
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:MCC-DBN1 (FusionGDB2 ID:52152) |
Fusion Gene Summary for MCC-DBN1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: MCC-DBN1 | Fusion gene ID: 52152 | Hgene | Tgene | Gene symbol | MCC | DBN1 | Gene ID | 4163 | 1627 |
| Gene name | MCC regulator of WNT signaling pathway | drebrin 1 | |
| Synonyms | MCC1 | D0S117E | |
| Cytomap | 5q22.2 | 5q35.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | colorectal mutant cancer proteinMCC, WNT signaling pathway regulatormutated in colorectal cancers | drebrindevelopmentally-regulated brain proteindrebrin Adrebrin Edrebrin E2 | |
| Modification date | 20200313 | 20200320 | |
| UniProtAcc | . | Q16643 | |
| Ensembl transtripts involved in fusion gene | ENST00000302475, ENST00000514701, ENST00000408903, ENST00000515367, | ENST00000393563, ENST00000512501, ENST00000292385, ENST00000309007, ENST00000393565, | |
| Fusion gene scores | * DoF score | 11 X 8 X 5=440 | 10 X 9 X 7=630 |
| # samples | 12 | 10 | |
| ** MAII score | log2(12/440*10)=-1.87446911791614 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(10/630*10)=-2.65535182861255 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: MCC [Title/Abstract] AND DBN1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | MCC(112630026)-DBN1(176887704), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | MCC | GO:0045184 | establishment of protein localization | 18591935 |
| Hgene | MCC | GO:0050680 | negative regulation of epithelial cell proliferation | 18591935 |
| Hgene | MCC | GO:0090090 | negative regulation of canonical Wnt signaling pathway | 18591935 |
| Tgene | DBN1 | GO:0051220 | cytoplasmic sequestering of protein | 28966017 |
| Fusion gene breakpoints across MCC (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across DBN1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
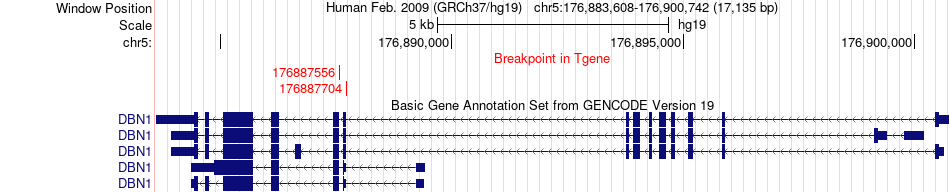 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | LIHC | TCGA-BC-A10T-01A | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887556 | - |
| ChimerDB4 | LIHC | TCGA-BC-A10T-01A | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887704 | - |
Top |
Fusion Gene ORF analysis for MCC-DBN1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-5UTR | ENST00000302475 | ENST00000393563 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887704 | - |
| 5CDS-5UTR | ENST00000302475 | ENST00000512501 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887704 | - |
| 5UTR-3CDS | ENST00000514701 | ENST00000292385 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887556 | - |
| 5UTR-3CDS | ENST00000514701 | ENST00000292385 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887704 | - |
| 5UTR-3CDS | ENST00000514701 | ENST00000309007 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887556 | - |
| 5UTR-3CDS | ENST00000514701 | ENST00000309007 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887704 | - |
| 5UTR-3CDS | ENST00000514701 | ENST00000393563 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887556 | - |
| 5UTR-3CDS | ENST00000514701 | ENST00000393565 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887556 | - |
| 5UTR-3CDS | ENST00000514701 | ENST00000393565 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887704 | - |
| 5UTR-3CDS | ENST00000514701 | ENST00000512501 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887556 | - |
| 5UTR-5UTR | ENST00000514701 | ENST00000393563 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887704 | - |
| 5UTR-5UTR | ENST00000514701 | ENST00000512501 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887704 | - |
| In-frame | ENST00000302475 | ENST00000292385 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887556 | - |
| In-frame | ENST00000302475 | ENST00000292385 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887704 | - |
| In-frame | ENST00000302475 | ENST00000309007 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887556 | - |
| In-frame | ENST00000302475 | ENST00000309007 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887704 | - |
| In-frame | ENST00000302475 | ENST00000393563 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887556 | - |
| In-frame | ENST00000302475 | ENST00000393565 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887556 | - |
| In-frame | ENST00000302475 | ENST00000393565 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887704 | - |
| In-frame | ENST00000302475 | ENST00000512501 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887556 | - |
| intron-3CDS | ENST00000408903 | ENST00000292385 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887556 | - |
| intron-3CDS | ENST00000408903 | ENST00000292385 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887704 | - |
| intron-3CDS | ENST00000408903 | ENST00000309007 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887556 | - |
| intron-3CDS | ENST00000408903 | ENST00000309007 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887704 | - |
| intron-3CDS | ENST00000408903 | ENST00000393563 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887556 | - |
| intron-3CDS | ENST00000408903 | ENST00000393565 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887556 | - |
| intron-3CDS | ENST00000408903 | ENST00000393565 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887704 | - |
| intron-3CDS | ENST00000408903 | ENST00000512501 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887556 | - |
| intron-3CDS | ENST00000515367 | ENST00000292385 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887556 | - |
| intron-3CDS | ENST00000515367 | ENST00000292385 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887704 | - |
| intron-3CDS | ENST00000515367 | ENST00000309007 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887556 | - |
| intron-3CDS | ENST00000515367 | ENST00000309007 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887704 | - |
| intron-3CDS | ENST00000515367 | ENST00000393563 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887556 | - |
| intron-3CDS | ENST00000515367 | ENST00000393565 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887556 | - |
| intron-3CDS | ENST00000515367 | ENST00000393565 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887704 | - |
| intron-3CDS | ENST00000515367 | ENST00000512501 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887556 | - |
| intron-5UTR | ENST00000408903 | ENST00000393563 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887704 | - |
| intron-5UTR | ENST00000408903 | ENST00000512501 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887704 | - |
| intron-5UTR | ENST00000515367 | ENST00000393563 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887704 | - |
| intron-5UTR | ENST00000515367 | ENST00000512501 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887704 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000302475 | MCC | chr5 | 112630026 | - | ENST00000309007 | DBN1 | chr5 | 176887704 | - | 2625 | 621 | 564 | 1799 | 411 |
| ENST00000302475 | MCC | chr5 | 112630026 | - | ENST00000292385 | DBN1 | chr5 | 176887704 | - | 2306 | 621 | 564 | 1799 | 411 |
| ENST00000302475 | MCC | chr5 | 112630026 | - | ENST00000393565 | DBN1 | chr5 | 176887704 | - | 2435 | 621 | 564 | 1937 | 457 |
| ENST00000302475 | MCC | chr5 | 112630026 | - | ENST00000309007 | DBN1 | chr5 | 176887556 | - | 2565 | 621 | 564 | 1739 | 391 |
| ENST00000302475 | MCC | chr5 | 112630026 | - | ENST00000292385 | DBN1 | chr5 | 176887556 | - | 2246 | 621 | 564 | 1739 | 391 |
| ENST00000302475 | MCC | chr5 | 112630026 | - | ENST00000393565 | DBN1 | chr5 | 176887556 | - | 2375 | 621 | 564 | 1877 | 437 |
| ENST00000302475 | MCC | chr5 | 112630026 | - | ENST00000393563 | DBN1 | chr5 | 176887556 | - | 1806 | 621 | 564 | 1739 | 391 |
| ENST00000302475 | MCC | chr5 | 112630026 | - | ENST00000512501 | DBN1 | chr5 | 176887556 | - | 2257 | 621 | 564 | 1769 | 401 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000302475 | ENST00000309007 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887704 | - | 0.00876442 | 0.9912356 |
| ENST00000302475 | ENST00000292385 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887704 | - | 0.010533752 | 0.98946625 |
| ENST00000302475 | ENST00000393565 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887704 | - | 0.012428736 | 0.98757124 |
| ENST00000302475 | ENST00000309007 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887556 | - | 0.011445856 | 0.9885542 |
| ENST00000302475 | ENST00000292385 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887556 | - | 0.013888639 | 0.9861114 |
| ENST00000302475 | ENST00000393565 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887556 | - | 0.025791978 | 0.974208 |
| ENST00000302475 | ENST00000393563 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887556 | - | 0.014480311 | 0.98551977 |
| ENST00000302475 | ENST00000512501 | MCC | chr5 | 112630026 | - | DBN1 | chr5 | 176887556 | - | 0.046184443 | 0.9538155 |
Top |
Fusion Genomic Features for MCC-DBN1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for MCC-DBN1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr5:112630026/chr5:176887704) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | DBN1 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Actin cytoskeleton-organizing protein that plays a role in the formation of cell projections (PubMed:20215400). Required for actin polymerization at immunological synapses (IS) and for the recruitment of the chemokine receptor CXCR4 to IS (PubMed:20215400). Plays a role in dendritic spine morphogenesis and organization, including the localization of the dopamine receptor DRD1 to the dendritic spines (By similarity). Involved in memory-related synaptic plasticity in the hippocampus (By similarity). {ECO:0000250|UniProtKB:Q9QXS6, ECO:0000269|PubMed:20215400}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | MCC | chr5:112630026 | chr5:176887556 | ENST00000302475 | - | 1 | 17 | 766_782 | 19 | 830.0 | Motif | Nuclear localization signal |
| Hgene | MCC | chr5:112630026 | chr5:176887556 | ENST00000302475 | - | 1 | 17 | 826_829 | 19 | 830.0 | Motif | Note=PDZ-binding |
| Hgene | MCC | chr5:112630026 | chr5:176887556 | ENST00000408903 | - | 1 | 19 | 766_782 | 0 | 1020.0 | Motif | Nuclear localization signal |
| Hgene | MCC | chr5:112630026 | chr5:176887556 | ENST00000408903 | - | 1 | 19 | 826_829 | 0 | 1020.0 | Motif | Note=PDZ-binding |
| Hgene | MCC | chr5:112630026 | chr5:176887704 | ENST00000302475 | - | 1 | 17 | 766_782 | 19 | 830.0 | Motif | Nuclear localization signal |
| Hgene | MCC | chr5:112630026 | chr5:176887704 | ENST00000302475 | - | 1 | 17 | 826_829 | 19 | 830.0 | Motif | Note=PDZ-binding |
| Hgene | MCC | chr5:112630026 | chr5:176887704 | ENST00000408903 | - | 1 | 19 | 766_782 | 0 | 1020.0 | Motif | Nuclear localization signal |
| Hgene | MCC | chr5:112630026 | chr5:176887704 | ENST00000408903 | - | 1 | 19 | 826_829 | 0 | 1020.0 | Motif | Note=PDZ-binding |
| Tgene | DBN1 | chr5:112630026 | chr5:176887556 | ENST00000292385 | 9 | 15 | 3_134 | 279 | 652.0 | Domain | ADF-H | |
| Tgene | DBN1 | chr5:112630026 | chr5:176887556 | ENST00000309007 | 8 | 14 | 3_134 | 277 | 650.0 | Domain | ADF-H | |
| Tgene | DBN1 | chr5:112630026 | chr5:176887556 | ENST00000393565 | 8 | 15 | 3_134 | 277 | 696.0 | Domain | ADF-H | |
| Tgene | DBN1 | chr5:112630026 | chr5:176887704 | ENST00000292385 | 8 | 15 | 3_134 | 259 | 652.0 | Domain | ADF-H | |
| Tgene | DBN1 | chr5:112630026 | chr5:176887704 | ENST00000309007 | 7 | 14 | 3_134 | 257 | 650.0 | Domain | ADF-H | |
| Tgene | DBN1 | chr5:112630026 | chr5:176887704 | ENST00000393565 | 7 | 15 | 3_134 | 257 | 696.0 | Domain | ADF-H |
Top |
Fusion Gene Sequence for MCC-DBN1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >52152_52152_1_MCC-DBN1_MCC_chr5_112630026_ENST00000302475_DBN1_chr5_176887556_ENST00000292385_length(transcript)=2246nt_BP=621nt AGAAACCACTTACAACTCCAGACGATTCGAAGGGGAAACTTCGGCGTGAAGTGCAGCTCCGCTCCGGCTCCCTCTAGCTTTCTTTCCTTC TCTGGAATCCGAGGCGCGGATCTTCCTCGCCCCACCGCCCTAGTTTTTTCGGGAGCTCGCCGGTGCCCTCTAGGGTGTCGGCTCGTGCTG GGAAGTGCCCTCCATCCTGGTAATGGGGGGCGGCGAGGCACCGTAGGAGTGGCGAGGCGGCGCCCAGGGTGGCACTGCCCCGGAACGGGG CGCTGGGTGCGCGCGGGAGGGTCCCCGCGCGGGCTCCGCCGCTGCCGCAGCTGCGAGCGCGCCGCGCCACCGAGCCTCCTGCAGCAATGG CTCGTCCGTGAAACGCGAGCCACGGCTGCTCTTTTTAAGAGTGCCTGCATCCTCCGTTTGCGCTTCGCAACTGTCCTGGGTGAAAATGGC TGTCTAGACTAAAATGTGGCAGAAGGGACCAAGCAGTGGATATTGAGCCTGTGAAGTCCAACTCTTAAGCTCCGAGACCTGGGGGACTGA GAGCCCAGCTCTGAAAAGTGCATCATGAATTCCGGAGTTGCCATGAAATATGGAAACGACTCCTCGGCCGAGCTGAGTGAGGAGGCAGCA GCTATTATTGCCCAGCGGCCTGACAACCCAAGGGAGTTCTTCAAGCAGCAGGAAAGAGTCGCATCGGCCTCTGCGGGCAGCTGTGATGTA CCCTCGCCCTTCAACCATCGACCAGGCAGCCACCTGGACAGCCACCGGAGGATGGCGCCCACTCCCATCCCCACGCGGAGCCCGTCTGAC TCCAGCACCGCCTCCACCCCTGTCGCTGAGCAGATAGAGCGGGCCCTGGATGAGGTCACCTCCTCGCAGCCTCCACCACTGCCACCGCCA CCCCCACCAGCCCAAGAGACCCAGGAGCCCAGCCCCATCCTAGACAGTGAGGAGACCAGAGCAGCAGCCCCTCAGGCCTGGGCCGGCCCC ATGGAGGAGCCCCCTCAGGCACAGGCGCCTCCCCGGGGGCCAGGCAGCCCTGCAGAGGACTTGATGTTCATGGAGTCTGCAGAGCAGGCT GTCCTGGCTGCTCCCGTGGAGCCTGCCACAGCTGACGCCACGGAGATCCACGATGCAGCTGACACCATTGAAACTGACACTGCCACTGCT GACACCACTGTTGCCAACAACGTACCCCCCGCCGCCACCAGCCTCATTGACCTATGGCCTGGCAACGGGGAAGGGGCCTCCACACTCCAG GGTGAGCCCAGGGCCCCCACGCCACCCTCGGGTACTGAGGTCACCCTGGCAGAGGTGCCCCTGCTGGATGAGGTGGCTCCGGAGCCACTG CTGCCAGCAGGCGAAGGCTGTGCCACCCTTCTCAACTTTGATGAGCTGCCTGAGCCGCCAGCCACCTTCTGTGACCCAGAGGAAGTGGAA GGGGAGTCCCTGGCTGCCCCCCAGACCCCAACTCTGCCCTCAGCCCTTGAGGAGCTGGAGCAAGAGCAGGAGCCGGAGCCCCACCTGCTA ACCAATGGCGAGACCACCCAGAAGGAGGGGACCCAGGCCAGTGAGGGGTACTTCAGTCAATCACAGGAGGAGGAGTTTGCCCAATCGGAA GAGCTCTGTGCCAAGGCTCCGCCTCCTGTGTTCTACAACAAGCCTCCAGAGATCGACATCACATGCTGGGATGCAGACCCAGTTCCAGAA GAGGAGGAGGGCTTCGAGGGTGGTGATTAGCGGTGGCGCCAGCCCTAGGCTACCCTTGCCAAGGCCGCCCACCTGCATCAGCCTCTGGCC AGACGGCCCGCCGTGCCTGCATTCGCAGCAGCTCCGCCTGGCACCCACTCCGGATTCCGGCCCTGGCTGGGGACTTGGCCGCTTCCCTAC CCACAGGGCCTGACTTTTACAGCTTTTCTCTTTTTTTAAAAAGTTGATAGGAGACTTGTACAGTTGACTGGCTTTCCTCTCGTTGGTAGT TGAGACGCTGTTGCAAATTCCACCCCTCCTTCCCTGGTCCAGATTGTAGCTCTTAGTCCTCCCTGCTCAGCTGGCCGGGTTGGAGGCCTC ACCCTGCTTGGGGCCTGGCGTGGGGGGAGCTCTGGTGGGAAAATGTCCCCCACCTCTTTTCCTAGTTTTATGTTTCTTGGGAAAATATCA >52152_52152_1_MCC-DBN1_MCC_chr5_112630026_ENST00000302475_DBN1_chr5_176887556_ENST00000292385_length(amino acids)=391AA_BP=19 MNSGVAMKYGNDSSAELSEEAAAIIAQRPDNPREFFKQQERVASASAGSCDVPSPFNHRPGSHLDSHRRMAPTPIPTRSPSDSSTASTPV AEQIERALDEVTSSQPPPLPPPPPPAQETQEPSPILDSEETRAAAPQAWAGPMEEPPQAQAPPRGPGSPAEDLMFMESAEQAVLAAPVEP ATADATEIHDAADTIETDTATADTTVANNVPPAATSLIDLWPGNGEGASTLQGEPRAPTPPSGTEVTLAEVPLLDEVAPEPLLPAGEGCA TLLNFDELPEPPATFCDPEEVEGESLAAPQTPTLPSALEELEQEQEPEPHLLTNGETTQKEGTQASEGYFSQSQEEEFAQSEELCAKAPP -------------------------------------------------------------- >52152_52152_2_MCC-DBN1_MCC_chr5_112630026_ENST00000302475_DBN1_chr5_176887556_ENST00000309007_length(transcript)=2565nt_BP=621nt AGAAACCACTTACAACTCCAGACGATTCGAAGGGGAAACTTCGGCGTGAAGTGCAGCTCCGCTCCGGCTCCCTCTAGCTTTCTTTCCTTC TCTGGAATCCGAGGCGCGGATCTTCCTCGCCCCACCGCCCTAGTTTTTTCGGGAGCTCGCCGGTGCCCTCTAGGGTGTCGGCTCGTGCTG GGAAGTGCCCTCCATCCTGGTAATGGGGGGCGGCGAGGCACCGTAGGAGTGGCGAGGCGGCGCCCAGGGTGGCACTGCCCCGGAACGGGG CGCTGGGTGCGCGCGGGAGGGTCCCCGCGCGGGCTCCGCCGCTGCCGCAGCTGCGAGCGCGCCGCGCCACCGAGCCTCCTGCAGCAATGG CTCGTCCGTGAAACGCGAGCCACGGCTGCTCTTTTTAAGAGTGCCTGCATCCTCCGTTTGCGCTTCGCAACTGTCCTGGGTGAAAATGGC TGTCTAGACTAAAATGTGGCAGAAGGGACCAAGCAGTGGATATTGAGCCTGTGAAGTCCAACTCTTAAGCTCCGAGACCTGGGGGACTGA GAGCCCAGCTCTGAAAAGTGCATCATGAATTCCGGAGTTGCCATGAAATATGGAAACGACTCCTCGGCCGAGCTGAGTGAGGAGGCAGCA GCTATTATTGCCCAGCGGCCTGACAACCCAAGGGAGTTCTTCAAGCAGCAGGAAAGAGTCGCATCGGCCTCTGCGGGCAGCTGTGATGTA CCCTCGCCCTTCAACCATCGACCAGGCAGCCACCTGGACAGCCACCGGAGGATGGCGCCCACTCCCATCCCCACGCGGAGCCCGTCTGAC TCCAGCACCGCCTCCACCCCTGTCGCTGAGCAGATAGAGCGGGCCCTGGATGAGGTCACCTCCTCGCAGCCTCCACCACTGCCACCGCCA CCCCCACCAGCCCAAGAGACCCAGGAGCCCAGCCCCATCCTAGACAGTGAGGAGACCAGAGCAGCAGCCCCTCAGGCCTGGGCCGGCCCC ATGGAGGAGCCCCCTCAGGCACAGGCGCCTCCCCGGGGGCCAGGCAGCCCTGCAGAGGACTTGATGTTCATGGAGTCTGCAGAGCAGGCT GTCCTGGCTGCTCCCGTGGAGCCTGCCACAGCTGACGCCACGGAGATCCACGATGCAGCTGACACCATTGAAACTGACACTGCCACTGCT GACACCACTGTTGCCAACAACGTACCCCCCGCCGCCACCAGCCTCATTGACCTATGGCCTGGCAACGGGGAAGGGGCCTCCACACTCCAG GGTGAGCCCAGGGCCCCCACGCCACCCTCGGGTACTGAGGTCACCCTGGCAGAGGTGCCCCTGCTGGATGAGGTGGCTCCGGAGCCACTG CTGCCAGCAGGCGAAGGCTGTGCCACCCTTCTCAACTTTGATGAGCTGCCTGAGCCGCCAGCCACCTTCTGTGACCCAGAGGAAGTGGAA GGGGAGTCCCTGGCTGCCCCCCAGACCCCAACTCTGCCCTCAGCCCTTGAGGAGCTGGAGCAAGAGCAGGAGCCGGAGCCCCACCTGCTA ACCAATGGCGAGACCACCCAGAAGGAGGGGACCCAGGCCAGTGAGGGGTACTTCAGTCAATCACAGGAGGAGGAGTTTGCCCAATCGGAA GAGCTCTGTGCCAAGGCTCCGCCTCCTGTGTTCTACAACAAGCCTCCAGAGATCGACATCACATGCTGGGATGCAGACCCAGTTCCAGAA GAGGAGGAGGGCTTCGAGGGTGGTGATTAGCGGTGGCGCCAGCCCTAGGCTACCCTTGCCAAGGCCGCCCACCTGCATCAGCCTCTGGCC AGACGGCCCGCCGTGCCTGCATTCGCAGCAGCTCCGCCTGGCACCCACTCCGGATTCCGGCCCTGGCTGGGGACTTGGCCGCTTCCCTAC CCACAGGGCCTGACTTTTACAGCTTTTCTCTTTTTTTAAAAAGTTGATAGGAGACTTGTACAGTTGACTGGCTTTCCTCTCGTTGGTAGT TGAGACGCTGTTGCAAATTCCACCCCTCCTTCCCTGGTCCAGATTGTAGCTCTTAGTCCTCCCTGCTCAGCTGGCCGGGTTGGAGGCCTC ACCCTGCTTGGGGCCTGGCGTGGGGGGAGCTCTGGTGGGAAAATGTCCCCCACCTCTTTTCCTAGTTTTATGTTTCTTGGGAAAATATCA CTTTGTATTCTCTGTCCAGGGCTTCAGATATTTTGCACGAATTTTAAAACATGGCAATAAATGGCTCGTGGGCTCTGGCTCCCTGGGACC CCCTCCCCGCCCTTCTTTTGACCCCTTCCTGTCTGGCCCAAAGGAAGTAGCAGGCCCAGCTGGGGCCCCTCGGCTACCCCCCGTCTCCTG CCGGGCAGGTCCCAGGTTGGAGGCCCTAGGCGCGGTTCAGGTCAGGGCTATGGATGGGGCCCAGGGGCTTTGGTGGCCCCTCCCCAACTC CTTCCTCTTTGCTTGGGTTCCTTTTTCACGTTTAGTAACTGTTTTTTTTTTTTTTTTTTTTTTTTTTTTGGAAAGCACAAACTTCTGTAA >52152_52152_2_MCC-DBN1_MCC_chr5_112630026_ENST00000302475_DBN1_chr5_176887556_ENST00000309007_length(amino acids)=391AA_BP=19 MNSGVAMKYGNDSSAELSEEAAAIIAQRPDNPREFFKQQERVASASAGSCDVPSPFNHRPGSHLDSHRRMAPTPIPTRSPSDSSTASTPV AEQIERALDEVTSSQPPPLPPPPPPAQETQEPSPILDSEETRAAAPQAWAGPMEEPPQAQAPPRGPGSPAEDLMFMESAEQAVLAAPVEP ATADATEIHDAADTIETDTATADTTVANNVPPAATSLIDLWPGNGEGASTLQGEPRAPTPPSGTEVTLAEVPLLDEVAPEPLLPAGEGCA TLLNFDELPEPPATFCDPEEVEGESLAAPQTPTLPSALEELEQEQEPEPHLLTNGETTQKEGTQASEGYFSQSQEEEFAQSEELCAKAPP -------------------------------------------------------------- >52152_52152_3_MCC-DBN1_MCC_chr5_112630026_ENST00000302475_DBN1_chr5_176887556_ENST00000393563_length(transcript)=1806nt_BP=621nt AGAAACCACTTACAACTCCAGACGATTCGAAGGGGAAACTTCGGCGTGAAGTGCAGCTCCGCTCCGGCTCCCTCTAGCTTTCTTTCCTTC TCTGGAATCCGAGGCGCGGATCTTCCTCGCCCCACCGCCCTAGTTTTTTCGGGAGCTCGCCGGTGCCCTCTAGGGTGTCGGCTCGTGCTG GGAAGTGCCCTCCATCCTGGTAATGGGGGGCGGCGAGGCACCGTAGGAGTGGCGAGGCGGCGCCCAGGGTGGCACTGCCCCGGAACGGGG CGCTGGGTGCGCGCGGGAGGGTCCCCGCGCGGGCTCCGCCGCTGCCGCAGCTGCGAGCGCGCCGCGCCACCGAGCCTCCTGCAGCAATGG CTCGTCCGTGAAACGCGAGCCACGGCTGCTCTTTTTAAGAGTGCCTGCATCCTCCGTTTGCGCTTCGCAACTGTCCTGGGTGAAAATGGC TGTCTAGACTAAAATGTGGCAGAAGGGACCAAGCAGTGGATATTGAGCCTGTGAAGTCCAACTCTTAAGCTCCGAGACCTGGGGGACTGA GAGCCCAGCTCTGAAAAGTGCATCATGAATTCCGGAGTTGCCATGAAATATGGAAACGACTCCTCGGCCGAGCTGAGTGAGGAGGCAGCA GCTATTATTGCCCAGCGGCCTGACAACCCAAGGGAGTTCTTCAAGCAGCAGGAAAGAGTCGCATCGGCCTCTGCGGGCAGCTGTGATGTA CCCTCGCCCTTCAACCATCGACCAGGCAGCCACCTGGACAGCCACCGGAGGATGGCGCCCACTCCCATCCCCACGCGGAGCCCGTCTGAC TCCAGCACCGCCTCCACCCCTGTCGCTGAGCAGATAGAGCGGGCCCTGGATGAGGTCACCTCCTCGCAGCCTCCACCACTGCCACCGCCA CCCCCACCAGCCCAAGAGACCCAGGAGCCCAGCCCCATCCTAGACAGTGAGGAGACCAGAGCAGCAGCCCCTCAGGCCTGGGCCGGCCCC ATGGAGGAGCCCCCTCAGGCACAGGCGCCTCCCCGGGGGCCAGGCAGCCCTGCAGAGGACTTGATGTTCATGGAGTCTGCAGAGCAGGCT GTCCTGGCTGCTCCCGTGGAGCCTGCCACAGCTGACGCCACGGAGATCCACGATGCAGCTGACACCATTGAAACTGACACTGCCACTGCT GACACCACTGTTGCCAACAACGTACCCCCCGCCGCCACCAGCCTCATTGACCTATGGCCTGGCAACGGGGAAGGGGCCTCCACACTCCAG GGTGAGCCCAGGGCCCCCACGCCACCCTCGGGTACTGAGGTCACCCTGGCAGAGGTGCCCCTGCTGGATGAGGTGGCTCCGGAGCCACTG CTGCCAGCAGGCGAAGGCTGTGCCACCCTTCTCAACTTTGATGAGCTGCCTGAGCCGCCAGCCACCTTCTGTGACCCAGAGGAAGTGGAA GGGGAGTCCCTGGCTGCCCCCCAGACCCCAACTCTGCCCTCAGCCCTTGAGGAGCTGGAGCAAGAGCAGGAGCCGGAGCCCCACCTGCTA ACCAATGGCGAGACCACCCAGAAGGAGGGGACCCAGGCCAGTGAGGGGTACTTCAGTCAATCACAGGAGGAGGAGTTTGCCCAATCGGAA GAGCTCTGTGCCAAGGCTCCGCCTCCTGTGTTCTACAACAAGCCTCCAGAGATCGACATCACATGCTGGGATGCAGACCCAGTTCCAGAA GAGGAGGAGGGCTTCGAGGGTGGTGATTAGCGGTGGCGCCAGCCCTAGGCTACCCTTGCCAAGGCCGCCCACCTGCATCAGCCTCTGGCC >52152_52152_3_MCC-DBN1_MCC_chr5_112630026_ENST00000302475_DBN1_chr5_176887556_ENST00000393563_length(amino acids)=391AA_BP=19 MNSGVAMKYGNDSSAELSEEAAAIIAQRPDNPREFFKQQERVASASAGSCDVPSPFNHRPGSHLDSHRRMAPTPIPTRSPSDSSTASTPV AEQIERALDEVTSSQPPPLPPPPPPAQETQEPSPILDSEETRAAAPQAWAGPMEEPPQAQAPPRGPGSPAEDLMFMESAEQAVLAAPVEP ATADATEIHDAADTIETDTATADTTVANNVPPAATSLIDLWPGNGEGASTLQGEPRAPTPPSGTEVTLAEVPLLDEVAPEPLLPAGEGCA TLLNFDELPEPPATFCDPEEVEGESLAAPQTPTLPSALEELEQEQEPEPHLLTNGETTQKEGTQASEGYFSQSQEEEFAQSEELCAKAPP -------------------------------------------------------------- >52152_52152_4_MCC-DBN1_MCC_chr5_112630026_ENST00000302475_DBN1_chr5_176887556_ENST00000393565_length(transcript)=2375nt_BP=621nt AGAAACCACTTACAACTCCAGACGATTCGAAGGGGAAACTTCGGCGTGAAGTGCAGCTCCGCTCCGGCTCCCTCTAGCTTTCTTTCCTTC TCTGGAATCCGAGGCGCGGATCTTCCTCGCCCCACCGCCCTAGTTTTTTCGGGAGCTCGCCGGTGCCCTCTAGGGTGTCGGCTCGTGCTG GGAAGTGCCCTCCATCCTGGTAATGGGGGGCGGCGAGGCACCGTAGGAGTGGCGAGGCGGCGCCCAGGGTGGCACTGCCCCGGAACGGGG CGCTGGGTGCGCGCGGGAGGGTCCCCGCGCGGGCTCCGCCGCTGCCGCAGCTGCGAGCGCGCCGCGCCACCGAGCCTCCTGCAGCAATGG CTCGTCCGTGAAACGCGAGCCACGGCTGCTCTTTTTAAGAGTGCCTGCATCCTCCGTTTGCGCTTCGCAACTGTCCTGGGTGAAAATGGC TGTCTAGACTAAAATGTGGCAGAAGGGACCAAGCAGTGGATATTGAGCCTGTGAAGTCCAACTCTTAAGCTCCGAGACCTGGGGGACTGA GAGCCCAGCTCTGAAAAGTGCATCATGAATTCCGGAGTTGCCATGAAATATGGAAACGACTCCTCGGCCGAGCTGAGTGAGGAGGCAGCA GCTATTATTGCCCAGCGGCCTGACAACCCAAGGGAGTTCTTCAAGCAGCAGGAAAGAGTCGCATCGGCCTCTGCGGGCAGCTGTGATGTA CCCTCGCCCTTCAACCATCGACCAGGTCGTCCGTACTGCCCTTTCATAAAGGCATCGGACAGTGGGCCTTCCTCCTCCTCCTCTTCCTCC TCCTCCCCTCCACGGACTCCCTTTCCCTATATCACCTGCCACCGCACCCCAAACCTCTCTTCCTCCCTCCCATGCAGCCACCTGGACAGC CACCGGAGGATGGCGCCCACTCCCATCCCCACGCGGAGCCCGTCTGACTCCAGCACCGCCTCCACCCCTGTCGCTGAGCAGATAGAGCGG GCCCTGGATGAGGTCACCTCCTCGCAGCCTCCACCACTGCCACCGCCACCCCCACCAGCCCAAGAGACCCAGGAGCCCAGCCCCATCCTA GACAGTGAGGAGACCAGAGCAGCAGCCCCTCAGGCCTGGGCCGGCCCCATGGAGGAGCCCCCTCAGGCACAGGCGCCTCCCCGGGGGCCA GGCAGCCCTGCAGAGGACTTGATGTTCATGGAGTCTGCAGAGCAGGCTGTCCTGGCTGCTCCCGTGGAGCCTGCCACAGCTGACGCCACG GAGATCCACGATGCAGCTGACACCATTGAAACTGACACTGCCACTGCTGACACCACTGTTGCCAACAACGTACCCCCCGCCGCCACCAGC CTCATTGACCTATGGCCTGGCAACGGGGAAGGGGCCTCCACACTCCAGGGTGAGCCCAGGGCCCCCACGCCACCCTCGGGTACTGAGGTC ACCCTGGCAGAGGTGCCCCTGCTGGATGAGGTGGCTCCGGAGCCACTGCTGCCAGCAGGCGAAGGCTGTGCCACCCTTCTCAACTTTGAT GAGCTGCCTGAGCCGCCAGCCACCTTCTGTGACCCAGAGGAAGTGGAAGGGGAGTCCCTGGCTGCCCCCCAGACCCCAACTCTGCCCTCA GCCCTTGAGGAGCTGGAGCAAGAGCAGGAGCCGGAGCCCCACCTGCTAACCAATGGCGAGACCACCCAGAAGGAGGGGACCCAGGCCAGT GAGGGGTACTTCAGTCAATCACAGGAGGAGGAGTTTGCCCAATCGGAAGAGCTCTGTGCCAAGGCTCCGCCTCCTGTGTTCTACAACAAG CCTCCAGAGATCGACATCACATGCTGGGATGCAGACCCAGTTCCAGAAGAGGAGGAGGGCTTCGAGGGTGGTGATTAGCGGTGGCGCCAG CCCTAGGCTACCCTTGCCAAGGCCGCCCACCTGCATCAGCCTCTGGCCAGACGGCCCGCCGTGCCTGCATTCGCAGCAGCTCCGCCTGGC ACCCACTCCGGATTCCGGCCCTGGCTGGGGACTTGGCCGCTTCCCTACCCACAGGGCCTGACTTTTACAGCTTTTCTCTTTTTTTAAAAA GTTGATAGGAGACTTGTACAGTTGACTGGCTTTCCTCTCGTTGGTAGTTGAGACGCTGTTGCAAATTCCACCCCTCCTTCCCTGGTCCAG ATTGTAGCTCTTAGTCCTCCCTGCTCAGCTGGCCGGGTTGGAGGCCTCACCCTGCTTGGGGCCTGGCGTGGGGGGAGCTCTGGTGGGAAA ATGTCCCCCACCTCTTTTCCTAGTTTTATGTTTCTTGGGAAAATATCACTTTGTATTCTCTGTCCAGGGCTTCAGATATTTTGCACGAAT >52152_52152_4_MCC-DBN1_MCC_chr5_112630026_ENST00000302475_DBN1_chr5_176887556_ENST00000393565_length(amino acids)=437AA_BP=19 MNSGVAMKYGNDSSAELSEEAAAIIAQRPDNPREFFKQQERVASASAGSCDVPSPFNHRPGRPYCPFIKASDSGPSSSSSSSSSPPRTPF PYITCHRTPNLSSSLPCSHLDSHRRMAPTPIPTRSPSDSSTASTPVAEQIERALDEVTSSQPPPLPPPPPPAQETQEPSPILDSEETRAA APQAWAGPMEEPPQAQAPPRGPGSPAEDLMFMESAEQAVLAAPVEPATADATEIHDAADTIETDTATADTTVANNVPPAATSLIDLWPGN GEGASTLQGEPRAPTPPSGTEVTLAEVPLLDEVAPEPLLPAGEGCATLLNFDELPEPPATFCDPEEVEGESLAAPQTPTLPSALEELEQE -------------------------------------------------------------- >52152_52152_5_MCC-DBN1_MCC_chr5_112630026_ENST00000302475_DBN1_chr5_176887556_ENST00000512501_length(transcript)=2257nt_BP=621nt AGAAACCACTTACAACTCCAGACGATTCGAAGGGGAAACTTCGGCGTGAAGTGCAGCTCCGCTCCGGCTCCCTCTAGCTTTCTTTCCTTC TCTGGAATCCGAGGCGCGGATCTTCCTCGCCCCACCGCCCTAGTTTTTTCGGGAGCTCGCCGGTGCCCTCTAGGGTGTCGGCTCGTGCTG GGAAGTGCCCTCCATCCTGGTAATGGGGGGCGGCGAGGCACCGTAGGAGTGGCGAGGCGGCGCCCAGGGTGGCACTGCCCCGGAACGGGG CGCTGGGTGCGCGCGGGAGGGTCCCCGCGCGGGCTCCGCCGCTGCCGCAGCTGCGAGCGCGCCGCGCCACCGAGCCTCCTGCAGCAATGG CTCGTCCGTGAAACGCGAGCCACGGCTGCTCTTTTTAAGAGTGCCTGCATCCTCCGTTTGCGCTTCGCAACTGTCCTGGGTGAAAATGGC TGTCTAGACTAAAATGTGGCAGAAGGGACCAAGCAGTGGATATTGAGCCTGTGAAGTCCAACTCTTAAGCTCCGAGACCTGGGGGACTGA GAGCCCAGCTCTGAAAAGTGCATCATGAATTCCGGAGTTGCCATGAAATATGGAAACGACTCCTCGGCCGAGCTGAGTGAGGAGGCAGCA GCTATTATTGCCCAGCGGCCTGACAACCCAAGGGAGTTCTTCAAGCAGCAGGAAAGAGTCGCATCGGCCTCTGCGGGCAGCTGTGATGTA CCCTCGCCCTTCAACCATCGACCAGGCAGCCACCTGGACAGCCACCGGAGGATGGCGCCCACTCCCATCCCCACGCGGAGCCCGTCTGAC TCCAGCACCGCCTCCACCCCTGTCGCTGAGCAGATAGAGCGGGCCCTGGATGAGGTCACCTCCTCGCAGCCTCCACCACTGCCACCGCCA CCCCCACCAGCCCAAGAGACCCAGGAGCCCAGCCCCATCCTAGACAGTGAGGAGACCAGAGCAGCAGCCCCTCAGGCCTGGGCCGGCCCC ATGGAGGAGCCCCCTCAGGCACAGGCGCCTCCCCGGGGGCCAGGCAGCCCTGCAGAGGACTTGATGTTCATGGAGTCTGCAGAGCAGGCT GTCCTGGCTGCTCCCGTGGAGCCTGCCACAGCTGACGCCACGGAGATCCACGATGCAGCTGACACCATTGAAACTGACACTGCCACTGCT GACACCACTGTTGCCAACAACGTACCCCCCGCCGCCACCAGCCTCATTGACCTATGGCCTGGCAACGGGGAAGGGGCCTCCACACTCCAG GGTGAGCCCAGGGCCCCCACGCCACCCTCGGGTACTGAGGTCACCCTGGCAGAGGTGCCCCTGCTGGATGAGGTGGCTCCGGAGCCACTG CTGCCAGCAGGCGAAGGCTGTGCCACCCTTCTCAACTTTGATGAGCTGCCTGAGCCGCCAGCCACCTTCTGTGACCCAGAGGAAGTGGAA GGGGAGTCCCTGGCTGCCCCCCAGACCCCAACTCTGCCCTCAGCCCTTGAGGAGCTGGAGCAAGAGCAGGAGCCGGAGCCCCACCTGCTA ACCAATGGCGAGACCACCCAGAAGGAGGGGACCCAGGTGCGGCAGGGACTGCCTGGTGGGAGGGATGGGAGGGAGTGGGGGCTGAGCAGG GTGCTGGCCCTGCATTCCTCATGCTTGCACCAGTACCCCCTTCTCTGTGACCCACATTATTTGAGGGGAAGTCCATCCCACCCTCCCTCC CTGGGCCGGCTCTGCTTTTGTTCCCAAGGCAGGCATCCTTGTTTCCCTGGCAACCACTGATGGAATCATTGGTTGCTGGGGAAACGGGCT CAGGCCTGATAGGTCAGCCCCAGTCCTGCTGGGTGGGGCCAAGTGACCTGATGCTTTCCCCTGCAGGCCAGTGAGGGGTACTTCAGTCAA TCACAGGAGGAGGAGTTTGCCCAATCGGAAGAGCTCTGTGCCAAGGCTCCGCCTCCTGTGTTCTACAACAAGCCTCCAGGTAGTACTGGG CTGGATGATGGGGAGGAATTTGGGTGCGGGGGCTGGATTTGAGTGTGGGTAGCCACCCCACCACTACCCACCGCTCACAGAGGCTGGGGA CACAAGCGGTCTGCTAGGTCCCTAACTCCTCTCCCTTTCTAACGCCACAGAGATCGACATCACATGCTGGGATGCAGACCCAGTTCCAGA AGAGGAGGAGGGCTTCGAGGGTGGTGATTAGCGGTGGCGCCAGCCCTAGGCTACCCTTGCCAAGGCCGCCCACCTGCATCAGCCTCTGGC >52152_52152_5_MCC-DBN1_MCC_chr5_112630026_ENST00000302475_DBN1_chr5_176887556_ENST00000512501_length(amino acids)=401AA_BP=19 MNSGVAMKYGNDSSAELSEEAAAIIAQRPDNPREFFKQQERVASASAGSCDVPSPFNHRPGSHLDSHRRMAPTPIPTRSPSDSSTASTPV AEQIERALDEVTSSQPPPLPPPPPPAQETQEPSPILDSEETRAAAPQAWAGPMEEPPQAQAPPRGPGSPAEDLMFMESAEQAVLAAPVEP ATADATEIHDAADTIETDTATADTTVANNVPPAATSLIDLWPGNGEGASTLQGEPRAPTPPSGTEVTLAEVPLLDEVAPEPLLPAGEGCA TLLNFDELPEPPATFCDPEEVEGESLAAPQTPTLPSALEELEQEQEPEPHLLTNGETTQKEGTQVRQGLPGGRDGREWGLSRVLALHSSC -------------------------------------------------------------- >52152_52152_6_MCC-DBN1_MCC_chr5_112630026_ENST00000302475_DBN1_chr5_176887704_ENST00000292385_length(transcript)=2306nt_BP=621nt AGAAACCACTTACAACTCCAGACGATTCGAAGGGGAAACTTCGGCGTGAAGTGCAGCTCCGCTCCGGCTCCCTCTAGCTTTCTTTCCTTC TCTGGAATCCGAGGCGCGGATCTTCCTCGCCCCACCGCCCTAGTTTTTTCGGGAGCTCGCCGGTGCCCTCTAGGGTGTCGGCTCGTGCTG GGAAGTGCCCTCCATCCTGGTAATGGGGGGCGGCGAGGCACCGTAGGAGTGGCGAGGCGGCGCCCAGGGTGGCACTGCCCCGGAACGGGG CGCTGGGTGCGCGCGGGAGGGTCCCCGCGCGGGCTCCGCCGCTGCCGCAGCTGCGAGCGCGCCGCGCCACCGAGCCTCCTGCAGCAATGG CTCGTCCGTGAAACGCGAGCCACGGCTGCTCTTTTTAAGAGTGCCTGCATCCTCCGTTTGCGCTTCGCAACTGTCCTGGGTGAAAATGGC TGTCTAGACTAAAATGTGGCAGAAGGGACCAAGCAGTGGATATTGAGCCTGTGAAGTCCAACTCTTAAGCTCCGAGACCTGGGGGACTGA GAGCCCAGCTCTGAAAAGTGCATCATGAATTCCGGAGTTGCCATGAAATATGGAAACGACTCCTCGGCCGAGCTGAGTGAGGGTGACCAT CGGGATGAGGAGGAAGAGACCCACATGAAGAAGTCAGAGTCGGAGGTGGAGGAGGCAGCAGCTATTATTGCCCAGCGGCCTGACAACCCA AGGGAGTTCTTCAAGCAGCAGGAAAGAGTCGCATCGGCCTCTGCGGGCAGCTGTGATGTACCCTCGCCCTTCAACCATCGACCAGGCAGC CACCTGGACAGCCACCGGAGGATGGCGCCCACTCCCATCCCCACGCGGAGCCCGTCTGACTCCAGCACCGCCTCCACCCCTGTCGCTGAG CAGATAGAGCGGGCCCTGGATGAGGTCACCTCCTCGCAGCCTCCACCACTGCCACCGCCACCCCCACCAGCCCAAGAGACCCAGGAGCCC AGCCCCATCCTAGACAGTGAGGAGACCAGAGCAGCAGCCCCTCAGGCCTGGGCCGGCCCCATGGAGGAGCCCCCTCAGGCACAGGCGCCT CCCCGGGGGCCAGGCAGCCCTGCAGAGGACTTGATGTTCATGGAGTCTGCAGAGCAGGCTGTCCTGGCTGCTCCCGTGGAGCCTGCCACA GCTGACGCCACGGAGATCCACGATGCAGCTGACACCATTGAAACTGACACTGCCACTGCTGACACCACTGTTGCCAACAACGTACCCCCC GCCGCCACCAGCCTCATTGACCTATGGCCTGGCAACGGGGAAGGGGCCTCCACACTCCAGGGTGAGCCCAGGGCCCCCACGCCACCCTCG GGTACTGAGGTCACCCTGGCAGAGGTGCCCCTGCTGGATGAGGTGGCTCCGGAGCCACTGCTGCCAGCAGGCGAAGGCTGTGCCACCCTT CTCAACTTTGATGAGCTGCCTGAGCCGCCAGCCACCTTCTGTGACCCAGAGGAAGTGGAAGGGGAGTCCCTGGCTGCCCCCCAGACCCCA ACTCTGCCCTCAGCCCTTGAGGAGCTGGAGCAAGAGCAGGAGCCGGAGCCCCACCTGCTAACCAATGGCGAGACCACCCAGAAGGAGGGG ACCCAGGCCAGTGAGGGGTACTTCAGTCAATCACAGGAGGAGGAGTTTGCCCAATCGGAAGAGCTCTGTGCCAAGGCTCCGCCTCCTGTG TTCTACAACAAGCCTCCAGAGATCGACATCACATGCTGGGATGCAGACCCAGTTCCAGAAGAGGAGGAGGGCTTCGAGGGTGGTGATTAG CGGTGGCGCCAGCCCTAGGCTACCCTTGCCAAGGCCGCCCACCTGCATCAGCCTCTGGCCAGACGGCCCGCCGTGCCTGCATTCGCAGCA GCTCCGCCTGGCACCCACTCCGGATTCCGGCCCTGGCTGGGGACTTGGCCGCTTCCCTACCCACAGGGCCTGACTTTTACAGCTTTTCTC TTTTTTTAAAAAGTTGATAGGAGACTTGTACAGTTGACTGGCTTTCCTCTCGTTGGTAGTTGAGACGCTGTTGCAAATTCCACCCCTCCT TCCCTGGTCCAGATTGTAGCTCTTAGTCCTCCCTGCTCAGCTGGCCGGGTTGGAGGCCTCACCCTGCTTGGGGCCTGGCGTGGGGGGAGC TCTGGTGGGAAAATGTCCCCCACCTCTTTTCCTAGTTTTATGTTTCTTGGGAAAATATCACTTTGTATTCTCTGTCCAGGGCTTCAGATA >52152_52152_6_MCC-DBN1_MCC_chr5_112630026_ENST00000302475_DBN1_chr5_176887704_ENST00000292385_length(amino acids)=411AA_BP=19 MNSGVAMKYGNDSSAELSEGDHRDEEEETHMKKSESEVEEAAAIIAQRPDNPREFFKQQERVASASAGSCDVPSPFNHRPGSHLDSHRRM APTPIPTRSPSDSSTASTPVAEQIERALDEVTSSQPPPLPPPPPPAQETQEPSPILDSEETRAAAPQAWAGPMEEPPQAQAPPRGPGSPA EDLMFMESAEQAVLAAPVEPATADATEIHDAADTIETDTATADTTVANNVPPAATSLIDLWPGNGEGASTLQGEPRAPTPPSGTEVTLAE VPLLDEVAPEPLLPAGEGCATLLNFDELPEPPATFCDPEEVEGESLAAPQTPTLPSALEELEQEQEPEPHLLTNGETTQKEGTQASEGYF -------------------------------------------------------------- >52152_52152_7_MCC-DBN1_MCC_chr5_112630026_ENST00000302475_DBN1_chr5_176887704_ENST00000309007_length(transcript)=2625nt_BP=621nt AGAAACCACTTACAACTCCAGACGATTCGAAGGGGAAACTTCGGCGTGAAGTGCAGCTCCGCTCCGGCTCCCTCTAGCTTTCTTTCCTTC TCTGGAATCCGAGGCGCGGATCTTCCTCGCCCCACCGCCCTAGTTTTTTCGGGAGCTCGCCGGTGCCCTCTAGGGTGTCGGCTCGTGCTG GGAAGTGCCCTCCATCCTGGTAATGGGGGGCGGCGAGGCACCGTAGGAGTGGCGAGGCGGCGCCCAGGGTGGCACTGCCCCGGAACGGGG CGCTGGGTGCGCGCGGGAGGGTCCCCGCGCGGGCTCCGCCGCTGCCGCAGCTGCGAGCGCGCCGCGCCACCGAGCCTCCTGCAGCAATGG CTCGTCCGTGAAACGCGAGCCACGGCTGCTCTTTTTAAGAGTGCCTGCATCCTCCGTTTGCGCTTCGCAACTGTCCTGGGTGAAAATGGC TGTCTAGACTAAAATGTGGCAGAAGGGACCAAGCAGTGGATATTGAGCCTGTGAAGTCCAACTCTTAAGCTCCGAGACCTGGGGGACTGA GAGCCCAGCTCTGAAAAGTGCATCATGAATTCCGGAGTTGCCATGAAATATGGAAACGACTCCTCGGCCGAGCTGAGTGAGGGTGACCAT CGGGATGAGGAGGAAGAGACCCACATGAAGAAGTCAGAGTCGGAGGTGGAGGAGGCAGCAGCTATTATTGCCCAGCGGCCTGACAACCCA AGGGAGTTCTTCAAGCAGCAGGAAAGAGTCGCATCGGCCTCTGCGGGCAGCTGTGATGTACCCTCGCCCTTCAACCATCGACCAGGCAGC CACCTGGACAGCCACCGGAGGATGGCGCCCACTCCCATCCCCACGCGGAGCCCGTCTGACTCCAGCACCGCCTCCACCCCTGTCGCTGAG CAGATAGAGCGGGCCCTGGATGAGGTCACCTCCTCGCAGCCTCCACCACTGCCACCGCCACCCCCACCAGCCCAAGAGACCCAGGAGCCC AGCCCCATCCTAGACAGTGAGGAGACCAGAGCAGCAGCCCCTCAGGCCTGGGCCGGCCCCATGGAGGAGCCCCCTCAGGCACAGGCGCCT CCCCGGGGGCCAGGCAGCCCTGCAGAGGACTTGATGTTCATGGAGTCTGCAGAGCAGGCTGTCCTGGCTGCTCCCGTGGAGCCTGCCACA GCTGACGCCACGGAGATCCACGATGCAGCTGACACCATTGAAACTGACACTGCCACTGCTGACACCACTGTTGCCAACAACGTACCCCCC GCCGCCACCAGCCTCATTGACCTATGGCCTGGCAACGGGGAAGGGGCCTCCACACTCCAGGGTGAGCCCAGGGCCCCCACGCCACCCTCG GGTACTGAGGTCACCCTGGCAGAGGTGCCCCTGCTGGATGAGGTGGCTCCGGAGCCACTGCTGCCAGCAGGCGAAGGCTGTGCCACCCTT CTCAACTTTGATGAGCTGCCTGAGCCGCCAGCCACCTTCTGTGACCCAGAGGAAGTGGAAGGGGAGTCCCTGGCTGCCCCCCAGACCCCA ACTCTGCCCTCAGCCCTTGAGGAGCTGGAGCAAGAGCAGGAGCCGGAGCCCCACCTGCTAACCAATGGCGAGACCACCCAGAAGGAGGGG ACCCAGGCCAGTGAGGGGTACTTCAGTCAATCACAGGAGGAGGAGTTTGCCCAATCGGAAGAGCTCTGTGCCAAGGCTCCGCCTCCTGTG TTCTACAACAAGCCTCCAGAGATCGACATCACATGCTGGGATGCAGACCCAGTTCCAGAAGAGGAGGAGGGCTTCGAGGGTGGTGATTAG CGGTGGCGCCAGCCCTAGGCTACCCTTGCCAAGGCCGCCCACCTGCATCAGCCTCTGGCCAGACGGCCCGCCGTGCCTGCATTCGCAGCA GCTCCGCCTGGCACCCACTCCGGATTCCGGCCCTGGCTGGGGACTTGGCCGCTTCCCTACCCACAGGGCCTGACTTTTACAGCTTTTCTC TTTTTTTAAAAAGTTGATAGGAGACTTGTACAGTTGACTGGCTTTCCTCTCGTTGGTAGTTGAGACGCTGTTGCAAATTCCACCCCTCCT TCCCTGGTCCAGATTGTAGCTCTTAGTCCTCCCTGCTCAGCTGGCCGGGTTGGAGGCCTCACCCTGCTTGGGGCCTGGCGTGGGGGGAGC TCTGGTGGGAAAATGTCCCCCACCTCTTTTCCTAGTTTTATGTTTCTTGGGAAAATATCACTTTGTATTCTCTGTCCAGGGCTTCAGATA TTTTGCACGAATTTTAAAACATGGCAATAAATGGCTCGTGGGCTCTGGCTCCCTGGGACCCCCTCCCCGCCCTTCTTTTGACCCCTTCCT GTCTGGCCCAAAGGAAGTAGCAGGCCCAGCTGGGGCCCCTCGGCTACCCCCCGTCTCCTGCCGGGCAGGTCCCAGGTTGGAGGCCCTAGG CGCGGTTCAGGTCAGGGCTATGGATGGGGCCCAGGGGCTTTGGTGGCCCCTCCCCAACTCCTTCCTCTTTGCTTGGGTTCCTTTTTCACG TTTAGTAACTGTTTTTTTTTTTTTTTTTTTTTTTTTTTTGGAAAGCACAAACTTCTGTAACGGGTCGTGCTCATGTCTGTTAATAAAGAA >52152_52152_7_MCC-DBN1_MCC_chr5_112630026_ENST00000302475_DBN1_chr5_176887704_ENST00000309007_length(amino acids)=411AA_BP=19 MNSGVAMKYGNDSSAELSEGDHRDEEEETHMKKSESEVEEAAAIIAQRPDNPREFFKQQERVASASAGSCDVPSPFNHRPGSHLDSHRRM APTPIPTRSPSDSSTASTPVAEQIERALDEVTSSQPPPLPPPPPPAQETQEPSPILDSEETRAAAPQAWAGPMEEPPQAQAPPRGPGSPA EDLMFMESAEQAVLAAPVEPATADATEIHDAADTIETDTATADTTVANNVPPAATSLIDLWPGNGEGASTLQGEPRAPTPPSGTEVTLAE VPLLDEVAPEPLLPAGEGCATLLNFDELPEPPATFCDPEEVEGESLAAPQTPTLPSALEELEQEQEPEPHLLTNGETTQKEGTQASEGYF -------------------------------------------------------------- >52152_52152_8_MCC-DBN1_MCC_chr5_112630026_ENST00000302475_DBN1_chr5_176887704_ENST00000393565_length(transcript)=2435nt_BP=621nt AGAAACCACTTACAACTCCAGACGATTCGAAGGGGAAACTTCGGCGTGAAGTGCAGCTCCGCTCCGGCTCCCTCTAGCTTTCTTTCCTTC TCTGGAATCCGAGGCGCGGATCTTCCTCGCCCCACCGCCCTAGTTTTTTCGGGAGCTCGCCGGTGCCCTCTAGGGTGTCGGCTCGTGCTG GGAAGTGCCCTCCATCCTGGTAATGGGGGGCGGCGAGGCACCGTAGGAGTGGCGAGGCGGCGCCCAGGGTGGCACTGCCCCGGAACGGGG CGCTGGGTGCGCGCGGGAGGGTCCCCGCGCGGGCTCCGCCGCTGCCGCAGCTGCGAGCGCGCCGCGCCACCGAGCCTCCTGCAGCAATGG CTCGTCCGTGAAACGCGAGCCACGGCTGCTCTTTTTAAGAGTGCCTGCATCCTCCGTTTGCGCTTCGCAACTGTCCTGGGTGAAAATGGC TGTCTAGACTAAAATGTGGCAGAAGGGACCAAGCAGTGGATATTGAGCCTGTGAAGTCCAACTCTTAAGCTCCGAGACCTGGGGGACTGA GAGCCCAGCTCTGAAAAGTGCATCATGAATTCCGGAGTTGCCATGAAATATGGAAACGACTCCTCGGCCGAGCTGAGTGAGGGTGACCAT CGGGATGAGGAGGAAGAGACCCACATGAAGAAGTCAGAGTCGGAGGTGGAGGAGGCAGCAGCTATTATTGCCCAGCGGCCTGACAACCCA AGGGAGTTCTTCAAGCAGCAGGAAAGAGTCGCATCGGCCTCTGCGGGCAGCTGTGATGTACCCTCGCCCTTCAACCATCGACCAGGTCGT CCGTACTGCCCTTTCATAAAGGCATCGGACAGTGGGCCTTCCTCCTCCTCCTCTTCCTCCTCCTCCCCTCCACGGACTCCCTTTCCCTAT ATCACCTGCCACCGCACCCCAAACCTCTCTTCCTCCCTCCCATGCAGCCACCTGGACAGCCACCGGAGGATGGCGCCCACTCCCATCCCC ACGCGGAGCCCGTCTGACTCCAGCACCGCCTCCACCCCTGTCGCTGAGCAGATAGAGCGGGCCCTGGATGAGGTCACCTCCTCGCAGCCT CCACCACTGCCACCGCCACCCCCACCAGCCCAAGAGACCCAGGAGCCCAGCCCCATCCTAGACAGTGAGGAGACCAGAGCAGCAGCCCCT CAGGCCTGGGCCGGCCCCATGGAGGAGCCCCCTCAGGCACAGGCGCCTCCCCGGGGGCCAGGCAGCCCTGCAGAGGACTTGATGTTCATG GAGTCTGCAGAGCAGGCTGTCCTGGCTGCTCCCGTGGAGCCTGCCACAGCTGACGCCACGGAGATCCACGATGCAGCTGACACCATTGAA ACTGACACTGCCACTGCTGACACCACTGTTGCCAACAACGTACCCCCCGCCGCCACCAGCCTCATTGACCTATGGCCTGGCAACGGGGAA GGGGCCTCCACACTCCAGGGTGAGCCCAGGGCCCCCACGCCACCCTCGGGTACTGAGGTCACCCTGGCAGAGGTGCCCCTGCTGGATGAG GTGGCTCCGGAGCCACTGCTGCCAGCAGGCGAAGGCTGTGCCACCCTTCTCAACTTTGATGAGCTGCCTGAGCCGCCAGCCACCTTCTGT GACCCAGAGGAAGTGGAAGGGGAGTCCCTGGCTGCCCCCCAGACCCCAACTCTGCCCTCAGCCCTTGAGGAGCTGGAGCAAGAGCAGGAG CCGGAGCCCCACCTGCTAACCAATGGCGAGACCACCCAGAAGGAGGGGACCCAGGCCAGTGAGGGGTACTTCAGTCAATCACAGGAGGAG GAGTTTGCCCAATCGGAAGAGCTCTGTGCCAAGGCTCCGCCTCCTGTGTTCTACAACAAGCCTCCAGAGATCGACATCACATGCTGGGAT GCAGACCCAGTTCCAGAAGAGGAGGAGGGCTTCGAGGGTGGTGATTAGCGGTGGCGCCAGCCCTAGGCTACCCTTGCCAAGGCCGCCCAC CTGCATCAGCCTCTGGCCAGACGGCCCGCCGTGCCTGCATTCGCAGCAGCTCCGCCTGGCACCCACTCCGGATTCCGGCCCTGGCTGGGG ACTTGGCCGCTTCCCTACCCACAGGGCCTGACTTTTACAGCTTTTCTCTTTTTTTAAAAAGTTGATAGGAGACTTGTACAGTTGACTGGC TTTCCTCTCGTTGGTAGTTGAGACGCTGTTGCAAATTCCACCCCTCCTTCCCTGGTCCAGATTGTAGCTCTTAGTCCTCCCTGCTCAGCT GGCCGGGTTGGAGGCCTCACCCTGCTTGGGGCCTGGCGTGGGGGGAGCTCTGGTGGGAAAATGTCCCCCACCTCTTTTCCTAGTTTTATG TTTCTTGGGAAAATATCACTTTGTATTCTCTGTCCAGGGCTTCAGATATTTTGCACGAATTTTAAAACATGGCAATAAATGGCTCGTGGG >52152_52152_8_MCC-DBN1_MCC_chr5_112630026_ENST00000302475_DBN1_chr5_176887704_ENST00000393565_length(amino acids)=457AA_BP=19 MNSGVAMKYGNDSSAELSEGDHRDEEEETHMKKSESEVEEAAAIIAQRPDNPREFFKQQERVASASAGSCDVPSPFNHRPGRPYCPFIKA SDSGPSSSSSSSSSPPRTPFPYITCHRTPNLSSSLPCSHLDSHRRMAPTPIPTRSPSDSSTASTPVAEQIERALDEVTSSQPPPLPPPPP PAQETQEPSPILDSEETRAAAPQAWAGPMEEPPQAQAPPRGPGSPAEDLMFMESAEQAVLAAPVEPATADATEIHDAADTIETDTATADT TVANNVPPAATSLIDLWPGNGEGASTLQGEPRAPTPPSGTEVTLAEVPLLDEVAPEPLLPAGEGCATLLNFDELPEPPATFCDPEEVEGE SLAAPQTPTLPSALEELEQEQEPEPHLLTNGETTQKEGTQASEGYFSQSQEEEFAQSEELCAKAPPPVFYNKPPEIDITCWDADPVPEEE -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for MCC-DBN1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for MCC-DBN1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for MCC-DBN1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies