
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:MTAP-EEF1A2 (FusionGDB2 ID:55506) |
Fusion Gene Summary for MTAP-EEF1A2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: MTAP-EEF1A2 | Fusion gene ID: 55506 | Hgene | Tgene | Gene symbol | MTAP | EEF1A2 | Gene ID | 4507 | 1917 |
| Gene name | methylthioadenosine phosphorylase | eukaryotic translation elongation factor 1 alpha 2 | |
| Synonyms | BDMF|DMSFH|DMSMFH|HEL-249|LGMBF|MSAP|c86fus | EEF1AL|EF-1-alpha-2|EF1A|EIEE33|HS1|MRD38|STN|STNL | |
| Cytomap | 9p21.3 | 20q13.33 | |
| Type of gene | protein-coding | protein-coding | |
| Description | S-methyl-5'-thioadenosine phosphorylase5'-methylthioadenosine phosphorylaseMTA phosphorylaseMTAPaseMeSAdo phosphorylaseepididymis luminal protein 249epididymis secretory sperm binding protein | elongation factor 1-alpha 2eukaryotic elongation factor 1 A-2statin-S1 | |
| Modification date | 20200313 | 20200329 | |
| UniProtAcc | Q13126 | Q05639 | |
| Ensembl transtripts involved in fusion gene | ENST00000460874, ENST00000380172, ENST00000580900, ENST00000427788, | ENST00000217182, ENST00000298049, | |
| Fusion gene scores | * DoF score | 13 X 9 X 9=1053 | 3 X 3 X 3=27 |
| # samples | 17 | 3 | |
| ** MAII score | log2(17/1053*10)=-2.63089878488802 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(3/27*10)=0.15200309344505 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | |
| Context | PubMed: MTAP [Title/Abstract] AND EEF1A2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | MTAP(21802780)-EEF1A2(62127388), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | MTAP | GO:0006738 | nicotinamide riboside catabolic process | 19001417 |
| Tgene | EEF1A2 | GO:0090218 | positive regulation of lipid kinase activity | 17088255 |
| Fusion gene breakpoints across MTAP (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across EEF1A2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | LUSC | TCGA-63-A5MM-01A | MTAP | chr9 | 21802780 | - | EEF1A2 | chr20 | 62127388 | - |
| ChimerDB4 | LUSC | TCGA-63-A5MM-01A | MTAP | chr9 | 21802780 | + | EEF1A2 | chr20 | 62127388 | - |
| ChimerDB4 | LUSC | TCGA-63-A5MM | MTAP | chr9 | 21802780 | + | EEF1A2 | chr20 | 62127388 | - |
Top |
Fusion Gene ORF analysis for MTAP-EEF1A2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5UTR-3CDS | ENST00000460874 | ENST00000217182 | MTAP | chr9 | 21802780 | + | EEF1A2 | chr20 | 62127388 | - |
| 5UTR-3CDS | ENST00000460874 | ENST00000298049 | MTAP | chr9 | 21802780 | + | EEF1A2 | chr20 | 62127388 | - |
| In-frame | ENST00000380172 | ENST00000217182 | MTAP | chr9 | 21802780 | + | EEF1A2 | chr20 | 62127388 | - |
| In-frame | ENST00000380172 | ENST00000298049 | MTAP | chr9 | 21802780 | + | EEF1A2 | chr20 | 62127388 | - |
| In-frame | ENST00000580900 | ENST00000217182 | MTAP | chr9 | 21802780 | + | EEF1A2 | chr20 | 62127388 | - |
| In-frame | ENST00000580900 | ENST00000298049 | MTAP | chr9 | 21802780 | + | EEF1A2 | chr20 | 62127388 | - |
| intron-3CDS | ENST00000427788 | ENST00000217182 | MTAP | chr9 | 21802780 | + | EEF1A2 | chr20 | 62127388 | - |
| intron-3CDS | ENST00000427788 | ENST00000298049 | MTAP | chr9 | 21802780 | + | EEF1A2 | chr20 | 62127388 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000580900 | MTAP | chr9 | 21802780 | + | ENST00000298049 | EEF1A2 | chr20 | 62127388 | - | 1666 | 133 | 100 | 1380 | 426 |
| ENST00000580900 | MTAP | chr9 | 21802780 | + | ENST00000217182 | EEF1A2 | chr20 | 62127388 | - | 1666 | 133 | 100 | 1380 | 426 |
| ENST00000380172 | MTAP | chr9 | 21802780 | + | ENST00000298049 | EEF1A2 | chr20 | 62127388 | - | 1772 | 239 | 206 | 1486 | 426 |
| ENST00000380172 | MTAP | chr9 | 21802780 | + | ENST00000217182 | EEF1A2 | chr20 | 62127388 | - | 1772 | 239 | 206 | 1486 | 426 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000580900 | ENST00000298049 | MTAP | chr9 | 21802780 | + | EEF1A2 | chr20 | 62127388 | - | 0.00478549 | 0.99521446 |
| ENST00000580900 | ENST00000217182 | MTAP | chr9 | 21802780 | + | EEF1A2 | chr20 | 62127388 | - | 0.00478549 | 0.99521446 |
| ENST00000380172 | ENST00000298049 | MTAP | chr9 | 21802780 | + | EEF1A2 | chr20 | 62127388 | - | 0.004710507 | 0.99528944 |
| ENST00000380172 | ENST00000217182 | MTAP | chr9 | 21802780 | + | EEF1A2 | chr20 | 62127388 | - | 0.004710507 | 0.99528944 |
Top |
Fusion Genomic Features for MTAP-EEF1A2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
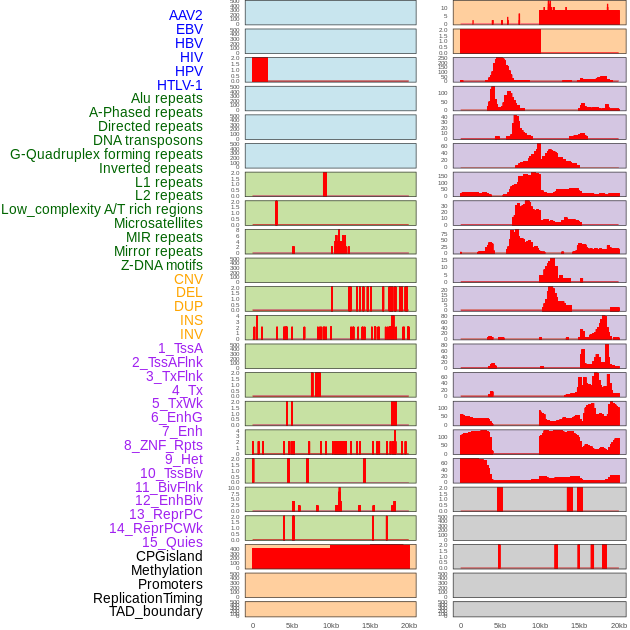 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for MTAP-EEF1A2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr9:21802780/chr20:62127388) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| MTAP | EEF1A2 |
| FUNCTION: Catalyzes the reversible phosphorylation of S-methyl-5'-thioadenosine (MTA) to adenine and 5-methylthioribose-1-phosphate. Involved in the breakdown of MTA, a major by-product of polyamine biosynthesis. Responsible for the first step in the methionine salvage pathway after MTA has been generated from S-adenosylmethionine. Has broad substrate specificity with 6-aminopurine nucleosides as preferred substrates. {ECO:0000255|HAMAP-Rule:MF_03155, ECO:0000269|PubMed:3091600}. | FUNCTION: This protein promotes the GTP-dependent binding of aminoacyl-tRNA to the A-site of ribosomes during protein biosynthesis. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | EEF1A2 | chr9:21802780 | chr20:62127388 | ENST00000217182 | 1 | 8 | 91_95 | 48 | 464.0 | Nucleotide binding | GTP | |
| Tgene | EEF1A2 | chr9:21802780 | chr20:62127388 | ENST00000298049 | 0 | 7 | 91_95 | 48 | 464.0 | Nucleotide binding | GTP | |
| Tgene | EEF1A2 | chr9:21802780 | chr20:62127388 | ENST00000217182 | 1 | 8 | 153_156 | 48 | 464.0 | Region | G4 | |
| Tgene | EEF1A2 | chr9:21802780 | chr20:62127388 | ENST00000217182 | 1 | 8 | 194_196 | 48 | 464.0 | Region | G5 | |
| Tgene | EEF1A2 | chr9:21802780 | chr20:62127388 | ENST00000217182 | 1 | 8 | 70_74 | 48 | 464.0 | Region | G2 | |
| Tgene | EEF1A2 | chr9:21802780 | chr20:62127388 | ENST00000217182 | 1 | 8 | 91_94 | 48 | 464.0 | Region | G3 | |
| Tgene | EEF1A2 | chr9:21802780 | chr20:62127388 | ENST00000298049 | 0 | 7 | 153_156 | 48 | 464.0 | Region | G4 | |
| Tgene | EEF1A2 | chr9:21802780 | chr20:62127388 | ENST00000298049 | 0 | 7 | 194_196 | 48 | 464.0 | Region | G5 | |
| Tgene | EEF1A2 | chr9:21802780 | chr20:62127388 | ENST00000298049 | 0 | 7 | 70_74 | 48 | 464.0 | Region | G2 | |
| Tgene | EEF1A2 | chr9:21802780 | chr20:62127388 | ENST00000298049 | 0 | 7 | 91_94 | 48 | 464.0 | Region | G3 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | MTAP | chr9:21802780 | chr20:62127388 | ENST00000380172 | + | 1 | 8 | 220_222 | 11 | 284.0 | Region | Note=Substrate binding |
| Hgene | MTAP | chr9:21802780 | chr20:62127388 | ENST00000380172 | + | 1 | 8 | 60_61 | 11 | 284.0 | Region | Note=Phosphate binding |
| Hgene | MTAP | chr9:21802780 | chr20:62127388 | ENST00000380172 | + | 1 | 8 | 93_94 | 11 | 284.0 | Region | Note=Phosphate binding |
| Hgene | MTAP | chr9:21802780 | chr20:62127388 | ENST00000580900 | + | 1 | 8 | 220_222 | 11 | 335.0 | Region | Note=Substrate binding |
| Hgene | MTAP | chr9:21802780 | chr20:62127388 | ENST00000580900 | + | 1 | 8 | 60_61 | 11 | 335.0 | Region | Note=Phosphate binding |
| Hgene | MTAP | chr9:21802780 | chr20:62127388 | ENST00000580900 | + | 1 | 8 | 93_94 | 11 | 335.0 | Region | Note=Phosphate binding |
| Tgene | EEF1A2 | chr9:21802780 | chr20:62127388 | ENST00000217182 | 1 | 8 | 5_242 | 48 | 464.0 | Domain | Note=tr-type G | |
| Tgene | EEF1A2 | chr9:21802780 | chr20:62127388 | ENST00000298049 | 0 | 7 | 5_242 | 48 | 464.0 | Domain | Note=tr-type G | |
| Tgene | EEF1A2 | chr9:21802780 | chr20:62127388 | ENST00000217182 | 1 | 8 | 14_21 | 48 | 464.0 | Region | G1 | |
| Tgene | EEF1A2 | chr9:21802780 | chr20:62127388 | ENST00000298049 | 0 | 7 | 14_21 | 48 | 464.0 | Region | G1 |
Top |
Fusion Gene Sequence for MTAP-EEF1A2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >55506_55506_1_MTAP-EEF1A2_MTAP_chr9_21802780_ENST00000380172_EEF1A2_chr20_62127388_ENST00000217182_length(transcript)=1772nt_BP=239nt GATTTGGGGAAGGGGTGGCGGGGGAGATCCCACACAAGCAGCCAATCCAGCTGTCCCGGGGAGGAAGAGGAGGAGTCAAGGCCCGCCCCT GGTCTCCGCACTGCTCACTCCCGCGCAGTGAGGTTGGCACAGCCACCGCTCTGTGGCTCGCTTGGTTCCCTTAGTCCCGAGCGCTCGCCC ACTGCAGATTCCTTTCCCGTGCAGACATGGCCTCTGGCACCACCACCACCGCCGTGAAGATGGGGAAGGGATCCTTCAAGTATGCCTGGG TGCTGGACAAGCTGAAGGCGGAGCGTGAGCGCGGCATCACCATCGACATCTCCCTCTGGAAGTTCGAGACCACCAAGTACTACATCACCA TCATCGATGCCCCCGGCCACCGCGACTTCATCAAGAACATGATCACGGGTACATCCCAGGCGGACTGCGCAGTGCTGATCGTGGCGGCGG GCGTGGGCGAGTTCGAGGCGGGCATCTCCAAGAATGGGCAGACGCGGGAGCATGCCCTGCTGGCCTACACGCTGGGTGTGAAGCAGCTCA TCGTGGGCGTGAACAAAATGGACTCCACAGAGCCGGCCTACAGCGAGAAGCGCTACGACGAGATCGTCAAGGAAGTCAGCGCCTACATCA AGAAGATCGGCTACAACCCGGCCACCGTGCCCTTTGTGCCCATCTCCGGCTGGCACGGTGACAACATGCTGGAGCCCTCCCCCAACATGC CGTGGTTCAAGGGCTGGAAGGTGGAGCGTAAGGAGGGCAACGCAAGCGGCGTGTCCCTGCTGGAGGCCCTGGACACCATCCTGCCCCCCA CGCGCCCCACGGACAAGCCCCTGCGCCTGCCGCTGCAGGACGTGTACAAGATTGGCGGCATTGGCACGGTGCCCGTGGGCCGGGTGGAGA CCGGCATCCTGCGGCCGGGCATGGTGGTGACCTTTGCGCCAGTGAACATCACCACTGAGGTGAAGTCAGTGGAGATGCACCACGAGGCTC TGAGCGAAGCTCTGCCCGGCGACAACGTCGGCTTCAATGTGAAGAACGTGTCGGTGAAGGACATCCGGCGGGGCAACGTGTGTGGGGACA GCAAGTCTGACCCGCCGCAGGAGGCTGCTCAGTTCACCTCCCAGGTCATCATCCTGAACCACCCGGGGCAGATTAGCGCCGGCTACTCCC CGGTCATCGACTGCCACACAGCCCACATCGCCTGCAAGTTTGCGGAGCTGAAGGAGAAGATTGACCGGCGCTCTGGCAAGAAGCTGGAGG ACAACCCCAAGTCCCTGAAGTCTGGAGACGCGGCCATCGTGGAGATGGTGCCGGGAAAGCCCATGTGTGTGGAGAGCTTCTCCCAGTACC CGCCTCTCGGCCGCTTCGCCGTGCGCGACATGAGGCAGACGGTGGCCGTAGGCGTCATCAAGAACGTGGAGAAGAAGAGCGGCGGCGCCG GCAAGGTCACCAAGTCGGCGCAGAAGGCGCAGAAGGCGGGCAAGTGAAGCGCGGGCGCCCGCGGCGCGACCCTCCCCGGCGGTGCCGCGC TCCGAACCCCGGGCCCGGGCCCCCGCCCCGCCCCCGCCCCGCGCGCCGGTCCGGCGCCCCGCACCCCCGCCAGGCGCATGTCTGCACCTC CGCTTGCCAGAGGCCCTCGGTCAGCGACTGGATGCTCGCCATCAAGGTCCAGTGGAAGTTCTTCAAGAGGAAAGGCGCCCCCGCCCCAGG >55506_55506_1_MTAP-EEF1A2_MTAP_chr9_21802780_ENST00000380172_EEF1A2_chr20_62127388_ENST00000217182_length(amino acids)=426AA_BP=11 MASGTTTTAVKMGKGSFKYAWVLDKLKAERERGITIDISLWKFETTKYYITIIDAPGHRDFIKNMITGTSQADCAVLIVAAGVGEFEAGI SKNGQTREHALLAYTLGVKQLIVGVNKMDSTEPAYSEKRYDEIVKEVSAYIKKIGYNPATVPFVPISGWHGDNMLEPSPNMPWFKGWKVE RKEGNASGVSLLEALDTILPPTRPTDKPLRLPLQDVYKIGGIGTVPVGRVETGILRPGMVVTFAPVNITTEVKSVEMHHEALSEALPGDN VGFNVKNVSVKDIRRGNVCGDSKSDPPQEAAQFTSQVIILNHPGQISAGYSPVIDCHTAHIACKFAELKEKIDRRSGKKLEDNPKSLKSG -------------------------------------------------------------- >55506_55506_2_MTAP-EEF1A2_MTAP_chr9_21802780_ENST00000380172_EEF1A2_chr20_62127388_ENST00000298049_length(transcript)=1772nt_BP=239nt GATTTGGGGAAGGGGTGGCGGGGGAGATCCCACACAAGCAGCCAATCCAGCTGTCCCGGGGAGGAAGAGGAGGAGTCAAGGCCCGCCCCT GGTCTCCGCACTGCTCACTCCCGCGCAGTGAGGTTGGCACAGCCACCGCTCTGTGGCTCGCTTGGTTCCCTTAGTCCCGAGCGCTCGCCC ACTGCAGATTCCTTTCCCGTGCAGACATGGCCTCTGGCACCACCACCACCGCCGTGAAGATGGGGAAGGGATCCTTCAAGTATGCCTGGG TGCTGGACAAGCTGAAGGCGGAGCGTGAGCGCGGCATCACCATCGACATCTCCCTCTGGAAGTTCGAGACCACCAAGTACTACATCACCA TCATCGATGCCCCCGGCCACCGCGACTTCATCAAGAACATGATCACGGGTACATCCCAGGCGGACTGCGCAGTGCTGATCGTGGCGGCGG GCGTGGGCGAGTTCGAGGCGGGCATCTCCAAGAATGGGCAGACGCGGGAGCATGCCCTGCTGGCCTACACGCTGGGTGTGAAGCAGCTCA TCGTGGGCGTGAACAAAATGGACTCCACAGAGCCGGCCTACAGCGAGAAGCGCTACGACGAGATCGTCAAGGAAGTCAGCGCCTACATCA AGAAGATCGGCTACAACCCGGCCACCGTGCCCTTTGTGCCCATCTCCGGCTGGCACGGTGACAACATGCTGGAGCCCTCCCCCAACATGC CGTGGTTCAAGGGCTGGAAGGTGGAGCGTAAGGAGGGCAACGCAAGCGGCGTGTCCCTGCTGGAGGCCCTGGACACCATCCTGCCCCCCA CGCGCCCCACGGACAAGCCCCTGCGCCTGCCGCTGCAGGACGTGTACAAGATTGGCGGCATTGGCACGGTGCCCGTGGGCCGGGTGGAGA CCGGCATCCTGCGGCCGGGCATGGTGGTGACCTTTGCGCCAGTGAACATCACCACTGAGGTGAAGTCAGTGGAGATGCACCACGAGGCTC TGAGCGAAGCTCTGCCCGGCGACAACGTCGGCTTCAATGTGAAGAACGTGTCGGTGAAGGACATCCGGCGGGGCAACGTGTGTGGGGACA GCAAGTCTGACCCGCCGCAGGAGGCTGCTCAGTTCACCTCCCAGGTCATCATCCTGAACCACCCGGGGCAGATTAGCGCCGGCTACTCCC CGGTCATCGACTGCCACACAGCCCACATCGCCTGCAAGTTTGCGGAGCTGAAGGAGAAGATTGACCGGCGCTCTGGCAAGAAGCTGGAGG ACAACCCCAAGTCCCTGAAGTCTGGAGACGCGGCCATCGTGGAGATGGTGCCGGGAAAGCCCATGTGTGTGGAGAGCTTCTCCCAGTACC CGCCTCTCGGCCGCTTCGCCGTGCGCGACATGAGGCAGACGGTGGCCGTAGGCGTCATCAAGAACGTGGAGAAGAAGAGCGGCGGCGCCG GCAAGGTCACCAAGTCGGCGCAGAAGGCGCAGAAGGCGGGCAAGTGAAGCGCGGGCGCCCGCGGCGCGACCCTCCCCGGCGGTGCCGCGC TCCGAACCCCGGGCCCGGGCCCCCGCCCCGCCCCCGCCCCGCGCGCCGGTCCGGCGCCCCGCACCCCCGCCAGGCGCATGTCTGCACCTC CGCTTGCCAGAGGCCCTCGGTCAGCGACTGGATGCTCGCCATCAAGGTCCAGTGGAAGTTCTTCAAGAGGAAAGGCGCCCCCGCCCCAGG >55506_55506_2_MTAP-EEF1A2_MTAP_chr9_21802780_ENST00000380172_EEF1A2_chr20_62127388_ENST00000298049_length(amino acids)=426AA_BP=11 MASGTTTTAVKMGKGSFKYAWVLDKLKAERERGITIDISLWKFETTKYYITIIDAPGHRDFIKNMITGTSQADCAVLIVAAGVGEFEAGI SKNGQTREHALLAYTLGVKQLIVGVNKMDSTEPAYSEKRYDEIVKEVSAYIKKIGYNPATVPFVPISGWHGDNMLEPSPNMPWFKGWKVE RKEGNASGVSLLEALDTILPPTRPTDKPLRLPLQDVYKIGGIGTVPVGRVETGILRPGMVVTFAPVNITTEVKSVEMHHEALSEALPGDN VGFNVKNVSVKDIRRGNVCGDSKSDPPQEAAQFTSQVIILNHPGQISAGYSPVIDCHTAHIACKFAELKEKIDRRSGKKLEDNPKSLKSG -------------------------------------------------------------- >55506_55506_3_MTAP-EEF1A2_MTAP_chr9_21802780_ENST00000580900_EEF1A2_chr20_62127388_ENST00000217182_length(transcript)=1666nt_BP=133nt ACTCCCGCGCAGTGAGGTTGGCACAGCCACCGCTCTGTGGCTCGCTTGGTTCCCTTAGTCCCGAGCGCTCGCCCACTGCAGATTCCTTTC CCGTGCAGACATGGCCTCTGGCACCACCACCACCGCCGTGAAGATGGGGAAGGGATCCTTCAAGTATGCCTGGGTGCTGGACAAGCTGAA GGCGGAGCGTGAGCGCGGCATCACCATCGACATCTCCCTCTGGAAGTTCGAGACCACCAAGTACTACATCACCATCATCGATGCCCCCGG CCACCGCGACTTCATCAAGAACATGATCACGGGTACATCCCAGGCGGACTGCGCAGTGCTGATCGTGGCGGCGGGCGTGGGCGAGTTCGA GGCGGGCATCTCCAAGAATGGGCAGACGCGGGAGCATGCCCTGCTGGCCTACACGCTGGGTGTGAAGCAGCTCATCGTGGGCGTGAACAA AATGGACTCCACAGAGCCGGCCTACAGCGAGAAGCGCTACGACGAGATCGTCAAGGAAGTCAGCGCCTACATCAAGAAGATCGGCTACAA CCCGGCCACCGTGCCCTTTGTGCCCATCTCCGGCTGGCACGGTGACAACATGCTGGAGCCCTCCCCCAACATGCCGTGGTTCAAGGGCTG GAAGGTGGAGCGTAAGGAGGGCAACGCAAGCGGCGTGTCCCTGCTGGAGGCCCTGGACACCATCCTGCCCCCCACGCGCCCCACGGACAA GCCCCTGCGCCTGCCGCTGCAGGACGTGTACAAGATTGGCGGCATTGGCACGGTGCCCGTGGGCCGGGTGGAGACCGGCATCCTGCGGCC GGGCATGGTGGTGACCTTTGCGCCAGTGAACATCACCACTGAGGTGAAGTCAGTGGAGATGCACCACGAGGCTCTGAGCGAAGCTCTGCC CGGCGACAACGTCGGCTTCAATGTGAAGAACGTGTCGGTGAAGGACATCCGGCGGGGCAACGTGTGTGGGGACAGCAAGTCTGACCCGCC GCAGGAGGCTGCTCAGTTCACCTCCCAGGTCATCATCCTGAACCACCCGGGGCAGATTAGCGCCGGCTACTCCCCGGTCATCGACTGCCA CACAGCCCACATCGCCTGCAAGTTTGCGGAGCTGAAGGAGAAGATTGACCGGCGCTCTGGCAAGAAGCTGGAGGACAACCCCAAGTCCCT GAAGTCTGGAGACGCGGCCATCGTGGAGATGGTGCCGGGAAAGCCCATGTGTGTGGAGAGCTTCTCCCAGTACCCGCCTCTCGGCCGCTT CGCCGTGCGCGACATGAGGCAGACGGTGGCCGTAGGCGTCATCAAGAACGTGGAGAAGAAGAGCGGCGGCGCCGGCAAGGTCACCAAGTC GGCGCAGAAGGCGCAGAAGGCGGGCAAGTGAAGCGCGGGCGCCCGCGGCGCGACCCTCCCCGGCGGTGCCGCGCTCCGAACCCCGGGCCC GGGCCCCCGCCCCGCCCCCGCCCCGCGCGCCGGTCCGGCGCCCCGCACCCCCGCCAGGCGCATGTCTGCACCTCCGCTTGCCAGAGGCCC TCGGTCAGCGACTGGATGCTCGCCATCAAGGTCCAGTGGAAGTTCTTCAAGAGGAAAGGCGCCCCCGCCCCAGGCTTCCGCGCCCAGCGC >55506_55506_3_MTAP-EEF1A2_MTAP_chr9_21802780_ENST00000580900_EEF1A2_chr20_62127388_ENST00000217182_length(amino acids)=426AA_BP=11 MASGTTTTAVKMGKGSFKYAWVLDKLKAERERGITIDISLWKFETTKYYITIIDAPGHRDFIKNMITGTSQADCAVLIVAAGVGEFEAGI SKNGQTREHALLAYTLGVKQLIVGVNKMDSTEPAYSEKRYDEIVKEVSAYIKKIGYNPATVPFVPISGWHGDNMLEPSPNMPWFKGWKVE RKEGNASGVSLLEALDTILPPTRPTDKPLRLPLQDVYKIGGIGTVPVGRVETGILRPGMVVTFAPVNITTEVKSVEMHHEALSEALPGDN VGFNVKNVSVKDIRRGNVCGDSKSDPPQEAAQFTSQVIILNHPGQISAGYSPVIDCHTAHIACKFAELKEKIDRRSGKKLEDNPKSLKSG -------------------------------------------------------------- >55506_55506_4_MTAP-EEF1A2_MTAP_chr9_21802780_ENST00000580900_EEF1A2_chr20_62127388_ENST00000298049_length(transcript)=1666nt_BP=133nt ACTCCCGCGCAGTGAGGTTGGCACAGCCACCGCTCTGTGGCTCGCTTGGTTCCCTTAGTCCCGAGCGCTCGCCCACTGCAGATTCCTTTC CCGTGCAGACATGGCCTCTGGCACCACCACCACCGCCGTGAAGATGGGGAAGGGATCCTTCAAGTATGCCTGGGTGCTGGACAAGCTGAA GGCGGAGCGTGAGCGCGGCATCACCATCGACATCTCCCTCTGGAAGTTCGAGACCACCAAGTACTACATCACCATCATCGATGCCCCCGG CCACCGCGACTTCATCAAGAACATGATCACGGGTACATCCCAGGCGGACTGCGCAGTGCTGATCGTGGCGGCGGGCGTGGGCGAGTTCGA GGCGGGCATCTCCAAGAATGGGCAGACGCGGGAGCATGCCCTGCTGGCCTACACGCTGGGTGTGAAGCAGCTCATCGTGGGCGTGAACAA AATGGACTCCACAGAGCCGGCCTACAGCGAGAAGCGCTACGACGAGATCGTCAAGGAAGTCAGCGCCTACATCAAGAAGATCGGCTACAA CCCGGCCACCGTGCCCTTTGTGCCCATCTCCGGCTGGCACGGTGACAACATGCTGGAGCCCTCCCCCAACATGCCGTGGTTCAAGGGCTG GAAGGTGGAGCGTAAGGAGGGCAACGCAAGCGGCGTGTCCCTGCTGGAGGCCCTGGACACCATCCTGCCCCCCACGCGCCCCACGGACAA GCCCCTGCGCCTGCCGCTGCAGGACGTGTACAAGATTGGCGGCATTGGCACGGTGCCCGTGGGCCGGGTGGAGACCGGCATCCTGCGGCC GGGCATGGTGGTGACCTTTGCGCCAGTGAACATCACCACTGAGGTGAAGTCAGTGGAGATGCACCACGAGGCTCTGAGCGAAGCTCTGCC CGGCGACAACGTCGGCTTCAATGTGAAGAACGTGTCGGTGAAGGACATCCGGCGGGGCAACGTGTGTGGGGACAGCAAGTCTGACCCGCC GCAGGAGGCTGCTCAGTTCACCTCCCAGGTCATCATCCTGAACCACCCGGGGCAGATTAGCGCCGGCTACTCCCCGGTCATCGACTGCCA CACAGCCCACATCGCCTGCAAGTTTGCGGAGCTGAAGGAGAAGATTGACCGGCGCTCTGGCAAGAAGCTGGAGGACAACCCCAAGTCCCT GAAGTCTGGAGACGCGGCCATCGTGGAGATGGTGCCGGGAAAGCCCATGTGTGTGGAGAGCTTCTCCCAGTACCCGCCTCTCGGCCGCTT CGCCGTGCGCGACATGAGGCAGACGGTGGCCGTAGGCGTCATCAAGAACGTGGAGAAGAAGAGCGGCGGCGCCGGCAAGGTCACCAAGTC GGCGCAGAAGGCGCAGAAGGCGGGCAAGTGAAGCGCGGGCGCCCGCGGCGCGACCCTCCCCGGCGGTGCCGCGCTCCGAACCCCGGGCCC GGGCCCCCGCCCCGCCCCCGCCCCGCGCGCCGGTCCGGCGCCCCGCACCCCCGCCAGGCGCATGTCTGCACCTCCGCTTGCCAGAGGCCC TCGGTCAGCGACTGGATGCTCGCCATCAAGGTCCAGTGGAAGTTCTTCAAGAGGAAAGGCGCCCCCGCCCCAGGCTTCCGCGCCCAGCGC >55506_55506_4_MTAP-EEF1A2_MTAP_chr9_21802780_ENST00000580900_EEF1A2_chr20_62127388_ENST00000298049_length(amino acids)=426AA_BP=11 MASGTTTTAVKMGKGSFKYAWVLDKLKAERERGITIDISLWKFETTKYYITIIDAPGHRDFIKNMITGTSQADCAVLIVAAGVGEFEAGI SKNGQTREHALLAYTLGVKQLIVGVNKMDSTEPAYSEKRYDEIVKEVSAYIKKIGYNPATVPFVPISGWHGDNMLEPSPNMPWFKGWKVE RKEGNASGVSLLEALDTILPPTRPTDKPLRLPLQDVYKIGGIGTVPVGRVETGILRPGMVVTFAPVNITTEVKSVEMHHEALSEALPGDN VGFNVKNVSVKDIRRGNVCGDSKSDPPQEAAQFTSQVIILNHPGQISAGYSPVIDCHTAHIACKFAELKEKIDRRSGKKLEDNPKSLKSG -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for MTAP-EEF1A2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for MTAP-EEF1A2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for MTAP-EEF1A2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies