
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:GNB2-EEF2 (FusionGDB2 ID:33700) |
Fusion Gene Summary for GNB2-EEF2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: GNB2-EEF2 | Fusion gene ID: 33700 | Hgene | Tgene | Gene symbol | GNB2 | EEF2 | Gene ID | 2783 | 1938 |
| Gene name | G protein subunit beta 2 | eukaryotic translation elongation factor 2 | |
| Synonyms | - | EEF-2|EF-2|EF2|SCA26 | |
| Cytomap | 7q22.1 | 19p13.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | guanine nucleotide-binding protein G(I)/G(S)/G(T) subunit beta-2G protein, beta-2 subunitepididymis secretory sperm binding proteing protein subunit beta-2guanine nucleotide binding protein (G protein), beta polypeptide 2guanine nucleotide-binding pr | elongation factor 2epididymis secretory sperm binding proteinpolypeptidyl-tRNA translocase | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | Q96G04 | |
| Ensembl transtripts involved in fusion gene | ENST00000303210, ENST00000393924, ENST00000393926, ENST00000424361, ENST00000436220, ENST00000419828, ENST00000427895, | ENST00000600720, ENST00000309311, | |
| Fusion gene scores | * DoF score | 4 X 5 X 4=80 | 17 X 23 X 7=2737 |
| # samples | 5 | 28 | |
| ** MAII score | log2(5/80*10)=-0.678071905112638 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(28/2737*10)=-3.28909670241999 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: GNB2 [Title/Abstract] AND EEF2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | GNB2(100275038)-EEF2(3978170), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across GNB2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across EEF2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | OV | TCGA-61-1728 | GNB2 | chr7 | 100275038 | + | EEF2 | chr19 | 3978170 | - |
Top |
Fusion Gene ORF analysis for GNB2-EEF2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000303210 | ENST00000600720 | GNB2 | chr7 | 100275038 | + | EEF2 | chr19 | 3978170 | - |
| 5CDS-intron | ENST00000393924 | ENST00000600720 | GNB2 | chr7 | 100275038 | + | EEF2 | chr19 | 3978170 | - |
| 5CDS-intron | ENST00000393926 | ENST00000600720 | GNB2 | chr7 | 100275038 | + | EEF2 | chr19 | 3978170 | - |
| 5CDS-intron | ENST00000424361 | ENST00000600720 | GNB2 | chr7 | 100275038 | + | EEF2 | chr19 | 3978170 | - |
| 5CDS-intron | ENST00000436220 | ENST00000600720 | GNB2 | chr7 | 100275038 | + | EEF2 | chr19 | 3978170 | - |
| 5UTR-3CDS | ENST00000419828 | ENST00000309311 | GNB2 | chr7 | 100275038 | + | EEF2 | chr19 | 3978170 | - |
| 5UTR-intron | ENST00000419828 | ENST00000600720 | GNB2 | chr7 | 100275038 | + | EEF2 | chr19 | 3978170 | - |
| In-frame | ENST00000303210 | ENST00000309311 | GNB2 | chr7 | 100275038 | + | EEF2 | chr19 | 3978170 | - |
| In-frame | ENST00000393924 | ENST00000309311 | GNB2 | chr7 | 100275038 | + | EEF2 | chr19 | 3978170 | - |
| In-frame | ENST00000393926 | ENST00000309311 | GNB2 | chr7 | 100275038 | + | EEF2 | chr19 | 3978170 | - |
| In-frame | ENST00000424361 | ENST00000309311 | GNB2 | chr7 | 100275038 | + | EEF2 | chr19 | 3978170 | - |
| In-frame | ENST00000436220 | ENST00000309311 | GNB2 | chr7 | 100275038 | + | EEF2 | chr19 | 3978170 | - |
| intron-3CDS | ENST00000427895 | ENST00000309311 | GNB2 | chr7 | 100275038 | + | EEF2 | chr19 | 3978170 | - |
| intron-intron | ENST00000427895 | ENST00000600720 | GNB2 | chr7 | 100275038 | + | EEF2 | chr19 | 3978170 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000303210 | GNB2 | chr7 | 100275038 | + | ENST00000309311 | EEF2 | chr19 | 3978170 | - | 2111 | 749 | 461 | 1612 | 383 |
| ENST00000436220 | GNB2 | chr7 | 100275038 | + | ENST00000309311 | EEF2 | chr19 | 3978170 | - | 1738 | 376 | 196 | 1239 | 347 |
| ENST00000424361 | GNB2 | chr7 | 100275038 | + | ENST00000309311 | EEF2 | chr19 | 3978170 | - | 1747 | 385 | 205 | 1248 | 347 |
| ENST00000393926 | GNB2 | chr7 | 100275038 | + | ENST00000309311 | EEF2 | chr19 | 3978170 | - | 1874 | 512 | 224 | 1375 | 383 |
| ENST00000393924 | GNB2 | chr7 | 100275038 | + | ENST00000309311 | EEF2 | chr19 | 3978170 | - | 1757 | 395 | 14 | 1258 | 414 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000303210 | ENST00000309311 | GNB2 | chr7 | 100275038 | + | EEF2 | chr19 | 3978170 | - | 0.004804627 | 0.9951953 |
| ENST00000436220 | ENST00000309311 | GNB2 | chr7 | 100275038 | + | EEF2 | chr19 | 3978170 | - | 0.008030494 | 0.9919695 |
| ENST00000424361 | ENST00000309311 | GNB2 | chr7 | 100275038 | + | EEF2 | chr19 | 3978170 | - | 0.008008323 | 0.9919917 |
| ENST00000393926 | ENST00000309311 | GNB2 | chr7 | 100275038 | + | EEF2 | chr19 | 3978170 | - | 0.005256906 | 0.9947431 |
| ENST00000393924 | ENST00000309311 | GNB2 | chr7 | 100275038 | + | EEF2 | chr19 | 3978170 | - | 0.005381746 | 0.99461824 |
Top |
Fusion Genomic Features for GNB2-EEF2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
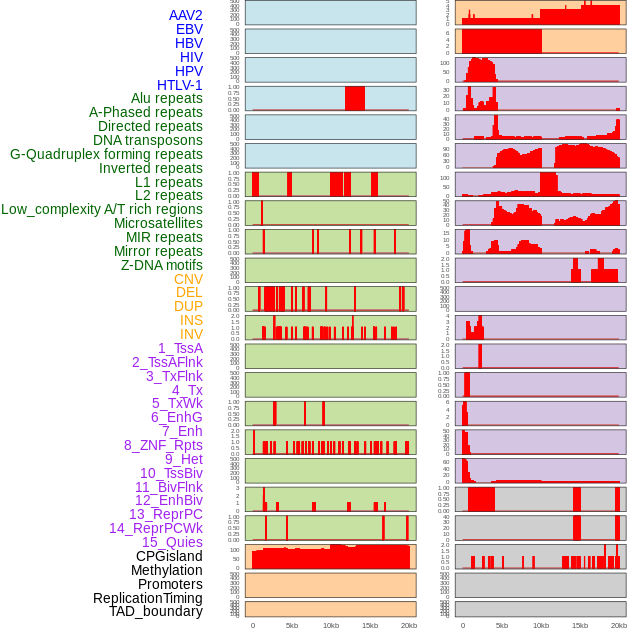 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for GNB2-EEF2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr7:100275038/chr19:3978170) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | EEF2 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Catalyzes the trimethylation of eukaryotic elongation factor 2 (EEF2) on 'Lys-525'. {ECO:0000269|PubMed:25231979}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | GNB2 | chr7:100275038 | chr19:3978170 | ENST00000303210 | + | 5 | 10 | 53_83 | 89 | 341.0 | Repeat | Note=WD 1 |
| Hgene | GNB2 | chr7:100275038 | chr19:3978170 | ENST00000393924 | + | 4 | 9 | 53_83 | 89 | 341.0 | Repeat | Note=WD 1 |
| Hgene | GNB2 | chr7:100275038 | chr19:3978170 | ENST00000393926 | + | 5 | 10 | 53_83 | 89 | 341.0 | Repeat | Note=WD 1 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | GNB2 | chr7:100275038 | chr19:3978170 | ENST00000303210 | + | 5 | 10 | 141_170 | 89 | 341.0 | Repeat | Note=WD 3 |
| Hgene | GNB2 | chr7:100275038 | chr19:3978170 | ENST00000303210 | + | 5 | 10 | 182_212 | 89 | 341.0 | Repeat | Note=WD 4 |
| Hgene | GNB2 | chr7:100275038 | chr19:3978170 | ENST00000303210 | + | 5 | 10 | 224_254 | 89 | 341.0 | Repeat | Note=WD 5 |
| Hgene | GNB2 | chr7:100275038 | chr19:3978170 | ENST00000303210 | + | 5 | 10 | 268_298 | 89 | 341.0 | Repeat | Note=WD 6 |
| Hgene | GNB2 | chr7:100275038 | chr19:3978170 | ENST00000303210 | + | 5 | 10 | 310_340 | 89 | 341.0 | Repeat | Note=WD 7 |
| Hgene | GNB2 | chr7:100275038 | chr19:3978170 | ENST00000303210 | + | 5 | 10 | 95_125 | 89 | 341.0 | Repeat | Note=WD 2 |
| Hgene | GNB2 | chr7:100275038 | chr19:3978170 | ENST00000393924 | + | 4 | 9 | 141_170 | 89 | 341.0 | Repeat | Note=WD 3 |
| Hgene | GNB2 | chr7:100275038 | chr19:3978170 | ENST00000393924 | + | 4 | 9 | 182_212 | 89 | 341.0 | Repeat | Note=WD 4 |
| Hgene | GNB2 | chr7:100275038 | chr19:3978170 | ENST00000393924 | + | 4 | 9 | 224_254 | 89 | 341.0 | Repeat | Note=WD 5 |
| Hgene | GNB2 | chr7:100275038 | chr19:3978170 | ENST00000393924 | + | 4 | 9 | 268_298 | 89 | 341.0 | Repeat | Note=WD 6 |
| Hgene | GNB2 | chr7:100275038 | chr19:3978170 | ENST00000393924 | + | 4 | 9 | 310_340 | 89 | 341.0 | Repeat | Note=WD 7 |
| Hgene | GNB2 | chr7:100275038 | chr19:3978170 | ENST00000393924 | + | 4 | 9 | 95_125 | 89 | 341.0 | Repeat | Note=WD 2 |
| Hgene | GNB2 | chr7:100275038 | chr19:3978170 | ENST00000393926 | + | 5 | 10 | 141_170 | 89 | 341.0 | Repeat | Note=WD 3 |
| Hgene | GNB2 | chr7:100275038 | chr19:3978170 | ENST00000393926 | + | 5 | 10 | 182_212 | 89 | 341.0 | Repeat | Note=WD 4 |
| Hgene | GNB2 | chr7:100275038 | chr19:3978170 | ENST00000393926 | + | 5 | 10 | 224_254 | 89 | 341.0 | Repeat | Note=WD 5 |
| Hgene | GNB2 | chr7:100275038 | chr19:3978170 | ENST00000393926 | + | 5 | 10 | 268_298 | 89 | 341.0 | Repeat | Note=WD 6 |
| Hgene | GNB2 | chr7:100275038 | chr19:3978170 | ENST00000393926 | + | 5 | 10 | 310_340 | 89 | 341.0 | Repeat | Note=WD 7 |
| Hgene | GNB2 | chr7:100275038 | chr19:3978170 | ENST00000393926 | + | 5 | 10 | 95_125 | 89 | 341.0 | Repeat | Note=WD 2 |
| Tgene | EEF2 | chr7:100275038 | chr19:3978170 | ENST00000309311 | 10 | 15 | 17_362 | 571 | 859.0 | Domain | tr-type G | |
| Tgene | EEF2 | chr7:100275038 | chr19:3978170 | ENST00000309311 | 10 | 15 | 104_108 | 571 | 859.0 | Nucleotide binding | GTP | |
| Tgene | EEF2 | chr7:100275038 | chr19:3978170 | ENST00000309311 | 10 | 15 | 158_161 | 571 | 859.0 | Nucleotide binding | GTP | |
| Tgene | EEF2 | chr7:100275038 | chr19:3978170 | ENST00000309311 | 10 | 15 | 26_33 | 571 | 859.0 | Nucleotide binding | GTP |
Top |
Fusion Gene Sequence for GNB2-EEF2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >33700_33700_1_GNB2-EEF2_GNB2_chr7_100275038_ENST00000303210_EEF2_chr19_3978170_ENST00000309311_length(transcript)=2111nt_BP=749nt TCCAGTCCCAGAGGGGGGATGTCTTACTCCTTTCCGTGAAGCAAACCCTTTGAGTACGGTTTGCGTCCACAAAGCGTAGGGTGAGAACCT TGGGAGCGACTGGGCCCGTCTTTGCTCCCTCGGTGGGGTTTTGTCTCCTGGCTTCCCCCAAGTGCGAGGCAGTTGGTCTCGCCCAGCCGG GTCCTGGGCGCGGCGGCGGCAGCCGCGTCACTGGCGGGCGGGATCCCTCCGCTCTGGGGAGGCAGCGCTGGCGGCGGGGCTGGGGCCACT GAGGAAATCCATCCGCGCCGCCGCCGCCGCCGCCGCCGCCGCCGCCGCCGCCTCCGCCGCGGAGGAAGACAGCGCCGCCCGCGCACCGCC AGCGACCTCCGCCGCAGAGTCCCACCGCCACAGGCCTCGGGCCAGCGGCCAGGAGCTGCCTCCCCCAGCCCCCGTCCCGCGGCCCCCAGC CGCCCCCAACCCTGCCCCACGGGCCCGGCGCCATGAGTGAGCTGGAGCAACTGAGACAGGAGGCCGAGCAGCTCCGGAACCAGATCCGGG ATGCCCGAAAAGCATGTGGGGACTCAACACTGACCCAGATCACAGCTGGGCTGGACCCAGTGGGGAGAATCCAGATGAGGACCCGGAGGA CCCTCCGTGGGCACCTGGCAAAGATCTATGCCATGCACTGGGGGACCGACTCAAGGCTGCTGGTCAGCGCCTCCCAGGATGGGAAGCTCA TCATCTGGGACAGCTACACCACCAACAAGAAATCTGACCCGGTCGTCTCGTACCGCGAGACGGTCAGTGAAGAGTCGAACGTGCTCTGCC TCTCCAAGTCCCCCAACAAGCACAACCGGCTGTACATGAAGGCGCGGCCCTTCCCCGACGGCCTGGCCGAGGACATCGATAAAGGCGAGG TGTCCGCCCGTCAGGAGCTCAAGCAGCGGGCGCGCTACCTGGCCGAGAAGTACGAGTGGGACGTGGCTGAGGCCCGCAAGATCTGGTGCT TTGGGCCCGACGGCACCGGCCCCAACATCCTCACCGACATCACCAAGGGTGTGCAGTACCTCAACGAGATCAAGGACAGTGTGGTGGCCG GCTTCCAGTGGGCCACCAAGGAGGGCGCACTGTGTGAGGAGAACATGCGGGGTGTGCGCTTCGACGTCCACGACGTCACCCTGCACGCCG ACGCCATCCACCGCGGAGGGGGCCAGATCATCCCCACAGCACGGCGCTGCCTCTATGCCAGTGTGCTGACCGCCCAGCCACGCCTCATGG AGCCCATCTACCTTGTGGAGATCCAGTGTCCAGAGCAGGTGGTCGGTGGCATCTACGGGGTTTTGAACAGGAAGCGGGGCCACGTGTTCG AGGAGTCCCAGGTGGCCGGCACCCCCATGTTTGTGGTCAAGGCCTATCTGCCCGTCAACGAGTCCTTTGGCTTCACCGCTGACCTGAGGT CCAACACGGGCGGCCAGGCGTTCCCCCAGTGTGTGTTTGACCACTGGCAGATCCTGCCCGGAGACCCCTTCGACAACAGCAGCCGCCCCA GCCAGGTGGTGGCGGAGACCCGCAAGCGCAAGGGCCTGAAAGAAGGCATCCCTGCCCTGGACAACTTCCTGGACAAATTGTAGGCGGCCC TTCCTGCAGCGCCTGCCGCCCCGGGGACTCGCAGCACCCACAGCACCACGTCCTCGAATTCTCAGACGACACCTGGAGACTGTCCCGACA CAGCGACGCTCCCCTGAGAGGTTTCTGGGGCCCGCTGCGTGCCATCACTCAACCATAACACTTGATGCCGTTTCTTTCAATATTTATTTC CAGAGTCCGGAGGCAGCAGACACGCCCTCTTAGTAGGGACTTAATGGGCCGGTCGGGGAGGGGGAGGCGGGATGGGACACCCAACACTTT TTCCATTTCTTCAGAGGGAAACTCAGATGTCCAAACTAATTTTAACAAACGCATTAAGAGGTTTATTTGGGTACATGGCCCGCAGTGGCT TTTGCCCCAGAAAGGGGAAAGGAACACGCGGGTAGATGATTTCTAGCAGGCAGGAAGTCCTGTGCGGTGTCACCATGAGCACCTCCAGCT >33700_33700_1_GNB2-EEF2_GNB2_chr7_100275038_ENST00000303210_EEF2_chr19_3978170_ENST00000309311_length(amino acids)=383AA_BP=96 MPHGPGAMSELEQLRQEAEQLRNQIRDARKACGDSTLTQITAGLDPVGRIQMRTRRTLRGHLAKIYAMHWGTDSRLLVSASQDGKLIIWD SYTTNKKSDPVVSYRETVSEESNVLCLSKSPNKHNRLYMKARPFPDGLAEDIDKGEVSARQELKQRARYLAEKYEWDVAEARKIWCFGPD GTGPNILTDITKGVQYLNEIKDSVVAGFQWATKEGALCEENMRGVRFDVHDVTLHADAIHRGGGQIIPTARRCLYASVLTAQPRLMEPIY LVEIQCPEQVVGGIYGVLNRKRGHVFEESQVAGTPMFVVKAYLPVNESFGFTADLRSNTGGQAFPQCVFDHWQILPGDPFDNSSRPSQVV -------------------------------------------------------------- >33700_33700_2_GNB2-EEF2_GNB2_chr7_100275038_ENST00000393924_EEF2_chr19_3978170_ENST00000309311_length(transcript)=1757nt_BP=395nt CGGCGGCCTCGGGCCTGACGTCAGCCCTGCATCCCCCAGGCCTCGGGCCAGCGGCCAGGAGCTGCCTCCCCCAGCCCCCGTCCCGCGGCC CCCAGCCGCCCCCAACCCTGCCCCACGGGCCCGGCGCCATGAGTGAGCTGGAGCAACTGAGACAGGAGGCCGAGCAGCTCCGGAACCAGA TCCGGGATGCCCGAAAAGCATGTGGGGACTCAACACTGACCCAGATCACAGCTGGGCTGGACCCAGTGGGGAGAATCCAGATGAGGACCC GGAGGACCCTCCGTGGGCACCTGGCAAAGATCTATGCCATGCACTGGGGGACCGACTCAAGGCTGCTGGTCAGCGCCTCCCAGGATGGGA AGCTCATCATCTGGGACAGCTACACCACCAACAAGAAATCTGACCCGGTCGTCTCGTACCGCGAGACGGTCAGTGAAGAGTCGAACGTGC TCTGCCTCTCCAAGTCCCCCAACAAGCACAACCGGCTGTACATGAAGGCGCGGCCCTTCCCCGACGGCCTGGCCGAGGACATCGATAAAG GCGAGGTGTCCGCCCGTCAGGAGCTCAAGCAGCGGGCGCGCTACCTGGCCGAGAAGTACGAGTGGGACGTGGCTGAGGCCCGCAAGATCT GGTGCTTTGGGCCCGACGGCACCGGCCCCAACATCCTCACCGACATCACCAAGGGTGTGCAGTACCTCAACGAGATCAAGGACAGTGTGG TGGCCGGCTTCCAGTGGGCCACCAAGGAGGGCGCACTGTGTGAGGAGAACATGCGGGGTGTGCGCTTCGACGTCCACGACGTCACCCTGC ACGCCGACGCCATCCACCGCGGAGGGGGCCAGATCATCCCCACAGCACGGCGCTGCCTCTATGCCAGTGTGCTGACCGCCCAGCCACGCC TCATGGAGCCCATCTACCTTGTGGAGATCCAGTGTCCAGAGCAGGTGGTCGGTGGCATCTACGGGGTTTTGAACAGGAAGCGGGGCCACG TGTTCGAGGAGTCCCAGGTGGCCGGCACCCCCATGTTTGTGGTCAAGGCCTATCTGCCCGTCAACGAGTCCTTTGGCTTCACCGCTGACC TGAGGTCCAACACGGGCGGCCAGGCGTTCCCCCAGTGTGTGTTTGACCACTGGCAGATCCTGCCCGGAGACCCCTTCGACAACAGCAGCC GCCCCAGCCAGGTGGTGGCGGAGACCCGCAAGCGCAAGGGCCTGAAAGAAGGCATCCCTGCCCTGGACAACTTCCTGGACAAATTGTAGG CGGCCCTTCCTGCAGCGCCTGCCGCCCCGGGGACTCGCAGCACCCACAGCACCACGTCCTCGAATTCTCAGACGACACCTGGAGACTGTC CCGACACAGCGACGCTCCCCTGAGAGGTTTCTGGGGCCCGCTGCGTGCCATCACTCAACCATAACACTTGATGCCGTTTCTTTCAATATT TATTTCCAGAGTCCGGAGGCAGCAGACACGCCCTCTTAGTAGGGACTTAATGGGCCGGTCGGGGAGGGGGAGGCGGGATGGGACACCCAA CACTTTTTCCATTTCTTCAGAGGGAAACTCAGATGTCCAAACTAATTTTAACAAACGCATTAAGAGGTTTATTTGGGTACATGGCCCGCA GTGGCTTTTGCCCCAGAAAGGGGAAAGGAACACGCGGGTAGATGATTTCTAGCAGGCAGGAAGTCCTGTGCGGTGTCACCATGAGCACCT >33700_33700_2_GNB2-EEF2_GNB2_chr7_100275038_ENST00000393924_EEF2_chr19_3978170_ENST00000309311_length(amino acids)=414AA_BP=127 MTSALHPPGLGPAARSCLPQPPSRGPQPPPTLPHGPGAMSELEQLRQEAEQLRNQIRDARKACGDSTLTQITAGLDPVGRIQMRTRRTLR GHLAKIYAMHWGTDSRLLVSASQDGKLIIWDSYTTNKKSDPVVSYRETVSEESNVLCLSKSPNKHNRLYMKARPFPDGLAEDIDKGEVSA RQELKQRARYLAEKYEWDVAEARKIWCFGPDGTGPNILTDITKGVQYLNEIKDSVVAGFQWATKEGALCEENMRGVRFDVHDVTLHADAI HRGGGQIIPTARRCLYASVLTAQPRLMEPIYLVEIQCPEQVVGGIYGVLNRKRGHVFEESQVAGTPMFVVKAYLPVNESFGFTADLRSNT -------------------------------------------------------------- >33700_33700_3_GNB2-EEF2_GNB2_chr7_100275038_ENST00000393926_EEF2_chr19_3978170_ENST00000309311_length(transcript)=1874nt_BP=512nt CTCGAGAGCGGCTCCCACGGGCTTTCTGCGGGCGCGGCGGGGCGGGCGGTCCCTGCGCTGGAGGGAGCAGCGGCTCGGGGCTGCCTTCCC CGCCGCTGTCACCCCCACCCGCGGCGGACGGCTAATGGGGCGCAGCCGGACCGGGGATTATCCGGGGCCTCGGGCCAGCGGCCAGGAGCT GCCTCCCCCAGCCCCCGTCCCGCGGCCCCCAGCCGCCCCCAACCCTGCCCCACGGGCCCGGCGCCATGAGTGAGCTGGAGCAACTGAGAC AGGAGGCCGAGCAGCTCCGGAACCAGATCCGGGATGCCCGAAAAGCATGTGGGGACTCAACACTGACCCAGATCACAGCTGGGCTGGACC CAGTGGGGAGAATCCAGATGAGGACCCGGAGGACCCTCCGTGGGCACCTGGCAAAGATCTATGCCATGCACTGGGGGACCGACTCAAGGC TGCTGGTCAGCGCCTCCCAGGATGGGAAGCTCATCATCTGGGACAGCTACACCACCAACAAGAAATCTGACCCGGTCGTCTCGTACCGCG AGACGGTCAGTGAAGAGTCGAACGTGCTCTGCCTCTCCAAGTCCCCCAACAAGCACAACCGGCTGTACATGAAGGCGCGGCCCTTCCCCG ACGGCCTGGCCGAGGACATCGATAAAGGCGAGGTGTCCGCCCGTCAGGAGCTCAAGCAGCGGGCGCGCTACCTGGCCGAGAAGTACGAGT GGGACGTGGCTGAGGCCCGCAAGATCTGGTGCTTTGGGCCCGACGGCACCGGCCCCAACATCCTCACCGACATCACCAAGGGTGTGCAGT ACCTCAACGAGATCAAGGACAGTGTGGTGGCCGGCTTCCAGTGGGCCACCAAGGAGGGCGCACTGTGTGAGGAGAACATGCGGGGTGTGC GCTTCGACGTCCACGACGTCACCCTGCACGCCGACGCCATCCACCGCGGAGGGGGCCAGATCATCCCCACAGCACGGCGCTGCCTCTATG CCAGTGTGCTGACCGCCCAGCCACGCCTCATGGAGCCCATCTACCTTGTGGAGATCCAGTGTCCAGAGCAGGTGGTCGGTGGCATCTACG GGGTTTTGAACAGGAAGCGGGGCCACGTGTTCGAGGAGTCCCAGGTGGCCGGCACCCCCATGTTTGTGGTCAAGGCCTATCTGCCCGTCA ACGAGTCCTTTGGCTTCACCGCTGACCTGAGGTCCAACACGGGCGGCCAGGCGTTCCCCCAGTGTGTGTTTGACCACTGGCAGATCCTGC CCGGAGACCCCTTCGACAACAGCAGCCGCCCCAGCCAGGTGGTGGCGGAGACCCGCAAGCGCAAGGGCCTGAAAGAAGGCATCCCTGCCC TGGACAACTTCCTGGACAAATTGTAGGCGGCCCTTCCTGCAGCGCCTGCCGCCCCGGGGACTCGCAGCACCCACAGCACCACGTCCTCGA ATTCTCAGACGACACCTGGAGACTGTCCCGACACAGCGACGCTCCCCTGAGAGGTTTCTGGGGCCCGCTGCGTGCCATCACTCAACCATA ACACTTGATGCCGTTTCTTTCAATATTTATTTCCAGAGTCCGGAGGCAGCAGACACGCCCTCTTAGTAGGGACTTAATGGGCCGGTCGGG GAGGGGGAGGCGGGATGGGACACCCAACACTTTTTCCATTTCTTCAGAGGGAAACTCAGATGTCCAAACTAATTTTAACAAACGCATTAA GAGGTTTATTTGGGTACATGGCCCGCAGTGGCTTTTGCCCCAGAAAGGGGAAAGGAACACGCGGGTAGATGATTTCTAGCAGGCAGGAAG >33700_33700_3_GNB2-EEF2_GNB2_chr7_100275038_ENST00000393926_EEF2_chr19_3978170_ENST00000309311_length(amino acids)=383AA_BP=96 MPHGPGAMSELEQLRQEAEQLRNQIRDARKACGDSTLTQITAGLDPVGRIQMRTRRTLRGHLAKIYAMHWGTDSRLLVSASQDGKLIIWD SYTTNKKSDPVVSYRETVSEESNVLCLSKSPNKHNRLYMKARPFPDGLAEDIDKGEVSARQELKQRARYLAEKYEWDVAEARKIWCFGPD GTGPNILTDITKGVQYLNEIKDSVVAGFQWATKEGALCEENMRGVRFDVHDVTLHADAIHRGGGQIIPTARRCLYASVLTAQPRLMEPIY LVEIQCPEQVVGGIYGVLNRKRGHVFEESQVAGTPMFVVKAYLPVNESFGFTADLRSNTGGQAFPQCVFDHWQILPGDPFDNSSRPSQVV -------------------------------------------------------------- >33700_33700_4_GNB2-EEF2_GNB2_chr7_100275038_ENST00000424361_EEF2_chr19_3978170_ENST00000309311_length(transcript)=1747nt_BP=385nt CGGGATCCCTCCGCTCTGGGGAGGCAGCGCTGGCGGCGGGGCTGGGGCCACTGAGGAAATCCATCCGCGCCGCCGCCGCCGCCGCCGCCG CCGCCGCCGCCGCCTCCGCCGCGGAGGAAGACAGCGCCGCCCGCGCACCGCCAGCGACCTCCGCCGCAGAGTCCCACCGCCACAGGATGC CCGAAAAGCATGTGGGGACTCAACACTGACCCAGATCACAGCTGGGCTGGACCCAGTGGGGAGAATCCAGATGAGGACCCGGAGGACCCT CCGTGGGCACCTGGCAAAGATCTATGCCATGCACTGGGGGACCGACTCAAGGCTGCTGGTCAGCGCCTCCCAGGATGGGAAGCTCATCAT CTGGGACAGCTACACCACCAACAAGAAATCTGACCCGGTCGTCTCGTACCGCGAGACGGTCAGTGAAGAGTCGAACGTGCTCTGCCTCTC CAAGTCCCCCAACAAGCACAACCGGCTGTACATGAAGGCGCGGCCCTTCCCCGACGGCCTGGCCGAGGACATCGATAAAGGCGAGGTGTC CGCCCGTCAGGAGCTCAAGCAGCGGGCGCGCTACCTGGCCGAGAAGTACGAGTGGGACGTGGCTGAGGCCCGCAAGATCTGGTGCTTTGG GCCCGACGGCACCGGCCCCAACATCCTCACCGACATCACCAAGGGTGTGCAGTACCTCAACGAGATCAAGGACAGTGTGGTGGCCGGCTT CCAGTGGGCCACCAAGGAGGGCGCACTGTGTGAGGAGAACATGCGGGGTGTGCGCTTCGACGTCCACGACGTCACCCTGCACGCCGACGC CATCCACCGCGGAGGGGGCCAGATCATCCCCACAGCACGGCGCTGCCTCTATGCCAGTGTGCTGACCGCCCAGCCACGCCTCATGGAGCC CATCTACCTTGTGGAGATCCAGTGTCCAGAGCAGGTGGTCGGTGGCATCTACGGGGTTTTGAACAGGAAGCGGGGCCACGTGTTCGAGGA GTCCCAGGTGGCCGGCACCCCCATGTTTGTGGTCAAGGCCTATCTGCCCGTCAACGAGTCCTTTGGCTTCACCGCTGACCTGAGGTCCAA CACGGGCGGCCAGGCGTTCCCCCAGTGTGTGTTTGACCACTGGCAGATCCTGCCCGGAGACCCCTTCGACAACAGCAGCCGCCCCAGCCA GGTGGTGGCGGAGACCCGCAAGCGCAAGGGCCTGAAAGAAGGCATCCCTGCCCTGGACAACTTCCTGGACAAATTGTAGGCGGCCCTTCC TGCAGCGCCTGCCGCCCCGGGGACTCGCAGCACCCACAGCACCACGTCCTCGAATTCTCAGACGACACCTGGAGACTGTCCCGACACAGC GACGCTCCCCTGAGAGGTTTCTGGGGCCCGCTGCGTGCCATCACTCAACCATAACACTTGATGCCGTTTCTTTCAATATTTATTTCCAGA GTCCGGAGGCAGCAGACACGCCCTCTTAGTAGGGACTTAATGGGCCGGTCGGGGAGGGGGAGGCGGGATGGGACACCCAACACTTTTTCC ATTTCTTCAGAGGGAAACTCAGATGTCCAAACTAATTTTAACAAACGCATTAAGAGGTTTATTTGGGTACATGGCCCGCAGTGGCTTTTG CCCCAGAAAGGGGAAAGGAACACGCGGGTAGATGATTTCTAGCAGGCAGGAAGTCCTGTGCGGTGTCACCATGAGCACCTCCAGCTGTAC >33700_33700_4_GNB2-EEF2_GNB2_chr7_100275038_ENST00000424361_EEF2_chr19_3978170_ENST00000309311_length(amino acids)=347AA_BP=60 MTQITAGLDPVGRIQMRTRRTLRGHLAKIYAMHWGTDSRLLVSASQDGKLIIWDSYTTNKKSDPVVSYRETVSEESNVLCLSKSPNKHNR LYMKARPFPDGLAEDIDKGEVSARQELKQRARYLAEKYEWDVAEARKIWCFGPDGTGPNILTDITKGVQYLNEIKDSVVAGFQWATKEGA LCEENMRGVRFDVHDVTLHADAIHRGGGQIIPTARRCLYASVLTAQPRLMEPIYLVEIQCPEQVVGGIYGVLNRKRGHVFEESQVAGTPM -------------------------------------------------------------- >33700_33700_5_GNB2-EEF2_GNB2_chr7_100275038_ENST00000436220_EEF2_chr19_3978170_ENST00000309311_length(transcript)=1738nt_BP=376nt CGGGCGGGATCCCTCCGCTCTGGGGAGGCAGCGCTGGCGGCGGGGCTGGGGCCACTGAGGAAATCCATCCGCGCCGCCGCCGCCGCCGCC GCCGCCGCCGCCGCCGCCTCCGCCGCGGAGGAAGACAGCGCCGCCCGCGCACCGCCAGCGACCTCCGCCGCAGAGTCCCACCGCCACAGC ATGTGGGGACTCAACACTGACCCAGATCACAGCTGGGCTGGACCCAGTGGGGAGAATCCAGATGAGGACCCGGAGGACCCTCCGTGGGCA CCTGGCAAAGATCTATGCCATGCACTGGGGGACCGACTCAAGGCTGCTGGTCAGCGCCTCCCAGGATGGGAAGCTCATCATCTGGGACAG CTACACCACCAACAAGAAATCTGACCCGGTCGTCTCGTACCGCGAGACGGTCAGTGAAGAGTCGAACGTGCTCTGCCTCTCCAAGTCCCC CAACAAGCACAACCGGCTGTACATGAAGGCGCGGCCCTTCCCCGACGGCCTGGCCGAGGACATCGATAAAGGCGAGGTGTCCGCCCGTCA GGAGCTCAAGCAGCGGGCGCGCTACCTGGCCGAGAAGTACGAGTGGGACGTGGCTGAGGCCCGCAAGATCTGGTGCTTTGGGCCCGACGG CACCGGCCCCAACATCCTCACCGACATCACCAAGGGTGTGCAGTACCTCAACGAGATCAAGGACAGTGTGGTGGCCGGCTTCCAGTGGGC CACCAAGGAGGGCGCACTGTGTGAGGAGAACATGCGGGGTGTGCGCTTCGACGTCCACGACGTCACCCTGCACGCCGACGCCATCCACCG CGGAGGGGGCCAGATCATCCCCACAGCACGGCGCTGCCTCTATGCCAGTGTGCTGACCGCCCAGCCACGCCTCATGGAGCCCATCTACCT TGTGGAGATCCAGTGTCCAGAGCAGGTGGTCGGTGGCATCTACGGGGTTTTGAACAGGAAGCGGGGCCACGTGTTCGAGGAGTCCCAGGT GGCCGGCACCCCCATGTTTGTGGTCAAGGCCTATCTGCCCGTCAACGAGTCCTTTGGCTTCACCGCTGACCTGAGGTCCAACACGGGCGG CCAGGCGTTCCCCCAGTGTGTGTTTGACCACTGGCAGATCCTGCCCGGAGACCCCTTCGACAACAGCAGCCGCCCCAGCCAGGTGGTGGC GGAGACCCGCAAGCGCAAGGGCCTGAAAGAAGGCATCCCTGCCCTGGACAACTTCCTGGACAAATTGTAGGCGGCCCTTCCTGCAGCGCC TGCCGCCCCGGGGACTCGCAGCACCCACAGCACCACGTCCTCGAATTCTCAGACGACACCTGGAGACTGTCCCGACACAGCGACGCTCCC CTGAGAGGTTTCTGGGGCCCGCTGCGTGCCATCACTCAACCATAACACTTGATGCCGTTTCTTTCAATATTTATTTCCAGAGTCCGGAGG CAGCAGACACGCCCTCTTAGTAGGGACTTAATGGGCCGGTCGGGGAGGGGGAGGCGGGATGGGACACCCAACACTTTTTCCATTTCTTCA GAGGGAAACTCAGATGTCCAAACTAATTTTAACAAACGCATTAAGAGGTTTATTTGGGTACATGGCCCGCAGTGGCTTTTGCCCCAGAAA GGGGAAAGGAACACGCGGGTAGATGATTTCTAGCAGGCAGGAAGTCCTGTGCGGTGTCACCATGAGCACCTCCAGCTGTACTAGTGCCAT >33700_33700_5_GNB2-EEF2_GNB2_chr7_100275038_ENST00000436220_EEF2_chr19_3978170_ENST00000309311_length(amino acids)=347AA_BP=60 MTQITAGLDPVGRIQMRTRRTLRGHLAKIYAMHWGTDSRLLVSASQDGKLIIWDSYTTNKKSDPVVSYRETVSEESNVLCLSKSPNKHNR LYMKARPFPDGLAEDIDKGEVSARQELKQRARYLAEKYEWDVAEARKIWCFGPDGTGPNILTDITKGVQYLNEIKDSVVAGFQWATKEGA LCEENMRGVRFDVHDVTLHADAIHRGGGQIIPTARRCLYASVLTAQPRLMEPIYLVEIQCPEQVVGGIYGVLNRKRGHVFEESQVAGTPM -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for GNB2-EEF2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for GNB2-EEF2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for GNB2-EEF2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies