
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:GIGYF2-CHRND (FusionGDB2 ID:33092) |
Fusion Gene Summary for GIGYF2-CHRND |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: GIGYF2-CHRND | Fusion gene ID: 33092 | Hgene | Tgene | Gene symbol | GIGYF2 | CHRND | Gene ID | 26058 | 1144 |
| Gene name | GRB10 interacting GYF protein 2 | cholinergic receptor nicotinic delta subunit | |
| Synonyms | GYF2|PARK11|PERQ2|PERQ3|TNRC15 | ACHRD|CMS2A|CMS3A|CMS3B|CMS3C|FCCMS|SCCMS | |
| Cytomap | 2q37.1 | 2q37.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | GRB10-interacting GYF protein 2PERQ amino acid rich, with GYF domain 3PERQ amino acid-rich with GYF domain-containing protein 2Parkinson disease (autosomal recessive, early onset) 11trinucleotide repeat-containing gene 15 protein | acetylcholine receptor subunit deltaacetylcholine receptor, nicotinic, delta (muscle)cholinergic receptor, nicotinic deltacholinergic receptor, nicotinic, delta (muscle)cholinergic receptor, nicotinic, delta polypeptide | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q6Y7W6 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000373563, ENST00000373566, ENST00000409196, ENST00000409451, ENST00000409480, ENST00000409547, ENST00000452341, ENST00000482666, | ENST00000457943, ENST00000536614, ENST00000258385, ENST00000543200, | |
| Fusion gene scores | * DoF score | 24 X 20 X 15=7200 | 1 X 1 X 1=1 |
| # samples | 34 | 1 | |
| ** MAII score | log2(34/7200*10)=-4.40439025507934 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(1/1*10)=3.32192809488736 | |
| Context | PubMed: GIGYF2 [Title/Abstract] AND CHRND [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | GIGYF2(233613792)-CHRND(233398641), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | GIGYF2 | GO:0016441 | posttranscriptional gene silencing | 27157137 |
| Hgene | GIGYF2 | GO:0061157 | mRNA destabilization | 27157137 |
| Fusion gene breakpoints across GIGYF2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
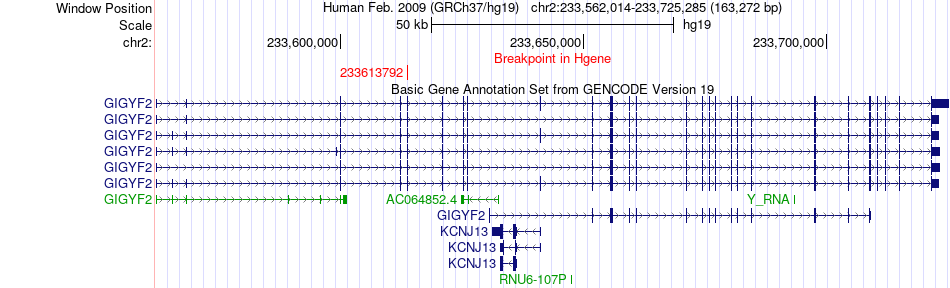 |
| Fusion gene breakpoints across CHRND (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-AR-A256-01A | GIGYF2 | chr2 | 233613792 | - | CHRND | chr2 | 233398641 | + |
| ChimerDB4 | BRCA | TCGA-AR-A256-01A | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + |
Top |
Fusion Gene ORF analysis for GIGYF2-CHRND |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000373563 | ENST00000457943 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + |
| 5CDS-intron | ENST00000373563 | ENST00000536614 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + |
| 5CDS-intron | ENST00000373566 | ENST00000457943 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + |
| 5CDS-intron | ENST00000373566 | ENST00000536614 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + |
| 5CDS-intron | ENST00000409196 | ENST00000457943 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + |
| 5CDS-intron | ENST00000409196 | ENST00000536614 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + |
| 5CDS-intron | ENST00000409451 | ENST00000457943 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + |
| 5CDS-intron | ENST00000409451 | ENST00000536614 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + |
| 5CDS-intron | ENST00000409480 | ENST00000457943 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + |
| 5CDS-intron | ENST00000409480 | ENST00000536614 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + |
| 5CDS-intron | ENST00000409547 | ENST00000457943 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + |
| 5CDS-intron | ENST00000409547 | ENST00000536614 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + |
| In-frame | ENST00000373563 | ENST00000258385 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + |
| In-frame | ENST00000373563 | ENST00000543200 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + |
| In-frame | ENST00000373566 | ENST00000258385 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + |
| In-frame | ENST00000373566 | ENST00000543200 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + |
| In-frame | ENST00000409196 | ENST00000258385 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + |
| In-frame | ENST00000409196 | ENST00000543200 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + |
| In-frame | ENST00000409451 | ENST00000258385 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + |
| In-frame | ENST00000409451 | ENST00000543200 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + |
| In-frame | ENST00000409480 | ENST00000258385 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + |
| In-frame | ENST00000409480 | ENST00000543200 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + |
| In-frame | ENST00000409547 | ENST00000258385 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + |
| In-frame | ENST00000409547 | ENST00000543200 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + |
| intron-3CDS | ENST00000452341 | ENST00000258385 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + |
| intron-3CDS | ENST00000452341 | ENST00000543200 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + |
| intron-3CDS | ENST00000482666 | ENST00000258385 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + |
| intron-3CDS | ENST00000482666 | ENST00000543200 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + |
| intron-intron | ENST00000452341 | ENST00000457943 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + |
| intron-intron | ENST00000452341 | ENST00000536614 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + |
| intron-intron | ENST00000482666 | ENST00000457943 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + |
| intron-intron | ENST00000482666 | ENST00000536614 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000373566 | GIGYF2 | chr2 | 233613792 | + | ENST00000543200 | CHRND | chr2 | 233398641 | + | 1234 | 464 | 197 | 970 | 257 |
| ENST00000373566 | GIGYF2 | chr2 | 233613792 | + | ENST00000258385 | CHRND | chr2 | 233398641 | + | 1497 | 464 | 197 | 970 | 257 |
| ENST00000373563 | GIGYF2 | chr2 | 233613792 | + | ENST00000543200 | CHRND | chr2 | 233398641 | + | 1232 | 462 | 195 | 968 | 257 |
| ENST00000373563 | GIGYF2 | chr2 | 233613792 | + | ENST00000258385 | CHRND | chr2 | 233398641 | + | 1495 | 462 | 195 | 968 | 257 |
| ENST00000409480 | GIGYF2 | chr2 | 233613792 | + | ENST00000543200 | CHRND | chr2 | 233398641 | + | 1299 | 529 | 262 | 1035 | 257 |
| ENST00000409480 | GIGYF2 | chr2 | 233613792 | + | ENST00000258385 | CHRND | chr2 | 233398641 | + | 1562 | 529 | 262 | 1035 | 257 |
| ENST00000409547 | GIGYF2 | chr2 | 233613792 | + | ENST00000543200 | CHRND | chr2 | 233398641 | + | 1348 | 578 | 311 | 1084 | 257 |
| ENST00000409547 | GIGYF2 | chr2 | 233613792 | + | ENST00000258385 | CHRND | chr2 | 233398641 | + | 1611 | 578 | 311 | 1084 | 257 |
| ENST00000409196 | GIGYF2 | chr2 | 233613792 | + | ENST00000543200 | CHRND | chr2 | 233398641 | + | 1135 | 365 | 98 | 871 | 257 |
| ENST00000409196 | GIGYF2 | chr2 | 233613792 | + | ENST00000258385 | CHRND | chr2 | 233398641 | + | 1398 | 365 | 98 | 871 | 257 |
| ENST00000409451 | GIGYF2 | chr2 | 233613792 | + | ENST00000543200 | CHRND | chr2 | 233398641 | + | 1263 | 493 | 226 | 999 | 257 |
| ENST00000409451 | GIGYF2 | chr2 | 233613792 | + | ENST00000258385 | CHRND | chr2 | 233398641 | + | 1526 | 493 | 226 | 999 | 257 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000373566 | ENST00000543200 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + | 0.009049302 | 0.9909507 |
| ENST00000373566 | ENST00000258385 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + | 0.009965301 | 0.99003476 |
| ENST00000373563 | ENST00000543200 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + | 0.008527317 | 0.9914726 |
| ENST00000373563 | ENST00000258385 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + | 0.009336025 | 0.990664 |
| ENST00000409480 | ENST00000543200 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + | 0.009113809 | 0.9908862 |
| ENST00000409480 | ENST00000258385 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + | 0.009315604 | 0.9906844 |
| ENST00000409547 | ENST00000543200 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + | 0.011164399 | 0.98883563 |
| ENST00000409547 | ENST00000258385 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + | 0.012551562 | 0.9874485 |
| ENST00000409196 | ENST00000543200 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + | 0.010746304 | 0.9892537 |
| ENST00000409196 | ENST00000258385 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + | 0.011715596 | 0.98828435 |
| ENST00000409451 | ENST00000543200 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + | 0.010011775 | 0.98998827 |
| ENST00000409451 | ENST00000258385 | GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398641 | + | 0.010019056 | 0.9899809 |
Top |
Fusion Genomic Features for GIGYF2-CHRND |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398640 | + | 5.47E-10 | 1 |
| GIGYF2 | chr2 | 233613792 | + | CHRND | chr2 | 233398640 | + | 5.47E-10 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
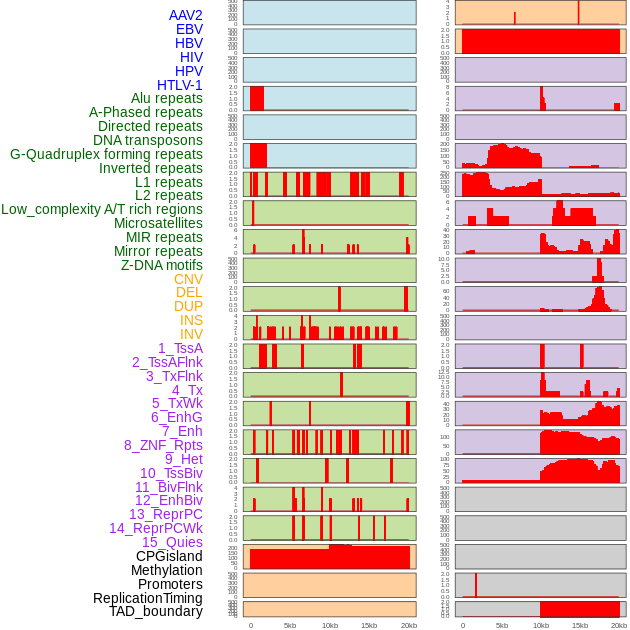 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
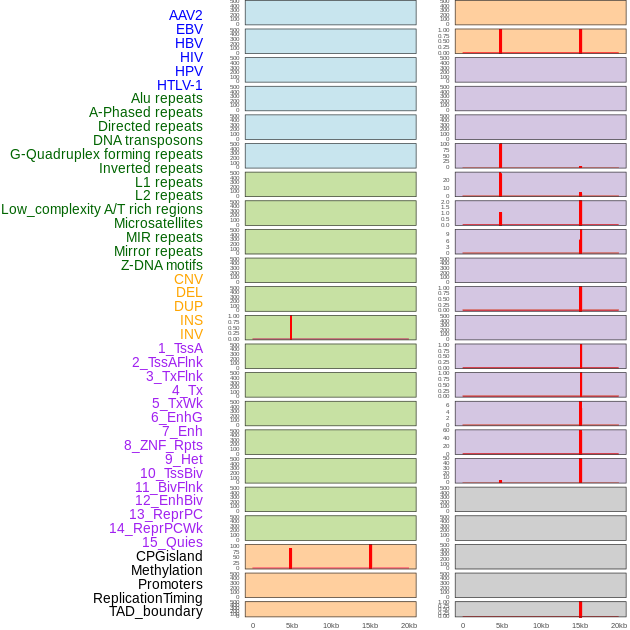 |
Top |
Fusion Protein Features for GIGYF2-CHRND |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr2:233613792/chr2:233398641) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| GIGYF2 | . |
| FUNCTION: Key component of the 4EHP-GYF2 complex, a multiprotein complex that acts as a repressor of translation initiation (PubMed:22751931, PubMed:31439631). In the 4EHP-GYF2 complex, acts as a factor that bridges EIF4E2 to ZFP36/TTP, linking translation repression with mRNA decay (PubMed:31439631). Also recruits and bridges the association of the 4EHP complex with the decapping effector protein DDX6, which is required for the ZFP36/TTP-mediated down-regulation of AU-rich mRNA (PubMed:31439631). May act cooperatively with GRB10 to regulate tyrosine kinase receptor signaling, including IGF1 and insulin receptors (PubMed:12771153). {ECO:0000269|PubMed:12771153, ECO:0000269|PubMed:22751931, ECO:0000269|PubMed:31439631}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | GIGYF2 | chr2:233613792 | chr2:233398641 | ENST00000373563 | + | 5 | 29 | 40_50 | 89 | 1300.0 | Motif | 4EHP-binding motif |
| Hgene | GIGYF2 | chr2:233613792 | chr2:233398641 | ENST00000409451 | + | 6 | 31 | 40_50 | 89 | 1321.0 | Motif | 4EHP-binding motif |
| Hgene | GIGYF2 | chr2:233613792 | chr2:233398641 | ENST00000409547 | + | 7 | 31 | 40_50 | 89 | 1300.0 | Motif | 4EHP-binding motif |
| Tgene | CHRND | chr2:233613792 | chr2:233398641 | ENST00000543200 | 7 | 11 | 334_471 | 334 | 503.0 | Topological domain | Cytoplasmic | |
| Tgene | CHRND | chr2:233613792 | chr2:233398641 | ENST00000258385 | 8 | 12 | 472_490 | 349 | 518.0 | Transmembrane | Helical | |
| Tgene | CHRND | chr2:233613792 | chr2:233398641 | ENST00000543200 | 7 | 11 | 472_490 | 334 | 503.0 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | GIGYF2 | chr2:233613792 | chr2:233398641 | ENST00000373563 | + | 5 | 29 | 106_111 | 89 | 1300.0 | Compositional bias | Note=Poly-Gly |
| Hgene | GIGYF2 | chr2:233613792 | chr2:233398641 | ENST00000373563 | + | 5 | 29 | 118_272 | 89 | 1300.0 | Compositional bias | Note=Arg-rich |
| Hgene | GIGYF2 | chr2:233613792 | chr2:233398641 | ENST00000373563 | + | 5 | 29 | 1198_1252 | 89 | 1300.0 | Compositional bias | Note=Gln-rich |
| Hgene | GIGYF2 | chr2:233613792 | chr2:233398641 | ENST00000373563 | + | 5 | 29 | 436_473 | 89 | 1300.0 | Compositional bias | Note=Pro-rich |
| Hgene | GIGYF2 | chr2:233613792 | chr2:233398641 | ENST00000373563 | + | 5 | 29 | 607_1025 | 89 | 1300.0 | Compositional bias | Note=Gln-rich |
| Hgene | GIGYF2 | chr2:233613792 | chr2:233398641 | ENST00000373563 | + | 5 | 29 | 738_888 | 89 | 1300.0 | Compositional bias | Note=Glu-rich |
| Hgene | GIGYF2 | chr2:233613792 | chr2:233398641 | ENST00000409451 | + | 6 | 31 | 106_111 | 89 | 1321.0 | Compositional bias | Note=Poly-Gly |
| Hgene | GIGYF2 | chr2:233613792 | chr2:233398641 | ENST00000409451 | + | 6 | 31 | 118_272 | 89 | 1321.0 | Compositional bias | Note=Arg-rich |
| Hgene | GIGYF2 | chr2:233613792 | chr2:233398641 | ENST00000409451 | + | 6 | 31 | 1198_1252 | 89 | 1321.0 | Compositional bias | Note=Gln-rich |
| Hgene | GIGYF2 | chr2:233613792 | chr2:233398641 | ENST00000409451 | + | 6 | 31 | 436_473 | 89 | 1321.0 | Compositional bias | Note=Pro-rich |
| Hgene | GIGYF2 | chr2:233613792 | chr2:233398641 | ENST00000409451 | + | 6 | 31 | 607_1025 | 89 | 1321.0 | Compositional bias | Note=Gln-rich |
| Hgene | GIGYF2 | chr2:233613792 | chr2:233398641 | ENST00000409451 | + | 6 | 31 | 738_888 | 89 | 1321.0 | Compositional bias | Note=Glu-rich |
| Hgene | GIGYF2 | chr2:233613792 | chr2:233398641 | ENST00000409547 | + | 7 | 31 | 106_111 | 89 | 1300.0 | Compositional bias | Note=Poly-Gly |
| Hgene | GIGYF2 | chr2:233613792 | chr2:233398641 | ENST00000409547 | + | 7 | 31 | 118_272 | 89 | 1300.0 | Compositional bias | Note=Arg-rich |
| Hgene | GIGYF2 | chr2:233613792 | chr2:233398641 | ENST00000409547 | + | 7 | 31 | 1198_1252 | 89 | 1300.0 | Compositional bias | Note=Gln-rich |
| Hgene | GIGYF2 | chr2:233613792 | chr2:233398641 | ENST00000409547 | + | 7 | 31 | 436_473 | 89 | 1300.0 | Compositional bias | Note=Pro-rich |
| Hgene | GIGYF2 | chr2:233613792 | chr2:233398641 | ENST00000409547 | + | 7 | 31 | 607_1025 | 89 | 1300.0 | Compositional bias | Note=Gln-rich |
| Hgene | GIGYF2 | chr2:233613792 | chr2:233398641 | ENST00000409547 | + | 7 | 31 | 738_888 | 89 | 1300.0 | Compositional bias | Note=Glu-rich |
| Hgene | GIGYF2 | chr2:233613792 | chr2:233398641 | ENST00000373563 | + | 5 | 29 | 533_581 | 89 | 1300.0 | Domain | GYF |
| Hgene | GIGYF2 | chr2:233613792 | chr2:233398641 | ENST00000409451 | + | 6 | 31 | 533_581 | 89 | 1321.0 | Domain | GYF |
| Hgene | GIGYF2 | chr2:233613792 | chr2:233398641 | ENST00000409547 | + | 7 | 31 | 533_581 | 89 | 1300.0 | Domain | GYF |
| Hgene | GIGYF2 | chr2:233613792 | chr2:233398641 | ENST00000373563 | + | 5 | 29 | 280_310 | 89 | 1300.0 | Motif | DDX6 binding motif |
| Hgene | GIGYF2 | chr2:233613792 | chr2:233398641 | ENST00000409451 | + | 6 | 31 | 280_310 | 89 | 1321.0 | Motif | DDX6 binding motif |
| Hgene | GIGYF2 | chr2:233613792 | chr2:233398641 | ENST00000409547 | + | 7 | 31 | 280_310 | 89 | 1300.0 | Motif | DDX6 binding motif |
| Hgene | GIGYF2 | chr2:233613792 | chr2:233398641 | ENST00000373563 | + | 5 | 29 | 547_563 | 89 | 1300.0 | Region | Required for GRB10-binding |
| Hgene | GIGYF2 | chr2:233613792 | chr2:233398641 | ENST00000409451 | + | 6 | 31 | 547_563 | 89 | 1321.0 | Region | Required for GRB10-binding |
| Hgene | GIGYF2 | chr2:233613792 | chr2:233398641 | ENST00000409547 | + | 7 | 31 | 547_563 | 89 | 1300.0 | Region | Required for GRB10-binding |
| Tgene | CHRND | chr2:233613792 | chr2:233398641 | ENST00000258385 | 8 | 12 | 22_245 | 349 | 518.0 | Topological domain | Extracellular | |
| Tgene | CHRND | chr2:233613792 | chr2:233398641 | ENST00000258385 | 8 | 12 | 334_471 | 349 | 518.0 | Topological domain | Cytoplasmic | |
| Tgene | CHRND | chr2:233613792 | chr2:233398641 | ENST00000543200 | 7 | 11 | 22_245 | 334 | 503.0 | Topological domain | Extracellular | |
| Tgene | CHRND | chr2:233613792 | chr2:233398641 | ENST00000258385 | 8 | 12 | 246_270 | 349 | 518.0 | Transmembrane | Helical | |
| Tgene | CHRND | chr2:233613792 | chr2:233398641 | ENST00000258385 | 8 | 12 | 278_299 | 349 | 518.0 | Transmembrane | Helical | |
| Tgene | CHRND | chr2:233613792 | chr2:233398641 | ENST00000258385 | 8 | 12 | 312_333 | 349 | 518.0 | Transmembrane | Helical | |
| Tgene | CHRND | chr2:233613792 | chr2:233398641 | ENST00000543200 | 7 | 11 | 246_270 | 334 | 503.0 | Transmembrane | Helical | |
| Tgene | CHRND | chr2:233613792 | chr2:233398641 | ENST00000543200 | 7 | 11 | 278_299 | 334 | 503.0 | Transmembrane | Helical | |
| Tgene | CHRND | chr2:233613792 | chr2:233398641 | ENST00000543200 | 7 | 11 | 312_333 | 334 | 503.0 | Transmembrane | Helical |
Top |
Fusion Gene Sequence for GIGYF2-CHRND |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >33092_33092_1_GIGYF2-CHRND_GIGYF2_chr2_233613792_ENST00000373563_CHRND_chr2_233398641_ENST00000258385_length(transcript)=1495nt_BP=462nt GACGTGCGTGGCGACGTGTCGGCCATCTTGTGTTGTTGAGGCTGAGGACTGACTGGGGTTCTGAGACTCCCTGTCCCGGACCGCAGCGTT AAAAGGATCTGAACAAAGTCTGCTCAAATCTCCTGCTGTGAACCAGCAGAATTTTTGAACAGGTTTCTTCACATATAAAAATCTATTGTA AAAATACGGAAAAGAATGGCAGCGGAAACGCAGACACTGAACTTTGGGCCTGAATGGCTCCGAGCTCTGTCCAGTGGTGGGAGTATTACA TCCCCTCCTCTTTCTCCAGCATTGCCGAAGTATAAATTAGCAGATTATCGTTACGGCAGAGAAGAAATGTTAGCACTTTTCCTTAAAGAC AACAAGATACCTTCAGACCTTCTGGATAAAGAATTTCTGCCTATCCTCCAGGAGGAACCCCTTCCACCATTGGCTCTGGTACCCTTTACA GAAGAAGAACAGCTCTTCCTGGAGACCCTGCCGGAGCTCCTGCACATGTCCCGCCCAGCAGAGGATGGACCCAGCCCTGGGGCCCTGGTG CGGAGGAGCAGCTCCCTGGGATACATCTCCAAGGCCGAGGAGTACTTCCTGCTCAAGTCCCGCAGTGACCTCATGTTCGAGAAGCAGTCA GAGCGGCATGGGCTGGCCAGGCGCCTCACCACTGCACGCCGGCCCCCAGCAAGCTCTGAGCAGGCCCAGCAGGAACTCTTCAATGAGCTG AAGCCAGCTGTGGATGGGGCAAACTTCATTGTTAACCACATGAGGGACCAGAACAATTACAATGAGGAGAAAGACAGCTGGAACCGAGTG GCCCGCACAGTGGACCGCCTCTGCCTGTTTGTGGTGACGCCTGTCATGGTGGTGGGCACAGCCTGGATCTTCCTGCAGGGCGTTTACAAC CAGCCACCACCCCAGCCTTTTCCTGGGGACCCCTACTCCTACAACGTGCAGGACAAGCGCTTCATCTAGGGTGGGCCTGTTGGGGAGCCA GGAGACAGCAGGGTCTGAGAGAGGAGCCACAGTCCCTAATGACACCCACTCCTAGCCCTGAGGCTCGTGCCCCTCAGACTGGGGAAGAGT CCAAGGAAGGGAGGGAGCAGCCACTCCTCAATGCTCAATGGCTCCCCTGAAATCAAGACAGGGGCCACCCGAGATGGTCTGAGGGTGGAC ATCGGCTACAGTGGGTGGGCAGGACGATTTGGGGGGAGGCCCGAGGCTGGCTCAGGGGCCAGGGAGGAGGCCACTCAGGGTGGCCTCAGG GGGAGAGCTCTGATAGGGGTGAGACAGATAGGGCCCCTTCTCTGCTTCTCCTCCCCCAAGGTGTGGGGTAGAGCAGGCAGGAATCTGCGC CTTCACTCTCTGGCCCCTCCAGCCTCCCTCTTCCTACCTACCCTTCAACCTCAGGCTTCTGAGGCCTCACCTGGGACTGAGGTTGAGGAC >33092_33092_1_GIGYF2-CHRND_GIGYF2_chr2_233613792_ENST00000373563_CHRND_chr2_233398641_ENST00000258385_length(amino acids)=257AA_BP=88 MAAETQTLNFGPEWLRALSSGGSITSPPLSPALPKYKLADYRYGREEMLALFLKDNKIPSDLLDKEFLPILQEEPLPPLALVPFTEEEQL FLETLPELLHMSRPAEDGPSPGALVRRSSSLGYISKAEEYFLLKSRSDLMFEKQSERHGLARRLTTARRPPASSEQAQQELFNELKPAVD -------------------------------------------------------------- >33092_33092_2_GIGYF2-CHRND_GIGYF2_chr2_233613792_ENST00000373563_CHRND_chr2_233398641_ENST00000543200_length(transcript)=1232nt_BP=462nt GACGTGCGTGGCGACGTGTCGGCCATCTTGTGTTGTTGAGGCTGAGGACTGACTGGGGTTCTGAGACTCCCTGTCCCGGACCGCAGCGTT AAAAGGATCTGAACAAAGTCTGCTCAAATCTCCTGCTGTGAACCAGCAGAATTTTTGAACAGGTTTCTTCACATATAAAAATCTATTGTA AAAATACGGAAAAGAATGGCAGCGGAAACGCAGACACTGAACTTTGGGCCTGAATGGCTCCGAGCTCTGTCCAGTGGTGGGAGTATTACA TCCCCTCCTCTTTCTCCAGCATTGCCGAAGTATAAATTAGCAGATTATCGTTACGGCAGAGAAGAAATGTTAGCACTTTTCCTTAAAGAC AACAAGATACCTTCAGACCTTCTGGATAAAGAATTTCTGCCTATCCTCCAGGAGGAACCCCTTCCACCATTGGCTCTGGTACCCTTTACA GAAGAAGAACAGCTCTTCCTGGAGACCCTGCCGGAGCTCCTGCACATGTCCCGCCCAGCAGAGGATGGACCCAGCCCTGGGGCCCTGGTG CGGAGGAGCAGCTCCCTGGGATACATCTCCAAGGCCGAGGAGTACTTCCTGCTCAAGTCCCGCAGTGACCTCATGTTCGAGAAGCAGTCA GAGCGGCATGGGCTGGCCAGGCGCCTCACCACTGCACGCCGGCCCCCAGCAAGCTCTGAGCAGGCCCAGCAGGAACTCTTCAATGAGCTG AAGCCAGCTGTGGATGGGGCAAACTTCATTGTTAACCACATGAGGGACCAGAACAATTACAATGAGGAGAAAGACAGCTGGAACCGAGTG GCCCGCACAGTGGACCGCCTCTGCCTGTTTGTGGTGACGCCTGTCATGGTGGTGGGCACAGCCTGGATCTTCCTGCAGGGCGTTTACAAC CAGCCACCACCCCAGCCTTTTCCTGGGGACCCCTACTCCTACAACGTGCAGGACAAGCGCTTCATCTAGGGTGGGCCTGTTGGGGAGCCA GGAGACAGCAGGGTCTGAGAGAGGAGCCACAGTCCCTAATGACACCCACTCCTAGCCCTGAGGCTCGTGCCCCTCAGACTGGGGAAGAGT CCAAGGAAGGGAGGGAGCAGCCACTCCTCAATGCTCAATGGCTCCCCTGAAATCAAGACAGGGGCCACCCGAGATGGTCTGAGGGTGGAC >33092_33092_2_GIGYF2-CHRND_GIGYF2_chr2_233613792_ENST00000373563_CHRND_chr2_233398641_ENST00000543200_length(amino acids)=257AA_BP=88 MAAETQTLNFGPEWLRALSSGGSITSPPLSPALPKYKLADYRYGREEMLALFLKDNKIPSDLLDKEFLPILQEEPLPPLALVPFTEEEQL FLETLPELLHMSRPAEDGPSPGALVRRSSSLGYISKAEEYFLLKSRSDLMFEKQSERHGLARRLTTARRPPASSEQAQQELFNELKPAVD -------------------------------------------------------------- >33092_33092_3_GIGYF2-CHRND_GIGYF2_chr2_233613792_ENST00000373566_CHRND_chr2_233398641_ENST00000258385_length(transcript)=1497nt_BP=464nt GTGACGTGCGTGGCGACGTGTCGGCCATCTTGTGTTGTTGAGGCTGAGGACTGACTGGGGTTCTGAGACTCCCTGTCCCGGACCGCAGCG TTAAAAGGATCTGAACAAAGTCTGCTCAAATCTCCTGCTGTGAACCAGCAGAATTTTTGAACAGGTTTCTTCACATATAAAAATCTATTG TAAAAATACGGAAAAGAATGGCAGCGGAAACGCAGACACTGAACTTTGGGCCTGAATGGCTCCGAGCTCTGTCCAGTGGTGGGAGTATTA CATCCCCTCCTCTTTCTCCAGCATTGCCGAAGTATAAATTAGCAGATTATCGTTACGGCAGAGAAGAAATGTTAGCACTTTTCCTTAAAG ACAACAAGATACCTTCAGACCTTCTGGATAAAGAATTTCTGCCTATCCTCCAGGAGGAACCCCTTCCACCATTGGCTCTGGTACCCTTTA CAGAAGAAGAACAGCTCTTCCTGGAGACCCTGCCGGAGCTCCTGCACATGTCCCGCCCAGCAGAGGATGGACCCAGCCCTGGGGCCCTGG TGCGGAGGAGCAGCTCCCTGGGATACATCTCCAAGGCCGAGGAGTACTTCCTGCTCAAGTCCCGCAGTGACCTCATGTTCGAGAAGCAGT CAGAGCGGCATGGGCTGGCCAGGCGCCTCACCACTGCACGCCGGCCCCCAGCAAGCTCTGAGCAGGCCCAGCAGGAACTCTTCAATGAGC TGAAGCCAGCTGTGGATGGGGCAAACTTCATTGTTAACCACATGAGGGACCAGAACAATTACAATGAGGAGAAAGACAGCTGGAACCGAG TGGCCCGCACAGTGGACCGCCTCTGCCTGTTTGTGGTGACGCCTGTCATGGTGGTGGGCACAGCCTGGATCTTCCTGCAGGGCGTTTACA ACCAGCCACCACCCCAGCCTTTTCCTGGGGACCCCTACTCCTACAACGTGCAGGACAAGCGCTTCATCTAGGGTGGGCCTGTTGGGGAGC CAGGAGACAGCAGGGTCTGAGAGAGGAGCCACAGTCCCTAATGACACCCACTCCTAGCCCTGAGGCTCGTGCCCCTCAGACTGGGGAAGA GTCCAAGGAAGGGAGGGAGCAGCCACTCCTCAATGCTCAATGGCTCCCCTGAAATCAAGACAGGGGCCACCCGAGATGGTCTGAGGGTGG ACATCGGCTACAGTGGGTGGGCAGGACGATTTGGGGGGAGGCCCGAGGCTGGCTCAGGGGCCAGGGAGGAGGCCACTCAGGGTGGCCTCA GGGGGAGAGCTCTGATAGGGGTGAGACAGATAGGGCCCCTTCTCTGCTTCTCCTCCCCCAAGGTGTGGGGTAGAGCAGGCAGGAATCTGC GCCTTCACTCTCTGGCCCCTCCAGCCTCCCTCTTCCTACCTACCCTTCAACCTCAGGCTTCTGAGGCCTCACCTGGGACTGAGGTTGAGG >33092_33092_3_GIGYF2-CHRND_GIGYF2_chr2_233613792_ENST00000373566_CHRND_chr2_233398641_ENST00000258385_length(amino acids)=257AA_BP=88 MAAETQTLNFGPEWLRALSSGGSITSPPLSPALPKYKLADYRYGREEMLALFLKDNKIPSDLLDKEFLPILQEEPLPPLALVPFTEEEQL FLETLPELLHMSRPAEDGPSPGALVRRSSSLGYISKAEEYFLLKSRSDLMFEKQSERHGLARRLTTARRPPASSEQAQQELFNELKPAVD -------------------------------------------------------------- >33092_33092_4_GIGYF2-CHRND_GIGYF2_chr2_233613792_ENST00000373566_CHRND_chr2_233398641_ENST00000543200_length(transcript)=1234nt_BP=464nt GTGACGTGCGTGGCGACGTGTCGGCCATCTTGTGTTGTTGAGGCTGAGGACTGACTGGGGTTCTGAGACTCCCTGTCCCGGACCGCAGCG TTAAAAGGATCTGAACAAAGTCTGCTCAAATCTCCTGCTGTGAACCAGCAGAATTTTTGAACAGGTTTCTTCACATATAAAAATCTATTG TAAAAATACGGAAAAGAATGGCAGCGGAAACGCAGACACTGAACTTTGGGCCTGAATGGCTCCGAGCTCTGTCCAGTGGTGGGAGTATTA CATCCCCTCCTCTTTCTCCAGCATTGCCGAAGTATAAATTAGCAGATTATCGTTACGGCAGAGAAGAAATGTTAGCACTTTTCCTTAAAG ACAACAAGATACCTTCAGACCTTCTGGATAAAGAATTTCTGCCTATCCTCCAGGAGGAACCCCTTCCACCATTGGCTCTGGTACCCTTTA CAGAAGAAGAACAGCTCTTCCTGGAGACCCTGCCGGAGCTCCTGCACATGTCCCGCCCAGCAGAGGATGGACCCAGCCCTGGGGCCCTGG TGCGGAGGAGCAGCTCCCTGGGATACATCTCCAAGGCCGAGGAGTACTTCCTGCTCAAGTCCCGCAGTGACCTCATGTTCGAGAAGCAGT CAGAGCGGCATGGGCTGGCCAGGCGCCTCACCACTGCACGCCGGCCCCCAGCAAGCTCTGAGCAGGCCCAGCAGGAACTCTTCAATGAGC TGAAGCCAGCTGTGGATGGGGCAAACTTCATTGTTAACCACATGAGGGACCAGAACAATTACAATGAGGAGAAAGACAGCTGGAACCGAG TGGCCCGCACAGTGGACCGCCTCTGCCTGTTTGTGGTGACGCCTGTCATGGTGGTGGGCACAGCCTGGATCTTCCTGCAGGGCGTTTACA ACCAGCCACCACCCCAGCCTTTTCCTGGGGACCCCTACTCCTACAACGTGCAGGACAAGCGCTTCATCTAGGGTGGGCCTGTTGGGGAGC CAGGAGACAGCAGGGTCTGAGAGAGGAGCCACAGTCCCTAATGACACCCACTCCTAGCCCTGAGGCTCGTGCCCCTCAGACTGGGGAAGA GTCCAAGGAAGGGAGGGAGCAGCCACTCCTCAATGCTCAATGGCTCCCCTGAAATCAAGACAGGGGCCACCCGAGATGGTCTGAGGGTGG >33092_33092_4_GIGYF2-CHRND_GIGYF2_chr2_233613792_ENST00000373566_CHRND_chr2_233398641_ENST00000543200_length(amino acids)=257AA_BP=88 MAAETQTLNFGPEWLRALSSGGSITSPPLSPALPKYKLADYRYGREEMLALFLKDNKIPSDLLDKEFLPILQEEPLPPLALVPFTEEEQL FLETLPELLHMSRPAEDGPSPGALVRRSSSLGYISKAEEYFLLKSRSDLMFEKQSERHGLARRLTTARRPPASSEQAQQELFNELKPAVD -------------------------------------------------------------- >33092_33092_5_GIGYF2-CHRND_GIGYF2_chr2_233613792_ENST00000409196_CHRND_chr2_233398641_ENST00000258385_length(transcript)=1398nt_BP=365nt GTTGTTGAGGCTGAGGACTGACTGGGGTTCTGAGACTCCCTGTCCCGGACCGCAGGTTTCTTCACATATAAAAATCTATTGTAAAAATAC GGAAAAGAATGGCAGCGGAAACGCAGACACTGAACTTTGGGCCTGAATGGCTCCGAGCTCTGTCCAGTGGTGGGAGTATTACATCCCCTC CTCTTTCTCCAGCATTGCCGAAGTATAAATTAGCAGATTATCGTTACGGCAGAGAAGAAATGTTAGCACTTTTCCTTAAAGACAACAAGA TACCTTCAGACCTTCTGGATAAAGAATTTCTGCCTATCCTCCAGGAGGAACCCCTTCCACCATTGGCTCTGGTACCCTTTACAGAAGAAG AACAGCTCTTCCTGGAGACCCTGCCGGAGCTCCTGCACATGTCCCGCCCAGCAGAGGATGGACCCAGCCCTGGGGCCCTGGTGCGGAGGA GCAGCTCCCTGGGATACATCTCCAAGGCCGAGGAGTACTTCCTGCTCAAGTCCCGCAGTGACCTCATGTTCGAGAAGCAGTCAGAGCGGC ATGGGCTGGCCAGGCGCCTCACCACTGCACGCCGGCCCCCAGCAAGCTCTGAGCAGGCCCAGCAGGAACTCTTCAATGAGCTGAAGCCAG CTGTGGATGGGGCAAACTTCATTGTTAACCACATGAGGGACCAGAACAATTACAATGAGGAGAAAGACAGCTGGAACCGAGTGGCCCGCA CAGTGGACCGCCTCTGCCTGTTTGTGGTGACGCCTGTCATGGTGGTGGGCACAGCCTGGATCTTCCTGCAGGGCGTTTACAACCAGCCAC CACCCCAGCCTTTTCCTGGGGACCCCTACTCCTACAACGTGCAGGACAAGCGCTTCATCTAGGGTGGGCCTGTTGGGGAGCCAGGAGACA GCAGGGTCTGAGAGAGGAGCCACAGTCCCTAATGACACCCACTCCTAGCCCTGAGGCTCGTGCCCCTCAGACTGGGGAAGAGTCCAAGGA AGGGAGGGAGCAGCCACTCCTCAATGCTCAATGGCTCCCCTGAAATCAAGACAGGGGCCACCCGAGATGGTCTGAGGGTGGACATCGGCT ACAGTGGGTGGGCAGGACGATTTGGGGGGAGGCCCGAGGCTGGCTCAGGGGCCAGGGAGGAGGCCACTCAGGGTGGCCTCAGGGGGAGAG CTCTGATAGGGGTGAGACAGATAGGGCCCCTTCTCTGCTTCTCCTCCCCCAAGGTGTGGGGTAGAGCAGGCAGGAATCTGCGCCTTCACT CTCTGGCCCCTCCAGCCTCCCTCTTCCTACCTACCCTTCAACCTCAGGCTTCTGAGGCCTCACCTGGGACTGAGGTTGAGGACACCTCCC >33092_33092_5_GIGYF2-CHRND_GIGYF2_chr2_233613792_ENST00000409196_CHRND_chr2_233398641_ENST00000258385_length(amino acids)=257AA_BP=88 MAAETQTLNFGPEWLRALSSGGSITSPPLSPALPKYKLADYRYGREEMLALFLKDNKIPSDLLDKEFLPILQEEPLPPLALVPFTEEEQL FLETLPELLHMSRPAEDGPSPGALVRRSSSLGYISKAEEYFLLKSRSDLMFEKQSERHGLARRLTTARRPPASSEQAQQELFNELKPAVD -------------------------------------------------------------- >33092_33092_6_GIGYF2-CHRND_GIGYF2_chr2_233613792_ENST00000409196_CHRND_chr2_233398641_ENST00000543200_length(transcript)=1135nt_BP=365nt GTTGTTGAGGCTGAGGACTGACTGGGGTTCTGAGACTCCCTGTCCCGGACCGCAGGTTTCTTCACATATAAAAATCTATTGTAAAAATAC GGAAAAGAATGGCAGCGGAAACGCAGACACTGAACTTTGGGCCTGAATGGCTCCGAGCTCTGTCCAGTGGTGGGAGTATTACATCCCCTC CTCTTTCTCCAGCATTGCCGAAGTATAAATTAGCAGATTATCGTTACGGCAGAGAAGAAATGTTAGCACTTTTCCTTAAAGACAACAAGA TACCTTCAGACCTTCTGGATAAAGAATTTCTGCCTATCCTCCAGGAGGAACCCCTTCCACCATTGGCTCTGGTACCCTTTACAGAAGAAG AACAGCTCTTCCTGGAGACCCTGCCGGAGCTCCTGCACATGTCCCGCCCAGCAGAGGATGGACCCAGCCCTGGGGCCCTGGTGCGGAGGA GCAGCTCCCTGGGATACATCTCCAAGGCCGAGGAGTACTTCCTGCTCAAGTCCCGCAGTGACCTCATGTTCGAGAAGCAGTCAGAGCGGC ATGGGCTGGCCAGGCGCCTCACCACTGCACGCCGGCCCCCAGCAAGCTCTGAGCAGGCCCAGCAGGAACTCTTCAATGAGCTGAAGCCAG CTGTGGATGGGGCAAACTTCATTGTTAACCACATGAGGGACCAGAACAATTACAATGAGGAGAAAGACAGCTGGAACCGAGTGGCCCGCA CAGTGGACCGCCTCTGCCTGTTTGTGGTGACGCCTGTCATGGTGGTGGGCACAGCCTGGATCTTCCTGCAGGGCGTTTACAACCAGCCAC CACCCCAGCCTTTTCCTGGGGACCCCTACTCCTACAACGTGCAGGACAAGCGCTTCATCTAGGGTGGGCCTGTTGGGGAGCCAGGAGACA GCAGGGTCTGAGAGAGGAGCCACAGTCCCTAATGACACCCACTCCTAGCCCTGAGGCTCGTGCCCCTCAGACTGGGGAAGAGTCCAAGGA AGGGAGGGAGCAGCCACTCCTCAATGCTCAATGGCTCCCCTGAAATCAAGACAGGGGCCACCCGAGATGGTCTGAGGGTGGACATCGGCT >33092_33092_6_GIGYF2-CHRND_GIGYF2_chr2_233613792_ENST00000409196_CHRND_chr2_233398641_ENST00000543200_length(amino acids)=257AA_BP=88 MAAETQTLNFGPEWLRALSSGGSITSPPLSPALPKYKLADYRYGREEMLALFLKDNKIPSDLLDKEFLPILQEEPLPPLALVPFTEEEQL FLETLPELLHMSRPAEDGPSPGALVRRSSSLGYISKAEEYFLLKSRSDLMFEKQSERHGLARRLTTARRPPASSEQAQQELFNELKPAVD -------------------------------------------------------------- >33092_33092_7_GIGYF2-CHRND_GIGYF2_chr2_233613792_ENST00000409451_CHRND_chr2_233398641_ENST00000258385_length(transcript)=1526nt_BP=493nt GGCTGAGGACTGACTGGGGTTCTGAGACTCCCTGTCCCGGACCGCAGATTATAGTGGGACCAGTCTCATTAGGTTGAATCTACAGCCTAT GTTGGTGTTAACCCAGGTCTCTTAGAGCGTTAAAAGGATCTGAACAAAGTCTGCTCAAATCTCCTGCTGTGAACCAGCAGAATTTTTGAA CAGGTTTCTTCACATATAAAAATCTATTGTAAAAATACGGAAAAGAATGGCAGCGGAAACGCAGACACTGAACTTTGGGCCTGAATGGCT CCGAGCTCTGTCCAGTGGTGGGAGTATTACATCCCCTCCTCTTTCTCCAGCATTGCCGAAGTATAAATTAGCAGATTATCGTTACGGCAG AGAAGAAATGTTAGCACTTTTCCTTAAAGACAACAAGATACCTTCAGACCTTCTGGATAAAGAATTTCTGCCTATCCTCCAGGAGGAACC CCTTCCACCATTGGCTCTGGTACCCTTTACAGAAGAAGAACAGCTCTTCCTGGAGACCCTGCCGGAGCTCCTGCACATGTCCCGCCCAGC AGAGGATGGACCCAGCCCTGGGGCCCTGGTGCGGAGGAGCAGCTCCCTGGGATACATCTCCAAGGCCGAGGAGTACTTCCTGCTCAAGTC CCGCAGTGACCTCATGTTCGAGAAGCAGTCAGAGCGGCATGGGCTGGCCAGGCGCCTCACCACTGCACGCCGGCCCCCAGCAAGCTCTGA GCAGGCCCAGCAGGAACTCTTCAATGAGCTGAAGCCAGCTGTGGATGGGGCAAACTTCATTGTTAACCACATGAGGGACCAGAACAATTA CAATGAGGAGAAAGACAGCTGGAACCGAGTGGCCCGCACAGTGGACCGCCTCTGCCTGTTTGTGGTGACGCCTGTCATGGTGGTGGGCAC AGCCTGGATCTTCCTGCAGGGCGTTTACAACCAGCCACCACCCCAGCCTTTTCCTGGGGACCCCTACTCCTACAACGTGCAGGACAAGCG CTTCATCTAGGGTGGGCCTGTTGGGGAGCCAGGAGACAGCAGGGTCTGAGAGAGGAGCCACAGTCCCTAATGACACCCACTCCTAGCCCT GAGGCTCGTGCCCCTCAGACTGGGGAAGAGTCCAAGGAAGGGAGGGAGCAGCCACTCCTCAATGCTCAATGGCTCCCCTGAAATCAAGAC AGGGGCCACCCGAGATGGTCTGAGGGTGGACATCGGCTACAGTGGGTGGGCAGGACGATTTGGGGGGAGGCCCGAGGCTGGCTCAGGGGC CAGGGAGGAGGCCACTCAGGGTGGCCTCAGGGGGAGAGCTCTGATAGGGGTGAGACAGATAGGGCCCCTTCTCTGCTTCTCCTCCCCCAA GGTGTGGGGTAGAGCAGGCAGGAATCTGCGCCTTCACTCTCTGGCCCCTCCAGCCTCCCTCTTCCTACCTACCCTTCAACCTCAGGCTTC >33092_33092_7_GIGYF2-CHRND_GIGYF2_chr2_233613792_ENST00000409451_CHRND_chr2_233398641_ENST00000258385_length(amino acids)=257AA_BP=88 MAAETQTLNFGPEWLRALSSGGSITSPPLSPALPKYKLADYRYGREEMLALFLKDNKIPSDLLDKEFLPILQEEPLPPLALVPFTEEEQL FLETLPELLHMSRPAEDGPSPGALVRRSSSLGYISKAEEYFLLKSRSDLMFEKQSERHGLARRLTTARRPPASSEQAQQELFNELKPAVD -------------------------------------------------------------- >33092_33092_8_GIGYF2-CHRND_GIGYF2_chr2_233613792_ENST00000409451_CHRND_chr2_233398641_ENST00000543200_length(transcript)=1263nt_BP=493nt GGCTGAGGACTGACTGGGGTTCTGAGACTCCCTGTCCCGGACCGCAGATTATAGTGGGACCAGTCTCATTAGGTTGAATCTACAGCCTAT GTTGGTGTTAACCCAGGTCTCTTAGAGCGTTAAAAGGATCTGAACAAAGTCTGCTCAAATCTCCTGCTGTGAACCAGCAGAATTTTTGAA CAGGTTTCTTCACATATAAAAATCTATTGTAAAAATACGGAAAAGAATGGCAGCGGAAACGCAGACACTGAACTTTGGGCCTGAATGGCT CCGAGCTCTGTCCAGTGGTGGGAGTATTACATCCCCTCCTCTTTCTCCAGCATTGCCGAAGTATAAATTAGCAGATTATCGTTACGGCAG AGAAGAAATGTTAGCACTTTTCCTTAAAGACAACAAGATACCTTCAGACCTTCTGGATAAAGAATTTCTGCCTATCCTCCAGGAGGAACC CCTTCCACCATTGGCTCTGGTACCCTTTACAGAAGAAGAACAGCTCTTCCTGGAGACCCTGCCGGAGCTCCTGCACATGTCCCGCCCAGC AGAGGATGGACCCAGCCCTGGGGCCCTGGTGCGGAGGAGCAGCTCCCTGGGATACATCTCCAAGGCCGAGGAGTACTTCCTGCTCAAGTC CCGCAGTGACCTCATGTTCGAGAAGCAGTCAGAGCGGCATGGGCTGGCCAGGCGCCTCACCACTGCACGCCGGCCCCCAGCAAGCTCTGA GCAGGCCCAGCAGGAACTCTTCAATGAGCTGAAGCCAGCTGTGGATGGGGCAAACTTCATTGTTAACCACATGAGGGACCAGAACAATTA CAATGAGGAGAAAGACAGCTGGAACCGAGTGGCCCGCACAGTGGACCGCCTCTGCCTGTTTGTGGTGACGCCTGTCATGGTGGTGGGCAC AGCCTGGATCTTCCTGCAGGGCGTTTACAACCAGCCACCACCCCAGCCTTTTCCTGGGGACCCCTACTCCTACAACGTGCAGGACAAGCG CTTCATCTAGGGTGGGCCTGTTGGGGAGCCAGGAGACAGCAGGGTCTGAGAGAGGAGCCACAGTCCCTAATGACACCCACTCCTAGCCCT GAGGCTCGTGCCCCTCAGACTGGGGAAGAGTCCAAGGAAGGGAGGGAGCAGCCACTCCTCAATGCTCAATGGCTCCCCTGAAATCAAGAC AGGGGCCACCCGAGATGGTCTGAGGGTGGACATCGGCTACAGTGGGTGGGCAGGACGATTTGGGGGGAGGCCCGAGGCTGGCTCAGGGGC >33092_33092_8_GIGYF2-CHRND_GIGYF2_chr2_233613792_ENST00000409451_CHRND_chr2_233398641_ENST00000543200_length(amino acids)=257AA_BP=88 MAAETQTLNFGPEWLRALSSGGSITSPPLSPALPKYKLADYRYGREEMLALFLKDNKIPSDLLDKEFLPILQEEPLPPLALVPFTEEEQL FLETLPELLHMSRPAEDGPSPGALVRRSSSLGYISKAEEYFLLKSRSDLMFEKQSERHGLARRLTTARRPPASSEQAQQELFNELKPAVD -------------------------------------------------------------- >33092_33092_9_GIGYF2-CHRND_GIGYF2_chr2_233613792_ENST00000409480_CHRND_chr2_233398641_ENST00000258385_length(transcript)=1562nt_BP=529nt GTGCGTGGCGACGTGTCGGCCATCTTGTGTTGTTGAGGCTGAGGACTGACTGGGGTTCTGAGACTCCCTGTCCCGGACCGCAGATTATAG TGGGACCAGTCTCATTAGGTTGAATCTACAGCCTATGTTGGTGTTAACCCAGGTCTCTTAGAGCGTTAAAAGGATCTGAACAAAGTCTGC TCAAATCTCCTGCTGTGAACCAGCAGAATTTTTGAACAGGTTTCTTCACATATAAAAATCTATTGTAAAAATACGGAAAAGAATGGCAGC GGAAACGCAGACACTGAACTTTGGGCCTGAATGGCTCCGAGCTCTGTCCAGTGGTGGGAGTATTACATCCCCTCCTCTTTCTCCAGCATT GCCGAAGTATAAATTAGCAGATTATCGTTACGGCAGAGAAGAAATGTTAGCACTTTTCCTTAAAGACAACAAGATACCTTCAGACCTTCT GGATAAAGAATTTCTGCCTATCCTCCAGGAGGAACCCCTTCCACCATTGGCTCTGGTACCCTTTACAGAAGAAGAACAGCTCTTCCTGGA GACCCTGCCGGAGCTCCTGCACATGTCCCGCCCAGCAGAGGATGGACCCAGCCCTGGGGCCCTGGTGCGGAGGAGCAGCTCCCTGGGATA CATCTCCAAGGCCGAGGAGTACTTCCTGCTCAAGTCCCGCAGTGACCTCATGTTCGAGAAGCAGTCAGAGCGGCATGGGCTGGCCAGGCG CCTCACCACTGCACGCCGGCCCCCAGCAAGCTCTGAGCAGGCCCAGCAGGAACTCTTCAATGAGCTGAAGCCAGCTGTGGATGGGGCAAA CTTCATTGTTAACCACATGAGGGACCAGAACAATTACAATGAGGAGAAAGACAGCTGGAACCGAGTGGCCCGCACAGTGGACCGCCTCTG CCTGTTTGTGGTGACGCCTGTCATGGTGGTGGGCACAGCCTGGATCTTCCTGCAGGGCGTTTACAACCAGCCACCACCCCAGCCTTTTCC TGGGGACCCCTACTCCTACAACGTGCAGGACAAGCGCTTCATCTAGGGTGGGCCTGTTGGGGAGCCAGGAGACAGCAGGGTCTGAGAGAG GAGCCACAGTCCCTAATGACACCCACTCCTAGCCCTGAGGCTCGTGCCCCTCAGACTGGGGAAGAGTCCAAGGAAGGGAGGGAGCAGCCA CTCCTCAATGCTCAATGGCTCCCCTGAAATCAAGACAGGGGCCACCCGAGATGGTCTGAGGGTGGACATCGGCTACAGTGGGTGGGCAGG ACGATTTGGGGGGAGGCCCGAGGCTGGCTCAGGGGCCAGGGAGGAGGCCACTCAGGGTGGCCTCAGGGGGAGAGCTCTGATAGGGGTGAG ACAGATAGGGCCCCTTCTCTGCTTCTCCTCCCCCAAGGTGTGGGGTAGAGCAGGCAGGAATCTGCGCCTTCACTCTCTGGCCCCTCCAGC CTCCCTCTTCCTACCTACCCTTCAACCTCAGGCTTCTGAGGCCTCACCTGGGACTGAGGTTGAGGACACCTCCCTCCCTCCAGACCCCAG >33092_33092_9_GIGYF2-CHRND_GIGYF2_chr2_233613792_ENST00000409480_CHRND_chr2_233398641_ENST00000258385_length(amino acids)=257AA_BP=88 MAAETQTLNFGPEWLRALSSGGSITSPPLSPALPKYKLADYRYGREEMLALFLKDNKIPSDLLDKEFLPILQEEPLPPLALVPFTEEEQL FLETLPELLHMSRPAEDGPSPGALVRRSSSLGYISKAEEYFLLKSRSDLMFEKQSERHGLARRLTTARRPPASSEQAQQELFNELKPAVD -------------------------------------------------------------- >33092_33092_10_GIGYF2-CHRND_GIGYF2_chr2_233613792_ENST00000409480_CHRND_chr2_233398641_ENST00000543200_length(transcript)=1299nt_BP=529nt GTGCGTGGCGACGTGTCGGCCATCTTGTGTTGTTGAGGCTGAGGACTGACTGGGGTTCTGAGACTCCCTGTCCCGGACCGCAGATTATAG TGGGACCAGTCTCATTAGGTTGAATCTACAGCCTATGTTGGTGTTAACCCAGGTCTCTTAGAGCGTTAAAAGGATCTGAACAAAGTCTGC TCAAATCTCCTGCTGTGAACCAGCAGAATTTTTGAACAGGTTTCTTCACATATAAAAATCTATTGTAAAAATACGGAAAAGAATGGCAGC GGAAACGCAGACACTGAACTTTGGGCCTGAATGGCTCCGAGCTCTGTCCAGTGGTGGGAGTATTACATCCCCTCCTCTTTCTCCAGCATT GCCGAAGTATAAATTAGCAGATTATCGTTACGGCAGAGAAGAAATGTTAGCACTTTTCCTTAAAGACAACAAGATACCTTCAGACCTTCT GGATAAAGAATTTCTGCCTATCCTCCAGGAGGAACCCCTTCCACCATTGGCTCTGGTACCCTTTACAGAAGAAGAACAGCTCTTCCTGGA GACCCTGCCGGAGCTCCTGCACATGTCCCGCCCAGCAGAGGATGGACCCAGCCCTGGGGCCCTGGTGCGGAGGAGCAGCTCCCTGGGATA CATCTCCAAGGCCGAGGAGTACTTCCTGCTCAAGTCCCGCAGTGACCTCATGTTCGAGAAGCAGTCAGAGCGGCATGGGCTGGCCAGGCG CCTCACCACTGCACGCCGGCCCCCAGCAAGCTCTGAGCAGGCCCAGCAGGAACTCTTCAATGAGCTGAAGCCAGCTGTGGATGGGGCAAA CTTCATTGTTAACCACATGAGGGACCAGAACAATTACAATGAGGAGAAAGACAGCTGGAACCGAGTGGCCCGCACAGTGGACCGCCTCTG CCTGTTTGTGGTGACGCCTGTCATGGTGGTGGGCACAGCCTGGATCTTCCTGCAGGGCGTTTACAACCAGCCACCACCCCAGCCTTTTCC TGGGGACCCCTACTCCTACAACGTGCAGGACAAGCGCTTCATCTAGGGTGGGCCTGTTGGGGAGCCAGGAGACAGCAGGGTCTGAGAGAG GAGCCACAGTCCCTAATGACACCCACTCCTAGCCCTGAGGCTCGTGCCCCTCAGACTGGGGAAGAGTCCAAGGAAGGGAGGGAGCAGCCA CTCCTCAATGCTCAATGGCTCCCCTGAAATCAAGACAGGGGCCACCCGAGATGGTCTGAGGGTGGACATCGGCTACAGTGGGTGGGCAGG >33092_33092_10_GIGYF2-CHRND_GIGYF2_chr2_233613792_ENST00000409480_CHRND_chr2_233398641_ENST00000543200_length(amino acids)=257AA_BP=88 MAAETQTLNFGPEWLRALSSGGSITSPPLSPALPKYKLADYRYGREEMLALFLKDNKIPSDLLDKEFLPILQEEPLPPLALVPFTEEEQL FLETLPELLHMSRPAEDGPSPGALVRRSSSLGYISKAEEYFLLKSRSDLMFEKQSERHGLARRLTTARRPPASSEQAQQELFNELKPAVD -------------------------------------------------------------- >33092_33092_11_GIGYF2-CHRND_GIGYF2_chr2_233613792_ENST00000409547_CHRND_chr2_233398641_ENST00000258385_length(transcript)=1611nt_BP=578nt ATCTTGTGTTGTTGAGGCTGAGGACTGACTGGGGTTCTGAGACTCCCTGTCCCGGACCGCAGATTATAGTGGGACCAGTCTCATTAGGTT GAATCTACAGCCTATGTTGGTGTTAACCCAGGTCTCTTAGAGCGTTAAAAGGATCTGAACAAAGTCTGCTCAAATCTCCTGCTGTGAACC AGCAGAATTTTTGAACAGAGACCACGTCTCCACCTCCTGGGCTCCAACGATTCTCCCATCTTGGCCTCCCAAAGCGCTGGATTTACAGGT TTCTTCACATATAAAAATCTATTGTAAAAATACGGAAAAGAATGGCAGCGGAAACGCAGACACTGAACTTTGGGCCTGAATGGCTCCGAG CTCTGTCCAGTGGTGGGAGTATTACATCCCCTCCTCTTTCTCCAGCATTGCCGAAGTATAAATTAGCAGATTATCGTTACGGCAGAGAAG AAATGTTAGCACTTTTCCTTAAAGACAACAAGATACCTTCAGACCTTCTGGATAAAGAATTTCTGCCTATCCTCCAGGAGGAACCCCTTC CACCATTGGCTCTGGTACCCTTTACAGAAGAAGAACAGCTCTTCCTGGAGACCCTGCCGGAGCTCCTGCACATGTCCCGCCCAGCAGAGG ATGGACCCAGCCCTGGGGCCCTGGTGCGGAGGAGCAGCTCCCTGGGATACATCTCCAAGGCCGAGGAGTACTTCCTGCTCAAGTCCCGCA GTGACCTCATGTTCGAGAAGCAGTCAGAGCGGCATGGGCTGGCCAGGCGCCTCACCACTGCACGCCGGCCCCCAGCAAGCTCTGAGCAGG CCCAGCAGGAACTCTTCAATGAGCTGAAGCCAGCTGTGGATGGGGCAAACTTCATTGTTAACCACATGAGGGACCAGAACAATTACAATG AGGAGAAAGACAGCTGGAACCGAGTGGCCCGCACAGTGGACCGCCTCTGCCTGTTTGTGGTGACGCCTGTCATGGTGGTGGGCACAGCCT GGATCTTCCTGCAGGGCGTTTACAACCAGCCACCACCCCAGCCTTTTCCTGGGGACCCCTACTCCTACAACGTGCAGGACAAGCGCTTCA TCTAGGGTGGGCCTGTTGGGGAGCCAGGAGACAGCAGGGTCTGAGAGAGGAGCCACAGTCCCTAATGACACCCACTCCTAGCCCTGAGGC TCGTGCCCCTCAGACTGGGGAAGAGTCCAAGGAAGGGAGGGAGCAGCCACTCCTCAATGCTCAATGGCTCCCCTGAAATCAAGACAGGGG CCACCCGAGATGGTCTGAGGGTGGACATCGGCTACAGTGGGTGGGCAGGACGATTTGGGGGGAGGCCCGAGGCTGGCTCAGGGGCCAGGG AGGAGGCCACTCAGGGTGGCCTCAGGGGGAGAGCTCTGATAGGGGTGAGACAGATAGGGCCCCTTCTCTGCTTCTCCTCCCCCAAGGTGT GGGGTAGAGCAGGCAGGAATCTGCGCCTTCACTCTCTGGCCCCTCCAGCCTCCCTCTTCCTACCTACCCTTCAACCTCAGGCTTCTGAGG >33092_33092_11_GIGYF2-CHRND_GIGYF2_chr2_233613792_ENST00000409547_CHRND_chr2_233398641_ENST00000258385_length(amino acids)=257AA_BP=88 MAAETQTLNFGPEWLRALSSGGSITSPPLSPALPKYKLADYRYGREEMLALFLKDNKIPSDLLDKEFLPILQEEPLPPLALVPFTEEEQL FLETLPELLHMSRPAEDGPSPGALVRRSSSLGYISKAEEYFLLKSRSDLMFEKQSERHGLARRLTTARRPPASSEQAQQELFNELKPAVD -------------------------------------------------------------- >33092_33092_12_GIGYF2-CHRND_GIGYF2_chr2_233613792_ENST00000409547_CHRND_chr2_233398641_ENST00000543200_length(transcript)=1348nt_BP=578nt ATCTTGTGTTGTTGAGGCTGAGGACTGACTGGGGTTCTGAGACTCCCTGTCCCGGACCGCAGATTATAGTGGGACCAGTCTCATTAGGTT GAATCTACAGCCTATGTTGGTGTTAACCCAGGTCTCTTAGAGCGTTAAAAGGATCTGAACAAAGTCTGCTCAAATCTCCTGCTGTGAACC AGCAGAATTTTTGAACAGAGACCACGTCTCCACCTCCTGGGCTCCAACGATTCTCCCATCTTGGCCTCCCAAAGCGCTGGATTTACAGGT TTCTTCACATATAAAAATCTATTGTAAAAATACGGAAAAGAATGGCAGCGGAAACGCAGACACTGAACTTTGGGCCTGAATGGCTCCGAG CTCTGTCCAGTGGTGGGAGTATTACATCCCCTCCTCTTTCTCCAGCATTGCCGAAGTATAAATTAGCAGATTATCGTTACGGCAGAGAAG AAATGTTAGCACTTTTCCTTAAAGACAACAAGATACCTTCAGACCTTCTGGATAAAGAATTTCTGCCTATCCTCCAGGAGGAACCCCTTC CACCATTGGCTCTGGTACCCTTTACAGAAGAAGAACAGCTCTTCCTGGAGACCCTGCCGGAGCTCCTGCACATGTCCCGCCCAGCAGAGG ATGGACCCAGCCCTGGGGCCCTGGTGCGGAGGAGCAGCTCCCTGGGATACATCTCCAAGGCCGAGGAGTACTTCCTGCTCAAGTCCCGCA GTGACCTCATGTTCGAGAAGCAGTCAGAGCGGCATGGGCTGGCCAGGCGCCTCACCACTGCACGCCGGCCCCCAGCAAGCTCTGAGCAGG CCCAGCAGGAACTCTTCAATGAGCTGAAGCCAGCTGTGGATGGGGCAAACTTCATTGTTAACCACATGAGGGACCAGAACAATTACAATG AGGAGAAAGACAGCTGGAACCGAGTGGCCCGCACAGTGGACCGCCTCTGCCTGTTTGTGGTGACGCCTGTCATGGTGGTGGGCACAGCCT GGATCTTCCTGCAGGGCGTTTACAACCAGCCACCACCCCAGCCTTTTCCTGGGGACCCCTACTCCTACAACGTGCAGGACAAGCGCTTCA TCTAGGGTGGGCCTGTTGGGGAGCCAGGAGACAGCAGGGTCTGAGAGAGGAGCCACAGTCCCTAATGACACCCACTCCTAGCCCTGAGGC TCGTGCCCCTCAGACTGGGGAAGAGTCCAAGGAAGGGAGGGAGCAGCCACTCCTCAATGCTCAATGGCTCCCCTGAAATCAAGACAGGGG >33092_33092_12_GIGYF2-CHRND_GIGYF2_chr2_233613792_ENST00000409547_CHRND_chr2_233398641_ENST00000543200_length(amino acids)=257AA_BP=88 MAAETQTLNFGPEWLRALSSGGSITSPPLSPALPKYKLADYRYGREEMLALFLKDNKIPSDLLDKEFLPILQEEPLPPLALVPFTEEEQL FLETLPELLHMSRPAEDGPSPGALVRRSSSLGYISKAEEYFLLKSRSDLMFEKQSERHGLARRLTTARRPPASSEQAQQELFNELKPAVD -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for GIGYF2-CHRND |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for GIGYF2-CHRND |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for GIGYF2-CHRND |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies