
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:AP3S2-CERS3 (FusionGDB2 ID:5301) |
Fusion Gene Summary for AP3S2-CERS3 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: AP3S2-CERS3 | Fusion gene ID: 5301 | Hgene | Tgene | Gene symbol | AP3S2 | CERS3 | Gene ID | 10239 | 204219 |
| Gene name | adaptor related protein complex 3 subunit sigma 2 | ceramide synthase 3 | |
| Synonyms | AP3S3|sigma3b | ARCI9|LASS3 | |
| Cytomap | 15q26.1 | 15q26.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | AP-3 complex subunit sigma-2AP-3 complex subunit sigma-3Badapter-related protein complex 3 subunit sigma-2adaptor complex sigma3Badaptor related protein complex 3 sigma 2 subunitclathrin-associated/assembly/adaptor protein, small 4, 22-kDsigma-3B-ad | ceramide synthase 3LAG1 homolog, ceramide synthase 3LAG1 longevity assurance homolog 3dihydroceramide synthase 3sphingosine N-acyltransferase CERS3 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | Q8IU89 | |
| Ensembl transtripts involved in fusion gene | ENST00000336418, ENST00000558011, ENST00000560940, ENST00000560771, | ENST00000560944, ENST00000284382, ENST00000394113, ENST00000538112, | |
| Fusion gene scores | * DoF score | 3 X 1 X 2=6 | 8 X 7 X 7=392 |
| # samples | 3 | 11 | |
| ** MAII score | log2(3/6*10)=2.32192809488736 | log2(11/392*10)=-1.83335013059055 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: AP3S2 [Title/Abstract] AND CERS3 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | AP3S2(90414707)-CERS3(101024873), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | CERS3 | GO:0046513 | ceramide biosynthetic process | 17977534|22038835 |
| Fusion gene breakpoints across AP3S2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across CERS3 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
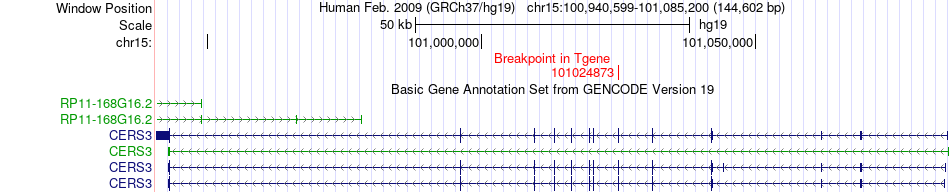 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-C8-A1HI-01A | AP3S2 | chr15 | 90414707 | - | CERS3 | chr15 | 101024873 | - |
Top |
Fusion Gene ORF analysis for AP3S2-CERS3 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000336418 | ENST00000560944 | AP3S2 | chr15 | 90414707 | - | CERS3 | chr15 | 101024873 | - |
| 5CDS-intron | ENST00000558011 | ENST00000560944 | AP3S2 | chr15 | 90414707 | - | CERS3 | chr15 | 101024873 | - |
| 5CDS-intron | ENST00000560940 | ENST00000560944 | AP3S2 | chr15 | 90414707 | - | CERS3 | chr15 | 101024873 | - |
| In-frame | ENST00000336418 | ENST00000284382 | AP3S2 | chr15 | 90414707 | - | CERS3 | chr15 | 101024873 | - |
| In-frame | ENST00000336418 | ENST00000394113 | AP3S2 | chr15 | 90414707 | - | CERS3 | chr15 | 101024873 | - |
| In-frame | ENST00000336418 | ENST00000538112 | AP3S2 | chr15 | 90414707 | - | CERS3 | chr15 | 101024873 | - |
| In-frame | ENST00000558011 | ENST00000284382 | AP3S2 | chr15 | 90414707 | - | CERS3 | chr15 | 101024873 | - |
| In-frame | ENST00000558011 | ENST00000394113 | AP3S2 | chr15 | 90414707 | - | CERS3 | chr15 | 101024873 | - |
| In-frame | ENST00000558011 | ENST00000538112 | AP3S2 | chr15 | 90414707 | - | CERS3 | chr15 | 101024873 | - |
| In-frame | ENST00000560940 | ENST00000284382 | AP3S2 | chr15 | 90414707 | - | CERS3 | chr15 | 101024873 | - |
| In-frame | ENST00000560940 | ENST00000394113 | AP3S2 | chr15 | 90414707 | - | CERS3 | chr15 | 101024873 | - |
| In-frame | ENST00000560940 | ENST00000538112 | AP3S2 | chr15 | 90414707 | - | CERS3 | chr15 | 101024873 | - |
| intron-3CDS | ENST00000560771 | ENST00000284382 | AP3S2 | chr15 | 90414707 | - | CERS3 | chr15 | 101024873 | - |
| intron-3CDS | ENST00000560771 | ENST00000394113 | AP3S2 | chr15 | 90414707 | - | CERS3 | chr15 | 101024873 | - |
| intron-3CDS | ENST00000560771 | ENST00000538112 | AP3S2 | chr15 | 90414707 | - | CERS3 | chr15 | 101024873 | - |
| intron-intron | ENST00000560771 | ENST00000560944 | AP3S2 | chr15 | 90414707 | - | CERS3 | chr15 | 101024873 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000336418 | AP3S2 | chr15 | 90414707 | - | ENST00000284382 | CERS3 | chr15 | 101024873 | - | 3920 | 738 | 369 | 1601 | 410 |
| ENST00000336418 | AP3S2 | chr15 | 90414707 | - | ENST00000538112 | CERS3 | chr15 | 101024873 | - | 1804 | 738 | 369 | 1601 | 410 |
| ENST00000336418 | AP3S2 | chr15 | 90414707 | - | ENST00000394113 | CERS3 | chr15 | 101024873 | - | 1804 | 738 | 369 | 1601 | 410 |
| ENST00000558011 | AP3S2 | chr15 | 90414707 | - | ENST00000284382 | CERS3 | chr15 | 101024873 | - | 3608 | 426 | 21 | 1289 | 422 |
| ENST00000558011 | AP3S2 | chr15 | 90414707 | - | ENST00000538112 | CERS3 | chr15 | 101024873 | - | 1492 | 426 | 21 | 1289 | 422 |
| ENST00000558011 | AP3S2 | chr15 | 90414707 | - | ENST00000394113 | CERS3 | chr15 | 101024873 | - | 1492 | 426 | 21 | 1289 | 422 |
| ENST00000560940 | AP3S2 | chr15 | 90414707 | - | ENST00000284382 | CERS3 | chr15 | 101024873 | - | 3559 | 377 | 8 | 1240 | 410 |
| ENST00000560940 | AP3S2 | chr15 | 90414707 | - | ENST00000538112 | CERS3 | chr15 | 101024873 | - | 1443 | 377 | 8 | 1240 | 410 |
| ENST00000560940 | AP3S2 | chr15 | 90414707 | - | ENST00000394113 | CERS3 | chr15 | 101024873 | - | 1443 | 377 | 8 | 1240 | 410 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000336418 | ENST00000284382 | AP3S2 | chr15 | 90414707 | - | CERS3 | chr15 | 101024873 | - | 0.002685812 | 0.99731416 |
| ENST00000336418 | ENST00000538112 | AP3S2 | chr15 | 90414707 | - | CERS3 | chr15 | 101024873 | - | 0.004644795 | 0.99535525 |
| ENST00000336418 | ENST00000394113 | AP3S2 | chr15 | 90414707 | - | CERS3 | chr15 | 101024873 | - | 0.004644795 | 0.99535525 |
| ENST00000558011 | ENST00000284382 | AP3S2 | chr15 | 90414707 | - | CERS3 | chr15 | 101024873 | - | 0.001874565 | 0.9981254 |
| ENST00000558011 | ENST00000538112 | AP3S2 | chr15 | 90414707 | - | CERS3 | chr15 | 101024873 | - | 0.002265393 | 0.99773455 |
| ENST00000558011 | ENST00000394113 | AP3S2 | chr15 | 90414707 | - | CERS3 | chr15 | 101024873 | - | 0.002265393 | 0.99773455 |
| ENST00000560940 | ENST00000284382 | AP3S2 | chr15 | 90414707 | - | CERS3 | chr15 | 101024873 | - | 0.001690084 | 0.99830997 |
| ENST00000560940 | ENST00000538112 | AP3S2 | chr15 | 90414707 | - | CERS3 | chr15 | 101024873 | - | 0.002034783 | 0.9979652 |
| ENST00000560940 | ENST00000394113 | AP3S2 | chr15 | 90414707 | - | CERS3 | chr15 | 101024873 | - | 0.002034783 | 0.9979652 |
Top |
Fusion Genomic Features for AP3S2-CERS3 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
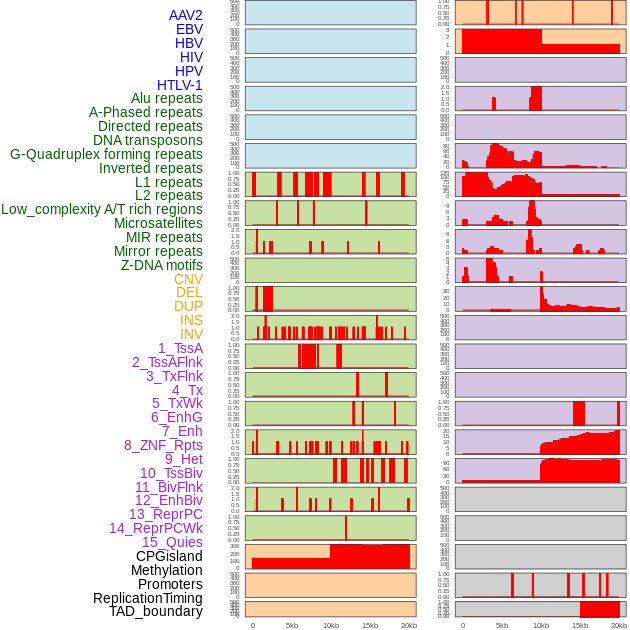 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for AP3S2-CERS3 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr15:90414707/chr15:101024873) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | CERS3 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Ceramide synthase that catalyzes formation of ceramide from sphinganine and acyl-CoA substrates, with high selectivity toward very-long (C22:0-C24:0) and ultra long chain (more than C26:0) as acyl donor (PubMed:17977534, PubMed:22038835, PubMed:26887952). It is crucial for the synthesis of ultra long-chain ceramides in the epidermis, to maintain epidermal lipid homeostasis and terminal differentiation (PubMed:23754960). {ECO:0000269|PubMed:17977534, ECO:0000269|PubMed:22038835, ECO:0000269|PubMed:23754960, ECO:0000269|PubMed:26887952}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | CERS3 | chr15:90414707 | chr15:101024873 | ENST00000284382 | 4 | 13 | 346_355 | 96 | 384.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | CERS3 | chr15:90414707 | chr15:101024873 | ENST00000394113 | 5 | 14 | 346_355 | 96 | 384.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | CERS3 | chr15:90414707 | chr15:101024873 | ENST00000538112 | 4 | 13 | 346_355 | 96 | 384.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | CERS3 | chr15:90414707 | chr15:101024873 | ENST00000284382 | 4 | 13 | 130_331 | 96 | 384.0 | Domain | TLC | |
| Tgene | CERS3 | chr15:90414707 | chr15:101024873 | ENST00000394113 | 5 | 14 | 130_331 | 96 | 384.0 | Domain | TLC | |
| Tgene | CERS3 | chr15:90414707 | chr15:101024873 | ENST00000538112 | 4 | 13 | 130_331 | 96 | 384.0 | Domain | TLC | |
| Tgene | CERS3 | chr15:90414707 | chr15:101024873 | ENST00000284382 | 4 | 13 | 319_383 | 96 | 384.0 | Topological domain | Cytoplasmic | |
| Tgene | CERS3 | chr15:90414707 | chr15:101024873 | ENST00000394113 | 5 | 14 | 319_383 | 96 | 384.0 | Topological domain | Cytoplasmic | |
| Tgene | CERS3 | chr15:90414707 | chr15:101024873 | ENST00000538112 | 4 | 13 | 319_383 | 96 | 384.0 | Topological domain | Cytoplasmic | |
| Tgene | CERS3 | chr15:90414707 | chr15:101024873 | ENST00000284382 | 4 | 13 | 139_159 | 96 | 384.0 | Transmembrane | Helical | |
| Tgene | CERS3 | chr15:90414707 | chr15:101024873 | ENST00000284382 | 4 | 13 | 174_194 | 96 | 384.0 | Transmembrane | Helical | |
| Tgene | CERS3 | chr15:90414707 | chr15:101024873 | ENST00000284382 | 4 | 13 | 205_225 | 96 | 384.0 | Transmembrane | Helical | |
| Tgene | CERS3 | chr15:90414707 | chr15:101024873 | ENST00000284382 | 4 | 13 | 264_284 | 96 | 384.0 | Transmembrane | Helical | |
| Tgene | CERS3 | chr15:90414707 | chr15:101024873 | ENST00000284382 | 4 | 13 | 298_318 | 96 | 384.0 | Transmembrane | Helical | |
| Tgene | CERS3 | chr15:90414707 | chr15:101024873 | ENST00000394113 | 5 | 14 | 139_159 | 96 | 384.0 | Transmembrane | Helical | |
| Tgene | CERS3 | chr15:90414707 | chr15:101024873 | ENST00000394113 | 5 | 14 | 174_194 | 96 | 384.0 | Transmembrane | Helical | |
| Tgene | CERS3 | chr15:90414707 | chr15:101024873 | ENST00000394113 | 5 | 14 | 205_225 | 96 | 384.0 | Transmembrane | Helical | |
| Tgene | CERS3 | chr15:90414707 | chr15:101024873 | ENST00000394113 | 5 | 14 | 264_284 | 96 | 384.0 | Transmembrane | Helical | |
| Tgene | CERS3 | chr15:90414707 | chr15:101024873 | ENST00000394113 | 5 | 14 | 298_318 | 96 | 384.0 | Transmembrane | Helical | |
| Tgene | CERS3 | chr15:90414707 | chr15:101024873 | ENST00000538112 | 4 | 13 | 139_159 | 96 | 384.0 | Transmembrane | Helical | |
| Tgene | CERS3 | chr15:90414707 | chr15:101024873 | ENST00000538112 | 4 | 13 | 174_194 | 96 | 384.0 | Transmembrane | Helical | |
| Tgene | CERS3 | chr15:90414707 | chr15:101024873 | ENST00000538112 | 4 | 13 | 205_225 | 96 | 384.0 | Transmembrane | Helical | |
| Tgene | CERS3 | chr15:90414707 | chr15:101024873 | ENST00000538112 | 4 | 13 | 264_284 | 96 | 384.0 | Transmembrane | Helical | |
| Tgene | CERS3 | chr15:90414707 | chr15:101024873 | ENST00000538112 | 4 | 13 | 298_318 | 96 | 384.0 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | CERS3 | chr15:90414707 | chr15:101024873 | ENST00000284382 | 4 | 13 | 66_127 | 96 | 384.0 | Region | Homeobox-like | |
| Tgene | CERS3 | chr15:90414707 | chr15:101024873 | ENST00000394113 | 5 | 14 | 66_127 | 96 | 384.0 | Region | Homeobox-like | |
| Tgene | CERS3 | chr15:90414707 | chr15:101024873 | ENST00000538112 | 4 | 13 | 66_127 | 96 | 384.0 | Region | Homeobox-like | |
| Tgene | CERS3 | chr15:90414707 | chr15:101024873 | ENST00000284382 | 4 | 13 | 32_52 | 96 | 384.0 | Transmembrane | Helical | |
| Tgene | CERS3 | chr15:90414707 | chr15:101024873 | ENST00000394113 | 5 | 14 | 32_52 | 96 | 384.0 | Transmembrane | Helical | |
| Tgene | CERS3 | chr15:90414707 | chr15:101024873 | ENST00000538112 | 4 | 13 | 32_52 | 96 | 384.0 | Transmembrane | Helical |
Top |
Fusion Gene Sequence for AP3S2-CERS3 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >5301_5301_1_AP3S2-CERS3_AP3S2_chr15_90414707_ENST00000336418_CERS3_chr15_101024873_ENST00000284382_length(transcript)=3920nt_BP=738nt ACGTTCTGCGAGCGCTAAGGGGATGGCGGGAGTGCATGATTTGGAGCGGGCGGTGAGAAAAGCAAGCTCCCGCCGCCTCTCCGTTTTGGC AACCCGGCTGACGGTCGTTTCGGCTTCTGGGGCCAGCCGTCGGTCTGGGCGAGGGACATAGATCCGGATTCGCATCCTGACTGGCCAACC AACGCTGGCCGAGGTGACCACTCTCCTCGGCATCCGCACCTGCCCTCCAAGGCGTCAGAGAGGCCGGACCCTTGGGTGCTAGGGCTCGTG AGCGCCGGGGCCAAGTTTCCGAGTGCCGCTCTCAGCAGCGCACCAACCGGAAGTGATCGTGTTGTGGCGGAAGGAGGAGCTTTCTGGGAG TAGCCGGTGCTGAGAGAACCGTGGCTGGCAAAGATGATTCAGGCGATTCTGGTTTTCAACAACCATGGGAAGCCACGGCTAGTCCGCTTC TACCAGCGTTTCCCAGAAGAAATTCAACAGCAGATTGTTCGAGAGACTTTCCATCTAGTCCTCAAGCGGGATGACAACATCTGTAACTTC TTGGAGGGTGGAAGTTTGATTGGTGGCTCTGACTACAAACTGATCTACCGGCACTATGCTACCCTCTACTTTGTATTTTGTGTGGATTCC TCAGAGAGTGAACTTGGAATCTTGGACCTCATCCAGGTTTTTGTGGAAACTCTGGATAAGTGTTTCGAAAATGTGTGTGAATTGGATTTG ATCTTCCATATGGATAAGACTGATATTTATGGACTGGCAAAGAAGTGTAACTTGACGGAGCGCCAGGTGGAAAGATGGTTTAGGAGTCGG CGGAATCAAGAGAGGCCTTCCAGGCTGAAGAAATTCCAGGAAGCTTGCTGGAGATTTGCATTTTACTTAATGATCACTGTTGCTGGAATT GCGTTTCTTTATGATAAACCTTGGCTATATGACTTATGGGAGGTTTGGAATGGCTATCCCAAACAGCCCCTGCTGCCATCCCAGTACTGG TACTACATTTTAGAAATGAGTTTTTATTGGTCTCTGTTATTTAGACTTGGCTTTGATGTCAAGAGAAAGGATTTTCTAGCTCATATCATC CACCACCTGGCTGCTATTAGTCTGATGAGCTTCTCTTGGTGTGCTAATTATATTCGCAGTGGGACCCTCGTGATGATTGTACACGATGTG GCTGACATTTGGCTGGAGTCTGCTAAGATGTTTTCTTATGCTGGATGGACGCAGACCTGTAACACCCTGTTTTTCATCTTCTCCACCATA TTTTTCATCAGCCGCCTCATTGTTTTTCCTTTCTGGATTTTATATTGCACGCTGATCTTGCCTATGTATCACCTCGAGCCTTTCTTTTCA TACATCTTCCTCAACCTACAGCTCATGATCTTGCAGGTCCTTCACCTTTACTGGGGTTATTACATCTTGAAGATGCTCAACAGATGTATA TTCATGAAGAGCATCCAGGATGTGAGGAGTGATGACGAGGATTATGAAGAGGAAGAGGAAGAGGAAGAAGAAGAGGCTACCAAAGGCAAA GAGATGGATTGTTTAAAGAACGGCCTCAGGGCTGAGAGGCACCTCATTCCCAATGGCCAGCATGGCCATTAGCTGGAAGCCTACAGGACT CCCATGGCACAGCATGCTGCAAGTACTGTTGGCAGCCTGGCTTCCAGGCCCCACACCGACCCCACATTCTGCCCTTCCCTCTTTCTCACC ACCGCCTTCCCTCCCACCTAAGATGTGTTTACCAAAATGTTGTTAACTTGTGTTAAAATGTTAAATATAAGCATGCCCATGGATTTTTAC TGCAGTTAGGACTCAGACTGGTCAAAGATTTCAAAGATTTCTCCACAGAACCGTCTCAGTTCTAATTGCACTCCCTCATGCATGTCACTT TCTCAGGGGCTCGCTTTGTTATAGACCCTTTCGCCTCGCCACCTTGCCTGTCCTCAGGACGCTTTCACAGGTGCTAAGTGATCTCATTTT TCCCAGGTGTGTTTGGCCACAAAGAGCAGCTTCTTTCTCAAAATGAGTTAGAAGTGGCAGTGGGACAGGAGCGGAAGGACCACACCAGGA GACACTTCCATCCTGAAGCTTAGGTGCCTCATCTCCACAGGGCGGTGGCAGTCCCTGCCTGCCACCCCACAGGGTTACAGCAAGGATTAA GTGAGATCACAGAAGTTTAAGTACACACTGTCAACCGTGGGGTCATCGTGAACCAACCCACTTTGCACTGTTTGGGAGACAGAAACCTGG CTAAACATGGCACTGCAATGGGCCTGAACAAAAGGCAGAATCTTTAAAAATTCCTCTTAAATGACTCTGGAGATACCTGGAAATGAAAGT GCCAAGAAAGGTGTTCCATTTTATTTGCTAACTATTTATGCATTAGCTCCCCAAGGGTCATTCTCAGATTCTCCTGGAATTCTTCTCCCT CAGGACCCATGGTTCAAGGAAGGAAGCTTAGGCCCTGTTCCTTCCTGTCCTTTGCTGGTCTTTCCCTTTTTTCCTTTCTAGGAGGGAAGC TTCTGTGCTGCTGCCCTGAGCCCTTCCTTCAGGCCAGCACAGTACCTGGGGACCTCCACGGGGGAATGGGATCCAGGCCAGGTTGCTTGC TGAGCCTCATCACCCAGGAGGCCTGAGCCTCTGGGGAGGGCACGCATGTACACTGCCAGACCCAGGGGAGATCTTGGGAACAGAGGATGC TACGTGATTTCCTCTGGCTTCCAACCCAATCAGCCTGCATCACAGTGAAACACAACACAAAAGGCCATAAAAGGCATACCCCTGAGAAAT GTTTAAGGGCAGGTGCTAGAGTCAGTGCCAGCTCCCTGGGAGGAGGGATAGGGACGGGCAGATCAGTAGCCAGCTTGTCCTCACCCTCCG GAAGGGAGCACCGGAGAAGACTTGCACACGTCCCTGCCTCCCTTGCGGCCTTGTCACCAGAGGGACACATCTCCTGGGCACAATGTGCAG GGCTGACCTGGGAGACTTCTCAGGTGGCTGCTGGCTGAGGAGAGGCCAGGCCTTCCCAAGGAAGACCCTGAGTAAAATCTGCATCTGTCC TCACCACCTGGCACAGTCTCTCATAACGGTCAGATTTTGTATGTTCATCCTATTTATTCAGGGGCTCGTACTAGAAAGCCACAGGAGAGG TCGGCTTGTAGGGACTGGAAAATCAGCCCCAAGCAGAGCAGCTGCAGGGCCCCTGGAGCCGGAAGGACACTGCACAGAACAGACTGCGTT ATTGTTATTTTTAAATAAAAATATACATTTGAAACCTTAAGGCTAAACAAAAATAAACAAAAAATCCTTTAGAATTCTTTCCACAACAAT ATCTCTTTCTGAGAAATTGTTACAAACAAGGTCAGATTTTCTCTGTATAACATTTGCTTTTATGAGGACAATATCATATGCATTATATGC ATAATATGATATTATAAATCAAAATGCCTGCACCCACTTTAGGGTATAGCTATTGACTTATTATTAATATTATATTATTATTATTTTGCT GGAAGAAGGTCACACTAAGATATAATTTTTTATGTTTTCAGTTAACGGTATGCTTTCTTCTTTGCTTATTTGGTTTTTGTCTCTGTACCA AATATCTTCTTGCTTAAGGTAGAAAAGTATTTGTTTACCTCTATCTCCAGTTTTTTTTCTTATTTGAATGTTGAAGGTAAAATTGATATA CCAATTTTAACTATTTCTGATACAGCTGAAAGCACTAAACTACTTCATAAGAAGTAGATACTCATTTTTGTAACACTATTTAGGGCTTTT GTGGTTAATTTTAAAGGAAACCACTCTTTCTACAGGAAACAAGGGCTCAGGATTCTTCAGATGACCTTATAAAAATGCAGTCCACAGTGC >5301_5301_1_AP3S2-CERS3_AP3S2_chr15_90414707_ENST00000336418_CERS3_chr15_101024873_ENST00000284382_length(amino acids)=410AA_BP=123 MREPWLAKMIQAILVFNNHGKPRLVRFYQRFPEEIQQQIVRETFHLVLKRDDNICNFLEGGSLIGGSDYKLIYRHYATLYFVFCVDSSES ELGILDLIQVFVETLDKCFENVCELDLIFHMDKTDIYGLAKKCNLTERQVERWFRSRRNQERPSRLKKFQEACWRFAFYLMITVAGIAFL YDKPWLYDLWEVWNGYPKQPLLPSQYWYYILEMSFYWSLLFRLGFDVKRKDFLAHIIHHLAAISLMSFSWCANYIRSGTLVMIVHDVADI WLESAKMFSYAGWTQTCNTLFFIFSTIFFISRLIVFPFWILYCTLILPMYHLEPFFSYIFLNLQLMILQVLHLYWGYYILKMLNRCIFMK -------------------------------------------------------------- >5301_5301_2_AP3S2-CERS3_AP3S2_chr15_90414707_ENST00000336418_CERS3_chr15_101024873_ENST00000394113_length(transcript)=1804nt_BP=738nt ACGTTCTGCGAGCGCTAAGGGGATGGCGGGAGTGCATGATTTGGAGCGGGCGGTGAGAAAAGCAAGCTCCCGCCGCCTCTCCGTTTTGGC AACCCGGCTGACGGTCGTTTCGGCTTCTGGGGCCAGCCGTCGGTCTGGGCGAGGGACATAGATCCGGATTCGCATCCTGACTGGCCAACC AACGCTGGCCGAGGTGACCACTCTCCTCGGCATCCGCACCTGCCCTCCAAGGCGTCAGAGAGGCCGGACCCTTGGGTGCTAGGGCTCGTG AGCGCCGGGGCCAAGTTTCCGAGTGCCGCTCTCAGCAGCGCACCAACCGGAAGTGATCGTGTTGTGGCGGAAGGAGGAGCTTTCTGGGAG TAGCCGGTGCTGAGAGAACCGTGGCTGGCAAAGATGATTCAGGCGATTCTGGTTTTCAACAACCATGGGAAGCCACGGCTAGTCCGCTTC TACCAGCGTTTCCCAGAAGAAATTCAACAGCAGATTGTTCGAGAGACTTTCCATCTAGTCCTCAAGCGGGATGACAACATCTGTAACTTC TTGGAGGGTGGAAGTTTGATTGGTGGCTCTGACTACAAACTGATCTACCGGCACTATGCTACCCTCTACTTTGTATTTTGTGTGGATTCC TCAGAGAGTGAACTTGGAATCTTGGACCTCATCCAGGTTTTTGTGGAAACTCTGGATAAGTGTTTCGAAAATGTGTGTGAATTGGATTTG ATCTTCCATATGGATAAGACTGATATTTATGGACTGGCAAAGAAGTGTAACTTGACGGAGCGCCAGGTGGAAAGATGGTTTAGGAGTCGG CGGAATCAAGAGAGGCCTTCCAGGCTGAAGAAATTCCAGGAAGCTTGCTGGAGATTTGCATTTTACTTAATGATCACTGTTGCTGGAATT GCGTTTCTTTATGATAAACCTTGGCTATATGACTTATGGGAGGTTTGGAATGGCTATCCCAAACAGCCCCTGCTGCCATCCCAGTACTGG TACTACATTTTAGAAATGAGTTTTTATTGGTCTCTGTTATTTAGACTTGGCTTTGATGTCAAGAGAAAGGATTTTCTAGCTCATATCATC CACCACCTGGCTGCTATTAGTCTGATGAGCTTCTCTTGGTGTGCTAATTATATTCGCAGTGGGACCCTCGTGATGATTGTACACGATGTG GCTGACATTTGGCTGGAGTCTGCTAAGATGTTTTCTTATGCTGGATGGACGCAGACCTGTAACACCCTGTTTTTCATCTTCTCCACCATA TTTTTCATCAGCCGCCTCATTGTTTTTCCTTTCTGGATTTTATATTGCACGCTGATCTTGCCTATGTATCACCTCGAGCCTTTCTTTTCA TACATCTTCCTCAACCTACAGCTCATGATCTTGCAGGTCCTTCACCTTTACTGGGGTTATTACATCTTGAAGATGCTCAACAGATGTATA TTCATGAAGAGCATCCAGGATGTGAGGAGTGATGACGAGGATTATGAAGAGGAAGAGGAAGAGGAAGAAGAAGAGGCTACCAAAGGCAAA GAGATGGATTGTTTAAAGAACGGCCTCAGGGCTGAGAGGCACCTCATTCCCAATGGCCAGCATGGCCATTAGCTGGAAGCCTACAGGACT CCCATGGCACAGCATGCTGCAAGTACTGTTGGCAGCCTGGCTTCCAGGCCCCACACCGACCCCACATTCTGCCCTTCCCTCTTTCTCACC ACCGCCTTCCCTCCCACCTAAGATGTGTTTACCAAAATGTTGTTAACTTGTGTTAAAATGTTAAATATAAGCATGCCCATGGATTTTTAC >5301_5301_2_AP3S2-CERS3_AP3S2_chr15_90414707_ENST00000336418_CERS3_chr15_101024873_ENST00000394113_length(amino acids)=410AA_BP=123 MREPWLAKMIQAILVFNNHGKPRLVRFYQRFPEEIQQQIVRETFHLVLKRDDNICNFLEGGSLIGGSDYKLIYRHYATLYFVFCVDSSES ELGILDLIQVFVETLDKCFENVCELDLIFHMDKTDIYGLAKKCNLTERQVERWFRSRRNQERPSRLKKFQEACWRFAFYLMITVAGIAFL YDKPWLYDLWEVWNGYPKQPLLPSQYWYYILEMSFYWSLLFRLGFDVKRKDFLAHIIHHLAAISLMSFSWCANYIRSGTLVMIVHDVADI WLESAKMFSYAGWTQTCNTLFFIFSTIFFISRLIVFPFWILYCTLILPMYHLEPFFSYIFLNLQLMILQVLHLYWGYYILKMLNRCIFMK -------------------------------------------------------------- >5301_5301_3_AP3S2-CERS3_AP3S2_chr15_90414707_ENST00000336418_CERS3_chr15_101024873_ENST00000538112_length(transcript)=1804nt_BP=738nt ACGTTCTGCGAGCGCTAAGGGGATGGCGGGAGTGCATGATTTGGAGCGGGCGGTGAGAAAAGCAAGCTCCCGCCGCCTCTCCGTTTTGGC AACCCGGCTGACGGTCGTTTCGGCTTCTGGGGCCAGCCGTCGGTCTGGGCGAGGGACATAGATCCGGATTCGCATCCTGACTGGCCAACC AACGCTGGCCGAGGTGACCACTCTCCTCGGCATCCGCACCTGCCCTCCAAGGCGTCAGAGAGGCCGGACCCTTGGGTGCTAGGGCTCGTG AGCGCCGGGGCCAAGTTTCCGAGTGCCGCTCTCAGCAGCGCACCAACCGGAAGTGATCGTGTTGTGGCGGAAGGAGGAGCTTTCTGGGAG TAGCCGGTGCTGAGAGAACCGTGGCTGGCAAAGATGATTCAGGCGATTCTGGTTTTCAACAACCATGGGAAGCCACGGCTAGTCCGCTTC TACCAGCGTTTCCCAGAAGAAATTCAACAGCAGATTGTTCGAGAGACTTTCCATCTAGTCCTCAAGCGGGATGACAACATCTGTAACTTC TTGGAGGGTGGAAGTTTGATTGGTGGCTCTGACTACAAACTGATCTACCGGCACTATGCTACCCTCTACTTTGTATTTTGTGTGGATTCC TCAGAGAGTGAACTTGGAATCTTGGACCTCATCCAGGTTTTTGTGGAAACTCTGGATAAGTGTTTCGAAAATGTGTGTGAATTGGATTTG ATCTTCCATATGGATAAGACTGATATTTATGGACTGGCAAAGAAGTGTAACTTGACGGAGCGCCAGGTGGAAAGATGGTTTAGGAGTCGG CGGAATCAAGAGAGGCCTTCCAGGCTGAAGAAATTCCAGGAAGCTTGCTGGAGATTTGCATTTTACTTAATGATCACTGTTGCTGGAATT GCGTTTCTTTATGATAAACCTTGGCTATATGACTTATGGGAGGTTTGGAATGGCTATCCCAAACAGCCCCTGCTGCCATCCCAGTACTGG TACTACATTTTAGAAATGAGTTTTTATTGGTCTCTGTTATTTAGACTTGGCTTTGATGTCAAGAGAAAGGATTTTCTAGCTCATATCATC CACCACCTGGCTGCTATTAGTCTGATGAGCTTCTCTTGGTGTGCTAATTATATTCGCAGTGGGACCCTCGTGATGATTGTACACGATGTG GCTGACATTTGGCTGGAGTCTGCTAAGATGTTTTCTTATGCTGGATGGACGCAGACCTGTAACACCCTGTTTTTCATCTTCTCCACCATA TTTTTCATCAGCCGCCTCATTGTTTTTCCTTTCTGGATTTTATATTGCACGCTGATCTTGCCTATGTATCACCTCGAGCCTTTCTTTTCA TACATCTTCCTCAACCTACAGCTCATGATCTTGCAGGTCCTTCACCTTTACTGGGGTTATTACATCTTGAAGATGCTCAACAGATGTATA TTCATGAAGAGCATCCAGGATGTGAGGAGTGATGACGAGGATTATGAAGAGGAAGAGGAAGAGGAAGAAGAAGAGGCTACCAAAGGCAAA GAGATGGATTGTTTAAAGAACGGCCTCAGGGCTGAGAGGCACCTCATTCCCAATGGCCAGCATGGCCATTAGCTGGAAGCCTACAGGACT CCCATGGCACAGCATGCTGCAAGTACTGTTGGCAGCCTGGCTTCCAGGCCCCACACCGACCCCACATTCTGCCCTTCCCTCTTTCTCACC ACCGCCTTCCCTCCCACCTAAGATGTGTTTACCAAAATGTTGTTAACTTGTGTTAAAATGTTAAATATAAGCATGCCCATGGATTTTTAC >5301_5301_3_AP3S2-CERS3_AP3S2_chr15_90414707_ENST00000336418_CERS3_chr15_101024873_ENST00000538112_length(amino acids)=410AA_BP=123 MREPWLAKMIQAILVFNNHGKPRLVRFYQRFPEEIQQQIVRETFHLVLKRDDNICNFLEGGSLIGGSDYKLIYRHYATLYFVFCVDSSES ELGILDLIQVFVETLDKCFENVCELDLIFHMDKTDIYGLAKKCNLTERQVERWFRSRRNQERPSRLKKFQEACWRFAFYLMITVAGIAFL YDKPWLYDLWEVWNGYPKQPLLPSQYWYYILEMSFYWSLLFRLGFDVKRKDFLAHIIHHLAAISLMSFSWCANYIRSGTLVMIVHDVADI WLESAKMFSYAGWTQTCNTLFFIFSTIFFISRLIVFPFWILYCTLILPMYHLEPFFSYIFLNLQLMILQVLHLYWGYYILKMLNRCIFMK -------------------------------------------------------------- >5301_5301_4_AP3S2-CERS3_AP3S2_chr15_90414707_ENST00000558011_CERS3_chr15_101024873_ENST00000284382_length(transcript)=3608nt_BP=426nt GCTTTCTGGGAGTAGCCGGTGCTGAGAGAACCGTGGCTGGCAAAGATGATTCAGGCGATTCTGGTTTTCAACAACCATGGGAAGCCACGG CTAGTCCGCTTCTACCAGCGTTTCCCAGAAGAAATTCAACAGCAGATTGTTCGAGAGACTTTCCATCTAGTCCTCAAGCGGGATGACAAC ATCTGTAACTTCTTGGAGGGTGGAAGTTTGATTGGTGGCTCTGACTACAAACTGATCTACCGGCACTATGCTACCCTCTACTTTGTATTT TGTGTGGATTCCTCAGAGAGTGAACTTGGAATCTTGGACCTCATCCAGGTACATCTGGAAGTTGTTTTCTTCATAGCTCCCAAGGTTTTT GTGGAAACTCTGGATAAGTGTTTCGAAAATGTGTGTGAATTGGATTTGATCTTCCATATGGATAAGACTGATATTTATGGACTGGCAAAG AAGTGTAACTTGACGGAGCGCCAGGTGGAAAGATGGTTTAGGAGTCGGCGGAATCAAGAGAGGCCTTCCAGGCTGAAGAAATTCCAGGAA GCTTGCTGGAGATTTGCATTTTACTTAATGATCACTGTTGCTGGAATTGCGTTTCTTTATGATAAACCTTGGCTATATGACTTATGGGAG GTTTGGAATGGCTATCCCAAACAGCCCCTGCTGCCATCCCAGTACTGGTACTACATTTTAGAAATGAGTTTTTATTGGTCTCTGTTATTT AGACTTGGCTTTGATGTCAAGAGAAAGGATTTTCTAGCTCATATCATCCACCACCTGGCTGCTATTAGTCTGATGAGCTTCTCTTGGTGT GCTAATTATATTCGCAGTGGGACCCTCGTGATGATTGTACACGATGTGGCTGACATTTGGCTGGAGTCTGCTAAGATGTTTTCTTATGCT GGATGGACGCAGACCTGTAACACCCTGTTTTTCATCTTCTCCACCATATTTTTCATCAGCCGCCTCATTGTTTTTCCTTTCTGGATTTTA TATTGCACGCTGATCTTGCCTATGTATCACCTCGAGCCTTTCTTTTCATACATCTTCCTCAACCTACAGCTCATGATCTTGCAGGTCCTT CACCTTTACTGGGGTTATTACATCTTGAAGATGCTCAACAGATGTATATTCATGAAGAGCATCCAGGATGTGAGGAGTGATGACGAGGAT TATGAAGAGGAAGAGGAAGAGGAAGAAGAAGAGGCTACCAAAGGCAAAGAGATGGATTGTTTAAAGAACGGCCTCAGGGCTGAGAGGCAC CTCATTCCCAATGGCCAGCATGGCCATTAGCTGGAAGCCTACAGGACTCCCATGGCACAGCATGCTGCAAGTACTGTTGGCAGCCTGGCT TCCAGGCCCCACACCGACCCCACATTCTGCCCTTCCCTCTTTCTCACCACCGCCTTCCCTCCCACCTAAGATGTGTTTACCAAAATGTTG TTAACTTGTGTTAAAATGTTAAATATAAGCATGCCCATGGATTTTTACTGCAGTTAGGACTCAGACTGGTCAAAGATTTCAAAGATTTCT CCACAGAACCGTCTCAGTTCTAATTGCACTCCCTCATGCATGTCACTTTCTCAGGGGCTCGCTTTGTTATAGACCCTTTCGCCTCGCCAC CTTGCCTGTCCTCAGGACGCTTTCACAGGTGCTAAGTGATCTCATTTTTCCCAGGTGTGTTTGGCCACAAAGAGCAGCTTCTTTCTCAAA ATGAGTTAGAAGTGGCAGTGGGACAGGAGCGGAAGGACCACACCAGGAGACACTTCCATCCTGAAGCTTAGGTGCCTCATCTCCACAGGG CGGTGGCAGTCCCTGCCTGCCACCCCACAGGGTTACAGCAAGGATTAAGTGAGATCACAGAAGTTTAAGTACACACTGTCAACCGTGGGG TCATCGTGAACCAACCCACTTTGCACTGTTTGGGAGACAGAAACCTGGCTAAACATGGCACTGCAATGGGCCTGAACAAAAGGCAGAATC TTTAAAAATTCCTCTTAAATGACTCTGGAGATACCTGGAAATGAAAGTGCCAAGAAAGGTGTTCCATTTTATTTGCTAACTATTTATGCA TTAGCTCCCCAAGGGTCATTCTCAGATTCTCCTGGAATTCTTCTCCCTCAGGACCCATGGTTCAAGGAAGGAAGCTTAGGCCCTGTTCCT TCCTGTCCTTTGCTGGTCTTTCCCTTTTTTCCTTTCTAGGAGGGAAGCTTCTGTGCTGCTGCCCTGAGCCCTTCCTTCAGGCCAGCACAG TACCTGGGGACCTCCACGGGGGAATGGGATCCAGGCCAGGTTGCTTGCTGAGCCTCATCACCCAGGAGGCCTGAGCCTCTGGGGAGGGCA CGCATGTACACTGCCAGACCCAGGGGAGATCTTGGGAACAGAGGATGCTACGTGATTTCCTCTGGCTTCCAACCCAATCAGCCTGCATCA CAGTGAAACACAACACAAAAGGCCATAAAAGGCATACCCCTGAGAAATGTTTAAGGGCAGGTGCTAGAGTCAGTGCCAGCTCCCTGGGAG GAGGGATAGGGACGGGCAGATCAGTAGCCAGCTTGTCCTCACCCTCCGGAAGGGAGCACCGGAGAAGACTTGCACACGTCCCTGCCTCCC TTGCGGCCTTGTCACCAGAGGGACACATCTCCTGGGCACAATGTGCAGGGCTGACCTGGGAGACTTCTCAGGTGGCTGCTGGCTGAGGAG AGGCCAGGCCTTCCCAAGGAAGACCCTGAGTAAAATCTGCATCTGTCCTCACCACCTGGCACAGTCTCTCATAACGGTCAGATTTTGTAT GTTCATCCTATTTATTCAGGGGCTCGTACTAGAAAGCCACAGGAGAGGTCGGCTTGTAGGGACTGGAAAATCAGCCCCAAGCAGAGCAGC TGCAGGGCCCCTGGAGCCGGAAGGACACTGCACAGAACAGACTGCGTTATTGTTATTTTTAAATAAAAATATACATTTGAAACCTTAAGG CTAAACAAAAATAAACAAAAAATCCTTTAGAATTCTTTCCACAACAATATCTCTTTCTGAGAAATTGTTACAAACAAGGTCAGATTTTCT CTGTATAACATTTGCTTTTATGAGGACAATATCATATGCATTATATGCATAATATGATATTATAAATCAAAATGCCTGCACCCACTTTAG GGTATAGCTATTGACTTATTATTAATATTATATTATTATTATTTTGCTGGAAGAAGGTCACACTAAGATATAATTTTTTATGTTTTCAGT TAACGGTATGCTTTCTTCTTTGCTTATTTGGTTTTTGTCTCTGTACCAAATATCTTCTTGCTTAAGGTAGAAAAGTATTTGTTTACCTCT ATCTCCAGTTTTTTTTCTTATTTGAATGTTGAAGGTAAAATTGATATACCAATTTTAACTATTTCTGATACAGCTGAAAGCACTAAACTA CTTCATAAGAAGTAGATACTCATTTTTGTAACACTATTTAGGGCTTTTGTGGTTAATTTTAAAGGAAACCACTCTTTCTACAGGAAACAA GGGCTCAGGATTCTTCAGATGACCTTATAAAAATGCAGTCCACAGTGCTATCAATATTGTAACAGTAATGACTACAATAAAGCCAAAAGT >5301_5301_4_AP3S2-CERS3_AP3S2_chr15_90414707_ENST00000558011_CERS3_chr15_101024873_ENST00000284382_length(amino acids)=422AA_BP=135 MREPWLAKMIQAILVFNNHGKPRLVRFYQRFPEEIQQQIVRETFHLVLKRDDNICNFLEGGSLIGGSDYKLIYRHYATLYFVFCVDSSES ELGILDLIQVHLEVVFFIAPKVFVETLDKCFENVCELDLIFHMDKTDIYGLAKKCNLTERQVERWFRSRRNQERPSRLKKFQEACWRFAF YLMITVAGIAFLYDKPWLYDLWEVWNGYPKQPLLPSQYWYYILEMSFYWSLLFRLGFDVKRKDFLAHIIHHLAAISLMSFSWCANYIRSG TLVMIVHDVADIWLESAKMFSYAGWTQTCNTLFFIFSTIFFISRLIVFPFWILYCTLILPMYHLEPFFSYIFLNLQLMILQVLHLYWGYY -------------------------------------------------------------- >5301_5301_5_AP3S2-CERS3_AP3S2_chr15_90414707_ENST00000558011_CERS3_chr15_101024873_ENST00000394113_length(transcript)=1492nt_BP=426nt GCTTTCTGGGAGTAGCCGGTGCTGAGAGAACCGTGGCTGGCAAAGATGATTCAGGCGATTCTGGTTTTCAACAACCATGGGAAGCCACGG CTAGTCCGCTTCTACCAGCGTTTCCCAGAAGAAATTCAACAGCAGATTGTTCGAGAGACTTTCCATCTAGTCCTCAAGCGGGATGACAAC ATCTGTAACTTCTTGGAGGGTGGAAGTTTGATTGGTGGCTCTGACTACAAACTGATCTACCGGCACTATGCTACCCTCTACTTTGTATTT TGTGTGGATTCCTCAGAGAGTGAACTTGGAATCTTGGACCTCATCCAGGTACATCTGGAAGTTGTTTTCTTCATAGCTCCCAAGGTTTTT GTGGAAACTCTGGATAAGTGTTTCGAAAATGTGTGTGAATTGGATTTGATCTTCCATATGGATAAGACTGATATTTATGGACTGGCAAAG AAGTGTAACTTGACGGAGCGCCAGGTGGAAAGATGGTTTAGGAGTCGGCGGAATCAAGAGAGGCCTTCCAGGCTGAAGAAATTCCAGGAA GCTTGCTGGAGATTTGCATTTTACTTAATGATCACTGTTGCTGGAATTGCGTTTCTTTATGATAAACCTTGGCTATATGACTTATGGGAG GTTTGGAATGGCTATCCCAAACAGCCCCTGCTGCCATCCCAGTACTGGTACTACATTTTAGAAATGAGTTTTTATTGGTCTCTGTTATTT AGACTTGGCTTTGATGTCAAGAGAAAGGATTTTCTAGCTCATATCATCCACCACCTGGCTGCTATTAGTCTGATGAGCTTCTCTTGGTGT GCTAATTATATTCGCAGTGGGACCCTCGTGATGATTGTACACGATGTGGCTGACATTTGGCTGGAGTCTGCTAAGATGTTTTCTTATGCT GGATGGACGCAGACCTGTAACACCCTGTTTTTCATCTTCTCCACCATATTTTTCATCAGCCGCCTCATTGTTTTTCCTTTCTGGATTTTA TATTGCACGCTGATCTTGCCTATGTATCACCTCGAGCCTTTCTTTTCATACATCTTCCTCAACCTACAGCTCATGATCTTGCAGGTCCTT CACCTTTACTGGGGTTATTACATCTTGAAGATGCTCAACAGATGTATATTCATGAAGAGCATCCAGGATGTGAGGAGTGATGACGAGGAT TATGAAGAGGAAGAGGAAGAGGAAGAAGAAGAGGCTACCAAAGGCAAAGAGATGGATTGTTTAAAGAACGGCCTCAGGGCTGAGAGGCAC CTCATTCCCAATGGCCAGCATGGCCATTAGCTGGAAGCCTACAGGACTCCCATGGCACAGCATGCTGCAAGTACTGTTGGCAGCCTGGCT TCCAGGCCCCACACCGACCCCACATTCTGCCCTTCCCTCTTTCTCACCACCGCCTTCCCTCCCACCTAAGATGTGTTTACCAAAATGTTG >5301_5301_5_AP3S2-CERS3_AP3S2_chr15_90414707_ENST00000558011_CERS3_chr15_101024873_ENST00000394113_length(amino acids)=422AA_BP=135 MREPWLAKMIQAILVFNNHGKPRLVRFYQRFPEEIQQQIVRETFHLVLKRDDNICNFLEGGSLIGGSDYKLIYRHYATLYFVFCVDSSES ELGILDLIQVHLEVVFFIAPKVFVETLDKCFENVCELDLIFHMDKTDIYGLAKKCNLTERQVERWFRSRRNQERPSRLKKFQEACWRFAF YLMITVAGIAFLYDKPWLYDLWEVWNGYPKQPLLPSQYWYYILEMSFYWSLLFRLGFDVKRKDFLAHIIHHLAAISLMSFSWCANYIRSG TLVMIVHDVADIWLESAKMFSYAGWTQTCNTLFFIFSTIFFISRLIVFPFWILYCTLILPMYHLEPFFSYIFLNLQLMILQVLHLYWGYY -------------------------------------------------------------- >5301_5301_6_AP3S2-CERS3_AP3S2_chr15_90414707_ENST00000558011_CERS3_chr15_101024873_ENST00000538112_length(transcript)=1492nt_BP=426nt GCTTTCTGGGAGTAGCCGGTGCTGAGAGAACCGTGGCTGGCAAAGATGATTCAGGCGATTCTGGTTTTCAACAACCATGGGAAGCCACGG CTAGTCCGCTTCTACCAGCGTTTCCCAGAAGAAATTCAACAGCAGATTGTTCGAGAGACTTTCCATCTAGTCCTCAAGCGGGATGACAAC ATCTGTAACTTCTTGGAGGGTGGAAGTTTGATTGGTGGCTCTGACTACAAACTGATCTACCGGCACTATGCTACCCTCTACTTTGTATTT TGTGTGGATTCCTCAGAGAGTGAACTTGGAATCTTGGACCTCATCCAGGTACATCTGGAAGTTGTTTTCTTCATAGCTCCCAAGGTTTTT GTGGAAACTCTGGATAAGTGTTTCGAAAATGTGTGTGAATTGGATTTGATCTTCCATATGGATAAGACTGATATTTATGGACTGGCAAAG AAGTGTAACTTGACGGAGCGCCAGGTGGAAAGATGGTTTAGGAGTCGGCGGAATCAAGAGAGGCCTTCCAGGCTGAAGAAATTCCAGGAA GCTTGCTGGAGATTTGCATTTTACTTAATGATCACTGTTGCTGGAATTGCGTTTCTTTATGATAAACCTTGGCTATATGACTTATGGGAG GTTTGGAATGGCTATCCCAAACAGCCCCTGCTGCCATCCCAGTACTGGTACTACATTTTAGAAATGAGTTTTTATTGGTCTCTGTTATTT AGACTTGGCTTTGATGTCAAGAGAAAGGATTTTCTAGCTCATATCATCCACCACCTGGCTGCTATTAGTCTGATGAGCTTCTCTTGGTGT GCTAATTATATTCGCAGTGGGACCCTCGTGATGATTGTACACGATGTGGCTGACATTTGGCTGGAGTCTGCTAAGATGTTTTCTTATGCT GGATGGACGCAGACCTGTAACACCCTGTTTTTCATCTTCTCCACCATATTTTTCATCAGCCGCCTCATTGTTTTTCCTTTCTGGATTTTA TATTGCACGCTGATCTTGCCTATGTATCACCTCGAGCCTTTCTTTTCATACATCTTCCTCAACCTACAGCTCATGATCTTGCAGGTCCTT CACCTTTACTGGGGTTATTACATCTTGAAGATGCTCAACAGATGTATATTCATGAAGAGCATCCAGGATGTGAGGAGTGATGACGAGGAT TATGAAGAGGAAGAGGAAGAGGAAGAAGAAGAGGCTACCAAAGGCAAAGAGATGGATTGTTTAAAGAACGGCCTCAGGGCTGAGAGGCAC CTCATTCCCAATGGCCAGCATGGCCATTAGCTGGAAGCCTACAGGACTCCCATGGCACAGCATGCTGCAAGTACTGTTGGCAGCCTGGCT TCCAGGCCCCACACCGACCCCACATTCTGCCCTTCCCTCTTTCTCACCACCGCCTTCCCTCCCACCTAAGATGTGTTTACCAAAATGTTG >5301_5301_6_AP3S2-CERS3_AP3S2_chr15_90414707_ENST00000558011_CERS3_chr15_101024873_ENST00000538112_length(amino acids)=422AA_BP=135 MREPWLAKMIQAILVFNNHGKPRLVRFYQRFPEEIQQQIVRETFHLVLKRDDNICNFLEGGSLIGGSDYKLIYRHYATLYFVFCVDSSES ELGILDLIQVHLEVVFFIAPKVFVETLDKCFENVCELDLIFHMDKTDIYGLAKKCNLTERQVERWFRSRRNQERPSRLKKFQEACWRFAF YLMITVAGIAFLYDKPWLYDLWEVWNGYPKQPLLPSQYWYYILEMSFYWSLLFRLGFDVKRKDFLAHIIHHLAAISLMSFSWCANYIRSG TLVMIVHDVADIWLESAKMFSYAGWTQTCNTLFFIFSTIFFISRLIVFPFWILYCTLILPMYHLEPFFSYIFLNLQLMILQVLHLYWGYY -------------------------------------------------------------- >5301_5301_7_AP3S2-CERS3_AP3S2_chr15_90414707_ENST00000560940_CERS3_chr15_101024873_ENST00000284382_length(transcript)=3559nt_BP=377nt AGCCGGTGCTGAGAGAACCGTGGCTGGCAAAGATGATTCAGGCGATTCTGGTTTTCAACAACCATGGGAAGCCACGGCTAGTCCGCTTCT ACCAGCGTTTCCCAGAAGAAATTCAACAGCAGATTGTTCGAGAGACTTTCCATCTAGTCCTCAAGCGGGATGACAACATCTGTAACTTCT TGGAGGGTGGAAGTTTGATTGGTGGCTCTGACTACAAACTGATCTACCGGCACTATGCTACCCTCTACTTTGTATTTTGTGTGGATTCCT CAGAGAGTGAACTTGGAATCTTGGACCTCATCCAGGTTTTTGTGGAAACTCTGGATAAGTGTTTCGAAAATGTGTGTGAATTGGATTTGA TCTTCCATATGGATAAGACTGATATTTATGGACTGGCAAAGAAGTGTAACTTGACGGAGCGCCAGGTGGAAAGATGGTTTAGGAGTCGGC GGAATCAAGAGAGGCCTTCCAGGCTGAAGAAATTCCAGGAAGCTTGCTGGAGATTTGCATTTTACTTAATGATCACTGTTGCTGGAATTG CGTTTCTTTATGATAAACCTTGGCTATATGACTTATGGGAGGTTTGGAATGGCTATCCCAAACAGCCCCTGCTGCCATCCCAGTACTGGT ACTACATTTTAGAAATGAGTTTTTATTGGTCTCTGTTATTTAGACTTGGCTTTGATGTCAAGAGAAAGGATTTTCTAGCTCATATCATCC ACCACCTGGCTGCTATTAGTCTGATGAGCTTCTCTTGGTGTGCTAATTATATTCGCAGTGGGACCCTCGTGATGATTGTACACGATGTGG CTGACATTTGGCTGGAGTCTGCTAAGATGTTTTCTTATGCTGGATGGACGCAGACCTGTAACACCCTGTTTTTCATCTTCTCCACCATAT TTTTCATCAGCCGCCTCATTGTTTTTCCTTTCTGGATTTTATATTGCACGCTGATCTTGCCTATGTATCACCTCGAGCCTTTCTTTTCAT ACATCTTCCTCAACCTACAGCTCATGATCTTGCAGGTCCTTCACCTTTACTGGGGTTATTACATCTTGAAGATGCTCAACAGATGTATAT TCATGAAGAGCATCCAGGATGTGAGGAGTGATGACGAGGATTATGAAGAGGAAGAGGAAGAGGAAGAAGAAGAGGCTACCAAAGGCAAAG AGATGGATTGTTTAAAGAACGGCCTCAGGGCTGAGAGGCACCTCATTCCCAATGGCCAGCATGGCCATTAGCTGGAAGCCTACAGGACTC CCATGGCACAGCATGCTGCAAGTACTGTTGGCAGCCTGGCTTCCAGGCCCCACACCGACCCCACATTCTGCCCTTCCCTCTTTCTCACCA CCGCCTTCCCTCCCACCTAAGATGTGTTTACCAAAATGTTGTTAACTTGTGTTAAAATGTTAAATATAAGCATGCCCATGGATTTTTACT GCAGTTAGGACTCAGACTGGTCAAAGATTTCAAAGATTTCTCCACAGAACCGTCTCAGTTCTAATTGCACTCCCTCATGCATGTCACTTT CTCAGGGGCTCGCTTTGTTATAGACCCTTTCGCCTCGCCACCTTGCCTGTCCTCAGGACGCTTTCACAGGTGCTAAGTGATCTCATTTTT CCCAGGTGTGTTTGGCCACAAAGAGCAGCTTCTTTCTCAAAATGAGTTAGAAGTGGCAGTGGGACAGGAGCGGAAGGACCACACCAGGAG ACACTTCCATCCTGAAGCTTAGGTGCCTCATCTCCACAGGGCGGTGGCAGTCCCTGCCTGCCACCCCACAGGGTTACAGCAAGGATTAAG TGAGATCACAGAAGTTTAAGTACACACTGTCAACCGTGGGGTCATCGTGAACCAACCCACTTTGCACTGTTTGGGAGACAGAAACCTGGC TAAACATGGCACTGCAATGGGCCTGAACAAAAGGCAGAATCTTTAAAAATTCCTCTTAAATGACTCTGGAGATACCTGGAAATGAAAGTG CCAAGAAAGGTGTTCCATTTTATTTGCTAACTATTTATGCATTAGCTCCCCAAGGGTCATTCTCAGATTCTCCTGGAATTCTTCTCCCTC AGGACCCATGGTTCAAGGAAGGAAGCTTAGGCCCTGTTCCTTCCTGTCCTTTGCTGGTCTTTCCCTTTTTTCCTTTCTAGGAGGGAAGCT TCTGTGCTGCTGCCCTGAGCCCTTCCTTCAGGCCAGCACAGTACCTGGGGACCTCCACGGGGGAATGGGATCCAGGCCAGGTTGCTTGCT GAGCCTCATCACCCAGGAGGCCTGAGCCTCTGGGGAGGGCACGCATGTACACTGCCAGACCCAGGGGAGATCTTGGGAACAGAGGATGCT ACGTGATTTCCTCTGGCTTCCAACCCAATCAGCCTGCATCACAGTGAAACACAACACAAAAGGCCATAAAAGGCATACCCCTGAGAAATG TTTAAGGGCAGGTGCTAGAGTCAGTGCCAGCTCCCTGGGAGGAGGGATAGGGACGGGCAGATCAGTAGCCAGCTTGTCCTCACCCTCCGG AAGGGAGCACCGGAGAAGACTTGCACACGTCCCTGCCTCCCTTGCGGCCTTGTCACCAGAGGGACACATCTCCTGGGCACAATGTGCAGG GCTGACCTGGGAGACTTCTCAGGTGGCTGCTGGCTGAGGAGAGGCCAGGCCTTCCCAAGGAAGACCCTGAGTAAAATCTGCATCTGTCCT CACCACCTGGCACAGTCTCTCATAACGGTCAGATTTTGTATGTTCATCCTATTTATTCAGGGGCTCGTACTAGAAAGCCACAGGAGAGGT CGGCTTGTAGGGACTGGAAAATCAGCCCCAAGCAGAGCAGCTGCAGGGCCCCTGGAGCCGGAAGGACACTGCACAGAACAGACTGCGTTA TTGTTATTTTTAAATAAAAATATACATTTGAAACCTTAAGGCTAAACAAAAATAAACAAAAAATCCTTTAGAATTCTTTCCACAACAATA TCTCTTTCTGAGAAATTGTTACAAACAAGGTCAGATTTTCTCTGTATAACATTTGCTTTTATGAGGACAATATCATATGCATTATATGCA TAATATGATATTATAAATCAAAATGCCTGCACCCACTTTAGGGTATAGCTATTGACTTATTATTAATATTATATTATTATTATTTTGCTG GAAGAAGGTCACACTAAGATATAATTTTTTATGTTTTCAGTTAACGGTATGCTTTCTTCTTTGCTTATTTGGTTTTTGTCTCTGTACCAA ATATCTTCTTGCTTAAGGTAGAAAAGTATTTGTTTACCTCTATCTCCAGTTTTTTTTCTTATTTGAATGTTGAAGGTAAAATTGATATAC CAATTTTAACTATTTCTGATACAGCTGAAAGCACTAAACTACTTCATAAGAAGTAGATACTCATTTTTGTAACACTATTTAGGGCTTTTG TGGTTAATTTTAAAGGAAACCACTCTTTCTACAGGAAACAAGGGCTCAGGATTCTTCAGATGACCTTATAAAAATGCAGTCCACAGTGCT >5301_5301_7_AP3S2-CERS3_AP3S2_chr15_90414707_ENST00000560940_CERS3_chr15_101024873_ENST00000284382_length(amino acids)=410AA_BP=123 MREPWLAKMIQAILVFNNHGKPRLVRFYQRFPEEIQQQIVRETFHLVLKRDDNICNFLEGGSLIGGSDYKLIYRHYATLYFVFCVDSSES ELGILDLIQVFVETLDKCFENVCELDLIFHMDKTDIYGLAKKCNLTERQVERWFRSRRNQERPSRLKKFQEACWRFAFYLMITVAGIAFL YDKPWLYDLWEVWNGYPKQPLLPSQYWYYILEMSFYWSLLFRLGFDVKRKDFLAHIIHHLAAISLMSFSWCANYIRSGTLVMIVHDVADI WLESAKMFSYAGWTQTCNTLFFIFSTIFFISRLIVFPFWILYCTLILPMYHLEPFFSYIFLNLQLMILQVLHLYWGYYILKMLNRCIFMK -------------------------------------------------------------- >5301_5301_8_AP3S2-CERS3_AP3S2_chr15_90414707_ENST00000560940_CERS3_chr15_101024873_ENST00000394113_length(transcript)=1443nt_BP=377nt AGCCGGTGCTGAGAGAACCGTGGCTGGCAAAGATGATTCAGGCGATTCTGGTTTTCAACAACCATGGGAAGCCACGGCTAGTCCGCTTCT ACCAGCGTTTCCCAGAAGAAATTCAACAGCAGATTGTTCGAGAGACTTTCCATCTAGTCCTCAAGCGGGATGACAACATCTGTAACTTCT TGGAGGGTGGAAGTTTGATTGGTGGCTCTGACTACAAACTGATCTACCGGCACTATGCTACCCTCTACTTTGTATTTTGTGTGGATTCCT CAGAGAGTGAACTTGGAATCTTGGACCTCATCCAGGTTTTTGTGGAAACTCTGGATAAGTGTTTCGAAAATGTGTGTGAATTGGATTTGA TCTTCCATATGGATAAGACTGATATTTATGGACTGGCAAAGAAGTGTAACTTGACGGAGCGCCAGGTGGAAAGATGGTTTAGGAGTCGGC GGAATCAAGAGAGGCCTTCCAGGCTGAAGAAATTCCAGGAAGCTTGCTGGAGATTTGCATTTTACTTAATGATCACTGTTGCTGGAATTG CGTTTCTTTATGATAAACCTTGGCTATATGACTTATGGGAGGTTTGGAATGGCTATCCCAAACAGCCCCTGCTGCCATCCCAGTACTGGT ACTACATTTTAGAAATGAGTTTTTATTGGTCTCTGTTATTTAGACTTGGCTTTGATGTCAAGAGAAAGGATTTTCTAGCTCATATCATCC ACCACCTGGCTGCTATTAGTCTGATGAGCTTCTCTTGGTGTGCTAATTATATTCGCAGTGGGACCCTCGTGATGATTGTACACGATGTGG CTGACATTTGGCTGGAGTCTGCTAAGATGTTTTCTTATGCTGGATGGACGCAGACCTGTAACACCCTGTTTTTCATCTTCTCCACCATAT TTTTCATCAGCCGCCTCATTGTTTTTCCTTTCTGGATTTTATATTGCACGCTGATCTTGCCTATGTATCACCTCGAGCCTTTCTTTTCAT ACATCTTCCTCAACCTACAGCTCATGATCTTGCAGGTCCTTCACCTTTACTGGGGTTATTACATCTTGAAGATGCTCAACAGATGTATAT TCATGAAGAGCATCCAGGATGTGAGGAGTGATGACGAGGATTATGAAGAGGAAGAGGAAGAGGAAGAAGAAGAGGCTACCAAAGGCAAAG AGATGGATTGTTTAAAGAACGGCCTCAGGGCTGAGAGGCACCTCATTCCCAATGGCCAGCATGGCCATTAGCTGGAAGCCTACAGGACTC CCATGGCACAGCATGCTGCAAGTACTGTTGGCAGCCTGGCTTCCAGGCCCCACACCGACCCCACATTCTGCCCTTCCCTCTTTCTCACCA CCGCCTTCCCTCCCACCTAAGATGTGTTTACCAAAATGTTGTTAACTTGTGTTAAAATGTTAAATATAAGCATGCCCATGGATTTTTACT >5301_5301_8_AP3S2-CERS3_AP3S2_chr15_90414707_ENST00000560940_CERS3_chr15_101024873_ENST00000394113_length(amino acids)=410AA_BP=123 MREPWLAKMIQAILVFNNHGKPRLVRFYQRFPEEIQQQIVRETFHLVLKRDDNICNFLEGGSLIGGSDYKLIYRHYATLYFVFCVDSSES ELGILDLIQVFVETLDKCFENVCELDLIFHMDKTDIYGLAKKCNLTERQVERWFRSRRNQERPSRLKKFQEACWRFAFYLMITVAGIAFL YDKPWLYDLWEVWNGYPKQPLLPSQYWYYILEMSFYWSLLFRLGFDVKRKDFLAHIIHHLAAISLMSFSWCANYIRSGTLVMIVHDVADI WLESAKMFSYAGWTQTCNTLFFIFSTIFFISRLIVFPFWILYCTLILPMYHLEPFFSYIFLNLQLMILQVLHLYWGYYILKMLNRCIFMK -------------------------------------------------------------- >5301_5301_9_AP3S2-CERS3_AP3S2_chr15_90414707_ENST00000560940_CERS3_chr15_101024873_ENST00000538112_length(transcript)=1443nt_BP=377nt AGCCGGTGCTGAGAGAACCGTGGCTGGCAAAGATGATTCAGGCGATTCTGGTTTTCAACAACCATGGGAAGCCACGGCTAGTCCGCTTCT ACCAGCGTTTCCCAGAAGAAATTCAACAGCAGATTGTTCGAGAGACTTTCCATCTAGTCCTCAAGCGGGATGACAACATCTGTAACTTCT TGGAGGGTGGAAGTTTGATTGGTGGCTCTGACTACAAACTGATCTACCGGCACTATGCTACCCTCTACTTTGTATTTTGTGTGGATTCCT CAGAGAGTGAACTTGGAATCTTGGACCTCATCCAGGTTTTTGTGGAAACTCTGGATAAGTGTTTCGAAAATGTGTGTGAATTGGATTTGA TCTTCCATATGGATAAGACTGATATTTATGGACTGGCAAAGAAGTGTAACTTGACGGAGCGCCAGGTGGAAAGATGGTTTAGGAGTCGGC GGAATCAAGAGAGGCCTTCCAGGCTGAAGAAATTCCAGGAAGCTTGCTGGAGATTTGCATTTTACTTAATGATCACTGTTGCTGGAATTG CGTTTCTTTATGATAAACCTTGGCTATATGACTTATGGGAGGTTTGGAATGGCTATCCCAAACAGCCCCTGCTGCCATCCCAGTACTGGT ACTACATTTTAGAAATGAGTTTTTATTGGTCTCTGTTATTTAGACTTGGCTTTGATGTCAAGAGAAAGGATTTTCTAGCTCATATCATCC ACCACCTGGCTGCTATTAGTCTGATGAGCTTCTCTTGGTGTGCTAATTATATTCGCAGTGGGACCCTCGTGATGATTGTACACGATGTGG CTGACATTTGGCTGGAGTCTGCTAAGATGTTTTCTTATGCTGGATGGACGCAGACCTGTAACACCCTGTTTTTCATCTTCTCCACCATAT TTTTCATCAGCCGCCTCATTGTTTTTCCTTTCTGGATTTTATATTGCACGCTGATCTTGCCTATGTATCACCTCGAGCCTTTCTTTTCAT ACATCTTCCTCAACCTACAGCTCATGATCTTGCAGGTCCTTCACCTTTACTGGGGTTATTACATCTTGAAGATGCTCAACAGATGTATAT TCATGAAGAGCATCCAGGATGTGAGGAGTGATGACGAGGATTATGAAGAGGAAGAGGAAGAGGAAGAAGAAGAGGCTACCAAAGGCAAAG AGATGGATTGTTTAAAGAACGGCCTCAGGGCTGAGAGGCACCTCATTCCCAATGGCCAGCATGGCCATTAGCTGGAAGCCTACAGGACTC CCATGGCACAGCATGCTGCAAGTACTGTTGGCAGCCTGGCTTCCAGGCCCCACACCGACCCCACATTCTGCCCTTCCCTCTTTCTCACCA CCGCCTTCCCTCCCACCTAAGATGTGTTTACCAAAATGTTGTTAACTTGTGTTAAAATGTTAAATATAAGCATGCCCATGGATTTTTACT >5301_5301_9_AP3S2-CERS3_AP3S2_chr15_90414707_ENST00000560940_CERS3_chr15_101024873_ENST00000538112_length(amino acids)=410AA_BP=123 MREPWLAKMIQAILVFNNHGKPRLVRFYQRFPEEIQQQIVRETFHLVLKRDDNICNFLEGGSLIGGSDYKLIYRHYATLYFVFCVDSSES ELGILDLIQVFVETLDKCFENVCELDLIFHMDKTDIYGLAKKCNLTERQVERWFRSRRNQERPSRLKKFQEACWRFAFYLMITVAGIAFL YDKPWLYDLWEVWNGYPKQPLLPSQYWYYILEMSFYWSLLFRLGFDVKRKDFLAHIIHHLAAISLMSFSWCANYIRSGTLVMIVHDVADI WLESAKMFSYAGWTQTCNTLFFIFSTIFFISRLIVFPFWILYCTLILPMYHLEPFFSYIFLNLQLMILQVLHLYWGYYILKMLNRCIFMK -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for AP3S2-CERS3 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for AP3S2-CERS3 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for AP3S2-CERS3 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies