
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:KPNA1-GOLGB1 (FusionGDB2 ID:43361) |
Fusion Gene Summary for KPNA1-GOLGB1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: KPNA1-GOLGB1 | Fusion gene ID: 43361 | Hgene | Tgene | Gene symbol | KPNA1 | GOLGB1 | Gene ID | 3836 | 2804 |
| Gene name | karyopherin subunit alpha 1 | golgin B1 | |
| Synonyms | IPOA5|NPI-1|RCH2|SRP1 | GCP|GCP372|GOLIM1 | |
| Cytomap | 3q21.1 | 3q13.33 | |
| Type of gene | protein-coding | protein-coding | |
| Description | importin subunit alpha-5RAG cohort protein 2SRP1-betaimportin alpha 5importin subunit alpha-1importin-alpha-S1karyopherin alpha 1 (importin alpha 5)nucleoprotein interactor 1recombination activating gene cohort 2 | golgin subfamily B member 1372 kDa Golgi complex-associated proteingiantingolgi autoantigen, golgin subfamily b, macrogolgin (with transmembrane signal), 1golgi integral membrane protein 1golgin B1, golgi integral membrane protein | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | P52294 | Q14789 | |
| Ensembl transtripts involved in fusion gene | ENST00000344337, ENST00000466923, | ENST00000472829, ENST00000340645, ENST00000393667, | |
| Fusion gene scores | * DoF score | 19 X 10 X 13=2470 | 12 X 11 X 4=528 |
| # samples | 26 | 13 | |
| ** MAII score | log2(26/2470*10)=-3.24792751344359 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(13/528*10)=-2.02202630633 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: KPNA1 [Title/Abstract] AND GOLGB1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | KPNA1(122215283)-GOLGB1(121388202), # samples:1 KPNA1(122215284)-GOLGB1(121388202), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across KPNA1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
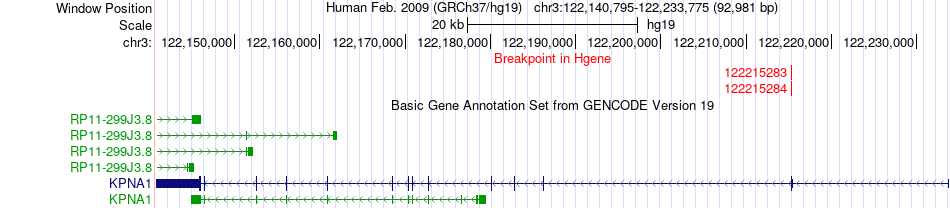 |
| Fusion gene breakpoints across GOLGB1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-A2-A04U-01A | KPNA1 | chr3 | 122215284 | - | GOLGB1 | chr3 | 121388202 | - |
| ChimerDB4 | BRCA | TCGA-A2-A04U | KPNA1 | chr3 | 122215283 | - | GOLGB1 | chr3 | 121388202 | - |
Top |
Fusion Gene ORF analysis for KPNA1-GOLGB1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000344337 | ENST00000472829 | KPNA1 | chr3 | 122215284 | - | GOLGB1 | chr3 | 121388202 | - |
| 5CDS-intron | ENST00000344337 | ENST00000472829 | KPNA1 | chr3 | 122215283 | - | GOLGB1 | chr3 | 121388202 | - |
| In-frame | ENST00000344337 | ENST00000340645 | KPNA1 | chr3 | 122215284 | - | GOLGB1 | chr3 | 121388202 | - |
| In-frame | ENST00000344337 | ENST00000340645 | KPNA1 | chr3 | 122215283 | - | GOLGB1 | chr3 | 121388202 | - |
| In-frame | ENST00000344337 | ENST00000393667 | KPNA1 | chr3 | 122215284 | - | GOLGB1 | chr3 | 121388202 | - |
| In-frame | ENST00000344337 | ENST00000393667 | KPNA1 | chr3 | 122215283 | - | GOLGB1 | chr3 | 121388202 | - |
| intron-3CDS | ENST00000466923 | ENST00000340645 | KPNA1 | chr3 | 122215284 | - | GOLGB1 | chr3 | 121388202 | - |
| intron-3CDS | ENST00000466923 | ENST00000340645 | KPNA1 | chr3 | 122215283 | - | GOLGB1 | chr3 | 121388202 | - |
| intron-3CDS | ENST00000466923 | ENST00000393667 | KPNA1 | chr3 | 122215284 | - | GOLGB1 | chr3 | 121388202 | - |
| intron-3CDS | ENST00000466923 | ENST00000393667 | KPNA1 | chr3 | 122215283 | - | GOLGB1 | chr3 | 121388202 | - |
| intron-intron | ENST00000466923 | ENST00000472829 | KPNA1 | chr3 | 122215284 | - | GOLGB1 | chr3 | 121388202 | - |
| intron-intron | ENST00000466923 | ENST00000472829 | KPNA1 | chr3 | 122215283 | - | GOLGB1 | chr3 | 121388202 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000344337 | KPNA1 | chr3 | 122215283 | - | ENST00000340645 | GOLGB1 | chr3 | 121388202 | - | 2205 | 306 | 51 | 923 | 290 |
| ENST00000344337 | KPNA1 | chr3 | 122215283 | - | ENST00000393667 | GOLGB1 | chr3 | 121388202 | - | 2216 | 306 | 51 | 938 | 295 |
| ENST00000344337 | KPNA1 | chr3 | 122215284 | - | ENST00000340645 | GOLGB1 | chr3 | 121388202 | - | 2205 | 306 | 51 | 923 | 290 |
| ENST00000344337 | KPNA1 | chr3 | 122215284 | - | ENST00000393667 | GOLGB1 | chr3 | 121388202 | - | 2216 | 306 | 51 | 938 | 295 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000344337 | ENST00000340645 | KPNA1 | chr3 | 122215283 | - | GOLGB1 | chr3 | 121388202 | - | 0.013991602 | 0.98600835 |
| ENST00000344337 | ENST00000393667 | KPNA1 | chr3 | 122215283 | - | GOLGB1 | chr3 | 121388202 | - | 0.014591682 | 0.98540837 |
| ENST00000344337 | ENST00000340645 | KPNA1 | chr3 | 122215284 | - | GOLGB1 | chr3 | 121388202 | - | 0.013991602 | 0.98600835 |
| ENST00000344337 | ENST00000393667 | KPNA1 | chr3 | 122215284 | - | GOLGB1 | chr3 | 121388202 | - | 0.014591682 | 0.98540837 |
Top |
Fusion Genomic Features for KPNA1-GOLGB1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
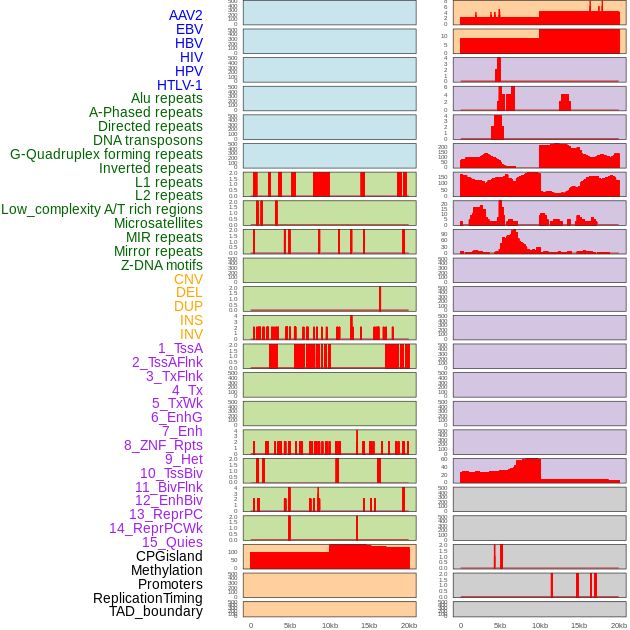 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for KPNA1-GOLGB1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr3:122215283/chr3:121388202) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| KPNA1 | GOLGB1 |
| FUNCTION: Functions in nuclear protein import as an adapter protein for nuclear receptor KPNB1. Binds specifically and directly to substrates containing either a simple or bipartite NLS motif. Docking of the importin/substrate complex to the nuclear pore complex (NPC) is mediated by KPNB1 through binding to nucleoporin FxFG repeats and the complex is subsequently translocated through the pore by an energy requiring, Ran-dependent mechanism. At the nucleoplasmic side of the NPC, Ran binds to importin-beta and the three components separate and importin-alpha and -beta are re-exported from the nucleus to the cytoplasm where GTP hydrolysis releases Ran from importin. The directionality of nuclear import is thought to be conferred by an asymmetric distribution of the GTP- and GDP-bound forms of Ran between the cytoplasm and nucleus. In vitro, mediates the nuclear import of human cytomegalovirus UL84 by recognizing a non-classical NLS. | FUNCTION: May participate in forming intercisternal cross-bridges of the Golgi complex. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | KPNA1 | chr3:122215283 | chr3:121388202 | ENST00000344337 | - | 2 | 14 | 25_28 | 43 | 539.0 | Compositional bias | Note=Poly-Arg |
| Hgene | KPNA1 | chr3:122215284 | chr3:121388202 | ENST00000344337 | - | 2 | 14 | 25_28 | 43 | 539.0 | Compositional bias | Note=Poly-Arg |
| Tgene | GOLGB1 | chr3:122215283 | chr3:121388202 | ENST00000340645 | 16 | 22 | 3257_3259 | 3054 | 3260.0 | Topological domain | Lumenal | |
| Tgene | GOLGB1 | chr3:122215283 | chr3:121388202 | ENST00000393667 | 16 | 22 | 3257_3259 | 3059 | 3270.0 | Topological domain | Lumenal | |
| Tgene | GOLGB1 | chr3:122215284 | chr3:121388202 | ENST00000340645 | 16 | 22 | 3257_3259 | 3054 | 3260.0 | Topological domain | Lumenal | |
| Tgene | GOLGB1 | chr3:122215284 | chr3:121388202 | ENST00000393667 | 16 | 22 | 3257_3259 | 3059 | 3270.0 | Topological domain | Lumenal | |
| Tgene | GOLGB1 | chr3:122215283 | chr3:121388202 | ENST00000340645 | 16 | 22 | 3236_3256 | 3054 | 3260.0 | Transmembrane | Helical | |
| Tgene | GOLGB1 | chr3:122215283 | chr3:121388202 | ENST00000393667 | 16 | 22 | 3236_3256 | 3059 | 3270.0 | Transmembrane | Helical | |
| Tgene | GOLGB1 | chr3:122215284 | chr3:121388202 | ENST00000340645 | 16 | 22 | 3236_3256 | 3054 | 3260.0 | Transmembrane | Helical | |
| Tgene | GOLGB1 | chr3:122215284 | chr3:121388202 | ENST00000393667 | 16 | 22 | 3236_3256 | 3059 | 3270.0 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | KPNA1 | chr3:122215283 | chr3:121388202 | ENST00000344337 | - | 2 | 14 | 1_57 | 43 | 539.0 | Domain | IBB |
| Hgene | KPNA1 | chr3:122215284 | chr3:121388202 | ENST00000344337 | - | 2 | 14 | 1_57 | 43 | 539.0 | Domain | IBB |
| Hgene | KPNA1 | chr3:122215283 | chr3:121388202 | ENST00000344337 | - | 2 | 14 | 42_51 | 43 | 539.0 | Motif | Nuclear localization signal |
| Hgene | KPNA1 | chr3:122215284 | chr3:121388202 | ENST00000344337 | - | 2 | 14 | 42_51 | 43 | 539.0 | Motif | Nuclear localization signal |
| Hgene | KPNA1 | chr3:122215283 | chr3:121388202 | ENST00000344337 | - | 2 | 14 | 149_241 | 43 | 539.0 | Region | NLS binding site (major) |
| Hgene | KPNA1 | chr3:122215283 | chr3:121388202 | ENST00000344337 | - | 2 | 14 | 245_437 | 43 | 539.0 | Region | Note=Binding to RAG1 |
| Hgene | KPNA1 | chr3:122215283 | chr3:121388202 | ENST00000344337 | - | 2 | 14 | 318_406 | 43 | 539.0 | Region | NLS binding site (minor) |
| Hgene | KPNA1 | chr3:122215284 | chr3:121388202 | ENST00000344337 | - | 2 | 14 | 149_241 | 43 | 539.0 | Region | NLS binding site (major) |
| Hgene | KPNA1 | chr3:122215284 | chr3:121388202 | ENST00000344337 | - | 2 | 14 | 245_437 | 43 | 539.0 | Region | Note=Binding to RAG1 |
| Hgene | KPNA1 | chr3:122215284 | chr3:121388202 | ENST00000344337 | - | 2 | 14 | 318_406 | 43 | 539.0 | Region | NLS binding site (minor) |
| Hgene | KPNA1 | chr3:122215283 | chr3:121388202 | ENST00000344337 | - | 2 | 14 | 118_161 | 43 | 539.0 | Repeat | Note=ARM 2 |
| Hgene | KPNA1 | chr3:122215283 | chr3:121388202 | ENST00000344337 | - | 2 | 14 | 162_206 | 43 | 539.0 | Repeat | Note=ARM 3 |
| Hgene | KPNA1 | chr3:122215283 | chr3:121388202 | ENST00000344337 | - | 2 | 14 | 207_245 | 43 | 539.0 | Repeat | Note=ARM 4 |
| Hgene | KPNA1 | chr3:122215283 | chr3:121388202 | ENST00000344337 | - | 2 | 14 | 246_290 | 43 | 539.0 | Repeat | Note=ARM 5 |
| Hgene | KPNA1 | chr3:122215283 | chr3:121388202 | ENST00000344337 | - | 2 | 14 | 291_330 | 43 | 539.0 | Repeat | Note=ARM 6 |
| Hgene | KPNA1 | chr3:122215283 | chr3:121388202 | ENST00000344337 | - | 2 | 14 | 331_372 | 43 | 539.0 | Repeat | Note=ARM 7 |
| Hgene | KPNA1 | chr3:122215283 | chr3:121388202 | ENST00000344337 | - | 2 | 14 | 373_412 | 43 | 539.0 | Repeat | Note=ARM 8 |
| Hgene | KPNA1 | chr3:122215283 | chr3:121388202 | ENST00000344337 | - | 2 | 14 | 413_457 | 43 | 539.0 | Repeat | Note=ARM 9 |
| Hgene | KPNA1 | chr3:122215283 | chr3:121388202 | ENST00000344337 | - | 2 | 14 | 460_504 | 43 | 539.0 | Repeat | Note=ARM 10%3B atypical |
| Hgene | KPNA1 | chr3:122215283 | chr3:121388202 | ENST00000344337 | - | 2 | 14 | 77_117 | 43 | 539.0 | Repeat | Note=ARM 1%3B truncated |
| Hgene | KPNA1 | chr3:122215284 | chr3:121388202 | ENST00000344337 | - | 2 | 14 | 118_161 | 43 | 539.0 | Repeat | Note=ARM 2 |
| Hgene | KPNA1 | chr3:122215284 | chr3:121388202 | ENST00000344337 | - | 2 | 14 | 162_206 | 43 | 539.0 | Repeat | Note=ARM 3 |
| Hgene | KPNA1 | chr3:122215284 | chr3:121388202 | ENST00000344337 | - | 2 | 14 | 207_245 | 43 | 539.0 | Repeat | Note=ARM 4 |
| Hgene | KPNA1 | chr3:122215284 | chr3:121388202 | ENST00000344337 | - | 2 | 14 | 246_290 | 43 | 539.0 | Repeat | Note=ARM 5 |
| Hgene | KPNA1 | chr3:122215284 | chr3:121388202 | ENST00000344337 | - | 2 | 14 | 291_330 | 43 | 539.0 | Repeat | Note=ARM 6 |
| Hgene | KPNA1 | chr3:122215284 | chr3:121388202 | ENST00000344337 | - | 2 | 14 | 331_372 | 43 | 539.0 | Repeat | Note=ARM 7 |
| Hgene | KPNA1 | chr3:122215284 | chr3:121388202 | ENST00000344337 | - | 2 | 14 | 373_412 | 43 | 539.0 | Repeat | Note=ARM 8 |
| Hgene | KPNA1 | chr3:122215284 | chr3:121388202 | ENST00000344337 | - | 2 | 14 | 413_457 | 43 | 539.0 | Repeat | Note=ARM 9 |
| Hgene | KPNA1 | chr3:122215284 | chr3:121388202 | ENST00000344337 | - | 2 | 14 | 460_504 | 43 | 539.0 | Repeat | Note=ARM 10%3B atypical |
| Hgene | KPNA1 | chr3:122215284 | chr3:121388202 | ENST00000344337 | - | 2 | 14 | 77_117 | 43 | 539.0 | Repeat | Note=ARM 1%3B truncated |
| Tgene | GOLGB1 | chr3:122215283 | chr3:121388202 | ENST00000340645 | 16 | 22 | 1062_1245 | 3054 | 3260.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | GOLGB1 | chr3:122215283 | chr3:121388202 | ENST00000340645 | 16 | 22 | 1301_1779 | 3054 | 3260.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | GOLGB1 | chr3:122215283 | chr3:121388202 | ENST00000340645 | 16 | 22 | 1828_3185 | 3054 | 3260.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | GOLGB1 | chr3:122215283 | chr3:121388202 | ENST00000340645 | 16 | 22 | 48_593 | 3054 | 3260.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | GOLGB1 | chr3:122215283 | chr3:121388202 | ENST00000340645 | 16 | 22 | 677_1028 | 3054 | 3260.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | GOLGB1 | chr3:122215283 | chr3:121388202 | ENST00000393667 | 16 | 22 | 1062_1245 | 3059 | 3270.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | GOLGB1 | chr3:122215283 | chr3:121388202 | ENST00000393667 | 16 | 22 | 1301_1779 | 3059 | 3270.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | GOLGB1 | chr3:122215283 | chr3:121388202 | ENST00000393667 | 16 | 22 | 1828_3185 | 3059 | 3270.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | GOLGB1 | chr3:122215283 | chr3:121388202 | ENST00000393667 | 16 | 22 | 48_593 | 3059 | 3270.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | GOLGB1 | chr3:122215283 | chr3:121388202 | ENST00000393667 | 16 | 22 | 677_1028 | 3059 | 3270.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | GOLGB1 | chr3:122215284 | chr3:121388202 | ENST00000340645 | 16 | 22 | 1062_1245 | 3054 | 3260.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | GOLGB1 | chr3:122215284 | chr3:121388202 | ENST00000340645 | 16 | 22 | 1301_1779 | 3054 | 3260.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | GOLGB1 | chr3:122215284 | chr3:121388202 | ENST00000340645 | 16 | 22 | 1828_3185 | 3054 | 3260.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | GOLGB1 | chr3:122215284 | chr3:121388202 | ENST00000340645 | 16 | 22 | 48_593 | 3054 | 3260.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | GOLGB1 | chr3:122215284 | chr3:121388202 | ENST00000340645 | 16 | 22 | 677_1028 | 3054 | 3260.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | GOLGB1 | chr3:122215284 | chr3:121388202 | ENST00000393667 | 16 | 22 | 1062_1245 | 3059 | 3270.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | GOLGB1 | chr3:122215284 | chr3:121388202 | ENST00000393667 | 16 | 22 | 1301_1779 | 3059 | 3270.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | GOLGB1 | chr3:122215284 | chr3:121388202 | ENST00000393667 | 16 | 22 | 1828_3185 | 3059 | 3270.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | GOLGB1 | chr3:122215284 | chr3:121388202 | ENST00000393667 | 16 | 22 | 48_593 | 3059 | 3270.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | GOLGB1 | chr3:122215284 | chr3:121388202 | ENST00000393667 | 16 | 22 | 677_1028 | 3059 | 3270.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | GOLGB1 | chr3:122215283 | chr3:121388202 | ENST00000340645 | 16 | 22 | 2420_2423 | 3054 | 3260.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | GOLGB1 | chr3:122215283 | chr3:121388202 | ENST00000340645 | 16 | 22 | 2993_2996 | 3054 | 3260.0 | Compositional bias | Note=Poly-Ser | |
| Tgene | GOLGB1 | chr3:122215283 | chr3:121388202 | ENST00000393667 | 16 | 22 | 2420_2423 | 3059 | 3270.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | GOLGB1 | chr3:122215283 | chr3:121388202 | ENST00000393667 | 16 | 22 | 2993_2996 | 3059 | 3270.0 | Compositional bias | Note=Poly-Ser | |
| Tgene | GOLGB1 | chr3:122215284 | chr3:121388202 | ENST00000340645 | 16 | 22 | 2420_2423 | 3054 | 3260.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | GOLGB1 | chr3:122215284 | chr3:121388202 | ENST00000340645 | 16 | 22 | 2993_2996 | 3054 | 3260.0 | Compositional bias | Note=Poly-Ser | |
| Tgene | GOLGB1 | chr3:122215284 | chr3:121388202 | ENST00000393667 | 16 | 22 | 2420_2423 | 3059 | 3270.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | GOLGB1 | chr3:122215284 | chr3:121388202 | ENST00000393667 | 16 | 22 | 2993_2996 | 3059 | 3270.0 | Compositional bias | Note=Poly-Ser | |
| Tgene | GOLGB1 | chr3:122215283 | chr3:121388202 | ENST00000340645 | 16 | 22 | 1_3235 | 3054 | 3260.0 | Topological domain | Cytoplasmic | |
| Tgene | GOLGB1 | chr3:122215283 | chr3:121388202 | ENST00000393667 | 16 | 22 | 1_3235 | 3059 | 3270.0 | Topological domain | Cytoplasmic | |
| Tgene | GOLGB1 | chr3:122215284 | chr3:121388202 | ENST00000340645 | 16 | 22 | 1_3235 | 3054 | 3260.0 | Topological domain | Cytoplasmic | |
| Tgene | GOLGB1 | chr3:122215284 | chr3:121388202 | ENST00000393667 | 16 | 22 | 1_3235 | 3059 | 3270.0 | Topological domain | Cytoplasmic |
Top |
Fusion Gene Sequence for KPNA1-GOLGB1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >43361_43361_1_KPNA1-GOLGB1_KPNA1_chr3_122215283_ENST00000344337_GOLGB1_chr3_121388202_ENST00000340645_length(transcript)=2205nt_BP=306nt GCCGGCTGAGCTGAGTCTCGCTGCTCGGTGCGAGGCGGCGGAGAGCGAGGCCTGGTGAGCACCGCCGAGGCGCGGGCCAGCTCTTCGAGG TTGTGCGCGGGAGTGGCACGGCGGGCGGGCGAGCGAGGGGCTAACTTCAGCGGTGGCACCGGGATCGGTTGCCTTGAGCCTGAAATCATG ACCACCCCAGGAAAAGAGAACTTTCGCCTGAAAAGTTACAAGAACAAATCTCTGAATCCCGATGAGATGCGCAGGAGGAGGGAGGAAGAA GGACTGCAGTTACGAAAGCAGAAAAGAGAAGAGCAGTTCTCTCAGCTACTGGAAGAGAAAAACACCCTTTCCATTCAGCTCTGCGATACC AGTCAGAGTCTTCGTGAGAACCAGCAGCACTATGGTGACCTTTTAAATCACTGTGCAGTCTTGGAGAAGCAGGTTCAAGAGCTGCAGGCG GGGCCACTAAATATAGATGTTGCTCCAGGAGCTCCCCAGGAAAAGAATGGAGTTCACAGAAAGAGTGACCCTGAGGAACTAAGGGAACCG CAGCAAAGCTTTTCTGAAGCTCAGCAGCAGCTATGCAACACCAGACAGGAAGTGAATGAATTAAGGAAGCTGCTGGAAGAAGAACGAGAC CAAAGAGTGGCTGCTGAGAATGCTCTCTCTGTGGCCGAGGAGCAGATCAGACGGTTAGAGCACAGTGAATGGGACTCTTCCCGGACTCCT ATCATTGGCTCCTGTGGCACTCAGGAGCAGGCACTGTTAATAGATCTTACAAGCAACAGTTGTCGAAGGACCCGGAGTGGCGTTGGATGG AAGCGAGTCCTGCGTTCACTCTGTCATTCACGGACCCGAGTGCCACTTCTAGCAGCCATCTACTTTCTAATGATTCATGTCCTGCTCATT CTGTGTTTTACGGGCCATCTATAGACTTAGTTGTTACTCTTTGGACCACTCCCCTCAAAACTTGGAATTCTCTCACCTCTAACATCAGAA CATCAATTCCAGTGGAACAGTCTTCCCATTTACAGGTCTTCTCTCCAACTCTTCACGGAAAGTGCCTGCAAAAACAGAGGTGGATACGAG GACAGGTTGGAGCTGCAGGGACTGGCGAGTCTGCTTTCTTCTACTGCCCTGAGCCTGAACGCTTCTGCTTAATCTGAGAATCACATTTGG TTTGTTGAGCCTAATATTTGTTGAGATTTTGCAGGACCCTGATCTTTTGTGGTCCTGTAAAAGATACTGAGGAATGTCTTTCAGCCAAGC CAAGAGGATGGTTTCAATAAACCTAATAATCTGAAGTTCAGTATCATTTTGATTGATAACTTTCTTTGCCTTGTTTGCCTGTATTTTCTC CTGTTTCAGGGGGAAGGTGGCTCTGCCATAAACAGAGTTCAGGGAAATGAACATGTCACCTCATAGGACATCTGATTTAGGTCTCTTGCA GAATAGGGTGGTGAAAGCTGAAGGAACTCCCTAGGGGTTTTAGCTGTTAGATCACATGGGAGGACAGCATCTTCTTCCCTGCCAATTTCA GATATAATTGGAGGGAGAATTTCAGGTCTTAGACTATAAGGATAGAATCCCTTTGCTTTTGCCCTTGATCACATGTATACTAAGGTATTA AGTGGCCCAAGTCTTTCCTTTCACCAAAGGGCAGGGAGAAGTGTCTATGGACAGCAGGGTTCCAATTCTTGTCATTCCAGGAATATCTGA ATATTCCTGGAATGTGGACCCTGAGACAGTGCTCAGGGGCCACTGGGAGCCAATATTAGGCATTGACTCTCAGCCAGGAGTCTGACTGGT CTAACACCACACTGCAACTCCTGACCTCTTGAAGTACTAAGCTACTTTGCTGTTAGTGACAGTTATTACAGTTTCTCAGCCCCATTGTCT CTGCCCTCTGTGGCAATGGAAGGAGAATATAGAGAAGACAAAATTAAATATAGATAGACCTGAGAAGGACAGCCAGGATAGAATTCCATT TGTGCCTATTCCCTGCCTCCCCTCCCCTCCCCCATCCTACCAGTTGGTTATTTTCTCATTGCATACGTGATGTGTTCACTGCCTAGCCTC TCCCTAAAGAAGAGAGAAGACAAGTGGGCTGACTGATCTGCTCTAAATCTACTGTGGTGATTAAATCTTGGTTACAACATCCTGGGAAGT >43361_43361_1_KPNA1-GOLGB1_KPNA1_chr3_122215283_ENST00000344337_GOLGB1_chr3_121388202_ENST00000340645_length(amino acids)=290AA_BP=84 MVSTAEARASSSRLCAGVARRAGERGANFSGGTGIGCLEPEIMTTPGKENFRLKSYKNKSLNPDEMRRRREEEGLQLRKQKREEQFSQLL EEKNTLSIQLCDTSQSLRENQQHYGDLLNHCAVLEKQVQELQAGPLNIDVAPGAPQEKNGVHRKSDPEELREPQQSFSEAQQQLCNTRQE VNELRKLLEEERDQRVAAENALSVAEEQIRRLEHSEWDSSRTPIIGSCGTQEQALLIDLTSNSCRRTRSGVGWKRVLRSLCHSRTRVPLL -------------------------------------------------------------- >43361_43361_2_KPNA1-GOLGB1_KPNA1_chr3_122215283_ENST00000344337_GOLGB1_chr3_121388202_ENST00000393667_length(transcript)=2216nt_BP=306nt GCCGGCTGAGCTGAGTCTCGCTGCTCGGTGCGAGGCGGCGGAGAGCGAGGCCTGGTGAGCACCGCCGAGGCGCGGGCCAGCTCTTCGAGG TTGTGCGCGGGAGTGGCACGGCGGGCGGGCGAGCGAGGGGCTAACTTCAGCGGTGGCACCGGGATCGGTTGCCTTGAGCCTGAAATCATG ACCACCCCAGGAAAAGAGAACTTTCGCCTGAAAAGTTACAAGAACAAATCTCTGAATCCCGATGAGATGCGCAGGAGGAGGGAGGAAGAA GGACTGCAGTTACGAAAGCAGAAAAGAGAAGAGCAGTTCTCTCAGCTACTGGAAGAGAAAAACACCCTTTCCATTCAGCTCTGCGATACC AGTCAGAGTCTTCGTGAGAACCAGCAGCACTATGGTGACCTTTTAAATCACTGTGCAGTCTTGGAGAAGCAGGTTCAAGAGCTGCAGGCG GTGAGTAAAGAGAAGGGGCCACTAAATATAGATGTTGCTCCAGGAGCTCCCCAGGAAAAGAATGGAGTTCACAGAAAGAGTGACCCTGAG GAACTAAGGGAACCGCAGCAAAGCTTTTCTGAAGCTCAGCAGCAGCTATGCAACACCAGACAGGAAGTGAATGAATTAAGGAAGCTGCTG GAAGAAGAACGAGACCAAAGAGTGGCTGCTGAGAATGCTCTCTCTGTGGCCGAGGAGCAGATCAGACGGTTAGAGCACAGTGAATGGGAC TCTTCCCGGACTCCTATCATTGGCTCCTGTGGCACTCAGGAGCAGGCACTGTTAATAGATCTTACAAGCAACAGTTGTCGAAGGACCCGG AGTGGCGTTGGATGGAAGCGAGTCCTGCGTTCACTCTGTCATTCACGGACCCGAGTGCCACTTCTAGCAGCCATCTACTTTCTAATGATT CATGTCCTGCTCATTCTGTGTTTTACGGGCCATCTATAGACTTAGTTGTTACTCTTTGGACCACTCCCCTCAAAACTTGGAATTCTCTCA CCTCTAACATCAGAACATCAATTCCAGTGGAACAGTCTTCCCATTTACAGGTCTTCTCTCCAACTCTTCACGGAAAGTGCCTGCAAAAAC AGAGGTGGATACGAGGACAGGTTGGAGCTGCAGGGACTGGCGAGTCTGCTTTCTTCTACTGCCCTGAGCCTGAACGCTTCTGCTTAATCT GAGAATCACATTTGGTTTGTTGAGCCTAATATTTGTTGAGATTTTGCAGGACCCTGATCTTTTGTGGTCCTGTAAAAGATACTGAGGAAT GTCTTTCAGCCAAGCCAAGAGGATGGTTTCAATAAACCTAATAATCTGAAGTTCAGTATCATTTTGATTGATAACTTTCTTTGCCTTGTT TGCCTGTATTTTCTCCTGTTTCAGGGGGAAGGTGGCTCTGCCATAAACAGAGTTCAGGGAAATGAACATGTCACCTCATAGGACATCTGA TTTAGGTCTCTTGCAGAATAGGGTGGTGAAAGCTGAAGGAACTCCCTAGGGGTTTTAGCTGTTAGATCACATGGGAGGACAGCATCTTCT TCCCTGCCAATTTCAGATATAATTGGAGGGAGAATTTCAGGTCTTAGACTATAAGGATAGAATCCCTTTGCTTTTGCCCTTGATCACATG TATACTAAGGTATTAAGTGGCCCAAGTCTTTCCTTTCACCAAAGGGCAGGGAGAAGTGTCTATGGACAGCAGGGTTCCAATTCTTGTCAT TCCAGGAATATCTGAATATTCCTGGAATGTGGACCCTGAGACAGTGCTCAGGGGCCACTGGGAGCCAATATTAGGCATTGACTCTCAGCC AGGAGTCTGACTGGTCTAACACCACACTGCAACTCCTGACCTCTTGAAGTACTAAGCTACTTTGCTGTTAGTGACAGTTATTACAGTTTC TCAGCCCCATTGTCTCTGCCCTCTGTGGCAATGGAAGGAGAATATAGAGAAGACAAAATTAAATATAGATAGACCTGAGAAGGACAGCCA GGATAGAATTCCATTTGTGCCTATTCCCTGCCTCCCCTCCCCTCCCCCATCCTACCAGTTGGTTATTTTCTCATTGCATACGTGATGTGT TCACTGCCTAGCCTCTCCCTAAAGAAGAGAGAAGACAAGTGGGCTGACTGATCTGCTCTAAATCTACTGTGGTGATTAAATCTTGGTTAC >43361_43361_2_KPNA1-GOLGB1_KPNA1_chr3_122215283_ENST00000344337_GOLGB1_chr3_121388202_ENST00000393667_length(amino acids)=295AA_BP=84 MVSTAEARASSSRLCAGVARRAGERGANFSGGTGIGCLEPEIMTTPGKENFRLKSYKNKSLNPDEMRRRREEEGLQLRKQKREEQFSQLL EEKNTLSIQLCDTSQSLRENQQHYGDLLNHCAVLEKQVQELQAVSKEKGPLNIDVAPGAPQEKNGVHRKSDPEELREPQQSFSEAQQQLC NTRQEVNELRKLLEEERDQRVAAENALSVAEEQIRRLEHSEWDSSRTPIIGSCGTQEQALLIDLTSNSCRRTRSGVGWKRVLRSLCHSRT -------------------------------------------------------------- >43361_43361_3_KPNA1-GOLGB1_KPNA1_chr3_122215284_ENST00000344337_GOLGB1_chr3_121388202_ENST00000340645_length(transcript)=2205nt_BP=306nt GCCGGCTGAGCTGAGTCTCGCTGCTCGGTGCGAGGCGGCGGAGAGCGAGGCCTGGTGAGCACCGCCGAGGCGCGGGCCAGCTCTTCGAGG TTGTGCGCGGGAGTGGCACGGCGGGCGGGCGAGCGAGGGGCTAACTTCAGCGGTGGCACCGGGATCGGTTGCCTTGAGCCTGAAATCATG ACCACCCCAGGAAAAGAGAACTTTCGCCTGAAAAGTTACAAGAACAAATCTCTGAATCCCGATGAGATGCGCAGGAGGAGGGAGGAAGAA GGACTGCAGTTACGAAAGCAGAAAAGAGAAGAGCAGTTCTCTCAGCTACTGGAAGAGAAAAACACCCTTTCCATTCAGCTCTGCGATACC AGTCAGAGTCTTCGTGAGAACCAGCAGCACTATGGTGACCTTTTAAATCACTGTGCAGTCTTGGAGAAGCAGGTTCAAGAGCTGCAGGCG GGGCCACTAAATATAGATGTTGCTCCAGGAGCTCCCCAGGAAAAGAATGGAGTTCACAGAAAGAGTGACCCTGAGGAACTAAGGGAACCG CAGCAAAGCTTTTCTGAAGCTCAGCAGCAGCTATGCAACACCAGACAGGAAGTGAATGAATTAAGGAAGCTGCTGGAAGAAGAACGAGAC CAAAGAGTGGCTGCTGAGAATGCTCTCTCTGTGGCCGAGGAGCAGATCAGACGGTTAGAGCACAGTGAATGGGACTCTTCCCGGACTCCT ATCATTGGCTCCTGTGGCACTCAGGAGCAGGCACTGTTAATAGATCTTACAAGCAACAGTTGTCGAAGGACCCGGAGTGGCGTTGGATGG AAGCGAGTCCTGCGTTCACTCTGTCATTCACGGACCCGAGTGCCACTTCTAGCAGCCATCTACTTTCTAATGATTCATGTCCTGCTCATT CTGTGTTTTACGGGCCATCTATAGACTTAGTTGTTACTCTTTGGACCACTCCCCTCAAAACTTGGAATTCTCTCACCTCTAACATCAGAA CATCAATTCCAGTGGAACAGTCTTCCCATTTACAGGTCTTCTCTCCAACTCTTCACGGAAAGTGCCTGCAAAAACAGAGGTGGATACGAG GACAGGTTGGAGCTGCAGGGACTGGCGAGTCTGCTTTCTTCTACTGCCCTGAGCCTGAACGCTTCTGCTTAATCTGAGAATCACATTTGG TTTGTTGAGCCTAATATTTGTTGAGATTTTGCAGGACCCTGATCTTTTGTGGTCCTGTAAAAGATACTGAGGAATGTCTTTCAGCCAAGC CAAGAGGATGGTTTCAATAAACCTAATAATCTGAAGTTCAGTATCATTTTGATTGATAACTTTCTTTGCCTTGTTTGCCTGTATTTTCTC CTGTTTCAGGGGGAAGGTGGCTCTGCCATAAACAGAGTTCAGGGAAATGAACATGTCACCTCATAGGACATCTGATTTAGGTCTCTTGCA GAATAGGGTGGTGAAAGCTGAAGGAACTCCCTAGGGGTTTTAGCTGTTAGATCACATGGGAGGACAGCATCTTCTTCCCTGCCAATTTCA GATATAATTGGAGGGAGAATTTCAGGTCTTAGACTATAAGGATAGAATCCCTTTGCTTTTGCCCTTGATCACATGTATACTAAGGTATTA AGTGGCCCAAGTCTTTCCTTTCACCAAAGGGCAGGGAGAAGTGTCTATGGACAGCAGGGTTCCAATTCTTGTCATTCCAGGAATATCTGA ATATTCCTGGAATGTGGACCCTGAGACAGTGCTCAGGGGCCACTGGGAGCCAATATTAGGCATTGACTCTCAGCCAGGAGTCTGACTGGT CTAACACCACACTGCAACTCCTGACCTCTTGAAGTACTAAGCTACTTTGCTGTTAGTGACAGTTATTACAGTTTCTCAGCCCCATTGTCT CTGCCCTCTGTGGCAATGGAAGGAGAATATAGAGAAGACAAAATTAAATATAGATAGACCTGAGAAGGACAGCCAGGATAGAATTCCATT TGTGCCTATTCCCTGCCTCCCCTCCCCTCCCCCATCCTACCAGTTGGTTATTTTCTCATTGCATACGTGATGTGTTCACTGCCTAGCCTC TCCCTAAAGAAGAGAGAAGACAAGTGGGCTGACTGATCTGCTCTAAATCTACTGTGGTGATTAAATCTTGGTTACAACATCCTGGGAAGT >43361_43361_3_KPNA1-GOLGB1_KPNA1_chr3_122215284_ENST00000344337_GOLGB1_chr3_121388202_ENST00000340645_length(amino acids)=290AA_BP=84 MVSTAEARASSSRLCAGVARRAGERGANFSGGTGIGCLEPEIMTTPGKENFRLKSYKNKSLNPDEMRRRREEEGLQLRKQKREEQFSQLL EEKNTLSIQLCDTSQSLRENQQHYGDLLNHCAVLEKQVQELQAGPLNIDVAPGAPQEKNGVHRKSDPEELREPQQSFSEAQQQLCNTRQE VNELRKLLEEERDQRVAAENALSVAEEQIRRLEHSEWDSSRTPIIGSCGTQEQALLIDLTSNSCRRTRSGVGWKRVLRSLCHSRTRVPLL -------------------------------------------------------------- >43361_43361_4_KPNA1-GOLGB1_KPNA1_chr3_122215284_ENST00000344337_GOLGB1_chr3_121388202_ENST00000393667_length(transcript)=2216nt_BP=306nt GCCGGCTGAGCTGAGTCTCGCTGCTCGGTGCGAGGCGGCGGAGAGCGAGGCCTGGTGAGCACCGCCGAGGCGCGGGCCAGCTCTTCGAGG TTGTGCGCGGGAGTGGCACGGCGGGCGGGCGAGCGAGGGGCTAACTTCAGCGGTGGCACCGGGATCGGTTGCCTTGAGCCTGAAATCATG ACCACCCCAGGAAAAGAGAACTTTCGCCTGAAAAGTTACAAGAACAAATCTCTGAATCCCGATGAGATGCGCAGGAGGAGGGAGGAAGAA GGACTGCAGTTACGAAAGCAGAAAAGAGAAGAGCAGTTCTCTCAGCTACTGGAAGAGAAAAACACCCTTTCCATTCAGCTCTGCGATACC AGTCAGAGTCTTCGTGAGAACCAGCAGCACTATGGTGACCTTTTAAATCACTGTGCAGTCTTGGAGAAGCAGGTTCAAGAGCTGCAGGCG GTGAGTAAAGAGAAGGGGCCACTAAATATAGATGTTGCTCCAGGAGCTCCCCAGGAAAAGAATGGAGTTCACAGAAAGAGTGACCCTGAG GAACTAAGGGAACCGCAGCAAAGCTTTTCTGAAGCTCAGCAGCAGCTATGCAACACCAGACAGGAAGTGAATGAATTAAGGAAGCTGCTG GAAGAAGAACGAGACCAAAGAGTGGCTGCTGAGAATGCTCTCTCTGTGGCCGAGGAGCAGATCAGACGGTTAGAGCACAGTGAATGGGAC TCTTCCCGGACTCCTATCATTGGCTCCTGTGGCACTCAGGAGCAGGCACTGTTAATAGATCTTACAAGCAACAGTTGTCGAAGGACCCGG AGTGGCGTTGGATGGAAGCGAGTCCTGCGTTCACTCTGTCATTCACGGACCCGAGTGCCACTTCTAGCAGCCATCTACTTTCTAATGATT CATGTCCTGCTCATTCTGTGTTTTACGGGCCATCTATAGACTTAGTTGTTACTCTTTGGACCACTCCCCTCAAAACTTGGAATTCTCTCA CCTCTAACATCAGAACATCAATTCCAGTGGAACAGTCTTCCCATTTACAGGTCTTCTCTCCAACTCTTCACGGAAAGTGCCTGCAAAAAC AGAGGTGGATACGAGGACAGGTTGGAGCTGCAGGGACTGGCGAGTCTGCTTTCTTCTACTGCCCTGAGCCTGAACGCTTCTGCTTAATCT GAGAATCACATTTGGTTTGTTGAGCCTAATATTTGTTGAGATTTTGCAGGACCCTGATCTTTTGTGGTCCTGTAAAAGATACTGAGGAAT GTCTTTCAGCCAAGCCAAGAGGATGGTTTCAATAAACCTAATAATCTGAAGTTCAGTATCATTTTGATTGATAACTTTCTTTGCCTTGTT TGCCTGTATTTTCTCCTGTTTCAGGGGGAAGGTGGCTCTGCCATAAACAGAGTTCAGGGAAATGAACATGTCACCTCATAGGACATCTGA TTTAGGTCTCTTGCAGAATAGGGTGGTGAAAGCTGAAGGAACTCCCTAGGGGTTTTAGCTGTTAGATCACATGGGAGGACAGCATCTTCT TCCCTGCCAATTTCAGATATAATTGGAGGGAGAATTTCAGGTCTTAGACTATAAGGATAGAATCCCTTTGCTTTTGCCCTTGATCACATG TATACTAAGGTATTAAGTGGCCCAAGTCTTTCCTTTCACCAAAGGGCAGGGAGAAGTGTCTATGGACAGCAGGGTTCCAATTCTTGTCAT TCCAGGAATATCTGAATATTCCTGGAATGTGGACCCTGAGACAGTGCTCAGGGGCCACTGGGAGCCAATATTAGGCATTGACTCTCAGCC AGGAGTCTGACTGGTCTAACACCACACTGCAACTCCTGACCTCTTGAAGTACTAAGCTACTTTGCTGTTAGTGACAGTTATTACAGTTTC TCAGCCCCATTGTCTCTGCCCTCTGTGGCAATGGAAGGAGAATATAGAGAAGACAAAATTAAATATAGATAGACCTGAGAAGGACAGCCA GGATAGAATTCCATTTGTGCCTATTCCCTGCCTCCCCTCCCCTCCCCCATCCTACCAGTTGGTTATTTTCTCATTGCATACGTGATGTGT TCACTGCCTAGCCTCTCCCTAAAGAAGAGAGAAGACAAGTGGGCTGACTGATCTGCTCTAAATCTACTGTGGTGATTAAATCTTGGTTAC >43361_43361_4_KPNA1-GOLGB1_KPNA1_chr3_122215284_ENST00000344337_GOLGB1_chr3_121388202_ENST00000393667_length(amino acids)=295AA_BP=84 MVSTAEARASSSRLCAGVARRAGERGANFSGGTGIGCLEPEIMTTPGKENFRLKSYKNKSLNPDEMRRRREEEGLQLRKQKREEQFSQLL EEKNTLSIQLCDTSQSLRENQQHYGDLLNHCAVLEKQVQELQAVSKEKGPLNIDVAPGAPQEKNGVHRKSDPEELREPQQSFSEAQQQLC NTRQEVNELRKLLEEERDQRVAAENALSVAEEQIRRLEHSEWDSSRTPIIGSCGTQEQALLIDLTSNSCRRTRSGVGWKRVLRSLCHSRT -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for KPNA1-GOLGB1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for KPNA1-GOLGB1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for KPNA1-GOLGB1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies