
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:IGLL5-XBP1 (FusionGDB2 ID:39220) |
Fusion Gene Summary for IGLL5-XBP1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: IGLL5-XBP1 | Fusion gene ID: 39220 | Hgene | Tgene | Gene symbol | IGLL5 | XBP1 | Gene ID | 100423062 | 7494 |
| Gene name | immunoglobulin lambda like polypeptide 5 | X-box binding protein 1 | |
| Synonyms | IGL|IGLV|VL-MAR | TREB-5|TREB5|XBP-1|XBP2 | |
| Cytomap | 22q11.22 | 22q12.1|22q12 | |
| Type of gene | protein-coding | protein-coding | |
| Description | immunoglobulin lambda-like polypeptide 5G lambda-1anti HBs antibody light-chain Fab fragmentgermline immunoglobulin lambda 1immunoglobin anti-granzymeB light chain variable regionimmunoglobulin lambda 1 light chainimmunoglobulin lambda 2 light chain | X-box-binding protein 1tax-responsive element-binding protein 5 | |
| Modification date | 20200313 | 20200329 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000526893, ENST00000531372, ENST00000532223, | ENST00000216037, ENST00000344347, ENST00000403532, ENST00000405219, | |
| Fusion gene scores | * DoF score | 16 X 8 X 5=640 | 10 X 11 X 7=770 |
| # samples | 16 | 12 | |
| ** MAII score | log2(16/640*10)=-2 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(12/770*10)=-2.68182403997375 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: IGLL5 [Title/Abstract] AND XBP1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | IGLL5(23230439)-XBP1(29195141), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | XBP1 | GO:0002639 | positive regulation of immunoglobulin production | 11460154 |
| Tgene | XBP1 | GO:0008284 | positive regulation of cell proliferation | 25656649 |
| Tgene | XBP1 | GO:0030335 | positive regulation of cell migration | 25656649 |
| Tgene | XBP1 | GO:0035470 | positive regulation of vascular wound healing | 25656649 |
| Tgene | XBP1 | GO:0045579 | positive regulation of B cell differentiation | 11460154 |
| Tgene | XBP1 | GO:0045582 | positive regulation of T cell differentiation | 11460154 |
| Tgene | XBP1 | GO:0045944 | positive regulation of transcription by RNA polymerase II | 8657566 |
| Tgene | XBP1 | GO:0071222 | cellular response to lipopolysaccharide | 11460154 |
| Tgene | XBP1 | GO:1900100 | positive regulation of plasma cell differentiation | 11460154 |
| Tgene | XBP1 | GO:1902236 | negative regulation of endoplasmic reticulum stress-induced intrinsic apoptotic signaling pathway | 19135031 |
| Fusion gene breakpoints across IGLL5 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across XBP1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-CG-5724-01A | IGLL5 | chr22 | 23230439 | + | XBP1 | chr22 | 29195141 | - |
Top |
Fusion Gene ORF analysis for IGLL5-XBP1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| In-frame | ENST00000526893 | ENST00000216037 | IGLL5 | chr22 | 23230439 | + | XBP1 | chr22 | 29195141 | - |
| In-frame | ENST00000526893 | ENST00000344347 | IGLL5 | chr22 | 23230439 | + | XBP1 | chr22 | 29195141 | - |
| In-frame | ENST00000526893 | ENST00000403532 | IGLL5 | chr22 | 23230439 | + | XBP1 | chr22 | 29195141 | - |
| In-frame | ENST00000526893 | ENST00000405219 | IGLL5 | chr22 | 23230439 | + | XBP1 | chr22 | 29195141 | - |
| In-frame | ENST00000531372 | ENST00000216037 | IGLL5 | chr22 | 23230439 | + | XBP1 | chr22 | 29195141 | - |
| In-frame | ENST00000531372 | ENST00000344347 | IGLL5 | chr22 | 23230439 | + | XBP1 | chr22 | 29195141 | - |
| In-frame | ENST00000531372 | ENST00000403532 | IGLL5 | chr22 | 23230439 | + | XBP1 | chr22 | 29195141 | - |
| In-frame | ENST00000531372 | ENST00000405219 | IGLL5 | chr22 | 23230439 | + | XBP1 | chr22 | 29195141 | - |
| In-frame | ENST00000532223 | ENST00000216037 | IGLL5 | chr22 | 23230439 | + | XBP1 | chr22 | 29195141 | - |
| In-frame | ENST00000532223 | ENST00000344347 | IGLL5 | chr22 | 23230439 | + | XBP1 | chr22 | 29195141 | - |
| In-frame | ENST00000532223 | ENST00000403532 | IGLL5 | chr22 | 23230439 | + | XBP1 | chr22 | 29195141 | - |
| In-frame | ENST00000532223 | ENST00000405219 | IGLL5 | chr22 | 23230439 | + | XBP1 | chr22 | 29195141 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000526893 | IGLL5 | chr22 | 23230439 | + | ENST00000216037 | XBP1 | chr22 | 29195141 | - | 2030 | 480 | 274 | 1038 | 254 |
| ENST00000526893 | IGLL5 | chr22 | 23230439 | + | ENST00000403532 | XBP1 | chr22 | 29195141 | - | 2043 | 480 | 274 | 1053 | 259 |
| ENST00000526893 | IGLL5 | chr22 | 23230439 | + | ENST00000405219 | XBP1 | chr22 | 29195141 | - | 1996 | 480 | 274 | 1038 | 254 |
| ENST00000526893 | IGLL5 | chr22 | 23230439 | + | ENST00000344347 | XBP1 | chr22 | 29195141 | - | 1384 | 480 | 274 | 1383 | 370 |
| ENST00000532223 | IGLL5 | chr22 | 23230439 | + | ENST00000216037 | XBP1 | chr22 | 29195141 | - | 2030 | 480 | 274 | 1038 | 254 |
| ENST00000532223 | IGLL5 | chr22 | 23230439 | + | ENST00000403532 | XBP1 | chr22 | 29195141 | - | 2043 | 480 | 274 | 1053 | 259 |
| ENST00000532223 | IGLL5 | chr22 | 23230439 | + | ENST00000405219 | XBP1 | chr22 | 29195141 | - | 1996 | 480 | 274 | 1038 | 254 |
| ENST00000532223 | IGLL5 | chr22 | 23230439 | + | ENST00000344347 | XBP1 | chr22 | 29195141 | - | 1384 | 480 | 274 | 1383 | 370 |
| ENST00000531372 | IGLL5 | chr22 | 23230439 | + | ENST00000216037 | XBP1 | chr22 | 29195141 | - | 1981 | 431 | 225 | 989 | 254 |
| ENST00000531372 | IGLL5 | chr22 | 23230439 | + | ENST00000403532 | XBP1 | chr22 | 29195141 | - | 1994 | 431 | 225 | 1004 | 259 |
| ENST00000531372 | IGLL5 | chr22 | 23230439 | + | ENST00000405219 | XBP1 | chr22 | 29195141 | - | 1947 | 431 | 225 | 989 | 254 |
| ENST00000531372 | IGLL5 | chr22 | 23230439 | + | ENST00000344347 | XBP1 | chr22 | 29195141 | - | 1335 | 431 | 225 | 1334 | 369 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000526893 | ENST00000216037 | IGLL5 | chr22 | 23230439 | + | XBP1 | chr22 | 29195141 | - | 0.14428692 | 0.8557131 |
| ENST00000526893 | ENST00000403532 | IGLL5 | chr22 | 23230439 | + | XBP1 | chr22 | 29195141 | - | 0.16193701 | 0.83806294 |
| ENST00000526893 | ENST00000405219 | IGLL5 | chr22 | 23230439 | + | XBP1 | chr22 | 29195141 | - | 0.15145656 | 0.84854347 |
| ENST00000526893 | ENST00000344347 | IGLL5 | chr22 | 23230439 | + | XBP1 | chr22 | 29195141 | - | 0.004132799 | 0.99586725 |
| ENST00000532223 | ENST00000216037 | IGLL5 | chr22 | 23230439 | + | XBP1 | chr22 | 29195141 | - | 0.14428692 | 0.8557131 |
| ENST00000532223 | ENST00000403532 | IGLL5 | chr22 | 23230439 | + | XBP1 | chr22 | 29195141 | - | 0.16193701 | 0.83806294 |
| ENST00000532223 | ENST00000405219 | IGLL5 | chr22 | 23230439 | + | XBP1 | chr22 | 29195141 | - | 0.15145656 | 0.84854347 |
| ENST00000532223 | ENST00000344347 | IGLL5 | chr22 | 23230439 | + | XBP1 | chr22 | 29195141 | - | 0.004132799 | 0.99586725 |
| ENST00000531372 | ENST00000216037 | IGLL5 | chr22 | 23230439 | + | XBP1 | chr22 | 29195141 | - | 0.14317283 | 0.8568272 |
| ENST00000531372 | ENST00000403532 | IGLL5 | chr22 | 23230439 | + | XBP1 | chr22 | 29195141 | - | 0.15417805 | 0.8458219 |
| ENST00000531372 | ENST00000405219 | IGLL5 | chr22 | 23230439 | + | XBP1 | chr22 | 29195141 | - | 0.14455603 | 0.855444 |
| ENST00000531372 | ENST00000344347 | IGLL5 | chr22 | 23230439 | + | XBP1 | chr22 | 29195141 | - | 0.00439854 | 0.9956014 |
Top |
Fusion Genomic Features for IGLL5-XBP1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
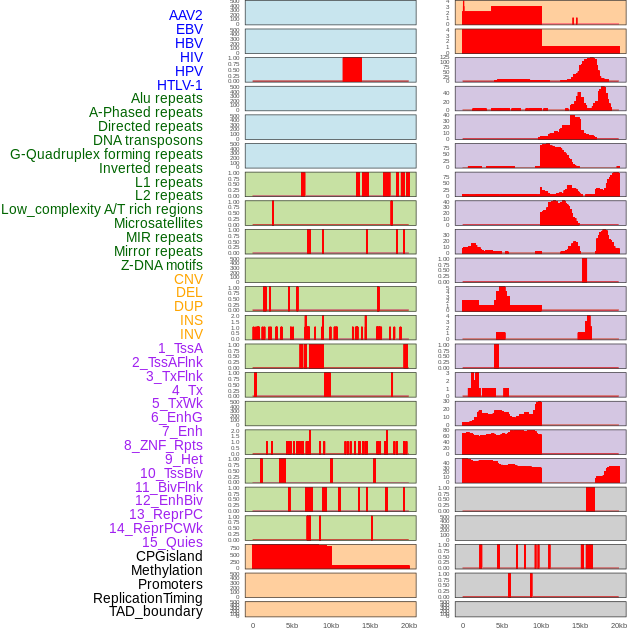
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for IGLL5-XBP1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr22:23230439/chr22:29195141) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | XBP1 | chr22:23230439 | chr22:29195141 | ENST00000216037 | 0 | 5 | 235_261 | 75 | 262.0 | Region | Necessary for the translational pausing of its own mRNA | |
| Tgene | XBP1 | chr22:23230439 | chr22:29195141 | ENST00000216037 | 0 | 5 | 75_92 | 75 | 262.0 | Region | Nuclear localization signal (NLS)%3B in isoforms 1 and isoform 2 | |
| Tgene | XBP1 | chr22:23230439 | chr22:29195141 | ENST00000216037 | 0 | 5 | 98_133 | 75 | 262.0 | Region | Leucine-zipper | |
| Tgene | XBP1 | chr22:23230439 | chr22:29195141 | ENST00000344347 | 0 | 6 | 235_261 | 75 | 377.0 | Region | Necessary for the translational pausing of its own mRNA | |
| Tgene | XBP1 | chr22:23230439 | chr22:29195141 | ENST00000344347 | 0 | 6 | 75_92 | 75 | 377.0 | Region | Nuclear localization signal (NLS)%3B in isoforms 1 and isoform 2 | |
| Tgene | XBP1 | chr22:23230439 | chr22:29195141 | ENST00000344347 | 0 | 6 | 98_133 | 75 | 377.0 | Region | Leucine-zipper | |
| Tgene | XBP1 | chr22:23230439 | chr22:29195141 | ENST00000216037 | 0 | 5 | 204_261 | 75 | 262.0 | Topological domain | Lumenal | |
| Tgene | XBP1 | chr22:23230439 | chr22:29195141 | ENST00000344347 | 0 | 6 | 204_261 | 75 | 377.0 | Topological domain | Lumenal | |
| Tgene | XBP1 | chr22:23230439 | chr22:29195141 | ENST00000216037 | 0 | 5 | 186_203 | 75 | 262.0 | Transmembrane | Helical%3B Signal-anchor for type II membrane protein | |
| Tgene | XBP1 | chr22:23230439 | chr22:29195141 | ENST00000344347 | 0 | 6 | 186_203 | 75 | 377.0 | Transmembrane | Helical%3B Signal-anchor for type II membrane protein |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | IGLL5 | chr22:23230439 | chr22:29195141 | ENST00000526893 | + | 1 | 3 | 115_209 | 68 | 215.0 | Domain | Note=Ig-like C1-type |
| Hgene | IGLL5 | chr22:23230439 | chr22:29195141 | ENST00000531372 | + | 1 | 2 | 115_209 | 68 | 85.0 | Domain | Note=Ig-like C1-type |
| Hgene | IGLL5 | chr22:23230439 | chr22:29195141 | ENST00000532223 | + | 1 | 3 | 7_101 | 68 | 216.0 | Domain | Ig-like |
| Hgene | IGLL5 | chr22:23230439 | chr22:29195141 | ENST00000526893 | + | 1 | 3 | 110_214 | 68 | 215.0 | Region | Note=C region (By similarity to lambda light-chain) |
| Hgene | IGLL5 | chr22:23230439 | chr22:29195141 | ENST00000526893 | + | 1 | 3 | 98_109 | 68 | 215.0 | Region | Note=J region (By similarity to lambda light-chain) |
| Hgene | IGLL5 | chr22:23230439 | chr22:29195141 | ENST00000531372 | + | 1 | 2 | 110_214 | 68 | 85.0 | Region | Note=C region (By similarity to lambda light-chain) |
| Hgene | IGLL5 | chr22:23230439 | chr22:29195141 | ENST00000531372 | + | 1 | 2 | 98_109 | 68 | 85.0 | Region | Note=J region (By similarity to lambda light-chain) |
| Tgene | XBP1 | chr22:23230439 | chr22:29195141 | ENST00000216037 | 0 | 5 | 70_133 | 75 | 262.0 | Domain | bZIP | |
| Tgene | XBP1 | chr22:23230439 | chr22:29195141 | ENST00000344347 | 0 | 6 | 70_133 | 75 | 377.0 | Domain | bZIP | |
| Tgene | XBP1 | chr22:23230439 | chr22:29195141 | ENST00000216037 | 0 | 5 | 72_94 | 75 | 262.0 | Region | Basic motif | |
| Tgene | XBP1 | chr22:23230439 | chr22:29195141 | ENST00000344347 | 0 | 6 | 72_94 | 75 | 377.0 | Region | Basic motif | |
| Tgene | XBP1 | chr22:23230439 | chr22:29195141 | ENST00000216037 | 0 | 5 | 1_185 | 75 | 262.0 | Topological domain | Cytoplasmic | |
| Tgene | XBP1 | chr22:23230439 | chr22:29195141 | ENST00000344347 | 0 | 6 | 1_185 | 75 | 377.0 | Topological domain | Cytoplasmic |
Top |
Fusion Gene Sequence for IGLL5-XBP1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >39220_39220_1_IGLL5-XBP1_IGLL5_chr22_23230439_ENST00000526893_XBP1_chr22_29195141_ENST00000216037_length(transcript)=2030nt_BP=480nt AGCCGGCTGTGGTGGGAGGCAGTTGAGCCCTGGATTGTGACCGCTTCAGGGCAGTTGGTAGATGCCCCTCTGGGAGAGATCCCCAGGGGT GACAGCCATGGACCCTGGAAGGGCCTGGGCTAGGGACAGGGACCAGAGCCAGTCCAGGGAGAGGACAGAGCCAATGGACTGGGGTGTACT GTAACAGCCCTGCTGGCGAGAGGGACCAGGGCACCGTCCTCCAGGGAGCCCATGCTGCAAGTCGGGCCAGAGGTGCCCCTGAACCTGAAG GCCAATGAGACCCAAGACAGGCCAAGTGGGTTGTGAGACCCCTGAGGAGCTGGGCCCTGGTCCCAGGCAGCGCTGGCCCCTGCTGCTGCT GGGTCTGGCCATGGTCGCCCATGGCCTGCTGCGCCCAATGGTTGCACCGCAAAGCGGGGACCCAGACCCTGGAGCCTCAGTTGGAAGCAG CCGATCCAGCCTGCGGAGCCTGTGGGGCAGGAAACTGAAAAACAGAGTAGCAGCTCAGACTGCCAGAGATCGAAAGAAGGCTCGAATGAG TGAGCTGGAACAGCAAGTGGTAGATTTAGAAGAAGAGAACCAAAAACTTTTGCTAGAAAATCAGCTTTTACGAGAGAAAACTCATGGCCT TGTAGTTGAGAACCAGGAGTTAAGACAGCGCTTGGGGATGGATGCCCTGGTTGCTGAAGAGGAGGCGGAAGCCAAGGGGAATGAAGTGAG GCCAGTGGCCGGGTCTGCTGAGTCCGCAGCACTCAGACTACGTGCACCTCTGCAGCAGGTGCAGGCCCAGTTGTCACCCCTCCAGAACAT CTCCCCATGGATTCTGGCGGTATTGACTCTTCAGATTCAGAGTCTGATATCCTGTTGGGCATTCTGGACAACTTGGACCCAGTCATGTTC TTCAAATGCCCTTCCCCAGAGCCTGCCAGCCTGGAGGAGCTCCCAGAGGTCTACCCAGAAGGACCCAGTTCCTTACCAGCCTCCCTTTCT CTGTCAGTGGGGACGTCATCAGCCAAGCTGGAAGCCATTAATGAACTAATTCGTTTTGACCACATATATACCAAGCCCCTAGTCTTAGAG ATACCCTCTGAGACAGAGAGCCAAGCTAATGTGGTAGTGAAAATCGAGGAAGCACCTCTCAGCCCCTCAGAGAATGATCACCCTGAATTC ATTGTCTCAGTGAAGGAAGAACCTGTAGAAGATGACCTCGTTCCGGAGCTGGGTATCTCAAATCTGCTTTCATCCAGCCACTGCCCAAAG CCATCTTCCTGCCTACTGGATGCTTACAGTGACTGTGGATACGGGGGTTCCCTTTCCCCATTCAGTGACATGTCCTCTCTGCTTGGTGTA AACCATTCTTGGGAGGACACTTTTGCCAATGAACTCTTTCCCCAGCTGATTAGTGTCTAAGGAATGATCCAATACTGTTGCCCTTTTCCT TGACTATTACACTGCCTGGAGGATAGCAGAGAAGCCTGTCTGTACTTCATTCAAAAAGCCAAAATAGAGAGTATACAGTCCTAGAGAATT CCTCTATTTGTTCAGATCTCATAGATGACCCCCAGGTATTGTCTTTTGACATCCAGCAGTCCAAGGTATTGAGACATATTACTGGAAGTA AGAAATATTACTATAATTGAGAACTACAGCTTTTAAGATTGTACTTTTATCTTAAAAGGGTGGTAGTTTTCCCTAAAATACTTATTATGT AAGGGTCATTAGACAAATGTCTTGAAGTAGACATGGAATTTATGAATGGTTCTTTATCATTTCTCTTCCCCCTTTTTGGCATCCTGGCTT GCCTCCAGTTTTAGGTCCTTTAGTTTGCTTCTGTAAGCAACGGGAACACCTGCTGAGGGGGCTCTTTCCCTCATGTATACTTCAAGTAAG ATCAAGAATCTTTTGTGAAATTATAGAAATTTACTATGTAAATGCTTGATGGAATTTTTTCCTGCTAGTGTAGCTTCTGAAAGGTGCTTT >39220_39220_1_IGLL5-XBP1_IGLL5_chr22_23230439_ENST00000526893_XBP1_chr22_29195141_ENST00000216037_length(amino acids)=254AA_BP=68 MRPKTGQVGCETPEELGPGPRQRWPLLLLGLAMVAHGLLRPMVAPQSGDPDPGASVGSSRSSLRSLWGRKLKNRVAAQTARDRKKARMSE LEQQVVDLEEENQKLLLENQLLREKTHGLVVENQELRQRLGMDALVAEEEAEAKGNEVRPVAGSAESAALRLRAPLQQVQAQLSPLQNIS -------------------------------------------------------------- >39220_39220_2_IGLL5-XBP1_IGLL5_chr22_23230439_ENST00000526893_XBP1_chr22_29195141_ENST00000344347_length(transcript)=1384nt_BP=480nt AGCCGGCTGTGGTGGGAGGCAGTTGAGCCCTGGATTGTGACCGCTTCAGGGCAGTTGGTAGATGCCCCTCTGGGAGAGATCCCCAGGGGT GACAGCCATGGACCCTGGAAGGGCCTGGGCTAGGGACAGGGACCAGAGCCAGTCCAGGGAGAGGACAGAGCCAATGGACTGGGGTGTACT GTAACAGCCCTGCTGGCGAGAGGGACCAGGGCACCGTCCTCCAGGGAGCCCATGCTGCAAGTCGGGCCAGAGGTGCCCCTGAACCTGAAG GCCAATGAGACCCAAGACAGGCCAAGTGGGTTGTGAGACCCCTGAGGAGCTGGGCCCTGGTCCCAGGCAGCGCTGGCCCCTGCTGCTGCT GGGTCTGGCCATGGTCGCCCATGGCCTGCTGCGCCCAATGGTTGCACCGCAAAGCGGGGACCCAGACCCTGGAGCCTCAGTTGGAAGCAG CCGATCCAGCCTGCGGAGCCTGTGGGGCAGGAAACTGAAAAACAGAGTAGCAGCTCAGACTGCCAGAGATCGAAAGAAGGCTCGAATGAG TGAGCTGGAACAGCAAGTGGTAGATTTAGAAGAAGAGAACCAAAAACTTTTGCTAGAAAATCAGCTTTTACGAGAGAAAACTCATGGCCT TGTAGTTGAGAACCAGGAGTTAAGACAGCGCTTGGGGATGGATGCCCTGGTTGCTGAAGAGGAGGCGGAAGCCAAGGGGAATGAAGTGAG GCCAGTGGCCGGGTCTGCTGAGTCCGCAGCAGGTGCAGGCCCAGTTGTCACCCCTCCAGAACATCTCCCCATGGATTCTGGCGGTATTGA CTCTTCAGATTCAGAGTCTGATATCCTGTTGGGCATTCTGGACAACTTGGACCCAGTCATGTTCTTCAAATGCCCTTCCCCAGAGCCTGC CAGCCTGGAGGAGCTCCCAGAGGTCTACCCAGAAGGACCCAGTTCCTTACCAGCCTCCCTTTCTCTGTCAGTGGGGACGTCATCAGCCAA GCTGGAAGCCATTAATGAACTAATTCGTTTTGACCACATATATACCAAGCCCCTAGTCTTAGAGATACCCTCTGAGACAGAGAGCCAAGC TAATGTGGTAGTGAAAATCGAGGAAGCACCTCTCAGCCCCTCAGAGAATGATCACCCTGAATTCATTGTCTCAGTGAAGGAAGAACCTGT AGAAGATGACCTCGTTCCGGAGCTGGGTATCTCAAATCTGCTTTCATCCAGCCACTGCCCAAAGCCATCTTCCTGCCTACTGGATGCTTA CAGTGACTGTGGATACGGGGGTTCCCTTTCCCCATTCAGTGACATGTCCTCTCTGCTTGGTGTAAACCATTCTTGGGAGGACACTTTTGC >39220_39220_2_IGLL5-XBP1_IGLL5_chr22_23230439_ENST00000526893_XBP1_chr22_29195141_ENST00000344347_length(amino acids)=370AA_BP=68 MRPKTGQVGCETPEELGPGPRQRWPLLLLGLAMVAHGLLRPMVAPQSGDPDPGASVGSSRSSLRSLWGRKLKNRVAAQTARDRKKARMSE LEQQVVDLEEENQKLLLENQLLREKTHGLVVENQELRQRLGMDALVAEEEAEAKGNEVRPVAGSAESAAGAGPVVTPPEHLPMDSGGIDS SDSESDILLGILDNLDPVMFFKCPSPEPASLEELPEVYPEGPSSLPASLSLSVGTSSAKLEAINELIRFDHIYTKPLVLEIPSETESQAN VVVKIEEAPLSPSENDHPEFIVSVKEEPVEDDLVPELGISNLLSSSHCPKPSSCLLDAYSDCGYGGSLSPFSDMSSLLGVNHSWEDTFAN -------------------------------------------------------------- >39220_39220_3_IGLL5-XBP1_IGLL5_chr22_23230439_ENST00000526893_XBP1_chr22_29195141_ENST00000403532_length(transcript)=2043nt_BP=480nt AGCCGGCTGTGGTGGGAGGCAGTTGAGCCCTGGATTGTGACCGCTTCAGGGCAGTTGGTAGATGCCCCTCTGGGAGAGATCCCCAGGGGT GACAGCCATGGACCCTGGAAGGGCCTGGGCTAGGGACAGGGACCAGAGCCAGTCCAGGGAGAGGACAGAGCCAATGGACTGGGGTGTACT GTAACAGCCCTGCTGGCGAGAGGGACCAGGGCACCGTCCTCCAGGGAGCCCATGCTGCAAGTCGGGCCAGAGGTGCCCCTGAACCTGAAG GCCAATGAGACCCAAGACAGGCCAAGTGGGTTGTGAGACCCCTGAGGAGCTGGGCCCTGGTCCCAGGCAGCGCTGGCCCCTGCTGCTGCT GGGTCTGGCCATGGTCGCCCATGGCCTGCTGCGCCCAATGGTTGCACCGCAAAGCGGGGACCCAGACCCTGGAGCCTCAGTTGGAAGCAG CCGATCCAGCCTGCGGAGCCTGTGGGGCAGGAAACTGAAAAACAGAGTAGCAGCTCAGACTGCCAGAGATCGAAAGAAGGCTCGAATGAG TGAGCTGGAACAGCAAGTGGTAGATTTAGAAGAAGAGGTAAAACTACTTAAGAACCAAAAACTTTTGCTAGAAAATCAGCTTTTACGAGA GAAAACTCATGGCCTTGTAGTTGAGAACCAGGAGTTAAGACAGCGCTTGGGGATGGATGCCCTGGTTGCTGAAGAGGAGGCGGAAGCCAA GGGGAATGAAGTGAGGCCAGTGGCCGGGTCTGCTGAGTCCGCAGCACTCAGACTACGTGCACCTCTGCAGCAGGTGCAGGCCCAGTTGTC ACCCCTCCAGAACATCTCCCCATGGATTCTGGCGGTATTGACTCTTCAGATTCAGAGTCTGATATCCTGTTGGGCATTCTGGACAACTTG GACCCAGTCATGTTCTTCAAATGCCCTTCCCCAGAGCCTGCCAGCCTGGAGGAGCTCCCAGAGGTCTACCCAGAAGGACCCAGTTCCTTA CCAGCCTCCCTTTCTCTGTCAGTGGGGACGTCATCAGCCAAGCTGGAAGCCATTAATGAACTAATTCGTTTTGACCACATATATACCAAG CCCCTAGTCTTAGAGATACCCTCTGAGACAGAGAGCCAAGCTAATGTGGTAGTGAAAATCGAGGAAGCACCTCTCAGCCCCTCAGAGAAT GATCACCCTGAATTCATTGTCTCAGTGAAGGAAGAACCTGTAGAAGATGACCTCGTTCCGGAGCTGGGTATCTCAAATCTGCTTTCATCC AGCCACTGCCCAAAGCCATCTTCCTGCCTACTGGATGCTTACAGTGACTGTGGATACGGGGGTTCCCTTTCCCCATTCAGTGACATGTCC TCTCTGCTTGGTGTAAACCATTCTTGGGAGGACACTTTTGCCAATGAACTCTTTCCCCAGCTGATTAGTGTCTAAGGAATGATCCAATAC TGTTGCCCTTTTCCTTGACTATTACACTGCCTGGAGGATAGCAGAGAAGCCTGTCTGTACTTCATTCAAAAAGCCAAAATAGAGAGTATA CAGTCCTAGAGAATTCCTCTATTTGTTCAGATCTCATAGATGACCCCCAGGTATTGTCTTTTGACATCCAGCAGTCCAAGGTATTGAGAC ATATTACTGGAAGTAAGAAATATTACTATAATTGAGAACTACAGCTTTTAAGATTGTACTTTTATCTTAAAAGGGTGGTAGTTTTCCCTA AAATACTTATTATGTAAGGGTCATTAGACAAATGTCTTGAAGTAGACATGGAATTTATGAATGGTTCTTTATCATTTCTCTTCCCCCTTT TTGGCATCCTGGCTTGCCTCCAGTTTTAGGTCCTTTAGTTTGCTTCTGTAAGCAACGGGAACACCTGCTGAGGGGGCTCTTTCCCTCATG TATACTTCAAGTAAGATCAAGAATCTTTTGTGAAATTATAGAAATTTACTATGTAAATGCTTGATGGAATTTTTTCCTGCTAGTGTAGCT >39220_39220_3_IGLL5-XBP1_IGLL5_chr22_23230439_ENST00000526893_XBP1_chr22_29195141_ENST00000403532_length(amino acids)=259AA_BP=68 MRPKTGQVGCETPEELGPGPRQRWPLLLLGLAMVAHGLLRPMVAPQSGDPDPGASVGSSRSSLRSLWGRKLKNRVAAQTARDRKKARMSE LEQQVVDLEEEVKLLKNQKLLLENQLLREKTHGLVVENQELRQRLGMDALVAEEEAEAKGNEVRPVAGSAESAALRLRAPLQQVQAQLSP -------------------------------------------------------------- >39220_39220_4_IGLL5-XBP1_IGLL5_chr22_23230439_ENST00000526893_XBP1_chr22_29195141_ENST00000405219_length(transcript)=1996nt_BP=480nt AGCCGGCTGTGGTGGGAGGCAGTTGAGCCCTGGATTGTGACCGCTTCAGGGCAGTTGGTAGATGCCCCTCTGGGAGAGATCCCCAGGGGT GACAGCCATGGACCCTGGAAGGGCCTGGGCTAGGGACAGGGACCAGAGCCAGTCCAGGGAGAGGACAGAGCCAATGGACTGGGGTGTACT GTAACAGCCCTGCTGGCGAGAGGGACCAGGGCACCGTCCTCCAGGGAGCCCATGCTGCAAGTCGGGCCAGAGGTGCCCCTGAACCTGAAG GCCAATGAGACCCAAGACAGGCCAAGTGGGTTGTGAGACCCCTGAGGAGCTGGGCCCTGGTCCCAGGCAGCGCTGGCCCCTGCTGCTGCT GGGTCTGGCCATGGTCGCCCATGGCCTGCTGCGCCCAATGGTTGCACCGCAAAGCGGGGACCCAGACCCTGGAGCCTCAGTTGGAAGCAG CCGATCCAGCCTGCGGAGCCTGTGGGGCAGGAAACTGAAAAACAGAGTAGCAGCTCAGACTGCCAGAGATCGAAAGAAGGCTCGAATGAG TGAGCTGGAACAGCAAGTGGTAGATTTAGAAGAAGAGAACCAAAAACTTTTGCTAGAAAATCAGCTTTTACGAGAGAAAACTCATGGCCT TGTAGTTGAGAACCAGGAGTTAAGACAGCGCTTGGGGATGGATGCCCTGGTTGCTGAAGAGGAGGCGGAAGCCAAGGGGAATGAAGTGAG GCCAGTGGCCGGGTCTGCTGAGTCCGCAGCACTCAGACTACGTGCACCTCTGCAGCAGGTGCAGGCCCAGTTGTCACCCCTCCAGAACAT CTCCCCATGGATTCTGGCGGTATTGACTCTTCAGATTCAGAGTCTGATATCCTGTTGGGCATTCTGGACAACTTGGACCCAGTCATGTTC TTCAAATGCCCTTCCCCAGAGCCTGCCAGCCTGGAGGAGCTCCCAGAGGTCTACCCAGAAGGACCCAGTTCCTTACCAGCCTCCCTTTCT CTGTCAGTGGGGACGTCATCAGCCAAGCTGGAAGCCATTAATGAACTAATTCGTTTTGACCACATATATACCAAGCCCCTAGTCTTAGAG ATACCCTCTGAGACAGAGAGCCAAGCTAATGTGGTAGTGAAAATCGAGGAAGCACCTCTCAGCCCCTCAGAGAATGATCACCCTGAATTC ATTGTCTCAGTGAAGGAAGAACCTGTAGAAGATGACCTCGTTCCGGAGCTGGGTATCTCAAATCTGCTTTCATCCAGCCACTGCCCAAAG CCATCTTCCTGCCTACTGGATGCTTACAGTGACTGTGGATACGGGGGTTCCCTTTCCCCATTCAGTGACATGTCCTCTCTGCTTGGTGTA AACCATTCTTGGGAGGACACTTTTGCCAATGAACTCTTTCCCCAGCTGATTAGTGTCTAAGGAATGATCCAATACTGTTGCCCTTTTCCT TGACTATTACACTGCCTGGAGGATAGCAGAGAAGCCTGTCTGTACTTCATTCAAAAAGCCAAAATAGAGAGTATACAGTCCTAGAGAATT CCTCTATTTGTTCAGATCTCATAGATGACCCCCAGGTATTGTCTTTTGACATCCAGCAGTCCAAGGTATTGAGACATATTACTGGAAGTA AGAAATATTACTATAATTGAGAACTACAGCTTTTAAGATTGTACTTTTATCTTAAAAGGGTGGTAGTTTTCCCTAAAATACTTATTATGT AAGGGTCATTAGACAAATGTCTTGAAGTAGACATGGAATTTATGAATGGTTCTTTATCATTTCTCTTCCCCCTTTTTGGCATCCTGGCTT GCCTCCAGTTTTAGGTCCTTTAGTTTGCTTCTGTAAGCAACGGGAACACCTGCTGAGGGGGCTCTTTCCCTCATGTATACTTCAAGTAAG ATCAAGAATCTTTTGTGAAATTATAGAAATTTACTATGTAAATGCTTGATGGAATTTTTTCCTGCTAGTGTAGCTTCTGAAAGGTGCTTT >39220_39220_4_IGLL5-XBP1_IGLL5_chr22_23230439_ENST00000526893_XBP1_chr22_29195141_ENST00000405219_length(amino acids)=254AA_BP=68 MRPKTGQVGCETPEELGPGPRQRWPLLLLGLAMVAHGLLRPMVAPQSGDPDPGASVGSSRSSLRSLWGRKLKNRVAAQTARDRKKARMSE LEQQVVDLEEENQKLLLENQLLREKTHGLVVENQELRQRLGMDALVAEEEAEAKGNEVRPVAGSAESAALRLRAPLQQVQAQLSPLQNIS -------------------------------------------------------------- >39220_39220_5_IGLL5-XBP1_IGLL5_chr22_23230439_ENST00000531372_XBP1_chr22_29195141_ENST00000216037_length(transcript)=1981nt_BP=431nt GGCAGTTGGTAGATGCCCCTCTGGGAGAGATCCCCAGGGGTGACAGCCATGGACCCTGGAAGGGCCTGGGCTAGGGACAGGGACCAGAGC CAGTCCAGGGAGAGGACAGAGCCAATGGACTGGGGTGTACTGTAACAGCCCTGCTGGCGAGAGGGACCAGGGCACCGTCCTCCAGGGAGC CCATGCTGCAAGTCGGGCCAGAGGTGCCCCTGAACCTGAAGGCCAATGAGACCCAAGACAGGCCAAGTGGGTTGTGAGACCCCTGAGGAG CTGGGCCCTGGTCCCAGGCAGCGCTGGCCCCTGCTGCTGCTGGGTCTGGCCATGGTCGCCCATGGCCTGCTGCGCCCAATGGTTGCACCG CAAAGCGGGGACCCAGACCCTGGAGCCTCAGTTGGAAGCAGCCGATCCAGCCTGCGGAGCCTGTGGGGCAGGAAACTGAAAAACAGAGTA GCAGCTCAGACTGCCAGAGATCGAAAGAAGGCTCGAATGAGTGAGCTGGAACAGCAAGTGGTAGATTTAGAAGAAGAGAACCAAAAACTT TTGCTAGAAAATCAGCTTTTACGAGAGAAAACTCATGGCCTTGTAGTTGAGAACCAGGAGTTAAGACAGCGCTTGGGGATGGATGCCCTG GTTGCTGAAGAGGAGGCGGAAGCCAAGGGGAATGAAGTGAGGCCAGTGGCCGGGTCTGCTGAGTCCGCAGCACTCAGACTACGTGCACCT CTGCAGCAGGTGCAGGCCCAGTTGTCACCCCTCCAGAACATCTCCCCATGGATTCTGGCGGTATTGACTCTTCAGATTCAGAGTCTGATA TCCTGTTGGGCATTCTGGACAACTTGGACCCAGTCATGTTCTTCAAATGCCCTTCCCCAGAGCCTGCCAGCCTGGAGGAGCTCCCAGAGG TCTACCCAGAAGGACCCAGTTCCTTACCAGCCTCCCTTTCTCTGTCAGTGGGGACGTCATCAGCCAAGCTGGAAGCCATTAATGAACTAA TTCGTTTTGACCACATATATACCAAGCCCCTAGTCTTAGAGATACCCTCTGAGACAGAGAGCCAAGCTAATGTGGTAGTGAAAATCGAGG AAGCACCTCTCAGCCCCTCAGAGAATGATCACCCTGAATTCATTGTCTCAGTGAAGGAAGAACCTGTAGAAGATGACCTCGTTCCGGAGC TGGGTATCTCAAATCTGCTTTCATCCAGCCACTGCCCAAAGCCATCTTCCTGCCTACTGGATGCTTACAGTGACTGTGGATACGGGGGTT CCCTTTCCCCATTCAGTGACATGTCCTCTCTGCTTGGTGTAAACCATTCTTGGGAGGACACTTTTGCCAATGAACTCTTTCCCCAGCTGA TTAGTGTCTAAGGAATGATCCAATACTGTTGCCCTTTTCCTTGACTATTACACTGCCTGGAGGATAGCAGAGAAGCCTGTCTGTACTTCA TTCAAAAAGCCAAAATAGAGAGTATACAGTCCTAGAGAATTCCTCTATTTGTTCAGATCTCATAGATGACCCCCAGGTATTGTCTTTTGA CATCCAGCAGTCCAAGGTATTGAGACATATTACTGGAAGTAAGAAATATTACTATAATTGAGAACTACAGCTTTTAAGATTGTACTTTTA TCTTAAAAGGGTGGTAGTTTTCCCTAAAATACTTATTATGTAAGGGTCATTAGACAAATGTCTTGAAGTAGACATGGAATTTATGAATGG TTCTTTATCATTTCTCTTCCCCCTTTTTGGCATCCTGGCTTGCCTCCAGTTTTAGGTCCTTTAGTTTGCTTCTGTAAGCAACGGGAACAC CTGCTGAGGGGGCTCTTTCCCTCATGTATACTTCAAGTAAGATCAAGAATCTTTTGTGAAATTATAGAAATTTACTATGTAAATGCTTGA TGGAATTTTTTCCTGCTAGTGTAGCTTCTGAAAGGTGCTTTCTCCATTTATTTAAAACTACCCATGCAATTAAAAGGTACAATGCAGCAT >39220_39220_5_IGLL5-XBP1_IGLL5_chr22_23230439_ENST00000531372_XBP1_chr22_29195141_ENST00000216037_length(amino acids)=254AA_BP=68 MRPKTGQVGCETPEELGPGPRQRWPLLLLGLAMVAHGLLRPMVAPQSGDPDPGASVGSSRSSLRSLWGRKLKNRVAAQTARDRKKARMSE LEQQVVDLEEENQKLLLENQLLREKTHGLVVENQELRQRLGMDALVAEEEAEAKGNEVRPVAGSAESAALRLRAPLQQVQAQLSPLQNIS -------------------------------------------------------------- >39220_39220_6_IGLL5-XBP1_IGLL5_chr22_23230439_ENST00000531372_XBP1_chr22_29195141_ENST00000344347_length(transcript)=1335nt_BP=431nt GGCAGTTGGTAGATGCCCCTCTGGGAGAGATCCCCAGGGGTGACAGCCATGGACCCTGGAAGGGCCTGGGCTAGGGACAGGGACCAGAGC CAGTCCAGGGAGAGGACAGAGCCAATGGACTGGGGTGTACTGTAACAGCCCTGCTGGCGAGAGGGACCAGGGCACCGTCCTCCAGGGAGC CCATGCTGCAAGTCGGGCCAGAGGTGCCCCTGAACCTGAAGGCCAATGAGACCCAAGACAGGCCAAGTGGGTTGTGAGACCCCTGAGGAG CTGGGCCCTGGTCCCAGGCAGCGCTGGCCCCTGCTGCTGCTGGGTCTGGCCATGGTCGCCCATGGCCTGCTGCGCCCAATGGTTGCACCG CAAAGCGGGGACCCAGACCCTGGAGCCTCAGTTGGAAGCAGCCGATCCAGCCTGCGGAGCCTGTGGGGCAGGAAACTGAAAAACAGAGTA GCAGCTCAGACTGCCAGAGATCGAAAGAAGGCTCGAATGAGTGAGCTGGAACAGCAAGTGGTAGATTTAGAAGAAGAGAACCAAAAACTT TTGCTAGAAAATCAGCTTTTACGAGAGAAAACTCATGGCCTTGTAGTTGAGAACCAGGAGTTAAGACAGCGCTTGGGGATGGATGCCCTG GTTGCTGAAGAGGAGGCGGAAGCCAAGGGGAATGAAGTGAGGCCAGTGGCCGGGTCTGCTGAGTCCGCAGCAGGTGCAGGCCCAGTTGTC ACCCCTCCAGAACATCTCCCCATGGATTCTGGCGGTATTGACTCTTCAGATTCAGAGTCTGATATCCTGTTGGGCATTCTGGACAACTTG GACCCAGTCATGTTCTTCAAATGCCCTTCCCCAGAGCCTGCCAGCCTGGAGGAGCTCCCAGAGGTCTACCCAGAAGGACCCAGTTCCTTA CCAGCCTCCCTTTCTCTGTCAGTGGGGACGTCATCAGCCAAGCTGGAAGCCATTAATGAACTAATTCGTTTTGACCACATATATACCAAG CCCCTAGTCTTAGAGATACCCTCTGAGACAGAGAGCCAAGCTAATGTGGTAGTGAAAATCGAGGAAGCACCTCTCAGCCCCTCAGAGAAT GATCACCCTGAATTCATTGTCTCAGTGAAGGAAGAACCTGTAGAAGATGACCTCGTTCCGGAGCTGGGTATCTCAAATCTGCTTTCATCC AGCCACTGCCCAAAGCCATCTTCCTGCCTACTGGATGCTTACAGTGACTGTGGATACGGGGGTTCCCTTTCCCCATTCAGTGACATGTCC >39220_39220_6_IGLL5-XBP1_IGLL5_chr22_23230439_ENST00000531372_XBP1_chr22_29195141_ENST00000344347_length(amino acids)=369AA_BP=68 MRPKTGQVGCETPEELGPGPRQRWPLLLLGLAMVAHGLLRPMVAPQSGDPDPGASVGSSRSSLRSLWGRKLKNRVAAQTARDRKKARMSE LEQQVVDLEEENQKLLLENQLLREKTHGLVVENQELRQRLGMDALVAEEEAEAKGNEVRPVAGSAESAAGAGPVVTPPEHLPMDSGGIDS SDSESDILLGILDNLDPVMFFKCPSPEPASLEELPEVYPEGPSSLPASLSLSVGTSSAKLEAINELIRFDHIYTKPLVLEIPSETESQAN VVVKIEEAPLSPSENDHPEFIVSVKEEPVEDDLVPELGISNLLSSSHCPKPSSCLLDAYSDCGYGGSLSPFSDMSSLLGVNHSWEDTFAN -------------------------------------------------------------- >39220_39220_7_IGLL5-XBP1_IGLL5_chr22_23230439_ENST00000531372_XBP1_chr22_29195141_ENST00000403532_length(transcript)=1994nt_BP=431nt GGCAGTTGGTAGATGCCCCTCTGGGAGAGATCCCCAGGGGTGACAGCCATGGACCCTGGAAGGGCCTGGGCTAGGGACAGGGACCAGAGC CAGTCCAGGGAGAGGACAGAGCCAATGGACTGGGGTGTACTGTAACAGCCCTGCTGGCGAGAGGGACCAGGGCACCGTCCTCCAGGGAGC CCATGCTGCAAGTCGGGCCAGAGGTGCCCCTGAACCTGAAGGCCAATGAGACCCAAGACAGGCCAAGTGGGTTGTGAGACCCCTGAGGAG CTGGGCCCTGGTCCCAGGCAGCGCTGGCCCCTGCTGCTGCTGGGTCTGGCCATGGTCGCCCATGGCCTGCTGCGCCCAATGGTTGCACCG CAAAGCGGGGACCCAGACCCTGGAGCCTCAGTTGGAAGCAGCCGATCCAGCCTGCGGAGCCTGTGGGGCAGGAAACTGAAAAACAGAGTA GCAGCTCAGACTGCCAGAGATCGAAAGAAGGCTCGAATGAGTGAGCTGGAACAGCAAGTGGTAGATTTAGAAGAAGAGGTAAAACTACTT AAGAACCAAAAACTTTTGCTAGAAAATCAGCTTTTACGAGAGAAAACTCATGGCCTTGTAGTTGAGAACCAGGAGTTAAGACAGCGCTTG GGGATGGATGCCCTGGTTGCTGAAGAGGAGGCGGAAGCCAAGGGGAATGAAGTGAGGCCAGTGGCCGGGTCTGCTGAGTCCGCAGCACTC AGACTACGTGCACCTCTGCAGCAGGTGCAGGCCCAGTTGTCACCCCTCCAGAACATCTCCCCATGGATTCTGGCGGTATTGACTCTTCAG ATTCAGAGTCTGATATCCTGTTGGGCATTCTGGACAACTTGGACCCAGTCATGTTCTTCAAATGCCCTTCCCCAGAGCCTGCCAGCCTGG AGGAGCTCCCAGAGGTCTACCCAGAAGGACCCAGTTCCTTACCAGCCTCCCTTTCTCTGTCAGTGGGGACGTCATCAGCCAAGCTGGAAG CCATTAATGAACTAATTCGTTTTGACCACATATATACCAAGCCCCTAGTCTTAGAGATACCCTCTGAGACAGAGAGCCAAGCTAATGTGG TAGTGAAAATCGAGGAAGCACCTCTCAGCCCCTCAGAGAATGATCACCCTGAATTCATTGTCTCAGTGAAGGAAGAACCTGTAGAAGATG ACCTCGTTCCGGAGCTGGGTATCTCAAATCTGCTTTCATCCAGCCACTGCCCAAAGCCATCTTCCTGCCTACTGGATGCTTACAGTGACT GTGGATACGGGGGTTCCCTTTCCCCATTCAGTGACATGTCCTCTCTGCTTGGTGTAAACCATTCTTGGGAGGACACTTTTGCCAATGAAC TCTTTCCCCAGCTGATTAGTGTCTAAGGAATGATCCAATACTGTTGCCCTTTTCCTTGACTATTACACTGCCTGGAGGATAGCAGAGAAG CCTGTCTGTACTTCATTCAAAAAGCCAAAATAGAGAGTATACAGTCCTAGAGAATTCCTCTATTTGTTCAGATCTCATAGATGACCCCCA GGTATTGTCTTTTGACATCCAGCAGTCCAAGGTATTGAGACATATTACTGGAAGTAAGAAATATTACTATAATTGAGAACTACAGCTTTT AAGATTGTACTTTTATCTTAAAAGGGTGGTAGTTTTCCCTAAAATACTTATTATGTAAGGGTCATTAGACAAATGTCTTGAAGTAGACAT GGAATTTATGAATGGTTCTTTATCATTTCTCTTCCCCCTTTTTGGCATCCTGGCTTGCCTCCAGTTTTAGGTCCTTTAGTTTGCTTCTGT AAGCAACGGGAACACCTGCTGAGGGGGCTCTTTCCCTCATGTATACTTCAAGTAAGATCAAGAATCTTTTGTGAAATTATAGAAATTTAC TATGTAAATGCTTGATGGAATTTTTTCCTGCTAGTGTAGCTTCTGAAAGGTGCTTTCTCCATTTATTTAAAACTACCCATGCAATTAAAA >39220_39220_7_IGLL5-XBP1_IGLL5_chr22_23230439_ENST00000531372_XBP1_chr22_29195141_ENST00000403532_length(amino acids)=259AA_BP=68 MRPKTGQVGCETPEELGPGPRQRWPLLLLGLAMVAHGLLRPMVAPQSGDPDPGASVGSSRSSLRSLWGRKLKNRVAAQTARDRKKARMSE LEQQVVDLEEEVKLLKNQKLLLENQLLREKTHGLVVENQELRQRLGMDALVAEEEAEAKGNEVRPVAGSAESAALRLRAPLQQVQAQLSP -------------------------------------------------------------- >39220_39220_8_IGLL5-XBP1_IGLL5_chr22_23230439_ENST00000531372_XBP1_chr22_29195141_ENST00000405219_length(transcript)=1947nt_BP=431nt GGCAGTTGGTAGATGCCCCTCTGGGAGAGATCCCCAGGGGTGACAGCCATGGACCCTGGAAGGGCCTGGGCTAGGGACAGGGACCAGAGC CAGTCCAGGGAGAGGACAGAGCCAATGGACTGGGGTGTACTGTAACAGCCCTGCTGGCGAGAGGGACCAGGGCACCGTCCTCCAGGGAGC CCATGCTGCAAGTCGGGCCAGAGGTGCCCCTGAACCTGAAGGCCAATGAGACCCAAGACAGGCCAAGTGGGTTGTGAGACCCCTGAGGAG CTGGGCCCTGGTCCCAGGCAGCGCTGGCCCCTGCTGCTGCTGGGTCTGGCCATGGTCGCCCATGGCCTGCTGCGCCCAATGGTTGCACCG CAAAGCGGGGACCCAGACCCTGGAGCCTCAGTTGGAAGCAGCCGATCCAGCCTGCGGAGCCTGTGGGGCAGGAAACTGAAAAACAGAGTA GCAGCTCAGACTGCCAGAGATCGAAAGAAGGCTCGAATGAGTGAGCTGGAACAGCAAGTGGTAGATTTAGAAGAAGAGAACCAAAAACTT TTGCTAGAAAATCAGCTTTTACGAGAGAAAACTCATGGCCTTGTAGTTGAGAACCAGGAGTTAAGACAGCGCTTGGGGATGGATGCCCTG GTTGCTGAAGAGGAGGCGGAAGCCAAGGGGAATGAAGTGAGGCCAGTGGCCGGGTCTGCTGAGTCCGCAGCACTCAGACTACGTGCACCT CTGCAGCAGGTGCAGGCCCAGTTGTCACCCCTCCAGAACATCTCCCCATGGATTCTGGCGGTATTGACTCTTCAGATTCAGAGTCTGATA TCCTGTTGGGCATTCTGGACAACTTGGACCCAGTCATGTTCTTCAAATGCCCTTCCCCAGAGCCTGCCAGCCTGGAGGAGCTCCCAGAGG TCTACCCAGAAGGACCCAGTTCCTTACCAGCCTCCCTTTCTCTGTCAGTGGGGACGTCATCAGCCAAGCTGGAAGCCATTAATGAACTAA TTCGTTTTGACCACATATATACCAAGCCCCTAGTCTTAGAGATACCCTCTGAGACAGAGAGCCAAGCTAATGTGGTAGTGAAAATCGAGG AAGCACCTCTCAGCCCCTCAGAGAATGATCACCCTGAATTCATTGTCTCAGTGAAGGAAGAACCTGTAGAAGATGACCTCGTTCCGGAGC TGGGTATCTCAAATCTGCTTTCATCCAGCCACTGCCCAAAGCCATCTTCCTGCCTACTGGATGCTTACAGTGACTGTGGATACGGGGGTT CCCTTTCCCCATTCAGTGACATGTCCTCTCTGCTTGGTGTAAACCATTCTTGGGAGGACACTTTTGCCAATGAACTCTTTCCCCAGCTGA TTAGTGTCTAAGGAATGATCCAATACTGTTGCCCTTTTCCTTGACTATTACACTGCCTGGAGGATAGCAGAGAAGCCTGTCTGTACTTCA TTCAAAAAGCCAAAATAGAGAGTATACAGTCCTAGAGAATTCCTCTATTTGTTCAGATCTCATAGATGACCCCCAGGTATTGTCTTTTGA CATCCAGCAGTCCAAGGTATTGAGACATATTACTGGAAGTAAGAAATATTACTATAATTGAGAACTACAGCTTTTAAGATTGTACTTTTA TCTTAAAAGGGTGGTAGTTTTCCCTAAAATACTTATTATGTAAGGGTCATTAGACAAATGTCTTGAAGTAGACATGGAATTTATGAATGG TTCTTTATCATTTCTCTTCCCCCTTTTTGGCATCCTGGCTTGCCTCCAGTTTTAGGTCCTTTAGTTTGCTTCTGTAAGCAACGGGAACAC CTGCTGAGGGGGCTCTTTCCCTCATGTATACTTCAAGTAAGATCAAGAATCTTTTGTGAAATTATAGAAATTTACTATGTAAATGCTTGA >39220_39220_8_IGLL5-XBP1_IGLL5_chr22_23230439_ENST00000531372_XBP1_chr22_29195141_ENST00000405219_length(amino acids)=254AA_BP=68 MRPKTGQVGCETPEELGPGPRQRWPLLLLGLAMVAHGLLRPMVAPQSGDPDPGASVGSSRSSLRSLWGRKLKNRVAAQTARDRKKARMSE LEQQVVDLEEENQKLLLENQLLREKTHGLVVENQELRQRLGMDALVAEEEAEAKGNEVRPVAGSAESAALRLRAPLQQVQAQLSPLQNIS -------------------------------------------------------------- >39220_39220_9_IGLL5-XBP1_IGLL5_chr22_23230439_ENST00000532223_XBP1_chr22_29195141_ENST00000216037_length(transcript)=2030nt_BP=480nt AGCCGGCTGTGGTGGGAGGCAGTTGAGCCCTGGATTGTGACCGCTTCAGGGCAGTTGGTAGATGCCCCTCTGGGAGAGATCCCCAGGGGT GACAGCCATGGACCCTGGAAGGGCCTGGGCTAGGGACAGGGACCAGAGCCAGTCCAGGGAGAGGACAGAGCCAATGGACTGGGGTGTACT GTAACAGCCCTGCTGGCGAGAGGGACCAGGGCACCGTCCTCCAGGGAGCCCATGCTGCAAGTCGGGCCAGAGGTGCCCCTGAACCTGAAG GCCAATGAGACCCAAGACAGGCCAAGTGGGTTGTGAGACCCCTGAGGAGCTGGGCCCTGGTCCCAGGCAGCGCTGGCCCCTGCTGCTGCT GGGTCTGGCCATGGTCGCCCATGGCCTGCTGCGCCCAATGGTTGCACCGCAAAGCGGGGACCCAGACCCTGGAGCCTCAGTTGGAAGCAG CCGATCCAGCCTGCGGAGCCTGTGGGGCAGGAAACTGAAAAACAGAGTAGCAGCTCAGACTGCCAGAGATCGAAAGAAGGCTCGAATGAG TGAGCTGGAACAGCAAGTGGTAGATTTAGAAGAAGAGAACCAAAAACTTTTGCTAGAAAATCAGCTTTTACGAGAGAAAACTCATGGCCT TGTAGTTGAGAACCAGGAGTTAAGACAGCGCTTGGGGATGGATGCCCTGGTTGCTGAAGAGGAGGCGGAAGCCAAGGGGAATGAAGTGAG GCCAGTGGCCGGGTCTGCTGAGTCCGCAGCACTCAGACTACGTGCACCTCTGCAGCAGGTGCAGGCCCAGTTGTCACCCCTCCAGAACAT CTCCCCATGGATTCTGGCGGTATTGACTCTTCAGATTCAGAGTCTGATATCCTGTTGGGCATTCTGGACAACTTGGACCCAGTCATGTTC TTCAAATGCCCTTCCCCAGAGCCTGCCAGCCTGGAGGAGCTCCCAGAGGTCTACCCAGAAGGACCCAGTTCCTTACCAGCCTCCCTTTCT CTGTCAGTGGGGACGTCATCAGCCAAGCTGGAAGCCATTAATGAACTAATTCGTTTTGACCACATATATACCAAGCCCCTAGTCTTAGAG ATACCCTCTGAGACAGAGAGCCAAGCTAATGTGGTAGTGAAAATCGAGGAAGCACCTCTCAGCCCCTCAGAGAATGATCACCCTGAATTC ATTGTCTCAGTGAAGGAAGAACCTGTAGAAGATGACCTCGTTCCGGAGCTGGGTATCTCAAATCTGCTTTCATCCAGCCACTGCCCAAAG CCATCTTCCTGCCTACTGGATGCTTACAGTGACTGTGGATACGGGGGTTCCCTTTCCCCATTCAGTGACATGTCCTCTCTGCTTGGTGTA AACCATTCTTGGGAGGACACTTTTGCCAATGAACTCTTTCCCCAGCTGATTAGTGTCTAAGGAATGATCCAATACTGTTGCCCTTTTCCT TGACTATTACACTGCCTGGAGGATAGCAGAGAAGCCTGTCTGTACTTCATTCAAAAAGCCAAAATAGAGAGTATACAGTCCTAGAGAATT CCTCTATTTGTTCAGATCTCATAGATGACCCCCAGGTATTGTCTTTTGACATCCAGCAGTCCAAGGTATTGAGACATATTACTGGAAGTA AGAAATATTACTATAATTGAGAACTACAGCTTTTAAGATTGTACTTTTATCTTAAAAGGGTGGTAGTTTTCCCTAAAATACTTATTATGT AAGGGTCATTAGACAAATGTCTTGAAGTAGACATGGAATTTATGAATGGTTCTTTATCATTTCTCTTCCCCCTTTTTGGCATCCTGGCTT GCCTCCAGTTTTAGGTCCTTTAGTTTGCTTCTGTAAGCAACGGGAACACCTGCTGAGGGGGCTCTTTCCCTCATGTATACTTCAAGTAAG ATCAAGAATCTTTTGTGAAATTATAGAAATTTACTATGTAAATGCTTGATGGAATTTTTTCCTGCTAGTGTAGCTTCTGAAAGGTGCTTT >39220_39220_9_IGLL5-XBP1_IGLL5_chr22_23230439_ENST00000532223_XBP1_chr22_29195141_ENST00000216037_length(amino acids)=254AA_BP=68 MRPKTGQVGCETPEELGPGPRQRWPLLLLGLAMVAHGLLRPMVAPQSGDPDPGASVGSSRSSLRSLWGRKLKNRVAAQTARDRKKARMSE LEQQVVDLEEENQKLLLENQLLREKTHGLVVENQELRQRLGMDALVAEEEAEAKGNEVRPVAGSAESAALRLRAPLQQVQAQLSPLQNIS -------------------------------------------------------------- >39220_39220_10_IGLL5-XBP1_IGLL5_chr22_23230439_ENST00000532223_XBP1_chr22_29195141_ENST00000344347_length(transcript)=1384nt_BP=480nt AGCCGGCTGTGGTGGGAGGCAGTTGAGCCCTGGATTGTGACCGCTTCAGGGCAGTTGGTAGATGCCCCTCTGGGAGAGATCCCCAGGGGT GACAGCCATGGACCCTGGAAGGGCCTGGGCTAGGGACAGGGACCAGAGCCAGTCCAGGGAGAGGACAGAGCCAATGGACTGGGGTGTACT GTAACAGCCCTGCTGGCGAGAGGGACCAGGGCACCGTCCTCCAGGGAGCCCATGCTGCAAGTCGGGCCAGAGGTGCCCCTGAACCTGAAG GCCAATGAGACCCAAGACAGGCCAAGTGGGTTGTGAGACCCCTGAGGAGCTGGGCCCTGGTCCCAGGCAGCGCTGGCCCCTGCTGCTGCT GGGTCTGGCCATGGTCGCCCATGGCCTGCTGCGCCCAATGGTTGCACCGCAAAGCGGGGACCCAGACCCTGGAGCCTCAGTTGGAAGCAG CCGATCCAGCCTGCGGAGCCTGTGGGGCAGGAAACTGAAAAACAGAGTAGCAGCTCAGACTGCCAGAGATCGAAAGAAGGCTCGAATGAG TGAGCTGGAACAGCAAGTGGTAGATTTAGAAGAAGAGAACCAAAAACTTTTGCTAGAAAATCAGCTTTTACGAGAGAAAACTCATGGCCT TGTAGTTGAGAACCAGGAGTTAAGACAGCGCTTGGGGATGGATGCCCTGGTTGCTGAAGAGGAGGCGGAAGCCAAGGGGAATGAAGTGAG GCCAGTGGCCGGGTCTGCTGAGTCCGCAGCAGGTGCAGGCCCAGTTGTCACCCCTCCAGAACATCTCCCCATGGATTCTGGCGGTATTGA CTCTTCAGATTCAGAGTCTGATATCCTGTTGGGCATTCTGGACAACTTGGACCCAGTCATGTTCTTCAAATGCCCTTCCCCAGAGCCTGC CAGCCTGGAGGAGCTCCCAGAGGTCTACCCAGAAGGACCCAGTTCCTTACCAGCCTCCCTTTCTCTGTCAGTGGGGACGTCATCAGCCAA GCTGGAAGCCATTAATGAACTAATTCGTTTTGACCACATATATACCAAGCCCCTAGTCTTAGAGATACCCTCTGAGACAGAGAGCCAAGC TAATGTGGTAGTGAAAATCGAGGAAGCACCTCTCAGCCCCTCAGAGAATGATCACCCTGAATTCATTGTCTCAGTGAAGGAAGAACCTGT AGAAGATGACCTCGTTCCGGAGCTGGGTATCTCAAATCTGCTTTCATCCAGCCACTGCCCAAAGCCATCTTCCTGCCTACTGGATGCTTA CAGTGACTGTGGATACGGGGGTTCCCTTTCCCCATTCAGTGACATGTCCTCTCTGCTTGGTGTAAACCATTCTTGGGAGGACACTTTTGC >39220_39220_10_IGLL5-XBP1_IGLL5_chr22_23230439_ENST00000532223_XBP1_chr22_29195141_ENST00000344347_length(amino acids)=370AA_BP=68 MRPKTGQVGCETPEELGPGPRQRWPLLLLGLAMVAHGLLRPMVAPQSGDPDPGASVGSSRSSLRSLWGRKLKNRVAAQTARDRKKARMSE LEQQVVDLEEENQKLLLENQLLREKTHGLVVENQELRQRLGMDALVAEEEAEAKGNEVRPVAGSAESAAGAGPVVTPPEHLPMDSGGIDS SDSESDILLGILDNLDPVMFFKCPSPEPASLEELPEVYPEGPSSLPASLSLSVGTSSAKLEAINELIRFDHIYTKPLVLEIPSETESQAN VVVKIEEAPLSPSENDHPEFIVSVKEEPVEDDLVPELGISNLLSSSHCPKPSSCLLDAYSDCGYGGSLSPFSDMSSLLGVNHSWEDTFAN -------------------------------------------------------------- >39220_39220_11_IGLL5-XBP1_IGLL5_chr22_23230439_ENST00000532223_XBP1_chr22_29195141_ENST00000403532_length(transcript)=2043nt_BP=480nt AGCCGGCTGTGGTGGGAGGCAGTTGAGCCCTGGATTGTGACCGCTTCAGGGCAGTTGGTAGATGCCCCTCTGGGAGAGATCCCCAGGGGT GACAGCCATGGACCCTGGAAGGGCCTGGGCTAGGGACAGGGACCAGAGCCAGTCCAGGGAGAGGACAGAGCCAATGGACTGGGGTGTACT GTAACAGCCCTGCTGGCGAGAGGGACCAGGGCACCGTCCTCCAGGGAGCCCATGCTGCAAGTCGGGCCAGAGGTGCCCCTGAACCTGAAG GCCAATGAGACCCAAGACAGGCCAAGTGGGTTGTGAGACCCCTGAGGAGCTGGGCCCTGGTCCCAGGCAGCGCTGGCCCCTGCTGCTGCT GGGTCTGGCCATGGTCGCCCATGGCCTGCTGCGCCCAATGGTTGCACCGCAAAGCGGGGACCCAGACCCTGGAGCCTCAGTTGGAAGCAG CCGATCCAGCCTGCGGAGCCTGTGGGGCAGGAAACTGAAAAACAGAGTAGCAGCTCAGACTGCCAGAGATCGAAAGAAGGCTCGAATGAG TGAGCTGGAACAGCAAGTGGTAGATTTAGAAGAAGAGGTAAAACTACTTAAGAACCAAAAACTTTTGCTAGAAAATCAGCTTTTACGAGA GAAAACTCATGGCCTTGTAGTTGAGAACCAGGAGTTAAGACAGCGCTTGGGGATGGATGCCCTGGTTGCTGAAGAGGAGGCGGAAGCCAA GGGGAATGAAGTGAGGCCAGTGGCCGGGTCTGCTGAGTCCGCAGCACTCAGACTACGTGCACCTCTGCAGCAGGTGCAGGCCCAGTTGTC ACCCCTCCAGAACATCTCCCCATGGATTCTGGCGGTATTGACTCTTCAGATTCAGAGTCTGATATCCTGTTGGGCATTCTGGACAACTTG GACCCAGTCATGTTCTTCAAATGCCCTTCCCCAGAGCCTGCCAGCCTGGAGGAGCTCCCAGAGGTCTACCCAGAAGGACCCAGTTCCTTA CCAGCCTCCCTTTCTCTGTCAGTGGGGACGTCATCAGCCAAGCTGGAAGCCATTAATGAACTAATTCGTTTTGACCACATATATACCAAG CCCCTAGTCTTAGAGATACCCTCTGAGACAGAGAGCCAAGCTAATGTGGTAGTGAAAATCGAGGAAGCACCTCTCAGCCCCTCAGAGAAT GATCACCCTGAATTCATTGTCTCAGTGAAGGAAGAACCTGTAGAAGATGACCTCGTTCCGGAGCTGGGTATCTCAAATCTGCTTTCATCC AGCCACTGCCCAAAGCCATCTTCCTGCCTACTGGATGCTTACAGTGACTGTGGATACGGGGGTTCCCTTTCCCCATTCAGTGACATGTCC TCTCTGCTTGGTGTAAACCATTCTTGGGAGGACACTTTTGCCAATGAACTCTTTCCCCAGCTGATTAGTGTCTAAGGAATGATCCAATAC TGTTGCCCTTTTCCTTGACTATTACACTGCCTGGAGGATAGCAGAGAAGCCTGTCTGTACTTCATTCAAAAAGCCAAAATAGAGAGTATA CAGTCCTAGAGAATTCCTCTATTTGTTCAGATCTCATAGATGACCCCCAGGTATTGTCTTTTGACATCCAGCAGTCCAAGGTATTGAGAC ATATTACTGGAAGTAAGAAATATTACTATAATTGAGAACTACAGCTTTTAAGATTGTACTTTTATCTTAAAAGGGTGGTAGTTTTCCCTA AAATACTTATTATGTAAGGGTCATTAGACAAATGTCTTGAAGTAGACATGGAATTTATGAATGGTTCTTTATCATTTCTCTTCCCCCTTT TTGGCATCCTGGCTTGCCTCCAGTTTTAGGTCCTTTAGTTTGCTTCTGTAAGCAACGGGAACACCTGCTGAGGGGGCTCTTTCCCTCATG TATACTTCAAGTAAGATCAAGAATCTTTTGTGAAATTATAGAAATTTACTATGTAAATGCTTGATGGAATTTTTTCCTGCTAGTGTAGCT >39220_39220_11_IGLL5-XBP1_IGLL5_chr22_23230439_ENST00000532223_XBP1_chr22_29195141_ENST00000403532_length(amino acids)=259AA_BP=68 MRPKTGQVGCETPEELGPGPRQRWPLLLLGLAMVAHGLLRPMVAPQSGDPDPGASVGSSRSSLRSLWGRKLKNRVAAQTARDRKKARMSE LEQQVVDLEEEVKLLKNQKLLLENQLLREKTHGLVVENQELRQRLGMDALVAEEEAEAKGNEVRPVAGSAESAALRLRAPLQQVQAQLSP -------------------------------------------------------------- >39220_39220_12_IGLL5-XBP1_IGLL5_chr22_23230439_ENST00000532223_XBP1_chr22_29195141_ENST00000405219_length(transcript)=1996nt_BP=480nt AGCCGGCTGTGGTGGGAGGCAGTTGAGCCCTGGATTGTGACCGCTTCAGGGCAGTTGGTAGATGCCCCTCTGGGAGAGATCCCCAGGGGT GACAGCCATGGACCCTGGAAGGGCCTGGGCTAGGGACAGGGACCAGAGCCAGTCCAGGGAGAGGACAGAGCCAATGGACTGGGGTGTACT GTAACAGCCCTGCTGGCGAGAGGGACCAGGGCACCGTCCTCCAGGGAGCCCATGCTGCAAGTCGGGCCAGAGGTGCCCCTGAACCTGAAG GCCAATGAGACCCAAGACAGGCCAAGTGGGTTGTGAGACCCCTGAGGAGCTGGGCCCTGGTCCCAGGCAGCGCTGGCCCCTGCTGCTGCT GGGTCTGGCCATGGTCGCCCATGGCCTGCTGCGCCCAATGGTTGCACCGCAAAGCGGGGACCCAGACCCTGGAGCCTCAGTTGGAAGCAG CCGATCCAGCCTGCGGAGCCTGTGGGGCAGGAAACTGAAAAACAGAGTAGCAGCTCAGACTGCCAGAGATCGAAAGAAGGCTCGAATGAG TGAGCTGGAACAGCAAGTGGTAGATTTAGAAGAAGAGAACCAAAAACTTTTGCTAGAAAATCAGCTTTTACGAGAGAAAACTCATGGCCT TGTAGTTGAGAACCAGGAGTTAAGACAGCGCTTGGGGATGGATGCCCTGGTTGCTGAAGAGGAGGCGGAAGCCAAGGGGAATGAAGTGAG GCCAGTGGCCGGGTCTGCTGAGTCCGCAGCACTCAGACTACGTGCACCTCTGCAGCAGGTGCAGGCCCAGTTGTCACCCCTCCAGAACAT CTCCCCATGGATTCTGGCGGTATTGACTCTTCAGATTCAGAGTCTGATATCCTGTTGGGCATTCTGGACAACTTGGACCCAGTCATGTTC TTCAAATGCCCTTCCCCAGAGCCTGCCAGCCTGGAGGAGCTCCCAGAGGTCTACCCAGAAGGACCCAGTTCCTTACCAGCCTCCCTTTCT CTGTCAGTGGGGACGTCATCAGCCAAGCTGGAAGCCATTAATGAACTAATTCGTTTTGACCACATATATACCAAGCCCCTAGTCTTAGAG ATACCCTCTGAGACAGAGAGCCAAGCTAATGTGGTAGTGAAAATCGAGGAAGCACCTCTCAGCCCCTCAGAGAATGATCACCCTGAATTC ATTGTCTCAGTGAAGGAAGAACCTGTAGAAGATGACCTCGTTCCGGAGCTGGGTATCTCAAATCTGCTTTCATCCAGCCACTGCCCAAAG CCATCTTCCTGCCTACTGGATGCTTACAGTGACTGTGGATACGGGGGTTCCCTTTCCCCATTCAGTGACATGTCCTCTCTGCTTGGTGTA AACCATTCTTGGGAGGACACTTTTGCCAATGAACTCTTTCCCCAGCTGATTAGTGTCTAAGGAATGATCCAATACTGTTGCCCTTTTCCT TGACTATTACACTGCCTGGAGGATAGCAGAGAAGCCTGTCTGTACTTCATTCAAAAAGCCAAAATAGAGAGTATACAGTCCTAGAGAATT CCTCTATTTGTTCAGATCTCATAGATGACCCCCAGGTATTGTCTTTTGACATCCAGCAGTCCAAGGTATTGAGACATATTACTGGAAGTA AGAAATATTACTATAATTGAGAACTACAGCTTTTAAGATTGTACTTTTATCTTAAAAGGGTGGTAGTTTTCCCTAAAATACTTATTATGT AAGGGTCATTAGACAAATGTCTTGAAGTAGACATGGAATTTATGAATGGTTCTTTATCATTTCTCTTCCCCCTTTTTGGCATCCTGGCTT GCCTCCAGTTTTAGGTCCTTTAGTTTGCTTCTGTAAGCAACGGGAACACCTGCTGAGGGGGCTCTTTCCCTCATGTATACTTCAAGTAAG ATCAAGAATCTTTTGTGAAATTATAGAAATTTACTATGTAAATGCTTGATGGAATTTTTTCCTGCTAGTGTAGCTTCTGAAAGGTGCTTT >39220_39220_12_IGLL5-XBP1_IGLL5_chr22_23230439_ENST00000532223_XBP1_chr22_29195141_ENST00000405219_length(amino acids)=254AA_BP=68 MRPKTGQVGCETPEELGPGPRQRWPLLLLGLAMVAHGLLRPMVAPQSGDPDPGASVGSSRSSLRSLWGRKLKNRVAAQTARDRKKARMSE LEQQVVDLEEENQKLLLENQLLREKTHGLVVENQELRQRLGMDALVAEEEAEAKGNEVRPVAGSAESAALRLRAPLQQVQAQLSPLQNIS -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for IGLL5-XBP1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for IGLL5-XBP1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for IGLL5-XBP1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies