
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:GSDMD-RANGAP1 (FusionGDB2 ID:34995) |
Fusion Gene Summary for GSDMD-RANGAP1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: GSDMD-RANGAP1 | Fusion gene ID: 34995 | Hgene | Tgene | Gene symbol | GSDMD | RANGAP1 | Gene ID | 79792 | 5905 |
| Gene name | gasdermin D | Ran GTPase activating protein 1 | |
| Synonyms | DF5L|DFNA5L|FKSG10|GSDMDC1 | Fug1|RANGAP|SD | |
| Cytomap | 8q24.3 | 22q13.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | gasdermin-Dgasdermin domain containing 1gasdermin domain-containing protein 1 | ran GTPase-activating protein 1segregation distorter homologsegregation distortion | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | P57764 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000262580, ENST00000526406, ENST00000533063, | ENST00000356244, ENST00000405486, ENST00000407260, ENST00000455915, | |
| Fusion gene scores | * DoF score | 2 X 3 X 2=12 | 11 X 10 X 7=770 |
| # samples | 3 | 12 | |
| ** MAII score | log2(3/12*10)=1.32192809488736 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | log2(12/770*10)=-2.68182403997375 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: GSDMD [Title/Abstract] AND RANGAP1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | GSDMD(144644228)-RANGAP1(41648995), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | RANGAP1 | GO:0046826 | negative regulation of protein export from nucleus | 16449645 |
| Tgene | RANGAP1 | GO:0090630 | activation of GTPase activity | 16428860 |
| Fusion gene breakpoints across GSDMD (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across RANGAP1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | COAD | TCGA-AA-A03F-01A | GSDMD | chr8 | 144644228 | + | RANGAP1 | chr22 | 41648995 | - |
Top |
Fusion Gene ORF analysis for GSDMD-RANGAP1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| In-frame | ENST00000262580 | ENST00000356244 | GSDMD | chr8 | 144644228 | + | RANGAP1 | chr22 | 41648995 | - |
| In-frame | ENST00000262580 | ENST00000405486 | GSDMD | chr8 | 144644228 | + | RANGAP1 | chr22 | 41648995 | - |
| In-frame | ENST00000262580 | ENST00000407260 | GSDMD | chr8 | 144644228 | + | RANGAP1 | chr22 | 41648995 | - |
| In-frame | ENST00000262580 | ENST00000455915 | GSDMD | chr8 | 144644228 | + | RANGAP1 | chr22 | 41648995 | - |
| In-frame | ENST00000526406 | ENST00000356244 | GSDMD | chr8 | 144644228 | + | RANGAP1 | chr22 | 41648995 | - |
| In-frame | ENST00000526406 | ENST00000405486 | GSDMD | chr8 | 144644228 | + | RANGAP1 | chr22 | 41648995 | - |
| In-frame | ENST00000526406 | ENST00000407260 | GSDMD | chr8 | 144644228 | + | RANGAP1 | chr22 | 41648995 | - |
| In-frame | ENST00000526406 | ENST00000455915 | GSDMD | chr8 | 144644228 | + | RANGAP1 | chr22 | 41648995 | - |
| In-frame | ENST00000533063 | ENST00000356244 | GSDMD | chr8 | 144644228 | + | RANGAP1 | chr22 | 41648995 | - |
| In-frame | ENST00000533063 | ENST00000405486 | GSDMD | chr8 | 144644228 | + | RANGAP1 | chr22 | 41648995 | - |
| In-frame | ENST00000533063 | ENST00000407260 | GSDMD | chr8 | 144644228 | + | RANGAP1 | chr22 | 41648995 | - |
| In-frame | ENST00000533063 | ENST00000455915 | GSDMD | chr8 | 144644228 | + | RANGAP1 | chr22 | 41648995 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000526406 | GSDMD | chr8 | 144644228 | + | ENST00000405486 | RANGAP1 | chr22 | 41648995 | - | 3275 | 1779 | 808 | 1866 | 352 |
| ENST00000526406 | GSDMD | chr8 | 144644228 | + | ENST00000356244 | RANGAP1 | chr22 | 41648995 | - | 3275 | 1779 | 808 | 1866 | 352 |
| ENST00000526406 | GSDMD | chr8 | 144644228 | + | ENST00000455915 | RANGAP1 | chr22 | 41648995 | - | 3271 | 1779 | 808 | 1866 | 352 |
| ENST00000526406 | GSDMD | chr8 | 144644228 | + | ENST00000407260 | RANGAP1 | chr22 | 41648995 | - | 2443 | 1779 | 808 | 1866 | 352 |
| ENST00000533063 | GSDMD | chr8 | 144644228 | + | ENST00000405486 | RANGAP1 | chr22 | 41648995 | - | 2579 | 1083 | 16 | 1170 | 384 |
| ENST00000533063 | GSDMD | chr8 | 144644228 | + | ENST00000356244 | RANGAP1 | chr22 | 41648995 | - | 2579 | 1083 | 16 | 1170 | 384 |
| ENST00000533063 | GSDMD | chr8 | 144644228 | + | ENST00000455915 | RANGAP1 | chr22 | 41648995 | - | 2575 | 1083 | 16 | 1170 | 384 |
| ENST00000533063 | GSDMD | chr8 | 144644228 | + | ENST00000407260 | RANGAP1 | chr22 | 41648995 | - | 1747 | 1083 | 16 | 1170 | 384 |
| ENST00000262580 | GSDMD | chr8 | 144644228 | + | ENST00000405486 | RANGAP1 | chr22 | 41648995 | - | 2541 | 1045 | 74 | 1132 | 352 |
| ENST00000262580 | GSDMD | chr8 | 144644228 | + | ENST00000356244 | RANGAP1 | chr22 | 41648995 | - | 2541 | 1045 | 74 | 1132 | 352 |
| ENST00000262580 | GSDMD | chr8 | 144644228 | + | ENST00000455915 | RANGAP1 | chr22 | 41648995 | - | 2537 | 1045 | 74 | 1132 | 352 |
| ENST00000262580 | GSDMD | chr8 | 144644228 | + | ENST00000407260 | RANGAP1 | chr22 | 41648995 | - | 1709 | 1045 | 74 | 1132 | 352 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000526406 | ENST00000405486 | GSDMD | chr8 | 144644228 | + | RANGAP1 | chr22 | 41648995 | - | 0.21287538 | 0.7871247 |
| ENST00000526406 | ENST00000356244 | GSDMD | chr8 | 144644228 | + | RANGAP1 | chr22 | 41648995 | - | 0.21287538 | 0.7871247 |
| ENST00000526406 | ENST00000455915 | GSDMD | chr8 | 144644228 | + | RANGAP1 | chr22 | 41648995 | - | 0.20997338 | 0.79002655 |
| ENST00000526406 | ENST00000407260 | GSDMD | chr8 | 144644228 | + | RANGAP1 | chr22 | 41648995 | - | 0.15036318 | 0.84963685 |
| ENST00000533063 | ENST00000405486 | GSDMD | chr8 | 144644228 | + | RANGAP1 | chr22 | 41648995 | - | 0.25669912 | 0.74330086 |
| ENST00000533063 | ENST00000356244 | GSDMD | chr8 | 144644228 | + | RANGAP1 | chr22 | 41648995 | - | 0.25669912 | 0.74330086 |
| ENST00000533063 | ENST00000455915 | GSDMD | chr8 | 144644228 | + | RANGAP1 | chr22 | 41648995 | - | 0.25198066 | 0.7480194 |
| ENST00000533063 | ENST00000407260 | GSDMD | chr8 | 144644228 | + | RANGAP1 | chr22 | 41648995 | - | 0.119764484 | 0.88023555 |
| ENST00000262580 | ENST00000405486 | GSDMD | chr8 | 144644228 | + | RANGAP1 | chr22 | 41648995 | - | 0.19381276 | 0.8061872 |
| ENST00000262580 | ENST00000356244 | GSDMD | chr8 | 144644228 | + | RANGAP1 | chr22 | 41648995 | - | 0.19381276 | 0.8061872 |
| ENST00000262580 | ENST00000455915 | GSDMD | chr8 | 144644228 | + | RANGAP1 | chr22 | 41648995 | - | 0.18951932 | 0.8104807 |
| ENST00000262580 | ENST00000407260 | GSDMD | chr8 | 144644228 | + | RANGAP1 | chr22 | 41648995 | - | 0.08859417 | 0.9114058 |
Top |
Fusion Genomic Features for GSDMD-RANGAP1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
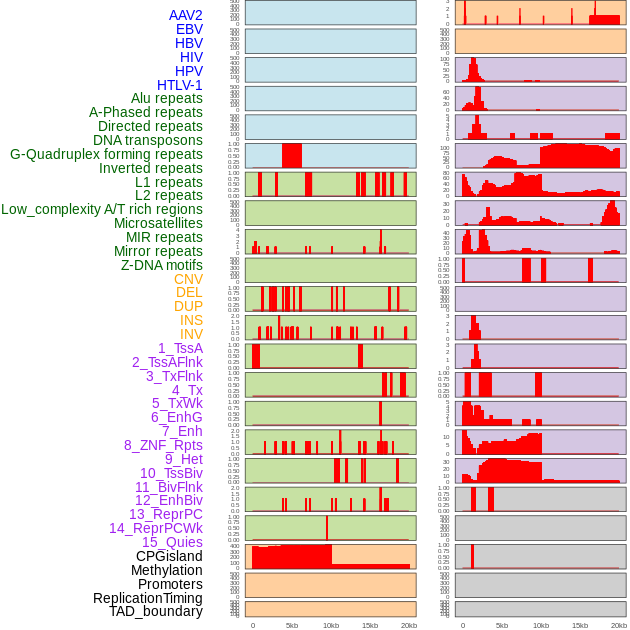
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for GSDMD-RANGAP1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr8:144644228/chr22:41648995) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| GSDMD | . |
| FUNCTION: [Gasdermin-D]: Precursor of a pore-forming protein that plays a key role in host defense against pathogen infection and danger signals (PubMed:26375003, PubMed:26375259, PubMed:27281216). This form constitutes the precursor of the pore-forming protein: upon cleavage, the released N-terminal moiety (Gasdermin-D, N-terminal) binds to membranes and forms pores, triggering pyroptosis (PubMed:26375003, PubMed:26375259, PubMed:27281216). {ECO:0000269|PubMed:26375003, ECO:0000269|PubMed:26375259, ECO:0000269|PubMed:27281216}.; FUNCTION: [Gasdermin-D, N-terminal]: Promotes pyroptosis in response to microbial infection and danger signals (PubMed:26375003, PubMed:26375259, PubMed:27418190, PubMed:28392147, PubMed:32820063). Produced by the cleavage of gasdermin-D by inflammatory caspases CASP1, CASP4 or CASP5 in response to canonical, as well as non-canonical (such as cytosolic LPS) inflammasome activators (PubMed:26375003, PubMed:26375259, PubMed:27418190). After cleavage, moves to the plasma membrane where it strongly binds to inner leaflet lipids, including monophosphorylated phosphatidylinositols, such as phosphatidylinositol 4-phosphate, bisphosphorylated phosphatidylinositols, such as phosphatidylinositol (4,5)-bisphosphate, as well as phosphatidylinositol (3,4,5)-bisphosphate, and more weakly to phosphatidic acid and phosphatidylserine (PubMed:27281216, PubMed:29898893). Homooligomerizes within the membrane and forms pores of 10-15 nanometers (nm) of inner diameter, allowing the release of mature IL1B and triggering pyroptosis (PubMed:27418190, PubMed:27281216, PubMed:29898893). Exhibits bactericidal activity (PubMed:27281216). Gasdermin-D, N-terminal released from pyroptotic cells into the extracellular milieu rapidly binds to and kills both Gram-negative and Gram-positive bacteria, without harming neighboring mammalian cells, as it does not disrupt the plasma membrane from the outside due to lipid-binding specificity (PubMed:27281216). Under cell culture conditions, also active against intracellular bacteria, such as Listeria monocytogenes (By similarity). Also active in response to MAP3K7/TAK1 inactivation by Yersinia toxin YopJ, which triggers cleavage by CASP8 and subsequent activation (By similarity). Strongly binds to bacterial and mitochondrial lipids, including cardiolipin (PubMed:27281216). Does not bind to unphosphorylated phosphatidylinositol, phosphatidylethanolamine nor phosphatidylcholine (PubMed:27281216). {ECO:0000250|UniProtKB:Q9D8T2, ECO:0000269|PubMed:26375003, ECO:0000269|PubMed:26375259, ECO:0000269|PubMed:27281216, ECO:0000269|PubMed:27418190, ECO:0000269|PubMed:28392147, ECO:0000269|PubMed:29898893, ECO:0000269|PubMed:32820063}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | RANGAP1 | chr8:144644228 | chr22:41648995 | ENST00000356244 | 10 | 16 | 523_526 | 420 | 588.0 | Motif | Note=SUMO conjugation | |
| Tgene | RANGAP1 | chr8:144644228 | chr22:41648995 | ENST00000405486 | 11 | 17 | 523_526 | 420 | 588.0 | Motif | Note=SUMO conjugation | |
| Tgene | RANGAP1 | chr8:144644228 | chr22:41648995 | ENST00000455915 | 9 | 15 | 523_526 | 420 | 588.0 | Motif | Note=SUMO conjugation |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | RANGAP1 | chr8:144644228 | chr22:41648995 | ENST00000356244 | 10 | 16 | 359_397 | 420 | 588.0 | Compositional bias | Note=Asp/Glu-rich (highly acidic) | |
| Tgene | RANGAP1 | chr8:144644228 | chr22:41648995 | ENST00000356244 | 10 | 16 | 359_399 | 420 | 588.0 | Compositional bias | Note=Asp/Glu-rich (highly acidic) | |
| Tgene | RANGAP1 | chr8:144644228 | chr22:41648995 | ENST00000405486 | 11 | 17 | 359_397 | 420 | 588.0 | Compositional bias | Note=Asp/Glu-rich (highly acidic) | |
| Tgene | RANGAP1 | chr8:144644228 | chr22:41648995 | ENST00000405486 | 11 | 17 | 359_399 | 420 | 588.0 | Compositional bias | Note=Asp/Glu-rich (highly acidic) | |
| Tgene | RANGAP1 | chr8:144644228 | chr22:41648995 | ENST00000455915 | 9 | 15 | 359_397 | 420 | 588.0 | Compositional bias | Note=Asp/Glu-rich (highly acidic) | |
| Tgene | RANGAP1 | chr8:144644228 | chr22:41648995 | ENST00000455915 | 9 | 15 | 359_399 | 420 | 588.0 | Compositional bias | Note=Asp/Glu-rich (highly acidic) | |
| Tgene | RANGAP1 | chr8:144644228 | chr22:41648995 | ENST00000356244 | 10 | 16 | 111_134 | 420 | 588.0 | Repeat | Note=LRR 2 | |
| Tgene | RANGAP1 | chr8:144644228 | chr22:41648995 | ENST00000356244 | 10 | 16 | 207_230 | 420 | 588.0 | Repeat | Note=LRR 3 | |
| Tgene | RANGAP1 | chr8:144644228 | chr22:41648995 | ENST00000356244 | 10 | 16 | 235_258 | 420 | 588.0 | Repeat | Note=LRR 4 | |
| Tgene | RANGAP1 | chr8:144644228 | chr22:41648995 | ENST00000356244 | 10 | 16 | 292_319 | 420 | 588.0 | Repeat | Note=LRR 5 | |
| Tgene | RANGAP1 | chr8:144644228 | chr22:41648995 | ENST00000356244 | 10 | 16 | 320_343 | 420 | 588.0 | Repeat | Note=LRR 6 | |
| Tgene | RANGAP1 | chr8:144644228 | chr22:41648995 | ENST00000356244 | 10 | 16 | 48_71 | 420 | 588.0 | Repeat | Note=LRR 1 | |
| Tgene | RANGAP1 | chr8:144644228 | chr22:41648995 | ENST00000405486 | 11 | 17 | 111_134 | 420 | 588.0 | Repeat | Note=LRR 2 | |
| Tgene | RANGAP1 | chr8:144644228 | chr22:41648995 | ENST00000405486 | 11 | 17 | 207_230 | 420 | 588.0 | Repeat | Note=LRR 3 | |
| Tgene | RANGAP1 | chr8:144644228 | chr22:41648995 | ENST00000405486 | 11 | 17 | 235_258 | 420 | 588.0 | Repeat | Note=LRR 4 | |
| Tgene | RANGAP1 | chr8:144644228 | chr22:41648995 | ENST00000405486 | 11 | 17 | 292_319 | 420 | 588.0 | Repeat | Note=LRR 5 | |
| Tgene | RANGAP1 | chr8:144644228 | chr22:41648995 | ENST00000405486 | 11 | 17 | 320_343 | 420 | 588.0 | Repeat | Note=LRR 6 | |
| Tgene | RANGAP1 | chr8:144644228 | chr22:41648995 | ENST00000405486 | 11 | 17 | 48_71 | 420 | 588.0 | Repeat | Note=LRR 1 | |
| Tgene | RANGAP1 | chr8:144644228 | chr22:41648995 | ENST00000455915 | 9 | 15 | 111_134 | 420 | 588.0 | Repeat | Note=LRR 2 | |
| Tgene | RANGAP1 | chr8:144644228 | chr22:41648995 | ENST00000455915 | 9 | 15 | 207_230 | 420 | 588.0 | Repeat | Note=LRR 3 | |
| Tgene | RANGAP1 | chr8:144644228 | chr22:41648995 | ENST00000455915 | 9 | 15 | 235_258 | 420 | 588.0 | Repeat | Note=LRR 4 | |
| Tgene | RANGAP1 | chr8:144644228 | chr22:41648995 | ENST00000455915 | 9 | 15 | 292_319 | 420 | 588.0 | Repeat | Note=LRR 5 | |
| Tgene | RANGAP1 | chr8:144644228 | chr22:41648995 | ENST00000455915 | 9 | 15 | 320_343 | 420 | 588.0 | Repeat | Note=LRR 6 | |
| Tgene | RANGAP1 | chr8:144644228 | chr22:41648995 | ENST00000455915 | 9 | 15 | 48_71 | 420 | 588.0 | Repeat | Note=LRR 1 |
Top |
Fusion Gene Sequence for GSDMD-RANGAP1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >34995_34995_1_GSDMD-RANGAP1_GSDMD_chr8_144644228_ENST00000262580_RANGAP1_chr22_41648995_ENST00000356244_length(transcript)=2541nt_BP=1045nt GTTCCGGGAGGGCGTCCTGGGCGGGCCCTGCGTCAGGTTGCAGTTTCACTTTTAGCTCTGGGCACCTCCAGCTCCTGCTCGCCGGACGGC TCCCAGGGAGAGCAGACGCGCCAGACGCGCCACCCTCGGGGCGCCGACGGTCACGGAGCATGGGGTCGGCCTTTGAGCGGGTAGTCCGGA GAGTGGTCCAGGAGCTGGACCATGGTGGGGAGTTCATCCCTGTGACCAGCCTGCAGAGCTCCACTGGCTTCCAGCCCTACTGCCTGGTGG TTAGGAAGCCCTCAAGCTCATGGTTCTGGAAACCCCGTTATAAGTGTGTCAACCTGTCTATCAAGGACATCCTGGAGCCGGATGCCGCGG AACCAGACGTGCAGCGTGGCAGGAGCTTCCACTTCTACGATGCCATGGATGGGCAGATACAGGGCAGCGTGGAGCTGGCAGCCCCAGGAC AGGCAAAGATCGCAGGCGGGGCCGCGGTGTCTGACAGCTCCAGCACCTCAATGAATGTGTACTCGCTGAGTGTGGACCCTAACACCTGGC AGACTCTGCTCCATGAGAGGCACCTGCGGCAGCCAGAACACAAAGTCCTGCAGCAGCTGCGCAGCCGCGGGGACAACGTGTACGTGGTGA CTGAGGTGCTGCAGACACAGAAGGAGGTGGAAGTCACGCGCACCCACAAGCGGGAGGGCTCGGGCCGGTTTTCCCTGCCCGGAGCCACGT GCTTGCAGGGTGAGGGCCAGGGCCATCTGAGCCAGAAGAAGACGGTCACCATCCCCTCAGGCAGCACCCTCGCATTCCGGGTGGCCCAGC TGGTTATTGACTCTGACTTGGACGTCCTTCTCTTCCCGGATAAGAAGCAGAGGACCTTCCAGCCACCCGCGACAGGCCACAAGCGTTCCA CGAGCGAAGGCGCCTGGCCACAGCTGCCCTCTGGCCTCTCCATGATGAGGTGCCTCCACAACTTCCTGACAGGTGCCAGCTGCTGCTGGA GGGCCTGGAGGGGGTGCTGCGGGACCAGCTGGCCCTGCGAGCCTTGGAGGAGGCGGAGCCAGCTCCCGTGCTGTCCTCCCCACCTCCTGC AGACGTCTCCACCTTCCTGGCTTTTCCCTCTCCAGAGAAGCTGCTGCGCCTAGGGCCCAAGAGCTCCGTGCTGATAGCCCAGCAGACTGA CACGTCTGACCCCGAGAAGGTGGTCTCTGCCTTCCTAAAGGTGTCATCTGTGTTCAAGGACGAAGCTACTGTGAGGATGGCAGTGCAGGA TGCAGTAGATGCCCTGATGCAGAAGGCTTTCAACTCCTCGTCCTTCAACTCCAACACCTTCCTCACCAGGCTGCTCGTGCACATGGGTCT GCTCAAGAGTGAAGACAAGGTCAAGGCCATTGCCAACCTGTACGGCCCCCTGATGGCGCTGAACCACATGGTGCAGCAGGACTATTTCCC CAAGGCCCTTGCACCCCTGCTGCTGGCGTTCGTGACCAAGCCCAACAGCGCCCTGGAATCCTGCTCCTTCGCCCGCCACAGTCTGCTGCA GACGCTGTACAAGGTCTAGACTCAAAGCCTCTCCCATCCCTTGGCCTGGACCAGTGAGCTGGGGAGGGACTCGGATGAACTGAGGCGCAG CCTACGCCATTGCCTTGGACAGGACTCTGGCCACAGGCAGGGCGGGTCTGTGTCCCATGTGTCCTGTCAGTCCCCTGAGTATGTGTGTGG GTGTGGCGCATGTGCAGGTCTGTGCCTCCTGTCGGGATTTGGGTTTTAACGTCTTCTGCTGGCCCAGCCCTGCTCTGTTGTGGGGAGTTG GCCCCCAGGGGAAAGGGCTGTGAGCTGCTCCGCCATTAAACTCACCTCCACCTGAGGGCGCTCTGCTGATCTCCGCCTGGGCCCTGATGG CCGTCCCCACCCACCTGCCTTCCGGCCCGGCTCCCTGGCGGAGCCAGAACCCAGGGAGTTGCCCGCGTGCTGTCCTTCCCCTCTGTGTTG TGATTGGGTTGTTTCCTGCCCTGCCTGGGGCTGCTTCTCGTCACCAAGCCCTGGTCCTGCGGCAGCTGTCACCCCTACCATCCATACCAC TGTGCTGACCGCTCAGCCTGAAGAGCAGAGAATGCCATGGGTGGGACTGTGGGGGTCGGATCGTGGGGTTGTTGGCAGAGGGCAACCCTG GGCCCCACACCGTGTGGACAGGCAGACACCAGATTGTCCAGGAGCAGGAGCTGCTGGGACTGCGCTGGCCCCGGACCTAGTGGGCCTTCT CCTGGCTGCTGAGATGTCGTCTGTGACTGGCCTGGCTGGAGGGGGAGTGTTGACAACCCAAAGCTGTTCTCCAGTCTGGGGAGGGAGAGG CAGGGTCCCCAATGTCCGAGCTGCATCTGGACGCTGCTCTTAAAGGACCTCCTGGGGCAGGGGAGCGGTAGGGTCTGGACTGGGCAGATG CTGTATGACCTCCCTGAGCACCCGTGACTGCCCCATGCTTTCCCCTTTGTGCTCTGTGTGTGTCTGGGCTGTGCCCGGGGGCTTCACAAA >34995_34995_1_GSDMD-RANGAP1_GSDMD_chr8_144644228_ENST00000262580_RANGAP1_chr22_41648995_ENST00000356244_length(amino acids)=352AA_BP=323 MLAGRLPGRADAPDAPPSGRRRSRSMGSAFERVVRRVVQELDHGGEFIPVTSLQSSTGFQPYCLVVRKPSSSWFWKPRYKCVNLSIKDIL EPDAAEPDVQRGRSFHFYDAMDGQIQGSVELAAPGQAKIAGGAAVSDSSSTSMNVYSLSVDPNTWQTLLHERHLRQPEHKVLQQLRSRGD NVYVVTEVLQTQKEVEVTRTHKREGSGRFSLPGATCLQGEGQGHLSQKKTVTIPSGSTLAFRVAQLVIDSDLDVLLFPDKKQRTFQPPAT -------------------------------------------------------------- >34995_34995_2_GSDMD-RANGAP1_GSDMD_chr8_144644228_ENST00000262580_RANGAP1_chr22_41648995_ENST00000405486_length(transcript)=2541nt_BP=1045nt GTTCCGGGAGGGCGTCCTGGGCGGGCCCTGCGTCAGGTTGCAGTTTCACTTTTAGCTCTGGGCACCTCCAGCTCCTGCTCGCCGGACGGC TCCCAGGGAGAGCAGACGCGCCAGACGCGCCACCCTCGGGGCGCCGACGGTCACGGAGCATGGGGTCGGCCTTTGAGCGGGTAGTCCGGA GAGTGGTCCAGGAGCTGGACCATGGTGGGGAGTTCATCCCTGTGACCAGCCTGCAGAGCTCCACTGGCTTCCAGCCCTACTGCCTGGTGG TTAGGAAGCCCTCAAGCTCATGGTTCTGGAAACCCCGTTATAAGTGTGTCAACCTGTCTATCAAGGACATCCTGGAGCCGGATGCCGCGG AACCAGACGTGCAGCGTGGCAGGAGCTTCCACTTCTACGATGCCATGGATGGGCAGATACAGGGCAGCGTGGAGCTGGCAGCCCCAGGAC AGGCAAAGATCGCAGGCGGGGCCGCGGTGTCTGACAGCTCCAGCACCTCAATGAATGTGTACTCGCTGAGTGTGGACCCTAACACCTGGC AGACTCTGCTCCATGAGAGGCACCTGCGGCAGCCAGAACACAAAGTCCTGCAGCAGCTGCGCAGCCGCGGGGACAACGTGTACGTGGTGA CTGAGGTGCTGCAGACACAGAAGGAGGTGGAAGTCACGCGCACCCACAAGCGGGAGGGCTCGGGCCGGTTTTCCCTGCCCGGAGCCACGT GCTTGCAGGGTGAGGGCCAGGGCCATCTGAGCCAGAAGAAGACGGTCACCATCCCCTCAGGCAGCACCCTCGCATTCCGGGTGGCCCAGC TGGTTATTGACTCTGACTTGGACGTCCTTCTCTTCCCGGATAAGAAGCAGAGGACCTTCCAGCCACCCGCGACAGGCCACAAGCGTTCCA CGAGCGAAGGCGCCTGGCCACAGCTGCCCTCTGGCCTCTCCATGATGAGGTGCCTCCACAACTTCCTGACAGGTGCCAGCTGCTGCTGGA GGGCCTGGAGGGGGTGCTGCGGGACCAGCTGGCCCTGCGAGCCTTGGAGGAGGCGGAGCCAGCTCCCGTGCTGTCCTCCCCACCTCCTGC AGACGTCTCCACCTTCCTGGCTTTTCCCTCTCCAGAGAAGCTGCTGCGCCTAGGGCCCAAGAGCTCCGTGCTGATAGCCCAGCAGACTGA CACGTCTGACCCCGAGAAGGTGGTCTCTGCCTTCCTAAAGGTGTCATCTGTGTTCAAGGACGAAGCTACTGTGAGGATGGCAGTGCAGGA TGCAGTAGATGCCCTGATGCAGAAGGCTTTCAACTCCTCGTCCTTCAACTCCAACACCTTCCTCACCAGGCTGCTCGTGCACATGGGTCT GCTCAAGAGTGAAGACAAGGTCAAGGCCATTGCCAACCTGTACGGCCCCCTGATGGCGCTGAACCACATGGTGCAGCAGGACTATTTCCC CAAGGCCCTTGCACCCCTGCTGCTGGCGTTCGTGACCAAGCCCAACAGCGCCCTGGAATCCTGCTCCTTCGCCCGCCACAGTCTGCTGCA GACGCTGTACAAGGTCTAGACTCAAAGCCTCTCCCATCCCTTGGCCTGGACCAGTGAGCTGGGGAGGGACTCGGATGAACTGAGGCGCAG CCTACGCCATTGCCTTGGACAGGACTCTGGCCACAGGCAGGGCGGGTCTGTGTCCCATGTGTCCTGTCAGTCCCCTGAGTATGTGTGTGG GTGTGGCGCATGTGCAGGTCTGTGCCTCCTGTCGGGATTTGGGTTTTAACGTCTTCTGCTGGCCCAGCCCTGCTCTGTTGTGGGGAGTTG GCCCCCAGGGGAAAGGGCTGTGAGCTGCTCCGCCATTAAACTCACCTCCACCTGAGGGCGCTCTGCTGATCTCCGCCTGGGCCCTGATGG CCGTCCCCACCCACCTGCCTTCCGGCCCGGCTCCCTGGCGGAGCCAGAACCCAGGGAGTTGCCCGCGTGCTGTCCTTCCCCTCTGTGTTG TGATTGGGTTGTTTCCTGCCCTGCCTGGGGCTGCTTCTCGTCACCAAGCCCTGGTCCTGCGGCAGCTGTCACCCCTACCATCCATACCAC TGTGCTGACCGCTCAGCCTGAAGAGCAGAGAATGCCATGGGTGGGACTGTGGGGGTCGGATCGTGGGGTTGTTGGCAGAGGGCAACCCTG GGCCCCACACCGTGTGGACAGGCAGACACCAGATTGTCCAGGAGCAGGAGCTGCTGGGACTGCGCTGGCCCCGGACCTAGTGGGCCTTCT CCTGGCTGCTGAGATGTCGTCTGTGACTGGCCTGGCTGGAGGGGGAGTGTTGACAACCCAAAGCTGTTCTCCAGTCTGGGGAGGGAGAGG CAGGGTCCCCAATGTCCGAGCTGCATCTGGACGCTGCTCTTAAAGGACCTCCTGGGGCAGGGGAGCGGTAGGGTCTGGACTGGGCAGATG CTGTATGACCTCCCTGAGCACCCGTGACTGCCCCATGCTTTCCCCTTTGTGCTCTGTGTGTGTCTGGGCTGTGCCCGGGGGCTTCACAAA >34995_34995_2_GSDMD-RANGAP1_GSDMD_chr8_144644228_ENST00000262580_RANGAP1_chr22_41648995_ENST00000405486_length(amino acids)=352AA_BP=323 MLAGRLPGRADAPDAPPSGRRRSRSMGSAFERVVRRVVQELDHGGEFIPVTSLQSSTGFQPYCLVVRKPSSSWFWKPRYKCVNLSIKDIL EPDAAEPDVQRGRSFHFYDAMDGQIQGSVELAAPGQAKIAGGAAVSDSSSTSMNVYSLSVDPNTWQTLLHERHLRQPEHKVLQQLRSRGD NVYVVTEVLQTQKEVEVTRTHKREGSGRFSLPGATCLQGEGQGHLSQKKTVTIPSGSTLAFRVAQLVIDSDLDVLLFPDKKQRTFQPPAT -------------------------------------------------------------- >34995_34995_3_GSDMD-RANGAP1_GSDMD_chr8_144644228_ENST00000262580_RANGAP1_chr22_41648995_ENST00000407260_length(transcript)=1709nt_BP=1045nt GTTCCGGGAGGGCGTCCTGGGCGGGCCCTGCGTCAGGTTGCAGTTTCACTTTTAGCTCTGGGCACCTCCAGCTCCTGCTCGCCGGACGGC TCCCAGGGAGAGCAGACGCGCCAGACGCGCCACCCTCGGGGCGCCGACGGTCACGGAGCATGGGGTCGGCCTTTGAGCGGGTAGTCCGGA GAGTGGTCCAGGAGCTGGACCATGGTGGGGAGTTCATCCCTGTGACCAGCCTGCAGAGCTCCACTGGCTTCCAGCCCTACTGCCTGGTGG TTAGGAAGCCCTCAAGCTCATGGTTCTGGAAACCCCGTTATAAGTGTGTCAACCTGTCTATCAAGGACATCCTGGAGCCGGATGCCGCGG AACCAGACGTGCAGCGTGGCAGGAGCTTCCACTTCTACGATGCCATGGATGGGCAGATACAGGGCAGCGTGGAGCTGGCAGCCCCAGGAC AGGCAAAGATCGCAGGCGGGGCCGCGGTGTCTGACAGCTCCAGCACCTCAATGAATGTGTACTCGCTGAGTGTGGACCCTAACACCTGGC AGACTCTGCTCCATGAGAGGCACCTGCGGCAGCCAGAACACAAAGTCCTGCAGCAGCTGCGCAGCCGCGGGGACAACGTGTACGTGGTGA CTGAGGTGCTGCAGACACAGAAGGAGGTGGAAGTCACGCGCACCCACAAGCGGGAGGGCTCGGGCCGGTTTTCCCTGCCCGGAGCCACGT GCTTGCAGGGTGAGGGCCAGGGCCATCTGAGCCAGAAGAAGACGGTCACCATCCCCTCAGGCAGCACCCTCGCATTCCGGGTGGCCCAGC TGGTTATTGACTCTGACTTGGACGTCCTTCTCTTCCCGGATAAGAAGCAGAGGACCTTCCAGCCACCCGCGACAGGCCACAAGCGTTCCA CGAGCGAAGGCGCCTGGCCACAGCTGCCCTCTGGCCTCTCCATGATGAGGTGCCTCCACAACTTCCTGACAGGTGCCAGCTGCTGCTGGA GGGCCTGGAGGGGGTGCTGCGGGACCAGCTGGCCCTGCGAGCCTTGGAGGAGGCGGAGCCAGCTCCCGTGCTGTCCTCCCCACCTCCTGC AGACGTCTCCACCTTCCTGGCTTTTCCCTCTCCAGAGAAGCTGCTGCGCCTAGGGCCCAAGAGCTCCGTGCTGATAGCCCAGCAGACTGA CACGTCTGACCCCGAGAAGGTGGTCTCTGCCTTCCTAAAGGTGTCATCTGTGTTCAAGGACGAAGCTACTGTGAGGATGGCAGTGCAGGA TGCAGTAGATGCCCTGATGCAGAAGGCTTTCAACTCCTCGTCCTTCAACTCCAACACCTTCCTCACCAGGCTGCTCGTGCACATGGGTCT GCTCAAGAGTGAAGACAAGGTCAAGGCCATTGCCAACCTGTACGGCCCCCTGATGGCGCTGAACCACATGGTGCAGCAGGACTATTTCCC CAAGGCCCTTGCACCCCTGCTGCTGGCGTTCGTGACCAAGCCCAACAGCGCCCTGGAATCCTGCTCCTTCGCCCGCCACAGTCTGCTGCA GACGCTGTACAAGGTCTAGACTCAAAGCCTCTCCCATCCCTTGGCCTGGACCAGTGAGCTGGGGAGGGACTCGGATGAACTGAGGCGCAG >34995_34995_3_GSDMD-RANGAP1_GSDMD_chr8_144644228_ENST00000262580_RANGAP1_chr22_41648995_ENST00000407260_length(amino acids)=352AA_BP=323 MLAGRLPGRADAPDAPPSGRRRSRSMGSAFERVVRRVVQELDHGGEFIPVTSLQSSTGFQPYCLVVRKPSSSWFWKPRYKCVNLSIKDIL EPDAAEPDVQRGRSFHFYDAMDGQIQGSVELAAPGQAKIAGGAAVSDSSSTSMNVYSLSVDPNTWQTLLHERHLRQPEHKVLQQLRSRGD NVYVVTEVLQTQKEVEVTRTHKREGSGRFSLPGATCLQGEGQGHLSQKKTVTIPSGSTLAFRVAQLVIDSDLDVLLFPDKKQRTFQPPAT -------------------------------------------------------------- >34995_34995_4_GSDMD-RANGAP1_GSDMD_chr8_144644228_ENST00000262580_RANGAP1_chr22_41648995_ENST00000455915_length(transcript)=2537nt_BP=1045nt GTTCCGGGAGGGCGTCCTGGGCGGGCCCTGCGTCAGGTTGCAGTTTCACTTTTAGCTCTGGGCACCTCCAGCTCCTGCTCGCCGGACGGC TCCCAGGGAGAGCAGACGCGCCAGACGCGCCACCCTCGGGGCGCCGACGGTCACGGAGCATGGGGTCGGCCTTTGAGCGGGTAGTCCGGA GAGTGGTCCAGGAGCTGGACCATGGTGGGGAGTTCATCCCTGTGACCAGCCTGCAGAGCTCCACTGGCTTCCAGCCCTACTGCCTGGTGG TTAGGAAGCCCTCAAGCTCATGGTTCTGGAAACCCCGTTATAAGTGTGTCAACCTGTCTATCAAGGACATCCTGGAGCCGGATGCCGCGG AACCAGACGTGCAGCGTGGCAGGAGCTTCCACTTCTACGATGCCATGGATGGGCAGATACAGGGCAGCGTGGAGCTGGCAGCCCCAGGAC AGGCAAAGATCGCAGGCGGGGCCGCGGTGTCTGACAGCTCCAGCACCTCAATGAATGTGTACTCGCTGAGTGTGGACCCTAACACCTGGC AGACTCTGCTCCATGAGAGGCACCTGCGGCAGCCAGAACACAAAGTCCTGCAGCAGCTGCGCAGCCGCGGGGACAACGTGTACGTGGTGA CTGAGGTGCTGCAGACACAGAAGGAGGTGGAAGTCACGCGCACCCACAAGCGGGAGGGCTCGGGCCGGTTTTCCCTGCCCGGAGCCACGT GCTTGCAGGGTGAGGGCCAGGGCCATCTGAGCCAGAAGAAGACGGTCACCATCCCCTCAGGCAGCACCCTCGCATTCCGGGTGGCCCAGC TGGTTATTGACTCTGACTTGGACGTCCTTCTCTTCCCGGATAAGAAGCAGAGGACCTTCCAGCCACCCGCGACAGGCCACAAGCGTTCCA CGAGCGAAGGCGCCTGGCCACAGCTGCCCTCTGGCCTCTCCATGATGAGGTGCCTCCACAACTTCCTGACAGGTGCCAGCTGCTGCTGGA GGGCCTGGAGGGGGTGCTGCGGGACCAGCTGGCCCTGCGAGCCTTGGAGGAGGCGGAGCCAGCTCCCGTGCTGTCCTCCCCACCTCCTGC AGACGTCTCCACCTTCCTGGCTTTTCCCTCTCCAGAGAAGCTGCTGCGCCTAGGGCCCAAGAGCTCCGTGCTGATAGCCCAGCAGACTGA CACGTCTGACCCCGAGAAGGTGGTCTCTGCCTTCCTAAAGGTGTCATCTGTGTTCAAGGACGAAGCTACTGTGAGGATGGCAGTGCAGGA TGCAGTAGATGCCCTGATGCAGAAGGCTTTCAACTCCTCGTCCTTCAACTCCAACACCTTCCTCACCAGGCTGCTCGTGCACATGGGTCT GCTCAAGAGTGAAGACAAGGTCAAGGCCATTGCCAACCTGTACGGCCCCCTGATGGCGCTGAACCACATGGTGCAGCAGGACTATTTCCC CAAGGCCCTTGCACCCCTGCTGCTGGCGTTCGTGACCAAGCCCAACAGCGCCCTGGAATCCTGCTCCTTCGCCCGCCACAGTCTGCTGCA GACGCTGTACAAGGTCTAGACTCAAAGCCTCTCCCATCCCTTGGCCTGGACCAGTGAGCTGGGGAGGGACTCGGATGAACTGAGGCGCAG CCTACGCCATTGCCTTGGACAGGACTCTGGCCACAGGCAGGGCGGGTCTGTGTCCCATGTGTCCTGTCAGTCCCCTGAGTATGTGTGTGG GTGTGGCGCATGTGCAGGTCTGTGCCTCCTGTCGGGATTTGGGTTTTAACGTCTTCTGCTGGCCCAGCCCTGCTCTGTTGTGGGGAGTTG GCCCCCAGGGGAAAGGGCTGTGAGCTGCTCCGCCATTAAACTCACCTCCACCTGAGGGCGCTCTGCTGATCTCCGCCTGGGCCCTGATGG CCGTCCCCACCCACCTGCCTTCCGGCCCGGCTCCCTGGCGGAGCCAGAACCCAGGGAGTTGCCCGCGTGCTGTCCTTCCCCTCTGTGTTG TGATTGGGTTGTTTCCTGCCCTGCCTGGGGCTGCTTCTCGTCACCAAGCCCTGGTCCTGCGGCAGCTGTCACCCCTACCATCCATACCAC TGTGCTGACCGCTCAGCCTGAAGAGCAGAGAATGCCATGGGTGGGACTGTGGGGGTCGGATCGTGGGGTTGTTGGCAGAGGGCAACCCTG GGCCCCACACCGTGTGGACAGGCAGACACCAGATTGTCCAGGAGCAGGAGCTGCTGGGACTGCGCTGGCCCCGGACCTAGTGGGCCTTCT CCTGGCTGCTGAGATGTCGTCTGTGACTGGCCTGGCTGGAGGGGGAGTGTTGACAACCCAAAGCTGTTCTCCAGTCTGGGGAGGGAGAGG CAGGGTCCCCAATGTCCGAGCTGCATCTGGACGCTGCTCTTAAAGGACCTCCTGGGGCAGGGGAGCGGTAGGGTCTGGACTGGGCAGATG CTGTATGACCTCCCTGAGCACCCGTGACTGCCCCATGCTTTCCCCTTTGTGCTCTGTGTGTGTCTGGGCTGTGCCCGGGGGCTTCACAAA >34995_34995_4_GSDMD-RANGAP1_GSDMD_chr8_144644228_ENST00000262580_RANGAP1_chr22_41648995_ENST00000455915_length(amino acids)=352AA_BP=323 MLAGRLPGRADAPDAPPSGRRRSRSMGSAFERVVRRVVQELDHGGEFIPVTSLQSSTGFQPYCLVVRKPSSSWFWKPRYKCVNLSIKDIL EPDAAEPDVQRGRSFHFYDAMDGQIQGSVELAAPGQAKIAGGAAVSDSSSTSMNVYSLSVDPNTWQTLLHERHLRQPEHKVLQQLRSRGD NVYVVTEVLQTQKEVEVTRTHKREGSGRFSLPGATCLQGEGQGHLSQKKTVTIPSGSTLAFRVAQLVIDSDLDVLLFPDKKQRTFQPPAT -------------------------------------------------------------- >34995_34995_5_GSDMD-RANGAP1_GSDMD_chr8_144644228_ENST00000526406_RANGAP1_chr22_41648995_ENST00000356244_length(transcript)=3275nt_BP=1779nt CTTCCCGGCTCGGGGATTACCTCTCTGGCTGGTCCCCTCCTCCGTGCTCTGCGCGCCTCCACCCTAGCGCTTGTCTTGGCTCCTAGAACC AGGGGCCTGGACGCTGCTCAGGGCAGAGGCGCCCCCTCTGAGGGGCTGGCCCCTCAGCCGCACTCCGAGACAGCCGCCCCCGGGACCGCC CTTCCTTGGAGCCCCGCCGCCCGCCGCTCACTCTGCACACGCAGCAGAAGGGACGTGGTGTTCCCCAGGCTCTGGCCCCCCAGGACCTGC GCGGATCTGGCCCAGGGCGCCTCGCCGACTTCCGTAAACTGGGCGGAGGGATGAACCCCGACCCAGGGGACGGAGGCGCTCGCCCTCTCG CTGCAGGGTTCTGCCCTCAACACTTCTGGCCCCGCCTGTGAATGGGGGCCGGAGCGATGGGGCGGGGCCGGCCTCCCTCCCTCCTCCCAG GCTGACCTCTGCCCTCCTTCGAGCACTTCCCGTTCGGGGTGATGATTGAAGAACTGAGTGTGGACAGAGCACCTGTCCTCGCCAGCGCCC AGCTGGAAGCTGAGTTATTTGTGGCTGCAGCATTCCAACGCACACACCACCAGAAATCCCCTTCAGCATACTGGCCTCAGACCTACCAGG GCAGAGACCTTGTCTTGTTTGCTGCTAGAACCCAGGATCGCTGGAAAATCACCTAGCAGCAGCCAGGTGCGGTGACTCACGCCTGTAATC CCAGCACTTTGGAAGGCCAAGGCGGGTGGATAGCAAGGTCAAGAGATCGAGACCAGCCTGGCCAACATGCTCTGGGCACCTCCAGCTCCT GCTCGCCGGACGGCTCCCAGGGAGAGCAGACGCGCCAGACGCGCCACCCTCGGGGCGCCGACGGTCACGGAGCATGGGGTCGGCCTTTGA GCGGGTAGTCCGGAGAGTGGTCCAGGAGCTGGACCATGGTGGGGAGTTCATCCCTGTGACCAGCCTGCAGAGCTCCACTGGCTTCCAGCC CTACTGCCTGGTGGTTAGGAAGCCCTCAAGCTCATGGTTCTGGAAACCCCGTTATAAGTGTGTCAACCTGTCTATCAAGGACATCCTGGA GCCGGATGCCGCGGAACCAGACGTGCAGCGTGGCAGGAGCTTCCACTTCTACGATGCCATGGATGGGCAGATACAGGGCAGCGTGGAGCT GGCAGCCCCAGGACAGGCAAAGATCGCAGGCGGGGCCGCGGTGTCTGACAGCTCCAGCACCTCAATGAATGTGTACTCGCTGAGTGTGGA CCCTAACACCTGGCAGACTCTGCTCCATGAGAGGCACCTGCGGCAGCCAGAACACAAAGTCCTGCAGCAGCTGCGCAGCCGCGGGGACAA CGTGTACGTGGTGACTGAGGTGCTGCAGACACAGAAGGAGGTGGAAGTCACGCGCACCCACAAGCGGGAGGGCTCGGGCCGGTTTTCCCT GCCCGGAGCCACGTGCTTGCAGGGTGAGGGCCAGGGCCATCTGAGCCAGAAGAAGACGGTCACCATCCCCTCAGGCAGCACCCTCGCATT CCGGGTGGCCCAGCTGGTTATTGACTCTGACTTGGACGTCCTTCTCTTCCCGGATAAGAAGCAGAGGACCTTCCAGCCACCCGCGACAGG CCACAAGCGTTCCACGAGCGAAGGCGCCTGGCCACAGCTGCCCTCTGGCCTCTCCATGATGAGGTGCCTCCACAACTTCCTGACAGGTGC CAGCTGCTGCTGGAGGGCCTGGAGGGGGTGCTGCGGGACCAGCTGGCCCTGCGAGCCTTGGAGGAGGCGGAGCCAGCTCCCGTGCTGTCC TCCCCACCTCCTGCAGACGTCTCCACCTTCCTGGCTTTTCCCTCTCCAGAGAAGCTGCTGCGCCTAGGGCCCAAGAGCTCCGTGCTGATA GCCCAGCAGACTGACACGTCTGACCCCGAGAAGGTGGTCTCTGCCTTCCTAAAGGTGTCATCTGTGTTCAAGGACGAAGCTACTGTGAGG ATGGCAGTGCAGGATGCAGTAGATGCCCTGATGCAGAAGGCTTTCAACTCCTCGTCCTTCAACTCCAACACCTTCCTCACCAGGCTGCTC GTGCACATGGGTCTGCTCAAGAGTGAAGACAAGGTCAAGGCCATTGCCAACCTGTACGGCCCCCTGATGGCGCTGAACCACATGGTGCAG CAGGACTATTTCCCCAAGGCCCTTGCACCCCTGCTGCTGGCGTTCGTGACCAAGCCCAACAGCGCCCTGGAATCCTGCTCCTTCGCCCGC CACAGTCTGCTGCAGACGCTGTACAAGGTCTAGACTCAAAGCCTCTCCCATCCCTTGGCCTGGACCAGTGAGCTGGGGAGGGACTCGGAT GAACTGAGGCGCAGCCTACGCCATTGCCTTGGACAGGACTCTGGCCACAGGCAGGGCGGGTCTGTGTCCCATGTGTCCTGTCAGTCCCCT GAGTATGTGTGTGGGTGTGGCGCATGTGCAGGTCTGTGCCTCCTGTCGGGATTTGGGTTTTAACGTCTTCTGCTGGCCCAGCCCTGCTCT GTTGTGGGGAGTTGGCCCCCAGGGGAAAGGGCTGTGAGCTGCTCCGCCATTAAACTCACCTCCACCTGAGGGCGCTCTGCTGATCTCCGC CTGGGCCCTGATGGCCGTCCCCACCCACCTGCCTTCCGGCCCGGCTCCCTGGCGGAGCCAGAACCCAGGGAGTTGCCCGCGTGCTGTCCT TCCCCTCTGTGTTGTGATTGGGTTGTTTCCTGCCCTGCCTGGGGCTGCTTCTCGTCACCAAGCCCTGGTCCTGCGGCAGCTGTCACCCCT ACCATCCATACCACTGTGCTGACCGCTCAGCCTGAAGAGCAGAGAATGCCATGGGTGGGACTGTGGGGGTCGGATCGTGGGGTTGTTGGC AGAGGGCAACCCTGGGCCCCACACCGTGTGGACAGGCAGACACCAGATTGTCCAGGAGCAGGAGCTGCTGGGACTGCGCTGGCCCCGGAC CTAGTGGGCCTTCTCCTGGCTGCTGAGATGTCGTCTGTGACTGGCCTGGCTGGAGGGGGAGTGTTGACAACCCAAAGCTGTTCTCCAGTC TGGGGAGGGAGAGGCAGGGTCCCCAATGTCCGAGCTGCATCTGGACGCTGCTCTTAAAGGACCTCCTGGGGCAGGGGAGCGGTAGGGTCT GGACTGGGCAGATGCTGTATGACCTCCCTGAGCACCCGTGACTGCCCCATGCTTTCCCCTTTGTGCTCTGTGTGTGTCTGGGCTGTGCCC >34995_34995_5_GSDMD-RANGAP1_GSDMD_chr8_144644228_ENST00000526406_RANGAP1_chr22_41648995_ENST00000356244_length(amino acids)=352AA_BP=323 MLAGRLPGRADAPDAPPSGRRRSRSMGSAFERVVRRVVQELDHGGEFIPVTSLQSSTGFQPYCLVVRKPSSSWFWKPRYKCVNLSIKDIL EPDAAEPDVQRGRSFHFYDAMDGQIQGSVELAAPGQAKIAGGAAVSDSSSTSMNVYSLSVDPNTWQTLLHERHLRQPEHKVLQQLRSRGD NVYVVTEVLQTQKEVEVTRTHKREGSGRFSLPGATCLQGEGQGHLSQKKTVTIPSGSTLAFRVAQLVIDSDLDVLLFPDKKQRTFQPPAT -------------------------------------------------------------- >34995_34995_6_GSDMD-RANGAP1_GSDMD_chr8_144644228_ENST00000526406_RANGAP1_chr22_41648995_ENST00000405486_length(transcript)=3275nt_BP=1779nt CTTCCCGGCTCGGGGATTACCTCTCTGGCTGGTCCCCTCCTCCGTGCTCTGCGCGCCTCCACCCTAGCGCTTGTCTTGGCTCCTAGAACC AGGGGCCTGGACGCTGCTCAGGGCAGAGGCGCCCCCTCTGAGGGGCTGGCCCCTCAGCCGCACTCCGAGACAGCCGCCCCCGGGACCGCC CTTCCTTGGAGCCCCGCCGCCCGCCGCTCACTCTGCACACGCAGCAGAAGGGACGTGGTGTTCCCCAGGCTCTGGCCCCCCAGGACCTGC GCGGATCTGGCCCAGGGCGCCTCGCCGACTTCCGTAAACTGGGCGGAGGGATGAACCCCGACCCAGGGGACGGAGGCGCTCGCCCTCTCG CTGCAGGGTTCTGCCCTCAACACTTCTGGCCCCGCCTGTGAATGGGGGCCGGAGCGATGGGGCGGGGCCGGCCTCCCTCCCTCCTCCCAG GCTGACCTCTGCCCTCCTTCGAGCACTTCCCGTTCGGGGTGATGATTGAAGAACTGAGTGTGGACAGAGCACCTGTCCTCGCCAGCGCCC AGCTGGAAGCTGAGTTATTTGTGGCTGCAGCATTCCAACGCACACACCACCAGAAATCCCCTTCAGCATACTGGCCTCAGACCTACCAGG GCAGAGACCTTGTCTTGTTTGCTGCTAGAACCCAGGATCGCTGGAAAATCACCTAGCAGCAGCCAGGTGCGGTGACTCACGCCTGTAATC CCAGCACTTTGGAAGGCCAAGGCGGGTGGATAGCAAGGTCAAGAGATCGAGACCAGCCTGGCCAACATGCTCTGGGCACCTCCAGCTCCT GCTCGCCGGACGGCTCCCAGGGAGAGCAGACGCGCCAGACGCGCCACCCTCGGGGCGCCGACGGTCACGGAGCATGGGGTCGGCCTTTGA GCGGGTAGTCCGGAGAGTGGTCCAGGAGCTGGACCATGGTGGGGAGTTCATCCCTGTGACCAGCCTGCAGAGCTCCACTGGCTTCCAGCC CTACTGCCTGGTGGTTAGGAAGCCCTCAAGCTCATGGTTCTGGAAACCCCGTTATAAGTGTGTCAACCTGTCTATCAAGGACATCCTGGA GCCGGATGCCGCGGAACCAGACGTGCAGCGTGGCAGGAGCTTCCACTTCTACGATGCCATGGATGGGCAGATACAGGGCAGCGTGGAGCT GGCAGCCCCAGGACAGGCAAAGATCGCAGGCGGGGCCGCGGTGTCTGACAGCTCCAGCACCTCAATGAATGTGTACTCGCTGAGTGTGGA CCCTAACACCTGGCAGACTCTGCTCCATGAGAGGCACCTGCGGCAGCCAGAACACAAAGTCCTGCAGCAGCTGCGCAGCCGCGGGGACAA CGTGTACGTGGTGACTGAGGTGCTGCAGACACAGAAGGAGGTGGAAGTCACGCGCACCCACAAGCGGGAGGGCTCGGGCCGGTTTTCCCT GCCCGGAGCCACGTGCTTGCAGGGTGAGGGCCAGGGCCATCTGAGCCAGAAGAAGACGGTCACCATCCCCTCAGGCAGCACCCTCGCATT CCGGGTGGCCCAGCTGGTTATTGACTCTGACTTGGACGTCCTTCTCTTCCCGGATAAGAAGCAGAGGACCTTCCAGCCACCCGCGACAGG CCACAAGCGTTCCACGAGCGAAGGCGCCTGGCCACAGCTGCCCTCTGGCCTCTCCATGATGAGGTGCCTCCACAACTTCCTGACAGGTGC CAGCTGCTGCTGGAGGGCCTGGAGGGGGTGCTGCGGGACCAGCTGGCCCTGCGAGCCTTGGAGGAGGCGGAGCCAGCTCCCGTGCTGTCC TCCCCACCTCCTGCAGACGTCTCCACCTTCCTGGCTTTTCCCTCTCCAGAGAAGCTGCTGCGCCTAGGGCCCAAGAGCTCCGTGCTGATA GCCCAGCAGACTGACACGTCTGACCCCGAGAAGGTGGTCTCTGCCTTCCTAAAGGTGTCATCTGTGTTCAAGGACGAAGCTACTGTGAGG ATGGCAGTGCAGGATGCAGTAGATGCCCTGATGCAGAAGGCTTTCAACTCCTCGTCCTTCAACTCCAACACCTTCCTCACCAGGCTGCTC GTGCACATGGGTCTGCTCAAGAGTGAAGACAAGGTCAAGGCCATTGCCAACCTGTACGGCCCCCTGATGGCGCTGAACCACATGGTGCAG CAGGACTATTTCCCCAAGGCCCTTGCACCCCTGCTGCTGGCGTTCGTGACCAAGCCCAACAGCGCCCTGGAATCCTGCTCCTTCGCCCGC CACAGTCTGCTGCAGACGCTGTACAAGGTCTAGACTCAAAGCCTCTCCCATCCCTTGGCCTGGACCAGTGAGCTGGGGAGGGACTCGGAT GAACTGAGGCGCAGCCTACGCCATTGCCTTGGACAGGACTCTGGCCACAGGCAGGGCGGGTCTGTGTCCCATGTGTCCTGTCAGTCCCCT GAGTATGTGTGTGGGTGTGGCGCATGTGCAGGTCTGTGCCTCCTGTCGGGATTTGGGTTTTAACGTCTTCTGCTGGCCCAGCCCTGCTCT GTTGTGGGGAGTTGGCCCCCAGGGGAAAGGGCTGTGAGCTGCTCCGCCATTAAACTCACCTCCACCTGAGGGCGCTCTGCTGATCTCCGC CTGGGCCCTGATGGCCGTCCCCACCCACCTGCCTTCCGGCCCGGCTCCCTGGCGGAGCCAGAACCCAGGGAGTTGCCCGCGTGCTGTCCT TCCCCTCTGTGTTGTGATTGGGTTGTTTCCTGCCCTGCCTGGGGCTGCTTCTCGTCACCAAGCCCTGGTCCTGCGGCAGCTGTCACCCCT ACCATCCATACCACTGTGCTGACCGCTCAGCCTGAAGAGCAGAGAATGCCATGGGTGGGACTGTGGGGGTCGGATCGTGGGGTTGTTGGC AGAGGGCAACCCTGGGCCCCACACCGTGTGGACAGGCAGACACCAGATTGTCCAGGAGCAGGAGCTGCTGGGACTGCGCTGGCCCCGGAC CTAGTGGGCCTTCTCCTGGCTGCTGAGATGTCGTCTGTGACTGGCCTGGCTGGAGGGGGAGTGTTGACAACCCAAAGCTGTTCTCCAGTC TGGGGAGGGAGAGGCAGGGTCCCCAATGTCCGAGCTGCATCTGGACGCTGCTCTTAAAGGACCTCCTGGGGCAGGGGAGCGGTAGGGTCT GGACTGGGCAGATGCTGTATGACCTCCCTGAGCACCCGTGACTGCCCCATGCTTTCCCCTTTGTGCTCTGTGTGTGTCTGGGCTGTGCCC >34995_34995_6_GSDMD-RANGAP1_GSDMD_chr8_144644228_ENST00000526406_RANGAP1_chr22_41648995_ENST00000405486_length(amino acids)=352AA_BP=323 MLAGRLPGRADAPDAPPSGRRRSRSMGSAFERVVRRVVQELDHGGEFIPVTSLQSSTGFQPYCLVVRKPSSSWFWKPRYKCVNLSIKDIL EPDAAEPDVQRGRSFHFYDAMDGQIQGSVELAAPGQAKIAGGAAVSDSSSTSMNVYSLSVDPNTWQTLLHERHLRQPEHKVLQQLRSRGD NVYVVTEVLQTQKEVEVTRTHKREGSGRFSLPGATCLQGEGQGHLSQKKTVTIPSGSTLAFRVAQLVIDSDLDVLLFPDKKQRTFQPPAT -------------------------------------------------------------- >34995_34995_7_GSDMD-RANGAP1_GSDMD_chr8_144644228_ENST00000526406_RANGAP1_chr22_41648995_ENST00000407260_length(transcript)=2443nt_BP=1779nt CTTCCCGGCTCGGGGATTACCTCTCTGGCTGGTCCCCTCCTCCGTGCTCTGCGCGCCTCCACCCTAGCGCTTGTCTTGGCTCCTAGAACC AGGGGCCTGGACGCTGCTCAGGGCAGAGGCGCCCCCTCTGAGGGGCTGGCCCCTCAGCCGCACTCCGAGACAGCCGCCCCCGGGACCGCC CTTCCTTGGAGCCCCGCCGCCCGCCGCTCACTCTGCACACGCAGCAGAAGGGACGTGGTGTTCCCCAGGCTCTGGCCCCCCAGGACCTGC GCGGATCTGGCCCAGGGCGCCTCGCCGACTTCCGTAAACTGGGCGGAGGGATGAACCCCGACCCAGGGGACGGAGGCGCTCGCCCTCTCG CTGCAGGGTTCTGCCCTCAACACTTCTGGCCCCGCCTGTGAATGGGGGCCGGAGCGATGGGGCGGGGCCGGCCTCCCTCCCTCCTCCCAG GCTGACCTCTGCCCTCCTTCGAGCACTTCCCGTTCGGGGTGATGATTGAAGAACTGAGTGTGGACAGAGCACCTGTCCTCGCCAGCGCCC AGCTGGAAGCTGAGTTATTTGTGGCTGCAGCATTCCAACGCACACACCACCAGAAATCCCCTTCAGCATACTGGCCTCAGACCTACCAGG GCAGAGACCTTGTCTTGTTTGCTGCTAGAACCCAGGATCGCTGGAAAATCACCTAGCAGCAGCCAGGTGCGGTGACTCACGCCTGTAATC CCAGCACTTTGGAAGGCCAAGGCGGGTGGATAGCAAGGTCAAGAGATCGAGACCAGCCTGGCCAACATGCTCTGGGCACCTCCAGCTCCT GCTCGCCGGACGGCTCCCAGGGAGAGCAGACGCGCCAGACGCGCCACCCTCGGGGCGCCGACGGTCACGGAGCATGGGGTCGGCCTTTGA GCGGGTAGTCCGGAGAGTGGTCCAGGAGCTGGACCATGGTGGGGAGTTCATCCCTGTGACCAGCCTGCAGAGCTCCACTGGCTTCCAGCC CTACTGCCTGGTGGTTAGGAAGCCCTCAAGCTCATGGTTCTGGAAACCCCGTTATAAGTGTGTCAACCTGTCTATCAAGGACATCCTGGA GCCGGATGCCGCGGAACCAGACGTGCAGCGTGGCAGGAGCTTCCACTTCTACGATGCCATGGATGGGCAGATACAGGGCAGCGTGGAGCT GGCAGCCCCAGGACAGGCAAAGATCGCAGGCGGGGCCGCGGTGTCTGACAGCTCCAGCACCTCAATGAATGTGTACTCGCTGAGTGTGGA CCCTAACACCTGGCAGACTCTGCTCCATGAGAGGCACCTGCGGCAGCCAGAACACAAAGTCCTGCAGCAGCTGCGCAGCCGCGGGGACAA CGTGTACGTGGTGACTGAGGTGCTGCAGACACAGAAGGAGGTGGAAGTCACGCGCACCCACAAGCGGGAGGGCTCGGGCCGGTTTTCCCT GCCCGGAGCCACGTGCTTGCAGGGTGAGGGCCAGGGCCATCTGAGCCAGAAGAAGACGGTCACCATCCCCTCAGGCAGCACCCTCGCATT CCGGGTGGCCCAGCTGGTTATTGACTCTGACTTGGACGTCCTTCTCTTCCCGGATAAGAAGCAGAGGACCTTCCAGCCACCCGCGACAGG CCACAAGCGTTCCACGAGCGAAGGCGCCTGGCCACAGCTGCCCTCTGGCCTCTCCATGATGAGGTGCCTCCACAACTTCCTGACAGGTGC CAGCTGCTGCTGGAGGGCCTGGAGGGGGTGCTGCGGGACCAGCTGGCCCTGCGAGCCTTGGAGGAGGCGGAGCCAGCTCCCGTGCTGTCC TCCCCACCTCCTGCAGACGTCTCCACCTTCCTGGCTTTTCCCTCTCCAGAGAAGCTGCTGCGCCTAGGGCCCAAGAGCTCCGTGCTGATA GCCCAGCAGACTGACACGTCTGACCCCGAGAAGGTGGTCTCTGCCTTCCTAAAGGTGTCATCTGTGTTCAAGGACGAAGCTACTGTGAGG ATGGCAGTGCAGGATGCAGTAGATGCCCTGATGCAGAAGGCTTTCAACTCCTCGTCCTTCAACTCCAACACCTTCCTCACCAGGCTGCTC GTGCACATGGGTCTGCTCAAGAGTGAAGACAAGGTCAAGGCCATTGCCAACCTGTACGGCCCCCTGATGGCGCTGAACCACATGGTGCAG CAGGACTATTTCCCCAAGGCCCTTGCACCCCTGCTGCTGGCGTTCGTGACCAAGCCCAACAGCGCCCTGGAATCCTGCTCCTTCGCCCGC CACAGTCTGCTGCAGACGCTGTACAAGGTCTAGACTCAAAGCCTCTCCCATCCCTTGGCCTGGACCAGTGAGCTGGGGAGGGACTCGGAT GAACTGAGGCGCAGCCTACGCCATTGCCTTGGACAGGACTCTGGCCACAGGCAGGGCGGGTCTGTGTCCCATGTGTCCTGTCAGTCCCCT >34995_34995_7_GSDMD-RANGAP1_GSDMD_chr8_144644228_ENST00000526406_RANGAP1_chr22_41648995_ENST00000407260_length(amino acids)=352AA_BP=323 MLAGRLPGRADAPDAPPSGRRRSRSMGSAFERVVRRVVQELDHGGEFIPVTSLQSSTGFQPYCLVVRKPSSSWFWKPRYKCVNLSIKDIL EPDAAEPDVQRGRSFHFYDAMDGQIQGSVELAAPGQAKIAGGAAVSDSSSTSMNVYSLSVDPNTWQTLLHERHLRQPEHKVLQQLRSRGD NVYVVTEVLQTQKEVEVTRTHKREGSGRFSLPGATCLQGEGQGHLSQKKTVTIPSGSTLAFRVAQLVIDSDLDVLLFPDKKQRTFQPPAT -------------------------------------------------------------- >34995_34995_8_GSDMD-RANGAP1_GSDMD_chr8_144644228_ENST00000526406_RANGAP1_chr22_41648995_ENST00000455915_length(transcript)=3271nt_BP=1779nt CTTCCCGGCTCGGGGATTACCTCTCTGGCTGGTCCCCTCCTCCGTGCTCTGCGCGCCTCCACCCTAGCGCTTGTCTTGGCTCCTAGAACC AGGGGCCTGGACGCTGCTCAGGGCAGAGGCGCCCCCTCTGAGGGGCTGGCCCCTCAGCCGCACTCCGAGACAGCCGCCCCCGGGACCGCC CTTCCTTGGAGCCCCGCCGCCCGCCGCTCACTCTGCACACGCAGCAGAAGGGACGTGGTGTTCCCCAGGCTCTGGCCCCCCAGGACCTGC GCGGATCTGGCCCAGGGCGCCTCGCCGACTTCCGTAAACTGGGCGGAGGGATGAACCCCGACCCAGGGGACGGAGGCGCTCGCCCTCTCG CTGCAGGGTTCTGCCCTCAACACTTCTGGCCCCGCCTGTGAATGGGGGCCGGAGCGATGGGGCGGGGCCGGCCTCCCTCCCTCCTCCCAG GCTGACCTCTGCCCTCCTTCGAGCACTTCCCGTTCGGGGTGATGATTGAAGAACTGAGTGTGGACAGAGCACCTGTCCTCGCCAGCGCCC AGCTGGAAGCTGAGTTATTTGTGGCTGCAGCATTCCAACGCACACACCACCAGAAATCCCCTTCAGCATACTGGCCTCAGACCTACCAGG GCAGAGACCTTGTCTTGTTTGCTGCTAGAACCCAGGATCGCTGGAAAATCACCTAGCAGCAGCCAGGTGCGGTGACTCACGCCTGTAATC CCAGCACTTTGGAAGGCCAAGGCGGGTGGATAGCAAGGTCAAGAGATCGAGACCAGCCTGGCCAACATGCTCTGGGCACCTCCAGCTCCT GCTCGCCGGACGGCTCCCAGGGAGAGCAGACGCGCCAGACGCGCCACCCTCGGGGCGCCGACGGTCACGGAGCATGGGGTCGGCCTTTGA GCGGGTAGTCCGGAGAGTGGTCCAGGAGCTGGACCATGGTGGGGAGTTCATCCCTGTGACCAGCCTGCAGAGCTCCACTGGCTTCCAGCC CTACTGCCTGGTGGTTAGGAAGCCCTCAAGCTCATGGTTCTGGAAACCCCGTTATAAGTGTGTCAACCTGTCTATCAAGGACATCCTGGA GCCGGATGCCGCGGAACCAGACGTGCAGCGTGGCAGGAGCTTCCACTTCTACGATGCCATGGATGGGCAGATACAGGGCAGCGTGGAGCT GGCAGCCCCAGGACAGGCAAAGATCGCAGGCGGGGCCGCGGTGTCTGACAGCTCCAGCACCTCAATGAATGTGTACTCGCTGAGTGTGGA CCCTAACACCTGGCAGACTCTGCTCCATGAGAGGCACCTGCGGCAGCCAGAACACAAAGTCCTGCAGCAGCTGCGCAGCCGCGGGGACAA CGTGTACGTGGTGACTGAGGTGCTGCAGACACAGAAGGAGGTGGAAGTCACGCGCACCCACAAGCGGGAGGGCTCGGGCCGGTTTTCCCT GCCCGGAGCCACGTGCTTGCAGGGTGAGGGCCAGGGCCATCTGAGCCAGAAGAAGACGGTCACCATCCCCTCAGGCAGCACCCTCGCATT CCGGGTGGCCCAGCTGGTTATTGACTCTGACTTGGACGTCCTTCTCTTCCCGGATAAGAAGCAGAGGACCTTCCAGCCACCCGCGACAGG CCACAAGCGTTCCACGAGCGAAGGCGCCTGGCCACAGCTGCCCTCTGGCCTCTCCATGATGAGGTGCCTCCACAACTTCCTGACAGGTGC CAGCTGCTGCTGGAGGGCCTGGAGGGGGTGCTGCGGGACCAGCTGGCCCTGCGAGCCTTGGAGGAGGCGGAGCCAGCTCCCGTGCTGTCC TCCCCACCTCCTGCAGACGTCTCCACCTTCCTGGCTTTTCCCTCTCCAGAGAAGCTGCTGCGCCTAGGGCCCAAGAGCTCCGTGCTGATA GCCCAGCAGACTGACACGTCTGACCCCGAGAAGGTGGTCTCTGCCTTCCTAAAGGTGTCATCTGTGTTCAAGGACGAAGCTACTGTGAGG ATGGCAGTGCAGGATGCAGTAGATGCCCTGATGCAGAAGGCTTTCAACTCCTCGTCCTTCAACTCCAACACCTTCCTCACCAGGCTGCTC GTGCACATGGGTCTGCTCAAGAGTGAAGACAAGGTCAAGGCCATTGCCAACCTGTACGGCCCCCTGATGGCGCTGAACCACATGGTGCAG CAGGACTATTTCCCCAAGGCCCTTGCACCCCTGCTGCTGGCGTTCGTGACCAAGCCCAACAGCGCCCTGGAATCCTGCTCCTTCGCCCGC CACAGTCTGCTGCAGACGCTGTACAAGGTCTAGACTCAAAGCCTCTCCCATCCCTTGGCCTGGACCAGTGAGCTGGGGAGGGACTCGGAT GAACTGAGGCGCAGCCTACGCCATTGCCTTGGACAGGACTCTGGCCACAGGCAGGGCGGGTCTGTGTCCCATGTGTCCTGTCAGTCCCCT GAGTATGTGTGTGGGTGTGGCGCATGTGCAGGTCTGTGCCTCCTGTCGGGATTTGGGTTTTAACGTCTTCTGCTGGCCCAGCCCTGCTCT GTTGTGGGGAGTTGGCCCCCAGGGGAAAGGGCTGTGAGCTGCTCCGCCATTAAACTCACCTCCACCTGAGGGCGCTCTGCTGATCTCCGC CTGGGCCCTGATGGCCGTCCCCACCCACCTGCCTTCCGGCCCGGCTCCCTGGCGGAGCCAGAACCCAGGGAGTTGCCCGCGTGCTGTCCT TCCCCTCTGTGTTGTGATTGGGTTGTTTCCTGCCCTGCCTGGGGCTGCTTCTCGTCACCAAGCCCTGGTCCTGCGGCAGCTGTCACCCCT ACCATCCATACCACTGTGCTGACCGCTCAGCCTGAAGAGCAGAGAATGCCATGGGTGGGACTGTGGGGGTCGGATCGTGGGGTTGTTGGC AGAGGGCAACCCTGGGCCCCACACCGTGTGGACAGGCAGACACCAGATTGTCCAGGAGCAGGAGCTGCTGGGACTGCGCTGGCCCCGGAC CTAGTGGGCCTTCTCCTGGCTGCTGAGATGTCGTCTGTGACTGGCCTGGCTGGAGGGGGAGTGTTGACAACCCAAAGCTGTTCTCCAGTC TGGGGAGGGAGAGGCAGGGTCCCCAATGTCCGAGCTGCATCTGGACGCTGCTCTTAAAGGACCTCCTGGGGCAGGGGAGCGGTAGGGTCT GGACTGGGCAGATGCTGTATGACCTCCCTGAGCACCCGTGACTGCCCCATGCTTTCCCCTTTGTGCTCTGTGTGTGTCTGGGCTGTGCCC >34995_34995_8_GSDMD-RANGAP1_GSDMD_chr8_144644228_ENST00000526406_RANGAP1_chr22_41648995_ENST00000455915_length(amino acids)=352AA_BP=323 MLAGRLPGRADAPDAPPSGRRRSRSMGSAFERVVRRVVQELDHGGEFIPVTSLQSSTGFQPYCLVVRKPSSSWFWKPRYKCVNLSIKDIL EPDAAEPDVQRGRSFHFYDAMDGQIQGSVELAAPGQAKIAGGAAVSDSSSTSMNVYSLSVDPNTWQTLLHERHLRQPEHKVLQQLRSRGD NVYVVTEVLQTQKEVEVTRTHKREGSGRFSLPGATCLQGEGQGHLSQKKTVTIPSGSTLAFRVAQLVIDSDLDVLLFPDKKQRTFQPPAT -------------------------------------------------------------- >34995_34995_9_GSDMD-RANGAP1_GSDMD_chr8_144644228_ENST00000533063_RANGAP1_chr22_41648995_ENST00000356244_length(transcript)=2579nt_BP=1083nt GAGACGGAGTCTCACTCTGTCGCCCAGGCTGGAGTACAATGGCATGATCTCGGCTCACTGCAACCTACACCTCCCAGGTTCAAGCGATTC TCTTGCCTCAGCCTCCCAGCTCCTGCTCGCCGGACGGCTCCCAGGGAGAGCAGACGCGCCAGACGCGCCACCCTCGGGGCGCCGACGGTC ACGGAGCATGGGGTCGGCCTTTGAGCGGGTAGTCCGGAGAGTGGTCCAGGAGCTGGACCATGGTGGGGAGTTCATCCCTGTGACCAGCCT GCAGAGCTCCACTGGCTTCCAGCCCTACTGCCTGGTGGTTAGGAAGCCCTCAAGCTCATGGTTCTGGAAACCCCGTTATAAGTGTGTCAA CCTGTCTATCAAGGACATCCTGGAGCCGGATGCCGCGGAACCAGACGTGCAGCGTGGCAGGAGCTTCCACTTCTACGATGCCATGGATGG GCAGATACAGGGCAGCGTGGAGCTGGCAGCCCCAGGACAGGCAAAGATCGCAGGCGGGGCCGCGGTGTCTGACAGCTCCAGCACCTCAAT GAATGTGTACTCGCTGAGTGTGGACCCTAACACCTGGCAGACTCTGCTCCATGAGAGGCACCTGCGGCAGCCAGAACACAAAGTCCTGCA GCAGCTGCGCAGCCGCGGGGACAACGTGTACGTGGTGACTGAGGTGCTGCAGACACAGAAGGAGGTGGAAGTCACGCGCACCCACAAGCG GGAGGGCTCGGGCCGGTTTTCCCTGCCCGGAGCCACGTGCTTGCAGGGTGAGGGCCAGGGCCATCTGAGCCAGAAGAAGACGGTCACCAT CCCCTCAGGCAGCACCCTCGCATTCCGGGTGGCCCAGCTGGTTATTGACTCTGACTTGGACGTCCTTCTCTTCCCGGATAAGAAGCAGAG GACCTTCCAGCCACCCGCGACAGGCCACAAGCGTTCCACGAGCGAAGGCGCCTGGCCACAGCTGCCCTCTGGCCTCTCCATGATGAGGTG CCTCCACAACTTCCTGACAGGTGCCAGCTGCTGCTGGAGGGCCTGGAGGGGGTGCTGCGGGACCAGCTGGCCCTGCGAGCCTTGGAGGAG GCGGAGCCAGCTCCCGTGCTGTCCTCCCCACCTCCTGCAGACGTCTCCACCTTCCTGGCTTTTCCCTCTCCAGAGAAGCTGCTGCGCCTA GGGCCCAAGAGCTCCGTGCTGATAGCCCAGCAGACTGACACGTCTGACCCCGAGAAGGTGGTCTCTGCCTTCCTAAAGGTGTCATCTGTG TTCAAGGACGAAGCTACTGTGAGGATGGCAGTGCAGGATGCAGTAGATGCCCTGATGCAGAAGGCTTTCAACTCCTCGTCCTTCAACTCC AACACCTTCCTCACCAGGCTGCTCGTGCACATGGGTCTGCTCAAGAGTGAAGACAAGGTCAAGGCCATTGCCAACCTGTACGGCCCCCTG ATGGCGCTGAACCACATGGTGCAGCAGGACTATTTCCCCAAGGCCCTTGCACCCCTGCTGCTGGCGTTCGTGACCAAGCCCAACAGCGCC CTGGAATCCTGCTCCTTCGCCCGCCACAGTCTGCTGCAGACGCTGTACAAGGTCTAGACTCAAAGCCTCTCCCATCCCTTGGCCTGGACC AGTGAGCTGGGGAGGGACTCGGATGAACTGAGGCGCAGCCTACGCCATTGCCTTGGACAGGACTCTGGCCACAGGCAGGGCGGGTCTGTG TCCCATGTGTCCTGTCAGTCCCCTGAGTATGTGTGTGGGTGTGGCGCATGTGCAGGTCTGTGCCTCCTGTCGGGATTTGGGTTTTAACGT CTTCTGCTGGCCCAGCCCTGCTCTGTTGTGGGGAGTTGGCCCCCAGGGGAAAGGGCTGTGAGCTGCTCCGCCATTAAACTCACCTCCACC TGAGGGCGCTCTGCTGATCTCCGCCTGGGCCCTGATGGCCGTCCCCACCCACCTGCCTTCCGGCCCGGCTCCCTGGCGGAGCCAGAACCC AGGGAGTTGCCCGCGTGCTGTCCTTCCCCTCTGTGTTGTGATTGGGTTGTTTCCTGCCCTGCCTGGGGCTGCTTCTCGTCACCAAGCCCT GGTCCTGCGGCAGCTGTCACCCCTACCATCCATACCACTGTGCTGACCGCTCAGCCTGAAGAGCAGAGAATGCCATGGGTGGGACTGTGG GGGTCGGATCGTGGGGTTGTTGGCAGAGGGCAACCCTGGGCCCCACACCGTGTGGACAGGCAGACACCAGATTGTCCAGGAGCAGGAGCT GCTGGGACTGCGCTGGCCCCGGACCTAGTGGGCCTTCTCCTGGCTGCTGAGATGTCGTCTGTGACTGGCCTGGCTGGAGGGGGAGTGTTG ACAACCCAAAGCTGTTCTCCAGTCTGGGGAGGGAGAGGCAGGGTCCCCAATGTCCGAGCTGCATCTGGACGCTGCTCTTAAAGGACCTCC TGGGGCAGGGGAGCGGTAGGGTCTGGACTGGGCAGATGCTGTATGACCTCCCTGAGCACCCGTGACTGCCCCATGCTTTCCCCTTTGTGC >34995_34995_9_GSDMD-RANGAP1_GSDMD_chr8_144644228_ENST00000533063_RANGAP1_chr22_41648995_ENST00000356244_length(amino acids)=384AA_BP=2 MSPRLEYNGMISAHCNLHLPGSSDSLASASQLLLAGRLPGRADAPDAPPSGRRRSRSMGSAFERVVRRVVQELDHGGEFIPVTSLQSSTG FQPYCLVVRKPSSSWFWKPRYKCVNLSIKDILEPDAAEPDVQRGRSFHFYDAMDGQIQGSVELAAPGQAKIAGGAAVSDSSSTSMNVYSL SVDPNTWQTLLHERHLRQPEHKVLQQLRSRGDNVYVVTEVLQTQKEVEVTRTHKREGSGRFSLPGATCLQGEGQGHLSQKKTVTIPSGST LAFRVAQLVIDSDLDVLLFPDKKQRTFQPPATGHKRSTSEGAWPQLPSGLSMMRCLHNFLTGASCCWRAWRGCCGTSWPCEPWRRRSQLP -------------------------------------------------------------- >34995_34995_10_GSDMD-RANGAP1_GSDMD_chr8_144644228_ENST00000533063_RANGAP1_chr22_41648995_ENST00000405486_length(transcript)=2579nt_BP=1083nt GAGACGGAGTCTCACTCTGTCGCCCAGGCTGGAGTACAATGGCATGATCTCGGCTCACTGCAACCTACACCTCCCAGGTTCAAGCGATTC TCTTGCCTCAGCCTCCCAGCTCCTGCTCGCCGGACGGCTCCCAGGGAGAGCAGACGCGCCAGACGCGCCACCCTCGGGGCGCCGACGGTC ACGGAGCATGGGGTCGGCCTTTGAGCGGGTAGTCCGGAGAGTGGTCCAGGAGCTGGACCATGGTGGGGAGTTCATCCCTGTGACCAGCCT GCAGAGCTCCACTGGCTTCCAGCCCTACTGCCTGGTGGTTAGGAAGCCCTCAAGCTCATGGTTCTGGAAACCCCGTTATAAGTGTGTCAA CCTGTCTATCAAGGACATCCTGGAGCCGGATGCCGCGGAACCAGACGTGCAGCGTGGCAGGAGCTTCCACTTCTACGATGCCATGGATGG GCAGATACAGGGCAGCGTGGAGCTGGCAGCCCCAGGACAGGCAAAGATCGCAGGCGGGGCCGCGGTGTCTGACAGCTCCAGCACCTCAAT GAATGTGTACTCGCTGAGTGTGGACCCTAACACCTGGCAGACTCTGCTCCATGAGAGGCACCTGCGGCAGCCAGAACACAAAGTCCTGCA GCAGCTGCGCAGCCGCGGGGACAACGTGTACGTGGTGACTGAGGTGCTGCAGACACAGAAGGAGGTGGAAGTCACGCGCACCCACAAGCG GGAGGGCTCGGGCCGGTTTTCCCTGCCCGGAGCCACGTGCTTGCAGGGTGAGGGCCAGGGCCATCTGAGCCAGAAGAAGACGGTCACCAT CCCCTCAGGCAGCACCCTCGCATTCCGGGTGGCCCAGCTGGTTATTGACTCTGACTTGGACGTCCTTCTCTTCCCGGATAAGAAGCAGAG GACCTTCCAGCCACCCGCGACAGGCCACAAGCGTTCCACGAGCGAAGGCGCCTGGCCACAGCTGCCCTCTGGCCTCTCCATGATGAGGTG CCTCCACAACTTCCTGACAGGTGCCAGCTGCTGCTGGAGGGCCTGGAGGGGGTGCTGCGGGACCAGCTGGCCCTGCGAGCCTTGGAGGAG GCGGAGCCAGCTCCCGTGCTGTCCTCCCCACCTCCTGCAGACGTCTCCACCTTCCTGGCTTTTCCCTCTCCAGAGAAGCTGCTGCGCCTA GGGCCCAAGAGCTCCGTGCTGATAGCCCAGCAGACTGACACGTCTGACCCCGAGAAGGTGGTCTCTGCCTTCCTAAAGGTGTCATCTGTG TTCAAGGACGAAGCTACTGTGAGGATGGCAGTGCAGGATGCAGTAGATGCCCTGATGCAGAAGGCTTTCAACTCCTCGTCCTTCAACTCC AACACCTTCCTCACCAGGCTGCTCGTGCACATGGGTCTGCTCAAGAGTGAAGACAAGGTCAAGGCCATTGCCAACCTGTACGGCCCCCTG ATGGCGCTGAACCACATGGTGCAGCAGGACTATTTCCCCAAGGCCCTTGCACCCCTGCTGCTGGCGTTCGTGACCAAGCCCAACAGCGCC CTGGAATCCTGCTCCTTCGCCCGCCACAGTCTGCTGCAGACGCTGTACAAGGTCTAGACTCAAAGCCTCTCCCATCCCTTGGCCTGGACC AGTGAGCTGGGGAGGGACTCGGATGAACTGAGGCGCAGCCTACGCCATTGCCTTGGACAGGACTCTGGCCACAGGCAGGGCGGGTCTGTG TCCCATGTGTCCTGTCAGTCCCCTGAGTATGTGTGTGGGTGTGGCGCATGTGCAGGTCTGTGCCTCCTGTCGGGATTTGGGTTTTAACGT CTTCTGCTGGCCCAGCCCTGCTCTGTTGTGGGGAGTTGGCCCCCAGGGGAAAGGGCTGTGAGCTGCTCCGCCATTAAACTCACCTCCACC TGAGGGCGCTCTGCTGATCTCCGCCTGGGCCCTGATGGCCGTCCCCACCCACCTGCCTTCCGGCCCGGCTCCCTGGCGGAGCCAGAACCC AGGGAGTTGCCCGCGTGCTGTCCTTCCCCTCTGTGTTGTGATTGGGTTGTTTCCTGCCCTGCCTGGGGCTGCTTCTCGTCACCAAGCCCT GGTCCTGCGGCAGCTGTCACCCCTACCATCCATACCACTGTGCTGACCGCTCAGCCTGAAGAGCAGAGAATGCCATGGGTGGGACTGTGG GGGTCGGATCGTGGGGTTGTTGGCAGAGGGCAACCCTGGGCCCCACACCGTGTGGACAGGCAGACACCAGATTGTCCAGGAGCAGGAGCT GCTGGGACTGCGCTGGCCCCGGACCTAGTGGGCCTTCTCCTGGCTGCTGAGATGTCGTCTGTGACTGGCCTGGCTGGAGGGGGAGTGTTG ACAACCCAAAGCTGTTCTCCAGTCTGGGGAGGGAGAGGCAGGGTCCCCAATGTCCGAGCTGCATCTGGACGCTGCTCTTAAAGGACCTCC TGGGGCAGGGGAGCGGTAGGGTCTGGACTGGGCAGATGCTGTATGACCTCCCTGAGCACCCGTGACTGCCCCATGCTTTCCCCTTTGTGC >34995_34995_10_GSDMD-RANGAP1_GSDMD_chr8_144644228_ENST00000533063_RANGAP1_chr22_41648995_ENST00000405486_length(amino acids)=384AA_BP=2 MSPRLEYNGMISAHCNLHLPGSSDSLASASQLLLAGRLPGRADAPDAPPSGRRRSRSMGSAFERVVRRVVQELDHGGEFIPVTSLQSSTG FQPYCLVVRKPSSSWFWKPRYKCVNLSIKDILEPDAAEPDVQRGRSFHFYDAMDGQIQGSVELAAPGQAKIAGGAAVSDSSSTSMNVYSL SVDPNTWQTLLHERHLRQPEHKVLQQLRSRGDNVYVVTEVLQTQKEVEVTRTHKREGSGRFSLPGATCLQGEGQGHLSQKKTVTIPSGST LAFRVAQLVIDSDLDVLLFPDKKQRTFQPPATGHKRSTSEGAWPQLPSGLSMMRCLHNFLTGASCCWRAWRGCCGTSWPCEPWRRRSQLP -------------------------------------------------------------- >34995_34995_11_GSDMD-RANGAP1_GSDMD_chr8_144644228_ENST00000533063_RANGAP1_chr22_41648995_ENST00000407260_length(transcript)=1747nt_BP=1083nt GAGACGGAGTCTCACTCTGTCGCCCAGGCTGGAGTACAATGGCATGATCTCGGCTCACTGCAACCTACACCTCCCAGGTTCAAGCGATTC TCTTGCCTCAGCCTCCCAGCTCCTGCTCGCCGGACGGCTCCCAGGGAGAGCAGACGCGCCAGACGCGCCACCCTCGGGGCGCCGACGGTC ACGGAGCATGGGGTCGGCCTTTGAGCGGGTAGTCCGGAGAGTGGTCCAGGAGCTGGACCATGGTGGGGAGTTCATCCCTGTGACCAGCCT GCAGAGCTCCACTGGCTTCCAGCCCTACTGCCTGGTGGTTAGGAAGCCCTCAAGCTCATGGTTCTGGAAACCCCGTTATAAGTGTGTCAA CCTGTCTATCAAGGACATCCTGGAGCCGGATGCCGCGGAACCAGACGTGCAGCGTGGCAGGAGCTTCCACTTCTACGATGCCATGGATGG GCAGATACAGGGCAGCGTGGAGCTGGCAGCCCCAGGACAGGCAAAGATCGCAGGCGGGGCCGCGGTGTCTGACAGCTCCAGCACCTCAAT GAATGTGTACTCGCTGAGTGTGGACCCTAACACCTGGCAGACTCTGCTCCATGAGAGGCACCTGCGGCAGCCAGAACACAAAGTCCTGCA GCAGCTGCGCAGCCGCGGGGACAACGTGTACGTGGTGACTGAGGTGCTGCAGACACAGAAGGAGGTGGAAGTCACGCGCACCCACAAGCG GGAGGGCTCGGGCCGGTTTTCCCTGCCCGGAGCCACGTGCTTGCAGGGTGAGGGCCAGGGCCATCTGAGCCAGAAGAAGACGGTCACCAT CCCCTCAGGCAGCACCCTCGCATTCCGGGTGGCCCAGCTGGTTATTGACTCTGACTTGGACGTCCTTCTCTTCCCGGATAAGAAGCAGAG GACCTTCCAGCCACCCGCGACAGGCCACAAGCGTTCCACGAGCGAAGGCGCCTGGCCACAGCTGCCCTCTGGCCTCTCCATGATGAGGTG CCTCCACAACTTCCTGACAGGTGCCAGCTGCTGCTGGAGGGCCTGGAGGGGGTGCTGCGGGACCAGCTGGCCCTGCGAGCCTTGGAGGAG GCGGAGCCAGCTCCCGTGCTGTCCTCCCCACCTCCTGCAGACGTCTCCACCTTCCTGGCTTTTCCCTCTCCAGAGAAGCTGCTGCGCCTA GGGCCCAAGAGCTCCGTGCTGATAGCCCAGCAGACTGACACGTCTGACCCCGAGAAGGTGGTCTCTGCCTTCCTAAAGGTGTCATCTGTG TTCAAGGACGAAGCTACTGTGAGGATGGCAGTGCAGGATGCAGTAGATGCCCTGATGCAGAAGGCTTTCAACTCCTCGTCCTTCAACTCC AACACCTTCCTCACCAGGCTGCTCGTGCACATGGGTCTGCTCAAGAGTGAAGACAAGGTCAAGGCCATTGCCAACCTGTACGGCCCCCTG ATGGCGCTGAACCACATGGTGCAGCAGGACTATTTCCCCAAGGCCCTTGCACCCCTGCTGCTGGCGTTCGTGACCAAGCCCAACAGCGCC CTGGAATCCTGCTCCTTCGCCCGCCACAGTCTGCTGCAGACGCTGTACAAGGTCTAGACTCAAAGCCTCTCCCATCCCTTGGCCTGGACC AGTGAGCTGGGGAGGGACTCGGATGAACTGAGGCGCAGCCTACGCCATTGCCTTGGACAGGACTCTGGCCACAGGCAGGGCGGGTCTGTG >34995_34995_11_GSDMD-RANGAP1_GSDMD_chr8_144644228_ENST00000533063_RANGAP1_chr22_41648995_ENST00000407260_length(amino acids)=384AA_BP=2 MSPRLEYNGMISAHCNLHLPGSSDSLASASQLLLAGRLPGRADAPDAPPSGRRRSRSMGSAFERVVRRVVQELDHGGEFIPVTSLQSSTG FQPYCLVVRKPSSSWFWKPRYKCVNLSIKDILEPDAAEPDVQRGRSFHFYDAMDGQIQGSVELAAPGQAKIAGGAAVSDSSSTSMNVYSL SVDPNTWQTLLHERHLRQPEHKVLQQLRSRGDNVYVVTEVLQTQKEVEVTRTHKREGSGRFSLPGATCLQGEGQGHLSQKKTVTIPSGST LAFRVAQLVIDSDLDVLLFPDKKQRTFQPPATGHKRSTSEGAWPQLPSGLSMMRCLHNFLTGASCCWRAWRGCCGTSWPCEPWRRRSQLP -------------------------------------------------------------- >34995_34995_12_GSDMD-RANGAP1_GSDMD_chr8_144644228_ENST00000533063_RANGAP1_chr22_41648995_ENST00000455915_length(transcript)=2575nt_BP=1083nt GAGACGGAGTCTCACTCTGTCGCCCAGGCTGGAGTACAATGGCATGATCTCGGCTCACTGCAACCTACACCTCCCAGGTTCAAGCGATTC TCTTGCCTCAGCCTCCCAGCTCCTGCTCGCCGGACGGCTCCCAGGGAGAGCAGACGCGCCAGACGCGCCACCCTCGGGGCGCCGACGGTC ACGGAGCATGGGGTCGGCCTTTGAGCGGGTAGTCCGGAGAGTGGTCCAGGAGCTGGACCATGGTGGGGAGTTCATCCCTGTGACCAGCCT GCAGAGCTCCACTGGCTTCCAGCCCTACTGCCTGGTGGTTAGGAAGCCCTCAAGCTCATGGTTCTGGAAACCCCGTTATAAGTGTGTCAA CCTGTCTATCAAGGACATCCTGGAGCCGGATGCCGCGGAACCAGACGTGCAGCGTGGCAGGAGCTTCCACTTCTACGATGCCATGGATGG GCAGATACAGGGCAGCGTGGAGCTGGCAGCCCCAGGACAGGCAAAGATCGCAGGCGGGGCCGCGGTGTCTGACAGCTCCAGCACCTCAAT GAATGTGTACTCGCTGAGTGTGGACCCTAACACCTGGCAGACTCTGCTCCATGAGAGGCACCTGCGGCAGCCAGAACACAAAGTCCTGCA GCAGCTGCGCAGCCGCGGGGACAACGTGTACGTGGTGACTGAGGTGCTGCAGACACAGAAGGAGGTGGAAGTCACGCGCACCCACAAGCG GGAGGGCTCGGGCCGGTTTTCCCTGCCCGGAGCCACGTGCTTGCAGGGTGAGGGCCAGGGCCATCTGAGCCAGAAGAAGACGGTCACCAT CCCCTCAGGCAGCACCCTCGCATTCCGGGTGGCCCAGCTGGTTATTGACTCTGACTTGGACGTCCTTCTCTTCCCGGATAAGAAGCAGAG GACCTTCCAGCCACCCGCGACAGGCCACAAGCGTTCCACGAGCGAAGGCGCCTGGCCACAGCTGCCCTCTGGCCTCTCCATGATGAGGTG CCTCCACAACTTCCTGACAGGTGCCAGCTGCTGCTGGAGGGCCTGGAGGGGGTGCTGCGGGACCAGCTGGCCCTGCGAGCCTTGGAGGAG GCGGAGCCAGCTCCCGTGCTGTCCTCCCCACCTCCTGCAGACGTCTCCACCTTCCTGGCTTTTCCCTCTCCAGAGAAGCTGCTGCGCCTA GGGCCCAAGAGCTCCGTGCTGATAGCCCAGCAGACTGACACGTCTGACCCCGAGAAGGTGGTCTCTGCCTTCCTAAAGGTGTCATCTGTG TTCAAGGACGAAGCTACTGTGAGGATGGCAGTGCAGGATGCAGTAGATGCCCTGATGCAGAAGGCTTTCAACTCCTCGTCCTTCAACTCC AACACCTTCCTCACCAGGCTGCTCGTGCACATGGGTCTGCTCAAGAGTGAAGACAAGGTCAAGGCCATTGCCAACCTGTACGGCCCCCTG ATGGCGCTGAACCACATGGTGCAGCAGGACTATTTCCCCAAGGCCCTTGCACCCCTGCTGCTGGCGTTCGTGACCAAGCCCAACAGCGCC CTGGAATCCTGCTCCTTCGCCCGCCACAGTCTGCTGCAGACGCTGTACAAGGTCTAGACTCAAAGCCTCTCCCATCCCTTGGCCTGGACC AGTGAGCTGGGGAGGGACTCGGATGAACTGAGGCGCAGCCTACGCCATTGCCTTGGACAGGACTCTGGCCACAGGCAGGGCGGGTCTGTG TCCCATGTGTCCTGTCAGTCCCCTGAGTATGTGTGTGGGTGTGGCGCATGTGCAGGTCTGTGCCTCCTGTCGGGATTTGGGTTTTAACGT CTTCTGCTGGCCCAGCCCTGCTCTGTTGTGGGGAGTTGGCCCCCAGGGGAAAGGGCTGTGAGCTGCTCCGCCATTAAACTCACCTCCACC TGAGGGCGCTCTGCTGATCTCCGCCTGGGCCCTGATGGCCGTCCCCACCCACCTGCCTTCCGGCCCGGCTCCCTGGCGGAGCCAGAACCC AGGGAGTTGCCCGCGTGCTGTCCTTCCCCTCTGTGTTGTGATTGGGTTGTTTCCTGCCCTGCCTGGGGCTGCTTCTCGTCACCAAGCCCT GGTCCTGCGGCAGCTGTCACCCCTACCATCCATACCACTGTGCTGACCGCTCAGCCTGAAGAGCAGAGAATGCCATGGGTGGGACTGTGG GGGTCGGATCGTGGGGTTGTTGGCAGAGGGCAACCCTGGGCCCCACACCGTGTGGACAGGCAGACACCAGATTGTCCAGGAGCAGGAGCT GCTGGGACTGCGCTGGCCCCGGACCTAGTGGGCCTTCTCCTGGCTGCTGAGATGTCGTCTGTGACTGGCCTGGCTGGAGGGGGAGTGTTG ACAACCCAAAGCTGTTCTCCAGTCTGGGGAGGGAGAGGCAGGGTCCCCAATGTCCGAGCTGCATCTGGACGCTGCTCTTAAAGGACCTCC TGGGGCAGGGGAGCGGTAGGGTCTGGACTGGGCAGATGCTGTATGACCTCCCTGAGCACCCGTGACTGCCCCATGCTTTCCCCTTTGTGC >34995_34995_12_GSDMD-RANGAP1_GSDMD_chr8_144644228_ENST00000533063_RANGAP1_chr22_41648995_ENST00000455915_length(amino acids)=384AA_BP=2 MSPRLEYNGMISAHCNLHLPGSSDSLASASQLLLAGRLPGRADAPDAPPSGRRRSRSMGSAFERVVRRVVQELDHGGEFIPVTSLQSSTG FQPYCLVVRKPSSSWFWKPRYKCVNLSIKDILEPDAAEPDVQRGRSFHFYDAMDGQIQGSVELAAPGQAKIAGGAAVSDSSSTSMNVYSL SVDPNTWQTLLHERHLRQPEHKVLQQLRSRGDNVYVVTEVLQTQKEVEVTRTHKREGSGRFSLPGATCLQGEGQGHLSQKKTVTIPSGST LAFRVAQLVIDSDLDVLLFPDKKQRTFQPPATGHKRSTSEGAWPQLPSGLSMMRCLHNFLTGASCCWRAWRGCCGTSWPCEPWRRRSQLP -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for GSDMD-RANGAP1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for GSDMD-RANGAP1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for GSDMD-RANGAP1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies