
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:MSRA-CSGALNACT1 (FusionGDB2 ID:55407) |
Fusion Gene Summary for MSRA-CSGALNACT1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: MSRA-CSGALNACT1 | Fusion gene ID: 55407 | Hgene | Tgene | Gene symbol | MSRA | CSGALNACT1 | Gene ID | 4482 | 55790 |
| Gene name | methionine sulfoxide reductase A | chondroitin sulfate N-acetylgalactosaminyltransferase 1 | |
| Synonyms | PMSR | CSGalNAcT-1|ChGn|ChGn-1|beta4GalNAcT | |
| Cytomap | 8p23.1 | 8p21.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | mitochondrial peptide methionine sulfoxide reductasecytosolic methionine-S-sulfoxide reductasepeptide Met(O) reductasepeptide met (O) reductasepeptide-methionine (S)-S-oxide reductase | chondroitin sulfate N-acetylgalactosaminyltransferase 1beta4GalNAcT-1chondroitin beta-1,4-N-acetylgalactosaminyltransferase 1chondroitin beta1,4 N-acetylgalactosaminyltransferaseglucuronylgalactosylproteoglycan 4-beta-N- acetylgalactosaminyltransferas | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | . | Q8TDX6 | |
| Ensembl transtripts involved in fusion gene | ENST00000317173, ENST00000382490, ENST00000441698, ENST00000518255, ENST00000528246, ENST00000517594, ENST00000521209, | ENST00000518542, ENST00000311540, ENST00000332246, ENST00000454498, ENST00000522854, ENST00000544602, | |
| Fusion gene scores | * DoF score | 12 X 9 X 6=648 | 6 X 6 X 4=144 |
| # samples | 13 | 7 | |
| ** MAII score | log2(13/648*10)=-2.31748218985617 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(7/144*10)=-1.04064198449735 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: MSRA [Title/Abstract] AND CSGALNACT1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | MSRA(10177499)-CSGALNACT1(19266205), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | CSGALNACT1 | GO:0019276 | UDP-N-acetylgalactosamine metabolic process | 11514575 |
| Tgene | CSGALNACT1 | GO:0030206 | chondroitin sulfate biosynthetic process | 11514575|12163485 |
| Tgene | CSGALNACT1 | GO:0046398 | UDP-glucuronate metabolic process | 11514575 |
| Tgene | CSGALNACT1 | GO:0050653 | chondroitin sulfate proteoglycan biosynthetic process, polysaccharide chain biosynthetic process | 12163485 |
| Fusion gene breakpoints across MSRA (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
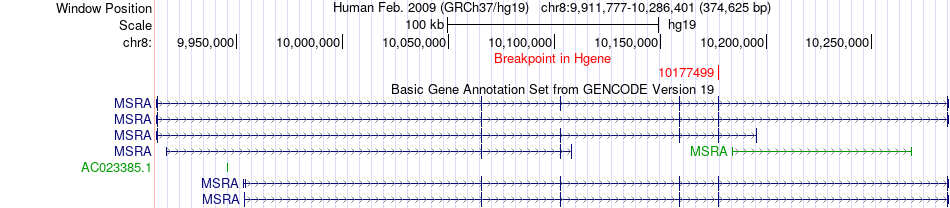 |
| Fusion gene breakpoints across CSGALNACT1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | SKCM | TCGA-EB-A3XF-01A | MSRA | chr8 | 10177499 | - | CSGALNACT1 | chr8 | 19266205 | - |
| ChimerDB4 | SKCM | TCGA-EB-A3XF-01A | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
Top |
Fusion Gene ORF analysis for MSRA-CSGALNACT1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000317173 | ENST00000518542 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| 5CDS-intron | ENST00000382490 | ENST00000518542 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| 5CDS-intron | ENST00000441698 | ENST00000518542 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| 5CDS-intron | ENST00000518255 | ENST00000518542 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| 5CDS-intron | ENST00000528246 | ENST00000518542 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| In-frame | ENST00000317173 | ENST00000311540 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| In-frame | ENST00000317173 | ENST00000332246 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| In-frame | ENST00000317173 | ENST00000454498 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| In-frame | ENST00000317173 | ENST00000522854 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| In-frame | ENST00000317173 | ENST00000544602 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| In-frame | ENST00000382490 | ENST00000311540 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| In-frame | ENST00000382490 | ENST00000332246 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| In-frame | ENST00000382490 | ENST00000454498 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| In-frame | ENST00000382490 | ENST00000522854 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| In-frame | ENST00000382490 | ENST00000544602 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| In-frame | ENST00000441698 | ENST00000311540 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| In-frame | ENST00000441698 | ENST00000332246 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| In-frame | ENST00000441698 | ENST00000454498 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| In-frame | ENST00000441698 | ENST00000522854 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| In-frame | ENST00000441698 | ENST00000544602 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| In-frame | ENST00000518255 | ENST00000311540 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| In-frame | ENST00000518255 | ENST00000332246 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| In-frame | ENST00000518255 | ENST00000454498 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| In-frame | ENST00000518255 | ENST00000522854 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| In-frame | ENST00000518255 | ENST00000544602 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| In-frame | ENST00000528246 | ENST00000311540 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| In-frame | ENST00000528246 | ENST00000332246 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| In-frame | ENST00000528246 | ENST00000454498 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| In-frame | ENST00000528246 | ENST00000522854 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| In-frame | ENST00000528246 | ENST00000544602 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| intron-3CDS | ENST00000517594 | ENST00000311540 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| intron-3CDS | ENST00000517594 | ENST00000332246 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| intron-3CDS | ENST00000517594 | ENST00000454498 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| intron-3CDS | ENST00000517594 | ENST00000522854 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| intron-3CDS | ENST00000517594 | ENST00000544602 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| intron-3CDS | ENST00000521209 | ENST00000311540 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| intron-3CDS | ENST00000521209 | ENST00000332246 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| intron-3CDS | ENST00000521209 | ENST00000454498 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| intron-3CDS | ENST00000521209 | ENST00000522854 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| intron-3CDS | ENST00000521209 | ENST00000544602 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| intron-intron | ENST00000517594 | ENST00000518542 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| intron-intron | ENST00000521209 | ENST00000518542 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000317173 | MSRA | chr8 | 10177499 | + | ENST00000454498 | CSGALNACT1 | chr8 | 19266205 | - | 2783 | 792 | 249 | 1163 | 304 |
| ENST00000317173 | MSRA | chr8 | 10177499 | + | ENST00000332246 | CSGALNACT1 | chr8 | 19266205 | - | 2783 | 792 | 249 | 1163 | 304 |
| ENST00000317173 | MSRA | chr8 | 10177499 | + | ENST00000311540 | CSGALNACT1 | chr8 | 19266205 | - | 2782 | 792 | 249 | 1163 | 304 |
| ENST00000317173 | MSRA | chr8 | 10177499 | + | ENST00000522854 | CSGALNACT1 | chr8 | 19266205 | - | 1164 | 792 | 249 | 1163 | 304 |
| ENST00000317173 | MSRA | chr8 | 10177499 | + | ENST00000544602 | CSGALNACT1 | chr8 | 19266205 | - | 1164 | 792 | 249 | 1163 | 304 |
| ENST00000441698 | MSRA | chr8 | 10177499 | + | ENST00000454498 | CSGALNACT1 | chr8 | 19266205 | - | 2561 | 570 | 147 | 941 | 264 |
| ENST00000441698 | MSRA | chr8 | 10177499 | + | ENST00000332246 | CSGALNACT1 | chr8 | 19266205 | - | 2561 | 570 | 147 | 941 | 264 |
| ENST00000441698 | MSRA | chr8 | 10177499 | + | ENST00000311540 | CSGALNACT1 | chr8 | 19266205 | - | 2560 | 570 | 147 | 941 | 264 |
| ENST00000441698 | MSRA | chr8 | 10177499 | + | ENST00000522854 | CSGALNACT1 | chr8 | 19266205 | - | 942 | 570 | 147 | 941 | 264 |
| ENST00000441698 | MSRA | chr8 | 10177499 | + | ENST00000544602 | CSGALNACT1 | chr8 | 19266205 | - | 942 | 570 | 147 | 941 | 264 |
| ENST00000518255 | MSRA | chr8 | 10177499 | + | ENST00000454498 | CSGALNACT1 | chr8 | 19266205 | - | 2550 | 559 | 16 | 930 | 304 |
| ENST00000518255 | MSRA | chr8 | 10177499 | + | ENST00000332246 | CSGALNACT1 | chr8 | 19266205 | - | 2550 | 559 | 16 | 930 | 304 |
| ENST00000518255 | MSRA | chr8 | 10177499 | + | ENST00000311540 | CSGALNACT1 | chr8 | 19266205 | - | 2549 | 559 | 16 | 930 | 304 |
| ENST00000518255 | MSRA | chr8 | 10177499 | + | ENST00000522854 | CSGALNACT1 | chr8 | 19266205 | - | 931 | 559 | 16 | 930 | 305 |
| ENST00000518255 | MSRA | chr8 | 10177499 | + | ENST00000544602 | CSGALNACT1 | chr8 | 19266205 | - | 931 | 559 | 16 | 930 | 305 |
| ENST00000528246 | MSRA | chr8 | 10177499 | + | ENST00000454498 | CSGALNACT1 | chr8 | 19266205 | - | 2959 | 968 | 623 | 1339 | 238 |
| ENST00000528246 | MSRA | chr8 | 10177499 | + | ENST00000332246 | CSGALNACT1 | chr8 | 19266205 | - | 2959 | 968 | 623 | 1339 | 238 |
| ENST00000528246 | MSRA | chr8 | 10177499 | + | ENST00000311540 | CSGALNACT1 | chr8 | 19266205 | - | 2958 | 968 | 623 | 1339 | 238 |
| ENST00000528246 | MSRA | chr8 | 10177499 | + | ENST00000522854 | CSGALNACT1 | chr8 | 19266205 | - | 1340 | 968 | 623 | 1339 | 239 |
| ENST00000528246 | MSRA | chr8 | 10177499 | + | ENST00000544602 | CSGALNACT1 | chr8 | 19266205 | - | 1340 | 968 | 623 | 1339 | 239 |
| ENST00000382490 | MSRA | chr8 | 10177499 | + | ENST00000454498 | CSGALNACT1 | chr8 | 19266205 | - | 2709 | 718 | 250 | 1089 | 279 |
| ENST00000382490 | MSRA | chr8 | 10177499 | + | ENST00000332246 | CSGALNACT1 | chr8 | 19266205 | - | 2709 | 718 | 250 | 1089 | 279 |
| ENST00000382490 | MSRA | chr8 | 10177499 | + | ENST00000311540 | CSGALNACT1 | chr8 | 19266205 | - | 2708 | 718 | 250 | 1089 | 279 |
| ENST00000382490 | MSRA | chr8 | 10177499 | + | ENST00000522854 | CSGALNACT1 | chr8 | 19266205 | - | 1090 | 718 | 250 | 1089 | 280 |
| ENST00000382490 | MSRA | chr8 | 10177499 | + | ENST00000544602 | CSGALNACT1 | chr8 | 19266205 | - | 1090 | 718 | 250 | 1089 | 280 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000317173 | ENST00000454498 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - | 0.001151843 | 0.9988481 |
| ENST00000317173 | ENST00000332246 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - | 0.001151843 | 0.9988481 |
| ENST00000317173 | ENST00000311540 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - | 0.001142194 | 0.99885786 |
| ENST00000317173 | ENST00000522854 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - | 0.002388713 | 0.9976113 |
| ENST00000317173 | ENST00000544602 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - | 0.002388713 | 0.9976113 |
| ENST00000441698 | ENST00000454498 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - | 0.002399138 | 0.99760085 |
| ENST00000441698 | ENST00000332246 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - | 0.002399138 | 0.99760085 |
| ENST00000441698 | ENST00000311540 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - | 0.002374215 | 0.99762577 |
| ENST00000441698 | ENST00000522854 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - | 0.002376498 | 0.9976235 |
| ENST00000441698 | ENST00000544602 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - | 0.002376498 | 0.9976235 |
| ENST00000518255 | ENST00000454498 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - | 0.000974033 | 0.99902594 |
| ENST00000518255 | ENST00000332246 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - | 0.000974033 | 0.99902594 |
| ENST00000518255 | ENST00000311540 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - | 0.000967228 | 0.99903274 |
| ENST00000518255 | ENST00000522854 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - | 0.002154875 | 0.9978452 |
| ENST00000518255 | ENST00000544602 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - | 0.002154875 | 0.9978452 |
| ENST00000528246 | ENST00000454498 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - | 0.001973659 | 0.9980263 |
| ENST00000528246 | ENST00000332246 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - | 0.001973659 | 0.9980263 |
| ENST00000528246 | ENST00000311540 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - | 0.001967214 | 0.99803275 |
| ENST00000528246 | ENST00000522854 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - | 0.007082847 | 0.9929172 |
| ENST00000528246 | ENST00000544602 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - | 0.007082847 | 0.9929172 |
| ENST00000382490 | ENST00000454498 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - | 0.001126504 | 0.99887353 |
| ENST00000382490 | ENST00000332246 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - | 0.001126504 | 0.99887353 |
| ENST00000382490 | ENST00000311540 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - | 0.001123563 | 0.9988764 |
| ENST00000382490 | ENST00000522854 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - | 0.003665349 | 0.9963347 |
| ENST00000382490 | ENST00000544602 | MSRA | chr8 | 10177499 | + | CSGALNACT1 | chr8 | 19266205 | - | 0.003665349 | 0.9963347 |
Top |
Fusion Genomic Features for MSRA-CSGALNACT1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
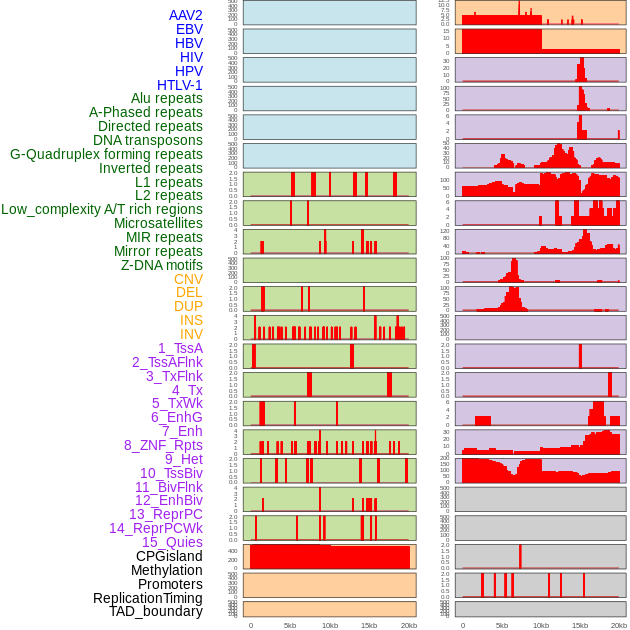 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for MSRA-CSGALNACT1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr8:10177499/chr8:19266205) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| . | CSGALNACT1 |
| FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. | FUNCTION: Transfers 1,4-N-acetylgalactosamine (GalNAc) from UDP-GalNAc to the non-reducing end of glucuronic acid (GlcUA). Required for addition of the first GalNAc to the core tetrasaccharide linker and for elongation of chondroitin chains. Important role in chondroitin chain biosynthesis in cartilage formation and subsequent endochondral ossification (PubMed:11788602, PubMed:12163485, PubMed:12446672, PubMed:17145758, PubMed:31705726). Moreover, is involved in the metabolism of aggrecan (By similarity). {ECO:0000250|UniProtKB:Q8BJQ9, ECO:0000269|PubMed:11788602, ECO:0000269|PubMed:12163485, ECO:0000269|PubMed:12446672, ECO:0000269|PubMed:17145758, ECO:0000269|PubMed:21160489, ECO:0000269|PubMed:27599773, ECO:0000269|PubMed:31705726}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | CSGALNACT1 | chr8:10177499 | chr8:19266205 | ENST00000311540 | 6 | 9 | 57_100 | 409 | 533.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CSGALNACT1 | chr8:10177499 | chr8:19266205 | ENST00000332246 | 7 | 10 | 57_100 | 409 | 533.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CSGALNACT1 | chr8:10177499 | chr8:19266205 | ENST00000454498 | 7 | 10 | 57_100 | 409 | 533.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CSGALNACT1 | chr8:10177499 | chr8:19266205 | ENST00000522854 | 5 | 8 | 57_100 | 409 | 533.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CSGALNACT1 | chr8:10177499 | chr8:19266205 | ENST00000544602 | 6 | 9 | 57_100 | 409 | 533.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | CSGALNACT1 | chr8:10177499 | chr8:19266205 | ENST00000311540 | 6 | 9 | 1_14 | 409 | 533.0 | Topological domain | Cytoplasmic | |
| Tgene | CSGALNACT1 | chr8:10177499 | chr8:19266205 | ENST00000311540 | 6 | 9 | 36_532 | 409 | 533.0 | Topological domain | Lumenal | |
| Tgene | CSGALNACT1 | chr8:10177499 | chr8:19266205 | ENST00000332246 | 7 | 10 | 1_14 | 409 | 533.0 | Topological domain | Cytoplasmic | |
| Tgene | CSGALNACT1 | chr8:10177499 | chr8:19266205 | ENST00000332246 | 7 | 10 | 36_532 | 409 | 533.0 | Topological domain | Lumenal | |
| Tgene | CSGALNACT1 | chr8:10177499 | chr8:19266205 | ENST00000454498 | 7 | 10 | 1_14 | 409 | 533.0 | Topological domain | Cytoplasmic | |
| Tgene | CSGALNACT1 | chr8:10177499 | chr8:19266205 | ENST00000454498 | 7 | 10 | 36_532 | 409 | 533.0 | Topological domain | Lumenal | |
| Tgene | CSGALNACT1 | chr8:10177499 | chr8:19266205 | ENST00000522854 | 5 | 8 | 1_14 | 409 | 533.0 | Topological domain | Cytoplasmic | |
| Tgene | CSGALNACT1 | chr8:10177499 | chr8:19266205 | ENST00000522854 | 5 | 8 | 36_532 | 409 | 533.0 | Topological domain | Lumenal | |
| Tgene | CSGALNACT1 | chr8:10177499 | chr8:19266205 | ENST00000544602 | 6 | 9 | 1_14 | 409 | 533.0 | Topological domain | Cytoplasmic | |
| Tgene | CSGALNACT1 | chr8:10177499 | chr8:19266205 | ENST00000544602 | 6 | 9 | 36_532 | 409 | 533.0 | Topological domain | Lumenal | |
| Tgene | CSGALNACT1 | chr8:10177499 | chr8:19266205 | ENST00000311540 | 6 | 9 | 15_35 | 409 | 533.0 | Transmembrane | Helical%3B Signal-anchor for type II membrane protein | |
| Tgene | CSGALNACT1 | chr8:10177499 | chr8:19266205 | ENST00000332246 | 7 | 10 | 15_35 | 409 | 533.0 | Transmembrane | Helical%3B Signal-anchor for type II membrane protein | |
| Tgene | CSGALNACT1 | chr8:10177499 | chr8:19266205 | ENST00000454498 | 7 | 10 | 15_35 | 409 | 533.0 | Transmembrane | Helical%3B Signal-anchor for type II membrane protein | |
| Tgene | CSGALNACT1 | chr8:10177499 | chr8:19266205 | ENST00000522854 | 5 | 8 | 15_35 | 409 | 533.0 | Transmembrane | Helical%3B Signal-anchor for type II membrane protein | |
| Tgene | CSGALNACT1 | chr8:10177499 | chr8:19266205 | ENST00000544602 | 6 | 9 | 15_35 | 409 | 533.0 | Transmembrane | Helical%3B Signal-anchor for type II membrane protein |
Top |
Fusion Gene Sequence for MSRA-CSGALNACT1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >55407_55407_1_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000317173_CSGALNACT1_chr8_19266205_ENST00000311540_length(transcript)=2782nt_BP=792nt GGAACTCGCCGGGCCACACCCCCTGTCCAGGGAAGGAACACGCCCCCGGTGACAGCCGGTACGGCCCCGGGTTTGGGCAACCTCGATTAC GGGCGGCCTCCAGCCCCGCCAGCAGCGCCCCGCGCCCGCCCGCCCGCGCCCCTGCCGCCCCCCGGTTCCGGCCGCGGACCCCACTCTCTG CCGTTCCGGCTGCGGCTCCGCTGCCGGTAGCGCCGTCCCCCGGGACCACCCTTCGGCTGGCGCCCTCCCATGCTCTCGGCCACCCGGAGG GCTTGCCAGCTCCTCCTCCTCCACAGCCTCTTTCCCGTCCCGAGGATGGGCAACTCGGCCTCGAACATCGTCAGCCCCCAGGAGGCCTTG CCGGGCCGGAAGGAACAGACCCCTGTAGCGGCCAAACATCATGTCAATGGCAACAGAACAGTCGAACCTTTCCCAGAGGGAACACAGATG GCTGTATTTGGAATGGGATGTTTCTGGGGAGCTGAAAGGAAATTCTGGGTCTTGAAAGGAGTGTATTCAACTCAAGTTGGTTTTGCAGGA GGCTATACTTCAAATCCTACTTATAAAGAAGTCTGCTCAGAAAAAACTGGCCATGCAGAAGTCGTCCGAGTGGTGTACCAGCCAGAACAC ATGAGTTTTGAGGAACTGCTCAAGGTCTTCTGGGAGAATCACGACCCGACCCAAGGTATGCGCCAGGGGAACGACCATGGCACTCAGTAC CGCTCGGCCATCTACCCGACCTCTGCCAAGCAAATGGAGGCAGCCCTGAGCTCCAAAGAGAACTACCAAAAGGTCATAAAGAAGGAAACT GGATTTTGGAGAGACTTTGGATTTGGGATGACGTGTCAGTATCGGTCAGACTTCATCAATATAGGTGGGTTTGATCTGGACATCAAAGGC TGGGGCGGAGAGGATGTGCACCTTTATCGCAAGTATCTCCACAGCAACCTCATAGTGGTACGGACGCCTGTGCGAGGACTCTTCCACCTC TGGCATGAGAAGCGCTGCATGGACGAGCTGACCCCCGAGCAGTACAAGATGTGCATGCAGTCCAAGGCCATGAACGAGGCATCCCACGGC CAGCTGGGCATGCTGGTGTTCAGGCACGAGATAGAGGCTCACCTTCGCAAACAGAAACAGAAGACAAGTAGCAAAAAAACATGAACTCCC AGAGAAGGATTGTGGGAGACACTTTTTCTTTCCTTTTGCAATTACTGAAAGTGGCTGCAACAGAGAAAAGACTTCCATAAAGGACGACAA AAGAATTGGACTGATGGGTCAGAGATGAGAAAGCCTCCGATTTCTCTCTGTTGGGCTTTTTACAACAGAAATCAAAATCTCCGCTTTGCC TGCAAAAGTAACCCAGTTGCACCCTGTGAAGTGTCTGACAAAGGCAGAATGCTTGTGAGATTATAAGCCTAATGGTGTGGAGGTTTTGAT GGTGTTTACAACACACTGAGACCTGTTGTTTTGTGTGCTCATTGAAATATTCATGATTTAAGAGCAGTTTTGTAAAAAATTCATTAGCAT GAAAGGCAAGCATATTTCTCCTCATATGAATGAGCCTATCAGCAGGGCTCTAGTTTCTAGGAATGCTAAAATATCAGAAGGCAGGAGAGG AGATAGGCTTATTATGATACTAGTGAGTACATTAAGTAAAATAAAATGGACCAGAAAAGAAAAGAAACCATAAATATCGTGTCATATTTT CCCCAAGATTAACCAAAAATAATCTGCTTATCTTTTTGGTTGTCCTTTTAACTGTCTCCGTTTTTTTCTTTTATTTAAAAATGCACTTTT TTTCCCTTGTGAGTTATAGTCTGCTTATTTAATTACCACTTTGCAAGCCTTACAAGAGAGCACAAGTTGGCCTACATTTTTATATTTTTT AAGAAGATACTTTGAGATGCATTATGAGAACTTTCAGTTCAAAGCATCAAATTGATGCCATATCCAAGGACATGCCAAATGCTGATTCTG TCAGGCACTGAATGTCAGGCATTGAGACATAGGGAAGGAATGGTTTGTACTAATACAGACGTACAGATACTTTCTCTGAAGAGTATTTTC GAAGAGGAGCAACTGAACACTGGAGGAAAAGAAAATGACACTTTCTGCTTTACAGAAAAGGAAACTCATTCAGACTGGTGATATCGTGAT GTACCTAAAAGTCAGAAACCACATTTTCTCCTCAGAAGTAGGGACCGCTTTCTTACCTGTTTAAATAAACCAAAGTATACCGTGTGAACC AAACAATCTCTTTTCAAAACAGGGTGCTCCTCCTGGCTTCTGGCTTCCATAAGAAGAAATGGAGAAAAAAATATATATATATATATTGTG AAAGATCAATCCATCTGCCAGAATCTAGTGGGATGGAAGTTTTTGCTACATGTTATCCACCCCAGGCCAGGTGGAAGTAACTGAATTATT TTTTAAATTAAGCAGTTCTACTCGATCACCAAGATGCTTCTGAAAATTGCATTTTATTACCATTTCAAACTATTTTTTAAAAATAAATAC AGTTAACATAGAGTGGTTTCTTCATTCATGTGAAAATTATTAGCCAGCACCAGATGCATGAGCTAATTATCTCTTTGAGTCCTTGCTTCT GTTTGCTCACAGTAAACTCATTGTTTAAAAGCTTCAAGAACATTCAAGCTGTTGGTGTGTTAAAAAATGCATTGTATTGATTTGTACTGG >55407_55407_1_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000317173_CSGALNACT1_chr8_19266205_ENST00000311540_length(amino acids)=304AA_BP=181 MLSATRRACQLLLLHSLFPVPRMGNSASNIVSPQEALPGRKEQTPVAAKHHVNGNRTVEPFPEGTQMAVFGMGCFWGAERKFWVLKGVYS TQVGFAGGYTSNPTYKEVCSEKTGHAEVVRVVYQPEHMSFEELLKVFWENHDPTQGMRQGNDHGTQYRSAIYPTSAKQMEAALSSKENYQ KVIKKETGFWRDFGFGMTCQYRSDFINIGGFDLDIKGWGGEDVHLYRKYLHSNLIVVRTPVRGLFHLWHEKRCMDELTPEQYKMCMQSKA -------------------------------------------------------------- >55407_55407_2_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000317173_CSGALNACT1_chr8_19266205_ENST00000332246_length(transcript)=2783nt_BP=792nt GGAACTCGCCGGGCCACACCCCCTGTCCAGGGAAGGAACACGCCCCCGGTGACAGCCGGTACGGCCCCGGGTTTGGGCAACCTCGATTAC GGGCGGCCTCCAGCCCCGCCAGCAGCGCCCCGCGCCCGCCCGCCCGCGCCCCTGCCGCCCCCCGGTTCCGGCCGCGGACCCCACTCTCTG CCGTTCCGGCTGCGGCTCCGCTGCCGGTAGCGCCGTCCCCCGGGACCACCCTTCGGCTGGCGCCCTCCCATGCTCTCGGCCACCCGGAGG GCTTGCCAGCTCCTCCTCCTCCACAGCCTCTTTCCCGTCCCGAGGATGGGCAACTCGGCCTCGAACATCGTCAGCCCCCAGGAGGCCTTG CCGGGCCGGAAGGAACAGACCCCTGTAGCGGCCAAACATCATGTCAATGGCAACAGAACAGTCGAACCTTTCCCAGAGGGAACACAGATG GCTGTATTTGGAATGGGATGTTTCTGGGGAGCTGAAAGGAAATTCTGGGTCTTGAAAGGAGTGTATTCAACTCAAGTTGGTTTTGCAGGA GGCTATACTTCAAATCCTACTTATAAAGAAGTCTGCTCAGAAAAAACTGGCCATGCAGAAGTCGTCCGAGTGGTGTACCAGCCAGAACAC ATGAGTTTTGAGGAACTGCTCAAGGTCTTCTGGGAGAATCACGACCCGACCCAAGGTATGCGCCAGGGGAACGACCATGGCACTCAGTAC CGCTCGGCCATCTACCCGACCTCTGCCAAGCAAATGGAGGCAGCCCTGAGCTCCAAAGAGAACTACCAAAAGGTCATAAAGAAGGAAACT GGATTTTGGAGAGACTTTGGATTTGGGATGACGTGTCAGTATCGGTCAGACTTCATCAATATAGGTGGGTTTGATCTGGACATCAAAGGC TGGGGCGGAGAGGATGTGCACCTTTATCGCAAGTATCTCCACAGCAACCTCATAGTGGTACGGACGCCTGTGCGAGGACTCTTCCACCTC TGGCATGAGAAGCGCTGCATGGACGAGCTGACCCCCGAGCAGTACAAGATGTGCATGCAGTCCAAGGCCATGAACGAGGCATCCCACGGC CAGCTGGGCATGCTGGTGTTCAGGCACGAGATAGAGGCTCACCTTCGCAAACAGAAACAGAAGACAAGTAGCAAAAAAACATGAACTCCC AGAGAAGGATTGTGGGAGACACTTTTTCTTTCCTTTTGCAATTACTGAAAGTGGCTGCAACAGAGAAAAGACTTCCATAAAGGACGACAA AAGAATTGGACTGATGGGTCAGAGATGAGAAAGCCTCCGATTTCTCTCTGTTGGGCTTTTTACAACAGAAATCAAAATCTCCGCTTTGCC TGCAAAAGTAACCCAGTTGCACCCTGTGAAGTGTCTGACAAAGGCAGAATGCTTGTGAGATTATAAGCCTAATGGTGTGGAGGTTTTGAT GGTGTTTACAACACACTGAGACCTGTTGTTTTGTGTGCTCATTGAAATATTCATGATTTAAGAGCAGTTTTGTAAAAAATTCATTAGCAT GAAAGGCAAGCATATTTCTCCTCATATGAATGAGCCTATCAGCAGGGCTCTAGTTTCTAGGAATGCTAAAATATCAGAAGGCAGGAGAGG AGATAGGCTTATTATGATACTAGTGAGTACATTAAGTAAAATAAAATGGACCAGAAAAGAAAAGAAACCATAAATATCGTGTCATATTTT CCCCAAGATTAACCAAAAATAATCTGCTTATCTTTTTGGTTGTCCTTTTAACTGTCTCCGTTTTTTTCTTTTATTTAAAAATGCACTTTT TTTCCCTTGTGAGTTATAGTCTGCTTATTTAATTACCACTTTGCAAGCCTTACAAGAGAGCACAAGTTGGCCTACATTTTTATATTTTTT AAGAAGATACTTTGAGATGCATTATGAGAACTTTCAGTTCAAAGCATCAAATTGATGCCATATCCAAGGACATGCCAAATGCTGATTCTG TCAGGCACTGAATGTCAGGCATTGAGACATAGGGAAGGAATGGTTTGTACTAATACAGACGTACAGATACTTTCTCTGAAGAGTATTTTC GAAGAGGAGCAACTGAACACTGGAGGAAAAGAAAATGACACTTTCTGCTTTACAGAAAAGGAAACTCATTCAGACTGGTGATATCGTGAT GTACCTAAAAGTCAGAAACCACATTTTCTCCTCAGAAGTAGGGACCGCTTTCTTACCTGTTTAAATAAACCAAAGTATACCGTGTGAACC AAACAATCTCTTTTCAAAACAGGGTGCTCCTCCTGGCTTCTGGCTTCCATAAGAAGAAATGGAGAAAAAAATATATATATATATATTGTG AAAGATCAATCCATCTGCCAGAATCTAGTGGGATGGAAGTTTTTGCTACATGTTATCCACCCCAGGCCAGGTGGAAGTAACTGAATTATT TTTTAAATTAAGCAGTTCTACTCGATCACCAAGATGCTTCTGAAAATTGCATTTTATTACCATTTCAAACTATTTTTTAAAAATAAATAC AGTTAACATAGAGTGGTTTCTTCATTCATGTGAAAATTATTAGCCAGCACCAGATGCATGAGCTAATTATCTCTTTGAGTCCTTGCTTCT GTTTGCTCACAGTAAACTCATTGTTTAAAAGCTTCAAGAACATTCAAGCTGTTGGTGTGTTAAAAAATGCATTGTATTGATTTGTACTGG >55407_55407_2_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000317173_CSGALNACT1_chr8_19266205_ENST00000332246_length(amino acids)=304AA_BP=181 MLSATRRACQLLLLHSLFPVPRMGNSASNIVSPQEALPGRKEQTPVAAKHHVNGNRTVEPFPEGTQMAVFGMGCFWGAERKFWVLKGVYS TQVGFAGGYTSNPTYKEVCSEKTGHAEVVRVVYQPEHMSFEELLKVFWENHDPTQGMRQGNDHGTQYRSAIYPTSAKQMEAALSSKENYQ KVIKKETGFWRDFGFGMTCQYRSDFINIGGFDLDIKGWGGEDVHLYRKYLHSNLIVVRTPVRGLFHLWHEKRCMDELTPEQYKMCMQSKA -------------------------------------------------------------- >55407_55407_3_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000317173_CSGALNACT1_chr8_19266205_ENST00000454498_length(transcript)=2783nt_BP=792nt GGAACTCGCCGGGCCACACCCCCTGTCCAGGGAAGGAACACGCCCCCGGTGACAGCCGGTACGGCCCCGGGTTTGGGCAACCTCGATTAC GGGCGGCCTCCAGCCCCGCCAGCAGCGCCCCGCGCCCGCCCGCCCGCGCCCCTGCCGCCCCCCGGTTCCGGCCGCGGACCCCACTCTCTG CCGTTCCGGCTGCGGCTCCGCTGCCGGTAGCGCCGTCCCCCGGGACCACCCTTCGGCTGGCGCCCTCCCATGCTCTCGGCCACCCGGAGG GCTTGCCAGCTCCTCCTCCTCCACAGCCTCTTTCCCGTCCCGAGGATGGGCAACTCGGCCTCGAACATCGTCAGCCCCCAGGAGGCCTTG CCGGGCCGGAAGGAACAGACCCCTGTAGCGGCCAAACATCATGTCAATGGCAACAGAACAGTCGAACCTTTCCCAGAGGGAACACAGATG GCTGTATTTGGAATGGGATGTTTCTGGGGAGCTGAAAGGAAATTCTGGGTCTTGAAAGGAGTGTATTCAACTCAAGTTGGTTTTGCAGGA GGCTATACTTCAAATCCTACTTATAAAGAAGTCTGCTCAGAAAAAACTGGCCATGCAGAAGTCGTCCGAGTGGTGTACCAGCCAGAACAC ATGAGTTTTGAGGAACTGCTCAAGGTCTTCTGGGAGAATCACGACCCGACCCAAGGTATGCGCCAGGGGAACGACCATGGCACTCAGTAC CGCTCGGCCATCTACCCGACCTCTGCCAAGCAAATGGAGGCAGCCCTGAGCTCCAAAGAGAACTACCAAAAGGTCATAAAGAAGGAAACT GGATTTTGGAGAGACTTTGGATTTGGGATGACGTGTCAGTATCGGTCAGACTTCATCAATATAGGTGGGTTTGATCTGGACATCAAAGGC TGGGGCGGAGAGGATGTGCACCTTTATCGCAAGTATCTCCACAGCAACCTCATAGTGGTACGGACGCCTGTGCGAGGACTCTTCCACCTC TGGCATGAGAAGCGCTGCATGGACGAGCTGACCCCCGAGCAGTACAAGATGTGCATGCAGTCCAAGGCCATGAACGAGGCATCCCACGGC CAGCTGGGCATGCTGGTGTTCAGGCACGAGATAGAGGCTCACCTTCGCAAACAGAAACAGAAGACAAGTAGCAAAAAAACATGAACTCCC AGAGAAGGATTGTGGGAGACACTTTTTCTTTCCTTTTGCAATTACTGAAAGTGGCTGCAACAGAGAAAAGACTTCCATAAAGGACGACAA AAGAATTGGACTGATGGGTCAGAGATGAGAAAGCCTCCGATTTCTCTCTGTTGGGCTTTTTACAACAGAAATCAAAATCTCCGCTTTGCC TGCAAAAGTAACCCAGTTGCACCCTGTGAAGTGTCTGACAAAGGCAGAATGCTTGTGAGATTATAAGCCTAATGGTGTGGAGGTTTTGAT GGTGTTTACAACACACTGAGACCTGTTGTTTTGTGTGCTCATTGAAATATTCATGATTTAAGAGCAGTTTTGTAAAAAATTCATTAGCAT GAAAGGCAAGCATATTTCTCCTCATATGAATGAGCCTATCAGCAGGGCTCTAGTTTCTAGGAATGCTAAAATATCAGAAGGCAGGAGAGG AGATAGGCTTATTATGATACTAGTGAGTACATTAAGTAAAATAAAATGGACCAGAAAAGAAAAGAAACCATAAATATCGTGTCATATTTT CCCCAAGATTAACCAAAAATAATCTGCTTATCTTTTTGGTTGTCCTTTTAACTGTCTCCGTTTTTTTCTTTTATTTAAAAATGCACTTTT TTTCCCTTGTGAGTTATAGTCTGCTTATTTAATTACCACTTTGCAAGCCTTACAAGAGAGCACAAGTTGGCCTACATTTTTATATTTTTT AAGAAGATACTTTGAGATGCATTATGAGAACTTTCAGTTCAAAGCATCAAATTGATGCCATATCCAAGGACATGCCAAATGCTGATTCTG TCAGGCACTGAATGTCAGGCATTGAGACATAGGGAAGGAATGGTTTGTACTAATACAGACGTACAGATACTTTCTCTGAAGAGTATTTTC GAAGAGGAGCAACTGAACACTGGAGGAAAAGAAAATGACACTTTCTGCTTTACAGAAAAGGAAACTCATTCAGACTGGTGATATCGTGAT GTACCTAAAAGTCAGAAACCACATTTTCTCCTCAGAAGTAGGGACCGCTTTCTTACCTGTTTAAATAAACCAAAGTATACCGTGTGAACC AAACAATCTCTTTTCAAAACAGGGTGCTCCTCCTGGCTTCTGGCTTCCATAAGAAGAAATGGAGAAAAAAATATATATATATATATTGTG AAAGATCAATCCATCTGCCAGAATCTAGTGGGATGGAAGTTTTTGCTACATGTTATCCACCCCAGGCCAGGTGGAAGTAACTGAATTATT TTTTAAATTAAGCAGTTCTACTCGATCACCAAGATGCTTCTGAAAATTGCATTTTATTACCATTTCAAACTATTTTTTAAAAATAAATAC AGTTAACATAGAGTGGTTTCTTCATTCATGTGAAAATTATTAGCCAGCACCAGATGCATGAGCTAATTATCTCTTTGAGTCCTTGCTTCT GTTTGCTCACAGTAAACTCATTGTTTAAAAGCTTCAAGAACATTCAAGCTGTTGGTGTGTTAAAAAATGCATTGTATTGATTTGTACTGG >55407_55407_3_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000317173_CSGALNACT1_chr8_19266205_ENST00000454498_length(amino acids)=304AA_BP=181 MLSATRRACQLLLLHSLFPVPRMGNSASNIVSPQEALPGRKEQTPVAAKHHVNGNRTVEPFPEGTQMAVFGMGCFWGAERKFWVLKGVYS TQVGFAGGYTSNPTYKEVCSEKTGHAEVVRVVYQPEHMSFEELLKVFWENHDPTQGMRQGNDHGTQYRSAIYPTSAKQMEAALSSKENYQ KVIKKETGFWRDFGFGMTCQYRSDFINIGGFDLDIKGWGGEDVHLYRKYLHSNLIVVRTPVRGLFHLWHEKRCMDELTPEQYKMCMQSKA -------------------------------------------------------------- >55407_55407_4_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000317173_CSGALNACT1_chr8_19266205_ENST00000522854_length(transcript)=1164nt_BP=792nt GGAACTCGCCGGGCCACACCCCCTGTCCAGGGAAGGAACACGCCCCCGGTGACAGCCGGTACGGCCCCGGGTTTGGGCAACCTCGATTAC GGGCGGCCTCCAGCCCCGCCAGCAGCGCCCCGCGCCCGCCCGCCCGCGCCCCTGCCGCCCCCCGGTTCCGGCCGCGGACCCCACTCTCTG CCGTTCCGGCTGCGGCTCCGCTGCCGGTAGCGCCGTCCCCCGGGACCACCCTTCGGCTGGCGCCCTCCCATGCTCTCGGCCACCCGGAGG GCTTGCCAGCTCCTCCTCCTCCACAGCCTCTTTCCCGTCCCGAGGATGGGCAACTCGGCCTCGAACATCGTCAGCCCCCAGGAGGCCTTG CCGGGCCGGAAGGAACAGACCCCTGTAGCGGCCAAACATCATGTCAATGGCAACAGAACAGTCGAACCTTTCCCAGAGGGAACACAGATG GCTGTATTTGGAATGGGATGTTTCTGGGGAGCTGAAAGGAAATTCTGGGTCTTGAAAGGAGTGTATTCAACTCAAGTTGGTTTTGCAGGA GGCTATACTTCAAATCCTACTTATAAAGAAGTCTGCTCAGAAAAAACTGGCCATGCAGAAGTCGTCCGAGTGGTGTACCAGCCAGAACAC ATGAGTTTTGAGGAACTGCTCAAGGTCTTCTGGGAGAATCACGACCCGACCCAAGGTATGCGCCAGGGGAACGACCATGGCACTCAGTAC CGCTCGGCCATCTACCCGACCTCTGCCAAGCAAATGGAGGCAGCCCTGAGCTCCAAAGAGAACTACCAAAAGGTCATAAAGAAGGAAACT GGATTTTGGAGAGACTTTGGATTTGGGATGACGTGTCAGTATCGGTCAGACTTCATCAATATAGGTGGGTTTGATCTGGACATCAAAGGC TGGGGCGGAGAGGATGTGCACCTTTATCGCAAGTATCTCCACAGCAACCTCATAGTGGTACGGACGCCTGTGCGAGGACTCTTCCACCTC TGGCATGAGAAGCGCTGCATGGACGAGCTGACCCCCGAGCAGTACAAGATGTGCATGCAGTCCAAGGCCATGAACGAGGCATCCCACGGC >55407_55407_4_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000317173_CSGALNACT1_chr8_19266205_ENST00000522854_length(amino acids)=304AA_BP=181 MLSATRRACQLLLLHSLFPVPRMGNSASNIVSPQEALPGRKEQTPVAAKHHVNGNRTVEPFPEGTQMAVFGMGCFWGAERKFWVLKGVYS TQVGFAGGYTSNPTYKEVCSEKTGHAEVVRVVYQPEHMSFEELLKVFWENHDPTQGMRQGNDHGTQYRSAIYPTSAKQMEAALSSKENYQ KVIKKETGFWRDFGFGMTCQYRSDFINIGGFDLDIKGWGGEDVHLYRKYLHSNLIVVRTPVRGLFHLWHEKRCMDELTPEQYKMCMQSKA -------------------------------------------------------------- >55407_55407_5_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000317173_CSGALNACT1_chr8_19266205_ENST00000544602_length(transcript)=1164nt_BP=792nt GGAACTCGCCGGGCCACACCCCCTGTCCAGGGAAGGAACACGCCCCCGGTGACAGCCGGTACGGCCCCGGGTTTGGGCAACCTCGATTAC GGGCGGCCTCCAGCCCCGCCAGCAGCGCCCCGCGCCCGCCCGCCCGCGCCCCTGCCGCCCCCCGGTTCCGGCCGCGGACCCCACTCTCTG CCGTTCCGGCTGCGGCTCCGCTGCCGGTAGCGCCGTCCCCCGGGACCACCCTTCGGCTGGCGCCCTCCCATGCTCTCGGCCACCCGGAGG GCTTGCCAGCTCCTCCTCCTCCACAGCCTCTTTCCCGTCCCGAGGATGGGCAACTCGGCCTCGAACATCGTCAGCCCCCAGGAGGCCTTG CCGGGCCGGAAGGAACAGACCCCTGTAGCGGCCAAACATCATGTCAATGGCAACAGAACAGTCGAACCTTTCCCAGAGGGAACACAGATG GCTGTATTTGGAATGGGATGTTTCTGGGGAGCTGAAAGGAAATTCTGGGTCTTGAAAGGAGTGTATTCAACTCAAGTTGGTTTTGCAGGA GGCTATACTTCAAATCCTACTTATAAAGAAGTCTGCTCAGAAAAAACTGGCCATGCAGAAGTCGTCCGAGTGGTGTACCAGCCAGAACAC ATGAGTTTTGAGGAACTGCTCAAGGTCTTCTGGGAGAATCACGACCCGACCCAAGGTATGCGCCAGGGGAACGACCATGGCACTCAGTAC CGCTCGGCCATCTACCCGACCTCTGCCAAGCAAATGGAGGCAGCCCTGAGCTCCAAAGAGAACTACCAAAAGGTCATAAAGAAGGAAACT GGATTTTGGAGAGACTTTGGATTTGGGATGACGTGTCAGTATCGGTCAGACTTCATCAATATAGGTGGGTTTGATCTGGACATCAAAGGC TGGGGCGGAGAGGATGTGCACCTTTATCGCAAGTATCTCCACAGCAACCTCATAGTGGTACGGACGCCTGTGCGAGGACTCTTCCACCTC TGGCATGAGAAGCGCTGCATGGACGAGCTGACCCCCGAGCAGTACAAGATGTGCATGCAGTCCAAGGCCATGAACGAGGCATCCCACGGC >55407_55407_5_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000317173_CSGALNACT1_chr8_19266205_ENST00000544602_length(amino acids)=304AA_BP=181 MLSATRRACQLLLLHSLFPVPRMGNSASNIVSPQEALPGRKEQTPVAAKHHVNGNRTVEPFPEGTQMAVFGMGCFWGAERKFWVLKGVYS TQVGFAGGYTSNPTYKEVCSEKTGHAEVVRVVYQPEHMSFEELLKVFWENHDPTQGMRQGNDHGTQYRSAIYPTSAKQMEAALSSKENYQ KVIKKETGFWRDFGFGMTCQYRSDFINIGGFDLDIKGWGGEDVHLYRKYLHSNLIVVRTPVRGLFHLWHEKRCMDELTPEQYKMCMQSKA -------------------------------------------------------------- >55407_55407_6_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000382490_CSGALNACT1_chr8_19266205_ENST00000311540_length(transcript)=2708nt_BP=718nt AAACTTAGAAGGCTTTTTAAGTCTCTTGGGCTATTTGAAAGTGTTGGTACATACAATGACGTTTAGTCACCAGTATTAAGGGAAATAAAA GCCTTTTTCAAAACGAAGCTTCCATAGTGTCCATGCATTTGGGAAATACTATATTTGATTTTTTGCATGTATGATTATACCATGAGAGAC AGGATTAATATAGAAGATGGCAAGGCAAATTTCTAATTAGAGGGAATATTAATTTTCTACAAAATAAAGTTTGTTCATCAATACAAACCT GCTTTCAAATCAAATCAGAAAGACATCCTTCGGAATGTGTTCAGAACCCAAACATCATGTCAATGGCAACAGAACAGTCGAACCTTTCCC AGAGGGAACACAGATGGCTGTATTTGGAATGGGATGTTTCTGGGGAGCTGAAAGGAAATTCTGGGTCTTGAAAGGAGTGTATTCAACTCA AGTTGGTTTTGCAGGAGGCTATACTTCAAATCCTACTTATAAAGAAGTCTGCTCAGAAAAAACTGGCCATGCAGAAGTCGTCCGAGTGGT GTACCAGCCAGAACACATGAGTTTTGAGGAACTGCTCAAGGTCTTCTGGGAGAATCACGACCCGACCCAAGGTATGCGCCAGGGGAACGA CCATGGCACTCAGTACCGCTCGGCCATCTACCCGACCTCTGCCAAGCAAATGGAGGCAGCCCTGAGCTCCAAAGAGAACTACCAAAAGGT CATAAAGAAGGAAACTGGATTTTGGAGAGACTTTGGATTTGGGATGACGTGTCAGTATCGGTCAGACTTCATCAATATAGGTGGGTTTGA TCTGGACATCAAAGGCTGGGGCGGAGAGGATGTGCACCTTTATCGCAAGTATCTCCACAGCAACCTCATAGTGGTACGGACGCCTGTGCG AGGACTCTTCCACCTCTGGCATGAGAAGCGCTGCATGGACGAGCTGACCCCCGAGCAGTACAAGATGTGCATGCAGTCCAAGGCCATGAA CGAGGCATCCCACGGCCAGCTGGGCATGCTGGTGTTCAGGCACGAGATAGAGGCTCACCTTCGCAAACAGAAACAGAAGACAAGTAGCAA AAAAACATGAACTCCCAGAGAAGGATTGTGGGAGACACTTTTTCTTTCCTTTTGCAATTACTGAAAGTGGCTGCAACAGAGAAAAGACTT CCATAAAGGACGACAAAAGAATTGGACTGATGGGTCAGAGATGAGAAAGCCTCCGATTTCTCTCTGTTGGGCTTTTTACAACAGAAATCA AAATCTCCGCTTTGCCTGCAAAAGTAACCCAGTTGCACCCTGTGAAGTGTCTGACAAAGGCAGAATGCTTGTGAGATTATAAGCCTAATG GTGTGGAGGTTTTGATGGTGTTTACAACACACTGAGACCTGTTGTTTTGTGTGCTCATTGAAATATTCATGATTTAAGAGCAGTTTTGTA AAAAATTCATTAGCATGAAAGGCAAGCATATTTCTCCTCATATGAATGAGCCTATCAGCAGGGCTCTAGTTTCTAGGAATGCTAAAATAT CAGAAGGCAGGAGAGGAGATAGGCTTATTATGATACTAGTGAGTACATTAAGTAAAATAAAATGGACCAGAAAAGAAAAGAAACCATAAA TATCGTGTCATATTTTCCCCAAGATTAACCAAAAATAATCTGCTTATCTTTTTGGTTGTCCTTTTAACTGTCTCCGTTTTTTTCTTTTAT TTAAAAATGCACTTTTTTTCCCTTGTGAGTTATAGTCTGCTTATTTAATTACCACTTTGCAAGCCTTACAAGAGAGCACAAGTTGGCCTA CATTTTTATATTTTTTAAGAAGATACTTTGAGATGCATTATGAGAACTTTCAGTTCAAAGCATCAAATTGATGCCATATCCAAGGACATG CCAAATGCTGATTCTGTCAGGCACTGAATGTCAGGCATTGAGACATAGGGAAGGAATGGTTTGTACTAATACAGACGTACAGATACTTTC TCTGAAGAGTATTTTCGAAGAGGAGCAACTGAACACTGGAGGAAAAGAAAATGACACTTTCTGCTTTACAGAAAAGGAAACTCATTCAGA CTGGTGATATCGTGATGTACCTAAAAGTCAGAAACCACATTTTCTCCTCAGAAGTAGGGACCGCTTTCTTACCTGTTTAAATAAACCAAA GTATACCGTGTGAACCAAACAATCTCTTTTCAAAACAGGGTGCTCCTCCTGGCTTCTGGCTTCCATAAGAAGAAATGGAGAAAAAAATAT ATATATATATATTGTGAAAGATCAATCCATCTGCCAGAATCTAGTGGGATGGAAGTTTTTGCTACATGTTATCCACCCCAGGCCAGGTGG AAGTAACTGAATTATTTTTTAAATTAAGCAGTTCTACTCGATCACCAAGATGCTTCTGAAAATTGCATTTTATTACCATTTCAAACTATT TTTTAAAAATAAATACAGTTAACATAGAGTGGTTTCTTCATTCATGTGAAAATTATTAGCCAGCACCAGATGCATGAGCTAATTATCTCT TTGAGTCCTTGCTTCTGTTTGCTCACAGTAAACTCATTGTTTAAAAGCTTCAAGAACATTCAAGCTGTTGGTGTGTTAAAAAATGCATTG TATTGATTTGTACTGGTAGTTTATGAAATTTAATTAAAACACAGGCCATGAATGGAAGGTGGTATTGCACAGCTAATAAAATATGATTTG >55407_55407_6_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000382490_CSGALNACT1_chr8_19266205_ENST00000311540_length(amino acids)=279AA_BP=156 MFINTNLLSNQIRKTSFGMCSEPKHHVNGNRTVEPFPEGTQMAVFGMGCFWGAERKFWVLKGVYSTQVGFAGGYTSNPTYKEVCSEKTGH AEVVRVVYQPEHMSFEELLKVFWENHDPTQGMRQGNDHGTQYRSAIYPTSAKQMEAALSSKENYQKVIKKETGFWRDFGFGMTCQYRSDF INIGGFDLDIKGWGGEDVHLYRKYLHSNLIVVRTPVRGLFHLWHEKRCMDELTPEQYKMCMQSKAMNEASHGQLGMLVFRHEIEAHLRKQ -------------------------------------------------------------- >55407_55407_7_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000382490_CSGALNACT1_chr8_19266205_ENST00000332246_length(transcript)=2709nt_BP=718nt AAACTTAGAAGGCTTTTTAAGTCTCTTGGGCTATTTGAAAGTGTTGGTACATACAATGACGTTTAGTCACCAGTATTAAGGGAAATAAAA GCCTTTTTCAAAACGAAGCTTCCATAGTGTCCATGCATTTGGGAAATACTATATTTGATTTTTTGCATGTATGATTATACCATGAGAGAC AGGATTAATATAGAAGATGGCAAGGCAAATTTCTAATTAGAGGGAATATTAATTTTCTACAAAATAAAGTTTGTTCATCAATACAAACCT GCTTTCAAATCAAATCAGAAAGACATCCTTCGGAATGTGTTCAGAACCCAAACATCATGTCAATGGCAACAGAACAGTCGAACCTTTCCC AGAGGGAACACAGATGGCTGTATTTGGAATGGGATGTTTCTGGGGAGCTGAAAGGAAATTCTGGGTCTTGAAAGGAGTGTATTCAACTCA AGTTGGTTTTGCAGGAGGCTATACTTCAAATCCTACTTATAAAGAAGTCTGCTCAGAAAAAACTGGCCATGCAGAAGTCGTCCGAGTGGT GTACCAGCCAGAACACATGAGTTTTGAGGAACTGCTCAAGGTCTTCTGGGAGAATCACGACCCGACCCAAGGTATGCGCCAGGGGAACGA CCATGGCACTCAGTACCGCTCGGCCATCTACCCGACCTCTGCCAAGCAAATGGAGGCAGCCCTGAGCTCCAAAGAGAACTACCAAAAGGT CATAAAGAAGGAAACTGGATTTTGGAGAGACTTTGGATTTGGGATGACGTGTCAGTATCGGTCAGACTTCATCAATATAGGTGGGTTTGA TCTGGACATCAAAGGCTGGGGCGGAGAGGATGTGCACCTTTATCGCAAGTATCTCCACAGCAACCTCATAGTGGTACGGACGCCTGTGCG AGGACTCTTCCACCTCTGGCATGAGAAGCGCTGCATGGACGAGCTGACCCCCGAGCAGTACAAGATGTGCATGCAGTCCAAGGCCATGAA CGAGGCATCCCACGGCCAGCTGGGCATGCTGGTGTTCAGGCACGAGATAGAGGCTCACCTTCGCAAACAGAAACAGAAGACAAGTAGCAA AAAAACATGAACTCCCAGAGAAGGATTGTGGGAGACACTTTTTCTTTCCTTTTGCAATTACTGAAAGTGGCTGCAACAGAGAAAAGACTT CCATAAAGGACGACAAAAGAATTGGACTGATGGGTCAGAGATGAGAAAGCCTCCGATTTCTCTCTGTTGGGCTTTTTACAACAGAAATCA AAATCTCCGCTTTGCCTGCAAAAGTAACCCAGTTGCACCCTGTGAAGTGTCTGACAAAGGCAGAATGCTTGTGAGATTATAAGCCTAATG GTGTGGAGGTTTTGATGGTGTTTACAACACACTGAGACCTGTTGTTTTGTGTGCTCATTGAAATATTCATGATTTAAGAGCAGTTTTGTA AAAAATTCATTAGCATGAAAGGCAAGCATATTTCTCCTCATATGAATGAGCCTATCAGCAGGGCTCTAGTTTCTAGGAATGCTAAAATAT CAGAAGGCAGGAGAGGAGATAGGCTTATTATGATACTAGTGAGTACATTAAGTAAAATAAAATGGACCAGAAAAGAAAAGAAACCATAAA TATCGTGTCATATTTTCCCCAAGATTAACCAAAAATAATCTGCTTATCTTTTTGGTTGTCCTTTTAACTGTCTCCGTTTTTTTCTTTTAT TTAAAAATGCACTTTTTTTCCCTTGTGAGTTATAGTCTGCTTATTTAATTACCACTTTGCAAGCCTTACAAGAGAGCACAAGTTGGCCTA CATTTTTATATTTTTTAAGAAGATACTTTGAGATGCATTATGAGAACTTTCAGTTCAAAGCATCAAATTGATGCCATATCCAAGGACATG CCAAATGCTGATTCTGTCAGGCACTGAATGTCAGGCATTGAGACATAGGGAAGGAATGGTTTGTACTAATACAGACGTACAGATACTTTC TCTGAAGAGTATTTTCGAAGAGGAGCAACTGAACACTGGAGGAAAAGAAAATGACACTTTCTGCTTTACAGAAAAGGAAACTCATTCAGA CTGGTGATATCGTGATGTACCTAAAAGTCAGAAACCACATTTTCTCCTCAGAAGTAGGGACCGCTTTCTTACCTGTTTAAATAAACCAAA GTATACCGTGTGAACCAAACAATCTCTTTTCAAAACAGGGTGCTCCTCCTGGCTTCTGGCTTCCATAAGAAGAAATGGAGAAAAAAATAT ATATATATATATTGTGAAAGATCAATCCATCTGCCAGAATCTAGTGGGATGGAAGTTTTTGCTACATGTTATCCACCCCAGGCCAGGTGG AAGTAACTGAATTATTTTTTAAATTAAGCAGTTCTACTCGATCACCAAGATGCTTCTGAAAATTGCATTTTATTACCATTTCAAACTATT TTTTAAAAATAAATACAGTTAACATAGAGTGGTTTCTTCATTCATGTGAAAATTATTAGCCAGCACCAGATGCATGAGCTAATTATCTCT TTGAGTCCTTGCTTCTGTTTGCTCACAGTAAACTCATTGTTTAAAAGCTTCAAGAACATTCAAGCTGTTGGTGTGTTAAAAAATGCATTG TATTGATTTGTACTGGTAGTTTATGAAATTTAATTAAAACACAGGCCATGAATGGAAGGTGGTATTGCACAGCTAATAAAATATGATTTG >55407_55407_7_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000382490_CSGALNACT1_chr8_19266205_ENST00000332246_length(amino acids)=279AA_BP=156 MFINTNLLSNQIRKTSFGMCSEPKHHVNGNRTVEPFPEGTQMAVFGMGCFWGAERKFWVLKGVYSTQVGFAGGYTSNPTYKEVCSEKTGH AEVVRVVYQPEHMSFEELLKVFWENHDPTQGMRQGNDHGTQYRSAIYPTSAKQMEAALSSKENYQKVIKKETGFWRDFGFGMTCQYRSDF INIGGFDLDIKGWGGEDVHLYRKYLHSNLIVVRTPVRGLFHLWHEKRCMDELTPEQYKMCMQSKAMNEASHGQLGMLVFRHEIEAHLRKQ -------------------------------------------------------------- >55407_55407_8_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000382490_CSGALNACT1_chr8_19266205_ENST00000454498_length(transcript)=2709nt_BP=718nt AAACTTAGAAGGCTTTTTAAGTCTCTTGGGCTATTTGAAAGTGTTGGTACATACAATGACGTTTAGTCACCAGTATTAAGGGAAATAAAA GCCTTTTTCAAAACGAAGCTTCCATAGTGTCCATGCATTTGGGAAATACTATATTTGATTTTTTGCATGTATGATTATACCATGAGAGAC AGGATTAATATAGAAGATGGCAAGGCAAATTTCTAATTAGAGGGAATATTAATTTTCTACAAAATAAAGTTTGTTCATCAATACAAACCT GCTTTCAAATCAAATCAGAAAGACATCCTTCGGAATGTGTTCAGAACCCAAACATCATGTCAATGGCAACAGAACAGTCGAACCTTTCCC AGAGGGAACACAGATGGCTGTATTTGGAATGGGATGTTTCTGGGGAGCTGAAAGGAAATTCTGGGTCTTGAAAGGAGTGTATTCAACTCA AGTTGGTTTTGCAGGAGGCTATACTTCAAATCCTACTTATAAAGAAGTCTGCTCAGAAAAAACTGGCCATGCAGAAGTCGTCCGAGTGGT GTACCAGCCAGAACACATGAGTTTTGAGGAACTGCTCAAGGTCTTCTGGGAGAATCACGACCCGACCCAAGGTATGCGCCAGGGGAACGA CCATGGCACTCAGTACCGCTCGGCCATCTACCCGACCTCTGCCAAGCAAATGGAGGCAGCCCTGAGCTCCAAAGAGAACTACCAAAAGGT CATAAAGAAGGAAACTGGATTTTGGAGAGACTTTGGATTTGGGATGACGTGTCAGTATCGGTCAGACTTCATCAATATAGGTGGGTTTGA TCTGGACATCAAAGGCTGGGGCGGAGAGGATGTGCACCTTTATCGCAAGTATCTCCACAGCAACCTCATAGTGGTACGGACGCCTGTGCG AGGACTCTTCCACCTCTGGCATGAGAAGCGCTGCATGGACGAGCTGACCCCCGAGCAGTACAAGATGTGCATGCAGTCCAAGGCCATGAA CGAGGCATCCCACGGCCAGCTGGGCATGCTGGTGTTCAGGCACGAGATAGAGGCTCACCTTCGCAAACAGAAACAGAAGACAAGTAGCAA AAAAACATGAACTCCCAGAGAAGGATTGTGGGAGACACTTTTTCTTTCCTTTTGCAATTACTGAAAGTGGCTGCAACAGAGAAAAGACTT CCATAAAGGACGACAAAAGAATTGGACTGATGGGTCAGAGATGAGAAAGCCTCCGATTTCTCTCTGTTGGGCTTTTTACAACAGAAATCA AAATCTCCGCTTTGCCTGCAAAAGTAACCCAGTTGCACCCTGTGAAGTGTCTGACAAAGGCAGAATGCTTGTGAGATTATAAGCCTAATG GTGTGGAGGTTTTGATGGTGTTTACAACACACTGAGACCTGTTGTTTTGTGTGCTCATTGAAATATTCATGATTTAAGAGCAGTTTTGTA AAAAATTCATTAGCATGAAAGGCAAGCATATTTCTCCTCATATGAATGAGCCTATCAGCAGGGCTCTAGTTTCTAGGAATGCTAAAATAT CAGAAGGCAGGAGAGGAGATAGGCTTATTATGATACTAGTGAGTACATTAAGTAAAATAAAATGGACCAGAAAAGAAAAGAAACCATAAA TATCGTGTCATATTTTCCCCAAGATTAACCAAAAATAATCTGCTTATCTTTTTGGTTGTCCTTTTAACTGTCTCCGTTTTTTTCTTTTAT TTAAAAATGCACTTTTTTTCCCTTGTGAGTTATAGTCTGCTTATTTAATTACCACTTTGCAAGCCTTACAAGAGAGCACAAGTTGGCCTA CATTTTTATATTTTTTAAGAAGATACTTTGAGATGCATTATGAGAACTTTCAGTTCAAAGCATCAAATTGATGCCATATCCAAGGACATG CCAAATGCTGATTCTGTCAGGCACTGAATGTCAGGCATTGAGACATAGGGAAGGAATGGTTTGTACTAATACAGACGTACAGATACTTTC TCTGAAGAGTATTTTCGAAGAGGAGCAACTGAACACTGGAGGAAAAGAAAATGACACTTTCTGCTTTACAGAAAAGGAAACTCATTCAGA CTGGTGATATCGTGATGTACCTAAAAGTCAGAAACCACATTTTCTCCTCAGAAGTAGGGACCGCTTTCTTACCTGTTTAAATAAACCAAA GTATACCGTGTGAACCAAACAATCTCTTTTCAAAACAGGGTGCTCCTCCTGGCTTCTGGCTTCCATAAGAAGAAATGGAGAAAAAAATAT ATATATATATATTGTGAAAGATCAATCCATCTGCCAGAATCTAGTGGGATGGAAGTTTTTGCTACATGTTATCCACCCCAGGCCAGGTGG AAGTAACTGAATTATTTTTTAAATTAAGCAGTTCTACTCGATCACCAAGATGCTTCTGAAAATTGCATTTTATTACCATTTCAAACTATT TTTTAAAAATAAATACAGTTAACATAGAGTGGTTTCTTCATTCATGTGAAAATTATTAGCCAGCACCAGATGCATGAGCTAATTATCTCT TTGAGTCCTTGCTTCTGTTTGCTCACAGTAAACTCATTGTTTAAAAGCTTCAAGAACATTCAAGCTGTTGGTGTGTTAAAAAATGCATTG TATTGATTTGTACTGGTAGTTTATGAAATTTAATTAAAACACAGGCCATGAATGGAAGGTGGTATTGCACAGCTAATAAAATATGATTTG >55407_55407_8_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000382490_CSGALNACT1_chr8_19266205_ENST00000454498_length(amino acids)=279AA_BP=156 MFINTNLLSNQIRKTSFGMCSEPKHHVNGNRTVEPFPEGTQMAVFGMGCFWGAERKFWVLKGVYSTQVGFAGGYTSNPTYKEVCSEKTGH AEVVRVVYQPEHMSFEELLKVFWENHDPTQGMRQGNDHGTQYRSAIYPTSAKQMEAALSSKENYQKVIKKETGFWRDFGFGMTCQYRSDF INIGGFDLDIKGWGGEDVHLYRKYLHSNLIVVRTPVRGLFHLWHEKRCMDELTPEQYKMCMQSKAMNEASHGQLGMLVFRHEIEAHLRKQ -------------------------------------------------------------- >55407_55407_9_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000382490_CSGALNACT1_chr8_19266205_ENST00000522854_length(transcript)=1090nt_BP=718nt AAACTTAGAAGGCTTTTTAAGTCTCTTGGGCTATTTGAAAGTGTTGGTACATACAATGACGTTTAGTCACCAGTATTAAGGGAAATAAAA GCCTTTTTCAAAACGAAGCTTCCATAGTGTCCATGCATTTGGGAAATACTATATTTGATTTTTTGCATGTATGATTATACCATGAGAGAC AGGATTAATATAGAAGATGGCAAGGCAAATTTCTAATTAGAGGGAATATTAATTTTCTACAAAATAAAGTTTGTTCATCAATACAAACCT GCTTTCAAATCAAATCAGAAAGACATCCTTCGGAATGTGTTCAGAACCCAAACATCATGTCAATGGCAACAGAACAGTCGAACCTTTCCC AGAGGGAACACAGATGGCTGTATTTGGAATGGGATGTTTCTGGGGAGCTGAAAGGAAATTCTGGGTCTTGAAAGGAGTGTATTCAACTCA AGTTGGTTTTGCAGGAGGCTATACTTCAAATCCTACTTATAAAGAAGTCTGCTCAGAAAAAACTGGCCATGCAGAAGTCGTCCGAGTGGT GTACCAGCCAGAACACATGAGTTTTGAGGAACTGCTCAAGGTCTTCTGGGAGAATCACGACCCGACCCAAGGTATGCGCCAGGGGAACGA CCATGGCACTCAGTACCGCTCGGCCATCTACCCGACCTCTGCCAAGCAAATGGAGGCAGCCCTGAGCTCCAAAGAGAACTACCAAAAGGT CATAAAGAAGGAAACTGGATTTTGGAGAGACTTTGGATTTGGGATGACGTGTCAGTATCGGTCAGACTTCATCAATATAGGTGGGTTTGA TCTGGACATCAAAGGCTGGGGCGGAGAGGATGTGCACCTTTATCGCAAGTATCTCCACAGCAACCTCATAGTGGTACGGACGCCTGTGCG AGGACTCTTCCACCTCTGGCATGAGAAGCGCTGCATGGACGAGCTGACCCCCGAGCAGTACAAGATGTGCATGCAGTCCAAGGCCATGAA CGAGGCATCCCACGGCCAGCTGGGCATGCTGGTGTTCAGGCACGAGATAGAGGCTCACCTTCGCAAACAGAAACAGAAGACAAGTAGCAA >55407_55407_9_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000382490_CSGALNACT1_chr8_19266205_ENST00000522854_length(amino acids)=280AA_BP=156 MFINTNLLSNQIRKTSFGMCSEPKHHVNGNRTVEPFPEGTQMAVFGMGCFWGAERKFWVLKGVYSTQVGFAGGYTSNPTYKEVCSEKTGH AEVVRVVYQPEHMSFEELLKVFWENHDPTQGMRQGNDHGTQYRSAIYPTSAKQMEAALSSKENYQKVIKKETGFWRDFGFGMTCQYRSDF INIGGFDLDIKGWGGEDVHLYRKYLHSNLIVVRTPVRGLFHLWHEKRCMDELTPEQYKMCMQSKAMNEASHGQLGMLVFRHEIEAHLRKQ -------------------------------------------------------------- >55407_55407_10_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000382490_CSGALNACT1_chr8_19266205_ENST00000544602_length(transcript)=1090nt_BP=718nt AAACTTAGAAGGCTTTTTAAGTCTCTTGGGCTATTTGAAAGTGTTGGTACATACAATGACGTTTAGTCACCAGTATTAAGGGAAATAAAA GCCTTTTTCAAAACGAAGCTTCCATAGTGTCCATGCATTTGGGAAATACTATATTTGATTTTTTGCATGTATGATTATACCATGAGAGAC AGGATTAATATAGAAGATGGCAAGGCAAATTTCTAATTAGAGGGAATATTAATTTTCTACAAAATAAAGTTTGTTCATCAATACAAACCT GCTTTCAAATCAAATCAGAAAGACATCCTTCGGAATGTGTTCAGAACCCAAACATCATGTCAATGGCAACAGAACAGTCGAACCTTTCCC AGAGGGAACACAGATGGCTGTATTTGGAATGGGATGTTTCTGGGGAGCTGAAAGGAAATTCTGGGTCTTGAAAGGAGTGTATTCAACTCA AGTTGGTTTTGCAGGAGGCTATACTTCAAATCCTACTTATAAAGAAGTCTGCTCAGAAAAAACTGGCCATGCAGAAGTCGTCCGAGTGGT GTACCAGCCAGAACACATGAGTTTTGAGGAACTGCTCAAGGTCTTCTGGGAGAATCACGACCCGACCCAAGGTATGCGCCAGGGGAACGA CCATGGCACTCAGTACCGCTCGGCCATCTACCCGACCTCTGCCAAGCAAATGGAGGCAGCCCTGAGCTCCAAAGAGAACTACCAAAAGGT CATAAAGAAGGAAACTGGATTTTGGAGAGACTTTGGATTTGGGATGACGTGTCAGTATCGGTCAGACTTCATCAATATAGGTGGGTTTGA TCTGGACATCAAAGGCTGGGGCGGAGAGGATGTGCACCTTTATCGCAAGTATCTCCACAGCAACCTCATAGTGGTACGGACGCCTGTGCG AGGACTCTTCCACCTCTGGCATGAGAAGCGCTGCATGGACGAGCTGACCCCCGAGCAGTACAAGATGTGCATGCAGTCCAAGGCCATGAA CGAGGCATCCCACGGCCAGCTGGGCATGCTGGTGTTCAGGCACGAGATAGAGGCTCACCTTCGCAAACAGAAACAGAAGACAAGTAGCAA >55407_55407_10_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000382490_CSGALNACT1_chr8_19266205_ENST00000544602_length(amino acids)=280AA_BP=156 MFINTNLLSNQIRKTSFGMCSEPKHHVNGNRTVEPFPEGTQMAVFGMGCFWGAERKFWVLKGVYSTQVGFAGGYTSNPTYKEVCSEKTGH AEVVRVVYQPEHMSFEELLKVFWENHDPTQGMRQGNDHGTQYRSAIYPTSAKQMEAALSSKENYQKVIKKETGFWRDFGFGMTCQYRSDF INIGGFDLDIKGWGGEDVHLYRKYLHSNLIVVRTPVRGLFHLWHEKRCMDELTPEQYKMCMQSKAMNEASHGQLGMLVFRHEIEAHLRKQ -------------------------------------------------------------- >55407_55407_11_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000441698_CSGALNACT1_chr8_19266205_ENST00000311540_length(transcript)=2560nt_BP=570nt GCCCCGCCAGCAGCGCCCCGCGCCCGCCCGCCCGCGCCCCTGCCGCCCCCCGGTTCCGGCCGCGGACCCCACTCTCTGCCGTTCCGGCTG CGGCTCCGCTGCCGGTAGCGCCGTCCCCCGGGACCACCCTTCGGCTGGCGCCCTCCCATGCTCTCGGCCACCCGGAGGGCTTGCCAGCTC CTCCTCCTCCACAGCCTCTTTCCCGTCCCGAGGATGGGCAACTCGGCCTCGAACATCGTCAGCCCCCAGGAGGCCTTGCCGGGCCGGAAG GAACAGACCCCTGTAGCGGCCAAACATCATGTCAATGGCAACAGAACAGTCGAACCTTTCCCAGAGGGAACACAGATGGCTGTATTTGAA AAAACTGGCCATGCAGAAGTCGTCCGAGTGGTGTACCAGCCAGAACACATGAGTTTTGAGGAACTGCTCAAGGTCTTCTGGGAGAATCAC GACCCGACCCAAGGTATGCGCCAGGGGAACGACCATGGCACTCAGTACCGCTCGGCCATCTACCCGACCTCTGCCAAGCAAATGGAGGCA GCCCTGAGCTCCAAAGAGAACTACCAAAAGGTCATAAAGAAGGAAACTGGATTTTGGAGAGACTTTGGATTTGGGATGACGTGTCAGTAT CGGTCAGACTTCATCAATATAGGTGGGTTTGATCTGGACATCAAAGGCTGGGGCGGAGAGGATGTGCACCTTTATCGCAAGTATCTCCAC AGCAACCTCATAGTGGTACGGACGCCTGTGCGAGGACTCTTCCACCTCTGGCATGAGAAGCGCTGCATGGACGAGCTGACCCCCGAGCAG TACAAGATGTGCATGCAGTCCAAGGCCATGAACGAGGCATCCCACGGCCAGCTGGGCATGCTGGTGTTCAGGCACGAGATAGAGGCTCAC CTTCGCAAACAGAAACAGAAGACAAGTAGCAAAAAAACATGAACTCCCAGAGAAGGATTGTGGGAGACACTTTTTCTTTCCTTTTGCAAT TACTGAAAGTGGCTGCAACAGAGAAAAGACTTCCATAAAGGACGACAAAAGAATTGGACTGATGGGTCAGAGATGAGAAAGCCTCCGATT TCTCTCTGTTGGGCTTTTTACAACAGAAATCAAAATCTCCGCTTTGCCTGCAAAAGTAACCCAGTTGCACCCTGTGAAGTGTCTGACAAA GGCAGAATGCTTGTGAGATTATAAGCCTAATGGTGTGGAGGTTTTGATGGTGTTTACAACACACTGAGACCTGTTGTTTTGTGTGCTCAT TGAAATATTCATGATTTAAGAGCAGTTTTGTAAAAAATTCATTAGCATGAAAGGCAAGCATATTTCTCCTCATATGAATGAGCCTATCAG CAGGGCTCTAGTTTCTAGGAATGCTAAAATATCAGAAGGCAGGAGAGGAGATAGGCTTATTATGATACTAGTGAGTACATTAAGTAAAAT AAAATGGACCAGAAAAGAAAAGAAACCATAAATATCGTGTCATATTTTCCCCAAGATTAACCAAAAATAATCTGCTTATCTTTTTGGTTG TCCTTTTAACTGTCTCCGTTTTTTTCTTTTATTTAAAAATGCACTTTTTTTCCCTTGTGAGTTATAGTCTGCTTATTTAATTACCACTTT GCAAGCCTTACAAGAGAGCACAAGTTGGCCTACATTTTTATATTTTTTAAGAAGATACTTTGAGATGCATTATGAGAACTTTCAGTTCAA AGCATCAAATTGATGCCATATCCAAGGACATGCCAAATGCTGATTCTGTCAGGCACTGAATGTCAGGCATTGAGACATAGGGAAGGAATG GTTTGTACTAATACAGACGTACAGATACTTTCTCTGAAGAGTATTTTCGAAGAGGAGCAACTGAACACTGGAGGAAAAGAAAATGACACT TTCTGCTTTACAGAAAAGGAAACTCATTCAGACTGGTGATATCGTGATGTACCTAAAAGTCAGAAACCACATTTTCTCCTCAGAAGTAGG GACCGCTTTCTTACCTGTTTAAATAAACCAAAGTATACCGTGTGAACCAAACAATCTCTTTTCAAAACAGGGTGCTCCTCCTGGCTTCTG GCTTCCATAAGAAGAAATGGAGAAAAAAATATATATATATATATTGTGAAAGATCAATCCATCTGCCAGAATCTAGTGGGATGGAAGTTT TTGCTACATGTTATCCACCCCAGGCCAGGTGGAAGTAACTGAATTATTTTTTAAATTAAGCAGTTCTACTCGATCACCAAGATGCTTCTG AAAATTGCATTTTATTACCATTTCAAACTATTTTTTAAAAATAAATACAGTTAACATAGAGTGGTTTCTTCATTCATGTGAAAATTATTA GCCAGCACCAGATGCATGAGCTAATTATCTCTTTGAGTCCTTGCTTCTGTTTGCTCACAGTAAACTCATTGTTTAAAAGCTTCAAGAACA TTCAAGCTGTTGGTGTGTTAAAAAATGCATTGTATTGATTTGTACTGGTAGTTTATGAAATTTAATTAAAACACAGGCCATGAATGGAAG >55407_55407_11_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000441698_CSGALNACT1_chr8_19266205_ENST00000311540_length(amino acids)=264AA_BP=141 MLSATRRACQLLLLHSLFPVPRMGNSASNIVSPQEALPGRKEQTPVAAKHHVNGNRTVEPFPEGTQMAVFEKTGHAEVVRVVYQPEHMSF EELLKVFWENHDPTQGMRQGNDHGTQYRSAIYPTSAKQMEAALSSKENYQKVIKKETGFWRDFGFGMTCQYRSDFINIGGFDLDIKGWGG -------------------------------------------------------------- >55407_55407_12_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000441698_CSGALNACT1_chr8_19266205_ENST00000332246_length(transcript)=2561nt_BP=570nt GCCCCGCCAGCAGCGCCCCGCGCCCGCCCGCCCGCGCCCCTGCCGCCCCCCGGTTCCGGCCGCGGACCCCACTCTCTGCCGTTCCGGCTG CGGCTCCGCTGCCGGTAGCGCCGTCCCCCGGGACCACCCTTCGGCTGGCGCCCTCCCATGCTCTCGGCCACCCGGAGGGCTTGCCAGCTC CTCCTCCTCCACAGCCTCTTTCCCGTCCCGAGGATGGGCAACTCGGCCTCGAACATCGTCAGCCCCCAGGAGGCCTTGCCGGGCCGGAAG GAACAGACCCCTGTAGCGGCCAAACATCATGTCAATGGCAACAGAACAGTCGAACCTTTCCCAGAGGGAACACAGATGGCTGTATTTGAA AAAACTGGCCATGCAGAAGTCGTCCGAGTGGTGTACCAGCCAGAACACATGAGTTTTGAGGAACTGCTCAAGGTCTTCTGGGAGAATCAC GACCCGACCCAAGGTATGCGCCAGGGGAACGACCATGGCACTCAGTACCGCTCGGCCATCTACCCGACCTCTGCCAAGCAAATGGAGGCA GCCCTGAGCTCCAAAGAGAACTACCAAAAGGTCATAAAGAAGGAAACTGGATTTTGGAGAGACTTTGGATTTGGGATGACGTGTCAGTAT CGGTCAGACTTCATCAATATAGGTGGGTTTGATCTGGACATCAAAGGCTGGGGCGGAGAGGATGTGCACCTTTATCGCAAGTATCTCCAC AGCAACCTCATAGTGGTACGGACGCCTGTGCGAGGACTCTTCCACCTCTGGCATGAGAAGCGCTGCATGGACGAGCTGACCCCCGAGCAG TACAAGATGTGCATGCAGTCCAAGGCCATGAACGAGGCATCCCACGGCCAGCTGGGCATGCTGGTGTTCAGGCACGAGATAGAGGCTCAC CTTCGCAAACAGAAACAGAAGACAAGTAGCAAAAAAACATGAACTCCCAGAGAAGGATTGTGGGAGACACTTTTTCTTTCCTTTTGCAAT TACTGAAAGTGGCTGCAACAGAGAAAAGACTTCCATAAAGGACGACAAAAGAATTGGACTGATGGGTCAGAGATGAGAAAGCCTCCGATT TCTCTCTGTTGGGCTTTTTACAACAGAAATCAAAATCTCCGCTTTGCCTGCAAAAGTAACCCAGTTGCACCCTGTGAAGTGTCTGACAAA GGCAGAATGCTTGTGAGATTATAAGCCTAATGGTGTGGAGGTTTTGATGGTGTTTACAACACACTGAGACCTGTTGTTTTGTGTGCTCAT TGAAATATTCATGATTTAAGAGCAGTTTTGTAAAAAATTCATTAGCATGAAAGGCAAGCATATTTCTCCTCATATGAATGAGCCTATCAG CAGGGCTCTAGTTTCTAGGAATGCTAAAATATCAGAAGGCAGGAGAGGAGATAGGCTTATTATGATACTAGTGAGTACATTAAGTAAAAT AAAATGGACCAGAAAAGAAAAGAAACCATAAATATCGTGTCATATTTTCCCCAAGATTAACCAAAAATAATCTGCTTATCTTTTTGGTTG TCCTTTTAACTGTCTCCGTTTTTTTCTTTTATTTAAAAATGCACTTTTTTTCCCTTGTGAGTTATAGTCTGCTTATTTAATTACCACTTT GCAAGCCTTACAAGAGAGCACAAGTTGGCCTACATTTTTATATTTTTTAAGAAGATACTTTGAGATGCATTATGAGAACTTTCAGTTCAA AGCATCAAATTGATGCCATATCCAAGGACATGCCAAATGCTGATTCTGTCAGGCACTGAATGTCAGGCATTGAGACATAGGGAAGGAATG GTTTGTACTAATACAGACGTACAGATACTTTCTCTGAAGAGTATTTTCGAAGAGGAGCAACTGAACACTGGAGGAAAAGAAAATGACACT TTCTGCTTTACAGAAAAGGAAACTCATTCAGACTGGTGATATCGTGATGTACCTAAAAGTCAGAAACCACATTTTCTCCTCAGAAGTAGG GACCGCTTTCTTACCTGTTTAAATAAACCAAAGTATACCGTGTGAACCAAACAATCTCTTTTCAAAACAGGGTGCTCCTCCTGGCTTCTG GCTTCCATAAGAAGAAATGGAGAAAAAAATATATATATATATATTGTGAAAGATCAATCCATCTGCCAGAATCTAGTGGGATGGAAGTTT TTGCTACATGTTATCCACCCCAGGCCAGGTGGAAGTAACTGAATTATTTTTTAAATTAAGCAGTTCTACTCGATCACCAAGATGCTTCTG AAAATTGCATTTTATTACCATTTCAAACTATTTTTTAAAAATAAATACAGTTAACATAGAGTGGTTTCTTCATTCATGTGAAAATTATTA GCCAGCACCAGATGCATGAGCTAATTATCTCTTTGAGTCCTTGCTTCTGTTTGCTCACAGTAAACTCATTGTTTAAAAGCTTCAAGAACA TTCAAGCTGTTGGTGTGTTAAAAAATGCATTGTATTGATTTGTACTGGTAGTTTATGAAATTTAATTAAAACACAGGCCATGAATGGAAG >55407_55407_12_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000441698_CSGALNACT1_chr8_19266205_ENST00000332246_length(amino acids)=264AA_BP=141 MLSATRRACQLLLLHSLFPVPRMGNSASNIVSPQEALPGRKEQTPVAAKHHVNGNRTVEPFPEGTQMAVFEKTGHAEVVRVVYQPEHMSF EELLKVFWENHDPTQGMRQGNDHGTQYRSAIYPTSAKQMEAALSSKENYQKVIKKETGFWRDFGFGMTCQYRSDFINIGGFDLDIKGWGG -------------------------------------------------------------- >55407_55407_13_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000441698_CSGALNACT1_chr8_19266205_ENST00000454498_length(transcript)=2561nt_BP=570nt GCCCCGCCAGCAGCGCCCCGCGCCCGCCCGCCCGCGCCCCTGCCGCCCCCCGGTTCCGGCCGCGGACCCCACTCTCTGCCGTTCCGGCTG CGGCTCCGCTGCCGGTAGCGCCGTCCCCCGGGACCACCCTTCGGCTGGCGCCCTCCCATGCTCTCGGCCACCCGGAGGGCTTGCCAGCTC CTCCTCCTCCACAGCCTCTTTCCCGTCCCGAGGATGGGCAACTCGGCCTCGAACATCGTCAGCCCCCAGGAGGCCTTGCCGGGCCGGAAG GAACAGACCCCTGTAGCGGCCAAACATCATGTCAATGGCAACAGAACAGTCGAACCTTTCCCAGAGGGAACACAGATGGCTGTATTTGAA AAAACTGGCCATGCAGAAGTCGTCCGAGTGGTGTACCAGCCAGAACACATGAGTTTTGAGGAACTGCTCAAGGTCTTCTGGGAGAATCAC GACCCGACCCAAGGTATGCGCCAGGGGAACGACCATGGCACTCAGTACCGCTCGGCCATCTACCCGACCTCTGCCAAGCAAATGGAGGCA GCCCTGAGCTCCAAAGAGAACTACCAAAAGGTCATAAAGAAGGAAACTGGATTTTGGAGAGACTTTGGATTTGGGATGACGTGTCAGTAT CGGTCAGACTTCATCAATATAGGTGGGTTTGATCTGGACATCAAAGGCTGGGGCGGAGAGGATGTGCACCTTTATCGCAAGTATCTCCAC AGCAACCTCATAGTGGTACGGACGCCTGTGCGAGGACTCTTCCACCTCTGGCATGAGAAGCGCTGCATGGACGAGCTGACCCCCGAGCAG TACAAGATGTGCATGCAGTCCAAGGCCATGAACGAGGCATCCCACGGCCAGCTGGGCATGCTGGTGTTCAGGCACGAGATAGAGGCTCAC CTTCGCAAACAGAAACAGAAGACAAGTAGCAAAAAAACATGAACTCCCAGAGAAGGATTGTGGGAGACACTTTTTCTTTCCTTTTGCAAT TACTGAAAGTGGCTGCAACAGAGAAAAGACTTCCATAAAGGACGACAAAAGAATTGGACTGATGGGTCAGAGATGAGAAAGCCTCCGATT TCTCTCTGTTGGGCTTTTTACAACAGAAATCAAAATCTCCGCTTTGCCTGCAAAAGTAACCCAGTTGCACCCTGTGAAGTGTCTGACAAA GGCAGAATGCTTGTGAGATTATAAGCCTAATGGTGTGGAGGTTTTGATGGTGTTTACAACACACTGAGACCTGTTGTTTTGTGTGCTCAT TGAAATATTCATGATTTAAGAGCAGTTTTGTAAAAAATTCATTAGCATGAAAGGCAAGCATATTTCTCCTCATATGAATGAGCCTATCAG CAGGGCTCTAGTTTCTAGGAATGCTAAAATATCAGAAGGCAGGAGAGGAGATAGGCTTATTATGATACTAGTGAGTACATTAAGTAAAAT AAAATGGACCAGAAAAGAAAAGAAACCATAAATATCGTGTCATATTTTCCCCAAGATTAACCAAAAATAATCTGCTTATCTTTTTGGTTG TCCTTTTAACTGTCTCCGTTTTTTTCTTTTATTTAAAAATGCACTTTTTTTCCCTTGTGAGTTATAGTCTGCTTATTTAATTACCACTTT GCAAGCCTTACAAGAGAGCACAAGTTGGCCTACATTTTTATATTTTTTAAGAAGATACTTTGAGATGCATTATGAGAACTTTCAGTTCAA AGCATCAAATTGATGCCATATCCAAGGACATGCCAAATGCTGATTCTGTCAGGCACTGAATGTCAGGCATTGAGACATAGGGAAGGAATG GTTTGTACTAATACAGACGTACAGATACTTTCTCTGAAGAGTATTTTCGAAGAGGAGCAACTGAACACTGGAGGAAAAGAAAATGACACT TTCTGCTTTACAGAAAAGGAAACTCATTCAGACTGGTGATATCGTGATGTACCTAAAAGTCAGAAACCACATTTTCTCCTCAGAAGTAGG GACCGCTTTCTTACCTGTTTAAATAAACCAAAGTATACCGTGTGAACCAAACAATCTCTTTTCAAAACAGGGTGCTCCTCCTGGCTTCTG GCTTCCATAAGAAGAAATGGAGAAAAAAATATATATATATATATTGTGAAAGATCAATCCATCTGCCAGAATCTAGTGGGATGGAAGTTT TTGCTACATGTTATCCACCCCAGGCCAGGTGGAAGTAACTGAATTATTTTTTAAATTAAGCAGTTCTACTCGATCACCAAGATGCTTCTG AAAATTGCATTTTATTACCATTTCAAACTATTTTTTAAAAATAAATACAGTTAACATAGAGTGGTTTCTTCATTCATGTGAAAATTATTA GCCAGCACCAGATGCATGAGCTAATTATCTCTTTGAGTCCTTGCTTCTGTTTGCTCACAGTAAACTCATTGTTTAAAAGCTTCAAGAACA TTCAAGCTGTTGGTGTGTTAAAAAATGCATTGTATTGATTTGTACTGGTAGTTTATGAAATTTAATTAAAACACAGGCCATGAATGGAAG >55407_55407_13_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000441698_CSGALNACT1_chr8_19266205_ENST00000454498_length(amino acids)=264AA_BP=141 MLSATRRACQLLLLHSLFPVPRMGNSASNIVSPQEALPGRKEQTPVAAKHHVNGNRTVEPFPEGTQMAVFEKTGHAEVVRVVYQPEHMSF EELLKVFWENHDPTQGMRQGNDHGTQYRSAIYPTSAKQMEAALSSKENYQKVIKKETGFWRDFGFGMTCQYRSDFINIGGFDLDIKGWGG -------------------------------------------------------------- >55407_55407_14_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000441698_CSGALNACT1_chr8_19266205_ENST00000522854_length(transcript)=942nt_BP=570nt GCCCCGCCAGCAGCGCCCCGCGCCCGCCCGCCCGCGCCCCTGCCGCCCCCCGGTTCCGGCCGCGGACCCCACTCTCTGCCGTTCCGGCTG CGGCTCCGCTGCCGGTAGCGCCGTCCCCCGGGACCACCCTTCGGCTGGCGCCCTCCCATGCTCTCGGCCACCCGGAGGGCTTGCCAGCTC CTCCTCCTCCACAGCCTCTTTCCCGTCCCGAGGATGGGCAACTCGGCCTCGAACATCGTCAGCCCCCAGGAGGCCTTGCCGGGCCGGAAG GAACAGACCCCTGTAGCGGCCAAACATCATGTCAATGGCAACAGAACAGTCGAACCTTTCCCAGAGGGAACACAGATGGCTGTATTTGAA AAAACTGGCCATGCAGAAGTCGTCCGAGTGGTGTACCAGCCAGAACACATGAGTTTTGAGGAACTGCTCAAGGTCTTCTGGGAGAATCAC GACCCGACCCAAGGTATGCGCCAGGGGAACGACCATGGCACTCAGTACCGCTCGGCCATCTACCCGACCTCTGCCAAGCAAATGGAGGCA GCCCTGAGCTCCAAAGAGAACTACCAAAAGGTCATAAAGAAGGAAACTGGATTTTGGAGAGACTTTGGATTTGGGATGACGTGTCAGTAT CGGTCAGACTTCATCAATATAGGTGGGTTTGATCTGGACATCAAAGGCTGGGGCGGAGAGGATGTGCACCTTTATCGCAAGTATCTCCAC AGCAACCTCATAGTGGTACGGACGCCTGTGCGAGGACTCTTCCACCTCTGGCATGAGAAGCGCTGCATGGACGAGCTGACCCCCGAGCAG TACAAGATGTGCATGCAGTCCAAGGCCATGAACGAGGCATCCCACGGCCAGCTGGGCATGCTGGTGTTCAGGCACGAGATAGAGGCTCAC >55407_55407_14_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000441698_CSGALNACT1_chr8_19266205_ENST00000522854_length(amino acids)=264AA_BP=141 MLSATRRACQLLLLHSLFPVPRMGNSASNIVSPQEALPGRKEQTPVAAKHHVNGNRTVEPFPEGTQMAVFEKTGHAEVVRVVYQPEHMSF EELLKVFWENHDPTQGMRQGNDHGTQYRSAIYPTSAKQMEAALSSKENYQKVIKKETGFWRDFGFGMTCQYRSDFINIGGFDLDIKGWGG -------------------------------------------------------------- >55407_55407_15_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000441698_CSGALNACT1_chr8_19266205_ENST00000544602_length(transcript)=942nt_BP=570nt GCCCCGCCAGCAGCGCCCCGCGCCCGCCCGCCCGCGCCCCTGCCGCCCCCCGGTTCCGGCCGCGGACCCCACTCTCTGCCGTTCCGGCTG CGGCTCCGCTGCCGGTAGCGCCGTCCCCCGGGACCACCCTTCGGCTGGCGCCCTCCCATGCTCTCGGCCACCCGGAGGGCTTGCCAGCTC CTCCTCCTCCACAGCCTCTTTCCCGTCCCGAGGATGGGCAACTCGGCCTCGAACATCGTCAGCCCCCAGGAGGCCTTGCCGGGCCGGAAG GAACAGACCCCTGTAGCGGCCAAACATCATGTCAATGGCAACAGAACAGTCGAACCTTTCCCAGAGGGAACACAGATGGCTGTATTTGAA AAAACTGGCCATGCAGAAGTCGTCCGAGTGGTGTACCAGCCAGAACACATGAGTTTTGAGGAACTGCTCAAGGTCTTCTGGGAGAATCAC GACCCGACCCAAGGTATGCGCCAGGGGAACGACCATGGCACTCAGTACCGCTCGGCCATCTACCCGACCTCTGCCAAGCAAATGGAGGCA GCCCTGAGCTCCAAAGAGAACTACCAAAAGGTCATAAAGAAGGAAACTGGATTTTGGAGAGACTTTGGATTTGGGATGACGTGTCAGTAT CGGTCAGACTTCATCAATATAGGTGGGTTTGATCTGGACATCAAAGGCTGGGGCGGAGAGGATGTGCACCTTTATCGCAAGTATCTCCAC AGCAACCTCATAGTGGTACGGACGCCTGTGCGAGGACTCTTCCACCTCTGGCATGAGAAGCGCTGCATGGACGAGCTGACCCCCGAGCAG TACAAGATGTGCATGCAGTCCAAGGCCATGAACGAGGCATCCCACGGCCAGCTGGGCATGCTGGTGTTCAGGCACGAGATAGAGGCTCAC >55407_55407_15_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000441698_CSGALNACT1_chr8_19266205_ENST00000544602_length(amino acids)=264AA_BP=141 MLSATRRACQLLLLHSLFPVPRMGNSASNIVSPQEALPGRKEQTPVAAKHHVNGNRTVEPFPEGTQMAVFEKTGHAEVVRVVYQPEHMSF EELLKVFWENHDPTQGMRQGNDHGTQYRSAIYPTSAKQMEAALSSKENYQKVIKKETGFWRDFGFGMTCQYRSDFINIGGFDLDIKGWGG -------------------------------------------------------------- >55407_55407_16_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000518255_CSGALNACT1_chr8_19266205_ENST00000311540_length(transcript)=2549nt_BP=559nt CGGCTGGCGCCCTCCCATGCTCTCGGCCACCCGGAGGGCTTGCCAGCTCCTCCTCCTCCACAGCCTCTTTCCCGTCCCGAGGATGGGCAA CTCGGCCTCGAACATCGTCAGCCCCCAGGAGGCCTTGCCGGGCCGGAAGGAACAGACCCCTGTAGCGGCCAAACATCATGTCAATGGCAA CAGAACAGTCGAACCTTTCCCAGAGGGAACACAGATGGCTGTATTTGGAATGGGATGTTTCTGGGGAGCTGAAAGGAAATTCTGGGTCTT GAAAGGAGTGTATTCAACTCAAGTTGGTTTTGCAGGAGGCTATACTTCAAATCCTACTTATAAAGAAGTCTGCTCAGAAAAAACTGGCCA TGCAGAAGTCGTCCGAGTGGTGTACCAGCCAGAACACATGAGTTTTGAGGAACTGCTCAAGGTCTTCTGGGAGAATCACGACCCGACCCA AGGTATGCGCCAGGGGAACGACCATGGCACTCAGTACCGCTCGGCCATCTACCCGACCTCTGCCAAGCAAATGGAGGCAGCCCTGAGCTC CAAAGAGAACTACCAAAAGGTCATAAAGAAGGAAACTGGATTTTGGAGAGACTTTGGATTTGGGATGACGTGTCAGTATCGGTCAGACTT CATCAATATAGGTGGGTTTGATCTGGACATCAAAGGCTGGGGCGGAGAGGATGTGCACCTTTATCGCAAGTATCTCCACAGCAACCTCAT AGTGGTACGGACGCCTGTGCGAGGACTCTTCCACCTCTGGCATGAGAAGCGCTGCATGGACGAGCTGACCCCCGAGCAGTACAAGATGTG CATGCAGTCCAAGGCCATGAACGAGGCATCCCACGGCCAGCTGGGCATGCTGGTGTTCAGGCACGAGATAGAGGCTCACCTTCGCAAACA GAAACAGAAGACAAGTAGCAAAAAAACATGAACTCCCAGAGAAGGATTGTGGGAGACACTTTTTCTTTCCTTTTGCAATTACTGAAAGTG GCTGCAACAGAGAAAAGACTTCCATAAAGGACGACAAAAGAATTGGACTGATGGGTCAGAGATGAGAAAGCCTCCGATTTCTCTCTGTTG GGCTTTTTACAACAGAAATCAAAATCTCCGCTTTGCCTGCAAAAGTAACCCAGTTGCACCCTGTGAAGTGTCTGACAAAGGCAGAATGCT TGTGAGATTATAAGCCTAATGGTGTGGAGGTTTTGATGGTGTTTACAACACACTGAGACCTGTTGTTTTGTGTGCTCATTGAAATATTCA TGATTTAAGAGCAGTTTTGTAAAAAATTCATTAGCATGAAAGGCAAGCATATTTCTCCTCATATGAATGAGCCTATCAGCAGGGCTCTAG TTTCTAGGAATGCTAAAATATCAGAAGGCAGGAGAGGAGATAGGCTTATTATGATACTAGTGAGTACATTAAGTAAAATAAAATGGACCA GAAAAGAAAAGAAACCATAAATATCGTGTCATATTTTCCCCAAGATTAACCAAAAATAATCTGCTTATCTTTTTGGTTGTCCTTTTAACT GTCTCCGTTTTTTTCTTTTATTTAAAAATGCACTTTTTTTCCCTTGTGAGTTATAGTCTGCTTATTTAATTACCACTTTGCAAGCCTTAC AAGAGAGCACAAGTTGGCCTACATTTTTATATTTTTTAAGAAGATACTTTGAGATGCATTATGAGAACTTTCAGTTCAAAGCATCAAATT GATGCCATATCCAAGGACATGCCAAATGCTGATTCTGTCAGGCACTGAATGTCAGGCATTGAGACATAGGGAAGGAATGGTTTGTACTAA TACAGACGTACAGATACTTTCTCTGAAGAGTATTTTCGAAGAGGAGCAACTGAACACTGGAGGAAAAGAAAATGACACTTTCTGCTTTAC AGAAAAGGAAACTCATTCAGACTGGTGATATCGTGATGTACCTAAAAGTCAGAAACCACATTTTCTCCTCAGAAGTAGGGACCGCTTTCT TACCTGTTTAAATAAACCAAAGTATACCGTGTGAACCAAACAATCTCTTTTCAAAACAGGGTGCTCCTCCTGGCTTCTGGCTTCCATAAG AAGAAATGGAGAAAAAAATATATATATATATATTGTGAAAGATCAATCCATCTGCCAGAATCTAGTGGGATGGAAGTTTTTGCTACATGT TATCCACCCCAGGCCAGGTGGAAGTAACTGAATTATTTTTTAAATTAAGCAGTTCTACTCGATCACCAAGATGCTTCTGAAAATTGCATT TTATTACCATTTCAAACTATTTTTTAAAAATAAATACAGTTAACATAGAGTGGTTTCTTCATTCATGTGAAAATTATTAGCCAGCACCAG ATGCATGAGCTAATTATCTCTTTGAGTCCTTGCTTCTGTTTGCTCACAGTAAACTCATTGTTTAAAAGCTTCAAGAACATTCAAGCTGTT GGTGTGTTAAAAAATGCATTGTATTGATTTGTACTGGTAGTTTATGAAATTTAATTAAAACACAGGCCATGAATGGAAGGTGGTATTGCA >55407_55407_16_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000518255_CSGALNACT1_chr8_19266205_ENST00000311540_length(amino acids)=304AA_BP=181 MLSATRRACQLLLLHSLFPVPRMGNSASNIVSPQEALPGRKEQTPVAAKHHVNGNRTVEPFPEGTQMAVFGMGCFWGAERKFWVLKGVYS TQVGFAGGYTSNPTYKEVCSEKTGHAEVVRVVYQPEHMSFEELLKVFWENHDPTQGMRQGNDHGTQYRSAIYPTSAKQMEAALSSKENYQ KVIKKETGFWRDFGFGMTCQYRSDFINIGGFDLDIKGWGGEDVHLYRKYLHSNLIVVRTPVRGLFHLWHEKRCMDELTPEQYKMCMQSKA -------------------------------------------------------------- >55407_55407_17_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000518255_CSGALNACT1_chr8_19266205_ENST00000332246_length(transcript)=2550nt_BP=559nt CGGCTGGCGCCCTCCCATGCTCTCGGCCACCCGGAGGGCTTGCCAGCTCCTCCTCCTCCACAGCCTCTTTCCCGTCCCGAGGATGGGCAA CTCGGCCTCGAACATCGTCAGCCCCCAGGAGGCCTTGCCGGGCCGGAAGGAACAGACCCCTGTAGCGGCCAAACATCATGTCAATGGCAA CAGAACAGTCGAACCTTTCCCAGAGGGAACACAGATGGCTGTATTTGGAATGGGATGTTTCTGGGGAGCTGAAAGGAAATTCTGGGTCTT GAAAGGAGTGTATTCAACTCAAGTTGGTTTTGCAGGAGGCTATACTTCAAATCCTACTTATAAAGAAGTCTGCTCAGAAAAAACTGGCCA TGCAGAAGTCGTCCGAGTGGTGTACCAGCCAGAACACATGAGTTTTGAGGAACTGCTCAAGGTCTTCTGGGAGAATCACGACCCGACCCA AGGTATGCGCCAGGGGAACGACCATGGCACTCAGTACCGCTCGGCCATCTACCCGACCTCTGCCAAGCAAATGGAGGCAGCCCTGAGCTC CAAAGAGAACTACCAAAAGGTCATAAAGAAGGAAACTGGATTTTGGAGAGACTTTGGATTTGGGATGACGTGTCAGTATCGGTCAGACTT CATCAATATAGGTGGGTTTGATCTGGACATCAAAGGCTGGGGCGGAGAGGATGTGCACCTTTATCGCAAGTATCTCCACAGCAACCTCAT AGTGGTACGGACGCCTGTGCGAGGACTCTTCCACCTCTGGCATGAGAAGCGCTGCATGGACGAGCTGACCCCCGAGCAGTACAAGATGTG CATGCAGTCCAAGGCCATGAACGAGGCATCCCACGGCCAGCTGGGCATGCTGGTGTTCAGGCACGAGATAGAGGCTCACCTTCGCAAACA GAAACAGAAGACAAGTAGCAAAAAAACATGAACTCCCAGAGAAGGATTGTGGGAGACACTTTTTCTTTCCTTTTGCAATTACTGAAAGTG GCTGCAACAGAGAAAAGACTTCCATAAAGGACGACAAAAGAATTGGACTGATGGGTCAGAGATGAGAAAGCCTCCGATTTCTCTCTGTTG GGCTTTTTACAACAGAAATCAAAATCTCCGCTTTGCCTGCAAAAGTAACCCAGTTGCACCCTGTGAAGTGTCTGACAAAGGCAGAATGCT TGTGAGATTATAAGCCTAATGGTGTGGAGGTTTTGATGGTGTTTACAACACACTGAGACCTGTTGTTTTGTGTGCTCATTGAAATATTCA TGATTTAAGAGCAGTTTTGTAAAAAATTCATTAGCATGAAAGGCAAGCATATTTCTCCTCATATGAATGAGCCTATCAGCAGGGCTCTAG TTTCTAGGAATGCTAAAATATCAGAAGGCAGGAGAGGAGATAGGCTTATTATGATACTAGTGAGTACATTAAGTAAAATAAAATGGACCA GAAAAGAAAAGAAACCATAAATATCGTGTCATATTTTCCCCAAGATTAACCAAAAATAATCTGCTTATCTTTTTGGTTGTCCTTTTAACT GTCTCCGTTTTTTTCTTTTATTTAAAAATGCACTTTTTTTCCCTTGTGAGTTATAGTCTGCTTATTTAATTACCACTTTGCAAGCCTTAC AAGAGAGCACAAGTTGGCCTACATTTTTATATTTTTTAAGAAGATACTTTGAGATGCATTATGAGAACTTTCAGTTCAAAGCATCAAATT GATGCCATATCCAAGGACATGCCAAATGCTGATTCTGTCAGGCACTGAATGTCAGGCATTGAGACATAGGGAAGGAATGGTTTGTACTAA TACAGACGTACAGATACTTTCTCTGAAGAGTATTTTCGAAGAGGAGCAACTGAACACTGGAGGAAAAGAAAATGACACTTTCTGCTTTAC AGAAAAGGAAACTCATTCAGACTGGTGATATCGTGATGTACCTAAAAGTCAGAAACCACATTTTCTCCTCAGAAGTAGGGACCGCTTTCT TACCTGTTTAAATAAACCAAAGTATACCGTGTGAACCAAACAATCTCTTTTCAAAACAGGGTGCTCCTCCTGGCTTCTGGCTTCCATAAG AAGAAATGGAGAAAAAAATATATATATATATATTGTGAAAGATCAATCCATCTGCCAGAATCTAGTGGGATGGAAGTTTTTGCTACATGT TATCCACCCCAGGCCAGGTGGAAGTAACTGAATTATTTTTTAAATTAAGCAGTTCTACTCGATCACCAAGATGCTTCTGAAAATTGCATT TTATTACCATTTCAAACTATTTTTTAAAAATAAATACAGTTAACATAGAGTGGTTTCTTCATTCATGTGAAAATTATTAGCCAGCACCAG ATGCATGAGCTAATTATCTCTTTGAGTCCTTGCTTCTGTTTGCTCACAGTAAACTCATTGTTTAAAAGCTTCAAGAACATTCAAGCTGTT GGTGTGTTAAAAAATGCATTGTATTGATTTGTACTGGTAGTTTATGAAATTTAATTAAAACACAGGCCATGAATGGAAGGTGGTATTGCA >55407_55407_17_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000518255_CSGALNACT1_chr8_19266205_ENST00000332246_length(amino acids)=304AA_BP=181 MLSATRRACQLLLLHSLFPVPRMGNSASNIVSPQEALPGRKEQTPVAAKHHVNGNRTVEPFPEGTQMAVFGMGCFWGAERKFWVLKGVYS TQVGFAGGYTSNPTYKEVCSEKTGHAEVVRVVYQPEHMSFEELLKVFWENHDPTQGMRQGNDHGTQYRSAIYPTSAKQMEAALSSKENYQ KVIKKETGFWRDFGFGMTCQYRSDFINIGGFDLDIKGWGGEDVHLYRKYLHSNLIVVRTPVRGLFHLWHEKRCMDELTPEQYKMCMQSKA -------------------------------------------------------------- >55407_55407_18_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000518255_CSGALNACT1_chr8_19266205_ENST00000454498_length(transcript)=2550nt_BP=559nt CGGCTGGCGCCCTCCCATGCTCTCGGCCACCCGGAGGGCTTGCCAGCTCCTCCTCCTCCACAGCCTCTTTCCCGTCCCGAGGATGGGCAA CTCGGCCTCGAACATCGTCAGCCCCCAGGAGGCCTTGCCGGGCCGGAAGGAACAGACCCCTGTAGCGGCCAAACATCATGTCAATGGCAA CAGAACAGTCGAACCTTTCCCAGAGGGAACACAGATGGCTGTATTTGGAATGGGATGTTTCTGGGGAGCTGAAAGGAAATTCTGGGTCTT GAAAGGAGTGTATTCAACTCAAGTTGGTTTTGCAGGAGGCTATACTTCAAATCCTACTTATAAAGAAGTCTGCTCAGAAAAAACTGGCCA TGCAGAAGTCGTCCGAGTGGTGTACCAGCCAGAACACATGAGTTTTGAGGAACTGCTCAAGGTCTTCTGGGAGAATCACGACCCGACCCA AGGTATGCGCCAGGGGAACGACCATGGCACTCAGTACCGCTCGGCCATCTACCCGACCTCTGCCAAGCAAATGGAGGCAGCCCTGAGCTC CAAAGAGAACTACCAAAAGGTCATAAAGAAGGAAACTGGATTTTGGAGAGACTTTGGATTTGGGATGACGTGTCAGTATCGGTCAGACTT CATCAATATAGGTGGGTTTGATCTGGACATCAAAGGCTGGGGCGGAGAGGATGTGCACCTTTATCGCAAGTATCTCCACAGCAACCTCAT AGTGGTACGGACGCCTGTGCGAGGACTCTTCCACCTCTGGCATGAGAAGCGCTGCATGGACGAGCTGACCCCCGAGCAGTACAAGATGTG CATGCAGTCCAAGGCCATGAACGAGGCATCCCACGGCCAGCTGGGCATGCTGGTGTTCAGGCACGAGATAGAGGCTCACCTTCGCAAACA GAAACAGAAGACAAGTAGCAAAAAAACATGAACTCCCAGAGAAGGATTGTGGGAGACACTTTTTCTTTCCTTTTGCAATTACTGAAAGTG GCTGCAACAGAGAAAAGACTTCCATAAAGGACGACAAAAGAATTGGACTGATGGGTCAGAGATGAGAAAGCCTCCGATTTCTCTCTGTTG GGCTTTTTACAACAGAAATCAAAATCTCCGCTTTGCCTGCAAAAGTAACCCAGTTGCACCCTGTGAAGTGTCTGACAAAGGCAGAATGCT TGTGAGATTATAAGCCTAATGGTGTGGAGGTTTTGATGGTGTTTACAACACACTGAGACCTGTTGTTTTGTGTGCTCATTGAAATATTCA TGATTTAAGAGCAGTTTTGTAAAAAATTCATTAGCATGAAAGGCAAGCATATTTCTCCTCATATGAATGAGCCTATCAGCAGGGCTCTAG TTTCTAGGAATGCTAAAATATCAGAAGGCAGGAGAGGAGATAGGCTTATTATGATACTAGTGAGTACATTAAGTAAAATAAAATGGACCA GAAAAGAAAAGAAACCATAAATATCGTGTCATATTTTCCCCAAGATTAACCAAAAATAATCTGCTTATCTTTTTGGTTGTCCTTTTAACT GTCTCCGTTTTTTTCTTTTATTTAAAAATGCACTTTTTTTCCCTTGTGAGTTATAGTCTGCTTATTTAATTACCACTTTGCAAGCCTTAC AAGAGAGCACAAGTTGGCCTACATTTTTATATTTTTTAAGAAGATACTTTGAGATGCATTATGAGAACTTTCAGTTCAAAGCATCAAATT GATGCCATATCCAAGGACATGCCAAATGCTGATTCTGTCAGGCACTGAATGTCAGGCATTGAGACATAGGGAAGGAATGGTTTGTACTAA TACAGACGTACAGATACTTTCTCTGAAGAGTATTTTCGAAGAGGAGCAACTGAACACTGGAGGAAAAGAAAATGACACTTTCTGCTTTAC AGAAAAGGAAACTCATTCAGACTGGTGATATCGTGATGTACCTAAAAGTCAGAAACCACATTTTCTCCTCAGAAGTAGGGACCGCTTTCT TACCTGTTTAAATAAACCAAAGTATACCGTGTGAACCAAACAATCTCTTTTCAAAACAGGGTGCTCCTCCTGGCTTCTGGCTTCCATAAG AAGAAATGGAGAAAAAAATATATATATATATATTGTGAAAGATCAATCCATCTGCCAGAATCTAGTGGGATGGAAGTTTTTGCTACATGT TATCCACCCCAGGCCAGGTGGAAGTAACTGAATTATTTTTTAAATTAAGCAGTTCTACTCGATCACCAAGATGCTTCTGAAAATTGCATT TTATTACCATTTCAAACTATTTTTTAAAAATAAATACAGTTAACATAGAGTGGTTTCTTCATTCATGTGAAAATTATTAGCCAGCACCAG ATGCATGAGCTAATTATCTCTTTGAGTCCTTGCTTCTGTTTGCTCACAGTAAACTCATTGTTTAAAAGCTTCAAGAACATTCAAGCTGTT GGTGTGTTAAAAAATGCATTGTATTGATTTGTACTGGTAGTTTATGAAATTTAATTAAAACACAGGCCATGAATGGAAGGTGGTATTGCA >55407_55407_18_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000518255_CSGALNACT1_chr8_19266205_ENST00000454498_length(amino acids)=304AA_BP=181 MLSATRRACQLLLLHSLFPVPRMGNSASNIVSPQEALPGRKEQTPVAAKHHVNGNRTVEPFPEGTQMAVFGMGCFWGAERKFWVLKGVYS TQVGFAGGYTSNPTYKEVCSEKTGHAEVVRVVYQPEHMSFEELLKVFWENHDPTQGMRQGNDHGTQYRSAIYPTSAKQMEAALSSKENYQ KVIKKETGFWRDFGFGMTCQYRSDFINIGGFDLDIKGWGGEDVHLYRKYLHSNLIVVRTPVRGLFHLWHEKRCMDELTPEQYKMCMQSKA -------------------------------------------------------------- >55407_55407_19_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000518255_CSGALNACT1_chr8_19266205_ENST00000522854_length(transcript)=931nt_BP=559nt CGGCTGGCGCCCTCCCATGCTCTCGGCCACCCGGAGGGCTTGCCAGCTCCTCCTCCTCCACAGCCTCTTTCCCGTCCCGAGGATGGGCAA CTCGGCCTCGAACATCGTCAGCCCCCAGGAGGCCTTGCCGGGCCGGAAGGAACAGACCCCTGTAGCGGCCAAACATCATGTCAATGGCAA CAGAACAGTCGAACCTTTCCCAGAGGGAACACAGATGGCTGTATTTGGAATGGGATGTTTCTGGGGAGCTGAAAGGAAATTCTGGGTCTT GAAAGGAGTGTATTCAACTCAAGTTGGTTTTGCAGGAGGCTATACTTCAAATCCTACTTATAAAGAAGTCTGCTCAGAAAAAACTGGCCA TGCAGAAGTCGTCCGAGTGGTGTACCAGCCAGAACACATGAGTTTTGAGGAACTGCTCAAGGTCTTCTGGGAGAATCACGACCCGACCCA AGGTATGCGCCAGGGGAACGACCATGGCACTCAGTACCGCTCGGCCATCTACCCGACCTCTGCCAAGCAAATGGAGGCAGCCCTGAGCTC CAAAGAGAACTACCAAAAGGTCATAAAGAAGGAAACTGGATTTTGGAGAGACTTTGGATTTGGGATGACGTGTCAGTATCGGTCAGACTT CATCAATATAGGTGGGTTTGATCTGGACATCAAAGGCTGGGGCGGAGAGGATGTGCACCTTTATCGCAAGTATCTCCACAGCAACCTCAT AGTGGTACGGACGCCTGTGCGAGGACTCTTCCACCTCTGGCATGAGAAGCGCTGCATGGACGAGCTGACCCCCGAGCAGTACAAGATGTG CATGCAGTCCAAGGCCATGAACGAGGCATCCCACGGCCAGCTGGGCATGCTGGTGTTCAGGCACGAGATAGAGGCTCACCTTCGCAAACA >55407_55407_19_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000518255_CSGALNACT1_chr8_19266205_ENST00000522854_length(amino acids)=305AA_BP=181 MLSATRRACQLLLLHSLFPVPRMGNSASNIVSPQEALPGRKEQTPVAAKHHVNGNRTVEPFPEGTQMAVFGMGCFWGAERKFWVLKGVYS TQVGFAGGYTSNPTYKEVCSEKTGHAEVVRVVYQPEHMSFEELLKVFWENHDPTQGMRQGNDHGTQYRSAIYPTSAKQMEAALSSKENYQ KVIKKETGFWRDFGFGMTCQYRSDFINIGGFDLDIKGWGGEDVHLYRKYLHSNLIVVRTPVRGLFHLWHEKRCMDELTPEQYKMCMQSKA -------------------------------------------------------------- >55407_55407_20_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000518255_CSGALNACT1_chr8_19266205_ENST00000544602_length(transcript)=931nt_BP=559nt CGGCTGGCGCCCTCCCATGCTCTCGGCCACCCGGAGGGCTTGCCAGCTCCTCCTCCTCCACAGCCTCTTTCCCGTCCCGAGGATGGGCAA CTCGGCCTCGAACATCGTCAGCCCCCAGGAGGCCTTGCCGGGCCGGAAGGAACAGACCCCTGTAGCGGCCAAACATCATGTCAATGGCAA CAGAACAGTCGAACCTTTCCCAGAGGGAACACAGATGGCTGTATTTGGAATGGGATGTTTCTGGGGAGCTGAAAGGAAATTCTGGGTCTT GAAAGGAGTGTATTCAACTCAAGTTGGTTTTGCAGGAGGCTATACTTCAAATCCTACTTATAAAGAAGTCTGCTCAGAAAAAACTGGCCA TGCAGAAGTCGTCCGAGTGGTGTACCAGCCAGAACACATGAGTTTTGAGGAACTGCTCAAGGTCTTCTGGGAGAATCACGACCCGACCCA AGGTATGCGCCAGGGGAACGACCATGGCACTCAGTACCGCTCGGCCATCTACCCGACCTCTGCCAAGCAAATGGAGGCAGCCCTGAGCTC CAAAGAGAACTACCAAAAGGTCATAAAGAAGGAAACTGGATTTTGGAGAGACTTTGGATTTGGGATGACGTGTCAGTATCGGTCAGACTT CATCAATATAGGTGGGTTTGATCTGGACATCAAAGGCTGGGGCGGAGAGGATGTGCACCTTTATCGCAAGTATCTCCACAGCAACCTCAT AGTGGTACGGACGCCTGTGCGAGGACTCTTCCACCTCTGGCATGAGAAGCGCTGCATGGACGAGCTGACCCCCGAGCAGTACAAGATGTG CATGCAGTCCAAGGCCATGAACGAGGCATCCCACGGCCAGCTGGGCATGCTGGTGTTCAGGCACGAGATAGAGGCTCACCTTCGCAAACA >55407_55407_20_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000518255_CSGALNACT1_chr8_19266205_ENST00000544602_length(amino acids)=305AA_BP=181 MLSATRRACQLLLLHSLFPVPRMGNSASNIVSPQEALPGRKEQTPVAAKHHVNGNRTVEPFPEGTQMAVFGMGCFWGAERKFWVLKGVYS TQVGFAGGYTSNPTYKEVCSEKTGHAEVVRVVYQPEHMSFEELLKVFWENHDPTQGMRQGNDHGTQYRSAIYPTSAKQMEAALSSKENYQ KVIKKETGFWRDFGFGMTCQYRSDFINIGGFDLDIKGWGGEDVHLYRKYLHSNLIVVRTPVRGLFHLWHEKRCMDELTPEQYKMCMQSKA -------------------------------------------------------------- >55407_55407_21_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000528246_CSGALNACT1_chr8_19266205_ENST00000311540_length(transcript)=2958nt_BP=968nt GAGTGAGAGAGAGAAAGAGGGAGAGAGAGAGGCAGAGGGAGAGCTGAGGAAAGAAAAAAAGGCAAGACTTGGCACAGCTCAGTCAAATCA GCTTCTTTTGTCTGCTTTCTCGGCTTGAGCTTCAGGAAAGAAAACCGTCCTGGGGTACAGAAAAACTCAGAACTTTTTGGTTTTCAAACT TAGAAGGCTTTTTAAGTCTCTTGGGCTATTTGAAAGTGTTGGTACATACAATGACGTTTAGTCACCAGTATTAAGGGAAATAAAAGCCTT TTTCAAAACGAAGCTTCCATAGTGTCCATGCATTTGGGAAATACTATATTTGATTTTTTGCATGTATGATTATACCATGAGAGACAGGAT TAATATAGAAGATGGCAAGGCAAATTTCTAATTAGAGGGAATATTAATTTTCTACAAAATAAAGTTTGTTCATCAATACAAACCTGCTTT CAAATCAAATCAGAAAGACATCCTTCGGAATGTGTTCAGAACCAATTAGTGACAACACTGAAGACCAGAAAGGCAAGCTGAAGACACCAG ACTTCGCTTGAAGGGCAAACAAGAAATCCAAACATCATGTCAATGGCAACAGAACAGTCGAACCTTTCCCAGAGGGAACACAGATGGCTG TATTTGGAATGGGATGTTTCTGGGGAGCTGAAAGGAAATTCTGGGTCTTGAAAGGAGTGTATTCAACTCAAGTTGGTTTTGCAGGAGGCT ATACTTCAAATCCTACTTATAAAGAAGTCTGCTCAGAAAAAACTGGCCATGCAGAAGTCGTCCGAGTGGTGTACCAGCCAGAACACATGA GTTTTGAGGAACTGCTCAAGGTCTTCTGGGAGAATCACGACCCGACCCAAGGTATGCGCCAGGGGAACGACCATGGCACTCAGTACCGCT CGGCCATCTACCCGACCTCTGCCAAGCAAATGGAGGCAGCCCTGAGCTCCAAAGAGAACTACCAAAAGGTCATAAAGAAGGAAACTGGAT TTTGGAGAGACTTTGGATTTGGGATGACGTGTCAGTATCGGTCAGACTTCATCAATATAGGTGGGTTTGATCTGGACATCAAAGGCTGGG GCGGAGAGGATGTGCACCTTTATCGCAAGTATCTCCACAGCAACCTCATAGTGGTACGGACGCCTGTGCGAGGACTCTTCCACCTCTGGC ATGAGAAGCGCTGCATGGACGAGCTGACCCCCGAGCAGTACAAGATGTGCATGCAGTCCAAGGCCATGAACGAGGCATCCCACGGCCAGC TGGGCATGCTGGTGTTCAGGCACGAGATAGAGGCTCACCTTCGCAAACAGAAACAGAAGACAAGTAGCAAAAAAACATGAACTCCCAGAG AAGGATTGTGGGAGACACTTTTTCTTTCCTTTTGCAATTACTGAAAGTGGCTGCAACAGAGAAAAGACTTCCATAAAGGACGACAAAAGA ATTGGACTGATGGGTCAGAGATGAGAAAGCCTCCGATTTCTCTCTGTTGGGCTTTTTACAACAGAAATCAAAATCTCCGCTTTGCCTGCA AAAGTAACCCAGTTGCACCCTGTGAAGTGTCTGACAAAGGCAGAATGCTTGTGAGATTATAAGCCTAATGGTGTGGAGGTTTTGATGGTG TTTACAACACACTGAGACCTGTTGTTTTGTGTGCTCATTGAAATATTCATGATTTAAGAGCAGTTTTGTAAAAAATTCATTAGCATGAAA GGCAAGCATATTTCTCCTCATATGAATGAGCCTATCAGCAGGGCTCTAGTTTCTAGGAATGCTAAAATATCAGAAGGCAGGAGAGGAGAT AGGCTTATTATGATACTAGTGAGTACATTAAGTAAAATAAAATGGACCAGAAAAGAAAAGAAACCATAAATATCGTGTCATATTTTCCCC AAGATTAACCAAAAATAATCTGCTTATCTTTTTGGTTGTCCTTTTAACTGTCTCCGTTTTTTTCTTTTATTTAAAAATGCACTTTTTTTC CCTTGTGAGTTATAGTCTGCTTATTTAATTACCACTTTGCAAGCCTTACAAGAGAGCACAAGTTGGCCTACATTTTTATATTTTTTAAGA AGATACTTTGAGATGCATTATGAGAACTTTCAGTTCAAAGCATCAAATTGATGCCATATCCAAGGACATGCCAAATGCTGATTCTGTCAG GCACTGAATGTCAGGCATTGAGACATAGGGAAGGAATGGTTTGTACTAATACAGACGTACAGATACTTTCTCTGAAGAGTATTTTCGAAG AGGAGCAACTGAACACTGGAGGAAAAGAAAATGACACTTTCTGCTTTACAGAAAAGGAAACTCATTCAGACTGGTGATATCGTGATGTAC CTAAAAGTCAGAAACCACATTTTCTCCTCAGAAGTAGGGACCGCTTTCTTACCTGTTTAAATAAACCAAAGTATACCGTGTGAACCAAAC AATCTCTTTTCAAAACAGGGTGCTCCTCCTGGCTTCTGGCTTCCATAAGAAGAAATGGAGAAAAAAATATATATATATATATTGTGAAAG ATCAATCCATCTGCCAGAATCTAGTGGGATGGAAGTTTTTGCTACATGTTATCCACCCCAGGCCAGGTGGAAGTAACTGAATTATTTTTT AAATTAAGCAGTTCTACTCGATCACCAAGATGCTTCTGAAAATTGCATTTTATTACCATTTCAAACTATTTTTTAAAAATAAATACAGTT AACATAGAGTGGTTTCTTCATTCATGTGAAAATTATTAGCCAGCACCAGATGCATGAGCTAATTATCTCTTTGAGTCCTTGCTTCTGTTT GCTCACAGTAAACTCATTGTTTAAAAGCTTCAAGAACATTCAAGCTGTTGGTGTGTTAAAAAATGCATTGTATTGATTTGTACTGGTAGT >55407_55407_21_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000528246_CSGALNACT1_chr8_19266205_ENST00000311540_length(amino acids)=238AA_BP=115 MAVFGMGCFWGAERKFWVLKGVYSTQVGFAGGYTSNPTYKEVCSEKTGHAEVVRVVYQPEHMSFEELLKVFWENHDPTQGMRQGNDHGTQ YRSAIYPTSAKQMEAALSSKENYQKVIKKETGFWRDFGFGMTCQYRSDFINIGGFDLDIKGWGGEDVHLYRKYLHSNLIVVRTPVRGLFH -------------------------------------------------------------- >55407_55407_22_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000528246_CSGALNACT1_chr8_19266205_ENST00000332246_length(transcript)=2959nt_BP=968nt GAGTGAGAGAGAGAAAGAGGGAGAGAGAGAGGCAGAGGGAGAGCTGAGGAAAGAAAAAAAGGCAAGACTTGGCACAGCTCAGTCAAATCA GCTTCTTTTGTCTGCTTTCTCGGCTTGAGCTTCAGGAAAGAAAACCGTCCTGGGGTACAGAAAAACTCAGAACTTTTTGGTTTTCAAACT TAGAAGGCTTTTTAAGTCTCTTGGGCTATTTGAAAGTGTTGGTACATACAATGACGTTTAGTCACCAGTATTAAGGGAAATAAAAGCCTT TTTCAAAACGAAGCTTCCATAGTGTCCATGCATTTGGGAAATACTATATTTGATTTTTTGCATGTATGATTATACCATGAGAGACAGGAT TAATATAGAAGATGGCAAGGCAAATTTCTAATTAGAGGGAATATTAATTTTCTACAAAATAAAGTTTGTTCATCAATACAAACCTGCTTT CAAATCAAATCAGAAAGACATCCTTCGGAATGTGTTCAGAACCAATTAGTGACAACACTGAAGACCAGAAAGGCAAGCTGAAGACACCAG ACTTCGCTTGAAGGGCAAACAAGAAATCCAAACATCATGTCAATGGCAACAGAACAGTCGAACCTTTCCCAGAGGGAACACAGATGGCTG TATTTGGAATGGGATGTTTCTGGGGAGCTGAAAGGAAATTCTGGGTCTTGAAAGGAGTGTATTCAACTCAAGTTGGTTTTGCAGGAGGCT ATACTTCAAATCCTACTTATAAAGAAGTCTGCTCAGAAAAAACTGGCCATGCAGAAGTCGTCCGAGTGGTGTACCAGCCAGAACACATGA GTTTTGAGGAACTGCTCAAGGTCTTCTGGGAGAATCACGACCCGACCCAAGGTATGCGCCAGGGGAACGACCATGGCACTCAGTACCGCT CGGCCATCTACCCGACCTCTGCCAAGCAAATGGAGGCAGCCCTGAGCTCCAAAGAGAACTACCAAAAGGTCATAAAGAAGGAAACTGGAT TTTGGAGAGACTTTGGATTTGGGATGACGTGTCAGTATCGGTCAGACTTCATCAATATAGGTGGGTTTGATCTGGACATCAAAGGCTGGG GCGGAGAGGATGTGCACCTTTATCGCAAGTATCTCCACAGCAACCTCATAGTGGTACGGACGCCTGTGCGAGGACTCTTCCACCTCTGGC ATGAGAAGCGCTGCATGGACGAGCTGACCCCCGAGCAGTACAAGATGTGCATGCAGTCCAAGGCCATGAACGAGGCATCCCACGGCCAGC TGGGCATGCTGGTGTTCAGGCACGAGATAGAGGCTCACCTTCGCAAACAGAAACAGAAGACAAGTAGCAAAAAAACATGAACTCCCAGAG AAGGATTGTGGGAGACACTTTTTCTTTCCTTTTGCAATTACTGAAAGTGGCTGCAACAGAGAAAAGACTTCCATAAAGGACGACAAAAGA ATTGGACTGATGGGTCAGAGATGAGAAAGCCTCCGATTTCTCTCTGTTGGGCTTTTTACAACAGAAATCAAAATCTCCGCTTTGCCTGCA AAAGTAACCCAGTTGCACCCTGTGAAGTGTCTGACAAAGGCAGAATGCTTGTGAGATTATAAGCCTAATGGTGTGGAGGTTTTGATGGTG TTTACAACACACTGAGACCTGTTGTTTTGTGTGCTCATTGAAATATTCATGATTTAAGAGCAGTTTTGTAAAAAATTCATTAGCATGAAA GGCAAGCATATTTCTCCTCATATGAATGAGCCTATCAGCAGGGCTCTAGTTTCTAGGAATGCTAAAATATCAGAAGGCAGGAGAGGAGAT AGGCTTATTATGATACTAGTGAGTACATTAAGTAAAATAAAATGGACCAGAAAAGAAAAGAAACCATAAATATCGTGTCATATTTTCCCC AAGATTAACCAAAAATAATCTGCTTATCTTTTTGGTTGTCCTTTTAACTGTCTCCGTTTTTTTCTTTTATTTAAAAATGCACTTTTTTTC CCTTGTGAGTTATAGTCTGCTTATTTAATTACCACTTTGCAAGCCTTACAAGAGAGCACAAGTTGGCCTACATTTTTATATTTTTTAAGA AGATACTTTGAGATGCATTATGAGAACTTTCAGTTCAAAGCATCAAATTGATGCCATATCCAAGGACATGCCAAATGCTGATTCTGTCAG GCACTGAATGTCAGGCATTGAGACATAGGGAAGGAATGGTTTGTACTAATACAGACGTACAGATACTTTCTCTGAAGAGTATTTTCGAAG AGGAGCAACTGAACACTGGAGGAAAAGAAAATGACACTTTCTGCTTTACAGAAAAGGAAACTCATTCAGACTGGTGATATCGTGATGTAC CTAAAAGTCAGAAACCACATTTTCTCCTCAGAAGTAGGGACCGCTTTCTTACCTGTTTAAATAAACCAAAGTATACCGTGTGAACCAAAC AATCTCTTTTCAAAACAGGGTGCTCCTCCTGGCTTCTGGCTTCCATAAGAAGAAATGGAGAAAAAAATATATATATATATATTGTGAAAG ATCAATCCATCTGCCAGAATCTAGTGGGATGGAAGTTTTTGCTACATGTTATCCACCCCAGGCCAGGTGGAAGTAACTGAATTATTTTTT AAATTAAGCAGTTCTACTCGATCACCAAGATGCTTCTGAAAATTGCATTTTATTACCATTTCAAACTATTTTTTAAAAATAAATACAGTT AACATAGAGTGGTTTCTTCATTCATGTGAAAATTATTAGCCAGCACCAGATGCATGAGCTAATTATCTCTTTGAGTCCTTGCTTCTGTTT GCTCACAGTAAACTCATTGTTTAAAAGCTTCAAGAACATTCAAGCTGTTGGTGTGTTAAAAAATGCATTGTATTGATTTGTACTGGTAGT >55407_55407_22_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000528246_CSGALNACT1_chr8_19266205_ENST00000332246_length(amino acids)=238AA_BP=115 MAVFGMGCFWGAERKFWVLKGVYSTQVGFAGGYTSNPTYKEVCSEKTGHAEVVRVVYQPEHMSFEELLKVFWENHDPTQGMRQGNDHGTQ YRSAIYPTSAKQMEAALSSKENYQKVIKKETGFWRDFGFGMTCQYRSDFINIGGFDLDIKGWGGEDVHLYRKYLHSNLIVVRTPVRGLFH -------------------------------------------------------------- >55407_55407_23_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000528246_CSGALNACT1_chr8_19266205_ENST00000454498_length(transcript)=2959nt_BP=968nt GAGTGAGAGAGAGAAAGAGGGAGAGAGAGAGGCAGAGGGAGAGCTGAGGAAAGAAAAAAAGGCAAGACTTGGCACAGCTCAGTCAAATCA GCTTCTTTTGTCTGCTTTCTCGGCTTGAGCTTCAGGAAAGAAAACCGTCCTGGGGTACAGAAAAACTCAGAACTTTTTGGTTTTCAAACT TAGAAGGCTTTTTAAGTCTCTTGGGCTATTTGAAAGTGTTGGTACATACAATGACGTTTAGTCACCAGTATTAAGGGAAATAAAAGCCTT TTTCAAAACGAAGCTTCCATAGTGTCCATGCATTTGGGAAATACTATATTTGATTTTTTGCATGTATGATTATACCATGAGAGACAGGAT TAATATAGAAGATGGCAAGGCAAATTTCTAATTAGAGGGAATATTAATTTTCTACAAAATAAAGTTTGTTCATCAATACAAACCTGCTTT CAAATCAAATCAGAAAGACATCCTTCGGAATGTGTTCAGAACCAATTAGTGACAACACTGAAGACCAGAAAGGCAAGCTGAAGACACCAG ACTTCGCTTGAAGGGCAAACAAGAAATCCAAACATCATGTCAATGGCAACAGAACAGTCGAACCTTTCCCAGAGGGAACACAGATGGCTG TATTTGGAATGGGATGTTTCTGGGGAGCTGAAAGGAAATTCTGGGTCTTGAAAGGAGTGTATTCAACTCAAGTTGGTTTTGCAGGAGGCT ATACTTCAAATCCTACTTATAAAGAAGTCTGCTCAGAAAAAACTGGCCATGCAGAAGTCGTCCGAGTGGTGTACCAGCCAGAACACATGA GTTTTGAGGAACTGCTCAAGGTCTTCTGGGAGAATCACGACCCGACCCAAGGTATGCGCCAGGGGAACGACCATGGCACTCAGTACCGCT CGGCCATCTACCCGACCTCTGCCAAGCAAATGGAGGCAGCCCTGAGCTCCAAAGAGAACTACCAAAAGGTCATAAAGAAGGAAACTGGAT TTTGGAGAGACTTTGGATTTGGGATGACGTGTCAGTATCGGTCAGACTTCATCAATATAGGTGGGTTTGATCTGGACATCAAAGGCTGGG GCGGAGAGGATGTGCACCTTTATCGCAAGTATCTCCACAGCAACCTCATAGTGGTACGGACGCCTGTGCGAGGACTCTTCCACCTCTGGC ATGAGAAGCGCTGCATGGACGAGCTGACCCCCGAGCAGTACAAGATGTGCATGCAGTCCAAGGCCATGAACGAGGCATCCCACGGCCAGC TGGGCATGCTGGTGTTCAGGCACGAGATAGAGGCTCACCTTCGCAAACAGAAACAGAAGACAAGTAGCAAAAAAACATGAACTCCCAGAG AAGGATTGTGGGAGACACTTTTTCTTTCCTTTTGCAATTACTGAAAGTGGCTGCAACAGAGAAAAGACTTCCATAAAGGACGACAAAAGA ATTGGACTGATGGGTCAGAGATGAGAAAGCCTCCGATTTCTCTCTGTTGGGCTTTTTACAACAGAAATCAAAATCTCCGCTTTGCCTGCA AAAGTAACCCAGTTGCACCCTGTGAAGTGTCTGACAAAGGCAGAATGCTTGTGAGATTATAAGCCTAATGGTGTGGAGGTTTTGATGGTG TTTACAACACACTGAGACCTGTTGTTTTGTGTGCTCATTGAAATATTCATGATTTAAGAGCAGTTTTGTAAAAAATTCATTAGCATGAAA GGCAAGCATATTTCTCCTCATATGAATGAGCCTATCAGCAGGGCTCTAGTTTCTAGGAATGCTAAAATATCAGAAGGCAGGAGAGGAGAT AGGCTTATTATGATACTAGTGAGTACATTAAGTAAAATAAAATGGACCAGAAAAGAAAAGAAACCATAAATATCGTGTCATATTTTCCCC AAGATTAACCAAAAATAATCTGCTTATCTTTTTGGTTGTCCTTTTAACTGTCTCCGTTTTTTTCTTTTATTTAAAAATGCACTTTTTTTC CCTTGTGAGTTATAGTCTGCTTATTTAATTACCACTTTGCAAGCCTTACAAGAGAGCACAAGTTGGCCTACATTTTTATATTTTTTAAGA AGATACTTTGAGATGCATTATGAGAACTTTCAGTTCAAAGCATCAAATTGATGCCATATCCAAGGACATGCCAAATGCTGATTCTGTCAG GCACTGAATGTCAGGCATTGAGACATAGGGAAGGAATGGTTTGTACTAATACAGACGTACAGATACTTTCTCTGAAGAGTATTTTCGAAG AGGAGCAACTGAACACTGGAGGAAAAGAAAATGACACTTTCTGCTTTACAGAAAAGGAAACTCATTCAGACTGGTGATATCGTGATGTAC CTAAAAGTCAGAAACCACATTTTCTCCTCAGAAGTAGGGACCGCTTTCTTACCTGTTTAAATAAACCAAAGTATACCGTGTGAACCAAAC AATCTCTTTTCAAAACAGGGTGCTCCTCCTGGCTTCTGGCTTCCATAAGAAGAAATGGAGAAAAAAATATATATATATATATTGTGAAAG ATCAATCCATCTGCCAGAATCTAGTGGGATGGAAGTTTTTGCTACATGTTATCCACCCCAGGCCAGGTGGAAGTAACTGAATTATTTTTT AAATTAAGCAGTTCTACTCGATCACCAAGATGCTTCTGAAAATTGCATTTTATTACCATTTCAAACTATTTTTTAAAAATAAATACAGTT AACATAGAGTGGTTTCTTCATTCATGTGAAAATTATTAGCCAGCACCAGATGCATGAGCTAATTATCTCTTTGAGTCCTTGCTTCTGTTT GCTCACAGTAAACTCATTGTTTAAAAGCTTCAAGAACATTCAAGCTGTTGGTGTGTTAAAAAATGCATTGTATTGATTTGTACTGGTAGT >55407_55407_23_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000528246_CSGALNACT1_chr8_19266205_ENST00000454498_length(amino acids)=238AA_BP=115 MAVFGMGCFWGAERKFWVLKGVYSTQVGFAGGYTSNPTYKEVCSEKTGHAEVVRVVYQPEHMSFEELLKVFWENHDPTQGMRQGNDHGTQ YRSAIYPTSAKQMEAALSSKENYQKVIKKETGFWRDFGFGMTCQYRSDFINIGGFDLDIKGWGGEDVHLYRKYLHSNLIVVRTPVRGLFH -------------------------------------------------------------- >55407_55407_24_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000528246_CSGALNACT1_chr8_19266205_ENST00000522854_length(transcript)=1340nt_BP=968nt GAGTGAGAGAGAGAAAGAGGGAGAGAGAGAGGCAGAGGGAGAGCTGAGGAAAGAAAAAAAGGCAAGACTTGGCACAGCTCAGTCAAATCA GCTTCTTTTGTCTGCTTTCTCGGCTTGAGCTTCAGGAAAGAAAACCGTCCTGGGGTACAGAAAAACTCAGAACTTTTTGGTTTTCAAACT TAGAAGGCTTTTTAAGTCTCTTGGGCTATTTGAAAGTGTTGGTACATACAATGACGTTTAGTCACCAGTATTAAGGGAAATAAAAGCCTT TTTCAAAACGAAGCTTCCATAGTGTCCATGCATTTGGGAAATACTATATTTGATTTTTTGCATGTATGATTATACCATGAGAGACAGGAT TAATATAGAAGATGGCAAGGCAAATTTCTAATTAGAGGGAATATTAATTTTCTACAAAATAAAGTTTGTTCATCAATACAAACCTGCTTT CAAATCAAATCAGAAAGACATCCTTCGGAATGTGTTCAGAACCAATTAGTGACAACACTGAAGACCAGAAAGGCAAGCTGAAGACACCAG ACTTCGCTTGAAGGGCAAACAAGAAATCCAAACATCATGTCAATGGCAACAGAACAGTCGAACCTTTCCCAGAGGGAACACAGATGGCTG TATTTGGAATGGGATGTTTCTGGGGAGCTGAAAGGAAATTCTGGGTCTTGAAAGGAGTGTATTCAACTCAAGTTGGTTTTGCAGGAGGCT ATACTTCAAATCCTACTTATAAAGAAGTCTGCTCAGAAAAAACTGGCCATGCAGAAGTCGTCCGAGTGGTGTACCAGCCAGAACACATGA GTTTTGAGGAACTGCTCAAGGTCTTCTGGGAGAATCACGACCCGACCCAAGGTATGCGCCAGGGGAACGACCATGGCACTCAGTACCGCT CGGCCATCTACCCGACCTCTGCCAAGCAAATGGAGGCAGCCCTGAGCTCCAAAGAGAACTACCAAAAGGTCATAAAGAAGGAAACTGGAT TTTGGAGAGACTTTGGATTTGGGATGACGTGTCAGTATCGGTCAGACTTCATCAATATAGGTGGGTTTGATCTGGACATCAAAGGCTGGG GCGGAGAGGATGTGCACCTTTATCGCAAGTATCTCCACAGCAACCTCATAGTGGTACGGACGCCTGTGCGAGGACTCTTCCACCTCTGGC ATGAGAAGCGCTGCATGGACGAGCTGACCCCCGAGCAGTACAAGATGTGCATGCAGTCCAAGGCCATGAACGAGGCATCCCACGGCCAGC >55407_55407_24_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000528246_CSGALNACT1_chr8_19266205_ENST00000522854_length(amino acids)=239AA_BP=115 MAVFGMGCFWGAERKFWVLKGVYSTQVGFAGGYTSNPTYKEVCSEKTGHAEVVRVVYQPEHMSFEELLKVFWENHDPTQGMRQGNDHGTQ YRSAIYPTSAKQMEAALSSKENYQKVIKKETGFWRDFGFGMTCQYRSDFINIGGFDLDIKGWGGEDVHLYRKYLHSNLIVVRTPVRGLFH -------------------------------------------------------------- >55407_55407_25_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000528246_CSGALNACT1_chr8_19266205_ENST00000544602_length(transcript)=1340nt_BP=968nt GAGTGAGAGAGAGAAAGAGGGAGAGAGAGAGGCAGAGGGAGAGCTGAGGAAAGAAAAAAAGGCAAGACTTGGCACAGCTCAGTCAAATCA GCTTCTTTTGTCTGCTTTCTCGGCTTGAGCTTCAGGAAAGAAAACCGTCCTGGGGTACAGAAAAACTCAGAACTTTTTGGTTTTCAAACT TAGAAGGCTTTTTAAGTCTCTTGGGCTATTTGAAAGTGTTGGTACATACAATGACGTTTAGTCACCAGTATTAAGGGAAATAAAAGCCTT TTTCAAAACGAAGCTTCCATAGTGTCCATGCATTTGGGAAATACTATATTTGATTTTTTGCATGTATGATTATACCATGAGAGACAGGAT TAATATAGAAGATGGCAAGGCAAATTTCTAATTAGAGGGAATATTAATTTTCTACAAAATAAAGTTTGTTCATCAATACAAACCTGCTTT CAAATCAAATCAGAAAGACATCCTTCGGAATGTGTTCAGAACCAATTAGTGACAACACTGAAGACCAGAAAGGCAAGCTGAAGACACCAG ACTTCGCTTGAAGGGCAAACAAGAAATCCAAACATCATGTCAATGGCAACAGAACAGTCGAACCTTTCCCAGAGGGAACACAGATGGCTG TATTTGGAATGGGATGTTTCTGGGGAGCTGAAAGGAAATTCTGGGTCTTGAAAGGAGTGTATTCAACTCAAGTTGGTTTTGCAGGAGGCT ATACTTCAAATCCTACTTATAAAGAAGTCTGCTCAGAAAAAACTGGCCATGCAGAAGTCGTCCGAGTGGTGTACCAGCCAGAACACATGA GTTTTGAGGAACTGCTCAAGGTCTTCTGGGAGAATCACGACCCGACCCAAGGTATGCGCCAGGGGAACGACCATGGCACTCAGTACCGCT CGGCCATCTACCCGACCTCTGCCAAGCAAATGGAGGCAGCCCTGAGCTCCAAAGAGAACTACCAAAAGGTCATAAAGAAGGAAACTGGAT TTTGGAGAGACTTTGGATTTGGGATGACGTGTCAGTATCGGTCAGACTTCATCAATATAGGTGGGTTTGATCTGGACATCAAAGGCTGGG GCGGAGAGGATGTGCACCTTTATCGCAAGTATCTCCACAGCAACCTCATAGTGGTACGGACGCCTGTGCGAGGACTCTTCCACCTCTGGC ATGAGAAGCGCTGCATGGACGAGCTGACCCCCGAGCAGTACAAGATGTGCATGCAGTCCAAGGCCATGAACGAGGCATCCCACGGCCAGC >55407_55407_25_MSRA-CSGALNACT1_MSRA_chr8_10177499_ENST00000528246_CSGALNACT1_chr8_19266205_ENST00000544602_length(amino acids)=239AA_BP=115 MAVFGMGCFWGAERKFWVLKGVYSTQVGFAGGYTSNPTYKEVCSEKTGHAEVVRVVYQPEHMSFEELLKVFWENHDPTQGMRQGNDHGTQ YRSAIYPTSAKQMEAALSSKENYQKVIKKETGFWRDFGFGMTCQYRSDFINIGGFDLDIKGWGGEDVHLYRKYLHSNLIVVRTPVRGLFH -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for MSRA-CSGALNACT1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for MSRA-CSGALNACT1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for MSRA-CSGALNACT1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies