
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:GOLGA4-TATDN2 (FusionGDB2 ID:33910) |
Fusion Gene Summary for GOLGA4-TATDN2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: GOLGA4-TATDN2 | Fusion gene ID: 33910 | Hgene | Tgene | Gene symbol | GOLGA4 | TATDN2 | Gene ID | 2803 | 9797 |
| Gene name | golgin A4 | TatD DNase domain containing 2 | |
| Synonyms | CRPF46|GCP2|GOLG|MU-RMS-40.18|p230 | - | |
| Cytomap | 3p22.2 | 3p25.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | golgin subfamily A member 4256 kDa golgin72.1 proteincentrosome-related protein F46golgi autoantigen, golgin subfamily a, 4golgin-240golgin-245protein 72.1trans-Golgi p230 | putative deoxyribonuclease TATDN2 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000356847, ENST00000361924, ENST00000444882, ENST00000435830, | ENST00000496355, ENST00000287652, ENST00000448281, | |
| Fusion gene scores | * DoF score | 24 X 16 X 11=4224 | 5 X 5 X 3=75 |
| # samples | 27 | 6 | |
| ** MAII score | log2(27/4224*10)=-3.96757852230762 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(6/75*10)=-0.321928094887362 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: GOLGA4 [Title/Abstract] AND TATDN2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | GOLGA4(37292975)-TATDN2(10318044), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | GOLGA4 | GO:0043001 | Golgi to plasma membrane protein transport | 15265687 |
| Hgene | GOLGA4 | GO:0045773 | positive regulation of axon extension | 22705394 |
| Fusion gene breakpoints across GOLGA4 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across TATDN2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-HU-A4GY | GOLGA4 | chr3 | 37292975 | + | TATDN2 | chr3 | 10318044 | + |
Top |
Fusion Gene ORF analysis for GOLGA4-TATDN2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000356847 | ENST00000496355 | GOLGA4 | chr3 | 37292975 | + | TATDN2 | chr3 | 10318044 | + |
| 5CDS-intron | ENST00000361924 | ENST00000496355 | GOLGA4 | chr3 | 37292975 | + | TATDN2 | chr3 | 10318044 | + |
| 5CDS-intron | ENST00000444882 | ENST00000496355 | GOLGA4 | chr3 | 37292975 | + | TATDN2 | chr3 | 10318044 | + |
| In-frame | ENST00000356847 | ENST00000287652 | GOLGA4 | chr3 | 37292975 | + | TATDN2 | chr3 | 10318044 | + |
| In-frame | ENST00000356847 | ENST00000448281 | GOLGA4 | chr3 | 37292975 | + | TATDN2 | chr3 | 10318044 | + |
| In-frame | ENST00000361924 | ENST00000287652 | GOLGA4 | chr3 | 37292975 | + | TATDN2 | chr3 | 10318044 | + |
| In-frame | ENST00000361924 | ENST00000448281 | GOLGA4 | chr3 | 37292975 | + | TATDN2 | chr3 | 10318044 | + |
| In-frame | ENST00000444882 | ENST00000287652 | GOLGA4 | chr3 | 37292975 | + | TATDN2 | chr3 | 10318044 | + |
| In-frame | ENST00000444882 | ENST00000448281 | GOLGA4 | chr3 | 37292975 | + | TATDN2 | chr3 | 10318044 | + |
| intron-3CDS | ENST00000435830 | ENST00000287652 | GOLGA4 | chr3 | 37292975 | + | TATDN2 | chr3 | 10318044 | + |
| intron-3CDS | ENST00000435830 | ENST00000448281 | GOLGA4 | chr3 | 37292975 | + | TATDN2 | chr3 | 10318044 | + |
| intron-intron | ENST00000435830 | ENST00000496355 | GOLGA4 | chr3 | 37292975 | + | TATDN2 | chr3 | 10318044 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000361924 | GOLGA4 | chr3 | 37292975 | + | ENST00000287652 | TATDN2 | chr3 | 10318044 | + | 2994 | 536 | 374 | 988 | 204 |
| ENST00000361924 | GOLGA4 | chr3 | 37292975 | + | ENST00000448281 | TATDN2 | chr3 | 10318044 | + | 3025 | 536 | 374 | 988 | 204 |
| ENST00000444882 | GOLGA4 | chr3 | 37292975 | + | ENST00000287652 | TATDN2 | chr3 | 10318044 | + | 2924 | 466 | 304 | 918 | 204 |
| ENST00000444882 | GOLGA4 | chr3 | 37292975 | + | ENST00000448281 | TATDN2 | chr3 | 10318044 | + | 2955 | 466 | 304 | 918 | 204 |
| ENST00000356847 | GOLGA4 | chr3 | 37292975 | + | ENST00000287652 | TATDN2 | chr3 | 10318044 | + | 2919 | 461 | 299 | 913 | 204 |
| ENST00000356847 | GOLGA4 | chr3 | 37292975 | + | ENST00000448281 | TATDN2 | chr3 | 10318044 | + | 2950 | 461 | 299 | 913 | 204 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000361924 | ENST00000287652 | GOLGA4 | chr3 | 37292975 | + | TATDN2 | chr3 | 10318044 | + | 0.005609228 | 0.9943908 |
| ENST00000361924 | ENST00000448281 | GOLGA4 | chr3 | 37292975 | + | TATDN2 | chr3 | 10318044 | + | 0.004037326 | 0.9959627 |
| ENST00000444882 | ENST00000287652 | GOLGA4 | chr3 | 37292975 | + | TATDN2 | chr3 | 10318044 | + | 0.005544332 | 0.99445564 |
| ENST00000444882 | ENST00000448281 | GOLGA4 | chr3 | 37292975 | + | TATDN2 | chr3 | 10318044 | + | 0.005212001 | 0.99478805 |
| ENST00000356847 | ENST00000287652 | GOLGA4 | chr3 | 37292975 | + | TATDN2 | chr3 | 10318044 | + | 0.004087651 | 0.9959124 |
| ENST00000356847 | ENST00000448281 | GOLGA4 | chr3 | 37292975 | + | TATDN2 | chr3 | 10318044 | + | 0.003975201 | 0.99602485 |
Top |
Fusion Genomic Features for GOLGA4-TATDN2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| GOLGA4 | chr3 | 37292975 | + | TATDN2 | chr3 | 10318044 | + | 5.59E-12 | 1 |
| GOLGA4 | chr3 | 37292975 | + | TATDN2 | chr3 | 10318044 | + | 5.59E-12 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
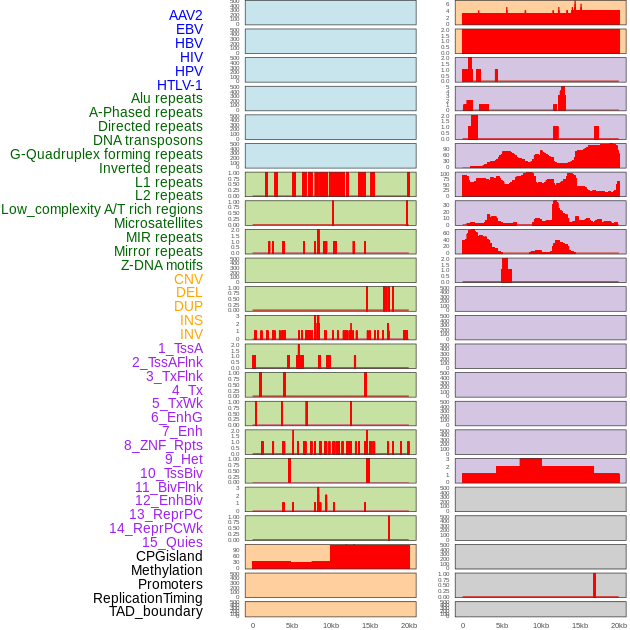 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
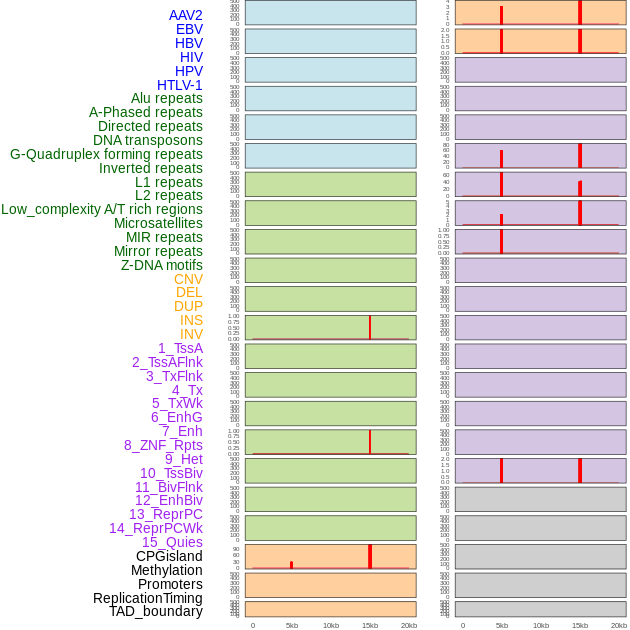 |
Top |
Fusion Protein Features for GOLGA4-TATDN2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr3:37292975/chr3:10318044) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | GOLGA4 | chr3:37292975 | chr3:10318044 | ENST00000356847 | + | 2 | 23 | 133_2185 | 54 | 2244.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | GOLGA4 | chr3:37292975 | chr3:10318044 | ENST00000361924 | + | 2 | 24 | 133_2185 | 54 | 2306.3333333333335 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | GOLGA4 | chr3:37292975 | chr3:10318044 | ENST00000356847 | + | 2 | 23 | 252_2096 | 54 | 2244.0 | Compositional bias | Note=Glu-rich |
| Hgene | GOLGA4 | chr3:37292975 | chr3:10318044 | ENST00000361924 | + | 2 | 24 | 252_2096 | 54 | 2306.3333333333335 | Compositional bias | Note=Glu-rich |
| Hgene | GOLGA4 | chr3:37292975 | chr3:10318044 | ENST00000356847 | + | 2 | 23 | 2168_2215 | 54 | 2244.0 | Domain | GRIP |
| Hgene | GOLGA4 | chr3:37292975 | chr3:10318044 | ENST00000361924 | + | 2 | 24 | 2168_2215 | 54 | 2306.3333333333335 | Domain | GRIP |
Top |
Fusion Gene Sequence for GOLGA4-TATDN2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >33910_33910_1_GOLGA4-TATDN2_GOLGA4_chr3_37292975_ENST00000356847_TATDN2_chr3_10318044_ENST00000287652_length(transcript)=2919nt_BP=461nt GCAAGCGCCCTTGGCGCACAGTTCACCTGCTGCCGTTGTCGTCGCCGCCGCGGCTCCCGGGGCTGGATGGGGGGCCGAGGCCAGCCAGTG GCACCCGGAAGAAAGAGACGCGGCGGCGGCGACGCCGACACCCTCAGGACGAGTGTCCGGACTTGCCCACAGCCTCAAGGAGGAGACGGC GAGGCCCGGCCCCCGCTGTCCCTGGTGTAAAGAAGTCGCCGTAGCCGTCGCGGCCGGGACTCCCCGGGCTCTCGCCCTTCAGGTTTCGTT GACACTCAGGACCGTACGTACGCTGCGCCATGTTCAAGAAACTGAAGCAAAAGATCAGCGAGGAGCAGCAGCAGCTCCAGCAGGCGCTGG CTCCTGCTCAGGCGTCCTCCAATTCTTCAACACCAACAAGAATGAGGAGCAGGACATCTTCATTTACAGAGCAACTTGATGAAGGTACAC CCAATAGAGAGGTATTTGAGAGACAGCTGCAGCTGGCTGTGTCTCTAAAGAAGCCCTTGGTGATCCACTGCCGAGAAGCTGATGAAGATC TGCTAGAAATCATGAAAAAGTTTGTGCCCCCTGACTACAAGATCCATAGGCATTGCTTCACCGGCAGCTACCCGGTCATTGAGCCCCTGC TGAAGTACTTTCCCAACATGTCTGTGGGCTTCACGGCAGTGCTGACATACTCCTCTGCCTGGGAGGCCCGGGAAGCCTTGAGGCAGATCC CACTGGAGAGAATCATCGTGGAAACGGATGCTCCCTATTTCCTCCCTCGCCAGGTTCCCAAAAGCCTTTGCCAGTATGCCCACCCGGGCC TGGCCTTGCATACGGTCCGAGAGATTGCCAGAGTCAAAGATCAGCCACTCTCCCTCACCTTGGCTGCCTTGCGTGAGAACACCAGTCGCC TCTACAGTCTTTAAGCAGAGAAGGGCGACCAGCAGCCTGACAGAACACAGGCTGGCTTGAAGTCTGTGTCTCAGGTCGAGGATGTGTTTA GAGAGCTGATTGGAACACAGAAAACCAGGACAGGATGTTTTCCTCCAAGCGGGTCATAAGGCTTCAGCTTCTGGGTGGTGGGTGGGGTGG GGTGGGCATGGAATGAGGGGTATGGGGACTGCCTGTAATAGCACTGGGATTTTGCCTCCCAGCCAAAATGCTCCAGGGTAGGCAGCAAAG AAGAAAGAGTGCGATATGAGGGTACAGTGAGTTTGGCAGTCCAAATTCTGTTCTCTGCAGCCTGTTTTTGAGTAGTTGGTGAATAAAGTC ACCCGCCTACTTGTCTAAGCACATGTGGGTGTGTAACTCAGTTCCTGGTTCTCGGTTCTAAAAACAGACTTCCAACTGGGAAACTTTTTG GGGGAAATTAACTGGACACCTATCTCGGAGGTTTATTTTCTTGCAACCAGTGAAGTCGTCCTCCTCCCTTCCCTGGATAACTCTTCAGTT TGACTGTCACTGTTCTGGTGTCAACTCCAGCGTCGGCACAGGCAGAAGGACTTCAGCTGCTGGTCTCATTGGTTCCACTGCCATTGATAT GGGGGGGTGCAGAGGAGCACTCATTGTCCATGATGGAGATCCAGGACAGACTGGGGGACTCCGGGAAGAGGCTTTCTTGGGGAAGAGGAC CCCAAAGGAGGTACTTCCTCCTCACTGATGCCCTCAGGGCTGCTGTGTGGGTGTGTTAAGCTGATAAGGTTCAGTTTGCGGCGGAAACTA CCTGCTAGTCTTGTGTCAGGGGCTGCCAGCCTCCTTTTGTTTCACTTTTGCCCCCTTCTTGGGAACATTTGACCAAAAATAATCCTCATT TCATCTTGTGTACAGTCCTTTGTGTACCCCGCCCAGGTTGAGAGGTGAATCAGCGTAATTCTCCGAAGCTCTGCTGGGCAGCTCAGCCAT GTTACATTGTCTATGCAGAATAAGCAGGCCTGGTGTCTGCAAATGTACCAGTCCTTCTCCCGCATCTCCTGGGTGCCCCCTTGGCTTTGC CTCTCCTGTGTCCTGTCTTTCTGCGTTTTAGAAGTGAGAGCCTCTCCTTCACCTTTTGAGCAACTGAGTCATCTCAAGTCCTGAGCTCTG CTCTGCCGCCTGCTGGTGCCTTGTAAAGGTATACTCGTTACAGGCCCTAGAGGTTCTAATGGTCCAGGGTTAAGTGAGAGGAGACTGTAC TTTGTTTCAAAGGATCCTTCACCCTGATCTGCAGTGAGGTGGATAGATCACCTGGAGTCCCTCGTCTGTGGTCTTGGAGGCTTAAATTGT AAAATACATCCCTTATGGAATCCTAAATTCCTCTAGGTGTTTTTGGAAGGCGCATTTGAGCCTTGTGAGCTAAAATGGAATGGATTTAAT ATTTCCTATCTGGCATTTCCATCTTGCCCCTGGTACACAAGTCACTGGCCTGGAACTCAGCCTTGATTCACTGTCCGTCTTCACGGATTA GCTGTGCTGTTATGTTGTCTGTGCTGCAGATTGGCCCATGTGGGAAGTCGGGGGGGACCTGATTTCCTGCTTGGAAGACTTGGGGGACTG CCGAGCATATCAAAGTGTTTATAGTCACCAAGTGAACTGCAGCACAACCATCTCCTCTCCAGCAAGCCCTGAAGTCAGTAGTGCCTGCAG GTGAAACCAACCAGCCCTGTGTTAGAGGAGGAAAAGCGGAGATGACATGGAAGTCTCCAAGCCTGTGCCATCCACCTGCCAAGGAAAAGC ACAAGGTGCTATCTACTTTTCTCTCTAGGATTTAGATTATCATTTATGTGCTGTTGCACAGTGAAACCTCACCTGTGTGGGCGTGAAAGC TGATTGGCATTGTTTTTGATTCAGCTTTTTGGATGGCTAATTGTTTTCACTGTGCTGTGGGAATGCCTCTGTATTTTTTCCCCTCTTTGG >33910_33910_1_GOLGA4-TATDN2_GOLGA4_chr3_37292975_ENST00000356847_TATDN2_chr3_10318044_ENST00000287652_length(amino acids)=204AA_BP=54 MFKKLKQKISEEQQQLQQALAPAQASSNSSTPTRMRSRTSSFTEQLDEGTPNREVFERQLQLAVSLKKPLVIHCREADEDLLEIMKKFVP PDYKIHRHCFTGSYPVIEPLLKYFPNMSVGFTAVLTYSSAWEAREALRQIPLERIIVETDAPYFLPRQVPKSLCQYAHPGLALHTVREIA -------------------------------------------------------------- >33910_33910_2_GOLGA4-TATDN2_GOLGA4_chr3_37292975_ENST00000356847_TATDN2_chr3_10318044_ENST00000448281_length(transcript)=2950nt_BP=461nt GCAAGCGCCCTTGGCGCACAGTTCACCTGCTGCCGTTGTCGTCGCCGCCGCGGCTCCCGGGGCTGGATGGGGGGCCGAGGCCAGCCAGTG GCACCCGGAAGAAAGAGACGCGGCGGCGGCGACGCCGACACCCTCAGGACGAGTGTCCGGACTTGCCCACAGCCTCAAGGAGGAGACGGC GAGGCCCGGCCCCCGCTGTCCCTGGTGTAAAGAAGTCGCCGTAGCCGTCGCGGCCGGGACTCCCCGGGCTCTCGCCCTTCAGGTTTCGTT GACACTCAGGACCGTACGTACGCTGCGCCATGTTCAAGAAACTGAAGCAAAAGATCAGCGAGGAGCAGCAGCAGCTCCAGCAGGCGCTGG CTCCTGCTCAGGCGTCCTCCAATTCTTCAACACCAACAAGAATGAGGAGCAGGACATCTTCATTTACAGAGCAACTTGATGAAGGTACAC CCAATAGAGAGGTATTTGAGAGACAGCTGCAGCTGGCTGTGTCTCTAAAGAAGCCCTTGGTGATCCACTGCCGAGAAGCTGATGAAGATC TGCTAGAAATCATGAAAAAGTTTGTGCCCCCTGACTACAAGATCCATAGGCATTGCTTCACCGGCAGCTACCCGGTCATTGAGCCCCTGC TGAAGTACTTTCCCAACATGTCTGTGGGCTTCACGGCAGTGCTGACATACTCCTCTGCCTGGGAGGCCCGGGAAGCCTTGAGGCAGATCC CACTGGAGAGAATCATCGTGGAAACGGATGCTCCCTATTTCCTCCCTCGCCAGGTTCCCAAAAGCCTTTGCCAGTATGCCCACCCGGGCC TGGCCTTGCATACGGTCCGAGAGATTGCCAGAGTCAAAGATCAGCCACTCTCCCTCACCTTGGCTGCCTTGCGTGAGAACACCAGTCGCC TCTACAGTCTTTAAGCAGAGAAGGTACAGTCCTCGGGAGTCTCCTAGAAAAGGGCGACCAGCAGCCTGACAGAACACAGGCTGGCTTGAA GTCTGTGTCTCAGGTCGAGGATGTGTTTAGAGAGCTGATTGGAACACAGAAAACCAGGACAGGATGTTTTCCTCCAAGCGGGTCATAAGG CTTCAGCTTCTGGGTGGTGGGTGGGGTGGGGTGGGCATGGAATGAGGGGTATGGGGACTGCCTGTAATAGCACTGGGATTTTGCCTCCCA GCCAAAATGCTCCAGGGTAGGCAGCAAAGAAGAAAGAGTGCGATATGAGGGTACAGTGAGTTTGGCAGTCCAAATTCTGTTCTCTGCAGC CTGTTTTTGAGTAGTTGGTGAATAAAGTCACCCGCCTACTTGTCTAAGCACATGTGGGTGTGTAACTCAGTTCCTGGTTCTCGGTTCTAA AAACAGACTTCCAACTGGGAAACTTTTTGGGGGAAATTAACTGGACACCTATCTCGGAGGTTTATTTTCTTGCAACCAGTGAAGTCGTCC TCCTCCCTTCCCTGGATAACTCTTCAGTTTGACTGTCACTGTTCTGGTGTCAACTCCAGCGTCGGCACAGGCAGAAGGACTTCAGCTGCT GGTCTCATTGGTTCCACTGCCATTGATATGGGGGGGTGCAGAGGAGCACTCATTGTCCATGATGGAGATCCAGGACAGACTGGGGGACTC CGGGAAGAGGCTTTCTTGGGGAAGAGGACCCCAAAGGAGGTACTTCCTCCTCACTGATGCCCTCAGGGCTGCTGTGTGGGTGTGTTAAGC TGATAAGGTTCAGTTTGCGGCGGAAACTACCTGCTAGTCTTGTGTCAGGGGCTGCCAGCCTCCTTTTGTTTCACTTTTGCCCCCTTCTTG GGAACATTTGACCAAAAATAATCCTCATTTCATCTTGTGTACAGTCCTTTGTGTACCCCGCCCAGGTTGAGAGGTGAATCAGCGTAATTC TCCGAAGCTCTGCTGGGCAGCTCAGCCATGTTACATTGTCTATGCAGAATAAGCAGGCCTGGTGTCTGCAAATGTACCAGTCCTTCTCCC GCATCTCCTGGGTGCCCCCTTGGCTTTGCCTCTCCTGTGTCCTGTCTTTCTGCGTTTTAGAAGTGAGAGCCTCTCCTTCACCTTTTGAGC AACTGAGTCATCTCAAGTCCTGAGCTCTGCTCTGCCGCCTGCTGGTGCCTTGTAAAGGTATACTCGTTACAGGCCCTAGAGGTTCTAATG GTCCAGGGTTAAGTGAGAGGAGACTGTACTTTGTTTCAAAGGATCCTTCACCCTGATCTGCAGTGAGGTGGATAGATCACCTGGAGTCCC TCGTCTGTGGTCTTGGAGGCTTAAATTGTAAAATACATCCCTTATGGAATCCTAAATTCCTCTAGGTGTTTTTGGAAGGCGCATTTGAGC CTTGTGAGCTAAAATGGAATGGATTTAATATTTCCTATCTGGCATTTCCATCTTGCCCCTGGTACACAAGTCACTGGCCTGGAACTCAGC CTTGATTCACTGTCCGTCTTCACGGATTAGCTGTGCTGTTATGTTGTCTGTGCTGCAGATTGGCCCATGTGGGAAGTCGGGGGGGACCTG ATTTCCTGCTTGGAAGACTTGGGGGACTGCCGAGCATATCAAAGTGTTTATAGTCACCAAGTGAACTGCAGCACAACCATCTCCTCTCCA GCAAGCCCTGAAGTCAGTAGTGCCTGCAGGTGAAACCAACCAGCCCTGTGTTAGAGGAGGAAAAGCGGAGATGACATGGAAGTCTCCAAG CCTGTGCCATCCACCTGCCAAGGAAAAGCACAAGGTGCTATCTACTTTTCTCTCTAGGATTTAGATTATCATTTATGTGCTGTTGCACAG TGAAACCTCACCTGTGTGGGCGTGAAAGCTGATTGGCATTGTTTTTGATTCAGCTTTTTGGATGGCTAATTGTTTTCACTGTGCTGTGGG >33910_33910_2_GOLGA4-TATDN2_GOLGA4_chr3_37292975_ENST00000356847_TATDN2_chr3_10318044_ENST00000448281_length(amino acids)=204AA_BP=54 MFKKLKQKISEEQQQLQQALAPAQASSNSSTPTRMRSRTSSFTEQLDEGTPNREVFERQLQLAVSLKKPLVIHCREADEDLLEIMKKFVP PDYKIHRHCFTGSYPVIEPLLKYFPNMSVGFTAVLTYSSAWEAREALRQIPLERIIVETDAPYFLPRQVPKSLCQYAHPGLALHTVREIA -------------------------------------------------------------- >33910_33910_3_GOLGA4-TATDN2_GOLGA4_chr3_37292975_ENST00000361924_TATDN2_chr3_10318044_ENST00000287652_length(transcript)=2994nt_BP=536nt ATGTGCGGGACCCGACATTGTGCTTGTCCCATCCGGTGCTCCGTAGTTAGCCTCTGTGAGCTCCACGTAGGCCGCGCAAGCGCCCTTGGC GCACAGTTCACCTGCTGCCGTTGTCGTCGCCGCCGCGGCTCCCGGGGCTGGATGGGGGGCCGAGGCCAGCCAGTGGCACCCGGAAGAAAG AGACGCGGCGGCGGCGACGCCGACACCCTCAGGACGAGTGTCCGGACTTGCCCACAGCCTCAAGGAGGAGACGGCGAGGCCCGGCCCCCG CTGTCCCTGGTGTAAAGAAGTCGCCGTAGCCGTCGCGGCCGGGACTCCCCGGGCTCTCGCCCTTCAGGTTTCGTTGACACTCAGGACCGT ACGTACGCTGCGCCATGTTCAAGAAACTGAAGCAAAAGATCAGCGAGGAGCAGCAGCAGCTCCAGCAGGCGCTGGCTCCTGCTCAGGCGT CCTCCAATTCTTCAACACCAACAAGAATGAGGAGCAGGACATCTTCATTTACAGAGCAACTTGATGAAGGTACACCCAATAGAGAGGTAT TTGAGAGACAGCTGCAGCTGGCTGTGTCTCTAAAGAAGCCCTTGGTGATCCACTGCCGAGAAGCTGATGAAGATCTGCTAGAAATCATGA AAAAGTTTGTGCCCCCTGACTACAAGATCCATAGGCATTGCTTCACCGGCAGCTACCCGGTCATTGAGCCCCTGCTGAAGTACTTTCCCA ACATGTCTGTGGGCTTCACGGCAGTGCTGACATACTCCTCTGCCTGGGAGGCCCGGGAAGCCTTGAGGCAGATCCCACTGGAGAGAATCA TCGTGGAAACGGATGCTCCCTATTTCCTCCCTCGCCAGGTTCCCAAAAGCCTTTGCCAGTATGCCCACCCGGGCCTGGCCTTGCATACGG TCCGAGAGATTGCCAGAGTCAAAGATCAGCCACTCTCCCTCACCTTGGCTGCCTTGCGTGAGAACACCAGTCGCCTCTACAGTCTTTAAG CAGAGAAGGGCGACCAGCAGCCTGACAGAACACAGGCTGGCTTGAAGTCTGTGTCTCAGGTCGAGGATGTGTTTAGAGAGCTGATTGGAA CACAGAAAACCAGGACAGGATGTTTTCCTCCAAGCGGGTCATAAGGCTTCAGCTTCTGGGTGGTGGGTGGGGTGGGGTGGGCATGGAATG AGGGGTATGGGGACTGCCTGTAATAGCACTGGGATTTTGCCTCCCAGCCAAAATGCTCCAGGGTAGGCAGCAAAGAAGAAAGAGTGCGAT ATGAGGGTACAGTGAGTTTGGCAGTCCAAATTCTGTTCTCTGCAGCCTGTTTTTGAGTAGTTGGTGAATAAAGTCACCCGCCTACTTGTC TAAGCACATGTGGGTGTGTAACTCAGTTCCTGGTTCTCGGTTCTAAAAACAGACTTCCAACTGGGAAACTTTTTGGGGGAAATTAACTGG ACACCTATCTCGGAGGTTTATTTTCTTGCAACCAGTGAAGTCGTCCTCCTCCCTTCCCTGGATAACTCTTCAGTTTGACTGTCACTGTTC TGGTGTCAACTCCAGCGTCGGCACAGGCAGAAGGACTTCAGCTGCTGGTCTCATTGGTTCCACTGCCATTGATATGGGGGGGTGCAGAGG AGCACTCATTGTCCATGATGGAGATCCAGGACAGACTGGGGGACTCCGGGAAGAGGCTTTCTTGGGGAAGAGGACCCCAAAGGAGGTACT TCCTCCTCACTGATGCCCTCAGGGCTGCTGTGTGGGTGTGTTAAGCTGATAAGGTTCAGTTTGCGGCGGAAACTACCTGCTAGTCTTGTG TCAGGGGCTGCCAGCCTCCTTTTGTTTCACTTTTGCCCCCTTCTTGGGAACATTTGACCAAAAATAATCCTCATTTCATCTTGTGTACAG TCCTTTGTGTACCCCGCCCAGGTTGAGAGGTGAATCAGCGTAATTCTCCGAAGCTCTGCTGGGCAGCTCAGCCATGTTACATTGTCTATG CAGAATAAGCAGGCCTGGTGTCTGCAAATGTACCAGTCCTTCTCCCGCATCTCCTGGGTGCCCCCTTGGCTTTGCCTCTCCTGTGTCCTG TCTTTCTGCGTTTTAGAAGTGAGAGCCTCTCCTTCACCTTTTGAGCAACTGAGTCATCTCAAGTCCTGAGCTCTGCTCTGCCGCCTGCTG GTGCCTTGTAAAGGTATACTCGTTACAGGCCCTAGAGGTTCTAATGGTCCAGGGTTAAGTGAGAGGAGACTGTACTTTGTTTCAAAGGAT CCTTCACCCTGATCTGCAGTGAGGTGGATAGATCACCTGGAGTCCCTCGTCTGTGGTCTTGGAGGCTTAAATTGTAAAATACATCCCTTA TGGAATCCTAAATTCCTCTAGGTGTTTTTGGAAGGCGCATTTGAGCCTTGTGAGCTAAAATGGAATGGATTTAATATTTCCTATCTGGCA TTTCCATCTTGCCCCTGGTACACAAGTCACTGGCCTGGAACTCAGCCTTGATTCACTGTCCGTCTTCACGGATTAGCTGTGCTGTTATGT TGTCTGTGCTGCAGATTGGCCCATGTGGGAAGTCGGGGGGGACCTGATTTCCTGCTTGGAAGACTTGGGGGACTGCCGAGCATATCAAAG TGTTTATAGTCACCAAGTGAACTGCAGCACAACCATCTCCTCTCCAGCAAGCCCTGAAGTCAGTAGTGCCTGCAGGTGAAACCAACCAGC CCTGTGTTAGAGGAGGAAAAGCGGAGATGACATGGAAGTCTCCAAGCCTGTGCCATCCACCTGCCAAGGAAAAGCACAAGGTGCTATCTA CTTTTCTCTCTAGGATTTAGATTATCATTTATGTGCTGTTGCACAGTGAAACCTCACCTGTGTGGGCGTGAAAGCTGATTGGCATTGTTT TTGATTCAGCTTTTTGGATGGCTAATTGTTTTCACTGTGCTGTGGGAATGCCTCTGTATTTTTTCCCCTCTTTGGCCATCTTTTTCTGAA >33910_33910_3_GOLGA4-TATDN2_GOLGA4_chr3_37292975_ENST00000361924_TATDN2_chr3_10318044_ENST00000287652_length(amino acids)=204AA_BP=54 MFKKLKQKISEEQQQLQQALAPAQASSNSSTPTRMRSRTSSFTEQLDEGTPNREVFERQLQLAVSLKKPLVIHCREADEDLLEIMKKFVP PDYKIHRHCFTGSYPVIEPLLKYFPNMSVGFTAVLTYSSAWEAREALRQIPLERIIVETDAPYFLPRQVPKSLCQYAHPGLALHTVREIA -------------------------------------------------------------- >33910_33910_4_GOLGA4-TATDN2_GOLGA4_chr3_37292975_ENST00000361924_TATDN2_chr3_10318044_ENST00000448281_length(transcript)=3025nt_BP=536nt ATGTGCGGGACCCGACATTGTGCTTGTCCCATCCGGTGCTCCGTAGTTAGCCTCTGTGAGCTCCACGTAGGCCGCGCAAGCGCCCTTGGC GCACAGTTCACCTGCTGCCGTTGTCGTCGCCGCCGCGGCTCCCGGGGCTGGATGGGGGGCCGAGGCCAGCCAGTGGCACCCGGAAGAAAG AGACGCGGCGGCGGCGACGCCGACACCCTCAGGACGAGTGTCCGGACTTGCCCACAGCCTCAAGGAGGAGACGGCGAGGCCCGGCCCCCG CTGTCCCTGGTGTAAAGAAGTCGCCGTAGCCGTCGCGGCCGGGACTCCCCGGGCTCTCGCCCTTCAGGTTTCGTTGACACTCAGGACCGT ACGTACGCTGCGCCATGTTCAAGAAACTGAAGCAAAAGATCAGCGAGGAGCAGCAGCAGCTCCAGCAGGCGCTGGCTCCTGCTCAGGCGT CCTCCAATTCTTCAACACCAACAAGAATGAGGAGCAGGACATCTTCATTTACAGAGCAACTTGATGAAGGTACACCCAATAGAGAGGTAT TTGAGAGACAGCTGCAGCTGGCTGTGTCTCTAAAGAAGCCCTTGGTGATCCACTGCCGAGAAGCTGATGAAGATCTGCTAGAAATCATGA AAAAGTTTGTGCCCCCTGACTACAAGATCCATAGGCATTGCTTCACCGGCAGCTACCCGGTCATTGAGCCCCTGCTGAAGTACTTTCCCA ACATGTCTGTGGGCTTCACGGCAGTGCTGACATACTCCTCTGCCTGGGAGGCCCGGGAAGCCTTGAGGCAGATCCCACTGGAGAGAATCA TCGTGGAAACGGATGCTCCCTATTTCCTCCCTCGCCAGGTTCCCAAAAGCCTTTGCCAGTATGCCCACCCGGGCCTGGCCTTGCATACGG TCCGAGAGATTGCCAGAGTCAAAGATCAGCCACTCTCCCTCACCTTGGCTGCCTTGCGTGAGAACACCAGTCGCCTCTACAGTCTTTAAG CAGAGAAGGTACAGTCCTCGGGAGTCTCCTAGAAAAGGGCGACCAGCAGCCTGACAGAACACAGGCTGGCTTGAAGTCTGTGTCTCAGGT CGAGGATGTGTTTAGAGAGCTGATTGGAACACAGAAAACCAGGACAGGATGTTTTCCTCCAAGCGGGTCATAAGGCTTCAGCTTCTGGGT GGTGGGTGGGGTGGGGTGGGCATGGAATGAGGGGTATGGGGACTGCCTGTAATAGCACTGGGATTTTGCCTCCCAGCCAAAATGCTCCAG GGTAGGCAGCAAAGAAGAAAGAGTGCGATATGAGGGTACAGTGAGTTTGGCAGTCCAAATTCTGTTCTCTGCAGCCTGTTTTTGAGTAGT TGGTGAATAAAGTCACCCGCCTACTTGTCTAAGCACATGTGGGTGTGTAACTCAGTTCCTGGTTCTCGGTTCTAAAAACAGACTTCCAAC TGGGAAACTTTTTGGGGGAAATTAACTGGACACCTATCTCGGAGGTTTATTTTCTTGCAACCAGTGAAGTCGTCCTCCTCCCTTCCCTGG ATAACTCTTCAGTTTGACTGTCACTGTTCTGGTGTCAACTCCAGCGTCGGCACAGGCAGAAGGACTTCAGCTGCTGGTCTCATTGGTTCC ACTGCCATTGATATGGGGGGGTGCAGAGGAGCACTCATTGTCCATGATGGAGATCCAGGACAGACTGGGGGACTCCGGGAAGAGGCTTTC TTGGGGAAGAGGACCCCAAAGGAGGTACTTCCTCCTCACTGATGCCCTCAGGGCTGCTGTGTGGGTGTGTTAAGCTGATAAGGTTCAGTT TGCGGCGGAAACTACCTGCTAGTCTTGTGTCAGGGGCTGCCAGCCTCCTTTTGTTTCACTTTTGCCCCCTTCTTGGGAACATTTGACCAA AAATAATCCTCATTTCATCTTGTGTACAGTCCTTTGTGTACCCCGCCCAGGTTGAGAGGTGAATCAGCGTAATTCTCCGAAGCTCTGCTG GGCAGCTCAGCCATGTTACATTGTCTATGCAGAATAAGCAGGCCTGGTGTCTGCAAATGTACCAGTCCTTCTCCCGCATCTCCTGGGTGC CCCCTTGGCTTTGCCTCTCCTGTGTCCTGTCTTTCTGCGTTTTAGAAGTGAGAGCCTCTCCTTCACCTTTTGAGCAACTGAGTCATCTCA AGTCCTGAGCTCTGCTCTGCCGCCTGCTGGTGCCTTGTAAAGGTATACTCGTTACAGGCCCTAGAGGTTCTAATGGTCCAGGGTTAAGTG AGAGGAGACTGTACTTTGTTTCAAAGGATCCTTCACCCTGATCTGCAGTGAGGTGGATAGATCACCTGGAGTCCCTCGTCTGTGGTCTTG GAGGCTTAAATTGTAAAATACATCCCTTATGGAATCCTAAATTCCTCTAGGTGTTTTTGGAAGGCGCATTTGAGCCTTGTGAGCTAAAAT GGAATGGATTTAATATTTCCTATCTGGCATTTCCATCTTGCCCCTGGTACACAAGTCACTGGCCTGGAACTCAGCCTTGATTCACTGTCC GTCTTCACGGATTAGCTGTGCTGTTATGTTGTCTGTGCTGCAGATTGGCCCATGTGGGAAGTCGGGGGGGACCTGATTTCCTGCTTGGAA GACTTGGGGGACTGCCGAGCATATCAAAGTGTTTATAGTCACCAAGTGAACTGCAGCACAACCATCTCCTCTCCAGCAAGCCCTGAAGTC AGTAGTGCCTGCAGGTGAAACCAACCAGCCCTGTGTTAGAGGAGGAAAAGCGGAGATGACATGGAAGTCTCCAAGCCTGTGCCATCCACC TGCCAAGGAAAAGCACAAGGTGCTATCTACTTTTCTCTCTAGGATTTAGATTATCATTTATGTGCTGTTGCACAGTGAAACCTCACCTGT GTGGGCGTGAAAGCTGATTGGCATTGTTTTTGATTCAGCTTTTTGGATGGCTAATTGTTTTCACTGTGCTGTGGGAATGCCTCTGTATTT >33910_33910_4_GOLGA4-TATDN2_GOLGA4_chr3_37292975_ENST00000361924_TATDN2_chr3_10318044_ENST00000448281_length(amino acids)=204AA_BP=54 MFKKLKQKISEEQQQLQQALAPAQASSNSSTPTRMRSRTSSFTEQLDEGTPNREVFERQLQLAVSLKKPLVIHCREADEDLLEIMKKFVP PDYKIHRHCFTGSYPVIEPLLKYFPNMSVGFTAVLTYSSAWEAREALRQIPLERIIVETDAPYFLPRQVPKSLCQYAHPGLALHTVREIA -------------------------------------------------------------- >33910_33910_5_GOLGA4-TATDN2_GOLGA4_chr3_37292975_ENST00000444882_TATDN2_chr3_10318044_ENST00000287652_length(transcript)=2924nt_BP=466nt GCCGCGCAAGCGCCCTTGGCGCACAGTTCACCTGCTGCCGTTGTCGTCGCCGCCGCGGCTCCCGGGGCTGGATGGGGGGCCGAGGCCAGC CAGTGGCACCCGGAAGAAAGAGACGCGGCGGCGGCGACGCCGACACCCTCAGGACGAGTGTCCGGACTTGCCCACAGCCTCAAGGAGGAG ACGGCGAGGCCCGGCCCCCGCTGTCCCTGGTGTAAAGAAGTCGCCGTAGCCGTCGCGGCCGGGACTCCCCGGGCTCTCGCCCTTCAGGTT TCGTTGACACTCAGGACCGTACGTACGCTGCGCCATGTTCAAGAAACTGAAGCAAAAGATCAGCGAGGAGCAGCAGCAGCTCCAGCAGGC GCTGGCTCCTGCTCAGGCGTCCTCCAATTCTTCAACACCAACAAGAATGAGGAGCAGGACATCTTCATTTACAGAGCAACTTGATGAAGG TACACCCAATAGAGAGGTATTTGAGAGACAGCTGCAGCTGGCTGTGTCTCTAAAGAAGCCCTTGGTGATCCACTGCCGAGAAGCTGATGA AGATCTGCTAGAAATCATGAAAAAGTTTGTGCCCCCTGACTACAAGATCCATAGGCATTGCTTCACCGGCAGCTACCCGGTCATTGAGCC CCTGCTGAAGTACTTTCCCAACATGTCTGTGGGCTTCACGGCAGTGCTGACATACTCCTCTGCCTGGGAGGCCCGGGAAGCCTTGAGGCA GATCCCACTGGAGAGAATCATCGTGGAAACGGATGCTCCCTATTTCCTCCCTCGCCAGGTTCCCAAAAGCCTTTGCCAGTATGCCCACCC GGGCCTGGCCTTGCATACGGTCCGAGAGATTGCCAGAGTCAAAGATCAGCCACTCTCCCTCACCTTGGCTGCCTTGCGTGAGAACACCAG TCGCCTCTACAGTCTTTAAGCAGAGAAGGGCGACCAGCAGCCTGACAGAACACAGGCTGGCTTGAAGTCTGTGTCTCAGGTCGAGGATGT GTTTAGAGAGCTGATTGGAACACAGAAAACCAGGACAGGATGTTTTCCTCCAAGCGGGTCATAAGGCTTCAGCTTCTGGGTGGTGGGTGG GGTGGGGTGGGCATGGAATGAGGGGTATGGGGACTGCCTGTAATAGCACTGGGATTTTGCCTCCCAGCCAAAATGCTCCAGGGTAGGCAG CAAAGAAGAAAGAGTGCGATATGAGGGTACAGTGAGTTTGGCAGTCCAAATTCTGTTCTCTGCAGCCTGTTTTTGAGTAGTTGGTGAATA AAGTCACCCGCCTACTTGTCTAAGCACATGTGGGTGTGTAACTCAGTTCCTGGTTCTCGGTTCTAAAAACAGACTTCCAACTGGGAAACT TTTTGGGGGAAATTAACTGGACACCTATCTCGGAGGTTTATTTTCTTGCAACCAGTGAAGTCGTCCTCCTCCCTTCCCTGGATAACTCTT CAGTTTGACTGTCACTGTTCTGGTGTCAACTCCAGCGTCGGCACAGGCAGAAGGACTTCAGCTGCTGGTCTCATTGGTTCCACTGCCATT GATATGGGGGGGTGCAGAGGAGCACTCATTGTCCATGATGGAGATCCAGGACAGACTGGGGGACTCCGGGAAGAGGCTTTCTTGGGGAAG AGGACCCCAAAGGAGGTACTTCCTCCTCACTGATGCCCTCAGGGCTGCTGTGTGGGTGTGTTAAGCTGATAAGGTTCAGTTTGCGGCGGA AACTACCTGCTAGTCTTGTGTCAGGGGCTGCCAGCCTCCTTTTGTTTCACTTTTGCCCCCTTCTTGGGAACATTTGACCAAAAATAATCC TCATTTCATCTTGTGTACAGTCCTTTGTGTACCCCGCCCAGGTTGAGAGGTGAATCAGCGTAATTCTCCGAAGCTCTGCTGGGCAGCTCA GCCATGTTACATTGTCTATGCAGAATAAGCAGGCCTGGTGTCTGCAAATGTACCAGTCCTTCTCCCGCATCTCCTGGGTGCCCCCTTGGC TTTGCCTCTCCTGTGTCCTGTCTTTCTGCGTTTTAGAAGTGAGAGCCTCTCCTTCACCTTTTGAGCAACTGAGTCATCTCAAGTCCTGAG CTCTGCTCTGCCGCCTGCTGGTGCCTTGTAAAGGTATACTCGTTACAGGCCCTAGAGGTTCTAATGGTCCAGGGTTAAGTGAGAGGAGAC TGTACTTTGTTTCAAAGGATCCTTCACCCTGATCTGCAGTGAGGTGGATAGATCACCTGGAGTCCCTCGTCTGTGGTCTTGGAGGCTTAA ATTGTAAAATACATCCCTTATGGAATCCTAAATTCCTCTAGGTGTTTTTGGAAGGCGCATTTGAGCCTTGTGAGCTAAAATGGAATGGAT TTAATATTTCCTATCTGGCATTTCCATCTTGCCCCTGGTACACAAGTCACTGGCCTGGAACTCAGCCTTGATTCACTGTCCGTCTTCACG GATTAGCTGTGCTGTTATGTTGTCTGTGCTGCAGATTGGCCCATGTGGGAAGTCGGGGGGGACCTGATTTCCTGCTTGGAAGACTTGGGG GACTGCCGAGCATATCAAAGTGTTTATAGTCACCAAGTGAACTGCAGCACAACCATCTCCTCTCCAGCAAGCCCTGAAGTCAGTAGTGCC TGCAGGTGAAACCAACCAGCCCTGTGTTAGAGGAGGAAAAGCGGAGATGACATGGAAGTCTCCAAGCCTGTGCCATCCACCTGCCAAGGA AAAGCACAAGGTGCTATCTACTTTTCTCTCTAGGATTTAGATTATCATTTATGTGCTGTTGCACAGTGAAACCTCACCTGTGTGGGCGTG AAAGCTGATTGGCATTGTTTTTGATTCAGCTTTTTGGATGGCTAATTGTTTTCACTGTGCTGTGGGAATGCCTCTGTATTTTTTCCCCTC >33910_33910_5_GOLGA4-TATDN2_GOLGA4_chr3_37292975_ENST00000444882_TATDN2_chr3_10318044_ENST00000287652_length(amino acids)=204AA_BP=54 MFKKLKQKISEEQQQLQQALAPAQASSNSSTPTRMRSRTSSFTEQLDEGTPNREVFERQLQLAVSLKKPLVIHCREADEDLLEIMKKFVP PDYKIHRHCFTGSYPVIEPLLKYFPNMSVGFTAVLTYSSAWEAREALRQIPLERIIVETDAPYFLPRQVPKSLCQYAHPGLALHTVREIA -------------------------------------------------------------- >33910_33910_6_GOLGA4-TATDN2_GOLGA4_chr3_37292975_ENST00000444882_TATDN2_chr3_10318044_ENST00000448281_length(transcript)=2955nt_BP=466nt GCCGCGCAAGCGCCCTTGGCGCACAGTTCACCTGCTGCCGTTGTCGTCGCCGCCGCGGCTCCCGGGGCTGGATGGGGGGCCGAGGCCAGC CAGTGGCACCCGGAAGAAAGAGACGCGGCGGCGGCGACGCCGACACCCTCAGGACGAGTGTCCGGACTTGCCCACAGCCTCAAGGAGGAG ACGGCGAGGCCCGGCCCCCGCTGTCCCTGGTGTAAAGAAGTCGCCGTAGCCGTCGCGGCCGGGACTCCCCGGGCTCTCGCCCTTCAGGTT TCGTTGACACTCAGGACCGTACGTACGCTGCGCCATGTTCAAGAAACTGAAGCAAAAGATCAGCGAGGAGCAGCAGCAGCTCCAGCAGGC GCTGGCTCCTGCTCAGGCGTCCTCCAATTCTTCAACACCAACAAGAATGAGGAGCAGGACATCTTCATTTACAGAGCAACTTGATGAAGG TACACCCAATAGAGAGGTATTTGAGAGACAGCTGCAGCTGGCTGTGTCTCTAAAGAAGCCCTTGGTGATCCACTGCCGAGAAGCTGATGA AGATCTGCTAGAAATCATGAAAAAGTTTGTGCCCCCTGACTACAAGATCCATAGGCATTGCTTCACCGGCAGCTACCCGGTCATTGAGCC CCTGCTGAAGTACTTTCCCAACATGTCTGTGGGCTTCACGGCAGTGCTGACATACTCCTCTGCCTGGGAGGCCCGGGAAGCCTTGAGGCA GATCCCACTGGAGAGAATCATCGTGGAAACGGATGCTCCCTATTTCCTCCCTCGCCAGGTTCCCAAAAGCCTTTGCCAGTATGCCCACCC GGGCCTGGCCTTGCATACGGTCCGAGAGATTGCCAGAGTCAAAGATCAGCCACTCTCCCTCACCTTGGCTGCCTTGCGTGAGAACACCAG TCGCCTCTACAGTCTTTAAGCAGAGAAGGTACAGTCCTCGGGAGTCTCCTAGAAAAGGGCGACCAGCAGCCTGACAGAACACAGGCTGGC TTGAAGTCTGTGTCTCAGGTCGAGGATGTGTTTAGAGAGCTGATTGGAACACAGAAAACCAGGACAGGATGTTTTCCTCCAAGCGGGTCA TAAGGCTTCAGCTTCTGGGTGGTGGGTGGGGTGGGGTGGGCATGGAATGAGGGGTATGGGGACTGCCTGTAATAGCACTGGGATTTTGCC TCCCAGCCAAAATGCTCCAGGGTAGGCAGCAAAGAAGAAAGAGTGCGATATGAGGGTACAGTGAGTTTGGCAGTCCAAATTCTGTTCTCT GCAGCCTGTTTTTGAGTAGTTGGTGAATAAAGTCACCCGCCTACTTGTCTAAGCACATGTGGGTGTGTAACTCAGTTCCTGGTTCTCGGT TCTAAAAACAGACTTCCAACTGGGAAACTTTTTGGGGGAAATTAACTGGACACCTATCTCGGAGGTTTATTTTCTTGCAACCAGTGAAGT CGTCCTCCTCCCTTCCCTGGATAACTCTTCAGTTTGACTGTCACTGTTCTGGTGTCAACTCCAGCGTCGGCACAGGCAGAAGGACTTCAG CTGCTGGTCTCATTGGTTCCACTGCCATTGATATGGGGGGGTGCAGAGGAGCACTCATTGTCCATGATGGAGATCCAGGACAGACTGGGG GACTCCGGGAAGAGGCTTTCTTGGGGAAGAGGACCCCAAAGGAGGTACTTCCTCCTCACTGATGCCCTCAGGGCTGCTGTGTGGGTGTGT TAAGCTGATAAGGTTCAGTTTGCGGCGGAAACTACCTGCTAGTCTTGTGTCAGGGGCTGCCAGCCTCCTTTTGTTTCACTTTTGCCCCCT TCTTGGGAACATTTGACCAAAAATAATCCTCATTTCATCTTGTGTACAGTCCTTTGTGTACCCCGCCCAGGTTGAGAGGTGAATCAGCGT AATTCTCCGAAGCTCTGCTGGGCAGCTCAGCCATGTTACATTGTCTATGCAGAATAAGCAGGCCTGGTGTCTGCAAATGTACCAGTCCTT CTCCCGCATCTCCTGGGTGCCCCCTTGGCTTTGCCTCTCCTGTGTCCTGTCTTTCTGCGTTTTAGAAGTGAGAGCCTCTCCTTCACCTTT TGAGCAACTGAGTCATCTCAAGTCCTGAGCTCTGCTCTGCCGCCTGCTGGTGCCTTGTAAAGGTATACTCGTTACAGGCCCTAGAGGTTC TAATGGTCCAGGGTTAAGTGAGAGGAGACTGTACTTTGTTTCAAAGGATCCTTCACCCTGATCTGCAGTGAGGTGGATAGATCACCTGGA GTCCCTCGTCTGTGGTCTTGGAGGCTTAAATTGTAAAATACATCCCTTATGGAATCCTAAATTCCTCTAGGTGTTTTTGGAAGGCGCATT TGAGCCTTGTGAGCTAAAATGGAATGGATTTAATATTTCCTATCTGGCATTTCCATCTTGCCCCTGGTACACAAGTCACTGGCCTGGAAC TCAGCCTTGATTCACTGTCCGTCTTCACGGATTAGCTGTGCTGTTATGTTGTCTGTGCTGCAGATTGGCCCATGTGGGAAGTCGGGGGGG ACCTGATTTCCTGCTTGGAAGACTTGGGGGACTGCCGAGCATATCAAAGTGTTTATAGTCACCAAGTGAACTGCAGCACAACCATCTCCT CTCCAGCAAGCCCTGAAGTCAGTAGTGCCTGCAGGTGAAACCAACCAGCCCTGTGTTAGAGGAGGAAAAGCGGAGATGACATGGAAGTCT CCAAGCCTGTGCCATCCACCTGCCAAGGAAAAGCACAAGGTGCTATCTACTTTTCTCTCTAGGATTTAGATTATCATTTATGTGCTGTTG CACAGTGAAACCTCACCTGTGTGGGCGTGAAAGCTGATTGGCATTGTTTTTGATTCAGCTTTTTGGATGGCTAATTGTTTTCACTGTGCT >33910_33910_6_GOLGA4-TATDN2_GOLGA4_chr3_37292975_ENST00000444882_TATDN2_chr3_10318044_ENST00000448281_length(amino acids)=204AA_BP=54 MFKKLKQKISEEQQQLQQALAPAQASSNSSTPTRMRSRTSSFTEQLDEGTPNREVFERQLQLAVSLKKPLVIHCREADEDLLEIMKKFVP PDYKIHRHCFTGSYPVIEPLLKYFPNMSVGFTAVLTYSSAWEAREALRQIPLERIIVETDAPYFLPRQVPKSLCQYAHPGLALHTVREIA -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for GOLGA4-TATDN2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Hgene | GOLGA4 | chr3:37292975 | chr3:10318044 | ENST00000356847 | + | 2 | 23 | 133_203 | 54.0 | 2244.0 | MACF1 |
| Hgene | GOLGA4 | chr3:37292975 | chr3:10318044 | ENST00000361924 | + | 2 | 24 | 133_203 | 54.0 | 2306.3333333333335 | MACF1 |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for GOLGA4-TATDN2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for GOLGA4-TATDN2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies