
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:GNAQ-HNRNPH1 (FusionGDB2 ID:33599) |
Fusion Gene Summary for GNAQ-HNRNPH1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: GNAQ-HNRNPH1 | Fusion gene ID: 33599 | Hgene | Tgene | Gene symbol | GNAQ | HNRNPH1 | Gene ID | 2776 | 3187 |
| Gene name | G protein subunit alpha q | heterogeneous nuclear ribonucleoprotein H1 | |
| Synonyms | CMC1|G-ALPHA-q|GAQ|SWS | HNRPH|HNRPH1|hnRNPH | |
| Cytomap | 9q21.2 | 5q35.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | guanine nucleotide-binding protein G(q) subunit alphaepididymis secretory sperm binding proteinguanine nucleotide binding protein (G protein), q polypeptideguanine nucleotide-binding protein alpha-q | heterogeneous nuclear ribonucleoprotein Hepididymis secretory sperm binding proteinheterogeneous nuclear ribonucleoprotein H1 (H) | |
| Modification date | 20200313 | 20200320 | |
| UniProtAcc | P50148 | P31943 | |
| Ensembl transtripts involved in fusion gene | ENST00000286548, ENST00000397476, | ENST00000511300, ENST00000524180, ENST00000329433, ENST00000356731, ENST00000393432, ENST00000442819, ENST00000510411, | |
| Fusion gene scores | * DoF score | 13 X 11 X 6=858 | 13 X 10 X 5=650 |
| # samples | 16 | 14 | |
| ** MAII score | log2(16/858*10)=-2.42290574261218 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(14/650*10)=-2.21501289097085 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: GNAQ [Title/Abstract] AND HNRNPH1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | GNAQ(80412435)-HNRNPH1(179045324), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | HNRNPH1 | GO:0043484 | regulation of RNA splicing | 16946708 |
| Fusion gene breakpoints across GNAQ (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across HNRNPH1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | Non-Cancer | 231N | GNAQ | chr9 | 80412435 | - | HNRNPH1 | chr5 | 179045324 | - |
Top |
Fusion Gene ORF analysis for GNAQ-HNRNPH1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000286548 | ENST00000511300 | GNAQ | chr9 | 80412435 | - | HNRNPH1 | chr5 | 179045324 | - |
| 5CDS-intron | ENST00000286548 | ENST00000524180 | GNAQ | chr9 | 80412435 | - | HNRNPH1 | chr5 | 179045324 | - |
| 5UTR-3CDS | ENST00000397476 | ENST00000329433 | GNAQ | chr9 | 80412435 | - | HNRNPH1 | chr5 | 179045324 | - |
| 5UTR-3CDS | ENST00000397476 | ENST00000356731 | GNAQ | chr9 | 80412435 | - | HNRNPH1 | chr5 | 179045324 | - |
| 5UTR-3CDS | ENST00000397476 | ENST00000393432 | GNAQ | chr9 | 80412435 | - | HNRNPH1 | chr5 | 179045324 | - |
| 5UTR-3CDS | ENST00000397476 | ENST00000442819 | GNAQ | chr9 | 80412435 | - | HNRNPH1 | chr5 | 179045324 | - |
| 5UTR-3CDS | ENST00000397476 | ENST00000510411 | GNAQ | chr9 | 80412435 | - | HNRNPH1 | chr5 | 179045324 | - |
| 5UTR-intron | ENST00000397476 | ENST00000511300 | GNAQ | chr9 | 80412435 | - | HNRNPH1 | chr5 | 179045324 | - |
| 5UTR-intron | ENST00000397476 | ENST00000524180 | GNAQ | chr9 | 80412435 | - | HNRNPH1 | chr5 | 179045324 | - |
| In-frame | ENST00000286548 | ENST00000329433 | GNAQ | chr9 | 80412435 | - | HNRNPH1 | chr5 | 179045324 | - |
| In-frame | ENST00000286548 | ENST00000356731 | GNAQ | chr9 | 80412435 | - | HNRNPH1 | chr5 | 179045324 | - |
| In-frame | ENST00000286548 | ENST00000393432 | GNAQ | chr9 | 80412435 | - | HNRNPH1 | chr5 | 179045324 | - |
| In-frame | ENST00000286548 | ENST00000442819 | GNAQ | chr9 | 80412435 | - | HNRNPH1 | chr5 | 179045324 | - |
| In-frame | ENST00000286548 | ENST00000510411 | GNAQ | chr9 | 80412435 | - | HNRNPH1 | chr5 | 179045324 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000286548 | GNAQ | chr9 | 80412435 | - | ENST00000393432 | HNRNPH1 | chr5 | 179045324 | - | 2424 | 828 | 199 | 1641 | 480 |
| ENST00000286548 | GNAQ | chr9 | 80412435 | - | ENST00000442819 | HNRNPH1 | chr5 | 179045324 | - | 2423 | 828 | 199 | 1641 | 480 |
| ENST00000286548 | GNAQ | chr9 | 80412435 | - | ENST00000356731 | HNRNPH1 | chr5 | 179045324 | - | 2423 | 828 | 199 | 1641 | 480 |
| ENST00000286548 | GNAQ | chr9 | 80412435 | - | ENST00000329433 | HNRNPH1 | chr5 | 179045324 | - | 2371 | 828 | 199 | 1710 | 503 |
| ENST00000286548 | GNAQ | chr9 | 80412435 | - | ENST00000510411 | HNRNPH1 | chr5 | 179045324 | - | 2361 | 828 | 199 | 1581 | 460 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000286548 | ENST00000393432 | GNAQ | chr9 | 80412435 | - | HNRNPH1 | chr5 | 179045324 | - | 0.000259202 | 0.9997408 |
| ENST00000286548 | ENST00000442819 | GNAQ | chr9 | 80412435 | - | HNRNPH1 | chr5 | 179045324 | - | 0.000256729 | 0.9997433 |
| ENST00000286548 | ENST00000356731 | GNAQ | chr9 | 80412435 | - | HNRNPH1 | chr5 | 179045324 | - | 0.000256729 | 0.9997433 |
| ENST00000286548 | ENST00000329433 | GNAQ | chr9 | 80412435 | - | HNRNPH1 | chr5 | 179045324 | - | 0.000265959 | 0.999734 |
| ENST00000286548 | ENST00000510411 | GNAQ | chr9 | 80412435 | - | HNRNPH1 | chr5 | 179045324 | - | 0.000235837 | 0.99976414 |
Top |
Fusion Genomic Features for GNAQ-HNRNPH1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
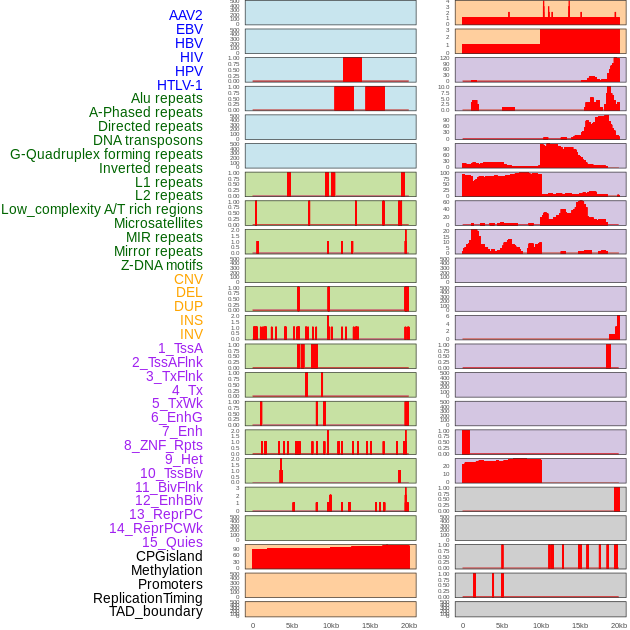 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for GNAQ-HNRNPH1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr9:80412435/chr5:179045324) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| GNAQ | HNRNPH1 |
| FUNCTION: Guanine nucleotide-binding proteins (G proteins) are involved as modulators or transducers in various transmembrane signaling systems. Regulates B-cell selection and survival and is required to prevent B-cell-dependent autoimmunity. Regulates chemotaxis of BM-derived neutrophils and dendritic cells (in vitro) (By similarity). Transduces FFAR4 signaling in response to long-chain fatty acids (LCFAs). {ECO:0000250, ECO:0000269|PubMed:27852822}. | FUNCTION: This protein is a component of the heterogeneous nuclear ribonucleoprotein (hnRNP) complexes which provide the substrate for the processing events that pre-mRNAs undergo before becoming functional, translatable mRNAs in the cytoplasm. Mediates pre-mRNA alternative splicing regulation. Inhibits, together with CUGBP1, insulin receptor (IR) pre-mRNA exon 11 inclusion in myoblast. Binds to the IR RNA. Binds poly(RG). {ECO:0000269|PubMed:11003644, ECO:0000269|PubMed:16946708}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | GNAQ | chr9:80412435 | chr5:179045324 | ENST00000286548 | - | 4 | 7 | 180_186 | 201 | 360.0 | Nucleotide binding | GTP |
| Hgene | GNAQ | chr9:80412435 | chr5:179045324 | ENST00000286548 | - | 4 | 7 | 46_53 | 201 | 360.0 | Nucleotide binding | GTP |
| Hgene | GNAQ | chr9:80412435 | chr5:179045324 | ENST00000286548 | - | 4 | 7 | 178_186 | 201 | 360.0 | Region | G2 motif |
| Hgene | GNAQ | chr9:80412435 | chr5:179045324 | ENST00000286548 | - | 4 | 7 | 41_54 | 201 | 360.0 | Region | G1 motif |
| Tgene | HNRNPH1 | chr9:80412435 | chr5:179045324 | ENST00000356731 | 3 | 13 | 289_364 | 178 | 130.66666666666666 | Domain | RRM 3 | |
| Tgene | HNRNPH1 | chr9:80412435 | chr5:179045324 | ENST00000393432 | 4 | 14 | 289_364 | 178 | 646.0 | Domain | RRM 3 | |
| Tgene | HNRNPH1 | chr9:80412435 | chr5:179045324 | ENST00000442819 | 4 | 14 | 289_364 | 178 | 655.6666666666666 | Domain | RRM 3 | |
| Tgene | HNRNPH1 | chr9:80412435 | chr5:179045324 | ENST00000356731 | 3 | 13 | 234_433 | 178 | 130.66666666666666 | Region | Note=2 X 16 AA Gly-rich approximate repeats | |
| Tgene | HNRNPH1 | chr9:80412435 | chr5:179045324 | ENST00000356731 | 3 | 13 | 354_392 | 178 | 130.66666666666666 | Region | Note=2 X 19 AA perfect repeats | |
| Tgene | HNRNPH1 | chr9:80412435 | chr5:179045324 | ENST00000393432 | 4 | 14 | 234_433 | 178 | 646.0 | Region | Note=2 X 16 AA Gly-rich approximate repeats | |
| Tgene | HNRNPH1 | chr9:80412435 | chr5:179045324 | ENST00000393432 | 4 | 14 | 354_392 | 178 | 646.0 | Region | Note=2 X 19 AA perfect repeats | |
| Tgene | HNRNPH1 | chr9:80412435 | chr5:179045324 | ENST00000442819 | 4 | 14 | 234_433 | 178 | 655.6666666666666 | Region | Note=2 X 16 AA Gly-rich approximate repeats | |
| Tgene | HNRNPH1 | chr9:80412435 | chr5:179045324 | ENST00000442819 | 4 | 14 | 354_392 | 178 | 655.6666666666666 | Region | Note=2 X 19 AA perfect repeats | |
| Tgene | HNRNPH1 | chr9:80412435 | chr5:179045324 | ENST00000356731 | 3 | 13 | 234_249 | 178 | 130.66666666666666 | Repeat | Note=1-1 | |
| Tgene | HNRNPH1 | chr9:80412435 | chr5:179045324 | ENST00000356731 | 3 | 13 | 354_372 | 178 | 130.66666666666666 | Repeat | Note=2-1 | |
| Tgene | HNRNPH1 | chr9:80412435 | chr5:179045324 | ENST00000356731 | 3 | 13 | 374_392 | 178 | 130.66666666666666 | Repeat | Note=2-2 | |
| Tgene | HNRNPH1 | chr9:80412435 | chr5:179045324 | ENST00000356731 | 3 | 13 | 418_433 | 178 | 130.66666666666666 | Repeat | Note=1-2 | |
| Tgene | HNRNPH1 | chr9:80412435 | chr5:179045324 | ENST00000393432 | 4 | 14 | 234_249 | 178 | 646.0 | Repeat | Note=1-1 | |
| Tgene | HNRNPH1 | chr9:80412435 | chr5:179045324 | ENST00000393432 | 4 | 14 | 354_372 | 178 | 646.0 | Repeat | Note=2-1 | |
| Tgene | HNRNPH1 | chr9:80412435 | chr5:179045324 | ENST00000393432 | 4 | 14 | 374_392 | 178 | 646.0 | Repeat | Note=2-2 | |
| Tgene | HNRNPH1 | chr9:80412435 | chr5:179045324 | ENST00000393432 | 4 | 14 | 418_433 | 178 | 646.0 | Repeat | Note=1-2 | |
| Tgene | HNRNPH1 | chr9:80412435 | chr5:179045324 | ENST00000442819 | 4 | 14 | 234_249 | 178 | 655.6666666666666 | Repeat | Note=1-1 | |
| Tgene | HNRNPH1 | chr9:80412435 | chr5:179045324 | ENST00000442819 | 4 | 14 | 354_372 | 178 | 655.6666666666666 | Repeat | Note=2-1 | |
| Tgene | HNRNPH1 | chr9:80412435 | chr5:179045324 | ENST00000442819 | 4 | 14 | 374_392 | 178 | 655.6666666666666 | Repeat | Note=2-2 | |
| Tgene | HNRNPH1 | chr9:80412435 | chr5:179045324 | ENST00000442819 | 4 | 14 | 418_433 | 178 | 655.6666666666666 | Repeat | Note=1-2 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | GNAQ | chr9:80412435 | chr5:179045324 | ENST00000286548 | - | 4 | 7 | 38_359 | 201 | 360.0 | Domain | G-alpha |
| Hgene | GNAQ | chr9:80412435 | chr5:179045324 | ENST00000286548 | - | 4 | 7 | 205_209 | 201 | 360.0 | Nucleotide binding | GTP |
| Hgene | GNAQ | chr9:80412435 | chr5:179045324 | ENST00000286548 | - | 4 | 7 | 274_277 | 201 | 360.0 | Nucleotide binding | GTP |
| Hgene | GNAQ | chr9:80412435 | chr5:179045324 | ENST00000286548 | - | 4 | 7 | 201_210 | 201 | 360.0 | Region | G3 motif |
| Hgene | GNAQ | chr9:80412435 | chr5:179045324 | ENST00000286548 | - | 4 | 7 | 270_277 | 201 | 360.0 | Region | G4 motif |
| Hgene | GNAQ | chr9:80412435 | chr5:179045324 | ENST00000286548 | - | 4 | 7 | 329_334 | 201 | 360.0 | Region | G5 motif |
| Tgene | HNRNPH1 | chr9:80412435 | chr5:179045324 | ENST00000356731 | 3 | 13 | 111_188 | 178 | 130.66666666666666 | Domain | RRM 2 | |
| Tgene | HNRNPH1 | chr9:80412435 | chr5:179045324 | ENST00000356731 | 3 | 13 | 11_90 | 178 | 130.66666666666666 | Domain | RRM 1 | |
| Tgene | HNRNPH1 | chr9:80412435 | chr5:179045324 | ENST00000393432 | 4 | 14 | 111_188 | 178 | 646.0 | Domain | RRM 2 | |
| Tgene | HNRNPH1 | chr9:80412435 | chr5:179045324 | ENST00000393432 | 4 | 14 | 11_90 | 178 | 646.0 | Domain | RRM 1 | |
| Tgene | HNRNPH1 | chr9:80412435 | chr5:179045324 | ENST00000442819 | 4 | 14 | 111_188 | 178 | 655.6666666666666 | Domain | RRM 2 | |
| Tgene | HNRNPH1 | chr9:80412435 | chr5:179045324 | ENST00000442819 | 4 | 14 | 11_90 | 178 | 655.6666666666666 | Domain | RRM 1 |
Top |
Fusion Gene Sequence for GNAQ-HNRNPH1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >33599_33599_1_GNAQ-HNRNPH1_GNAQ_chr9_80412435_ENST00000286548_HNRNPH1_chr5_179045324_ENST00000329433_length(transcript)=2371nt_BP=828nt CGTCGGCCCAGACTATCCGCTCCCACCGCGCCCCCGGCCCACCTGGTGGCCCCGGCCCTGGCCGCCGCCCCCGCGGCGGTTCCCGGAGCT CGTCCCGGACGCGCGCCCGGGCGGCGGGGGCTCGGCGGCCACCGCTGCCTCGGGGGAGCGAGGGCGGGAGGGTGTGTGTGCGCGCTGTGA GCAGGGGGTGCCGGCGGGGCTGCAGCGGAGGCACTTTGGAAGAATGACTCTGGAGTCCATCATGGCGTGCTGCCTGAGCGAGGAGGCCAA GGAAGCCCGGCGGATCAACGACGAGATCGAGCGGCAGCTCCGCAGGGACAAGCGGGACGCCCGCCGGGAGCTCAAGCTGCTGCTGCTCGG GACAGGAGAGAGTGGCAAGAGTACGTTTATCAAGCAGATGAGAATCATCCATGGGTCAGGATACTCTGATGAAGATAAAAGGGGCTTCAC CAAGCTGGTGTATCAGAACATCTTCACGGCCATGCAGGCCATGATCAGAGCCATGGACACACTCAAGATCCCATACAAGTATGAGCACAA TAAGGCTCATGCACAATTAGTTCGAGAAGTTGATGTGGAGAAGGTGTCTGCTTTTGAGAATCCATATGTAGATGCAATAAAGAGTTTATG GAATGATCCTGGAATCCAGGAATGCTATGATAGACGACGAGAATATCAATTATCTGACTCTACCAAATACTATCTTAATGACTTGGACCG CGTAGCTGACCCTGCCTACCTGCCTACGCAACAAGATGTGCTTAGAGTTCGAGTCCCCACCACAGGGATCATCGAATACCCCTTTGACTT ACAAAGTGTCATTTTCAGGTATATTGAAATCTTTAAGAGCAGTAGAGCTGAAGTTAGAACTCATTATGATCCACCACGAAAGCTTATGGC CATGCAGCGGCCAGGTCCTTATGACAGACCTGGGGCTGGTAGAGGGTATAACAGCATTGGCAGAGGAGCTGGCTTTGAGAGGATGAGGCG TGGTGCTTATGGTGGAGGCTATGGAGGCTATGATGATTACAATGGCTATAATGATGGCTATGGATTTGGGTCAGATAGATTTGGAAGAGA CCTCAATTACTGTTTTTCAGGAATGTCTGATCACAGATACGGGGATGGTGGCTCTACTTTCCAGAGCACAACAGGACACTGTGTACACAT GCGGGGATTACCTTACAGAGCTACTGAGAATGACATTTATAATTTTTTTTCACCGCTCAACCCTGTGAGAGTACACATTGAAATTGGTCC TGATGGCAGAGTAACTGGTGAAGCAGATGTCGAGTTCGCAACTCATGAAGATGCTGTGGCAGCTATGTCAAAAGACAAAGCAAATATGCA ACACAGATATGTAGAACTCTTCTTGAATTCTACAGCAGGAGCAAGCGGTGGTGCTTACGAACACAGATATGTAGAACTCTTCTTGAATTC TACAGCAGGAGCAAGCGGTGGTGCTTATGGTAGCCAAATGATGGGAGGCATGGGCTTGTCAAACCAGTCCAGCTACGGGGGCCCAGCCAG CCAGCAGCTGAGTGGGGGTTACGGAGGCGGCTACGGTGGCCAGAGCAGCATGAGTGGATACGGTAACCAAGGAGCAGTGAACAGCAGCTA CTACAGTAGTGGAAGCCGTGCATCTATGGGCGTGAACGGAATGGGAGGGTTGTCTAGCATGTCCAGTATGAGTGGTGGATGGGGAATGTA ATTGATCGATCCTGATCACTGACTCTTGGTCAACCTTTTTTTTTTTTTTTTTTTTTTCTTTAAGAAAACTTCAGTTTAACAGTTTCTGCA ATACAAGCTTGTGATTTATGCTTACTCTAAGTGGAAATCAGGATTGTTATGAAGACTTAAGGCCCAGTATTTTTGAATACAATACTCATC TAGGATGTAACAGTGAAGCTGAGTAAACTATAACTGTTAAACTTAAGTTCCAGCTTTTCTCAAGTTAGTTATAGGATGTACTTAAGCAGT AAGCGTATTTAGGTAAAAGCAGTTGAATTATGTTAAATGTTGCCCTTTGCCACGTTAAATTGAACACTGTTTTGGATGCATGTTGAAAGA CATGCTTTTATTTTTTTGTAAAACAATATAGGAGCTGTGTCTACTATTAAAAGTGAAACATTTTGGCATGTTTGTTAATTCTAGTTTCAT TTAATAACCTGTAAGGCACGTAAGTTTAAGCTTTTTTTTTTTTTAAGTTAATGGGAAAAATTTGAGACGCAATACCAATACTTAGGATTT TGGTCTTGGTGTTTGTATGAAATTCTGAGGCCTTGATTTAAATCTTTCATTGTATTGTGATTTCCTTTTAGGTATATTGCGCTAAGTGAA >33599_33599_1_GNAQ-HNRNPH1_GNAQ_chr9_80412435_ENST00000286548_HNRNPH1_chr5_179045324_ENST00000329433_length(amino acids)=503AA_BP=208 MQRRHFGRMTLESIMACCLSEEAKEARRINDEIERQLRRDKRDARRELKLLLLGTGESGKSTFIKQMRIIHGSGYSDEDKRGFTKLVYQN IFTAMQAMIRAMDTLKIPYKYEHNKAHAQLVREVDVEKVSAFENPYVDAIKSLWNDPGIQECYDRRREYQLSDSTKYYLNDLDRVADPAY LPTQQDVLRVRVPTTGIIEYPFDLQSVIFRYIEIFKSSRAEVRTHYDPPRKLMAMQRPGPYDRPGAGRGYNSIGRGAGFERMRRGAYGGG YGGYDDYNGYNDGYGFGSDRFGRDLNYCFSGMSDHRYGDGGSTFQSTTGHCVHMRGLPYRATENDIYNFFSPLNPVRVHIEIGPDGRVTG EADVEFATHEDAVAAMSKDKANMQHRYVELFLNSTAGASGGAYEHRYVELFLNSTAGASGGAYGSQMMGGMGLSNQSSYGGPASQQLSGG -------------------------------------------------------------- >33599_33599_2_GNAQ-HNRNPH1_GNAQ_chr9_80412435_ENST00000286548_HNRNPH1_chr5_179045324_ENST00000356731_length(transcript)=2423nt_BP=828nt CGTCGGCCCAGACTATCCGCTCCCACCGCGCCCCCGGCCCACCTGGTGGCCCCGGCCCTGGCCGCCGCCCCCGCGGCGGTTCCCGGAGCT CGTCCCGGACGCGCGCCCGGGCGGCGGGGGCTCGGCGGCCACCGCTGCCTCGGGGGAGCGAGGGCGGGAGGGTGTGTGTGCGCGCTGTGA GCAGGGGGTGCCGGCGGGGCTGCAGCGGAGGCACTTTGGAAGAATGACTCTGGAGTCCATCATGGCGTGCTGCCTGAGCGAGGAGGCCAA GGAAGCCCGGCGGATCAACGACGAGATCGAGCGGCAGCTCCGCAGGGACAAGCGGGACGCCCGCCGGGAGCTCAAGCTGCTGCTGCTCGG GACAGGAGAGAGTGGCAAGAGTACGTTTATCAAGCAGATGAGAATCATCCATGGGTCAGGATACTCTGATGAAGATAAAAGGGGCTTCAC CAAGCTGGTGTATCAGAACATCTTCACGGCCATGCAGGCCATGATCAGAGCCATGGACACACTCAAGATCCCATACAAGTATGAGCACAA TAAGGCTCATGCACAATTAGTTCGAGAAGTTGATGTGGAGAAGGTGTCTGCTTTTGAGAATCCATATGTAGATGCAATAAAGAGTTTATG GAATGATCCTGGAATCCAGGAATGCTATGATAGACGACGAGAATATCAATTATCTGACTCTACCAAATACTATCTTAATGACTTGGACCG CGTAGCTGACCCTGCCTACCTGCCTACGCAACAAGATGTGCTTAGAGTTCGAGTCCCCACCACAGGGATCATCGAATACCCCTTTGACTT ACAAAGTGTCATTTTCAGGTATATTGAAATCTTTAAGAGCAGTAGAGCTGAAGTTAGAACTCATTATGATCCACCACGAAAGCTTATGGC CATGCAGCGGCCAGGTCCTTATGACAGACCTGGGGCTGGTAGAGGGTATAACAGCATTGGCAGAGGAGCTGGCTTTGAGAGGATGAGGCG TGGTGCTTATGGTGGAGGCTATGGAGGCTATGATGATTACAATGGCTATAATGATGGCTATGGATTTGGGTCAGATAGATTTGGAAGAGA CCTCAATTACTGTTTTTCAGGAATGTCTGATCACAGATACGGGGATGGTGGCTCTACTTTCCAGAGCACAACAGGACACTGTGTACACAT GCGGGGATTACCTTACAGAGCTACTGAGAATGACATTTATAATTTTTTTTCACCGCTCAACCCTGTGAGAGTACACATTGAAATTGGTCC TGATGGCAGAGTAACTGGTGAAGCAGATGTCGAGTTCGCAACTCATGAAGATGCTGTGGCAGCTATGTCAAAAGACAAAGCAAATATGCA ACACAGATATGTAGAACTCTTCTTGAATTCTACAGCAGGAGCAAGCGGTGGTGCTTACGAACACAGATATGTAGAACTCTTCTTGAATTC TACAGCAGGAGCAAGCGGTGGTGCTTATGGTAGCCAAATGATGGGAGGCATGGGCTTGTCAAACCAGTCCAGCTACGGGGGCCCAGCCAG CCAGCAGCTGAGTGGGGGTTACGGAGGCGGCTACGGTGGCCAGAGCAGCATGAGTGGATACGACCAAGTTTTACAGGAAAACTCCAGTGA TTTTCAATCAAACATTGCATAGGTAACCAAGGAGCAGTGAACAGCAGCTACTACAGTAGTGGAAGCCGTGCATCTATGGGCGTGAACGGA ATGGGAGGGTTGTCTAGCATGTCCAGTATGAGTGGTGGATGGGGAATGTAATTGATCGATCCTGATCACTGACTCTTGGTCAACCTTTTT TTTTTTTTTTTTTTTTTCTTTAAGAAAACTTCAGTTTAACAGTTTCTGCAATACAAGCTTGTGATTTATGCTTACTCTAAGTGGAAATCA GGATTGTTATGAAGACTTAAGGCCCAGTATTTTTGAATACAATACTCATCTAGGATGTAACAGTGAAGCTGAGTAAACTATAACTGTTAA ACTTAAGTTCCAGCTTTTCTCAAGTTAGTTATAGGATGTACTTAAGCAGTAAGCGTATTTAGGTAAAAGCAGTTGAATTATGTTAAATGT TGCCCTTTGCCACGTTAAATTGAACACTGTTTTGGATGCATGTTGAAAGACATGCTTTTATTTTTTTGTAAAACAATATAGGAGCTGTGT CTACTATTAAAAGTGAAACATTTTGGCATGTTTGTTAATTCTAGTTTCATTTAATAACCTGTAAGGCACGTAAGTTTAAGCTTTTTTTTT TTTTAAGTTAATGGGAAAAATTTGAGACGCAATACCAATACTTAGGATTTTGGTCTTGGTGTTTGTATGAAATTCTGAGGCCTTGATTTA >33599_33599_2_GNAQ-HNRNPH1_GNAQ_chr9_80412435_ENST00000286548_HNRNPH1_chr5_179045324_ENST00000356731_length(amino acids)=480AA_BP=208 MQRRHFGRMTLESIMACCLSEEAKEARRINDEIERQLRRDKRDARRELKLLLLGTGESGKSTFIKQMRIIHGSGYSDEDKRGFTKLVYQN IFTAMQAMIRAMDTLKIPYKYEHNKAHAQLVREVDVEKVSAFENPYVDAIKSLWNDPGIQECYDRRREYQLSDSTKYYLNDLDRVADPAY LPTQQDVLRVRVPTTGIIEYPFDLQSVIFRYIEIFKSSRAEVRTHYDPPRKLMAMQRPGPYDRPGAGRGYNSIGRGAGFERMRRGAYGGG YGGYDDYNGYNDGYGFGSDRFGRDLNYCFSGMSDHRYGDGGSTFQSTTGHCVHMRGLPYRATENDIYNFFSPLNPVRVHIEIGPDGRVTG EADVEFATHEDAVAAMSKDKANMQHRYVELFLNSTAGASGGAYEHRYVELFLNSTAGASGGAYGSQMMGGMGLSNQSSYGGPASQQLSGG -------------------------------------------------------------- >33599_33599_3_GNAQ-HNRNPH1_GNAQ_chr9_80412435_ENST00000286548_HNRNPH1_chr5_179045324_ENST00000393432_length(transcript)=2424nt_BP=828nt CGTCGGCCCAGACTATCCGCTCCCACCGCGCCCCCGGCCCACCTGGTGGCCCCGGCCCTGGCCGCCGCCCCCGCGGCGGTTCCCGGAGCT CGTCCCGGACGCGCGCCCGGGCGGCGGGGGCTCGGCGGCCACCGCTGCCTCGGGGGAGCGAGGGCGGGAGGGTGTGTGTGCGCGCTGTGA GCAGGGGGTGCCGGCGGGGCTGCAGCGGAGGCACTTTGGAAGAATGACTCTGGAGTCCATCATGGCGTGCTGCCTGAGCGAGGAGGCCAA GGAAGCCCGGCGGATCAACGACGAGATCGAGCGGCAGCTCCGCAGGGACAAGCGGGACGCCCGCCGGGAGCTCAAGCTGCTGCTGCTCGG GACAGGAGAGAGTGGCAAGAGTACGTTTATCAAGCAGATGAGAATCATCCATGGGTCAGGATACTCTGATGAAGATAAAAGGGGCTTCAC CAAGCTGGTGTATCAGAACATCTTCACGGCCATGCAGGCCATGATCAGAGCCATGGACACACTCAAGATCCCATACAAGTATGAGCACAA TAAGGCTCATGCACAATTAGTTCGAGAAGTTGATGTGGAGAAGGTGTCTGCTTTTGAGAATCCATATGTAGATGCAATAAAGAGTTTATG GAATGATCCTGGAATCCAGGAATGCTATGATAGACGACGAGAATATCAATTATCTGACTCTACCAAATACTATCTTAATGACTTGGACCG CGTAGCTGACCCTGCCTACCTGCCTACGCAACAAGATGTGCTTAGAGTTCGAGTCCCCACCACAGGGATCATCGAATACCCCTTTGACTT ACAAAGTGTCATTTTCAGGTATATTGAAATCTTTAAGAGCAGTAGAGCTGAAGTTAGAACTCATTATGATCCACCACGAAAGCTTATGGC CATGCAGCGGCCAGGTCCTTATGACAGACCTGGGGCTGGTAGAGGGTATAACAGCATTGGCAGAGGAGCTGGCTTTGAGAGGATGAGGCG TGGTGCTTATGGTGGAGGCTATGGAGGCTATGATGATTACAATGGCTATAATGATGGCTATGGATTTGGGTCAGATAGATTTGGAAGAGA CCTCAATTACTGTTTTTCAGGAATGTCTGATCACAGATACGGGGATGGTGGCTCTACTTTCCAGAGCACAACAGGACACTGTGTACACAT GCGGGGATTACCTTACAGAGCTACTGAGAATGACATTTATAATTTTTTTTCACCGCTCAACCCTGTGAGAGTACACATTGAAATTGGTCC TGATGGCAGAGTAACTGGTGAAGCAGATGTCGAGTTCGCAACTCATGAAGATGCTGTGGCAGCTATGTCAAAAGACAAAGCAAATATGCA ACACAGATATGTAGAACTCTTCTTGAATTCTACAGCAGGAGCAAGCGGTGGTGCTTACGAACACAGATATGTAGAACTCTTCTTGAATTC TACAGCAGGAGCAAGCGGTGGTGCTTATGGTAGCCAAATGATGGGAGGCATGGGCTTGTCAAACCAGTCCAGCTACGGGGGCCCAGCCAG CCAGCAGCTGAGTGGGGGTTACGGAGGCGGCTACGGTGGCCAGAGCAGCATGAGTGGATACGACCAAGTTTTACAGGAAAACTCCAGTGA TTTTCAATCAAACATTGCATAGGTAACCAAGGAGCAGTGAACAGCAGCTACTACAGTAGTGGAAGCCGTGCATCTATGGGCGTGAACGGA ATGGGAGGGTTGTCTAGCATGTCCAGTATGAGTGGTGGATGGGGAATGTAATTGATCGATCCTGATCACTGACTCTTGGTCAACCTTTTT TTTTTTTTTTTTTTTTTCTTTAAGAAAACTTCAGTTTAACAGTTTCTGCAATACAAGCTTGTGATTTATGCTTACTCTAAGTGGAAATCA GGATTGTTATGAAGACTTAAGGCCCAGTATTTTTGAATACAATACTCATCTAGGATGTAACAGTGAAGCTGAGTAAACTATAACTGTTAA ACTTAAGTTCCAGCTTTTCTCAAGTTAGTTATAGGATGTACTTAAGCAGTAAGCGTATTTAGGTAAAAGCAGTTGAATTATGTTAAATGT TGCCCTTTGCCACGTTAAATTGAACACTGTTTTGGATGCATGTTGAAAGACATGCTTTTATTTTTTTGTAAAACAATATAGGAGCTGTGT CTACTATTAAAAGTGAAACATTTTGGCATGTTTGTTAATTCTAGTTTCATTTAATAACCTGTAAGGCACGTAAGTTTAAGCTTTTTTTTT TTTTAAGTTAATGGGAAAAATTTGAGACGCAATACCAATACTTAGGATTTTGGTCTTGGTGTTTGTATGAAATTCTGAGGCCTTGATTTA >33599_33599_3_GNAQ-HNRNPH1_GNAQ_chr9_80412435_ENST00000286548_HNRNPH1_chr5_179045324_ENST00000393432_length(amino acids)=480AA_BP=208 MQRRHFGRMTLESIMACCLSEEAKEARRINDEIERQLRRDKRDARRELKLLLLGTGESGKSTFIKQMRIIHGSGYSDEDKRGFTKLVYQN IFTAMQAMIRAMDTLKIPYKYEHNKAHAQLVREVDVEKVSAFENPYVDAIKSLWNDPGIQECYDRRREYQLSDSTKYYLNDLDRVADPAY LPTQQDVLRVRVPTTGIIEYPFDLQSVIFRYIEIFKSSRAEVRTHYDPPRKLMAMQRPGPYDRPGAGRGYNSIGRGAGFERMRRGAYGGG YGGYDDYNGYNDGYGFGSDRFGRDLNYCFSGMSDHRYGDGGSTFQSTTGHCVHMRGLPYRATENDIYNFFSPLNPVRVHIEIGPDGRVTG EADVEFATHEDAVAAMSKDKANMQHRYVELFLNSTAGASGGAYEHRYVELFLNSTAGASGGAYGSQMMGGMGLSNQSSYGGPASQQLSGG -------------------------------------------------------------- >33599_33599_4_GNAQ-HNRNPH1_GNAQ_chr9_80412435_ENST00000286548_HNRNPH1_chr5_179045324_ENST00000442819_length(transcript)=2423nt_BP=828nt CGTCGGCCCAGACTATCCGCTCCCACCGCGCCCCCGGCCCACCTGGTGGCCCCGGCCCTGGCCGCCGCCCCCGCGGCGGTTCCCGGAGCT CGTCCCGGACGCGCGCCCGGGCGGCGGGGGCTCGGCGGCCACCGCTGCCTCGGGGGAGCGAGGGCGGGAGGGTGTGTGTGCGCGCTGTGA GCAGGGGGTGCCGGCGGGGCTGCAGCGGAGGCACTTTGGAAGAATGACTCTGGAGTCCATCATGGCGTGCTGCCTGAGCGAGGAGGCCAA GGAAGCCCGGCGGATCAACGACGAGATCGAGCGGCAGCTCCGCAGGGACAAGCGGGACGCCCGCCGGGAGCTCAAGCTGCTGCTGCTCGG GACAGGAGAGAGTGGCAAGAGTACGTTTATCAAGCAGATGAGAATCATCCATGGGTCAGGATACTCTGATGAAGATAAAAGGGGCTTCAC CAAGCTGGTGTATCAGAACATCTTCACGGCCATGCAGGCCATGATCAGAGCCATGGACACACTCAAGATCCCATACAAGTATGAGCACAA TAAGGCTCATGCACAATTAGTTCGAGAAGTTGATGTGGAGAAGGTGTCTGCTTTTGAGAATCCATATGTAGATGCAATAAAGAGTTTATG GAATGATCCTGGAATCCAGGAATGCTATGATAGACGACGAGAATATCAATTATCTGACTCTACCAAATACTATCTTAATGACTTGGACCG CGTAGCTGACCCTGCCTACCTGCCTACGCAACAAGATGTGCTTAGAGTTCGAGTCCCCACCACAGGGATCATCGAATACCCCTTTGACTT ACAAAGTGTCATTTTCAGGTATATTGAAATCTTTAAGAGCAGTAGAGCTGAAGTTAGAACTCATTATGATCCACCACGAAAGCTTATGGC CATGCAGCGGCCAGGTCCTTATGACAGACCTGGGGCTGGTAGAGGGTATAACAGCATTGGCAGAGGAGCTGGCTTTGAGAGGATGAGGCG TGGTGCTTATGGTGGAGGCTATGGAGGCTATGATGATTACAATGGCTATAATGATGGCTATGGATTTGGGTCAGATAGATTTGGAAGAGA CCTCAATTACTGTTTTTCAGGAATGTCTGATCACAGATACGGGGATGGTGGCTCTACTTTCCAGAGCACAACAGGACACTGTGTACACAT GCGGGGATTACCTTACAGAGCTACTGAGAATGACATTTATAATTTTTTTTCACCGCTCAACCCTGTGAGAGTACACATTGAAATTGGTCC TGATGGCAGAGTAACTGGTGAAGCAGATGTCGAGTTCGCAACTCATGAAGATGCTGTGGCAGCTATGTCAAAAGACAAAGCAAATATGCA ACACAGATATGTAGAACTCTTCTTGAATTCTACAGCAGGAGCAAGCGGTGGTGCTTACGAACACAGATATGTAGAACTCTTCTTGAATTC TACAGCAGGAGCAAGCGGTGGTGCTTATGGTAGCCAAATGATGGGAGGCATGGGCTTGTCAAACCAGTCCAGCTACGGGGGCCCAGCCAG CCAGCAGCTGAGTGGGGGTTACGGAGGCGGCTACGGTGGCCAGAGCAGCATGAGTGGATACGACCAAGTTTTACAGGAAAACTCCAGTGA TTTTCAATCAAACATTGCATAGGTAACCAAGGAGCAGTGAACAGCAGCTACTACAGTAGTGGAAGCCGTGCATCTATGGGCGTGAACGGA ATGGGAGGGTTGTCTAGCATGTCCAGTATGAGTGGTGGATGGGGAATGTAATTGATCGATCCTGATCACTGACTCTTGGTCAACCTTTTT TTTTTTTTTTTTTTTTTCTTTAAGAAAACTTCAGTTTAACAGTTTCTGCAATACAAGCTTGTGATTTATGCTTACTCTAAGTGGAAATCA GGATTGTTATGAAGACTTAAGGCCCAGTATTTTTGAATACAATACTCATCTAGGATGTAACAGTGAAGCTGAGTAAACTATAACTGTTAA ACTTAAGTTCCAGCTTTTCTCAAGTTAGTTATAGGATGTACTTAAGCAGTAAGCGTATTTAGGTAAAAGCAGTTGAATTATGTTAAATGT TGCCCTTTGCCACGTTAAATTGAACACTGTTTTGGATGCATGTTGAAAGACATGCTTTTATTTTTTTGTAAAACAATATAGGAGCTGTGT CTACTATTAAAAGTGAAACATTTTGGCATGTTTGTTAATTCTAGTTTCATTTAATAACCTGTAAGGCACGTAAGTTTAAGCTTTTTTTTT TTTTAAGTTAATGGGAAAAATTTGAGACGCAATACCAATACTTAGGATTTTGGTCTTGGTGTTTGTATGAAATTCTGAGGCCTTGATTTA >33599_33599_4_GNAQ-HNRNPH1_GNAQ_chr9_80412435_ENST00000286548_HNRNPH1_chr5_179045324_ENST00000442819_length(amino acids)=480AA_BP=208 MQRRHFGRMTLESIMACCLSEEAKEARRINDEIERQLRRDKRDARRELKLLLLGTGESGKSTFIKQMRIIHGSGYSDEDKRGFTKLVYQN IFTAMQAMIRAMDTLKIPYKYEHNKAHAQLVREVDVEKVSAFENPYVDAIKSLWNDPGIQECYDRRREYQLSDSTKYYLNDLDRVADPAY LPTQQDVLRVRVPTTGIIEYPFDLQSVIFRYIEIFKSSRAEVRTHYDPPRKLMAMQRPGPYDRPGAGRGYNSIGRGAGFERMRRGAYGGG YGGYDDYNGYNDGYGFGSDRFGRDLNYCFSGMSDHRYGDGGSTFQSTTGHCVHMRGLPYRATENDIYNFFSPLNPVRVHIEIGPDGRVTG EADVEFATHEDAVAAMSKDKANMQHRYVELFLNSTAGASGGAYEHRYVELFLNSTAGASGGAYGSQMMGGMGLSNQSSYGGPASQQLSGG -------------------------------------------------------------- >33599_33599_5_GNAQ-HNRNPH1_GNAQ_chr9_80412435_ENST00000286548_HNRNPH1_chr5_179045324_ENST00000510411_length(transcript)=2361nt_BP=828nt CGTCGGCCCAGACTATCCGCTCCCACCGCGCCCCCGGCCCACCTGGTGGCCCCGGCCCTGGCCGCCGCCCCCGCGGCGGTTCCCGGAGCT CGTCCCGGACGCGCGCCCGGGCGGCGGGGGCTCGGCGGCCACCGCTGCCTCGGGGGAGCGAGGGCGGGAGGGTGTGTGTGCGCGCTGTGA GCAGGGGGTGCCGGCGGGGCTGCAGCGGAGGCACTTTGGAAGAATGACTCTGGAGTCCATCATGGCGTGCTGCCTGAGCGAGGAGGCCAA GGAAGCCCGGCGGATCAACGACGAGATCGAGCGGCAGCTCCGCAGGGACAAGCGGGACGCCCGCCGGGAGCTCAAGCTGCTGCTGCTCGG GACAGGAGAGAGTGGCAAGAGTACGTTTATCAAGCAGATGAGAATCATCCATGGGTCAGGATACTCTGATGAAGATAAAAGGGGCTTCAC CAAGCTGGTGTATCAGAACATCTTCACGGCCATGCAGGCCATGATCAGAGCCATGGACACACTCAAGATCCCATACAAGTATGAGCACAA TAAGGCTCATGCACAATTAGTTCGAGAAGTTGATGTGGAGAAGGTGTCTGCTTTTGAGAATCCATATGTAGATGCAATAAAGAGTTTATG GAATGATCCTGGAATCCAGGAATGCTATGATAGACGACGAGAATATCAATTATCTGACTCTACCAAATACTATCTTAATGACTTGGACCG CGTAGCTGACCCTGCCTACCTGCCTACGCAACAAGATGTGCTTAGAGTTCGAGTCCCCACCACAGGGATCATCGAATACCCCTTTGACTT ACAAAGTGTCATTTTCAGGTATATTGAAATCTTTAAGAGCAGTAGAGCTGAAGTTAGAACTCATTATGATCCACCACGAAAGCTTATGGC CATGCAGCGGCCAGGTCCTTATGACAGACCTGGGGCTGGTAGAGGGTATAACAGCATTGGCAGAGGAGCTGGCTTTGAGAGGATGAGGCG TGGTGCTTATGGTGGAGGCTATGGAGGCTATGATGATTACAATGGCTATAATGATGGCTATGGATTTGGGTCAGATAGATTTGGAAGAGA CCTCAATTACTGTTTTTCAGGAATGTCTGATCACAGATACGGGGATGGTGGCTCTACTTTCCAGAGCACAACAGGACACTGTGTACACAT GCGGGGATTACCTTACAGAGCTACTGAGAATGACATTTATAATTTTTTTTCACCGCTCAACCCTGTGAGAGTACACATTGAAATTGGTCC TGATGGCAGAGTAACTGGTGAAGCAGATGTCGAGTTCGCAACTCATGAAGATGCTGTGGCAGCTATGTCAAAAGACAAAGCAAATATGCA ACACAGATATGTAGAACTCTTCTTGAATTCTACAGCAGGAGCAAGCGGTGGTGCTTACGGTAGCCAAATGCTAGGAGGCATGGGTTTGTC AAACCAGTCCAGCTACGGGGGCCCAGCCAGCCAGCAGCTGAGTGGGGGTTACGGAGGCGGCTACGGTGGCCAGAGCAGCATGAGTGGATA CGACCAAGTTTTACAGGAAAACTCCAGTGATTTTCAATCAAACATTGCATAGGTAACCAAGGAGCAGTGAACAGCAGCTACTACAGTAGT GGAAGCCGTGCATCTATGGGCGTGAACGGAATGGGAGGGTTGTCTAGCATGTCCAGTATGAGTGGTGGATGGGGAATGTAATTGATCGAT CCTGATCACTGACTCTTGGTCAACCTTTTTTTTTTTTTTTTTTTTTTCTTTAAGAAAACTTCAGTTTAACAGTTTCTGCAATACAAGCTT GTGATTTATGCTTACTCTAAGTGGAAATCAGGATTGTTATGAAGACTTAAGGCCCAGTATTTTTGAATACAATACTCATCTAGGATGTAA CAGTGAAGCTGAGTAAACTATAACTGTTAAACTTAAGTTCCAGCTTTTCTCAAGTTAGTTATAGGATGTACTTAAGCAGTAAGCGTATTT AGGTAAAAGCAGTTGAATTATGTTAAATGTTGCCCTTTGCCACGTTAAATTGAACACTGTTTTGGATGCATGTTGAAAGACATGCTTTTA TTTTTTTGTAAAACAATATAGGAGCTGTGTCTACTATTAAAAGTGAAACATTTTGGCATGTTTGTTAATTCTAGTTTCATTTAATAACCT GTAAGGCACGTAAGTTTAAGCTTTTTTTTTTTTTAAGTTAATGGGAAAAATTTGAGACGCAATACCAATACTTAGGATTTTGGTCTTGGT GTTTGTATGAAATTCTGAGGCCTTGATTTAAATCTTTCATTGTATTGTGATTTCCTTTTAGGTATATTGCGCTAAGTGAAACTTGTCAAA >33599_33599_5_GNAQ-HNRNPH1_GNAQ_chr9_80412435_ENST00000286548_HNRNPH1_chr5_179045324_ENST00000510411_length(amino acids)=460AA_BP=208 MQRRHFGRMTLESIMACCLSEEAKEARRINDEIERQLRRDKRDARRELKLLLLGTGESGKSTFIKQMRIIHGSGYSDEDKRGFTKLVYQN IFTAMQAMIRAMDTLKIPYKYEHNKAHAQLVREVDVEKVSAFENPYVDAIKSLWNDPGIQECYDRRREYQLSDSTKYYLNDLDRVADPAY LPTQQDVLRVRVPTTGIIEYPFDLQSVIFRYIEIFKSSRAEVRTHYDPPRKLMAMQRPGPYDRPGAGRGYNSIGRGAGFERMRRGAYGGG YGGYDDYNGYNDGYGFGSDRFGRDLNYCFSGMSDHRYGDGGSTFQSTTGHCVHMRGLPYRATENDIYNFFSPLNPVRVHIEIGPDGRVTG EADVEFATHEDAVAAMSKDKANMQHRYVELFLNSTAGASGGAYGSQMLGGMGLSNQSSYGGPASQQLSGGYGGGYGGQSSMSGYDQVLQE -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for GNAQ-HNRNPH1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for GNAQ-HNRNPH1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for GNAQ-HNRNPH1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies