
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:AP2A1-VRK3 (FusionGDB2 ID:5222) |
Fusion Gene Summary for AP2A1-VRK3 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: AP2A1-VRK3 | Fusion gene ID: 5222 | Hgene | Tgene | Gene symbol | AP2A1 | VRK3 | Gene ID | 160 | 51231 |
| Gene name | adaptor related protein complex 2 subunit alpha 1 | VRK serine/threonine kinase 3 | |
| Synonyms | ADTAA|AP2-ALPHA|CLAPA1 | - | |
| Cytomap | 19q13.33 | 19q13.33 | |
| Type of gene | protein-coding | protein-coding | |
| Description | AP-2 complex subunit alpha-1100 kDa coated vesicle protein Aadapter-related protein complex 2 alpha-1 subunitadapter-related protein complex 2 subunit alpha-1adaptin, alpha Aadaptor protein complex AP-2 subunit alpha-1adaptor related protein complex | inactive serine/threonine-protein kinase VRK3serine/threonine-protein kinase VRK3serine/threonine-protein pseudokinase VRK3vaccinia related kinase 3 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | O95782 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000600199, ENST00000354293, ENST00000359032, | ENST00000316763, ENST00000377011, ENST00000443401, ENST00000594948, ENST00000599538, ENST00000601341, ENST00000424804, ENST00000593919, ENST00000594092, ENST00000601912, | |
| Fusion gene scores | * DoF score | 8 X 10 X 7=560 | 6 X 6 X 5=180 |
| # samples | 12 | 7 | |
| ** MAII score | log2(12/560*10)=-2.22239242133645 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(7/180*10)=-1.36257007938471 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: AP2A1 [Title/Abstract] AND VRK3 [Title/Abstract] AND fusion [Title/Abstract] | ||
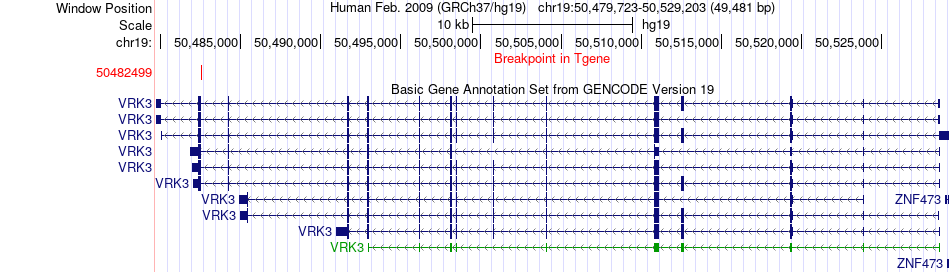
| Most frequent breakpoint | AP2A1(50295321)-VRK3(50482499), # samples:2 | ||
| Anticipated loss of major functional domain due to fusion event. | AP2A1-VRK3 seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. AP2A1-VRK3 seems lost the major protein functional domain in Tgene partner, which is a IUPHAR drug target due to the frame-shifted ORF. AP2A1-VRK3 seems lost the major protein functional domain in Tgene partner, which is a kinase due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | AP2A1 | GO:0072583 | clathrin-dependent endocytosis | 23676497 |
| Hgene | AP2A1 | GO:1900126 | negative regulation of hyaluronan biosynthetic process | 24251095 |
| Fusion gene breakpoints across AP2A1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across VRK3 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | CESC | TCGA-IR-A3LH-01A | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - |
| ChimerDB4 | SKCM | TCGA-D3-A2JN-06A | AP2A1 | chr19 | 50295321 | - | VRK3 | chr19 | 50482499 | - |
| ChimerDB4 | SKCM | TCGA-D3-A2JN-06A | AP2A1 | chr19 | 50295321 | + | VRK3 | chr19 | 50482499 | - |
Top |
Fusion Gene ORF analysis for AP2A1-VRK3 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 3UTR-3CDS | ENST00000600199 | ENST00000316763 | AP2A1 | chr19 | 50295321 | + | VRK3 | chr19 | 50482499 | - |
| 3UTR-3CDS | ENST00000600199 | ENST00000377011 | AP2A1 | chr19 | 50295321 | + | VRK3 | chr19 | 50482499 | - |
| 3UTR-3CDS | ENST00000600199 | ENST00000443401 | AP2A1 | chr19 | 50295321 | + | VRK3 | chr19 | 50482499 | - |
| 3UTR-3CDS | ENST00000600199 | ENST00000594948 | AP2A1 | chr19 | 50295321 | + | VRK3 | chr19 | 50482499 | - |
| 3UTR-3CDS | ENST00000600199 | ENST00000599538 | AP2A1 | chr19 | 50295321 | + | VRK3 | chr19 | 50482499 | - |
| 3UTR-3CDS | ENST00000600199 | ENST00000601341 | AP2A1 | chr19 | 50295321 | + | VRK3 | chr19 | 50482499 | - |
| 3UTR-intron | ENST00000600199 | ENST00000424804 | AP2A1 | chr19 | 50295321 | + | VRK3 | chr19 | 50482499 | - |
| 3UTR-intron | ENST00000600199 | ENST00000593919 | AP2A1 | chr19 | 50295321 | + | VRK3 | chr19 | 50482499 | - |
| 3UTR-intron | ENST00000600199 | ENST00000594092 | AP2A1 | chr19 | 50295321 | + | VRK3 | chr19 | 50482499 | - |
| 3UTR-intron | ENST00000600199 | ENST00000601912 | AP2A1 | chr19 | 50295321 | + | VRK3 | chr19 | 50482499 | - |
| 5CDS-intron | ENST00000354293 | ENST00000424804 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - |
| 5CDS-intron | ENST00000354293 | ENST00000424804 | AP2A1 | chr19 | 50295321 | + | VRK3 | chr19 | 50482499 | - |
| 5CDS-intron | ENST00000354293 | ENST00000593919 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - |
| 5CDS-intron | ENST00000354293 | ENST00000593919 | AP2A1 | chr19 | 50295321 | + | VRK3 | chr19 | 50482499 | - |
| 5CDS-intron | ENST00000354293 | ENST00000594092 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - |
| 5CDS-intron | ENST00000354293 | ENST00000594092 | AP2A1 | chr19 | 50295321 | + | VRK3 | chr19 | 50482499 | - |
| 5CDS-intron | ENST00000354293 | ENST00000601912 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - |
| 5CDS-intron | ENST00000354293 | ENST00000601912 | AP2A1 | chr19 | 50295321 | + | VRK3 | chr19 | 50482499 | - |
| 5CDS-intron | ENST00000359032 | ENST00000424804 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - |
| 5CDS-intron | ENST00000359032 | ENST00000424804 | AP2A1 | chr19 | 50295321 | + | VRK3 | chr19 | 50482499 | - |
| 5CDS-intron | ENST00000359032 | ENST00000593919 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - |
| 5CDS-intron | ENST00000359032 | ENST00000593919 | AP2A1 | chr19 | 50295321 | + | VRK3 | chr19 | 50482499 | - |
| 5CDS-intron | ENST00000359032 | ENST00000594092 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - |
| 5CDS-intron | ENST00000359032 | ENST00000594092 | AP2A1 | chr19 | 50295321 | + | VRK3 | chr19 | 50482499 | - |
| 5CDS-intron | ENST00000359032 | ENST00000601912 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - |
| 5CDS-intron | ENST00000359032 | ENST00000601912 | AP2A1 | chr19 | 50295321 | + | VRK3 | chr19 | 50482499 | - |
| Frame-shift | ENST00000354293 | ENST00000316763 | AP2A1 | chr19 | 50295321 | + | VRK3 | chr19 | 50482499 | - |
| Frame-shift | ENST00000354293 | ENST00000377011 | AP2A1 | chr19 | 50295321 | + | VRK3 | chr19 | 50482499 | - |
| Frame-shift | ENST00000354293 | ENST00000443401 | AP2A1 | chr19 | 50295321 | + | VRK3 | chr19 | 50482499 | - |
| Frame-shift | ENST00000354293 | ENST00000594948 | AP2A1 | chr19 | 50295321 | + | VRK3 | chr19 | 50482499 | - |
| Frame-shift | ENST00000354293 | ENST00000599538 | AP2A1 | chr19 | 50295321 | + | VRK3 | chr19 | 50482499 | - |
| Frame-shift | ENST00000354293 | ENST00000601341 | AP2A1 | chr19 | 50295321 | + | VRK3 | chr19 | 50482499 | - |
| Frame-shift | ENST00000359032 | ENST00000316763 | AP2A1 | chr19 | 50295321 | + | VRK3 | chr19 | 50482499 | - |
| Frame-shift | ENST00000359032 | ENST00000377011 | AP2A1 | chr19 | 50295321 | + | VRK3 | chr19 | 50482499 | - |
| Frame-shift | ENST00000359032 | ENST00000443401 | AP2A1 | chr19 | 50295321 | + | VRK3 | chr19 | 50482499 | - |
| Frame-shift | ENST00000359032 | ENST00000594948 | AP2A1 | chr19 | 50295321 | + | VRK3 | chr19 | 50482499 | - |
| Frame-shift | ENST00000359032 | ENST00000599538 | AP2A1 | chr19 | 50295321 | + | VRK3 | chr19 | 50482499 | - |
| Frame-shift | ENST00000359032 | ENST00000601341 | AP2A1 | chr19 | 50295321 | + | VRK3 | chr19 | 50482499 | - |
| In-frame | ENST00000354293 | ENST00000316763 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - |
| In-frame | ENST00000354293 | ENST00000377011 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - |
| In-frame | ENST00000354293 | ENST00000443401 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - |
| In-frame | ENST00000354293 | ENST00000594948 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - |
| In-frame | ENST00000354293 | ENST00000599538 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - |
| In-frame | ENST00000354293 | ENST00000601341 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - |
| In-frame | ENST00000359032 | ENST00000316763 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - |
| In-frame | ENST00000359032 | ENST00000377011 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - |
| In-frame | ENST00000359032 | ENST00000443401 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - |
| In-frame | ENST00000359032 | ENST00000594948 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - |
| In-frame | ENST00000359032 | ENST00000599538 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - |
| In-frame | ENST00000359032 | ENST00000601341 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - |
| intron-3CDS | ENST00000600199 | ENST00000316763 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - |
| intron-3CDS | ENST00000600199 | ENST00000377011 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - |
| intron-3CDS | ENST00000600199 | ENST00000443401 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - |
| intron-3CDS | ENST00000600199 | ENST00000594948 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - |
| intron-3CDS | ENST00000600199 | ENST00000599538 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - |
| intron-3CDS | ENST00000600199 | ENST00000601341 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - |
| intron-intron | ENST00000600199 | ENST00000424804 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - |
| intron-intron | ENST00000600199 | ENST00000593919 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - |
| intron-intron | ENST00000600199 | ENST00000594092 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - |
| intron-intron | ENST00000600199 | ENST00000601912 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000354293 | AP2A1 | chr19 | 50308833 | + | ENST00000316763 | VRK3 | chr19 | 50482499 | - | 3112 | 2634 | 67 | 2679 | 870 |
| ENST00000354293 | AP2A1 | chr19 | 50308833 | + | ENST00000377011 | VRK3 | chr19 | 50482499 | - | 3087 | 2634 | 67 | 2679 | 870 |
| ENST00000354293 | AP2A1 | chr19 | 50308833 | + | ENST00000599538 | VRK3 | chr19 | 50482499 | - | 2819 | 2634 | 67 | 2679 | 870 |
| ENST00000354293 | AP2A1 | chr19 | 50308833 | + | ENST00000443401 | VRK3 | chr19 | 50482499 | - | 3308 | 2634 | 67 | 2679 | 870 |
| ENST00000354293 | AP2A1 | chr19 | 50308833 | + | ENST00000601341 | VRK3 | chr19 | 50482499 | - | 3164 | 2634 | 67 | 2679 | 870 |
| ENST00000354293 | AP2A1 | chr19 | 50308833 | + | ENST00000594948 | VRK3 | chr19 | 50482499 | - | 3117 | 2634 | 67 | 2679 | 870 |
| ENST00000359032 | AP2A1 | chr19 | 50308833 | + | ENST00000316763 | VRK3 | chr19 | 50482499 | - | 3012 | 2534 | 0 | 2579 | 859 |
| ENST00000359032 | AP2A1 | chr19 | 50308833 | + | ENST00000377011 | VRK3 | chr19 | 50482499 | - | 2987 | 2534 | 0 | 2579 | 859 |
| ENST00000359032 | AP2A1 | chr19 | 50308833 | + | ENST00000599538 | VRK3 | chr19 | 50482499 | - | 2719 | 2534 | 0 | 2579 | 859 |
| ENST00000359032 | AP2A1 | chr19 | 50308833 | + | ENST00000443401 | VRK3 | chr19 | 50482499 | - | 3208 | 2534 | 0 | 2579 | 859 |
| ENST00000359032 | AP2A1 | chr19 | 50308833 | + | ENST00000601341 | VRK3 | chr19 | 50482499 | - | 3064 | 2534 | 0 | 2579 | 859 |
| ENST00000359032 | AP2A1 | chr19 | 50308833 | + | ENST00000594948 | VRK3 | chr19 | 50482499 | - | 3017 | 2534 | 0 | 2579 | 859 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000354293 | ENST00000316763 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - | 0.008138616 | 0.99186134 |
| ENST00000354293 | ENST00000377011 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - | 0.009006212 | 0.9909938 |
| ENST00000354293 | ENST00000599538 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - | 0.011026491 | 0.98897356 |
| ENST00000354293 | ENST00000443401 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - | 0.009647041 | 0.9903529 |
| ENST00000354293 | ENST00000601341 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - | 0.010433559 | 0.98956645 |
| ENST00000354293 | ENST00000594948 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - | 0.010916363 | 0.9890836 |
| ENST00000359032 | ENST00000316763 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - | 0.008247815 | 0.9917522 |
| ENST00000359032 | ENST00000377011 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - | 0.009225592 | 0.99077445 |
| ENST00000359032 | ENST00000599538 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - | 0.012228943 | 0.98777103 |
| ENST00000359032 | ENST00000443401 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - | 0.009385517 | 0.99061453 |
| ENST00000359032 | ENST00000601341 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - | 0.010110305 | 0.9898896 |
| ENST00000359032 | ENST00000594948 | AP2A1 | chr19 | 50308833 | + | VRK3 | chr19 | 50482499 | - | 0.010531609 | 0.9894684 |
Top |
Fusion Genomic Features for AP2A1-VRK3 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
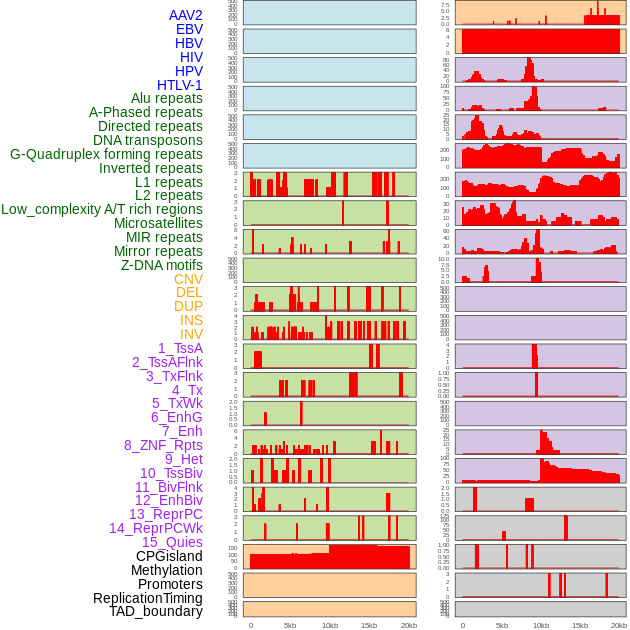 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for AP2A1-VRK3 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr19:50295321/chr19:50482499) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| AP2A1 | . |
| FUNCTION: Component of the adaptor protein complex 2 (AP-2). Adaptor protein complexes function in protein transport via transport vesicles in different membrane traffic pathways. Adaptor protein complexes are vesicle coat components and appear to be involved in cargo selection and vesicle formation. AP-2 is involved in clathrin-dependent endocytosis in which cargo proteins are incorporated into vesicles surrounded by clathrin (clathrin-coated vesicles, CCVs) which are destined for fusion with the early endosome. The clathrin lattice serves as a mechanical scaffold but is itself unable to bind directly to membrane components. Clathrin-associated adaptor protein (AP) complexes which can bind directly to both the clathrin lattice and to the lipid and protein components of membranes are considered to be the major clathrin adaptors contributing the CCV formation. AP-2 also serves as a cargo receptor to selectively sort the membrane proteins involved in receptor-mediated endocytosis. AP-2 seems to play a role in the recycling of synaptic vesicle membranes from the presynaptic surface. AP-2 recognizes Y-X-X-[FILMV] (Y-X-X-Phi) and [ED]-X-X-X-L-[LI] endocytosis signal motifs within the cytosolic tails of transmembrane cargo molecules. AP-2 may also play a role in maintaining normal post-endocytic trafficking through the ARF6-regulated, non-clathrin pathway. During long-term potentiation in hippocampal neurons, AP-2 is responsible for the endocytosis of ADAM10 (PubMed:23676497). The AP-2 alpha subunit binds polyphosphoinositide-containing lipids, positioning AP-2 on the membrane. The AP-2 alpha subunit acts via its C-terminal appendage domain as a scaffolding platform for endocytic accessory proteins. The AP-2 alpha and AP-2 sigma subunits are thought to contribute to the recognition of the [ED]-X-X-X-L-[LI] motif (By similarity). {ECO:0000250, ECO:0000269|PubMed:14745134, ECO:0000269|PubMed:15473838, ECO:0000269|PubMed:19033387, ECO:0000269|PubMed:23676497}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | VRK3 | chr19:50308833 | chr19:50482499 | ENST00000594092 | 0 | 13 | 166_457 | 0 | 413.0 | Domain | Protein kinase | |
| Tgene | VRK3 | chr19:50308833 | chr19:50482499 | ENST00000594092 | 0 | 13 | 49_64 | 0 | 413.0 | Motif | Nuclear localization signal |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | VRK3 | chr19:50308833 | chr19:50482499 | ENST00000316763 | 12 | 15 | 166_457 | 425 | 573.3333333333334 | Domain | Protein kinase | |
| Tgene | VRK3 | chr19:50308833 | chr19:50482499 | ENST00000377011 | 11 | 14 | 166_457 | 375 | 519.6666666666666 | Domain | Protein kinase | |
| Tgene | VRK3 | chr19:50308833 | chr19:50482499 | ENST00000594948 | 12 | 14 | 166_457 | 425 | 475.0 | Domain | Protein kinase | |
| Tgene | VRK3 | chr19:50308833 | chr19:50482499 | ENST00000599538 | 12 | 15 | 166_457 | 425 | 315.3333333333333 | Domain | Protein kinase | |
| Tgene | VRK3 | chr19:50308833 | chr19:50482499 | ENST00000601341 | 11 | 13 | 166_457 | 375 | 425.0 | Domain | Protein kinase | |
| Tgene | VRK3 | chr19:50308833 | chr19:50482499 | ENST00000316763 | 12 | 15 | 49_64 | 425 | 573.3333333333334 | Motif | Nuclear localization signal | |
| Tgene | VRK3 | chr19:50308833 | chr19:50482499 | ENST00000377011 | 11 | 14 | 49_64 | 375 | 519.6666666666666 | Motif | Nuclear localization signal | |
| Tgene | VRK3 | chr19:50308833 | chr19:50482499 | ENST00000594948 | 12 | 14 | 49_64 | 425 | 475.0 | Motif | Nuclear localization signal | |
| Tgene | VRK3 | chr19:50308833 | chr19:50482499 | ENST00000599538 | 12 | 15 | 49_64 | 425 | 315.3333333333333 | Motif | Nuclear localization signal | |
| Tgene | VRK3 | chr19:50308833 | chr19:50482499 | ENST00000601341 | 11 | 13 | 49_64 | 375 | 425.0 | Motif | Nuclear localization signal |
Top |
Fusion Gene Sequence for AP2A1-VRK3 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >5222_5222_1_AP2A1-VRK3_AP2A1_chr19_50308833_ENST00000354293_VRK3_chr19_50482499_ENST00000316763_length(transcript)=3112nt_BP=2634nt GGTGCCACGGCCTGCCAGCCCGCCCGCCCGCCCGCCAGCCAGCCCTCCCCGCGGCCGGCTCGGCTCCTTGGCGCTGCCTGGGGTCCTTTC CGCCCGGTCCCCGCTTGCCAGCCCCCGCTGCTCTGTGCCCTGTCCGGCCAGGCCTGGAGCCGACACCACCGCCATCATGCCGGCCGTGTC CAAGGGCGATGGGATGCGGGGGCTCGCGGTGTTCATCTCCGACATCCGGAACTGTAAGAGCAAAGAGGCGGAAATTAAGAGAATCAACAA GGAACTGGCCAACATCCGCTCCAAGTTCAAAGGAGACAAAGCCTTGGATGGCTACAGTAAGAAAAAATATGTGTGTAAACTGCTTTTCAT CTTCCTGCTTGGCCATGACATTGACTTTGGGCACATGGAGGCTGTGAATCTGTTGAGTTCCAATAAATACACAGAGAAGCAAATAGGTTA CCTGTTCATTTCTGTGCTGGTGAACTCGAACTCGGAGCTGATCCGCCTCATCAACAACGCCATCAAGAATGACCTGGCCAGCCGCAACCC CACCTTCATGTGCCTGGCCCTGCACTGCATCGCCAACGTGGGCAGCCGGGAGATGGGCGAGGCCTTTGCCGCTGACATCCCCCGCATCCT GGTGGCCGGGGACAGCATGGACAGTGTCAAGCAGAGTGCGGCCCTGTGCCTCCTTCGACTGTACAAGGCCTCGCCTGACCTGGTGCCCAT GGGCGAGTGGACGGCGCGTGTGGTACACCTGCTCAATGACCAGCACATGGGTGTGGTCACGGCCGCCGTCAGCCTCATCACCTGTCTCTG CAAGAAGAACCCAGATGACTTCAAGACGTGCGTCTCTCTGGCTGTGTCGCGCCTGAGCCGGATCGTCTCCTCTGCCTCCACCGACCTCCA GGACTACACCTACTACTTCGTCCCAGCACCCTGGCTCTCGGTGAAGCTCCTGCGGCTGCTGCAGTGCTACCCGCCTCCAGAGGATGCGGC TGTGAAGGGGCGGCTGGTGGAATGTCTGGAGACTGTGCTCAACAAGGCCCAGGAGCCCCCCAAATCCAAGAAGGTGCAGCATTCCAACGC CAAGAACGCCATCCTCTTCGAGACCATCAGCCTCATCATCCACTATGACAGTGAGCCCAACCTCCTGGTTCGGGCCTGCAACCAGCTGGG CCAGTTCCTGCAGCACCGGGAGACCAACCTGCGCTACCTGGCCCTGGAGAGCATGTGCACGCTGGCCAGCTCCGAGTTCTCCCATGAAGC CGTCAAGACGCACATTGACACCGTCATCAATGCCCTCAAGACGGAGCGGGACGTCAGCGTGCGGCAGCGGGCGGCTGACCTCCTCTACGC CATGTGTGACCGGAGCAATGCCAAGCAGATCGTGTCGGAGATGCTGCGGTACCTGGAGACGGCAGACTACGCCATCCGCGAGGAGATCGT CCTGAAGGTGGCCATCCTGGCCGAGAAGTACGCCGTGGACTACAGCTGGTACGTGGACACCATCCTCAACCTCATCCGCATTGCGGGCGA CTACGTGAGTGAGGAGGTGTGGTACCGTGTGCTACAGATCGTCACCAACCGTGATGACGTCCAGGGCTATGCCGCCAAGACCGTCTTTGA GGCGCTCCAGGCCCCTGCCTGTCACGAGAACATGGTGAAGGTTGGCGGCTACATCCTTGGGGAGTTTGGGAACCTGATTGCTGGGGACCC CCGCTCCAGCCCCCCAGTGCAGTTCTCCCTGCTCCACTCCAAGTTCCATCTGTGCAGCGTGGCCACGCGGGCGCTGCTGCTGTCCACCTA CATCAAGTTCATCAACCTCTTCCCCGAGACCAAGGCCACCATCCAGGGCGTCCTGCGGGCCGGCTCCCAGCTGCGCAATGCTGACGTGGA GCTGCAGCAGCGAGCCGTGGAGTACCTCACCCTCAGCTCAGTGGCCAGCACCGACGTCCTGGCCACGGTGCTGGAGGAGATGCCGCCCTT CCCCGAGCGCGAGTCGTCCATCCTGGCCAAGCTGAAACGCAAGAAGGGGCCAGGGGCCGGCAGCGCCCTGGACGATGGCCGGAGGGACCC CAGCAGCAACGACATCAACGGGGGCATGGAGCCCACCCCCAGCACTGTGTCGACGCCCTCGCCCTCCGCCGACCTCCTGGGGCTGCGGGC AGCCCCTCCCCCGGCAGCACCCCCGGCTTCTGCAGGAGCAGGGAACCTTCTGGTGGACGTCTTCGATGGCCCGGCCGCCCAGCCCAGCCT GGGGCCCACCCCCGAGGAGGCCTTCCTCAGCCCAGGTCCTGAGGACATCGGCCCTCCCATTCCGGAAGCCGATGAGTTGCTGAATAAGTT TGTGTGTAAGAACAACGGGGTCCTGTTCGAGAACCAGCTGCTGCAGATCGGAGTCAAGTCAGAGTTCCGACAGAACCTGGGCCGCATGTA TCTCTTCTATGGCAACAAGACCTCGGTGCAGTTCCAGAATTTCTCACCCACTGTGGTTCACCCGGGAGACCTCCAGACTCAGCTGGCTGT GCAGACCAAGCGCGTGGCGGCGCAGGTGGACGGCGGCGCGCAGGTGCAGCAGGTGCTCAATATCGAGTGCCTGCGGGACTTCCTGACGCC CCCGCTGCTGTCCGTGCGCTTCCGAGACCCTGCAGAAGTACCTGAAGGTGGTGATGGCCCTCACGTATGAGGAGAAGCCGCCCTACGCCA TGCTGAGGAACAACCTAGAAGCTTTGCTGCAGGATCTGCGTGTGTCTCCATATGACCCCATTGGCCTCCCGATGGTGCCCTAGGTGGAAT CCAGAACTTTCCATTTGCAGTGTGCAACAGAAAAAAAAAAATGAAGTAATGTGACTCAAGGCCTGCTGTTTAATCACAGATAAGCTTCTA GAACAAGCCCTGGAATGTGCATTCCTGCCACTGGTTTCAGGATACTCATCAGTCCTGATTAGCCTCCCGGAGGGCCCCAGTTTCCCTCCC GTGAATGTGAAGTTCCCCATCTTGGTGGCCTGCCCTTCAGCCAGTGTCCTAGCAAAGCTGGATGGGGTTGGGCCGGCCCACAGGGGGGAC >5222_5222_1_AP2A1-VRK3_AP2A1_chr19_50308833_ENST00000354293_VRK3_chr19_50482499_ENST00000316763_length(amino acids)=870AA_BP=855 MALPGVLSARSPLASPRCSVPCPARPGADTTAIMPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKK YVCKLLFIFLLGHDIDFGHMEAVNLLSSNKYTEKQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMCLALHCIANVGSREMGEAF AADIPRILVAGDSMDSVKQSAALCLLRLYKASPDLVPMGEWTARVVHLLNDQHMGVVTAAVSLITCLCKKNPDDFKTCVSLAVSRLSRIV SSASTDLQDYTYYFVPAPWLSVKLLRLLQCYPPPEDAAVKGRLVECLETVLNKAQEPPKSKKVQHSNAKNAILFETISLIIHYDSEPNLL VRACNQLGQFLQHRETNLRYLALESMCTLASSEFSHEAVKTHIDTVINALKTERDVSVRQRAADLLYAMCDRSNAKQIVSEMLRYLETAD YAIREEIVLKVAILAEKYAVDYSWYVDTILNLIRIAGDYVSEEVWYRVLQIVTNRDDVQGYAAKTVFEALQAPACHENMVKVGGYILGEF GNLIAGDPRSSPPVQFSLLHSKFHLCSVATRALLLSTYIKFINLFPETKATIQGVLRAGSQLRNADVELQQRAVEYLTLSSVASTDVLAT VLEEMPPFPERESSILAKLKRKKGPGAGSALDDGRRDPSSNDINGGMEPTPSTVSTPSPSADLLGLRAAPPPAAPPASAGAGNLLVDVFD GPAAQPSLGPTPEEAFLSPGPEDIGPPIPEADELLNKFVCKNNGVLFENQLLQIGVKSEFRQNLGRMYLFYGNKTSVQFQNFSPTVVHPG -------------------------------------------------------------- >5222_5222_2_AP2A1-VRK3_AP2A1_chr19_50308833_ENST00000354293_VRK3_chr19_50482499_ENST00000377011_length(transcript)=3087nt_BP=2634nt GGTGCCACGGCCTGCCAGCCCGCCCGCCCGCCCGCCAGCCAGCCCTCCCCGCGGCCGGCTCGGCTCCTTGGCGCTGCCTGGGGTCCTTTC CGCCCGGTCCCCGCTTGCCAGCCCCCGCTGCTCTGTGCCCTGTCCGGCCAGGCCTGGAGCCGACACCACCGCCATCATGCCGGCCGTGTC CAAGGGCGATGGGATGCGGGGGCTCGCGGTGTTCATCTCCGACATCCGGAACTGTAAGAGCAAAGAGGCGGAAATTAAGAGAATCAACAA GGAACTGGCCAACATCCGCTCCAAGTTCAAAGGAGACAAAGCCTTGGATGGCTACAGTAAGAAAAAATATGTGTGTAAACTGCTTTTCAT CTTCCTGCTTGGCCATGACATTGACTTTGGGCACATGGAGGCTGTGAATCTGTTGAGTTCCAATAAATACACAGAGAAGCAAATAGGTTA CCTGTTCATTTCTGTGCTGGTGAACTCGAACTCGGAGCTGATCCGCCTCATCAACAACGCCATCAAGAATGACCTGGCCAGCCGCAACCC CACCTTCATGTGCCTGGCCCTGCACTGCATCGCCAACGTGGGCAGCCGGGAGATGGGCGAGGCCTTTGCCGCTGACATCCCCCGCATCCT GGTGGCCGGGGACAGCATGGACAGTGTCAAGCAGAGTGCGGCCCTGTGCCTCCTTCGACTGTACAAGGCCTCGCCTGACCTGGTGCCCAT GGGCGAGTGGACGGCGCGTGTGGTACACCTGCTCAATGACCAGCACATGGGTGTGGTCACGGCCGCCGTCAGCCTCATCACCTGTCTCTG CAAGAAGAACCCAGATGACTTCAAGACGTGCGTCTCTCTGGCTGTGTCGCGCCTGAGCCGGATCGTCTCCTCTGCCTCCACCGACCTCCA GGACTACACCTACTACTTCGTCCCAGCACCCTGGCTCTCGGTGAAGCTCCTGCGGCTGCTGCAGTGCTACCCGCCTCCAGAGGATGCGGC TGTGAAGGGGCGGCTGGTGGAATGTCTGGAGACTGTGCTCAACAAGGCCCAGGAGCCCCCCAAATCCAAGAAGGTGCAGCATTCCAACGC CAAGAACGCCATCCTCTTCGAGACCATCAGCCTCATCATCCACTATGACAGTGAGCCCAACCTCCTGGTTCGGGCCTGCAACCAGCTGGG CCAGTTCCTGCAGCACCGGGAGACCAACCTGCGCTACCTGGCCCTGGAGAGCATGTGCACGCTGGCCAGCTCCGAGTTCTCCCATGAAGC CGTCAAGACGCACATTGACACCGTCATCAATGCCCTCAAGACGGAGCGGGACGTCAGCGTGCGGCAGCGGGCGGCTGACCTCCTCTACGC CATGTGTGACCGGAGCAATGCCAAGCAGATCGTGTCGGAGATGCTGCGGTACCTGGAGACGGCAGACTACGCCATCCGCGAGGAGATCGT CCTGAAGGTGGCCATCCTGGCCGAGAAGTACGCCGTGGACTACAGCTGGTACGTGGACACCATCCTCAACCTCATCCGCATTGCGGGCGA CTACGTGAGTGAGGAGGTGTGGTACCGTGTGCTACAGATCGTCACCAACCGTGATGACGTCCAGGGCTATGCCGCCAAGACCGTCTTTGA GGCGCTCCAGGCCCCTGCCTGTCACGAGAACATGGTGAAGGTTGGCGGCTACATCCTTGGGGAGTTTGGGAACCTGATTGCTGGGGACCC CCGCTCCAGCCCCCCAGTGCAGTTCTCCCTGCTCCACTCCAAGTTCCATCTGTGCAGCGTGGCCACGCGGGCGCTGCTGCTGTCCACCTA CATCAAGTTCATCAACCTCTTCCCCGAGACCAAGGCCACCATCCAGGGCGTCCTGCGGGCCGGCTCCCAGCTGCGCAATGCTGACGTGGA GCTGCAGCAGCGAGCCGTGGAGTACCTCACCCTCAGCTCAGTGGCCAGCACCGACGTCCTGGCCACGGTGCTGGAGGAGATGCCGCCCTT CCCCGAGCGCGAGTCGTCCATCCTGGCCAAGCTGAAACGCAAGAAGGGGCCAGGGGCCGGCAGCGCCCTGGACGATGGCCGGAGGGACCC CAGCAGCAACGACATCAACGGGGGCATGGAGCCCACCCCCAGCACTGTGTCGACGCCCTCGCCCTCCGCCGACCTCCTGGGGCTGCGGGC AGCCCCTCCCCCGGCAGCACCCCCGGCTTCTGCAGGAGCAGGGAACCTTCTGGTGGACGTCTTCGATGGCCCGGCCGCCCAGCCCAGCCT GGGGCCCACCCCCGAGGAGGCCTTCCTCAGCCCAGGTCCTGAGGACATCGGCCCTCCCATTCCGGAAGCCGATGAGTTGCTGAATAAGTT TGTGTGTAAGAACAACGGGGTCCTGTTCGAGAACCAGCTGCTGCAGATCGGAGTCAAGTCAGAGTTCCGACAGAACCTGGGCCGCATGTA TCTCTTCTATGGCAACAAGACCTCGGTGCAGTTCCAGAATTTCTCACCCACTGTGGTTCACCCGGGAGACCTCCAGACTCAGCTGGCTGT GCAGACCAAGCGCGTGGCGGCGCAGGTGGACGGCGGCGCGCAGGTGCAGCAGGTGCTCAATATCGAGTGCCTGCGGGACTTCCTGACGCC CCCGCTGCTGTCCGTGCGCTTCCGAGACCCTGCAGAAGTACCTGAAGGTGGTGATGGCCCTCACGTATGAGGAGAAGCCGCCCTACGCCA TGCTGAGGAACAACCTAGAAGCTTTGCTGCAGGATCTGCGTGTGTCTCCATATGACCCCATTGGCCTCCCGATGGTGCCCTAGGTGGAAT CCAGAACTTTCCATTTGCAGTGTGCAACAGAAAAAAAAAAATGAAGTAATGTGACTCAAGGCCTGCTGTTTAATCACAGATAAGCTTCTA GAACAAGCCCTGGAATGTGCATTCCTGCCACTGGTTTCAGGATACTCATCAGTCCTGATTAGCCTCCCGGAGGGCCCCAGTTTCCCTCCC GTGAATGTGAAGTTCCCCATCTTGGTGGCCTGCCCTTCAGCCAGTGTCCTAGCAAAGCTGGATGGGGTTGGGCCGGCCCACAGGGGGGAC >5222_5222_2_AP2A1-VRK3_AP2A1_chr19_50308833_ENST00000354293_VRK3_chr19_50482499_ENST00000377011_length(amino acids)=870AA_BP=855 MALPGVLSARSPLASPRCSVPCPARPGADTTAIMPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKK YVCKLLFIFLLGHDIDFGHMEAVNLLSSNKYTEKQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMCLALHCIANVGSREMGEAF AADIPRILVAGDSMDSVKQSAALCLLRLYKASPDLVPMGEWTARVVHLLNDQHMGVVTAAVSLITCLCKKNPDDFKTCVSLAVSRLSRIV SSASTDLQDYTYYFVPAPWLSVKLLRLLQCYPPPEDAAVKGRLVECLETVLNKAQEPPKSKKVQHSNAKNAILFETISLIIHYDSEPNLL VRACNQLGQFLQHRETNLRYLALESMCTLASSEFSHEAVKTHIDTVINALKTERDVSVRQRAADLLYAMCDRSNAKQIVSEMLRYLETAD YAIREEIVLKVAILAEKYAVDYSWYVDTILNLIRIAGDYVSEEVWYRVLQIVTNRDDVQGYAAKTVFEALQAPACHENMVKVGGYILGEF GNLIAGDPRSSPPVQFSLLHSKFHLCSVATRALLLSTYIKFINLFPETKATIQGVLRAGSQLRNADVELQQRAVEYLTLSSVASTDVLAT VLEEMPPFPERESSILAKLKRKKGPGAGSALDDGRRDPSSNDINGGMEPTPSTVSTPSPSADLLGLRAAPPPAAPPASAGAGNLLVDVFD GPAAQPSLGPTPEEAFLSPGPEDIGPPIPEADELLNKFVCKNNGVLFENQLLQIGVKSEFRQNLGRMYLFYGNKTSVQFQNFSPTVVHPG -------------------------------------------------------------- >5222_5222_3_AP2A1-VRK3_AP2A1_chr19_50308833_ENST00000354293_VRK3_chr19_50482499_ENST00000443401_length(transcript)=3308nt_BP=2634nt GGTGCCACGGCCTGCCAGCCCGCCCGCCCGCCCGCCAGCCAGCCCTCCCCGCGGCCGGCTCGGCTCCTTGGCGCTGCCTGGGGTCCTTTC CGCCCGGTCCCCGCTTGCCAGCCCCCGCTGCTCTGTGCCCTGTCCGGCCAGGCCTGGAGCCGACACCACCGCCATCATGCCGGCCGTGTC CAAGGGCGATGGGATGCGGGGGCTCGCGGTGTTCATCTCCGACATCCGGAACTGTAAGAGCAAAGAGGCGGAAATTAAGAGAATCAACAA GGAACTGGCCAACATCCGCTCCAAGTTCAAAGGAGACAAAGCCTTGGATGGCTACAGTAAGAAAAAATATGTGTGTAAACTGCTTTTCAT CTTCCTGCTTGGCCATGACATTGACTTTGGGCACATGGAGGCTGTGAATCTGTTGAGTTCCAATAAATACACAGAGAAGCAAATAGGTTA CCTGTTCATTTCTGTGCTGGTGAACTCGAACTCGGAGCTGATCCGCCTCATCAACAACGCCATCAAGAATGACCTGGCCAGCCGCAACCC CACCTTCATGTGCCTGGCCCTGCACTGCATCGCCAACGTGGGCAGCCGGGAGATGGGCGAGGCCTTTGCCGCTGACATCCCCCGCATCCT GGTGGCCGGGGACAGCATGGACAGTGTCAAGCAGAGTGCGGCCCTGTGCCTCCTTCGACTGTACAAGGCCTCGCCTGACCTGGTGCCCAT GGGCGAGTGGACGGCGCGTGTGGTACACCTGCTCAATGACCAGCACATGGGTGTGGTCACGGCCGCCGTCAGCCTCATCACCTGTCTCTG CAAGAAGAACCCAGATGACTTCAAGACGTGCGTCTCTCTGGCTGTGTCGCGCCTGAGCCGGATCGTCTCCTCTGCCTCCACCGACCTCCA GGACTACACCTACTACTTCGTCCCAGCACCCTGGCTCTCGGTGAAGCTCCTGCGGCTGCTGCAGTGCTACCCGCCTCCAGAGGATGCGGC TGTGAAGGGGCGGCTGGTGGAATGTCTGGAGACTGTGCTCAACAAGGCCCAGGAGCCCCCCAAATCCAAGAAGGTGCAGCATTCCAACGC CAAGAACGCCATCCTCTTCGAGACCATCAGCCTCATCATCCACTATGACAGTGAGCCCAACCTCCTGGTTCGGGCCTGCAACCAGCTGGG CCAGTTCCTGCAGCACCGGGAGACCAACCTGCGCTACCTGGCCCTGGAGAGCATGTGCACGCTGGCCAGCTCCGAGTTCTCCCATGAAGC CGTCAAGACGCACATTGACACCGTCATCAATGCCCTCAAGACGGAGCGGGACGTCAGCGTGCGGCAGCGGGCGGCTGACCTCCTCTACGC CATGTGTGACCGGAGCAATGCCAAGCAGATCGTGTCGGAGATGCTGCGGTACCTGGAGACGGCAGACTACGCCATCCGCGAGGAGATCGT CCTGAAGGTGGCCATCCTGGCCGAGAAGTACGCCGTGGACTACAGCTGGTACGTGGACACCATCCTCAACCTCATCCGCATTGCGGGCGA CTACGTGAGTGAGGAGGTGTGGTACCGTGTGCTACAGATCGTCACCAACCGTGATGACGTCCAGGGCTATGCCGCCAAGACCGTCTTTGA GGCGCTCCAGGCCCCTGCCTGTCACGAGAACATGGTGAAGGTTGGCGGCTACATCCTTGGGGAGTTTGGGAACCTGATTGCTGGGGACCC CCGCTCCAGCCCCCCAGTGCAGTTCTCCCTGCTCCACTCCAAGTTCCATCTGTGCAGCGTGGCCACGCGGGCGCTGCTGCTGTCCACCTA CATCAAGTTCATCAACCTCTTCCCCGAGACCAAGGCCACCATCCAGGGCGTCCTGCGGGCCGGCTCCCAGCTGCGCAATGCTGACGTGGA GCTGCAGCAGCGAGCCGTGGAGTACCTCACCCTCAGCTCAGTGGCCAGCACCGACGTCCTGGCCACGGTGCTGGAGGAGATGCCGCCCTT CCCCGAGCGCGAGTCGTCCATCCTGGCCAAGCTGAAACGCAAGAAGGGGCCAGGGGCCGGCAGCGCCCTGGACGATGGCCGGAGGGACCC CAGCAGCAACGACATCAACGGGGGCATGGAGCCCACCCCCAGCACTGTGTCGACGCCCTCGCCCTCCGCCGACCTCCTGGGGCTGCGGGC AGCCCCTCCCCCGGCAGCACCCCCGGCTTCTGCAGGAGCAGGGAACCTTCTGGTGGACGTCTTCGATGGCCCGGCCGCCCAGCCCAGCCT GGGGCCCACCCCCGAGGAGGCCTTCCTCAGCCCAGGTCCTGAGGACATCGGCCCTCCCATTCCGGAAGCCGATGAGTTGCTGAATAAGTT TGTGTGTAAGAACAACGGGGTCCTGTTCGAGAACCAGCTGCTGCAGATCGGAGTCAAGTCAGAGTTCCGACAGAACCTGGGCCGCATGTA TCTCTTCTATGGCAACAAGACCTCGGTGCAGTTCCAGAATTTCTCACCCACTGTGGTTCACCCGGGAGACCTCCAGACTCAGCTGGCTGT GCAGACCAAGCGCGTGGCGGCGCAGGTGGACGGCGGCGCGCAGGTGCAGCAGGTGCTCAATATCGAGTGCCTGCGGGACTTCCTGACGCC CCCGCTGCTGTCCGTGCGCTTCCGAGACCCTGCAGAAGTACCTGAAGGTGGTGATGGCCCTCACGTATGAGGAGAAGCCGCCCTACGCCA TGCTGAGGAACAACCTAGAAGCTTTGCTGCAGGATCTGCGTGTGTCTCCATATGACCCCATTGGCCTCCCGATGGTGCCCTAGGTGGAAT CCAGGTGGGAAGAGCTTGTGAGGCTTAAGCCTCTCACCCCTTGCCCTCACCCGAGCCCTGCCCCAGGCTCCAGGAGACACTTCCCAGAGG CTGTTCCACGTTCATACCAGGGCCCAGCTTCCCAGGGAGACACTGGGTTTTTCCGCACGGTCCTTGAACTTCCCAGCCTCAAGGAATGGC AAGTAGCAGAAACCCGGCTCAACTTGGCTTTAAGAAAAGTGGGGATTGATTGGCTGTTGTAGCTAGAAAATTACAAGGGGGAGCTTCAGG CACAACGGGATTCAGGGCCTCAAAAATAGCATCAAGACGTTGTTTGTCTCTCGCCATCTTCTGTCCCTTCTTGCATCCATGCCTCCCTCT GTCCTTCCACCCGGCCACCTGTAGTCTCTACTTTCCTTTGGCCTGGCCCCCTTGGCGCCCCCATACACAAAAGGTAGCTGCTCCATGCCT >5222_5222_3_AP2A1-VRK3_AP2A1_chr19_50308833_ENST00000354293_VRK3_chr19_50482499_ENST00000443401_length(amino acids)=870AA_BP=855 MALPGVLSARSPLASPRCSVPCPARPGADTTAIMPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKK YVCKLLFIFLLGHDIDFGHMEAVNLLSSNKYTEKQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMCLALHCIANVGSREMGEAF AADIPRILVAGDSMDSVKQSAALCLLRLYKASPDLVPMGEWTARVVHLLNDQHMGVVTAAVSLITCLCKKNPDDFKTCVSLAVSRLSRIV SSASTDLQDYTYYFVPAPWLSVKLLRLLQCYPPPEDAAVKGRLVECLETVLNKAQEPPKSKKVQHSNAKNAILFETISLIIHYDSEPNLL VRACNQLGQFLQHRETNLRYLALESMCTLASSEFSHEAVKTHIDTVINALKTERDVSVRQRAADLLYAMCDRSNAKQIVSEMLRYLETAD YAIREEIVLKVAILAEKYAVDYSWYVDTILNLIRIAGDYVSEEVWYRVLQIVTNRDDVQGYAAKTVFEALQAPACHENMVKVGGYILGEF GNLIAGDPRSSPPVQFSLLHSKFHLCSVATRALLLSTYIKFINLFPETKATIQGVLRAGSQLRNADVELQQRAVEYLTLSSVASTDVLAT VLEEMPPFPERESSILAKLKRKKGPGAGSALDDGRRDPSSNDINGGMEPTPSTVSTPSPSADLLGLRAAPPPAAPPASAGAGNLLVDVFD GPAAQPSLGPTPEEAFLSPGPEDIGPPIPEADELLNKFVCKNNGVLFENQLLQIGVKSEFRQNLGRMYLFYGNKTSVQFQNFSPTVVHPG -------------------------------------------------------------- >5222_5222_4_AP2A1-VRK3_AP2A1_chr19_50308833_ENST00000354293_VRK3_chr19_50482499_ENST00000594948_length(transcript)=3117nt_BP=2634nt GGTGCCACGGCCTGCCAGCCCGCCCGCCCGCCCGCCAGCCAGCCCTCCCCGCGGCCGGCTCGGCTCCTTGGCGCTGCCTGGGGTCCTTTC CGCCCGGTCCCCGCTTGCCAGCCCCCGCTGCTCTGTGCCCTGTCCGGCCAGGCCTGGAGCCGACACCACCGCCATCATGCCGGCCGTGTC CAAGGGCGATGGGATGCGGGGGCTCGCGGTGTTCATCTCCGACATCCGGAACTGTAAGAGCAAAGAGGCGGAAATTAAGAGAATCAACAA GGAACTGGCCAACATCCGCTCCAAGTTCAAAGGAGACAAAGCCTTGGATGGCTACAGTAAGAAAAAATATGTGTGTAAACTGCTTTTCAT CTTCCTGCTTGGCCATGACATTGACTTTGGGCACATGGAGGCTGTGAATCTGTTGAGTTCCAATAAATACACAGAGAAGCAAATAGGTTA CCTGTTCATTTCTGTGCTGGTGAACTCGAACTCGGAGCTGATCCGCCTCATCAACAACGCCATCAAGAATGACCTGGCCAGCCGCAACCC CACCTTCATGTGCCTGGCCCTGCACTGCATCGCCAACGTGGGCAGCCGGGAGATGGGCGAGGCCTTTGCCGCTGACATCCCCCGCATCCT GGTGGCCGGGGACAGCATGGACAGTGTCAAGCAGAGTGCGGCCCTGTGCCTCCTTCGACTGTACAAGGCCTCGCCTGACCTGGTGCCCAT GGGCGAGTGGACGGCGCGTGTGGTACACCTGCTCAATGACCAGCACATGGGTGTGGTCACGGCCGCCGTCAGCCTCATCACCTGTCTCTG CAAGAAGAACCCAGATGACTTCAAGACGTGCGTCTCTCTGGCTGTGTCGCGCCTGAGCCGGATCGTCTCCTCTGCCTCCACCGACCTCCA GGACTACACCTACTACTTCGTCCCAGCACCCTGGCTCTCGGTGAAGCTCCTGCGGCTGCTGCAGTGCTACCCGCCTCCAGAGGATGCGGC TGTGAAGGGGCGGCTGGTGGAATGTCTGGAGACTGTGCTCAACAAGGCCCAGGAGCCCCCCAAATCCAAGAAGGTGCAGCATTCCAACGC CAAGAACGCCATCCTCTTCGAGACCATCAGCCTCATCATCCACTATGACAGTGAGCCCAACCTCCTGGTTCGGGCCTGCAACCAGCTGGG CCAGTTCCTGCAGCACCGGGAGACCAACCTGCGCTACCTGGCCCTGGAGAGCATGTGCACGCTGGCCAGCTCCGAGTTCTCCCATGAAGC CGTCAAGACGCACATTGACACCGTCATCAATGCCCTCAAGACGGAGCGGGACGTCAGCGTGCGGCAGCGGGCGGCTGACCTCCTCTACGC CATGTGTGACCGGAGCAATGCCAAGCAGATCGTGTCGGAGATGCTGCGGTACCTGGAGACGGCAGACTACGCCATCCGCGAGGAGATCGT CCTGAAGGTGGCCATCCTGGCCGAGAAGTACGCCGTGGACTACAGCTGGTACGTGGACACCATCCTCAACCTCATCCGCATTGCGGGCGA CTACGTGAGTGAGGAGGTGTGGTACCGTGTGCTACAGATCGTCACCAACCGTGATGACGTCCAGGGCTATGCCGCCAAGACCGTCTTTGA GGCGCTCCAGGCCCCTGCCTGTCACGAGAACATGGTGAAGGTTGGCGGCTACATCCTTGGGGAGTTTGGGAACCTGATTGCTGGGGACCC CCGCTCCAGCCCCCCAGTGCAGTTCTCCCTGCTCCACTCCAAGTTCCATCTGTGCAGCGTGGCCACGCGGGCGCTGCTGCTGTCCACCTA CATCAAGTTCATCAACCTCTTCCCCGAGACCAAGGCCACCATCCAGGGCGTCCTGCGGGCCGGCTCCCAGCTGCGCAATGCTGACGTGGA GCTGCAGCAGCGAGCCGTGGAGTACCTCACCCTCAGCTCAGTGGCCAGCACCGACGTCCTGGCCACGGTGCTGGAGGAGATGCCGCCCTT CCCCGAGCGCGAGTCGTCCATCCTGGCCAAGCTGAAACGCAAGAAGGGGCCAGGGGCCGGCAGCGCCCTGGACGATGGCCGGAGGGACCC CAGCAGCAACGACATCAACGGGGGCATGGAGCCCACCCCCAGCACTGTGTCGACGCCCTCGCCCTCCGCCGACCTCCTGGGGCTGCGGGC AGCCCCTCCCCCGGCAGCACCCCCGGCTTCTGCAGGAGCAGGGAACCTTCTGGTGGACGTCTTCGATGGCCCGGCCGCCCAGCCCAGCCT GGGGCCCACCCCCGAGGAGGCCTTCCTCAGCCCAGGTCCTGAGGACATCGGCCCTCCCATTCCGGAAGCCGATGAGTTGCTGAATAAGTT TGTGTGTAAGAACAACGGGGTCCTGTTCGAGAACCAGCTGCTGCAGATCGGAGTCAAGTCAGAGTTCCGACAGAACCTGGGCCGCATGTA TCTCTTCTATGGCAACAAGACCTCGGTGCAGTTCCAGAATTTCTCACCCACTGTGGTTCACCCGGGAGACCTCCAGACTCAGCTGGCTGT GCAGACCAAGCGCGTGGCGGCGCAGGTGGACGGCGGCGCGCAGGTGCAGCAGGTGCTCAATATCGAGTGCCTGCGGGACTTCCTGACGCC CCCGCTGCTGTCCGTGCGCTTCCGAGACCCTGCAGAAGTACCTGAAGGTGGTGATGGCCCTCACGTATGAGGAGAAGCCGCCCTACGCCA TGCTGAGGAACAACCTAGAAGCTTTGCTGCAGGATCTGCGTGTGTCTCCATATGACCCCATTGGCCTCCCGATGGTGCCCTAGGTGGAAT CCAGGTGGGAAGAGCTTGTGAGGCTTAAGCCTCTCACCCCTTGCCCTCACCCGAGCCCTGCCCCAGGCTCCAGGAGACACTTCCCAGAGG CTGTTCCACGTTCATACCAGGGCCCAGCTTCCCAGGGAGACACTGGGTTTTTCCGCACGGTCCTTGAACTTCCCAGCCTCAAGGAATGGC AAGTAGCAGAAACCCGGCTCAACTTGGCTTTAAGAAAAGTGGGGATTGATTGGCTGTTGTAGCTAGAAAATTACAAGGGGGAGCTTCAGG >5222_5222_4_AP2A1-VRK3_AP2A1_chr19_50308833_ENST00000354293_VRK3_chr19_50482499_ENST00000594948_length(amino acids)=870AA_BP=855 MALPGVLSARSPLASPRCSVPCPARPGADTTAIMPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKK YVCKLLFIFLLGHDIDFGHMEAVNLLSSNKYTEKQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMCLALHCIANVGSREMGEAF AADIPRILVAGDSMDSVKQSAALCLLRLYKASPDLVPMGEWTARVVHLLNDQHMGVVTAAVSLITCLCKKNPDDFKTCVSLAVSRLSRIV SSASTDLQDYTYYFVPAPWLSVKLLRLLQCYPPPEDAAVKGRLVECLETVLNKAQEPPKSKKVQHSNAKNAILFETISLIIHYDSEPNLL VRACNQLGQFLQHRETNLRYLALESMCTLASSEFSHEAVKTHIDTVINALKTERDVSVRQRAADLLYAMCDRSNAKQIVSEMLRYLETAD YAIREEIVLKVAILAEKYAVDYSWYVDTILNLIRIAGDYVSEEVWYRVLQIVTNRDDVQGYAAKTVFEALQAPACHENMVKVGGYILGEF GNLIAGDPRSSPPVQFSLLHSKFHLCSVATRALLLSTYIKFINLFPETKATIQGVLRAGSQLRNADVELQQRAVEYLTLSSVASTDVLAT VLEEMPPFPERESSILAKLKRKKGPGAGSALDDGRRDPSSNDINGGMEPTPSTVSTPSPSADLLGLRAAPPPAAPPASAGAGNLLVDVFD GPAAQPSLGPTPEEAFLSPGPEDIGPPIPEADELLNKFVCKNNGVLFENQLLQIGVKSEFRQNLGRMYLFYGNKTSVQFQNFSPTVVHPG -------------------------------------------------------------- >5222_5222_5_AP2A1-VRK3_AP2A1_chr19_50308833_ENST00000354293_VRK3_chr19_50482499_ENST00000599538_length(transcript)=2819nt_BP=2634nt GGTGCCACGGCCTGCCAGCCCGCCCGCCCGCCCGCCAGCCAGCCCTCCCCGCGGCCGGCTCGGCTCCTTGGCGCTGCCTGGGGTCCTTTC CGCCCGGTCCCCGCTTGCCAGCCCCCGCTGCTCTGTGCCCTGTCCGGCCAGGCCTGGAGCCGACACCACCGCCATCATGCCGGCCGTGTC CAAGGGCGATGGGATGCGGGGGCTCGCGGTGTTCATCTCCGACATCCGGAACTGTAAGAGCAAAGAGGCGGAAATTAAGAGAATCAACAA GGAACTGGCCAACATCCGCTCCAAGTTCAAAGGAGACAAAGCCTTGGATGGCTACAGTAAGAAAAAATATGTGTGTAAACTGCTTTTCAT CTTCCTGCTTGGCCATGACATTGACTTTGGGCACATGGAGGCTGTGAATCTGTTGAGTTCCAATAAATACACAGAGAAGCAAATAGGTTA CCTGTTCATTTCTGTGCTGGTGAACTCGAACTCGGAGCTGATCCGCCTCATCAACAACGCCATCAAGAATGACCTGGCCAGCCGCAACCC CACCTTCATGTGCCTGGCCCTGCACTGCATCGCCAACGTGGGCAGCCGGGAGATGGGCGAGGCCTTTGCCGCTGACATCCCCCGCATCCT GGTGGCCGGGGACAGCATGGACAGTGTCAAGCAGAGTGCGGCCCTGTGCCTCCTTCGACTGTACAAGGCCTCGCCTGACCTGGTGCCCAT GGGCGAGTGGACGGCGCGTGTGGTACACCTGCTCAATGACCAGCACATGGGTGTGGTCACGGCCGCCGTCAGCCTCATCACCTGTCTCTG CAAGAAGAACCCAGATGACTTCAAGACGTGCGTCTCTCTGGCTGTGTCGCGCCTGAGCCGGATCGTCTCCTCTGCCTCCACCGACCTCCA GGACTACACCTACTACTTCGTCCCAGCACCCTGGCTCTCGGTGAAGCTCCTGCGGCTGCTGCAGTGCTACCCGCCTCCAGAGGATGCGGC TGTGAAGGGGCGGCTGGTGGAATGTCTGGAGACTGTGCTCAACAAGGCCCAGGAGCCCCCCAAATCCAAGAAGGTGCAGCATTCCAACGC CAAGAACGCCATCCTCTTCGAGACCATCAGCCTCATCATCCACTATGACAGTGAGCCCAACCTCCTGGTTCGGGCCTGCAACCAGCTGGG CCAGTTCCTGCAGCACCGGGAGACCAACCTGCGCTACCTGGCCCTGGAGAGCATGTGCACGCTGGCCAGCTCCGAGTTCTCCCATGAAGC CGTCAAGACGCACATTGACACCGTCATCAATGCCCTCAAGACGGAGCGGGACGTCAGCGTGCGGCAGCGGGCGGCTGACCTCCTCTACGC CATGTGTGACCGGAGCAATGCCAAGCAGATCGTGTCGGAGATGCTGCGGTACCTGGAGACGGCAGACTACGCCATCCGCGAGGAGATCGT CCTGAAGGTGGCCATCCTGGCCGAGAAGTACGCCGTGGACTACAGCTGGTACGTGGACACCATCCTCAACCTCATCCGCATTGCGGGCGA CTACGTGAGTGAGGAGGTGTGGTACCGTGTGCTACAGATCGTCACCAACCGTGATGACGTCCAGGGCTATGCCGCCAAGACCGTCTTTGA GGCGCTCCAGGCCCCTGCCTGTCACGAGAACATGGTGAAGGTTGGCGGCTACATCCTTGGGGAGTTTGGGAACCTGATTGCTGGGGACCC CCGCTCCAGCCCCCCAGTGCAGTTCTCCCTGCTCCACTCCAAGTTCCATCTGTGCAGCGTGGCCACGCGGGCGCTGCTGCTGTCCACCTA CATCAAGTTCATCAACCTCTTCCCCGAGACCAAGGCCACCATCCAGGGCGTCCTGCGGGCCGGCTCCCAGCTGCGCAATGCTGACGTGGA GCTGCAGCAGCGAGCCGTGGAGTACCTCACCCTCAGCTCAGTGGCCAGCACCGACGTCCTGGCCACGGTGCTGGAGGAGATGCCGCCCTT CCCCGAGCGCGAGTCGTCCATCCTGGCCAAGCTGAAACGCAAGAAGGGGCCAGGGGCCGGCAGCGCCCTGGACGATGGCCGGAGGGACCC CAGCAGCAACGACATCAACGGGGGCATGGAGCCCACCCCCAGCACTGTGTCGACGCCCTCGCCCTCCGCCGACCTCCTGGGGCTGCGGGC AGCCCCTCCCCCGGCAGCACCCCCGGCTTCTGCAGGAGCAGGGAACCTTCTGGTGGACGTCTTCGATGGCCCGGCCGCCCAGCCCAGCCT GGGGCCCACCCCCGAGGAGGCCTTCCTCAGCCCAGGTCCTGAGGACATCGGCCCTCCCATTCCGGAAGCCGATGAGTTGCTGAATAAGTT TGTGTGTAAGAACAACGGGGTCCTGTTCGAGAACCAGCTGCTGCAGATCGGAGTCAAGTCAGAGTTCCGACAGAACCTGGGCCGCATGTA TCTCTTCTATGGCAACAAGACCTCGGTGCAGTTCCAGAATTTCTCACCCACTGTGGTTCACCCGGGAGACCTCCAGACTCAGCTGGCTGT GCAGACCAAGCGCGTGGCGGCGCAGGTGGACGGCGGCGCGCAGGTGCAGCAGGTGCTCAATATCGAGTGCCTGCGGGACTTCCTGACGCC CCCGCTGCTGTCCGTGCGCTTCCGAGACCCTGCAGAAGTACCTGAAGGTGGTGATGGCCCTCACGTATGAGGAGAAGCCGCCCTACGCCA TGCTGAGGAACAACCTAGAAGCTTTGCTGCAGGATCTGCGTGTGTCTCCATATGACCCCATTGGCCTCCCGATGGTGCCCTAGGTGGAAT >5222_5222_5_AP2A1-VRK3_AP2A1_chr19_50308833_ENST00000354293_VRK3_chr19_50482499_ENST00000599538_length(amino acids)=870AA_BP=855 MALPGVLSARSPLASPRCSVPCPARPGADTTAIMPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKK YVCKLLFIFLLGHDIDFGHMEAVNLLSSNKYTEKQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMCLALHCIANVGSREMGEAF AADIPRILVAGDSMDSVKQSAALCLLRLYKASPDLVPMGEWTARVVHLLNDQHMGVVTAAVSLITCLCKKNPDDFKTCVSLAVSRLSRIV SSASTDLQDYTYYFVPAPWLSVKLLRLLQCYPPPEDAAVKGRLVECLETVLNKAQEPPKSKKVQHSNAKNAILFETISLIIHYDSEPNLL VRACNQLGQFLQHRETNLRYLALESMCTLASSEFSHEAVKTHIDTVINALKTERDVSVRQRAADLLYAMCDRSNAKQIVSEMLRYLETAD YAIREEIVLKVAILAEKYAVDYSWYVDTILNLIRIAGDYVSEEVWYRVLQIVTNRDDVQGYAAKTVFEALQAPACHENMVKVGGYILGEF GNLIAGDPRSSPPVQFSLLHSKFHLCSVATRALLLSTYIKFINLFPETKATIQGVLRAGSQLRNADVELQQRAVEYLTLSSVASTDVLAT VLEEMPPFPERESSILAKLKRKKGPGAGSALDDGRRDPSSNDINGGMEPTPSTVSTPSPSADLLGLRAAPPPAAPPASAGAGNLLVDVFD GPAAQPSLGPTPEEAFLSPGPEDIGPPIPEADELLNKFVCKNNGVLFENQLLQIGVKSEFRQNLGRMYLFYGNKTSVQFQNFSPTVVHPG -------------------------------------------------------------- >5222_5222_6_AP2A1-VRK3_AP2A1_chr19_50308833_ENST00000354293_VRK3_chr19_50482499_ENST00000601341_length(transcript)=3164nt_BP=2634nt GGTGCCACGGCCTGCCAGCCCGCCCGCCCGCCCGCCAGCCAGCCCTCCCCGCGGCCGGCTCGGCTCCTTGGCGCTGCCTGGGGTCCTTTC CGCCCGGTCCCCGCTTGCCAGCCCCCGCTGCTCTGTGCCCTGTCCGGCCAGGCCTGGAGCCGACACCACCGCCATCATGCCGGCCGTGTC CAAGGGCGATGGGATGCGGGGGCTCGCGGTGTTCATCTCCGACATCCGGAACTGTAAGAGCAAAGAGGCGGAAATTAAGAGAATCAACAA GGAACTGGCCAACATCCGCTCCAAGTTCAAAGGAGACAAAGCCTTGGATGGCTACAGTAAGAAAAAATATGTGTGTAAACTGCTTTTCAT CTTCCTGCTTGGCCATGACATTGACTTTGGGCACATGGAGGCTGTGAATCTGTTGAGTTCCAATAAATACACAGAGAAGCAAATAGGTTA CCTGTTCATTTCTGTGCTGGTGAACTCGAACTCGGAGCTGATCCGCCTCATCAACAACGCCATCAAGAATGACCTGGCCAGCCGCAACCC CACCTTCATGTGCCTGGCCCTGCACTGCATCGCCAACGTGGGCAGCCGGGAGATGGGCGAGGCCTTTGCCGCTGACATCCCCCGCATCCT GGTGGCCGGGGACAGCATGGACAGTGTCAAGCAGAGTGCGGCCCTGTGCCTCCTTCGACTGTACAAGGCCTCGCCTGACCTGGTGCCCAT GGGCGAGTGGACGGCGCGTGTGGTACACCTGCTCAATGACCAGCACATGGGTGTGGTCACGGCCGCCGTCAGCCTCATCACCTGTCTCTG CAAGAAGAACCCAGATGACTTCAAGACGTGCGTCTCTCTGGCTGTGTCGCGCCTGAGCCGGATCGTCTCCTCTGCCTCCACCGACCTCCA GGACTACACCTACTACTTCGTCCCAGCACCCTGGCTCTCGGTGAAGCTCCTGCGGCTGCTGCAGTGCTACCCGCCTCCAGAGGATGCGGC TGTGAAGGGGCGGCTGGTGGAATGTCTGGAGACTGTGCTCAACAAGGCCCAGGAGCCCCCCAAATCCAAGAAGGTGCAGCATTCCAACGC CAAGAACGCCATCCTCTTCGAGACCATCAGCCTCATCATCCACTATGACAGTGAGCCCAACCTCCTGGTTCGGGCCTGCAACCAGCTGGG CCAGTTCCTGCAGCACCGGGAGACCAACCTGCGCTACCTGGCCCTGGAGAGCATGTGCACGCTGGCCAGCTCCGAGTTCTCCCATGAAGC CGTCAAGACGCACATTGACACCGTCATCAATGCCCTCAAGACGGAGCGGGACGTCAGCGTGCGGCAGCGGGCGGCTGACCTCCTCTACGC CATGTGTGACCGGAGCAATGCCAAGCAGATCGTGTCGGAGATGCTGCGGTACCTGGAGACGGCAGACTACGCCATCCGCGAGGAGATCGT CCTGAAGGTGGCCATCCTGGCCGAGAAGTACGCCGTGGACTACAGCTGGTACGTGGACACCATCCTCAACCTCATCCGCATTGCGGGCGA CTACGTGAGTGAGGAGGTGTGGTACCGTGTGCTACAGATCGTCACCAACCGTGATGACGTCCAGGGCTATGCCGCCAAGACCGTCTTTGA GGCGCTCCAGGCCCCTGCCTGTCACGAGAACATGGTGAAGGTTGGCGGCTACATCCTTGGGGAGTTTGGGAACCTGATTGCTGGGGACCC CCGCTCCAGCCCCCCAGTGCAGTTCTCCCTGCTCCACTCCAAGTTCCATCTGTGCAGCGTGGCCACGCGGGCGCTGCTGCTGTCCACCTA CATCAAGTTCATCAACCTCTTCCCCGAGACCAAGGCCACCATCCAGGGCGTCCTGCGGGCCGGCTCCCAGCTGCGCAATGCTGACGTGGA GCTGCAGCAGCGAGCCGTGGAGTACCTCACCCTCAGCTCAGTGGCCAGCACCGACGTCCTGGCCACGGTGCTGGAGGAGATGCCGCCCTT CCCCGAGCGCGAGTCGTCCATCCTGGCCAAGCTGAAACGCAAGAAGGGGCCAGGGGCCGGCAGCGCCCTGGACGATGGCCGGAGGGACCC CAGCAGCAACGACATCAACGGGGGCATGGAGCCCACCCCCAGCACTGTGTCGACGCCCTCGCCCTCCGCCGACCTCCTGGGGCTGCGGGC AGCCCCTCCCCCGGCAGCACCCCCGGCTTCTGCAGGAGCAGGGAACCTTCTGGTGGACGTCTTCGATGGCCCGGCCGCCCAGCCCAGCCT GGGGCCCACCCCCGAGGAGGCCTTCCTCAGCCCAGGTCCTGAGGACATCGGCCCTCCCATTCCGGAAGCCGATGAGTTGCTGAATAAGTT TGTGTGTAAGAACAACGGGGTCCTGTTCGAGAACCAGCTGCTGCAGATCGGAGTCAAGTCAGAGTTCCGACAGAACCTGGGCCGCATGTA TCTCTTCTATGGCAACAAGACCTCGGTGCAGTTCCAGAATTTCTCACCCACTGTGGTTCACCCGGGAGACCTCCAGACTCAGCTGGCTGT GCAGACCAAGCGCGTGGCGGCGCAGGTGGACGGCGGCGCGCAGGTGCAGCAGGTGCTCAATATCGAGTGCCTGCGGGACTTCCTGACGCC CCCGCTGCTGTCCGTGCGCTTCCGAGACCCTGCAGAAGTACCTGAAGGTGGTGATGGCCCTCACGTATGAGGAGAAGCCGCCCTACGCCA TGCTGAGGAACAACCTAGAAGCTTTGCTGCAGGATCTGCGTGTGTCTCCATATGACCCCATTGGCCTCCCGATGGTGCCCTAGGTGGAAT CCAGGTGGGAAGAGCTTGTGAGGCTTAAGCCTCTCACCCCTTGCCCTCACCCGAGCCCTGCCCCAGGCTCCAGGAGACACTTCCCAGAGG CTGTTCCACGTTCATACCAGGGCCCAGCTTCCCAGGGAGACACTGGGTTTTTCCGCACGGTCCTTGAACTTCCCAGCCTCAAGGAATGGC AAGTAGCAGAAACCCGGCTCAACTTGGCTTTAAGAAAAGTGGGGATTGATTGGCTGTTGTAGCTAGAAAATTACAAGGGGGAGCTTCAGG CACAACGGGATTCAGGGCCTCAAAAATAGCATCAAGACGTTGTTTGTCTCTCGCCATCTTCTGTCCCTTCTTGCATCCATGCCTCCCTCT >5222_5222_6_AP2A1-VRK3_AP2A1_chr19_50308833_ENST00000354293_VRK3_chr19_50482499_ENST00000601341_length(amino acids)=870AA_BP=855 MALPGVLSARSPLASPRCSVPCPARPGADTTAIMPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKK YVCKLLFIFLLGHDIDFGHMEAVNLLSSNKYTEKQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMCLALHCIANVGSREMGEAF AADIPRILVAGDSMDSVKQSAALCLLRLYKASPDLVPMGEWTARVVHLLNDQHMGVVTAAVSLITCLCKKNPDDFKTCVSLAVSRLSRIV SSASTDLQDYTYYFVPAPWLSVKLLRLLQCYPPPEDAAVKGRLVECLETVLNKAQEPPKSKKVQHSNAKNAILFETISLIIHYDSEPNLL VRACNQLGQFLQHRETNLRYLALESMCTLASSEFSHEAVKTHIDTVINALKTERDVSVRQRAADLLYAMCDRSNAKQIVSEMLRYLETAD YAIREEIVLKVAILAEKYAVDYSWYVDTILNLIRIAGDYVSEEVWYRVLQIVTNRDDVQGYAAKTVFEALQAPACHENMVKVGGYILGEF GNLIAGDPRSSPPVQFSLLHSKFHLCSVATRALLLSTYIKFINLFPETKATIQGVLRAGSQLRNADVELQQRAVEYLTLSSVASTDVLAT VLEEMPPFPERESSILAKLKRKKGPGAGSALDDGRRDPSSNDINGGMEPTPSTVSTPSPSADLLGLRAAPPPAAPPASAGAGNLLVDVFD GPAAQPSLGPTPEEAFLSPGPEDIGPPIPEADELLNKFVCKNNGVLFENQLLQIGVKSEFRQNLGRMYLFYGNKTSVQFQNFSPTVVHPG -------------------------------------------------------------- >5222_5222_7_AP2A1-VRK3_AP2A1_chr19_50308833_ENST00000359032_VRK3_chr19_50482499_ENST00000316763_length(transcript)=3012nt_BP=2534nt ATGCCGGCCGTGTCCAAGGGCGATGGGATGCGGGGGCTCGCGGTGTTCATCTCCGACATCCGGAACTGTAAGAGCAAAGAGGCGGAAATT AAGAGAATCAACAAGGAACTGGCCAACATCCGCTCCAAGTTCAAAGGAGACAAAGCCTTGGATGGCTACAGTAAGAAAAAATATGTGTGT AAACTGCTTTTCATCTTCCTGCTTGGCCATGACATTGACTTTGGGCACATGGAGGCTGTGAATCTGTTGAGTTCCAATAAATACACAGAG AAGCAAATAGGTTACCTGTTCATTTCTGTGCTGGTGAACTCGAACTCGGAGCTGATCCGCCTCATCAACAACGCCATCAAGAATGACCTG GCCAGCCGCAACCCCACCTTCATGTGCCTGGCCCTGCACTGCATCGCCAACGTGGGCAGCCGGGAGATGGGCGAGGCCTTTGCCGCTGAC ATCCCCCGCATCCTGGTGGCCGGGGACAGCATGGACAGTGTCAAGCAGAGTGCGGCCCTGTGCCTCCTTCGACTGTACAAGGCCTCGCCT GACCTGGTGCCCATGGGCGAGTGGACGGCGCGTGTGGTACACCTGCTCAATGACCAGCACATGGGTGTGGTCACGGCCGCCGTCAGCCTC ATCACCTGTCTCTGCAAGAAGAACCCAGATGACTTCAAGACGTGCGTCTCTCTGGCTGTGTCGCGCCTGAGCCGGATCGTCTCCTCTGCC TCCACCGACCTCCAGGACTACACCTACTACTTCGTCCCAGCACCCTGGCTCTCGGTGAAGCTCCTGCGGCTGCTGCAGTGCTACCCGCCT CCAGAGGATGCGGCTGTGAAGGGGCGGCTGGTGGAATGTCTGGAGACTGTGCTCAACAAGGCCCAGGAGCCCCCCAAATCCAAGAAGGTG CAGCATTCCAACGCCAAGAACGCCATCCTCTTCGAGACCATCAGCCTCATCATCCACTATGACAGTGAGCCCAACCTCCTGGTTCGGGCC TGCAACCAGCTGGGCCAGTTCCTGCAGCACCGGGAGACCAACCTGCGCTACCTGGCCCTGGAGAGCATGTGCACGCTGGCCAGCTCCGAG TTCTCCCATGAAGCCGTCAAGACGCACATTGACACCGTCATCAATGCCCTCAAGACGGAGCGGGACGTCAGCGTGCGGCAGCGGGCGGCT GACCTCCTCTACGCCATGTGTGACCGGAGCAATGCCAAGCAGATCGTGTCGGAGATGCTGCGGTACCTGGAGACGGCAGACTACGCCATC CGCGAGGAGATCGTCCTGAAGGTGGCCATCCTGGCCGAGAAGTACGCCGTGGACTACAGCTGGTACGTGGACACCATCCTCAACCTCATC CGCATTGCGGGCGACTACGTGAGTGAGGAGGTGTGGTACCGTGTGCTACAGATCGTCACCAACCGTGATGACGTCCAGGGCTATGCCGCC AAGACCGTCTTTGAGGCGCTCCAGGCCCCTGCCTGTCACGAGAACATGGTGAAGGTTGGCGGCTACATCCTTGGGGAGTTTGGGAACCTG ATTGCTGGGGACCCCCGCTCCAGCCCCCCAGTGCAGTTCTCCCTGCTCCACTCCAAGTTCCATCTGTGCAGCGTGGCCACGCGGGCGCTG CTGCTGTCCACCTACATCAAGTTCATCAACCTCTTCCCCGAGACCAAGGCCACCATCCAGGGCGTCCTGCGGGCCGGCTCCCAGCTGCGC AATGCTGACGTGGAGCTGCAGCAGCGAGCCGTGGAGTACCTCACCCTCAGCTCAGTGGCCAGCACCGACGTCCTGGCCACGGTGCTGGAG GAGATGCCGCCCTTCCCCGAGCGCGAGTCGTCCATCCTGGCCAAGCTGAAACGCAAGAAGGGGCCAGGGGCCGGCAGCGCCCTGGACGAT GGCCGGAGGGACCCCAGCAGCAACGACATCAACGGGGGCATGGAGCCCACCCCCAGCACTGTGTCGACGCCCTCGCCCTCCGCCGACCTC CTGGGGCTGCGGGCAGCCCCTCCCCCGGCAGCACCCCCGGCTTCTGCAGGAGCAGGGAACCTTCTGGTGGACGTCTTCGATGGCCCGGCC GCCCAGCCCAGCCTGGGGCCCACCCCCGAGGAGGCCTTCCTCAGCGAGCTGGAGCCGCCTGCCCCCGAGAGCCCCATGGCTTTGCTGGCT GACCCAGCTCCAGCTGCTGACCCAGGTCCTGAGGACATCGGCCCTCCCATTCCGGAAGCCGATGAGTTGCTGAATAAGTTTGTGTGTAAG AACAACGGGGTCCTGTTCGAGAACCAGCTGCTGCAGATCGGAGTCAAGTCAGAGTTCCGACAGAACCTGGGCCGCATGTATCTCTTCTAT GGCAACAAGACCTCGGTGCAGTTCCAGAATTTCTCACCCACTGTGGTTCACCCGGGAGACCTCCAGACTCAGCTGGCTGTGCAGACCAAG CGCGTGGCGGCGCAGGTGGACGGCGGCGCGCAGGTGCAGCAGGTGCTCAATATCGAGTGCCTGCGGGACTTCCTGACGCCCCCGCTGCTG TCCGTGCGCTTCCGAGACCCTGCAGAAGTACCTGAAGGTGGTGATGGCCCTCACGTATGAGGAGAAGCCGCCCTACGCCATGCTGAGGAA CAACCTAGAAGCTTTGCTGCAGGATCTGCGTGTGTCTCCATATGACCCCATTGGCCTCCCGATGGTGCCCTAGGTGGAATCCAGAACTTT CCATTTGCAGTGTGCAACAGAAAAAAAAAAATGAAGTAATGTGACTCAAGGCCTGCTGTTTAATCACAGATAAGCTTCTAGAACAAGCCC TGGAATGTGCATTCCTGCCACTGGTTTCAGGATACTCATCAGTCCTGATTAGCCTCCCGGAGGGCCCCAGTTTCCCTCCCGTGAATGTGA AGTTCCCCATCTTGGTGGCCTGCCCTTCAGCCAGTGTCCTAGCAAAGCTGGATGGGGTTGGGCCGGCCCACAGGGGGGACCCCTCCTACC >5222_5222_7_AP2A1-VRK3_AP2A1_chr19_50308833_ENST00000359032_VRK3_chr19_50482499_ENST00000316763_length(amino acids)=859AA_BP=844 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNKYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMCLALHCIANVGSREMGEAFAADIPRILVAGDSMDSVKQSAALCLLRLYKASP DLVPMGEWTARVVHLLNDQHMGVVTAAVSLITCLCKKNPDDFKTCVSLAVSRLSRIVSSASTDLQDYTYYFVPAPWLSVKLLRLLQCYPP PEDAAVKGRLVECLETVLNKAQEPPKSKKVQHSNAKNAILFETISLIIHYDSEPNLLVRACNQLGQFLQHRETNLRYLALESMCTLASSE FSHEAVKTHIDTVINALKTERDVSVRQRAADLLYAMCDRSNAKQIVSEMLRYLETADYAIREEIVLKVAILAEKYAVDYSWYVDTILNLI RIAGDYVSEEVWYRVLQIVTNRDDVQGYAAKTVFEALQAPACHENMVKVGGYILGEFGNLIAGDPRSSPPVQFSLLHSKFHLCSVATRAL LLSTYIKFINLFPETKATIQGVLRAGSQLRNADVELQQRAVEYLTLSSVASTDVLATVLEEMPPFPERESSILAKLKRKKGPGAGSALDD GRRDPSSNDINGGMEPTPSTVSTPSPSADLLGLRAAPPPAAPPASAGAGNLLVDVFDGPAAQPSLGPTPEEAFLSELEPPAPESPMALLA DPAPAADPGPEDIGPPIPEADELLNKFVCKNNGVLFENQLLQIGVKSEFRQNLGRMYLFYGNKTSVQFQNFSPTVVHPGDLQTQLAVQTK -------------------------------------------------------------- >5222_5222_8_AP2A1-VRK3_AP2A1_chr19_50308833_ENST00000359032_VRK3_chr19_50482499_ENST00000377011_length(transcript)=2987nt_BP=2534nt ATGCCGGCCGTGTCCAAGGGCGATGGGATGCGGGGGCTCGCGGTGTTCATCTCCGACATCCGGAACTGTAAGAGCAAAGAGGCGGAAATT AAGAGAATCAACAAGGAACTGGCCAACATCCGCTCCAAGTTCAAAGGAGACAAAGCCTTGGATGGCTACAGTAAGAAAAAATATGTGTGT AAACTGCTTTTCATCTTCCTGCTTGGCCATGACATTGACTTTGGGCACATGGAGGCTGTGAATCTGTTGAGTTCCAATAAATACACAGAG AAGCAAATAGGTTACCTGTTCATTTCTGTGCTGGTGAACTCGAACTCGGAGCTGATCCGCCTCATCAACAACGCCATCAAGAATGACCTG GCCAGCCGCAACCCCACCTTCATGTGCCTGGCCCTGCACTGCATCGCCAACGTGGGCAGCCGGGAGATGGGCGAGGCCTTTGCCGCTGAC ATCCCCCGCATCCTGGTGGCCGGGGACAGCATGGACAGTGTCAAGCAGAGTGCGGCCCTGTGCCTCCTTCGACTGTACAAGGCCTCGCCT GACCTGGTGCCCATGGGCGAGTGGACGGCGCGTGTGGTACACCTGCTCAATGACCAGCACATGGGTGTGGTCACGGCCGCCGTCAGCCTC ATCACCTGTCTCTGCAAGAAGAACCCAGATGACTTCAAGACGTGCGTCTCTCTGGCTGTGTCGCGCCTGAGCCGGATCGTCTCCTCTGCC TCCACCGACCTCCAGGACTACACCTACTACTTCGTCCCAGCACCCTGGCTCTCGGTGAAGCTCCTGCGGCTGCTGCAGTGCTACCCGCCT CCAGAGGATGCGGCTGTGAAGGGGCGGCTGGTGGAATGTCTGGAGACTGTGCTCAACAAGGCCCAGGAGCCCCCCAAATCCAAGAAGGTG CAGCATTCCAACGCCAAGAACGCCATCCTCTTCGAGACCATCAGCCTCATCATCCACTATGACAGTGAGCCCAACCTCCTGGTTCGGGCC TGCAACCAGCTGGGCCAGTTCCTGCAGCACCGGGAGACCAACCTGCGCTACCTGGCCCTGGAGAGCATGTGCACGCTGGCCAGCTCCGAG TTCTCCCATGAAGCCGTCAAGACGCACATTGACACCGTCATCAATGCCCTCAAGACGGAGCGGGACGTCAGCGTGCGGCAGCGGGCGGCT GACCTCCTCTACGCCATGTGTGACCGGAGCAATGCCAAGCAGATCGTGTCGGAGATGCTGCGGTACCTGGAGACGGCAGACTACGCCATC CGCGAGGAGATCGTCCTGAAGGTGGCCATCCTGGCCGAGAAGTACGCCGTGGACTACAGCTGGTACGTGGACACCATCCTCAACCTCATC CGCATTGCGGGCGACTACGTGAGTGAGGAGGTGTGGTACCGTGTGCTACAGATCGTCACCAACCGTGATGACGTCCAGGGCTATGCCGCC AAGACCGTCTTTGAGGCGCTCCAGGCCCCTGCCTGTCACGAGAACATGGTGAAGGTTGGCGGCTACATCCTTGGGGAGTTTGGGAACCTG ATTGCTGGGGACCCCCGCTCCAGCCCCCCAGTGCAGTTCTCCCTGCTCCACTCCAAGTTCCATCTGTGCAGCGTGGCCACGCGGGCGCTG CTGCTGTCCACCTACATCAAGTTCATCAACCTCTTCCCCGAGACCAAGGCCACCATCCAGGGCGTCCTGCGGGCCGGCTCCCAGCTGCGC AATGCTGACGTGGAGCTGCAGCAGCGAGCCGTGGAGTACCTCACCCTCAGCTCAGTGGCCAGCACCGACGTCCTGGCCACGGTGCTGGAG GAGATGCCGCCCTTCCCCGAGCGCGAGTCGTCCATCCTGGCCAAGCTGAAACGCAAGAAGGGGCCAGGGGCCGGCAGCGCCCTGGACGAT GGCCGGAGGGACCCCAGCAGCAACGACATCAACGGGGGCATGGAGCCCACCCCCAGCACTGTGTCGACGCCCTCGCCCTCCGCCGACCTC CTGGGGCTGCGGGCAGCCCCTCCCCCGGCAGCACCCCCGGCTTCTGCAGGAGCAGGGAACCTTCTGGTGGACGTCTTCGATGGCCCGGCC GCCCAGCCCAGCCTGGGGCCCACCCCCGAGGAGGCCTTCCTCAGCGAGCTGGAGCCGCCTGCCCCCGAGAGCCCCATGGCTTTGCTGGCT GACCCAGCTCCAGCTGCTGACCCAGGTCCTGAGGACATCGGCCCTCCCATTCCGGAAGCCGATGAGTTGCTGAATAAGTTTGTGTGTAAG AACAACGGGGTCCTGTTCGAGAACCAGCTGCTGCAGATCGGAGTCAAGTCAGAGTTCCGACAGAACCTGGGCCGCATGTATCTCTTCTAT GGCAACAAGACCTCGGTGCAGTTCCAGAATTTCTCACCCACTGTGGTTCACCCGGGAGACCTCCAGACTCAGCTGGCTGTGCAGACCAAG CGCGTGGCGGCGCAGGTGGACGGCGGCGCGCAGGTGCAGCAGGTGCTCAATATCGAGTGCCTGCGGGACTTCCTGACGCCCCCGCTGCTG TCCGTGCGCTTCCGAGACCCTGCAGAAGTACCTGAAGGTGGTGATGGCCCTCACGTATGAGGAGAAGCCGCCCTACGCCATGCTGAGGAA CAACCTAGAAGCTTTGCTGCAGGATCTGCGTGTGTCTCCATATGACCCCATTGGCCTCCCGATGGTGCCCTAGGTGGAATCCAGAACTTT CCATTTGCAGTGTGCAACAGAAAAAAAAAAATGAAGTAATGTGACTCAAGGCCTGCTGTTTAATCACAGATAAGCTTCTAGAACAAGCCC TGGAATGTGCATTCCTGCCACTGGTTTCAGGATACTCATCAGTCCTGATTAGCCTCCCGGAGGGCCCCAGTTTCCCTCCCGTGAATGTGA AGTTCCCCATCTTGGTGGCCTGCCCTTCAGCCAGTGTCCTAGCAAAGCTGGATGGGGTTGGGCCGGCCCACAGGGGGGACCCCTCCTACC >5222_5222_8_AP2A1-VRK3_AP2A1_chr19_50308833_ENST00000359032_VRK3_chr19_50482499_ENST00000377011_length(amino acids)=859AA_BP=844 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNKYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMCLALHCIANVGSREMGEAFAADIPRILVAGDSMDSVKQSAALCLLRLYKASP DLVPMGEWTARVVHLLNDQHMGVVTAAVSLITCLCKKNPDDFKTCVSLAVSRLSRIVSSASTDLQDYTYYFVPAPWLSVKLLRLLQCYPP PEDAAVKGRLVECLETVLNKAQEPPKSKKVQHSNAKNAILFETISLIIHYDSEPNLLVRACNQLGQFLQHRETNLRYLALESMCTLASSE FSHEAVKTHIDTVINALKTERDVSVRQRAADLLYAMCDRSNAKQIVSEMLRYLETADYAIREEIVLKVAILAEKYAVDYSWYVDTILNLI RIAGDYVSEEVWYRVLQIVTNRDDVQGYAAKTVFEALQAPACHENMVKVGGYILGEFGNLIAGDPRSSPPVQFSLLHSKFHLCSVATRAL LLSTYIKFINLFPETKATIQGVLRAGSQLRNADVELQQRAVEYLTLSSVASTDVLATVLEEMPPFPERESSILAKLKRKKGPGAGSALDD GRRDPSSNDINGGMEPTPSTVSTPSPSADLLGLRAAPPPAAPPASAGAGNLLVDVFDGPAAQPSLGPTPEEAFLSELEPPAPESPMALLA DPAPAADPGPEDIGPPIPEADELLNKFVCKNNGVLFENQLLQIGVKSEFRQNLGRMYLFYGNKTSVQFQNFSPTVVHPGDLQTQLAVQTK -------------------------------------------------------------- >5222_5222_9_AP2A1-VRK3_AP2A1_chr19_50308833_ENST00000359032_VRK3_chr19_50482499_ENST00000443401_length(transcript)=3208nt_BP=2534nt ATGCCGGCCGTGTCCAAGGGCGATGGGATGCGGGGGCTCGCGGTGTTCATCTCCGACATCCGGAACTGTAAGAGCAAAGAGGCGGAAATT AAGAGAATCAACAAGGAACTGGCCAACATCCGCTCCAAGTTCAAAGGAGACAAAGCCTTGGATGGCTACAGTAAGAAAAAATATGTGTGT AAACTGCTTTTCATCTTCCTGCTTGGCCATGACATTGACTTTGGGCACATGGAGGCTGTGAATCTGTTGAGTTCCAATAAATACACAGAG AAGCAAATAGGTTACCTGTTCATTTCTGTGCTGGTGAACTCGAACTCGGAGCTGATCCGCCTCATCAACAACGCCATCAAGAATGACCTG GCCAGCCGCAACCCCACCTTCATGTGCCTGGCCCTGCACTGCATCGCCAACGTGGGCAGCCGGGAGATGGGCGAGGCCTTTGCCGCTGAC ATCCCCCGCATCCTGGTGGCCGGGGACAGCATGGACAGTGTCAAGCAGAGTGCGGCCCTGTGCCTCCTTCGACTGTACAAGGCCTCGCCT GACCTGGTGCCCATGGGCGAGTGGACGGCGCGTGTGGTACACCTGCTCAATGACCAGCACATGGGTGTGGTCACGGCCGCCGTCAGCCTC ATCACCTGTCTCTGCAAGAAGAACCCAGATGACTTCAAGACGTGCGTCTCTCTGGCTGTGTCGCGCCTGAGCCGGATCGTCTCCTCTGCC TCCACCGACCTCCAGGACTACACCTACTACTTCGTCCCAGCACCCTGGCTCTCGGTGAAGCTCCTGCGGCTGCTGCAGTGCTACCCGCCT CCAGAGGATGCGGCTGTGAAGGGGCGGCTGGTGGAATGTCTGGAGACTGTGCTCAACAAGGCCCAGGAGCCCCCCAAATCCAAGAAGGTG CAGCATTCCAACGCCAAGAACGCCATCCTCTTCGAGACCATCAGCCTCATCATCCACTATGACAGTGAGCCCAACCTCCTGGTTCGGGCC TGCAACCAGCTGGGCCAGTTCCTGCAGCACCGGGAGACCAACCTGCGCTACCTGGCCCTGGAGAGCATGTGCACGCTGGCCAGCTCCGAG TTCTCCCATGAAGCCGTCAAGACGCACATTGACACCGTCATCAATGCCCTCAAGACGGAGCGGGACGTCAGCGTGCGGCAGCGGGCGGCT GACCTCCTCTACGCCATGTGTGACCGGAGCAATGCCAAGCAGATCGTGTCGGAGATGCTGCGGTACCTGGAGACGGCAGACTACGCCATC CGCGAGGAGATCGTCCTGAAGGTGGCCATCCTGGCCGAGAAGTACGCCGTGGACTACAGCTGGTACGTGGACACCATCCTCAACCTCATC CGCATTGCGGGCGACTACGTGAGTGAGGAGGTGTGGTACCGTGTGCTACAGATCGTCACCAACCGTGATGACGTCCAGGGCTATGCCGCC AAGACCGTCTTTGAGGCGCTCCAGGCCCCTGCCTGTCACGAGAACATGGTGAAGGTTGGCGGCTACATCCTTGGGGAGTTTGGGAACCTG ATTGCTGGGGACCCCCGCTCCAGCCCCCCAGTGCAGTTCTCCCTGCTCCACTCCAAGTTCCATCTGTGCAGCGTGGCCACGCGGGCGCTG CTGCTGTCCACCTACATCAAGTTCATCAACCTCTTCCCCGAGACCAAGGCCACCATCCAGGGCGTCCTGCGGGCCGGCTCCCAGCTGCGC AATGCTGACGTGGAGCTGCAGCAGCGAGCCGTGGAGTACCTCACCCTCAGCTCAGTGGCCAGCACCGACGTCCTGGCCACGGTGCTGGAG GAGATGCCGCCCTTCCCCGAGCGCGAGTCGTCCATCCTGGCCAAGCTGAAACGCAAGAAGGGGCCAGGGGCCGGCAGCGCCCTGGACGAT GGCCGGAGGGACCCCAGCAGCAACGACATCAACGGGGGCATGGAGCCCACCCCCAGCACTGTGTCGACGCCCTCGCCCTCCGCCGACCTC CTGGGGCTGCGGGCAGCCCCTCCCCCGGCAGCACCCCCGGCTTCTGCAGGAGCAGGGAACCTTCTGGTGGACGTCTTCGATGGCCCGGCC GCCCAGCCCAGCCTGGGGCCCACCCCCGAGGAGGCCTTCCTCAGCGAGCTGGAGCCGCCTGCCCCCGAGAGCCCCATGGCTTTGCTGGCT GACCCAGCTCCAGCTGCTGACCCAGGTCCTGAGGACATCGGCCCTCCCATTCCGGAAGCCGATGAGTTGCTGAATAAGTTTGTGTGTAAG AACAACGGGGTCCTGTTCGAGAACCAGCTGCTGCAGATCGGAGTCAAGTCAGAGTTCCGACAGAACCTGGGCCGCATGTATCTCTTCTAT GGCAACAAGACCTCGGTGCAGTTCCAGAATTTCTCACCCACTGTGGTTCACCCGGGAGACCTCCAGACTCAGCTGGCTGTGCAGACCAAG CGCGTGGCGGCGCAGGTGGACGGCGGCGCGCAGGTGCAGCAGGTGCTCAATATCGAGTGCCTGCGGGACTTCCTGACGCCCCCGCTGCTG TCCGTGCGCTTCCGAGACCCTGCAGAAGTACCTGAAGGTGGTGATGGCCCTCACGTATGAGGAGAAGCCGCCCTACGCCATGCTGAGGAA CAACCTAGAAGCTTTGCTGCAGGATCTGCGTGTGTCTCCATATGACCCCATTGGCCTCCCGATGGTGCCCTAGGTGGAATCCAGGTGGGA AGAGCTTGTGAGGCTTAAGCCTCTCACCCCTTGCCCTCACCCGAGCCCTGCCCCAGGCTCCAGGAGACACTTCCCAGAGGCTGTTCCACG TTCATACCAGGGCCCAGCTTCCCAGGGAGACACTGGGTTTTTCCGCACGGTCCTTGAACTTCCCAGCCTCAAGGAATGGCAAGTAGCAGA AACCCGGCTCAACTTGGCTTTAAGAAAAGTGGGGATTGATTGGCTGTTGTAGCTAGAAAATTACAAGGGGGAGCTTCAGGCACAACGGGA TTCAGGGCCTCAAAAATAGCATCAAGACGTTGTTTGTCTCTCGCCATCTTCTGTCCCTTCTTGCATCCATGCCTCCCTCTGTCCTTCCAC CCGGCCACCTGTAGTCTCTACTTTCCTTTGGCCTGGCCCCCTTGGCGCCCCCATACACAAAAGGTAGCTGCTCCATGCCTTCGGGTCTCG >5222_5222_9_AP2A1-VRK3_AP2A1_chr19_50308833_ENST00000359032_VRK3_chr19_50482499_ENST00000443401_length(amino acids)=859AA_BP=844 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNKYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMCLALHCIANVGSREMGEAFAADIPRILVAGDSMDSVKQSAALCLLRLYKASP DLVPMGEWTARVVHLLNDQHMGVVTAAVSLITCLCKKNPDDFKTCVSLAVSRLSRIVSSASTDLQDYTYYFVPAPWLSVKLLRLLQCYPP PEDAAVKGRLVECLETVLNKAQEPPKSKKVQHSNAKNAILFETISLIIHYDSEPNLLVRACNQLGQFLQHRETNLRYLALESMCTLASSE FSHEAVKTHIDTVINALKTERDVSVRQRAADLLYAMCDRSNAKQIVSEMLRYLETADYAIREEIVLKVAILAEKYAVDYSWYVDTILNLI RIAGDYVSEEVWYRVLQIVTNRDDVQGYAAKTVFEALQAPACHENMVKVGGYILGEFGNLIAGDPRSSPPVQFSLLHSKFHLCSVATRAL LLSTYIKFINLFPETKATIQGVLRAGSQLRNADVELQQRAVEYLTLSSVASTDVLATVLEEMPPFPERESSILAKLKRKKGPGAGSALDD GRRDPSSNDINGGMEPTPSTVSTPSPSADLLGLRAAPPPAAPPASAGAGNLLVDVFDGPAAQPSLGPTPEEAFLSELEPPAPESPMALLA DPAPAADPGPEDIGPPIPEADELLNKFVCKNNGVLFENQLLQIGVKSEFRQNLGRMYLFYGNKTSVQFQNFSPTVVHPGDLQTQLAVQTK -------------------------------------------------------------- >5222_5222_10_AP2A1-VRK3_AP2A1_chr19_50308833_ENST00000359032_VRK3_chr19_50482499_ENST00000594948_length(transcript)=3017nt_BP=2534nt ATGCCGGCCGTGTCCAAGGGCGATGGGATGCGGGGGCTCGCGGTGTTCATCTCCGACATCCGGAACTGTAAGAGCAAAGAGGCGGAAATT AAGAGAATCAACAAGGAACTGGCCAACATCCGCTCCAAGTTCAAAGGAGACAAAGCCTTGGATGGCTACAGTAAGAAAAAATATGTGTGT AAACTGCTTTTCATCTTCCTGCTTGGCCATGACATTGACTTTGGGCACATGGAGGCTGTGAATCTGTTGAGTTCCAATAAATACACAGAG AAGCAAATAGGTTACCTGTTCATTTCTGTGCTGGTGAACTCGAACTCGGAGCTGATCCGCCTCATCAACAACGCCATCAAGAATGACCTG GCCAGCCGCAACCCCACCTTCATGTGCCTGGCCCTGCACTGCATCGCCAACGTGGGCAGCCGGGAGATGGGCGAGGCCTTTGCCGCTGAC ATCCCCCGCATCCTGGTGGCCGGGGACAGCATGGACAGTGTCAAGCAGAGTGCGGCCCTGTGCCTCCTTCGACTGTACAAGGCCTCGCCT GACCTGGTGCCCATGGGCGAGTGGACGGCGCGTGTGGTACACCTGCTCAATGACCAGCACATGGGTGTGGTCACGGCCGCCGTCAGCCTC ATCACCTGTCTCTGCAAGAAGAACCCAGATGACTTCAAGACGTGCGTCTCTCTGGCTGTGTCGCGCCTGAGCCGGATCGTCTCCTCTGCC TCCACCGACCTCCAGGACTACACCTACTACTTCGTCCCAGCACCCTGGCTCTCGGTGAAGCTCCTGCGGCTGCTGCAGTGCTACCCGCCT CCAGAGGATGCGGCTGTGAAGGGGCGGCTGGTGGAATGTCTGGAGACTGTGCTCAACAAGGCCCAGGAGCCCCCCAAATCCAAGAAGGTG CAGCATTCCAACGCCAAGAACGCCATCCTCTTCGAGACCATCAGCCTCATCATCCACTATGACAGTGAGCCCAACCTCCTGGTTCGGGCC TGCAACCAGCTGGGCCAGTTCCTGCAGCACCGGGAGACCAACCTGCGCTACCTGGCCCTGGAGAGCATGTGCACGCTGGCCAGCTCCGAG TTCTCCCATGAAGCCGTCAAGACGCACATTGACACCGTCATCAATGCCCTCAAGACGGAGCGGGACGTCAGCGTGCGGCAGCGGGCGGCT GACCTCCTCTACGCCATGTGTGACCGGAGCAATGCCAAGCAGATCGTGTCGGAGATGCTGCGGTACCTGGAGACGGCAGACTACGCCATC CGCGAGGAGATCGTCCTGAAGGTGGCCATCCTGGCCGAGAAGTACGCCGTGGACTACAGCTGGTACGTGGACACCATCCTCAACCTCATC CGCATTGCGGGCGACTACGTGAGTGAGGAGGTGTGGTACCGTGTGCTACAGATCGTCACCAACCGTGATGACGTCCAGGGCTATGCCGCC AAGACCGTCTTTGAGGCGCTCCAGGCCCCTGCCTGTCACGAGAACATGGTGAAGGTTGGCGGCTACATCCTTGGGGAGTTTGGGAACCTG ATTGCTGGGGACCCCCGCTCCAGCCCCCCAGTGCAGTTCTCCCTGCTCCACTCCAAGTTCCATCTGTGCAGCGTGGCCACGCGGGCGCTG CTGCTGTCCACCTACATCAAGTTCATCAACCTCTTCCCCGAGACCAAGGCCACCATCCAGGGCGTCCTGCGGGCCGGCTCCCAGCTGCGC AATGCTGACGTGGAGCTGCAGCAGCGAGCCGTGGAGTACCTCACCCTCAGCTCAGTGGCCAGCACCGACGTCCTGGCCACGGTGCTGGAG GAGATGCCGCCCTTCCCCGAGCGCGAGTCGTCCATCCTGGCCAAGCTGAAACGCAAGAAGGGGCCAGGGGCCGGCAGCGCCCTGGACGAT GGCCGGAGGGACCCCAGCAGCAACGACATCAACGGGGGCATGGAGCCCACCCCCAGCACTGTGTCGACGCCCTCGCCCTCCGCCGACCTC CTGGGGCTGCGGGCAGCCCCTCCCCCGGCAGCACCCCCGGCTTCTGCAGGAGCAGGGAACCTTCTGGTGGACGTCTTCGATGGCCCGGCC GCCCAGCCCAGCCTGGGGCCCACCCCCGAGGAGGCCTTCCTCAGCGAGCTGGAGCCGCCTGCCCCCGAGAGCCCCATGGCTTTGCTGGCT GACCCAGCTCCAGCTGCTGACCCAGGTCCTGAGGACATCGGCCCTCCCATTCCGGAAGCCGATGAGTTGCTGAATAAGTTTGTGTGTAAG AACAACGGGGTCCTGTTCGAGAACCAGCTGCTGCAGATCGGAGTCAAGTCAGAGTTCCGACAGAACCTGGGCCGCATGTATCTCTTCTAT GGCAACAAGACCTCGGTGCAGTTCCAGAATTTCTCACCCACTGTGGTTCACCCGGGAGACCTCCAGACTCAGCTGGCTGTGCAGACCAAG CGCGTGGCGGCGCAGGTGGACGGCGGCGCGCAGGTGCAGCAGGTGCTCAATATCGAGTGCCTGCGGGACTTCCTGACGCCCCCGCTGCTG TCCGTGCGCTTCCGAGACCCTGCAGAAGTACCTGAAGGTGGTGATGGCCCTCACGTATGAGGAGAAGCCGCCCTACGCCATGCTGAGGAA CAACCTAGAAGCTTTGCTGCAGGATCTGCGTGTGTCTCCATATGACCCCATTGGCCTCCCGATGGTGCCCTAGGTGGAATCCAGGTGGGA AGAGCTTGTGAGGCTTAAGCCTCTCACCCCTTGCCCTCACCCGAGCCCTGCCCCAGGCTCCAGGAGACACTTCCCAGAGGCTGTTCCACG TTCATACCAGGGCCCAGCTTCCCAGGGAGACACTGGGTTTTTCCGCACGGTCCTTGAACTTCCCAGCCTCAAGGAATGGCAAGTAGCAGA AACCCGGCTCAACTTGGCTTTAAGAAAAGTGGGGATTGATTGGCTGTTGTAGCTAGAAAATTACAAGGGGGAGCTTCAGGCACAACGGGA >5222_5222_10_AP2A1-VRK3_AP2A1_chr19_50308833_ENST00000359032_VRK3_chr19_50482499_ENST00000594948_length(amino acids)=859AA_BP=844 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNKYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMCLALHCIANVGSREMGEAFAADIPRILVAGDSMDSVKQSAALCLLRLYKASP DLVPMGEWTARVVHLLNDQHMGVVTAAVSLITCLCKKNPDDFKTCVSLAVSRLSRIVSSASTDLQDYTYYFVPAPWLSVKLLRLLQCYPP PEDAAVKGRLVECLETVLNKAQEPPKSKKVQHSNAKNAILFETISLIIHYDSEPNLLVRACNQLGQFLQHRETNLRYLALESMCTLASSE FSHEAVKTHIDTVINALKTERDVSVRQRAADLLYAMCDRSNAKQIVSEMLRYLETADYAIREEIVLKVAILAEKYAVDYSWYVDTILNLI RIAGDYVSEEVWYRVLQIVTNRDDVQGYAAKTVFEALQAPACHENMVKVGGYILGEFGNLIAGDPRSSPPVQFSLLHSKFHLCSVATRAL LLSTYIKFINLFPETKATIQGVLRAGSQLRNADVELQQRAVEYLTLSSVASTDVLATVLEEMPPFPERESSILAKLKRKKGPGAGSALDD GRRDPSSNDINGGMEPTPSTVSTPSPSADLLGLRAAPPPAAPPASAGAGNLLVDVFDGPAAQPSLGPTPEEAFLSELEPPAPESPMALLA DPAPAADPGPEDIGPPIPEADELLNKFVCKNNGVLFENQLLQIGVKSEFRQNLGRMYLFYGNKTSVQFQNFSPTVVHPGDLQTQLAVQTK -------------------------------------------------------------- >5222_5222_11_AP2A1-VRK3_AP2A1_chr19_50308833_ENST00000359032_VRK3_chr19_50482499_ENST00000599538_length(transcript)=2719nt_BP=2534nt ATGCCGGCCGTGTCCAAGGGCGATGGGATGCGGGGGCTCGCGGTGTTCATCTCCGACATCCGGAACTGTAAGAGCAAAGAGGCGGAAATT AAGAGAATCAACAAGGAACTGGCCAACATCCGCTCCAAGTTCAAAGGAGACAAAGCCTTGGATGGCTACAGTAAGAAAAAATATGTGTGT AAACTGCTTTTCATCTTCCTGCTTGGCCATGACATTGACTTTGGGCACATGGAGGCTGTGAATCTGTTGAGTTCCAATAAATACACAGAG AAGCAAATAGGTTACCTGTTCATTTCTGTGCTGGTGAACTCGAACTCGGAGCTGATCCGCCTCATCAACAACGCCATCAAGAATGACCTG GCCAGCCGCAACCCCACCTTCATGTGCCTGGCCCTGCACTGCATCGCCAACGTGGGCAGCCGGGAGATGGGCGAGGCCTTTGCCGCTGAC ATCCCCCGCATCCTGGTGGCCGGGGACAGCATGGACAGTGTCAAGCAGAGTGCGGCCCTGTGCCTCCTTCGACTGTACAAGGCCTCGCCT GACCTGGTGCCCATGGGCGAGTGGACGGCGCGTGTGGTACACCTGCTCAATGACCAGCACATGGGTGTGGTCACGGCCGCCGTCAGCCTC ATCACCTGTCTCTGCAAGAAGAACCCAGATGACTTCAAGACGTGCGTCTCTCTGGCTGTGTCGCGCCTGAGCCGGATCGTCTCCTCTGCC TCCACCGACCTCCAGGACTACACCTACTACTTCGTCCCAGCACCCTGGCTCTCGGTGAAGCTCCTGCGGCTGCTGCAGTGCTACCCGCCT CCAGAGGATGCGGCTGTGAAGGGGCGGCTGGTGGAATGTCTGGAGACTGTGCTCAACAAGGCCCAGGAGCCCCCCAAATCCAAGAAGGTG CAGCATTCCAACGCCAAGAACGCCATCCTCTTCGAGACCATCAGCCTCATCATCCACTATGACAGTGAGCCCAACCTCCTGGTTCGGGCC TGCAACCAGCTGGGCCAGTTCCTGCAGCACCGGGAGACCAACCTGCGCTACCTGGCCCTGGAGAGCATGTGCACGCTGGCCAGCTCCGAG TTCTCCCATGAAGCCGTCAAGACGCACATTGACACCGTCATCAATGCCCTCAAGACGGAGCGGGACGTCAGCGTGCGGCAGCGGGCGGCT GACCTCCTCTACGCCATGTGTGACCGGAGCAATGCCAAGCAGATCGTGTCGGAGATGCTGCGGTACCTGGAGACGGCAGACTACGCCATC CGCGAGGAGATCGTCCTGAAGGTGGCCATCCTGGCCGAGAAGTACGCCGTGGACTACAGCTGGTACGTGGACACCATCCTCAACCTCATC CGCATTGCGGGCGACTACGTGAGTGAGGAGGTGTGGTACCGTGTGCTACAGATCGTCACCAACCGTGATGACGTCCAGGGCTATGCCGCC AAGACCGTCTTTGAGGCGCTCCAGGCCCCTGCCTGTCACGAGAACATGGTGAAGGTTGGCGGCTACATCCTTGGGGAGTTTGGGAACCTG ATTGCTGGGGACCCCCGCTCCAGCCCCCCAGTGCAGTTCTCCCTGCTCCACTCCAAGTTCCATCTGTGCAGCGTGGCCACGCGGGCGCTG CTGCTGTCCACCTACATCAAGTTCATCAACCTCTTCCCCGAGACCAAGGCCACCATCCAGGGCGTCCTGCGGGCCGGCTCCCAGCTGCGC AATGCTGACGTGGAGCTGCAGCAGCGAGCCGTGGAGTACCTCACCCTCAGCTCAGTGGCCAGCACCGACGTCCTGGCCACGGTGCTGGAG GAGATGCCGCCCTTCCCCGAGCGCGAGTCGTCCATCCTGGCCAAGCTGAAACGCAAGAAGGGGCCAGGGGCCGGCAGCGCCCTGGACGAT GGCCGGAGGGACCCCAGCAGCAACGACATCAACGGGGGCATGGAGCCCACCCCCAGCACTGTGTCGACGCCCTCGCCCTCCGCCGACCTC CTGGGGCTGCGGGCAGCCCCTCCCCCGGCAGCACCCCCGGCTTCTGCAGGAGCAGGGAACCTTCTGGTGGACGTCTTCGATGGCCCGGCC GCCCAGCCCAGCCTGGGGCCCACCCCCGAGGAGGCCTTCCTCAGCGAGCTGGAGCCGCCTGCCCCCGAGAGCCCCATGGCTTTGCTGGCT GACCCAGCTCCAGCTGCTGACCCAGGTCCTGAGGACATCGGCCCTCCCATTCCGGAAGCCGATGAGTTGCTGAATAAGTTTGTGTGTAAG AACAACGGGGTCCTGTTCGAGAACCAGCTGCTGCAGATCGGAGTCAAGTCAGAGTTCCGACAGAACCTGGGCCGCATGTATCTCTTCTAT GGCAACAAGACCTCGGTGCAGTTCCAGAATTTCTCACCCACTGTGGTTCACCCGGGAGACCTCCAGACTCAGCTGGCTGTGCAGACCAAG CGCGTGGCGGCGCAGGTGGACGGCGGCGCGCAGGTGCAGCAGGTGCTCAATATCGAGTGCCTGCGGGACTTCCTGACGCCCCCGCTGCTG TCCGTGCGCTTCCGAGACCCTGCAGAAGTACCTGAAGGTGGTGATGGCCCTCACGTATGAGGAGAAGCCGCCCTACGCCATGCTGAGGAA CAACCTAGAAGCTTTGCTGCAGGATCTGCGTGTGTCTCCATATGACCCCATTGGCCTCCCGATGGTGCCCTAGGTGGAATCCAGAACTTT >5222_5222_11_AP2A1-VRK3_AP2A1_chr19_50308833_ENST00000359032_VRK3_chr19_50482499_ENST00000599538_length(amino acids)=859AA_BP=844 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNKYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMCLALHCIANVGSREMGEAFAADIPRILVAGDSMDSVKQSAALCLLRLYKASP DLVPMGEWTARVVHLLNDQHMGVVTAAVSLITCLCKKNPDDFKTCVSLAVSRLSRIVSSASTDLQDYTYYFVPAPWLSVKLLRLLQCYPP PEDAAVKGRLVECLETVLNKAQEPPKSKKVQHSNAKNAILFETISLIIHYDSEPNLLVRACNQLGQFLQHRETNLRYLALESMCTLASSE FSHEAVKTHIDTVINALKTERDVSVRQRAADLLYAMCDRSNAKQIVSEMLRYLETADYAIREEIVLKVAILAEKYAVDYSWYVDTILNLI RIAGDYVSEEVWYRVLQIVTNRDDVQGYAAKTVFEALQAPACHENMVKVGGYILGEFGNLIAGDPRSSPPVQFSLLHSKFHLCSVATRAL LLSTYIKFINLFPETKATIQGVLRAGSQLRNADVELQQRAVEYLTLSSVASTDVLATVLEEMPPFPERESSILAKLKRKKGPGAGSALDD GRRDPSSNDINGGMEPTPSTVSTPSPSADLLGLRAAPPPAAPPASAGAGNLLVDVFDGPAAQPSLGPTPEEAFLSELEPPAPESPMALLA DPAPAADPGPEDIGPPIPEADELLNKFVCKNNGVLFENQLLQIGVKSEFRQNLGRMYLFYGNKTSVQFQNFSPTVVHPGDLQTQLAVQTK -------------------------------------------------------------- >5222_5222_12_AP2A1-VRK3_AP2A1_chr19_50308833_ENST00000359032_VRK3_chr19_50482499_ENST00000601341_length(transcript)=3064nt_BP=2534nt ATGCCGGCCGTGTCCAAGGGCGATGGGATGCGGGGGCTCGCGGTGTTCATCTCCGACATCCGGAACTGTAAGAGCAAAGAGGCGGAAATT AAGAGAATCAACAAGGAACTGGCCAACATCCGCTCCAAGTTCAAAGGAGACAAAGCCTTGGATGGCTACAGTAAGAAAAAATATGTGTGT AAACTGCTTTTCATCTTCCTGCTTGGCCATGACATTGACTTTGGGCACATGGAGGCTGTGAATCTGTTGAGTTCCAATAAATACACAGAG AAGCAAATAGGTTACCTGTTCATTTCTGTGCTGGTGAACTCGAACTCGGAGCTGATCCGCCTCATCAACAACGCCATCAAGAATGACCTG GCCAGCCGCAACCCCACCTTCATGTGCCTGGCCCTGCACTGCATCGCCAACGTGGGCAGCCGGGAGATGGGCGAGGCCTTTGCCGCTGAC ATCCCCCGCATCCTGGTGGCCGGGGACAGCATGGACAGTGTCAAGCAGAGTGCGGCCCTGTGCCTCCTTCGACTGTACAAGGCCTCGCCT GACCTGGTGCCCATGGGCGAGTGGACGGCGCGTGTGGTACACCTGCTCAATGACCAGCACATGGGTGTGGTCACGGCCGCCGTCAGCCTC ATCACCTGTCTCTGCAAGAAGAACCCAGATGACTTCAAGACGTGCGTCTCTCTGGCTGTGTCGCGCCTGAGCCGGATCGTCTCCTCTGCC TCCACCGACCTCCAGGACTACACCTACTACTTCGTCCCAGCACCCTGGCTCTCGGTGAAGCTCCTGCGGCTGCTGCAGTGCTACCCGCCT CCAGAGGATGCGGCTGTGAAGGGGCGGCTGGTGGAATGTCTGGAGACTGTGCTCAACAAGGCCCAGGAGCCCCCCAAATCCAAGAAGGTG CAGCATTCCAACGCCAAGAACGCCATCCTCTTCGAGACCATCAGCCTCATCATCCACTATGACAGTGAGCCCAACCTCCTGGTTCGGGCC TGCAACCAGCTGGGCCAGTTCCTGCAGCACCGGGAGACCAACCTGCGCTACCTGGCCCTGGAGAGCATGTGCACGCTGGCCAGCTCCGAG TTCTCCCATGAAGCCGTCAAGACGCACATTGACACCGTCATCAATGCCCTCAAGACGGAGCGGGACGTCAGCGTGCGGCAGCGGGCGGCT GACCTCCTCTACGCCATGTGTGACCGGAGCAATGCCAAGCAGATCGTGTCGGAGATGCTGCGGTACCTGGAGACGGCAGACTACGCCATC CGCGAGGAGATCGTCCTGAAGGTGGCCATCCTGGCCGAGAAGTACGCCGTGGACTACAGCTGGTACGTGGACACCATCCTCAACCTCATC CGCATTGCGGGCGACTACGTGAGTGAGGAGGTGTGGTACCGTGTGCTACAGATCGTCACCAACCGTGATGACGTCCAGGGCTATGCCGCC AAGACCGTCTTTGAGGCGCTCCAGGCCCCTGCCTGTCACGAGAACATGGTGAAGGTTGGCGGCTACATCCTTGGGGAGTTTGGGAACCTG ATTGCTGGGGACCCCCGCTCCAGCCCCCCAGTGCAGTTCTCCCTGCTCCACTCCAAGTTCCATCTGTGCAGCGTGGCCACGCGGGCGCTG CTGCTGTCCACCTACATCAAGTTCATCAACCTCTTCCCCGAGACCAAGGCCACCATCCAGGGCGTCCTGCGGGCCGGCTCCCAGCTGCGC AATGCTGACGTGGAGCTGCAGCAGCGAGCCGTGGAGTACCTCACCCTCAGCTCAGTGGCCAGCACCGACGTCCTGGCCACGGTGCTGGAG GAGATGCCGCCCTTCCCCGAGCGCGAGTCGTCCATCCTGGCCAAGCTGAAACGCAAGAAGGGGCCAGGGGCCGGCAGCGCCCTGGACGAT GGCCGGAGGGACCCCAGCAGCAACGACATCAACGGGGGCATGGAGCCCACCCCCAGCACTGTGTCGACGCCCTCGCCCTCCGCCGACCTC CTGGGGCTGCGGGCAGCCCCTCCCCCGGCAGCACCCCCGGCTTCTGCAGGAGCAGGGAACCTTCTGGTGGACGTCTTCGATGGCCCGGCC GCCCAGCCCAGCCTGGGGCCCACCCCCGAGGAGGCCTTCCTCAGCGAGCTGGAGCCGCCTGCCCCCGAGAGCCCCATGGCTTTGCTGGCT GACCCAGCTCCAGCTGCTGACCCAGGTCCTGAGGACATCGGCCCTCCCATTCCGGAAGCCGATGAGTTGCTGAATAAGTTTGTGTGTAAG AACAACGGGGTCCTGTTCGAGAACCAGCTGCTGCAGATCGGAGTCAAGTCAGAGTTCCGACAGAACCTGGGCCGCATGTATCTCTTCTAT GGCAACAAGACCTCGGTGCAGTTCCAGAATTTCTCACCCACTGTGGTTCACCCGGGAGACCTCCAGACTCAGCTGGCTGTGCAGACCAAG CGCGTGGCGGCGCAGGTGGACGGCGGCGCGCAGGTGCAGCAGGTGCTCAATATCGAGTGCCTGCGGGACTTCCTGACGCCCCCGCTGCTG TCCGTGCGCTTCCGAGACCCTGCAGAAGTACCTGAAGGTGGTGATGGCCCTCACGTATGAGGAGAAGCCGCCCTACGCCATGCTGAGGAA CAACCTAGAAGCTTTGCTGCAGGATCTGCGTGTGTCTCCATATGACCCCATTGGCCTCCCGATGGTGCCCTAGGTGGAATCCAGGTGGGA AGAGCTTGTGAGGCTTAAGCCTCTCACCCCTTGCCCTCACCCGAGCCCTGCCCCAGGCTCCAGGAGACACTTCCCAGAGGCTGTTCCACG TTCATACCAGGGCCCAGCTTCCCAGGGAGACACTGGGTTTTTCCGCACGGTCCTTGAACTTCCCAGCCTCAAGGAATGGCAAGTAGCAGA AACCCGGCTCAACTTGGCTTTAAGAAAAGTGGGGATTGATTGGCTGTTGTAGCTAGAAAATTACAAGGGGGAGCTTCAGGCACAACGGGA TTCAGGGCCTCAAAAATAGCATCAAGACGTTGTTTGTCTCTCGCCATCTTCTGTCCCTTCTTGCATCCATGCCTCCCTCTGTCCTTCCAC >5222_5222_12_AP2A1-VRK3_AP2A1_chr19_50308833_ENST00000359032_VRK3_chr19_50482499_ENST00000601341_length(amino acids)=859AA_BP=844 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNKYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMCLALHCIANVGSREMGEAFAADIPRILVAGDSMDSVKQSAALCLLRLYKASP DLVPMGEWTARVVHLLNDQHMGVVTAAVSLITCLCKKNPDDFKTCVSLAVSRLSRIVSSASTDLQDYTYYFVPAPWLSVKLLRLLQCYPP PEDAAVKGRLVECLETVLNKAQEPPKSKKVQHSNAKNAILFETISLIIHYDSEPNLLVRACNQLGQFLQHRETNLRYLALESMCTLASSE FSHEAVKTHIDTVINALKTERDVSVRQRAADLLYAMCDRSNAKQIVSEMLRYLETADYAIREEIVLKVAILAEKYAVDYSWYVDTILNLI RIAGDYVSEEVWYRVLQIVTNRDDVQGYAAKTVFEALQAPACHENMVKVGGYILGEFGNLIAGDPRSSPPVQFSLLHSKFHLCSVATRAL LLSTYIKFINLFPETKATIQGVLRAGSQLRNADVELQQRAVEYLTLSSVASTDVLATVLEEMPPFPERESSILAKLKRKKGPGAGSALDD GRRDPSSNDINGGMEPTPSTVSTPSPSADLLGLRAAPPPAAPPASAGAGNLLVDVFDGPAAQPSLGPTPEEAFLSELEPPAPESPMALLA DPAPAADPGPEDIGPPIPEADELLNKFVCKNNGVLFENQLLQIGVKSEFRQNLGRMYLFYGNKTSVQFQNFSPTVVHPGDLQTQLAVQTK -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for AP2A1-VRK3 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for AP2A1-VRK3 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for AP2A1-VRK3 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies