
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:LPAR1-TMOD1 (FusionGDB2 ID:49476) |
Fusion Gene Summary for LPAR1-TMOD1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: LPAR1-TMOD1 | Fusion gene ID: 49476 | Hgene | Tgene | Gene symbol | LPAR1 | TMOD1 | Gene ID | 1902 | 7111 |
| Gene name | lysophosphatidic acid receptor 1 | tropomodulin 1 | |
| Synonyms | EDG2|GPR26|Gpcr26|LPA1|Mrec1.3|VZG1|edg-2|rec.1.3|vzg-1 | D9S57E|ETMOD|TMOD | |
| Cytomap | 9q31.3 | 9q22.33 | |
| Type of gene | protein-coding | protein-coding | |
| Description | lysophosphatidic acid receptor 1LPA receptor 1LPA-1endothelial differentiation, lysophosphatidic acid G-protein-coupled receptor, 2lysophosphatidic acid receptor Edg-2ventricular zone gene 1 | tropomodulin-1E-Tmode-tropomodulinerythrocyte tropomodulin | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q92633 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000538760, ENST00000541779, ENST00000358883, ENST00000374430, ENST00000374431, | ENST00000259365, ENST00000375175, ENST00000395211, | |
| Fusion gene scores | * DoF score | 4 X 3 X 3=36 | 6 X 6 X 3=108 |
| # samples | 4 | 6 | |
| ** MAII score | log2(4/36*10)=0.15200309344505 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | log2(6/108*10)=-0.84799690655495 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: LPAR1 [Title/Abstract] AND TMOD1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | LPAR1(113703701)-TMOD1(100353573), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | LPAR1-TMOD1 seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. LPAR1-TMOD1 seems lost the major protein functional domain in Hgene partner, which is a IUPHAR drug target due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | LPAR1 | GO:0007202 | activation of phospholipase C activity | 19306925 |
| Fusion gene breakpoints across LPAR1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across TMOD1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | GBM | TCGA-06-0132-01A | LPAR1 | chr9 | 113703701 | - | TMOD1 | chr9 | 100353573 | + |
Top |
Fusion Gene ORF analysis for LPAR1-TMOD1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| Frame-shift | ENST00000538760 | ENST00000259365 | LPAR1 | chr9 | 113703701 | - | TMOD1 | chr9 | 100353573 | + |
| Frame-shift | ENST00000538760 | ENST00000375175 | LPAR1 | chr9 | 113703701 | - | TMOD1 | chr9 | 100353573 | + |
| Frame-shift | ENST00000538760 | ENST00000395211 | LPAR1 | chr9 | 113703701 | - | TMOD1 | chr9 | 100353573 | + |
| Frame-shift | ENST00000541779 | ENST00000259365 | LPAR1 | chr9 | 113703701 | - | TMOD1 | chr9 | 100353573 | + |
| Frame-shift | ENST00000541779 | ENST00000375175 | LPAR1 | chr9 | 113703701 | - | TMOD1 | chr9 | 100353573 | + |
| Frame-shift | ENST00000541779 | ENST00000395211 | LPAR1 | chr9 | 113703701 | - | TMOD1 | chr9 | 100353573 | + |
| In-frame | ENST00000358883 | ENST00000259365 | LPAR1 | chr9 | 113703701 | - | TMOD1 | chr9 | 100353573 | + |
| In-frame | ENST00000358883 | ENST00000375175 | LPAR1 | chr9 | 113703701 | - | TMOD1 | chr9 | 100353573 | + |
| In-frame | ENST00000358883 | ENST00000395211 | LPAR1 | chr9 | 113703701 | - | TMOD1 | chr9 | 100353573 | + |
| In-frame | ENST00000374430 | ENST00000259365 | LPAR1 | chr9 | 113703701 | - | TMOD1 | chr9 | 100353573 | + |
| In-frame | ENST00000374430 | ENST00000375175 | LPAR1 | chr9 | 113703701 | - | TMOD1 | chr9 | 100353573 | + |
| In-frame | ENST00000374430 | ENST00000395211 | LPAR1 | chr9 | 113703701 | - | TMOD1 | chr9 | 100353573 | + |
| In-frame | ENST00000374431 | ENST00000259365 | LPAR1 | chr9 | 113703701 | - | TMOD1 | chr9 | 100353573 | + |
| In-frame | ENST00000374431 | ENST00000375175 | LPAR1 | chr9 | 113703701 | - | TMOD1 | chr9 | 100353573 | + |
| In-frame | ENST00000374431 | ENST00000395211 | LPAR1 | chr9 | 113703701 | - | TMOD1 | chr9 | 100353573 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000374431 | LPAR1 | chr9 | 113703701 | - | ENST00000395211 | TMOD1 | chr9 | 100353573 | + | 3430 | 1177 | 384 | 1316 | 310 |
| ENST00000374431 | LPAR1 | chr9 | 113703701 | - | ENST00000259365 | TMOD1 | chr9 | 100353573 | + | 3437 | 1177 | 384 | 1316 | 310 |
| ENST00000374431 | LPAR1 | chr9 | 113703701 | - | ENST00000375175 | TMOD1 | chr9 | 100353573 | + | 2943 | 1177 | 384 | 1316 | 310 |
| ENST00000374430 | LPAR1 | chr9 | 113703701 | - | ENST00000395211 | TMOD1 | chr9 | 100353573 | + | 3301 | 1048 | 255 | 1187 | 310 |
| ENST00000374430 | LPAR1 | chr9 | 113703701 | - | ENST00000259365 | TMOD1 | chr9 | 100353573 | + | 3308 | 1048 | 255 | 1187 | 310 |
| ENST00000374430 | LPAR1 | chr9 | 113703701 | - | ENST00000375175 | TMOD1 | chr9 | 100353573 | + | 2814 | 1048 | 255 | 1187 | 310 |
| ENST00000358883 | LPAR1 | chr9 | 113703701 | - | ENST00000395211 | TMOD1 | chr9 | 100353573 | + | 3394 | 1141 | 348 | 1280 | 310 |
| ENST00000358883 | LPAR1 | chr9 | 113703701 | - | ENST00000259365 | TMOD1 | chr9 | 100353573 | + | 3401 | 1141 | 348 | 1280 | 310 |
| ENST00000358883 | LPAR1 | chr9 | 113703701 | - | ENST00000375175 | TMOD1 | chr9 | 100353573 | + | 2907 | 1141 | 348 | 1280 | 310 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000374431 | ENST00000395211 | LPAR1 | chr9 | 113703701 | - | TMOD1 | chr9 | 100353573 | + | 0.000860872 | 0.9991391 |
| ENST00000374431 | ENST00000259365 | LPAR1 | chr9 | 113703701 | - | TMOD1 | chr9 | 100353573 | + | 0.000839656 | 0.9991604 |
| ENST00000374431 | ENST00000375175 | LPAR1 | chr9 | 113703701 | - | TMOD1 | chr9 | 100353573 | + | 0.000685753 | 0.9993143 |
| ENST00000374430 | ENST00000395211 | LPAR1 | chr9 | 113703701 | - | TMOD1 | chr9 | 100353573 | + | 0.000685784 | 0.9993142 |
| ENST00000374430 | ENST00000259365 | LPAR1 | chr9 | 113703701 | - | TMOD1 | chr9 | 100353573 | + | 0.000671572 | 0.9993285 |
| ENST00000374430 | ENST00000375175 | LPAR1 | chr9 | 113703701 | - | TMOD1 | chr9 | 100353573 | + | 0.000580543 | 0.99941945 |
| ENST00000358883 | ENST00000395211 | LPAR1 | chr9 | 113703701 | - | TMOD1 | chr9 | 100353573 | + | 0.000859426 | 0.9991405 |
| ENST00000358883 | ENST00000259365 | LPAR1 | chr9 | 113703701 | - | TMOD1 | chr9 | 100353573 | + | 0.000847678 | 0.9991523 |
| ENST00000358883 | ENST00000375175 | LPAR1 | chr9 | 113703701 | - | TMOD1 | chr9 | 100353573 | + | 0.000713198 | 0.99928683 |
Top |
Fusion Genomic Features for LPAR1-TMOD1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| LPAR1 | chr9 | 113703700 | - | TMOD1 | chr9 | 100353572 | + | 2.00E-09 | 1 |
| LPAR1 | chr9 | 113703700 | - | TMOD1 | chr9 | 100353572 | + | 2.00E-09 | 1 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
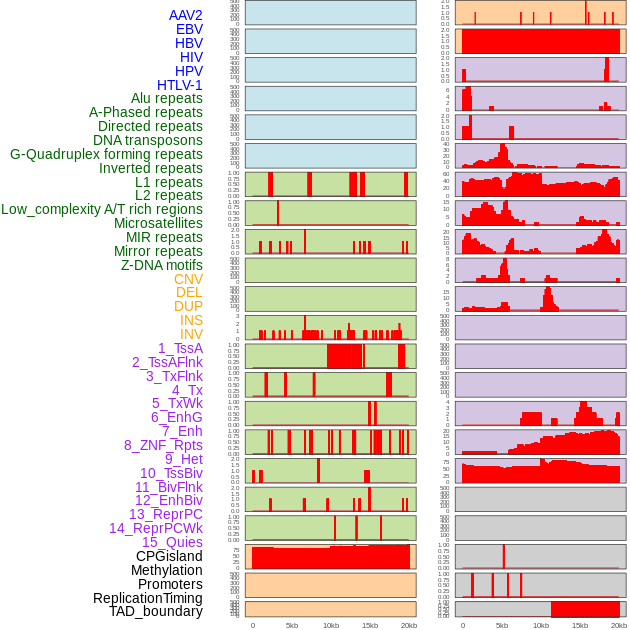 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
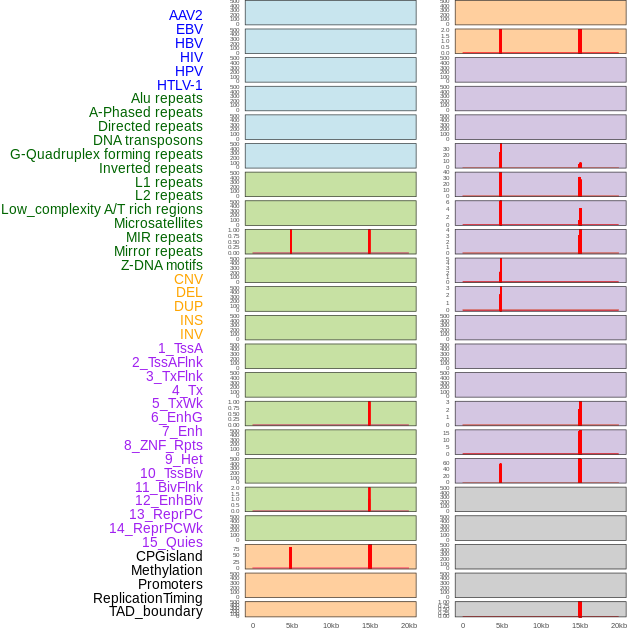 |
Top |
Fusion Protein Features for LPAR1-TMOD1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr9:113703701/chr9:100353573) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| LPAR1 | . |
| FUNCTION: Receptor for lysophosphatidic acid (LPA) (PubMed:9070858, PubMed:19306925, PubMed:25025571, PubMed:26091040). Plays a role in the reorganization of the actin cytoskeleton, cell migration, differentiation and proliferation, and thereby contributes to the responses to tissue damage and infectious agents. Activates downstream signaling cascades via the G(i)/G(o), G(12)/G(13), and G(q) families of heteromeric G proteins. Signaling inhibits adenylyl cyclase activity and decreases cellular cAMP levels (PubMed:26091040). Signaling triggers an increase of cytoplasmic Ca(2+) levels (PubMed:19656035, PubMed:19733258, PubMed:26091040). Activates RALA; this leads to the activation of phospholipase C (PLC) and the formation of inositol 1,4,5-trisphosphate (PubMed:19306925). Signaling mediates activation of down-stream MAP kinases (By similarity). Contributes to the regulation of cell shape. Promotes Rho-dependent reorganization of the actin cytoskeleton in neuronal cells and neurite retraction (PubMed:26091040). Promotes the activation of Rho and the formation of actin stress fibers (PubMed:26091040). Promotes formation of lamellipodia at the leading edge of migrating cells via activation of RAC1 (By similarity). Through its function as lysophosphatidic acid receptor, plays a role in chemotaxis and cell migration, including responses to injury and wounding (PubMed:18066075, PubMed:19656035, PubMed:19733258). Plays a role in triggering inflammation in response to bacterial lipopolysaccharide (LPS) via its interaction with CD14. Promotes cell proliferation in response to lysophosphatidic acid. Required for normal skeleton development. May play a role in osteoblast differentiation. Required for normal brain development. Required for normal proliferation, survival and maturation of newly formed neurons in the adult dentate gyrus. Plays a role in pain perception and in the initiation of neuropathic pain (By similarity). {ECO:0000250|UniProtKB:P61793, ECO:0000269|PubMed:18066075, ECO:0000269|PubMed:19306925, ECO:0000269|PubMed:19656035, ECO:0000269|PubMed:19733258, ECO:0000269|PubMed:25025571, ECO:0000269|PubMed:26091040, ECO:0000269|PubMed:9070858, ECO:0000305|PubMed:11093753, ECO:0000305|PubMed:9069262}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000358883 | - | 3 | 4 | 124_129 | 264 | 365.0 | Region | Lysophosphatidic acid binding |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000374430 | - | 4 | 5 | 124_129 | 264 | 365.0 | Region | Lysophosphatidic acid binding |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000374431 | - | 4 | 5 | 124_129 | 264 | 365.0 | Region | Lysophosphatidic acid binding |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000358883 | - | 3 | 4 | 108_121 | 264 | 365.0 | Topological domain | Note=Extracellular |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000358883 | - | 3 | 4 | 145_163 | 264 | 365.0 | Topological domain | Note=Cytoplasmic |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000358883 | - | 3 | 4 | 185_204 | 264 | 365.0 | Topological domain | Note=Extracellular |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000358883 | - | 3 | 4 | 1_50 | 264 | 365.0 | Topological domain | Note=Extracellular |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000358883 | - | 3 | 4 | 226_255 | 264 | 365.0 | Topological domain | Note=Cytoplasmic |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000358883 | - | 3 | 4 | 76_83 | 264 | 365.0 | Topological domain | Note=Cytoplasmic |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000374430 | - | 4 | 5 | 108_121 | 264 | 365.0 | Topological domain | Note=Extracellular |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000374430 | - | 4 | 5 | 145_163 | 264 | 365.0 | Topological domain | Note=Cytoplasmic |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000374430 | - | 4 | 5 | 185_204 | 264 | 365.0 | Topological domain | Note=Extracellular |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000374430 | - | 4 | 5 | 1_50 | 264 | 365.0 | Topological domain | Note=Extracellular |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000374430 | - | 4 | 5 | 226_255 | 264 | 365.0 | Topological domain | Note=Cytoplasmic |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000374430 | - | 4 | 5 | 76_83 | 264 | 365.0 | Topological domain | Note=Cytoplasmic |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000374431 | - | 4 | 5 | 108_121 | 264 | 365.0 | Topological domain | Note=Extracellular |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000374431 | - | 4 | 5 | 145_163 | 264 | 365.0 | Topological domain | Note=Cytoplasmic |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000374431 | - | 4 | 5 | 185_204 | 264 | 365.0 | Topological domain | Note=Extracellular |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000374431 | - | 4 | 5 | 1_50 | 264 | 365.0 | Topological domain | Note=Extracellular |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000374431 | - | 4 | 5 | 226_255 | 264 | 365.0 | Topological domain | Note=Cytoplasmic |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000374431 | - | 4 | 5 | 76_83 | 264 | 365.0 | Topological domain | Note=Cytoplasmic |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000358883 | - | 3 | 4 | 122_144 | 264 | 365.0 | Transmembrane | Note=Helical%3B Name%3D3 |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000358883 | - | 3 | 4 | 164_184 | 264 | 365.0 | Transmembrane | Note=Helical%3B Name%3D4 |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000358883 | - | 3 | 4 | 205_225 | 264 | 365.0 | Transmembrane | Note=Helical%3B Name%3D5 |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000358883 | - | 3 | 4 | 51_75 | 264 | 365.0 | Transmembrane | Note=Helical%3B Name%3D1 |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000358883 | - | 3 | 4 | 84_107 | 264 | 365.0 | Transmembrane | Note=Helical%3B Name%3D2 |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000374430 | - | 4 | 5 | 122_144 | 264 | 365.0 | Transmembrane | Note=Helical%3B Name%3D3 |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000374430 | - | 4 | 5 | 164_184 | 264 | 365.0 | Transmembrane | Note=Helical%3B Name%3D4 |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000374430 | - | 4 | 5 | 205_225 | 264 | 365.0 | Transmembrane | Note=Helical%3B Name%3D5 |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000374430 | - | 4 | 5 | 51_75 | 264 | 365.0 | Transmembrane | Note=Helical%3B Name%3D1 |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000374430 | - | 4 | 5 | 84_107 | 264 | 365.0 | Transmembrane | Note=Helical%3B Name%3D2 |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000374431 | - | 4 | 5 | 122_144 | 264 | 365.0 | Transmembrane | Note=Helical%3B Name%3D3 |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000374431 | - | 4 | 5 | 164_184 | 264 | 365.0 | Transmembrane | Note=Helical%3B Name%3D4 |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000374431 | - | 4 | 5 | 205_225 | 264 | 365.0 | Transmembrane | Note=Helical%3B Name%3D5 |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000374431 | - | 4 | 5 | 51_75 | 264 | 365.0 | Transmembrane | Note=Helical%3B Name%3D1 |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000374431 | - | 4 | 5 | 84_107 | 264 | 365.0 | Transmembrane | Note=Helical%3B Name%3D2 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000358883 | - | 3 | 4 | 281_294 | 264 | 365.0 | Topological domain | Note=Extracellular |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000358883 | - | 3 | 4 | 316_364 | 264 | 365.0 | Topological domain | Note=Cytoplasmic |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000374430 | - | 4 | 5 | 281_294 | 264 | 365.0 | Topological domain | Note=Extracellular |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000374430 | - | 4 | 5 | 316_364 | 264 | 365.0 | Topological domain | Note=Cytoplasmic |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000374431 | - | 4 | 5 | 281_294 | 264 | 365.0 | Topological domain | Note=Extracellular |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000374431 | - | 4 | 5 | 316_364 | 264 | 365.0 | Topological domain | Note=Cytoplasmic |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000358883 | - | 3 | 4 | 256_280 | 264 | 365.0 | Transmembrane | Note=Helical%3B Name%3D6 |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000358883 | - | 3 | 4 | 295_315 | 264 | 365.0 | Transmembrane | Note=Helical%3B Name%3D7 |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000374430 | - | 4 | 5 | 256_280 | 264 | 365.0 | Transmembrane | Note=Helical%3B Name%3D6 |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000374430 | - | 4 | 5 | 295_315 | 264 | 365.0 | Transmembrane | Note=Helical%3B Name%3D7 |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000374431 | - | 4 | 5 | 256_280 | 264 | 365.0 | Transmembrane | Note=Helical%3B Name%3D6 |
| Hgene | LPAR1 | chr9:113703701 | chr9:100353573 | ENST00000374431 | - | 4 | 5 | 295_315 | 264 | 365.0 | Transmembrane | Note=Helical%3B Name%3D7 |
| Tgene | TMOD1 | chr9:113703701 | chr9:100353573 | ENST00000259365 | 7 | 10 | 39_138 | 290 | 360.0 | Region | Tropomyosin-binding | |
| Tgene | TMOD1 | chr9:113703701 | chr9:100353573 | ENST00000395211 | 7 | 10 | 39_138 | 290 | 360.0 | Region | Tropomyosin-binding |
Top |
Fusion Gene Sequence for LPAR1-TMOD1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >49476_49476_1_LPAR1-TMOD1_LPAR1_chr9_113703701_ENST00000358883_TMOD1_chr9_100353573_ENST00000259365_length(transcript)=3401nt_BP=1141nt ACGGCGCGCTGGGCTCACACTGTCCCGCCGCGGACGGGCTTTGTGGTTGGGGGCGCGCGTGCGAGTGCCAGTGAGAGTGTGGGTGCGCGC TGTGGGCCGCGGCGCGGGTGGGTGGCCGTGCGTTCTTGCGAGCCGGCCTGCAGGAGGCGAGGCTCCCCTGGCCTCCCGCACCCAGCGGCG GACCGAGCCCCTGGAGGGAAGTTGCCGCAGCCGCCCGGGCCGCCGGCCCTCCTGTCCCGCGCCAGGTACACAGCTTCTCCTAGCATGACT TCGATCTGATCAGCAAACAAGAAAATTTGTCTCCCGTAGTTCTGGGGCGTGTTCACCACCTACAACCACAGAGCTGTCATGGCTGCCATC TCTACTTCCATCCCTGTAATTTCACAGCCCCAGTTCACAGCCATGAATGAACCACAGTGCTTCTACAACGAGTCCATTGCCTTCTTTTAT AACCGAAGTGGAAAGCATCTTGCCACAGAATGGAACACAGTCAGCAAGCTGGTGATGGGACTTGGAATCACTGTTTGTATCTTCATCATG TTGGCCAACCTATTGGTCATGGTGGCAATCTATGTCAACCGCCGCTTCCATTTTCCTATTTATTACCTAATGGCTAATCTGGCTGCTGCA GACTTCTTTGCTGGGTTGGCCTACTTCTATCTCATGTTCAACACAGGACCCAATACTCGGAGACTGACTGTTAGCACATGGCTCCTTCGT CAGGGCCTCATTGACACCAGCCTGACGGCATCTGTGGCCAACTTACTGGCTATTGCAATCGAGAGGCACATTACGGTTTTCCGCATGCAG CTCCACACACGGATGAGCAACCGGCGGGTAGTGGTGGTCATTGTGGTCATCTGGACTATGGCCATCGTTATGGGTGCTATACCCAGTGTG GGCTGGAACTGTATCTGTGATATTGAAAATTGTTCCAACATGGCACCCCTCTACAGTGACTCTTACTTAGTCTTCTGGGCCATTTTCAAC TTGGTGACCTTTGTGGTAATGGTGGTTCTCTATGCTCACATCTTTGGCTATGTTCGCCAGAGGACTATGAGAATGTCTCGGCATAGTTCT GGACCCCGGCGGAATCGGGATACCATGATGAGTCTTCTGAAGACTGTGGTCATTGTGCTTGAGCCAGCCCCTGGGCAACAAAGTGGAAAT GGAGATTGTGAGCATGTTGGAAAAAAACGCAACACTTCTCAAATTCGGCTACCACTTTACCCAGCAAGGACCCCGGCTTCGGGCATCCAA CGCAATGATGAACAACAATGACCTTGTGAGGAAGAGGAGGCTTGCGGACCTGACTGGGCCCATCATTCCCAAGTGCCGGAGTGGTGTCTA GTGTGTGGCGGTGGAGTCCATGCCTTTGAACTGGATGTGTTCTATTGATGACCTGTGCTCTGCAGGGGAAACCAGAAGGCAAAATGCTGG CAGCATGAAACCCTTTTGTGGTTCAGTTCTTTATGCACTAAGGTTTTAGGTTGACTAGTGGTTGTAGTTGAAAATTTTATAAAATACCGT TAATGTGAAGTTTTTCTTTAGTCACAGAAGTTGAATCTGGTTATTATTTAAAAACTAGAAGCCCCCAAACCAGCAGATCTTACTGAAGAT GATGTTCCAGCAGCAGCGACTTAGCCCCAGGAGCCCAGTTTCAATGGCCTTGCTGTGTGGTGTTTCAAGTGCATTTAAAATGTGTGACAC AGAAACGGCACACTCTTCCACATGCTTTTGAAGTATTATAAAACACTTTATTACAAATTTGTCTTAGCTATTAGCAAATAAAACTGATTA TCATTCTTTATTAACCCTCCTTGGAATTTTGAAAACCTCGATTAAAGTTGCCAAATTGATTACTGGATCCAGAACACAATTTTCCCCTCA GAACAGATAGACAGACTGAAGCCACTGAACTCTGCCAGGAGTCAACATGAGATTCCTTTTGCTGGATATGCAGAAATGATAGGAAAAAAA CCAATGGTGAAATTTCAAGTTTCAAAAACCAACCTTTCATTACCAATCCCAGGCAACAAACATGTCCCTGAGTGTTCTTTAAGAACATTT GGGATTTATGTACAATTTAATACTGGAGTTAGAACTTTTTCCTTATTGAATGCCAACCTTATGATGGATGTGAAAATCTACGGCCAAATA CTTTTGAAAACACCTTTCTATATTGCACAGTGGGCAAATGGCTTATGTGAGGTAAGACACTAGAGGGATAAATTTCCAGATCAACATGGC TATGGTATTTAGTAATGGCCCAGCTTAGAGACTTCAGCTACTGATCTCATCACTTATTAGACAAATTGCTGCTGACCTTACGCCTGTATA TTAAGCCTCCGCAGGATGCCGGACAATGGTGAAGAAACTCCAGATATCAAGGAATTGGGAAATCCTGGCCAAACCACCCCAAGATGATTA CACTGAAATGTAGTATTAGTACTGCTGCCAGATCTCTTTTTAACATCATGTGCGTCTCTTGGGATCCAGCAAAAGTGTTAAGCCACAATG CCCTTGTGCCTTTTAATATACCACAGTGCCAGTTAAACTAATATTTTTGTTTGTTGCTTTTGGGAGTTATTTTCATTAGTGATTTCAGCA AATCTCATGATAAAGGACAAGGTCAAGAACTCCAGAGCACTGAGCAGAGAGGCTGGTGATGAAAAGGTGAAGGCCTGCGCACTGAACTGT AAGGCAGTGGGCAGTACAGGGTAACTGGAGGCGGGGCCAGGGCCTCAGCGCTATGGAAGAGTGTCCACTGAGGCTGCACATGGCCCAGGA GTGGCACCATGTTGCAGGGACAACCATCCCCATTTGGCTTCTCCTTAAAACACAATTGCAGCTGCATTCTGCATCGCTGAAAACTGCAAT ATAATATTAAATCTGTTGGTCTATGCATGGCTGCGTATGTGTTTCTTGGAACCTGTGTGACAGGGACATGTGCCTGGCACACTGGCCAGA AGACTGGGCAGCCACCATGGCAGTGCTGGATGACCTCAGTAAGAATGTGTCATGTATTCCAGGTGCTGATCTAAAAACTGTGGCTCAAAT GTCACCGAGCTTATATGAAGCTCCCAGAGAGAACATTTAAAAGCTCAGAGAGTAAGTGCTGGGGAAAGCAGAGCTATCAGAGGAAATCTC TCATAGAAACGAAACCAAACCAACAGAAAATGAAGAAGGCCACATCTTTAAGGCCACCTCTGCCTCTATCAGATGAGCTGCTGGTCTAGA TCAGGGGCTGGCAAACTTTTCTGTAAAAGGCCAGACAGTAAAAATTTCCGATTTTGCAGGCCACATAGTGTCTGTTGCAACTATTCAACT >49476_49476_1_LPAR1-TMOD1_LPAR1_chr9_113703701_ENST00000358883_TMOD1_chr9_100353573_ENST00000259365_length(amino acids)=310AA_BP=264 MAAISTSIPVISQPQFTAMNEPQCFYNESIAFFYNRSGKHLATEWNTVSKLVMGLGITVCIFIMLANLLVMVAIYVNRRFHFPIYYLMAN LAAADFFAGLAYFYLMFNTGPNTRRLTVSTWLLRQGLIDTSLTASVANLLAIAIERHITVFRMQLHTRMSNRRVVVVIVVIWTMAIVMGA IPSVGWNCICDIENCSNMAPLYSDSYLVFWAIFNLVTFVVMVVLYAHIFGYVRQRTMRMSRHSSGPRRNRDTMMSLLKTVVIVLEPAPGQ -------------------------------------------------------------- >49476_49476_2_LPAR1-TMOD1_LPAR1_chr9_113703701_ENST00000358883_TMOD1_chr9_100353573_ENST00000375175_length(transcript)=2907nt_BP=1141nt ACGGCGCGCTGGGCTCACACTGTCCCGCCGCGGACGGGCTTTGTGGTTGGGGGCGCGCGTGCGAGTGCCAGTGAGAGTGTGGGTGCGCGC TGTGGGCCGCGGCGCGGGTGGGTGGCCGTGCGTTCTTGCGAGCCGGCCTGCAGGAGGCGAGGCTCCCCTGGCCTCCCGCACCCAGCGGCG GACCGAGCCCCTGGAGGGAAGTTGCCGCAGCCGCCCGGGCCGCCGGCCCTCCTGTCCCGCGCCAGGTACACAGCTTCTCCTAGCATGACT TCGATCTGATCAGCAAACAAGAAAATTTGTCTCCCGTAGTTCTGGGGCGTGTTCACCACCTACAACCACAGAGCTGTCATGGCTGCCATC TCTACTTCCATCCCTGTAATTTCACAGCCCCAGTTCACAGCCATGAATGAACCACAGTGCTTCTACAACGAGTCCATTGCCTTCTTTTAT AACCGAAGTGGAAAGCATCTTGCCACAGAATGGAACACAGTCAGCAAGCTGGTGATGGGACTTGGAATCACTGTTTGTATCTTCATCATG TTGGCCAACCTATTGGTCATGGTGGCAATCTATGTCAACCGCCGCTTCCATTTTCCTATTTATTACCTAATGGCTAATCTGGCTGCTGCA GACTTCTTTGCTGGGTTGGCCTACTTCTATCTCATGTTCAACACAGGACCCAATACTCGGAGACTGACTGTTAGCACATGGCTCCTTCGT CAGGGCCTCATTGACACCAGCCTGACGGCATCTGTGGCCAACTTACTGGCTATTGCAATCGAGAGGCACATTACGGTTTTCCGCATGCAG CTCCACACACGGATGAGCAACCGGCGGGTAGTGGTGGTCATTGTGGTCATCTGGACTATGGCCATCGTTATGGGTGCTATACCCAGTGTG GGCTGGAACTGTATCTGTGATATTGAAAATTGTTCCAACATGGCACCCCTCTACAGTGACTCTTACTTAGTCTTCTGGGCCATTTTCAAC TTGGTGACCTTTGTGGTAATGGTGGTTCTCTATGCTCACATCTTTGGCTATGTTCGCCAGAGGACTATGAGAATGTCTCGGCATAGTTCT GGACCCCGGCGGAATCGGGATACCATGATGAGTCTTCTGAAGACTGTGGTCATTGTGCTTGAGCCAGCCCCTGGGCAACAAAGTGGAAAT GGAGATTGTGAGCATGTTGGAAAAAAACGCAACACTTCTCAAATTCGGCTACCACTTTACCCAGCAAGGACCCCGGCTTCGGGCATCCAA CGCAATGATGAACAACAATGACCTTGTGAGGAAGAGGAGGCTTGCGGACCTGACTGGGCCCATCATTCCCAAGTGCCGGAGTGGTGTCTA GTGTGTGGCGGTGGAGTCCATGCCTTTGAACTGGATGTGTTCTATTGATGACCTGTGCTCTGCAGGGGAAACCAGAAGGCAAAATGCTGG CAGCATGAAACCCTTTTGTGGTTCAGTTCTTTATGCACTAAGGTTTTAGGTTGACTAGTGGTTGTAGTTGAAAATTTTATAAAATACCGT TAATGTGAAGTTTTTCTTTAGTCACAGAAGTTGAATCTGGTTATTATTTAAAAACTAGAAGCCCCCAAACCAGCAGATCTTACTGAAGAT GATGTTCCAGCAGCAGCGACTTAGCCCCAGGAGCCCAGTTTCAATGGCCTTGCTGTGTGGTGTTTCAAGTGCATTTAAAATGTGTGACAC AGAAACGGCACACTCTTCCACATGCTTTTGAAGTATTATAAAACACTTTATTACAAATTTGTCTTAGCTATTAGCAAATAAAACTGATTA TCATTCTTTATTAACCCTCCTTGGAATTTTGAAAACCTCGATTAAAGTTGCCAAATTGATTACTGGATCCAGAACACAATTTTCCCCTCA GAACAGATAGACAGACTGAAGCCACTGAACTCTGCCAGGAGTCAACATGAGATTCCTTTTGCTGGATATGCAGAAATGATAGGAAAAAAA CCAATGGTGAAATTTCAAGTTTCAAAAACCAACCTTTCATTACCAATCCCAGGCAACAAACATGTCCCTGAGTGTTCTTTAAGAACATTT GGGATTTATGTACAATTTAATACTGGAGTTAGAACTTTTTCCTTATTGAATGCCAACCTTATGATGGATGTGAAAATCTACGGCCAAATA CTTTTGAAAACACCTTTCTATATTGCACAGTGGGCAAATGGCTTATGTGAGGTAAGACACTAGAGGGATAAATTTCCAGATCAACATGGC TATGGTATTTAGTAATGGCCCAGCTTAGAGACTTCAGCTACTGATCTCATCACTTATTAGACAAATTGCTGCTGACCTTACGCCTGTATA TTAAGCCTCCGCAGGATGCCGGACAATGGTGAAGAAACTCCAGATATCAAGGAATTGGGAAATCCTGGCCAAACCACCCCAAGATGATTA CACTGAAATGTAGTATTAGTACTGCTGCCAGATCTCTTTTTAACATCATGTGCGTCTCTTGGGATCCAGCAAAAGTGTTAAGCCACAATG CCCTTGTGCCTTTTAATATACCACAGTGCCAGTTAAACTAATATTTTTGTTTGTTGCTTTTGGGAGTTATTTTCATTAGTGATTTCAGCA AATCTCATGATAAAGGACAAGGTCAAGAACTCCAGAGCACTGAGCAGAGAGGCTGGTGATGAAAAGGTGAAGGCCTGCGCACTGAACTGT AAGGCAGTGGGCAGTACAGGGTAACTGGAGGCGGGGCCAGGGCCTCAGCGCTATGGAAGAGTGTCCACTGAGGCTGCACATGGCCCAGGA GTGGCACCATGTTGCAGGGACAACCATCCCCATTTGGCTTCTCCTTAAAACACAATTGCAGCTGCATTCTGCATCGCTGAAAACTGCAAT >49476_49476_2_LPAR1-TMOD1_LPAR1_chr9_113703701_ENST00000358883_TMOD1_chr9_100353573_ENST00000375175_length(amino acids)=310AA_BP=264 MAAISTSIPVISQPQFTAMNEPQCFYNESIAFFYNRSGKHLATEWNTVSKLVMGLGITVCIFIMLANLLVMVAIYVNRRFHFPIYYLMAN LAAADFFAGLAYFYLMFNTGPNTRRLTVSTWLLRQGLIDTSLTASVANLLAIAIERHITVFRMQLHTRMSNRRVVVVIVVIWTMAIVMGA IPSVGWNCICDIENCSNMAPLYSDSYLVFWAIFNLVTFVVMVVLYAHIFGYVRQRTMRMSRHSSGPRRNRDTMMSLLKTVVIVLEPAPGQ -------------------------------------------------------------- >49476_49476_3_LPAR1-TMOD1_LPAR1_chr9_113703701_ENST00000358883_TMOD1_chr9_100353573_ENST00000395211_length(transcript)=3394nt_BP=1141nt ACGGCGCGCTGGGCTCACACTGTCCCGCCGCGGACGGGCTTTGTGGTTGGGGGCGCGCGTGCGAGTGCCAGTGAGAGTGTGGGTGCGCGC TGTGGGCCGCGGCGCGGGTGGGTGGCCGTGCGTTCTTGCGAGCCGGCCTGCAGGAGGCGAGGCTCCCCTGGCCTCCCGCACCCAGCGGCG GACCGAGCCCCTGGAGGGAAGTTGCCGCAGCCGCCCGGGCCGCCGGCCCTCCTGTCCCGCGCCAGGTACACAGCTTCTCCTAGCATGACT TCGATCTGATCAGCAAACAAGAAAATTTGTCTCCCGTAGTTCTGGGGCGTGTTCACCACCTACAACCACAGAGCTGTCATGGCTGCCATC TCTACTTCCATCCCTGTAATTTCACAGCCCCAGTTCACAGCCATGAATGAACCACAGTGCTTCTACAACGAGTCCATTGCCTTCTTTTAT AACCGAAGTGGAAAGCATCTTGCCACAGAATGGAACACAGTCAGCAAGCTGGTGATGGGACTTGGAATCACTGTTTGTATCTTCATCATG TTGGCCAACCTATTGGTCATGGTGGCAATCTATGTCAACCGCCGCTTCCATTTTCCTATTTATTACCTAATGGCTAATCTGGCTGCTGCA GACTTCTTTGCTGGGTTGGCCTACTTCTATCTCATGTTCAACACAGGACCCAATACTCGGAGACTGACTGTTAGCACATGGCTCCTTCGT CAGGGCCTCATTGACACCAGCCTGACGGCATCTGTGGCCAACTTACTGGCTATTGCAATCGAGAGGCACATTACGGTTTTCCGCATGCAG CTCCACACACGGATGAGCAACCGGCGGGTAGTGGTGGTCATTGTGGTCATCTGGACTATGGCCATCGTTATGGGTGCTATACCCAGTGTG GGCTGGAACTGTATCTGTGATATTGAAAATTGTTCCAACATGGCACCCCTCTACAGTGACTCTTACTTAGTCTTCTGGGCCATTTTCAAC TTGGTGACCTTTGTGGTAATGGTGGTTCTCTATGCTCACATCTTTGGCTATGTTCGCCAGAGGACTATGAGAATGTCTCGGCATAGTTCT GGACCCCGGCGGAATCGGGATACCATGATGAGTCTTCTGAAGACTGTGGTCATTGTGCTTGAGCCAGCCCCTGGGCAACAAAGTGGAAAT GGAGATTGTGAGCATGTTGGAAAAAAACGCAACACTTCTCAAATTCGGCTACCACTTTACCCAGCAAGGACCCCGGCTTCGGGCATCCAA CGCAATGATGAACAACAATGACCTTGTGAGGAAGAGGAGGCTTGCGGACCTGACTGGGCCCATCATTCCCAAGTGCCGGAGTGGTGTCTA GTGTGTGGCGGTGGAGTCCATGCCTTTGAACTGGATGTGTTCTATTGATGACCTGTGCTCTGCAGGGGAAACCAGAAGGCAAAATGCTGG CAGCATGAAACCCTTTTGTGGTTCAGTTCTTTATGCACTAAGGTTTTAGGTTGACTAGTGGTTGTAGTTGAAAATTTTATAAAATACCGT TAATGTGAAGTTTTTCTTTAGTCACAGAAGTTGAATCTGGTTATTATTTAAAAACTAGAAGCCCCCAAACCAGCAGATCTTACTGAAGAT GATGTTCCAGCAGCAGCGACTTAGCCCCAGGAGCCCAGTTTCAATGGCCTTGCTGTGTGGTGTTTCAAGTGCATTTAAAATGTGTGACAC AGAAACGGCACACTCTTCCACATGCTTTTGAAGTATTATAAAACACTTTATTACAAATTTGTCTTAGCTATTAGCAAATAAAACTGATTA TCATTCTTTATTAACCCTCCTTGGAATTTTGAAAACCTCGATTAAAGTTGCCAAATTGATTACTGGATCCAGAACACAATTTTCCCCTCA GAACAGATAGACAGACTGAAGCCACTGAACTCTGCCAGGAGTCAACATGAGATTCCTTTTGCTGGATATGCAGAAATGATAGGAAAAAAA CCAATGGTGAAATTTCAAGTTTCAAAAACCAACCTTTCATTACCAATCCCAGGCAACAAACATGTCCCTGAGTGTTCTTTAAGAACATTT GGGATTTATGTACAATTTAATACTGGAGTTAGAACTTTTTCCTTATTGAATGCCAACCTTATGATGGATGTGAAAATCTACGGCCAAATA CTTTTGAAAACACCTTTCTATATTGCACAGTGGGCAAATGGCTTATGTGAGGTAAGACACTAGAGGGATAAATTTCCAGATCAACATGGC TATGGTATTTAGTAATGGCCCAGCTTAGAGACTTCAGCTACTGATCTCATCACTTATTAGACAAATTGCTGCTGACCTTACGCCTGTATA TTAAGCCTCCGCAGGATGCCGGACAATGGTGAAGAAACTCCAGATATCAAGGAATTGGGAAATCCTGGCCAAACCACCCCAAGATGATTA CACTGAAATGTAGTATTAGTACTGCTGCCAGATCTCTTTTTAACATCATGTGCGTCTCTTGGGATCCAGCAAAAGTGTTAAGCCACAATG CCCTTGTGCCTTTTAATATACCACAGTGCCAGTTAAACTAATATTTTTGTTTGTTGCTTTTGGGAGTTATTTTCATTAGTGATTTCAGCA AATCTCATGATAAAGGACAAGGTCAAGAACTCCAGAGCACTGAGCAGAGAGGCTGGTGATGAAAAGGTGAAGGCCTGCGCACTGAACTGT AAGGCAGTGGGCAGTACAGGGTAACTGGAGGCGGGGCCAGGGCCTCAGCGCTATGGAAGAGTGTCCACTGAGGCTGCACATGGCCCAGGA GTGGCACCATGTTGCAGGGACAACCATCCCCATTTGGCTTCTCCTTAAAACACAATTGCAGCTGCATTCTGCATCGCTGAAAACTGCAAT ATAATATTAAATCTGTTGGTCTATGCATGGCTGCGTATGTGTTTCTTGGAACCTGTGTGACAGGGACATGTGCCTGGCACACTGGCCAGA AGACTGGGCAGCCACCATGGCAGTGCTGGATGACCTCAGTAAGAATGTGTCATGTATTCCAGGTGCTGATCTAAAAACTGTGGCTCAAAT GTCACCGAGCTTATATGAAGCTCCCAGAGAGAACATTTAAAAGCTCAGAGAGTAAGTGCTGGGGAAAGCAGAGCTATCAGAGGAAATCTC TCATAGAAACGAAACCAAACCAACAGAAAATGAAGAAGGCCACATCTTTAAGGCCACCTCTGCCTCTATCAGATGAGCTGCTGGTCTAGA TCAGGGGCTGGCAAACTTTTCTGTAAAAGGCCAGACAGTAAAAATTTCCGATTTTGCAGGCCACATAGTGTCTGTTGCAACTATTCAACT >49476_49476_3_LPAR1-TMOD1_LPAR1_chr9_113703701_ENST00000358883_TMOD1_chr9_100353573_ENST00000395211_length(amino acids)=310AA_BP=264 MAAISTSIPVISQPQFTAMNEPQCFYNESIAFFYNRSGKHLATEWNTVSKLVMGLGITVCIFIMLANLLVMVAIYVNRRFHFPIYYLMAN LAAADFFAGLAYFYLMFNTGPNTRRLTVSTWLLRQGLIDTSLTASVANLLAIAIERHITVFRMQLHTRMSNRRVVVVIVVIWTMAIVMGA IPSVGWNCICDIENCSNMAPLYSDSYLVFWAIFNLVTFVVMVVLYAHIFGYVRQRTMRMSRHSSGPRRNRDTMMSLLKTVVIVLEPAPGQ -------------------------------------------------------------- >49476_49476_4_LPAR1-TMOD1_LPAR1_chr9_113703701_ENST00000374430_TMOD1_chr9_100353573_ENST00000259365_length(transcript)=3308nt_BP=1048nt AGAAAGCAGGGCTGCATGGTGTGGGGATGCTGCTGCTACTCATTCCTGCTCATTCCAGTGTTCTGGAAAATGAGGTGGACGTCTGATTTA TGAAGCTCCCCATCCACCTATCTGAGTACCTGACTTCTCAGGACTGACACCTACAGCATCAGGTACACAGCTTCTCCTAGCATGACTTCG ATCTGATCAGCAAACAAGAAAATTTGTCTCCCGTAGTTCTGGGGCGTGTTCACCACCTACAACCACAGAGCTGTCATGGCTGCCATCTCT ACTTCCATCCCTGTAATTTCACAGCCCCAGTTCACAGCCATGAATGAACCACAGTGCTTCTACAACGAGTCCATTGCCTTCTTTTATAAC CGAAGTGGAAAGCATCTTGCCACAGAATGGAACACAGTCAGCAAGCTGGTGATGGGACTTGGAATCACTGTTTGTATCTTCATCATGTTG GCCAACCTATTGGTCATGGTGGCAATCTATGTCAACCGCCGCTTCCATTTTCCTATTTATTACCTAATGGCTAATCTGGCTGCTGCAGAC TTCTTTGCTGGGTTGGCCTACTTCTATCTCATGTTCAACACAGGACCCAATACTCGGAGACTGACTGTTAGCACATGGCTCCTTCGTCAG GGCCTCATTGACACCAGCCTGACGGCATCTGTGGCCAACTTACTGGCTATTGCAATCGAGAGGCACATTACGGTTTTCCGCATGCAGCTC CACACACGGATGAGCAACCGGCGGGTAGTGGTGGTCATTGTGGTCATCTGGACTATGGCCATCGTTATGGGTGCTATACCCAGTGTGGGC TGGAACTGTATCTGTGATATTGAAAATTGTTCCAACATGGCACCCCTCTACAGTGACTCTTACTTAGTCTTCTGGGCCATTTTCAACTTG GTGACCTTTGTGGTAATGGTGGTTCTCTATGCTCACATCTTTGGCTATGTTCGCCAGAGGACTATGAGAATGTCTCGGCATAGTTCTGGA CCCCGGCGGAATCGGGATACCATGATGAGTCTTCTGAAGACTGTGGTCATTGTGCTTGAGCCAGCCCCTGGGCAACAAAGTGGAAATGGA GATTGTGAGCATGTTGGAAAAAAACGCAACACTTCTCAAATTCGGCTACCACTTTACCCAGCAAGGACCCCGGCTTCGGGCATCCAACGC AATGATGAACAACAATGACCTTGTGAGGAAGAGGAGGCTTGCGGACCTGACTGGGCCCATCATTCCCAAGTGCCGGAGTGGTGTCTAGTG TGTGGCGGTGGAGTCCATGCCTTTGAACTGGATGTGTTCTATTGATGACCTGTGCTCTGCAGGGGAAACCAGAAGGCAAAATGCTGGCAG CATGAAACCCTTTTGTGGTTCAGTTCTTTATGCACTAAGGTTTTAGGTTGACTAGTGGTTGTAGTTGAAAATTTTATAAAATACCGTTAA TGTGAAGTTTTTCTTTAGTCACAGAAGTTGAATCTGGTTATTATTTAAAAACTAGAAGCCCCCAAACCAGCAGATCTTACTGAAGATGAT GTTCCAGCAGCAGCGACTTAGCCCCAGGAGCCCAGTTTCAATGGCCTTGCTGTGTGGTGTTTCAAGTGCATTTAAAATGTGTGACACAGA AACGGCACACTCTTCCACATGCTTTTGAAGTATTATAAAACACTTTATTACAAATTTGTCTTAGCTATTAGCAAATAAAACTGATTATCA TTCTTTATTAACCCTCCTTGGAATTTTGAAAACCTCGATTAAAGTTGCCAAATTGATTACTGGATCCAGAACACAATTTTCCCCTCAGAA CAGATAGACAGACTGAAGCCACTGAACTCTGCCAGGAGTCAACATGAGATTCCTTTTGCTGGATATGCAGAAATGATAGGAAAAAAACCA ATGGTGAAATTTCAAGTTTCAAAAACCAACCTTTCATTACCAATCCCAGGCAACAAACATGTCCCTGAGTGTTCTTTAAGAACATTTGGG ATTTATGTACAATTTAATACTGGAGTTAGAACTTTTTCCTTATTGAATGCCAACCTTATGATGGATGTGAAAATCTACGGCCAAATACTT TTGAAAACACCTTTCTATATTGCACAGTGGGCAAATGGCTTATGTGAGGTAAGACACTAGAGGGATAAATTTCCAGATCAACATGGCTAT GGTATTTAGTAATGGCCCAGCTTAGAGACTTCAGCTACTGATCTCATCACTTATTAGACAAATTGCTGCTGACCTTACGCCTGTATATTA AGCCTCCGCAGGATGCCGGACAATGGTGAAGAAACTCCAGATATCAAGGAATTGGGAAATCCTGGCCAAACCACCCCAAGATGATTACAC TGAAATGTAGTATTAGTACTGCTGCCAGATCTCTTTTTAACATCATGTGCGTCTCTTGGGATCCAGCAAAAGTGTTAAGCCACAATGCCC TTGTGCCTTTTAATATACCACAGTGCCAGTTAAACTAATATTTTTGTTTGTTGCTTTTGGGAGTTATTTTCATTAGTGATTTCAGCAAAT CTCATGATAAAGGACAAGGTCAAGAACTCCAGAGCACTGAGCAGAGAGGCTGGTGATGAAAAGGTGAAGGCCTGCGCACTGAACTGTAAG GCAGTGGGCAGTACAGGGTAACTGGAGGCGGGGCCAGGGCCTCAGCGCTATGGAAGAGTGTCCACTGAGGCTGCACATGGCCCAGGAGTG GCACCATGTTGCAGGGACAACCATCCCCATTTGGCTTCTCCTTAAAACACAATTGCAGCTGCATTCTGCATCGCTGAAAACTGCAATATA ATATTAAATCTGTTGGTCTATGCATGGCTGCGTATGTGTTTCTTGGAACCTGTGTGACAGGGACATGTGCCTGGCACACTGGCCAGAAGA CTGGGCAGCCACCATGGCAGTGCTGGATGACCTCAGTAAGAATGTGTCATGTATTCCAGGTGCTGATCTAAAAACTGTGGCTCAAATGTC ACCGAGCTTATATGAAGCTCCCAGAGAGAACATTTAAAAGCTCAGAGAGTAAGTGCTGGGGAAAGCAGAGCTATCAGAGGAAATCTCTCA TAGAAACGAAACCAAACCAACAGAAAATGAAGAAGGCCACATCTTTAAGGCCACCTCTGCCTCTATCAGATGAGCTGCTGGTCTAGATCA GGGGCTGGCAAACTTTTCTGTAAAAGGCCAGACAGTAAAAATTTCCGATTTTGCAGGCCACATAGTGTCTGTTGCAACTATTCAACTCTG >49476_49476_4_LPAR1-TMOD1_LPAR1_chr9_113703701_ENST00000374430_TMOD1_chr9_100353573_ENST00000259365_length(amino acids)=310AA_BP=264 MAAISTSIPVISQPQFTAMNEPQCFYNESIAFFYNRSGKHLATEWNTVSKLVMGLGITVCIFIMLANLLVMVAIYVNRRFHFPIYYLMAN LAAADFFAGLAYFYLMFNTGPNTRRLTVSTWLLRQGLIDTSLTASVANLLAIAIERHITVFRMQLHTRMSNRRVVVVIVVIWTMAIVMGA IPSVGWNCICDIENCSNMAPLYSDSYLVFWAIFNLVTFVVMVVLYAHIFGYVRQRTMRMSRHSSGPRRNRDTMMSLLKTVVIVLEPAPGQ -------------------------------------------------------------- >49476_49476_5_LPAR1-TMOD1_LPAR1_chr9_113703701_ENST00000374430_TMOD1_chr9_100353573_ENST00000375175_length(transcript)=2814nt_BP=1048nt AGAAAGCAGGGCTGCATGGTGTGGGGATGCTGCTGCTACTCATTCCTGCTCATTCCAGTGTTCTGGAAAATGAGGTGGACGTCTGATTTA TGAAGCTCCCCATCCACCTATCTGAGTACCTGACTTCTCAGGACTGACACCTACAGCATCAGGTACACAGCTTCTCCTAGCATGACTTCG ATCTGATCAGCAAACAAGAAAATTTGTCTCCCGTAGTTCTGGGGCGTGTTCACCACCTACAACCACAGAGCTGTCATGGCTGCCATCTCT ACTTCCATCCCTGTAATTTCACAGCCCCAGTTCACAGCCATGAATGAACCACAGTGCTTCTACAACGAGTCCATTGCCTTCTTTTATAAC CGAAGTGGAAAGCATCTTGCCACAGAATGGAACACAGTCAGCAAGCTGGTGATGGGACTTGGAATCACTGTTTGTATCTTCATCATGTTG GCCAACCTATTGGTCATGGTGGCAATCTATGTCAACCGCCGCTTCCATTTTCCTATTTATTACCTAATGGCTAATCTGGCTGCTGCAGAC TTCTTTGCTGGGTTGGCCTACTTCTATCTCATGTTCAACACAGGACCCAATACTCGGAGACTGACTGTTAGCACATGGCTCCTTCGTCAG GGCCTCATTGACACCAGCCTGACGGCATCTGTGGCCAACTTACTGGCTATTGCAATCGAGAGGCACATTACGGTTTTCCGCATGCAGCTC CACACACGGATGAGCAACCGGCGGGTAGTGGTGGTCATTGTGGTCATCTGGACTATGGCCATCGTTATGGGTGCTATACCCAGTGTGGGC TGGAACTGTATCTGTGATATTGAAAATTGTTCCAACATGGCACCCCTCTACAGTGACTCTTACTTAGTCTTCTGGGCCATTTTCAACTTG GTGACCTTTGTGGTAATGGTGGTTCTCTATGCTCACATCTTTGGCTATGTTCGCCAGAGGACTATGAGAATGTCTCGGCATAGTTCTGGA CCCCGGCGGAATCGGGATACCATGATGAGTCTTCTGAAGACTGTGGTCATTGTGCTTGAGCCAGCCCCTGGGCAACAAAGTGGAAATGGA GATTGTGAGCATGTTGGAAAAAAACGCAACACTTCTCAAATTCGGCTACCACTTTACCCAGCAAGGACCCCGGCTTCGGGCATCCAACGC AATGATGAACAACAATGACCTTGTGAGGAAGAGGAGGCTTGCGGACCTGACTGGGCCCATCATTCCCAAGTGCCGGAGTGGTGTCTAGTG TGTGGCGGTGGAGTCCATGCCTTTGAACTGGATGTGTTCTATTGATGACCTGTGCTCTGCAGGGGAAACCAGAAGGCAAAATGCTGGCAG CATGAAACCCTTTTGTGGTTCAGTTCTTTATGCACTAAGGTTTTAGGTTGACTAGTGGTTGTAGTTGAAAATTTTATAAAATACCGTTAA TGTGAAGTTTTTCTTTAGTCACAGAAGTTGAATCTGGTTATTATTTAAAAACTAGAAGCCCCCAAACCAGCAGATCTTACTGAAGATGAT GTTCCAGCAGCAGCGACTTAGCCCCAGGAGCCCAGTTTCAATGGCCTTGCTGTGTGGTGTTTCAAGTGCATTTAAAATGTGTGACACAGA AACGGCACACTCTTCCACATGCTTTTGAAGTATTATAAAACACTTTATTACAAATTTGTCTTAGCTATTAGCAAATAAAACTGATTATCA TTCTTTATTAACCCTCCTTGGAATTTTGAAAACCTCGATTAAAGTTGCCAAATTGATTACTGGATCCAGAACACAATTTTCCCCTCAGAA CAGATAGACAGACTGAAGCCACTGAACTCTGCCAGGAGTCAACATGAGATTCCTTTTGCTGGATATGCAGAAATGATAGGAAAAAAACCA ATGGTGAAATTTCAAGTTTCAAAAACCAACCTTTCATTACCAATCCCAGGCAACAAACATGTCCCTGAGTGTTCTTTAAGAACATTTGGG ATTTATGTACAATTTAATACTGGAGTTAGAACTTTTTCCTTATTGAATGCCAACCTTATGATGGATGTGAAAATCTACGGCCAAATACTT TTGAAAACACCTTTCTATATTGCACAGTGGGCAAATGGCTTATGTGAGGTAAGACACTAGAGGGATAAATTTCCAGATCAACATGGCTAT GGTATTTAGTAATGGCCCAGCTTAGAGACTTCAGCTACTGATCTCATCACTTATTAGACAAATTGCTGCTGACCTTACGCCTGTATATTA AGCCTCCGCAGGATGCCGGACAATGGTGAAGAAACTCCAGATATCAAGGAATTGGGAAATCCTGGCCAAACCACCCCAAGATGATTACAC TGAAATGTAGTATTAGTACTGCTGCCAGATCTCTTTTTAACATCATGTGCGTCTCTTGGGATCCAGCAAAAGTGTTAAGCCACAATGCCC TTGTGCCTTTTAATATACCACAGTGCCAGTTAAACTAATATTTTTGTTTGTTGCTTTTGGGAGTTATTTTCATTAGTGATTTCAGCAAAT CTCATGATAAAGGACAAGGTCAAGAACTCCAGAGCACTGAGCAGAGAGGCTGGTGATGAAAAGGTGAAGGCCTGCGCACTGAACTGTAAG GCAGTGGGCAGTACAGGGTAACTGGAGGCGGGGCCAGGGCCTCAGCGCTATGGAAGAGTGTCCACTGAGGCTGCACATGGCCCAGGAGTG GCACCATGTTGCAGGGACAACCATCCCCATTTGGCTTCTCCTTAAAACACAATTGCAGCTGCATTCTGCATCGCTGAAAACTGCAATATA >49476_49476_5_LPAR1-TMOD1_LPAR1_chr9_113703701_ENST00000374430_TMOD1_chr9_100353573_ENST00000375175_length(amino acids)=310AA_BP=264 MAAISTSIPVISQPQFTAMNEPQCFYNESIAFFYNRSGKHLATEWNTVSKLVMGLGITVCIFIMLANLLVMVAIYVNRRFHFPIYYLMAN LAAADFFAGLAYFYLMFNTGPNTRRLTVSTWLLRQGLIDTSLTASVANLLAIAIERHITVFRMQLHTRMSNRRVVVVIVVIWTMAIVMGA IPSVGWNCICDIENCSNMAPLYSDSYLVFWAIFNLVTFVVMVVLYAHIFGYVRQRTMRMSRHSSGPRRNRDTMMSLLKTVVIVLEPAPGQ -------------------------------------------------------------- >49476_49476_6_LPAR1-TMOD1_LPAR1_chr9_113703701_ENST00000374430_TMOD1_chr9_100353573_ENST00000395211_length(transcript)=3301nt_BP=1048nt AGAAAGCAGGGCTGCATGGTGTGGGGATGCTGCTGCTACTCATTCCTGCTCATTCCAGTGTTCTGGAAAATGAGGTGGACGTCTGATTTA TGAAGCTCCCCATCCACCTATCTGAGTACCTGACTTCTCAGGACTGACACCTACAGCATCAGGTACACAGCTTCTCCTAGCATGACTTCG ATCTGATCAGCAAACAAGAAAATTTGTCTCCCGTAGTTCTGGGGCGTGTTCACCACCTACAACCACAGAGCTGTCATGGCTGCCATCTCT ACTTCCATCCCTGTAATTTCACAGCCCCAGTTCACAGCCATGAATGAACCACAGTGCTTCTACAACGAGTCCATTGCCTTCTTTTATAAC CGAAGTGGAAAGCATCTTGCCACAGAATGGAACACAGTCAGCAAGCTGGTGATGGGACTTGGAATCACTGTTTGTATCTTCATCATGTTG GCCAACCTATTGGTCATGGTGGCAATCTATGTCAACCGCCGCTTCCATTTTCCTATTTATTACCTAATGGCTAATCTGGCTGCTGCAGAC TTCTTTGCTGGGTTGGCCTACTTCTATCTCATGTTCAACACAGGACCCAATACTCGGAGACTGACTGTTAGCACATGGCTCCTTCGTCAG GGCCTCATTGACACCAGCCTGACGGCATCTGTGGCCAACTTACTGGCTATTGCAATCGAGAGGCACATTACGGTTTTCCGCATGCAGCTC CACACACGGATGAGCAACCGGCGGGTAGTGGTGGTCATTGTGGTCATCTGGACTATGGCCATCGTTATGGGTGCTATACCCAGTGTGGGC TGGAACTGTATCTGTGATATTGAAAATTGTTCCAACATGGCACCCCTCTACAGTGACTCTTACTTAGTCTTCTGGGCCATTTTCAACTTG GTGACCTTTGTGGTAATGGTGGTTCTCTATGCTCACATCTTTGGCTATGTTCGCCAGAGGACTATGAGAATGTCTCGGCATAGTTCTGGA CCCCGGCGGAATCGGGATACCATGATGAGTCTTCTGAAGACTGTGGTCATTGTGCTTGAGCCAGCCCCTGGGCAACAAAGTGGAAATGGA GATTGTGAGCATGTTGGAAAAAAACGCAACACTTCTCAAATTCGGCTACCACTTTACCCAGCAAGGACCCCGGCTTCGGGCATCCAACGC AATGATGAACAACAATGACCTTGTGAGGAAGAGGAGGCTTGCGGACCTGACTGGGCCCATCATTCCCAAGTGCCGGAGTGGTGTCTAGTG TGTGGCGGTGGAGTCCATGCCTTTGAACTGGATGTGTTCTATTGATGACCTGTGCTCTGCAGGGGAAACCAGAAGGCAAAATGCTGGCAG CATGAAACCCTTTTGTGGTTCAGTTCTTTATGCACTAAGGTTTTAGGTTGACTAGTGGTTGTAGTTGAAAATTTTATAAAATACCGTTAA TGTGAAGTTTTTCTTTAGTCACAGAAGTTGAATCTGGTTATTATTTAAAAACTAGAAGCCCCCAAACCAGCAGATCTTACTGAAGATGAT GTTCCAGCAGCAGCGACTTAGCCCCAGGAGCCCAGTTTCAATGGCCTTGCTGTGTGGTGTTTCAAGTGCATTTAAAATGTGTGACACAGA AACGGCACACTCTTCCACATGCTTTTGAAGTATTATAAAACACTTTATTACAAATTTGTCTTAGCTATTAGCAAATAAAACTGATTATCA TTCTTTATTAACCCTCCTTGGAATTTTGAAAACCTCGATTAAAGTTGCCAAATTGATTACTGGATCCAGAACACAATTTTCCCCTCAGAA CAGATAGACAGACTGAAGCCACTGAACTCTGCCAGGAGTCAACATGAGATTCCTTTTGCTGGATATGCAGAAATGATAGGAAAAAAACCA ATGGTGAAATTTCAAGTTTCAAAAACCAACCTTTCATTACCAATCCCAGGCAACAAACATGTCCCTGAGTGTTCTTTAAGAACATTTGGG ATTTATGTACAATTTAATACTGGAGTTAGAACTTTTTCCTTATTGAATGCCAACCTTATGATGGATGTGAAAATCTACGGCCAAATACTT TTGAAAACACCTTTCTATATTGCACAGTGGGCAAATGGCTTATGTGAGGTAAGACACTAGAGGGATAAATTTCCAGATCAACATGGCTAT GGTATTTAGTAATGGCCCAGCTTAGAGACTTCAGCTACTGATCTCATCACTTATTAGACAAATTGCTGCTGACCTTACGCCTGTATATTA AGCCTCCGCAGGATGCCGGACAATGGTGAAGAAACTCCAGATATCAAGGAATTGGGAAATCCTGGCCAAACCACCCCAAGATGATTACAC TGAAATGTAGTATTAGTACTGCTGCCAGATCTCTTTTTAACATCATGTGCGTCTCTTGGGATCCAGCAAAAGTGTTAAGCCACAATGCCC TTGTGCCTTTTAATATACCACAGTGCCAGTTAAACTAATATTTTTGTTTGTTGCTTTTGGGAGTTATTTTCATTAGTGATTTCAGCAAAT CTCATGATAAAGGACAAGGTCAAGAACTCCAGAGCACTGAGCAGAGAGGCTGGTGATGAAAAGGTGAAGGCCTGCGCACTGAACTGTAAG GCAGTGGGCAGTACAGGGTAACTGGAGGCGGGGCCAGGGCCTCAGCGCTATGGAAGAGTGTCCACTGAGGCTGCACATGGCCCAGGAGTG GCACCATGTTGCAGGGACAACCATCCCCATTTGGCTTCTCCTTAAAACACAATTGCAGCTGCATTCTGCATCGCTGAAAACTGCAATATA ATATTAAATCTGTTGGTCTATGCATGGCTGCGTATGTGTTTCTTGGAACCTGTGTGACAGGGACATGTGCCTGGCACACTGGCCAGAAGA CTGGGCAGCCACCATGGCAGTGCTGGATGACCTCAGTAAGAATGTGTCATGTATTCCAGGTGCTGATCTAAAAACTGTGGCTCAAATGTC ACCGAGCTTATATGAAGCTCCCAGAGAGAACATTTAAAAGCTCAGAGAGTAAGTGCTGGGGAAAGCAGAGCTATCAGAGGAAATCTCTCA TAGAAACGAAACCAAACCAACAGAAAATGAAGAAGGCCACATCTTTAAGGCCACCTCTGCCTCTATCAGATGAGCTGCTGGTCTAGATCA GGGGCTGGCAAACTTTTCTGTAAAAGGCCAGACAGTAAAAATTTCCGATTTTGCAGGCCACATAGTGTCTGTTGCAACTATTCAACTCTG >49476_49476_6_LPAR1-TMOD1_LPAR1_chr9_113703701_ENST00000374430_TMOD1_chr9_100353573_ENST00000395211_length(amino acids)=310AA_BP=264 MAAISTSIPVISQPQFTAMNEPQCFYNESIAFFYNRSGKHLATEWNTVSKLVMGLGITVCIFIMLANLLVMVAIYVNRRFHFPIYYLMAN LAAADFFAGLAYFYLMFNTGPNTRRLTVSTWLLRQGLIDTSLTASVANLLAIAIERHITVFRMQLHTRMSNRRVVVVIVVIWTMAIVMGA IPSVGWNCICDIENCSNMAPLYSDSYLVFWAIFNLVTFVVMVVLYAHIFGYVRQRTMRMSRHSSGPRRNRDTMMSLLKTVVIVLEPAPGQ -------------------------------------------------------------- >49476_49476_7_LPAR1-TMOD1_LPAR1_chr9_113703701_ENST00000374431_TMOD1_chr9_100353573_ENST00000259365_length(transcript)=3437nt_BP=1177nt GTGGTTGGGGGCGCGCGTGCGAGTGCCAGTGAGAGTGTGGGTGCGCGCTGTGGGCCGCGGCGCGGGTGGGTGGCCGTGCGTTCTTGCGAG CCGGCCTGCAGGAGGCGAGGCTCCCCTGGCCTCCCGCACCCAGCGGCGGACCGAGCCCCTGGAGGGAAGTTGCCGCAGCCGCCCGGGCCG CCGGCCCTCCTGTCCCGCGCCAGGTGGACGTCTGATTTATGAAGCTCCCCATCCACCTATCTGAGTACCTGACTTCTCAGGACTGACACC TACAGCATCAGGTACACAGCTTCTCCTAGCATGACTTCGATCTGATCAGCAAACAAGAAAATTTGTCTCCCGTAGTTCTGGGGCGTGTTC ACCACCTACAACCACAGAGCTGTCATGGCTGCCATCTCTACTTCCATCCCTGTAATTTCACAGCCCCAGTTCACAGCCATGAATGAACCA CAGTGCTTCTACAACGAGTCCATTGCCTTCTTTTATAACCGAAGTGGAAAGCATCTTGCCACAGAATGGAACACAGTCAGCAAGCTGGTG ATGGGACTTGGAATCACTGTTTGTATCTTCATCATGTTGGCCAACCTATTGGTCATGGTGGCAATCTATGTCAACCGCCGCTTCCATTTT CCTATTTATTACCTAATGGCTAATCTGGCTGCTGCAGACTTCTTTGCTGGGTTGGCCTACTTCTATCTCATGTTCAACACAGGACCCAAT ACTCGGAGACTGACTGTTAGCACATGGCTCCTTCGTCAGGGCCTCATTGACACCAGCCTGACGGCATCTGTGGCCAACTTACTGGCTATT GCAATCGAGAGGCACATTACGGTTTTCCGCATGCAGCTCCACACACGGATGAGCAACCGGCGGGTAGTGGTGGTCATTGTGGTCATCTGG ACTATGGCCATCGTTATGGGTGCTATACCCAGTGTGGGCTGGAACTGTATCTGTGATATTGAAAATTGTTCCAACATGGCACCCCTCTAC AGTGACTCTTACTTAGTCTTCTGGGCCATTTTCAACTTGGTGACCTTTGTGGTAATGGTGGTTCTCTATGCTCACATCTTTGGCTATGTT CGCCAGAGGACTATGAGAATGTCTCGGCATAGTTCTGGACCCCGGCGGAATCGGGATACCATGATGAGTCTTCTGAAGACTGTGGTCATT GTGCTTGAGCCAGCCCCTGGGCAACAAAGTGGAAATGGAGATTGTGAGCATGTTGGAAAAAAACGCAACACTTCTCAAATTCGGCTACCA CTTTACCCAGCAAGGACCCCGGCTTCGGGCATCCAACGCAATGATGAACAACAATGACCTTGTGAGGAAGAGGAGGCTTGCGGACCTGAC TGGGCCCATCATTCCCAAGTGCCGGAGTGGTGTCTAGTGTGTGGCGGTGGAGTCCATGCCTTTGAACTGGATGTGTTCTATTGATGACCT GTGCTCTGCAGGGGAAACCAGAAGGCAAAATGCTGGCAGCATGAAACCCTTTTGTGGTTCAGTTCTTTATGCACTAAGGTTTTAGGTTGA CTAGTGGTTGTAGTTGAAAATTTTATAAAATACCGTTAATGTGAAGTTTTTCTTTAGTCACAGAAGTTGAATCTGGTTATTATTTAAAAA CTAGAAGCCCCCAAACCAGCAGATCTTACTGAAGATGATGTTCCAGCAGCAGCGACTTAGCCCCAGGAGCCCAGTTTCAATGGCCTTGCT GTGTGGTGTTTCAAGTGCATTTAAAATGTGTGACACAGAAACGGCACACTCTTCCACATGCTTTTGAAGTATTATAAAACACTTTATTAC AAATTTGTCTTAGCTATTAGCAAATAAAACTGATTATCATTCTTTATTAACCCTCCTTGGAATTTTGAAAACCTCGATTAAAGTTGCCAA ATTGATTACTGGATCCAGAACACAATTTTCCCCTCAGAACAGATAGACAGACTGAAGCCACTGAACTCTGCCAGGAGTCAACATGAGATT CCTTTTGCTGGATATGCAGAAATGATAGGAAAAAAACCAATGGTGAAATTTCAAGTTTCAAAAACCAACCTTTCATTACCAATCCCAGGC AACAAACATGTCCCTGAGTGTTCTTTAAGAACATTTGGGATTTATGTACAATTTAATACTGGAGTTAGAACTTTTTCCTTATTGAATGCC AACCTTATGATGGATGTGAAAATCTACGGCCAAATACTTTTGAAAACACCTTTCTATATTGCACAGTGGGCAAATGGCTTATGTGAGGTA AGACACTAGAGGGATAAATTTCCAGATCAACATGGCTATGGTATTTAGTAATGGCCCAGCTTAGAGACTTCAGCTACTGATCTCATCACT TATTAGACAAATTGCTGCTGACCTTACGCCTGTATATTAAGCCTCCGCAGGATGCCGGACAATGGTGAAGAAACTCCAGATATCAAGGAA TTGGGAAATCCTGGCCAAACCACCCCAAGATGATTACACTGAAATGTAGTATTAGTACTGCTGCCAGATCTCTTTTTAACATCATGTGCG TCTCTTGGGATCCAGCAAAAGTGTTAAGCCACAATGCCCTTGTGCCTTTTAATATACCACAGTGCCAGTTAAACTAATATTTTTGTTTGT TGCTTTTGGGAGTTATTTTCATTAGTGATTTCAGCAAATCTCATGATAAAGGACAAGGTCAAGAACTCCAGAGCACTGAGCAGAGAGGCT GGTGATGAAAAGGTGAAGGCCTGCGCACTGAACTGTAAGGCAGTGGGCAGTACAGGGTAACTGGAGGCGGGGCCAGGGCCTCAGCGCTAT GGAAGAGTGTCCACTGAGGCTGCACATGGCCCAGGAGTGGCACCATGTTGCAGGGACAACCATCCCCATTTGGCTTCTCCTTAAAACACA ATTGCAGCTGCATTCTGCATCGCTGAAAACTGCAATATAATATTAAATCTGTTGGTCTATGCATGGCTGCGTATGTGTTTCTTGGAACCT GTGTGACAGGGACATGTGCCTGGCACACTGGCCAGAAGACTGGGCAGCCACCATGGCAGTGCTGGATGACCTCAGTAAGAATGTGTCATG TATTCCAGGTGCTGATCTAAAAACTGTGGCTCAAATGTCACCGAGCTTATATGAAGCTCCCAGAGAGAACATTTAAAAGCTCAGAGAGTA AGTGCTGGGGAAAGCAGAGCTATCAGAGGAAATCTCTCATAGAAACGAAACCAAACCAACAGAAAATGAAGAAGGCCACATCTTTAAGGC CACCTCTGCCTCTATCAGATGAGCTGCTGGTCTAGATCAGGGGCTGGCAAACTTTTCTGTAAAAGGCCAGACAGTAAAAATTTCCGATTT TGCAGGCCACATAGTGTCTGTTGCAACTATTCAACTCTGCCATAGATCATGTGTAAAGGAATGGGTGTGGCTGTTCAATAAACTATACAG >49476_49476_7_LPAR1-TMOD1_LPAR1_chr9_113703701_ENST00000374431_TMOD1_chr9_100353573_ENST00000259365_length(amino acids)=310AA_BP=264 MAAISTSIPVISQPQFTAMNEPQCFYNESIAFFYNRSGKHLATEWNTVSKLVMGLGITVCIFIMLANLLVMVAIYVNRRFHFPIYYLMAN LAAADFFAGLAYFYLMFNTGPNTRRLTVSTWLLRQGLIDTSLTASVANLLAIAIERHITVFRMQLHTRMSNRRVVVVIVVIWTMAIVMGA IPSVGWNCICDIENCSNMAPLYSDSYLVFWAIFNLVTFVVMVVLYAHIFGYVRQRTMRMSRHSSGPRRNRDTMMSLLKTVVIVLEPAPGQ -------------------------------------------------------------- >49476_49476_8_LPAR1-TMOD1_LPAR1_chr9_113703701_ENST00000374431_TMOD1_chr9_100353573_ENST00000375175_length(transcript)=2943nt_BP=1177nt GTGGTTGGGGGCGCGCGTGCGAGTGCCAGTGAGAGTGTGGGTGCGCGCTGTGGGCCGCGGCGCGGGTGGGTGGCCGTGCGTTCTTGCGAG CCGGCCTGCAGGAGGCGAGGCTCCCCTGGCCTCCCGCACCCAGCGGCGGACCGAGCCCCTGGAGGGAAGTTGCCGCAGCCGCCCGGGCCG CCGGCCCTCCTGTCCCGCGCCAGGTGGACGTCTGATTTATGAAGCTCCCCATCCACCTATCTGAGTACCTGACTTCTCAGGACTGACACC TACAGCATCAGGTACACAGCTTCTCCTAGCATGACTTCGATCTGATCAGCAAACAAGAAAATTTGTCTCCCGTAGTTCTGGGGCGTGTTC ACCACCTACAACCACAGAGCTGTCATGGCTGCCATCTCTACTTCCATCCCTGTAATTTCACAGCCCCAGTTCACAGCCATGAATGAACCA CAGTGCTTCTACAACGAGTCCATTGCCTTCTTTTATAACCGAAGTGGAAAGCATCTTGCCACAGAATGGAACACAGTCAGCAAGCTGGTG ATGGGACTTGGAATCACTGTTTGTATCTTCATCATGTTGGCCAACCTATTGGTCATGGTGGCAATCTATGTCAACCGCCGCTTCCATTTT CCTATTTATTACCTAATGGCTAATCTGGCTGCTGCAGACTTCTTTGCTGGGTTGGCCTACTTCTATCTCATGTTCAACACAGGACCCAAT ACTCGGAGACTGACTGTTAGCACATGGCTCCTTCGTCAGGGCCTCATTGACACCAGCCTGACGGCATCTGTGGCCAACTTACTGGCTATT GCAATCGAGAGGCACATTACGGTTTTCCGCATGCAGCTCCACACACGGATGAGCAACCGGCGGGTAGTGGTGGTCATTGTGGTCATCTGG ACTATGGCCATCGTTATGGGTGCTATACCCAGTGTGGGCTGGAACTGTATCTGTGATATTGAAAATTGTTCCAACATGGCACCCCTCTAC AGTGACTCTTACTTAGTCTTCTGGGCCATTTTCAACTTGGTGACCTTTGTGGTAATGGTGGTTCTCTATGCTCACATCTTTGGCTATGTT CGCCAGAGGACTATGAGAATGTCTCGGCATAGTTCTGGACCCCGGCGGAATCGGGATACCATGATGAGTCTTCTGAAGACTGTGGTCATT GTGCTTGAGCCAGCCCCTGGGCAACAAAGTGGAAATGGAGATTGTGAGCATGTTGGAAAAAAACGCAACACTTCTCAAATTCGGCTACCA CTTTACCCAGCAAGGACCCCGGCTTCGGGCATCCAACGCAATGATGAACAACAATGACCTTGTGAGGAAGAGGAGGCTTGCGGACCTGAC TGGGCCCATCATTCCCAAGTGCCGGAGTGGTGTCTAGTGTGTGGCGGTGGAGTCCATGCCTTTGAACTGGATGTGTTCTATTGATGACCT GTGCTCTGCAGGGGAAACCAGAAGGCAAAATGCTGGCAGCATGAAACCCTTTTGTGGTTCAGTTCTTTATGCACTAAGGTTTTAGGTTGA CTAGTGGTTGTAGTTGAAAATTTTATAAAATACCGTTAATGTGAAGTTTTTCTTTAGTCACAGAAGTTGAATCTGGTTATTATTTAAAAA CTAGAAGCCCCCAAACCAGCAGATCTTACTGAAGATGATGTTCCAGCAGCAGCGACTTAGCCCCAGGAGCCCAGTTTCAATGGCCTTGCT GTGTGGTGTTTCAAGTGCATTTAAAATGTGTGACACAGAAACGGCACACTCTTCCACATGCTTTTGAAGTATTATAAAACACTTTATTAC AAATTTGTCTTAGCTATTAGCAAATAAAACTGATTATCATTCTTTATTAACCCTCCTTGGAATTTTGAAAACCTCGATTAAAGTTGCCAA ATTGATTACTGGATCCAGAACACAATTTTCCCCTCAGAACAGATAGACAGACTGAAGCCACTGAACTCTGCCAGGAGTCAACATGAGATT CCTTTTGCTGGATATGCAGAAATGATAGGAAAAAAACCAATGGTGAAATTTCAAGTTTCAAAAACCAACCTTTCATTACCAATCCCAGGC AACAAACATGTCCCTGAGTGTTCTTTAAGAACATTTGGGATTTATGTACAATTTAATACTGGAGTTAGAACTTTTTCCTTATTGAATGCC AACCTTATGATGGATGTGAAAATCTACGGCCAAATACTTTTGAAAACACCTTTCTATATTGCACAGTGGGCAAATGGCTTATGTGAGGTA AGACACTAGAGGGATAAATTTCCAGATCAACATGGCTATGGTATTTAGTAATGGCCCAGCTTAGAGACTTCAGCTACTGATCTCATCACT TATTAGACAAATTGCTGCTGACCTTACGCCTGTATATTAAGCCTCCGCAGGATGCCGGACAATGGTGAAGAAACTCCAGATATCAAGGAA TTGGGAAATCCTGGCCAAACCACCCCAAGATGATTACACTGAAATGTAGTATTAGTACTGCTGCCAGATCTCTTTTTAACATCATGTGCG TCTCTTGGGATCCAGCAAAAGTGTTAAGCCACAATGCCCTTGTGCCTTTTAATATACCACAGTGCCAGTTAAACTAATATTTTTGTTTGT TGCTTTTGGGAGTTATTTTCATTAGTGATTTCAGCAAATCTCATGATAAAGGACAAGGTCAAGAACTCCAGAGCACTGAGCAGAGAGGCT GGTGATGAAAAGGTGAAGGCCTGCGCACTGAACTGTAAGGCAGTGGGCAGTACAGGGTAACTGGAGGCGGGGCCAGGGCCTCAGCGCTAT GGAAGAGTGTCCACTGAGGCTGCACATGGCCCAGGAGTGGCACCATGTTGCAGGGACAACCATCCCCATTTGGCTTCTCCTTAAAACACA >49476_49476_8_LPAR1-TMOD1_LPAR1_chr9_113703701_ENST00000374431_TMOD1_chr9_100353573_ENST00000375175_length(amino acids)=310AA_BP=264 MAAISTSIPVISQPQFTAMNEPQCFYNESIAFFYNRSGKHLATEWNTVSKLVMGLGITVCIFIMLANLLVMVAIYVNRRFHFPIYYLMAN LAAADFFAGLAYFYLMFNTGPNTRRLTVSTWLLRQGLIDTSLTASVANLLAIAIERHITVFRMQLHTRMSNRRVVVVIVVIWTMAIVMGA IPSVGWNCICDIENCSNMAPLYSDSYLVFWAIFNLVTFVVMVVLYAHIFGYVRQRTMRMSRHSSGPRRNRDTMMSLLKTVVIVLEPAPGQ -------------------------------------------------------------- >49476_49476_9_LPAR1-TMOD1_LPAR1_chr9_113703701_ENST00000374431_TMOD1_chr9_100353573_ENST00000395211_length(transcript)=3430nt_BP=1177nt GTGGTTGGGGGCGCGCGTGCGAGTGCCAGTGAGAGTGTGGGTGCGCGCTGTGGGCCGCGGCGCGGGTGGGTGGCCGTGCGTTCTTGCGAG CCGGCCTGCAGGAGGCGAGGCTCCCCTGGCCTCCCGCACCCAGCGGCGGACCGAGCCCCTGGAGGGAAGTTGCCGCAGCCGCCCGGGCCG CCGGCCCTCCTGTCCCGCGCCAGGTGGACGTCTGATTTATGAAGCTCCCCATCCACCTATCTGAGTACCTGACTTCTCAGGACTGACACC TACAGCATCAGGTACACAGCTTCTCCTAGCATGACTTCGATCTGATCAGCAAACAAGAAAATTTGTCTCCCGTAGTTCTGGGGCGTGTTC ACCACCTACAACCACAGAGCTGTCATGGCTGCCATCTCTACTTCCATCCCTGTAATTTCACAGCCCCAGTTCACAGCCATGAATGAACCA CAGTGCTTCTACAACGAGTCCATTGCCTTCTTTTATAACCGAAGTGGAAAGCATCTTGCCACAGAATGGAACACAGTCAGCAAGCTGGTG ATGGGACTTGGAATCACTGTTTGTATCTTCATCATGTTGGCCAACCTATTGGTCATGGTGGCAATCTATGTCAACCGCCGCTTCCATTTT CCTATTTATTACCTAATGGCTAATCTGGCTGCTGCAGACTTCTTTGCTGGGTTGGCCTACTTCTATCTCATGTTCAACACAGGACCCAAT ACTCGGAGACTGACTGTTAGCACATGGCTCCTTCGTCAGGGCCTCATTGACACCAGCCTGACGGCATCTGTGGCCAACTTACTGGCTATT GCAATCGAGAGGCACATTACGGTTTTCCGCATGCAGCTCCACACACGGATGAGCAACCGGCGGGTAGTGGTGGTCATTGTGGTCATCTGG ACTATGGCCATCGTTATGGGTGCTATACCCAGTGTGGGCTGGAACTGTATCTGTGATATTGAAAATTGTTCCAACATGGCACCCCTCTAC AGTGACTCTTACTTAGTCTTCTGGGCCATTTTCAACTTGGTGACCTTTGTGGTAATGGTGGTTCTCTATGCTCACATCTTTGGCTATGTT CGCCAGAGGACTATGAGAATGTCTCGGCATAGTTCTGGACCCCGGCGGAATCGGGATACCATGATGAGTCTTCTGAAGACTGTGGTCATT GTGCTTGAGCCAGCCCCTGGGCAACAAAGTGGAAATGGAGATTGTGAGCATGTTGGAAAAAAACGCAACACTTCTCAAATTCGGCTACCA CTTTACCCAGCAAGGACCCCGGCTTCGGGCATCCAACGCAATGATGAACAACAATGACCTTGTGAGGAAGAGGAGGCTTGCGGACCTGAC TGGGCCCATCATTCCCAAGTGCCGGAGTGGTGTCTAGTGTGTGGCGGTGGAGTCCATGCCTTTGAACTGGATGTGTTCTATTGATGACCT GTGCTCTGCAGGGGAAACCAGAAGGCAAAATGCTGGCAGCATGAAACCCTTTTGTGGTTCAGTTCTTTATGCACTAAGGTTTTAGGTTGA CTAGTGGTTGTAGTTGAAAATTTTATAAAATACCGTTAATGTGAAGTTTTTCTTTAGTCACAGAAGTTGAATCTGGTTATTATTTAAAAA CTAGAAGCCCCCAAACCAGCAGATCTTACTGAAGATGATGTTCCAGCAGCAGCGACTTAGCCCCAGGAGCCCAGTTTCAATGGCCTTGCT GTGTGGTGTTTCAAGTGCATTTAAAATGTGTGACACAGAAACGGCACACTCTTCCACATGCTTTTGAAGTATTATAAAACACTTTATTAC AAATTTGTCTTAGCTATTAGCAAATAAAACTGATTATCATTCTTTATTAACCCTCCTTGGAATTTTGAAAACCTCGATTAAAGTTGCCAA ATTGATTACTGGATCCAGAACACAATTTTCCCCTCAGAACAGATAGACAGACTGAAGCCACTGAACTCTGCCAGGAGTCAACATGAGATT CCTTTTGCTGGATATGCAGAAATGATAGGAAAAAAACCAATGGTGAAATTTCAAGTTTCAAAAACCAACCTTTCATTACCAATCCCAGGC AACAAACATGTCCCTGAGTGTTCTTTAAGAACATTTGGGATTTATGTACAATTTAATACTGGAGTTAGAACTTTTTCCTTATTGAATGCC AACCTTATGATGGATGTGAAAATCTACGGCCAAATACTTTTGAAAACACCTTTCTATATTGCACAGTGGGCAAATGGCTTATGTGAGGTA AGACACTAGAGGGATAAATTTCCAGATCAACATGGCTATGGTATTTAGTAATGGCCCAGCTTAGAGACTTCAGCTACTGATCTCATCACT TATTAGACAAATTGCTGCTGACCTTACGCCTGTATATTAAGCCTCCGCAGGATGCCGGACAATGGTGAAGAAACTCCAGATATCAAGGAA TTGGGAAATCCTGGCCAAACCACCCCAAGATGATTACACTGAAATGTAGTATTAGTACTGCTGCCAGATCTCTTTTTAACATCATGTGCG TCTCTTGGGATCCAGCAAAAGTGTTAAGCCACAATGCCCTTGTGCCTTTTAATATACCACAGTGCCAGTTAAACTAATATTTTTGTTTGT TGCTTTTGGGAGTTATTTTCATTAGTGATTTCAGCAAATCTCATGATAAAGGACAAGGTCAAGAACTCCAGAGCACTGAGCAGAGAGGCT GGTGATGAAAAGGTGAAGGCCTGCGCACTGAACTGTAAGGCAGTGGGCAGTACAGGGTAACTGGAGGCGGGGCCAGGGCCTCAGCGCTAT GGAAGAGTGTCCACTGAGGCTGCACATGGCCCAGGAGTGGCACCATGTTGCAGGGACAACCATCCCCATTTGGCTTCTCCTTAAAACACA ATTGCAGCTGCATTCTGCATCGCTGAAAACTGCAATATAATATTAAATCTGTTGGTCTATGCATGGCTGCGTATGTGTTTCTTGGAACCT GTGTGACAGGGACATGTGCCTGGCACACTGGCCAGAAGACTGGGCAGCCACCATGGCAGTGCTGGATGACCTCAGTAAGAATGTGTCATG TATTCCAGGTGCTGATCTAAAAACTGTGGCTCAAATGTCACCGAGCTTATATGAAGCTCCCAGAGAGAACATTTAAAAGCTCAGAGAGTA AGTGCTGGGGAAAGCAGAGCTATCAGAGGAAATCTCTCATAGAAACGAAACCAAACCAACAGAAAATGAAGAAGGCCACATCTTTAAGGC CACCTCTGCCTCTATCAGATGAGCTGCTGGTCTAGATCAGGGGCTGGCAAACTTTTCTGTAAAAGGCCAGACAGTAAAAATTTCCGATTT TGCAGGCCACATAGTGTCTGTTGCAACTATTCAACTCTGCCATAGATCATGTGTAAAGGAATGGGTGTGGCTGTTCAATAAACTATACAG >49476_49476_9_LPAR1-TMOD1_LPAR1_chr9_113703701_ENST00000374431_TMOD1_chr9_100353573_ENST00000395211_length(amino acids)=310AA_BP=264 MAAISTSIPVISQPQFTAMNEPQCFYNESIAFFYNRSGKHLATEWNTVSKLVMGLGITVCIFIMLANLLVMVAIYVNRRFHFPIYYLMAN LAAADFFAGLAYFYLMFNTGPNTRRLTVSTWLLRQGLIDTSLTASVANLLAIAIERHITVFRMQLHTRMSNRRVVVVIVVIWTMAIVMGA IPSVGWNCICDIENCSNMAPLYSDSYLVFWAIFNLVTFVVMVVLYAHIFGYVRQRTMRMSRHSSGPRRNRDTMMSLLKTVVIVLEPAPGQ -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for LPAR1-TMOD1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for LPAR1-TMOD1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for LPAR1-TMOD1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies