
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:HMGA2-CHMP1A (FusionGDB2 ID:36825) |
Fusion Gene Summary for HMGA2-CHMP1A |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: HMGA2-CHMP1A | Fusion gene ID: 36825 | Hgene | Tgene | Gene symbol | HMGA2 | CHMP1A | Gene ID | 8091 | 5119 |
| Gene name | high mobility group AT-hook 2 | charged multivesicular body protein 1A | |
| Synonyms | BABL|HMGI-C|HMGIC|LIPO|STQTL9 | CHMP1|PCH8|PCOLN3|PRSM1|VPS46-1|VPS46A | |
| Cytomap | 12q14.3 | 16q24.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | high mobility group protein HMGI-CHMGA2/KRT121P fusionhigh-mobility group (nonhistone chromosomal) protein isoform I-C | charged multivesicular body protein 1acharged multivesicular body protein 1/chromatin modifying protein 1chromatin modifying protein 1Aprocollagen (type III) N-endopeptidaseprotease, metallo, 1, 33kDvacuolar protein sorting-associated protein 46-1 | |
| Modification date | 20200329 | 20200313 | |
| UniProtAcc | P52926 | Q9HD42 | |
| Ensembl transtripts involved in fusion gene | ENST00000354636, ENST00000393577, ENST00000393578, ENST00000403681, ENST00000425208, ENST00000536545, ENST00000541363, | ENST00000547614, ENST00000253475, ENST00000397901, ENST00000535997, ENST00000550102, | |
| Fusion gene scores | * DoF score | 43 X 25 X 15=16125 | 45 X 11 X 21=10395 |
| # samples | 43 | 48 | |
| ** MAII score | log2(43/16125*10)=-5.22881869049588 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(48/10395*10)=-4.43671154213721 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: HMGA2 [Title/Abstract] AND CHMP1A [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | HMGA2(66221867)-CHMP1A(89713739), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | HMGA2-CHMP1A seems lost the major protein functional domain in Hgene partner, which is a CGC due to the frame-shifted ORF. HMGA2-CHMP1A seems lost the major protein functional domain in Hgene partner, which is a transcription factor due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | HMGA2 | GO:0000122 | negative regulation of transcription by RNA polymerase II | 14627817 |
| Hgene | HMGA2 | GO:0002062 | chondrocyte differentiation | 21484705 |
| Hgene | HMGA2 | GO:0006284 | base-excision repair | 19465398 |
| Hgene | HMGA2 | GO:0007095 | mitotic G2 DNA damage checkpoint | 16061642 |
| Hgene | HMGA2 | GO:0010564 | regulation of cell cycle process | 14645522 |
| Hgene | HMGA2 | GO:0010628 | positive regulation of gene expression | 18832382 |
| Hgene | HMGA2 | GO:0031052 | chromosome breakage | 19549901 |
| Hgene | HMGA2 | GO:0031507 | heterochromatin assembly | 16901784 |
| Hgene | HMGA2 | GO:0035978 | histone H2A-S139 phosphorylation | 16061642 |
| Hgene | HMGA2 | GO:0035986 | senescence-associated heterochromatin focus assembly | 16901784 |
| Hgene | HMGA2 | GO:0035988 | chondrocyte proliferation | 21484705 |
| Hgene | HMGA2 | GO:0042769 | DNA damage response, detection of DNA damage | 19465398 |
| Hgene | HMGA2 | GO:0043065 | positive regulation of apoptotic process | 16061642 |
| Hgene | HMGA2 | GO:0043066 | negative regulation of apoptotic process | 19465398 |
| Hgene | HMGA2 | GO:0043392 | negative regulation of DNA binding | 14645522 |
| Hgene | HMGA2 | GO:0043922 | negative regulation by host of viral transcription | 17005673 |
| Hgene | HMGA2 | GO:0045869 | negative regulation of single stranded viral RNA replication via double stranded DNA intermediate | 17005673 |
| Hgene | HMGA2 | GO:0045892 | negative regulation of transcription, DNA-templated | 18832382 |
| Hgene | HMGA2 | GO:0045893 | positive regulation of transcription, DNA-templated | 15225648|15755872|17005673|17324944|17426251 |
| Hgene | HMGA2 | GO:0045944 | positive regulation of transcription by RNA polymerase II | 14645522|18832382 |
| Hgene | HMGA2 | GO:0071158 | positive regulation of cell cycle arrest | 16061642 |
| Hgene | HMGA2 | GO:0071902 | positive regulation of protein serine/threonine kinase activity | 19549901 |
| Hgene | HMGA2 | GO:0090402 | oncogene-induced cell senescence | 16901784 |
| Hgene | HMGA2 | GO:2000648 | positive regulation of stem cell proliferation | 21484705 |
| Hgene | HMGA2 | GO:2000679 | positive regulation of transcription regulatory region DNA binding | 18832382 |
| Hgene | HMGA2 | GO:2000685 | positive regulation of cellular response to X-ray | 16061642 |
| Hgene | HMGA2 | GO:2001022 | positive regulation of response to DNA damage stimulus | 16061642|19465398 |
| Hgene | HMGA2 | GO:2001033 | negative regulation of double-strand break repair via nonhomologous end joining | 19549901 |
| Hgene | HMGA2 | GO:2001038 | regulation of cellular response to drug | 16061642 |
| Tgene | CHMP1A | GO:0007076 | mitotic chromosome condensation | 11559747 |
| Tgene | CHMP1A | GO:0016192 | vesicle-mediated transport | 11559748 |
| Tgene | CHMP1A | GO:0016458 | gene silencing | 11559747 |
| Tgene | CHMP1A | GO:0045892 | negative regulation of transcription, DNA-templated | 11559747 |
| Fusion gene breakpoints across HMGA2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
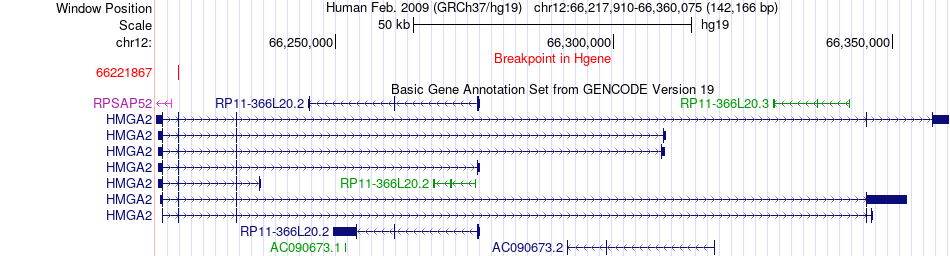 |
| Fusion gene breakpoints across CHMP1A (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
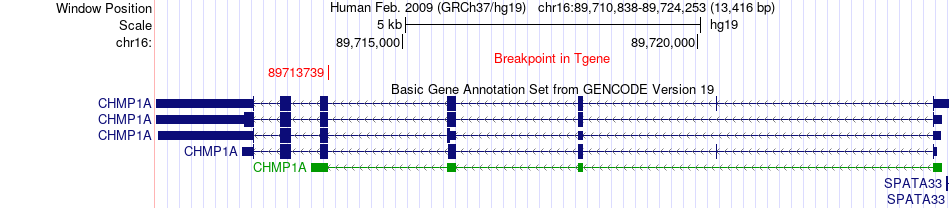 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | KIRC | TCGA-B0-4698-01A | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - |
Top |
Fusion Gene ORF analysis for HMGA2-CHMP1A |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-5UTR | ENST00000354636 | ENST00000547614 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - |
| 5CDS-5UTR | ENST00000393577 | ENST00000547614 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - |
| 5CDS-5UTR | ENST00000393578 | ENST00000547614 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - |
| 5CDS-5UTR | ENST00000403681 | ENST00000547614 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - |
| 5CDS-5UTR | ENST00000425208 | ENST00000547614 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - |
| 5CDS-5UTR | ENST00000536545 | ENST00000547614 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - |
| 5CDS-5UTR | ENST00000541363 | ENST00000547614 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - |
| Frame-shift | ENST00000354636 | ENST00000253475 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - |
| Frame-shift | ENST00000393577 | ENST00000253475 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - |
| Frame-shift | ENST00000393578 | ENST00000253475 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - |
| Frame-shift | ENST00000403681 | ENST00000253475 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - |
| Frame-shift | ENST00000425208 | ENST00000253475 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - |
| Frame-shift | ENST00000536545 | ENST00000253475 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - |
| Frame-shift | ENST00000541363 | ENST00000253475 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - |
| In-frame | ENST00000354636 | ENST00000397901 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - |
| In-frame | ENST00000354636 | ENST00000535997 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - |
| In-frame | ENST00000354636 | ENST00000550102 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - |
| In-frame | ENST00000393577 | ENST00000397901 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - |
| In-frame | ENST00000393577 | ENST00000535997 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - |
| In-frame | ENST00000393577 | ENST00000550102 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - |
| In-frame | ENST00000393578 | ENST00000397901 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - |
| In-frame | ENST00000393578 | ENST00000535997 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - |
| In-frame | ENST00000393578 | ENST00000550102 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - |
| In-frame | ENST00000403681 | ENST00000397901 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - |
| In-frame | ENST00000403681 | ENST00000535997 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - |
| In-frame | ENST00000403681 | ENST00000550102 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - |
| In-frame | ENST00000425208 | ENST00000397901 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - |
| In-frame | ENST00000425208 | ENST00000535997 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - |
| In-frame | ENST00000425208 | ENST00000550102 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - |
| In-frame | ENST00000536545 | ENST00000397901 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - |
| In-frame | ENST00000536545 | ENST00000535997 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - |
| In-frame | ENST00000536545 | ENST00000550102 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - |
| In-frame | ENST00000541363 | ENST00000397901 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - |
| In-frame | ENST00000541363 | ENST00000535997 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - |
| In-frame | ENST00000541363 | ENST00000550102 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000403681 | HMGA2 | chr12 | 66221867 | + | ENST00000397901 | CHMP1A | chr16 | 89713739 | - | 3312 | 1338 | 114 | 992 | 292 |
| ENST00000403681 | HMGA2 | chr12 | 66221867 | + | ENST00000535997 | CHMP1A | chr16 | 89713739 | - | 3280 | 1338 | 114 | 992 | 292 |
| ENST00000403681 | HMGA2 | chr12 | 66221867 | + | ENST00000550102 | CHMP1A | chr16 | 89713739 | - | 1854 | 1338 | 114 | 992 | 292 |
| ENST00000541363 | HMGA2 | chr12 | 66221867 | + | ENST00000397901 | CHMP1A | chr16 | 89713739 | - | 2545 | 571 | 373 | 909 | 178 |
| ENST00000541363 | HMGA2 | chr12 | 66221867 | + | ENST00000535997 | CHMP1A | chr16 | 89713739 | - | 2513 | 571 | 373 | 909 | 178 |
| ENST00000541363 | HMGA2 | chr12 | 66221867 | + | ENST00000550102 | CHMP1A | chr16 | 89713739 | - | 1087 | 571 | 373 | 909 | 178 |
| ENST00000393577 | HMGA2 | chr12 | 66221867 | + | ENST00000397901 | CHMP1A | chr16 | 89713739 | - | 2320 | 346 | 148 | 684 | 178 |
| ENST00000393577 | HMGA2 | chr12 | 66221867 | + | ENST00000535997 | CHMP1A | chr16 | 89713739 | - | 2288 | 346 | 148 | 684 | 178 |
| ENST00000393577 | HMGA2 | chr12 | 66221867 | + | ENST00000550102 | CHMP1A | chr16 | 89713739 | - | 862 | 346 | 148 | 684 | 178 |
| ENST00000393578 | HMGA2 | chr12 | 66221867 | + | ENST00000397901 | CHMP1A | chr16 | 89713739 | - | 2983 | 1009 | 1 | 663 | 220 |
| ENST00000393578 | HMGA2 | chr12 | 66221867 | + | ENST00000535997 | CHMP1A | chr16 | 89713739 | - | 2951 | 1009 | 1 | 663 | 220 |
| ENST00000393578 | HMGA2 | chr12 | 66221867 | + | ENST00000550102 | CHMP1A | chr16 | 89713739 | - | 1525 | 1009 | 1 | 663 | 220 |
| ENST00000425208 | HMGA2 | chr12 | 66221867 | + | ENST00000397901 | CHMP1A | chr16 | 89713739 | - | 2983 | 1009 | 1 | 663 | 220 |
| ENST00000425208 | HMGA2 | chr12 | 66221867 | + | ENST00000535997 | CHMP1A | chr16 | 89713739 | - | 2951 | 1009 | 1 | 663 | 220 |
| ENST00000425208 | HMGA2 | chr12 | 66221867 | + | ENST00000550102 | CHMP1A | chr16 | 89713739 | - | 1525 | 1009 | 1 | 663 | 220 |
| ENST00000536545 | HMGA2 | chr12 | 66221867 | + | ENST00000397901 | CHMP1A | chr16 | 89713739 | - | 2983 | 1009 | 1 | 663 | 220 |
| ENST00000536545 | HMGA2 | chr12 | 66221867 | + | ENST00000535997 | CHMP1A | chr16 | 89713739 | - | 2951 | 1009 | 1 | 663 | 220 |
| ENST00000536545 | HMGA2 | chr12 | 66221867 | + | ENST00000550102 | CHMP1A | chr16 | 89713739 | - | 1525 | 1009 | 1 | 663 | 220 |
| ENST00000354636 | HMGA2 | chr12 | 66221867 | + | ENST00000397901 | CHMP1A | chr16 | 89713739 | - | 2983 | 1009 | 1 | 663 | 220 |
| ENST00000354636 | HMGA2 | chr12 | 66221867 | + | ENST00000535997 | CHMP1A | chr16 | 89713739 | - | 2951 | 1009 | 1 | 663 | 220 |
| ENST00000354636 | HMGA2 | chr12 | 66221867 | + | ENST00000550102 | CHMP1A | chr16 | 89713739 | - | 1525 | 1009 | 1 | 663 | 220 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000403681 | ENST00000397901 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - | 0.005774459 | 0.99422556 |
| ENST00000403681 | ENST00000535997 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - | 0.006809338 | 0.9931907 |
| ENST00000403681 | ENST00000550102 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - | 0.003657549 | 0.9963425 |
| ENST00000541363 | ENST00000397901 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - | 0.009392807 | 0.99060714 |
| ENST00000541363 | ENST00000535997 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - | 0.010421442 | 0.98957855 |
| ENST00000541363 | ENST00000550102 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - | 0.002920928 | 0.99707913 |
| ENST00000393577 | ENST00000397901 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - | 0.00987918 | 0.9901209 |
| ENST00000393577 | ENST00000535997 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - | 0.009589052 | 0.9904109 |
| ENST00000393577 | ENST00000550102 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - | 0.003886311 | 0.99611366 |
| ENST00000393578 | ENST00000397901 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - | 0.003259347 | 0.99674064 |
| ENST00000393578 | ENST00000535997 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - | 0.003490001 | 0.99650997 |
| ENST00000393578 | ENST00000550102 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - | 0.002803211 | 0.9971968 |
| ENST00000425208 | ENST00000397901 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - | 0.003259347 | 0.99674064 |
| ENST00000425208 | ENST00000535997 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - | 0.003490001 | 0.99650997 |
| ENST00000425208 | ENST00000550102 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - | 0.002803211 | 0.9971968 |
| ENST00000536545 | ENST00000397901 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - | 0.003259347 | 0.99674064 |
| ENST00000536545 | ENST00000535997 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - | 0.003490001 | 0.99650997 |
| ENST00000536545 | ENST00000550102 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - | 0.002803211 | 0.9971968 |
| ENST00000354636 | ENST00000397901 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - | 0.003259347 | 0.99674064 |
| ENST00000354636 | ENST00000535997 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - | 0.003490001 | 0.99650997 |
| ENST00000354636 | ENST00000550102 | HMGA2 | chr12 | 66221867 | + | CHMP1A | chr16 | 89713739 | - | 0.002803211 | 0.9971968 |
Top |
Fusion Genomic Features for HMGA2-CHMP1A |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
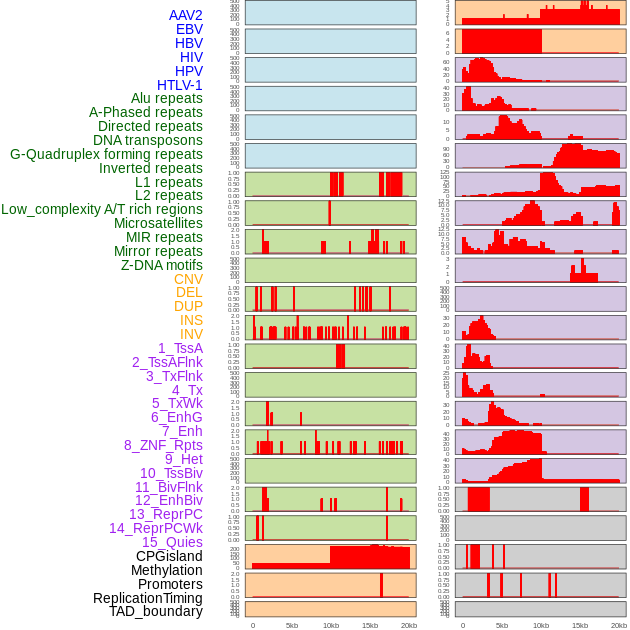 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for HMGA2-CHMP1A |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr12:66221867/chr16:89713739) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| HMGA2 | CHMP1A |
| FUNCTION: Functions as a transcriptional regulator. Functions in cell cycle regulation through CCNA2. Plays an important role in chromosome condensation during the meiotic G2/M transition of spermatocytes. Plays a role in postnatal myogenesis, is involved in satellite cell activation (By similarity). Positively regulates IGF2 expression through PLAG1 and in a PLAG1-independent manner (PubMed:28796236). {ECO:0000250|UniProtKB:P52927, ECO:0000269|PubMed:14645522, ECO:0000269|PubMed:28796236}. | FUNCTION: Probable peripherally associated component of the endosomal sorting required for transport complex III (ESCRT-III) which is involved in multivesicular bodies (MVBs) formation and sorting of endosomal cargo proteins into MVBs. MVBs contain intraluminal vesicles (ILVs) that are generated by invagination and scission from the limiting membrane of the endosome and mostly are delivered to lysosomes enabling degradation of membrane proteins, such as stimulated growth factor receptors, lysosomal enzymes and lipids. The MVB pathway appears to require the sequential function of ESCRT-O, -I,-II and -III complexes. ESCRT-III proteins mostly dissociate from the invaginating membrane before the ILV is released. The ESCRT machinery also functions in topologically equivalent membrane fission events, such as the terminal stages of cytokinesis and the budding of enveloped viruses (HIV-1 and other lentiviruses). ESCRT-III proteins are believed to mediate the necessary vesicle extrusion and/or membrane fission activities, possibly in conjunction with the AAA ATPase VPS4. Involved in cytokinesis. Involved in recruiting VPS4A and/or VPS4B to the midbody of dividing cells. May also be involved in chromosome condensation. Targets the Polycomb group (PcG) protein BMI1/PCGF4 to regions of condensed chromatin. May play a role in stable cell cycle progression and in PcG gene silencing. {ECO:0000269|PubMed:11559747, ECO:0000269|PubMed:11559748, ECO:0000269|PubMed:19129479, ECO:0000269|PubMed:23045692}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | HMGA2 | chr12:66221867 | chr16:89713739 | ENST00000354636 | + | 2 | 4 | 24_34 | 66 | 107.0 | DNA binding | Note=A.T hook 1 |
| Hgene | HMGA2 | chr12:66221867 | chr16:89713739 | ENST00000354636 | + | 2 | 4 | 44_54 | 66 | 107.0 | DNA binding | Note=A.T hook 2 |
| Hgene | HMGA2 | chr12:66221867 | chr16:89713739 | ENST00000393578 | + | 2 | 4 | 24_34 | 66 | 91.0 | DNA binding | Note=A.T hook 1 |
| Hgene | HMGA2 | chr12:66221867 | chr16:89713739 | ENST00000393578 | + | 2 | 4 | 44_54 | 66 | 91.0 | DNA binding | Note=A.T hook 2 |
| Hgene | HMGA2 | chr12:66221867 | chr16:89713739 | ENST00000403681 | + | 2 | 5 | 24_34 | 66 | 110.0 | DNA binding | Note=A.T hook 1 |
| Hgene | HMGA2 | chr12:66221867 | chr16:89713739 | ENST00000403681 | + | 2 | 5 | 44_54 | 66 | 110.0 | DNA binding | Note=A.T hook 2 |
| Hgene | HMGA2 | chr12:66221867 | chr16:89713739 | ENST00000425208 | + | 2 | 4 | 24_34 | 66 | 93.0 | DNA binding | Note=A.T hook 1 |
| Hgene | HMGA2 | chr12:66221867 | chr16:89713739 | ENST00000425208 | + | 2 | 4 | 44_54 | 66 | 93.0 | DNA binding | Note=A.T hook 2 |
| Tgene | CHMP1A | chr12:66221867 | chr16:89713739 | ENST00000397901 | 3 | 7 | 102_124 | 84 | 197.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CHMP1A | chr12:66221867 | chr16:89713739 | ENST00000397901 | 3 | 7 | 185_195 | 84 | 197.0 | Motif | Note=MIT-interacting motif |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | HMGA2 | chr12:66221867 | chr16:89713739 | ENST00000354636 | + | 2 | 4 | 71_82 | 66 | 107.0 | DNA binding | Note=A.T hook 3 |
| Hgene | HMGA2 | chr12:66221867 | chr16:89713739 | ENST00000393578 | + | 2 | 4 | 71_82 | 66 | 91.0 | DNA binding | Note=A.T hook 3 |
| Hgene | HMGA2 | chr12:66221867 | chr16:89713739 | ENST00000403681 | + | 2 | 5 | 71_82 | 66 | 110.0 | DNA binding | Note=A.T hook 3 |
| Hgene | HMGA2 | chr12:66221867 | chr16:89713739 | ENST00000425208 | + | 2 | 4 | 71_82 | 66 | 93.0 | DNA binding | Note=A.T hook 3 |
| Tgene | CHMP1A | chr12:66221867 | chr16:89713739 | ENST00000397901 | 3 | 7 | 5_47 | 84 | 197.0 | Coiled coil | Ontology_term=ECO:0000255 |
Top |
Fusion Gene Sequence for HMGA2-CHMP1A |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >36825_36825_1_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000354636_CHMP1A_chr16_89713739_ENST00000397901_length(transcript)=2983nt_BP=1009nt CTTGAATCTTGGGGCAGGAACTCAGAAAACTTCCAGCCCGGGCAGCGCGCGCTTGGTGCAAGACTCAGGAGCTAGCAGCCCGTCCCCCTC CGACTCTCCGGTGCCGCCGCTGCCTGCTCCCGCCACCCTAGGAGGCGCGGTGCCACCCACTACTCTGTCCTCTGCCTGTGCTCCGTGCCC GACCCTATCCCGGCGGAGTCTCCCCATCCTCCTTTGCTTTCCGACTGCCCAAGGCACTTTCAATCTCAATCTCTTCTCTCTCTCTCTCTC TCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCGCAGGGTGGGGGGAAGAGGAGGAGGAATTCTTTCCCCGCCTAACATTTCA AGGGACACAATTCACTCCAAGTCTCTTCCCTTTCCAAGCCGCTTCCGAAGTGCTCCCGGTGCCCGCAACTCCTGATCCCAACCCGCGAGA GGAGCCTCTGCGACCTCAAAGCCTCTCTTCCTTCTCCCTCGCTTCCCTCCTCCTCTTGCTACCTCCACCTCCACCGCCACCTCCACCTCC GGCACCCACCCACCGCCGCCGCCGCCACCGGCAGCGCCTCCTCCTCTCCTCCTCCTCCTCCCCTCTTCTCTTTTTGGCAGCCGCTGGACG TCCGGTGTTGATGGTGGCAGCGGCGGCAGCCTAAGCAACAGCAGCCCTCGCAGCCCGCCAGCTCGCGCTCGCCCCGCCGGCGTCCCCAGC CCTATCACCTCATCTCCCGAAAGGTGCTGGGCAGCTCCGGGGCGGTCGAGGCGAAGCGGCTGCAGCGGCGGTAGCGGCGGCGGGAGGCAG GATGAGCGCACGCGGTGAGGGCGCGGGGCAGCCGTCCACTTCAGCCCAGGGACAACCTGCCGCCCCAGCGCCTCAGAAGAGAGGACGCGG CCGCCCCAGGAAGCAGCAGCAAGAACCAACCGGTGAGCCCTCTCCTAAGAGACCCAGGGGAAGACCCAAAGGCAGCAAAAACAAGAGTCC CTCTAAAGCAGCTCAAAAGGTGACCAAGAATATGGCCCAGGTGACCAAAGCCCTGGACAAGGCCCTGAGCACCATGGACCTGCAGAAGGT CTCCTCAGTGATGGACAGGTTCGAGCAGCAGGTGCAGAACCTGGACGTCCATACATCGGTGATGGAGGACTCCATGAGCTCGGCCACCAC CCTGACCACGCCGCAGGAGCAGGTGGACAGCCTCATCATGCAGATCGCCGAGGAGAATGGCCTGGAGGTGCTGGACCAGCTCAGCCAGCT GCCCGAGGGCGCCTCTGCCGTGGGCGAGAGCTCTGTGCGCAGCCAGGAGGACCAGCTGTCACGGAGGTTGGCCGCCTTGAGGAACTAGCC GTGCCCCGCCGGTGTGCACCGCCTCTGCCCCGTGATGTGCTGGAAGGCTCCTGTCCTCTCCCCACCGCGTCTTGCCTTTGTGCTGACCCC GCGGGGCTGCGGCCGGCAGCCACTCTGCGTCTCTCACCTGCCAGGCCTGCGTGGCCTTAGGGTTGTTCCTGTTCTTTTAGGTTGGGCGGT GGGTCTGTGTCCTGGTGTTGAGTTTCTGCAAATTTCTGGGGGTGATTTCTGTGACTCTGGGCCCACAGCGGGGAGGCCAAGAGGGGCCCT GTGGACTTTCACCCAGCACTGTGGGGGCCTTCAGACTCTGGGGCAGCAGACATGCTGCTTCCCATCAGCCAGAGGGGGTCAGGGCTGCCC TGTTGCCAAACAACTCCCTGAGGCCTCTCCGCACCACCTCAGCGGGCAGGAGGTCCCACCATGTGGACAGACATAGCCCAAGGAGGCACC ACAGGTCTATGTGTGCTGGGGGATGTCAGGTGCCACCCAACGCTGTCCTGGTGGTATTTACAATGACATCCTCCTCCTCCATCACTCCAG GGGTGGTGTCTCGGCCGCCCCTACCAGCTGGCTGAGCCCCCTGGCCTCCTGCGCTCCCTCACTTCCCTCAGTTCCCAAAGCTGCCCAGTC CATGGGGACAGAACCGTCACTCAGATCCACATTCAAGTGTGCCCACCCTGCAGTCTTCATCCTCACTCAGCTGCTGCCTCTGGAGGTGCC TTTGGCCACATGTGCTGTGCTGTTTGTCTCCTCGACAGGGAGCCTGTCCACCAGCAGGCTGCGGTCCCAGCGGGTGCGTCTGCAGCTCCT CCCCTTGGGCAGCCTGGTTCTCCCGGAGGACCTTTCCTTGGGGCCCTGCTTCATGACGATGCTGCCTGTGTCACCCTCTACCATCTGTAA ACAACTGGGTGCCTTCCCCGACCACACCCCAATGCCTTCCCAGCTTGGAAGCCAAGGCAGCTGATGAAGGGAGCTCAGGAGAGCCGTCTT CAGCTGGGCTGGGGTTGGGGCTGCTGTGAGGAAAACCTGCCATTGTGGCCCTGGAGAGTCACCAGCAGCTCTTGGGAAGGACTTGCTGGG AGGCTGAGAGAGGCTTTGGGCACAGCCTGCTGTCTTTTCCATTTCCTAAAGTTTACTTCATTGTCTTGAGGCTTCCAGGTTTTGTTTTTG TTTTTGCCAAAGTAGAAAAGGCAGGTGGTGGGCGGCTGGCAGGGAGTGCGGGTCCCCGCCCCTCTTCAGTCCTGCCCTCCCCTCCTCAGT CCTGCCCACCCCGTGCAGCCCATGCTGAGGCTGCAGTGGTGTCGTGGGTGTTACGTGCAGGAACGTGGAGACCCTGACGTGGGCTCACTG CGTTTGGTTTTCTTTTCAGAACTTGGGAGCCCCCAGGGAGGGGCTAGTGTTGGTAGGTCCTAGACGTGGTTCCCTCCAGCCTCCCCAAAA TCAACCCTGGTGTTGAGAGAACGTCCTTCTGTCCATCGTGGGTAACAGCCTTGGGGAGGGTGCAGAGCTCTGCAGAGCCATGGGCCAGGT GGGGCTGCCTCAGTCCTGTCCCCTTGGGCACTGAGGAGAGGGGCCCATTCACCTTTCTCCTAGAATGCTGTTGTAAATAAACAAATGGAT >36825_36825_1_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000354636_CHMP1A_chr16_89713739_ENST00000397901_length(amino acids)=220AA_BP= LNLGAGTQKTSSPGSARLVQDSGASSPSPSDSPVPPLPAPATLGGAVPPTTLSSACAPCPTLSRRSLPILLCFPTAQGTFNLNLFSLSLS LSLSLSLSLSLSLAGWGEEEEEFFPRLTFQGTQFTPSLFPFQAASEVLPVPATPDPNPREEPLRPQSLSSFSLASLLLLLPPPPPPPPPP -------------------------------------------------------------- >36825_36825_2_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000354636_CHMP1A_chr16_89713739_ENST00000535997_length(transcript)=2951nt_BP=1009nt CTTGAATCTTGGGGCAGGAACTCAGAAAACTTCCAGCCCGGGCAGCGCGCGCTTGGTGCAAGACTCAGGAGCTAGCAGCCCGTCCCCCTC CGACTCTCCGGTGCCGCCGCTGCCTGCTCCCGCCACCCTAGGAGGCGCGGTGCCACCCACTACTCTGTCCTCTGCCTGTGCTCCGTGCCC GACCCTATCCCGGCGGAGTCTCCCCATCCTCCTTTGCTTTCCGACTGCCCAAGGCACTTTCAATCTCAATCTCTTCTCTCTCTCTCTCTC TCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCGCAGGGTGGGGGGAAGAGGAGGAGGAATTCTTTCCCCGCCTAACATTTCA AGGGACACAATTCACTCCAAGTCTCTTCCCTTTCCAAGCCGCTTCCGAAGTGCTCCCGGTGCCCGCAACTCCTGATCCCAACCCGCGAGA GGAGCCTCTGCGACCTCAAAGCCTCTCTTCCTTCTCCCTCGCTTCCCTCCTCCTCTTGCTACCTCCACCTCCACCGCCACCTCCACCTCC GGCACCCACCCACCGCCGCCGCCGCCACCGGCAGCGCCTCCTCCTCTCCTCCTCCTCCTCCCCTCTTCTCTTTTTGGCAGCCGCTGGACG TCCGGTGTTGATGGTGGCAGCGGCGGCAGCCTAAGCAACAGCAGCCCTCGCAGCCCGCCAGCTCGCGCTCGCCCCGCCGGCGTCCCCAGC CCTATCACCTCATCTCCCGAAAGGTGCTGGGCAGCTCCGGGGCGGTCGAGGCGAAGCGGCTGCAGCGGCGGTAGCGGCGGCGGGAGGCAG GATGAGCGCACGCGGTGAGGGCGCGGGGCAGCCGTCCACTTCAGCCCAGGGACAACCTGCCGCCCCAGCGCCTCAGAAGAGAGGACGCGG CCGCCCCAGGAAGCAGCAGCAAGAACCAACCGGTGAGCCCTCTCCTAAGAGACCCAGGGGAAGACCCAAAGGCAGCAAAAACAAGAGTCC CTCTAAAGCAGCTCAAAAGGTGACCAAGAATATGGCCCAGGTGACCAAAGCCCTGGACAAGGCCCTGAGCACCATGGACCTGCAGAAGGT CTCCTCAGTGATGGACAGGTTCGAGCAGCAGGTGCAGAACCTGGACGTCCATACATCGGTGATGGAGGACTCCATGAGCTCGGCCACCAC CCTGACCACGCCGCAGGAGCAGGTGGACAGCCTCATCATGCAGATCGCCGAGGAGAATGGCCTGGAGGTGCTGGACCAGCTCAGCCAGCT GCCCGAGGGCGCCTCTGCCGTGGGCGAGAGCTCTGTGCGCAGCCAGGAGGACCAGCTGTCACGGAGGTTGGCCGCCTTGAGGAACTAGCC GTGCCCCGCCGGTGTGCACCGCCTCTGCCCCGTGATGTGCTGGAAGGCTCCTGTCCTCTCCCCACCGCGTCTTGCCTTTGTGCTGACCCC GCGGGGCTGCGGCCGGCAGCCACTCTGCGTCTCTCACCTGCCAGGCCTGCGTGGCCTTAGGGTTGTTCCTGTTCTTTTAGGTTGGGCGGT GGGTCTGTGTCCTGGTGTTGAGTTTCTGCAAATTTCTGGGGGTGATTTCTGTGACTCTGGGCCCACAGCGGGGAGGCCAAGAGGGGCCCT GTGGACTTTCACCCAGCACTGTGGGGGCCTTCAGACTCTGGGGCAGCAGACATGCTGCTTCCCATCAGCCAGAGGGGGTCAGGGCTGCCC TGTTGCCAAACAACTCCCTGAGGCCTCTCCGCACCACCTCAGCGGGCAGGAGGTCCCACCATGTGGACAGACATAGCCCAAGGAGGCACC ACAGGTCTATGTGTGCTGGGGGATGTCAGGTGCCACCCAACGCTGTCCTGGTGGTATTTACAATGACATCCTCCTCCTCCATCACTCCAG GGGTGGTGTCTCGGCCGCCCCTACCAGCTGGCTGAGCCCCCTGGCCTCCTGCGCTCCCTCACTTCCCTCAGTTCCCAAAGCTGCCCAGTC CATGGGGACAGAACCGTCACTCAGATCCACATTCAAGTGTGCCCACCCTGCAGTCTTCATCCTCACTCAGCTGCTGCCTCTGGAGGTGCC TTTGGCCACATGTGCTGTGCTGTTTGTCTCCTCGACAGGGAGCCTGTCCACCAGCAGGCTGCGGTCCCAGCGGGTGCGTCTGCAGCTCCT CCCCTTGGGCAGCCTGGTTCTCCCGGAGGACCTTTCCTTGGGGCCCTGCTTCATGACGATGCTGCCTGTGTCACCCTCTACCATCTGTAA ACAACTGGGTGCCTTCCCCGACCACACCCCAATGCCTTCCCAGCTTGGAAGCCAAGGCAGCTGATGAAGGGAGCTCAGGAGAGCCGTCTT CAGCTGGGCTGGGGTTGGGGCTGCTGTGAGGAAAACCTGCCATTGTGGCCCTGGAGAGTCACCAGCAGCTCTTGGGAAGGACTTGCTGGG AGGCTGAGAGAGGCTTTGGGCACAGCCTGCTGTCTTTTCCATTTCCTAAAGTTTACTTCATTGTCTTGAGGCTTCCAGGTTTTGTTTTTG TTTTTGCCAAAGTAGAAAAGGCAGGTGGTGGGCGGCTGGCAGGGAGTGCGGGTCCCCGCCCCTCTTCAGTCCTGCCCTCCCCTCCTCAGT CCTGCCCACCCCGTGCAGCCCATGCTGAGGCTGCAGTGGTGTCGTGGGTGTTACGTGCAGGAACGTGGAGACCCTGACGTGGGCTCACTG CGTTTGGTTTTCTTTTCAGAACTTGGGAGCCCCCAGGGAGGGGCTAGTGTTGGTAGGTCCTAGACGTGGTTCCCTCCAGCCTCCCCAAAA TCAACCCTGGTGTTGAGAGAACGTCCTTCTGTCCATCGTGGGTAACAGCCTTGGGGAGGGTGCAGAGCTCTGCAGAGCCATGGGCCAGGT >36825_36825_2_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000354636_CHMP1A_chr16_89713739_ENST00000535997_length(amino acids)=220AA_BP= LNLGAGTQKTSSPGSARLVQDSGASSPSPSDSPVPPLPAPATLGGAVPPTTLSSACAPCPTLSRRSLPILLCFPTAQGTFNLNLFSLSLS LSLSLSLSLSLSLAGWGEEEEEFFPRLTFQGTQFTPSLFPFQAASEVLPVPATPDPNPREEPLRPQSLSSFSLASLLLLLPPPPPPPPPP -------------------------------------------------------------- >36825_36825_3_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000354636_CHMP1A_chr16_89713739_ENST00000550102_length(transcript)=1525nt_BP=1009nt CTTGAATCTTGGGGCAGGAACTCAGAAAACTTCCAGCCCGGGCAGCGCGCGCTTGGTGCAAGACTCAGGAGCTAGCAGCCCGTCCCCCTC CGACTCTCCGGTGCCGCCGCTGCCTGCTCCCGCCACCCTAGGAGGCGCGGTGCCACCCACTACTCTGTCCTCTGCCTGTGCTCCGTGCCC GACCCTATCCCGGCGGAGTCTCCCCATCCTCCTTTGCTTTCCGACTGCCCAAGGCACTTTCAATCTCAATCTCTTCTCTCTCTCTCTCTC TCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCGCAGGGTGGGGGGAAGAGGAGGAGGAATTCTTTCCCCGCCTAACATTTCA AGGGACACAATTCACTCCAAGTCTCTTCCCTTTCCAAGCCGCTTCCGAAGTGCTCCCGGTGCCCGCAACTCCTGATCCCAACCCGCGAGA GGAGCCTCTGCGACCTCAAAGCCTCTCTTCCTTCTCCCTCGCTTCCCTCCTCCTCTTGCTACCTCCACCTCCACCGCCACCTCCACCTCC GGCACCCACCCACCGCCGCCGCCGCCACCGGCAGCGCCTCCTCCTCTCCTCCTCCTCCTCCCCTCTTCTCTTTTTGGCAGCCGCTGGACG TCCGGTGTTGATGGTGGCAGCGGCGGCAGCCTAAGCAACAGCAGCCCTCGCAGCCCGCCAGCTCGCGCTCGCCCCGCCGGCGTCCCCAGC CCTATCACCTCATCTCCCGAAAGGTGCTGGGCAGCTCCGGGGCGGTCGAGGCGAAGCGGCTGCAGCGGCGGTAGCGGCGGCGGGAGGCAG GATGAGCGCACGCGGTGAGGGCGCGGGGCAGCCGTCCACTTCAGCCCAGGGACAACCTGCCGCCCCAGCGCCTCAGAAGAGAGGACGCGG CCGCCCCAGGAAGCAGCAGCAAGAACCAACCGGTGAGCCCTCTCCTAAGAGACCCAGGGGAAGACCCAAAGGCAGCAAAAACAAGAGTCC CTCTAAAGCAGCTCAAAAGGTGACCAAGAATATGGCCCAGGTGACCAAAGCCCTGGACAAGGCCCTGAGCACCATGGACCTGCAGAAGGT CTCCTCAGTGATGGACAGGTTCGAGCAGCAGGTGCAGAACCTGGACGTCCATACATCGGTGATGGAGGACTCCATGAGCTCGGCCACCAC CCTGACCACGCCGCAGGAGCAGGTGGACAGCCTCATCATGCAGATCGCCGAGGAGAATGGCCTGGAGGTGCTGGACCAGCTCAGCCAGCT GCCCGAGGGCGCCTCTGCCGTGGGCGAGAGCTCTGTGCGCAGCCAGGAGGACCAGCTGTCACGGAGGTTGGCCGCCTTGAGGAACTAGCC GTGCCCCGCCGGTGTGCACCGCCTCTGCCCCGTGATGTGCTGGAAGGCTCCTGTCCTCTCCCCACCGCGTCTTGCCTTTGTGCTGACCCC >36825_36825_3_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000354636_CHMP1A_chr16_89713739_ENST00000550102_length(amino acids)=220AA_BP= LNLGAGTQKTSSPGSARLVQDSGASSPSPSDSPVPPLPAPATLGGAVPPTTLSSACAPCPTLSRRSLPILLCFPTAQGTFNLNLFSLSLS LSLSLSLSLSLSLAGWGEEEEEFFPRLTFQGTQFTPSLFPFQAASEVLPVPATPDPNPREEPLRPQSLSSFSLASLLLLLPPPPPPPPPP -------------------------------------------------------------- >36825_36825_4_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000393577_CHMP1A_chr16_89713739_ENST00000397901_length(transcript)=2320nt_BP=346nt AGCAACAGCAGCCCTCGCAGCCCGCCAGCTCGCGCTCGCCCCGCCGGCGTCCCCAGCCCTATCACCTCATCTCCCGAAAGGTGCTGGGCA GCTCCGGGGCGGTCGAGGCGAAGCGGCTGCAGCGGCGGTAGCGGCGGCGGGAGGCAGGATGAGCGCACGCGGTGAGGGCGCGGGGCAGCC GTCCACTTCAGCCCAGGGACAACCTGCCGCCCCAGCGCCTCAGAAGAGAGGACGCGGCCGCCCCAGGAAGCAGCAGCAAGAACCAACCGG TGAGCCCTCTCCTAAGAGACCCAGGGGAAGACCCAAAGGCAGCAAAAACAAGAGTCCCTCTAAAGCAGCTCAAAAGGTGACCAAGAATAT GGCCCAGGTGACCAAAGCCCTGGACAAGGCCCTGAGCACCATGGACCTGCAGAAGGTCTCCTCAGTGATGGACAGGTTCGAGCAGCAGGT GCAGAACCTGGACGTCCATACATCGGTGATGGAGGACTCCATGAGCTCGGCCACCACCCTGACCACGCCGCAGGAGCAGGTGGACAGCCT CATCATGCAGATCGCCGAGGAGAATGGCCTGGAGGTGCTGGACCAGCTCAGCCAGCTGCCCGAGGGCGCCTCTGCCGTGGGCGAGAGCTC TGTGCGCAGCCAGGAGGACCAGCTGTCACGGAGGTTGGCCGCCTTGAGGAACTAGCCGTGCCCCGCCGGTGTGCACCGCCTCTGCCCCGT GATGTGCTGGAAGGCTCCTGTCCTCTCCCCACCGCGTCTTGCCTTTGTGCTGACCCCGCGGGGCTGCGGCCGGCAGCCACTCTGCGTCTC TCACCTGCCAGGCCTGCGTGGCCTTAGGGTTGTTCCTGTTCTTTTAGGTTGGGCGGTGGGTCTGTGTCCTGGTGTTGAGTTTCTGCAAAT TTCTGGGGGTGATTTCTGTGACTCTGGGCCCACAGCGGGGAGGCCAAGAGGGGCCCTGTGGACTTTCACCCAGCACTGTGGGGGCCTTCA GACTCTGGGGCAGCAGACATGCTGCTTCCCATCAGCCAGAGGGGGTCAGGGCTGCCCTGTTGCCAAACAACTCCCTGAGGCCTCTCCGCA CCACCTCAGCGGGCAGGAGGTCCCACCATGTGGACAGACATAGCCCAAGGAGGCACCACAGGTCTATGTGTGCTGGGGGATGTCAGGTGC CACCCAACGCTGTCCTGGTGGTATTTACAATGACATCCTCCTCCTCCATCACTCCAGGGGTGGTGTCTCGGCCGCCCCTACCAGCTGGCT GAGCCCCCTGGCCTCCTGCGCTCCCTCACTTCCCTCAGTTCCCAAAGCTGCCCAGTCCATGGGGACAGAACCGTCACTCAGATCCACATT CAAGTGTGCCCACCCTGCAGTCTTCATCCTCACTCAGCTGCTGCCTCTGGAGGTGCCTTTGGCCACATGTGCTGTGCTGTTTGTCTCCTC GACAGGGAGCCTGTCCACCAGCAGGCTGCGGTCCCAGCGGGTGCGTCTGCAGCTCCTCCCCTTGGGCAGCCTGGTTCTCCCGGAGGACCT TTCCTTGGGGCCCTGCTTCATGACGATGCTGCCTGTGTCACCCTCTACCATCTGTAAACAACTGGGTGCCTTCCCCGACCACACCCCAAT GCCTTCCCAGCTTGGAAGCCAAGGCAGCTGATGAAGGGAGCTCAGGAGAGCCGTCTTCAGCTGGGCTGGGGTTGGGGCTGCTGTGAGGAA AACCTGCCATTGTGGCCCTGGAGAGTCACCAGCAGCTCTTGGGAAGGACTTGCTGGGAGGCTGAGAGAGGCTTTGGGCACAGCCTGCTGT CTTTTCCATTTCCTAAAGTTTACTTCATTGTCTTGAGGCTTCCAGGTTTTGTTTTTGTTTTTGCCAAAGTAGAAAAGGCAGGTGGTGGGC GGCTGGCAGGGAGTGCGGGTCCCCGCCCCTCTTCAGTCCTGCCCTCCCCTCCTCAGTCCTGCCCACCCCGTGCAGCCCATGCTGAGGCTG CAGTGGTGTCGTGGGTGTTACGTGCAGGAACGTGGAGACCCTGACGTGGGCTCACTGCGTTTGGTTTTCTTTTCAGAACTTGGGAGCCCC CAGGGAGGGGCTAGTGTTGGTAGGTCCTAGACGTGGTTCCCTCCAGCCTCCCCAAAATCAACCCTGGTGTTGAGAGAACGTCCTTCTGTC CATCGTGGGTAACAGCCTTGGGGAGGGTGCAGAGCTCTGCAGAGCCATGGGCCAGGTGGGGCTGCCTCAGTCCTGTCCCCTTGGGCACTG >36825_36825_4_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000393577_CHMP1A_chr16_89713739_ENST00000397901_length(amino acids)=178AA_BP=66 MSARGEGAGQPSTSAQGQPAAPAPQKRGRGRPRKQQQEPTGEPSPKRPRGRPKGSKNKSPSKAAQKVTKNMAQVTKALDKALSTMDLQKV -------------------------------------------------------------- >36825_36825_5_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000393577_CHMP1A_chr16_89713739_ENST00000535997_length(transcript)=2288nt_BP=346nt AGCAACAGCAGCCCTCGCAGCCCGCCAGCTCGCGCTCGCCCCGCCGGCGTCCCCAGCCCTATCACCTCATCTCCCGAAAGGTGCTGGGCA GCTCCGGGGCGGTCGAGGCGAAGCGGCTGCAGCGGCGGTAGCGGCGGCGGGAGGCAGGATGAGCGCACGCGGTGAGGGCGCGGGGCAGCC GTCCACTTCAGCCCAGGGACAACCTGCCGCCCCAGCGCCTCAGAAGAGAGGACGCGGCCGCCCCAGGAAGCAGCAGCAAGAACCAACCGG TGAGCCCTCTCCTAAGAGACCCAGGGGAAGACCCAAAGGCAGCAAAAACAAGAGTCCCTCTAAAGCAGCTCAAAAGGTGACCAAGAATAT GGCCCAGGTGACCAAAGCCCTGGACAAGGCCCTGAGCACCATGGACCTGCAGAAGGTCTCCTCAGTGATGGACAGGTTCGAGCAGCAGGT GCAGAACCTGGACGTCCATACATCGGTGATGGAGGACTCCATGAGCTCGGCCACCACCCTGACCACGCCGCAGGAGCAGGTGGACAGCCT CATCATGCAGATCGCCGAGGAGAATGGCCTGGAGGTGCTGGACCAGCTCAGCCAGCTGCCCGAGGGCGCCTCTGCCGTGGGCGAGAGCTC TGTGCGCAGCCAGGAGGACCAGCTGTCACGGAGGTTGGCCGCCTTGAGGAACTAGCCGTGCCCCGCCGGTGTGCACCGCCTCTGCCCCGT GATGTGCTGGAAGGCTCCTGTCCTCTCCCCACCGCGTCTTGCCTTTGTGCTGACCCCGCGGGGCTGCGGCCGGCAGCCACTCTGCGTCTC TCACCTGCCAGGCCTGCGTGGCCTTAGGGTTGTTCCTGTTCTTTTAGGTTGGGCGGTGGGTCTGTGTCCTGGTGTTGAGTTTCTGCAAAT TTCTGGGGGTGATTTCTGTGACTCTGGGCCCACAGCGGGGAGGCCAAGAGGGGCCCTGTGGACTTTCACCCAGCACTGTGGGGGCCTTCA GACTCTGGGGCAGCAGACATGCTGCTTCCCATCAGCCAGAGGGGGTCAGGGCTGCCCTGTTGCCAAACAACTCCCTGAGGCCTCTCCGCA CCACCTCAGCGGGCAGGAGGTCCCACCATGTGGACAGACATAGCCCAAGGAGGCACCACAGGTCTATGTGTGCTGGGGGATGTCAGGTGC CACCCAACGCTGTCCTGGTGGTATTTACAATGACATCCTCCTCCTCCATCACTCCAGGGGTGGTGTCTCGGCCGCCCCTACCAGCTGGCT GAGCCCCCTGGCCTCCTGCGCTCCCTCACTTCCCTCAGTTCCCAAAGCTGCCCAGTCCATGGGGACAGAACCGTCACTCAGATCCACATT CAAGTGTGCCCACCCTGCAGTCTTCATCCTCACTCAGCTGCTGCCTCTGGAGGTGCCTTTGGCCACATGTGCTGTGCTGTTTGTCTCCTC GACAGGGAGCCTGTCCACCAGCAGGCTGCGGTCCCAGCGGGTGCGTCTGCAGCTCCTCCCCTTGGGCAGCCTGGTTCTCCCGGAGGACCT TTCCTTGGGGCCCTGCTTCATGACGATGCTGCCTGTGTCACCCTCTACCATCTGTAAACAACTGGGTGCCTTCCCCGACCACACCCCAAT GCCTTCCCAGCTTGGAAGCCAAGGCAGCTGATGAAGGGAGCTCAGGAGAGCCGTCTTCAGCTGGGCTGGGGTTGGGGCTGCTGTGAGGAA AACCTGCCATTGTGGCCCTGGAGAGTCACCAGCAGCTCTTGGGAAGGACTTGCTGGGAGGCTGAGAGAGGCTTTGGGCACAGCCTGCTGT CTTTTCCATTTCCTAAAGTTTACTTCATTGTCTTGAGGCTTCCAGGTTTTGTTTTTGTTTTTGCCAAAGTAGAAAAGGCAGGTGGTGGGC GGCTGGCAGGGAGTGCGGGTCCCCGCCCCTCTTCAGTCCTGCCCTCCCCTCCTCAGTCCTGCCCACCCCGTGCAGCCCATGCTGAGGCTG CAGTGGTGTCGTGGGTGTTACGTGCAGGAACGTGGAGACCCTGACGTGGGCTCACTGCGTTTGGTTTTCTTTTCAGAACTTGGGAGCCCC CAGGGAGGGGCTAGTGTTGGTAGGTCCTAGACGTGGTTCCCTCCAGCCTCCCCAAAATCAACCCTGGTGTTGAGAGAACGTCCTTCTGTC CATCGTGGGTAACAGCCTTGGGGAGGGTGCAGAGCTCTGCAGAGCCATGGGCCAGGTGGGGCTGCCTCAGTCCTGTCCCCTTGGGCACTG >36825_36825_5_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000393577_CHMP1A_chr16_89713739_ENST00000535997_length(amino acids)=178AA_BP=66 MSARGEGAGQPSTSAQGQPAAPAPQKRGRGRPRKQQQEPTGEPSPKRPRGRPKGSKNKSPSKAAQKVTKNMAQVTKALDKALSTMDLQKV -------------------------------------------------------------- >36825_36825_6_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000393577_CHMP1A_chr16_89713739_ENST00000550102_length(transcript)=862nt_BP=346nt AGCAACAGCAGCCCTCGCAGCCCGCCAGCTCGCGCTCGCCCCGCCGGCGTCCCCAGCCCTATCACCTCATCTCCCGAAAGGTGCTGGGCA GCTCCGGGGCGGTCGAGGCGAAGCGGCTGCAGCGGCGGTAGCGGCGGCGGGAGGCAGGATGAGCGCACGCGGTGAGGGCGCGGGGCAGCC GTCCACTTCAGCCCAGGGACAACCTGCCGCCCCAGCGCCTCAGAAGAGAGGACGCGGCCGCCCCAGGAAGCAGCAGCAAGAACCAACCGG TGAGCCCTCTCCTAAGAGACCCAGGGGAAGACCCAAAGGCAGCAAAAACAAGAGTCCCTCTAAAGCAGCTCAAAAGGTGACCAAGAATAT GGCCCAGGTGACCAAAGCCCTGGACAAGGCCCTGAGCACCATGGACCTGCAGAAGGTCTCCTCAGTGATGGACAGGTTCGAGCAGCAGGT GCAGAACCTGGACGTCCATACATCGGTGATGGAGGACTCCATGAGCTCGGCCACCACCCTGACCACGCCGCAGGAGCAGGTGGACAGCCT CATCATGCAGATCGCCGAGGAGAATGGCCTGGAGGTGCTGGACCAGCTCAGCCAGCTGCCCGAGGGCGCCTCTGCCGTGGGCGAGAGCTC TGTGCGCAGCCAGGAGGACCAGCTGTCACGGAGGTTGGCCGCCTTGAGGAACTAGCCGTGCCCCGCCGGTGTGCACCGCCTCTGCCCCGT GATGTGCTGGAAGGCTCCTGTCCTCTCCCCACCGCGTCTTGCCTTTGTGCTGACCCCGCGGGGCTGCGGCCGGCAGCCACTCTGCGTCTC >36825_36825_6_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000393577_CHMP1A_chr16_89713739_ENST00000550102_length(amino acids)=178AA_BP=66 MSARGEGAGQPSTSAQGQPAAPAPQKRGRGRPRKQQQEPTGEPSPKRPRGRPKGSKNKSPSKAAQKVTKNMAQVTKALDKALSTMDLQKV -------------------------------------------------------------- >36825_36825_7_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000393578_CHMP1A_chr16_89713739_ENST00000397901_length(transcript)=2983nt_BP=1009nt CTTGAATCTTGGGGCAGGAACTCAGAAAACTTCCAGCCCGGGCAGCGCGCGCTTGGTGCAAGACTCAGGAGCTAGCAGCCCGTCCCCCTC CGACTCTCCGGTGCCGCCGCTGCCTGCTCCCGCCACCCTAGGAGGCGCGGTGCCACCCACTACTCTGTCCTCTGCCTGTGCTCCGTGCCC GACCCTATCCCGGCGGAGTCTCCCCATCCTCCTTTGCTTTCCGACTGCCCAAGGCACTTTCAATCTCAATCTCTTCTCTCTCTCTCTCTC TCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCGCAGGGTGGGGGGAAGAGGAGGAGGAATTCTTTCCCCGCCTAACATTTCA AGGGACACAATTCACTCCAAGTCTCTTCCCTTTCCAAGCCGCTTCCGAAGTGCTCCCGGTGCCCGCAACTCCTGATCCCAACCCGCGAGA GGAGCCTCTGCGACCTCAAAGCCTCTCTTCCTTCTCCCTCGCTTCCCTCCTCCTCTTGCTACCTCCACCTCCACCGCCACCTCCACCTCC GGCACCCACCCACCGCCGCCGCCGCCACCGGCAGCGCCTCCTCCTCTCCTCCTCCTCCTCCCCTCTTCTCTTTTTGGCAGCCGCTGGACG TCCGGTGTTGATGGTGGCAGCGGCGGCAGCCTAAGCAACAGCAGCCCTCGCAGCCCGCCAGCTCGCGCTCGCCCCGCCGGCGTCCCCAGC CCTATCACCTCATCTCCCGAAAGGTGCTGGGCAGCTCCGGGGCGGTCGAGGCGAAGCGGCTGCAGCGGCGGTAGCGGCGGCGGGAGGCAG GATGAGCGCACGCGGTGAGGGCGCGGGGCAGCCGTCCACTTCAGCCCAGGGACAACCTGCCGCCCCAGCGCCTCAGAAGAGAGGACGCGG CCGCCCCAGGAAGCAGCAGCAAGAACCAACCGGTGAGCCCTCTCCTAAGAGACCCAGGGGAAGACCCAAAGGCAGCAAAAACAAGAGTCC CTCTAAAGCAGCTCAAAAGGTGACCAAGAATATGGCCCAGGTGACCAAAGCCCTGGACAAGGCCCTGAGCACCATGGACCTGCAGAAGGT CTCCTCAGTGATGGACAGGTTCGAGCAGCAGGTGCAGAACCTGGACGTCCATACATCGGTGATGGAGGACTCCATGAGCTCGGCCACCAC CCTGACCACGCCGCAGGAGCAGGTGGACAGCCTCATCATGCAGATCGCCGAGGAGAATGGCCTGGAGGTGCTGGACCAGCTCAGCCAGCT GCCCGAGGGCGCCTCTGCCGTGGGCGAGAGCTCTGTGCGCAGCCAGGAGGACCAGCTGTCACGGAGGTTGGCCGCCTTGAGGAACTAGCC GTGCCCCGCCGGTGTGCACCGCCTCTGCCCCGTGATGTGCTGGAAGGCTCCTGTCCTCTCCCCACCGCGTCTTGCCTTTGTGCTGACCCC GCGGGGCTGCGGCCGGCAGCCACTCTGCGTCTCTCACCTGCCAGGCCTGCGTGGCCTTAGGGTTGTTCCTGTTCTTTTAGGTTGGGCGGT GGGTCTGTGTCCTGGTGTTGAGTTTCTGCAAATTTCTGGGGGTGATTTCTGTGACTCTGGGCCCACAGCGGGGAGGCCAAGAGGGGCCCT GTGGACTTTCACCCAGCACTGTGGGGGCCTTCAGACTCTGGGGCAGCAGACATGCTGCTTCCCATCAGCCAGAGGGGGTCAGGGCTGCCC TGTTGCCAAACAACTCCCTGAGGCCTCTCCGCACCACCTCAGCGGGCAGGAGGTCCCACCATGTGGACAGACATAGCCCAAGGAGGCACC ACAGGTCTATGTGTGCTGGGGGATGTCAGGTGCCACCCAACGCTGTCCTGGTGGTATTTACAATGACATCCTCCTCCTCCATCACTCCAG GGGTGGTGTCTCGGCCGCCCCTACCAGCTGGCTGAGCCCCCTGGCCTCCTGCGCTCCCTCACTTCCCTCAGTTCCCAAAGCTGCCCAGTC CATGGGGACAGAACCGTCACTCAGATCCACATTCAAGTGTGCCCACCCTGCAGTCTTCATCCTCACTCAGCTGCTGCCTCTGGAGGTGCC TTTGGCCACATGTGCTGTGCTGTTTGTCTCCTCGACAGGGAGCCTGTCCACCAGCAGGCTGCGGTCCCAGCGGGTGCGTCTGCAGCTCCT CCCCTTGGGCAGCCTGGTTCTCCCGGAGGACCTTTCCTTGGGGCCCTGCTTCATGACGATGCTGCCTGTGTCACCCTCTACCATCTGTAA ACAACTGGGTGCCTTCCCCGACCACACCCCAATGCCTTCCCAGCTTGGAAGCCAAGGCAGCTGATGAAGGGAGCTCAGGAGAGCCGTCTT CAGCTGGGCTGGGGTTGGGGCTGCTGTGAGGAAAACCTGCCATTGTGGCCCTGGAGAGTCACCAGCAGCTCTTGGGAAGGACTTGCTGGG AGGCTGAGAGAGGCTTTGGGCACAGCCTGCTGTCTTTTCCATTTCCTAAAGTTTACTTCATTGTCTTGAGGCTTCCAGGTTTTGTTTTTG TTTTTGCCAAAGTAGAAAAGGCAGGTGGTGGGCGGCTGGCAGGGAGTGCGGGTCCCCGCCCCTCTTCAGTCCTGCCCTCCCCTCCTCAGT CCTGCCCACCCCGTGCAGCCCATGCTGAGGCTGCAGTGGTGTCGTGGGTGTTACGTGCAGGAACGTGGAGACCCTGACGTGGGCTCACTG CGTTTGGTTTTCTTTTCAGAACTTGGGAGCCCCCAGGGAGGGGCTAGTGTTGGTAGGTCCTAGACGTGGTTCCCTCCAGCCTCCCCAAAA TCAACCCTGGTGTTGAGAGAACGTCCTTCTGTCCATCGTGGGTAACAGCCTTGGGGAGGGTGCAGAGCTCTGCAGAGCCATGGGCCAGGT GGGGCTGCCTCAGTCCTGTCCCCTTGGGCACTGAGGAGAGGGGCCCATTCACCTTTCTCCTAGAATGCTGTTGTAAATAAACAAATGGAT >36825_36825_7_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000393578_CHMP1A_chr16_89713739_ENST00000397901_length(amino acids)=220AA_BP= LNLGAGTQKTSSPGSARLVQDSGASSPSPSDSPVPPLPAPATLGGAVPPTTLSSACAPCPTLSRRSLPILLCFPTAQGTFNLNLFSLSLS LSLSLSLSLSLSLAGWGEEEEEFFPRLTFQGTQFTPSLFPFQAASEVLPVPATPDPNPREEPLRPQSLSSFSLASLLLLLPPPPPPPPPP -------------------------------------------------------------- >36825_36825_8_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000393578_CHMP1A_chr16_89713739_ENST00000535997_length(transcript)=2951nt_BP=1009nt CTTGAATCTTGGGGCAGGAACTCAGAAAACTTCCAGCCCGGGCAGCGCGCGCTTGGTGCAAGACTCAGGAGCTAGCAGCCCGTCCCCCTC CGACTCTCCGGTGCCGCCGCTGCCTGCTCCCGCCACCCTAGGAGGCGCGGTGCCACCCACTACTCTGTCCTCTGCCTGTGCTCCGTGCCC GACCCTATCCCGGCGGAGTCTCCCCATCCTCCTTTGCTTTCCGACTGCCCAAGGCACTTTCAATCTCAATCTCTTCTCTCTCTCTCTCTC TCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCGCAGGGTGGGGGGAAGAGGAGGAGGAATTCTTTCCCCGCCTAACATTTCA AGGGACACAATTCACTCCAAGTCTCTTCCCTTTCCAAGCCGCTTCCGAAGTGCTCCCGGTGCCCGCAACTCCTGATCCCAACCCGCGAGA GGAGCCTCTGCGACCTCAAAGCCTCTCTTCCTTCTCCCTCGCTTCCCTCCTCCTCTTGCTACCTCCACCTCCACCGCCACCTCCACCTCC GGCACCCACCCACCGCCGCCGCCGCCACCGGCAGCGCCTCCTCCTCTCCTCCTCCTCCTCCCCTCTTCTCTTTTTGGCAGCCGCTGGACG TCCGGTGTTGATGGTGGCAGCGGCGGCAGCCTAAGCAACAGCAGCCCTCGCAGCCCGCCAGCTCGCGCTCGCCCCGCCGGCGTCCCCAGC CCTATCACCTCATCTCCCGAAAGGTGCTGGGCAGCTCCGGGGCGGTCGAGGCGAAGCGGCTGCAGCGGCGGTAGCGGCGGCGGGAGGCAG GATGAGCGCACGCGGTGAGGGCGCGGGGCAGCCGTCCACTTCAGCCCAGGGACAACCTGCCGCCCCAGCGCCTCAGAAGAGAGGACGCGG CCGCCCCAGGAAGCAGCAGCAAGAACCAACCGGTGAGCCCTCTCCTAAGAGACCCAGGGGAAGACCCAAAGGCAGCAAAAACAAGAGTCC CTCTAAAGCAGCTCAAAAGGTGACCAAGAATATGGCCCAGGTGACCAAAGCCCTGGACAAGGCCCTGAGCACCATGGACCTGCAGAAGGT CTCCTCAGTGATGGACAGGTTCGAGCAGCAGGTGCAGAACCTGGACGTCCATACATCGGTGATGGAGGACTCCATGAGCTCGGCCACCAC CCTGACCACGCCGCAGGAGCAGGTGGACAGCCTCATCATGCAGATCGCCGAGGAGAATGGCCTGGAGGTGCTGGACCAGCTCAGCCAGCT GCCCGAGGGCGCCTCTGCCGTGGGCGAGAGCTCTGTGCGCAGCCAGGAGGACCAGCTGTCACGGAGGTTGGCCGCCTTGAGGAACTAGCC GTGCCCCGCCGGTGTGCACCGCCTCTGCCCCGTGATGTGCTGGAAGGCTCCTGTCCTCTCCCCACCGCGTCTTGCCTTTGTGCTGACCCC GCGGGGCTGCGGCCGGCAGCCACTCTGCGTCTCTCACCTGCCAGGCCTGCGTGGCCTTAGGGTTGTTCCTGTTCTTTTAGGTTGGGCGGT GGGTCTGTGTCCTGGTGTTGAGTTTCTGCAAATTTCTGGGGGTGATTTCTGTGACTCTGGGCCCACAGCGGGGAGGCCAAGAGGGGCCCT GTGGACTTTCACCCAGCACTGTGGGGGCCTTCAGACTCTGGGGCAGCAGACATGCTGCTTCCCATCAGCCAGAGGGGGTCAGGGCTGCCC TGTTGCCAAACAACTCCCTGAGGCCTCTCCGCACCACCTCAGCGGGCAGGAGGTCCCACCATGTGGACAGACATAGCCCAAGGAGGCACC ACAGGTCTATGTGTGCTGGGGGATGTCAGGTGCCACCCAACGCTGTCCTGGTGGTATTTACAATGACATCCTCCTCCTCCATCACTCCAG GGGTGGTGTCTCGGCCGCCCCTACCAGCTGGCTGAGCCCCCTGGCCTCCTGCGCTCCCTCACTTCCCTCAGTTCCCAAAGCTGCCCAGTC CATGGGGACAGAACCGTCACTCAGATCCACATTCAAGTGTGCCCACCCTGCAGTCTTCATCCTCACTCAGCTGCTGCCTCTGGAGGTGCC TTTGGCCACATGTGCTGTGCTGTTTGTCTCCTCGACAGGGAGCCTGTCCACCAGCAGGCTGCGGTCCCAGCGGGTGCGTCTGCAGCTCCT CCCCTTGGGCAGCCTGGTTCTCCCGGAGGACCTTTCCTTGGGGCCCTGCTTCATGACGATGCTGCCTGTGTCACCCTCTACCATCTGTAA ACAACTGGGTGCCTTCCCCGACCACACCCCAATGCCTTCCCAGCTTGGAAGCCAAGGCAGCTGATGAAGGGAGCTCAGGAGAGCCGTCTT CAGCTGGGCTGGGGTTGGGGCTGCTGTGAGGAAAACCTGCCATTGTGGCCCTGGAGAGTCACCAGCAGCTCTTGGGAAGGACTTGCTGGG AGGCTGAGAGAGGCTTTGGGCACAGCCTGCTGTCTTTTCCATTTCCTAAAGTTTACTTCATTGTCTTGAGGCTTCCAGGTTTTGTTTTTG TTTTTGCCAAAGTAGAAAAGGCAGGTGGTGGGCGGCTGGCAGGGAGTGCGGGTCCCCGCCCCTCTTCAGTCCTGCCCTCCCCTCCTCAGT CCTGCCCACCCCGTGCAGCCCATGCTGAGGCTGCAGTGGTGTCGTGGGTGTTACGTGCAGGAACGTGGAGACCCTGACGTGGGCTCACTG CGTTTGGTTTTCTTTTCAGAACTTGGGAGCCCCCAGGGAGGGGCTAGTGTTGGTAGGTCCTAGACGTGGTTCCCTCCAGCCTCCCCAAAA TCAACCCTGGTGTTGAGAGAACGTCCTTCTGTCCATCGTGGGTAACAGCCTTGGGGAGGGTGCAGAGCTCTGCAGAGCCATGGGCCAGGT >36825_36825_8_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000393578_CHMP1A_chr16_89713739_ENST00000535997_length(amino acids)=220AA_BP= LNLGAGTQKTSSPGSARLVQDSGASSPSPSDSPVPPLPAPATLGGAVPPTTLSSACAPCPTLSRRSLPILLCFPTAQGTFNLNLFSLSLS LSLSLSLSLSLSLAGWGEEEEEFFPRLTFQGTQFTPSLFPFQAASEVLPVPATPDPNPREEPLRPQSLSSFSLASLLLLLPPPPPPPPPP -------------------------------------------------------------- >36825_36825_9_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000393578_CHMP1A_chr16_89713739_ENST00000550102_length(transcript)=1525nt_BP=1009nt CTTGAATCTTGGGGCAGGAACTCAGAAAACTTCCAGCCCGGGCAGCGCGCGCTTGGTGCAAGACTCAGGAGCTAGCAGCCCGTCCCCCTC CGACTCTCCGGTGCCGCCGCTGCCTGCTCCCGCCACCCTAGGAGGCGCGGTGCCACCCACTACTCTGTCCTCTGCCTGTGCTCCGTGCCC GACCCTATCCCGGCGGAGTCTCCCCATCCTCCTTTGCTTTCCGACTGCCCAAGGCACTTTCAATCTCAATCTCTTCTCTCTCTCTCTCTC TCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCGCAGGGTGGGGGGAAGAGGAGGAGGAATTCTTTCCCCGCCTAACATTTCA AGGGACACAATTCACTCCAAGTCTCTTCCCTTTCCAAGCCGCTTCCGAAGTGCTCCCGGTGCCCGCAACTCCTGATCCCAACCCGCGAGA GGAGCCTCTGCGACCTCAAAGCCTCTCTTCCTTCTCCCTCGCTTCCCTCCTCCTCTTGCTACCTCCACCTCCACCGCCACCTCCACCTCC GGCACCCACCCACCGCCGCCGCCGCCACCGGCAGCGCCTCCTCCTCTCCTCCTCCTCCTCCCCTCTTCTCTTTTTGGCAGCCGCTGGACG TCCGGTGTTGATGGTGGCAGCGGCGGCAGCCTAAGCAACAGCAGCCCTCGCAGCCCGCCAGCTCGCGCTCGCCCCGCCGGCGTCCCCAGC CCTATCACCTCATCTCCCGAAAGGTGCTGGGCAGCTCCGGGGCGGTCGAGGCGAAGCGGCTGCAGCGGCGGTAGCGGCGGCGGGAGGCAG GATGAGCGCACGCGGTGAGGGCGCGGGGCAGCCGTCCACTTCAGCCCAGGGACAACCTGCCGCCCCAGCGCCTCAGAAGAGAGGACGCGG CCGCCCCAGGAAGCAGCAGCAAGAACCAACCGGTGAGCCCTCTCCTAAGAGACCCAGGGGAAGACCCAAAGGCAGCAAAAACAAGAGTCC CTCTAAAGCAGCTCAAAAGGTGACCAAGAATATGGCCCAGGTGACCAAAGCCCTGGACAAGGCCCTGAGCACCATGGACCTGCAGAAGGT CTCCTCAGTGATGGACAGGTTCGAGCAGCAGGTGCAGAACCTGGACGTCCATACATCGGTGATGGAGGACTCCATGAGCTCGGCCACCAC CCTGACCACGCCGCAGGAGCAGGTGGACAGCCTCATCATGCAGATCGCCGAGGAGAATGGCCTGGAGGTGCTGGACCAGCTCAGCCAGCT GCCCGAGGGCGCCTCTGCCGTGGGCGAGAGCTCTGTGCGCAGCCAGGAGGACCAGCTGTCACGGAGGTTGGCCGCCTTGAGGAACTAGCC GTGCCCCGCCGGTGTGCACCGCCTCTGCCCCGTGATGTGCTGGAAGGCTCCTGTCCTCTCCCCACCGCGTCTTGCCTTTGTGCTGACCCC >36825_36825_9_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000393578_CHMP1A_chr16_89713739_ENST00000550102_length(amino acids)=220AA_BP= LNLGAGTQKTSSPGSARLVQDSGASSPSPSDSPVPPLPAPATLGGAVPPTTLSSACAPCPTLSRRSLPILLCFPTAQGTFNLNLFSLSLS LSLSLSLSLSLSLAGWGEEEEEFFPRLTFQGTQFTPSLFPFQAASEVLPVPATPDPNPREEPLRPQSLSSFSLASLLLLLPPPPPPPPPP -------------------------------------------------------------- >36825_36825_10_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000403681_CHMP1A_chr16_89713739_ENST00000397901_length(transcript)=3312nt_BP=1338nt CAGCCCGGGATCCCCGGCCTGTCCCTTTAACCCCGCCGCCGGGCGGGAGCACGTGAGCGGGGCTCCGGGTGGCACCCGGGCGCCGCCGCC GCCGAGGCAGTTGTATTTCGAACGCTGCCTCTGGCTAGCAGCCAGGCGCCTTGGCTCGGCGGTCCGCCTGGCCTCCCTCCTCCTCATACT TTTCTTCCTGCGCAACCCCCTCCCCTTTATCCGCCCACGATTAGAGGTGGGCACTCCCCCCACCACCACCCCCTCCCCAAGCGCAAGCGC GTGCACGCACACACACCACACACACTCACACTCACACACACTCACACACACTCATCCCACTTGAATCTTGGGGCAGGAACTCAGAAAACT TCCAGCCCGGGCAGCGCGCGCTTGGTGCAAGACTCAGGAGCTAGCAGCCCGTCCCCCTCCGACTCTCCGGTGCCGCCGCTGCCTGCTCCC GCCACCCTAGGAGGCGCGGTGCCACCCACTACTCTGTCCTCTGCCTGTGCTCCGTGCCCGACCCTATCCCGGCGGAGTCTCCCCATCCTC CTTTGCTTTCCGACTGCCCAAGGCACTTTCAATCTCAATCTCTTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCT CTCTCTCTCGCAGGGTGGGGGGAAGAGGAGGAGGAATTCTTTCCCCGCCTAACATTTCAAGGGACACAATTCACTCCAAGTCTCTTCCCT TTCCAAGCCGCTTCCGAAGTGCTCCCGGTGCCCGCAACTCCTGATCCCAACCCGCGAGAGGAGCCTCTGCGACCTCAAAGCCTCTCTTCC TTCTCCCTCGCTTCCCTCCTCCTCTTGCTACCTCCACCTCCACCGCCACCTCCACCTCCGGCACCCACCCACCGCCGCCGCCGCCACCGG CAGCGCCTCCTCCTCTCCTCCTCCTCCTCCCCTCTTCTCTTTTTGGCAGCCGCTGGACGTCCGGTGTTGATGGTGGCAGCGGCGGCAGCC TAAGCAACAGCAGCCCTCGCAGCCCGCCAGCTCGCGCTCGCCCCGCCGGCGTCCCCAGCCCTATCACCTCATCTCCCGAAAGGTGCTGGG CAGCTCCGGGGCGGTCGAGGCGAAGCGGCTGCAGCGGCGGTAGCGGCGGCGGGAGGCAGGATGAGCGCACGCGGTGAGGGCGCGGGGCAG CCGTCCACTTCAGCCCAGGGACAACCTGCCGCCCCAGCGCCTCAGAAGAGAGGACGCGGCCGCCCCAGGAAGCAGCAGCAAGAACCAACC GGTGAGCCCTCTCCTAAGAGACCCAGGGGAAGACCCAAAGGCAGCAAAAACAAGAGTCCCTCTAAAGCAGCTCAAAAGGTGACCAAGAAT ATGGCCCAGGTGACCAAAGCCCTGGACAAGGCCCTGAGCACCATGGACCTGCAGAAGGTCTCCTCAGTGATGGACAGGTTCGAGCAGCAG GTGCAGAACCTGGACGTCCATACATCGGTGATGGAGGACTCCATGAGCTCGGCCACCACCCTGACCACGCCGCAGGAGCAGGTGGACAGC CTCATCATGCAGATCGCCGAGGAGAATGGCCTGGAGGTGCTGGACCAGCTCAGCCAGCTGCCCGAGGGCGCCTCTGCCGTGGGCGAGAGC TCTGTGCGCAGCCAGGAGGACCAGCTGTCACGGAGGTTGGCCGCCTTGAGGAACTAGCCGTGCCCCGCCGGTGTGCACCGCCTCTGCCCC GTGATGTGCTGGAAGGCTCCTGTCCTCTCCCCACCGCGTCTTGCCTTTGTGCTGACCCCGCGGGGCTGCGGCCGGCAGCCACTCTGCGTC TCTCACCTGCCAGGCCTGCGTGGCCTTAGGGTTGTTCCTGTTCTTTTAGGTTGGGCGGTGGGTCTGTGTCCTGGTGTTGAGTTTCTGCAA ATTTCTGGGGGTGATTTCTGTGACTCTGGGCCCACAGCGGGGAGGCCAAGAGGGGCCCTGTGGACTTTCACCCAGCACTGTGGGGGCCTT CAGACTCTGGGGCAGCAGACATGCTGCTTCCCATCAGCCAGAGGGGGTCAGGGCTGCCCTGTTGCCAAACAACTCCCTGAGGCCTCTCCG CACCACCTCAGCGGGCAGGAGGTCCCACCATGTGGACAGACATAGCCCAAGGAGGCACCACAGGTCTATGTGTGCTGGGGGATGTCAGGT GCCACCCAACGCTGTCCTGGTGGTATTTACAATGACATCCTCCTCCTCCATCACTCCAGGGGTGGTGTCTCGGCCGCCCCTACCAGCTGG CTGAGCCCCCTGGCCTCCTGCGCTCCCTCACTTCCCTCAGTTCCCAAAGCTGCCCAGTCCATGGGGACAGAACCGTCACTCAGATCCACA TTCAAGTGTGCCCACCCTGCAGTCTTCATCCTCACTCAGCTGCTGCCTCTGGAGGTGCCTTTGGCCACATGTGCTGTGCTGTTTGTCTCC TCGACAGGGAGCCTGTCCACCAGCAGGCTGCGGTCCCAGCGGGTGCGTCTGCAGCTCCTCCCCTTGGGCAGCCTGGTTCTCCCGGAGGAC CTTTCCTTGGGGCCCTGCTTCATGACGATGCTGCCTGTGTCACCCTCTACCATCTGTAAACAACTGGGTGCCTTCCCCGACCACACCCCA ATGCCTTCCCAGCTTGGAAGCCAAGGCAGCTGATGAAGGGAGCTCAGGAGAGCCGTCTTCAGCTGGGCTGGGGTTGGGGCTGCTGTGAGG AAAACCTGCCATTGTGGCCCTGGAGAGTCACCAGCAGCTCTTGGGAAGGACTTGCTGGGAGGCTGAGAGAGGCTTTGGGCACAGCCTGCT GTCTTTTCCATTTCCTAAAGTTTACTTCATTGTCTTGAGGCTTCCAGGTTTTGTTTTTGTTTTTGCCAAAGTAGAAAAGGCAGGTGGTGG GCGGCTGGCAGGGAGTGCGGGTCCCCGCCCCTCTTCAGTCCTGCCCTCCCCTCCTCAGTCCTGCCCACCCCGTGCAGCCCATGCTGAGGC TGCAGTGGTGTCGTGGGTGTTACGTGCAGGAACGTGGAGACCCTGACGTGGGCTCACTGCGTTTGGTTTTCTTTTCAGAACTTGGGAGCC CCCAGGGAGGGGCTAGTGTTGGTAGGTCCTAGACGTGGTTCCCTCCAGCCTCCCCAAAATCAACCCTGGTGTTGAGAGAACGTCCTTCTG TCCATCGTGGGTAACAGCCTTGGGGAGGGTGCAGAGCTCTGCAGAGCCATGGGCCAGGTGGGGCTGCCTCAGTCCTGTCCCCTTGGGCAC >36825_36825_10_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000403681_CHMP1A_chr16_89713739_ENST00000397901_length(amino acids)=292AA_BP= MPLASSQAPWLGGPPGLPPPHTFLPAQPPPLYPPTIRGGHSPHHHPLPKRKRVHAHTPHTLTLTHTHTHSSHLNLGAGTQKTSSPGSARL VQDSGASSPSPSDSPVPPLPAPATLGGAVPPTTLSSACAPCPTLSRRSLPILLCFPTAQGTFNLNLFSLSLSLSLSLSLSLSLSLAGWGE EEEEFFPRLTFQGTQFTPSLFPFQAASEVLPVPATPDPNPREEPLRPQSLSSFSLASLLLLLPPPPPPPPPPAPTHRRRRHRQRLLLSSS -------------------------------------------------------------- >36825_36825_11_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000403681_CHMP1A_chr16_89713739_ENST00000535997_length(transcript)=3280nt_BP=1338nt CAGCCCGGGATCCCCGGCCTGTCCCTTTAACCCCGCCGCCGGGCGGGAGCACGTGAGCGGGGCTCCGGGTGGCACCCGGGCGCCGCCGCC GCCGAGGCAGTTGTATTTCGAACGCTGCCTCTGGCTAGCAGCCAGGCGCCTTGGCTCGGCGGTCCGCCTGGCCTCCCTCCTCCTCATACT TTTCTTCCTGCGCAACCCCCTCCCCTTTATCCGCCCACGATTAGAGGTGGGCACTCCCCCCACCACCACCCCCTCCCCAAGCGCAAGCGC GTGCACGCACACACACCACACACACTCACACTCACACACACTCACACACACTCATCCCACTTGAATCTTGGGGCAGGAACTCAGAAAACT TCCAGCCCGGGCAGCGCGCGCTTGGTGCAAGACTCAGGAGCTAGCAGCCCGTCCCCCTCCGACTCTCCGGTGCCGCCGCTGCCTGCTCCC GCCACCCTAGGAGGCGCGGTGCCACCCACTACTCTGTCCTCTGCCTGTGCTCCGTGCCCGACCCTATCCCGGCGGAGTCTCCCCATCCTC CTTTGCTTTCCGACTGCCCAAGGCACTTTCAATCTCAATCTCTTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCT CTCTCTCTCGCAGGGTGGGGGGAAGAGGAGGAGGAATTCTTTCCCCGCCTAACATTTCAAGGGACACAATTCACTCCAAGTCTCTTCCCT TTCCAAGCCGCTTCCGAAGTGCTCCCGGTGCCCGCAACTCCTGATCCCAACCCGCGAGAGGAGCCTCTGCGACCTCAAAGCCTCTCTTCC TTCTCCCTCGCTTCCCTCCTCCTCTTGCTACCTCCACCTCCACCGCCACCTCCACCTCCGGCACCCACCCACCGCCGCCGCCGCCACCGG CAGCGCCTCCTCCTCTCCTCCTCCTCCTCCCCTCTTCTCTTTTTGGCAGCCGCTGGACGTCCGGTGTTGATGGTGGCAGCGGCGGCAGCC TAAGCAACAGCAGCCCTCGCAGCCCGCCAGCTCGCGCTCGCCCCGCCGGCGTCCCCAGCCCTATCACCTCATCTCCCGAAAGGTGCTGGG CAGCTCCGGGGCGGTCGAGGCGAAGCGGCTGCAGCGGCGGTAGCGGCGGCGGGAGGCAGGATGAGCGCACGCGGTGAGGGCGCGGGGCAG CCGTCCACTTCAGCCCAGGGACAACCTGCCGCCCCAGCGCCTCAGAAGAGAGGACGCGGCCGCCCCAGGAAGCAGCAGCAAGAACCAACC GGTGAGCCCTCTCCTAAGAGACCCAGGGGAAGACCCAAAGGCAGCAAAAACAAGAGTCCCTCTAAAGCAGCTCAAAAGGTGACCAAGAAT ATGGCCCAGGTGACCAAAGCCCTGGACAAGGCCCTGAGCACCATGGACCTGCAGAAGGTCTCCTCAGTGATGGACAGGTTCGAGCAGCAG GTGCAGAACCTGGACGTCCATACATCGGTGATGGAGGACTCCATGAGCTCGGCCACCACCCTGACCACGCCGCAGGAGCAGGTGGACAGC CTCATCATGCAGATCGCCGAGGAGAATGGCCTGGAGGTGCTGGACCAGCTCAGCCAGCTGCCCGAGGGCGCCTCTGCCGTGGGCGAGAGC TCTGTGCGCAGCCAGGAGGACCAGCTGTCACGGAGGTTGGCCGCCTTGAGGAACTAGCCGTGCCCCGCCGGTGTGCACCGCCTCTGCCCC GTGATGTGCTGGAAGGCTCCTGTCCTCTCCCCACCGCGTCTTGCCTTTGTGCTGACCCCGCGGGGCTGCGGCCGGCAGCCACTCTGCGTC TCTCACCTGCCAGGCCTGCGTGGCCTTAGGGTTGTTCCTGTTCTTTTAGGTTGGGCGGTGGGTCTGTGTCCTGGTGTTGAGTTTCTGCAA ATTTCTGGGGGTGATTTCTGTGACTCTGGGCCCACAGCGGGGAGGCCAAGAGGGGCCCTGTGGACTTTCACCCAGCACTGTGGGGGCCTT CAGACTCTGGGGCAGCAGACATGCTGCTTCCCATCAGCCAGAGGGGGTCAGGGCTGCCCTGTTGCCAAACAACTCCCTGAGGCCTCTCCG CACCACCTCAGCGGGCAGGAGGTCCCACCATGTGGACAGACATAGCCCAAGGAGGCACCACAGGTCTATGTGTGCTGGGGGATGTCAGGT GCCACCCAACGCTGTCCTGGTGGTATTTACAATGACATCCTCCTCCTCCATCACTCCAGGGGTGGTGTCTCGGCCGCCCCTACCAGCTGG CTGAGCCCCCTGGCCTCCTGCGCTCCCTCACTTCCCTCAGTTCCCAAAGCTGCCCAGTCCATGGGGACAGAACCGTCACTCAGATCCACA TTCAAGTGTGCCCACCCTGCAGTCTTCATCCTCACTCAGCTGCTGCCTCTGGAGGTGCCTTTGGCCACATGTGCTGTGCTGTTTGTCTCC TCGACAGGGAGCCTGTCCACCAGCAGGCTGCGGTCCCAGCGGGTGCGTCTGCAGCTCCTCCCCTTGGGCAGCCTGGTTCTCCCGGAGGAC CTTTCCTTGGGGCCCTGCTTCATGACGATGCTGCCTGTGTCACCCTCTACCATCTGTAAACAACTGGGTGCCTTCCCCGACCACACCCCA ATGCCTTCCCAGCTTGGAAGCCAAGGCAGCTGATGAAGGGAGCTCAGGAGAGCCGTCTTCAGCTGGGCTGGGGTTGGGGCTGCTGTGAGG AAAACCTGCCATTGTGGCCCTGGAGAGTCACCAGCAGCTCTTGGGAAGGACTTGCTGGGAGGCTGAGAGAGGCTTTGGGCACAGCCTGCT GTCTTTTCCATTTCCTAAAGTTTACTTCATTGTCTTGAGGCTTCCAGGTTTTGTTTTTGTTTTTGCCAAAGTAGAAAAGGCAGGTGGTGG GCGGCTGGCAGGGAGTGCGGGTCCCCGCCCCTCTTCAGTCCTGCCCTCCCCTCCTCAGTCCTGCCCACCCCGTGCAGCCCATGCTGAGGC TGCAGTGGTGTCGTGGGTGTTACGTGCAGGAACGTGGAGACCCTGACGTGGGCTCACTGCGTTTGGTTTTCTTTTCAGAACTTGGGAGCC CCCAGGGAGGGGCTAGTGTTGGTAGGTCCTAGACGTGGTTCCCTCCAGCCTCCCCAAAATCAACCCTGGTGTTGAGAGAACGTCCTTCTG TCCATCGTGGGTAACAGCCTTGGGGAGGGTGCAGAGCTCTGCAGAGCCATGGGCCAGGTGGGGCTGCCTCAGTCCTGTCCCCTTGGGCAC >36825_36825_11_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000403681_CHMP1A_chr16_89713739_ENST00000535997_length(amino acids)=292AA_BP= MPLASSQAPWLGGPPGLPPPHTFLPAQPPPLYPPTIRGGHSPHHHPLPKRKRVHAHTPHTLTLTHTHTHSSHLNLGAGTQKTSSPGSARL VQDSGASSPSPSDSPVPPLPAPATLGGAVPPTTLSSACAPCPTLSRRSLPILLCFPTAQGTFNLNLFSLSLSLSLSLSLSLSLSLAGWGE EEEEFFPRLTFQGTQFTPSLFPFQAASEVLPVPATPDPNPREEPLRPQSLSSFSLASLLLLLPPPPPPPPPPAPTHRRRRHRQRLLLSSS -------------------------------------------------------------- >36825_36825_12_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000403681_CHMP1A_chr16_89713739_ENST00000550102_length(transcript)=1854nt_BP=1338nt CAGCCCGGGATCCCCGGCCTGTCCCTTTAACCCCGCCGCCGGGCGGGAGCACGTGAGCGGGGCTCCGGGTGGCACCCGGGCGCCGCCGCC GCCGAGGCAGTTGTATTTCGAACGCTGCCTCTGGCTAGCAGCCAGGCGCCTTGGCTCGGCGGTCCGCCTGGCCTCCCTCCTCCTCATACT TTTCTTCCTGCGCAACCCCCTCCCCTTTATCCGCCCACGATTAGAGGTGGGCACTCCCCCCACCACCACCCCCTCCCCAAGCGCAAGCGC GTGCACGCACACACACCACACACACTCACACTCACACACACTCACACACACTCATCCCACTTGAATCTTGGGGCAGGAACTCAGAAAACT TCCAGCCCGGGCAGCGCGCGCTTGGTGCAAGACTCAGGAGCTAGCAGCCCGTCCCCCTCCGACTCTCCGGTGCCGCCGCTGCCTGCTCCC GCCACCCTAGGAGGCGCGGTGCCACCCACTACTCTGTCCTCTGCCTGTGCTCCGTGCCCGACCCTATCCCGGCGGAGTCTCCCCATCCTC CTTTGCTTTCCGACTGCCCAAGGCACTTTCAATCTCAATCTCTTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCT CTCTCTCTCGCAGGGTGGGGGGAAGAGGAGGAGGAATTCTTTCCCCGCCTAACATTTCAAGGGACACAATTCACTCCAAGTCTCTTCCCT TTCCAAGCCGCTTCCGAAGTGCTCCCGGTGCCCGCAACTCCTGATCCCAACCCGCGAGAGGAGCCTCTGCGACCTCAAAGCCTCTCTTCC TTCTCCCTCGCTTCCCTCCTCCTCTTGCTACCTCCACCTCCACCGCCACCTCCACCTCCGGCACCCACCCACCGCCGCCGCCGCCACCGG CAGCGCCTCCTCCTCTCCTCCTCCTCCTCCCCTCTTCTCTTTTTGGCAGCCGCTGGACGTCCGGTGTTGATGGTGGCAGCGGCGGCAGCC TAAGCAACAGCAGCCCTCGCAGCCCGCCAGCTCGCGCTCGCCCCGCCGGCGTCCCCAGCCCTATCACCTCATCTCCCGAAAGGTGCTGGG CAGCTCCGGGGCGGTCGAGGCGAAGCGGCTGCAGCGGCGGTAGCGGCGGCGGGAGGCAGGATGAGCGCACGCGGTGAGGGCGCGGGGCAG CCGTCCACTTCAGCCCAGGGACAACCTGCCGCCCCAGCGCCTCAGAAGAGAGGACGCGGCCGCCCCAGGAAGCAGCAGCAAGAACCAACC GGTGAGCCCTCTCCTAAGAGACCCAGGGGAAGACCCAAAGGCAGCAAAAACAAGAGTCCCTCTAAAGCAGCTCAAAAGGTGACCAAGAAT ATGGCCCAGGTGACCAAAGCCCTGGACAAGGCCCTGAGCACCATGGACCTGCAGAAGGTCTCCTCAGTGATGGACAGGTTCGAGCAGCAG GTGCAGAACCTGGACGTCCATACATCGGTGATGGAGGACTCCATGAGCTCGGCCACCACCCTGACCACGCCGCAGGAGCAGGTGGACAGC CTCATCATGCAGATCGCCGAGGAGAATGGCCTGGAGGTGCTGGACCAGCTCAGCCAGCTGCCCGAGGGCGCCTCTGCCGTGGGCGAGAGC TCTGTGCGCAGCCAGGAGGACCAGCTGTCACGGAGGTTGGCCGCCTTGAGGAACTAGCCGTGCCCCGCCGGTGTGCACCGCCTCTGCCCC GTGATGTGCTGGAAGGCTCCTGTCCTCTCCCCACCGCGTCTTGCCTTTGTGCTGACCCCGCGGGGCTGCGGCCGGCAGCCACTCTGCGTC >36825_36825_12_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000403681_CHMP1A_chr16_89713739_ENST00000550102_length(amino acids)=292AA_BP= MPLASSQAPWLGGPPGLPPPHTFLPAQPPPLYPPTIRGGHSPHHHPLPKRKRVHAHTPHTLTLTHTHTHSSHLNLGAGTQKTSSPGSARL VQDSGASSPSPSDSPVPPLPAPATLGGAVPPTTLSSACAPCPTLSRRSLPILLCFPTAQGTFNLNLFSLSLSLSLSLSLSLSLSLAGWGE EEEEFFPRLTFQGTQFTPSLFPFQAASEVLPVPATPDPNPREEPLRPQSLSSFSLASLLLLLPPPPPPPPPPAPTHRRRRHRQRLLLSSS -------------------------------------------------------------- >36825_36825_13_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000425208_CHMP1A_chr16_89713739_ENST00000397901_length(transcript)=2983nt_BP=1009nt CTTGAATCTTGGGGCAGGAACTCAGAAAACTTCCAGCCCGGGCAGCGCGCGCTTGGTGCAAGACTCAGGAGCTAGCAGCCCGTCCCCCTC CGACTCTCCGGTGCCGCCGCTGCCTGCTCCCGCCACCCTAGGAGGCGCGGTGCCACCCACTACTCTGTCCTCTGCCTGTGCTCCGTGCCC GACCCTATCCCGGCGGAGTCTCCCCATCCTCCTTTGCTTTCCGACTGCCCAAGGCACTTTCAATCTCAATCTCTTCTCTCTCTCTCTCTC TCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCGCAGGGTGGGGGGAAGAGGAGGAGGAATTCTTTCCCCGCCTAACATTTCA AGGGACACAATTCACTCCAAGTCTCTTCCCTTTCCAAGCCGCTTCCGAAGTGCTCCCGGTGCCCGCAACTCCTGATCCCAACCCGCGAGA GGAGCCTCTGCGACCTCAAAGCCTCTCTTCCTTCTCCCTCGCTTCCCTCCTCCTCTTGCTACCTCCACCTCCACCGCCACCTCCACCTCC GGCACCCACCCACCGCCGCCGCCGCCACCGGCAGCGCCTCCTCCTCTCCTCCTCCTCCTCCCCTCTTCTCTTTTTGGCAGCCGCTGGACG TCCGGTGTTGATGGTGGCAGCGGCGGCAGCCTAAGCAACAGCAGCCCTCGCAGCCCGCCAGCTCGCGCTCGCCCCGCCGGCGTCCCCAGC CCTATCACCTCATCTCCCGAAAGGTGCTGGGCAGCTCCGGGGCGGTCGAGGCGAAGCGGCTGCAGCGGCGGTAGCGGCGGCGGGAGGCAG GATGAGCGCACGCGGTGAGGGCGCGGGGCAGCCGTCCACTTCAGCCCAGGGACAACCTGCCGCCCCAGCGCCTCAGAAGAGAGGACGCGG CCGCCCCAGGAAGCAGCAGCAAGAACCAACCGGTGAGCCCTCTCCTAAGAGACCCAGGGGAAGACCCAAAGGCAGCAAAAACAAGAGTCC CTCTAAAGCAGCTCAAAAGGTGACCAAGAATATGGCCCAGGTGACCAAAGCCCTGGACAAGGCCCTGAGCACCATGGACCTGCAGAAGGT CTCCTCAGTGATGGACAGGTTCGAGCAGCAGGTGCAGAACCTGGACGTCCATACATCGGTGATGGAGGACTCCATGAGCTCGGCCACCAC CCTGACCACGCCGCAGGAGCAGGTGGACAGCCTCATCATGCAGATCGCCGAGGAGAATGGCCTGGAGGTGCTGGACCAGCTCAGCCAGCT GCCCGAGGGCGCCTCTGCCGTGGGCGAGAGCTCTGTGCGCAGCCAGGAGGACCAGCTGTCACGGAGGTTGGCCGCCTTGAGGAACTAGCC GTGCCCCGCCGGTGTGCACCGCCTCTGCCCCGTGATGTGCTGGAAGGCTCCTGTCCTCTCCCCACCGCGTCTTGCCTTTGTGCTGACCCC GCGGGGCTGCGGCCGGCAGCCACTCTGCGTCTCTCACCTGCCAGGCCTGCGTGGCCTTAGGGTTGTTCCTGTTCTTTTAGGTTGGGCGGT GGGTCTGTGTCCTGGTGTTGAGTTTCTGCAAATTTCTGGGGGTGATTTCTGTGACTCTGGGCCCACAGCGGGGAGGCCAAGAGGGGCCCT GTGGACTTTCACCCAGCACTGTGGGGGCCTTCAGACTCTGGGGCAGCAGACATGCTGCTTCCCATCAGCCAGAGGGGGTCAGGGCTGCCC TGTTGCCAAACAACTCCCTGAGGCCTCTCCGCACCACCTCAGCGGGCAGGAGGTCCCACCATGTGGACAGACATAGCCCAAGGAGGCACC ACAGGTCTATGTGTGCTGGGGGATGTCAGGTGCCACCCAACGCTGTCCTGGTGGTATTTACAATGACATCCTCCTCCTCCATCACTCCAG GGGTGGTGTCTCGGCCGCCCCTACCAGCTGGCTGAGCCCCCTGGCCTCCTGCGCTCCCTCACTTCCCTCAGTTCCCAAAGCTGCCCAGTC CATGGGGACAGAACCGTCACTCAGATCCACATTCAAGTGTGCCCACCCTGCAGTCTTCATCCTCACTCAGCTGCTGCCTCTGGAGGTGCC TTTGGCCACATGTGCTGTGCTGTTTGTCTCCTCGACAGGGAGCCTGTCCACCAGCAGGCTGCGGTCCCAGCGGGTGCGTCTGCAGCTCCT CCCCTTGGGCAGCCTGGTTCTCCCGGAGGACCTTTCCTTGGGGCCCTGCTTCATGACGATGCTGCCTGTGTCACCCTCTACCATCTGTAA ACAACTGGGTGCCTTCCCCGACCACACCCCAATGCCTTCCCAGCTTGGAAGCCAAGGCAGCTGATGAAGGGAGCTCAGGAGAGCCGTCTT CAGCTGGGCTGGGGTTGGGGCTGCTGTGAGGAAAACCTGCCATTGTGGCCCTGGAGAGTCACCAGCAGCTCTTGGGAAGGACTTGCTGGG AGGCTGAGAGAGGCTTTGGGCACAGCCTGCTGTCTTTTCCATTTCCTAAAGTTTACTTCATTGTCTTGAGGCTTCCAGGTTTTGTTTTTG TTTTTGCCAAAGTAGAAAAGGCAGGTGGTGGGCGGCTGGCAGGGAGTGCGGGTCCCCGCCCCTCTTCAGTCCTGCCCTCCCCTCCTCAGT CCTGCCCACCCCGTGCAGCCCATGCTGAGGCTGCAGTGGTGTCGTGGGTGTTACGTGCAGGAACGTGGAGACCCTGACGTGGGCTCACTG CGTTTGGTTTTCTTTTCAGAACTTGGGAGCCCCCAGGGAGGGGCTAGTGTTGGTAGGTCCTAGACGTGGTTCCCTCCAGCCTCCCCAAAA TCAACCCTGGTGTTGAGAGAACGTCCTTCTGTCCATCGTGGGTAACAGCCTTGGGGAGGGTGCAGAGCTCTGCAGAGCCATGGGCCAGGT GGGGCTGCCTCAGTCCTGTCCCCTTGGGCACTGAGGAGAGGGGCCCATTCACCTTTCTCCTAGAATGCTGTTGTAAATAAACAAATGGAT >36825_36825_13_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000425208_CHMP1A_chr16_89713739_ENST00000397901_length(amino acids)=220AA_BP= LNLGAGTQKTSSPGSARLVQDSGASSPSPSDSPVPPLPAPATLGGAVPPTTLSSACAPCPTLSRRSLPILLCFPTAQGTFNLNLFSLSLS LSLSLSLSLSLSLAGWGEEEEEFFPRLTFQGTQFTPSLFPFQAASEVLPVPATPDPNPREEPLRPQSLSSFSLASLLLLLPPPPPPPPPP -------------------------------------------------------------- >36825_36825_14_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000425208_CHMP1A_chr16_89713739_ENST00000535997_length(transcript)=2951nt_BP=1009nt CTTGAATCTTGGGGCAGGAACTCAGAAAACTTCCAGCCCGGGCAGCGCGCGCTTGGTGCAAGACTCAGGAGCTAGCAGCCCGTCCCCCTC CGACTCTCCGGTGCCGCCGCTGCCTGCTCCCGCCACCCTAGGAGGCGCGGTGCCACCCACTACTCTGTCCTCTGCCTGTGCTCCGTGCCC GACCCTATCCCGGCGGAGTCTCCCCATCCTCCTTTGCTTTCCGACTGCCCAAGGCACTTTCAATCTCAATCTCTTCTCTCTCTCTCTCTC TCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCGCAGGGTGGGGGGAAGAGGAGGAGGAATTCTTTCCCCGCCTAACATTTCA AGGGACACAATTCACTCCAAGTCTCTTCCCTTTCCAAGCCGCTTCCGAAGTGCTCCCGGTGCCCGCAACTCCTGATCCCAACCCGCGAGA GGAGCCTCTGCGACCTCAAAGCCTCTCTTCCTTCTCCCTCGCTTCCCTCCTCCTCTTGCTACCTCCACCTCCACCGCCACCTCCACCTCC GGCACCCACCCACCGCCGCCGCCGCCACCGGCAGCGCCTCCTCCTCTCCTCCTCCTCCTCCCCTCTTCTCTTTTTGGCAGCCGCTGGACG TCCGGTGTTGATGGTGGCAGCGGCGGCAGCCTAAGCAACAGCAGCCCTCGCAGCCCGCCAGCTCGCGCTCGCCCCGCCGGCGTCCCCAGC CCTATCACCTCATCTCCCGAAAGGTGCTGGGCAGCTCCGGGGCGGTCGAGGCGAAGCGGCTGCAGCGGCGGTAGCGGCGGCGGGAGGCAG GATGAGCGCACGCGGTGAGGGCGCGGGGCAGCCGTCCACTTCAGCCCAGGGACAACCTGCCGCCCCAGCGCCTCAGAAGAGAGGACGCGG CCGCCCCAGGAAGCAGCAGCAAGAACCAACCGGTGAGCCCTCTCCTAAGAGACCCAGGGGAAGACCCAAAGGCAGCAAAAACAAGAGTCC CTCTAAAGCAGCTCAAAAGGTGACCAAGAATATGGCCCAGGTGACCAAAGCCCTGGACAAGGCCCTGAGCACCATGGACCTGCAGAAGGT CTCCTCAGTGATGGACAGGTTCGAGCAGCAGGTGCAGAACCTGGACGTCCATACATCGGTGATGGAGGACTCCATGAGCTCGGCCACCAC CCTGACCACGCCGCAGGAGCAGGTGGACAGCCTCATCATGCAGATCGCCGAGGAGAATGGCCTGGAGGTGCTGGACCAGCTCAGCCAGCT GCCCGAGGGCGCCTCTGCCGTGGGCGAGAGCTCTGTGCGCAGCCAGGAGGACCAGCTGTCACGGAGGTTGGCCGCCTTGAGGAACTAGCC GTGCCCCGCCGGTGTGCACCGCCTCTGCCCCGTGATGTGCTGGAAGGCTCCTGTCCTCTCCCCACCGCGTCTTGCCTTTGTGCTGACCCC GCGGGGCTGCGGCCGGCAGCCACTCTGCGTCTCTCACCTGCCAGGCCTGCGTGGCCTTAGGGTTGTTCCTGTTCTTTTAGGTTGGGCGGT GGGTCTGTGTCCTGGTGTTGAGTTTCTGCAAATTTCTGGGGGTGATTTCTGTGACTCTGGGCCCACAGCGGGGAGGCCAAGAGGGGCCCT GTGGACTTTCACCCAGCACTGTGGGGGCCTTCAGACTCTGGGGCAGCAGACATGCTGCTTCCCATCAGCCAGAGGGGGTCAGGGCTGCCC TGTTGCCAAACAACTCCCTGAGGCCTCTCCGCACCACCTCAGCGGGCAGGAGGTCCCACCATGTGGACAGACATAGCCCAAGGAGGCACC ACAGGTCTATGTGTGCTGGGGGATGTCAGGTGCCACCCAACGCTGTCCTGGTGGTATTTACAATGACATCCTCCTCCTCCATCACTCCAG GGGTGGTGTCTCGGCCGCCCCTACCAGCTGGCTGAGCCCCCTGGCCTCCTGCGCTCCCTCACTTCCCTCAGTTCCCAAAGCTGCCCAGTC CATGGGGACAGAACCGTCACTCAGATCCACATTCAAGTGTGCCCACCCTGCAGTCTTCATCCTCACTCAGCTGCTGCCTCTGGAGGTGCC TTTGGCCACATGTGCTGTGCTGTTTGTCTCCTCGACAGGGAGCCTGTCCACCAGCAGGCTGCGGTCCCAGCGGGTGCGTCTGCAGCTCCT CCCCTTGGGCAGCCTGGTTCTCCCGGAGGACCTTTCCTTGGGGCCCTGCTTCATGACGATGCTGCCTGTGTCACCCTCTACCATCTGTAA ACAACTGGGTGCCTTCCCCGACCACACCCCAATGCCTTCCCAGCTTGGAAGCCAAGGCAGCTGATGAAGGGAGCTCAGGAGAGCCGTCTT CAGCTGGGCTGGGGTTGGGGCTGCTGTGAGGAAAACCTGCCATTGTGGCCCTGGAGAGTCACCAGCAGCTCTTGGGAAGGACTTGCTGGG AGGCTGAGAGAGGCTTTGGGCACAGCCTGCTGTCTTTTCCATTTCCTAAAGTTTACTTCATTGTCTTGAGGCTTCCAGGTTTTGTTTTTG TTTTTGCCAAAGTAGAAAAGGCAGGTGGTGGGCGGCTGGCAGGGAGTGCGGGTCCCCGCCCCTCTTCAGTCCTGCCCTCCCCTCCTCAGT CCTGCCCACCCCGTGCAGCCCATGCTGAGGCTGCAGTGGTGTCGTGGGTGTTACGTGCAGGAACGTGGAGACCCTGACGTGGGCTCACTG CGTTTGGTTTTCTTTTCAGAACTTGGGAGCCCCCAGGGAGGGGCTAGTGTTGGTAGGTCCTAGACGTGGTTCCCTCCAGCCTCCCCAAAA TCAACCCTGGTGTTGAGAGAACGTCCTTCTGTCCATCGTGGGTAACAGCCTTGGGGAGGGTGCAGAGCTCTGCAGAGCCATGGGCCAGGT >36825_36825_14_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000425208_CHMP1A_chr16_89713739_ENST00000535997_length(amino acids)=220AA_BP= LNLGAGTQKTSSPGSARLVQDSGASSPSPSDSPVPPLPAPATLGGAVPPTTLSSACAPCPTLSRRSLPILLCFPTAQGTFNLNLFSLSLS LSLSLSLSLSLSLAGWGEEEEEFFPRLTFQGTQFTPSLFPFQAASEVLPVPATPDPNPREEPLRPQSLSSFSLASLLLLLPPPPPPPPPP -------------------------------------------------------------- >36825_36825_15_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000425208_CHMP1A_chr16_89713739_ENST00000550102_length(transcript)=1525nt_BP=1009nt CTTGAATCTTGGGGCAGGAACTCAGAAAACTTCCAGCCCGGGCAGCGCGCGCTTGGTGCAAGACTCAGGAGCTAGCAGCCCGTCCCCCTC CGACTCTCCGGTGCCGCCGCTGCCTGCTCCCGCCACCCTAGGAGGCGCGGTGCCACCCACTACTCTGTCCTCTGCCTGTGCTCCGTGCCC GACCCTATCCCGGCGGAGTCTCCCCATCCTCCTTTGCTTTCCGACTGCCCAAGGCACTTTCAATCTCAATCTCTTCTCTCTCTCTCTCTC TCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCGCAGGGTGGGGGGAAGAGGAGGAGGAATTCTTTCCCCGCCTAACATTTCA AGGGACACAATTCACTCCAAGTCTCTTCCCTTTCCAAGCCGCTTCCGAAGTGCTCCCGGTGCCCGCAACTCCTGATCCCAACCCGCGAGA GGAGCCTCTGCGACCTCAAAGCCTCTCTTCCTTCTCCCTCGCTTCCCTCCTCCTCTTGCTACCTCCACCTCCACCGCCACCTCCACCTCC GGCACCCACCCACCGCCGCCGCCGCCACCGGCAGCGCCTCCTCCTCTCCTCCTCCTCCTCCCCTCTTCTCTTTTTGGCAGCCGCTGGACG TCCGGTGTTGATGGTGGCAGCGGCGGCAGCCTAAGCAACAGCAGCCCTCGCAGCCCGCCAGCTCGCGCTCGCCCCGCCGGCGTCCCCAGC CCTATCACCTCATCTCCCGAAAGGTGCTGGGCAGCTCCGGGGCGGTCGAGGCGAAGCGGCTGCAGCGGCGGTAGCGGCGGCGGGAGGCAG GATGAGCGCACGCGGTGAGGGCGCGGGGCAGCCGTCCACTTCAGCCCAGGGACAACCTGCCGCCCCAGCGCCTCAGAAGAGAGGACGCGG CCGCCCCAGGAAGCAGCAGCAAGAACCAACCGGTGAGCCCTCTCCTAAGAGACCCAGGGGAAGACCCAAAGGCAGCAAAAACAAGAGTCC CTCTAAAGCAGCTCAAAAGGTGACCAAGAATATGGCCCAGGTGACCAAAGCCCTGGACAAGGCCCTGAGCACCATGGACCTGCAGAAGGT CTCCTCAGTGATGGACAGGTTCGAGCAGCAGGTGCAGAACCTGGACGTCCATACATCGGTGATGGAGGACTCCATGAGCTCGGCCACCAC CCTGACCACGCCGCAGGAGCAGGTGGACAGCCTCATCATGCAGATCGCCGAGGAGAATGGCCTGGAGGTGCTGGACCAGCTCAGCCAGCT GCCCGAGGGCGCCTCTGCCGTGGGCGAGAGCTCTGTGCGCAGCCAGGAGGACCAGCTGTCACGGAGGTTGGCCGCCTTGAGGAACTAGCC GTGCCCCGCCGGTGTGCACCGCCTCTGCCCCGTGATGTGCTGGAAGGCTCCTGTCCTCTCCCCACCGCGTCTTGCCTTTGTGCTGACCCC >36825_36825_15_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000425208_CHMP1A_chr16_89713739_ENST00000550102_length(amino acids)=220AA_BP= LNLGAGTQKTSSPGSARLVQDSGASSPSPSDSPVPPLPAPATLGGAVPPTTLSSACAPCPTLSRRSLPILLCFPTAQGTFNLNLFSLSLS LSLSLSLSLSLSLAGWGEEEEEFFPRLTFQGTQFTPSLFPFQAASEVLPVPATPDPNPREEPLRPQSLSSFSLASLLLLLPPPPPPPPPP -------------------------------------------------------------- >36825_36825_16_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000536545_CHMP1A_chr16_89713739_ENST00000397901_length(transcript)=2983nt_BP=1009nt CTTGAATCTTGGGGCAGGAACTCAGAAAACTTCCAGCCCGGGCAGCGCGCGCTTGGTGCAAGACTCAGGAGCTAGCAGCCCGTCCCCCTC CGACTCTCCGGTGCCGCCGCTGCCTGCTCCCGCCACCCTAGGAGGCGCGGTGCCACCCACTACTCTGTCCTCTGCCTGTGCTCCGTGCCC GACCCTATCCCGGCGGAGTCTCCCCATCCTCCTTTGCTTTCCGACTGCCCAAGGCACTTTCAATCTCAATCTCTTCTCTCTCTCTCTCTC TCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCGCAGGGTGGGGGGAAGAGGAGGAGGAATTCTTTCCCCGCCTAACATTTCA AGGGACACAATTCACTCCAAGTCTCTTCCCTTTCCAAGCCGCTTCCGAAGTGCTCCCGGTGCCCGCAACTCCTGATCCCAACCCGCGAGA GGAGCCTCTGCGACCTCAAAGCCTCTCTTCCTTCTCCCTCGCTTCCCTCCTCCTCTTGCTACCTCCACCTCCACCGCCACCTCCACCTCC GGCACCCACCCACCGCCGCCGCCGCCACCGGCAGCGCCTCCTCCTCTCCTCCTCCTCCTCCCCTCTTCTCTTTTTGGCAGCCGCTGGACG TCCGGTGTTGATGGTGGCAGCGGCGGCAGCCTAAGCAACAGCAGCCCTCGCAGCCCGCCAGCTCGCGCTCGCCCCGCCGGCGTCCCCAGC CCTATCACCTCATCTCCCGAAAGGTGCTGGGCAGCTCCGGGGCGGTCGAGGCGAAGCGGCTGCAGCGGCGGTAGCGGCGGCGGGAGGCAG GATGAGCGCACGCGGTGAGGGCGCGGGGCAGCCGTCCACTTCAGCCCAGGGACAACCTGCCGCCCCAGCGCCTCAGAAGAGAGGACGCGG CCGCCCCAGGAAGCAGCAGCAAGAACCAACCGGTGAGCCCTCTCCTAAGAGACCCAGGGGAAGACCCAAAGGCAGCAAAAACAAGAGTCC CTCTAAAGCAGCTCAAAAGGTGACCAAGAATATGGCCCAGGTGACCAAAGCCCTGGACAAGGCCCTGAGCACCATGGACCTGCAGAAGGT CTCCTCAGTGATGGACAGGTTCGAGCAGCAGGTGCAGAACCTGGACGTCCATACATCGGTGATGGAGGACTCCATGAGCTCGGCCACCAC CCTGACCACGCCGCAGGAGCAGGTGGACAGCCTCATCATGCAGATCGCCGAGGAGAATGGCCTGGAGGTGCTGGACCAGCTCAGCCAGCT GCCCGAGGGCGCCTCTGCCGTGGGCGAGAGCTCTGTGCGCAGCCAGGAGGACCAGCTGTCACGGAGGTTGGCCGCCTTGAGGAACTAGCC GTGCCCCGCCGGTGTGCACCGCCTCTGCCCCGTGATGTGCTGGAAGGCTCCTGTCCTCTCCCCACCGCGTCTTGCCTTTGTGCTGACCCC GCGGGGCTGCGGCCGGCAGCCACTCTGCGTCTCTCACCTGCCAGGCCTGCGTGGCCTTAGGGTTGTTCCTGTTCTTTTAGGTTGGGCGGT GGGTCTGTGTCCTGGTGTTGAGTTTCTGCAAATTTCTGGGGGTGATTTCTGTGACTCTGGGCCCACAGCGGGGAGGCCAAGAGGGGCCCT GTGGACTTTCACCCAGCACTGTGGGGGCCTTCAGACTCTGGGGCAGCAGACATGCTGCTTCCCATCAGCCAGAGGGGGTCAGGGCTGCCC TGTTGCCAAACAACTCCCTGAGGCCTCTCCGCACCACCTCAGCGGGCAGGAGGTCCCACCATGTGGACAGACATAGCCCAAGGAGGCACC ACAGGTCTATGTGTGCTGGGGGATGTCAGGTGCCACCCAACGCTGTCCTGGTGGTATTTACAATGACATCCTCCTCCTCCATCACTCCAG GGGTGGTGTCTCGGCCGCCCCTACCAGCTGGCTGAGCCCCCTGGCCTCCTGCGCTCCCTCACTTCCCTCAGTTCCCAAAGCTGCCCAGTC CATGGGGACAGAACCGTCACTCAGATCCACATTCAAGTGTGCCCACCCTGCAGTCTTCATCCTCACTCAGCTGCTGCCTCTGGAGGTGCC TTTGGCCACATGTGCTGTGCTGTTTGTCTCCTCGACAGGGAGCCTGTCCACCAGCAGGCTGCGGTCCCAGCGGGTGCGTCTGCAGCTCCT CCCCTTGGGCAGCCTGGTTCTCCCGGAGGACCTTTCCTTGGGGCCCTGCTTCATGACGATGCTGCCTGTGTCACCCTCTACCATCTGTAA ACAACTGGGTGCCTTCCCCGACCACACCCCAATGCCTTCCCAGCTTGGAAGCCAAGGCAGCTGATGAAGGGAGCTCAGGAGAGCCGTCTT CAGCTGGGCTGGGGTTGGGGCTGCTGTGAGGAAAACCTGCCATTGTGGCCCTGGAGAGTCACCAGCAGCTCTTGGGAAGGACTTGCTGGG AGGCTGAGAGAGGCTTTGGGCACAGCCTGCTGTCTTTTCCATTTCCTAAAGTTTACTTCATTGTCTTGAGGCTTCCAGGTTTTGTTTTTG TTTTTGCCAAAGTAGAAAAGGCAGGTGGTGGGCGGCTGGCAGGGAGTGCGGGTCCCCGCCCCTCTTCAGTCCTGCCCTCCCCTCCTCAGT CCTGCCCACCCCGTGCAGCCCATGCTGAGGCTGCAGTGGTGTCGTGGGTGTTACGTGCAGGAACGTGGAGACCCTGACGTGGGCTCACTG CGTTTGGTTTTCTTTTCAGAACTTGGGAGCCCCCAGGGAGGGGCTAGTGTTGGTAGGTCCTAGACGTGGTTCCCTCCAGCCTCCCCAAAA TCAACCCTGGTGTTGAGAGAACGTCCTTCTGTCCATCGTGGGTAACAGCCTTGGGGAGGGTGCAGAGCTCTGCAGAGCCATGGGCCAGGT GGGGCTGCCTCAGTCCTGTCCCCTTGGGCACTGAGGAGAGGGGCCCATTCACCTTTCTCCTAGAATGCTGTTGTAAATAAACAAATGGAT >36825_36825_16_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000536545_CHMP1A_chr16_89713739_ENST00000397901_length(amino acids)=220AA_BP= LNLGAGTQKTSSPGSARLVQDSGASSPSPSDSPVPPLPAPATLGGAVPPTTLSSACAPCPTLSRRSLPILLCFPTAQGTFNLNLFSLSLS LSLSLSLSLSLSLAGWGEEEEEFFPRLTFQGTQFTPSLFPFQAASEVLPVPATPDPNPREEPLRPQSLSSFSLASLLLLLPPPPPPPPPP -------------------------------------------------------------- >36825_36825_17_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000536545_CHMP1A_chr16_89713739_ENST00000535997_length(transcript)=2951nt_BP=1009nt CTTGAATCTTGGGGCAGGAACTCAGAAAACTTCCAGCCCGGGCAGCGCGCGCTTGGTGCAAGACTCAGGAGCTAGCAGCCCGTCCCCCTC CGACTCTCCGGTGCCGCCGCTGCCTGCTCCCGCCACCCTAGGAGGCGCGGTGCCACCCACTACTCTGTCCTCTGCCTGTGCTCCGTGCCC GACCCTATCCCGGCGGAGTCTCCCCATCCTCCTTTGCTTTCCGACTGCCCAAGGCACTTTCAATCTCAATCTCTTCTCTCTCTCTCTCTC TCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCGCAGGGTGGGGGGAAGAGGAGGAGGAATTCTTTCCCCGCCTAACATTTCA AGGGACACAATTCACTCCAAGTCTCTTCCCTTTCCAAGCCGCTTCCGAAGTGCTCCCGGTGCCCGCAACTCCTGATCCCAACCCGCGAGA GGAGCCTCTGCGACCTCAAAGCCTCTCTTCCTTCTCCCTCGCTTCCCTCCTCCTCTTGCTACCTCCACCTCCACCGCCACCTCCACCTCC GGCACCCACCCACCGCCGCCGCCGCCACCGGCAGCGCCTCCTCCTCTCCTCCTCCTCCTCCCCTCTTCTCTTTTTGGCAGCCGCTGGACG TCCGGTGTTGATGGTGGCAGCGGCGGCAGCCTAAGCAACAGCAGCCCTCGCAGCCCGCCAGCTCGCGCTCGCCCCGCCGGCGTCCCCAGC CCTATCACCTCATCTCCCGAAAGGTGCTGGGCAGCTCCGGGGCGGTCGAGGCGAAGCGGCTGCAGCGGCGGTAGCGGCGGCGGGAGGCAG GATGAGCGCACGCGGTGAGGGCGCGGGGCAGCCGTCCACTTCAGCCCAGGGACAACCTGCCGCCCCAGCGCCTCAGAAGAGAGGACGCGG CCGCCCCAGGAAGCAGCAGCAAGAACCAACCGGTGAGCCCTCTCCTAAGAGACCCAGGGGAAGACCCAAAGGCAGCAAAAACAAGAGTCC CTCTAAAGCAGCTCAAAAGGTGACCAAGAATATGGCCCAGGTGACCAAAGCCCTGGACAAGGCCCTGAGCACCATGGACCTGCAGAAGGT CTCCTCAGTGATGGACAGGTTCGAGCAGCAGGTGCAGAACCTGGACGTCCATACATCGGTGATGGAGGACTCCATGAGCTCGGCCACCAC CCTGACCACGCCGCAGGAGCAGGTGGACAGCCTCATCATGCAGATCGCCGAGGAGAATGGCCTGGAGGTGCTGGACCAGCTCAGCCAGCT GCCCGAGGGCGCCTCTGCCGTGGGCGAGAGCTCTGTGCGCAGCCAGGAGGACCAGCTGTCACGGAGGTTGGCCGCCTTGAGGAACTAGCC GTGCCCCGCCGGTGTGCACCGCCTCTGCCCCGTGATGTGCTGGAAGGCTCCTGTCCTCTCCCCACCGCGTCTTGCCTTTGTGCTGACCCC GCGGGGCTGCGGCCGGCAGCCACTCTGCGTCTCTCACCTGCCAGGCCTGCGTGGCCTTAGGGTTGTTCCTGTTCTTTTAGGTTGGGCGGT GGGTCTGTGTCCTGGTGTTGAGTTTCTGCAAATTTCTGGGGGTGATTTCTGTGACTCTGGGCCCACAGCGGGGAGGCCAAGAGGGGCCCT GTGGACTTTCACCCAGCACTGTGGGGGCCTTCAGACTCTGGGGCAGCAGACATGCTGCTTCCCATCAGCCAGAGGGGGTCAGGGCTGCCC TGTTGCCAAACAACTCCCTGAGGCCTCTCCGCACCACCTCAGCGGGCAGGAGGTCCCACCATGTGGACAGACATAGCCCAAGGAGGCACC ACAGGTCTATGTGTGCTGGGGGATGTCAGGTGCCACCCAACGCTGTCCTGGTGGTATTTACAATGACATCCTCCTCCTCCATCACTCCAG GGGTGGTGTCTCGGCCGCCCCTACCAGCTGGCTGAGCCCCCTGGCCTCCTGCGCTCCCTCACTTCCCTCAGTTCCCAAAGCTGCCCAGTC CATGGGGACAGAACCGTCACTCAGATCCACATTCAAGTGTGCCCACCCTGCAGTCTTCATCCTCACTCAGCTGCTGCCTCTGGAGGTGCC TTTGGCCACATGTGCTGTGCTGTTTGTCTCCTCGACAGGGAGCCTGTCCACCAGCAGGCTGCGGTCCCAGCGGGTGCGTCTGCAGCTCCT CCCCTTGGGCAGCCTGGTTCTCCCGGAGGACCTTTCCTTGGGGCCCTGCTTCATGACGATGCTGCCTGTGTCACCCTCTACCATCTGTAA ACAACTGGGTGCCTTCCCCGACCACACCCCAATGCCTTCCCAGCTTGGAAGCCAAGGCAGCTGATGAAGGGAGCTCAGGAGAGCCGTCTT CAGCTGGGCTGGGGTTGGGGCTGCTGTGAGGAAAACCTGCCATTGTGGCCCTGGAGAGTCACCAGCAGCTCTTGGGAAGGACTTGCTGGG AGGCTGAGAGAGGCTTTGGGCACAGCCTGCTGTCTTTTCCATTTCCTAAAGTTTACTTCATTGTCTTGAGGCTTCCAGGTTTTGTTTTTG TTTTTGCCAAAGTAGAAAAGGCAGGTGGTGGGCGGCTGGCAGGGAGTGCGGGTCCCCGCCCCTCTTCAGTCCTGCCCTCCCCTCCTCAGT CCTGCCCACCCCGTGCAGCCCATGCTGAGGCTGCAGTGGTGTCGTGGGTGTTACGTGCAGGAACGTGGAGACCCTGACGTGGGCTCACTG CGTTTGGTTTTCTTTTCAGAACTTGGGAGCCCCCAGGGAGGGGCTAGTGTTGGTAGGTCCTAGACGTGGTTCCCTCCAGCCTCCCCAAAA TCAACCCTGGTGTTGAGAGAACGTCCTTCTGTCCATCGTGGGTAACAGCCTTGGGGAGGGTGCAGAGCTCTGCAGAGCCATGGGCCAGGT >36825_36825_17_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000536545_CHMP1A_chr16_89713739_ENST00000535997_length(amino acids)=220AA_BP= LNLGAGTQKTSSPGSARLVQDSGASSPSPSDSPVPPLPAPATLGGAVPPTTLSSACAPCPTLSRRSLPILLCFPTAQGTFNLNLFSLSLS LSLSLSLSLSLSLAGWGEEEEEFFPRLTFQGTQFTPSLFPFQAASEVLPVPATPDPNPREEPLRPQSLSSFSLASLLLLLPPPPPPPPPP -------------------------------------------------------------- >36825_36825_18_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000536545_CHMP1A_chr16_89713739_ENST00000550102_length(transcript)=1525nt_BP=1009nt CTTGAATCTTGGGGCAGGAACTCAGAAAACTTCCAGCCCGGGCAGCGCGCGCTTGGTGCAAGACTCAGGAGCTAGCAGCCCGTCCCCCTC CGACTCTCCGGTGCCGCCGCTGCCTGCTCCCGCCACCCTAGGAGGCGCGGTGCCACCCACTACTCTGTCCTCTGCCTGTGCTCCGTGCCC GACCCTATCCCGGCGGAGTCTCCCCATCCTCCTTTGCTTTCCGACTGCCCAAGGCACTTTCAATCTCAATCTCTTCTCTCTCTCTCTCTC TCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCTCGCAGGGTGGGGGGAAGAGGAGGAGGAATTCTTTCCCCGCCTAACATTTCA AGGGACACAATTCACTCCAAGTCTCTTCCCTTTCCAAGCCGCTTCCGAAGTGCTCCCGGTGCCCGCAACTCCTGATCCCAACCCGCGAGA GGAGCCTCTGCGACCTCAAAGCCTCTCTTCCTTCTCCCTCGCTTCCCTCCTCCTCTTGCTACCTCCACCTCCACCGCCACCTCCACCTCC GGCACCCACCCACCGCCGCCGCCGCCACCGGCAGCGCCTCCTCCTCTCCTCCTCCTCCTCCCCTCTTCTCTTTTTGGCAGCCGCTGGACG TCCGGTGTTGATGGTGGCAGCGGCGGCAGCCTAAGCAACAGCAGCCCTCGCAGCCCGCCAGCTCGCGCTCGCCCCGCCGGCGTCCCCAGC CCTATCACCTCATCTCCCGAAAGGTGCTGGGCAGCTCCGGGGCGGTCGAGGCGAAGCGGCTGCAGCGGCGGTAGCGGCGGCGGGAGGCAG GATGAGCGCACGCGGTGAGGGCGCGGGGCAGCCGTCCACTTCAGCCCAGGGACAACCTGCCGCCCCAGCGCCTCAGAAGAGAGGACGCGG CCGCCCCAGGAAGCAGCAGCAAGAACCAACCGGTGAGCCCTCTCCTAAGAGACCCAGGGGAAGACCCAAAGGCAGCAAAAACAAGAGTCC CTCTAAAGCAGCTCAAAAGGTGACCAAGAATATGGCCCAGGTGACCAAAGCCCTGGACAAGGCCCTGAGCACCATGGACCTGCAGAAGGT CTCCTCAGTGATGGACAGGTTCGAGCAGCAGGTGCAGAACCTGGACGTCCATACATCGGTGATGGAGGACTCCATGAGCTCGGCCACCAC CCTGACCACGCCGCAGGAGCAGGTGGACAGCCTCATCATGCAGATCGCCGAGGAGAATGGCCTGGAGGTGCTGGACCAGCTCAGCCAGCT GCCCGAGGGCGCCTCTGCCGTGGGCGAGAGCTCTGTGCGCAGCCAGGAGGACCAGCTGTCACGGAGGTTGGCCGCCTTGAGGAACTAGCC GTGCCCCGCCGGTGTGCACCGCCTCTGCCCCGTGATGTGCTGGAAGGCTCCTGTCCTCTCCCCACCGCGTCTTGCCTTTGTGCTGACCCC >36825_36825_18_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000536545_CHMP1A_chr16_89713739_ENST00000550102_length(amino acids)=220AA_BP= LNLGAGTQKTSSPGSARLVQDSGASSPSPSDSPVPPLPAPATLGGAVPPTTLSSACAPCPTLSRRSLPILLCFPTAQGTFNLNLFSLSLS LSLSLSLSLSLSLAGWGEEEEEFFPRLTFQGTQFTPSLFPFQAASEVLPVPATPDPNPREEPLRPQSLSSFSLASLLLLLPPPPPPPPPP -------------------------------------------------------------- >36825_36825_19_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000541363_CHMP1A_chr16_89713739_ENST00000397901_length(transcript)=2545nt_BP=571nt CAACCCGCGAGAGGAGCCTCTGCGACCTCAAAGCCTCTCTTCCTTCTCCCTCGCTTCCCTCCTCCTCTTGCTACCTCCACCTCCACCGCC ACCTCCACCTCCGGCACCCACCCACCGCCGCCGCCGCCACCGGCAGCGCCTCCTCCTCTCCTCCTCCTCCTCCCCTCTTCTCTTTTTGGC AGCCGCTGGACGTCCGGTGTTGATGGTGGCAGCGGCGGCAGCCTAAGCAACAGCAGCCCTCGCAGCCCGCCAGCTCGCGCTCGCCCCGCC GGCGTCCCCAGCCCTATCACCTCATCTCCCGAAAGGTGCTGGGCAGCTCCGGGGCGGTCGAGGCGAAGCGGCTGCAGCGGCGGTAGCGGC GGCGGGAGGCAGGATGAGCGCACGCGGTGAGGGCGCGGGGCAGCCGTCCACTTCAGCCCAGGGACAACCTGCCGCCCCAGCGCCTCAGAA GAGAGGACGCGGCCGCCCCAGGAAGCAGCAGCAAGAACCAACCGGTGAGCCCTCTCCTAAGAGACCCAGGGGAAGACCCAAAGGCAGCAA AAACAAGAGTCCCTCTAAAGCAGCTCAAAAGGTGACCAAGAATATGGCCCAGGTGACCAAAGCCCTGGACAAGGCCCTGAGCACCATGGA CCTGCAGAAGGTCTCCTCAGTGATGGACAGGTTCGAGCAGCAGGTGCAGAACCTGGACGTCCATACATCGGTGATGGAGGACTCCATGAG CTCGGCCACCACCCTGACCACGCCGCAGGAGCAGGTGGACAGCCTCATCATGCAGATCGCCGAGGAGAATGGCCTGGAGGTGCTGGACCA GCTCAGCCAGCTGCCCGAGGGCGCCTCTGCCGTGGGCGAGAGCTCTGTGCGCAGCCAGGAGGACCAGCTGTCACGGAGGTTGGCCGCCTT GAGGAACTAGCCGTGCCCCGCCGGTGTGCACCGCCTCTGCCCCGTGATGTGCTGGAAGGCTCCTGTCCTCTCCCCACCGCGTCTTGCCTT TGTGCTGACCCCGCGGGGCTGCGGCCGGCAGCCACTCTGCGTCTCTCACCTGCCAGGCCTGCGTGGCCTTAGGGTTGTTCCTGTTCTTTT AGGTTGGGCGGTGGGTCTGTGTCCTGGTGTTGAGTTTCTGCAAATTTCTGGGGGTGATTTCTGTGACTCTGGGCCCACAGCGGGGAGGCC AAGAGGGGCCCTGTGGACTTTCACCCAGCACTGTGGGGGCCTTCAGACTCTGGGGCAGCAGACATGCTGCTTCCCATCAGCCAGAGGGGG TCAGGGCTGCCCTGTTGCCAAACAACTCCCTGAGGCCTCTCCGCACCACCTCAGCGGGCAGGAGGTCCCACCATGTGGACAGACATAGCC CAAGGAGGCACCACAGGTCTATGTGTGCTGGGGGATGTCAGGTGCCACCCAACGCTGTCCTGGTGGTATTTACAATGACATCCTCCTCCT CCATCACTCCAGGGGTGGTGTCTCGGCCGCCCCTACCAGCTGGCTGAGCCCCCTGGCCTCCTGCGCTCCCTCACTTCCCTCAGTTCCCAA AGCTGCCCAGTCCATGGGGACAGAACCGTCACTCAGATCCACATTCAAGTGTGCCCACCCTGCAGTCTTCATCCTCACTCAGCTGCTGCC TCTGGAGGTGCCTTTGGCCACATGTGCTGTGCTGTTTGTCTCCTCGACAGGGAGCCTGTCCACCAGCAGGCTGCGGTCCCAGCGGGTGCG TCTGCAGCTCCTCCCCTTGGGCAGCCTGGTTCTCCCGGAGGACCTTTCCTTGGGGCCCTGCTTCATGACGATGCTGCCTGTGTCACCCTC TACCATCTGTAAACAACTGGGTGCCTTCCCCGACCACACCCCAATGCCTTCCCAGCTTGGAAGCCAAGGCAGCTGATGAAGGGAGCTCAG GAGAGCCGTCTTCAGCTGGGCTGGGGTTGGGGCTGCTGTGAGGAAAACCTGCCATTGTGGCCCTGGAGAGTCACCAGCAGCTCTTGGGAA GGACTTGCTGGGAGGCTGAGAGAGGCTTTGGGCACAGCCTGCTGTCTTTTCCATTTCCTAAAGTTTACTTCATTGTCTTGAGGCTTCCAG GTTTTGTTTTTGTTTTTGCCAAAGTAGAAAAGGCAGGTGGTGGGCGGCTGGCAGGGAGTGCGGGTCCCCGCCCCTCTTCAGTCCTGCCCT CCCCTCCTCAGTCCTGCCCACCCCGTGCAGCCCATGCTGAGGCTGCAGTGGTGTCGTGGGTGTTACGTGCAGGAACGTGGAGACCCTGAC GTGGGCTCACTGCGTTTGGTTTTCTTTTCAGAACTTGGGAGCCCCCAGGGAGGGGCTAGTGTTGGTAGGTCCTAGACGTGGTTCCCTCCA GCCTCCCCAAAATCAACCCTGGTGTTGAGAGAACGTCCTTCTGTCCATCGTGGGTAACAGCCTTGGGGAGGGTGCAGAGCTCTGCAGAGC CATGGGCCAGGTGGGGCTGCCTCAGTCCTGTCCCCTTGGGCACTGAGGAGAGGGGCCCATTCACCTTTCTCCTAGAATGCTGTTGTAAAT >36825_36825_19_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000541363_CHMP1A_chr16_89713739_ENST00000397901_length(amino acids)=178AA_BP=66 MSARGEGAGQPSTSAQGQPAAPAPQKRGRGRPRKQQQEPTGEPSPKRPRGRPKGSKNKSPSKAAQKVTKNMAQVTKALDKALSTMDLQKV -------------------------------------------------------------- >36825_36825_20_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000541363_CHMP1A_chr16_89713739_ENST00000535997_length(transcript)=2513nt_BP=571nt CAACCCGCGAGAGGAGCCTCTGCGACCTCAAAGCCTCTCTTCCTTCTCCCTCGCTTCCCTCCTCCTCTTGCTACCTCCACCTCCACCGCC ACCTCCACCTCCGGCACCCACCCACCGCCGCCGCCGCCACCGGCAGCGCCTCCTCCTCTCCTCCTCCTCCTCCCCTCTTCTCTTTTTGGC AGCCGCTGGACGTCCGGTGTTGATGGTGGCAGCGGCGGCAGCCTAAGCAACAGCAGCCCTCGCAGCCCGCCAGCTCGCGCTCGCCCCGCC GGCGTCCCCAGCCCTATCACCTCATCTCCCGAAAGGTGCTGGGCAGCTCCGGGGCGGTCGAGGCGAAGCGGCTGCAGCGGCGGTAGCGGC GGCGGGAGGCAGGATGAGCGCACGCGGTGAGGGCGCGGGGCAGCCGTCCACTTCAGCCCAGGGACAACCTGCCGCCCCAGCGCCTCAGAA GAGAGGACGCGGCCGCCCCAGGAAGCAGCAGCAAGAACCAACCGGTGAGCCCTCTCCTAAGAGACCCAGGGGAAGACCCAAAGGCAGCAA AAACAAGAGTCCCTCTAAAGCAGCTCAAAAGGTGACCAAGAATATGGCCCAGGTGACCAAAGCCCTGGACAAGGCCCTGAGCACCATGGA CCTGCAGAAGGTCTCCTCAGTGATGGACAGGTTCGAGCAGCAGGTGCAGAACCTGGACGTCCATACATCGGTGATGGAGGACTCCATGAG CTCGGCCACCACCCTGACCACGCCGCAGGAGCAGGTGGACAGCCTCATCATGCAGATCGCCGAGGAGAATGGCCTGGAGGTGCTGGACCA GCTCAGCCAGCTGCCCGAGGGCGCCTCTGCCGTGGGCGAGAGCTCTGTGCGCAGCCAGGAGGACCAGCTGTCACGGAGGTTGGCCGCCTT GAGGAACTAGCCGTGCCCCGCCGGTGTGCACCGCCTCTGCCCCGTGATGTGCTGGAAGGCTCCTGTCCTCTCCCCACCGCGTCTTGCCTT TGTGCTGACCCCGCGGGGCTGCGGCCGGCAGCCACTCTGCGTCTCTCACCTGCCAGGCCTGCGTGGCCTTAGGGTTGTTCCTGTTCTTTT AGGTTGGGCGGTGGGTCTGTGTCCTGGTGTTGAGTTTCTGCAAATTTCTGGGGGTGATTTCTGTGACTCTGGGCCCACAGCGGGGAGGCC AAGAGGGGCCCTGTGGACTTTCACCCAGCACTGTGGGGGCCTTCAGACTCTGGGGCAGCAGACATGCTGCTTCCCATCAGCCAGAGGGGG TCAGGGCTGCCCTGTTGCCAAACAACTCCCTGAGGCCTCTCCGCACCACCTCAGCGGGCAGGAGGTCCCACCATGTGGACAGACATAGCC CAAGGAGGCACCACAGGTCTATGTGTGCTGGGGGATGTCAGGTGCCACCCAACGCTGTCCTGGTGGTATTTACAATGACATCCTCCTCCT CCATCACTCCAGGGGTGGTGTCTCGGCCGCCCCTACCAGCTGGCTGAGCCCCCTGGCCTCCTGCGCTCCCTCACTTCCCTCAGTTCCCAA AGCTGCCCAGTCCATGGGGACAGAACCGTCACTCAGATCCACATTCAAGTGTGCCCACCCTGCAGTCTTCATCCTCACTCAGCTGCTGCC TCTGGAGGTGCCTTTGGCCACATGTGCTGTGCTGTTTGTCTCCTCGACAGGGAGCCTGTCCACCAGCAGGCTGCGGTCCCAGCGGGTGCG TCTGCAGCTCCTCCCCTTGGGCAGCCTGGTTCTCCCGGAGGACCTTTCCTTGGGGCCCTGCTTCATGACGATGCTGCCTGTGTCACCCTC TACCATCTGTAAACAACTGGGTGCCTTCCCCGACCACACCCCAATGCCTTCCCAGCTTGGAAGCCAAGGCAGCTGATGAAGGGAGCTCAG GAGAGCCGTCTTCAGCTGGGCTGGGGTTGGGGCTGCTGTGAGGAAAACCTGCCATTGTGGCCCTGGAGAGTCACCAGCAGCTCTTGGGAA GGACTTGCTGGGAGGCTGAGAGAGGCTTTGGGCACAGCCTGCTGTCTTTTCCATTTCCTAAAGTTTACTTCATTGTCTTGAGGCTTCCAG GTTTTGTTTTTGTTTTTGCCAAAGTAGAAAAGGCAGGTGGTGGGCGGCTGGCAGGGAGTGCGGGTCCCCGCCCCTCTTCAGTCCTGCCCT CCCCTCCTCAGTCCTGCCCACCCCGTGCAGCCCATGCTGAGGCTGCAGTGGTGTCGTGGGTGTTACGTGCAGGAACGTGGAGACCCTGAC GTGGGCTCACTGCGTTTGGTTTTCTTTTCAGAACTTGGGAGCCCCCAGGGAGGGGCTAGTGTTGGTAGGTCCTAGACGTGGTTCCCTCCA GCCTCCCCAAAATCAACCCTGGTGTTGAGAGAACGTCCTTCTGTCCATCGTGGGTAACAGCCTTGGGGAGGGTGCAGAGCTCTGCAGAGC >36825_36825_20_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000541363_CHMP1A_chr16_89713739_ENST00000535997_length(amino acids)=178AA_BP=66 MSARGEGAGQPSTSAQGQPAAPAPQKRGRGRPRKQQQEPTGEPSPKRPRGRPKGSKNKSPSKAAQKVTKNMAQVTKALDKALSTMDLQKV -------------------------------------------------------------- >36825_36825_21_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000541363_CHMP1A_chr16_89713739_ENST00000550102_length(transcript)=1087nt_BP=571nt CAACCCGCGAGAGGAGCCTCTGCGACCTCAAAGCCTCTCTTCCTTCTCCCTCGCTTCCCTCCTCCTCTTGCTACCTCCACCTCCACCGCC ACCTCCACCTCCGGCACCCACCCACCGCCGCCGCCGCCACCGGCAGCGCCTCCTCCTCTCCTCCTCCTCCTCCCCTCTTCTCTTTTTGGC AGCCGCTGGACGTCCGGTGTTGATGGTGGCAGCGGCGGCAGCCTAAGCAACAGCAGCCCTCGCAGCCCGCCAGCTCGCGCTCGCCCCGCC GGCGTCCCCAGCCCTATCACCTCATCTCCCGAAAGGTGCTGGGCAGCTCCGGGGCGGTCGAGGCGAAGCGGCTGCAGCGGCGGTAGCGGC GGCGGGAGGCAGGATGAGCGCACGCGGTGAGGGCGCGGGGCAGCCGTCCACTTCAGCCCAGGGACAACCTGCCGCCCCAGCGCCTCAGAA GAGAGGACGCGGCCGCCCCAGGAAGCAGCAGCAAGAACCAACCGGTGAGCCCTCTCCTAAGAGACCCAGGGGAAGACCCAAAGGCAGCAA AAACAAGAGTCCCTCTAAAGCAGCTCAAAAGGTGACCAAGAATATGGCCCAGGTGACCAAAGCCCTGGACAAGGCCCTGAGCACCATGGA CCTGCAGAAGGTCTCCTCAGTGATGGACAGGTTCGAGCAGCAGGTGCAGAACCTGGACGTCCATACATCGGTGATGGAGGACTCCATGAG CTCGGCCACCACCCTGACCACGCCGCAGGAGCAGGTGGACAGCCTCATCATGCAGATCGCCGAGGAGAATGGCCTGGAGGTGCTGGACCA GCTCAGCCAGCTGCCCGAGGGCGCCTCTGCCGTGGGCGAGAGCTCTGTGCGCAGCCAGGAGGACCAGCTGTCACGGAGGTTGGCCGCCTT GAGGAACTAGCCGTGCCCCGCCGGTGTGCACCGCCTCTGCCCCGTGATGTGCTGGAAGGCTCCTGTCCTCTCCCCACCGCGTCTTGCCTT TGTGCTGACCCCGCGGGGCTGCGGCCGGCAGCCACTCTGCGTCTCTCACCTGCCAGGCCTGCGTGGCCTTAGGGTTGTTCCTGTTCTTTT >36825_36825_21_HMGA2-CHMP1A_HMGA2_chr12_66221867_ENST00000541363_CHMP1A_chr16_89713739_ENST00000550102_length(amino acids)=178AA_BP=66 MSARGEGAGQPSTSAQGQPAAPAPQKRGRGRPRKQQQEPTGEPSPKRPRGRPKGSKNKSPSKAAQKVTKNMAQVTKALDKALSTMDLQKV -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for HMGA2-CHMP1A |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| Hgene | HMGA2 | chr12:66221867 | chr16:89713739 | ENST00000354636 | + | 2 | 4 | 44_63 | 66.0 | 107.0 | E4F1 |
| Hgene | HMGA2 | chr12:66221867 | chr16:89713739 | ENST00000393578 | + | 2 | 4 | 44_63 | 66.0 | 91.0 | E4F1 |
| Hgene | HMGA2 | chr12:66221867 | chr16:89713739 | ENST00000403681 | + | 2 | 5 | 44_63 | 66.0 | 110.0 | E4F1 |
| Hgene | HMGA2 | chr12:66221867 | chr16:89713739 | ENST00000425208 | + | 2 | 4 | 44_63 | 66.0 | 93.0 | E4F1 |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for HMGA2-CHMP1A |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for HMGA2-CHMP1A |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies