
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:IL20RB-NR4A1 (FusionGDB2 ID:39508) |
Fusion Gene Summary for IL20RB-NR4A1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: IL20RB-NR4A1 | Fusion gene ID: 39508 | Hgene | Tgene | Gene symbol | IL20RB | NR4A1 | Gene ID | 53833 | 3164 |
| Gene name | interleukin 20 receptor subunit beta | nuclear receptor subfamily 4 group A member 1 | |
| Synonyms | DIRS1|FNDC6|IL-20R2 | GFRP1|HMR|N10|NAK-1|NGFIB|NP10|NUR77|TR3 | |
| Cytomap | 3q22.3 | 12q13.13 | |
| Type of gene | protein-coding | protein-coding | |
| Description | interleukin-20 receptor subunit betaIL-20 receptor subunit betaIL-20R-betaIL-20RBfibronectin type III domain containing 6interleukin 20 receptor beta subunitinterleukin-20 receptor II | nuclear receptor subfamily 4 group A member 1ST-59TR3 orphan receptorearly response protein NAK1growth factor-inducible nuclear protein N10hormone receptornerve growth factor IB nuclear receptor variant 1nuclear hormone receptor NUR/77orphan nucle | |
| Modification date | 20200313 | 20200329 | |
| UniProtAcc | Q6UXL0 | P22736 | |
| Ensembl transtripts involved in fusion gene | ENST00000484501, ENST00000329582, ENST00000309741, | ENST00000360284, ENST00000545748, ENST00000550082, ENST00000547206, ENST00000243050, ENST00000394824, ENST00000394825, ENST00000548232, | |
| Fusion gene scores | * DoF score | 5 X 3 X 3=45 | 15 X 14 X 4=840 |
| # samples | 5 | 16 | |
| ** MAII score | log2(5/45*10)=0.15200309344505 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | log2(16/840*10)=-2.39231742277876 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: IL20RB [Title/Abstract] AND NR4A1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | NR4A1(52435713)-IL20RB(136699308), # samples:3 IL20RB(136677043)-NR4A1(52448111), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | NR4A1 | GO:0002042 | cell migration involved in sprouting angiogenesis | 18059339 |
| Tgene | NR4A1 | GO:0045944 | positive regulation of transcription by RNA polymerase II | 22427340 |
| Fusion gene breakpoints across IL20RB (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across NR4A1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
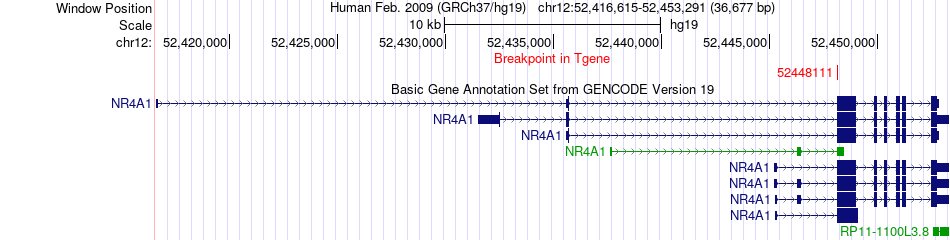 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | HNSC | TCGA-BA-6871-01A | IL20RB | chr3 | 136677043 | - | NR4A1 | chr12 | 52448111 | + |
Top |
Fusion Gene ORF analysis for IL20RB-NR4A1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000484501 | ENST00000360284 | IL20RB | chr3 | 136677043 | - | NR4A1 | chr12 | 52448111 | + |
| 3UTR-3CDS | ENST00000484501 | ENST00000545748 | IL20RB | chr3 | 136677043 | - | NR4A1 | chr12 | 52448111 | + |
| 3UTR-3CDS | ENST00000484501 | ENST00000550082 | IL20RB | chr3 | 136677043 | - | NR4A1 | chr12 | 52448111 | + |
| 3UTR-3UTR | ENST00000484501 | ENST00000547206 | IL20RB | chr3 | 136677043 | - | NR4A1 | chr12 | 52448111 | + |
| 3UTR-5UTR | ENST00000484501 | ENST00000243050 | IL20RB | chr3 | 136677043 | - | NR4A1 | chr12 | 52448111 | + |
| 3UTR-5UTR | ENST00000484501 | ENST00000394824 | IL20RB | chr3 | 136677043 | - | NR4A1 | chr12 | 52448111 | + |
| 3UTR-5UTR | ENST00000484501 | ENST00000394825 | IL20RB | chr3 | 136677043 | - | NR4A1 | chr12 | 52448111 | + |
| 3UTR-5UTR | ENST00000484501 | ENST00000548232 | IL20RB | chr3 | 136677043 | - | NR4A1 | chr12 | 52448111 | + |
| 5CDS-3UTR | ENST00000329582 | ENST00000547206 | IL20RB | chr3 | 136677043 | - | NR4A1 | chr12 | 52448111 | + |
| 5CDS-5UTR | ENST00000329582 | ENST00000243050 | IL20RB | chr3 | 136677043 | - | NR4A1 | chr12 | 52448111 | + |
| 5CDS-5UTR | ENST00000329582 | ENST00000394824 | IL20RB | chr3 | 136677043 | - | NR4A1 | chr12 | 52448111 | + |
| 5CDS-5UTR | ENST00000329582 | ENST00000394825 | IL20RB | chr3 | 136677043 | - | NR4A1 | chr12 | 52448111 | + |
| 5CDS-5UTR | ENST00000329582 | ENST00000548232 | IL20RB | chr3 | 136677043 | - | NR4A1 | chr12 | 52448111 | + |
| 5UTR-3CDS | ENST00000309741 | ENST00000360284 | IL20RB | chr3 | 136677043 | - | NR4A1 | chr12 | 52448111 | + |
| 5UTR-3CDS | ENST00000309741 | ENST00000545748 | IL20RB | chr3 | 136677043 | - | NR4A1 | chr12 | 52448111 | + |
| 5UTR-3CDS | ENST00000309741 | ENST00000550082 | IL20RB | chr3 | 136677043 | - | NR4A1 | chr12 | 52448111 | + |
| 5UTR-3UTR | ENST00000309741 | ENST00000547206 | IL20RB | chr3 | 136677043 | - | NR4A1 | chr12 | 52448111 | + |
| 5UTR-5UTR | ENST00000309741 | ENST00000243050 | IL20RB | chr3 | 136677043 | - | NR4A1 | chr12 | 52448111 | + |
| 5UTR-5UTR | ENST00000309741 | ENST00000394824 | IL20RB | chr3 | 136677043 | - | NR4A1 | chr12 | 52448111 | + |
| 5UTR-5UTR | ENST00000309741 | ENST00000394825 | IL20RB | chr3 | 136677043 | - | NR4A1 | chr12 | 52448111 | + |
| 5UTR-5UTR | ENST00000309741 | ENST00000548232 | IL20RB | chr3 | 136677043 | - | NR4A1 | chr12 | 52448111 | + |
| In-frame | ENST00000329582 | ENST00000360284 | IL20RB | chr3 | 136677043 | - | NR4A1 | chr12 | 52448111 | + |
| In-frame | ENST00000329582 | ENST00000545748 | IL20RB | chr3 | 136677043 | - | NR4A1 | chr12 | 52448111 | + |
| In-frame | ENST00000329582 | ENST00000550082 | IL20RB | chr3 | 136677043 | - | NR4A1 | chr12 | 52448111 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000329582 | IL20RB | chr3 | 136677043 | - | ENST00000360284 | NR4A1 | chr12 | 52448111 | + | 2241 | 337 | 249 | 2135 | 628 |
| ENST00000329582 | IL20RB | chr3 | 136677043 | - | ENST00000545748 | NR4A1 | chr12 | 52448111 | + | 2693 | 337 | 249 | 2135 | 628 |
| ENST00000329582 | IL20RB | chr3 | 136677043 | - | ENST00000550082 | NR4A1 | chr12 | 52448111 | + | 2241 | 337 | 249 | 2135 | 628 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000329582 | ENST00000360284 | IL20RB | chr3 | 136677043 | - | NR4A1 | chr12 | 52448111 | + | 0.07938572 | 0.9206143 |
| ENST00000329582 | ENST00000545748 | IL20RB | chr3 | 136677043 | - | NR4A1 | chr12 | 52448111 | + | 0.036258236 | 0.9637418 |
| ENST00000329582 | ENST00000550082 | IL20RB | chr3 | 136677043 | - | NR4A1 | chr12 | 52448111 | + | 0.07938572 | 0.9206143 |
Top |
Fusion Genomic Features for IL20RB-NR4A1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for IL20RB-NR4A1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr3:52435713/chr12:136699308) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| IL20RB | NR4A1 |
| FUNCTION: The IL20RA/IL20RB dimer is a receptor for IL19, IL20 and IL24. The IL22RA1/IL20RB dimer is a receptor for IL20 and IL24. | FUNCTION: Orphan nuclear receptor. May act concomitantly with NURR1 in regulating the expression of delayed-early genes during liver regeneration. Binds the NGFI-B response element (NBRE) 5'-AAAAGGTCA-3' (By similarity). May inhibit NF-kappa-B transactivation of IL2. Participates in energy homeostasis by sequestrating the kinase STK11 in the nucleus, thereby attenuating cytoplasmic AMPK activation. Plays a role in the vascular response to injury (By similarity). {ECO:0000250, ECO:0000250|UniProtKB:P12813, ECO:0000269|PubMed:15466594, ECO:0000269|PubMed:22983157}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000243050 | 1 | 8 | 583_586 | 0 | 599.0 | Compositional bias | Note=Poly-Pro | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000243050 | 1 | 8 | 82_92 | 0 | 599.0 | Compositional bias | Note=Poly-Ser | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000360284 | 1 | 8 | 583_586 | 12 | 612.0 | Compositional bias | Note=Poly-Pro | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000360284 | 1 | 8 | 82_92 | 12 | 612.0 | Compositional bias | Note=Poly-Ser | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000394824 | 1 | 8 | 583_586 | 0 | 599.0 | Compositional bias | Note=Poly-Pro | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000394824 | 1 | 8 | 82_92 | 0 | 599.0 | Compositional bias | Note=Poly-Ser | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000394825 | 0 | 7 | 583_586 | 0 | 599.0 | Compositional bias | Note=Poly-Pro | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000394825 | 0 | 7 | 82_92 | 0 | 599.0 | Compositional bias | Note=Poly-Ser | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000548232 | 0 | 2 | 583_586 | 0 | 326.0 | Compositional bias | Note=Poly-Pro | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000548232 | 0 | 2 | 82_92 | 0 | 326.0 | Compositional bias | Note=Poly-Ser | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000550082 | 0 | 7 | 583_586 | 12 | 612.0 | Compositional bias | Note=Poly-Pro | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000550082 | 0 | 7 | 82_92 | 12 | 612.0 | Compositional bias | Note=Poly-Ser | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000243050 | 1 | 8 | 264_339 | 0 | 599.0 | DNA binding | Nuclear receptor | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000360284 | 1 | 8 | 264_339 | 12 | 612.0 | DNA binding | Nuclear receptor | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000394824 | 1 | 8 | 264_339 | 0 | 599.0 | DNA binding | Nuclear receptor | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000394825 | 0 | 7 | 264_339 | 0 | 599.0 | DNA binding | Nuclear receptor | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000548232 | 0 | 2 | 264_339 | 0 | 326.0 | DNA binding | Nuclear receptor | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000550082 | 0 | 7 | 264_339 | 12 | 612.0 | DNA binding | Nuclear receptor | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000243050 | 1 | 8 | 360_595 | 0 | 599.0 | Domain | NR LBD | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000360284 | 1 | 8 | 360_595 | 12 | 612.0 | Domain | NR LBD | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000394824 | 1 | 8 | 360_595 | 0 | 599.0 | Domain | NR LBD | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000394825 | 0 | 7 | 360_595 | 0 | 599.0 | Domain | NR LBD | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000548232 | 0 | 2 | 360_595 | 0 | 326.0 | Domain | NR LBD | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000550082 | 0 | 7 | 360_595 | 12 | 612.0 | Domain | NR LBD | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000243050 | 1 | 8 | 171_466 | 0 | 599.0 | Region | Required for nuclear import | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000360284 | 1 | 8 | 171_466 | 12 | 612.0 | Region | Required for nuclear import | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000394824 | 1 | 8 | 171_466 | 0 | 599.0 | Region | Required for nuclear import | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000394825 | 0 | 7 | 171_466 | 0 | 599.0 | Region | Required for nuclear import | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000548232 | 0 | 2 | 171_466 | 0 | 326.0 | Region | Required for nuclear import | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000550082 | 0 | 7 | 171_466 | 12 | 612.0 | Region | Required for nuclear import | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000243050 | 1 | 8 | 267_287 | 0 | 599.0 | Zinc finger | NR C4-type | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000243050 | 1 | 8 | 303_327 | 0 | 599.0 | Zinc finger | NR C4-type | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000360284 | 1 | 8 | 267_287 | 12 | 612.0 | Zinc finger | NR C4-type | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000360284 | 1 | 8 | 303_327 | 12 | 612.0 | Zinc finger | NR C4-type | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000394824 | 1 | 8 | 267_287 | 0 | 599.0 | Zinc finger | NR C4-type | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000394824 | 1 | 8 | 303_327 | 0 | 599.0 | Zinc finger | NR C4-type | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000394825 | 0 | 7 | 267_287 | 0 | 599.0 | Zinc finger | NR C4-type | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000394825 | 0 | 7 | 303_327 | 0 | 599.0 | Zinc finger | NR C4-type | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000548232 | 0 | 2 | 267_287 | 0 | 326.0 | Zinc finger | NR C4-type | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000548232 | 0 | 2 | 303_327 | 0 | 326.0 | Zinc finger | NR C4-type | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000550082 | 0 | 7 | 267_287 | 12 | 612.0 | Zinc finger | NR C4-type | |
| Tgene | NR4A1 | chr3:136677043 | chr12:52448111 | ENST00000550082 | 0 | 7 | 303_327 | 12 | 612.0 | Zinc finger | NR C4-type |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | IL20RB | chr3:136677043 | chr12:52448111 | ENST00000329582 | - | 1 | 7 | 144_228 | 29 | 312.0 | Domain | Fibronectin type-III 2 |
| Hgene | IL20RB | chr3:136677043 | chr12:52448111 | ENST00000329582 | - | 1 | 7 | 37_136 | 29 | 312.0 | Domain | Fibronectin type-III 1 |
| Hgene | IL20RB | chr3:136677043 | chr12:52448111 | ENST00000329582 | - | 1 | 7 | 255_311 | 29 | 312.0 | Topological domain | Cytoplasmic |
| Hgene | IL20RB | chr3:136677043 | chr12:52448111 | ENST00000329582 | - | 1 | 7 | 30_233 | 29 | 312.0 | Topological domain | Extracellular |
| Hgene | IL20RB | chr3:136677043 | chr12:52448111 | ENST00000329582 | - | 1 | 7 | 234_254 | 29 | 312.0 | Transmembrane | Helical |
Top |
Fusion Gene Sequence for IL20RB-NR4A1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >39508_39508_1_IL20RB-NR4A1_IL20RB_chr3_136677043_ENST00000329582_NR4A1_chr12_52448111_ENST00000360284_length(transcript)=2241nt_BP=337nt AAAGTTACATTTTCTCTGGAACTCTCCTAGGCCACTCCCTGCTGATGCAACATCTGGGTTTGGGCAGAAAGGAGGGTGCTTCGGAGCCCG CCCTTTCTGAGCTTCCTGGGCCGGCTCTAGAACAATTCAGGCTTCGCTGCGACTCAGACCTCAGCTCCAACATATGCATTCTGAAGAAAG ATGGCTGAGATGGACAGAATGCTTTATTTTGGAAAGAAACAATGTTCTAGGTCAAACTGAGTCTACCAAATGCAGACTTTCACAATGGTT CTAGAAGAAATCTGGACAAGTCTTTTCATGTGGTTTTTCTACGCATTGATTCCATGTTTGCTCACAGAGATGCCCTGTATCCAAGCCCAA TATGGGACACCAGCACCGAGTCCGGGACCCCGTGACCACCTGGCAAGCGACCCCCTGACCCCTGAGTTCATCAAGCCCACCATGGACCTG GCCAGCCCCGAGGCAGCCCCCGCTGCCCCCACTGCCCTGCCCAGCTTCAGCACCTTCATGGACGGCTACACAGGAGAGTTTGACACCTTC CTCTACCAGCTGCCAGGAACAGTCCAGCCATGCTCCTCAGCCTCCTCCTCGGCCTCCTCCACATCCTCGTCCTCAGCCACCTCCCCTGCC TCTGCCTCCTTCAAGTTCGAGGACTTCCAGGTGTACGGCTGCTACCCCGGCCCCCTGAGCGGCCCAGTGGATGAGGCCCTGTCCTCCAGT GGCTCTGACTACTATGGCAGCCCCTGCTCGGCCCCGTCGCCCTCCACGCCCAGCTTCCAGCCGCCCCAGCTCTCTCCCTGGGATGGCTCC TTCGGCCACTTCTCGCCCAGCCAGACTTACGAAGGCCTGCGGGCATGGACAGAGCAGCTGCCCAAAGCCTCTGGGCCCCCACAGCCTCCA GCCTTCTTTTCCTTCAGTCCTCCCACCGGCCCCAGCCCCAGCCTGGCCCAGAGCCCCCTGAAGTTGTTCCCCTCACAGGCCACCCACCAG CTGGGGGAGGGAGAGAGCTATTCCATGCCTACGGCCTTCCCAGGTTTGGCACCCACTTCTCCACACCTTGAGGGCTCGGGGATACTGGAT ACACCCGTGACCTCAACCAAGGCCCGGAGCGGGGCCCCAGGTGGAAGTGAAGGCCGCTGTGCTGTGTGTGGGGACAACGCTTCATGCCAG CATTATGGTGTCCGCACATGTGAGGGCTGCAAGGGCTTCTTCAAGCGCACAGTGCAGAAAAACGCCAAGTACATCTGCCTGGCTAACAAG GACTGCCCTGTGGACAAGAGGCGGCGAAACCGCTGCCAGTTCTGCCGCTTCCAGAAGTGCCTGGCGGTGGGCATGGTGAAGGAAGTTGTC CGAACAGACAGCCTGAAGGGGCGGCGGGGCCGGCTACCTTCAAAACCCAAGCAGCCCCCAGATGCCTCCCCTGCCAATCTCCTCACTTCC CTGGTCCGTGCACACCTGGACTCAGGGCCCAGCACTGCCAAACTGGACTACTCCAAGTTCCAGGAGCTGGTGCTGCCCCACTTTGGGAAG GAAGATGCTGGGGATGTACAGCAGTTCTACGACCTGCTCTCCGGTTCTCTGGAGGTCATCCGCAAGTGGGCGGAGAAGATCCCTGGCTTT GCTGAGCTGTCACCGGCTGACCAGGACCTGTTGCTGGAGTCGGCCTTCCTGGAGCTCTTCATCCTCCGCCTGGCGTACAGGTCTAAGCCA GGCGAGGGCAAGCTCATCTTCTGCTCAGGCCTGGTGCTACACCGGCTGCAGTGTGCCCGTGGCTTCGGGGACTGGATTGACAGTATCCTG GCCTTCTCAAGGTCCCTGCACAGCTTGCTTGTCGATGTCCCTGCCTTCGCCTGCCTCTCTGCCCTTGTCCTCATCACCGACCGGCATGGG CTGCAGGAGCCGCGGCGGGTGGAGGAGCTGCAGAACCGCATCGCCAGCTGCCTGAAGGAGCACGTGGCAGCTGTGGCGGGCGAGCCCCAG CCAGCCAGCTGCCTGTCACGTCTGTTGGGCAAACTGCCCGAGCTGCGGACCCTGTGCACCCAGGGCCTGCAGCGCATCTTCTACCTCAAG CTGGAGGACTTGGTGCCCCCTCCACCCATCATTGACAAGATCTTCATGGACACGCTGCCCTTCTGACCCCTGCCTGGGAACACGTGTGCA >39508_39508_1_IL20RB-NR4A1_IL20RB_chr3_136677043_ENST00000329582_NR4A1_chr12_52448111_ENST00000360284_length(amino acids)=628AA_BP=29 MQTFTMVLEEIWTSLFMWFFYALIPCLLTEMPCIQAQYGTPAPSPGPRDHLASDPLTPEFIKPTMDLASPEAAPAAPTALPSFSTFMDGY TGEFDTFLYQLPGTVQPCSSASSSASSTSSSSATSPASASFKFEDFQVYGCYPGPLSGPVDEALSSSGSDYYGSPCSAPSPSTPSFQPPQ LSPWDGSFGHFSPSQTYEGLRAWTEQLPKASGPPQPPAFFSFSPPTGPSPSLAQSPLKLFPSQATHQLGEGESYSMPTAFPGLAPTSPHL EGSGILDTPVTSTKARSGAPGGSEGRCAVCGDNASCQHYGVRTCEGCKGFFKRTVQKNAKYICLANKDCPVDKRRRNRCQFCRFQKCLAV GMVKEVVRTDSLKGRRGRLPSKPKQPPDASPANLLTSLVRAHLDSGPSTAKLDYSKFQELVLPHFGKEDAGDVQQFYDLLSGSLEVIRKW AEKIPGFAELSPADQDLLLESAFLELFILRLAYRSKPGEGKLIFCSGLVLHRLQCARGFGDWIDSILAFSRSLHSLLVDVPAFACLSALV -------------------------------------------------------------- >39508_39508_2_IL20RB-NR4A1_IL20RB_chr3_136677043_ENST00000329582_NR4A1_chr12_52448111_ENST00000545748_length(transcript)=2693nt_BP=337nt AAAGTTACATTTTCTCTGGAACTCTCCTAGGCCACTCCCTGCTGATGCAACATCTGGGTTTGGGCAGAAAGGAGGGTGCTTCGGAGCCCG CCCTTTCTGAGCTTCCTGGGCCGGCTCTAGAACAATTCAGGCTTCGCTGCGACTCAGACCTCAGCTCCAACATATGCATTCTGAAGAAAG ATGGCTGAGATGGACAGAATGCTTTATTTTGGAAAGAAACAATGTTCTAGGTCAAACTGAGTCTACCAAATGCAGACTTTCACAATGGTT CTAGAAGAAATCTGGACAAGTCTTTTCATGTGGTTTTTCTACGCATTGATTCCATGTTTGCTCACAGAGATGCCCTGTATCCAAGCCCAA TATGGGACACCAGCACCGAGTCCGGGACCCCGTGACCACCTGGCAAGCGACCCCCTGACCCCTGAGTTCATCAAGCCCACCATGGACCTG GCCAGCCCCGAGGCAGCCCCCGCTGCCCCCACTGCCCTGCCCAGCTTCAGCACCTTCATGGACGGCTACACAGGAGAGTTTGACACCTTC CTCTACCAGCTGCCAGGAACAGTCCAGCCATGCTCCTCAGCCTCCTCCTCGGCCTCCTCCACATCCTCGTCCTCAGCCACCTCCCCTGCC TCTGCCTCCTTCAAGTTCGAGGACTTCCAGGTGTACGGCTGCTACCCCGGCCCCCTGAGCGGCCCAGTGGATGAGGCCCTGTCCTCCAGT GGCTCTGACTACTATGGCAGCCCCTGCTCGGCCCCGTCGCCCTCCACGCCCAGCTTCCAGCCGCCCCAGCTCTCTCCCTGGGATGGCTCC TTCGGCCACTTCTCGCCCAGCCAGACTTACGAAGGCCTGCGGGCATGGACAGAGCAGCTGCCCAAAGCCTCTGGGCCCCCACAGCCTCCA GCCTTCTTTTCCTTCAGTCCTCCCACCGGCCCCAGCCCCAGCCTGGCCCAGAGCCCCCTGAAGTTGTTCCCCTCACAGGCCACCCACCAG CTGGGGGAGGGAGAGAGCTATTCCATGCCTACGGCCTTCCCAGGTTTGGCACCCACTTCTCCACACCTTGAGGGCTCGGGGATACTGGAT ACACCCGTGACCTCAACCAAGGCCCGGAGCGGGGCCCCAGGTGGAAGTGAAGGCCGCTGTGCTGTGTGTGGGGACAACGCTTCATGCCAG CATTATGGTGTCCGCACATGTGAGGGCTGCAAGGGCTTCTTCAAGCGCACAGTGCAGAAAAACGCCAAGTACATCTGCCTGGCTAACAAG GACTGCCCTGTGGACAAGAGGCGGCGAAACCGCTGCCAGTTCTGCCGCTTCCAGAAGTGCCTGGCGGTGGGCATGGTGAAGGAAGTTGTC CGAACAGACAGCCTGAAGGGGCGGCGGGGCCGGCTACCTTCAAAACCCAAGCAGCCCCCAGATGCCTCCCCTGCCAATCTCCTCACTTCC CTGGTCCGTGCACACCTGGACTCAGGGCCCAGCACTGCCAAACTGGACTACTCCAAGTTCCAGGAGCTGGTGCTGCCCCACTTTGGGAAG GAAGATGCTGGGGATGTACAGCAGTTCTACGACCTGCTCTCCGGTTCTCTGGAGGTCATCCGCAAGTGGGCGGAGAAGATCCCTGGCTTT GCTGAGCTGTCACCGGCTGACCAGGACCTGTTGCTGGAGTCGGCCTTCCTGGAGCTCTTCATCCTCCGCCTGGCGTACAGGTCTAAGCCA GGCGAGGGCAAGCTCATCTTCTGCTCAGGCCTGGTGCTACACCGGCTGCAGTGTGCCCGTGGCTTCGGGGACTGGATTGACAGTATCCTG GCCTTCTCAAGGTCCCTGCACAGCTTGCTTGTCGATGTCCCTGCCTTCGCCTGCCTCTCTGCCCTTGTCCTCATCACCGACCGGCATGGG CTGCAGGAGCCGCGGCGGGTGGAGGAGCTGCAGAACCGCATCGCCAGCTGCCTGAAGGAGCACGTGGCAGCTGTGGCGGGCGAGCCCCAG CCAGCCAGCTGCCTGTCACGTCTGTTGGGCAAACTGCCCGAGCTGCGGACCCTGTGCACCCAGGGCCTGCAGCGCATCTTCTACCTCAAG CTGGAGGACTTGGTGCCCCCTCCACCCATCATTGACAAGATCTTCATGGACACGCTGCCCTTCTGACCCCTGCCTGGGAACACGTGTGCA CATGCGCACTCTCATATGCCACCCCATGTGCCTTTAGTCCACGGACCCCCAGAGCACCCCCAAGCCTGGGCTTGAGCTGCAGAATGACTC CACCTTCTCACCTGCTCCAGGAGGTTTGCAGGGAGCTCAAGCCCTTGGGGAGGGGGATGCCTTCATGGGGGTGACCCCACGATTTGTCTT ATCCCCCCCAGCCTGGCCCCGGCCTTTATGTTTTTTGTAAGATAAACCGTTTTTAACACATAGCGCCGTGCTGTAAATAAGCCCAGTGCT GCTGTAAATACAGGAAGAAAGAGCTTGAGGTGGGAGCGGGGCTGGGAGGAAGGGATGGGCCCCGCCTTCCTGGGCAGCCTTTCCAGCCTC CTGCTGGCTCTCTCTTCCTACCCTCCTTCCACATGTACATAAACTGTCACTCTAGGAAGAAGACAAATGACAGATTCTGACATTTATATT >39508_39508_2_IL20RB-NR4A1_IL20RB_chr3_136677043_ENST00000329582_NR4A1_chr12_52448111_ENST00000545748_length(amino acids)=628AA_BP=29 MQTFTMVLEEIWTSLFMWFFYALIPCLLTEMPCIQAQYGTPAPSPGPRDHLASDPLTPEFIKPTMDLASPEAAPAAPTALPSFSTFMDGY TGEFDTFLYQLPGTVQPCSSASSSASSTSSSSATSPASASFKFEDFQVYGCYPGPLSGPVDEALSSSGSDYYGSPCSAPSPSTPSFQPPQ LSPWDGSFGHFSPSQTYEGLRAWTEQLPKASGPPQPPAFFSFSPPTGPSPSLAQSPLKLFPSQATHQLGEGESYSMPTAFPGLAPTSPHL EGSGILDTPVTSTKARSGAPGGSEGRCAVCGDNASCQHYGVRTCEGCKGFFKRTVQKNAKYICLANKDCPVDKRRRNRCQFCRFQKCLAV GMVKEVVRTDSLKGRRGRLPSKPKQPPDASPANLLTSLVRAHLDSGPSTAKLDYSKFQELVLPHFGKEDAGDVQQFYDLLSGSLEVIRKW AEKIPGFAELSPADQDLLLESAFLELFILRLAYRSKPGEGKLIFCSGLVLHRLQCARGFGDWIDSILAFSRSLHSLLVDVPAFACLSALV -------------------------------------------------------------- >39508_39508_3_IL20RB-NR4A1_IL20RB_chr3_136677043_ENST00000329582_NR4A1_chr12_52448111_ENST00000550082_length(transcript)=2241nt_BP=337nt AAAGTTACATTTTCTCTGGAACTCTCCTAGGCCACTCCCTGCTGATGCAACATCTGGGTTTGGGCAGAAAGGAGGGTGCTTCGGAGCCCG CCCTTTCTGAGCTTCCTGGGCCGGCTCTAGAACAATTCAGGCTTCGCTGCGACTCAGACCTCAGCTCCAACATATGCATTCTGAAGAAAG ATGGCTGAGATGGACAGAATGCTTTATTTTGGAAAGAAACAATGTTCTAGGTCAAACTGAGTCTACCAAATGCAGACTTTCACAATGGTT CTAGAAGAAATCTGGACAAGTCTTTTCATGTGGTTTTTCTACGCATTGATTCCATGTTTGCTCACAGAGATGCCCTGTATCCAAGCCCAA TATGGGACACCAGCACCGAGTCCGGGACCCCGTGACCACCTGGCAAGCGACCCCCTGACCCCTGAGTTCATCAAGCCCACCATGGACCTG GCCAGCCCCGAGGCAGCCCCCGCTGCCCCCACTGCCCTGCCCAGCTTCAGCACCTTCATGGACGGCTACACAGGAGAGTTTGACACCTTC CTCTACCAGCTGCCAGGAACAGTCCAGCCATGCTCCTCAGCCTCCTCCTCGGCCTCCTCCACATCCTCGTCCTCAGCCACCTCCCCTGCC TCTGCCTCCTTCAAGTTCGAGGACTTCCAGGTGTACGGCTGCTACCCCGGCCCCCTGAGCGGCCCAGTGGATGAGGCCCTGTCCTCCAGT GGCTCTGACTACTATGGCAGCCCCTGCTCGGCCCCGTCGCCCTCCACGCCCAGCTTCCAGCCGCCCCAGCTCTCTCCCTGGGATGGCTCC TTCGGCCACTTCTCGCCCAGCCAGACTTACGAAGGCCTGCGGGCATGGACAGAGCAGCTGCCCAAAGCCTCTGGGCCCCCACAGCCTCCA GCCTTCTTTTCCTTCAGTCCTCCCACCGGCCCCAGCCCCAGCCTGGCCCAGAGCCCCCTGAAGTTGTTCCCCTCACAGGCCACCCACCAG CTGGGGGAGGGAGAGAGCTATTCCATGCCTACGGCCTTCCCAGGTTTGGCACCCACTTCTCCACACCTTGAGGGCTCGGGGATACTGGAT ACACCCGTGACCTCAACCAAGGCCCGGAGCGGGGCCCCAGGTGGAAGTGAAGGCCGCTGTGCTGTGTGTGGGGACAACGCTTCATGCCAG CATTATGGTGTCCGCACATGTGAGGGCTGCAAGGGCTTCTTCAAGCGCACAGTGCAGAAAAACGCCAAGTACATCTGCCTGGCTAACAAG GACTGCCCTGTGGACAAGAGGCGGCGAAACCGCTGCCAGTTCTGCCGCTTCCAGAAGTGCCTGGCGGTGGGCATGGTGAAGGAAGTTGTC CGAACAGACAGCCTGAAGGGGCGGCGGGGCCGGCTACCTTCAAAACCCAAGCAGCCCCCAGATGCCTCCCCTGCCAATCTCCTCACTTCC CTGGTCCGTGCACACCTGGACTCAGGGCCCAGCACTGCCAAACTGGACTACTCCAAGTTCCAGGAGCTGGTGCTGCCCCACTTTGGGAAG GAAGATGCTGGGGATGTACAGCAGTTCTACGACCTGCTCTCCGGTTCTCTGGAGGTCATCCGCAAGTGGGCGGAGAAGATCCCTGGCTTT GCTGAGCTGTCACCGGCTGACCAGGACCTGTTGCTGGAGTCGGCCTTCCTGGAGCTCTTCATCCTCCGCCTGGCGTACAGGTCTAAGCCA GGCGAGGGCAAGCTCATCTTCTGCTCAGGCCTGGTGCTACACCGGCTGCAGTGTGCCCGTGGCTTCGGGGACTGGATTGACAGTATCCTG GCCTTCTCAAGGTCCCTGCACAGCTTGCTTGTCGATGTCCCTGCCTTCGCCTGCCTCTCTGCCCTTGTCCTCATCACCGACCGGCATGGG CTGCAGGAGCCGCGGCGGGTGGAGGAGCTGCAGAACCGCATCGCCAGCTGCCTGAAGGAGCACGTGGCAGCTGTGGCGGGCGAGCCCCAG CCAGCCAGCTGCCTGTCACGTCTGTTGGGCAAACTGCCCGAGCTGCGGACCCTGTGCACCCAGGGCCTGCAGCGCATCTTCTACCTCAAG CTGGAGGACTTGGTGCCCCCTCCACCCATCATTGACAAGATCTTCATGGACACGCTGCCCTTCTGACCCCTGCCTGGGAACACGTGTGCA >39508_39508_3_IL20RB-NR4A1_IL20RB_chr3_136677043_ENST00000329582_NR4A1_chr12_52448111_ENST00000550082_length(amino acids)=628AA_BP=29 MQTFTMVLEEIWTSLFMWFFYALIPCLLTEMPCIQAQYGTPAPSPGPRDHLASDPLTPEFIKPTMDLASPEAAPAAPTALPSFSTFMDGY TGEFDTFLYQLPGTVQPCSSASSSASSTSSSSATSPASASFKFEDFQVYGCYPGPLSGPVDEALSSSGSDYYGSPCSAPSPSTPSFQPPQ LSPWDGSFGHFSPSQTYEGLRAWTEQLPKASGPPQPPAFFSFSPPTGPSPSLAQSPLKLFPSQATHQLGEGESYSMPTAFPGLAPTSPHL EGSGILDTPVTSTKARSGAPGGSEGRCAVCGDNASCQHYGVRTCEGCKGFFKRTVQKNAKYICLANKDCPVDKRRRNRCQFCRFQKCLAV GMVKEVVRTDSLKGRRGRLPSKPKQPPDASPANLLTSLVRAHLDSGPSTAKLDYSKFQELVLPHFGKEDAGDVQQFYDLLSGSLEVIRKW AEKIPGFAELSPADQDLLLESAFLELFILRLAYRSKPGEGKLIFCSGLVLHRLQCARGFGDWIDSILAFSRSLHSLLVDVPAFACLSALV -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for IL20RB-NR4A1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for IL20RB-NR4A1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for IL20RB-NR4A1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies