
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ING4-A2ML1 (FusionGDB2 ID:39745) |
Fusion Gene Summary for ING4-A2ML1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ING4-A2ML1 | Fusion gene ID: 39745 | Hgene | Tgene | Gene symbol | ING4 | A2ML1 | Gene ID | 51147 | 144568 |
| Gene name | inhibitor of growth family member 4 | alpha-2-macroglobulin like 1 | |
| Synonyms | my036|p29ING4 | CPAMD9|OMS|p170 | |
| Cytomap | 12p13.31 | 12p13.31 | |
| Type of gene | protein-coding | protein-coding | |
| Description | inhibitor of growth protein 4brain my036 proteincandidate tumor suppressor p33 ING1 homolog | alpha-2-macroglobulin-like protein 1C3 and PZP-like, alpha-2-macroglobulin domain containing 9 | |
| Modification date | 20200322 | 20200313 | |
| UniProtAcc | Q9UNL4 | A8K2U0 | |
| Ensembl transtripts involved in fusion gene | ENST00000341550, ENST00000396807, ENST00000412586, ENST00000423703, ENST00000444704, ENST00000446105, ENST00000486287, | ENST00000540049, ENST00000299698, ENST00000539547, | |
| Fusion gene scores | * DoF score | 3 X 3 X 3=27 | 7 X 6 X 4=168 |
| # samples | 3 | 6 | |
| ** MAII score | log2(3/27*10)=0.15200309344505 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | log2(6/168*10)=-1.48542682717024 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: ING4 [Title/Abstract] AND A2ML1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ING4(6772231)-A2ML1(9027021), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | ING4 | GO:0006260 | DNA replication | 16387653 |
| Hgene | ING4 | GO:0006473 | protein acetylation | 12750254 |
| Hgene | ING4 | GO:0006915 | apoptotic process | 15251430 |
| Hgene | ING4 | GO:0006978 | DNA damage response, signal transduction by p53 class mediator resulting in transcription of p21 class mediator | 16387653 |
| Hgene | ING4 | GO:0007050 | cell cycle arrest | 15251430 |
| Hgene | ING4 | GO:0008285 | negative regulation of cell proliferation | 12750254|15251430 |
| Hgene | ING4 | GO:0043065 | positive regulation of apoptotic process | 16387653 |
| Hgene | ING4 | GO:0043966 | histone H3 acetylation | 16387653 |
| Hgene | ING4 | GO:0043981 | histone H4-K5 acetylation | 16387653 |
| Hgene | ING4 | GO:0043982 | histone H4-K8 acetylation | 16387653 |
| Hgene | ING4 | GO:0043983 | histone H4-K12 acetylation | 16387653 |
| Hgene | ING4 | GO:0043984 | histone H4-K16 acetylation | 16387653 |
| Hgene | ING4 | GO:0045892 | negative regulation of transcription, DNA-templated | 15029197 |
| Hgene | ING4 | GO:0045926 | negative regulation of growth | 12750254 |
| Tgene | A2ML1 | GO:0052548 | regulation of endopeptidase activity | 16298998 |
| Fusion gene breakpoints across ING4 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across A2ML1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | SKCM | TCGA-D3-A3CC-06A | ING4 | chr12 | 6772231 | - | A2ML1 | chr12 | 9027021 | + |
Top |
Fusion Gene ORF analysis for ING4-A2ML1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000341550 | ENST00000540049 | ING4 | chr12 | 6772231 | - | A2ML1 | chr12 | 9027021 | + |
| 5CDS-intron | ENST00000396807 | ENST00000540049 | ING4 | chr12 | 6772231 | - | A2ML1 | chr12 | 9027021 | + |
| 5CDS-intron | ENST00000412586 | ENST00000540049 | ING4 | chr12 | 6772231 | - | A2ML1 | chr12 | 9027021 | + |
| 5CDS-intron | ENST00000423703 | ENST00000540049 | ING4 | chr12 | 6772231 | - | A2ML1 | chr12 | 9027021 | + |
| 5CDS-intron | ENST00000444704 | ENST00000540049 | ING4 | chr12 | 6772231 | - | A2ML1 | chr12 | 9027021 | + |
| 5CDS-intron | ENST00000446105 | ENST00000540049 | ING4 | chr12 | 6772231 | - | A2ML1 | chr12 | 9027021 | + |
| In-frame | ENST00000341550 | ENST00000299698 | ING4 | chr12 | 6772231 | - | A2ML1 | chr12 | 9027021 | + |
| In-frame | ENST00000341550 | ENST00000539547 | ING4 | chr12 | 6772231 | - | A2ML1 | chr12 | 9027021 | + |
| In-frame | ENST00000396807 | ENST00000299698 | ING4 | chr12 | 6772231 | - | A2ML1 | chr12 | 9027021 | + |
| In-frame | ENST00000396807 | ENST00000539547 | ING4 | chr12 | 6772231 | - | A2ML1 | chr12 | 9027021 | + |
| In-frame | ENST00000412586 | ENST00000299698 | ING4 | chr12 | 6772231 | - | A2ML1 | chr12 | 9027021 | + |
| In-frame | ENST00000412586 | ENST00000539547 | ING4 | chr12 | 6772231 | - | A2ML1 | chr12 | 9027021 | + |
| In-frame | ENST00000423703 | ENST00000299698 | ING4 | chr12 | 6772231 | - | A2ML1 | chr12 | 9027021 | + |
| In-frame | ENST00000423703 | ENST00000539547 | ING4 | chr12 | 6772231 | - | A2ML1 | chr12 | 9027021 | + |
| In-frame | ENST00000444704 | ENST00000299698 | ING4 | chr12 | 6772231 | - | A2ML1 | chr12 | 9027021 | + |
| In-frame | ENST00000444704 | ENST00000539547 | ING4 | chr12 | 6772231 | - | A2ML1 | chr12 | 9027021 | + |
| In-frame | ENST00000446105 | ENST00000299698 | ING4 | chr12 | 6772231 | - | A2ML1 | chr12 | 9027021 | + |
| In-frame | ENST00000446105 | ENST00000539547 | ING4 | chr12 | 6772231 | - | A2ML1 | chr12 | 9027021 | + |
| intron-3CDS | ENST00000486287 | ENST00000299698 | ING4 | chr12 | 6772231 | - | A2ML1 | chr12 | 9027021 | + |
| intron-3CDS | ENST00000486287 | ENST00000539547 | ING4 | chr12 | 6772231 | - | A2ML1 | chr12 | 9027021 | + |
| intron-intron | ENST00000486287 | ENST00000540049 | ING4 | chr12 | 6772231 | - | A2ML1 | chr12 | 9027021 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000341550 | ING4 | chr12 | 6772231 | - | ENST00000299698 | A2ML1 | chr12 | 9027021 | + | 957 | 84 | 786 | 496 | 96 |
| ENST00000341550 | ING4 | chr12 | 6772231 | - | ENST00000539547 | A2ML1 | chr12 | 9027021 | + | 628 | 84 | 27 | 227 | 66 |
| ENST00000396807 | ING4 | chr12 | 6772231 | - | ENST00000299698 | A2ML1 | chr12 | 9027021 | + | 949 | 76 | 778 | 488 | 96 |
| ENST00000396807 | ING4 | chr12 | 6772231 | - | ENST00000539547 | A2ML1 | chr12 | 9027021 | + | 620 | 76 | 19 | 219 | 66 |
| ENST00000446105 | ING4 | chr12 | 6772231 | - | ENST00000299698 | A2ML1 | chr12 | 9027021 | + | 951 | 78 | 780 | 490 | 96 |
| ENST00000446105 | ING4 | chr12 | 6772231 | - | ENST00000539547 | A2ML1 | chr12 | 9027021 | + | 622 | 78 | 21 | 221 | 66 |
| ENST00000444704 | ING4 | chr12 | 6772231 | - | ENST00000299698 | A2ML1 | chr12 | 9027021 | + | 910 | 37 | 739 | 449 | 96 |
| ENST00000444704 | ING4 | chr12 | 6772231 | - | ENST00000539547 | A2ML1 | chr12 | 9027021 | + | 581 | 37 | 4 | 180 | 58 |
| ENST00000423703 | ING4 | chr12 | 6772231 | - | ENST00000299698 | A2ML1 | chr12 | 9027021 | + | 910 | 37 | 739 | 449 | 96 |
| ENST00000423703 | ING4 | chr12 | 6772231 | - | ENST00000539547 | A2ML1 | chr12 | 9027021 | + | 581 | 37 | 4 | 180 | 58 |
| ENST00000412586 | ING4 | chr12 | 6772231 | - | ENST00000299698 | A2ML1 | chr12 | 9027021 | + | 910 | 37 | 739 | 449 | 96 |
| ENST00000412586 | ING4 | chr12 | 6772231 | - | ENST00000539547 | A2ML1 | chr12 | 9027021 | + | 581 | 37 | 4 | 180 | 58 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000341550 | ENST00000299698 | ING4 | chr12 | 6772231 | - | A2ML1 | chr12 | 9027021 | + | 0.92511386 | 0.07488609 |
| ENST00000341550 | ENST00000539547 | ING4 | chr12 | 6772231 | - | A2ML1 | chr12 | 9027021 | + | 0.32635444 | 0.67364556 |
| ENST00000396807 | ENST00000299698 | ING4 | chr12 | 6772231 | - | A2ML1 | chr12 | 9027021 | + | 0.89101493 | 0.108985096 |
| ENST00000396807 | ENST00000539547 | ING4 | chr12 | 6772231 | - | A2ML1 | chr12 | 9027021 | + | 0.21817514 | 0.7818249 |
| ENST00000446105 | ENST00000299698 | ING4 | chr12 | 6772231 | - | A2ML1 | chr12 | 9027021 | + | 0.9072365 | 0.09276349 |
| ENST00000446105 | ENST00000539547 | ING4 | chr12 | 6772231 | - | A2ML1 | chr12 | 9027021 | + | 0.24214247 | 0.7578575 |
| ENST00000444704 | ENST00000299698 | ING4 | chr12 | 6772231 | - | A2ML1 | chr12 | 9027021 | + | 0.85087997 | 0.14912003 |
| ENST00000444704 | ENST00000539547 | ING4 | chr12 | 6772231 | - | A2ML1 | chr12 | 9027021 | + | 0.13617256 | 0.8638274 |
| ENST00000423703 | ENST00000299698 | ING4 | chr12 | 6772231 | - | A2ML1 | chr12 | 9027021 | + | 0.85087997 | 0.14912003 |
| ENST00000423703 | ENST00000539547 | ING4 | chr12 | 6772231 | - | A2ML1 | chr12 | 9027021 | + | 0.13617256 | 0.8638274 |
| ENST00000412586 | ENST00000299698 | ING4 | chr12 | 6772231 | - | A2ML1 | chr12 | 9027021 | + | 0.85087997 | 0.14912003 |
| ENST00000412586 | ENST00000539547 | ING4 | chr12 | 6772231 | - | A2ML1 | chr12 | 9027021 | + | 0.13617256 | 0.8638274 |
Top |
Fusion Genomic Features for ING4-A2ML1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| ING4 | chr12 | 6772230 | - | A2ML1 | chr12 | 9027020 | + | 3.80E-07 | 0.99999964 |
| ING4 | chr12 | 6772230 | - | A2ML1 | chr12 | 9027020 | + | 3.80E-07 | 0.99999964 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
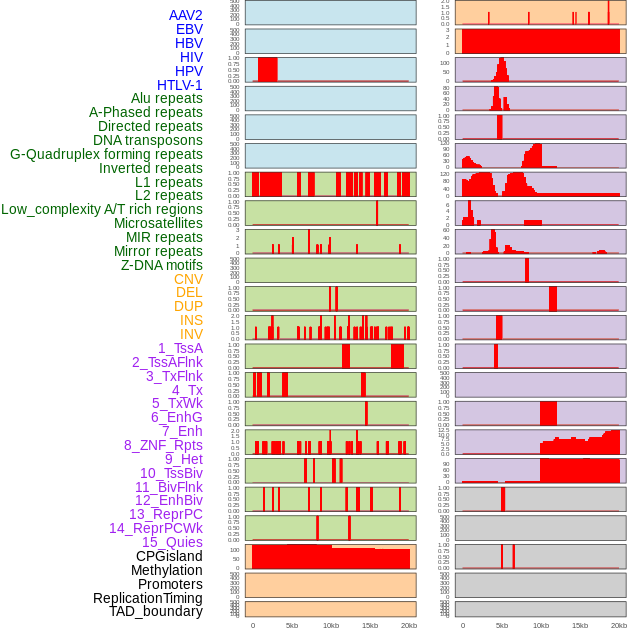 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
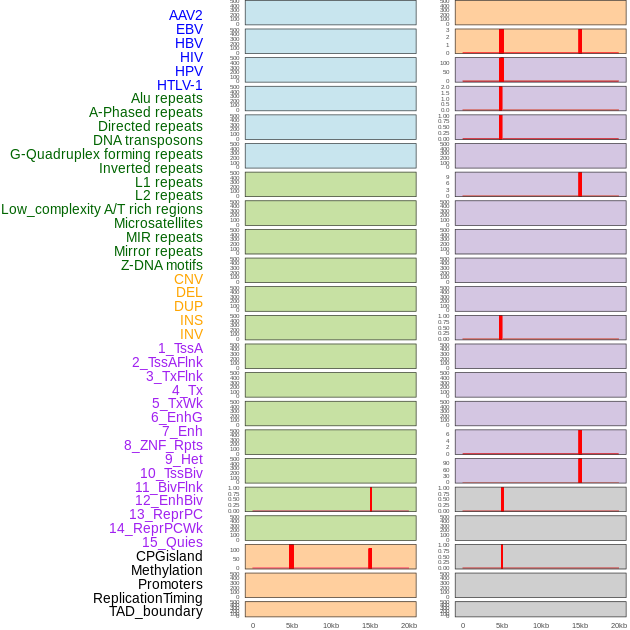 |
Top |
Fusion Protein Features for ING4-A2ML1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr12:6772231/chr12:9027021) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| ING4 | A2ML1 |
| FUNCTION: Component of HBO1 complexes, which specifically mediate acetylation of histone H3 at 'Lys-14' (H3K14ac), and have reduced activity toward histone H4 (PubMed:16387653). Through chromatin acetylation it may function in DNA replication (PubMed:16387653). May inhibit tumor progression by modulating the transcriptional output of signaling pathways which regulate cell proliferation (PubMed:15251430, PubMed:15528276). Can suppress brain tumor angiogenesis through transcriptional repression of RELA/NFKB3 target genes when complexed with RELA (PubMed:15029197). May also specifically suppress loss of contact inhibition elicited by activated oncogenes such as MYC (PubMed:15029197). Represses hypoxia inducible factor's (HIF) activity by interacting with HIF prolyl hydroxylase 2 (EGLN1) (PubMed:15897452). Can enhance apoptosis induced by serum starvation in mammary epithelial cell line HC11 (By similarity). {ECO:0000250|UniProtKB:Q8C0D7, ECO:0000269|PubMed:15029197, ECO:0000269|PubMed:15251430, ECO:0000269|PubMed:15528276, ECO:0000269|PubMed:15897452, ECO:0000269|PubMed:16387653}. | FUNCTION: Is able to inhibit all four classes of proteinases by a unique 'trapping' mechanism. This protein has a peptide stretch, called the 'bait region' which contains specific cleavage sites for different proteinases. When a proteinase cleaves the bait region, a conformational change is induced in the protein which traps the proteinase. The entrapped enzyme remains active against low molecular weight substrates (activity against high molecular weight substrates is greatly reduced). Following cleavage in the bait region a thioester bond is hydrolyzed and mediates the covalent binding of the protein to the proteinase (By similarity). Displays inhibitory activity against chymotrypsin, papain, thermolysin, subtilisin A and, to a lesser extent, elastase but not trypsin. May play an important role during desquamation by inhibiting extracellular proteases. {ECO:0000250|UniProtKB:P01023, ECO:0000269|PubMed:16298998}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ING4 | chr12:6772231 | chr12:9027021 | ENST00000341550 | - | 1 | 8 | 25_118 | 12 | 249.0 | Coiled coil | Ontology_term=ECO:0000269 |
| Hgene | ING4 | chr12:6772231 | chr12:9027021 | ENST00000396807 | - | 1 | 8 | 25_118 | 12 | 250.0 | Coiled coil | Ontology_term=ECO:0000269 |
| Hgene | ING4 | chr12:6772231 | chr12:9027021 | ENST00000412586 | - | 1 | 8 | 25_118 | 12 | 247.0 | Coiled coil | Ontology_term=ECO:0000269 |
| Hgene | ING4 | chr12:6772231 | chr12:9027021 | ENST00000423703 | - | 1 | 7 | 25_118 | 12 | 177.66666666666666 | Coiled coil | Ontology_term=ECO:0000269 |
| Hgene | ING4 | chr12:6772231 | chr12:9027021 | ENST00000444704 | - | 1 | 7 | 25_118 | 12 | 226.0 | Coiled coil | Ontology_term=ECO:0000269 |
| Hgene | ING4 | chr12:6772231 | chr12:9027021 | ENST00000446105 | - | 1 | 8 | 25_118 | 12 | 246.0 | Coiled coil | Ontology_term=ECO:0000269 |
| Hgene | ING4 | chr12:6772231 | chr12:9027021 | ENST00000341550 | - | 1 | 8 | 127_148 | 12 | 249.0 | Motif | Note=Bipartite nuclear localization signal |
| Hgene | ING4 | chr12:6772231 | chr12:9027021 | ENST00000396807 | - | 1 | 8 | 127_148 | 12 | 250.0 | Motif | Note=Bipartite nuclear localization signal |
| Hgene | ING4 | chr12:6772231 | chr12:9027021 | ENST00000412586 | - | 1 | 8 | 127_148 | 12 | 247.0 | Motif | Note=Bipartite nuclear localization signal |
| Hgene | ING4 | chr12:6772231 | chr12:9027021 | ENST00000423703 | - | 1 | 7 | 127_148 | 12 | 177.66666666666666 | Motif | Note=Bipartite nuclear localization signal |
| Hgene | ING4 | chr12:6772231 | chr12:9027021 | ENST00000444704 | - | 1 | 7 | 127_148 | 12 | 226.0 | Motif | Note=Bipartite nuclear localization signal |
| Hgene | ING4 | chr12:6772231 | chr12:9027021 | ENST00000446105 | - | 1 | 8 | 127_148 | 12 | 246.0 | Motif | Note=Bipartite nuclear localization signal |
| Hgene | ING4 | chr12:6772231 | chr12:9027021 | ENST00000341550 | - | 1 | 8 | 196_245 | 12 | 249.0 | Zinc finger | PHD-type |
| Hgene | ING4 | chr12:6772231 | chr12:9027021 | ENST00000396807 | - | 1 | 8 | 196_245 | 12 | 250.0 | Zinc finger | PHD-type |
| Hgene | ING4 | chr12:6772231 | chr12:9027021 | ENST00000412586 | - | 1 | 8 | 196_245 | 12 | 247.0 | Zinc finger | PHD-type |
| Hgene | ING4 | chr12:6772231 | chr12:9027021 | ENST00000423703 | - | 1 | 7 | 196_245 | 12 | 177.66666666666666 | Zinc finger | PHD-type |
| Hgene | ING4 | chr12:6772231 | chr12:9027021 | ENST00000444704 | - | 1 | 7 | 196_245 | 12 | 226.0 | Zinc finger | PHD-type |
| Hgene | ING4 | chr12:6772231 | chr12:9027021 | ENST00000446105 | - | 1 | 8 | 196_245 | 12 | 246.0 | Zinc finger | PHD-type |
| Tgene | A2ML1 | chr12:6772231 | chr12:9027021 | ENST00000299698 | 32 | 36 | 695_726 | 1407 | 1617.0 | Region | Bait region |
Top |
Fusion Gene Sequence for ING4-A2ML1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >39745_39745_1_ING4-A2ML1_ING4_chr12_6772231_ENST00000341550_A2ML1_chr12_9027021_ENST00000299698_length(transcript)=957nt_BP=84nt ACAGTCACTTCCGGGGCGGATCGGAAGTTGCTTTGTTTTGCTTCGAGATGGCTGCGGGGATGTATTTGGAACATTATCTGGACACTCATT AAGAACACTCAGACTTACACCTTCACCATCAGCCAAAGTGTGCTGGTCACCAACTTGAAACCAGCAACCATCAAGGTCTATGACTACTAC CTACCAGATGAACAGGCAACAATTCAGTATTCTGATCCCTGTGAATGAGGATAGGAGCTGGAAACTCAATTAGTCCTCTGTGACATTTAC TGGAGGGTGGAACATTCTTCTGTCGCTTGAAGCAGAACTCATTCAATCAAATAATTTAATTTCTCTGACTAGTATATGGGTAACAAATGA ATATGTCTGAACCTCAGCTATAATACTTTCTACTACCTTTGCAAGGAGATGGGATAGGAACAATCACTCAGAGGAGGCGTTGCATGGGCA GGGTCATAGGGGGAAGAAAGGTGGTTTAGCTGTTTTATTTAGCCATTCAGGGGGCTCTCCAGAGAGGAGACGGTGGTAGAGGGTGAACTA GAGAAGATAAGAATGTCTTCCTAGGCCGGATGCGGTGGCTCACGCCTGTAATCCCAGCACTTTGGGATTGCGAGGTGGGCGGATCACTTG AGGTCAGGAGTTCAAGACCAGCCTGGCCAACATGGTAAAACCCGTCTCTACTAACAATACAAAGATTAGCCTGGTGTGGTGGCACGGGCC TGTAATCGCAGCCCCTTGGAAGGCCAAGGCAGGAGAATCGCCTCAACACTGGAGGTGGAGGTTGCAGTGAGCTGAGATTGTGCCACTGCA CTCCAGCCTGGGCAATGAGGCAAGACCCTGTCTCAAAAAATAATAAATAATAATAATAATAATGTTTTTCTAGAGTTTCAGTCTAAGGGA >39745_39745_1_ING4-A2ML1_ING4_chr12_6772231_ENST00000341550_A2ML1_chr12_9027021_ENST00000299698_length(amino acids)=96AA_BP= MQPPPPVLRRFSCLGLPRGCDYRPVPPHQANLCIVSRDGFYHVGQAGLELLTSSDPPTSQSQSAGITGVSHRIRPRKTFLSSLVHPLPPS -------------------------------------------------------------- >39745_39745_2_ING4-A2ML1_ING4_chr12_6772231_ENST00000341550_A2ML1_chr12_9027021_ENST00000539547_length(transcript)=628nt_BP=84nt ACAGTCACTTCCGGGGCGGATCGGAAGTTGCTTTGTTTTGCTTCGAGATGGCTGCGGGGATGTATTTGGAACATTATCTGGACACTCATT AAGAACACTCAGACTTACACCTTCACCATCAGCCAAAGTGTGCTGGTCACCAACTTGAAACCAGCAACCATCAAGGTCTATGACTACTAC CTACCAGATGAACAGGCAACAATTCAGTATTCTGATCCCTGTGAATGAGGATAGGAGCTGGAAACTCAATTAGTCCTCTGTGACATTTAC TGGAGGGTGGAACATTCTTCTGTCGCTTGAAGCAGAACTCATTCAATCAAATAATTTAATTTCTCTGACTAGTATATGGGTAACAAATGA ATATGTCTGAACCTCAGCTATAATACTTTCTACTACCTTTGCAAGGAGATGGGATAGGAACAATCACTCAGAGGAGGCGTTGCATGGGCA GGGTCATAGGGGGAAGAAAGGTGGTTTAGCTGTTTTATTTAGCCATTCAGGGGGCTCTCCAGAGAGGAGACGGTGGTAGAGGGTGAACTA >39745_39745_2_ING4-A2ML1_ING4_chr12_6772231_ENST00000341550_A2ML1_chr12_9027021_ENST00000539547_length(amino acids)=66AA_BP=19 -------------------------------------------------------------- >39745_39745_3_ING4-A2ML1_ING4_chr12_6772231_ENST00000396807_A2ML1_chr12_9027021_ENST00000299698_length(transcript)=949nt_BP=76nt TTCCGGGGCGGATCGGAAGTTGCTTTGTTTTGCTTCGAGATGGCTGCGGGGATGTATTTGGAACATTATCTGGACACTCATTAAGAACAC TCAGACTTACACCTTCACCATCAGCCAAAGTGTGCTGGTCACCAACTTGAAACCAGCAACCATCAAGGTCTATGACTACTACCTACCAGA TGAACAGGCAACAATTCAGTATTCTGATCCCTGTGAATGAGGATAGGAGCTGGAAACTCAATTAGTCCTCTGTGACATTTACTGGAGGGT GGAACATTCTTCTGTCGCTTGAAGCAGAACTCATTCAATCAAATAATTTAATTTCTCTGACTAGTATATGGGTAACAAATGAATATGTCT GAACCTCAGCTATAATACTTTCTACTACCTTTGCAAGGAGATGGGATAGGAACAATCACTCAGAGGAGGCGTTGCATGGGCAGGGTCATA GGGGGAAGAAAGGTGGTTTAGCTGTTTTATTTAGCCATTCAGGGGGCTCTCCAGAGAGGAGACGGTGGTAGAGGGTGAACTAGAGAAGAT AAGAATGTCTTCCTAGGCCGGATGCGGTGGCTCACGCCTGTAATCCCAGCACTTTGGGATTGCGAGGTGGGCGGATCACTTGAGGTCAGG AGTTCAAGACCAGCCTGGCCAACATGGTAAAACCCGTCTCTACTAACAATACAAAGATTAGCCTGGTGTGGTGGCACGGGCCTGTAATCG CAGCCCCTTGGAAGGCCAAGGCAGGAGAATCGCCTCAACACTGGAGGTGGAGGTTGCAGTGAGCTGAGATTGTGCCACTGCACTCCAGCC TGGGCAATGAGGCAAGACCCTGTCTCAAAAAATAATAAATAATAATAATAATAATGTTTTTCTAGAGTTTCAGTCTAAGGGAAAATGTGA >39745_39745_3_ING4-A2ML1_ING4_chr12_6772231_ENST00000396807_A2ML1_chr12_9027021_ENST00000299698_length(amino acids)=96AA_BP= MQPPPPVLRRFSCLGLPRGCDYRPVPPHQANLCIVSRDGFYHVGQAGLELLTSSDPPTSQSQSAGITGVSHRIRPRKTFLSSLVHPLPPS -------------------------------------------------------------- >39745_39745_4_ING4-A2ML1_ING4_chr12_6772231_ENST00000396807_A2ML1_chr12_9027021_ENST00000539547_length(transcript)=620nt_BP=76nt TTCCGGGGCGGATCGGAAGTTGCTTTGTTTTGCTTCGAGATGGCTGCGGGGATGTATTTGGAACATTATCTGGACACTCATTAAGAACAC TCAGACTTACACCTTCACCATCAGCCAAAGTGTGCTGGTCACCAACTTGAAACCAGCAACCATCAAGGTCTATGACTACTACCTACCAGA TGAACAGGCAACAATTCAGTATTCTGATCCCTGTGAATGAGGATAGGAGCTGGAAACTCAATTAGTCCTCTGTGACATTTACTGGAGGGT GGAACATTCTTCTGTCGCTTGAAGCAGAACTCATTCAATCAAATAATTTAATTTCTCTGACTAGTATATGGGTAACAAATGAATATGTCT GAACCTCAGCTATAATACTTTCTACTACCTTTGCAAGGAGATGGGATAGGAACAATCACTCAGAGGAGGCGTTGCATGGGCAGGGTCATA GGGGGAAGAAAGGTGGTTTAGCTGTTTTATTTAGCCATTCAGGGGGCTCTCCAGAGAGGAGACGGTGGTAGAGGGTGAACTAGAGAAGAT >39745_39745_4_ING4-A2ML1_ING4_chr12_6772231_ENST00000396807_A2ML1_chr12_9027021_ENST00000539547_length(amino acids)=66AA_BP=19 -------------------------------------------------------------- >39745_39745_5_ING4-A2ML1_ING4_chr12_6772231_ENST00000412586_A2ML1_chr12_9027021_ENST00000299698_length(transcript)=910nt_BP=37nt ATGGCTGCGGGGATGTATTTGGAACATTATCTGGACACTCATTAAGAACACTCAGACTTACACCTTCACCATCAGCCAAAGTGTGCTGGT CACCAACTTGAAACCAGCAACCATCAAGGTCTATGACTACTACCTACCAGATGAACAGGCAACAATTCAGTATTCTGATCCCTGTGAATG AGGATAGGAGCTGGAAACTCAATTAGTCCTCTGTGACATTTACTGGAGGGTGGAACATTCTTCTGTCGCTTGAAGCAGAACTCATTCAAT CAAATAATTTAATTTCTCTGACTAGTATATGGGTAACAAATGAATATGTCTGAACCTCAGCTATAATACTTTCTACTACCTTTGCAAGGA GATGGGATAGGAACAATCACTCAGAGGAGGCGTTGCATGGGCAGGGTCATAGGGGGAAGAAAGGTGGTTTAGCTGTTTTATTTAGCCATT CAGGGGGCTCTCCAGAGAGGAGACGGTGGTAGAGGGTGAACTAGAGAAGATAAGAATGTCTTCCTAGGCCGGATGCGGTGGCTCACGCCT GTAATCCCAGCACTTTGGGATTGCGAGGTGGGCGGATCACTTGAGGTCAGGAGTTCAAGACCAGCCTGGCCAACATGGTAAAACCCGTCT CTACTAACAATACAAAGATTAGCCTGGTGTGGTGGCACGGGCCTGTAATCGCAGCCCCTTGGAAGGCCAAGGCAGGAGAATCGCCTCAAC ACTGGAGGTGGAGGTTGCAGTGAGCTGAGATTGTGCCACTGCACTCCAGCCTGGGCAATGAGGCAAGACCCTGTCTCAAAAAATAATAAA TAATAATAATAATAATGTTTTTCTAGAGTTTCAGTCTAAGGGAAAATGTGATTTAGGGCTTTGGAAATTGGCTAAAAAAATAAAAATGGA >39745_39745_5_ING4-A2ML1_ING4_chr12_6772231_ENST00000412586_A2ML1_chr12_9027021_ENST00000299698_length(amino acids)=96AA_BP= MQPPPPVLRRFSCLGLPRGCDYRPVPPHQANLCIVSRDGFYHVGQAGLELLTSSDPPTSQSQSAGITGVSHRIRPRKTFLSSLVHPLPPS -------------------------------------------------------------- >39745_39745_6_ING4-A2ML1_ING4_chr12_6772231_ENST00000412586_A2ML1_chr12_9027021_ENST00000539547_length(transcript)=581nt_BP=37nt ATGGCTGCGGGGATGTATTTGGAACATTATCTGGACACTCATTAAGAACACTCAGACTTACACCTTCACCATCAGCCAAAGTGTGCTGGT CACCAACTTGAAACCAGCAACCATCAAGGTCTATGACTACTACCTACCAGATGAACAGGCAACAATTCAGTATTCTGATCCCTGTGAATG AGGATAGGAGCTGGAAACTCAATTAGTCCTCTGTGACATTTACTGGAGGGTGGAACATTCTTCTGTCGCTTGAAGCAGAACTCATTCAAT CAAATAATTTAATTTCTCTGACTAGTATATGGGTAACAAATGAATATGTCTGAACCTCAGCTATAATACTTTCTACTACCTTTGCAAGGA GATGGGATAGGAACAATCACTCAGAGGAGGCGTTGCATGGGCAGGGTCATAGGGGGAAGAAAGGTGGTTTAGCTGTTTTATTTAGCCATT CAGGGGGCTCTCCAGAGAGGAGACGGTGGTAGAGGGTGAACTAGAGAAGATAAGAATGTCTTCCTAGGCCGGATGCGGTGGCTCACGCCT >39745_39745_6_ING4-A2ML1_ING4_chr12_6772231_ENST00000412586_A2ML1_chr12_9027021_ENST00000539547_length(amino acids)=58AA_BP=11 -------------------------------------------------------------- >39745_39745_7_ING4-A2ML1_ING4_chr12_6772231_ENST00000423703_A2ML1_chr12_9027021_ENST00000299698_length(transcript)=910nt_BP=37nt ATGGCTGCGGGGATGTATTTGGAACATTATCTGGACACTCATTAAGAACACTCAGACTTACACCTTCACCATCAGCCAAAGTGTGCTGGT CACCAACTTGAAACCAGCAACCATCAAGGTCTATGACTACTACCTACCAGATGAACAGGCAACAATTCAGTATTCTGATCCCTGTGAATG AGGATAGGAGCTGGAAACTCAATTAGTCCTCTGTGACATTTACTGGAGGGTGGAACATTCTTCTGTCGCTTGAAGCAGAACTCATTCAAT CAAATAATTTAATTTCTCTGACTAGTATATGGGTAACAAATGAATATGTCTGAACCTCAGCTATAATACTTTCTACTACCTTTGCAAGGA GATGGGATAGGAACAATCACTCAGAGGAGGCGTTGCATGGGCAGGGTCATAGGGGGAAGAAAGGTGGTTTAGCTGTTTTATTTAGCCATT CAGGGGGCTCTCCAGAGAGGAGACGGTGGTAGAGGGTGAACTAGAGAAGATAAGAATGTCTTCCTAGGCCGGATGCGGTGGCTCACGCCT GTAATCCCAGCACTTTGGGATTGCGAGGTGGGCGGATCACTTGAGGTCAGGAGTTCAAGACCAGCCTGGCCAACATGGTAAAACCCGTCT CTACTAACAATACAAAGATTAGCCTGGTGTGGTGGCACGGGCCTGTAATCGCAGCCCCTTGGAAGGCCAAGGCAGGAGAATCGCCTCAAC ACTGGAGGTGGAGGTTGCAGTGAGCTGAGATTGTGCCACTGCACTCCAGCCTGGGCAATGAGGCAAGACCCTGTCTCAAAAAATAATAAA TAATAATAATAATAATGTTTTTCTAGAGTTTCAGTCTAAGGGAAAATGTGATTTAGGGCTTTGGAAATTGGCTAAAAAAATAAAAATGGA >39745_39745_7_ING4-A2ML1_ING4_chr12_6772231_ENST00000423703_A2ML1_chr12_9027021_ENST00000299698_length(amino acids)=96AA_BP= MQPPPPVLRRFSCLGLPRGCDYRPVPPHQANLCIVSRDGFYHVGQAGLELLTSSDPPTSQSQSAGITGVSHRIRPRKTFLSSLVHPLPPS -------------------------------------------------------------- >39745_39745_8_ING4-A2ML1_ING4_chr12_6772231_ENST00000423703_A2ML1_chr12_9027021_ENST00000539547_length(transcript)=581nt_BP=37nt ATGGCTGCGGGGATGTATTTGGAACATTATCTGGACACTCATTAAGAACACTCAGACTTACACCTTCACCATCAGCCAAAGTGTGCTGGT CACCAACTTGAAACCAGCAACCATCAAGGTCTATGACTACTACCTACCAGATGAACAGGCAACAATTCAGTATTCTGATCCCTGTGAATG AGGATAGGAGCTGGAAACTCAATTAGTCCTCTGTGACATTTACTGGAGGGTGGAACATTCTTCTGTCGCTTGAAGCAGAACTCATTCAAT CAAATAATTTAATTTCTCTGACTAGTATATGGGTAACAAATGAATATGTCTGAACCTCAGCTATAATACTTTCTACTACCTTTGCAAGGA GATGGGATAGGAACAATCACTCAGAGGAGGCGTTGCATGGGCAGGGTCATAGGGGGAAGAAAGGTGGTTTAGCTGTTTTATTTAGCCATT CAGGGGGCTCTCCAGAGAGGAGACGGTGGTAGAGGGTGAACTAGAGAAGATAAGAATGTCTTCCTAGGCCGGATGCGGTGGCTCACGCCT >39745_39745_8_ING4-A2ML1_ING4_chr12_6772231_ENST00000423703_A2ML1_chr12_9027021_ENST00000539547_length(amino acids)=58AA_BP=11 -------------------------------------------------------------- >39745_39745_9_ING4-A2ML1_ING4_chr12_6772231_ENST00000444704_A2ML1_chr12_9027021_ENST00000299698_length(transcript)=910nt_BP=37nt ATGGCTGCGGGGATGTATTTGGAACATTATCTGGACACTCATTAAGAACACTCAGACTTACACCTTCACCATCAGCCAAAGTGTGCTGGT CACCAACTTGAAACCAGCAACCATCAAGGTCTATGACTACTACCTACCAGATGAACAGGCAACAATTCAGTATTCTGATCCCTGTGAATG AGGATAGGAGCTGGAAACTCAATTAGTCCTCTGTGACATTTACTGGAGGGTGGAACATTCTTCTGTCGCTTGAAGCAGAACTCATTCAAT CAAATAATTTAATTTCTCTGACTAGTATATGGGTAACAAATGAATATGTCTGAACCTCAGCTATAATACTTTCTACTACCTTTGCAAGGA GATGGGATAGGAACAATCACTCAGAGGAGGCGTTGCATGGGCAGGGTCATAGGGGGAAGAAAGGTGGTTTAGCTGTTTTATTTAGCCATT CAGGGGGCTCTCCAGAGAGGAGACGGTGGTAGAGGGTGAACTAGAGAAGATAAGAATGTCTTCCTAGGCCGGATGCGGTGGCTCACGCCT GTAATCCCAGCACTTTGGGATTGCGAGGTGGGCGGATCACTTGAGGTCAGGAGTTCAAGACCAGCCTGGCCAACATGGTAAAACCCGTCT CTACTAACAATACAAAGATTAGCCTGGTGTGGTGGCACGGGCCTGTAATCGCAGCCCCTTGGAAGGCCAAGGCAGGAGAATCGCCTCAAC ACTGGAGGTGGAGGTTGCAGTGAGCTGAGATTGTGCCACTGCACTCCAGCCTGGGCAATGAGGCAAGACCCTGTCTCAAAAAATAATAAA TAATAATAATAATAATGTTTTTCTAGAGTTTCAGTCTAAGGGAAAATGTGATTTAGGGCTTTGGAAATTGGCTAAAAAAATAAAAATGGA >39745_39745_9_ING4-A2ML1_ING4_chr12_6772231_ENST00000444704_A2ML1_chr12_9027021_ENST00000299698_length(amino acids)=96AA_BP= MQPPPPVLRRFSCLGLPRGCDYRPVPPHQANLCIVSRDGFYHVGQAGLELLTSSDPPTSQSQSAGITGVSHRIRPRKTFLSSLVHPLPPS -------------------------------------------------------------- >39745_39745_10_ING4-A2ML1_ING4_chr12_6772231_ENST00000444704_A2ML1_chr12_9027021_ENST00000539547_length(transcript)=581nt_BP=37nt ATGGCTGCGGGGATGTATTTGGAACATTATCTGGACACTCATTAAGAACACTCAGACTTACACCTTCACCATCAGCCAAAGTGTGCTGGT CACCAACTTGAAACCAGCAACCATCAAGGTCTATGACTACTACCTACCAGATGAACAGGCAACAATTCAGTATTCTGATCCCTGTGAATG AGGATAGGAGCTGGAAACTCAATTAGTCCTCTGTGACATTTACTGGAGGGTGGAACATTCTTCTGTCGCTTGAAGCAGAACTCATTCAAT CAAATAATTTAATTTCTCTGACTAGTATATGGGTAACAAATGAATATGTCTGAACCTCAGCTATAATACTTTCTACTACCTTTGCAAGGA GATGGGATAGGAACAATCACTCAGAGGAGGCGTTGCATGGGCAGGGTCATAGGGGGAAGAAAGGTGGTTTAGCTGTTTTATTTAGCCATT CAGGGGGCTCTCCAGAGAGGAGACGGTGGTAGAGGGTGAACTAGAGAAGATAAGAATGTCTTCCTAGGCCGGATGCGGTGGCTCACGCCT >39745_39745_10_ING4-A2ML1_ING4_chr12_6772231_ENST00000444704_A2ML1_chr12_9027021_ENST00000539547_length(amino acids)=58AA_BP=11 -------------------------------------------------------------- >39745_39745_11_ING4-A2ML1_ING4_chr12_6772231_ENST00000446105_A2ML1_chr12_9027021_ENST00000299698_length(transcript)=951nt_BP=78nt ACTTCCGGGGCGGATCGGAAGTTGCTTTGTTTTGCTTCGAGATGGCTGCGGGGATGTATTTGGAACATTATCTGGACACTCATTAAGAAC ACTCAGACTTACACCTTCACCATCAGCCAAAGTGTGCTGGTCACCAACTTGAAACCAGCAACCATCAAGGTCTATGACTACTACCTACCA GATGAACAGGCAACAATTCAGTATTCTGATCCCTGTGAATGAGGATAGGAGCTGGAAACTCAATTAGTCCTCTGTGACATTTACTGGAGG GTGGAACATTCTTCTGTCGCTTGAAGCAGAACTCATTCAATCAAATAATTTAATTTCTCTGACTAGTATATGGGTAACAAATGAATATGT CTGAACCTCAGCTATAATACTTTCTACTACCTTTGCAAGGAGATGGGATAGGAACAATCACTCAGAGGAGGCGTTGCATGGGCAGGGTCA TAGGGGGAAGAAAGGTGGTTTAGCTGTTTTATTTAGCCATTCAGGGGGCTCTCCAGAGAGGAGACGGTGGTAGAGGGTGAACTAGAGAAG ATAAGAATGTCTTCCTAGGCCGGATGCGGTGGCTCACGCCTGTAATCCCAGCACTTTGGGATTGCGAGGTGGGCGGATCACTTGAGGTCA GGAGTTCAAGACCAGCCTGGCCAACATGGTAAAACCCGTCTCTACTAACAATACAAAGATTAGCCTGGTGTGGTGGCACGGGCCTGTAAT CGCAGCCCCTTGGAAGGCCAAGGCAGGAGAATCGCCTCAACACTGGAGGTGGAGGTTGCAGTGAGCTGAGATTGTGCCACTGCACTCCAG CCTGGGCAATGAGGCAAGACCCTGTCTCAAAAAATAATAAATAATAATAATAATAATGTTTTTCTAGAGTTTCAGTCTAAGGGAAAATGT >39745_39745_11_ING4-A2ML1_ING4_chr12_6772231_ENST00000446105_A2ML1_chr12_9027021_ENST00000299698_length(amino acids)=96AA_BP= MQPPPPVLRRFSCLGLPRGCDYRPVPPHQANLCIVSRDGFYHVGQAGLELLTSSDPPTSQSQSAGITGVSHRIRPRKTFLSSLVHPLPPS -------------------------------------------------------------- >39745_39745_12_ING4-A2ML1_ING4_chr12_6772231_ENST00000446105_A2ML1_chr12_9027021_ENST00000539547_length(transcript)=622nt_BP=78nt ACTTCCGGGGCGGATCGGAAGTTGCTTTGTTTTGCTTCGAGATGGCTGCGGGGATGTATTTGGAACATTATCTGGACACTCATTAAGAAC ACTCAGACTTACACCTTCACCATCAGCCAAAGTGTGCTGGTCACCAACTTGAAACCAGCAACCATCAAGGTCTATGACTACTACCTACCA GATGAACAGGCAACAATTCAGTATTCTGATCCCTGTGAATGAGGATAGGAGCTGGAAACTCAATTAGTCCTCTGTGACATTTACTGGAGG GTGGAACATTCTTCTGTCGCTTGAAGCAGAACTCATTCAATCAAATAATTTAATTTCTCTGACTAGTATATGGGTAACAAATGAATATGT CTGAACCTCAGCTATAATACTTTCTACTACCTTTGCAAGGAGATGGGATAGGAACAATCACTCAGAGGAGGCGTTGCATGGGCAGGGTCA TAGGGGGAAGAAAGGTGGTTTAGCTGTTTTATTTAGCCATTCAGGGGGCTCTCCAGAGAGGAGACGGTGGTAGAGGGTGAACTAGAGAAG >39745_39745_12_ING4-A2ML1_ING4_chr12_6772231_ENST00000446105_A2ML1_chr12_9027021_ENST00000539547_length(amino acids)=66AA_BP=19 -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ING4-A2ML1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ING4-A2ML1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ING4-A2ML1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies