
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:FOS-MAST2 (FusionGDB2 ID:31036) |
Fusion Gene Summary for FOS-MAST2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: FOS-MAST2 | Fusion gene ID: 31036 | Hgene | Tgene | Gene symbol | FOS | MAST2 | Gene ID | 2353 | 23139 |
| Gene name | Fos proto-oncogene, AP-1 transcription factor subunit | microtubule associated serine/threonine kinase 2 | |
| Synonyms | AP-1|C-FOS|p55 | MAST205|MTSSK | |
| Cytomap | 14q24.3 | 1p34.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | proto-oncogene c-FosFBJ murine osteosarcoma viral (v-fos) oncogene homolog (oncogene FOS)FBJ murine osteosarcoma viral oncogene homologFos proto-oncogene, AP-1 trancription factor subunitG0/G1 switch regulatory protein 7activator protein 1cellular o | microtubule-associated serine/threonine-protein kinase 2microtubule associated testis specific serine/threonine protein kinase | |
| Modification date | 20200329 | 20200313 | |
| UniProtAcc | P01100 | Q6P0Q8 | |
| Ensembl transtripts involved in fusion gene | ENST00000303562, ENST00000535987, ENST00000555347, ENST00000555686, ENST00000554617, ENST00000555242, ENST00000556324, | ENST00000477968, ENST00000361297, ENST00000372009, | |
| Fusion gene scores | * DoF score | 6 X 9 X 1=54 | 14 X 16 X 10=2240 |
| # samples | 9 | 17 | |
| ** MAII score | log2(9/54*10)=0.736965594166206 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | log2(17/2240*10)=-3.71989208080727 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: FOS [Title/Abstract] AND MAST2 [Title/Abstract] AND fusion [Title/Abstract] | ||
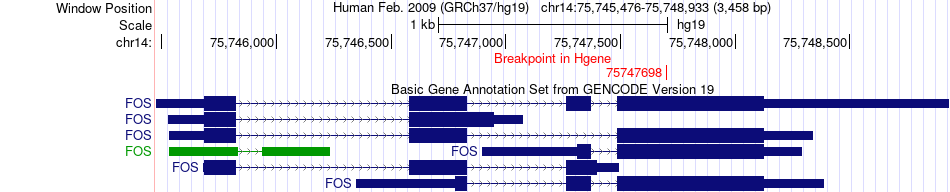
| Most frequent breakpoint | FOS(75747698)-MAST2(46496700), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | FOS-MAST2 seems lost the major protein functional domain in Hgene partner, which is a transcription factor due to the frame-shifted ORF. FOS-MAST2 seems lost the major protein functional domain in Tgene partner, which is a IUPHAR drug target due to the frame-shifted ORF. FOS-MAST2 seems lost the major protein functional domain in Tgene partner, which is a kinase due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | FOS | GO:0007179 | transforming growth factor beta receptor signaling pathway | 9732876 |
| Hgene | FOS | GO:0034614 | cellular response to reactive oxygen species | 17217916 |
| Hgene | FOS | GO:0045893 | positive regulation of transcription, DNA-templated | 9732876 |
| Hgene | FOS | GO:0045944 | positive regulation of transcription by RNA polymerase II | 10508860 |
| Hgene | FOS | GO:0060395 | SMAD protein signal transduction | 9732876 |
| Fusion gene breakpoints across FOS (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across MAST2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChiTaRS5.0 | N/A | BF904848 | FOS | chr14 | 75747698 | + | MAST2 | chr1 | 46496700 | + |
Top |
Fusion Gene ORF analysis for FOS-MAST2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000303562 | ENST00000477968 | FOS | chr14 | 75747698 | + | MAST2 | chr1 | 46496700 | + |
| 5CDS-intron | ENST00000535987 | ENST00000477968 | FOS | chr14 | 75747698 | + | MAST2 | chr1 | 46496700 | + |
| 5CDS-intron | ENST00000555347 | ENST00000477968 | FOS | chr14 | 75747698 | + | MAST2 | chr1 | 46496700 | + |
| 5CDS-intron | ENST00000555686 | ENST00000477968 | FOS | chr14 | 75747698 | + | MAST2 | chr1 | 46496700 | + |
| Frame-shift | ENST00000555347 | ENST00000361297 | FOS | chr14 | 75747698 | + | MAST2 | chr1 | 46496700 | + |
| Frame-shift | ENST00000555347 | ENST00000372009 | FOS | chr14 | 75747698 | + | MAST2 | chr1 | 46496700 | + |
| In-frame | ENST00000303562 | ENST00000361297 | FOS | chr14 | 75747698 | + | MAST2 | chr1 | 46496700 | + |
| In-frame | ENST00000303562 | ENST00000372009 | FOS | chr14 | 75747698 | + | MAST2 | chr1 | 46496700 | + |
| In-frame | ENST00000535987 | ENST00000361297 | FOS | chr14 | 75747698 | + | MAST2 | chr1 | 46496700 | + |
| In-frame | ENST00000535987 | ENST00000372009 | FOS | chr14 | 75747698 | + | MAST2 | chr1 | 46496700 | + |
| In-frame | ENST00000555686 | ENST00000361297 | FOS | chr14 | 75747698 | + | MAST2 | chr1 | 46496700 | + |
| In-frame | ENST00000555686 | ENST00000372009 | FOS | chr14 | 75747698 | + | MAST2 | chr1 | 46496700 | + |
| intron-3CDS | ENST00000554617 | ENST00000361297 | FOS | chr14 | 75747698 | + | MAST2 | chr1 | 46496700 | + |
| intron-3CDS | ENST00000554617 | ENST00000372009 | FOS | chr14 | 75747698 | + | MAST2 | chr1 | 46496700 | + |
| intron-3CDS | ENST00000555242 | ENST00000361297 | FOS | chr14 | 75747698 | + | MAST2 | chr1 | 46496700 | + |
| intron-3CDS | ENST00000555242 | ENST00000372009 | FOS | chr14 | 75747698 | + | MAST2 | chr1 | 46496700 | + |
| intron-3CDS | ENST00000556324 | ENST00000361297 | FOS | chr14 | 75747698 | + | MAST2 | chr1 | 46496700 | + |
| intron-3CDS | ENST00000556324 | ENST00000372009 | FOS | chr14 | 75747698 | + | MAST2 | chr1 | 46496700 | + |
| intron-intron | ENST00000554617 | ENST00000477968 | FOS | chr14 | 75747698 | + | MAST2 | chr1 | 46496700 | + |
| intron-intron | ENST00000555242 | ENST00000477968 | FOS | chr14 | 75747698 | + | MAST2 | chr1 | 46496700 | + |
| intron-intron | ENST00000556324 | ENST00000477968 | FOS | chr14 | 75747698 | + | MAST2 | chr1 | 46496700 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000303562 | FOS | chr14 | 75747698 | + | ENST00000372009 | MAST2 | chr1 | 46496700 | + | 4252 | 1945 | 1939 | 4251 | 771 |
| ENST00000303562 | FOS | chr14 | 75747698 | + | ENST00000361297 | MAST2 | chr1 | 46496700 | + | 4670 | 1945 | 1939 | 4611 | 890 |
| ENST00000535987 | FOS | chr14 | 75747698 | + | ENST00000372009 | MAST2 | chr1 | 46496700 | + | 3496 | 1189 | 1228 | 3495 | 756 |
| ENST00000535987 | FOS | chr14 | 75747698 | + | ENST00000361297 | MAST2 | chr1 | 46496700 | + | 3914 | 1189 | 1228 | 3855 | 875 |
| ENST00000555686 | FOS | chr14 | 75747698 | + | ENST00000372009 | MAST2 | chr1 | 46496700 | + | 3590 | 1283 | 1322 | 3589 | 756 |
| ENST00000555686 | FOS | chr14 | 75747698 | + | ENST00000361297 | MAST2 | chr1 | 46496700 | + | 4008 | 1283 | 1322 | 3949 | 875 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000303562 | ENST00000372009 | FOS | chr14 | 75747698 | + | MAST2 | chr1 | 46496700 | + | 0.0285393 | 0.9714607 |
| ENST00000303562 | ENST00000361297 | FOS | chr14 | 75747698 | + | MAST2 | chr1 | 46496700 | + | 0.04074297 | 0.95925707 |
| ENST00000535987 | ENST00000372009 | FOS | chr14 | 75747698 | + | MAST2 | chr1 | 46496700 | + | 0.06127257 | 0.93872744 |
| ENST00000535987 | ENST00000361297 | FOS | chr14 | 75747698 | + | MAST2 | chr1 | 46496700 | + | 0.035141822 | 0.9648582 |
| ENST00000555686 | ENST00000372009 | FOS | chr14 | 75747698 | + | MAST2 | chr1 | 46496700 | + | 0.049851764 | 0.9501482 |
| ENST00000555686 | ENST00000361297 | FOS | chr14 | 75747698 | + | MAST2 | chr1 | 46496700 | + | 0.031540196 | 0.9684598 |
Top |
Fusion Genomic Features for FOS-MAST2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
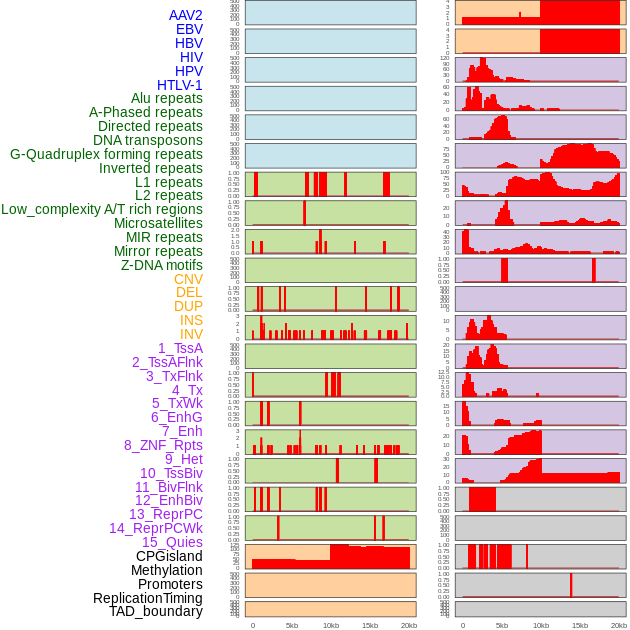
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for FOS-MAST2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr14:75747698/chr1:46496700) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| FOS | MAST2 |
| FUNCTION: Nuclear phosphoprotein which forms a tight but non-covalently linked complex with the JUN/AP-1 transcription factor. In the heterodimer, FOS and JUN/AP-1 basic regions each seems to interact with symmetrical DNA half sites. On TGF-beta activation, forms a multimeric SMAD3/SMAD4/JUN/FOS complex at the AP1/SMAD-binding site to regulate TGF-beta-mediated signaling. Has a critical function in regulating the development of cells destined to form and maintain the skeleton. It is thought to have an important role in signal transduction, cell proliferation and differentiation. In growing cells, activates phospholipid synthesis, possibly by activating CDS1 and PI4K2A. This activity requires Tyr-dephosphorylation and association with the endoplasmic reticulum. {ECO:0000269|PubMed:16055710, ECO:0000269|PubMed:17160021, ECO:0000269|PubMed:22105363, ECO:0000269|PubMed:7588633, ECO:0000269|PubMed:9732876}. | FUNCTION: Appears to link the dystrophin/utrophin network with microtubule filaments via the syntrophins. Phosphorylation of DMD or UTRN may modulate their affinities for associated proteins. Functions in a multi-protein complex in spermatid maturation. Regulates lipopolysaccharide-induced IL-12 synthesis in macrophages by forming a complex with TRAF6, resulting in the inhibition of TRAF6 NF-kappa-B activation (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | MAST2 | chr14:75747698 | chr1:46496700 | ENST00000361297 | 0 | 29 | 1104_1192 | 0 | 1799.0 | Domain | PDZ | |
| Tgene | MAST2 | chr14:75747698 | chr1:46496700 | ENST00000361297 | 0 | 29 | 512_785 | 0 | 1799.0 | Domain | Protein kinase | |
| Tgene | MAST2 | chr14:75747698 | chr1:46496700 | ENST00000361297 | 0 | 29 | 786_854 | 0 | 1799.0 | Domain | AGC-kinase C-terminal | |
| Tgene | MAST2 | chr14:75747698 | chr1:46496700 | ENST00000361297 | 0 | 29 | 518_526 | 0 | 1799.0 | Nucleotide binding | ATP |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | FOS | chr14:75747698 | chr1:46496700 | ENST00000303562 | + | 1 | 4 | 137_200 | 0 | 381.0 | Domain | bZIP |
| Hgene | FOS | chr14:75747698 | chr1:46496700 | ENST00000303562 | + | 1 | 4 | 139_159 | 0 | 381.0 | Region | Note=Basic motif%3B required for the activation of phospholipid synthesis%2C but not for CDS1-binding |
| Hgene | FOS | chr14:75747698 | chr1:46496700 | ENST00000303562 | + | 1 | 4 | 165_193 | 0 | 381.0 | Region | Leucine-zipper |
Top |
Fusion Gene Sequence for FOS-MAST2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >31036_31036_1_FOS-MAST2_FOS_chr14_75747698_ENST00000303562_MAST2_chr1_46496700_ENST00000361297_length(transcript)=4670nt_BP=1945nt ACTCATTCATAAAACGCTTGTTATAAAAGCAGTGGCTGCGGCGCCTCGTACTCCAACCGCATCTGCAGCGAGCATCTGAGAAGCCAAGAC TGAGCCGGCGGCCGCGGCGCAGCGAACGAGCAGTGACCGTGCTCCTACCCAGCTCTGCTCCACAGCGCCCACCTGTCTCCGCCCCTCGGC CCCTCGCCCGGCTTTGCCTAACCGCCACGATGATGTTCTCGGGCTTCAACGCAGACTACGAGGCGTCATCCTCCCGCTGCAGCAGCGCGT CCCCGGCCGGGGATAGCCTCTCTTACTACCACTCACCCGCAGACTCCTTCTCCAGCATGGGCTCGCCTGTCAACGCGCAGGACTTCTGCA CGGACCTGGCCGTCTCCAGTGCCAACTTCATTCCCACGGTCACTGCCATCTCGACCAGTCCGGACCTGCAGTGGCTGGTGCAGCCCGCCC TCGTCTCCTCCGTGGCCCCATCGCAGACCAGAGCCCCTCACCCTTTCGGAGTCCCCGCCCCCTCCGCTGGGGCTTACTCCAGGGCTGGCG TTGTGAAGACCATGACAGGAGGCCGAGCGCAGAGCATTGGCAGGAGGGGCAAGGTGGAACAGTTATCTCCAGAAGAAGAAGAGAAAAGGA GAATCCGAAGGGAAAGGAATAAGATGGCTGCAGCCAAATGCCGCAACCGGAGGAGGGAGCTGACTGATACACTCCAAGCGTTCACCCTGC CTCTCCTCAATGACCCTGAGCCCAAGCCCTCAGTGGAACCTGTCAAGAGCATCAGCAGCATGGAGCTGAAGACCGAGCCCTTTGATGACT TCCTGTTCCCAGCATCATCCAGGCCCAGTGGCTCTGAGACAGCCCGCTCCGTGCCAGACATGGACCTATCTGGGTCCTTCTATGCAGCAG ACTGGGAGCCTCTGCACAGTGGCTCCCTGGGGATGGGGCCCATGGCCACAGAGCTGGAGCCCCTGTGCACTCCGGTGGTCACCTGTACTC CCAGCTGCACTGCTTACACGTCTTCCTTCGTCTTCACCTACCCCGAGGCTGACTCCTTCCCCAGCTGTGCAGCTGCCCACCGCAAGGGCA GCAGCAGCAATGAGCCTTCCTCTGACTCGCTCAGCTCACCCACGCTGCTGGCCCTGTGAGGGGGCAGGGAAGGGGAGGCAGCCGGCACCC ACAAGTGCCACTGCCCGAGCTGGTGCATTACAGAGAGGAGAAACACATCTTCCCTAGAGGGTTCCTGTAGACCTAGGGAGGACCTTATCT GTGCGTGAAACACACCAGGCTGTGGGCCTCAAGGACTTGAAAGCATCCATGTGTGGACTCAAGTCCTTACCTCTTCCGGAGATGTAGCAA AACGCATGGAGTGTGTATTGTTCCCAGTGACACTTCAGAGAGCTGGTAGTTAGTAGCATGTTGAGCCAGGCCTGGGTCTGTGTCTCTTTT CTCTTTCTCCTTAGTCTTCTCATAGCATTAACTAATCTATTGGGTTCATTATTGGAATTAACCTGGTGCTGGATATTTTCAAATTGTATC TAGTGCAGCTGATTTTAACAATAACTACTGTGTTCCTGGCAATAGTGTGTTCTGATTAGAAATGACCAATATTATACTAAGAAAAGATAC GACTTTATTTTCTGGTAGATAGAAATAAATAGCTATATCCATGTACTGTAGTTTTTCTTCAACATCAATGTTCATTGTAATGTTACTGAT CATGCATTGTTGAGGTGGTCTGAATGTTCTGACATTAACAGTTTTCCATGAAAACGTTTTATTGTGTTTTTAATTTATTTATTAAGATGG ATTCTCAGATATTTATATTTTTATTTTATTTTTTTCTACCTTGAGGTCTTTTGACATGTGGAAAGTGAATTTGAATGAAAAATTTAAGCA TTGTTTGCTTATTGTTCCAAGACATTGTCAATAAAAGCATTTAAGTTGAATGCGATCTGAGTCATCCCACACAGAGAGTGACTCAAGCCC TCCAATGACAGTGCGACGCCGCTGCTCAGGCCTCCTGGATGCGCCTCGGTTCCCGGAGGGCCCTGAGGAGGCCAGCAGCACCCTCAGGAG GCAACCACAGGAGGGTATATGGGTCCTGACACCCCCATCTGGAGAGGGGGTATCTGGGCCTGTCACTGAACACTCAGGGGAGCAGCGGCC AAAGCTGGATGAGGAAGCTGTTGGCCGGAGCAGTGGTTCCAGTCCAGCTATGGAGACCCGAGGCCGTGGGACCTCACAGCTGGCTGAGGG AGCCACAGCCAAGGCCATCAGTGACCTGGCTGTGCGTAGGGCCCGCCACCGGCTGCTCTCTGGGGACTCAACAGAGAAGCGCACTGCTCG CCCTGTCAACAAAGTGATCAAGTCCGCCTCAGCCACAGCCCTCTCACTCCTCATTCCTTCGGAACACCACACCTGCTCCCCGTTGGCCAG CCCCATGTCCCCACATTCTCAGTCGTCCAACCCATCATCCCGGGACTCTTCTCCAAGCAGGGACTTCTTGCCAGCCCTTGGCAGCATGAG GCCTCCCATCATCATCCACCGAGCTGGCAAGAAGTATGGCTTCACCCTGCGGGCCATTCGCGTCTACATGGGTGACTCCGATGTCTACAC CGTGCACCATATGGTGTGGCACGTGGAGGATGGAGGTCCGGCCAGTGAGGCAGGGCTTCGTCAAGGTGACCTCATCACCCATGTCAATGG GGAACCTGTGCATGGCCTGGTGCACACGGAGGTGGTAGAGCTGATCCTGAAGAGTGGAAACAAGGTGGCCATTTCAACAACTCCCCTGGA GAACACATCCATTAAAGTGGGGCCAGCTCGGAAGGGCAGCTACAAGGCCAAGATGGCCCGAAGGAGCAAGAGGAGCCGCGGCAAGGATGG GCAAGAAAGCAGAAAAAGGAGCTCCCTGTTCCGCAAGATCACCAAGCAAGCATCCCTGCTCCACACCAGCCGCAGCCTTTCTTCCCTTAA CCGCTCCTTGTCATCAGGGGAGAGTGGGCCAGGCTCTCCCACACACAGCCACAGCCTTTCCCCCCGATCTCCCACTCAAGGCTACCGGGT GACCCCCGATGCTGTGCATTCAGTGGGAGGGAATTCATCACAGAGCAGCTCCCCCAGCTCCAGCGTGCCCAGTTCCCCAGCCGGCTCTGG GCACACACGGCCCAGCTCCCTCCACGGTCTGGCACCCAAGCTCCAACGCCAGTACCGCTCTCCACGGCGCAAGTCAGCAGGCAGCATCCC ACTGTCACCACTGGCCCACACCCCTTCTCCCCCACCCCCAACAGCTTCACCTCAGCGGTCCCCATCGCCCCTGTCTGGCCATGTAGCCCA GGCCTTTCCCACAAAGCTTCACTTGTCACCTCCCCTGGGCAGGCAACTCTCACGGCCCAAGAGTGCGGAGCCACCCCGTTCACCACTACT CAAGAGGGTGCAGTCGGCTGAGAAACTGGCAGCAGCACTTGCCGCCTCTGAGAAGAAGCTAGCCACTTCTCGCAAGCACAGCCTTGACCT GCCCCACTCTGAACTAAAGAAGGAACTGCCGCCCAGGGAAGTGAGCCCTCTGGAGGTAGTTGGAGCCAGGAGTGTGCTGTCTGGCAAGGG GGCCCTGCCAGGGAAGGGGGTGCTGCAGCCTGCTCCCTCACGGGCCCTAGGCACCCTCCGGCAGGACCGAGCCGAACGACGGGAGTCGCT GCAGAAGCAAGAAGCCATTCGTGAGGTGGACTCCTCAGAGGACGACACCGAGGAAGGGCCTGAGAACAGCCAGGGTGCACAGGAGCTGAG CTTGGCACCTCACCCAGAAGTGAGCCAGAGTGTGGCCCCTAAAGGAGCAGGAGAGAGTGGGGAAGAGGATCCTTTCCCGTCCAGAGACCC TAGGAGCCTGGGCCCAATGGTCCCAAGCCTATTGACAGGGATCACACTGGGGCCTCCCAGAATGGAAAGTCCCAGTGGTCCCCACAGGAG GCTCGGGAGCCCACAAGCCATTGAGGAGGCTGCCAGCTCCTCCTCAGCAGGCCCCAACCTAGGTCAGTCTGGAGCCACAGACCCCATCCC TCCTGAAGGTTGCTGGAAGGCCCAGCACCTCCACACCCAGGCACTAACAGCACTTTCTCCCAGCACTTCGGGACTCACCCCCACCAGCAG TTGCTCTCCTCCCAGCTCCACCTCTGGGAAGCTGAGCATGTGGTCCTGGAAATCCCTTATTGAGGGCCCAGACAGGGCATCCCCAAGCAG AAAGGCAACCATGGCAGGTGGGCTAGCCAACCTCCAGGATTTGGAAAACACAACTCCAGCCCAGCCTAAGAACCTGTCTCCCAGGGAGCA GGGGAAGACACAGCCACCTAGTGCCCCCAGACTGGCCCATCCATCTTATGAGGATCCCAGCCAGGGCTGGCTATGGGAGTCTGAGTGTGC ACAAGCAGTGAAAGAGGATCCAGCCCTGAGCATCACCCAAGTGCCTGATGCCTCAGGTGACAGAAGGCAGGACGTTCCATGCCGAGGCTG CCCCCTCACCCAGAAGTCTGAGCCCAGCCTCAGGAGGGGCCAAGAACCAGGGGGCCATCAAAAGCATCGGGATTTGGCATTGGTTCCAGA >31036_31036_1_FOS-MAST2_FOS_chr14_75747698_ENST00000303562_MAST2_chr1_46496700_ENST00000361297_length(amino acids)=890AA_BP=2 MRSESSHTESDSSPPMTVRRRCSGLLDAPRFPEGPEEASSTLRRQPQEGIWVLTPPSGEGVSGPVTEHSGEQRPKLDEEAVGRSSGSSPA METRGRGTSQLAEGATAKAISDLAVRRARHRLLSGDSTEKRTARPVNKVIKSASATALSLLIPSEHHTCSPLASPMSPHSQSSNPSSRDS SPSRDFLPALGSMRPPIIIHRAGKKYGFTLRAIRVYMGDSDVYTVHHMVWHVEDGGPASEAGLRQGDLITHVNGEPVHGLVHTEVVELIL KSGNKVAISTTPLENTSIKVGPARKGSYKAKMARRSKRSRGKDGQESRKRSSLFRKITKQASLLHTSRSLSSLNRSLSSGESGPGSPTHS HSLSPRSPTQGYRVTPDAVHSVGGNSSQSSSPSSSVPSSPAGSGHTRPSSLHGLAPKLQRQYRSPRRKSAGSIPLSPLAHTPSPPPPTAS PQRSPSPLSGHVAQAFPTKLHLSPPLGRQLSRPKSAEPPRSPLLKRVQSAEKLAAALAASEKKLATSRKHSLDLPHSELKKELPPREVSP LEVVGARSVLSGKGALPGKGVLQPAPSRALGTLRQDRAERRESLQKQEAIREVDSSEDDTEEGPENSQGAQELSLAPHPEVSQSVAPKGA GESGEEDPFPSRDPRSLGPMVPSLLTGITLGPPRMESPSGPHRRLGSPQAIEEAASSSSAGPNLGQSGATDPIPPEGCWKAQHLHTQALT ALSPSTSGLTPTSSCSPPSSTSGKLSMWSWKSLIEGPDRASPSRKATMAGGLANLQDLENTTPAQPKNLSPREQGKTQPPSAPRLAHPSY -------------------------------------------------------------- >31036_31036_2_FOS-MAST2_FOS_chr14_75747698_ENST00000303562_MAST2_chr1_46496700_ENST00000372009_length(transcript)=4252nt_BP=1945nt ACTCATTCATAAAACGCTTGTTATAAAAGCAGTGGCTGCGGCGCCTCGTACTCCAACCGCATCTGCAGCGAGCATCTGAGAAGCCAAGAC TGAGCCGGCGGCCGCGGCGCAGCGAACGAGCAGTGACCGTGCTCCTACCCAGCTCTGCTCCACAGCGCCCACCTGTCTCCGCCCCTCGGC CCCTCGCCCGGCTTTGCCTAACCGCCACGATGATGTTCTCGGGCTTCAACGCAGACTACGAGGCGTCATCCTCCCGCTGCAGCAGCGCGT CCCCGGCCGGGGATAGCCTCTCTTACTACCACTCACCCGCAGACTCCTTCTCCAGCATGGGCTCGCCTGTCAACGCGCAGGACTTCTGCA CGGACCTGGCCGTCTCCAGTGCCAACTTCATTCCCACGGTCACTGCCATCTCGACCAGTCCGGACCTGCAGTGGCTGGTGCAGCCCGCCC TCGTCTCCTCCGTGGCCCCATCGCAGACCAGAGCCCCTCACCCTTTCGGAGTCCCCGCCCCCTCCGCTGGGGCTTACTCCAGGGCTGGCG TTGTGAAGACCATGACAGGAGGCCGAGCGCAGAGCATTGGCAGGAGGGGCAAGGTGGAACAGTTATCTCCAGAAGAAGAAGAGAAAAGGA GAATCCGAAGGGAAAGGAATAAGATGGCTGCAGCCAAATGCCGCAACCGGAGGAGGGAGCTGACTGATACACTCCAAGCGTTCACCCTGC CTCTCCTCAATGACCCTGAGCCCAAGCCCTCAGTGGAACCTGTCAAGAGCATCAGCAGCATGGAGCTGAAGACCGAGCCCTTTGATGACT TCCTGTTCCCAGCATCATCCAGGCCCAGTGGCTCTGAGACAGCCCGCTCCGTGCCAGACATGGACCTATCTGGGTCCTTCTATGCAGCAG ACTGGGAGCCTCTGCACAGTGGCTCCCTGGGGATGGGGCCCATGGCCACAGAGCTGGAGCCCCTGTGCACTCCGGTGGTCACCTGTACTC CCAGCTGCACTGCTTACACGTCTTCCTTCGTCTTCACCTACCCCGAGGCTGACTCCTTCCCCAGCTGTGCAGCTGCCCACCGCAAGGGCA GCAGCAGCAATGAGCCTTCCTCTGACTCGCTCAGCTCACCCACGCTGCTGGCCCTGTGAGGGGGCAGGGAAGGGGAGGCAGCCGGCACCC ACAAGTGCCACTGCCCGAGCTGGTGCATTACAGAGAGGAGAAACACATCTTCCCTAGAGGGTTCCTGTAGACCTAGGGAGGACCTTATCT GTGCGTGAAACACACCAGGCTGTGGGCCTCAAGGACTTGAAAGCATCCATGTGTGGACTCAAGTCCTTACCTCTTCCGGAGATGTAGCAA AACGCATGGAGTGTGTATTGTTCCCAGTGACACTTCAGAGAGCTGGTAGTTAGTAGCATGTTGAGCCAGGCCTGGGTCTGTGTCTCTTTT CTCTTTCTCCTTAGTCTTCTCATAGCATTAACTAATCTATTGGGTTCATTATTGGAATTAACCTGGTGCTGGATATTTTCAAATTGTATC TAGTGCAGCTGATTTTAACAATAACTACTGTGTTCCTGGCAATAGTGTGTTCTGATTAGAAATGACCAATATTATACTAAGAAAAGATAC GACTTTATTTTCTGGTAGATAGAAATAAATAGCTATATCCATGTACTGTAGTTTTTCTTCAACATCAATGTTCATTGTAATGTTACTGAT CATGCATTGTTGAGGTGGTCTGAATGTTCTGACATTAACAGTTTTCCATGAAAACGTTTTATTGTGTTTTTAATTTATTTATTAAGATGG ATTCTCAGATATTTATATTTTTATTTTATTTTTTTCTACCTTGAGGTCTTTTGACATGTGGAAAGTGAATTTGAATGAAAAATTTAAGCA TTGTTTGCTTATTGTTCCAAGACATTGTCAATAAAAGCATTTAAGTTGAATGCGATCTGAGTCATCCCACACAGAGAGTGACTCAAGCCC TCCAATGACAGTGCGACGCCGCTGCTCAGGCCTCCTGGATGCGCCTCGGTTCCCGGAGGGCCCTGAGGAGGCCAGCAGCACCCTCAGGAG GCAACCACAGGAGGGTATATGGGTCCTGACACCCCCATCTGGAGAGGGGGTATCTGGGCCTGTCACTGAACACTCAGGGGAGCAGCGGCC AAAGCTGGATGAGGAAGCTGTTGGCCGGAGCAGTGGTTCCAGTCCAGCTATGGAGACCCGAGGCCGTGGGACCTCACAGCTGGCTGAGGG AGCCACAGCCAAGGCCATCAGTGACCTGGCTGTGCGTAGGGCCCGCCACCGGCTGCTCTCTGGGGACTCAACAGAGAAGCGCACTGCTCG CCCTGTCAACAAAGTGATCAAGTCCGCCTCAGCCACAGCCCTCTCACTCCTCATTCCTTCGGAACACCACACCTGCTCCCCGTTGGCCAG CCCCATGTCCCCACATTCTCAGTCGTCCAACCCATCATCCCGGGACTCTTCTCCATATGGCTTCACCCTGCGGGCCATTCGCGTCTACAT GGGTGACTCCGATGTCTACACCGTGCACCATATGGTGTGGCACGTGGAGGATGGAGGTCCGGCCAGTGAGGCAGGGCTTCGTCAAGGTGA CCTCATCACCCATGTCAATGGGGAACCTGTGCATGGCCTGGTGCACACGGAGGTGGTAGAGCTGATCCTGAAGAGTGGAAACAAGGTGGC CATTTCAACAACTCCCCTGGAGAACACATCCATTAAAGTGGGGCCAGCTCGGAAGGGCAGCTACAAGGCCAAGATGGCCCGAAGGAGCAA GAGGAGCCGCGGCAAGGATGGGCAAGAAAGCAGAAAAAGGAGCTCCCTGTTCCGCAAGATCACCAAGCAAGCATCCCTGCTCCACACCAG CCGCAGCCTTTCTTCCCTTAACCGCTCCTTGTCATCAGGGGAGAGTGGGCCAGGCTCTCCCACACACAGCCACAGCCTTTCCCCCCGATC TCCCACTCAAGGCTACCGGGTGACCCCCGATGCTGTGCATTCAGAACTCTCACGGCCCAAGAGTGCGGAGCCACCCCGTTCACCACTACT CAAGAGGGTGCAGTCGGCTGAGAAACTGGCAGCAGCACTTGCCGCCTCTGAGAAGAAGCTAGCCACTTCTCGCAAGCACAGCCTTGACCT GCCCCACTCTGAACTAAAGAAGGAACTGCCGCCCAGGGAAGTGAGCCCTCTGGAGGTAGTTGGAGCCAGGAGTGTGCTGTCTGGCAAGGG GGCCCTGCCAGGGAAGGGGGTGCTGCAGCCTGCTCCCTCACGGGCCCTAGGCACCCTCCGGCAGGACCGAGCCGAACGACGGGAGTCGCT GCAGAAGCAAGAAGCCATTCGTGAGGTGGACTCCTCAGAGGACGACACCGAGGAAGGGCCTGAGAACAGCCAGGGTGCACAGGAGCTGAG CTTGGCACCTCACCCAGAAGTGAGCCAGAGTGTGGCCCCTAAAGGAGCAGGAGAGAGTGGGGAAGAGGATCCTTTCCCGTCCAGAGACCC TAGGAGCCTGGGCCCAATGGTCCCAAGCCTATTGACAGGGATCACACTGGGGCCTCCCAGAATGGAAAGTCCCAGTGGTCCCCACAGGAG GCTCGGGAGCCCACAAGCCATTGAGGAGGCTGCCAGCTCCTCCTCAGCAGGCCCCAACCTAGGTCAGTCTGGAGCCACAGACCCCATCCC TCCTGAAGGTTGCTGGAAGGCCCAGCACCTCCACACCCAGGCACTAACAGCACTTTCTCCCAGCACTTCGGGACTCACCCCCACCAGCAG TTGCTCTCCTCCCAGCTCCACCTCTGGGAAGCTGAGCATGTGGTCCTGGAAATCCCTTATTGAGGGCCCAGACAGGGCATCCCCAAGCAG AAAGGCAACCATGGCAGGTGGGCTAGCCAACCTCCAGGATTTGGAAAACACAACTCCAGCCCAGCCTAAGAACCTGTCTCCCAGGGAGCA GGGGAAGACACAGCCACCTAGTGCCCCCAGACTGGCCCATCCATCTTATGAGGATCCCAGCCAGGGCTGGCTATGGGAGTCTGAGTGTGC ACAAGCAGTGAAAGAGGATCCAGCCCTGAGCATCACCCAAGTGCCTGATGCCTCAGGTGACAGAAGGCAGGACGTTCCATGCCGAGGCTG CCCCCTCACCCAGAAGTCTGAGCCCAGCCTCAGGAGGGGCCAAGAACCAGGGGGCCATCAAAAGCATCGGGATTTGGCATTGGTTCCAGA >31036_31036_2_FOS-MAST2_FOS_chr14_75747698_ENST00000303562_MAST2_chr1_46496700_ENST00000372009_length(amino acids)=771AA_BP=2 MRSESSHTESDSSPPMTVRRRCSGLLDAPRFPEGPEEASSTLRRQPQEGIWVLTPPSGEGVSGPVTEHSGEQRPKLDEEAVGRSSGSSPA METRGRGTSQLAEGATAKAISDLAVRRARHRLLSGDSTEKRTARPVNKVIKSASATALSLLIPSEHHTCSPLASPMSPHSQSSNPSSRDS SPYGFTLRAIRVYMGDSDVYTVHHMVWHVEDGGPASEAGLRQGDLITHVNGEPVHGLVHTEVVELILKSGNKVAISTTPLENTSIKVGPA RKGSYKAKMARRSKRSRGKDGQESRKRSSLFRKITKQASLLHTSRSLSSLNRSLSSGESGPGSPTHSHSLSPRSPTQGYRVTPDAVHSEL SRPKSAEPPRSPLLKRVQSAEKLAAALAASEKKLATSRKHSLDLPHSELKKELPPREVSPLEVVGARSVLSGKGALPGKGVLQPAPSRAL GTLRQDRAERRESLQKQEAIREVDSSEDDTEEGPENSQGAQELSLAPHPEVSQSVAPKGAGESGEEDPFPSRDPRSLGPMVPSLLTGITL GPPRMESPSGPHRRLGSPQAIEEAASSSSAGPNLGQSGATDPIPPEGCWKAQHLHTQALTALSPSTSGLTPTSSCSPPSSTSGKLSMWSW KSLIEGPDRASPSRKATMAGGLANLQDLENTTPAQPKNLSPREQGKTQPPSAPRLAHPSYEDPSQGWLWESECAQAVKEDPALSITQVPD -------------------------------------------------------------- >31036_31036_3_FOS-MAST2_FOS_chr14_75747698_ENST00000535987_MAST2_chr1_46496700_ENST00000361297_length(transcript)=3914nt_BP=1189nt AACCGCATCTGCAGCGAGCATCTGAGAAGCCAAGACTGAGCCGGCGGCCGCGGCGCAGCGAACGAGCAGTGACCGTGCTCCTACCCAGCT CTGCTCCACAGCGCCCACCTGTCTCCGCCCCTCGGCCCCTCGCCCGGCTTTGCCTAACCGCCACGATGATGTTCTCGGGCTTCAACGCAG ACTACGAGGCGTCATCCTCCCGCTGCAGCAGCGCGTCCCCGGCCGGGGATAGCCTCTCTTACTACCACTCACCCGCAGACTCCTTCTCCA GCATGGGCTCGCCTGTCAACGCGCAGGACTTCTGCACGGACCTGGCCGTCTCCAGTGCCAACTTCATTCCCACGGTCACTGCCATCTCGA CCAGTCCGGACCTGCAGTGGCTGGTGCAGCCCGCCCTCGTCTCCTCCGTGGCCCCATCGCAGACCAGAGCCCCTCACCCTTTCGGAGTCC CCGCCCCCTCCGCTGGGGCTTACTCCAGGGCTGGCGTTGTGAAGACCATGACAGGAGGCCGAGCGCAGAGCATTGGCAGGAGGGGCAAGG TGGAACAGTTCACCCTGCCTCTCCTCAATGACCCTGAGCCCAAGCCCTCAGTGGAACCTGTCAAGAGCATCAGCAGCATGGAGCTGAAGA CCGAGCCCTTTGATGACTTCCTGTTCCCAGCATCATCCAGGCCCAGTGGCTCTGAGACAGCCCGCTCCGTGCCAGACATGGACCTATCTG GGTCCTTCTATGCAGCAGACTGGGAGCCTCTGCACAGTGGCTCCCTGGGGATGGGGCCCATGGCCACAGAGCTGGAGCCCCTGTGCACTC CGGTGGTCACCTGTACTCCCAGCTGCACTGCTTACACGTCTTCCTTCGTCTTCACCTACCCCGAGGCTGACTCCTTCCCCAGCTGTGCAG CTGCCCACCGCAAGGGCAGCAGCAGCAATGAGCCTTCCTCTGACTCGCTCAGCTCACCCACGCTGCTGGCCCTGTGAGGGGGCAGGGAAG GGGAGGCAGCCGGCACCCACAAGTGCCACTGCCCGAGCTGGTGCATTACAGAGAGGAGAAACACATCTTCCCTAGAGGGTTCCTGTAGAC CTAGGGAGGACCTTATCTGTGCGTGAAACACACCAGGCTGTGGGCCTCAAGGACTTGAAAGCATCCATGTGTGGACTCAAGTCCTTACCT CTTCCGGAGATGTAGCAAATCTGAGTCATCCCACACAGAGAGTGACTCAAGCCCTCCAATGACAGTGCGACGCCGCTGCTCAGGCCTCCT GGATGCGCCTCGGTTCCCGGAGGGCCCTGAGGAGGCCAGCAGCACCCTCAGGAGGCAACCACAGGAGGGTATATGGGTCCTGACACCCCC ATCTGGAGAGGGGGTATCTGGGCCTGTCACTGAACACTCAGGGGAGCAGCGGCCAAAGCTGGATGAGGAAGCTGTTGGCCGGAGCAGTGG TTCCAGTCCAGCTATGGAGACCCGAGGCCGTGGGACCTCACAGCTGGCTGAGGGAGCCACAGCCAAGGCCATCAGTGACCTGGCTGTGCG TAGGGCCCGCCACCGGCTGCTCTCTGGGGACTCAACAGAGAAGCGCACTGCTCGCCCTGTCAACAAAGTGATCAAGTCCGCCTCAGCCAC AGCCCTCTCACTCCTCATTCCTTCGGAACACCACACCTGCTCCCCGTTGGCCAGCCCCATGTCCCCACATTCTCAGTCGTCCAACCCATC ATCCCGGGACTCTTCTCCAAGCAGGGACTTCTTGCCAGCCCTTGGCAGCATGAGGCCTCCCATCATCATCCACCGAGCTGGCAAGAAGTA TGGCTTCACCCTGCGGGCCATTCGCGTCTACATGGGTGACTCCGATGTCTACACCGTGCACCATATGGTGTGGCACGTGGAGGATGGAGG TCCGGCCAGTGAGGCAGGGCTTCGTCAAGGTGACCTCATCACCCATGTCAATGGGGAACCTGTGCATGGCCTGGTGCACACGGAGGTGGT AGAGCTGATCCTGAAGAGTGGAAACAAGGTGGCCATTTCAACAACTCCCCTGGAGAACACATCCATTAAAGTGGGGCCAGCTCGGAAGGG CAGCTACAAGGCCAAGATGGCCCGAAGGAGCAAGAGGAGCCGCGGCAAGGATGGGCAAGAAAGCAGAAAAAGGAGCTCCCTGTTCCGCAA GATCACCAAGCAAGCATCCCTGCTCCACACCAGCCGCAGCCTTTCTTCCCTTAACCGCTCCTTGTCATCAGGGGAGAGTGGGCCAGGCTC TCCCACACACAGCCACAGCCTTTCCCCCCGATCTCCCACTCAAGGCTACCGGGTGACCCCCGATGCTGTGCATTCAGTGGGAGGGAATTC ATCACAGAGCAGCTCCCCCAGCTCCAGCGTGCCCAGTTCCCCAGCCGGCTCTGGGCACACACGGCCCAGCTCCCTCCACGGTCTGGCACC CAAGCTCCAACGCCAGTACCGCTCTCCACGGCGCAAGTCAGCAGGCAGCATCCCACTGTCACCACTGGCCCACACCCCTTCTCCCCCACC CCCAACAGCTTCACCTCAGCGGTCCCCATCGCCCCTGTCTGGCCATGTAGCCCAGGCCTTTCCCACAAAGCTTCACTTGTCACCTCCCCT GGGCAGGCAACTCTCACGGCCCAAGAGTGCGGAGCCACCCCGTTCACCACTACTCAAGAGGGTGCAGTCGGCTGAGAAACTGGCAGCAGC ACTTGCCGCCTCTGAGAAGAAGCTAGCCACTTCTCGCAAGCACAGCCTTGACCTGCCCCACTCTGAACTAAAGAAGGAACTGCCGCCCAG GGAAGTGAGCCCTCTGGAGGTAGTTGGAGCCAGGAGTGTGCTGTCTGGCAAGGGGGCCCTGCCAGGGAAGGGGGTGCTGCAGCCTGCTCC CTCACGGGCCCTAGGCACCCTCCGGCAGGACCGAGCCGAACGACGGGAGTCGCTGCAGAAGCAAGAAGCCATTCGTGAGGTGGACTCCTC AGAGGACGACACCGAGGAAGGGCCTGAGAACAGCCAGGGTGCACAGGAGCTGAGCTTGGCACCTCACCCAGAAGTGAGCCAGAGTGTGGC CCCTAAAGGAGCAGGAGAGAGTGGGGAAGAGGATCCTTTCCCGTCCAGAGACCCTAGGAGCCTGGGCCCAATGGTCCCAAGCCTATTGAC AGGGATCACACTGGGGCCTCCCAGAATGGAAAGTCCCAGTGGTCCCCACAGGAGGCTCGGGAGCCCACAAGCCATTGAGGAGGCTGCCAG CTCCTCCTCAGCAGGCCCCAACCTAGGTCAGTCTGGAGCCACAGACCCCATCCCTCCTGAAGGTTGCTGGAAGGCCCAGCACCTCCACAC CCAGGCACTAACAGCACTTTCTCCCAGCACTTCGGGACTCACCCCCACCAGCAGTTGCTCTCCTCCCAGCTCCACCTCTGGGAAGCTGAG CATGTGGTCCTGGAAATCCCTTATTGAGGGCCCAGACAGGGCATCCCCAAGCAGAAAGGCAACCATGGCAGGTGGGCTAGCCAACCTCCA GGATTTGGAAAACACAACTCCAGCCCAGCCTAAGAACCTGTCTCCCAGGGAGCAGGGGAAGACACAGCCACCTAGTGCCCCCAGACTGGC CCATCCATCTTATGAGGATCCCAGCCAGGGCTGGCTATGGGAGTCTGAGTGTGCACAAGCAGTGAAAGAGGATCCAGCCCTGAGCATCAC CCAAGTGCCTGATGCCTCAGGTGACAGAAGGCAGGACGTTCCATGCCGAGGCTGCCCCCTCACCCAGAAGTCTGAGCCCAGCCTCAGGAG GGGCCAAGAACCAGGGGGCCATCAAAAGCATCGGGATTTGGCATTGGTTCCAGATGAGCTTTTAAAGCAAACATAGCAGTTGTTTGCCAT >31036_31036_3_FOS-MAST2_FOS_chr14_75747698_ENST00000535987_MAST2_chr1_46496700_ENST00000361297_length(amino acids)=875AA_BP= MTVRRRCSGLLDAPRFPEGPEEASSTLRRQPQEGIWVLTPPSGEGVSGPVTEHSGEQRPKLDEEAVGRSSGSSPAMETRGRGTSQLAEGA TAKAISDLAVRRARHRLLSGDSTEKRTARPVNKVIKSASATALSLLIPSEHHTCSPLASPMSPHSQSSNPSSRDSSPSRDFLPALGSMRP PIIIHRAGKKYGFTLRAIRVYMGDSDVYTVHHMVWHVEDGGPASEAGLRQGDLITHVNGEPVHGLVHTEVVELILKSGNKVAISTTPLEN TSIKVGPARKGSYKAKMARRSKRSRGKDGQESRKRSSLFRKITKQASLLHTSRSLSSLNRSLSSGESGPGSPTHSHSLSPRSPTQGYRVT PDAVHSVGGNSSQSSSPSSSVPSSPAGSGHTRPSSLHGLAPKLQRQYRSPRRKSAGSIPLSPLAHTPSPPPPTASPQRSPSPLSGHVAQA FPTKLHLSPPLGRQLSRPKSAEPPRSPLLKRVQSAEKLAAALAASEKKLATSRKHSLDLPHSELKKELPPREVSPLEVVGARSVLSGKGA LPGKGVLQPAPSRALGTLRQDRAERRESLQKQEAIREVDSSEDDTEEGPENSQGAQELSLAPHPEVSQSVAPKGAGESGEEDPFPSRDPR SLGPMVPSLLTGITLGPPRMESPSGPHRRLGSPQAIEEAASSSSAGPNLGQSGATDPIPPEGCWKAQHLHTQALTALSPSTSGLTPTSSC SPPSSTSGKLSMWSWKSLIEGPDRASPSRKATMAGGLANLQDLENTTPAQPKNLSPREQGKTQPPSAPRLAHPSYEDPSQGWLWESECAQ -------------------------------------------------------------- >31036_31036_4_FOS-MAST2_FOS_chr14_75747698_ENST00000535987_MAST2_chr1_46496700_ENST00000372009_length(transcript)=3496nt_BP=1189nt AACCGCATCTGCAGCGAGCATCTGAGAAGCCAAGACTGAGCCGGCGGCCGCGGCGCAGCGAACGAGCAGTGACCGTGCTCCTACCCAGCT CTGCTCCACAGCGCCCACCTGTCTCCGCCCCTCGGCCCCTCGCCCGGCTTTGCCTAACCGCCACGATGATGTTCTCGGGCTTCAACGCAG ACTACGAGGCGTCATCCTCCCGCTGCAGCAGCGCGTCCCCGGCCGGGGATAGCCTCTCTTACTACCACTCACCCGCAGACTCCTTCTCCA GCATGGGCTCGCCTGTCAACGCGCAGGACTTCTGCACGGACCTGGCCGTCTCCAGTGCCAACTTCATTCCCACGGTCACTGCCATCTCGA CCAGTCCGGACCTGCAGTGGCTGGTGCAGCCCGCCCTCGTCTCCTCCGTGGCCCCATCGCAGACCAGAGCCCCTCACCCTTTCGGAGTCC CCGCCCCCTCCGCTGGGGCTTACTCCAGGGCTGGCGTTGTGAAGACCATGACAGGAGGCCGAGCGCAGAGCATTGGCAGGAGGGGCAAGG TGGAACAGTTCACCCTGCCTCTCCTCAATGACCCTGAGCCCAAGCCCTCAGTGGAACCTGTCAAGAGCATCAGCAGCATGGAGCTGAAGA CCGAGCCCTTTGATGACTTCCTGTTCCCAGCATCATCCAGGCCCAGTGGCTCTGAGACAGCCCGCTCCGTGCCAGACATGGACCTATCTG GGTCCTTCTATGCAGCAGACTGGGAGCCTCTGCACAGTGGCTCCCTGGGGATGGGGCCCATGGCCACAGAGCTGGAGCCCCTGTGCACTC CGGTGGTCACCTGTACTCCCAGCTGCACTGCTTACACGTCTTCCTTCGTCTTCACCTACCCCGAGGCTGACTCCTTCCCCAGCTGTGCAG CTGCCCACCGCAAGGGCAGCAGCAGCAATGAGCCTTCCTCTGACTCGCTCAGCTCACCCACGCTGCTGGCCCTGTGAGGGGGCAGGGAAG GGGAGGCAGCCGGCACCCACAAGTGCCACTGCCCGAGCTGGTGCATTACAGAGAGGAGAAACACATCTTCCCTAGAGGGTTCCTGTAGAC CTAGGGAGGACCTTATCTGTGCGTGAAACACACCAGGCTGTGGGCCTCAAGGACTTGAAAGCATCCATGTGTGGACTCAAGTCCTTACCT CTTCCGGAGATGTAGCAAATCTGAGTCATCCCACACAGAGAGTGACTCAAGCCCTCCAATGACAGTGCGACGCCGCTGCTCAGGCCTCCT GGATGCGCCTCGGTTCCCGGAGGGCCCTGAGGAGGCCAGCAGCACCCTCAGGAGGCAACCACAGGAGGGTATATGGGTCCTGACACCCCC ATCTGGAGAGGGGGTATCTGGGCCTGTCACTGAACACTCAGGGGAGCAGCGGCCAAAGCTGGATGAGGAAGCTGTTGGCCGGAGCAGTGG TTCCAGTCCAGCTATGGAGACCCGAGGCCGTGGGACCTCACAGCTGGCTGAGGGAGCCACAGCCAAGGCCATCAGTGACCTGGCTGTGCG TAGGGCCCGCCACCGGCTGCTCTCTGGGGACTCAACAGAGAAGCGCACTGCTCGCCCTGTCAACAAAGTGATCAAGTCCGCCTCAGCCAC AGCCCTCTCACTCCTCATTCCTTCGGAACACCACACCTGCTCCCCGTTGGCCAGCCCCATGTCCCCACATTCTCAGTCGTCCAACCCATC ATCCCGGGACTCTTCTCCATATGGCTTCACCCTGCGGGCCATTCGCGTCTACATGGGTGACTCCGATGTCTACACCGTGCACCATATGGT GTGGCACGTGGAGGATGGAGGTCCGGCCAGTGAGGCAGGGCTTCGTCAAGGTGACCTCATCACCCATGTCAATGGGGAACCTGTGCATGG CCTGGTGCACACGGAGGTGGTAGAGCTGATCCTGAAGAGTGGAAACAAGGTGGCCATTTCAACAACTCCCCTGGAGAACACATCCATTAA AGTGGGGCCAGCTCGGAAGGGCAGCTACAAGGCCAAGATGGCCCGAAGGAGCAAGAGGAGCCGCGGCAAGGATGGGCAAGAAAGCAGAAA AAGGAGCTCCCTGTTCCGCAAGATCACCAAGCAAGCATCCCTGCTCCACACCAGCCGCAGCCTTTCTTCCCTTAACCGCTCCTTGTCATC AGGGGAGAGTGGGCCAGGCTCTCCCACACACAGCCACAGCCTTTCCCCCCGATCTCCCACTCAAGGCTACCGGGTGACCCCCGATGCTGT GCATTCAGAACTCTCACGGCCCAAGAGTGCGGAGCCACCCCGTTCACCACTACTCAAGAGGGTGCAGTCGGCTGAGAAACTGGCAGCAGC ACTTGCCGCCTCTGAGAAGAAGCTAGCCACTTCTCGCAAGCACAGCCTTGACCTGCCCCACTCTGAACTAAAGAAGGAACTGCCGCCCAG GGAAGTGAGCCCTCTGGAGGTAGTTGGAGCCAGGAGTGTGCTGTCTGGCAAGGGGGCCCTGCCAGGGAAGGGGGTGCTGCAGCCTGCTCC CTCACGGGCCCTAGGCACCCTCCGGCAGGACCGAGCCGAACGACGGGAGTCGCTGCAGAAGCAAGAAGCCATTCGTGAGGTGGACTCCTC AGAGGACGACACCGAGGAAGGGCCTGAGAACAGCCAGGGTGCACAGGAGCTGAGCTTGGCACCTCACCCAGAAGTGAGCCAGAGTGTGGC CCCTAAAGGAGCAGGAGAGAGTGGGGAAGAGGATCCTTTCCCGTCCAGAGACCCTAGGAGCCTGGGCCCAATGGTCCCAAGCCTATTGAC AGGGATCACACTGGGGCCTCCCAGAATGGAAAGTCCCAGTGGTCCCCACAGGAGGCTCGGGAGCCCACAAGCCATTGAGGAGGCTGCCAG CTCCTCCTCAGCAGGCCCCAACCTAGGTCAGTCTGGAGCCACAGACCCCATCCCTCCTGAAGGTTGCTGGAAGGCCCAGCACCTCCACAC CCAGGCACTAACAGCACTTTCTCCCAGCACTTCGGGACTCACCCCCACCAGCAGTTGCTCTCCTCCCAGCTCCACCTCTGGGAAGCTGAG CATGTGGTCCTGGAAATCCCTTATTGAGGGCCCAGACAGGGCATCCCCAAGCAGAAAGGCAACCATGGCAGGTGGGCTAGCCAACCTCCA GGATTTGGAAAACACAACTCCAGCCCAGCCTAAGAACCTGTCTCCCAGGGAGCAGGGGAAGACACAGCCACCTAGTGCCCCCAGACTGGC CCATCCATCTTATGAGGATCCCAGCCAGGGCTGGCTATGGGAGTCTGAGTGTGCACAAGCAGTGAAAGAGGATCCAGCCCTGAGCATCAC CCAAGTGCCTGATGCCTCAGGTGACAGAAGGCAGGACGTTCCATGCCGAGGCTGCCCCCTCACCCAGAAGTCTGAGCCCAGCCTCAGGAG >31036_31036_4_FOS-MAST2_FOS_chr14_75747698_ENST00000535987_MAST2_chr1_46496700_ENST00000372009_length(amino acids)=756AA_BP= MTVRRRCSGLLDAPRFPEGPEEASSTLRRQPQEGIWVLTPPSGEGVSGPVTEHSGEQRPKLDEEAVGRSSGSSPAMETRGRGTSQLAEGA TAKAISDLAVRRARHRLLSGDSTEKRTARPVNKVIKSASATALSLLIPSEHHTCSPLASPMSPHSQSSNPSSRDSSPYGFTLRAIRVYMG DSDVYTVHHMVWHVEDGGPASEAGLRQGDLITHVNGEPVHGLVHTEVVELILKSGNKVAISTTPLENTSIKVGPARKGSYKAKMARRSKR SRGKDGQESRKRSSLFRKITKQASLLHTSRSLSSLNRSLSSGESGPGSPTHSHSLSPRSPTQGYRVTPDAVHSELSRPKSAEPPRSPLLK RVQSAEKLAAALAASEKKLATSRKHSLDLPHSELKKELPPREVSPLEVVGARSVLSGKGALPGKGVLQPAPSRALGTLRQDRAERRESLQ KQEAIREVDSSEDDTEEGPENSQGAQELSLAPHPEVSQSVAPKGAGESGEEDPFPSRDPRSLGPMVPSLLTGITLGPPRMESPSGPHRRL GSPQAIEEAASSSSAGPNLGQSGATDPIPPEGCWKAQHLHTQALTALSPSTSGLTPTSSCSPPSSTSGKLSMWSWKSLIEGPDRASPSRK ATMAGGLANLQDLENTTPAQPKNLSPREQGKTQPPSAPRLAHPSYEDPSQGWLWESECAQAVKEDPALSITQVPDASGDRRQDVPCRGCP -------------------------------------------------------------- >31036_31036_5_FOS-MAST2_FOS_chr14_75747698_ENST00000555686_MAST2_chr1_46496700_ENST00000361297_length(transcript)=4008nt_BP=1283nt GATGCTGAAGGGATAACGGGAACGCAGCGGCAGGATGGAAGAGACAGGCACTGCGCTGCGGAATGCCTGGGAGGAAAAGGGGGAGACCTT TCATCCAGGATGAGGGACATTTAAGATGAAATGTCCGTGGCAGGATCGTTTCTCTTCACTGCTGCATGCGGCACTGGGAACTCGCCCCAC CTGTGTCCGGAACCTGCTCGCTCACGTCGGCTTTCCCCTTCTGTTTTGTTCTAGGACTTCTGCACGGACCTGGCCGTCTCCAGTGCCAAC TTCATTCCCACGGTCACTGCCATCTCGACCAGTCCGGACCTGCAGTGGCTGGTGCAGCCCGCCCTCGTCTCCTCCGTGGCCCCATCGCAG ACCAGAGCCCCTCACCCTTTCGGAGTCCCCGCCCCCTCCGCTGGGGCTTACTCCAGGGCTGGCGTTGTGAAGACCATGACAGGAGGCCGA GCGCAGAGCATTGGCAGGAGGGGCAAGGTGGAACAGTTATCTCCAGAAGAAGAAGAGAAAAGGAGAATCCGAAGGGAAAGGAATAAGATG GCTGCAGCCAAATGCCGCAACCGGAGGAGGGAGCTGACTGATACACTCCAAGCGTTCACCCTGCCTCTCCTCAATGACCCTGAGCCCAAG CCCTCAGTGGAACCTGTCAAGAGCATCAGCAGCATGGAGCTGAAGACCGAGCCCTTTGATGACTTCCTGTTCCCAGCATCATCCAGGCCC AGTGGCTCTGAGACAGCCCGCTCCGTGCCAGACATGGACCTATCTGGGTCCTTCTATGCAGCAGACTGGGAGCCTCTGCACAGTGGCTCC CTGGGGATGGGGCCCATGGCCACAGAGCTGGAGCCCCTGTGCACTCCGGTGGTCACCTGTACTCCCAGCTGCACTGCTTACACGTCTTCC TTCGTCTTCACCTACCCCGAGGCTGACTCCTTCCCCAGCTGTGCAGCTGCCCACCGCAAGGGCAGCAGCAGCAATGAGCCTTCCTCTGAC TCGCTCAGCTCACCCACGCTGCTGGCCCTGTGAGGGGGCAGGGAAGGGGAGGCAGCCGGCACCCACAAGTGCCACTGCCCGAGCTGGTGC ATTACAGAGAGGAGAAACACATCTTCCCTAGAGGGTTCCTGTAGACCTAGGGAGGACCTTATCTGTGCGTGAAACACACCAGGCTGTGGG CCTCAAGGACTTGAAAGCATCCATGTGTGGACTCAAGTCCTTACCTCTTCCGGAGATGTAGCAAAACGCATGGAGTGTGTATTGTTCCCA GTGACACTTCAGAGAGCTGGTAGTCTGAGTCATCCCACACAGAGAGTGACTCAAGCCCTCCAATGACAGTGCGACGCCGCTGCTCAGGCC TCCTGGATGCGCCTCGGTTCCCGGAGGGCCCTGAGGAGGCCAGCAGCACCCTCAGGAGGCAACCACAGGAGGGTATATGGGTCCTGACAC CCCCATCTGGAGAGGGGGTATCTGGGCCTGTCACTGAACACTCAGGGGAGCAGCGGCCAAAGCTGGATGAGGAAGCTGTTGGCCGGAGCA GTGGTTCCAGTCCAGCTATGGAGACCCGAGGCCGTGGGACCTCACAGCTGGCTGAGGGAGCCACAGCCAAGGCCATCAGTGACCTGGCTG TGCGTAGGGCCCGCCACCGGCTGCTCTCTGGGGACTCAACAGAGAAGCGCACTGCTCGCCCTGTCAACAAAGTGATCAAGTCCGCCTCAG CCACAGCCCTCTCACTCCTCATTCCTTCGGAACACCACACCTGCTCCCCGTTGGCCAGCCCCATGTCCCCACATTCTCAGTCGTCCAACC CATCATCCCGGGACTCTTCTCCAAGCAGGGACTTCTTGCCAGCCCTTGGCAGCATGAGGCCTCCCATCATCATCCACCGAGCTGGCAAGA AGTATGGCTTCACCCTGCGGGCCATTCGCGTCTACATGGGTGACTCCGATGTCTACACCGTGCACCATATGGTGTGGCACGTGGAGGATG GAGGTCCGGCCAGTGAGGCAGGGCTTCGTCAAGGTGACCTCATCACCCATGTCAATGGGGAACCTGTGCATGGCCTGGTGCACACGGAGG TGGTAGAGCTGATCCTGAAGAGTGGAAACAAGGTGGCCATTTCAACAACTCCCCTGGAGAACACATCCATTAAAGTGGGGCCAGCTCGGA AGGGCAGCTACAAGGCCAAGATGGCCCGAAGGAGCAAGAGGAGCCGCGGCAAGGATGGGCAAGAAAGCAGAAAAAGGAGCTCCCTGTTCC GCAAGATCACCAAGCAAGCATCCCTGCTCCACACCAGCCGCAGCCTTTCTTCCCTTAACCGCTCCTTGTCATCAGGGGAGAGTGGGCCAG GCTCTCCCACACACAGCCACAGCCTTTCCCCCCGATCTCCCACTCAAGGCTACCGGGTGACCCCCGATGCTGTGCATTCAGTGGGAGGGA ATTCATCACAGAGCAGCTCCCCCAGCTCCAGCGTGCCCAGTTCCCCAGCCGGCTCTGGGCACACACGGCCCAGCTCCCTCCACGGTCTGG CACCCAAGCTCCAACGCCAGTACCGCTCTCCACGGCGCAAGTCAGCAGGCAGCATCCCACTGTCACCACTGGCCCACACCCCTTCTCCCC CACCCCCAACAGCTTCACCTCAGCGGTCCCCATCGCCCCTGTCTGGCCATGTAGCCCAGGCCTTTCCCACAAAGCTTCACTTGTCACCTC CCCTGGGCAGGCAACTCTCACGGCCCAAGAGTGCGGAGCCACCCCGTTCACCACTACTCAAGAGGGTGCAGTCGGCTGAGAAACTGGCAG CAGCACTTGCCGCCTCTGAGAAGAAGCTAGCCACTTCTCGCAAGCACAGCCTTGACCTGCCCCACTCTGAACTAAAGAAGGAACTGCCGC CCAGGGAAGTGAGCCCTCTGGAGGTAGTTGGAGCCAGGAGTGTGCTGTCTGGCAAGGGGGCCCTGCCAGGGAAGGGGGTGCTGCAGCCTG CTCCCTCACGGGCCCTAGGCACCCTCCGGCAGGACCGAGCCGAACGACGGGAGTCGCTGCAGAAGCAAGAAGCCATTCGTGAGGTGGACT CCTCAGAGGACGACACCGAGGAAGGGCCTGAGAACAGCCAGGGTGCACAGGAGCTGAGCTTGGCACCTCACCCAGAAGTGAGCCAGAGTG TGGCCCCTAAAGGAGCAGGAGAGAGTGGGGAAGAGGATCCTTTCCCGTCCAGAGACCCTAGGAGCCTGGGCCCAATGGTCCCAAGCCTAT TGACAGGGATCACACTGGGGCCTCCCAGAATGGAAAGTCCCAGTGGTCCCCACAGGAGGCTCGGGAGCCCACAAGCCATTGAGGAGGCTG CCAGCTCCTCCTCAGCAGGCCCCAACCTAGGTCAGTCTGGAGCCACAGACCCCATCCCTCCTGAAGGTTGCTGGAAGGCCCAGCACCTCC ACACCCAGGCACTAACAGCACTTTCTCCCAGCACTTCGGGACTCACCCCCACCAGCAGTTGCTCTCCTCCCAGCTCCACCTCTGGGAAGC TGAGCATGTGGTCCTGGAAATCCCTTATTGAGGGCCCAGACAGGGCATCCCCAAGCAGAAAGGCAACCATGGCAGGTGGGCTAGCCAACC TCCAGGATTTGGAAAACACAACTCCAGCCCAGCCTAAGAACCTGTCTCCCAGGGAGCAGGGGAAGACACAGCCACCTAGTGCCCCCAGAC TGGCCCATCCATCTTATGAGGATCCCAGCCAGGGCTGGCTATGGGAGTCTGAGTGTGCACAAGCAGTGAAAGAGGATCCAGCCCTGAGCA TCACCCAAGTGCCTGATGCCTCAGGTGACAGAAGGCAGGACGTTCCATGCCGAGGCTGCCCCCTCACCCAGAAGTCTGAGCCCAGCCTCA GGAGGGGCCAAGAACCAGGGGGCCATCAAAAGCATCGGGATTTGGCATTGGTTCCAGATGAGCTTTTAAAGCAAACATAGCAGTTGTTTG >31036_31036_5_FOS-MAST2_FOS_chr14_75747698_ENST00000555686_MAST2_chr1_46496700_ENST00000361297_length(amino acids)=875AA_BP= MTVRRRCSGLLDAPRFPEGPEEASSTLRRQPQEGIWVLTPPSGEGVSGPVTEHSGEQRPKLDEEAVGRSSGSSPAMETRGRGTSQLAEGA TAKAISDLAVRRARHRLLSGDSTEKRTARPVNKVIKSASATALSLLIPSEHHTCSPLASPMSPHSQSSNPSSRDSSPSRDFLPALGSMRP PIIIHRAGKKYGFTLRAIRVYMGDSDVYTVHHMVWHVEDGGPASEAGLRQGDLITHVNGEPVHGLVHTEVVELILKSGNKVAISTTPLEN TSIKVGPARKGSYKAKMARRSKRSRGKDGQESRKRSSLFRKITKQASLLHTSRSLSSLNRSLSSGESGPGSPTHSHSLSPRSPTQGYRVT PDAVHSVGGNSSQSSSPSSSVPSSPAGSGHTRPSSLHGLAPKLQRQYRSPRRKSAGSIPLSPLAHTPSPPPPTASPQRSPSPLSGHVAQA FPTKLHLSPPLGRQLSRPKSAEPPRSPLLKRVQSAEKLAAALAASEKKLATSRKHSLDLPHSELKKELPPREVSPLEVVGARSVLSGKGA LPGKGVLQPAPSRALGTLRQDRAERRESLQKQEAIREVDSSEDDTEEGPENSQGAQELSLAPHPEVSQSVAPKGAGESGEEDPFPSRDPR SLGPMVPSLLTGITLGPPRMESPSGPHRRLGSPQAIEEAASSSSAGPNLGQSGATDPIPPEGCWKAQHLHTQALTALSPSTSGLTPTSSC SPPSSTSGKLSMWSWKSLIEGPDRASPSRKATMAGGLANLQDLENTTPAQPKNLSPREQGKTQPPSAPRLAHPSYEDPSQGWLWESECAQ -------------------------------------------------------------- >31036_31036_6_FOS-MAST2_FOS_chr14_75747698_ENST00000555686_MAST2_chr1_46496700_ENST00000372009_length(transcript)=3590nt_BP=1283nt GATGCTGAAGGGATAACGGGAACGCAGCGGCAGGATGGAAGAGACAGGCACTGCGCTGCGGAATGCCTGGGAGGAAAAGGGGGAGACCTT TCATCCAGGATGAGGGACATTTAAGATGAAATGTCCGTGGCAGGATCGTTTCTCTTCACTGCTGCATGCGGCACTGGGAACTCGCCCCAC CTGTGTCCGGAACCTGCTCGCTCACGTCGGCTTTCCCCTTCTGTTTTGTTCTAGGACTTCTGCACGGACCTGGCCGTCTCCAGTGCCAAC TTCATTCCCACGGTCACTGCCATCTCGACCAGTCCGGACCTGCAGTGGCTGGTGCAGCCCGCCCTCGTCTCCTCCGTGGCCCCATCGCAG ACCAGAGCCCCTCACCCTTTCGGAGTCCCCGCCCCCTCCGCTGGGGCTTACTCCAGGGCTGGCGTTGTGAAGACCATGACAGGAGGCCGA GCGCAGAGCATTGGCAGGAGGGGCAAGGTGGAACAGTTATCTCCAGAAGAAGAAGAGAAAAGGAGAATCCGAAGGGAAAGGAATAAGATG GCTGCAGCCAAATGCCGCAACCGGAGGAGGGAGCTGACTGATACACTCCAAGCGTTCACCCTGCCTCTCCTCAATGACCCTGAGCCCAAG CCCTCAGTGGAACCTGTCAAGAGCATCAGCAGCATGGAGCTGAAGACCGAGCCCTTTGATGACTTCCTGTTCCCAGCATCATCCAGGCCC AGTGGCTCTGAGACAGCCCGCTCCGTGCCAGACATGGACCTATCTGGGTCCTTCTATGCAGCAGACTGGGAGCCTCTGCACAGTGGCTCC CTGGGGATGGGGCCCATGGCCACAGAGCTGGAGCCCCTGTGCACTCCGGTGGTCACCTGTACTCCCAGCTGCACTGCTTACACGTCTTCC TTCGTCTTCACCTACCCCGAGGCTGACTCCTTCCCCAGCTGTGCAGCTGCCCACCGCAAGGGCAGCAGCAGCAATGAGCCTTCCTCTGAC TCGCTCAGCTCACCCACGCTGCTGGCCCTGTGAGGGGGCAGGGAAGGGGAGGCAGCCGGCACCCACAAGTGCCACTGCCCGAGCTGGTGC ATTACAGAGAGGAGAAACACATCTTCCCTAGAGGGTTCCTGTAGACCTAGGGAGGACCTTATCTGTGCGTGAAACACACCAGGCTGTGGG CCTCAAGGACTTGAAAGCATCCATGTGTGGACTCAAGTCCTTACCTCTTCCGGAGATGTAGCAAAACGCATGGAGTGTGTATTGTTCCCA GTGACACTTCAGAGAGCTGGTAGTCTGAGTCATCCCACACAGAGAGTGACTCAAGCCCTCCAATGACAGTGCGACGCCGCTGCTCAGGCC TCCTGGATGCGCCTCGGTTCCCGGAGGGCCCTGAGGAGGCCAGCAGCACCCTCAGGAGGCAACCACAGGAGGGTATATGGGTCCTGACAC CCCCATCTGGAGAGGGGGTATCTGGGCCTGTCACTGAACACTCAGGGGAGCAGCGGCCAAAGCTGGATGAGGAAGCTGTTGGCCGGAGCA GTGGTTCCAGTCCAGCTATGGAGACCCGAGGCCGTGGGACCTCACAGCTGGCTGAGGGAGCCACAGCCAAGGCCATCAGTGACCTGGCTG TGCGTAGGGCCCGCCACCGGCTGCTCTCTGGGGACTCAACAGAGAAGCGCACTGCTCGCCCTGTCAACAAAGTGATCAAGTCCGCCTCAG CCACAGCCCTCTCACTCCTCATTCCTTCGGAACACCACACCTGCTCCCCGTTGGCCAGCCCCATGTCCCCACATTCTCAGTCGTCCAACC CATCATCCCGGGACTCTTCTCCATATGGCTTCACCCTGCGGGCCATTCGCGTCTACATGGGTGACTCCGATGTCTACACCGTGCACCATA TGGTGTGGCACGTGGAGGATGGAGGTCCGGCCAGTGAGGCAGGGCTTCGTCAAGGTGACCTCATCACCCATGTCAATGGGGAACCTGTGC ATGGCCTGGTGCACACGGAGGTGGTAGAGCTGATCCTGAAGAGTGGAAACAAGGTGGCCATTTCAACAACTCCCCTGGAGAACACATCCA TTAAAGTGGGGCCAGCTCGGAAGGGCAGCTACAAGGCCAAGATGGCCCGAAGGAGCAAGAGGAGCCGCGGCAAGGATGGGCAAGAAAGCA GAAAAAGGAGCTCCCTGTTCCGCAAGATCACCAAGCAAGCATCCCTGCTCCACACCAGCCGCAGCCTTTCTTCCCTTAACCGCTCCTTGT CATCAGGGGAGAGTGGGCCAGGCTCTCCCACACACAGCCACAGCCTTTCCCCCCGATCTCCCACTCAAGGCTACCGGGTGACCCCCGATG CTGTGCATTCAGAACTCTCACGGCCCAAGAGTGCGGAGCCACCCCGTTCACCACTACTCAAGAGGGTGCAGTCGGCTGAGAAACTGGCAG CAGCACTTGCCGCCTCTGAGAAGAAGCTAGCCACTTCTCGCAAGCACAGCCTTGACCTGCCCCACTCTGAACTAAAGAAGGAACTGCCGC CCAGGGAAGTGAGCCCTCTGGAGGTAGTTGGAGCCAGGAGTGTGCTGTCTGGCAAGGGGGCCCTGCCAGGGAAGGGGGTGCTGCAGCCTG CTCCCTCACGGGCCCTAGGCACCCTCCGGCAGGACCGAGCCGAACGACGGGAGTCGCTGCAGAAGCAAGAAGCCATTCGTGAGGTGGACT CCTCAGAGGACGACACCGAGGAAGGGCCTGAGAACAGCCAGGGTGCACAGGAGCTGAGCTTGGCACCTCACCCAGAAGTGAGCCAGAGTG TGGCCCCTAAAGGAGCAGGAGAGAGTGGGGAAGAGGATCCTTTCCCGTCCAGAGACCCTAGGAGCCTGGGCCCAATGGTCCCAAGCCTAT TGACAGGGATCACACTGGGGCCTCCCAGAATGGAAAGTCCCAGTGGTCCCCACAGGAGGCTCGGGAGCCCACAAGCCATTGAGGAGGCTG CCAGCTCCTCCTCAGCAGGCCCCAACCTAGGTCAGTCTGGAGCCACAGACCCCATCCCTCCTGAAGGTTGCTGGAAGGCCCAGCACCTCC ACACCCAGGCACTAACAGCACTTTCTCCCAGCACTTCGGGACTCACCCCCACCAGCAGTTGCTCTCCTCCCAGCTCCACCTCTGGGAAGC TGAGCATGTGGTCCTGGAAATCCCTTATTGAGGGCCCAGACAGGGCATCCCCAAGCAGAAAGGCAACCATGGCAGGTGGGCTAGCCAACC TCCAGGATTTGGAAAACACAACTCCAGCCCAGCCTAAGAACCTGTCTCCCAGGGAGCAGGGGAAGACACAGCCACCTAGTGCCCCCAGAC TGGCCCATCCATCTTATGAGGATCCCAGCCAGGGCTGGCTATGGGAGTCTGAGTGTGCACAAGCAGTGAAAGAGGATCCAGCCCTGAGCA TCACCCAAGTGCCTGATGCCTCAGGTGACAGAAGGCAGGACGTTCCATGCCGAGGCTGCCCCCTCACCCAGAAGTCTGAGCCCAGCCTCA >31036_31036_6_FOS-MAST2_FOS_chr14_75747698_ENST00000555686_MAST2_chr1_46496700_ENST00000372009_length(amino acids)=756AA_BP= MTVRRRCSGLLDAPRFPEGPEEASSTLRRQPQEGIWVLTPPSGEGVSGPVTEHSGEQRPKLDEEAVGRSSGSSPAMETRGRGTSQLAEGA TAKAISDLAVRRARHRLLSGDSTEKRTARPVNKVIKSASATALSLLIPSEHHTCSPLASPMSPHSQSSNPSSRDSSPYGFTLRAIRVYMG DSDVYTVHHMVWHVEDGGPASEAGLRQGDLITHVNGEPVHGLVHTEVVELILKSGNKVAISTTPLENTSIKVGPARKGSYKAKMARRSKR SRGKDGQESRKRSSLFRKITKQASLLHTSRSLSSLNRSLSSGESGPGSPTHSHSLSPRSPTQGYRVTPDAVHSELSRPKSAEPPRSPLLK RVQSAEKLAAALAASEKKLATSRKHSLDLPHSELKKELPPREVSPLEVVGARSVLSGKGALPGKGVLQPAPSRALGTLRQDRAERRESLQ KQEAIREVDSSEDDTEEGPENSQGAQELSLAPHPEVSQSVAPKGAGESGEEDPFPSRDPRSLGPMVPSLLTGITLGPPRMESPSGPHRRL GSPQAIEEAASSSSAGPNLGQSGATDPIPPEGCWKAQHLHTQALTALSPSTSGLTPTSSCSPPSSTSGKLSMWSWKSLIEGPDRASPSRK ATMAGGLANLQDLENTTPAQPKNLSPREQGKTQPPSAPRLAHPSYEDPSQGWLWESECAQAVKEDPALSITQVPDASGDRRQDVPCRGCP -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for FOS-MAST2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for FOS-MAST2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for FOS-MAST2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies