
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:LIG1-NUCB1 (FusionGDB2 ID:44664) |
Fusion Gene Summary for LIG1-NUCB1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: LIG1-NUCB1 | Fusion gene ID: 44664 | Hgene | Tgene | Gene symbol | LIG1 | NUCB1 | Gene ID | 26018 | 4924 |
| Gene name | leucine rich repeats and immunoglobulin like domains 1 | nucleobindin 1 | |
| Synonyms | LIG-1|LIG1 | CALNUC|NUC | |
| Cytomap | 3p14.1 | 19q13.33 | |
| Type of gene | protein-coding | protein-coding | |
| Description | leucine-rich repeats and immunoglobulin-like domains protein 1leucine-rich repeat protein LRIG1ortholog of mouse integral membrane glycoprotein LIG-1 | nucleobindin-1 | |
| Modification date | 20200320 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000263274, ENST00000427526, ENST00000536218, ENST00000599165, | ENST00000263273, ENST00000485798, ENST00000405315, ENST00000407032, | |
| Fusion gene scores | * DoF score | 3 X 3 X 3=27 | 7 X 7 X 4=196 |
| # samples | 3 | 8 | |
| ** MAII score | log2(3/27*10)=0.15200309344505 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | log2(8/196*10)=-1.29278174922785 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: LIG1 [Title/Abstract] AND NUCB1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | LIG1(48660270)-NUCB1(49414430), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across LIG1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across NUCB1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-E9-A1NA-01A | LIG1 | chr19 | 48660270 | - | NUCB1 | chr19 | 49414430 | - |
Top |
Fusion Gene ORF analysis for LIG1-NUCB1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000263274 | ENST00000263273 | LIG1 | chr19 | 48660270 | - | NUCB1 | chr19 | 49414430 | - |
| 5CDS-intron | ENST00000263274 | ENST00000485798 | LIG1 | chr19 | 48660270 | - | NUCB1 | chr19 | 49414430 | - |
| 5CDS-intron | ENST00000427526 | ENST00000263273 | LIG1 | chr19 | 48660270 | - | NUCB1 | chr19 | 49414430 | - |
| 5CDS-intron | ENST00000427526 | ENST00000485798 | LIG1 | chr19 | 48660270 | - | NUCB1 | chr19 | 49414430 | - |
| 5CDS-intron | ENST00000536218 | ENST00000263273 | LIG1 | chr19 | 48660270 | - | NUCB1 | chr19 | 49414430 | - |
| 5CDS-intron | ENST00000536218 | ENST00000485798 | LIG1 | chr19 | 48660270 | - | NUCB1 | chr19 | 49414430 | - |
| In-frame | ENST00000263274 | ENST00000405315 | LIG1 | chr19 | 48660270 | - | NUCB1 | chr19 | 49414430 | - |
| In-frame | ENST00000263274 | ENST00000407032 | LIG1 | chr19 | 48660270 | - | NUCB1 | chr19 | 49414430 | - |
| In-frame | ENST00000427526 | ENST00000405315 | LIG1 | chr19 | 48660270 | - | NUCB1 | chr19 | 49414430 | - |
| In-frame | ENST00000427526 | ENST00000407032 | LIG1 | chr19 | 48660270 | - | NUCB1 | chr19 | 49414430 | - |
| In-frame | ENST00000536218 | ENST00000405315 | LIG1 | chr19 | 48660270 | - | NUCB1 | chr19 | 49414430 | - |
| In-frame | ENST00000536218 | ENST00000407032 | LIG1 | chr19 | 48660270 | - | NUCB1 | chr19 | 49414430 | - |
| intron-3CDS | ENST00000599165 | ENST00000405315 | LIG1 | chr19 | 48660270 | - | NUCB1 | chr19 | 49414430 | - |
| intron-3CDS | ENST00000599165 | ENST00000407032 | LIG1 | chr19 | 48660270 | - | NUCB1 | chr19 | 49414430 | - |
| intron-intron | ENST00000599165 | ENST00000263273 | LIG1 | chr19 | 48660270 | - | NUCB1 | chr19 | 49414430 | - |
| intron-intron | ENST00000599165 | ENST00000485798 | LIG1 | chr19 | 48660270 | - | NUCB1 | chr19 | 49414430 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000263274 | LIG1 | chr19 | 48660270 | - | ENST00000405315 | NUCB1 | chr19 | 49414430 | - | 2723 | 790 | 791 | 1774 | 327 |
| ENST00000263274 | LIG1 | chr19 | 48660270 | - | ENST00000407032 | NUCB1 | chr19 | 49414430 | - | 2483 | 790 | 791 | 1774 | 327 |
| ENST00000536218 | LIG1 | chr19 | 48660270 | - | ENST00000405315 | NUCB1 | chr19 | 49414430 | - | 2434 | 501 | 502 | 1485 | 327 |
| ENST00000536218 | LIG1 | chr19 | 48660270 | - | ENST00000407032 | NUCB1 | chr19 | 49414430 | - | 2194 | 501 | 502 | 1485 | 327 |
| ENST00000427526 | LIG1 | chr19 | 48660270 | - | ENST00000405315 | NUCB1 | chr19 | 49414430 | - | 2374 | 441 | 442 | 1425 | 327 |
| ENST00000427526 | LIG1 | chr19 | 48660270 | - | ENST00000407032 | NUCB1 | chr19 | 49414430 | - | 2134 | 441 | 442 | 1425 | 327 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000263274 | ENST00000405315 | LIG1 | chr19 | 48660270 | - | NUCB1 | chr19 | 49414430 | - | 0.003247575 | 0.9967525 |
| ENST00000263274 | ENST00000407032 | LIG1 | chr19 | 48660270 | - | NUCB1 | chr19 | 49414430 | - | 0.004009097 | 0.99599093 |
| ENST00000536218 | ENST00000405315 | LIG1 | chr19 | 48660270 | - | NUCB1 | chr19 | 49414430 | - | 0.003049888 | 0.9969501 |
| ENST00000536218 | ENST00000407032 | LIG1 | chr19 | 48660270 | - | NUCB1 | chr19 | 49414430 | - | 0.003603716 | 0.99639636 |
| ENST00000427526 | ENST00000405315 | LIG1 | chr19 | 48660270 | - | NUCB1 | chr19 | 49414430 | - | 0.003063065 | 0.9969369 |
| ENST00000427526 | ENST00000407032 | LIG1 | chr19 | 48660270 | - | NUCB1 | chr19 | 49414430 | - | 0.003699749 | 0.9963003 |
Top |
Fusion Genomic Features for LIG1-NUCB1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
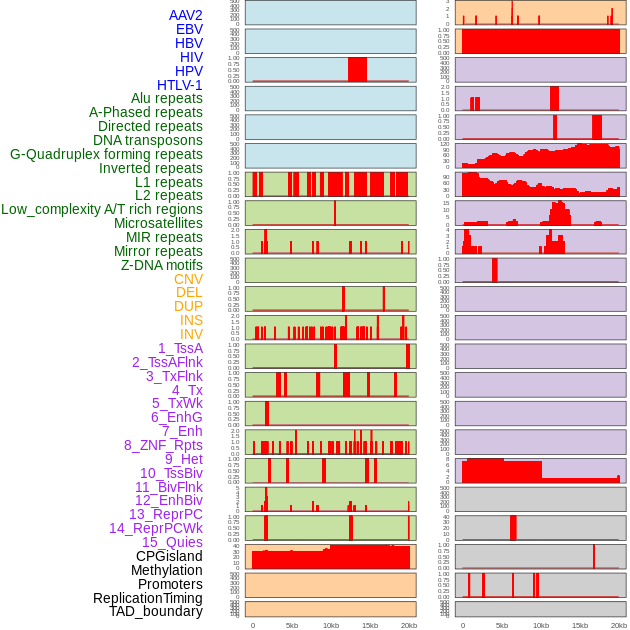
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for LIG1-NUCB1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr19:48660270/chr19:49414430) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | NUCB1 | chr19:48660270 | chr19:49414430 | ENST00000263273 | 0 | 12 | 253_264 | 0 | 462.0 | Calcium binding | 1 | |
| Tgene | NUCB1 | chr19:48660270 | chr19:49414430 | ENST00000263273 | 0 | 12 | 305_316 | 0 | 462.0 | Calcium binding | 2 | |
| Tgene | NUCB1 | chr19:48660270 | chr19:49414430 | ENST00000405315 | 0 | 13 | 253_264 | 0 | 462.0 | Calcium binding | 1 | |
| Tgene | NUCB1 | chr19:48660270 | chr19:49414430 | ENST00000405315 | 0 | 13 | 305_316 | 0 | 462.0 | Calcium binding | 2 | |
| Tgene | NUCB1 | chr19:48660270 | chr19:49414430 | ENST00000407032 | 0 | 14 | 253_264 | 0 | 666.6666666666666 | Calcium binding | 1 | |
| Tgene | NUCB1 | chr19:48660270 | chr19:49414430 | ENST00000407032 | 0 | 14 | 305_316 | 0 | 666.6666666666666 | Calcium binding | 2 | |
| Tgene | NUCB1 | chr19:48660270 | chr19:49414430 | ENST00000263273 | 0 | 12 | 150_218 | 0 | 462.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | NUCB1 | chr19:48660270 | chr19:49414430 | ENST00000263273 | 0 | 12 | 341_407 | 0 | 462.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | NUCB1 | chr19:48660270 | chr19:49414430 | ENST00000405315 | 0 | 13 | 150_218 | 0 | 462.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | NUCB1 | chr19:48660270 | chr19:49414430 | ENST00000405315 | 0 | 13 | 341_407 | 0 | 462.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | NUCB1 | chr19:48660270 | chr19:49414430 | ENST00000407032 | 0 | 14 | 150_218 | 0 | 666.6666666666666 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | NUCB1 | chr19:48660270 | chr19:49414430 | ENST00000407032 | 0 | 14 | 341_407 | 0 | 666.6666666666666 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | NUCB1 | chr19:48660270 | chr19:49414430 | ENST00000263273 | 0 | 12 | 401_407 | 0 | 462.0 | Compositional bias | Note=Poly-Gln | |
| Tgene | NUCB1 | chr19:48660270 | chr19:49414430 | ENST00000405315 | 0 | 13 | 401_407 | 0 | 462.0 | Compositional bias | Note=Poly-Gln | |
| Tgene | NUCB1 | chr19:48660270 | chr19:49414430 | ENST00000407032 | 0 | 14 | 401_407 | 0 | 666.6666666666666 | Compositional bias | Note=Poly-Gln | |
| Tgene | NUCB1 | chr19:48660270 | chr19:49414430 | ENST00000263273 | 0 | 12 | 172_218 | 0 | 462.0 | DNA binding | Ontology_term=ECO:0000255 | |
| Tgene | NUCB1 | chr19:48660270 | chr19:49414430 | ENST00000405315 | 0 | 13 | 172_218 | 0 | 462.0 | DNA binding | Ontology_term=ECO:0000255 | |
| Tgene | NUCB1 | chr19:48660270 | chr19:49414430 | ENST00000407032 | 0 | 14 | 172_218 | 0 | 666.6666666666666 | DNA binding | Ontology_term=ECO:0000255 | |
| Tgene | NUCB1 | chr19:48660270 | chr19:49414430 | ENST00000263273 | 0 | 12 | 240_275 | 0 | 462.0 | Domain | EF-hand 1 | |
| Tgene | NUCB1 | chr19:48660270 | chr19:49414430 | ENST00000263273 | 0 | 12 | 292_327 | 0 | 462.0 | Domain | EF-hand 2 | |
| Tgene | NUCB1 | chr19:48660270 | chr19:49414430 | ENST00000405315 | 0 | 13 | 240_275 | 0 | 462.0 | Domain | EF-hand 1 | |
| Tgene | NUCB1 | chr19:48660270 | chr19:49414430 | ENST00000405315 | 0 | 13 | 292_327 | 0 | 462.0 | Domain | EF-hand 2 | |
| Tgene | NUCB1 | chr19:48660270 | chr19:49414430 | ENST00000407032 | 0 | 14 | 240_275 | 0 | 666.6666666666666 | Domain | EF-hand 1 | |
| Tgene | NUCB1 | chr19:48660270 | chr19:49414430 | ENST00000407032 | 0 | 14 | 292_327 | 0 | 666.6666666666666 | Domain | EF-hand 2 | |
| Tgene | NUCB1 | chr19:48660270 | chr19:49414430 | ENST00000263273 | 0 | 12 | 303_333 | 0 | 462.0 | Motif | GBA | |
| Tgene | NUCB1 | chr19:48660270 | chr19:49414430 | ENST00000405315 | 0 | 13 | 303_333 | 0 | 462.0 | Motif | GBA | |
| Tgene | NUCB1 | chr19:48660270 | chr19:49414430 | ENST00000407032 | 0 | 14 | 303_333 | 0 | 666.6666666666666 | Motif | GBA | |
| Tgene | NUCB1 | chr19:48660270 | chr19:49414430 | ENST00000263273 | 0 | 12 | 228_321 | 0 | 462.0 | Region | Binds to GNAI2 and GNAI3 | |
| Tgene | NUCB1 | chr19:48660270 | chr19:49414430 | ENST00000263273 | 0 | 12 | 42_51 | 0 | 462.0 | Region | Note=O-glycosylated at one site | |
| Tgene | NUCB1 | chr19:48660270 | chr19:49414430 | ENST00000405315 | 0 | 13 | 228_321 | 0 | 462.0 | Region | Binds to GNAI2 and GNAI3 | |
| Tgene | NUCB1 | chr19:48660270 | chr19:49414430 | ENST00000405315 | 0 | 13 | 42_51 | 0 | 462.0 | Region | Note=O-glycosylated at one site | |
| Tgene | NUCB1 | chr19:48660270 | chr19:49414430 | ENST00000407032 | 0 | 14 | 228_321 | 0 | 666.6666666666666 | Region | Binds to GNAI2 and GNAI3 | |
| Tgene | NUCB1 | chr19:48660270 | chr19:49414430 | ENST00000407032 | 0 | 14 | 42_51 | 0 | 666.6666666666666 | Region | Note=O-glycosylated at one site |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
Top |
Fusion Gene Sequence for LIG1-NUCB1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >44664_44664_1_LIG1-NUCB1_LIG1_chr19_48660270_ENST00000263274_NUCB1_chr19_49414430_ENST00000405315_length(transcript)=2723nt_BP=790nt CTCGCGGGGGCGCTTCCACCGATTCCTCCTCTTTCCCTGCCAGTCACTCCTCAGACCCTCAGCCACACCCGCTCATCCAGGGCGAGGGAA AGCGCGGGCATTTTCCCAGTGTGCTCTGCGGGAGGGCTCGCCCCACTTCACCCCTTTTCCCGCCCTCCTCCCATTCGGGAGACTACGACT CCCAGTGTCCTCCGCGCGACGGCGGCGGTGCGGACGGTGCCCAGGTCCCGCCCCTAGGCTCTGCCCCGCCCCCGCCCGCAGACGTCTGCG CGCGAATGCCGTGGCGCGAACTTGGGACTGCAGAGGCGCGCCTGGCGGATCTGAGTGTGTTGCCCGGGCAGCGGCGCGCGGGACCAACGC AAGGAGCAGCTGACAGACGAAGAAAAGTGCTGGACAGGAAGGGAGAATTCTGACGCCAACATGCAGCGAAGTATCATGTCATTTTTCCAC CCCAAGAAAGAGGGTAAAGCAAAGAAGCCTGAGAAGGAGGCATCCAATAGCAGCAGAGAGACGGAGCCCCCTCCAAAGGCGGCACTGAAG GAGTGGAATGGAGTGGTGTCCGAGAGTGACTCTCCGGTGAAGAGGCCAGGGAGGAAGGCGGCCCGGGTCCTGGGCAGCGAAGGGGAAGAG GAGGATGAAGCCCTTAGCCCTGCTAAAGGCCAGAAGCCTGCCCTGGACTGCTCACAGGTCTCCCCGCCCCGTCCTGCCACATCTCCTGAG AACAATGCTTCCCTCTCTGACACCTCTCCCATGGACAGTTCCCCATCAGGGATTCCGAAGCGTCGCACAGCCTGAAACAGTTTGAACACC TGGACCCTCAGAACCAGCATACATTCGAGGCCCGCGACCTGGAGCTGCTGATCCAGACGGCCACCCGGGACCTTGCCCAGTACGACGCAG CCCATCATGAAGAGTTCAAGCGCTACGAGATGCTTAAGGAACACGAGAGACGGCGTTATCTGGAGTCACTGGGAGAGGAGCAGAGAAAGG AGGCGGAGAGGAAGCTGGAAGAGCAACAGCGCCGGCACCGCGAGCACCCTAAAGTCAACGTGCCTGGCAGCCAAGCCCAGTTGAAGGAGG TGTGGGAGGAGCTGGATGGACTGGACCCCAACAGGTTTAACCCCAAGACCTTCTTCATACTGCATGATATCAACAGTGATGGTGTCCTGG ATGAGCAGGAGCTGGAGGCACTCTTCACCAAGGAGCTGGAGAAAGTGTACGACCCAAAGAATGAGGAGGACGACATGCGGGAGATGGAGG AGGAGCGACTGCGCATGCGGGAGCATGTGATGAAGAATGTGGACACCAACCAGGACCGCCTCGTGACCCTGGAGGAGTTCCTCGCATCCA CTCAGAGGAAGGAGTTTGGGGACACCGGGGAGGGCTGGGAGACAGTGGAGATGCACCCTGCCTACACCGAGGAAGAGCTGAGGCGCTTTG AAGAGGAGCTGGCTGCCCGGGAGGCAGAGCTGAATGCCAAGGCCCAGCGCCTCAGCCAGGAGACAGAGGCTCTAGGGCGGTCCCAGGGCC GCCTGGAGGCCCAGAAGAGAGAGCTGCAGCAGGCTGTGCTGCACATGGAGCAGCGGAAGCAGCAGCAGCAGCAGCAGCAAGGCCACAAGG CCCCGGCTGCCCACCCTGAGGGGCAGCTCAAGTTCCACCCAGACACAGACGATGTACCTGTCCCAGCTCCAGCCGGTGACCAGAAGGAGG TGGACACTTCAGAAAAGAAACTTCTCGAGCGGCTCCCTGAGGTTGAGGTGCCCCAGCATCTGTGATCCTCCGGGACCCCAGCCCTCAGGA TTCCTGATGCTCCAAGGCGACTGATGGGCGCTGGATGAAGTGGCACAGTCAGCTTCCCTGGGGGCTGGTGTCATGTTGGGCTCCTGGGGC GGGGGCACGGCCTGGCATTTCACGCATTGCTGCCACCCCAGGTCCACCTGTCTCCACTTTCACAGCCTCCAAGTCTGTGGCTCTTCCCTT CTGTCCTCCGAGGGGCTTGCCTTCTCTCGTGTCCAGTGAGGTGCTCAGTGATCGGCTTAACTTAGAGAAGCCCGCCCCCTCCCCTTCTCC GTCTGTCCCAAGAGGGTCTGCTCTGAGCCTGCGTTCCTAGGTGGCTCGGCCTCAGCTGCCTGGGTTGTGGCCGCCCTAGCATCCTGTATG CCCACAGCTACTGGAATCCCCGCTGCTGCTCCGGGCCAAGCTTCTGGTTGATTAATGAGGGCATGGGGTGGTCCCTCAAGACCTTCCCCT ACCTTTTGTGGAACCAGTGATGCCTCAAAGACAGTGTCCCCTCCACAGCTGGGTGCCAGGGGCAGGGGATCCTCAGTATAGCCGGTGAAC CCTGATACCAGGAGCCTGGGCCTCCCTGAACCCCTGGCTTCCAGCCATCTCATCGCCAGCCTCCTCCTGGACCTCTTGGCCCCCAGCCCC TTCCCCACACAGCCCCAGAAGGGTCCCAGAGCTGACCCCACTCCAGGACCTAGGCCCAGCCCCTCAGCCTCATCTGGAGCCCCTGAAGAC CAGTCCCACCCACCTTTCTGGCCTCATCTGACACTGCTCCGCATCCTGCTGTGTGTCCTGTTCCATGTTCCGGTTCCATCCAAATACACT TTCTGGAACAAATGCATGGCTCCATGCCTGTGTATCTGGACTGGTCCCTCCAAAACGCTATTGCCACGTCACCTGCCGGAGTCCTCATCT >44664_44664_1_LIG1-NUCB1_LIG1_chr19_48660270_ENST00000263274_NUCB1_chr19_49414430_ENST00000405315_length(amino acids)=327AA_BP=1 MKQFEHLDPQNQHTFEARDLELLIQTATRDLAQYDAAHHEEFKRYEMLKEHERRRYLESLGEEQRKEAERKLEEQQRRHREHPKVNVPGS QAQLKEVWEELDGLDPNRFNPKTFFILHDINSDGVLDEQELEALFTKELEKVYDPKNEEDDMREMEEERLRMREHVMKNVDTNQDRLVTL EEFLASTQRKEFGDTGEGWETVEMHPAYTEEELRRFEEELAAREAELNAKAQRLSQETEALGRSQGRLEAQKRELQQAVLHMEQRKQQQQ -------------------------------------------------------------- >44664_44664_2_LIG1-NUCB1_LIG1_chr19_48660270_ENST00000263274_NUCB1_chr19_49414430_ENST00000407032_length(transcript)=2483nt_BP=790nt CTCGCGGGGGCGCTTCCACCGATTCCTCCTCTTTCCCTGCCAGTCACTCCTCAGACCCTCAGCCACACCCGCTCATCCAGGGCGAGGGAA AGCGCGGGCATTTTCCCAGTGTGCTCTGCGGGAGGGCTCGCCCCACTTCACCCCTTTTCCCGCCCTCCTCCCATTCGGGAGACTACGACT CCCAGTGTCCTCCGCGCGACGGCGGCGGTGCGGACGGTGCCCAGGTCCCGCCCCTAGGCTCTGCCCCGCCCCCGCCCGCAGACGTCTGCG CGCGAATGCCGTGGCGCGAACTTGGGACTGCAGAGGCGCGCCTGGCGGATCTGAGTGTGTTGCCCGGGCAGCGGCGCGCGGGACCAACGC AAGGAGCAGCTGACAGACGAAGAAAAGTGCTGGACAGGAAGGGAGAATTCTGACGCCAACATGCAGCGAAGTATCATGTCATTTTTCCAC CCCAAGAAAGAGGGTAAAGCAAAGAAGCCTGAGAAGGAGGCATCCAATAGCAGCAGAGAGACGGAGCCCCCTCCAAAGGCGGCACTGAAG GAGTGGAATGGAGTGGTGTCCGAGAGTGACTCTCCGGTGAAGAGGCCAGGGAGGAAGGCGGCCCGGGTCCTGGGCAGCGAAGGGGAAGAG GAGGATGAAGCCCTTAGCCCTGCTAAAGGCCAGAAGCCTGCCCTGGACTGCTCACAGGTCTCCCCGCCCCGTCCTGCCACATCTCCTGAG AACAATGCTTCCCTCTCTGACACCTCTCCCATGGACAGTTCCCCATCAGGGATTCCGAAGCGTCGCACAGCCTGAAACAGTTTGAACACC TGGACCCTCAGAACCAGCATACATTCGAGGCCCGCGACCTGGAGCTGCTGATCCAGACGGCCACCCGGGACCTTGCCCAGTACGACGCAG CCCATCATGAAGAGTTCAAGCGCTACGAGATGCTTAAGGAACACGAGAGACGGCGTTATCTGGAGTCACTGGGAGAGGAGCAGAGAAAGG AGGCGGAGAGGAAGCTGGAAGAGCAACAGCGCCGGCACCGCGAGCACCCTAAAGTCAACGTGCCTGGCAGCCAAGCCCAGTTGAAGGAGG TGTGGGAGGAGCTGGATGGACTGGACCCCAACAGGTTTAACCCCAAGACCTTCTTCATACTGCATGATATCAACAGTGATGGTGTCCTGG ATGAGCAGGAGCTGGAGGCACTCTTCACCAAGGAGCTGGAGAAAGTGTACGACCCAAAGAATGAGGAGGACGACATGCGGGAGATGGAGG AGGAGCGACTGCGCATGCGGGAGCATGTGATGAAGAATGTGGACACCAACCAGGACCGCCTCGTGACCCTGGAGGAGTTCCTCGCATCCA CTCAGAGGAAGGAGTTTGGGGACACCGGGGAGGGCTGGGAGACAGTGGAGATGCACCCTGCCTACACCGAGGAAGAGCTGAGGCGCTTTG AAGAGGAGCTGGCTGCCCGGGAGGCAGAGCTGAATGCCAAGGCCCAGCGCCTCAGCCAGGAGACAGAGGCTCTAGGGCGGTCCCAGGGCC GCCTGGAGGCCCAGAAGAGAGAGCTGCAGCAGGCTGTGCTGCACATGGAGCAGCGGAAGCAGCAGCAGCAGCAGCAGCAAGGCCACAAGG CCCCGGCTGCCCACCCTGAGGGGCAGCTCAAGTTCCACCCAGACACAGACGATGTACCTGTCCCAGCTCCAGCCGGTGACCAGAAGGAGG TGGACACTTCAGAAAAGAAACTTCTCGAGCGGCTCCCTGAGGTTGAGGTGCCCCAGCATCTGTGATCCTCCGGGACCCCAGCCCTCAGGA TTCCTGATGCTCCAAGCCTCCAAGTCTGTGGCTCTTCCCTTCTGTCCTCCGAGGGGCTTGCCTTCTCTCGTGTCCAGTGAGGTGCTCAGT GATCGGCTTAACTTAGAGAAGCCCGCCCCCTCCCCTTCTCCGTCTGTCCCAAGAGGGTCTGCTCTGAGCCTGCGTTCCTAGGTGGCTCGG CCTCAGCTGCCTGGGTTGTGGCCGCCCTAGCATCCTGTATGCCCACAGCTACTGGAATCCCCGCTGCTGCTCCGGGCCAAGCTTCTGGTT GATTAATGAGGGCATGGGGTGGTCCCTCAAGACCTTCCCCTACCTTTTGTGGAACCAGTGATGCCTCAAAGACAGTGTCCCCTCCACAGC TGGGTGCCAGGGGCAGGGGATCCTCAGTATAGCCGGTGAACCCTGATACCAGGAGCCTGGGCCTCCCTGAACCCCTGGCTTCCAGCCATC TCATCGCCAGCCTCCTCCTGGACCTCTTGGCCCCCAGCCCCTTCCCCACACAGCCCCAGAAGGGTCCCAGAGCTGACCCCACTCCAGGAC CTAGGCCCAGCCCCTCAGCCTCATCTGGAGCCCCTGAAGACCAGTCCCACCCACCTTTCTGGCCTCATCTGACACTGCTCCGCATCCTGC >44664_44664_2_LIG1-NUCB1_LIG1_chr19_48660270_ENST00000263274_NUCB1_chr19_49414430_ENST00000407032_length(amino acids)=327AA_BP=1 MKQFEHLDPQNQHTFEARDLELLIQTATRDLAQYDAAHHEEFKRYEMLKEHERRRYLESLGEEQRKEAERKLEEQQRRHREHPKVNVPGS QAQLKEVWEELDGLDPNRFNPKTFFILHDINSDGVLDEQELEALFTKELEKVYDPKNEEDDMREMEEERLRMREHVMKNVDTNQDRLVTL EEFLASTQRKEFGDTGEGWETVEMHPAYTEEELRRFEEELAAREAELNAKAQRLSQETEALGRSQGRLEAQKRELQQAVLHMEQRKQQQQ -------------------------------------------------------------- >44664_44664_3_LIG1-NUCB1_LIG1_chr19_48660270_ENST00000427526_NUCB1_chr19_49414430_ENST00000405315_length(transcript)=2374nt_BP=441nt AGACGTCTGCGCGCGAATGCCGTGGCGCGAACTTGGGACTGCAGAGGCGCGCCTGGCGGATCTGAGTGTGTTGCCCGGGCAGCGGCGCGC GGGACCAACGCAAGGAGCAGCTGACAGACGAAGAAAAGTGCTGGACAGGAAGGGAGAATTCTGACGCCAACATGCAGCGAAGTATCATGG CGGCACTGAAGGAGTGGAATGGAGTGGTGTCCGAGAGTGACTCTCCGGTGAAGAGGCCAGGGAGGAAGGCGGCCCGGGTCCTGGGCAGCG AAGGGGAAGAGGAGGATGAAGCCCTTAGCCCTGCTAAAGGCCAGAAGCCTGCCCTGGACTGCTCACAGGTCTCCCCGCCCCGTCCTGCCA CATCTCCTGAGAACAATGCTTCCCTCTCTGACACCTCTCCCATGGACAGTTCCCCATCAGGGATTCCGAAGCGTCGCACAGCCTGAAACA GTTTGAACACCTGGACCCTCAGAACCAGCATACATTCGAGGCCCGCGACCTGGAGCTGCTGATCCAGACGGCCACCCGGGACCTTGCCCA GTACGACGCAGCCCATCATGAAGAGTTCAAGCGCTACGAGATGCTTAAGGAACACGAGAGACGGCGTTATCTGGAGTCACTGGGAGAGGA GCAGAGAAAGGAGGCGGAGAGGAAGCTGGAAGAGCAACAGCGCCGGCACCGCGAGCACCCTAAAGTCAACGTGCCTGGCAGCCAAGCCCA GTTGAAGGAGGTGTGGGAGGAGCTGGATGGACTGGACCCCAACAGGTTTAACCCCAAGACCTTCTTCATACTGCATGATATCAACAGTGA TGGTGTCCTGGATGAGCAGGAGCTGGAGGCACTCTTCACCAAGGAGCTGGAGAAAGTGTACGACCCAAAGAATGAGGAGGACGACATGCG GGAGATGGAGGAGGAGCGACTGCGCATGCGGGAGCATGTGATGAAGAATGTGGACACCAACCAGGACCGCCTCGTGACCCTGGAGGAGTT CCTCGCATCCACTCAGAGGAAGGAGTTTGGGGACACCGGGGAGGGCTGGGAGACAGTGGAGATGCACCCTGCCTACACCGAGGAAGAGCT GAGGCGCTTTGAAGAGGAGCTGGCTGCCCGGGAGGCAGAGCTGAATGCCAAGGCCCAGCGCCTCAGCCAGGAGACAGAGGCTCTAGGGCG GTCCCAGGGCCGCCTGGAGGCCCAGAAGAGAGAGCTGCAGCAGGCTGTGCTGCACATGGAGCAGCGGAAGCAGCAGCAGCAGCAGCAGCA AGGCCACAAGGCCCCGGCTGCCCACCCTGAGGGGCAGCTCAAGTTCCACCCAGACACAGACGATGTACCTGTCCCAGCTCCAGCCGGTGA CCAGAAGGAGGTGGACACTTCAGAAAAGAAACTTCTCGAGCGGCTCCCTGAGGTTGAGGTGCCCCAGCATCTGTGATCCTCCGGGACCCC AGCCCTCAGGATTCCTGATGCTCCAAGGCGACTGATGGGCGCTGGATGAAGTGGCACAGTCAGCTTCCCTGGGGGCTGGTGTCATGTTGG GCTCCTGGGGCGGGGGCACGGCCTGGCATTTCACGCATTGCTGCCACCCCAGGTCCACCTGTCTCCACTTTCACAGCCTCCAAGTCTGTG GCTCTTCCCTTCTGTCCTCCGAGGGGCTTGCCTTCTCTCGTGTCCAGTGAGGTGCTCAGTGATCGGCTTAACTTAGAGAAGCCCGCCCCC TCCCCTTCTCCGTCTGTCCCAAGAGGGTCTGCTCTGAGCCTGCGTTCCTAGGTGGCTCGGCCTCAGCTGCCTGGGTTGTGGCCGCCCTAG CATCCTGTATGCCCACAGCTACTGGAATCCCCGCTGCTGCTCCGGGCCAAGCTTCTGGTTGATTAATGAGGGCATGGGGTGGTCCCTCAA GACCTTCCCCTACCTTTTGTGGAACCAGTGATGCCTCAAAGACAGTGTCCCCTCCACAGCTGGGTGCCAGGGGCAGGGGATCCTCAGTAT AGCCGGTGAACCCTGATACCAGGAGCCTGGGCCTCCCTGAACCCCTGGCTTCCAGCCATCTCATCGCCAGCCTCCTCCTGGACCTCTTGG CCCCCAGCCCCTTCCCCACACAGCCCCAGAAGGGTCCCAGAGCTGACCCCACTCCAGGACCTAGGCCCAGCCCCTCAGCCTCATCTGGAG CCCCTGAAGACCAGTCCCACCCACCTTTCTGGCCTCATCTGACACTGCTCCGCATCCTGCTGTGTGTCCTGTTCCATGTTCCGGTTCCAT CCAAATACACTTTCTGGAACAAATGCATGGCTCCATGCCTGTGTATCTGGACTGGTCCCTCCAAAACGCTATTGCCACGTCACCTGCCGG >44664_44664_3_LIG1-NUCB1_LIG1_chr19_48660270_ENST00000427526_NUCB1_chr19_49414430_ENST00000405315_length(amino acids)=327AA_BP=1 MKQFEHLDPQNQHTFEARDLELLIQTATRDLAQYDAAHHEEFKRYEMLKEHERRRYLESLGEEQRKEAERKLEEQQRRHREHPKVNVPGS QAQLKEVWEELDGLDPNRFNPKTFFILHDINSDGVLDEQELEALFTKELEKVYDPKNEEDDMREMEEERLRMREHVMKNVDTNQDRLVTL EEFLASTQRKEFGDTGEGWETVEMHPAYTEEELRRFEEELAAREAELNAKAQRLSQETEALGRSQGRLEAQKRELQQAVLHMEQRKQQQQ -------------------------------------------------------------- >44664_44664_4_LIG1-NUCB1_LIG1_chr19_48660270_ENST00000427526_NUCB1_chr19_49414430_ENST00000407032_length(transcript)=2134nt_BP=441nt AGACGTCTGCGCGCGAATGCCGTGGCGCGAACTTGGGACTGCAGAGGCGCGCCTGGCGGATCTGAGTGTGTTGCCCGGGCAGCGGCGCGC GGGACCAACGCAAGGAGCAGCTGACAGACGAAGAAAAGTGCTGGACAGGAAGGGAGAATTCTGACGCCAACATGCAGCGAAGTATCATGG CGGCACTGAAGGAGTGGAATGGAGTGGTGTCCGAGAGTGACTCTCCGGTGAAGAGGCCAGGGAGGAAGGCGGCCCGGGTCCTGGGCAGCG AAGGGGAAGAGGAGGATGAAGCCCTTAGCCCTGCTAAAGGCCAGAAGCCTGCCCTGGACTGCTCACAGGTCTCCCCGCCCCGTCCTGCCA CATCTCCTGAGAACAATGCTTCCCTCTCTGACACCTCTCCCATGGACAGTTCCCCATCAGGGATTCCGAAGCGTCGCACAGCCTGAAACA GTTTGAACACCTGGACCCTCAGAACCAGCATACATTCGAGGCCCGCGACCTGGAGCTGCTGATCCAGACGGCCACCCGGGACCTTGCCCA GTACGACGCAGCCCATCATGAAGAGTTCAAGCGCTACGAGATGCTTAAGGAACACGAGAGACGGCGTTATCTGGAGTCACTGGGAGAGGA GCAGAGAAAGGAGGCGGAGAGGAAGCTGGAAGAGCAACAGCGCCGGCACCGCGAGCACCCTAAAGTCAACGTGCCTGGCAGCCAAGCCCA GTTGAAGGAGGTGTGGGAGGAGCTGGATGGACTGGACCCCAACAGGTTTAACCCCAAGACCTTCTTCATACTGCATGATATCAACAGTGA TGGTGTCCTGGATGAGCAGGAGCTGGAGGCACTCTTCACCAAGGAGCTGGAGAAAGTGTACGACCCAAAGAATGAGGAGGACGACATGCG GGAGATGGAGGAGGAGCGACTGCGCATGCGGGAGCATGTGATGAAGAATGTGGACACCAACCAGGACCGCCTCGTGACCCTGGAGGAGTT CCTCGCATCCACTCAGAGGAAGGAGTTTGGGGACACCGGGGAGGGCTGGGAGACAGTGGAGATGCACCCTGCCTACACCGAGGAAGAGCT GAGGCGCTTTGAAGAGGAGCTGGCTGCCCGGGAGGCAGAGCTGAATGCCAAGGCCCAGCGCCTCAGCCAGGAGACAGAGGCTCTAGGGCG GTCCCAGGGCCGCCTGGAGGCCCAGAAGAGAGAGCTGCAGCAGGCTGTGCTGCACATGGAGCAGCGGAAGCAGCAGCAGCAGCAGCAGCA AGGCCACAAGGCCCCGGCTGCCCACCCTGAGGGGCAGCTCAAGTTCCACCCAGACACAGACGATGTACCTGTCCCAGCTCCAGCCGGTGA CCAGAAGGAGGTGGACACTTCAGAAAAGAAACTTCTCGAGCGGCTCCCTGAGGTTGAGGTGCCCCAGCATCTGTGATCCTCCGGGACCCC AGCCCTCAGGATTCCTGATGCTCCAAGCCTCCAAGTCTGTGGCTCTTCCCTTCTGTCCTCCGAGGGGCTTGCCTTCTCTCGTGTCCAGTG AGGTGCTCAGTGATCGGCTTAACTTAGAGAAGCCCGCCCCCTCCCCTTCTCCGTCTGTCCCAAGAGGGTCTGCTCTGAGCCTGCGTTCCT AGGTGGCTCGGCCTCAGCTGCCTGGGTTGTGGCCGCCCTAGCATCCTGTATGCCCACAGCTACTGGAATCCCCGCTGCTGCTCCGGGCCA AGCTTCTGGTTGATTAATGAGGGCATGGGGTGGTCCCTCAAGACCTTCCCCTACCTTTTGTGGAACCAGTGATGCCTCAAAGACAGTGTC CCCTCCACAGCTGGGTGCCAGGGGCAGGGGATCCTCAGTATAGCCGGTGAACCCTGATACCAGGAGCCTGGGCCTCCCTGAACCCCTGGC TTCCAGCCATCTCATCGCCAGCCTCCTCCTGGACCTCTTGGCCCCCAGCCCCTTCCCCACACAGCCCCAGAAGGGTCCCAGAGCTGACCC CACTCCAGGACCTAGGCCCAGCCCCTCAGCCTCATCTGGAGCCCCTGAAGACCAGTCCCACCCACCTTTCTGGCCTCATCTGACACTGCT >44664_44664_4_LIG1-NUCB1_LIG1_chr19_48660270_ENST00000427526_NUCB1_chr19_49414430_ENST00000407032_length(amino acids)=327AA_BP=1 MKQFEHLDPQNQHTFEARDLELLIQTATRDLAQYDAAHHEEFKRYEMLKEHERRRYLESLGEEQRKEAERKLEEQQRRHREHPKVNVPGS QAQLKEVWEELDGLDPNRFNPKTFFILHDINSDGVLDEQELEALFTKELEKVYDPKNEEDDMREMEEERLRMREHVMKNVDTNQDRLVTL EEFLASTQRKEFGDTGEGWETVEMHPAYTEEELRRFEEELAAREAELNAKAQRLSQETEALGRSQGRLEAQKRELQQAVLHMEQRKQQQQ -------------------------------------------------------------- >44664_44664_5_LIG1-NUCB1_LIG1_chr19_48660270_ENST00000536218_NUCB1_chr19_49414430_ENST00000405315_length(transcript)=2434nt_BP=501nt ACTTGGGACTGCAGAGGCGCGCCTGGCGGATCTGAGTGTGTTGCCCGGGCAGCGGCGCGCGGGACCAACGCAAGGAGCAGCTGACAGACG AAGAAAAGTGCTGGACAGGAAGGGAGAATTCTGACGCCAACATGCAGCGAAGTATCATGTCATTTTTCCACCCCAAGAAAGAGGGTAAAG CAAAGAAGCCTGAGAAGGAGGCATCCAATAGCAGCAGAGAGACGGAGCCCCCTCCAAAGGCGGCACTGAAGGAGTGGAATGGAGTGGTGT CCGAGAGTGACTCTCCGGTGAAGAGGCCAGGGAGGAAGGCGGCCCGGGTCCTGGGCAGCGAAGGGGAAGAGGAGGATGAAGCCCTTAGCC CTGCTAAAGGCCAGAAGCCTGCCCTGGACTGCTCACAGGTCTCCCCGCCCCGTCCTGCCACATCTCCTGAGAACAATGCTTCCCTCTCTG ACACCTCTCCCATGGACAGTTCCCCATCAGGGATTCCGAAGCGTCGCACAGCCTGAAACAGTTTGAACACCTGGACCCTCAGAACCAGCA TACATTCGAGGCCCGCGACCTGGAGCTGCTGATCCAGACGGCCACCCGGGACCTTGCCCAGTACGACGCAGCCCATCATGAAGAGTTCAA GCGCTACGAGATGCTTAAGGAACACGAGAGACGGCGTTATCTGGAGTCACTGGGAGAGGAGCAGAGAAAGGAGGCGGAGAGGAAGCTGGA AGAGCAACAGCGCCGGCACCGCGAGCACCCTAAAGTCAACGTGCCTGGCAGCCAAGCCCAGTTGAAGGAGGTGTGGGAGGAGCTGGATGG ACTGGACCCCAACAGGTTTAACCCCAAGACCTTCTTCATACTGCATGATATCAACAGTGATGGTGTCCTGGATGAGCAGGAGCTGGAGGC ACTCTTCACCAAGGAGCTGGAGAAAGTGTACGACCCAAAGAATGAGGAGGACGACATGCGGGAGATGGAGGAGGAGCGACTGCGCATGCG GGAGCATGTGATGAAGAATGTGGACACCAACCAGGACCGCCTCGTGACCCTGGAGGAGTTCCTCGCATCCACTCAGAGGAAGGAGTTTGG GGACACCGGGGAGGGCTGGGAGACAGTGGAGATGCACCCTGCCTACACCGAGGAAGAGCTGAGGCGCTTTGAAGAGGAGCTGGCTGCCCG GGAGGCAGAGCTGAATGCCAAGGCCCAGCGCCTCAGCCAGGAGACAGAGGCTCTAGGGCGGTCCCAGGGCCGCCTGGAGGCCCAGAAGAG AGAGCTGCAGCAGGCTGTGCTGCACATGGAGCAGCGGAAGCAGCAGCAGCAGCAGCAGCAAGGCCACAAGGCCCCGGCTGCCCACCCTGA GGGGCAGCTCAAGTTCCACCCAGACACAGACGATGTACCTGTCCCAGCTCCAGCCGGTGACCAGAAGGAGGTGGACACTTCAGAAAAGAA ACTTCTCGAGCGGCTCCCTGAGGTTGAGGTGCCCCAGCATCTGTGATCCTCCGGGACCCCAGCCCTCAGGATTCCTGATGCTCCAAGGCG ACTGATGGGCGCTGGATGAAGTGGCACAGTCAGCTTCCCTGGGGGCTGGTGTCATGTTGGGCTCCTGGGGCGGGGGCACGGCCTGGCATT TCACGCATTGCTGCCACCCCAGGTCCACCTGTCTCCACTTTCACAGCCTCCAAGTCTGTGGCTCTTCCCTTCTGTCCTCCGAGGGGCTTG CCTTCTCTCGTGTCCAGTGAGGTGCTCAGTGATCGGCTTAACTTAGAGAAGCCCGCCCCCTCCCCTTCTCCGTCTGTCCCAAGAGGGTCT GCTCTGAGCCTGCGTTCCTAGGTGGCTCGGCCTCAGCTGCCTGGGTTGTGGCCGCCCTAGCATCCTGTATGCCCACAGCTACTGGAATCC CCGCTGCTGCTCCGGGCCAAGCTTCTGGTTGATTAATGAGGGCATGGGGTGGTCCCTCAAGACCTTCCCCTACCTTTTGTGGAACCAGTG ATGCCTCAAAGACAGTGTCCCCTCCACAGCTGGGTGCCAGGGGCAGGGGATCCTCAGTATAGCCGGTGAACCCTGATACCAGGAGCCTGG GCCTCCCTGAACCCCTGGCTTCCAGCCATCTCATCGCCAGCCTCCTCCTGGACCTCTTGGCCCCCAGCCCCTTCCCCACACAGCCCCAGA AGGGTCCCAGAGCTGACCCCACTCCAGGACCTAGGCCCAGCCCCTCAGCCTCATCTGGAGCCCCTGAAGACCAGTCCCACCCACCTTTCT GGCCTCATCTGACACTGCTCCGCATCCTGCTGTGTGTCCTGTTCCATGTTCCGGTTCCATCCAAATACACTTTCTGGAACAAATGCATGG CTCCATGCCTGTGTATCTGGACTGGTCCCTCCAAAACGCTATTGCCACGTCACCTGCCGGAGTCCTCATCTTTGAAGACTGGATTCAAGC >44664_44664_5_LIG1-NUCB1_LIG1_chr19_48660270_ENST00000536218_NUCB1_chr19_49414430_ENST00000405315_length(amino acids)=327AA_BP=1 MKQFEHLDPQNQHTFEARDLELLIQTATRDLAQYDAAHHEEFKRYEMLKEHERRRYLESLGEEQRKEAERKLEEQQRRHREHPKVNVPGS QAQLKEVWEELDGLDPNRFNPKTFFILHDINSDGVLDEQELEALFTKELEKVYDPKNEEDDMREMEEERLRMREHVMKNVDTNQDRLVTL EEFLASTQRKEFGDTGEGWETVEMHPAYTEEELRRFEEELAAREAELNAKAQRLSQETEALGRSQGRLEAQKRELQQAVLHMEQRKQQQQ -------------------------------------------------------------- >44664_44664_6_LIG1-NUCB1_LIG1_chr19_48660270_ENST00000536218_NUCB1_chr19_49414430_ENST00000407032_length(transcript)=2194nt_BP=501nt ACTTGGGACTGCAGAGGCGCGCCTGGCGGATCTGAGTGTGTTGCCCGGGCAGCGGCGCGCGGGACCAACGCAAGGAGCAGCTGACAGACG AAGAAAAGTGCTGGACAGGAAGGGAGAATTCTGACGCCAACATGCAGCGAAGTATCATGTCATTTTTCCACCCCAAGAAAGAGGGTAAAG CAAAGAAGCCTGAGAAGGAGGCATCCAATAGCAGCAGAGAGACGGAGCCCCCTCCAAAGGCGGCACTGAAGGAGTGGAATGGAGTGGTGT CCGAGAGTGACTCTCCGGTGAAGAGGCCAGGGAGGAAGGCGGCCCGGGTCCTGGGCAGCGAAGGGGAAGAGGAGGATGAAGCCCTTAGCC CTGCTAAAGGCCAGAAGCCTGCCCTGGACTGCTCACAGGTCTCCCCGCCCCGTCCTGCCACATCTCCTGAGAACAATGCTTCCCTCTCTG ACACCTCTCCCATGGACAGTTCCCCATCAGGGATTCCGAAGCGTCGCACAGCCTGAAACAGTTTGAACACCTGGACCCTCAGAACCAGCA TACATTCGAGGCCCGCGACCTGGAGCTGCTGATCCAGACGGCCACCCGGGACCTTGCCCAGTACGACGCAGCCCATCATGAAGAGTTCAA GCGCTACGAGATGCTTAAGGAACACGAGAGACGGCGTTATCTGGAGTCACTGGGAGAGGAGCAGAGAAAGGAGGCGGAGAGGAAGCTGGA AGAGCAACAGCGCCGGCACCGCGAGCACCCTAAAGTCAACGTGCCTGGCAGCCAAGCCCAGTTGAAGGAGGTGTGGGAGGAGCTGGATGG ACTGGACCCCAACAGGTTTAACCCCAAGACCTTCTTCATACTGCATGATATCAACAGTGATGGTGTCCTGGATGAGCAGGAGCTGGAGGC ACTCTTCACCAAGGAGCTGGAGAAAGTGTACGACCCAAAGAATGAGGAGGACGACATGCGGGAGATGGAGGAGGAGCGACTGCGCATGCG GGAGCATGTGATGAAGAATGTGGACACCAACCAGGACCGCCTCGTGACCCTGGAGGAGTTCCTCGCATCCACTCAGAGGAAGGAGTTTGG GGACACCGGGGAGGGCTGGGAGACAGTGGAGATGCACCCTGCCTACACCGAGGAAGAGCTGAGGCGCTTTGAAGAGGAGCTGGCTGCCCG GGAGGCAGAGCTGAATGCCAAGGCCCAGCGCCTCAGCCAGGAGACAGAGGCTCTAGGGCGGTCCCAGGGCCGCCTGGAGGCCCAGAAGAG AGAGCTGCAGCAGGCTGTGCTGCACATGGAGCAGCGGAAGCAGCAGCAGCAGCAGCAGCAAGGCCACAAGGCCCCGGCTGCCCACCCTGA GGGGCAGCTCAAGTTCCACCCAGACACAGACGATGTACCTGTCCCAGCTCCAGCCGGTGACCAGAAGGAGGTGGACACTTCAGAAAAGAA ACTTCTCGAGCGGCTCCCTGAGGTTGAGGTGCCCCAGCATCTGTGATCCTCCGGGACCCCAGCCCTCAGGATTCCTGATGCTCCAAGCCT CCAAGTCTGTGGCTCTTCCCTTCTGTCCTCCGAGGGGCTTGCCTTCTCTCGTGTCCAGTGAGGTGCTCAGTGATCGGCTTAACTTAGAGA AGCCCGCCCCCTCCCCTTCTCCGTCTGTCCCAAGAGGGTCTGCTCTGAGCCTGCGTTCCTAGGTGGCTCGGCCTCAGCTGCCTGGGTTGT GGCCGCCCTAGCATCCTGTATGCCCACAGCTACTGGAATCCCCGCTGCTGCTCCGGGCCAAGCTTCTGGTTGATTAATGAGGGCATGGGG TGGTCCCTCAAGACCTTCCCCTACCTTTTGTGGAACCAGTGATGCCTCAAAGACAGTGTCCCCTCCACAGCTGGGTGCCAGGGGCAGGGG ATCCTCAGTATAGCCGGTGAACCCTGATACCAGGAGCCTGGGCCTCCCTGAACCCCTGGCTTCCAGCCATCTCATCGCCAGCCTCCTCCT GGACCTCTTGGCCCCCAGCCCCTTCCCCACACAGCCCCAGAAGGGTCCCAGAGCTGACCCCACTCCAGGACCTAGGCCCAGCCCCTCAGC CTCATCTGGAGCCCCTGAAGACCAGTCCCACCCACCTTTCTGGCCTCATCTGACACTGCTCCGCATCCTGCTGTGTGTCCTGTTCCATGT >44664_44664_6_LIG1-NUCB1_LIG1_chr19_48660270_ENST00000536218_NUCB1_chr19_49414430_ENST00000407032_length(amino acids)=327AA_BP=1 MKQFEHLDPQNQHTFEARDLELLIQTATRDLAQYDAAHHEEFKRYEMLKEHERRRYLESLGEEQRKEAERKLEEQQRRHREHPKVNVPGS QAQLKEVWEELDGLDPNRFNPKTFFILHDINSDGVLDEQELEALFTKELEKVYDPKNEEDDMREMEEERLRMREHVMKNVDTNQDRLVTL EEFLASTQRKEFGDTGEGWETVEMHPAYTEEELRRFEEELAAREAELNAKAQRLSQETEALGRSQGRLEAQKRELQQAVLHMEQRKQQQQ -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for LIG1-NUCB1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Hgene | LIG1 | chr19:48660270 | chr19:49414430 | ENST00000263274 | - | 5 | 28 | 449_458 | 123.33333333333333 | 920.0 | target DNA |
| Hgene | LIG1 | chr19:48660270 | chr19:49414430 | ENST00000263274 | - | 5 | 28 | 642_644 | 123.33333333333333 | 920.0 | target DNA |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for LIG1-NUCB1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for LIG1-NUCB1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies