
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:GDA-C9orf85 (FusionGDB2 ID:32817) |
Fusion Gene Summary for GDA-C9orf85 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: GDA-C9orf85 | Fusion gene ID: 32817 | Hgene | Tgene | Gene symbol | GDA | C9orf85 | Gene ID | 9615 | 138241 |
| Gene name | guanine deaminase | chromosome 9 open reading frame 85 | |
| Synonyms | CYPIN|GAH|GUANASE|NEDASIN | - | |
| Cytomap | 9q21.13 | 9q21.13 | |
| Type of gene | protein-coding | protein-coding | |
| Description | guanine deaminasecytoplasmic PSD95 interactorguanine aminaseguanine aminohydrolasep51-nedasin | uncharacterized protein C9orf85 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q9Y2T3 | Q96MD7 | |
| Ensembl transtripts involved in fusion gene | ENST00000477618, ENST00000238018, ENST00000358399, ENST00000376986, ENST00000376989, ENST00000545168, | ENST00000334731, ENST00000377031, ENST00000486911, | |
| Fusion gene scores | * DoF score | 8 X 7 X 6=336 | 4 X 5 X 2=40 |
| # samples | 9 | 4 | |
| ** MAII score | log2(9/336*10)=-1.90046432644909 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(4/40*10)=0 | |
| Context | PubMed: GDA [Title/Abstract] AND C9orf85 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | GDA(74817658)-C9orf85(74533341), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across GDA (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
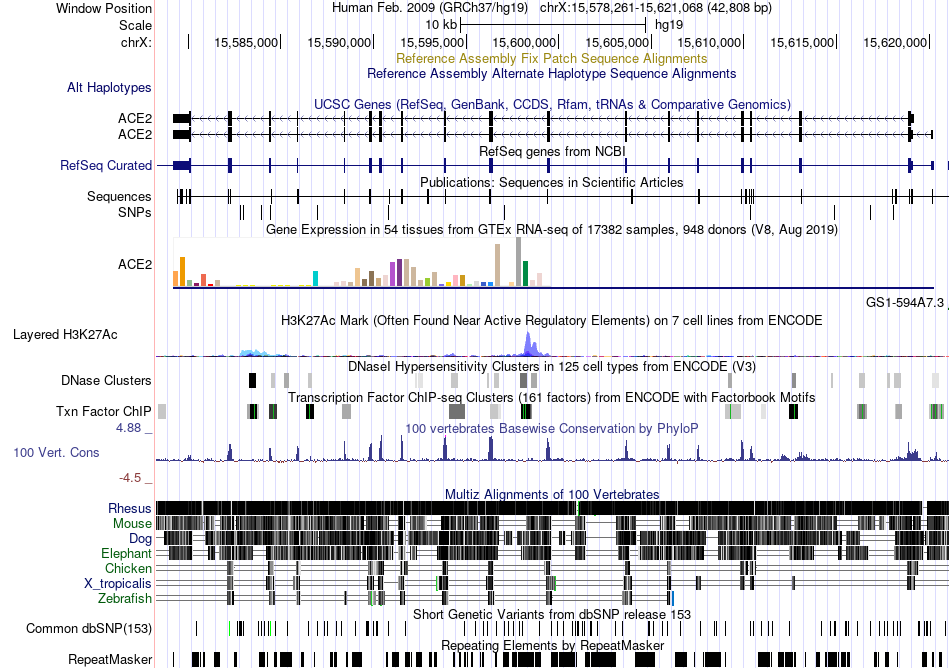 |
| Fusion gene breakpoints across C9orf85 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
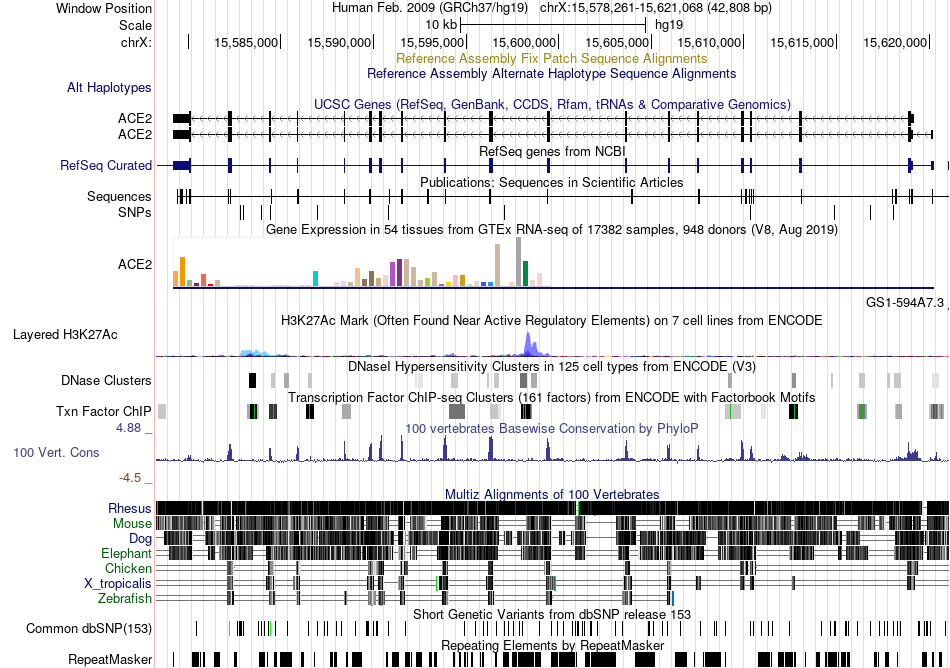 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-VQ-A8PE-01A | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74533341 | + |
| ChimerDB4 | STAD | TCGA-VQ-A8PE-01A | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74561922 | + |
Top |
Fusion Gene ORF analysis for GDA-C9orf85 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000477618 | ENST00000334731 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74561922 | + |
| 3UTR-3CDS | ENST00000477618 | ENST00000377031 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74561922 | + |
| 3UTR-3CDS | ENST00000477618 | ENST00000486911 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74561922 | + |
| 3UTR-intron | ENST00000477618 | ENST00000334731 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74533341 | + |
| 3UTR-intron | ENST00000477618 | ENST00000377031 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74533341 | + |
| 3UTR-intron | ENST00000477618 | ENST00000486911 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74533341 | + |
| 5CDS-intron | ENST00000238018 | ENST00000334731 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74533341 | + |
| 5CDS-intron | ENST00000238018 | ENST00000377031 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74533341 | + |
| 5CDS-intron | ENST00000238018 | ENST00000486911 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74533341 | + |
| 5CDS-intron | ENST00000358399 | ENST00000334731 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74533341 | + |
| 5CDS-intron | ENST00000358399 | ENST00000377031 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74533341 | + |
| 5CDS-intron | ENST00000358399 | ENST00000486911 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74533341 | + |
| 5CDS-intron | ENST00000376986 | ENST00000334731 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74533341 | + |
| 5CDS-intron | ENST00000376986 | ENST00000377031 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74533341 | + |
| 5CDS-intron | ENST00000376986 | ENST00000486911 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74533341 | + |
| 5CDS-intron | ENST00000376989 | ENST00000334731 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74533341 | + |
| 5CDS-intron | ENST00000376989 | ENST00000377031 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74533341 | + |
| 5CDS-intron | ENST00000376989 | ENST00000486911 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74533341 | + |
| 5CDS-intron | ENST00000545168 | ENST00000334731 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74533341 | + |
| 5CDS-intron | ENST00000545168 | ENST00000377031 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74533341 | + |
| 5CDS-intron | ENST00000545168 | ENST00000486911 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74533341 | + |
| In-frame | ENST00000238018 | ENST00000334731 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74561922 | + |
| In-frame | ENST00000238018 | ENST00000377031 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74561922 | + |
| In-frame | ENST00000238018 | ENST00000486911 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74561922 | + |
| In-frame | ENST00000358399 | ENST00000334731 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74561922 | + |
| In-frame | ENST00000358399 | ENST00000377031 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74561922 | + |
| In-frame | ENST00000358399 | ENST00000486911 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74561922 | + |
| In-frame | ENST00000376986 | ENST00000334731 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74561922 | + |
| In-frame | ENST00000376986 | ENST00000377031 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74561922 | + |
| In-frame | ENST00000376986 | ENST00000486911 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74561922 | + |
| In-frame | ENST00000376989 | ENST00000334731 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74561922 | + |
| In-frame | ENST00000376989 | ENST00000377031 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74561922 | + |
| In-frame | ENST00000376989 | ENST00000486911 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74561922 | + |
| In-frame | ENST00000545168 | ENST00000334731 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74561922 | + |
| In-frame | ENST00000545168 | ENST00000377031 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74561922 | + |
| In-frame | ENST00000545168 | ENST00000486911 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74561922 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000545168 | GDA | chr9 | 74817658 | + | ENST00000334731 | C9orf85 | chr9 | 74561922 | + | 1487 | 500 | 275 | 871 | 198 |
| ENST00000545168 | GDA | chr9 | 74817658 | + | ENST00000377031 | C9orf85 | chr9 | 74561922 | + | 1315 | 500 | 275 | 937 | 220 |
| ENST00000545168 | GDA | chr9 | 74817658 | + | ENST00000486911 | C9orf85 | chr9 | 74561922 | + | 3645 | 500 | 275 | 607 | 110 |
| ENST00000376989 | GDA | chr9 | 74817658 | + | ENST00000334731 | C9orf85 | chr9 | 74561922 | + | 1554 | 567 | 15 | 938 | 307 |
| ENST00000376989 | GDA | chr9 | 74817658 | + | ENST00000377031 | C9orf85 | chr9 | 74561922 | + | 1382 | 567 | 15 | 1004 | 329 |
| ENST00000376989 | GDA | chr9 | 74817658 | + | ENST00000486911 | C9orf85 | chr9 | 74561922 | + | 3712 | 567 | 15 | 674 | 219 |
| ENST00000238018 | GDA | chr9 | 74817658 | + | ENST00000334731 | C9orf85 | chr9 | 74561922 | + | 1554 | 567 | 15 | 938 | 307 |
| ENST00000238018 | GDA | chr9 | 74817658 | + | ENST00000377031 | C9orf85 | chr9 | 74561922 | + | 1382 | 567 | 15 | 1004 | 329 |
| ENST00000238018 | GDA | chr9 | 74817658 | + | ENST00000486911 | C9orf85 | chr9 | 74561922 | + | 3712 | 567 | 15 | 674 | 219 |
| ENST00000376986 | GDA | chr9 | 74817658 | + | ENST00000334731 | C9orf85 | chr9 | 74561922 | + | 1474 | 487 | 169 | 858 | 229 |
| ENST00000376986 | GDA | chr9 | 74817658 | + | ENST00000377031 | C9orf85 | chr9 | 74561922 | + | 1302 | 487 | 169 | 924 | 251 |
| ENST00000376986 | GDA | chr9 | 74817658 | + | ENST00000486911 | C9orf85 | chr9 | 74561922 | + | 3632 | 487 | 169 | 594 | 141 |
| ENST00000358399 | GDA | chr9 | 74817658 | + | ENST00000334731 | C9orf85 | chr9 | 74561922 | + | 1464 | 477 | 75 | 848 | 257 |
| ENST00000358399 | GDA | chr9 | 74817658 | + | ENST00000377031 | C9orf85 | chr9 | 74561922 | + | 1292 | 477 | 75 | 914 | 279 |
| ENST00000358399 | GDA | chr9 | 74817658 | + | ENST00000486911 | C9orf85 | chr9 | 74561922 | + | 3622 | 477 | 75 | 584 | 169 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000545168 | ENST00000334731 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74561922 | + | 0.005566374 | 0.9944337 |
| ENST00000545168 | ENST00000377031 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74561922 | + | 0.007361539 | 0.99263847 |
| ENST00000545168 | ENST00000486911 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74561922 | + | 0.014401221 | 0.9855988 |
| ENST00000376989 | ENST00000334731 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74561922 | + | 0.001248506 | 0.9987515 |
| ENST00000376989 | ENST00000377031 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74561922 | + | 0.005732714 | 0.9942673 |
| ENST00000376989 | ENST00000486911 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74561922 | + | 0.001368052 | 0.9986319 |
| ENST00000238018 | ENST00000334731 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74561922 | + | 0.001248506 | 0.9987515 |
| ENST00000238018 | ENST00000377031 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74561922 | + | 0.005732714 | 0.9942673 |
| ENST00000238018 | ENST00000486911 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74561922 | + | 0.001368052 | 0.9986319 |
| ENST00000376986 | ENST00000334731 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74561922 | + | 0.00515871 | 0.9948413 |
| ENST00000376986 | ENST00000377031 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74561922 | + | 0.007011772 | 0.9929883 |
| ENST00000376986 | ENST00000486911 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74561922 | + | 0.008747538 | 0.9912525 |
| ENST00000358399 | ENST00000334731 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74561922 | + | 0.001255685 | 0.99874425 |
| ENST00000358399 | ENST00000377031 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74561922 | + | 0.004919958 | 0.99508 |
| ENST00000358399 | ENST00000486911 | GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74561922 | + | 0.001332641 | 0.99866736 |
Top |
Fusion Genomic Features for GDA-C9orf85 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74561921 | + | 5.55E-10 | 1 |
| GDA | chr9 | 74817658 | + | C9orf85 | chr9 | 74561921 | + | 5.55E-10 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
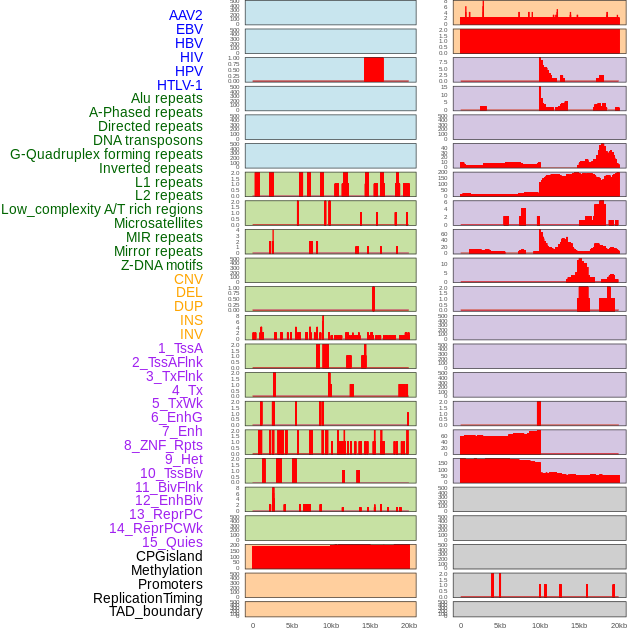 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
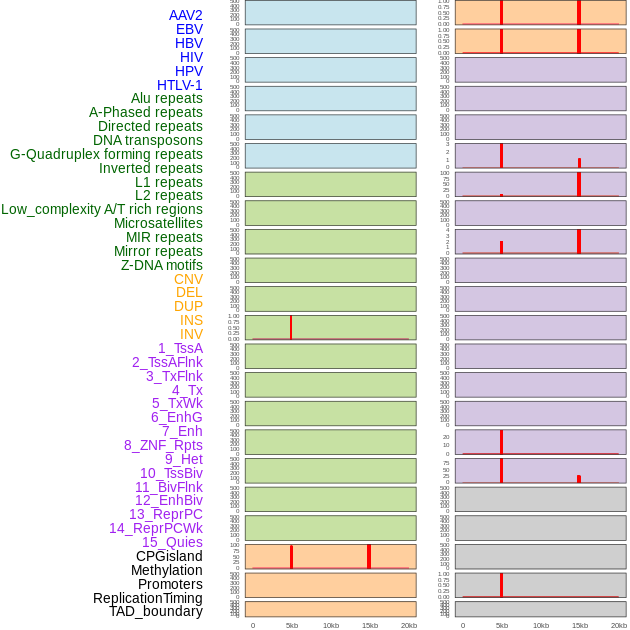 |
Top |
Fusion Protein Features for GDA-C9orf85 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr9:74817658/chr9:74533341) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| GDA | C9orf85 |
| FUNCTION: Catalyzes the hydrolytic deamination of guanine, producing xanthine and ammonia. {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | GDA | chr9:74817658 | chr9:74561922 | ENST00000238018 | + | 3 | 15 | 84_87 | 128 | 472.0 | Region | Substrate binding |
| Hgene | GDA | chr9:74817658 | chr9:74561922 | ENST00000358399 | + | 3 | 14 | 84_87 | 128 | 455.0 | Region | Substrate binding |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | GDA | chr9:74817658 | chr9:74561922 | ENST00000238018 | + | 3 | 15 | 213_214 | 128 | 472.0 | Region | Substrate binding |
| Hgene | GDA | chr9:74817658 | chr9:74561922 | ENST00000238018 | + | 3 | 15 | 240_243 | 128 | 472.0 | Region | Substrate binding |
| Hgene | GDA | chr9:74817658 | chr9:74561922 | ENST00000358399 | + | 3 | 14 | 213_214 | 128 | 455.0 | Region | Substrate binding |
| Hgene | GDA | chr9:74817658 | chr9:74561922 | ENST00000358399 | + | 3 | 14 | 240_243 | 128 | 455.0 | Region | Substrate binding |
| Hgene | GDA | chr9:74817658 | chr9:74561922 | ENST00000545168 | + | 3 | 14 | 213_214 | 54 | 381.0 | Region | Substrate binding |
| Hgene | GDA | chr9:74817658 | chr9:74561922 | ENST00000545168 | + | 3 | 14 | 240_243 | 54 | 381.0 | Region | Substrate binding |
| Hgene | GDA | chr9:74817658 | chr9:74561922 | ENST00000545168 | + | 3 | 14 | 84_87 | 54 | 381.0 | Region | Substrate binding |
| Tgene | C9orf85 | chr9:74817658 | chr9:74561922 | ENST00000334731 | 0 | 4 | 23_79 | 34 | 158.0 | Compositional bias | Note=Lys-rich | |
| Tgene | C9orf85 | chr9:74817658 | chr9:74561922 | ENST00000377031 | 0 | 4 | 23_79 | 34 | 180.0 | Compositional bias | Note=Lys-rich |
Top |
Fusion Gene Sequence for GDA-C9orf85 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >32817_32817_1_GDA-C9orf85_GDA_chr9_74817658_ENST00000238018_C9orf85_chr9_74561922_ENST00000334731_length(transcript)=1554nt_BP=567nt GTAGGGAGCCAGCCCCTGGGCGCGGCCTGCAGGGTACCGGCAACCGCCCGGGTAAGCGGGGGCAGGACAAGGCCGGAGCCTGTGTCCGCC CGGCAGCCGCCCGCAGCTGCAGAGAGTCCCGCTGCGTCTCCGCCGCGTGCGCCCTCCTCGACCAGCAGACCCGCGCTGCGCTCCGCCGCT GACATGTGTGCCGCTCAGATGCCGCCCCTGGCGCACATCTTCCGAGGGACGTTCGTCCACTCCACCTGGACCTGCCCCATGGAGGTGCTG CGGGATCACCTCCTCGGCGTGAGCGACAGCGGCAAAATAGTGTTTTTAGAAGAAGCATCTCAACAGGAAAAACTGGCCAAAGAATGGTGC TTCAAGCCGTGTGAAATAAGAGAACTGAGCCACCATGAGTTCTTCATGCCTGGGCTGGTTGATACACACATCCATGCCTCTCAGTATTCC TTTGCTGGAAGTAGCATAGACCTGCCACTCTTGGAGTGGCTGACCAAGTACACATTTCCTGCAGAACACAGATTCCAGAACATCGACTTT GCAGAAGAAGTATATACCAGAGTTGTCAAAATTAATGCAAAACTTCATGATGGAGTATGTCAGCGCTGTAAAGAAGTTCTTGAGTGGCGT GTAAAATACAGCAAATACAAACCATTATCAAAACCTAAAAAGTGTGTTAAATGTTTACAAAAGACAGTGAAGGATTCTTATCACATAATG TGCAGGCCATGTGCCTGTGAACTTGAAGTTTGCGCAAAATGTGGAAAGAAAGAAGACATTGTTATTCCGTTGAATAAAGAAACAGAAAAA ATAGAACATACTGAAAATAATCTAAGTTCCAACCATAGAAGAAGCTGCAGAAGAAATGAAGAAAGTGATGATGATTTAGATTTTGATATT GATTTAGAAGACACAGGAGGAGACCATCAAATGAATTAATATCACTGTATTAAAAGTCTGCCGGGCACAGTGGCTCACGCCTGTAATCCC AACACTTTGGGAGGCCAAGGAGGGTGGATCACCTGAGGTCAGGAGTTCGAGACCAGCCTGGCCAACATGGCGGAACCCCATCTCCACTAA AAGTACAAAAAATTAGCTGGGCGTGGTGGCTCATGCCTGTAATCCCAGCTACTCAGGAGGCTGAGGCAGGAGGATTGCTTGAACCCTGGA GGCGGAGATTGAAGTGAGCTGAGTTCGTGCCATTACACTCCAGCCTGGGTGACAGAGTGAGACTCTGTCTCAAAAAAAATAAAATAAAAA GTCAATTTAGAATGTGAAATTCTGACCACCTTTTGGCTTTGAGTATTTTCCAAAAGATATTTGAAATCCTAATGAGGAAATCAGAAAAAG CTATGGAAAAATAGACAAATTTCATACATGAACAATATAAATTGTGTATATTACTTAACATCAAACTAAACAAGATTCAGAATTGATGGT TGTATAAGAACTAGCTCATGTAAAAATAAAATAACATTATTACATTGCCTCAAAAATTGGTCCTCGGTAAGTGCCTTTTGATAAATGATC >32817_32817_1_GDA-C9orf85_GDA_chr9_74817658_ENST00000238018_C9orf85_chr9_74561922_ENST00000334731_length(amino acids)=307AA_BP=184 MGAACRVPATARVSGGRTRPEPVSARQPPAAAESPAASPPRAPSSTSRPALRSAADMCAAQMPPLAHIFRGTFVHSTWTCPMEVLRDHLL GVSDSGKIVFLEEASQQEKLAKEWCFKPCEIRELSHHEFFMPGLVDTHIHASQYSFAGSSIDLPLLEWLTKYTFPAEHRFQNIDFAEEVY TRVVKINAKLHDGVCQRCKEVLEWRVKYSKYKPLSKPKKCVKCLQKTVKDSYHIMCRPCACELEVCAKCGKKEDIVIPLNKETEKIEHTE -------------------------------------------------------------- >32817_32817_2_GDA-C9orf85_GDA_chr9_74817658_ENST00000238018_C9orf85_chr9_74561922_ENST00000377031_length(transcript)=1382nt_BP=567nt GTAGGGAGCCAGCCCCTGGGCGCGGCCTGCAGGGTACCGGCAACCGCCCGGGTAAGCGGGGGCAGGACAAGGCCGGAGCCTGTGTCCGCC CGGCAGCCGCCCGCAGCTGCAGAGAGTCCCGCTGCGTCTCCGCCGCGTGCGCCCTCCTCGACCAGCAGACCCGCGCTGCGCTCCGCCGCT GACATGTGTGCCGCTCAGATGCCGCCCCTGGCGCACATCTTCCGAGGGACGTTCGTCCACTCCACCTGGACCTGCCCCATGGAGGTGCTG CGGGATCACCTCCTCGGCGTGAGCGACAGCGGCAAAATAGTGTTTTTAGAAGAAGCATCTCAACAGGAAAAACTGGCCAAAGAATGGTGC TTCAAGCCGTGTGAAATAAGAGAACTGAGCCACCATGAGTTCTTCATGCCTGGGCTGGTTGATACACACATCCATGCCTCTCAGTATTCC TTTGCTGGAAGTAGCATAGACCTGCCACTCTTGGAGTGGCTGACCAAGTACACATTTCCTGCAGAACACAGATTCCAGAACATCGACTTT GCAGAAGAAGTATATACCAGAGTTGTCAAAATTAATGCAAAACTTCATGATGGAGTATGTCAGCGCTGTAAAGAAGTTCTTGAGTGGCGT GTAAAATACAGCAAATACAAACCATTATCAAAACCTAAAAAGTGTGTTAAATGTTTACAAAAGACAGTGAAGGATTCTTATCACATAATG TGCAGGCCATGTGCCTGTGAACTTGAAGTTTGCGCAAAATGTGGAAAGAAAGAAGACATTGTTATTCCATGGAGTCTCCCTCTGTTGCCC AGGCTGGAGTGCAGTGGCAGGATCTTGGCTCACCACAACCTCCGCCTCCCTTGTTCAAGTGATTCTCCTGCCTCAGCCTCTCGAGTAGCT GGGACTACAGGCGCACACCACCATGCCCAGCTAATCTTTGTATTTTTAGTAGAGATGGGGTTTCACTATGTTGGCCAGGCCGGTCTCGAA CTCCTGACCTCATGATCTGCCTGCCTCAACCTCCCAAAGTGCTGGAATTACAGGTGTGAGCCATCATGCCTGGCCTAATTTGTATATTTC TAATGACTCATGATGTTGACTGAGCATCTTTTCTTTTCTTTTCTTTTTTTTTTTCCTTGTTTTTTGAGATGGAGTCTTGCTCTATAGCCC GGGCTGGAGTGCAGTGGCACCATTTCAGCTCAATGCAACCTCTGCCTCCTAGGTTCAAGTGATTCTCCTGCCTCAGCCTCCCGAGTAGCT GGGATTACAGGCACACACCACCATGCCCAGCTAATTTTTGTATTTTTAGTAGAAACAGGTTTTCACAATGTTGGCCAGGATGGTCTCCAT >32817_32817_2_GDA-C9orf85_GDA_chr9_74817658_ENST00000238018_C9orf85_chr9_74561922_ENST00000377031_length(amino acids)=329AA_BP=184 MGAACRVPATARVSGGRTRPEPVSARQPPAAAESPAASPPRAPSSTSRPALRSAADMCAAQMPPLAHIFRGTFVHSTWTCPMEVLRDHLL GVSDSGKIVFLEEASQQEKLAKEWCFKPCEIRELSHHEFFMPGLVDTHIHASQYSFAGSSIDLPLLEWLTKYTFPAEHRFQNIDFAEEVY TRVVKINAKLHDGVCQRCKEVLEWRVKYSKYKPLSKPKKCVKCLQKTVKDSYHIMCRPCACELEVCAKCGKKEDIVIPWSLPLLPRLECS -------------------------------------------------------------- >32817_32817_3_GDA-C9orf85_GDA_chr9_74817658_ENST00000238018_C9orf85_chr9_74561922_ENST00000486911_length(transcript)=3712nt_BP=567nt GTAGGGAGCCAGCCCCTGGGCGCGGCCTGCAGGGTACCGGCAACCGCCCGGGTAAGCGGGGGCAGGACAAGGCCGGAGCCTGTGTCCGCC CGGCAGCCGCCCGCAGCTGCAGAGAGTCCCGCTGCGTCTCCGCCGCGTGCGCCCTCCTCGACCAGCAGACCCGCGCTGCGCTCCGCCGCT GACATGTGTGCCGCTCAGATGCCGCCCCTGGCGCACATCTTCCGAGGGACGTTCGTCCACTCCACCTGGACCTGCCCCATGGAGGTGCTG CGGGATCACCTCCTCGGCGTGAGCGACAGCGGCAAAATAGTGTTTTTAGAAGAAGCATCTCAACAGGAAAAACTGGCCAAAGAATGGTGC TTCAAGCCGTGTGAAATAAGAGAACTGAGCCACCATGAGTTCTTCATGCCTGGGCTGGTTGATACACACATCCATGCCTCTCAGTATTCC TTTGCTGGAAGTAGCATAGACCTGCCACTCTTGGAGTGGCTGACCAAGTACACATTTCCTGCAGAACACAGATTCCAGAACATCGACTTT GCAGAAGAAGTATATACCAGAGTTGTCAAAATTAATGCAAAACTTCATGATGGAGTATGTCAGCGCTGTAAAGAAGTTCTTGAGTGGCGT GTAAAATACAGCAAATACAAACCATTATCAAAACCTAAAAAGTGATGGAGTCTTGCTCTATAGCCCGGGCTGGAGTGCAGTGGCACCATT TCAGCTCAATGCAACCTCTGCCTCCTAGGTTCAAGTGATTCTCCTGCCTCAGCCTCCCGAGTAGCTGGGATTACAGGCACACACCACCAT GCCCAGCTAATTTTTGTATTTTTAGTAGAAACAGGTTTTCACAATGTTGGCCAGGATGGTCTCCATCTACTGACCTTGTGATCCGCCCCC CTAGGCCTCCCAAAGTGCTGGGCTTACAGGCATGAGCCACTGCACCCAGCCGACTGAACATCTTTTCATGTGTTTATTAGCCAATCCTAT ATCTTCACTGGTGAAATGTCTATTCAGATGTGTTGCCCATTTTAAAAATTGGGTTGTTTTCTTACCATTGAGTTATGAGTCTTTTATATA TATTCTAGATACAAGTCCTTTATCAGATATAATTTGGAAATATTTTCTCGCTGTCTGTAATGTGTTATACATCAATTTTGAGATATCCTT CACATTAAGAAACTAACGGTGTGGATAATAATCCTGGTATTGACAGAGGTTTGGACTCCTGAAGCCTGAAAGTCTATCTGCTGCCACGCC TGGGCACATACTGCATCATTTACAAAACTGTAGAGCACCTGTTGTGTGTGCAGTTGTGATTTCTTATAGATTTTTAGAATTGGAAGGCAT GTAAAGAACACGTAATCTGGTACATTGCTTCAGTAGGTAAGTCAGTATGAACTTCTAAGAATTTTTGTTTTCTTCTGTATTGGGTCTATT GTGGGTATGTCCAACGTGACAGGGGAGGTAAGGGAAGTGGCATCCCCTGAGATAGTGACTGAAATGGCTTTCATCATCTTTAAGTCAAAG TGAGATGCCAGTAATAGGATATATGTATGTATGTACTTGTGTCTCTGTATGTATGTAAATAAACAAACATGCTGGAAGGAGGAGGTGATT CAATCAGGGACTTTGTGAAAGAAAAAAAGAATAACTGGACCTTCCTTTAATGATGAAAACTGTTTATACAGCAAACCATCAAAGCCAAAA TGTGAATTTTGGTATTAGCCCGATTTTTCCTAAGAAACTGTTGATGTAACCACTGTAGTTGCAGAGATCGTTTTGGTATATTCTAGACCC TCTTTGTTTTGTTCTGTTTGGGGTTTCTTCCCCCTCAAGTTGCTCTTGTCCACCACTAGACTGGCTGCCTTTTATTCCATAGCAGACAGT CCTTAAGTCTTTGCATATGTCCTTATTCAAAAATTAATCTTCATCAGTTTTTTTCTGCAGAAAACAGTTTTTTAAATATCTTACATGAGA ATGCTCTGCACCTGCAATCTCTGGTTGATGCAGTTTCCTTTCTCTCTTCTCTGTTCCCATTGGTAGAATAAATCTGCTCCTTCTTAAATC CTGAGCTGAAAATGTCCACACTTCCCAGAAGTGTACTTTAGAATCACCTGTAACATGTATTTAAAATACAGATTCCCCAGCTCCACGGGC AAAGCTCTCCTGCCATGTGACACCCTGATACAGTTCAGGGAGCCACTAAGGCAGGCCAAAATGGCTCAGCAGGCAAAGGTCCAAGCTGCC AGGGTAGTGTGTCATTACAGCATGCTTAGCATAGCTAGGAGGACAGGCTCACACCCAGCCCCACAGCTGTTGCGCTACAGACTCAGGCAC AGGGCTGTCTAACTGGCAGATGTGGGCCACAACTGTTGGAGACAAGCCAGCCATATTTGGGAAAATCTTATTGTAAGGGGCAAGTGTGAG TGAGATTTAGGAGTCATGGGAAAATACACCAACACAGTAAATCTTGTGTTATAGGAGAGATGTGGAAGAAAGAGATAAACTACTGGCCAG GGTGTCTCCTGACTGGGTGACTTGCCACCACATGGGCCAGGCAGGTTGCGGCAGCTCTGCCTTTGGGAGGTGGCTGGAGGAGGGGAGGAG AGAGAGGCATGATGAAGACAGATGCACCCTTTCCTGAGCAGGGGTTAACATTCAGGGTGCCGAAAGGAATTCCACAGCCTGTTTCCCATC TCTCTTGTCCTCATCAAGTACTGGTCCTCGTGTATGTGTTCTGCTTCCGCTTTCTCAGGATGTTTACGTTTTTGCAAATACGTTTATGGA AAAGAGTTACCTCACCCACCTCTCCAAACATCTATTTGTTTTACATTTTTATTGCGGGGGAGTGATCTCTTTACATAGCTTCAAATGGCA TAACATTCAGCAGTATCCAAGCTTAGATATATCTGATGAGAGGAAAGTAATTGTGAGGCCTTTGTTCTAGTTACAACTTTGTCACTATCT GACTCCATGACTCCAGCAAATTGCTTCAACTGTCTGGCCTGCAGTTTTTTTCTTGCGTTAAATAACAGACTTAGTCTAGATCGGTGGTTC TTATCATGTGGTTTCTGGACTAGCAGCATCAATATTACCTGGGAAACTTGTTAGAAATGCAAATTCTTGGGCTCTGCCCTAGACCTACTG AAACATACTCTGTGGGCGGGGCCCAGCAATCTGTGTTTGAAACGCGATTCTGATTATTTGACAAAAGTTTGCAAACCACTGGTCTAGATA AGTAGCTCTTAGCCTTGGCTGCACATTAAAATCATCTGGGCAACTTTTATAACCTACCAATCCTGGCCTCTTCCTCCAAAGATTCTGACT TAAATGGTTTCAGATGGGGACCATTGTTATGCGGTTATAGCCGACGCCTAGGTGCTACCTGAGGTCTTCAAAGCTAAAGGTCAGTGTTTC CCAGCCGTAAATGCATACCTCTAGACCTGGCCTTCTCAAGCCACTAGGTGTTGCTATAATAGAGAAGAAAAGGCATTTTCAGAACCGTCT TTGGATATGGATGAGGAGGAGGAAAATGTATTTCTTAGCTTCTGATAAGAGATTATTTTGTTATTTTAATCTGAGTGCAATTTGCTAAAT ATTCATTTGCAACTTGTTAAATTTATTCAAAGAAATTAAATGCCCATAAGTGACAGAAAGAATAAAGAATTGTGATATATATTTACAATA >32817_32817_3_GDA-C9orf85_GDA_chr9_74817658_ENST00000238018_C9orf85_chr9_74561922_ENST00000486911_length(amino acids)=219AA_BP=184 MGAACRVPATARVSGGRTRPEPVSARQPPAAAESPAASPPRAPSSTSRPALRSAADMCAAQMPPLAHIFRGTFVHSTWTCPMEVLRDHLL GVSDSGKIVFLEEASQQEKLAKEWCFKPCEIRELSHHEFFMPGLVDTHIHASQYSFAGSSIDLPLLEWLTKYTFPAEHRFQNIDFAEEVY -------------------------------------------------------------- >32817_32817_4_GDA-C9orf85_GDA_chr9_74817658_ENST00000358399_C9orf85_chr9_74561922_ENST00000334731_length(transcript)=1464nt_BP=477nt CGGCAGCCGCCCGCAGCTGCAGAGAGTCCCGCTGCGTCTCCGCCGCGTGCGCCCTCCTCGACCAGCAGACCCGCGCTGCGCTCCGCCGCT GACATGTGTGCCGCTCAGATGCCGCCCCTGGCGCACATCTTCCGAGGGACGTTCGTCCACTCCACCTGGACCTGCCCCATGGAGGTGCTG CGGGATCACCTCCTCGGCGTGAGCGACAGCGGCAAAATAGTGTTTTTAGAAGAAGCATCTCAACAGGAAAAACTGGCCAAAGAATGGTGC TTCAAGCCGTGTGAAATAAGAGAACTGAGCCACCATGAGTTCTTCATGCCTGGGCTGGTTGATACACACATCCATGCCTCTCAGTATTCC TTTGCTGGAAGTAGCATAGACCTGCCACTCTTGGAGTGGCTGACCAAGTACACATTTCCTGCAGAACACAGATTCCAGAACATCGACTTT GCAGAAGAAGTATATACCAGAGTTGTCAAAATTAATGCAAAACTTCATGATGGAGTATGTCAGCGCTGTAAAGAAGTTCTTGAGTGGCGT GTAAAATACAGCAAATACAAACCATTATCAAAACCTAAAAAGTGTGTTAAATGTTTACAAAAGACAGTGAAGGATTCTTATCACATAATG TGCAGGCCATGTGCCTGTGAACTTGAAGTTTGCGCAAAATGTGGAAAGAAAGAAGACATTGTTATTCCGTTGAATAAAGAAACAGAAAAA ATAGAACATACTGAAAATAATCTAAGTTCCAACCATAGAAGAAGCTGCAGAAGAAATGAAGAAAGTGATGATGATTTAGATTTTGATATT GATTTAGAAGACACAGGAGGAGACCATCAAATGAATTAATATCACTGTATTAAAAGTCTGCCGGGCACAGTGGCTCACGCCTGTAATCCC AACACTTTGGGAGGCCAAGGAGGGTGGATCACCTGAGGTCAGGAGTTCGAGACCAGCCTGGCCAACATGGCGGAACCCCATCTCCACTAA AAGTACAAAAAATTAGCTGGGCGTGGTGGCTCATGCCTGTAATCCCAGCTACTCAGGAGGCTGAGGCAGGAGGATTGCTTGAACCCTGGA GGCGGAGATTGAAGTGAGCTGAGTTCGTGCCATTACACTCCAGCCTGGGTGACAGAGTGAGACTCTGTCTCAAAAAAAATAAAATAAAAA GTCAATTTAGAATGTGAAATTCTGACCACCTTTTGGCTTTGAGTATTTTCCAAAAGATATTTGAAATCCTAATGAGGAAATCAGAAAAAG CTATGGAAAAATAGACAAATTTCATACATGAACAATATAAATTGTGTATATTACTTAACATCAAACTAAACAAGATTCAGAATTGATGGT TGTATAAGAACTAGCTCATGTAAAAATAAAATAACATTATTACATTGCCTCAAAAATTGGTCCTCGGTAAGTGCCTTTTGATAAATGATC >32817_32817_4_GDA-C9orf85_GDA_chr9_74817658_ENST00000358399_C9orf85_chr9_74561922_ENST00000334731_length(amino acids)=257AA_BP=134 MRSAADMCAAQMPPLAHIFRGTFVHSTWTCPMEVLRDHLLGVSDSGKIVFLEEASQQEKLAKEWCFKPCEIRELSHHEFFMPGLVDTHIH ASQYSFAGSSIDLPLLEWLTKYTFPAEHRFQNIDFAEEVYTRVVKINAKLHDGVCQRCKEVLEWRVKYSKYKPLSKPKKCVKCLQKTVKD -------------------------------------------------------------- >32817_32817_5_GDA-C9orf85_GDA_chr9_74817658_ENST00000358399_C9orf85_chr9_74561922_ENST00000377031_length(transcript)=1292nt_BP=477nt CGGCAGCCGCCCGCAGCTGCAGAGAGTCCCGCTGCGTCTCCGCCGCGTGCGCCCTCCTCGACCAGCAGACCCGCGCTGCGCTCCGCCGCT GACATGTGTGCCGCTCAGATGCCGCCCCTGGCGCACATCTTCCGAGGGACGTTCGTCCACTCCACCTGGACCTGCCCCATGGAGGTGCTG CGGGATCACCTCCTCGGCGTGAGCGACAGCGGCAAAATAGTGTTTTTAGAAGAAGCATCTCAACAGGAAAAACTGGCCAAAGAATGGTGC TTCAAGCCGTGTGAAATAAGAGAACTGAGCCACCATGAGTTCTTCATGCCTGGGCTGGTTGATACACACATCCATGCCTCTCAGTATTCC TTTGCTGGAAGTAGCATAGACCTGCCACTCTTGGAGTGGCTGACCAAGTACACATTTCCTGCAGAACACAGATTCCAGAACATCGACTTT GCAGAAGAAGTATATACCAGAGTTGTCAAAATTAATGCAAAACTTCATGATGGAGTATGTCAGCGCTGTAAAGAAGTTCTTGAGTGGCGT GTAAAATACAGCAAATACAAACCATTATCAAAACCTAAAAAGTGTGTTAAATGTTTACAAAAGACAGTGAAGGATTCTTATCACATAATG TGCAGGCCATGTGCCTGTGAACTTGAAGTTTGCGCAAAATGTGGAAAGAAAGAAGACATTGTTATTCCATGGAGTCTCCCTCTGTTGCCC AGGCTGGAGTGCAGTGGCAGGATCTTGGCTCACCACAACCTCCGCCTCCCTTGTTCAAGTGATTCTCCTGCCTCAGCCTCTCGAGTAGCT GGGACTACAGGCGCACACCACCATGCCCAGCTAATCTTTGTATTTTTAGTAGAGATGGGGTTTCACTATGTTGGCCAGGCCGGTCTCGAA CTCCTGACCTCATGATCTGCCTGCCTCAACCTCCCAAAGTGCTGGAATTACAGGTGTGAGCCATCATGCCTGGCCTAATTTGTATATTTC TAATGACTCATGATGTTGACTGAGCATCTTTTCTTTTCTTTTCTTTTTTTTTTTCCTTGTTTTTTGAGATGGAGTCTTGCTCTATAGCCC GGGCTGGAGTGCAGTGGCACCATTTCAGCTCAATGCAACCTCTGCCTCCTAGGTTCAAGTGATTCTCCTGCCTCAGCCTCCCGAGTAGCT GGGATTACAGGCACACACCACCATGCCCAGCTAATTTTTGTATTTTTAGTAGAAACAGGTTTTCACAATGTTGGCCAGGATGGTCTCCAT >32817_32817_5_GDA-C9orf85_GDA_chr9_74817658_ENST00000358399_C9orf85_chr9_74561922_ENST00000377031_length(amino acids)=279AA_BP=134 MRSAADMCAAQMPPLAHIFRGTFVHSTWTCPMEVLRDHLLGVSDSGKIVFLEEASQQEKLAKEWCFKPCEIRELSHHEFFMPGLVDTHIH ASQYSFAGSSIDLPLLEWLTKYTFPAEHRFQNIDFAEEVYTRVVKINAKLHDGVCQRCKEVLEWRVKYSKYKPLSKPKKCVKCLQKTVKD SYHIMCRPCACELEVCAKCGKKEDIVIPWSLPLLPRLECSGRILAHHNLRLPCSSDSPASASRVAGTTGAHHHAQLIFVFLVEMGFHYVG -------------------------------------------------------------- >32817_32817_6_GDA-C9orf85_GDA_chr9_74817658_ENST00000358399_C9orf85_chr9_74561922_ENST00000486911_length(transcript)=3622nt_BP=477nt CGGCAGCCGCCCGCAGCTGCAGAGAGTCCCGCTGCGTCTCCGCCGCGTGCGCCCTCCTCGACCAGCAGACCCGCGCTGCGCTCCGCCGCT GACATGTGTGCCGCTCAGATGCCGCCCCTGGCGCACATCTTCCGAGGGACGTTCGTCCACTCCACCTGGACCTGCCCCATGGAGGTGCTG CGGGATCACCTCCTCGGCGTGAGCGACAGCGGCAAAATAGTGTTTTTAGAAGAAGCATCTCAACAGGAAAAACTGGCCAAAGAATGGTGC TTCAAGCCGTGTGAAATAAGAGAACTGAGCCACCATGAGTTCTTCATGCCTGGGCTGGTTGATACACACATCCATGCCTCTCAGTATTCC TTTGCTGGAAGTAGCATAGACCTGCCACTCTTGGAGTGGCTGACCAAGTACACATTTCCTGCAGAACACAGATTCCAGAACATCGACTTT GCAGAAGAAGTATATACCAGAGTTGTCAAAATTAATGCAAAACTTCATGATGGAGTATGTCAGCGCTGTAAAGAAGTTCTTGAGTGGCGT GTAAAATACAGCAAATACAAACCATTATCAAAACCTAAAAAGTGATGGAGTCTTGCTCTATAGCCCGGGCTGGAGTGCAGTGGCACCATT TCAGCTCAATGCAACCTCTGCCTCCTAGGTTCAAGTGATTCTCCTGCCTCAGCCTCCCGAGTAGCTGGGATTACAGGCACACACCACCAT GCCCAGCTAATTTTTGTATTTTTAGTAGAAACAGGTTTTCACAATGTTGGCCAGGATGGTCTCCATCTACTGACCTTGTGATCCGCCCCC CTAGGCCTCCCAAAGTGCTGGGCTTACAGGCATGAGCCACTGCACCCAGCCGACTGAACATCTTTTCATGTGTTTATTAGCCAATCCTAT ATCTTCACTGGTGAAATGTCTATTCAGATGTGTTGCCCATTTTAAAAATTGGGTTGTTTTCTTACCATTGAGTTATGAGTCTTTTATATA TATTCTAGATACAAGTCCTTTATCAGATATAATTTGGAAATATTTTCTCGCTGTCTGTAATGTGTTATACATCAATTTTGAGATATCCTT CACATTAAGAAACTAACGGTGTGGATAATAATCCTGGTATTGACAGAGGTTTGGACTCCTGAAGCCTGAAAGTCTATCTGCTGCCACGCC TGGGCACATACTGCATCATTTACAAAACTGTAGAGCACCTGTTGTGTGTGCAGTTGTGATTTCTTATAGATTTTTAGAATTGGAAGGCAT GTAAAGAACACGTAATCTGGTACATTGCTTCAGTAGGTAAGTCAGTATGAACTTCTAAGAATTTTTGTTTTCTTCTGTATTGGGTCTATT GTGGGTATGTCCAACGTGACAGGGGAGGTAAGGGAAGTGGCATCCCCTGAGATAGTGACTGAAATGGCTTTCATCATCTTTAAGTCAAAG TGAGATGCCAGTAATAGGATATATGTATGTATGTACTTGTGTCTCTGTATGTATGTAAATAAACAAACATGCTGGAAGGAGGAGGTGATT CAATCAGGGACTTTGTGAAAGAAAAAAAGAATAACTGGACCTTCCTTTAATGATGAAAACTGTTTATACAGCAAACCATCAAAGCCAAAA TGTGAATTTTGGTATTAGCCCGATTTTTCCTAAGAAACTGTTGATGTAACCACTGTAGTTGCAGAGATCGTTTTGGTATATTCTAGACCC TCTTTGTTTTGTTCTGTTTGGGGTTTCTTCCCCCTCAAGTTGCTCTTGTCCACCACTAGACTGGCTGCCTTTTATTCCATAGCAGACAGT CCTTAAGTCTTTGCATATGTCCTTATTCAAAAATTAATCTTCATCAGTTTTTTTCTGCAGAAAACAGTTTTTTAAATATCTTACATGAGA ATGCTCTGCACCTGCAATCTCTGGTTGATGCAGTTTCCTTTCTCTCTTCTCTGTTCCCATTGGTAGAATAAATCTGCTCCTTCTTAAATC CTGAGCTGAAAATGTCCACACTTCCCAGAAGTGTACTTTAGAATCACCTGTAACATGTATTTAAAATACAGATTCCCCAGCTCCACGGGC AAAGCTCTCCTGCCATGTGACACCCTGATACAGTTCAGGGAGCCACTAAGGCAGGCCAAAATGGCTCAGCAGGCAAAGGTCCAAGCTGCC AGGGTAGTGTGTCATTACAGCATGCTTAGCATAGCTAGGAGGACAGGCTCACACCCAGCCCCACAGCTGTTGCGCTACAGACTCAGGCAC AGGGCTGTCTAACTGGCAGATGTGGGCCACAACTGTTGGAGACAAGCCAGCCATATTTGGGAAAATCTTATTGTAAGGGGCAAGTGTGAG TGAGATTTAGGAGTCATGGGAAAATACACCAACACAGTAAATCTTGTGTTATAGGAGAGATGTGGAAGAAAGAGATAAACTACTGGCCAG GGTGTCTCCTGACTGGGTGACTTGCCACCACATGGGCCAGGCAGGTTGCGGCAGCTCTGCCTTTGGGAGGTGGCTGGAGGAGGGGAGGAG AGAGAGGCATGATGAAGACAGATGCACCCTTTCCTGAGCAGGGGTTAACATTCAGGGTGCCGAAAGGAATTCCACAGCCTGTTTCCCATC TCTCTTGTCCTCATCAAGTACTGGTCCTCGTGTATGTGTTCTGCTTCCGCTTTCTCAGGATGTTTACGTTTTTGCAAATACGTTTATGGA AAAGAGTTACCTCACCCACCTCTCCAAACATCTATTTGTTTTACATTTTTATTGCGGGGGAGTGATCTCTTTACATAGCTTCAAATGGCA TAACATTCAGCAGTATCCAAGCTTAGATATATCTGATGAGAGGAAAGTAATTGTGAGGCCTTTGTTCTAGTTACAACTTTGTCACTATCT GACTCCATGACTCCAGCAAATTGCTTCAACTGTCTGGCCTGCAGTTTTTTTCTTGCGTTAAATAACAGACTTAGTCTAGATCGGTGGTTC TTATCATGTGGTTTCTGGACTAGCAGCATCAATATTACCTGGGAAACTTGTTAGAAATGCAAATTCTTGGGCTCTGCCCTAGACCTACTG AAACATACTCTGTGGGCGGGGCCCAGCAATCTGTGTTTGAAACGCGATTCTGATTATTTGACAAAAGTTTGCAAACCACTGGTCTAGATA AGTAGCTCTTAGCCTTGGCTGCACATTAAAATCATCTGGGCAACTTTTATAACCTACCAATCCTGGCCTCTTCCTCCAAAGATTCTGACT TAAATGGTTTCAGATGGGGACCATTGTTATGCGGTTATAGCCGACGCCTAGGTGCTACCTGAGGTCTTCAAAGCTAAAGGTCAGTGTTTC CCAGCCGTAAATGCATACCTCTAGACCTGGCCTTCTCAAGCCACTAGGTGTTGCTATAATAGAGAAGAAAAGGCATTTTCAGAACCGTCT TTGGATATGGATGAGGAGGAGGAAAATGTATTTCTTAGCTTCTGATAAGAGATTATTTTGTTATTTTAATCTGAGTGCAATTTGCTAAAT ATTCATTTGCAACTTGTTAAATTTATTCAAAGAAATTAAATGCCCATAAGTGACAGAAAGAATAAAGAATTGTGATATATATTTACAATA >32817_32817_6_GDA-C9orf85_GDA_chr9_74817658_ENST00000358399_C9orf85_chr9_74561922_ENST00000486911_length(amino acids)=169AA_BP=134 MRSAADMCAAQMPPLAHIFRGTFVHSTWTCPMEVLRDHLLGVSDSGKIVFLEEASQQEKLAKEWCFKPCEIRELSHHEFFMPGLVDTHIH -------------------------------------------------------------- >32817_32817_7_GDA-C9orf85_GDA_chr9_74817658_ENST00000376986_C9orf85_chr9_74561922_ENST00000334731_length(transcript)=1474nt_BP=487nt AGCCTGTGTCCGCCCGGCAGCCGCCCGCAGCTGCAGAGAGTCCCGCTGCGTCTCCGCCGCGTGCGCCCTCCTCGACCAGCAGACCCGCGC TGCGCTCCGCCGCTGACATGTGTGCCGCTCAGATGCCGCCCCTGGCGCACATCTTCCGAGGGACGTTCGTCCACTCCACCTGGACCTGCC CCATGGAGGTGCTGCGGGATCACCTCCTCGGCGTGAGCGACAGCGGCAAATGTTTTTAGAAGAAGCATCTCAACAGGAAAAACTGGCCAA AGAATGGTGCTTCAAGCCGTGTGAAATAAGAGAACTGAGCCACCATGAGTTCTTCATGCCTGGGCTGGTTGATACACACATCCATGCCTC TCAGTATTCCTTTGCTGGAAGTAGCATAGACCTGCCACTCTTGGAGTGGCTGACCAAGTACACATTTCCTGCAGAACACAGATTCCAGAA CATCGACTTTGCAGAAGAAGTATATACCAGAGTTGTCAAAATTAATGCAAAACTTCATGATGGAGTATGTCAGCGCTGTAAAGAAGTTCT TGAGTGGCGTGTAAAATACAGCAAATACAAACCATTATCAAAACCTAAAAAGTGTGTTAAATGTTTACAAAAGACAGTGAAGGATTCTTA TCACATAATGTGCAGGCCATGTGCCTGTGAACTTGAAGTTTGCGCAAAATGTGGAAAGAAAGAAGACATTGTTATTCCGTTGAATAAAGA AACAGAAAAAATAGAACATACTGAAAATAATCTAAGTTCCAACCATAGAAGAAGCTGCAGAAGAAATGAAGAAAGTGATGATGATTTAGA TTTTGATATTGATTTAGAAGACACAGGAGGAGACCATCAAATGAATTAATATCACTGTATTAAAAGTCTGCCGGGCACAGTGGCTCACGC CTGTAATCCCAACACTTTGGGAGGCCAAGGAGGGTGGATCACCTGAGGTCAGGAGTTCGAGACCAGCCTGGCCAACATGGCGGAACCCCA TCTCCACTAAAAGTACAAAAAATTAGCTGGGCGTGGTGGCTCATGCCTGTAATCCCAGCTACTCAGGAGGCTGAGGCAGGAGGATTGCTT GAACCCTGGAGGCGGAGATTGAAGTGAGCTGAGTTCGTGCCATTACACTCCAGCCTGGGTGACAGAGTGAGACTCTGTCTCAAAAAAAAT AAAATAAAAAGTCAATTTAGAATGTGAAATTCTGACCACCTTTTGGCTTTGAGTATTTTCCAAAAGATATTTGAAATCCTAATGAGGAAA TCAGAAAAAGCTATGGAAAAATAGACAAATTTCATACATGAACAATATAAATTGTGTATATTACTTAACATCAAACTAAACAAGATTCAG AATTGATGGTTGTATAAGAACTAGCTCATGTAAAAATAAAATAACATTATTACATTGCCTCAAAAATTGGTCCTCGGTAAGTGCCTTTTG >32817_32817_7_GDA-C9orf85_GDA_chr9_74817658_ENST00000376986_C9orf85_chr9_74561922_ENST00000334731_length(amino acids)=229AA_BP=106 MDLPHGGAAGSPPRRERQRQMFLEEASQQEKLAKEWCFKPCEIRELSHHEFFMPGLVDTHIHASQYSFAGSSIDLPLLEWLTKYTFPAEH RFQNIDFAEEVYTRVVKINAKLHDGVCQRCKEVLEWRVKYSKYKPLSKPKKCVKCLQKTVKDSYHIMCRPCACELEVCAKCGKKEDIVIP -------------------------------------------------------------- >32817_32817_8_GDA-C9orf85_GDA_chr9_74817658_ENST00000376986_C9orf85_chr9_74561922_ENST00000377031_length(transcript)=1302nt_BP=487nt AGCCTGTGTCCGCCCGGCAGCCGCCCGCAGCTGCAGAGAGTCCCGCTGCGTCTCCGCCGCGTGCGCCCTCCTCGACCAGCAGACCCGCGC TGCGCTCCGCCGCTGACATGTGTGCCGCTCAGATGCCGCCCCTGGCGCACATCTTCCGAGGGACGTTCGTCCACTCCACCTGGACCTGCC CCATGGAGGTGCTGCGGGATCACCTCCTCGGCGTGAGCGACAGCGGCAAATGTTTTTAGAAGAAGCATCTCAACAGGAAAAACTGGCCAA AGAATGGTGCTTCAAGCCGTGTGAAATAAGAGAACTGAGCCACCATGAGTTCTTCATGCCTGGGCTGGTTGATACACACATCCATGCCTC TCAGTATTCCTTTGCTGGAAGTAGCATAGACCTGCCACTCTTGGAGTGGCTGACCAAGTACACATTTCCTGCAGAACACAGATTCCAGAA CATCGACTTTGCAGAAGAAGTATATACCAGAGTTGTCAAAATTAATGCAAAACTTCATGATGGAGTATGTCAGCGCTGTAAAGAAGTTCT TGAGTGGCGTGTAAAATACAGCAAATACAAACCATTATCAAAACCTAAAAAGTGTGTTAAATGTTTACAAAAGACAGTGAAGGATTCTTA TCACATAATGTGCAGGCCATGTGCCTGTGAACTTGAAGTTTGCGCAAAATGTGGAAAGAAAGAAGACATTGTTATTCCATGGAGTCTCCC TCTGTTGCCCAGGCTGGAGTGCAGTGGCAGGATCTTGGCTCACCACAACCTCCGCCTCCCTTGTTCAAGTGATTCTCCTGCCTCAGCCTC TCGAGTAGCTGGGACTACAGGCGCACACCACCATGCCCAGCTAATCTTTGTATTTTTAGTAGAGATGGGGTTTCACTATGTTGGCCAGGC CGGTCTCGAACTCCTGACCTCATGATCTGCCTGCCTCAACCTCCCAAAGTGCTGGAATTACAGGTGTGAGCCATCATGCCTGGCCTAATT TGTATATTTCTAATGACTCATGATGTTGACTGAGCATCTTTTCTTTTCTTTTCTTTTTTTTTTTCCTTGTTTTTTGAGATGGAGTCTTGC TCTATAGCCCGGGCTGGAGTGCAGTGGCACCATTTCAGCTCAATGCAACCTCTGCCTCCTAGGTTCAAGTGATTCTCCTGCCTCAGCCTC CCGAGTAGCTGGGATTACAGGCACACACCACCATGCCCAGCTAATTTTTGTATTTTTAGTAGAAACAGGTTTTCACAATGTTGGCCAGGA >32817_32817_8_GDA-C9orf85_GDA_chr9_74817658_ENST00000376986_C9orf85_chr9_74561922_ENST00000377031_length(amino acids)=251AA_BP=106 MDLPHGGAAGSPPRRERQRQMFLEEASQQEKLAKEWCFKPCEIRELSHHEFFMPGLVDTHIHASQYSFAGSSIDLPLLEWLTKYTFPAEH RFQNIDFAEEVYTRVVKINAKLHDGVCQRCKEVLEWRVKYSKYKPLSKPKKCVKCLQKTVKDSYHIMCRPCACELEVCAKCGKKEDIVIP -------------------------------------------------------------- >32817_32817_9_GDA-C9orf85_GDA_chr9_74817658_ENST00000376986_C9orf85_chr9_74561922_ENST00000486911_length(transcript)=3632nt_BP=487nt AGCCTGTGTCCGCCCGGCAGCCGCCCGCAGCTGCAGAGAGTCCCGCTGCGTCTCCGCCGCGTGCGCCCTCCTCGACCAGCAGACCCGCGC TGCGCTCCGCCGCTGACATGTGTGCCGCTCAGATGCCGCCCCTGGCGCACATCTTCCGAGGGACGTTCGTCCACTCCACCTGGACCTGCC CCATGGAGGTGCTGCGGGATCACCTCCTCGGCGTGAGCGACAGCGGCAAATGTTTTTAGAAGAAGCATCTCAACAGGAAAAACTGGCCAA AGAATGGTGCTTCAAGCCGTGTGAAATAAGAGAACTGAGCCACCATGAGTTCTTCATGCCTGGGCTGGTTGATACACACATCCATGCCTC TCAGTATTCCTTTGCTGGAAGTAGCATAGACCTGCCACTCTTGGAGTGGCTGACCAAGTACACATTTCCTGCAGAACACAGATTCCAGAA CATCGACTTTGCAGAAGAAGTATATACCAGAGTTGTCAAAATTAATGCAAAACTTCATGATGGAGTATGTCAGCGCTGTAAAGAAGTTCT TGAGTGGCGTGTAAAATACAGCAAATACAAACCATTATCAAAACCTAAAAAGTGATGGAGTCTTGCTCTATAGCCCGGGCTGGAGTGCAG TGGCACCATTTCAGCTCAATGCAACCTCTGCCTCCTAGGTTCAAGTGATTCTCCTGCCTCAGCCTCCCGAGTAGCTGGGATTACAGGCAC ACACCACCATGCCCAGCTAATTTTTGTATTTTTAGTAGAAACAGGTTTTCACAATGTTGGCCAGGATGGTCTCCATCTACTGACCTTGTG ATCCGCCCCCCTAGGCCTCCCAAAGTGCTGGGCTTACAGGCATGAGCCACTGCACCCAGCCGACTGAACATCTTTTCATGTGTTTATTAG CCAATCCTATATCTTCACTGGTGAAATGTCTATTCAGATGTGTTGCCCATTTTAAAAATTGGGTTGTTTTCTTACCATTGAGTTATGAGT CTTTTATATATATTCTAGATACAAGTCCTTTATCAGATATAATTTGGAAATATTTTCTCGCTGTCTGTAATGTGTTATACATCAATTTTG AGATATCCTTCACATTAAGAAACTAACGGTGTGGATAATAATCCTGGTATTGACAGAGGTTTGGACTCCTGAAGCCTGAAAGTCTATCTG CTGCCACGCCTGGGCACATACTGCATCATTTACAAAACTGTAGAGCACCTGTTGTGTGTGCAGTTGTGATTTCTTATAGATTTTTAGAAT TGGAAGGCATGTAAAGAACACGTAATCTGGTACATTGCTTCAGTAGGTAAGTCAGTATGAACTTCTAAGAATTTTTGTTTTCTTCTGTAT TGGGTCTATTGTGGGTATGTCCAACGTGACAGGGGAGGTAAGGGAAGTGGCATCCCCTGAGATAGTGACTGAAATGGCTTTCATCATCTT TAAGTCAAAGTGAGATGCCAGTAATAGGATATATGTATGTATGTACTTGTGTCTCTGTATGTATGTAAATAAACAAACATGCTGGAAGGA GGAGGTGATTCAATCAGGGACTTTGTGAAAGAAAAAAAGAATAACTGGACCTTCCTTTAATGATGAAAACTGTTTATACAGCAAACCATC AAAGCCAAAATGTGAATTTTGGTATTAGCCCGATTTTTCCTAAGAAACTGTTGATGTAACCACTGTAGTTGCAGAGATCGTTTTGGTATA TTCTAGACCCTCTTTGTTTTGTTCTGTTTGGGGTTTCTTCCCCCTCAAGTTGCTCTTGTCCACCACTAGACTGGCTGCCTTTTATTCCAT AGCAGACAGTCCTTAAGTCTTTGCATATGTCCTTATTCAAAAATTAATCTTCATCAGTTTTTTTCTGCAGAAAACAGTTTTTTAAATATC TTACATGAGAATGCTCTGCACCTGCAATCTCTGGTTGATGCAGTTTCCTTTCTCTCTTCTCTGTTCCCATTGGTAGAATAAATCTGCTCC TTCTTAAATCCTGAGCTGAAAATGTCCACACTTCCCAGAAGTGTACTTTAGAATCACCTGTAACATGTATTTAAAATACAGATTCCCCAG CTCCACGGGCAAAGCTCTCCTGCCATGTGACACCCTGATACAGTTCAGGGAGCCACTAAGGCAGGCCAAAATGGCTCAGCAGGCAAAGGT CCAAGCTGCCAGGGTAGTGTGTCATTACAGCATGCTTAGCATAGCTAGGAGGACAGGCTCACACCCAGCCCCACAGCTGTTGCGCTACAG ACTCAGGCACAGGGCTGTCTAACTGGCAGATGTGGGCCACAACTGTTGGAGACAAGCCAGCCATATTTGGGAAAATCTTATTGTAAGGGG CAAGTGTGAGTGAGATTTAGGAGTCATGGGAAAATACACCAACACAGTAAATCTTGTGTTATAGGAGAGATGTGGAAGAAAGAGATAAAC TACTGGCCAGGGTGTCTCCTGACTGGGTGACTTGCCACCACATGGGCCAGGCAGGTTGCGGCAGCTCTGCCTTTGGGAGGTGGCTGGAGG AGGGGAGGAGAGAGAGGCATGATGAAGACAGATGCACCCTTTCCTGAGCAGGGGTTAACATTCAGGGTGCCGAAAGGAATTCCACAGCCT GTTTCCCATCTCTCTTGTCCTCATCAAGTACTGGTCCTCGTGTATGTGTTCTGCTTCCGCTTTCTCAGGATGTTTACGTTTTTGCAAATA CGTTTATGGAAAAGAGTTACCTCACCCACCTCTCCAAACATCTATTTGTTTTACATTTTTATTGCGGGGGAGTGATCTCTTTACATAGCT TCAAATGGCATAACATTCAGCAGTATCCAAGCTTAGATATATCTGATGAGAGGAAAGTAATTGTGAGGCCTTTGTTCTAGTTACAACTTT GTCACTATCTGACTCCATGACTCCAGCAAATTGCTTCAACTGTCTGGCCTGCAGTTTTTTTCTTGCGTTAAATAACAGACTTAGTCTAGA TCGGTGGTTCTTATCATGTGGTTTCTGGACTAGCAGCATCAATATTACCTGGGAAACTTGTTAGAAATGCAAATTCTTGGGCTCTGCCCT AGACCTACTGAAACATACTCTGTGGGCGGGGCCCAGCAATCTGTGTTTGAAACGCGATTCTGATTATTTGACAAAAGTTTGCAAACCACT GGTCTAGATAAGTAGCTCTTAGCCTTGGCTGCACATTAAAATCATCTGGGCAACTTTTATAACCTACCAATCCTGGCCTCTTCCTCCAAA GATTCTGACTTAAATGGTTTCAGATGGGGACCATTGTTATGCGGTTATAGCCGACGCCTAGGTGCTACCTGAGGTCTTCAAAGCTAAAGG TCAGTGTTTCCCAGCCGTAAATGCATACCTCTAGACCTGGCCTTCTCAAGCCACTAGGTGTTGCTATAATAGAGAAGAAAAGGCATTTTC AGAACCGTCTTTGGATATGGATGAGGAGGAGGAAAATGTATTTCTTAGCTTCTGATAAGAGATTATTTTGTTATTTTAATCTGAGTGCAA TTTGCTAAATATTCATTTGCAACTTGTTAAATTTATTCAAAGAAATTAAATGCCCATAAGTGACAGAAAGAATAAAGAATTGTGATATAT >32817_32817_9_GDA-C9orf85_GDA_chr9_74817658_ENST00000376986_C9orf85_chr9_74561922_ENST00000486911_length(amino acids)=141AA_BP=106 MDLPHGGAAGSPPRRERQRQMFLEEASQQEKLAKEWCFKPCEIRELSHHEFFMPGLVDTHIHASQYSFAGSSIDLPLLEWLTKYTFPAEH -------------------------------------------------------------- >32817_32817_10_GDA-C9orf85_GDA_chr9_74817658_ENST00000376989_C9orf85_chr9_74561922_ENST00000334731_length(transcript)=1554nt_BP=567nt GTAGGGAGCCAGCCCCTGGGCGCGGCCTGCAGGGTACCGGCAACCGCCCGGGTAAGCGGGGGCAGGACAAGGCCGGAGCCTGTGTCCGCC CGGCAGCCGCCCGCAGCTGCAGAGAGTCCCGCTGCGTCTCCGCCGCGTGCGCCCTCCTCGACCAGCAGACCCGCGCTGCGCTCCGCCGCT GACATGTGTGCCGCTCAGATGCCGCCCCTGGCGCACATCTTCCGAGGGACGTTCGTCCACTCCACCTGGACCTGCCCCATGGAGGTGCTG CGGGATCACCTCCTCGGCGTGAGCGACAGCGGCAAAATAGTGTTTTTAGAAGAAGCATCTCAACAGGAAAAACTGGCCAAAGAATGGTGC TTCAAGCCGTGTGAAATAAGAGAACTGAGCCACCATGAGTTCTTCATGCCTGGGCTGGTTGATACACACATCCATGCCTCTCAGTATTCC TTTGCTGGAAGTAGCATAGACCTGCCACTCTTGGAGTGGCTGACCAAGTACACATTTCCTGCAGAACACAGATTCCAGAACATCGACTTT GCAGAAGAAGTATATACCAGAGTTGTCAAAATTAATGCAAAACTTCATGATGGAGTATGTCAGCGCTGTAAAGAAGTTCTTGAGTGGCGT GTAAAATACAGCAAATACAAACCATTATCAAAACCTAAAAAGTGTGTTAAATGTTTACAAAAGACAGTGAAGGATTCTTATCACATAATG TGCAGGCCATGTGCCTGTGAACTTGAAGTTTGCGCAAAATGTGGAAAGAAAGAAGACATTGTTATTCCGTTGAATAAAGAAACAGAAAAA ATAGAACATACTGAAAATAATCTAAGTTCCAACCATAGAAGAAGCTGCAGAAGAAATGAAGAAAGTGATGATGATTTAGATTTTGATATT GATTTAGAAGACACAGGAGGAGACCATCAAATGAATTAATATCACTGTATTAAAAGTCTGCCGGGCACAGTGGCTCACGCCTGTAATCCC AACACTTTGGGAGGCCAAGGAGGGTGGATCACCTGAGGTCAGGAGTTCGAGACCAGCCTGGCCAACATGGCGGAACCCCATCTCCACTAA AAGTACAAAAAATTAGCTGGGCGTGGTGGCTCATGCCTGTAATCCCAGCTACTCAGGAGGCTGAGGCAGGAGGATTGCTTGAACCCTGGA GGCGGAGATTGAAGTGAGCTGAGTTCGTGCCATTACACTCCAGCCTGGGTGACAGAGTGAGACTCTGTCTCAAAAAAAATAAAATAAAAA GTCAATTTAGAATGTGAAATTCTGACCACCTTTTGGCTTTGAGTATTTTCCAAAAGATATTTGAAATCCTAATGAGGAAATCAGAAAAAG CTATGGAAAAATAGACAAATTTCATACATGAACAATATAAATTGTGTATATTACTTAACATCAAACTAAACAAGATTCAGAATTGATGGT TGTATAAGAACTAGCTCATGTAAAAATAAAATAACATTATTACATTGCCTCAAAAATTGGTCCTCGGTAAGTGCCTTTTGATAAATGATC >32817_32817_10_GDA-C9orf85_GDA_chr9_74817658_ENST00000376989_C9orf85_chr9_74561922_ENST00000334731_length(amino acids)=307AA_BP=184 MGAACRVPATARVSGGRTRPEPVSARQPPAAAESPAASPPRAPSSTSRPALRSAADMCAAQMPPLAHIFRGTFVHSTWTCPMEVLRDHLL GVSDSGKIVFLEEASQQEKLAKEWCFKPCEIRELSHHEFFMPGLVDTHIHASQYSFAGSSIDLPLLEWLTKYTFPAEHRFQNIDFAEEVY TRVVKINAKLHDGVCQRCKEVLEWRVKYSKYKPLSKPKKCVKCLQKTVKDSYHIMCRPCACELEVCAKCGKKEDIVIPLNKETEKIEHTE -------------------------------------------------------------- >32817_32817_11_GDA-C9orf85_GDA_chr9_74817658_ENST00000376989_C9orf85_chr9_74561922_ENST00000377031_length(transcript)=1382nt_BP=567nt GTAGGGAGCCAGCCCCTGGGCGCGGCCTGCAGGGTACCGGCAACCGCCCGGGTAAGCGGGGGCAGGACAAGGCCGGAGCCTGTGTCCGCC CGGCAGCCGCCCGCAGCTGCAGAGAGTCCCGCTGCGTCTCCGCCGCGTGCGCCCTCCTCGACCAGCAGACCCGCGCTGCGCTCCGCCGCT GACATGTGTGCCGCTCAGATGCCGCCCCTGGCGCACATCTTCCGAGGGACGTTCGTCCACTCCACCTGGACCTGCCCCATGGAGGTGCTG CGGGATCACCTCCTCGGCGTGAGCGACAGCGGCAAAATAGTGTTTTTAGAAGAAGCATCTCAACAGGAAAAACTGGCCAAAGAATGGTGC TTCAAGCCGTGTGAAATAAGAGAACTGAGCCACCATGAGTTCTTCATGCCTGGGCTGGTTGATACACACATCCATGCCTCTCAGTATTCC TTTGCTGGAAGTAGCATAGACCTGCCACTCTTGGAGTGGCTGACCAAGTACACATTTCCTGCAGAACACAGATTCCAGAACATCGACTTT GCAGAAGAAGTATATACCAGAGTTGTCAAAATTAATGCAAAACTTCATGATGGAGTATGTCAGCGCTGTAAAGAAGTTCTTGAGTGGCGT GTAAAATACAGCAAATACAAACCATTATCAAAACCTAAAAAGTGTGTTAAATGTTTACAAAAGACAGTGAAGGATTCTTATCACATAATG TGCAGGCCATGTGCCTGTGAACTTGAAGTTTGCGCAAAATGTGGAAAGAAAGAAGACATTGTTATTCCATGGAGTCTCCCTCTGTTGCCC AGGCTGGAGTGCAGTGGCAGGATCTTGGCTCACCACAACCTCCGCCTCCCTTGTTCAAGTGATTCTCCTGCCTCAGCCTCTCGAGTAGCT GGGACTACAGGCGCACACCACCATGCCCAGCTAATCTTTGTATTTTTAGTAGAGATGGGGTTTCACTATGTTGGCCAGGCCGGTCTCGAA CTCCTGACCTCATGATCTGCCTGCCTCAACCTCCCAAAGTGCTGGAATTACAGGTGTGAGCCATCATGCCTGGCCTAATTTGTATATTTC TAATGACTCATGATGTTGACTGAGCATCTTTTCTTTTCTTTTCTTTTTTTTTTTCCTTGTTTTTTGAGATGGAGTCTTGCTCTATAGCCC GGGCTGGAGTGCAGTGGCACCATTTCAGCTCAATGCAACCTCTGCCTCCTAGGTTCAAGTGATTCTCCTGCCTCAGCCTCCCGAGTAGCT GGGATTACAGGCACACACCACCATGCCCAGCTAATTTTTGTATTTTTAGTAGAAACAGGTTTTCACAATGTTGGCCAGGATGGTCTCCAT >32817_32817_11_GDA-C9orf85_GDA_chr9_74817658_ENST00000376989_C9orf85_chr9_74561922_ENST00000377031_length(amino acids)=329AA_BP=184 MGAACRVPATARVSGGRTRPEPVSARQPPAAAESPAASPPRAPSSTSRPALRSAADMCAAQMPPLAHIFRGTFVHSTWTCPMEVLRDHLL GVSDSGKIVFLEEASQQEKLAKEWCFKPCEIRELSHHEFFMPGLVDTHIHASQYSFAGSSIDLPLLEWLTKYTFPAEHRFQNIDFAEEVY TRVVKINAKLHDGVCQRCKEVLEWRVKYSKYKPLSKPKKCVKCLQKTVKDSYHIMCRPCACELEVCAKCGKKEDIVIPWSLPLLPRLECS -------------------------------------------------------------- >32817_32817_12_GDA-C9orf85_GDA_chr9_74817658_ENST00000376989_C9orf85_chr9_74561922_ENST00000486911_length(transcript)=3712nt_BP=567nt GTAGGGAGCCAGCCCCTGGGCGCGGCCTGCAGGGTACCGGCAACCGCCCGGGTAAGCGGGGGCAGGACAAGGCCGGAGCCTGTGTCCGCC CGGCAGCCGCCCGCAGCTGCAGAGAGTCCCGCTGCGTCTCCGCCGCGTGCGCCCTCCTCGACCAGCAGACCCGCGCTGCGCTCCGCCGCT GACATGTGTGCCGCTCAGATGCCGCCCCTGGCGCACATCTTCCGAGGGACGTTCGTCCACTCCACCTGGACCTGCCCCATGGAGGTGCTG CGGGATCACCTCCTCGGCGTGAGCGACAGCGGCAAAATAGTGTTTTTAGAAGAAGCATCTCAACAGGAAAAACTGGCCAAAGAATGGTGC TTCAAGCCGTGTGAAATAAGAGAACTGAGCCACCATGAGTTCTTCATGCCTGGGCTGGTTGATACACACATCCATGCCTCTCAGTATTCC TTTGCTGGAAGTAGCATAGACCTGCCACTCTTGGAGTGGCTGACCAAGTACACATTTCCTGCAGAACACAGATTCCAGAACATCGACTTT GCAGAAGAAGTATATACCAGAGTTGTCAAAATTAATGCAAAACTTCATGATGGAGTATGTCAGCGCTGTAAAGAAGTTCTTGAGTGGCGT GTAAAATACAGCAAATACAAACCATTATCAAAACCTAAAAAGTGATGGAGTCTTGCTCTATAGCCCGGGCTGGAGTGCAGTGGCACCATT TCAGCTCAATGCAACCTCTGCCTCCTAGGTTCAAGTGATTCTCCTGCCTCAGCCTCCCGAGTAGCTGGGATTACAGGCACACACCACCAT GCCCAGCTAATTTTTGTATTTTTAGTAGAAACAGGTTTTCACAATGTTGGCCAGGATGGTCTCCATCTACTGACCTTGTGATCCGCCCCC CTAGGCCTCCCAAAGTGCTGGGCTTACAGGCATGAGCCACTGCACCCAGCCGACTGAACATCTTTTCATGTGTTTATTAGCCAATCCTAT ATCTTCACTGGTGAAATGTCTATTCAGATGTGTTGCCCATTTTAAAAATTGGGTTGTTTTCTTACCATTGAGTTATGAGTCTTTTATATA TATTCTAGATACAAGTCCTTTATCAGATATAATTTGGAAATATTTTCTCGCTGTCTGTAATGTGTTATACATCAATTTTGAGATATCCTT CACATTAAGAAACTAACGGTGTGGATAATAATCCTGGTATTGACAGAGGTTTGGACTCCTGAAGCCTGAAAGTCTATCTGCTGCCACGCC TGGGCACATACTGCATCATTTACAAAACTGTAGAGCACCTGTTGTGTGTGCAGTTGTGATTTCTTATAGATTTTTAGAATTGGAAGGCAT GTAAAGAACACGTAATCTGGTACATTGCTTCAGTAGGTAAGTCAGTATGAACTTCTAAGAATTTTTGTTTTCTTCTGTATTGGGTCTATT GTGGGTATGTCCAACGTGACAGGGGAGGTAAGGGAAGTGGCATCCCCTGAGATAGTGACTGAAATGGCTTTCATCATCTTTAAGTCAAAG TGAGATGCCAGTAATAGGATATATGTATGTATGTACTTGTGTCTCTGTATGTATGTAAATAAACAAACATGCTGGAAGGAGGAGGTGATT CAATCAGGGACTTTGTGAAAGAAAAAAAGAATAACTGGACCTTCCTTTAATGATGAAAACTGTTTATACAGCAAACCATCAAAGCCAAAA TGTGAATTTTGGTATTAGCCCGATTTTTCCTAAGAAACTGTTGATGTAACCACTGTAGTTGCAGAGATCGTTTTGGTATATTCTAGACCC TCTTTGTTTTGTTCTGTTTGGGGTTTCTTCCCCCTCAAGTTGCTCTTGTCCACCACTAGACTGGCTGCCTTTTATTCCATAGCAGACAGT CCTTAAGTCTTTGCATATGTCCTTATTCAAAAATTAATCTTCATCAGTTTTTTTCTGCAGAAAACAGTTTTTTAAATATCTTACATGAGA ATGCTCTGCACCTGCAATCTCTGGTTGATGCAGTTTCCTTTCTCTCTTCTCTGTTCCCATTGGTAGAATAAATCTGCTCCTTCTTAAATC CTGAGCTGAAAATGTCCACACTTCCCAGAAGTGTACTTTAGAATCACCTGTAACATGTATTTAAAATACAGATTCCCCAGCTCCACGGGC AAAGCTCTCCTGCCATGTGACACCCTGATACAGTTCAGGGAGCCACTAAGGCAGGCCAAAATGGCTCAGCAGGCAAAGGTCCAAGCTGCC AGGGTAGTGTGTCATTACAGCATGCTTAGCATAGCTAGGAGGACAGGCTCACACCCAGCCCCACAGCTGTTGCGCTACAGACTCAGGCAC AGGGCTGTCTAACTGGCAGATGTGGGCCACAACTGTTGGAGACAAGCCAGCCATATTTGGGAAAATCTTATTGTAAGGGGCAAGTGTGAG TGAGATTTAGGAGTCATGGGAAAATACACCAACACAGTAAATCTTGTGTTATAGGAGAGATGTGGAAGAAAGAGATAAACTACTGGCCAG GGTGTCTCCTGACTGGGTGACTTGCCACCACATGGGCCAGGCAGGTTGCGGCAGCTCTGCCTTTGGGAGGTGGCTGGAGGAGGGGAGGAG AGAGAGGCATGATGAAGACAGATGCACCCTTTCCTGAGCAGGGGTTAACATTCAGGGTGCCGAAAGGAATTCCACAGCCTGTTTCCCATC TCTCTTGTCCTCATCAAGTACTGGTCCTCGTGTATGTGTTCTGCTTCCGCTTTCTCAGGATGTTTACGTTTTTGCAAATACGTTTATGGA AAAGAGTTACCTCACCCACCTCTCCAAACATCTATTTGTTTTACATTTTTATTGCGGGGGAGTGATCTCTTTACATAGCTTCAAATGGCA TAACATTCAGCAGTATCCAAGCTTAGATATATCTGATGAGAGGAAAGTAATTGTGAGGCCTTTGTTCTAGTTACAACTTTGTCACTATCT GACTCCATGACTCCAGCAAATTGCTTCAACTGTCTGGCCTGCAGTTTTTTTCTTGCGTTAAATAACAGACTTAGTCTAGATCGGTGGTTC TTATCATGTGGTTTCTGGACTAGCAGCATCAATATTACCTGGGAAACTTGTTAGAAATGCAAATTCTTGGGCTCTGCCCTAGACCTACTG AAACATACTCTGTGGGCGGGGCCCAGCAATCTGTGTTTGAAACGCGATTCTGATTATTTGACAAAAGTTTGCAAACCACTGGTCTAGATA AGTAGCTCTTAGCCTTGGCTGCACATTAAAATCATCTGGGCAACTTTTATAACCTACCAATCCTGGCCTCTTCCTCCAAAGATTCTGACT TAAATGGTTTCAGATGGGGACCATTGTTATGCGGTTATAGCCGACGCCTAGGTGCTACCTGAGGTCTTCAAAGCTAAAGGTCAGTGTTTC CCAGCCGTAAATGCATACCTCTAGACCTGGCCTTCTCAAGCCACTAGGTGTTGCTATAATAGAGAAGAAAAGGCATTTTCAGAACCGTCT TTGGATATGGATGAGGAGGAGGAAAATGTATTTCTTAGCTTCTGATAAGAGATTATTTTGTTATTTTAATCTGAGTGCAATTTGCTAAAT ATTCATTTGCAACTTGTTAAATTTATTCAAAGAAATTAAATGCCCATAAGTGACAGAAAGAATAAAGAATTGTGATATATATTTACAATA >32817_32817_12_GDA-C9orf85_GDA_chr9_74817658_ENST00000376989_C9orf85_chr9_74561922_ENST00000486911_length(amino acids)=219AA_BP=184 MGAACRVPATARVSGGRTRPEPVSARQPPAAAESPAASPPRAPSSTSRPALRSAADMCAAQMPPLAHIFRGTFVHSTWTCPMEVLRDHLL GVSDSGKIVFLEEASQQEKLAKEWCFKPCEIRELSHHEFFMPGLVDTHIHASQYSFAGSSIDLPLLEWLTKYTFPAEHRFQNIDFAEEVY -------------------------------------------------------------- >32817_32817_13_GDA-C9orf85_GDA_chr9_74817658_ENST00000545168_C9orf85_chr9_74561922_ENST00000334731_length(transcript)=1487nt_BP=500nt ATTCTCCCGCCTCAGTCTCCTGAGTAGCCGGGACTACAGGCACCCGCTACAACGCCCGGCTAATTTTTTTTGTATTTCCCCTTCCTTCTT TGCTTTCAAAATCCAGGCTTAGGGGTACAAAAACCTATATTGTCTGAGACAGGAAGCACTCCGAAGTTTGAAGAAGAGGGCAGCAGCCCA ACTCAGAAGAACTGGACTCCCCAGCACTATAAGGAGAGAGGGTGGTGGTTCCACCAGAGATAGTGTTTTTAGAAGAAGCATCTCAACAGG AAAAACTGGCCAAAGAATGGTGCTTCAAGCCGTGTGAAATAAGAGAACTGAGCCACCATGAGTTCTTCATGCCTGGGCTGGTTGATACAC ACATCCATGCCTCTCAGTATTCCTTTGCTGGAAGTAGCATAGACCTGCCACTCTTGGAGTGGCTGACCAAGTACACATTTCCTGCAGAAC ACAGATTCCAGAACATCGACTTTGCAGAAGAAGTATATACCAGAGTTGTCAAAATTAATGCAAAACTTCATGATGGAGTATGTCAGCGCT GTAAAGAAGTTCTTGAGTGGCGTGTAAAATACAGCAAATACAAACCATTATCAAAACCTAAAAAGTGTGTTAAATGTTTACAAAAGACAG TGAAGGATTCTTATCACATAATGTGCAGGCCATGTGCCTGTGAACTTGAAGTTTGCGCAAAATGTGGAAAGAAAGAAGACATTGTTATTC CGTTGAATAAAGAAACAGAAAAAATAGAACATACTGAAAATAATCTAAGTTCCAACCATAGAAGAAGCTGCAGAAGAAATGAAGAAAGTG ATGATGATTTAGATTTTGATATTGATTTAGAAGACACAGGAGGAGACCATCAAATGAATTAATATCACTGTATTAAAAGTCTGCCGGGCA CAGTGGCTCACGCCTGTAATCCCAACACTTTGGGAGGCCAAGGAGGGTGGATCACCTGAGGTCAGGAGTTCGAGACCAGCCTGGCCAACA TGGCGGAACCCCATCTCCACTAAAAGTACAAAAAATTAGCTGGGCGTGGTGGCTCATGCCTGTAATCCCAGCTACTCAGGAGGCTGAGGC AGGAGGATTGCTTGAACCCTGGAGGCGGAGATTGAAGTGAGCTGAGTTCGTGCCATTACACTCCAGCCTGGGTGACAGAGTGAGACTCTG TCTCAAAAAAAATAAAATAAAAAGTCAATTTAGAATGTGAAATTCTGACCACCTTTTGGCTTTGAGTATTTTCCAAAAGATATTTGAAAT CCTAATGAGGAAATCAGAAAAAGCTATGGAAAAATAGACAAATTTCATACATGAACAATATAAATTGTGTATATTACTTAACATCAAACT AAACAAGATTCAGAATTGATGGTTGTATAAGAACTAGCTCATGTAAAAATAAAATAACATTATTACATTGCCTCAAAAATTGGTCCTCGG >32817_32817_13_GDA-C9orf85_GDA_chr9_74817658_ENST00000545168_C9orf85_chr9_74561922_ENST00000334731_length(amino acids)=198AA_BP=75 MAKEWCFKPCEIRELSHHEFFMPGLVDTHIHASQYSFAGSSIDLPLLEWLTKYTFPAEHRFQNIDFAEEVYTRVVKINAKLHDGVCQRCK EVLEWRVKYSKYKPLSKPKKCVKCLQKTVKDSYHIMCRPCACELEVCAKCGKKEDIVIPLNKETEKIEHTENNLSSNHRRSCRRNEESDD -------------------------------------------------------------- >32817_32817_14_GDA-C9orf85_GDA_chr9_74817658_ENST00000545168_C9orf85_chr9_74561922_ENST00000377031_length(transcript)=1315nt_BP=500nt ATTCTCCCGCCTCAGTCTCCTGAGTAGCCGGGACTACAGGCACCCGCTACAACGCCCGGCTAATTTTTTTTGTATTTCCCCTTCCTTCTT TGCTTTCAAAATCCAGGCTTAGGGGTACAAAAACCTATATTGTCTGAGACAGGAAGCACTCCGAAGTTTGAAGAAGAGGGCAGCAGCCCA ACTCAGAAGAACTGGACTCCCCAGCACTATAAGGAGAGAGGGTGGTGGTTCCACCAGAGATAGTGTTTTTAGAAGAAGCATCTCAACAGG AAAAACTGGCCAAAGAATGGTGCTTCAAGCCGTGTGAAATAAGAGAACTGAGCCACCATGAGTTCTTCATGCCTGGGCTGGTTGATACAC ACATCCATGCCTCTCAGTATTCCTTTGCTGGAAGTAGCATAGACCTGCCACTCTTGGAGTGGCTGACCAAGTACACATTTCCTGCAGAAC ACAGATTCCAGAACATCGACTTTGCAGAAGAAGTATATACCAGAGTTGTCAAAATTAATGCAAAACTTCATGATGGAGTATGTCAGCGCT GTAAAGAAGTTCTTGAGTGGCGTGTAAAATACAGCAAATACAAACCATTATCAAAACCTAAAAAGTGTGTTAAATGTTTACAAAAGACAG TGAAGGATTCTTATCACATAATGTGCAGGCCATGTGCCTGTGAACTTGAAGTTTGCGCAAAATGTGGAAAGAAAGAAGACATTGTTATTC CATGGAGTCTCCCTCTGTTGCCCAGGCTGGAGTGCAGTGGCAGGATCTTGGCTCACCACAACCTCCGCCTCCCTTGTTCAAGTGATTCTC CTGCCTCAGCCTCTCGAGTAGCTGGGACTACAGGCGCACACCACCATGCCCAGCTAATCTTTGTATTTTTAGTAGAGATGGGGTTTCACT ATGTTGGCCAGGCCGGTCTCGAACTCCTGACCTCATGATCTGCCTGCCTCAACCTCCCAAAGTGCTGGAATTACAGGTGTGAGCCATCAT GCCTGGCCTAATTTGTATATTTCTAATGACTCATGATGTTGACTGAGCATCTTTTCTTTTCTTTTCTTTTTTTTTTTCCTTGTTTTTTGA GATGGAGTCTTGCTCTATAGCCCGGGCTGGAGTGCAGTGGCACCATTTCAGCTCAATGCAACCTCTGCCTCCTAGGTTCAAGTGATTCTC CTGCCTCAGCCTCCCGAGTAGCTGGGATTACAGGCACACACCACCATGCCCAGCTAATTTTTGTATTTTTAGTAGAAACAGGTTTTCACA >32817_32817_14_GDA-C9orf85_GDA_chr9_74817658_ENST00000545168_C9orf85_chr9_74561922_ENST00000377031_length(amino acids)=220AA_BP=75 MAKEWCFKPCEIRELSHHEFFMPGLVDTHIHASQYSFAGSSIDLPLLEWLTKYTFPAEHRFQNIDFAEEVYTRVVKINAKLHDGVCQRCK EVLEWRVKYSKYKPLSKPKKCVKCLQKTVKDSYHIMCRPCACELEVCAKCGKKEDIVIPWSLPLLPRLECSGRILAHHNLRLPCSSDSPA -------------------------------------------------------------- >32817_32817_15_GDA-C9orf85_GDA_chr9_74817658_ENST00000545168_C9orf85_chr9_74561922_ENST00000486911_length(transcript)=3645nt_BP=500nt ATTCTCCCGCCTCAGTCTCCTGAGTAGCCGGGACTACAGGCACCCGCTACAACGCCCGGCTAATTTTTTTTGTATTTCCCCTTCCTTCTT TGCTTTCAAAATCCAGGCTTAGGGGTACAAAAACCTATATTGTCTGAGACAGGAAGCACTCCGAAGTTTGAAGAAGAGGGCAGCAGCCCA ACTCAGAAGAACTGGACTCCCCAGCACTATAAGGAGAGAGGGTGGTGGTTCCACCAGAGATAGTGTTTTTAGAAGAAGCATCTCAACAGG AAAAACTGGCCAAAGAATGGTGCTTCAAGCCGTGTGAAATAAGAGAACTGAGCCACCATGAGTTCTTCATGCCTGGGCTGGTTGATACAC ACATCCATGCCTCTCAGTATTCCTTTGCTGGAAGTAGCATAGACCTGCCACTCTTGGAGTGGCTGACCAAGTACACATTTCCTGCAGAAC ACAGATTCCAGAACATCGACTTTGCAGAAGAAGTATATACCAGAGTTGTCAAAATTAATGCAAAACTTCATGATGGAGTATGTCAGCGCT GTAAAGAAGTTCTTGAGTGGCGTGTAAAATACAGCAAATACAAACCATTATCAAAACCTAAAAAGTGATGGAGTCTTGCTCTATAGCCCG GGCTGGAGTGCAGTGGCACCATTTCAGCTCAATGCAACCTCTGCCTCCTAGGTTCAAGTGATTCTCCTGCCTCAGCCTCCCGAGTAGCTG GGATTACAGGCACACACCACCATGCCCAGCTAATTTTTGTATTTTTAGTAGAAACAGGTTTTCACAATGTTGGCCAGGATGGTCTCCATC TACTGACCTTGTGATCCGCCCCCCTAGGCCTCCCAAAGTGCTGGGCTTACAGGCATGAGCCACTGCACCCAGCCGACTGAACATCTTTTC ATGTGTTTATTAGCCAATCCTATATCTTCACTGGTGAAATGTCTATTCAGATGTGTTGCCCATTTTAAAAATTGGGTTGTTTTCTTACCA TTGAGTTATGAGTCTTTTATATATATTCTAGATACAAGTCCTTTATCAGATATAATTTGGAAATATTTTCTCGCTGTCTGTAATGTGTTA TACATCAATTTTGAGATATCCTTCACATTAAGAAACTAACGGTGTGGATAATAATCCTGGTATTGACAGAGGTTTGGACTCCTGAAGCCT GAAAGTCTATCTGCTGCCACGCCTGGGCACATACTGCATCATTTACAAAACTGTAGAGCACCTGTTGTGTGTGCAGTTGTGATTTCTTAT AGATTTTTAGAATTGGAAGGCATGTAAAGAACACGTAATCTGGTACATTGCTTCAGTAGGTAAGTCAGTATGAACTTCTAAGAATTTTTG TTTTCTTCTGTATTGGGTCTATTGTGGGTATGTCCAACGTGACAGGGGAGGTAAGGGAAGTGGCATCCCCTGAGATAGTGACTGAAATGG CTTTCATCATCTTTAAGTCAAAGTGAGATGCCAGTAATAGGATATATGTATGTATGTACTTGTGTCTCTGTATGTATGTAAATAAACAAA CATGCTGGAAGGAGGAGGTGATTCAATCAGGGACTTTGTGAAAGAAAAAAAGAATAACTGGACCTTCCTTTAATGATGAAAACTGTTTAT ACAGCAAACCATCAAAGCCAAAATGTGAATTTTGGTATTAGCCCGATTTTTCCTAAGAAACTGTTGATGTAACCACTGTAGTTGCAGAGA TCGTTTTGGTATATTCTAGACCCTCTTTGTTTTGTTCTGTTTGGGGTTTCTTCCCCCTCAAGTTGCTCTTGTCCACCACTAGACTGGCTG CCTTTTATTCCATAGCAGACAGTCCTTAAGTCTTTGCATATGTCCTTATTCAAAAATTAATCTTCATCAGTTTTTTTCTGCAGAAAACAG TTTTTTAAATATCTTACATGAGAATGCTCTGCACCTGCAATCTCTGGTTGATGCAGTTTCCTTTCTCTCTTCTCTGTTCCCATTGGTAGA ATAAATCTGCTCCTTCTTAAATCCTGAGCTGAAAATGTCCACACTTCCCAGAAGTGTACTTTAGAATCACCTGTAACATGTATTTAAAAT ACAGATTCCCCAGCTCCACGGGCAAAGCTCTCCTGCCATGTGACACCCTGATACAGTTCAGGGAGCCACTAAGGCAGGCCAAAATGGCTC AGCAGGCAAAGGTCCAAGCTGCCAGGGTAGTGTGTCATTACAGCATGCTTAGCATAGCTAGGAGGACAGGCTCACACCCAGCCCCACAGC TGTTGCGCTACAGACTCAGGCACAGGGCTGTCTAACTGGCAGATGTGGGCCACAACTGTTGGAGACAAGCCAGCCATATTTGGGAAAATC TTATTGTAAGGGGCAAGTGTGAGTGAGATTTAGGAGTCATGGGAAAATACACCAACACAGTAAATCTTGTGTTATAGGAGAGATGTGGAA GAAAGAGATAAACTACTGGCCAGGGTGTCTCCTGACTGGGTGACTTGCCACCACATGGGCCAGGCAGGTTGCGGCAGCTCTGCCTTTGGG AGGTGGCTGGAGGAGGGGAGGAGAGAGAGGCATGATGAAGACAGATGCACCCTTTCCTGAGCAGGGGTTAACATTCAGGGTGCCGAAAGG AATTCCACAGCCTGTTTCCCATCTCTCTTGTCCTCATCAAGTACTGGTCCTCGTGTATGTGTTCTGCTTCCGCTTTCTCAGGATGTTTAC GTTTTTGCAAATACGTTTATGGAAAAGAGTTACCTCACCCACCTCTCCAAACATCTATTTGTTTTACATTTTTATTGCGGGGGAGTGATC TCTTTACATAGCTTCAAATGGCATAACATTCAGCAGTATCCAAGCTTAGATATATCTGATGAGAGGAAAGTAATTGTGAGGCCTTTGTTC TAGTTACAACTTTGTCACTATCTGACTCCATGACTCCAGCAAATTGCTTCAACTGTCTGGCCTGCAGTTTTTTTCTTGCGTTAAATAACA GACTTAGTCTAGATCGGTGGTTCTTATCATGTGGTTTCTGGACTAGCAGCATCAATATTACCTGGGAAACTTGTTAGAAATGCAAATTCT TGGGCTCTGCCCTAGACCTACTGAAACATACTCTGTGGGCGGGGCCCAGCAATCTGTGTTTGAAACGCGATTCTGATTATTTGACAAAAG TTTGCAAACCACTGGTCTAGATAAGTAGCTCTTAGCCTTGGCTGCACATTAAAATCATCTGGGCAACTTTTATAACCTACCAATCCTGGC CTCTTCCTCCAAAGATTCTGACTTAAATGGTTTCAGATGGGGACCATTGTTATGCGGTTATAGCCGACGCCTAGGTGCTACCTGAGGTCT TCAAAGCTAAAGGTCAGTGTTTCCCAGCCGTAAATGCATACCTCTAGACCTGGCCTTCTCAAGCCACTAGGTGTTGCTATAATAGAGAAG AAAAGGCATTTTCAGAACCGTCTTTGGATATGGATGAGGAGGAGGAAAATGTATTTCTTAGCTTCTGATAAGAGATTATTTTGTTATTTT AATCTGAGTGCAATTTGCTAAATATTCATTTGCAACTTGTTAAATTTATTCAAAGAAATTAAATGCCCATAAGTGACAGAAAGAATAAAG >32817_32817_15_GDA-C9orf85_GDA_chr9_74817658_ENST00000545168_C9orf85_chr9_74561922_ENST00000486911_length(amino acids)=110AA_BP=75 MAKEWCFKPCEIRELSHHEFFMPGLVDTHIHASQYSFAGSSIDLPLLEWLTKYTFPAEHRFQNIDFAEEVYTRVVKINAKLHDGVCQRCK -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for GDA-C9orf85 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for GDA-C9orf85 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for GDA-C9orf85 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies