
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:HSF1-CPSF3L (FusionGDB2 ID:37706) |
Fusion Gene Summary for HSF1-CPSF3L |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: HSF1-CPSF3L | Fusion gene ID: 37706 | Hgene | Tgene | Gene symbol | HSF1 | CPSF3L | Gene ID | 3297 | 54973 |
| Gene name | heat shock transcription factor 1 | integrator complex subunit 11 | |
| Synonyms | HSTF1 | CPSF3L|CPSF73L|INT11|RC-68|RC68 | |
| Cytomap | 8q24.3 | 1p36.33 | |
| Type of gene | protein-coding | protein-coding | |
| Description | heat shock factor protein 1 | integrator complex subunit 11CPSF3-like proteincleavage and polyadenylation specific factor 3-likecleavage and polyadenylation-specific factor 3-like proteinprotein related to CPSF subunits of 68 kDarelated to CPSF subunits 68 kDa | |
| Modification date | 20200322 | 20200313 | |
| UniProtAcc | Q00613 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000528842, ENST00000400780, ENST00000528838, | ENST00000411962, ENST00000435064, ENST00000419704, ENST00000421495, ENST00000462432, ENST00000540437, ENST00000450926, ENST00000545578, | |
| Fusion gene scores | * DoF score | 10 X 6 X 8=480 | 8 X 8 X 6=384 |
| # samples | 12 | 10 | |
| ** MAII score | log2(12/480*10)=-2 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(10/384*10)=-1.94110631094643 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: HSF1 [Title/Abstract] AND CPSF3L [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | HSF1(145537302)-CPSF3L(1250998), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | HSF1 | GO:0000122 | negative regulation of transcription by RNA polymerase II | 8926278|9341107 |
| Hgene | HSF1 | GO:0000165 | MAPK cascade | 12917326 |
| Hgene | HSF1 | GO:0009299 | mRNA transcription | 21597468 |
| Hgene | HSF1 | GO:0034605 | cellular response to heat | 7935471|9222587|9341107|10359787|10413683|10747973|11514557|11583998|12917326|14707147|16554823|17897941|21085490|26159920 |
| Hgene | HSF1 | GO:0034620 | cellular response to unfolded protein | 15016915 |
| Hgene | HSF1 | GO:0034622 | cellular protein-containing complex assembly | 11583998 |
| Hgene | HSF1 | GO:0045944 | positive regulation of transcription by RNA polymerase II | 9341107|10561509|11514557|12917326|16278218|21085490 |
| Hgene | HSF1 | GO:0061408 | positive regulation of transcription from RNA polymerase II promoter in response to heat stress | 7760831|9499401|10747973|12659875|12665592|15016915|25963659|26754925 |
| Hgene | HSF1 | GO:0071276 | cellular response to cadmium ion | 10359787|11514557|15016915|25963659 |
| Hgene | HSF1 | GO:0071280 | cellular response to copper ion | 15016915 |
| Hgene | HSF1 | GO:0071480 | cellular response to gamma radiation | 26359349 |
| Hgene | HSF1 | GO:0072738 | cellular response to diamide | 15016915 |
| Hgene | HSF1 | GO:1900034 | regulation of cellular response to heat | 11583998 |
| Hgene | HSF1 | GO:1903936 | cellular response to sodium arsenite | 15016915 |
| Tgene | CPSF3L | GO:0016180 | snRNA processing | 16239144 |
| Fusion gene breakpoints across HSF1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across CPSF3L (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | Non-Cancer | 67N | HSF1 | chr8 | 145537302 | + | CPSF3L | chr1 | 1250998 | - |
Top |
Fusion Gene ORF analysis for HSF1-CPSF3L |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000528842 | ENST00000411962 | HSF1 | chr8 | 145537302 | + | CPSF3L | chr1 | 1250998 | - |
| 3UTR-3CDS | ENST00000528842 | ENST00000435064 | HSF1 | chr8 | 145537302 | + | CPSF3L | chr1 | 1250998 | - |
| 3UTR-5UTR | ENST00000528842 | ENST00000419704 | HSF1 | chr8 | 145537302 | + | CPSF3L | chr1 | 1250998 | - |
| 3UTR-5UTR | ENST00000528842 | ENST00000421495 | HSF1 | chr8 | 145537302 | + | CPSF3L | chr1 | 1250998 | - |
| 3UTR-5UTR | ENST00000528842 | ENST00000462432 | HSF1 | chr8 | 145537302 | + | CPSF3L | chr1 | 1250998 | - |
| 3UTR-5UTR | ENST00000528842 | ENST00000540437 | HSF1 | chr8 | 145537302 | + | CPSF3L | chr1 | 1250998 | - |
| 3UTR-intron | ENST00000528842 | ENST00000450926 | HSF1 | chr8 | 145537302 | + | CPSF3L | chr1 | 1250998 | - |
| 3UTR-intron | ENST00000528842 | ENST00000545578 | HSF1 | chr8 | 145537302 | + | CPSF3L | chr1 | 1250998 | - |
| 5CDS-5UTR | ENST00000400780 | ENST00000419704 | HSF1 | chr8 | 145537302 | + | CPSF3L | chr1 | 1250998 | - |
| 5CDS-5UTR | ENST00000400780 | ENST00000421495 | HSF1 | chr8 | 145537302 | + | CPSF3L | chr1 | 1250998 | - |
| 5CDS-5UTR | ENST00000400780 | ENST00000462432 | HSF1 | chr8 | 145537302 | + | CPSF3L | chr1 | 1250998 | - |
| 5CDS-5UTR | ENST00000400780 | ENST00000540437 | HSF1 | chr8 | 145537302 | + | CPSF3L | chr1 | 1250998 | - |
| 5CDS-5UTR | ENST00000528838 | ENST00000419704 | HSF1 | chr8 | 145537302 | + | CPSF3L | chr1 | 1250998 | - |
| 5CDS-5UTR | ENST00000528838 | ENST00000421495 | HSF1 | chr8 | 145537302 | + | CPSF3L | chr1 | 1250998 | - |
| 5CDS-5UTR | ENST00000528838 | ENST00000462432 | HSF1 | chr8 | 145537302 | + | CPSF3L | chr1 | 1250998 | - |
| 5CDS-5UTR | ENST00000528838 | ENST00000540437 | HSF1 | chr8 | 145537302 | + | CPSF3L | chr1 | 1250998 | - |
| 5CDS-intron | ENST00000400780 | ENST00000450926 | HSF1 | chr8 | 145537302 | + | CPSF3L | chr1 | 1250998 | - |
| 5CDS-intron | ENST00000400780 | ENST00000545578 | HSF1 | chr8 | 145537302 | + | CPSF3L | chr1 | 1250998 | - |
| 5CDS-intron | ENST00000528838 | ENST00000450926 | HSF1 | chr8 | 145537302 | + | CPSF3L | chr1 | 1250998 | - |
| 5CDS-intron | ENST00000528838 | ENST00000545578 | HSF1 | chr8 | 145537302 | + | CPSF3L | chr1 | 1250998 | - |
| In-frame | ENST00000400780 | ENST00000411962 | HSF1 | chr8 | 145537302 | + | CPSF3L | chr1 | 1250998 | - |
| In-frame | ENST00000400780 | ENST00000435064 | HSF1 | chr8 | 145537302 | + | CPSF3L | chr1 | 1250998 | - |
| In-frame | ENST00000528838 | ENST00000411962 | HSF1 | chr8 | 145537302 | + | CPSF3L | chr1 | 1250998 | - |
| In-frame | ENST00000528838 | ENST00000435064 | HSF1 | chr8 | 145537302 | + | CPSF3L | chr1 | 1250998 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000528838 | HSF1 | chr8 | 145537302 | + | ENST00000435064 | CPSF3L | chr1 | 1250998 | - | 3044 | 1408 | 43 | 2781 | 912 |
| ENST00000528838 | HSF1 | chr8 | 145537302 | + | ENST00000411962 | CPSF3L | chr1 | 1250998 | - | 3040 | 1408 | 43 | 2781 | 912 |
| ENST00000400780 | HSF1 | chr8 | 145537302 | + | ENST00000435064 | CPSF3L | chr1 | 1250998 | - | 2852 | 1216 | 52 | 2589 | 845 |
| ENST00000400780 | HSF1 | chr8 | 145537302 | + | ENST00000411962 | CPSF3L | chr1 | 1250998 | - | 2848 | 1216 | 52 | 2589 | 845 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000528838 | ENST00000435064 | HSF1 | chr8 | 145537302 | + | CPSF3L | chr1 | 1250998 | - | 0.017449873 | 0.9825501 |
| ENST00000528838 | ENST00000411962 | HSF1 | chr8 | 145537302 | + | CPSF3L | chr1 | 1250998 | - | 0.017541101 | 0.98245883 |
| ENST00000400780 | ENST00000435064 | HSF1 | chr8 | 145537302 | + | CPSF3L | chr1 | 1250998 | - | 0.018593827 | 0.9814062 |
| ENST00000400780 | ENST00000411962 | HSF1 | chr8 | 145537302 | + | CPSF3L | chr1 | 1250998 | - | 0.018735742 | 0.98126423 |
Top |
Fusion Genomic Features for HSF1-CPSF3L |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
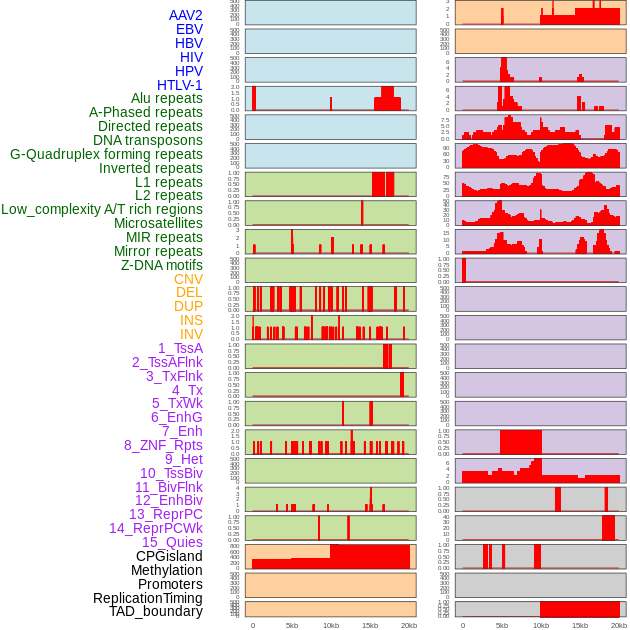 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for HSF1-CPSF3L |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr8:145537302/chr1:1250998) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| HSF1 | . |
| FUNCTION: Functions as a stress-inducible and DNA-binding transcription factor that plays a central role in the transcriptional activation of the heat shock response (HSR), leading to the expression of a large class of molecular chaperones heat shock proteins (HSPs) that protect cells from cellular insults' damage (PubMed:1871105, PubMed:11447121, PubMed:1986252, PubMed:7760831, PubMed:7623826, PubMed:8946918, PubMed:8940068, PubMed:9341107, PubMed:9121459, PubMed:9727490, PubMed:9499401, PubMed:9535852, PubMed:12659875, PubMed:12917326, PubMed:15016915, PubMed:25963659, PubMed:26754925). In unstressed cells, is present in a HSP90-containing multichaperone complex that maintains it in a non-DNA-binding inactivated monomeric form (PubMed:9727490, PubMed:11583998, PubMed:16278218). Upon exposure to heat and other stress stimuli, undergoes homotrimerization and activates HSP gene transcription through binding to site-specific heat shock elements (HSEs) present in the promoter regions of HSP genes (PubMed:1871105, PubMed:1986252, PubMed:8455624, PubMed:7935471, PubMed:7623826, PubMed:8940068, PubMed:9727490, PubMed:9499401, PubMed:10359787, PubMed:11583998, PubMed:12659875, PubMed:16278218, PubMed:25963659, PubMed:26754925). Activation is reversible, and during the attenuation and recovery phase period of the HSR, returns to its unactivated form (PubMed:11583998, PubMed:16278218). Binds to inverted 5'-NGAAN-3' pentamer DNA sequences (PubMed:1986252, PubMed:26727489). Binds to chromatin at heat shock gene promoters (PubMed:25963659). Plays also several other functions independently of its transcriptional activity. Involved in the repression of Ras-induced transcriptional activation of the c-fos gene in heat-stressed cells (PubMed:9341107). Positively regulates pre-mRNA 3'-end processing and polyadenylation of HSP70 mRNA upon heat-stressed cells in a symplekin (SYMPK)-dependent manner (PubMed:14707147). Plays a role in nuclear export of stress-induced HSP70 mRNA (PubMed:17897941). Plays a role in the regulation of mitotic progression (PubMed:18794143). Plays also a role as a negative regulator of non-homologous end joining (NHEJ) repair activity in a DNA damage-dependent manner (PubMed:26359349). Involved in stress-induced cancer cell proliferation in a IER5-dependent manner (PubMed:26754925). {ECO:0000269|PubMed:10359787, ECO:0000269|PubMed:11447121, ECO:0000269|PubMed:11583998, ECO:0000269|PubMed:12659875, ECO:0000269|PubMed:12917326, ECO:0000269|PubMed:14707147, ECO:0000269|PubMed:15016915, ECO:0000269|PubMed:16278218, ECO:0000269|PubMed:17897941, ECO:0000269|PubMed:1871105, ECO:0000269|PubMed:18794143, ECO:0000269|PubMed:1986252, ECO:0000269|PubMed:25963659, ECO:0000269|PubMed:26359349, ECO:0000269|PubMed:26727489, ECO:0000269|PubMed:26754925, ECO:0000269|PubMed:7623826, ECO:0000269|PubMed:7760831, ECO:0000269|PubMed:7935471, ECO:0000269|PubMed:8455624, ECO:0000269|PubMed:8940068, ECO:0000269|PubMed:8946918, ECO:0000269|PubMed:9121459, ECO:0000269|PubMed:9341107, ECO:0000269|PubMed:9499401, ECO:0000269|PubMed:9535852, ECO:0000269|PubMed:9727490}.; FUNCTION: (Microbial infection) Plays a role in latent human immunodeficiency virus (HIV-1) transcriptional reactivation. Binds to the HIV-1 long terminal repeat promoter (LTR) to reactivate viral transcription by recruiting cellular transcriptional elongation factors, such as CDK9, CCNT1 and EP300. {ECO:0000269|PubMed:27189267}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | HSF1 | chr8:145537302 | chr1:1250998 | ENST00000528838 | + | 10 | 13 | 130_203 | 416 | 530.0 | Region | Hydrophobic repeat HR-A/B |
| Hgene | HSF1 | chr8:145537302 | chr1:1250998 | ENST00000528838 | + | 10 | 13 | 15_120 | 416 | 530.0 | Region | DNA-binding domain |
| Hgene | HSF1 | chr8:145537302 | chr1:1250998 | ENST00000528838 | + | 10 | 13 | 203_224 | 416 | 530.0 | Region | D domain |
| Hgene | HSF1 | chr8:145537302 | chr1:1250998 | ENST00000528838 | + | 10 | 13 | 221_310 | 416 | 530.0 | Region | Regulatory domain |
| Hgene | HSF1 | chr8:145537302 | chr1:1250998 | ENST00000528838 | + | 10 | 13 | 384_409 | 416 | 530.0 | Region | Hydrophobic repeat HR-C |
| Tgene | CPSF3L | chr8:145537302 | chr1:1250998 | ENST00000419704 | 1 | 15 | 68_73 | 42 | 500.0 | Motif | Note=HXHXDH motif | |
| Tgene | CPSF3L | chr8:145537302 | chr1:1250998 | ENST00000450926 | 0 | 17 | 68_73 | 0 | 579.0 | Motif | Note=HXHXDH motif |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | HSF1 | chr8:145537302 | chr1:1250998 | ENST00000528838 | + | 10 | 13 | 412_420 | 416 | 530.0 | Motif | 9aaTAD |
| Hgene | HSF1 | chr8:145537302 | chr1:1250998 | ENST00000528838 | + | 10 | 13 | 371_529 | 416 | 530.0 | Region | Transactivation domain |
| Tgene | CPSF3L | chr8:145537302 | chr1:1250998 | ENST00000435064 | 3 | 17 | 68_73 | 143 | 601.0 | Motif | Note=HXHXDH motif | |
| Tgene | CPSF3L | chr8:145537302 | chr1:1250998 | ENST00000540437 | 5 | 19 | 68_73 | 149 | 607.0 | Motif | Note=HXHXDH motif | |
| Tgene | CPSF3L | chr8:145537302 | chr1:1250998 | ENST00000545578 | 4 | 18 | 68_73 | 114 | 572.0 | Motif | Note=HXHXDH motif |
Top |
Fusion Gene Sequence for HSF1-CPSF3L |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >37706_37706_1_HSF1-CPSF3L_HSF1_chr8_145537302_ENST00000400780_CPSF3L_chr1_1250998_ENST00000411962_length(transcript)=2848nt_BP=1216nt GAGCGGGAACAGCTTCCACGTGTTCGACCAGGGCCAGTTTGCCAAGGAGGTGCTGCCCAAGTACTTCAAGCACAACAACATGGCCAGCTT CGTGCGGCAGCTCAACATGTATGGCTTCCGGAAAGTGGTCCACATCGAGCAGGGCGGCCTGGTCAAGCCAGAGAGAGACGACACGGAGTT CCAGCACCCATGCTTCCTGCGTGGCCAGGAGCAGCTCCTTGAGAACATCAAGAGGAAAGTGACCAGTGTGTCCACCCTGAAGAGTGAAGA CATAAAGATCCGCCAGGACAGCGTCACCAAGCTGCTGACGGACGTGCAGCTGATGAAGGGGAAGCAGGAGTGCATGGACTCCAAGCTCCT GGCCATGAAGCATGAGAATGAGGCTCTGTGGCGGGAGGTGGCCAGCCTTCGGCAGAAGCATGCCCAGCAACAGAAAGTCGTCAACAAGCT CATTCAGTTCCTGATCTCACTGGTGCAGTCAAACCGGATCCTGGGGGTGAAGAGAAAGATCCCCCTGATGCTGAACGACAGTGGCTCAGC ACATTCCATGCCCAAGTATAGCCGGCAGTTCTCCCTGGAGCACGTCCACGGCTCGGGCCCCTACTCGGCCCCCTCCCCAGCCTACAGCAG CTCCAGCCTCTACGCCCCTGATGCTGTGGCCAGCTCTGGACCCATCATCTCCGACATCACCGAGCTGGCTCCTGCCAGCCCCATGGCCTC CCCCGGCGGGAGCATAGACGAGAGGCCCCTATCCAGCAGCCCCCTGGTGCGTGTCAAGGAGGAGCCCCCCAGCCCGCCTCAGAGCCCCCG GGTAGAGGAGGCGAGTCCCGGGCGCCCATCTTCCGTGGACACCCTCTTGTCCCCGACCGCCCTCATTGACTCCATCCTGCGGGAGAGTGA ACCTGCCCCCGCCTCCGTCACAGCCCTCACGGACGCCAGGGGCCACACGGACACCGAGGGCCGGCCTCCCTCCCCCCCGCCCACCTCCAC CCCTGAAAAGTGCCTCAGCGTAGCCTGCCTGGACAATTTGGCTCGCACTCCACAGATGTCTAGGGTCGCCCGCCTCTTCCCCTGCCCCTC TTCCTCTCCGCATGGCCAAGTCCAGCCAGGGAATGAGCTCAGTGACCACTTGGATGCTATGGACTCCAACCTGGATAACCTGCAGACCAT GCTGAGCAGCCACGGCTTCAGCGTGGACACCAGTGCCCTGCTGGACGTAGATGATGAGCTGGAGATCAAGGCCTACTATGCAGGCCACGT GCTGGGGGCAGCCATGTTCCAGATTAAAGTGGGCTCAGAGTCTGTGGTCTACACGGGTGATTATAACATGACCCCAGACCGACACTTAGG AGCTGCCTGGATTGACAAGTGCCGCCCCAACCTGCTCATCACAGAGTCCACGTACGCCACGACCATCCGTGACTCCAAGCGCTGCCGGGA GCGAGACTTCCTGAAGAAAGTCCACGAGACCGTGGAGCGTGGTGGGAAGGTGCTGATACCTGTGTTCGCGCTGGGCCGCGCCCAGGAGCT CTGCATCCTCCTGGAGACCTTCTGGGAGCGCATGAACCTGAAGGTGCCCATCTACTTCTCCACGGGGCTGACCGAGAAGGCCAACCACTA CTACAAGCTGTTCATCCCCTGGACCAACCAGAAGATCCGCAAGACTTTCGTGCAGAGGAACATGTTTGAGTTCAAGCACATCAAGGCCTT CGACCGGGCTTTTGCTGACAACCCAGGACCGATGGTTGTGTTTGCCACGCCAGGAATGCTGCACGCTGGGCAGTCCCTGCAGATCTTCCG GAAATGGGCCGGAAACGAAAAGAACATGGTCATCATGCCCGGCTACTGCGTGCAGGGCACCGTCGGCCACAAGATCCTCAGCGGGCAGCG GAAGCTCGAGATGGAGGGGCGGCAGGTGCTGGAGGTCAAGATGCAGGTGGAGTACATGTCATTCAGCGCACACGCGGACGCCAAGGGCAT CATGCAGCTGGTGGGCCAGGCAGAGCCGGAGAGCGTGCTGCTGGTGCATGGCGAGGCCAAGAAGATGGAGTTCCTGAAGCAGAAGATCGA GCAGGAGCTCCGGGTCAACTGCTACATGCCGGCCAATGGCGAGACGGTGACGCTGCCCACAAGCCCCAGCATCCCCGTAGGCATCTCGCT GGGGCTGCTGAAGCGGGAGATGGCGCAGGGGCTGCTCCCTGAGGCCAAGAAGCCTCGGCTCCTGCACGGCACCCTGATCATGAAGGACAG CAACTTCCGGCTGGTGTCCTCAGAGCAAGCCCTCAAAGAGCTGGGTCTGGCTGAGCACCAGCTGCGCTTCACCTGCCGCGTGCACCTGCA TGACACACGCAAGGAGCAGGAGACGGCATTGCGCGTCTACAGCCACCTCAAGAGCGTCCTGAAGGACCACTGTGTGCAGCACCTCCCAGA CGGCTCTGTGACTGTGGAGTCCGTCCTCCTCCAGGCCGCCGCCCCTTCTGAGGACCCAGGCACCAAGGTGCTGCTGGTCTCCTGGACCTA CCAGGACGAGGAGCTGGGGAGCTTCCTCACATCTCTGCTGAAGAAGGGCCTCCCCCAGGCCCCCAGCTGAGGCCGGCAACTCACCCAGCC GCCACCTCTGCCCTCTCCCAGCTGGACAGACCCTGGGCCTGCACTTCAGGACTGTGGGTGCCCTGGGTGAACAGACCCTGCAGGTCCCAT CCCTGGGGACAGAGGCCTTGTGTCACCTGCCTGCCCAGGCAGCTGTTTGCAGCTGAAGAAACAAACTGGTCTCCAGGCTGTCTTGCCTTT >37706_37706_1_HSF1-CPSF3L_HSF1_chr8_145537302_ENST00000400780_CPSF3L_chr1_1250998_ENST00000411962_length(amino acids)=845AA_BP=185 MPKYFKHNNMASFVRQLNMYGFRKVVHIEQGGLVKPERDDTEFQHPCFLRGQEQLLENIKRKVTSVSTLKSEDIKIRQDSVTKLLTDVQL MKGKQECMDSKLLAMKHENEALWREVASLRQKHAQQQKVVNKLIQFLISLVQSNRILGVKRKIPLMLNDSGSAHSMPKYSRQFSLEHVHG SGPYSAPSPAYSSSSLYAPDAVASSGPIISDITELAPASPMASPGGSIDERPLSSSPLVRVKEEPPSPPQSPRVEEASPGRPSSVDTLLS PTALIDSILRESEPAPASVTALTDARGHTDTEGRPPSPPPTSTPEKCLSVACLDNLARTPQMSRVARLFPCPSSSPHGQVQPGNELSDHL DAMDSNLDNLQTMLSSHGFSVDTSALLDVDDELEIKAYYAGHVLGAAMFQIKVGSESVVYTGDYNMTPDRHLGAAWIDKCRPNLLITEST YATTIRDSKRCRERDFLKKVHETVERGGKVLIPVFALGRAQELCILLETFWERMNLKVPIYFSTGLTEKANHYYKLFIPWTNQKIRKTFV QRNMFEFKHIKAFDRAFADNPGPMVVFATPGMLHAGQSLQIFRKWAGNEKNMVIMPGYCVQGTVGHKILSGQRKLEMEGRQVLEVKMQVE YMSFSAHADAKGIMQLVGQAEPESVLLVHGEAKKMEFLKQKIEQELRVNCYMPANGETVTLPTSPSIPVGISLGLLKREMAQGLLPEAKK PRLLHGTLIMKDSNFRLVSSEQALKELGLAEHQLRFTCRVHLHDTRKEQETALRVYSHLKSVLKDHCVQHLPDGSVTVESVLLQAAAPSE -------------------------------------------------------------- >37706_37706_2_HSF1-CPSF3L_HSF1_chr8_145537302_ENST00000400780_CPSF3L_chr1_1250998_ENST00000435064_length(transcript)=2852nt_BP=1216nt GAGCGGGAACAGCTTCCACGTGTTCGACCAGGGCCAGTTTGCCAAGGAGGTGCTGCCCAAGTACTTCAAGCACAACAACATGGCCAGCTT CGTGCGGCAGCTCAACATGTATGGCTTCCGGAAAGTGGTCCACATCGAGCAGGGCGGCCTGGTCAAGCCAGAGAGAGACGACACGGAGTT CCAGCACCCATGCTTCCTGCGTGGCCAGGAGCAGCTCCTTGAGAACATCAAGAGGAAAGTGACCAGTGTGTCCACCCTGAAGAGTGAAGA CATAAAGATCCGCCAGGACAGCGTCACCAAGCTGCTGACGGACGTGCAGCTGATGAAGGGGAAGCAGGAGTGCATGGACTCCAAGCTCCT GGCCATGAAGCATGAGAATGAGGCTCTGTGGCGGGAGGTGGCCAGCCTTCGGCAGAAGCATGCCCAGCAACAGAAAGTCGTCAACAAGCT CATTCAGTTCCTGATCTCACTGGTGCAGTCAAACCGGATCCTGGGGGTGAAGAGAAAGATCCCCCTGATGCTGAACGACAGTGGCTCAGC ACATTCCATGCCCAAGTATAGCCGGCAGTTCTCCCTGGAGCACGTCCACGGCTCGGGCCCCTACTCGGCCCCCTCCCCAGCCTACAGCAG CTCCAGCCTCTACGCCCCTGATGCTGTGGCCAGCTCTGGACCCATCATCTCCGACATCACCGAGCTGGCTCCTGCCAGCCCCATGGCCTC CCCCGGCGGGAGCATAGACGAGAGGCCCCTATCCAGCAGCCCCCTGGTGCGTGTCAAGGAGGAGCCCCCCAGCCCGCCTCAGAGCCCCCG GGTAGAGGAGGCGAGTCCCGGGCGCCCATCTTCCGTGGACACCCTCTTGTCCCCGACCGCCCTCATTGACTCCATCCTGCGGGAGAGTGA ACCTGCCCCCGCCTCCGTCACAGCCCTCACGGACGCCAGGGGCCACACGGACACCGAGGGCCGGCCTCCCTCCCCCCCGCCCACCTCCAC CCCTGAAAAGTGCCTCAGCGTAGCCTGCCTGGACAATTTGGCTCGCACTCCACAGATGTCTAGGGTCGCCCGCCTCTTCCCCTGCCCCTC TTCCTCTCCGCATGGCCAAGTCCAGCCAGGGAATGAGCTCAGTGACCACTTGGATGCTATGGACTCCAACCTGGATAACCTGCAGACCAT GCTGAGCAGCCACGGCTTCAGCGTGGACACCAGTGCCCTGCTGGACGTAGATGATGAGCTGGAGATCAAGGCCTACTATGCAGGCCACGT GCTGGGGGCAGCCATGTTCCAGATTAAAGTGGGCTCAGAGTCTGTGGTCTACACGGGTGATTATAACATGACCCCAGACCGACACTTAGG AGCTGCCTGGATTGACAAGTGCCGCCCCAACCTGCTCATCACAGAGTCCACGTACGCCACGACCATCCGTGACTCCAAGCGCTGCCGGGA GCGAGACTTCCTGAAGAAAGTCCACGAGACCGTGGAGCGTGGTGGGAAGGTGCTGATACCTGTGTTCGCGCTGGGCCGCGCCCAGGAGCT CTGCATCCTCCTGGAGACCTTCTGGGAGCGCATGAACCTGAAGGTGCCCATCTACTTCTCCACGGGGCTGACCGAGAAGGCCAACCACTA CTACAAGCTGTTCATCCCCTGGACCAACCAGAAGATCCGCAAGACTTTCGTGCAGAGGAACATGTTTGAGTTCAAGCACATCAAGGCCTT CGACCGGGCTTTTGCTGACAACCCAGGACCGATGGTTGTGTTTGCCACGCCAGGAATGCTGCACGCTGGGCAGTCCCTGCAGATCTTCCG GAAATGGGCCGGAAACGAAAAGAACATGGTCATCATGCCCGGCTACTGCGTGCAGGGCACCGTCGGCCACAAGATCCTCAGCGGGCAGCG GAAGCTCGAGATGGAGGGGCGGCAGGTGCTGGAGGTCAAGATGCAGGTGGAGTACATGTCATTCAGCGCACACGCGGACGCCAAGGGCAT CATGCAGCTGGTGGGCCAGGCAGAGCCGGAGAGCGTGCTGCTGGTGCATGGCGAGGCCAAGAAGATGGAGTTCCTGAAGCAGAAGATCGA GCAGGAGCTCCGGGTCAACTGCTACATGCCGGCCAATGGCGAGACGGTGACGCTGCCCACAAGCCCCAGCATCCCCGTAGGCATCTCGCT GGGGCTGCTGAAGCGGGAGATGGCGCAGGGGCTGCTCCCTGAGGCCAAGAAGCCTCGGCTCCTGCACGGCACCCTGATCATGAAGGACAG CAACTTCCGGCTGGTGTCCTCAGAGCAAGCCCTCAAAGAGCTGGGTCTGGCTGAGCACCAGCTGCGCTTCACCTGCCGCGTGCACCTGCA TGACACACGCAAGGAGCAGGAGACGGCATTGCGCGTCTACAGCCACCTCAAGAGCGTCCTGAAGGACCACTGTGTGCAGCACCTCCCAGA CGGCTCTGTGACTGTGGAGTCCGTCCTCCTCCAGGCCGCCGCCCCTTCTGAGGACCCAGGCACCAAGGTGCTGCTGGTCTCCTGGACCTA CCAGGACGAGGAGCTGGGGAGCTTCCTCACATCTCTGCTGAAGAAGGGCCTCCCCCAGGCCCCCAGCTGAGGCCGGCAACTCACCCAGCC GCCACCTCTGCCCTCTCCCAGCTGGACAGACCCTGGGCCTGCACTTCAGGACTGTGGGTGCCCTGGGTGAACAGACCCTGCAGGTCCCAT CCCTGGGGACAGAGGCCTTGTGTCACCTGCCTGCCCAGGCAGCTGTTTGCAGCTGAAGAAACAAACTGGTCTCCAGGCTGTCTTGCCTTT >37706_37706_2_HSF1-CPSF3L_HSF1_chr8_145537302_ENST00000400780_CPSF3L_chr1_1250998_ENST00000435064_length(amino acids)=845AA_BP=185 MPKYFKHNNMASFVRQLNMYGFRKVVHIEQGGLVKPERDDTEFQHPCFLRGQEQLLENIKRKVTSVSTLKSEDIKIRQDSVTKLLTDVQL MKGKQECMDSKLLAMKHENEALWREVASLRQKHAQQQKVVNKLIQFLISLVQSNRILGVKRKIPLMLNDSGSAHSMPKYSRQFSLEHVHG SGPYSAPSPAYSSSSLYAPDAVASSGPIISDITELAPASPMASPGGSIDERPLSSSPLVRVKEEPPSPPQSPRVEEASPGRPSSVDTLLS PTALIDSILRESEPAPASVTALTDARGHTDTEGRPPSPPPTSTPEKCLSVACLDNLARTPQMSRVARLFPCPSSSPHGQVQPGNELSDHL DAMDSNLDNLQTMLSSHGFSVDTSALLDVDDELEIKAYYAGHVLGAAMFQIKVGSESVVYTGDYNMTPDRHLGAAWIDKCRPNLLITEST YATTIRDSKRCRERDFLKKVHETVERGGKVLIPVFALGRAQELCILLETFWERMNLKVPIYFSTGLTEKANHYYKLFIPWTNQKIRKTFV QRNMFEFKHIKAFDRAFADNPGPMVVFATPGMLHAGQSLQIFRKWAGNEKNMVIMPGYCVQGTVGHKILSGQRKLEMEGRQVLEVKMQVE YMSFSAHADAKGIMQLVGQAEPESVLLVHGEAKKMEFLKQKIEQELRVNCYMPANGETVTLPTSPSIPVGISLGLLKREMAQGLLPEAKK PRLLHGTLIMKDSNFRLVSSEQALKELGLAEHQLRFTCRVHLHDTRKEQETALRVYSHLKSVLKDHCVQHLPDGSVTVESVLLQAAAPSE -------------------------------------------------------------- >37706_37706_3_HSF1-CPSF3L_HSF1_chr8_145537302_ENST00000528838_CPSF3L_chr1_1250998_ENST00000411962_length(transcript)=3040nt_BP=1408nt CGCGCCCGTTGCAAGATGGCGGCGGCCATGCTGGGCCCCGGGGCTGTGTGTGCGCAGCGGGCGGCGGCGCGGCCCGGAAGGCTGGCGCGG CGACGGCGTTAGCCCGGCCCTCGGCCCCTCTTTGCGGCCGCTCCCTCCGCCTATTCCCTCCTTGCTCGAGATGGATCTGCCCGTGGGCCC CGGCGCGGCGGGGCCCAGCAACGTCCCGGCCTTCCTGACCAAGCTGTGGACCCTCGTGAGCGACCCGGACACCGACGCGCTCATCTGCTG GAGCCCGAGCGGGAACAGCTTCCACGTGTTCGACCAGGGCCAGTTTGCCAAGGAGGTGCTGCCCAAGTACTTCAAGCACAACAACATGGC CAGCTTCGTGCGGCAGCTCAACATGTATGGCTTCCGGAAAGTGGTCCACATCGAGCAGGGCGGCCTGGTCAAGCCAGAGAGAGACGACAC GGAGTTCCAGCACCCATGCTTCCTGCGTGGCCAGGAGCAGCTCCTTGAGAACATCAAGAGGAAAGTGACCAGTGTGTCCACCCTGAAGAG TGAAGACATAAAGATCCGCCAGGACAGCGTCACCAAGCTGCTGACGGACGTGCAGCTGATGAAGGGGAAGCAGGAGTGCATGGACTCCAA GCTCCTGGCCATGAAGCATGAGAATGAGGCTCTGTGGCGGGAGGTGGCCAGCCTTCGGCAGAAGCATGCCCAGCAACAGAAAGTCGTCAA CAAGCTCATTCAGTTCCTGATCTCACTGGTGCAGTCAAACCGGATCCTGGGGGTGAAGAGAAAGATCCCCCTGATGCTGAACGACAGTGG CTCAGCACATTCCATGCCCAAGTATAGCCGGCAGTTCTCCCTGGAGCACGTCCACGGCTCGGGCCCCTACTCGGCCCCCTCCCCAGCCTA CAGCAGCTCCAGCCTCTACGCCCCTGATGCTGTGGCCAGCTCTGGACCCATCATCTCCGACATCACCGAGCTGGCTCCTGCCAGCCCCAT GGCCTCCCCCGGCGGGAGCATAGACGAGAGGCCCCTATCCAGCAGCCCCCTGGTGCGTGTCAAGGAGGAGCCCCCCAGCCCGCCTCAGAG CCCCCGGGTAGAGGAGGCGAGTCCCGGGCGCCCATCTTCCGTGGACACCCTCTTGTCCCCGACCGCCCTCATTGACTCCATCCTGCGGGA GAGTGAACCTGCCCCCGCCTCCGTCACAGCCCTCACGGACGCCAGGGGCCACACGGACACCGAGGGCCGGCCTCCCTCCCCCCCGCCCAC CTCCACCCCTGAAAAGTGCCTCAGCGTAGCCTGCCTGGACAAGAATGAGCTCAGTGACCACTTGGATGCTATGGACTCCAACCTGGATAA CCTGCAGACCATGCTGAGCAGCCACGGCTTCAGCGTGGACACCAGTGCCCTGCTGGACGTAGATGATGAGCTGGAGATCAAGGCCTACTA TGCAGGCCACGTGCTGGGGGCAGCCATGTTCCAGATTAAAGTGGGCTCAGAGTCTGTGGTCTACACGGGTGATTATAACATGACCCCAGA CCGACACTTAGGAGCTGCCTGGATTGACAAGTGCCGCCCCAACCTGCTCATCACAGAGTCCACGTACGCCACGACCATCCGTGACTCCAA GCGCTGCCGGGAGCGAGACTTCCTGAAGAAAGTCCACGAGACCGTGGAGCGTGGTGGGAAGGTGCTGATACCTGTGTTCGCGCTGGGCCG CGCCCAGGAGCTCTGCATCCTCCTGGAGACCTTCTGGGAGCGCATGAACCTGAAGGTGCCCATCTACTTCTCCACGGGGCTGACCGAGAA GGCCAACCACTACTACAAGCTGTTCATCCCCTGGACCAACCAGAAGATCCGCAAGACTTTCGTGCAGAGGAACATGTTTGAGTTCAAGCA CATCAAGGCCTTCGACCGGGCTTTTGCTGACAACCCAGGACCGATGGTTGTGTTTGCCACGCCAGGAATGCTGCACGCTGGGCAGTCCCT GCAGATCTTCCGGAAATGGGCCGGAAACGAAAAGAACATGGTCATCATGCCCGGCTACTGCGTGCAGGGCACCGTCGGCCACAAGATCCT CAGCGGGCAGCGGAAGCTCGAGATGGAGGGGCGGCAGGTGCTGGAGGTCAAGATGCAGGTGGAGTACATGTCATTCAGCGCACACGCGGA CGCCAAGGGCATCATGCAGCTGGTGGGCCAGGCAGAGCCGGAGAGCGTGCTGCTGGTGCATGGCGAGGCCAAGAAGATGGAGTTCCTGAA GCAGAAGATCGAGCAGGAGCTCCGGGTCAACTGCTACATGCCGGCCAATGGCGAGACGGTGACGCTGCCCACAAGCCCCAGCATCCCCGT AGGCATCTCGCTGGGGCTGCTGAAGCGGGAGATGGCGCAGGGGCTGCTCCCTGAGGCCAAGAAGCCTCGGCTCCTGCACGGCACCCTGAT CATGAAGGACAGCAACTTCCGGCTGGTGTCCTCAGAGCAAGCCCTCAAAGAGCTGGGTCTGGCTGAGCACCAGCTGCGCTTCACCTGCCG CGTGCACCTGCATGACACACGCAAGGAGCAGGAGACGGCATTGCGCGTCTACAGCCACCTCAAGAGCGTCCTGAAGGACCACTGTGTGCA GCACCTCCCAGACGGCTCTGTGACTGTGGAGTCCGTCCTCCTCCAGGCCGCCGCCCCTTCTGAGGACCCAGGCACCAAGGTGCTGCTGGT CTCCTGGACCTACCAGGACGAGGAGCTGGGGAGCTTCCTCACATCTCTGCTGAAGAAGGGCCTCCCCCAGGCCCCCAGCTGAGGCCGGCA ACTCACCCAGCCGCCACCTCTGCCCTCTCCCAGCTGGACAGACCCTGGGCCTGCACTTCAGGACTGTGGGTGCCCTGGGTGAACAGACCC TGCAGGTCCCATCCCTGGGGACAGAGGCCTTGTGTCACCTGCCTGCCCAGGCAGCTGTTTGCAGCTGAAGAAACAAACTGGTCTCCAGGC >37706_37706_3_HSF1-CPSF3L_HSF1_chr8_145537302_ENST00000528838_CPSF3L_chr1_1250998_ENST00000411962_length(amino acids)=912AA_BP=280 MCVRSGRRRGPEGWRGDGVSPALGPSLRPLPPPIPSLLEMDLPVGPGAAGPSNVPAFLTKLWTLVSDPDTDALICWSPSGNSFHVFDQGQ FAKEVLPKYFKHNNMASFVRQLNMYGFRKVVHIEQGGLVKPERDDTEFQHPCFLRGQEQLLENIKRKVTSVSTLKSEDIKIRQDSVTKLL TDVQLMKGKQECMDSKLLAMKHENEALWREVASLRQKHAQQQKVVNKLIQFLISLVQSNRILGVKRKIPLMLNDSGSAHSMPKYSRQFSL EHVHGSGPYSAPSPAYSSSSLYAPDAVASSGPIISDITELAPASPMASPGGSIDERPLSSSPLVRVKEEPPSPPQSPRVEEASPGRPSSV DTLLSPTALIDSILRESEPAPASVTALTDARGHTDTEGRPPSPPPTSTPEKCLSVACLDKNELSDHLDAMDSNLDNLQTMLSSHGFSVDT SALLDVDDELEIKAYYAGHVLGAAMFQIKVGSESVVYTGDYNMTPDRHLGAAWIDKCRPNLLITESTYATTIRDSKRCRERDFLKKVHET VERGGKVLIPVFALGRAQELCILLETFWERMNLKVPIYFSTGLTEKANHYYKLFIPWTNQKIRKTFVQRNMFEFKHIKAFDRAFADNPGP MVVFATPGMLHAGQSLQIFRKWAGNEKNMVIMPGYCVQGTVGHKILSGQRKLEMEGRQVLEVKMQVEYMSFSAHADAKGIMQLVGQAEPE SVLLVHGEAKKMEFLKQKIEQELRVNCYMPANGETVTLPTSPSIPVGISLGLLKREMAQGLLPEAKKPRLLHGTLIMKDSNFRLVSSEQA LKELGLAEHQLRFTCRVHLHDTRKEQETALRVYSHLKSVLKDHCVQHLPDGSVTVESVLLQAAAPSEDPGTKVLLVSWTYQDEELGSFLT -------------------------------------------------------------- >37706_37706_4_HSF1-CPSF3L_HSF1_chr8_145537302_ENST00000528838_CPSF3L_chr1_1250998_ENST00000435064_length(transcript)=3044nt_BP=1408nt CGCGCCCGTTGCAAGATGGCGGCGGCCATGCTGGGCCCCGGGGCTGTGTGTGCGCAGCGGGCGGCGGCGCGGCCCGGAAGGCTGGCGCGG CGACGGCGTTAGCCCGGCCCTCGGCCCCTCTTTGCGGCCGCTCCCTCCGCCTATTCCCTCCTTGCTCGAGATGGATCTGCCCGTGGGCCC CGGCGCGGCGGGGCCCAGCAACGTCCCGGCCTTCCTGACCAAGCTGTGGACCCTCGTGAGCGACCCGGACACCGACGCGCTCATCTGCTG GAGCCCGAGCGGGAACAGCTTCCACGTGTTCGACCAGGGCCAGTTTGCCAAGGAGGTGCTGCCCAAGTACTTCAAGCACAACAACATGGC CAGCTTCGTGCGGCAGCTCAACATGTATGGCTTCCGGAAAGTGGTCCACATCGAGCAGGGCGGCCTGGTCAAGCCAGAGAGAGACGACAC GGAGTTCCAGCACCCATGCTTCCTGCGTGGCCAGGAGCAGCTCCTTGAGAACATCAAGAGGAAAGTGACCAGTGTGTCCACCCTGAAGAG TGAAGACATAAAGATCCGCCAGGACAGCGTCACCAAGCTGCTGACGGACGTGCAGCTGATGAAGGGGAAGCAGGAGTGCATGGACTCCAA GCTCCTGGCCATGAAGCATGAGAATGAGGCTCTGTGGCGGGAGGTGGCCAGCCTTCGGCAGAAGCATGCCCAGCAACAGAAAGTCGTCAA CAAGCTCATTCAGTTCCTGATCTCACTGGTGCAGTCAAACCGGATCCTGGGGGTGAAGAGAAAGATCCCCCTGATGCTGAACGACAGTGG CTCAGCACATTCCATGCCCAAGTATAGCCGGCAGTTCTCCCTGGAGCACGTCCACGGCTCGGGCCCCTACTCGGCCCCCTCCCCAGCCTA CAGCAGCTCCAGCCTCTACGCCCCTGATGCTGTGGCCAGCTCTGGACCCATCATCTCCGACATCACCGAGCTGGCTCCTGCCAGCCCCAT GGCCTCCCCCGGCGGGAGCATAGACGAGAGGCCCCTATCCAGCAGCCCCCTGGTGCGTGTCAAGGAGGAGCCCCCCAGCCCGCCTCAGAG CCCCCGGGTAGAGGAGGCGAGTCCCGGGCGCCCATCTTCCGTGGACACCCTCTTGTCCCCGACCGCCCTCATTGACTCCATCCTGCGGGA GAGTGAACCTGCCCCCGCCTCCGTCACAGCCCTCACGGACGCCAGGGGCCACACGGACACCGAGGGCCGGCCTCCCTCCCCCCCGCCCAC CTCCACCCCTGAAAAGTGCCTCAGCGTAGCCTGCCTGGACAAGAATGAGCTCAGTGACCACTTGGATGCTATGGACTCCAACCTGGATAA CCTGCAGACCATGCTGAGCAGCCACGGCTTCAGCGTGGACACCAGTGCCCTGCTGGACGTAGATGATGAGCTGGAGATCAAGGCCTACTA TGCAGGCCACGTGCTGGGGGCAGCCATGTTCCAGATTAAAGTGGGCTCAGAGTCTGTGGTCTACACGGGTGATTATAACATGACCCCAGA CCGACACTTAGGAGCTGCCTGGATTGACAAGTGCCGCCCCAACCTGCTCATCACAGAGTCCACGTACGCCACGACCATCCGTGACTCCAA GCGCTGCCGGGAGCGAGACTTCCTGAAGAAAGTCCACGAGACCGTGGAGCGTGGTGGGAAGGTGCTGATACCTGTGTTCGCGCTGGGCCG CGCCCAGGAGCTCTGCATCCTCCTGGAGACCTTCTGGGAGCGCATGAACCTGAAGGTGCCCATCTACTTCTCCACGGGGCTGACCGAGAA GGCCAACCACTACTACAAGCTGTTCATCCCCTGGACCAACCAGAAGATCCGCAAGACTTTCGTGCAGAGGAACATGTTTGAGTTCAAGCA CATCAAGGCCTTCGACCGGGCTTTTGCTGACAACCCAGGACCGATGGTTGTGTTTGCCACGCCAGGAATGCTGCACGCTGGGCAGTCCCT GCAGATCTTCCGGAAATGGGCCGGAAACGAAAAGAACATGGTCATCATGCCCGGCTACTGCGTGCAGGGCACCGTCGGCCACAAGATCCT CAGCGGGCAGCGGAAGCTCGAGATGGAGGGGCGGCAGGTGCTGGAGGTCAAGATGCAGGTGGAGTACATGTCATTCAGCGCACACGCGGA CGCCAAGGGCATCATGCAGCTGGTGGGCCAGGCAGAGCCGGAGAGCGTGCTGCTGGTGCATGGCGAGGCCAAGAAGATGGAGTTCCTGAA GCAGAAGATCGAGCAGGAGCTCCGGGTCAACTGCTACATGCCGGCCAATGGCGAGACGGTGACGCTGCCCACAAGCCCCAGCATCCCCGT AGGCATCTCGCTGGGGCTGCTGAAGCGGGAGATGGCGCAGGGGCTGCTCCCTGAGGCCAAGAAGCCTCGGCTCCTGCACGGCACCCTGAT CATGAAGGACAGCAACTTCCGGCTGGTGTCCTCAGAGCAAGCCCTCAAAGAGCTGGGTCTGGCTGAGCACCAGCTGCGCTTCACCTGCCG CGTGCACCTGCATGACACACGCAAGGAGCAGGAGACGGCATTGCGCGTCTACAGCCACCTCAAGAGCGTCCTGAAGGACCACTGTGTGCA GCACCTCCCAGACGGCTCTGTGACTGTGGAGTCCGTCCTCCTCCAGGCCGCCGCCCCTTCTGAGGACCCAGGCACCAAGGTGCTGCTGGT CTCCTGGACCTACCAGGACGAGGAGCTGGGGAGCTTCCTCACATCTCTGCTGAAGAAGGGCCTCCCCCAGGCCCCCAGCTGAGGCCGGCA ACTCACCCAGCCGCCACCTCTGCCCTCTCCCAGCTGGACAGACCCTGGGCCTGCACTTCAGGACTGTGGGTGCCCTGGGTGAACAGACCC TGCAGGTCCCATCCCTGGGGACAGAGGCCTTGTGTCACCTGCCTGCCCAGGCAGCTGTTTGCAGCTGAAGAAACAAACTGGTCTCCAGGC >37706_37706_4_HSF1-CPSF3L_HSF1_chr8_145537302_ENST00000528838_CPSF3L_chr1_1250998_ENST00000435064_length(amino acids)=912AA_BP=280 MCVRSGRRRGPEGWRGDGVSPALGPSLRPLPPPIPSLLEMDLPVGPGAAGPSNVPAFLTKLWTLVSDPDTDALICWSPSGNSFHVFDQGQ FAKEVLPKYFKHNNMASFVRQLNMYGFRKVVHIEQGGLVKPERDDTEFQHPCFLRGQEQLLENIKRKVTSVSTLKSEDIKIRQDSVTKLL TDVQLMKGKQECMDSKLLAMKHENEALWREVASLRQKHAQQQKVVNKLIQFLISLVQSNRILGVKRKIPLMLNDSGSAHSMPKYSRQFSL EHVHGSGPYSAPSPAYSSSSLYAPDAVASSGPIISDITELAPASPMASPGGSIDERPLSSSPLVRVKEEPPSPPQSPRVEEASPGRPSSV DTLLSPTALIDSILRESEPAPASVTALTDARGHTDTEGRPPSPPPTSTPEKCLSVACLDKNELSDHLDAMDSNLDNLQTMLSSHGFSVDT SALLDVDDELEIKAYYAGHVLGAAMFQIKVGSESVVYTGDYNMTPDRHLGAAWIDKCRPNLLITESTYATTIRDSKRCRERDFLKKVHET VERGGKVLIPVFALGRAQELCILLETFWERMNLKVPIYFSTGLTEKANHYYKLFIPWTNQKIRKTFVQRNMFEFKHIKAFDRAFADNPGP MVVFATPGMLHAGQSLQIFRKWAGNEKNMVIMPGYCVQGTVGHKILSGQRKLEMEGRQVLEVKMQVEYMSFSAHADAKGIMQLVGQAEPE SVLLVHGEAKKMEFLKQKIEQELRVNCYMPANGETVTLPTSPSIPVGISLGLLKREMAQGLLPEAKKPRLLHGTLIMKDSNFRLVSSEQA LKELGLAEHQLRFTCRVHLHDTRKEQETALRVYSHLKSVLKDHCVQHLPDGSVTVESVLLQAAAPSEDPGTKVLLVSWTYQDEELGSFLT -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for HSF1-CPSF3L |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for HSF1-CPSF3L |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for HSF1-CPSF3L |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies