
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:KNDC1-CRIP1 (FusionGDB2 ID:43321) |
Fusion Gene Summary for KNDC1-CRIP1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: KNDC1-CRIP1 | Fusion gene ID: 43321 | Hgene | Tgene | Gene symbol | KNDC1 | CRIP1 | Gene ID | 85442 | 25927 |
| Gene name | kinase non-catalytic C-lobe domain containing 1 | cannabinoid receptor interacting protein 1 | |
| Synonyms | C10orf23|RASGEF2|Very-KIND|bB439H18.3|v-KIND | C2orf32|CRIP-1|CRIP1 | |
| Cytomap | 10q26.3 | 2p14 | |
| Type of gene | protein-coding | protein-coding | |
| Description | kinase non-catalytic C-lobe domain-containing protein 1KIND domain-containing protein 1RasGEF domain family, member 2cerebral protein 9kinase non-catalytic C-lobe domain (KIND) containing 1protein very KINDras-GEF domain-containing family member 2 | CB1 cannabinoid receptor-interacting protein 1cannabinoid receptor CB1-interacting protein 1 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q76NI1 | P50238 | |
| Ensembl transtripts involved in fusion gene | ENST00000304613, ENST00000368571, ENST00000368572, ENST00000530127, | ENST00000330233, ENST00000392531, ENST00000409393, ENST00000551180, | |
| Fusion gene scores | * DoF score | 2 X 2 X 2=8 | 1 X 1 X 1=1 |
| # samples | 2 | 1 | |
| ** MAII score | log2(2/8*10)=1.32192809488736 | log2(1/1*10)=3.32192809488736 | |
| Context | PubMed: KNDC1 [Title/Abstract] AND CRIP1 [Title/Abstract] AND fusion [Title/Abstract] | ||
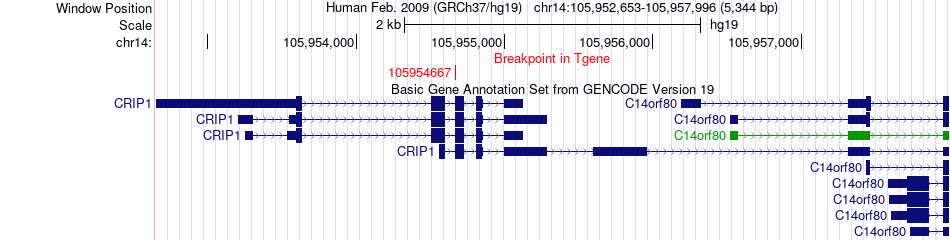
| Most frequent breakpoint | KNDC1(134996878)-CRIP1(105954667), # samples:6 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across KNDC1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across CRIP1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | COAD | TCGA-AA-A004-01A | KNDC1 | chr10 | 134996878 | + | CRIP1 | chr14 | 105954667 | + |
| ChimerDB4 | COAD | TCGA-AZ-4681-01A | KNDC1 | chr10 | 134996878 | + | CRIP1 | chr14 | 105954667 | + |
| ChimerDB4 | UCEC | TCGA-AX-A06J-01A | KNDC1 | chr10 | 134996878 | + | CRIP1 | chr14 | 105954667 | + |
| ChimerDB4 | UCEC | TCGA-B5-A0KB-01B | KNDC1 | chr10 | 134996878 | + | CRIP1 | chr14 | 105954667 | + |
| ChimerDB4 | UCEC | TCGA-D1-A16E-01A | KNDC1 | chr10 | 134996878 | + | CRIP1 | chr14 | 105954667 | + |
| ChimerDB4 | UCEC | TCGA-D1-A177-01A | KNDC1 | chr10 | 134996878 | + | CRIP1 | chr14 | 105954667 | + |
Top |
Fusion Gene ORF analysis for KNDC1-CRIP1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| In-frame | ENST00000304613 | ENST00000330233 | KNDC1 | chr10 | 134996878 | + | CRIP1 | chr14 | 105954667 | + |
| In-frame | ENST00000304613 | ENST00000392531 | KNDC1 | chr10 | 134996878 | + | CRIP1 | chr14 | 105954667 | + |
| In-frame | ENST00000304613 | ENST00000409393 | KNDC1 | chr10 | 134996878 | + | CRIP1 | chr14 | 105954667 | + |
| In-frame | ENST00000304613 | ENST00000551180 | KNDC1 | chr10 | 134996878 | + | CRIP1 | chr14 | 105954667 | + |
| In-frame | ENST00000368571 | ENST00000330233 | KNDC1 | chr10 | 134996878 | + | CRIP1 | chr14 | 105954667 | + |
| In-frame | ENST00000368571 | ENST00000392531 | KNDC1 | chr10 | 134996878 | + | CRIP1 | chr14 | 105954667 | + |
| In-frame | ENST00000368571 | ENST00000409393 | KNDC1 | chr10 | 134996878 | + | CRIP1 | chr14 | 105954667 | + |
| In-frame | ENST00000368571 | ENST00000551180 | KNDC1 | chr10 | 134996878 | + | CRIP1 | chr14 | 105954667 | + |
| In-frame | ENST00000368572 | ENST00000330233 | KNDC1 | chr10 | 134996878 | + | CRIP1 | chr14 | 105954667 | + |
| In-frame | ENST00000368572 | ENST00000392531 | KNDC1 | chr10 | 134996878 | + | CRIP1 | chr14 | 105954667 | + |
| In-frame | ENST00000368572 | ENST00000409393 | KNDC1 | chr10 | 134996878 | + | CRIP1 | chr14 | 105954667 | + |
| In-frame | ENST00000368572 | ENST00000551180 | KNDC1 | chr10 | 134996878 | + | CRIP1 | chr14 | 105954667 | + |
| intron-3CDS | ENST00000530127 | ENST00000330233 | KNDC1 | chr10 | 134996878 | + | CRIP1 | chr14 | 105954667 | + |
| intron-3CDS | ENST00000530127 | ENST00000392531 | KNDC1 | chr10 | 134996878 | + | CRIP1 | chr14 | 105954667 | + |
| intron-3CDS | ENST00000530127 | ENST00000409393 | KNDC1 | chr10 | 134996878 | + | CRIP1 | chr14 | 105954667 | + |
| intron-3CDS | ENST00000530127 | ENST00000551180 | KNDC1 | chr10 | 134996878 | + | CRIP1 | chr14 | 105954667 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000304613 | KNDC1 | chr10 | 134996878 | + | ENST00000330233 | CRIP1 | chr14 | 105954667 | + | 730 | 497 | 536 | 0 | 179 |
| ENST00000304613 | KNDC1 | chr10 | 134996878 | + | ENST00000409393 | CRIP1 | chr14 | 105954667 | + | 886 | 497 | 536 | 0 | 179 |
| ENST00000304613 | KNDC1 | chr10 | 134996878 | + | ENST00000392531 | CRIP1 | chr14 | 105954667 | + | 730 | 497 | 536 | 0 | 179 |
| ENST00000304613 | KNDC1 | chr10 | 134996878 | + | ENST00000551180 | CRIP1 | chr14 | 105954667 | + | 1437 | 497 | 778 | 83 | 231 |
| ENST00000368572 | KNDC1 | chr10 | 134996878 | + | ENST00000330233 | CRIP1 | chr14 | 105954667 | + | 710 | 477 | 516 | 1 | 172 |
| ENST00000368572 | KNDC1 | chr10 | 134996878 | + | ENST00000409393 | CRIP1 | chr14 | 105954667 | + | 866 | 477 | 516 | 1 | 172 |
| ENST00000368572 | KNDC1 | chr10 | 134996878 | + | ENST00000392531 | CRIP1 | chr14 | 105954667 | + | 710 | 477 | 516 | 1 | 172 |
| ENST00000368572 | KNDC1 | chr10 | 134996878 | + | ENST00000551180 | CRIP1 | chr14 | 105954667 | + | 1417 | 477 | 758 | 63 | 231 |
| ENST00000368571 | KNDC1 | chr10 | 134996878 | + | ENST00000330233 | CRIP1 | chr14 | 105954667 | + | 804 | 571 | 610 | 62 | 182 |
| ENST00000368571 | KNDC1 | chr10 | 134996878 | + | ENST00000409393 | CRIP1 | chr14 | 105954667 | + | 960 | 571 | 610 | 62 | 182 |
| ENST00000368571 | KNDC1 | chr10 | 134996878 | + | ENST00000392531 | CRIP1 | chr14 | 105954667 | + | 804 | 571 | 610 | 62 | 182 |
| ENST00000368571 | KNDC1 | chr10 | 134996878 | + | ENST00000551180 | CRIP1 | chr14 | 105954667 | + | 1511 | 571 | 852 | 172 | 226 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000304613 | ENST00000330233 | KNDC1 | chr10 | 134996878 | + | CRIP1 | chr14 | 105954667 | + | 0.021177378 | 0.97882265 |
| ENST00000304613 | ENST00000409393 | KNDC1 | chr10 | 134996878 | + | CRIP1 | chr14 | 105954667 | + | 0.01953127 | 0.98046875 |
| ENST00000304613 | ENST00000392531 | KNDC1 | chr10 | 134996878 | + | CRIP1 | chr14 | 105954667 | + | 0.021177378 | 0.97882265 |
| ENST00000304613 | ENST00000551180 | KNDC1 | chr10 | 134996878 | + | CRIP1 | chr14 | 105954667 | + | 0.046552904 | 0.9534471 |
| ENST00000368572 | ENST00000330233 | KNDC1 | chr10 | 134996878 | + | CRIP1 | chr14 | 105954667 | + | 0.023866018 | 0.97613394 |
| ENST00000368572 | ENST00000409393 | KNDC1 | chr10 | 134996878 | + | CRIP1 | chr14 | 105954667 | + | 0.023495458 | 0.97650456 |
| ENST00000368572 | ENST00000392531 | KNDC1 | chr10 | 134996878 | + | CRIP1 | chr14 | 105954667 | + | 0.023866018 | 0.97613394 |
| ENST00000368572 | ENST00000551180 | KNDC1 | chr10 | 134996878 | + | CRIP1 | chr14 | 105954667 | + | 0.042020284 | 0.95797974 |
| ENST00000368571 | ENST00000330233 | KNDC1 | chr10 | 134996878 | + | CRIP1 | chr14 | 105954667 | + | 0.5776029 | 0.4223971 |
| ENST00000368571 | ENST00000409393 | KNDC1 | chr10 | 134996878 | + | CRIP1 | chr14 | 105954667 | + | 0.6327618 | 0.36723816 |
| ENST00000368571 | ENST00000392531 | KNDC1 | chr10 | 134996878 | + | CRIP1 | chr14 | 105954667 | + | 0.5776029 | 0.4223971 |
| ENST00000368571 | ENST00000551180 | KNDC1 | chr10 | 134996878 | + | CRIP1 | chr14 | 105954667 | + | 0.8321475 | 0.16785255 |
Top |
Fusion Genomic Features for KNDC1-CRIP1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
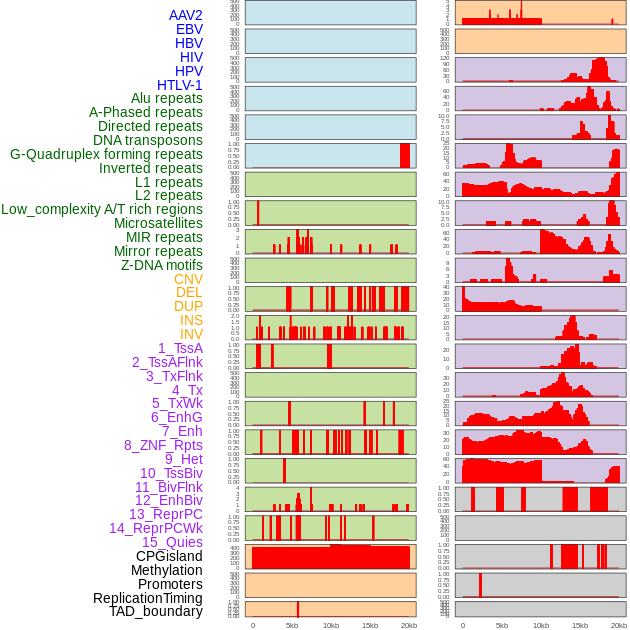
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for KNDC1-CRIP1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr10:134996878/chr14:105954667) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| KNDC1 | CRIP1 |
| FUNCTION: RAS-Guanine nucleotide exchange factor (GEF) that controls the negative regulation of neuronal dendrite growth by mediating a signaling pathway linking RAS and MAP2 (By similarity). May be involved in cellular senescence (PubMed:24788352). {ECO:0000250|UniProtKB:Q0KK55, ECO:0000269|PubMed:24788352}. | FUNCTION: Seems to have a role in zinc absorption and may function as an intracellular zinc transport protein. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | CRIP1 | chr10:134996878 | chr14:105954667 | ENST00000330233 | 1 | 5 | 62_70 | 45 | -206.66666666666666 | Compositional bias | Note=Gly-rich | |
| Tgene | CRIP1 | chr10:134996878 | chr14:105954667 | ENST00000392531 | 2 | 6 | 62_70 | 45 | 102.33333333333333 | Compositional bias | Note=Gly-rich | |
| Tgene | CRIP1 | chr10:134996878 | chr14:105954667 | ENST00000409393 | 2 | 6 | 62_70 | 45 | 137.66666666666666 | Compositional bias | Note=Gly-rich |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | KNDC1 | chr10:134996878 | chr14:105954667 | ENST00000304613 | + | 1 | 30 | 1133_1190 | 0 | 1750.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | KNDC1 | chr10:134996878 | chr14:105954667 | ENST00000368571 | + | 1 | 18 | 1133_1190 | 0 | 1142.0 | Coiled coil | Ontology_term=ECO:0000255 |
| Hgene | KNDC1 | chr10:134996878 | chr14:105954667 | ENST00000304613 | + | 1 | 30 | 724_885 | 0 | 1750.0 | Compositional bias | Note=Pro-rich |
| Hgene | KNDC1 | chr10:134996878 | chr14:105954667 | ENST00000368571 | + | 1 | 18 | 724_885 | 0 | 1142.0 | Compositional bias | Note=Pro-rich |
| Hgene | KNDC1 | chr10:134996878 | chr14:105954667 | ENST00000304613 | + | 1 | 30 | 1246_1371 | 0 | 1750.0 | Domain | N-terminal Ras-GEF |
| Hgene | KNDC1 | chr10:134996878 | chr14:105954667 | ENST00000304613 | + | 1 | 30 | 1468_1719 | 0 | 1750.0 | Domain | Ras-GEF |
| Hgene | KNDC1 | chr10:134996878 | chr14:105954667 | ENST00000304613 | + | 1 | 30 | 37_217 | 0 | 1750.0 | Domain | KIND 1 |
| Hgene | KNDC1 | chr10:134996878 | chr14:105954667 | ENST00000304613 | + | 1 | 30 | 444_608 | 0 | 1750.0 | Domain | KIND 2 |
| Hgene | KNDC1 | chr10:134996878 | chr14:105954667 | ENST00000368571 | + | 1 | 18 | 1246_1371 | 0 | 1142.0 | Domain | N-terminal Ras-GEF |
| Hgene | KNDC1 | chr10:134996878 | chr14:105954667 | ENST00000368571 | + | 1 | 18 | 1468_1719 | 0 | 1142.0 | Domain | Ras-GEF |
| Hgene | KNDC1 | chr10:134996878 | chr14:105954667 | ENST00000368571 | + | 1 | 18 | 37_217 | 0 | 1142.0 | Domain | KIND 1 |
| Hgene | KNDC1 | chr10:134996878 | chr14:105954667 | ENST00000368571 | + | 1 | 18 | 444_608 | 0 | 1142.0 | Domain | KIND 2 |
| Tgene | CRIP1 | chr10:134996878 | chr14:105954667 | ENST00000330233 | 1 | 5 | 2_63 | 45 | -206.66666666666666 | Domain | LIM zinc-binding | |
| Tgene | CRIP1 | chr10:134996878 | chr14:105954667 | ENST00000392531 | 2 | 6 | 2_63 | 45 | 102.33333333333333 | Domain | LIM zinc-binding | |
| Tgene | CRIP1 | chr10:134996878 | chr14:105954667 | ENST00000409393 | 2 | 6 | 2_63 | 45 | 137.66666666666666 | Domain | LIM zinc-binding |
Top |
Fusion Gene Sequence for KNDC1-CRIP1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >43321_43321_1_KNDC1-CRIP1_KNDC1_chr10_134996878_ENST00000304613_CRIP1_chr14_105954667_ENST00000330233_length(transcript)=730nt_BP=497nt GGTGCGCGGCGCGGCCGCAGGATGCAGGCCATGGACCCGGCCGCGGCGGATCTTTACGAGGAGGACGGCAAAGACCTGGACTTCTACGAC TTCGAGCCGCTGCCCACCCTCCCCGAGGACGAGGAGAACGTGTCTCTGGCTGACATCCTCTCCCTGCGGGACCGCGGCCTCAGCGAGCAG GAAGCCTGGGCCGTGTGCCTGGAGTGCAGCCTGTCCATGCGGAGCGTGGCCCACGCCGCCATCTTCCAGAGCCTGTGCATCACGCCCGAC ACCCTGGCCTTCAACACCAGCGGGAACGTGTGTTTCATGGAGCAGCTCAGCGACGACCCTGAGGGTGCCTTCGTTCCCCCCGAGTTCGAC GTGACCGGGAACACCTTTGAGAGGCCGCCCTCGAGTACGTGGCAGAGCCCACACTGGAACCCAGGCTGAGCCAAGACCTCGAGGCGCTGC TGAGCCGGATGCAGGCGGAGGACCCCGGGGACCGGCCGGACCTTGAGCACGAAGGCAAACCCTACTGCAACCACCCCTGCTACGCAGCCA TGTTTGGGCCTAAAGGCTTTGGGCGGGGCGGAGCCGAGAGCCACACTTTCAAGTAAACCAGGTGGTGGAGACCCCATCCTTGGCTGCTTG CAGGGCCACTGTCCAGGCAAATGCCAGGCCTTGTCCCCAGATGCCCAGGGCTCCCTTGTTGCCCCTAATGCTCTCAGTAAACCTGAACAC >43321_43321_1_KNDC1-CRIP1_KNDC1_chr10_134996878_ENST00000304613_CRIP1_chr14_105954667_ENST00000330233_length(amino acids)=179AA_BP=1 MRSRGGCSRVCLRAQGPAGPRGPPPASGSAAPRGLGSAWVPVWALPRTRGRPLKGVPGHVELGGNEGTLRVVAELLHETHVPAGVEGQGV -------------------------------------------------------------- >43321_43321_2_KNDC1-CRIP1_KNDC1_chr10_134996878_ENST00000304613_CRIP1_chr14_105954667_ENST00000392531_length(transcript)=730nt_BP=497nt GGTGCGCGGCGCGGCCGCAGGATGCAGGCCATGGACCCGGCCGCGGCGGATCTTTACGAGGAGGACGGCAAAGACCTGGACTTCTACGAC TTCGAGCCGCTGCCCACCCTCCCCGAGGACGAGGAGAACGTGTCTCTGGCTGACATCCTCTCCCTGCGGGACCGCGGCCTCAGCGAGCAG GAAGCCTGGGCCGTGTGCCTGGAGTGCAGCCTGTCCATGCGGAGCGTGGCCCACGCCGCCATCTTCCAGAGCCTGTGCATCACGCCCGAC ACCCTGGCCTTCAACACCAGCGGGAACGTGTGTTTCATGGAGCAGCTCAGCGACGACCCTGAGGGTGCCTTCGTTCCCCCCGAGTTCGAC GTGACCGGGAACACCTTTGAGAGGCCGCCCTCGAGTACGTGGCAGAGCCCACACTGGAACCCAGGCTGAGCCAAGACCTCGAGGCGCTGC TGAGCCGGATGCAGGCGGAGGACCCCGGGGACCGGCCGGACCTTGAGCACGAAGGCAAACCCTACTGCAACCACCCCTGCTACGCAGCCA TGTTTGGGCCTAAAGGCTTTGGGCGGGGCGGAGCCGAGAGCCACACTTTCAAGTAAACCAGGTGGTGGAGACCCCATCCTTGGCTGCTTG CAGGGCCACTGTCCAGGCAAATGCCAGGCCTTGTCCCCAGATGCCCAGGGCTCCCTTGTTGCCCCTAATGCTCTCAGTAAACCTGAACAC >43321_43321_2_KNDC1-CRIP1_KNDC1_chr10_134996878_ENST00000304613_CRIP1_chr14_105954667_ENST00000392531_length(amino acids)=179AA_BP=1 MRSRGGCSRVCLRAQGPAGPRGPPPASGSAAPRGLGSAWVPVWALPRTRGRPLKGVPGHVELGGNEGTLRVVAELLHETHVPAGVEGQGV -------------------------------------------------------------- >43321_43321_3_KNDC1-CRIP1_KNDC1_chr10_134996878_ENST00000304613_CRIP1_chr14_105954667_ENST00000409393_length(transcript)=886nt_BP=497nt GGTGCGCGGCGCGGCCGCAGGATGCAGGCCATGGACCCGGCCGCGGCGGATCTTTACGAGGAGGACGGCAAAGACCTGGACTTCTACGAC TTCGAGCCGCTGCCCACCCTCCCCGAGGACGAGGAGAACGTGTCTCTGGCTGACATCCTCTCCCTGCGGGACCGCGGCCTCAGCGAGCAG GAAGCCTGGGCCGTGTGCCTGGAGTGCAGCCTGTCCATGCGGAGCGTGGCCCACGCCGCCATCTTCCAGAGCCTGTGCATCACGCCCGAC ACCCTGGCCTTCAACACCAGCGGGAACGTGTGTTTCATGGAGCAGCTCAGCGACGACCCTGAGGGTGCCTTCGTTCCCCCCGAGTTCGAC GTGACCGGGAACACCTTTGAGAGGCCGCCCTCGAGTACGTGGCAGAGCCCACACTGGAACCCAGGCTGAGCCAAGACCTCGAGGCGCTGC TGAGCCGGATGCAGGCGGAGGACCCCGGGGACCGGCCGGACCTTGAGCACGAAGGCAAACCCTACTGCAACCACCCCTGCTACGCAGCCA TGTTTGGGCCTAAAGGCTTTGGGCGGGGCGGAGCCGAGAGCCACACTTTCAAGTAAACCAGGTGGTGGAGACCCCATCCTTGGCTGCTTG CAGGGCCACTGTCCAGGCAAATGCCAGGCCTTGTCCCCAGATGCCCAGGGCTCCCTTGTTGCCCCTAATGCTCTCAGTAAACCTGAACAC TTGGAAAACCTGTGTGTGTACATGCGCGTGTGTGCTGGGGAGTGCCAAGGGAGCTGCAGTGGGGTCCTGGCAGCAGGCTCTGCCACCGGC >43321_43321_3_KNDC1-CRIP1_KNDC1_chr10_134996878_ENST00000304613_CRIP1_chr14_105954667_ENST00000409393_length(amino acids)=179AA_BP=1 MRSRGGCSRVCLRAQGPAGPRGPPPASGSAAPRGLGSAWVPVWALPRTRGRPLKGVPGHVELGGNEGTLRVVAELLHETHVPAGVEGQGV -------------------------------------------------------------- >43321_43321_4_KNDC1-CRIP1_KNDC1_chr10_134996878_ENST00000304613_CRIP1_chr14_105954667_ENST00000551180_length(transcript)=1437nt_BP=497nt GGTGCGCGGCGCGGCCGCAGGATGCAGGCCATGGACCCGGCCGCGGCGGATCTTTACGAGGAGGACGGCAAAGACCTGGACTTCTACGAC TTCGAGCCGCTGCCCACCCTCCCCGAGGACGAGGAGAACGTGTCTCTGGCTGACATCCTCTCCCTGCGGGACCGCGGCCTCAGCGAGCAG GAAGCCTGGGCCGTGTGCCTGGAGTGCAGCCTGTCCATGCGGAGCGTGGCCCACGCCGCCATCTTCCAGAGCCTGTGCATCACGCCCGAC ACCCTGGCCTTCAACACCAGCGGGAACGTGTGTTTCATGGAGCAGCTCAGCGACGACCCTGAGGGTGCCTTCGTTCCCCCCGAGTTCGAC GTGACCGGGAACACCTTTGAGAGGCCGCCCTCGAGTACGTGGCAGAGCCCACACTGGAACCCAGGCTGAGCCAAGACCTCGAGGCGCTGC TGAGCCGGATGCAGGCGGAGGACCCCGGGGACCGGCCGGACCTTGAGCACGAAGGCAAACCCTACTGCAACCACCCCTGCTACGCAGCCA TGTTTGGGCCTAAAGGCTTTGGGCGGGGCGGAGCCGAGAGCCACACTTTCAAGTAAACCAGGTGGTGGAGACCCCATCCTTGGCTGCTTG CAGGGCCACTGTCCAGGCAAATGCCAGGCCTTGTCCCCAGATGCCCAGGGCTCCCTTGTTGCCCCTAATGCTCTCAGTAAACCTGAACAC TTGGAAAACCTGTGTGTGTACATGCGCGTGTGTGCTGGGGAGTGCCAAGGGAGCTGCAGTGGGGTCCTGGCAGCAGGCTCTGCCACCGGC GCCTGCTCTTCTGCTGCCCATTGCCCTCCCCAGGGGGCCGTTCCAGGGTCTCATAGGCGAGGGCTCCCTGTGCAGGGCCAGGCCCAGCTT CTGCAAGGGCCTGATGAGGCTGCTCTGCCCCTGACCCAGGCACCACTGCCCCATGTGCGTCCTCATCTGCCATCTACCCTGTGCCCAGGG ACTTACCCAGTGGCCCGGCGTCCAGTGGGGAACTTGAGTACCGGCCGTGCACAGGGGCTGGGGGGCCTTCTGGAAACTCCCTTGTCAACT CAGCCAGCCGCTGCTGACTGGCCACCTTCAGAGACCCTCTTCCCCACACTGGCTACTTAGATACCGGCCTTGGCAGAAGGCCACCCCTCC GGACACCCACTGGTTTAAAAGAGCCCAGGGGTCTGGCCCTGCCTTAGGGCTGTGGTGGGTGTGCTGCAGGCTCAGCTCGACAGCCCTGCC AGGAGCCCGGAAGTGGGTCCGCACGAGACAGAATAGACTACACTCAAACTCCAGGGGAACCGTTCATTGGGCTTGGACACGAAGGCGGGA >43321_43321_4_KNDC1-CRIP1_KNDC1_chr10_134996878_ENST00000304613_CRIP1_chr14_105954667_ENST00000551180_length(amino acids)=231AA_BP=1 MQLPWHSPAHTRMYTHRFSKCSGLLRALGATREPWASGDKAWHLPGQWPCKQPRMGSPPPGLLESVALGSAPPKAFRPKHGCVAGVVAVG FAFVLKVRPVPGVLRLHPAQQRLEVLAQPGFQCGLCHVLEGGLSKVFPVTSNSGGTKAPSGSSLSCSMKHTFPLVLKARVSGVMHRLWKM -------------------------------------------------------------- >43321_43321_5_KNDC1-CRIP1_KNDC1_chr10_134996878_ENST00000368571_CRIP1_chr14_105954667_ENST00000330233_length(transcript)=804nt_BP=571nt GTTCCGTGGCTCTGACGTCCAGGGAACAGCAGGACGACTCTTGAAACAAAATGAGACGTGGTCTAAAGCCCTTTCCCTGACCCACGCGTT GAAACGCTGCCACGAGTCGTCCGTTTCCCCAGGGAATCGTCTCGGTGGGGGTGCCGGGGCCTGGCTGGGGGTCCTGCCGGGCTCACGGCC AGGGCCGGTCTTGGCAGGAGAACGTGTCTCTGGCTGACATCCTCTCCCTGCGGGACCGCGGCCTCAGCGAGCAGGAAGCCTGGGCCGTGT GCCTGGAGTGCAGCCTGTCCATGCGGAGCGTGGCCCACGCCGCCATCTTCCAGAGCCTGTGCATCACGCCCGACACCCTGGCCTTCAACA CCAGCGGGAACGTGTGTTTCATGGAGCAGCTCAGCGACGACCCTGAGGGTGCCTTCGTTCCCCCCGAGTTCGACGTGACCGGGAACACCT TTGAGAGGCCGCCCTCGAGTACGTGGCAGAGCCCACACTGGAACCCAGGCTGAGCCAAGACCTCGAGGCGCTGCTGAGCCGGATGCAGGC GGAGGACCCCGGGGACCGGCCGGACCTTGAGCACGAAGGCAAACCCTACTGCAACCACCCCTGCTACGCAGCCATGTTTGGGCCTAAAGG CTTTGGGCGGGGCGGAGCCGAGAGCCACACTTTCAAGTAAACCAGGTGGTGGAGACCCCATCCTTGGCTGCTTGCAGGGCCACTGTCCAG >43321_43321_5_KNDC1-CRIP1_KNDC1_chr10_134996878_ENST00000368571_CRIP1_chr14_105954667_ENST00000330233_length(amino acids)=182AA_BP=1 MRSRGGCSRVCLRAQGPAGPRGPPPASGSAAPRGLGSAWVPVWALPRTRGRPLKGVPGHVELGGNEGTLRVVAELLHETHVPAGVEGQGV GRDAQALEDGGVGHAPHGQAALQAHGPGFLLAEAAVPQGEDVSQRHVLLPRPALAVSPAGPPARPRHPHRDDSLGKRTTRGSVSTRGSGK -------------------------------------------------------------- >43321_43321_6_KNDC1-CRIP1_KNDC1_chr10_134996878_ENST00000368571_CRIP1_chr14_105954667_ENST00000392531_length(transcript)=804nt_BP=571nt GTTCCGTGGCTCTGACGTCCAGGGAACAGCAGGACGACTCTTGAAACAAAATGAGACGTGGTCTAAAGCCCTTTCCCTGACCCACGCGTT GAAACGCTGCCACGAGTCGTCCGTTTCCCCAGGGAATCGTCTCGGTGGGGGTGCCGGGGCCTGGCTGGGGGTCCTGCCGGGCTCACGGCC AGGGCCGGTCTTGGCAGGAGAACGTGTCTCTGGCTGACATCCTCTCCCTGCGGGACCGCGGCCTCAGCGAGCAGGAAGCCTGGGCCGTGT GCCTGGAGTGCAGCCTGTCCATGCGGAGCGTGGCCCACGCCGCCATCTTCCAGAGCCTGTGCATCACGCCCGACACCCTGGCCTTCAACA CCAGCGGGAACGTGTGTTTCATGGAGCAGCTCAGCGACGACCCTGAGGGTGCCTTCGTTCCCCCCGAGTTCGACGTGACCGGGAACACCT TTGAGAGGCCGCCCTCGAGTACGTGGCAGAGCCCACACTGGAACCCAGGCTGAGCCAAGACCTCGAGGCGCTGCTGAGCCGGATGCAGGC GGAGGACCCCGGGGACCGGCCGGACCTTGAGCACGAAGGCAAACCCTACTGCAACCACCCCTGCTACGCAGCCATGTTTGGGCCTAAAGG CTTTGGGCGGGGCGGAGCCGAGAGCCACACTTTCAAGTAAACCAGGTGGTGGAGACCCCATCCTTGGCTGCTTGCAGGGCCACTGTCCAG >43321_43321_6_KNDC1-CRIP1_KNDC1_chr10_134996878_ENST00000368571_CRIP1_chr14_105954667_ENST00000392531_length(amino acids)=182AA_BP=1 MRSRGGCSRVCLRAQGPAGPRGPPPASGSAAPRGLGSAWVPVWALPRTRGRPLKGVPGHVELGGNEGTLRVVAELLHETHVPAGVEGQGV GRDAQALEDGGVGHAPHGQAALQAHGPGFLLAEAAVPQGEDVSQRHVLLPRPALAVSPAGPPARPRHPHRDDSLGKRTTRGSVSTRGSGK -------------------------------------------------------------- >43321_43321_7_KNDC1-CRIP1_KNDC1_chr10_134996878_ENST00000368571_CRIP1_chr14_105954667_ENST00000409393_length(transcript)=960nt_BP=571nt GTTCCGTGGCTCTGACGTCCAGGGAACAGCAGGACGACTCTTGAAACAAAATGAGACGTGGTCTAAAGCCCTTTCCCTGACCCACGCGTT GAAACGCTGCCACGAGTCGTCCGTTTCCCCAGGGAATCGTCTCGGTGGGGGTGCCGGGGCCTGGCTGGGGGTCCTGCCGGGCTCACGGCC AGGGCCGGTCTTGGCAGGAGAACGTGTCTCTGGCTGACATCCTCTCCCTGCGGGACCGCGGCCTCAGCGAGCAGGAAGCCTGGGCCGTGT GCCTGGAGTGCAGCCTGTCCATGCGGAGCGTGGCCCACGCCGCCATCTTCCAGAGCCTGTGCATCACGCCCGACACCCTGGCCTTCAACA CCAGCGGGAACGTGTGTTTCATGGAGCAGCTCAGCGACGACCCTGAGGGTGCCTTCGTTCCCCCCGAGTTCGACGTGACCGGGAACACCT TTGAGAGGCCGCCCTCGAGTACGTGGCAGAGCCCACACTGGAACCCAGGCTGAGCCAAGACCTCGAGGCGCTGCTGAGCCGGATGCAGGC GGAGGACCCCGGGGACCGGCCGGACCTTGAGCACGAAGGCAAACCCTACTGCAACCACCCCTGCTACGCAGCCATGTTTGGGCCTAAAGG CTTTGGGCGGGGCGGAGCCGAGAGCCACACTTTCAAGTAAACCAGGTGGTGGAGACCCCATCCTTGGCTGCTTGCAGGGCCACTGTCCAG GCAAATGCCAGGCCTTGTCCCCAGATGCCCAGGGCTCCCTTGTTGCCCCTAATGCTCTCAGTAAACCTGAACACTTGGAAAACCTGTGTG TGTACATGCGCGTGTGTGCTGGGGAGTGCCAAGGGAGCTGCAGTGGGGTCCTGGCAGCAGGCTCTGCCACCGGCGCCTGCTCTTCTGCTG >43321_43321_7_KNDC1-CRIP1_KNDC1_chr10_134996878_ENST00000368571_CRIP1_chr14_105954667_ENST00000409393_length(amino acids)=182AA_BP=1 MRSRGGCSRVCLRAQGPAGPRGPPPASGSAAPRGLGSAWVPVWALPRTRGRPLKGVPGHVELGGNEGTLRVVAELLHETHVPAGVEGQGV GRDAQALEDGGVGHAPHGQAALQAHGPGFLLAEAAVPQGEDVSQRHVLLPRPALAVSPAGPPARPRHPHRDDSLGKRTTRGSVSTRGSGK -------------------------------------------------------------- >43321_43321_8_KNDC1-CRIP1_KNDC1_chr10_134996878_ENST00000368571_CRIP1_chr14_105954667_ENST00000551180_length(transcript)=1511nt_BP=571nt GTTCCGTGGCTCTGACGTCCAGGGAACAGCAGGACGACTCTTGAAACAAAATGAGACGTGGTCTAAAGCCCTTTCCCTGACCCACGCGTT GAAACGCTGCCACGAGTCGTCCGTTTCCCCAGGGAATCGTCTCGGTGGGGGTGCCGGGGCCTGGCTGGGGGTCCTGCCGGGCTCACGGCC AGGGCCGGTCTTGGCAGGAGAACGTGTCTCTGGCTGACATCCTCTCCCTGCGGGACCGCGGCCTCAGCGAGCAGGAAGCCTGGGCCGTGT GCCTGGAGTGCAGCCTGTCCATGCGGAGCGTGGCCCACGCCGCCATCTTCCAGAGCCTGTGCATCACGCCCGACACCCTGGCCTTCAACA CCAGCGGGAACGTGTGTTTCATGGAGCAGCTCAGCGACGACCCTGAGGGTGCCTTCGTTCCCCCCGAGTTCGACGTGACCGGGAACACCT TTGAGAGGCCGCCCTCGAGTACGTGGCAGAGCCCACACTGGAACCCAGGCTGAGCCAAGACCTCGAGGCGCTGCTGAGCCGGATGCAGGC GGAGGACCCCGGGGACCGGCCGGACCTTGAGCACGAAGGCAAACCCTACTGCAACCACCCCTGCTACGCAGCCATGTTTGGGCCTAAAGG CTTTGGGCGGGGCGGAGCCGAGAGCCACACTTTCAAGTAAACCAGGTGGTGGAGACCCCATCCTTGGCTGCTTGCAGGGCCACTGTCCAG GCAAATGCCAGGCCTTGTCCCCAGATGCCCAGGGCTCCCTTGTTGCCCCTAATGCTCTCAGTAAACCTGAACACTTGGAAAACCTGTGTG TGTACATGCGCGTGTGTGCTGGGGAGTGCCAAGGGAGCTGCAGTGGGGTCCTGGCAGCAGGCTCTGCCACCGGCGCCTGCTCTTCTGCTG CCCATTGCCCTCCCCAGGGGGCCGTTCCAGGGTCTCATAGGCGAGGGCTCCCTGTGCAGGGCCAGGCCCAGCTTCTGCAAGGGCCTGATG AGGCTGCTCTGCCCCTGACCCAGGCACCACTGCCCCATGTGCGTCCTCATCTGCCATCTACCCTGTGCCCAGGGACTTACCCAGTGGCCC GGCGTCCAGTGGGGAACTTGAGTACCGGCCGTGCACAGGGGCTGGGGGGCCTTCTGGAAACTCCCTTGTCAACTCAGCCAGCCGCTGCTG ACTGGCCACCTTCAGAGACCCTCTTCCCCACACTGGCTACTTAGATACCGGCCTTGGCAGAAGGCCACCCCTCCGGACACCCACTGGTTT AAAAGAGCCCAGGGGTCTGGCCCTGCCTTAGGGCTGTGGTGGGTGTGCTGCAGGCTCAGCTCGACAGCCCTGCCAGGAGCCCGGAAGTGG GTCCGCACGAGACAGAATAGACTACACTCAAACTCCAGGGGAACCGTTCATTGGGCTTGGACACGAAGGCGGGACCCTGCCGACGCAGTG >43321_43321_8_KNDC1-CRIP1_KNDC1_chr10_134996878_ENST00000368571_CRIP1_chr14_105954667_ENST00000551180_length(amino acids)=226AA_BP=1 MQLPWHSPAHTRMYTHRFSKCSGLLRALGATREPWASGDKAWHLPGQWPCKQPRMGSPPPGLLESVALGSAPPKAFRPKHGCVAGVVAVG FAFVLKVRPVPGVLRLHPAQQRLEVLAQPGFQCGLCHVLEGGLSKVFPVTSNSGGTKAPSGSSLSCSMKHTFPLVLKARVSGVMHRLWKM -------------------------------------------------------------- >43321_43321_9_KNDC1-CRIP1_KNDC1_chr10_134996878_ENST00000368572_CRIP1_chr14_105954667_ENST00000330233_length(transcript)=710nt_BP=477nt GATGCAGGCCATGGACCCGGCCGCGGCGGATCTTTACGAGGAGGACGGCAAAGACCTGGACTTCTACGACTTCGAGCCGCTGCCCACCCT CCCCGAGGACGAGGAGAACGTGTCTCTGGCTGACATCCTCTCCCTGCGGGACCGCGGCCTCAGCGAGCAGGAAGCCTGGGCCGTGTGCCT GGAGTGCAGCCTGTCCATGCGGAGCGTGGCCCACGCCGCCATCTTCCAGAGCCTGTGCATCACGCCCGACACCCTGGCCTTCAACACCAG CGGGAACGTGTGTTTCATGGAGCAGCTCAGCGACGACCCTGAGGGTGCCTTCGTTCCCCCCGAGTTCGACGTGACCGGGAACACCTTTGA GAGGCCGCCCTCGAGTACGTGGCAGAGCCCACACTGGAACCCAGGCTGAGCCAAGACCTCGAGGCGCTGCTGAGCCGGATGCAGGCGGAG GACCCCGGGGACCGGCCGGACCTTGAGCACGAAGGCAAACCCTACTGCAACCACCCCTGCTACGCAGCCATGTTTGGGCCTAAAGGCTTT GGGCGGGGCGGAGCCGAGAGCCACACTTTCAAGTAAACCAGGTGGTGGAGACCCCATCCTTGGCTGCTTGCAGGGCCACTGTCCAGGCAA >43321_43321_9_KNDC1-CRIP1_KNDC1_chr10_134996878_ENST00000368572_CRIP1_chr14_105954667_ENST00000330233_length(amino acids)=172AA_BP=1 MRSRGGCSRVCLRAQGPAGPRGPPPASGSAAPRGLGSAWVPVWALPRTRGRPLKGVPGHVELGGNEGTLRVVAELLHETHVPAGVEGQGV -------------------------------------------------------------- >43321_43321_10_KNDC1-CRIP1_KNDC1_chr10_134996878_ENST00000368572_CRIP1_chr14_105954667_ENST00000392531_length(transcript)=710nt_BP=477nt GATGCAGGCCATGGACCCGGCCGCGGCGGATCTTTACGAGGAGGACGGCAAAGACCTGGACTTCTACGACTTCGAGCCGCTGCCCACCCT CCCCGAGGACGAGGAGAACGTGTCTCTGGCTGACATCCTCTCCCTGCGGGACCGCGGCCTCAGCGAGCAGGAAGCCTGGGCCGTGTGCCT GGAGTGCAGCCTGTCCATGCGGAGCGTGGCCCACGCCGCCATCTTCCAGAGCCTGTGCATCACGCCCGACACCCTGGCCTTCAACACCAG CGGGAACGTGTGTTTCATGGAGCAGCTCAGCGACGACCCTGAGGGTGCCTTCGTTCCCCCCGAGTTCGACGTGACCGGGAACACCTTTGA GAGGCCGCCCTCGAGTACGTGGCAGAGCCCACACTGGAACCCAGGCTGAGCCAAGACCTCGAGGCGCTGCTGAGCCGGATGCAGGCGGAG GACCCCGGGGACCGGCCGGACCTTGAGCACGAAGGCAAACCCTACTGCAACCACCCCTGCTACGCAGCCATGTTTGGGCCTAAAGGCTTT GGGCGGGGCGGAGCCGAGAGCCACACTTTCAAGTAAACCAGGTGGTGGAGACCCCATCCTTGGCTGCTTGCAGGGCCACTGTCCAGGCAA >43321_43321_10_KNDC1-CRIP1_KNDC1_chr10_134996878_ENST00000368572_CRIP1_chr14_105954667_ENST00000392531_length(amino acids)=172AA_BP=1 MRSRGGCSRVCLRAQGPAGPRGPPPASGSAAPRGLGSAWVPVWALPRTRGRPLKGVPGHVELGGNEGTLRVVAELLHETHVPAGVEGQGV -------------------------------------------------------------- >43321_43321_11_KNDC1-CRIP1_KNDC1_chr10_134996878_ENST00000368572_CRIP1_chr14_105954667_ENST00000409393_length(transcript)=866nt_BP=477nt GATGCAGGCCATGGACCCGGCCGCGGCGGATCTTTACGAGGAGGACGGCAAAGACCTGGACTTCTACGACTTCGAGCCGCTGCCCACCCT CCCCGAGGACGAGGAGAACGTGTCTCTGGCTGACATCCTCTCCCTGCGGGACCGCGGCCTCAGCGAGCAGGAAGCCTGGGCCGTGTGCCT GGAGTGCAGCCTGTCCATGCGGAGCGTGGCCCACGCCGCCATCTTCCAGAGCCTGTGCATCACGCCCGACACCCTGGCCTTCAACACCAG CGGGAACGTGTGTTTCATGGAGCAGCTCAGCGACGACCCTGAGGGTGCCTTCGTTCCCCCCGAGTTCGACGTGACCGGGAACACCTTTGA GAGGCCGCCCTCGAGTACGTGGCAGAGCCCACACTGGAACCCAGGCTGAGCCAAGACCTCGAGGCGCTGCTGAGCCGGATGCAGGCGGAG GACCCCGGGGACCGGCCGGACCTTGAGCACGAAGGCAAACCCTACTGCAACCACCCCTGCTACGCAGCCATGTTTGGGCCTAAAGGCTTT GGGCGGGGCGGAGCCGAGAGCCACACTTTCAAGTAAACCAGGTGGTGGAGACCCCATCCTTGGCTGCTTGCAGGGCCACTGTCCAGGCAA ATGCCAGGCCTTGTCCCCAGATGCCCAGGGCTCCCTTGTTGCCCCTAATGCTCTCAGTAAACCTGAACACTTGGAAAACCTGTGTGTGTA CATGCGCGTGTGTGCTGGGGAGTGCCAAGGGAGCTGCAGTGGGGTCCTGGCAGCAGGCTCTGCCACCGGCGCCTGCTCTTCTGCTGCCCA >43321_43321_11_KNDC1-CRIP1_KNDC1_chr10_134996878_ENST00000368572_CRIP1_chr14_105954667_ENST00000409393_length(amino acids)=172AA_BP=1 MRSRGGCSRVCLRAQGPAGPRGPPPASGSAAPRGLGSAWVPVWALPRTRGRPLKGVPGHVELGGNEGTLRVVAELLHETHVPAGVEGQGV -------------------------------------------------------------- >43321_43321_12_KNDC1-CRIP1_KNDC1_chr10_134996878_ENST00000368572_CRIP1_chr14_105954667_ENST00000551180_length(transcript)=1417nt_BP=477nt GATGCAGGCCATGGACCCGGCCGCGGCGGATCTTTACGAGGAGGACGGCAAAGACCTGGACTTCTACGACTTCGAGCCGCTGCCCACCCT CCCCGAGGACGAGGAGAACGTGTCTCTGGCTGACATCCTCTCCCTGCGGGACCGCGGCCTCAGCGAGCAGGAAGCCTGGGCCGTGTGCCT GGAGTGCAGCCTGTCCATGCGGAGCGTGGCCCACGCCGCCATCTTCCAGAGCCTGTGCATCACGCCCGACACCCTGGCCTTCAACACCAG CGGGAACGTGTGTTTCATGGAGCAGCTCAGCGACGACCCTGAGGGTGCCTTCGTTCCCCCCGAGTTCGACGTGACCGGGAACACCTTTGA GAGGCCGCCCTCGAGTACGTGGCAGAGCCCACACTGGAACCCAGGCTGAGCCAAGACCTCGAGGCGCTGCTGAGCCGGATGCAGGCGGAG GACCCCGGGGACCGGCCGGACCTTGAGCACGAAGGCAAACCCTACTGCAACCACCCCTGCTACGCAGCCATGTTTGGGCCTAAAGGCTTT GGGCGGGGCGGAGCCGAGAGCCACACTTTCAAGTAAACCAGGTGGTGGAGACCCCATCCTTGGCTGCTTGCAGGGCCACTGTCCAGGCAA ATGCCAGGCCTTGTCCCCAGATGCCCAGGGCTCCCTTGTTGCCCCTAATGCTCTCAGTAAACCTGAACACTTGGAAAACCTGTGTGTGTA CATGCGCGTGTGTGCTGGGGAGTGCCAAGGGAGCTGCAGTGGGGTCCTGGCAGCAGGCTCTGCCACCGGCGCCTGCTCTTCTGCTGCCCA TTGCCCTCCCCAGGGGGCCGTTCCAGGGTCTCATAGGCGAGGGCTCCCTGTGCAGGGCCAGGCCCAGCTTCTGCAAGGGCCTGATGAGGC TGCTCTGCCCCTGACCCAGGCACCACTGCCCCATGTGCGTCCTCATCTGCCATCTACCCTGTGCCCAGGGACTTACCCAGTGGCCCGGCG TCCAGTGGGGAACTTGAGTACCGGCCGTGCACAGGGGCTGGGGGGCCTTCTGGAAACTCCCTTGTCAACTCAGCCAGCCGCTGCTGACTG GCCACCTTCAGAGACCCTCTTCCCCACACTGGCTACTTAGATACCGGCCTTGGCAGAAGGCCACCCCTCCGGACACCCACTGGTTTAAAA GAGCCCAGGGGTCTGGCCCTGCCTTAGGGCTGTGGTGGGTGTGCTGCAGGCTCAGCTCGACAGCCCTGCCAGGAGCCCGGAAGTGGGTCC GCACGAGACAGAATAGACTACACTCAAACTCCAGGGGAACCGTTCATTGGGCTTGGACACGAAGGCGGGACCCTGCCGACGCAGTGATTG >43321_43321_12_KNDC1-CRIP1_KNDC1_chr10_134996878_ENST00000368572_CRIP1_chr14_105954667_ENST00000551180_length(amino acids)=231AA_BP=1 MQLPWHSPAHTRMYTHRFSKCSGLLRALGATREPWASGDKAWHLPGQWPCKQPRMGSPPPGLLESVALGSAPPKAFRPKHGCVAGVVAVG FAFVLKVRPVPGVLRLHPAQQRLEVLAQPGFQCGLCHVLEGGLSKVFPVTSNSGGTKAPSGSSLSCSMKHTFPLVLKARVSGVMHRLWKM -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for KNDC1-CRIP1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for KNDC1-CRIP1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for KNDC1-CRIP1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies