
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:GLUD1-MLPH (FusionGDB2 ID:33394) |
Fusion Gene Summary for GLUD1-MLPH |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: GLUD1-MLPH | Fusion gene ID: 33394 | Hgene | Tgene | Gene symbol | GLUD1 | MLPH | Gene ID | 2746 | 79083 |
| Gene name | glutamate dehydrogenase 1 | melanophilin | |
| Synonyms | GDH|GDH1|GLUD | SLAC2-A | |
| Cytomap | 10q23.2 | 2q37.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | glutamate dehydrogenase 1, mitochondrialepididymis secretory sperm binding proteinepididymis tissue sperm binding protein Li 18mPglutamate dehydrogenase (NAD(P)+) | melanophilinexophilin-3slp homolog lacking C2 domains asynaptotagmin-like protein 2a | |
| Modification date | 20200329 | 20200320 | |
| UniProtAcc | P00367 | Q9BV36 | |
| Ensembl transtripts involved in fusion gene | ENST00000277865, ENST00000537649, ENST00000544149, ENST00000465164, | ENST00000338530, ENST00000409373, ENST00000468178, ENST00000264605, ENST00000410032, ENST00000445024, | |
| Fusion gene scores | * DoF score | 3 X 3 X 2=18 | 12 X 13 X 9=1404 |
| # samples | 3 | 14 | |
| ** MAII score | log2(3/18*10)=0.736965594166206 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | log2(14/1404*10)=-3.32604420335959 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: GLUD1 [Title/Abstract] AND MLPH [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | GLUD1(88834308)-MLPH(238427182), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | GLUD1 | GO:0006537 | glutamate biosynthetic process | 11032875 |
| Hgene | GLUD1 | GO:0006538 | glutamate catabolic process | 6121377|11032875 |
| Fusion gene breakpoints across GLUD1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across MLPH (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-FP-8210-01A | GLUD1 | chr10 | 88834308 | - | MLPH | chr2 | 238427182 | + |
Top |
Fusion Gene ORF analysis for GLUD1-MLPH |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-3UTR | ENST00000277865 | ENST00000338530 | GLUD1 | chr10 | 88834308 | - | MLPH | chr2 | 238427182 | + |
| 5CDS-3UTR | ENST00000277865 | ENST00000409373 | GLUD1 | chr10 | 88834308 | - | MLPH | chr2 | 238427182 | + |
| 5CDS-3UTR | ENST00000277865 | ENST00000468178 | GLUD1 | chr10 | 88834308 | - | MLPH | chr2 | 238427182 | + |
| 5CDS-3UTR | ENST00000537649 | ENST00000338530 | GLUD1 | chr10 | 88834308 | - | MLPH | chr2 | 238427182 | + |
| 5CDS-3UTR | ENST00000537649 | ENST00000409373 | GLUD1 | chr10 | 88834308 | - | MLPH | chr2 | 238427182 | + |
| 5CDS-3UTR | ENST00000537649 | ENST00000468178 | GLUD1 | chr10 | 88834308 | - | MLPH | chr2 | 238427182 | + |
| 5CDS-3UTR | ENST00000544149 | ENST00000338530 | GLUD1 | chr10 | 88834308 | - | MLPH | chr2 | 238427182 | + |
| 5CDS-3UTR | ENST00000544149 | ENST00000409373 | GLUD1 | chr10 | 88834308 | - | MLPH | chr2 | 238427182 | + |
| 5CDS-3UTR | ENST00000544149 | ENST00000468178 | GLUD1 | chr10 | 88834308 | - | MLPH | chr2 | 238427182 | + |
| In-frame | ENST00000277865 | ENST00000264605 | GLUD1 | chr10 | 88834308 | - | MLPH | chr2 | 238427182 | + |
| In-frame | ENST00000277865 | ENST00000410032 | GLUD1 | chr10 | 88834308 | - | MLPH | chr2 | 238427182 | + |
| In-frame | ENST00000277865 | ENST00000445024 | GLUD1 | chr10 | 88834308 | - | MLPH | chr2 | 238427182 | + |
| In-frame | ENST00000537649 | ENST00000264605 | GLUD1 | chr10 | 88834308 | - | MLPH | chr2 | 238427182 | + |
| In-frame | ENST00000537649 | ENST00000410032 | GLUD1 | chr10 | 88834308 | - | MLPH | chr2 | 238427182 | + |
| In-frame | ENST00000537649 | ENST00000445024 | GLUD1 | chr10 | 88834308 | - | MLPH | chr2 | 238427182 | + |
| In-frame | ENST00000544149 | ENST00000264605 | GLUD1 | chr10 | 88834308 | - | MLPH | chr2 | 238427182 | + |
| In-frame | ENST00000544149 | ENST00000410032 | GLUD1 | chr10 | 88834308 | - | MLPH | chr2 | 238427182 | + |
| In-frame | ENST00000544149 | ENST00000445024 | GLUD1 | chr10 | 88834308 | - | MLPH | chr2 | 238427182 | + |
| intron-3CDS | ENST00000465164 | ENST00000264605 | GLUD1 | chr10 | 88834308 | - | MLPH | chr2 | 238427182 | + |
| intron-3CDS | ENST00000465164 | ENST00000410032 | GLUD1 | chr10 | 88834308 | - | MLPH | chr2 | 238427182 | + |
| intron-3CDS | ENST00000465164 | ENST00000445024 | GLUD1 | chr10 | 88834308 | - | MLPH | chr2 | 238427182 | + |
| intron-3UTR | ENST00000465164 | ENST00000338530 | GLUD1 | chr10 | 88834308 | - | MLPH | chr2 | 238427182 | + |
| intron-3UTR | ENST00000465164 | ENST00000409373 | GLUD1 | chr10 | 88834308 | - | MLPH | chr2 | 238427182 | + |
| intron-3UTR | ENST00000465164 | ENST00000468178 | GLUD1 | chr10 | 88834308 | - | MLPH | chr2 | 238427182 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000277865 | GLUD1 | chr10 | 88834308 | - | ENST00000410032 | MLPH | chr2 | 238427182 | + | 2076 | 743 | 97 | 1671 | 524 |
| ENST00000277865 | GLUD1 | chr10 | 88834308 | - | ENST00000264605 | MLPH | chr2 | 238427182 | + | 3827 | 743 | 97 | 2100 | 667 |
| ENST00000277865 | GLUD1 | chr10 | 88834308 | - | ENST00000445024 | MLPH | chr2 | 238427182 | + | 2360 | 743 | 97 | 1953 | 618 |
| ENST00000537649 | GLUD1 | chr10 | 88834308 | - | ENST00000410032 | MLPH | chr2 | 238427182 | + | 2025 | 692 | 457 | 1620 | 387 |
| ENST00000537649 | GLUD1 | chr10 | 88834308 | - | ENST00000264605 | MLPH | chr2 | 238427182 | + | 3776 | 692 | 457 | 2049 | 530 |
| ENST00000537649 | GLUD1 | chr10 | 88834308 | - | ENST00000445024 | MLPH | chr2 | 238427182 | + | 2309 | 692 | 457 | 1902 | 481 |
| ENST00000544149 | GLUD1 | chr10 | 88834308 | - | ENST00000410032 | MLPH | chr2 | 238427182 | + | 1689 | 356 | 31 | 1284 | 417 |
| ENST00000544149 | GLUD1 | chr10 | 88834308 | - | ENST00000264605 | MLPH | chr2 | 238427182 | + | 3440 | 356 | 31 | 1713 | 560 |
| ENST00000544149 | GLUD1 | chr10 | 88834308 | - | ENST00000445024 | MLPH | chr2 | 238427182 | + | 1973 | 356 | 31 | 1566 | 511 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000277865 | ENST00000410032 | GLUD1 | chr10 | 88834308 | - | MLPH | chr2 | 238427182 | + | 0.004419601 | 0.9955804 |
| ENST00000277865 | ENST00000264605 | GLUD1 | chr10 | 88834308 | - | MLPH | chr2 | 238427182 | + | 0.00548432 | 0.9945156 |
| ENST00000277865 | ENST00000445024 | GLUD1 | chr10 | 88834308 | - | MLPH | chr2 | 238427182 | + | 0.01293003 | 0.98706996 |
| ENST00000537649 | ENST00000410032 | GLUD1 | chr10 | 88834308 | - | MLPH | chr2 | 238427182 | + | 0.001379617 | 0.9986204 |
| ENST00000537649 | ENST00000264605 | GLUD1 | chr10 | 88834308 | - | MLPH | chr2 | 238427182 | + | 0.001656586 | 0.99834335 |
| ENST00000537649 | ENST00000445024 | GLUD1 | chr10 | 88834308 | - | MLPH | chr2 | 238427182 | + | 0.00359379 | 0.99640614 |
| ENST00000544149 | ENST00000410032 | GLUD1 | chr10 | 88834308 | - | MLPH | chr2 | 238427182 | + | 0.0069787 | 0.9930213 |
| ENST00000544149 | ENST00000264605 | GLUD1 | chr10 | 88834308 | - | MLPH | chr2 | 238427182 | + | 0.00482804 | 0.99517196 |
| ENST00000544149 | ENST00000445024 | GLUD1 | chr10 | 88834308 | - | MLPH | chr2 | 238427182 | + | 0.009510817 | 0.9904891 |
Top |
Fusion Genomic Features for GLUD1-MLPH |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| GLUD1 | chr10 | 88834307 | - | MLPH | chr2 | 238427181 | + | 5.30E-07 | 0.9999995 |
| GLUD1 | chr10 | 88834307 | - | MLPH | chr2 | 238427181 | + | 5.30E-07 | 0.9999995 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
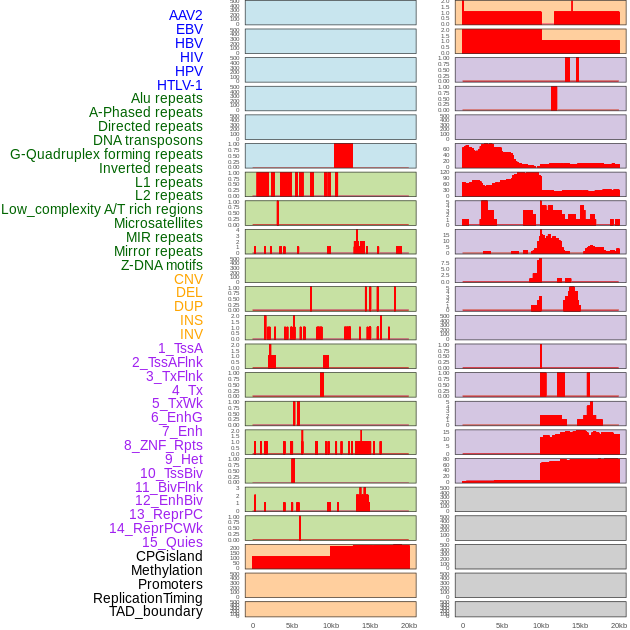 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
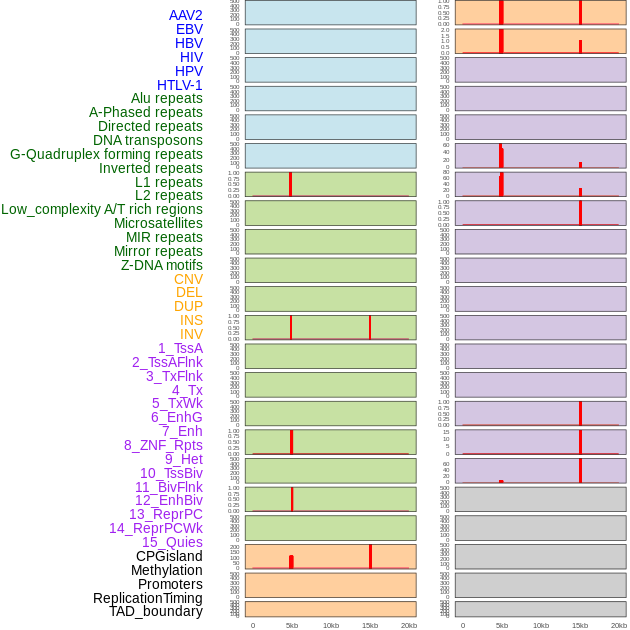 |
Top |
Fusion Protein Features for GLUD1-MLPH |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr10:88834308/chr2:238427182) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| GLUD1 | MLPH |
| FUNCTION: Mitochondrial glutamate dehydrogenase that catalyzes the conversion of L-glutamate into alpha-ketoglutarate. Plays a key role in glutamine anaplerosis by producing alpha-ketoglutarate, an important intermediate in the tricarboxylic acid cycle (PubMed:11032875, PubMed:16959573, PubMed:11254391, PubMed:16023112). Plays a role in insulin homeostasis (PubMed:9571255, PubMed:11297618). May be involved in learning and memory reactions by increasing the turnover of the excitatory neurotransmitter glutamate (By similarity). {ECO:0000250|UniProtKB:P10860, ECO:0000269|PubMed:11032875, ECO:0000269|PubMed:11254391, ECO:0000269|PubMed:11297618, ECO:0000269|PubMed:16023112, ECO:0000269|PubMed:16959573, ECO:0000269|PubMed:9571255}. | FUNCTION: Rab effector protein involved in melanosome transport. Serves as link between melanosome-bound RAB27A and the motor protein MYO5A. {ECO:0000269|PubMed:12062444}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | GLUD1 | chr10:88834308 | chr2:238427182 | ENST00000277865 | - | 4 | 13 | 141_143 | 215 | 559.0 | Nucleotide binding | NAD |
| Tgene | MLPH | chr10:88834308 | chr2:238427182 | ENST00000264605 | 3 | 16 | 373_496 | 148 | 601.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | MLPH | chr10:88834308 | chr2:238427182 | ENST00000338530 | 3 | 15 | 373_496 | 148 | 573.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | MLPH | chr10:88834308 | chr2:238427182 | ENST00000409373 | 3 | 13 | 373_496 | 148 | 481.0 | Coiled coil | Ontology_term=ECO:0000255 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | MLPH | chr10:88834308 | chr2:238427182 | ENST00000264605 | 3 | 16 | 4_124 | 148 | 601.0 | Domain | RabBD | |
| Tgene | MLPH | chr10:88834308 | chr2:238427182 | ENST00000338530 | 3 | 15 | 4_124 | 148 | 573.0 | Domain | RabBD | |
| Tgene | MLPH | chr10:88834308 | chr2:238427182 | ENST00000409373 | 3 | 13 | 4_124 | 148 | 481.0 | Domain | RabBD | |
| Tgene | MLPH | chr10:88834308 | chr2:238427182 | ENST00000264605 | 3 | 16 | 64_107 | 148 | 601.0 | Zinc finger | Note=FYVE-type | |
| Tgene | MLPH | chr10:88834308 | chr2:238427182 | ENST00000338530 | 3 | 15 | 64_107 | 148 | 573.0 | Zinc finger | Note=FYVE-type | |
| Tgene | MLPH | chr10:88834308 | chr2:238427182 | ENST00000409373 | 3 | 13 | 64_107 | 148 | 481.0 | Zinc finger | Note=FYVE-type |
Top |
Fusion Gene Sequence for GLUD1-MLPH |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >33394_33394_1_GLUD1-MLPH_GLUD1_chr10_88834308_ENST00000277865_MLPH_chr2_238427182_ENST00000264605_length(transcript)=3827nt_BP=743nt GGGCAACCCGCGCGGGACCCTTCCTCCCTAGTCGCGGGGAGTCTGAGAAAGCGCGCCTGTTTCGCGACCATCACGCACCTCCCCTCCGCT TGTGGCCATGTACCGCTACCTGGGCGAAGCGCTGTTGCTGTCCCGGGCCGGGCCCGCTGCCCTGGGCTCGGCGTCCGCCGACTCGGCCGC GTTGCTGGGCTGGGCCCGGGGACAGCCCGCCGCCGCCCCGCAGCCGGGGCTGGCATTGGCCGCCCGGCGCCACTACAGCGAGGCGGTGGC CGACCGCGAGGACGACCCCAACTTCTTCAAGATGGTGGAGGGCTTCTTCGATCGCGGCGCCAGCATCGTGGAGGACAAGCTGGTGGAGGA CCTGAGGACCCGGGAGAGCGAGGAGCAGAAGCGGAACCGGGTGCGCGGCATCCTGCGGATCATCAAGCCCTGCAACCATGTGCTGAGTCT CTCCTTCCCCATCCGGCGCGACGACGGCTCCTGGGAGGTCATCGAAGGCTACCGGGCCCAGCACAGCCAGCACCGCACGCCCTGCAAGGG AGGTATCCGTTACAGCACTGATGTGAGTGTAGATGAAGTAAAAGCTTTGGCTTCTCTGATGACATACAAGTGTGCAGTGGTTGATGTGCC GTTTGGGGGTGCTAAAGCTGGTGTTAAGATCAATCCCAAGAACTATACTGATAATGAATTGGAAAAGATCACAAGGAGGTTCACCATGGA GCTAGCAAAAAAGGGCTTTATTGCTGGGCCTGAACTGATATCTGAAGAGAGAAGTGGAGACAGCGACCAGACAGATGAGGATGGAGAACC TGGCTCAGAGGCCCAGGCCCAGGCCCAGCCCTTTGGCAGCAAAAAAAAGCGCCTCCTCTCCGTCCACGACTTCGACTTCGAGGGAGACTC AGATGACTCCACTCAGCCTCAAGGTCACTCCCTGCACCTGTCCTCAGTCCCTGAGGCCAGGGACAGCCCACAGTCCCTCACAGATGAGTC CTGCTCAGAGAAGGCAGCCCCTCACAAGGCTGAGGGCCTGGAGGAGGCTGATACTGGGGCCTCTGGGTGCCACTCCCATCCGGAAGAGCA GCCGACCAGCATCTCACCTTCCAGACACGGCGCCCTGGCTGAGCTCTGCCCGCCTGGAGGCTCCCACAGGATGGCCCTGGGGACTGCTGC TGCACTCGGGTCGAATGTCATCAGGAATGAGCAGCTGCCCCTGCAGTACTTGGCCGATGTGGACACCTCTGATGAGGAAAGCATCCGGGC TCACGTGATGGCCTCCCACCATTCCAAGCGGAGAGGCCGGGCGTCTTCTGAGAGTCAGATCTTTGAGCTGAATAAGCATATTTCAGCTGT GGAATGCCTGCTGACCTACCTGGAGAACACAGTTGTGCCTCCCTTGGCCAAGGGTCTAGGTGCTGGAGTGCGCACGGAGGCCGATGTAGA GGAGGAGGCCCTGAGGAGGAAGCTGGAGGAGCTGACCAGCAACGTCAGTGACCAGGAGACCTCGTCCGAGGAGGAGGAAGCCAAGGACGA AAAGGCAGAGCCCAACAGGGACAAATCAGTTGGGCCTCTCCCCCAGGCGGACCCGGAGGTGGGCACGGCTGCCCATCAAACCAACAGACA GGAAAAAAGCCCCCAGGACCCTGGGGACCCCGTCCAGTACAACAGGACCACAGATGAGGAGCTGTCAGAGCTGGAGGACAGAGTGGCAGT GACGGCCTCAGAAGTCCAGCAGGCAGAGAGCGAGGTTTCAGACATTGAATCCAGGATTGCAGCCCTGAGGGCCGCAGGGCTCACGGTGAA GCCCTCGGGAAAGCCCCGGAGGAAGTCAAACCTCCCGATATTTCTCCCTCGAGTGGCTGGGAAACTTGGCAAGAGACCAGAGGACCCAAA TGCAGACCCTTCAAGTGAGGCCAAGGCAATGGCTGTGCCCTATCTTCTGAGAAGAAAGTTCAGTAATTCCCTGAAAAGTCAAGGTAAAGA TGATGATTCTTTTGATCGGAAATCAGTGTACCGAGGCTCGCTGACACAGAGAAACCCCAACGCGAGGAAAGGAATGGCCAGCCACACCTT CGCGAAACCTGTGGTGGCCCACCAGTCCTAACGGGACAGGACAGAGAGACAGAGCAGCCCTGCACTGTTTTCCCTCCACCACAGCCATCC TGTCCCTCATTGGCTCTGTGCTTTCCACTATACACAGTCACCGTCCCAATGAGAAACAAGAAGGAGCACCCTCCACATGGACTCCCACCT GCAAGTGGACAGCGACATTCAGTCCTGCACTGCTCACCTGGGTTTACTGATGACTCCTGGCTGCCCCACCATCCTCTCTGATCTGTGAGA AACAGCTAAGCTGCTGTGACTTCCCTTTAGGACAATGTTGTGTAAATCTTTGAAGGACACACCGAAGACCTTTATACTGTGATCTTTTAC CCCTTTCACTCTTGGCTTTCTTATGTTGCTTTCATGAATGGAATGGAAAAAAGATGACTCAGTTAAGGCACCAGCCATATGTGTATTCTT GATGGTCTATATCGGGGTGTGAGCAGATGTTTGCGTATTTCTTGTGGGTGTGACTGGATATTAGACATCCGGACAAGTGACTGAACTAAT GATCTGCTGAATAATGAAGGAGGAATAGACACCCCAGTCCCCACCCTACGTGCACCCGCTCTGCAAGTTCCCATGTGATCTGTAGACCAG GGGAAATTACACTGCGGTCAAGGGCAGAGCCTGCACATGACAGCAAGTGAGCATTTGATAGATGCTCAGATGCTAGTGCAGAGAGCCTGC TGGGAGACGAAGAGACAGCAGGCAGAGCTCCAGATGGGCAAGGAAGAGGCTTGGTTCTAGCCTGGCTCTGCCCCTCACTGCAGTGGATCC AGTGGGGCAGAGGACAGAGGGTCACAACCAATGAGGGATGTCTGCCAAGGATGGGGGTGCAGAGGCCACAGGAGTCAGCTTGCCACTCGC CCATTGGTTACATAGATGATCTCTCAGACAGGCTGGGACTCAGAGTTATTTCCTAGTATCGGTGTGCCCCATCCAGTTTTAAGTGGAGCC CTCCAAGACTCTCCAGAGCTGCCTTTGAACATCCTAACAGTAATCACATCTCACCCTCCCTGAGGTTCACTTTAGACAGGACCCAATGGC TGCACTGCCTTTGTCAGAGGGGGTGCTGAGAGGAGTGGCTTCTTTTAGAATCAAACAGTAGAGACAAGAGTCAAGCCTTGTGTCTTCAAG CATTGACCAAGTTAAGTGTTTCCTTCCCTCTCTCAATAAGACACTTCCAGGAGCTTTCCAATCTCTCACTTAAAACTAAGGTTTGAATCT CAAAGTGTTGCTGGGAGGCTGATACTCCTGCAACTTCAGGAGACCTGTGAGCACACATTAGCAGCTGTTTCTCTGACTCCTTGTGGCATC AGATAAAAACGTGGGAGTTTTTCCATATAATTCCCAGCCTTACTTATAAATTCTATTCTTTGAAAAAATTATTCAGGCTAGGTAAGGTGG CTCATACCTATAATCCCAGCCCTTTGAGAGGCCAAGGTGGGAGAATTGCTTGAGGCCAGGAGTTTGAGACCTCCTGGGCAACATAGTGAG ATCCCATCTCTACAAAAAACAAAACAAAAAAATTACCCAAGCATGATGGTATATGCCTGTAGTCGTACCTACTTACTTAGGAGGCTGAGG CAGGAGGATCACTTGAGCCCTGGAGGTTGGGGCTGCAGTGAGCCATGATCGCATCACTATACTCGAGCCTGGGCAACAGAGTGAGACCTT >33394_33394_1_GLUD1-MLPH_GLUD1_chr10_88834308_ENST00000277865_MLPH_chr2_238427182_ENST00000264605_length(amino acids)=667AA_BP=215 MYRYLGEALLLSRAGPAALGSASADSAALLGWARGQPAAAPQPGLALAARRHYSEAVADREDDPNFFKMVEGFFDRGASIVEDKLVEDLR TRESEEQKRNRVRGILRIIKPCNHVLSLSFPIRRDDGSWEVIEGYRAQHSQHRTPCKGGIRYSTDVSVDEVKALASLMTYKCAVVDVPFG GAKAGVKINPKNYTDNELEKITRRFTMELAKKGFIAGPELISEERSGDSDQTDEDGEPGSEAQAQAQPFGSKKKRLLSVHDFDFEGDSDD STQPQGHSLHLSSVPEARDSPQSLTDESCSEKAAPHKAEGLEEADTGASGCHSHPEEQPTSISPSRHGALAELCPPGGSHRMALGTAAAL GSNVIRNEQLPLQYLADVDTSDEESIRAHVMASHHSKRRGRASSESQIFELNKHISAVECLLTYLENTVVPPLAKGLGAGVRTEADVEEE ALRRKLEELTSNVSDQETSSEEEEAKDEKAEPNRDKSVGPLPQADPEVGTAAHQTNRQEKSPQDPGDPVQYNRTTDEELSELEDRVAVTA SEVQQAESEVSDIESRIAALRAAGLTVKPSGKPRRKSNLPIFLPRVAGKLGKRPEDPNADPSSEAKAMAVPYLLRRKFSNSLKSQGKDDD -------------------------------------------------------------- >33394_33394_2_GLUD1-MLPH_GLUD1_chr10_88834308_ENST00000277865_MLPH_chr2_238427182_ENST00000410032_length(transcript)=2076nt_BP=743nt GGGCAACCCGCGCGGGACCCTTCCTCCCTAGTCGCGGGGAGTCTGAGAAAGCGCGCCTGTTTCGCGACCATCACGCACCTCCCCTCCGCT TGTGGCCATGTACCGCTACCTGGGCGAAGCGCTGTTGCTGTCCCGGGCCGGGCCCGCTGCCCTGGGCTCGGCGTCCGCCGACTCGGCCGC GTTGCTGGGCTGGGCCCGGGGACAGCCCGCCGCCGCCCCGCAGCCGGGGCTGGCATTGGCCGCCCGGCGCCACTACAGCGAGGCGGTGGC CGACCGCGAGGACGACCCCAACTTCTTCAAGATGGTGGAGGGCTTCTTCGATCGCGGCGCCAGCATCGTGGAGGACAAGCTGGTGGAGGA CCTGAGGACCCGGGAGAGCGAGGAGCAGAAGCGGAACCGGGTGCGCGGCATCCTGCGGATCATCAAGCCCTGCAACCATGTGCTGAGTCT CTCCTTCCCCATCCGGCGCGACGACGGCTCCTGGGAGGTCATCGAAGGCTACCGGGCCCAGCACAGCCAGCACCGCACGCCCTGCAAGGG AGGTATCCGTTACAGCACTGATGTGAGTGTAGATGAAGTAAAAGCTTTGGCTTCTCTGATGACATACAAGTGTGCAGTGGTTGATGTGCC GTTTGGGGGTGCTAAAGCTGGTGTTAAGATCAATCCCAAGAACTATACTGATAATGAATTGGAAAAGATCACAAGGAGGTTCACCATGGA GCTAGCAAAAAAGGGCTTTATTGCTGGGCCTGAACTGATATCTGAAGAGAGAAGTGGAGACAGCGACCAGACAGATGAGGATGGAGAACC TGGCTCAGAGGCCCAGGCCCAGGCCCAGCCCTTTGGCAGCAAAAAAAAGCGCCTCCTCTCCGTCCACGACTTCGACTTCGAGGGAGACTC AGATGACTCCACTCAGCCTCAAGGTCACTCCCTGCACCTGTCCTCAGTCCCTGAGGCCAGGGACAGCCCACAGGGTCTAGGTGCTGGAGT GCGCACGGAGGCCGATGTAGAGGAGGAGGCCCTGAGGAGGAAGCTGGAGGAGCTGACCAGCAACGTCAGTGACCAGGAGACCTCGTCCGA GGAGGAGGAAGCCAAGGACGAAAAGGCAGAGCCCAACAGGGACAAATCAGTTGGGCCTCTCCCCCAGGCGGACCCGGAGGTGGGCACGGC TGCCCATCAAACCAACAGACAGGAAAAAAGCCCCCAGGACCCTGGGGACCCCGTCCAGTACAACAGGACCACAGATGAGGAGCTGTCAGA GCTGGAGGACAGAGTGGCAGTGACGGCCTCAGAAGTCCAGCAGGCAGAGAGCGAGGTTTCAGACATTGAATCCAGGATTGCAGCCCTGAG GGCCGCAGGGCTCACGGTGAAGCCCTCGGGAAAGCCCCGGAGGAAGTCAAACCTCCCGATATTTCTCCCTCGAGTGGCTGGGAAACTTGG CAAGAGACCAGAGGACCCAAATGCAGACCCTTCAAGTGAGGCCAAGGCAATGGCTGTGCCCTATCTTCTGAGAAGAAAGTTCAGTAATTC CCTGAAAAGTCAAGGTAAAGATGATGATTCTTTTGATCGGAAATCAGTGTACCGAGGCTCGCTGACACAGAGAAACCCCAACGCGAGGAA AGGAATGGCCAGCCACACCTTCGCGAAACCTGTGGTGGCCCACCAGTCCTAACGGGACAGGACAGAGAGACAGAGCAGCCCTGCACTGTT TTCCCTCCACCACAGCCATCCTGTCCCTCATTGGCTCTGTGCTTTCCACTATACACAGTCACCGTCCCAATGAGAAACAAGAAGGAGCAC CCTCCACATGGACTCCCACCTGCAAGTGGACAGCGACATTCAGTCCTGCACTGCTCACCTGGGTTTACTGATGACTCCTGGCTGCCCCAC CATCCTCTCTGATCTGTGAGAAACAGCTAAGCTGCTGTGACTTCCCTTTAGGACAATGTTGTGTAAATCTTTGAAGGACACACCGAAGAC CTTTATACTGTGATCTTTTACCCCTTTCACTCTTGGCTTTCTTATGTTGCTTTCATGAATGGAATGGAAAAAAGATGACTCAGTTAAGGC >33394_33394_2_GLUD1-MLPH_GLUD1_chr10_88834308_ENST00000277865_MLPH_chr2_238427182_ENST00000410032_length(amino acids)=524AA_BP=215 MYRYLGEALLLSRAGPAALGSASADSAALLGWARGQPAAAPQPGLALAARRHYSEAVADREDDPNFFKMVEGFFDRGASIVEDKLVEDLR TRESEEQKRNRVRGILRIIKPCNHVLSLSFPIRRDDGSWEVIEGYRAQHSQHRTPCKGGIRYSTDVSVDEVKALASLMTYKCAVVDVPFG GAKAGVKINPKNYTDNELEKITRRFTMELAKKGFIAGPELISEERSGDSDQTDEDGEPGSEAQAQAQPFGSKKKRLLSVHDFDFEGDSDD STQPQGHSLHLSSVPEARDSPQGLGAGVRTEADVEEEALRRKLEELTSNVSDQETSSEEEEAKDEKAEPNRDKSVGPLPQADPEVGTAAH QTNRQEKSPQDPGDPVQYNRTTDEELSELEDRVAVTASEVQQAESEVSDIESRIAALRAAGLTVKPSGKPRRKSNLPIFLPRVAGKLGKR -------------------------------------------------------------- >33394_33394_3_GLUD1-MLPH_GLUD1_chr10_88834308_ENST00000277865_MLPH_chr2_238427182_ENST00000445024_length(transcript)=2360nt_BP=743nt GGGCAACCCGCGCGGGACCCTTCCTCCCTAGTCGCGGGGAGTCTGAGAAAGCGCGCCTGTTTCGCGACCATCACGCACCTCCCCTCCGCT TGTGGCCATGTACCGCTACCTGGGCGAAGCGCTGTTGCTGTCCCGGGCCGGGCCCGCTGCCCTGGGCTCGGCGTCCGCCGACTCGGCCGC GTTGCTGGGCTGGGCCCGGGGACAGCCCGCCGCCGCCCCGCAGCCGGGGCTGGCATTGGCCGCCCGGCGCCACTACAGCGAGGCGGTGGC CGACCGCGAGGACGACCCCAACTTCTTCAAGATGGTGGAGGGCTTCTTCGATCGCGGCGCCAGCATCGTGGAGGACAAGCTGGTGGAGGA CCTGAGGACCCGGGAGAGCGAGGAGCAGAAGCGGAACCGGGTGCGCGGCATCCTGCGGATCATCAAGCCCTGCAACCATGTGCTGAGTCT CTCCTTCCCCATCCGGCGCGACGACGGCTCCTGGGAGGTCATCGAAGGCTACCGGGCCCAGCACAGCCAGCACCGCACGCCCTGCAAGGG AGGTATCCGTTACAGCACTGATGTGAGTGTAGATGAAGTAAAAGCTTTGGCTTCTCTGATGACATACAAGTGTGCAGTGGTTGATGTGCC GTTTGGGGGTGCTAAAGCTGGTGTTAAGATCAATCCCAAGAACTATACTGATAATGAATTGGAAAAGATCACAAGGAGGTTCACCATGGA GCTAGCAAAAAAGGGCTTTATTGCTGGGCCTGAACTGATATCTGAAGAGAGAAGTGGAGACAGCGACCAGACAGATGAGGATGGAGAACC TGGCTCAGAGGCCCAGGCCCAGGCCCAGCCCTTTGGCAGCAAAAAAAAGCGCCTCCTCTCCGTCCACGACTTCGACTTCGAGGGAGACTC AGATGACTCCACTCAGCCTCAAGGTCACTCCCTGCACCTGTCCTCAGTCCCTGAGGCCAGGGACAGCCCACAGTCCCTCACAGATGAGTC CTGCTCAGAGAAGGCAGCCCCTCACAAGGCTGAGGGCCTGGAGGAGGCTGATACTGGGGCCTCTGGGTGCCACTCCCATCCGGAAGAGCA GCCGACCAGCATCTCACCTTCCAGACACGGCGCCCTGGCTGAGCTCTGCCCGCCTGGAGGCTCCCACAGGATGGCCCTGGGGACTGCTGC TGCACTCGGGTCGAATGTCATCAGGAATGAGCAGCTGCCCCTGCAGTACTTGGCCGATGTGGACACCTCTGATGAGGAAAGCATCCGGGC TCACGTGATGGCCTCCCACCATTCCAAGCGGAGAGGCCGGGCGTCTTCTGAGAGTCAGATCTTTGAGCTGAATAAGCATATTTCAGCTGT GGAATGCCTGCTGACCTACCTGGAGAACACAGTTGTGCCTCCCTTGGCCAAGGGTCTAGGTGCTGGAGTGCGCACGGAGGCCGATGTAGA GGAGGAGGCCCTGAGGAGGAAGCTGGAGGAGCTGACCAGCAACGTCAGTGACCAGGAGACCTCGTCCGAGGAGGAGGAAGCCAAGGACGA AAAGGCAGAGCCCAACAGGGACAAATCAGTTGGGCCTCTCCCCCAGGCGGACCCGGAGGTGGGCACGGCTGCCCATCAAACCAACAGACA GGAAAAAAGCCCCCAGGACCCTGGGGACCCCGTCCAGTACAACAGGACCACAGATGAGGAGCTGTCAGAGCTGGAGGACAGAGTGGCAGT GACGGCCTCAGAAGTCCAGCAGGCAGAGAGCGAGGTTTCAGACATTGAATCCAGGATTGCAGCCCTGAGGGCCGCAGGGCTCACGGTGAA GCCCTCGGGAAAGCCCCGGAGGAAGTCAAACCTCCCGGCTCTTTATGAGGGGACTCTGAGCCTCTGCTCTGAGGATCTGAAACACACACA CCCTGACAGTGTAAAATCCAAAAGGAGCCGCCTGAATCATGTTGCCTCATGTGGAAATCCTTAGTCCGCCGCCACGTGAAGATGGATGTG ACTAGAACGGAGGGCGCGGGAGGCTCACATCAGAGGAGCTGCTCACATATTTCTCCCTCGAGTGGCTGGGAAACTTGGCAAGAGACCAGA GGACCCAAATGCAGACCCTTCAAGTGAGGCCAAGGCAATGGCTGTGCCCTATCTTCTGAGAAGAAAGTTCAGTAATTCCCTGAAAAGTCA AGGTAAAGATGATGATTCTTTTGATCGGAAATCAGTGTACCGAGGCTCGCTGACACAGAGAAACCCCAACGCGAGGAAAGGAATGGCCAG CCACACCTTCGCGAAACCTGTGGTGGCCCACCAGTCCTAACGGGACAGGACAGAGAGACAGAGCAGCCCTGCACTGTTTTCCCTCCACCA >33394_33394_3_GLUD1-MLPH_GLUD1_chr10_88834308_ENST00000277865_MLPH_chr2_238427182_ENST00000445024_length(amino acids)=618AA_BP=215 MYRYLGEALLLSRAGPAALGSASADSAALLGWARGQPAAAPQPGLALAARRHYSEAVADREDDPNFFKMVEGFFDRGASIVEDKLVEDLR TRESEEQKRNRVRGILRIIKPCNHVLSLSFPIRRDDGSWEVIEGYRAQHSQHRTPCKGGIRYSTDVSVDEVKALASLMTYKCAVVDVPFG GAKAGVKINPKNYTDNELEKITRRFTMELAKKGFIAGPELISEERSGDSDQTDEDGEPGSEAQAQAQPFGSKKKRLLSVHDFDFEGDSDD STQPQGHSLHLSSVPEARDSPQSLTDESCSEKAAPHKAEGLEEADTGASGCHSHPEEQPTSISPSRHGALAELCPPGGSHRMALGTAAAL GSNVIRNEQLPLQYLADVDTSDEESIRAHVMASHHSKRRGRASSESQIFELNKHISAVECLLTYLENTVVPPLAKGLGAGVRTEADVEEE ALRRKLEELTSNVSDQETSSEEEEAKDEKAEPNRDKSVGPLPQADPEVGTAAHQTNRQEKSPQDPGDPVQYNRTTDEELSELEDRVAVTA -------------------------------------------------------------- >33394_33394_4_GLUD1-MLPH_GLUD1_chr10_88834308_ENST00000537649_MLPH_chr2_238427182_ENST00000264605_length(transcript)=3776nt_BP=692nt ATGCAGAGTAGACGCTGCACCGGTCTCCTTTTGGTCCCGGTGTCTGTGTCACACACGGCGGGTCCTGCCGAAATGCACTTCTAGGAAAGG GAATGACCTGCCCGTGTGATAATGCCTCGTCAGTGTTCTTGGGCTTTTATGCCCAGCTCTCTCCTGTTTTTATAAGTCGCAGCTCCGCAA ACTCACTGAAGCAACTCGTTTACCATAGTTTTTACTACATGTACCTGAGGCCGTTAGATTTGTCTGTGTTAAGGATTTGAAAGGAGGCAG AAATTAATACAGATTCAAGTGTTCACTATCAAGTCGGAATTGTTAATATGTGAAATACTACTGTTAAAGGCAGGAAAGGCTTTATTAAGG ACAAGAAGACAAACTAGGAGAAGGAGCTACTCAAGACCTTCCGATTATCTTTACAAAAAGGCAACTACACCTAGAAGATTCTGCAGCCAC ACACATTCTGCCTTCACTTGAGGTCAACTGCCTTCACCAAGGTATCCGTTACAGCACTGATGTGAGTGTAGATGAAGTAAAAGCTTTGGC TTCTCTGATGACATACAAGTGTGCAGTGGTTGATGTGCCGTTTGGGGGTGCTAAAGCTGGTGTTAAGATCAATCCCAAGAACTATACTGA TAATGAATTGGAAAAGATCACAAGGAGGTTCACCATGGAGCTAGCAAAAAAGGGCTTTATTGCTGGGCCTGAACTGATATCTGAAGAGAG AAGTGGAGACAGCGACCAGACAGATGAGGATGGAGAACCTGGCTCAGAGGCCCAGGCCCAGGCCCAGCCCTTTGGCAGCAAAAAAAAGCG CCTCCTCTCCGTCCACGACTTCGACTTCGAGGGAGACTCAGATGACTCCACTCAGCCTCAAGGTCACTCCCTGCACCTGTCCTCAGTCCC TGAGGCCAGGGACAGCCCACAGTCCCTCACAGATGAGTCCTGCTCAGAGAAGGCAGCCCCTCACAAGGCTGAGGGCCTGGAGGAGGCTGA TACTGGGGCCTCTGGGTGCCACTCCCATCCGGAAGAGCAGCCGACCAGCATCTCACCTTCCAGACACGGCGCCCTGGCTGAGCTCTGCCC GCCTGGAGGCTCCCACAGGATGGCCCTGGGGACTGCTGCTGCACTCGGGTCGAATGTCATCAGGAATGAGCAGCTGCCCCTGCAGTACTT GGCCGATGTGGACACCTCTGATGAGGAAAGCATCCGGGCTCACGTGATGGCCTCCCACCATTCCAAGCGGAGAGGCCGGGCGTCTTCTGA GAGTCAGATCTTTGAGCTGAATAAGCATATTTCAGCTGTGGAATGCCTGCTGACCTACCTGGAGAACACAGTTGTGCCTCCCTTGGCCAA GGGTCTAGGTGCTGGAGTGCGCACGGAGGCCGATGTAGAGGAGGAGGCCCTGAGGAGGAAGCTGGAGGAGCTGACCAGCAACGTCAGTGA CCAGGAGACCTCGTCCGAGGAGGAGGAAGCCAAGGACGAAAAGGCAGAGCCCAACAGGGACAAATCAGTTGGGCCTCTCCCCCAGGCGGA CCCGGAGGTGGGCACGGCTGCCCATCAAACCAACAGACAGGAAAAAAGCCCCCAGGACCCTGGGGACCCCGTCCAGTACAACAGGACCAC AGATGAGGAGCTGTCAGAGCTGGAGGACAGAGTGGCAGTGACGGCCTCAGAAGTCCAGCAGGCAGAGAGCGAGGTTTCAGACATTGAATC CAGGATTGCAGCCCTGAGGGCCGCAGGGCTCACGGTGAAGCCCTCGGGAAAGCCCCGGAGGAAGTCAAACCTCCCGATATTTCTCCCTCG AGTGGCTGGGAAACTTGGCAAGAGACCAGAGGACCCAAATGCAGACCCTTCAAGTGAGGCCAAGGCAATGGCTGTGCCCTATCTTCTGAG AAGAAAGTTCAGTAATTCCCTGAAAAGTCAAGGTAAAGATGATGATTCTTTTGATCGGAAATCAGTGTACCGAGGCTCGCTGACACAGAG AAACCCCAACGCGAGGAAAGGAATGGCCAGCCACACCTTCGCGAAACCTGTGGTGGCCCACCAGTCCTAACGGGACAGGACAGAGAGACA GAGCAGCCCTGCACTGTTTTCCCTCCACCACAGCCATCCTGTCCCTCATTGGCTCTGTGCTTTCCACTATACACAGTCACCGTCCCAATG AGAAACAAGAAGGAGCACCCTCCACATGGACTCCCACCTGCAAGTGGACAGCGACATTCAGTCCTGCACTGCTCACCTGGGTTTACTGAT GACTCCTGGCTGCCCCACCATCCTCTCTGATCTGTGAGAAACAGCTAAGCTGCTGTGACTTCCCTTTAGGACAATGTTGTGTAAATCTTT GAAGGACACACCGAAGACCTTTATACTGTGATCTTTTACCCCTTTCACTCTTGGCTTTCTTATGTTGCTTTCATGAATGGAATGGAAAAA AGATGACTCAGTTAAGGCACCAGCCATATGTGTATTCTTGATGGTCTATATCGGGGTGTGAGCAGATGTTTGCGTATTTCTTGTGGGTGT GACTGGATATTAGACATCCGGACAAGTGACTGAACTAATGATCTGCTGAATAATGAAGGAGGAATAGACACCCCAGTCCCCACCCTACGT GCACCCGCTCTGCAAGTTCCCATGTGATCTGTAGACCAGGGGAAATTACACTGCGGTCAAGGGCAGAGCCTGCACATGACAGCAAGTGAG CATTTGATAGATGCTCAGATGCTAGTGCAGAGAGCCTGCTGGGAGACGAAGAGACAGCAGGCAGAGCTCCAGATGGGCAAGGAAGAGGCT TGGTTCTAGCCTGGCTCTGCCCCTCACTGCAGTGGATCCAGTGGGGCAGAGGACAGAGGGTCACAACCAATGAGGGATGTCTGCCAAGGA TGGGGGTGCAGAGGCCACAGGAGTCAGCTTGCCACTCGCCCATTGGTTACATAGATGATCTCTCAGACAGGCTGGGACTCAGAGTTATTT CCTAGTATCGGTGTGCCCCATCCAGTTTTAAGTGGAGCCCTCCAAGACTCTCCAGAGCTGCCTTTGAACATCCTAACAGTAATCACATCT CACCCTCCCTGAGGTTCACTTTAGACAGGACCCAATGGCTGCACTGCCTTTGTCAGAGGGGGTGCTGAGAGGAGTGGCTTCTTTTAGAAT CAAACAGTAGAGACAAGAGTCAAGCCTTGTGTCTTCAAGCATTGACCAAGTTAAGTGTTTCCTTCCCTCTCTCAATAAGACACTTCCAGG AGCTTTCCAATCTCTCACTTAAAACTAAGGTTTGAATCTCAAAGTGTTGCTGGGAGGCTGATACTCCTGCAACTTCAGGAGACCTGTGAG CACACATTAGCAGCTGTTTCTCTGACTCCTTGTGGCATCAGATAAAAACGTGGGAGTTTTTCCATATAATTCCCAGCCTTACTTATAAAT TCTATTCTTTGAAAAAATTATTCAGGCTAGGTAAGGTGGCTCATACCTATAATCCCAGCCCTTTGAGAGGCCAAGGTGGGAGAATTGCTT GAGGCCAGGAGTTTGAGACCTCCTGGGCAACATAGTGAGATCCCATCTCTACAAAAAACAAAACAAAAAAATTACCCAAGCATGATGGTA TATGCCTGTAGTCGTACCTACTTACTTAGGAGGCTGAGGCAGGAGGATCACTTGAGCCCTGGAGGTTGGGGCTGCAGTGAGCCATGATCG >33394_33394_4_GLUD1-MLPH_GLUD1_chr10_88834308_ENST00000537649_MLPH_chr2_238427182_ENST00000264605_length(amino acids)=530AA_BP=78 MPSLEVNCLHQGIRYSTDVSVDEVKALASLMTYKCAVVDVPFGGAKAGVKINPKNYTDNELEKITRRFTMELAKKGFIAGPELISEERSG DSDQTDEDGEPGSEAQAQAQPFGSKKKRLLSVHDFDFEGDSDDSTQPQGHSLHLSSVPEARDSPQSLTDESCSEKAAPHKAEGLEEADTG ASGCHSHPEEQPTSISPSRHGALAELCPPGGSHRMALGTAAALGSNVIRNEQLPLQYLADVDTSDEESIRAHVMASHHSKRRGRASSESQ IFELNKHISAVECLLTYLENTVVPPLAKGLGAGVRTEADVEEEALRRKLEELTSNVSDQETSSEEEEAKDEKAEPNRDKSVGPLPQADPE VGTAAHQTNRQEKSPQDPGDPVQYNRTTDEELSELEDRVAVTASEVQQAESEVSDIESRIAALRAAGLTVKPSGKPRRKSNLPIFLPRVA -------------------------------------------------------------- >33394_33394_5_GLUD1-MLPH_GLUD1_chr10_88834308_ENST00000537649_MLPH_chr2_238427182_ENST00000410032_length(transcript)=2025nt_BP=692nt ATGCAGAGTAGACGCTGCACCGGTCTCCTTTTGGTCCCGGTGTCTGTGTCACACACGGCGGGTCCTGCCGAAATGCACTTCTAGGAAAGG GAATGACCTGCCCGTGTGATAATGCCTCGTCAGTGTTCTTGGGCTTTTATGCCCAGCTCTCTCCTGTTTTTATAAGTCGCAGCTCCGCAA ACTCACTGAAGCAACTCGTTTACCATAGTTTTTACTACATGTACCTGAGGCCGTTAGATTTGTCTGTGTTAAGGATTTGAAAGGAGGCAG AAATTAATACAGATTCAAGTGTTCACTATCAAGTCGGAATTGTTAATATGTGAAATACTACTGTTAAAGGCAGGAAAGGCTTTATTAAGG ACAAGAAGACAAACTAGGAGAAGGAGCTACTCAAGACCTTCCGATTATCTTTACAAAAAGGCAACTACACCTAGAAGATTCTGCAGCCAC ACACATTCTGCCTTCACTTGAGGTCAACTGCCTTCACCAAGGTATCCGTTACAGCACTGATGTGAGTGTAGATGAAGTAAAAGCTTTGGC TTCTCTGATGACATACAAGTGTGCAGTGGTTGATGTGCCGTTTGGGGGTGCTAAAGCTGGTGTTAAGATCAATCCCAAGAACTATACTGA TAATGAATTGGAAAAGATCACAAGGAGGTTCACCATGGAGCTAGCAAAAAAGGGCTTTATTGCTGGGCCTGAACTGATATCTGAAGAGAG AAGTGGAGACAGCGACCAGACAGATGAGGATGGAGAACCTGGCTCAGAGGCCCAGGCCCAGGCCCAGCCCTTTGGCAGCAAAAAAAAGCG CCTCCTCTCCGTCCACGACTTCGACTTCGAGGGAGACTCAGATGACTCCACTCAGCCTCAAGGTCACTCCCTGCACCTGTCCTCAGTCCC TGAGGCCAGGGACAGCCCACAGGGTCTAGGTGCTGGAGTGCGCACGGAGGCCGATGTAGAGGAGGAGGCCCTGAGGAGGAAGCTGGAGGA GCTGACCAGCAACGTCAGTGACCAGGAGACCTCGTCCGAGGAGGAGGAAGCCAAGGACGAAAAGGCAGAGCCCAACAGGGACAAATCAGT TGGGCCTCTCCCCCAGGCGGACCCGGAGGTGGGCACGGCTGCCCATCAAACCAACAGACAGGAAAAAAGCCCCCAGGACCCTGGGGACCC CGTCCAGTACAACAGGACCACAGATGAGGAGCTGTCAGAGCTGGAGGACAGAGTGGCAGTGACGGCCTCAGAAGTCCAGCAGGCAGAGAG CGAGGTTTCAGACATTGAATCCAGGATTGCAGCCCTGAGGGCCGCAGGGCTCACGGTGAAGCCCTCGGGAAAGCCCCGGAGGAAGTCAAA CCTCCCGATATTTCTCCCTCGAGTGGCTGGGAAACTTGGCAAGAGACCAGAGGACCCAAATGCAGACCCTTCAAGTGAGGCCAAGGCAAT GGCTGTGCCCTATCTTCTGAGAAGAAAGTTCAGTAATTCCCTGAAAAGTCAAGGTAAAGATGATGATTCTTTTGATCGGAAATCAGTGTA CCGAGGCTCGCTGACACAGAGAAACCCCAACGCGAGGAAAGGAATGGCCAGCCACACCTTCGCGAAACCTGTGGTGGCCCACCAGTCCTA ACGGGACAGGACAGAGAGACAGAGCAGCCCTGCACTGTTTTCCCTCCACCACAGCCATCCTGTCCCTCATTGGCTCTGTGCTTTCCACTA TACACAGTCACCGTCCCAATGAGAAACAAGAAGGAGCACCCTCCACATGGACTCCCACCTGCAAGTGGACAGCGACATTCAGTCCTGCAC TGCTCACCTGGGTTTACTGATGACTCCTGGCTGCCCCACCATCCTCTCTGATCTGTGAGAAACAGCTAAGCTGCTGTGACTTCCCTTTAG GACAATGTTGTGTAAATCTTTGAAGGACACACCGAAGACCTTTATACTGTGATCTTTTACCCCTTTCACTCTTGGCTTTCTTATGTTGCT >33394_33394_5_GLUD1-MLPH_GLUD1_chr10_88834308_ENST00000537649_MLPH_chr2_238427182_ENST00000410032_length(amino acids)=387AA_BP=78 MPSLEVNCLHQGIRYSTDVSVDEVKALASLMTYKCAVVDVPFGGAKAGVKINPKNYTDNELEKITRRFTMELAKKGFIAGPELISEERSG DSDQTDEDGEPGSEAQAQAQPFGSKKKRLLSVHDFDFEGDSDDSTQPQGHSLHLSSVPEARDSPQGLGAGVRTEADVEEEALRRKLEELT SNVSDQETSSEEEEAKDEKAEPNRDKSVGPLPQADPEVGTAAHQTNRQEKSPQDPGDPVQYNRTTDEELSELEDRVAVTASEVQQAESEV SDIESRIAALRAAGLTVKPSGKPRRKSNLPIFLPRVAGKLGKRPEDPNADPSSEAKAMAVPYLLRRKFSNSLKSQGKDDDSFDRKSVYRG -------------------------------------------------------------- >33394_33394_6_GLUD1-MLPH_GLUD1_chr10_88834308_ENST00000537649_MLPH_chr2_238427182_ENST00000445024_length(transcript)=2309nt_BP=692nt ATGCAGAGTAGACGCTGCACCGGTCTCCTTTTGGTCCCGGTGTCTGTGTCACACACGGCGGGTCCTGCCGAAATGCACTTCTAGGAAAGG GAATGACCTGCCCGTGTGATAATGCCTCGTCAGTGTTCTTGGGCTTTTATGCCCAGCTCTCTCCTGTTTTTATAAGTCGCAGCTCCGCAA ACTCACTGAAGCAACTCGTTTACCATAGTTTTTACTACATGTACCTGAGGCCGTTAGATTTGTCTGTGTTAAGGATTTGAAAGGAGGCAG AAATTAATACAGATTCAAGTGTTCACTATCAAGTCGGAATTGTTAATATGTGAAATACTACTGTTAAAGGCAGGAAAGGCTTTATTAAGG ACAAGAAGACAAACTAGGAGAAGGAGCTACTCAAGACCTTCCGATTATCTTTACAAAAAGGCAACTACACCTAGAAGATTCTGCAGCCAC ACACATTCTGCCTTCACTTGAGGTCAACTGCCTTCACCAAGGTATCCGTTACAGCACTGATGTGAGTGTAGATGAAGTAAAAGCTTTGGC TTCTCTGATGACATACAAGTGTGCAGTGGTTGATGTGCCGTTTGGGGGTGCTAAAGCTGGTGTTAAGATCAATCCCAAGAACTATACTGA TAATGAATTGGAAAAGATCACAAGGAGGTTCACCATGGAGCTAGCAAAAAAGGGCTTTATTGCTGGGCCTGAACTGATATCTGAAGAGAG AAGTGGAGACAGCGACCAGACAGATGAGGATGGAGAACCTGGCTCAGAGGCCCAGGCCCAGGCCCAGCCCTTTGGCAGCAAAAAAAAGCG CCTCCTCTCCGTCCACGACTTCGACTTCGAGGGAGACTCAGATGACTCCACTCAGCCTCAAGGTCACTCCCTGCACCTGTCCTCAGTCCC TGAGGCCAGGGACAGCCCACAGTCCCTCACAGATGAGTCCTGCTCAGAGAAGGCAGCCCCTCACAAGGCTGAGGGCCTGGAGGAGGCTGA TACTGGGGCCTCTGGGTGCCACTCCCATCCGGAAGAGCAGCCGACCAGCATCTCACCTTCCAGACACGGCGCCCTGGCTGAGCTCTGCCC GCCTGGAGGCTCCCACAGGATGGCCCTGGGGACTGCTGCTGCACTCGGGTCGAATGTCATCAGGAATGAGCAGCTGCCCCTGCAGTACTT GGCCGATGTGGACACCTCTGATGAGGAAAGCATCCGGGCTCACGTGATGGCCTCCCACCATTCCAAGCGGAGAGGCCGGGCGTCTTCTGA GAGTCAGATCTTTGAGCTGAATAAGCATATTTCAGCTGTGGAATGCCTGCTGACCTACCTGGAGAACACAGTTGTGCCTCCCTTGGCCAA GGGTCTAGGTGCTGGAGTGCGCACGGAGGCCGATGTAGAGGAGGAGGCCCTGAGGAGGAAGCTGGAGGAGCTGACCAGCAACGTCAGTGA CCAGGAGACCTCGTCCGAGGAGGAGGAAGCCAAGGACGAAAAGGCAGAGCCCAACAGGGACAAATCAGTTGGGCCTCTCCCCCAGGCGGA CCCGGAGGTGGGCACGGCTGCCCATCAAACCAACAGACAGGAAAAAAGCCCCCAGGACCCTGGGGACCCCGTCCAGTACAACAGGACCAC AGATGAGGAGCTGTCAGAGCTGGAGGACAGAGTGGCAGTGACGGCCTCAGAAGTCCAGCAGGCAGAGAGCGAGGTTTCAGACATTGAATC CAGGATTGCAGCCCTGAGGGCCGCAGGGCTCACGGTGAAGCCCTCGGGAAAGCCCCGGAGGAAGTCAAACCTCCCGGCTCTTTATGAGGG GACTCTGAGCCTCTGCTCTGAGGATCTGAAACACACACACCCTGACAGTGTAAAATCCAAAAGGAGCCGCCTGAATCATGTTGCCTCATG TGGAAATCCTTAGTCCGCCGCCACGTGAAGATGGATGTGACTAGAACGGAGGGCGCGGGAGGCTCACATCAGAGGAGCTGCTCACATATT TCTCCCTCGAGTGGCTGGGAAACTTGGCAAGAGACCAGAGGACCCAAATGCAGACCCTTCAAGTGAGGCCAAGGCAATGGCTGTGCCCTA TCTTCTGAGAAGAAAGTTCAGTAATTCCCTGAAAAGTCAAGGTAAAGATGATGATTCTTTTGATCGGAAATCAGTGTACCGAGGCTCGCT GACACAGAGAAACCCCAACGCGAGGAAAGGAATGGCCAGCCACACCTTCGCGAAACCTGTGGTGGCCCACCAGTCCTAACGGGACAGGAC >33394_33394_6_GLUD1-MLPH_GLUD1_chr10_88834308_ENST00000537649_MLPH_chr2_238427182_ENST00000445024_length(amino acids)=481AA_BP=78 MPSLEVNCLHQGIRYSTDVSVDEVKALASLMTYKCAVVDVPFGGAKAGVKINPKNYTDNELEKITRRFTMELAKKGFIAGPELISEERSG DSDQTDEDGEPGSEAQAQAQPFGSKKKRLLSVHDFDFEGDSDDSTQPQGHSLHLSSVPEARDSPQSLTDESCSEKAAPHKAEGLEEADTG ASGCHSHPEEQPTSISPSRHGALAELCPPGGSHRMALGTAAALGSNVIRNEQLPLQYLADVDTSDEESIRAHVMASHHSKRRGRASSESQ IFELNKHISAVECLLTYLENTVVPPLAKGLGAGVRTEADVEEEALRRKLEELTSNVSDQETSSEEEEAKDEKAEPNRDKSVGPLPQADPE VGTAAHQTNRQEKSPQDPGDPVQYNRTTDEELSELEDRVAVTASEVQQAESEVSDIESRIAALRAAGLTVKPSGKPRRKSNLPALYEGTL -------------------------------------------------------------- >33394_33394_7_GLUD1-MLPH_GLUD1_chr10_88834308_ENST00000544149_MLPH_chr2_238427182_ENST00000264605_length(transcript)=3440nt_BP=356nt GTATATGCTGATCTTGCATGCAGAGTAGACGCTGCACCGGTCTCCTTTTGGTCCCGGTGTCTGTGTCACACACGGCGGGTCCTGCCGAAA TGCACTTCTAGGAAAGGGAATGACCTGCCCGTGTGATAATGCCTCGTCAGTGTTCTTGGGCTTTTGTATCCGTTACAGCACTGATGTGAG TGTAGATGAAGTAAAAGCTTTGGCTTCTCTGATGACATACAAGTGTGCAGTGGTTGATGTGCCGTTTGGGGGTGCTAAAGCTGGTGTTAA GATCAATCCCAAGAACTATACTGATAATGAATTGGAAAAGATCACAAGGAGGTTCACCATGGAGCTAGCAAAAAAGGGCTTTATTGCTGG GCCTGAACTGATATCTGAAGAGAGAAGTGGAGACAGCGACCAGACAGATGAGGATGGAGAACCTGGCTCAGAGGCCCAGGCCCAGGCCCA GCCCTTTGGCAGCAAAAAAAAGCGCCTCCTCTCCGTCCACGACTTCGACTTCGAGGGAGACTCAGATGACTCCACTCAGCCTCAAGGTCA CTCCCTGCACCTGTCCTCAGTCCCTGAGGCCAGGGACAGCCCACAGTCCCTCACAGATGAGTCCTGCTCAGAGAAGGCAGCCCCTCACAA GGCTGAGGGCCTGGAGGAGGCTGATACTGGGGCCTCTGGGTGCCACTCCCATCCGGAAGAGCAGCCGACCAGCATCTCACCTTCCAGACA CGGCGCCCTGGCTGAGCTCTGCCCGCCTGGAGGCTCCCACAGGATGGCCCTGGGGACTGCTGCTGCACTCGGGTCGAATGTCATCAGGAA TGAGCAGCTGCCCCTGCAGTACTTGGCCGATGTGGACACCTCTGATGAGGAAAGCATCCGGGCTCACGTGATGGCCTCCCACCATTCCAA GCGGAGAGGCCGGGCGTCTTCTGAGAGTCAGATCTTTGAGCTGAATAAGCATATTTCAGCTGTGGAATGCCTGCTGACCTACCTGGAGAA CACAGTTGTGCCTCCCTTGGCCAAGGGTCTAGGTGCTGGAGTGCGCACGGAGGCCGATGTAGAGGAGGAGGCCCTGAGGAGGAAGCTGGA GGAGCTGACCAGCAACGTCAGTGACCAGGAGACCTCGTCCGAGGAGGAGGAAGCCAAGGACGAAAAGGCAGAGCCCAACAGGGACAAATC AGTTGGGCCTCTCCCCCAGGCGGACCCGGAGGTGGGCACGGCTGCCCATCAAACCAACAGACAGGAAAAAAGCCCCCAGGACCCTGGGGA CCCCGTCCAGTACAACAGGACCACAGATGAGGAGCTGTCAGAGCTGGAGGACAGAGTGGCAGTGACGGCCTCAGAAGTCCAGCAGGCAGA GAGCGAGGTTTCAGACATTGAATCCAGGATTGCAGCCCTGAGGGCCGCAGGGCTCACGGTGAAGCCCTCGGGAAAGCCCCGGAGGAAGTC AAACCTCCCGATATTTCTCCCTCGAGTGGCTGGGAAACTTGGCAAGAGACCAGAGGACCCAAATGCAGACCCTTCAAGTGAGGCCAAGGC AATGGCTGTGCCCTATCTTCTGAGAAGAAAGTTCAGTAATTCCCTGAAAAGTCAAGGTAAAGATGATGATTCTTTTGATCGGAAATCAGT GTACCGAGGCTCGCTGACACAGAGAAACCCCAACGCGAGGAAAGGAATGGCCAGCCACACCTTCGCGAAACCTGTGGTGGCCCACCAGTC CTAACGGGACAGGACAGAGAGACAGAGCAGCCCTGCACTGTTTTCCCTCCACCACAGCCATCCTGTCCCTCATTGGCTCTGTGCTTTCCA CTATACACAGTCACCGTCCCAATGAGAAACAAGAAGGAGCACCCTCCACATGGACTCCCACCTGCAAGTGGACAGCGACATTCAGTCCTG CACTGCTCACCTGGGTTTACTGATGACTCCTGGCTGCCCCACCATCCTCTCTGATCTGTGAGAAACAGCTAAGCTGCTGTGACTTCCCTT TAGGACAATGTTGTGTAAATCTTTGAAGGACACACCGAAGACCTTTATACTGTGATCTTTTACCCCTTTCACTCTTGGCTTTCTTATGTT GCTTTCATGAATGGAATGGAAAAAAGATGACTCAGTTAAGGCACCAGCCATATGTGTATTCTTGATGGTCTATATCGGGGTGTGAGCAGA TGTTTGCGTATTTCTTGTGGGTGTGACTGGATATTAGACATCCGGACAAGTGACTGAACTAATGATCTGCTGAATAATGAAGGAGGAATA GACACCCCAGTCCCCACCCTACGTGCACCCGCTCTGCAAGTTCCCATGTGATCTGTAGACCAGGGGAAATTACACTGCGGTCAAGGGCAG AGCCTGCACATGACAGCAAGTGAGCATTTGATAGATGCTCAGATGCTAGTGCAGAGAGCCTGCTGGGAGACGAAGAGACAGCAGGCAGAG CTCCAGATGGGCAAGGAAGAGGCTTGGTTCTAGCCTGGCTCTGCCCCTCACTGCAGTGGATCCAGTGGGGCAGAGGACAGAGGGTCACAA CCAATGAGGGATGTCTGCCAAGGATGGGGGTGCAGAGGCCACAGGAGTCAGCTTGCCACTCGCCCATTGGTTACATAGATGATCTCTCAG ACAGGCTGGGACTCAGAGTTATTTCCTAGTATCGGTGTGCCCCATCCAGTTTTAAGTGGAGCCCTCCAAGACTCTCCAGAGCTGCCTTTG AACATCCTAACAGTAATCACATCTCACCCTCCCTGAGGTTCACTTTAGACAGGACCCAATGGCTGCACTGCCTTTGTCAGAGGGGGTGCT GAGAGGAGTGGCTTCTTTTAGAATCAAACAGTAGAGACAAGAGTCAAGCCTTGTGTCTTCAAGCATTGACCAAGTTAAGTGTTTCCTTCC CTCTCTCAATAAGACACTTCCAGGAGCTTTCCAATCTCTCACTTAAAACTAAGGTTTGAATCTCAAAGTGTTGCTGGGAGGCTGATACTC CTGCAACTTCAGGAGACCTGTGAGCACACATTAGCAGCTGTTTCTCTGACTCCTTGTGGCATCAGATAAAAACGTGGGAGTTTTTCCATA TAATTCCCAGCCTTACTTATAAATTCTATTCTTTGAAAAAATTATTCAGGCTAGGTAAGGTGGCTCATACCTATAATCCCAGCCCTTTGA GAGGCCAAGGTGGGAGAATTGCTTGAGGCCAGGAGTTTGAGACCTCCTGGGCAACATAGTGAGATCCCATCTCTACAAAAAACAAAACAA AAAAATTACCCAAGCATGATGGTATATGCCTGTAGTCGTACCTACTTACTTAGGAGGCTGAGGCAGGAGGATCACTTGAGCCCTGGAGGT TGGGGCTGCAGTGAGCCATGATCGCATCACTATACTCGAGCCTGGGCAACAGAGTGAGACCTTGTCTCTTAAAAAAATTAATAATAAATA >33394_33394_7_GLUD1-MLPH_GLUD1_chr10_88834308_ENST00000544149_MLPH_chr2_238427182_ENST00000264605_length(amino acids)=560AA_BP=108 MHRSPFGPGVCVTHGGSCRNALLGKGMTCPCDNASSVFLGFCIRYSTDVSVDEVKALASLMTYKCAVVDVPFGGAKAGVKINPKNYTDNE LEKITRRFTMELAKKGFIAGPELISEERSGDSDQTDEDGEPGSEAQAQAQPFGSKKKRLLSVHDFDFEGDSDDSTQPQGHSLHLSSVPEA RDSPQSLTDESCSEKAAPHKAEGLEEADTGASGCHSHPEEQPTSISPSRHGALAELCPPGGSHRMALGTAAALGSNVIRNEQLPLQYLAD VDTSDEESIRAHVMASHHSKRRGRASSESQIFELNKHISAVECLLTYLENTVVPPLAKGLGAGVRTEADVEEEALRRKLEELTSNVSDQE TSSEEEEAKDEKAEPNRDKSVGPLPQADPEVGTAAHQTNRQEKSPQDPGDPVQYNRTTDEELSELEDRVAVTASEVQQAESEVSDIESRI AALRAAGLTVKPSGKPRRKSNLPIFLPRVAGKLGKRPEDPNADPSSEAKAMAVPYLLRRKFSNSLKSQGKDDDSFDRKSVYRGSLTQRNP -------------------------------------------------------------- >33394_33394_8_GLUD1-MLPH_GLUD1_chr10_88834308_ENST00000544149_MLPH_chr2_238427182_ENST00000410032_length(transcript)=1689nt_BP=356nt GTATATGCTGATCTTGCATGCAGAGTAGACGCTGCACCGGTCTCCTTTTGGTCCCGGTGTCTGTGTCACACACGGCGGGTCCTGCCGAAA TGCACTTCTAGGAAAGGGAATGACCTGCCCGTGTGATAATGCCTCGTCAGTGTTCTTGGGCTTTTGTATCCGTTACAGCACTGATGTGAG TGTAGATGAAGTAAAAGCTTTGGCTTCTCTGATGACATACAAGTGTGCAGTGGTTGATGTGCCGTTTGGGGGTGCTAAAGCTGGTGTTAA GATCAATCCCAAGAACTATACTGATAATGAATTGGAAAAGATCACAAGGAGGTTCACCATGGAGCTAGCAAAAAAGGGCTTTATTGCTGG GCCTGAACTGATATCTGAAGAGAGAAGTGGAGACAGCGACCAGACAGATGAGGATGGAGAACCTGGCTCAGAGGCCCAGGCCCAGGCCCA GCCCTTTGGCAGCAAAAAAAAGCGCCTCCTCTCCGTCCACGACTTCGACTTCGAGGGAGACTCAGATGACTCCACTCAGCCTCAAGGTCA CTCCCTGCACCTGTCCTCAGTCCCTGAGGCCAGGGACAGCCCACAGGGTCTAGGTGCTGGAGTGCGCACGGAGGCCGATGTAGAGGAGGA GGCCCTGAGGAGGAAGCTGGAGGAGCTGACCAGCAACGTCAGTGACCAGGAGACCTCGTCCGAGGAGGAGGAAGCCAAGGACGAAAAGGC AGAGCCCAACAGGGACAAATCAGTTGGGCCTCTCCCCCAGGCGGACCCGGAGGTGGGCACGGCTGCCCATCAAACCAACAGACAGGAAAA AAGCCCCCAGGACCCTGGGGACCCCGTCCAGTACAACAGGACCACAGATGAGGAGCTGTCAGAGCTGGAGGACAGAGTGGCAGTGACGGC CTCAGAAGTCCAGCAGGCAGAGAGCGAGGTTTCAGACATTGAATCCAGGATTGCAGCCCTGAGGGCCGCAGGGCTCACGGTGAAGCCCTC GGGAAAGCCCCGGAGGAAGTCAAACCTCCCGATATTTCTCCCTCGAGTGGCTGGGAAACTTGGCAAGAGACCAGAGGACCCAAATGCAGA CCCTTCAAGTGAGGCCAAGGCAATGGCTGTGCCCTATCTTCTGAGAAGAAAGTTCAGTAATTCCCTGAAAAGTCAAGGTAAAGATGATGA TTCTTTTGATCGGAAATCAGTGTACCGAGGCTCGCTGACACAGAGAAACCCCAACGCGAGGAAAGGAATGGCCAGCCACACCTTCGCGAA ACCTGTGGTGGCCCACCAGTCCTAACGGGACAGGACAGAGAGACAGAGCAGCCCTGCACTGTTTTCCCTCCACCACAGCCATCCTGTCCC TCATTGGCTCTGTGCTTTCCACTATACACAGTCACCGTCCCAATGAGAAACAAGAAGGAGCACCCTCCACATGGACTCCCACCTGCAAGT GGACAGCGACATTCAGTCCTGCACTGCTCACCTGGGTTTACTGATGACTCCTGGCTGCCCCACCATCCTCTCTGATCTGTGAGAAACAGC TAAGCTGCTGTGACTTCCCTTTAGGACAATGTTGTGTAAATCTTTGAAGGACACACCGAAGACCTTTATACTGTGATCTTTTACCCCTTT >33394_33394_8_GLUD1-MLPH_GLUD1_chr10_88834308_ENST00000544149_MLPH_chr2_238427182_ENST00000410032_length(amino acids)=417AA_BP=108 MHRSPFGPGVCVTHGGSCRNALLGKGMTCPCDNASSVFLGFCIRYSTDVSVDEVKALASLMTYKCAVVDVPFGGAKAGVKINPKNYTDNE LEKITRRFTMELAKKGFIAGPELISEERSGDSDQTDEDGEPGSEAQAQAQPFGSKKKRLLSVHDFDFEGDSDDSTQPQGHSLHLSSVPEA RDSPQGLGAGVRTEADVEEEALRRKLEELTSNVSDQETSSEEEEAKDEKAEPNRDKSVGPLPQADPEVGTAAHQTNRQEKSPQDPGDPVQ YNRTTDEELSELEDRVAVTASEVQQAESEVSDIESRIAALRAAGLTVKPSGKPRRKSNLPIFLPRVAGKLGKRPEDPNADPSSEAKAMAV -------------------------------------------------------------- >33394_33394_9_GLUD1-MLPH_GLUD1_chr10_88834308_ENST00000544149_MLPH_chr2_238427182_ENST00000445024_length(transcript)=1973nt_BP=356nt GTATATGCTGATCTTGCATGCAGAGTAGACGCTGCACCGGTCTCCTTTTGGTCCCGGTGTCTGTGTCACACACGGCGGGTCCTGCCGAAA TGCACTTCTAGGAAAGGGAATGACCTGCCCGTGTGATAATGCCTCGTCAGTGTTCTTGGGCTTTTGTATCCGTTACAGCACTGATGTGAG TGTAGATGAAGTAAAAGCTTTGGCTTCTCTGATGACATACAAGTGTGCAGTGGTTGATGTGCCGTTTGGGGGTGCTAAAGCTGGTGTTAA GATCAATCCCAAGAACTATACTGATAATGAATTGGAAAAGATCACAAGGAGGTTCACCATGGAGCTAGCAAAAAAGGGCTTTATTGCTGG GCCTGAACTGATATCTGAAGAGAGAAGTGGAGACAGCGACCAGACAGATGAGGATGGAGAACCTGGCTCAGAGGCCCAGGCCCAGGCCCA GCCCTTTGGCAGCAAAAAAAAGCGCCTCCTCTCCGTCCACGACTTCGACTTCGAGGGAGACTCAGATGACTCCACTCAGCCTCAAGGTCA CTCCCTGCACCTGTCCTCAGTCCCTGAGGCCAGGGACAGCCCACAGTCCCTCACAGATGAGTCCTGCTCAGAGAAGGCAGCCCCTCACAA GGCTGAGGGCCTGGAGGAGGCTGATACTGGGGCCTCTGGGTGCCACTCCCATCCGGAAGAGCAGCCGACCAGCATCTCACCTTCCAGACA CGGCGCCCTGGCTGAGCTCTGCCCGCCTGGAGGCTCCCACAGGATGGCCCTGGGGACTGCTGCTGCACTCGGGTCGAATGTCATCAGGAA TGAGCAGCTGCCCCTGCAGTACTTGGCCGATGTGGACACCTCTGATGAGGAAAGCATCCGGGCTCACGTGATGGCCTCCCACCATTCCAA GCGGAGAGGCCGGGCGTCTTCTGAGAGTCAGATCTTTGAGCTGAATAAGCATATTTCAGCTGTGGAATGCCTGCTGACCTACCTGGAGAA CACAGTTGTGCCTCCCTTGGCCAAGGGTCTAGGTGCTGGAGTGCGCACGGAGGCCGATGTAGAGGAGGAGGCCCTGAGGAGGAAGCTGGA GGAGCTGACCAGCAACGTCAGTGACCAGGAGACCTCGTCCGAGGAGGAGGAAGCCAAGGACGAAAAGGCAGAGCCCAACAGGGACAAATC AGTTGGGCCTCTCCCCCAGGCGGACCCGGAGGTGGGCACGGCTGCCCATCAAACCAACAGACAGGAAAAAAGCCCCCAGGACCCTGGGGA CCCCGTCCAGTACAACAGGACCACAGATGAGGAGCTGTCAGAGCTGGAGGACAGAGTGGCAGTGACGGCCTCAGAAGTCCAGCAGGCAGA GAGCGAGGTTTCAGACATTGAATCCAGGATTGCAGCCCTGAGGGCCGCAGGGCTCACGGTGAAGCCCTCGGGAAAGCCCCGGAGGAAGTC AAACCTCCCGGCTCTTTATGAGGGGACTCTGAGCCTCTGCTCTGAGGATCTGAAACACACACACCCTGACAGTGTAAAATCCAAAAGGAG CCGCCTGAATCATGTTGCCTCATGTGGAAATCCTTAGTCCGCCGCCACGTGAAGATGGATGTGACTAGAACGGAGGGCGCGGGAGGCTCA CATCAGAGGAGCTGCTCACATATTTCTCCCTCGAGTGGCTGGGAAACTTGGCAAGAGACCAGAGGACCCAAATGCAGACCCTTCAAGTGA GGCCAAGGCAATGGCTGTGCCCTATCTTCTGAGAAGAAAGTTCAGTAATTCCCTGAAAAGTCAAGGTAAAGATGATGATTCTTTTGATCG GAAATCAGTGTACCGAGGCTCGCTGACACAGAGAAACCCCAACGCGAGGAAAGGAATGGCCAGCCACACCTTCGCGAAACCTGTGGTGGC >33394_33394_9_GLUD1-MLPH_GLUD1_chr10_88834308_ENST00000544149_MLPH_chr2_238427182_ENST00000445024_length(amino acids)=511AA_BP=108 MHRSPFGPGVCVTHGGSCRNALLGKGMTCPCDNASSVFLGFCIRYSTDVSVDEVKALASLMTYKCAVVDVPFGGAKAGVKINPKNYTDNE LEKITRRFTMELAKKGFIAGPELISEERSGDSDQTDEDGEPGSEAQAQAQPFGSKKKRLLSVHDFDFEGDSDDSTQPQGHSLHLSSVPEA RDSPQSLTDESCSEKAAPHKAEGLEEADTGASGCHSHPEEQPTSISPSRHGALAELCPPGGSHRMALGTAAALGSNVIRNEQLPLQYLAD VDTSDEESIRAHVMASHHSKRRGRASSESQIFELNKHISAVECLLTYLENTVVPPLAKGLGAGVRTEADVEEEALRRKLEELTSNVSDQE TSSEEEEAKDEKAEPNRDKSVGPLPQADPEVGTAAHQTNRQEKSPQDPGDPVQYNRTTDEELSELEDRVAVTASEVQQAESEVSDIESRI -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for GLUD1-MLPH |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for GLUD1-MLPH |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for GLUD1-MLPH |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies