
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:IL1RAP-TMEM207 (FusionGDB2 ID:39488) |
Fusion Gene Summary for IL1RAP-TMEM207 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: IL1RAP-TMEM207 | Fusion gene ID: 39488 | Hgene | Tgene | Gene symbol | IL1RAP | TMEM207 | Gene ID | 3556 | 131920 |
| Gene name | interleukin 1 receptor accessory protein | transmembrane protein 207 | |
| Synonyms | C3orf13|IL-1RAcP|IL1R3 | UNQ846 | |
| Cytomap | 3q28 | 3q28 | |
| Type of gene | protein-coding | protein-coding | |
| Description | interleukin-1 receptor accessory proteinIL-1 receptor accessory proteininterleukin-1 receptor 3interleukin-1 receptor accessory protein beta | transmembrane protein 207SRSR846 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q9NPH3 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000072516, ENST00000317757, ENST00000412504, ENST00000422485, ENST00000422940, ENST00000434491, ENST00000439062, ENST00000443369, ENST00000447382, ENST00000465496, | ENST00000354905, | |
| Fusion gene scores | * DoF score | 7 X 5 X 4=140 | 4 X 2 X 2=16 |
| # samples | 10 | 4 | |
| ** MAII score | log2(10/140*10)=-0.485426827170242 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(4/16*10)=1.32192809488736 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | |
| Context | PubMed: IL1RAP [Title/Abstract] AND TMEM207 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | IL1RAP(190326970)-TMEM207(190165616), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across IL1RAP (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across TMEM207 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | LUSC | TCGA-22-5491-01A | IL1RAP | chr3 | 190326970 | - | TMEM207 | chr3 | 190165616 | - |
| ChimerDB4 | LUSC | TCGA-22-5491-01A | IL1RAP | chr3 | 190326970 | + | TMEM207 | chr3 | 190165616 | - |
Top |
Fusion Gene ORF analysis for IL1RAP-TMEM207 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| In-frame | ENST00000072516 | ENST00000354905 | IL1RAP | chr3 | 190326970 | + | TMEM207 | chr3 | 190165616 | - |
| In-frame | ENST00000317757 | ENST00000354905 | IL1RAP | chr3 | 190326970 | + | TMEM207 | chr3 | 190165616 | - |
| In-frame | ENST00000412504 | ENST00000354905 | IL1RAP | chr3 | 190326970 | + | TMEM207 | chr3 | 190165616 | - |
| In-frame | ENST00000422485 | ENST00000354905 | IL1RAP | chr3 | 190326970 | + | TMEM207 | chr3 | 190165616 | - |
| In-frame | ENST00000422940 | ENST00000354905 | IL1RAP | chr3 | 190326970 | + | TMEM207 | chr3 | 190165616 | - |
| In-frame | ENST00000434491 | ENST00000354905 | IL1RAP | chr3 | 190326970 | + | TMEM207 | chr3 | 190165616 | - |
| In-frame | ENST00000439062 | ENST00000354905 | IL1RAP | chr3 | 190326970 | + | TMEM207 | chr3 | 190165616 | - |
| In-frame | ENST00000443369 | ENST00000354905 | IL1RAP | chr3 | 190326970 | + | TMEM207 | chr3 | 190165616 | - |
| In-frame | ENST00000447382 | ENST00000354905 | IL1RAP | chr3 | 190326970 | + | TMEM207 | chr3 | 190165616 | - |
| intron-3CDS | ENST00000465496 | ENST00000354905 | IL1RAP | chr3 | 190326970 | + | TMEM207 | chr3 | 190165616 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000412504 | IL1RAP | chr3 | 190326970 | + | ENST00000354905 | TMEM207 | chr3 | 190165616 | - | 2095 | 789 | 252 | 1154 | 300 |
| ENST00000072516 | IL1RAP | chr3 | 190326970 | + | ENST00000354905 | TMEM207 | chr3 | 190165616 | - | 2013 | 707 | 50 | 1072 | 340 |
| ENST00000443369 | IL1RAP | chr3 | 190326970 | + | ENST00000354905 | TMEM207 | chr3 | 190165616 | - | 2013 | 707 | 50 | 1072 | 340 |
| ENST00000439062 | IL1RAP | chr3 | 190326970 | + | ENST00000354905 | TMEM207 | chr3 | 190165616 | - | 2256 | 950 | 386 | 1315 | 309 |
| ENST00000447382 | IL1RAP | chr3 | 190326970 | + | ENST00000354905 | TMEM207 | chr3 | 190165616 | - | 2092 | 786 | 222 | 1151 | 309 |
| ENST00000422485 | IL1RAP | chr3 | 190326970 | + | ENST00000354905 | TMEM207 | chr3 | 190165616 | - | 2053 | 747 | 183 | 1112 | 309 |
| ENST00000434491 | IL1RAP | chr3 | 190326970 | + | ENST00000354905 | TMEM207 | chr3 | 190165616 | - | 1611 | 305 | 29 | 670 | 213 |
| ENST00000422940 | IL1RAP | chr3 | 190326970 | + | ENST00000354905 | TMEM207 | chr3 | 190165616 | - | 1962 | 656 | 29 | 1021 | 330 |
| ENST00000317757 | IL1RAP | chr3 | 190326970 | + | ENST00000354905 | TMEM207 | chr3 | 190165616 | - | 2049 | 743 | 179 | 1108 | 309 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000412504 | ENST00000354905 | IL1RAP | chr3 | 190326970 | + | TMEM207 | chr3 | 190165616 | - | 0.002752521 | 0.9972474 |
| ENST00000072516 | ENST00000354905 | IL1RAP | chr3 | 190326970 | + | TMEM207 | chr3 | 190165616 | - | 0.002429313 | 0.9975707 |
| ENST00000443369 | ENST00000354905 | IL1RAP | chr3 | 190326970 | + | TMEM207 | chr3 | 190165616 | - | 0.002429313 | 0.9975707 |
| ENST00000439062 | ENST00000354905 | IL1RAP | chr3 | 190326970 | + | TMEM207 | chr3 | 190165616 | - | 0.002960523 | 0.9970395 |
| ENST00000447382 | ENST00000354905 | IL1RAP | chr3 | 190326970 | + | TMEM207 | chr3 | 190165616 | - | 0.002993827 | 0.99700624 |
| ENST00000422485 | ENST00000354905 | IL1RAP | chr3 | 190326970 | + | TMEM207 | chr3 | 190165616 | - | 0.002329003 | 0.99767095 |
| ENST00000434491 | ENST00000354905 | IL1RAP | chr3 | 190326970 | + | TMEM207 | chr3 | 190165616 | - | 0.008829994 | 0.99117005 |
| ENST00000422940 | ENST00000354905 | IL1RAP | chr3 | 190326970 | + | TMEM207 | chr3 | 190165616 | - | 0.002154401 | 0.99784565 |
| ENST00000317757 | ENST00000354905 | IL1RAP | chr3 | 190326970 | + | TMEM207 | chr3 | 190165616 | - | 0.002313936 | 0.997686 |
Top |
Fusion Genomic Features for IL1RAP-TMEM207 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
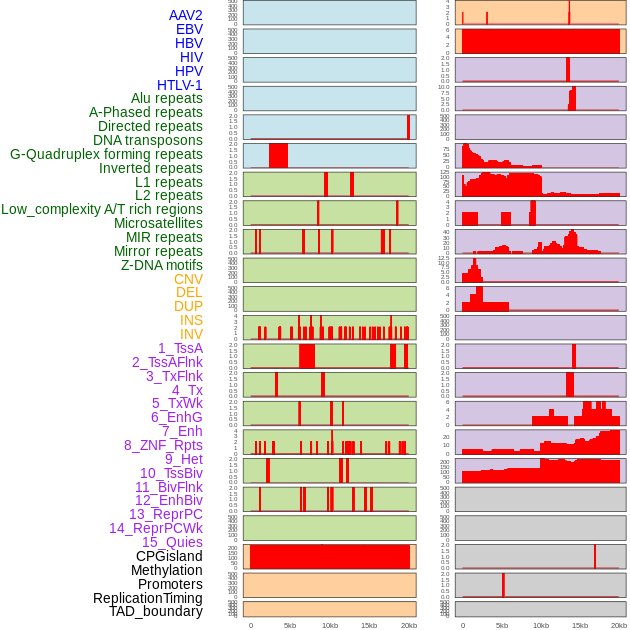
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for IL1RAP-TMEM207 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr3:190326970/chr3:190165616) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| IL1RAP | . |
| FUNCTION: Coreceptor for IL1RL2 in the IL-36 signaling system (By similarity). Coreceptor with IL1R1 in the IL-1 signaling system. Associates with IL1R1 bound to IL1B to form the high affinity interleukin-1 receptor complex which mediates interleukin-1-dependent activation of NF-kappa-B and other pathways. Signaling involves the recruitment of adapter molecules such as TOLLIP, MYD88, and IRAK1 or IRAK2 via the respective TIR domains of the receptor/coreceptor subunits. Recruits TOLLIP to the signaling complex. Does not bind to interleukin-1 alone; binding of IL1RN to IL1R1, prevents its association with IL1R1 to form a signaling complex. The cellular response is modulated through a non-signaling association with the membrane IL1R2 decoy receptor. Coreceptor for IL1RL1 in the IL-33 signaling system. Can bidirectionally induce pre- and postsynaptic differentiation of neurons by trans-synaptically binding to PTPRD (By similarity). May play a role in IL1B-mediated costimulation of IFNG production from T-helper 1 (Th1) cells (Probable). {ECO:0000250|UniProtKB:Q61730, ECO:0000269|PubMed:10799889, ECO:0000269|PubMed:9371760, ECO:0000305|PubMed:10653850, ECO:0000305|PubMed:19836339}.; FUNCTION: [Isoform 2]: Associates with secreted ligand-bound IL1R2 and increases the affinity of secreted IL1R2 for IL1B; this complex formation may be the dominant mechanism for neutralization of IL1B by secreted/soluble receptors (PubMed:12530978). Enhances the ability of secreted IL1R1 to inhibit IL-33 signaling (By similarity). {ECO:0000250|UniProtKB:Q61730, ECO:0000269|PubMed:12530978}.; FUNCTION: [Isoform 4]: Unable to mediate canonical IL-1 signaling (PubMed:19481478). Required for Src phosphorylation by IL1B. May be involved in IL1B-potentiated NMDA-induced calcium influx in neurons (By similarity). {ECO:0000250|UniProtKB:Q61730, ECO:0000269|PubMed:19481478}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000072516 | + | 4 | 11 | 21_128 | 179 | 571.0 | Domain | Note=Ig-like C2-type 1 |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000317757 | + | 5 | 12 | 21_128 | 179 | 688.0 | Domain | Note=Ig-like C2-type 1 |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000412504 | + | 4 | 11 | 21_128 | 179 | 571.0 | Domain | Note=Ig-like C2-type 1 |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000422485 | + | 5 | 9 | 21_128 | 179 | 357.0 | Domain | Note=Ig-like C2-type 1 |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000422940 | + | 4 | 8 | 21_128 | 179 | 357.0 | Domain | Note=Ig-like C2-type 1 |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000439062 | + | 6 | 13 | 21_128 | 179 | 571.0 | Domain | Note=Ig-like C2-type 1 |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000443369 | + | 4 | 11 | 21_128 | 179 | 688.0 | Domain | Note=Ig-like C2-type 1 |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000447382 | + | 5 | 12 | 21_128 | 179 | 571.0 | Domain | Note=Ig-like C2-type 1 |
| Tgene | TMEM207 | chr3:190326970 | chr3:190165616 | ENST00000354905 | 0 | 5 | 52_72 | 25 | 147.0 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000072516 | + | 4 | 11 | 141_230 | 179 | 571.0 | Domain | Note=Ig-like C2-type 2 |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000072516 | + | 4 | 11 | 242_348 | 179 | 571.0 | Domain | Note=Ig-like C2-type 3 |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000072516 | + | 4 | 11 | 403_546 | 179 | 571.0 | Domain | TIR |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000317757 | + | 5 | 12 | 141_230 | 179 | 688.0 | Domain | Note=Ig-like C2-type 2 |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000317757 | + | 5 | 12 | 242_348 | 179 | 688.0 | Domain | Note=Ig-like C2-type 3 |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000317757 | + | 5 | 12 | 403_546 | 179 | 688.0 | Domain | TIR |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000412504 | + | 4 | 11 | 141_230 | 179 | 571.0 | Domain | Note=Ig-like C2-type 2 |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000412504 | + | 4 | 11 | 242_348 | 179 | 571.0 | Domain | Note=Ig-like C2-type 3 |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000412504 | + | 4 | 11 | 403_546 | 179 | 571.0 | Domain | TIR |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000422485 | + | 5 | 9 | 141_230 | 179 | 357.0 | Domain | Note=Ig-like C2-type 2 |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000422485 | + | 5 | 9 | 242_348 | 179 | 357.0 | Domain | Note=Ig-like C2-type 3 |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000422485 | + | 5 | 9 | 403_546 | 179 | 357.0 | Domain | TIR |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000422940 | + | 4 | 8 | 141_230 | 179 | 357.0 | Domain | Note=Ig-like C2-type 2 |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000422940 | + | 4 | 8 | 242_348 | 179 | 357.0 | Domain | Note=Ig-like C2-type 3 |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000422940 | + | 4 | 8 | 403_546 | 179 | 357.0 | Domain | TIR |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000439062 | + | 6 | 13 | 141_230 | 179 | 571.0 | Domain | Note=Ig-like C2-type 2 |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000439062 | + | 6 | 13 | 242_348 | 179 | 571.0 | Domain | Note=Ig-like C2-type 3 |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000439062 | + | 6 | 13 | 403_546 | 179 | 571.0 | Domain | TIR |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000443369 | + | 4 | 11 | 141_230 | 179 | 688.0 | Domain | Note=Ig-like C2-type 2 |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000443369 | + | 4 | 11 | 242_348 | 179 | 688.0 | Domain | Note=Ig-like C2-type 3 |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000443369 | + | 4 | 11 | 403_546 | 179 | 688.0 | Domain | TIR |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000447382 | + | 5 | 12 | 141_230 | 179 | 571.0 | Domain | Note=Ig-like C2-type 2 |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000447382 | + | 5 | 12 | 242_348 | 179 | 571.0 | Domain | Note=Ig-like C2-type 3 |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000447382 | + | 5 | 12 | 403_546 | 179 | 571.0 | Domain | TIR |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000072516 | + | 4 | 11 | 21_367 | 179 | 571.0 | Topological domain | Extracellular |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000072516 | + | 4 | 11 | 389_570 | 179 | 571.0 | Topological domain | Cytoplasmic |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000317757 | + | 5 | 12 | 21_367 | 179 | 688.0 | Topological domain | Extracellular |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000317757 | + | 5 | 12 | 389_570 | 179 | 688.0 | Topological domain | Cytoplasmic |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000412504 | + | 4 | 11 | 21_367 | 179 | 571.0 | Topological domain | Extracellular |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000412504 | + | 4 | 11 | 389_570 | 179 | 571.0 | Topological domain | Cytoplasmic |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000422485 | + | 5 | 9 | 21_367 | 179 | 357.0 | Topological domain | Extracellular |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000422485 | + | 5 | 9 | 389_570 | 179 | 357.0 | Topological domain | Cytoplasmic |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000422940 | + | 4 | 8 | 21_367 | 179 | 357.0 | Topological domain | Extracellular |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000422940 | + | 4 | 8 | 389_570 | 179 | 357.0 | Topological domain | Cytoplasmic |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000439062 | + | 6 | 13 | 21_367 | 179 | 571.0 | Topological domain | Extracellular |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000439062 | + | 6 | 13 | 389_570 | 179 | 571.0 | Topological domain | Cytoplasmic |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000443369 | + | 4 | 11 | 21_367 | 179 | 688.0 | Topological domain | Extracellular |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000443369 | + | 4 | 11 | 389_570 | 179 | 688.0 | Topological domain | Cytoplasmic |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000447382 | + | 5 | 12 | 21_367 | 179 | 571.0 | Topological domain | Extracellular |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000447382 | + | 5 | 12 | 389_570 | 179 | 571.0 | Topological domain | Cytoplasmic |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000072516 | + | 4 | 11 | 368_388 | 179 | 571.0 | Transmembrane | Helical |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000317757 | + | 5 | 12 | 368_388 | 179 | 688.0 | Transmembrane | Helical |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000412504 | + | 4 | 11 | 368_388 | 179 | 571.0 | Transmembrane | Helical |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000422485 | + | 5 | 9 | 368_388 | 179 | 357.0 | Transmembrane | Helical |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000422940 | + | 4 | 8 | 368_388 | 179 | 357.0 | Transmembrane | Helical |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000439062 | + | 6 | 13 | 368_388 | 179 | 571.0 | Transmembrane | Helical |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000443369 | + | 4 | 11 | 368_388 | 179 | 688.0 | Transmembrane | Helical |
| Hgene | IL1RAP | chr3:190326970 | chr3:190165616 | ENST00000447382 | + | 5 | 12 | 368_388 | 179 | 571.0 | Transmembrane | Helical |
Top |
Fusion Gene Sequence for IL1RAP-TMEM207 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >39488_39488_1_IL1RAP-TMEM207_IL1RAP_chr3_190326970_ENST00000072516_TMEM207_chr3_190165616_ENST00000354905_length(transcript)=2013nt_BP=707nt AAAGGGGGAAAAGAAAGTGCGGCGGAAAGTAAGAGGCTCACTGGGGAAGACTGCCGGGATCCAGGTCTCCGGGGTCCGCTTTGGCCAGAG GCGCGGAAGGAAGCAGTGCCCGGCGACACTGCACCCATCCCGGCTGCTTTTGCTGCGCCCTCTCAGCTTCCCAAGAAAGGATGACACTTC TGTGGTGTGTAGTGAGTCTCTACTTTTATGGAATCCTGCAAAGTGATGCCTCAGAACGCTGCGATGACTGGGGACTAGACACCATGAGGC AAATCCAAGTGTTTGAAGATGAGCCAGCTCGCATCAAGTGCCCACTCTTTGAACACTTCTTGAAATTCAACTACAGCACAGCCCATTCAG CTGGCCTTACTCTGATCTGGTATTGGACTAGGCAGGACCGGGACCTTGAGGAGCCAATTAACTTCCGCCTCCCCGAGAACCGCATTAGTA AGGAGAAAGATGTGCTGTGGTTCCGGCCCACTCTCCTCAATGACACTGGCAACTATACCTGCATGTTAAGGAACACTACATATTGCAGCA AAGTTGCATTTCCCTTGGAAGTTGTTCAAAAAGACAGCTGTTTCAATTCCCCCATGAAACTCCCAGTGCATAAACTGTATATAGAATATG GCATTCAGAGGATCACTTGTCCAAATGTAGATGGATATTTTCCTTCCAGTGTCAAACCGACTATCACTTGGTATATGTTGGTGCTCTCGG ACCTACCATGCGAAGAAGATGAAATGTGTGTAAATTATAATGACCAACACCCTAATGGCTGGTATATCTGGATCCTCCTGCTGCTGGTTT TGGTGGCAGCTCTTCTCTGTGGAGCTGTGGTCCTCTGCCTCCAGTGCTGGCTGAGGAGACCCCGAATTGATTCTCACAGGCGCACCATGG CAGTTTTTGCTGTTGGAGACTTGGACTCTATTTATGGGACAGAAGCAGCTGTGAGTCCAACTGTTGGAATTCACCTTCAAACTCAAACCC CTGACCTATATCCTGTTCCTGCTCCATGTTTTGGCCCTTTAGGCTCCCCACCTCCATATGAAGAAATTGTAAAAACAACCTGATTTTAGG TGTGGATTATCAATTTAAAGTATTAACGACATCTGTAATTCCAAAACATCAAATTTAGGAATAGTTATTTCAGTTGTTGGAAATGTCCAG AGATCTATTCATATAGTCTGAGGAAGGACAATTCGACAAAAGAATGGATGTTGGAAAAAATTTTGGTCATGGAGATGTTTAAATAGTAAA GTAGCAGGCTTTTGATGTGTCACTGCTGTATCATACTTTTATGCTACACAACCAAATTAATGCTTCTCCACTAGTATCCAAACAGGCAAC AATTAGGTGCTGGAAGTAGTTTCCATCACATTTAGGACTCCACTGCAGTATACAGCACACCATTTTCTGCTTTAAACTCTTTCCTAGCAT GGGGTCCATAAAAATTATTATAATTTAACAATAGCCCAAGCCGAGAATCCAACATGTCCAGAACCAGAACCAGAAAGATAGTATTTGAAT GAAGGTGAGGGGAGAGAGTAGGAAAAAGAAAAGTTTGGAGTTGAAGGGTAAAGGATAAATGAAGAGGAAAAGGAAAAGATTACAAGTCTC AGCAAAAACAAGAGGTTTTATGCCCCAACCTGAAGAGGAAGAAATTGTAGATAGAAGGTGAAGGAGATTGCTGAAGATATAGAGCACATA TAATGCCAACACGGGGAGAAAAGAAAAGTTCCCCTTTTACAGTAATGAATGTGGCCTCCATAGTCCATAGTGTTTCTCTGGAGCCTCAGG GCTTGGCATTTATTGCAGCATCATGCTAAGAACCTTCGGCATAGGTATCTGTTCCCATGAGGACTGCAGAAGTAGCAATGAGACATCTTC AAGTGGCATTTTGGCAGTGGCCATCAGCAGGGGGACAGACAAAAACATCCATCACAGATGACATATGATCTTCAGCTGACAAATTTGTTG >39488_39488_1_IL1RAP-TMEM207_IL1RAP_chr3_190326970_ENST00000072516_TMEM207_chr3_190165616_ENST00000354905_length(amino acids)=340AA_BP=219 MPGSRSPGSALARGAEGSSARRHCTHPGCFCCALSASQERMTLLWCVVSLYFYGILQSDASERCDDWGLDTMRQIQVFEDEPARIKCPLF EHFLKFNYSTAHSAGLTLIWYWTRQDRDLEEPINFRLPENRISKEKDVLWFRPTLLNDTGNYTCMLRNTTYCSKVAFPLEVVQKDSCFNS PMKLPVHKLYIEYGIQRITCPNVDGYFPSSVKPTITWYMLVLSDLPCEEDEMCVNYNDQHPNGWYIWILLLLVLVAALLCGAVVLCLQCW -------------------------------------------------------------- >39488_39488_2_IL1RAP-TMEM207_IL1RAP_chr3_190326970_ENST00000317757_TMEM207_chr3_190165616_ENST00000354905_length(transcript)=2049nt_BP=743nt TGCCGGGATCCAGGTCTCCGGGGTCCGCTTTGGCCAGAGGCGCGGAAGGAAGCAGTGCCCGGCGACACTGCACCCATCCCGGCTGCTTTT GCTGCGCCCTCTCAGCTTCCCAAGAAAGGCATCGTCATGTGATCATCACCTAAGAACTAGAACATCAGCAGGCCCTAGAAGCCTCACTCT TGCCCCTCCCTTTAATATCTCAAAGGATGACACTTCTGTGGTGTGTAGTGAGTCTCTACTTTTATGGAATCCTGCAAAGTGATGCCTCAG AACGCTGCGATGACTGGGGACTAGACACCATGAGGCAAATCCAAGTGTTTGAAGATGAGCCAGCTCGCATCAAGTGCCCACTCTTTGAAC ACTTCTTGAAATTCAACTACAGCACAGCCCATTCAGCTGGCCTTACTCTGATCTGGTATTGGACTAGGCAGGACCGGGACCTTGAGGAGC CAATTAACTTCCGCCTCCCCGAGAACCGCATTAGTAAGGAGAAAGATGTGCTGTGGTTCCGGCCCACTCTCCTCAATGACACTGGCAACT ATACCTGCATGTTAAGGAACACTACATATTGCAGCAAAGTTGCATTTCCCTTGGAAGTTGTTCAAAAAGACAGCTGTTTCAATTCCCCCA TGAAACTCCCAGTGCATAAACTGTATATAGAATATGGCATTCAGAGGATCACTTGTCCAAATGTAGATGGATATTTTCCTTCCAGTGTCA AACCGACTATCACTTGGTATATGTTGGTGCTCTCGGACCTACCATGCGAAGAAGATGAAATGTGTGTAAATTATAATGACCAACACCCTA ATGGCTGGTATATCTGGATCCTCCTGCTGCTGGTTTTGGTGGCAGCTCTTCTCTGTGGAGCTGTGGTCCTCTGCCTCCAGTGCTGGCTGA GGAGACCCCGAATTGATTCTCACAGGCGCACCATGGCAGTTTTTGCTGTTGGAGACTTGGACTCTATTTATGGGACAGAAGCAGCTGTGA GTCCAACTGTTGGAATTCACCTTCAAACTCAAACCCCTGACCTATATCCTGTTCCTGCTCCATGTTTTGGCCCTTTAGGCTCCCCACCTC CATATGAAGAAATTGTAAAAACAACCTGATTTTAGGTGTGGATTATCAATTTAAAGTATTAACGACATCTGTAATTCCAAAACATCAAAT TTAGGAATAGTTATTTCAGTTGTTGGAAATGTCCAGAGATCTATTCATATAGTCTGAGGAAGGACAATTCGACAAAAGAATGGATGTTGG AAAAAATTTTGGTCATGGAGATGTTTAAATAGTAAAGTAGCAGGCTTTTGATGTGTCACTGCTGTATCATACTTTTATGCTACACAACCA AATTAATGCTTCTCCACTAGTATCCAAACAGGCAACAATTAGGTGCTGGAAGTAGTTTCCATCACATTTAGGACTCCACTGCAGTATACA GCACACCATTTTCTGCTTTAAACTCTTTCCTAGCATGGGGTCCATAAAAATTATTATAATTTAACAATAGCCCAAGCCGAGAATCCAACA TGTCCAGAACCAGAACCAGAAAGATAGTATTTGAATGAAGGTGAGGGGAGAGAGTAGGAAAAAGAAAAGTTTGGAGTTGAAGGGTAAAGG ATAAATGAAGAGGAAAAGGAAAAGATTACAAGTCTCAGCAAAAACAAGAGGTTTTATGCCCCAACCTGAAGAGGAAGAAATTGTAGATAG AAGGTGAAGGAGATTGCTGAAGATATAGAGCACATATAATGCCAACACGGGGAGAAAAGAAAAGTTCCCCTTTTACAGTAATGAATGTGG CCTCCATAGTCCATAGTGTTTCTCTGGAGCCTCAGGGCTTGGCATTTATTGCAGCATCATGCTAAGAACCTTCGGCATAGGTATCTGTTC CCATGAGGACTGCAGAAGTAGCAATGAGACATCTTCAAGTGGCATTTTGGCAGTGGCCATCAGCAGGGGGACAGACAAAAACATCCATCA >39488_39488_2_IL1RAP-TMEM207_IL1RAP_chr3_190326970_ENST00000317757_TMEM207_chr3_190165616_ENST00000354905_length(amino acids)=309AA_BP=188 MPLPLISQRMTLLWCVVSLYFYGILQSDASERCDDWGLDTMRQIQVFEDEPARIKCPLFEHFLKFNYSTAHSAGLTLIWYWTRQDRDLEE PINFRLPENRISKEKDVLWFRPTLLNDTGNYTCMLRNTTYCSKVAFPLEVVQKDSCFNSPMKLPVHKLYIEYGIQRITCPNVDGYFPSSV KPTITWYMLVLSDLPCEEDEMCVNYNDQHPNGWYIWILLLLVLVAALLCGAVVLCLQCWLRRPRIDSHRRTMAVFAVGDLDSIYGTEAAV -------------------------------------------------------------- >39488_39488_3_IL1RAP-TMEM207_IL1RAP_chr3_190326970_ENST00000412504_TMEM207_chr3_190165616_ENST00000354905_length(transcript)=2095nt_BP=789nt AAAGGGGGAAAAGAAAGTGCGGCGGAAAGTAAGAGGCTCACTGGGGAAGACTGCCGGGATCCAGGTCTCCGGGGTCCGCTTTGGCCAGAG GCGCGGAAGGAAGCAGTGCCCGGCGACACTGCACCCATCCCGGCTGCTTTTGCTGCGCCCTCTCAGCTTCCCAAGAAAGGTGAGTCTCGC GCCGCCGTGAGGGCTCAGAAGTCACCAAGCCGCAGAATCTCAGGGTAGACGGATTCTTAGAGATCTTACAGGATGACACTTCTGTGGTGT GTAGTGAGTCTCTACTTTTATGGAATCCTGCAAAGTGATGCCTCAGAACGCTGCGATGACTGGGGACTAGACACCATGAGGCAAATCCAA GTGTTTGAAGATGAGCCAGCTCGCATCAAGTGCCCACTCTTTGAACACTTCTTGAAATTCAACTACAGCACAGCCCATTCAGCTGGCCTT ACTCTGATCTGGTATTGGACTAGGCAGGACCGGGACCTTGAGGAGCCAATTAACTTCCGCCTCCCCGAGAACCGCATTAGTAAGGAGAAA GATGTGCTGTGGTTCCGGCCCACTCTCCTCAATGACACTGGCAACTATACCTGCATGTTAAGGAACACTACATATTGCAGCAAAGTTGCA TTTCCCTTGGAAGTTGTTCAAAAAGACAGCTGTTTCAATTCCCCCATGAAACTCCCAGTGCATAAACTGTATATAGAATATGGCATTCAG AGGATCACTTGTCCAAATGTAGATGGATATTTTCCTTCCAGTGTCAAACCGACTATCACTTGGTATATGTTGGTGCTCTCGGACCTACCA TGCGAAGAAGATGAAATGTGTGTAAATTATAATGACCAACACCCTAATGGCTGGTATATCTGGATCCTCCTGCTGCTGGTTTTGGTGGCA GCTCTTCTCTGTGGAGCTGTGGTCCTCTGCCTCCAGTGCTGGCTGAGGAGACCCCGAATTGATTCTCACAGGCGCACCATGGCAGTTTTT GCTGTTGGAGACTTGGACTCTATTTATGGGACAGAAGCAGCTGTGAGTCCAACTGTTGGAATTCACCTTCAAACTCAAACCCCTGACCTA TATCCTGTTCCTGCTCCATGTTTTGGCCCTTTAGGCTCCCCACCTCCATATGAAGAAATTGTAAAAACAACCTGATTTTAGGTGTGGATT ATCAATTTAAAGTATTAACGACATCTGTAATTCCAAAACATCAAATTTAGGAATAGTTATTTCAGTTGTTGGAAATGTCCAGAGATCTAT TCATATAGTCTGAGGAAGGACAATTCGACAAAAGAATGGATGTTGGAAAAAATTTTGGTCATGGAGATGTTTAAATAGTAAAGTAGCAGG CTTTTGATGTGTCACTGCTGTATCATACTTTTATGCTACACAACCAAATTAATGCTTCTCCACTAGTATCCAAACAGGCAACAATTAGGT GCTGGAAGTAGTTTCCATCACATTTAGGACTCCACTGCAGTATACAGCACACCATTTTCTGCTTTAAACTCTTTCCTAGCATGGGGTCCA TAAAAATTATTATAATTTAACAATAGCCCAAGCCGAGAATCCAACATGTCCAGAACCAGAACCAGAAAGATAGTATTTGAATGAAGGTGA GGGGAGAGAGTAGGAAAAAGAAAAGTTTGGAGTTGAAGGGTAAAGGATAAATGAAGAGGAAAAGGAAAAGATTACAAGTCTCAGCAAAAA CAAGAGGTTTTATGCCCCAACCTGAAGAGGAAGAAATTGTAGATAGAAGGTGAAGGAGATTGCTGAAGATATAGAGCACATATAATGCCA ACACGGGGAGAAAAGAAAAGTTCCCCTTTTACAGTAATGAATGTGGCCTCCATAGTCCATAGTGTTTCTCTGGAGCCTCAGGGCTTGGCA TTTATTGCAGCATCATGCTAAGAACCTTCGGCATAGGTATCTGTTCCCATGAGGACTGCAGAAGTAGCAATGAGACATCTTCAAGTGGCA TTTTGGCAGTGGCCATCAGCAGGGGGACAGACAAAAACATCCATCACAGATGACATATGATCTTCAGCTGACAAATTTGTTGAACAAAAC >39488_39488_3_IL1RAP-TMEM207_IL1RAP_chr3_190326970_ENST00000412504_TMEM207_chr3_190165616_ENST00000354905_length(amino acids)=300AA_BP=179 MTLLWCVVSLYFYGILQSDASERCDDWGLDTMRQIQVFEDEPARIKCPLFEHFLKFNYSTAHSAGLTLIWYWTRQDRDLEEPINFRLPEN RISKEKDVLWFRPTLLNDTGNYTCMLRNTTYCSKVAFPLEVVQKDSCFNSPMKLPVHKLYIEYGIQRITCPNVDGYFPSSVKPTITWYML VLSDLPCEEDEMCVNYNDQHPNGWYIWILLLLVLVAALLCGAVVLCLQCWLRRPRIDSHRRTMAVFAVGDLDSIYGTEAAVSPTVGIHLQ -------------------------------------------------------------- >39488_39488_4_IL1RAP-TMEM207_IL1RAP_chr3_190326970_ENST00000422485_TMEM207_chr3_190165616_ENST00000354905_length(transcript)=2053nt_BP=747nt AGACTGCCGGGATCCAGGTCTCCGGGGTCCGCTTTGGCCAGAGGCGCGGAAGGAAGCAGTGCCCGGCGACACTGCACCCATCCCGGCTGC TTTTGCTGCGCCCTCTCAGCTTCCCAAGAAAGGCATCGTCATGTGATCATCACCTAAGAACTAGAACATCAGCAGGCCCTAGAAGCCTCA CTCTTGCCCCTCCCTTTAATATCTCAAAGGATGACACTTCTGTGGTGTGTAGTGAGTCTCTACTTTTATGGAATCCTGCAAAGTGATGCC TCAGAACGCTGCGATGACTGGGGACTAGACACCATGAGGCAAATCCAAGTGTTTGAAGATGAGCCAGCTCGCATCAAGTGCCCACTCTTT GAACACTTCTTGAAATTCAACTACAGCACAGCCCATTCAGCTGGCCTTACTCTGATCTGGTATTGGACTAGGCAGGACCGGGACCTTGAG GAGCCAATTAACTTCCGCCTCCCCGAGAACCGCATTAGTAAGGAGAAAGATGTGCTGTGGTTCCGGCCCACTCTCCTCAATGACACTGGC AACTATACCTGCATGTTAAGGAACACTACATATTGCAGCAAAGTTGCATTTCCCTTGGAAGTTGTTCAAAAAGACAGCTGTTTCAATTCC CCCATGAAACTCCCAGTGCATAAACTGTATATAGAATATGGCATTCAGAGGATCACTTGTCCAAATGTAGATGGATATTTTCCTTCCAGT GTCAAACCGACTATCACTTGGTATATGTTGGTGCTCTCGGACCTACCATGCGAAGAAGATGAAATGTGTGTAAATTATAATGACCAACAC CCTAATGGCTGGTATATCTGGATCCTCCTGCTGCTGGTTTTGGTGGCAGCTCTTCTCTGTGGAGCTGTGGTCCTCTGCCTCCAGTGCTGG CTGAGGAGACCCCGAATTGATTCTCACAGGCGCACCATGGCAGTTTTTGCTGTTGGAGACTTGGACTCTATTTATGGGACAGAAGCAGCT GTGAGTCCAACTGTTGGAATTCACCTTCAAACTCAAACCCCTGACCTATATCCTGTTCCTGCTCCATGTTTTGGCCCTTTAGGCTCCCCA CCTCCATATGAAGAAATTGTAAAAACAACCTGATTTTAGGTGTGGATTATCAATTTAAAGTATTAACGACATCTGTAATTCCAAAACATC AAATTTAGGAATAGTTATTTCAGTTGTTGGAAATGTCCAGAGATCTATTCATATAGTCTGAGGAAGGACAATTCGACAAAAGAATGGATG TTGGAAAAAATTTTGGTCATGGAGATGTTTAAATAGTAAAGTAGCAGGCTTTTGATGTGTCACTGCTGTATCATACTTTTATGCTACACA ACCAAATTAATGCTTCTCCACTAGTATCCAAACAGGCAACAATTAGGTGCTGGAAGTAGTTTCCATCACATTTAGGACTCCACTGCAGTA TACAGCACACCATTTTCTGCTTTAAACTCTTTCCTAGCATGGGGTCCATAAAAATTATTATAATTTAACAATAGCCCAAGCCGAGAATCC AACATGTCCAGAACCAGAACCAGAAAGATAGTATTTGAATGAAGGTGAGGGGAGAGAGTAGGAAAAAGAAAAGTTTGGAGTTGAAGGGTA AAGGATAAATGAAGAGGAAAAGGAAAAGATTACAAGTCTCAGCAAAAACAAGAGGTTTTATGCCCCAACCTGAAGAGGAAGAAATTGTAG ATAGAAGGTGAAGGAGATTGCTGAAGATATAGAGCACATATAATGCCAACACGGGGAGAAAAGAAAAGTTCCCCTTTTACAGTAATGAAT GTGGCCTCCATAGTCCATAGTGTTTCTCTGGAGCCTCAGGGCTTGGCATTTATTGCAGCATCATGCTAAGAACCTTCGGCATAGGTATCT GTTCCCATGAGGACTGCAGAAGTAGCAATGAGACATCTTCAAGTGGCATTTTGGCAGTGGCCATCAGCAGGGGGACAGACAAAAACATCC >39488_39488_4_IL1RAP-TMEM207_IL1RAP_chr3_190326970_ENST00000422485_TMEM207_chr3_190165616_ENST00000354905_length(amino acids)=309AA_BP=188 MPLPLISQRMTLLWCVVSLYFYGILQSDASERCDDWGLDTMRQIQVFEDEPARIKCPLFEHFLKFNYSTAHSAGLTLIWYWTRQDRDLEE PINFRLPENRISKEKDVLWFRPTLLNDTGNYTCMLRNTTYCSKVAFPLEVVQKDSCFNSPMKLPVHKLYIEYGIQRITCPNVDGYFPSSV KPTITWYMLVLSDLPCEEDEMCVNYNDQHPNGWYIWILLLLVLVAALLCGAVVLCLQCWLRRPRIDSHRRTMAVFAVGDLDSIYGTEAAV -------------------------------------------------------------- >39488_39488_5_IL1RAP-TMEM207_IL1RAP_chr3_190326970_ENST00000422940_TMEM207_chr3_190165616_ENST00000354905_length(transcript)=1962nt_BP=656nt TGCCGGGATCCAGGTCTCCGGGGTCCGCTTTGGCCAGAGGCGCGGAAGGAAGCAGTGCCCGGCGACACTGCACCCATCCCGGCTGCTTTT GCTGCGCCCTCTCAGCTTCCCAAGAAAGGATGACACTTCTGTGGTGTGTAGTGAGTCTCTACTTTTATGGAATCCTGCAAAGTGATGCCT CAGAACGCTGCGATGACTGGGGACTAGACACCATGAGGCAAATCCAAGTGTTTGAAGATGAGCCAGCTCGCATCAAGTGCCCACTCTTTG AACACTTCTTGAAATTCAACTACAGCACAGCCCATTCAGCTGGCCTTACTCTGATCTGGTATTGGACTAGGCAGGACCGGGACCTTGAGG AGCCAATTAACTTCCGCCTCCCCGAGAACCGCATTAGTAAGGAGAAAGATGTGCTGTGGTTCCGGCCCACTCTCCTCAATGACACTGGCA ACTATACCTGCATGTTAAGGAACACTACATATTGCAGCAAAGTTGCATTTCCCTTGGAAGTTGTTCAAAAAGACAGCTGTTTCAATTCCC CCATGAAACTCCCAGTGCATAAACTGTATATAGAATATGGCATTCAGAGGATCACTTGTCCAAATGTAGATGGATATTTTCCTTCCAGTG TCAAACCGACTATCACTTGGTATATGTTGGTGCTCTCGGACCTACCATGCGAAGAAGATGAAATGTGTGTAAATTATAATGACCAACACC CTAATGGCTGGTATATCTGGATCCTCCTGCTGCTGGTTTTGGTGGCAGCTCTTCTCTGTGGAGCTGTGGTCCTCTGCCTCCAGTGCTGGC TGAGGAGACCCCGAATTGATTCTCACAGGCGCACCATGGCAGTTTTTGCTGTTGGAGACTTGGACTCTATTTATGGGACAGAAGCAGCTG TGAGTCCAACTGTTGGAATTCACCTTCAAACTCAAACCCCTGACCTATATCCTGTTCCTGCTCCATGTTTTGGCCCTTTAGGCTCCCCAC CTCCATATGAAGAAATTGTAAAAACAACCTGATTTTAGGTGTGGATTATCAATTTAAAGTATTAACGACATCTGTAATTCCAAAACATCA AATTTAGGAATAGTTATTTCAGTTGTTGGAAATGTCCAGAGATCTATTCATATAGTCTGAGGAAGGACAATTCGACAAAAGAATGGATGT TGGAAAAAATTTTGGTCATGGAGATGTTTAAATAGTAAAGTAGCAGGCTTTTGATGTGTCACTGCTGTATCATACTTTTATGCTACACAA CCAAATTAATGCTTCTCCACTAGTATCCAAACAGGCAACAATTAGGTGCTGGAAGTAGTTTCCATCACATTTAGGACTCCACTGCAGTAT ACAGCACACCATTTTCTGCTTTAAACTCTTTCCTAGCATGGGGTCCATAAAAATTATTATAATTTAACAATAGCCCAAGCCGAGAATCCA ACATGTCCAGAACCAGAACCAGAAAGATAGTATTTGAATGAAGGTGAGGGGAGAGAGTAGGAAAAAGAAAAGTTTGGAGTTGAAGGGTAA AGGATAAATGAAGAGGAAAAGGAAAAGATTACAAGTCTCAGCAAAAACAAGAGGTTTTATGCCCCAACCTGAAGAGGAAGAAATTGTAGA TAGAAGGTGAAGGAGATTGCTGAAGATATAGAGCACATATAATGCCAACACGGGGAGAAAAGAAAAGTTCCCCTTTTACAGTAATGAATG TGGCCTCCATAGTCCATAGTGTTTCTCTGGAGCCTCAGGGCTTGGCATTTATTGCAGCATCATGCTAAGAACCTTCGGCATAGGTATCTG TTCCCATGAGGACTGCAGAAGTAGCAATGAGACATCTTCAAGTGGCATTTTGGCAGTGGCCATCAGCAGGGGGACAGACAAAAACATCCA >39488_39488_5_IL1RAP-TMEM207_IL1RAP_chr3_190326970_ENST00000422940_TMEM207_chr3_190165616_ENST00000354905_length(amino acids)=330AA_BP=209 MARGAEGSSARRHCTHPGCFCCALSASQERMTLLWCVVSLYFYGILQSDASERCDDWGLDTMRQIQVFEDEPARIKCPLFEHFLKFNYST AHSAGLTLIWYWTRQDRDLEEPINFRLPENRISKEKDVLWFRPTLLNDTGNYTCMLRNTTYCSKVAFPLEVVQKDSCFNSPMKLPVHKLY IEYGIQRITCPNVDGYFPSSVKPTITWYMLVLSDLPCEEDEMCVNYNDQHPNGWYIWILLLLVLVAALLCGAVVLCLQCWLRRPRIDSHR -------------------------------------------------------------- >39488_39488_6_IL1RAP-TMEM207_IL1RAP_chr3_190326970_ENST00000434491_TMEM207_chr3_190165616_ENST00000354905_length(transcript)=1611nt_BP=305nt TGCCGGGATCCAGGTCTCCGGGGTCCGCTTTGGCCAGAGGCGCGGAAGGAAGCAGTGCCCGGCGACACTGCACCCATCCCGGCTGCTTTT GCTGCGCCCTCTCAGCTTCCCAAGAAAGGAACACTACATATTGCAGCAAAGTTGCATTTCCCTTGGAAGTTGTTCAAAAAGACAGCTGTT TCAATTCCCCCATGAAACTCCCAGTGCATAAACTGTATATAGAATATGGCATTCAGAGGATCACTTGTCCAAATGTAGATGGATATTTTC CTTCCAGTGTCAAACCGACTATCACTTGGTATATGTTGGTGCTCTCGGACCTACCATGCGAAGAAGATGAAATGTGTGTAAATTATAATG ACCAACACCCTAATGGCTGGTATATCTGGATCCTCCTGCTGCTGGTTTTGGTGGCAGCTCTTCTCTGTGGAGCTGTGGTCCTCTGCCTCC AGTGCTGGCTGAGGAGACCCCGAATTGATTCTCACAGGCGCACCATGGCAGTTTTTGCTGTTGGAGACTTGGACTCTATTTATGGGACAG AAGCAGCTGTGAGTCCAACTGTTGGAATTCACCTTCAAACTCAAACCCCTGACCTATATCCTGTTCCTGCTCCATGTTTTGGCCCTTTAG GCTCCCCACCTCCATATGAAGAAATTGTAAAAACAACCTGATTTTAGGTGTGGATTATCAATTTAAAGTATTAACGACATCTGTAATTCC AAAACATCAAATTTAGGAATAGTTATTTCAGTTGTTGGAAATGTCCAGAGATCTATTCATATAGTCTGAGGAAGGACAATTCGACAAAAG AATGGATGTTGGAAAAAATTTTGGTCATGGAGATGTTTAAATAGTAAAGTAGCAGGCTTTTGATGTGTCACTGCTGTATCATACTTTTAT GCTACACAACCAAATTAATGCTTCTCCACTAGTATCCAAACAGGCAACAATTAGGTGCTGGAAGTAGTTTCCATCACATTTAGGACTCCA CTGCAGTATACAGCACACCATTTTCTGCTTTAAACTCTTTCCTAGCATGGGGTCCATAAAAATTATTATAATTTAACAATAGCCCAAGCC GAGAATCCAACATGTCCAGAACCAGAACCAGAAAGATAGTATTTGAATGAAGGTGAGGGGAGAGAGTAGGAAAAAGAAAAGTTTGGAGTT GAAGGGTAAAGGATAAATGAAGAGGAAAAGGAAAAGATTACAAGTCTCAGCAAAAACAAGAGGTTTTATGCCCCAACCTGAAGAGGAAGA AATTGTAGATAGAAGGTGAAGGAGATTGCTGAAGATATAGAGCACATATAATGCCAACACGGGGAGAAAAGAAAAGTTCCCCTTTTACAG TAATGAATGTGGCCTCCATAGTCCATAGTGTTTCTCTGGAGCCTCAGGGCTTGGCATTTATTGCAGCATCATGCTAAGAACCTTCGGCAT AGGTATCTGTTCCCATGAGGACTGCAGAAGTAGCAATGAGACATCTTCAAGTGGCATTTTGGCAGTGGCCATCAGCAGGGGGACAGACAA >39488_39488_6_IL1RAP-TMEM207_IL1RAP_chr3_190326970_ENST00000434491_TMEM207_chr3_190165616_ENST00000354905_length(amino acids)=213AA_BP=92 MARGAEGSSARRHCTHPGCFCCALSASQERNTTYCSKVAFPLEVVQKDSCFNSPMKLPVHKLYIEYGIQRITCPNVDGYFPSSVKPTITW YMLVLSDLPCEEDEMCVNYNDQHPNGWYIWILLLLVLVAALLCGAVVLCLQCWLRRPRIDSHRRTMAVFAVGDLDSIYGTEAAVSPTVGI -------------------------------------------------------------- >39488_39488_7_IL1RAP-TMEM207_IL1RAP_chr3_190326970_ENST00000439062_TMEM207_chr3_190165616_ENST00000354905_length(transcript)=2256nt_BP=950nt AAAAGAAAGTGCGGCGGAAAGTAAGAGGCTCACTGGGGAAGACTGCCGGGATCCAGGTCTCCGGGGTCCGCTTTGGCCAGAGGCGCGGAA GGAAGCAGTGCCCGGCGACACTGCACCCATCCCGGCTGCTTTTGCTGCGCCCTCTCAGCTTCCCAAGAAAGGGCTTTGACCTGAAGCTTG AAATTGAGTTTGGGACAATAATGTGTCTCATGGGGAATTGCATGGACTCCTTATCATAAGCCAAATGCTGAGGTAAAGCTGCGGAATTGA GTCGTCCTCCAAGAAGGGAGAGAAAATGATGTCTTGTGACATTTCCAGATAACTGGCATCGTCATGTGATCATCACCTAAGAACTAGAAC ATCAGCAGGCCCTAGAAGCCTCACTCTTGCCCCTCCCTTTAATATCTCAAAGGATGACACTTCTGTGGTGTGTAGTGAGTCTCTACTTTT ATGGAATCCTGCAAAGTGATGCCTCAGAACGCTGCGATGACTGGGGACTAGACACCATGAGGCAAATCCAAGTGTTTGAAGATGAGCCAG CTCGCATCAAGTGCCCACTCTTTGAACACTTCTTGAAATTCAACTACAGCACAGCCCATTCAGCTGGCCTTACTCTGATCTGGTATTGGA CTAGGCAGGACCGGGACCTTGAGGAGCCAATTAACTTCCGCCTCCCCGAGAACCGCATTAGTAAGGAGAAAGATGTGCTGTGGTTCCGGC CCACTCTCCTCAATGACACTGGCAACTATACCTGCATGTTAAGGAACACTACATATTGCAGCAAAGTTGCATTTCCCTTGGAAGTTGTTC AAAAAGACAGCTGTTTCAATTCCCCCATGAAACTCCCAGTGCATAAACTGTATATAGAATATGGCATTCAGAGGATCACTTGTCCAAATG TAGATGGATATTTTCCTTCCAGTGTCAAACCGACTATCACTTGGTATATGTTGGTGCTCTCGGACCTACCATGCGAAGAAGATGAAATGT GTGTAAATTATAATGACCAACACCCTAATGGCTGGTATATCTGGATCCTCCTGCTGCTGGTTTTGGTGGCAGCTCTTCTCTGTGGAGCTG TGGTCCTCTGCCTCCAGTGCTGGCTGAGGAGACCCCGAATTGATTCTCACAGGCGCACCATGGCAGTTTTTGCTGTTGGAGACTTGGACT CTATTTATGGGACAGAAGCAGCTGTGAGTCCAACTGTTGGAATTCACCTTCAAACTCAAACCCCTGACCTATATCCTGTTCCTGCTCCAT GTTTTGGCCCTTTAGGCTCCCCACCTCCATATGAAGAAATTGTAAAAACAACCTGATTTTAGGTGTGGATTATCAATTTAAAGTATTAAC GACATCTGTAATTCCAAAACATCAAATTTAGGAATAGTTATTTCAGTTGTTGGAAATGTCCAGAGATCTATTCATATAGTCTGAGGAAGG ACAATTCGACAAAAGAATGGATGTTGGAAAAAATTTTGGTCATGGAGATGTTTAAATAGTAAAGTAGCAGGCTTTTGATGTGTCACTGCT GTATCATACTTTTATGCTACACAACCAAATTAATGCTTCTCCACTAGTATCCAAACAGGCAACAATTAGGTGCTGGAAGTAGTTTCCATC ACATTTAGGACTCCACTGCAGTATACAGCACACCATTTTCTGCTTTAAACTCTTTCCTAGCATGGGGTCCATAAAAATTATTATAATTTA ACAATAGCCCAAGCCGAGAATCCAACATGTCCAGAACCAGAACCAGAAAGATAGTATTTGAATGAAGGTGAGGGGAGAGAGTAGGAAAAA GAAAAGTTTGGAGTTGAAGGGTAAAGGATAAATGAAGAGGAAAAGGAAAAGATTACAAGTCTCAGCAAAAACAAGAGGTTTTATGCCCCA ACCTGAAGAGGAAGAAATTGTAGATAGAAGGTGAAGGAGATTGCTGAAGATATAGAGCACATATAATGCCAACACGGGGAGAAAAGAAAA GTTCCCCTTTTACAGTAATGAATGTGGCCTCCATAGTCCATAGTGTTTCTCTGGAGCCTCAGGGCTTGGCATTTATTGCAGCATCATGCT AAGAACCTTCGGCATAGGTATCTGTTCCCATGAGGACTGCAGAAGTAGCAATGAGACATCTTCAAGTGGCATTTTGGCAGTGGCCATCAG CAGGGGGACAGACAAAAACATCCATCACAGATGACATATGATCTTCAGCTGACAAATTTGTTGAACAAAACAATAAACATCAATAGATAT >39488_39488_7_IL1RAP-TMEM207_IL1RAP_chr3_190326970_ENST00000439062_TMEM207_chr3_190165616_ENST00000354905_length(amino acids)=309AA_BP=188 MPLPLISQRMTLLWCVVSLYFYGILQSDASERCDDWGLDTMRQIQVFEDEPARIKCPLFEHFLKFNYSTAHSAGLTLIWYWTRQDRDLEE PINFRLPENRISKEKDVLWFRPTLLNDTGNYTCMLRNTTYCSKVAFPLEVVQKDSCFNSPMKLPVHKLYIEYGIQRITCPNVDGYFPSSV KPTITWYMLVLSDLPCEEDEMCVNYNDQHPNGWYIWILLLLVLVAALLCGAVVLCLQCWLRRPRIDSHRRTMAVFAVGDLDSIYGTEAAV -------------------------------------------------------------- >39488_39488_8_IL1RAP-TMEM207_IL1RAP_chr3_190326970_ENST00000443369_TMEM207_chr3_190165616_ENST00000354905_length(transcript)=2013nt_BP=707nt AAAGGGGGAAAAGAAAGTGCGGCGGAAAGTAAGAGGCTCACTGGGGAAGACTGCCGGGATCCAGGTCTCCGGGGTCCGCTTTGGCCAGAG GCGCGGAAGGAAGCAGTGCCCGGCGACACTGCACCCATCCCGGCTGCTTTTGCTGCGCCCTCTCAGCTTCCCAAGAAAGGATGACACTTC TGTGGTGTGTAGTGAGTCTCTACTTTTATGGAATCCTGCAAAGTGATGCCTCAGAACGCTGCGATGACTGGGGACTAGACACCATGAGGC AAATCCAAGTGTTTGAAGATGAGCCAGCTCGCATCAAGTGCCCACTCTTTGAACACTTCTTGAAATTCAACTACAGCACAGCCCATTCAG CTGGCCTTACTCTGATCTGGTATTGGACTAGGCAGGACCGGGACCTTGAGGAGCCAATTAACTTCCGCCTCCCCGAGAACCGCATTAGTA AGGAGAAAGATGTGCTGTGGTTCCGGCCCACTCTCCTCAATGACACTGGCAACTATACCTGCATGTTAAGGAACACTACATATTGCAGCA AAGTTGCATTTCCCTTGGAAGTTGTTCAAAAAGACAGCTGTTTCAATTCCCCCATGAAACTCCCAGTGCATAAACTGTATATAGAATATG GCATTCAGAGGATCACTTGTCCAAATGTAGATGGATATTTTCCTTCCAGTGTCAAACCGACTATCACTTGGTATATGTTGGTGCTCTCGG ACCTACCATGCGAAGAAGATGAAATGTGTGTAAATTATAATGACCAACACCCTAATGGCTGGTATATCTGGATCCTCCTGCTGCTGGTTT TGGTGGCAGCTCTTCTCTGTGGAGCTGTGGTCCTCTGCCTCCAGTGCTGGCTGAGGAGACCCCGAATTGATTCTCACAGGCGCACCATGG CAGTTTTTGCTGTTGGAGACTTGGACTCTATTTATGGGACAGAAGCAGCTGTGAGTCCAACTGTTGGAATTCACCTTCAAACTCAAACCC CTGACCTATATCCTGTTCCTGCTCCATGTTTTGGCCCTTTAGGCTCCCCACCTCCATATGAAGAAATTGTAAAAACAACCTGATTTTAGG TGTGGATTATCAATTTAAAGTATTAACGACATCTGTAATTCCAAAACATCAAATTTAGGAATAGTTATTTCAGTTGTTGGAAATGTCCAG AGATCTATTCATATAGTCTGAGGAAGGACAATTCGACAAAAGAATGGATGTTGGAAAAAATTTTGGTCATGGAGATGTTTAAATAGTAAA GTAGCAGGCTTTTGATGTGTCACTGCTGTATCATACTTTTATGCTACACAACCAAATTAATGCTTCTCCACTAGTATCCAAACAGGCAAC AATTAGGTGCTGGAAGTAGTTTCCATCACATTTAGGACTCCACTGCAGTATACAGCACACCATTTTCTGCTTTAAACTCTTTCCTAGCAT GGGGTCCATAAAAATTATTATAATTTAACAATAGCCCAAGCCGAGAATCCAACATGTCCAGAACCAGAACCAGAAAGATAGTATTTGAAT GAAGGTGAGGGGAGAGAGTAGGAAAAAGAAAAGTTTGGAGTTGAAGGGTAAAGGATAAATGAAGAGGAAAAGGAAAAGATTACAAGTCTC AGCAAAAACAAGAGGTTTTATGCCCCAACCTGAAGAGGAAGAAATTGTAGATAGAAGGTGAAGGAGATTGCTGAAGATATAGAGCACATA TAATGCCAACACGGGGAGAAAAGAAAAGTTCCCCTTTTACAGTAATGAATGTGGCCTCCATAGTCCATAGTGTTTCTCTGGAGCCTCAGG GCTTGGCATTTATTGCAGCATCATGCTAAGAACCTTCGGCATAGGTATCTGTTCCCATGAGGACTGCAGAAGTAGCAATGAGACATCTTC AAGTGGCATTTTGGCAGTGGCCATCAGCAGGGGGACAGACAAAAACATCCATCACAGATGACATATGATCTTCAGCTGACAAATTTGTTG >39488_39488_8_IL1RAP-TMEM207_IL1RAP_chr3_190326970_ENST00000443369_TMEM207_chr3_190165616_ENST00000354905_length(amino acids)=340AA_BP=219 MPGSRSPGSALARGAEGSSARRHCTHPGCFCCALSASQERMTLLWCVVSLYFYGILQSDASERCDDWGLDTMRQIQVFEDEPARIKCPLF EHFLKFNYSTAHSAGLTLIWYWTRQDRDLEEPINFRLPENRISKEKDVLWFRPTLLNDTGNYTCMLRNTTYCSKVAFPLEVVQKDSCFNS PMKLPVHKLYIEYGIQRITCPNVDGYFPSSVKPTITWYMLVLSDLPCEEDEMCVNYNDQHPNGWYIWILLLLVLVAALLCGAVVLCLQCW -------------------------------------------------------------- >39488_39488_9_IL1RAP-TMEM207_IL1RAP_chr3_190326970_ENST00000447382_TMEM207_chr3_190165616_ENST00000354905_length(transcript)=2092nt_BP=786nt AAAAGAAAGTGCGGCGGAAAGTAAGAGGCTCACTGGGGAAGACTGCCGGGATCCAGGTCTCCGGGGTCCGCTTTGGCCAGAGGCGCGGAA GGAAGCAGTGCCCGGCGACACTGCACCCATCCCGGCTGCTTTTGCTGCGCCCTCTCAGCTTCCCAAGAAAGGCATCGTCATGTGATCATC ACCTAAGAACTAGAACATCAGCAGGCCCTAGAAGCCTCACTCTTGCCCCTCCCTTTAATATCTCAAAGGATGACACTTCTGTGGTGTGTA GTGAGTCTCTACTTTTATGGAATCCTGCAAAGTGATGCCTCAGAACGCTGCGATGACTGGGGACTAGACACCATGAGGCAAATCCAAGTG TTTGAAGATGAGCCAGCTCGCATCAAGTGCCCACTCTTTGAACACTTCTTGAAATTCAACTACAGCACAGCCCATTCAGCTGGCCTTACT CTGATCTGGTATTGGACTAGGCAGGACCGGGACCTTGAGGAGCCAATTAACTTCCGCCTCCCCGAGAACCGCATTAGTAAGGAGAAAGAT GTGCTGTGGTTCCGGCCCACTCTCCTCAATGACACTGGCAACTATACCTGCATGTTAAGGAACACTACATATTGCAGCAAAGTTGCATTT CCCTTGGAAGTTGTTCAAAAAGACAGCTGTTTCAATTCCCCCATGAAACTCCCAGTGCATAAACTGTATATAGAATATGGCATTCAGAGG ATCACTTGTCCAAATGTAGATGGATATTTTCCTTCCAGTGTCAAACCGACTATCACTTGGTATATGTTGGTGCTCTCGGACCTACCATGC GAAGAAGATGAAATGTGTGTAAATTATAATGACCAACACCCTAATGGCTGGTATATCTGGATCCTCCTGCTGCTGGTTTTGGTGGCAGCT CTTCTCTGTGGAGCTGTGGTCCTCTGCCTCCAGTGCTGGCTGAGGAGACCCCGAATTGATTCTCACAGGCGCACCATGGCAGTTTTTGCT GTTGGAGACTTGGACTCTATTTATGGGACAGAAGCAGCTGTGAGTCCAACTGTTGGAATTCACCTTCAAACTCAAACCCCTGACCTATAT CCTGTTCCTGCTCCATGTTTTGGCCCTTTAGGCTCCCCACCTCCATATGAAGAAATTGTAAAAACAACCTGATTTTAGGTGTGGATTATC AATTTAAAGTATTAACGACATCTGTAATTCCAAAACATCAAATTTAGGAATAGTTATTTCAGTTGTTGGAAATGTCCAGAGATCTATTCA TATAGTCTGAGGAAGGACAATTCGACAAAAGAATGGATGTTGGAAAAAATTTTGGTCATGGAGATGTTTAAATAGTAAAGTAGCAGGCTT TTGATGTGTCACTGCTGTATCATACTTTTATGCTACACAACCAAATTAATGCTTCTCCACTAGTATCCAAACAGGCAACAATTAGGTGCT GGAAGTAGTTTCCATCACATTTAGGACTCCACTGCAGTATACAGCACACCATTTTCTGCTTTAAACTCTTTCCTAGCATGGGGTCCATAA AAATTATTATAATTTAACAATAGCCCAAGCCGAGAATCCAACATGTCCAGAACCAGAACCAGAAAGATAGTATTTGAATGAAGGTGAGGG GAGAGAGTAGGAAAAAGAAAAGTTTGGAGTTGAAGGGTAAAGGATAAATGAAGAGGAAAAGGAAAAGATTACAAGTCTCAGCAAAAACAA GAGGTTTTATGCCCCAACCTGAAGAGGAAGAAATTGTAGATAGAAGGTGAAGGAGATTGCTGAAGATATAGAGCACATATAATGCCAACA CGGGGAGAAAAGAAAAGTTCCCCTTTTACAGTAATGAATGTGGCCTCCATAGTCCATAGTGTTTCTCTGGAGCCTCAGGGCTTGGCATTT ATTGCAGCATCATGCTAAGAACCTTCGGCATAGGTATCTGTTCCCATGAGGACTGCAGAAGTAGCAATGAGACATCTTCAAGTGGCATTT TGGCAGTGGCCATCAGCAGGGGGACAGACAAAAACATCCATCACAGATGACATATGATCTTCAGCTGACAAATTTGTTGAACAAAACAAT >39488_39488_9_IL1RAP-TMEM207_IL1RAP_chr3_190326970_ENST00000447382_TMEM207_chr3_190165616_ENST00000354905_length(amino acids)=309AA_BP=188 MPLPLISQRMTLLWCVVSLYFYGILQSDASERCDDWGLDTMRQIQVFEDEPARIKCPLFEHFLKFNYSTAHSAGLTLIWYWTRQDRDLEE PINFRLPENRISKEKDVLWFRPTLLNDTGNYTCMLRNTTYCSKVAFPLEVVQKDSCFNSPMKLPVHKLYIEYGIQRITCPNVDGYFPSSV KPTITWYMLVLSDLPCEEDEMCVNYNDQHPNGWYIWILLLLVLVAALLCGAVVLCLQCWLRRPRIDSHRRTMAVFAVGDLDSIYGTEAAV -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for IL1RAP-TMEM207 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for IL1RAP-TMEM207 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for IL1RAP-TMEM207 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies