
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:LMCD1-ZNF589 (FusionGDB2 ID:45771) |
Fusion Gene Summary for LMCD1-ZNF589 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: LMCD1-ZNF589 | Fusion gene ID: 45771 | Hgene | Tgene | Gene symbol | LMCD1 | ZNF589 | Gene ID | 29995 | 51385 |
| Gene name | LIM and cysteine rich domains 1 | zinc finger protein 589 | |
| Synonyms | - | SZF1 | |
| Cytomap | 3p25.3 | 3p21.31 | |
| Type of gene | protein-coding | protein-coding | |
| Description | LIM and cysteine-rich domains protein 1dyxin | zinc finger protein 589KRAB-zinc finger protein SZF1-1stem cell zinc finger protein 1 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | . | |
| Ensembl transtripts involved in fusion gene | ENST00000157600, ENST00000535732, ENST00000397386, ENST00000454244, | ENST00000454212, ENST00000354698, ENST00000412564, ENST00000427617, ENST00000440261, | |
| Fusion gene scores | * DoF score | 2 X 2 X 2=8 | 5 X 4 X 3=60 |
| # samples | 2 | 5 | |
| ** MAII score | log2(2/8*10)=1.32192809488736 | log2(5/60*10)=-0.263034405833794 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: LMCD1 [Title/Abstract] AND ZNF589 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | LMCD1(8543666)-ZNF589(48302303), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | ZNF589 | GO:0000122 | negative regulation of transcription by RNA polymerase II | 12097288 |
| Fusion gene breakpoints across LMCD1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across ZNF589 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | PRAD | TCGA-KK-A7B1-01A | LMCD1 | chr3 | 8543666 | - | ZNF589 | chr3 | 48302303 | + |
| ChimerDB4 | PRAD | TCGA-KK-A7B1-01A | LMCD1 | chr3 | 8543666 | + | ZNF589 | chr3 | 48302303 | + |
| ChimerDB4 | PRAD | TCGA-KK-A7B1 | LMCD1 | chr3 | 8543666 | + | ZNF589 | chr3 | 48302303 | + |
Top |
Fusion Gene ORF analysis for LMCD1-ZNF589 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-3UTR | ENST00000157600 | ENST00000454212 | LMCD1 | chr3 | 8543666 | + | ZNF589 | chr3 | 48302303 | + |
| 5CDS-3UTR | ENST00000535732 | ENST00000454212 | LMCD1 | chr3 | 8543666 | + | ZNF589 | chr3 | 48302303 | + |
| 5UTR-3CDS | ENST00000397386 | ENST00000354698 | LMCD1 | chr3 | 8543666 | + | ZNF589 | chr3 | 48302303 | + |
| 5UTR-3CDS | ENST00000397386 | ENST00000412564 | LMCD1 | chr3 | 8543666 | + | ZNF589 | chr3 | 48302303 | + |
| 5UTR-3CDS | ENST00000397386 | ENST00000427617 | LMCD1 | chr3 | 8543666 | + | ZNF589 | chr3 | 48302303 | + |
| 5UTR-3CDS | ENST00000397386 | ENST00000440261 | LMCD1 | chr3 | 8543666 | + | ZNF589 | chr3 | 48302303 | + |
| 5UTR-3CDS | ENST00000454244 | ENST00000354698 | LMCD1 | chr3 | 8543666 | + | ZNF589 | chr3 | 48302303 | + |
| 5UTR-3CDS | ENST00000454244 | ENST00000412564 | LMCD1 | chr3 | 8543666 | + | ZNF589 | chr3 | 48302303 | + |
| 5UTR-3CDS | ENST00000454244 | ENST00000427617 | LMCD1 | chr3 | 8543666 | + | ZNF589 | chr3 | 48302303 | + |
| 5UTR-3CDS | ENST00000454244 | ENST00000440261 | LMCD1 | chr3 | 8543666 | + | ZNF589 | chr3 | 48302303 | + |
| 5UTR-3UTR | ENST00000397386 | ENST00000454212 | LMCD1 | chr3 | 8543666 | + | ZNF589 | chr3 | 48302303 | + |
| 5UTR-3UTR | ENST00000454244 | ENST00000454212 | LMCD1 | chr3 | 8543666 | + | ZNF589 | chr3 | 48302303 | + |
| In-frame | ENST00000157600 | ENST00000354698 | LMCD1 | chr3 | 8543666 | + | ZNF589 | chr3 | 48302303 | + |
| In-frame | ENST00000157600 | ENST00000412564 | LMCD1 | chr3 | 8543666 | + | ZNF589 | chr3 | 48302303 | + |
| In-frame | ENST00000157600 | ENST00000427617 | LMCD1 | chr3 | 8543666 | + | ZNF589 | chr3 | 48302303 | + |
| In-frame | ENST00000157600 | ENST00000440261 | LMCD1 | chr3 | 8543666 | + | ZNF589 | chr3 | 48302303 | + |
| In-frame | ENST00000535732 | ENST00000354698 | LMCD1 | chr3 | 8543666 | + | ZNF589 | chr3 | 48302303 | + |
| In-frame | ENST00000535732 | ENST00000412564 | LMCD1 | chr3 | 8543666 | + | ZNF589 | chr3 | 48302303 | + |
| In-frame | ENST00000535732 | ENST00000427617 | LMCD1 | chr3 | 8543666 | + | ZNF589 | chr3 | 48302303 | + |
| In-frame | ENST00000535732 | ENST00000440261 | LMCD1 | chr3 | 8543666 | + | ZNF589 | chr3 | 48302303 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000157600 | LMCD1 | chr3 | 8543666 | + | ENST00000354698 | ZNF589 | chr3 | 48302303 | + | 3474 | 274 | 13 | 1272 | 419 |
| ENST00000157600 | LMCD1 | chr3 | 8543666 | + | ENST00000427617 | ZNF589 | chr3 | 48302303 | + | 1783 | 274 | 13 | 468 | 151 |
| ENST00000157600 | LMCD1 | chr3 | 8543666 | + | ENST00000412564 | ZNF589 | chr3 | 48302303 | + | 700 | 274 | 13 | 420 | 135 |
| ENST00000157600 | LMCD1 | chr3 | 8543666 | + | ENST00000440261 | ZNF589 | chr3 | 48302303 | + | 1029 | 274 | 13 | 711 | 232 |
| ENST00000535732 | LMCD1 | chr3 | 8543666 | + | ENST00000354698 | ZNF589 | chr3 | 48302303 | + | 3356 | 156 | 27 | 1154 | 375 |
| ENST00000535732 | LMCD1 | chr3 | 8543666 | + | ENST00000427617 | ZNF589 | chr3 | 48302303 | + | 1665 | 156 | 777 | 436 | 113 |
| ENST00000535732 | LMCD1 | chr3 | 8543666 | + | ENST00000412564 | ZNF589 | chr3 | 48302303 | + | 582 | 156 | 27 | 302 | 91 |
| ENST00000535732 | LMCD1 | chr3 | 8543666 | + | ENST00000440261 | ZNF589 | chr3 | 48302303 | + | 911 | 156 | 27 | 593 | 188 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000157600 | ENST00000354698 | LMCD1 | chr3 | 8543666 | + | ZNF589 | chr3 | 48302303 | + | 0.022410743 | 0.9775892 |
| ENST00000157600 | ENST00000427617 | LMCD1 | chr3 | 8543666 | + | ZNF589 | chr3 | 48302303 | + | 0.19789597 | 0.80210406 |
| ENST00000157600 | ENST00000412564 | LMCD1 | chr3 | 8543666 | + | ZNF589 | chr3 | 48302303 | + | 0.3745124 | 0.62548757 |
| ENST00000157600 | ENST00000440261 | LMCD1 | chr3 | 8543666 | + | ZNF589 | chr3 | 48302303 | + | 0.021379787 | 0.9786202 |
| ENST00000535732 | ENST00000354698 | LMCD1 | chr3 | 8543666 | + | ZNF589 | chr3 | 48302303 | + | 0.016662313 | 0.9833377 |
| ENST00000535732 | ENST00000427617 | LMCD1 | chr3 | 8543666 | + | ZNF589 | chr3 | 48302303 | + | 0.18597122 | 0.8140288 |
| ENST00000535732 | ENST00000412564 | LMCD1 | chr3 | 8543666 | + | ZNF589 | chr3 | 48302303 | + | 0.220479 | 0.779521 |
| ENST00000535732 | ENST00000440261 | LMCD1 | chr3 | 8543666 | + | ZNF589 | chr3 | 48302303 | + | 0.015332301 | 0.9846677 |
Top |
Fusion Genomic Features for LMCD1-ZNF589 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| LMCD1 | chr3 | 8543666 | + | ZNF589 | chr3 | 48302302 | + | 9.97E-05 | 0.99990034 |
| LMCD1 | chr3 | 8543666 | + | ZNF589 | chr3 | 48302302 | + | 9.97E-05 | 0.99990034 |
| LMCD1 | chr3 | 8543666 | + | ZNF589 | chr3 | 48302302 | + | 9.97E-05 | 0.99990034 |
| LMCD1 | chr3 | 8543666 | + | ZNF589 | chr3 | 48302302 | + | 9.97E-05 | 0.99990034 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
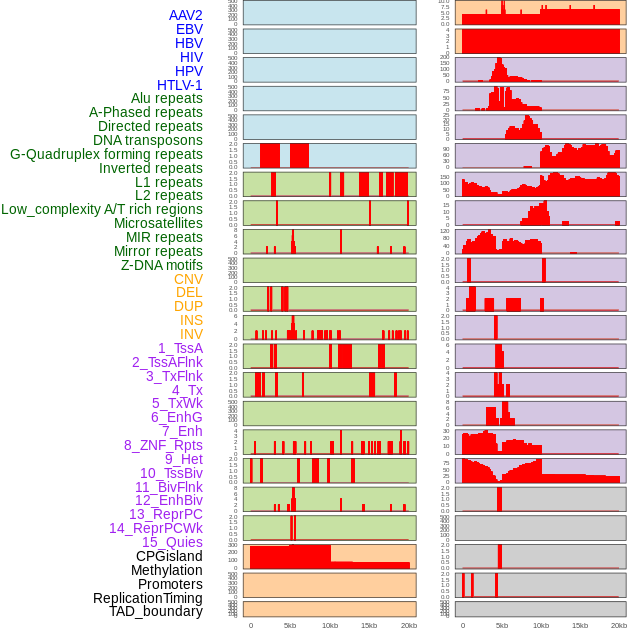 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
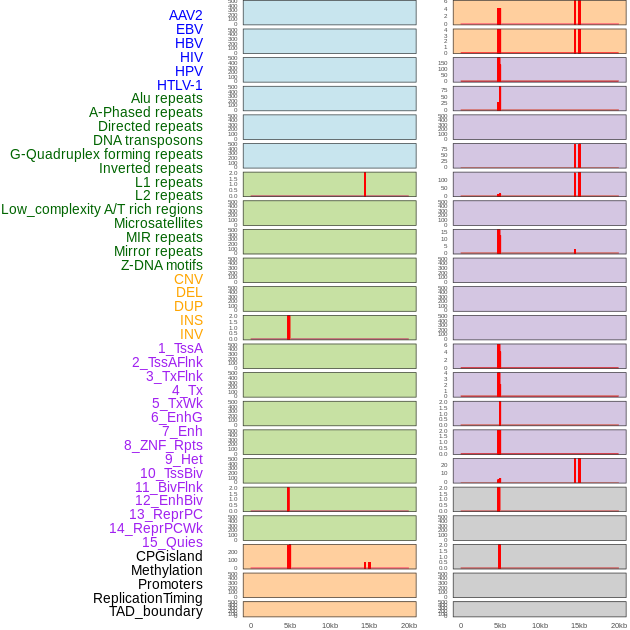 |
Top |
Fusion Protein Features for LMCD1-ZNF589 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr3:8543666/chr3:48302303) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | . |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | ZNF589 | chr3:8543666 | chr3:48302303 | ENST00000354698 | 1 | 4 | 35_108 | 32 | 365.0 | Domain | KRAB | |
| Tgene | ZNF589 | chr3:8543666 | chr3:48302303 | ENST00000354698 | 1 | 4 | 248_270 | 32 | 365.0 | Zinc finger | C2H2-type 1 | |
| Tgene | ZNF589 | chr3:8543666 | chr3:48302303 | ENST00000354698 | 1 | 4 | 276_298 | 32 | 365.0 | Zinc finger | C2H2-type 2 | |
| Tgene | ZNF589 | chr3:8543666 | chr3:48302303 | ENST00000354698 | 1 | 4 | 304_326 | 32 | 365.0 | Zinc finger | C2H2-type 3 | |
| Tgene | ZNF589 | chr3:8543666 | chr3:48302303 | ENST00000354698 | 1 | 4 | 332_354 | 32 | 365.0 | Zinc finger | C2H2-type 4 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | LMCD1 | chr3:8543666 | chr3:48302303 | ENST00000157600 | + | 1 | 6 | 28_58 | 14 | 366.0 | Compositional bias | Note=Cys-rich |
| Hgene | LMCD1 | chr3:8543666 | chr3:48302303 | ENST00000157600 | + | 1 | 6 | 241_306 | 14 | 366.0 | Domain | LIM zinc-binding 1 |
| Hgene | LMCD1 | chr3:8543666 | chr3:48302303 | ENST00000157600 | + | 1 | 6 | 307_365 | 14 | 366.0 | Domain | LIM zinc-binding 2 |
| Hgene | LMCD1 | chr3:8543666 | chr3:48302303 | ENST00000157600 | + | 1 | 6 | 99_206 | 14 | 366.0 | Domain | PET |
Top |
Fusion Gene Sequence for LMCD1-ZNF589 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >45771_45771_1_LMCD1-ZNF589_LMCD1_chr3_8543666_ENST00000157600_ZNF589_chr3_48302303_ENST00000354698_length(transcript)=3474nt_BP=274nt GGACAGCCTCGCGCTGGGATTGGCTGGCCTCGCGCGAGCGCCGGCGCGGAGTGGCTGGCGAGGTTTTAGAGGGAGTCCCGCTCTCCAATT AAAGCGGCCCAGCTGCGCCTGGCTGCGCACAGAGCTCCCTCCCAGGCCCGCGAACTTGGCCATTCAGCCGCCGCTGTCCCCGCTGCGCGC CCTCGCGCCTCTGCCTGAGAAGCCAGGCGCTGTTCCCCCACCCCAGAAGAGGATGGCAAAGGTGGCTAAGGACCTCAACCCAGGAGTTAA AAAGGGACCAGTGACTTTCGAGGATGTGGCTGTGCTTTTCACTGAGGCAGAGTGGAAGAGACTGAGCCTTGAGCAGAGGAACCTATACAA AGAAGTGATGCTGGAAAATCTCAGGAATCTGGTCTCATTGGCAGAATCAAAGCCAGAAGTCCATACCTGCCCTTCTTGCCCTCTGGCCTT TGGCAGTCAGCAGTTCCTCAGCCAAGATGAGCTACACAATCATCCTATTCCAGGTTTCCATGCAGGAAATCAACTCCACCCAGGAAATCC CTGCCCAGAGGATCAGCCACAGTCACAACATCCTTCTGATAAAAATCACAGGGGGGCTGAAGCAGAAGATCAACGAGTGGAAGGAGGCGT CAGACCCTTGTTTTGGAGTACAAATGAAAGGGGGGCTTTAGTGGGTTTCTCTAGCCTGTTCCAGAGACCACCAATAAGCTCTTGGGGAGG CAACAGAATATTAGAGATACAGCTCAGTCCAGCCCAGAATGCAAGCTCTGAGGAAGTAGACAGAATTTCCAAGAGGGCAGAAACCCCAGG GTTTGGAGCAGTCACGTTTGGGGAGTGTGCACTAGCTTTTAACCAGAAGTCAAACCTGTTCAGACAGAAGGCAGTCACAGCAGAAAAATC TTCAGACAAAAGGCAGTCACAGGTGTGCAGGGAGTGTGGGCGAGGCTTTAGCAGGAAGTCACAGCTCATCATACACCAGAGGACACACAC AGGAGAAAAGCCTTATGTCTGCGGAGAGTGTGGGCGAGGCTTTATAGTTGAGTCAGTCCTCCGCAACCACCTGAGTACACACTCCGGGGA GAAACCTTATGTGTGCAGCCATTGTGGGCGAGGCTTTAGCTGCAAGCCATACCTCATCAGACATCAGAGGACACACACAAGGGAGAAATC GTTTATGTGCACAGTGTGTGGGCGAGGCTTTCGTGAAAAGTCAGAGCTCATTAAGCACCAGAGAATTCACACGGGGGATAAGCCTTATGT GTGCAGAGATTGAGGCCGAGGCTTTGTAAGGAGATCATGTCTCAACACACACCAGAGGATACATTCAGATGAGAAGCCTTTTGTTTGCAG AGAGTGTGGGCGAGGCTTTCGTGCTAAATCAACTCTCCTCCTACACCAGTGGACACATTCAGAGGTGAAACCTCACGTGTGTGAGGAGTG TGGGCATGGATTTAGCCAGAAGTCGTCGCTCAAATCACATCGGAGAACACACTCAGGGGAGAAGCCTTATGTGTGTGGGGAATGTGGGCG GGGATTTAGCCGGAGGATAGTCCTCAATGGACACTGGAGGACACACACGGGAGAGAAGCCTTACACGTGCTTTGAGTGTGGGCGAAACTT TAGCCTCAAGTCCGCTCTTAGTGTACATCAGAGGATACACTCTGGGGAGAAGCCTTATGCATGCACGGAGTGTGGGCAAGGCTTTATCAC GAAATCACAGCTCATCAGACACCAGAGGACACACACAGGAGAAAAGCCTTATGTCTGCGGAGAGTGTGGGCGAGGCTTTATAGCTCAGTC AACCCTCCACTACCACCGGAGTACACACTCCAAGGAAAAACCTTATGTGTGCAGCCAGTGTGGGCGAGGCTTTTGTGATAAATCAACTCT CCTCGCACACGAGCAGACACATTCAGGGGAGAAGCCTTATGTGTGTGGGGAATGTGGGCGGGGATTTGGCCGGAAGATACTCCTCAACAG ACACTGGAGGACACACACAGGAGAGAAACCTTACGCATGCATCGAGTGTGGGCGAAACTTTAGCCACAAGTCCACTCTCAGCTTACATCA GAGGATACACTCGGGGGAGAAGCCTTATGCATGCGTGGAGTGTGGGCAAAGCTTTAGGAGAAAGTCACAGCTCATCATACACCAGAAGAT ACACTCGGGGAAAAGCTTTAGAGGTGCAAGGAGTGAGGATGTGATTTTAGCAACAAGTCAGCCATCAGCCACACCAGCGGAAATGCTTAG GGAGAAGCCTTGTTTGTAAGGTAATGTGGACAGAGCTGTACGTGGACATCATTACTTGTCACGTGTCAGAGGACACACTCGGGAGAAACC TTCATGGAGTGAGAGTAAGGTGTTGGCTGGAAGTGGCCCCTTAAGAGATACTTGGAGTCAAATCTATCCACTGTACGCCCACCCCACTCT TGTTCTAAGAGCTTTGGGGACAGTCTTTTGACCCCTTACATTCCTTTAGATGTGAAGATGACAGAGATCTAACTTCTGAGAGCAGAGGTG TCAAGTGACGGTCCCCTTGGAGGAATGGTCTTTGCATCTGACTACTTCCTTCTGCAACTGTGTTCTTCCATTAGCTTCCATGACACTCTC CTGCTTTATTTTTTTCTACATCTCTAGCCTTTGCTGTTTCCTCTCCTACCCCACCTTTAGATTTTACTCAGAGTTCAGTCTCCAGCCCTA CAATCTGAGGGACACCTTTACCAGGTCCCCTTCCTAACCCTCCAGTCCCAAATCCAAGATTCTTTAACCACACTCTAAAAGTTCTTCAGA CTCAGGACTTAAACATAGCCACGCCACCTTGGCCTTCAATGACAGGGATCTAGCAATGCTGCATCATCAGCCTTCCAATACCAGGTTTAA GGGTATTTTAAACACAGCTCCTCTTAAATCCTCCAATCTCAGTACCCAGTGTTTTAGCCATGCTCGGGTGGCTAAATTACATCCAGGAAT GGTGCCAGGGCCTTTAGCCATTTGTCTCTCCTCACACTCCAGGGCCCATATGGCCCAGGTTCTGACAGTTTGCCTTACTCCCTTGGGCTG GGGCTAGCCCTACCTGATACCCTGTGTCAATGAGTGTACCTTGGAGAGCTATCCACTCAGGCCCCAGTGCCTCTATTTGCTAAGGGACTC TGCCACAGAAAAGAAGGGGAGAGATGTTCATGTAACCTCAAAATACTTAGGCTTGGTTTTGATGCTAGAGAGGAAAAAGGACTTGGAGAG AGAGAAGGAATGGCTGGTCCAGAGGCTTTTGTCCACTCCCTCTCACTGGAAGTGGTTGATCTCCAGGGAATCCCCAAGGTTAGCCTGCTT AGGGGAAGGGCTAGGGGTACCTGGAATGTAGGATCTCCCCCATGCCTGGCCTACCACCCTAATGTGTCTGGAATTGGTGGGTTCTTGGTC >45771_45771_1_LMCD1-ZNF589_LMCD1_chr3_8543666_ENST00000157600_ZNF589_chr3_48302303_ENST00000354698_length(amino acids)=419AA_BP=87 MGLAGLARAPARSGWRGFRGSPALQLKRPSCAWLRTELPPRPANLAIQPPLSPLRALAPLPEKPGAVPPPQKRMAKVAKDLNPGVKKGPV TFEDVAVLFTEAEWKRLSLEQRNLYKEVMLENLRNLVSLAESKPEVHTCPSCPLAFGSQQFLSQDELHNHPIPGFHAGNQLHPGNPCPED QPQSQHPSDKNHRGAEAEDQRVEGGVRPLFWSTNERGALVGFSSLFQRPPISSWGGNRILEIQLSPAQNASSEEVDRISKRAETPGFGAV TFGECALAFNQKSNLFRQKAVTAEKSSDKRQSQVCRECGRGFSRKSQLIIHQRTHTGEKPYVCGECGRGFIVESVLRNHLSTHSGEKPYV -------------------------------------------------------------- >45771_45771_2_LMCD1-ZNF589_LMCD1_chr3_8543666_ENST00000157600_ZNF589_chr3_48302303_ENST00000412564_length(transcript)=700nt_BP=274nt GGACAGCCTCGCGCTGGGATTGGCTGGCCTCGCGCGAGCGCCGGCGCGGAGTGGCTGGCGAGGTTTTAGAGGGAGTCCCGCTCTCCAATT AAAGCGGCCCAGCTGCGCCTGGCTGCGCACAGAGCTCCCTCCCAGGCCCGCGAACTTGGCCATTCAGCCGCCGCTGTCCCCGCTGCGCGC CCTCGCGCCTCTGCCTGAGAAGCCAGGCGCTGTTCCCCCACCCCAGAAGAGGATGGCAAAGGTGGCTAAGGACCTCAACCCAGGAGTTAA AAAGGGACCAGTGACTTTCGAGGATGTGGCTGTGCTTTTCACTGAGGCAGAGTGGAAGAGACTGAGCCTTGAGCAGAGGAACCTATACAA AGAAGTGATGCTGGAAAATCTCAGGAATCTGGTCTCATTGGTGCTCTCCTATCAAATCTAGAATTGGAAGATTGATGGACAGCAACTGAG GTGCTACCAGGATACCAAAAAGTCTGCTGGATAAACACCATCTCTATTCTAATATTATGGAGAGATCAGGATCTCCTGTGCCCAAATCAA ACCTGTTAATACACTCAGCTGTCCTCAGTGGTAACACTGAGGTCAACACACAACTCCAACATCAGGAACAAGTCATAACCATTTTGCATC >45771_45771_2_LMCD1-ZNF589_LMCD1_chr3_8543666_ENST00000157600_ZNF589_chr3_48302303_ENST00000412564_length(amino acids)=135AA_BP=87 MGLAGLARAPARSGWRGFRGSPALQLKRPSCAWLRTELPPRPANLAIQPPLSPLRALAPLPEKPGAVPPPQKRMAKVAKDLNPGVKKGPV -------------------------------------------------------------- >45771_45771_3_LMCD1-ZNF589_LMCD1_chr3_8543666_ENST00000157600_ZNF589_chr3_48302303_ENST00000427617_length(transcript)=1783nt_BP=274nt GGACAGCCTCGCGCTGGGATTGGCTGGCCTCGCGCGAGCGCCGGCGCGGAGTGGCTGGCGAGGTTTTAGAGGGAGTCCCGCTCTCCAATT AAAGCGGCCCAGCTGCGCCTGGCTGCGCACAGAGCTCCCTCCCAGGCCCGCGAACTTGGCCATTCAGCCGCCGCTGTCCCCGCTGCGCGC CCTCGCGCCTCTGCCTGAGAAGCCAGGCGCTGTTCCCCCACCCCAGAAGAGGATGGCAAAGGTGGCTAAGGACCTCAACCCAGGAGTTAA AAAGGGACCAGTGACTTTCGAGGATGTGGCTGTGCTTTTCACTGAGGCAGAGTGGAAGAGACTGAGCCTTGAGCAGAGGAACCTATACAA AGAAGTGATGCTGGAAAATCTCAGGAATCTGGTCTCATTGGTTCTGGAACTGGGAAGTCCAAGATCAGGGCTCCTGCCCCTGGACCTGAA CCTGGATCTTTGGCTTTGATGTTGGACCTTGTGTGTGGATATGAACTTTGAACCTGCACCTTGGAACTAAACCTCTGACTTGGATTTGTT CTGCATTTTGGAACTCACCTTAGACCTGAACCTTGGTCATGAAATGGATCTGAATCATTCTTGGGTCTTGGACATGGGACTTGGACCTCC ATGTGTATCTTGGACTTAGGACCATGATCTGGACCTTGTAAATTGACTTGGACTTTGGACTTGGACCTTGGACTAGAATTTGTCCCTGGC TGTGGACCTCGTCTTTGGATCTGGATCTGGACCTGGTCTTGGATGTTGGACCTAGATGCAGGCCTTGATTTGATTTGGAACATGGACTTG GTCCTTGCACATGGCCCAACACCCGCGTCTTTGGAACTGCATCTTGGACCTTGGATCTGAAATTTAAACAGGGAGGTGACCTTCATTTCT TGTATTTGACTTTATAACTGGAAATTCAATCTCTACCTGGATCTTGGACCTGGATCTCAGACCTTGCTTTTTATTGGGCCATGGATCTTA TACCTTAAACATGGAAATTGTACCTGGATTTGGACCTTTGACTTGGACCTGGATCTGGACCCAGGGATAAGATTTGGACCTCACTTGCAA ATTTTGGTAATGAAATTTTCCTTTGCTCCTGTAGTCCTTGGACCTAGGCTTCAGTCATGGATTTAGACCTTAGACGTGACCATCAGACCT TAGAGTTGAACCTAAATTCCTGGTCCCCAGTCCTATAACTCAGAATGATTATGCATAACCTTGGACTTAGAACTTAGATCTGGATCTTAG AGCTGATACTTGACCTGGTACTGGATATTTAACCTTGGACTTCAGACATGGATTTAATCTGGGCCTTGGGATGATTTAAGATCTAGAAGT GGACCTAGAATTAGACCTTGGACTTATGTGCCTGAGCCTGGACTTTGGAAGTGGACTTTGGGCCTTGTAACTCAACCTTGAATATGAGCC TCAAATGTAGACTGTGGGCCAGGCACAGTGGCTCACATCTGTAATCCCAGCACTTTGGGTGGAAAGCTGAGGCAGGTGGATCACTTGAGC TCAGGAATTCAAGACCAGCCTGGGGAACATGGTGAAAACCTGGCTCTACAAAAAATAAAAAAATTAGCCAGGCTTGGTGGCACACACCTG TAGTTCCAGGTACTCAGGAGGCTGAGGCAGGAGGTTCACTTGGGCCCAGGAGGCAGAGGTTGCAGTGAGCTGAGCTTGTACAGCTGCACT >45771_45771_3_LMCD1-ZNF589_LMCD1_chr3_8543666_ENST00000157600_ZNF589_chr3_48302303_ENST00000427617_length(amino acids)=151AA_BP=87 MGLAGLARAPARSGWRGFRGSPALQLKRPSCAWLRTELPPRPANLAIQPPLSPLRALAPLPEKPGAVPPPQKRMAKVAKDLNPGVKKGPV -------------------------------------------------------------- >45771_45771_4_LMCD1-ZNF589_LMCD1_chr3_8543666_ENST00000157600_ZNF589_chr3_48302303_ENST00000440261_length(transcript)=1029nt_BP=274nt GGACAGCCTCGCGCTGGGATTGGCTGGCCTCGCGCGAGCGCCGGCGCGGAGTGGCTGGCGAGGTTTTAGAGGGAGTCCCGCTCTCCAATT AAAGCGGCCCAGCTGCGCCTGGCTGCGCACAGAGCTCCCTCCCAGGCCCGCGAACTTGGCCATTCAGCCGCCGCTGTCCCCGCTGCGCGC CCTCGCGCCTCTGCCTGAGAAGCCAGGCGCTGTTCCCCCACCCCAGAAGAGGATGGCAAAGGTGGCTAAGGACCTCAACCCAGGAGTTAA AAAGGGACCAGTGACTTTCGAGGATGTGGCTGTGCTTTTCACTGAGGCAGAGTGGAAGAGACTGAGCCTTGAGCAGAGGAACCTATACAA AGAAGTGATGCTGGAAAATCTCAGGAATCTGGTCTCATTGGAATCAAAGCCAGAAGTCCATACCTGCCCTTCTTGCCCTCTGGCCTTTGG CAGTCAGCAGTTCCTCAGCCAAGATGAGCTACACAATCATCCTATTCCAGGTTTCCATGCAGGAAATCAACTCCACCCAGGAAATCCCTG CCCAGAGGATCAGCCACAGTCACAACATCCTTCTGATAAAAATCACAGGGGGGCTGAAGCAGAAGATCAACGAGTGGAAGGAGGCGTCAG ACCCTTGTTTTGGATTCTGGAACTGGGAAGTCCAAGATCAGGGCTCCTGCCCCTGGACCTGAACCTGGATCTTTGGCTTTGATGTTGGAC CTTGTGTGTGGATATGAACTTTGAACCTGCACCTTGGAACTAAACCTCTGACTTGGATTTGTTCTGCATTTTGGAACTCACCTTAGACCT GAACCTTGGTCATGAAATGGATCTGAATCATTCTTGGGTCTTGGACATGGGACTTGGACCTCCATGTGTATCTTGGACTTAGGACCATGA TCTGGACCTTGTAAATTGACTTGGACTTTGGACTTGGACCTTGGACTAGAATTTGTCCCTGGCTGTGGACCTCGTCTTTGGATCTGGATC >45771_45771_4_LMCD1-ZNF589_LMCD1_chr3_8543666_ENST00000157600_ZNF589_chr3_48302303_ENST00000440261_length(amino acids)=232AA_BP=87 MGLAGLARAPARSGWRGFRGSPALQLKRPSCAWLRTELPPRPANLAIQPPLSPLRALAPLPEKPGAVPPPQKRMAKVAKDLNPGVKKGPV TFEDVAVLFTEAEWKRLSLEQRNLYKEVMLENLRNLVSLESKPEVHTCPSCPLAFGSQQFLSQDELHNHPIPGFHAGNQLHPGNPCPEDQ -------------------------------------------------------------- >45771_45771_5_LMCD1-ZNF589_LMCD1_chr3_8543666_ENST00000535732_ZNF589_chr3_48302303_ENST00000354698_length(transcript)=3356nt_BP=156nt ACAGAGCTCCCTCCCAGGCCCGCGAACTTGGCCATTCAGCCGCCGCTGTCCCCGCTGCGCGCCCTCGCGCCTCTGCCTGAGAAGCCAGGC GCTGTTCCCCCACCCCAGAAGAGGATGGCAAAGGTGGCTAAGGACCTCAACCCAGGAGTTAAAAAGGGACCAGTGACTTTCGAGGATGTG GCTGTGCTTTTCACTGAGGCAGAGTGGAAGAGACTGAGCCTTGAGCAGAGGAACCTATACAAAGAAGTGATGCTGGAAAATCTCAGGAAT CTGGTCTCATTGGCAGAATCAAAGCCAGAAGTCCATACCTGCCCTTCTTGCCCTCTGGCCTTTGGCAGTCAGCAGTTCCTCAGCCAAGAT GAGCTACACAATCATCCTATTCCAGGTTTCCATGCAGGAAATCAACTCCACCCAGGAAATCCCTGCCCAGAGGATCAGCCACAGTCACAA CATCCTTCTGATAAAAATCACAGGGGGGCTGAAGCAGAAGATCAACGAGTGGAAGGAGGCGTCAGACCCTTGTTTTGGAGTACAAATGAA AGGGGGGCTTTAGTGGGTTTCTCTAGCCTGTTCCAGAGACCACCAATAAGCTCTTGGGGAGGCAACAGAATATTAGAGATACAGCTCAGT CCAGCCCAGAATGCAAGCTCTGAGGAAGTAGACAGAATTTCCAAGAGGGCAGAAACCCCAGGGTTTGGAGCAGTCACGTTTGGGGAGTGT GCACTAGCTTTTAACCAGAAGTCAAACCTGTTCAGACAGAAGGCAGTCACAGCAGAAAAATCTTCAGACAAAAGGCAGTCACAGGTGTGC AGGGAGTGTGGGCGAGGCTTTAGCAGGAAGTCACAGCTCATCATACACCAGAGGACACACACAGGAGAAAAGCCTTATGTCTGCGGAGAG TGTGGGCGAGGCTTTATAGTTGAGTCAGTCCTCCGCAACCACCTGAGTACACACTCCGGGGAGAAACCTTATGTGTGCAGCCATTGTGGG CGAGGCTTTAGCTGCAAGCCATACCTCATCAGACATCAGAGGACACACACAAGGGAGAAATCGTTTATGTGCACAGTGTGTGGGCGAGGC TTTCGTGAAAAGTCAGAGCTCATTAAGCACCAGAGAATTCACACGGGGGATAAGCCTTATGTGTGCAGAGATTGAGGCCGAGGCTTTGTA AGGAGATCATGTCTCAACACACACCAGAGGATACATTCAGATGAGAAGCCTTTTGTTTGCAGAGAGTGTGGGCGAGGCTTTCGTGCTAAA TCAACTCTCCTCCTACACCAGTGGACACATTCAGAGGTGAAACCTCACGTGTGTGAGGAGTGTGGGCATGGATTTAGCCAGAAGTCGTCG CTCAAATCACATCGGAGAACACACTCAGGGGAGAAGCCTTATGTGTGTGGGGAATGTGGGCGGGGATTTAGCCGGAGGATAGTCCTCAAT GGACACTGGAGGACACACACGGGAGAGAAGCCTTACACGTGCTTTGAGTGTGGGCGAAACTTTAGCCTCAAGTCCGCTCTTAGTGTACAT CAGAGGATACACTCTGGGGAGAAGCCTTATGCATGCACGGAGTGTGGGCAAGGCTTTATCACGAAATCACAGCTCATCAGACACCAGAGG ACACACACAGGAGAAAAGCCTTATGTCTGCGGAGAGTGTGGGCGAGGCTTTATAGCTCAGTCAACCCTCCACTACCACCGGAGTACACAC TCCAAGGAAAAACCTTATGTGTGCAGCCAGTGTGGGCGAGGCTTTTGTGATAAATCAACTCTCCTCGCACACGAGCAGACACATTCAGGG GAGAAGCCTTATGTGTGTGGGGAATGTGGGCGGGGATTTGGCCGGAAGATACTCCTCAACAGACACTGGAGGACACACACAGGAGAGAAA CCTTACGCATGCATCGAGTGTGGGCGAAACTTTAGCCACAAGTCCACTCTCAGCTTACATCAGAGGATACACTCGGGGGAGAAGCCTTAT GCATGCGTGGAGTGTGGGCAAAGCTTTAGGAGAAAGTCACAGCTCATCATACACCAGAAGATACACTCGGGGAAAAGCTTTAGAGGTGCA AGGAGTGAGGATGTGATTTTAGCAACAAGTCAGCCATCAGCCACACCAGCGGAAATGCTTAGGGAGAAGCCTTGTTTGTAAGGTAATGTG GACAGAGCTGTACGTGGACATCATTACTTGTCACGTGTCAGAGGACACACTCGGGAGAAACCTTCATGGAGTGAGAGTAAGGTGTTGGCT GGAAGTGGCCCCTTAAGAGATACTTGGAGTCAAATCTATCCACTGTACGCCCACCCCACTCTTGTTCTAAGAGCTTTGGGGACAGTCTTT TGACCCCTTACATTCCTTTAGATGTGAAGATGACAGAGATCTAACTTCTGAGAGCAGAGGTGTCAAGTGACGGTCCCCTTGGAGGAATGG TCTTTGCATCTGACTACTTCCTTCTGCAACTGTGTTCTTCCATTAGCTTCCATGACACTCTCCTGCTTTATTTTTTTCTACATCTCTAGC CTTTGCTGTTTCCTCTCCTACCCCACCTTTAGATTTTACTCAGAGTTCAGTCTCCAGCCCTACAATCTGAGGGACACCTTTACCAGGTCC CCTTCCTAACCCTCCAGTCCCAAATCCAAGATTCTTTAACCACACTCTAAAAGTTCTTCAGACTCAGGACTTAAACATAGCCACGCCACC TTGGCCTTCAATGACAGGGATCTAGCAATGCTGCATCATCAGCCTTCCAATACCAGGTTTAAGGGTATTTTAAACACAGCTCCTCTTAAA TCCTCCAATCTCAGTACCCAGTGTTTTAGCCATGCTCGGGTGGCTAAATTACATCCAGGAATGGTGCCAGGGCCTTTAGCCATTTGTCTC TCCTCACACTCCAGGGCCCATATGGCCCAGGTTCTGACAGTTTGCCTTACTCCCTTGGGCTGGGGCTAGCCCTACCTGATACCCTGTGTC AATGAGTGTACCTTGGAGAGCTATCCACTCAGGCCCCAGTGCCTCTATTTGCTAAGGGACTCTGCCACAGAAAAGAAGGGGAGAGATGTT CATGTAACCTCAAAATACTTAGGCTTGGTTTTGATGCTAGAGAGGAAAAAGGACTTGGAGAGAGAGAAGGAATGGCTGGTCCAGAGGCTT TTGTCCACTCCCTCTCACTGGAAGTGGTTGATCTCCAGGGAATCCCCAAGGTTAGCCTGCTTAGGGGAAGGGCTAGGGGTACCTGGAATG TAGGATCTCCCCCATGCCTGGCCTACCACCCTAATGTGTCTGGAATTGGTGGGTTCTTGGTCTTGCTGACTTCAAGAATGAAGCCGTGGA >45771_45771_5_LMCD1-ZNF589_LMCD1_chr3_8543666_ENST00000535732_ZNF589_chr3_48302303_ENST00000354698_length(amino acids)=375AA_BP=43 MAIQPPLSPLRALAPLPEKPGAVPPPQKRMAKVAKDLNPGVKKGPVTFEDVAVLFTEAEWKRLSLEQRNLYKEVMLENLRNLVSLAESKP EVHTCPSCPLAFGSQQFLSQDELHNHPIPGFHAGNQLHPGNPCPEDQPQSQHPSDKNHRGAEAEDQRVEGGVRPLFWSTNERGALVGFSS LFQRPPISSWGGNRILEIQLSPAQNASSEEVDRISKRAETPGFGAVTFGECALAFNQKSNLFRQKAVTAEKSSDKRQSQVCRECGRGFSR KSQLIIHQRTHTGEKPYVCGECGRGFIVESVLRNHLSTHSGEKPYVCSHCGRGFSCKPYLIRHQRTHTREKSFMCTVCGRGFREKSELIK -------------------------------------------------------------- >45771_45771_6_LMCD1-ZNF589_LMCD1_chr3_8543666_ENST00000535732_ZNF589_chr3_48302303_ENST00000412564_length(transcript)=582nt_BP=156nt ACAGAGCTCCCTCCCAGGCCCGCGAACTTGGCCATTCAGCCGCCGCTGTCCCCGCTGCGCGCCCTCGCGCCTCTGCCTGAGAAGCCAGGC GCTGTTCCCCCACCCCAGAAGAGGATGGCAAAGGTGGCTAAGGACCTCAACCCAGGAGTTAAAAAGGGACCAGTGACTTTCGAGGATGTG GCTGTGCTTTTCACTGAGGCAGAGTGGAAGAGACTGAGCCTTGAGCAGAGGAACCTATACAAAGAAGTGATGCTGGAAAATCTCAGGAAT CTGGTCTCATTGGTGCTCTCCTATCAAATCTAGAATTGGAAGATTGATGGACAGCAACTGAGGTGCTACCAGGATACCAAAAAGTCTGCT GGATAAACACCATCTCTATTCTAATATTATGGAGAGATCAGGATCTCCTGTGCCCAAATCAAACCTGTTAATACACTCAGCTGTCCTCAG TGGTAACACTGAGGTCAACACACAACTCCAACATCAGGAACAAGTCATAACCATTTTGCATCTGAAACAGTGCCTGACACAAAGGTGCTT >45771_45771_6_LMCD1-ZNF589_LMCD1_chr3_8543666_ENST00000535732_ZNF589_chr3_48302303_ENST00000412564_length(amino acids)=91AA_BP=43 MAIQPPLSPLRALAPLPEKPGAVPPPQKRMAKVAKDLNPGVKKGPVTFEDVAVLFTEAEWKRLSLEQRNLYKEVMLENLRNLVSLVLSYQ -------------------------------------------------------------- >45771_45771_7_LMCD1-ZNF589_LMCD1_chr3_8543666_ENST00000535732_ZNF589_chr3_48302303_ENST00000427617_length(transcript)=1665nt_BP=156nt ACAGAGCTCCCTCCCAGGCCCGCGAACTTGGCCATTCAGCCGCCGCTGTCCCCGCTGCGCGCCCTCGCGCCTCTGCCTGAGAAGCCAGGC GCTGTTCCCCCACCCCAGAAGAGGATGGCAAAGGTGGCTAAGGACCTCAACCCAGGAGTTAAAAAGGGACCAGTGACTTTCGAGGATGTG GCTGTGCTTTTCACTGAGGCAGAGTGGAAGAGACTGAGCCTTGAGCAGAGGAACCTATACAAAGAAGTGATGCTGGAAAATCTCAGGAAT CTGGTCTCATTGGTTCTGGAACTGGGAAGTCCAAGATCAGGGCTCCTGCCCCTGGACCTGAACCTGGATCTTTGGCTTTGATGTTGGACC TTGTGTGTGGATATGAACTTTGAACCTGCACCTTGGAACTAAACCTCTGACTTGGATTTGTTCTGCATTTTGGAACTCACCTTAGACCTG AACCTTGGTCATGAAATGGATCTGAATCATTCTTGGGTCTTGGACATGGGACTTGGACCTCCATGTGTATCTTGGACTTAGGACCATGAT CTGGACCTTGTAAATTGACTTGGACTTTGGACTTGGACCTTGGACTAGAATTTGTCCCTGGCTGTGGACCTCGTCTTTGGATCTGGATCT GGACCTGGTCTTGGATGTTGGACCTAGATGCAGGCCTTGATTTGATTTGGAACATGGACTTGGTCCTTGCACATGGCCCAACACCCGCGT CTTTGGAACTGCATCTTGGACCTTGGATCTGAAATTTAAACAGGGAGGTGACCTTCATTTCTTGTATTTGACTTTATAACTGGAAATTCA ATCTCTACCTGGATCTTGGACCTGGATCTCAGACCTTGCTTTTTATTGGGCCATGGATCTTATACCTTAAACATGGAAATTGTACCTGGA TTTGGACCTTTGACTTGGACCTGGATCTGGACCCAGGGATAAGATTTGGACCTCACTTGCAAATTTTGGTAATGAAATTTTCCTTTGCTC CTGTAGTCCTTGGACCTAGGCTTCAGTCATGGATTTAGACCTTAGACGTGACCATCAGACCTTAGAGTTGAACCTAAATTCCTGGTCCCC AGTCCTATAACTCAGAATGATTATGCATAACCTTGGACTTAGAACTTAGATCTGGATCTTAGAGCTGATACTTGACCTGGTACTGGATAT TTAACCTTGGACTTCAGACATGGATTTAATCTGGGCCTTGGGATGATTTAAGATCTAGAAGTGGACCTAGAATTAGACCTTGGACTTATG TGCCTGAGCCTGGACTTTGGAAGTGGACTTTGGGCCTTGTAACTCAACCTTGAATATGAGCCTCAAATGTAGACTGTGGGCCAGGCACAG TGGCTCACATCTGTAATCCCAGCACTTTGGGTGGAAAGCTGAGGCAGGTGGATCACTTGAGCTCAGGAATTCAAGACCAGCCTGGGGAAC ATGGTGAAAACCTGGCTCTACAAAAAATAAAAAAATTAGCCAGGCTTGGTGGCACACACCTGTAGTTCCAGGTACTCAGGAGGCTGAGGC AGGAGGTTCACTTGGGCCCAGGAGGCAGAGGTTGCAGTGAGCTGAGCTTGTACAGCTGCACTCCAGCCTGGAGGACAGAGTGAGACTCTG >45771_45771_7_LMCD1-ZNF589_LMCD1_chr3_8543666_ENST00000535732_ZNF589_chr3_48302303_ENST00000427617_length(amino acids)=113AA_BP= MKVTSLFKFQIQGPRCSSKDAGVGPCARTKSMFQIKSRPASRSNIQDQVQIQIQRRGPQPGTNSSPRSKSKVQVNLQGPDHGPKSKIHME -------------------------------------------------------------- >45771_45771_8_LMCD1-ZNF589_LMCD1_chr3_8543666_ENST00000535732_ZNF589_chr3_48302303_ENST00000440261_length(transcript)=911nt_BP=156nt ACAGAGCTCCCTCCCAGGCCCGCGAACTTGGCCATTCAGCCGCCGCTGTCCCCGCTGCGCGCCCTCGCGCCTCTGCCTGAGAAGCCAGGC GCTGTTCCCCCACCCCAGAAGAGGATGGCAAAGGTGGCTAAGGACCTCAACCCAGGAGTTAAAAAGGGACCAGTGACTTTCGAGGATGTG GCTGTGCTTTTCACTGAGGCAGAGTGGAAGAGACTGAGCCTTGAGCAGAGGAACCTATACAAAGAAGTGATGCTGGAAAATCTCAGGAAT CTGGTCTCATTGGAATCAAAGCCAGAAGTCCATACCTGCCCTTCTTGCCCTCTGGCCTTTGGCAGTCAGCAGTTCCTCAGCCAAGATGAG CTACACAATCATCCTATTCCAGGTTTCCATGCAGGAAATCAACTCCACCCAGGAAATCCCTGCCCAGAGGATCAGCCACAGTCACAACAT CCTTCTGATAAAAATCACAGGGGGGCTGAAGCAGAAGATCAACGAGTGGAAGGAGGCGTCAGACCCTTGTTTTGGATTCTGGAACTGGGA AGTCCAAGATCAGGGCTCCTGCCCCTGGACCTGAACCTGGATCTTTGGCTTTGATGTTGGACCTTGTGTGTGGATATGAACTTTGAACCT GCACCTTGGAACTAAACCTCTGACTTGGATTTGTTCTGCATTTTGGAACTCACCTTAGACCTGAACCTTGGTCATGAAATGGATCTGAAT CATTCTTGGGTCTTGGACATGGGACTTGGACCTCCATGTGTATCTTGGACTTAGGACCATGATCTGGACCTTGTAAATTGACTTGGACTT TGGACTTGGACCTTGGACTAGAATTTGTCCCTGGCTGTGGACCTCGTCTTTGGATCTGGATCTGGACCTGGTCTTGGATGTTGGACCTAG >45771_45771_8_LMCD1-ZNF589_LMCD1_chr3_8543666_ENST00000535732_ZNF589_chr3_48302303_ENST00000440261_length(amino acids)=188AA_BP=43 MAIQPPLSPLRALAPLPEKPGAVPPPQKRMAKVAKDLNPGVKKGPVTFEDVAVLFTEAEWKRLSLEQRNLYKEVMLENLRNLVSLESKPE VHTCPSCPLAFGSQQFLSQDELHNHPIPGFHAGNQLHPGNPCPEDQPQSQHPSDKNHRGAEAEDQRVEGGVRPLFWILELGSPRSGLLPL -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for LMCD1-ZNF589 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for LMCD1-ZNF589 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for LMCD1-ZNF589 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies