
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:ANXA2-RNF114 (FusionGDB2 ID:5038) |
Fusion Gene Summary for ANXA2-RNF114 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: ANXA2-RNF114 | Fusion gene ID: 5038 | Hgene | Tgene | Gene symbol | ANXA2 | RNF114 | Gene ID | 302 | 55905 |
| Gene name | annexin A2 | ring finger protein 114 | |
| Synonyms | ANX2|ANX2L4|CAL1H|HEL-S-270|LIP2|LPC2|LPC2D|P36|PAP-IV | PSORS12|ZNF313 | |
| Cytomap | 15q22.2 | 20q13.13 | |
| Type of gene | protein-coding | protein-coding | |
| Description | annexin A2annexin IIannexin-2calpactin I heavy chaincalpactin I heavy polypeptidecalpactin-1 heavy chainchromobindin 8epididymis secretory protein Li 270epididymis secretory sperm binding proteinlipocortin IIplacental anticoagulant protein IVpr | E3 ubiquitin-protein ligase RNF114RING-type E3 ubiquitin transferase RNF114zinc finger protein 228zinc finger protein 313 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | P07355 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000332680, ENST00000396024, ENST00000421017, ENST00000451270, ENST00000557937, | ENST00000244061, | |
| Fusion gene scores | * DoF score | 22 X 20 X 7=3080 | 9 X 9 X 5=405 |
| # samples | 23 | 10 | |
| ** MAII score | log2(23/3080*10)=-3.74322458463789 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(10/405*10)=-2.01792190799726 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: ANXA2 [Title/Abstract] AND RNF114 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | ANXA2(60643392)-RNF114(48565785), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | ANXA2 | GO:0001921 | positive regulation of receptor recycling | 22848640 |
| Hgene | ANXA2 | GO:0031340 | positive regulation of vesicle fusion | 2138016 |
| Hgene | ANXA2 | GO:0032804 | negative regulation of low-density lipoprotein particle receptor catabolic process | 22848640 |
| Hgene | ANXA2 | GO:0036035 | osteoclast development | 7961821 |
| Hgene | ANXA2 | GO:1905581 | positive regulation of low-density lipoprotein particle clearance | 22848640 |
| Hgene | ANXA2 | GO:1905597 | positive regulation of low-density lipoprotein particle receptor binding | 22848640 |
| Hgene | ANXA2 | GO:1905602 | positive regulation of receptor-mediated endocytosis involved in cholesterol transport | 22848640 |
| Fusion gene breakpoints across ANXA2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across RNF114 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-C8-A12P-01A | ANXA2 | chr15 | 60643391 | - | RNF114 | chr20 | 48565784 | + |
| ChimerDB4 | BRCA | TCGA-C8-A12P-01A | ANXA2 | chr15 | 60643392 | - | RNF114 | chr20 | 48565785 | + |
| ChimerDB4 | BRCA | TCGA-C8-A12P | ANXA2 | chr15 | 60643391 | - | RNF114 | chr20 | 48565784 | + |
Top |
Fusion Gene ORF analysis for ANXA2-RNF114 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| In-frame | ENST00000332680 | ENST00000244061 | ANXA2 | chr15 | 60643392 | - | RNF114 | chr20 | 48565785 | + |
| In-frame | ENST00000332680 | ENST00000244061 | ANXA2 | chr15 | 60643391 | - | RNF114 | chr20 | 48565784 | + |
| In-frame | ENST00000396024 | ENST00000244061 | ANXA2 | chr15 | 60643392 | - | RNF114 | chr20 | 48565785 | + |
| In-frame | ENST00000396024 | ENST00000244061 | ANXA2 | chr15 | 60643391 | - | RNF114 | chr20 | 48565784 | + |
| In-frame | ENST00000421017 | ENST00000244061 | ANXA2 | chr15 | 60643392 | - | RNF114 | chr20 | 48565785 | + |
| In-frame | ENST00000421017 | ENST00000244061 | ANXA2 | chr15 | 60643391 | - | RNF114 | chr20 | 48565784 | + |
| In-frame | ENST00000451270 | ENST00000244061 | ANXA2 | chr15 | 60643392 | - | RNF114 | chr20 | 48565785 | + |
| In-frame | ENST00000451270 | ENST00000244061 | ANXA2 | chr15 | 60643391 | - | RNF114 | chr20 | 48565784 | + |
| intron-3CDS | ENST00000557937 | ENST00000244061 | ANXA2 | chr15 | 60643392 | - | RNF114 | chr20 | 48565785 | + |
| intron-3CDS | ENST00000557937 | ENST00000244061 | ANXA2 | chr15 | 60643391 | - | RNF114 | chr20 | 48565784 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000396024 | ANXA2 | chr15 | 60643392 | - | ENST00000244061 | RNF114 | chr20 | 48565785 | + | 2922 | 997 | 139 | 1170 | 343 |
| ENST00000451270 | ANXA2 | chr15 | 60643392 | - | ENST00000244061 | RNF114 | chr20 | 48565785 | + | 2874 | 949 | 55 | 1122 | 355 |
| ENST00000332680 | ANXA2 | chr15 | 60643392 | - | ENST00000244061 | RNF114 | chr20 | 48565785 | + | 2888 | 963 | 72 | 1136 | 354 |
| ENST00000421017 | ANXA2 | chr15 | 60643392 | - | ENST00000244061 | RNF114 | chr20 | 48565785 | + | 2898 | 973 | 136 | 1146 | 336 |
| ENST00000396024 | ANXA2 | chr15 | 60643391 | - | ENST00000244061 | RNF114 | chr20 | 48565784 | + | 2922 | 997 | 139 | 1170 | 343 |
| ENST00000451270 | ANXA2 | chr15 | 60643391 | - | ENST00000244061 | RNF114 | chr20 | 48565784 | + | 2874 | 949 | 55 | 1122 | 355 |
| ENST00000332680 | ANXA2 | chr15 | 60643391 | - | ENST00000244061 | RNF114 | chr20 | 48565784 | + | 2888 | 963 | 72 | 1136 | 354 |
| ENST00000421017 | ANXA2 | chr15 | 60643391 | - | ENST00000244061 | RNF114 | chr20 | 48565784 | + | 2898 | 973 | 136 | 1146 | 336 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000396024 | ENST00000244061 | ANXA2 | chr15 | 60643392 | - | RNF114 | chr20 | 48565785 | + | 0.000302136 | 0.9996979 |
| ENST00000451270 | ENST00000244061 | ANXA2 | chr15 | 60643392 | - | RNF114 | chr20 | 48565785 | + | 0.000340021 | 0.99966 |
| ENST00000332680 | ENST00000244061 | ANXA2 | chr15 | 60643392 | - | RNF114 | chr20 | 48565785 | + | 0.000400319 | 0.99959975 |
| ENST00000421017 | ENST00000244061 | ANXA2 | chr15 | 60643392 | - | RNF114 | chr20 | 48565785 | + | 0.000337379 | 0.99966264 |
| ENST00000396024 | ENST00000244061 | ANXA2 | chr15 | 60643391 | - | RNF114 | chr20 | 48565784 | + | 0.000302136 | 0.9996979 |
| ENST00000451270 | ENST00000244061 | ANXA2 | chr15 | 60643391 | - | RNF114 | chr20 | 48565784 | + | 0.000340021 | 0.99966 |
| ENST00000332680 | ENST00000244061 | ANXA2 | chr15 | 60643391 | - | RNF114 | chr20 | 48565784 | + | 0.000400319 | 0.99959975 |
| ENST00000421017 | ENST00000244061 | ANXA2 | chr15 | 60643391 | - | RNF114 | chr20 | 48565784 | + | 0.000337379 | 0.99966264 |
Top |
Fusion Genomic Features for ANXA2-RNF114 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| ANXA2 | chr15 | 60643391 | - | RNF114 | chr20 | 48565784 | + | 0.00050576 | 0.9994942 |
| ANXA2 | chr15 | 60643391 | - | RNF114 | chr20 | 48565784 | + | 0.00050576 | 0.9994942 |
| ANXA2 | chr15 | 60643391 | - | RNF114 | chr20 | 48565784 | + | 0.00050576 | 0.9994942 |
| ANXA2 | chr15 | 60643391 | - | RNF114 | chr20 | 48565784 | + | 0.00050576 | 0.9994942 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
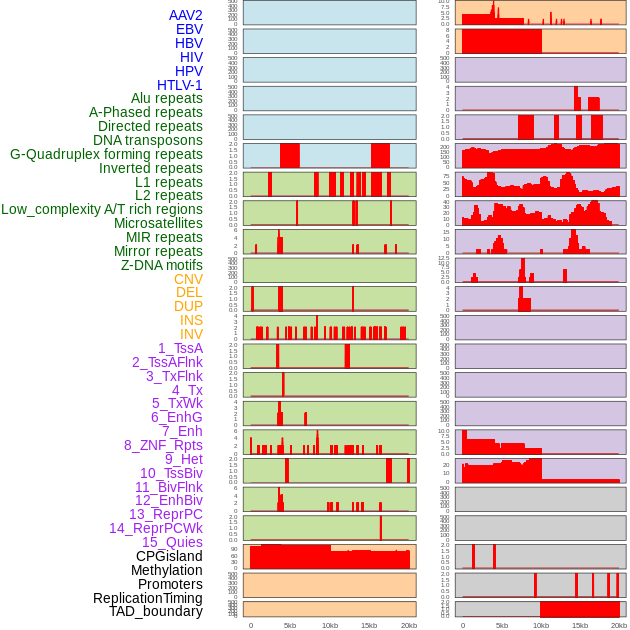 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
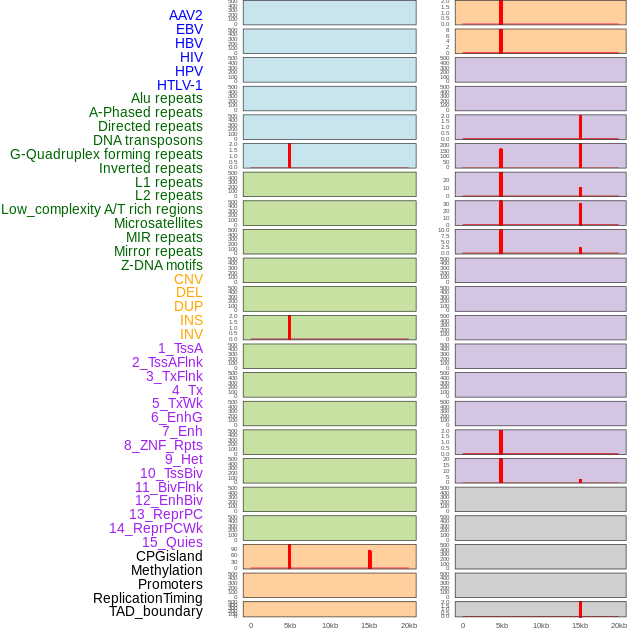 |
Top |
Fusion Protein Features for ANXA2-RNF114 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr15:60643392/chr20:48565785) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| ANXA2 | . |
| FUNCTION: Calcium-regulated membrane-binding protein whose affinity for calcium is greatly enhanced by anionic phospholipids. It binds two calcium ions with high affinity. May be involved in heat-stress response. Inhibits PCSK9-enhanced LDLR degradation, probably reduces PCSK9 protein levels via a translational mechanism but also competes with LDLR for binding with PCSK9 (PubMed:18799458, PubMed:24808179, PubMed:22848640). {ECO:0000269|PubMed:18799458, ECO:0000269|PubMed:22848640, ECO:0000269|PubMed:24808179}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ANXA2 | chr15:60643391 | chr20:48565784 | ENST00000332680 | - | 11 | 13 | 2_24 | 297 | 358.0 | Region | S100A10-binding site |
| Hgene | ANXA2 | chr15:60643391 | chr20:48565784 | ENST00000396024 | - | 12 | 14 | 2_24 | 279 | 340.0 | Region | S100A10-binding site |
| Hgene | ANXA2 | chr15:60643391 | chr20:48565784 | ENST00000421017 | - | 12 | 14 | 2_24 | 279 | 340.0 | Region | S100A10-binding site |
| Hgene | ANXA2 | chr15:60643391 | chr20:48565784 | ENST00000451270 | - | 11 | 13 | 2_24 | 279 | 340.0 | Region | S100A10-binding site |
| Hgene | ANXA2 | chr15:60643392 | chr20:48565785 | ENST00000332680 | - | 11 | 13 | 2_24 | 297 | 358.0 | Region | S100A10-binding site |
| Hgene | ANXA2 | chr15:60643392 | chr20:48565785 | ENST00000396024 | - | 12 | 14 | 2_24 | 279 | 340.0 | Region | S100A10-binding site |
| Hgene | ANXA2 | chr15:60643392 | chr20:48565785 | ENST00000421017 | - | 12 | 14 | 2_24 | 279 | 340.0 | Region | S100A10-binding site |
| Hgene | ANXA2 | chr15:60643392 | chr20:48565785 | ENST00000451270 | - | 11 | 13 | 2_24 | 279 | 340.0 | Region | S100A10-binding site |
| Hgene | ANXA2 | chr15:60643391 | chr20:48565784 | ENST00000332680 | - | 11 | 13 | 105_176 | 297 | 358.0 | Repeat | Annexin 2 |
| Hgene | ANXA2 | chr15:60643391 | chr20:48565784 | ENST00000332680 | - | 11 | 13 | 189_261 | 297 | 358.0 | Repeat | Annexin 3 |
| Hgene | ANXA2 | chr15:60643391 | chr20:48565784 | ENST00000332680 | - | 11 | 13 | 33_104 | 297 | 358.0 | Repeat | Annexin 1 |
| Hgene | ANXA2 | chr15:60643391 | chr20:48565784 | ENST00000396024 | - | 12 | 14 | 105_176 | 279 | 340.0 | Repeat | Annexin 2 |
| Hgene | ANXA2 | chr15:60643391 | chr20:48565784 | ENST00000396024 | - | 12 | 14 | 189_261 | 279 | 340.0 | Repeat | Annexin 3 |
| Hgene | ANXA2 | chr15:60643391 | chr20:48565784 | ENST00000396024 | - | 12 | 14 | 33_104 | 279 | 340.0 | Repeat | Annexin 1 |
| Hgene | ANXA2 | chr15:60643391 | chr20:48565784 | ENST00000421017 | - | 12 | 14 | 105_176 | 279 | 340.0 | Repeat | Annexin 2 |
| Hgene | ANXA2 | chr15:60643391 | chr20:48565784 | ENST00000421017 | - | 12 | 14 | 189_261 | 279 | 340.0 | Repeat | Annexin 3 |
| Hgene | ANXA2 | chr15:60643391 | chr20:48565784 | ENST00000421017 | - | 12 | 14 | 33_104 | 279 | 340.0 | Repeat | Annexin 1 |
| Hgene | ANXA2 | chr15:60643391 | chr20:48565784 | ENST00000451270 | - | 11 | 13 | 105_176 | 279 | 340.0 | Repeat | Annexin 2 |
| Hgene | ANXA2 | chr15:60643391 | chr20:48565784 | ENST00000451270 | - | 11 | 13 | 189_261 | 279 | 340.0 | Repeat | Annexin 3 |
| Hgene | ANXA2 | chr15:60643391 | chr20:48565784 | ENST00000451270 | - | 11 | 13 | 33_104 | 279 | 340.0 | Repeat | Annexin 1 |
| Hgene | ANXA2 | chr15:60643392 | chr20:48565785 | ENST00000332680 | - | 11 | 13 | 105_176 | 297 | 358.0 | Repeat | Annexin 2 |
| Hgene | ANXA2 | chr15:60643392 | chr20:48565785 | ENST00000332680 | - | 11 | 13 | 189_261 | 297 | 358.0 | Repeat | Annexin 3 |
| Hgene | ANXA2 | chr15:60643392 | chr20:48565785 | ENST00000332680 | - | 11 | 13 | 33_104 | 297 | 358.0 | Repeat | Annexin 1 |
| Hgene | ANXA2 | chr15:60643392 | chr20:48565785 | ENST00000396024 | - | 12 | 14 | 105_176 | 279 | 340.0 | Repeat | Annexin 2 |
| Hgene | ANXA2 | chr15:60643392 | chr20:48565785 | ENST00000396024 | - | 12 | 14 | 189_261 | 279 | 340.0 | Repeat | Annexin 3 |
| Hgene | ANXA2 | chr15:60643392 | chr20:48565785 | ENST00000396024 | - | 12 | 14 | 33_104 | 279 | 340.0 | Repeat | Annexin 1 |
| Hgene | ANXA2 | chr15:60643392 | chr20:48565785 | ENST00000421017 | - | 12 | 14 | 105_176 | 279 | 340.0 | Repeat | Annexin 2 |
| Hgene | ANXA2 | chr15:60643392 | chr20:48565785 | ENST00000421017 | - | 12 | 14 | 189_261 | 279 | 340.0 | Repeat | Annexin 3 |
| Hgene | ANXA2 | chr15:60643392 | chr20:48565785 | ENST00000421017 | - | 12 | 14 | 33_104 | 279 | 340.0 | Repeat | Annexin 1 |
| Hgene | ANXA2 | chr15:60643392 | chr20:48565785 | ENST00000451270 | - | 11 | 13 | 105_176 | 279 | 340.0 | Repeat | Annexin 2 |
| Hgene | ANXA2 | chr15:60643392 | chr20:48565785 | ENST00000451270 | - | 11 | 13 | 189_261 | 279 | 340.0 | Repeat | Annexin 3 |
| Hgene | ANXA2 | chr15:60643392 | chr20:48565785 | ENST00000451270 | - | 11 | 13 | 33_104 | 279 | 340.0 | Repeat | Annexin 1 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | ANXA2 | chr15:60643391 | chr20:48565784 | ENST00000332680 | - | 11 | 13 | 265_336 | 297 | 358.0 | Repeat | Annexin 4 |
| Hgene | ANXA2 | chr15:60643391 | chr20:48565784 | ENST00000396024 | - | 12 | 14 | 265_336 | 279 | 340.0 | Repeat | Annexin 4 |
| Hgene | ANXA2 | chr15:60643391 | chr20:48565784 | ENST00000421017 | - | 12 | 14 | 265_336 | 279 | 340.0 | Repeat | Annexin 4 |
| Hgene | ANXA2 | chr15:60643391 | chr20:48565784 | ENST00000451270 | - | 11 | 13 | 265_336 | 279 | 340.0 | Repeat | Annexin 4 |
| Hgene | ANXA2 | chr15:60643392 | chr20:48565785 | ENST00000332680 | - | 11 | 13 | 265_336 | 297 | 358.0 | Repeat | Annexin 4 |
| Hgene | ANXA2 | chr15:60643392 | chr20:48565785 | ENST00000396024 | - | 12 | 14 | 265_336 | 279 | 340.0 | Repeat | Annexin 4 |
| Hgene | ANXA2 | chr15:60643392 | chr20:48565785 | ENST00000421017 | - | 12 | 14 | 265_336 | 279 | 340.0 | Repeat | Annexin 4 |
| Hgene | ANXA2 | chr15:60643392 | chr20:48565785 | ENST00000451270 | - | 11 | 13 | 265_336 | 279 | 340.0 | Repeat | Annexin 4 |
| Tgene | RNF114 | chr15:60643391 | chr20:48565784 | ENST00000244061 | 3 | 6 | 29_68 | 171 | 229.0 | Zinc finger | RING-type | |
| Tgene | RNF114 | chr15:60643391 | chr20:48565784 | ENST00000244061 | 3 | 6 | 91_110 | 171 | 229.0 | Zinc finger | C2HC RNF-type | |
| Tgene | RNF114 | chr15:60643392 | chr20:48565785 | ENST00000244061 | 3 | 6 | 29_68 | 171 | 229.0 | Zinc finger | RING-type | |
| Tgene | RNF114 | chr15:60643392 | chr20:48565785 | ENST00000244061 | 3 | 6 | 91_110 | 171 | 229.0 | Zinc finger | C2HC RNF-type |
Top |
Fusion Gene Sequence for ANXA2-RNF114 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >5038_5038_1_ANXA2-RNF114_ANXA2_chr15_60643391_ENST00000332680_RNF114_chr20_48565784_ENST00000244061_length(transcript)=2888nt_BP=963nt CTCAGCATTTGGGGACGCTCTCAGCTCTCGGCGCACGGCCCAGGTAAGCGGGGCGCGCCCTGCCCGCCCGCGATGGGCCGCCAGCTAGCG GGGTGTGGAGACGCTGGGAAGAAGGCTTCCTTCAAAATGTCTACTGTTCACGAAATCCTGTGCAAGCTCAGCTTGGAGGGTGATCACTCT ACACCCCCAAGTGCATATGGGTCTGTCAAAGCCTATACTAACTTTGATGCTGAGCGGGATGCTTTGAACATTGAAACAGCCATCAAGACC AAAGGTGTGGATGAGGTCACCATTGTCAACATTTTGACCAACCGCAGCAATGCACAGAGACAGGATATTGCCTTCGCCTACCAGAGAAGG ACCAAAAAGGAACTTGCATCAGCACTGAAGTCAGCCTTATCTGGCCACCTGGAGACGGTGATTTTGGGCCTATTGAAGACACCTGCTCAG TATGACGCTTCTGAGCTAAAAGCTTCCATGAAGGGGCTGGGAACCGACGAGGACTCTCTCATTGAGATCATCTGCTCCAGAACCAACCAG GAGCTGCAGGAAATTAACAGAGTCTACAAGGAAATGTACAAGACTGATCTGGAGAAGGACATTATTTCGGACACATCTGGTGACTTCCGC AAGCTGATGGTTGCCCTGGCAAAGGGTAGAAGAGCAGAGGATGGCTCTGTCATTGATTATGAACTGATTGACCAAGATGCTCGGGATCTC TATGACGCTGGAGTGAAGAGGAAAGGAACTGATGTTCCCAAGTGGATCAGCATCATGACCGAGCGGAGCGTGCCCCACCTCCAGAAAGTA TTTGATAGGTACAAGAGTTACAGCCCTTATGACATGTTGGAAAGCATCAGGAAAGAGGTTAAAGGAGACCTGGAAAATGCTTTCCTGAAC CTGGTTCAGTGCATTCAGAACAAGCCCCTGTATTTTGCTGATCGGCTGTATGACTCCATGAAGGTTTGTCCGATATGTGCCTCGATGCCC TGGGGAGACCCCAACTACCGCAGCGCCAACTTCAGAGAGCACATCCAGCGCCGGCACCGGTTTTCTTATGACACTTTTGTGGATTATGAT GTTGATGAAGAGGACATGATGAATCAGGTGTTGCAGCGCTCCATCATCGACCAGTGAGCAGAGTCCGTGCTTGCTATCTGTCTCATGTTA CAGAGCTTCCATTACATATTAAACGTGAAATCTATGACTCCTGTACCTTACCTGTTCAACAGACCTGAAAATGAGCCATGGCATTGGGAC AGGGTCACTTCTGACAGGGGAAGTGGGTCCCCAGGTCAGCCCTTCTCTTCCCTTTGGGCTCTTGCCAAAGCTGTCTTCCCCTACTGTTAA CCTTGTTTGTCACACGGTCGAGTTCGTATTGGTTCTCGGCTACTTCCTGGAGCTTCTGCCGCCTCCTGTGGAAGATAATCTAGCTTCTCC ACCTCTTGTTTCACACTCATTCCTCCCATCCAGTGTTTGTCTCTCGGGTCCTTCAAGCCAGCCAGGACCTTTTCTGGGTCATGAATAGCA CAATGAAGCAAGTGTCTCCTTTCCTTGTCCCCAAGGTGTGCAGACTTTGGCAGCCGTGCACCTGACCAGAGCTGAAGCTCCCGCTGGGCT GTGGGGTTGCCAGAAGCTGGGGTTGCCATCCCGGGGTACATGTCACCAGTCCTCTTGGGGTTTTGTACCATCTGATGCTGGAAGTTTTGA TTAGTGATATTTTCTACTACTACATATTTAGAGTTCACTGGTTCAGTCTTAAATGCCTGCATGGTGCCTTTTTAGGATAAGGTATAACCA TACATTTTTGGTGGAAGTGTTTCTGGGTTAGGGAAGTTAAAGTCTGTTTATCCGTAAGTGGGGAGGAGGGTCAGCTAAGAGAAGTGGGAG GGCCAGAGCTTTTTGGTTCTGATTTACAAATTAATGAAGTAGTTTCAAACAACGCGGTCATGTTTACCTCTCCATTTGGGAGCCTGCCTA CATTCTTGTTCTAGAAGCACAAAAAATCCTCAGATGAATTAGAAGAAAGAGGTTTGGGGACTCAGCGGATACTAGTTCTTTTACCTTCTG CTTGGTAACTTAGATTAAACTGAGCATTGTTTTTCTGTCACAAATGTTTTCCTTATGACACTGGTTTCGACATGTAAAATGTGTTTGAAA ACCTGCTTTGTAGATGCAGAGAGAAGCTATAGGAAACCCAGTACCACCCCTGGTCTGTTCTGACGAGACATCGTTCATAAGGCACAGCAC ATCGCAAGATGAACAGTTGTTAATAAAAGCTGTTGCTGGAAACTTGCTTTAGGAACAGCTCAAGAACCTTGGAGTTCATATTTCACAAAT ATTAATAAATATAAGTCCAAGAGCTGTCAGCCTAATCTGTAGGAGCAGAACCTCTGATTGACCAAAAGGCATATGGGTTTAGGTTGGTTT TTTGATGTCATATGTCTCTGATGGGGCTGCAAGTGCTACCTCGCGCTTGTACACTGCTGCTGTGGGGCTCCGCGCCTGCCGGTGAAGAGC TGCAGATGCCGAGAAGCCAGCAAACACAGGGCCCACTGGAAAAAAATAGTTTTTTCATTAGTATTTCTCGGGAGGACCCAAAAGTTAAGG TCAGCTTGTTCACTGTAATTTCTGGAAGAAGTTCACTCAGACCTTCCTGAATTCAGATCATCTCAGAAGTCTGGAGGGAAATCTGGCGAA ACCTTCGTTTGAGGGACTGATGTGAGTGTATGTCCACCTCACTGGTGGCACCGAGAAACTTACTTCCTTGTATTAAGTGCACTTCTTGTA TTTCTAATAAGATGACTTTCCAGAAAGTGAGATTTGTTATGTTCTGGCTTTTAAAAGGTAAAATATAAATAAATTTCATAACTTAATCTA >5038_5038_1_ANXA2-RNF114_ANXA2_chr15_60643391_ENST00000332680_RNF114_chr20_48565784_ENST00000244061_length(amino acids)=354AA_BP=296 MGRQLAGCGDAGKKASFKMSTVHEILCKLSLEGDHSTPPSAYGSVKAYTNFDAERDALNIETAIKTKGVDEVTIVNILTNRSNAQRQDIA FAYQRRTKKELASALKSALSGHLETVILGLLKTPAQYDASELKASMKGLGTDEDSLIEIICSRTNQELQEINRVYKEMYKTDLEKDIISD TSGDFRKLMVALAKGRRAEDGSVIDYELIDQDARDLYDAGVKRKGTDVPKWISIMTERSVPHLQKVFDRYKSYSPYDMLESIRKEVKGDL -------------------------------------------------------------- >5038_5038_2_ANXA2-RNF114_ANXA2_chr15_60643391_ENST00000396024_RNF114_chr20_48565784_ENST00000244061_length(transcript)=2922nt_BP=997nt GCTCAGCATTTGGGGACGCTCTCAGCTCTCGGCGCACGGCCCAGGGTGAAAATGTTTGCCATTAAACTCACATGAAGTAGGAAATATTTA TATGGATACAAAAGGCACCTGCATGGGATAATGTCAAATTTCATAGATACTGCTTTGTGCTTCCTTCAAAATGTCTACTGTTCACGAAAT CCTGTGCAAGCTCAGCTTGGAGGGTGATCACTCTACACCCCCAAGTGCATATGGGTCTGTCAAAGCCTATACTAACTTTGATGCTGAGCG GGATGCTTTGAACATTGAAACAGCCATCAAGACCAAAGGTGTGGATGAGGTCACCATTGTCAACATTTTGACCAACCGCAGCAATGCACA GAGACAGGATATTGCCTTCGCCTACCAGAGAAGGACCAAAAAGGAACTTGCATCAGCACTGAAGTCAGCCTTATCTGGCCACCTGGAGAC GGTGATTTTGGGCCTATTGAAGACACCTGCTCAGTATGACGCTTCTGAGCTAAAAGCTTCCATGAAGGGGCTGGGAACCGACGAGGACTC TCTCATTGAGATCATCTGCTCCAGAACCAACCAGGAGCTGCAGGAAATTAACAGAGTCTACAAGGAAATGTACAAGACTGATCTGGAGAA GGACATTATTTCGGACACATCTGGTGACTTCCGCAAGCTGATGGTTGCCCTGGCAAAGGGTAGAAGAGCAGAGGATGGCTCTGTCATTGA TTATGAACTGATTGACCAAGATGCTCGGGATCTCTATGACGCTGGAGTGAAGAGGAAAGGAACTGATGTTCCCAAGTGGATCAGCATCAT GACCGAGCGGAGCGTGCCCCACCTCCAGAAAGTATTTGATAGGTACAAGAGTTACAGCCCTTATGACATGTTGGAAAGCATCAGGAAAGA GGTTAAAGGAGACCTGGAAAATGCTTTCCTGAACCTGGTTCAGTGCATTCAGAACAAGCCCCTGTATTTTGCTGATCGGCTGTATGACTC CATGAAGGTTTGTCCGATATGTGCCTCGATGCCCTGGGGAGACCCCAACTACCGCAGCGCCAACTTCAGAGAGCACATCCAGCGCCGGCA CCGGTTTTCTTATGACACTTTTGTGGATTATGATGTTGATGAAGAGGACATGATGAATCAGGTGTTGCAGCGCTCCATCATCGACCAGTG AGCAGAGTCCGTGCTTGCTATCTGTCTCATGTTACAGAGCTTCCATTACATATTAAACGTGAAATCTATGACTCCTGTACCTTACCTGTT CAACAGACCTGAAAATGAGCCATGGCATTGGGACAGGGTCACTTCTGACAGGGGAAGTGGGTCCCCAGGTCAGCCCTTCTCTTCCCTTTG GGCTCTTGCCAAAGCTGTCTTCCCCTACTGTTAACCTTGTTTGTCACACGGTCGAGTTCGTATTGGTTCTCGGCTACTTCCTGGAGCTTC TGCCGCCTCCTGTGGAAGATAATCTAGCTTCTCCACCTCTTGTTTCACACTCATTCCTCCCATCCAGTGTTTGTCTCTCGGGTCCTTCAA GCCAGCCAGGACCTTTTCTGGGTCATGAATAGCACAATGAAGCAAGTGTCTCCTTTCCTTGTCCCCAAGGTGTGCAGACTTTGGCAGCCG TGCACCTGACCAGAGCTGAAGCTCCCGCTGGGCTGTGGGGTTGCCAGAAGCTGGGGTTGCCATCCCGGGGTACATGTCACCAGTCCTCTT GGGGTTTTGTACCATCTGATGCTGGAAGTTTTGATTAGTGATATTTTCTACTACTACATATTTAGAGTTCACTGGTTCAGTCTTAAATGC CTGCATGGTGCCTTTTTAGGATAAGGTATAACCATACATTTTTGGTGGAAGTGTTTCTGGGTTAGGGAAGTTAAAGTCTGTTTATCCGTA AGTGGGGAGGAGGGTCAGCTAAGAGAAGTGGGAGGGCCAGAGCTTTTTGGTTCTGATTTACAAATTAATGAAGTAGTTTCAAACAACGCG GTCATGTTTACCTCTCCATTTGGGAGCCTGCCTACATTCTTGTTCTAGAAGCACAAAAAATCCTCAGATGAATTAGAAGAAAGAGGTTTG GGGACTCAGCGGATACTAGTTCTTTTACCTTCTGCTTGGTAACTTAGATTAAACTGAGCATTGTTTTTCTGTCACAAATGTTTTCCTTAT GACACTGGTTTCGACATGTAAAATGTGTTTGAAAACCTGCTTTGTAGATGCAGAGAGAAGCTATAGGAAACCCAGTACCACCCCTGGTCT GTTCTGACGAGACATCGTTCATAAGGCACAGCACATCGCAAGATGAACAGTTGTTAATAAAAGCTGTTGCTGGAAACTTGCTTTAGGAAC AGCTCAAGAACCTTGGAGTTCATATTTCACAAATATTAATAAATATAAGTCCAAGAGCTGTCAGCCTAATCTGTAGGAGCAGAACCTCTG ATTGACCAAAAGGCATATGGGTTTAGGTTGGTTTTTTGATGTCATATGTCTCTGATGGGGCTGCAAGTGCTACCTCGCGCTTGTACACTG CTGCTGTGGGGCTCCGCGCCTGCCGGTGAAGAGCTGCAGATGCCGAGAAGCCAGCAAACACAGGGCCCACTGGAAAAAAATAGTTTTTTC ATTAGTATTTCTCGGGAGGACCCAAAAGTTAAGGTCAGCTTGTTCACTGTAATTTCTGGAAGAAGTTCACTCAGACCTTCCTGAATTCAG ATCATCTCAGAAGTCTGGAGGGAAATCTGGCGAAACCTTCGTTTGAGGGACTGATGTGAGTGTATGTCCACCTCACTGGTGGCACCGAGA AACTTACTTCCTTGTATTAAGTGCACTTCTTGTATTTCTAATAAGATGACTTTCCAGAAAGTGAGATTTGTTATGTTCTGGCTTTTAAAA >5038_5038_2_ANXA2-RNF114_ANXA2_chr15_60643391_ENST00000396024_RNF114_chr20_48565784_ENST00000244061_length(amino acids)=343AA_BP=285 MLCASFKMSTVHEILCKLSLEGDHSTPPSAYGSVKAYTNFDAERDALNIETAIKTKGVDEVTIVNILTNRSNAQRQDIAFAYQRRTKKEL ASALKSALSGHLETVILGLLKTPAQYDASELKASMKGLGTDEDSLIEIICSRTNQELQEINRVYKEMYKTDLEKDIISDTSGDFRKLMVA LAKGRRAEDGSVIDYELIDQDARDLYDAGVKRKGTDVPKWISIMTERSVPHLQKVFDRYKSYSPYDMLESIRKEVKGDLENAFLNLVQCI -------------------------------------------------------------- >5038_5038_3_ANXA2-RNF114_ANXA2_chr15_60643391_ENST00000421017_RNF114_chr20_48565784_ENST00000244061_length(transcript)=2898nt_BP=973nt GCTCAGCATTTGGGGACGCTCTCAGCTCTCGGCGCACGGCCCAGGTTATCTTGTAGCATAGCAACTTCGGATTTCACTCTACCCGGAGAG TTTCCCGCTTGGTTGAACACATTGGCCTCAGGAAGCTTCCTTCAAAATGTCTACTGTTCACGAAATCCTGTGCAAGCTCAGCTTGGAGGG TGATCACTCTACACCCCCAAGTGCATATGGGTCTGTCAAAGCCTATACTAACTTTGATGCTGAGCGGGATGCTTTGAACATTGAAACAGC CATCAAGACCAAAGGTGTGGATGAGGTCACCATTGTCAACATTTTGACCAACCGCAGCAATGCACAGAGACAGGATATTGCCTTCGCCTA CCAGAGAAGGACCAAAAAGGAACTTGCATCAGCACTGAAGTCAGCCTTATCTGGCCACCTGGAGACGGTGATTTTGGGCCTATTGAAGAC ACCTGCTCAGTATGACGCTTCTGAGCTAAAAGCTTCCATGAAGGGGCTGGGAACCGACGAGGACTCTCTCATTGAGATCATCTGCTCCAG AACCAACCAGGAGCTGCAGGAAATTAACAGAGTCTACAAGGAAATGTACAAGACTGATCTGGAGAAGGACATTATTTCGGACACATCTGG TGACTTCCGCAAGCTGATGGTTGCCCTGGCAAAGGGTAGAAGAGCAGAGGATGGCTCTGTCATTGATTATGAACTGATTGACCAAGATGC TCGGGATCTCTATGACGCTGGAGTGAAGAGGAAAGGAACTGATGTTCCCAAGTGGATCAGCATCATGACCGAGCGGAGCGTGCCCCACCT CCAGAAAGTATTTGATAGGTACAAGAGTTACAGCCCTTATGACATGTTGGAAAGCATCAGGAAAGAGGTTAAAGGAGACCTGGAAAATGC TTTCCTGAACCTGGTTCAGTGCATTCAGAACAAGCCCCTGTATTTTGCTGATCGGCTGTATGACTCCATGAAGGTTTGTCCGATATGTGC CTCGATGCCCTGGGGAGACCCCAACTACCGCAGCGCCAACTTCAGAGAGCACATCCAGCGCCGGCACCGGTTTTCTTATGACACTTTTGT GGATTATGATGTTGATGAAGAGGACATGATGAATCAGGTGTTGCAGCGCTCCATCATCGACCAGTGAGCAGAGTCCGTGCTTGCTATCTG TCTCATGTTACAGAGCTTCCATTACATATTAAACGTGAAATCTATGACTCCTGTACCTTACCTGTTCAACAGACCTGAAAATGAGCCATG GCATTGGGACAGGGTCACTTCTGACAGGGGAAGTGGGTCCCCAGGTCAGCCCTTCTCTTCCCTTTGGGCTCTTGCCAAAGCTGTCTTCCC CTACTGTTAACCTTGTTTGTCACACGGTCGAGTTCGTATTGGTTCTCGGCTACTTCCTGGAGCTTCTGCCGCCTCCTGTGGAAGATAATC TAGCTTCTCCACCTCTTGTTTCACACTCATTCCTCCCATCCAGTGTTTGTCTCTCGGGTCCTTCAAGCCAGCCAGGACCTTTTCTGGGTC ATGAATAGCACAATGAAGCAAGTGTCTCCTTTCCTTGTCCCCAAGGTGTGCAGACTTTGGCAGCCGTGCACCTGACCAGAGCTGAAGCTC CCGCTGGGCTGTGGGGTTGCCAGAAGCTGGGGTTGCCATCCCGGGGTACATGTCACCAGTCCTCTTGGGGTTTTGTACCATCTGATGCTG GAAGTTTTGATTAGTGATATTTTCTACTACTACATATTTAGAGTTCACTGGTTCAGTCTTAAATGCCTGCATGGTGCCTTTTTAGGATAA GGTATAACCATACATTTTTGGTGGAAGTGTTTCTGGGTTAGGGAAGTTAAAGTCTGTTTATCCGTAAGTGGGGAGGAGGGTCAGCTAAGA GAAGTGGGAGGGCCAGAGCTTTTTGGTTCTGATTTACAAATTAATGAAGTAGTTTCAAACAACGCGGTCATGTTTACCTCTCCATTTGGG AGCCTGCCTACATTCTTGTTCTAGAAGCACAAAAAATCCTCAGATGAATTAGAAGAAAGAGGTTTGGGGACTCAGCGGATACTAGTTCTT TTACCTTCTGCTTGGTAACTTAGATTAAACTGAGCATTGTTTTTCTGTCACAAATGTTTTCCTTATGACACTGGTTTCGACATGTAAAAT GTGTTTGAAAACCTGCTTTGTAGATGCAGAGAGAAGCTATAGGAAACCCAGTACCACCCCTGGTCTGTTCTGACGAGACATCGTTCATAA GGCACAGCACATCGCAAGATGAACAGTTGTTAATAAAAGCTGTTGCTGGAAACTTGCTTTAGGAACAGCTCAAGAACCTTGGAGTTCATA TTTCACAAATATTAATAAATATAAGTCCAAGAGCTGTCAGCCTAATCTGTAGGAGCAGAACCTCTGATTGACCAAAAGGCATATGGGTTT AGGTTGGTTTTTTGATGTCATATGTCTCTGATGGGGCTGCAAGTGCTACCTCGCGCTTGTACACTGCTGCTGTGGGGCTCCGCGCCTGCC GGTGAAGAGCTGCAGATGCCGAGAAGCCAGCAAACACAGGGCCCACTGGAAAAAAATAGTTTTTTCATTAGTATTTCTCGGGAGGACCCA AAAGTTAAGGTCAGCTTGTTCACTGTAATTTCTGGAAGAAGTTCACTCAGACCTTCCTGAATTCAGATCATCTCAGAAGTCTGGAGGGAA ATCTGGCGAAACCTTCGTTTGAGGGACTGATGTGAGTGTATGTCCACCTCACTGGTGGCACCGAGAAACTTACTTCCTTGTATTAAGTGC ACTTCTTGTATTTCTAATAAGATGACTTTCCAGAAAGTGAGATTTGTTATGTTCTGGCTTTTAAAAGGTAAAATATAAATAAATTTCATA >5038_5038_3_ANXA2-RNF114_ANXA2_chr15_60643391_ENST00000421017_RNF114_chr20_48565784_ENST00000244061_length(amino acids)=336AA_BP=278 MSTVHEILCKLSLEGDHSTPPSAYGSVKAYTNFDAERDALNIETAIKTKGVDEVTIVNILTNRSNAQRQDIAFAYQRRTKKELASALKSA LSGHLETVILGLLKTPAQYDASELKASMKGLGTDEDSLIEIICSRTNQELQEINRVYKEMYKTDLEKDIISDTSGDFRKLMVALAKGRRA EDGSVIDYELIDQDARDLYDAGVKRKGTDVPKWISIMTERSVPHLQKVFDRYKSYSPYDMLESIRKEVKGDLENAFLNLVQCIQNKPLYF -------------------------------------------------------------- >5038_5038_4_ANXA2-RNF114_ANXA2_chr15_60643391_ENST00000451270_RNF114_chr20_48565784_ENST00000244061_length(transcript)=2874nt_BP=949nt GCCTCGCCTAGGGAGGATGTGGCGGGTATAAAAGCCCCACCCAGGCCAGCCGGCTCTGCTCAGCATTTGGGGACGCTCTCAGCTCTCGGC GCACGGCCCAGCTTCCTTCAAAATGTCTACTGTTCACGAAATCCTGTGCAAGCTCAGCTTGGAGGGTGATCACTCTACACCCCCAAGTGC ATATGGGTCTGTCAAAGCCTATACTAACTTTGATGCTGAGCGGGATGCTTTGAACATTGAAACAGCCATCAAGACCAAAGGTGTGGATGA GGTCACCATTGTCAACATTTTGACCAACCGCAGCAATGCACAGAGACAGGATATTGCCTTCGCCTACCAGAGAAGGACCAAAAAGGAACT TGCATCAGCACTGAAGTCAGCCTTATCTGGCCACCTGGAGACGGTGATTTTGGGCCTATTGAAGACACCTGCTCAGTATGACGCTTCTGA GCTAAAAGCTTCCATGAAGGGGCTGGGAACCGACGAGGACTCTCTCATTGAGATCATCTGCTCCAGAACCAACCAGGAGCTGCAGGAAAT TAACAGAGTCTACAAGGAAATGTACAAGACTGATCTGGAGAAGGACATTATTTCGGACACATCTGGTGACTTCCGCAAGCTGATGGTTGC CCTGGCAAAGGGTAGAAGAGCAGAGGATGGCTCTGTCATTGATTATGAACTGATTGACCAAGATGCTCGGGATCTCTATGACGCTGGAGT GAAGAGGAAAGGAACTGATGTTCCCAAGTGGATCAGCATCATGACCGAGCGGAGCGTGCCCCACCTCCAGAAAGTATTTGATAGGTACAA GAGTTACAGCCCTTATGACATGTTGGAAAGCATCAGGAAAGAGGTTAAAGGAGACCTGGAAAATGCTTTCCTGAACCTGGTTCAGTGCAT TCAGAACAAGCCCCTGTATTTTGCTGATCGGCTGTATGACTCCATGAAGGTTTGTCCGATATGTGCCTCGATGCCCTGGGGAGACCCCAA CTACCGCAGCGCCAACTTCAGAGAGCACATCCAGCGCCGGCACCGGTTTTCTTATGACACTTTTGTGGATTATGATGTTGATGAAGAGGA CATGATGAATCAGGTGTTGCAGCGCTCCATCATCGACCAGTGAGCAGAGTCCGTGCTTGCTATCTGTCTCATGTTACAGAGCTTCCATTA CATATTAAACGTGAAATCTATGACTCCTGTACCTTACCTGTTCAACAGACCTGAAAATGAGCCATGGCATTGGGACAGGGTCACTTCTGA CAGGGGAAGTGGGTCCCCAGGTCAGCCCTTCTCTTCCCTTTGGGCTCTTGCCAAAGCTGTCTTCCCCTACTGTTAACCTTGTTTGTCACA CGGTCGAGTTCGTATTGGTTCTCGGCTACTTCCTGGAGCTTCTGCCGCCTCCTGTGGAAGATAATCTAGCTTCTCCACCTCTTGTTTCAC ACTCATTCCTCCCATCCAGTGTTTGTCTCTCGGGTCCTTCAAGCCAGCCAGGACCTTTTCTGGGTCATGAATAGCACAATGAAGCAAGTG TCTCCTTTCCTTGTCCCCAAGGTGTGCAGACTTTGGCAGCCGTGCACCTGACCAGAGCTGAAGCTCCCGCTGGGCTGTGGGGTTGCCAGA AGCTGGGGTTGCCATCCCGGGGTACATGTCACCAGTCCTCTTGGGGTTTTGTACCATCTGATGCTGGAAGTTTTGATTAGTGATATTTTC TACTACTACATATTTAGAGTTCACTGGTTCAGTCTTAAATGCCTGCATGGTGCCTTTTTAGGATAAGGTATAACCATACATTTTTGGTGG AAGTGTTTCTGGGTTAGGGAAGTTAAAGTCTGTTTATCCGTAAGTGGGGAGGAGGGTCAGCTAAGAGAAGTGGGAGGGCCAGAGCTTTTT GGTTCTGATTTACAAATTAATGAAGTAGTTTCAAACAACGCGGTCATGTTTACCTCTCCATTTGGGAGCCTGCCTACATTCTTGTTCTAG AAGCACAAAAAATCCTCAGATGAATTAGAAGAAAGAGGTTTGGGGACTCAGCGGATACTAGTTCTTTTACCTTCTGCTTGGTAACTTAGA TTAAACTGAGCATTGTTTTTCTGTCACAAATGTTTTCCTTATGACACTGGTTTCGACATGTAAAATGTGTTTGAAAACCTGCTTTGTAGA TGCAGAGAGAAGCTATAGGAAACCCAGTACCACCCCTGGTCTGTTCTGACGAGACATCGTTCATAAGGCACAGCACATCGCAAGATGAAC AGTTGTTAATAAAAGCTGTTGCTGGAAACTTGCTTTAGGAACAGCTCAAGAACCTTGGAGTTCATATTTCACAAATATTAATAAATATAA GTCCAAGAGCTGTCAGCCTAATCTGTAGGAGCAGAACCTCTGATTGACCAAAAGGCATATGGGTTTAGGTTGGTTTTTTGATGTCATATG TCTCTGATGGGGCTGCAAGTGCTACCTCGCGCTTGTACACTGCTGCTGTGGGGCTCCGCGCCTGCCGGTGAAGAGCTGCAGATGCCGAGA AGCCAGCAAACACAGGGCCCACTGGAAAAAAATAGTTTTTTCATTAGTATTTCTCGGGAGGACCCAAAAGTTAAGGTCAGCTTGTTCACT GTAATTTCTGGAAGAAGTTCACTCAGACCTTCCTGAATTCAGATCATCTCAGAAGTCTGGAGGGAAATCTGGCGAAACCTTCGTTTGAGG GACTGATGTGAGTGTATGTCCACCTCACTGGTGGCACCGAGAAACTTACTTCCTTGTATTAAGTGCACTTCTTGTATTTCTAATAAGATG >5038_5038_4_ANXA2-RNF114_ANXA2_chr15_60643391_ENST00000451270_RNF114_chr20_48565784_ENST00000244061_length(amino acids)=355AA_BP=297 MLSIWGRSQLSAHGPASFKMSTVHEILCKLSLEGDHSTPPSAYGSVKAYTNFDAERDALNIETAIKTKGVDEVTIVNILTNRSNAQRQDI AFAYQRRTKKELASALKSALSGHLETVILGLLKTPAQYDASELKASMKGLGTDEDSLIEIICSRTNQELQEINRVYKEMYKTDLEKDIIS DTSGDFRKLMVALAKGRRAEDGSVIDYELIDQDARDLYDAGVKRKGTDVPKWISIMTERSVPHLQKVFDRYKSYSPYDMLESIRKEVKGD -------------------------------------------------------------- >5038_5038_5_ANXA2-RNF114_ANXA2_chr15_60643392_ENST00000332680_RNF114_chr20_48565785_ENST00000244061_length(transcript)=2888nt_BP=963nt CTCAGCATTTGGGGACGCTCTCAGCTCTCGGCGCACGGCCCAGGTAAGCGGGGCGCGCCCTGCCCGCCCGCGATGGGCCGCCAGCTAGCG GGGTGTGGAGACGCTGGGAAGAAGGCTTCCTTCAAAATGTCTACTGTTCACGAAATCCTGTGCAAGCTCAGCTTGGAGGGTGATCACTCT ACACCCCCAAGTGCATATGGGTCTGTCAAAGCCTATACTAACTTTGATGCTGAGCGGGATGCTTTGAACATTGAAACAGCCATCAAGACC AAAGGTGTGGATGAGGTCACCATTGTCAACATTTTGACCAACCGCAGCAATGCACAGAGACAGGATATTGCCTTCGCCTACCAGAGAAGG ACCAAAAAGGAACTTGCATCAGCACTGAAGTCAGCCTTATCTGGCCACCTGGAGACGGTGATTTTGGGCCTATTGAAGACACCTGCTCAG TATGACGCTTCTGAGCTAAAAGCTTCCATGAAGGGGCTGGGAACCGACGAGGACTCTCTCATTGAGATCATCTGCTCCAGAACCAACCAG GAGCTGCAGGAAATTAACAGAGTCTACAAGGAAATGTACAAGACTGATCTGGAGAAGGACATTATTTCGGACACATCTGGTGACTTCCGC AAGCTGATGGTTGCCCTGGCAAAGGGTAGAAGAGCAGAGGATGGCTCTGTCATTGATTATGAACTGATTGACCAAGATGCTCGGGATCTC TATGACGCTGGAGTGAAGAGGAAAGGAACTGATGTTCCCAAGTGGATCAGCATCATGACCGAGCGGAGCGTGCCCCACCTCCAGAAAGTA TTTGATAGGTACAAGAGTTACAGCCCTTATGACATGTTGGAAAGCATCAGGAAAGAGGTTAAAGGAGACCTGGAAAATGCTTTCCTGAAC CTGGTTCAGTGCATTCAGAACAAGCCCCTGTATTTTGCTGATCGGCTGTATGACTCCATGAAGGTTTGTCCGATATGTGCCTCGATGCCC TGGGGAGACCCCAACTACCGCAGCGCCAACTTCAGAGAGCACATCCAGCGCCGGCACCGGTTTTCTTATGACACTTTTGTGGATTATGAT GTTGATGAAGAGGACATGATGAATCAGGTGTTGCAGCGCTCCATCATCGACCAGTGAGCAGAGTCCGTGCTTGCTATCTGTCTCATGTTA CAGAGCTTCCATTACATATTAAACGTGAAATCTATGACTCCTGTACCTTACCTGTTCAACAGACCTGAAAATGAGCCATGGCATTGGGAC AGGGTCACTTCTGACAGGGGAAGTGGGTCCCCAGGTCAGCCCTTCTCTTCCCTTTGGGCTCTTGCCAAAGCTGTCTTCCCCTACTGTTAA CCTTGTTTGTCACACGGTCGAGTTCGTATTGGTTCTCGGCTACTTCCTGGAGCTTCTGCCGCCTCCTGTGGAAGATAATCTAGCTTCTCC ACCTCTTGTTTCACACTCATTCCTCCCATCCAGTGTTTGTCTCTCGGGTCCTTCAAGCCAGCCAGGACCTTTTCTGGGTCATGAATAGCA CAATGAAGCAAGTGTCTCCTTTCCTTGTCCCCAAGGTGTGCAGACTTTGGCAGCCGTGCACCTGACCAGAGCTGAAGCTCCCGCTGGGCT GTGGGGTTGCCAGAAGCTGGGGTTGCCATCCCGGGGTACATGTCACCAGTCCTCTTGGGGTTTTGTACCATCTGATGCTGGAAGTTTTGA TTAGTGATATTTTCTACTACTACATATTTAGAGTTCACTGGTTCAGTCTTAAATGCCTGCATGGTGCCTTTTTAGGATAAGGTATAACCA TACATTTTTGGTGGAAGTGTTTCTGGGTTAGGGAAGTTAAAGTCTGTTTATCCGTAAGTGGGGAGGAGGGTCAGCTAAGAGAAGTGGGAG GGCCAGAGCTTTTTGGTTCTGATTTACAAATTAATGAAGTAGTTTCAAACAACGCGGTCATGTTTACCTCTCCATTTGGGAGCCTGCCTA CATTCTTGTTCTAGAAGCACAAAAAATCCTCAGATGAATTAGAAGAAAGAGGTTTGGGGACTCAGCGGATACTAGTTCTTTTACCTTCTG CTTGGTAACTTAGATTAAACTGAGCATTGTTTTTCTGTCACAAATGTTTTCCTTATGACACTGGTTTCGACATGTAAAATGTGTTTGAAA ACCTGCTTTGTAGATGCAGAGAGAAGCTATAGGAAACCCAGTACCACCCCTGGTCTGTTCTGACGAGACATCGTTCATAAGGCACAGCAC ATCGCAAGATGAACAGTTGTTAATAAAAGCTGTTGCTGGAAACTTGCTTTAGGAACAGCTCAAGAACCTTGGAGTTCATATTTCACAAAT ATTAATAAATATAAGTCCAAGAGCTGTCAGCCTAATCTGTAGGAGCAGAACCTCTGATTGACCAAAAGGCATATGGGTTTAGGTTGGTTT TTTGATGTCATATGTCTCTGATGGGGCTGCAAGTGCTACCTCGCGCTTGTACACTGCTGCTGTGGGGCTCCGCGCCTGCCGGTGAAGAGC TGCAGATGCCGAGAAGCCAGCAAACACAGGGCCCACTGGAAAAAAATAGTTTTTTCATTAGTATTTCTCGGGAGGACCCAAAAGTTAAGG TCAGCTTGTTCACTGTAATTTCTGGAAGAAGTTCACTCAGACCTTCCTGAATTCAGATCATCTCAGAAGTCTGGAGGGAAATCTGGCGAA ACCTTCGTTTGAGGGACTGATGTGAGTGTATGTCCACCTCACTGGTGGCACCGAGAAACTTACTTCCTTGTATTAAGTGCACTTCTTGTA TTTCTAATAAGATGACTTTCCAGAAAGTGAGATTTGTTATGTTCTGGCTTTTAAAAGGTAAAATATAAATAAATTTCATAACTTAATCTA >5038_5038_5_ANXA2-RNF114_ANXA2_chr15_60643392_ENST00000332680_RNF114_chr20_48565785_ENST00000244061_length(amino acids)=354AA_BP=296 MGRQLAGCGDAGKKASFKMSTVHEILCKLSLEGDHSTPPSAYGSVKAYTNFDAERDALNIETAIKTKGVDEVTIVNILTNRSNAQRQDIA FAYQRRTKKELASALKSALSGHLETVILGLLKTPAQYDASELKASMKGLGTDEDSLIEIICSRTNQELQEINRVYKEMYKTDLEKDIISD TSGDFRKLMVALAKGRRAEDGSVIDYELIDQDARDLYDAGVKRKGTDVPKWISIMTERSVPHLQKVFDRYKSYSPYDMLESIRKEVKGDL -------------------------------------------------------------- >5038_5038_6_ANXA2-RNF114_ANXA2_chr15_60643392_ENST00000396024_RNF114_chr20_48565785_ENST00000244061_length(transcript)=2922nt_BP=997nt GCTCAGCATTTGGGGACGCTCTCAGCTCTCGGCGCACGGCCCAGGGTGAAAATGTTTGCCATTAAACTCACATGAAGTAGGAAATATTTA TATGGATACAAAAGGCACCTGCATGGGATAATGTCAAATTTCATAGATACTGCTTTGTGCTTCCTTCAAAATGTCTACTGTTCACGAAAT CCTGTGCAAGCTCAGCTTGGAGGGTGATCACTCTACACCCCCAAGTGCATATGGGTCTGTCAAAGCCTATACTAACTTTGATGCTGAGCG GGATGCTTTGAACATTGAAACAGCCATCAAGACCAAAGGTGTGGATGAGGTCACCATTGTCAACATTTTGACCAACCGCAGCAATGCACA GAGACAGGATATTGCCTTCGCCTACCAGAGAAGGACCAAAAAGGAACTTGCATCAGCACTGAAGTCAGCCTTATCTGGCCACCTGGAGAC GGTGATTTTGGGCCTATTGAAGACACCTGCTCAGTATGACGCTTCTGAGCTAAAAGCTTCCATGAAGGGGCTGGGAACCGACGAGGACTC TCTCATTGAGATCATCTGCTCCAGAACCAACCAGGAGCTGCAGGAAATTAACAGAGTCTACAAGGAAATGTACAAGACTGATCTGGAGAA GGACATTATTTCGGACACATCTGGTGACTTCCGCAAGCTGATGGTTGCCCTGGCAAAGGGTAGAAGAGCAGAGGATGGCTCTGTCATTGA TTATGAACTGATTGACCAAGATGCTCGGGATCTCTATGACGCTGGAGTGAAGAGGAAAGGAACTGATGTTCCCAAGTGGATCAGCATCAT GACCGAGCGGAGCGTGCCCCACCTCCAGAAAGTATTTGATAGGTACAAGAGTTACAGCCCTTATGACATGTTGGAAAGCATCAGGAAAGA GGTTAAAGGAGACCTGGAAAATGCTTTCCTGAACCTGGTTCAGTGCATTCAGAACAAGCCCCTGTATTTTGCTGATCGGCTGTATGACTC CATGAAGGTTTGTCCGATATGTGCCTCGATGCCCTGGGGAGACCCCAACTACCGCAGCGCCAACTTCAGAGAGCACATCCAGCGCCGGCA CCGGTTTTCTTATGACACTTTTGTGGATTATGATGTTGATGAAGAGGACATGATGAATCAGGTGTTGCAGCGCTCCATCATCGACCAGTG AGCAGAGTCCGTGCTTGCTATCTGTCTCATGTTACAGAGCTTCCATTACATATTAAACGTGAAATCTATGACTCCTGTACCTTACCTGTT CAACAGACCTGAAAATGAGCCATGGCATTGGGACAGGGTCACTTCTGACAGGGGAAGTGGGTCCCCAGGTCAGCCCTTCTCTTCCCTTTG GGCTCTTGCCAAAGCTGTCTTCCCCTACTGTTAACCTTGTTTGTCACACGGTCGAGTTCGTATTGGTTCTCGGCTACTTCCTGGAGCTTC TGCCGCCTCCTGTGGAAGATAATCTAGCTTCTCCACCTCTTGTTTCACACTCATTCCTCCCATCCAGTGTTTGTCTCTCGGGTCCTTCAA GCCAGCCAGGACCTTTTCTGGGTCATGAATAGCACAATGAAGCAAGTGTCTCCTTTCCTTGTCCCCAAGGTGTGCAGACTTTGGCAGCCG TGCACCTGACCAGAGCTGAAGCTCCCGCTGGGCTGTGGGGTTGCCAGAAGCTGGGGTTGCCATCCCGGGGTACATGTCACCAGTCCTCTT GGGGTTTTGTACCATCTGATGCTGGAAGTTTTGATTAGTGATATTTTCTACTACTACATATTTAGAGTTCACTGGTTCAGTCTTAAATGC CTGCATGGTGCCTTTTTAGGATAAGGTATAACCATACATTTTTGGTGGAAGTGTTTCTGGGTTAGGGAAGTTAAAGTCTGTTTATCCGTA AGTGGGGAGGAGGGTCAGCTAAGAGAAGTGGGAGGGCCAGAGCTTTTTGGTTCTGATTTACAAATTAATGAAGTAGTTTCAAACAACGCG GTCATGTTTACCTCTCCATTTGGGAGCCTGCCTACATTCTTGTTCTAGAAGCACAAAAAATCCTCAGATGAATTAGAAGAAAGAGGTTTG GGGACTCAGCGGATACTAGTTCTTTTACCTTCTGCTTGGTAACTTAGATTAAACTGAGCATTGTTTTTCTGTCACAAATGTTTTCCTTAT GACACTGGTTTCGACATGTAAAATGTGTTTGAAAACCTGCTTTGTAGATGCAGAGAGAAGCTATAGGAAACCCAGTACCACCCCTGGTCT GTTCTGACGAGACATCGTTCATAAGGCACAGCACATCGCAAGATGAACAGTTGTTAATAAAAGCTGTTGCTGGAAACTTGCTTTAGGAAC AGCTCAAGAACCTTGGAGTTCATATTTCACAAATATTAATAAATATAAGTCCAAGAGCTGTCAGCCTAATCTGTAGGAGCAGAACCTCTG ATTGACCAAAAGGCATATGGGTTTAGGTTGGTTTTTTGATGTCATATGTCTCTGATGGGGCTGCAAGTGCTACCTCGCGCTTGTACACTG CTGCTGTGGGGCTCCGCGCCTGCCGGTGAAGAGCTGCAGATGCCGAGAAGCCAGCAAACACAGGGCCCACTGGAAAAAAATAGTTTTTTC ATTAGTATTTCTCGGGAGGACCCAAAAGTTAAGGTCAGCTTGTTCACTGTAATTTCTGGAAGAAGTTCACTCAGACCTTCCTGAATTCAG ATCATCTCAGAAGTCTGGAGGGAAATCTGGCGAAACCTTCGTTTGAGGGACTGATGTGAGTGTATGTCCACCTCACTGGTGGCACCGAGA AACTTACTTCCTTGTATTAAGTGCACTTCTTGTATTTCTAATAAGATGACTTTCCAGAAAGTGAGATTTGTTATGTTCTGGCTTTTAAAA >5038_5038_6_ANXA2-RNF114_ANXA2_chr15_60643392_ENST00000396024_RNF114_chr20_48565785_ENST00000244061_length(amino acids)=343AA_BP=285 MLCASFKMSTVHEILCKLSLEGDHSTPPSAYGSVKAYTNFDAERDALNIETAIKTKGVDEVTIVNILTNRSNAQRQDIAFAYQRRTKKEL ASALKSALSGHLETVILGLLKTPAQYDASELKASMKGLGTDEDSLIEIICSRTNQELQEINRVYKEMYKTDLEKDIISDTSGDFRKLMVA LAKGRRAEDGSVIDYELIDQDARDLYDAGVKRKGTDVPKWISIMTERSVPHLQKVFDRYKSYSPYDMLESIRKEVKGDLENAFLNLVQCI -------------------------------------------------------------- >5038_5038_7_ANXA2-RNF114_ANXA2_chr15_60643392_ENST00000421017_RNF114_chr20_48565785_ENST00000244061_length(transcript)=2898nt_BP=973nt GCTCAGCATTTGGGGACGCTCTCAGCTCTCGGCGCACGGCCCAGGTTATCTTGTAGCATAGCAACTTCGGATTTCACTCTACCCGGAGAG TTTCCCGCTTGGTTGAACACATTGGCCTCAGGAAGCTTCCTTCAAAATGTCTACTGTTCACGAAATCCTGTGCAAGCTCAGCTTGGAGGG TGATCACTCTACACCCCCAAGTGCATATGGGTCTGTCAAAGCCTATACTAACTTTGATGCTGAGCGGGATGCTTTGAACATTGAAACAGC CATCAAGACCAAAGGTGTGGATGAGGTCACCATTGTCAACATTTTGACCAACCGCAGCAATGCACAGAGACAGGATATTGCCTTCGCCTA CCAGAGAAGGACCAAAAAGGAACTTGCATCAGCACTGAAGTCAGCCTTATCTGGCCACCTGGAGACGGTGATTTTGGGCCTATTGAAGAC ACCTGCTCAGTATGACGCTTCTGAGCTAAAAGCTTCCATGAAGGGGCTGGGAACCGACGAGGACTCTCTCATTGAGATCATCTGCTCCAG AACCAACCAGGAGCTGCAGGAAATTAACAGAGTCTACAAGGAAATGTACAAGACTGATCTGGAGAAGGACATTATTTCGGACACATCTGG TGACTTCCGCAAGCTGATGGTTGCCCTGGCAAAGGGTAGAAGAGCAGAGGATGGCTCTGTCATTGATTATGAACTGATTGACCAAGATGC TCGGGATCTCTATGACGCTGGAGTGAAGAGGAAAGGAACTGATGTTCCCAAGTGGATCAGCATCATGACCGAGCGGAGCGTGCCCCACCT CCAGAAAGTATTTGATAGGTACAAGAGTTACAGCCCTTATGACATGTTGGAAAGCATCAGGAAAGAGGTTAAAGGAGACCTGGAAAATGC TTTCCTGAACCTGGTTCAGTGCATTCAGAACAAGCCCCTGTATTTTGCTGATCGGCTGTATGACTCCATGAAGGTTTGTCCGATATGTGC CTCGATGCCCTGGGGAGACCCCAACTACCGCAGCGCCAACTTCAGAGAGCACATCCAGCGCCGGCACCGGTTTTCTTATGACACTTTTGT GGATTATGATGTTGATGAAGAGGACATGATGAATCAGGTGTTGCAGCGCTCCATCATCGACCAGTGAGCAGAGTCCGTGCTTGCTATCTG TCTCATGTTACAGAGCTTCCATTACATATTAAACGTGAAATCTATGACTCCTGTACCTTACCTGTTCAACAGACCTGAAAATGAGCCATG GCATTGGGACAGGGTCACTTCTGACAGGGGAAGTGGGTCCCCAGGTCAGCCCTTCTCTTCCCTTTGGGCTCTTGCCAAAGCTGTCTTCCC CTACTGTTAACCTTGTTTGTCACACGGTCGAGTTCGTATTGGTTCTCGGCTACTTCCTGGAGCTTCTGCCGCCTCCTGTGGAAGATAATC TAGCTTCTCCACCTCTTGTTTCACACTCATTCCTCCCATCCAGTGTTTGTCTCTCGGGTCCTTCAAGCCAGCCAGGACCTTTTCTGGGTC ATGAATAGCACAATGAAGCAAGTGTCTCCTTTCCTTGTCCCCAAGGTGTGCAGACTTTGGCAGCCGTGCACCTGACCAGAGCTGAAGCTC CCGCTGGGCTGTGGGGTTGCCAGAAGCTGGGGTTGCCATCCCGGGGTACATGTCACCAGTCCTCTTGGGGTTTTGTACCATCTGATGCTG GAAGTTTTGATTAGTGATATTTTCTACTACTACATATTTAGAGTTCACTGGTTCAGTCTTAAATGCCTGCATGGTGCCTTTTTAGGATAA GGTATAACCATACATTTTTGGTGGAAGTGTTTCTGGGTTAGGGAAGTTAAAGTCTGTTTATCCGTAAGTGGGGAGGAGGGTCAGCTAAGA GAAGTGGGAGGGCCAGAGCTTTTTGGTTCTGATTTACAAATTAATGAAGTAGTTTCAAACAACGCGGTCATGTTTACCTCTCCATTTGGG AGCCTGCCTACATTCTTGTTCTAGAAGCACAAAAAATCCTCAGATGAATTAGAAGAAAGAGGTTTGGGGACTCAGCGGATACTAGTTCTT TTACCTTCTGCTTGGTAACTTAGATTAAACTGAGCATTGTTTTTCTGTCACAAATGTTTTCCTTATGACACTGGTTTCGACATGTAAAAT GTGTTTGAAAACCTGCTTTGTAGATGCAGAGAGAAGCTATAGGAAACCCAGTACCACCCCTGGTCTGTTCTGACGAGACATCGTTCATAA GGCACAGCACATCGCAAGATGAACAGTTGTTAATAAAAGCTGTTGCTGGAAACTTGCTTTAGGAACAGCTCAAGAACCTTGGAGTTCATA TTTCACAAATATTAATAAATATAAGTCCAAGAGCTGTCAGCCTAATCTGTAGGAGCAGAACCTCTGATTGACCAAAAGGCATATGGGTTT AGGTTGGTTTTTTGATGTCATATGTCTCTGATGGGGCTGCAAGTGCTACCTCGCGCTTGTACACTGCTGCTGTGGGGCTCCGCGCCTGCC GGTGAAGAGCTGCAGATGCCGAGAAGCCAGCAAACACAGGGCCCACTGGAAAAAAATAGTTTTTTCATTAGTATTTCTCGGGAGGACCCA AAAGTTAAGGTCAGCTTGTTCACTGTAATTTCTGGAAGAAGTTCACTCAGACCTTCCTGAATTCAGATCATCTCAGAAGTCTGGAGGGAA ATCTGGCGAAACCTTCGTTTGAGGGACTGATGTGAGTGTATGTCCACCTCACTGGTGGCACCGAGAAACTTACTTCCTTGTATTAAGTGC ACTTCTTGTATTTCTAATAAGATGACTTTCCAGAAAGTGAGATTTGTTATGTTCTGGCTTTTAAAAGGTAAAATATAAATAAATTTCATA >5038_5038_7_ANXA2-RNF114_ANXA2_chr15_60643392_ENST00000421017_RNF114_chr20_48565785_ENST00000244061_length(amino acids)=336AA_BP=278 MSTVHEILCKLSLEGDHSTPPSAYGSVKAYTNFDAERDALNIETAIKTKGVDEVTIVNILTNRSNAQRQDIAFAYQRRTKKELASALKSA LSGHLETVILGLLKTPAQYDASELKASMKGLGTDEDSLIEIICSRTNQELQEINRVYKEMYKTDLEKDIISDTSGDFRKLMVALAKGRRA EDGSVIDYELIDQDARDLYDAGVKRKGTDVPKWISIMTERSVPHLQKVFDRYKSYSPYDMLESIRKEVKGDLENAFLNLVQCIQNKPLYF -------------------------------------------------------------- >5038_5038_8_ANXA2-RNF114_ANXA2_chr15_60643392_ENST00000451270_RNF114_chr20_48565785_ENST00000244061_length(transcript)=2874nt_BP=949nt GCCTCGCCTAGGGAGGATGTGGCGGGTATAAAAGCCCCACCCAGGCCAGCCGGCTCTGCTCAGCATTTGGGGACGCTCTCAGCTCTCGGC GCACGGCCCAGCTTCCTTCAAAATGTCTACTGTTCACGAAATCCTGTGCAAGCTCAGCTTGGAGGGTGATCACTCTACACCCCCAAGTGC ATATGGGTCTGTCAAAGCCTATACTAACTTTGATGCTGAGCGGGATGCTTTGAACATTGAAACAGCCATCAAGACCAAAGGTGTGGATGA GGTCACCATTGTCAACATTTTGACCAACCGCAGCAATGCACAGAGACAGGATATTGCCTTCGCCTACCAGAGAAGGACCAAAAAGGAACT TGCATCAGCACTGAAGTCAGCCTTATCTGGCCACCTGGAGACGGTGATTTTGGGCCTATTGAAGACACCTGCTCAGTATGACGCTTCTGA GCTAAAAGCTTCCATGAAGGGGCTGGGAACCGACGAGGACTCTCTCATTGAGATCATCTGCTCCAGAACCAACCAGGAGCTGCAGGAAAT TAACAGAGTCTACAAGGAAATGTACAAGACTGATCTGGAGAAGGACATTATTTCGGACACATCTGGTGACTTCCGCAAGCTGATGGTTGC CCTGGCAAAGGGTAGAAGAGCAGAGGATGGCTCTGTCATTGATTATGAACTGATTGACCAAGATGCTCGGGATCTCTATGACGCTGGAGT GAAGAGGAAAGGAACTGATGTTCCCAAGTGGATCAGCATCATGACCGAGCGGAGCGTGCCCCACCTCCAGAAAGTATTTGATAGGTACAA GAGTTACAGCCCTTATGACATGTTGGAAAGCATCAGGAAAGAGGTTAAAGGAGACCTGGAAAATGCTTTCCTGAACCTGGTTCAGTGCAT TCAGAACAAGCCCCTGTATTTTGCTGATCGGCTGTATGACTCCATGAAGGTTTGTCCGATATGTGCCTCGATGCCCTGGGGAGACCCCAA CTACCGCAGCGCCAACTTCAGAGAGCACATCCAGCGCCGGCACCGGTTTTCTTATGACACTTTTGTGGATTATGATGTTGATGAAGAGGA CATGATGAATCAGGTGTTGCAGCGCTCCATCATCGACCAGTGAGCAGAGTCCGTGCTTGCTATCTGTCTCATGTTACAGAGCTTCCATTA CATATTAAACGTGAAATCTATGACTCCTGTACCTTACCTGTTCAACAGACCTGAAAATGAGCCATGGCATTGGGACAGGGTCACTTCTGA CAGGGGAAGTGGGTCCCCAGGTCAGCCCTTCTCTTCCCTTTGGGCTCTTGCCAAAGCTGTCTTCCCCTACTGTTAACCTTGTTTGTCACA CGGTCGAGTTCGTATTGGTTCTCGGCTACTTCCTGGAGCTTCTGCCGCCTCCTGTGGAAGATAATCTAGCTTCTCCACCTCTTGTTTCAC ACTCATTCCTCCCATCCAGTGTTTGTCTCTCGGGTCCTTCAAGCCAGCCAGGACCTTTTCTGGGTCATGAATAGCACAATGAAGCAAGTG TCTCCTTTCCTTGTCCCCAAGGTGTGCAGACTTTGGCAGCCGTGCACCTGACCAGAGCTGAAGCTCCCGCTGGGCTGTGGGGTTGCCAGA AGCTGGGGTTGCCATCCCGGGGTACATGTCACCAGTCCTCTTGGGGTTTTGTACCATCTGATGCTGGAAGTTTTGATTAGTGATATTTTC TACTACTACATATTTAGAGTTCACTGGTTCAGTCTTAAATGCCTGCATGGTGCCTTTTTAGGATAAGGTATAACCATACATTTTTGGTGG AAGTGTTTCTGGGTTAGGGAAGTTAAAGTCTGTTTATCCGTAAGTGGGGAGGAGGGTCAGCTAAGAGAAGTGGGAGGGCCAGAGCTTTTT GGTTCTGATTTACAAATTAATGAAGTAGTTTCAAACAACGCGGTCATGTTTACCTCTCCATTTGGGAGCCTGCCTACATTCTTGTTCTAG AAGCACAAAAAATCCTCAGATGAATTAGAAGAAAGAGGTTTGGGGACTCAGCGGATACTAGTTCTTTTACCTTCTGCTTGGTAACTTAGA TTAAACTGAGCATTGTTTTTCTGTCACAAATGTTTTCCTTATGACACTGGTTTCGACATGTAAAATGTGTTTGAAAACCTGCTTTGTAGA TGCAGAGAGAAGCTATAGGAAACCCAGTACCACCCCTGGTCTGTTCTGACGAGACATCGTTCATAAGGCACAGCACATCGCAAGATGAAC AGTTGTTAATAAAAGCTGTTGCTGGAAACTTGCTTTAGGAACAGCTCAAGAACCTTGGAGTTCATATTTCACAAATATTAATAAATATAA GTCCAAGAGCTGTCAGCCTAATCTGTAGGAGCAGAACCTCTGATTGACCAAAAGGCATATGGGTTTAGGTTGGTTTTTTGATGTCATATG TCTCTGATGGGGCTGCAAGTGCTACCTCGCGCTTGTACACTGCTGCTGTGGGGCTCCGCGCCTGCCGGTGAAGAGCTGCAGATGCCGAGA AGCCAGCAAACACAGGGCCCACTGGAAAAAAATAGTTTTTTCATTAGTATTTCTCGGGAGGACCCAAAAGTTAAGGTCAGCTTGTTCACT GTAATTTCTGGAAGAAGTTCACTCAGACCTTCCTGAATTCAGATCATCTCAGAAGTCTGGAGGGAAATCTGGCGAAACCTTCGTTTGAGG GACTGATGTGAGTGTATGTCCACCTCACTGGTGGCACCGAGAAACTTACTTCCTTGTATTAAGTGCACTTCTTGTATTTCTAATAAGATG >5038_5038_8_ANXA2-RNF114_ANXA2_chr15_60643392_ENST00000451270_RNF114_chr20_48565785_ENST00000244061_length(amino acids)=355AA_BP=297 MLSIWGRSQLSAHGPASFKMSTVHEILCKLSLEGDHSTPPSAYGSVKAYTNFDAERDALNIETAIKTKGVDEVTIVNILTNRSNAQRQDI AFAYQRRTKKELASALKSALSGHLETVILGLLKTPAQYDASELKASMKGLGTDEDSLIEIICSRTNQELQEINRVYKEMYKTDLEKDIIS DTSGDFRKLMVALAKGRRAEDGSVIDYELIDQDARDLYDAGVKRKGTDVPKWISIMTERSVPHLQKVFDRYKSYSPYDMLESIRKEVKGD -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for ANXA2-RNF114 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for ANXA2-RNF114 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for ANXA2-RNF114 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies