
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:MCCC2-NNT (FusionGDB2 ID:52150) |
Fusion Gene Summary for MCCC2-NNT |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: MCCC2-NNT | Fusion gene ID: 52150 | Hgene | Tgene | Gene symbol | MCCC2 | NNT | Gene ID | 64087 | 23530 |
| Gene name | methylcrotonoyl-CoA carboxylase 2 | nicotinamide nucleotide transhydrogenase | |
| Synonyms | MCCB | GCCD4 | |
| Cytomap | 5q13.2 | 5p12 | |
| Type of gene | protein-coding | protein-coding | |
| Description | methylcrotonoyl-CoA carboxylase beta chain, mitochondrial3-methylcrotonyl-CoA carboxylase 23-methylcrotonyl-CoA carboxylase non-biotin-containing subunit3-methylcrotonyl-CoA:carbon dioxide ligase subunit betaMCCase subunit betabiotin carboxylasemeth | NAD(P) transhydrogenase, mitochondrialpyridine nucleotide transhydrogenase | |
| Modification date | 20200322 | 20200313 | |
| UniProtAcc | Q9HCC0 | Q13423 | |
| Ensembl transtripts involved in fusion gene | ENST00000510895, ENST00000323375, ENST00000340941, ENST00000509358, | ENST00000264663, ENST00000344920, ENST00000512996, | |
| Fusion gene scores | * DoF score | 4 X 5 X 3=60 | 9 X 6 X 6=324 |
| # samples | 5 | 9 | |
| ** MAII score | log2(5/60*10)=-0.263034405833794 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(9/324*10)=-1.84799690655495 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: MCCC2 [Title/Abstract] AND NNT [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | MCCC2(70900295)-NNT(43675613), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across MCCC2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across NNT (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
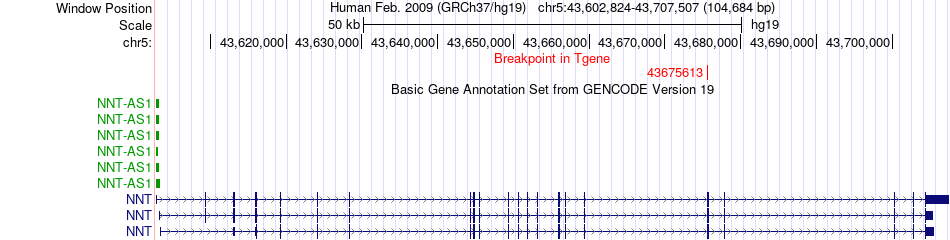 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | SKCM | TCGA-D3-A51N-06A | MCCC2 | chr5 | 70900295 | - | NNT | chr5 | 43675613 | + |
| ChimerDB4 | SKCM | TCGA-D3-A51N-06A | MCCC2 | chr5 | 70900295 | + | NNT | chr5 | 43675613 | + |
Top |
Fusion Gene ORF analysis for MCCC2-NNT |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000510895 | ENST00000264663 | MCCC2 | chr5 | 70900295 | + | NNT | chr5 | 43675613 | + |
| 3UTR-3CDS | ENST00000510895 | ENST00000344920 | MCCC2 | chr5 | 70900295 | + | NNT | chr5 | 43675613 | + |
| 3UTR-3CDS | ENST00000510895 | ENST00000512996 | MCCC2 | chr5 | 70900295 | + | NNT | chr5 | 43675613 | + |
| In-frame | ENST00000323375 | ENST00000264663 | MCCC2 | chr5 | 70900295 | + | NNT | chr5 | 43675613 | + |
| In-frame | ENST00000323375 | ENST00000344920 | MCCC2 | chr5 | 70900295 | + | NNT | chr5 | 43675613 | + |
| In-frame | ENST00000323375 | ENST00000512996 | MCCC2 | chr5 | 70900295 | + | NNT | chr5 | 43675613 | + |
| In-frame | ENST00000340941 | ENST00000264663 | MCCC2 | chr5 | 70900295 | + | NNT | chr5 | 43675613 | + |
| In-frame | ENST00000340941 | ENST00000344920 | MCCC2 | chr5 | 70900295 | + | NNT | chr5 | 43675613 | + |
| In-frame | ENST00000340941 | ENST00000512996 | MCCC2 | chr5 | 70900295 | + | NNT | chr5 | 43675613 | + |
| In-frame | ENST00000509358 | ENST00000264663 | MCCC2 | chr5 | 70900295 | + | NNT | chr5 | 43675613 | + |
| In-frame | ENST00000509358 | ENST00000344920 | MCCC2 | chr5 | 70900295 | + | NNT | chr5 | 43675613 | + |
| In-frame | ENST00000509358 | ENST00000512996 | MCCC2 | chr5 | 70900295 | + | NNT | chr5 | 43675613 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000340941 | MCCC2 | chr5 | 70900295 | + | ENST00000264663 | NNT | chr5 | 43675613 | + | 4381 | 753 | 129 | 1379 | 416 |
| ENST00000340941 | MCCC2 | chr5 | 70900295 | + | ENST00000344920 | NNT | chr5 | 43675613 | + | 2208 | 753 | 129 | 1379 | 416 |
| ENST00000340941 | MCCC2 | chr5 | 70900295 | + | ENST00000512996 | NNT | chr5 | 43675613 | + | 2462 | 753 | 129 | 1379 | 416 |
| ENST00000509358 | MCCC2 | chr5 | 70900295 | + | ENST00000264663 | NNT | chr5 | 43675613 | + | 4348 | 720 | 96 | 1346 | 416 |
| ENST00000509358 | MCCC2 | chr5 | 70900295 | + | ENST00000344920 | NNT | chr5 | 43675613 | + | 2175 | 720 | 96 | 1346 | 416 |
| ENST00000509358 | MCCC2 | chr5 | 70900295 | + | ENST00000512996 | NNT | chr5 | 43675613 | + | 2429 | 720 | 96 | 1346 | 416 |
| ENST00000323375 | MCCC2 | chr5 | 70900295 | + | ENST00000264663 | NNT | chr5 | 43675613 | + | 4310 | 682 | 58 | 1308 | 416 |
| ENST00000323375 | MCCC2 | chr5 | 70900295 | + | ENST00000344920 | NNT | chr5 | 43675613 | + | 2137 | 682 | 58 | 1308 | 416 |
| ENST00000323375 | MCCC2 | chr5 | 70900295 | + | ENST00000512996 | NNT | chr5 | 43675613 | + | 2391 | 682 | 58 | 1308 | 416 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000340941 | ENST00000264663 | MCCC2 | chr5 | 70900295 | + | NNT | chr5 | 43675613 | + | 0.000286581 | 0.99971336 |
| ENST00000340941 | ENST00000344920 | MCCC2 | chr5 | 70900295 | + | NNT | chr5 | 43675613 | + | 0.001591776 | 0.99840826 |
| ENST00000340941 | ENST00000512996 | MCCC2 | chr5 | 70900295 | + | NNT | chr5 | 43675613 | + | 0.001207039 | 0.9987929 |
| ENST00000509358 | ENST00000264663 | MCCC2 | chr5 | 70900295 | + | NNT | chr5 | 43675613 | + | 0.0002741 | 0.9997259 |
| ENST00000509358 | ENST00000344920 | MCCC2 | chr5 | 70900295 | + | NNT | chr5 | 43675613 | + | 0.001383605 | 0.99861634 |
| ENST00000509358 | ENST00000512996 | MCCC2 | chr5 | 70900295 | + | NNT | chr5 | 43675613 | + | 0.001106485 | 0.99889356 |
| ENST00000323375 | ENST00000264663 | MCCC2 | chr5 | 70900295 | + | NNT | chr5 | 43675613 | + | 0.000265257 | 0.9997347 |
| ENST00000323375 | ENST00000344920 | MCCC2 | chr5 | 70900295 | + | NNT | chr5 | 43675613 | + | 0.001201957 | 0.998798 |
| ENST00000323375 | ENST00000512996 | MCCC2 | chr5 | 70900295 | + | NNT | chr5 | 43675613 | + | 0.000985439 | 0.9990145 |
Top |
Fusion Genomic Features for MCCC2-NNT |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
 |
Top |
Fusion Protein Features for MCCC2-NNT |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr5:70900295/chr5:43675613) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| MCCC2 | NNT |
| FUNCTION: Carboxyltransferase subunit of the 3-methylcrotonyl-CoA carboxylase, an enzyme that catalyzes the conversion of 3-methylcrotonyl-CoA to 3-methylglutaconyl-CoA, a critical step for leucine and isovaleric acid catabolism. {ECO:0000269|PubMed:17360195}. | FUNCTION: The transhydrogenation between NADH and NADP is coupled to respiration and ATP hydrolysis and functions as a proton pump across the membrane (By similarity). May play a role in reactive oxygen species (ROS) detoxification in the adrenal gland (PubMed:22634753). {ECO:0000250|UniProtKB:P07001, ECO:0000269|PubMed:22634753}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000264663 | 16 | 22 | 1007_1011 | 878 | 1087.0 | Nucleotide binding | NADP | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000264663 | 16 | 22 | 1026_1027 | 878 | 1087.0 | Nucleotide binding | NADP | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000264663 | 16 | 22 | 1042_1049 | 878 | 1087.0 | Nucleotide binding | NADP | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000264663 | 16 | 22 | 1068_1069 | 878 | 1087.0 | Nucleotide binding | NADP | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000264663 | 16 | 22 | 965_970 | 878 | 1087.0 | Nucleotide binding | NADP | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000344920 | 16 | 22 | 1007_1011 | 878 | 1087.0 | Nucleotide binding | NADP | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000344920 | 16 | 22 | 1026_1027 | 878 | 1087.0 | Nucleotide binding | NADP | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000344920 | 16 | 22 | 1042_1049 | 878 | 1087.0 | Nucleotide binding | NADP | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000344920 | 16 | 22 | 1068_1069 | 878 | 1087.0 | Nucleotide binding | NADP | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000344920 | 16 | 22 | 965_970 | 878 | 1087.0 | Nucleotide binding | NADP | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000264663 | 16 | 22 | 880_1086 | 878 | 1087.0 | Topological domain | Mitochondrial matrix | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000344920 | 16 | 22 | 880_1086 | 878 | 1087.0 | Topological domain | Mitochondrial matrix |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | MCCC2 | chr5:70900295 | chr5:43675613 | ENST00000323375 | + | 6 | 16 | 309_555 | 208 | 526.0 | Domain | CoA carboxyltransferase C-terminal |
| Hgene | MCCC2 | chr5:70900295 | chr5:43675613 | ENST00000323375 | + | 6 | 16 | 49_306 | 208 | 526.0 | Domain | CoA carboxyltransferase N-terminal |
| Hgene | MCCC2 | chr5:70900295 | chr5:43675613 | ENST00000340941 | + | 6 | 17 | 309_555 | 208 | 564.0 | Domain | CoA carboxyltransferase C-terminal |
| Hgene | MCCC2 | chr5:70900295 | chr5:43675613 | ENST00000340941 | + | 6 | 17 | 49_306 | 208 | 564.0 | Domain | CoA carboxyltransferase N-terminal |
| Hgene | MCCC2 | chr5:70900295 | chr5:43675613 | ENST00000323375 | + | 6 | 16 | 343_372 | 208 | 526.0 | Region | Acyl-CoA binding |
| Hgene | MCCC2 | chr5:70900295 | chr5:43675613 | ENST00000323375 | + | 6 | 16 | 49_555 | 208 | 526.0 | Region | Carboxyltransferase |
| Hgene | MCCC2 | chr5:70900295 | chr5:43675613 | ENST00000340941 | + | 6 | 17 | 343_372 | 208 | 564.0 | Region | Acyl-CoA binding |
| Hgene | MCCC2 | chr5:70900295 | chr5:43675613 | ENST00000340941 | + | 6 | 17 | 49_555 | 208 | 564.0 | Region | Carboxyltransferase |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000264663 | 16 | 22 | 182_184 | 878 | 1087.0 | Nucleotide binding | NAD | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000264663 | 16 | 22 | 257_259 | 878 | 1087.0 | Nucleotide binding | NAD | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000344920 | 16 | 22 | 182_184 | 878 | 1087.0 | Nucleotide binding | NAD | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000344920 | 16 | 22 | 257_259 | 878 | 1087.0 | Nucleotide binding | NAD | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000264663 | 16 | 22 | 44_474 | 878 | 1087.0 | Topological domain | Mitochondrial matrix | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000264663 | 16 | 22 | 579_595 | 878 | 1087.0 | Topological domain | Mitochondrial matrix | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000264663 | 16 | 22 | 723_739 | 878 | 1087.0 | Topological domain | Cytoplasmic | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000344920 | 16 | 22 | 44_474 | 878 | 1087.0 | Topological domain | Mitochondrial matrix | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000344920 | 16 | 22 | 579_595 | 878 | 1087.0 | Topological domain | Mitochondrial matrix | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000344920 | 16 | 22 | 723_739 | 878 | 1087.0 | Topological domain | Cytoplasmic | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000264663 | 16 | 22 | 475_493 | 878 | 1087.0 | Transmembrane | Helical | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000264663 | 16 | 22 | 501_521 | 878 | 1087.0 | Transmembrane | Helical | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000264663 | 16 | 22 | 527_546 | 878 | 1087.0 | Transmembrane | Helical | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000264663 | 16 | 22 | 558_578 | 878 | 1087.0 | Transmembrane | Helical | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000264663 | 16 | 22 | 596_616 | 878 | 1087.0 | Transmembrane | Helical | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000264663 | 16 | 22 | 622_642 | 878 | 1087.0 | Transmembrane | Helical | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000264663 | 16 | 22 | 646_666 | 878 | 1087.0 | Transmembrane | Helical | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000264663 | 16 | 22 | 672_691 | 878 | 1087.0 | Transmembrane | Helical | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000264663 | 16 | 22 | 702_722 | 878 | 1087.0 | Transmembrane | Helical | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000264663 | 16 | 22 | 740_760 | 878 | 1087.0 | Transmembrane | Helical | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000264663 | 16 | 22 | 778_797 | 878 | 1087.0 | Transmembrane | Helical | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000264663 | 16 | 22 | 801_819 | 878 | 1087.0 | Transmembrane | Helical | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000264663 | 16 | 22 | 833_853 | 878 | 1087.0 | Transmembrane | Helical | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000264663 | 16 | 22 | 857_879 | 878 | 1087.0 | Transmembrane | Helical | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000344920 | 16 | 22 | 475_493 | 878 | 1087.0 | Transmembrane | Helical | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000344920 | 16 | 22 | 501_521 | 878 | 1087.0 | Transmembrane | Helical | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000344920 | 16 | 22 | 527_546 | 878 | 1087.0 | Transmembrane | Helical | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000344920 | 16 | 22 | 558_578 | 878 | 1087.0 | Transmembrane | Helical | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000344920 | 16 | 22 | 596_616 | 878 | 1087.0 | Transmembrane | Helical | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000344920 | 16 | 22 | 622_642 | 878 | 1087.0 | Transmembrane | Helical | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000344920 | 16 | 22 | 646_666 | 878 | 1087.0 | Transmembrane | Helical | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000344920 | 16 | 22 | 672_691 | 878 | 1087.0 | Transmembrane | Helical | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000344920 | 16 | 22 | 702_722 | 878 | 1087.0 | Transmembrane | Helical | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000344920 | 16 | 22 | 740_760 | 878 | 1087.0 | Transmembrane | Helical | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000344920 | 16 | 22 | 778_797 | 878 | 1087.0 | Transmembrane | Helical | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000344920 | 16 | 22 | 801_819 | 878 | 1087.0 | Transmembrane | Helical | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000344920 | 16 | 22 | 833_853 | 878 | 1087.0 | Transmembrane | Helical | |
| Tgene | NNT | chr5:70900295 | chr5:43675613 | ENST00000344920 | 16 | 22 | 857_879 | 878 | 1087.0 | Transmembrane | Helical |
Top |
Fusion Gene Sequence for MCCC2-NNT |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >52150_52150_1_MCCC2-NNT_MCCC2_chr5_70900295_ENST00000323375_NNT_chr5_43675613_ENST00000264663_length(transcript)=4310nt_BP=682nt GGGGAAAGCACCGGCTCCAGGCCAGCGTGGGCCGCTCTCTCGCTCGGTGCCCGCCGCCATGTGGGCCGTCCTGAGGTTAGCCCTGCGGCC GTGTGCCCGCGCCTCTCCCGCCGGGCCGCGCGCCTATCACGGGGACTCGGTGGCCTCGCTGGGCACCCAGCCGGACTTGGGCTCTGCCCT CTACCAGGAGAACTACAAGCAGATGAAAGCACTAGTAAATCAGCTCCATGAACGAGTGGAGCATATAAAACTAGGAGGTGGTGAGAAAGC CCGAGCACTTCACATATCAAGAGGAAAACTATTGCCCAGAGAAAGAATTGACAATCTCATAGACCCAGGGTCTCCATTTCTGGAATTATC CCAGTTTGCAGGTTACCAGTTATATGACAATGAGGAGGTGCCAGGAGGTGGCATTATTACAGGCATTGGAAGAGTATCAGGAGTAGAATG CATGATTATTGCCAATGATGCCACCGTCAAAGGAGGTGCCTACTACCCAGTGACTGTGAAAAAACAATTACGGGCCCAAGAAATTGCCAT GCAAAACAGGCTCCCCTGCATCTACTTAGTTGATTCGGGAGGAGCATACTTACCTCGACAAGCAGATGTGTTTCCAGATCGAGACCACTT TGGCCGTACATTCTATAATCAGGCAATTATGTCTTCTAAAAATATTGCACAGGCAATGAATCGCTCCCTGGCTAATGTGATTCTTGGAGG CTATGGCACCACTTCAACAGCTGGTGGAAAACCCATGGAAATTTCTGGCACACATACGGAAATCAACCTTGACAATGCAATTGACATGAT TCGAGAAGCTAATAGCATTATTATTACACCAGGCTATGGTCTCTGTGCAGCCAAAGCTCAATACCCCATTGCTGATTTGGTAAAGATGCT CACTGAGCAAGGCAAAAAAGTCAGGTTTGGAATTCACCCAGTTGCAGGCCGAATGCCTGGTCAGCTTAATGTGCTGCTGGCTGAGGCTGG TGTGCCATATGACATTGTGTTGGAAATGGATGAGATCAACCATGATTTTCCAGATACTGATTTGGTCCTTGTAATTGGAGCTAATGACAC TGTTAATTCAGCAGCTCAAGAAGATCCCAACTCTATTATTGCAGGCATGCCAGTCCTTGAGGTCTGGAAATCAAAGCAGGTGATTGTTAT GAAGAGGTCTTTGGGTGTTGGCTATGCTGCAGTGGACAATCCAATCTTCTACAAACCTAACACGGCCATGCTTCTAGGTGATGCCAAGAA AACATGTGACGCGCTCCAGGCGAAAGTTAGAGAATCCTATCAGAAGTAAATATTAAGGATCAAGCTGTTAGCTAATAATGCCACCTCTGC AGTTTTGGGAACAGGCAAATAAAGTATCAGTATACATGGTGATGTACATCTGTAGCAAAGCTCTTGGAGAAAATGAAGACTGAAGAAAGC AAAGCAAAAACTGTATAGAGAGATTTTTCAAAAGCAGTAATCCCTCAATTTTAAAAAAGGATTGAAAATTCTAAATGTCTTTCTGTGCAT ATTTTTTGTGTTAGGAATCAAAAGTATTTTATAAAAGGAGAAAGAACAGCCTCATTTTAGATGTAGTCCTGTTGGATTTTTTATGCCTCC TCAGTAACCAGAAATGTTTTAAAAAACTAAGTGTTTAGGATTTCAAGACAACATTATACATGGCTCTGAAATATCTGACACAATGTAAAC ATTGCAGGCACCTGCATTTTATGTTTTTTTTTTCAACAAATGTGACTAATTTGAAACTTTTATGAACTTCTGAGCTGTCCCCTTGCAATT CAACCGCAGTTTGAATTAATCATATCAAATCAGTTTTAATTTTTTAAATTGTACTTCAGAGTCTATATTTCAAGGGCACATTTTCTCACT ACTATTTTAATACATTAAAGGACTAAATAATCTTTCAGAGATGCTGGAAACAAATCATTTGCTTTATATGTTTCATTAGAATACCAATGA AACATACAACTTGAAAATTAGTAATAGTATTTTTGAAGATCCCATTTCTAATTGGAGATCTCTTTAATTTCGATCAACTTATAATGTGTA GTACTATATTAAGTGCACTTGAGTGGAATTCAACATTTGACTAATAAAATGAGTTCATCATGTTGGCAAGTGATGTGGCAATTATCTCTG GTGACAAAAGAGTAAAATCAAATATTTCTGCCTGTTACAAATATCAAGGAAGACCTGCTACTATGAAATAGATGACATTAATCTGTCTTC ACTGTTTATAATACGGATGGATTTTTTTTCAAATCAGTGTGTGTTTTGAGGTCTTATGTAATTGATGACATTTGAGAGAAATGGTGGCTT TTTTTAGCTACCTCTTTGTTCATTTAAGCACCAGTAAAGATCATGTCTTTTTATAGAAGTGTAGATTTTCTTTGTGACTTTGCTATCGTG CCTAAAGCTCTAAATATAGGTGAATGTGTGATGAATACTCAGATTATTTGTCTCTCTATATAATTAGTTTGGTACTAAGTTTCTCAAAAA ATTATTAACACATGAAAGACAATCTCTAAACCAGAAAAAGAAGTAGTACAAATTTTGTTACTGTAATGCTCGCGTTTAGTGAGTTTAAAA CACACAGTATCTTTTGGTTTTATAATCAGTTTCTATTTTGCTGTGCCTGAGATTAAGATCTGTGTATGTGTGTGTGTGTGTGTGTGCGTT TGTGTGTTAAAGCAGAAAAGACTTTTTTAAAAGTTTTAAGTGATAAATGCAATTTGTTAATTGATCTTAGATCACTAGTAAACTCAGGGC TGAATTATACCATGTATATTCTATTAGAAGAAAGTAAACACCATCTTTATTCCTGCCCTTTTTCTTCTCTCAAAGTAGTTGTAGTTATAT CTAGAAAGAAGCAATTTTGATTTCTTGAAAAGGTAGTTCCTGCACTCAGTTTAAACTAAAAATAATCATACTTGGATTTTATTTATTTTT GTCATAGTAAAAATTTTAATTTATATATATTTTTATTTAGTATTATCTTATTCTTTGCTATTTGCCAATCCTTTGTCATCAATTGTGTTA AATGAATTGAAAATTCATGCCCTGTTCATTTTATTTTACTTTATTGGTTAGGATATTTAAAGGATTTTTGTATATATAATTTCTTAAATT AATATTCCAAAAGGTTAGTGGACTTAGATTATAAATTATGGCAAAAATCTAAAAACAACAAAAATGATTTTTATACATTCTATTTCATTA TTCCTCTTTTTCCAATAAGTCATACAATTGGTAGATATGACTTATTTTATTTTTGTATTATTCACTATATCTTTATGATATTTAAGTATA AATAATTAAAAAAATTTATTGTACCTTATAGTCTGTCACCAAAAAAAAAAAATTATCTGTAGGTAGTGAAATGCTAATGTTGATTTGTCT TTAAGGGCTTGTTAACTATCCTTTATTTTCTCATTTGTCTTAAATTAGGAGTTTGTGTTTAAATTACTCATCTAAGCAAAAAATGTATAT AAATCCCATTACTGGGTATATACCCAAAGGATTATAAATCATGCTGCTATAAAGACACATGCACACGTATGTTTATTGCAGCACTATTCA CAATAGCAAAGACTTGGAACCAACCCAAATGTCCATCAATGATAGACTTGATTAAGAAAATGTGCACATATACACCATGGAATACTATGC AGCCATAAAAAAGGATGAGTTCATGTCCTTTGTAGGGACATGGATAAAGCTGGAAACCATCATTCTGAGCAAACTATTGCAAGGACAGAA AACCAAACACTGCATGTTCTCACTCATAGGTGGGAATTGAACAATGAGAACACTTGGACACAAGGTGGGGAACACCACACACCAGGGCCT GTCATGGGGTGGGGGGAGTGGGGAGGGATAGCATTAGGAGATATACCTAATGTAAATGATGAGTTAATGGGTGCAGCACACCAACATGGC ACATGTATACATATGTAGCAAACCTGCACGTTGTGCACATGTACCCTAGAACTTAAAGTATAATTAAAAAAAAAAAGAAAACAGAAGCTA TTTATAAAGAAGTTATTTGCTGAAATAAATGTGATCTTTCCCATTAAAAAAATAAAGAAATTTTGGGGTAAAAAAACACAATATATTGTA TTCTTGAAAAATTCTAAGAGAGTGGATGTGAAGTGTTCTCACCACAAAAGTGATAACTAATTGAGGTAATGCACATATTAATTAGAAAGA >52150_52150_1_MCCC2-NNT_MCCC2_chr5_70900295_ENST00000323375_NNT_chr5_43675613_ENST00000264663_length(amino acids)=416AA_BP=208 MWAVLRLALRPCARASPAGPRAYHGDSVASLGTQPDLGSALYQENYKQMKALVNQLHERVEHIKLGGGEKARALHISRGKLLPRERIDNL IDPGSPFLELSQFAGYQLYDNEEVPGGGIITGIGRVSGVECMIIANDATVKGGAYYPVTVKKQLRAQEIAMQNRLPCIYLVDSGGAYLPR QADVFPDRDHFGRTFYNQAIMSSKNIAQAMNRSLANVILGGYGTTSTAGGKPMEISGTHTEINLDNAIDMIREANSIIITPGYGLCAAKA QYPIADLVKMLTEQGKKVRFGIHPVAGRMPGQLNVLLAEAGVPYDIVLEMDEINHDFPDTDLVLVIGANDTVNSAAQEDPNSIIAGMPVL -------------------------------------------------------------- >52150_52150_2_MCCC2-NNT_MCCC2_chr5_70900295_ENST00000323375_NNT_chr5_43675613_ENST00000344920_length(transcript)=2137nt_BP=682nt GGGGAAAGCACCGGCTCCAGGCCAGCGTGGGCCGCTCTCTCGCTCGGTGCCCGCCGCCATGTGGGCCGTCCTGAGGTTAGCCCTGCGGCC GTGTGCCCGCGCCTCTCCCGCCGGGCCGCGCGCCTATCACGGGGACTCGGTGGCCTCGCTGGGCACCCAGCCGGACTTGGGCTCTGCCCT CTACCAGGAGAACTACAAGCAGATGAAAGCACTAGTAAATCAGCTCCATGAACGAGTGGAGCATATAAAACTAGGAGGTGGTGAGAAAGC CCGAGCACTTCACATATCAAGAGGAAAACTATTGCCCAGAGAAAGAATTGACAATCTCATAGACCCAGGGTCTCCATTTCTGGAATTATC CCAGTTTGCAGGTTACCAGTTATATGACAATGAGGAGGTGCCAGGAGGTGGCATTATTACAGGCATTGGAAGAGTATCAGGAGTAGAATG CATGATTATTGCCAATGATGCCACCGTCAAAGGAGGTGCCTACTACCCAGTGACTGTGAAAAAACAATTACGGGCCCAAGAAATTGCCAT GCAAAACAGGCTCCCCTGCATCTACTTAGTTGATTCGGGAGGAGCATACTTACCTCGACAAGCAGATGTGTTTCCAGATCGAGACCACTT TGGCCGTACATTCTATAATCAGGCAATTATGTCTTCTAAAAATATTGCACAGGCAATGAATCGCTCCCTGGCTAATGTGATTCTTGGAGG CTATGGCACCACTTCAACAGCTGGTGGAAAACCCATGGAAATTTCTGGCACACATACGGAAATCAACCTTGACAATGCAATTGACATGAT TCGAGAAGCTAATAGCATTATTATTACACCAGGCTATGGTCTCTGTGCAGCCAAAGCTCAATACCCCATTGCTGATTTGGTAAAGATGCT CACTGAGCAAGGCAAAAAAGTCAGGTTTGGAATTCACCCAGTTGCAGGCCGAATGCCTGGTCAGCTTAATGTGCTGCTGGCTGAGGCTGG TGTGCCATATGACATTGTGTTGGAAATGGATGAGATCAACCATGATTTTCCAGATACTGATTTGGTCCTTGTAATTGGAGCTAATGACAC TGTTAATTCAGCAGCTCAAGAAGATCCCAACTCTATTATTGCAGGCATGCCAGTCCTTGAGGTCTGGAAATCAAAGCAGGTGATTGTTAT GAAGAGGTCTTTGGGTGTTGGCTATGCTGCAGTGGACAATCCAATCTTCTACAAACCTAACACGGCCATGCTTCTAGGTGATGCCAAGAA AACATGTGACGCGCTCCAGGCGAAAGTTAGAGAATCCTATCAGAAGTAAATATTAAGGATCAAGCTGTTAGCTAATAATGCCACCTCTGC AGTTTTGGGAACAGGCAAATAAAGTATCAGTATACATGGTGATGTACATCTGTAGCAAAGCTCTTGGAGAAAATGAAGACTGAAGAAAGC AAAGCAAAAACTGTATAGAGAGATTTTTCAAAAGCAGTAATCCCTCAATTTTAAAAAAGGATTGAAAATTCTAAATGTCTTTCTGTGCAT ATTTTTTGTGTTAGGAATCAAAAGTATTTTATAAAAGGAGAAAGAACAGCCTCATTTTAGATGTAGTCCTGTTGGATTTTTTATGCCTCC TCAGTAACCAGAAATGTTTTAAAAAACTAAGTGTTTAGGATTTCAAGACAACATTATACATGGCTCTGAAATATCTGACACAATGTAAAC ATTGCAGGCACCTGCATTTTATGTTTTTTTTTTCAACAAATGTGACTAATTTGAAACTTTTATGAACTTCTGAGCTGTCCCCTTGCAATT CAACCGCAGTTTGAATTAATCATATCAAATCAGTTTTAATTTTTTAAATTGTACTTCAGAGTCTATATTTCAAGGGCACATTTTCTCACT ACTATTTTAATACATTAAAGGACTAAATAATCTTTCAGAGATGCTGGAAACAAATCATTTGCTTTATATGTTTCATTAGAATACCAATGA AACATACAACTTGAAAATTAGTAATAGTATTTTTGAAGATCCCATTTCTAATTGGAGATCTCTTTAATTTCGATCAACTTATAATGTGTA >52150_52150_2_MCCC2-NNT_MCCC2_chr5_70900295_ENST00000323375_NNT_chr5_43675613_ENST00000344920_length(amino acids)=416AA_BP=208 MWAVLRLALRPCARASPAGPRAYHGDSVASLGTQPDLGSALYQENYKQMKALVNQLHERVEHIKLGGGEKARALHISRGKLLPRERIDNL IDPGSPFLELSQFAGYQLYDNEEVPGGGIITGIGRVSGVECMIIANDATVKGGAYYPVTVKKQLRAQEIAMQNRLPCIYLVDSGGAYLPR QADVFPDRDHFGRTFYNQAIMSSKNIAQAMNRSLANVILGGYGTTSTAGGKPMEISGTHTEINLDNAIDMIREANSIIITPGYGLCAAKA QYPIADLVKMLTEQGKKVRFGIHPVAGRMPGQLNVLLAEAGVPYDIVLEMDEINHDFPDTDLVLVIGANDTVNSAAQEDPNSIIAGMPVL -------------------------------------------------------------- >52150_52150_3_MCCC2-NNT_MCCC2_chr5_70900295_ENST00000323375_NNT_chr5_43675613_ENST00000512996_length(transcript)=2391nt_BP=682nt GGGGAAAGCACCGGCTCCAGGCCAGCGTGGGCCGCTCTCTCGCTCGGTGCCCGCCGCCATGTGGGCCGTCCTGAGGTTAGCCCTGCGGCC GTGTGCCCGCGCCTCTCCCGCCGGGCCGCGCGCCTATCACGGGGACTCGGTGGCCTCGCTGGGCACCCAGCCGGACTTGGGCTCTGCCCT CTACCAGGAGAACTACAAGCAGATGAAAGCACTAGTAAATCAGCTCCATGAACGAGTGGAGCATATAAAACTAGGAGGTGGTGAGAAAGC CCGAGCACTTCACATATCAAGAGGAAAACTATTGCCCAGAGAAAGAATTGACAATCTCATAGACCCAGGGTCTCCATTTCTGGAATTATC CCAGTTTGCAGGTTACCAGTTATATGACAATGAGGAGGTGCCAGGAGGTGGCATTATTACAGGCATTGGAAGAGTATCAGGAGTAGAATG CATGATTATTGCCAATGATGCCACCGTCAAAGGAGGTGCCTACTACCCAGTGACTGTGAAAAAACAATTACGGGCCCAAGAAATTGCCAT GCAAAACAGGCTCCCCTGCATCTACTTAGTTGATTCGGGAGGAGCATACTTACCTCGACAAGCAGATGTGTTTCCAGATCGAGACCACTT TGGCCGTACATTCTATAATCAGGCAATTATGTCTTCTAAAAATATTGCACAGGCAATGAATCGCTCCCTGGCTAATGTGATTCTTGGAGG CTATGGCACCACTTCAACAGCTGGTGGAAAACCCATGGAAATTTCTGGCACACATACGGAAATCAACCTTGACAATGCAATTGACATGAT TCGAGAAGCTAATAGCATTATTATTACACCAGGCTATGGTCTCTGTGCAGCCAAAGCTCAATACCCCATTGCTGATTTGGTAAAGATGCT CACTGAGCAAGGCAAAAAAGTCAGGTTTGGAATTCACCCAGTTGCAGGCCGAATGCCTGGTCAGCTTAATGTGCTGCTGGCTGAGGCTGG TGTGCCATATGACATTGTGTTGGAAATGGATGAGATCAACCATGATTTTCCAGATACTGATTTGGTCCTTGTAATTGGAGCTAATGACAC TGTTAATTCAGCAGCTCAAGAAGATCCCAACTCTATTATTGCAGGCATGCCAGTCCTTGAGGTCTGGAAATCAAAGCAGGTGATTGTTAT GAAGAGGTCTTTGGGTGTTGGCTATGCTGCAGTGGACAATCCAATCTTCTACAAACCTAACACGGCCATGCTTCTAGGTGATGCCAAGAA AACATGTGACGCGCTCCAGGCGAAAGTTAGAGAATCCTATCAGAAGTAAATATTAAGGATCAAGCTGTTAGCTAATAATGCCACCTCTGC AGTTTTGGGAACAGGCAAATAAAGTATCAGTATACATGGTGATGTACATCTGTAGCAAAGCTCTTGGAGAAAATGAAGACTGAAGAAAGC AAAGCAAAAACTGTATAGAGAGATTTTTCAAAAGCAGTAATCCCTCAATTTTAAAAAAGGATTGAAAATTCTAAATGTCTTTCTGTGCAT ATTTTTTGTGTTAGGAATCAAAAGTATTTTATAAAAGGAGAAAGAACAGCCTCATTTTAGATGTAGTCCTGTTGGATTTTTTATGCCTCC TCAGTAACCAGAAATGTTTTAAAAAACTAAGTGTTTAGGATTTCAAGACAACATTATACATGGCTCTGAAATATCTGACACAATGTAAAC ATTGCAGGCACCTGCATTTTATGTTTTTTTTTTCAACAAATGTGACTAATTTGAAACTTTTATGAACTTCTGAGCTGTCCCCTTGCAATT CAACCGCAGTTTGAATTAATCATATCAAATCAGTTTTAATTTTTTAAATTGTACTTCAGAGTCTATATTTCAAGGGCACATTTTCTCACT ACTATTTTAATACATTAAAGGACTAAATAATCTTTCAGAGATGCTGGAAACAAATCATTTGCTTTATATGTTTCATTAGAATACCAATGA AACATACAACTTGAAAATTAGTAATAGTATTTTTGAAGATCCCATTTCTAATTGGAGATCTCTTTAATTTCGATCAACTTATAATGTGTA GTACTATATTAAGTGCACTTGAGTGGAATTCAACATTTGACTAATAAAATGAGTTCATCATGTTGGCAAGTGATGTGGCAATTATCTCTG GTGACAAAAGAGTAAAATCAAATATTTCTGCCTGTTACAAATATCAAGGAAGACCTGCTACTATGAAATAGATGACATTAATCTGTCTTC ACTGTTTATAATACGGATGGATTTTTTTTCAAATCAGTGTGTGTTTTGAGGTCTTATGTAATTGATGACATTTGAGAGAAATGGTGGCTT >52150_52150_3_MCCC2-NNT_MCCC2_chr5_70900295_ENST00000323375_NNT_chr5_43675613_ENST00000512996_length(amino acids)=416AA_BP=208 MWAVLRLALRPCARASPAGPRAYHGDSVASLGTQPDLGSALYQENYKQMKALVNQLHERVEHIKLGGGEKARALHISRGKLLPRERIDNL IDPGSPFLELSQFAGYQLYDNEEVPGGGIITGIGRVSGVECMIIANDATVKGGAYYPVTVKKQLRAQEIAMQNRLPCIYLVDSGGAYLPR QADVFPDRDHFGRTFYNQAIMSSKNIAQAMNRSLANVILGGYGTTSTAGGKPMEISGTHTEINLDNAIDMIREANSIIITPGYGLCAAKA QYPIADLVKMLTEQGKKVRFGIHPVAGRMPGQLNVLLAEAGVPYDIVLEMDEINHDFPDTDLVLVIGANDTVNSAAQEDPNSIIAGMPVL -------------------------------------------------------------- >52150_52150_4_MCCC2-NNT_MCCC2_chr5_70900295_ENST00000340941_NNT_chr5_43675613_ENST00000264663_length(transcript)=4381nt_BP=753nt AGAATCAGAGAAACCTTCTCTGGGGCTGCAAGGACCTGAGCTCAGCTTCCGCCCCAGCCAGGGAAGCGGCAGGGGAAAGCACCGGCTCCA GGCCAGCGTGGGCCGCTCTCTCGCTCGGTGCCCGCCGCCATGTGGGCCGTCCTGAGGTTAGCCCTGCGGCCGTGTGCCCGCGCCTCTCCC GCCGGGCCGCGCGCCTATCACGGGGACTCGGTGGCCTCGCTGGGCACCCAGCCGGACTTGGGCTCTGCCCTCTACCAGGAGAACTACAAG CAGATGAAAGCACTAGTAAATCAGCTCCATGAACGAGTGGAGCATATAAAACTAGGAGGTGGTGAGAAAGCCCGAGCACTTCACATATCA AGAGGAAAACTATTGCCCAGAGAAAGAATTGACAATCTCATAGACCCAGGGTCTCCATTTCTGGAATTATCCCAGTTTGCAGGTTACCAG TTATATGACAATGAGGAGGTGCCAGGAGGTGGCATTATTACAGGCATTGGAAGAGTATCAGGAGTAGAATGCATGATTATTGCCAATGAT GCCACCGTCAAAGGAGGTGCCTACTACCCAGTGACTGTGAAAAAACAATTACGGGCCCAAGAAATTGCCATGCAAAACAGGCTCCCCTGC ATCTACTTAGTTGATTCGGGAGGAGCATACTTACCTCGACAAGCAGATGTGTTTCCAGATCGAGACCACTTTGGCCGTACATTCTATAAT CAGGCAATTATGTCTTCTAAAAATATTGCACAGGCAATGAATCGCTCCCTGGCTAATGTGATTCTTGGAGGCTATGGCACCACTTCAACA GCTGGTGGAAAACCCATGGAAATTTCTGGCACACATACGGAAATCAACCTTGACAATGCAATTGACATGATTCGAGAAGCTAATAGCATT ATTATTACACCAGGCTATGGTCTCTGTGCAGCCAAAGCTCAATACCCCATTGCTGATTTGGTAAAGATGCTCACTGAGCAAGGCAAAAAA GTCAGGTTTGGAATTCACCCAGTTGCAGGCCGAATGCCTGGTCAGCTTAATGTGCTGCTGGCTGAGGCTGGTGTGCCATATGACATTGTG TTGGAAATGGATGAGATCAACCATGATTTTCCAGATACTGATTTGGTCCTTGTAATTGGAGCTAATGACACTGTTAATTCAGCAGCTCAA GAAGATCCCAACTCTATTATTGCAGGCATGCCAGTCCTTGAGGTCTGGAAATCAAAGCAGGTGATTGTTATGAAGAGGTCTTTGGGTGTT GGCTATGCTGCAGTGGACAATCCAATCTTCTACAAACCTAACACGGCCATGCTTCTAGGTGATGCCAAGAAAACATGTGACGCGCTCCAG GCGAAAGTTAGAGAATCCTATCAGAAGTAAATATTAAGGATCAAGCTGTTAGCTAATAATGCCACCTCTGCAGTTTTGGGAACAGGCAAA TAAAGTATCAGTATACATGGTGATGTACATCTGTAGCAAAGCTCTTGGAGAAAATGAAGACTGAAGAAAGCAAAGCAAAAACTGTATAGA GAGATTTTTCAAAAGCAGTAATCCCTCAATTTTAAAAAAGGATTGAAAATTCTAAATGTCTTTCTGTGCATATTTTTTGTGTTAGGAATC AAAAGTATTTTATAAAAGGAGAAAGAACAGCCTCATTTTAGATGTAGTCCTGTTGGATTTTTTATGCCTCCTCAGTAACCAGAAATGTTT TAAAAAACTAAGTGTTTAGGATTTCAAGACAACATTATACATGGCTCTGAAATATCTGACACAATGTAAACATTGCAGGCACCTGCATTT TATGTTTTTTTTTTCAACAAATGTGACTAATTTGAAACTTTTATGAACTTCTGAGCTGTCCCCTTGCAATTCAACCGCAGTTTGAATTAA TCATATCAAATCAGTTTTAATTTTTTAAATTGTACTTCAGAGTCTATATTTCAAGGGCACATTTTCTCACTACTATTTTAATACATTAAA GGACTAAATAATCTTTCAGAGATGCTGGAAACAAATCATTTGCTTTATATGTTTCATTAGAATACCAATGAAACATACAACTTGAAAATT AGTAATAGTATTTTTGAAGATCCCATTTCTAATTGGAGATCTCTTTAATTTCGATCAACTTATAATGTGTAGTACTATATTAAGTGCACT TGAGTGGAATTCAACATTTGACTAATAAAATGAGTTCATCATGTTGGCAAGTGATGTGGCAATTATCTCTGGTGACAAAAGAGTAAAATC AAATATTTCTGCCTGTTACAAATATCAAGGAAGACCTGCTACTATGAAATAGATGACATTAATCTGTCTTCACTGTTTATAATACGGATG GATTTTTTTTCAAATCAGTGTGTGTTTTGAGGTCTTATGTAATTGATGACATTTGAGAGAAATGGTGGCTTTTTTTAGCTACCTCTTTGT TCATTTAAGCACCAGTAAAGATCATGTCTTTTTATAGAAGTGTAGATTTTCTTTGTGACTTTGCTATCGTGCCTAAAGCTCTAAATATAG GTGAATGTGTGATGAATACTCAGATTATTTGTCTCTCTATATAATTAGTTTGGTACTAAGTTTCTCAAAAAATTATTAACACATGAAAGA CAATCTCTAAACCAGAAAAAGAAGTAGTACAAATTTTGTTACTGTAATGCTCGCGTTTAGTGAGTTTAAAACACACAGTATCTTTTGGTT TTATAATCAGTTTCTATTTTGCTGTGCCTGAGATTAAGATCTGTGTATGTGTGTGTGTGTGTGTGTGCGTTTGTGTGTTAAAGCAGAAAA GACTTTTTTAAAAGTTTTAAGTGATAAATGCAATTTGTTAATTGATCTTAGATCACTAGTAAACTCAGGGCTGAATTATACCATGTATAT TCTATTAGAAGAAAGTAAACACCATCTTTATTCCTGCCCTTTTTCTTCTCTCAAAGTAGTTGTAGTTATATCTAGAAAGAAGCAATTTTG ATTTCTTGAAAAGGTAGTTCCTGCACTCAGTTTAAACTAAAAATAATCATACTTGGATTTTATTTATTTTTGTCATAGTAAAAATTTTAA TTTATATATATTTTTATTTAGTATTATCTTATTCTTTGCTATTTGCCAATCCTTTGTCATCAATTGTGTTAAATGAATTGAAAATTCATG CCCTGTTCATTTTATTTTACTTTATTGGTTAGGATATTTAAAGGATTTTTGTATATATAATTTCTTAAATTAATATTCCAAAAGGTTAGT GGACTTAGATTATAAATTATGGCAAAAATCTAAAAACAACAAAAATGATTTTTATACATTCTATTTCATTATTCCTCTTTTTCCAATAAG TCATACAATTGGTAGATATGACTTATTTTATTTTTGTATTATTCACTATATCTTTATGATATTTAAGTATAAATAATTAAAAAAATTTAT TGTACCTTATAGTCTGTCACCAAAAAAAAAAAATTATCTGTAGGTAGTGAAATGCTAATGTTGATTTGTCTTTAAGGGCTTGTTAACTAT CCTTTATTTTCTCATTTGTCTTAAATTAGGAGTTTGTGTTTAAATTACTCATCTAAGCAAAAAATGTATATAAATCCCATTACTGGGTAT ATACCCAAAGGATTATAAATCATGCTGCTATAAAGACACATGCACACGTATGTTTATTGCAGCACTATTCACAATAGCAAAGACTTGGAA CCAACCCAAATGTCCATCAATGATAGACTTGATTAAGAAAATGTGCACATATACACCATGGAATACTATGCAGCCATAAAAAAGGATGAG TTCATGTCCTTTGTAGGGACATGGATAAAGCTGGAAACCATCATTCTGAGCAAACTATTGCAAGGACAGAAAACCAAACACTGCATGTTC TCACTCATAGGTGGGAATTGAACAATGAGAACACTTGGACACAAGGTGGGGAACACCACACACCAGGGCCTGTCATGGGGTGGGGGGAGT GGGGAGGGATAGCATTAGGAGATATACCTAATGTAAATGATGAGTTAATGGGTGCAGCACACCAACATGGCACATGTATACATATGTAGC AAACCTGCACGTTGTGCACATGTACCCTAGAACTTAAAGTATAATTAAAAAAAAAAAGAAAACAGAAGCTATTTATAAAGAAGTTATTTG CTGAAATAAATGTGATCTTTCCCATTAAAAAAATAAAGAAATTTTGGGGTAAAAAAACACAATATATTGTATTCTTGAAAAATTCTAAGA GAGTGGATGTGAAGTGTTCTCACCACAAAAGTGATAACTAATTGAGGTAATGCACATATTAATTAGAAAGATTTTGTCATTCCACAATGT >52150_52150_4_MCCC2-NNT_MCCC2_chr5_70900295_ENST00000340941_NNT_chr5_43675613_ENST00000264663_length(amino acids)=416AA_BP=208 MWAVLRLALRPCARASPAGPRAYHGDSVASLGTQPDLGSALYQENYKQMKALVNQLHERVEHIKLGGGEKARALHISRGKLLPRERIDNL IDPGSPFLELSQFAGYQLYDNEEVPGGGIITGIGRVSGVECMIIANDATVKGGAYYPVTVKKQLRAQEIAMQNRLPCIYLVDSGGAYLPR QADVFPDRDHFGRTFYNQAIMSSKNIAQAMNRSLANVILGGYGTTSTAGGKPMEISGTHTEINLDNAIDMIREANSIIITPGYGLCAAKA QYPIADLVKMLTEQGKKVRFGIHPVAGRMPGQLNVLLAEAGVPYDIVLEMDEINHDFPDTDLVLVIGANDTVNSAAQEDPNSIIAGMPVL -------------------------------------------------------------- >52150_52150_5_MCCC2-NNT_MCCC2_chr5_70900295_ENST00000340941_NNT_chr5_43675613_ENST00000344920_length(transcript)=2208nt_BP=753nt AGAATCAGAGAAACCTTCTCTGGGGCTGCAAGGACCTGAGCTCAGCTTCCGCCCCAGCCAGGGAAGCGGCAGGGGAAAGCACCGGCTCCA GGCCAGCGTGGGCCGCTCTCTCGCTCGGTGCCCGCCGCCATGTGGGCCGTCCTGAGGTTAGCCCTGCGGCCGTGTGCCCGCGCCTCTCCC GCCGGGCCGCGCGCCTATCACGGGGACTCGGTGGCCTCGCTGGGCACCCAGCCGGACTTGGGCTCTGCCCTCTACCAGGAGAACTACAAG CAGATGAAAGCACTAGTAAATCAGCTCCATGAACGAGTGGAGCATATAAAACTAGGAGGTGGTGAGAAAGCCCGAGCACTTCACATATCA AGAGGAAAACTATTGCCCAGAGAAAGAATTGACAATCTCATAGACCCAGGGTCTCCATTTCTGGAATTATCCCAGTTTGCAGGTTACCAG TTATATGACAATGAGGAGGTGCCAGGAGGTGGCATTATTACAGGCATTGGAAGAGTATCAGGAGTAGAATGCATGATTATTGCCAATGAT GCCACCGTCAAAGGAGGTGCCTACTACCCAGTGACTGTGAAAAAACAATTACGGGCCCAAGAAATTGCCATGCAAAACAGGCTCCCCTGC ATCTACTTAGTTGATTCGGGAGGAGCATACTTACCTCGACAAGCAGATGTGTTTCCAGATCGAGACCACTTTGGCCGTACATTCTATAAT CAGGCAATTATGTCTTCTAAAAATATTGCACAGGCAATGAATCGCTCCCTGGCTAATGTGATTCTTGGAGGCTATGGCACCACTTCAACA GCTGGTGGAAAACCCATGGAAATTTCTGGCACACATACGGAAATCAACCTTGACAATGCAATTGACATGATTCGAGAAGCTAATAGCATT ATTATTACACCAGGCTATGGTCTCTGTGCAGCCAAAGCTCAATACCCCATTGCTGATTTGGTAAAGATGCTCACTGAGCAAGGCAAAAAA GTCAGGTTTGGAATTCACCCAGTTGCAGGCCGAATGCCTGGTCAGCTTAATGTGCTGCTGGCTGAGGCTGGTGTGCCATATGACATTGTG TTGGAAATGGATGAGATCAACCATGATTTTCCAGATACTGATTTGGTCCTTGTAATTGGAGCTAATGACACTGTTAATTCAGCAGCTCAA GAAGATCCCAACTCTATTATTGCAGGCATGCCAGTCCTTGAGGTCTGGAAATCAAAGCAGGTGATTGTTATGAAGAGGTCTTTGGGTGTT GGCTATGCTGCAGTGGACAATCCAATCTTCTACAAACCTAACACGGCCATGCTTCTAGGTGATGCCAAGAAAACATGTGACGCGCTCCAG GCGAAAGTTAGAGAATCCTATCAGAAGTAAATATTAAGGATCAAGCTGTTAGCTAATAATGCCACCTCTGCAGTTTTGGGAACAGGCAAA TAAAGTATCAGTATACATGGTGATGTACATCTGTAGCAAAGCTCTTGGAGAAAATGAAGACTGAAGAAAGCAAAGCAAAAACTGTATAGA GAGATTTTTCAAAAGCAGTAATCCCTCAATTTTAAAAAAGGATTGAAAATTCTAAATGTCTTTCTGTGCATATTTTTTGTGTTAGGAATC AAAAGTATTTTATAAAAGGAGAAAGAACAGCCTCATTTTAGATGTAGTCCTGTTGGATTTTTTATGCCTCCTCAGTAACCAGAAATGTTT TAAAAAACTAAGTGTTTAGGATTTCAAGACAACATTATACATGGCTCTGAAATATCTGACACAATGTAAACATTGCAGGCACCTGCATTT TATGTTTTTTTTTTCAACAAATGTGACTAATTTGAAACTTTTATGAACTTCTGAGCTGTCCCCTTGCAATTCAACCGCAGTTTGAATTAA TCATATCAAATCAGTTTTAATTTTTTAAATTGTACTTCAGAGTCTATATTTCAAGGGCACATTTTCTCACTACTATTTTAATACATTAAA GGACTAAATAATCTTTCAGAGATGCTGGAAACAAATCATTTGCTTTATATGTTTCATTAGAATACCAATGAAACATACAACTTGAAAATT AGTAATAGTATTTTTGAAGATCCCATTTCTAATTGGAGATCTCTTTAATTTCGATCAACTTATAATGTGTAGTACTATATTAAGTGCACT >52150_52150_5_MCCC2-NNT_MCCC2_chr5_70900295_ENST00000340941_NNT_chr5_43675613_ENST00000344920_length(amino acids)=416AA_BP=208 MWAVLRLALRPCARASPAGPRAYHGDSVASLGTQPDLGSALYQENYKQMKALVNQLHERVEHIKLGGGEKARALHISRGKLLPRERIDNL IDPGSPFLELSQFAGYQLYDNEEVPGGGIITGIGRVSGVECMIIANDATVKGGAYYPVTVKKQLRAQEIAMQNRLPCIYLVDSGGAYLPR QADVFPDRDHFGRTFYNQAIMSSKNIAQAMNRSLANVILGGYGTTSTAGGKPMEISGTHTEINLDNAIDMIREANSIIITPGYGLCAAKA QYPIADLVKMLTEQGKKVRFGIHPVAGRMPGQLNVLLAEAGVPYDIVLEMDEINHDFPDTDLVLVIGANDTVNSAAQEDPNSIIAGMPVL -------------------------------------------------------------- >52150_52150_6_MCCC2-NNT_MCCC2_chr5_70900295_ENST00000340941_NNT_chr5_43675613_ENST00000512996_length(transcript)=2462nt_BP=753nt AGAATCAGAGAAACCTTCTCTGGGGCTGCAAGGACCTGAGCTCAGCTTCCGCCCCAGCCAGGGAAGCGGCAGGGGAAAGCACCGGCTCCA GGCCAGCGTGGGCCGCTCTCTCGCTCGGTGCCCGCCGCCATGTGGGCCGTCCTGAGGTTAGCCCTGCGGCCGTGTGCCCGCGCCTCTCCC GCCGGGCCGCGCGCCTATCACGGGGACTCGGTGGCCTCGCTGGGCACCCAGCCGGACTTGGGCTCTGCCCTCTACCAGGAGAACTACAAG CAGATGAAAGCACTAGTAAATCAGCTCCATGAACGAGTGGAGCATATAAAACTAGGAGGTGGTGAGAAAGCCCGAGCACTTCACATATCA AGAGGAAAACTATTGCCCAGAGAAAGAATTGACAATCTCATAGACCCAGGGTCTCCATTTCTGGAATTATCCCAGTTTGCAGGTTACCAG TTATATGACAATGAGGAGGTGCCAGGAGGTGGCATTATTACAGGCATTGGAAGAGTATCAGGAGTAGAATGCATGATTATTGCCAATGAT GCCACCGTCAAAGGAGGTGCCTACTACCCAGTGACTGTGAAAAAACAATTACGGGCCCAAGAAATTGCCATGCAAAACAGGCTCCCCTGC ATCTACTTAGTTGATTCGGGAGGAGCATACTTACCTCGACAAGCAGATGTGTTTCCAGATCGAGACCACTTTGGCCGTACATTCTATAAT CAGGCAATTATGTCTTCTAAAAATATTGCACAGGCAATGAATCGCTCCCTGGCTAATGTGATTCTTGGAGGCTATGGCACCACTTCAACA GCTGGTGGAAAACCCATGGAAATTTCTGGCACACATACGGAAATCAACCTTGACAATGCAATTGACATGATTCGAGAAGCTAATAGCATT ATTATTACACCAGGCTATGGTCTCTGTGCAGCCAAAGCTCAATACCCCATTGCTGATTTGGTAAAGATGCTCACTGAGCAAGGCAAAAAA GTCAGGTTTGGAATTCACCCAGTTGCAGGCCGAATGCCTGGTCAGCTTAATGTGCTGCTGGCTGAGGCTGGTGTGCCATATGACATTGTG TTGGAAATGGATGAGATCAACCATGATTTTCCAGATACTGATTTGGTCCTTGTAATTGGAGCTAATGACACTGTTAATTCAGCAGCTCAA GAAGATCCCAACTCTATTATTGCAGGCATGCCAGTCCTTGAGGTCTGGAAATCAAAGCAGGTGATTGTTATGAAGAGGTCTTTGGGTGTT GGCTATGCTGCAGTGGACAATCCAATCTTCTACAAACCTAACACGGCCATGCTTCTAGGTGATGCCAAGAAAACATGTGACGCGCTCCAG GCGAAAGTTAGAGAATCCTATCAGAAGTAAATATTAAGGATCAAGCTGTTAGCTAATAATGCCACCTCTGCAGTTTTGGGAACAGGCAAA TAAAGTATCAGTATACATGGTGATGTACATCTGTAGCAAAGCTCTTGGAGAAAATGAAGACTGAAGAAAGCAAAGCAAAAACTGTATAGA GAGATTTTTCAAAAGCAGTAATCCCTCAATTTTAAAAAAGGATTGAAAATTCTAAATGTCTTTCTGTGCATATTTTTTGTGTTAGGAATC AAAAGTATTTTATAAAAGGAGAAAGAACAGCCTCATTTTAGATGTAGTCCTGTTGGATTTTTTATGCCTCCTCAGTAACCAGAAATGTTT TAAAAAACTAAGTGTTTAGGATTTCAAGACAACATTATACATGGCTCTGAAATATCTGACACAATGTAAACATTGCAGGCACCTGCATTT TATGTTTTTTTTTTCAACAAATGTGACTAATTTGAAACTTTTATGAACTTCTGAGCTGTCCCCTTGCAATTCAACCGCAGTTTGAATTAA TCATATCAAATCAGTTTTAATTTTTTAAATTGTACTTCAGAGTCTATATTTCAAGGGCACATTTTCTCACTACTATTTTAATACATTAAA GGACTAAATAATCTTTCAGAGATGCTGGAAACAAATCATTTGCTTTATATGTTTCATTAGAATACCAATGAAACATACAACTTGAAAATT AGTAATAGTATTTTTGAAGATCCCATTTCTAATTGGAGATCTCTTTAATTTCGATCAACTTATAATGTGTAGTACTATATTAAGTGCACT TGAGTGGAATTCAACATTTGACTAATAAAATGAGTTCATCATGTTGGCAAGTGATGTGGCAATTATCTCTGGTGACAAAAGAGTAAAATC AAATATTTCTGCCTGTTACAAATATCAAGGAAGACCTGCTACTATGAAATAGATGACATTAATCTGTCTTCACTGTTTATAATACGGATG GATTTTTTTTCAAATCAGTGTGTGTTTTGAGGTCTTATGTAATTGATGACATTTGAGAGAAATGGTGGCTTTTTTTAGCTACCTCTTTGT >52150_52150_6_MCCC2-NNT_MCCC2_chr5_70900295_ENST00000340941_NNT_chr5_43675613_ENST00000512996_length(amino acids)=416AA_BP=208 MWAVLRLALRPCARASPAGPRAYHGDSVASLGTQPDLGSALYQENYKQMKALVNQLHERVEHIKLGGGEKARALHISRGKLLPRERIDNL IDPGSPFLELSQFAGYQLYDNEEVPGGGIITGIGRVSGVECMIIANDATVKGGAYYPVTVKKQLRAQEIAMQNRLPCIYLVDSGGAYLPR QADVFPDRDHFGRTFYNQAIMSSKNIAQAMNRSLANVILGGYGTTSTAGGKPMEISGTHTEINLDNAIDMIREANSIIITPGYGLCAAKA QYPIADLVKMLTEQGKKVRFGIHPVAGRMPGQLNVLLAEAGVPYDIVLEMDEINHDFPDTDLVLVIGANDTVNSAAQEDPNSIIAGMPVL -------------------------------------------------------------- >52150_52150_7_MCCC2-NNT_MCCC2_chr5_70900295_ENST00000509358_NNT_chr5_43675613_ENST00000264663_length(transcript)=4348nt_BP=720nt ACCTGAGCTCAGCTTCCGCCCCAGCCAGGGAAGCGGCAGGGGAAAGCACCGGCTCCAGGCCAGCGTGGGCCGCTCTCTCGCTCGGTGCCC GCCGCCATGTGGGCCGTCCTGAGGTTAGCCCTGCGGCCGTGTGCCCGCGCCTCTCCCGCCGGGCCGCGCGCCTATCACGGGGACTCGGTG GCCTCGCTGGGCACCCAGCCGGACTTGGGCTCTGCCCTCTACCAGGAGAACTACAAGCAGATGAAAGCACTAGTAAATCAGCTCCATGAA CGAGTGGAGCATATAAAACTAGGAGGTGGTGAGAAAGCCCGAGCACTTCACATATCAAGAGGAAAACTATTGCCCAGAGAAAGAATTGAC AATCTCATAGACCCAGGGTCTCCATTTCTGGAATTATCCCAGTTTGCAGGTTACCAGTTATATGACAATGAGGAGGTGCCAGGAGGTGGC ATTATTACAGGCATTGGAAGAGTATCAGGAGTAGAATGCATGATTATTGCCAATGATGCCACCGTCAAAGGAGGTGCCTACTACCCAGTG ACTGTGAAAAAACAATTACGGGCCCAAGAAATTGCCATGCAAAACAGGCTCCCCTGCATCTACTTAGTTGATTCGGGAGGAGCATACTTA CCTCGACAAGCAGATGTGTTTCCAGATCGAGACCACTTTGGCCGTACATTCTATAATCAGGCAATTATGTCTTCTAAAAATATTGCACAG GCAATGAATCGCTCCCTGGCTAATGTGATTCTTGGAGGCTATGGCACCACTTCAACAGCTGGTGGAAAACCCATGGAAATTTCTGGCACA CATACGGAAATCAACCTTGACAATGCAATTGACATGATTCGAGAAGCTAATAGCATTATTATTACACCAGGCTATGGTCTCTGTGCAGCC AAAGCTCAATACCCCATTGCTGATTTGGTAAAGATGCTCACTGAGCAAGGCAAAAAAGTCAGGTTTGGAATTCACCCAGTTGCAGGCCGA ATGCCTGGTCAGCTTAATGTGCTGCTGGCTGAGGCTGGTGTGCCATATGACATTGTGTTGGAAATGGATGAGATCAACCATGATTTTCCA GATACTGATTTGGTCCTTGTAATTGGAGCTAATGACACTGTTAATTCAGCAGCTCAAGAAGATCCCAACTCTATTATTGCAGGCATGCCA GTCCTTGAGGTCTGGAAATCAAAGCAGGTGATTGTTATGAAGAGGTCTTTGGGTGTTGGCTATGCTGCAGTGGACAATCCAATCTTCTAC AAACCTAACACGGCCATGCTTCTAGGTGATGCCAAGAAAACATGTGACGCGCTCCAGGCGAAAGTTAGAGAATCCTATCAGAAGTAAATA TTAAGGATCAAGCTGTTAGCTAATAATGCCACCTCTGCAGTTTTGGGAACAGGCAAATAAAGTATCAGTATACATGGTGATGTACATCTG TAGCAAAGCTCTTGGAGAAAATGAAGACTGAAGAAAGCAAAGCAAAAACTGTATAGAGAGATTTTTCAAAAGCAGTAATCCCTCAATTTT AAAAAAGGATTGAAAATTCTAAATGTCTTTCTGTGCATATTTTTTGTGTTAGGAATCAAAAGTATTTTATAAAAGGAGAAAGAACAGCCT CATTTTAGATGTAGTCCTGTTGGATTTTTTATGCCTCCTCAGTAACCAGAAATGTTTTAAAAAACTAAGTGTTTAGGATTTCAAGACAAC ATTATACATGGCTCTGAAATATCTGACACAATGTAAACATTGCAGGCACCTGCATTTTATGTTTTTTTTTTCAACAAATGTGACTAATTT GAAACTTTTATGAACTTCTGAGCTGTCCCCTTGCAATTCAACCGCAGTTTGAATTAATCATATCAAATCAGTTTTAATTTTTTAAATTGT ACTTCAGAGTCTATATTTCAAGGGCACATTTTCTCACTACTATTTTAATACATTAAAGGACTAAATAATCTTTCAGAGATGCTGGAAACA AATCATTTGCTTTATATGTTTCATTAGAATACCAATGAAACATACAACTTGAAAATTAGTAATAGTATTTTTGAAGATCCCATTTCTAAT TGGAGATCTCTTTAATTTCGATCAACTTATAATGTGTAGTACTATATTAAGTGCACTTGAGTGGAATTCAACATTTGACTAATAAAATGA GTTCATCATGTTGGCAAGTGATGTGGCAATTATCTCTGGTGACAAAAGAGTAAAATCAAATATTTCTGCCTGTTACAAATATCAAGGAAG ACCTGCTACTATGAAATAGATGACATTAATCTGTCTTCACTGTTTATAATACGGATGGATTTTTTTTCAAATCAGTGTGTGTTTTGAGGT CTTATGTAATTGATGACATTTGAGAGAAATGGTGGCTTTTTTTAGCTACCTCTTTGTTCATTTAAGCACCAGTAAAGATCATGTCTTTTT ATAGAAGTGTAGATTTTCTTTGTGACTTTGCTATCGTGCCTAAAGCTCTAAATATAGGTGAATGTGTGATGAATACTCAGATTATTTGTC TCTCTATATAATTAGTTTGGTACTAAGTTTCTCAAAAAATTATTAACACATGAAAGACAATCTCTAAACCAGAAAAAGAAGTAGTACAAA TTTTGTTACTGTAATGCTCGCGTTTAGTGAGTTTAAAACACACAGTATCTTTTGGTTTTATAATCAGTTTCTATTTTGCTGTGCCTGAGA TTAAGATCTGTGTATGTGTGTGTGTGTGTGTGTGCGTTTGTGTGTTAAAGCAGAAAAGACTTTTTTAAAAGTTTTAAGTGATAAATGCAA TTTGTTAATTGATCTTAGATCACTAGTAAACTCAGGGCTGAATTATACCATGTATATTCTATTAGAAGAAAGTAAACACCATCTTTATTC CTGCCCTTTTTCTTCTCTCAAAGTAGTTGTAGTTATATCTAGAAAGAAGCAATTTTGATTTCTTGAAAAGGTAGTTCCTGCACTCAGTTT AAACTAAAAATAATCATACTTGGATTTTATTTATTTTTGTCATAGTAAAAATTTTAATTTATATATATTTTTATTTAGTATTATCTTATT CTTTGCTATTTGCCAATCCTTTGTCATCAATTGTGTTAAATGAATTGAAAATTCATGCCCTGTTCATTTTATTTTACTTTATTGGTTAGG ATATTTAAAGGATTTTTGTATATATAATTTCTTAAATTAATATTCCAAAAGGTTAGTGGACTTAGATTATAAATTATGGCAAAAATCTAA AAACAACAAAAATGATTTTTATACATTCTATTTCATTATTCCTCTTTTTCCAATAAGTCATACAATTGGTAGATATGACTTATTTTATTT TTGTATTATTCACTATATCTTTATGATATTTAAGTATAAATAATTAAAAAAATTTATTGTACCTTATAGTCTGTCACCAAAAAAAAAAAA TTATCTGTAGGTAGTGAAATGCTAATGTTGATTTGTCTTTAAGGGCTTGTTAACTATCCTTTATTTTCTCATTTGTCTTAAATTAGGAGT TTGTGTTTAAATTACTCATCTAAGCAAAAAATGTATATAAATCCCATTACTGGGTATATACCCAAAGGATTATAAATCATGCTGCTATAA AGACACATGCACACGTATGTTTATTGCAGCACTATTCACAATAGCAAAGACTTGGAACCAACCCAAATGTCCATCAATGATAGACTTGAT TAAGAAAATGTGCACATATACACCATGGAATACTATGCAGCCATAAAAAAGGATGAGTTCATGTCCTTTGTAGGGACATGGATAAAGCTG GAAACCATCATTCTGAGCAAACTATTGCAAGGACAGAAAACCAAACACTGCATGTTCTCACTCATAGGTGGGAATTGAACAATGAGAACA CTTGGACACAAGGTGGGGAACACCACACACCAGGGCCTGTCATGGGGTGGGGGGAGTGGGGAGGGATAGCATTAGGAGATATACCTAATG TAAATGATGAGTTAATGGGTGCAGCACACCAACATGGCACATGTATACATATGTAGCAAACCTGCACGTTGTGCACATGTACCCTAGAAC TTAAAGTATAATTAAAAAAAAAAAGAAAACAGAAGCTATTTATAAAGAAGTTATTTGCTGAAATAAATGTGATCTTTCCCATTAAAAAAA TAAAGAAATTTTGGGGTAAAAAAACACAATATATTGTATTCTTGAAAAATTCTAAGAGAGTGGATGTGAAGTGTTCTCACCACAAAAGTG ATAACTAATTGAGGTAATGCACATATTAATTAGAAAGATTTTGTCATTCCACAATGTATATATACTTAAAAATATGTTATACACAATAAA >52150_52150_7_MCCC2-NNT_MCCC2_chr5_70900295_ENST00000509358_NNT_chr5_43675613_ENST00000264663_length(amino acids)=416AA_BP=208 MWAVLRLALRPCARASPAGPRAYHGDSVASLGTQPDLGSALYQENYKQMKALVNQLHERVEHIKLGGGEKARALHISRGKLLPRERIDNL IDPGSPFLELSQFAGYQLYDNEEVPGGGIITGIGRVSGVECMIIANDATVKGGAYYPVTVKKQLRAQEIAMQNRLPCIYLVDSGGAYLPR QADVFPDRDHFGRTFYNQAIMSSKNIAQAMNRSLANVILGGYGTTSTAGGKPMEISGTHTEINLDNAIDMIREANSIIITPGYGLCAAKA QYPIADLVKMLTEQGKKVRFGIHPVAGRMPGQLNVLLAEAGVPYDIVLEMDEINHDFPDTDLVLVIGANDTVNSAAQEDPNSIIAGMPVL -------------------------------------------------------------- >52150_52150_8_MCCC2-NNT_MCCC2_chr5_70900295_ENST00000509358_NNT_chr5_43675613_ENST00000344920_length(transcript)=2175nt_BP=720nt ACCTGAGCTCAGCTTCCGCCCCAGCCAGGGAAGCGGCAGGGGAAAGCACCGGCTCCAGGCCAGCGTGGGCCGCTCTCTCGCTCGGTGCCC GCCGCCATGTGGGCCGTCCTGAGGTTAGCCCTGCGGCCGTGTGCCCGCGCCTCTCCCGCCGGGCCGCGCGCCTATCACGGGGACTCGGTG GCCTCGCTGGGCACCCAGCCGGACTTGGGCTCTGCCCTCTACCAGGAGAACTACAAGCAGATGAAAGCACTAGTAAATCAGCTCCATGAA CGAGTGGAGCATATAAAACTAGGAGGTGGTGAGAAAGCCCGAGCACTTCACATATCAAGAGGAAAACTATTGCCCAGAGAAAGAATTGAC AATCTCATAGACCCAGGGTCTCCATTTCTGGAATTATCCCAGTTTGCAGGTTACCAGTTATATGACAATGAGGAGGTGCCAGGAGGTGGC ATTATTACAGGCATTGGAAGAGTATCAGGAGTAGAATGCATGATTATTGCCAATGATGCCACCGTCAAAGGAGGTGCCTACTACCCAGTG ACTGTGAAAAAACAATTACGGGCCCAAGAAATTGCCATGCAAAACAGGCTCCCCTGCATCTACTTAGTTGATTCGGGAGGAGCATACTTA CCTCGACAAGCAGATGTGTTTCCAGATCGAGACCACTTTGGCCGTACATTCTATAATCAGGCAATTATGTCTTCTAAAAATATTGCACAG GCAATGAATCGCTCCCTGGCTAATGTGATTCTTGGAGGCTATGGCACCACTTCAACAGCTGGTGGAAAACCCATGGAAATTTCTGGCACA CATACGGAAATCAACCTTGACAATGCAATTGACATGATTCGAGAAGCTAATAGCATTATTATTACACCAGGCTATGGTCTCTGTGCAGCC AAAGCTCAATACCCCATTGCTGATTTGGTAAAGATGCTCACTGAGCAAGGCAAAAAAGTCAGGTTTGGAATTCACCCAGTTGCAGGCCGA ATGCCTGGTCAGCTTAATGTGCTGCTGGCTGAGGCTGGTGTGCCATATGACATTGTGTTGGAAATGGATGAGATCAACCATGATTTTCCA GATACTGATTTGGTCCTTGTAATTGGAGCTAATGACACTGTTAATTCAGCAGCTCAAGAAGATCCCAACTCTATTATTGCAGGCATGCCA GTCCTTGAGGTCTGGAAATCAAAGCAGGTGATTGTTATGAAGAGGTCTTTGGGTGTTGGCTATGCTGCAGTGGACAATCCAATCTTCTAC AAACCTAACACGGCCATGCTTCTAGGTGATGCCAAGAAAACATGTGACGCGCTCCAGGCGAAAGTTAGAGAATCCTATCAGAAGTAAATA TTAAGGATCAAGCTGTTAGCTAATAATGCCACCTCTGCAGTTTTGGGAACAGGCAAATAAAGTATCAGTATACATGGTGATGTACATCTG TAGCAAAGCTCTTGGAGAAAATGAAGACTGAAGAAAGCAAAGCAAAAACTGTATAGAGAGATTTTTCAAAAGCAGTAATCCCTCAATTTT AAAAAAGGATTGAAAATTCTAAATGTCTTTCTGTGCATATTTTTTGTGTTAGGAATCAAAAGTATTTTATAAAAGGAGAAAGAACAGCCT CATTTTAGATGTAGTCCTGTTGGATTTTTTATGCCTCCTCAGTAACCAGAAATGTTTTAAAAAACTAAGTGTTTAGGATTTCAAGACAAC ATTATACATGGCTCTGAAATATCTGACACAATGTAAACATTGCAGGCACCTGCATTTTATGTTTTTTTTTTCAACAAATGTGACTAATTT GAAACTTTTATGAACTTCTGAGCTGTCCCCTTGCAATTCAACCGCAGTTTGAATTAATCATATCAAATCAGTTTTAATTTTTTAAATTGT ACTTCAGAGTCTATATTTCAAGGGCACATTTTCTCACTACTATTTTAATACATTAAAGGACTAAATAATCTTTCAGAGATGCTGGAAACA AATCATTTGCTTTATATGTTTCATTAGAATACCAATGAAACATACAACTTGAAAATTAGTAATAGTATTTTTGAAGATCCCATTTCTAAT TGGAGATCTCTTTAATTTCGATCAACTTATAATGTGTAGTACTATATTAAGTGCACTTGAGTGGAATTCAACATTTGACTAATAAAATGA >52150_52150_8_MCCC2-NNT_MCCC2_chr5_70900295_ENST00000509358_NNT_chr5_43675613_ENST00000344920_length(amino acids)=416AA_BP=208 MWAVLRLALRPCARASPAGPRAYHGDSVASLGTQPDLGSALYQENYKQMKALVNQLHERVEHIKLGGGEKARALHISRGKLLPRERIDNL IDPGSPFLELSQFAGYQLYDNEEVPGGGIITGIGRVSGVECMIIANDATVKGGAYYPVTVKKQLRAQEIAMQNRLPCIYLVDSGGAYLPR QADVFPDRDHFGRTFYNQAIMSSKNIAQAMNRSLANVILGGYGTTSTAGGKPMEISGTHTEINLDNAIDMIREANSIIITPGYGLCAAKA QYPIADLVKMLTEQGKKVRFGIHPVAGRMPGQLNVLLAEAGVPYDIVLEMDEINHDFPDTDLVLVIGANDTVNSAAQEDPNSIIAGMPVL -------------------------------------------------------------- >52150_52150_9_MCCC2-NNT_MCCC2_chr5_70900295_ENST00000509358_NNT_chr5_43675613_ENST00000512996_length(transcript)=2429nt_BP=720nt ACCTGAGCTCAGCTTCCGCCCCAGCCAGGGAAGCGGCAGGGGAAAGCACCGGCTCCAGGCCAGCGTGGGCCGCTCTCTCGCTCGGTGCCC GCCGCCATGTGGGCCGTCCTGAGGTTAGCCCTGCGGCCGTGTGCCCGCGCCTCTCCCGCCGGGCCGCGCGCCTATCACGGGGACTCGGTG GCCTCGCTGGGCACCCAGCCGGACTTGGGCTCTGCCCTCTACCAGGAGAACTACAAGCAGATGAAAGCACTAGTAAATCAGCTCCATGAA CGAGTGGAGCATATAAAACTAGGAGGTGGTGAGAAAGCCCGAGCACTTCACATATCAAGAGGAAAACTATTGCCCAGAGAAAGAATTGAC AATCTCATAGACCCAGGGTCTCCATTTCTGGAATTATCCCAGTTTGCAGGTTACCAGTTATATGACAATGAGGAGGTGCCAGGAGGTGGC ATTATTACAGGCATTGGAAGAGTATCAGGAGTAGAATGCATGATTATTGCCAATGATGCCACCGTCAAAGGAGGTGCCTACTACCCAGTG ACTGTGAAAAAACAATTACGGGCCCAAGAAATTGCCATGCAAAACAGGCTCCCCTGCATCTACTTAGTTGATTCGGGAGGAGCATACTTA CCTCGACAAGCAGATGTGTTTCCAGATCGAGACCACTTTGGCCGTACATTCTATAATCAGGCAATTATGTCTTCTAAAAATATTGCACAG GCAATGAATCGCTCCCTGGCTAATGTGATTCTTGGAGGCTATGGCACCACTTCAACAGCTGGTGGAAAACCCATGGAAATTTCTGGCACA CATACGGAAATCAACCTTGACAATGCAATTGACATGATTCGAGAAGCTAATAGCATTATTATTACACCAGGCTATGGTCTCTGTGCAGCC AAAGCTCAATACCCCATTGCTGATTTGGTAAAGATGCTCACTGAGCAAGGCAAAAAAGTCAGGTTTGGAATTCACCCAGTTGCAGGCCGA ATGCCTGGTCAGCTTAATGTGCTGCTGGCTGAGGCTGGTGTGCCATATGACATTGTGTTGGAAATGGATGAGATCAACCATGATTTTCCA GATACTGATTTGGTCCTTGTAATTGGAGCTAATGACACTGTTAATTCAGCAGCTCAAGAAGATCCCAACTCTATTATTGCAGGCATGCCA GTCCTTGAGGTCTGGAAATCAAAGCAGGTGATTGTTATGAAGAGGTCTTTGGGTGTTGGCTATGCTGCAGTGGACAATCCAATCTTCTAC AAACCTAACACGGCCATGCTTCTAGGTGATGCCAAGAAAACATGTGACGCGCTCCAGGCGAAAGTTAGAGAATCCTATCAGAAGTAAATA TTAAGGATCAAGCTGTTAGCTAATAATGCCACCTCTGCAGTTTTGGGAACAGGCAAATAAAGTATCAGTATACATGGTGATGTACATCTG TAGCAAAGCTCTTGGAGAAAATGAAGACTGAAGAAAGCAAAGCAAAAACTGTATAGAGAGATTTTTCAAAAGCAGTAATCCCTCAATTTT AAAAAAGGATTGAAAATTCTAAATGTCTTTCTGTGCATATTTTTTGTGTTAGGAATCAAAAGTATTTTATAAAAGGAGAAAGAACAGCCT CATTTTAGATGTAGTCCTGTTGGATTTTTTATGCCTCCTCAGTAACCAGAAATGTTTTAAAAAACTAAGTGTTTAGGATTTCAAGACAAC ATTATACATGGCTCTGAAATATCTGACACAATGTAAACATTGCAGGCACCTGCATTTTATGTTTTTTTTTTCAACAAATGTGACTAATTT GAAACTTTTATGAACTTCTGAGCTGTCCCCTTGCAATTCAACCGCAGTTTGAATTAATCATATCAAATCAGTTTTAATTTTTTAAATTGT ACTTCAGAGTCTATATTTCAAGGGCACATTTTCTCACTACTATTTTAATACATTAAAGGACTAAATAATCTTTCAGAGATGCTGGAAACA AATCATTTGCTTTATATGTTTCATTAGAATACCAATGAAACATACAACTTGAAAATTAGTAATAGTATTTTTGAAGATCCCATTTCTAAT TGGAGATCTCTTTAATTTCGATCAACTTATAATGTGTAGTACTATATTAAGTGCACTTGAGTGGAATTCAACATTTGACTAATAAAATGA GTTCATCATGTTGGCAAGTGATGTGGCAATTATCTCTGGTGACAAAAGAGTAAAATCAAATATTTCTGCCTGTTACAAATATCAAGGAAG ACCTGCTACTATGAAATAGATGACATTAATCTGTCTTCACTGTTTATAATACGGATGGATTTTTTTTCAAATCAGTGTGTGTTTTGAGGT >52150_52150_9_MCCC2-NNT_MCCC2_chr5_70900295_ENST00000509358_NNT_chr5_43675613_ENST00000512996_length(amino acids)=416AA_BP=208 MWAVLRLALRPCARASPAGPRAYHGDSVASLGTQPDLGSALYQENYKQMKALVNQLHERVEHIKLGGGEKARALHISRGKLLPRERIDNL IDPGSPFLELSQFAGYQLYDNEEVPGGGIITGIGRVSGVECMIIANDATVKGGAYYPVTVKKQLRAQEIAMQNRLPCIYLVDSGGAYLPR QADVFPDRDHFGRTFYNQAIMSSKNIAQAMNRSLANVILGGYGTTSTAGGKPMEISGTHTEINLDNAIDMIREANSIIITPGYGLCAAKA QYPIADLVKMLTEQGKKVRFGIHPVAGRMPGQLNVLLAEAGVPYDIVLEMDEINHDFPDTDLVLVIGANDTVNSAAQEDPNSIIAGMPVL -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for MCCC2-NNT |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for MCCC2-NNT |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for MCCC2-NNT |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies