
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:FRS2-PIP4K2C (FusionGDB2 ID:31451) |
Fusion Gene Summary for FRS2-PIP4K2C |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: FRS2-PIP4K2C | Fusion gene ID: 31451 | Hgene | Tgene | Gene symbol | FRS2 | PIP4K2C | Gene ID | 10818 | 79837 |
| Gene name | fibroblast growth factor receptor substrate 2 | phosphatidylinositol-5-phosphate 4-kinase type 2 gamma | |
| Synonyms | FRS1A|FRS2A|FRS2alpha|SNT|SNT-1|SNT1 | PIP5K2C | |
| Cytomap | 12q15 | 12q13.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | fibroblast growth factor receptor substrate 2FGFR signalling adaptorFGFR substrate 2FGFR-signaling adaptor SNTepididymis secretory sperm binding proteinsuc1-associated neurotrophic factor target 1 | phosphatidylinositol 5-phosphate 4-kinase type-2 gammaPI(5)P 4-kinase type II gammaPIP4KII-gammaphosphatidylinositol 4-phosphate 5-kinasephosphatidylinositol 5-phosphate 4-kinase type II gammaphosphatidylinositol-4-phosphate 5-kinase, type II, gamma | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000299293, ENST00000397997, ENST00000549921, ENST00000550389, | ENST00000354947, ENST00000422156, ENST00000540759, ENST00000550465, | |
| Fusion gene scores | * DoF score | 71 X 15 X 14=14910 | 10 X 15 X 6=900 |
| # samples | 73 | 15 | |
| ** MAII score | log2(73/14910*10)=-4.35223998340343 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(15/900*10)=-2.58496250072116 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: FRS2 [Title/Abstract] AND PIP4K2C [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | FRS2(69962876)-PIP4K2C(57994107), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across FRS2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across PIP4K2C (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | LUAD | TCGA-55-7907-01A | FRS2 | chr12 | 69962876 | - | PIP4K2C | chr12 | 57994107 | + |
| ChimerDB4 | LUAD | TCGA-55-7907-01A | FRS2 | chr12 | 69962876 | + | PIP4K2C | chr12 | 57994107 | + |
Top |
Fusion Gene ORF analysis for FRS2-PIP4K2C |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| In-frame | ENST00000299293 | ENST00000354947 | FRS2 | chr12 | 69962876 | + | PIP4K2C | chr12 | 57994107 | + |
| In-frame | ENST00000299293 | ENST00000422156 | FRS2 | chr12 | 69962876 | + | PIP4K2C | chr12 | 57994107 | + |
| In-frame | ENST00000299293 | ENST00000540759 | FRS2 | chr12 | 69962876 | + | PIP4K2C | chr12 | 57994107 | + |
| In-frame | ENST00000299293 | ENST00000550465 | FRS2 | chr12 | 69962876 | + | PIP4K2C | chr12 | 57994107 | + |
| In-frame | ENST00000397997 | ENST00000354947 | FRS2 | chr12 | 69962876 | + | PIP4K2C | chr12 | 57994107 | + |
| In-frame | ENST00000397997 | ENST00000422156 | FRS2 | chr12 | 69962876 | + | PIP4K2C | chr12 | 57994107 | + |
| In-frame | ENST00000397997 | ENST00000540759 | FRS2 | chr12 | 69962876 | + | PIP4K2C | chr12 | 57994107 | + |
| In-frame | ENST00000397997 | ENST00000550465 | FRS2 | chr12 | 69962876 | + | PIP4K2C | chr12 | 57994107 | + |
| In-frame | ENST00000549921 | ENST00000354947 | FRS2 | chr12 | 69962876 | + | PIP4K2C | chr12 | 57994107 | + |
| In-frame | ENST00000549921 | ENST00000422156 | FRS2 | chr12 | 69962876 | + | PIP4K2C | chr12 | 57994107 | + |
| In-frame | ENST00000549921 | ENST00000540759 | FRS2 | chr12 | 69962876 | + | PIP4K2C | chr12 | 57994107 | + |
| In-frame | ENST00000549921 | ENST00000550465 | FRS2 | chr12 | 69962876 | + | PIP4K2C | chr12 | 57994107 | + |
| In-frame | ENST00000550389 | ENST00000354947 | FRS2 | chr12 | 69962876 | + | PIP4K2C | chr12 | 57994107 | + |
| In-frame | ENST00000550389 | ENST00000422156 | FRS2 | chr12 | 69962876 | + | PIP4K2C | chr12 | 57994107 | + |
| In-frame | ENST00000550389 | ENST00000540759 | FRS2 | chr12 | 69962876 | + | PIP4K2C | chr12 | 57994107 | + |
| In-frame | ENST00000550389 | ENST00000550465 | FRS2 | chr12 | 69962876 | + | PIP4K2C | chr12 | 57994107 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000299293 | FRS2 | chr12 | 69962876 | + | ENST00000422156 | PIP4K2C | chr12 | 57994107 | + | 1463 | 576 | 510 | 1142 | 210 |
| ENST00000299293 | FRS2 | chr12 | 69962876 | + | ENST00000540759 | PIP4K2C | chr12 | 57994107 | + | 2663 | 576 | 510 | 1142 | 210 |
| ENST00000299293 | FRS2 | chr12 | 69962876 | + | ENST00000550465 | PIP4K2C | chr12 | 57994107 | + | 1416 | 576 | 510 | 1142 | 210 |
| ENST00000299293 | FRS2 | chr12 | 69962876 | + | ENST00000354947 | PIP4K2C | chr12 | 57994107 | + | 2785 | 576 | 510 | 1142 | 210 |
| ENST00000549921 | FRS2 | chr12 | 69962876 | + | ENST00000422156 | PIP4K2C | chr12 | 57994107 | + | 1369 | 482 | 416 | 1048 | 210 |
| ENST00000549921 | FRS2 | chr12 | 69962876 | + | ENST00000540759 | PIP4K2C | chr12 | 57994107 | + | 2569 | 482 | 416 | 1048 | 210 |
| ENST00000549921 | FRS2 | chr12 | 69962876 | + | ENST00000550465 | PIP4K2C | chr12 | 57994107 | + | 1322 | 482 | 416 | 1048 | 210 |
| ENST00000549921 | FRS2 | chr12 | 69962876 | + | ENST00000354947 | PIP4K2C | chr12 | 57994107 | + | 2691 | 482 | 416 | 1048 | 210 |
| ENST00000550389 | FRS2 | chr12 | 69962876 | + | ENST00000422156 | PIP4K2C | chr12 | 57994107 | + | 1199 | 312 | 246 | 878 | 210 |
| ENST00000550389 | FRS2 | chr12 | 69962876 | + | ENST00000540759 | PIP4K2C | chr12 | 57994107 | + | 2399 | 312 | 246 | 878 | 210 |
| ENST00000550389 | FRS2 | chr12 | 69962876 | + | ENST00000550465 | PIP4K2C | chr12 | 57994107 | + | 1152 | 312 | 246 | 878 | 210 |
| ENST00000550389 | FRS2 | chr12 | 69962876 | + | ENST00000354947 | PIP4K2C | chr12 | 57994107 | + | 2521 | 312 | 246 | 878 | 210 |
| ENST00000397997 | FRS2 | chr12 | 69962876 | + | ENST00000422156 | PIP4K2C | chr12 | 57994107 | + | 1255 | 368 | 302 | 934 | 210 |
| ENST00000397997 | FRS2 | chr12 | 69962876 | + | ENST00000540759 | PIP4K2C | chr12 | 57994107 | + | 2455 | 368 | 302 | 934 | 210 |
| ENST00000397997 | FRS2 | chr12 | 69962876 | + | ENST00000550465 | PIP4K2C | chr12 | 57994107 | + | 1208 | 368 | 302 | 934 | 210 |
| ENST00000397997 | FRS2 | chr12 | 69962876 | + | ENST00000354947 | PIP4K2C | chr12 | 57994107 | + | 2577 | 368 | 302 | 934 | 210 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000299293 | ENST00000422156 | FRS2 | chr12 | 69962876 | + | PIP4K2C | chr12 | 57994107 | + | 0.000813323 | 0.9991867 |
| ENST00000299293 | ENST00000540759 | FRS2 | chr12 | 69962876 | + | PIP4K2C | chr12 | 57994107 | + | 0.001273495 | 0.99872655 |
| ENST00000299293 | ENST00000550465 | FRS2 | chr12 | 69962876 | + | PIP4K2C | chr12 | 57994107 | + | 0.000818381 | 0.99918157 |
| ENST00000299293 | ENST00000354947 | FRS2 | chr12 | 69962876 | + | PIP4K2C | chr12 | 57994107 | + | 0.001064496 | 0.9989355 |
| ENST00000549921 | ENST00000422156 | FRS2 | chr12 | 69962876 | + | PIP4K2C | chr12 | 57994107 | + | 0.000762565 | 0.9992374 |
| ENST00000549921 | ENST00000540759 | FRS2 | chr12 | 69962876 | + | PIP4K2C | chr12 | 57994107 | + | 0.001431322 | 0.99856865 |
| ENST00000549921 | ENST00000550465 | FRS2 | chr12 | 69962876 | + | PIP4K2C | chr12 | 57994107 | + | 0.000778708 | 0.9992213 |
| ENST00000549921 | ENST00000354947 | FRS2 | chr12 | 69962876 | + | PIP4K2C | chr12 | 57994107 | + | 0.0012995 | 0.9987005 |
| ENST00000550389 | ENST00000422156 | FRS2 | chr12 | 69962876 | + | PIP4K2C | chr12 | 57994107 | + | 0.000715384 | 0.9992847 |
| ENST00000550389 | ENST00000540759 | FRS2 | chr12 | 69962876 | + | PIP4K2C | chr12 | 57994107 | + | 0.001285373 | 0.9987147 |
| ENST00000550389 | ENST00000550465 | FRS2 | chr12 | 69962876 | + | PIP4K2C | chr12 | 57994107 | + | 0.000699869 | 0.9993001 |
| ENST00000550389 | ENST00000354947 | FRS2 | chr12 | 69962876 | + | PIP4K2C | chr12 | 57994107 | + | 0.001477814 | 0.9985222 |
| ENST00000397997 | ENST00000422156 | FRS2 | chr12 | 69962876 | + | PIP4K2C | chr12 | 57994107 | + | 0.000760162 | 0.9992398 |
| ENST00000397997 | ENST00000540759 | FRS2 | chr12 | 69962876 | + | PIP4K2C | chr12 | 57994107 | + | 0.001451166 | 0.9985488 |
| ENST00000397997 | ENST00000550465 | FRS2 | chr12 | 69962876 | + | PIP4K2C | chr12 | 57994107 | + | 0.000761849 | 0.99923813 |
| ENST00000397997 | ENST00000354947 | FRS2 | chr12 | 69962876 | + | PIP4K2C | chr12 | 57994107 | + | 0.001416545 | 0.99858344 |
Top |
Fusion Genomic Features for FRS2-PIP4K2C |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| FRS2 | chr12 | 69962876 | + | PIP4K2C | chr12 | 57994106 | + | 8.09E-06 | 0.9999919 |
| FRS2 | chr12 | 69962876 | + | PIP4K2C | chr12 | 57994106 | + | 8.09E-06 | 0.9999919 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
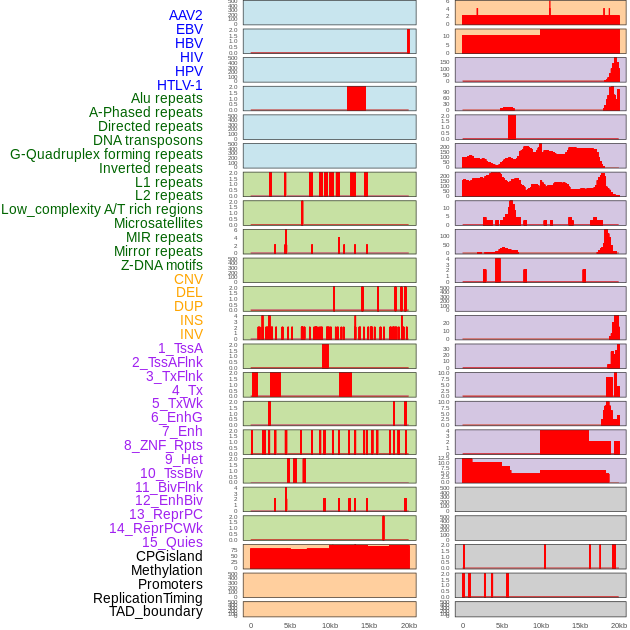 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
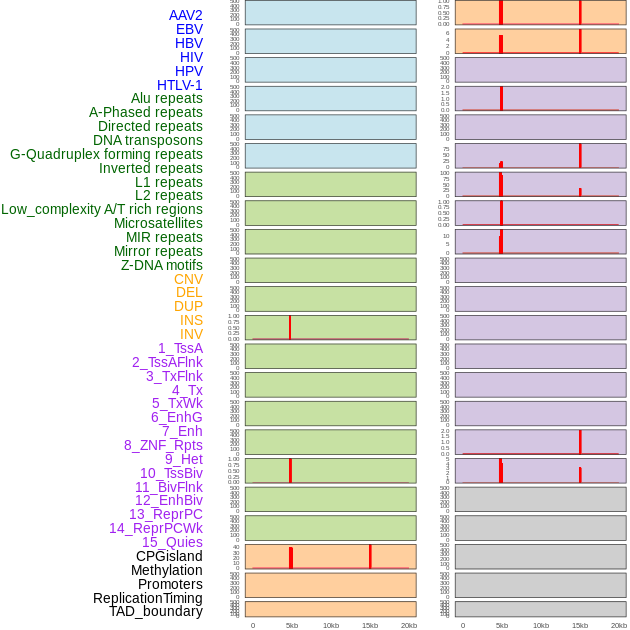 |
Top |
Fusion Protein Features for FRS2-PIP4K2C |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr12:69962876/chr12:57994107) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | FRS2 | chr12:69962876 | chr12:57994107 | ENST00000299293 | + | 6 | 10 | 13_115 | 22 | 509.0 | Domain | IRS-type PTB |
| Hgene | FRS2 | chr12:69962876 | chr12:57994107 | ENST00000397997 | + | 4 | 8 | 13_115 | 22 | 509.0 | Domain | IRS-type PTB |
| Hgene | FRS2 | chr12:69962876 | chr12:57994107 | ENST00000549921 | + | 5 | 9 | 13_115 | 22 | 509.0 | Domain | IRS-type PTB |
| Hgene | FRS2 | chr12:69962876 | chr12:57994107 | ENST00000550389 | + | 3 | 7 | 13_115 | 22 | 509.0 | Domain | IRS-type PTB |
| Tgene | PIP4K2C | chr12:69962876 | chr12:57994107 | ENST00000354947 | 5 | 10 | 43_420 | 233 | 422.0 | Domain | PIPK | |
| Tgene | PIP4K2C | chr12:69962876 | chr12:57994107 | ENST00000422156 | 4 | 9 | 43_420 | 185 | 374.0 | Domain | PIPK | |
| Tgene | PIP4K2C | chr12:69962876 | chr12:57994107 | ENST00000540759 | 5 | 11 | 43_420 | 233 | 831.6666666666666 | Domain | PIPK | |
| Tgene | PIP4K2C | chr12:69962876 | chr12:57994107 | ENST00000550465 | 5 | 10 | 43_420 | 215 | 404.0 | Domain | PIPK |
Top |
Fusion Gene Sequence for FRS2-PIP4K2C |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >31451_31451_1_FRS2-PIP4K2C_FRS2_chr12_69962876_ENST00000299293_PIP4K2C_chr12_57994107_ENST00000354947_length(transcript)=2785nt_BP=576nt AAAACCCTTCCCTCCCCCGCTCCCCCGGAAGTGCTTTTCCAAGATTCGGGCCGGAGAGAGGCCTTGTAGGCACAGCGGCTGAGACTCGAT CTGCTCCAAGTAGGGGCTCCAGCGCGGGTCGGAGTCTGGGGGTTCGCGCCCGCCGACCCGCGCCCTGCTCCCTCTCAGCACCTGGGCGGA CGAAATGACCATTAAGAAGTAGATGCCCAGATGCAAAAGTGATGAAACAGTCCATTTGTCATAAAGTAAGATGCAGCTGTGGCATGTCAA CCAGCTTGGAACAAAATTGTATCTGTTTTTCTCAGAAGAGAATTCCACAAGGAGATTTTCTTCTTTCTACCATCATCAAGATCAAGCAGG CAAGTTTACTTGCTGTCATCTTCTGCAAGGTTAAATCAGCAAACAAAGAAAACATGGTATTTTGAAATATGATTAAACTCCTGATGCTGC AGCAGAGGCTAAGAATATTAATGGCCAGATCTAGTGCACACATGGTCTTCTGAAGAAGCCATGGGTAGCTGTTGTAGCTGTCCAGATAAA GACACTGTCCCAGATAACCATCGGAACAAGTTTAAGGTTAAAGAATTGCCCACCCTTAAGGATATGGACTTTCTCAACAAGAACCAGAAA GTATATATTGGTGAAGAGGAGAAGAAAATATTTCTGGAGAAGCTGAAGAGAGATGTGGAGTTTCTAGTGCAGCTGAAGATCATGGACTAC AGCCTTCTGCTAGGCATCCACGACATCATTCGGGGCTCTGAACCAGAGGAGGAAGCGCCCGTGCGGGAGGATGAGTCAGAGGTGGATGGG GACTGCAGCCTGACTGGACCTCCTGCTCTTGTGGGCTCCTATGGCACCTCCCCAGAGGGTATCGGAGGCTACATCCATTCCCATCGGCCC CTGGGCCCAGGAGAGTTTGAGTCCTTCATTGATGTCTATGCCATCCGGAGTGCTGAAGGAGCCCCCCAGAAGGAGGTCTACTTCATGGGC CTCATTGATATCCTTACACAGTATGATGCTAAGAAGAAAGCAGCTCATGCAGCCAAAACTGTCAAGCATGGGGCTGGGGCAGAGATCTCT ACTGTCCATCCGGAGCAGTATGCTAAGCGATTCCTGGATTTTATTACCAACATCTTTGCCTAAGAGACTGCCTGGTTCTCTCTGATGTTC AAGGTGGTGGGGTTCTGAGACACTTGGGGGAATTGTGGGGATATTCTAGCCACCAGTTCTCTTCTTCCTTTGCTAAATTCAGGCTGCAGG CTCCTTCCATCCAGATAACTCCATCCTGTCGAGTAGGCTCTTTCTGACCCTCAGAAATACATTGTCCTTTTTCCTCTTTGCCCATTTTTC TTCCCTCTCTTCCTCCCCATGAGAAGTCTGCTTGTAGTATTAGAATGTTATTGTTGACTCTCTCCCAAGTGCCTTGATCTTTGTAATATC TCCTGTTGTTTCTATGATATAGGAGCTAGGGGAAGGGGGTTGTTTGCCTTCTTCAGGACCTGACTGGACAGATGGACCTGGCTCAAGCAA CTACTCTGGATGCACTTTGCTGTGTGGGATGAACTAAAAGTGTCTGAATTTTGCTGATAACTTTATAAAACTCACTATGGCATGCTTCCC TCCTGGTGGGCCCTAGGATGGATGACACTCAAGATACTACAGATGTGGGTGCAGGCATGCACACACACGATGGAATATGGCCATTCCTAC ACAGGTGGGGTAGAGAGTGGGTCAGCAGCCTGGCACCTCACAGAGGTGGGACCTAAGAGGACTCATGATTATGCAGAGAATTGGATTGGG TCTCTGTCATAGATTGAGTAATCTCTTCCCTTACCTCAATTCCATCTCCACCCATCTCTACATCTGGGCACAGCAACCCAGAGATGGCCA AAAGCATTCAAGCCTGGGGGAAGATGTTTGACTATTGCTGCTCTTCACCAGAACCTCACACCTCTCCTGGGACTGGAACCCTTCAGTGGG TGTGTGGCCAGTTTTGGAGGCTGGAATGATGGGCCAGGGTGTAGGATTCATTCTCCATGTAAAGTTTCCTTTCATCCTGCCTAGCCATCC CCAAGGTTTATTTCCAGAAGAAAGGAATATCTCTACTTGGATCAATTCTGGTCATTTCAAGAGGATGGAGGCCTCAAGTGTGGGAACTTC CCCTACTCCCTGGATGTGTGTACCTAGCACACTTCCTTCTCCCACCCCTTTTTCCAGTTGGATTTGTTTTTCTGTTCTCTTCTGTCCTGT CTTATACTGCAACTGTGTCTCCTAGGGGACAGATGGCCTTCTTTGTCATCTTCACTCTCCACCCCCAGAGAGGAGTCAGAGCCATAACTC AATCACTCAGCCCCTCCAAAGATAGTTGATGTGTGATAATCTCATAATGTTGAGAACCCTGATGAGATACATTGTCTTCCTCTCCCTACA ATGCCTCTGGGGCCAAGGCACCCATTCTTCTTGCTATCCTCCATCCCCCTTGAGGCTTCCACTTTTTTTTTTTTTAGACATAAAGCTGGG CATCAGCAACTGGCCTGTGGTGATGCAAAGCTGCTTTGCTCTGTATCTGGCTGGACTGATCTGTCTCACAAGAAGCCATGAGGCCATAGG GAGAAGCTCCCTCTCCCCTTCATCTTCTGCTCCAAAGGTGGTAGCAAGAGGAGTACCCAGTTAGGGGTTGGAGCCCCCATATAACATCTT >31451_31451_1_FRS2-PIP4K2C_FRS2_chr12_69962876_ENST00000299293_PIP4K2C_chr12_57994107_ENST00000354947_length(amino acids)=210AA_BP=22 MGSCCSCPDKDTVPDNHRNKFKVKELPTLKDMDFLNKNQKVYIGEEEKKIFLEKLKRDVEFLVQLKIMDYSLLLGIHDIIRGSEPEEEAP VREDESEVDGDCSLTGPPALVGSYGTSPEGIGGYIHSHRPLGPGEFESFIDVYAIRSAEGAPQKEVYFMGLIDILTQYDAKKKAAHAAKT -------------------------------------------------------------- >31451_31451_2_FRS2-PIP4K2C_FRS2_chr12_69962876_ENST00000299293_PIP4K2C_chr12_57994107_ENST00000422156_length(transcript)=1463nt_BP=576nt AAAACCCTTCCCTCCCCCGCTCCCCCGGAAGTGCTTTTCCAAGATTCGGGCCGGAGAGAGGCCTTGTAGGCACAGCGGCTGAGACTCGAT CTGCTCCAAGTAGGGGCTCCAGCGCGGGTCGGAGTCTGGGGGTTCGCGCCCGCCGACCCGCGCCCTGCTCCCTCTCAGCACCTGGGCGGA CGAAATGACCATTAAGAAGTAGATGCCCAGATGCAAAAGTGATGAAACAGTCCATTTGTCATAAAGTAAGATGCAGCTGTGGCATGTCAA CCAGCTTGGAACAAAATTGTATCTGTTTTTCTCAGAAGAGAATTCCACAAGGAGATTTTCTTCTTTCTACCATCATCAAGATCAAGCAGG CAAGTTTACTTGCTGTCATCTTCTGCAAGGTTAAATCAGCAAACAAAGAAAACATGGTATTTTGAAATATGATTAAACTCCTGATGCTGC AGCAGAGGCTAAGAATATTAATGGCCAGATCTAGTGCACACATGGTCTTCTGAAGAAGCCATGGGTAGCTGTTGTAGCTGTCCAGATAAA GACACTGTCCCAGATAACCATCGGAACAAGTTTAAGGTTAAAGAATTGCCCACCCTTAAGGATATGGACTTTCTCAACAAGAACCAGAAA GTATATATTGGTGAAGAGGAGAAGAAAATATTTCTGGAGAAGCTGAAGAGAGATGTGGAGTTTCTAGTGCAGCTGAAGATCATGGACTAC AGCCTTCTGCTAGGCATCCACGACATCATTCGGGGCTCTGAACCAGAGGAGGAAGCGCCCGTGCGGGAGGATGAGTCAGAGGTGGATGGG GACTGCAGCCTGACTGGACCTCCTGCTCTTGTGGGCTCCTATGGCACCTCCCCAGAGGGTATCGGAGGCTACATCCATTCCCATCGGCCC CTGGGCCCAGGAGAGTTTGAGTCCTTCATTGATGTCTATGCCATCCGGAGTGCTGAAGGAGCCCCCCAGAAGGAGGTCTACTTCATGGGC CTCATTGATATCCTTACACAGTATGATGCTAAGAAGAAAGCAGCTCATGCAGCCAAAACTGTCAAGCATGGGGCTGGGGCAGAGATCTCT ACTGTCCATCCGGAGCAGTATGCTAAGCGATTCCTGGATTTTATTACCAACATCTTTGCCTAAGAGACTGCCTGGTTCTCTCTGATGTTC AAGGTGGTGGGGTTCTGAGACACTTGGGGGAATTGTGGGGATATTCTAGCCACCAGTTCTCTTCTTCCTTTGCTAAATTCAGGCTGCAGG CTCCTTCCATCCAGATAACTCCATCCTGTCGAGTAGGCTCTTTCTGACCCTCAGAAATACATTGTCCTTTTTCCTCTTTGCCCATTTTTC TTCCCTCTCTTCCTCCCCATGAGAAGTCTGCTTGTAGTATTAGAATGTTATTGTTGACTCTCTCCCAAGTGCCTTGATCTTTGTAATATC >31451_31451_2_FRS2-PIP4K2C_FRS2_chr12_69962876_ENST00000299293_PIP4K2C_chr12_57994107_ENST00000422156_length(amino acids)=210AA_BP=22 MGSCCSCPDKDTVPDNHRNKFKVKELPTLKDMDFLNKNQKVYIGEEEKKIFLEKLKRDVEFLVQLKIMDYSLLLGIHDIIRGSEPEEEAP VREDESEVDGDCSLTGPPALVGSYGTSPEGIGGYIHSHRPLGPGEFESFIDVYAIRSAEGAPQKEVYFMGLIDILTQYDAKKKAAHAAKT -------------------------------------------------------------- >31451_31451_3_FRS2-PIP4K2C_FRS2_chr12_69962876_ENST00000299293_PIP4K2C_chr12_57994107_ENST00000540759_length(transcript)=2663nt_BP=576nt AAAACCCTTCCCTCCCCCGCTCCCCCGGAAGTGCTTTTCCAAGATTCGGGCCGGAGAGAGGCCTTGTAGGCACAGCGGCTGAGACTCGAT CTGCTCCAAGTAGGGGCTCCAGCGCGGGTCGGAGTCTGGGGGTTCGCGCCCGCCGACCCGCGCCCTGCTCCCTCTCAGCACCTGGGCGGA CGAAATGACCATTAAGAAGTAGATGCCCAGATGCAAAAGTGATGAAACAGTCCATTTGTCATAAAGTAAGATGCAGCTGTGGCATGTCAA CCAGCTTGGAACAAAATTGTATCTGTTTTTCTCAGAAGAGAATTCCACAAGGAGATTTTCTTCTTTCTACCATCATCAAGATCAAGCAGG CAAGTTTACTTGCTGTCATCTTCTGCAAGGTTAAATCAGCAAACAAAGAAAACATGGTATTTTGAAATATGATTAAACTCCTGATGCTGC AGCAGAGGCTAAGAATATTAATGGCCAGATCTAGTGCACACATGGTCTTCTGAAGAAGCCATGGGTAGCTGTTGTAGCTGTCCAGATAAA GACACTGTCCCAGATAACCATCGGAACAAGTTTAAGGTTAAAGAATTGCCCACCCTTAAGGATATGGACTTTCTCAACAAGAACCAGAAA GTATATATTGGTGAAGAGGAGAAGAAAATATTTCTGGAGAAGCTGAAGAGAGATGTGGAGTTTCTAGTGCAGCTGAAGATCATGGACTAC AGCCTTCTGCTAGGCATCCACGACATCATTCGGGGCTCTGAACCAGAGGAGGAAGCGCCCGTGCGGGAGGATGAGTCAGAGGTGGATGGG GACTGCAGCCTGACTGGACCTCCTGCTCTTGTGGGCTCCTATGGCACCTCCCCAGAGGGTATCGGAGGCTACATCCATTCCCATCGGCCC CTGGGCCCAGGAGAGTTTGAGTCCTTCATTGATGTCTATGCCATCCGGAGTGCTGAAGGAGCCCCCCAGAAGGAGGTCTACTTCATGGGC CTCATTGATATCCTTACACAGTATGATGCTAAGAAGAAAGCAGCTCATGCAGCCAAAACTGTCAAGCATGGGGCTGGGGCAGAGATCTCT ACTGTCCATCCGGAGCAGTATGCTAAGCGATTCCTGGATTTTATTACCAACATCTTTGCCTAAGAGACTGCCTGGTTCTCTCTGATGTTC AAGGAGCTAGGGGAAGGGGGTTGTTTGCCTTCTTCAGGACCTGACTGGACAGATGGACCTGGCTCAAGCAACTACTCTGGATGCACTTTG CTGTGTGGGATGAACTAAAAGTGTCTGAATTTTGCTGATAACTTTATAAAACTCACTATGGCATGCTTCCCTCCTGGTGGGCCCTAGGAT GGATGACACTCAAGATACTACAGATGTGGGTGCAGGCATGCACACACACGATGGAATATGGCCATTCCTACACAGGTGGGGTAGAGAGTG GGTCAGCAGCCTGGCACCTCACAGAGGTGGGACCTAAGAGGACTCATGATTATGCAGAGAATTGGATTGGGTCTCTGTCATAGATTGAGT AATCTCTTCCCTTACCTCAATTCCATCTCCACCCATCTCTACATCTGGGCACAGCAACCCAGAGATGGCCAAAAGCATTCAAGCCTGGGG GAAGATGTTTGACTATTGCTGCTCTTCACCAGAACCTCACACCTCTCCTGGGACTGGAACCCTTCAGTGGGTGTGTGGCCAGTTTTGGAG GCTGGAATGATGGGCCAGGGTGTAGGATTCATTCTCCATGTAAAGTTTCCTTTCATCCTGCCTAGCCATCCCCAAGGTTTATTTCCAGAA GAAAGGAATATCTCTACTTGGATCAATTCTGGTCATTTCAAGAGGATGGAGGCCTCAAGTGTGGGAACTTCCCCTACTCCCTGGATGTGT GTACCTAGCACACTTCCTTCTCCCACCCCTTTTTCCAGTTGGATTTGTTTTTCTGTTCTCTTCTGTCCTGTCTTATACTGCAACTGTGTC TCCTAGGGGACAGATGGCCTTCTTTGTCATCTTCACTCTCCACCCCCAGAGAGGAGTCAGAGCCATAACTCAATCACTCAGCCCCTCCAA AGATAGTTGATGTGTGATAATCTCATAATGTTGAGAACCCTGATGAGATACATTGTCTTCCTCTCCCTACAATGCCTCTGGGGCCAAGGC ACCCATTCTTCTTGCTATCCTCCATCCCCCTTGAGGCTTCCACTTTTTTTTTTTTTAGACATAAAGCTGGGCATCAGCAACTGGCCTGTG GTGATGCAAAGCTGCTTTGCTCTGTATCTGGCTGGACTGATCTGTCTCACAAGAAGCCATGAGGCCATAGGGAGAAGCTCCCTCTCCCCT TCATCTTCTGCTCCAAAGGTGGTAGCAAGAGGAGTACCCAGTTAGGGGTTGGAGCCCCCATATAACATCTTCCTGTCAGAAGACTGATGG ATCTTTTTCATTCCAACCATCTCCCTTTCCCCCGATGAATGCAATAAAACTCTGTGACACCAGCAACCATTGCTCTTTAGAAATGGGTTT TCTGATCATATGGCTGATGTGTTATGGGCAGTATGGATGTCTTCATTTGTTGCTTCTGTTTTTCATCTTTTTTGTTTTATTAATAAAAAT >31451_31451_3_FRS2-PIP4K2C_FRS2_chr12_69962876_ENST00000299293_PIP4K2C_chr12_57994107_ENST00000540759_length(amino acids)=210AA_BP=22 MGSCCSCPDKDTVPDNHRNKFKVKELPTLKDMDFLNKNQKVYIGEEEKKIFLEKLKRDVEFLVQLKIMDYSLLLGIHDIIRGSEPEEEAP VREDESEVDGDCSLTGPPALVGSYGTSPEGIGGYIHSHRPLGPGEFESFIDVYAIRSAEGAPQKEVYFMGLIDILTQYDAKKKAAHAAKT -------------------------------------------------------------- >31451_31451_4_FRS2-PIP4K2C_FRS2_chr12_69962876_ENST00000299293_PIP4K2C_chr12_57994107_ENST00000550465_length(transcript)=1416nt_BP=576nt AAAACCCTTCCCTCCCCCGCTCCCCCGGAAGTGCTTTTCCAAGATTCGGGCCGGAGAGAGGCCTTGTAGGCACAGCGGCTGAGACTCGAT CTGCTCCAAGTAGGGGCTCCAGCGCGGGTCGGAGTCTGGGGGTTCGCGCCCGCCGACCCGCGCCCTGCTCCCTCTCAGCACCTGGGCGGA CGAAATGACCATTAAGAAGTAGATGCCCAGATGCAAAAGTGATGAAACAGTCCATTTGTCATAAAGTAAGATGCAGCTGTGGCATGTCAA CCAGCTTGGAACAAAATTGTATCTGTTTTTCTCAGAAGAGAATTCCACAAGGAGATTTTCTTCTTTCTACCATCATCAAGATCAAGCAGG CAAGTTTACTTGCTGTCATCTTCTGCAAGGTTAAATCAGCAAACAAAGAAAACATGGTATTTTGAAATATGATTAAACTCCTGATGCTGC AGCAGAGGCTAAGAATATTAATGGCCAGATCTAGTGCACACATGGTCTTCTGAAGAAGCCATGGGTAGCTGTTGTAGCTGTCCAGATAAA GACACTGTCCCAGATAACCATCGGAACAAGTTTAAGGTTAAAGAATTGCCCACCCTTAAGGATATGGACTTTCTCAACAAGAACCAGAAA GTATATATTGGTGAAGAGGAGAAGAAAATATTTCTGGAGAAGCTGAAGAGAGATGTGGAGTTTCTAGTGCAGCTGAAGATCATGGACTAC AGCCTTCTGCTAGGCATCCACGACATCATTCGGGGCTCTGAACCAGAGGAGGAAGCGCCCGTGCGGGAGGATGAGTCAGAGGTGGATGGG GACTGCAGCCTGACTGGACCTCCTGCTCTTGTGGGCTCCTATGGCACCTCCCCAGAGGGTATCGGAGGCTACATCCATTCCCATCGGCCC CTGGGCCCAGGAGAGTTTGAGTCCTTCATTGATGTCTATGCCATCCGGAGTGCTGAAGGAGCCCCCCAGAAGGAGGTCTACTTCATGGGC CTCATTGATATCCTTACACAGTATGATGCTAAGAAGAAAGCAGCTCATGCAGCCAAAACTGTCAAGCATGGGGCTGGGGCAGAGATCTCT ACTGTCCATCCGGAGCAGTATGCTAAGCGATTCCTGGATTTTATTACCAACATCTTTGCCTAAGAGACTGCCTGGTTCTCTCTGATGTTC AAGGTGGTGGGGTTCTGAGACACTTGGGGGAATTGTGGGGATATTCTAGCCACCAGTTCTCTTCTTCCTTTGCTAAATTCAGGCTGCAGG CTCCTTCCATCCAGATAACTCCATCCTGTCGAGTAGGCTCTTTCTGACCCTCAGAAATACATTGTCCTTTTTCCTCTTTGCCCATTTTTC >31451_31451_4_FRS2-PIP4K2C_FRS2_chr12_69962876_ENST00000299293_PIP4K2C_chr12_57994107_ENST00000550465_length(amino acids)=210AA_BP=22 MGSCCSCPDKDTVPDNHRNKFKVKELPTLKDMDFLNKNQKVYIGEEEKKIFLEKLKRDVEFLVQLKIMDYSLLLGIHDIIRGSEPEEEAP VREDESEVDGDCSLTGPPALVGSYGTSPEGIGGYIHSHRPLGPGEFESFIDVYAIRSAEGAPQKEVYFMGLIDILTQYDAKKKAAHAAKT -------------------------------------------------------------- >31451_31451_5_FRS2-PIP4K2C_FRS2_chr12_69962876_ENST00000397997_PIP4K2C_chr12_57994107_ENST00000354947_length(transcript)=2577nt_BP=368nt TATTCAAGAGTAACATTCTTAATAACTTAACCTATATTTCAGAAATGACCATTAAGAAGTAGATGCCCAGATGCAAAAGTGATGAAACAG TCCATTTGTCATAAAGTAAGATGCAGCTGTGGCATGTCAACCAGCTTGGAACAAAATTGTATCTGTTTTTCTCAGAAGAGAATTCCACAA GGTTAAATCAGCAAACAAAGAAAACATGGTATTTTGAAATATGATTAAACTCCTGATGCTGCAGCAGAGGCTAAGAATATTAATGGCCAG ATCTAGTGCACACATGGTCTTCTGAAGAAGCCATGGGTAGCTGTTGTAGCTGTCCAGATAAAGACACTGTCCCAGATAACCATCGGAACA AGTTTAAGGTTAAAGAATTGCCCACCCTTAAGGATATGGACTTTCTCAACAAGAACCAGAAAGTATATATTGGTGAAGAGGAGAAGAAAA TATTTCTGGAGAAGCTGAAGAGAGATGTGGAGTTTCTAGTGCAGCTGAAGATCATGGACTACAGCCTTCTGCTAGGCATCCACGACATCA TTCGGGGCTCTGAACCAGAGGAGGAAGCGCCCGTGCGGGAGGATGAGTCAGAGGTGGATGGGGACTGCAGCCTGACTGGACCTCCTGCTC TTGTGGGCTCCTATGGCACCTCCCCAGAGGGTATCGGAGGCTACATCCATTCCCATCGGCCCCTGGGCCCAGGAGAGTTTGAGTCCTTCA TTGATGTCTATGCCATCCGGAGTGCTGAAGGAGCCCCCCAGAAGGAGGTCTACTTCATGGGCCTCATTGATATCCTTACACAGTATGATG CTAAGAAGAAAGCAGCTCATGCAGCCAAAACTGTCAAGCATGGGGCTGGGGCAGAGATCTCTACTGTCCATCCGGAGCAGTATGCTAAGC GATTCCTGGATTTTATTACCAACATCTTTGCCTAAGAGACTGCCTGGTTCTCTCTGATGTTCAAGGTGGTGGGGTTCTGAGACACTTGGG GGAATTGTGGGGATATTCTAGCCACCAGTTCTCTTCTTCCTTTGCTAAATTCAGGCTGCAGGCTCCTTCCATCCAGATAACTCCATCCTG TCGAGTAGGCTCTTTCTGACCCTCAGAAATACATTGTCCTTTTTCCTCTTTGCCCATTTTTCTTCCCTCTCTTCCTCCCCATGAGAAGTC TGCTTGTAGTATTAGAATGTTATTGTTGACTCTCTCCCAAGTGCCTTGATCTTTGTAATATCTCCTGTTGTTTCTATGATATAGGAGCTA GGGGAAGGGGGTTGTTTGCCTTCTTCAGGACCTGACTGGACAGATGGACCTGGCTCAAGCAACTACTCTGGATGCACTTTGCTGTGTGGG ATGAACTAAAAGTGTCTGAATTTTGCTGATAACTTTATAAAACTCACTATGGCATGCTTCCCTCCTGGTGGGCCCTAGGATGGATGACAC TCAAGATACTACAGATGTGGGTGCAGGCATGCACACACACGATGGAATATGGCCATTCCTACACAGGTGGGGTAGAGAGTGGGTCAGCAG CCTGGCACCTCACAGAGGTGGGACCTAAGAGGACTCATGATTATGCAGAGAATTGGATTGGGTCTCTGTCATAGATTGAGTAATCTCTTC CCTTACCTCAATTCCATCTCCACCCATCTCTACATCTGGGCACAGCAACCCAGAGATGGCCAAAAGCATTCAAGCCTGGGGGAAGATGTT TGACTATTGCTGCTCTTCACCAGAACCTCACACCTCTCCTGGGACTGGAACCCTTCAGTGGGTGTGTGGCCAGTTTTGGAGGCTGGAATG ATGGGCCAGGGTGTAGGATTCATTCTCCATGTAAAGTTTCCTTTCATCCTGCCTAGCCATCCCCAAGGTTTATTTCCAGAAGAAAGGAAT ATCTCTACTTGGATCAATTCTGGTCATTTCAAGAGGATGGAGGCCTCAAGTGTGGGAACTTCCCCTACTCCCTGGATGTGTGTACCTAGC ACACTTCCTTCTCCCACCCCTTTTTCCAGTTGGATTTGTTTTTCTGTTCTCTTCTGTCCTGTCTTATACTGCAACTGTGTCTCCTAGGGG ACAGATGGCCTTCTTTGTCATCTTCACTCTCCACCCCCAGAGAGGAGTCAGAGCCATAACTCAATCACTCAGCCCCTCCAAAGATAGTTG ATGTGTGATAATCTCATAATGTTGAGAACCCTGATGAGATACATTGTCTTCCTCTCCCTACAATGCCTCTGGGGCCAAGGCACCCATTCT TCTTGCTATCCTCCATCCCCCTTGAGGCTTCCACTTTTTTTTTTTTTAGACATAAAGCTGGGCATCAGCAACTGGCCTGTGGTGATGCAA AGCTGCTTTGCTCTGTATCTGGCTGGACTGATCTGTCTCACAAGAAGCCATGAGGCCATAGGGAGAAGCTCCCTCTCCCCTTCATCTTCT GCTCCAAAGGTGGTAGCAAGAGGAGTACCCAGTTAGGGGTTGGAGCCCCCATATAACATCTTCCTGTCAGAAGACTGATGGATCTTTTTC >31451_31451_5_FRS2-PIP4K2C_FRS2_chr12_69962876_ENST00000397997_PIP4K2C_chr12_57994107_ENST00000354947_length(amino acids)=210AA_BP=22 MGSCCSCPDKDTVPDNHRNKFKVKELPTLKDMDFLNKNQKVYIGEEEKKIFLEKLKRDVEFLVQLKIMDYSLLLGIHDIIRGSEPEEEAP VREDESEVDGDCSLTGPPALVGSYGTSPEGIGGYIHSHRPLGPGEFESFIDVYAIRSAEGAPQKEVYFMGLIDILTQYDAKKKAAHAAKT -------------------------------------------------------------- >31451_31451_6_FRS2-PIP4K2C_FRS2_chr12_69962876_ENST00000397997_PIP4K2C_chr12_57994107_ENST00000422156_length(transcript)=1255nt_BP=368nt TATTCAAGAGTAACATTCTTAATAACTTAACCTATATTTCAGAAATGACCATTAAGAAGTAGATGCCCAGATGCAAAAGTGATGAAACAG TCCATTTGTCATAAAGTAAGATGCAGCTGTGGCATGTCAACCAGCTTGGAACAAAATTGTATCTGTTTTTCTCAGAAGAGAATTCCACAA GGTTAAATCAGCAAACAAAGAAAACATGGTATTTTGAAATATGATTAAACTCCTGATGCTGCAGCAGAGGCTAAGAATATTAATGGCCAG ATCTAGTGCACACATGGTCTTCTGAAGAAGCCATGGGTAGCTGTTGTAGCTGTCCAGATAAAGACACTGTCCCAGATAACCATCGGAACA AGTTTAAGGTTAAAGAATTGCCCACCCTTAAGGATATGGACTTTCTCAACAAGAACCAGAAAGTATATATTGGTGAAGAGGAGAAGAAAA TATTTCTGGAGAAGCTGAAGAGAGATGTGGAGTTTCTAGTGCAGCTGAAGATCATGGACTACAGCCTTCTGCTAGGCATCCACGACATCA TTCGGGGCTCTGAACCAGAGGAGGAAGCGCCCGTGCGGGAGGATGAGTCAGAGGTGGATGGGGACTGCAGCCTGACTGGACCTCCTGCTC TTGTGGGCTCCTATGGCACCTCCCCAGAGGGTATCGGAGGCTACATCCATTCCCATCGGCCCCTGGGCCCAGGAGAGTTTGAGTCCTTCA TTGATGTCTATGCCATCCGGAGTGCTGAAGGAGCCCCCCAGAAGGAGGTCTACTTCATGGGCCTCATTGATATCCTTACACAGTATGATG CTAAGAAGAAAGCAGCTCATGCAGCCAAAACTGTCAAGCATGGGGCTGGGGCAGAGATCTCTACTGTCCATCCGGAGCAGTATGCTAAGC GATTCCTGGATTTTATTACCAACATCTTTGCCTAAGAGACTGCCTGGTTCTCTCTGATGTTCAAGGTGGTGGGGTTCTGAGACACTTGGG GGAATTGTGGGGATATTCTAGCCACCAGTTCTCTTCTTCCTTTGCTAAATTCAGGCTGCAGGCTCCTTCCATCCAGATAACTCCATCCTG TCGAGTAGGCTCTTTCTGACCCTCAGAAATACATTGTCCTTTTTCCTCTTTGCCCATTTTTCTTCCCTCTCTTCCTCCCCATGAGAAGTC >31451_31451_6_FRS2-PIP4K2C_FRS2_chr12_69962876_ENST00000397997_PIP4K2C_chr12_57994107_ENST00000422156_length(amino acids)=210AA_BP=22 MGSCCSCPDKDTVPDNHRNKFKVKELPTLKDMDFLNKNQKVYIGEEEKKIFLEKLKRDVEFLVQLKIMDYSLLLGIHDIIRGSEPEEEAP VREDESEVDGDCSLTGPPALVGSYGTSPEGIGGYIHSHRPLGPGEFESFIDVYAIRSAEGAPQKEVYFMGLIDILTQYDAKKKAAHAAKT -------------------------------------------------------------- >31451_31451_7_FRS2-PIP4K2C_FRS2_chr12_69962876_ENST00000397997_PIP4K2C_chr12_57994107_ENST00000540759_length(transcript)=2455nt_BP=368nt TATTCAAGAGTAACATTCTTAATAACTTAACCTATATTTCAGAAATGACCATTAAGAAGTAGATGCCCAGATGCAAAAGTGATGAAACAG TCCATTTGTCATAAAGTAAGATGCAGCTGTGGCATGTCAACCAGCTTGGAACAAAATTGTATCTGTTTTTCTCAGAAGAGAATTCCACAA GGTTAAATCAGCAAACAAAGAAAACATGGTATTTTGAAATATGATTAAACTCCTGATGCTGCAGCAGAGGCTAAGAATATTAATGGCCAG ATCTAGTGCACACATGGTCTTCTGAAGAAGCCATGGGTAGCTGTTGTAGCTGTCCAGATAAAGACACTGTCCCAGATAACCATCGGAACA AGTTTAAGGTTAAAGAATTGCCCACCCTTAAGGATATGGACTTTCTCAACAAGAACCAGAAAGTATATATTGGTGAAGAGGAGAAGAAAA TATTTCTGGAGAAGCTGAAGAGAGATGTGGAGTTTCTAGTGCAGCTGAAGATCATGGACTACAGCCTTCTGCTAGGCATCCACGACATCA TTCGGGGCTCTGAACCAGAGGAGGAAGCGCCCGTGCGGGAGGATGAGTCAGAGGTGGATGGGGACTGCAGCCTGACTGGACCTCCTGCTC TTGTGGGCTCCTATGGCACCTCCCCAGAGGGTATCGGAGGCTACATCCATTCCCATCGGCCCCTGGGCCCAGGAGAGTTTGAGTCCTTCA TTGATGTCTATGCCATCCGGAGTGCTGAAGGAGCCCCCCAGAAGGAGGTCTACTTCATGGGCCTCATTGATATCCTTACACAGTATGATG CTAAGAAGAAAGCAGCTCATGCAGCCAAAACTGTCAAGCATGGGGCTGGGGCAGAGATCTCTACTGTCCATCCGGAGCAGTATGCTAAGC GATTCCTGGATTTTATTACCAACATCTTTGCCTAAGAGACTGCCTGGTTCTCTCTGATGTTCAAGGAGCTAGGGGAAGGGGGTTGTTTGC CTTCTTCAGGACCTGACTGGACAGATGGACCTGGCTCAAGCAACTACTCTGGATGCACTTTGCTGTGTGGGATGAACTAAAAGTGTCTGA ATTTTGCTGATAACTTTATAAAACTCACTATGGCATGCTTCCCTCCTGGTGGGCCCTAGGATGGATGACACTCAAGATACTACAGATGTG GGTGCAGGCATGCACACACACGATGGAATATGGCCATTCCTACACAGGTGGGGTAGAGAGTGGGTCAGCAGCCTGGCACCTCACAGAGGT GGGACCTAAGAGGACTCATGATTATGCAGAGAATTGGATTGGGTCTCTGTCATAGATTGAGTAATCTCTTCCCTTACCTCAATTCCATCT CCACCCATCTCTACATCTGGGCACAGCAACCCAGAGATGGCCAAAAGCATTCAAGCCTGGGGGAAGATGTTTGACTATTGCTGCTCTTCA CCAGAACCTCACACCTCTCCTGGGACTGGAACCCTTCAGTGGGTGTGTGGCCAGTTTTGGAGGCTGGAATGATGGGCCAGGGTGTAGGAT TCATTCTCCATGTAAAGTTTCCTTTCATCCTGCCTAGCCATCCCCAAGGTTTATTTCCAGAAGAAAGGAATATCTCTACTTGGATCAATT CTGGTCATTTCAAGAGGATGGAGGCCTCAAGTGTGGGAACTTCCCCTACTCCCTGGATGTGTGTACCTAGCACACTTCCTTCTCCCACCC CTTTTTCCAGTTGGATTTGTTTTTCTGTTCTCTTCTGTCCTGTCTTATACTGCAACTGTGTCTCCTAGGGGACAGATGGCCTTCTTTGTC ATCTTCACTCTCCACCCCCAGAGAGGAGTCAGAGCCATAACTCAATCACTCAGCCCCTCCAAAGATAGTTGATGTGTGATAATCTCATAA TGTTGAGAACCCTGATGAGATACATTGTCTTCCTCTCCCTACAATGCCTCTGGGGCCAAGGCACCCATTCTTCTTGCTATCCTCCATCCC CCTTGAGGCTTCCACTTTTTTTTTTTTTAGACATAAAGCTGGGCATCAGCAACTGGCCTGTGGTGATGCAAAGCTGCTTTGCTCTGTATC TGGCTGGACTGATCTGTCTCACAAGAAGCCATGAGGCCATAGGGAGAAGCTCCCTCTCCCCTTCATCTTCTGCTCCAAAGGTGGTAGCAA GAGGAGTACCCAGTTAGGGGTTGGAGCCCCCATATAACATCTTCCTGTCAGAAGACTGATGGATCTTTTTCATTCCAACCATCTCCCTTT CCCCCGATGAATGCAATAAAACTCTGTGACACCAGCAACCATTGCTCTTTAGAAATGGGTTTTCTGATCATATGGCTGATGTGTTATGGG CAGTATGGATGTCTTCATTTGTTGCTTCTGTTTTTCATCTTTTTTGTTTTATTAATAAAAATTTATGTATTTGCTCCTGTTACTATAATA >31451_31451_7_FRS2-PIP4K2C_FRS2_chr12_69962876_ENST00000397997_PIP4K2C_chr12_57994107_ENST00000540759_length(amino acids)=210AA_BP=22 MGSCCSCPDKDTVPDNHRNKFKVKELPTLKDMDFLNKNQKVYIGEEEKKIFLEKLKRDVEFLVQLKIMDYSLLLGIHDIIRGSEPEEEAP VREDESEVDGDCSLTGPPALVGSYGTSPEGIGGYIHSHRPLGPGEFESFIDVYAIRSAEGAPQKEVYFMGLIDILTQYDAKKKAAHAAKT -------------------------------------------------------------- >31451_31451_8_FRS2-PIP4K2C_FRS2_chr12_69962876_ENST00000397997_PIP4K2C_chr12_57994107_ENST00000550465_length(transcript)=1208nt_BP=368nt TATTCAAGAGTAACATTCTTAATAACTTAACCTATATTTCAGAAATGACCATTAAGAAGTAGATGCCCAGATGCAAAAGTGATGAAACAG TCCATTTGTCATAAAGTAAGATGCAGCTGTGGCATGTCAACCAGCTTGGAACAAAATTGTATCTGTTTTTCTCAGAAGAGAATTCCACAA GGTTAAATCAGCAAACAAAGAAAACATGGTATTTTGAAATATGATTAAACTCCTGATGCTGCAGCAGAGGCTAAGAATATTAATGGCCAG ATCTAGTGCACACATGGTCTTCTGAAGAAGCCATGGGTAGCTGTTGTAGCTGTCCAGATAAAGACACTGTCCCAGATAACCATCGGAACA AGTTTAAGGTTAAAGAATTGCCCACCCTTAAGGATATGGACTTTCTCAACAAGAACCAGAAAGTATATATTGGTGAAGAGGAGAAGAAAA TATTTCTGGAGAAGCTGAAGAGAGATGTGGAGTTTCTAGTGCAGCTGAAGATCATGGACTACAGCCTTCTGCTAGGCATCCACGACATCA TTCGGGGCTCTGAACCAGAGGAGGAAGCGCCCGTGCGGGAGGATGAGTCAGAGGTGGATGGGGACTGCAGCCTGACTGGACCTCCTGCTC TTGTGGGCTCCTATGGCACCTCCCCAGAGGGTATCGGAGGCTACATCCATTCCCATCGGCCCCTGGGCCCAGGAGAGTTTGAGTCCTTCA TTGATGTCTATGCCATCCGGAGTGCTGAAGGAGCCCCCCAGAAGGAGGTCTACTTCATGGGCCTCATTGATATCCTTACACAGTATGATG CTAAGAAGAAAGCAGCTCATGCAGCCAAAACTGTCAAGCATGGGGCTGGGGCAGAGATCTCTACTGTCCATCCGGAGCAGTATGCTAAGC GATTCCTGGATTTTATTACCAACATCTTTGCCTAAGAGACTGCCTGGTTCTCTCTGATGTTCAAGGTGGTGGGGTTCTGAGACACTTGGG GGAATTGTGGGGATATTCTAGCCACCAGTTCTCTTCTTCCTTTGCTAAATTCAGGCTGCAGGCTCCTTCCATCCAGATAACTCCATCCTG TCGAGTAGGCTCTTTCTGACCCTCAGAAATACATTGTCCTTTTTCCTCTTTGCCCATTTTTCTTCCCTCTCTTCCTCCCCATGAGAAGTC >31451_31451_8_FRS2-PIP4K2C_FRS2_chr12_69962876_ENST00000397997_PIP4K2C_chr12_57994107_ENST00000550465_length(amino acids)=210AA_BP=22 MGSCCSCPDKDTVPDNHRNKFKVKELPTLKDMDFLNKNQKVYIGEEEKKIFLEKLKRDVEFLVQLKIMDYSLLLGIHDIIRGSEPEEEAP VREDESEVDGDCSLTGPPALVGSYGTSPEGIGGYIHSHRPLGPGEFESFIDVYAIRSAEGAPQKEVYFMGLIDILTQYDAKKKAAHAAKT -------------------------------------------------------------- >31451_31451_9_FRS2-PIP4K2C_FRS2_chr12_69962876_ENST00000549921_PIP4K2C_chr12_57994107_ENST00000354947_length(transcript)=2691nt_BP=482nt GGAAGTGCTTTTCCAAGATTCGGGCCGGAGAGAGGCCTTGTAGGCACAGCGGCTGAGACTCGATCTGCTCCAAGTAGGGGCTCCAGCGCG GGTCGGAGTCTGGGGGTTCGCGCCCGCCGACCCGCGCCCTGCTCCCTCTCAGCACCTGGGCGGACGAAATGACCATTAAGAAGTAGATGC CCAGATGCAAAAGTGATGAAACAGTCCATTTGTCATAAAGTAAGATGCAGCTGTGGCATGTCAACCAGCTTGGAACAAAATTGTATCTGT TTTTCTCAGAAGAGAATTCCACAAGGTTAAATCAGCAAACAAAGAAAACATGGTATTTTGAAATATGATTAAACTCCTGATGCTGCAGCA GAGGCTAAGAATATTAATGGCCAGATCTAGTGCACACATGGTCTTCTGAAGAAGCCATGGGTAGCTGTTGTAGCTGTCCAGATAAAGACA CTGTCCCAGATAACCATCGGAACAAGTTTAAGGTTAAAGAATTGCCCACCCTTAAGGATATGGACTTTCTCAACAAGAACCAGAAAGTAT ATATTGGTGAAGAGGAGAAGAAAATATTTCTGGAGAAGCTGAAGAGAGATGTGGAGTTTCTAGTGCAGCTGAAGATCATGGACTACAGCC TTCTGCTAGGCATCCACGACATCATTCGGGGCTCTGAACCAGAGGAGGAAGCGCCCGTGCGGGAGGATGAGTCAGAGGTGGATGGGGACT GCAGCCTGACTGGACCTCCTGCTCTTGTGGGCTCCTATGGCACCTCCCCAGAGGGTATCGGAGGCTACATCCATTCCCATCGGCCCCTGG GCCCAGGAGAGTTTGAGTCCTTCATTGATGTCTATGCCATCCGGAGTGCTGAAGGAGCCCCCCAGAAGGAGGTCTACTTCATGGGCCTCA TTGATATCCTTACACAGTATGATGCTAAGAAGAAAGCAGCTCATGCAGCCAAAACTGTCAAGCATGGGGCTGGGGCAGAGATCTCTACTG TCCATCCGGAGCAGTATGCTAAGCGATTCCTGGATTTTATTACCAACATCTTTGCCTAAGAGACTGCCTGGTTCTCTCTGATGTTCAAGG TGGTGGGGTTCTGAGACACTTGGGGGAATTGTGGGGATATTCTAGCCACCAGTTCTCTTCTTCCTTTGCTAAATTCAGGCTGCAGGCTCC TTCCATCCAGATAACTCCATCCTGTCGAGTAGGCTCTTTCTGACCCTCAGAAATACATTGTCCTTTTTCCTCTTTGCCCATTTTTCTTCC CTCTCTTCCTCCCCATGAGAAGTCTGCTTGTAGTATTAGAATGTTATTGTTGACTCTCTCCCAAGTGCCTTGATCTTTGTAATATCTCCT GTTGTTTCTATGATATAGGAGCTAGGGGAAGGGGGTTGTTTGCCTTCTTCAGGACCTGACTGGACAGATGGACCTGGCTCAAGCAACTAC TCTGGATGCACTTTGCTGTGTGGGATGAACTAAAAGTGTCTGAATTTTGCTGATAACTTTATAAAACTCACTATGGCATGCTTCCCTCCT GGTGGGCCCTAGGATGGATGACACTCAAGATACTACAGATGTGGGTGCAGGCATGCACACACACGATGGAATATGGCCATTCCTACACAG GTGGGGTAGAGAGTGGGTCAGCAGCCTGGCACCTCACAGAGGTGGGACCTAAGAGGACTCATGATTATGCAGAGAATTGGATTGGGTCTC TGTCATAGATTGAGTAATCTCTTCCCTTACCTCAATTCCATCTCCACCCATCTCTACATCTGGGCACAGCAACCCAGAGATGGCCAAAAG CATTCAAGCCTGGGGGAAGATGTTTGACTATTGCTGCTCTTCACCAGAACCTCACACCTCTCCTGGGACTGGAACCCTTCAGTGGGTGTG TGGCCAGTTTTGGAGGCTGGAATGATGGGCCAGGGTGTAGGATTCATTCTCCATGTAAAGTTTCCTTTCATCCTGCCTAGCCATCCCCAA GGTTTATTTCCAGAAGAAAGGAATATCTCTACTTGGATCAATTCTGGTCATTTCAAGAGGATGGAGGCCTCAAGTGTGGGAACTTCCCCT ACTCCCTGGATGTGTGTACCTAGCACACTTCCTTCTCCCACCCCTTTTTCCAGTTGGATTTGTTTTTCTGTTCTCTTCTGTCCTGTCTTA TACTGCAACTGTGTCTCCTAGGGGACAGATGGCCTTCTTTGTCATCTTCACTCTCCACCCCCAGAGAGGAGTCAGAGCCATAACTCAATC ACTCAGCCCCTCCAAAGATAGTTGATGTGTGATAATCTCATAATGTTGAGAACCCTGATGAGATACATTGTCTTCCTCTCCCTACAATGC CTCTGGGGCCAAGGCACCCATTCTTCTTGCTATCCTCCATCCCCCTTGAGGCTTCCACTTTTTTTTTTTTTAGACATAAAGCTGGGCATC AGCAACTGGCCTGTGGTGATGCAAAGCTGCTTTGCTCTGTATCTGGCTGGACTGATCTGTCTCACAAGAAGCCATGAGGCCATAGGGAGA AGCTCCCTCTCCCCTTCATCTTCTGCTCCAAAGGTGGTAGCAAGAGGAGTACCCAGTTAGGGGTTGGAGCCCCCATATAACATCTTCCTG >31451_31451_9_FRS2-PIP4K2C_FRS2_chr12_69962876_ENST00000549921_PIP4K2C_chr12_57994107_ENST00000354947_length(amino acids)=210AA_BP=22 MGSCCSCPDKDTVPDNHRNKFKVKELPTLKDMDFLNKNQKVYIGEEEKKIFLEKLKRDVEFLVQLKIMDYSLLLGIHDIIRGSEPEEEAP VREDESEVDGDCSLTGPPALVGSYGTSPEGIGGYIHSHRPLGPGEFESFIDVYAIRSAEGAPQKEVYFMGLIDILTQYDAKKKAAHAAKT -------------------------------------------------------------- >31451_31451_10_FRS2-PIP4K2C_FRS2_chr12_69962876_ENST00000549921_PIP4K2C_chr12_57994107_ENST00000422156_length(transcript)=1369nt_BP=482nt GGAAGTGCTTTTCCAAGATTCGGGCCGGAGAGAGGCCTTGTAGGCACAGCGGCTGAGACTCGATCTGCTCCAAGTAGGGGCTCCAGCGCG GGTCGGAGTCTGGGGGTTCGCGCCCGCCGACCCGCGCCCTGCTCCCTCTCAGCACCTGGGCGGACGAAATGACCATTAAGAAGTAGATGC CCAGATGCAAAAGTGATGAAACAGTCCATTTGTCATAAAGTAAGATGCAGCTGTGGCATGTCAACCAGCTTGGAACAAAATTGTATCTGT TTTTCTCAGAAGAGAATTCCACAAGGTTAAATCAGCAAACAAAGAAAACATGGTATTTTGAAATATGATTAAACTCCTGATGCTGCAGCA GAGGCTAAGAATATTAATGGCCAGATCTAGTGCACACATGGTCTTCTGAAGAAGCCATGGGTAGCTGTTGTAGCTGTCCAGATAAAGACA CTGTCCCAGATAACCATCGGAACAAGTTTAAGGTTAAAGAATTGCCCACCCTTAAGGATATGGACTTTCTCAACAAGAACCAGAAAGTAT ATATTGGTGAAGAGGAGAAGAAAATATTTCTGGAGAAGCTGAAGAGAGATGTGGAGTTTCTAGTGCAGCTGAAGATCATGGACTACAGCC TTCTGCTAGGCATCCACGACATCATTCGGGGCTCTGAACCAGAGGAGGAAGCGCCCGTGCGGGAGGATGAGTCAGAGGTGGATGGGGACT GCAGCCTGACTGGACCTCCTGCTCTTGTGGGCTCCTATGGCACCTCCCCAGAGGGTATCGGAGGCTACATCCATTCCCATCGGCCCCTGG GCCCAGGAGAGTTTGAGTCCTTCATTGATGTCTATGCCATCCGGAGTGCTGAAGGAGCCCCCCAGAAGGAGGTCTACTTCATGGGCCTCA TTGATATCCTTACACAGTATGATGCTAAGAAGAAAGCAGCTCATGCAGCCAAAACTGTCAAGCATGGGGCTGGGGCAGAGATCTCTACTG TCCATCCGGAGCAGTATGCTAAGCGATTCCTGGATTTTATTACCAACATCTTTGCCTAAGAGACTGCCTGGTTCTCTCTGATGTTCAAGG TGGTGGGGTTCTGAGACACTTGGGGGAATTGTGGGGATATTCTAGCCACCAGTTCTCTTCTTCCTTTGCTAAATTCAGGCTGCAGGCTCC TTCCATCCAGATAACTCCATCCTGTCGAGTAGGCTCTTTCTGACCCTCAGAAATACATTGTCCTTTTTCCTCTTTGCCCATTTTTCTTCC CTCTCTTCCTCCCCATGAGAAGTCTGCTTGTAGTATTAGAATGTTATTGTTGACTCTCTCCCAAGTGCCTTGATCTTTGTAATATCTCCT >31451_31451_10_FRS2-PIP4K2C_FRS2_chr12_69962876_ENST00000549921_PIP4K2C_chr12_57994107_ENST00000422156_length(amino acids)=210AA_BP=22 MGSCCSCPDKDTVPDNHRNKFKVKELPTLKDMDFLNKNQKVYIGEEEKKIFLEKLKRDVEFLVQLKIMDYSLLLGIHDIIRGSEPEEEAP VREDESEVDGDCSLTGPPALVGSYGTSPEGIGGYIHSHRPLGPGEFESFIDVYAIRSAEGAPQKEVYFMGLIDILTQYDAKKKAAHAAKT -------------------------------------------------------------- >31451_31451_11_FRS2-PIP4K2C_FRS2_chr12_69962876_ENST00000549921_PIP4K2C_chr12_57994107_ENST00000540759_length(transcript)=2569nt_BP=482nt GGAAGTGCTTTTCCAAGATTCGGGCCGGAGAGAGGCCTTGTAGGCACAGCGGCTGAGACTCGATCTGCTCCAAGTAGGGGCTCCAGCGCG GGTCGGAGTCTGGGGGTTCGCGCCCGCCGACCCGCGCCCTGCTCCCTCTCAGCACCTGGGCGGACGAAATGACCATTAAGAAGTAGATGC CCAGATGCAAAAGTGATGAAACAGTCCATTTGTCATAAAGTAAGATGCAGCTGTGGCATGTCAACCAGCTTGGAACAAAATTGTATCTGT TTTTCTCAGAAGAGAATTCCACAAGGTTAAATCAGCAAACAAAGAAAACATGGTATTTTGAAATATGATTAAACTCCTGATGCTGCAGCA GAGGCTAAGAATATTAATGGCCAGATCTAGTGCACACATGGTCTTCTGAAGAAGCCATGGGTAGCTGTTGTAGCTGTCCAGATAAAGACA CTGTCCCAGATAACCATCGGAACAAGTTTAAGGTTAAAGAATTGCCCACCCTTAAGGATATGGACTTTCTCAACAAGAACCAGAAAGTAT ATATTGGTGAAGAGGAGAAGAAAATATTTCTGGAGAAGCTGAAGAGAGATGTGGAGTTTCTAGTGCAGCTGAAGATCATGGACTACAGCC TTCTGCTAGGCATCCACGACATCATTCGGGGCTCTGAACCAGAGGAGGAAGCGCCCGTGCGGGAGGATGAGTCAGAGGTGGATGGGGACT GCAGCCTGACTGGACCTCCTGCTCTTGTGGGCTCCTATGGCACCTCCCCAGAGGGTATCGGAGGCTACATCCATTCCCATCGGCCCCTGG GCCCAGGAGAGTTTGAGTCCTTCATTGATGTCTATGCCATCCGGAGTGCTGAAGGAGCCCCCCAGAAGGAGGTCTACTTCATGGGCCTCA TTGATATCCTTACACAGTATGATGCTAAGAAGAAAGCAGCTCATGCAGCCAAAACTGTCAAGCATGGGGCTGGGGCAGAGATCTCTACTG TCCATCCGGAGCAGTATGCTAAGCGATTCCTGGATTTTATTACCAACATCTTTGCCTAAGAGACTGCCTGGTTCTCTCTGATGTTCAAGG AGCTAGGGGAAGGGGGTTGTTTGCCTTCTTCAGGACCTGACTGGACAGATGGACCTGGCTCAAGCAACTACTCTGGATGCACTTTGCTGT GTGGGATGAACTAAAAGTGTCTGAATTTTGCTGATAACTTTATAAAACTCACTATGGCATGCTTCCCTCCTGGTGGGCCCTAGGATGGAT GACACTCAAGATACTACAGATGTGGGTGCAGGCATGCACACACACGATGGAATATGGCCATTCCTACACAGGTGGGGTAGAGAGTGGGTC AGCAGCCTGGCACCTCACAGAGGTGGGACCTAAGAGGACTCATGATTATGCAGAGAATTGGATTGGGTCTCTGTCATAGATTGAGTAATC TCTTCCCTTACCTCAATTCCATCTCCACCCATCTCTACATCTGGGCACAGCAACCCAGAGATGGCCAAAAGCATTCAAGCCTGGGGGAAG ATGTTTGACTATTGCTGCTCTTCACCAGAACCTCACACCTCTCCTGGGACTGGAACCCTTCAGTGGGTGTGTGGCCAGTTTTGGAGGCTG GAATGATGGGCCAGGGTGTAGGATTCATTCTCCATGTAAAGTTTCCTTTCATCCTGCCTAGCCATCCCCAAGGTTTATTTCCAGAAGAAA GGAATATCTCTACTTGGATCAATTCTGGTCATTTCAAGAGGATGGAGGCCTCAAGTGTGGGAACTTCCCCTACTCCCTGGATGTGTGTAC CTAGCACACTTCCTTCTCCCACCCCTTTTTCCAGTTGGATTTGTTTTTCTGTTCTCTTCTGTCCTGTCTTATACTGCAACTGTGTCTCCT AGGGGACAGATGGCCTTCTTTGTCATCTTCACTCTCCACCCCCAGAGAGGAGTCAGAGCCATAACTCAATCACTCAGCCCCTCCAAAGAT AGTTGATGTGTGATAATCTCATAATGTTGAGAACCCTGATGAGATACATTGTCTTCCTCTCCCTACAATGCCTCTGGGGCCAAGGCACCC ATTCTTCTTGCTATCCTCCATCCCCCTTGAGGCTTCCACTTTTTTTTTTTTTAGACATAAAGCTGGGCATCAGCAACTGGCCTGTGGTGA TGCAAAGCTGCTTTGCTCTGTATCTGGCTGGACTGATCTGTCTCACAAGAAGCCATGAGGCCATAGGGAGAAGCTCCCTCTCCCCTTCAT CTTCTGCTCCAAAGGTGGTAGCAAGAGGAGTACCCAGTTAGGGGTTGGAGCCCCCATATAACATCTTCCTGTCAGAAGACTGATGGATCT TTTTCATTCCAACCATCTCCCTTTCCCCCGATGAATGCAATAAAACTCTGTGACACCAGCAACCATTGCTCTTTAGAAATGGGTTTTCTG ATCATATGGCTGATGTGTTATGGGCAGTATGGATGTCTTCATTTGTTGCTTCTGTTTTTCATCTTTTTTGTTTTATTAATAAAAATTTAT >31451_31451_11_FRS2-PIP4K2C_FRS2_chr12_69962876_ENST00000549921_PIP4K2C_chr12_57994107_ENST00000540759_length(amino acids)=210AA_BP=22 MGSCCSCPDKDTVPDNHRNKFKVKELPTLKDMDFLNKNQKVYIGEEEKKIFLEKLKRDVEFLVQLKIMDYSLLLGIHDIIRGSEPEEEAP VREDESEVDGDCSLTGPPALVGSYGTSPEGIGGYIHSHRPLGPGEFESFIDVYAIRSAEGAPQKEVYFMGLIDILTQYDAKKKAAHAAKT -------------------------------------------------------------- >31451_31451_12_FRS2-PIP4K2C_FRS2_chr12_69962876_ENST00000549921_PIP4K2C_chr12_57994107_ENST00000550465_length(transcript)=1322nt_BP=482nt GGAAGTGCTTTTCCAAGATTCGGGCCGGAGAGAGGCCTTGTAGGCACAGCGGCTGAGACTCGATCTGCTCCAAGTAGGGGCTCCAGCGCG GGTCGGAGTCTGGGGGTTCGCGCCCGCCGACCCGCGCCCTGCTCCCTCTCAGCACCTGGGCGGACGAAATGACCATTAAGAAGTAGATGC CCAGATGCAAAAGTGATGAAACAGTCCATTTGTCATAAAGTAAGATGCAGCTGTGGCATGTCAACCAGCTTGGAACAAAATTGTATCTGT TTTTCTCAGAAGAGAATTCCACAAGGTTAAATCAGCAAACAAAGAAAACATGGTATTTTGAAATATGATTAAACTCCTGATGCTGCAGCA GAGGCTAAGAATATTAATGGCCAGATCTAGTGCACACATGGTCTTCTGAAGAAGCCATGGGTAGCTGTTGTAGCTGTCCAGATAAAGACA CTGTCCCAGATAACCATCGGAACAAGTTTAAGGTTAAAGAATTGCCCACCCTTAAGGATATGGACTTTCTCAACAAGAACCAGAAAGTAT ATATTGGTGAAGAGGAGAAGAAAATATTTCTGGAGAAGCTGAAGAGAGATGTGGAGTTTCTAGTGCAGCTGAAGATCATGGACTACAGCC TTCTGCTAGGCATCCACGACATCATTCGGGGCTCTGAACCAGAGGAGGAAGCGCCCGTGCGGGAGGATGAGTCAGAGGTGGATGGGGACT GCAGCCTGACTGGACCTCCTGCTCTTGTGGGCTCCTATGGCACCTCCCCAGAGGGTATCGGAGGCTACATCCATTCCCATCGGCCCCTGG GCCCAGGAGAGTTTGAGTCCTTCATTGATGTCTATGCCATCCGGAGTGCTGAAGGAGCCCCCCAGAAGGAGGTCTACTTCATGGGCCTCA TTGATATCCTTACACAGTATGATGCTAAGAAGAAAGCAGCTCATGCAGCCAAAACTGTCAAGCATGGGGCTGGGGCAGAGATCTCTACTG TCCATCCGGAGCAGTATGCTAAGCGATTCCTGGATTTTATTACCAACATCTTTGCCTAAGAGACTGCCTGGTTCTCTCTGATGTTCAAGG TGGTGGGGTTCTGAGACACTTGGGGGAATTGTGGGGATATTCTAGCCACCAGTTCTCTTCTTCCTTTGCTAAATTCAGGCTGCAGGCTCC TTCCATCCAGATAACTCCATCCTGTCGAGTAGGCTCTTTCTGACCCTCAGAAATACATTGTCCTTTTTCCTCTTTGCCCATTTTTCTTCC >31451_31451_12_FRS2-PIP4K2C_FRS2_chr12_69962876_ENST00000549921_PIP4K2C_chr12_57994107_ENST00000550465_length(amino acids)=210AA_BP=22 MGSCCSCPDKDTVPDNHRNKFKVKELPTLKDMDFLNKNQKVYIGEEEKKIFLEKLKRDVEFLVQLKIMDYSLLLGIHDIIRGSEPEEEAP VREDESEVDGDCSLTGPPALVGSYGTSPEGIGGYIHSHRPLGPGEFESFIDVYAIRSAEGAPQKEVYFMGLIDILTQYDAKKKAAHAAKT -------------------------------------------------------------- >31451_31451_13_FRS2-PIP4K2C_FRS2_chr12_69962876_ENST00000550389_PIP4K2C_chr12_57994107_ENST00000354947_length(transcript)=2521nt_BP=312nt GAGGCCTTGTAGGCACAGCGGCTGAGACTCGATCTGCTCCAAGTAGGGGCTCCAGCGCGGGTCGGAGTCTGGGGGTTCGCGCCCGCCGAC CCGCGCCCTGCTCCCTCTCAGCACCTGGGCGGACGGTTAAATCAGCAAACAAAGAAAACATGGTATTTTGAAATATGATTAAACTCCTGA TGCTGCAGCAGAGGCTAAGAATATTAATGGCCAGATCTAGTGCACACATGGTCTTCTGAAGAAGCCATGGGTAGCTGTTGTAGCTGTCCA GATAAAGACACTGTCCCAGATAACCATCGGAACAAGTTTAAGGTTAAAGAATTGCCCACCCTTAAGGATATGGACTTTCTCAACAAGAAC CAGAAAGTATATATTGGTGAAGAGGAGAAGAAAATATTTCTGGAGAAGCTGAAGAGAGATGTGGAGTTTCTAGTGCAGCTGAAGATCATG GACTACAGCCTTCTGCTAGGCATCCACGACATCATTCGGGGCTCTGAACCAGAGGAGGAAGCGCCCGTGCGGGAGGATGAGTCAGAGGTG GATGGGGACTGCAGCCTGACTGGACCTCCTGCTCTTGTGGGCTCCTATGGCACCTCCCCAGAGGGTATCGGAGGCTACATCCATTCCCAT CGGCCCCTGGGCCCAGGAGAGTTTGAGTCCTTCATTGATGTCTATGCCATCCGGAGTGCTGAAGGAGCCCCCCAGAAGGAGGTCTACTTC ATGGGCCTCATTGATATCCTTACACAGTATGATGCTAAGAAGAAAGCAGCTCATGCAGCCAAAACTGTCAAGCATGGGGCTGGGGCAGAG ATCTCTACTGTCCATCCGGAGCAGTATGCTAAGCGATTCCTGGATTTTATTACCAACATCTTTGCCTAAGAGACTGCCTGGTTCTCTCTG ATGTTCAAGGTGGTGGGGTTCTGAGACACTTGGGGGAATTGTGGGGATATTCTAGCCACCAGTTCTCTTCTTCCTTTGCTAAATTCAGGC TGCAGGCTCCTTCCATCCAGATAACTCCATCCTGTCGAGTAGGCTCTTTCTGACCCTCAGAAATACATTGTCCTTTTTCCTCTTTGCCCA TTTTTCTTCCCTCTCTTCCTCCCCATGAGAAGTCTGCTTGTAGTATTAGAATGTTATTGTTGACTCTCTCCCAAGTGCCTTGATCTTTGT AATATCTCCTGTTGTTTCTATGATATAGGAGCTAGGGGAAGGGGGTTGTTTGCCTTCTTCAGGACCTGACTGGACAGATGGACCTGGCTC AAGCAACTACTCTGGATGCACTTTGCTGTGTGGGATGAACTAAAAGTGTCTGAATTTTGCTGATAACTTTATAAAACTCACTATGGCATG CTTCCCTCCTGGTGGGCCCTAGGATGGATGACACTCAAGATACTACAGATGTGGGTGCAGGCATGCACACACACGATGGAATATGGCCAT TCCTACACAGGTGGGGTAGAGAGTGGGTCAGCAGCCTGGCACCTCACAGAGGTGGGACCTAAGAGGACTCATGATTATGCAGAGAATTGG ATTGGGTCTCTGTCATAGATTGAGTAATCTCTTCCCTTACCTCAATTCCATCTCCACCCATCTCTACATCTGGGCACAGCAACCCAGAGA TGGCCAAAAGCATTCAAGCCTGGGGGAAGATGTTTGACTATTGCTGCTCTTCACCAGAACCTCACACCTCTCCTGGGACTGGAACCCTTC AGTGGGTGTGTGGCCAGTTTTGGAGGCTGGAATGATGGGCCAGGGTGTAGGATTCATTCTCCATGTAAAGTTTCCTTTCATCCTGCCTAG CCATCCCCAAGGTTTATTTCCAGAAGAAAGGAATATCTCTACTTGGATCAATTCTGGTCATTTCAAGAGGATGGAGGCCTCAAGTGTGGG AACTTCCCCTACTCCCTGGATGTGTGTACCTAGCACACTTCCTTCTCCCACCCCTTTTTCCAGTTGGATTTGTTTTTCTGTTCTCTTCTG TCCTGTCTTATACTGCAACTGTGTCTCCTAGGGGACAGATGGCCTTCTTTGTCATCTTCACTCTCCACCCCCAGAGAGGAGTCAGAGCCA TAACTCAATCACTCAGCCCCTCCAAAGATAGTTGATGTGTGATAATCTCATAATGTTGAGAACCCTGATGAGATACATTGTCTTCCTCTC CCTACAATGCCTCTGGGGCCAAGGCACCCATTCTTCTTGCTATCCTCCATCCCCCTTGAGGCTTCCACTTTTTTTTTTTTTAGACATAAA GCTGGGCATCAGCAACTGGCCTGTGGTGATGCAAAGCTGCTTTGCTCTGTATCTGGCTGGACTGATCTGTCTCACAAGAAGCCATGAGGC CATAGGGAGAAGCTCCCTCTCCCCTTCATCTTCTGCTCCAAAGGTGGTAGCAAGAGGAGTACCCAGTTAGGGGTTGGAGCCCCCATATAA CATCTTCCTGTCAGAAGACTGATGGATCTTTTTCATTCCAACCATCTCCCTTTCCCCCGATGAATGCAATAAAACTCTGTGACACCAGCA >31451_31451_13_FRS2-PIP4K2C_FRS2_chr12_69962876_ENST00000550389_PIP4K2C_chr12_57994107_ENST00000354947_length(amino acids)=210AA_BP=22 MGSCCSCPDKDTVPDNHRNKFKVKELPTLKDMDFLNKNQKVYIGEEEKKIFLEKLKRDVEFLVQLKIMDYSLLLGIHDIIRGSEPEEEAP VREDESEVDGDCSLTGPPALVGSYGTSPEGIGGYIHSHRPLGPGEFESFIDVYAIRSAEGAPQKEVYFMGLIDILTQYDAKKKAAHAAKT -------------------------------------------------------------- >31451_31451_14_FRS2-PIP4K2C_FRS2_chr12_69962876_ENST00000550389_PIP4K2C_chr12_57994107_ENST00000422156_length(transcript)=1199nt_BP=312nt GAGGCCTTGTAGGCACAGCGGCTGAGACTCGATCTGCTCCAAGTAGGGGCTCCAGCGCGGGTCGGAGTCTGGGGGTTCGCGCCCGCCGAC CCGCGCCCTGCTCCCTCTCAGCACCTGGGCGGACGGTTAAATCAGCAAACAAAGAAAACATGGTATTTTGAAATATGATTAAACTCCTGA TGCTGCAGCAGAGGCTAAGAATATTAATGGCCAGATCTAGTGCACACATGGTCTTCTGAAGAAGCCATGGGTAGCTGTTGTAGCTGTCCA GATAAAGACACTGTCCCAGATAACCATCGGAACAAGTTTAAGGTTAAAGAATTGCCCACCCTTAAGGATATGGACTTTCTCAACAAGAAC CAGAAAGTATATATTGGTGAAGAGGAGAAGAAAATATTTCTGGAGAAGCTGAAGAGAGATGTGGAGTTTCTAGTGCAGCTGAAGATCATG GACTACAGCCTTCTGCTAGGCATCCACGACATCATTCGGGGCTCTGAACCAGAGGAGGAAGCGCCCGTGCGGGAGGATGAGTCAGAGGTG GATGGGGACTGCAGCCTGACTGGACCTCCTGCTCTTGTGGGCTCCTATGGCACCTCCCCAGAGGGTATCGGAGGCTACATCCATTCCCAT CGGCCCCTGGGCCCAGGAGAGTTTGAGTCCTTCATTGATGTCTATGCCATCCGGAGTGCTGAAGGAGCCCCCCAGAAGGAGGTCTACTTC ATGGGCCTCATTGATATCCTTACACAGTATGATGCTAAGAAGAAAGCAGCTCATGCAGCCAAAACTGTCAAGCATGGGGCTGGGGCAGAG ATCTCTACTGTCCATCCGGAGCAGTATGCTAAGCGATTCCTGGATTTTATTACCAACATCTTTGCCTAAGAGACTGCCTGGTTCTCTCTG ATGTTCAAGGTGGTGGGGTTCTGAGACACTTGGGGGAATTGTGGGGATATTCTAGCCACCAGTTCTCTTCTTCCTTTGCTAAATTCAGGC TGCAGGCTCCTTCCATCCAGATAACTCCATCCTGTCGAGTAGGCTCTTTCTGACCCTCAGAAATACATTGTCCTTTTTCCTCTTTGCCCA TTTTTCTTCCCTCTCTTCCTCCCCATGAGAAGTCTGCTTGTAGTATTAGAATGTTATTGTTGACTCTCTCCCAAGTGCCTTGATCTTTGT >31451_31451_14_FRS2-PIP4K2C_FRS2_chr12_69962876_ENST00000550389_PIP4K2C_chr12_57994107_ENST00000422156_length(amino acids)=210AA_BP=22 MGSCCSCPDKDTVPDNHRNKFKVKELPTLKDMDFLNKNQKVYIGEEEKKIFLEKLKRDVEFLVQLKIMDYSLLLGIHDIIRGSEPEEEAP VREDESEVDGDCSLTGPPALVGSYGTSPEGIGGYIHSHRPLGPGEFESFIDVYAIRSAEGAPQKEVYFMGLIDILTQYDAKKKAAHAAKT -------------------------------------------------------------- >31451_31451_15_FRS2-PIP4K2C_FRS2_chr12_69962876_ENST00000550389_PIP4K2C_chr12_57994107_ENST00000540759_length(transcript)=2399nt_BP=312nt GAGGCCTTGTAGGCACAGCGGCTGAGACTCGATCTGCTCCAAGTAGGGGCTCCAGCGCGGGTCGGAGTCTGGGGGTTCGCGCCCGCCGAC CCGCGCCCTGCTCCCTCTCAGCACCTGGGCGGACGGTTAAATCAGCAAACAAAGAAAACATGGTATTTTGAAATATGATTAAACTCCTGA TGCTGCAGCAGAGGCTAAGAATATTAATGGCCAGATCTAGTGCACACATGGTCTTCTGAAGAAGCCATGGGTAGCTGTTGTAGCTGTCCA GATAAAGACACTGTCCCAGATAACCATCGGAACAAGTTTAAGGTTAAAGAATTGCCCACCCTTAAGGATATGGACTTTCTCAACAAGAAC CAGAAAGTATATATTGGTGAAGAGGAGAAGAAAATATTTCTGGAGAAGCTGAAGAGAGATGTGGAGTTTCTAGTGCAGCTGAAGATCATG GACTACAGCCTTCTGCTAGGCATCCACGACATCATTCGGGGCTCTGAACCAGAGGAGGAAGCGCCCGTGCGGGAGGATGAGTCAGAGGTG GATGGGGACTGCAGCCTGACTGGACCTCCTGCTCTTGTGGGCTCCTATGGCACCTCCCCAGAGGGTATCGGAGGCTACATCCATTCCCAT CGGCCCCTGGGCCCAGGAGAGTTTGAGTCCTTCATTGATGTCTATGCCATCCGGAGTGCTGAAGGAGCCCCCCAGAAGGAGGTCTACTTC ATGGGCCTCATTGATATCCTTACACAGTATGATGCTAAGAAGAAAGCAGCTCATGCAGCCAAAACTGTCAAGCATGGGGCTGGGGCAGAG ATCTCTACTGTCCATCCGGAGCAGTATGCTAAGCGATTCCTGGATTTTATTACCAACATCTTTGCCTAAGAGACTGCCTGGTTCTCTCTG ATGTTCAAGGAGCTAGGGGAAGGGGGTTGTTTGCCTTCTTCAGGACCTGACTGGACAGATGGACCTGGCTCAAGCAACTACTCTGGATGC ACTTTGCTGTGTGGGATGAACTAAAAGTGTCTGAATTTTGCTGATAACTTTATAAAACTCACTATGGCATGCTTCCCTCCTGGTGGGCCC TAGGATGGATGACACTCAAGATACTACAGATGTGGGTGCAGGCATGCACACACACGATGGAATATGGCCATTCCTACACAGGTGGGGTAG AGAGTGGGTCAGCAGCCTGGCACCTCACAGAGGTGGGACCTAAGAGGACTCATGATTATGCAGAGAATTGGATTGGGTCTCTGTCATAGA TTGAGTAATCTCTTCCCTTACCTCAATTCCATCTCCACCCATCTCTACATCTGGGCACAGCAACCCAGAGATGGCCAAAAGCATTCAAGC CTGGGGGAAGATGTTTGACTATTGCTGCTCTTCACCAGAACCTCACACCTCTCCTGGGACTGGAACCCTTCAGTGGGTGTGTGGCCAGTT TTGGAGGCTGGAATGATGGGCCAGGGTGTAGGATTCATTCTCCATGTAAAGTTTCCTTTCATCCTGCCTAGCCATCCCCAAGGTTTATTT CCAGAAGAAAGGAATATCTCTACTTGGATCAATTCTGGTCATTTCAAGAGGATGGAGGCCTCAAGTGTGGGAACTTCCCCTACTCCCTGG ATGTGTGTACCTAGCACACTTCCTTCTCCCACCCCTTTTTCCAGTTGGATTTGTTTTTCTGTTCTCTTCTGTCCTGTCTTATACTGCAAC TGTGTCTCCTAGGGGACAGATGGCCTTCTTTGTCATCTTCACTCTCCACCCCCAGAGAGGAGTCAGAGCCATAACTCAATCACTCAGCCC CTCCAAAGATAGTTGATGTGTGATAATCTCATAATGTTGAGAACCCTGATGAGATACATTGTCTTCCTCTCCCTACAATGCCTCTGGGGC CAAGGCACCCATTCTTCTTGCTATCCTCCATCCCCCTTGAGGCTTCCACTTTTTTTTTTTTTAGACATAAAGCTGGGCATCAGCAACTGG CCTGTGGTGATGCAAAGCTGCTTTGCTCTGTATCTGGCTGGACTGATCTGTCTCACAAGAAGCCATGAGGCCATAGGGAGAAGCTCCCTC TCCCCTTCATCTTCTGCTCCAAAGGTGGTAGCAAGAGGAGTACCCAGTTAGGGGTTGGAGCCCCCATATAACATCTTCCTGTCAGAAGAC TGATGGATCTTTTTCATTCCAACCATCTCCCTTTCCCCCGATGAATGCAATAAAACTCTGTGACACCAGCAACCATTGCTCTTTAGAAAT GGGTTTTCTGATCATATGGCTGATGTGTTATGGGCAGTATGGATGTCTTCATTTGTTGCTTCTGTTTTTCATCTTTTTTGTTTTATTAAT >31451_31451_15_FRS2-PIP4K2C_FRS2_chr12_69962876_ENST00000550389_PIP4K2C_chr12_57994107_ENST00000540759_length(amino acids)=210AA_BP=22 MGSCCSCPDKDTVPDNHRNKFKVKELPTLKDMDFLNKNQKVYIGEEEKKIFLEKLKRDVEFLVQLKIMDYSLLLGIHDIIRGSEPEEEAP VREDESEVDGDCSLTGPPALVGSYGTSPEGIGGYIHSHRPLGPGEFESFIDVYAIRSAEGAPQKEVYFMGLIDILTQYDAKKKAAHAAKT -------------------------------------------------------------- >31451_31451_16_FRS2-PIP4K2C_FRS2_chr12_69962876_ENST00000550389_PIP4K2C_chr12_57994107_ENST00000550465_length(transcript)=1152nt_BP=312nt GAGGCCTTGTAGGCACAGCGGCTGAGACTCGATCTGCTCCAAGTAGGGGCTCCAGCGCGGGTCGGAGTCTGGGGGTTCGCGCCCGCCGAC CCGCGCCCTGCTCCCTCTCAGCACCTGGGCGGACGGTTAAATCAGCAAACAAAGAAAACATGGTATTTTGAAATATGATTAAACTCCTGA TGCTGCAGCAGAGGCTAAGAATATTAATGGCCAGATCTAGTGCACACATGGTCTTCTGAAGAAGCCATGGGTAGCTGTTGTAGCTGTCCA GATAAAGACACTGTCCCAGATAACCATCGGAACAAGTTTAAGGTTAAAGAATTGCCCACCCTTAAGGATATGGACTTTCTCAACAAGAAC CAGAAAGTATATATTGGTGAAGAGGAGAAGAAAATATTTCTGGAGAAGCTGAAGAGAGATGTGGAGTTTCTAGTGCAGCTGAAGATCATG GACTACAGCCTTCTGCTAGGCATCCACGACATCATTCGGGGCTCTGAACCAGAGGAGGAAGCGCCCGTGCGGGAGGATGAGTCAGAGGTG GATGGGGACTGCAGCCTGACTGGACCTCCTGCTCTTGTGGGCTCCTATGGCACCTCCCCAGAGGGTATCGGAGGCTACATCCATTCCCAT CGGCCCCTGGGCCCAGGAGAGTTTGAGTCCTTCATTGATGTCTATGCCATCCGGAGTGCTGAAGGAGCCCCCCAGAAGGAGGTCTACTTC ATGGGCCTCATTGATATCCTTACACAGTATGATGCTAAGAAGAAAGCAGCTCATGCAGCCAAAACTGTCAAGCATGGGGCTGGGGCAGAG ATCTCTACTGTCCATCCGGAGCAGTATGCTAAGCGATTCCTGGATTTTATTACCAACATCTTTGCCTAAGAGACTGCCTGGTTCTCTCTG ATGTTCAAGGTGGTGGGGTTCTGAGACACTTGGGGGAATTGTGGGGATATTCTAGCCACCAGTTCTCTTCTTCCTTTGCTAAATTCAGGC TGCAGGCTCCTTCCATCCAGATAACTCCATCCTGTCGAGTAGGCTCTTTCTGACCCTCAGAAATACATTGTCCTTTTTCCTCTTTGCCCA >31451_31451_16_FRS2-PIP4K2C_FRS2_chr12_69962876_ENST00000550389_PIP4K2C_chr12_57994107_ENST00000550465_length(amino acids)=210AA_BP=22 MGSCCSCPDKDTVPDNHRNKFKVKELPTLKDMDFLNKNQKVYIGEEEKKIFLEKLKRDVEFLVQLKIMDYSLLLGIHDIIRGSEPEEEAP VREDESEVDGDCSLTGPPALVGSYGTSPEGIGGYIHSHRPLGPGEFESFIDVYAIRSAEGAPQKEVYFMGLIDILTQYDAKKKAAHAAKT -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for FRS2-PIP4K2C |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for FRS2-PIP4K2C |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for FRS2-PIP4K2C |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies