
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:AKR1C3-AKR1E2 (FusionGDB2 ID:3448) |
Fusion Gene Summary for AKR1C3-AKR1E2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: AKR1C3-AKR1E2 | Fusion gene ID: 3448 | Hgene | Tgene | Gene symbol | AKR1C3 | AKR1E2 | Gene ID | 8644 | 83592 |
| Gene name | aldo-keto reductase family 1 member C3 | aldo-keto reductase family 1 member E2 | |
| Synonyms | DD3|DDX|HA1753|HAKRB|HAKRe|HSD17B5|PGFS|hluPGFS | AKR1CL2|AKRDC1|LoopADR|TAKR|hTSP|htAKR | |
| Cytomap | 10p15.1 | 10p15.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | aldo-keto reductase family 1 member C33-alpha hydroxysteroid dehydrogenase, type II3-alpha-HSD type II, brainchlordecone reductase homolog HAKRbdihydrodiol dehydrogenase 3dihydrodiol dehydrogenase Xindanol dehydrogenaseprostaglandin F synthasetest | 1,5-anhydro-D-fructose reductaseAF reductasealdo-keto reductase family 1 member C-like protein 2aldo-keto reductase family 1, member C-like 2aldo-keto reductase loopADRtestis aldo-keto reductasetestis-specific protein | |
| Modification date | 20200320 | 20200313 | |
| UniProtAcc | P42330 | Q96JD6 | |
| Ensembl transtripts involved in fusion gene | ENST00000380554, ENST00000439082, ENST00000605149, ENST00000470862, | ENST00000334019, ENST00000345253, ENST00000525281, ENST00000532248, ENST00000298375, | |
| Fusion gene scores | * DoF score | 2 X 3 X 2=12 | 6 X 3 X 6=108 |
| # samples | 3 | 8 | |
| ** MAII score | log2(3/12*10)=1.32192809488736 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | log2(8/108*10)=-0.432959407276106 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: AKR1C3 [Title/Abstract] AND AKR1E2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | AKR1C3(5144842)-AKR1E2(4877867), # samples:1 AKR1C3(5139742)-AKR1E2(4872867), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | AKR1C3 | GO:0007186 | G protein-coupled receptor signaling pathway | 18508192 |
| Hgene | AKR1C3 | GO:0008284 | positive regulation of cell proliferation | 18508192|20036328 |
| Hgene | AKR1C3 | GO:0010942 | positive regulation of cell death | 21787718 |
| Hgene | AKR1C3 | GO:0016488 | farnesol catabolic process | 21187079 |
| Hgene | AKR1C3 | GO:0034614 | cellular response to reactive oxygen species | 21787718 |
| Hgene | AKR1C3 | GO:0042448 | progesterone metabolic process | 21232532 |
| Hgene | AKR1C3 | GO:0042574 | retinal metabolic process | 21851338 |
| Hgene | AKR1C3 | GO:0048385 | regulation of retinoic acid receptor signaling pathway | 21851338 |
| Hgene | AKR1C3 | GO:0051897 | positive regulation of protein kinase B signaling | 18508192 |
| Hgene | AKR1C3 | GO:0055114 | oxidation-reduction process | 16983398|19442656|21232532 |
| Hgene | AKR1C3 | GO:0071276 | cellular response to cadmium ion | 21787718 |
| Hgene | AKR1C3 | GO:0071277 | cellular response to calcium ion | 22170488 |
| Hgene | AKR1C3 | GO:0071379 | cellular response to prostaglandin stimulus | 22170488 |
| Hgene | AKR1C3 | GO:0071384 | cellular response to corticosteroid stimulus | 19336506 |
| Hgene | AKR1C3 | GO:0071395 | cellular response to jasmonic acid stimulus | 19487289 |
| Hgene | AKR1C3 | GO:0071799 | cellular response to prostaglandin D stimulus | 18508192 |
| Hgene | AKR1C3 | GO:1900053 | negative regulation of retinoic acid biosynthetic process | 21851338 |
| Hgene | AKR1C3 | GO:2000353 | positive regulation of endothelial cell apoptotic process | 19442656 |
| Hgene | AKR1C3 | GO:2000379 | positive regulation of reactive oxygen species metabolic process | 19442656 |
| Tgene | AKR1E2 | GO:0055114 | oxidation-reduction process | 15118078 |
| Fusion gene breakpoints across AKR1C3 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across AKR1E2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | LUSC | TCGA-66-2759-01A | AKR1C3 | chr10 | 5144842 | + | AKR1E2 | chr10 | 4877867 | + |
| ChimerDB4 | LUSC | TCGA-68-A59J-01A | AKR1C3 | chr10 | 5139742 | + | AKR1E2 | chr10 | 4872867 | + |
Top |
Fusion Gene ORF analysis for AKR1C3-AKR1E2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-3UTR | ENST00000380554 | ENST00000334019 | AKR1C3 | chr10 | 5144842 | + | AKR1E2 | chr10 | 4877867 | + |
| 5CDS-3UTR | ENST00000380554 | ENST00000334019 | AKR1C3 | chr10 | 5139742 | + | AKR1E2 | chr10 | 4872867 | + |
| 5CDS-3UTR | ENST00000380554 | ENST00000345253 | AKR1C3 | chr10 | 5144842 | + | AKR1E2 | chr10 | 4877867 | + |
| 5CDS-3UTR | ENST00000380554 | ENST00000345253 | AKR1C3 | chr10 | 5139742 | + | AKR1E2 | chr10 | 4872867 | + |
| 5CDS-3UTR | ENST00000380554 | ENST00000525281 | AKR1C3 | chr10 | 5144842 | + | AKR1E2 | chr10 | 4877867 | + |
| 5CDS-3UTR | ENST00000380554 | ENST00000525281 | AKR1C3 | chr10 | 5139742 | + | AKR1E2 | chr10 | 4872867 | + |
| 5CDS-3UTR | ENST00000380554 | ENST00000532248 | AKR1C3 | chr10 | 5144842 | + | AKR1E2 | chr10 | 4877867 | + |
| 5CDS-3UTR | ENST00000380554 | ENST00000532248 | AKR1C3 | chr10 | 5139742 | + | AKR1E2 | chr10 | 4872867 | + |
| 5CDS-3UTR | ENST00000439082 | ENST00000334019 | AKR1C3 | chr10 | 5144842 | + | AKR1E2 | chr10 | 4877867 | + |
| 5CDS-3UTR | ENST00000439082 | ENST00000334019 | AKR1C3 | chr10 | 5139742 | + | AKR1E2 | chr10 | 4872867 | + |
| 5CDS-3UTR | ENST00000439082 | ENST00000345253 | AKR1C3 | chr10 | 5144842 | + | AKR1E2 | chr10 | 4877867 | + |
| 5CDS-3UTR | ENST00000439082 | ENST00000345253 | AKR1C3 | chr10 | 5139742 | + | AKR1E2 | chr10 | 4872867 | + |
| 5CDS-3UTR | ENST00000439082 | ENST00000525281 | AKR1C3 | chr10 | 5144842 | + | AKR1E2 | chr10 | 4877867 | + |
| 5CDS-3UTR | ENST00000439082 | ENST00000525281 | AKR1C3 | chr10 | 5139742 | + | AKR1E2 | chr10 | 4872867 | + |
| 5CDS-3UTR | ENST00000439082 | ENST00000532248 | AKR1C3 | chr10 | 5144842 | + | AKR1E2 | chr10 | 4877867 | + |
| 5CDS-3UTR | ENST00000439082 | ENST00000532248 | AKR1C3 | chr10 | 5139742 | + | AKR1E2 | chr10 | 4872867 | + |
| 5CDS-3UTR | ENST00000605149 | ENST00000334019 | AKR1C3 | chr10 | 5144842 | + | AKR1E2 | chr10 | 4877867 | + |
| 5CDS-3UTR | ENST00000605149 | ENST00000334019 | AKR1C3 | chr10 | 5139742 | + | AKR1E2 | chr10 | 4872867 | + |
| 5CDS-3UTR | ENST00000605149 | ENST00000345253 | AKR1C3 | chr10 | 5144842 | + | AKR1E2 | chr10 | 4877867 | + |
| 5CDS-3UTR | ENST00000605149 | ENST00000345253 | AKR1C3 | chr10 | 5139742 | + | AKR1E2 | chr10 | 4872867 | + |
| 5CDS-3UTR | ENST00000605149 | ENST00000525281 | AKR1C3 | chr10 | 5144842 | + | AKR1E2 | chr10 | 4877867 | + |
| 5CDS-3UTR | ENST00000605149 | ENST00000525281 | AKR1C3 | chr10 | 5139742 | + | AKR1E2 | chr10 | 4872867 | + |
| 5CDS-3UTR | ENST00000605149 | ENST00000532248 | AKR1C3 | chr10 | 5144842 | + | AKR1E2 | chr10 | 4877867 | + |
| 5CDS-3UTR | ENST00000605149 | ENST00000532248 | AKR1C3 | chr10 | 5139742 | + | AKR1E2 | chr10 | 4872867 | + |
| In-frame | ENST00000380554 | ENST00000298375 | AKR1C3 | chr10 | 5144842 | + | AKR1E2 | chr10 | 4877867 | + |
| In-frame | ENST00000380554 | ENST00000298375 | AKR1C3 | chr10 | 5139742 | + | AKR1E2 | chr10 | 4872867 | + |
| In-frame | ENST00000439082 | ENST00000298375 | AKR1C3 | chr10 | 5144842 | + | AKR1E2 | chr10 | 4877867 | + |
| In-frame | ENST00000439082 | ENST00000298375 | AKR1C3 | chr10 | 5139742 | + | AKR1E2 | chr10 | 4872867 | + |
| In-frame | ENST00000605149 | ENST00000298375 | AKR1C3 | chr10 | 5144842 | + | AKR1E2 | chr10 | 4877867 | + |
| In-frame | ENST00000605149 | ENST00000298375 | AKR1C3 | chr10 | 5139742 | + | AKR1E2 | chr10 | 4872867 | + |
| intron-3CDS | ENST00000470862 | ENST00000298375 | AKR1C3 | chr10 | 5144842 | + | AKR1E2 | chr10 | 4877867 | + |
| intron-3CDS | ENST00000470862 | ENST00000298375 | AKR1C3 | chr10 | 5139742 | + | AKR1E2 | chr10 | 4872867 | + |
| intron-3UTR | ENST00000470862 | ENST00000334019 | AKR1C3 | chr10 | 5144842 | + | AKR1E2 | chr10 | 4877867 | + |
| intron-3UTR | ENST00000470862 | ENST00000334019 | AKR1C3 | chr10 | 5139742 | + | AKR1E2 | chr10 | 4872867 | + |
| intron-3UTR | ENST00000470862 | ENST00000345253 | AKR1C3 | chr10 | 5144842 | + | AKR1E2 | chr10 | 4877867 | + |
| intron-3UTR | ENST00000470862 | ENST00000345253 | AKR1C3 | chr10 | 5139742 | + | AKR1E2 | chr10 | 4872867 | + |
| intron-3UTR | ENST00000470862 | ENST00000525281 | AKR1C3 | chr10 | 5144842 | + | AKR1E2 | chr10 | 4877867 | + |
| intron-3UTR | ENST00000470862 | ENST00000525281 | AKR1C3 | chr10 | 5139742 | + | AKR1E2 | chr10 | 4872867 | + |
| intron-3UTR | ENST00000470862 | ENST00000532248 | AKR1C3 | chr10 | 5144842 | + | AKR1E2 | chr10 | 4877867 | + |
| intron-3UTR | ENST00000470862 | ENST00000532248 | AKR1C3 | chr10 | 5139742 | + | AKR1E2 | chr10 | 4872867 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000605149 | AKR1C3 | chr10 | 5144842 | + | ENST00000298375 | AKR1E2 | chr10 | 4877867 | + | 2273 | 1102 | 325 | 1740 | 471 |
| ENST00000439082 | AKR1C3 | chr10 | 5144842 | + | ENST00000298375 | AKR1E2 | chr10 | 4877867 | + | 2130 | 959 | 182 | 1597 | 471 |
| ENST00000380554 | AKR1C3 | chr10 | 5144842 | + | ENST00000298375 | AKR1E2 | chr10 | 4877867 | + | 2669 | 1498 | 652 | 2136 | 494 |
| ENST00000605149 | AKR1C3 | chr10 | 5139742 | + | ENST00000298375 | AKR1E2 | chr10 | 4872867 | + | 2081 | 625 | 325 | 1548 | 407 |
| ENST00000439082 | AKR1C3 | chr10 | 5139742 | + | ENST00000298375 | AKR1E2 | chr10 | 4872867 | + | 1938 | 482 | 182 | 1405 | 407 |
| ENST00000380554 | AKR1C3 | chr10 | 5139742 | + | ENST00000298375 | AKR1E2 | chr10 | 4872867 | + | 2477 | 1021 | 652 | 1944 | 430 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000605149 | ENST00000298375 | AKR1C3 | chr10 | 5144842 | + | AKR1E2 | chr10 | 4877867 | + | 0.001116619 | 0.9988834 |
| ENST00000439082 | ENST00000298375 | AKR1C3 | chr10 | 5144842 | + | AKR1E2 | chr10 | 4877867 | + | 0.001442648 | 0.9985574 |
| ENST00000380554 | ENST00000298375 | AKR1C3 | chr10 | 5144842 | + | AKR1E2 | chr10 | 4877867 | + | 0.000434898 | 0.99956506 |
| ENST00000605149 | ENST00000298375 | AKR1C3 | chr10 | 5139742 | + | AKR1E2 | chr10 | 4872867 | + | 0.00061322 | 0.9993868 |
| ENST00000439082 | ENST00000298375 | AKR1C3 | chr10 | 5139742 | + | AKR1E2 | chr10 | 4872867 | + | 0.000788401 | 0.99921155 |
| ENST00000380554 | ENST00000298375 | AKR1C3 | chr10 | 5139742 | + | AKR1E2 | chr10 | 4872867 | + | 0.000628977 | 0.999371 |
Top |
Fusion Genomic Features for AKR1C3-AKR1E2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| AKR1C3 | chr10 | 5139742 | + | AKR1E2 | chr10 | 4872866 | + | 1.14E-05 | 0.99998856 |
| AKR1C3 | chr10 | 5144842 | + | AKR1E2 | chr10 | 4877866 | + | 4.16E-06 | 0.9999958 |
| AKR1C3 | chr10 | 5139742 | + | AKR1E2 | chr10 | 4872866 | + | 1.14E-05 | 0.99998856 |
| AKR1C3 | chr10 | 5144842 | + | AKR1E2 | chr10 | 4877866 | + | 4.16E-06 | 0.9999958 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
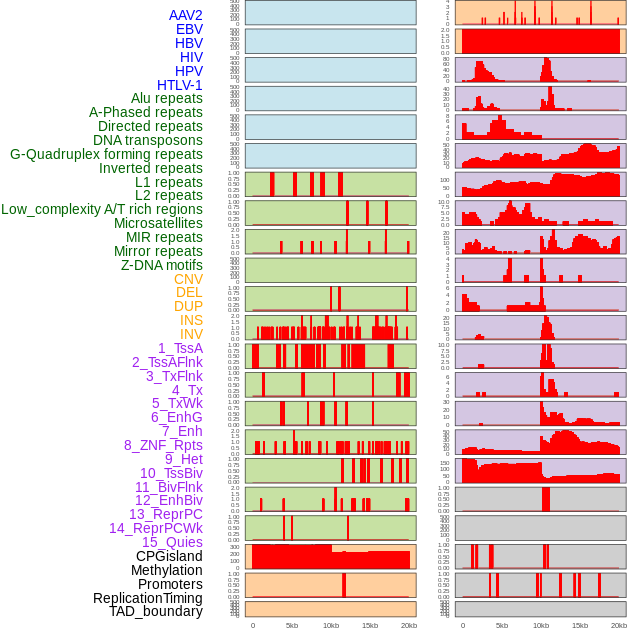 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
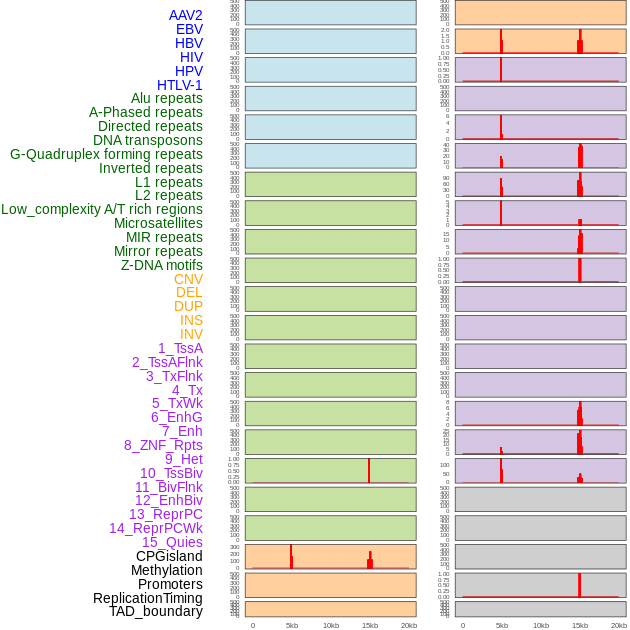 |
Top |
Fusion Protein Features for AKR1C3-AKR1E2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr10:5144842/chr10:4877867) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| AKR1C3 | AKR1E2 |
| FUNCTION: Cytosolic aldo-keto reductase that catalyzes the NADH and NADPH-dependent reduction of ketosteroids to hydroxysteroids. Acts as a NAD(P)(H)-dependent 3-, 17- and 20-ketosteroid reductase on the steroid nucleus and side chain and regulates the metabolism of androgens, estrogens and progesterone (PubMed:10622721, PubMed:11165022, PubMed:7650035, PubMed:9415401, PubMed:9927279). Displays the ability to catalyze both oxidation and reduction in vitro, but most probably acts as a reductase in vivo since the oxidase activity measured in vitro is inhibited by physiological concentration of NADPH (PubMed:14672942, PubMed:11165022). Acts preferentially as a 17-ketosteroid reductase and has the highest catalytic efficiency of the AKR1C enzyme for the reduction of delta4-androstenedione to form testosterone (PubMed:20036328). Reduces prostaglandin (PG) D2 to 11beta-prostaglandin F2, progesterone to 20alpha-hydroxyprogesterone and estrone to 17beta-estradiol (PubMed:15047184, PubMed:20036328, PubMed:10622721, PubMed:11165022, PubMed:10998348, PubMed:19010934). Catalyzes the transformation of the potent androgen dihydrotestosterone (DHT) into the less active form, 5-alpha-androstan-3-alpha,17-beta-diol (3-alpha-diol) (PubMed:10998348, PubMed:14672942, PubMed:11165022, PubMed:7650035, PubMed:9415401, PubMed:10557352). Displays also retinaldehyde reductase activity toward 9-cis-retinal (PubMed:21851338). {ECO:0000269|PubMed:10557352, ECO:0000269|PubMed:10622721, ECO:0000269|PubMed:10998348, ECO:0000269|PubMed:11165022, ECO:0000269|PubMed:14672942, ECO:0000269|PubMed:15047184, ECO:0000269|PubMed:19010934, ECO:0000269|PubMed:20036328, ECO:0000269|PubMed:21851338, ECO:0000269|PubMed:7650035, ECO:0000269|PubMed:9415401, ECO:0000269|PubMed:9927279}. | FUNCTION: Catalyzes the NADPH-dependent reduction of 1,5-anhydro-D-fructose (AF) to 1,5-anhydro-D-glucitol (By similarity). Has low NADPH-dependent reductase activity towards 9,10-phenanthrenequinone (in vitro) (PubMed:12604216, PubMed:15118078). {ECO:0000250|UniProtKB:Q9DCT1, ECO:0000269|PubMed:12604216, ECO:0000269|PubMed:15118078}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | AKR1C3 | chr10:5139742 | chr10:4872867 | ENST00000380554 | + | 3 | 9 | 23_24 | 123 | 324.0 | Nucleotide binding | NADP |
| Hgene | AKR1C3 | chr10:5144842 | chr10:4877867 | ENST00000380554 | + | 7 | 9 | 166_167 | 282 | 324.0 | Nucleotide binding | NADP |
| Hgene | AKR1C3 | chr10:5144842 | chr10:4877867 | ENST00000380554 | + | 7 | 9 | 216_222 | 282 | 324.0 | Nucleotide binding | NADP |
| Hgene | AKR1C3 | chr10:5144842 | chr10:4877867 | ENST00000380554 | + | 7 | 9 | 23_24 | 282 | 324.0 | Nucleotide binding | NADP |
| Hgene | AKR1C3 | chr10:5144842 | chr10:4877867 | ENST00000380554 | + | 7 | 9 | 270_272 | 282 | 324.0 | Nucleotide binding | NADP |
| Hgene | AKR1C3 | chr10:5144842 | chr10:4877867 | ENST00000380554 | + | 7 | 9 | 276_280 | 282 | 324.0 | Nucleotide binding | NADP |
| Tgene | AKR1E2 | chr10:5139742 | chr10:4872867 | ENST00000298375 | 0 | 10 | 265_277 | 13 | 321.0 | Nucleotide binding | NADP | |
| Tgene | AKR1E2 | chr10:5139742 | chr10:4872867 | ENST00000334019 | 0 | 8 | 265_277 | 13 | 264.0 | Nucleotide binding | NADP | |
| Tgene | AKR1E2 | chr10:5139742 | chr10:4872867 | ENST00000345253 | 0 | 7 | 265_277 | 13 | 223.0 | Nucleotide binding | NADP | |
| Tgene | AKR1E2 | chr10:5139742 | chr10:4872867 | ENST00000532248 | 0 | 7 | 265_277 | 13 | 251.0 | Nucleotide binding | NADP | |
| Tgene | AKR1E2 | chr10:5144842 | chr10:4877867 | ENST00000298375 | 2 | 10 | 265_277 | 108 | 321.0 | Nucleotide binding | NADP | |
| Tgene | AKR1E2 | chr10:5144842 | chr10:4877867 | ENST00000334019 | 2 | 8 | 265_277 | 108 | 264.0 | Nucleotide binding | NADP | |
| Tgene | AKR1E2 | chr10:5144842 | chr10:4877867 | ENST00000345253 | 2 | 7 | 265_277 | 108 | 223.0 | Nucleotide binding | NADP | |
| Tgene | AKR1E2 | chr10:5144842 | chr10:4877867 | ENST00000532248 | 2 | 7 | 265_277 | 108 | 251.0 | Nucleotide binding | NADP |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | AKR1C3 | chr10:5139742 | chr10:4872867 | ENST00000380554 | + | 3 | 9 | 166_167 | 123 | 324.0 | Nucleotide binding | NADP |
| Hgene | AKR1C3 | chr10:5139742 | chr10:4872867 | ENST00000380554 | + | 3 | 9 | 216_222 | 123 | 324.0 | Nucleotide binding | NADP |
| Hgene | AKR1C3 | chr10:5139742 | chr10:4872867 | ENST00000380554 | + | 3 | 9 | 270_272 | 123 | 324.0 | Nucleotide binding | NADP |
| Hgene | AKR1C3 | chr10:5139742 | chr10:4872867 | ENST00000380554 | + | 3 | 9 | 276_280 | 123 | 324.0 | Nucleotide binding | NADP |
Top |
Fusion Gene Sequence for AKR1C3-AKR1E2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >3448_3448_1_AKR1C3-AKR1E2_AKR1C3_chr10_5139742_ENST00000380554_AKR1E2_chr10_4872867_ENST00000298375_length(transcript)=2477nt_BP=1021nt CCCTCATCAGGATTACAGCTTTATCAGGACTGCATCTTCTTCAGAAATGAATATTTCTCTTACAACGCAAAGAAAGAAAAATCAAAATAA ATTTTCTGATTGAAAATGTAAAAAGGCAAATATTTTTACAGTTTTAACTTTAATTTTTTATTGAGGACCAACTATTTGAAAAATTCTCAT TAGTCATTCCTTTAAATTATGTGTATGTGAGAGAAAGACGTAAGATGGTTAATTATTTCAAATGATGCAGTATAAAGAAGGGGCATTATC ACGGCAGAAACGAAAAAAGATATTTGTAGCTGGAGGTTTTTATAGTCTAACATATGGTTGCTATTTGTTCTACAAATCCTTTTGAATAAT TTAATATAGAGATTTAGAATAGAAAATAATACTTTAGATAGAAATTAATGAGTTTATTATAACCATATATTATAATAATTTACTTAGGAA TTCTCTTTGATAAGAAACAAATGAACTGAATGCAATTTTCTCCACAGACCATATAAGACTGCCTATGTACCTCCTCCTACATGCCATTGG TTAACCATCAGTCAGTTTGCAGGGGTGGGGGGAGGGGTTTCCTGCCCATTGTTTTTGTAATCTCTGAGGAGAAGCAGCAGCAAACATTTG CTAGTCAGACAAGTGACAGGGAATGGATTCCAAACACCAGTGTGTAAAGCTAAATGATGGCCACTTCATGCCTGTATTGGGATTTGGCAC CTATGCACCTCCAGAGGTTCCGAGAAGTAAAGCTTTGGAGGTCACAAAATTAGCAATAGAAGCTGGGTTCCGCCATATAGATTCTGCTCA TTTATACAATAATGAGGAGCAGGTTGGACTGGCCATCCGAAGCAAGATTGCAGATGGCAGTGTGAAGAGAGAAGACATATTCTACACTTC AAAGCTTTGGTCCACTTTTCATCGACCAGAGTTGGTCCGACCAGCCTTGGAAAACTCACTGAAGAAAGCTCAATTGGACTATGTTGACCT CTATCTTATTCATTCTCCAATGTCTCTAAAGGCTTCTCCAGGGAAAGTGACCGAGGCAGTGAAAGAGGCCATTGACGCAGGGTACCGGCA CTTCGACTGTGCTTACTTTTACCACAATGAGAGGGAGGTTGGAGCAGGGATCCGTTGCAAGATCAAGGAAGGCGCTGTAAGACGGGAGGA TCTGTTCATTGCCACTAAGCTGTGGTGCACCTGCCATAAGAAGTCCTTGGTGGAAACAGCATGCAGAAAGAGTCTCAAGGCCTTGAAGCT GAACTATTTGGACCTCTACCTCATACACTGGCCCATGGGTTTCAAGCCTCCTCATCCAGAATGGATCATGAGCTGCAGTGAACTTTCCTT CTGCCTCTCACATCCTCGAGTGCAGGACTTGCCTCTGGACGAGAGCAACATGGTTATTCCCAGTGACACGGACTTCCTGGACACGTGGGA GGCCATGGAGGACCTGGTGATCACCGGGCTGGTGAAGAACATCGGGGTGTCAAACTTCAACCATGAACAGCTTGAGAGGCTTTTGAATAA GCCTGGGTTGAGGTTCAAGCCACTAACCAACCAGATTGAGTGCCACCCATATCTTACTCAGAAGAATCTGATCAGTTTTTGCCAATCCAG AGATGTGTCCGTGACTGCTTACCGTCCTCTTGGTGGCTCGTGTGAGGGGGTTGACCTGATAGACAACCCTGTGATCAAGAGGATTGCAAA GGAGCACGGCAAGTCTCCTGCTCAGATTTTGATCCGATTTCAAATCCAGAGGAATGTGATAGTGATCCCCGGATCTATCACCCCAAGTCA CATTAAAGAGAATATCCAGGTGTTTGATTTTGAATTAACACAGCACGATATGGATAACATCCTCAGCCTAAACAGGAATCTCCGACTGGC CATGTTCCCCATAACTAAAAATCACAAAGACTATCCTTTCCACATAGAATACTGAGGACGCTTCCCCTTCCTTGTTTCTGCTCAGCCCAG ATGCACAGACACTATTGGCAATGTTGACCCTCCTCTGTCATCACAGCGCCAGGGCAGCTGTGCCTGGGACAGGAGCCACACAGTCAGAGG GGGATGTAAGAGCCACCTTCTCTGACAAATCTGGAGAATTGAGTGTGTTCTAAGTGAAGGCAATGGGGTTTCTCCAAGACAGCCTGTGTG GCCTCTACTCTGAACAAATACACTGATGAGTCATCAGTGAAATTTGCCTTCACATTTTAAGAAAACTTTATCTTATGGAGTTATTTAAGC CATCTACAGAGCTGAGGAAACAGTGTAATGTGTCTCTGCCCCATTGCGCAGCTCCACCCATTGTGCCCCAGGCCAGCCCGCGTCACCTAC ACTTCCTTCTGTGCCCTGCCAGTGACCCCCAGGTTATTCTAAAGCAGAGTCCTTCCCTTCCCCCAGTGAGAAGGAAAATGGGATAAGTCT >3448_3448_1_AKR1C3-AKR1E2_AKR1C3_chr10_5139742_ENST00000380554_AKR1E2_chr10_4872867_ENST00000298375_length(amino acids)=430AA_BP=121 MDSKHQCVKLNDGHFMPVLGFGTYAPPEVPRSKALEVTKLAIEAGFRHIDSAHLYNNEEQVGLAIRSKIADGSVKREDIFYTSKLWSTFH RPELVRPALENSLKKAQLDYVDLYLIHSPMSLKASPGKVTEAVKEAIDAGYRHFDCAYFYHNEREVGAGIRCKIKEGAVRREDLFIATKL WCTCHKKSLVETACRKSLKALKLNYLDLYLIHWPMGFKPPHPEWIMSCSELSFCLSHPRVQDLPLDESNMVIPSDTDFLDTWEAMEDLVI TGLVKNIGVSNFNHEQLERLLNKPGLRFKPLTNQIECHPYLTQKNLISFCQSRDVSVTAYRPLGGSCEGVDLIDNPVIKRIAKEHGKSPA -------------------------------------------------------------- >3448_3448_2_AKR1C3-AKR1E2_AKR1C3_chr10_5139742_ENST00000439082_AKR1E2_chr10_4872867_ENST00000298375_length(transcript)=1938nt_BP=482nt AACATGTTCCTTGAGGTTGAAGCAAATCTGACCGATTTTCAATGTAAAAATAACATATAAAAACTGTTCTCGGAGTTATTTCTAAACAGA ACTAAGATCAGAATTCTTTGAATCATCAGAATCATCTCTTTTGAAAAATCGATTCATCAAATGAATCTTCAGCCAACAACTGTTCAAGAA GGATGCAAATATCACAGGTTCCGAGAAGTAAAGCTTTGGAGGTCACAAAATTAGCAATAGAAGCTGGGTTCCGCCATATAGATTCTGCTC ATTTATACAATAATGAGGAGCAGGTTGGACTGGCCATCCGAAGCAAGATTGCAGATGGCAGTGTGAAGAGAGAAGACATATTCTACACTT CAAAGCTTTGGTCCACTTTTCATCGACCAGAGTTGGTCCGACCAGCCTTGGAAAACTCACTGAAGAAAGCTCAATTGGACTATGTTGACC TCTATCTTATTCATTCTCCAATGTCTCTAAAGGCTTCTCCAGGGAAAGTGACCGAGGCAGTGAAAGAGGCCATTGACGCAGGGTACCGGC ACTTCGACTGTGCTTACTTTTACCACAATGAGAGGGAGGTTGGAGCAGGGATCCGTTGCAAGATCAAGGAAGGCGCTGTAAGACGGGAGG ATCTGTTCATTGCCACTAAGCTGTGGTGCACCTGCCATAAGAAGTCCTTGGTGGAAACAGCATGCAGAAAGAGTCTCAAGGCCTTGAAGC TGAACTATTTGGACCTCTACCTCATACACTGGCCCATGGGTTTCAAGCCTCCTCATCCAGAATGGATCATGAGCTGCAGTGAACTTTCCT TCTGCCTCTCACATCCTCGAGTGCAGGACTTGCCTCTGGACGAGAGCAACATGGTTATTCCCAGTGACACGGACTTCCTGGACACGTGGG AGGCCATGGAGGACCTGGTGATCACCGGGCTGGTGAAGAACATCGGGGTGTCAAACTTCAACCATGAACAGCTTGAGAGGCTTTTGAATA AGCCTGGGTTGAGGTTCAAGCCACTAACCAACCAGATTGAGTGCCACCCATATCTTACTCAGAAGAATCTGATCAGTTTTTGCCAATCCA GAGATGTGTCCGTGACTGCTTACCGTCCTCTTGGTGGCTCGTGTGAGGGGGTTGACCTGATAGACAACCCTGTGATCAAGAGGATTGCAA AGGAGCACGGCAAGTCTCCTGCTCAGATTTTGATCCGATTTCAAATCCAGAGGAATGTGATAGTGATCCCCGGATCTATCACCCCAAGTC ACATTAAAGAGAATATCCAGGTGTTTGATTTTGAATTAACACAGCACGATATGGATAACATCCTCAGCCTAAACAGGAATCTCCGACTGG CCATGTTCCCCATAACTAAAAATCACAAAGACTATCCTTTCCACATAGAATACTGAGGACGCTTCCCCTTCCTTGTTTCTGCTCAGCCCA GATGCACAGACACTATTGGCAATGTTGACCCTCCTCTGTCATCACAGCGCCAGGGCAGCTGTGCCTGGGACAGGAGCCACACAGTCAGAG GGGGATGTAAGAGCCACCTTCTCTGACAAATCTGGAGAATTGAGTGTGTTCTAAGTGAAGGCAATGGGGTTTCTCCAAGACAGCCTGTGT GGCCTCTACTCTGAACAAATACACTGATGAGTCATCAGTGAAATTTGCCTTCACATTTTAAGAAAACTTTATCTTATGGAGTTATTTAAG CCATCTACAGAGCTGAGGAAACAGTGTAATGTGTCTCTGCCCCATTGCGCAGCTCCACCCATTGTGCCCCAGGCCAGCCCGCGTCACCTA CACTTCCTTCTGTGCCCTGCCAGTGACCCCCAGGTTATTCTAAAGCAGAGTCCTTCCCTTCCCCCAGTGAGAAGGAAAATGGGATAAGTC >3448_3448_2_AKR1C3-AKR1E2_AKR1C3_chr10_5139742_ENST00000439082_AKR1E2_chr10_4872867_ENST00000298375_length(amino acids)=407AA_BP=98 MQISQVPRSKALEVTKLAIEAGFRHIDSAHLYNNEEQVGLAIRSKIADGSVKREDIFYTSKLWSTFHRPELVRPALENSLKKAQLDYVDL YLIHSPMSLKASPGKVTEAVKEAIDAGYRHFDCAYFYHNEREVGAGIRCKIKEGAVRREDLFIATKLWCTCHKKSLVETACRKSLKALKL NYLDLYLIHWPMGFKPPHPEWIMSCSELSFCLSHPRVQDLPLDESNMVIPSDTDFLDTWEAMEDLVITGLVKNIGVSNFNHEQLERLLNK PGLRFKPLTNQIECHPYLTQKNLISFCQSRDVSVTAYRPLGGSCEGVDLIDNPVIKRIAKEHGKSPAQILIRFQIQRNVIVIPGSITPSH -------------------------------------------------------------- >3448_3448_3_AKR1C3-AKR1E2_AKR1C3_chr10_5139742_ENST00000605149_AKR1E2_chr10_4872867_ENST00000298375_length(transcript)=2081nt_BP=625nt TTTTTGCTGAACATTCCCCTTAGTAAAATGGCAGGATGGTTTGCTTGCCATTGAAACTAACCAAACATTTAATCCTTTTCCCTTTAGAGA AAAAAGAAAAAAAAAGGTGCAGCTCACTGCCAGTGCCCATTTAGTTTTACATTAACATGTTCCTTGAGGTTGAAGCAAATCTGACCGATT TTCAATGTAAAAATAACATATAAAAACTGTTCTCGGAGTTATTTCTAAACAGAACTAAGATCAGAATTCTTTGAATCATCAGAATCATCT CTTTTGAAAAATCGATTCATCAAATGAATCTTCAGCCAACAACTGTTCAAGAAGGATGCAAATATCACAGGTTCCGAGAAGTAAAGCTTT GGAGGTCACAAAATTAGCAATAGAAGCTGGGTTCCGCCATATAGATTCTGCTCATTTATACAATAATGAGGAGCAGGTTGGACTGGCCAT CCGAAGCAAGATTGCAGATGGCAGTGTGAAGAGAGAAGACATATTCTACACTTCAAAGCTTTGGTCCACTTTTCATCGACCAGAGTTGGT CCGACCAGCCTTGGAAAACTCACTGAAGAAAGCTCAATTGGACTATGTTGACCTCTATCTTATTCATTCTCCAATGTCTCTAAAGGCTTC TCCAGGGAAAGTGACCGAGGCAGTGAAAGAGGCCATTGACGCAGGGTACCGGCACTTCGACTGTGCTTACTTTTACCACAATGAGAGGGA GGTTGGAGCAGGGATCCGTTGCAAGATCAAGGAAGGCGCTGTAAGACGGGAGGATCTGTTCATTGCCACTAAGCTGTGGTGCACCTGCCA TAAGAAGTCCTTGGTGGAAACAGCATGCAGAAAGAGTCTCAAGGCCTTGAAGCTGAACTATTTGGACCTCTACCTCATACACTGGCCCAT GGGTTTCAAGCCTCCTCATCCAGAATGGATCATGAGCTGCAGTGAACTTTCCTTCTGCCTCTCACATCCTCGAGTGCAGGACTTGCCTCT GGACGAGAGCAACATGGTTATTCCCAGTGACACGGACTTCCTGGACACGTGGGAGGCCATGGAGGACCTGGTGATCACCGGGCTGGTGAA GAACATCGGGGTGTCAAACTTCAACCATGAACAGCTTGAGAGGCTTTTGAATAAGCCTGGGTTGAGGTTCAAGCCACTAACCAACCAGAT TGAGTGCCACCCATATCTTACTCAGAAGAATCTGATCAGTTTTTGCCAATCCAGAGATGTGTCCGTGACTGCTTACCGTCCTCTTGGTGG CTCGTGTGAGGGGGTTGACCTGATAGACAACCCTGTGATCAAGAGGATTGCAAAGGAGCACGGCAAGTCTCCTGCTCAGATTTTGATCCG ATTTCAAATCCAGAGGAATGTGATAGTGATCCCCGGATCTATCACCCCAAGTCACATTAAAGAGAATATCCAGGTGTTTGATTTTGAATT AACACAGCACGATATGGATAACATCCTCAGCCTAAACAGGAATCTCCGACTGGCCATGTTCCCCATAACTAAAAATCACAAAGACTATCC TTTCCACATAGAATACTGAGGACGCTTCCCCTTCCTTGTTTCTGCTCAGCCCAGATGCACAGACACTATTGGCAATGTTGACCCTCCTCT GTCATCACAGCGCCAGGGCAGCTGTGCCTGGGACAGGAGCCACACAGTCAGAGGGGGATGTAAGAGCCACCTTCTCTGACAAATCTGGAG AATTGAGTGTGTTCTAAGTGAAGGCAATGGGGTTTCTCCAAGACAGCCTGTGTGGCCTCTACTCTGAACAAATACACTGATGAGTCATCA GTGAAATTTGCCTTCACATTTTAAGAAAACTTTATCTTATGGAGTTATTTAAGCCATCTACAGAGCTGAGGAAACAGTGTAATGTGTCTC TGCCCCATTGCGCAGCTCCACCCATTGTGCCCCAGGCCAGCCCGCGTCACCTACACTTCCTTCTGTGCCCTGCCAGTGACCCCCAGGTTA TTCTAAAGCAGAGTCCTTCCCTTCCCCCAGTGAGAAGGAAAATGGGATAAGTCTGGGACACTGTTTCAGTTCAATAAAGAGGCTTTTTTC >3448_3448_3_AKR1C3-AKR1E2_AKR1C3_chr10_5139742_ENST00000605149_AKR1E2_chr10_4872867_ENST00000298375_length(amino acids)=407AA_BP=98 MQISQVPRSKALEVTKLAIEAGFRHIDSAHLYNNEEQVGLAIRSKIADGSVKREDIFYTSKLWSTFHRPELVRPALENSLKKAQLDYVDL YLIHSPMSLKASPGKVTEAVKEAIDAGYRHFDCAYFYHNEREVGAGIRCKIKEGAVRREDLFIATKLWCTCHKKSLVETACRKSLKALKL NYLDLYLIHWPMGFKPPHPEWIMSCSELSFCLSHPRVQDLPLDESNMVIPSDTDFLDTWEAMEDLVITGLVKNIGVSNFNHEQLERLLNK PGLRFKPLTNQIECHPYLTQKNLISFCQSRDVSVTAYRPLGGSCEGVDLIDNPVIKRIAKEHGKSPAQILIRFQIQRNVIVIPGSITPSH -------------------------------------------------------------- >3448_3448_4_AKR1C3-AKR1E2_AKR1C3_chr10_5144842_ENST00000380554_AKR1E2_chr10_4877867_ENST00000298375_length(transcript)=2669nt_BP=1498nt CCCTCATCAGGATTACAGCTTTATCAGGACTGCATCTTCTTCAGAAATGAATATTTCTCTTACAACGCAAAGAAAGAAAAATCAAAATAA ATTTTCTGATTGAAAATGTAAAAAGGCAAATATTTTTACAGTTTTAACTTTAATTTTTTATTGAGGACCAACTATTTGAAAAATTCTCAT TAGTCATTCCTTTAAATTATGTGTATGTGAGAGAAAGACGTAAGATGGTTAATTATTTCAAATGATGCAGTATAAAGAAGGGGCATTATC ACGGCAGAAACGAAAAAAGATATTTGTAGCTGGAGGTTTTTATAGTCTAACATATGGTTGCTATTTGTTCTACAAATCCTTTTGAATAAT TTAATATAGAGATTTAGAATAGAAAATAATACTTTAGATAGAAATTAATGAGTTTATTATAACCATATATTATAATAATTTACTTAGGAA TTCTCTTTGATAAGAAACAAATGAACTGAATGCAATTTTCTCCACAGACCATATAAGACTGCCTATGTACCTCCTCCTACATGCCATTGG TTAACCATCAGTCAGTTTGCAGGGGTGGGGGGAGGGGTTTCCTGCCCATTGTTTTTGTAATCTCTGAGGAGAAGCAGCAGCAAACATTTG CTAGTCAGACAAGTGACAGGGAATGGATTCCAAACACCAGTGTGTAAAGCTAAATGATGGCCACTTCATGCCTGTATTGGGATTTGGCAC CTATGCACCTCCAGAGGTTCCGAGAAGTAAAGCTTTGGAGGTCACAAAATTAGCAATAGAAGCTGGGTTCCGCCATATAGATTCTGCTCA TTTATACAATAATGAGGAGCAGGTTGGACTGGCCATCCGAAGCAAGATTGCAGATGGCAGTGTGAAGAGAGAAGACATATTCTACACTTC AAAGCTTTGGTCCACTTTTCATCGACCAGAGTTGGTCCGACCAGCCTTGGAAAACTCACTGAAGAAAGCTCAATTGGACTATGTTGACCT CTATCTTATTCATTCTCCAATGTCTCTAAAGCCAGGTGAGGAACTTTCACCAACAGATGAAAATGGAAAAGTAATATTTGACATAGTGGA TCTCTGTACCACCTGGGAGGCCATGGAGAAGTGTAAGGATGCAGGATTGGCCAAGTCCATTGGGGTGTCAAACTTCAACCGCAGGCAGCT GGAGATGATCCTCAACAAGCCAGGACTCAAGTACAAGCCTGTCTGCAACCAGGTAGAATGTCATCCGTATTTCAACCGGAGTAAATTGCT AGATTTCTGCAAGTCGAAAGATATTGTTCTGGTTGCCTATAGTGCTCTGGGATCTCAACGAGACAAACGATGGGTGGACCCGAACTCCCC GGTGCTCTTGGAGGACCCAGTCCTTTGTGCCTTGGCAAAAAAGCACAAGCGAACCCCAGCCCTGATTGCCCTGCGCTACCAGCTGCAGCG TGGGGTTGTGGTCCTGGCCAAGAGCTACAATGAGCAGCGCATCAGACAGAACGTGCAGCCTCCTCATCCAGAATGGATCATGAGCTGCAG TGAACTTTCCTTCTGCCTCTCACATCCTCGAGTGCAGGACTTGCCTCTGGACGAGAGCAACATGGTTATTCCCAGTGACACGGACTTCCT GGACACGTGGGAGGCCATGGAGGACCTGGTGATCACCGGGCTGGTGAAGAACATCGGGGTGTCAAACTTCAACCATGAACAGCTTGAGAG GCTTTTGAATAAGCCTGGGTTGAGGTTCAAGCCACTAACCAACCAGATTGAGTGCCACCCATATCTTACTCAGAAGAATCTGATCAGTTT TTGCCAATCCAGAGATGTGTCCGTGACTGCTTACCGTCCTCTTGGTGGCTCGTGTGAGGGGGTTGACCTGATAGACAACCCTGTGATCAA GAGGATTGCAAAGGAGCACGGCAAGTCTCCTGCTCAGATTTTGATCCGATTTCAAATCCAGAGGAATGTGATAGTGATCCCCGGATCTAT CACCCCAAGTCACATTAAAGAGAATATCCAGGTGTTTGATTTTGAATTAACACAGCACGATATGGATAACATCCTCAGCCTAAACAGGAA TCTCCGACTGGCCATGTTCCCCATAACTAAAAATCACAAAGACTATCCTTTCCACATAGAATACTGAGGACGCTTCCCCTTCCTTGTTTC TGCTCAGCCCAGATGCACAGACACTATTGGCAATGTTGACCCTCCTCTGTCATCACAGCGCCAGGGCAGCTGTGCCTGGGACAGGAGCCA CACAGTCAGAGGGGGATGTAAGAGCCACCTTCTCTGACAAATCTGGAGAATTGAGTGTGTTCTAAGTGAAGGCAATGGGGTTTCTCCAAG ACAGCCTGTGTGGCCTCTACTCTGAACAAATACACTGATGAGTCATCAGTGAAATTTGCCTTCACATTTTAAGAAAACTTTATCTTATGG AGTTATTTAAGCCATCTACAGAGCTGAGGAAACAGTGTAATGTGTCTCTGCCCCATTGCGCAGCTCCACCCATTGTGCCCCAGGCCAGCC CGCGTCACCTACACTTCCTTCTGTGCCCTGCCAGTGACCCCCAGGTTATTCTAAAGCAGAGTCCTTCCCTTCCCCCAGTGAGAAGGAAAA >3448_3448_4_AKR1C3-AKR1E2_AKR1C3_chr10_5144842_ENST00000380554_AKR1E2_chr10_4877867_ENST00000298375_length(amino acids)=494AA_BP=281 MDSKHQCVKLNDGHFMPVLGFGTYAPPEVPRSKALEVTKLAIEAGFRHIDSAHLYNNEEQVGLAIRSKIADGSVKREDIFYTSKLWSTFH RPELVRPALENSLKKAQLDYVDLYLIHSPMSLKPGEELSPTDENGKVIFDIVDLCTTWEAMEKCKDAGLAKSIGVSNFNRRQLEMILNKP GLKYKPVCNQVECHPYFNRSKLLDFCKSKDIVLVAYSALGSQRDKRWVDPNSPVLLEDPVLCALAKKHKRTPALIALRYQLQRGVVVLAK SYNEQRIRQNVQPPHPEWIMSCSELSFCLSHPRVQDLPLDESNMVIPSDTDFLDTWEAMEDLVITGLVKNIGVSNFNHEQLERLLNKPGL RFKPLTNQIECHPYLTQKNLISFCQSRDVSVTAYRPLGGSCEGVDLIDNPVIKRIAKEHGKSPAQILIRFQIQRNVIVIPGSITPSHIKE -------------------------------------------------------------- >3448_3448_5_AKR1C3-AKR1E2_AKR1C3_chr10_5144842_ENST00000439082_AKR1E2_chr10_4877867_ENST00000298375_length(transcript)=2130nt_BP=959nt AACATGTTCCTTGAGGTTGAAGCAAATCTGACCGATTTTCAATGTAAAAATAACATATAAAAACTGTTCTCGGAGTTATTTCTAAACAGA ACTAAGATCAGAATTCTTTGAATCATCAGAATCATCTCTTTTGAAAAATCGATTCATCAAATGAATCTTCAGCCAACAACTGTTCAAGAA GGATGCAAATATCACAGGTTCCGAGAAGTAAAGCTTTGGAGGTCACAAAATTAGCAATAGAAGCTGGGTTCCGCCATATAGATTCTGCTC ATTTATACAATAATGAGGAGCAGGTTGGACTGGCCATCCGAAGCAAGATTGCAGATGGCAGTGTGAAGAGAGAAGACATATTCTACACTT CAAAGCTTTGGTCCACTTTTCATCGACCAGAGTTGGTCCGACCAGCCTTGGAAAACTCACTGAAGAAAGCTCAATTGGACTATGTTGACC TCTATCTTATTCATTCTCCAATGTCTCTAAAGCCAGGTGAGGAACTTTCACCAACAGATGAAAATGGAAAAGTAATATTTGACATAGTGG ATCTCTGTACCACCTGGGAGGCCATGGAGAAGTGTAAGGATGCAGGATTGGCCAAGTCCATTGGGGTGTCAAACTTCAACCGCAGGCAGC TGGAGATGATCCTCAACAAGCCAGGACTCAAGTACAAGCCTGTCTGCAACCAGGTAGAATGTCATCCGTATTTCAACCGGAGTAAATTGC TAGATTTCTGCAAGTCGAAAGATATTGTTCTGGTTGCCTATAGTGCTCTGGGATCTCAACGAGACAAACGATGGGTGGACCCGAACTCCC CGGTGCTCTTGGAGGACCCAGTCCTTTGTGCCTTGGCAAAAAAGCACAAGCGAACCCCAGCCCTGATTGCCCTGCGCTACCAGCTGCAGC GTGGGGTTGTGGTCCTGGCCAAGAGCTACAATGAGCAGCGCATCAGACAGAACGTGCAGCCTCCTCATCCAGAATGGATCATGAGCTGCA GTGAACTTTCCTTCTGCCTCTCACATCCTCGAGTGCAGGACTTGCCTCTGGACGAGAGCAACATGGTTATTCCCAGTGACACGGACTTCC TGGACACGTGGGAGGCCATGGAGGACCTGGTGATCACCGGGCTGGTGAAGAACATCGGGGTGTCAAACTTCAACCATGAACAGCTTGAGA GGCTTTTGAATAAGCCTGGGTTGAGGTTCAAGCCACTAACCAACCAGATTGAGTGCCACCCATATCTTACTCAGAAGAATCTGATCAGTT TTTGCCAATCCAGAGATGTGTCCGTGACTGCTTACCGTCCTCTTGGTGGCTCGTGTGAGGGGGTTGACCTGATAGACAACCCTGTGATCA AGAGGATTGCAAAGGAGCACGGCAAGTCTCCTGCTCAGATTTTGATCCGATTTCAAATCCAGAGGAATGTGATAGTGATCCCCGGATCTA TCACCCCAAGTCACATTAAAGAGAATATCCAGGTGTTTGATTTTGAATTAACACAGCACGATATGGATAACATCCTCAGCCTAAACAGGA ATCTCCGACTGGCCATGTTCCCCATAACTAAAAATCACAAAGACTATCCTTTCCACATAGAATACTGAGGACGCTTCCCCTTCCTTGTTT CTGCTCAGCCCAGATGCACAGACACTATTGGCAATGTTGACCCTCCTCTGTCATCACAGCGCCAGGGCAGCTGTGCCTGGGACAGGAGCC ACACAGTCAGAGGGGGATGTAAGAGCCACCTTCTCTGACAAATCTGGAGAATTGAGTGTGTTCTAAGTGAAGGCAATGGGGTTTCTCCAA GACAGCCTGTGTGGCCTCTACTCTGAACAAATACACTGATGAGTCATCAGTGAAATTTGCCTTCACATTTTAAGAAAACTTTATCTTATG GAGTTATTTAAGCCATCTACAGAGCTGAGGAAACAGTGTAATGTGTCTCTGCCCCATTGCGCAGCTCCACCCATTGTGCCCCAGGCCAGC CCGCGTCACCTACACTTCCTTCTGTGCCCTGCCAGTGACCCCCAGGTTATTCTAAAGCAGAGTCCTTCCCTTCCCCCAGTGAGAAGGAAA >3448_3448_5_AKR1C3-AKR1E2_AKR1C3_chr10_5144842_ENST00000439082_AKR1E2_chr10_4877867_ENST00000298375_length(amino acids)=471AA_BP=258 MQISQVPRSKALEVTKLAIEAGFRHIDSAHLYNNEEQVGLAIRSKIADGSVKREDIFYTSKLWSTFHRPELVRPALENSLKKAQLDYVDL YLIHSPMSLKPGEELSPTDENGKVIFDIVDLCTTWEAMEKCKDAGLAKSIGVSNFNRRQLEMILNKPGLKYKPVCNQVECHPYFNRSKLL DFCKSKDIVLVAYSALGSQRDKRWVDPNSPVLLEDPVLCALAKKHKRTPALIALRYQLQRGVVVLAKSYNEQRIRQNVQPPHPEWIMSCS ELSFCLSHPRVQDLPLDESNMVIPSDTDFLDTWEAMEDLVITGLVKNIGVSNFNHEQLERLLNKPGLRFKPLTNQIECHPYLTQKNLISF CQSRDVSVTAYRPLGGSCEGVDLIDNPVIKRIAKEHGKSPAQILIRFQIQRNVIVIPGSITPSHIKENIQVFDFELTQHDMDNILSLNRN -------------------------------------------------------------- >3448_3448_6_AKR1C3-AKR1E2_AKR1C3_chr10_5144842_ENST00000605149_AKR1E2_chr10_4877867_ENST00000298375_length(transcript)=2273nt_BP=1102nt TTTTTGCTGAACATTCCCCTTAGTAAAATGGCAGGATGGTTTGCTTGCCATTGAAACTAACCAAACATTTAATCCTTTTCCCTTTAGAGA AAAAAGAAAAAAAAAGGTGCAGCTCACTGCCAGTGCCCATTTAGTTTTACATTAACATGTTCCTTGAGGTTGAAGCAAATCTGACCGATT TTCAATGTAAAAATAACATATAAAAACTGTTCTCGGAGTTATTTCTAAACAGAACTAAGATCAGAATTCTTTGAATCATCAGAATCATCT CTTTTGAAAAATCGATTCATCAAATGAATCTTCAGCCAACAACTGTTCAAGAAGGATGCAAATATCACAGGTTCCGAGAAGTAAAGCTTT GGAGGTCACAAAATTAGCAATAGAAGCTGGGTTCCGCCATATAGATTCTGCTCATTTATACAATAATGAGGAGCAGGTTGGACTGGCCAT CCGAAGCAAGATTGCAGATGGCAGTGTGAAGAGAGAAGACATATTCTACACTTCAAAGCTTTGGTCCACTTTTCATCGACCAGAGTTGGT CCGACCAGCCTTGGAAAACTCACTGAAGAAAGCTCAATTGGACTATGTTGACCTCTATCTTATTCATTCTCCAATGTCTCTAAAGCCAGG TGAGGAACTTTCACCAACAGATGAAAATGGAAAAGTAATATTTGACATAGTGGATCTCTGTACCACCTGGGAGGCCATGGAGAAGTGTAA GGATGCAGGATTGGCCAAGTCCATTGGGGTGTCAAACTTCAACCGCAGGCAGCTGGAGATGATCCTCAACAAGCCAGGACTCAAGTACAA GCCTGTCTGCAACCAGGTAGAATGTCATCCGTATTTCAACCGGAGTAAATTGCTAGATTTCTGCAAGTCGAAAGATATTGTTCTGGTTGC CTATAGTGCTCTGGGATCTCAACGAGACAAACGATGGGTGGACCCGAACTCCCCGGTGCTCTTGGAGGACCCAGTCCTTTGTGCCTTGGC AAAAAAGCACAAGCGAACCCCAGCCCTGATTGCCCTGCGCTACCAGCTGCAGCGTGGGGTTGTGGTCCTGGCCAAGAGCTACAATGAGCA GCGCATCAGACAGAACGTGCAGCCTCCTCATCCAGAATGGATCATGAGCTGCAGTGAACTTTCCTTCTGCCTCTCACATCCTCGAGTGCA GGACTTGCCTCTGGACGAGAGCAACATGGTTATTCCCAGTGACACGGACTTCCTGGACACGTGGGAGGCCATGGAGGACCTGGTGATCAC CGGGCTGGTGAAGAACATCGGGGTGTCAAACTTCAACCATGAACAGCTTGAGAGGCTTTTGAATAAGCCTGGGTTGAGGTTCAAGCCACT AACCAACCAGATTGAGTGCCACCCATATCTTACTCAGAAGAATCTGATCAGTTTTTGCCAATCCAGAGATGTGTCCGTGACTGCTTACCG TCCTCTTGGTGGCTCGTGTGAGGGGGTTGACCTGATAGACAACCCTGTGATCAAGAGGATTGCAAAGGAGCACGGCAAGTCTCCTGCTCA GATTTTGATCCGATTTCAAATCCAGAGGAATGTGATAGTGATCCCCGGATCTATCACCCCAAGTCACATTAAAGAGAATATCCAGGTGTT TGATTTTGAATTAACACAGCACGATATGGATAACATCCTCAGCCTAAACAGGAATCTCCGACTGGCCATGTTCCCCATAACTAAAAATCA CAAAGACTATCCTTTCCACATAGAATACTGAGGACGCTTCCCCTTCCTTGTTTCTGCTCAGCCCAGATGCACAGACACTATTGGCAATGT TGACCCTCCTCTGTCATCACAGCGCCAGGGCAGCTGTGCCTGGGACAGGAGCCACACAGTCAGAGGGGGATGTAAGAGCCACCTTCTCTG ACAAATCTGGAGAATTGAGTGTGTTCTAAGTGAAGGCAATGGGGTTTCTCCAAGACAGCCTGTGTGGCCTCTACTCTGAACAAATACACT GATGAGTCATCAGTGAAATTTGCCTTCACATTTTAAGAAAACTTTATCTTATGGAGTTATTTAAGCCATCTACAGAGCTGAGGAAACAGT GTAATGTGTCTCTGCCCCATTGCGCAGCTCCACCCATTGTGCCCCAGGCCAGCCCGCGTCACCTACACTTCCTTCTGTGCCCTGCCAGTG ACCCCCAGGTTATTCTAAAGCAGAGTCCTTCCCTTCCCCCAGTGAGAAGGAAAATGGGATAAGTCTGGGACACTGTTTCAGTTCAATAAA >3448_3448_6_AKR1C3-AKR1E2_AKR1C3_chr10_5144842_ENST00000605149_AKR1E2_chr10_4877867_ENST00000298375_length(amino acids)=471AA_BP=258 MQISQVPRSKALEVTKLAIEAGFRHIDSAHLYNNEEQVGLAIRSKIADGSVKREDIFYTSKLWSTFHRPELVRPALENSLKKAQLDYVDL YLIHSPMSLKPGEELSPTDENGKVIFDIVDLCTTWEAMEKCKDAGLAKSIGVSNFNRRQLEMILNKPGLKYKPVCNQVECHPYFNRSKLL DFCKSKDIVLVAYSALGSQRDKRWVDPNSPVLLEDPVLCALAKKHKRTPALIALRYQLQRGVVVLAKSYNEQRIRQNVQPPHPEWIMSCS ELSFCLSHPRVQDLPLDESNMVIPSDTDFLDTWEAMEDLVITGLVKNIGVSNFNHEQLERLLNKPGLRFKPLTNQIECHPYLTQKNLISF CQSRDVSVTAYRPLGGSCEGVDLIDNPVIKRIAKEHGKSPAQILIRFQIQRNVIVIPGSITPSHIKENIQVFDFELTQHDMDNILSLNRN -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for AKR1C3-AKR1E2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for AKR1C3-AKR1E2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for AKR1C3-AKR1E2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies