
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:HK1-FUS (FusionGDB2 ID:36575) |
Fusion Gene Summary for HK1-FUS |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: HK1-FUS | Fusion gene ID: 36575 | Hgene | Tgene | Gene symbol | HK1 | FUS | Gene ID | 255061 | 2521 |
| Gene name | tachykinin precursor 4 | FUS RNA binding protein | |
| Synonyms | EK|HK-1|HK1|PPT-C | ALS6|ETM4|FUS1|HNRNPP2|POMP75|TLS | |
| Cytomap | 17q21.33 | 16p11.2 | |
| Type of gene | protein-coding | protein-coding | |
| Description | tachykinin-4endokininpreprotachykinin-Ctachykinin 4 (hemokinin) | RNA-binding protein FUS75 kDa DNA-pairing proteinfus-like proteinfused in sarcomafusion gene in myxoid liposarcomaheterogeneous nuclear ribonucleoprotein P2oncogene FUSoncogene TLStranslocated in liposarcoma protein | |
| Modification date | 20200313 | 20200329 | |
| UniProtAcc | . | P35637 | |
| Ensembl transtripts involved in fusion gene | ENST00000494253, ENST00000298649, ENST00000359426, ENST00000360289, ENST00000404387, ENST00000448642, | ENST00000254108, ENST00000380244, ENST00000568685, ENST00000474990, | |
| Fusion gene scores | * DoF score | 15 X 16 X 5=1200 | 20 X 13 X 10=2600 |
| # samples | 21 | 22 | |
| ** MAII score | log2(21/1200*10)=-2.51457317282976 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(22/2600*10)=-3.56293619439116 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: HK1 [Title/Abstract] AND FUS [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | HK1(71103745)-FUS(31199646), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | HK1 | GO:1902093 | positive regulation of flagellated sperm motility | 17437961 |
| Tgene | FUS | GO:0006355 | regulation of transcription, DNA-templated | 26124092 |
| Tgene | FUS | GO:0006357 | regulation of transcription by RNA polymerase II | 25453086 |
| Tgene | FUS | GO:0008380 | RNA splicing | 26124092 |
| Tgene | FUS | GO:0043484 | regulation of RNA splicing | 25453086|27731383 |
| Tgene | FUS | GO:0048255 | mRNA stabilization | 27378374 |
| Tgene | FUS | GO:0051260 | protein homooligomerization | 25453086 |
| Tgene | FUS | GO:1905168 | positive regulation of double-strand break repair via homologous recombination | 10567410 |
| Fusion gene breakpoints across HK1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
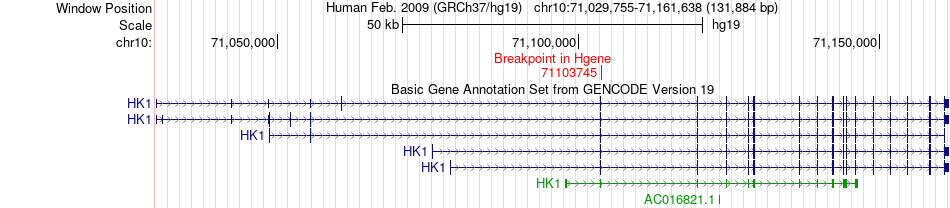 |
| Fusion gene breakpoints across FUS (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-FP-8211-01A | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + |
Top |
Fusion Gene ORF analysis for HK1-FUS |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000494253 | ENST00000254108 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + |
| 3UTR-3CDS | ENST00000494253 | ENST00000380244 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + |
| 3UTR-3CDS | ENST00000494253 | ENST00000568685 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + |
| 3UTR-3UTR | ENST00000494253 | ENST00000474990 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + |
| 5CDS-3UTR | ENST00000298649 | ENST00000474990 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + |
| 5CDS-3UTR | ENST00000359426 | ENST00000474990 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + |
| 5CDS-3UTR | ENST00000360289 | ENST00000474990 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + |
| 5CDS-3UTR | ENST00000404387 | ENST00000474990 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + |
| 5CDS-3UTR | ENST00000448642 | ENST00000474990 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + |
| In-frame | ENST00000298649 | ENST00000254108 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + |
| In-frame | ENST00000298649 | ENST00000380244 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + |
| In-frame | ENST00000298649 | ENST00000568685 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + |
| In-frame | ENST00000359426 | ENST00000254108 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + |
| In-frame | ENST00000359426 | ENST00000380244 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + |
| In-frame | ENST00000359426 | ENST00000568685 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + |
| In-frame | ENST00000360289 | ENST00000254108 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + |
| In-frame | ENST00000360289 | ENST00000380244 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + |
| In-frame | ENST00000360289 | ENST00000568685 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + |
| In-frame | ENST00000404387 | ENST00000254108 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + |
| In-frame | ENST00000404387 | ENST00000380244 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + |
| In-frame | ENST00000404387 | ENST00000568685 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + |
| In-frame | ENST00000448642 | ENST00000254108 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + |
| In-frame | ENST00000448642 | ENST00000380244 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + |
| In-frame | ENST00000448642 | ENST00000568685 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000360289 | HK1 | chr10 | 71103745 | + | ENST00000254108 | FUS | chr16 | 31199646 | + | 1839 | 689 | 481 | 1470 | 329 |
| ENST00000360289 | HK1 | chr10 | 71103745 | + | ENST00000380244 | FUS | chr16 | 31199646 | + | 1635 | 689 | 481 | 1470 | 329 |
| ENST00000360289 | HK1 | chr10 | 71103745 | + | ENST00000568685 | FUS | chr16 | 31199646 | + | 1611 | 689 | 481 | 1473 | 330 |
| ENST00000448642 | HK1 | chr10 | 71103745 | + | ENST00000254108 | FUS | chr16 | 31199646 | + | 1870 | 720 | 389 | 1501 | 370 |
| ENST00000448642 | HK1 | chr10 | 71103745 | + | ENST00000380244 | FUS | chr16 | 31199646 | + | 1666 | 720 | 389 | 1501 | 370 |
| ENST00000448642 | HK1 | chr10 | 71103745 | + | ENST00000568685 | FUS | chr16 | 31199646 | + | 1642 | 720 | 389 | 1504 | 371 |
| ENST00000404387 | HK1 | chr10 | 71103745 | + | ENST00000254108 | FUS | chr16 | 31199646 | + | 1388 | 238 | 0 | 1019 | 339 |
| ENST00000404387 | HK1 | chr10 | 71103745 | + | ENST00000380244 | FUS | chr16 | 31199646 | + | 1184 | 238 | 0 | 1019 | 339 |
| ENST00000404387 | HK1 | chr10 | 71103745 | + | ENST00000568685 | FUS | chr16 | 31199646 | + | 1160 | 238 | 0 | 1022 | 340 |
| ENST00000298649 | HK1 | chr10 | 71103745 | + | ENST00000254108 | FUS | chr16 | 31199646 | + | 1474 | 324 | 101 | 1105 | 334 |
| ENST00000298649 | HK1 | chr10 | 71103745 | + | ENST00000380244 | FUS | chr16 | 31199646 | + | 1270 | 324 | 101 | 1105 | 334 |
| ENST00000298649 | HK1 | chr10 | 71103745 | + | ENST00000568685 | FUS | chr16 | 31199646 | + | 1246 | 324 | 101 | 1108 | 335 |
| ENST00000359426 | HK1 | chr10 | 71103745 | + | ENST00000254108 | FUS | chr16 | 31199646 | + | 1480 | 330 | 50 | 1111 | 353 |
| ENST00000359426 | HK1 | chr10 | 71103745 | + | ENST00000380244 | FUS | chr16 | 31199646 | + | 1276 | 330 | 50 | 1111 | 353 |
| ENST00000359426 | HK1 | chr10 | 71103745 | + | ENST00000568685 | FUS | chr16 | 31199646 | + | 1252 | 330 | 50 | 1114 | 354 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000360289 | ENST00000254108 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + | 0.002116205 | 0.99788374 |
| ENST00000360289 | ENST00000380244 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + | 0.002391515 | 0.9976084 |
| ENST00000360289 | ENST00000568685 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + | 0.002653793 | 0.99734616 |
| ENST00000448642 | ENST00000254108 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + | 0.005528101 | 0.9944719 |
| ENST00000448642 | ENST00000380244 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + | 0.006535444 | 0.9934645 |
| ENST00000448642 | ENST00000568685 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + | 0.009064426 | 0.9909356 |
| ENST00000404387 | ENST00000254108 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + | 0.000555899 | 0.99944407 |
| ENST00000404387 | ENST00000380244 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + | 0.000589936 | 0.99941003 |
| ENST00000404387 | ENST00000568685 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + | 0.001156458 | 0.99884355 |
| ENST00000298649 | ENST00000254108 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + | 0.001362378 | 0.9986376 |
| ENST00000298649 | ENST00000380244 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + | 0.001393283 | 0.99860674 |
| ENST00000298649 | ENST00000568685 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + | 0.002228691 | 0.9977714 |
| ENST00000359426 | ENST00000254108 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + | 0.001446816 | 0.9985532 |
| ENST00000359426 | ENST00000380244 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + | 0.001392428 | 0.9986076 |
| ENST00000359426 | ENST00000568685 | HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199646 | + | 0.001993721 | 0.9980063 |
Top |
Fusion Genomic Features for HK1-FUS |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199645 | + | 2.29E-07 | 0.99999976 |
| HK1 | chr10 | 71103745 | + | FUS | chr16 | 31199645 | + | 2.29E-07 | 0.99999976 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
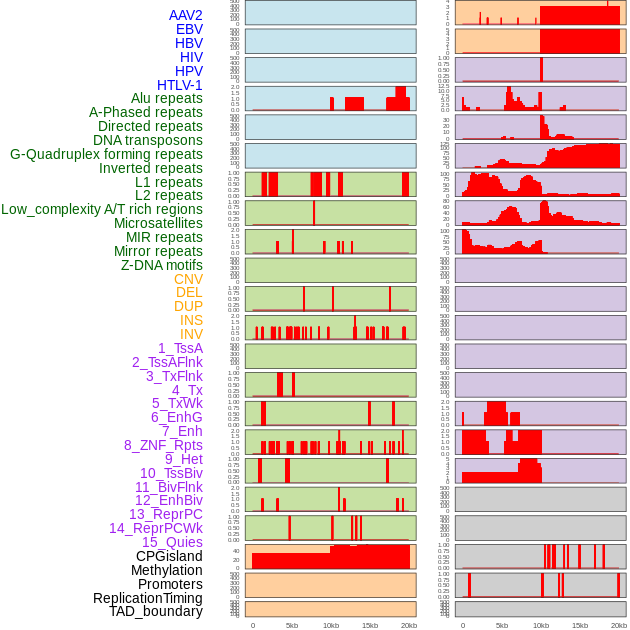 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
 |
Top |
Fusion Protein Features for HK1-FUS |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr10:71103745/chr16:31199646) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | FUS |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: DNA/RNA-binding protein that plays a role in various cellular processes such as transcription regulation, RNA splicing, RNA transport, DNA repair and damage response (PubMed:27731383). Binds to nascent pre-mRNAs and acts as a molecular mediator between RNA polymerase II and U1 small nuclear ribonucleoprotein thereby coupling transcription and splicing (PubMed:26124092). Binds also its own pre-mRNA and autoregulates its expression; this autoregulation mechanism is mediated by non-sense-mediated decay (PubMed:24204307). Plays a role in DNA repair mechanisms by promoting D-loop formation and homologous recombination during DNA double-strand break repair (PubMed:10567410). In neuronal cells, plays crucial roles in dendritic spine formation and stability, RNA transport, mRNA stability and synaptic homeostasis (By similarity). {ECO:0000250|UniProtKB:P56959, ECO:0000269|PubMed:10567410, ECO:0000269|PubMed:24204307, ECO:0000269|PubMed:26124092, ECO:0000269|PubMed:27731383}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000298649 | + | 2 | 18 | 1_10 | 74 | 917.0 | Region | Mitochondrial-binding peptide (MBP) |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000359426 | + | 2 | 18 | 1_10 | 75 | 918.0 | Region | Mitochondrial-binding peptide (MBP) |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000360289 | + | 6 | 22 | 1_10 | 63 | 906.0 | Region | Mitochondrial-binding peptide (MBP) |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000404387 | + | 3 | 19 | 1_10 | 79 | 922.0 | Region | Mitochondrial-binding peptide (MBP) |
| Tgene | FUS | chr10:71103745 | chr16:31199646 | ENST00000254108 | 6 | 15 | 371_526 | 266 | 527.0 | Compositional bias | Note=Arg/Gly-rich | |
| Tgene | FUS | chr10:71103745 | chr16:31199646 | ENST00000380244 | 6 | 15 | 371_526 | 265 | 526.0 | Compositional bias | Note=Arg/Gly-rich | |
| Tgene | FUS | chr10:71103745 | chr16:31199646 | ENST00000254108 | 6 | 15 | 285_371 | 266 | 527.0 | Domain | RRM | |
| Tgene | FUS | chr10:71103745 | chr16:31199646 | ENST00000380244 | 6 | 15 | 285_371 | 265 | 526.0 | Domain | RRM | |
| Tgene | FUS | chr10:71103745 | chr16:31199646 | ENST00000254108 | 6 | 15 | 422_453 | 266 | 527.0 | Zinc finger | RanBP2-type | |
| Tgene | FUS | chr10:71103745 | chr16:31199646 | ENST00000380244 | 6 | 15 | 422_453 | 265 | 526.0 | Zinc finger | RanBP2-type |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000298649 | + | 2 | 18 | 16_458 | 74 | 917.0 | Domain | Hexokinase 1 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000298649 | + | 2 | 18 | 464_906 | 74 | 917.0 | Domain | Hexokinase 2 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000359426 | + | 2 | 18 | 16_458 | 75 | 918.0 | Domain | Hexokinase 1 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000359426 | + | 2 | 18 | 464_906 | 75 | 918.0 | Domain | Hexokinase 2 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000360289 | + | 6 | 22 | 16_458 | 63 | 906.0 | Domain | Hexokinase 1 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000360289 | + | 6 | 22 | 464_906 | 63 | 906.0 | Domain | Hexokinase 2 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000404387 | + | 3 | 19 | 16_458 | 79 | 922.0 | Domain | Hexokinase 1 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000404387 | + | 3 | 19 | 464_906 | 79 | 922.0 | Domain | Hexokinase 2 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000298649 | + | 2 | 18 | 425_426 | 74 | 917.0 | Nucleotide binding | ATP 1 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000298649 | + | 2 | 18 | 532_537 | 74 | 917.0 | Nucleotide binding | ATP 2 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000298649 | + | 2 | 18 | 747_748 | 74 | 917.0 | Nucleotide binding | ATP 2 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000298649 | + | 2 | 18 | 784_788 | 74 | 917.0 | Nucleotide binding | ATP 2 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000298649 | + | 2 | 18 | 84_89 | 74 | 917.0 | Nucleotide binding | ATP 1 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000359426 | + | 2 | 18 | 425_426 | 75 | 918.0 | Nucleotide binding | ATP 1 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000359426 | + | 2 | 18 | 532_537 | 75 | 918.0 | Nucleotide binding | ATP 2 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000359426 | + | 2 | 18 | 747_748 | 75 | 918.0 | Nucleotide binding | ATP 2 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000359426 | + | 2 | 18 | 784_788 | 75 | 918.0 | Nucleotide binding | ATP 2 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000359426 | + | 2 | 18 | 84_89 | 75 | 918.0 | Nucleotide binding | ATP 1 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000360289 | + | 6 | 22 | 425_426 | 63 | 906.0 | Nucleotide binding | ATP 1 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000360289 | + | 6 | 22 | 532_537 | 63 | 906.0 | Nucleotide binding | ATP 2 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000360289 | + | 6 | 22 | 747_748 | 63 | 906.0 | Nucleotide binding | ATP 2 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000360289 | + | 6 | 22 | 784_788 | 63 | 906.0 | Nucleotide binding | ATP 2 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000360289 | + | 6 | 22 | 84_89 | 63 | 906.0 | Nucleotide binding | ATP 1 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000404387 | + | 3 | 19 | 425_426 | 79 | 922.0 | Nucleotide binding | ATP 1 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000404387 | + | 3 | 19 | 532_537 | 79 | 922.0 | Nucleotide binding | ATP 2 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000404387 | + | 3 | 19 | 747_748 | 79 | 922.0 | Nucleotide binding | ATP 2 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000404387 | + | 3 | 19 | 784_788 | 79 | 922.0 | Nucleotide binding | ATP 2 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000404387 | + | 3 | 19 | 84_89 | 79 | 922.0 | Nucleotide binding | ATP 1 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000298649 | + | 2 | 18 | 172_173 | 74 | 917.0 | Region | Substrate 1 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000298649 | + | 2 | 18 | 208_209 | 74 | 917.0 | Region | Substrate 1 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000298649 | + | 2 | 18 | 208_447 | 74 | 917.0 | Region | Hexokinase large subdomain 1 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000298649 | + | 2 | 18 | 291_294 | 74 | 917.0 | Region | Substrate 1 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000298649 | + | 2 | 18 | 413_415 | 74 | 917.0 | Region | Glucose-6-phosphate 1 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000298649 | + | 2 | 18 | 521_655 | 74 | 917.0 | Region | Hexokinase small subdomain 2 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000298649 | + | 2 | 18 | 532_536 | 74 | 917.0 | Region | Glucose-6-phosphate 2 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000298649 | + | 2 | 18 | 603_604 | 74 | 917.0 | Region | Substrate 2 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000298649 | + | 2 | 18 | 620_621 | 74 | 917.0 | Region | Substrate 2 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000298649 | + | 2 | 18 | 656_657 | 74 | 917.0 | Region | Substrate 2 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000298649 | + | 2 | 18 | 656_895 | 74 | 917.0 | Region | Hexokinase large subdomain 2 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000298649 | + | 2 | 18 | 682_683 | 74 | 917.0 | Region | Substrate 2 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000298649 | + | 2 | 18 | 73_207 | 74 | 917.0 | Region | Hexokinase small subdomain 1 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000298649 | + | 2 | 18 | 84_91 | 74 | 917.0 | Region | Glucose-6-phosphate 1 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000298649 | + | 2 | 18 | 861_863 | 74 | 917.0 | Region | Glucose-6-phosphate 2 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000359426 | + | 2 | 18 | 172_173 | 75 | 918.0 | Region | Substrate 1 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000359426 | + | 2 | 18 | 208_209 | 75 | 918.0 | Region | Substrate 1 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000359426 | + | 2 | 18 | 208_447 | 75 | 918.0 | Region | Hexokinase large subdomain 1 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000359426 | + | 2 | 18 | 291_294 | 75 | 918.0 | Region | Substrate 1 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000359426 | + | 2 | 18 | 413_415 | 75 | 918.0 | Region | Glucose-6-phosphate 1 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000359426 | + | 2 | 18 | 521_655 | 75 | 918.0 | Region | Hexokinase small subdomain 2 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000359426 | + | 2 | 18 | 532_536 | 75 | 918.0 | Region | Glucose-6-phosphate 2 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000359426 | + | 2 | 18 | 603_604 | 75 | 918.0 | Region | Substrate 2 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000359426 | + | 2 | 18 | 620_621 | 75 | 918.0 | Region | Substrate 2 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000359426 | + | 2 | 18 | 656_657 | 75 | 918.0 | Region | Substrate 2 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000359426 | + | 2 | 18 | 656_895 | 75 | 918.0 | Region | Hexokinase large subdomain 2 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000359426 | + | 2 | 18 | 682_683 | 75 | 918.0 | Region | Substrate 2 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000359426 | + | 2 | 18 | 73_207 | 75 | 918.0 | Region | Hexokinase small subdomain 1 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000359426 | + | 2 | 18 | 84_91 | 75 | 918.0 | Region | Glucose-6-phosphate 1 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000359426 | + | 2 | 18 | 861_863 | 75 | 918.0 | Region | Glucose-6-phosphate 2 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000360289 | + | 6 | 22 | 172_173 | 63 | 906.0 | Region | Substrate 1 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000360289 | + | 6 | 22 | 208_209 | 63 | 906.0 | Region | Substrate 1 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000360289 | + | 6 | 22 | 208_447 | 63 | 906.0 | Region | Hexokinase large subdomain 1 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000360289 | + | 6 | 22 | 291_294 | 63 | 906.0 | Region | Substrate 1 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000360289 | + | 6 | 22 | 413_415 | 63 | 906.0 | Region | Glucose-6-phosphate 1 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000360289 | + | 6 | 22 | 521_655 | 63 | 906.0 | Region | Hexokinase small subdomain 2 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000360289 | + | 6 | 22 | 532_536 | 63 | 906.0 | Region | Glucose-6-phosphate 2 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000360289 | + | 6 | 22 | 603_604 | 63 | 906.0 | Region | Substrate 2 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000360289 | + | 6 | 22 | 620_621 | 63 | 906.0 | Region | Substrate 2 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000360289 | + | 6 | 22 | 656_657 | 63 | 906.0 | Region | Substrate 2 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000360289 | + | 6 | 22 | 656_895 | 63 | 906.0 | Region | Hexokinase large subdomain 2 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000360289 | + | 6 | 22 | 682_683 | 63 | 906.0 | Region | Substrate 2 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000360289 | + | 6 | 22 | 73_207 | 63 | 906.0 | Region | Hexokinase small subdomain 1 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000360289 | + | 6 | 22 | 84_91 | 63 | 906.0 | Region | Glucose-6-phosphate 1 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000360289 | + | 6 | 22 | 861_863 | 63 | 906.0 | Region | Glucose-6-phosphate 2 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000404387 | + | 3 | 19 | 172_173 | 79 | 922.0 | Region | Substrate 1 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000404387 | + | 3 | 19 | 208_209 | 79 | 922.0 | Region | Substrate 1 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000404387 | + | 3 | 19 | 208_447 | 79 | 922.0 | Region | Hexokinase large subdomain 1 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000404387 | + | 3 | 19 | 291_294 | 79 | 922.0 | Region | Substrate 1 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000404387 | + | 3 | 19 | 413_415 | 79 | 922.0 | Region | Glucose-6-phosphate 1 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000404387 | + | 3 | 19 | 521_655 | 79 | 922.0 | Region | Hexokinase small subdomain 2 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000404387 | + | 3 | 19 | 532_536 | 79 | 922.0 | Region | Glucose-6-phosphate 2 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000404387 | + | 3 | 19 | 603_604 | 79 | 922.0 | Region | Substrate 2 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000404387 | + | 3 | 19 | 620_621 | 79 | 922.0 | Region | Substrate 2 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000404387 | + | 3 | 19 | 656_657 | 79 | 922.0 | Region | Substrate 2 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000404387 | + | 3 | 19 | 656_895 | 79 | 922.0 | Region | Hexokinase large subdomain 2 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000404387 | + | 3 | 19 | 682_683 | 79 | 922.0 | Region | Substrate 2 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000404387 | + | 3 | 19 | 73_207 | 79 | 922.0 | Region | Hexokinase small subdomain 1 |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000404387 | + | 3 | 19 | 84_91 | 79 | 922.0 | Region | Glucose-6-phosphate 1 binding |
| Hgene | HK1 | chr10:71103745 | chr16:31199646 | ENST00000404387 | + | 3 | 19 | 861_863 | 79 | 922.0 | Region | Glucose-6-phosphate 2 binding |
| Tgene | FUS | chr10:71103745 | chr16:31199646 | ENST00000254108 | 6 | 15 | 166_267 | 266 | 527.0 | Compositional bias | Note=Gly-rich | |
| Tgene | FUS | chr10:71103745 | chr16:31199646 | ENST00000254108 | 6 | 15 | 1_165 | 266 | 527.0 | Compositional bias | Note=Gln/Gly/Ser/Tyr-rich | |
| Tgene | FUS | chr10:71103745 | chr16:31199646 | ENST00000380244 | 6 | 15 | 166_267 | 265 | 526.0 | Compositional bias | Note=Gly-rich | |
| Tgene | FUS | chr10:71103745 | chr16:31199646 | ENST00000380244 | 6 | 15 | 1_165 | 265 | 526.0 | Compositional bias | Note=Gln/Gly/Ser/Tyr-rich |
Top |
Fusion Gene Sequence for HK1-FUS |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >36575_36575_1_HK1-FUS_HK1_chr10_71103745_ENST00000298649_FUS_chr16_31199646_ENST00000254108_length(transcript)=1474nt_BP=324nt CCTGGCTCAAAACTCTACCACAACCTGACACTGGGCAAGATGGCCCACCTGTGGCATCCCAGGTTCCTGCCCTGTAAAGAGGAGTCTGGG TGTATATCCAGATGGACTGTGAGCACAGCCTGAGTTTGCCCTGTCGAGGTGCTGAGGCCTGGGAGATTGGGATTGACAAGTATCTCTATG CCATGCGGCTCTCCGATGAAACTCTCATAGATATCATGACTCGCTTCAGGAAGGAGATGAAGAATGGCCTCTCCCGGGATTTTAATCCAA CAGCCACAGTCAAGATGTTGCCAACATTCGTAAGGTCCATTCCTGATGGCTCTGGCCCTCGGGACCAAGGATCACGTCATGACTCCGAAC AGGATAATTCAGACAACAACACCATCTTTGTGCAAGGCCTGGGTGAGAATGTTACAATTGAGTCTGTGGCTGATTACTTCAAGCAGATTG GTATTATTAAGACAAACAAGAAAACGGGACAGCCCATGATTAATTTGTACACAGACAGGGAAACTGGCAAGCTGAAGGGAGAGGCAACGG TCTCTTTTGATGACCCACCTTCAGCTAAAGCAGCTATTGACTGGTTTGATGGTAAAGAATTCTCCGGAAATCCTATCAAGGTCTCATTTG CTACTCGCCGGGCAGACTTTAATCGGGGTGGTGGCAATGGTCGTGGAGGCCGAGGGCGAGGAGGACCCATGGGCCGTGGAGGCTATGGAG GTGGTGGCAGTGGTGGTGGTGGCCGAGGAGGATTTCCCAGTGGAGGTGGTGGCGGTGGAGGACAGCAGCGAGCTGGTGACTGGAAGTGTC CTAATCCCACCTGTGAGAATATGAACTTCTCTTGGAGGAATGAATGCAACCAGTGTAAGGCCCCTAAACCAGATGGCCCAGGAGGGGGAC CAGGTGGCTCTCACATGGGGGGTAACTACGGGGATGATCGTCGTGGTGGCAGAGGAGGCTATGATCGAGGCGGCTACCGGGGCCGCGGCG GGGACCGTGGAGGCTTCCGAGGGGGCCGGGGTGGTGGGGACAGAGGTGGCTTTGGCCCTGGCAAGATGGATTCCAGGGGTGAGCACAGAC AGGATCGCAGGGAGAGGCCGTATTAATTAGCCTGGCTCCCCAGGTTCTGGAACAGCTTTTTGTCCTGTACCCAGTGTTACCCTCGTTATT TTGTAACCTTCCAATTCCTGATCACCCAAGGGTTTTTTTGTGTCGGACTATGTAATTGTAACTATACCTCTGGTTCCCATTAAAAGTGAC CATTTTAGTTAAATTTTGTTCCTCTTCCCCCTTTTCACTTTCCTGGAAGATCGATGTCCCGATCAGGAAGGTAGAGAGTTTTCCTGTTCA GATTACCCTGCCCAGCAGGAACTGGAATACAGTGTTCGGGGAGAAGGCCAAATGATATCCTTGAGAGCAGAGATTAAACTTTTCTGTCAT >36575_36575_1_HK1-FUS_HK1_chr10_71103745_ENST00000298649_FUS_chr16_31199646_ENST00000254108_length(amino acids)=334AA_BP=190 MDCEHSLSLPCRGAEAWEIGIDKYLYAMRLSDETLIDIMTRFRKEMKNGLSRDFNPTATVKMLPTFVRSIPDGSGPRDQGSRHDSEQDNS DNNTIFVQGLGENVTIESVADYFKQIGIIKTNKKTGQPMINLYTDRETGKLKGEATVSFDDPPSAKAAIDWFDGKEFSGNPIKVSFATRR ADFNRGGGNGRGGRGRGGPMGRGGYGGGGSGGGGRGGFPSGGGGGGGQQRAGDWKCPNPTCENMNFSWRNECNQCKAPKPDGPGGGPGGS -------------------------------------------------------------- >36575_36575_2_HK1-FUS_HK1_chr10_71103745_ENST00000298649_FUS_chr16_31199646_ENST00000380244_length(transcript)=1270nt_BP=324nt CCTGGCTCAAAACTCTACCACAACCTGACACTGGGCAAGATGGCCCACCTGTGGCATCCCAGGTTCCTGCCCTGTAAAGAGGAGTCTGGG TGTATATCCAGATGGACTGTGAGCACAGCCTGAGTTTGCCCTGTCGAGGTGCTGAGGCCTGGGAGATTGGGATTGACAAGTATCTCTATG CCATGCGGCTCTCCGATGAAACTCTCATAGATATCATGACTCGCTTCAGGAAGGAGATGAAGAATGGCCTCTCCCGGGATTTTAATCCAA CAGCCACAGTCAAGATGTTGCCAACATTCGTAAGGTCCATTCCTGATGGCTCTGGCCCTCGGGACCAAGGATCACGTCATGACTCCGAAC AGGATAATTCAGACAACAACACCATCTTTGTGCAAGGCCTGGGTGAGAATGTTACAATTGAGTCTGTGGCTGATTACTTCAAGCAGATTG GTATTATTAAGACAAACAAGAAAACGGGACAGCCCATGATTAATTTGTACACAGACAGGGAAACTGGCAAGCTGAAGGGAGAGGCAACGG TCTCTTTTGATGACCCACCTTCAGCTAAAGCAGCTATTGACTGGTTTGATGGTAAAGAATTCTCCGGAAATCCTATCAAGGTCTCATTTG CTACTCGCCGGGCAGACTTTAATCGGGGTGGTGGCAATGGTCGTGGAGGCCGAGGGCGAGGAGGACCCATGGGCCGTGGAGGCTATGGAG GTGGTGGCAGTGGTGGTGGTGGCCGAGGAGGATTTCCCAGTGGAGGTGGTGGCGGTGGAGGACAGCAGCGAGCTGGTGACTGGAAGTGTC CTAATCCCACCTGTGAGAATATGAACTTCTCTTGGAGGAATGAATGCAACCAGTGTAAGGCCCCTAAACCAGATGGCCCAGGAGGGGGAC CAGGTGGCTCTCACATGGGGGGTAACTACGGGGATGATCGTCGTGGTGGCAGAGGAGGCTATGATCGAGGCGGCTACCGGGGCCGCGGCG GGGACCGTGGAGGCTTCCGAGGGGGCCGGGGTGGTGGGGACAGAGGTGGCTTTGGCCCTGGCAAGATGGATTCCAGGGGTGAGCACAGAC AGGATCGCAGGGAGAGGCCGTATTAATTAGCCTGGCTCCCCAGGTTCTGGAACAGCTTTTTGTCCTGTACCCAGTGTTACCCTCGTTATT TTGTAACCTTCCAATTCCTGATCACCCAAGGGTTTTTTTGTGTCGGACTATGTAATTGTAACTATACCTCTGGTTCCCATTAAAAGTGAC >36575_36575_2_HK1-FUS_HK1_chr10_71103745_ENST00000298649_FUS_chr16_31199646_ENST00000380244_length(amino acids)=334AA_BP=190 MDCEHSLSLPCRGAEAWEIGIDKYLYAMRLSDETLIDIMTRFRKEMKNGLSRDFNPTATVKMLPTFVRSIPDGSGPRDQGSRHDSEQDNS DNNTIFVQGLGENVTIESVADYFKQIGIIKTNKKTGQPMINLYTDRETGKLKGEATVSFDDPPSAKAAIDWFDGKEFSGNPIKVSFATRR ADFNRGGGNGRGGRGRGGPMGRGGYGGGGSGGGGRGGFPSGGGGGGGQQRAGDWKCPNPTCENMNFSWRNECNQCKAPKPDGPGGGPGGS -------------------------------------------------------------- >36575_36575_3_HK1-FUS_HK1_chr10_71103745_ENST00000298649_FUS_chr16_31199646_ENST00000568685_length(transcript)=1246nt_BP=324nt CCTGGCTCAAAACTCTACCACAACCTGACACTGGGCAAGATGGCCCACCTGTGGCATCCCAGGTTCCTGCCCTGTAAAGAGGAGTCTGGG TGTATATCCAGATGGACTGTGAGCACAGCCTGAGTTTGCCCTGTCGAGGTGCTGAGGCCTGGGAGATTGGGATTGACAAGTATCTCTATG CCATGCGGCTCTCCGATGAAACTCTCATAGATATCATGACTCGCTTCAGGAAGGAGATGAAGAATGGCCTCTCCCGGGATTTTAATCCAA CAGCCACAGTCAAGATGTTGCCAACATTCGTAAGGTCCATTCCTGATGGCTCTGGCCCTCGGGACCAAGGATCACGTCATGACTCCGCAG AACAGGATAATTCAGACAACAACACCATCTTTGTGCAAGGCCTGGGTGAGAATGTTACAATTGAGTCTGTGGCTGATTACTTCAAGCAGA TTGGTATTATTAAGACAAACAAGAAAACGGGACAGCCCATGATTAATTTGTACACAGACAGGGAAACTGGCAAGCTGAAGGGAGAGGCAA CGGTCTCTTTTGATGACCCACCTTCAGCTAAAGCAGCTATTGACTGGTTTGATGGTAAAGAATTCTCCGGAAATCCTATCAAGGTCTCAT TTGCTACTCGCCGGGCAGACTTTAATCGGGGTGGTGGCAATGGTCGTGGAGGCCGAGGGCGAGGAGGACCCATGGGCCGTGGAGGCTATG GAGGTGGTGGCAGTGGTGGTGGTGGCCGAGGAGGATTTCCCAGTGGAGGTGGTGGCGGTGGAGGACAGCAGCGAGCTGGTGACTGGAAGT GTCCTAATCCCACCTGTGAGAATATGAACTTCTCTTGGAGGAATGAATGCAACCAGTGTAAGGCCCCTAAACCAGATGGCCCAGGAGGGG GACCAGGTGGCTCTCACATGGGGGGTAACTACGGGGATGATCGTCGTGGTGGCAGAGGAGGCTATGATCGAGGCGGCTACCGGGGCCGCG GCGGGGACCGTGGAGGCTTCCGAGGGGGCCGGGGTGGTGGGGACAGAGGTGGCTTTGGCCCTGGCAAGATGGATTCCAGGGGTGAGCACA GACAGGATCGCAGGGAGAGGCCGTATTAATTAGCCTGGCTCCCCAGGTTCTGGAACAGCTTTTTGTCCTGTACCCAGTGTTACCCTCGTT >36575_36575_3_HK1-FUS_HK1_chr10_71103745_ENST00000298649_FUS_chr16_31199646_ENST00000568685_length(amino acids)=335AA_BP=191 MDCEHSLSLPCRGAEAWEIGIDKYLYAMRLSDETLIDIMTRFRKEMKNGLSRDFNPTATVKMLPTFVRSIPDGSGPRDQGSRHDSAEQDN SDNNTIFVQGLGENVTIESVADYFKQIGIIKTNKKTGQPMINLYTDRETGKLKGEATVSFDDPPSAKAAIDWFDGKEFSGNPIKVSFATR RADFNRGGGNGRGGRGRGGPMGRGGYGGGGSGGGGRGGFPSGGGGGGGQQRAGDWKCPNPTCENMNFSWRNECNQCKAPKPDGPGGGPGG -------------------------------------------------------------- >36575_36575_4_HK1-FUS_HK1_chr10_71103745_ENST00000359426_FUS_chr16_31199646_ENST00000254108_length(transcript)=1480nt_BP=330nt GAGGAGGAGGAGCCGCCGAGCAGCCGCCGGAGGACCACGGCTCGCCAGGGCTGCGGAGGACCGACCGTCCCCACGCCTGCCGCCCCGCGA CCCCGACCGCCAGCATGATCGCCGCGCAGCTCCTGGCCTATTACTTCACGGAGCTGAAGGATGACCAGGTCAAAAAGATTGACAAGTATC TCTATGCCATGCGGCTCTCCGATGAAACTCTCATAGATATCATGACTCGCTTCAGGAAGGAGATGAAGAATGGCCTCTCCCGGGATTTTA ATCCAACAGCCACAGTCAAGATGTTGCCAACATTCGTAAGGTCCATTCCTGATGGCTCTGGCCCTCGGGACCAAGGATCACGTCATGACT CCGAACAGGATAATTCAGACAACAACACCATCTTTGTGCAAGGCCTGGGTGAGAATGTTACAATTGAGTCTGTGGCTGATTACTTCAAGC AGATTGGTATTATTAAGACAAACAAGAAAACGGGACAGCCCATGATTAATTTGTACACAGACAGGGAAACTGGCAAGCTGAAGGGAGAGG CAACGGTCTCTTTTGATGACCCACCTTCAGCTAAAGCAGCTATTGACTGGTTTGATGGTAAAGAATTCTCCGGAAATCCTATCAAGGTCT CATTTGCTACTCGCCGGGCAGACTTTAATCGGGGTGGTGGCAATGGTCGTGGAGGCCGAGGGCGAGGAGGACCCATGGGCCGTGGAGGCT ATGGAGGTGGTGGCAGTGGTGGTGGTGGCCGAGGAGGATTTCCCAGTGGAGGTGGTGGCGGTGGAGGACAGCAGCGAGCTGGTGACTGGA AGTGTCCTAATCCCACCTGTGAGAATATGAACTTCTCTTGGAGGAATGAATGCAACCAGTGTAAGGCCCCTAAACCAGATGGCCCAGGAG GGGGACCAGGTGGCTCTCACATGGGGGGTAACTACGGGGATGATCGTCGTGGTGGCAGAGGAGGCTATGATCGAGGCGGCTACCGGGGCC GCGGCGGGGACCGTGGAGGCTTCCGAGGGGGCCGGGGTGGTGGGGACAGAGGTGGCTTTGGCCCTGGCAAGATGGATTCCAGGGGTGAGC ACAGACAGGATCGCAGGGAGAGGCCGTATTAATTAGCCTGGCTCCCCAGGTTCTGGAACAGCTTTTTGTCCTGTACCCAGTGTTACCCTC GTTATTTTGTAACCTTCCAATTCCTGATCACCCAAGGGTTTTTTTGTGTCGGACTATGTAATTGTAACTATACCTCTGGTTCCCATTAAA AGTGACCATTTTAGTTAAATTTTGTTCCTCTTCCCCCTTTTCACTTTCCTGGAAGATCGATGTCCCGATCAGGAAGGTAGAGAGTTTTCC TGTTCAGATTACCCTGCCCAGCAGGAACTGGAATACAGTGTTCGGGGAGAAGGCCAAATGATATCCTTGAGAGCAGAGATTAAACTTTTC >36575_36575_4_HK1-FUS_HK1_chr10_71103745_ENST00000359426_FUS_chr16_31199646_ENST00000254108_length(amino acids)=353AA_BP=209 MRRTDRPHACRPATPTASMIAAQLLAYYFTELKDDQVKKIDKYLYAMRLSDETLIDIMTRFRKEMKNGLSRDFNPTATVKMLPTFVRSIP DGSGPRDQGSRHDSEQDNSDNNTIFVQGLGENVTIESVADYFKQIGIIKTNKKTGQPMINLYTDRETGKLKGEATVSFDDPPSAKAAIDW FDGKEFSGNPIKVSFATRRADFNRGGGNGRGGRGRGGPMGRGGYGGGGSGGGGRGGFPSGGGGGGGQQRAGDWKCPNPTCENMNFSWRNE -------------------------------------------------------------- >36575_36575_5_HK1-FUS_HK1_chr10_71103745_ENST00000359426_FUS_chr16_31199646_ENST00000380244_length(transcript)=1276nt_BP=330nt GAGGAGGAGGAGCCGCCGAGCAGCCGCCGGAGGACCACGGCTCGCCAGGGCTGCGGAGGACCGACCGTCCCCACGCCTGCCGCCCCGCGA CCCCGACCGCCAGCATGATCGCCGCGCAGCTCCTGGCCTATTACTTCACGGAGCTGAAGGATGACCAGGTCAAAAAGATTGACAAGTATC TCTATGCCATGCGGCTCTCCGATGAAACTCTCATAGATATCATGACTCGCTTCAGGAAGGAGATGAAGAATGGCCTCTCCCGGGATTTTA ATCCAACAGCCACAGTCAAGATGTTGCCAACATTCGTAAGGTCCATTCCTGATGGCTCTGGCCCTCGGGACCAAGGATCACGTCATGACT CCGAACAGGATAATTCAGACAACAACACCATCTTTGTGCAAGGCCTGGGTGAGAATGTTACAATTGAGTCTGTGGCTGATTACTTCAAGC AGATTGGTATTATTAAGACAAACAAGAAAACGGGACAGCCCATGATTAATTTGTACACAGACAGGGAAACTGGCAAGCTGAAGGGAGAGG CAACGGTCTCTTTTGATGACCCACCTTCAGCTAAAGCAGCTATTGACTGGTTTGATGGTAAAGAATTCTCCGGAAATCCTATCAAGGTCT CATTTGCTACTCGCCGGGCAGACTTTAATCGGGGTGGTGGCAATGGTCGTGGAGGCCGAGGGCGAGGAGGACCCATGGGCCGTGGAGGCT ATGGAGGTGGTGGCAGTGGTGGTGGTGGCCGAGGAGGATTTCCCAGTGGAGGTGGTGGCGGTGGAGGACAGCAGCGAGCTGGTGACTGGA AGTGTCCTAATCCCACCTGTGAGAATATGAACTTCTCTTGGAGGAATGAATGCAACCAGTGTAAGGCCCCTAAACCAGATGGCCCAGGAG GGGGACCAGGTGGCTCTCACATGGGGGGTAACTACGGGGATGATCGTCGTGGTGGCAGAGGAGGCTATGATCGAGGCGGCTACCGGGGCC GCGGCGGGGACCGTGGAGGCTTCCGAGGGGGCCGGGGTGGTGGGGACAGAGGTGGCTTTGGCCCTGGCAAGATGGATTCCAGGGGTGAGC ACAGACAGGATCGCAGGGAGAGGCCGTATTAATTAGCCTGGCTCCCCAGGTTCTGGAACAGCTTTTTGTCCTGTACCCAGTGTTACCCTC GTTATTTTGTAACCTTCCAATTCCTGATCACCCAAGGGTTTTTTTGTGTCGGACTATGTAATTGTAACTATACCTCTGGTTCCCATTAAA >36575_36575_5_HK1-FUS_HK1_chr10_71103745_ENST00000359426_FUS_chr16_31199646_ENST00000380244_length(amino acids)=353AA_BP=209 MRRTDRPHACRPATPTASMIAAQLLAYYFTELKDDQVKKIDKYLYAMRLSDETLIDIMTRFRKEMKNGLSRDFNPTATVKMLPTFVRSIP DGSGPRDQGSRHDSEQDNSDNNTIFVQGLGENVTIESVADYFKQIGIIKTNKKTGQPMINLYTDRETGKLKGEATVSFDDPPSAKAAIDW FDGKEFSGNPIKVSFATRRADFNRGGGNGRGGRGRGGPMGRGGYGGGGSGGGGRGGFPSGGGGGGGQQRAGDWKCPNPTCENMNFSWRNE -------------------------------------------------------------- >36575_36575_6_HK1-FUS_HK1_chr10_71103745_ENST00000359426_FUS_chr16_31199646_ENST00000568685_length(transcript)=1252nt_BP=330nt GAGGAGGAGGAGCCGCCGAGCAGCCGCCGGAGGACCACGGCTCGCCAGGGCTGCGGAGGACCGACCGTCCCCACGCCTGCCGCCCCGCGA CCCCGACCGCCAGCATGATCGCCGCGCAGCTCCTGGCCTATTACTTCACGGAGCTGAAGGATGACCAGGTCAAAAAGATTGACAAGTATC TCTATGCCATGCGGCTCTCCGATGAAACTCTCATAGATATCATGACTCGCTTCAGGAAGGAGATGAAGAATGGCCTCTCCCGGGATTTTA ATCCAACAGCCACAGTCAAGATGTTGCCAACATTCGTAAGGTCCATTCCTGATGGCTCTGGCCCTCGGGACCAAGGATCACGTCATGACT CCGCAGAACAGGATAATTCAGACAACAACACCATCTTTGTGCAAGGCCTGGGTGAGAATGTTACAATTGAGTCTGTGGCTGATTACTTCA AGCAGATTGGTATTATTAAGACAAACAAGAAAACGGGACAGCCCATGATTAATTTGTACACAGACAGGGAAACTGGCAAGCTGAAGGGAG AGGCAACGGTCTCTTTTGATGACCCACCTTCAGCTAAAGCAGCTATTGACTGGTTTGATGGTAAAGAATTCTCCGGAAATCCTATCAAGG TCTCATTTGCTACTCGCCGGGCAGACTTTAATCGGGGTGGTGGCAATGGTCGTGGAGGCCGAGGGCGAGGAGGACCCATGGGCCGTGGAG GCTATGGAGGTGGTGGCAGTGGTGGTGGTGGCCGAGGAGGATTTCCCAGTGGAGGTGGTGGCGGTGGAGGACAGCAGCGAGCTGGTGACT GGAAGTGTCCTAATCCCACCTGTGAGAATATGAACTTCTCTTGGAGGAATGAATGCAACCAGTGTAAGGCCCCTAAACCAGATGGCCCAG GAGGGGGACCAGGTGGCTCTCACATGGGGGGTAACTACGGGGATGATCGTCGTGGTGGCAGAGGAGGCTATGATCGAGGCGGCTACCGGG GCCGCGGCGGGGACCGTGGAGGCTTCCGAGGGGGCCGGGGTGGTGGGGACAGAGGTGGCTTTGGCCCTGGCAAGATGGATTCCAGGGGTG AGCACAGACAGGATCGCAGGGAGAGGCCGTATTAATTAGCCTGGCTCCCCAGGTTCTGGAACAGCTTTTTGTCCTGTACCCAGTGTTACC >36575_36575_6_HK1-FUS_HK1_chr10_71103745_ENST00000359426_FUS_chr16_31199646_ENST00000568685_length(amino acids)=354AA_BP=210 MRRTDRPHACRPATPTASMIAAQLLAYYFTELKDDQVKKIDKYLYAMRLSDETLIDIMTRFRKEMKNGLSRDFNPTATVKMLPTFVRSIP DGSGPRDQGSRHDSAEQDNSDNNTIFVQGLGENVTIESVADYFKQIGIIKTNKKTGQPMINLYTDRETGKLKGEATVSFDDPPSAKAAID WFDGKEFSGNPIKVSFATRRADFNRGGGNGRGGRGRGGPMGRGGYGGGGSGGGGRGGFPSGGGGGGGQQRAGDWKCPNPTCENMNFSWRN -------------------------------------------------------------- >36575_36575_7_HK1-FUS_HK1_chr10_71103745_ENST00000360289_FUS_chr16_31199646_ENST00000254108_length(transcript)=1839nt_BP=689nt AAAACATCTATCTTGCTGTGTTTGGACAGGCCAGCCCCTGAAACATCTTGGGCAATGGAGGGTTAACTTCTCAAAGTTTAATAGGCAAGA CCAGCAACCATGCAACAAGGACTTCAACTAACCAACTAAAGAACTGTTCCCCAGAGCATTGTTCCTGAGAAGGAAAAGAGTCCAAACACC TACCCACACCTGCTTTGTGCCAAGAATCCACAGTTGGATTGCAAGGACAGTGTATGTTGTCCTTTTGGAAAAATGAGAGTGAGCCCAAAT GAAGAACAAGCAAAGGCGTTCAAGACCCAGCTGTTGAGAGTAGAAAAGCAGAAGAAAGGACCCGAGGTCAGCAAGTGCCCTCCCCACAAT GGGGCAGATCTGCCAGCGAGAATCGGCTACAGCAGCTGAAAAACCAAAACTTCATCTACTTGCTGAAAGTGAGCATTGTTGATGCTCTTG AGAGCATCAGCCAGGACATTAATGTGCACCACTGTGGTGGCGTGGAAAGATGGCAAAAAGAGCCCTGCATGATTTTATTGACAAGTATCT CTATGCCATGCGGCTCTCCGATGAAACTCTCATAGATATCATGACTCGCTTCAGGAAGGAGATGAAGAATGGCCTCTCCCGGGATTTTAA TCCAACAGCCACAGTCAAGATGTTGCCAACATTCGTAAGGTCCATTCCTGATGGCTCTGGCCCTCGGGACCAAGGATCACGTCATGACTC CGAACAGGATAATTCAGACAACAACACCATCTTTGTGCAAGGCCTGGGTGAGAATGTTACAATTGAGTCTGTGGCTGATTACTTCAAGCA GATTGGTATTATTAAGACAAACAAGAAAACGGGACAGCCCATGATTAATTTGTACACAGACAGGGAAACTGGCAAGCTGAAGGGAGAGGC AACGGTCTCTTTTGATGACCCACCTTCAGCTAAAGCAGCTATTGACTGGTTTGATGGTAAAGAATTCTCCGGAAATCCTATCAAGGTCTC ATTTGCTACTCGCCGGGCAGACTTTAATCGGGGTGGTGGCAATGGTCGTGGAGGCCGAGGGCGAGGAGGACCCATGGGCCGTGGAGGCTA TGGAGGTGGTGGCAGTGGTGGTGGTGGCCGAGGAGGATTTCCCAGTGGAGGTGGTGGCGGTGGAGGACAGCAGCGAGCTGGTGACTGGAA GTGTCCTAATCCCACCTGTGAGAATATGAACTTCTCTTGGAGGAATGAATGCAACCAGTGTAAGGCCCCTAAACCAGATGGCCCAGGAGG GGGACCAGGTGGCTCTCACATGGGGGGTAACTACGGGGATGATCGTCGTGGTGGCAGAGGAGGCTATGATCGAGGCGGCTACCGGGGCCG CGGCGGGGACCGTGGAGGCTTCCGAGGGGGCCGGGGTGGTGGGGACAGAGGTGGCTTTGGCCCTGGCAAGATGGATTCCAGGGGTGAGCA CAGACAGGATCGCAGGGAGAGGCCGTATTAATTAGCCTGGCTCCCCAGGTTCTGGAACAGCTTTTTGTCCTGTACCCAGTGTTACCCTCG TTATTTTGTAACCTTCCAATTCCTGATCACCCAAGGGTTTTTTTGTGTCGGACTATGTAATTGTAACTATACCTCTGGTTCCCATTAAAA GTGACCATTTTAGTTAAATTTTGTTCCTCTTCCCCCTTTTCACTTTCCTGGAAGATCGATGTCCCGATCAGGAAGGTAGAGAGTTTTCCT GTTCAGATTACCCTGCCCAGCAGGAACTGGAATACAGTGTTCGGGGAGAAGGCCAAATGATATCCTTGAGAGCAGAGATTAAACTTTTCT >36575_36575_7_HK1-FUS_HK1_chr10_71103745_ENST00000360289_FUS_chr16_31199646_ENST00000254108_length(amino acids)=329AA_BP=185 MWWRGKMAKRALHDFIDKYLYAMRLSDETLIDIMTRFRKEMKNGLSRDFNPTATVKMLPTFVRSIPDGSGPRDQGSRHDSEQDNSDNNTI FVQGLGENVTIESVADYFKQIGIIKTNKKTGQPMINLYTDRETGKLKGEATVSFDDPPSAKAAIDWFDGKEFSGNPIKVSFATRRADFNR GGGNGRGGRGRGGPMGRGGYGGGGSGGGGRGGFPSGGGGGGGQQRAGDWKCPNPTCENMNFSWRNECNQCKAPKPDGPGGGPGGSHMGGN -------------------------------------------------------------- >36575_36575_8_HK1-FUS_HK1_chr10_71103745_ENST00000360289_FUS_chr16_31199646_ENST00000380244_length(transcript)=1635nt_BP=689nt AAAACATCTATCTTGCTGTGTTTGGACAGGCCAGCCCCTGAAACATCTTGGGCAATGGAGGGTTAACTTCTCAAAGTTTAATAGGCAAGA CCAGCAACCATGCAACAAGGACTTCAACTAACCAACTAAAGAACTGTTCCCCAGAGCATTGTTCCTGAGAAGGAAAAGAGTCCAAACACC TACCCACACCTGCTTTGTGCCAAGAATCCACAGTTGGATTGCAAGGACAGTGTATGTTGTCCTTTTGGAAAAATGAGAGTGAGCCCAAAT GAAGAACAAGCAAAGGCGTTCAAGACCCAGCTGTTGAGAGTAGAAAAGCAGAAGAAAGGACCCGAGGTCAGCAAGTGCCCTCCCCACAAT GGGGCAGATCTGCCAGCGAGAATCGGCTACAGCAGCTGAAAAACCAAAACTTCATCTACTTGCTGAAAGTGAGCATTGTTGATGCTCTTG AGAGCATCAGCCAGGACATTAATGTGCACCACTGTGGTGGCGTGGAAAGATGGCAAAAAGAGCCCTGCATGATTTTATTGACAAGTATCT CTATGCCATGCGGCTCTCCGATGAAACTCTCATAGATATCATGACTCGCTTCAGGAAGGAGATGAAGAATGGCCTCTCCCGGGATTTTAA TCCAACAGCCACAGTCAAGATGTTGCCAACATTCGTAAGGTCCATTCCTGATGGCTCTGGCCCTCGGGACCAAGGATCACGTCATGACTC CGAACAGGATAATTCAGACAACAACACCATCTTTGTGCAAGGCCTGGGTGAGAATGTTACAATTGAGTCTGTGGCTGATTACTTCAAGCA GATTGGTATTATTAAGACAAACAAGAAAACGGGACAGCCCATGATTAATTTGTACACAGACAGGGAAACTGGCAAGCTGAAGGGAGAGGC AACGGTCTCTTTTGATGACCCACCTTCAGCTAAAGCAGCTATTGACTGGTTTGATGGTAAAGAATTCTCCGGAAATCCTATCAAGGTCTC ATTTGCTACTCGCCGGGCAGACTTTAATCGGGGTGGTGGCAATGGTCGTGGAGGCCGAGGGCGAGGAGGACCCATGGGCCGTGGAGGCTA TGGAGGTGGTGGCAGTGGTGGTGGTGGCCGAGGAGGATTTCCCAGTGGAGGTGGTGGCGGTGGAGGACAGCAGCGAGCTGGTGACTGGAA GTGTCCTAATCCCACCTGTGAGAATATGAACTTCTCTTGGAGGAATGAATGCAACCAGTGTAAGGCCCCTAAACCAGATGGCCCAGGAGG GGGACCAGGTGGCTCTCACATGGGGGGTAACTACGGGGATGATCGTCGTGGTGGCAGAGGAGGCTATGATCGAGGCGGCTACCGGGGCCG CGGCGGGGACCGTGGAGGCTTCCGAGGGGGCCGGGGTGGTGGGGACAGAGGTGGCTTTGGCCCTGGCAAGATGGATTCCAGGGGTGAGCA CAGACAGGATCGCAGGGAGAGGCCGTATTAATTAGCCTGGCTCCCCAGGTTCTGGAACAGCTTTTTGTCCTGTACCCAGTGTTACCCTCG TTATTTTGTAACCTTCCAATTCCTGATCACCCAAGGGTTTTTTTGTGTCGGACTATGTAATTGTAACTATACCTCTGGTTCCCATTAAAA >36575_36575_8_HK1-FUS_HK1_chr10_71103745_ENST00000360289_FUS_chr16_31199646_ENST00000380244_length(amino acids)=329AA_BP=185 MWWRGKMAKRALHDFIDKYLYAMRLSDETLIDIMTRFRKEMKNGLSRDFNPTATVKMLPTFVRSIPDGSGPRDQGSRHDSEQDNSDNNTI FVQGLGENVTIESVADYFKQIGIIKTNKKTGQPMINLYTDRETGKLKGEATVSFDDPPSAKAAIDWFDGKEFSGNPIKVSFATRRADFNR GGGNGRGGRGRGGPMGRGGYGGGGSGGGGRGGFPSGGGGGGGQQRAGDWKCPNPTCENMNFSWRNECNQCKAPKPDGPGGGPGGSHMGGN -------------------------------------------------------------- >36575_36575_9_HK1-FUS_HK1_chr10_71103745_ENST00000360289_FUS_chr16_31199646_ENST00000568685_length(transcript)=1611nt_BP=689nt AAAACATCTATCTTGCTGTGTTTGGACAGGCCAGCCCCTGAAACATCTTGGGCAATGGAGGGTTAACTTCTCAAAGTTTAATAGGCAAGA CCAGCAACCATGCAACAAGGACTTCAACTAACCAACTAAAGAACTGTTCCCCAGAGCATTGTTCCTGAGAAGGAAAAGAGTCCAAACACC TACCCACACCTGCTTTGTGCCAAGAATCCACAGTTGGATTGCAAGGACAGTGTATGTTGTCCTTTTGGAAAAATGAGAGTGAGCCCAAAT GAAGAACAAGCAAAGGCGTTCAAGACCCAGCTGTTGAGAGTAGAAAAGCAGAAGAAAGGACCCGAGGTCAGCAAGTGCCCTCCCCACAAT GGGGCAGATCTGCCAGCGAGAATCGGCTACAGCAGCTGAAAAACCAAAACTTCATCTACTTGCTGAAAGTGAGCATTGTTGATGCTCTTG AGAGCATCAGCCAGGACATTAATGTGCACCACTGTGGTGGCGTGGAAAGATGGCAAAAAGAGCCCTGCATGATTTTATTGACAAGTATCT CTATGCCATGCGGCTCTCCGATGAAACTCTCATAGATATCATGACTCGCTTCAGGAAGGAGATGAAGAATGGCCTCTCCCGGGATTTTAA TCCAACAGCCACAGTCAAGATGTTGCCAACATTCGTAAGGTCCATTCCTGATGGCTCTGGCCCTCGGGACCAAGGATCACGTCATGACTC CGCAGAACAGGATAATTCAGACAACAACACCATCTTTGTGCAAGGCCTGGGTGAGAATGTTACAATTGAGTCTGTGGCTGATTACTTCAA GCAGATTGGTATTATTAAGACAAACAAGAAAACGGGACAGCCCATGATTAATTTGTACACAGACAGGGAAACTGGCAAGCTGAAGGGAGA GGCAACGGTCTCTTTTGATGACCCACCTTCAGCTAAAGCAGCTATTGACTGGTTTGATGGTAAAGAATTCTCCGGAAATCCTATCAAGGT CTCATTTGCTACTCGCCGGGCAGACTTTAATCGGGGTGGTGGCAATGGTCGTGGAGGCCGAGGGCGAGGAGGACCCATGGGCCGTGGAGG CTATGGAGGTGGTGGCAGTGGTGGTGGTGGCCGAGGAGGATTTCCCAGTGGAGGTGGTGGCGGTGGAGGACAGCAGCGAGCTGGTGACTG GAAGTGTCCTAATCCCACCTGTGAGAATATGAACTTCTCTTGGAGGAATGAATGCAACCAGTGTAAGGCCCCTAAACCAGATGGCCCAGG AGGGGGACCAGGTGGCTCTCACATGGGGGGTAACTACGGGGATGATCGTCGTGGTGGCAGAGGAGGCTATGATCGAGGCGGCTACCGGGG CCGCGGCGGGGACCGTGGAGGCTTCCGAGGGGGCCGGGGTGGTGGGGACAGAGGTGGCTTTGGCCCTGGCAAGATGGATTCCAGGGGTGA GCACAGACAGGATCGCAGGGAGAGGCCGTATTAATTAGCCTGGCTCCCCAGGTTCTGGAACAGCTTTTTGTCCTGTACCCAGTGTTACCC >36575_36575_9_HK1-FUS_HK1_chr10_71103745_ENST00000360289_FUS_chr16_31199646_ENST00000568685_length(amino acids)=330AA_BP=186 MWWRGKMAKRALHDFIDKYLYAMRLSDETLIDIMTRFRKEMKNGLSRDFNPTATVKMLPTFVRSIPDGSGPRDQGSRHDSAEQDNSDNNT IFVQGLGENVTIESVADYFKQIGIIKTNKKTGQPMINLYTDRETGKLKGEATVSFDDPPSAKAAIDWFDGKEFSGNPIKVSFATRRADFN RGGGNGRGGRGRGGPMGRGGYGGGGSGGGGRGGFPSGGGGGGGQQRAGDWKCPNPTCENMNFSWRNECNQCKAPKPDGPGGGPGGSHMGG -------------------------------------------------------------- >36575_36575_10_HK1-FUS_HK1_chr10_71103745_ENST00000404387_FUS_chr16_31199646_ENST00000254108_length(transcript)=1388nt_BP=238nt ATGGGGCAGATCTGCCAGCGAGAATCGGCTACAGCAGCTGAAAAACCAAAACTTCATCTACTTGCTGAAAGTGAGATTGACAAGTATCTC TATGCCATGCGGCTCTCCGATGAAACTCTCATAGATATCATGACTCGCTTCAGGAAGGAGATGAAGAATGGCCTCTCCCGGGATTTTAAT CCAACAGCCACAGTCAAGATGTTGCCAACATTCGTAAGGTCCATTCCTGATGGCTCTGGCCCTCGGGACCAAGGATCACGTCATGACTCC GAACAGGATAATTCAGACAACAACACCATCTTTGTGCAAGGCCTGGGTGAGAATGTTACAATTGAGTCTGTGGCTGATTACTTCAAGCAG ATTGGTATTATTAAGACAAACAAGAAAACGGGACAGCCCATGATTAATTTGTACACAGACAGGGAAACTGGCAAGCTGAAGGGAGAGGCA ACGGTCTCTTTTGATGACCCACCTTCAGCTAAAGCAGCTATTGACTGGTTTGATGGTAAAGAATTCTCCGGAAATCCTATCAAGGTCTCA TTTGCTACTCGCCGGGCAGACTTTAATCGGGGTGGTGGCAATGGTCGTGGAGGCCGAGGGCGAGGAGGACCCATGGGCCGTGGAGGCTAT GGAGGTGGTGGCAGTGGTGGTGGTGGCCGAGGAGGATTTCCCAGTGGAGGTGGTGGCGGTGGAGGACAGCAGCGAGCTGGTGACTGGAAG TGTCCTAATCCCACCTGTGAGAATATGAACTTCTCTTGGAGGAATGAATGCAACCAGTGTAAGGCCCCTAAACCAGATGGCCCAGGAGGG GGACCAGGTGGCTCTCACATGGGGGGTAACTACGGGGATGATCGTCGTGGTGGCAGAGGAGGCTATGATCGAGGCGGCTACCGGGGCCGC GGCGGGGACCGTGGAGGCTTCCGAGGGGGCCGGGGTGGTGGGGACAGAGGTGGCTTTGGCCCTGGCAAGATGGATTCCAGGGGTGAGCAC AGACAGGATCGCAGGGAGAGGCCGTATTAATTAGCCTGGCTCCCCAGGTTCTGGAACAGCTTTTTGTCCTGTACCCAGTGTTACCCTCGT TATTTTGTAACCTTCCAATTCCTGATCACCCAAGGGTTTTTTTGTGTCGGACTATGTAATTGTAACTATACCTCTGGTTCCCATTAAAAG TGACCATTTTAGTTAAATTTTGTTCCTCTTCCCCCTTTTCACTTTCCTGGAAGATCGATGTCCCGATCAGGAAGGTAGAGAGTTTTCCTG TTCAGATTACCCTGCCCAGCAGGAACTGGAATACAGTGTTCGGGGAGAAGGCCAAATGATATCCTTGAGAGCAGAGATTAAACTTTTCTG >36575_36575_10_HK1-FUS_HK1_chr10_71103745_ENST00000404387_FUS_chr16_31199646_ENST00000254108_length(amino acids)=339AA_BP=195 MGQICQRESATAAEKPKLHLLAESEIDKYLYAMRLSDETLIDIMTRFRKEMKNGLSRDFNPTATVKMLPTFVRSIPDGSGPRDQGSRHDS EQDNSDNNTIFVQGLGENVTIESVADYFKQIGIIKTNKKTGQPMINLYTDRETGKLKGEATVSFDDPPSAKAAIDWFDGKEFSGNPIKVS FATRRADFNRGGGNGRGGRGRGGPMGRGGYGGGGSGGGGRGGFPSGGGGGGGQQRAGDWKCPNPTCENMNFSWRNECNQCKAPKPDGPGG -------------------------------------------------------------- >36575_36575_11_HK1-FUS_HK1_chr10_71103745_ENST00000404387_FUS_chr16_31199646_ENST00000380244_length(transcript)=1184nt_BP=238nt ATGGGGCAGATCTGCCAGCGAGAATCGGCTACAGCAGCTGAAAAACCAAAACTTCATCTACTTGCTGAAAGTGAGATTGACAAGTATCTC TATGCCATGCGGCTCTCCGATGAAACTCTCATAGATATCATGACTCGCTTCAGGAAGGAGATGAAGAATGGCCTCTCCCGGGATTTTAAT CCAACAGCCACAGTCAAGATGTTGCCAACATTCGTAAGGTCCATTCCTGATGGCTCTGGCCCTCGGGACCAAGGATCACGTCATGACTCC GAACAGGATAATTCAGACAACAACACCATCTTTGTGCAAGGCCTGGGTGAGAATGTTACAATTGAGTCTGTGGCTGATTACTTCAAGCAG ATTGGTATTATTAAGACAAACAAGAAAACGGGACAGCCCATGATTAATTTGTACACAGACAGGGAAACTGGCAAGCTGAAGGGAGAGGCA ACGGTCTCTTTTGATGACCCACCTTCAGCTAAAGCAGCTATTGACTGGTTTGATGGTAAAGAATTCTCCGGAAATCCTATCAAGGTCTCA TTTGCTACTCGCCGGGCAGACTTTAATCGGGGTGGTGGCAATGGTCGTGGAGGCCGAGGGCGAGGAGGACCCATGGGCCGTGGAGGCTAT GGAGGTGGTGGCAGTGGTGGTGGTGGCCGAGGAGGATTTCCCAGTGGAGGTGGTGGCGGTGGAGGACAGCAGCGAGCTGGTGACTGGAAG TGTCCTAATCCCACCTGTGAGAATATGAACTTCTCTTGGAGGAATGAATGCAACCAGTGTAAGGCCCCTAAACCAGATGGCCCAGGAGGG GGACCAGGTGGCTCTCACATGGGGGGTAACTACGGGGATGATCGTCGTGGTGGCAGAGGAGGCTATGATCGAGGCGGCTACCGGGGCCGC GGCGGGGACCGTGGAGGCTTCCGAGGGGGCCGGGGTGGTGGGGACAGAGGTGGCTTTGGCCCTGGCAAGATGGATTCCAGGGGTGAGCAC AGACAGGATCGCAGGGAGAGGCCGTATTAATTAGCCTGGCTCCCCAGGTTCTGGAACAGCTTTTTGTCCTGTACCCAGTGTTACCCTCGT TATTTTGTAACCTTCCAATTCCTGATCACCCAAGGGTTTTTTTGTGTCGGACTATGTAATTGTAACTATACCTCTGGTTCCCATTAAAAG >36575_36575_11_HK1-FUS_HK1_chr10_71103745_ENST00000404387_FUS_chr16_31199646_ENST00000380244_length(amino acids)=339AA_BP=195 MGQICQRESATAAEKPKLHLLAESEIDKYLYAMRLSDETLIDIMTRFRKEMKNGLSRDFNPTATVKMLPTFVRSIPDGSGPRDQGSRHDS EQDNSDNNTIFVQGLGENVTIESVADYFKQIGIIKTNKKTGQPMINLYTDRETGKLKGEATVSFDDPPSAKAAIDWFDGKEFSGNPIKVS FATRRADFNRGGGNGRGGRGRGGPMGRGGYGGGGSGGGGRGGFPSGGGGGGGQQRAGDWKCPNPTCENMNFSWRNECNQCKAPKPDGPGG -------------------------------------------------------------- >36575_36575_12_HK1-FUS_HK1_chr10_71103745_ENST00000404387_FUS_chr16_31199646_ENST00000568685_length(transcript)=1160nt_BP=238nt ATGGGGCAGATCTGCCAGCGAGAATCGGCTACAGCAGCTGAAAAACCAAAACTTCATCTACTTGCTGAAAGTGAGATTGACAAGTATCTC TATGCCATGCGGCTCTCCGATGAAACTCTCATAGATATCATGACTCGCTTCAGGAAGGAGATGAAGAATGGCCTCTCCCGGGATTTTAAT CCAACAGCCACAGTCAAGATGTTGCCAACATTCGTAAGGTCCATTCCTGATGGCTCTGGCCCTCGGGACCAAGGATCACGTCATGACTCC GCAGAACAGGATAATTCAGACAACAACACCATCTTTGTGCAAGGCCTGGGTGAGAATGTTACAATTGAGTCTGTGGCTGATTACTTCAAG CAGATTGGTATTATTAAGACAAACAAGAAAACGGGACAGCCCATGATTAATTTGTACACAGACAGGGAAACTGGCAAGCTGAAGGGAGAG GCAACGGTCTCTTTTGATGACCCACCTTCAGCTAAAGCAGCTATTGACTGGTTTGATGGTAAAGAATTCTCCGGAAATCCTATCAAGGTC TCATTTGCTACTCGCCGGGCAGACTTTAATCGGGGTGGTGGCAATGGTCGTGGAGGCCGAGGGCGAGGAGGACCCATGGGCCGTGGAGGC TATGGAGGTGGTGGCAGTGGTGGTGGTGGCCGAGGAGGATTTCCCAGTGGAGGTGGTGGCGGTGGAGGACAGCAGCGAGCTGGTGACTGG AAGTGTCCTAATCCCACCTGTGAGAATATGAACTTCTCTTGGAGGAATGAATGCAACCAGTGTAAGGCCCCTAAACCAGATGGCCCAGGA GGGGGACCAGGTGGCTCTCACATGGGGGGTAACTACGGGGATGATCGTCGTGGTGGCAGAGGAGGCTATGATCGAGGCGGCTACCGGGGC CGCGGCGGGGACCGTGGAGGCTTCCGAGGGGGCCGGGGTGGTGGGGACAGAGGTGGCTTTGGCCCTGGCAAGATGGATTCCAGGGGTGAG CACAGACAGGATCGCAGGGAGAGGCCGTATTAATTAGCCTGGCTCCCCAGGTTCTGGAACAGCTTTTTGTCCTGTACCCAGTGTTACCCT >36575_36575_12_HK1-FUS_HK1_chr10_71103745_ENST00000404387_FUS_chr16_31199646_ENST00000568685_length(amino acids)=340AA_BP=196 MGQICQRESATAAEKPKLHLLAESEIDKYLYAMRLSDETLIDIMTRFRKEMKNGLSRDFNPTATVKMLPTFVRSIPDGSGPRDQGSRHDS AEQDNSDNNTIFVQGLGENVTIESVADYFKQIGIIKTNKKTGQPMINLYTDRETGKLKGEATVSFDDPPSAKAAIDWFDGKEFSGNPIKV SFATRRADFNRGGGNGRGGRGRGGPMGRGGYGGGGSGGGGRGGFPSGGGGGGGQQRAGDWKCPNPTCENMNFSWRNECNQCKAPKPDGPG -------------------------------------------------------------- >36575_36575_13_HK1-FUS_HK1_chr10_71103745_ENST00000448642_FUS_chr16_31199646_ENST00000254108_length(transcript)=1870nt_BP=720nt ATCTATCTTGCTGTGTTTGGACAGGCCAGCCCCTGAAACATCTTGGGCAATGGAGGGTTAACTTCTCAAAGTTTAATAGGCAAGACCAGC AACCATGCAACAAGAAGATACTCTATAAATGATGATTCAATGAATGCCAAGCCCTGTTCTATGCACTGAAGACCAAAAGAAATAAAAGAC ATCATTCCTGCTCTGACTTCAACTAACCAACTAAAGAACTGTTCCCCAGAGCATTGTTCCTGAGAAGGAAAAGAGTCCAAACACCTACCC ACACCTGCTTTGTGCCAAGAATCCACAGTTGGATTGCAAGGACAGTGCGTTCAAGACCCAGCTGTTGAGAGTAGAAAAGCAGAAGAAAGG ACCCGAGGTCAGCAAGTGCCCTCCCCACAATGGGGCAGATCTGCCAGCGAGAATCGAGACAGGGTCTTGCTATGTTGCCCAGGCTGTTCT TAAATCCCTGGCGTCAAGTGATCCTCCTGCCTCAGCCTCCTAAAGTGCTGGGATTACAGGCTACAGCAGCTGAAAAACCAAAACTTCATC TACTTGCTGAAAGTGAGATTGACAAGTATCTCTATGCCATGCGGCTCTCCGATGAAACTCTCATAGATATCATGACTCGCTTCAGGAAGG AGATGAAGAATGGCCTCTCCCGGGATTTTAATCCAACAGCCACAGTCAAGATGTTGCCAACATTCGTAAGGTCCATTCCTGATGGCTCTG GCCCTCGGGACCAAGGATCACGTCATGACTCCGAACAGGATAATTCAGACAACAACACCATCTTTGTGCAAGGCCTGGGTGAGAATGTTA CAATTGAGTCTGTGGCTGATTACTTCAAGCAGATTGGTATTATTAAGACAAACAAGAAAACGGGACAGCCCATGATTAATTTGTACACAG ACAGGGAAACTGGCAAGCTGAAGGGAGAGGCAACGGTCTCTTTTGATGACCCACCTTCAGCTAAAGCAGCTATTGACTGGTTTGATGGTA AAGAATTCTCCGGAAATCCTATCAAGGTCTCATTTGCTACTCGCCGGGCAGACTTTAATCGGGGTGGTGGCAATGGTCGTGGAGGCCGAG GGCGAGGAGGACCCATGGGCCGTGGAGGCTATGGAGGTGGTGGCAGTGGTGGTGGTGGCCGAGGAGGATTTCCCAGTGGAGGTGGTGGCG GTGGAGGACAGCAGCGAGCTGGTGACTGGAAGTGTCCTAATCCCACCTGTGAGAATATGAACTTCTCTTGGAGGAATGAATGCAACCAGT GTAAGGCCCCTAAACCAGATGGCCCAGGAGGGGGACCAGGTGGCTCTCACATGGGGGGTAACTACGGGGATGATCGTCGTGGTGGCAGAG GAGGCTATGATCGAGGCGGCTACCGGGGCCGCGGCGGGGACCGTGGAGGCTTCCGAGGGGGCCGGGGTGGTGGGGACAGAGGTGGCTTTG GCCCTGGCAAGATGGATTCCAGGGGTGAGCACAGACAGGATCGCAGGGAGAGGCCGTATTAATTAGCCTGGCTCCCCAGGTTCTGGAACA GCTTTTTGTCCTGTACCCAGTGTTACCCTCGTTATTTTGTAACCTTCCAATTCCTGATCACCCAAGGGTTTTTTTGTGTCGGACTATGTA ATTGTAACTATACCTCTGGTTCCCATTAAAAGTGACCATTTTAGTTAAATTTTGTTCCTCTTCCCCCTTTTCACTTTCCTGGAAGATCGA TGTCCCGATCAGGAAGGTAGAGAGTTTTCCTGTTCAGATTACCCTGCCCAGCAGGAACTGGAATACAGTGTTCGGGGAGAAGGCCAAATG >36575_36575_13_HK1-FUS_HK1_chr10_71103745_ENST00000448642_FUS_chr16_31199646_ENST00000254108_length(amino acids)=370AA_BP=9 MGQICQRESRQGLAMLPRLFLNPWRQVILLPQPPKVLGLQATAAEKPKLHLLAESEIDKYLYAMRLSDETLIDIMTRFRKEMKNGLSRDF NPTATVKMLPTFVRSIPDGSGPRDQGSRHDSEQDNSDNNTIFVQGLGENVTIESVADYFKQIGIIKTNKKTGQPMINLYTDRETGKLKGE ATVSFDDPPSAKAAIDWFDGKEFSGNPIKVSFATRRADFNRGGGNGRGGRGRGGPMGRGGYGGGGSGGGGRGGFPSGGGGGGGQQRAGDW KCPNPTCENMNFSWRNECNQCKAPKPDGPGGGPGGSHMGGNYGDDRRGGRGGYDRGGYRGRGGDRGGFRGGRGGGDRGGFGPGKMDSRGE -------------------------------------------------------------- >36575_36575_14_HK1-FUS_HK1_chr10_71103745_ENST00000448642_FUS_chr16_31199646_ENST00000380244_length(transcript)=1666nt_BP=720nt ATCTATCTTGCTGTGTTTGGACAGGCCAGCCCCTGAAACATCTTGGGCAATGGAGGGTTAACTTCTCAAAGTTTAATAGGCAAGACCAGC AACCATGCAACAAGAAGATACTCTATAAATGATGATTCAATGAATGCCAAGCCCTGTTCTATGCACTGAAGACCAAAAGAAATAAAAGAC ATCATTCCTGCTCTGACTTCAACTAACCAACTAAAGAACTGTTCCCCAGAGCATTGTTCCTGAGAAGGAAAAGAGTCCAAACACCTACCC ACACCTGCTTTGTGCCAAGAATCCACAGTTGGATTGCAAGGACAGTGCGTTCAAGACCCAGCTGTTGAGAGTAGAAAAGCAGAAGAAAGG ACCCGAGGTCAGCAAGTGCCCTCCCCACAATGGGGCAGATCTGCCAGCGAGAATCGAGACAGGGTCTTGCTATGTTGCCCAGGCTGTTCT TAAATCCCTGGCGTCAAGTGATCCTCCTGCCTCAGCCTCCTAAAGTGCTGGGATTACAGGCTACAGCAGCTGAAAAACCAAAACTTCATC TACTTGCTGAAAGTGAGATTGACAAGTATCTCTATGCCATGCGGCTCTCCGATGAAACTCTCATAGATATCATGACTCGCTTCAGGAAGG AGATGAAGAATGGCCTCTCCCGGGATTTTAATCCAACAGCCACAGTCAAGATGTTGCCAACATTCGTAAGGTCCATTCCTGATGGCTCTG GCCCTCGGGACCAAGGATCACGTCATGACTCCGAACAGGATAATTCAGACAACAACACCATCTTTGTGCAAGGCCTGGGTGAGAATGTTA CAATTGAGTCTGTGGCTGATTACTTCAAGCAGATTGGTATTATTAAGACAAACAAGAAAACGGGACAGCCCATGATTAATTTGTACACAG ACAGGGAAACTGGCAAGCTGAAGGGAGAGGCAACGGTCTCTTTTGATGACCCACCTTCAGCTAAAGCAGCTATTGACTGGTTTGATGGTA AAGAATTCTCCGGAAATCCTATCAAGGTCTCATTTGCTACTCGCCGGGCAGACTTTAATCGGGGTGGTGGCAATGGTCGTGGAGGCCGAG GGCGAGGAGGACCCATGGGCCGTGGAGGCTATGGAGGTGGTGGCAGTGGTGGTGGTGGCCGAGGAGGATTTCCCAGTGGAGGTGGTGGCG GTGGAGGACAGCAGCGAGCTGGTGACTGGAAGTGTCCTAATCCCACCTGTGAGAATATGAACTTCTCTTGGAGGAATGAATGCAACCAGT GTAAGGCCCCTAAACCAGATGGCCCAGGAGGGGGACCAGGTGGCTCTCACATGGGGGGTAACTACGGGGATGATCGTCGTGGTGGCAGAG GAGGCTATGATCGAGGCGGCTACCGGGGCCGCGGCGGGGACCGTGGAGGCTTCCGAGGGGGCCGGGGTGGTGGGGACAGAGGTGGCTTTG GCCCTGGCAAGATGGATTCCAGGGGTGAGCACAGACAGGATCGCAGGGAGAGGCCGTATTAATTAGCCTGGCTCCCCAGGTTCTGGAACA GCTTTTTGTCCTGTACCCAGTGTTACCCTCGTTATTTTGTAACCTTCCAATTCCTGATCACCCAAGGGTTTTTTTGTGTCGGACTATGTA >36575_36575_14_HK1-FUS_HK1_chr10_71103745_ENST00000448642_FUS_chr16_31199646_ENST00000380244_length(amino acids)=370AA_BP=9 MGQICQRESRQGLAMLPRLFLNPWRQVILLPQPPKVLGLQATAAEKPKLHLLAESEIDKYLYAMRLSDETLIDIMTRFRKEMKNGLSRDF NPTATVKMLPTFVRSIPDGSGPRDQGSRHDSEQDNSDNNTIFVQGLGENVTIESVADYFKQIGIIKTNKKTGQPMINLYTDRETGKLKGE ATVSFDDPPSAKAAIDWFDGKEFSGNPIKVSFATRRADFNRGGGNGRGGRGRGGPMGRGGYGGGGSGGGGRGGFPSGGGGGGGQQRAGDW KCPNPTCENMNFSWRNECNQCKAPKPDGPGGGPGGSHMGGNYGDDRRGGRGGYDRGGYRGRGGDRGGFRGGRGGGDRGGFGPGKMDSRGE -------------------------------------------------------------- >36575_36575_15_HK1-FUS_HK1_chr10_71103745_ENST00000448642_FUS_chr16_31199646_ENST00000568685_length(transcript)=1642nt_BP=720nt ATCTATCTTGCTGTGTTTGGACAGGCCAGCCCCTGAAACATCTTGGGCAATGGAGGGTTAACTTCTCAAAGTTTAATAGGCAAGACCAGC AACCATGCAACAAGAAGATACTCTATAAATGATGATTCAATGAATGCCAAGCCCTGTTCTATGCACTGAAGACCAAAAGAAATAAAAGAC ATCATTCCTGCTCTGACTTCAACTAACCAACTAAAGAACTGTTCCCCAGAGCATTGTTCCTGAGAAGGAAAAGAGTCCAAACACCTACCC ACACCTGCTTTGTGCCAAGAATCCACAGTTGGATTGCAAGGACAGTGCGTTCAAGACCCAGCTGTTGAGAGTAGAAAAGCAGAAGAAAGG ACCCGAGGTCAGCAAGTGCCCTCCCCACAATGGGGCAGATCTGCCAGCGAGAATCGAGACAGGGTCTTGCTATGTTGCCCAGGCTGTTCT TAAATCCCTGGCGTCAAGTGATCCTCCTGCCTCAGCCTCCTAAAGTGCTGGGATTACAGGCTACAGCAGCTGAAAAACCAAAACTTCATC TACTTGCTGAAAGTGAGATTGACAAGTATCTCTATGCCATGCGGCTCTCCGATGAAACTCTCATAGATATCATGACTCGCTTCAGGAAGG AGATGAAGAATGGCCTCTCCCGGGATTTTAATCCAACAGCCACAGTCAAGATGTTGCCAACATTCGTAAGGTCCATTCCTGATGGCTCTG GCCCTCGGGACCAAGGATCACGTCATGACTCCGCAGAACAGGATAATTCAGACAACAACACCATCTTTGTGCAAGGCCTGGGTGAGAATG TTACAATTGAGTCTGTGGCTGATTACTTCAAGCAGATTGGTATTATTAAGACAAACAAGAAAACGGGACAGCCCATGATTAATTTGTACA CAGACAGGGAAACTGGCAAGCTGAAGGGAGAGGCAACGGTCTCTTTTGATGACCCACCTTCAGCTAAAGCAGCTATTGACTGGTTTGATG GTAAAGAATTCTCCGGAAATCCTATCAAGGTCTCATTTGCTACTCGCCGGGCAGACTTTAATCGGGGTGGTGGCAATGGTCGTGGAGGCC GAGGGCGAGGAGGACCCATGGGCCGTGGAGGCTATGGAGGTGGTGGCAGTGGTGGTGGTGGCCGAGGAGGATTTCCCAGTGGAGGTGGTG GCGGTGGAGGACAGCAGCGAGCTGGTGACTGGAAGTGTCCTAATCCCACCTGTGAGAATATGAACTTCTCTTGGAGGAATGAATGCAACC AGTGTAAGGCCCCTAAACCAGATGGCCCAGGAGGGGGACCAGGTGGCTCTCACATGGGGGGTAACTACGGGGATGATCGTCGTGGTGGCA GAGGAGGCTATGATCGAGGCGGCTACCGGGGCCGCGGCGGGGACCGTGGAGGCTTCCGAGGGGGCCGGGGTGGTGGGGACAGAGGTGGCT TTGGCCCTGGCAAGATGGATTCCAGGGGTGAGCACAGACAGGATCGCAGGGAGAGGCCGTATTAATTAGCCTGGCTCCCCAGGTTCTGGA ACAGCTTTTTGTCCTGTACCCAGTGTTACCCTCGTTATTTTGTAACCTTCCAATTCCTGATCACCCAAGGGTTTTTTTGTGTCGGACTAT >36575_36575_15_HK1-FUS_HK1_chr10_71103745_ENST00000448642_FUS_chr16_31199646_ENST00000568685_length(amino acids)=371AA_BP=9 MGQICQRESRQGLAMLPRLFLNPWRQVILLPQPPKVLGLQATAAEKPKLHLLAESEIDKYLYAMRLSDETLIDIMTRFRKEMKNGLSRDF NPTATVKMLPTFVRSIPDGSGPRDQGSRHDSAEQDNSDNNTIFVQGLGENVTIESVADYFKQIGIIKTNKKTGQPMINLYTDRETGKLKG EATVSFDDPPSAKAAIDWFDGKEFSGNPIKVSFATRRADFNRGGGNGRGGRGRGGPMGRGGYGGGGSGGGGRGGFPSGGGGGGGQQRAGD WKCPNPTCENMNFSWRNECNQCKAPKPDGPGGGPGGSHMGGNYGDDRRGGRGGYDRGGYRGRGGDRGGFRGGRGGGDRGGFGPGKMDSRG -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for HK1-FUS |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for HK1-FUS |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for HK1-FUS |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies