
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:GRIPAP1-AP1M2 (FusionGDB2 ID:34856) |
Fusion Gene Summary for GRIPAP1-AP1M2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: GRIPAP1-AP1M2 | Fusion gene ID: 34856 | Hgene | Tgene | Gene symbol | GRIPAP1 | AP1M2 | Gene ID | 56850 | 10053 |
| Gene name | GRIP1 associated protein 1 | adaptor related protein complex 1 subunit mu 2 | |
| Synonyms | GRASP-1 | AP1-mu2|HSMU1B|MU-1B|MU1B|mu2 | |
| Cytomap | Xp11.23 | 19p13.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | GRIP1-associated protein 1 | AP-1 complex subunit mu-2AP-mu chain family member mu1BHA1 47 kDa subunit 2adaptor protein complex AP-1 mu-2 subunitadaptor related protein complex 1 mu 2 subunitclathrin assembly protein complex 1 mu-2 medium chain 2clathrin coat assembly protein A | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q4V328 | Q9Y6Q5 | |
| Ensembl transtripts involved in fusion gene | ENST00000376425, ENST00000376441, ENST00000376444, ENST00000376423, ENST00000473581, | ENST00000250244, ENST00000590923, | |
| Fusion gene scores | * DoF score | 4 X 3 X 3=36 | 7 X 6 X 5=210 |
| # samples | 4 | 9 | |
| ** MAII score | log2(4/36*10)=0.15200309344505 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | log2(9/210*10)=-1.22239242133645 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: GRIPAP1 [Title/Abstract] AND AP1M2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | GRIPAP1(48834717)-AP1M2(10694746), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across GRIPAP1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across AP1M2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-B7-5818-01A | GRIPAP1 | chrX | 48834717 | - | AP1M2 | chr19 | 10694746 | - |
Top |
Fusion Gene ORF analysis for GRIPAP1-AP1M2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| In-frame | ENST00000376425 | ENST00000250244 | GRIPAP1 | chrX | 48834717 | - | AP1M2 | chr19 | 10694746 | - |
| In-frame | ENST00000376425 | ENST00000590923 | GRIPAP1 | chrX | 48834717 | - | AP1M2 | chr19 | 10694746 | - |
| In-frame | ENST00000376441 | ENST00000250244 | GRIPAP1 | chrX | 48834717 | - | AP1M2 | chr19 | 10694746 | - |
| In-frame | ENST00000376441 | ENST00000590923 | GRIPAP1 | chrX | 48834717 | - | AP1M2 | chr19 | 10694746 | - |
| In-frame | ENST00000376444 | ENST00000250244 | GRIPAP1 | chrX | 48834717 | - | AP1M2 | chr19 | 10694746 | - |
| In-frame | ENST00000376444 | ENST00000590923 | GRIPAP1 | chrX | 48834717 | - | AP1M2 | chr19 | 10694746 | - |
| intron-3CDS | ENST00000376423 | ENST00000250244 | GRIPAP1 | chrX | 48834717 | - | AP1M2 | chr19 | 10694746 | - |
| intron-3CDS | ENST00000376423 | ENST00000590923 | GRIPAP1 | chrX | 48834717 | - | AP1M2 | chr19 | 10694746 | - |
| intron-3CDS | ENST00000473581 | ENST00000250244 | GRIPAP1 | chrX | 48834717 | - | AP1M2 | chr19 | 10694746 | - |
| intron-3CDS | ENST00000473581 | ENST00000590923 | GRIPAP1 | chrX | 48834717 | - | AP1M2 | chr19 | 10694746 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000376425 | GRIPAP1 | chrX | 48834717 | - | ENST00000590923 | AP1M2 | chr19 | 10694746 | - | 3604 | 1973 | 5 | 3208 | 1067 |
| ENST00000376425 | GRIPAP1 | chrX | 48834717 | - | ENST00000250244 | AP1M2 | chr19 | 10694746 | - | 3597 | 1973 | 5 | 3202 | 1065 |
| ENST00000376444 | GRIPAP1 | chrX | 48834717 | - | ENST00000590923 | AP1M2 | chr19 | 10694746 | - | 3577 | 1946 | 20 | 3181 | 1053 |
| ENST00000376444 | GRIPAP1 | chrX | 48834717 | - | ENST00000250244 | AP1M2 | chr19 | 10694746 | - | 3570 | 1946 | 20 | 3175 | 1051 |
| ENST00000376441 | GRIPAP1 | chrX | 48834717 | - | ENST00000590923 | AP1M2 | chr19 | 10694746 | - | 3727 | 2096 | 35 | 3331 | 1098 |
| ENST00000376441 | GRIPAP1 | chrX | 48834717 | - | ENST00000250244 | AP1M2 | chr19 | 10694746 | - | 3720 | 2096 | 35 | 3325 | 1096 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000376425 | ENST00000590923 | GRIPAP1 | chrX | 48834717 | - | AP1M2 | chr19 | 10694746 | - | 0.019240448 | 0.98075956 |
| ENST00000376425 | ENST00000250244 | GRIPAP1 | chrX | 48834717 | - | AP1M2 | chr19 | 10694746 | - | 0.01733827 | 0.9826617 |
| ENST00000376444 | ENST00000590923 | GRIPAP1 | chrX | 48834717 | - | AP1M2 | chr19 | 10694746 | - | 0.017562503 | 0.98243743 |
| ENST00000376444 | ENST00000250244 | GRIPAP1 | chrX | 48834717 | - | AP1M2 | chr19 | 10694746 | - | 0.017946105 | 0.9820539 |
| ENST00000376441 | ENST00000590923 | GRIPAP1 | chrX | 48834717 | - | AP1M2 | chr19 | 10694746 | - | 0.019466866 | 0.9805331 |
| ENST00000376441 | ENST00000250244 | GRIPAP1 | chrX | 48834717 | - | AP1M2 | chr19 | 10694746 | - | 0.019371228 | 0.9806287 |
Top |
Fusion Genomic Features for GRIPAP1-AP1M2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
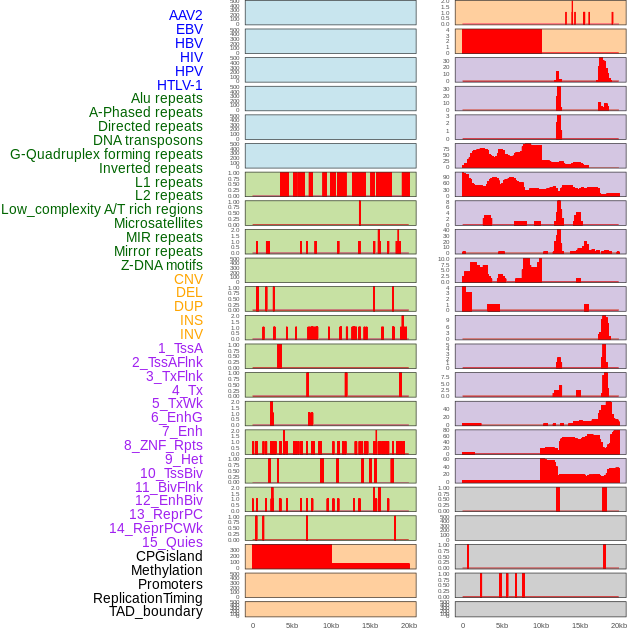 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for GRIPAP1-AP1M2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chrX:48834717/chr19:10694746) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| GRIPAP1 | AP1M2 |
| FUNCTION: Regulates the endosomal recycling back to the neuronal plasma membrane, possibly by connecting early and late recycling endosomal domains and promoting segregation of recycling endosomes from early endosomal membranes. Involved in the localization of recycling endosomes to dendritic spines, thereby playing a role in the maintenance of dendritic spine morphology. Required for the activity-induced AMPA receptor recycling to dendrite membranes and for long-term potentiation and synaptic plasticity (By similarity). {ECO:0000250|UniProtKB:Q9JHZ4}.; FUNCTION: [GRASP-1 C-terminal chain]: Functions as a scaffold protein to facilitate MAP3K1/MEKK1-mediated activation of the JNK1 kinase by phosphorylation, possibly by bringing MAP3K1/MEKK1 and JNK1 in close proximity. {ECO:0000269|PubMed:17761173}. | FUNCTION: Subunit of clathrin-associated adaptor protein complex 1 that plays a role in protein sorting in the trans-Golgi network (TGN) and endosomes. The AP complexes mediate the recruitment of clathrin to membranes and the recognition of sorting signals within the cytosolic tails of transmembrane cargo molecules. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | GRIPAP1 | chrX:48834717 | chr19:10694746 | ENST00000376425 | - | 21 | 25 | 208_641 | 656 | 811.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | GRIPAP1 | chrX:48834717 | chr19:10694746 | ENST00000376425 | - | 21 | 25 | 4_161 | 656 | 811.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | GRIPAP1 | chrX:48834717 | chr19:10694746 | ENST00000376441 | - | 22 | 26 | 208_641 | 687 | 842.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | GRIPAP1 | chrX:48834717 | chr19:10694746 | ENST00000376441 | - | 22 | 26 | 4_161 | 687 | 842.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Tgene | AP1M2 | chrX:48834717 | chr19:10694746 | ENST00000250244 | 0 | 12 | 168_421 | 14 | 424.0 | Domain | MHD | |
| Tgene | AP1M2 | chrX:48834717 | chr19:10694746 | ENST00000590923 | 0 | 12 | 168_421 | 14 | 426.0 | Domain | MHD |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | GRIPAP1 | chrX:48834717 | chr19:10694746 | ENST00000376423 | - | 1 | 20 | 208_641 | 0 | 626.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | GRIPAP1 | chrX:48834717 | chr19:10694746 | ENST00000376423 | - | 1 | 20 | 4_161 | 0 | 626.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | GRIPAP1 | chrX:48834717 | chr19:10694746 | ENST00000376423 | - | 1 | 20 | 701_735 | 0 | 626.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | GRIPAP1 | chrX:48834717 | chr19:10694746 | ENST00000376423 | - | 1 | 20 | 785_814 | 0 | 626.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | GRIPAP1 | chrX:48834717 | chr19:10694746 | ENST00000376425 | - | 21 | 25 | 701_735 | 656 | 811.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | GRIPAP1 | chrX:48834717 | chr19:10694746 | ENST00000376425 | - | 21 | 25 | 785_814 | 656 | 811.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | GRIPAP1 | chrX:48834717 | chr19:10694746 | ENST00000376441 | - | 22 | 26 | 701_735 | 687 | 842.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | GRIPAP1 | chrX:48834717 | chr19:10694746 | ENST00000376441 | - | 22 | 26 | 785_814 | 687 | 842.0 | Coiled coil | Ontology_term=ECO:0000255 |
Top |
Fusion Gene Sequence for GRIPAP1-AP1M2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >34856_34856_1_GRIPAP1-AP1M2_GRIPAP1_chrX_48834717_ENST00000376425_AP1M2_chr19_10694746_ENST00000250244_length(transcript)=3597nt_BP=1973nt GGAACATGGCGCAAGCTCTGTCTGAGGAGGAGTTTCAGCGGATGCAGGCTCAGCTCCTGGAACTCCGGACAAACAACTACCAGCTTTCAG ATGAACTACGCAAGAATGGTGTTGAACTCACCAGTCTTCGACAGAAGGTCGCCTACTTGGATAAGGAGTTCAGCAAAGCTCAGAAGGCAC TGAGCAAGAGCAAGAAAGCTCAGGAAGTCGAGGTATTGCTGAGTGAAAATGAGATGCTGCAGGCAAAGCTGCACAGCCAGGAGGAGGACT TCCGTTTGCAGAACAGCACACTAATGGCCGAGTTCAGCAAGCTCTGCAGCCAGATGGAACAGCTGGAGCAAGAGAACCAGCAACTGAAGG AGGGGGCTGCAGGAGCAGGGGTTGCCCAAGCTGGGCCCCTCGTGGATGGGGAGCTGCTGAGGCTACAGGCTGAAAACACAGCCTTGCAGA AGAACGTGGCAGCCCTGCAGGAACGCTATGGGAAAGAAGCCGGGAAGTTCTCAGCTGTCAGTGAGGGCCAGGGGGATCCCCCAGGGGGCC CGGCCCCCACCGTCCTGGCCCCCATGCCGTTGGCAGAGGTGGAGCTGAAATGGGAAATGGAGAAAGAGGAGAAGAGATTGCTCTGGGAAC AGCTGCAAGGCTTAGAGAGCTCAAAGCAGGCCGAAACATCCAGGCTGCAGGAGGAACTTGCTAAGCTCTCCGAGAAACTGAAAAAGAAAC AAGAAAGTTTTTGCCGTCTGCAGACAGAAAAGGAGACTCTGTTTAATGACAGCAGGAACAAGATTGAGGAATTACAACAACGGAAGGAAG CTGATCACAAAGCCCAGTTGGCTCGAACCCAGAAGCTGCAGCAGGAACTTGAGGCTGCCAATCAGAGCTTGGCAGAGCTGAGAGATCAGC GGCAGGGGGAGCGCCTGGAACATGCAGCAGCTTTGCGGGCCCTACAAGATCAGATCCAAACAGCAAAGACCCAAGAACTGAATATGCTCC GGGAACAGACCACTGGGCTGGCAGCTGAGTTGCAGCAGCAGCAGGCTGAGTACGAGGACCTTATGGGACAGAAAGATGACCTCAACTCCC AGCTCCAGGAGTCATTACGGGCCAATAGTCGACTGCTGGAACAACTTCAAGAAATAGGGCAGGAGAAGGAGCAGTTGACCCAGGAATTAC AGGAGGCTCGGAAGAGTGCGGAGAAGCGGAAGGCCATGCTGGATGAGCTAGCAATGGAAACGCTGCAAGAGAAGTCCCAGCACAAGGAAG AGCTGGGAGCAGTTCGTCTACGGCATGAGAAGGAGGTGCTGGGGGTGCGTGCCCGCTATGAGCGTGAGCTCCGAGAGCTGCATGAAGACA AGAAGCGTCAGGAGGAGGAGCTCCGTGGGCAGATCCGGGAGGAGAAGGCCCGGACACGGGAGCTGGAGACTCTCCAGCAGACAGTGGAAG AACTTCAAGCTCAGGTACATTCCATGGATGGAGCCAAGGGCTGGTTTGAACGGCGCTTGAAGGAAGCCGAGGAATCCCTGCAGCAGCAGC AGCAGGAACAAGAGGAAGCCCTCAAGCAGTGTCGGGAGCAGCACGCTGCCGAGCTGAAGGGCAAGGAGGAGGAGCTACAGGATGTACGGG ATCAGCTCGAGCAGGCCCAGGAGGAGCGGGACTGCCACCTGAAGACCATTAGCAGCCTGAAGCAGGAGGTGAAGGACACAGTGGATGGGC AGAGGATCCTGGAGAAGAAGGGCAGTGCTGCGCTCAAGGACCTCAAGCGGCAGCTGCATTTGGAGCGGAAACGGGCAGATAAGCTGCAGG AGCGACTGCAGGACATCCTCACTAACAGCAAGAGCCGCTCAGGCCTTGAGGAGCTGGTTCTCTCAGAGATGAACTCACCAAGCCGGACCC AGACAGGGGACAGCAGTAGCATCTCCTCCTTCAGCTACCGGGAGATCTTGCGGGAAAAGGAGAGCTCGGCTGTTCCAGCCAGGCCATTGA TCAGCCGCAACTACAAGGGCGATGTGGCCATGAGCAAGATTGAGCACTTCATGCCTTTGCTGGTACAGCGGGAGGAGGAAGGCGCCCTGG CCCCGCTGCTGAGCCACGGCCAGGTCCACTTCCTATGGATCAAACACAGCAACCTCTACTTGGTGGCCACCACATCGAAGAATGCCAATG CCTCCCTGGTGTACTCCTTCCTGTATAAGACAATAGAGGTATTCTGCGAATACTTCAAGGAGCTGGAGGAGGAGAGCATCCGGGACAACT TTGTCATCGTCTACGAGTTGCTGGACGAGCTCATGGACTTTGGCTTCCCGCAGACCACCGACAGCAAGATCCTGCAGGAGTACATCACTC AGCAGAGCAACAAGCTGGAGACGGGCAAGTCACGGGTGCCACCCACTGTCACCAACGCTGTGTCCTGGCGCTCCGAGGGTATCAAGTATA AGAAGAACGAGGTCTTCATTGATGTCATAGAGTCTGTCAACCTGCTGGTCAATGCCAACGGCAGCGTCCTTCTGAGCGAAATCGTCGGTA CCATCAAGCTCAAGGTGTTTCTGTCAGGAATGCCAGAGCTGCGGCTGGGCCTCAATGACCGCGTGCTCTTCGAGCTCACTGGCCGCAGCA AGAACAAATCAGTAGAGCTGGAGGATGTAAAATTCCACCAGTGCGTGCGGCTCTCTCGCTTTGACAACGACCGCACCATCTCCTTCATCC CGCCTGATGGTGACTTTGAGCTCATGTCATACCGCCTCAGCACCCAGGTCAAGCCACTGATCTGGATTGAGTCTGTCATTGAGAAGTTCT CCCACAGCCGCGTGGAGATCATGGTCAAGGCCAAGGGGCAGTTTAAGAAACAGTCAGTGGCCAACGGTGTGGAGATATCTGTGCCTGTAC CCAGCGATGCCGACTCCCCCAGATTCAAGACCAGTGTGGGCAGCGCCAAGTATGTGCCGGAGAGAAACGTCGTGATTTGGAGTATTAAGT CTTTCCCGGGGGGCAAGGAGTACTTGATGCGAGCCCACTTTGGCCTCCCCAGTGTGGAAAAGGAAGAGGTGGAGGGCCGGCCCCCCATCG GGGTCAAGTTTGAGATCCCCTACTTCACCGTCTCTGGGATCCAGGTCCGATACATGAAGATCATTGAGAAAAGTGGTTACCAGGCCCTGC CCTGGGTTCGCTACATCACCCAGAGTGGCGATTACCAACTTCGTACCAGCTAGAAGGGAGAAGAGATGGGGGCTTGAACACGGGGCTTCC TTACAGCCCCGGATGCAGATTTTAGAGGGAGGGCAGGTGCGGGCTGTGTGTGTCTGTGTGAGGGCAGGTCCTGGACTTGGCAGTTTCTTG CTCCCAGCACCCGCCCCTTCCTCACCTCTTCCTTATTCCATAGGCTGGGAGAGAAACTCTCTCTGCTTCCCTCGCCCTTGGAGCTTTCCC CATCCCCCTGATTTTATATGAAGAAATAGAAGAGGGGCTTGAAGTCCTCCTCGCGAGTGCCTTCTTGCAATTACCTGCCTTAGCGGGTGT >34856_34856_1_GRIPAP1-AP1M2_GRIPAP1_chrX_48834717_ENST00000376425_AP1M2_chr19_10694746_ENST00000250244_length(amino acids)=1065AA_BP=656 MAQALSEEEFQRMQAQLLELRTNNYQLSDELRKNGVELTSLRQKVAYLDKEFSKAQKALSKSKKAQEVEVLLSENEMLQAKLHSQEEDFR LQNSTLMAEFSKLCSQMEQLEQENQQLKEGAAGAGVAQAGPLVDGELLRLQAENTALQKNVAALQERYGKEAGKFSAVSEGQGDPPGGPA PTVLAPMPLAEVELKWEMEKEEKRLLWEQLQGLESSKQAETSRLQEELAKLSEKLKKKQESFCRLQTEKETLFNDSRNKIEELQQRKEAD HKAQLARTQKLQQELEAANQSLAELRDQRQGERLEHAAALRALQDQIQTAKTQELNMLREQTTGLAAELQQQQAEYEDLMGQKDDLNSQL QESLRANSRLLEQLQEIGQEKEQLTQELQEARKSAEKRKAMLDELAMETLQEKSQHKEELGAVRLRHEKEVLGVRARYERELRELHEDKK RQEEELRGQIREEKARTRELETLQQTVEELQAQVHSMDGAKGWFERRLKEAEESLQQQQQEQEEALKQCREQHAAELKGKEEELQDVRDQ LEQAQEERDCHLKTISSLKQEVKDTVDGQRILEKKGSAALKDLKRQLHLERKRADKLQERLQDILTNSKSRSGLEELVLSEMNSPSRTQT GDSSSISSFSYREILREKESSAVPARPLISRNYKGDVAMSKIEHFMPLLVQREEEGALAPLLSHGQVHFLWIKHSNLYLVATTSKNANAS LVYSFLYKTIEVFCEYFKELEEESIRDNFVIVYELLDELMDFGFPQTTDSKILQEYITQQSNKLETGKSRVPPTVTNAVSWRSEGIKYKK NEVFIDVIESVNLLVNANGSVLLSEIVGTIKLKVFLSGMPELRLGLNDRVLFELTGRSKNKSVELEDVKFHQCVRLSRFDNDRTISFIPP DGDFELMSYRLSTQVKPLIWIESVIEKFSHSRVEIMVKAKGQFKKQSVANGVEISVPVPSDADSPRFKTSVGSAKYVPERNVVIWSIKSF -------------------------------------------------------------- >34856_34856_2_GRIPAP1-AP1M2_GRIPAP1_chrX_48834717_ENST00000376425_AP1M2_chr19_10694746_ENST00000590923_length(transcript)=3604nt_BP=1973nt GGAACATGGCGCAAGCTCTGTCTGAGGAGGAGTTTCAGCGGATGCAGGCTCAGCTCCTGGAACTCCGGACAAACAACTACCAGCTTTCAG ATGAACTACGCAAGAATGGTGTTGAACTCACCAGTCTTCGACAGAAGGTCGCCTACTTGGATAAGGAGTTCAGCAAAGCTCAGAAGGCAC TGAGCAAGAGCAAGAAAGCTCAGGAAGTCGAGGTATTGCTGAGTGAAAATGAGATGCTGCAGGCAAAGCTGCACAGCCAGGAGGAGGACT TCCGTTTGCAGAACAGCACACTAATGGCCGAGTTCAGCAAGCTCTGCAGCCAGATGGAACAGCTGGAGCAAGAGAACCAGCAACTGAAGG AGGGGGCTGCAGGAGCAGGGGTTGCCCAAGCTGGGCCCCTCGTGGATGGGGAGCTGCTGAGGCTACAGGCTGAAAACACAGCCTTGCAGA AGAACGTGGCAGCCCTGCAGGAACGCTATGGGAAAGAAGCCGGGAAGTTCTCAGCTGTCAGTGAGGGCCAGGGGGATCCCCCAGGGGGCC CGGCCCCCACCGTCCTGGCCCCCATGCCGTTGGCAGAGGTGGAGCTGAAATGGGAAATGGAGAAAGAGGAGAAGAGATTGCTCTGGGAAC AGCTGCAAGGCTTAGAGAGCTCAAAGCAGGCCGAAACATCCAGGCTGCAGGAGGAACTTGCTAAGCTCTCCGAGAAACTGAAAAAGAAAC AAGAAAGTTTTTGCCGTCTGCAGACAGAAAAGGAGACTCTGTTTAATGACAGCAGGAACAAGATTGAGGAATTACAACAACGGAAGGAAG CTGATCACAAAGCCCAGTTGGCTCGAACCCAGAAGCTGCAGCAGGAACTTGAGGCTGCCAATCAGAGCTTGGCAGAGCTGAGAGATCAGC GGCAGGGGGAGCGCCTGGAACATGCAGCAGCTTTGCGGGCCCTACAAGATCAGATCCAAACAGCAAAGACCCAAGAACTGAATATGCTCC GGGAACAGACCACTGGGCTGGCAGCTGAGTTGCAGCAGCAGCAGGCTGAGTACGAGGACCTTATGGGACAGAAAGATGACCTCAACTCCC AGCTCCAGGAGTCATTACGGGCCAATAGTCGACTGCTGGAACAACTTCAAGAAATAGGGCAGGAGAAGGAGCAGTTGACCCAGGAATTAC AGGAGGCTCGGAAGAGTGCGGAGAAGCGGAAGGCCATGCTGGATGAGCTAGCAATGGAAACGCTGCAAGAGAAGTCCCAGCACAAGGAAG AGCTGGGAGCAGTTCGTCTACGGCATGAGAAGGAGGTGCTGGGGGTGCGTGCCCGCTATGAGCGTGAGCTCCGAGAGCTGCATGAAGACA AGAAGCGTCAGGAGGAGGAGCTCCGTGGGCAGATCCGGGAGGAGAAGGCCCGGACACGGGAGCTGGAGACTCTCCAGCAGACAGTGGAAG AACTTCAAGCTCAGGTACATTCCATGGATGGAGCCAAGGGCTGGTTTGAACGGCGCTTGAAGGAAGCCGAGGAATCCCTGCAGCAGCAGC AGCAGGAACAAGAGGAAGCCCTCAAGCAGTGTCGGGAGCAGCACGCTGCCGAGCTGAAGGGCAAGGAGGAGGAGCTACAGGATGTACGGG ATCAGCTCGAGCAGGCCCAGGAGGAGCGGGACTGCCACCTGAAGACCATTAGCAGCCTGAAGCAGGAGGTGAAGGACACAGTGGATGGGC AGAGGATCCTGGAGAAGAAGGGCAGTGCTGCGCTCAAGGACCTCAAGCGGCAGCTGCATTTGGAGCGGAAACGGGCAGATAAGCTGCAGG AGCGACTGCAGGACATCCTCACTAACAGCAAGAGCCGCTCAGGCCTTGAGGAGCTGGTTCTCTCAGAGATGAACTCACCAAGCCGGACCC AGACAGGGGACAGCAGTAGCATCTCCTCCTTCAGCTACCGGGAGATCTTGCGGGAAAAGGAGAGCTCGGCTGTTCCAGCCAGGCCATTGA TCAGCCGCAACTACAAGGGCGATGTGGCCATGAGCAAGATTGAGCACTTCATGCCTTTGCTGGTACAGCGGGAGGAGGAAGGCGCCCTGG CCCCGCTGCTGAGCCACGGCCAGGTCCACTTCCTATGGATCAAACACAGCAACCTCTACTTGGTGGCCACCACATCGAAGAATGCCAATG CCTCCCTGGTGTACTCCTTCCTGTATAAGACAATAGAGGTATTCTGCGAATACTTCAAGGAGCTGGAGGAGGAGAGCATCCGGGACAACT TTGTCATCGTCTACGAGTTGCTGGACGAGCTCATGGACTTTGGCTTCCCGCAGACCACCGACAGCAAGATCCTGCAGGAGTACATCACTC AGCAGAGCAACAAGCTGGAGACGGGCAAGTCACGGGTGCCACCCACTGTCACCAACGCTGTGTCCTGGCGCTCCGAGGGTATCAAGTATA AGAAGAACGAGGTCTTCATTGATGTCATAGAGTCTGTCAACCTGCTGGTCAATGCCAACGGCAGCGTCCTTCTGAGCGAAATCGTCGGTA CCATCAAGCTCAAGGTGTTTCTGTCAGGAATGCCAGAGCTGCGGCTGGGCCTCAATGACCGCGTGCTCTTCGAGCTCACTGGCCTTTCAG GCAGCAAGAACAAATCAGTAGAGCTGGAGGATGTAAAATTCCACCAGTGCGTGCGGCTCTCTCGCTTTGACAACGACCGCACCATCTCCT TCATCCCGCCTGATGGTGACTTTGAGCTCATGTCATACCGCCTCAGCACCCAGGTCAAGCCACTGATCTGGATTGAGTCTGTCATTGAGA AGTTCTCCCACAGCCGCGTGGAGATCATGGTCAAGGCCAAGGGGCAGTTTAAGAAACAGTCAGTGGCCAACGGTGTGGAGATATCTGTGC CTGTACCCAGCGATGCCGACTCCCCCAGATTCAAGACCAGTGTGGGCAGCGCCAAGTATGTGCCGGAGAGAAACGTCGTGATTTGGAGTA TTAAGTCTTTCCCGGGGGGCAAGGAGTACTTGATGCGAGCCCACTTTGGCCTCCCCAGTGTGGAAAAGGAAGAGGTGGAGGGCCGGCCCC CCATCGGGGTCAAGTTTGAGATCCCCTACTTCACCGTCTCTGGGATCCAGGTCCGATACATGAAGATCATTGAGAAAAGTGGTTACCAGG CCCTGCCCTGGGTTCGCTACATCACCCAGAGTGGCGATTACCAACTTCGTACCAGCTAGAAGGGAGAAGAGATGGGGGCTTGAACACGGG GCTTCCTTACAGCCCCGGATGCAGATTTTAGAGGGAGGGCAGGTGCGGGCTGTGTGTGTCTGTGTGAGGGCAGGTCCTGGACTTGGCAGT TTCTTGCTCCCAGCACCCGCCCCTTCCTCACCTCTTCCTTATTCCATAGGCTGGGAGAGAAACTCTCTCTGCTTCCCTCGCCCTTGGAGC TTTCCCCATCCCCCTGATTTTATATGAAGAAATAGAAGAGGGGCTTGAAGTCCTCCTCGCGAGTGCCTTCTTGCAATTACCTGCCTTAGC GGGTGTTGCGGGTCCCTCCTTCACAGCCGCTGAGCCCAGAGGTCCCGCTGGCCCCTCCTCTGAATTTTAGGATGTCATTAAAAAGATGAA >34856_34856_2_GRIPAP1-AP1M2_GRIPAP1_chrX_48834717_ENST00000376425_AP1M2_chr19_10694746_ENST00000590923_length(amino acids)=1067AA_BP=656 MAQALSEEEFQRMQAQLLELRTNNYQLSDELRKNGVELTSLRQKVAYLDKEFSKAQKALSKSKKAQEVEVLLSENEMLQAKLHSQEEDFR LQNSTLMAEFSKLCSQMEQLEQENQQLKEGAAGAGVAQAGPLVDGELLRLQAENTALQKNVAALQERYGKEAGKFSAVSEGQGDPPGGPA PTVLAPMPLAEVELKWEMEKEEKRLLWEQLQGLESSKQAETSRLQEELAKLSEKLKKKQESFCRLQTEKETLFNDSRNKIEELQQRKEAD HKAQLARTQKLQQELEAANQSLAELRDQRQGERLEHAAALRALQDQIQTAKTQELNMLREQTTGLAAELQQQQAEYEDLMGQKDDLNSQL QESLRANSRLLEQLQEIGQEKEQLTQELQEARKSAEKRKAMLDELAMETLQEKSQHKEELGAVRLRHEKEVLGVRARYERELRELHEDKK RQEEELRGQIREEKARTRELETLQQTVEELQAQVHSMDGAKGWFERRLKEAEESLQQQQQEQEEALKQCREQHAAELKGKEEELQDVRDQ LEQAQEERDCHLKTISSLKQEVKDTVDGQRILEKKGSAALKDLKRQLHLERKRADKLQERLQDILTNSKSRSGLEELVLSEMNSPSRTQT GDSSSISSFSYREILREKESSAVPARPLISRNYKGDVAMSKIEHFMPLLVQREEEGALAPLLSHGQVHFLWIKHSNLYLVATTSKNANAS LVYSFLYKTIEVFCEYFKELEEESIRDNFVIVYELLDELMDFGFPQTTDSKILQEYITQQSNKLETGKSRVPPTVTNAVSWRSEGIKYKK NEVFIDVIESVNLLVNANGSVLLSEIVGTIKLKVFLSGMPELRLGLNDRVLFELTGLSGSKNKSVELEDVKFHQCVRLSRFDNDRTISFI PPDGDFELMSYRLSTQVKPLIWIESVIEKFSHSRVEIMVKAKGQFKKQSVANGVEISVPVPSDADSPRFKTSVGSAKYVPERNVVIWSIK -------------------------------------------------------------- >34856_34856_3_GRIPAP1-AP1M2_GRIPAP1_chrX_48834717_ENST00000376441_AP1M2_chr19_10694746_ENST00000250244_length(transcript)=3720nt_BP=2096nt GCGCAGAAAGCTGGCGGGGGGGTGGGGGGAGGAACATGGCGCAAGCTCTGTCTGAGGAGGAGTTTCAGCGGATGCAGGCTCAGCTCCTGG AACTCCGGACAAACAACTACCAGCTTTCAGATGAACTACGCAAGAATGGTGTTGAACTCACCAGTCTTCGACAGAAGGTCGCCTACTTGG ATAAGGAGTTCAGCAAAGCTCAGAAGGCACTGAGCAAGAGCAAGAAAGCTCAGGAAGTCGAGGTATTGCTGAGTGAAAATGAGATGCTGC AGGCAAAGCTGCACAGCCAGGAGGAGGACTTCCGTTTGCAGAACAGCACACTAATGGCCGAGTTCAGCAAGCTCTGCAGCCAGATGGAAC AGCTGGAGCAAGAGAACCAGCAACTGAAGGAGGGGGCTGCAGGAGCAGGGGTTGCCCAAGCTGGGCCCCTCGTGGATGGGGAGCTGCTGA GGCTACAGGCTGAAAACACAGCCTTGCAGAAGAACGTGGCAGCCCTGCAGGAACGCTATGGGAAAGAAGCCGGGAAGTTCTCAGCTGTCA GTGAGGGCCAGGGGGATCCCCCAGGGGGCCCGGCCCCCACCGTCCTGGCCCCCATGCCGTTGGCAGAGGTGGAGCTGAAATGGGAAATGG AGAAAGAGGAGAAGAGATTGCTCTGGGAACAGCTGCAAGGCTTAGAGAGCTCAAAGCAGGCCGAAACATCCAGGCTGCAGGAGGAACTTG CTAAGCTCTCCGAGAAACTGAAAAAGAAACAAGAAAGTTTTTGCCGTCTGCAGACAGAAAAGGAGACTCTGTTTAATGACAGCAGGAACA AGATTGAGGAATTACAACAACGGAAGGAAGCTGATCACAAAGCCCAGTTGGCTCGAACCCAGAAGCTGCAGCAGGAACTTGAGGCTGCCA ATCAGAGCTTGGCAGAGCTGAGAGATCAGCGGCAGGGGGAGCGCCTGGAACATGCAGCAGCTTTGCGGGCCCTACAAGATCAGGTATCCA TCCAGAGTGCAGATGCACAGGAACAAGTGGAAGGGCTTTTGGCTGAGAACAATGCCTTGAGGACTAGCCTGGCTGCCCTGGAGCAGATCC AAACAGCAAAGACCCAAGAACTGAATATGCTCCGGGAACAGACCACTGGGCTGGCAGCTGAGTTGCAGCAGCAGCAGGCTGAGTACGAGG ACCTTATGGGACAGAAAGATGACCTCAACTCCCAGCTCCAGGAGTCATTACGGGCCAATAGTCGACTGCTGGAACAACTTCAAGAAATAG GGCAGGAGAAGGAGCAGTTGACCCAGGAATTACAGGAGGCTCGGAAGAGTGCGGAGAAGCGGAAGGCCATGCTGGATGAGCTAGCAATGG AAACGCTGCAAGAGAAGTCCCAGCACAAGGAAGAGCTGGGAGCAGTTCGTCTACGGCATGAGAAGGAGGTGCTGGGGGTGCGTGCCCGCT ATGAGCGTGAGCTCCGAGAGCTGCATGAAGACAAGAAGCGTCAGGAGGAGGAGCTCCGTGGGCAGATCCGGGAGGAGAAGGCCCGGACAC GGGAGCTGGAGACTCTCCAGCAGACAGTGGAAGAACTTCAAGCTCAGGTACATTCCATGGATGGAGCCAAGGGCTGGTTTGAACGGCGCT TGAAGGAAGCCGAGGAATCCCTGCAGCAGCAGCAGCAGGAACAAGAGGAAGCCCTCAAGCAGTGTCGGGAGCAGCACGCTGCCGAGCTGA AGGGCAAGGAGGAGGAGCTACAGGATGTACGGGATCAGCTCGAGCAGGCCCAGGAGGAGCGGGACTGCCACCTGAAGACCATTAGCAGCC TGAAGCAGGAGGTGAAGGACACAGTGGATGGGCAGAGGATCCTGGAGAAGAAGGGCAGTGCTGCGCTCAAGGACCTCAAGCGGCAGCTGC ATTTGGAGCGGAAACGGGCAGATAAGCTGCAGGAGCGACTGCAGGACATCCTCACTAACAGCAAGAGCCGCTCAGGCCTTGAGGAGCTGG TTCTCTCAGAGATGAACTCACCAAGCCGGACCCAGACAGGGGACAGCAGTAGCATCTCCTCCTTCAGCTACCGGGAGATCTTGCGGGAAA AGGAGAGCTCGGCTGTTCCAGCCAGGCCATTGATCAGCCGCAACTACAAGGGCGATGTGGCCATGAGCAAGATTGAGCACTTCATGCCTT TGCTGGTACAGCGGGAGGAGGAAGGCGCCCTGGCCCCGCTGCTGAGCCACGGCCAGGTCCACTTCCTATGGATCAAACACAGCAACCTCT ACTTGGTGGCCACCACATCGAAGAATGCCAATGCCTCCCTGGTGTACTCCTTCCTGTATAAGACAATAGAGGTATTCTGCGAATACTTCA AGGAGCTGGAGGAGGAGAGCATCCGGGACAACTTTGTCATCGTCTACGAGTTGCTGGACGAGCTCATGGACTTTGGCTTCCCGCAGACCA CCGACAGCAAGATCCTGCAGGAGTACATCACTCAGCAGAGCAACAAGCTGGAGACGGGCAAGTCACGGGTGCCACCCACTGTCACCAACG CTGTGTCCTGGCGCTCCGAGGGTATCAAGTATAAGAAGAACGAGGTCTTCATTGATGTCATAGAGTCTGTCAACCTGCTGGTCAATGCCA ACGGCAGCGTCCTTCTGAGCGAAATCGTCGGTACCATCAAGCTCAAGGTGTTTCTGTCAGGAATGCCAGAGCTGCGGCTGGGCCTCAATG ACCGCGTGCTCTTCGAGCTCACTGGCCGCAGCAAGAACAAATCAGTAGAGCTGGAGGATGTAAAATTCCACCAGTGCGTGCGGCTCTCTC GCTTTGACAACGACCGCACCATCTCCTTCATCCCGCCTGATGGTGACTTTGAGCTCATGTCATACCGCCTCAGCACCCAGGTCAAGCCAC TGATCTGGATTGAGTCTGTCATTGAGAAGTTCTCCCACAGCCGCGTGGAGATCATGGTCAAGGCCAAGGGGCAGTTTAAGAAACAGTCAG TGGCCAACGGTGTGGAGATATCTGTGCCTGTACCCAGCGATGCCGACTCCCCCAGATTCAAGACCAGTGTGGGCAGCGCCAAGTATGTGC CGGAGAGAAACGTCGTGATTTGGAGTATTAAGTCTTTCCCGGGGGGCAAGGAGTACTTGATGCGAGCCCACTTTGGCCTCCCCAGTGTGG AAAAGGAAGAGGTGGAGGGCCGGCCCCCCATCGGGGTCAAGTTTGAGATCCCCTACTTCACCGTCTCTGGGATCCAGGTCCGATACATGA AGATCATTGAGAAAAGTGGTTACCAGGCCCTGCCCTGGGTTCGCTACATCACCCAGAGTGGCGATTACCAACTTCGTACCAGCTAGAAGG GAGAAGAGATGGGGGCTTGAACACGGGGCTTCCTTACAGCCCCGGATGCAGATTTTAGAGGGAGGGCAGGTGCGGGCTGTGTGTGTCTGT GTGAGGGCAGGTCCTGGACTTGGCAGTTTCTTGCTCCCAGCACCCGCCCCTTCCTCACCTCTTCCTTATTCCATAGGCTGGGAGAGAAAC TCTCTCTGCTTCCCTCGCCCTTGGAGCTTTCCCCATCCCCCTGATTTTATATGAAGAAATAGAAGAGGGGCTTGAAGTCCTCCTCGCGAG TGCCTTCTTGCAATTACCTGCCTTAGCGGGTGTTGCGGGTCCCTCCTTCACAGCCGCTGAGCCCAGAGGTCCCGCTGGCCCCTCCTCTGA >34856_34856_3_GRIPAP1-AP1M2_GRIPAP1_chrX_48834717_ENST00000376441_AP1M2_chr19_10694746_ENST00000250244_length(amino acids)=1096AA_BP=687 MAQALSEEEFQRMQAQLLELRTNNYQLSDELRKNGVELTSLRQKVAYLDKEFSKAQKALSKSKKAQEVEVLLSENEMLQAKLHSQEEDFR LQNSTLMAEFSKLCSQMEQLEQENQQLKEGAAGAGVAQAGPLVDGELLRLQAENTALQKNVAALQERYGKEAGKFSAVSEGQGDPPGGPA PTVLAPMPLAEVELKWEMEKEEKRLLWEQLQGLESSKQAETSRLQEELAKLSEKLKKKQESFCRLQTEKETLFNDSRNKIEELQQRKEAD HKAQLARTQKLQQELEAANQSLAELRDQRQGERLEHAAALRALQDQVSIQSADAQEQVEGLLAENNALRTSLAALEQIQTAKTQELNMLR EQTTGLAAELQQQQAEYEDLMGQKDDLNSQLQESLRANSRLLEQLQEIGQEKEQLTQELQEARKSAEKRKAMLDELAMETLQEKSQHKEE LGAVRLRHEKEVLGVRARYERELRELHEDKKRQEEELRGQIREEKARTRELETLQQTVEELQAQVHSMDGAKGWFERRLKEAEESLQQQQ QEQEEALKQCREQHAAELKGKEEELQDVRDQLEQAQEERDCHLKTISSLKQEVKDTVDGQRILEKKGSAALKDLKRQLHLERKRADKLQE RLQDILTNSKSRSGLEELVLSEMNSPSRTQTGDSSSISSFSYREILREKESSAVPARPLISRNYKGDVAMSKIEHFMPLLVQREEEGALA PLLSHGQVHFLWIKHSNLYLVATTSKNANASLVYSFLYKTIEVFCEYFKELEEESIRDNFVIVYELLDELMDFGFPQTTDSKILQEYITQ QSNKLETGKSRVPPTVTNAVSWRSEGIKYKKNEVFIDVIESVNLLVNANGSVLLSEIVGTIKLKVFLSGMPELRLGLNDRVLFELTGRSK NKSVELEDVKFHQCVRLSRFDNDRTISFIPPDGDFELMSYRLSTQVKPLIWIESVIEKFSHSRVEIMVKAKGQFKKQSVANGVEISVPVP SDADSPRFKTSVGSAKYVPERNVVIWSIKSFPGGKEYLMRAHFGLPSVEKEEVEGRPPIGVKFEIPYFTVSGIQVRYMKIIEKSGYQALP -------------------------------------------------------------- >34856_34856_4_GRIPAP1-AP1M2_GRIPAP1_chrX_48834717_ENST00000376441_AP1M2_chr19_10694746_ENST00000590923_length(transcript)=3727nt_BP=2096nt GCGCAGAAAGCTGGCGGGGGGGTGGGGGGAGGAACATGGCGCAAGCTCTGTCTGAGGAGGAGTTTCAGCGGATGCAGGCTCAGCTCCTGG AACTCCGGACAAACAACTACCAGCTTTCAGATGAACTACGCAAGAATGGTGTTGAACTCACCAGTCTTCGACAGAAGGTCGCCTACTTGG ATAAGGAGTTCAGCAAAGCTCAGAAGGCACTGAGCAAGAGCAAGAAAGCTCAGGAAGTCGAGGTATTGCTGAGTGAAAATGAGATGCTGC AGGCAAAGCTGCACAGCCAGGAGGAGGACTTCCGTTTGCAGAACAGCACACTAATGGCCGAGTTCAGCAAGCTCTGCAGCCAGATGGAAC AGCTGGAGCAAGAGAACCAGCAACTGAAGGAGGGGGCTGCAGGAGCAGGGGTTGCCCAAGCTGGGCCCCTCGTGGATGGGGAGCTGCTGA GGCTACAGGCTGAAAACACAGCCTTGCAGAAGAACGTGGCAGCCCTGCAGGAACGCTATGGGAAAGAAGCCGGGAAGTTCTCAGCTGTCA GTGAGGGCCAGGGGGATCCCCCAGGGGGCCCGGCCCCCACCGTCCTGGCCCCCATGCCGTTGGCAGAGGTGGAGCTGAAATGGGAAATGG AGAAAGAGGAGAAGAGATTGCTCTGGGAACAGCTGCAAGGCTTAGAGAGCTCAAAGCAGGCCGAAACATCCAGGCTGCAGGAGGAACTTG CTAAGCTCTCCGAGAAACTGAAAAAGAAACAAGAAAGTTTTTGCCGTCTGCAGACAGAAAAGGAGACTCTGTTTAATGACAGCAGGAACA AGATTGAGGAATTACAACAACGGAAGGAAGCTGATCACAAAGCCCAGTTGGCTCGAACCCAGAAGCTGCAGCAGGAACTTGAGGCTGCCA ATCAGAGCTTGGCAGAGCTGAGAGATCAGCGGCAGGGGGAGCGCCTGGAACATGCAGCAGCTTTGCGGGCCCTACAAGATCAGGTATCCA TCCAGAGTGCAGATGCACAGGAACAAGTGGAAGGGCTTTTGGCTGAGAACAATGCCTTGAGGACTAGCCTGGCTGCCCTGGAGCAGATCC AAACAGCAAAGACCCAAGAACTGAATATGCTCCGGGAACAGACCACTGGGCTGGCAGCTGAGTTGCAGCAGCAGCAGGCTGAGTACGAGG ACCTTATGGGACAGAAAGATGACCTCAACTCCCAGCTCCAGGAGTCATTACGGGCCAATAGTCGACTGCTGGAACAACTTCAAGAAATAG GGCAGGAGAAGGAGCAGTTGACCCAGGAATTACAGGAGGCTCGGAAGAGTGCGGAGAAGCGGAAGGCCATGCTGGATGAGCTAGCAATGG AAACGCTGCAAGAGAAGTCCCAGCACAAGGAAGAGCTGGGAGCAGTTCGTCTACGGCATGAGAAGGAGGTGCTGGGGGTGCGTGCCCGCT ATGAGCGTGAGCTCCGAGAGCTGCATGAAGACAAGAAGCGTCAGGAGGAGGAGCTCCGTGGGCAGATCCGGGAGGAGAAGGCCCGGACAC GGGAGCTGGAGACTCTCCAGCAGACAGTGGAAGAACTTCAAGCTCAGGTACATTCCATGGATGGAGCCAAGGGCTGGTTTGAACGGCGCT TGAAGGAAGCCGAGGAATCCCTGCAGCAGCAGCAGCAGGAACAAGAGGAAGCCCTCAAGCAGTGTCGGGAGCAGCACGCTGCCGAGCTGA AGGGCAAGGAGGAGGAGCTACAGGATGTACGGGATCAGCTCGAGCAGGCCCAGGAGGAGCGGGACTGCCACCTGAAGACCATTAGCAGCC TGAAGCAGGAGGTGAAGGACACAGTGGATGGGCAGAGGATCCTGGAGAAGAAGGGCAGTGCTGCGCTCAAGGACCTCAAGCGGCAGCTGC ATTTGGAGCGGAAACGGGCAGATAAGCTGCAGGAGCGACTGCAGGACATCCTCACTAACAGCAAGAGCCGCTCAGGCCTTGAGGAGCTGG TTCTCTCAGAGATGAACTCACCAAGCCGGACCCAGACAGGGGACAGCAGTAGCATCTCCTCCTTCAGCTACCGGGAGATCTTGCGGGAAA AGGAGAGCTCGGCTGTTCCAGCCAGGCCATTGATCAGCCGCAACTACAAGGGCGATGTGGCCATGAGCAAGATTGAGCACTTCATGCCTT TGCTGGTACAGCGGGAGGAGGAAGGCGCCCTGGCCCCGCTGCTGAGCCACGGCCAGGTCCACTTCCTATGGATCAAACACAGCAACCTCT ACTTGGTGGCCACCACATCGAAGAATGCCAATGCCTCCCTGGTGTACTCCTTCCTGTATAAGACAATAGAGGTATTCTGCGAATACTTCA AGGAGCTGGAGGAGGAGAGCATCCGGGACAACTTTGTCATCGTCTACGAGTTGCTGGACGAGCTCATGGACTTTGGCTTCCCGCAGACCA CCGACAGCAAGATCCTGCAGGAGTACATCACTCAGCAGAGCAACAAGCTGGAGACGGGCAAGTCACGGGTGCCACCCACTGTCACCAACG CTGTGTCCTGGCGCTCCGAGGGTATCAAGTATAAGAAGAACGAGGTCTTCATTGATGTCATAGAGTCTGTCAACCTGCTGGTCAATGCCA ACGGCAGCGTCCTTCTGAGCGAAATCGTCGGTACCATCAAGCTCAAGGTGTTTCTGTCAGGAATGCCAGAGCTGCGGCTGGGCCTCAATG ACCGCGTGCTCTTCGAGCTCACTGGCCTTTCAGGCAGCAAGAACAAATCAGTAGAGCTGGAGGATGTAAAATTCCACCAGTGCGTGCGGC TCTCTCGCTTTGACAACGACCGCACCATCTCCTTCATCCCGCCTGATGGTGACTTTGAGCTCATGTCATACCGCCTCAGCACCCAGGTCA AGCCACTGATCTGGATTGAGTCTGTCATTGAGAAGTTCTCCCACAGCCGCGTGGAGATCATGGTCAAGGCCAAGGGGCAGTTTAAGAAAC AGTCAGTGGCCAACGGTGTGGAGATATCTGTGCCTGTACCCAGCGATGCCGACTCCCCCAGATTCAAGACCAGTGTGGGCAGCGCCAAGT ATGTGCCGGAGAGAAACGTCGTGATTTGGAGTATTAAGTCTTTCCCGGGGGGCAAGGAGTACTTGATGCGAGCCCACTTTGGCCTCCCCA GTGTGGAAAAGGAAGAGGTGGAGGGCCGGCCCCCCATCGGGGTCAAGTTTGAGATCCCCTACTTCACCGTCTCTGGGATCCAGGTCCGAT ACATGAAGATCATTGAGAAAAGTGGTTACCAGGCCCTGCCCTGGGTTCGCTACATCACCCAGAGTGGCGATTACCAACTTCGTACCAGCT AGAAGGGAGAAGAGATGGGGGCTTGAACACGGGGCTTCCTTACAGCCCCGGATGCAGATTTTAGAGGGAGGGCAGGTGCGGGCTGTGTGT GTCTGTGTGAGGGCAGGTCCTGGACTTGGCAGTTTCTTGCTCCCAGCACCCGCCCCTTCCTCACCTCTTCCTTATTCCATAGGCTGGGAG AGAAACTCTCTCTGCTTCCCTCGCCCTTGGAGCTTTCCCCATCCCCCTGATTTTATATGAAGAAATAGAAGAGGGGCTTGAAGTCCTCCT CGCGAGTGCCTTCTTGCAATTACCTGCCTTAGCGGGTGTTGCGGGTCCCTCCTTCACAGCCGCTGAGCCCAGAGGTCCCGCTGGCCCCTC >34856_34856_4_GRIPAP1-AP1M2_GRIPAP1_chrX_48834717_ENST00000376441_AP1M2_chr19_10694746_ENST00000590923_length(amino acids)=1098AA_BP=687 MAQALSEEEFQRMQAQLLELRTNNYQLSDELRKNGVELTSLRQKVAYLDKEFSKAQKALSKSKKAQEVEVLLSENEMLQAKLHSQEEDFR LQNSTLMAEFSKLCSQMEQLEQENQQLKEGAAGAGVAQAGPLVDGELLRLQAENTALQKNVAALQERYGKEAGKFSAVSEGQGDPPGGPA PTVLAPMPLAEVELKWEMEKEEKRLLWEQLQGLESSKQAETSRLQEELAKLSEKLKKKQESFCRLQTEKETLFNDSRNKIEELQQRKEAD HKAQLARTQKLQQELEAANQSLAELRDQRQGERLEHAAALRALQDQVSIQSADAQEQVEGLLAENNALRTSLAALEQIQTAKTQELNMLR EQTTGLAAELQQQQAEYEDLMGQKDDLNSQLQESLRANSRLLEQLQEIGQEKEQLTQELQEARKSAEKRKAMLDELAMETLQEKSQHKEE LGAVRLRHEKEVLGVRARYERELRELHEDKKRQEEELRGQIREEKARTRELETLQQTVEELQAQVHSMDGAKGWFERRLKEAEESLQQQQ QEQEEALKQCREQHAAELKGKEEELQDVRDQLEQAQEERDCHLKTISSLKQEVKDTVDGQRILEKKGSAALKDLKRQLHLERKRADKLQE RLQDILTNSKSRSGLEELVLSEMNSPSRTQTGDSSSISSFSYREILREKESSAVPARPLISRNYKGDVAMSKIEHFMPLLVQREEEGALA PLLSHGQVHFLWIKHSNLYLVATTSKNANASLVYSFLYKTIEVFCEYFKELEEESIRDNFVIVYELLDELMDFGFPQTTDSKILQEYITQ QSNKLETGKSRVPPTVTNAVSWRSEGIKYKKNEVFIDVIESVNLLVNANGSVLLSEIVGTIKLKVFLSGMPELRLGLNDRVLFELTGLSG SKNKSVELEDVKFHQCVRLSRFDNDRTISFIPPDGDFELMSYRLSTQVKPLIWIESVIEKFSHSRVEIMVKAKGQFKKQSVANGVEISVP VPSDADSPRFKTSVGSAKYVPERNVVIWSIKSFPGGKEYLMRAHFGLPSVEKEEVEGRPPIGVKFEIPYFTVSGIQVRYMKIIEKSGYQA -------------------------------------------------------------- >34856_34856_5_GRIPAP1-AP1M2_GRIPAP1_chrX_48834717_ENST00000376444_AP1M2_chr19_10694746_ENST00000250244_length(transcript)=3570nt_BP=1946nt GGGGGGGTGGGGGGAGGAACATGGCGCAAGCTCTGTCTGAGGAGGAGTTTCAGCGGATGCAGGCTCAGCTCCTGGAACTCCGGACAAACA ACTACCAGCTTTCAGATGAACTACGCAAGAATGGTGTTGAACTCACCAGTCTTCGACAGAAGGTCGCCTACTTGGATAAGGAGTTCAGCA AAGCTCAGAAGCTCTGCAGCCAGATGGAACAGCTGGAGCAAGAGAACCAGCAACTGAAGGAGGGGGCTGCAGGAGCAGGGGTTGCCCAAG CTGGGCCCCTCGTGGATGGGGAGCTGCTGAGGCTACAGGCTGAAAACACAGCCTTGCAGAAGAACGTGGCAGCCCTGCAGGAACGCTATG GGAAAGAAGCCGGGAAGTTCTCAGCTGTCAGTGAGGGCCAGGGGGATCCCCCAGGGGGCCCGGCCCCCACCGTCCTGGCCCCCATGCCGT TGGCAGAGGTGGAGCTGAAATGGGAAATGGAGAAAGAGGAGAAGAGATTGCTCTGGGAACAGCTGCAAGGCTTAGAGAGCTCAAAGCAGG CCGAAACATCCAGGCTGCAGGAGGAACTTGCTAAGCTCTCCGAGAAACTGAAAAAGAAACAAGAAAGTTTTTGCCGTCTGCAGACAGAAA AGGAGACTCTGTTTAATGACAGCAGGAACAAGATTGAGGAATTACAACAACGGAAGGAAGCTGATCACAAAGCCCAGTTGGCTCGAACCC AGAAGCTGCAGCAGGAACTTGAGGCTGCCAATCAGAGCTTGGCAGAGCTGAGAGATCAGCGGCAGGGGGAGCGCCTGGAACATGCAGCAG CTTTGCGGGCCCTACAAGATCAGGTATCCATCCAGAGTGCAGATGCACAGGAACAAGTGGAAGGGCTTTTGGCTGAGAACAATGCCTTGA GGACTAGCCTGGCTGCCCTGGAGCAGATCCAAACAGCAAAGACCCAAGAACTGAATATGCTCCGGGAACAGACCACTGGGCTGGCAGCTG AGTTGCAGCAGCAGCAGGCTGAGTACGAGGACCTTATGGGACAGAAAGATGACCTCAACTCCCAGCTCCAGGAGTCATTACGGGCCAATA GTCGACTGCTGGAACAACTTCAAGAAATAGGGCAGGAGAAGGAGCAGTTGACCCAGGAATTACAGGAGGCTCGGAAGAGTGCGGAGAAGC GGAAGGCCATGCTGGATGAGCTAGCAATGGAAACGCTGCAAGAGAAGTCCCAGCACAAGGAAGAGCTGGGAGCAGTTCGTCTACGGCATG AGAAGGAGGTGCTGGGGGTGCGTGCCCGCTATGAGCGTGAGCTCCGAGAGCTGCATGAAGACAAGAAGCGTCAGGAGGAGGAGCTCCGTG GGCAGATCCGGGAGGAGAAGGCCCGGACACGGGAGCTGGAGACTCTCCAGCAGACAGTGGAAGAACTTCAAGCTCAGGTACATTCCATGG ATGGAGCCAAGGGCTGGTTTGAACGGCGCTTGAAGGAAGCCGAGGAATCCCTGCAGCAGCAGCAGCAGGAACAAGAGGAAGCCCTCAAGC AGTGTCGGGAGCAGCACGCTGCCGAGCTGAAGGGCAAGGAGGAGGAGCTACAGGATGTACGGGATCAGCTCGAGCAGGCCCAGGAGGAGC GGGACTGCCACCTGAAGACCATTAGCAGCCTGAAGCAGGAGGTGAAGGACACAGTGGATGGGCAGAGGATCCTGGAGAAGAAGGGCAGTG CTGCGCTCAAGGACCTCAAGCGGCAGCTGCATTTGGAGCGGAAACGGGCAGATAAGCTGCAGGAGCGACTGCAGGACATCCTCACTAACA GCAAGAGCCGCTCAGGCCTTGAGGAGCTGGTTCTCTCAGAGATGAACTCACCAAGCCGGACCCAGACAGGGGACAGCAGTAGCATCTCCT CCTTCAGCTACCGGGAGATCTTGCGGGAAAAGGAGAGCTCGGCTGTTCCAGCCAGGCCATTGATCAGCCGCAACTACAAGGGCGATGTGG CCATGAGCAAGATTGAGCACTTCATGCCTTTGCTGGTACAGCGGGAGGAGGAAGGCGCCCTGGCCCCGCTGCTGAGCCACGGCCAGGTCC ACTTCCTATGGATCAAACACAGCAACCTCTACTTGGTGGCCACCACATCGAAGAATGCCAATGCCTCCCTGGTGTACTCCTTCCTGTATA AGACAATAGAGGTATTCTGCGAATACTTCAAGGAGCTGGAGGAGGAGAGCATCCGGGACAACTTTGTCATCGTCTACGAGTTGCTGGACG AGCTCATGGACTTTGGCTTCCCGCAGACCACCGACAGCAAGATCCTGCAGGAGTACATCACTCAGCAGAGCAACAAGCTGGAGACGGGCA AGTCACGGGTGCCACCCACTGTCACCAACGCTGTGTCCTGGCGCTCCGAGGGTATCAAGTATAAGAAGAACGAGGTCTTCATTGATGTCA TAGAGTCTGTCAACCTGCTGGTCAATGCCAACGGCAGCGTCCTTCTGAGCGAAATCGTCGGTACCATCAAGCTCAAGGTGTTTCTGTCAG GAATGCCAGAGCTGCGGCTGGGCCTCAATGACCGCGTGCTCTTCGAGCTCACTGGCCGCAGCAAGAACAAATCAGTAGAGCTGGAGGATG TAAAATTCCACCAGTGCGTGCGGCTCTCTCGCTTTGACAACGACCGCACCATCTCCTTCATCCCGCCTGATGGTGACTTTGAGCTCATGT CATACCGCCTCAGCACCCAGGTCAAGCCACTGATCTGGATTGAGTCTGTCATTGAGAAGTTCTCCCACAGCCGCGTGGAGATCATGGTCA AGGCCAAGGGGCAGTTTAAGAAACAGTCAGTGGCCAACGGTGTGGAGATATCTGTGCCTGTACCCAGCGATGCCGACTCCCCCAGATTCA AGACCAGTGTGGGCAGCGCCAAGTATGTGCCGGAGAGAAACGTCGTGATTTGGAGTATTAAGTCTTTCCCGGGGGGCAAGGAGTACTTGA TGCGAGCCCACTTTGGCCTCCCCAGTGTGGAAAAGGAAGAGGTGGAGGGCCGGCCCCCCATCGGGGTCAAGTTTGAGATCCCCTACTTCA CCGTCTCTGGGATCCAGGTCCGATACATGAAGATCATTGAGAAAAGTGGTTACCAGGCCCTGCCCTGGGTTCGCTACATCACCCAGAGTG GCGATTACCAACTTCGTACCAGCTAGAAGGGAGAAGAGATGGGGGCTTGAACACGGGGCTTCCTTACAGCCCCGGATGCAGATTTTAGAG GGAGGGCAGGTGCGGGCTGTGTGTGTCTGTGTGAGGGCAGGTCCTGGACTTGGCAGTTTCTTGCTCCCAGCACCCGCCCCTTCCTCACCT CTTCCTTATTCCATAGGCTGGGAGAGAAACTCTCTCTGCTTCCCTCGCCCTTGGAGCTTTCCCCATCCCCCTGATTTTATATGAAGAAAT AGAAGAGGGGCTTGAAGTCCTCCTCGCGAGTGCCTTCTTGCAATTACCTGCCTTAGCGGGTGTTGCGGGTCCCTCCTTCACAGCCGCTGA >34856_34856_5_GRIPAP1-AP1M2_GRIPAP1_chrX_48834717_ENST00000376444_AP1M2_chr19_10694746_ENST00000250244_length(amino acids)=1051AA_BP=642 MAQALSEEEFQRMQAQLLELRTNNYQLSDELRKNGVELTSLRQKVAYLDKEFSKAQKLCSQMEQLEQENQQLKEGAAGAGVAQAGPLVDG ELLRLQAENTALQKNVAALQERYGKEAGKFSAVSEGQGDPPGGPAPTVLAPMPLAEVELKWEMEKEEKRLLWEQLQGLESSKQAETSRLQ EELAKLSEKLKKKQESFCRLQTEKETLFNDSRNKIEELQQRKEADHKAQLARTQKLQQELEAANQSLAELRDQRQGERLEHAAALRALQD QVSIQSADAQEQVEGLLAENNALRTSLAALEQIQTAKTQELNMLREQTTGLAAELQQQQAEYEDLMGQKDDLNSQLQESLRANSRLLEQL QEIGQEKEQLTQELQEARKSAEKRKAMLDELAMETLQEKSQHKEELGAVRLRHEKEVLGVRARYERELRELHEDKKRQEEELRGQIREEK ARTRELETLQQTVEELQAQVHSMDGAKGWFERRLKEAEESLQQQQQEQEEALKQCREQHAAELKGKEEELQDVRDQLEQAQEERDCHLKT ISSLKQEVKDTVDGQRILEKKGSAALKDLKRQLHLERKRADKLQERLQDILTNSKSRSGLEELVLSEMNSPSRTQTGDSSSISSFSYREI LREKESSAVPARPLISRNYKGDVAMSKIEHFMPLLVQREEEGALAPLLSHGQVHFLWIKHSNLYLVATTSKNANASLVYSFLYKTIEVFC EYFKELEEESIRDNFVIVYELLDELMDFGFPQTTDSKILQEYITQQSNKLETGKSRVPPTVTNAVSWRSEGIKYKKNEVFIDVIESVNLL VNANGSVLLSEIVGTIKLKVFLSGMPELRLGLNDRVLFELTGRSKNKSVELEDVKFHQCVRLSRFDNDRTISFIPPDGDFELMSYRLSTQ VKPLIWIESVIEKFSHSRVEIMVKAKGQFKKQSVANGVEISVPVPSDADSPRFKTSVGSAKYVPERNVVIWSIKSFPGGKEYLMRAHFGL -------------------------------------------------------------- >34856_34856_6_GRIPAP1-AP1M2_GRIPAP1_chrX_48834717_ENST00000376444_AP1M2_chr19_10694746_ENST00000590923_length(transcript)=3577nt_BP=1946nt GGGGGGGTGGGGGGAGGAACATGGCGCAAGCTCTGTCTGAGGAGGAGTTTCAGCGGATGCAGGCTCAGCTCCTGGAACTCCGGACAAACA ACTACCAGCTTTCAGATGAACTACGCAAGAATGGTGTTGAACTCACCAGTCTTCGACAGAAGGTCGCCTACTTGGATAAGGAGTTCAGCA AAGCTCAGAAGCTCTGCAGCCAGATGGAACAGCTGGAGCAAGAGAACCAGCAACTGAAGGAGGGGGCTGCAGGAGCAGGGGTTGCCCAAG CTGGGCCCCTCGTGGATGGGGAGCTGCTGAGGCTACAGGCTGAAAACACAGCCTTGCAGAAGAACGTGGCAGCCCTGCAGGAACGCTATG GGAAAGAAGCCGGGAAGTTCTCAGCTGTCAGTGAGGGCCAGGGGGATCCCCCAGGGGGCCCGGCCCCCACCGTCCTGGCCCCCATGCCGT TGGCAGAGGTGGAGCTGAAATGGGAAATGGAGAAAGAGGAGAAGAGATTGCTCTGGGAACAGCTGCAAGGCTTAGAGAGCTCAAAGCAGG CCGAAACATCCAGGCTGCAGGAGGAACTTGCTAAGCTCTCCGAGAAACTGAAAAAGAAACAAGAAAGTTTTTGCCGTCTGCAGACAGAAA AGGAGACTCTGTTTAATGACAGCAGGAACAAGATTGAGGAATTACAACAACGGAAGGAAGCTGATCACAAAGCCCAGTTGGCTCGAACCC AGAAGCTGCAGCAGGAACTTGAGGCTGCCAATCAGAGCTTGGCAGAGCTGAGAGATCAGCGGCAGGGGGAGCGCCTGGAACATGCAGCAG CTTTGCGGGCCCTACAAGATCAGGTATCCATCCAGAGTGCAGATGCACAGGAACAAGTGGAAGGGCTTTTGGCTGAGAACAATGCCTTGA GGACTAGCCTGGCTGCCCTGGAGCAGATCCAAACAGCAAAGACCCAAGAACTGAATATGCTCCGGGAACAGACCACTGGGCTGGCAGCTG AGTTGCAGCAGCAGCAGGCTGAGTACGAGGACCTTATGGGACAGAAAGATGACCTCAACTCCCAGCTCCAGGAGTCATTACGGGCCAATA GTCGACTGCTGGAACAACTTCAAGAAATAGGGCAGGAGAAGGAGCAGTTGACCCAGGAATTACAGGAGGCTCGGAAGAGTGCGGAGAAGC GGAAGGCCATGCTGGATGAGCTAGCAATGGAAACGCTGCAAGAGAAGTCCCAGCACAAGGAAGAGCTGGGAGCAGTTCGTCTACGGCATG AGAAGGAGGTGCTGGGGGTGCGTGCCCGCTATGAGCGTGAGCTCCGAGAGCTGCATGAAGACAAGAAGCGTCAGGAGGAGGAGCTCCGTG GGCAGATCCGGGAGGAGAAGGCCCGGACACGGGAGCTGGAGACTCTCCAGCAGACAGTGGAAGAACTTCAAGCTCAGGTACATTCCATGG ATGGAGCCAAGGGCTGGTTTGAACGGCGCTTGAAGGAAGCCGAGGAATCCCTGCAGCAGCAGCAGCAGGAACAAGAGGAAGCCCTCAAGC AGTGTCGGGAGCAGCACGCTGCCGAGCTGAAGGGCAAGGAGGAGGAGCTACAGGATGTACGGGATCAGCTCGAGCAGGCCCAGGAGGAGC GGGACTGCCACCTGAAGACCATTAGCAGCCTGAAGCAGGAGGTGAAGGACACAGTGGATGGGCAGAGGATCCTGGAGAAGAAGGGCAGTG CTGCGCTCAAGGACCTCAAGCGGCAGCTGCATTTGGAGCGGAAACGGGCAGATAAGCTGCAGGAGCGACTGCAGGACATCCTCACTAACA GCAAGAGCCGCTCAGGCCTTGAGGAGCTGGTTCTCTCAGAGATGAACTCACCAAGCCGGACCCAGACAGGGGACAGCAGTAGCATCTCCT CCTTCAGCTACCGGGAGATCTTGCGGGAAAAGGAGAGCTCGGCTGTTCCAGCCAGGCCATTGATCAGCCGCAACTACAAGGGCGATGTGG CCATGAGCAAGATTGAGCACTTCATGCCTTTGCTGGTACAGCGGGAGGAGGAAGGCGCCCTGGCCCCGCTGCTGAGCCACGGCCAGGTCC ACTTCCTATGGATCAAACACAGCAACCTCTACTTGGTGGCCACCACATCGAAGAATGCCAATGCCTCCCTGGTGTACTCCTTCCTGTATA AGACAATAGAGGTATTCTGCGAATACTTCAAGGAGCTGGAGGAGGAGAGCATCCGGGACAACTTTGTCATCGTCTACGAGTTGCTGGACG AGCTCATGGACTTTGGCTTCCCGCAGACCACCGACAGCAAGATCCTGCAGGAGTACATCACTCAGCAGAGCAACAAGCTGGAGACGGGCA AGTCACGGGTGCCACCCACTGTCACCAACGCTGTGTCCTGGCGCTCCGAGGGTATCAAGTATAAGAAGAACGAGGTCTTCATTGATGTCA TAGAGTCTGTCAACCTGCTGGTCAATGCCAACGGCAGCGTCCTTCTGAGCGAAATCGTCGGTACCATCAAGCTCAAGGTGTTTCTGTCAG GAATGCCAGAGCTGCGGCTGGGCCTCAATGACCGCGTGCTCTTCGAGCTCACTGGCCTTTCAGGCAGCAAGAACAAATCAGTAGAGCTGG AGGATGTAAAATTCCACCAGTGCGTGCGGCTCTCTCGCTTTGACAACGACCGCACCATCTCCTTCATCCCGCCTGATGGTGACTTTGAGC TCATGTCATACCGCCTCAGCACCCAGGTCAAGCCACTGATCTGGATTGAGTCTGTCATTGAGAAGTTCTCCCACAGCCGCGTGGAGATCA TGGTCAAGGCCAAGGGGCAGTTTAAGAAACAGTCAGTGGCCAACGGTGTGGAGATATCTGTGCCTGTACCCAGCGATGCCGACTCCCCCA GATTCAAGACCAGTGTGGGCAGCGCCAAGTATGTGCCGGAGAGAAACGTCGTGATTTGGAGTATTAAGTCTTTCCCGGGGGGCAAGGAGT ACTTGATGCGAGCCCACTTTGGCCTCCCCAGTGTGGAAAAGGAAGAGGTGGAGGGCCGGCCCCCCATCGGGGTCAAGTTTGAGATCCCCT ACTTCACCGTCTCTGGGATCCAGGTCCGATACATGAAGATCATTGAGAAAAGTGGTTACCAGGCCCTGCCCTGGGTTCGCTACATCACCC AGAGTGGCGATTACCAACTTCGTACCAGCTAGAAGGGAGAAGAGATGGGGGCTTGAACACGGGGCTTCCTTACAGCCCCGGATGCAGATT TTAGAGGGAGGGCAGGTGCGGGCTGTGTGTGTCTGTGTGAGGGCAGGTCCTGGACTTGGCAGTTTCTTGCTCCCAGCACCCGCCCCTTCC TCACCTCTTCCTTATTCCATAGGCTGGGAGAGAAACTCTCTCTGCTTCCCTCGCCCTTGGAGCTTTCCCCATCCCCCTGATTTTATATGA AGAAATAGAAGAGGGGCTTGAAGTCCTCCTCGCGAGTGCCTTCTTGCAATTACCTGCCTTAGCGGGTGTTGCGGGTCCCTCCTTCACAGC >34856_34856_6_GRIPAP1-AP1M2_GRIPAP1_chrX_48834717_ENST00000376444_AP1M2_chr19_10694746_ENST00000590923_length(amino acids)=1053AA_BP=642 MAQALSEEEFQRMQAQLLELRTNNYQLSDELRKNGVELTSLRQKVAYLDKEFSKAQKLCSQMEQLEQENQQLKEGAAGAGVAQAGPLVDG ELLRLQAENTALQKNVAALQERYGKEAGKFSAVSEGQGDPPGGPAPTVLAPMPLAEVELKWEMEKEEKRLLWEQLQGLESSKQAETSRLQ EELAKLSEKLKKKQESFCRLQTEKETLFNDSRNKIEELQQRKEADHKAQLARTQKLQQELEAANQSLAELRDQRQGERLEHAAALRALQD QVSIQSADAQEQVEGLLAENNALRTSLAALEQIQTAKTQELNMLREQTTGLAAELQQQQAEYEDLMGQKDDLNSQLQESLRANSRLLEQL QEIGQEKEQLTQELQEARKSAEKRKAMLDELAMETLQEKSQHKEELGAVRLRHEKEVLGVRARYERELRELHEDKKRQEEELRGQIREEK ARTRELETLQQTVEELQAQVHSMDGAKGWFERRLKEAEESLQQQQQEQEEALKQCREQHAAELKGKEEELQDVRDQLEQAQEERDCHLKT ISSLKQEVKDTVDGQRILEKKGSAALKDLKRQLHLERKRADKLQERLQDILTNSKSRSGLEELVLSEMNSPSRTQTGDSSSISSFSYREI LREKESSAVPARPLISRNYKGDVAMSKIEHFMPLLVQREEEGALAPLLSHGQVHFLWIKHSNLYLVATTSKNANASLVYSFLYKTIEVFC EYFKELEEESIRDNFVIVYELLDELMDFGFPQTTDSKILQEYITQQSNKLETGKSRVPPTVTNAVSWRSEGIKYKKNEVFIDVIESVNLL VNANGSVLLSEIVGTIKLKVFLSGMPELRLGLNDRVLFELTGLSGSKNKSVELEDVKFHQCVRLSRFDNDRTISFIPPDGDFELMSYRLS TQVKPLIWIESVIEKFSHSRVEIMVKAKGQFKKQSVANGVEISVPVPSDADSPRFKTSVGSAKYVPERNVVIWSIKSFPGGKEYLMRAHF -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for GRIPAP1-AP1M2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for GRIPAP1-AP1M2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for GRIPAP1-AP1M2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies