
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:GAK-PLEKHG2 (FusionGDB2 ID:32177) |
Fusion Gene Summary for GAK-PLEKHG2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: GAK-PLEKHG2 | Fusion gene ID: 32177 | Hgene | Tgene | Gene symbol | GAK | PLEKHG2 | Gene ID | 2580 | 64857 |
| Gene name | cyclin G associated kinase | pleckstrin homology and RhoGEF domain containing G2 | |
| Synonyms | DNAJ26|DNAJC26 | ARHGEF42|CLG|CTB-60E11.4|LDAMD | |
| Cytomap | 4p16.3 | 19q13.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | cyclin-G-associated kinaseauxilin-2 | pleckstrin homology domain-containing family G member 2PH domain-containing family G member 2common-site lymphoma/leukemia guanine nucleotide exchange factorpleckstrin homology domain containing, family G (with RhoGef domain) member 2 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000314167, ENST00000511163, ENST00000509566, | ENST00000378550, ENST00000409794, ENST00000409797, ENST00000425673, ENST00000458508, | |
| Fusion gene scores | * DoF score | 16 X 17 X 8=2176 | 5 X 5 X 3=75 |
| # samples | 18 | 5 | |
| ** MAII score | log2(18/2176*10)=-3.59560974492067 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(5/75*10)=-0.584962500721156 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: GAK [Title/Abstract] AND PLEKHG2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | GAK(891821)-PLEKHG2(39912755), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | GAK | GO:0010977 | negative regulation of neuron projection development | 24510904 |
| Fusion gene breakpoints across GAK (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across PLEKHG2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | Non-Cancer | TCGA-HU-A4GC-11A | GAK | chr4 | 891821 | - | PLEKHG2 | chr19 | 39912755 | + |
Top |
Fusion Gene ORF analysis for GAK-PLEKHG2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| In-frame | ENST00000314167 | ENST00000378550 | GAK | chr4 | 891821 | - | PLEKHG2 | chr19 | 39912755 | + |
| In-frame | ENST00000314167 | ENST00000409794 | GAK | chr4 | 891821 | - | PLEKHG2 | chr19 | 39912755 | + |
| In-frame | ENST00000314167 | ENST00000409797 | GAK | chr4 | 891821 | - | PLEKHG2 | chr19 | 39912755 | + |
| In-frame | ENST00000314167 | ENST00000425673 | GAK | chr4 | 891821 | - | PLEKHG2 | chr19 | 39912755 | + |
| In-frame | ENST00000314167 | ENST00000458508 | GAK | chr4 | 891821 | - | PLEKHG2 | chr19 | 39912755 | + |
| In-frame | ENST00000511163 | ENST00000378550 | GAK | chr4 | 891821 | - | PLEKHG2 | chr19 | 39912755 | + |
| In-frame | ENST00000511163 | ENST00000409794 | GAK | chr4 | 891821 | - | PLEKHG2 | chr19 | 39912755 | + |
| In-frame | ENST00000511163 | ENST00000409797 | GAK | chr4 | 891821 | - | PLEKHG2 | chr19 | 39912755 | + |
| In-frame | ENST00000511163 | ENST00000425673 | GAK | chr4 | 891821 | - | PLEKHG2 | chr19 | 39912755 | + |
| In-frame | ENST00000511163 | ENST00000458508 | GAK | chr4 | 891821 | - | PLEKHG2 | chr19 | 39912755 | + |
| intron-3CDS | ENST00000509566 | ENST00000378550 | GAK | chr4 | 891821 | - | PLEKHG2 | chr19 | 39912755 | + |
| intron-3CDS | ENST00000509566 | ENST00000409794 | GAK | chr4 | 891821 | - | PLEKHG2 | chr19 | 39912755 | + |
| intron-3CDS | ENST00000509566 | ENST00000409797 | GAK | chr4 | 891821 | - | PLEKHG2 | chr19 | 39912755 | + |
| intron-3CDS | ENST00000509566 | ENST00000425673 | GAK | chr4 | 891821 | - | PLEKHG2 | chr19 | 39912755 | + |
| intron-3CDS | ENST00000509566 | ENST00000458508 | GAK | chr4 | 891821 | - | PLEKHG2 | chr19 | 39912755 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000314167 | GAK | chr4 | 891821 | - | ENST00000409794 | PLEKHG2 | chr19 | 39912755 | + | 3640 | 762 | 111 | 3419 | 1102 |
| ENST00000314167 | GAK | chr4 | 891821 | - | ENST00000378550 | PLEKHG2 | chr19 | 39912755 | + | 993 | 762 | 111 | 992 | 293 |
| ENST00000314167 | GAK | chr4 | 891821 | - | ENST00000425673 | PLEKHG2 | chr19 | 39912755 | + | 6540 | 762 | 111 | 3419 | 1102 |
| ENST00000314167 | GAK | chr4 | 891821 | - | ENST00000458508 | PLEKHG2 | chr19 | 39912755 | + | 3208 | 762 | 111 | 3149 | 1012 |
| ENST00000314167 | GAK | chr4 | 891821 | - | ENST00000409797 | PLEKHG2 | chr19 | 39912755 | + | 1215 | 762 | 111 | 992 | 293 |
| ENST00000511163 | GAK | chr4 | 891821 | - | ENST00000409794 | PLEKHG2 | chr19 | 39912755 | + | 3478 | 600 | 186 | 3257 | 1023 |
| ENST00000511163 | GAK | chr4 | 891821 | - | ENST00000378550 | PLEKHG2 | chr19 | 39912755 | + | 831 | 600 | 186 | 830 | 214 |
| ENST00000511163 | GAK | chr4 | 891821 | - | ENST00000425673 | PLEKHG2 | chr19 | 39912755 | + | 6378 | 600 | 186 | 3257 | 1023 |
| ENST00000511163 | GAK | chr4 | 891821 | - | ENST00000458508 | PLEKHG2 | chr19 | 39912755 | + | 3046 | 600 | 186 | 2987 | 933 |
| ENST00000511163 | GAK | chr4 | 891821 | - | ENST00000409797 | PLEKHG2 | chr19 | 39912755 | + | 1053 | 600 | 186 | 830 | 214 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000314167 | ENST00000409794 | GAK | chr4 | 891821 | - | PLEKHG2 | chr19 | 39912755 | + | 0.0048515 | 0.9951485 |
| ENST00000314167 | ENST00000378550 | GAK | chr4 | 891821 | - | PLEKHG2 | chr19 | 39912755 | + | 0.006750914 | 0.99324906 |
| ENST00000314167 | ENST00000425673 | GAK | chr4 | 891821 | - | PLEKHG2 | chr19 | 39912755 | + | 0.002287214 | 0.99771273 |
| ENST00000314167 | ENST00000458508 | GAK | chr4 | 891821 | - | PLEKHG2 | chr19 | 39912755 | + | 0.005378032 | 0.994622 |
| ENST00000314167 | ENST00000409797 | GAK | chr4 | 891821 | - | PLEKHG2 | chr19 | 39912755 | + | 0.004753301 | 0.9952467 |
| ENST00000511163 | ENST00000409794 | GAK | chr4 | 891821 | - | PLEKHG2 | chr19 | 39912755 | + | 0.005876014 | 0.994124 |
| ENST00000511163 | ENST00000378550 | GAK | chr4 | 891821 | - | PLEKHG2 | chr19 | 39912755 | + | 0.012441477 | 0.9875585 |
| ENST00000511163 | ENST00000425673 | GAK | chr4 | 891821 | - | PLEKHG2 | chr19 | 39912755 | + | 0.002949561 | 0.9970504 |
| ENST00000511163 | ENST00000458508 | GAK | chr4 | 891821 | - | PLEKHG2 | chr19 | 39912755 | + | 0.006840897 | 0.9931591 |
| ENST00000511163 | ENST00000409797 | GAK | chr4 | 891821 | - | PLEKHG2 | chr19 | 39912755 | + | 0.007814669 | 0.9921853 |
Top |
Fusion Genomic Features for GAK-PLEKHG2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| GAK | chr4 | 891820 | - | PLEKHG2 | chr19 | 39912754 | + | 5.27E-06 | 0.99999475 |
| GAK | chr4 | 891820 | - | PLEKHG2 | chr19 | 39912754 | + | 5.27E-06 | 0.99999475 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
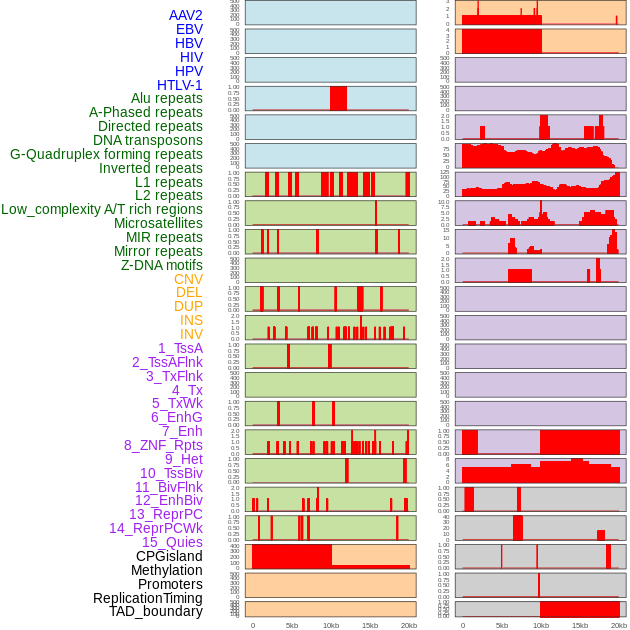 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
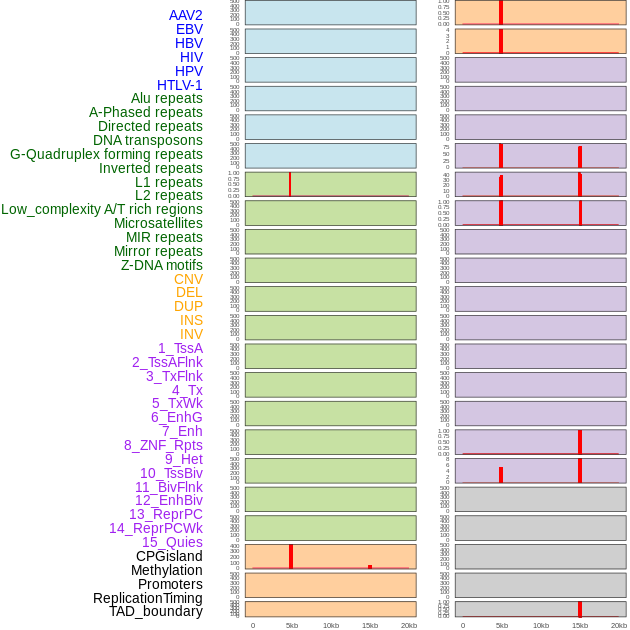 |
Top |
Fusion Protein Features for GAK-PLEKHG2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr4:891821/chr19:39912755) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | PLEKHG2 | chr4:891821 | chr19:39912755 | ENST00000378550 | 15 | 18 | 1067_1184 | 501 | 578.0 | Compositional bias | Note=Pro-rich | |
| Tgene | PLEKHG2 | chr4:891821 | chr19:39912755 | ENST00000378550 | 15 | 18 | 1319_1328 | 501 | 578.0 | Compositional bias | Note=Poly-Pro | |
| Tgene | PLEKHG2 | chr4:891821 | chr19:39912755 | ENST00000378550 | 15 | 18 | 1344_1347 | 501 | 578.0 | Compositional bias | Note=Poly-Gly | |
| Tgene | PLEKHG2 | chr4:891821 | chr19:39912755 | ENST00000378550 | 15 | 18 | 593_600 | 501 | 578.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | PLEKHG2 | chr4:891821 | chr19:39912755 | ENST00000409794 | 15 | 19 | 1067_1184 | 501 | 1387.0 | Compositional bias | Note=Pro-rich | |
| Tgene | PLEKHG2 | chr4:891821 | chr19:39912755 | ENST00000409794 | 15 | 19 | 1319_1328 | 501 | 1387.0 | Compositional bias | Note=Poly-Pro | |
| Tgene | PLEKHG2 | chr4:891821 | chr19:39912755 | ENST00000409794 | 15 | 19 | 1344_1347 | 501 | 1387.0 | Compositional bias | Note=Poly-Gly | |
| Tgene | PLEKHG2 | chr4:891821 | chr19:39912755 | ENST00000409794 | 15 | 19 | 593_600 | 501 | 1387.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | PLEKHG2 | chr4:891821 | chr19:39912755 | ENST00000409797 | 15 | 18 | 1067_1184 | 501 | 578.0 | Compositional bias | Note=Pro-rich | |
| Tgene | PLEKHG2 | chr4:891821 | chr19:39912755 | ENST00000409797 | 15 | 18 | 1319_1328 | 501 | 578.0 | Compositional bias | Note=Poly-Pro | |
| Tgene | PLEKHG2 | chr4:891821 | chr19:39912755 | ENST00000409797 | 15 | 18 | 1344_1347 | 501 | 578.0 | Compositional bias | Note=Poly-Gly | |
| Tgene | PLEKHG2 | chr4:891821 | chr19:39912755 | ENST00000409797 | 15 | 18 | 593_600 | 501 | 578.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | PLEKHG2 | chr4:891821 | chr19:39912755 | ENST00000425673 | 13 | 17 | 1067_1184 | 472 | 1358.0 | Compositional bias | Note=Pro-rich | |
| Tgene | PLEKHG2 | chr4:891821 | chr19:39912755 | ENST00000425673 | 13 | 17 | 1319_1328 | 472 | 1358.0 | Compositional bias | Note=Poly-Pro | |
| Tgene | PLEKHG2 | chr4:891821 | chr19:39912755 | ENST00000425673 | 13 | 17 | 1344_1347 | 472 | 1358.0 | Compositional bias | Note=Poly-Gly | |
| Tgene | PLEKHG2 | chr4:891821 | chr19:39912755 | ENST00000425673 | 13 | 17 | 593_600 | 472 | 1358.0 | Compositional bias | Note=Poly-Glu |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | GAK | chr4:891821 | chr19:39912755 | ENST00000314167 | - | 6 | 28 | 347_350 | 217 | 1312.0 | Compositional bias | Note=Poly-Pro |
| Hgene | GAK | chr4:891821 | chr19:39912755 | ENST00000314167 | - | 6 | 28 | 1247_1311 | 217 | 1312.0 | Domain | J |
| Hgene | GAK | chr4:891821 | chr19:39912755 | ENST00000314167 | - | 6 | 28 | 399_566 | 217 | 1312.0 | Domain | Phosphatase tensin-type |
| Hgene | GAK | chr4:891821 | chr19:39912755 | ENST00000314167 | - | 6 | 28 | 40_314 | 217 | 1312.0 | Domain | Protein kinase |
| Hgene | GAK | chr4:891821 | chr19:39912755 | ENST00000314167 | - | 6 | 28 | 572_710 | 217 | 1312.0 | Domain | C2 tensin-type |
| Tgene | PLEKHG2 | chr4:891821 | chr19:39912755 | ENST00000378550 | 15 | 18 | 102_283 | 501 | 578.0 | Domain | DH | |
| Tgene | PLEKHG2 | chr4:891821 | chr19:39912755 | ENST00000378550 | 15 | 18 | 313_411 | 501 | 578.0 | Domain | PH | |
| Tgene | PLEKHG2 | chr4:891821 | chr19:39912755 | ENST00000409794 | 15 | 19 | 102_283 | 501 | 1387.0 | Domain | DH | |
| Tgene | PLEKHG2 | chr4:891821 | chr19:39912755 | ENST00000409794 | 15 | 19 | 313_411 | 501 | 1387.0 | Domain | PH | |
| Tgene | PLEKHG2 | chr4:891821 | chr19:39912755 | ENST00000409797 | 15 | 18 | 102_283 | 501 | 578.0 | Domain | DH | |
| Tgene | PLEKHG2 | chr4:891821 | chr19:39912755 | ENST00000409797 | 15 | 18 | 313_411 | 501 | 578.0 | Domain | PH | |
| Tgene | PLEKHG2 | chr4:891821 | chr19:39912755 | ENST00000425673 | 13 | 17 | 102_283 | 472 | 1358.0 | Domain | DH | |
| Tgene | PLEKHG2 | chr4:891821 | chr19:39912755 | ENST00000425673 | 13 | 17 | 313_411 | 472 | 1358.0 | Domain | PH |
Top |
Fusion Gene Sequence for GAK-PLEKHG2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >32177_32177_1_GAK-PLEKHG2_GAK_chr4_891821_ENST00000314167_PLEKHG2_chr19_39912755_ENST00000378550_length(transcript)=993nt_BP=762nt GAAGATGGTGCACCTCCGGGCCGGCGGTTGCTGAGCTGACCCGGACGGCGAGGGAGCGGGAGCCCGAGCCCGACCACTCCGGCTGCCGCG GGGTGCGGCGCAGCCACCGCCATGTCGCTGCTGCAGTCGGCGCTCGACTTCTTGGCGGGTCCAGGCTCCCTGGGCGGTGCTTCCGGCCGC GACCAGAGTGACTTCGTGGGGCAGACGGTGGAACTGGGCGAGCTGCGGCTGCGGGTGCGGCGGGTCCTGGCCGAAGGAGGGTTTGCATTT GTGTATGAAGCTCAAGATGTGGGGAGTGGCAGAGAGTATGCATTAAAGAGGCTATTATCCAATGAAGAGGAAAAGAACAGAGCCATCATT CAAGAAGTTTGCTTCATGAAAAAGCTTTCCGGCCACCCGAACATTGTCCAGTTTTGTTCTGCAGCGTCTATAGGAAAAGAGGAGTCAGAC ACGGGGCAGGCTGAGTTCCTCTTGCTCACAGAGCTCTGTAAAGGGCAGCTGGTGGAATTTTTGAAGAAAATGGAATCTCGAGGCCCCCTT TCGTGCGACACGGTTCTGAAGATCTTCTACCAGACGTGCCGCGCCGTGCAGCACATGCACCGGCAGAAGCCGCCCATCATCCACAGGGAC CTCAAGGTTGAGAACTTGTTGCTTAGTAACCAAGGGACCATTAAGCTGTGTGACTTTGGCAGTGCCACGACCATCTCGCACTACCCTGAC TACAGCTGGAGCGCCCAGAGGCGAGCCCTGGTGGAGGAAGAGCACGCTGGCAGCGAAGGGGAACTCTACCCTCCAGAATCTCAGCCACCA GTTTCAGGCTCTGCACCCCCTGAGGACCTGGAGGATGCTGGACCCCCAACACTGGACCCCTCTGGGACCTCAATCACTGAAGAAATCCTG GAACTGCTGAATCAGCGAGGCCTTCGAGATCCAGGGGAATCTATGGGCCTTCACAGGGCCCAGGGGGCTCCTGATGCCCCCTTCCACATG >32177_32177_1_GAK-PLEKHG2_GAK_chr4_891821_ENST00000314167_PLEKHG2_chr19_39912755_ENST00000378550_length(amino acids)=293AA_BP=217 MSLLQSALDFLAGPGSLGGASGRDQSDFVGQTVELGELRLRVRRVLAEGGFAFVYEAQDVGSGREYALKRLLSNEEEKNRAIIQEVCFMK KLSGHPNIVQFCSAASIGKEESDTGQAEFLLLTELCKGQLVEFLKKMESRGPLSCDTVLKIFYQTCRAVQHMHRQKPPIIHRDLKVENLL LSNQGTIKLCDFGSATTISHYPDYSWSAQRRALVEEEHAGSEGELYPPESQPPVSGSAPPEDLEDAGPPTLDPSGTSITEEILELLNQRG -------------------------------------------------------------- >32177_32177_2_GAK-PLEKHG2_GAK_chr4_891821_ENST00000314167_PLEKHG2_chr19_39912755_ENST00000409794_length(transcript)=3640nt_BP=762nt GAAGATGGTGCACCTCCGGGCCGGCGGTTGCTGAGCTGACCCGGACGGCGAGGGAGCGGGAGCCCGAGCCCGACCACTCCGGCTGCCGCG GGGTGCGGCGCAGCCACCGCCATGTCGCTGCTGCAGTCGGCGCTCGACTTCTTGGCGGGTCCAGGCTCCCTGGGCGGTGCTTCCGGCCGC GACCAGAGTGACTTCGTGGGGCAGACGGTGGAACTGGGCGAGCTGCGGCTGCGGGTGCGGCGGGTCCTGGCCGAAGGAGGGTTTGCATTT GTGTATGAAGCTCAAGATGTGGGGAGTGGCAGAGAGTATGCATTAAAGAGGCTATTATCCAATGAAGAGGAAAAGAACAGAGCCATCATT CAAGAAGTTTGCTTCATGAAAAAGCTTTCCGGCCACCCGAACATTGTCCAGTTTTGTTCTGCAGCGTCTATAGGAAAAGAGGAGTCAGAC ACGGGGCAGGCTGAGTTCCTCTTGCTCACAGAGCTCTGTAAAGGGCAGCTGGTGGAATTTTTGAAGAAAATGGAATCTCGAGGCCCCCTT TCGTGCGACACGGTTCTGAAGATCTTCTACCAGACGTGCCGCGCCGTGCAGCACATGCACCGGCAGAAGCCGCCCATCATCCACAGGGAC CTCAAGGTTGAGAACTTGTTGCTTAGTAACCAAGGGACCATTAAGCTGTGTGACTTTGGCAGTGCCACGACCATCTCGCACTACCCTGAC TACAGCTGGAGCGCCCAGAGGCGAGCCCTGGTGGAGGAAGAGCACGCTGGCAGCGAAGGGGAACTCTACCCTCCAGAATCTCAGCCACCA GTTTCAGGCTCTGCACCCCCTGAGGACCTGGAGGATGCTGGACCCCCAACACTGGACCCCTCTGGGACCTCAATCACTGAAGAAATCCTG GAACTGCTGAATCAGCGAGGCCTTCGAGATCCAGGGCCGTCCACCCATGACATTCCCAAGTTCCCCGGAGACTCCCAGGTGCCTGGCGAC AGCGAAACCCTCACATTCCAAGCCCTGCCCAGCCGGGACTCTTCAGAAGAGGAGGAGGAGGAAGAGGAAGGGCTGGAGATGGATGAACGG GGGCCTTCCCCACTCCACGTCCTGGAAGGGCTCGAAAGTTCCATTGCAGCTGAAATGCCCAGCATTCCCTGCCTTACCAAAATTCCTGAC GTGCCCAACCTTCCTGAAATTCCCAGCCGCTGTGAAATTCCCGAAGGTTCTCGCCTTCCTAGTCTCTCTGACATTTCCGATGTTTTTGAG ATGCCCTGCCTTCCAGCCATACCTAGTGTCCCCAACACCCCCAGTCTGTCTAGCACTCCCACCCTCTCCTGTGACTCCTGGCTCCAAGGG CCTCTGCAGGAACCAGCTGAGGCTCCAGCCACCAGGAGAGAACTGTTTTCTGGGAGCAATCCTGGGAAACTGGGAGAGCCGCCTTCAGGA GGCAAGGCAGGGCCAGAGGAGGATGAAGAAGGGGTATCATTCACAGACTTCCAGCCCCAGGATGTCACCCAACATCAGGGATTCCCAGAT GAGCTGGCATTCCGCTCTTGCTCAGAAATCCGGAGCGCCTGGCAGGCATTGGAACAGGGACAGCTGGCCCGGCCAGGCTTCCCAGAGCCA CTGCTGATCCTGGAGGATTCGGATCTGGGTGGAGACAGCGGGAGCGGGAAGGCAGGAGCCCCGAGTTCAGAAAGGACGGCGTCCCGAGTG CGAGAGCTGGCCCGGCTTTACAGCGAGCGGATCCAGCAGATGCAGCGGGCGGAGACTCGGGCATCAGCCAATGCCCCGCGCCGCCGGCCT CGGGTTCTGGCCCAACCCCAGCCATCCCCCTGTCTGCCCCAGGAGCAGGCAGAGCCAGGGCTCCTGCCTGCCTTTGGACACGTGCTGGTA TGTGAGCTGGCCTTCCCACTGACATGTGCCCAGGAGTCTGTCCCCCTGGGTCCTGCTGTCTGGGTTCAAGCTGCCATACCTTTGTCAAAG CAGGGAGGCAGCCCGGATGGCCAGGGTCTACATGTTTCCAATTTGCCTAAGCAAGACCTTCCGGGCATCCACGTTTCAGCTGCTACCCTT TTGCCTGAGCAAGGAGGTTCCCGGCATGTCCAGGCTCCAGCCGCCACACCTTTGCCCAAGCAAGAAGGCCCCCTGCACCTCCAGGTGCCG GCTCTTACAACTTTCTCTGATCAAGGCCACCCAGAAATCCAAGTTCCAGCCACCACTCCTTTGCCTGAGCATAGAAGTCACATGGTTATA CCAGCTCCATCCACCGCCTTTTGTCCTGAGCAGGGACACTGTGCGGACATCCACGTTCCCACCACTCCAGCTTTGCCCAAGGAGATTTGT TCTGATTTCACAGTTTCAGTCACCACCCCTGTGCCCAAGCAAGAAGGTCACCTAGACAGCGAGAGCCCAACCAATATCCCACTGACAAAG CAAGGAGGTTCCAGGGATGTTCAGGGCCCAGACCCTGTCTGCAGTCAACCCATCCAGCCTTTGTCTTGGCATGGAAGCAGCCTGGATCCC CAGGGCCCAGGCGACACCCTACCACCCTTGCCATGTCACCTCCCAGACCTTCAGATTCCAGGTACCTCACCTTTGCCTGCACATGGAAGC CACCTGGACCATCGGATCCCAGCCAACGCCCCACTGTCTTTGTCCCAGGAGCTCCCAGACACTCAGGTTCCAGCTACCACACCTTTGCCC CTGCCACAAGTCCTCACAGACATCTGGGTCCAAGCCCTCCCAACTTCACCCAAGCAGGGAAGCCTCCCAGACATCCAGGGTCCAGCGGCT GCACCTCCACTTCCGGAGCCAAGCCTTACAGATACACAGGTCCAAAAACTCACACCTTCGTTGGAGCAGAAGAGCCTCATAGATGCCCAT GTTCCAGCTGCCACACCTTTACCTGAGAGAGGAGGCTCTCTAGACATTCAGGGCCTCTCACCCACCCCAGTTCAGACCACCATGGTTTTG TCCAAACCAGGAGGCTCCTTAGCCTCTCACGTTGCCAGGTTGGAGTCTTCAGACTTGACGCCACCTCATAGTCCCCCACCTTCCAGCCGT CAGCTCCTGGGCCCCAATGCAGCTGCCCTCTCCAGATACCTGGCAGCCTCATATATCAGCCAGAGCCTGGCTCGGCGGCAGGGGCCTGGG GGAGGGGCCCCCGCAGCCTCCCGGGGCTCCTGGTCCTCTGCTCCCACGTCACGGGCATCTTCGCCGCCCCCCCAGCCCCAGCCACCACCT CCCCCAGCCAGGCGGCTCAGCTATGCCACGACGGTTAACATCCACGTGGGCGGGGGTGGGCGGCTGCGGCCAGCCAAGGCCCAGGTCCGG TTGAACCACCCTGCTCTCTTGGCCTCCACACAGGAATCTATGGGCCTTCACAGGGCCCAGGGGGCTCCTGATGCCCCCTTCCACATGTGA GCCAGGACATGAGGCTTCCCTGAAGCAAGGATTTCAGCCAGATGCCATAGACCCTCAGAACTTGACCTGGAAGTCCAGACACTGAACGCA GGCCTCAAAACTGCTGCGGCCTTCCAACTCCTGGTATCTGCATCGGCGAATGGCCCTTCTTGCCTTGATCCACAGGGATGGGGAAGGGAG >32177_32177_2_GAK-PLEKHG2_GAK_chr4_891821_ENST00000314167_PLEKHG2_chr19_39912755_ENST00000409794_length(amino acids)=1102AA_BP=217 MSLLQSALDFLAGPGSLGGASGRDQSDFVGQTVELGELRLRVRRVLAEGGFAFVYEAQDVGSGREYALKRLLSNEEEKNRAIIQEVCFMK KLSGHPNIVQFCSAASIGKEESDTGQAEFLLLTELCKGQLVEFLKKMESRGPLSCDTVLKIFYQTCRAVQHMHRQKPPIIHRDLKVENLL LSNQGTIKLCDFGSATTISHYPDYSWSAQRRALVEEEHAGSEGELYPPESQPPVSGSAPPEDLEDAGPPTLDPSGTSITEEILELLNQRG LRDPGPSTHDIPKFPGDSQVPGDSETLTFQALPSRDSSEEEEEEEEGLEMDERGPSPLHVLEGLESSIAAEMPSIPCLTKIPDVPNLPEI PSRCEIPEGSRLPSLSDISDVFEMPCLPAIPSVPNTPSLSSTPTLSCDSWLQGPLQEPAEAPATRRELFSGSNPGKLGEPPSGGKAGPEE DEEGVSFTDFQPQDVTQHQGFPDELAFRSCSEIRSAWQALEQGQLARPGFPEPLLILEDSDLGGDSGSGKAGAPSSERTASRVRELARLY SERIQQMQRAETRASANAPRRRPRVLAQPQPSPCLPQEQAEPGLLPAFGHVLVCELAFPLTCAQESVPLGPAVWVQAAIPLSKQGGSPDG QGLHVSNLPKQDLPGIHVSAATLLPEQGGSRHVQAPAATPLPKQEGPLHLQVPALTTFSDQGHPEIQVPATTPLPEHRSHMVIPAPSTAF CPEQGHCADIHVPTTPALPKEICSDFTVSVTTPVPKQEGHLDSESPTNIPLTKQGGSRDVQGPDPVCSQPIQPLSWHGSSLDPQGPGDTL PPLPCHLPDLQIPGTSPLPAHGSHLDHRIPANAPLSLSQELPDTQVPATTPLPLPQVLTDIWVQALPTSPKQGSLPDIQGPAAAPPLPEP SLTDTQVQKLTPSLEQKSLIDAHVPAATPLPERGGSLDIQGLSPTPVQTTMVLSKPGGSLASHVARLESSDLTPPHSPPPSSRQLLGPNA AALSRYLAASYISQSLARRQGPGGGAPAASRGSWSSAPTSRASSPPPQPQPPPPPARRLSYATTVNIHVGGGGRLRPAKAQVRLNHPALL -------------------------------------------------------------- >32177_32177_3_GAK-PLEKHG2_GAK_chr4_891821_ENST00000314167_PLEKHG2_chr19_39912755_ENST00000409797_length(transcript)=1215nt_BP=762nt GAAGATGGTGCACCTCCGGGCCGGCGGTTGCTGAGCTGACCCGGACGGCGAGGGAGCGGGAGCCCGAGCCCGACCACTCCGGCTGCCGCG GGGTGCGGCGCAGCCACCGCCATGTCGCTGCTGCAGTCGGCGCTCGACTTCTTGGCGGGTCCAGGCTCCCTGGGCGGTGCTTCCGGCCGC GACCAGAGTGACTTCGTGGGGCAGACGGTGGAACTGGGCGAGCTGCGGCTGCGGGTGCGGCGGGTCCTGGCCGAAGGAGGGTTTGCATTT GTGTATGAAGCTCAAGATGTGGGGAGTGGCAGAGAGTATGCATTAAAGAGGCTATTATCCAATGAAGAGGAAAAGAACAGAGCCATCATT CAAGAAGTTTGCTTCATGAAAAAGCTTTCCGGCCACCCGAACATTGTCCAGTTTTGTTCTGCAGCGTCTATAGGAAAAGAGGAGTCAGAC ACGGGGCAGGCTGAGTTCCTCTTGCTCACAGAGCTCTGTAAAGGGCAGCTGGTGGAATTTTTGAAGAAAATGGAATCTCGAGGCCCCCTT TCGTGCGACACGGTTCTGAAGATCTTCTACCAGACGTGCCGCGCCGTGCAGCACATGCACCGGCAGAAGCCGCCCATCATCCACAGGGAC CTCAAGGTTGAGAACTTGTTGCTTAGTAACCAAGGGACCATTAAGCTGTGTGACTTTGGCAGTGCCACGACCATCTCGCACTACCCTGAC TACAGCTGGAGCGCCCAGAGGCGAGCCCTGGTGGAGGAAGAGCACGCTGGCAGCGAAGGGGAACTCTACCCTCCAGAATCTCAGCCACCA GTTTCAGGCTCTGCACCCCCTGAGGACCTGGAGGATGCTGGACCCCCAACACTGGACCCCTCTGGGACCTCAATCACTGAAGAAATCCTG GAACTGCTGAATCAGCGAGGCCTTCGAGATCCAGGGGAATCTATGGGCCTTCACAGGGCCCAGGGGGCTCCTGATGCCCCCTTCCACATG TGAGCCAGGACATGAGGCTTCCCTGAAGCAAGGATTTCAGCCAGATGCCATAGACCCTCAGAACTTGACCTGGAAGTCCAGACACTGAAC GCAGGCCTCAAAACTGCTGCGGCCTTCCAACTCCTGGTATCTGCATCGGCGAATGGCCCTTCTTGCCTTGATCCACAGGGATGGGGAAGG >32177_32177_3_GAK-PLEKHG2_GAK_chr4_891821_ENST00000314167_PLEKHG2_chr19_39912755_ENST00000409797_length(amino acids)=293AA_BP=217 MSLLQSALDFLAGPGSLGGASGRDQSDFVGQTVELGELRLRVRRVLAEGGFAFVYEAQDVGSGREYALKRLLSNEEEKNRAIIQEVCFMK KLSGHPNIVQFCSAASIGKEESDTGQAEFLLLTELCKGQLVEFLKKMESRGPLSCDTVLKIFYQTCRAVQHMHRQKPPIIHRDLKVENLL LSNQGTIKLCDFGSATTISHYPDYSWSAQRRALVEEEHAGSEGELYPPESQPPVSGSAPPEDLEDAGPPTLDPSGTSITEEILELLNQRG -------------------------------------------------------------- >32177_32177_4_GAK-PLEKHG2_GAK_chr4_891821_ENST00000314167_PLEKHG2_chr19_39912755_ENST00000425673_length(transcript)=6540nt_BP=762nt GAAGATGGTGCACCTCCGGGCCGGCGGTTGCTGAGCTGACCCGGACGGCGAGGGAGCGGGAGCCCGAGCCCGACCACTCCGGCTGCCGCG GGGTGCGGCGCAGCCACCGCCATGTCGCTGCTGCAGTCGGCGCTCGACTTCTTGGCGGGTCCAGGCTCCCTGGGCGGTGCTTCCGGCCGC GACCAGAGTGACTTCGTGGGGCAGACGGTGGAACTGGGCGAGCTGCGGCTGCGGGTGCGGCGGGTCCTGGCCGAAGGAGGGTTTGCATTT GTGTATGAAGCTCAAGATGTGGGGAGTGGCAGAGAGTATGCATTAAAGAGGCTATTATCCAATGAAGAGGAAAAGAACAGAGCCATCATT CAAGAAGTTTGCTTCATGAAAAAGCTTTCCGGCCACCCGAACATTGTCCAGTTTTGTTCTGCAGCGTCTATAGGAAAAGAGGAGTCAGAC ACGGGGCAGGCTGAGTTCCTCTTGCTCACAGAGCTCTGTAAAGGGCAGCTGGTGGAATTTTTGAAGAAAATGGAATCTCGAGGCCCCCTT TCGTGCGACACGGTTCTGAAGATCTTCTACCAGACGTGCCGCGCCGTGCAGCACATGCACCGGCAGAAGCCGCCCATCATCCACAGGGAC CTCAAGGTTGAGAACTTGTTGCTTAGTAACCAAGGGACCATTAAGCTGTGTGACTTTGGCAGTGCCACGACCATCTCGCACTACCCTGAC TACAGCTGGAGCGCCCAGAGGCGAGCCCTGGTGGAGGAAGAGCACGCTGGCAGCGAAGGGGAACTCTACCCTCCAGAATCTCAGCCACCA GTTTCAGGCTCTGCACCCCCTGAGGACCTGGAGGATGCTGGACCCCCAACACTGGACCCCTCTGGGACCTCAATCACTGAAGAAATCCTG GAACTGCTGAATCAGCGAGGCCTTCGAGATCCAGGGCCGTCCACCCATGACATTCCCAAGTTCCCCGGAGACTCCCAGGTGCCTGGCGAC AGCGAAACCCTCACATTCCAAGCCCTGCCCAGCCGGGACTCTTCAGAAGAGGAGGAGGAGGAAGAGGAAGGGCTGGAGATGGATGAACGG GGGCCTTCCCCACTCCACGTCCTGGAAGGGCTCGAAAGTTCCATTGCAGCTGAAATGCCCAGCATTCCCTGCCTTACCAAAATTCCTGAC GTGCCCAACCTTCCTGAAATTCCCAGCCGCTGTGAAATTCCCGAAGGTTCTCGCCTTCCTAGTCTCTCTGACATTTCCGATGTTTTTGAG ATGCCCTGCCTTCCAGCCATACCTAGTGTCCCCAACACCCCCAGTCTGTCTAGCACTCCCACCCTCTCCTGTGACTCCTGGCTCCAAGGG CCTCTGCAGGAACCAGCTGAGGCTCCAGCCACCAGGAGAGAACTGTTTTCTGGGAGCAATCCTGGGAAACTGGGAGAGCCGCCTTCAGGA GGCAAGGCAGGGCCAGAGGAGGATGAAGAAGGGGTATCATTCACAGACTTCCAGCCCCAGGATGTCACCCAACATCAGGGATTCCCAGAT GAGCTGGCATTCCGCTCTTGCTCAGAAATCCGGAGCGCCTGGCAGGCATTGGAACAGGGACAGCTGGCCCGGCCAGGCTTCCCAGAGCCA CTGCTGATCCTGGAGGATTCGGATCTGGGTGGAGACAGCGGGAGCGGGAAGGCAGGAGCCCCGAGTTCAGAAAGGACGGCGTCCCGAGTG CGAGAGCTGGCCCGGCTTTACAGCGAGCGGATCCAGCAGATGCAGCGGGCGGAGACTCGGGCATCAGCCAATGCCCCGCGCCGCCGGCCT CGGGTTCTGGCCCAACCCCAGCCATCCCCCTGTCTGCCCCAGGAGCAGGCAGAGCCAGGGCTCCTGCCTGCCTTTGGACACGTGCTGGTA TGTGAGCTGGCCTTCCCACTGACATGTGCCCAGGAGTCTGTCCCCCTGGGTCCTGCTGTCTGGGTTCAAGCTGCCATACCTTTGTCAAAG CAGGGAGGCAGCCCGGATGGCCAGGGTCTACATGTTTCCAATTTGCCTAAGCAAGACCTTCCGGGCATCCACGTTTCAGCTGCTACCCTT TTGCCTGAGCAAGGAGGTTCCCGGCATGTCCAGGCTCCAGCCGCCACACCTTTGCCCAAGCAAGAAGGCCCCCTGCACCTCCAGGTGCCG GCTCTTACAACTTTCTCTGATCAAGGCCACCCAGAAATCCAAGTTCCAGCCACCACTCCTTTGCCTGAGCATAGAAGTCACATGGTTATA CCAGCTCCATCCACCGCCTTTTGTCCTGAGCAGGGACACTGTGCGGACATCCACGTTCCCACCACTCCAGCTTTGCCCAAGGAGATTTGT TCTGATTTCACAGTTTCAGTCACCACCCCTGTGCCCAAGCAAGAAGGTCACCTAGACAGCGAGAGCCCAACCAATATCCCACTGACAAAG CAAGGAGGTTCCAGGGATGTTCAGGGCCCAGACCCTGTCTGCAGTCAACCCATCCAGCCTTTGTCTTGGCATGGAAGCAGCCTGGATCCC CAGGGCCCAGGCGACACCCTACCACCCTTGCCATGTCACCTCCCAGACCTTCAGATTCCAGGTACCTCACCTTTGCCTGCACATGGAAGC CACCTGGACCATCGGATCCCAGCCAACGCCCCACTGTCTTTGTCCCAGGAGCTCCCAGACACTCAGGTTCCAGCTACCACACCTTTGCCC CTGCCACAAGTCCTCACAGACATCTGGGTCCAAGCCCTCCCAACTTCACCCAAGCAGGGAAGCCTCCCAGACATCCAGGGTCCAGCGGCT GCACCTCCACTTCCGGAGCCAAGCCTTACAGATACACAGGTCCAAAAACTCACACCTTCGTTGGAGCAGAAGAGCCTCATAGATGCCCAT GTTCCAGCTGCCACACCTTTACCTGAGAGAGGAGGCTCTCTAGACATTCAGGGCCTCTCACCCACCCCAGTTCAGACCACCATGGTTTTG TCCAAACCAGGAGGCTCCTTAGCCTCTCACGTTGCCAGGTTGGAGTCTTCAGACTTGACGCCACCTCATAGTCCCCCACCTTCCAGCCGT CAGCTCCTGGGCCCCAATGCAGCTGCCCTCTCCAGATACCTGGCAGCCTCATATATCAGCCAGAGCCTGGCTCGGCGGCAGGGGCCTGGG GGAGGGGCCCCCGCAGCCTCCCGGGGCTCCTGGTCCTCTGCTCCCACGTCACGGGCATCTTCGCCGCCCCCCCAGCCCCAGCCACCACCT CCCCCAGCCAGGCGGCTCAGCTATGCCACGACGGTTAACATCCACGTGGGCGGGGGTGGGCGGCTGCGGCCAGCCAAGGCCCAGGTCCGG TTGAACCACCCTGCTCTCTTGGCCTCCACACAGGAATCTATGGGCCTTCACAGGGCCCAGGGGGCTCCTGATGCCCCCTTCCACATGTGA GCCAGGACATGAGGCTTCCCTGAAGCAAGGATTTCAGCCAGATGCCATAGACCCTCAGAACTTGACCTGGAAGTCCAGACACTGAACGCA GGCCTCAAAACTGCTGCGGCCTTCCAACTCCTGGTATCTGCATCGGCGAATGGCCCTTCTTGCCTTGATCCACAGGGATGGGGAAGGGAG GAATGTCATTAATGTTTTGTTAATACTGATTCTTTCATGCAATGATGTGTATTTTCCCATTCTGGAGGCTGTGGGAGATGACAAGACAAT GAATGGGAAGGTCTGACACAGAACAAATCAGCGGTTCTGAAAGCTTGGGGAATCTCAGACTCCTTTGAGAATTATTGGAAAATGGACCCA CTATAACTTGGCGTGTGTGTGAACTGCTTGATGCCCATCCAGGAAAGCCAAGTTAAGAAGCTTTGCTTCAAGTAGACACTAGAAATCCAT TCCCTTGGCAATTTATACAGTTCACGTCTCCCACCATCCGTTCATCTCACCCACCCTGCCATCTCTCCACCTATCCATCTGGCTATTGCT CCATCTAGCTTTCCCGCTCCATCTACCCATCTTCCAATCCATCATCTCACGTATCTGCCTTGCTTATCCAACTGTCTGCCTTATTCACCC ACCCATCCCTTTATCATTCTAACCCCATCTGGCATTCCATCCCTCCATTTATCCATCTTCCCACTTACCCATCTTCTCCATCCAGCACTC CGTTCATCAGTCCGTCTCTCCCTCCATATTTCCATCTGTCCATTCATCCACTCATTTTGCCATCCATACATATTCACCCAGCCATCTCCC AATCCATCGACATACCCCATCCCTCCCTCACTGGACTCTCCGGGGTCTTAGTACTATGATACTTCAGAGACAATTCCATGCTGATACGGG GGAGATCAATTTTGGGGCTCTGGGATAAGTCTGTCCCACATCTGTCTGATTTCCCTTGGCATCCTTCCCGTCAGTTCCTCTTGAATATCC CAGTTCTTGTACCCACTCACATACCTCAGATCCCTTCACTCCTCCCCGCAGTTTGCAGCCTCTACAATTCATCCACATGCTCCCTCCCCC AGCAAAATAATTCAGGTCGTGGAGACAAAAGGCTTTTATGTTAGGTTCTGTCTGCCCCCTTGTTCCAGCAGTGGTATGCCCAGTGAGAGG CACAATTTAAACGGTTTCTTTGGTGATGATATTAGCTACTTTCATCAAATACTTAGCCTCTTGTGCTTTAGCACATTATTTATGTAAGCT CCCCTAGGATTCTCTGAAGCACCCTGGTGTCCTGGCTGTGAATTCAAGTCCCATCTTTACTTATTTGGTGTGGGTCCTCCCTCTGAGCCG GTTTTCTCATCTACAAAATGAAGACAACAGTACTTCCCTCCTGGGATCATTGAAAGATTTAGGGAGCATATCCTTCCACTTCCCAAACAT ATTTGAACCTCTGACTTGCTTAGGAGCATCATTCAAATCACAGATCCCCCAGTATCTAGTCCCAACCTATTGAATCAGGATCCCCAGGGA AGGAGGAGCTTGGGAATCTGATTTTTTTTTTTTTTTTTAGATAAAGTCTCACTCTGTCACCCAGGCTTGAGTGCAGTGGCAAAATCTTGG CTCATTGCAACCTCCACCTCCTGGGTTCAAGCAATTCTCATGCCTCAGCTTCCCGACATAGCTGGGATTATAGGCGTGCACCACCATGCC CAGCTAATTTTTCGTTGTTGTTGTTGTTGTTTTGTTTTTGAGACAGAGTCTCGCTCTGTTGCCCAGGCTGGAGTACAGTGGCACGATCTT GGCTCACTGCAAGCTCCGCTTCCCGGGTTCACGCCATTCTCCTGCCTCAGCCTCCCGAGTAGCTGGGACCACAGGTGCCCGCCACCACGC CCGGCTAATTTTTTTGGTATTTTTAGTAGAGACGGGGTTTTACCATGTTAGCCAGGATGGTCTCGATCTCCTGACCTCGTGATCCTCCCG CCTCGGCCTCCCAAAGTGCTGGCATTACAGGCGTGAGCCATCATTCCTGGCTGGGAATCCGAATTTTTTTTTTTTTTTAGACGGAGTTTC GCTCTTGTTGCCCAGGCTGGAGTTCAATAGCATGATCTCGGCTCACTGCAACCTCTGCCTCCCAGGTTCAAGTGATTCTCCTGCCTCTAG CTGGGATTGCAGGCGCCCACGACCACGCCCAGCTAATTTTTGTATTTTGTAGTAGAGACGGGATTTCGCCATATTGGCCAGGCCATAGTG GTCTTGGACTCCTGACCTCAGGTGATCCGCCCACCTCGGCCTCCCAAAGTGTTGGGTTTACAGGCGTGAGCTACCATACCCTGCCCAGGA ATCTGAATTTTTAGCAATCAGTTAGCAGCAAATAAGCTGAGATTTCCTGGGTACTAAGCACATACTATGAGCATTACAGCCGCTTTATAT AAGCTCGTTCACTGTCCTCATTACATTCCTAATATGCAAGTGAGCATGTTTTTTAATCCTCAGTCTAGAGGTGAGGAAACTGAGGCAGGC ACAGAGAGGCTAAGGGATTTGCCTAGTCGCACAGCTAGGAAGGTGCAGCACTGAGACTCGAATCCACACAGCTTGGCTTAAGTCTACCAT TAAATTTGCCTGTCCTGGCCAGGTGCGGTGGCTCACGCCTGTAATCCCAACACTTCGTGAGGCCAAGGCAGGTGGATCACTTGAAGTGAG GAGTTCGAGACCACACCAGCCTGGCCAACATGGTGAAATCCCGTCTTTACTAAAAATACAAAAAATTAGCTGGGCGTGGTGGTGGGTGCC GGTAATCCTAGCTACTCAGGAGGCTGAGGCAGGAGAATCACTTGAACCTGGGAGGTGGAGGTTGCAGTGAACCGAGATTGCGCCACTAGA CTCCAGCCTGGGAGACGAGCAAAACTGTCTCAAAAAAATAAAATGAAATACATAAATAAATGTGCCTATCCTGTGCCGGGTGCTGTTCTT GCCAGTGGGGATACATGAGAGAACACTGCCTTGCCCGCATGAGGCTTGTGGCCTGGTACTGTGCACACCTCAGGGGATTCTGATAATTAG >32177_32177_4_GAK-PLEKHG2_GAK_chr4_891821_ENST00000314167_PLEKHG2_chr19_39912755_ENST00000425673_length(amino acids)=1102AA_BP=217 MSLLQSALDFLAGPGSLGGASGRDQSDFVGQTVELGELRLRVRRVLAEGGFAFVYEAQDVGSGREYALKRLLSNEEEKNRAIIQEVCFMK KLSGHPNIVQFCSAASIGKEESDTGQAEFLLLTELCKGQLVEFLKKMESRGPLSCDTVLKIFYQTCRAVQHMHRQKPPIIHRDLKVENLL LSNQGTIKLCDFGSATTISHYPDYSWSAQRRALVEEEHAGSEGELYPPESQPPVSGSAPPEDLEDAGPPTLDPSGTSITEEILELLNQRG LRDPGPSTHDIPKFPGDSQVPGDSETLTFQALPSRDSSEEEEEEEEGLEMDERGPSPLHVLEGLESSIAAEMPSIPCLTKIPDVPNLPEI PSRCEIPEGSRLPSLSDISDVFEMPCLPAIPSVPNTPSLSSTPTLSCDSWLQGPLQEPAEAPATRRELFSGSNPGKLGEPPSGGKAGPEE DEEGVSFTDFQPQDVTQHQGFPDELAFRSCSEIRSAWQALEQGQLARPGFPEPLLILEDSDLGGDSGSGKAGAPSSERTASRVRELARLY SERIQQMQRAETRASANAPRRRPRVLAQPQPSPCLPQEQAEPGLLPAFGHVLVCELAFPLTCAQESVPLGPAVWVQAAIPLSKQGGSPDG QGLHVSNLPKQDLPGIHVSAATLLPEQGGSRHVQAPAATPLPKQEGPLHLQVPALTTFSDQGHPEIQVPATTPLPEHRSHMVIPAPSTAF CPEQGHCADIHVPTTPALPKEICSDFTVSVTTPVPKQEGHLDSESPTNIPLTKQGGSRDVQGPDPVCSQPIQPLSWHGSSLDPQGPGDTL PPLPCHLPDLQIPGTSPLPAHGSHLDHRIPANAPLSLSQELPDTQVPATTPLPLPQVLTDIWVQALPTSPKQGSLPDIQGPAAAPPLPEP SLTDTQVQKLTPSLEQKSLIDAHVPAATPLPERGGSLDIQGLSPTPVQTTMVLSKPGGSLASHVARLESSDLTPPHSPPPSSRQLLGPNA AALSRYLAASYISQSLARRQGPGGGAPAASRGSWSSAPTSRASSPPPQPQPPPPPARRLSYATTVNIHVGGGGRLRPAKAQVRLNHPALL -------------------------------------------------------------- >32177_32177_5_GAK-PLEKHG2_GAK_chr4_891821_ENST00000314167_PLEKHG2_chr19_39912755_ENST00000458508_length(transcript)=3208nt_BP=762nt GAAGATGGTGCACCTCCGGGCCGGCGGTTGCTGAGCTGACCCGGACGGCGAGGGAGCGGGAGCCCGAGCCCGACCACTCCGGCTGCCGCG GGGTGCGGCGCAGCCACCGCCATGTCGCTGCTGCAGTCGGCGCTCGACTTCTTGGCGGGTCCAGGCTCCCTGGGCGGTGCTTCCGGCCGC GACCAGAGTGACTTCGTGGGGCAGACGGTGGAACTGGGCGAGCTGCGGCTGCGGGTGCGGCGGGTCCTGGCCGAAGGAGGGTTTGCATTT GTGTATGAAGCTCAAGATGTGGGGAGTGGCAGAGAGTATGCATTAAAGAGGCTATTATCCAATGAAGAGGAAAAGAACAGAGCCATCATT CAAGAAGTTTGCTTCATGAAAAAGCTTTCCGGCCACCCGAACATTGTCCAGTTTTGTTCTGCAGCGTCTATAGGAAAAGAGGAGTCAGAC ACGGGGCAGGCTGAGTTCCTCTTGCTCACAGAGCTCTGTAAAGGGCAGCTGGTGGAATTTTTGAAGAAAATGGAATCTCGAGGCCCCCTT TCGTGCGACACGGTTCTGAAGATCTTCTACCAGACGTGCCGCGCCGTGCAGCACATGCACCGGCAGAAGCCGCCCATCATCCACAGGGAC CTCAAGGTTGAGAACTTGTTGCTTAGTAACCAAGGGACCATTAAGCTGTGTGACTTTGGCAGTGCCACGACCATCTCGCACTACCCTGAC TACAGCTGGAGCGCCCAGAGGCGAGCCCTGGTGGAGGAAGAGCACGCTGGCAGCGAAGGGGAACTCTACCCTCCAGAATCTCAGCCACCA GTTTCAGGCTCTGCACCCCCTGAGGACCTGGAGGATGCTGGACCCCCAACACTGGACCCCTCTGGGACCTCAATCACTGAAGAAATCCTG GAACTGCTGAATCAGCGAGGCCTTCGAGATCCAGGGCCGTCCACCCATGACATTCCCAAGTTCCCCGGAGACTCCCAGGTGCCTGGCGAC AGCGAAACCCTCACATTCCAAGCCCTGCCCAGCCGGGACTCTTCAGAAGAGGAGGAGGAGGAAGAGGAAGGGCTGGAGATGGATGAACGG GGGCCTTCCCCACTCCACGTCCTGGAAGGGCTCGAAAGTTCCATTGCAGCTGAAATGCCCAGCATTCCCTGCCTTACCAAAATTCCTGAC GTGCCCAACCTTCCTGAAATTCCCAGCCGCTGTGAAATTCCCGAAGGTTCTCGCCTTCCTAGTCTCTCTGACATTTCCGATGTTTTTGAG ATGCCCTGCCTTCCAGCCATACCTAGTGTCCCCAACACCCCCAGTCTGTCTAGCACTCCCACCCTCTCCTGTGACTCCTGGCTCCAAGGG CCTCTGCAGGAACCAGCTGAGGCTCCAGCCACCAGGAGAGAACTGTTTTCTGGGAGCAATCCTGGGAAACTGGGAGAGCCGCCTTCAGGA GGCAAGGCAGGGCCAGAGGAGGATGAAGAAGGGGTATCATTCACAGACTTCCAGCCCCAGGATGTCACCCAACATCAGGGATTCCCAGAT GAGCTGGCATTCCGCTCTTGCTCAGAAATCCGGAGCGCCTGGCAGGCATTGGAACAGGGACAGCTGGCCCGGCCAGGCTTCCCAGAGCCA CTGCTGATCCTGGAGGATTCGGATCTGGGTGGAGACAGCGGGAGCGGGAAGGCAGGAGCCCCGAGTTCAGAAAGGACGGCGTCCCGAGTG CGAGAGCTGGCCCGGCTTTACAGCGAGCGGATCCAGCAGATGCAGCGGGCGGAGACTCGGGCATCAGCCAATGCCCCGCGCCGCCGGCCT CGGGTTCTGGCCCAACCCCAGCCATCCCCCTGTCTGCCCCAGGAGCAGGCAGAGCCAGGGCTCCTGCCTGCCTTTGGACACGTGCTGGTA TGTGAGCTGGCCTTCCCACTGACATGTGCCCAGGAGTCTGTCCCCCTGGGTCCTGCTGTCTGGGTTCAAGCTGCCATACCTTTGTCAAAG CAGGGAGGCAGCCCGGATGGCCAGGGTCTACATGTTTCCAATTTGCCTAAGCAAGACCTTCCGGGCATCCACGTTTCAGCTGCTACCCTT TTGCCTGAGCAAGGAGGTTCCCGGCATGTCCAGGCTCCAGCCGCCACACCTTTGCCCAAGCAAGAAGGCCCCCTGCACCTCCAGGTGCCG GCTCTTACAACTTTCTCTGATCAAGGCCACCCAGAAATCCAAGTTCCAGCCACCACTCCTTTGCCTGAGCATAGAAGTCACATGGTTATA CCAGCTCCATCCACCGCCTTTTGTCCTGAGCAGGGACACTGTGCGGACATCCACGTTCCCACCACTCCAGCTTTGCCCAAGGAGATTTGT TCTGATTTCACAGTTTCAGTCACCACCCCTGTGCCCAAGCAAGAAGGTCACCTAGACAGCGAGAGCCCAACCAATATCCCACTGACAAAG CAAGGAGGTTCCAGGGATGTTCAGGGCCCAGACCCTGTCTGCAGTCAACCCATCCAGCCTTTGTCTTGGCATGGAAGCAGCCTGGATCCC CAGGGCCCAGGCGACACCCTACCACCCTTGCCATGTCACCTCCCAGACCTTCAGATTCCAGGTACCTCACCTTTGCCTGCACATGGAAGC CACCTGGACCATCGGATCCCAGCCAACGCCCCACTGTCTTTGTCCCAGGAGCTCCCAGACACTCAGGTTCCAGCTACCACACCTTTGCCC CTGCCACAAGTCCTCACAGACATCTGGGTCCAAGCCCTCCCAACTTCACCCAAGCAGGGAAGCCTCCCAGACATCCAGGGTCCAGCGGCT GCACCTCCACTTCCGGAGCCAAGCCTTACAGATACACAGGTCCAAAAACTCACACCTTCGTTGGAGCAGAAGAGCCTCATAGATGCCCAT GTTCCAGCTGCCACACCTTTACCTGAGAGAGGAGGCTCTCTAGACATTCAGGGCCTCTCACCCACCCCAGTTCAGACCACCATGGTTTTG TCCAAACCAGGAGGCTCCTTAGCCTCTCACGTTGCCAGGAATCTATGGGCCTTCACAGGGCCCAGGGGGCTCCTGATGCCCCCTTCCACA TGTGAGCCAGGACATGAGGCTTCCCTGAAGCAAGGATTTCAGCCAGATGCCATAGACCCTCAGAACTTGACCTGGAAGTCCAGACACTGA >32177_32177_5_GAK-PLEKHG2_GAK_chr4_891821_ENST00000314167_PLEKHG2_chr19_39912755_ENST00000458508_length(amino acids)=1012AA_BP=217 MSLLQSALDFLAGPGSLGGASGRDQSDFVGQTVELGELRLRVRRVLAEGGFAFVYEAQDVGSGREYALKRLLSNEEEKNRAIIQEVCFMK KLSGHPNIVQFCSAASIGKEESDTGQAEFLLLTELCKGQLVEFLKKMESRGPLSCDTVLKIFYQTCRAVQHMHRQKPPIIHRDLKVENLL LSNQGTIKLCDFGSATTISHYPDYSWSAQRRALVEEEHAGSEGELYPPESQPPVSGSAPPEDLEDAGPPTLDPSGTSITEEILELLNQRG LRDPGPSTHDIPKFPGDSQVPGDSETLTFQALPSRDSSEEEEEEEEGLEMDERGPSPLHVLEGLESSIAAEMPSIPCLTKIPDVPNLPEI PSRCEIPEGSRLPSLSDISDVFEMPCLPAIPSVPNTPSLSSTPTLSCDSWLQGPLQEPAEAPATRRELFSGSNPGKLGEPPSGGKAGPEE DEEGVSFTDFQPQDVTQHQGFPDELAFRSCSEIRSAWQALEQGQLARPGFPEPLLILEDSDLGGDSGSGKAGAPSSERTASRVRELARLY SERIQQMQRAETRASANAPRRRPRVLAQPQPSPCLPQEQAEPGLLPAFGHVLVCELAFPLTCAQESVPLGPAVWVQAAIPLSKQGGSPDG QGLHVSNLPKQDLPGIHVSAATLLPEQGGSRHVQAPAATPLPKQEGPLHLQVPALTTFSDQGHPEIQVPATTPLPEHRSHMVIPAPSTAF CPEQGHCADIHVPTTPALPKEICSDFTVSVTTPVPKQEGHLDSESPTNIPLTKQGGSRDVQGPDPVCSQPIQPLSWHGSSLDPQGPGDTL PPLPCHLPDLQIPGTSPLPAHGSHLDHRIPANAPLSLSQELPDTQVPATTPLPLPQVLTDIWVQALPTSPKQGSLPDIQGPAAAPPLPEP SLTDTQVQKLTPSLEQKSLIDAHVPAATPLPERGGSLDIQGLSPTPVQTTMVLSKPGGSLASHVARNLWAFTGPRGLLMPPSTCEPGHEA -------------------------------------------------------------- >32177_32177_6_GAK-PLEKHG2_GAK_chr4_891821_ENST00000511163_PLEKHG2_chr19_39912755_ENST00000378550_length(transcript)=831nt_BP=600nt AGGGGACGGGGCTAGGCCGGGTCGCCGCCTGACGCGACGCGTCCTCACGGGCGCCTACGTCACGGCGTCGAGGCGGAAGATGGTGCACCT CCGGGCCGGCGGTTGCTGAGCTGACCCGGACGGCGAGGGAGCGGGAGCCCGAGCCCGACCACTCCGGCTGCCGCGGGGTGCGGCGCAGCC ACCGCCATGTCGCTGCTGCAGTCGGCGCTCGACTTCTTGGCGGGTCCAGGCTCCCTGGGCGGTGCTTCCGGCCGCGACCAGAGTGACTTC GTGGGGCAGACGGTGGAACTGGGCGAGCTGCGGCTGCGGGTGCGGCGGGTCCTGGCCGAAGGGCAGCTGGTGGAATTTTTGAAGAAAATG GAATCTCGAGGCCCCCTTTCGTGCGACACGGTTCTGAAGATCTTCTACCAGACGTGCCGCGCCGTGCAGCACATGCACCGGCAGAAGCCG CCCATCATCCACAGGGACCTCAAGGTTGAGAACTTGTTGCTTAGTAACCAAGGGACCATTAAGCTGTGTGACTTTGGCAGTGCCACGACC ATCTCGCACTACCCTGACTACAGCTGGAGCGCCCAGAGGCGAGCCCTGGTGGAGGAAGAGCACGCTGGCAGCGAAGGGGAACTCTACCCT CCAGAATCTCAGCCACCAGTTTCAGGCTCTGCACCCCCTGAGGACCTGGAGGATGCTGGACCCCCAACACTGGACCCCTCTGGGACCTCA ATCACTGAAGAAATCCTGGAACTGCTGAATCAGCGAGGCCTTCGAGATCCAGGGGAATCTATGGGCCTTCACAGGGCCCAGGGGGCTCCT >32177_32177_6_GAK-PLEKHG2_GAK_chr4_891821_ENST00000511163_PLEKHG2_chr19_39912755_ENST00000378550_length(amino acids)=214AA_BP=138 MSLLQSALDFLAGPGSLGGASGRDQSDFVGQTVELGELRLRVRRVLAEGQLVEFLKKMESRGPLSCDTVLKIFYQTCRAVQHMHRQKPPI IHRDLKVENLLLSNQGTIKLCDFGSATTISHYPDYSWSAQRRALVEEEHAGSEGELYPPESQPPVSGSAPPEDLEDAGPPTLDPSGTSIT -------------------------------------------------------------- >32177_32177_7_GAK-PLEKHG2_GAK_chr4_891821_ENST00000511163_PLEKHG2_chr19_39912755_ENST00000409794_length(transcript)=3478nt_BP=600nt AGGGGACGGGGCTAGGCCGGGTCGCCGCCTGACGCGACGCGTCCTCACGGGCGCCTACGTCACGGCGTCGAGGCGGAAGATGGTGCACCT CCGGGCCGGCGGTTGCTGAGCTGACCCGGACGGCGAGGGAGCGGGAGCCCGAGCCCGACCACTCCGGCTGCCGCGGGGTGCGGCGCAGCC ACCGCCATGTCGCTGCTGCAGTCGGCGCTCGACTTCTTGGCGGGTCCAGGCTCCCTGGGCGGTGCTTCCGGCCGCGACCAGAGTGACTTC GTGGGGCAGACGGTGGAACTGGGCGAGCTGCGGCTGCGGGTGCGGCGGGTCCTGGCCGAAGGGCAGCTGGTGGAATTTTTGAAGAAAATG GAATCTCGAGGCCCCCTTTCGTGCGACACGGTTCTGAAGATCTTCTACCAGACGTGCCGCGCCGTGCAGCACATGCACCGGCAGAAGCCG CCCATCATCCACAGGGACCTCAAGGTTGAGAACTTGTTGCTTAGTAACCAAGGGACCATTAAGCTGTGTGACTTTGGCAGTGCCACGACC ATCTCGCACTACCCTGACTACAGCTGGAGCGCCCAGAGGCGAGCCCTGGTGGAGGAAGAGCACGCTGGCAGCGAAGGGGAACTCTACCCT CCAGAATCTCAGCCACCAGTTTCAGGCTCTGCACCCCCTGAGGACCTGGAGGATGCTGGACCCCCAACACTGGACCCCTCTGGGACCTCA ATCACTGAAGAAATCCTGGAACTGCTGAATCAGCGAGGCCTTCGAGATCCAGGGCCGTCCACCCATGACATTCCCAAGTTCCCCGGAGAC TCCCAGGTGCCTGGCGACAGCGAAACCCTCACATTCCAAGCCCTGCCCAGCCGGGACTCTTCAGAAGAGGAGGAGGAGGAAGAGGAAGGG CTGGAGATGGATGAACGGGGGCCTTCCCCACTCCACGTCCTGGAAGGGCTCGAAAGTTCCATTGCAGCTGAAATGCCCAGCATTCCCTGC CTTACCAAAATTCCTGACGTGCCCAACCTTCCTGAAATTCCCAGCCGCTGTGAAATTCCCGAAGGTTCTCGCCTTCCTAGTCTCTCTGAC ATTTCCGATGTTTTTGAGATGCCCTGCCTTCCAGCCATACCTAGTGTCCCCAACACCCCCAGTCTGTCTAGCACTCCCACCCTCTCCTGT GACTCCTGGCTCCAAGGGCCTCTGCAGGAACCAGCTGAGGCTCCAGCCACCAGGAGAGAACTGTTTTCTGGGAGCAATCCTGGGAAACTG GGAGAGCCGCCTTCAGGAGGCAAGGCAGGGCCAGAGGAGGATGAAGAAGGGGTATCATTCACAGACTTCCAGCCCCAGGATGTCACCCAA CATCAGGGATTCCCAGATGAGCTGGCATTCCGCTCTTGCTCAGAAATCCGGAGCGCCTGGCAGGCATTGGAACAGGGACAGCTGGCCCGG CCAGGCTTCCCAGAGCCACTGCTGATCCTGGAGGATTCGGATCTGGGTGGAGACAGCGGGAGCGGGAAGGCAGGAGCCCCGAGTTCAGAA AGGACGGCGTCCCGAGTGCGAGAGCTGGCCCGGCTTTACAGCGAGCGGATCCAGCAGATGCAGCGGGCGGAGACTCGGGCATCAGCCAAT GCCCCGCGCCGCCGGCCTCGGGTTCTGGCCCAACCCCAGCCATCCCCCTGTCTGCCCCAGGAGCAGGCAGAGCCAGGGCTCCTGCCTGCC TTTGGACACGTGCTGGTATGTGAGCTGGCCTTCCCACTGACATGTGCCCAGGAGTCTGTCCCCCTGGGTCCTGCTGTCTGGGTTCAAGCT GCCATACCTTTGTCAAAGCAGGGAGGCAGCCCGGATGGCCAGGGTCTACATGTTTCCAATTTGCCTAAGCAAGACCTTCCGGGCATCCAC GTTTCAGCTGCTACCCTTTTGCCTGAGCAAGGAGGTTCCCGGCATGTCCAGGCTCCAGCCGCCACACCTTTGCCCAAGCAAGAAGGCCCC CTGCACCTCCAGGTGCCGGCTCTTACAACTTTCTCTGATCAAGGCCACCCAGAAATCCAAGTTCCAGCCACCACTCCTTTGCCTGAGCAT AGAAGTCACATGGTTATACCAGCTCCATCCACCGCCTTTTGTCCTGAGCAGGGACACTGTGCGGACATCCACGTTCCCACCACTCCAGCT TTGCCCAAGGAGATTTGTTCTGATTTCACAGTTTCAGTCACCACCCCTGTGCCCAAGCAAGAAGGTCACCTAGACAGCGAGAGCCCAACC AATATCCCACTGACAAAGCAAGGAGGTTCCAGGGATGTTCAGGGCCCAGACCCTGTCTGCAGTCAACCCATCCAGCCTTTGTCTTGGCAT GGAAGCAGCCTGGATCCCCAGGGCCCAGGCGACACCCTACCACCCTTGCCATGTCACCTCCCAGACCTTCAGATTCCAGGTACCTCACCT TTGCCTGCACATGGAAGCCACCTGGACCATCGGATCCCAGCCAACGCCCCACTGTCTTTGTCCCAGGAGCTCCCAGACACTCAGGTTCCA GCTACCACACCTTTGCCCCTGCCACAAGTCCTCACAGACATCTGGGTCCAAGCCCTCCCAACTTCACCCAAGCAGGGAAGCCTCCCAGAC ATCCAGGGTCCAGCGGCTGCACCTCCACTTCCGGAGCCAAGCCTTACAGATACACAGGTCCAAAAACTCACACCTTCGTTGGAGCAGAAG AGCCTCATAGATGCCCATGTTCCAGCTGCCACACCTTTACCTGAGAGAGGAGGCTCTCTAGACATTCAGGGCCTCTCACCCACCCCAGTT CAGACCACCATGGTTTTGTCCAAACCAGGAGGCTCCTTAGCCTCTCACGTTGCCAGGTTGGAGTCTTCAGACTTGACGCCACCTCATAGT CCCCCACCTTCCAGCCGTCAGCTCCTGGGCCCCAATGCAGCTGCCCTCTCCAGATACCTGGCAGCCTCATATATCAGCCAGAGCCTGGCT CGGCGGCAGGGGCCTGGGGGAGGGGCCCCCGCAGCCTCCCGGGGCTCCTGGTCCTCTGCTCCCACGTCACGGGCATCTTCGCCGCCCCCC CAGCCCCAGCCACCACCTCCCCCAGCCAGGCGGCTCAGCTATGCCACGACGGTTAACATCCACGTGGGCGGGGGTGGGCGGCTGCGGCCA GCCAAGGCCCAGGTCCGGTTGAACCACCCTGCTCTCTTGGCCTCCACACAGGAATCTATGGGCCTTCACAGGGCCCAGGGGGCTCCTGAT GCCCCCTTCCACATGTGAGCCAGGACATGAGGCTTCCCTGAAGCAAGGATTTCAGCCAGATGCCATAGACCCTCAGAACTTGACCTGGAA GTCCAGACACTGAACGCAGGCCTCAAAACTGCTGCGGCCTTCCAACTCCTGGTATCTGCATCGGCGAATGGCCCTTCTTGCCTTGATCCA >32177_32177_7_GAK-PLEKHG2_GAK_chr4_891821_ENST00000511163_PLEKHG2_chr19_39912755_ENST00000409794_length(amino acids)=1023AA_BP=138 MSLLQSALDFLAGPGSLGGASGRDQSDFVGQTVELGELRLRVRRVLAEGQLVEFLKKMESRGPLSCDTVLKIFYQTCRAVQHMHRQKPPI IHRDLKVENLLLSNQGTIKLCDFGSATTISHYPDYSWSAQRRALVEEEHAGSEGELYPPESQPPVSGSAPPEDLEDAGPPTLDPSGTSIT EEILELLNQRGLRDPGPSTHDIPKFPGDSQVPGDSETLTFQALPSRDSSEEEEEEEEGLEMDERGPSPLHVLEGLESSIAAEMPSIPCLT KIPDVPNLPEIPSRCEIPEGSRLPSLSDISDVFEMPCLPAIPSVPNTPSLSSTPTLSCDSWLQGPLQEPAEAPATRRELFSGSNPGKLGE PPSGGKAGPEEDEEGVSFTDFQPQDVTQHQGFPDELAFRSCSEIRSAWQALEQGQLARPGFPEPLLILEDSDLGGDSGSGKAGAPSSERT ASRVRELARLYSERIQQMQRAETRASANAPRRRPRVLAQPQPSPCLPQEQAEPGLLPAFGHVLVCELAFPLTCAQESVPLGPAVWVQAAI PLSKQGGSPDGQGLHVSNLPKQDLPGIHVSAATLLPEQGGSRHVQAPAATPLPKQEGPLHLQVPALTTFSDQGHPEIQVPATTPLPEHRS HMVIPAPSTAFCPEQGHCADIHVPTTPALPKEICSDFTVSVTTPVPKQEGHLDSESPTNIPLTKQGGSRDVQGPDPVCSQPIQPLSWHGS SLDPQGPGDTLPPLPCHLPDLQIPGTSPLPAHGSHLDHRIPANAPLSLSQELPDTQVPATTPLPLPQVLTDIWVQALPTSPKQGSLPDIQ GPAAAPPLPEPSLTDTQVQKLTPSLEQKSLIDAHVPAATPLPERGGSLDIQGLSPTPVQTTMVLSKPGGSLASHVARLESSDLTPPHSPP PSSRQLLGPNAAALSRYLAASYISQSLARRQGPGGGAPAASRGSWSSAPTSRASSPPPQPQPPPPPARRLSYATTVNIHVGGGGRLRPAK -------------------------------------------------------------- >32177_32177_8_GAK-PLEKHG2_GAK_chr4_891821_ENST00000511163_PLEKHG2_chr19_39912755_ENST00000409797_length(transcript)=1053nt_BP=600nt AGGGGACGGGGCTAGGCCGGGTCGCCGCCTGACGCGACGCGTCCTCACGGGCGCCTACGTCACGGCGTCGAGGCGGAAGATGGTGCACCT CCGGGCCGGCGGTTGCTGAGCTGACCCGGACGGCGAGGGAGCGGGAGCCCGAGCCCGACCACTCCGGCTGCCGCGGGGTGCGGCGCAGCC ACCGCCATGTCGCTGCTGCAGTCGGCGCTCGACTTCTTGGCGGGTCCAGGCTCCCTGGGCGGTGCTTCCGGCCGCGACCAGAGTGACTTC GTGGGGCAGACGGTGGAACTGGGCGAGCTGCGGCTGCGGGTGCGGCGGGTCCTGGCCGAAGGGCAGCTGGTGGAATTTTTGAAGAAAATG GAATCTCGAGGCCCCCTTTCGTGCGACACGGTTCTGAAGATCTTCTACCAGACGTGCCGCGCCGTGCAGCACATGCACCGGCAGAAGCCG CCCATCATCCACAGGGACCTCAAGGTTGAGAACTTGTTGCTTAGTAACCAAGGGACCATTAAGCTGTGTGACTTTGGCAGTGCCACGACC ATCTCGCACTACCCTGACTACAGCTGGAGCGCCCAGAGGCGAGCCCTGGTGGAGGAAGAGCACGCTGGCAGCGAAGGGGAACTCTACCCT CCAGAATCTCAGCCACCAGTTTCAGGCTCTGCACCCCCTGAGGACCTGGAGGATGCTGGACCCCCAACACTGGACCCCTCTGGGACCTCA ATCACTGAAGAAATCCTGGAACTGCTGAATCAGCGAGGCCTTCGAGATCCAGGGGAATCTATGGGCCTTCACAGGGCCCAGGGGGCTCCT GATGCCCCCTTCCACATGTGAGCCAGGACATGAGGCTTCCCTGAAGCAAGGATTTCAGCCAGATGCCATAGACCCTCAGAACTTGACCTG GAAGTCCAGACACTGAACGCAGGCCTCAAAACTGCTGCGGCCTTCCAACTCCTGGTATCTGCATCGGCGAATGGCCCTTCTTGCCTTGAT >32177_32177_8_GAK-PLEKHG2_GAK_chr4_891821_ENST00000511163_PLEKHG2_chr19_39912755_ENST00000409797_length(amino acids)=214AA_BP=138 MSLLQSALDFLAGPGSLGGASGRDQSDFVGQTVELGELRLRVRRVLAEGQLVEFLKKMESRGPLSCDTVLKIFYQTCRAVQHMHRQKPPI IHRDLKVENLLLSNQGTIKLCDFGSATTISHYPDYSWSAQRRALVEEEHAGSEGELYPPESQPPVSGSAPPEDLEDAGPPTLDPSGTSIT -------------------------------------------------------------- >32177_32177_9_GAK-PLEKHG2_GAK_chr4_891821_ENST00000511163_PLEKHG2_chr19_39912755_ENST00000425673_length(transcript)=6378nt_BP=600nt AGGGGACGGGGCTAGGCCGGGTCGCCGCCTGACGCGACGCGTCCTCACGGGCGCCTACGTCACGGCGTCGAGGCGGAAGATGGTGCACCT CCGGGCCGGCGGTTGCTGAGCTGACCCGGACGGCGAGGGAGCGGGAGCCCGAGCCCGACCACTCCGGCTGCCGCGGGGTGCGGCGCAGCC ACCGCCATGTCGCTGCTGCAGTCGGCGCTCGACTTCTTGGCGGGTCCAGGCTCCCTGGGCGGTGCTTCCGGCCGCGACCAGAGTGACTTC GTGGGGCAGACGGTGGAACTGGGCGAGCTGCGGCTGCGGGTGCGGCGGGTCCTGGCCGAAGGGCAGCTGGTGGAATTTTTGAAGAAAATG GAATCTCGAGGCCCCCTTTCGTGCGACACGGTTCTGAAGATCTTCTACCAGACGTGCCGCGCCGTGCAGCACATGCACCGGCAGAAGCCG CCCATCATCCACAGGGACCTCAAGGTTGAGAACTTGTTGCTTAGTAACCAAGGGACCATTAAGCTGTGTGACTTTGGCAGTGCCACGACC ATCTCGCACTACCCTGACTACAGCTGGAGCGCCCAGAGGCGAGCCCTGGTGGAGGAAGAGCACGCTGGCAGCGAAGGGGAACTCTACCCT CCAGAATCTCAGCCACCAGTTTCAGGCTCTGCACCCCCTGAGGACCTGGAGGATGCTGGACCCCCAACACTGGACCCCTCTGGGACCTCA ATCACTGAAGAAATCCTGGAACTGCTGAATCAGCGAGGCCTTCGAGATCCAGGGCCGTCCACCCATGACATTCCCAAGTTCCCCGGAGAC TCCCAGGTGCCTGGCGACAGCGAAACCCTCACATTCCAAGCCCTGCCCAGCCGGGACTCTTCAGAAGAGGAGGAGGAGGAAGAGGAAGGG CTGGAGATGGATGAACGGGGGCCTTCCCCACTCCACGTCCTGGAAGGGCTCGAAAGTTCCATTGCAGCTGAAATGCCCAGCATTCCCTGC CTTACCAAAATTCCTGACGTGCCCAACCTTCCTGAAATTCCCAGCCGCTGTGAAATTCCCGAAGGTTCTCGCCTTCCTAGTCTCTCTGAC ATTTCCGATGTTTTTGAGATGCCCTGCCTTCCAGCCATACCTAGTGTCCCCAACACCCCCAGTCTGTCTAGCACTCCCACCCTCTCCTGT GACTCCTGGCTCCAAGGGCCTCTGCAGGAACCAGCTGAGGCTCCAGCCACCAGGAGAGAACTGTTTTCTGGGAGCAATCCTGGGAAACTG GGAGAGCCGCCTTCAGGAGGCAAGGCAGGGCCAGAGGAGGATGAAGAAGGGGTATCATTCACAGACTTCCAGCCCCAGGATGTCACCCAA CATCAGGGATTCCCAGATGAGCTGGCATTCCGCTCTTGCTCAGAAATCCGGAGCGCCTGGCAGGCATTGGAACAGGGACAGCTGGCCCGG CCAGGCTTCCCAGAGCCACTGCTGATCCTGGAGGATTCGGATCTGGGTGGAGACAGCGGGAGCGGGAAGGCAGGAGCCCCGAGTTCAGAA AGGACGGCGTCCCGAGTGCGAGAGCTGGCCCGGCTTTACAGCGAGCGGATCCAGCAGATGCAGCGGGCGGAGACTCGGGCATCAGCCAAT GCCCCGCGCCGCCGGCCTCGGGTTCTGGCCCAACCCCAGCCATCCCCCTGTCTGCCCCAGGAGCAGGCAGAGCCAGGGCTCCTGCCTGCC TTTGGACACGTGCTGGTATGTGAGCTGGCCTTCCCACTGACATGTGCCCAGGAGTCTGTCCCCCTGGGTCCTGCTGTCTGGGTTCAAGCT GCCATACCTTTGTCAAAGCAGGGAGGCAGCCCGGATGGCCAGGGTCTACATGTTTCCAATTTGCCTAAGCAAGACCTTCCGGGCATCCAC GTTTCAGCTGCTACCCTTTTGCCTGAGCAAGGAGGTTCCCGGCATGTCCAGGCTCCAGCCGCCACACCTTTGCCCAAGCAAGAAGGCCCC CTGCACCTCCAGGTGCCGGCTCTTACAACTTTCTCTGATCAAGGCCACCCAGAAATCCAAGTTCCAGCCACCACTCCTTTGCCTGAGCAT AGAAGTCACATGGTTATACCAGCTCCATCCACCGCCTTTTGTCCTGAGCAGGGACACTGTGCGGACATCCACGTTCCCACCACTCCAGCT TTGCCCAAGGAGATTTGTTCTGATTTCACAGTTTCAGTCACCACCCCTGTGCCCAAGCAAGAAGGTCACCTAGACAGCGAGAGCCCAACC AATATCCCACTGACAAAGCAAGGAGGTTCCAGGGATGTTCAGGGCCCAGACCCTGTCTGCAGTCAACCCATCCAGCCTTTGTCTTGGCAT GGAAGCAGCCTGGATCCCCAGGGCCCAGGCGACACCCTACCACCCTTGCCATGTCACCTCCCAGACCTTCAGATTCCAGGTACCTCACCT TTGCCTGCACATGGAAGCCACCTGGACCATCGGATCCCAGCCAACGCCCCACTGTCTTTGTCCCAGGAGCTCCCAGACACTCAGGTTCCA GCTACCACACCTTTGCCCCTGCCACAAGTCCTCACAGACATCTGGGTCCAAGCCCTCCCAACTTCACCCAAGCAGGGAAGCCTCCCAGAC ATCCAGGGTCCAGCGGCTGCACCTCCACTTCCGGAGCCAAGCCTTACAGATACACAGGTCCAAAAACTCACACCTTCGTTGGAGCAGAAG AGCCTCATAGATGCCCATGTTCCAGCTGCCACACCTTTACCTGAGAGAGGAGGCTCTCTAGACATTCAGGGCCTCTCACCCACCCCAGTT CAGACCACCATGGTTTTGTCCAAACCAGGAGGCTCCTTAGCCTCTCACGTTGCCAGGTTGGAGTCTTCAGACTTGACGCCACCTCATAGT CCCCCACCTTCCAGCCGTCAGCTCCTGGGCCCCAATGCAGCTGCCCTCTCCAGATACCTGGCAGCCTCATATATCAGCCAGAGCCTGGCT CGGCGGCAGGGGCCTGGGGGAGGGGCCCCCGCAGCCTCCCGGGGCTCCTGGTCCTCTGCTCCCACGTCACGGGCATCTTCGCCGCCCCCC CAGCCCCAGCCACCACCTCCCCCAGCCAGGCGGCTCAGCTATGCCACGACGGTTAACATCCACGTGGGCGGGGGTGGGCGGCTGCGGCCA GCCAAGGCCCAGGTCCGGTTGAACCACCCTGCTCTCTTGGCCTCCACACAGGAATCTATGGGCCTTCACAGGGCCCAGGGGGCTCCTGAT GCCCCCTTCCACATGTGAGCCAGGACATGAGGCTTCCCTGAAGCAAGGATTTCAGCCAGATGCCATAGACCCTCAGAACTTGACCTGGAA GTCCAGACACTGAACGCAGGCCTCAAAACTGCTGCGGCCTTCCAACTCCTGGTATCTGCATCGGCGAATGGCCCTTCTTGCCTTGATCCA CAGGGATGGGGAAGGGAGGAATGTCATTAATGTTTTGTTAATACTGATTCTTTCATGCAATGATGTGTATTTTCCCATTCTGGAGGCTGT GGGAGATGACAAGACAATGAATGGGAAGGTCTGACACAGAACAAATCAGCGGTTCTGAAAGCTTGGGGAATCTCAGACTCCTTTGAGAAT TATTGGAAAATGGACCCACTATAACTTGGCGTGTGTGTGAACTGCTTGATGCCCATCCAGGAAAGCCAAGTTAAGAAGCTTTGCTTCAAG TAGACACTAGAAATCCATTCCCTTGGCAATTTATACAGTTCACGTCTCCCACCATCCGTTCATCTCACCCACCCTGCCATCTCTCCACCT ATCCATCTGGCTATTGCTCCATCTAGCTTTCCCGCTCCATCTACCCATCTTCCAATCCATCATCTCACGTATCTGCCTTGCTTATCCAAC TGTCTGCCTTATTCACCCACCCATCCCTTTATCATTCTAACCCCATCTGGCATTCCATCCCTCCATTTATCCATCTTCCCACTTACCCAT CTTCTCCATCCAGCACTCCGTTCATCAGTCCGTCTCTCCCTCCATATTTCCATCTGTCCATTCATCCACTCATTTTGCCATCCATACATA TTCACCCAGCCATCTCCCAATCCATCGACATACCCCATCCCTCCCTCACTGGACTCTCCGGGGTCTTAGTACTATGATACTTCAGAGACA ATTCCATGCTGATACGGGGGAGATCAATTTTGGGGCTCTGGGATAAGTCTGTCCCACATCTGTCTGATTTCCCTTGGCATCCTTCCCGTC AGTTCCTCTTGAATATCCCAGTTCTTGTACCCACTCACATACCTCAGATCCCTTCACTCCTCCCCGCAGTTTGCAGCCTCTACAATTCAT CCACATGCTCCCTCCCCCAGCAAAATAATTCAGGTCGTGGAGACAAAAGGCTTTTATGTTAGGTTCTGTCTGCCCCCTTGTTCCAGCAGT GGTATGCCCAGTGAGAGGCACAATTTAAACGGTTTCTTTGGTGATGATATTAGCTACTTTCATCAAATACTTAGCCTCTTGTGCTTTAGC ACATTATTTATGTAAGCTCCCCTAGGATTCTCTGAAGCACCCTGGTGTCCTGGCTGTGAATTCAAGTCCCATCTTTACTTATTTGGTGTG GGTCCTCCCTCTGAGCCGGTTTTCTCATCTACAAAATGAAGACAACAGTACTTCCCTCCTGGGATCATTGAAAGATTTAGGGAGCATATC CTTCCACTTCCCAAACATATTTGAACCTCTGACTTGCTTAGGAGCATCATTCAAATCACAGATCCCCCAGTATCTAGTCCCAACCTATTG AATCAGGATCCCCAGGGAAGGAGGAGCTTGGGAATCTGATTTTTTTTTTTTTTTTTAGATAAAGTCTCACTCTGTCACCCAGGCTTGAGT GCAGTGGCAAAATCTTGGCTCATTGCAACCTCCACCTCCTGGGTTCAAGCAATTCTCATGCCTCAGCTTCCCGACATAGCTGGGATTATA GGCGTGCACCACCATGCCCAGCTAATTTTTCGTTGTTGTTGTTGTTGTTTTGTTTTTGAGACAGAGTCTCGCTCTGTTGCCCAGGCTGGA GTACAGTGGCACGATCTTGGCTCACTGCAAGCTCCGCTTCCCGGGTTCACGCCATTCTCCTGCCTCAGCCTCCCGAGTAGCTGGGACCAC AGGTGCCCGCCACCACGCCCGGCTAATTTTTTTGGTATTTTTAGTAGAGACGGGGTTTTACCATGTTAGCCAGGATGGTCTCGATCTCCT GACCTCGTGATCCTCCCGCCTCGGCCTCCCAAAGTGCTGGCATTACAGGCGTGAGCCATCATTCCTGGCTGGGAATCCGAATTTTTTTTT TTTTTTAGACGGAGTTTCGCTCTTGTTGCCCAGGCTGGAGTTCAATAGCATGATCTCGGCTCACTGCAACCTCTGCCTCCCAGGTTCAAG TGATTCTCCTGCCTCTAGCTGGGATTGCAGGCGCCCACGACCACGCCCAGCTAATTTTTGTATTTTGTAGTAGAGACGGGATTTCGCCAT ATTGGCCAGGCCATAGTGGTCTTGGACTCCTGACCTCAGGTGATCCGCCCACCTCGGCCTCCCAAAGTGTTGGGTTTACAGGCGTGAGCT ACCATACCCTGCCCAGGAATCTGAATTTTTAGCAATCAGTTAGCAGCAAATAAGCTGAGATTTCCTGGGTACTAAGCACATACTATGAGC ATTACAGCCGCTTTATATAAGCTCGTTCACTGTCCTCATTACATTCCTAATATGCAAGTGAGCATGTTTTTTAATCCTCAGTCTAGAGGT GAGGAAACTGAGGCAGGCACAGAGAGGCTAAGGGATTTGCCTAGTCGCACAGCTAGGAAGGTGCAGCACTGAGACTCGAATCCACACAGC TTGGCTTAAGTCTACCATTAAATTTGCCTGTCCTGGCCAGGTGCGGTGGCTCACGCCTGTAATCCCAACACTTCGTGAGGCCAAGGCAGG TGGATCACTTGAAGTGAGGAGTTCGAGACCACACCAGCCTGGCCAACATGGTGAAATCCCGTCTTTACTAAAAATACAAAAAATTAGCTG GGCGTGGTGGTGGGTGCCGGTAATCCTAGCTACTCAGGAGGCTGAGGCAGGAGAATCACTTGAACCTGGGAGGTGGAGGTTGCAGTGAAC CGAGATTGCGCCACTAGACTCCAGCCTGGGAGACGAGCAAAACTGTCTCAAAAAAATAAAATGAAATACATAAATAAATGTGCCTATCCT GTGCCGGGTGCTGTTCTTGCCAGTGGGGATACATGAGAGAACACTGCCTTGCCCGCATGAGGCTTGTGGCCTGGTACTGTGCACACCTCA >32177_32177_9_GAK-PLEKHG2_GAK_chr4_891821_ENST00000511163_PLEKHG2_chr19_39912755_ENST00000425673_length(amino acids)=1023AA_BP=138 MSLLQSALDFLAGPGSLGGASGRDQSDFVGQTVELGELRLRVRRVLAEGQLVEFLKKMESRGPLSCDTVLKIFYQTCRAVQHMHRQKPPI IHRDLKVENLLLSNQGTIKLCDFGSATTISHYPDYSWSAQRRALVEEEHAGSEGELYPPESQPPVSGSAPPEDLEDAGPPTLDPSGTSIT EEILELLNQRGLRDPGPSTHDIPKFPGDSQVPGDSETLTFQALPSRDSSEEEEEEEEGLEMDERGPSPLHVLEGLESSIAAEMPSIPCLT KIPDVPNLPEIPSRCEIPEGSRLPSLSDISDVFEMPCLPAIPSVPNTPSLSSTPTLSCDSWLQGPLQEPAEAPATRRELFSGSNPGKLGE PPSGGKAGPEEDEEGVSFTDFQPQDVTQHQGFPDELAFRSCSEIRSAWQALEQGQLARPGFPEPLLILEDSDLGGDSGSGKAGAPSSERT ASRVRELARLYSERIQQMQRAETRASANAPRRRPRVLAQPQPSPCLPQEQAEPGLLPAFGHVLVCELAFPLTCAQESVPLGPAVWVQAAI PLSKQGGSPDGQGLHVSNLPKQDLPGIHVSAATLLPEQGGSRHVQAPAATPLPKQEGPLHLQVPALTTFSDQGHPEIQVPATTPLPEHRS HMVIPAPSTAFCPEQGHCADIHVPTTPALPKEICSDFTVSVTTPVPKQEGHLDSESPTNIPLTKQGGSRDVQGPDPVCSQPIQPLSWHGS SLDPQGPGDTLPPLPCHLPDLQIPGTSPLPAHGSHLDHRIPANAPLSLSQELPDTQVPATTPLPLPQVLTDIWVQALPTSPKQGSLPDIQ GPAAAPPLPEPSLTDTQVQKLTPSLEQKSLIDAHVPAATPLPERGGSLDIQGLSPTPVQTTMVLSKPGGSLASHVARLESSDLTPPHSPP PSSRQLLGPNAAALSRYLAASYISQSLARRQGPGGGAPAASRGSWSSAPTSRASSPPPQPQPPPPPARRLSYATTVNIHVGGGGRLRPAK -------------------------------------------------------------- >32177_32177_10_GAK-PLEKHG2_GAK_chr4_891821_ENST00000511163_PLEKHG2_chr19_39912755_ENST00000458508_length(transcript)=3046nt_BP=600nt AGGGGACGGGGCTAGGCCGGGTCGCCGCCTGACGCGACGCGTCCTCACGGGCGCCTACGTCACGGCGTCGAGGCGGAAGATGGTGCACCT CCGGGCCGGCGGTTGCTGAGCTGACCCGGACGGCGAGGGAGCGGGAGCCCGAGCCCGACCACTCCGGCTGCCGCGGGGTGCGGCGCAGCC ACCGCCATGTCGCTGCTGCAGTCGGCGCTCGACTTCTTGGCGGGTCCAGGCTCCCTGGGCGGTGCTTCCGGCCGCGACCAGAGTGACTTC GTGGGGCAGACGGTGGAACTGGGCGAGCTGCGGCTGCGGGTGCGGCGGGTCCTGGCCGAAGGGCAGCTGGTGGAATTTTTGAAGAAAATG GAATCTCGAGGCCCCCTTTCGTGCGACACGGTTCTGAAGATCTTCTACCAGACGTGCCGCGCCGTGCAGCACATGCACCGGCAGAAGCCG CCCATCATCCACAGGGACCTCAAGGTTGAGAACTTGTTGCTTAGTAACCAAGGGACCATTAAGCTGTGTGACTTTGGCAGTGCCACGACC ATCTCGCACTACCCTGACTACAGCTGGAGCGCCCAGAGGCGAGCCCTGGTGGAGGAAGAGCACGCTGGCAGCGAAGGGGAACTCTACCCT CCAGAATCTCAGCCACCAGTTTCAGGCTCTGCACCCCCTGAGGACCTGGAGGATGCTGGACCCCCAACACTGGACCCCTCTGGGACCTCA ATCACTGAAGAAATCCTGGAACTGCTGAATCAGCGAGGCCTTCGAGATCCAGGGCCGTCCACCCATGACATTCCCAAGTTCCCCGGAGAC TCCCAGGTGCCTGGCGACAGCGAAACCCTCACATTCCAAGCCCTGCCCAGCCGGGACTCTTCAGAAGAGGAGGAGGAGGAAGAGGAAGGG CTGGAGATGGATGAACGGGGGCCTTCCCCACTCCACGTCCTGGAAGGGCTCGAAAGTTCCATTGCAGCTGAAATGCCCAGCATTCCCTGC CTTACCAAAATTCCTGACGTGCCCAACCTTCCTGAAATTCCCAGCCGCTGTGAAATTCCCGAAGGTTCTCGCCTTCCTAGTCTCTCTGAC ATTTCCGATGTTTTTGAGATGCCCTGCCTTCCAGCCATACCTAGTGTCCCCAACACCCCCAGTCTGTCTAGCACTCCCACCCTCTCCTGT GACTCCTGGCTCCAAGGGCCTCTGCAGGAACCAGCTGAGGCTCCAGCCACCAGGAGAGAACTGTTTTCTGGGAGCAATCCTGGGAAACTG GGAGAGCCGCCTTCAGGAGGCAAGGCAGGGCCAGAGGAGGATGAAGAAGGGGTATCATTCACAGACTTCCAGCCCCAGGATGTCACCCAA CATCAGGGATTCCCAGATGAGCTGGCATTCCGCTCTTGCTCAGAAATCCGGAGCGCCTGGCAGGCATTGGAACAGGGACAGCTGGCCCGG CCAGGCTTCCCAGAGCCACTGCTGATCCTGGAGGATTCGGATCTGGGTGGAGACAGCGGGAGCGGGAAGGCAGGAGCCCCGAGTTCAGAA AGGACGGCGTCCCGAGTGCGAGAGCTGGCCCGGCTTTACAGCGAGCGGATCCAGCAGATGCAGCGGGCGGAGACTCGGGCATCAGCCAAT GCCCCGCGCCGCCGGCCTCGGGTTCTGGCCCAACCCCAGCCATCCCCCTGTCTGCCCCAGGAGCAGGCAGAGCCAGGGCTCCTGCCTGCC TTTGGACACGTGCTGGTATGTGAGCTGGCCTTCCCACTGACATGTGCCCAGGAGTCTGTCCCCCTGGGTCCTGCTGTCTGGGTTCAAGCT GCCATACCTTTGTCAAAGCAGGGAGGCAGCCCGGATGGCCAGGGTCTACATGTTTCCAATTTGCCTAAGCAAGACCTTCCGGGCATCCAC GTTTCAGCTGCTACCCTTTTGCCTGAGCAAGGAGGTTCCCGGCATGTCCAGGCTCCAGCCGCCACACCTTTGCCCAAGCAAGAAGGCCCC CTGCACCTCCAGGTGCCGGCTCTTACAACTTTCTCTGATCAAGGCCACCCAGAAATCCAAGTTCCAGCCACCACTCCTTTGCCTGAGCAT AGAAGTCACATGGTTATACCAGCTCCATCCACCGCCTTTTGTCCTGAGCAGGGACACTGTGCGGACATCCACGTTCCCACCACTCCAGCT TTGCCCAAGGAGATTTGTTCTGATTTCACAGTTTCAGTCACCACCCCTGTGCCCAAGCAAGAAGGTCACCTAGACAGCGAGAGCCCAACC AATATCCCACTGACAAAGCAAGGAGGTTCCAGGGATGTTCAGGGCCCAGACCCTGTCTGCAGTCAACCCATCCAGCCTTTGTCTTGGCAT GGAAGCAGCCTGGATCCCCAGGGCCCAGGCGACACCCTACCACCCTTGCCATGTCACCTCCCAGACCTTCAGATTCCAGGTACCTCACCT TTGCCTGCACATGGAAGCCACCTGGACCATCGGATCCCAGCCAACGCCCCACTGTCTTTGTCCCAGGAGCTCCCAGACACTCAGGTTCCA GCTACCACACCTTTGCCCCTGCCACAAGTCCTCACAGACATCTGGGTCCAAGCCCTCCCAACTTCACCCAAGCAGGGAAGCCTCCCAGAC ATCCAGGGTCCAGCGGCTGCACCTCCACTTCCGGAGCCAAGCCTTACAGATACACAGGTCCAAAAACTCACACCTTCGTTGGAGCAGAAG AGCCTCATAGATGCCCATGTTCCAGCTGCCACACCTTTACCTGAGAGAGGAGGCTCTCTAGACATTCAGGGCCTCTCACCCACCCCAGTT CAGACCACCATGGTTTTGTCCAAACCAGGAGGCTCCTTAGCCTCTCACGTTGCCAGGAATCTATGGGCCTTCACAGGGCCCAGGGGGCTC CTGATGCCCCCTTCCACATGTGAGCCAGGACATGAGGCTTCCCTGAAGCAAGGATTTCAGCCAGATGCCATAGACCCTCAGAACTTGACC >32177_32177_10_GAK-PLEKHG2_GAK_chr4_891821_ENST00000511163_PLEKHG2_chr19_39912755_ENST00000458508_length(amino acids)=933AA_BP=138 MSLLQSALDFLAGPGSLGGASGRDQSDFVGQTVELGELRLRVRRVLAEGQLVEFLKKMESRGPLSCDTVLKIFYQTCRAVQHMHRQKPPI IHRDLKVENLLLSNQGTIKLCDFGSATTISHYPDYSWSAQRRALVEEEHAGSEGELYPPESQPPVSGSAPPEDLEDAGPPTLDPSGTSIT EEILELLNQRGLRDPGPSTHDIPKFPGDSQVPGDSETLTFQALPSRDSSEEEEEEEEGLEMDERGPSPLHVLEGLESSIAAEMPSIPCLT KIPDVPNLPEIPSRCEIPEGSRLPSLSDISDVFEMPCLPAIPSVPNTPSLSSTPTLSCDSWLQGPLQEPAEAPATRRELFSGSNPGKLGE PPSGGKAGPEEDEEGVSFTDFQPQDVTQHQGFPDELAFRSCSEIRSAWQALEQGQLARPGFPEPLLILEDSDLGGDSGSGKAGAPSSERT ASRVRELARLYSERIQQMQRAETRASANAPRRRPRVLAQPQPSPCLPQEQAEPGLLPAFGHVLVCELAFPLTCAQESVPLGPAVWVQAAI PLSKQGGSPDGQGLHVSNLPKQDLPGIHVSAATLLPEQGGSRHVQAPAATPLPKQEGPLHLQVPALTTFSDQGHPEIQVPATTPLPEHRS HMVIPAPSTAFCPEQGHCADIHVPTTPALPKEICSDFTVSVTTPVPKQEGHLDSESPTNIPLTKQGGSRDVQGPDPVCSQPIQPLSWHGS SLDPQGPGDTLPPLPCHLPDLQIPGTSPLPAHGSHLDHRIPANAPLSLSQELPDTQVPATTPLPLPQVLTDIWVQALPTSPKQGSLPDIQ GPAAAPPLPEPSLTDTQVQKLTPSLEQKSLIDAHVPAATPLPERGGSLDIQGLSPTPVQTTMVLSKPGGSLASHVARNLWAFTGPRGLLM -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for GAK-PLEKHG2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for GAK-PLEKHG2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for GAK-PLEKHG2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies