
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:GNAS-RTFDC1 (FusionGDB2 ID:33643) |
Fusion Gene Summary for GNAS-RTFDC1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: GNAS-RTFDC1 | Fusion gene ID: 33643 | Hgene | Tgene | Gene symbol | GNAS | RTFDC1 | Gene ID | 2778 | 51507 |
| Gene name | GNAS complex locus | replication termination factor 2 | |
| Synonyms | AHO|C20orf45|GNAS1|GPSA|GSA|GSP|NESP|PITA3|POH|SCG6|SgVI | C20orf43|CDAO5|HSPC164|RTFDC1|SHUJUN-3 | |
| Cytomap | 20q13.32 | 20q13.31 | |
| Type of gene | protein-coding | protein-coding | |
| Description | protein ALEXprotein GNASprotein SCG6 (secretogranin VI)G protein subunit alpha Sadenylate cyclase-stimulating G alpha proteinalternative gene product encoded by XL-exonextra large alphas proteinguanine nucleotide binding protein (G protein), alpha | replication termination factor 2UPF0549 protein C20orf43protein RTF2 homologreplication termination factor 2 domain containing 1replication termination factor 2 domain-containing protein 1 | |
| Modification date | 20200329 | 20200313 | |
| UniProtAcc | P63092 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000313949, ENST00000371075, ENST00000371098, ENST00000464624, ENST00000265620, ENST00000306090, ENST00000354359, ENST00000371081, ENST00000371085, ENST00000371095, ENST00000371100, ENST00000371102, ENST00000306120, ENST00000371099, | ENST00000023939, ENST00000357348, ENST00000395881, ENST00000435342, ENST00000484084, | |
| Fusion gene scores | * DoF score | 44 X 25 X 16=17600 | 6 X 5 X 4=120 |
| # samples | 51 | 6 | |
| ** MAII score | log2(51/17600*10)=-5.10893437155316 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(6/120*10)=-1 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: GNAS [Title/Abstract] AND RTFDC1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | GNAS(57470739)-RTFDC1(55059167), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across GNAS (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
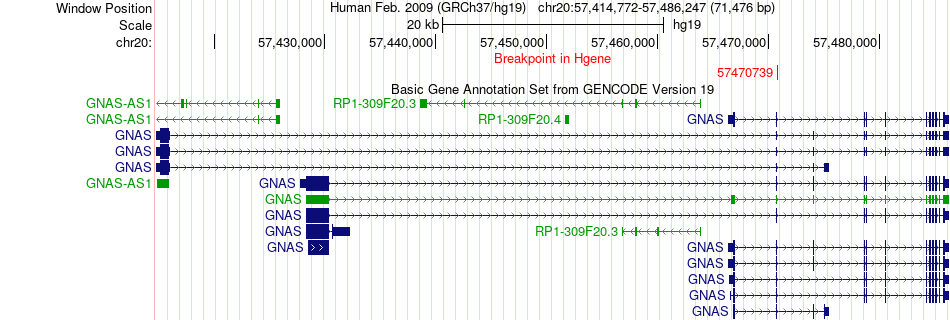 |
| Fusion gene breakpoints across RTFDC1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-C8-A12Q-01A | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
Top |
Fusion Gene ORF analysis for GNAS-RTFDC1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000313949 | ENST00000023939 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| 3UTR-3CDS | ENST00000313949 | ENST00000357348 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| 3UTR-3CDS | ENST00000313949 | ENST00000395881 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| 3UTR-3CDS | ENST00000371075 | ENST00000023939 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| 3UTR-3CDS | ENST00000371075 | ENST00000357348 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| 3UTR-3CDS | ENST00000371075 | ENST00000395881 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| 3UTR-3CDS | ENST00000371098 | ENST00000023939 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| 3UTR-3CDS | ENST00000371098 | ENST00000357348 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| 3UTR-3CDS | ENST00000371098 | ENST00000395881 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| 3UTR-3CDS | ENST00000464624 | ENST00000023939 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| 3UTR-3CDS | ENST00000464624 | ENST00000357348 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| 3UTR-3CDS | ENST00000464624 | ENST00000395881 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| 3UTR-intron | ENST00000313949 | ENST00000435342 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| 3UTR-intron | ENST00000313949 | ENST00000484084 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| 3UTR-intron | ENST00000371075 | ENST00000435342 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| 3UTR-intron | ENST00000371075 | ENST00000484084 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| 3UTR-intron | ENST00000371098 | ENST00000435342 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| 3UTR-intron | ENST00000371098 | ENST00000484084 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| 3UTR-intron | ENST00000464624 | ENST00000435342 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| 3UTR-intron | ENST00000464624 | ENST00000484084 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| 5CDS-intron | ENST00000265620 | ENST00000435342 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| 5CDS-intron | ENST00000265620 | ENST00000484084 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| 5CDS-intron | ENST00000306090 | ENST00000435342 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| 5CDS-intron | ENST00000306090 | ENST00000484084 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| 5CDS-intron | ENST00000354359 | ENST00000435342 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| 5CDS-intron | ENST00000354359 | ENST00000484084 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| 5CDS-intron | ENST00000371081 | ENST00000435342 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| 5CDS-intron | ENST00000371081 | ENST00000484084 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| 5CDS-intron | ENST00000371085 | ENST00000435342 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| 5CDS-intron | ENST00000371085 | ENST00000484084 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| 5CDS-intron | ENST00000371095 | ENST00000435342 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| 5CDS-intron | ENST00000371095 | ENST00000484084 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| 5CDS-intron | ENST00000371100 | ENST00000435342 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| 5CDS-intron | ENST00000371100 | ENST00000484084 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| 5CDS-intron | ENST00000371102 | ENST00000435342 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| 5CDS-intron | ENST00000371102 | ENST00000484084 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| In-frame | ENST00000265620 | ENST00000023939 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| In-frame | ENST00000265620 | ENST00000357348 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| In-frame | ENST00000265620 | ENST00000395881 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| In-frame | ENST00000306090 | ENST00000023939 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| In-frame | ENST00000306090 | ENST00000357348 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| In-frame | ENST00000306090 | ENST00000395881 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| In-frame | ENST00000354359 | ENST00000023939 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| In-frame | ENST00000354359 | ENST00000357348 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| In-frame | ENST00000354359 | ENST00000395881 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| In-frame | ENST00000371081 | ENST00000023939 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| In-frame | ENST00000371081 | ENST00000357348 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| In-frame | ENST00000371081 | ENST00000395881 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| In-frame | ENST00000371085 | ENST00000023939 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| In-frame | ENST00000371085 | ENST00000357348 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| In-frame | ENST00000371085 | ENST00000395881 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| In-frame | ENST00000371095 | ENST00000023939 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| In-frame | ENST00000371095 | ENST00000357348 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| In-frame | ENST00000371095 | ENST00000395881 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| In-frame | ENST00000371100 | ENST00000023939 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| In-frame | ENST00000371100 | ENST00000357348 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| In-frame | ENST00000371100 | ENST00000395881 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| In-frame | ENST00000371102 | ENST00000023939 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| In-frame | ENST00000371102 | ENST00000357348 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| In-frame | ENST00000371102 | ENST00000395881 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| intron-3CDS | ENST00000306120 | ENST00000023939 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| intron-3CDS | ENST00000306120 | ENST00000357348 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| intron-3CDS | ENST00000306120 | ENST00000395881 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| intron-3CDS | ENST00000371099 | ENST00000023939 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| intron-3CDS | ENST00000371099 | ENST00000357348 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| intron-3CDS | ENST00000371099 | ENST00000395881 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| intron-intron | ENST00000306120 | ENST00000435342 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| intron-intron | ENST00000306120 | ENST00000484084 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| intron-intron | ENST00000371099 | ENST00000435342 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| intron-intron | ENST00000371099 | ENST00000484084 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000371100 | GNAS | chr20 | 57470739 | + | ENST00000023939 | RTFDC1 | chr20 | 55059167 | + | 3838 | 2693 | 531 | 3215 | 894 |
| ENST00000371100 | GNAS | chr20 | 57470739 | + | ENST00000395881 | RTFDC1 | chr20 | 55059167 | + | 3783 | 2693 | 531 | 2987 | 818 |
| ENST00000371100 | GNAS | chr20 | 57470739 | + | ENST00000357348 | RTFDC1 | chr20 | 55059167 | + | 3625 | 2693 | 531 | 3215 | 894 |
| ENST00000371102 | GNAS | chr20 | 57470739 | + | ENST00000023939 | RTFDC1 | chr20 | 55059167 | + | 3289 | 2144 | 3 | 2666 | 887 |
| ENST00000371102 | GNAS | chr20 | 57470739 | + | ENST00000395881 | RTFDC1 | chr20 | 55059167 | + | 3234 | 2144 | 3 | 2438 | 811 |
| ENST00000371102 | GNAS | chr20 | 57470739 | + | ENST00000357348 | RTFDC1 | chr20 | 55059167 | + | 3076 | 2144 | 3 | 2666 | 887 |
| ENST00000371095 | GNAS | chr20 | 57470739 | + | ENST00000023939 | RTFDC1 | chr20 | 55059167 | + | 1782 | 637 | 425 | 1159 | 244 |
| ENST00000371095 | GNAS | chr20 | 57470739 | + | ENST00000395881 | RTFDC1 | chr20 | 55059167 | + | 1727 | 637 | 847 | 2 | 282 |
| ENST00000371095 | GNAS | chr20 | 57470739 | + | ENST00000357348 | RTFDC1 | chr20 | 55059167 | + | 1569 | 637 | 425 | 1159 | 244 |
| ENST00000371085 | GNAS | chr20 | 57470739 | + | ENST00000023939 | RTFDC1 | chr20 | 55059167 | + | 1781 | 636 | 424 | 1158 | 244 |
| ENST00000371085 | GNAS | chr20 | 57470739 | + | ENST00000395881 | RTFDC1 | chr20 | 55059167 | + | 1726 | 636 | 846 | 1 | 282 |
| ENST00000371085 | GNAS | chr20 | 57470739 | + | ENST00000357348 | RTFDC1 | chr20 | 55059167 | + | 1568 | 636 | 424 | 1158 | 244 |
| ENST00000354359 | GNAS | chr20 | 57470739 | + | ENST00000023939 | RTFDC1 | chr20 | 55059167 | + | 1781 | 636 | 424 | 1158 | 244 |
| ENST00000354359 | GNAS | chr20 | 57470739 | + | ENST00000395881 | RTFDC1 | chr20 | 55059167 | + | 1726 | 636 | 846 | 1 | 282 |
| ENST00000354359 | GNAS | chr20 | 57470739 | + | ENST00000357348 | RTFDC1 | chr20 | 55059167 | + | 1568 | 636 | 424 | 1158 | 244 |
| ENST00000265620 | GNAS | chr20 | 57470739 | + | ENST00000023939 | RTFDC1 | chr20 | 55059167 | + | 1720 | 575 | 363 | 1097 | 244 |
| ENST00000265620 | GNAS | chr20 | 57470739 | + | ENST00000395881 | RTFDC1 | chr20 | 55059167 | + | 1665 | 575 | 785 | 0 | 262 |
| ENST00000265620 | GNAS | chr20 | 57470739 | + | ENST00000357348 | RTFDC1 | chr20 | 55059167 | + | 1507 | 575 | 363 | 1097 | 244 |
| ENST00000306090 | GNAS | chr20 | 57470739 | + | ENST00000023939 | RTFDC1 | chr20 | 55059167 | + | 1499 | 354 | 142 | 876 | 244 |
| ENST00000306090 | GNAS | chr20 | 57470739 | + | ENST00000395881 | RTFDC1 | chr20 | 55059167 | + | 1444 | 354 | 564 | 1 | 188 |
| ENST00000306090 | GNAS | chr20 | 57470739 | + | ENST00000357348 | RTFDC1 | chr20 | 55059167 | + | 1286 | 354 | 142 | 876 | 244 |
| ENST00000371081 | GNAS | chr20 | 57470739 | + | ENST00000023939 | RTFDC1 | chr20 | 55059167 | + | 1368 | 223 | 11 | 745 | 244 |
| ENST00000371081 | GNAS | chr20 | 57470739 | + | ENST00000395881 | RTFDC1 | chr20 | 55059167 | + | 1313 | 223 | 11 | 517 | 168 |
| ENST00000371081 | GNAS | chr20 | 57470739 | + | ENST00000357348 | RTFDC1 | chr20 | 55059167 | + | 1155 | 223 | 11 | 745 | 244 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000371100 | ENST00000023939 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + | 0.003318445 | 0.9966815 |
| ENST00000371100 | ENST00000395881 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + | 0.005341558 | 0.9946584 |
| ENST00000371100 | ENST00000357348 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + | 0.004344195 | 0.9956558 |
| ENST00000371102 | ENST00000023939 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + | 0.004215274 | 0.9957847 |
| ENST00000371102 | ENST00000395881 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + | 0.006758435 | 0.99324155 |
| ENST00000371102 | ENST00000357348 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + | 0.00582664 | 0.99417335 |
| ENST00000371095 | ENST00000023939 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + | 0.005432057 | 0.994568 |
| ENST00000371095 | ENST00000395881 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + | 0.011546154 | 0.9884538 |
| ENST00000371095 | ENST00000357348 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + | 0.00528909 | 0.9947109 |
| ENST00000371085 | ENST00000023939 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + | 0.005151587 | 0.9948485 |
| ENST00000371085 | ENST00000395881 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + | 0.010751252 | 0.98924875 |
| ENST00000371085 | ENST00000357348 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + | 0.005152765 | 0.9948473 |
| ENST00000354359 | ENST00000023939 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + | 0.005151587 | 0.9948485 |
| ENST00000354359 | ENST00000395881 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + | 0.010751252 | 0.98924875 |
| ENST00000354359 | ENST00000357348 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + | 0.005152765 | 0.9948473 |
| ENST00000265620 | ENST00000023939 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + | 0.004916115 | 0.99508387 |
| ENST00000265620 | ENST00000395881 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + | 0.01095844 | 0.9890415 |
| ENST00000265620 | ENST00000357348 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + | 0.005260887 | 0.9947391 |
| ENST00000306090 | ENST00000023939 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + | 0.004305943 | 0.99569404 |
| ENST00000306090 | ENST00000395881 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + | 0.014198372 | 0.98580164 |
| ENST00000306090 | ENST00000357348 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + | 0.005061724 | 0.99493825 |
| ENST00000371081 | ENST00000023939 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + | 0.003143214 | 0.9968568 |
| ENST00000371081 | ENST00000395881 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + | 0.013190607 | 0.9868094 |
| ENST00000371081 | ENST00000357348 | GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059167 | + | 0.003461407 | 0.99653864 |
Top |
Fusion Genomic Features for GNAS-RTFDC1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059166 | + | 0.005330341 | 0.9946696 |
| GNAS | chr20 | 57470739 | + | RTFDC1 | chr20 | 55059166 | + | 0.005330341 | 0.9946696 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
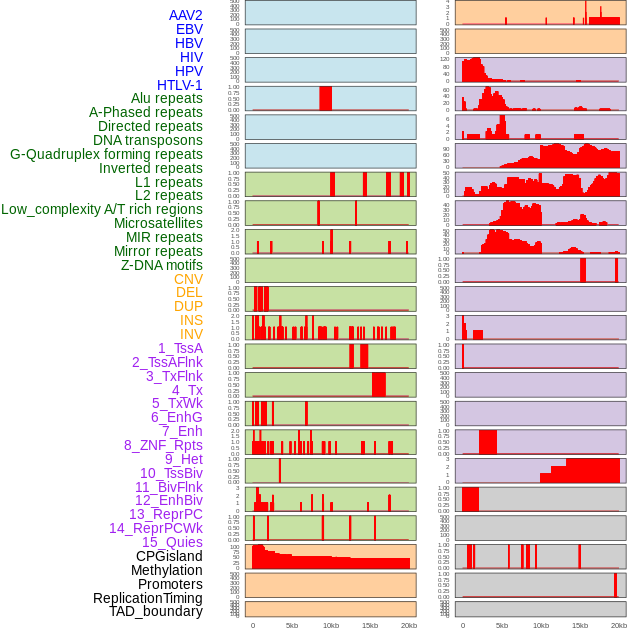 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
 |
Top |
Fusion Protein Features for GNAS-RTFDC1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr20:57470739/chr20:55059167) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| GNAS | . |
| FUNCTION: Guanine nucleotide-binding proteins (G proteins) function as transducers in numerous signaling pathways controlled by G protein-coupled receptors (GPCRs) (PubMed:17110384). Signaling involves the activation of adenylyl cyclases, resulting in increased levels of the signaling molecule cAMP (PubMed:26206488, PubMed:8702665). GNAS functions downstream of several GPCRs, including beta-adrenergic receptors (PubMed:21488135). Stimulates the Ras signaling pathway via RAPGEF2 (PubMed:12391161). {ECO:0000269|PubMed:12391161, ECO:0000269|PubMed:17110384, ECO:0000269|PubMed:21488135, ECO:0000269|PubMed:26206488, ECO:0000269|PubMed:8702665}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371100 | + | 2 | 13 | 641_667 | 713 | 1038.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371102 | + | 2 | 12 | 641_667 | 713 | 1024.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000313949 | + | 2 | 13 | 78_142 | 284 | 26.333333333333332 | Compositional bias | Glu-rich |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371075 | + | 2 | 13 | 78_142 | 284 | 36.333333333333336 | Compositional bias | Glu-rich |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371098 | + | 2 | 4 | 78_142 | 284 | 20.333333333333332 | Compositional bias | Glu-rich |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371100 | + | 2 | 13 | 358_522 | 713 | 1038.0 | Compositional bias | Ala-rich |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371102 | + | 2 | 12 | 358_522 | 713 | 1024.0 | Compositional bias | Ala-rich |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000265620 | + | 2 | 12 | 47_55 | 70 | 380.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000306090 | + | 3 | 13 | 47_55 | 70 | 381.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000354359 | + | 2 | 13 | 47_55 | 70 | 396.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371085 | + | 2 | 13 | 47_55 | 70 | 395.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371095 | + | 2 | 12 | 47_55 | 70 | 381.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371100 | + | 2 | 13 | 690_698 | 713 | 1038.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371102 | + | 2 | 12 | 690_698 | 713 | 1024.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000265620 | + | 2 | 12 | 42_55 | 70 | 380.0 | Region | G1 motif |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000306090 | + | 3 | 13 | 42_55 | 70 | 381.0 | Region | G1 motif |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000354359 | + | 2 | 13 | 42_55 | 70 | 396.0 | Region | G1 motif |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371085 | + | 2 | 13 | 42_55 | 70 | 395.0 | Region | G1 motif |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371095 | + | 2 | 12 | 42_55 | 70 | 381.0 | Region | G1 motif |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371100 | + | 2 | 13 | 685_698 | 713 | 1038.0 | Region | G1 motif |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371102 | + | 2 | 12 | 685_698 | 713 | 1024.0 | Region | G1 motif |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371100 | + | 2 | 13 | 730_756 | 713 | 1038.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371102 | + | 2 | 12 | 730_756 | 713 | 1024.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000306120 | + | 1 | 1 | 238_476 | 0 | 626.0 | Compositional bias | Pro-rich |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000265620 | + | 2 | 12 | 39_394 | 70 | 380.0 | Domain | G-alpha |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000306090 | + | 3 | 13 | 39_394 | 70 | 381.0 | Domain | G-alpha |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000354359 | + | 2 | 13 | 39_394 | 70 | 396.0 | Domain | G-alpha |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371085 | + | 2 | 13 | 39_394 | 70 | 395.0 | Domain | G-alpha |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371095 | + | 2 | 12 | 39_394 | 70 | 381.0 | Domain | G-alpha |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371100 | + | 2 | 13 | 682_1037 | 713 | 1038.0 | Domain | G-alpha |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371102 | + | 2 | 12 | 682_1037 | 713 | 1024.0 | Domain | G-alpha |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000265620 | + | 2 | 12 | 197_204 | 70 | 380.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000265620 | + | 2 | 12 | 223_227 | 70 | 380.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000265620 | + | 2 | 12 | 292_295 | 70 | 380.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000306090 | + | 3 | 13 | 197_204 | 70 | 381.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000306090 | + | 3 | 13 | 223_227 | 70 | 381.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000306090 | + | 3 | 13 | 292_295 | 70 | 381.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000354359 | + | 2 | 13 | 197_204 | 70 | 396.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000354359 | + | 2 | 13 | 223_227 | 70 | 396.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000354359 | + | 2 | 13 | 292_295 | 70 | 396.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371085 | + | 2 | 13 | 197_204 | 70 | 395.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371085 | + | 2 | 13 | 223_227 | 70 | 395.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371085 | + | 2 | 13 | 292_295 | 70 | 395.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371095 | + | 2 | 12 | 197_204 | 70 | 381.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371095 | + | 2 | 12 | 223_227 | 70 | 381.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371095 | + | 2 | 12 | 292_295 | 70 | 381.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371100 | + | 2 | 13 | 840_847 | 713 | 1038.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371100 | + | 2 | 13 | 866_870 | 713 | 1038.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371100 | + | 2 | 13 | 935_938 | 713 | 1038.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371102 | + | 2 | 12 | 840_847 | 713 | 1024.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371102 | + | 2 | 12 | 866_870 | 713 | 1024.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371102 | + | 2 | 12 | 935_938 | 713 | 1024.0 | Nucleotide binding | GTP |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000265620 | + | 2 | 12 | 196_204 | 70 | 380.0 | Region | G2 motif |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000265620 | + | 2 | 12 | 219_228 | 70 | 380.0 | Region | G3 motif |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000265620 | + | 2 | 12 | 288_295 | 70 | 380.0 | Region | G4 motif |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000265620 | + | 2 | 12 | 364_369 | 70 | 380.0 | Region | G5 motif |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000306090 | + | 3 | 13 | 196_204 | 70 | 381.0 | Region | G2 motif |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000306090 | + | 3 | 13 | 219_228 | 70 | 381.0 | Region | G3 motif |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000306090 | + | 3 | 13 | 288_295 | 70 | 381.0 | Region | G4 motif |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000306090 | + | 3 | 13 | 364_369 | 70 | 381.0 | Region | G5 motif |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000354359 | + | 2 | 13 | 196_204 | 70 | 396.0 | Region | G2 motif |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000354359 | + | 2 | 13 | 219_228 | 70 | 396.0 | Region | G3 motif |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000354359 | + | 2 | 13 | 288_295 | 70 | 396.0 | Region | G4 motif |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000354359 | + | 2 | 13 | 364_369 | 70 | 396.0 | Region | G5 motif |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371085 | + | 2 | 13 | 196_204 | 70 | 395.0 | Region | G2 motif |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371085 | + | 2 | 13 | 219_228 | 70 | 395.0 | Region | G3 motif |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371085 | + | 2 | 13 | 288_295 | 70 | 395.0 | Region | G4 motif |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371085 | + | 2 | 13 | 364_369 | 70 | 395.0 | Region | G5 motif |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371095 | + | 2 | 12 | 196_204 | 70 | 381.0 | Region | G2 motif |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371095 | + | 2 | 12 | 219_228 | 70 | 381.0 | Region | G3 motif |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371095 | + | 2 | 12 | 288_295 | 70 | 381.0 | Region | G4 motif |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371095 | + | 2 | 12 | 364_369 | 70 | 381.0 | Region | G5 motif |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371100 | + | 2 | 13 | 1007_1012 | 713 | 1038.0 | Region | G5 motif |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371100 | + | 2 | 13 | 839_847 | 713 | 1038.0 | Region | G2 motif |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371100 | + | 2 | 13 | 862_871 | 713 | 1038.0 | Region | G3 motif |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371100 | + | 2 | 13 | 931_938 | 713 | 1038.0 | Region | G4 motif |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371102 | + | 2 | 12 | 1007_1012 | 713 | 1024.0 | Region | G5 motif |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371102 | + | 2 | 12 | 839_847 | 713 | 1024.0 | Region | G2 motif |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371102 | + | 2 | 12 | 862_871 | 713 | 1024.0 | Region | G3 motif |
| Hgene | GNAS | chr20:57470739 | chr20:55059167 | ENST00000371102 | + | 2 | 12 | 931_938 | 713 | 1024.0 | Region | G4 motif |
Top |
Fusion Gene Sequence for GNAS-RTFDC1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >33643_33643_1_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000265620_RTFDC1_chr20_55059167_ENST00000023939_length(transcript)=1720nt_BP=575nt GGGCGGCGGCGGGGGCCCGGCCGAGGCAATAAGAGCGGCGGCGGCGGCAGCGGCGGCAGCAGCTCCCGCAGCTCCTGCTCTGGTCCGCCT CGGCCCGGCGGCGGCCATCAGCCCCCTCGGCCTCGGCTCGAGGGGCGGGGAGCTGCGCGCGCCCCTCGGTCCGACCGACACCCTCCCCTT CCCGCCCGTCCGCGCGCCCCGCGGCCCGCGGCCCGCAGTCCGCCCCGCGCGCTCCTTGCCGAGGAGCCGAGCCCGCGCCCGGCCCGCCCG CCCGGCGCTGCCCCGGCCCTCCCGGCCCGCGTGAGGCCGCCCGCGCCCGCCGCCGCCGCAGCCCGGCCGCGCCCCGCCGCCGCCGCCGCC GCCATGGGCTGCCTCGGGAACAGTAAGACCGAGGACCAGCGCAACGAGGAGAAGGCGCAGCGTGAGGCCAACAAAAAGATCGAGAAGCAG CTGCAGAAGGACAAGCAGGTCTACCGGGCCACGCACCGCCTGCTGCTGCTGGGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAG ATGAGGATCCTGCATGTTAATGGGTTTAATGGAGAGTTCTGCTTCCTTCGGTGCTGCGGCTGTGTGTTTTCTGAGCGAGCCTTGAAAGAG ATAAAAGCGGAAGTTTGCCACACGTGTGGGGCTGCCTTCCAGGAGGATGATGTCATCATGCTCAATGGCACCAAGGAGGATGTGGACGTG CTGAAGACAAGGATGGAGGAGAGAAGGCTGAGAGCGAAGCTGGAAAAGAAAACAAAGAAACCCAAGGCAGCAGAGTCTGTTTCAAAACCA GATGTCAGTGAAGAAGCCCCAGGGCCATCAAAAGTTAAGACAGGGAAGCCTGAAGAAGCCAGCCTTGATTCTAGAGAGAAGAAAACCAAC TTGGCTCCCAAAAGCACAGCAATGAATGAGAGCTCTTCTGGAAAAGCTGGGAAGCCTCCGTGTGGAGCCACAAAGAGGTCCATCGCTGAC AGTGAAGAATCGGAGGCCTACAAGTCCCTCTTTACCACTCACAGCTCCGCCAAGCGCTCCAAGGAGGAGTCTGCCCACTGGGTCACCCAC ACGTCCTACTGCTTCTGAAGCCCGCACTGCCACCGCTCCTGCCCCAGAAGGTTGTTTAGTTTCCACGTAGGCAGGTCGCTTTGTGCCTCT GAGTGCGCTGCTGTGTGTTCTCTCTATAGTTCTGTGTCATAAAGCTGTCCTGGCCAGCCTTCAAGCTGGTGTGGCCACTCTTGATGTGAG GCGTGTCGGTTCCAGGGGGGACATGGGAGGGGCTGCACAGTGGCCCGAGGTCATGCTTGCTTCCACCTGCAGGTGCATTTGGTCCTTTCC ATGGCCAGGAAGCCCTGTGGGCTGCACTTTTTATGCTTGCAGTAACAAGAGACTCCAGAGTCCTCACCGGTGCAGAGTTGGCACATATTA ATTAACTAAAATTCTAATGATCTTGCTACCAGCAATAAATCAAGTAGGCCAAGTGAAACTGGGCTTTAAAAAGGATGGATTTCAAATACA CTGTGCCCACTAGAAGCTTCGAAGGGCCTCGTCCCTCTGCTACAGCCCTGGGAGGAGCCAGGATCCTTGTTGGTCTAGCTAAATACTGTT AGGGGAGTGTGCCCCATCTCATCATTTCGAAGATAGCAGAGTCATAGTTGGGCACCCAGTGATTGGGTTCAAAAATAAAGCTGGTCTGCC >33643_33643_1_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000265620_RTFDC1_chr20_55059167_ENST00000023939_length(amino acids)=244AA_BP=71 MGCLGNSKTEDQRNEEKAQREANKKIEKQLQKDKQVYRATHRLLLLGAGESGKSTIVKQMRILHVNGFNGEFCFLRCCGCVFSERALKEI KAEVCHTCGAAFQEDDVIMLNGTKEDVDVLKTRMEERRLRAKLEKKTKKPKAAESVSKPDVSEEAPGPSKVKTGKPEEASLDSREKKTNL -------------------------------------------------------------- >33643_33643_2_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000265620_RTFDC1_chr20_55059167_ENST00000357348_length(transcript)=1507nt_BP=575nt GGGCGGCGGCGGGGGCCCGGCCGAGGCAATAAGAGCGGCGGCGGCGGCAGCGGCGGCAGCAGCTCCCGCAGCTCCTGCTCTGGTCCGCCT CGGCCCGGCGGCGGCCATCAGCCCCCTCGGCCTCGGCTCGAGGGGCGGGGAGCTGCGCGCGCCCCTCGGTCCGACCGACACCCTCCCCTT CCCGCCCGTCCGCGCGCCCCGCGGCCCGCGGCCCGCAGTCCGCCCCGCGCGCTCCTTGCCGAGGAGCCGAGCCCGCGCCCGGCCCGCCCG CCCGGCGCTGCCCCGGCCCTCCCGGCCCGCGTGAGGCCGCCCGCGCCCGCCGCCGCCGCAGCCCGGCCGCGCCCCGCCGCCGCCGCCGCC GCCATGGGCTGCCTCGGGAACAGTAAGACCGAGGACCAGCGCAACGAGGAGAAGGCGCAGCGTGAGGCCAACAAAAAGATCGAGAAGCAG CTGCAGAAGGACAAGCAGGTCTACCGGGCCACGCACCGCCTGCTGCTGCTGGGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAG ATGAGGATCCTGCATGTTAATGGGTTTAATGGAGAGTTCTGCTTCCTTCGGTGCTGCGGCTGTGTGTTTTCTGAGCGAGCCTTGAAAGAG ATAAAAGCGGAAGTTTGCCACACGTGTGGGGCTGCCTTCCAGGAGGATGATGTCATCATGCTCAATGGCACCAAGGAGGATGTGGACGTG CTGAAGACAAGGATGGAGGAGAGAAGGCTGAGAGCGAAGCTGGAAAAGAAAACAAAGAAACCCAAGGCAGCAGAGTCTGTTTCAAAACCA GATGTCAGTGAAGAAGCCCCAGGGCCATCAAAAGTTAAGACAGGGAAGCCTGAAGAAGCCAGCCTTGATTCTAGAGAGAAGAAAACCAAC TTGGCTCCCAAAAGCACAGCAATGAATGAGAGCTCTTCTGGAAAAGCTGGGAAGCCTCCGTGTGGAGCCACAAAGAGGTCCATCGCTGAC AGTGAAGAATCGGAGGCCTACAAGTCCCTCTTTACCACTCACAGCTCCGCCAAGCGCTCCAAGGAGGAGTCTGCCCACTGGGTCACCCAC ACGTCCTACTGCTTCTGAAGCCCGCACTGCCACCGCTCCTGCCCCAGAAGGTTGTTTAGTTTCCACGTAGGCAGGTCGCTTTGTGCCTCT GAGTGCGCTGCTGTGTGTTCTCTCTATAGTTCTGTGTCATAAAGCTGTCCTGGCCAGCCTTCAAGCTGGTGTGGCCACTCTTGATGTGAG GCGTGTCGGTTCCAGGGGGGACATGGGAGGGGCTGCACAGTGGCCCGAGGTCATGCTTGCTTCCACCTGCAGGTGCATTTGGTCCTTTCC ATGGCCAGGAAGCCCTGTGGGCTGCACTTTTTATGCTTGCAGTAACAAGAGACTCCAGAGTCCTCACCGGTGCAGAGTTGGCACATATTA >33643_33643_2_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000265620_RTFDC1_chr20_55059167_ENST00000357348_length(amino acids)=244AA_BP=71 MGCLGNSKTEDQRNEEKAQREANKKIEKQLQKDKQVYRATHRLLLLGAGESGKSTIVKQMRILHVNGFNGEFCFLRCCGCVFSERALKEI KAEVCHTCGAAFQEDDVIMLNGTKEDVDVLKTRMEERRLRAKLEKKTKKPKAAESVSKPDVSEEAPGPSKVKTGKPEEASLDSREKKTNL -------------------------------------------------------------- >33643_33643_3_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000265620_RTFDC1_chr20_55059167_ENST00000395881_length(transcript)=1665nt_BP=575nt GGGCGGCGGCGGGGGCCCGGCCGAGGCAATAAGAGCGGCGGCGGCGGCAGCGGCGGCAGCAGCTCCCGCAGCTCCTGCTCTGGTCCGCCT CGGCCCGGCGGCGGCCATCAGCCCCCTCGGCCTCGGCTCGAGGGGCGGGGAGCTGCGCGCGCCCCTCGGTCCGACCGACACCCTCCCCTT CCCGCCCGTCCGCGCGCCCCGCGGCCCGCGGCCCGCAGTCCGCCCCGCGCGCTCCTTGCCGAGGAGCCGAGCCCGCGCCCGGCCCGCCCG CCCGGCGCTGCCCCGGCCCTCCCGGCCCGCGTGAGGCCGCCCGCGCCCGCCGCCGCCGCAGCCCGGCCGCGCCCCGCCGCCGCCGCCGCC GCCATGGGCTGCCTCGGGAACAGTAAGACCGAGGACCAGCGCAACGAGGAGAAGGCGCAGCGTGAGGCCAACAAAAAGATCGAGAAGCAG CTGCAGAAGGACAAGCAGGTCTACCGGGCCACGCACCGCCTGCTGCTGCTGGGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAG ATGAGGATCCTGCATGTTAATGGGTTTAATGGAGAGTTCTGCTTCCTTCGGTGCTGCGGCTGTGTGTTTTCTGAGCGAGCCTTGAAAGAG ATAAAAGCGGAAGTTTGCCACACGTGTGGGGCTGCCTTCCAGGAGGATGATGTCATCATGCTCAATGGCACCAAGGAGGATGTGGACGTG CTGAAGACAAGGATGGAGGAGAGAAGGCTGAGAGCGAAGCTGGAAAAGAAGCCCCAGGGCCATCAAAAGTTAAGACAGGGAAGCCTGAAG AAGCCAGCCTTGATTCTAGAGAGAAGAAAACCAACTTGGCTCCCAAAAGCACAGCAATGAATGAGAGCTCTTCTGGAAAAGCTGGGAAGC CTCCGTGTGGAGCCACAAAGAGGTCCATCGCTGACAGTGAAGAATCGGAGGCCTACAAGTCCCTCTTTACCACTCACAGCTCCGCCAAGC GCTCCAAGGAGGAGTCTGCCCACTGGGTCACCCACACGTCCTACTGCTTCTGAAGCCCGCACTGCCACCGCTCCTGCCCCAGAAGGTTGT TTAGTTTCCACGTAGGCAGGTCGCTTTGTGCCTCTGAGTGCGCTGCTGTGTGTTCTCTCTATAGTTCTGTGTCATAAAGCTGTCCTGGCC AGCCTTCAAGCTGGTGTGGCCACTCTTGATGTGAGGCGTGTCGGTTCCAGGGGGGACATGGGAGGGGCTGCACAGTGGCCCGAGGTCATG CTTGCTTCCACCTGCAGGTGCATTTGGTCCTTTCCATGGCCAGGAAGCCCTGTGGGCTGCACTTTTTATGCTTGCAGTAACAAGAGACTC CAGAGTCCTCACCGGTGCAGAGTTGGCACATATTAATTAACTAAAATTCTAATGATCTTGCTACCAGCAATAAATCAAGTAGGCCAAGTG AAACTGGGCTTTAAAAAGGATGGATTTCAAATACACTGTGCCCACTAGAAGCTTCGAAGGGCCTCGTCCCTCTGCTACAGCCCTGGGAGG AGCCAGGATCCTTGTTGGTCTAGCTAAATACTGTTAGGGGAGTGTGCCCCATCTCATCATTTCGAAGATAGCAGAGTCATAGTTGGGCAC >33643_33643_3_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000265620_RTFDC1_chr20_55059167_ENST00000395881_length(amino acids)=262AA_BP=6 MMALGLLFQLRSQPSLLHPCLQHVHILLGAIEHDDIILLEGSPTRVANFRFYLFQGSLRKHTAAAPKEAELSIKPINMQDPHLLHNGAFT RFSSTQQQQAVRGPVDLLVLLQLLLDLFVGLTLRLLLVALVLGLTVPEAAHGGGGGGGARPGCGGGGRGRPHAGREGRGSAGRAGRARAR -------------------------------------------------------------- >33643_33643_4_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000306090_RTFDC1_chr20_55059167_ENST00000023939_length(transcript)=1499nt_BP=354nt CAGCGGCGGCAGCAGCTCCCGCAGCTCCTGCTCTGGTCCGCCTCGGCCCGGCGGCGGCCATCAGCCCCCTCGGCCTCGGCTCGAGGGGCG GGGAGCTGCGCGCGCCCCTCGGTCCGACCGACACCCTCCCCTTCCCGCCCCCATGGGCTGCCTCGGGAACAGTAAGACCGAGGACCAGCG CAACGAGGAGAAGGCGCAGCGTGAGGCCAACAAAAAGATCGAGAAGCAGCTGCAGAAGGACAAGCAGGTCTACCGGGCCACGCACCGCCT GCTGCTGCTGGGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTAATGGAGAGTTCTG CTTCCTTCGGTGCTGCGGCTGTGTGTTTTCTGAGCGAGCCTTGAAAGAGATAAAAGCGGAAGTTTGCCACACGTGTGGGGCTGCCTTCCA GGAGGATGATGTCATCATGCTCAATGGCACCAAGGAGGATGTGGACGTGCTGAAGACAAGGATGGAGGAGAGAAGGCTGAGAGCGAAGCT GGAAAAGAAAACAAAGAAACCCAAGGCAGCAGAGTCTGTTTCAAAACCAGATGTCAGTGAAGAAGCCCCAGGGCCATCAAAAGTTAAGAC AGGGAAGCCTGAAGAAGCCAGCCTTGATTCTAGAGAGAAGAAAACCAACTTGGCTCCCAAAAGCACAGCAATGAATGAGAGCTCTTCTGG AAAAGCTGGGAAGCCTCCGTGTGGAGCCACAAAGAGGTCCATCGCTGACAGTGAAGAATCGGAGGCCTACAAGTCCCTCTTTACCACTCA CAGCTCCGCCAAGCGCTCCAAGGAGGAGTCTGCCCACTGGGTCACCCACACGTCCTACTGCTTCTGAAGCCCGCACTGCCACCGCTCCTG CCCCAGAAGGTTGTTTAGTTTCCACGTAGGCAGGTCGCTTTGTGCCTCTGAGTGCGCTGCTGTGTGTTCTCTCTATAGTTCTGTGTCATA AAGCTGTCCTGGCCAGCCTTCAAGCTGGTGTGGCCACTCTTGATGTGAGGCGTGTCGGTTCCAGGGGGGACATGGGAGGGGCTGCACAGT GGCCCGAGGTCATGCTTGCTTCCACCTGCAGGTGCATTTGGTCCTTTCCATGGCCAGGAAGCCCTGTGGGCTGCACTTTTTATGCTTGCA GTAACAAGAGACTCCAGAGTCCTCACCGGTGCAGAGTTGGCACATATTAATTAACTAAAATTCTAATGATCTTGCTACCAGCAATAAATC AAGTAGGCCAAGTGAAACTGGGCTTTAAAAAGGATGGATTTCAAATACACTGTGCCCACTAGAAGCTTCGAAGGGCCTCGTCCCTCTGCT ACAGCCCTGGGAGGAGCCAGGATCCTTGTTGGTCTAGCTAAATACTGTTAGGGGAGTGTGCCCCATCTCATCATTTCGAAGATAGCAGAG >33643_33643_4_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000306090_RTFDC1_chr20_55059167_ENST00000023939_length(amino acids)=244AA_BP=71 MGCLGNSKTEDQRNEEKAQREANKKIEKQLQKDKQVYRATHRLLLLGAGESGKSTIVKQMRILHVNGFNGEFCFLRCCGCVFSERALKEI KAEVCHTCGAAFQEDDVIMLNGTKEDVDVLKTRMEERRLRAKLEKKTKKPKAAESVSKPDVSEEAPGPSKVKTGKPEEASLDSREKKTNL -------------------------------------------------------------- >33643_33643_5_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000306090_RTFDC1_chr20_55059167_ENST00000357348_length(transcript)=1286nt_BP=354nt CAGCGGCGGCAGCAGCTCCCGCAGCTCCTGCTCTGGTCCGCCTCGGCCCGGCGGCGGCCATCAGCCCCCTCGGCCTCGGCTCGAGGGGCG GGGAGCTGCGCGCGCCCCTCGGTCCGACCGACACCCTCCCCTTCCCGCCCCCATGGGCTGCCTCGGGAACAGTAAGACCGAGGACCAGCG CAACGAGGAGAAGGCGCAGCGTGAGGCCAACAAAAAGATCGAGAAGCAGCTGCAGAAGGACAAGCAGGTCTACCGGGCCACGCACCGCCT GCTGCTGCTGGGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTAATGGAGAGTTCTG CTTCCTTCGGTGCTGCGGCTGTGTGTTTTCTGAGCGAGCCTTGAAAGAGATAAAAGCGGAAGTTTGCCACACGTGTGGGGCTGCCTTCCA GGAGGATGATGTCATCATGCTCAATGGCACCAAGGAGGATGTGGACGTGCTGAAGACAAGGATGGAGGAGAGAAGGCTGAGAGCGAAGCT GGAAAAGAAAACAAAGAAACCCAAGGCAGCAGAGTCTGTTTCAAAACCAGATGTCAGTGAAGAAGCCCCAGGGCCATCAAAAGTTAAGAC AGGGAAGCCTGAAGAAGCCAGCCTTGATTCTAGAGAGAAGAAAACCAACTTGGCTCCCAAAAGCACAGCAATGAATGAGAGCTCTTCTGG AAAAGCTGGGAAGCCTCCGTGTGGAGCCACAAAGAGGTCCATCGCTGACAGTGAAGAATCGGAGGCCTACAAGTCCCTCTTTACCACTCA CAGCTCCGCCAAGCGCTCCAAGGAGGAGTCTGCCCACTGGGTCACCCACACGTCCTACTGCTTCTGAAGCCCGCACTGCCACCGCTCCTG CCCCAGAAGGTTGTTTAGTTTCCACGTAGGCAGGTCGCTTTGTGCCTCTGAGTGCGCTGCTGTGTGTTCTCTCTATAGTTCTGTGTCATA AAGCTGTCCTGGCCAGCCTTCAAGCTGGTGTGGCCACTCTTGATGTGAGGCGTGTCGGTTCCAGGGGGGACATGGGAGGGGCTGCACAGT GGCCCGAGGTCATGCTTGCTTCCACCTGCAGGTGCATTTGGTCCTTTCCATGGCCAGGAAGCCCTGTGGGCTGCACTTTTTATGCTTGCA GTAACAAGAGACTCCAGAGTCCTCACCGGTGCAGAGTTGGCACATATTAATTAACTAAAATTCTAATGATCTTGCTACCAGCAATAAATC >33643_33643_5_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000306090_RTFDC1_chr20_55059167_ENST00000357348_length(amino acids)=244AA_BP=71 MGCLGNSKTEDQRNEEKAQREANKKIEKQLQKDKQVYRATHRLLLLGAGESGKSTIVKQMRILHVNGFNGEFCFLRCCGCVFSERALKEI KAEVCHTCGAAFQEDDVIMLNGTKEDVDVLKTRMEERRLRAKLEKKTKKPKAAESVSKPDVSEEAPGPSKVKTGKPEEASLDSREKKTNL -------------------------------------------------------------- >33643_33643_6_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000306090_RTFDC1_chr20_55059167_ENST00000395881_length(transcript)=1444nt_BP=354nt CAGCGGCGGCAGCAGCTCCCGCAGCTCCTGCTCTGGTCCGCCTCGGCCCGGCGGCGGCCATCAGCCCCCTCGGCCTCGGCTCGAGGGGCG GGGAGCTGCGCGCGCCCCTCGGTCCGACCGACACCCTCCCCTTCCCGCCCCCATGGGCTGCCTCGGGAACAGTAAGACCGAGGACCAGCG CAACGAGGAGAAGGCGCAGCGTGAGGCCAACAAAAAGATCGAGAAGCAGCTGCAGAAGGACAAGCAGGTCTACCGGGCCACGCACCGCCT GCTGCTGCTGGGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTAATGGAGAGTTCTG CTTCCTTCGGTGCTGCGGCTGTGTGTTTTCTGAGCGAGCCTTGAAAGAGATAAAAGCGGAAGTTTGCCACACGTGTGGGGCTGCCTTCCA GGAGGATGATGTCATCATGCTCAATGGCACCAAGGAGGATGTGGACGTGCTGAAGACAAGGATGGAGGAGAGAAGGCTGAGAGCGAAGCT GGAAAAGAAGCCCCAGGGCCATCAAAAGTTAAGACAGGGAAGCCTGAAGAAGCCAGCCTTGATTCTAGAGAGAAGAAAACCAACTTGGCT CCCAAAAGCACAGCAATGAATGAGAGCTCTTCTGGAAAAGCTGGGAAGCCTCCGTGTGGAGCCACAAAGAGGTCCATCGCTGACAGTGAA GAATCGGAGGCCTACAAGTCCCTCTTTACCACTCACAGCTCCGCCAAGCGCTCCAAGGAGGAGTCTGCCCACTGGGTCACCCACACGTCC TACTGCTTCTGAAGCCCGCACTGCCACCGCTCCTGCCCCAGAAGGTTGTTTAGTTTCCACGTAGGCAGGTCGCTTTGTGCCTCTGAGTGC GCTGCTGTGTGTTCTCTCTATAGTTCTGTGTCATAAAGCTGTCCTGGCCAGCCTTCAAGCTGGTGTGGCCACTCTTGATGTGAGGCGTGT CGGTTCCAGGGGGGACATGGGAGGGGCTGCACAGTGGCCCGAGGTCATGCTTGCTTCCACCTGCAGGTGCATTTGGTCCTTTCCATGGCC AGGAAGCCCTGTGGGCTGCACTTTTTATGCTTGCAGTAACAAGAGACTCCAGAGTCCTCACCGGTGCAGAGTTGGCACATATTAATTAAC TAAAATTCTAATGATCTTGCTACCAGCAATAAATCAAGTAGGCCAAGTGAAACTGGGCTTTAAAAAGGATGGATTTCAAATACACTGTGC CCACTAGAAGCTTCGAAGGGCCTCGTCCCTCTGCTACAGCCCTGGGAGGAGCCAGGATCCTTGTTGGTCTAGCTAAATACTGTTAGGGGA GTGTGCCCCATCTCATCATTTCGAAGATAGCAGAGTCATAGTTGGGCACCCAGTGATTGGGTTCAAAAATAAAGCTGGTCTGCCTCTTCT >33643_33643_6_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000306090_RTFDC1_chr20_55059167_ENST00000395881_length(amino acids)=188AA_BP=6 MMALGLLFQLRSQPSLLHPCLQHVHILLGAIEHDDIILLEGSPTRVANFRFYLFQGSLRKHTAAAPKEAELSIKPINMQDPHLLHNGAFT RFSSTQQQQAVRGPVDLLVLLQLLLDLFVGLTLRLLLVALVLGLTVPEAAHGGGKGRVSVGPRGARSSPPLEPRPRGLMAAAGPRRTRAG -------------------------------------------------------------- >33643_33643_7_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000354359_RTFDC1_chr20_55059167_ENST00000023939_length(transcript)=1781nt_BP=636nt TCGCCGCCGCCGCCTCCTCCTCCCCCCGCCTCCCCCCGCCCGCCGCGGCGCTTTTGGCTCGGGGCGGCGGCGGGGGCCCGGCCGAGGCAA TAAGAGCGGCGGCGGCGGCAGCGGCGGCAGCAGCTCCCGCAGCTCCTGCTCTGGTCCGCCTCGGCCCGGCGGCGGCCATCAGCCCCCTCG GCCTCGGCTCGAGGGGCGGGGAGCTGCGCGCGCCCCTCGGTCCGACCGACACCCTCCCCTTCCCGCCCGTCCGCGCGCCCCGCGGCCCGC GGCCCGCAGTCCGCCCCGCGCGCTCCTTGCCGAGGAGCCGAGCCCGCGCCCGGCCCGCCCGCCCGGCGCTGCCCCGGCCCTCCCGGCCCG CGTGAGGCCGCCCGCGCCCGCCGCCGCCGCAGCCCGGCCGCGCCCCGCCGCCGCCGCCGCCGCCATGGGCTGCCTCGGGAACAGTAAGAC CGAGGACCAGCGCAACGAGGAGAAGGCGCAGCGTGAGGCCAACAAAAAGATCGAGAAGCAGCTGCAGAAGGACAAGCAGGTCTACCGGGC CACGCACCGCCTGCTGCTGCTGGGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTAA TGGAGAGTTCTGCTTCCTTCGGTGCTGCGGCTGTGTGTTTTCTGAGCGAGCCTTGAAAGAGATAAAAGCGGAAGTTTGCCACACGTGTGG GGCTGCCTTCCAGGAGGATGATGTCATCATGCTCAATGGCACCAAGGAGGATGTGGACGTGCTGAAGACAAGGATGGAGGAGAGAAGGCT GAGAGCGAAGCTGGAAAAGAAAACAAAGAAACCCAAGGCAGCAGAGTCTGTTTCAAAACCAGATGTCAGTGAAGAAGCCCCAGGGCCATC AAAAGTTAAGACAGGGAAGCCTGAAGAAGCCAGCCTTGATTCTAGAGAGAAGAAAACCAACTTGGCTCCCAAAAGCACAGCAATGAATGA GAGCTCTTCTGGAAAAGCTGGGAAGCCTCCGTGTGGAGCCACAAAGAGGTCCATCGCTGACAGTGAAGAATCGGAGGCCTACAAGTCCCT CTTTACCACTCACAGCTCCGCCAAGCGCTCCAAGGAGGAGTCTGCCCACTGGGTCACCCACACGTCCTACTGCTTCTGAAGCCCGCACTG CCACCGCTCCTGCCCCAGAAGGTTGTTTAGTTTCCACGTAGGCAGGTCGCTTTGTGCCTCTGAGTGCGCTGCTGTGTGTTCTCTCTATAG TTCTGTGTCATAAAGCTGTCCTGGCCAGCCTTCAAGCTGGTGTGGCCACTCTTGATGTGAGGCGTGTCGGTTCCAGGGGGGACATGGGAG GGGCTGCACAGTGGCCCGAGGTCATGCTTGCTTCCACCTGCAGGTGCATTTGGTCCTTTCCATGGCCAGGAAGCCCTGTGGGCTGCACTT TTTATGCTTGCAGTAACAAGAGACTCCAGAGTCCTCACCGGTGCAGAGTTGGCACATATTAATTAACTAAAATTCTAATGATCTTGCTAC CAGCAATAAATCAAGTAGGCCAAGTGAAACTGGGCTTTAAAAAGGATGGATTTCAAATACACTGTGCCCACTAGAAGCTTCGAAGGGCCT CGTCCCTCTGCTACAGCCCTGGGAGGAGCCAGGATCCTTGTTGGTCTAGCTAAATACTGTTAGGGGAGTGTGCCCCATCTCATCATTTCG >33643_33643_7_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000354359_RTFDC1_chr20_55059167_ENST00000023939_length(amino acids)=244AA_BP=71 MGCLGNSKTEDQRNEEKAQREANKKIEKQLQKDKQVYRATHRLLLLGAGESGKSTIVKQMRILHVNGFNGEFCFLRCCGCVFSERALKEI KAEVCHTCGAAFQEDDVIMLNGTKEDVDVLKTRMEERRLRAKLEKKTKKPKAAESVSKPDVSEEAPGPSKVKTGKPEEASLDSREKKTNL -------------------------------------------------------------- >33643_33643_8_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000354359_RTFDC1_chr20_55059167_ENST00000357348_length(transcript)=1568nt_BP=636nt TCGCCGCCGCCGCCTCCTCCTCCCCCCGCCTCCCCCCGCCCGCCGCGGCGCTTTTGGCTCGGGGCGGCGGCGGGGGCCCGGCCGAGGCAA TAAGAGCGGCGGCGGCGGCAGCGGCGGCAGCAGCTCCCGCAGCTCCTGCTCTGGTCCGCCTCGGCCCGGCGGCGGCCATCAGCCCCCTCG GCCTCGGCTCGAGGGGCGGGGAGCTGCGCGCGCCCCTCGGTCCGACCGACACCCTCCCCTTCCCGCCCGTCCGCGCGCCCCGCGGCCCGC GGCCCGCAGTCCGCCCCGCGCGCTCCTTGCCGAGGAGCCGAGCCCGCGCCCGGCCCGCCCGCCCGGCGCTGCCCCGGCCCTCCCGGCCCG CGTGAGGCCGCCCGCGCCCGCCGCCGCCGCAGCCCGGCCGCGCCCCGCCGCCGCCGCCGCCGCCATGGGCTGCCTCGGGAACAGTAAGAC CGAGGACCAGCGCAACGAGGAGAAGGCGCAGCGTGAGGCCAACAAAAAGATCGAGAAGCAGCTGCAGAAGGACAAGCAGGTCTACCGGGC CACGCACCGCCTGCTGCTGCTGGGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTAA TGGAGAGTTCTGCTTCCTTCGGTGCTGCGGCTGTGTGTTTTCTGAGCGAGCCTTGAAAGAGATAAAAGCGGAAGTTTGCCACACGTGTGG GGCTGCCTTCCAGGAGGATGATGTCATCATGCTCAATGGCACCAAGGAGGATGTGGACGTGCTGAAGACAAGGATGGAGGAGAGAAGGCT GAGAGCGAAGCTGGAAAAGAAAACAAAGAAACCCAAGGCAGCAGAGTCTGTTTCAAAACCAGATGTCAGTGAAGAAGCCCCAGGGCCATC AAAAGTTAAGACAGGGAAGCCTGAAGAAGCCAGCCTTGATTCTAGAGAGAAGAAAACCAACTTGGCTCCCAAAAGCACAGCAATGAATGA GAGCTCTTCTGGAAAAGCTGGGAAGCCTCCGTGTGGAGCCACAAAGAGGTCCATCGCTGACAGTGAAGAATCGGAGGCCTACAAGTCCCT CTTTACCACTCACAGCTCCGCCAAGCGCTCCAAGGAGGAGTCTGCCCACTGGGTCACCCACACGTCCTACTGCTTCTGAAGCCCGCACTG CCACCGCTCCTGCCCCAGAAGGTTGTTTAGTTTCCACGTAGGCAGGTCGCTTTGTGCCTCTGAGTGCGCTGCTGTGTGTTCTCTCTATAG TTCTGTGTCATAAAGCTGTCCTGGCCAGCCTTCAAGCTGGTGTGGCCACTCTTGATGTGAGGCGTGTCGGTTCCAGGGGGGACATGGGAG GGGCTGCACAGTGGCCCGAGGTCATGCTTGCTTCCACCTGCAGGTGCATTTGGTCCTTTCCATGGCCAGGAAGCCCTGTGGGCTGCACTT TTTATGCTTGCAGTAACAAGAGACTCCAGAGTCCTCACCGGTGCAGAGTTGGCACATATTAATTAACTAAAATTCTAATGATCTTGCTAC >33643_33643_8_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000354359_RTFDC1_chr20_55059167_ENST00000357348_length(amino acids)=244AA_BP=71 MGCLGNSKTEDQRNEEKAQREANKKIEKQLQKDKQVYRATHRLLLLGAGESGKSTIVKQMRILHVNGFNGEFCFLRCCGCVFSERALKEI KAEVCHTCGAAFQEDDVIMLNGTKEDVDVLKTRMEERRLRAKLEKKTKKPKAAESVSKPDVSEEAPGPSKVKTGKPEEASLDSREKKTNL -------------------------------------------------------------- >33643_33643_9_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000354359_RTFDC1_chr20_55059167_ENST00000395881_length(transcript)=1726nt_BP=636nt TCGCCGCCGCCGCCTCCTCCTCCCCCCGCCTCCCCCCGCCCGCCGCGGCGCTTTTGGCTCGGGGCGGCGGCGGGGGCCCGGCCGAGGCAA TAAGAGCGGCGGCGGCGGCAGCGGCGGCAGCAGCTCCCGCAGCTCCTGCTCTGGTCCGCCTCGGCCCGGCGGCGGCCATCAGCCCCCTCG GCCTCGGCTCGAGGGGCGGGGAGCTGCGCGCGCCCCTCGGTCCGACCGACACCCTCCCCTTCCCGCCCGTCCGCGCGCCCCGCGGCCCGC GGCCCGCAGTCCGCCCCGCGCGCTCCTTGCCGAGGAGCCGAGCCCGCGCCCGGCCCGCCCGCCCGGCGCTGCCCCGGCCCTCCCGGCCCG CGTGAGGCCGCCCGCGCCCGCCGCCGCCGCAGCCCGGCCGCGCCCCGCCGCCGCCGCCGCCGCCATGGGCTGCCTCGGGAACAGTAAGAC CGAGGACCAGCGCAACGAGGAGAAGGCGCAGCGTGAGGCCAACAAAAAGATCGAGAAGCAGCTGCAGAAGGACAAGCAGGTCTACCGGGC CACGCACCGCCTGCTGCTGCTGGGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTAA TGGAGAGTTCTGCTTCCTTCGGTGCTGCGGCTGTGTGTTTTCTGAGCGAGCCTTGAAAGAGATAAAAGCGGAAGTTTGCCACACGTGTGG GGCTGCCTTCCAGGAGGATGATGTCATCATGCTCAATGGCACCAAGGAGGATGTGGACGTGCTGAAGACAAGGATGGAGGAGAGAAGGCT GAGAGCGAAGCTGGAAAAGAAGCCCCAGGGCCATCAAAAGTTAAGACAGGGAAGCCTGAAGAAGCCAGCCTTGATTCTAGAGAGAAGAAA ACCAACTTGGCTCCCAAAAGCACAGCAATGAATGAGAGCTCTTCTGGAAAAGCTGGGAAGCCTCCGTGTGGAGCCACAAAGAGGTCCATC GCTGACAGTGAAGAATCGGAGGCCTACAAGTCCCTCTTTACCACTCACAGCTCCGCCAAGCGCTCCAAGGAGGAGTCTGCCCACTGGGTC ACCCACACGTCCTACTGCTTCTGAAGCCCGCACTGCCACCGCTCCTGCCCCAGAAGGTTGTTTAGTTTCCACGTAGGCAGGTCGCTTTGT GCCTCTGAGTGCGCTGCTGTGTGTTCTCTCTATAGTTCTGTGTCATAAAGCTGTCCTGGCCAGCCTTCAAGCTGGTGTGGCCACTCTTGA TGTGAGGCGTGTCGGTTCCAGGGGGGACATGGGAGGGGCTGCACAGTGGCCCGAGGTCATGCTTGCTTCCACCTGCAGGTGCATTTGGTC CTTTCCATGGCCAGGAAGCCCTGTGGGCTGCACTTTTTATGCTTGCAGTAACAAGAGACTCCAGAGTCCTCACCGGTGCAGAGTTGGCAC ATATTAATTAACTAAAATTCTAATGATCTTGCTACCAGCAATAAATCAAGTAGGCCAAGTGAAACTGGGCTTTAAAAAGGATGGATTTCA AATACACTGTGCCCACTAGAAGCTTCGAAGGGCCTCGTCCCTCTGCTACAGCCCTGGGAGGAGCCAGGATCCTTGTTGGTCTAGCTAAAT ACTGTTAGGGGAGTGTGCCCCATCTCATCATTTCGAAGATAGCAGAGTCATAGTTGGGCACCCAGTGATTGGGTTCAAAAATAAAGCTGG >33643_33643_9_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000354359_RTFDC1_chr20_55059167_ENST00000395881_length(amino acids)=282AA_BP=6 MMALGLLFQLRSQPSLLHPCLQHVHILLGAIEHDDIILLEGSPTRVANFRFYLFQGSLRKHTAAAPKEAELSIKPINMQDPHLLHNGAFT RFSSTQQQQAVRGPVDLLVLLQLLLDLFVGLTLRLLLVALVLGLTVPEAAHGGGGGGGARPGCGGGGRGRPHAGREGRGSAGRAGRARAR LLGKERAGRTAGRGPRGARTGGKGRVSVGPRGARSSPPLEPRPRGLMAAAGPRRTRAGAAGAAAAAAAAAALIASAGPPPPPRAKSAAAG -------------------------------------------------------------- >33643_33643_10_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000371081_RTFDC1_chr20_55059167_ENST00000023939_length(transcript)=1368nt_BP=223nt CCGCCGCCGCCATGGGCTGCCTCGGGAACAGTAAGACCGAGGACCAGCGCAACGAGGAGAAGGCGCAGCGTGAGGCCAACAAAAAGATCG AGAAGCAGCTGCAGAAGGACAAGCAGGTCTACCGGGCCACGCACCGCCTGCTGCTGCTGGGTGCTGGAGAATCTGGTAAAAGCACCATTG TGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTAATGGAGAGTTCTGCTTCCTTCGGTGCTGCGGCTGTGTGTTTTCTGAGCGAGCCT TGAAAGAGATAAAAGCGGAAGTTTGCCACACGTGTGGGGCTGCCTTCCAGGAGGATGATGTCATCATGCTCAATGGCACCAAGGAGGATG TGGACGTGCTGAAGACAAGGATGGAGGAGAGAAGGCTGAGAGCGAAGCTGGAAAAGAAAACAAAGAAACCCAAGGCAGCAGAGTCTGTTT CAAAACCAGATGTCAGTGAAGAAGCCCCAGGGCCATCAAAAGTTAAGACAGGGAAGCCTGAAGAAGCCAGCCTTGATTCTAGAGAGAAGA AAACCAACTTGGCTCCCAAAAGCACAGCAATGAATGAGAGCTCTTCTGGAAAAGCTGGGAAGCCTCCGTGTGGAGCCACAAAGAGGTCCA TCGCTGACAGTGAAGAATCGGAGGCCTACAAGTCCCTCTTTACCACTCACAGCTCCGCCAAGCGCTCCAAGGAGGAGTCTGCCCACTGGG TCACCCACACGTCCTACTGCTTCTGAAGCCCGCACTGCCACCGCTCCTGCCCCAGAAGGTTGTTTAGTTTCCACGTAGGCAGGTCGCTTT GTGCCTCTGAGTGCGCTGCTGTGTGTTCTCTCTATAGTTCTGTGTCATAAAGCTGTCCTGGCCAGCCTTCAAGCTGGTGTGGCCACTCTT GATGTGAGGCGTGTCGGTTCCAGGGGGGACATGGGAGGGGCTGCACAGTGGCCCGAGGTCATGCTTGCTTCCACCTGCAGGTGCATTTGG TCCTTTCCATGGCCAGGAAGCCCTGTGGGCTGCACTTTTTATGCTTGCAGTAACAAGAGACTCCAGAGTCCTCACCGGTGCAGAGTTGGC ACATATTAATTAACTAAAATTCTAATGATCTTGCTACCAGCAATAAATCAAGTAGGCCAAGTGAAACTGGGCTTTAAAAAGGATGGATTT CAAATACACTGTGCCCACTAGAAGCTTCGAAGGGCCTCGTCCCTCTGCTACAGCCCTGGGAGGAGCCAGGATCCTTGTTGGTCTAGCTAA ATACTGTTAGGGGAGTGTGCCCCATCTCATCATTTCGAAGATAGCAGAGTCATAGTTGGGCACCCAGTGATTGGGTTCAAAAATAAAGCT >33643_33643_10_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000371081_RTFDC1_chr20_55059167_ENST00000023939_length(amino acids)=244AA_BP=71 MGCLGNSKTEDQRNEEKAQREANKKIEKQLQKDKQVYRATHRLLLLGAGESGKSTIVKQMRILHVNGFNGEFCFLRCCGCVFSERALKEI KAEVCHTCGAAFQEDDVIMLNGTKEDVDVLKTRMEERRLRAKLEKKTKKPKAAESVSKPDVSEEAPGPSKVKTGKPEEASLDSREKKTNL -------------------------------------------------------------- >33643_33643_11_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000371081_RTFDC1_chr20_55059167_ENST00000357348_length(transcript)=1155nt_BP=223nt CCGCCGCCGCCATGGGCTGCCTCGGGAACAGTAAGACCGAGGACCAGCGCAACGAGGAGAAGGCGCAGCGTGAGGCCAACAAAAAGATCG AGAAGCAGCTGCAGAAGGACAAGCAGGTCTACCGGGCCACGCACCGCCTGCTGCTGCTGGGTGCTGGAGAATCTGGTAAAAGCACCATTG TGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTAATGGAGAGTTCTGCTTCCTTCGGTGCTGCGGCTGTGTGTTTTCTGAGCGAGCCT TGAAAGAGATAAAAGCGGAAGTTTGCCACACGTGTGGGGCTGCCTTCCAGGAGGATGATGTCATCATGCTCAATGGCACCAAGGAGGATG TGGACGTGCTGAAGACAAGGATGGAGGAGAGAAGGCTGAGAGCGAAGCTGGAAAAGAAAACAAAGAAACCCAAGGCAGCAGAGTCTGTTT CAAAACCAGATGTCAGTGAAGAAGCCCCAGGGCCATCAAAAGTTAAGACAGGGAAGCCTGAAGAAGCCAGCCTTGATTCTAGAGAGAAGA AAACCAACTTGGCTCCCAAAAGCACAGCAATGAATGAGAGCTCTTCTGGAAAAGCTGGGAAGCCTCCGTGTGGAGCCACAAAGAGGTCCA TCGCTGACAGTGAAGAATCGGAGGCCTACAAGTCCCTCTTTACCACTCACAGCTCCGCCAAGCGCTCCAAGGAGGAGTCTGCCCACTGGG TCACCCACACGTCCTACTGCTTCTGAAGCCCGCACTGCCACCGCTCCTGCCCCAGAAGGTTGTTTAGTTTCCACGTAGGCAGGTCGCTTT GTGCCTCTGAGTGCGCTGCTGTGTGTTCTCTCTATAGTTCTGTGTCATAAAGCTGTCCTGGCCAGCCTTCAAGCTGGTGTGGCCACTCTT GATGTGAGGCGTGTCGGTTCCAGGGGGGACATGGGAGGGGCTGCACAGTGGCCCGAGGTCATGCTTGCTTCCACCTGCAGGTGCATTTGG TCCTTTCCATGGCCAGGAAGCCCTGTGGGCTGCACTTTTTATGCTTGCAGTAACAAGAGACTCCAGAGTCCTCACCGGTGCAGAGTTGGC >33643_33643_11_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000371081_RTFDC1_chr20_55059167_ENST00000357348_length(amino acids)=244AA_BP=71 MGCLGNSKTEDQRNEEKAQREANKKIEKQLQKDKQVYRATHRLLLLGAGESGKSTIVKQMRILHVNGFNGEFCFLRCCGCVFSERALKEI KAEVCHTCGAAFQEDDVIMLNGTKEDVDVLKTRMEERRLRAKLEKKTKKPKAAESVSKPDVSEEAPGPSKVKTGKPEEASLDSREKKTNL -------------------------------------------------------------- >33643_33643_12_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000371081_RTFDC1_chr20_55059167_ENST00000395881_length(transcript)=1313nt_BP=223nt CCGCCGCCGCCATGGGCTGCCTCGGGAACAGTAAGACCGAGGACCAGCGCAACGAGGAGAAGGCGCAGCGTGAGGCCAACAAAAAGATCG AGAAGCAGCTGCAGAAGGACAAGCAGGTCTACCGGGCCACGCACCGCCTGCTGCTGCTGGGTGCTGGAGAATCTGGTAAAAGCACCATTG TGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTAATGGAGAGTTCTGCTTCCTTCGGTGCTGCGGCTGTGTGTTTTCTGAGCGAGCCT TGAAAGAGATAAAAGCGGAAGTTTGCCACACGTGTGGGGCTGCCTTCCAGGAGGATGATGTCATCATGCTCAATGGCACCAAGGAGGATG TGGACGTGCTGAAGACAAGGATGGAGGAGAGAAGGCTGAGAGCGAAGCTGGAAAAGAAGCCCCAGGGCCATCAAAAGTTAAGACAGGGAA GCCTGAAGAAGCCAGCCTTGATTCTAGAGAGAAGAAAACCAACTTGGCTCCCAAAAGCACAGCAATGAATGAGAGCTCTTCTGGAAAAGC TGGGAAGCCTCCGTGTGGAGCCACAAAGAGGTCCATCGCTGACAGTGAAGAATCGGAGGCCTACAAGTCCCTCTTTACCACTCACAGCTC CGCCAAGCGCTCCAAGGAGGAGTCTGCCCACTGGGTCACCCACACGTCCTACTGCTTCTGAAGCCCGCACTGCCACCGCTCCTGCCCCAG AAGGTTGTTTAGTTTCCACGTAGGCAGGTCGCTTTGTGCCTCTGAGTGCGCTGCTGTGTGTTCTCTCTATAGTTCTGTGTCATAAAGCTG TCCTGGCCAGCCTTCAAGCTGGTGTGGCCACTCTTGATGTGAGGCGTGTCGGTTCCAGGGGGGACATGGGAGGGGCTGCACAGTGGCCCG AGGTCATGCTTGCTTCCACCTGCAGGTGCATTTGGTCCTTTCCATGGCCAGGAAGCCCTGTGGGCTGCACTTTTTATGCTTGCAGTAACA AGAGACTCCAGAGTCCTCACCGGTGCAGAGTTGGCACATATTAATTAACTAAAATTCTAATGATCTTGCTACCAGCAATAAATCAAGTAG GCCAAGTGAAACTGGGCTTTAAAAAGGATGGATTTCAAATACACTGTGCCCACTAGAAGCTTCGAAGGGCCTCGTCCCTCTGCTACAGCC CTGGGAGGAGCCAGGATCCTTGTTGGTCTAGCTAAATACTGTTAGGGGAGTGTGCCCCATCTCATCATTTCGAAGATAGCAGAGTCATAG >33643_33643_12_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000371081_RTFDC1_chr20_55059167_ENST00000395881_length(amino acids)=168AA_BP=71 MGCLGNSKTEDQRNEEKAQREANKKIEKQLQKDKQVYRATHRLLLLGAGESGKSTIVKQMRILHVNGFNGEFCFLRCCGCVFSERALKEI -------------------------------------------------------------- >33643_33643_13_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000371085_RTFDC1_chr20_55059167_ENST00000023939_length(transcript)=1781nt_BP=636nt TCGCCGCCGCCGCCTCCTCCTCCCCCCGCCTCCCCCCGCCCGCCGCGGCGCTTTTGGCTCGGGGCGGCGGCGGGGGCCCGGCCGAGGCAA TAAGAGCGGCGGCGGCGGCAGCGGCGGCAGCAGCTCCCGCAGCTCCTGCTCTGGTCCGCCTCGGCCCGGCGGCGGCCATCAGCCCCCTCG GCCTCGGCTCGAGGGGCGGGGAGCTGCGCGCGCCCCTCGGTCCGACCGACACCCTCCCCTTCCCGCCCGTCCGCGCGCCCCGCGGCCCGC GGCCCGCAGTCCGCCCCGCGCGCTCCTTGCCGAGGAGCCGAGCCCGCGCCCGGCCCGCCCGCCCGGCGCTGCCCCGGCCCTCCCGGCCCG CGTGAGGCCGCCCGCGCCCGCCGCCGCCGCAGCCCGGCCGCGCCCCGCCGCCGCCGCCGCCGCCATGGGCTGCCTCGGGAACAGTAAGAC CGAGGACCAGCGCAACGAGGAGAAGGCGCAGCGTGAGGCCAACAAAAAGATCGAGAAGCAGCTGCAGAAGGACAAGCAGGTCTACCGGGC CACGCACCGCCTGCTGCTGCTGGGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTAA TGGAGAGTTCTGCTTCCTTCGGTGCTGCGGCTGTGTGTTTTCTGAGCGAGCCTTGAAAGAGATAAAAGCGGAAGTTTGCCACACGTGTGG GGCTGCCTTCCAGGAGGATGATGTCATCATGCTCAATGGCACCAAGGAGGATGTGGACGTGCTGAAGACAAGGATGGAGGAGAGAAGGCT GAGAGCGAAGCTGGAAAAGAAAACAAAGAAACCCAAGGCAGCAGAGTCTGTTTCAAAACCAGATGTCAGTGAAGAAGCCCCAGGGCCATC AAAAGTTAAGACAGGGAAGCCTGAAGAAGCCAGCCTTGATTCTAGAGAGAAGAAAACCAACTTGGCTCCCAAAAGCACAGCAATGAATGA GAGCTCTTCTGGAAAAGCTGGGAAGCCTCCGTGTGGAGCCACAAAGAGGTCCATCGCTGACAGTGAAGAATCGGAGGCCTACAAGTCCCT CTTTACCACTCACAGCTCCGCCAAGCGCTCCAAGGAGGAGTCTGCCCACTGGGTCACCCACACGTCCTACTGCTTCTGAAGCCCGCACTG CCACCGCTCCTGCCCCAGAAGGTTGTTTAGTTTCCACGTAGGCAGGTCGCTTTGTGCCTCTGAGTGCGCTGCTGTGTGTTCTCTCTATAG TTCTGTGTCATAAAGCTGTCCTGGCCAGCCTTCAAGCTGGTGTGGCCACTCTTGATGTGAGGCGTGTCGGTTCCAGGGGGGACATGGGAG GGGCTGCACAGTGGCCCGAGGTCATGCTTGCTTCCACCTGCAGGTGCATTTGGTCCTTTCCATGGCCAGGAAGCCCTGTGGGCTGCACTT TTTATGCTTGCAGTAACAAGAGACTCCAGAGTCCTCACCGGTGCAGAGTTGGCACATATTAATTAACTAAAATTCTAATGATCTTGCTAC CAGCAATAAATCAAGTAGGCCAAGTGAAACTGGGCTTTAAAAAGGATGGATTTCAAATACACTGTGCCCACTAGAAGCTTCGAAGGGCCT CGTCCCTCTGCTACAGCCCTGGGAGGAGCCAGGATCCTTGTTGGTCTAGCTAAATACTGTTAGGGGAGTGTGCCCCATCTCATCATTTCG >33643_33643_13_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000371085_RTFDC1_chr20_55059167_ENST00000023939_length(amino acids)=244AA_BP=71 MGCLGNSKTEDQRNEEKAQREANKKIEKQLQKDKQVYRATHRLLLLGAGESGKSTIVKQMRILHVNGFNGEFCFLRCCGCVFSERALKEI KAEVCHTCGAAFQEDDVIMLNGTKEDVDVLKTRMEERRLRAKLEKKTKKPKAAESVSKPDVSEEAPGPSKVKTGKPEEASLDSREKKTNL -------------------------------------------------------------- >33643_33643_14_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000371085_RTFDC1_chr20_55059167_ENST00000357348_length(transcript)=1568nt_BP=636nt TCGCCGCCGCCGCCTCCTCCTCCCCCCGCCTCCCCCCGCCCGCCGCGGCGCTTTTGGCTCGGGGCGGCGGCGGGGGCCCGGCCGAGGCAA TAAGAGCGGCGGCGGCGGCAGCGGCGGCAGCAGCTCCCGCAGCTCCTGCTCTGGTCCGCCTCGGCCCGGCGGCGGCCATCAGCCCCCTCG GCCTCGGCTCGAGGGGCGGGGAGCTGCGCGCGCCCCTCGGTCCGACCGACACCCTCCCCTTCCCGCCCGTCCGCGCGCCCCGCGGCCCGC GGCCCGCAGTCCGCCCCGCGCGCTCCTTGCCGAGGAGCCGAGCCCGCGCCCGGCCCGCCCGCCCGGCGCTGCCCCGGCCCTCCCGGCCCG CGTGAGGCCGCCCGCGCCCGCCGCCGCCGCAGCCCGGCCGCGCCCCGCCGCCGCCGCCGCCGCCATGGGCTGCCTCGGGAACAGTAAGAC CGAGGACCAGCGCAACGAGGAGAAGGCGCAGCGTGAGGCCAACAAAAAGATCGAGAAGCAGCTGCAGAAGGACAAGCAGGTCTACCGGGC CACGCACCGCCTGCTGCTGCTGGGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTAA TGGAGAGTTCTGCTTCCTTCGGTGCTGCGGCTGTGTGTTTTCTGAGCGAGCCTTGAAAGAGATAAAAGCGGAAGTTTGCCACACGTGTGG GGCTGCCTTCCAGGAGGATGATGTCATCATGCTCAATGGCACCAAGGAGGATGTGGACGTGCTGAAGACAAGGATGGAGGAGAGAAGGCT GAGAGCGAAGCTGGAAAAGAAAACAAAGAAACCCAAGGCAGCAGAGTCTGTTTCAAAACCAGATGTCAGTGAAGAAGCCCCAGGGCCATC AAAAGTTAAGACAGGGAAGCCTGAAGAAGCCAGCCTTGATTCTAGAGAGAAGAAAACCAACTTGGCTCCCAAAAGCACAGCAATGAATGA GAGCTCTTCTGGAAAAGCTGGGAAGCCTCCGTGTGGAGCCACAAAGAGGTCCATCGCTGACAGTGAAGAATCGGAGGCCTACAAGTCCCT CTTTACCACTCACAGCTCCGCCAAGCGCTCCAAGGAGGAGTCTGCCCACTGGGTCACCCACACGTCCTACTGCTTCTGAAGCCCGCACTG CCACCGCTCCTGCCCCAGAAGGTTGTTTAGTTTCCACGTAGGCAGGTCGCTTTGTGCCTCTGAGTGCGCTGCTGTGTGTTCTCTCTATAG TTCTGTGTCATAAAGCTGTCCTGGCCAGCCTTCAAGCTGGTGTGGCCACTCTTGATGTGAGGCGTGTCGGTTCCAGGGGGGACATGGGAG GGGCTGCACAGTGGCCCGAGGTCATGCTTGCTTCCACCTGCAGGTGCATTTGGTCCTTTCCATGGCCAGGAAGCCCTGTGGGCTGCACTT TTTATGCTTGCAGTAACAAGAGACTCCAGAGTCCTCACCGGTGCAGAGTTGGCACATATTAATTAACTAAAATTCTAATGATCTTGCTAC >33643_33643_14_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000371085_RTFDC1_chr20_55059167_ENST00000357348_length(amino acids)=244AA_BP=71 MGCLGNSKTEDQRNEEKAQREANKKIEKQLQKDKQVYRATHRLLLLGAGESGKSTIVKQMRILHVNGFNGEFCFLRCCGCVFSERALKEI KAEVCHTCGAAFQEDDVIMLNGTKEDVDVLKTRMEERRLRAKLEKKTKKPKAAESVSKPDVSEEAPGPSKVKTGKPEEASLDSREKKTNL -------------------------------------------------------------- >33643_33643_15_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000371085_RTFDC1_chr20_55059167_ENST00000395881_length(transcript)=1726nt_BP=636nt TCGCCGCCGCCGCCTCCTCCTCCCCCCGCCTCCCCCCGCCCGCCGCGGCGCTTTTGGCTCGGGGCGGCGGCGGGGGCCCGGCCGAGGCAA TAAGAGCGGCGGCGGCGGCAGCGGCGGCAGCAGCTCCCGCAGCTCCTGCTCTGGTCCGCCTCGGCCCGGCGGCGGCCATCAGCCCCCTCG GCCTCGGCTCGAGGGGCGGGGAGCTGCGCGCGCCCCTCGGTCCGACCGACACCCTCCCCTTCCCGCCCGTCCGCGCGCCCCGCGGCCCGC GGCCCGCAGTCCGCCCCGCGCGCTCCTTGCCGAGGAGCCGAGCCCGCGCCCGGCCCGCCCGCCCGGCGCTGCCCCGGCCCTCCCGGCCCG CGTGAGGCCGCCCGCGCCCGCCGCCGCCGCAGCCCGGCCGCGCCCCGCCGCCGCCGCCGCCGCCATGGGCTGCCTCGGGAACAGTAAGAC CGAGGACCAGCGCAACGAGGAGAAGGCGCAGCGTGAGGCCAACAAAAAGATCGAGAAGCAGCTGCAGAAGGACAAGCAGGTCTACCGGGC CACGCACCGCCTGCTGCTGCTGGGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTAA TGGAGAGTTCTGCTTCCTTCGGTGCTGCGGCTGTGTGTTTTCTGAGCGAGCCTTGAAAGAGATAAAAGCGGAAGTTTGCCACACGTGTGG GGCTGCCTTCCAGGAGGATGATGTCATCATGCTCAATGGCACCAAGGAGGATGTGGACGTGCTGAAGACAAGGATGGAGGAGAGAAGGCT GAGAGCGAAGCTGGAAAAGAAGCCCCAGGGCCATCAAAAGTTAAGACAGGGAAGCCTGAAGAAGCCAGCCTTGATTCTAGAGAGAAGAAA ACCAACTTGGCTCCCAAAAGCACAGCAATGAATGAGAGCTCTTCTGGAAAAGCTGGGAAGCCTCCGTGTGGAGCCACAAAGAGGTCCATC GCTGACAGTGAAGAATCGGAGGCCTACAAGTCCCTCTTTACCACTCACAGCTCCGCCAAGCGCTCCAAGGAGGAGTCTGCCCACTGGGTC ACCCACACGTCCTACTGCTTCTGAAGCCCGCACTGCCACCGCTCCTGCCCCAGAAGGTTGTTTAGTTTCCACGTAGGCAGGTCGCTTTGT GCCTCTGAGTGCGCTGCTGTGTGTTCTCTCTATAGTTCTGTGTCATAAAGCTGTCCTGGCCAGCCTTCAAGCTGGTGTGGCCACTCTTGA TGTGAGGCGTGTCGGTTCCAGGGGGGACATGGGAGGGGCTGCACAGTGGCCCGAGGTCATGCTTGCTTCCACCTGCAGGTGCATTTGGTC CTTTCCATGGCCAGGAAGCCCTGTGGGCTGCACTTTTTATGCTTGCAGTAACAAGAGACTCCAGAGTCCTCACCGGTGCAGAGTTGGCAC ATATTAATTAACTAAAATTCTAATGATCTTGCTACCAGCAATAAATCAAGTAGGCCAAGTGAAACTGGGCTTTAAAAAGGATGGATTTCA AATACACTGTGCCCACTAGAAGCTTCGAAGGGCCTCGTCCCTCTGCTACAGCCCTGGGAGGAGCCAGGATCCTTGTTGGTCTAGCTAAAT ACTGTTAGGGGAGTGTGCCCCATCTCATCATTTCGAAGATAGCAGAGTCATAGTTGGGCACCCAGTGATTGGGTTCAAAAATAAAGCTGG >33643_33643_15_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000371085_RTFDC1_chr20_55059167_ENST00000395881_length(amino acids)=282AA_BP=6 MMALGLLFQLRSQPSLLHPCLQHVHILLGAIEHDDIILLEGSPTRVANFRFYLFQGSLRKHTAAAPKEAELSIKPINMQDPHLLHNGAFT RFSSTQQQQAVRGPVDLLVLLQLLLDLFVGLTLRLLLVALVLGLTVPEAAHGGGGGGGARPGCGGGGRGRPHAGREGRGSAGRAGRARAR LLGKERAGRTAGRGPRGARTGGKGRVSVGPRGARSSPPLEPRPRGLMAAAGPRRTRAGAAGAAAAAAAAAALIASAGPPPPPRAKSAAAG -------------------------------------------------------------- >33643_33643_16_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000371095_RTFDC1_chr20_55059167_ENST00000023939_length(transcript)=1782nt_BP=637nt CTCGCCGCCGCCGCCTCCTCCTCCCCCCGCCTCCCCCCGCCCGCCGCGGCGCTTTTGGCTCGGGGCGGCGGCGGGGGCCCGGCCGAGGCA ATAAGAGCGGCGGCGGCGGCAGCGGCGGCAGCAGCTCCCGCAGCTCCTGCTCTGGTCCGCCTCGGCCCGGCGGCGGCCATCAGCCCCCTC GGCCTCGGCTCGAGGGGCGGGGAGCTGCGCGCGCCCCTCGGTCCGACCGACACCCTCCCCTTCCCGCCCGTCCGCGCGCCCCGCGGCCCG CGGCCCGCAGTCCGCCCCGCGCGCTCCTTGCCGAGGAGCCGAGCCCGCGCCCGGCCCGCCCGCCCGGCGCTGCCCCGGCCCTCCCGGCCC GCGTGAGGCCGCCCGCGCCCGCCGCCGCCGCAGCCCGGCCGCGCCCCGCCGCCGCCGCCGCCGCCATGGGCTGCCTCGGGAACAGTAAGA CCGAGGACCAGCGCAACGAGGAGAAGGCGCAGCGTGAGGCCAACAAAAAGATCGAGAAGCAGCTGCAGAAGGACAAGCAGGTCTACCGGG CCACGCACCGCCTGCTGCTGCTGGGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTA ATGGAGAGTTCTGCTTCCTTCGGTGCTGCGGCTGTGTGTTTTCTGAGCGAGCCTTGAAAGAGATAAAAGCGGAAGTTTGCCACACGTGTG GGGCTGCCTTCCAGGAGGATGATGTCATCATGCTCAATGGCACCAAGGAGGATGTGGACGTGCTGAAGACAAGGATGGAGGAGAGAAGGC TGAGAGCGAAGCTGGAAAAGAAAACAAAGAAACCCAAGGCAGCAGAGTCTGTTTCAAAACCAGATGTCAGTGAAGAAGCCCCAGGGCCAT CAAAAGTTAAGACAGGGAAGCCTGAAGAAGCCAGCCTTGATTCTAGAGAGAAGAAAACCAACTTGGCTCCCAAAAGCACAGCAATGAATG AGAGCTCTTCTGGAAAAGCTGGGAAGCCTCCGTGTGGAGCCACAAAGAGGTCCATCGCTGACAGTGAAGAATCGGAGGCCTACAAGTCCC TCTTTACCACTCACAGCTCCGCCAAGCGCTCCAAGGAGGAGTCTGCCCACTGGGTCACCCACACGTCCTACTGCTTCTGAAGCCCGCACT GCCACCGCTCCTGCCCCAGAAGGTTGTTTAGTTTCCACGTAGGCAGGTCGCTTTGTGCCTCTGAGTGCGCTGCTGTGTGTTCTCTCTATA GTTCTGTGTCATAAAGCTGTCCTGGCCAGCCTTCAAGCTGGTGTGGCCACTCTTGATGTGAGGCGTGTCGGTTCCAGGGGGGACATGGGA GGGGCTGCACAGTGGCCCGAGGTCATGCTTGCTTCCACCTGCAGGTGCATTTGGTCCTTTCCATGGCCAGGAAGCCCTGTGGGCTGCACT TTTTATGCTTGCAGTAACAAGAGACTCCAGAGTCCTCACCGGTGCAGAGTTGGCACATATTAATTAACTAAAATTCTAATGATCTTGCTA CCAGCAATAAATCAAGTAGGCCAAGTGAAACTGGGCTTTAAAAAGGATGGATTTCAAATACACTGTGCCCACTAGAAGCTTCGAAGGGCC TCGTCCCTCTGCTACAGCCCTGGGAGGAGCCAGGATCCTTGTTGGTCTAGCTAAATACTGTTAGGGGAGTGTGCCCCATCTCATCATTTC >33643_33643_16_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000371095_RTFDC1_chr20_55059167_ENST00000023939_length(amino acids)=244AA_BP=71 MGCLGNSKTEDQRNEEKAQREANKKIEKQLQKDKQVYRATHRLLLLGAGESGKSTIVKQMRILHVNGFNGEFCFLRCCGCVFSERALKEI KAEVCHTCGAAFQEDDVIMLNGTKEDVDVLKTRMEERRLRAKLEKKTKKPKAAESVSKPDVSEEAPGPSKVKTGKPEEASLDSREKKTNL -------------------------------------------------------------- >33643_33643_17_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000371095_RTFDC1_chr20_55059167_ENST00000357348_length(transcript)=1569nt_BP=637nt CTCGCCGCCGCCGCCTCCTCCTCCCCCCGCCTCCCCCCGCCCGCCGCGGCGCTTTTGGCTCGGGGCGGCGGCGGGGGCCCGGCCGAGGCA ATAAGAGCGGCGGCGGCGGCAGCGGCGGCAGCAGCTCCCGCAGCTCCTGCTCTGGTCCGCCTCGGCCCGGCGGCGGCCATCAGCCCCCTC GGCCTCGGCTCGAGGGGCGGGGAGCTGCGCGCGCCCCTCGGTCCGACCGACACCCTCCCCTTCCCGCCCGTCCGCGCGCCCCGCGGCCCG CGGCCCGCAGTCCGCCCCGCGCGCTCCTTGCCGAGGAGCCGAGCCCGCGCCCGGCCCGCCCGCCCGGCGCTGCCCCGGCCCTCCCGGCCC GCGTGAGGCCGCCCGCGCCCGCCGCCGCCGCAGCCCGGCCGCGCCCCGCCGCCGCCGCCGCCGCCATGGGCTGCCTCGGGAACAGTAAGA CCGAGGACCAGCGCAACGAGGAGAAGGCGCAGCGTGAGGCCAACAAAAAGATCGAGAAGCAGCTGCAGAAGGACAAGCAGGTCTACCGGG CCACGCACCGCCTGCTGCTGCTGGGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTA ATGGAGAGTTCTGCTTCCTTCGGTGCTGCGGCTGTGTGTTTTCTGAGCGAGCCTTGAAAGAGATAAAAGCGGAAGTTTGCCACACGTGTG GGGCTGCCTTCCAGGAGGATGATGTCATCATGCTCAATGGCACCAAGGAGGATGTGGACGTGCTGAAGACAAGGATGGAGGAGAGAAGGC TGAGAGCGAAGCTGGAAAAGAAAACAAAGAAACCCAAGGCAGCAGAGTCTGTTTCAAAACCAGATGTCAGTGAAGAAGCCCCAGGGCCAT CAAAAGTTAAGACAGGGAAGCCTGAAGAAGCCAGCCTTGATTCTAGAGAGAAGAAAACCAACTTGGCTCCCAAAAGCACAGCAATGAATG AGAGCTCTTCTGGAAAAGCTGGGAAGCCTCCGTGTGGAGCCACAAAGAGGTCCATCGCTGACAGTGAAGAATCGGAGGCCTACAAGTCCC TCTTTACCACTCACAGCTCCGCCAAGCGCTCCAAGGAGGAGTCTGCCCACTGGGTCACCCACACGTCCTACTGCTTCTGAAGCCCGCACT GCCACCGCTCCTGCCCCAGAAGGTTGTTTAGTTTCCACGTAGGCAGGTCGCTTTGTGCCTCTGAGTGCGCTGCTGTGTGTTCTCTCTATA GTTCTGTGTCATAAAGCTGTCCTGGCCAGCCTTCAAGCTGGTGTGGCCACTCTTGATGTGAGGCGTGTCGGTTCCAGGGGGGACATGGGA GGGGCTGCACAGTGGCCCGAGGTCATGCTTGCTTCCACCTGCAGGTGCATTTGGTCCTTTCCATGGCCAGGAAGCCCTGTGGGCTGCACT TTTTATGCTTGCAGTAACAAGAGACTCCAGAGTCCTCACCGGTGCAGAGTTGGCACATATTAATTAACTAAAATTCTAATGATCTTGCTA >33643_33643_17_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000371095_RTFDC1_chr20_55059167_ENST00000357348_length(amino acids)=244AA_BP=71 MGCLGNSKTEDQRNEEKAQREANKKIEKQLQKDKQVYRATHRLLLLGAGESGKSTIVKQMRILHVNGFNGEFCFLRCCGCVFSERALKEI KAEVCHTCGAAFQEDDVIMLNGTKEDVDVLKTRMEERRLRAKLEKKTKKPKAAESVSKPDVSEEAPGPSKVKTGKPEEASLDSREKKTNL -------------------------------------------------------------- >33643_33643_18_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000371095_RTFDC1_chr20_55059167_ENST00000395881_length(transcript)=1727nt_BP=637nt CTCGCCGCCGCCGCCTCCTCCTCCCCCCGCCTCCCCCCGCCCGCCGCGGCGCTTTTGGCTCGGGGCGGCGGCGGGGGCCCGGCCGAGGCA ATAAGAGCGGCGGCGGCGGCAGCGGCGGCAGCAGCTCCCGCAGCTCCTGCTCTGGTCCGCCTCGGCCCGGCGGCGGCCATCAGCCCCCTC GGCCTCGGCTCGAGGGGCGGGGAGCTGCGCGCGCCCCTCGGTCCGACCGACACCCTCCCCTTCCCGCCCGTCCGCGCGCCCCGCGGCCCG CGGCCCGCAGTCCGCCCCGCGCGCTCCTTGCCGAGGAGCCGAGCCCGCGCCCGGCCCGCCCGCCCGGCGCTGCCCCGGCCCTCCCGGCCC GCGTGAGGCCGCCCGCGCCCGCCGCCGCCGCAGCCCGGCCGCGCCCCGCCGCCGCCGCCGCCGCCATGGGCTGCCTCGGGAACAGTAAGA CCGAGGACCAGCGCAACGAGGAGAAGGCGCAGCGTGAGGCCAACAAAAAGATCGAGAAGCAGCTGCAGAAGGACAAGCAGGTCTACCGGG CCACGCACCGCCTGCTGCTGCTGGGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTA ATGGAGAGTTCTGCTTCCTTCGGTGCTGCGGCTGTGTGTTTTCTGAGCGAGCCTTGAAAGAGATAAAAGCGGAAGTTTGCCACACGTGTG GGGCTGCCTTCCAGGAGGATGATGTCATCATGCTCAATGGCACCAAGGAGGATGTGGACGTGCTGAAGACAAGGATGGAGGAGAGAAGGC TGAGAGCGAAGCTGGAAAAGAAGCCCCAGGGCCATCAAAAGTTAAGACAGGGAAGCCTGAAGAAGCCAGCCTTGATTCTAGAGAGAAGAA AACCAACTTGGCTCCCAAAAGCACAGCAATGAATGAGAGCTCTTCTGGAAAAGCTGGGAAGCCTCCGTGTGGAGCCACAAAGAGGTCCAT CGCTGACAGTGAAGAATCGGAGGCCTACAAGTCCCTCTTTACCACTCACAGCTCCGCCAAGCGCTCCAAGGAGGAGTCTGCCCACTGGGT CACCCACACGTCCTACTGCTTCTGAAGCCCGCACTGCCACCGCTCCTGCCCCAGAAGGTTGTTTAGTTTCCACGTAGGCAGGTCGCTTTG TGCCTCTGAGTGCGCTGCTGTGTGTTCTCTCTATAGTTCTGTGTCATAAAGCTGTCCTGGCCAGCCTTCAAGCTGGTGTGGCCACTCTTG ATGTGAGGCGTGTCGGTTCCAGGGGGGACATGGGAGGGGCTGCACAGTGGCCCGAGGTCATGCTTGCTTCCACCTGCAGGTGCATTTGGT CCTTTCCATGGCCAGGAAGCCCTGTGGGCTGCACTTTTTATGCTTGCAGTAACAAGAGACTCCAGAGTCCTCACCGGTGCAGAGTTGGCA CATATTAATTAACTAAAATTCTAATGATCTTGCTACCAGCAATAAATCAAGTAGGCCAAGTGAAACTGGGCTTTAAAAAGGATGGATTTC AAATACACTGTGCCCACTAGAAGCTTCGAAGGGCCTCGTCCCTCTGCTACAGCCCTGGGAGGAGCCAGGATCCTTGTTGGTCTAGCTAAA TACTGTTAGGGGAGTGTGCCCCATCTCATCATTTCGAAGATAGCAGAGTCATAGTTGGGCACCCAGTGATTGGGTTCAAAAATAAAGCTG >33643_33643_18_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000371095_RTFDC1_chr20_55059167_ENST00000395881_length(amino acids)=282AA_BP=6 MMALGLLFQLRSQPSLLHPCLQHVHILLGAIEHDDIILLEGSPTRVANFRFYLFQGSLRKHTAAAPKEAELSIKPINMQDPHLLHNGAFT RFSSTQQQQAVRGPVDLLVLLQLLLDLFVGLTLRLLLVALVLGLTVPEAAHGGGGGGGARPGCGGGGRGRPHAGREGRGSAGRAGRARAR LLGKERAGRTAGRGPRGARTGGKGRVSVGPRGARSSPPLEPRPRGLMAAAGPRRTRAGAAGAAAAAAAAAALIASAGPPPPPRAKSAAAG -------------------------------------------------------------- >33643_33643_19_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000371100_RTFDC1_chr20_55059167_ENST00000023939_length(transcript)=3838nt_BP=2693nt AAAGACTCCAAATCAGTCAGGGAGAGGAGTGGAAGGAGCCAAAACGTCCCTGCGAGGCCTGCGCTCACCAGCCCCCTTACCCAAAGTCCC GGGCCCCTGGCGCCAGGAGCAGGCTCCTGGAGCCGGAGCCAGCTCGGCACTGGAACCGGCGTCCTCTGGTGGCAGAGAGAGAGCGCTACT GGCGATTTTCGGACCGAATCGGCACGCTCGTCAGATCCAAGCAGGCGGGACTGGCCTGGAGCAAAAAGAAAGAGAGAGGAGGGCGTAAGG ATAGACCAAGGAAGAGGGGCTGGGGGGCAGCCTGGGGGCATGAAAAGTGGCCAGGAAGGAGCCAAGACTCCACCAGCAACAATTGAGTTG CTTCAGCCTCAGTCTAGGGTTCCTTCCAGGCCTTGAACCCCCCAACCTCACAAGGGTTGGAAAGTGAGGCCGGTGAACTTTCCAGCTGGT ACTTTGATTTTAAAATAATAATAATAATTTTTTCACCCTAGTTCGGTTGGGTGCTCCATCTTACGGAGCCCCAAACTTATTTTGAGAGGC CGCCACCGTGTTATGGGCGTGCGCAACTGCCTCTACGGCAATAATATGTCAGGACAACGCGATATCCCCCCTGAAATCGGGGAACAGCCC GAGCAACCACCTTTGGAGGCCCCAGGGGCAGCTGCCCCCGGTGCTGGGCCTAGCCCAGCCGAAGAGATGGAGACCGAACCGCCTCACAAC GAGCCCATCCCCGTCGAGAATGATGGCGAGGCCTGTGGACCCCCAGAGGTCTCCAGACCCAACTTTCAGGTCCTCAACCCGGCATTCAGG GAAGCTGGAGCCCATGGAAGCTACAGCCCACCTCCTGAGGAAGCAATGCCCTTCGAGGCTGAACAGCCCAGCTTGGGAGGCTTCTGGCCT ACACTGGAGCAGCCTGGATTCCCCAGTGGGGTCCATGCAGGCCTTGAGGCCTTCGGCCCAGCACTCATGGAGCCCGGAGCCTTCAGTGGT GCCAGACCAGGCCTGGGAGGATACAGCCCTCCACCAGAAGAAGCTATGCCCTTTGAGTTTGACCAGCCTGCCCAGAGAGGCTGCAGTCAA CTTCTCTTACAGGTCCCAGACCTTGCTCCAGGAGGCCCAGGTGCTGCAGGGGTCCCCGGAGCTCCTCCCGAGGAGCCCCAAGCCCTCAGG CCTGCAAAGGCTGGCTCCAGAGGAGGCTACAGCCCTCCCCCTGAGGAGACTATGCCATTTGAGCTTGATGGAGAAGGATTTGGGGACGAC AGCCCACCCCCGGGGCTTTCCCGAGTTATCGCACAAGTCGACGGCAGCAGCCAGTTCGCGGCAGTCGCGGCCTCGAGTGCGGTCCGCCTC ACTCCCGCCGCGAACGCGCCTCCCCTCTGGGTCCCAGGCGCCATCGGCAGCCCATCCCAAGAGGCTGTCAGACCTCCTTCTAACTTCACG GGCAGCAGCCCCTGGATGGAGATCTCCGGACCCCCGTTCGAGATTGGCAGCGCCCCCGCTGGGGTCGACGACACTCCCGTCAACATGGAC AGCCCCCCAATCGCGCTTGACGGCCCGCCCATCAAGGTCTCCGGAGCCCCAGATAAGAGAGAGCGAGCAGAGAGACCCCCAGTTGAGGAG GAAGCAGCAGAGATGGAAGGAGCCGCTGATGCCGCGGAGGGAGGAAAAGTACCCTCTCCGGGGTACGGATCCCCTGCCGCCGGGGCAGCC TCAGCGGATACCGCTGCCAGGGCAGCCCCTGCAGCCCCAGCCGATCCTGACTCCGGGGCAACCCCAGAAGATCCCGACTCCGGGACAGCA CCAGCCGATCCTGACTCCGGGGCATTCGCAGCCGATCCCGACTCCGGGGCAGCCCCTGCCGCCCCAGCCGATCCCGACTCCGGGGCGGCC CCTGACGCCCCAGCCGATCCCGACTCCGGGGCGGCCCCTGACGCCCCAGCCGATCCAGATGCCGGGGCGGCCCCTGAGGCTCCCGCCGCC CCTGCGGCTGCTGAGACCCGGGCAGCCCATGTCGCCCCAGCTGCGCCAGACGCAGGGGCTCCCACTGCCCCAGCCGCTTCTGCCACCCGG GCAGCCCAAGTCCGCCGGGCGGCCTCTGCAGCCCCTGCCTCCGGGGCCAGACGCAAGATCCATCTCAGACCCCCCAGCCCCGAGATCCAG GCTGCCGATCCGCCTACTCCGCGGCCTACTCGCGCGTCTGCCTGGCGGGGCAAGTCCGAGAGCAGCCGCGGCCGCCGCGTGTACTACGAT GAAGGGGTGGCCAGCAGCGACGATGACTCCAGCGGAGACGAGTCCGACGATGGGACCTCCGGATGCCTCCGCTGGTTTCAGCATCGGCGA AATCGCCGCCGCCGAAAGCCCCAGCGCAACTTACTCCGCAACTTTCTCGTGCAAGCCTTCGGGGGCTGCTTCGGTCGATCTGAGAGTCCC CAGCCCAAAGCCTCGCGCTCTCTCAAGGTCAAGAAGGTACCCCTGGCGGAGAAGCGCAGACAGATGCGCAAAGAAGCCCTGGAGAAGCGG GCCCAGAAGCGCGCAGAGAAGAAACGCAGTAAGCTCATCGACAAACAACTCCAGGACGAAAAGATGGGCTACATGTGTACGCACCGCCTG CTGCTTCTAGGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTAATGGAGAGTTCTGC TTCCTTCGGTGCTGCGGCTGTGTGTTTTCTGAGCGAGCCTTGAAAGAGATAAAAGCGGAAGTTTGCCACACGTGTGGGGCTGCCTTCCAG GAGGATGATGTCATCATGCTCAATGGCACCAAGGAGGATGTGGACGTGCTGAAGACAAGGATGGAGGAGAGAAGGCTGAGAGCGAAGCTG GAAAAGAAAACAAAGAAACCCAAGGCAGCAGAGTCTGTTTCAAAACCAGATGTCAGTGAAGAAGCCCCAGGGCCATCAAAAGTTAAGACA GGGAAGCCTGAAGAAGCCAGCCTTGATTCTAGAGAGAAGAAAACCAACTTGGCTCCCAAAAGCACAGCAATGAATGAGAGCTCTTCTGGA AAAGCTGGGAAGCCTCCGTGTGGAGCCACAAAGAGGTCCATCGCTGACAGTGAAGAATCGGAGGCCTACAAGTCCCTCTTTACCACTCAC AGCTCCGCCAAGCGCTCCAAGGAGGAGTCTGCCCACTGGGTCACCCACACGTCCTACTGCTTCTGAAGCCCGCACTGCCACCGCTCCTGC CCCAGAAGGTTGTTTAGTTTCCACGTAGGCAGGTCGCTTTGTGCCTCTGAGTGCGCTGCTGTGTGTTCTCTCTATAGTTCTGTGTCATAA AGCTGTCCTGGCCAGCCTTCAAGCTGGTGTGGCCACTCTTGATGTGAGGCGTGTCGGTTCCAGGGGGGACATGGGAGGGGCTGCACAGTG GCCCGAGGTCATGCTTGCTTCCACCTGCAGGTGCATTTGGTCCTTTCCATGGCCAGGAAGCCCTGTGGGCTGCACTTTTTATGCTTGCAG TAACAAGAGACTCCAGAGTCCTCACCGGTGCAGAGTTGGCACATATTAATTAACTAAAATTCTAATGATCTTGCTACCAGCAATAAATCA AGTAGGCCAAGTGAAACTGGGCTTTAAAAAGGATGGATTTCAAATACACTGTGCCCACTAGAAGCTTCGAAGGGCCTCGTCCCTCTGCTA CAGCCCTGGGAGGAGCCAGGATCCTTGTTGGTCTAGCTAAATACTGTTAGGGGAGTGTGCCCCATCTCATCATTTCGAAGATAGCAGAGT >33643_33643_19_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000371100_RTFDC1_chr20_55059167_ENST00000023939_length(amino acids)=894AA_BP=721 MRGRHRVMGVRNCLYGNNMSGQRDIPPEIGEQPEQPPLEAPGAAAPGAGPSPAEEMETEPPHNEPIPVENDGEACGPPEVSRPNFQVLNP AFREAGAHGSYSPPPEEAMPFEAEQPSLGGFWPTLEQPGFPSGVHAGLEAFGPALMEPGAFSGARPGLGGYSPPPEEAMPFEFDQPAQRG CSQLLLQVPDLAPGGPGAAGVPGAPPEEPQALRPAKAGSRGGYSPPPEETMPFELDGEGFGDDSPPPGLSRVIAQVDGSSQFAAVAASSA VRLTPAANAPPLWVPGAIGSPSQEAVRPPSNFTGSSPWMEISGPPFEIGSAPAGVDDTPVNMDSPPIALDGPPIKVSGAPDKRERAERPP VEEEAAEMEGAADAAEGGKVPSPGYGSPAAGAASADTAARAAPAAPADPDSGATPEDPDSGTAPADPDSGAFAADPDSGAAPAAPADPDS GAAPDAPADPDSGAAPDAPADPDAGAAPEAPAAPAAAETRAAHVAPAAPDAGAPTAPAASATRAAQVRRAASAAPASGARRKIHLRPPSP EIQAADPPTPRPTRASAWRGKSESSRGRRVYYDEGVASSDDDSSGDESDDGTSGCLRWFQHRRNRRRRKPQRNLLRNFLVQAFGGCFGRS ESPQPKASRSLKVKKVPLAEKRRQMRKEALEKRAQKRAEKKRSKLIDKQLQDEKMGYMCTHRLLLLGAGESGKSTIVKQMRILHVNGFNG EFCFLRCCGCVFSERALKEIKAEVCHTCGAAFQEDDVIMLNGTKEDVDVLKTRMEERRLRAKLEKKTKKPKAAESVSKPDVSEEAPGPSK -------------------------------------------------------------- >33643_33643_20_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000371100_RTFDC1_chr20_55059167_ENST00000357348_length(transcript)=3625nt_BP=2693nt AAAGACTCCAAATCAGTCAGGGAGAGGAGTGGAAGGAGCCAAAACGTCCCTGCGAGGCCTGCGCTCACCAGCCCCCTTACCCAAAGTCCC GGGCCCCTGGCGCCAGGAGCAGGCTCCTGGAGCCGGAGCCAGCTCGGCACTGGAACCGGCGTCCTCTGGTGGCAGAGAGAGAGCGCTACT GGCGATTTTCGGACCGAATCGGCACGCTCGTCAGATCCAAGCAGGCGGGACTGGCCTGGAGCAAAAAGAAAGAGAGAGGAGGGCGTAAGG ATAGACCAAGGAAGAGGGGCTGGGGGGCAGCCTGGGGGCATGAAAAGTGGCCAGGAAGGAGCCAAGACTCCACCAGCAACAATTGAGTTG CTTCAGCCTCAGTCTAGGGTTCCTTCCAGGCCTTGAACCCCCCAACCTCACAAGGGTTGGAAAGTGAGGCCGGTGAACTTTCCAGCTGGT ACTTTGATTTTAAAATAATAATAATAATTTTTTCACCCTAGTTCGGTTGGGTGCTCCATCTTACGGAGCCCCAAACTTATTTTGAGAGGC CGCCACCGTGTTATGGGCGTGCGCAACTGCCTCTACGGCAATAATATGTCAGGACAACGCGATATCCCCCCTGAAATCGGGGAACAGCCC GAGCAACCACCTTTGGAGGCCCCAGGGGCAGCTGCCCCCGGTGCTGGGCCTAGCCCAGCCGAAGAGATGGAGACCGAACCGCCTCACAAC GAGCCCATCCCCGTCGAGAATGATGGCGAGGCCTGTGGACCCCCAGAGGTCTCCAGACCCAACTTTCAGGTCCTCAACCCGGCATTCAGG GAAGCTGGAGCCCATGGAAGCTACAGCCCACCTCCTGAGGAAGCAATGCCCTTCGAGGCTGAACAGCCCAGCTTGGGAGGCTTCTGGCCT ACACTGGAGCAGCCTGGATTCCCCAGTGGGGTCCATGCAGGCCTTGAGGCCTTCGGCCCAGCACTCATGGAGCCCGGAGCCTTCAGTGGT GCCAGACCAGGCCTGGGAGGATACAGCCCTCCACCAGAAGAAGCTATGCCCTTTGAGTTTGACCAGCCTGCCCAGAGAGGCTGCAGTCAA CTTCTCTTACAGGTCCCAGACCTTGCTCCAGGAGGCCCAGGTGCTGCAGGGGTCCCCGGAGCTCCTCCCGAGGAGCCCCAAGCCCTCAGG CCTGCAAAGGCTGGCTCCAGAGGAGGCTACAGCCCTCCCCCTGAGGAGACTATGCCATTTGAGCTTGATGGAGAAGGATTTGGGGACGAC AGCCCACCCCCGGGGCTTTCCCGAGTTATCGCACAAGTCGACGGCAGCAGCCAGTTCGCGGCAGTCGCGGCCTCGAGTGCGGTCCGCCTC ACTCCCGCCGCGAACGCGCCTCCCCTCTGGGTCCCAGGCGCCATCGGCAGCCCATCCCAAGAGGCTGTCAGACCTCCTTCTAACTTCACG GGCAGCAGCCCCTGGATGGAGATCTCCGGACCCCCGTTCGAGATTGGCAGCGCCCCCGCTGGGGTCGACGACACTCCCGTCAACATGGAC AGCCCCCCAATCGCGCTTGACGGCCCGCCCATCAAGGTCTCCGGAGCCCCAGATAAGAGAGAGCGAGCAGAGAGACCCCCAGTTGAGGAG GAAGCAGCAGAGATGGAAGGAGCCGCTGATGCCGCGGAGGGAGGAAAAGTACCCTCTCCGGGGTACGGATCCCCTGCCGCCGGGGCAGCC TCAGCGGATACCGCTGCCAGGGCAGCCCCTGCAGCCCCAGCCGATCCTGACTCCGGGGCAACCCCAGAAGATCCCGACTCCGGGACAGCA CCAGCCGATCCTGACTCCGGGGCATTCGCAGCCGATCCCGACTCCGGGGCAGCCCCTGCCGCCCCAGCCGATCCCGACTCCGGGGCGGCC CCTGACGCCCCAGCCGATCCCGACTCCGGGGCGGCCCCTGACGCCCCAGCCGATCCAGATGCCGGGGCGGCCCCTGAGGCTCCCGCCGCC CCTGCGGCTGCTGAGACCCGGGCAGCCCATGTCGCCCCAGCTGCGCCAGACGCAGGGGCTCCCACTGCCCCAGCCGCTTCTGCCACCCGG GCAGCCCAAGTCCGCCGGGCGGCCTCTGCAGCCCCTGCCTCCGGGGCCAGACGCAAGATCCATCTCAGACCCCCCAGCCCCGAGATCCAG GCTGCCGATCCGCCTACTCCGCGGCCTACTCGCGCGTCTGCCTGGCGGGGCAAGTCCGAGAGCAGCCGCGGCCGCCGCGTGTACTACGAT GAAGGGGTGGCCAGCAGCGACGATGACTCCAGCGGAGACGAGTCCGACGATGGGACCTCCGGATGCCTCCGCTGGTTTCAGCATCGGCGA AATCGCCGCCGCCGAAAGCCCCAGCGCAACTTACTCCGCAACTTTCTCGTGCAAGCCTTCGGGGGCTGCTTCGGTCGATCTGAGAGTCCC CAGCCCAAAGCCTCGCGCTCTCTCAAGGTCAAGAAGGTACCCCTGGCGGAGAAGCGCAGACAGATGCGCAAAGAAGCCCTGGAGAAGCGG GCCCAGAAGCGCGCAGAGAAGAAACGCAGTAAGCTCATCGACAAACAACTCCAGGACGAAAAGATGGGCTACATGTGTACGCACCGCCTG CTGCTTCTAGGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTAATGGAGAGTTCTGC TTCCTTCGGTGCTGCGGCTGTGTGTTTTCTGAGCGAGCCTTGAAAGAGATAAAAGCGGAAGTTTGCCACACGTGTGGGGCTGCCTTCCAG GAGGATGATGTCATCATGCTCAATGGCACCAAGGAGGATGTGGACGTGCTGAAGACAAGGATGGAGGAGAGAAGGCTGAGAGCGAAGCTG GAAAAGAAAACAAAGAAACCCAAGGCAGCAGAGTCTGTTTCAAAACCAGATGTCAGTGAAGAAGCCCCAGGGCCATCAAAAGTTAAGACA GGGAAGCCTGAAGAAGCCAGCCTTGATTCTAGAGAGAAGAAAACCAACTTGGCTCCCAAAAGCACAGCAATGAATGAGAGCTCTTCTGGA AAAGCTGGGAAGCCTCCGTGTGGAGCCACAAAGAGGTCCATCGCTGACAGTGAAGAATCGGAGGCCTACAAGTCCCTCTTTACCACTCAC AGCTCCGCCAAGCGCTCCAAGGAGGAGTCTGCCCACTGGGTCACCCACACGTCCTACTGCTTCTGAAGCCCGCACTGCCACCGCTCCTGC CCCAGAAGGTTGTTTAGTTTCCACGTAGGCAGGTCGCTTTGTGCCTCTGAGTGCGCTGCTGTGTGTTCTCTCTATAGTTCTGTGTCATAA AGCTGTCCTGGCCAGCCTTCAAGCTGGTGTGGCCACTCTTGATGTGAGGCGTGTCGGTTCCAGGGGGGACATGGGAGGGGCTGCACAGTG GCCCGAGGTCATGCTTGCTTCCACCTGCAGGTGCATTTGGTCCTTTCCATGGCCAGGAAGCCCTGTGGGCTGCACTTTTTATGCTTGCAG TAACAAGAGACTCCAGAGTCCTCACCGGTGCAGAGTTGGCACATATTAATTAACTAAAATTCTAATGATCTTGCTACCAGCAATAAATCA >33643_33643_20_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000371100_RTFDC1_chr20_55059167_ENST00000357348_length(amino acids)=894AA_BP=721 MRGRHRVMGVRNCLYGNNMSGQRDIPPEIGEQPEQPPLEAPGAAAPGAGPSPAEEMETEPPHNEPIPVENDGEACGPPEVSRPNFQVLNP AFREAGAHGSYSPPPEEAMPFEAEQPSLGGFWPTLEQPGFPSGVHAGLEAFGPALMEPGAFSGARPGLGGYSPPPEEAMPFEFDQPAQRG CSQLLLQVPDLAPGGPGAAGVPGAPPEEPQALRPAKAGSRGGYSPPPEETMPFELDGEGFGDDSPPPGLSRVIAQVDGSSQFAAVAASSA VRLTPAANAPPLWVPGAIGSPSQEAVRPPSNFTGSSPWMEISGPPFEIGSAPAGVDDTPVNMDSPPIALDGPPIKVSGAPDKRERAERPP VEEEAAEMEGAADAAEGGKVPSPGYGSPAAGAASADTAARAAPAAPADPDSGATPEDPDSGTAPADPDSGAFAADPDSGAAPAAPADPDS GAAPDAPADPDSGAAPDAPADPDAGAAPEAPAAPAAAETRAAHVAPAAPDAGAPTAPAASATRAAQVRRAASAAPASGARRKIHLRPPSP EIQAADPPTPRPTRASAWRGKSESSRGRRVYYDEGVASSDDDSSGDESDDGTSGCLRWFQHRRNRRRRKPQRNLLRNFLVQAFGGCFGRS ESPQPKASRSLKVKKVPLAEKRRQMRKEALEKRAQKRAEKKRSKLIDKQLQDEKMGYMCTHRLLLLGAGESGKSTIVKQMRILHVNGFNG EFCFLRCCGCVFSERALKEIKAEVCHTCGAAFQEDDVIMLNGTKEDVDVLKTRMEERRLRAKLEKKTKKPKAAESVSKPDVSEEAPGPSK -------------------------------------------------------------- >33643_33643_21_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000371100_RTFDC1_chr20_55059167_ENST00000395881_length(transcript)=3783nt_BP=2693nt AAAGACTCCAAATCAGTCAGGGAGAGGAGTGGAAGGAGCCAAAACGTCCCTGCGAGGCCTGCGCTCACCAGCCCCCTTACCCAAAGTCCC GGGCCCCTGGCGCCAGGAGCAGGCTCCTGGAGCCGGAGCCAGCTCGGCACTGGAACCGGCGTCCTCTGGTGGCAGAGAGAGAGCGCTACT GGCGATTTTCGGACCGAATCGGCACGCTCGTCAGATCCAAGCAGGCGGGACTGGCCTGGAGCAAAAAGAAAGAGAGAGGAGGGCGTAAGG ATAGACCAAGGAAGAGGGGCTGGGGGGCAGCCTGGGGGCATGAAAAGTGGCCAGGAAGGAGCCAAGACTCCACCAGCAACAATTGAGTTG CTTCAGCCTCAGTCTAGGGTTCCTTCCAGGCCTTGAACCCCCCAACCTCACAAGGGTTGGAAAGTGAGGCCGGTGAACTTTCCAGCTGGT ACTTTGATTTTAAAATAATAATAATAATTTTTTCACCCTAGTTCGGTTGGGTGCTCCATCTTACGGAGCCCCAAACTTATTTTGAGAGGC CGCCACCGTGTTATGGGCGTGCGCAACTGCCTCTACGGCAATAATATGTCAGGACAACGCGATATCCCCCCTGAAATCGGGGAACAGCCC GAGCAACCACCTTTGGAGGCCCCAGGGGCAGCTGCCCCCGGTGCTGGGCCTAGCCCAGCCGAAGAGATGGAGACCGAACCGCCTCACAAC GAGCCCATCCCCGTCGAGAATGATGGCGAGGCCTGTGGACCCCCAGAGGTCTCCAGACCCAACTTTCAGGTCCTCAACCCGGCATTCAGG GAAGCTGGAGCCCATGGAAGCTACAGCCCACCTCCTGAGGAAGCAATGCCCTTCGAGGCTGAACAGCCCAGCTTGGGAGGCTTCTGGCCT ACACTGGAGCAGCCTGGATTCCCCAGTGGGGTCCATGCAGGCCTTGAGGCCTTCGGCCCAGCACTCATGGAGCCCGGAGCCTTCAGTGGT GCCAGACCAGGCCTGGGAGGATACAGCCCTCCACCAGAAGAAGCTATGCCCTTTGAGTTTGACCAGCCTGCCCAGAGAGGCTGCAGTCAA CTTCTCTTACAGGTCCCAGACCTTGCTCCAGGAGGCCCAGGTGCTGCAGGGGTCCCCGGAGCTCCTCCCGAGGAGCCCCAAGCCCTCAGG CCTGCAAAGGCTGGCTCCAGAGGAGGCTACAGCCCTCCCCCTGAGGAGACTATGCCATTTGAGCTTGATGGAGAAGGATTTGGGGACGAC AGCCCACCCCCGGGGCTTTCCCGAGTTATCGCACAAGTCGACGGCAGCAGCCAGTTCGCGGCAGTCGCGGCCTCGAGTGCGGTCCGCCTC ACTCCCGCCGCGAACGCGCCTCCCCTCTGGGTCCCAGGCGCCATCGGCAGCCCATCCCAAGAGGCTGTCAGACCTCCTTCTAACTTCACG GGCAGCAGCCCCTGGATGGAGATCTCCGGACCCCCGTTCGAGATTGGCAGCGCCCCCGCTGGGGTCGACGACACTCCCGTCAACATGGAC AGCCCCCCAATCGCGCTTGACGGCCCGCCCATCAAGGTCTCCGGAGCCCCAGATAAGAGAGAGCGAGCAGAGAGACCCCCAGTTGAGGAG GAAGCAGCAGAGATGGAAGGAGCCGCTGATGCCGCGGAGGGAGGAAAAGTACCCTCTCCGGGGTACGGATCCCCTGCCGCCGGGGCAGCC TCAGCGGATACCGCTGCCAGGGCAGCCCCTGCAGCCCCAGCCGATCCTGACTCCGGGGCAACCCCAGAAGATCCCGACTCCGGGACAGCA CCAGCCGATCCTGACTCCGGGGCATTCGCAGCCGATCCCGACTCCGGGGCAGCCCCTGCCGCCCCAGCCGATCCCGACTCCGGGGCGGCC CCTGACGCCCCAGCCGATCCCGACTCCGGGGCGGCCCCTGACGCCCCAGCCGATCCAGATGCCGGGGCGGCCCCTGAGGCTCCCGCCGCC CCTGCGGCTGCTGAGACCCGGGCAGCCCATGTCGCCCCAGCTGCGCCAGACGCAGGGGCTCCCACTGCCCCAGCCGCTTCTGCCACCCGG GCAGCCCAAGTCCGCCGGGCGGCCTCTGCAGCCCCTGCCTCCGGGGCCAGACGCAAGATCCATCTCAGACCCCCCAGCCCCGAGATCCAG GCTGCCGATCCGCCTACTCCGCGGCCTACTCGCGCGTCTGCCTGGCGGGGCAAGTCCGAGAGCAGCCGCGGCCGCCGCGTGTACTACGAT GAAGGGGTGGCCAGCAGCGACGATGACTCCAGCGGAGACGAGTCCGACGATGGGACCTCCGGATGCCTCCGCTGGTTTCAGCATCGGCGA AATCGCCGCCGCCGAAAGCCCCAGCGCAACTTACTCCGCAACTTTCTCGTGCAAGCCTTCGGGGGCTGCTTCGGTCGATCTGAGAGTCCC CAGCCCAAAGCCTCGCGCTCTCTCAAGGTCAAGAAGGTACCCCTGGCGGAGAAGCGCAGACAGATGCGCAAAGAAGCCCTGGAGAAGCGG GCCCAGAAGCGCGCAGAGAAGAAACGCAGTAAGCTCATCGACAAACAACTCCAGGACGAAAAGATGGGCTACATGTGTACGCACCGCCTG CTGCTTCTAGGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTAATGGAGAGTTCTGC TTCCTTCGGTGCTGCGGCTGTGTGTTTTCTGAGCGAGCCTTGAAAGAGATAAAAGCGGAAGTTTGCCACACGTGTGGGGCTGCCTTCCAG GAGGATGATGTCATCATGCTCAATGGCACCAAGGAGGATGTGGACGTGCTGAAGACAAGGATGGAGGAGAGAAGGCTGAGAGCGAAGCTG GAAAAGAAGCCCCAGGGCCATCAAAAGTTAAGACAGGGAAGCCTGAAGAAGCCAGCCTTGATTCTAGAGAGAAGAAAACCAACTTGGCTC CCAAAAGCACAGCAATGAATGAGAGCTCTTCTGGAAAAGCTGGGAAGCCTCCGTGTGGAGCCACAAAGAGGTCCATCGCTGACAGTGAAG AATCGGAGGCCTACAAGTCCCTCTTTACCACTCACAGCTCCGCCAAGCGCTCCAAGGAGGAGTCTGCCCACTGGGTCACCCACACGTCCT ACTGCTTCTGAAGCCCGCACTGCCACCGCTCCTGCCCCAGAAGGTTGTTTAGTTTCCACGTAGGCAGGTCGCTTTGTGCCTCTGAGTGCG CTGCTGTGTGTTCTCTCTATAGTTCTGTGTCATAAAGCTGTCCTGGCCAGCCTTCAAGCTGGTGTGGCCACTCTTGATGTGAGGCGTGTC GGTTCCAGGGGGGACATGGGAGGGGCTGCACAGTGGCCCGAGGTCATGCTTGCTTCCACCTGCAGGTGCATTTGGTCCTTTCCATGGCCA GGAAGCCCTGTGGGCTGCACTTTTTATGCTTGCAGTAACAAGAGACTCCAGAGTCCTCACCGGTGCAGAGTTGGCACATATTAATTAACT AAAATTCTAATGATCTTGCTACCAGCAATAAATCAAGTAGGCCAAGTGAAACTGGGCTTTAAAAAGGATGGATTTCAAATACACTGTGCC CACTAGAAGCTTCGAAGGGCCTCGTCCCTCTGCTACAGCCCTGGGAGGAGCCAGGATCCTTGTTGGTCTAGCTAAATACTGTTAGGGGAG TGTGCCCCATCTCATCATTTCGAAGATAGCAGAGTCATAGTTGGGCACCCAGTGATTGGGTTCAAAAATAAAGCTGGTCTGCCTCTTCTC >33643_33643_21_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000371100_RTFDC1_chr20_55059167_ENST00000395881_length(amino acids)=818AA_BP=721 MRGRHRVMGVRNCLYGNNMSGQRDIPPEIGEQPEQPPLEAPGAAAPGAGPSPAEEMETEPPHNEPIPVENDGEACGPPEVSRPNFQVLNP AFREAGAHGSYSPPPEEAMPFEAEQPSLGGFWPTLEQPGFPSGVHAGLEAFGPALMEPGAFSGARPGLGGYSPPPEEAMPFEFDQPAQRG CSQLLLQVPDLAPGGPGAAGVPGAPPEEPQALRPAKAGSRGGYSPPPEETMPFELDGEGFGDDSPPPGLSRVIAQVDGSSQFAAVAASSA VRLTPAANAPPLWVPGAIGSPSQEAVRPPSNFTGSSPWMEISGPPFEIGSAPAGVDDTPVNMDSPPIALDGPPIKVSGAPDKRERAERPP VEEEAAEMEGAADAAEGGKVPSPGYGSPAAGAASADTAARAAPAAPADPDSGATPEDPDSGTAPADPDSGAFAADPDSGAAPAAPADPDS GAAPDAPADPDSGAAPDAPADPDAGAAPEAPAAPAAAETRAAHVAPAAPDAGAPTAPAASATRAAQVRRAASAAPASGARRKIHLRPPSP EIQAADPPTPRPTRASAWRGKSESSRGRRVYYDEGVASSDDDSSGDESDDGTSGCLRWFQHRRNRRRRKPQRNLLRNFLVQAFGGCFGRS ESPQPKASRSLKVKKVPLAEKRRQMRKEALEKRAQKRAEKKRSKLIDKQLQDEKMGYMCTHRLLLLGAGESGKSTIVKQMRILHVNGFNG EFCFLRCCGCVFSERALKEIKAEVCHTCGAAFQEDDVIMLNGTKEDVDVLKTRMEERRLRAKLEKKPQGHQKLRQGSLKKPALILERRKP -------------------------------------------------------------- >33643_33643_22_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000371102_RTFDC1_chr20_55059167_ENST00000023939_length(transcript)=3289nt_BP=2144nt GTTATGGGCGTGCGCAACTGCCTCTACGGCAATAATATGTCAGGACAACGCGATATCCCCCCTGAAATCGGGGAACAGCCCGAGCAACCA CCTTTGGAGGCCCCAGGGGCAGCTGCCCCCGGTGCTGGGCCTAGCCCAGCCGAAGAGATGGAGACCGAACCGCCTCACAACGAGCCCATC CCCGTCGAGAATGATGGCGAGGCCTGTGGACCCCCAGAGGTCTCCAGACCCAACTTTCAGGTCCTCAACCCGGCATTCAGGGAAGCTGGA GCCCATGGAAGCTACAGCCCACCTCCTGAGGAAGCAATGCCCTTCGAGGCTGAACAGCCCAGCTTGGGAGGCTTCTGGCCTACACTGGAG CAGCCTGGATTCCCCAGTGGGGTCCATGCAGGCCTTGAGGCCTTCGGCCCAGCACTCATGGAGCCCGGAGCCTTCAGTGGTGCCAGACCA GGCCTGGGAGGATACAGCCCTCCACCAGAAGAAGCTATGCCCTTTGAGTTTGACCAGCCTGCCCAGAGAGGCTGCAGTCAACTTCTCTTA CAGGTCCCAGACCTTGCTCCAGGAGGCCCAGGTGCTGCAGGGGTCCCCGGAGCTCCTCCCGAGGAGCCCCAAGCCCTCAGGCCTGCAAAG GCTGGCTCCAGAGGAGGCTACAGCCCTCCCCCTGAGGAGACTATGCCATTTGAGCTTGATGGAGAAGGATTTGGGGACGACAGCCCACCC CCGGGGCTTTCCCGAGTTATCGCACAAGTCGACGGCAGCAGCCAGTTCGCGGCAGTCGCGGCCTCGAGTGCGGTCCGCCTCACTCCCGCC GCGAACGCGCCTCCCCTCTGGGTCCCAGGCGCCATCGGCAGCCCATCCCAAGAGGCTGTCAGACCTCCTTCTAACTTCACGGGCAGCAGC CCCTGGATGGAGATCTCCGGACCCCCGTTCGAGATTGGCAGCGCCCCCGCTGGGGTCGACGACACTCCCGTCAACATGGACAGCCCCCCA ATCGCGCTTGACGGCCCGCCCATCAAGGTCTCCGGAGCCCCAGATAAGAGAGAGCGAGCAGAGAGACCCCCAGTTGAGGAGGAAGCAGCA GAGATGGAAGGAGCCGCTGATGCCGCGGAGGGAGGAAAAGTACCCTCTCCGGGGTACGGATCCCCTGCCGCCGGGGCAGCCTCAGCGGAT ACCGCTGCCAGGGCAGCCCCTGCAGCCCCAGCCGATCCTGACTCCGGGGCAACCCCAGAAGATCCCGACTCCGGGACAGCACCAGCCGAT CCTGACTCCGGGGCATTCGCAGCCGATCCCGACTCCGGGGCAGCCCCTGCCGCCCCAGCCGATCCCGACTCCGGGGCGGCCCCTGACGCC CCAGCCGATCCCGACTCCGGGGCGGCCCCTGACGCCCCAGCCGATCCAGATGCCGGGGCGGCCCCTGAGGCTCCCGCCGCCCCTGCGGCT GCTGAGACCCGGGCAGCCCATGTCGCCCCAGCTGCGCCAGACGCAGGGGCTCCCACTGCCCCAGCCGCTTCTGCCACCCGGGCAGCCCAA GTCCGCCGGGCGGCCTCTGCAGCCCCTGCCTCCGGGGCCAGACGCAAGATCCATCTCAGACCCCCCAGCCCCGAGATCCAGGCTGCCGAT CCGCCTACTCCGCGGCCTACTCGCGCGTCTGCCTGGCGGGGCAAGTCCGAGAGCAGCCGCGGCCGCCGCGTGTACTACGATGAAGGGGTG GCCAGCAGCGACGATGACTCCAGCGGAGACGAGTCCGACGATGGGACCTCCGGATGCCTCCGCTGGTTTCAGCATCGGCGAAATCGCCGC CGCCGAAAGCCCCAGCGCAACTTACTCCGCAACTTTCTCGTGCAAGCCTTCGGGGGCTGCTTCGGTCGATCTGAGAGTCCCCAGCCCAAA GCCTCGCGCTCTCTCAAGGTCAAGAAGGTACCCCTGGCGGAGAAGCGCAGACAGATGCGCAAAGAAGCCCTGGAGAAGCGGGCCCAGAAG CGCGCAGAGAAGAAACGCAGTAAGCTCATCGACAAACAACTCCAGGACGAAAAGATGGGCTACATGTGTACGCACCGCCTGCTGCTTCTA GGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTAATGGAGAGTTCTGCTTCCTTCGG TGCTGCGGCTGTGTGTTTTCTGAGCGAGCCTTGAAAGAGATAAAAGCGGAAGTTTGCCACACGTGTGGGGCTGCCTTCCAGGAGGATGAT GTCATCATGCTCAATGGCACCAAGGAGGATGTGGACGTGCTGAAGACAAGGATGGAGGAGAGAAGGCTGAGAGCGAAGCTGGAAAAGAAA ACAAAGAAACCCAAGGCAGCAGAGTCTGTTTCAAAACCAGATGTCAGTGAAGAAGCCCCAGGGCCATCAAAAGTTAAGACAGGGAAGCCT GAAGAAGCCAGCCTTGATTCTAGAGAGAAGAAAACCAACTTGGCTCCCAAAAGCACAGCAATGAATGAGAGCTCTTCTGGAAAAGCTGGG AAGCCTCCGTGTGGAGCCACAAAGAGGTCCATCGCTGACAGTGAAGAATCGGAGGCCTACAAGTCCCTCTTTACCACTCACAGCTCCGCC AAGCGCTCCAAGGAGGAGTCTGCCCACTGGGTCACCCACACGTCCTACTGCTTCTGAAGCCCGCACTGCCACCGCTCCTGCCCCAGAAGG TTGTTTAGTTTCCACGTAGGCAGGTCGCTTTGTGCCTCTGAGTGCGCTGCTGTGTGTTCTCTCTATAGTTCTGTGTCATAAAGCTGTCCT GGCCAGCCTTCAAGCTGGTGTGGCCACTCTTGATGTGAGGCGTGTCGGTTCCAGGGGGGACATGGGAGGGGCTGCACAGTGGCCCGAGGT CATGCTTGCTTCCACCTGCAGGTGCATTTGGTCCTTTCCATGGCCAGGAAGCCCTGTGGGCTGCACTTTTTATGCTTGCAGTAACAAGAG ACTCCAGAGTCCTCACCGGTGCAGAGTTGGCACATATTAATTAACTAAAATTCTAATGATCTTGCTACCAGCAATAAATCAAGTAGGCCA AGTGAAACTGGGCTTTAAAAAGGATGGATTTCAAATACACTGTGCCCACTAGAAGCTTCGAAGGGCCTCGTCCCTCTGCTACAGCCCTGG GAGGAGCCAGGATCCTTGTTGGTCTAGCTAAATACTGTTAGGGGAGTGTGCCCCATCTCATCATTTCGAAGATAGCAGAGTCATAGTTGG >33643_33643_22_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000371102_RTFDC1_chr20_55059167_ENST00000023939_length(amino acids)=887AA_BP=714 MGVRNCLYGNNMSGQRDIPPEIGEQPEQPPLEAPGAAAPGAGPSPAEEMETEPPHNEPIPVENDGEACGPPEVSRPNFQVLNPAFREAGA HGSYSPPPEEAMPFEAEQPSLGGFWPTLEQPGFPSGVHAGLEAFGPALMEPGAFSGARPGLGGYSPPPEEAMPFEFDQPAQRGCSQLLLQ VPDLAPGGPGAAGVPGAPPEEPQALRPAKAGSRGGYSPPPEETMPFELDGEGFGDDSPPPGLSRVIAQVDGSSQFAAVAASSAVRLTPAA NAPPLWVPGAIGSPSQEAVRPPSNFTGSSPWMEISGPPFEIGSAPAGVDDTPVNMDSPPIALDGPPIKVSGAPDKRERAERPPVEEEAAE MEGAADAAEGGKVPSPGYGSPAAGAASADTAARAAPAAPADPDSGATPEDPDSGTAPADPDSGAFAADPDSGAAPAAPADPDSGAAPDAP ADPDSGAAPDAPADPDAGAAPEAPAAPAAAETRAAHVAPAAPDAGAPTAPAASATRAAQVRRAASAAPASGARRKIHLRPPSPEIQAADP PTPRPTRASAWRGKSESSRGRRVYYDEGVASSDDDSSGDESDDGTSGCLRWFQHRRNRRRRKPQRNLLRNFLVQAFGGCFGRSESPQPKA SRSLKVKKVPLAEKRRQMRKEALEKRAQKRAEKKRSKLIDKQLQDEKMGYMCTHRLLLLGAGESGKSTIVKQMRILHVNGFNGEFCFLRC CGCVFSERALKEIKAEVCHTCGAAFQEDDVIMLNGTKEDVDVLKTRMEERRLRAKLEKKTKKPKAAESVSKPDVSEEAPGPSKVKTGKPE -------------------------------------------------------------- >33643_33643_23_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000371102_RTFDC1_chr20_55059167_ENST00000357348_length(transcript)=3076nt_BP=2144nt GTTATGGGCGTGCGCAACTGCCTCTACGGCAATAATATGTCAGGACAACGCGATATCCCCCCTGAAATCGGGGAACAGCCCGAGCAACCA CCTTTGGAGGCCCCAGGGGCAGCTGCCCCCGGTGCTGGGCCTAGCCCAGCCGAAGAGATGGAGACCGAACCGCCTCACAACGAGCCCATC CCCGTCGAGAATGATGGCGAGGCCTGTGGACCCCCAGAGGTCTCCAGACCCAACTTTCAGGTCCTCAACCCGGCATTCAGGGAAGCTGGA GCCCATGGAAGCTACAGCCCACCTCCTGAGGAAGCAATGCCCTTCGAGGCTGAACAGCCCAGCTTGGGAGGCTTCTGGCCTACACTGGAG CAGCCTGGATTCCCCAGTGGGGTCCATGCAGGCCTTGAGGCCTTCGGCCCAGCACTCATGGAGCCCGGAGCCTTCAGTGGTGCCAGACCA GGCCTGGGAGGATACAGCCCTCCACCAGAAGAAGCTATGCCCTTTGAGTTTGACCAGCCTGCCCAGAGAGGCTGCAGTCAACTTCTCTTA CAGGTCCCAGACCTTGCTCCAGGAGGCCCAGGTGCTGCAGGGGTCCCCGGAGCTCCTCCCGAGGAGCCCCAAGCCCTCAGGCCTGCAAAG GCTGGCTCCAGAGGAGGCTACAGCCCTCCCCCTGAGGAGACTATGCCATTTGAGCTTGATGGAGAAGGATTTGGGGACGACAGCCCACCC CCGGGGCTTTCCCGAGTTATCGCACAAGTCGACGGCAGCAGCCAGTTCGCGGCAGTCGCGGCCTCGAGTGCGGTCCGCCTCACTCCCGCC GCGAACGCGCCTCCCCTCTGGGTCCCAGGCGCCATCGGCAGCCCATCCCAAGAGGCTGTCAGACCTCCTTCTAACTTCACGGGCAGCAGC CCCTGGATGGAGATCTCCGGACCCCCGTTCGAGATTGGCAGCGCCCCCGCTGGGGTCGACGACACTCCCGTCAACATGGACAGCCCCCCA ATCGCGCTTGACGGCCCGCCCATCAAGGTCTCCGGAGCCCCAGATAAGAGAGAGCGAGCAGAGAGACCCCCAGTTGAGGAGGAAGCAGCA GAGATGGAAGGAGCCGCTGATGCCGCGGAGGGAGGAAAAGTACCCTCTCCGGGGTACGGATCCCCTGCCGCCGGGGCAGCCTCAGCGGAT ACCGCTGCCAGGGCAGCCCCTGCAGCCCCAGCCGATCCTGACTCCGGGGCAACCCCAGAAGATCCCGACTCCGGGACAGCACCAGCCGAT CCTGACTCCGGGGCATTCGCAGCCGATCCCGACTCCGGGGCAGCCCCTGCCGCCCCAGCCGATCCCGACTCCGGGGCGGCCCCTGACGCC CCAGCCGATCCCGACTCCGGGGCGGCCCCTGACGCCCCAGCCGATCCAGATGCCGGGGCGGCCCCTGAGGCTCCCGCCGCCCCTGCGGCT GCTGAGACCCGGGCAGCCCATGTCGCCCCAGCTGCGCCAGACGCAGGGGCTCCCACTGCCCCAGCCGCTTCTGCCACCCGGGCAGCCCAA GTCCGCCGGGCGGCCTCTGCAGCCCCTGCCTCCGGGGCCAGACGCAAGATCCATCTCAGACCCCCCAGCCCCGAGATCCAGGCTGCCGAT CCGCCTACTCCGCGGCCTACTCGCGCGTCTGCCTGGCGGGGCAAGTCCGAGAGCAGCCGCGGCCGCCGCGTGTACTACGATGAAGGGGTG GCCAGCAGCGACGATGACTCCAGCGGAGACGAGTCCGACGATGGGACCTCCGGATGCCTCCGCTGGTTTCAGCATCGGCGAAATCGCCGC CGCCGAAAGCCCCAGCGCAACTTACTCCGCAACTTTCTCGTGCAAGCCTTCGGGGGCTGCTTCGGTCGATCTGAGAGTCCCCAGCCCAAA GCCTCGCGCTCTCTCAAGGTCAAGAAGGTACCCCTGGCGGAGAAGCGCAGACAGATGCGCAAAGAAGCCCTGGAGAAGCGGGCCCAGAAG CGCGCAGAGAAGAAACGCAGTAAGCTCATCGACAAACAACTCCAGGACGAAAAGATGGGCTACATGTGTACGCACCGCCTGCTGCTTCTA GGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTAATGGAGAGTTCTGCTTCCTTCGG TGCTGCGGCTGTGTGTTTTCTGAGCGAGCCTTGAAAGAGATAAAAGCGGAAGTTTGCCACACGTGTGGGGCTGCCTTCCAGGAGGATGAT GTCATCATGCTCAATGGCACCAAGGAGGATGTGGACGTGCTGAAGACAAGGATGGAGGAGAGAAGGCTGAGAGCGAAGCTGGAAAAGAAA ACAAAGAAACCCAAGGCAGCAGAGTCTGTTTCAAAACCAGATGTCAGTGAAGAAGCCCCAGGGCCATCAAAAGTTAAGACAGGGAAGCCT GAAGAAGCCAGCCTTGATTCTAGAGAGAAGAAAACCAACTTGGCTCCCAAAAGCACAGCAATGAATGAGAGCTCTTCTGGAAAAGCTGGG AAGCCTCCGTGTGGAGCCACAAAGAGGTCCATCGCTGACAGTGAAGAATCGGAGGCCTACAAGTCCCTCTTTACCACTCACAGCTCCGCC AAGCGCTCCAAGGAGGAGTCTGCCCACTGGGTCACCCACACGTCCTACTGCTTCTGAAGCCCGCACTGCCACCGCTCCTGCCCCAGAAGG TTGTTTAGTTTCCACGTAGGCAGGTCGCTTTGTGCCTCTGAGTGCGCTGCTGTGTGTTCTCTCTATAGTTCTGTGTCATAAAGCTGTCCT GGCCAGCCTTCAAGCTGGTGTGGCCACTCTTGATGTGAGGCGTGTCGGTTCCAGGGGGGACATGGGAGGGGCTGCACAGTGGCCCGAGGT CATGCTTGCTTCCACCTGCAGGTGCATTTGGTCCTTTCCATGGCCAGGAAGCCCTGTGGGCTGCACTTTTTATGCTTGCAGTAACAAGAG ACTCCAGAGTCCTCACCGGTGCAGAGTTGGCACATATTAATTAACTAAAATTCTAATGATCTTGCTACCAGCAATAAATCAAGTAGGCCA >33643_33643_23_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000371102_RTFDC1_chr20_55059167_ENST00000357348_length(amino acids)=887AA_BP=714 MGVRNCLYGNNMSGQRDIPPEIGEQPEQPPLEAPGAAAPGAGPSPAEEMETEPPHNEPIPVENDGEACGPPEVSRPNFQVLNPAFREAGA HGSYSPPPEEAMPFEAEQPSLGGFWPTLEQPGFPSGVHAGLEAFGPALMEPGAFSGARPGLGGYSPPPEEAMPFEFDQPAQRGCSQLLLQ VPDLAPGGPGAAGVPGAPPEEPQALRPAKAGSRGGYSPPPEETMPFELDGEGFGDDSPPPGLSRVIAQVDGSSQFAAVAASSAVRLTPAA NAPPLWVPGAIGSPSQEAVRPPSNFTGSSPWMEISGPPFEIGSAPAGVDDTPVNMDSPPIALDGPPIKVSGAPDKRERAERPPVEEEAAE MEGAADAAEGGKVPSPGYGSPAAGAASADTAARAAPAAPADPDSGATPEDPDSGTAPADPDSGAFAADPDSGAAPAAPADPDSGAAPDAP ADPDSGAAPDAPADPDAGAAPEAPAAPAAAETRAAHVAPAAPDAGAPTAPAASATRAAQVRRAASAAPASGARRKIHLRPPSPEIQAADP PTPRPTRASAWRGKSESSRGRRVYYDEGVASSDDDSSGDESDDGTSGCLRWFQHRRNRRRRKPQRNLLRNFLVQAFGGCFGRSESPQPKA SRSLKVKKVPLAEKRRQMRKEALEKRAQKRAEKKRSKLIDKQLQDEKMGYMCTHRLLLLGAGESGKSTIVKQMRILHVNGFNGEFCFLRC CGCVFSERALKEIKAEVCHTCGAAFQEDDVIMLNGTKEDVDVLKTRMEERRLRAKLEKKTKKPKAAESVSKPDVSEEAPGPSKVKTGKPE -------------------------------------------------------------- >33643_33643_24_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000371102_RTFDC1_chr20_55059167_ENST00000395881_length(transcript)=3234nt_BP=2144nt GTTATGGGCGTGCGCAACTGCCTCTACGGCAATAATATGTCAGGACAACGCGATATCCCCCCTGAAATCGGGGAACAGCCCGAGCAACCA CCTTTGGAGGCCCCAGGGGCAGCTGCCCCCGGTGCTGGGCCTAGCCCAGCCGAAGAGATGGAGACCGAACCGCCTCACAACGAGCCCATC CCCGTCGAGAATGATGGCGAGGCCTGTGGACCCCCAGAGGTCTCCAGACCCAACTTTCAGGTCCTCAACCCGGCATTCAGGGAAGCTGGA GCCCATGGAAGCTACAGCCCACCTCCTGAGGAAGCAATGCCCTTCGAGGCTGAACAGCCCAGCTTGGGAGGCTTCTGGCCTACACTGGAG CAGCCTGGATTCCCCAGTGGGGTCCATGCAGGCCTTGAGGCCTTCGGCCCAGCACTCATGGAGCCCGGAGCCTTCAGTGGTGCCAGACCA GGCCTGGGAGGATACAGCCCTCCACCAGAAGAAGCTATGCCCTTTGAGTTTGACCAGCCTGCCCAGAGAGGCTGCAGTCAACTTCTCTTA CAGGTCCCAGACCTTGCTCCAGGAGGCCCAGGTGCTGCAGGGGTCCCCGGAGCTCCTCCCGAGGAGCCCCAAGCCCTCAGGCCTGCAAAG GCTGGCTCCAGAGGAGGCTACAGCCCTCCCCCTGAGGAGACTATGCCATTTGAGCTTGATGGAGAAGGATTTGGGGACGACAGCCCACCC CCGGGGCTTTCCCGAGTTATCGCACAAGTCGACGGCAGCAGCCAGTTCGCGGCAGTCGCGGCCTCGAGTGCGGTCCGCCTCACTCCCGCC GCGAACGCGCCTCCCCTCTGGGTCCCAGGCGCCATCGGCAGCCCATCCCAAGAGGCTGTCAGACCTCCTTCTAACTTCACGGGCAGCAGC CCCTGGATGGAGATCTCCGGACCCCCGTTCGAGATTGGCAGCGCCCCCGCTGGGGTCGACGACACTCCCGTCAACATGGACAGCCCCCCA ATCGCGCTTGACGGCCCGCCCATCAAGGTCTCCGGAGCCCCAGATAAGAGAGAGCGAGCAGAGAGACCCCCAGTTGAGGAGGAAGCAGCA GAGATGGAAGGAGCCGCTGATGCCGCGGAGGGAGGAAAAGTACCCTCTCCGGGGTACGGATCCCCTGCCGCCGGGGCAGCCTCAGCGGAT ACCGCTGCCAGGGCAGCCCCTGCAGCCCCAGCCGATCCTGACTCCGGGGCAACCCCAGAAGATCCCGACTCCGGGACAGCACCAGCCGAT CCTGACTCCGGGGCATTCGCAGCCGATCCCGACTCCGGGGCAGCCCCTGCCGCCCCAGCCGATCCCGACTCCGGGGCGGCCCCTGACGCC CCAGCCGATCCCGACTCCGGGGCGGCCCCTGACGCCCCAGCCGATCCAGATGCCGGGGCGGCCCCTGAGGCTCCCGCCGCCCCTGCGGCT GCTGAGACCCGGGCAGCCCATGTCGCCCCAGCTGCGCCAGACGCAGGGGCTCCCACTGCCCCAGCCGCTTCTGCCACCCGGGCAGCCCAA GTCCGCCGGGCGGCCTCTGCAGCCCCTGCCTCCGGGGCCAGACGCAAGATCCATCTCAGACCCCCCAGCCCCGAGATCCAGGCTGCCGAT CCGCCTACTCCGCGGCCTACTCGCGCGTCTGCCTGGCGGGGCAAGTCCGAGAGCAGCCGCGGCCGCCGCGTGTACTACGATGAAGGGGTG GCCAGCAGCGACGATGACTCCAGCGGAGACGAGTCCGACGATGGGACCTCCGGATGCCTCCGCTGGTTTCAGCATCGGCGAAATCGCCGC CGCCGAAAGCCCCAGCGCAACTTACTCCGCAACTTTCTCGTGCAAGCCTTCGGGGGCTGCTTCGGTCGATCTGAGAGTCCCCAGCCCAAA GCCTCGCGCTCTCTCAAGGTCAAGAAGGTACCCCTGGCGGAGAAGCGCAGACAGATGCGCAAAGAAGCCCTGGAGAAGCGGGCCCAGAAG CGCGCAGAGAAGAAACGCAGTAAGCTCATCGACAAACAACTCCAGGACGAAAAGATGGGCTACATGTGTACGCACCGCCTGCTGCTTCTA GGTGCTGGAGAATCTGGTAAAAGCACCATTGTGAAGCAGATGAGGATCCTGCATGTTAATGGGTTTAATGGAGAGTTCTGCTTCCTTCGG TGCTGCGGCTGTGTGTTTTCTGAGCGAGCCTTGAAAGAGATAAAAGCGGAAGTTTGCCACACGTGTGGGGCTGCCTTCCAGGAGGATGAT GTCATCATGCTCAATGGCACCAAGGAGGATGTGGACGTGCTGAAGACAAGGATGGAGGAGAGAAGGCTGAGAGCGAAGCTGGAAAAGAAG CCCCAGGGCCATCAAAAGTTAAGACAGGGAAGCCTGAAGAAGCCAGCCTTGATTCTAGAGAGAAGAAAACCAACTTGGCTCCCAAAAGCA CAGCAATGAATGAGAGCTCTTCTGGAAAAGCTGGGAAGCCTCCGTGTGGAGCCACAAAGAGGTCCATCGCTGACAGTGAAGAATCGGAGG CCTACAAGTCCCTCTTTACCACTCACAGCTCCGCCAAGCGCTCCAAGGAGGAGTCTGCCCACTGGGTCACCCACACGTCCTACTGCTTCT GAAGCCCGCACTGCCACCGCTCCTGCCCCAGAAGGTTGTTTAGTTTCCACGTAGGCAGGTCGCTTTGTGCCTCTGAGTGCGCTGCTGTGT GTTCTCTCTATAGTTCTGTGTCATAAAGCTGTCCTGGCCAGCCTTCAAGCTGGTGTGGCCACTCTTGATGTGAGGCGTGTCGGTTCCAGG GGGGACATGGGAGGGGCTGCACAGTGGCCCGAGGTCATGCTTGCTTCCACCTGCAGGTGCATTTGGTCCTTTCCATGGCCAGGAAGCCCT GTGGGCTGCACTTTTTATGCTTGCAGTAACAAGAGACTCCAGAGTCCTCACCGGTGCAGAGTTGGCACATATTAATTAACTAAAATTCTA ATGATCTTGCTACCAGCAATAAATCAAGTAGGCCAAGTGAAACTGGGCTTTAAAAAGGATGGATTTCAAATACACTGTGCCCACTAGAAG CTTCGAAGGGCCTCGTCCCTCTGCTACAGCCCTGGGAGGAGCCAGGATCCTTGTTGGTCTAGCTAAATACTGTTAGGGGAGTGTGCCCCA >33643_33643_24_GNAS-RTFDC1_GNAS_chr20_57470739_ENST00000371102_RTFDC1_chr20_55059167_ENST00000395881_length(amino acids)=811AA_BP=714 MGVRNCLYGNNMSGQRDIPPEIGEQPEQPPLEAPGAAAPGAGPSPAEEMETEPPHNEPIPVENDGEACGPPEVSRPNFQVLNPAFREAGA HGSYSPPPEEAMPFEAEQPSLGGFWPTLEQPGFPSGVHAGLEAFGPALMEPGAFSGARPGLGGYSPPPEEAMPFEFDQPAQRGCSQLLLQ VPDLAPGGPGAAGVPGAPPEEPQALRPAKAGSRGGYSPPPEETMPFELDGEGFGDDSPPPGLSRVIAQVDGSSQFAAVAASSAVRLTPAA NAPPLWVPGAIGSPSQEAVRPPSNFTGSSPWMEISGPPFEIGSAPAGVDDTPVNMDSPPIALDGPPIKVSGAPDKRERAERPPVEEEAAE MEGAADAAEGGKVPSPGYGSPAAGAASADTAARAAPAAPADPDSGATPEDPDSGTAPADPDSGAFAADPDSGAAPAAPADPDSGAAPDAP ADPDSGAAPDAPADPDAGAAPEAPAAPAAAETRAAHVAPAAPDAGAPTAPAASATRAAQVRRAASAAPASGARRKIHLRPPSPEIQAADP PTPRPTRASAWRGKSESSRGRRVYYDEGVASSDDDSSGDESDDGTSGCLRWFQHRRNRRRRKPQRNLLRNFLVQAFGGCFGRSESPQPKA SRSLKVKKVPLAEKRRQMRKEALEKRAQKRAEKKRSKLIDKQLQDEKMGYMCTHRLLLLGAGESGKSTIVKQMRILHVNGFNGEFCFLRC CGCVFSERALKEIKAEVCHTCGAAFQEDDVIMLNGTKEDVDVLKTRMEERRLRAKLEKKPQGHQKLRQGSLKKPALILERRKPTWLPKAQ -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for GNAS-RTFDC1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for GNAS-RTFDC1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for GNAS-RTFDC1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies