
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:AP2A2-DRD4 (FusionGDB2 ID:5225) |
Fusion Gene Summary for AP2A2-DRD4 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: AP2A2-DRD4 | Fusion gene ID: 5225 | Hgene | Tgene | Gene symbol | AP2A2 | DRD4 | Gene ID | 161 | 1815 |
| Gene name | adaptor related protein complex 2 subunit alpha 2 | dopamine receptor D4 | |
| Synonyms | ADTAB|CLAPA2|HIP-9|HIP9|HYPJ | D4DR | |
| Cytomap | 11p15.5 | 11p15.5 | |
| Type of gene | protein-coding | protein-coding | |
| Description | AP-2 complex subunit alpha-2100 kDa coated vesicle protein Cadapter-related protein complex 2 subunit alpha-2adaptin, alpha Badaptor related protein complex 2 alpha 2 subunitalpha-adaptin C; Huntingtin interacting protein Jalpha2-adaptinclathrin as | D(4) dopamine receptorD(2C) dopamine receptordopamine D4 receptorseven transmembrane helix receptor | |
| Modification date | 20200313 | 20200329 | |
| UniProtAcc | O94973 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000332231, ENST00000448903, ENST00000534328, ENST00000525891, | ENST00000528733, ENST00000176183, | |
| Fusion gene scores | * DoF score | 13 X 10 X 12=1560 | 4 X 5 X 3=60 |
| # samples | 22 | 7 | |
| ** MAII score | log2(22/1560*10)=-2.82597060022495 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(7/60*10)=0.222392421336448 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | |
| Context | PubMed: AP2A2 [Title/Abstract] AND DRD4 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | AP2A2(977224)-DRD4(639432), # samples:1 AP2A2(977224)-DRD4(640401), # samples:1 AP2A2(977224)-DRD4(639433), # samples:1 AP2A2(970311)-DRD4(640401), # samples:1 AP2A2(977223)-DRD4(639432), # samples:1 AP2A2(977223)-DRD4(640400), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | AP2A2-DRD4 seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. AP2A2-DRD4 seems lost the major protein functional domain in Tgene partner, which is a IUPHAR drug target due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | AP2A2 | GO:0072583 | clathrin-dependent endocytosis | 23676497 |
| Tgene | DRD4 | GO:0000187 | activation of MAPK activity | 9843378|15755724 |
| Tgene | DRD4 | GO:0007195 | adenylate cyclase-inhibiting dopamine receptor signaling pathway | 7512953|9003072|9843378 |
| Tgene | DRD4 | GO:0007212 | dopamine receptor signaling pathway | 1840645 |
| Tgene | DRD4 | GO:0032417 | positive regulation of sodium:proton antiporter activity | 7512953 |
| Tgene | DRD4 | GO:0033674 | positive regulation of kinase activity | 15755724 |
| Tgene | DRD4 | GO:0034776 | response to histamine | 16839358 |
| Tgene | DRD4 | GO:0050482 | arachidonic acid secretion | 7512953 |
| Tgene | DRD4 | GO:0050709 | negative regulation of protein secretion | 16839358 |
| Tgene | DRD4 | GO:1901386 | negative regulation of voltage-gated calcium channel activity | 7921596 |
| Fusion gene breakpoints across AP2A2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across DRD4 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | ACC | TCGA-OR-A5J7-01A | AP2A2 | chr11 | 977223 | + | DRD4 | chr11 | 639432 | + |
| ChimerDB4 | ACC | TCGA-OR-A5J7-01A | AP2A2 | chr11 | 977223 | + | DRD4 | chr11 | 640400 | + |
| ChimerDB4 | ACC | TCGA-OR-A5J7-01A | AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 639433 | + |
| ChimerDB4 | ACC | TCGA-OR-A5J7-01A | AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 640401 | + |
| ChimerDB4 | ACC | TCGA-OR-A5J7 | AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 639432 | + |
| ChimerDB4 | UCEC | TCGA-EO-A3KW-01A | AP2A2 | chr11 | 970311 | + | DRD4 | chr11 | 640401 | + |
Top |
Fusion Gene ORF analysis for AP2A2-DRD4 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-3UTR | ENST00000332231 | ENST00000528733 | AP2A2 | chr11 | 977223 | + | DRD4 | chr11 | 639432 | + |
| 5CDS-3UTR | ENST00000332231 | ENST00000528733 | AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 639433 | + |
| 5CDS-3UTR | ENST00000332231 | ENST00000528733 | AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 639432 | + |
| 5CDS-3UTR | ENST00000448903 | ENST00000528733 | AP2A2 | chr11 | 977223 | + | DRD4 | chr11 | 639432 | + |
| 5CDS-3UTR | ENST00000448903 | ENST00000528733 | AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 639433 | + |
| 5CDS-3UTR | ENST00000448903 | ENST00000528733 | AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 639432 | + |
| 5CDS-3UTR | ENST00000534328 | ENST00000528733 | AP2A2 | chr11 | 977223 | + | DRD4 | chr11 | 639432 | + |
| 5CDS-3UTR | ENST00000534328 | ENST00000528733 | AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 639433 | + |
| 5CDS-3UTR | ENST00000534328 | ENST00000528733 | AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 639432 | + |
| 5CDS-intron | ENST00000332231 | ENST00000528733 | AP2A2 | chr11 | 977223 | + | DRD4 | chr11 | 640400 | + |
| 5CDS-intron | ENST00000332231 | ENST00000528733 | AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 640401 | + |
| 5CDS-intron | ENST00000332231 | ENST00000528733 | AP2A2 | chr11 | 970311 | + | DRD4 | chr11 | 640401 | + |
| 5CDS-intron | ENST00000448903 | ENST00000528733 | AP2A2 | chr11 | 977223 | + | DRD4 | chr11 | 640400 | + |
| 5CDS-intron | ENST00000448903 | ENST00000528733 | AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 640401 | + |
| 5CDS-intron | ENST00000448903 | ENST00000528733 | AP2A2 | chr11 | 970311 | + | DRD4 | chr11 | 640401 | + |
| 5CDS-intron | ENST00000534328 | ENST00000528733 | AP2A2 | chr11 | 977223 | + | DRD4 | chr11 | 640400 | + |
| 5CDS-intron | ENST00000534328 | ENST00000528733 | AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 640401 | + |
| 5CDS-intron | ENST00000534328 | ENST00000528733 | AP2A2 | chr11 | 970311 | + | DRD4 | chr11 | 640401 | + |
| Frame-shift | ENST00000332231 | ENST00000176183 | AP2A2 | chr11 | 977223 | + | DRD4 | chr11 | 640400 | + |
| Frame-shift | ENST00000332231 | ENST00000176183 | AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 640401 | + |
| Frame-shift | ENST00000332231 | ENST00000176183 | AP2A2 | chr11 | 970311 | + | DRD4 | chr11 | 640401 | + |
| Frame-shift | ENST00000448903 | ENST00000176183 | AP2A2 | chr11 | 977223 | + | DRD4 | chr11 | 640400 | + |
| Frame-shift | ENST00000448903 | ENST00000176183 | AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 640401 | + |
| Frame-shift | ENST00000448903 | ENST00000176183 | AP2A2 | chr11 | 970311 | + | DRD4 | chr11 | 640401 | + |
| Frame-shift | ENST00000534328 | ENST00000176183 | AP2A2 | chr11 | 977223 | + | DRD4 | chr11 | 640400 | + |
| Frame-shift | ENST00000534328 | ENST00000176183 | AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 640401 | + |
| Frame-shift | ENST00000534328 | ENST00000176183 | AP2A2 | chr11 | 970311 | + | DRD4 | chr11 | 640401 | + |
| In-frame | ENST00000332231 | ENST00000176183 | AP2A2 | chr11 | 977223 | + | DRD4 | chr11 | 639432 | + |
| In-frame | ENST00000332231 | ENST00000176183 | AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 639433 | + |
| In-frame | ENST00000332231 | ENST00000176183 | AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 639432 | + |
| In-frame | ENST00000448903 | ENST00000176183 | AP2A2 | chr11 | 977223 | + | DRD4 | chr11 | 639432 | + |
| In-frame | ENST00000448903 | ENST00000176183 | AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 639433 | + |
| In-frame | ENST00000448903 | ENST00000176183 | AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 639432 | + |
| In-frame | ENST00000534328 | ENST00000176183 | AP2A2 | chr11 | 977223 | + | DRD4 | chr11 | 639432 | + |
| In-frame | ENST00000534328 | ENST00000176183 | AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 639433 | + |
| In-frame | ENST00000534328 | ENST00000176183 | AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 639432 | + |
| intron-3CDS | ENST00000525891 | ENST00000176183 | AP2A2 | chr11 | 977223 | + | DRD4 | chr11 | 639432 | + |
| intron-3CDS | ENST00000525891 | ENST00000176183 | AP2A2 | chr11 | 977223 | + | DRD4 | chr11 | 640400 | + |
| intron-3CDS | ENST00000525891 | ENST00000176183 | AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 639433 | + |
| intron-3CDS | ENST00000525891 | ENST00000176183 | AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 640401 | + |
| intron-3CDS | ENST00000525891 | ENST00000176183 | AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 639432 | + |
| intron-3CDS | ENST00000525891 | ENST00000176183 | AP2A2 | chr11 | 970311 | + | DRD4 | chr11 | 640401 | + |
| intron-3UTR | ENST00000525891 | ENST00000528733 | AP2A2 | chr11 | 977223 | + | DRD4 | chr11 | 639432 | + |
| intron-3UTR | ENST00000525891 | ENST00000528733 | AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 639433 | + |
| intron-3UTR | ENST00000525891 | ENST00000528733 | AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 639432 | + |
| intron-intron | ENST00000525891 | ENST00000528733 | AP2A2 | chr11 | 977223 | + | DRD4 | chr11 | 640400 | + |
| intron-intron | ENST00000525891 | ENST00000528733 | AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 640401 | + |
| intron-intron | ENST00000525891 | ENST00000528733 | AP2A2 | chr11 | 970311 | + | DRD4 | chr11 | 640401 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000534328 | AP2A2 | chr11 | 977224 | + | ENST00000176183 | DRD4 | chr11 | 639432 | + | 1823 | 745 | 142 | 1719 | 525 |
| ENST00000332231 | AP2A2 | chr11 | 977224 | + | ENST00000176183 | DRD4 | chr11 | 639432 | + | 1822 | 744 | 141 | 1718 | 525 |
| ENST00000448903 | AP2A2 | chr11 | 977224 | + | ENST00000176183 | DRD4 | chr11 | 639432 | + | 1822 | 744 | 141 | 1718 | 525 |
| ENST00000534328 | AP2A2 | chr11 | 977224 | + | ENST00000176183 | DRD4 | chr11 | 639433 | + | 1823 | 745 | 142 | 1719 | 525 |
| ENST00000332231 | AP2A2 | chr11 | 977224 | + | ENST00000176183 | DRD4 | chr11 | 639433 | + | 1822 | 744 | 141 | 1718 | 525 |
| ENST00000448903 | AP2A2 | chr11 | 977224 | + | ENST00000176183 | DRD4 | chr11 | 639433 | + | 1822 | 744 | 141 | 1718 | 525 |
| ENST00000534328 | AP2A2 | chr11 | 977223 | + | ENST00000176183 | DRD4 | chr11 | 639432 | + | 1823 | 745 | 142 | 1719 | 525 |
| ENST00000332231 | AP2A2 | chr11 | 977223 | + | ENST00000176183 | DRD4 | chr11 | 639432 | + | 1822 | 744 | 141 | 1718 | 525 |
| ENST00000448903 | AP2A2 | chr11 | 977223 | + | ENST00000176183 | DRD4 | chr11 | 639432 | + | 1822 | 744 | 141 | 1718 | 525 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000534328 | ENST00000176183 | AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 639432 | + | 0.041698437 | 0.9583016 |
| ENST00000332231 | ENST00000176183 | AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 639432 | + | 0.041394025 | 0.95860595 |
| ENST00000448903 | ENST00000176183 | AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 639432 | + | 0.041394025 | 0.95860595 |
| ENST00000534328 | ENST00000176183 | AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 639433 | + | 0.041698437 | 0.9583016 |
| ENST00000332231 | ENST00000176183 | AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 639433 | + | 0.041394025 | 0.95860595 |
| ENST00000448903 | ENST00000176183 | AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 639433 | + | 0.041394025 | 0.95860595 |
| ENST00000534328 | ENST00000176183 | AP2A2 | chr11 | 977223 | + | DRD4 | chr11 | 639432 | + | 0.041698437 | 0.9583016 |
| ENST00000332231 | ENST00000176183 | AP2A2 | chr11 | 977223 | + | DRD4 | chr11 | 639432 | + | 0.041394025 | 0.95860595 |
| ENST00000448903 | ENST00000176183 | AP2A2 | chr11 | 977223 | + | DRD4 | chr11 | 639432 | + | 0.041394025 | 0.95860595 |
Top |
Fusion Genomic Features for AP2A2-DRD4 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| AP2A2 | chr11 | 970311 | + | DRD4 | chr11 | 640400 | + | 0.73491997 | 0.26508003 |
| AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 640400 | + | 0.24718441 | 0.75281554 |
| AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 639432 | + | 1.26E-07 | 0.9999999 |
| AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 639432 | + | 1.26E-07 | 0.9999999 |
| AP2A2 | chr11 | 970311 | + | DRD4 | chr11 | 640400 | + | 0.73491997 | 0.26508003 |
| AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 640400 | + | 0.24718441 | 0.75281554 |
| AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 639432 | + | 1.26E-07 | 0.9999999 |
| AP2A2 | chr11 | 977224 | + | DRD4 | chr11 | 639432 | + | 1.26E-07 | 0.9999999 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
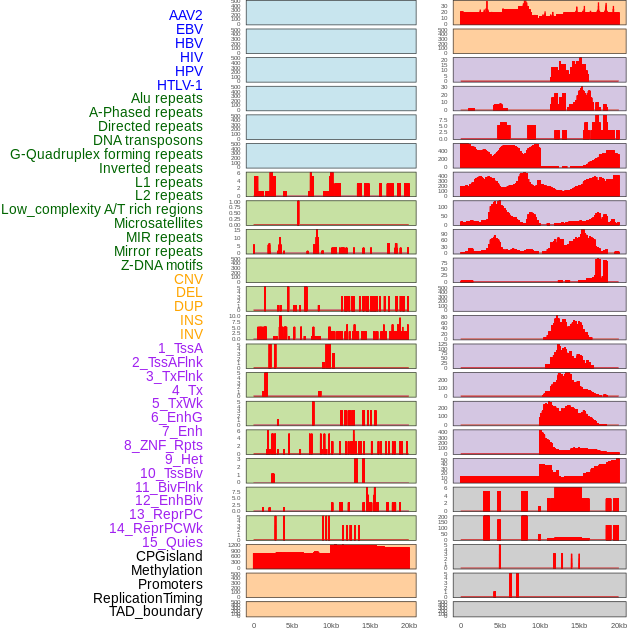 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
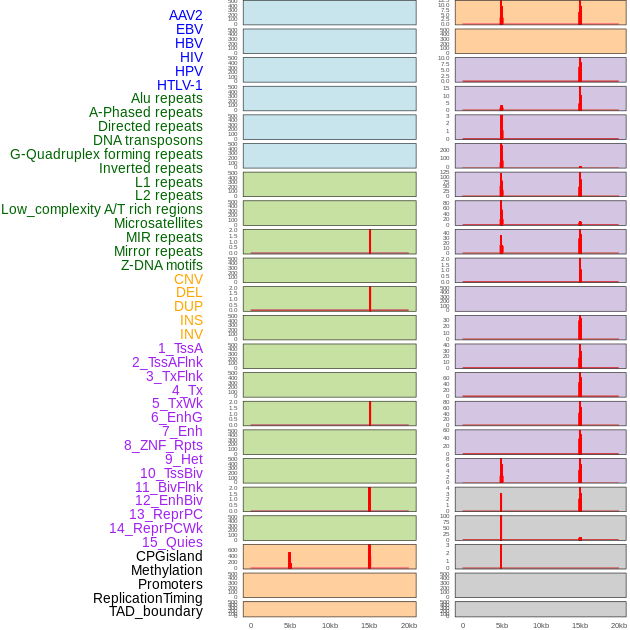 |
Top |
Fusion Protein Features for AP2A2-DRD4 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr11:977224/chr11:639432) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| AP2A2 | . |
| FUNCTION: Component of the adaptor protein complex 2 (AP-2). Adaptor protein complexes function in protein transport via transport vesicles in different membrane traffic pathways. Adaptor protein complexes are vesicle coat components and appear to be involved in cargo selection and vesicle formation. AP-2 is involved in clathrin-dependent endocytosis in which cargo proteins are incorporated into vesicles surrounded by clathrin (clathrin-coated vesicles, CCVs) which are destined for fusion with the early endosome. The clathrin lattice serves as a mechanical scaffold but is itself unable to bind directly to membrane components. Clathrin-associated adaptor protein (AP) complexes which can bind directly to both the clathrin lattice and to the lipid and protein components of membranes are considered to be the major clathrin adaptors contributing the CCV formation. AP-2 also serves as a cargo receptor to selectively sort the membrane proteins involved in receptor-mediated endocytosis. AP-2 seems to play a role in the recycling of synaptic vesicle membranes from the presynaptic surface. AP-2 recognizes Y-X-X-[FILMV] (Y-X-X-Phi) and [ED]-X-X-X-L-[LI] endocytosis signal motifs within the cytosolic tails of transmembrane cargo molecules. AP-2 may also play a role in maintaining normal post-endocytic trafficking through the ARF6-regulated, non-clathrin pathway. During long-term potentiation in hippocampal neurons, AP-2 is responsible for the endocytosis of ADAM10 (PubMed:23676497). The AP-2 alpha subunit binds polyphosphoinositide-containing lipids, positioning AP-2 on the membrane. The AP-2 alpha subunit acts via its C-terminal appendage domain as a scaffolding platform for endocytic accessory proteins. The AP-2 alpha and AP-2 sigma subunits are thought to contribute to the recognition of the [ED]-X-X-X-L-[LI] motif (By similarity). {ECO:0000250, ECO:0000269|PubMed:12960147, ECO:0000269|PubMed:14745134, ECO:0000269|PubMed:15473838, ECO:0000269|PubMed:19033387, ECO:0000269|PubMed:23676497}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | AP2A2 | chr11:977223 | chr11:639432 | ENST00000332231 | + | 5 | 22 | 11_12 | 201 | 941.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding |
| Hgene | AP2A2 | chr11:977223 | chr11:639432 | ENST00000332231 | + | 5 | 22 | 57_61 | 201 | 941.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding |
| Hgene | AP2A2 | chr11:977223 | chr11:639432 | ENST00000332231 | + | 5 | 22 | 5_80 | 201 | 941.0 | Region | Note=Lipid-binding |
| Hgene | AP2A2 | chr11:977223 | chr11:639432 | ENST00000448903 | + | 5 | 22 | 11_12 | 201 | 940.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding |
| Hgene | AP2A2 | chr11:977223 | chr11:639432 | ENST00000448903 | + | 5 | 22 | 57_61 | 201 | 940.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding |
| Hgene | AP2A2 | chr11:977223 | chr11:639432 | ENST00000448903 | + | 5 | 22 | 5_80 | 201 | 940.0 | Region | Note=Lipid-binding |
| Hgene | AP2A2 | chr11:977224 | chr11:639432 | ENST00000332231 | + | 5 | 22 | 11_12 | 201 | 941.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding |
| Hgene | AP2A2 | chr11:977224 | chr11:639432 | ENST00000332231 | + | 5 | 22 | 57_61 | 201 | 941.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding |
| Hgene | AP2A2 | chr11:977224 | chr11:639432 | ENST00000332231 | + | 5 | 22 | 5_80 | 201 | 941.0 | Region | Note=Lipid-binding |
| Hgene | AP2A2 | chr11:977224 | chr11:639432 | ENST00000448903 | + | 5 | 22 | 11_12 | 201 | 940.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding |
| Hgene | AP2A2 | chr11:977224 | chr11:639432 | ENST00000448903 | + | 5 | 22 | 57_61 | 201 | 940.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding |
| Hgene | AP2A2 | chr11:977224 | chr11:639432 | ENST00000448903 | + | 5 | 22 | 5_80 | 201 | 940.0 | Region | Note=Lipid-binding |
| Hgene | AP2A2 | chr11:977224 | chr11:639433 | ENST00000332231 | + | 5 | 22 | 11_12 | 201 | 941.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding |
| Hgene | AP2A2 | chr11:977224 | chr11:639433 | ENST00000332231 | + | 5 | 22 | 57_61 | 201 | 941.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding |
| Hgene | AP2A2 | chr11:977224 | chr11:639433 | ENST00000332231 | + | 5 | 22 | 5_80 | 201 | 941.0 | Region | Note=Lipid-binding |
| Hgene | AP2A2 | chr11:977224 | chr11:639433 | ENST00000448903 | + | 5 | 22 | 11_12 | 201 | 940.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding |
| Hgene | AP2A2 | chr11:977224 | chr11:639433 | ENST00000448903 | + | 5 | 22 | 57_61 | 201 | 940.0 | Region | Phosphatidylinositol 3%2C4%2C5-trisphosphate binding |
| Hgene | AP2A2 | chr11:977224 | chr11:639433 | ENST00000448903 | + | 5 | 22 | 5_80 | 201 | 940.0 | Region | Note=Lipid-binding |
| Tgene | DRD4 | chr11:977223 | chr11:639432 | ENST00000176183 | 0 | 4 | 249_312 | 95 | 420.0 | Region | Note=4 X 16 AA approximate tandem repeats of [PA]-A-P-G-L-P-[PQR]-[DG]-P-C-G-P-D-C-A-P | |
| Tgene | DRD4 | chr11:977224 | chr11:639432 | ENST00000176183 | 0 | 4 | 249_312 | 95 | 420.0 | Region | Note=4 X 16 AA approximate tandem repeats of [PA]-A-P-G-L-P-[PQR]-[DG]-P-C-G-P-D-C-A-P | |
| Tgene | DRD4 | chr11:977224 | chr11:639433 | ENST00000176183 | 0 | 4 | 249_312 | 95 | 420.0 | Region | Note=4 X 16 AA approximate tandem repeats of [PA]-A-P-G-L-P-[PQR]-[DG]-P-C-G-P-D-C-A-P | |
| Tgene | DRD4 | chr11:977223 | chr11:639432 | ENST00000176183 | 0 | 4 | 249_264 | 95 | 420.0 | Repeat | Note=1%3B approximate | |
| Tgene | DRD4 | chr11:977223 | chr11:639432 | ENST00000176183 | 0 | 4 | 265_280 | 95 | 420.0 | Repeat | Note=2 | |
| Tgene | DRD4 | chr11:977223 | chr11:639432 | ENST00000176183 | 0 | 4 | 281_296 | 95 | 420.0 | Repeat | Note=3 | |
| Tgene | DRD4 | chr11:977223 | chr11:639432 | ENST00000176183 | 0 | 4 | 297_312 | 95 | 420.0 | Repeat | Note=4%3B approximate | |
| Tgene | DRD4 | chr11:977224 | chr11:639432 | ENST00000176183 | 0 | 4 | 249_264 | 95 | 420.0 | Repeat | Note=1%3B approximate | |
| Tgene | DRD4 | chr11:977224 | chr11:639432 | ENST00000176183 | 0 | 4 | 265_280 | 95 | 420.0 | Repeat | Note=2 | |
| Tgene | DRD4 | chr11:977224 | chr11:639432 | ENST00000176183 | 0 | 4 | 281_296 | 95 | 420.0 | Repeat | Note=3 | |
| Tgene | DRD4 | chr11:977224 | chr11:639432 | ENST00000176183 | 0 | 4 | 297_312 | 95 | 420.0 | Repeat | Note=4%3B approximate | |
| Tgene | DRD4 | chr11:977224 | chr11:639433 | ENST00000176183 | 0 | 4 | 249_264 | 95 | 420.0 | Repeat | Note=1%3B approximate | |
| Tgene | DRD4 | chr11:977224 | chr11:639433 | ENST00000176183 | 0 | 4 | 265_280 | 95 | 420.0 | Repeat | Note=2 | |
| Tgene | DRD4 | chr11:977224 | chr11:639433 | ENST00000176183 | 0 | 4 | 281_296 | 95 | 420.0 | Repeat | Note=3 | |
| Tgene | DRD4 | chr11:977224 | chr11:639433 | ENST00000176183 | 0 | 4 | 297_312 | 95 | 420.0 | Repeat | Note=4%3B approximate | |
| Tgene | DRD4 | chr11:977223 | chr11:639432 | ENST00000176183 | 0 | 4 | 132_152 | 95 | 420.0 | Topological domain | Cytoplasmic | |
| Tgene | DRD4 | chr11:977223 | chr11:639432 | ENST00000176183 | 0 | 4 | 174_192 | 95 | 420.0 | Topological domain | Extracellular | |
| Tgene | DRD4 | chr11:977223 | chr11:639432 | ENST00000176183 | 0 | 4 | 214_346 | 95 | 420.0 | Topological domain | Cytoplasmic | |
| Tgene | DRD4 | chr11:977223 | chr11:639432 | ENST00000176183 | 0 | 4 | 368_382 | 95 | 420.0 | Topological domain | Extracellular | |
| Tgene | DRD4 | chr11:977223 | chr11:639432 | ENST00000176183 | 0 | 4 | 404_419 | 95 | 420.0 | Topological domain | Cytoplasmic | |
| Tgene | DRD4 | chr11:977223 | chr11:639432 | ENST00000176183 | 0 | 4 | 93_110 | 95 | 420.0 | Topological domain | Extracellular | |
| Tgene | DRD4 | chr11:977224 | chr11:639432 | ENST00000176183 | 0 | 4 | 132_152 | 95 | 420.0 | Topological domain | Cytoplasmic | |
| Tgene | DRD4 | chr11:977224 | chr11:639432 | ENST00000176183 | 0 | 4 | 174_192 | 95 | 420.0 | Topological domain | Extracellular | |
| Tgene | DRD4 | chr11:977224 | chr11:639432 | ENST00000176183 | 0 | 4 | 214_346 | 95 | 420.0 | Topological domain | Cytoplasmic | |
| Tgene | DRD4 | chr11:977224 | chr11:639432 | ENST00000176183 | 0 | 4 | 368_382 | 95 | 420.0 | Topological domain | Extracellular | |
| Tgene | DRD4 | chr11:977224 | chr11:639432 | ENST00000176183 | 0 | 4 | 404_419 | 95 | 420.0 | Topological domain | Cytoplasmic | |
| Tgene | DRD4 | chr11:977224 | chr11:639432 | ENST00000176183 | 0 | 4 | 93_110 | 95 | 420.0 | Topological domain | Extracellular | |
| Tgene | DRD4 | chr11:977224 | chr11:639433 | ENST00000176183 | 0 | 4 | 132_152 | 95 | 420.0 | Topological domain | Cytoplasmic | |
| Tgene | DRD4 | chr11:977224 | chr11:639433 | ENST00000176183 | 0 | 4 | 174_192 | 95 | 420.0 | Topological domain | Extracellular | |
| Tgene | DRD4 | chr11:977224 | chr11:639433 | ENST00000176183 | 0 | 4 | 214_346 | 95 | 420.0 | Topological domain | Cytoplasmic | |
| Tgene | DRD4 | chr11:977224 | chr11:639433 | ENST00000176183 | 0 | 4 | 368_382 | 95 | 420.0 | Topological domain | Extracellular | |
| Tgene | DRD4 | chr11:977224 | chr11:639433 | ENST00000176183 | 0 | 4 | 404_419 | 95 | 420.0 | Topological domain | Cytoplasmic | |
| Tgene | DRD4 | chr11:977224 | chr11:639433 | ENST00000176183 | 0 | 4 | 93_110 | 95 | 420.0 | Topological domain | Extracellular | |
| Tgene | DRD4 | chr11:977223 | chr11:639432 | ENST00000176183 | 0 | 4 | 111_131 | 95 | 420.0 | Transmembrane | Helical%3B Name%3D3 | |
| Tgene | DRD4 | chr11:977223 | chr11:639432 | ENST00000176183 | 0 | 4 | 153_173 | 95 | 420.0 | Transmembrane | Helical%3B Name%3D4 | |
| Tgene | DRD4 | chr11:977223 | chr11:639432 | ENST00000176183 | 0 | 4 | 193_213 | 95 | 420.0 | Transmembrane | Helical%3B Name%3D5 | |
| Tgene | DRD4 | chr11:977223 | chr11:639432 | ENST00000176183 | 0 | 4 | 347_367 | 95 | 420.0 | Transmembrane | Helical%3B Name%3D6 | |
| Tgene | DRD4 | chr11:977223 | chr11:639432 | ENST00000176183 | 0 | 4 | 383_403 | 95 | 420.0 | Transmembrane | Helical%3B Name%3D7 | |
| Tgene | DRD4 | chr11:977224 | chr11:639432 | ENST00000176183 | 0 | 4 | 111_131 | 95 | 420.0 | Transmembrane | Helical%3B Name%3D3 | |
| Tgene | DRD4 | chr11:977224 | chr11:639432 | ENST00000176183 | 0 | 4 | 153_173 | 95 | 420.0 | Transmembrane | Helical%3B Name%3D4 | |
| Tgene | DRD4 | chr11:977224 | chr11:639432 | ENST00000176183 | 0 | 4 | 193_213 | 95 | 420.0 | Transmembrane | Helical%3B Name%3D5 | |
| Tgene | DRD4 | chr11:977224 | chr11:639432 | ENST00000176183 | 0 | 4 | 347_367 | 95 | 420.0 | Transmembrane | Helical%3B Name%3D6 | |
| Tgene | DRD4 | chr11:977224 | chr11:639432 | ENST00000176183 | 0 | 4 | 383_403 | 95 | 420.0 | Transmembrane | Helical%3B Name%3D7 | |
| Tgene | DRD4 | chr11:977224 | chr11:639433 | ENST00000176183 | 0 | 4 | 111_131 | 95 | 420.0 | Transmembrane | Helical%3B Name%3D3 | |
| Tgene | DRD4 | chr11:977224 | chr11:639433 | ENST00000176183 | 0 | 4 | 153_173 | 95 | 420.0 | Transmembrane | Helical%3B Name%3D4 | |
| Tgene | DRD4 | chr11:977224 | chr11:639433 | ENST00000176183 | 0 | 4 | 193_213 | 95 | 420.0 | Transmembrane | Helical%3B Name%3D5 | |
| Tgene | DRD4 | chr11:977224 | chr11:639433 | ENST00000176183 | 0 | 4 | 347_367 | 95 | 420.0 | Transmembrane | Helical%3B Name%3D6 | |
| Tgene | DRD4 | chr11:977224 | chr11:639433 | ENST00000176183 | 0 | 4 | 383_403 | 95 | 420.0 | Transmembrane | Helical%3B Name%3D7 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | DRD4 | chr11:977223 | chr11:639432 | ENST00000176183 | 0 | 4 | 1_29 | 95 | 420.0 | Topological domain | Extracellular | |
| Tgene | DRD4 | chr11:977223 | chr11:639432 | ENST00000176183 | 0 | 4 | 51_71 | 95 | 420.0 | Topological domain | Cytoplasmic | |
| Tgene | DRD4 | chr11:977224 | chr11:639432 | ENST00000176183 | 0 | 4 | 1_29 | 95 | 420.0 | Topological domain | Extracellular | |
| Tgene | DRD4 | chr11:977224 | chr11:639432 | ENST00000176183 | 0 | 4 | 51_71 | 95 | 420.0 | Topological domain | Cytoplasmic | |
| Tgene | DRD4 | chr11:977224 | chr11:639433 | ENST00000176183 | 0 | 4 | 1_29 | 95 | 420.0 | Topological domain | Extracellular | |
| Tgene | DRD4 | chr11:977224 | chr11:639433 | ENST00000176183 | 0 | 4 | 51_71 | 95 | 420.0 | Topological domain | Cytoplasmic | |
| Tgene | DRD4 | chr11:977223 | chr11:639432 | ENST00000176183 | 0 | 4 | 30_50 | 95 | 420.0 | Transmembrane | Helical%3B Name%3D1 | |
| Tgene | DRD4 | chr11:977223 | chr11:639432 | ENST00000176183 | 0 | 4 | 72_92 | 95 | 420.0 | Transmembrane | Helical%3B Name%3D2 | |
| Tgene | DRD4 | chr11:977224 | chr11:639432 | ENST00000176183 | 0 | 4 | 30_50 | 95 | 420.0 | Transmembrane | Helical%3B Name%3D1 | |
| Tgene | DRD4 | chr11:977224 | chr11:639432 | ENST00000176183 | 0 | 4 | 72_92 | 95 | 420.0 | Transmembrane | Helical%3B Name%3D2 | |
| Tgene | DRD4 | chr11:977224 | chr11:639433 | ENST00000176183 | 0 | 4 | 30_50 | 95 | 420.0 | Transmembrane | Helical%3B Name%3D1 | |
| Tgene | DRD4 | chr11:977224 | chr11:639433 | ENST00000176183 | 0 | 4 | 72_92 | 95 | 420.0 | Transmembrane | Helical%3B Name%3D2 |
Top |
Fusion Gene Sequence for AP2A2-DRD4 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >5225_5225_1_AP2A2-DRD4_AP2A2_chr11_977223_ENST00000332231_DRD4_chr11_639432_ENST00000176183_length(transcript)=1822nt_BP=744nt CTGGGACCCTGAGGCGGCCGTGGTTAGGCGGCTCCCCGGCGGCTCCTCCGCGGCGGTGACGGCGACCGCACTCCCCGCTTCCCGCTCCCC GCGCTCCTCCGCCCGGGTCCGCCAGCCGAGGCCGCTCCCGAGCGTCGGAAGATGCCGGCCGTGTCCAAGGGGGACGGGATGCGGGGCCTG GCGGTCTTCATCTCGGATATCCGCAACTGTAAAAGTAAAGAAGCAGAAATAAAAAGGATAAACAAGGAACTGGCAAATATCAGATCAAAA TTTAAAGGTGACAAGGCTCTTGATGGCTATAGTAAAAAAAAGTACGTCTGCAAGTTGCTCTTCATCTTTCTCCTTGGTCATGACATTGAC TTTGGACACATGGAGGCTGTGAACCTGCTGAGTTCAAACAGATACACGGAAAAGCAGATCGGCTACCTTTTCATCTCTGTGTTGGTGAAC TCAAACAGTGAGCTGATCCGCCTGATCAACAACGCCATCAAGAATGACCTGGCCAGCCGCAACCCCACCTTCATGGGCCTGGCCCTGCAC TGCATCGCCAGCGTGGGCAGCCGGGAGATGGCCGAGGCCTTCGCCGGGGAGATCCCTAAGGTCCTCGTAGCCGGAGACACTATGGACAGC GTGAAGCAGAGCGCGGCCCTGTGCTTGCTGCGCCTGTACAGGACGTCCCCCGATCTTGTCCCCATGGGCGACTGGACATCCCGAGTGGTG CACCTGCTCAATGACCAGCACTTGGTCCAGGGTGGCGCGTGGCTGCTGAGCCCCCGCCTGTGCGACGCCCTCATGGCCATGGACGTCATG CTGTGCACCGCCTCCATCTTCAACCTGTGCGCCATCAGCGTGGACAGGTTCGTGGCCGTGGCCGTGCCGCTGCGCTACAACCGGCAGGGT GGGAGCCGCCGGCAGCTGCTGCTCATCGGCGCCACGTGGCTGCTGTCCGCGGCGGTGGCGGCGCCCGTACTGTGCGGCCTCAACGACGTG CGCGGCCGCGACCCCGCCGTGTGCCGCCTGGAGGACCGCGACTACGTGGTCTACTCGTCCGTGTGCTCCTTCTTCCTACCCTGCCCGCTC ATGCTGCTGCTCTACTGGGCCACGTTCCGCGGCCTGCAGCGCTGGGAGGTGGCACGTCGCGCCAAGCTGCACGGCCGCGCGCCCCGCCGA CCCAGCGGCCCTGGCCCGCCTTCCCCCACGCCACCCGCGCCCCGCCTCCCCCAGGACCCCTGCGGCCCCGACTGTGCGCCCCCCGCGCCC GGCCTTCCCCGGGGTCCCTGCGGCCCCGACTGTGCGCCCGCCGCGCCCAGCCTCCCCCAGGACCCCTGCGGCCCCGACTGTGCGCCCCCC GCGCCCGGCCTCCCCCCGGACCCCTGCGGCTCCAACTGTGCTCCCCCCGACGCCGTCAGAGCCGCCGCGCTCCCACCCCAGACTCCACCG CAGACCCGCAGGAGGCGGCGTGCCAAGATCACCGGCCGGGAGCGCAAGGCCATGAGGGTCCTGCCGGTGGTGGTCGGGGCCTTCCTGCTG TGCTGGACGCCCTTCTTCGTGGTGCACATCACGCAGGCGCTGTGTCCTGCCTGCTCCGTGCCCCCGCGGCTGGTCAGCGCCGTCACCTGG CTGGGCTACGTCAACAGCGCCCTCAACCCCGTCATCTACACTGTCTTCAACGCCGAGTTCCGCAACGTCTTCCGCAAGGCCCTGCGTGCC TGCTGCTGAGCCGGGCACCCCCGGACGCCCCCCGGCCTGATGGCCAGGCCTCAGGGACCAAGGAGATGGGGAGGGCGCTTTTGTACGTTA >5225_5225_1_AP2A2-DRD4_AP2A2_chr11_977223_ENST00000332231_DRD4_chr11_639432_ENST00000176183_length(amino acids)=525AA_BP=368 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLVQGGAWLLSPRLCDALMAMDVMLCTASIFNLCAISVDRFVAVAVPLRYNRQGGSRRQLLLIGATWLLSA AVAAPVLCGLNDVRGRDPAVCRLEDRDYVVYSSVCSFFLPCPLMLLLYWATFRGLQRWEVARRAKLHGRAPRRPSGPGPPSPTPPAPRLP QDPCGPDCAPPAPGLPRGPCGPDCAPAAPSLPQDPCGPDCAPPAPGLPPDPCGSNCAPPDAVRAAALPPQTPPQTRRRRRAKITGRERKA -------------------------------------------------------------- >5225_5225_2_AP2A2-DRD4_AP2A2_chr11_977223_ENST00000448903_DRD4_chr11_639432_ENST00000176183_length(transcript)=1822nt_BP=744nt CTGGGACCCTGAGGCGGCCGTGGTTAGGCGGCTCCCCGGCGGCTCCTCCGCGGCGGTGACGGCGACCGCACTCCCCGCTTCCCGCTCCCC GCGCTCCTCCGCCCGGGTCCGCCAGCCGAGGCCGCTCCCGAGCGTCGGAAGATGCCGGCCGTGTCCAAGGGGGACGGGATGCGGGGCCTG GCGGTCTTCATCTCGGATATCCGCAACTGTAAAAGTAAAGAAGCAGAAATAAAAAGGATAAACAAGGAACTGGCAAATATCAGATCAAAA TTTAAAGGTGACAAGGCTCTTGATGGCTATAGTAAAAAAAAGTACGTCTGCAAGTTGCTCTTCATCTTTCTCCTTGGTCATGACATTGAC TTTGGACACATGGAGGCTGTGAACCTGCTGAGTTCAAACAGATACACGGAAAAGCAGATCGGCTACCTTTTCATCTCTGTGTTGGTGAAC TCAAACAGTGAGCTGATCCGCCTGATCAACAACGCCATCAAGAATGACCTGGCCAGCCGCAACCCCACCTTCATGGGCCTGGCCCTGCAC TGCATCGCCAGCGTGGGCAGCCGGGAGATGGCCGAGGCCTTCGCCGGGGAGATCCCTAAGGTCCTCGTAGCCGGAGACACTATGGACAGC GTGAAGCAGAGCGCGGCCCTGTGCTTGCTGCGCCTGTACAGGACGTCCCCCGATCTTGTCCCCATGGGCGACTGGACATCCCGAGTGGTG CACCTGCTCAATGACCAGCACTTGGTCCAGGGTGGCGCGTGGCTGCTGAGCCCCCGCCTGTGCGACGCCCTCATGGCCATGGACGTCATG CTGTGCACCGCCTCCATCTTCAACCTGTGCGCCATCAGCGTGGACAGGTTCGTGGCCGTGGCCGTGCCGCTGCGCTACAACCGGCAGGGT GGGAGCCGCCGGCAGCTGCTGCTCATCGGCGCCACGTGGCTGCTGTCCGCGGCGGTGGCGGCGCCCGTACTGTGCGGCCTCAACGACGTG CGCGGCCGCGACCCCGCCGTGTGCCGCCTGGAGGACCGCGACTACGTGGTCTACTCGTCCGTGTGCTCCTTCTTCCTACCCTGCCCGCTC ATGCTGCTGCTCTACTGGGCCACGTTCCGCGGCCTGCAGCGCTGGGAGGTGGCACGTCGCGCCAAGCTGCACGGCCGCGCGCCCCGCCGA CCCAGCGGCCCTGGCCCGCCTTCCCCCACGCCACCCGCGCCCCGCCTCCCCCAGGACCCCTGCGGCCCCGACTGTGCGCCCCCCGCGCCC GGCCTTCCCCGGGGTCCCTGCGGCCCCGACTGTGCGCCCGCCGCGCCCAGCCTCCCCCAGGACCCCTGCGGCCCCGACTGTGCGCCCCCC GCGCCCGGCCTCCCCCCGGACCCCTGCGGCTCCAACTGTGCTCCCCCCGACGCCGTCAGAGCCGCCGCGCTCCCACCCCAGACTCCACCG CAGACCCGCAGGAGGCGGCGTGCCAAGATCACCGGCCGGGAGCGCAAGGCCATGAGGGTCCTGCCGGTGGTGGTCGGGGCCTTCCTGCTG TGCTGGACGCCCTTCTTCGTGGTGCACATCACGCAGGCGCTGTGTCCTGCCTGCTCCGTGCCCCCGCGGCTGGTCAGCGCCGTCACCTGG CTGGGCTACGTCAACAGCGCCCTCAACCCCGTCATCTACACTGTCTTCAACGCCGAGTTCCGCAACGTCTTCCGCAAGGCCCTGCGTGCC TGCTGCTGAGCCGGGCACCCCCGGACGCCCCCCGGCCTGATGGCCAGGCCTCAGGGACCAAGGAGATGGGGAGGGCGCTTTTGTACGTTA >5225_5225_2_AP2A2-DRD4_AP2A2_chr11_977223_ENST00000448903_DRD4_chr11_639432_ENST00000176183_length(amino acids)=525AA_BP=368 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLVQGGAWLLSPRLCDALMAMDVMLCTASIFNLCAISVDRFVAVAVPLRYNRQGGSRRQLLLIGATWLLSA AVAAPVLCGLNDVRGRDPAVCRLEDRDYVVYSSVCSFFLPCPLMLLLYWATFRGLQRWEVARRAKLHGRAPRRPSGPGPPSPTPPAPRLP QDPCGPDCAPPAPGLPRGPCGPDCAPAAPSLPQDPCGPDCAPPAPGLPPDPCGSNCAPPDAVRAAALPPQTPPQTRRRRRAKITGRERKA -------------------------------------------------------------- >5225_5225_3_AP2A2-DRD4_AP2A2_chr11_977223_ENST00000534328_DRD4_chr11_639432_ENST00000176183_length(transcript)=1823nt_BP=745nt GCTGGGACCCTGAGGCGGCCGTGGTTAGGCGGCTCCCCGGCGGCTCCTCCGCGGCGGTGACGGCGACCGCACTCCCCGCTTCCCGCTCCC CGCGCTCCTCCGCCCGGGTCCGCCAGCCGAGGCCGCTCCCGAGCGTCGGAAGATGCCGGCCGTGTCCAAGGGGGACGGGATGCGGGGCCT GGCGGTCTTCATCTCGGATATCCGCAACTGTAAAAGTAAAGAAGCAGAAATAAAAAGGATAAACAAGGAACTGGCAAATATCAGATCAAA ATTTAAAGGTGACAAGGCTCTTGATGGCTATAGTAAAAAAAAGTACGTCTGCAAGTTGCTCTTCATCTTTCTCCTTGGTCATGACATTGA CTTTGGACACATGGAGGCTGTGAACCTGCTGAGTTCAAACAGATACACGGAAAAGCAGATCGGCTACCTTTTCATCTCTGTGTTGGTGAA CTCAAACAGTGAGCTGATCCGCCTGATCAACAACGCCATCAAGAATGACCTGGCCAGCCGCAACCCCACCTTCATGGGCCTGGCCCTGCA CTGCATCGCCAGCGTGGGCAGCCGGGAGATGGCCGAGGCCTTCGCCGGGGAGATCCCTAAGGTCCTCGTAGCCGGAGACACTATGGACAG CGTGAAGCAGAGCGCGGCCCTGTGCTTGCTGCGCCTGTACAGGACGTCCCCCGATCTTGTCCCCATGGGCGACTGGACATCCCGAGTGGT GCACCTGCTCAATGACCAGCACTTGGTCCAGGGTGGCGCGTGGCTGCTGAGCCCCCGCCTGTGCGACGCCCTCATGGCCATGGACGTCAT GCTGTGCACCGCCTCCATCTTCAACCTGTGCGCCATCAGCGTGGACAGGTTCGTGGCCGTGGCCGTGCCGCTGCGCTACAACCGGCAGGG TGGGAGCCGCCGGCAGCTGCTGCTCATCGGCGCCACGTGGCTGCTGTCCGCGGCGGTGGCGGCGCCCGTACTGTGCGGCCTCAACGACGT GCGCGGCCGCGACCCCGCCGTGTGCCGCCTGGAGGACCGCGACTACGTGGTCTACTCGTCCGTGTGCTCCTTCTTCCTACCCTGCCCGCT CATGCTGCTGCTCTACTGGGCCACGTTCCGCGGCCTGCAGCGCTGGGAGGTGGCACGTCGCGCCAAGCTGCACGGCCGCGCGCCCCGCCG ACCCAGCGGCCCTGGCCCGCCTTCCCCCACGCCACCCGCGCCCCGCCTCCCCCAGGACCCCTGCGGCCCCGACTGTGCGCCCCCCGCGCC CGGCCTTCCCCGGGGTCCCTGCGGCCCCGACTGTGCGCCCGCCGCGCCCAGCCTCCCCCAGGACCCCTGCGGCCCCGACTGTGCGCCCCC CGCGCCCGGCCTCCCCCCGGACCCCTGCGGCTCCAACTGTGCTCCCCCCGACGCCGTCAGAGCCGCCGCGCTCCCACCCCAGACTCCACC GCAGACCCGCAGGAGGCGGCGTGCCAAGATCACCGGCCGGGAGCGCAAGGCCATGAGGGTCCTGCCGGTGGTGGTCGGGGCCTTCCTGCT GTGCTGGACGCCCTTCTTCGTGGTGCACATCACGCAGGCGCTGTGTCCTGCCTGCTCCGTGCCCCCGCGGCTGGTCAGCGCCGTCACCTG GCTGGGCTACGTCAACAGCGCCCTCAACCCCGTCATCTACACTGTCTTCAACGCCGAGTTCCGCAACGTCTTCCGCAAGGCCCTGCGTGC CTGCTGCTGAGCCGGGCACCCCCGGACGCCCCCCGGCCTGATGGCCAGGCCTCAGGGACCAAGGAGATGGGGAGGGCGCTTTTGTACGTT >5225_5225_3_AP2A2-DRD4_AP2A2_chr11_977223_ENST00000534328_DRD4_chr11_639432_ENST00000176183_length(amino acids)=525AA_BP=368 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLVQGGAWLLSPRLCDALMAMDVMLCTASIFNLCAISVDRFVAVAVPLRYNRQGGSRRQLLLIGATWLLSA AVAAPVLCGLNDVRGRDPAVCRLEDRDYVVYSSVCSFFLPCPLMLLLYWATFRGLQRWEVARRAKLHGRAPRRPSGPGPPSPTPPAPRLP QDPCGPDCAPPAPGLPRGPCGPDCAPAAPSLPQDPCGPDCAPPAPGLPPDPCGSNCAPPDAVRAAALPPQTPPQTRRRRRAKITGRERKA -------------------------------------------------------------- >5225_5225_4_AP2A2-DRD4_AP2A2_chr11_977224_ENST00000332231_DRD4_chr11_639432_ENST00000176183_length(transcript)=1822nt_BP=744nt CTGGGACCCTGAGGCGGCCGTGGTTAGGCGGCTCCCCGGCGGCTCCTCCGCGGCGGTGACGGCGACCGCACTCCCCGCTTCCCGCTCCCC GCGCTCCTCCGCCCGGGTCCGCCAGCCGAGGCCGCTCCCGAGCGTCGGAAGATGCCGGCCGTGTCCAAGGGGGACGGGATGCGGGGCCTG GCGGTCTTCATCTCGGATATCCGCAACTGTAAAAGTAAAGAAGCAGAAATAAAAAGGATAAACAAGGAACTGGCAAATATCAGATCAAAA TTTAAAGGTGACAAGGCTCTTGATGGCTATAGTAAAAAAAAGTACGTCTGCAAGTTGCTCTTCATCTTTCTCCTTGGTCATGACATTGAC TTTGGACACATGGAGGCTGTGAACCTGCTGAGTTCAAACAGATACACGGAAAAGCAGATCGGCTACCTTTTCATCTCTGTGTTGGTGAAC TCAAACAGTGAGCTGATCCGCCTGATCAACAACGCCATCAAGAATGACCTGGCCAGCCGCAACCCCACCTTCATGGGCCTGGCCCTGCAC TGCATCGCCAGCGTGGGCAGCCGGGAGATGGCCGAGGCCTTCGCCGGGGAGATCCCTAAGGTCCTCGTAGCCGGAGACACTATGGACAGC GTGAAGCAGAGCGCGGCCCTGTGCTTGCTGCGCCTGTACAGGACGTCCCCCGATCTTGTCCCCATGGGCGACTGGACATCCCGAGTGGTG CACCTGCTCAATGACCAGCACTTGGTCCAGGGTGGCGCGTGGCTGCTGAGCCCCCGCCTGTGCGACGCCCTCATGGCCATGGACGTCATG CTGTGCACCGCCTCCATCTTCAACCTGTGCGCCATCAGCGTGGACAGGTTCGTGGCCGTGGCCGTGCCGCTGCGCTACAACCGGCAGGGT GGGAGCCGCCGGCAGCTGCTGCTCATCGGCGCCACGTGGCTGCTGTCCGCGGCGGTGGCGGCGCCCGTACTGTGCGGCCTCAACGACGTG CGCGGCCGCGACCCCGCCGTGTGCCGCCTGGAGGACCGCGACTACGTGGTCTACTCGTCCGTGTGCTCCTTCTTCCTACCCTGCCCGCTC ATGCTGCTGCTCTACTGGGCCACGTTCCGCGGCCTGCAGCGCTGGGAGGTGGCACGTCGCGCCAAGCTGCACGGCCGCGCGCCCCGCCGA CCCAGCGGCCCTGGCCCGCCTTCCCCCACGCCACCCGCGCCCCGCCTCCCCCAGGACCCCTGCGGCCCCGACTGTGCGCCCCCCGCGCCC GGCCTTCCCCGGGGTCCCTGCGGCCCCGACTGTGCGCCCGCCGCGCCCAGCCTCCCCCAGGACCCCTGCGGCCCCGACTGTGCGCCCCCC GCGCCCGGCCTCCCCCCGGACCCCTGCGGCTCCAACTGTGCTCCCCCCGACGCCGTCAGAGCCGCCGCGCTCCCACCCCAGACTCCACCG CAGACCCGCAGGAGGCGGCGTGCCAAGATCACCGGCCGGGAGCGCAAGGCCATGAGGGTCCTGCCGGTGGTGGTCGGGGCCTTCCTGCTG TGCTGGACGCCCTTCTTCGTGGTGCACATCACGCAGGCGCTGTGTCCTGCCTGCTCCGTGCCCCCGCGGCTGGTCAGCGCCGTCACCTGG CTGGGCTACGTCAACAGCGCCCTCAACCCCGTCATCTACACTGTCTTCAACGCCGAGTTCCGCAACGTCTTCCGCAAGGCCCTGCGTGCC TGCTGCTGAGCCGGGCACCCCCGGACGCCCCCCGGCCTGATGGCCAGGCCTCAGGGACCAAGGAGATGGGGAGGGCGCTTTTGTACGTTA >5225_5225_4_AP2A2-DRD4_AP2A2_chr11_977224_ENST00000332231_DRD4_chr11_639432_ENST00000176183_length(amino acids)=525AA_BP=368 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLVQGGAWLLSPRLCDALMAMDVMLCTASIFNLCAISVDRFVAVAVPLRYNRQGGSRRQLLLIGATWLLSA AVAAPVLCGLNDVRGRDPAVCRLEDRDYVVYSSVCSFFLPCPLMLLLYWATFRGLQRWEVARRAKLHGRAPRRPSGPGPPSPTPPAPRLP QDPCGPDCAPPAPGLPRGPCGPDCAPAAPSLPQDPCGPDCAPPAPGLPPDPCGSNCAPPDAVRAAALPPQTPPQTRRRRRAKITGRERKA -------------------------------------------------------------- >5225_5225_5_AP2A2-DRD4_AP2A2_chr11_977224_ENST00000332231_DRD4_chr11_639433_ENST00000176183_length(transcript)=1822nt_BP=744nt CTGGGACCCTGAGGCGGCCGTGGTTAGGCGGCTCCCCGGCGGCTCCTCCGCGGCGGTGACGGCGACCGCACTCCCCGCTTCCCGCTCCCC GCGCTCCTCCGCCCGGGTCCGCCAGCCGAGGCCGCTCCCGAGCGTCGGAAGATGCCGGCCGTGTCCAAGGGGGACGGGATGCGGGGCCTG GCGGTCTTCATCTCGGATATCCGCAACTGTAAAAGTAAAGAAGCAGAAATAAAAAGGATAAACAAGGAACTGGCAAATATCAGATCAAAA TTTAAAGGTGACAAGGCTCTTGATGGCTATAGTAAAAAAAAGTACGTCTGCAAGTTGCTCTTCATCTTTCTCCTTGGTCATGACATTGAC TTTGGACACATGGAGGCTGTGAACCTGCTGAGTTCAAACAGATACACGGAAAAGCAGATCGGCTACCTTTTCATCTCTGTGTTGGTGAAC TCAAACAGTGAGCTGATCCGCCTGATCAACAACGCCATCAAGAATGACCTGGCCAGCCGCAACCCCACCTTCATGGGCCTGGCCCTGCAC TGCATCGCCAGCGTGGGCAGCCGGGAGATGGCCGAGGCCTTCGCCGGGGAGATCCCTAAGGTCCTCGTAGCCGGAGACACTATGGACAGC GTGAAGCAGAGCGCGGCCCTGTGCTTGCTGCGCCTGTACAGGACGTCCCCCGATCTTGTCCCCATGGGCGACTGGACATCCCGAGTGGTG CACCTGCTCAATGACCAGCACTTGGTCCAGGGTGGCGCGTGGCTGCTGAGCCCCCGCCTGTGCGACGCCCTCATGGCCATGGACGTCATG CTGTGCACCGCCTCCATCTTCAACCTGTGCGCCATCAGCGTGGACAGGTTCGTGGCCGTGGCCGTGCCGCTGCGCTACAACCGGCAGGGT GGGAGCCGCCGGCAGCTGCTGCTCATCGGCGCCACGTGGCTGCTGTCCGCGGCGGTGGCGGCGCCCGTACTGTGCGGCCTCAACGACGTG CGCGGCCGCGACCCCGCCGTGTGCCGCCTGGAGGACCGCGACTACGTGGTCTACTCGTCCGTGTGCTCCTTCTTCCTACCCTGCCCGCTC ATGCTGCTGCTCTACTGGGCCACGTTCCGCGGCCTGCAGCGCTGGGAGGTGGCACGTCGCGCCAAGCTGCACGGCCGCGCGCCCCGCCGA CCCAGCGGCCCTGGCCCGCCTTCCCCCACGCCACCCGCGCCCCGCCTCCCCCAGGACCCCTGCGGCCCCGACTGTGCGCCCCCCGCGCCC GGCCTTCCCCGGGGTCCCTGCGGCCCCGACTGTGCGCCCGCCGCGCCCAGCCTCCCCCAGGACCCCTGCGGCCCCGACTGTGCGCCCCCC GCGCCCGGCCTCCCCCCGGACCCCTGCGGCTCCAACTGTGCTCCCCCCGACGCCGTCAGAGCCGCCGCGCTCCCACCCCAGACTCCACCG CAGACCCGCAGGAGGCGGCGTGCCAAGATCACCGGCCGGGAGCGCAAGGCCATGAGGGTCCTGCCGGTGGTGGTCGGGGCCTTCCTGCTG TGCTGGACGCCCTTCTTCGTGGTGCACATCACGCAGGCGCTGTGTCCTGCCTGCTCCGTGCCCCCGCGGCTGGTCAGCGCCGTCACCTGG CTGGGCTACGTCAACAGCGCCCTCAACCCCGTCATCTACACTGTCTTCAACGCCGAGTTCCGCAACGTCTTCCGCAAGGCCCTGCGTGCC TGCTGCTGAGCCGGGCACCCCCGGACGCCCCCCGGCCTGATGGCCAGGCCTCAGGGACCAAGGAGATGGGGAGGGCGCTTTTGTACGTTA >5225_5225_5_AP2A2-DRD4_AP2A2_chr11_977224_ENST00000332231_DRD4_chr11_639433_ENST00000176183_length(amino acids)=525AA_BP=368 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLVQGGAWLLSPRLCDALMAMDVMLCTASIFNLCAISVDRFVAVAVPLRYNRQGGSRRQLLLIGATWLLSA AVAAPVLCGLNDVRGRDPAVCRLEDRDYVVYSSVCSFFLPCPLMLLLYWATFRGLQRWEVARRAKLHGRAPRRPSGPGPPSPTPPAPRLP QDPCGPDCAPPAPGLPRGPCGPDCAPAAPSLPQDPCGPDCAPPAPGLPPDPCGSNCAPPDAVRAAALPPQTPPQTRRRRRAKITGRERKA -------------------------------------------------------------- >5225_5225_6_AP2A2-DRD4_AP2A2_chr11_977224_ENST00000448903_DRD4_chr11_639432_ENST00000176183_length(transcript)=1822nt_BP=744nt CTGGGACCCTGAGGCGGCCGTGGTTAGGCGGCTCCCCGGCGGCTCCTCCGCGGCGGTGACGGCGACCGCACTCCCCGCTTCCCGCTCCCC GCGCTCCTCCGCCCGGGTCCGCCAGCCGAGGCCGCTCCCGAGCGTCGGAAGATGCCGGCCGTGTCCAAGGGGGACGGGATGCGGGGCCTG GCGGTCTTCATCTCGGATATCCGCAACTGTAAAAGTAAAGAAGCAGAAATAAAAAGGATAAACAAGGAACTGGCAAATATCAGATCAAAA TTTAAAGGTGACAAGGCTCTTGATGGCTATAGTAAAAAAAAGTACGTCTGCAAGTTGCTCTTCATCTTTCTCCTTGGTCATGACATTGAC TTTGGACACATGGAGGCTGTGAACCTGCTGAGTTCAAACAGATACACGGAAAAGCAGATCGGCTACCTTTTCATCTCTGTGTTGGTGAAC TCAAACAGTGAGCTGATCCGCCTGATCAACAACGCCATCAAGAATGACCTGGCCAGCCGCAACCCCACCTTCATGGGCCTGGCCCTGCAC TGCATCGCCAGCGTGGGCAGCCGGGAGATGGCCGAGGCCTTCGCCGGGGAGATCCCTAAGGTCCTCGTAGCCGGAGACACTATGGACAGC GTGAAGCAGAGCGCGGCCCTGTGCTTGCTGCGCCTGTACAGGACGTCCCCCGATCTTGTCCCCATGGGCGACTGGACATCCCGAGTGGTG CACCTGCTCAATGACCAGCACTTGGTCCAGGGTGGCGCGTGGCTGCTGAGCCCCCGCCTGTGCGACGCCCTCATGGCCATGGACGTCATG CTGTGCACCGCCTCCATCTTCAACCTGTGCGCCATCAGCGTGGACAGGTTCGTGGCCGTGGCCGTGCCGCTGCGCTACAACCGGCAGGGT GGGAGCCGCCGGCAGCTGCTGCTCATCGGCGCCACGTGGCTGCTGTCCGCGGCGGTGGCGGCGCCCGTACTGTGCGGCCTCAACGACGTG CGCGGCCGCGACCCCGCCGTGTGCCGCCTGGAGGACCGCGACTACGTGGTCTACTCGTCCGTGTGCTCCTTCTTCCTACCCTGCCCGCTC ATGCTGCTGCTCTACTGGGCCACGTTCCGCGGCCTGCAGCGCTGGGAGGTGGCACGTCGCGCCAAGCTGCACGGCCGCGCGCCCCGCCGA CCCAGCGGCCCTGGCCCGCCTTCCCCCACGCCACCCGCGCCCCGCCTCCCCCAGGACCCCTGCGGCCCCGACTGTGCGCCCCCCGCGCCC GGCCTTCCCCGGGGTCCCTGCGGCCCCGACTGTGCGCCCGCCGCGCCCAGCCTCCCCCAGGACCCCTGCGGCCCCGACTGTGCGCCCCCC GCGCCCGGCCTCCCCCCGGACCCCTGCGGCTCCAACTGTGCTCCCCCCGACGCCGTCAGAGCCGCCGCGCTCCCACCCCAGACTCCACCG CAGACCCGCAGGAGGCGGCGTGCCAAGATCACCGGCCGGGAGCGCAAGGCCATGAGGGTCCTGCCGGTGGTGGTCGGGGCCTTCCTGCTG TGCTGGACGCCCTTCTTCGTGGTGCACATCACGCAGGCGCTGTGTCCTGCCTGCTCCGTGCCCCCGCGGCTGGTCAGCGCCGTCACCTGG CTGGGCTACGTCAACAGCGCCCTCAACCCCGTCATCTACACTGTCTTCAACGCCGAGTTCCGCAACGTCTTCCGCAAGGCCCTGCGTGCC TGCTGCTGAGCCGGGCACCCCCGGACGCCCCCCGGCCTGATGGCCAGGCCTCAGGGACCAAGGAGATGGGGAGGGCGCTTTTGTACGTTA >5225_5225_6_AP2A2-DRD4_AP2A2_chr11_977224_ENST00000448903_DRD4_chr11_639432_ENST00000176183_length(amino acids)=525AA_BP=368 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLVQGGAWLLSPRLCDALMAMDVMLCTASIFNLCAISVDRFVAVAVPLRYNRQGGSRRQLLLIGATWLLSA AVAAPVLCGLNDVRGRDPAVCRLEDRDYVVYSSVCSFFLPCPLMLLLYWATFRGLQRWEVARRAKLHGRAPRRPSGPGPPSPTPPAPRLP QDPCGPDCAPPAPGLPRGPCGPDCAPAAPSLPQDPCGPDCAPPAPGLPPDPCGSNCAPPDAVRAAALPPQTPPQTRRRRRAKITGRERKA -------------------------------------------------------------- >5225_5225_7_AP2A2-DRD4_AP2A2_chr11_977224_ENST00000448903_DRD4_chr11_639433_ENST00000176183_length(transcript)=1822nt_BP=744nt CTGGGACCCTGAGGCGGCCGTGGTTAGGCGGCTCCCCGGCGGCTCCTCCGCGGCGGTGACGGCGACCGCACTCCCCGCTTCCCGCTCCCC GCGCTCCTCCGCCCGGGTCCGCCAGCCGAGGCCGCTCCCGAGCGTCGGAAGATGCCGGCCGTGTCCAAGGGGGACGGGATGCGGGGCCTG GCGGTCTTCATCTCGGATATCCGCAACTGTAAAAGTAAAGAAGCAGAAATAAAAAGGATAAACAAGGAACTGGCAAATATCAGATCAAAA TTTAAAGGTGACAAGGCTCTTGATGGCTATAGTAAAAAAAAGTACGTCTGCAAGTTGCTCTTCATCTTTCTCCTTGGTCATGACATTGAC TTTGGACACATGGAGGCTGTGAACCTGCTGAGTTCAAACAGATACACGGAAAAGCAGATCGGCTACCTTTTCATCTCTGTGTTGGTGAAC TCAAACAGTGAGCTGATCCGCCTGATCAACAACGCCATCAAGAATGACCTGGCCAGCCGCAACCCCACCTTCATGGGCCTGGCCCTGCAC TGCATCGCCAGCGTGGGCAGCCGGGAGATGGCCGAGGCCTTCGCCGGGGAGATCCCTAAGGTCCTCGTAGCCGGAGACACTATGGACAGC GTGAAGCAGAGCGCGGCCCTGTGCTTGCTGCGCCTGTACAGGACGTCCCCCGATCTTGTCCCCATGGGCGACTGGACATCCCGAGTGGTG CACCTGCTCAATGACCAGCACTTGGTCCAGGGTGGCGCGTGGCTGCTGAGCCCCCGCCTGTGCGACGCCCTCATGGCCATGGACGTCATG CTGTGCACCGCCTCCATCTTCAACCTGTGCGCCATCAGCGTGGACAGGTTCGTGGCCGTGGCCGTGCCGCTGCGCTACAACCGGCAGGGT GGGAGCCGCCGGCAGCTGCTGCTCATCGGCGCCACGTGGCTGCTGTCCGCGGCGGTGGCGGCGCCCGTACTGTGCGGCCTCAACGACGTG CGCGGCCGCGACCCCGCCGTGTGCCGCCTGGAGGACCGCGACTACGTGGTCTACTCGTCCGTGTGCTCCTTCTTCCTACCCTGCCCGCTC ATGCTGCTGCTCTACTGGGCCACGTTCCGCGGCCTGCAGCGCTGGGAGGTGGCACGTCGCGCCAAGCTGCACGGCCGCGCGCCCCGCCGA CCCAGCGGCCCTGGCCCGCCTTCCCCCACGCCACCCGCGCCCCGCCTCCCCCAGGACCCCTGCGGCCCCGACTGTGCGCCCCCCGCGCCC GGCCTTCCCCGGGGTCCCTGCGGCCCCGACTGTGCGCCCGCCGCGCCCAGCCTCCCCCAGGACCCCTGCGGCCCCGACTGTGCGCCCCCC GCGCCCGGCCTCCCCCCGGACCCCTGCGGCTCCAACTGTGCTCCCCCCGACGCCGTCAGAGCCGCCGCGCTCCCACCCCAGACTCCACCG CAGACCCGCAGGAGGCGGCGTGCCAAGATCACCGGCCGGGAGCGCAAGGCCATGAGGGTCCTGCCGGTGGTGGTCGGGGCCTTCCTGCTG TGCTGGACGCCCTTCTTCGTGGTGCACATCACGCAGGCGCTGTGTCCTGCCTGCTCCGTGCCCCCGCGGCTGGTCAGCGCCGTCACCTGG CTGGGCTACGTCAACAGCGCCCTCAACCCCGTCATCTACACTGTCTTCAACGCCGAGTTCCGCAACGTCTTCCGCAAGGCCCTGCGTGCC TGCTGCTGAGCCGGGCACCCCCGGACGCCCCCCGGCCTGATGGCCAGGCCTCAGGGACCAAGGAGATGGGGAGGGCGCTTTTGTACGTTA >5225_5225_7_AP2A2-DRD4_AP2A2_chr11_977224_ENST00000448903_DRD4_chr11_639433_ENST00000176183_length(amino acids)=525AA_BP=368 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLVQGGAWLLSPRLCDALMAMDVMLCTASIFNLCAISVDRFVAVAVPLRYNRQGGSRRQLLLIGATWLLSA AVAAPVLCGLNDVRGRDPAVCRLEDRDYVVYSSVCSFFLPCPLMLLLYWATFRGLQRWEVARRAKLHGRAPRRPSGPGPPSPTPPAPRLP QDPCGPDCAPPAPGLPRGPCGPDCAPAAPSLPQDPCGPDCAPPAPGLPPDPCGSNCAPPDAVRAAALPPQTPPQTRRRRRAKITGRERKA -------------------------------------------------------------- >5225_5225_8_AP2A2-DRD4_AP2A2_chr11_977224_ENST00000534328_DRD4_chr11_639432_ENST00000176183_length(transcript)=1823nt_BP=745nt GCTGGGACCCTGAGGCGGCCGTGGTTAGGCGGCTCCCCGGCGGCTCCTCCGCGGCGGTGACGGCGACCGCACTCCCCGCTTCCCGCTCCC CGCGCTCCTCCGCCCGGGTCCGCCAGCCGAGGCCGCTCCCGAGCGTCGGAAGATGCCGGCCGTGTCCAAGGGGGACGGGATGCGGGGCCT GGCGGTCTTCATCTCGGATATCCGCAACTGTAAAAGTAAAGAAGCAGAAATAAAAAGGATAAACAAGGAACTGGCAAATATCAGATCAAA ATTTAAAGGTGACAAGGCTCTTGATGGCTATAGTAAAAAAAAGTACGTCTGCAAGTTGCTCTTCATCTTTCTCCTTGGTCATGACATTGA CTTTGGACACATGGAGGCTGTGAACCTGCTGAGTTCAAACAGATACACGGAAAAGCAGATCGGCTACCTTTTCATCTCTGTGTTGGTGAA CTCAAACAGTGAGCTGATCCGCCTGATCAACAACGCCATCAAGAATGACCTGGCCAGCCGCAACCCCACCTTCATGGGCCTGGCCCTGCA CTGCATCGCCAGCGTGGGCAGCCGGGAGATGGCCGAGGCCTTCGCCGGGGAGATCCCTAAGGTCCTCGTAGCCGGAGACACTATGGACAG CGTGAAGCAGAGCGCGGCCCTGTGCTTGCTGCGCCTGTACAGGACGTCCCCCGATCTTGTCCCCATGGGCGACTGGACATCCCGAGTGGT GCACCTGCTCAATGACCAGCACTTGGTCCAGGGTGGCGCGTGGCTGCTGAGCCCCCGCCTGTGCGACGCCCTCATGGCCATGGACGTCAT GCTGTGCACCGCCTCCATCTTCAACCTGTGCGCCATCAGCGTGGACAGGTTCGTGGCCGTGGCCGTGCCGCTGCGCTACAACCGGCAGGG TGGGAGCCGCCGGCAGCTGCTGCTCATCGGCGCCACGTGGCTGCTGTCCGCGGCGGTGGCGGCGCCCGTACTGTGCGGCCTCAACGACGT GCGCGGCCGCGACCCCGCCGTGTGCCGCCTGGAGGACCGCGACTACGTGGTCTACTCGTCCGTGTGCTCCTTCTTCCTACCCTGCCCGCT CATGCTGCTGCTCTACTGGGCCACGTTCCGCGGCCTGCAGCGCTGGGAGGTGGCACGTCGCGCCAAGCTGCACGGCCGCGCGCCCCGCCG ACCCAGCGGCCCTGGCCCGCCTTCCCCCACGCCACCCGCGCCCCGCCTCCCCCAGGACCCCTGCGGCCCCGACTGTGCGCCCCCCGCGCC CGGCCTTCCCCGGGGTCCCTGCGGCCCCGACTGTGCGCCCGCCGCGCCCAGCCTCCCCCAGGACCCCTGCGGCCCCGACTGTGCGCCCCC CGCGCCCGGCCTCCCCCCGGACCCCTGCGGCTCCAACTGTGCTCCCCCCGACGCCGTCAGAGCCGCCGCGCTCCCACCCCAGACTCCACC GCAGACCCGCAGGAGGCGGCGTGCCAAGATCACCGGCCGGGAGCGCAAGGCCATGAGGGTCCTGCCGGTGGTGGTCGGGGCCTTCCTGCT GTGCTGGACGCCCTTCTTCGTGGTGCACATCACGCAGGCGCTGTGTCCTGCCTGCTCCGTGCCCCCGCGGCTGGTCAGCGCCGTCACCTG GCTGGGCTACGTCAACAGCGCCCTCAACCCCGTCATCTACACTGTCTTCAACGCCGAGTTCCGCAACGTCTTCCGCAAGGCCCTGCGTGC CTGCTGCTGAGCCGGGCACCCCCGGACGCCCCCCGGCCTGATGGCCAGGCCTCAGGGACCAAGGAGATGGGGAGGGCGCTTTTGTACGTT >5225_5225_8_AP2A2-DRD4_AP2A2_chr11_977224_ENST00000534328_DRD4_chr11_639432_ENST00000176183_length(amino acids)=525AA_BP=368 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLVQGGAWLLSPRLCDALMAMDVMLCTASIFNLCAISVDRFVAVAVPLRYNRQGGSRRQLLLIGATWLLSA AVAAPVLCGLNDVRGRDPAVCRLEDRDYVVYSSVCSFFLPCPLMLLLYWATFRGLQRWEVARRAKLHGRAPRRPSGPGPPSPTPPAPRLP QDPCGPDCAPPAPGLPRGPCGPDCAPAAPSLPQDPCGPDCAPPAPGLPPDPCGSNCAPPDAVRAAALPPQTPPQTRRRRRAKITGRERKA -------------------------------------------------------------- >5225_5225_9_AP2A2-DRD4_AP2A2_chr11_977224_ENST00000534328_DRD4_chr11_639433_ENST00000176183_length(transcript)=1823nt_BP=745nt GCTGGGACCCTGAGGCGGCCGTGGTTAGGCGGCTCCCCGGCGGCTCCTCCGCGGCGGTGACGGCGACCGCACTCCCCGCTTCCCGCTCCC CGCGCTCCTCCGCCCGGGTCCGCCAGCCGAGGCCGCTCCCGAGCGTCGGAAGATGCCGGCCGTGTCCAAGGGGGACGGGATGCGGGGCCT GGCGGTCTTCATCTCGGATATCCGCAACTGTAAAAGTAAAGAAGCAGAAATAAAAAGGATAAACAAGGAACTGGCAAATATCAGATCAAA ATTTAAAGGTGACAAGGCTCTTGATGGCTATAGTAAAAAAAAGTACGTCTGCAAGTTGCTCTTCATCTTTCTCCTTGGTCATGACATTGA CTTTGGACACATGGAGGCTGTGAACCTGCTGAGTTCAAACAGATACACGGAAAAGCAGATCGGCTACCTTTTCATCTCTGTGTTGGTGAA CTCAAACAGTGAGCTGATCCGCCTGATCAACAACGCCATCAAGAATGACCTGGCCAGCCGCAACCCCACCTTCATGGGCCTGGCCCTGCA CTGCATCGCCAGCGTGGGCAGCCGGGAGATGGCCGAGGCCTTCGCCGGGGAGATCCCTAAGGTCCTCGTAGCCGGAGACACTATGGACAG CGTGAAGCAGAGCGCGGCCCTGTGCTTGCTGCGCCTGTACAGGACGTCCCCCGATCTTGTCCCCATGGGCGACTGGACATCCCGAGTGGT GCACCTGCTCAATGACCAGCACTTGGTCCAGGGTGGCGCGTGGCTGCTGAGCCCCCGCCTGTGCGACGCCCTCATGGCCATGGACGTCAT GCTGTGCACCGCCTCCATCTTCAACCTGTGCGCCATCAGCGTGGACAGGTTCGTGGCCGTGGCCGTGCCGCTGCGCTACAACCGGCAGGG TGGGAGCCGCCGGCAGCTGCTGCTCATCGGCGCCACGTGGCTGCTGTCCGCGGCGGTGGCGGCGCCCGTACTGTGCGGCCTCAACGACGT GCGCGGCCGCGACCCCGCCGTGTGCCGCCTGGAGGACCGCGACTACGTGGTCTACTCGTCCGTGTGCTCCTTCTTCCTACCCTGCCCGCT CATGCTGCTGCTCTACTGGGCCACGTTCCGCGGCCTGCAGCGCTGGGAGGTGGCACGTCGCGCCAAGCTGCACGGCCGCGCGCCCCGCCG ACCCAGCGGCCCTGGCCCGCCTTCCCCCACGCCACCCGCGCCCCGCCTCCCCCAGGACCCCTGCGGCCCCGACTGTGCGCCCCCCGCGCC CGGCCTTCCCCGGGGTCCCTGCGGCCCCGACTGTGCGCCCGCCGCGCCCAGCCTCCCCCAGGACCCCTGCGGCCCCGACTGTGCGCCCCC CGCGCCCGGCCTCCCCCCGGACCCCTGCGGCTCCAACTGTGCTCCCCCCGACGCCGTCAGAGCCGCCGCGCTCCCACCCCAGACTCCACC GCAGACCCGCAGGAGGCGGCGTGCCAAGATCACCGGCCGGGAGCGCAAGGCCATGAGGGTCCTGCCGGTGGTGGTCGGGGCCTTCCTGCT GTGCTGGACGCCCTTCTTCGTGGTGCACATCACGCAGGCGCTGTGTCCTGCCTGCTCCGTGCCCCCGCGGCTGGTCAGCGCCGTCACCTG GCTGGGCTACGTCAACAGCGCCCTCAACCCCGTCATCTACACTGTCTTCAACGCCGAGTTCCGCAACGTCTTCCGCAAGGCCCTGCGTGC CTGCTGCTGAGCCGGGCACCCCCGGACGCCCCCCGGCCTGATGGCCAGGCCTCAGGGACCAAGGAGATGGGGAGGGCGCTTTTGTACGTT >5225_5225_9_AP2A2-DRD4_AP2A2_chr11_977224_ENST00000534328_DRD4_chr11_639433_ENST00000176183_length(amino acids)=525AA_BP=368 MPAVSKGDGMRGLAVFISDIRNCKSKEAEIKRINKELANIRSKFKGDKALDGYSKKKYVCKLLFIFLLGHDIDFGHMEAVNLLSSNRYTE KQIGYLFISVLVNSNSELIRLINNAIKNDLASRNPTFMGLALHCIASVGSREMAEAFAGEIPKVLVAGDTMDSVKQSAALCLLRLYRTSP DLVPMGDWTSRVVHLLNDQHLVQGGAWLLSPRLCDALMAMDVMLCTASIFNLCAISVDRFVAVAVPLRYNRQGGSRRQLLLIGATWLLSA AVAAPVLCGLNDVRGRDPAVCRLEDRDYVVYSSVCSFFLPCPLMLLLYWATFRGLQRWEVARRAKLHGRAPRRPSGPGPPSPTPPAPRLP QDPCGPDCAPPAPGLPRGPCGPDCAPAAPSLPQDPCGPDCAPPAPGLPPDPCGSNCAPPDAVRAAALPPQTPPQTRRRRRAKITGRERKA -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for AP2A2-DRD4 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for AP2A2-DRD4 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for AP2A2-DRD4 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies