
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ISCA1-LINGO2 (FusionGDB2 ID:40295) |
Fusion Gene Summary for ISCA1-LINGO2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ISCA1-LINGO2 | Fusion gene ID: 40295 | Hgene | Tgene | Gene symbol | ISCA1 | LINGO2 | Gene ID | 81689 | 158038 |
| Gene name | iron-sulfur cluster assembly 1 | leucine rich repeat and Ig domain containing 2 | |
| Synonyms | HBLD2|ISA1|MMDS5|hIscA | LERN3|LRRN6C | |
| Cytomap | 9q21.33 | 9p21.2-p21.1 | |
| Type of gene | protein-coding | protein-coding | |
| Description | iron-sulfur cluster assembly 1 homolog, mitochondrialHESB like domain containing 2HESB-like domain-containing protein 2iron-sulfur assembly protein IscA | leucine-rich repeat and immunoglobulin-like domain-containing nogo receptor-interacting protein 2leucine rich repeat neuronal 6Cleucine-rich repeat neuronal protein 3leucine-rich repeat neuronal protein 6C | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q9BUE6 | Q7L985 | |
| Ensembl transtripts involved in fusion gene | ENST00000326094, ENST00000375991, ENST00000452279, ENST00000311534, | ENST00000308675, ENST00000493941, ENST00000379992, | |
| Fusion gene scores | * DoF score | 5 X 4 X 4=80 | 11 X 8 X 8=704 |
| # samples | 5 | 13 | |
| ** MAII score | log2(5/80*10)=-0.678071905112638 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(13/704*10)=-2.43706380560884 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: ISCA1 [Title/Abstract] AND LINGO2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ISCA1(88897293)-LINGO2(28670278), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across ISCA1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across LINGO2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | PCPG | TCGA-P7-A5NX-01A | ISCA1 | chr9 | 88897293 | - | LINGO2 | chr9 | 28670278 | - |
Top |
Fusion Gene ORF analysis for ISCA1-LINGO2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000326094 | ENST00000308675 | ISCA1 | chr9 | 88897293 | - | LINGO2 | chr9 | 28670278 | - |
| 5CDS-intron | ENST00000326094 | ENST00000493941 | ISCA1 | chr9 | 88897293 | - | LINGO2 | chr9 | 28670278 | - |
| 5CDS-intron | ENST00000375991 | ENST00000308675 | ISCA1 | chr9 | 88897293 | - | LINGO2 | chr9 | 28670278 | - |
| 5CDS-intron | ENST00000375991 | ENST00000493941 | ISCA1 | chr9 | 88897293 | - | LINGO2 | chr9 | 28670278 | - |
| 5CDS-intron | ENST00000452279 | ENST00000308675 | ISCA1 | chr9 | 88897293 | - | LINGO2 | chr9 | 28670278 | - |
| 5CDS-intron | ENST00000452279 | ENST00000493941 | ISCA1 | chr9 | 88897293 | - | LINGO2 | chr9 | 28670278 | - |
| In-frame | ENST00000326094 | ENST00000379992 | ISCA1 | chr9 | 88897293 | - | LINGO2 | chr9 | 28670278 | - |
| In-frame | ENST00000375991 | ENST00000379992 | ISCA1 | chr9 | 88897293 | - | LINGO2 | chr9 | 28670278 | - |
| In-frame | ENST00000452279 | ENST00000379992 | ISCA1 | chr9 | 88897293 | - | LINGO2 | chr9 | 28670278 | - |
| intron-3CDS | ENST00000311534 | ENST00000379992 | ISCA1 | chr9 | 88897293 | - | LINGO2 | chr9 | 28670278 | - |
| intron-intron | ENST00000311534 | ENST00000308675 | ISCA1 | chr9 | 88897293 | - | LINGO2 | chr9 | 28670278 | - |
| intron-intron | ENST00000311534 | ENST00000493941 | ISCA1 | chr9 | 88897293 | - | LINGO2 | chr9 | 28670278 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000375991 | ISCA1 | chr9 | 88897293 | - | ENST00000379992 | LINGO2 | chr9 | 28670278 | - | 3196 | 152 | 602 | 2422 | 606 |
| ENST00000452279 | ISCA1 | chr9 | 88897293 | - | ENST00000379992 | LINGO2 | chr9 | 28670278 | - | 3428 | 384 | 834 | 2654 | 606 |
| ENST00000326094 | ISCA1 | chr9 | 88897293 | - | ENST00000379992 | LINGO2 | chr9 | 28670278 | - | 3205 | 161 | 611 | 2431 | 606 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000375991 | ENST00000379992 | ISCA1 | chr9 | 88897293 | - | LINGO2 | chr9 | 28670278 | - | 0.001477967 | 0.9985221 |
| ENST00000452279 | ENST00000379992 | ISCA1 | chr9 | 88897293 | - | LINGO2 | chr9 | 28670278 | - | 0.001935249 | 0.9980647 |
| ENST00000326094 | ENST00000379992 | ISCA1 | chr9 | 88897293 | - | LINGO2 | chr9 | 28670278 | - | 0.001495712 | 0.9985043 |
Top |
Fusion Genomic Features for ISCA1-LINGO2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
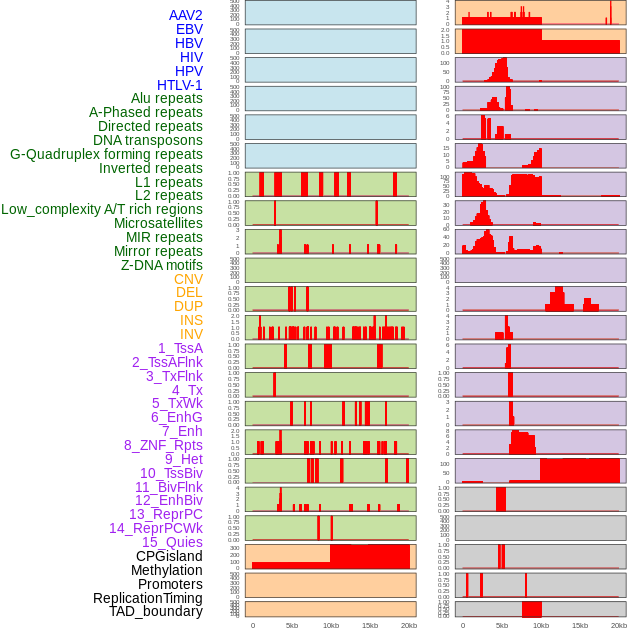 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for ISCA1-LINGO2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr9:88897293/chr9:28670278) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| ISCA1 | LINGO2 |
| FUNCTION: Involved in the maturation of mitochondrial 4Fe-4S proteins functioning late in the iron-sulfur cluster assembly pathway. Probably involved in the binding of an intermediate of Fe/S cluster assembly. {ECO:0000269|PubMed:15262227, ECO:0000269|PubMed:22323289}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | LINGO2 | chr9:88897293 | chr9:28670278 | ENST00000308675 | 0 | 4 | 28_57 | 0 | 607.0 | Domain | Note=LRRNT | |
| Tgene | LINGO2 | chr9:88897293 | chr9:28670278 | ENST00000308675 | 0 | 4 | 355_409 | 0 | 607.0 | Domain | Note=LRRCT | |
| Tgene | LINGO2 | chr9:88897293 | chr9:28670278 | ENST00000308675 | 0 | 4 | 410_499 | 0 | 607.0 | Domain | Note=Ig-like C2-type | |
| Tgene | LINGO2 | chr9:88897293 | chr9:28670278 | ENST00000379992 | -1 | 6 | 28_57 | 0 | 607.0 | Domain | Note=LRRNT | |
| Tgene | LINGO2 | chr9:88897293 | chr9:28670278 | ENST00000379992 | -1 | 6 | 355_409 | 0 | 607.0 | Domain | Note=LRRCT | |
| Tgene | LINGO2 | chr9:88897293 | chr9:28670278 | ENST00000379992 | -1 | 6 | 410_499 | 0 | 607.0 | Domain | Note=Ig-like C2-type | |
| Tgene | LINGO2 | chr9:88897293 | chr9:28670278 | ENST00000308675 | 0 | 4 | 106_127 | 0 | 607.0 | Repeat | Note=LRR 3 | |
| Tgene | LINGO2 | chr9:88897293 | chr9:28670278 | ENST00000308675 | 0 | 4 | 130_151 | 0 | 607.0 | Repeat | Note=LRR 4 | |
| Tgene | LINGO2 | chr9:88897293 | chr9:28670278 | ENST00000308675 | 0 | 4 | 154_175 | 0 | 607.0 | Repeat | Note=LRR 5 | |
| Tgene | LINGO2 | chr9:88897293 | chr9:28670278 | ENST00000308675 | 0 | 4 | 178_199 | 0 | 607.0 | Repeat | Note=LRR 6 | |
| Tgene | LINGO2 | chr9:88897293 | chr9:28670278 | ENST00000308675 | 0 | 4 | 202_223 | 0 | 607.0 | Repeat | Note=LRR 7 | |
| Tgene | LINGO2 | chr9:88897293 | chr9:28670278 | ENST00000308675 | 0 | 4 | 226_247 | 0 | 607.0 | Repeat | Note=LRR 8 | |
| Tgene | LINGO2 | chr9:88897293 | chr9:28670278 | ENST00000308675 | 0 | 4 | 250_271 | 0 | 607.0 | Repeat | Note=LRR 9 | |
| Tgene | LINGO2 | chr9:88897293 | chr9:28670278 | ENST00000308675 | 0 | 4 | 274_295 | 0 | 607.0 | Repeat | Note=LRR 10 | |
| Tgene | LINGO2 | chr9:88897293 | chr9:28670278 | ENST00000308675 | 0 | 4 | 298_319 | 0 | 607.0 | Repeat | Note=LRR 11 | |
| Tgene | LINGO2 | chr9:88897293 | chr9:28670278 | ENST00000308675 | 0 | 4 | 322_343 | 0 | 607.0 | Repeat | Note=LRR 12 | |
| Tgene | LINGO2 | chr9:88897293 | chr9:28670278 | ENST00000308675 | 0 | 4 | 58_79 | 0 | 607.0 | Repeat | Note=LRR 1 | |
| Tgene | LINGO2 | chr9:88897293 | chr9:28670278 | ENST00000308675 | 0 | 4 | 82_103 | 0 | 607.0 | Repeat | Note=LRR 2 | |
| Tgene | LINGO2 | chr9:88897293 | chr9:28670278 | ENST00000379992 | -1 | 6 | 106_127 | 0 | 607.0 | Repeat | Note=LRR 3 | |
| Tgene | LINGO2 | chr9:88897293 | chr9:28670278 | ENST00000379992 | -1 | 6 | 130_151 | 0 | 607.0 | Repeat | Note=LRR 4 | |
| Tgene | LINGO2 | chr9:88897293 | chr9:28670278 | ENST00000379992 | -1 | 6 | 154_175 | 0 | 607.0 | Repeat | Note=LRR 5 | |
| Tgene | LINGO2 | chr9:88897293 | chr9:28670278 | ENST00000379992 | -1 | 6 | 178_199 | 0 | 607.0 | Repeat | Note=LRR 6 | |
| Tgene | LINGO2 | chr9:88897293 | chr9:28670278 | ENST00000379992 | -1 | 6 | 202_223 | 0 | 607.0 | Repeat | Note=LRR 7 | |
| Tgene | LINGO2 | chr9:88897293 | chr9:28670278 | ENST00000379992 | -1 | 6 | 226_247 | 0 | 607.0 | Repeat | Note=LRR 8 | |
| Tgene | LINGO2 | chr9:88897293 | chr9:28670278 | ENST00000379992 | -1 | 6 | 250_271 | 0 | 607.0 | Repeat | Note=LRR 9 | |
| Tgene | LINGO2 | chr9:88897293 | chr9:28670278 | ENST00000379992 | -1 | 6 | 274_295 | 0 | 607.0 | Repeat | Note=LRR 10 | |
| Tgene | LINGO2 | chr9:88897293 | chr9:28670278 | ENST00000379992 | -1 | 6 | 298_319 | 0 | 607.0 | Repeat | Note=LRR 11 | |
| Tgene | LINGO2 | chr9:88897293 | chr9:28670278 | ENST00000379992 | -1 | 6 | 322_343 | 0 | 607.0 | Repeat | Note=LRR 12 | |
| Tgene | LINGO2 | chr9:88897293 | chr9:28670278 | ENST00000379992 | -1 | 6 | 58_79 | 0 | 607.0 | Repeat | Note=LRR 1 | |
| Tgene | LINGO2 | chr9:88897293 | chr9:28670278 | ENST00000379992 | -1 | 6 | 82_103 | 0 | 607.0 | Repeat | Note=LRR 2 | |
| Tgene | LINGO2 | chr9:88897293 | chr9:28670278 | ENST00000308675 | 0 | 4 | 28_545 | 0 | 607.0 | Topological domain | Extracellular | |
| Tgene | LINGO2 | chr9:88897293 | chr9:28670278 | ENST00000308675 | 0 | 4 | 567_606 | 0 | 607.0 | Topological domain | Cytoplasmic | |
| Tgene | LINGO2 | chr9:88897293 | chr9:28670278 | ENST00000379992 | -1 | 6 | 28_545 | 0 | 607.0 | Topological domain | Extracellular | |
| Tgene | LINGO2 | chr9:88897293 | chr9:28670278 | ENST00000379992 | -1 | 6 | 567_606 | 0 | 607.0 | Topological domain | Cytoplasmic | |
| Tgene | LINGO2 | chr9:88897293 | chr9:28670278 | ENST00000308675 | 0 | 4 | 546_566 | 0 | 607.0 | Transmembrane | Helical | |
| Tgene | LINGO2 | chr9:88897293 | chr9:28670278 | ENST00000379992 | -1 | 6 | 546_566 | 0 | 607.0 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
Top |
Fusion Gene Sequence for ISCA1-LINGO2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >40295_40295_1_ISCA1-LINGO2_ISCA1_chr9_88897293_ENST00000326094_LINGO2_chr9_28670278_ENST00000379992_length(transcript)=3205nt_BP=161nt AATGCGCCCGCCGTGTCCATGGAGAGAAGCTGAGGCGGCCGACCTTCGGCCCGAGGCACCGGGGCGCCGGGACGGCGAAGATGTCGGCTT CCTTAGTCCGGGCAACTGTCCGGGCTGTGAGCAAGAGGAAGCTGCAGCCCACCCGGGCAGCCCTCACCCTGTGTAGGAATTGATGAGTGC CATCAGAAAGCTGTATCATGAGCTGCCTGCACTTCTAAAGTGTCCAGTGGATTTTTAATCACATGAGCCTGGAAATAGGGTTATGAGAAG AAGCTCAGAGCAGAGCACCGAAAGTGGCCACTACCAGCATGAAGAGCCCAACAATTCAAACTGGTGAAGTGAGAAAAACAGAATGCAGCT TTCAAGGTTCGTTTCAAGCAGTTGGCTTGTGGGACTCTGAGAGATGCTGCTGCCCATGACATGCGGGAATTATCATGATCAACTACCCAG CTTGGATTTCACCCAGTGGCCAAGAGCTTTGTGTGGGAGACGGCAAGGGTTGGATTTTTCAAAAGAGTAAACCAGGATAAATCATGAGGA ACCTATAACCCTTTTGGCCACATGCAAAAAAGCAAGACCCGTGACCAAGGTGTAGACTAAGAAGTGGAGTCATGCTTCACACGGCCATAT CATGCTGGCAGCCATTCCTGGGTCTGGCTGTGGTGTTAATCTTCATGGGATCCACCATTGGCTGCCCCGCTCGCTGTGAGTGCTCTGCCC AGAACAAATCTGTTAGCTGTCACAGAAGGCGATTGATCGCCATCCCAGAGGGCATTCCCATCGAAACCAAAATCTTGGACCTCAGTAAAA ACAGGCTAAAAAGCGTCAACCCTGAAGAATTCATATCATATCCTCTGCTGGAAGAGATAGACTTGAGTGACAACATCATTGCCAATGTGG AACCAGGAGCATTCAACAATCTCTTTAACCTGCGTTCCCTCCGCCTAAAAGGCAATCGTCTAAAGCTGGTCCCTTTGGGAGTATTCACGG GGCTGTCCAATCTCACTAAGCTTGACATTAGTGAGAATAAGATTGTCATTTTACTAGACTACATGTTCCAAGATCTACATAACCTGAAGT CTCTAGAAGTGGGGGACAATGATTTGGTTTATATATCACACAGGGCATTCAGTGGGCTTCTTAGCTTGGAGCAGCTCACCCTGGAGAAAT GCAACTTAACAGCAGTACCAACAGAAGCCCTCTCCCACCTCCGCAGCCTCATCAGCCTGCATCTGAAGCATCTCAATATCAACAATATGC CTGTGTATGCCTTTAAAAGATTGTTCCACCTGAAACACCTAGAGATTGACTATTGGCCTTTACTGGATATGATGCCTGCCAATAGCCTCT ACGGTCTCAACCTCACATCCCTTTCAGTCACCAACACCAATCTGTCTACTGTACCCTTCCTTGCCTTTAAACACCTGGTATACCTGACTC ACCTTAACCTCTCCTACAATCCCATCAGCACTATTGAAGCAGGCATGTTCTCTGACCTGATCCGCCTTCAGGAGCTTCATATAGTGGGGG CCCAGCTTCGCACCATTGAGCCTCACTCCTTCCAAGGGCTCCGCTTCCTACGCGTGCTCAATGTGTCTCAGAACCTGCTGGAAACTTTGG AAGAGAATGTCTTCTCCTCCCCTAGGGCTCTGGAGGTCTTGAGCATTAACAACAACCCTCTGGCCTGTGACTGCCGCCTTCTCTGGATCT TGCAGCGACAGCCCACCCTGCAGTTTGGTGGCCAGCAACCTATGTGTGCTGGCCCAGACACCATCCGTGAGAGGTCTTTCAAGGATTTCC ATAGCACTGCCCTTTCTTTTTACTTTACCTGCAAAAAACCCAAAATCCGTGAAAAGAAGTTGCAGCATCTGCTAGTAGATGAAGGGCAGA CAGTCCAGCTAGAATGCAGTGCAGATGGAGACCCGCAGCCTGTGATTTCCTGGGTGACACCCCGAAGGCGTTTCATCACCACCAAGTCCA ATGGAAGAGCCACCGTGTTGGGTGATGGCACCTTGGAAATCCGCTTTGCCCAGGATCAAGACAGCGGGATGTATGTTTGCATCGCTAGCA ATGCTGCTGGGAATGATACCTTCACAGCCTCCTTAACTGTGAAAGGATTCGCTTCAGATCGTTTTCTTTATGCGAACAGGACCCCTATGT ACATGACCGACTCCAATGACACCATTTCCAATGGCACCAATGCCAATACTTTTTCCCTGGACCTTAAAACAATACTGGTGTCTACAGCTA TGGGCTGCTTCACATTCCTGGGAGTGGTTTTATTTTGTTTTCTTCTCCTTTTTGTGTGGAGCCGAGGGAAAGGCAAGCACAAAAACAGCA TTGACCTTGAGTATGTGCCCAGAAAAAACAATGGTGCTGTTGTGGAAGGGGAGGTAGCTGGACCCAGGAGGTTCAACATGAAAATGATTT GAAGGCCCACCCCTCACATTACTGTCTCTTTGTCAATGTGGGTAATCAGTAAGACAGTATGGCACAGTAAATTACTAGATTAAGAGGCAG CCATGTGCAGCTGCCCCTGTATCAAAAGCAGGGTCTATGGAAGCAGGAGGACTTCCAATGGAGACTCTCCATCGAAAGGCAGGCAGGCAG GCATGTGTCAGAGCCCTTCACACAGTGGGATACTAAGTGTTTGCGTTGCAAATATTGGCGTTCTGGGGATCTCAGTAATGAACCTGAATA TTTGGCTCACACTCACGGACAATTATTCAGCATTTTCTACCACTGCAAAAAACAAAAGAAAAAATAAAAAAGAACAACCTACAGTGTAGG ATTTACATATTAAAAAGACACATTTGTCTAAAACATACTCTACAGAAAAATTTGTATCTATGATTATCATTTGTTAAAGCCTTGCATCAT ACCATATTGTTGGTTCAGTACCACAAAGAGATCAATATATTCTTTTCTTCCTTTTTTGAAACATATATGCTGTACATGTTTTAAAGCAAT ATGAATGAGAGGTTGTGCTTTTAGTTACTCACCACTATAGATCCAAGTGTGATTTCACCTTCCGTTACCTACAGATGACCCTGAGACTAG ATCCCTGGAGTTATGGGCGGAGATATTTTGAGAGATGTGTTTGTCTGATGTAGGATGCCAAGAAACAGGACCCAAGGCAAAACTGCTCAA >40295_40295_1_ISCA1-LINGO2_ISCA1_chr9_88897293_ENST00000326094_LINGO2_chr9_28670278_ENST00000379992_length(amino acids)=606AA_BP= MLHTAISCWQPFLGLAVVLIFMGSTIGCPARCECSAQNKSVSCHRRRLIAIPEGIPIETKILDLSKNRLKSVNPEEFISYPLLEEIDLSD NIIANVEPGAFNNLFNLRSLRLKGNRLKLVPLGVFTGLSNLTKLDISENKIVILLDYMFQDLHNLKSLEVGDNDLVYISHRAFSGLLSLE QLTLEKCNLTAVPTEALSHLRSLISLHLKHLNINNMPVYAFKRLFHLKHLEIDYWPLLDMMPANSLYGLNLTSLSVTNTNLSTVPFLAFK HLVYLTHLNLSYNPISTIEAGMFSDLIRLQELHIVGAQLRTIEPHSFQGLRFLRVLNVSQNLLETLEENVFSSPRALEVLSINNNPLACD CRLLWILQRQPTLQFGGQQPMCAGPDTIRERSFKDFHSTALSFYFTCKKPKIREKKLQHLLVDEGQTVQLECSADGDPQPVISWVTPRRR FITTKSNGRATVLGDGTLEIRFAQDQDSGMYVCIASNAAGNDTFTASLTVKGFASDRFLYANRTPMYMTDSNDTISNGTNANTFSLDLKT -------------------------------------------------------------- >40295_40295_2_ISCA1-LINGO2_ISCA1_chr9_88897293_ENST00000375991_LINGO2_chr9_28670278_ENST00000379992_length(transcript)=3196nt_BP=152nt GCCGTGTCCATGGAGAGAAGCTGAGGCGGCCGACCTTCGGCCCGAGGCACCGGGGCGCCGGGACGGCGAAGATGTCGGCTTCCTTAGTCC GGGCAACTGTCCGGGCTGTGAGCAAGAGGAAGCTGCAGCCCACCCGGGCAGCCCTCACCCTGTGTAGGAATTGATGAGTGCCATCAGAAA GCTGTATCATGAGCTGCCTGCACTTCTAAAGTGTCCAGTGGATTTTTAATCACATGAGCCTGGAAATAGGGTTATGAGAAGAAGCTCAGA GCAGAGCACCGAAAGTGGCCACTACCAGCATGAAGAGCCCAACAATTCAAACTGGTGAAGTGAGAAAAACAGAATGCAGCTTTCAAGGTT CGTTTCAAGCAGTTGGCTTGTGGGACTCTGAGAGATGCTGCTGCCCATGACATGCGGGAATTATCATGATCAACTACCCAGCTTGGATTT CACCCAGTGGCCAAGAGCTTTGTGTGGGAGACGGCAAGGGTTGGATTTTTCAAAAGAGTAAACCAGGATAAATCATGAGGAACCTATAAC CCTTTTGGCCACATGCAAAAAAGCAAGACCCGTGACCAAGGTGTAGACTAAGAAGTGGAGTCATGCTTCACACGGCCATATCATGCTGGC AGCCATTCCTGGGTCTGGCTGTGGTGTTAATCTTCATGGGATCCACCATTGGCTGCCCCGCTCGCTGTGAGTGCTCTGCCCAGAACAAAT CTGTTAGCTGTCACAGAAGGCGATTGATCGCCATCCCAGAGGGCATTCCCATCGAAACCAAAATCTTGGACCTCAGTAAAAACAGGCTAA AAAGCGTCAACCCTGAAGAATTCATATCATATCCTCTGCTGGAAGAGATAGACTTGAGTGACAACATCATTGCCAATGTGGAACCAGGAG CATTCAACAATCTCTTTAACCTGCGTTCCCTCCGCCTAAAAGGCAATCGTCTAAAGCTGGTCCCTTTGGGAGTATTCACGGGGCTGTCCA ATCTCACTAAGCTTGACATTAGTGAGAATAAGATTGTCATTTTACTAGACTACATGTTCCAAGATCTACATAACCTGAAGTCTCTAGAAG TGGGGGACAATGATTTGGTTTATATATCACACAGGGCATTCAGTGGGCTTCTTAGCTTGGAGCAGCTCACCCTGGAGAAATGCAACTTAA CAGCAGTACCAACAGAAGCCCTCTCCCACCTCCGCAGCCTCATCAGCCTGCATCTGAAGCATCTCAATATCAACAATATGCCTGTGTATG CCTTTAAAAGATTGTTCCACCTGAAACACCTAGAGATTGACTATTGGCCTTTACTGGATATGATGCCTGCCAATAGCCTCTACGGTCTCA ACCTCACATCCCTTTCAGTCACCAACACCAATCTGTCTACTGTACCCTTCCTTGCCTTTAAACACCTGGTATACCTGACTCACCTTAACC TCTCCTACAATCCCATCAGCACTATTGAAGCAGGCATGTTCTCTGACCTGATCCGCCTTCAGGAGCTTCATATAGTGGGGGCCCAGCTTC GCACCATTGAGCCTCACTCCTTCCAAGGGCTCCGCTTCCTACGCGTGCTCAATGTGTCTCAGAACCTGCTGGAAACTTTGGAAGAGAATG TCTTCTCCTCCCCTAGGGCTCTGGAGGTCTTGAGCATTAACAACAACCCTCTGGCCTGTGACTGCCGCCTTCTCTGGATCTTGCAGCGAC AGCCCACCCTGCAGTTTGGTGGCCAGCAACCTATGTGTGCTGGCCCAGACACCATCCGTGAGAGGTCTTTCAAGGATTTCCATAGCACTG CCCTTTCTTTTTACTTTACCTGCAAAAAACCCAAAATCCGTGAAAAGAAGTTGCAGCATCTGCTAGTAGATGAAGGGCAGACAGTCCAGC TAGAATGCAGTGCAGATGGAGACCCGCAGCCTGTGATTTCCTGGGTGACACCCCGAAGGCGTTTCATCACCACCAAGTCCAATGGAAGAG CCACCGTGTTGGGTGATGGCACCTTGGAAATCCGCTTTGCCCAGGATCAAGACAGCGGGATGTATGTTTGCATCGCTAGCAATGCTGCTG GGAATGATACCTTCACAGCCTCCTTAACTGTGAAAGGATTCGCTTCAGATCGTTTTCTTTATGCGAACAGGACCCCTATGTACATGACCG ACTCCAATGACACCATTTCCAATGGCACCAATGCCAATACTTTTTCCCTGGACCTTAAAACAATACTGGTGTCTACAGCTATGGGCTGCT TCACATTCCTGGGAGTGGTTTTATTTTGTTTTCTTCTCCTTTTTGTGTGGAGCCGAGGGAAAGGCAAGCACAAAAACAGCATTGACCTTG AGTATGTGCCCAGAAAAAACAATGGTGCTGTTGTGGAAGGGGAGGTAGCTGGACCCAGGAGGTTCAACATGAAAATGATTTGAAGGCCCA CCCCTCACATTACTGTCTCTTTGTCAATGTGGGTAATCAGTAAGACAGTATGGCACAGTAAATTACTAGATTAAGAGGCAGCCATGTGCA GCTGCCCCTGTATCAAAAGCAGGGTCTATGGAAGCAGGAGGACTTCCAATGGAGACTCTCCATCGAAAGGCAGGCAGGCAGGCATGTGTC AGAGCCCTTCACACAGTGGGATACTAAGTGTTTGCGTTGCAAATATTGGCGTTCTGGGGATCTCAGTAATGAACCTGAATATTTGGCTCA CACTCACGGACAATTATTCAGCATTTTCTACCACTGCAAAAAACAAAAGAAAAAATAAAAAAGAACAACCTACAGTGTAGGATTTACATA TTAAAAAGACACATTTGTCTAAAACATACTCTACAGAAAAATTTGTATCTATGATTATCATTTGTTAAAGCCTTGCATCATACCATATTG TTGGTTCAGTACCACAAAGAGATCAATATATTCTTTTCTTCCTTTTTTGAAACATATATGCTGTACATGTTTTAAAGCAATATGAATGAG AGGTTGTGCTTTTAGTTACTCACCACTATAGATCCAAGTGTGATTTCACCTTCCGTTACCTACAGATGACCCTGAGACTAGATCCCTGGA GTTATGGGCGGAGATATTTTGAGAGATGTGTTTGTCTGATGTAGGATGCCAAGAAACAGGACCCAAGGCAAAACTGCTCAACTCTGTTAA >40295_40295_2_ISCA1-LINGO2_ISCA1_chr9_88897293_ENST00000375991_LINGO2_chr9_28670278_ENST00000379992_length(amino acids)=606AA_BP= MLHTAISCWQPFLGLAVVLIFMGSTIGCPARCECSAQNKSVSCHRRRLIAIPEGIPIETKILDLSKNRLKSVNPEEFISYPLLEEIDLSD NIIANVEPGAFNNLFNLRSLRLKGNRLKLVPLGVFTGLSNLTKLDISENKIVILLDYMFQDLHNLKSLEVGDNDLVYISHRAFSGLLSLE QLTLEKCNLTAVPTEALSHLRSLISLHLKHLNINNMPVYAFKRLFHLKHLEIDYWPLLDMMPANSLYGLNLTSLSVTNTNLSTVPFLAFK HLVYLTHLNLSYNPISTIEAGMFSDLIRLQELHIVGAQLRTIEPHSFQGLRFLRVLNVSQNLLETLEENVFSSPRALEVLSINNNPLACD CRLLWILQRQPTLQFGGQQPMCAGPDTIRERSFKDFHSTALSFYFTCKKPKIREKKLQHLLVDEGQTVQLECSADGDPQPVISWVTPRRR FITTKSNGRATVLGDGTLEIRFAQDQDSGMYVCIASNAAGNDTFTASLTVKGFASDRFLYANRTPMYMTDSNDTISNGTNANTFSLDLKT -------------------------------------------------------------- >40295_40295_3_ISCA1-LINGO2_ISCA1_chr9_88897293_ENST00000452279_LINGO2_chr9_28670278_ENST00000379992_length(transcript)=3428nt_BP=384nt GGCGGTGAAGACATTCCTCCCGGGCCCTGCGCCCTGCAGCGTGGTAACCCCACTGCCGGAGACCGTGCGCAACCCAGCTGCTAGACCCCC GGCGTTGAGCGGCAAAACCCCGCCCCGAGCGGCTTGCCCCGCCCCCGGCTCGTCACTCATGCAACTCACCCAATGGTGGCGGCGGGGGGC GGGGCTAGGACTGAGGGCGCCGTGCGCCGAAGCTTGTGGCGTCAATGCGCCCGCCGTGTCCATGGAGAGAAGCTGAGGCGGCCGACCTTC GGCCCGAGGCACCGGGGCGCCGGGACGGCGAAGATGTCGGCTTCCTTAGTCCGGGCAACTGTCCGGGCTGTGAGCAAGAGGAAGCTGCAG CCCACCCGGGCAGCCCTCACCCTGTGTAGGAATTGATGAGTGCCATCAGAAAGCTGTATCATGAGCTGCCTGCACTTCTAAAGTGTCCAG TGGATTTTTAATCACATGAGCCTGGAAATAGGGTTATGAGAAGAAGCTCAGAGCAGAGCACCGAAAGTGGCCACTACCAGCATGAAGAGC CCAACAATTCAAACTGGTGAAGTGAGAAAAACAGAATGCAGCTTTCAAGGTTCGTTTCAAGCAGTTGGCTTGTGGGACTCTGAGAGATGC TGCTGCCCATGACATGCGGGAATTATCATGATCAACTACCCAGCTTGGATTTCACCCAGTGGCCAAGAGCTTTGTGTGGGAGACGGCAAG GGTTGGATTTTTCAAAAGAGTAAACCAGGATAAATCATGAGGAACCTATAACCCTTTTGGCCACATGCAAAAAAGCAAGACCCGTGACCA AGGTGTAGACTAAGAAGTGGAGTCATGCTTCACACGGCCATATCATGCTGGCAGCCATTCCTGGGTCTGGCTGTGGTGTTAATCTTCATG GGATCCACCATTGGCTGCCCCGCTCGCTGTGAGTGCTCTGCCCAGAACAAATCTGTTAGCTGTCACAGAAGGCGATTGATCGCCATCCCA GAGGGCATTCCCATCGAAACCAAAATCTTGGACCTCAGTAAAAACAGGCTAAAAAGCGTCAACCCTGAAGAATTCATATCATATCCTCTG CTGGAAGAGATAGACTTGAGTGACAACATCATTGCCAATGTGGAACCAGGAGCATTCAACAATCTCTTTAACCTGCGTTCCCTCCGCCTA AAAGGCAATCGTCTAAAGCTGGTCCCTTTGGGAGTATTCACGGGGCTGTCCAATCTCACTAAGCTTGACATTAGTGAGAATAAGATTGTC ATTTTACTAGACTACATGTTCCAAGATCTACATAACCTGAAGTCTCTAGAAGTGGGGGACAATGATTTGGTTTATATATCACACAGGGCA TTCAGTGGGCTTCTTAGCTTGGAGCAGCTCACCCTGGAGAAATGCAACTTAACAGCAGTACCAACAGAAGCCCTCTCCCACCTCCGCAGC CTCATCAGCCTGCATCTGAAGCATCTCAATATCAACAATATGCCTGTGTATGCCTTTAAAAGATTGTTCCACCTGAAACACCTAGAGATT GACTATTGGCCTTTACTGGATATGATGCCTGCCAATAGCCTCTACGGTCTCAACCTCACATCCCTTTCAGTCACCAACACCAATCTGTCT ACTGTACCCTTCCTTGCCTTTAAACACCTGGTATACCTGACTCACCTTAACCTCTCCTACAATCCCATCAGCACTATTGAAGCAGGCATG TTCTCTGACCTGATCCGCCTTCAGGAGCTTCATATAGTGGGGGCCCAGCTTCGCACCATTGAGCCTCACTCCTTCCAAGGGCTCCGCTTC CTACGCGTGCTCAATGTGTCTCAGAACCTGCTGGAAACTTTGGAAGAGAATGTCTTCTCCTCCCCTAGGGCTCTGGAGGTCTTGAGCATT AACAACAACCCTCTGGCCTGTGACTGCCGCCTTCTCTGGATCTTGCAGCGACAGCCCACCCTGCAGTTTGGTGGCCAGCAACCTATGTGT GCTGGCCCAGACACCATCCGTGAGAGGTCTTTCAAGGATTTCCATAGCACTGCCCTTTCTTTTTACTTTACCTGCAAAAAACCCAAAATC CGTGAAAAGAAGTTGCAGCATCTGCTAGTAGATGAAGGGCAGACAGTCCAGCTAGAATGCAGTGCAGATGGAGACCCGCAGCCTGTGATT TCCTGGGTGACACCCCGAAGGCGTTTCATCACCACCAAGTCCAATGGAAGAGCCACCGTGTTGGGTGATGGCACCTTGGAAATCCGCTTT GCCCAGGATCAAGACAGCGGGATGTATGTTTGCATCGCTAGCAATGCTGCTGGGAATGATACCTTCACAGCCTCCTTAACTGTGAAAGGA TTCGCTTCAGATCGTTTTCTTTATGCGAACAGGACCCCTATGTACATGACCGACTCCAATGACACCATTTCCAATGGCACCAATGCCAAT ACTTTTTCCCTGGACCTTAAAACAATACTGGTGTCTACAGCTATGGGCTGCTTCACATTCCTGGGAGTGGTTTTATTTTGTTTTCTTCTC CTTTTTGTGTGGAGCCGAGGGAAAGGCAAGCACAAAAACAGCATTGACCTTGAGTATGTGCCCAGAAAAAACAATGGTGCTGTTGTGGAA GGGGAGGTAGCTGGACCCAGGAGGTTCAACATGAAAATGATTTGAAGGCCCACCCCTCACATTACTGTCTCTTTGTCAATGTGGGTAATC AGTAAGACAGTATGGCACAGTAAATTACTAGATTAAGAGGCAGCCATGTGCAGCTGCCCCTGTATCAAAAGCAGGGTCTATGGAAGCAGG AGGACTTCCAATGGAGACTCTCCATCGAAAGGCAGGCAGGCAGGCATGTGTCAGAGCCCTTCACACAGTGGGATACTAAGTGTTTGCGTT GCAAATATTGGCGTTCTGGGGATCTCAGTAATGAACCTGAATATTTGGCTCACACTCACGGACAATTATTCAGCATTTTCTACCACTGCA AAAAACAAAAGAAAAAATAAAAAAGAACAACCTACAGTGTAGGATTTACATATTAAAAAGACACATTTGTCTAAAACATACTCTACAGAA AAATTTGTATCTATGATTATCATTTGTTAAAGCCTTGCATCATACCATATTGTTGGTTCAGTACCACAAAGAGATCAATATATTCTTTTC TTCCTTTTTTGAAACATATATGCTGTACATGTTTTAAAGCAATATGAATGAGAGGTTGTGCTTTTAGTTACTCACCACTATAGATCCAAG TGTGATTTCACCTTCCGTTACCTACAGATGACCCTGAGACTAGATCCCTGGAGTTATGGGCGGAGATATTTTGAGAGATGTGTTTGTCTG ATGTAGGATGCCAAGAAACAGGACCCAAGGCAAAACTGCTCAACTCTGTTAACTTCTGTTACTATAAATAAAGGCATGTGCCTAGTTTTG >40295_40295_3_ISCA1-LINGO2_ISCA1_chr9_88897293_ENST00000452279_LINGO2_chr9_28670278_ENST00000379992_length(amino acids)=606AA_BP= MLHTAISCWQPFLGLAVVLIFMGSTIGCPARCECSAQNKSVSCHRRRLIAIPEGIPIETKILDLSKNRLKSVNPEEFISYPLLEEIDLSD NIIANVEPGAFNNLFNLRSLRLKGNRLKLVPLGVFTGLSNLTKLDISENKIVILLDYMFQDLHNLKSLEVGDNDLVYISHRAFSGLLSLE QLTLEKCNLTAVPTEALSHLRSLISLHLKHLNINNMPVYAFKRLFHLKHLEIDYWPLLDMMPANSLYGLNLTSLSVTNTNLSTVPFLAFK HLVYLTHLNLSYNPISTIEAGMFSDLIRLQELHIVGAQLRTIEPHSFQGLRFLRVLNVSQNLLETLEENVFSSPRALEVLSINNNPLACD CRLLWILQRQPTLQFGGQQPMCAGPDTIRERSFKDFHSTALSFYFTCKKPKIREKKLQHLLVDEGQTVQLECSADGDPQPVISWVTPRRR FITTKSNGRATVLGDGTLEIRFAQDQDSGMYVCIASNAAGNDTFTASLTVKGFASDRFLYANRTPMYMTDSNDTISNGTNANTFSLDLKT -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ISCA1-LINGO2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ISCA1-LINGO2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ISCA1-LINGO2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies