
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:KIAA1432-AARD (FusionGDB2 ID:42341) |
Fusion Gene Summary for KIAA1432-AARD |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: KIAA1432-AARD | Fusion gene ID: 42341 | Hgene | Tgene | Gene symbol | KIAA1432 | AARD | Gene ID | 57589 | 441376 |
| Gene name | RIC1 homolog, RAB6A GEF complex partner 1 | alanine and arginine rich domain containing protein | |
| Synonyms | CATIFA|CIP150|KIAA1432|bA207C16.1 | C8orf85 | |
| Cytomap | 9p24.1 | 8q24.11 | |
| Type of gene | protein-coding | protein-coding | |
| Description | RAB6A-GEF complex partner protein 1RAB6A GEF complex partner 1connexin 43-interacting protein 150 kDaconnexin-43-interacting protein of 150 kDaprotein RIC1 homolog | alanine and arginine-rich domain-containing protein | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000251879, ENST00000381532, ENST00000414202, ENST00000418622, ENST00000449720, | ENST00000523536, ENST00000378279, | |
| Fusion gene scores | * DoF score | 12 X 6 X 9=648 | 3 X 2 X 3=18 |
| # samples | 14 | 4 | |
| ** MAII score | log2(14/648*10)=-2.21056698593966 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(4/18*10)=1.15200309344505 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | |
| Context | PubMed: KIAA1432 [Title/Abstract] AND AARD [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | KIAA1432(5690038)-AARD(117954796), # samples:1 KIAA1432(5690038)-AARD(117954797), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | KIAA1432 | GO:0043547 | positive regulation of GTPase activity | 23091056 |
| Fusion gene breakpoints across KIAA1432 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across AARD (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | LUAD | TCGA-75-6207-01A | KIAA1432 | chr9 | 5690038 | + | AARD | chr8 | 117954797 | + |
| ChimerDB4 | LUAD | TCGA-75-6207 | KIAA1432 | chr9 | 5690038 | + | AARD | chr8 | 117954796 | + |
Top |
Fusion Gene ORF analysis for KIAA1432-AARD |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-3UTR | ENST00000251879 | ENST00000523536 | KIAA1432 | chr9 | 5690038 | + | AARD | chr8 | 117954797 | + |
| 5CDS-3UTR | ENST00000251879 | ENST00000523536 | KIAA1432 | chr9 | 5690038 | + | AARD | chr8 | 117954796 | + |
| 5CDS-3UTR | ENST00000381532 | ENST00000523536 | KIAA1432 | chr9 | 5690038 | + | AARD | chr8 | 117954797 | + |
| 5CDS-3UTR | ENST00000381532 | ENST00000523536 | KIAA1432 | chr9 | 5690038 | + | AARD | chr8 | 117954796 | + |
| 5CDS-3UTR | ENST00000414202 | ENST00000523536 | KIAA1432 | chr9 | 5690038 | + | AARD | chr8 | 117954797 | + |
| 5CDS-3UTR | ENST00000414202 | ENST00000523536 | KIAA1432 | chr9 | 5690038 | + | AARD | chr8 | 117954796 | + |
| 5CDS-3UTR | ENST00000418622 | ENST00000523536 | KIAA1432 | chr9 | 5690038 | + | AARD | chr8 | 117954797 | + |
| 5CDS-3UTR | ENST00000418622 | ENST00000523536 | KIAA1432 | chr9 | 5690038 | + | AARD | chr8 | 117954796 | + |
| 5CDS-3UTR | ENST00000449720 | ENST00000523536 | KIAA1432 | chr9 | 5690038 | + | AARD | chr8 | 117954797 | + |
| 5CDS-3UTR | ENST00000449720 | ENST00000523536 | KIAA1432 | chr9 | 5690038 | + | AARD | chr8 | 117954796 | + |
| In-frame | ENST00000251879 | ENST00000378279 | KIAA1432 | chr9 | 5690038 | + | AARD | chr8 | 117954797 | + |
| In-frame | ENST00000251879 | ENST00000378279 | KIAA1432 | chr9 | 5690038 | + | AARD | chr8 | 117954796 | + |
| In-frame | ENST00000381532 | ENST00000378279 | KIAA1432 | chr9 | 5690038 | + | AARD | chr8 | 117954797 | + |
| In-frame | ENST00000381532 | ENST00000378279 | KIAA1432 | chr9 | 5690038 | + | AARD | chr8 | 117954796 | + |
| In-frame | ENST00000414202 | ENST00000378279 | KIAA1432 | chr9 | 5690038 | + | AARD | chr8 | 117954797 | + |
| In-frame | ENST00000414202 | ENST00000378279 | KIAA1432 | chr9 | 5690038 | + | AARD | chr8 | 117954796 | + |
| In-frame | ENST00000418622 | ENST00000378279 | KIAA1432 | chr9 | 5690038 | + | AARD | chr8 | 117954797 | + |
| In-frame | ENST00000418622 | ENST00000378279 | KIAA1432 | chr9 | 5690038 | + | AARD | chr8 | 117954796 | + |
| In-frame | ENST00000449720 | ENST00000378279 | KIAA1432 | chr9 | 5690038 | + | AARD | chr8 | 117954797 | + |
| In-frame | ENST00000449720 | ENST00000378279 | KIAA1432 | chr9 | 5690038 | + | AARD | chr8 | 117954796 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000251879 | KIAA1432 | chr9 | 5690038 | + | ENST00000378279 | AARD | chr8 | 117954796 | + | 2547 | 617 | 48 | 668 | 206 |
| ENST00000414202 | KIAA1432 | chr9 | 5690038 | + | ENST00000378279 | AARD | chr8 | 117954796 | + | 2453 | 523 | 143 | 574 | 143 |
| ENST00000381532 | KIAA1432 | chr9 | 5690038 | + | ENST00000378279 | AARD | chr8 | 117954796 | + | 2245 | 315 | 13 | 366 | 117 |
| ENST00000418622 | KIAA1432 | chr9 | 5690038 | + | ENST00000378279 | AARD | chr8 | 117954796 | + | 2118 | 188 | 826 | 521 | 101 |
| ENST00000449720 | KIAA1432 | chr9 | 5690038 | + | ENST00000378279 | AARD | chr8 | 117954796 | + | 2047 | 117 | 755 | 450 | 101 |
| ENST00000251879 | KIAA1432 | chr9 | 5690038 | + | ENST00000378279 | AARD | chr8 | 117954797 | + | 2547 | 617 | 48 | 668 | 206 |
| ENST00000414202 | KIAA1432 | chr9 | 5690038 | + | ENST00000378279 | AARD | chr8 | 117954797 | + | 2453 | 523 | 143 | 574 | 143 |
| ENST00000381532 | KIAA1432 | chr9 | 5690038 | + | ENST00000378279 | AARD | chr8 | 117954797 | + | 2245 | 315 | 13 | 366 | 117 |
| ENST00000418622 | KIAA1432 | chr9 | 5690038 | + | ENST00000378279 | AARD | chr8 | 117954797 | + | 2118 | 188 | 826 | 521 | 101 |
| ENST00000449720 | KIAA1432 | chr9 | 5690038 | + | ENST00000378279 | AARD | chr8 | 117954797 | + | 2047 | 117 | 755 | 450 | 101 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000251879 | ENST00000378279 | KIAA1432 | chr9 | 5690038 | + | AARD | chr8 | 117954796 | + | 0.4924524 | 0.50754756 |
| ENST00000414202 | ENST00000378279 | KIAA1432 | chr9 | 5690038 | + | AARD | chr8 | 117954796 | + | 0.31286174 | 0.6871382 |
| ENST00000381532 | ENST00000378279 | KIAA1432 | chr9 | 5690038 | + | AARD | chr8 | 117954796 | + | 0.72820055 | 0.27179945 |
| ENST00000418622 | ENST00000378279 | KIAA1432 | chr9 | 5690038 | + | AARD | chr8 | 117954796 | + | 0.92261463 | 0.0773853 |
| ENST00000449720 | ENST00000378279 | KIAA1432 | chr9 | 5690038 | + | AARD | chr8 | 117954796 | + | 0.84971935 | 0.15028067 |
| ENST00000251879 | ENST00000378279 | KIAA1432 | chr9 | 5690038 | + | AARD | chr8 | 117954797 | + | 0.4924524 | 0.50754756 |
| ENST00000414202 | ENST00000378279 | KIAA1432 | chr9 | 5690038 | + | AARD | chr8 | 117954797 | + | 0.31286174 | 0.6871382 |
| ENST00000381532 | ENST00000378279 | KIAA1432 | chr9 | 5690038 | + | AARD | chr8 | 117954797 | + | 0.72820055 | 0.27179945 |
| ENST00000418622 | ENST00000378279 | KIAA1432 | chr9 | 5690038 | + | AARD | chr8 | 117954797 | + | 0.92261463 | 0.0773853 |
| ENST00000449720 | ENST00000378279 | KIAA1432 | chr9 | 5690038 | + | AARD | chr8 | 117954797 | + | 0.84971935 | 0.15028067 |
Top |
Fusion Genomic Features for KIAA1432-AARD |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| KIAA1432 | chr9 | 5690038 | + | AARD | chr8 | 117954796 | + | 2.86E-06 | 0.99999714 |
| KIAA1432 | chr9 | 5690038 | + | AARD | chr8 | 117954796 | + | 2.86E-06 | 0.99999714 |
| KIAA1432 | chr9 | 5690038 | + | AARD | chr8 | 117954796 | + | 2.86E-06 | 0.99999714 |
| KIAA1432 | chr9 | 5690038 | + | AARD | chr8 | 117954796 | + | 2.86E-06 | 0.99999714 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
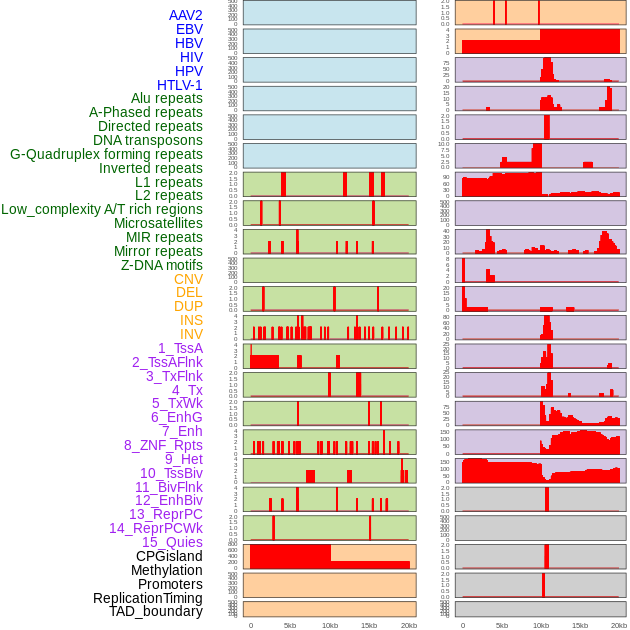 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
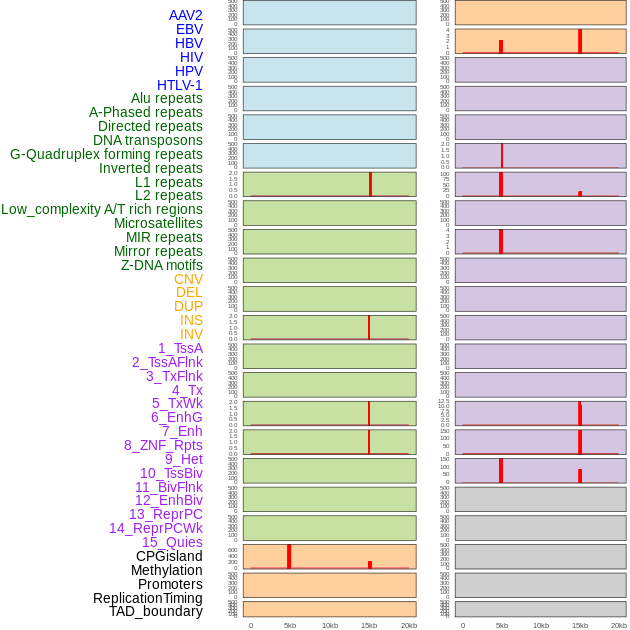 |
Top |
Fusion Protein Features for KIAA1432-AARD |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr9:5690038/chr8:117954796) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | KIAA1432 | chr9:5690038 | chr8:117954796 | ENST00000251879 | + | 3 | 22 | 64_103 | 110 | 1166.0 | Repeat | Note=WD 1 |
| Hgene | KIAA1432 | chr9:5690038 | chr8:117954796 | ENST00000414202 | + | 3 | 26 | 64_103 | 110 | 1424.0 | Repeat | Note=WD 1 |
| Hgene | KIAA1432 | chr9:5690038 | chr8:117954797 | ENST00000251879 | + | 3 | 22 | 64_103 | 110 | 1166.0 | Repeat | Note=WD 1 |
| Hgene | KIAA1432 | chr9:5690038 | chr8:117954797 | ENST00000414202 | + | 3 | 26 | 64_103 | 110 | 1424.0 | Repeat | Note=WD 1 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | KIAA1432 | chr9:5690038 | chr8:117954796 | ENST00000251879 | + | 3 | 22 | 304_343 | 110 | 1166.0 | Repeat | Note=WD 2 |
| Hgene | KIAA1432 | chr9:5690038 | chr8:117954796 | ENST00000381532 | + | 3 | 22 | 304_343 | 31 | 1087.0 | Repeat | Note=WD 2 |
| Hgene | KIAA1432 | chr9:5690038 | chr8:117954796 | ENST00000381532 | + | 3 | 22 | 64_103 | 31 | 1087.0 | Repeat | Note=WD 1 |
| Hgene | KIAA1432 | chr9:5690038 | chr8:117954796 | ENST00000414202 | + | 3 | 26 | 304_343 | 110 | 1424.0 | Repeat | Note=WD 2 |
| Hgene | KIAA1432 | chr9:5690038 | chr8:117954796 | ENST00000418622 | + | 2 | 25 | 304_343 | 31 | 1345.0 | Repeat | Note=WD 2 |
| Hgene | KIAA1432 | chr9:5690038 | chr8:117954796 | ENST00000418622 | + | 2 | 25 | 64_103 | 31 | 1345.0 | Repeat | Note=WD 1 |
| Hgene | KIAA1432 | chr9:5690038 | chr8:117954796 | ENST00000449720 | + | 2 | 24 | 304_343 | 31 | 1308.0 | Repeat | Note=WD 2 |
| Hgene | KIAA1432 | chr9:5690038 | chr8:117954796 | ENST00000449720 | + | 2 | 24 | 64_103 | 31 | 1308.0 | Repeat | Note=WD 1 |
| Hgene | KIAA1432 | chr9:5690038 | chr8:117954797 | ENST00000251879 | + | 3 | 22 | 304_343 | 110 | 1166.0 | Repeat | Note=WD 2 |
| Hgene | KIAA1432 | chr9:5690038 | chr8:117954797 | ENST00000381532 | + | 3 | 22 | 304_343 | 31 | 1087.0 | Repeat | Note=WD 2 |
| Hgene | KIAA1432 | chr9:5690038 | chr8:117954797 | ENST00000381532 | + | 3 | 22 | 64_103 | 31 | 1087.0 | Repeat | Note=WD 1 |
| Hgene | KIAA1432 | chr9:5690038 | chr8:117954797 | ENST00000414202 | + | 3 | 26 | 304_343 | 110 | 1424.0 | Repeat | Note=WD 2 |
| Hgene | KIAA1432 | chr9:5690038 | chr8:117954797 | ENST00000418622 | + | 2 | 25 | 304_343 | 31 | 1345.0 | Repeat | Note=WD 2 |
| Hgene | KIAA1432 | chr9:5690038 | chr8:117954797 | ENST00000418622 | + | 2 | 25 | 64_103 | 31 | 1345.0 | Repeat | Note=WD 1 |
| Hgene | KIAA1432 | chr9:5690038 | chr8:117954797 | ENST00000449720 | + | 2 | 24 | 304_343 | 31 | 1308.0 | Repeat | Note=WD 2 |
| Hgene | KIAA1432 | chr9:5690038 | chr8:117954797 | ENST00000449720 | + | 2 | 24 | 64_103 | 31 | 1308.0 | Repeat | Note=WD 1 |
| Tgene | AARD | chr9:5690038 | chr8:117954796 | ENST00000378279 | 0 | 2 | 60_105 | 108 | 156.0 | Compositional bias | Note=Ala/Arg-rich | |
| Tgene | AARD | chr9:5690038 | chr8:117954797 | ENST00000378279 | 0 | 2 | 60_105 | 108 | 156.0 | Compositional bias | Note=Ala/Arg-rich |
Top |
Fusion Gene Sequence for KIAA1432-AARD |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >42341_42341_1_KIAA1432-AARD_KIAA1432_chr9_5690038_ENST00000251879_AARD_chr8_117954796_ENST00000378279_length(transcript)=2547nt_BP=617nt GAGGAAGGGGCGGGGTCGGGGCGGGCCTCCGCGCTCCTCCCGCCCTCTCTGTGTCCCTACTCTCCCTCCCCTTCCCTCCCCCACACTCGG CCCCGTCAGCTTGGGGGTGCCTTCGTCGCGCAGCCTTGCGTCGGCCCGGCCCGGCCAGGCCAGCGGGCAGATGCCCCGAGCTGCCGCCGC CGCCGCCGCCGACTCGGCCGGTGGCGGTGTGGGAGGTGGGCGACCAGCCCGGGGCCGCTGAGTGTGACGGACGCAACTGGGGGCGCCGGG GGCTCCGCACGGACCATGTATTTTCTGAGCGGCTGGCCCAAGAGGCTGCTGTGCCCTCTGGGGAGCCCGGCCGAGGCGCCTTTCCACGTT CAGTCCGACCCGCAGAGGGCTTTCTTCGCCGTGCTGGCCGCGGCCCGCCTCAGCATCTGGTACAGCCGACCTAGTGTGTTAATTGTAACC TACAAGGAGCCTGCAAAATCATCTACTCAGTTTGGATCCTACAAGCAAGCTGAATGGAGGCCAGATAGTACCATGATAGCTGTATCAACG GCAAATGGATACATCTTGTTTTTTCATATTACATCTACAAGAGGGGACAAGTACCTTTATGAACCAGTGTATCCCAAGTGGAAATGCATT TCCAAAACCACCAGCTGGCTAGAACTTTACTGGACCTAAACATGAAAGTGCAGCAATTGAAAAAGGAGTATGAACTGGAAATTACATCAG ACTCCCAAAGCCCAAAAGATGATGCTGCGAATCCGGAATAAAGAAATGCACACGCAAGGGCTGGGCGCGGTGGCTCACGCCTGTAATCCC AGCACTTTGGGAGGCCGAGGCGGGCGGATCAAGACGTCAGGAGATTGAGACCATCCTGGCTAACACTGTGAAACCCTGCCTCTACTAAAA ATACAAAAAATTAGCCAGACGTGGTGGCAGGCACCTGTAGTCCCTGCTACTCAGGAGTCTGAGGCAGGAGAATGGCGTGAACCCAGGAGA CAGAGCTTGCAGTGAGCCGAAATCCTGCCACTGCACTCCAGCCTGGGTGACAGAGCAAGACTCCATCTCAAAAAAAAAAAAAAAAAAAAA AGCACACGCGAAGCTCTGGATCCTAAAACTAACGCATACAACCCTGAAACAATTCTGATGAACACATTATGCTTTGCATAAGTTTTGAGG GGCAATTTATAGACCCAAAACAAATGACAGGGGAAGGTGACAGAAAAACATCTAAGAGAGGGGAGAGAAAAATGATGTATTACCAAGTTT TAAAGTTATTTATTTGTTATTTTTACTGGGACATAGAAGTAAAATATAACTATAGATAAATCTCTCTCTGTCTCTCTCACTCAAAGAATG CTTTAATGCCAACTTTCGGTATTCAACCTTGTGTCACCTGACCTTTCTGGCATTGCCTGAGCTTTCAGAGTTTGTGCTTGTTTTGTTTTA CTTGATTATTCTCAGTTTGTCTGTCCAGCAGCCTGCCCTGCTTCTTGTGGAGAATTGTTTCTACTTGGATTCTAACCATGCCCTTTAGGT GGTCTGTGACTAAGGGTATTCCATCTTCCTGGATATAGTCATGCAGCTCAAGGCAGGCAGATGGGTTTGTCCTTAGGATTTTTGAATGGG CACTAAAAGAGTAGATGACTATTTCTGCCAGTAGAAGCTGTGGATCAGGGGCTTGGAAGCTGCTGGTGGTCACCATGTGAGAAAGCCCAC ACCCTAATGGAGGTGACTGAAACGGAACCACTAAAAGCACAAAAGGGGAGGGAGGGAGGGAGGGTGCTTCGCTTCCTTGTTCCTGGGGTC AAGCTGTATAAGACTCCAGGCCTTGCTCTTGTTTATGTACATGAAATATTCTGATATCCTTCTCATAAAATCTCTTTTTGCCTAAGTAAA TTCAAGCTGGAGTTTCATGACTTGTATCTAGTGTTCATAACTAATACAGTTGTTCAGTTTTAGGAGTTAAAATGGTTCTTACTGTTGAAT TGGACTATCTAACTGTACCCGAAAAGTGCTGTCTTTTTAATGCAAACAGTAAAGTTAATAAAAAATAGTTGCAGATCTAAGTGATATTTA TAATGGTTATTGTCTGCAAAATACAAATTAATTTATAACAAGCTATGTAATTTTAATATTTAATAAACTATAAAAATCAGTTCTTGAAGA CAAAGGAGAACAGAAGAGACACAGTCTTTCTCTTGTTAAAAGAAATACAAGGACAAGCATGGTGGATCACGCTTGTAATTCCAGCACTTT GGGAGGCTGAGGTGGGCAGATTGTTTGAGCTCAGGAGTTTGAGACCAGCCTGGTCAACATGGCAAAACCCCATCTCTACTAAAAATACAA AAATTAGCCAGGCGTGGTGGTGCTCGCCTATAGTACCAGCTACTCAGGAGGCTGAGGCATAAGAATCACTTGAACCTGGGAGATGGAGGT TGCAGTGAGCCGAGATCATGCCCCTGCACTCCAGCCTGGGTGACAGAGGGGGACTTGGCCTCGAAAAAATAAATAAATAATAAAAATAAA >42341_42341_1_KIAA1432-AARD_KIAA1432_chr9_5690038_ENST00000251879_AARD_chr8_117954796_ENST00000378279_length(amino acids)=206AA_BP=190 MCPYSPSPSLPHTRPRQLGGAFVAQPCVGPARPGQRADAPSCRRRRRRLGRWRCGRWATSPGPLSVTDATGGAGGSARTMYFLSGWPKRL LCPLGSPAEAPFHVQSDPQRAFFAVLAAARLSIWYSRPSVLIVTYKEPAKSSTQFGSYKQAEWRPDSTMIAVSTANGYILFFHITSTRGD -------------------------------------------------------------- >42341_42341_2_KIAA1432-AARD_KIAA1432_chr9_5690038_ENST00000251879_AARD_chr8_117954797_ENST00000378279_length(transcript)=2547nt_BP=617nt GAGGAAGGGGCGGGGTCGGGGCGGGCCTCCGCGCTCCTCCCGCCCTCTCTGTGTCCCTACTCTCCCTCCCCTTCCCTCCCCCACACTCGG CCCCGTCAGCTTGGGGGTGCCTTCGTCGCGCAGCCTTGCGTCGGCCCGGCCCGGCCAGGCCAGCGGGCAGATGCCCCGAGCTGCCGCCGC CGCCGCCGCCGACTCGGCCGGTGGCGGTGTGGGAGGTGGGCGACCAGCCCGGGGCCGCTGAGTGTGACGGACGCAACTGGGGGCGCCGGG GGCTCCGCACGGACCATGTATTTTCTGAGCGGCTGGCCCAAGAGGCTGCTGTGCCCTCTGGGGAGCCCGGCCGAGGCGCCTTTCCACGTT CAGTCCGACCCGCAGAGGGCTTTCTTCGCCGTGCTGGCCGCGGCCCGCCTCAGCATCTGGTACAGCCGACCTAGTGTGTTAATTGTAACC TACAAGGAGCCTGCAAAATCATCTACTCAGTTTGGATCCTACAAGCAAGCTGAATGGAGGCCAGATAGTACCATGATAGCTGTATCAACG GCAAATGGATACATCTTGTTTTTTCATATTACATCTACAAGAGGGGACAAGTACCTTTATGAACCAGTGTATCCCAAGTGGAAATGCATT TCCAAAACCACCAGCTGGCTAGAACTTTACTGGACCTAAACATGAAAGTGCAGCAATTGAAAAAGGAGTATGAACTGGAAATTACATCAG ACTCCCAAAGCCCAAAAGATGATGCTGCGAATCCGGAATAAAGAAATGCACACGCAAGGGCTGGGCGCGGTGGCTCACGCCTGTAATCCC AGCACTTTGGGAGGCCGAGGCGGGCGGATCAAGACGTCAGGAGATTGAGACCATCCTGGCTAACACTGTGAAACCCTGCCTCTACTAAAA ATACAAAAAATTAGCCAGACGTGGTGGCAGGCACCTGTAGTCCCTGCTACTCAGGAGTCTGAGGCAGGAGAATGGCGTGAACCCAGGAGA CAGAGCTTGCAGTGAGCCGAAATCCTGCCACTGCACTCCAGCCTGGGTGACAGAGCAAGACTCCATCTCAAAAAAAAAAAAAAAAAAAAA AGCACACGCGAAGCTCTGGATCCTAAAACTAACGCATACAACCCTGAAACAATTCTGATGAACACATTATGCTTTGCATAAGTTTTGAGG GGCAATTTATAGACCCAAAACAAATGACAGGGGAAGGTGACAGAAAAACATCTAAGAGAGGGGAGAGAAAAATGATGTATTACCAAGTTT TAAAGTTATTTATTTGTTATTTTTACTGGGACATAGAAGTAAAATATAACTATAGATAAATCTCTCTCTGTCTCTCTCACTCAAAGAATG CTTTAATGCCAACTTTCGGTATTCAACCTTGTGTCACCTGACCTTTCTGGCATTGCCTGAGCTTTCAGAGTTTGTGCTTGTTTTGTTTTA CTTGATTATTCTCAGTTTGTCTGTCCAGCAGCCTGCCCTGCTTCTTGTGGAGAATTGTTTCTACTTGGATTCTAACCATGCCCTTTAGGT GGTCTGTGACTAAGGGTATTCCATCTTCCTGGATATAGTCATGCAGCTCAAGGCAGGCAGATGGGTTTGTCCTTAGGATTTTTGAATGGG CACTAAAAGAGTAGATGACTATTTCTGCCAGTAGAAGCTGTGGATCAGGGGCTTGGAAGCTGCTGGTGGTCACCATGTGAGAAAGCCCAC ACCCTAATGGAGGTGACTGAAACGGAACCACTAAAAGCACAAAAGGGGAGGGAGGGAGGGAGGGTGCTTCGCTTCCTTGTTCCTGGGGTC AAGCTGTATAAGACTCCAGGCCTTGCTCTTGTTTATGTACATGAAATATTCTGATATCCTTCTCATAAAATCTCTTTTTGCCTAAGTAAA TTCAAGCTGGAGTTTCATGACTTGTATCTAGTGTTCATAACTAATACAGTTGTTCAGTTTTAGGAGTTAAAATGGTTCTTACTGTTGAAT TGGACTATCTAACTGTACCCGAAAAGTGCTGTCTTTTTAATGCAAACAGTAAAGTTAATAAAAAATAGTTGCAGATCTAAGTGATATTTA TAATGGTTATTGTCTGCAAAATACAAATTAATTTATAACAAGCTATGTAATTTTAATATTTAATAAACTATAAAAATCAGTTCTTGAAGA CAAAGGAGAACAGAAGAGACACAGTCTTTCTCTTGTTAAAAGAAATACAAGGACAAGCATGGTGGATCACGCTTGTAATTCCAGCACTTT GGGAGGCTGAGGTGGGCAGATTGTTTGAGCTCAGGAGTTTGAGACCAGCCTGGTCAACATGGCAAAACCCCATCTCTACTAAAAATACAA AAATTAGCCAGGCGTGGTGGTGCTCGCCTATAGTACCAGCTACTCAGGAGGCTGAGGCATAAGAATCACTTGAACCTGGGAGATGGAGGT TGCAGTGAGCCGAGATCATGCCCCTGCACTCCAGCCTGGGTGACAGAGGGGGACTTGGCCTCGAAAAAATAAATAAATAATAAAAATAAA >42341_42341_2_KIAA1432-AARD_KIAA1432_chr9_5690038_ENST00000251879_AARD_chr8_117954797_ENST00000378279_length(amino acids)=206AA_BP=190 MCPYSPSPSLPHTRPRQLGGAFVAQPCVGPARPGQRADAPSCRRRRRRLGRWRCGRWATSPGPLSVTDATGGAGGSARTMYFLSGWPKRL LCPLGSPAEAPFHVQSDPQRAFFAVLAAARLSIWYSRPSVLIVTYKEPAKSSTQFGSYKQAEWRPDSTMIAVSTANGYILFFHITSTRGD -------------------------------------------------------------- >42341_42341_3_KIAA1432-AARD_KIAA1432_chr9_5690038_ENST00000381532_AARD_chr8_117954796_ENST00000378279_length(transcript)=2245nt_BP=315nt CTGGCCCAAGAGGCTGCTGTGCCCTCTGGGGAGCCCGGCCGAGGCGCCTTTCCACGTTCAGTCCGACCCGCAGAGGGCTTTCTTCGCCGT GCTGGCCGCGGCCCGCCTCAGCATCTGGTACAGCCGACCTAGTGTGTTAATTGTAACCTACAAGGAGCCTGCAAAATCATCTACTCAGTT TGGATCCTACAAGCAAGCTGAATGGAGGCCAGATAGTACCATGATAGCTGTATCAACGGCAAATGGATACATCTTGTTTTTTCATATTAC ATCTACAAGAGGGGACAAGTACCTTTATGAACCAGTGTATCCCAAGTGGAAATGCATTTCCAAAACCACCAGCTGGCTAGAACTTTACTG GACCTAAACATGAAAGTGCAGCAATTGAAAAAGGAGTATGAACTGGAAATTACATCAGACTCCCAAAGCCCAAAAGATGATGCTGCGAAT CCGGAATAAAGAAATGCACACGCAAGGGCTGGGCGCGGTGGCTCACGCCTGTAATCCCAGCACTTTGGGAGGCCGAGGCGGGCGGATCAA GACGTCAGGAGATTGAGACCATCCTGGCTAACACTGTGAAACCCTGCCTCTACTAAAAATACAAAAAATTAGCCAGACGTGGTGGCAGGC ACCTGTAGTCCCTGCTACTCAGGAGTCTGAGGCAGGAGAATGGCGTGAACCCAGGAGACAGAGCTTGCAGTGAGCCGAAATCCTGCCACT GCACTCCAGCCTGGGTGACAGAGCAAGACTCCATCTCAAAAAAAAAAAAAAAAAAAAAAGCACACGCGAAGCTCTGGATCCTAAAACTAA CGCATACAACCCTGAAACAATTCTGATGAACACATTATGCTTTGCATAAGTTTTGAGGGGCAATTTATAGACCCAAAACAAATGACAGGG GAAGGTGACAGAAAAACATCTAAGAGAGGGGAGAGAAAAATGATGTATTACCAAGTTTTAAAGTTATTTATTTGTTATTTTTACTGGGAC ATAGAAGTAAAATATAACTATAGATAAATCTCTCTCTGTCTCTCTCACTCAAAGAATGCTTTAATGCCAACTTTCGGTATTCAACCTTGT GTCACCTGACCTTTCTGGCATTGCCTGAGCTTTCAGAGTTTGTGCTTGTTTTGTTTTACTTGATTATTCTCAGTTTGTCTGTCCAGCAGC CTGCCCTGCTTCTTGTGGAGAATTGTTTCTACTTGGATTCTAACCATGCCCTTTAGGTGGTCTGTGACTAAGGGTATTCCATCTTCCTGG ATATAGTCATGCAGCTCAAGGCAGGCAGATGGGTTTGTCCTTAGGATTTTTGAATGGGCACTAAAAGAGTAGATGACTATTTCTGCCAGT AGAAGCTGTGGATCAGGGGCTTGGAAGCTGCTGGTGGTCACCATGTGAGAAAGCCCACACCCTAATGGAGGTGACTGAAACGGAACCACT AAAAGCACAAAAGGGGAGGGAGGGAGGGAGGGTGCTTCGCTTCCTTGTTCCTGGGGTCAAGCTGTATAAGACTCCAGGCCTTGCTCTTGT TTATGTACATGAAATATTCTGATATCCTTCTCATAAAATCTCTTTTTGCCTAAGTAAATTCAAGCTGGAGTTTCATGACTTGTATCTAGT GTTCATAACTAATACAGTTGTTCAGTTTTAGGAGTTAAAATGGTTCTTACTGTTGAATTGGACTATCTAACTGTACCCGAAAAGTGCTGT CTTTTTAATGCAAACAGTAAAGTTAATAAAAAATAGTTGCAGATCTAAGTGATATTTATAATGGTTATTGTCTGCAAAATACAAATTAAT TTATAACAAGCTATGTAATTTTAATATTTAATAAACTATAAAAATCAGTTCTTGAAGACAAAGGAGAACAGAAGAGACACAGTCTTTCTC TTGTTAAAAGAAATACAAGGACAAGCATGGTGGATCACGCTTGTAATTCCAGCACTTTGGGAGGCTGAGGTGGGCAGATTGTTTGAGCTC AGGAGTTTGAGACCAGCCTGGTCAACATGGCAAAACCCCATCTCTACTAAAAATACAAAAATTAGCCAGGCGTGGTGGTGCTCGCCTATA GTACCAGCTACTCAGGAGGCTGAGGCATAAGAATCACTTGAACCTGGGAGATGGAGGTTGCAGTGAGCCGAGATCATGCCCCTGCACTCC >42341_42341_3_KIAA1432-AARD_KIAA1432_chr9_5690038_ENST00000381532_AARD_chr8_117954796_ENST00000378279_length(amino acids)=117AA_BP=101 MLCPLGSPAEAPFHVQSDPQRAFFAVLAAARLSIWYSRPSVLIVTYKEPAKSSTQFGSYKQAEWRPDSTMIAVSTANGYILFFHITSTRG -------------------------------------------------------------- >42341_42341_4_KIAA1432-AARD_KIAA1432_chr9_5690038_ENST00000381532_AARD_chr8_117954797_ENST00000378279_length(transcript)=2245nt_BP=315nt CTGGCCCAAGAGGCTGCTGTGCCCTCTGGGGAGCCCGGCCGAGGCGCCTTTCCACGTTCAGTCCGACCCGCAGAGGGCTTTCTTCGCCGT GCTGGCCGCGGCCCGCCTCAGCATCTGGTACAGCCGACCTAGTGTGTTAATTGTAACCTACAAGGAGCCTGCAAAATCATCTACTCAGTT TGGATCCTACAAGCAAGCTGAATGGAGGCCAGATAGTACCATGATAGCTGTATCAACGGCAAATGGATACATCTTGTTTTTTCATATTAC ATCTACAAGAGGGGACAAGTACCTTTATGAACCAGTGTATCCCAAGTGGAAATGCATTTCCAAAACCACCAGCTGGCTAGAACTTTACTG GACCTAAACATGAAAGTGCAGCAATTGAAAAAGGAGTATGAACTGGAAATTACATCAGACTCCCAAAGCCCAAAAGATGATGCTGCGAAT CCGGAATAAAGAAATGCACACGCAAGGGCTGGGCGCGGTGGCTCACGCCTGTAATCCCAGCACTTTGGGAGGCCGAGGCGGGCGGATCAA GACGTCAGGAGATTGAGACCATCCTGGCTAACACTGTGAAACCCTGCCTCTACTAAAAATACAAAAAATTAGCCAGACGTGGTGGCAGGC ACCTGTAGTCCCTGCTACTCAGGAGTCTGAGGCAGGAGAATGGCGTGAACCCAGGAGACAGAGCTTGCAGTGAGCCGAAATCCTGCCACT GCACTCCAGCCTGGGTGACAGAGCAAGACTCCATCTCAAAAAAAAAAAAAAAAAAAAAAGCACACGCGAAGCTCTGGATCCTAAAACTAA CGCATACAACCCTGAAACAATTCTGATGAACACATTATGCTTTGCATAAGTTTTGAGGGGCAATTTATAGACCCAAAACAAATGACAGGG GAAGGTGACAGAAAAACATCTAAGAGAGGGGAGAGAAAAATGATGTATTACCAAGTTTTAAAGTTATTTATTTGTTATTTTTACTGGGAC ATAGAAGTAAAATATAACTATAGATAAATCTCTCTCTGTCTCTCTCACTCAAAGAATGCTTTAATGCCAACTTTCGGTATTCAACCTTGT GTCACCTGACCTTTCTGGCATTGCCTGAGCTTTCAGAGTTTGTGCTTGTTTTGTTTTACTTGATTATTCTCAGTTTGTCTGTCCAGCAGC CTGCCCTGCTTCTTGTGGAGAATTGTTTCTACTTGGATTCTAACCATGCCCTTTAGGTGGTCTGTGACTAAGGGTATTCCATCTTCCTGG ATATAGTCATGCAGCTCAAGGCAGGCAGATGGGTTTGTCCTTAGGATTTTTGAATGGGCACTAAAAGAGTAGATGACTATTTCTGCCAGT AGAAGCTGTGGATCAGGGGCTTGGAAGCTGCTGGTGGTCACCATGTGAGAAAGCCCACACCCTAATGGAGGTGACTGAAACGGAACCACT AAAAGCACAAAAGGGGAGGGAGGGAGGGAGGGTGCTTCGCTTCCTTGTTCCTGGGGTCAAGCTGTATAAGACTCCAGGCCTTGCTCTTGT TTATGTACATGAAATATTCTGATATCCTTCTCATAAAATCTCTTTTTGCCTAAGTAAATTCAAGCTGGAGTTTCATGACTTGTATCTAGT GTTCATAACTAATACAGTTGTTCAGTTTTAGGAGTTAAAATGGTTCTTACTGTTGAATTGGACTATCTAACTGTACCCGAAAAGTGCTGT CTTTTTAATGCAAACAGTAAAGTTAATAAAAAATAGTTGCAGATCTAAGTGATATTTATAATGGTTATTGTCTGCAAAATACAAATTAAT TTATAACAAGCTATGTAATTTTAATATTTAATAAACTATAAAAATCAGTTCTTGAAGACAAAGGAGAACAGAAGAGACACAGTCTTTCTC TTGTTAAAAGAAATACAAGGACAAGCATGGTGGATCACGCTTGTAATTCCAGCACTTTGGGAGGCTGAGGTGGGCAGATTGTTTGAGCTC AGGAGTTTGAGACCAGCCTGGTCAACATGGCAAAACCCCATCTCTACTAAAAATACAAAAATTAGCCAGGCGTGGTGGTGCTCGCCTATA GTACCAGCTACTCAGGAGGCTGAGGCATAAGAATCACTTGAACCTGGGAGATGGAGGTTGCAGTGAGCCGAGATCATGCCCCTGCACTCC >42341_42341_4_KIAA1432-AARD_KIAA1432_chr9_5690038_ENST00000381532_AARD_chr8_117954797_ENST00000378279_length(amino acids)=117AA_BP=101 MLCPLGSPAEAPFHVQSDPQRAFFAVLAAARLSIWYSRPSVLIVTYKEPAKSSTQFGSYKQAEWRPDSTMIAVSTANGYILFFHITSTRG -------------------------------------------------------------- >42341_42341_5_KIAA1432-AARD_KIAA1432_chr9_5690038_ENST00000414202_AARD_chr8_117954796_ENST00000378279_length(transcript)=2453nt_BP=523nt GTCAGCTTGGGGGTGCCTTCGTCGCGCAGCCTTGCGTCGGCCCGGCCCGGCCAGGCCAGCGGGCAGATGCCCCGAGCTGCCGCCGCCGCC GCCGCCGACTCGGCCGGTGGCGGTGTGGGAGGTGGGCGACCAGCCCGGGGCCGCTGAGTGTGACGGACGCAACTGGGGGCGCCGGGGGCT CCGCACGGACCATGTATTTTCTGAGCGGCTGGCCCAAGAGGCTGCTGTGCCCTCTGGGGAGCCCGGCCGAGGCGCCTTTCCACGTTCAGT CCGACCCGCAGAGGGCTTTCTTCGCCGTGCTGGCCGCGGCCCGCCTCAGCATCTGGTACAGCCGACCTAGTGTGTTAATTGTAACCTACA AGGAGCCTGCAAAATCATCTACTCAGTTTGGATCCTACAAGCAAGCTGAATGGAGGCCAGATAGTACCATGATAGCTGTATCAACGGCAA ATGGATACATCTTGTTTTTTCATATTACATCTACAAGAGGGGACAAGTACCTTTATGAACCAGTGTATCCCAAGTGGAAATGCATTTCCA AAACCACCAGCTGGCTAGAACTTTACTGGACCTAAACATGAAAGTGCAGCAATTGAAAAAGGAGTATGAACTGGAAATTACATCAGACTC CCAAAGCCCAAAAGATGATGCTGCGAATCCGGAATAAAGAAATGCACACGCAAGGGCTGGGCGCGGTGGCTCACGCCTGTAATCCCAGCA CTTTGGGAGGCCGAGGCGGGCGGATCAAGACGTCAGGAGATTGAGACCATCCTGGCTAACACTGTGAAACCCTGCCTCTACTAAAAATAC AAAAAATTAGCCAGACGTGGTGGCAGGCACCTGTAGTCCCTGCTACTCAGGAGTCTGAGGCAGGAGAATGGCGTGAACCCAGGAGACAGA GCTTGCAGTGAGCCGAAATCCTGCCACTGCACTCCAGCCTGGGTGACAGAGCAAGACTCCATCTCAAAAAAAAAAAAAAAAAAAAAAGCA CACGCGAAGCTCTGGATCCTAAAACTAACGCATACAACCCTGAAACAATTCTGATGAACACATTATGCTTTGCATAAGTTTTGAGGGGCA ATTTATAGACCCAAAACAAATGACAGGGGAAGGTGACAGAAAAACATCTAAGAGAGGGGAGAGAAAAATGATGTATTACCAAGTTTTAAA GTTATTTATTTGTTATTTTTACTGGGACATAGAAGTAAAATATAACTATAGATAAATCTCTCTCTGTCTCTCTCACTCAAAGAATGCTTT AATGCCAACTTTCGGTATTCAACCTTGTGTCACCTGACCTTTCTGGCATTGCCTGAGCTTTCAGAGTTTGTGCTTGTTTTGTTTTACTTG ATTATTCTCAGTTTGTCTGTCCAGCAGCCTGCCCTGCTTCTTGTGGAGAATTGTTTCTACTTGGATTCTAACCATGCCCTTTAGGTGGTC TGTGACTAAGGGTATTCCATCTTCCTGGATATAGTCATGCAGCTCAAGGCAGGCAGATGGGTTTGTCCTTAGGATTTTTGAATGGGCACT AAAAGAGTAGATGACTATTTCTGCCAGTAGAAGCTGTGGATCAGGGGCTTGGAAGCTGCTGGTGGTCACCATGTGAGAAAGCCCACACCC TAATGGAGGTGACTGAAACGGAACCACTAAAAGCACAAAAGGGGAGGGAGGGAGGGAGGGTGCTTCGCTTCCTTGTTCCTGGGGTCAAGC TGTATAAGACTCCAGGCCTTGCTCTTGTTTATGTACATGAAATATTCTGATATCCTTCTCATAAAATCTCTTTTTGCCTAAGTAAATTCA AGCTGGAGTTTCATGACTTGTATCTAGTGTTCATAACTAATACAGTTGTTCAGTTTTAGGAGTTAAAATGGTTCTTACTGTTGAATTGGA CTATCTAACTGTACCCGAAAAGTGCTGTCTTTTTAATGCAAACAGTAAAGTTAATAAAAAATAGTTGCAGATCTAAGTGATATTTATAAT GGTTATTGTCTGCAAAATACAAATTAATTTATAACAAGCTATGTAATTTTAATATTTAATAAACTATAAAAATCAGTTCTTGAAGACAAA GGAGAACAGAAGAGACACAGTCTTTCTCTTGTTAAAAGAAATACAAGGACAAGCATGGTGGATCACGCTTGTAATTCCAGCACTTTGGGA GGCTGAGGTGGGCAGATTGTTTGAGCTCAGGAGTTTGAGACCAGCCTGGTCAACATGGCAAAACCCCATCTCTACTAAAAATACAAAAAT TAGCCAGGCGTGGTGGTGCTCGCCTATAGTACCAGCTACTCAGGAGGCTGAGGCATAAGAATCACTTGAACCTGGGAGATGGAGGTTGCA GTGAGCCGAGATCATGCCCCTGCACTCCAGCCTGGGTGACAGAGGGGGACTTGGCCTCGAAAAAATAAATAAATAATAAAAATAAAATAA >42341_42341_5_KIAA1432-AARD_KIAA1432_chr9_5690038_ENST00000414202_AARD_chr8_117954796_ENST00000378279_length(amino acids)=143AA_BP=127 MSVTDATGGAGGSARTMYFLSGWPKRLLCPLGSPAEAPFHVQSDPQRAFFAVLAAARLSIWYSRPSVLIVTYKEPAKSSTQFGSYKQAEW -------------------------------------------------------------- >42341_42341_6_KIAA1432-AARD_KIAA1432_chr9_5690038_ENST00000414202_AARD_chr8_117954797_ENST00000378279_length(transcript)=2453nt_BP=523nt GTCAGCTTGGGGGTGCCTTCGTCGCGCAGCCTTGCGTCGGCCCGGCCCGGCCAGGCCAGCGGGCAGATGCCCCGAGCTGCCGCCGCCGCC GCCGCCGACTCGGCCGGTGGCGGTGTGGGAGGTGGGCGACCAGCCCGGGGCCGCTGAGTGTGACGGACGCAACTGGGGGCGCCGGGGGCT CCGCACGGACCATGTATTTTCTGAGCGGCTGGCCCAAGAGGCTGCTGTGCCCTCTGGGGAGCCCGGCCGAGGCGCCTTTCCACGTTCAGT CCGACCCGCAGAGGGCTTTCTTCGCCGTGCTGGCCGCGGCCCGCCTCAGCATCTGGTACAGCCGACCTAGTGTGTTAATTGTAACCTACA AGGAGCCTGCAAAATCATCTACTCAGTTTGGATCCTACAAGCAAGCTGAATGGAGGCCAGATAGTACCATGATAGCTGTATCAACGGCAA ATGGATACATCTTGTTTTTTCATATTACATCTACAAGAGGGGACAAGTACCTTTATGAACCAGTGTATCCCAAGTGGAAATGCATTTCCA AAACCACCAGCTGGCTAGAACTTTACTGGACCTAAACATGAAAGTGCAGCAATTGAAAAAGGAGTATGAACTGGAAATTACATCAGACTC CCAAAGCCCAAAAGATGATGCTGCGAATCCGGAATAAAGAAATGCACACGCAAGGGCTGGGCGCGGTGGCTCACGCCTGTAATCCCAGCA CTTTGGGAGGCCGAGGCGGGCGGATCAAGACGTCAGGAGATTGAGACCATCCTGGCTAACACTGTGAAACCCTGCCTCTACTAAAAATAC AAAAAATTAGCCAGACGTGGTGGCAGGCACCTGTAGTCCCTGCTACTCAGGAGTCTGAGGCAGGAGAATGGCGTGAACCCAGGAGACAGA GCTTGCAGTGAGCCGAAATCCTGCCACTGCACTCCAGCCTGGGTGACAGAGCAAGACTCCATCTCAAAAAAAAAAAAAAAAAAAAAAGCA CACGCGAAGCTCTGGATCCTAAAACTAACGCATACAACCCTGAAACAATTCTGATGAACACATTATGCTTTGCATAAGTTTTGAGGGGCA ATTTATAGACCCAAAACAAATGACAGGGGAAGGTGACAGAAAAACATCTAAGAGAGGGGAGAGAAAAATGATGTATTACCAAGTTTTAAA GTTATTTATTTGTTATTTTTACTGGGACATAGAAGTAAAATATAACTATAGATAAATCTCTCTCTGTCTCTCTCACTCAAAGAATGCTTT AATGCCAACTTTCGGTATTCAACCTTGTGTCACCTGACCTTTCTGGCATTGCCTGAGCTTTCAGAGTTTGTGCTTGTTTTGTTTTACTTG ATTATTCTCAGTTTGTCTGTCCAGCAGCCTGCCCTGCTTCTTGTGGAGAATTGTTTCTACTTGGATTCTAACCATGCCCTTTAGGTGGTC TGTGACTAAGGGTATTCCATCTTCCTGGATATAGTCATGCAGCTCAAGGCAGGCAGATGGGTTTGTCCTTAGGATTTTTGAATGGGCACT AAAAGAGTAGATGACTATTTCTGCCAGTAGAAGCTGTGGATCAGGGGCTTGGAAGCTGCTGGTGGTCACCATGTGAGAAAGCCCACACCC TAATGGAGGTGACTGAAACGGAACCACTAAAAGCACAAAAGGGGAGGGAGGGAGGGAGGGTGCTTCGCTTCCTTGTTCCTGGGGTCAAGC TGTATAAGACTCCAGGCCTTGCTCTTGTTTATGTACATGAAATATTCTGATATCCTTCTCATAAAATCTCTTTTTGCCTAAGTAAATTCA AGCTGGAGTTTCATGACTTGTATCTAGTGTTCATAACTAATACAGTTGTTCAGTTTTAGGAGTTAAAATGGTTCTTACTGTTGAATTGGA CTATCTAACTGTACCCGAAAAGTGCTGTCTTTTTAATGCAAACAGTAAAGTTAATAAAAAATAGTTGCAGATCTAAGTGATATTTATAAT GGTTATTGTCTGCAAAATACAAATTAATTTATAACAAGCTATGTAATTTTAATATTTAATAAACTATAAAAATCAGTTCTTGAAGACAAA GGAGAACAGAAGAGACACAGTCTTTCTCTTGTTAAAAGAAATACAAGGACAAGCATGGTGGATCACGCTTGTAATTCCAGCACTTTGGGA GGCTGAGGTGGGCAGATTGTTTGAGCTCAGGAGTTTGAGACCAGCCTGGTCAACATGGCAAAACCCCATCTCTACTAAAAATACAAAAAT TAGCCAGGCGTGGTGGTGCTCGCCTATAGTACCAGCTACTCAGGAGGCTGAGGCATAAGAATCACTTGAACCTGGGAGATGGAGGTTGCA GTGAGCCGAGATCATGCCCCTGCACTCCAGCCTGGGTGACAGAGGGGGACTTGGCCTCGAAAAAATAAATAAATAATAAAAATAAAATAA >42341_42341_6_KIAA1432-AARD_KIAA1432_chr9_5690038_ENST00000414202_AARD_chr8_117954797_ENST00000378279_length(amino acids)=143AA_BP=127 MSVTDATGGAGGSARTMYFLSGWPKRLLCPLGSPAEAPFHVQSDPQRAFFAVLAAARLSIWYSRPSVLIVTYKEPAKSSTQFGSYKQAEW -------------------------------------------------------------- >42341_42341_7_KIAA1432-AARD_KIAA1432_chr9_5690038_ENST00000418622_AARD_chr8_117954796_ENST00000378279_length(transcript)=2118nt_BP=188nt CCTAGTGTGTTAATTGTAACCTACAAGGAGCCTGCAAAATCATCTACTCAGTTTGGATCCTACAAGCAAGCTGAATGGAGGCCAGATAGT ACCATGATAGCTGTATCAACGGCAAATGGATACATCTTGTTTTTTCATATTACATCTACAAGAGGGGACAAGTACCTTTATGAACCAGTG TATCCCAAGTGGAAATGCATTTCCAAAACCACCAGCTGGCTAGAACTTTACTGGACCTAAACATGAAAGTGCAGCAATTGAAAAAGGAGT ATGAACTGGAAATTACATCAGACTCCCAAAGCCCAAAAGATGATGCTGCGAATCCGGAATAAAGAAATGCACACGCAAGGGCTGGGCGCG GTGGCTCACGCCTGTAATCCCAGCACTTTGGGAGGCCGAGGCGGGCGGATCAAGACGTCAGGAGATTGAGACCATCCTGGCTAACACTGT GAAACCCTGCCTCTACTAAAAATACAAAAAATTAGCCAGACGTGGTGGCAGGCACCTGTAGTCCCTGCTACTCAGGAGTCTGAGGCAGGA GAATGGCGTGAACCCAGGAGACAGAGCTTGCAGTGAGCCGAAATCCTGCCACTGCACTCCAGCCTGGGTGACAGAGCAAGACTCCATCTC AAAAAAAAAAAAAAAAAAAAAAGCACACGCGAAGCTCTGGATCCTAAAACTAACGCATACAACCCTGAAACAATTCTGATGAACACATTA TGCTTTGCATAAGTTTTGAGGGGCAATTTATAGACCCAAAACAAATGACAGGGGAAGGTGACAGAAAAACATCTAAGAGAGGGGAGAGAA AAATGATGTATTACCAAGTTTTAAAGTTATTTATTTGTTATTTTTACTGGGACATAGAAGTAAAATATAACTATAGATAAATCTCTCTCT GTCTCTCTCACTCAAAGAATGCTTTAATGCCAACTTTCGGTATTCAACCTTGTGTCACCTGACCTTTCTGGCATTGCCTGAGCTTTCAGA GTTTGTGCTTGTTTTGTTTTACTTGATTATTCTCAGTTTGTCTGTCCAGCAGCCTGCCCTGCTTCTTGTGGAGAATTGTTTCTACTTGGA TTCTAACCATGCCCTTTAGGTGGTCTGTGACTAAGGGTATTCCATCTTCCTGGATATAGTCATGCAGCTCAAGGCAGGCAGATGGGTTTG TCCTTAGGATTTTTGAATGGGCACTAAAAGAGTAGATGACTATTTCTGCCAGTAGAAGCTGTGGATCAGGGGCTTGGAAGCTGCTGGTGG TCACCATGTGAGAAAGCCCACACCCTAATGGAGGTGACTGAAACGGAACCACTAAAAGCACAAAAGGGGAGGGAGGGAGGGAGGGTGCTT CGCTTCCTTGTTCCTGGGGTCAAGCTGTATAAGACTCCAGGCCTTGCTCTTGTTTATGTACATGAAATATTCTGATATCCTTCTCATAAA ATCTCTTTTTGCCTAAGTAAATTCAAGCTGGAGTTTCATGACTTGTATCTAGTGTTCATAACTAATACAGTTGTTCAGTTTTAGGAGTTA AAATGGTTCTTACTGTTGAATTGGACTATCTAACTGTACCCGAAAAGTGCTGTCTTTTTAATGCAAACAGTAAAGTTAATAAAAAATAGT TGCAGATCTAAGTGATATTTATAATGGTTATTGTCTGCAAAATACAAATTAATTTATAACAAGCTATGTAATTTTAATATTTAATAAACT ATAAAAATCAGTTCTTGAAGACAAAGGAGAACAGAAGAGACACAGTCTTTCTCTTGTTAAAAGAAATACAAGGACAAGCATGGTGGATCA CGCTTGTAATTCCAGCACTTTGGGAGGCTGAGGTGGGCAGATTGTTTGAGCTCAGGAGTTTGAGACCAGCCTGGTCAACATGGCAAAACC CCATCTCTACTAAAAATACAAAAATTAGCCAGGCGTGGTGGTGCTCGCCTATAGTACCAGCTACTCAGGAGGCTGAGGCATAAGAATCAC TTGAACCTGGGAGATGGAGGTTGCAGTGAGCCGAGATCATGCCCCTGCACTCCAGCCTGGGTGACAGAGGGGGACTTGGCCTCGAAAAAA >42341_42341_7_KIAA1432-AARD_KIAA1432_chr9_5690038_ENST00000418622_AARD_chr8_117954796_ENST00000378279_length(amino acids)=101AA_BP= MVIHHFSLPSLRCFSVTFPCHLFWVYKLPLKTYAKHNVFIRIVSGLYALVLGSRASRVLFFFFFFLRWSLALSPRLECSGRISAHCKLCL -------------------------------------------------------------- >42341_42341_8_KIAA1432-AARD_KIAA1432_chr9_5690038_ENST00000418622_AARD_chr8_117954797_ENST00000378279_length(transcript)=2118nt_BP=188nt CCTAGTGTGTTAATTGTAACCTACAAGGAGCCTGCAAAATCATCTACTCAGTTTGGATCCTACAAGCAAGCTGAATGGAGGCCAGATAGT ACCATGATAGCTGTATCAACGGCAAATGGATACATCTTGTTTTTTCATATTACATCTACAAGAGGGGACAAGTACCTTTATGAACCAGTG TATCCCAAGTGGAAATGCATTTCCAAAACCACCAGCTGGCTAGAACTTTACTGGACCTAAACATGAAAGTGCAGCAATTGAAAAAGGAGT ATGAACTGGAAATTACATCAGACTCCCAAAGCCCAAAAGATGATGCTGCGAATCCGGAATAAAGAAATGCACACGCAAGGGCTGGGCGCG GTGGCTCACGCCTGTAATCCCAGCACTTTGGGAGGCCGAGGCGGGCGGATCAAGACGTCAGGAGATTGAGACCATCCTGGCTAACACTGT GAAACCCTGCCTCTACTAAAAATACAAAAAATTAGCCAGACGTGGTGGCAGGCACCTGTAGTCCCTGCTACTCAGGAGTCTGAGGCAGGA GAATGGCGTGAACCCAGGAGACAGAGCTTGCAGTGAGCCGAAATCCTGCCACTGCACTCCAGCCTGGGTGACAGAGCAAGACTCCATCTC AAAAAAAAAAAAAAAAAAAAAAGCACACGCGAAGCTCTGGATCCTAAAACTAACGCATACAACCCTGAAACAATTCTGATGAACACATTA TGCTTTGCATAAGTTTTGAGGGGCAATTTATAGACCCAAAACAAATGACAGGGGAAGGTGACAGAAAAACATCTAAGAGAGGGGAGAGAA AAATGATGTATTACCAAGTTTTAAAGTTATTTATTTGTTATTTTTACTGGGACATAGAAGTAAAATATAACTATAGATAAATCTCTCTCT GTCTCTCTCACTCAAAGAATGCTTTAATGCCAACTTTCGGTATTCAACCTTGTGTCACCTGACCTTTCTGGCATTGCCTGAGCTTTCAGA GTTTGTGCTTGTTTTGTTTTACTTGATTATTCTCAGTTTGTCTGTCCAGCAGCCTGCCCTGCTTCTTGTGGAGAATTGTTTCTACTTGGA TTCTAACCATGCCCTTTAGGTGGTCTGTGACTAAGGGTATTCCATCTTCCTGGATATAGTCATGCAGCTCAAGGCAGGCAGATGGGTTTG TCCTTAGGATTTTTGAATGGGCACTAAAAGAGTAGATGACTATTTCTGCCAGTAGAAGCTGTGGATCAGGGGCTTGGAAGCTGCTGGTGG TCACCATGTGAGAAAGCCCACACCCTAATGGAGGTGACTGAAACGGAACCACTAAAAGCACAAAAGGGGAGGGAGGGAGGGAGGGTGCTT CGCTTCCTTGTTCCTGGGGTCAAGCTGTATAAGACTCCAGGCCTTGCTCTTGTTTATGTACATGAAATATTCTGATATCCTTCTCATAAA ATCTCTTTTTGCCTAAGTAAATTCAAGCTGGAGTTTCATGACTTGTATCTAGTGTTCATAACTAATACAGTTGTTCAGTTTTAGGAGTTA AAATGGTTCTTACTGTTGAATTGGACTATCTAACTGTACCCGAAAAGTGCTGTCTTTTTAATGCAAACAGTAAAGTTAATAAAAAATAGT TGCAGATCTAAGTGATATTTATAATGGTTATTGTCTGCAAAATACAAATTAATTTATAACAAGCTATGTAATTTTAATATTTAATAAACT ATAAAAATCAGTTCTTGAAGACAAAGGAGAACAGAAGAGACACAGTCTTTCTCTTGTTAAAAGAAATACAAGGACAAGCATGGTGGATCA CGCTTGTAATTCCAGCACTTTGGGAGGCTGAGGTGGGCAGATTGTTTGAGCTCAGGAGTTTGAGACCAGCCTGGTCAACATGGCAAAACC CCATCTCTACTAAAAATACAAAAATTAGCCAGGCGTGGTGGTGCTCGCCTATAGTACCAGCTACTCAGGAGGCTGAGGCATAAGAATCAC TTGAACCTGGGAGATGGAGGTTGCAGTGAGCCGAGATCATGCCCCTGCACTCCAGCCTGGGTGACAGAGGGGGACTTGGCCTCGAAAAAA >42341_42341_8_KIAA1432-AARD_KIAA1432_chr9_5690038_ENST00000418622_AARD_chr8_117954797_ENST00000378279_length(amino acids)=101AA_BP= MVIHHFSLPSLRCFSVTFPCHLFWVYKLPLKTYAKHNVFIRIVSGLYALVLGSRASRVLFFFFFFLRWSLALSPRLECSGRISAHCKLCL -------------------------------------------------------------- >42341_42341_9_KIAA1432-AARD_KIAA1432_chr9_5690038_ENST00000449720_AARD_chr8_117954796_ENST00000378279_length(transcript)=2047nt_BP=117nt TGAATGGAGGCCAGATAGTACCATGATAGCTGTATCAACGGCAAATGGATACATCTTGTTTTTTCATATTACATCTACAAGAGGGGACAA GTACCTTTATGAACCAGTGTATCCCAAGTGGAAATGCATTTCCAAAACCACCAGCTGGCTAGAACTTTACTGGACCTAAACATGAAAGTG CAGCAATTGAAAAAGGAGTATGAACTGGAAATTACATCAGACTCCCAAAGCCCAAAAGATGATGCTGCGAATCCGGAATAAAGAAATGCA CACGCAAGGGCTGGGCGCGGTGGCTCACGCCTGTAATCCCAGCACTTTGGGAGGCCGAGGCGGGCGGATCAAGACGTCAGGAGATTGAGA CCATCCTGGCTAACACTGTGAAACCCTGCCTCTACTAAAAATACAAAAAATTAGCCAGACGTGGTGGCAGGCACCTGTAGTCCCTGCTAC TCAGGAGTCTGAGGCAGGAGAATGGCGTGAACCCAGGAGACAGAGCTTGCAGTGAGCCGAAATCCTGCCACTGCACTCCAGCCTGGGTGA CAGAGCAAGACTCCATCTCAAAAAAAAAAAAAAAAAAAAAAGCACACGCGAAGCTCTGGATCCTAAAACTAACGCATACAACCCTGAAAC AATTCTGATGAACACATTATGCTTTGCATAAGTTTTGAGGGGCAATTTATAGACCCAAAACAAATGACAGGGGAAGGTGACAGAAAAACA TCTAAGAGAGGGGAGAGAAAAATGATGTATTACCAAGTTTTAAAGTTATTTATTTGTTATTTTTACTGGGACATAGAAGTAAAATATAAC TATAGATAAATCTCTCTCTGTCTCTCTCACTCAAAGAATGCTTTAATGCCAACTTTCGGTATTCAACCTTGTGTCACCTGACCTTTCTGG CATTGCCTGAGCTTTCAGAGTTTGTGCTTGTTTTGTTTTACTTGATTATTCTCAGTTTGTCTGTCCAGCAGCCTGCCCTGCTTCTTGTGG AGAATTGTTTCTACTTGGATTCTAACCATGCCCTTTAGGTGGTCTGTGACTAAGGGTATTCCATCTTCCTGGATATAGTCATGCAGCTCA AGGCAGGCAGATGGGTTTGTCCTTAGGATTTTTGAATGGGCACTAAAAGAGTAGATGACTATTTCTGCCAGTAGAAGCTGTGGATCAGGG GCTTGGAAGCTGCTGGTGGTCACCATGTGAGAAAGCCCACACCCTAATGGAGGTGACTGAAACGGAACCACTAAAAGCACAAAAGGGGAG GGAGGGAGGGAGGGTGCTTCGCTTCCTTGTTCCTGGGGTCAAGCTGTATAAGACTCCAGGCCTTGCTCTTGTTTATGTACATGAAATATT CTGATATCCTTCTCATAAAATCTCTTTTTGCCTAAGTAAATTCAAGCTGGAGTTTCATGACTTGTATCTAGTGTTCATAACTAATACAGT TGTTCAGTTTTAGGAGTTAAAATGGTTCTTACTGTTGAATTGGACTATCTAACTGTACCCGAAAAGTGCTGTCTTTTTAATGCAAACAGT AAAGTTAATAAAAAATAGTTGCAGATCTAAGTGATATTTATAATGGTTATTGTCTGCAAAATACAAATTAATTTATAACAAGCTATGTAA TTTTAATATTTAATAAACTATAAAAATCAGTTCTTGAAGACAAAGGAGAACAGAAGAGACACAGTCTTTCTCTTGTTAAAAGAAATACAA GGACAAGCATGGTGGATCACGCTTGTAATTCCAGCACTTTGGGAGGCTGAGGTGGGCAGATTGTTTGAGCTCAGGAGTTTGAGACCAGCC TGGTCAACATGGCAAAACCCCATCTCTACTAAAAATACAAAAATTAGCCAGGCGTGGTGGTGCTCGCCTATAGTACCAGCTACTCAGGAG GCTGAGGCATAAGAATCACTTGAACCTGGGAGATGGAGGTTGCAGTGAGCCGAGATCATGCCCCTGCACTCCAGCCTGGGTGACAGAGGG >42341_42341_9_KIAA1432-AARD_KIAA1432_chr9_5690038_ENST00000449720_AARD_chr8_117954796_ENST00000378279_length(amino acids)=101AA_BP= MVIHHFSLPSLRCFSVTFPCHLFWVYKLPLKTYAKHNVFIRIVSGLYALVLGSRASRVLFFFFFFLRWSLALSPRLECSGRISAHCKLCL -------------------------------------------------------------- >42341_42341_10_KIAA1432-AARD_KIAA1432_chr9_5690038_ENST00000449720_AARD_chr8_117954797_ENST00000378279_length(transcript)=2047nt_BP=117nt TGAATGGAGGCCAGATAGTACCATGATAGCTGTATCAACGGCAAATGGATACATCTTGTTTTTTCATATTACATCTACAAGAGGGGACAA GTACCTTTATGAACCAGTGTATCCCAAGTGGAAATGCATTTCCAAAACCACCAGCTGGCTAGAACTTTACTGGACCTAAACATGAAAGTG CAGCAATTGAAAAAGGAGTATGAACTGGAAATTACATCAGACTCCCAAAGCCCAAAAGATGATGCTGCGAATCCGGAATAAAGAAATGCA CACGCAAGGGCTGGGCGCGGTGGCTCACGCCTGTAATCCCAGCACTTTGGGAGGCCGAGGCGGGCGGATCAAGACGTCAGGAGATTGAGA CCATCCTGGCTAACACTGTGAAACCCTGCCTCTACTAAAAATACAAAAAATTAGCCAGACGTGGTGGCAGGCACCTGTAGTCCCTGCTAC TCAGGAGTCTGAGGCAGGAGAATGGCGTGAACCCAGGAGACAGAGCTTGCAGTGAGCCGAAATCCTGCCACTGCACTCCAGCCTGGGTGA CAGAGCAAGACTCCATCTCAAAAAAAAAAAAAAAAAAAAAAGCACACGCGAAGCTCTGGATCCTAAAACTAACGCATACAACCCTGAAAC AATTCTGATGAACACATTATGCTTTGCATAAGTTTTGAGGGGCAATTTATAGACCCAAAACAAATGACAGGGGAAGGTGACAGAAAAACA TCTAAGAGAGGGGAGAGAAAAATGATGTATTACCAAGTTTTAAAGTTATTTATTTGTTATTTTTACTGGGACATAGAAGTAAAATATAAC TATAGATAAATCTCTCTCTGTCTCTCTCACTCAAAGAATGCTTTAATGCCAACTTTCGGTATTCAACCTTGTGTCACCTGACCTTTCTGG CATTGCCTGAGCTTTCAGAGTTTGTGCTTGTTTTGTTTTACTTGATTATTCTCAGTTTGTCTGTCCAGCAGCCTGCCCTGCTTCTTGTGG AGAATTGTTTCTACTTGGATTCTAACCATGCCCTTTAGGTGGTCTGTGACTAAGGGTATTCCATCTTCCTGGATATAGTCATGCAGCTCA AGGCAGGCAGATGGGTTTGTCCTTAGGATTTTTGAATGGGCACTAAAAGAGTAGATGACTATTTCTGCCAGTAGAAGCTGTGGATCAGGG GCTTGGAAGCTGCTGGTGGTCACCATGTGAGAAAGCCCACACCCTAATGGAGGTGACTGAAACGGAACCACTAAAAGCACAAAAGGGGAG GGAGGGAGGGAGGGTGCTTCGCTTCCTTGTTCCTGGGGTCAAGCTGTATAAGACTCCAGGCCTTGCTCTTGTTTATGTACATGAAATATT CTGATATCCTTCTCATAAAATCTCTTTTTGCCTAAGTAAATTCAAGCTGGAGTTTCATGACTTGTATCTAGTGTTCATAACTAATACAGT TGTTCAGTTTTAGGAGTTAAAATGGTTCTTACTGTTGAATTGGACTATCTAACTGTACCCGAAAAGTGCTGTCTTTTTAATGCAAACAGT AAAGTTAATAAAAAATAGTTGCAGATCTAAGTGATATTTATAATGGTTATTGTCTGCAAAATACAAATTAATTTATAACAAGCTATGTAA TTTTAATATTTAATAAACTATAAAAATCAGTTCTTGAAGACAAAGGAGAACAGAAGAGACACAGTCTTTCTCTTGTTAAAAGAAATACAA GGACAAGCATGGTGGATCACGCTTGTAATTCCAGCACTTTGGGAGGCTGAGGTGGGCAGATTGTTTGAGCTCAGGAGTTTGAGACCAGCC TGGTCAACATGGCAAAACCCCATCTCTACTAAAAATACAAAAATTAGCCAGGCGTGGTGGTGCTCGCCTATAGTACCAGCTACTCAGGAG GCTGAGGCATAAGAATCACTTGAACCTGGGAGATGGAGGTTGCAGTGAGCCGAGATCATGCCCCTGCACTCCAGCCTGGGTGACAGAGGG >42341_42341_10_KIAA1432-AARD_KIAA1432_chr9_5690038_ENST00000449720_AARD_chr8_117954797_ENST00000378279_length(amino acids)=101AA_BP= MVIHHFSLPSLRCFSVTFPCHLFWVYKLPLKTYAKHNVFIRIVSGLYALVLGSRASRVLFFFFFFLRWSLALSPRLECSGRISAHCKLCL -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for KIAA1432-AARD |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for KIAA1432-AARD |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for KIAA1432-AARD |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies