
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:HSPA4-ERCC8 (FusionGDB2 ID:37865) |
Fusion Gene Summary for HSPA4-ERCC8 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: HSPA4-ERCC8 | Fusion gene ID: 37865 | Hgene | Tgene | Gene symbol | HSPA4 | ERCC8 | Gene ID | 3308 | 1161 |
| Gene name | heat shock protein family A (Hsp70) member 4 | ERCC excision repair 8, CSA ubiquitin ligase complex subunit | |
| Synonyms | APG-2|HEL-S-5a|HS24/P52|HSPH2|RY|hsp70|hsp70RY | CKN1|CSA|UVSS2 | |
| Cytomap | 5q31.1 | 5q12.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | heat shock 70 kDa protein 4epididymis secretory sperm binding protein Li 5aheat shock 70-related protein APG-2heat shock 70kD protein 4heat shock 70kDa protein 4heat shock protein, 110 kDahsp70 RY | DNA excision repair protein ERCC-8Cockayne syndrome WD-repeat protein CSAcockayne syndrome WD repeat protein CSAexcision repair cross-complementation group 8excision repair cross-complementing rodent repair deficiency, complementation group 8 | |
| Modification date | 20200327 | 20200322 | |
| UniProtAcc | P34932 | Q13216 | |
| Ensembl transtripts involved in fusion gene | ENST00000304858, ENST00000504328, | ENST00000462279, ENST00000543101, ENST00000265038, ENST00000426742, | |
| Fusion gene scores | * DoF score | 3 X 5 X 2=30 | 8 X 8 X 7=448 |
| # samples | 5 | 13 | |
| ** MAII score | log2(5/30*10)=0.736965594166206 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | log2(13/448*10)=-1.78498710902915 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: HSPA4 [Title/Abstract] AND ERCC8 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | HSPA4(132432978)-ERCC8(60200700), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | HSPA4 | GO:0045040 | protein import into mitochondrial outer membrane | 15644312 |
| Hgene | HSPA4 | GO:0051131 | chaperone-mediated protein complex assembly | 15644312 |
| Tgene | ERCC8 | GO:0000012 | single strand break repair | 29545921 |
| Tgene | ERCC8 | GO:0000209 | protein polyubiquitination | 12732143 |
| Tgene | ERCC8 | GO:0006283 | transcription-coupled nucleotide-excision repair | 12732143 |
| Tgene | ERCC8 | GO:0006974 | cellular response to DNA damage stimulus | 11782547 |
| Tgene | ERCC8 | GO:0006979 | response to oxidative stress | 11782547 |
| Tgene | ERCC8 | GO:0009411 | response to UV | 12732143 |
| Tgene | ERCC8 | GO:0043161 | proteasome-mediated ubiquitin-dependent protein catabolic process | 16751180 |
| Tgene | ERCC8 | GO:0051865 | protein autoubiquitination | 12732143 |
| Tgene | ERCC8 | GO:0097680 | double-strand break repair via classical nonhomologous end joining | 29545921 |
| Fusion gene breakpoints across HSPA4 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across ERCC8 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | OV | TCGA-24-2298-01A | HSPA4 | chr5 | 132432978 | + | ERCC8 | chr5 | 60200700 | - |
Top |
Fusion Gene ORF analysis for HSPA4-ERCC8 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-5UTR | ENST00000304858 | ENST00000462279 | HSPA4 | chr5 | 132432978 | + | ERCC8 | chr5 | 60200700 | - |
| 5CDS-intron | ENST00000304858 | ENST00000543101 | HSPA4 | chr5 | 132432978 | + | ERCC8 | chr5 | 60200700 | - |
| In-frame | ENST00000304858 | ENST00000265038 | HSPA4 | chr5 | 132432978 | + | ERCC8 | chr5 | 60200700 | - |
| In-frame | ENST00000304858 | ENST00000426742 | HSPA4 | chr5 | 132432978 | + | ERCC8 | chr5 | 60200700 | - |
| intron-3CDS | ENST00000504328 | ENST00000265038 | HSPA4 | chr5 | 132432978 | + | ERCC8 | chr5 | 60200700 | - |
| intron-3CDS | ENST00000504328 | ENST00000426742 | HSPA4 | chr5 | 132432978 | + | ERCC8 | chr5 | 60200700 | - |
| intron-5UTR | ENST00000504328 | ENST00000462279 | HSPA4 | chr5 | 132432978 | + | ERCC8 | chr5 | 60200700 | - |
| intron-intron | ENST00000504328 | ENST00000543101 | HSPA4 | chr5 | 132432978 | + | ERCC8 | chr5 | 60200700 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000304858 | HSPA4 | chr5 | 132432978 | + | ENST00000426742 | ERCC8 | chr5 | 60200700 | - | 3794 | 2218 | 289 | 3009 | 906 |
| ENST00000304858 | HSPA4 | chr5 | 132432978 | + | ENST00000265038 | ERCC8 | chr5 | 60200700 | - | 3793 | 2218 | 289 | 3009 | 906 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000304858 | ENST00000426742 | HSPA4 | chr5 | 132432978 | + | ERCC8 | chr5 | 60200700 | - | 0.000705909 | 0.99929404 |
| ENST00000304858 | ENST00000265038 | HSPA4 | chr5 | 132432978 | + | ERCC8 | chr5 | 60200700 | - | 0.00070446 | 0.9992955 |
Top |
Fusion Genomic Features for HSPA4-ERCC8 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
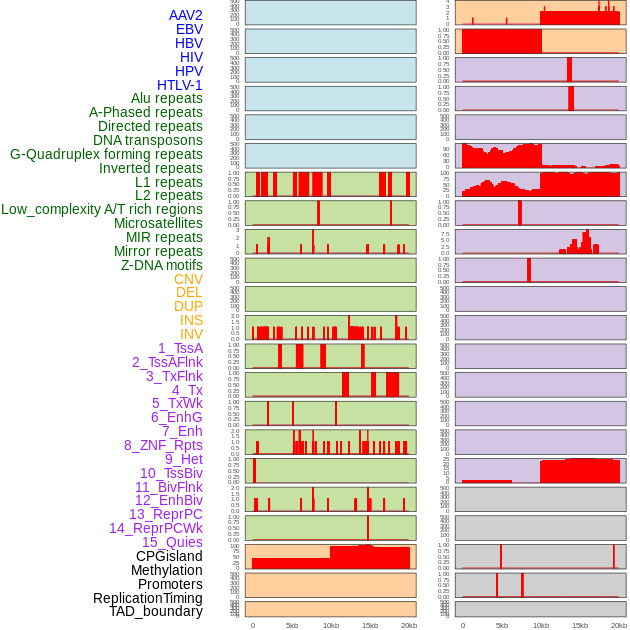 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for HSPA4-ERCC8 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr5:132432978/chr5:60200700) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| HSPA4 | ERCC8 |
| FUNCTION: Substrate-recognition component of the CSA complex, a DCX (DDB1-CUL4-X-box) E3 ubiquitin-protein ligase complex, involved in transcription-coupled nucleotide excision repair. The CSA complex (DCX(ERCC8) complex) promotes the ubiquitination and subsequent proteasomal degradation of ERCC6 in a UV-dependent manner; ERCC6 degradation is essential for the recovery of RNA synthesis after transcription-coupled repair. It is required for the recruitment of XAB2, HMGN1 and TCEA1/TFIIS to a transcription-coupled repair complex which removes RNA polymerase II-blocking lesions from the transcribed strand of active genes. Plays a role in DNA single-strand and double-strand breaks (DSSBs) repair; involved in repair of DSSBs by non-homologous end joining (NHEJ) (PubMed:29545921). {ECO:0000269|PubMed:16751180, ECO:0000269|PubMed:16916636, ECO:0000269|PubMed:16964240, ECO:0000269|PubMed:29545921}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | ERCC8 | chr5:132432978 | chr5:60200700 | ENST00000265038 | 3 | 12 | 133_173 | 133 | 397.0 | Repeat | Note=WD 3 | |
| Tgene | ERCC8 | chr5:132432978 | chr5:60200700 | ENST00000265038 | 3 | 12 | 177_216 | 133 | 397.0 | Repeat | Note=WD 4 | |
| Tgene | ERCC8 | chr5:132432978 | chr5:60200700 | ENST00000265038 | 3 | 12 | 235_274 | 133 | 397.0 | Repeat | Note=WD 5 | |
| Tgene | ERCC8 | chr5:132432978 | chr5:60200700 | ENST00000265038 | 3 | 12 | 281_321 | 133 | 397.0 | Repeat | Note=WD 6 | |
| Tgene | ERCC8 | chr5:132432978 | chr5:60200700 | ENST00000265038 | 3 | 12 | 325_363 | 133 | 397.0 | Repeat | Note=WD 7 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | ERCC8 | chr5:132432978 | chr5:60200700 | ENST00000265038 | 3 | 12 | 33_73 | 133 | 397.0 | Repeat | Note=WD 1 | |
| Tgene | ERCC8 | chr5:132432978 | chr5:60200700 | ENST00000265038 | 3 | 12 | 88_129 | 133 | 397.0 | Repeat | Note=WD 2 |
Top |
Fusion Gene Sequence for HSPA4-ERCC8 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >37865_37865_1_HSPA4-ERCC8_HSPA4_chr5_132432978_ENST00000304858_ERCC8_chr5_60200700_ENST00000265038_length(transcript)=3793nt_BP=2218nt CTTTCGTAGCTCTGGTGCTGCGGCTCCGCTCTCGTCGCAACGAGATCTTTCGAGATCTTCTCCGCCCCCGCTACCGGCGCCTCCTCTGCG GCCACTGAGCCGGAGCCGGCCTGAGCAGCGCTCTCGGTTGCAGTACCCACTGGAAGGACTTAGGCGCTCGCGTGGACACCGCAAGCCCCT CAGTAGCCTCGGCCCAAGAGGCCTGCTTTCCACTCGCTAGCCCCGCCGGGGGTCCGTGTCCTGTCTCGGTGGCCGGACCCGGGCCCGAGC CCGAGCAGTAGCCGGCGCCATGTCGGTGGTGGGCATAGACCTGGGCTTCCAGAGCTGCTACGTCGCTGTGGCCCGCGCCGGCGGCATCGA GACTATCGCTAATGAGTATAGCGACCGCTGCACGCCGGCTTGCATTTCTTTTGGTCCTAAGAATCGTTCAATTGGAGCAGCAGCTAAAAG CCAGGTAATTTCTAATGCAAAGAACACAGTCCAAGGATTTAAAAGATTCCATGGCCGAGCATTCTCTGATCCATTTGTGGAGGCAGAAAA ATCTAACCTTGCATATGATATTGTGCAGTTGCCTACAGGATTAACAGGTATAAAGGTGACATATATGGAGGAAGAGCGAAATTTTACCAC TGAGCAAGTGACTGCCATGCTTTTGTCCAAACTGAAGGAGACAGCCGAAAGTGTTCTTAAGAAGCCTGTAGTTGACTGTGTTGTTTCGGT TCCTTGTTTCTATACTGATGCAGAAAGACGATCAGTGATGGATGCAACACAGATTGCTGGTCTTAATTGCTTGCGATTAATGAATGAAAC CACTGCAGTTGCTCTTGCATATGGAATCTATAAGCAGGATCTTCCTGCCTTAGAAGAGAAACCAAGAAATGTAGTTTTTGTAGACATGGG CCACTCTGCTTATCAAGTTTCTGTATGTGCATTTAATAGAGGAAAACTGAAAGTTCTGGCCACTGCATTTGACACGACATTGGGAGGTAG AAAATTTGATGAAGTGTTAGTAAATCACTTCTGTGAAGAATTTGGGAAGAAATACAAGCTAGACATTAAGTCCAAAATCCGTGCATTATT ACGACTCTCTCAGGAGTGTGAGAAACTCAAGAAATTGATGAGTGCAAATGCTTCAGATCTCCCTTTGAGCATTGAATGTTTTATGAATGA TGTTGATGTATCTGGAACTATGAATAGAGGCAAATTTCTGGAGATGTGCAATGATCTCTTAGCTAGAGTGGAGCCACCACTTCGTAGTGT TTTGGAACAAACCAAGTTAAAGAAAGAAGATATTTATGCAGTGGAGATAGTTGGTGGTGCTACACGAATCCCTGCGGTAAAAGAGAAGAT CAGCAAATTTTTCGGTAAAGAACTTAGTACAACATTAAATGCTGATGAAGCTGTCACTCGAGGCTGTGCATTGCAGTGTGCCATCTTATC GCCTGCTTTCAAAGTCAGAGAATTTTCTATCACTGATGTAGTACCATATCCAATATCTCTGAGATGGAATTCTCCAGCTGAAGAAGGGTC AAGTGACTGTGAAGTCTTTTCCAAAAATCATGCTGCTCCTTTCTCTAAAGTTCTTACATTTTATAGAAAGGAACCTTTCACTCTTGAGGC CTACTACAGCTCTCCTCAGGATTTGCCCTATCCAGATCCTGCTATAGCTCAGTTTTCAGTTCAGAAAGTCACTCCTCAGTCTGATGGCTC CAGTTCAAAAGTGAAAGTCAAAGTTCGAGTAAATGTCCATGGCATTTTCAGTGTGTCCAGTGCATCTTTAGTGGAGGTTCACAAGTCTGA GGAAAATGAGGAGCCAATGGAAACAGATCAGAATGCAAAGGAGGAAGAGAAGATGCAAGTGGACCAGGAGGAACCACATGTTGAAGAGCA ACAGCAGCAGACACCAGCAGAAAATAAGGCAGAGTCTGAAGAAATGGAGACCTCTCAAGCTGGATCCAAGGATAAAAAGATGGACCAACC ACCCCAAGCCAAGAAGGCAAAAGTGAAGACCAGTACTGTGGACCTGCCAATCGAGAATCAGCTATTATGGCAGATAGACAGAGAGATGCT CAACTTGTACATTGAAAATGAGGGTAAGATGATCATGCAGGATAAACTGGAGAAGGAGCGGAATGATGCTAAGAACGCAGTGGAGGAATA TGTGTATGAAATGAGAGACAAGCTTAGTGGTGAATATGAGAAGTTTGTGAGTGAAGATACTGCAGATGTATTTAATTTTGAGGAAACAGT TTATAGTCATCATATGTCTCCAGTCTCCACCAAGCACTGTTTGGTAGCAGTTGGTACTAGAGGACCCAAAGTACAACTTTGTGACTTGAA GTCTGGATCCTGTTCTCACATTCTACAGGGTCACAGACAAGAAATATTAGCAGTTTCCTGGTCTCCACGTTATGACTATATCTTGGCAAC AGCAAGTGCTGACAGTAGAGTAAAATTATGGGATGTGAGAAGAGCATCAGGATGTTTGATTACTCTTGATCAACATAATGGGAAAAAGTC ACAAGCTGTTGAATCAGCAAACACTGCTCATAATGGGAAAGTTAATGGCTTATGTTTTACAAGTGATGGACTTCACCTCCTCACTGTTGG TACAGATAATCGAATGAGGCTCTGGAATAGTTCCAATGGAGAAAACACACTTGTGAACTATGGAAAAGTTTGTAATAACAGTAAAAAAGG ATTGAAATTCACTGTCTCCTGTGGCTGCAGTTCAGAATTTGTTTTTGTACCATATGGTAGCACCATTGCTGTTTATACAGTTTACTCAGG AGAACAGATAACTATGCTTAAGGGACATTATAAAACTGTTGACTGCTGTGTATTTCAGTCAAATTTCCAGGAACTTTATAGTGGTAGCAG AGACTGCAACATTCTGGCTTGGGTTCCATCCTTATATGAACCAGTTCCTGATGATGATGAGACTACAACAAAATCACAATTAAATCCGGC CTTTGAAGATGCCTGGAGCAGCAGTGATGAAGAAGGATGAATATCATCTTTAGTACCTTTTTGTCTCTGCTGAAACTTTTTAAATGAGAC TGTGTTTTTTTCAACTGTATGGTCTATTCCTGACAGCTAAATTAGCCCTAAATGTGGGTAATATTTTTCCTCATGTTTTAAAATGAGGTT AATATTTGCATAAAATCCTAAAACAGACTTCTGTATAGTTTATTTAGTCAAAATGTGTTCCTTGATCCCAGATGTTGTGGCCTGGGAAAG CCCTCATTGCTACAGTACAAGTAACACAAGTCGTTGTACCTCAGTTGTGACCTTCAGCAGATTTTATGAACTATAAGATGCAGTCTCAGA GGATCAGCAAGTGGAGGCCATCAGTATTGACTTTCTCTTACTTGCTGTACTATCAGCCTGCTCGTTTCCACCTTTAAGAATGATTTTGCC AAGAATGATTATATCAAAAATAGTAGTTGAAATGGTAACATCAAAATTATTTTATTCTTTCTTCTTCATGTATTCACATTTTTCAGTGGT TTCATTTAATTAACCATGCTTTATGTTAAACATTTTGGGGCTCAATGTCTCCTACTATCCAAAATGTGCATCACAGGAGGCTTTTAACTT TGTGAAAATCCCATGTTTGCTTTATTTTATTTTAATGTCAGAAGGCAGTTTGCGCTAATGCTTGAACTCTTTTTCTGTGAAACTCATTAA GGTATGACCAAATCCTGCCTCATTAATTCAAGCAGAAAATATCCTGGCAGGGAATCTGGCTTAAACATGAAATGCTGTAATAAAATTTCT >37865_37865_1_HSPA4-ERCC8_HSPA4_chr5_132432978_ENST00000304858_ERCC8_chr5_60200700_ENST00000265038_length(amino acids)=906AA_BP=643 MSVVGIDLGFQSCYVAVARAGGIETIANEYSDRCTPACISFGPKNRSIGAAAKSQVISNAKNTVQGFKRFHGRAFSDPFVEAEKSNLAYD IVQLPTGLTGIKVTYMEEERNFTTEQVTAMLLSKLKETAESVLKKPVVDCVVSVPCFYTDAERRSVMDATQIAGLNCLRLMNETTAVALA YGIYKQDLPALEEKPRNVVFVDMGHSAYQVSVCAFNRGKLKVLATAFDTTLGGRKFDEVLVNHFCEEFGKKYKLDIKSKIRALLRLSQEC EKLKKLMSANASDLPLSIECFMNDVDVSGTMNRGKFLEMCNDLLARVEPPLRSVLEQTKLKKEDIYAVEIVGGATRIPAVKEKISKFFGK ELSTTLNADEAVTRGCALQCAILSPAFKVREFSITDVVPYPISLRWNSPAEEGSSDCEVFSKNHAAPFSKVLTFYRKEPFTLEAYYSSPQ DLPYPDPAIAQFSVQKVTPQSDGSSSKVKVKVRVNVHGIFSVSSASLVEVHKSEENEEPMETDQNAKEEEKMQVDQEEPHVEEQQQQTPA ENKAESEEMETSQAGSKDKKMDQPPQAKKAKVKTSTVDLPIENQLLWQIDREMLNLYIENEGKMIMQDKLEKERNDAKNAVEEYVYEMRD KLSGEYEKFVSEDTADVFNFEETVYSHHMSPVSTKHCLVAVGTRGPKVQLCDLKSGSCSHILQGHRQEILAVSWSPRYDYILATASADSR VKLWDVRRASGCLITLDQHNGKKSQAVESANTAHNGKVNGLCFTSDGLHLLTVGTDNRMRLWNSSNGENTLVNYGKVCNNSKKGLKFTVS CGCSSEFVFVPYGSTIAVYTVYSGEQITMLKGHYKTVDCCVFQSNFQELYSGSRDCNILAWVPSLYEPVPDDDETTTKSQLNPAFEDAWS -------------------------------------------------------------- >37865_37865_2_HSPA4-ERCC8_HSPA4_chr5_132432978_ENST00000304858_ERCC8_chr5_60200700_ENST00000426742_length(transcript)=3794nt_BP=2218nt CTTTCGTAGCTCTGGTGCTGCGGCTCCGCTCTCGTCGCAACGAGATCTTTCGAGATCTTCTCCGCCCCCGCTACCGGCGCCTCCTCTGCG GCCACTGAGCCGGAGCCGGCCTGAGCAGCGCTCTCGGTTGCAGTACCCACTGGAAGGACTTAGGCGCTCGCGTGGACACCGCAAGCCCCT CAGTAGCCTCGGCCCAAGAGGCCTGCTTTCCACTCGCTAGCCCCGCCGGGGGTCCGTGTCCTGTCTCGGTGGCCGGACCCGGGCCCGAGC CCGAGCAGTAGCCGGCGCCATGTCGGTGGTGGGCATAGACCTGGGCTTCCAGAGCTGCTACGTCGCTGTGGCCCGCGCCGGCGGCATCGA GACTATCGCTAATGAGTATAGCGACCGCTGCACGCCGGCTTGCATTTCTTTTGGTCCTAAGAATCGTTCAATTGGAGCAGCAGCTAAAAG CCAGGTAATTTCTAATGCAAAGAACACAGTCCAAGGATTTAAAAGATTCCATGGCCGAGCATTCTCTGATCCATTTGTGGAGGCAGAAAA ATCTAACCTTGCATATGATATTGTGCAGTTGCCTACAGGATTAACAGGTATAAAGGTGACATATATGGAGGAAGAGCGAAATTTTACCAC TGAGCAAGTGACTGCCATGCTTTTGTCCAAACTGAAGGAGACAGCCGAAAGTGTTCTTAAGAAGCCTGTAGTTGACTGTGTTGTTTCGGT TCCTTGTTTCTATACTGATGCAGAAAGACGATCAGTGATGGATGCAACACAGATTGCTGGTCTTAATTGCTTGCGATTAATGAATGAAAC CACTGCAGTTGCTCTTGCATATGGAATCTATAAGCAGGATCTTCCTGCCTTAGAAGAGAAACCAAGAAATGTAGTTTTTGTAGACATGGG CCACTCTGCTTATCAAGTTTCTGTATGTGCATTTAATAGAGGAAAACTGAAAGTTCTGGCCACTGCATTTGACACGACATTGGGAGGTAG AAAATTTGATGAAGTGTTAGTAAATCACTTCTGTGAAGAATTTGGGAAGAAATACAAGCTAGACATTAAGTCCAAAATCCGTGCATTATT ACGACTCTCTCAGGAGTGTGAGAAACTCAAGAAATTGATGAGTGCAAATGCTTCAGATCTCCCTTTGAGCATTGAATGTTTTATGAATGA TGTTGATGTATCTGGAACTATGAATAGAGGCAAATTTCTGGAGATGTGCAATGATCTCTTAGCTAGAGTGGAGCCACCACTTCGTAGTGT TTTGGAACAAACCAAGTTAAAGAAAGAAGATATTTATGCAGTGGAGATAGTTGGTGGTGCTACACGAATCCCTGCGGTAAAAGAGAAGAT CAGCAAATTTTTCGGTAAAGAACTTAGTACAACATTAAATGCTGATGAAGCTGTCACTCGAGGCTGTGCATTGCAGTGTGCCATCTTATC GCCTGCTTTCAAAGTCAGAGAATTTTCTATCACTGATGTAGTACCATATCCAATATCTCTGAGATGGAATTCTCCAGCTGAAGAAGGGTC AAGTGACTGTGAAGTCTTTTCCAAAAATCATGCTGCTCCTTTCTCTAAAGTTCTTACATTTTATAGAAAGGAACCTTTCACTCTTGAGGC CTACTACAGCTCTCCTCAGGATTTGCCCTATCCAGATCCTGCTATAGCTCAGTTTTCAGTTCAGAAAGTCACTCCTCAGTCTGATGGCTC CAGTTCAAAAGTGAAAGTCAAAGTTCGAGTAAATGTCCATGGCATTTTCAGTGTGTCCAGTGCATCTTTAGTGGAGGTTCACAAGTCTGA GGAAAATGAGGAGCCAATGGAAACAGATCAGAATGCAAAGGAGGAAGAGAAGATGCAAGTGGACCAGGAGGAACCACATGTTGAAGAGCA ACAGCAGCAGACACCAGCAGAAAATAAGGCAGAGTCTGAAGAAATGGAGACCTCTCAAGCTGGATCCAAGGATAAAAAGATGGACCAACC ACCCCAAGCCAAGAAGGCAAAAGTGAAGACCAGTACTGTGGACCTGCCAATCGAGAATCAGCTATTATGGCAGATAGACAGAGAGATGCT CAACTTGTACATTGAAAATGAGGGTAAGATGATCATGCAGGATAAACTGGAGAAGGAGCGGAATGATGCTAAGAACGCAGTGGAGGAATA TGTGTATGAAATGAGAGACAAGCTTAGTGGTGAATATGAGAAGTTTGTGAGTGAAGATACTGCAGATGTATTTAATTTTGAGGAAACAGT TTATAGTCATCATATGTCTCCAGTCTCCACCAAGCACTGTTTGGTAGCAGTTGGTACTAGAGGACCCAAAGTACAACTTTGTGACTTGAA GTCTGGATCCTGTTCTCACATTCTACAGGGTCACAGACAAGAAATATTAGCAGTTTCCTGGTCTCCACGTTATGACTATATCTTGGCAAC AGCAAGTGCTGACAGTAGAGTAAAATTATGGGATGTGAGAAGAGCATCAGGATGTTTGATTACTCTTGATCAACATAATGGGAAAAAGTC ACAAGCTGTTGAATCAGCAAACACTGCTCATAATGGGAAAGTTAATGGCTTATGTTTTACAAGTGATGGACTTCACCTCCTCACTGTTGG TACAGATAATCGAATGAGGCTCTGGAATAGTTCCAATGGAGAAAACACACTTGTGAACTATGGAAAAGTTTGTAATAACAGTAAAAAAGG ATTGAAATTCACTGTCTCCTGTGGCTGCAGTTCAGAATTTGTTTTTGTACCATATGGTAGCACCATTGCTGTTTATACAGTTTACTCAGG AGAACAGATAACTATGCTTAAGGGACATTATAAAACTGTTGACTGCTGTGTATTTCAGTCAAATTTCCAGGAACTTTATAGTGGTAGCAG AGACTGCAACATTCTGGCTTGGGTTCCATCCTTATATGAACCAGTTCCTGATGATGATGAGACTACAACAAAATCACAATTAAATCCGGC CTTTGAAGATGCCTGGAGCAGCAGTGATGAAGAAGGATGAATATCATCTTTAGTACCTTTTTGTCTCTGCTGAAACTTTTTAAATGAGAC TGTGTTTTTTTCAACTGTATGGTCTATTCCTGACAGCTAAATTAGCCCTAAATGTGGGTAATATTTTTCCTCATGTTTTAAAATGAGGTT AATATTTGCATAAAATCCTAAAACAGACTTCTGTATAGTTTATTTAGTCAAAATGTGTTCCTTGATCCCAGATGTTGTGGCCTGGGAAAG CCCTCATTGCTACAGTACAAGTAACACAAGTCGTTGTACCTCAGTTGTGACCTTCAGCAGATTTTATGAACTATAAGATGCAGTCTCAGA GGATCAGCAAGTGGAGGCCATCAGTATTGACTTTCTCTTACTTGCTGTACTATCAGCCTGCTCGTTTCCACCTTTAAGAATGATTTTGCC AAGAATGATTATATCAAAAATAGTAGTTGAAATGGTAACATCAAAATTATTTTATTCTTTCTTCTTCATGTATTCACATTTTTCAGTGGT TTCATTTAATTAACCATGCTTTATGTTAAACATTTTGGGGCTCAATGTCTCCTACTATCCAAAATGTGCATCACAGGAGGCTTTTAACTT TGTGAAAATCCCATGTTTGCTTTATTTTATTTTAATGTCAGAAGGCAGTTTGCGCTAATGCTTGAACTCTTTTTCTGTGAAACTCATTAA GGTATGACCAAATCCTGCCTCATTAATTCAAGCAGAAAATATCCTGGCAGGGAATCTGGCTTAAACATGAAATGCTGTAATAAAATTTCT >37865_37865_2_HSPA4-ERCC8_HSPA4_chr5_132432978_ENST00000304858_ERCC8_chr5_60200700_ENST00000426742_length(amino acids)=906AA_BP=643 MSVVGIDLGFQSCYVAVARAGGIETIANEYSDRCTPACISFGPKNRSIGAAAKSQVISNAKNTVQGFKRFHGRAFSDPFVEAEKSNLAYD IVQLPTGLTGIKVTYMEEERNFTTEQVTAMLLSKLKETAESVLKKPVVDCVVSVPCFYTDAERRSVMDATQIAGLNCLRLMNETTAVALA YGIYKQDLPALEEKPRNVVFVDMGHSAYQVSVCAFNRGKLKVLATAFDTTLGGRKFDEVLVNHFCEEFGKKYKLDIKSKIRALLRLSQEC EKLKKLMSANASDLPLSIECFMNDVDVSGTMNRGKFLEMCNDLLARVEPPLRSVLEQTKLKKEDIYAVEIVGGATRIPAVKEKISKFFGK ELSTTLNADEAVTRGCALQCAILSPAFKVREFSITDVVPYPISLRWNSPAEEGSSDCEVFSKNHAAPFSKVLTFYRKEPFTLEAYYSSPQ DLPYPDPAIAQFSVQKVTPQSDGSSSKVKVKVRVNVHGIFSVSSASLVEVHKSEENEEPMETDQNAKEEEKMQVDQEEPHVEEQQQQTPA ENKAESEEMETSQAGSKDKKMDQPPQAKKAKVKTSTVDLPIENQLLWQIDREMLNLYIENEGKMIMQDKLEKERNDAKNAVEEYVYEMRD KLSGEYEKFVSEDTADVFNFEETVYSHHMSPVSTKHCLVAVGTRGPKVQLCDLKSGSCSHILQGHRQEILAVSWSPRYDYILATASADSR VKLWDVRRASGCLITLDQHNGKKSQAVESANTAHNGKVNGLCFTSDGLHLLTVGTDNRMRLWNSSNGENTLVNYGKVCNNSKKGLKFTVS CGCSSEFVFVPYGSTIAVYTVYSGEQITMLKGHYKTVDCCVFQSNFQELYSGSRDCNILAWVPSLYEPVPDDDETTTKSQLNPAFEDAWS -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for HSPA4-ERCC8 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for HSPA4-ERCC8 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for HSPA4-ERCC8 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies