
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:HNRNPH3-HNRNPH1 (FusionGDB2 ID:37211) |
Fusion Gene Summary for HNRNPH3-HNRNPH1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: HNRNPH3-HNRNPH1 | Fusion gene ID: 37211 | Hgene | Tgene | Gene symbol | HNRNPH3 | HNRNPH1 | Gene ID | 3189 | 3187 |
| Gene name | heterogeneous nuclear ribonucleoprotein H3 | heterogeneous nuclear ribonucleoprotein H1 | |
| Synonyms | 2H9|HNRPH3 | HNRPH|HNRPH1|hnRNPH | |
| Cytomap | 10q21.3 | 5q35.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | heterogeneous nuclear ribonucleoprotein H3heterogeneous nuclear ribonucleoprotein 2H9hnRNP 2H9hnRNP H3 | heterogeneous nuclear ribonucleoprotein Hepididymis secretory sperm binding proteinheterogeneous nuclear ribonucleoprotein H1 (H) | |
| Modification date | 20200313 | 20200320 | |
| UniProtAcc | P31942 | P31943 | |
| Ensembl transtripts involved in fusion gene | ENST00000469172, ENST00000265866, ENST00000354695, ENST00000441000, | ENST00000329433, ENST00000356731, ENST00000393432, ENST00000442819, ENST00000510411, ENST00000511300, ENST00000524180, | |
| Fusion gene scores | * DoF score | 9 X 7 X 6=378 | 13 X 10 X 5=650 |
| # samples | 10 | 14 | |
| ** MAII score | log2(10/378*10)=-1.91838623444635 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(14/650*10)=-2.21501289097085 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: HNRNPH3 [Title/Abstract] AND HNRNPH1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | HNRNPH1(179046269)-HNRNPH3(70098259), # samples:1 HNRNPH3(70097753)-HNRNPH1(179045324), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | HNRNPH1 | GO:0043484 | regulation of RNA splicing | 16946708 |
| Fusion gene breakpoints across HNRNPH3 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
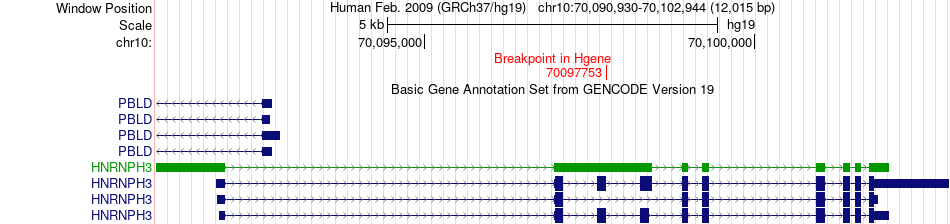 |
| Fusion gene breakpoints across HNRNPH1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | Non-Cancer | SPNT_185 | HNRNPH3 | chr10 | 70097753 | + | HNRNPH1 | chr5 | 179045324 | - |
Top |
Fusion Gene ORF analysis for HNRNPH3-HNRNPH1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000469172 | ENST00000329433 | HNRNPH3 | chr10 | 70097753 | + | HNRNPH1 | chr5 | 179045324 | - |
| 3UTR-3CDS | ENST00000469172 | ENST00000356731 | HNRNPH3 | chr10 | 70097753 | + | HNRNPH1 | chr5 | 179045324 | - |
| 3UTR-3CDS | ENST00000469172 | ENST00000393432 | HNRNPH3 | chr10 | 70097753 | + | HNRNPH1 | chr5 | 179045324 | - |
| 3UTR-3CDS | ENST00000469172 | ENST00000442819 | HNRNPH3 | chr10 | 70097753 | + | HNRNPH1 | chr5 | 179045324 | - |
| 3UTR-3CDS | ENST00000469172 | ENST00000510411 | HNRNPH3 | chr10 | 70097753 | + | HNRNPH1 | chr5 | 179045324 | - |
| 3UTR-intron | ENST00000469172 | ENST00000511300 | HNRNPH3 | chr10 | 70097753 | + | HNRNPH1 | chr5 | 179045324 | - |
| 3UTR-intron | ENST00000469172 | ENST00000524180 | HNRNPH3 | chr10 | 70097753 | + | HNRNPH1 | chr5 | 179045324 | - |
| 5CDS-intron | ENST00000265866 | ENST00000511300 | HNRNPH3 | chr10 | 70097753 | + | HNRNPH1 | chr5 | 179045324 | - |
| 5CDS-intron | ENST00000265866 | ENST00000524180 | HNRNPH3 | chr10 | 70097753 | + | HNRNPH1 | chr5 | 179045324 | - |
| 5CDS-intron | ENST00000354695 | ENST00000511300 | HNRNPH3 | chr10 | 70097753 | + | HNRNPH1 | chr5 | 179045324 | - |
| 5CDS-intron | ENST00000354695 | ENST00000524180 | HNRNPH3 | chr10 | 70097753 | + | HNRNPH1 | chr5 | 179045324 | - |
| In-frame | ENST00000265866 | ENST00000329433 | HNRNPH3 | chr10 | 70097753 | + | HNRNPH1 | chr5 | 179045324 | - |
| In-frame | ENST00000265866 | ENST00000356731 | HNRNPH3 | chr10 | 70097753 | + | HNRNPH1 | chr5 | 179045324 | - |
| In-frame | ENST00000265866 | ENST00000393432 | HNRNPH3 | chr10 | 70097753 | + | HNRNPH1 | chr5 | 179045324 | - |
| In-frame | ENST00000265866 | ENST00000442819 | HNRNPH3 | chr10 | 70097753 | + | HNRNPH1 | chr5 | 179045324 | - |
| In-frame | ENST00000265866 | ENST00000510411 | HNRNPH3 | chr10 | 70097753 | + | HNRNPH1 | chr5 | 179045324 | - |
| In-frame | ENST00000354695 | ENST00000329433 | HNRNPH3 | chr10 | 70097753 | + | HNRNPH1 | chr5 | 179045324 | - |
| In-frame | ENST00000354695 | ENST00000356731 | HNRNPH3 | chr10 | 70097753 | + | HNRNPH1 | chr5 | 179045324 | - |
| In-frame | ENST00000354695 | ENST00000393432 | HNRNPH3 | chr10 | 70097753 | + | HNRNPH1 | chr5 | 179045324 | - |
| In-frame | ENST00000354695 | ENST00000442819 | HNRNPH3 | chr10 | 70097753 | + | HNRNPH1 | chr5 | 179045324 | - |
| In-frame | ENST00000354695 | ENST00000510411 | HNRNPH3 | chr10 | 70097753 | + | HNRNPH1 | chr5 | 179045324 | - |
| intron-3CDS | ENST00000441000 | ENST00000329433 | HNRNPH3 | chr10 | 70097753 | + | HNRNPH1 | chr5 | 179045324 | - |
| intron-3CDS | ENST00000441000 | ENST00000356731 | HNRNPH3 | chr10 | 70097753 | + | HNRNPH1 | chr5 | 179045324 | - |
| intron-3CDS | ENST00000441000 | ENST00000393432 | HNRNPH3 | chr10 | 70097753 | + | HNRNPH1 | chr5 | 179045324 | - |
| intron-3CDS | ENST00000441000 | ENST00000442819 | HNRNPH3 | chr10 | 70097753 | + | HNRNPH1 | chr5 | 179045324 | - |
| intron-3CDS | ENST00000441000 | ENST00000510411 | HNRNPH3 | chr10 | 70097753 | + | HNRNPH1 | chr5 | 179045324 | - |
| intron-intron | ENST00000441000 | ENST00000511300 | HNRNPH3 | chr10 | 70097753 | + | HNRNPH1 | chr5 | 179045324 | - |
| intron-intron | ENST00000441000 | ENST00000524180 | HNRNPH3 | chr10 | 70097753 | + | HNRNPH1 | chr5 | 179045324 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000265866 | HNRNPH3 | chr10 | 70097753 | + | ENST00000393432 | HNRNPH1 | chr5 | 179045324 | - | 2012 | 416 | 165 | 1229 | 354 |
| ENST00000265866 | HNRNPH3 | chr10 | 70097753 | + | ENST00000442819 | HNRNPH1 | chr5 | 179045324 | - | 2011 | 416 | 165 | 1229 | 354 |
| ENST00000265866 | HNRNPH3 | chr10 | 70097753 | + | ENST00000356731 | HNRNPH1 | chr5 | 179045324 | - | 2011 | 416 | 165 | 1229 | 354 |
| ENST00000265866 | HNRNPH3 | chr10 | 70097753 | + | ENST00000329433 | HNRNPH1 | chr5 | 179045324 | - | 1959 | 416 | 165 | 1298 | 377 |
| ENST00000265866 | HNRNPH3 | chr10 | 70097753 | + | ENST00000510411 | HNRNPH1 | chr5 | 179045324 | - | 1949 | 416 | 165 | 1169 | 334 |
| ENST00000354695 | HNRNPH3 | chr10 | 70097753 | + | ENST00000393432 | HNRNPH1 | chr5 | 179045324 | - | 1965 | 369 | 118 | 1182 | 354 |
| ENST00000354695 | HNRNPH3 | chr10 | 70097753 | + | ENST00000442819 | HNRNPH1 | chr5 | 179045324 | - | 1964 | 369 | 118 | 1182 | 354 |
| ENST00000354695 | HNRNPH3 | chr10 | 70097753 | + | ENST00000356731 | HNRNPH1 | chr5 | 179045324 | - | 1964 | 369 | 118 | 1182 | 354 |
| ENST00000354695 | HNRNPH3 | chr10 | 70097753 | + | ENST00000329433 | HNRNPH1 | chr5 | 179045324 | - | 1912 | 369 | 118 | 1251 | 377 |
| ENST00000354695 | HNRNPH3 | chr10 | 70097753 | + | ENST00000510411 | HNRNPH1 | chr5 | 179045324 | - | 1902 | 369 | 118 | 1122 | 334 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
Top |
Fusion Genomic Features for HNRNPH3-HNRNPH1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for HNRNPH3-HNRNPH1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr10:179046269/chr5:70098259) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| HNRNPH3 | HNRNPH1 |
| FUNCTION: Involved in the splicing process and participates in early heat shock-induced splicing arrest. Due to their great structural variations the different isoforms may possess different functions in the splicing reaction. | FUNCTION: This protein is a component of the heterogeneous nuclear ribonucleoprotein (hnRNP) complexes which provide the substrate for the processing events that pre-mRNAs undergo before becoming functional, translatable mRNAs in the cytoplasm. Mediates pre-mRNA alternative splicing regulation. Inhibits, together with CUGBP1, insulin receptor (IR) pre-mRNA exon 11 inclusion in myoblast. Binds to the IR RNA. Binds poly(RG). {ECO:0000269|PubMed:11003644, ECO:0000269|PubMed:16946708}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | HNRNPH1 | chr10:70097753 | chr5:179045324 | ENST00000356731 | 3 | 13 | 289_364 | 178 | 130.66666666666666 | Domain | RRM 3 | |
| Tgene | HNRNPH1 | chr10:70097753 | chr5:179045324 | ENST00000393432 | 4 | 14 | 289_364 | 178 | 646.0 | Domain | RRM 3 | |
| Tgene | HNRNPH1 | chr10:70097753 | chr5:179045324 | ENST00000442819 | 4 | 14 | 289_364 | 178 | 655.6666666666666 | Domain | RRM 3 | |
| Tgene | HNRNPH1 | chr10:70097753 | chr5:179045324 | ENST00000356731 | 3 | 13 | 234_433 | 178 | 130.66666666666666 | Region | Note=2 X 16 AA Gly-rich approximate repeats | |
| Tgene | HNRNPH1 | chr10:70097753 | chr5:179045324 | ENST00000356731 | 3 | 13 | 354_392 | 178 | 130.66666666666666 | Region | Note=2 X 19 AA perfect repeats | |
| Tgene | HNRNPH1 | chr10:70097753 | chr5:179045324 | ENST00000393432 | 4 | 14 | 234_433 | 178 | 646.0 | Region | Note=2 X 16 AA Gly-rich approximate repeats | |
| Tgene | HNRNPH1 | chr10:70097753 | chr5:179045324 | ENST00000393432 | 4 | 14 | 354_392 | 178 | 646.0 | Region | Note=2 X 19 AA perfect repeats | |
| Tgene | HNRNPH1 | chr10:70097753 | chr5:179045324 | ENST00000442819 | 4 | 14 | 234_433 | 178 | 655.6666666666666 | Region | Note=2 X 16 AA Gly-rich approximate repeats | |
| Tgene | HNRNPH1 | chr10:70097753 | chr5:179045324 | ENST00000442819 | 4 | 14 | 354_392 | 178 | 655.6666666666666 | Region | Note=2 X 19 AA perfect repeats | |
| Tgene | HNRNPH1 | chr10:70097753 | chr5:179045324 | ENST00000356731 | 3 | 13 | 234_249 | 178 | 130.66666666666666 | Repeat | Note=1-1 | |
| Tgene | HNRNPH1 | chr10:70097753 | chr5:179045324 | ENST00000356731 | 3 | 13 | 354_372 | 178 | 130.66666666666666 | Repeat | Note=2-1 | |
| Tgene | HNRNPH1 | chr10:70097753 | chr5:179045324 | ENST00000356731 | 3 | 13 | 374_392 | 178 | 130.66666666666666 | Repeat | Note=2-2 | |
| Tgene | HNRNPH1 | chr10:70097753 | chr5:179045324 | ENST00000356731 | 3 | 13 | 418_433 | 178 | 130.66666666666666 | Repeat | Note=1-2 | |
| Tgene | HNRNPH1 | chr10:70097753 | chr5:179045324 | ENST00000393432 | 4 | 14 | 234_249 | 178 | 646.0 | Repeat | Note=1-1 | |
| Tgene | HNRNPH1 | chr10:70097753 | chr5:179045324 | ENST00000393432 | 4 | 14 | 354_372 | 178 | 646.0 | Repeat | Note=2-1 | |
| Tgene | HNRNPH1 | chr10:70097753 | chr5:179045324 | ENST00000393432 | 4 | 14 | 374_392 | 178 | 646.0 | Repeat | Note=2-2 | |
| Tgene | HNRNPH1 | chr10:70097753 | chr5:179045324 | ENST00000393432 | 4 | 14 | 418_433 | 178 | 646.0 | Repeat | Note=1-2 | |
| Tgene | HNRNPH1 | chr10:70097753 | chr5:179045324 | ENST00000442819 | 4 | 14 | 234_249 | 178 | 655.6666666666666 | Repeat | Note=1-1 | |
| Tgene | HNRNPH1 | chr10:70097753 | chr5:179045324 | ENST00000442819 | 4 | 14 | 354_372 | 178 | 655.6666666666666 | Repeat | Note=2-1 | |
| Tgene | HNRNPH1 | chr10:70097753 | chr5:179045324 | ENST00000442819 | 4 | 14 | 374_392 | 178 | 655.6666666666666 | Repeat | Note=2-2 | |
| Tgene | HNRNPH1 | chr10:70097753 | chr5:179045324 | ENST00000442819 | 4 | 14 | 418_433 | 178 | 655.6666666666666 | Repeat | Note=1-2 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | HNRNPH3 | chr10:70097753 | chr5:179045324 | ENST00000265866 | + | 3 | 10 | 108_344 | 83 | 347.0 | Compositional bias | Note=Gly-rich |
| Hgene | HNRNPH3 | chr10:70097753 | chr5:179045324 | ENST00000354695 | + | 3 | 10 | 108_344 | 83 | 332.0 | Compositional bias | Note=Gly-rich |
| Hgene | HNRNPH3 | chr10:70097753 | chr5:179045324 | ENST00000265866 | + | 3 | 10 | 16_93 | 83 | 347.0 | Domain | RRM 1 |
| Hgene | HNRNPH3 | chr10:70097753 | chr5:179045324 | ENST00000265866 | + | 3 | 10 | 195_270 | 83 | 347.0 | Domain | RRM 2 |
| Hgene | HNRNPH3 | chr10:70097753 | chr5:179045324 | ENST00000354695 | + | 3 | 10 | 16_93 | 83 | 332.0 | Domain | RRM 1 |
| Hgene | HNRNPH3 | chr10:70097753 | chr5:179045324 | ENST00000354695 | + | 3 | 10 | 195_270 | 83 | 332.0 | Domain | RRM 2 |
| Tgene | HNRNPH1 | chr10:70097753 | chr5:179045324 | ENST00000356731 | 3 | 13 | 111_188 | 178 | 130.66666666666666 | Domain | RRM 2 | |
| Tgene | HNRNPH1 | chr10:70097753 | chr5:179045324 | ENST00000356731 | 3 | 13 | 11_90 | 178 | 130.66666666666666 | Domain | RRM 1 | |
| Tgene | HNRNPH1 | chr10:70097753 | chr5:179045324 | ENST00000393432 | 4 | 14 | 111_188 | 178 | 646.0 | Domain | RRM 2 | |
| Tgene | HNRNPH1 | chr10:70097753 | chr5:179045324 | ENST00000393432 | 4 | 14 | 11_90 | 178 | 646.0 | Domain | RRM 1 | |
| Tgene | HNRNPH1 | chr10:70097753 | chr5:179045324 | ENST00000442819 | 4 | 14 | 111_188 | 178 | 655.6666666666666 | Domain | RRM 2 | |
| Tgene | HNRNPH1 | chr10:70097753 | chr5:179045324 | ENST00000442819 | 4 | 14 | 11_90 | 178 | 655.6666666666666 | Domain | RRM 1 |
Top |
Fusion Gene Sequence for HNRNPH3-HNRNPH1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >37211_37211_1_HNRNPH3-HNRNPH1_HNRNPH3_chr10_70097753_ENST00000265866_HNRNPH1_chr5_179045324_ENST00000329433_length(transcript)=1959nt_BP=416nt TGCGCAGCTCCCTAAGCGGTTGTCACCGCTGGAGACGGTTGGGAGAACCGTTGTGGCGAGCGCTACACGAGGCAAACGACTTCTCCCTTC TTTGAACTGGACCCCGCGAGCACCAGAGTCGGCGTAACTATCGCCTGACAGGCATTTAAATCAAACGGTATTGAGATGGATTGGGTTATG AAACATAATGGTCCAAATGACGCTAGTGATGGGACAGTACGACTTCGTGGACTACCATTTGGTTGCAGCAAAGAGGAAATAGTTCAGTTC TTTCAAGGGTTGGAAATCGTGCCAAATGGGATAACATTGACGATGGACTACCAGGGGAGAAGCACAGGGGAGGCCTTCGTGCAGTTTGCT TCAAAGGAGATAGCAGAAAATGCTCTGGGGAAACACAAGGAAAGAATAGGGCACAGGTATATTGAAATCTTTAAGAGCAGTAGAGCTGAA GTTAGAACTCATTATGATCCACCACGAAAGCTTATGGCCATGCAGCGGCCAGGTCCTTATGACAGACCTGGGGCTGGTAGAGGGTATAAC AGCATTGGCAGAGGAGCTGGCTTTGAGAGGATGAGGCGTGGTGCTTATGGTGGAGGCTATGGAGGCTATGATGATTACAATGGCTATAAT GATGGCTATGGATTTGGGTCAGATAGATTTGGAAGAGACCTCAATTACTGTTTTTCAGGAATGTCTGATCACAGATACGGGGATGGTGGC TCTACTTTCCAGAGCACAACAGGACACTGTGTACACATGCGGGGATTACCTTACAGAGCTACTGAGAATGACATTTATAATTTTTTTTCA CCGCTCAACCCTGTGAGAGTACACATTGAAATTGGTCCTGATGGCAGAGTAACTGGTGAAGCAGATGTCGAGTTCGCAACTCATGAAGAT GCTGTGGCAGCTATGTCAAAAGACAAAGCAAATATGCAACACAGATATGTAGAACTCTTCTTGAATTCTACAGCAGGAGCAAGCGGTGGT GCTTACGAACACAGATATGTAGAACTCTTCTTGAATTCTACAGCAGGAGCAAGCGGTGGTGCTTATGGTAGCCAAATGATGGGAGGCATG GGCTTGTCAAACCAGTCCAGCTACGGGGGCCCAGCCAGCCAGCAGCTGAGTGGGGGTTACGGAGGCGGCTACGGTGGCCAGAGCAGCATG AGTGGATACGGTAACCAAGGAGCAGTGAACAGCAGCTACTACAGTAGTGGAAGCCGTGCATCTATGGGCGTGAACGGAATGGGAGGGTTG TCTAGCATGTCCAGTATGAGTGGTGGATGGGGAATGTAATTGATCGATCCTGATCACTGACTCTTGGTCAACCTTTTTTTTTTTTTTTTT TTTTTCTTTAAGAAAACTTCAGTTTAACAGTTTCTGCAATACAAGCTTGTGATTTATGCTTACTCTAAGTGGAAATCAGGATTGTTATGA AGACTTAAGGCCCAGTATTTTTGAATACAATACTCATCTAGGATGTAACAGTGAAGCTGAGTAAACTATAACTGTTAAACTTAAGTTCCA GCTTTTCTCAAGTTAGTTATAGGATGTACTTAAGCAGTAAGCGTATTTAGGTAAAAGCAGTTGAATTATGTTAAATGTTGCCCTTTGCCA CGTTAAATTGAACACTGTTTTGGATGCATGTTGAAAGACATGCTTTTATTTTTTTGTAAAACAATATAGGAGCTGTGTCTACTATTAAAA GTGAAACATTTTGGCATGTTTGTTAATTCTAGTTTCATTTAATAACCTGTAAGGCACGTAAGTTTAAGCTTTTTTTTTTTTTAAGTTAAT GGGAAAAATTTGAGACGCAATACCAATACTTAGGATTTTGGTCTTGGTGTTTGTATGAAATTCTGAGGCCTTGATTTAAATCTTTCATTG >37211_37211_1_HNRNPH3-HNRNPH1_HNRNPH3_chr10_70097753_ENST00000265866_HNRNPH1_chr5_179045324_ENST00000329433_length(amino acids)=377AA_BP=7 MDWVMKHNGPNDASDGTVRLRGLPFGCSKEEIVQFFQGLEIVPNGITLTMDYQGRSTGEAFVQFASKEIAENALGKHKERIGHRYIEIFK SSRAEVRTHYDPPRKLMAMQRPGPYDRPGAGRGYNSIGRGAGFERMRRGAYGGGYGGYDDYNGYNDGYGFGSDRFGRDLNYCFSGMSDHR YGDGGSTFQSTTGHCVHMRGLPYRATENDIYNFFSPLNPVRVHIEIGPDGRVTGEADVEFATHEDAVAAMSKDKANMQHRYVELFLNSTA GASGGAYEHRYVELFLNSTAGASGGAYGSQMMGGMGLSNQSSYGGPASQQLSGGYGGGYGGQSSMSGYGNQGAVNSSYYSSGSRASMGVN -------------------------------------------------------------- >37211_37211_2_HNRNPH3-HNRNPH1_HNRNPH3_chr10_70097753_ENST00000265866_HNRNPH1_chr5_179045324_ENST00000356731_length(transcript)=2011nt_BP=416nt TGCGCAGCTCCCTAAGCGGTTGTCACCGCTGGAGACGGTTGGGAGAACCGTTGTGGCGAGCGCTACACGAGGCAAACGACTTCTCCCTTC TTTGAACTGGACCCCGCGAGCACCAGAGTCGGCGTAACTATCGCCTGACAGGCATTTAAATCAAACGGTATTGAGATGGATTGGGTTATG AAACATAATGGTCCAAATGACGCTAGTGATGGGACAGTACGACTTCGTGGACTACCATTTGGTTGCAGCAAAGAGGAAATAGTTCAGTTC TTTCAAGGGTTGGAAATCGTGCCAAATGGGATAACATTGACGATGGACTACCAGGGGAGAAGCACAGGGGAGGCCTTCGTGCAGTTTGCT TCAAAGGAGATAGCAGAAAATGCTCTGGGGAAACACAAGGAAAGAATAGGGCACAGGTATATTGAAATCTTTAAGAGCAGTAGAGCTGAA GTTAGAACTCATTATGATCCACCACGAAAGCTTATGGCCATGCAGCGGCCAGGTCCTTATGACAGACCTGGGGCTGGTAGAGGGTATAAC AGCATTGGCAGAGGAGCTGGCTTTGAGAGGATGAGGCGTGGTGCTTATGGTGGAGGCTATGGAGGCTATGATGATTACAATGGCTATAAT GATGGCTATGGATTTGGGTCAGATAGATTTGGAAGAGACCTCAATTACTGTTTTTCAGGAATGTCTGATCACAGATACGGGGATGGTGGC TCTACTTTCCAGAGCACAACAGGACACTGTGTACACATGCGGGGATTACCTTACAGAGCTACTGAGAATGACATTTATAATTTTTTTTCA CCGCTCAACCCTGTGAGAGTACACATTGAAATTGGTCCTGATGGCAGAGTAACTGGTGAAGCAGATGTCGAGTTCGCAACTCATGAAGAT GCTGTGGCAGCTATGTCAAAAGACAAAGCAAATATGCAACACAGATATGTAGAACTCTTCTTGAATTCTACAGCAGGAGCAAGCGGTGGT GCTTACGAACACAGATATGTAGAACTCTTCTTGAATTCTACAGCAGGAGCAAGCGGTGGTGCTTATGGTAGCCAAATGATGGGAGGCATG GGCTTGTCAAACCAGTCCAGCTACGGGGGCCCAGCCAGCCAGCAGCTGAGTGGGGGTTACGGAGGCGGCTACGGTGGCCAGAGCAGCATG AGTGGATACGACCAAGTTTTACAGGAAAACTCCAGTGATTTTCAATCAAACATTGCATAGGTAACCAAGGAGCAGTGAACAGCAGCTACT ACAGTAGTGGAAGCCGTGCATCTATGGGCGTGAACGGAATGGGAGGGTTGTCTAGCATGTCCAGTATGAGTGGTGGATGGGGAATGTAAT TGATCGATCCTGATCACTGACTCTTGGTCAACCTTTTTTTTTTTTTTTTTTTTTTCTTTAAGAAAACTTCAGTTTAACAGTTTCTGCAAT ACAAGCTTGTGATTTATGCTTACTCTAAGTGGAAATCAGGATTGTTATGAAGACTTAAGGCCCAGTATTTTTGAATACAATACTCATCTA GGATGTAACAGTGAAGCTGAGTAAACTATAACTGTTAAACTTAAGTTCCAGCTTTTCTCAAGTTAGTTATAGGATGTACTTAAGCAGTAA GCGTATTTAGGTAAAAGCAGTTGAATTATGTTAAATGTTGCCCTTTGCCACGTTAAATTGAACACTGTTTTGGATGCATGTTGAAAGACA TGCTTTTATTTTTTTGTAAAACAATATAGGAGCTGTGTCTACTATTAAAAGTGAAACATTTTGGCATGTTTGTTAATTCTAGTTTCATTT AATAACCTGTAAGGCACGTAAGTTTAAGCTTTTTTTTTTTTTAAGTTAATGGGAAAAATTTGAGACGCAATACCAATACTTAGGATTTTG GTCTTGGTGTTTGTATGAAATTCTGAGGCCTTGATTTAAATCTTTCATTGTATTGTGATTTCCTTTTAGGTATATTGCGCTAAGTGAAAC >37211_37211_2_HNRNPH3-HNRNPH1_HNRNPH3_chr10_70097753_ENST00000265866_HNRNPH1_chr5_179045324_ENST00000356731_length(amino acids)=354AA_BP=7 MDWVMKHNGPNDASDGTVRLRGLPFGCSKEEIVQFFQGLEIVPNGITLTMDYQGRSTGEAFVQFASKEIAENALGKHKERIGHRYIEIFK SSRAEVRTHYDPPRKLMAMQRPGPYDRPGAGRGYNSIGRGAGFERMRRGAYGGGYGGYDDYNGYNDGYGFGSDRFGRDLNYCFSGMSDHR YGDGGSTFQSTTGHCVHMRGLPYRATENDIYNFFSPLNPVRVHIEIGPDGRVTGEADVEFATHEDAVAAMSKDKANMQHRYVELFLNSTA -------------------------------------------------------------- >37211_37211_3_HNRNPH3-HNRNPH1_HNRNPH3_chr10_70097753_ENST00000265866_HNRNPH1_chr5_179045324_ENST00000393432_length(transcript)=2012nt_BP=416nt TGCGCAGCTCCCTAAGCGGTTGTCACCGCTGGAGACGGTTGGGAGAACCGTTGTGGCGAGCGCTACACGAGGCAAACGACTTCTCCCTTC TTTGAACTGGACCCCGCGAGCACCAGAGTCGGCGTAACTATCGCCTGACAGGCATTTAAATCAAACGGTATTGAGATGGATTGGGTTATG AAACATAATGGTCCAAATGACGCTAGTGATGGGACAGTACGACTTCGTGGACTACCATTTGGTTGCAGCAAAGAGGAAATAGTTCAGTTC TTTCAAGGGTTGGAAATCGTGCCAAATGGGATAACATTGACGATGGACTACCAGGGGAGAAGCACAGGGGAGGCCTTCGTGCAGTTTGCT TCAAAGGAGATAGCAGAAAATGCTCTGGGGAAACACAAGGAAAGAATAGGGCACAGGTATATTGAAATCTTTAAGAGCAGTAGAGCTGAA GTTAGAACTCATTATGATCCACCACGAAAGCTTATGGCCATGCAGCGGCCAGGTCCTTATGACAGACCTGGGGCTGGTAGAGGGTATAAC AGCATTGGCAGAGGAGCTGGCTTTGAGAGGATGAGGCGTGGTGCTTATGGTGGAGGCTATGGAGGCTATGATGATTACAATGGCTATAAT GATGGCTATGGATTTGGGTCAGATAGATTTGGAAGAGACCTCAATTACTGTTTTTCAGGAATGTCTGATCACAGATACGGGGATGGTGGC TCTACTTTCCAGAGCACAACAGGACACTGTGTACACATGCGGGGATTACCTTACAGAGCTACTGAGAATGACATTTATAATTTTTTTTCA CCGCTCAACCCTGTGAGAGTACACATTGAAATTGGTCCTGATGGCAGAGTAACTGGTGAAGCAGATGTCGAGTTCGCAACTCATGAAGAT GCTGTGGCAGCTATGTCAAAAGACAAAGCAAATATGCAACACAGATATGTAGAACTCTTCTTGAATTCTACAGCAGGAGCAAGCGGTGGT GCTTACGAACACAGATATGTAGAACTCTTCTTGAATTCTACAGCAGGAGCAAGCGGTGGTGCTTATGGTAGCCAAATGATGGGAGGCATG GGCTTGTCAAACCAGTCCAGCTACGGGGGCCCAGCCAGCCAGCAGCTGAGTGGGGGTTACGGAGGCGGCTACGGTGGCCAGAGCAGCATG AGTGGATACGACCAAGTTTTACAGGAAAACTCCAGTGATTTTCAATCAAACATTGCATAGGTAACCAAGGAGCAGTGAACAGCAGCTACT ACAGTAGTGGAAGCCGTGCATCTATGGGCGTGAACGGAATGGGAGGGTTGTCTAGCATGTCCAGTATGAGTGGTGGATGGGGAATGTAAT TGATCGATCCTGATCACTGACTCTTGGTCAACCTTTTTTTTTTTTTTTTTTTTTTCTTTAAGAAAACTTCAGTTTAACAGTTTCTGCAAT ACAAGCTTGTGATTTATGCTTACTCTAAGTGGAAATCAGGATTGTTATGAAGACTTAAGGCCCAGTATTTTTGAATACAATACTCATCTA GGATGTAACAGTGAAGCTGAGTAAACTATAACTGTTAAACTTAAGTTCCAGCTTTTCTCAAGTTAGTTATAGGATGTACTTAAGCAGTAA GCGTATTTAGGTAAAAGCAGTTGAATTATGTTAAATGTTGCCCTTTGCCACGTTAAATTGAACACTGTTTTGGATGCATGTTGAAAGACA TGCTTTTATTTTTTTGTAAAACAATATAGGAGCTGTGTCTACTATTAAAAGTGAAACATTTTGGCATGTTTGTTAATTCTAGTTTCATTT AATAACCTGTAAGGCACGTAAGTTTAAGCTTTTTTTTTTTTTAAGTTAATGGGAAAAATTTGAGACGCAATACCAATACTTAGGATTTTG GTCTTGGTGTTTGTATGAAATTCTGAGGCCTTGATTTAAATCTTTCATTGTATTGTGATTTCCTTTTAGGTATATTGCGCTAAGTGAAAC >37211_37211_3_HNRNPH3-HNRNPH1_HNRNPH3_chr10_70097753_ENST00000265866_HNRNPH1_chr5_179045324_ENST00000393432_length(amino acids)=354AA_BP=7 MDWVMKHNGPNDASDGTVRLRGLPFGCSKEEIVQFFQGLEIVPNGITLTMDYQGRSTGEAFVQFASKEIAENALGKHKERIGHRYIEIFK SSRAEVRTHYDPPRKLMAMQRPGPYDRPGAGRGYNSIGRGAGFERMRRGAYGGGYGGYDDYNGYNDGYGFGSDRFGRDLNYCFSGMSDHR YGDGGSTFQSTTGHCVHMRGLPYRATENDIYNFFSPLNPVRVHIEIGPDGRVTGEADVEFATHEDAVAAMSKDKANMQHRYVELFLNSTA -------------------------------------------------------------- >37211_37211_4_HNRNPH3-HNRNPH1_HNRNPH3_chr10_70097753_ENST00000265866_HNRNPH1_chr5_179045324_ENST00000442819_length(transcript)=2011nt_BP=416nt TGCGCAGCTCCCTAAGCGGTTGTCACCGCTGGAGACGGTTGGGAGAACCGTTGTGGCGAGCGCTACACGAGGCAAACGACTTCTCCCTTC TTTGAACTGGACCCCGCGAGCACCAGAGTCGGCGTAACTATCGCCTGACAGGCATTTAAATCAAACGGTATTGAGATGGATTGGGTTATG AAACATAATGGTCCAAATGACGCTAGTGATGGGACAGTACGACTTCGTGGACTACCATTTGGTTGCAGCAAAGAGGAAATAGTTCAGTTC TTTCAAGGGTTGGAAATCGTGCCAAATGGGATAACATTGACGATGGACTACCAGGGGAGAAGCACAGGGGAGGCCTTCGTGCAGTTTGCT TCAAAGGAGATAGCAGAAAATGCTCTGGGGAAACACAAGGAAAGAATAGGGCACAGGTATATTGAAATCTTTAAGAGCAGTAGAGCTGAA GTTAGAACTCATTATGATCCACCACGAAAGCTTATGGCCATGCAGCGGCCAGGTCCTTATGACAGACCTGGGGCTGGTAGAGGGTATAAC AGCATTGGCAGAGGAGCTGGCTTTGAGAGGATGAGGCGTGGTGCTTATGGTGGAGGCTATGGAGGCTATGATGATTACAATGGCTATAAT GATGGCTATGGATTTGGGTCAGATAGATTTGGAAGAGACCTCAATTACTGTTTTTCAGGAATGTCTGATCACAGATACGGGGATGGTGGC TCTACTTTCCAGAGCACAACAGGACACTGTGTACACATGCGGGGATTACCTTACAGAGCTACTGAGAATGACATTTATAATTTTTTTTCA CCGCTCAACCCTGTGAGAGTACACATTGAAATTGGTCCTGATGGCAGAGTAACTGGTGAAGCAGATGTCGAGTTCGCAACTCATGAAGAT GCTGTGGCAGCTATGTCAAAAGACAAAGCAAATATGCAACACAGATATGTAGAACTCTTCTTGAATTCTACAGCAGGAGCAAGCGGTGGT GCTTACGAACACAGATATGTAGAACTCTTCTTGAATTCTACAGCAGGAGCAAGCGGTGGTGCTTATGGTAGCCAAATGATGGGAGGCATG GGCTTGTCAAACCAGTCCAGCTACGGGGGCCCAGCCAGCCAGCAGCTGAGTGGGGGTTACGGAGGCGGCTACGGTGGCCAGAGCAGCATG AGTGGATACGACCAAGTTTTACAGGAAAACTCCAGTGATTTTCAATCAAACATTGCATAGGTAACCAAGGAGCAGTGAACAGCAGCTACT ACAGTAGTGGAAGCCGTGCATCTATGGGCGTGAACGGAATGGGAGGGTTGTCTAGCATGTCCAGTATGAGTGGTGGATGGGGAATGTAAT TGATCGATCCTGATCACTGACTCTTGGTCAACCTTTTTTTTTTTTTTTTTTTTTTCTTTAAGAAAACTTCAGTTTAACAGTTTCTGCAAT ACAAGCTTGTGATTTATGCTTACTCTAAGTGGAAATCAGGATTGTTATGAAGACTTAAGGCCCAGTATTTTTGAATACAATACTCATCTA GGATGTAACAGTGAAGCTGAGTAAACTATAACTGTTAAACTTAAGTTCCAGCTTTTCTCAAGTTAGTTATAGGATGTACTTAAGCAGTAA GCGTATTTAGGTAAAAGCAGTTGAATTATGTTAAATGTTGCCCTTTGCCACGTTAAATTGAACACTGTTTTGGATGCATGTTGAAAGACA TGCTTTTATTTTTTTGTAAAACAATATAGGAGCTGTGTCTACTATTAAAAGTGAAACATTTTGGCATGTTTGTTAATTCTAGTTTCATTT AATAACCTGTAAGGCACGTAAGTTTAAGCTTTTTTTTTTTTTAAGTTAATGGGAAAAATTTGAGACGCAATACCAATACTTAGGATTTTG GTCTTGGTGTTTGTATGAAATTCTGAGGCCTTGATTTAAATCTTTCATTGTATTGTGATTTCCTTTTAGGTATATTGCGCTAAGTGAAAC >37211_37211_4_HNRNPH3-HNRNPH1_HNRNPH3_chr10_70097753_ENST00000265866_HNRNPH1_chr5_179045324_ENST00000442819_length(amino acids)=354AA_BP=7 MDWVMKHNGPNDASDGTVRLRGLPFGCSKEEIVQFFQGLEIVPNGITLTMDYQGRSTGEAFVQFASKEIAENALGKHKERIGHRYIEIFK SSRAEVRTHYDPPRKLMAMQRPGPYDRPGAGRGYNSIGRGAGFERMRRGAYGGGYGGYDDYNGYNDGYGFGSDRFGRDLNYCFSGMSDHR YGDGGSTFQSTTGHCVHMRGLPYRATENDIYNFFSPLNPVRVHIEIGPDGRVTGEADVEFATHEDAVAAMSKDKANMQHRYVELFLNSTA -------------------------------------------------------------- >37211_37211_5_HNRNPH3-HNRNPH1_HNRNPH3_chr10_70097753_ENST00000265866_HNRNPH1_chr5_179045324_ENST00000510411_length(transcript)=1949nt_BP=416nt TGCGCAGCTCCCTAAGCGGTTGTCACCGCTGGAGACGGTTGGGAGAACCGTTGTGGCGAGCGCTACACGAGGCAAACGACTTCTCCCTTC TTTGAACTGGACCCCGCGAGCACCAGAGTCGGCGTAACTATCGCCTGACAGGCATTTAAATCAAACGGTATTGAGATGGATTGGGTTATG AAACATAATGGTCCAAATGACGCTAGTGATGGGACAGTACGACTTCGTGGACTACCATTTGGTTGCAGCAAAGAGGAAATAGTTCAGTTC TTTCAAGGGTTGGAAATCGTGCCAAATGGGATAACATTGACGATGGACTACCAGGGGAGAAGCACAGGGGAGGCCTTCGTGCAGTTTGCT TCAAAGGAGATAGCAGAAAATGCTCTGGGGAAACACAAGGAAAGAATAGGGCACAGGTATATTGAAATCTTTAAGAGCAGTAGAGCTGAA GTTAGAACTCATTATGATCCACCACGAAAGCTTATGGCCATGCAGCGGCCAGGTCCTTATGACAGACCTGGGGCTGGTAGAGGGTATAAC AGCATTGGCAGAGGAGCTGGCTTTGAGAGGATGAGGCGTGGTGCTTATGGTGGAGGCTATGGAGGCTATGATGATTACAATGGCTATAAT GATGGCTATGGATTTGGGTCAGATAGATTTGGAAGAGACCTCAATTACTGTTTTTCAGGAATGTCTGATCACAGATACGGGGATGGTGGC TCTACTTTCCAGAGCACAACAGGACACTGTGTACACATGCGGGGATTACCTTACAGAGCTACTGAGAATGACATTTATAATTTTTTTTCA CCGCTCAACCCTGTGAGAGTACACATTGAAATTGGTCCTGATGGCAGAGTAACTGGTGAAGCAGATGTCGAGTTCGCAACTCATGAAGAT GCTGTGGCAGCTATGTCAAAAGACAAAGCAAATATGCAACACAGATATGTAGAACTCTTCTTGAATTCTACAGCAGGAGCAAGCGGTGGT GCTTACGGTAGCCAAATGCTAGGAGGCATGGGTTTGTCAAACCAGTCCAGCTACGGGGGCCCAGCCAGCCAGCAGCTGAGTGGGGGTTAC GGAGGCGGCTACGGTGGCCAGAGCAGCATGAGTGGATACGACCAAGTTTTACAGGAAAACTCCAGTGATTTTCAATCAAACATTGCATAG GTAACCAAGGAGCAGTGAACAGCAGCTACTACAGTAGTGGAAGCCGTGCATCTATGGGCGTGAACGGAATGGGAGGGTTGTCTAGCATGT CCAGTATGAGTGGTGGATGGGGAATGTAATTGATCGATCCTGATCACTGACTCTTGGTCAACCTTTTTTTTTTTTTTTTTTTTTTCTTTA AGAAAACTTCAGTTTAACAGTTTCTGCAATACAAGCTTGTGATTTATGCTTACTCTAAGTGGAAATCAGGATTGTTATGAAGACTTAAGG CCCAGTATTTTTGAATACAATACTCATCTAGGATGTAACAGTGAAGCTGAGTAAACTATAACTGTTAAACTTAAGTTCCAGCTTTTCTCA AGTTAGTTATAGGATGTACTTAAGCAGTAAGCGTATTTAGGTAAAAGCAGTTGAATTATGTTAAATGTTGCCCTTTGCCACGTTAAATTG AACACTGTTTTGGATGCATGTTGAAAGACATGCTTTTATTTTTTTGTAAAACAATATAGGAGCTGTGTCTACTATTAAAAGTGAAACATT TTGGCATGTTTGTTAATTCTAGTTTCATTTAATAACCTGTAAGGCACGTAAGTTTAAGCTTTTTTTTTTTTTAAGTTAATGGGAAAAATT TGAGACGCAATACCAATACTTAGGATTTTGGTCTTGGTGTTTGTATGAAATTCTGAGGCCTTGATTTAAATCTTTCATTGTATTGTGATT >37211_37211_5_HNRNPH3-HNRNPH1_HNRNPH3_chr10_70097753_ENST00000265866_HNRNPH1_chr5_179045324_ENST00000510411_length(amino acids)=334AA_BP=7 MDWVMKHNGPNDASDGTVRLRGLPFGCSKEEIVQFFQGLEIVPNGITLTMDYQGRSTGEAFVQFASKEIAENALGKHKERIGHRYIEIFK SSRAEVRTHYDPPRKLMAMQRPGPYDRPGAGRGYNSIGRGAGFERMRRGAYGGGYGGYDDYNGYNDGYGFGSDRFGRDLNYCFSGMSDHR YGDGGSTFQSTTGHCVHMRGLPYRATENDIYNFFSPLNPVRVHIEIGPDGRVTGEADVEFATHEDAVAAMSKDKANMQHRYVELFLNSTA -------------------------------------------------------------- >37211_37211_6_HNRNPH3-HNRNPH1_HNRNPH3_chr10_70097753_ENST00000354695_HNRNPH1_chr5_179045324_ENST00000329433_length(transcript)=1912nt_BP=369nt CCGTTGTGGCGAGCGCTACACGAGGCAAACGACTTCTCCCTTCTTTGAACTGGACCCCGCGAGCACCAGAGTCGGCGTAACTATCGCCTG ACAGGCATTTAAATCAAACGGTATTGAGATGGATTGGGTTATGAAACATAATGGTCCAAATGACGCTAGTGATGGGACAGTACGACTTCG TGGACTACCATTTGGTTGCAGCAAAGAGGAAATAGTTCAGTTCTTTCAAGGGTTGGAAATCGTGCCAAATGGGATAACATTGACGATGGA CTACCAGGGGAGAAGCACAGGGGAGGCCTTCGTGCAGTTTGCTTCAAAGGAGATAGCAGAAAATGCTCTGGGGAAACACAAGGAAAGAAT AGGGCACAGGTATATTGAAATCTTTAAGAGCAGTAGAGCTGAAGTTAGAACTCATTATGATCCACCACGAAAGCTTATGGCCATGCAGCG GCCAGGTCCTTATGACAGACCTGGGGCTGGTAGAGGGTATAACAGCATTGGCAGAGGAGCTGGCTTTGAGAGGATGAGGCGTGGTGCTTA TGGTGGAGGCTATGGAGGCTATGATGATTACAATGGCTATAATGATGGCTATGGATTTGGGTCAGATAGATTTGGAAGAGACCTCAATTA CTGTTTTTCAGGAATGTCTGATCACAGATACGGGGATGGTGGCTCTACTTTCCAGAGCACAACAGGACACTGTGTACACATGCGGGGATT ACCTTACAGAGCTACTGAGAATGACATTTATAATTTTTTTTCACCGCTCAACCCTGTGAGAGTACACATTGAAATTGGTCCTGATGGCAG AGTAACTGGTGAAGCAGATGTCGAGTTCGCAACTCATGAAGATGCTGTGGCAGCTATGTCAAAAGACAAAGCAAATATGCAACACAGATA TGTAGAACTCTTCTTGAATTCTACAGCAGGAGCAAGCGGTGGTGCTTACGAACACAGATATGTAGAACTCTTCTTGAATTCTACAGCAGG AGCAAGCGGTGGTGCTTATGGTAGCCAAATGATGGGAGGCATGGGCTTGTCAAACCAGTCCAGCTACGGGGGCCCAGCCAGCCAGCAGCT GAGTGGGGGTTACGGAGGCGGCTACGGTGGCCAGAGCAGCATGAGTGGATACGGTAACCAAGGAGCAGTGAACAGCAGCTACTACAGTAG TGGAAGCCGTGCATCTATGGGCGTGAACGGAATGGGAGGGTTGTCTAGCATGTCCAGTATGAGTGGTGGATGGGGAATGTAATTGATCGA TCCTGATCACTGACTCTTGGTCAACCTTTTTTTTTTTTTTTTTTTTTTCTTTAAGAAAACTTCAGTTTAACAGTTTCTGCAATACAAGCT TGTGATTTATGCTTACTCTAAGTGGAAATCAGGATTGTTATGAAGACTTAAGGCCCAGTATTTTTGAATACAATACTCATCTAGGATGTA ACAGTGAAGCTGAGTAAACTATAACTGTTAAACTTAAGTTCCAGCTTTTCTCAAGTTAGTTATAGGATGTACTTAAGCAGTAAGCGTATT TAGGTAAAAGCAGTTGAATTATGTTAAATGTTGCCCTTTGCCACGTTAAATTGAACACTGTTTTGGATGCATGTTGAAAGACATGCTTTT ATTTTTTTGTAAAACAATATAGGAGCTGTGTCTACTATTAAAAGTGAAACATTTTGGCATGTTTGTTAATTCTAGTTTCATTTAATAACC TGTAAGGCACGTAAGTTTAAGCTTTTTTTTTTTTTAAGTTAATGGGAAAAATTTGAGACGCAATACCAATACTTAGGATTTTGGTCTTGG TGTTTGTATGAAATTCTGAGGCCTTGATTTAAATCTTTCATTGTATTGTGATTTCCTTTTAGGTATATTGCGCTAAGTGAAACTTGTCAA >37211_37211_6_HNRNPH3-HNRNPH1_HNRNPH3_chr10_70097753_ENST00000354695_HNRNPH1_chr5_179045324_ENST00000329433_length(amino acids)=377AA_BP=7 MDWVMKHNGPNDASDGTVRLRGLPFGCSKEEIVQFFQGLEIVPNGITLTMDYQGRSTGEAFVQFASKEIAENALGKHKERIGHRYIEIFK SSRAEVRTHYDPPRKLMAMQRPGPYDRPGAGRGYNSIGRGAGFERMRRGAYGGGYGGYDDYNGYNDGYGFGSDRFGRDLNYCFSGMSDHR YGDGGSTFQSTTGHCVHMRGLPYRATENDIYNFFSPLNPVRVHIEIGPDGRVTGEADVEFATHEDAVAAMSKDKANMQHRYVELFLNSTA GASGGAYEHRYVELFLNSTAGASGGAYGSQMMGGMGLSNQSSYGGPASQQLSGGYGGGYGGQSSMSGYGNQGAVNSSYYSSGSRASMGVN -------------------------------------------------------------- >37211_37211_7_HNRNPH3-HNRNPH1_HNRNPH3_chr10_70097753_ENST00000354695_HNRNPH1_chr5_179045324_ENST00000356731_length(transcript)=1964nt_BP=369nt CCGTTGTGGCGAGCGCTACACGAGGCAAACGACTTCTCCCTTCTTTGAACTGGACCCCGCGAGCACCAGAGTCGGCGTAACTATCGCCTG ACAGGCATTTAAATCAAACGGTATTGAGATGGATTGGGTTATGAAACATAATGGTCCAAATGACGCTAGTGATGGGACAGTACGACTTCG TGGACTACCATTTGGTTGCAGCAAAGAGGAAATAGTTCAGTTCTTTCAAGGGTTGGAAATCGTGCCAAATGGGATAACATTGACGATGGA CTACCAGGGGAGAAGCACAGGGGAGGCCTTCGTGCAGTTTGCTTCAAAGGAGATAGCAGAAAATGCTCTGGGGAAACACAAGGAAAGAAT AGGGCACAGGTATATTGAAATCTTTAAGAGCAGTAGAGCTGAAGTTAGAACTCATTATGATCCACCACGAAAGCTTATGGCCATGCAGCG GCCAGGTCCTTATGACAGACCTGGGGCTGGTAGAGGGTATAACAGCATTGGCAGAGGAGCTGGCTTTGAGAGGATGAGGCGTGGTGCTTA TGGTGGAGGCTATGGAGGCTATGATGATTACAATGGCTATAATGATGGCTATGGATTTGGGTCAGATAGATTTGGAAGAGACCTCAATTA CTGTTTTTCAGGAATGTCTGATCACAGATACGGGGATGGTGGCTCTACTTTCCAGAGCACAACAGGACACTGTGTACACATGCGGGGATT ACCTTACAGAGCTACTGAGAATGACATTTATAATTTTTTTTCACCGCTCAACCCTGTGAGAGTACACATTGAAATTGGTCCTGATGGCAG AGTAACTGGTGAAGCAGATGTCGAGTTCGCAACTCATGAAGATGCTGTGGCAGCTATGTCAAAAGACAAAGCAAATATGCAACACAGATA TGTAGAACTCTTCTTGAATTCTACAGCAGGAGCAAGCGGTGGTGCTTACGAACACAGATATGTAGAACTCTTCTTGAATTCTACAGCAGG AGCAAGCGGTGGTGCTTATGGTAGCCAAATGATGGGAGGCATGGGCTTGTCAAACCAGTCCAGCTACGGGGGCCCAGCCAGCCAGCAGCT GAGTGGGGGTTACGGAGGCGGCTACGGTGGCCAGAGCAGCATGAGTGGATACGACCAAGTTTTACAGGAAAACTCCAGTGATTTTCAATC AAACATTGCATAGGTAACCAAGGAGCAGTGAACAGCAGCTACTACAGTAGTGGAAGCCGTGCATCTATGGGCGTGAACGGAATGGGAGGG TTGTCTAGCATGTCCAGTATGAGTGGTGGATGGGGAATGTAATTGATCGATCCTGATCACTGACTCTTGGTCAACCTTTTTTTTTTTTTT TTTTTTTTCTTTAAGAAAACTTCAGTTTAACAGTTTCTGCAATACAAGCTTGTGATTTATGCTTACTCTAAGTGGAAATCAGGATTGTTA TGAAGACTTAAGGCCCAGTATTTTTGAATACAATACTCATCTAGGATGTAACAGTGAAGCTGAGTAAACTATAACTGTTAAACTTAAGTT CCAGCTTTTCTCAAGTTAGTTATAGGATGTACTTAAGCAGTAAGCGTATTTAGGTAAAAGCAGTTGAATTATGTTAAATGTTGCCCTTTG CCACGTTAAATTGAACACTGTTTTGGATGCATGTTGAAAGACATGCTTTTATTTTTTTGTAAAACAATATAGGAGCTGTGTCTACTATTA AAAGTGAAACATTTTGGCATGTTTGTTAATTCTAGTTTCATTTAATAACCTGTAAGGCACGTAAGTTTAAGCTTTTTTTTTTTTTAAGTT AATGGGAAAAATTTGAGACGCAATACCAATACTTAGGATTTTGGTCTTGGTGTTTGTATGAAATTCTGAGGCCTTGATTTAAATCTTTCA >37211_37211_7_HNRNPH3-HNRNPH1_HNRNPH3_chr10_70097753_ENST00000354695_HNRNPH1_chr5_179045324_ENST00000356731_length(amino acids)=354AA_BP=7 MDWVMKHNGPNDASDGTVRLRGLPFGCSKEEIVQFFQGLEIVPNGITLTMDYQGRSTGEAFVQFASKEIAENALGKHKERIGHRYIEIFK SSRAEVRTHYDPPRKLMAMQRPGPYDRPGAGRGYNSIGRGAGFERMRRGAYGGGYGGYDDYNGYNDGYGFGSDRFGRDLNYCFSGMSDHR YGDGGSTFQSTTGHCVHMRGLPYRATENDIYNFFSPLNPVRVHIEIGPDGRVTGEADVEFATHEDAVAAMSKDKANMQHRYVELFLNSTA -------------------------------------------------------------- >37211_37211_8_HNRNPH3-HNRNPH1_HNRNPH3_chr10_70097753_ENST00000354695_HNRNPH1_chr5_179045324_ENST00000393432_length(transcript)=1965nt_BP=369nt CCGTTGTGGCGAGCGCTACACGAGGCAAACGACTTCTCCCTTCTTTGAACTGGACCCCGCGAGCACCAGAGTCGGCGTAACTATCGCCTG ACAGGCATTTAAATCAAACGGTATTGAGATGGATTGGGTTATGAAACATAATGGTCCAAATGACGCTAGTGATGGGACAGTACGACTTCG TGGACTACCATTTGGTTGCAGCAAAGAGGAAATAGTTCAGTTCTTTCAAGGGTTGGAAATCGTGCCAAATGGGATAACATTGACGATGGA CTACCAGGGGAGAAGCACAGGGGAGGCCTTCGTGCAGTTTGCTTCAAAGGAGATAGCAGAAAATGCTCTGGGGAAACACAAGGAAAGAAT AGGGCACAGGTATATTGAAATCTTTAAGAGCAGTAGAGCTGAAGTTAGAACTCATTATGATCCACCACGAAAGCTTATGGCCATGCAGCG GCCAGGTCCTTATGACAGACCTGGGGCTGGTAGAGGGTATAACAGCATTGGCAGAGGAGCTGGCTTTGAGAGGATGAGGCGTGGTGCTTA TGGTGGAGGCTATGGAGGCTATGATGATTACAATGGCTATAATGATGGCTATGGATTTGGGTCAGATAGATTTGGAAGAGACCTCAATTA CTGTTTTTCAGGAATGTCTGATCACAGATACGGGGATGGTGGCTCTACTTTCCAGAGCACAACAGGACACTGTGTACACATGCGGGGATT ACCTTACAGAGCTACTGAGAATGACATTTATAATTTTTTTTCACCGCTCAACCCTGTGAGAGTACACATTGAAATTGGTCCTGATGGCAG AGTAACTGGTGAAGCAGATGTCGAGTTCGCAACTCATGAAGATGCTGTGGCAGCTATGTCAAAAGACAAAGCAAATATGCAACACAGATA TGTAGAACTCTTCTTGAATTCTACAGCAGGAGCAAGCGGTGGTGCTTACGAACACAGATATGTAGAACTCTTCTTGAATTCTACAGCAGG AGCAAGCGGTGGTGCTTATGGTAGCCAAATGATGGGAGGCATGGGCTTGTCAAACCAGTCCAGCTACGGGGGCCCAGCCAGCCAGCAGCT GAGTGGGGGTTACGGAGGCGGCTACGGTGGCCAGAGCAGCATGAGTGGATACGACCAAGTTTTACAGGAAAACTCCAGTGATTTTCAATC AAACATTGCATAGGTAACCAAGGAGCAGTGAACAGCAGCTACTACAGTAGTGGAAGCCGTGCATCTATGGGCGTGAACGGAATGGGAGGG TTGTCTAGCATGTCCAGTATGAGTGGTGGATGGGGAATGTAATTGATCGATCCTGATCACTGACTCTTGGTCAACCTTTTTTTTTTTTTT TTTTTTTTCTTTAAGAAAACTTCAGTTTAACAGTTTCTGCAATACAAGCTTGTGATTTATGCTTACTCTAAGTGGAAATCAGGATTGTTA TGAAGACTTAAGGCCCAGTATTTTTGAATACAATACTCATCTAGGATGTAACAGTGAAGCTGAGTAAACTATAACTGTTAAACTTAAGTT CCAGCTTTTCTCAAGTTAGTTATAGGATGTACTTAAGCAGTAAGCGTATTTAGGTAAAAGCAGTTGAATTATGTTAAATGTTGCCCTTTG CCACGTTAAATTGAACACTGTTTTGGATGCATGTTGAAAGACATGCTTTTATTTTTTTGTAAAACAATATAGGAGCTGTGTCTACTATTA AAAGTGAAACATTTTGGCATGTTTGTTAATTCTAGTTTCATTTAATAACCTGTAAGGCACGTAAGTTTAAGCTTTTTTTTTTTTTAAGTT AATGGGAAAAATTTGAGACGCAATACCAATACTTAGGATTTTGGTCTTGGTGTTTGTATGAAATTCTGAGGCCTTGATTTAAATCTTTCA >37211_37211_8_HNRNPH3-HNRNPH1_HNRNPH3_chr10_70097753_ENST00000354695_HNRNPH1_chr5_179045324_ENST00000393432_length(amino acids)=354AA_BP=7 MDWVMKHNGPNDASDGTVRLRGLPFGCSKEEIVQFFQGLEIVPNGITLTMDYQGRSTGEAFVQFASKEIAENALGKHKERIGHRYIEIFK SSRAEVRTHYDPPRKLMAMQRPGPYDRPGAGRGYNSIGRGAGFERMRRGAYGGGYGGYDDYNGYNDGYGFGSDRFGRDLNYCFSGMSDHR YGDGGSTFQSTTGHCVHMRGLPYRATENDIYNFFSPLNPVRVHIEIGPDGRVTGEADVEFATHEDAVAAMSKDKANMQHRYVELFLNSTA -------------------------------------------------------------- >37211_37211_9_HNRNPH3-HNRNPH1_HNRNPH3_chr10_70097753_ENST00000354695_HNRNPH1_chr5_179045324_ENST00000442819_length(transcript)=1964nt_BP=369nt CCGTTGTGGCGAGCGCTACACGAGGCAAACGACTTCTCCCTTCTTTGAACTGGACCCCGCGAGCACCAGAGTCGGCGTAACTATCGCCTG ACAGGCATTTAAATCAAACGGTATTGAGATGGATTGGGTTATGAAACATAATGGTCCAAATGACGCTAGTGATGGGACAGTACGACTTCG TGGACTACCATTTGGTTGCAGCAAAGAGGAAATAGTTCAGTTCTTTCAAGGGTTGGAAATCGTGCCAAATGGGATAACATTGACGATGGA CTACCAGGGGAGAAGCACAGGGGAGGCCTTCGTGCAGTTTGCTTCAAAGGAGATAGCAGAAAATGCTCTGGGGAAACACAAGGAAAGAAT AGGGCACAGGTATATTGAAATCTTTAAGAGCAGTAGAGCTGAAGTTAGAACTCATTATGATCCACCACGAAAGCTTATGGCCATGCAGCG GCCAGGTCCTTATGACAGACCTGGGGCTGGTAGAGGGTATAACAGCATTGGCAGAGGAGCTGGCTTTGAGAGGATGAGGCGTGGTGCTTA TGGTGGAGGCTATGGAGGCTATGATGATTACAATGGCTATAATGATGGCTATGGATTTGGGTCAGATAGATTTGGAAGAGACCTCAATTA CTGTTTTTCAGGAATGTCTGATCACAGATACGGGGATGGTGGCTCTACTTTCCAGAGCACAACAGGACACTGTGTACACATGCGGGGATT ACCTTACAGAGCTACTGAGAATGACATTTATAATTTTTTTTCACCGCTCAACCCTGTGAGAGTACACATTGAAATTGGTCCTGATGGCAG AGTAACTGGTGAAGCAGATGTCGAGTTCGCAACTCATGAAGATGCTGTGGCAGCTATGTCAAAAGACAAAGCAAATATGCAACACAGATA TGTAGAACTCTTCTTGAATTCTACAGCAGGAGCAAGCGGTGGTGCTTACGAACACAGATATGTAGAACTCTTCTTGAATTCTACAGCAGG AGCAAGCGGTGGTGCTTATGGTAGCCAAATGATGGGAGGCATGGGCTTGTCAAACCAGTCCAGCTACGGGGGCCCAGCCAGCCAGCAGCT GAGTGGGGGTTACGGAGGCGGCTACGGTGGCCAGAGCAGCATGAGTGGATACGACCAAGTTTTACAGGAAAACTCCAGTGATTTTCAATC AAACATTGCATAGGTAACCAAGGAGCAGTGAACAGCAGCTACTACAGTAGTGGAAGCCGTGCATCTATGGGCGTGAACGGAATGGGAGGG TTGTCTAGCATGTCCAGTATGAGTGGTGGATGGGGAATGTAATTGATCGATCCTGATCACTGACTCTTGGTCAACCTTTTTTTTTTTTTT TTTTTTTTCTTTAAGAAAACTTCAGTTTAACAGTTTCTGCAATACAAGCTTGTGATTTATGCTTACTCTAAGTGGAAATCAGGATTGTTA TGAAGACTTAAGGCCCAGTATTTTTGAATACAATACTCATCTAGGATGTAACAGTGAAGCTGAGTAAACTATAACTGTTAAACTTAAGTT CCAGCTTTTCTCAAGTTAGTTATAGGATGTACTTAAGCAGTAAGCGTATTTAGGTAAAAGCAGTTGAATTATGTTAAATGTTGCCCTTTG CCACGTTAAATTGAACACTGTTTTGGATGCATGTTGAAAGACATGCTTTTATTTTTTTGTAAAACAATATAGGAGCTGTGTCTACTATTA AAAGTGAAACATTTTGGCATGTTTGTTAATTCTAGTTTCATTTAATAACCTGTAAGGCACGTAAGTTTAAGCTTTTTTTTTTTTTAAGTT AATGGGAAAAATTTGAGACGCAATACCAATACTTAGGATTTTGGTCTTGGTGTTTGTATGAAATTCTGAGGCCTTGATTTAAATCTTTCA >37211_37211_9_HNRNPH3-HNRNPH1_HNRNPH3_chr10_70097753_ENST00000354695_HNRNPH1_chr5_179045324_ENST00000442819_length(amino acids)=354AA_BP=7 MDWVMKHNGPNDASDGTVRLRGLPFGCSKEEIVQFFQGLEIVPNGITLTMDYQGRSTGEAFVQFASKEIAENALGKHKERIGHRYIEIFK SSRAEVRTHYDPPRKLMAMQRPGPYDRPGAGRGYNSIGRGAGFERMRRGAYGGGYGGYDDYNGYNDGYGFGSDRFGRDLNYCFSGMSDHR YGDGGSTFQSTTGHCVHMRGLPYRATENDIYNFFSPLNPVRVHIEIGPDGRVTGEADVEFATHEDAVAAMSKDKANMQHRYVELFLNSTA -------------------------------------------------------------- >37211_37211_10_HNRNPH3-HNRNPH1_HNRNPH3_chr10_70097753_ENST00000354695_HNRNPH1_chr5_179045324_ENST00000510411_length(transcript)=1902nt_BP=369nt CCGTTGTGGCGAGCGCTACACGAGGCAAACGACTTCTCCCTTCTTTGAACTGGACCCCGCGAGCACCAGAGTCGGCGTAACTATCGCCTG ACAGGCATTTAAATCAAACGGTATTGAGATGGATTGGGTTATGAAACATAATGGTCCAAATGACGCTAGTGATGGGACAGTACGACTTCG TGGACTACCATTTGGTTGCAGCAAAGAGGAAATAGTTCAGTTCTTTCAAGGGTTGGAAATCGTGCCAAATGGGATAACATTGACGATGGA CTACCAGGGGAGAAGCACAGGGGAGGCCTTCGTGCAGTTTGCTTCAAAGGAGATAGCAGAAAATGCTCTGGGGAAACACAAGGAAAGAAT AGGGCACAGGTATATTGAAATCTTTAAGAGCAGTAGAGCTGAAGTTAGAACTCATTATGATCCACCACGAAAGCTTATGGCCATGCAGCG GCCAGGTCCTTATGACAGACCTGGGGCTGGTAGAGGGTATAACAGCATTGGCAGAGGAGCTGGCTTTGAGAGGATGAGGCGTGGTGCTTA TGGTGGAGGCTATGGAGGCTATGATGATTACAATGGCTATAATGATGGCTATGGATTTGGGTCAGATAGATTTGGAAGAGACCTCAATTA CTGTTTTTCAGGAATGTCTGATCACAGATACGGGGATGGTGGCTCTACTTTCCAGAGCACAACAGGACACTGTGTACACATGCGGGGATT ACCTTACAGAGCTACTGAGAATGACATTTATAATTTTTTTTCACCGCTCAACCCTGTGAGAGTACACATTGAAATTGGTCCTGATGGCAG AGTAACTGGTGAAGCAGATGTCGAGTTCGCAACTCATGAAGATGCTGTGGCAGCTATGTCAAAAGACAAAGCAAATATGCAACACAGATA TGTAGAACTCTTCTTGAATTCTACAGCAGGAGCAAGCGGTGGTGCTTACGGTAGCCAAATGCTAGGAGGCATGGGTTTGTCAAACCAGTC CAGCTACGGGGGCCCAGCCAGCCAGCAGCTGAGTGGGGGTTACGGAGGCGGCTACGGTGGCCAGAGCAGCATGAGTGGATACGACCAAGT TTTACAGGAAAACTCCAGTGATTTTCAATCAAACATTGCATAGGTAACCAAGGAGCAGTGAACAGCAGCTACTACAGTAGTGGAAGCCGT GCATCTATGGGCGTGAACGGAATGGGAGGGTTGTCTAGCATGTCCAGTATGAGTGGTGGATGGGGAATGTAATTGATCGATCCTGATCAC TGACTCTTGGTCAACCTTTTTTTTTTTTTTTTTTTTTTCTTTAAGAAAACTTCAGTTTAACAGTTTCTGCAATACAAGCTTGTGATTTAT GCTTACTCTAAGTGGAAATCAGGATTGTTATGAAGACTTAAGGCCCAGTATTTTTGAATACAATACTCATCTAGGATGTAACAGTGAAGC TGAGTAAACTATAACTGTTAAACTTAAGTTCCAGCTTTTCTCAAGTTAGTTATAGGATGTACTTAAGCAGTAAGCGTATTTAGGTAAAAG CAGTTGAATTATGTTAAATGTTGCCCTTTGCCACGTTAAATTGAACACTGTTTTGGATGCATGTTGAAAGACATGCTTTTATTTTTTTGT AAAACAATATAGGAGCTGTGTCTACTATTAAAAGTGAAACATTTTGGCATGTTTGTTAATTCTAGTTTCATTTAATAACCTGTAAGGCAC GTAAGTTTAAGCTTTTTTTTTTTTTAAGTTAATGGGAAAAATTTGAGACGCAATACCAATACTTAGGATTTTGGTCTTGGTGTTTGTATG AAATTCTGAGGCCTTGATTTAAATCTTTCATTGTATTGTGATTTCCTTTTAGGTATATTGCGCTAAGTGAAACTTGTCAAATAAATCCTC >37211_37211_10_HNRNPH3-HNRNPH1_HNRNPH3_chr10_70097753_ENST00000354695_HNRNPH1_chr5_179045324_ENST00000510411_length(amino acids)=334AA_BP=7 MDWVMKHNGPNDASDGTVRLRGLPFGCSKEEIVQFFQGLEIVPNGITLTMDYQGRSTGEAFVQFASKEIAENALGKHKERIGHRYIEIFK SSRAEVRTHYDPPRKLMAMQRPGPYDRPGAGRGYNSIGRGAGFERMRRGAYGGGYGGYDDYNGYNDGYGFGSDRFGRDLNYCFSGMSDHR YGDGGSTFQSTTGHCVHMRGLPYRATENDIYNFFSPLNPVRVHIEIGPDGRVTGEADVEFATHEDAVAAMSKDKANMQHRYVELFLNSTA -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for HNRNPH3-HNRNPH1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for HNRNPH3-HNRNPH1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for HNRNPH3-HNRNPH1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies