
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:GLE1-SPTAN1 (FusionGDB2 ID:33238) |
Fusion Gene Summary for GLE1-SPTAN1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: GLE1-SPTAN1 | Fusion gene ID: 33238 | Hgene | Tgene | Gene symbol | GLE1 | SPTAN1 | Gene ID | 2733 | 6709 |
| Gene name | GLE1 RNA export mediator | spectrin alpha, non-erythrocytic 1 | |
| Synonyms | CAAHC|CAAHD|GLE1L|LCCS|LCCS1|hGLE1 | EIEE5|NEAS|SPTA2 | |
| Cytomap | 9q34.11 | 9q34.11 | |
| Type of gene | protein-coding | protein-coding | |
| Description | nucleoporin GLE1GLE1 RNA export mediator homologGLE1 RNA export mediator-likeGLE1-like proteinGLE1-like, RNA export mediator | spectrin alpha chain, non-erythrocytic 1alpha-II spectrinalpha-fodrinepididymis secretory sperm binding proteinfodrin alpha chainspectrin, non-erythroid alpha chainspectrin, non-erythroid alpha subunit | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q53GS7 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000309971, ENST00000372770, ENST00000539582, ENST00000494417, | ENST00000475367, ENST00000358161, ENST00000372731, ENST00000372739, | |
| Fusion gene scores | * DoF score | 5 X 4 X 5=100 | 21 X 23 X 11=5313 |
| # samples | 5 | 25 | |
| ** MAII score | log2(5/100*10)=-1 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(25/5313*10)=-4.40952671281098 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: GLE1 [Title/Abstract] AND SPTAN1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | SPTAN1(131314975)-GLE1(131277808), # samples:2 SPTAN1(131337624)-GLE1(131284947), # samples:2 GLE1(131277918)-SPTAN1(131386607), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across GLE1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across SPTAN1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BLCA | TCGA-MV-A51V-01A | GLE1 | chr9 | 131277918 | + | SPTAN1 | chr9 | 131386607 | + |
Top |
Fusion Gene ORF analysis for GLE1-SPTAN1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000309971 | ENST00000475367 | GLE1 | chr9 | 131277918 | + | SPTAN1 | chr9 | 131386607 | + |
| 5CDS-intron | ENST00000372770 | ENST00000475367 | GLE1 | chr9 | 131277918 | + | SPTAN1 | chr9 | 131386607 | + |
| 5UTR-3CDS | ENST00000539582 | ENST00000358161 | GLE1 | chr9 | 131277918 | + | SPTAN1 | chr9 | 131386607 | + |
| 5UTR-3CDS | ENST00000539582 | ENST00000372731 | GLE1 | chr9 | 131277918 | + | SPTAN1 | chr9 | 131386607 | + |
| 5UTR-3CDS | ENST00000539582 | ENST00000372739 | GLE1 | chr9 | 131277918 | + | SPTAN1 | chr9 | 131386607 | + |
| 5UTR-intron | ENST00000539582 | ENST00000475367 | GLE1 | chr9 | 131277918 | + | SPTAN1 | chr9 | 131386607 | + |
| In-frame | ENST00000309971 | ENST00000358161 | GLE1 | chr9 | 131277918 | + | SPTAN1 | chr9 | 131386607 | + |
| In-frame | ENST00000309971 | ENST00000372731 | GLE1 | chr9 | 131277918 | + | SPTAN1 | chr9 | 131386607 | + |
| In-frame | ENST00000309971 | ENST00000372739 | GLE1 | chr9 | 131277918 | + | SPTAN1 | chr9 | 131386607 | + |
| In-frame | ENST00000372770 | ENST00000358161 | GLE1 | chr9 | 131277918 | + | SPTAN1 | chr9 | 131386607 | + |
| In-frame | ENST00000372770 | ENST00000372731 | GLE1 | chr9 | 131277918 | + | SPTAN1 | chr9 | 131386607 | + |
| In-frame | ENST00000372770 | ENST00000372739 | GLE1 | chr9 | 131277918 | + | SPTAN1 | chr9 | 131386607 | + |
| intron-3CDS | ENST00000494417 | ENST00000358161 | GLE1 | chr9 | 131277918 | + | SPTAN1 | chr9 | 131386607 | + |
| intron-3CDS | ENST00000494417 | ENST00000372731 | GLE1 | chr9 | 131277918 | + | SPTAN1 | chr9 | 131386607 | + |
| intron-3CDS | ENST00000494417 | ENST00000372739 | GLE1 | chr9 | 131277918 | + | SPTAN1 | chr9 | 131386607 | + |
| intron-intron | ENST00000494417 | ENST00000475367 | GLE1 | chr9 | 131277918 | + | SPTAN1 | chr9 | 131386607 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000309971 | GLE1 | chr9 | 131277918 | + | ENST00000358161 | SPTAN1 | chr9 | 131386607 | + | 2465 | 538 | 106 | 2139 | 677 |
| ENST00000309971 | GLE1 | chr9 | 131277918 | + | ENST00000372739 | SPTAN1 | chr9 | 131386607 | + | 2468 | 538 | 106 | 2139 | 677 |
| ENST00000309971 | GLE1 | chr9 | 131277918 | + | ENST00000372731 | SPTAN1 | chr9 | 131386607 | + | 2468 | 538 | 106 | 2139 | 677 |
| ENST00000372770 | GLE1 | chr9 | 131277918 | + | ENST00000358161 | SPTAN1 | chr9 | 131386607 | + | 2434 | 507 | 75 | 2108 | 677 |
| ENST00000372770 | GLE1 | chr9 | 131277918 | + | ENST00000372739 | SPTAN1 | chr9 | 131386607 | + | 2437 | 507 | 75 | 2108 | 677 |
| ENST00000372770 | GLE1 | chr9 | 131277918 | + | ENST00000372731 | SPTAN1 | chr9 | 131386607 | + | 2437 | 507 | 75 | 2108 | 677 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000309971 | ENST00000358161 | GLE1 | chr9 | 131277918 | + | SPTAN1 | chr9 | 131386607 | + | 0.0251227 | 0.97487736 |
| ENST00000309971 | ENST00000372739 | GLE1 | chr9 | 131277918 | + | SPTAN1 | chr9 | 131386607 | + | 0.025129778 | 0.9748702 |
| ENST00000309971 | ENST00000372731 | GLE1 | chr9 | 131277918 | + | SPTAN1 | chr9 | 131386607 | + | 0.025129778 | 0.9748702 |
| ENST00000372770 | ENST00000358161 | GLE1 | chr9 | 131277918 | + | SPTAN1 | chr9 | 131386607 | + | 0.026433662 | 0.97356635 |
| ENST00000372770 | ENST00000372739 | GLE1 | chr9 | 131277918 | + | SPTAN1 | chr9 | 131386607 | + | 0.026317643 | 0.9736823 |
| ENST00000372770 | ENST00000372731 | GLE1 | chr9 | 131277918 | + | SPTAN1 | chr9 | 131386607 | + | 0.026317643 | 0.9736823 |
Top |
Fusion Genomic Features for GLE1-SPTAN1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| GLE1 | chr9 | 131277918 | + | SPTAN1 | chr9 | 131386606 | + | 3.09E-10 | 1 |
| GLE1 | chr9 | 131277918 | + | SPTAN1 | chr9 | 131386606 | + | 3.09E-10 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
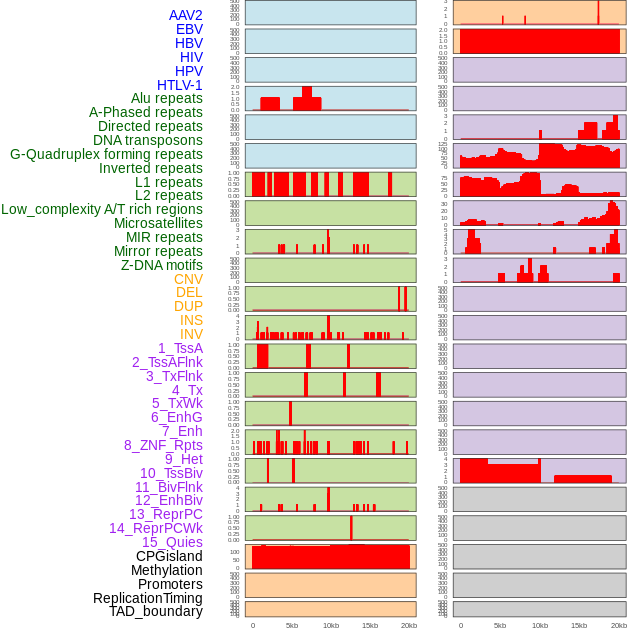 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
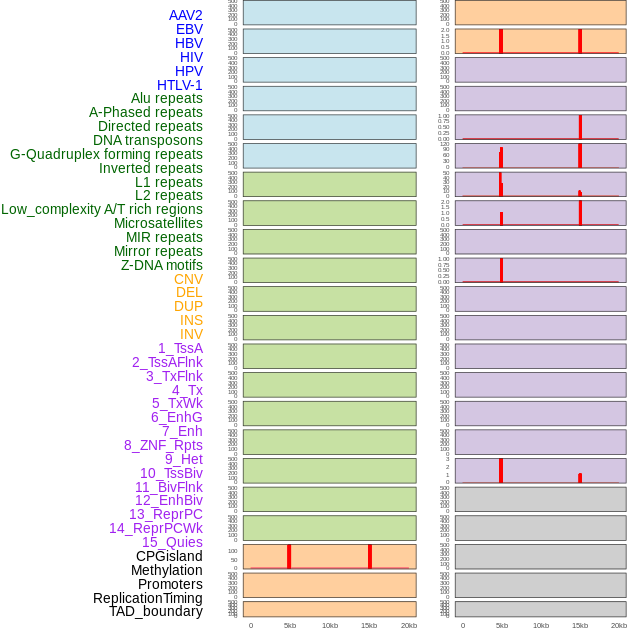 |
Top |
Fusion Protein Features for GLE1-SPTAN1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr9:131314975/chr9:131277808) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| GLE1 | . |
| FUNCTION: Required for the export of mRNAs containing poly(A) tails from the nucleus into the cytoplasm. May be involved in the terminal step of the mRNA transport through the nuclear pore complex (NPC). {ECO:0000269|PubMed:12668658, ECO:0000269|PubMed:16000379, ECO:0000269|PubMed:9618489}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372731 | 43 | 56 | 2336_2347 | 1939 | 2473.0 | Calcium binding | 1 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372731 | 43 | 56 | 2379_2390 | 1939 | 2473.0 | Calcium binding | 2 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372739 | 44 | 57 | 2336_2347 | 1944 | 2478.0 | Calcium binding | 1 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372739 | 44 | 57 | 2379_2390 | 1944 | 2478.0 | Calcium binding | 2 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372731 | 43 | 56 | 2323_2358 | 1939 | 2473.0 | Domain | EF-hand 1 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372731 | 43 | 56 | 2366_2401 | 1939 | 2473.0 | Domain | EF-hand 2 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372731 | 43 | 56 | 2404_2439 | 1939 | 2473.0 | Domain | EF-hand 3 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372739 | 44 | 57 | 2323_2358 | 1944 | 2478.0 | Domain | EF-hand 1 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372739 | 44 | 57 | 2366_2401 | 1944 | 2478.0 | Domain | EF-hand 2 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372739 | 44 | 57 | 2404_2439 | 1944 | 2478.0 | Domain | EF-hand 3 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372731 | 43 | 56 | 1978_2081 | 1939 | 2473.0 | Repeat | Spectrin 18 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372731 | 43 | 56 | 2092_2194 | 1939 | 2473.0 | Repeat | Spectrin 19 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372731 | 43 | 56 | 2206_2310 | 1939 | 2473.0 | Repeat | Spectrin 20 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372739 | 44 | 57 | 1978_2081 | 1944 | 2478.0 | Repeat | Spectrin 18 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372739 | 44 | 57 | 2092_2194 | 1944 | 2478.0 | Repeat | Spectrin 19 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372739 | 44 | 57 | 2206_2310 | 1944 | 2478.0 | Repeat | Spectrin 20 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | GLE1 | chr9:131277918 | chr9:131386607 | ENST00000309971 | + | 3 | 16 | 151_277 | 144 | 699.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | GLE1 | chr9:131277918 | chr9:131386607 | ENST00000309971 | + | 3 | 16 | 305_356 | 144 | 699.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | GLE1 | chr9:131277918 | chr9:131386607 | ENST00000372770 | + | 3 | 14 | 151_277 | 144 | 660.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | GLE1 | chr9:131277918 | chr9:131386607 | ENST00000372770 | + | 3 | 14 | 305_356 | 144 | 660.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | GLE1 | chr9:131277918 | chr9:131386607 | ENST00000309971 | + | 3 | 16 | 444_483 | 144 | 699.0 | Region | Note=Mediates the shuttling between the nucleus and the cytoplasm |
| Hgene | GLE1 | chr9:131277918 | chr9:131386607 | ENST00000372770 | + | 3 | 14 | 444_483 | 144 | 660.0 | Region | Note=Mediates the shuttling between the nucleus and the cytoplasm |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372731 | 43 | 56 | 967_1026 | 1939 | 2473.0 | Domain | SH3 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372739 | 44 | 57 | 967_1026 | 1944 | 2478.0 | Domain | SH3 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372731 | 43 | 56 | 1096_1166 | 1939 | 2473.0 | Repeat | Spectrin 10 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372731 | 43 | 56 | 1233_1336 | 1939 | 2473.0 | Repeat | Spectrin 11 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372731 | 43 | 56 | 1339_1442 | 1939 | 2473.0 | Repeat | Spectrin 12 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372731 | 43 | 56 | 1446_1549 | 1939 | 2473.0 | Repeat | Spectrin 13 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372731 | 43 | 56 | 150_251 | 1939 | 2473.0 | Repeat | Spectrin 2 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372731 | 43 | 56 | 1552_1656 | 1939 | 2473.0 | Repeat | Spectrin 14 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372731 | 43 | 56 | 1659_1762 | 1939 | 2473.0 | Repeat | Spectrin 15 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372731 | 43 | 56 | 1764_1868 | 1939 | 2473.0 | Repeat | Spectrin 16 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372731 | 43 | 56 | 1871_1974 | 1939 | 2473.0 | Repeat | Spectrin 17 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372731 | 43 | 56 | 256_358 | 1939 | 2473.0 | Repeat | Spectrin 3 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372731 | 43 | 56 | 361_465 | 1939 | 2473.0 | Repeat | Spectrin 4 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372731 | 43 | 56 | 45_146 | 1939 | 2473.0 | Repeat | Spectrin 1 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372731 | 43 | 56 | 468_570 | 1939 | 2473.0 | Repeat | Spectrin 5 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372731 | 43 | 56 | 574_676 | 1939 | 2473.0 | Repeat | Spectrin 6 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372731 | 43 | 56 | 679_781 | 1939 | 2473.0 | Repeat | Spectrin 7 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372731 | 43 | 56 | 785_888 | 1939 | 2473.0 | Repeat | Spectrin 8 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372731 | 43 | 56 | 891_969 | 1939 | 2473.0 | Repeat | Spectrin 9 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372739 | 44 | 57 | 1096_1166 | 1944 | 2478.0 | Repeat | Spectrin 10 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372739 | 44 | 57 | 1233_1336 | 1944 | 2478.0 | Repeat | Spectrin 11 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372739 | 44 | 57 | 1339_1442 | 1944 | 2478.0 | Repeat | Spectrin 12 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372739 | 44 | 57 | 1446_1549 | 1944 | 2478.0 | Repeat | Spectrin 13 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372739 | 44 | 57 | 150_251 | 1944 | 2478.0 | Repeat | Spectrin 2 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372739 | 44 | 57 | 1552_1656 | 1944 | 2478.0 | Repeat | Spectrin 14 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372739 | 44 | 57 | 1659_1762 | 1944 | 2478.0 | Repeat | Spectrin 15 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372739 | 44 | 57 | 1764_1868 | 1944 | 2478.0 | Repeat | Spectrin 16 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372739 | 44 | 57 | 1871_1974 | 1944 | 2478.0 | Repeat | Spectrin 17 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372739 | 44 | 57 | 256_358 | 1944 | 2478.0 | Repeat | Spectrin 3 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372739 | 44 | 57 | 361_465 | 1944 | 2478.0 | Repeat | Spectrin 4 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372739 | 44 | 57 | 45_146 | 1944 | 2478.0 | Repeat | Spectrin 1 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372739 | 44 | 57 | 468_570 | 1944 | 2478.0 | Repeat | Spectrin 5 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372739 | 44 | 57 | 574_676 | 1944 | 2478.0 | Repeat | Spectrin 6 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372739 | 44 | 57 | 679_781 | 1944 | 2478.0 | Repeat | Spectrin 7 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372739 | 44 | 57 | 785_888 | 1944 | 2478.0 | Repeat | Spectrin 8 | |
| Tgene | SPTAN1 | chr9:131277918 | chr9:131386607 | ENST00000372739 | 44 | 57 | 891_969 | 1944 | 2478.0 | Repeat | Spectrin 9 |
Top |
Fusion Gene Sequence for GLE1-SPTAN1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >33238_33238_1_GLE1-SPTAN1_GLE1_chr9_131277918_ENST00000309971_SPTAN1_chr9_131386607_ENST00000358161_length(transcript)=2465nt_BP=538nt GCGCGCGCGTCCCGGAAGCAGAAGCCTGTGTGGCCTTCCCGGCGGCTGATTCGAGGGCTTGTTTGGTCAGAAGGGGGGCGTCAGAGAAGC TGCCCCTTAGCCAACCATGCCGTCTGAGGGTCGCTGCTGGGAGACCTTGAAGGCCCTACGCAGTTCCGACAAAGGTCGCCTTTGCTACTA CCGCGACTGGCTGCTGCGGCGCGAGGATGTTTTAGAAGAATGTATGTCTCTTCCCAAGCTATCTTCTTATTCTGGATGGGTGGTAGAGCA CGTCCTACCCCATATGCAGGAGAACCAACCTCTGTCTGAGACTTCGCCATCCTCTACGTCAGCTTCAGCCCTAGATCAACCCTCATTTGT TCCCAAATCTCCTGACGCAAGCTCTGCCTTTTCCCCAGCCTCCCCTGCAACACCAAATGGAACCAAGGGCAAAGATGAGTCCCAGCACAC AGAATCTATGGTACTTCAGTCCTCACGGGGGATCAAAGTGGAAGGCTGCGTCCGAATGTACGAACTGGTACACAGAATGAAAGGAACAAA CAATCACCATGAGGAGAACATCTCTTCAAAGATGAAGGGCCTGAACGGGAAAGTGTCAGACCTGGAGAAAGCTGCAGCCCAGAGAAAGGC GAAGCTGGATGAGAACTCGGCCTTCCTTCAGTTCAACTGGAAGGCGGACGTGGTGGAGTCCTGGATCGGTGAAAAGGAGAACAGCTTGAA GACAGATGATTATGGCCGAGACCTGTCTTCTGTGCAGACGCTCCTCACCAAACAGGAAACTTTTGACGCTGGGCTGCAGGCCTTCCAGCA GGAAGGCATTGCCAACATCACTGCCCTCAAAGATCAGCTTCTCGCCGCCAAACACGTTCAGTCCAAGGCCATCGAGGCCCGGCACGCCTC CCTCATGAAGAGGTGGAGCCAGCTTCTGGCCAACTCAGCCGCCCGCAAGAAGAAGCTTCTGGAGGCTCAGAGTCACTTCCGCAAGGTGGA GGACCTCTTCCTGACCTTCGCCAAAAAGGCTTCTGCCTTCAACAGCTGGTTTGAAAATGCAGAGGAGGACTTAACAGACCCCGTGCGCTG CAACTCCTTGGAAGAAATCAAAGCTTTGCGCGAGGCCCACGACGCCTTCCGCTCCTCCCTCAGCTCTGCCCAGGCTGACTTCAACCAGCT GGCCGAGCTGGACCGCCAGATCAAGAGCTTCCGCGTAGCCTCCAACCCCTACACCTGGTTTACCATGGAGGCCCTGGAGGAGACCTGGAG GAACCTACAGAAAATCATCAAGGAGAGGGAGCTGGAGCTGCAGAAGGAACAGCGGCGGCAGGAGGAGAACGACAAGCTGCGCCAGGAGTT TGCCCAGCACGCCAACGCCTTCCACCAGTGGATCCAAGAGACCAGGTGCCAGCCCGCTGGGGCGTCCTGTATGGTGGAAGAGTCGGGGAC CCTCGAATCCCAGCTTGAAGCTACCAAACGCAAGCACCAGGAAATCCGAGCCATGAGAAGTCAGCTCAAAAAGATCGAGGACCTGGGGGC CGCCATGGAGGAGGCCCTCATCCTGGACAACAAGTACACGGAGCACAGCACCGTGGGCCTCGCCCAGCAGTGGGACCAGCTGGACCAGCT GGGCATGCGCATGCAGCACAACCTGGAGCAGCAGATCCAGGCCAGGAACACAACAGGTGTGACTGAGGAGGCCCTCAAAGAATTCAGCAT GATGTTTAAACACTTTGACAAGGACAAGTCTGGCAGGCTGAACCATCAGGAGTTCAAATCTTGCCTGCGCTCCCTGGGCTATGACCTGCC CATGGTGGAGGAAGGGGAACCTGACCCTGAGTTCGAGGCAATCCTGGACACGGTGGATCCGAACAGAGATGGCCATGTCTCCTTGCAAGA ATACATGGCTTTCATGATCAGCCGCGAAACTGAGAACGTCAAGTCCAGCGAGGAGATTGAGAGCGCCTTCCGGGCCCTCAGCTCAGAGGG AAAGCCTTACGTGACCAAGGAGGAGCTCTACCAGAACCTGACCCGGGAACAAGCCGACTACTGCGTCTCCCACATGAAGCCCTACGTGGA CGGCAAGGGCCGCGAGCTCCCCACCGCGTTCGACTACGTGGAGTTCACCCGCTCGCTTTTCGTGAACTGAGCCACTCCCTGGGTCACCCA CCCCTCGCTGCTTGCCCTGCGTCGCCTTGCTGCATGTCCGCTCCTCTGTGTGCTCTCACTTTCCACTGTAACCTTAAGCCTGCTTAGCTT GGAATAAGACTTAGGAGAAAATGGTGCTTCACTAACCCGCTTCCGGTCCAGTCACAATCATCATGTCACTGTGGGGACCCAGATCTGTGT CTTGAAGCAGCTGCCCTCATTCCGACTTCAGAAAATCGAAGCAGCTGGCTCCTCCCCTTGTTCTCTCTCCCACCCTCCCCCAAATCTGTT >33238_33238_1_GLE1-SPTAN1_GLE1_chr9_131277918_ENST00000309971_SPTAN1_chr9_131386607_ENST00000358161_length(amino acids)=677AA_BP=0 MPSEGRCWETLKALRSSDKGRLCYYRDWLLRREDVLEECMSLPKLSSYSGWVVEHVLPHMQENQPLSETSPSSTSASALDQPSFVPKSPD ASSAFSPASPATPNGTKGKDESQHTESMVLQSSRGIKVEGCVRMYELVHRMKGTNNHHEENISSKMKGLNGKVSDLEKAAAQRKAKLDEN SAFLQFNWKADVVESWIGEKENSLKTDDYGRDLSSVQTLLTKQETFDAGLQAFQQEGIANITALKDQLLAAKHVQSKAIEARHASLMKRW SQLLANSAARKKKLLEAQSHFRKVEDLFLTFAKKASAFNSWFENAEEDLTDPVRCNSLEEIKALREAHDAFRSSLSSAQADFNQLAELDR QIKSFRVASNPYTWFTMEALEETWRNLQKIIKERELELQKEQRRQEENDKLRQEFAQHANAFHQWIQETRCQPAGASCMVEESGTLESQL EATKRKHQEIRAMRSQLKKIEDLGAAMEEALILDNKYTEHSTVGLAQQWDQLDQLGMRMQHNLEQQIQARNTTGVTEEALKEFSMMFKHF DKDKSGRLNHQEFKSCLRSLGYDLPMVEEGEPDPEFEAILDTVDPNRDGHVSLQEYMAFMISRETENVKSSEEIESAFRALSSEGKPYVT -------------------------------------------------------------- >33238_33238_2_GLE1-SPTAN1_GLE1_chr9_131277918_ENST00000309971_SPTAN1_chr9_131386607_ENST00000372731_length(transcript)=2468nt_BP=538nt GCGCGCGCGTCCCGGAAGCAGAAGCCTGTGTGGCCTTCCCGGCGGCTGATTCGAGGGCTTGTTTGGTCAGAAGGGGGGCGTCAGAGAAGC TGCCCCTTAGCCAACCATGCCGTCTGAGGGTCGCTGCTGGGAGACCTTGAAGGCCCTACGCAGTTCCGACAAAGGTCGCCTTTGCTACTA CCGCGACTGGCTGCTGCGGCGCGAGGATGTTTTAGAAGAATGTATGTCTCTTCCCAAGCTATCTTCTTATTCTGGATGGGTGGTAGAGCA CGTCCTACCCCATATGCAGGAGAACCAACCTCTGTCTGAGACTTCGCCATCCTCTACGTCAGCTTCAGCCCTAGATCAACCCTCATTTGT TCCCAAATCTCCTGACGCAAGCTCTGCCTTTTCCCCAGCCTCCCCTGCAACACCAAATGGAACCAAGGGCAAAGATGAGTCCCAGCACAC AGAATCTATGGTACTTCAGTCCTCACGGGGGATCAAAGTGGAAGGCTGCGTCCGAATGTACGAACTGGTACACAGAATGAAAGGAACAAA CAATCACCATGAGGAGAACATCTCTTCAAAGATGAAGGGCCTGAACGGGAAAGTGTCAGACCTGGAGAAAGCTGCAGCCCAGAGAAAGGC GAAGCTGGATGAGAACTCGGCCTTCCTTCAGTTCAACTGGAAGGCGGACGTGGTGGAGTCCTGGATCGGTGAAAAGGAGAACAGCTTGAA GACAGATGATTATGGCCGAGACCTGTCTTCTGTGCAGACGCTCCTCACCAAACAGGAAACTTTTGACGCTGGGCTGCAGGCCTTCCAGCA GGAAGGCATTGCCAACATCACTGCCCTCAAAGATCAGCTTCTCGCCGCCAAACACGTTCAGTCCAAGGCCATCGAGGCCCGGCACGCCTC CCTCATGAAGAGGTGGAGCCAGCTTCTGGCCAACTCAGCCGCCCGCAAGAAGAAGCTTCTGGAGGCTCAGAGTCACTTCCGCAAGGTGGA GGACCTCTTCCTGACCTTCGCCAAAAAGGCTTCTGCCTTCAACAGCTGGTTTGAAAATGCAGAGGAGGACTTAACAGACCCCGTGCGCTG CAACTCCTTGGAAGAAATCAAAGCTTTGCGCGAGGCCCACGACGCCTTCCGCTCCTCCCTCAGCTCTGCCCAGGCTGACTTCAACCAGCT GGCCGAGCTGGACCGCCAGATCAAGAGCTTCCGCGTAGCCTCCAACCCCTACACCTGGTTTACCATGGAGGCCCTGGAGGAGACCTGGAG GAACCTACAGAAAATCATCAAGGAGAGGGAGCTGGAGCTGCAGAAGGAACAGCGGCGGCAGGAGGAGAACGACAAGCTGCGCCAGGAGTT TGCCCAGCACGCCAACGCCTTCCACCAGTGGATCCAAGAGACCAGGACATACCTCCTCGATGGGTCCTGTATGGTGGAAGAGTCGGGGAC CCTCGAATCCCAGCTTGAAGCTACCAAACGCAAGCACCAGGAAATCCGAGCCATGAGAAGTCAGCTCAAAAAGATCGAGGACCTGGGGGC CGCCATGGAGGAGGCCCTCATCCTGGACAACAAGTACACGGAGCACAGCACCGTGGGCCTCGCCCAGCAGTGGGACCAGCTGGACCAGCT GGGCATGCGCATGCAGCACAACCTGGAGCAGCAGATCCAGGCCAGGAACACAACAGGTGTGACTGAGGAGGCCCTCAAAGAATTCAGCAT GATGTTTAAACACTTTGACAAGGACAAGTCTGGCAGGCTGAACCATCAGGAGTTCAAATCTTGCCTGCGCTCCCTGGGCTATGACCTGCC CATGGTGGAGGAAGGGGAACCTGACCCTGAGTTCGAGGCAATCCTGGACACGGTGGATCCGAACAGAGATGGCCATGTCTCCTTGCAAGA ATACATGGCTTTCATGATCAGCCGCGAAACTGAGAACGTCAAGTCCAGCGAGGAGATTGAGAGCGCCTTCCGGGCCCTCAGCTCAGAGGG AAAGCCTTACGTGACCAAGGAGGAGCTCTACCAGAACCTGACCCGGGAACAAGCCGACTACTGCGTCTCCCACATGAAGCCCTACGTGGA CGGCAAGGGCCGCGAGCTCCCCACCGCGTTCGACTACGTGGAGTTCACCCGCTCGCTTTTCGTGAACTGAGCCACTCCCTGGGTCACCCA CCCCTCGCTGCTTGCCCTGCGTCGCCTTGCTGCATGTCCGCTCCTCTGTGTGCTCTCACTTTCCACTGTAACCTTAAGCCTGCTTAGCTT GGAATAAGACTTAGGAGAAAATGGTGCTTCACTAACCCGCTTCCGGTCCAGTCACAATCATCATGTCACTGTGGGGACCCAGATCTGTGT CTTGAAGCAGCTGCCCTCATTCCGACTTCAGAAAATCGAAGCAGCTGGCTCCTCCCCTTGTTCTCTCTCCCACCCTCCCCCAAATCTGTT >33238_33238_2_GLE1-SPTAN1_GLE1_chr9_131277918_ENST00000309971_SPTAN1_chr9_131386607_ENST00000372731_length(amino acids)=677AA_BP=0 MPSEGRCWETLKALRSSDKGRLCYYRDWLLRREDVLEECMSLPKLSSYSGWVVEHVLPHMQENQPLSETSPSSTSASALDQPSFVPKSPD ASSAFSPASPATPNGTKGKDESQHTESMVLQSSRGIKVEGCVRMYELVHRMKGTNNHHEENISSKMKGLNGKVSDLEKAAAQRKAKLDEN SAFLQFNWKADVVESWIGEKENSLKTDDYGRDLSSVQTLLTKQETFDAGLQAFQQEGIANITALKDQLLAAKHVQSKAIEARHASLMKRW SQLLANSAARKKKLLEAQSHFRKVEDLFLTFAKKASAFNSWFENAEEDLTDPVRCNSLEEIKALREAHDAFRSSLSSAQADFNQLAELDR QIKSFRVASNPYTWFTMEALEETWRNLQKIIKERELELQKEQRRQEENDKLRQEFAQHANAFHQWIQETRTYLLDGSCMVEESGTLESQL EATKRKHQEIRAMRSQLKKIEDLGAAMEEALILDNKYTEHSTVGLAQQWDQLDQLGMRMQHNLEQQIQARNTTGVTEEALKEFSMMFKHF DKDKSGRLNHQEFKSCLRSLGYDLPMVEEGEPDPEFEAILDTVDPNRDGHVSLQEYMAFMISRETENVKSSEEIESAFRALSSEGKPYVT -------------------------------------------------------------- >33238_33238_3_GLE1-SPTAN1_GLE1_chr9_131277918_ENST00000309971_SPTAN1_chr9_131386607_ENST00000372739_length(transcript)=2468nt_BP=538nt GCGCGCGCGTCCCGGAAGCAGAAGCCTGTGTGGCCTTCCCGGCGGCTGATTCGAGGGCTTGTTTGGTCAGAAGGGGGGCGTCAGAGAAGC TGCCCCTTAGCCAACCATGCCGTCTGAGGGTCGCTGCTGGGAGACCTTGAAGGCCCTACGCAGTTCCGACAAAGGTCGCCTTTGCTACTA CCGCGACTGGCTGCTGCGGCGCGAGGATGTTTTAGAAGAATGTATGTCTCTTCCCAAGCTATCTTCTTATTCTGGATGGGTGGTAGAGCA CGTCCTACCCCATATGCAGGAGAACCAACCTCTGTCTGAGACTTCGCCATCCTCTACGTCAGCTTCAGCCCTAGATCAACCCTCATTTGT TCCCAAATCTCCTGACGCAAGCTCTGCCTTTTCCCCAGCCTCCCCTGCAACACCAAATGGAACCAAGGGCAAAGATGAGTCCCAGCACAC AGAATCTATGGTACTTCAGTCCTCACGGGGGATCAAAGTGGAAGGCTGCGTCCGAATGTACGAACTGGTACACAGAATGAAAGGAACAAA CAATCACCATGAGGAGAACATCTCTTCAAAGATGAAGGGCCTGAACGGGAAAGTGTCAGACCTGGAGAAAGCTGCAGCCCAGAGAAAGGC GAAGCTGGATGAGAACTCGGCCTTCCTTCAGTTCAACTGGAAGGCGGACGTGGTGGAGTCCTGGATCGGTGAAAAGGAGAACAGCTTGAA GACAGATGATTATGGCCGAGACCTGTCTTCTGTGCAGACGCTCCTCACCAAACAGGAAACTTTTGACGCTGGGCTGCAGGCCTTCCAGCA GGAAGGCATTGCCAACATCACTGCCCTCAAAGATCAGCTTCTCGCCGCCAAACACGTTCAGTCCAAGGCCATCGAGGCCCGGCACGCCTC CCTCATGAAGAGGTGGAGCCAGCTTCTGGCCAACTCAGCCGCCCGCAAGAAGAAGCTTCTGGAGGCTCAGAGTCACTTCCGCAAGGTGGA GGACCTCTTCCTGACCTTCGCCAAAAAGGCTTCTGCCTTCAACAGCTGGTTTGAAAATGCAGAGGAGGACTTAACAGACCCCGTGCGCTG CAACTCCTTGGAAGAAATCAAAGCTTTGCGCGAGGCCCACGACGCCTTCCGCTCCTCCCTCAGCTCTGCCCAGGCTGACTTCAACCAGCT GGCCGAGCTGGACCGCCAGATCAAGAGCTTCCGCGTAGCCTCCAACCCCTACACCTGGTTTACCATGGAGGCCCTGGAGGAGACCTGGAG GAACCTACAGAAAATCATCAAGGAGAGGGAGCTGGAGCTGCAGAAGGAACAGCGGCGGCAGGAGGAGAACGACAAGCTGCGCCAGGAGTT TGCCCAGCACGCCAACGCCTTCCACCAGTGGATCCAAGAGACCAGGACATACCTCCTCGATGGGTCCTGTATGGTGGAAGAGTCGGGGAC CCTCGAATCCCAGCTTGAAGCTACCAAACGCAAGCACCAGGAAATCCGAGCCATGAGAAGTCAGCTCAAAAAGATCGAGGACCTGGGGGC CGCCATGGAGGAGGCCCTCATCCTGGACAACAAGTACACGGAGCACAGCACCGTGGGCCTCGCCCAGCAGTGGGACCAGCTGGACCAGCT GGGCATGCGCATGCAGCACAACCTGGAGCAGCAGATCCAGGCCAGGAACACAACAGGTGTGACTGAGGAGGCCCTCAAAGAATTCAGCAT GATGTTTAAACACTTTGACAAGGACAAGTCTGGCAGGCTGAACCATCAGGAGTTCAAATCTTGCCTGCGCTCCCTGGGCTATGACCTGCC CATGGTGGAGGAAGGGGAACCTGACCCTGAGTTCGAGGCAATCCTGGACACGGTGGATCCGAACAGAGATGGCCATGTCTCCTTGCAAGA ATACATGGCTTTCATGATCAGCCGCGAAACTGAGAACGTCAAGTCCAGCGAGGAGATTGAGAGCGCCTTCCGGGCCCTCAGCTCAGAGGG AAAGCCTTACGTGACCAAGGAGGAGCTCTACCAGAACCTGACCCGGGAACAAGCCGACTACTGCGTCTCCCACATGAAGCCCTACGTGGA CGGCAAGGGCCGCGAGCTCCCCACCGCGTTCGACTACGTGGAGTTCACCCGCTCGCTTTTCGTGAACTGAGCCACTCCCTGGGTCACCCA CCCCTCGCTGCTTGCCCTGCGTCGCCTTGCTGCATGTCCGCTCCTCTGTGTGCTCTCACTTTCCACTGTAACCTTAAGCCTGCTTAGCTT GGAATAAGACTTAGGAGAAAATGGTGCTTCACTAACCCGCTTCCGGTCCAGTCACAATCATCATGTCACTGTGGGGACCCAGATCTGTGT CTTGAAGCAGCTGCCCTCATTCCGACTTCAGAAAATCGAAGCAGCTGGCTCCTCCCCTTGTTCTCTCTCCCACCCTCCCCCAAATCTGTT >33238_33238_3_GLE1-SPTAN1_GLE1_chr9_131277918_ENST00000309971_SPTAN1_chr9_131386607_ENST00000372739_length(amino acids)=677AA_BP=0 MPSEGRCWETLKALRSSDKGRLCYYRDWLLRREDVLEECMSLPKLSSYSGWVVEHVLPHMQENQPLSETSPSSTSASALDQPSFVPKSPD ASSAFSPASPATPNGTKGKDESQHTESMVLQSSRGIKVEGCVRMYELVHRMKGTNNHHEENISSKMKGLNGKVSDLEKAAAQRKAKLDEN SAFLQFNWKADVVESWIGEKENSLKTDDYGRDLSSVQTLLTKQETFDAGLQAFQQEGIANITALKDQLLAAKHVQSKAIEARHASLMKRW SQLLANSAARKKKLLEAQSHFRKVEDLFLTFAKKASAFNSWFENAEEDLTDPVRCNSLEEIKALREAHDAFRSSLSSAQADFNQLAELDR QIKSFRVASNPYTWFTMEALEETWRNLQKIIKERELELQKEQRRQEENDKLRQEFAQHANAFHQWIQETRTYLLDGSCMVEESGTLESQL EATKRKHQEIRAMRSQLKKIEDLGAAMEEALILDNKYTEHSTVGLAQQWDQLDQLGMRMQHNLEQQIQARNTTGVTEEALKEFSMMFKHF DKDKSGRLNHQEFKSCLRSLGYDLPMVEEGEPDPEFEAILDTVDPNRDGHVSLQEYMAFMISRETENVKSSEEIESAFRALSSEGKPYVT -------------------------------------------------------------- >33238_33238_4_GLE1-SPTAN1_GLE1_chr9_131277918_ENST00000372770_SPTAN1_chr9_131386607_ENST00000358161_length(transcript)=2434nt_BP=507nt GGCCTTCCCGGCGGCTGATTCGAGGGCTTGTTTGGTCAGAAGGGGGGCGTCAGAGAAGCTGCCCCTTAGCCAACCATGCCGTCTGAGGGT CGCTGCTGGGAGACCTTGAAGGCCCTACGCAGTTCCGACAAAGGTCGCCTTTGCTACTACCGCGACTGGCTGCTGCGGCGCGAGGATGTT TTAGAAGAATGTATGTCTCTTCCCAAGCTATCTTCTTATTCTGGATGGGTGGTAGAGCACGTCCTACCCCATATGCAGGAGAACCAACCT CTGTCTGAGACTTCGCCATCCTCTACGTCAGCTTCAGCCCTAGATCAACCCTCATTTGTTCCCAAATCTCCTGACGCAAGCTCTGCCTTT TCCCCAGCCTCCCCTGCAACACCAAATGGAACCAAGGGCAAAGATGAGTCCCAGCACACAGAATCTATGGTACTTCAGTCCTCACGGGGG ATCAAAGTGGAAGGCTGCGTCCGAATGTACGAACTGGTACACAGAATGAAAGGAACAAACAATCACCATGAGGAGAACATCTCTTCAAAG ATGAAGGGCCTGAACGGGAAAGTGTCAGACCTGGAGAAAGCTGCAGCCCAGAGAAAGGCGAAGCTGGATGAGAACTCGGCCTTCCTTCAG TTCAACTGGAAGGCGGACGTGGTGGAGTCCTGGATCGGTGAAAAGGAGAACAGCTTGAAGACAGATGATTATGGCCGAGACCTGTCTTCT GTGCAGACGCTCCTCACCAAACAGGAAACTTTTGACGCTGGGCTGCAGGCCTTCCAGCAGGAAGGCATTGCCAACATCACTGCCCTCAAA GATCAGCTTCTCGCCGCCAAACACGTTCAGTCCAAGGCCATCGAGGCCCGGCACGCCTCCCTCATGAAGAGGTGGAGCCAGCTTCTGGCC AACTCAGCCGCCCGCAAGAAGAAGCTTCTGGAGGCTCAGAGTCACTTCCGCAAGGTGGAGGACCTCTTCCTGACCTTCGCCAAAAAGGCT TCTGCCTTCAACAGCTGGTTTGAAAATGCAGAGGAGGACTTAACAGACCCCGTGCGCTGCAACTCCTTGGAAGAAATCAAAGCTTTGCGC GAGGCCCACGACGCCTTCCGCTCCTCCCTCAGCTCTGCCCAGGCTGACTTCAACCAGCTGGCCGAGCTGGACCGCCAGATCAAGAGCTTC CGCGTAGCCTCCAACCCCTACACCTGGTTTACCATGGAGGCCCTGGAGGAGACCTGGAGGAACCTACAGAAAATCATCAAGGAGAGGGAG CTGGAGCTGCAGAAGGAACAGCGGCGGCAGGAGGAGAACGACAAGCTGCGCCAGGAGTTTGCCCAGCACGCCAACGCCTTCCACCAGTGG ATCCAAGAGACCAGGTGCCAGCCCGCTGGGGCGTCCTGTATGGTGGAAGAGTCGGGGACCCTCGAATCCCAGCTTGAAGCTACCAAACGC AAGCACCAGGAAATCCGAGCCATGAGAAGTCAGCTCAAAAAGATCGAGGACCTGGGGGCCGCCATGGAGGAGGCCCTCATCCTGGACAAC AAGTACACGGAGCACAGCACCGTGGGCCTCGCCCAGCAGTGGGACCAGCTGGACCAGCTGGGCATGCGCATGCAGCACAACCTGGAGCAG CAGATCCAGGCCAGGAACACAACAGGTGTGACTGAGGAGGCCCTCAAAGAATTCAGCATGATGTTTAAACACTTTGACAAGGACAAGTCT GGCAGGCTGAACCATCAGGAGTTCAAATCTTGCCTGCGCTCCCTGGGCTATGACCTGCCCATGGTGGAGGAAGGGGAACCTGACCCTGAG TTCGAGGCAATCCTGGACACGGTGGATCCGAACAGAGATGGCCATGTCTCCTTGCAAGAATACATGGCTTTCATGATCAGCCGCGAAACT GAGAACGTCAAGTCCAGCGAGGAGATTGAGAGCGCCTTCCGGGCCCTCAGCTCAGAGGGAAAGCCTTACGTGACCAAGGAGGAGCTCTAC CAGAACCTGACCCGGGAACAAGCCGACTACTGCGTCTCCCACATGAAGCCCTACGTGGACGGCAAGGGCCGCGAGCTCCCCACCGCGTTC GACTACGTGGAGTTCACCCGCTCGCTTTTCGTGAACTGAGCCACTCCCTGGGTCACCCACCCCTCGCTGCTTGCCCTGCGTCGCCTTGCT GCATGTCCGCTCCTCTGTGTGCTCTCACTTTCCACTGTAACCTTAAGCCTGCTTAGCTTGGAATAAGACTTAGGAGAAAATGGTGCTTCA CTAACCCGCTTCCGGTCCAGTCACAATCATCATGTCACTGTGGGGACCCAGATCTGTGTCTTGAAGCAGCTGCCCTCATTCCGACTTCAG AAAATCGAAGCAGCTGGCTCCTCCCCTTGTTCTCTCTCCCACCCTCCCCCAAATCTGTTTTCATGTAAAAGACAAATAAATGATGACTTC >33238_33238_4_GLE1-SPTAN1_GLE1_chr9_131277918_ENST00000372770_SPTAN1_chr9_131386607_ENST00000358161_length(amino acids)=677AA_BP=0 MPSEGRCWETLKALRSSDKGRLCYYRDWLLRREDVLEECMSLPKLSSYSGWVVEHVLPHMQENQPLSETSPSSTSASALDQPSFVPKSPD ASSAFSPASPATPNGTKGKDESQHTESMVLQSSRGIKVEGCVRMYELVHRMKGTNNHHEENISSKMKGLNGKVSDLEKAAAQRKAKLDEN SAFLQFNWKADVVESWIGEKENSLKTDDYGRDLSSVQTLLTKQETFDAGLQAFQQEGIANITALKDQLLAAKHVQSKAIEARHASLMKRW SQLLANSAARKKKLLEAQSHFRKVEDLFLTFAKKASAFNSWFENAEEDLTDPVRCNSLEEIKALREAHDAFRSSLSSAQADFNQLAELDR QIKSFRVASNPYTWFTMEALEETWRNLQKIIKERELELQKEQRRQEENDKLRQEFAQHANAFHQWIQETRCQPAGASCMVEESGTLESQL EATKRKHQEIRAMRSQLKKIEDLGAAMEEALILDNKYTEHSTVGLAQQWDQLDQLGMRMQHNLEQQIQARNTTGVTEEALKEFSMMFKHF DKDKSGRLNHQEFKSCLRSLGYDLPMVEEGEPDPEFEAILDTVDPNRDGHVSLQEYMAFMISRETENVKSSEEIESAFRALSSEGKPYVT -------------------------------------------------------------- >33238_33238_5_GLE1-SPTAN1_GLE1_chr9_131277918_ENST00000372770_SPTAN1_chr9_131386607_ENST00000372731_length(transcript)=2437nt_BP=507nt GGCCTTCCCGGCGGCTGATTCGAGGGCTTGTTTGGTCAGAAGGGGGGCGTCAGAGAAGCTGCCCCTTAGCCAACCATGCCGTCTGAGGGT CGCTGCTGGGAGACCTTGAAGGCCCTACGCAGTTCCGACAAAGGTCGCCTTTGCTACTACCGCGACTGGCTGCTGCGGCGCGAGGATGTT TTAGAAGAATGTATGTCTCTTCCCAAGCTATCTTCTTATTCTGGATGGGTGGTAGAGCACGTCCTACCCCATATGCAGGAGAACCAACCT CTGTCTGAGACTTCGCCATCCTCTACGTCAGCTTCAGCCCTAGATCAACCCTCATTTGTTCCCAAATCTCCTGACGCAAGCTCTGCCTTT TCCCCAGCCTCCCCTGCAACACCAAATGGAACCAAGGGCAAAGATGAGTCCCAGCACACAGAATCTATGGTACTTCAGTCCTCACGGGGG ATCAAAGTGGAAGGCTGCGTCCGAATGTACGAACTGGTACACAGAATGAAAGGAACAAACAATCACCATGAGGAGAACATCTCTTCAAAG ATGAAGGGCCTGAACGGGAAAGTGTCAGACCTGGAGAAAGCTGCAGCCCAGAGAAAGGCGAAGCTGGATGAGAACTCGGCCTTCCTTCAG TTCAACTGGAAGGCGGACGTGGTGGAGTCCTGGATCGGTGAAAAGGAGAACAGCTTGAAGACAGATGATTATGGCCGAGACCTGTCTTCT GTGCAGACGCTCCTCACCAAACAGGAAACTTTTGACGCTGGGCTGCAGGCCTTCCAGCAGGAAGGCATTGCCAACATCACTGCCCTCAAA GATCAGCTTCTCGCCGCCAAACACGTTCAGTCCAAGGCCATCGAGGCCCGGCACGCCTCCCTCATGAAGAGGTGGAGCCAGCTTCTGGCC AACTCAGCCGCCCGCAAGAAGAAGCTTCTGGAGGCTCAGAGTCACTTCCGCAAGGTGGAGGACCTCTTCCTGACCTTCGCCAAAAAGGCT TCTGCCTTCAACAGCTGGTTTGAAAATGCAGAGGAGGACTTAACAGACCCCGTGCGCTGCAACTCCTTGGAAGAAATCAAAGCTTTGCGC GAGGCCCACGACGCCTTCCGCTCCTCCCTCAGCTCTGCCCAGGCTGACTTCAACCAGCTGGCCGAGCTGGACCGCCAGATCAAGAGCTTC CGCGTAGCCTCCAACCCCTACACCTGGTTTACCATGGAGGCCCTGGAGGAGACCTGGAGGAACCTACAGAAAATCATCAAGGAGAGGGAG CTGGAGCTGCAGAAGGAACAGCGGCGGCAGGAGGAGAACGACAAGCTGCGCCAGGAGTTTGCCCAGCACGCCAACGCCTTCCACCAGTGG ATCCAAGAGACCAGGACATACCTCCTCGATGGGTCCTGTATGGTGGAAGAGTCGGGGACCCTCGAATCCCAGCTTGAAGCTACCAAACGC AAGCACCAGGAAATCCGAGCCATGAGAAGTCAGCTCAAAAAGATCGAGGACCTGGGGGCCGCCATGGAGGAGGCCCTCATCCTGGACAAC AAGTACACGGAGCACAGCACCGTGGGCCTCGCCCAGCAGTGGGACCAGCTGGACCAGCTGGGCATGCGCATGCAGCACAACCTGGAGCAG CAGATCCAGGCCAGGAACACAACAGGTGTGACTGAGGAGGCCCTCAAAGAATTCAGCATGATGTTTAAACACTTTGACAAGGACAAGTCT GGCAGGCTGAACCATCAGGAGTTCAAATCTTGCCTGCGCTCCCTGGGCTATGACCTGCCCATGGTGGAGGAAGGGGAACCTGACCCTGAG TTCGAGGCAATCCTGGACACGGTGGATCCGAACAGAGATGGCCATGTCTCCTTGCAAGAATACATGGCTTTCATGATCAGCCGCGAAACT GAGAACGTCAAGTCCAGCGAGGAGATTGAGAGCGCCTTCCGGGCCCTCAGCTCAGAGGGAAAGCCTTACGTGACCAAGGAGGAGCTCTAC CAGAACCTGACCCGGGAACAAGCCGACTACTGCGTCTCCCACATGAAGCCCTACGTGGACGGCAAGGGCCGCGAGCTCCCCACCGCGTTC GACTACGTGGAGTTCACCCGCTCGCTTTTCGTGAACTGAGCCACTCCCTGGGTCACCCACCCCTCGCTGCTTGCCCTGCGTCGCCTTGCT GCATGTCCGCTCCTCTGTGTGCTCTCACTTTCCACTGTAACCTTAAGCCTGCTTAGCTTGGAATAAGACTTAGGAGAAAATGGTGCTTCA CTAACCCGCTTCCGGTCCAGTCACAATCATCATGTCACTGTGGGGACCCAGATCTGTGTCTTGAAGCAGCTGCCCTCATTCCGACTTCAG AAAATCGAAGCAGCTGGCTCCTCCCCTTGTTCTCTCTCCCACCCTCCCCCAAATCTGTTTTCATGTAAAAGACAAATAAATGATGACTTC >33238_33238_5_GLE1-SPTAN1_GLE1_chr9_131277918_ENST00000372770_SPTAN1_chr9_131386607_ENST00000372731_length(amino acids)=677AA_BP=0 MPSEGRCWETLKALRSSDKGRLCYYRDWLLRREDVLEECMSLPKLSSYSGWVVEHVLPHMQENQPLSETSPSSTSASALDQPSFVPKSPD ASSAFSPASPATPNGTKGKDESQHTESMVLQSSRGIKVEGCVRMYELVHRMKGTNNHHEENISSKMKGLNGKVSDLEKAAAQRKAKLDEN SAFLQFNWKADVVESWIGEKENSLKTDDYGRDLSSVQTLLTKQETFDAGLQAFQQEGIANITALKDQLLAAKHVQSKAIEARHASLMKRW SQLLANSAARKKKLLEAQSHFRKVEDLFLTFAKKASAFNSWFENAEEDLTDPVRCNSLEEIKALREAHDAFRSSLSSAQADFNQLAELDR QIKSFRVASNPYTWFTMEALEETWRNLQKIIKERELELQKEQRRQEENDKLRQEFAQHANAFHQWIQETRTYLLDGSCMVEESGTLESQL EATKRKHQEIRAMRSQLKKIEDLGAAMEEALILDNKYTEHSTVGLAQQWDQLDQLGMRMQHNLEQQIQARNTTGVTEEALKEFSMMFKHF DKDKSGRLNHQEFKSCLRSLGYDLPMVEEGEPDPEFEAILDTVDPNRDGHVSLQEYMAFMISRETENVKSSEEIESAFRALSSEGKPYVT -------------------------------------------------------------- >33238_33238_6_GLE1-SPTAN1_GLE1_chr9_131277918_ENST00000372770_SPTAN1_chr9_131386607_ENST00000372739_length(transcript)=2437nt_BP=507nt GGCCTTCCCGGCGGCTGATTCGAGGGCTTGTTTGGTCAGAAGGGGGGCGTCAGAGAAGCTGCCCCTTAGCCAACCATGCCGTCTGAGGGT CGCTGCTGGGAGACCTTGAAGGCCCTACGCAGTTCCGACAAAGGTCGCCTTTGCTACTACCGCGACTGGCTGCTGCGGCGCGAGGATGTT TTAGAAGAATGTATGTCTCTTCCCAAGCTATCTTCTTATTCTGGATGGGTGGTAGAGCACGTCCTACCCCATATGCAGGAGAACCAACCT CTGTCTGAGACTTCGCCATCCTCTACGTCAGCTTCAGCCCTAGATCAACCCTCATTTGTTCCCAAATCTCCTGACGCAAGCTCTGCCTTT TCCCCAGCCTCCCCTGCAACACCAAATGGAACCAAGGGCAAAGATGAGTCCCAGCACACAGAATCTATGGTACTTCAGTCCTCACGGGGG ATCAAAGTGGAAGGCTGCGTCCGAATGTACGAACTGGTACACAGAATGAAAGGAACAAACAATCACCATGAGGAGAACATCTCTTCAAAG ATGAAGGGCCTGAACGGGAAAGTGTCAGACCTGGAGAAAGCTGCAGCCCAGAGAAAGGCGAAGCTGGATGAGAACTCGGCCTTCCTTCAG TTCAACTGGAAGGCGGACGTGGTGGAGTCCTGGATCGGTGAAAAGGAGAACAGCTTGAAGACAGATGATTATGGCCGAGACCTGTCTTCT GTGCAGACGCTCCTCACCAAACAGGAAACTTTTGACGCTGGGCTGCAGGCCTTCCAGCAGGAAGGCATTGCCAACATCACTGCCCTCAAA GATCAGCTTCTCGCCGCCAAACACGTTCAGTCCAAGGCCATCGAGGCCCGGCACGCCTCCCTCATGAAGAGGTGGAGCCAGCTTCTGGCC AACTCAGCCGCCCGCAAGAAGAAGCTTCTGGAGGCTCAGAGTCACTTCCGCAAGGTGGAGGACCTCTTCCTGACCTTCGCCAAAAAGGCT TCTGCCTTCAACAGCTGGTTTGAAAATGCAGAGGAGGACTTAACAGACCCCGTGCGCTGCAACTCCTTGGAAGAAATCAAAGCTTTGCGC GAGGCCCACGACGCCTTCCGCTCCTCCCTCAGCTCTGCCCAGGCTGACTTCAACCAGCTGGCCGAGCTGGACCGCCAGATCAAGAGCTTC CGCGTAGCCTCCAACCCCTACACCTGGTTTACCATGGAGGCCCTGGAGGAGACCTGGAGGAACCTACAGAAAATCATCAAGGAGAGGGAG CTGGAGCTGCAGAAGGAACAGCGGCGGCAGGAGGAGAACGACAAGCTGCGCCAGGAGTTTGCCCAGCACGCCAACGCCTTCCACCAGTGG ATCCAAGAGACCAGGACATACCTCCTCGATGGGTCCTGTATGGTGGAAGAGTCGGGGACCCTCGAATCCCAGCTTGAAGCTACCAAACGC AAGCACCAGGAAATCCGAGCCATGAGAAGTCAGCTCAAAAAGATCGAGGACCTGGGGGCCGCCATGGAGGAGGCCCTCATCCTGGACAAC AAGTACACGGAGCACAGCACCGTGGGCCTCGCCCAGCAGTGGGACCAGCTGGACCAGCTGGGCATGCGCATGCAGCACAACCTGGAGCAG CAGATCCAGGCCAGGAACACAACAGGTGTGACTGAGGAGGCCCTCAAAGAATTCAGCATGATGTTTAAACACTTTGACAAGGACAAGTCT GGCAGGCTGAACCATCAGGAGTTCAAATCTTGCCTGCGCTCCCTGGGCTATGACCTGCCCATGGTGGAGGAAGGGGAACCTGACCCTGAG TTCGAGGCAATCCTGGACACGGTGGATCCGAACAGAGATGGCCATGTCTCCTTGCAAGAATACATGGCTTTCATGATCAGCCGCGAAACT GAGAACGTCAAGTCCAGCGAGGAGATTGAGAGCGCCTTCCGGGCCCTCAGCTCAGAGGGAAAGCCTTACGTGACCAAGGAGGAGCTCTAC CAGAACCTGACCCGGGAACAAGCCGACTACTGCGTCTCCCACATGAAGCCCTACGTGGACGGCAAGGGCCGCGAGCTCCCCACCGCGTTC GACTACGTGGAGTTCACCCGCTCGCTTTTCGTGAACTGAGCCACTCCCTGGGTCACCCACCCCTCGCTGCTTGCCCTGCGTCGCCTTGCT GCATGTCCGCTCCTCTGTGTGCTCTCACTTTCCACTGTAACCTTAAGCCTGCTTAGCTTGGAATAAGACTTAGGAGAAAATGGTGCTTCA CTAACCCGCTTCCGGTCCAGTCACAATCATCATGTCACTGTGGGGACCCAGATCTGTGTCTTGAAGCAGCTGCCCTCATTCCGACTTCAG AAAATCGAAGCAGCTGGCTCCTCCCCTTGTTCTCTCTCCCACCCTCCCCCAAATCTGTTTTCATGTAAAAGACAAATAAATGATGACTTC >33238_33238_6_GLE1-SPTAN1_GLE1_chr9_131277918_ENST00000372770_SPTAN1_chr9_131386607_ENST00000372739_length(amino acids)=677AA_BP=0 MPSEGRCWETLKALRSSDKGRLCYYRDWLLRREDVLEECMSLPKLSSYSGWVVEHVLPHMQENQPLSETSPSSTSASALDQPSFVPKSPD ASSAFSPASPATPNGTKGKDESQHTESMVLQSSRGIKVEGCVRMYELVHRMKGTNNHHEENISSKMKGLNGKVSDLEKAAAQRKAKLDEN SAFLQFNWKADVVESWIGEKENSLKTDDYGRDLSSVQTLLTKQETFDAGLQAFQQEGIANITALKDQLLAAKHVQSKAIEARHASLMKRW SQLLANSAARKKKLLEAQSHFRKVEDLFLTFAKKASAFNSWFENAEEDLTDPVRCNSLEEIKALREAHDAFRSSLSSAQADFNQLAELDR QIKSFRVASNPYTWFTMEALEETWRNLQKIIKERELELQKEQRRQEENDKLRQEFAQHANAFHQWIQETRTYLLDGSCMVEESGTLESQL EATKRKHQEIRAMRSQLKKIEDLGAAMEEALILDNKYTEHSTVGLAQQWDQLDQLGMRMQHNLEQQIQARNTTGVTEEALKEFSMMFKHF DKDKSGRLNHQEFKSCLRSLGYDLPMVEEGEPDPEFEAILDTVDPNRDGHVSLQEYMAFMISRETENVKSSEEIESAFRALSSEGKPYVT -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for GLE1-SPTAN1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| Hgene | GLE1 | chr9:131277918 | chr9:131386607 | ENST00000309971 | + | 3 | 16 | 1_29 | 144.0 | 699.0 | NUP155 |
| Hgene | GLE1 | chr9:131277918 | chr9:131386607 | ENST00000372770 | + | 3 | 14 | 1_29 | 144.0 | 660.0 | NUP155 |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Hgene | GLE1 | chr9:131277918 | chr9:131386607 | ENST00000309971 | + | 3 | 16 | 656_698 | 144.0 | 699.0 | NUP42 |
| Hgene | GLE1 | chr9:131277918 | chr9:131386607 | ENST00000372770 | + | 3 | 14 | 656_698 | 144.0 | 660.0 | NUP42 |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for GLE1-SPTAN1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for GLE1-SPTAN1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies