCTCGGAAGTGCGCTGGGTTCCCTTAGC GGCCAGTGGGTTCTGGACTCGCTCAGCAGCAGCCTGAAAACTTGCTACAAGTATCTCAATCAGACCAGTCGCAGTTTCGCAGCTGTTATC CAGGCGCTGGATGGGGAAATGCGCAACGCAGTGTGCATATTTTATCTGGTTCTCCGAGCTCTGGACACACTGGAAGATGACATGACCATC AGTGTGGAAAAGAAGGTCCCGCTGTTACACAACTTTCACTCTTTCCTTTACCAACCAGACTGGCGGTTCATGGAGAGCAAGGAGAAGGAT CGCCAGGTGCTGGAGGACTTCCCAACGATCTCCCTTGAGTTTAGAAATCTGGCTGAGAAATACCAAACAGTGATTGCCGACATTTGCCGG AGAATGGGCATTGGGATGGCAGAGTTTTTGGATAAGCATGTGACCTCTGAACAGGAGTGGGACAAGGTAGAAGTGGACCCAATGTCTACA TACAAAAAATCTTTGCTTCATGTTGGCGACTGCAAGGTACTTGCCGGCCAAAATGTCTAAAAAACGAACAATATCGTATTTTGTGTGATA >30043_30043_14_FDFT1-DEFB135_FDFT1_chr8_11679387_ENST00000530664_DEFB135_chr8_11841930_ENST00000382208_length(amino acids)=174AA_BP=1 MGSLSGQWVLDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLLHNFHSFLYQPDWRFME -------------------------------------------------------------- >30043_30043_15_FDFT1-DEFB135_FDFT1_chr8_11679387_ENST00000538689_DEFB135_chr8_11841930_ENST00000382208_length(transcript)=1020nt_BP=850nt AAAAACGGTGGCAACACGCTGGGTTTGCTTTACAACGCTTGGGAAGCTTTGTTGTTTGCAATAAATTTTAATACTTGTCTGTTTCGGTCT GCACTGCCTTTATGAGCTGTAACACTCACAGGGTAGGTTTGCAGCTTCACTCCTGAAGCCAGTAAGACAACGAACCCACTGGGAGAAACA AACAACTCCAGACGCGCCGACTTAAGAGCTGTAATACTCGCTGTGACGGTCTGCAGCTTCACTCCTGAGCCAGCGAGACCACGAACCCAC CAGAAGGAAGAAACTCCGAACACATCTGAACATCAGAAGGAACAGACTCCGGACACGCCGCCTTTAAGAACTGTAACACTCACCGCGAGG GTGGGCGGTTTCATTCCTGAAGTCAGTGAGACCAAGAACCAACCAATTCCGGACACACTTGGACTCGACAGACTCTAAGGACTCGCTCAG CAGCAGCCTGAAAACTTGCTACAAGTATCTCAATCAGACCAGTCGCAGTTTCGCAGCTGTTATCCAGGCGCTGGATGGGGAAATGCGCAA CGCAGTGTGCATATTTTATCTGGTTCTCCGAGCTCTGGACACACTGGAAGATGACATGACCATCAGTGTGGAAAAGAAGGTCCCGCTGTT ACACAACTTTCACTCTTTCCTTTACCAACCAGACTGGCGGTTCATGGAGAGCAAGGAGAAGGATCGCCAGGTGCTGGAGGACTTCCCAAC GATCTCCCTTGAGTTTAGAAATCTGGCTGAGAAATACCAAACAGTGATTGCCGACATTTGCCGGAGAATGGGCATTGGGATGGCAGAGTT TTTGGATAAGCATGTGACCTCTGAACAGGAGTGGGACAAGGTAGAAGTGGACCCAATGTCTACATACAAAAAATCTTTGCTTCATGTTGG CGACTGCAAGGTACTTGCCGGCCAAAATGTCTAAAAAACGAACAATATCGTATTTTGTGTGATACTATACATTTGTGCTGTGTAAACCCA >30043_30043_15_FDFT1-DEFB135_FDFT1_chr8_11679387_ENST00000538689_DEFB135_chr8_11841930_ENST00000382208_length(amino acids)=185AA_BP=1 MKSVRPRTNQFRTHLDSTDSKDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLLHNFHS FLYQPDWRFMESKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKVEVDPMSTYKKSLLHVGDCKVL -------------------------------------------------------------- >30043_30043_16_FDFT1-DEFB135_FDFT1_chr8_11696082_ENST00000443614_DEFB135_chr8_11841930_ENST00000382208_length(transcript)=1377nt_BP=1207nt TCGAAGCACCTACTCCACAGGTCCAGCCGGCCGGTGAGCGCCTGGGGACCGCAGAGGTGAGAGTCGCGCCCGGGAGTCCGCCGCCTGCGC CAGGATGGAGTTCGTGAAATGCCTTGGCCACCCCGAAGAGTTCTACAACCTGGTGCGCTTCCGGATCGGGGGCAAGCGGAAGGTGATGCC CAAGATGGACCAGGACTCGCTCAGCAGCAGCCTGAAAACTTGCTACAAGTATCTCAATCAGACCAGTCGCAGTTTCGCAGCTGTTATCCA GGCGCTGGATGGGGAAATGCGCAACGCAGTGTGCATATTTTATCTGGTTCTCCGAGCTCTGGACACACTGGAAGATGACATGACCATCAG TGTGGAAAAGAAGGTCCCGCTGTTACACAACTTTCACTCTTTCCTTTACCAACCAGACTGGCGGTTCATGGAGAGCAAGGAGAAGGATCG CCAGGTGCTGGAGGACTTCCCAACGTACTGCCACTATGTTGCTGGGCTGGTCGGAATTGGCCTTTCCCGTCTTTTCTCAGCCTCAGAGTT TGAAGACCCCTTAGTTGGTGAAGATACAGAACGTGCCAACTCTATGGGCCTGTTTTTGCAGAAAACAAACATCATCCGTGACTATCTGGA AGACCAGCAAGGAGGAAGAGAGTTCTGGCCTCAAGAGGTTTGGAGCAGGTATGTTAAGAAGTTAGGGGATTTTGCTAAGCCGGAGAATAT TGACTTGGCCGTGCAGTGCCTGAATGAACTTATAACCAATGCACTGCACCACATCCCAGATGTCATCACCTACCTTTCGAGACTCAGAAA CCAGAGTGTGTTTAACTTCTGTGCTATTCCACAGGTGATGGCCATTGCCACTTTGGCTGCCTGTTATAATAACCAGCAGGTGTTCAAAGG GGCAGTGAAGATTCGGAAAGGGCAAGCAGTGACCCTGATGATGGATGCCACCAATATGCCAGCTGTCAAAGCCATCATATATCAGTATAT GGAAGAGGTAACAGAAGACTATGTTCAGACTGGAGAACACTGATCCCAAATTTGTCCATAGCTGAAGTCCACCATAAAGTGGATTTACTT TTTTTCTTTAAGGATGGATGTTGTGTTCTCTTTATTTTTTTCCTACTACTTTAATCCCTAAAAGAACGCTGTGTGGCTGGGACCTTTAGG AAAGTGAAATGCAGGTGAGAAGAACCTAAACATGAAAGTAGAAGTGGACCCAATGTCTACATACAAAAAATCTTTGCTTCATGTTGGCGA CTGCAAGGTACTTGCCGGCCAAAATGTCTAAAAAACGAACAATATCGTATTTTGTGTGATACTATACATTTGTGCTGTGTAAACCCAAAA >30043_30043_16_FDFT1-DEFB135_FDFT1_chr8_11696082_ENST00000443614_DEFB135_chr8_11841930_ENST00000382208_length(amino acids)=312AA_BP= MEFVKCLGHPEEFYNLVRFRIGGKRKVMPKMDQDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISV EKKVPLLHNFHSFLYQPDWRFMESKEKDRQVLEDFPTYCHYVAGLVGIGLSRLFSASEFEDPLVGEDTERANSMGLFLQKTNIIRDYLED QQGGREFWPQEVWSRYVKKLGDFAKPENIDLAVQCLNELITNALHHIPDVITYLSRLRNQSVFNFCAIPQVMAIATLAACYNNQQVFKGA -------------------------------------------------------------- >30043_30043_17_FDFT1-DEFB135_FDFT1_chr8_11696082_ENST00000528812_DEFB135_chr8_11841930_ENST00000382208_length(transcript)=1997nt_BP=1827nt ATCTGGGGCAAGGGGCGCGGCGAGCAGGGCCGACGCCTGGGTGTTCCCGTCCCCCTTTCCTCGAGCCTTCCCCCTGTAGGGCCCGGGTGG ACGCGGCCGTCCTGGCTGACCTGTCCCTGCCCCCGCAAGCCGCCCTGGGCATGAGCGACTTTTGCGTGGTTCCCGGTGGTTGCGCTCCCC GTTTCGTCCCCTCCGTGAGCATCGGCGCTTACCGGTATTTTAACCCGAGGGTTACACATCTGAGGCAATGTGGGTGGGTTACGCGGGAGA GGACGAGTGAGTTTTTTGGTAAGCGGAATGAACTATGCAGATAACATCACATGAAGGCCGTTTCTGGAATGAAGTCTGACTCCTCCAGTT TCACCACCTCTTCCGGAGCTCTCCCCGCCTTGCTGCCTTCCATCGCTTCATCCTCGGTGCTTCCTGAGTTTTAAAATCGCCTATCTACGC TTCCAAGTTCCAATGAGTTATCTAACGTCTATGGATTAGCTAGGTGGTTGGTGGAAGGACTCGCTCAGCAGCAGCCTGAAAACTTGCTAC AAGTATCTCAATCAGACCAGTCGCAGTTTCGCAGCTGTTATCCAGGCGCTGGATGGGGAAATGCGCAACGCAGTGTGCATATTTTATCTG GTTCTCCGAGCTCTGGACACACTGGAAGATGACATGACCATCAGTGTGGAAAAGAAGGTCCCGCTGTTACACAACTTTCACTCTTTCCTT TACCAACCAGACTGGCGGTTCATGGAGAGCAAGGAGAAGGATCGCCAGGTGCTGGAGGACTTCCCAACGATCTCCCTTGAGTTTAGAAAT CTGGCTGAGAAATACCAAACAGTGATTGCCGACATTTGCCGGAGAATGGGCATTGGGATGGCAGAGTTTTTGGATAAGCATGTGACCTCT GAACAGGAGTGGGACAAGTACTGCCACTATGTTGCTGGGCTGGTCGGAATTGGCCTTTCCCGTCTTTTCTCAGCCTCAGAGTTTGAAGAC CCCTTAGTTGGTGAAGATACAGAACGTGCCAACTCTATGGGCCTGTTTTTGCAGAAAACAAACATCATCCGTGACTATCTGGAAGACCAG CAAGGAGGAAGAGAGTTCTGGCCTCAAGAGGTTTGGAGCAGGTATGTTAAGAAGTTAGGGGATTTTGCTAAGCCGGAGAATATTGACTTG GCCGTGCAGTGCCTGAATGAACTTATAACCAATGCACTGCACCACATCCCAGATGTCATCACCTACCTTTCGAGACTCAGAAACCAGAGT GTGTTTAACTTCTGTGCTATTCCACAGGTGATGGCCATTGCCACTTTGGCTGCCTGTTATAATAACCAGCAGGTGTTCAAAGGGGCAGTG AAGATTCGGAAAGGGCAAGCAGTGACCCTGATGATGGATGCCACCAATATGCCAGCTGTCAAAGCCATCATATATCAGTATATGGAAGAG GTAACAGAAGACTATGTTCAGACTGGAGAACACTGATCCCAAATTTGTCCATAGCTGAAGTCCACCATAAAGTGGATTTACTTTTTTTCT TTAAGGATGGATGTTGTGTTCTCTTTATTTTTTTCCTACTACTTTAATCCCTAAAAGAACGCTGTGTGGCTGGGACCTTTAGGAAAGTGA AATGCAGGTGAGAAGAACCTAAACATGAAAGGAAAGGGTGCCTCATCCCAGCAACCTGTCCTTGTGGGTGATGATCACTGTGCTGCTTGT GGCTCATGGCAGAGCATTCAGTGCCACGGTTTAGGTGAAGTCGCTGCATATGTGACTGTCATGAGATCCTACTTAGTATGATCCTGGCTA GAATGATAATTAAAAGTATTTAATTTGGTAGAAGTGGACCCAATGTCTACATACAAAAAATCTTTGCTTCATGTTGGCGACTGCAAGGTA CTTGCCGGCCAAAATGTCTAAAAAACGAACAATATCGTATTTTGTGTGATACTATACATTTGTGCTGTGTAAACCCAAAATATTTACCTA >30043_30043_17_FDFT1-DEFB135_FDFT1_chr8_11696082_ENST00000528812_DEFB135_chr8_11841930_ENST00000382208_length(amino acids)=316AA_BP= MKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLLHNFHSFLYQPDWRFMESKEKDRQVLEDFPTIS LEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKYCHYVAGLVGIGLSRLFSASEFEDPLVGEDTERANSMGLFLQKTNIIRD YLEDQQGGREFWPQEVWSRYVKKLGDFAKPENIDLAVQCLNELITNALHHIPDVITYLSRLRNQSVFNFCAIPQVMAIATLAACYNNQQV -------------------------------------------------------------- >30043_30043_18_FDFT1-DEFB135_FDFT1_chr8_11696082_ENST00000530664_DEFB135_chr8_11841930_ENST00000382208_length(transcript)=1745nt_BP=1575nt AATTGATGGCGGGGGAGCCGGATGTCAGTGGATGGAAAATTATTACGAGGAAACACAGGGGTGTGCATTCTTGCTGAAGGCAGGCCAGAG TTATCAGACATCACCTGAGGGATGGAGGGGGATGTGGAACCTAATCGGCTGTCTAGGGTGATCAGATACTGAAGTTGGGGGATTCTGGTC AAATCAATTTAGCAGGATTCTTGGTAAAACTGGGCGATGCAAAGACAGATGCGTTGAGTACAAAGTCCAGGCCTTATTGGGAAGAGGATT TCAGCGGAGCCCGAGTAGAGTTTGGTCTAGGGAGACTCTGTCACTGGGAGGACGAGCGAGCCGCTCGGAAGTGCGCTGGGTTCCCTTAGC GGCCAGTGGGTTCTGGACTCGCTCAGCAGCAGCCTGAAAACTTGCTACAAGTATCTCAATCAGACCAGTCGCAGTTTCGCAGCTGTTATC CAGGCGCTGGATGGGGAAATGCGCAACGCAGTGTGCATATTTTATCTGGTTCTCCGAGCTCTGGACACACTGGAAGATGACATGACCATC AGTGTGGAAAAGAAGGTCCCGCTGTTACACAACTTTCACTCTTTCCTTTACCAACCAGACTGGCGGTTCATGGAGAGCAAGGAGAAGGAT CGCCAGGTGCTGGAGGACTTCCCAACGATCTCCCTTGAGTTTAGAAATCTGGCTGAGAAATACCAAACAGTGATTGCCGACATTTGCCGG AGAATGGGCATTGGGATGGCAGAGTTTTTGGATAAGCATGTGACCTCTGAACAGGAGTGGGACAAGTACTGCCACTATGTTGCTGGGCTG GTCGGAATTGGCCTTTCCCGTCTTTTCTCAGCCTCAGAGTTTGAAGACCCCTTAGTTGGTGAAGATACAGAACGTGCCAACTCTATGGGC CTGTTTTTGCAGAAAACAAACATCATCCGTGACTATCTGGAAGACCAGCAAGGAGGAAGAGAGTTCTGGCCTCAAGAGGTTTGGAGCAGG TATGTTAAGAAGTTAGGGGATTTTGCTAAGCCGGAGAATATTGACTTGGCCGTGCAGTGCCTGAATGAACTTATAACCAATGCACTGCAC CACATCCCAGATGTCATCACCTACCTTTCGAGACTCAGAAACCAGAGTGTGTTTAACTTCTGTGCTATTCCACAGGTGATGGCCATTGCC ACTTTGGCTGCCTGTTATAATAACCAGCAGGTGTTCAAAGGGGCAGTGAAGATTCGGAAAGGGCAAGCAGTGACCCTGATGATGGATGCC ACCAATATGCCAGCTGTCAAAGCCATCATATATCAGTATATGGAAGAGGTAACAGAAGACTATGTTCAGACTGGAGAACACTGATCCCAA ATTTGTCCATAGCTGAAGTCCACCATAAAGTGGATTTACTTTTTTTCTTTAAGGATGGATGTTGTGTTCTCTTTATTTTTTTCCTACTAC TTTAATCCCTAAAAGAACGCTGTGTGGCTGGGACCTTTAGGAAAGTGAAATGCAGGTGAGAAGAACCTAAACATGAAAGGAAAGGGTGCC TCATCCCAGCAACCTGTCCTTGTGGGTGATGATCACTGTGCTGCTGTAGAAGTGGACCCAATGTCTACATACAAAAAATCTTTGCTTCAT GTTGGCGACTGCAAGGTACTTGCCGGCCAAAATGTCTAAAAAACGAACAATATCGTATTTTGTGTGATACTATACATTTGTGCTGTGTAA >30043_30043_18_FDFT1-DEFB135_FDFT1_chr8_11696082_ENST00000530664_DEFB135_chr8_11841930_ENST00000382208_length(amino acids)=332AA_BP= MGSLSGQWVLDSLSSSLKTCYKYLNQTSRSFAAVIQALDGEMRNAVCIFYLVLRALDTLEDDMTISVEKKVPLLHNFHSFLYQPDWRFME SKEKDRQVLEDFPTISLEFRNLAEKYQTVIADICRRMGIGMAEFLDKHVTSEQEWDKYCHYVAGLVGIGLSRLFSASEFEDPLVGEDTER ANSMGLFLQKTNIIRDYLEDQQGGREFWPQEVWSRYVKKLGDFAKPENIDLAVQCLNELITNALHHIPDVITYLSRLRNQSVFNFCAIPQ -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for FDFT1-DEFB135 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for FDFT1-DEFB135 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for FDFT1-DEFB135 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies