
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:MACROD1-TBC1D22A (FusionGDB2 ID:50648) |
Fusion Gene Summary for MACROD1-TBC1D22A |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: MACROD1-TBC1D22A | Fusion gene ID: 50648 | Hgene | Tgene | Gene symbol | MACROD1 | TBC1D22A | Gene ID | 28992 | 25771 |
| Gene name | mono-ADP ribosylhydrolase 1 | TBC1 domain family member 22A | |
| Synonyms | LRP16 | C22orf4|HSC79E021 | |
| Cytomap | 11q13.1 | 22q13.31 | |
| Type of gene | protein-coding | protein-coding | |
| Description | ADP-ribose glycohydrolase MACROD1MACRO domain containing 1MACRO domain-containing protein 1O-acetyl-ADP-ribose deacetylase MACROD1[Protein ADP-ribosylaspartate] hydrolase MACROD1[Protein ADP-ribosylglutamate] hydrolase[Protein ADP-ribosylglutamate] | TBC1 domain family member 22Aputative GTPase activator | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q9BQ69 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000255681, ENST00000538595, | ENST00000406733, ENST00000472791, ENST00000337137, ENST00000355704, ENST00000380995, ENST00000407381, | |
| Fusion gene scores | * DoF score | 16 X 7 X 13=1456 | 22 X 24 X 11=5808 |
| # samples | 22 | 32 | |
| ** MAII score | log2(22/1456*10)=-2.72643492667404 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(32/5808*10)=-4.18189764310839 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: MACROD1 [Title/Abstract] AND TBC1D22A [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | MACROD1(63918711)-TBC1D22A(47274549), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | MACROD1 | GO:0042278 | purine nucleoside metabolic process | 21257746 |
| Hgene | MACROD1 | GO:0051725 | protein de-ADP-ribosylation | 23474712 |
| Fusion gene breakpoints across MACROD1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
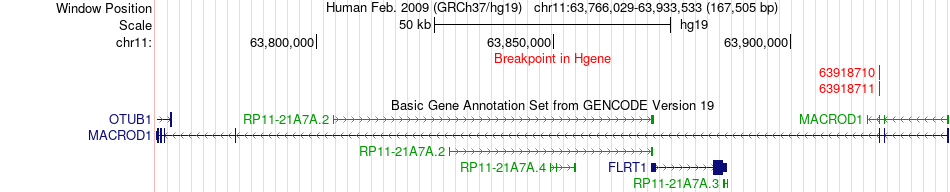 |
| Fusion gene breakpoints across TBC1D22A (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | OV | TCGA-61-2104-01A | MACROD1 | chr11 | 63918711 | - | TBC1D22A | chr22 | 47274549 | + |
| ChimerDB4 | OV | TCGA-61-2104 | MACROD1 | chr11 | 63918710 | - | TBC1D22A | chr22 | 47274548 | + |
Top |
Fusion Gene ORF analysis for MACROD1-TBC1D22A |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000255681 | ENST00000406733 | MACROD1 | chr11 | 63918711 | - | TBC1D22A | chr22 | 47274549 | + |
| 5CDS-intron | ENST00000255681 | ENST00000406733 | MACROD1 | chr11 | 63918710 | - | TBC1D22A | chr22 | 47274548 | + |
| 5CDS-intron | ENST00000255681 | ENST00000472791 | MACROD1 | chr11 | 63918711 | - | TBC1D22A | chr22 | 47274549 | + |
| 5CDS-intron | ENST00000255681 | ENST00000472791 | MACROD1 | chr11 | 63918710 | - | TBC1D22A | chr22 | 47274548 | + |
| 5UTR-3CDS | ENST00000538595 | ENST00000337137 | MACROD1 | chr11 | 63918711 | - | TBC1D22A | chr22 | 47274549 | + |
| 5UTR-3CDS | ENST00000538595 | ENST00000337137 | MACROD1 | chr11 | 63918710 | - | TBC1D22A | chr22 | 47274548 | + |
| 5UTR-3CDS | ENST00000538595 | ENST00000355704 | MACROD1 | chr11 | 63918711 | - | TBC1D22A | chr22 | 47274549 | + |
| 5UTR-3CDS | ENST00000538595 | ENST00000355704 | MACROD1 | chr11 | 63918710 | - | TBC1D22A | chr22 | 47274548 | + |
| 5UTR-3CDS | ENST00000538595 | ENST00000380995 | MACROD1 | chr11 | 63918711 | - | TBC1D22A | chr22 | 47274549 | + |
| 5UTR-3CDS | ENST00000538595 | ENST00000380995 | MACROD1 | chr11 | 63918710 | - | TBC1D22A | chr22 | 47274548 | + |
| 5UTR-3CDS | ENST00000538595 | ENST00000407381 | MACROD1 | chr11 | 63918711 | - | TBC1D22A | chr22 | 47274549 | + |
| 5UTR-3CDS | ENST00000538595 | ENST00000407381 | MACROD1 | chr11 | 63918710 | - | TBC1D22A | chr22 | 47274548 | + |
| 5UTR-intron | ENST00000538595 | ENST00000406733 | MACROD1 | chr11 | 63918711 | - | TBC1D22A | chr22 | 47274549 | + |
| 5UTR-intron | ENST00000538595 | ENST00000406733 | MACROD1 | chr11 | 63918710 | - | TBC1D22A | chr22 | 47274548 | + |
| 5UTR-intron | ENST00000538595 | ENST00000472791 | MACROD1 | chr11 | 63918711 | - | TBC1D22A | chr22 | 47274549 | + |
| 5UTR-intron | ENST00000538595 | ENST00000472791 | MACROD1 | chr11 | 63918710 | - | TBC1D22A | chr22 | 47274548 | + |
| In-frame | ENST00000255681 | ENST00000337137 | MACROD1 | chr11 | 63918711 | - | TBC1D22A | chr22 | 47274549 | + |
| In-frame | ENST00000255681 | ENST00000337137 | MACROD1 | chr11 | 63918710 | - | TBC1D22A | chr22 | 47274548 | + |
| In-frame | ENST00000255681 | ENST00000355704 | MACROD1 | chr11 | 63918711 | - | TBC1D22A | chr22 | 47274549 | + |
| In-frame | ENST00000255681 | ENST00000355704 | MACROD1 | chr11 | 63918710 | - | TBC1D22A | chr22 | 47274548 | + |
| In-frame | ENST00000255681 | ENST00000380995 | MACROD1 | chr11 | 63918711 | - | TBC1D22A | chr22 | 47274549 | + |
| In-frame | ENST00000255681 | ENST00000380995 | MACROD1 | chr11 | 63918710 | - | TBC1D22A | chr22 | 47274548 | + |
| In-frame | ENST00000255681 | ENST00000407381 | MACROD1 | chr11 | 63918711 | - | TBC1D22A | chr22 | 47274549 | + |
| In-frame | ENST00000255681 | ENST00000407381 | MACROD1 | chr11 | 63918710 | - | TBC1D22A | chr22 | 47274548 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000255681 | MACROD1 | chr11 | 63918711 | - | ENST00000337137 | TBC1D22A | chr22 | 47274549 | + | 3568 | 584 | 67 | 1500 | 477 |
| ENST00000255681 | MACROD1 | chr11 | 63918711 | - | ENST00000380995 | TBC1D22A | chr22 | 47274549 | + | 1063 | 584 | 67 | 1062 | 332 |
| ENST00000255681 | MACROD1 | chr11 | 63918711 | - | ENST00000407381 | TBC1D22A | chr22 | 47274549 | + | 1958 | 584 | 67 | 1500 | 477 |
| ENST00000255681 | MACROD1 | chr11 | 63918711 | - | ENST00000355704 | TBC1D22A | chr22 | 47274549 | + | 1961 | 584 | 67 | 1500 | 477 |
| ENST00000255681 | MACROD1 | chr11 | 63918710 | - | ENST00000337137 | TBC1D22A | chr22 | 47274548 | + | 3568 | 584 | 67 | 1500 | 477 |
| ENST00000255681 | MACROD1 | chr11 | 63918710 | - | ENST00000380995 | TBC1D22A | chr22 | 47274548 | + | 1063 | 584 | 67 | 1062 | 332 |
| ENST00000255681 | MACROD1 | chr11 | 63918710 | - | ENST00000407381 | TBC1D22A | chr22 | 47274548 | + | 1958 | 584 | 67 | 1500 | 477 |
| ENST00000255681 | MACROD1 | chr11 | 63918710 | - | ENST00000355704 | TBC1D22A | chr22 | 47274548 | + | 1961 | 584 | 67 | 1500 | 477 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000255681 | ENST00000337137 | MACROD1 | chr11 | 63918711 | - | TBC1D22A | chr22 | 47274549 | + | 0.002862833 | 0.9971372 |
| ENST00000255681 | ENST00000380995 | MACROD1 | chr11 | 63918711 | - | TBC1D22A | chr22 | 47274549 | + | 0.012619392 | 0.9873806 |
| ENST00000255681 | ENST00000407381 | MACROD1 | chr11 | 63918711 | - | TBC1D22A | chr22 | 47274549 | + | 0.005821439 | 0.99417853 |
| ENST00000255681 | ENST00000355704 | MACROD1 | chr11 | 63918711 | - | TBC1D22A | chr22 | 47274549 | + | 0.005832339 | 0.9941677 |
| ENST00000255681 | ENST00000337137 | MACROD1 | chr11 | 63918710 | - | TBC1D22A | chr22 | 47274548 | + | 0.002862833 | 0.9971372 |
| ENST00000255681 | ENST00000380995 | MACROD1 | chr11 | 63918710 | - | TBC1D22A | chr22 | 47274548 | + | 0.012619392 | 0.9873806 |
| ENST00000255681 | ENST00000407381 | MACROD1 | chr11 | 63918710 | - | TBC1D22A | chr22 | 47274548 | + | 0.005821439 | 0.99417853 |
| ENST00000255681 | ENST00000355704 | MACROD1 | chr11 | 63918710 | - | TBC1D22A | chr22 | 47274548 | + | 0.005832339 | 0.9941677 |
Top |
Fusion Genomic Features for MACROD1-TBC1D22A |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
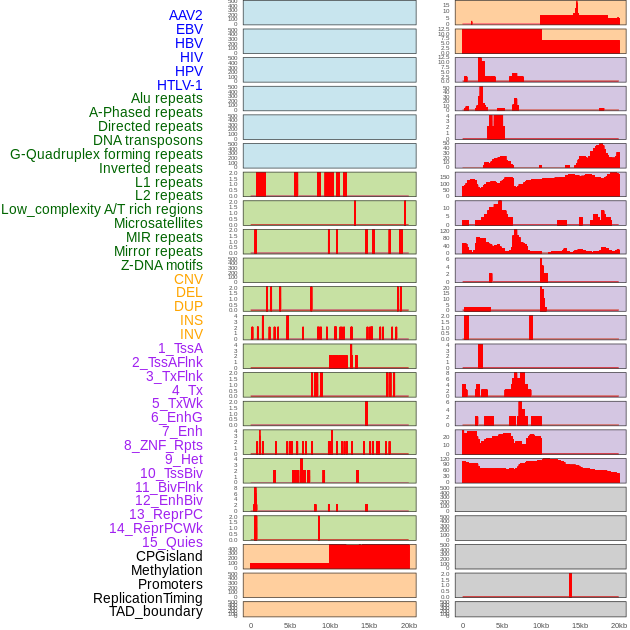 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
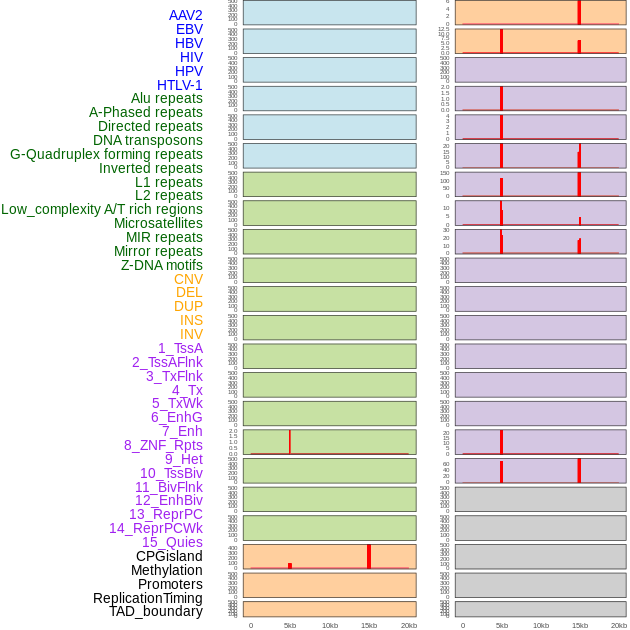 |
Top |
Fusion Protein Features for MACROD1-TBC1D22A |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr11:63918711/chr22:47274549) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| MACROD1 | . |
| FUNCTION: Removes ADP-ribose from asparatate and glutamate residues in proteins bearing a single ADP-ribose moiety (PubMed:23474714, PubMed:23474712). Inactive towards proteins bearing poly-ADP-ribose (PubMed:23474714, PubMed:23474712). Deacetylates O-acetyl-ADP ribose, a signaling molecule generated by the deacetylation of acetylated lysine residues in histones and other proteins (PubMed:21257746). Plays a role in estrogen signaling (PubMed:17893710, PubMed:17914104, PubMed:19403568). Binds to androgen receptor (AR) and amplifies the transactivation function of AR in response to androgen (PubMed:19022849). May play an important role in carcinogenesis and/or progression of hormone-dependent cancers by feed-forward mechanism that activates ESR1 transactivation (PubMed:17893710, PubMed:17914104). Could be an ESR1 coactivator, providing a positive feedback regulatory loop for ESR1 signal transduction (PubMed:17914104). Could be involved in invasive growth by down-regulating CDH1 in endometrial cancer cells (PubMed:17893710). Enhances ESR1-mediated transcription activity (PubMed:17914104). {ECO:0000269|PubMed:17893710, ECO:0000269|PubMed:17914104, ECO:0000269|PubMed:19022849, ECO:0000269|PubMed:19403568, ECO:0000269|PubMed:21257746, ECO:0000269|PubMed:23474712, ECO:0000269|PubMed:23474714}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | MACROD1 | chr11:63918710 | chr22:47274548 | ENST00000255681 | - | 3 | 11 | 159_161 | 172 | 225.33333333333334 | Region | Substrate binding |
| Hgene | MACROD1 | chr11:63918710 | chr22:47274548 | ENST00000255681 | - | 3 | 11 | 172_174 | 172 | 225.33333333333334 | Region | Substrate binding |
| Hgene | MACROD1 | chr11:63918711 | chr22:47274549 | ENST00000255681 | - | 3 | 11 | 159_161 | 172 | 225.33333333333334 | Region | Substrate binding |
| Hgene | MACROD1 | chr11:63918711 | chr22:47274549 | ENST00000255681 | - | 3 | 11 | 172_174 | 172 | 225.33333333333334 | Region | Substrate binding |
| Tgene | TBC1D22A | chr11:63918710 | chr22:47274548 | ENST00000337137 | 3 | 13 | 222_446 | 212 | 518.0 | Domain | Rab-GAP TBC | |
| Tgene | TBC1D22A | chr11:63918710 | chr22:47274548 | ENST00000355704 | 1 | 11 | 222_446 | 134 | 440.0 | Domain | Rab-GAP TBC | |
| Tgene | TBC1D22A | chr11:63918710 | chr22:47274548 | ENST00000380995 | 3 | 9 | 222_446 | 165 | 325.0 | Domain | Rab-GAP TBC | |
| Tgene | TBC1D22A | chr11:63918711 | chr22:47274549 | ENST00000337137 | 3 | 13 | 222_446 | 212 | 518.0 | Domain | Rab-GAP TBC | |
| Tgene | TBC1D22A | chr11:63918711 | chr22:47274549 | ENST00000355704 | 1 | 11 | 222_446 | 134 | 440.0 | Domain | Rab-GAP TBC | |
| Tgene | TBC1D22A | chr11:63918711 | chr22:47274549 | ENST00000380995 | 3 | 9 | 222_446 | 165 | 325.0 | Domain | Rab-GAP TBC |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | MACROD1 | chr11:63918710 | chr22:47274548 | ENST00000255681 | - | 3 | 11 | 141_322 | 172 | 225.33333333333334 | Domain | Macro |
| Hgene | MACROD1 | chr11:63918711 | chr22:47274549 | ENST00000255681 | - | 3 | 11 | 141_322 | 172 | 225.33333333333334 | Domain | Macro |
| Hgene | MACROD1 | chr11:63918710 | chr22:47274548 | ENST00000255681 | - | 3 | 11 | 179_184 | 172 | 225.33333333333334 | Region | Substrate binding |
| Hgene | MACROD1 | chr11:63918710 | chr22:47274548 | ENST00000255681 | - | 3 | 11 | 267_273 | 172 | 225.33333333333334 | Region | Substrate binding |
| Hgene | MACROD1 | chr11:63918711 | chr22:47274549 | ENST00000255681 | - | 3 | 11 | 179_184 | 172 | 225.33333333333334 | Region | Substrate binding |
| Hgene | MACROD1 | chr11:63918711 | chr22:47274549 | ENST00000255681 | - | 3 | 11 | 267_273 | 172 | 225.33333333333334 | Region | Substrate binding |
Top |
Fusion Gene Sequence for MACROD1-TBC1D22A |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >50648_50648_1_MACROD1-TBC1D22A_MACROD1_chr11_63918710_ENST00000255681_TBC1D22A_chr22_47274548_ENST00000337137_length(transcript)=3568nt_BP=584nt GAGAGACACTCCCGAGCGCCGTAAATAGAGTCCAAGTGGGCGGAGAGCCGTCCCGCGCCGCCCGCTCATGTCTCTACAGAGCCGACTGTC CGGCCGCCTGGCACAGCTGCGCGCGGCGGGGCAGCTGCTCGTCCCCCCGCGCCCCCGGCCCGGACACTTGGCGGGTGCCACGAGGACCCG CAGCAGCACGTGCGGTCCCCCGGCGTTCCTGGGCGTGTTCGGCCGCCGTGCGCGGACCTCGGCGGGAGTTGGGGCGTGGGGGGCGGCGGC GGTGGGGCGGACAGCCGGGGTGCGCACTTGGGCCCCCCTGGCCATGGCGGCGAAGGTGGACCTGAGCACCTCCACCGACTGGAAGGAGGC GAAATCCTTTCTGAAGGGCCTGAGTGACAAGCAGCGGGAGGAACATTACTTCTGCAAGGACTTTGTCAGGCTGAAGAAGATCCCGACATG GAAGGAGATGGCGAAAGGGGTGGCTGTGAAGGTGGAGGAGCCCAGGTATAAAAAGGACAAGCAGCTCAATGAGAAAATCTCCCTGCTCCG CAGCGACATCACCAAGCTGGAGGTGGACGCCATCGTCAACGCCGAGGAATTACGGAGGTTGAGCTGGTCCGGAATCCCTAAGCCAGTGCG TCCAATGACGTGGAAGCTCCTCTCAGGTTACCTTCCCGCCAATGTAGACCGGAGACCAGCCACTCTCCAGAGAAAACAAAAAGAATATTT TGCATTTATTGAGCACTATTACGATTCTAGGAACGACGAAGTTCACCAGGACACATACAGGCAGATCCACATAGACATCCCTCGCATGAG CCCTGAAGCGTTGATCCTGCAGCCCAAGGTGACGGAGATTTTTGAAAGGATCTTGTTCATATGGGCGATCCGCCACCCAGCCAGTGGATA CGTTCAGGGTATAAATGATCTCGTCACTCCTTTCTTTGTGGTCTTCATTTGTGAATACATAGAGGCAGAGGAGGTGGACACGGTGGACGT CTCCGGCGTGCCCGCAGAGGTGCTGTGCAACATCGAGGCCGACACCTACTGGTGCATGAGCAAGCTGCTGGATGGCATTCAGGACAACTA CACCTTTGCCCAACCTGGGATTCAAATGAAAGTGAAAATGTTAGAAGAACTCGTGAGCCGGATTGATGAGCAAGTGCACCGGCACCTGGA CCAACACGAAGTGAGATACCTGCAGTTTGCCTTCCGCTGGATGAACAACCTGCTGATGAGGGAGGTGCCCCTGCGTTGTACCATCCGCCT GTGGGACACCTACCAGTCTGAACCGGACGGCTTTTCTCATTTCCACTTGTACGTGTGCGCTGCTTTTCTCGTGAGATGGAGGAAGGAAAT ACTAGAAGAAAAAGATTTTCAAGAGCTGCTGCTCTTCCTCCAGAACCTGCCCACAGCCCACTGGGATGATGAGGACATCAGCCTGTTGCT GGCCGAGGCCTACCGCCTCAAGTTTGCTTTTGCCGACGCCCCCAATCACTACAAGAAATGAGCCCAGGCCCACCCGCAGCTGGCCTCACT GTCCCGGGTGGCGCGCCCCACCTGCCTGGCTGGTGGTAGGCCCCTGTGAGCTGGTCCCGGGCTGCTAAAAGGCCTTGTGAGGTGGCCCCA CCCTCCAGGGGAGCTGGTGAAGATGGGCCACAGACCTGGTCTAGGGCTGACAAAGACAGGGACAGCCTTTGTTTTCTGAGATACCAAAGA GAGCCAGGGGAGGGCCCCGGGTTCGGCGGCCAGAGGCAGGTCAGGGGTCCCCTCTCCCTCTCCCTGCAATGTCCTTGCCAAATGACTGCC TCGTGCTGCCCCTAGTCCGGGGCAGCCTAGGAGGCCGACCCTCTTTGGAGTCCTGCTGTCTGGGTGCCAGGGCCGGAACGAGGTAGTGGC CATCTCATACCTACTCTGAAATGCAAAACTTCTATTCTGTTGAGTGAAAGAATAAAATGTAGACAAAATCTAGACCGAGACGTTGCGCTG ACCCGGGGTCTCTGTGCCGCGAGGTCCCCTCACAGCTGTATTTCACTGCTGCTGGCCCTTTCCCTCCGTGTGTTTTCCTGCTTGCTTGGT TTAAACGTGGCTGGGAAGCTGAAGGCTGGAGTCCAAGCCGTGAGCCCGCCGAGTGCCTGGGAGGCCGTGGGACCAAAGGCTGGGAGCAGA GGGAGGCCTCGCCATCGCCTTACTTTCCACCTTGAACCTCTTTTACAAGAGAGAAACCCCCACCTCCCTGAGGTCCAGGGCCAAGTGGCC CCGCCACGCAGGTAGGCGCCGGCCTCAGCCAGAGCCCCTGGAGGCCCACCCAGGCTGTCGGGCCATGTTGGGCTGGCAGACGGGCAGGGG GTCGCGTCCCTGTCATCAAAGCCCTGAACCACAGTGCTCTTCTCACCGCAGCCTGGAAGCGGAATGAGCTTTTGGAGACTTCCTGGGACT TGCTGTCCTTGTCCAGGTCTGCCAGGTGTAGGGGAGGTGTGACTGGTTCCATCATGGACCGGTTCCTCCATGGACCGGTTCCTCCGTGGA CCGGTTCCGCCATGGACCGGTTCCGCCATGGACCACTCCTGCCCTGGACCACTCCTGCCCTGGACCGGTTCTGCCGTGGACTGGTTCCCG CCGTGGACCAGTTCCCGCTGTATACTGGTTCTGCCCTGGACTGGTTCCCGCTGTGGACTGGTTCCTTGGGGCTCTAAGTGCGGAAGGGCC CAGAGCTGGTCCCTGCCCAGCGCCCTGCTAGGGCTGTGTCCTTGGCTCCAGGGGCCTTGGGACTGGCTTCCCAGCGTTCCCTCGGTGTGT CACAGGCTGCATGACCCCTGGAATGCGGGCAGGGCCACAGCCACAGTCTGTCTGATCCCTGAGCCCAGGACAGGCTCACGTCCTCAGCGA CCCACTGGTGACTGACTTCCCAGACTCTCCTCTGTCCCTCAGGAGCAGCCGTGTCCTCTCCCAGGCCCTAGGACACTGCCAGAGACTGTG GGACATACAGGCATAAGTGATGTGTGTGTTTCTGCTTCTGTTTTAAAAATCCAGGGTCATTACACACAGCATGGAAATTAGCACAAAATG CTGTGCAAACGTCAGATGCTCCCAAACCAGCAAAGGGATGGGCTTGCTTCACATCAGATGCGGGCACGCCTTACCCCTGCCTTCCGTGTC CCCACCCCAGGGTCAAGGGTTCCTCAGACCAGCCATGCCTCCTCCTCCTGCCGCCTCCTTTTCTAGATGGGGAGGGGATTCCGTCACAAG AAGAGCCGCCCCTCGGCCGTGTGCAGGAAGCCCCATGTCGCTTTGCCGAGATCAGCCCTGGGAGGATCCCCTTCTCCAGCTCAGATCATG CCGTGTGGCCAGAAGGCTGCGGACACAACTGACCTGCTTCTCGAGGTGGTTGATGTTTTAAACAGGAAGCTCCACGGAGTTCAGCCCTGT GTGCATTTCCTCATGTATGTAAACGCCAAGACTGAATGTGAGAGGTGTTGGCCGCGGGCCTTAAGTCTGAGCAGATCCATCTGGAATGTT >50648_50648_1_MACROD1-TBC1D22A_MACROD1_chr11_63918710_ENST00000255681_TBC1D22A_chr22_47274548_ENST00000337137_length(amino acids)=477AA_BP=172 MSLQSRLSGRLAQLRAAGQLLVPPRPRPGHLAGATRTRSSTCGPPAFLGVFGRRARTSAGVGAWGAAAVGRTAGVRTWAPLAMAAKVDLS TSTDWKEAKSFLKGLSDKQREEHYFCKDFVRLKKIPTWKEMAKGVAVKVEEPRYKKDKQLNEKISLLRSDITKLEVDAIVNAEELRRLSW SGIPKPVRPMTWKLLSGYLPANVDRRPATLQRKQKEYFAFIEHYYDSRNDEVHQDTYRQIHIDIPRMSPEALILQPKVTEIFERILFIWA IRHPASGYVQGINDLVTPFFVVFICEYIEAEEVDTVDVSGVPAEVLCNIEADTYWCMSKLLDGIQDNYTFAQPGIQMKVKMLEELVSRID EQVHRHLDQHEVRYLQFAFRWMNNLLMREVPLRCTIRLWDTYQSEPDGFSHFHLYVCAAFLVRWRKEILEEKDFQELLLFLQNLPTAHWD -------------------------------------------------------------- >50648_50648_2_MACROD1-TBC1D22A_MACROD1_chr11_63918710_ENST00000255681_TBC1D22A_chr22_47274548_ENST00000355704_length(transcript)=1961nt_BP=584nt GAGAGACACTCCCGAGCGCCGTAAATAGAGTCCAAGTGGGCGGAGAGCCGTCCCGCGCCGCCCGCTCATGTCTCTACAGAGCCGACTGTC CGGCCGCCTGGCACAGCTGCGCGCGGCGGGGCAGCTGCTCGTCCCCCCGCGCCCCCGGCCCGGACACTTGGCGGGTGCCACGAGGACCCG CAGCAGCACGTGCGGTCCCCCGGCGTTCCTGGGCGTGTTCGGCCGCCGTGCGCGGACCTCGGCGGGAGTTGGGGCGTGGGGGGCGGCGGC GGTGGGGCGGACAGCCGGGGTGCGCACTTGGGCCCCCCTGGCCATGGCGGCGAAGGTGGACCTGAGCACCTCCACCGACTGGAAGGAGGC GAAATCCTTTCTGAAGGGCCTGAGTGACAAGCAGCGGGAGGAACATTACTTCTGCAAGGACTTTGTCAGGCTGAAGAAGATCCCGACATG GAAGGAGATGGCGAAAGGGGTGGCTGTGAAGGTGGAGGAGCCCAGGTATAAAAAGGACAAGCAGCTCAATGAGAAAATCTCCCTGCTCCG CAGCGACATCACCAAGCTGGAGGTGGACGCCATCGTCAACGCCGAGGAATTACGGAGGTTGAGCTGGTCCGGAATCCCTAAGCCAGTGCG TCCAATGACGTGGAAGCTCCTCTCAGGTTACCTTCCCGCCAATGTAGACCGGAGACCAGCCACTCTCCAGAGAAAACAAAAAGAATATTT TGCATTTATTGAGCACTATTACGATTCTAGGAACGACGAAGTTCACCAGGACACATACAGGCAGATCCACATAGACATCCCTCGCATGAG CCCTGAAGCGTTGATCCTGCAGCCCAAGGTGACGGAGATTTTTGAAAGGATCTTGTTCATATGGGCGATCCGCCACCCAGCCAGTGGATA CGTTCAGGGTATAAATGATCTCGTCACTCCTTTCTTTGTGGTCTTCATTTGTGAATACATAGAGGCAGAGGAGGTGGACACGGTGGACGT CTCCGGCGTGCCCGCAGAGGTGCTGTGCAACATCGAGGCCGACACCTACTGGTGCATGAGCAAGCTGCTGGATGGCATTCAGGACAACTA CACCTTTGCCCAACCTGGGATTCAAATGAAAGTGAAAATGTTAGAAGAACTCGTGAGCCGGATTGATGAGCAAGTGCACCGGCACCTGGA CCAACACGAAGTGAGATACCTGCAGTTTGCCTTCCGCTGGATGAACAACCTGCTGATGAGGGAGGTGCCCCTGCGTTGTACCATCCGCCT GTGGGACACCTACCAGTCTGAACCGGACGGCTTTTCTCATTTCCACTTGTACGTGTGCGCTGCTTTTCTCGTGAGATGGAGGAAGGAAAT ACTAGAAGAAAAAGATTTTCAAGAGCTGCTGCTCTTCCTCCAGAACCTGCCCACAGCCCACTGGGATGATGAGGACATCAGCCTGTTGCT GGCCGAGGCCTACCGCCTCAAGTTTGCTTTTGCCGACGCCCCCAATCACTACAAGAAATGAGCCCAGGCCCACCCGCAGCTGGCCTCACT GTCCCGGGTGGCGCGCCCCACCTGCCTGGCTGGTGGTAGGCCCCTGTGAGCTGGTCCCGGGCTGCTAAAAGGCCTTGTGAGGTGGCCCCA CCCTCCAGGGGAGCTGGTGAAGATGGGCCACAGACCTGGTCTAGGGCTGACAAAGACAGGGACAGCCTTTGTTTTCTGAGATACCAAAGA GAGCCAGGGGAGGGCCCCGGGTTCGGCGGCCAGAGGCAGGTCAGGGGTCCCCTCTCCCTCTCCCTGCAATGTCCTTGCCAAATGACTGCC TCGTGCTGCCCCTAGTCCGGGGCAGCCTAGGAGGCCGACCCTCTTTGGAGTCCTGCTGTCTGGGTGCCAGGGCCGGAACGAGGTAGTGGC >50648_50648_2_MACROD1-TBC1D22A_MACROD1_chr11_63918710_ENST00000255681_TBC1D22A_chr22_47274548_ENST00000355704_length(amino acids)=477AA_BP=172 MSLQSRLSGRLAQLRAAGQLLVPPRPRPGHLAGATRTRSSTCGPPAFLGVFGRRARTSAGVGAWGAAAVGRTAGVRTWAPLAMAAKVDLS TSTDWKEAKSFLKGLSDKQREEHYFCKDFVRLKKIPTWKEMAKGVAVKVEEPRYKKDKQLNEKISLLRSDITKLEVDAIVNAEELRRLSW SGIPKPVRPMTWKLLSGYLPANVDRRPATLQRKQKEYFAFIEHYYDSRNDEVHQDTYRQIHIDIPRMSPEALILQPKVTEIFERILFIWA IRHPASGYVQGINDLVTPFFVVFICEYIEAEEVDTVDVSGVPAEVLCNIEADTYWCMSKLLDGIQDNYTFAQPGIQMKVKMLEELVSRID EQVHRHLDQHEVRYLQFAFRWMNNLLMREVPLRCTIRLWDTYQSEPDGFSHFHLYVCAAFLVRWRKEILEEKDFQELLLFLQNLPTAHWD -------------------------------------------------------------- >50648_50648_3_MACROD1-TBC1D22A_MACROD1_chr11_63918710_ENST00000255681_TBC1D22A_chr22_47274548_ENST00000380995_length(transcript)=1063nt_BP=584nt GAGAGACACTCCCGAGCGCCGTAAATAGAGTCCAAGTGGGCGGAGAGCCGTCCCGCGCCGCCCGCTCATGTCTCTACAGAGCCGACTGTC CGGCCGCCTGGCACAGCTGCGCGCGGCGGGGCAGCTGCTCGTCCCCCCGCGCCCCCGGCCCGGACACTTGGCGGGTGCCACGAGGACCCG CAGCAGCACGTGCGGTCCCCCGGCGTTCCTGGGCGTGTTCGGCCGCCGTGCGCGGACCTCGGCGGGAGTTGGGGCGTGGGGGGCGGCGGC GGTGGGGCGGACAGCCGGGGTGCGCACTTGGGCCCCCCTGGCCATGGCGGCGAAGGTGGACCTGAGCACCTCCACCGACTGGAAGGAGGC GAAATCCTTTCTGAAGGGCCTGAGTGACAAGCAGCGGGAGGAACATTACTTCTGCAAGGACTTTGTCAGGCTGAAGAAGATCCCGACATG GAAGGAGATGGCGAAAGGGGTGGCTGTGAAGGTGGAGGAGCCCAGGTATAAAAAGGACAAGCAGCTCAATGAGAAAATCTCCCTGCTCCG CAGCGACATCACCAAGCTGGAGGTGGACGCCATCGTCAACGCCGAGGAATTACGGAGGTTGAGCTGGTCCGGAATCCCTAAGCCAGTGCG TCCAATGACGTGGAAGCTCCTCTCAGGTTACCTTCCCGCCAATGTAGACCGGAGACCAGCCACTCTCCAGAGAAAACAAAAAGAATATTT TGCATTTATTGAGCACTATTACGATTCTAGGAACGACGAAGTTCACCAGGACACATACAGGCAGATCCACATAGACATCCCTCGCATGAG CCCTGAAGCGTTGATCCTGCAGCCCAAGGTGACGGAGATTTTTGAAAGGATCTTGTTCATATGGGCGATCCGCCACCCAGCCAGTGGATA CGTTCAGGGTATAAATGATCTCGTCACTCCTTTCTTTGTGGTCTTCATTTGTGAATACATAGCCTTTCCAGGTTGTGGTCGGCCTCAGAT >50648_50648_3_MACROD1-TBC1D22A_MACROD1_chr11_63918710_ENST00000255681_TBC1D22A_chr22_47274548_ENST00000380995_length(amino acids)=332AA_BP=172 MSLQSRLSGRLAQLRAAGQLLVPPRPRPGHLAGATRTRSSTCGPPAFLGVFGRRARTSAGVGAWGAAAVGRTAGVRTWAPLAMAAKVDLS TSTDWKEAKSFLKGLSDKQREEHYFCKDFVRLKKIPTWKEMAKGVAVKVEEPRYKKDKQLNEKISLLRSDITKLEVDAIVNAEELRRLSW SGIPKPVRPMTWKLLSGYLPANVDRRPATLQRKQKEYFAFIEHYYDSRNDEVHQDTYRQIHIDIPRMSPEALILQPKVTEIFERILFIWA -------------------------------------------------------------- >50648_50648_4_MACROD1-TBC1D22A_MACROD1_chr11_63918710_ENST00000255681_TBC1D22A_chr22_47274548_ENST00000407381_length(transcript)=1958nt_BP=584nt GAGAGACACTCCCGAGCGCCGTAAATAGAGTCCAAGTGGGCGGAGAGCCGTCCCGCGCCGCCCGCTCATGTCTCTACAGAGCCGACTGTC CGGCCGCCTGGCACAGCTGCGCGCGGCGGGGCAGCTGCTCGTCCCCCCGCGCCCCCGGCCCGGACACTTGGCGGGTGCCACGAGGACCCG CAGCAGCACGTGCGGTCCCCCGGCGTTCCTGGGCGTGTTCGGCCGCCGTGCGCGGACCTCGGCGGGAGTTGGGGCGTGGGGGGCGGCGGC GGTGGGGCGGACAGCCGGGGTGCGCACTTGGGCCCCCCTGGCCATGGCGGCGAAGGTGGACCTGAGCACCTCCACCGACTGGAAGGAGGC GAAATCCTTTCTGAAGGGCCTGAGTGACAAGCAGCGGGAGGAACATTACTTCTGCAAGGACTTTGTCAGGCTGAAGAAGATCCCGACATG GAAGGAGATGGCGAAAGGGGTGGCTGTGAAGGTGGAGGAGCCCAGGTATAAAAAGGACAAGCAGCTCAATGAGAAAATCTCCCTGCTCCG CAGCGACATCACCAAGCTGGAGGTGGACGCCATCGTCAACGCCGAGGAATTACGGAGGTTGAGCTGGTCCGGAATCCCTAAGCCAGTGCG TCCAATGACGTGGAAGCTCCTCTCAGGTTACCTTCCCGCCAATGTAGACCGGAGACCAGCCACTCTCCAGAGAAAACAAAAAGAATATTT TGCATTTATTGAGCACTATTACGATTCTAGGAACGACGAAGTTCACCAGGACACATACAGGCAGATCCACATAGACATCCCTCGCATGAG CCCTGAAGCGTTGATCCTGCAGCCCAAGGTGACGGAGATTTTTGAAAGGATCTTGTTCATATGGGCGATCCGCCACCCAGCCAGTGGATA CGTTCAGGGTATAAATGATCTCGTCACTCCTTTCTTTGTGGTCTTCATTTGTGAATACATAGAGGCAGAGGAGGTGGACACGGTGGACGT CTCCGGCGTGCCCGCAGAGGTGCTGTGCAACATCGAGGCCGACACCTACTGGTGCATGAGCAAGCTGCTGGATGGCATTCAGGACAACTA CACCTTTGCCCAACCTGGGATTCAAATGAAAGTGAAAATGTTAGAAGAACTCGTGAGCCGGATTGATGAGCAAGTGCACCGGCACCTGGA CCAACACGAAGTGAGATACCTGCAGTTTGCCTTCCGCTGGATGAACAACCTGCTGATGAGGGAGGTGCCCCTGCGTTGTACCATCCGCCT GTGGGACACCTACCAGTCTGAACCGGACGGCTTTTCTCATTTCCACTTGTACGTGTGCGCTGCTTTTCTCGTGAGATGGAGGAAGGAAAT ACTAGAAGAAAAAGATTTTCAAGAGCTGCTGCTCTTCCTCCAGAACCTGCCCACAGCCCACTGGGATGATGAGGACATCAGCCTGTTGCT GGCCGAGGCCTACCGCCTCAAGTTTGCTTTTGCCGACGCCCCCAATCACTACAAGAAATGAGCCCAGGCCCACCCGCAGCTGGCCTCACT GTCCCGGGTGGCGCGCCCCACCTGCCTGGCTGGTGGTAGGCCCCTGTGAGCTGGTCCCGGGCTGCTAAAAGGCCTTGTGAGGTGGCCCCA CCCTCCAGGGGAGCTGGTGAAGATGGGCCACAGACCTGGTCTAGGGCTGACAAAGACAGGGACAGCCTTTGTTTTCTGAGATACCAAAGA GAGCCAGGGGAGGGCCCCGGGTTCGGCGGCCAGAGGCAGGTCAGGGGTCCCCTCTCCCTCTCCCTGCAATGTCCTTGCCAAATGACTGCC TCGTGCTGCCCCTAGTCCGGGGCAGCCTAGGAGGCCGACCCTCTTTGGAGTCCTGCTGTCTGGGTGCCAGGGCCGGAACGAGGTAGTGGC >50648_50648_4_MACROD1-TBC1D22A_MACROD1_chr11_63918710_ENST00000255681_TBC1D22A_chr22_47274548_ENST00000407381_length(amino acids)=477AA_BP=172 MSLQSRLSGRLAQLRAAGQLLVPPRPRPGHLAGATRTRSSTCGPPAFLGVFGRRARTSAGVGAWGAAAVGRTAGVRTWAPLAMAAKVDLS TSTDWKEAKSFLKGLSDKQREEHYFCKDFVRLKKIPTWKEMAKGVAVKVEEPRYKKDKQLNEKISLLRSDITKLEVDAIVNAEELRRLSW SGIPKPVRPMTWKLLSGYLPANVDRRPATLQRKQKEYFAFIEHYYDSRNDEVHQDTYRQIHIDIPRMSPEALILQPKVTEIFERILFIWA IRHPASGYVQGINDLVTPFFVVFICEYIEAEEVDTVDVSGVPAEVLCNIEADTYWCMSKLLDGIQDNYTFAQPGIQMKVKMLEELVSRID EQVHRHLDQHEVRYLQFAFRWMNNLLMREVPLRCTIRLWDTYQSEPDGFSHFHLYVCAAFLVRWRKEILEEKDFQELLLFLQNLPTAHWD -------------------------------------------------------------- >50648_50648_5_MACROD1-TBC1D22A_MACROD1_chr11_63918711_ENST00000255681_TBC1D22A_chr22_47274549_ENST00000337137_length(transcript)=3568nt_BP=584nt GAGAGACACTCCCGAGCGCCGTAAATAGAGTCCAAGTGGGCGGAGAGCCGTCCCGCGCCGCCCGCTCATGTCTCTACAGAGCCGACTGTC CGGCCGCCTGGCACAGCTGCGCGCGGCGGGGCAGCTGCTCGTCCCCCCGCGCCCCCGGCCCGGACACTTGGCGGGTGCCACGAGGACCCG CAGCAGCACGTGCGGTCCCCCGGCGTTCCTGGGCGTGTTCGGCCGCCGTGCGCGGACCTCGGCGGGAGTTGGGGCGTGGGGGGCGGCGGC GGTGGGGCGGACAGCCGGGGTGCGCACTTGGGCCCCCCTGGCCATGGCGGCGAAGGTGGACCTGAGCACCTCCACCGACTGGAAGGAGGC GAAATCCTTTCTGAAGGGCCTGAGTGACAAGCAGCGGGAGGAACATTACTTCTGCAAGGACTTTGTCAGGCTGAAGAAGATCCCGACATG GAAGGAGATGGCGAAAGGGGTGGCTGTGAAGGTGGAGGAGCCCAGGTATAAAAAGGACAAGCAGCTCAATGAGAAAATCTCCCTGCTCCG CAGCGACATCACCAAGCTGGAGGTGGACGCCATCGTCAACGCCGAGGAATTACGGAGGTTGAGCTGGTCCGGAATCCCTAAGCCAGTGCG TCCAATGACGTGGAAGCTCCTCTCAGGTTACCTTCCCGCCAATGTAGACCGGAGACCAGCCACTCTCCAGAGAAAACAAAAAGAATATTT TGCATTTATTGAGCACTATTACGATTCTAGGAACGACGAAGTTCACCAGGACACATACAGGCAGATCCACATAGACATCCCTCGCATGAG CCCTGAAGCGTTGATCCTGCAGCCCAAGGTGACGGAGATTTTTGAAAGGATCTTGTTCATATGGGCGATCCGCCACCCAGCCAGTGGATA CGTTCAGGGTATAAATGATCTCGTCACTCCTTTCTTTGTGGTCTTCATTTGTGAATACATAGAGGCAGAGGAGGTGGACACGGTGGACGT CTCCGGCGTGCCCGCAGAGGTGCTGTGCAACATCGAGGCCGACACCTACTGGTGCATGAGCAAGCTGCTGGATGGCATTCAGGACAACTA CACCTTTGCCCAACCTGGGATTCAAATGAAAGTGAAAATGTTAGAAGAACTCGTGAGCCGGATTGATGAGCAAGTGCACCGGCACCTGGA CCAACACGAAGTGAGATACCTGCAGTTTGCCTTCCGCTGGATGAACAACCTGCTGATGAGGGAGGTGCCCCTGCGTTGTACCATCCGCCT GTGGGACACCTACCAGTCTGAACCGGACGGCTTTTCTCATTTCCACTTGTACGTGTGCGCTGCTTTTCTCGTGAGATGGAGGAAGGAAAT ACTAGAAGAAAAAGATTTTCAAGAGCTGCTGCTCTTCCTCCAGAACCTGCCCACAGCCCACTGGGATGATGAGGACATCAGCCTGTTGCT GGCCGAGGCCTACCGCCTCAAGTTTGCTTTTGCCGACGCCCCCAATCACTACAAGAAATGAGCCCAGGCCCACCCGCAGCTGGCCTCACT GTCCCGGGTGGCGCGCCCCACCTGCCTGGCTGGTGGTAGGCCCCTGTGAGCTGGTCCCGGGCTGCTAAAAGGCCTTGTGAGGTGGCCCCA CCCTCCAGGGGAGCTGGTGAAGATGGGCCACAGACCTGGTCTAGGGCTGACAAAGACAGGGACAGCCTTTGTTTTCTGAGATACCAAAGA GAGCCAGGGGAGGGCCCCGGGTTCGGCGGCCAGAGGCAGGTCAGGGGTCCCCTCTCCCTCTCCCTGCAATGTCCTTGCCAAATGACTGCC TCGTGCTGCCCCTAGTCCGGGGCAGCCTAGGAGGCCGACCCTCTTTGGAGTCCTGCTGTCTGGGTGCCAGGGCCGGAACGAGGTAGTGGC CATCTCATACCTACTCTGAAATGCAAAACTTCTATTCTGTTGAGTGAAAGAATAAAATGTAGACAAAATCTAGACCGAGACGTTGCGCTG ACCCGGGGTCTCTGTGCCGCGAGGTCCCCTCACAGCTGTATTTCACTGCTGCTGGCCCTTTCCCTCCGTGTGTTTTCCTGCTTGCTTGGT TTAAACGTGGCTGGGAAGCTGAAGGCTGGAGTCCAAGCCGTGAGCCCGCCGAGTGCCTGGGAGGCCGTGGGACCAAAGGCTGGGAGCAGA GGGAGGCCTCGCCATCGCCTTACTTTCCACCTTGAACCTCTTTTACAAGAGAGAAACCCCCACCTCCCTGAGGTCCAGGGCCAAGTGGCC CCGCCACGCAGGTAGGCGCCGGCCTCAGCCAGAGCCCCTGGAGGCCCACCCAGGCTGTCGGGCCATGTTGGGCTGGCAGACGGGCAGGGG GTCGCGTCCCTGTCATCAAAGCCCTGAACCACAGTGCTCTTCTCACCGCAGCCTGGAAGCGGAATGAGCTTTTGGAGACTTCCTGGGACT TGCTGTCCTTGTCCAGGTCTGCCAGGTGTAGGGGAGGTGTGACTGGTTCCATCATGGACCGGTTCCTCCATGGACCGGTTCCTCCGTGGA CCGGTTCCGCCATGGACCGGTTCCGCCATGGACCACTCCTGCCCTGGACCACTCCTGCCCTGGACCGGTTCTGCCGTGGACTGGTTCCCG CCGTGGACCAGTTCCCGCTGTATACTGGTTCTGCCCTGGACTGGTTCCCGCTGTGGACTGGTTCCTTGGGGCTCTAAGTGCGGAAGGGCC CAGAGCTGGTCCCTGCCCAGCGCCCTGCTAGGGCTGTGTCCTTGGCTCCAGGGGCCTTGGGACTGGCTTCCCAGCGTTCCCTCGGTGTGT CACAGGCTGCATGACCCCTGGAATGCGGGCAGGGCCACAGCCACAGTCTGTCTGATCCCTGAGCCCAGGACAGGCTCACGTCCTCAGCGA CCCACTGGTGACTGACTTCCCAGACTCTCCTCTGTCCCTCAGGAGCAGCCGTGTCCTCTCCCAGGCCCTAGGACACTGCCAGAGACTGTG GGACATACAGGCATAAGTGATGTGTGTGTTTCTGCTTCTGTTTTAAAAATCCAGGGTCATTACACACAGCATGGAAATTAGCACAAAATG CTGTGCAAACGTCAGATGCTCCCAAACCAGCAAAGGGATGGGCTTGCTTCACATCAGATGCGGGCACGCCTTACCCCTGCCTTCCGTGTC CCCACCCCAGGGTCAAGGGTTCCTCAGACCAGCCATGCCTCCTCCTCCTGCCGCCTCCTTTTCTAGATGGGGAGGGGATTCCGTCACAAG AAGAGCCGCCCCTCGGCCGTGTGCAGGAAGCCCCATGTCGCTTTGCCGAGATCAGCCCTGGGAGGATCCCCTTCTCCAGCTCAGATCATG CCGTGTGGCCAGAAGGCTGCGGACACAACTGACCTGCTTCTCGAGGTGGTTGATGTTTTAAACAGGAAGCTCCACGGAGTTCAGCCCTGT GTGCATTTCCTCATGTATGTAAACGCCAAGACTGAATGTGAGAGGTGTTGGCCGCGGGCCTTAAGTCTGAGCAGATCCATCTGGAATGTT >50648_50648_5_MACROD1-TBC1D22A_MACROD1_chr11_63918711_ENST00000255681_TBC1D22A_chr22_47274549_ENST00000337137_length(amino acids)=477AA_BP=172 MSLQSRLSGRLAQLRAAGQLLVPPRPRPGHLAGATRTRSSTCGPPAFLGVFGRRARTSAGVGAWGAAAVGRTAGVRTWAPLAMAAKVDLS TSTDWKEAKSFLKGLSDKQREEHYFCKDFVRLKKIPTWKEMAKGVAVKVEEPRYKKDKQLNEKISLLRSDITKLEVDAIVNAEELRRLSW SGIPKPVRPMTWKLLSGYLPANVDRRPATLQRKQKEYFAFIEHYYDSRNDEVHQDTYRQIHIDIPRMSPEALILQPKVTEIFERILFIWA IRHPASGYVQGINDLVTPFFVVFICEYIEAEEVDTVDVSGVPAEVLCNIEADTYWCMSKLLDGIQDNYTFAQPGIQMKVKMLEELVSRID EQVHRHLDQHEVRYLQFAFRWMNNLLMREVPLRCTIRLWDTYQSEPDGFSHFHLYVCAAFLVRWRKEILEEKDFQELLLFLQNLPTAHWD -------------------------------------------------------------- >50648_50648_6_MACROD1-TBC1D22A_MACROD1_chr11_63918711_ENST00000255681_TBC1D22A_chr22_47274549_ENST00000355704_length(transcript)=1961nt_BP=584nt GAGAGACACTCCCGAGCGCCGTAAATAGAGTCCAAGTGGGCGGAGAGCCGTCCCGCGCCGCCCGCTCATGTCTCTACAGAGCCGACTGTC CGGCCGCCTGGCACAGCTGCGCGCGGCGGGGCAGCTGCTCGTCCCCCCGCGCCCCCGGCCCGGACACTTGGCGGGTGCCACGAGGACCCG CAGCAGCACGTGCGGTCCCCCGGCGTTCCTGGGCGTGTTCGGCCGCCGTGCGCGGACCTCGGCGGGAGTTGGGGCGTGGGGGGCGGCGGC GGTGGGGCGGACAGCCGGGGTGCGCACTTGGGCCCCCCTGGCCATGGCGGCGAAGGTGGACCTGAGCACCTCCACCGACTGGAAGGAGGC GAAATCCTTTCTGAAGGGCCTGAGTGACAAGCAGCGGGAGGAACATTACTTCTGCAAGGACTTTGTCAGGCTGAAGAAGATCCCGACATG GAAGGAGATGGCGAAAGGGGTGGCTGTGAAGGTGGAGGAGCCCAGGTATAAAAAGGACAAGCAGCTCAATGAGAAAATCTCCCTGCTCCG CAGCGACATCACCAAGCTGGAGGTGGACGCCATCGTCAACGCCGAGGAATTACGGAGGTTGAGCTGGTCCGGAATCCCTAAGCCAGTGCG TCCAATGACGTGGAAGCTCCTCTCAGGTTACCTTCCCGCCAATGTAGACCGGAGACCAGCCACTCTCCAGAGAAAACAAAAAGAATATTT TGCATTTATTGAGCACTATTACGATTCTAGGAACGACGAAGTTCACCAGGACACATACAGGCAGATCCACATAGACATCCCTCGCATGAG CCCTGAAGCGTTGATCCTGCAGCCCAAGGTGACGGAGATTTTTGAAAGGATCTTGTTCATATGGGCGATCCGCCACCCAGCCAGTGGATA CGTTCAGGGTATAAATGATCTCGTCACTCCTTTCTTTGTGGTCTTCATTTGTGAATACATAGAGGCAGAGGAGGTGGACACGGTGGACGT CTCCGGCGTGCCCGCAGAGGTGCTGTGCAACATCGAGGCCGACACCTACTGGTGCATGAGCAAGCTGCTGGATGGCATTCAGGACAACTA CACCTTTGCCCAACCTGGGATTCAAATGAAAGTGAAAATGTTAGAAGAACTCGTGAGCCGGATTGATGAGCAAGTGCACCGGCACCTGGA CCAACACGAAGTGAGATACCTGCAGTTTGCCTTCCGCTGGATGAACAACCTGCTGATGAGGGAGGTGCCCCTGCGTTGTACCATCCGCCT GTGGGACACCTACCAGTCTGAACCGGACGGCTTTTCTCATTTCCACTTGTACGTGTGCGCTGCTTTTCTCGTGAGATGGAGGAAGGAAAT ACTAGAAGAAAAAGATTTTCAAGAGCTGCTGCTCTTCCTCCAGAACCTGCCCACAGCCCACTGGGATGATGAGGACATCAGCCTGTTGCT GGCCGAGGCCTACCGCCTCAAGTTTGCTTTTGCCGACGCCCCCAATCACTACAAGAAATGAGCCCAGGCCCACCCGCAGCTGGCCTCACT GTCCCGGGTGGCGCGCCCCACCTGCCTGGCTGGTGGTAGGCCCCTGTGAGCTGGTCCCGGGCTGCTAAAAGGCCTTGTGAGGTGGCCCCA CCCTCCAGGGGAGCTGGTGAAGATGGGCCACAGACCTGGTCTAGGGCTGACAAAGACAGGGACAGCCTTTGTTTTCTGAGATACCAAAGA GAGCCAGGGGAGGGCCCCGGGTTCGGCGGCCAGAGGCAGGTCAGGGGTCCCCTCTCCCTCTCCCTGCAATGTCCTTGCCAAATGACTGCC TCGTGCTGCCCCTAGTCCGGGGCAGCCTAGGAGGCCGACCCTCTTTGGAGTCCTGCTGTCTGGGTGCCAGGGCCGGAACGAGGTAGTGGC >50648_50648_6_MACROD1-TBC1D22A_MACROD1_chr11_63918711_ENST00000255681_TBC1D22A_chr22_47274549_ENST00000355704_length(amino acids)=477AA_BP=172 MSLQSRLSGRLAQLRAAGQLLVPPRPRPGHLAGATRTRSSTCGPPAFLGVFGRRARTSAGVGAWGAAAVGRTAGVRTWAPLAMAAKVDLS TSTDWKEAKSFLKGLSDKQREEHYFCKDFVRLKKIPTWKEMAKGVAVKVEEPRYKKDKQLNEKISLLRSDITKLEVDAIVNAEELRRLSW SGIPKPVRPMTWKLLSGYLPANVDRRPATLQRKQKEYFAFIEHYYDSRNDEVHQDTYRQIHIDIPRMSPEALILQPKVTEIFERILFIWA IRHPASGYVQGINDLVTPFFVVFICEYIEAEEVDTVDVSGVPAEVLCNIEADTYWCMSKLLDGIQDNYTFAQPGIQMKVKMLEELVSRID EQVHRHLDQHEVRYLQFAFRWMNNLLMREVPLRCTIRLWDTYQSEPDGFSHFHLYVCAAFLVRWRKEILEEKDFQELLLFLQNLPTAHWD -------------------------------------------------------------- >50648_50648_7_MACROD1-TBC1D22A_MACROD1_chr11_63918711_ENST00000255681_TBC1D22A_chr22_47274549_ENST00000380995_length(transcript)=1063nt_BP=584nt GAGAGACACTCCCGAGCGCCGTAAATAGAGTCCAAGTGGGCGGAGAGCCGTCCCGCGCCGCCCGCTCATGTCTCTACAGAGCCGACTGTC CGGCCGCCTGGCACAGCTGCGCGCGGCGGGGCAGCTGCTCGTCCCCCCGCGCCCCCGGCCCGGACACTTGGCGGGTGCCACGAGGACCCG CAGCAGCACGTGCGGTCCCCCGGCGTTCCTGGGCGTGTTCGGCCGCCGTGCGCGGACCTCGGCGGGAGTTGGGGCGTGGGGGGCGGCGGC GGTGGGGCGGACAGCCGGGGTGCGCACTTGGGCCCCCCTGGCCATGGCGGCGAAGGTGGACCTGAGCACCTCCACCGACTGGAAGGAGGC GAAATCCTTTCTGAAGGGCCTGAGTGACAAGCAGCGGGAGGAACATTACTTCTGCAAGGACTTTGTCAGGCTGAAGAAGATCCCGACATG GAAGGAGATGGCGAAAGGGGTGGCTGTGAAGGTGGAGGAGCCCAGGTATAAAAAGGACAAGCAGCTCAATGAGAAAATCTCCCTGCTCCG CAGCGACATCACCAAGCTGGAGGTGGACGCCATCGTCAACGCCGAGGAATTACGGAGGTTGAGCTGGTCCGGAATCCCTAAGCCAGTGCG TCCAATGACGTGGAAGCTCCTCTCAGGTTACCTTCCCGCCAATGTAGACCGGAGACCAGCCACTCTCCAGAGAAAACAAAAAGAATATTT TGCATTTATTGAGCACTATTACGATTCTAGGAACGACGAAGTTCACCAGGACACATACAGGCAGATCCACATAGACATCCCTCGCATGAG CCCTGAAGCGTTGATCCTGCAGCCCAAGGTGACGGAGATTTTTGAAAGGATCTTGTTCATATGGGCGATCCGCCACCCAGCCAGTGGATA CGTTCAGGGTATAAATGATCTCGTCACTCCTTTCTTTGTGGTCTTCATTTGTGAATACATAGCCTTTCCAGGTTGTGGTCGGCCTCAGAT >50648_50648_7_MACROD1-TBC1D22A_MACROD1_chr11_63918711_ENST00000255681_TBC1D22A_chr22_47274549_ENST00000380995_length(amino acids)=332AA_BP=172 MSLQSRLSGRLAQLRAAGQLLVPPRPRPGHLAGATRTRSSTCGPPAFLGVFGRRARTSAGVGAWGAAAVGRTAGVRTWAPLAMAAKVDLS TSTDWKEAKSFLKGLSDKQREEHYFCKDFVRLKKIPTWKEMAKGVAVKVEEPRYKKDKQLNEKISLLRSDITKLEVDAIVNAEELRRLSW SGIPKPVRPMTWKLLSGYLPANVDRRPATLQRKQKEYFAFIEHYYDSRNDEVHQDTYRQIHIDIPRMSPEALILQPKVTEIFERILFIWA -------------------------------------------------------------- >50648_50648_8_MACROD1-TBC1D22A_MACROD1_chr11_63918711_ENST00000255681_TBC1D22A_chr22_47274549_ENST00000407381_length(transcript)=1958nt_BP=584nt GAGAGACACTCCCGAGCGCCGTAAATAGAGTCCAAGTGGGCGGAGAGCCGTCCCGCGCCGCCCGCTCATGTCTCTACAGAGCCGACTGTC CGGCCGCCTGGCACAGCTGCGCGCGGCGGGGCAGCTGCTCGTCCCCCCGCGCCCCCGGCCCGGACACTTGGCGGGTGCCACGAGGACCCG CAGCAGCACGTGCGGTCCCCCGGCGTTCCTGGGCGTGTTCGGCCGCCGTGCGCGGACCTCGGCGGGAGTTGGGGCGTGGGGGGCGGCGGC GGTGGGGCGGACAGCCGGGGTGCGCACTTGGGCCCCCCTGGCCATGGCGGCGAAGGTGGACCTGAGCACCTCCACCGACTGGAAGGAGGC GAAATCCTTTCTGAAGGGCCTGAGTGACAAGCAGCGGGAGGAACATTACTTCTGCAAGGACTTTGTCAGGCTGAAGAAGATCCCGACATG GAAGGAGATGGCGAAAGGGGTGGCTGTGAAGGTGGAGGAGCCCAGGTATAAAAAGGACAAGCAGCTCAATGAGAAAATCTCCCTGCTCCG CAGCGACATCACCAAGCTGGAGGTGGACGCCATCGTCAACGCCGAGGAATTACGGAGGTTGAGCTGGTCCGGAATCCCTAAGCCAGTGCG TCCAATGACGTGGAAGCTCCTCTCAGGTTACCTTCCCGCCAATGTAGACCGGAGACCAGCCACTCTCCAGAGAAAACAAAAAGAATATTT TGCATTTATTGAGCACTATTACGATTCTAGGAACGACGAAGTTCACCAGGACACATACAGGCAGATCCACATAGACATCCCTCGCATGAG CCCTGAAGCGTTGATCCTGCAGCCCAAGGTGACGGAGATTTTTGAAAGGATCTTGTTCATATGGGCGATCCGCCACCCAGCCAGTGGATA CGTTCAGGGTATAAATGATCTCGTCACTCCTTTCTTTGTGGTCTTCATTTGTGAATACATAGAGGCAGAGGAGGTGGACACGGTGGACGT CTCCGGCGTGCCCGCAGAGGTGCTGTGCAACATCGAGGCCGACACCTACTGGTGCATGAGCAAGCTGCTGGATGGCATTCAGGACAACTA CACCTTTGCCCAACCTGGGATTCAAATGAAAGTGAAAATGTTAGAAGAACTCGTGAGCCGGATTGATGAGCAAGTGCACCGGCACCTGGA CCAACACGAAGTGAGATACCTGCAGTTTGCCTTCCGCTGGATGAACAACCTGCTGATGAGGGAGGTGCCCCTGCGTTGTACCATCCGCCT GTGGGACACCTACCAGTCTGAACCGGACGGCTTTTCTCATTTCCACTTGTACGTGTGCGCTGCTTTTCTCGTGAGATGGAGGAAGGAAAT ACTAGAAGAAAAAGATTTTCAAGAGCTGCTGCTCTTCCTCCAGAACCTGCCCACAGCCCACTGGGATGATGAGGACATCAGCCTGTTGCT GGCCGAGGCCTACCGCCTCAAGTTTGCTTTTGCCGACGCCCCCAATCACTACAAGAAATGAGCCCAGGCCCACCCGCAGCTGGCCTCACT GTCCCGGGTGGCGCGCCCCACCTGCCTGGCTGGTGGTAGGCCCCTGTGAGCTGGTCCCGGGCTGCTAAAAGGCCTTGTGAGGTGGCCCCA CCCTCCAGGGGAGCTGGTGAAGATGGGCCACAGACCTGGTCTAGGGCTGACAAAGACAGGGACAGCCTTTGTTTTCTGAGATACCAAAGA GAGCCAGGGGAGGGCCCCGGGTTCGGCGGCCAGAGGCAGGTCAGGGGTCCCCTCTCCCTCTCCCTGCAATGTCCTTGCCAAATGACTGCC TCGTGCTGCCCCTAGTCCGGGGCAGCCTAGGAGGCCGACCCTCTTTGGAGTCCTGCTGTCTGGGTGCCAGGGCCGGAACGAGGTAGTGGC >50648_50648_8_MACROD1-TBC1D22A_MACROD1_chr11_63918711_ENST00000255681_TBC1D22A_chr22_47274549_ENST00000407381_length(amino acids)=477AA_BP=172 MSLQSRLSGRLAQLRAAGQLLVPPRPRPGHLAGATRTRSSTCGPPAFLGVFGRRARTSAGVGAWGAAAVGRTAGVRTWAPLAMAAKVDLS TSTDWKEAKSFLKGLSDKQREEHYFCKDFVRLKKIPTWKEMAKGVAVKVEEPRYKKDKQLNEKISLLRSDITKLEVDAIVNAEELRRLSW SGIPKPVRPMTWKLLSGYLPANVDRRPATLQRKQKEYFAFIEHYYDSRNDEVHQDTYRQIHIDIPRMSPEALILQPKVTEIFERILFIWA IRHPASGYVQGINDLVTPFFVVFICEYIEAEEVDTVDVSGVPAEVLCNIEADTYWCMSKLLDGIQDNYTFAQPGIQMKVKMLEELVSRID EQVHRHLDQHEVRYLQFAFRWMNNLLMREVPLRCTIRLWDTYQSEPDGFSHFHLYVCAAFLVRWRKEILEEKDFQELLLFLQNLPTAHWD -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for MACROD1-TBC1D22A |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for MACROD1-TBC1D22A |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for MACROD1-TBC1D22A |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies