
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:MTG1-GPR123 (FusionGDB2 ID:55664) |
Fusion Gene Summary for MTG1-GPR123 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: MTG1-GPR123 | Fusion gene ID: 55664 | Hgene | Tgene | Gene symbol | MTG1 | GPR123 | Gene ID | 92170 | 84435 |
| Gene name | mitochondrial ribosome associated GTPase 1 | adhesion G protein-coupled receptor A1 | |
| Synonyms | GTP|GTPBP7 | GPR123 | |
| Cytomap | 10q26.3 | 10q26.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | mitochondrial ribosome-associated GTPase 1GTP-binding protein 7 (putative)mitochondrial GTPase 1 homolog | adhesion G protein-coupled receptor A1G-protein coupled receptor 123probable G-protein coupled receptor 123 | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q9BT17 | . | |
| Ensembl transtripts involved in fusion gene | ENST00000317502, ENST00000477902, | ENST00000392606, ENST00000392607, ENST00000607359, | |
| Fusion gene scores | * DoF score | 6 X 3 X 2=36 | 3 X 2 X 3=18 |
| # samples | 7 | 3 | |
| ** MAII score | log2(7/36*10)=0.959358015502654 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | log2(3/18*10)=0.736965594166206 effective Gene in Pan-Cancer Fusion Genes (eGinPCFGs). DoF>8 and MAII>0 | |
| Context | PubMed: MTG1 [Title/Abstract] AND GPR123 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | MTG1(135216277)-GPR123(134940737), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Fusion gene breakpoints across MTG1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across GPR123 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | STAD | TCGA-HU-A4H0-01A | MTG1 | chr10 | 135216277 | + | GPR123 | chr10 | 134940737 | + |
Top |
Fusion Gene ORF analysis for MTG1-GPR123 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| In-frame | ENST00000317502 | ENST00000392606 | MTG1 | chr10 | 135216277 | + | GPR123 | chr10 | 134940737 | + |
| In-frame | ENST00000317502 | ENST00000392607 | MTG1 | chr10 | 135216277 | + | GPR123 | chr10 | 134940737 | + |
| In-frame | ENST00000317502 | ENST00000607359 | MTG1 | chr10 | 135216277 | + | GPR123 | chr10 | 134940737 | + |
| In-frame | ENST00000477902 | ENST00000392606 | MTG1 | chr10 | 135216277 | + | GPR123 | chr10 | 134940737 | + |
| In-frame | ENST00000477902 | ENST00000392607 | MTG1 | chr10 | 135216277 | + | GPR123 | chr10 | 134940737 | + |
| In-frame | ENST00000477902 | ENST00000607359 | MTG1 | chr10 | 135216277 | + | GPR123 | chr10 | 134940737 | + |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000477902 | MTG1 | chr10 | 135216277 | + | ENST00000607359 | GPR123 | chr10 | 134940737 | + | 4174 | 731 | 93 | 2009 | 638 |
| ENST00000477902 | MTG1 | chr10 | 135216277 | + | ENST00000392607 | GPR123 | chr10 | 134940737 | + | 4177 | 731 | 93 | 2012 | 639 |
| ENST00000477902 | MTG1 | chr10 | 135216277 | + | ENST00000392606 | GPR123 | chr10 | 134940737 | + | 3930 | 731 | 93 | 2012 | 639 |
| ENST00000317502 | MTG1 | chr10 | 135216277 | + | ENST00000607359 | GPR123 | chr10 | 134940737 | + | 4245 | 802 | 50 | 2080 | 676 |
| ENST00000317502 | MTG1 | chr10 | 135216277 | + | ENST00000392607 | GPR123 | chr10 | 134940737 | + | 4248 | 802 | 50 | 2083 | 677 |
| ENST00000317502 | MTG1 | chr10 | 135216277 | + | ENST00000392606 | GPR123 | chr10 | 134940737 | + | 4001 | 802 | 50 | 2083 | 677 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000477902 | ENST00000607359 | MTG1 | chr10 | 135216277 | + | GPR123 | chr10 | 134940737 | + | 0.020184932 | 0.979815 |
| ENST00000477902 | ENST00000392607 | MTG1 | chr10 | 135216277 | + | GPR123 | chr10 | 134940737 | + | 0.018089253 | 0.98191077 |
| ENST00000477902 | ENST00000392606 | MTG1 | chr10 | 135216277 | + | GPR123 | chr10 | 134940737 | + | 0.018373052 | 0.9816269 |
| ENST00000317502 | ENST00000607359 | MTG1 | chr10 | 135216277 | + | GPR123 | chr10 | 134940737 | + | 0.014500008 | 0.9854999 |
| ENST00000317502 | ENST00000392607 | MTG1 | chr10 | 135216277 | + | GPR123 | chr10 | 134940737 | + | 0.013313742 | 0.9866862 |
| ENST00000317502 | ENST00000392606 | MTG1 | chr10 | 135216277 | + | GPR123 | chr10 | 134940737 | + | 0.01346787 | 0.98653215 |
Top |
Fusion Genomic Features for MTG1-GPR123 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
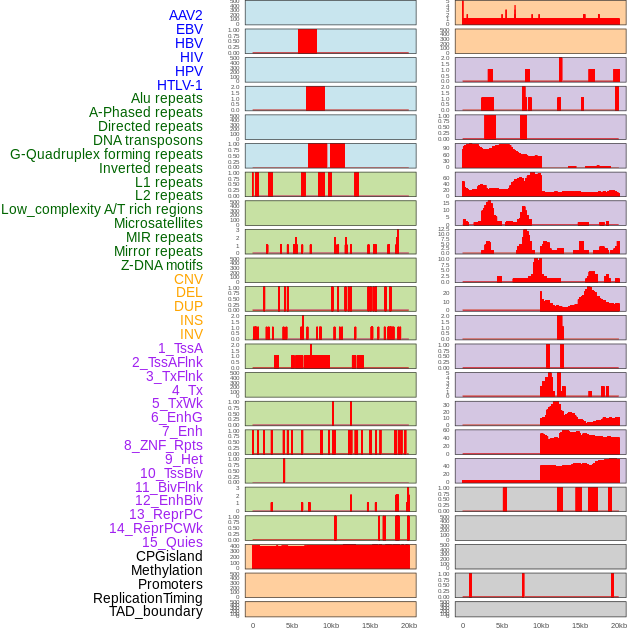 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
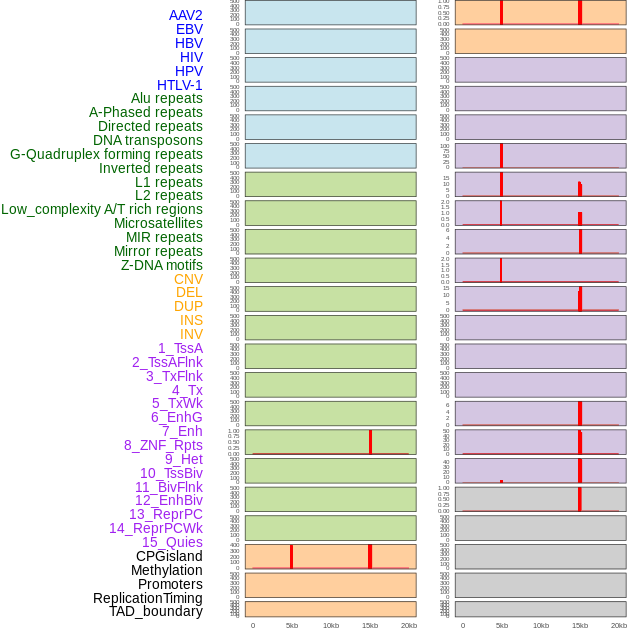 |
Top |
Fusion Protein Features for MTG1-GPR123 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr10:135216277/chr10:134940737) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| MTG1 | . |
| FUNCTION: Plays a role in the regulation of the mitochondrial ribosome assembly and of translational activity. Displays mitochondrial GTPase activity. {ECO:0000269|PubMed:23396448}. | FUNCTION: Transcriptional activator which is required for calcium-dependent dendritic growth and branching in cortical neurons. Recruits CREB-binding protein (CREBBP) to nuclear bodies. Component of the CREST-BRG1 complex, a multiprotein complex that regulates promoter activation by orchestrating a calcium-dependent release of a repressor complex and a recruitment of an activator complex. In resting neurons, transcription of the c-FOS promoter is inhibited by BRG1-dependent recruitment of a phospho-RB1-HDAC1 repressor complex. Upon calcium influx, RB1 is dephosphorylated by calcineurin, which leads to release of the repressor complex. At the same time, there is increased recruitment of CREBBP to the promoter by a CREST-dependent mechanism, which leads to transcriptional activation. The CREST-BRG1 complex also binds to the NR2B promoter, and activity-dependent induction of NR2B expression involves a release of HDAC1 and recruitment of CREBBP (By similarity). {ECO:0000250}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | MTG1 | chr10:135216277 | chr10:134940737 | ENST00000317502 | + | 9 | 11 | 36_209 | 250 | 335.0 | Domain | CP-type G |
| Hgene | MTG1 | chr10:135216277 | chr10:134940737 | ENST00000317502 | + | 9 | 11 | 153_158 | 250 | 335.0 | Nucleotide binding | GTP |
| Hgene | MTG1 | chr10:135216277 | chr10:134940737 | ENST00000317502 | + | 9 | 11 | 83_86 | 250 | 335.0 | Nucleotide binding | GTP |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000392606 | 1 | 4 | 106_134 | 36 | 464.0 | Topological domain | Cytoplasmic | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000392606 | 1 | 4 | 156_175 | 36 | 464.0 | Topological domain | Extracellular | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000392606 | 1 | 4 | 197_257 | 36 | 464.0 | Topological domain | Cytoplasmic | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000392606 | 1 | 4 | 279_284 | 36 | 464.0 | Topological domain | Extracellular | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000392606 | 1 | 4 | 306_560 | 36 | 464.0 | Topological domain | Cytoplasmic | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000392606 | 1 | 4 | 41_53 | 36 | 464.0 | Topological domain | Cytoplasmic | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000392606 | 1 | 4 | 75_84 | 36 | 464.0 | Topological domain | Extracellular | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000392607 | 4 | 7 | 156_175 | 133 | 561.0 | Topological domain | Extracellular | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000392607 | 4 | 7 | 197_257 | 133 | 561.0 | Topological domain | Cytoplasmic | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000392607 | 4 | 7 | 279_284 | 133 | 561.0 | Topological domain | Extracellular | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000392607 | 4 | 7 | 306_560 | 133 | 561.0 | Topological domain | Cytoplasmic | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000392606 | 1 | 4 | 135_155 | 36 | 464.0 | Transmembrane | Helical%3B Name%3D4 | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000392606 | 1 | 4 | 176_196 | 36 | 464.0 | Transmembrane | Helical%3B Name%3D5 | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000392606 | 1 | 4 | 258_278 | 36 | 464.0 | Transmembrane | Helical%3B Name%3D6 | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000392606 | 1 | 4 | 285_305 | 36 | 464.0 | Transmembrane | Helical%3B Name%3D7 | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000392606 | 1 | 4 | 54_74 | 36 | 464.0 | Transmembrane | Helical%3B Name%3D2 | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000392606 | 1 | 4 | 85_105 | 36 | 464.0 | Transmembrane | Helical%3B Name%3D3 | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000392607 | 4 | 7 | 135_155 | 133 | 561.0 | Transmembrane | Helical%3B Name%3D4 | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000392607 | 4 | 7 | 176_196 | 133 | 561.0 | Transmembrane | Helical%3B Name%3D5 | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000392607 | 4 | 7 | 258_278 | 133 | 561.0 | Transmembrane | Helical%3B Name%3D6 | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000392607 | 4 | 7 | 285_305 | 133 | 561.0 | Transmembrane | Helical%3B Name%3D7 |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000392606 | 1 | 4 | 1_19 | 36 | 464.0 | Topological domain | Extracellular | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000392607 | 4 | 7 | 106_134 | 133 | 561.0 | Topological domain | Cytoplasmic | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000392607 | 4 | 7 | 1_19 | 133 | 561.0 | Topological domain | Extracellular | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000392607 | 4 | 7 | 41_53 | 133 | 561.0 | Topological domain | Cytoplasmic | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000392607 | 4 | 7 | 75_84 | 133 | 561.0 | Topological domain | Extracellular | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000607359 | 13 | 16 | 106_134 | 853 | 1280.0 | Topological domain | Cytoplasmic | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000607359 | 13 | 16 | 156_175 | 853 | 1280.0 | Topological domain | Extracellular | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000607359 | 13 | 16 | 197_257 | 853 | 1280.0 | Topological domain | Cytoplasmic | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000607359 | 13 | 16 | 1_19 | 853 | 1280.0 | Topological domain | Extracellular | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000607359 | 13 | 16 | 279_284 | 853 | 1280.0 | Topological domain | Extracellular | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000607359 | 13 | 16 | 306_560 | 853 | 1280.0 | Topological domain | Cytoplasmic | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000607359 | 13 | 16 | 41_53 | 853 | 1280.0 | Topological domain | Cytoplasmic | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000607359 | 13 | 16 | 75_84 | 853 | 1280.0 | Topological domain | Extracellular | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000392606 | 1 | 4 | 20_40 | 36 | 464.0 | Transmembrane | Helical%3B Name%3D1 | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000392607 | 4 | 7 | 20_40 | 133 | 561.0 | Transmembrane | Helical%3B Name%3D1 | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000392607 | 4 | 7 | 54_74 | 133 | 561.0 | Transmembrane | Helical%3B Name%3D2 | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000392607 | 4 | 7 | 85_105 | 133 | 561.0 | Transmembrane | Helical%3B Name%3D3 | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000607359 | 13 | 16 | 135_155 | 853 | 1280.0 | Transmembrane | Helical%3B Name%3D4 | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000607359 | 13 | 16 | 176_196 | 853 | 1280.0 | Transmembrane | Helical%3B Name%3D5 | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000607359 | 13 | 16 | 20_40 | 853 | 1280.0 | Transmembrane | Helical%3B Name%3D1 | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000607359 | 13 | 16 | 258_278 | 853 | 1280.0 | Transmembrane | Helical%3B Name%3D6 | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000607359 | 13 | 16 | 285_305 | 853 | 1280.0 | Transmembrane | Helical%3B Name%3D7 | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000607359 | 13 | 16 | 54_74 | 853 | 1280.0 | Transmembrane | Helical%3B Name%3D2 | |
| Tgene | GPR123 | chr10:135216277 | chr10:134940737 | ENST00000607359 | 13 | 16 | 85_105 | 853 | 1280.0 | Transmembrane | Helical%3B Name%3D3 |
Top |
Fusion Gene Sequence for MTG1-GPR123 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >55664_55664_1_MTG1-GPR123_MTG1_chr10_135216277_ENST00000317502_GPR123_chr10_134940737_ENST00000392606_length(transcript)=4001nt_BP=802nt GCGGCGCAGAGGAGGTCAGCTGCGGGAGCGTTTCCGGGGACGGTGCCGCCATGAGATTGACCCCGCGCGCGCTGTGCAGCGCCGCCCAGG CCGCCTGGCGGGAGAACTTCCCCCTGTGCGGTCGCGACGTGGCGCGCTGGTTCCCGGGCCACATGGCCAAGGGGCTGAAGAAGATGCAGA GCAGCCTGAAGCTGGTGGACTGTATCATCGAGGTCCACGATGCCCGGATCCCACTTTCAGGCCGCAACCCTCTGTTTCAGGAAACCCTTG GGCTTAAGCCTCACTTGCTGGTCCTCAACAAGATGGACTTGGCGGATCTTACAGAGCAGCAGAAAATTATGCAACACTTAGAAGGAGAAG GCCTAAAAAATGTCATTTTTACCAACTGTGTAAAGGATGAAAATGTCAAGCAGATCATCCCGATGGTCACTGAACTGATTGGGAGAAGCC ACCGCTACCACCGAAAAGAGAACCTGGAGTACTGTATCATGGTCATTGGGGTCCCCAACGTGGGCAAGTCCTCCCTCATCAACTCCCTCC GGAGGCAGCACCTCAGGAAAGGGAAAGCCACCAGGGTGGGTGGCGAGCCTGGGATCACCAGAGCTGTGATGTCCAAAATTCAGGTCTCTG AGCGGCCCCTGATGTTCCTGTTGGACACTCCTGGCGTGCTGGCTCCTCGGATTGAAAGTGTGGAGACAGGCCTGAAGCTGGCCCTGTGTG GAACGGTGCTGGACCACCTGGTCGGGGAGGAGACCATGGCTGACTACCTGCTGTACACCCTCAACAAACACCAGCGCTTTGGGTTTTACC TCGTCAGCGGAGGGGTCCCCTTTATCATCTGTGGGGTCACGGCTGCCACGAACATCAGGAATTACGGGACAGAGGACGAGGACACGGCGT ACTGCTGGATGGCCTGGGAGCCCAGCCTGGGCGCCTTCTACGGCCCAGCCGCCATCATCACCCTGGTCACCTGTGTGTACTTCCTGGGCA CCTACGTGCAGCTGCGGCGCCACCCAGGGCGCAGGTACGAGCTGCGCACACAGCCCGAGGAGCAGCGGCGGCTGGCGACACCCGAGGGCG GCCGTGGGATCCGGCCAGGCACCCCACCCGCACACGATGCCCCCGGCGCCTCCGTGCTGCAGAACGAGCACTCATTCCAGGCACAGCTGC GCGCCGCCGCCTTCACGCTGTTCCTGTTCACGGCCACGTGGGCCTTCGGGGCGCTGGCGGTGTCACAGGGCCACTTCCTGGACATGGTCT TCAGCTGCCTGTACGGCGCCTTCTGCGTGACCCTGGGACTCTTCGTGCTCATCCACCACTGCGCCAAGCGTGAGGACGTGTGGCAGTGCT GGTGGGCATGCTGCCCGCCCCGCAAGGACGCCCACCCCGCACTTGACGCCAACGGGGCCGCGCTGGGCCGCGCCGCCTGCCTGCACTCGC CGGGACTGGGCCAGCCACGGGGCTTCGCGCACCCACCGGGCCCCTGCAAGATGACCAACCTGCAGGCCGCGCAGGGCCACGCCAGTTGCC TGTCACCGGCCACCCCGTGCTGCGCCAAGATGCACTGCGAGCCACTGACGGCGGACGAGGCGCACGTGCACCTGCAGGAGGAGGGCGCCT TCGGGCACGACCCCCACCTGCACGGGTGCCTTCAGGGCAGAACTAAGCCGCCCTACTTTAGCCGGCACCCAGCAGAGGAGCCCGAGTACG CCTACCACATCCCATCCAGCCTGGATGGCAGCCCCCGCAGCTCGCGCACAGACAGCCCCCCCAGCTCTCTGGATGGCCCGGCGGGGACAC ACACGCTGGCCTGCTGCACCCAGGGCGACCCCTTCCCCATGGTCACCCAGCCCGAGGGCAGTGATGGGAGCCCTGCCCTCTACAGCTGCC CCACGCAGCCGGGCAGGGAGGCAGCGCTCGGGCCCGGCCACTTGGAGATGCTGCGGAGGACACAGTCCCTGCCCTTTGGTGGCCCCAGCC AGAACGGGCTGCCCAAGGGTAAATTGCTAGAAGGCCTGCCGTTTGGCACCGACGGGACCGGCAACATCCGAACGGGACCCTGGAAAAACG AAACTACTGTGTAGATGGGGGCAGAGGACACGGTGTTCCTGGAGGAGCTTCAGAGCAGAGTGGGGGGCCCATCTGCCACATGAGGTCACT GGGGGTACCGAAGTGACCCCGCCTTTCAGAAGCCGTTCACACCCCTGCCCCTTCCTTGTGATCACACCCCTGCCCCTTCCTTGTGATCAC ACCCCTGCCCCTTCCTTGTGATCACACCCCTGCCCCTTCCTTGTGAAAGACCTCAGCGGGGAAACGCTCCGGGCCACGCCCACTCCCCTT ATCCCAATTCCGCGTGCTGGTCCCGCACACGGTCATCCGGTTTCTGTCCTGTGGTCTCCAGTCCTGGGGCACCCTAGAGGCAGAGCAGGG GATTCCATCAAAGGACCCACTGAGACCCCAGCATGGCCCTGCCCGAGATGCCCTGCTGCCCACGGAGTCCTGGCTTCCCCTGGTGTGGCC GGGCAGGGCCGAGATCGCAGGAGGGGGCTGCCCTGACCTTTCCCAGTGTTCAATGTGTGTGTCTTGCGTTCTACTCCGGGGGTGGCGGCG GCAGGTCTGTCCCCAGCATTCTCGCTCTGGGCAGAACCCTCGGGACCCTCCGCTGTCGTGTGTCTGAGCCACCCCTGCAGCTTCACAGGG CCCCTGCACACCTCTGCCCACTCAGTGTGCCCTGTCAGCCCTGTCCTTGTCGTAGCCCCAGCCCTGCAGGGCTGAGAGCACCACAGATGC TGGGGGCTGCTCTGGACTTTGGGGATGGCTGTCAGCCTCAGAGGGCCAATGGGGGGCTTTCACGGGCCCAAGGCTTGGGAAAATGCCCAG ACATCCTTTAGTGAAGACTCGACTTCCAAAACCAGCCACCGCTGGGACTGGATTCCACTCCAGTATAGGCACTTAGCAACACGAAGGTTT ATTCCAAAAAGAAAAGGGGCTGACAGACGGGAGATTCTCATGGACAAAATCCCTTTCCCTTTTTCTCGTCTCCATGAACATCTGGGTACC AAGCCCTGACTCAAAGGACAGATGTGGATGACAGCAAGACTTCTGTGAAAGCAAGTGGCCCGTCCCTAGGTGGGAGGGAGTCCAGAGGGT CATGGGTGTGAAACTGTGCACAGCTTTCCCTCCCTCCCTCTTCCTCCTTGTCTGTGACACATGTGCACCCACACACACACACACAAACAC ATGTGCATATCACACACATGCACACACACAAACACATGTGCATATCACACACGCGCACACACCCAAACACGTGCATATCACACACATGCA CACACACAAACACGTGCATATCACACACATGCACACAAACGTGCATATCACACACACGCACACACACCCAAACACGTGCATATCACACAC ACGCACACACACAAACACGTGCATATCACACACAAACACACGTGCACACATACTTAACACACACTTGCACCTGCTGTGCACATGTGCACA CACACGTAGTAGTGTGTTTTCCAGCCACCCACACACTGGGTTTGCATTGGAGATTGTTTCACCCTGCAAACGTCAACGTCAGCAGACTCG TCGGTGCGCTGTGCTATCCGGTTGGGAGGTCTCACCAGGAGCAGAGCCTCCCTAACGTGCACCTCCGAGAAGAGGGGTGTCGGGGAGTGT TCCCAGCACCTGCTCGGTGGAAGGGCTCTCCGGAGACTGGCACTCAGTATCTGAGTATGAGGAGCCTCACTTCCCGGGGTGTCGGTAAAC TTGACCGTGACTCAGTAACCCACAGCGTGCTCCTCCCAGCAAACCCCGTGTGTCCTTACAGGTCGACCAGACGGGCCGTCGGAGGACCAC CAGGTGGCTCTGCCTCTGCCTCACCTTCTCACCTGCTTCCATAGCTGATGTGAACCCGAATCCCCACGCTGTGCTGTGTACGCACTGTAG >55664_55664_1_MTG1-GPR123_MTG1_chr10_135216277_ENST00000317502_GPR123_chr10_134940737_ENST00000392606_length(amino acids)=677AA_BP=251 MRLTPRALCSAAQAAWRENFPLCGRDVARWFPGHMAKGLKKMQSSLKLVDCIIEVHDARIPLSGRNPLFQETLGLKPHLLVLNKMDLADL TEQQKIMQHLEGEGLKNVIFTNCVKDENVKQIIPMVTELIGRSHRYHRKENLEYCIMVIGVPNVGKSSLINSLRRQHLRKGKATRVGGEP GITRAVMSKIQVSERPLMFLLDTPGVLAPRIESVETGLKLALCGTVLDHLVGEETMADYLLYTLNKHQRFGFYLVSGGVPFIICGVTAAT NIRNYGTEDEDTAYCWMAWEPSLGAFYGPAAIITLVTCVYFLGTYVQLRRHPGRRYELRTQPEEQRRLATPEGGRGIRPGTPPAHDAPGA SVLQNEHSFQAQLRAAAFTLFLFTATWAFGALAVSQGHFLDMVFSCLYGAFCVTLGLFVLIHHCAKREDVWQCWWACCPPRKDAHPALDA NGAALGRAACLHSPGLGQPRGFAHPPGPCKMTNLQAAQGHASCLSPATPCCAKMHCEPLTADEAHVHLQEEGAFGHDPHLHGCLQGRTKP PYFSRHPAEEPEYAYHIPSSLDGSPRSSRTDSPPSSLDGPAGTHTLACCTQGDPFPMVTQPEGSDGSPALYSCPTQPGREAALGPGHLEM -------------------------------------------------------------- >55664_55664_2_MTG1-GPR123_MTG1_chr10_135216277_ENST00000317502_GPR123_chr10_134940737_ENST00000392607_length(transcript)=4248nt_BP=802nt GCGGCGCAGAGGAGGTCAGCTGCGGGAGCGTTTCCGGGGACGGTGCCGCCATGAGATTGACCCCGCGCGCGCTGTGCAGCGCCGCCCAGG CCGCCTGGCGGGAGAACTTCCCCCTGTGCGGTCGCGACGTGGCGCGCTGGTTCCCGGGCCACATGGCCAAGGGGCTGAAGAAGATGCAGA GCAGCCTGAAGCTGGTGGACTGTATCATCGAGGTCCACGATGCCCGGATCCCACTTTCAGGCCGCAACCCTCTGTTTCAGGAAACCCTTG GGCTTAAGCCTCACTTGCTGGTCCTCAACAAGATGGACTTGGCGGATCTTACAGAGCAGCAGAAAATTATGCAACACTTAGAAGGAGAAG GCCTAAAAAATGTCATTTTTACCAACTGTGTAAAGGATGAAAATGTCAAGCAGATCATCCCGATGGTCACTGAACTGATTGGGAGAAGCC ACCGCTACCACCGAAAAGAGAACCTGGAGTACTGTATCATGGTCATTGGGGTCCCCAACGTGGGCAAGTCCTCCCTCATCAACTCCCTCC GGAGGCAGCACCTCAGGAAAGGGAAAGCCACCAGGGTGGGTGGCGAGCCTGGGATCACCAGAGCTGTGATGTCCAAAATTCAGGTCTCTG AGCGGCCCCTGATGTTCCTGTTGGACACTCCTGGCGTGCTGGCTCCTCGGATTGAAAGTGTGGAGACAGGCCTGAAGCTGGCCCTGTGTG GAACGGTGCTGGACCACCTGGTCGGGGAGGAGACCATGGCTGACTACCTGCTGTACACCCTCAACAAACACCAGCGCTTTGGGTTTTACC TCGTCAGCGGAGGGGTCCCCTTTATCATCTGTGGGGTCACGGCTGCCACGAACATCAGGAATTACGGGACAGAGGACGAGGACACGGCGT ACTGCTGGATGGCCTGGGAGCCCAGCCTGGGCGCCTTCTACGGCCCAGCCGCCATCATCACCCTGGTCACCTGTGTGTACTTCCTGGGCA CCTACGTGCAGCTGCGGCGCCACCCAGGGCGCAGGTACGAGCTGCGCACACAGCCCGAGGAGCAGCGGCGGCTGGCGACACCCGAGGGCG GCCGTGGGATCCGGCCAGGCACCCCACCCGCACACGATGCCCCCGGCGCCTCCGTGCTGCAGAACGAGCACTCATTCCAGGCACAGCTGC GCGCCGCCGCCTTCACGCTGTTCCTGTTCACGGCCACGTGGGCCTTCGGGGCGCTGGCGGTGTCACAGGGCCACTTCCTGGACATGGTCT TCAGCTGCCTGTACGGCGCCTTCTGCGTGACCCTGGGACTCTTCGTGCTCATCCACCACTGCGCCAAGCGTGAGGACGTGTGGCAGTGCT GGTGGGCATGCTGCCCGCCCCGCAAGGACGCCCACCCCGCACTTGACGCCAACGGGGCCGCGCTGGGCCGCGCCGCCTGCCTGCACTCGC CGGGACTGGGCCAGCCACGGGGCTTCGCGCACCCACCGGGCCCCTGCAAGATGACCAACCTGCAGGCCGCGCAGGGCCACGCCAGTTGCC TGTCACCGGCCACCCCGTGCTGCGCCAAGATGCACTGCGAGCCACTGACGGCGGACGAGGCGCACGTGCACCTGCAGGAGGAGGGCGCCT TCGGGCACGACCCCCACCTGCACGGGTGCCTTCAGGGCAGAACTAAGCCGCCCTACTTTAGCCGGCACCCAGCAGAGGAGCCCGAGTACG CCTACCACATCCCATCCAGCCTGGATGGCAGCCCCCGCAGCTCGCGCACAGACAGCCCCCCCAGCTCTCTGGATGGCCCGGCGGGGACAC ACACGCTGGCCTGCTGCACCCAGGGCGACCCCTTCCCCATGGTCACCCAGCCCGAGGGCAGTGATGGGAGCCCTGCCCTCTACAGCTGCC CCACGCAGCCGGGCAGGGAGGCAGCGCTCGGGCCCGGCCACTTGGAGATGCTGCGGAGGACACAGTCCCTGCCCTTTGGTGGCCCCAGCC AGAACGGGCTGCCCAAGGGTAAATTGCTAGAAGGCCTGCCGTTTGGCACCGACGGGACCGGCAACATCCGAACGGGACCCTGGAAAAACG AAACTACTGTGTAGATGGGGGCAGAGGACACGGTGTTCCTGGAGGAGCTTCAGAGCAGAGTGGGGGGCCCATCTGCCACATGAGGTCACT GGGGGTACCGAAGTGACCCCGCCTTTCAGAAGCCGTTCACACCCCTGCCCCTTCCTTGTGATCACACCCCTGCCCCTTCCTTGTGATCAC ACCCCTGCCCCTTCCTTGTGATCACACCCCTGCCCCTTCCTTGTGAAAGACCTCAGCGGGGAAACGCTCCGGGCCACGCCCACTCCCCTT ATCCCAATTCCGCGTGCTGGTCCCGCACACGGTCATCCGGTTTCTGTCCTGTGGTCTCCAGTCCTGGGGCACCCTAGAGGCAGAGCAGGG GATTCCATCAAAGGACCCACTGAGACCCCAGCATGGCCCTGCCCGAGATGCCCTGCTGCCCACGGAGTCCTGGCTTCCCCTGGTGTGGCC GGGCAGGGCCGAGATCGCAGGAGGGGGCTGCCCTGACCTTTCCCAGTGTTCAATGTGTGTGTCTTGCGTTCTACTCCGGGGGTGGCGGCG GCAGGTCTGTCCCCAGCATTCTCGCTCTGGGCAGAACCCTCGGGACCCTCCGCTGTCGTGTGTCTGAGCCACCCCTGCAGCTTCACAGGG CCCCTGCACACCTCTGCCCACTCAGTGTGCCCTGTCAGCCCTGTCCTTGTCGTAGCCCCAGCCCTGCAGGGCTGAGAGCACCACAGATGC TGGGGGCTGCTCTGGACTTTGGGGATGGCTGTCAGCCTCAGAGGGCCAATGGGGGGCTTTCACGGGCCCAAGGCTTGGGAAAATGCCCAG ACATCCTTTAGTGAAGACTCGACTTCCAAAACCAGCCACCGCTGGGACTGGATTCCACTCCAGTATAGGCACTTAGCAACACGAAGGTTT ATTCCAAAAAGAAAAGGGGCTGACAGACGGGAGATTCTCATGGACAAAATCCCTTTCCCTTTTTCTCGTCTCCATGAACATCTGGGTACC AAGCCCTGACTCAAAGGACAGATGTGGATGACAGCAAGACTTCTGTGAAAGCAAGTGGCCCGTCCCTAGGTGGGAGGGAGTCCAGAGGGT CATGGGTGTGAAACTGTGCACAGCTTTCCCTCCCTCCCTCTTCCTCCTTGTCTGTGACACATGTGCACCCACACACACACACACAAACAC ATGTGCATATCACACACATGCACACACACAAACACATGTGCATATCACACACGCGCACACACCCAAACACGTGCATATCACACACATGCA CACACACAAACACGTGCATATCACACACATGCACACAAACGTGCATATCACACACACGCACACACACCCAAACACGTGCATATCACACAC ACGCACACACACAAACACGTGCATATCACACACAAACACACGTGCACACATACTTAACACACACTTGCACCTGCTGTGCACATGTGCACA CACACGTAGTAGTGTGTTTTCCAGCCACCCACACACTGGGTTTGCATTGGAGATTGTTTCACCCTGCAAACGTCAACGTCAGCAGACTCG TCGGTGCGCTGTGCTATCCGGTTGGGAGGTCTCACCAGGAGCAGAGCCTCCCTAACGTGCACCTCCGAGAAGAGGGGTGTCGGGGAGTGT TCCCAGCACCTGCTCGGTGGAAGGGCTCTCCGGAGACTGGCACTCAGTATCTGAGTATGAGGAGCCTCACTTCCCGGGGTGTCGGTAAAC TTGACCGTGACTCAGTAACCCACAGCGTGCTCCTCCCAGCAAACCCCGTGTGTCCTTACAGGTCGACCAGACGGGCCGTCGGAGGACCAC CAGGTGGCTCTGCCTCTGCCTCACCTTCTCACCTGCTTCCATAGCTGATGTGAACCCGAATCCCCACGCTGTGCTGTGTACGCACTGTAG GTGCAGAACCGTCCACACAAAAATACAGTCTTGGCATTGTTTGTTCTTTGTGAGGCTGGTTAATAGCATCCCCGTGTGTTTTTCTCACCC TCGATGGGGTAGAGGGGCACCTGAATGTGTGGCCCCCGTCTGTGTCCTGGATCCTGGGGCAGGGCTGCTCTCCCTGGCCCCTGCAGCCCC TCATGAACTTTCCACCCTCAGTGCCCCCGGCTGAGCAGAGAGGCGTCCCACCATTCAACCAAAGAAAGTCAACATTGAACATTAAACCTC >55664_55664_2_MTG1-GPR123_MTG1_chr10_135216277_ENST00000317502_GPR123_chr10_134940737_ENST00000392607_length(amino acids)=677AA_BP=251 MRLTPRALCSAAQAAWRENFPLCGRDVARWFPGHMAKGLKKMQSSLKLVDCIIEVHDARIPLSGRNPLFQETLGLKPHLLVLNKMDLADL TEQQKIMQHLEGEGLKNVIFTNCVKDENVKQIIPMVTELIGRSHRYHRKENLEYCIMVIGVPNVGKSSLINSLRRQHLRKGKATRVGGEP GITRAVMSKIQVSERPLMFLLDTPGVLAPRIESVETGLKLALCGTVLDHLVGEETMADYLLYTLNKHQRFGFYLVSGGVPFIICGVTAAT NIRNYGTEDEDTAYCWMAWEPSLGAFYGPAAIITLVTCVYFLGTYVQLRRHPGRRYELRTQPEEQRRLATPEGGRGIRPGTPPAHDAPGA SVLQNEHSFQAQLRAAAFTLFLFTATWAFGALAVSQGHFLDMVFSCLYGAFCVTLGLFVLIHHCAKREDVWQCWWACCPPRKDAHPALDA NGAALGRAACLHSPGLGQPRGFAHPPGPCKMTNLQAAQGHASCLSPATPCCAKMHCEPLTADEAHVHLQEEGAFGHDPHLHGCLQGRTKP PYFSRHPAEEPEYAYHIPSSLDGSPRSSRTDSPPSSLDGPAGTHTLACCTQGDPFPMVTQPEGSDGSPALYSCPTQPGREAALGPGHLEM -------------------------------------------------------------- >55664_55664_3_MTG1-GPR123_MTG1_chr10_135216277_ENST00000317502_GPR123_chr10_134940737_ENST00000607359_length(transcript)=4245nt_BP=802nt GCGGCGCAGAGGAGGTCAGCTGCGGGAGCGTTTCCGGGGACGGTGCCGCCATGAGATTGACCCCGCGCGCGCTGTGCAGCGCCGCCCAGG CCGCCTGGCGGGAGAACTTCCCCCTGTGCGGTCGCGACGTGGCGCGCTGGTTCCCGGGCCACATGGCCAAGGGGCTGAAGAAGATGCAGA GCAGCCTGAAGCTGGTGGACTGTATCATCGAGGTCCACGATGCCCGGATCCCACTTTCAGGCCGCAACCCTCTGTTTCAGGAAACCCTTG GGCTTAAGCCTCACTTGCTGGTCCTCAACAAGATGGACTTGGCGGATCTTACAGAGCAGCAGAAAATTATGCAACACTTAGAAGGAGAAG GCCTAAAAAATGTCATTTTTACCAACTGTGTAAAGGATGAAAATGTCAAGCAGATCATCCCGATGGTCACTGAACTGATTGGGAGAAGCC ACCGCTACCACCGAAAAGAGAACCTGGAGTACTGTATCATGGTCATTGGGGTCCCCAACGTGGGCAAGTCCTCCCTCATCAACTCCCTCC GGAGGCAGCACCTCAGGAAAGGGAAAGCCACCAGGGTGGGTGGCGAGCCTGGGATCACCAGAGCTGTGATGTCCAAAATTCAGGTCTCTG AGCGGCCCCTGATGTTCCTGTTGGACACTCCTGGCGTGCTGGCTCCTCGGATTGAAAGTGTGGAGACAGGCCTGAAGCTGGCCCTGTGTG GAACGGTGCTGGACCACCTGGTCGGGGAGGAGACCATGGCTGACTACCTGCTGTACACCCTCAACAAACACCAGCGCTTTGGGTTTTACC TCGTCAGCGGAGGGGTCCCCTTTATCATCTGTGGGGTCACGGCTGCCACGAACATCAGGAATTACGGGACAGAGGACGAGGACACGGCCT GCTGGATGGCCTGGGAGCCCAGCCTGGGCGCCTTCTACGGCCCAGCCGCCATCATCACCCTGGTCACCTGTGTGTACTTCCTGGGCACCT ACGTGCAGCTGCGGCGCCACCCAGGGCGCAGGTACGAGCTGCGCACACAGCCCGAGGAGCAGCGGCGGCTGGCGACACCCGAGGGCGGCC GTGGGATCCGGCCAGGCACCCCACCCGCACACGATGCCCCCGGCGCCTCCGTGCTGCAGAACGAGCACTCATTCCAGGCACAGCTGCGCG CCGCCGCCTTCACGCTGTTCCTGTTCACGGCCACGTGGGCCTTCGGGGCGCTGGCGGTGTCACAGGGCCACTTCCTGGACATGGTCTTCA GCTGCCTGTACGGCGCCTTCTGCGTGACCCTGGGACTCTTCGTGCTCATCCACCACTGCGCCAAGCGTGAGGACGTGTGGCAGTGCTGGT GGGCATGCTGCCCGCCCCGCAAGGACGCCCACCCCGCACTTGACGCCAACGGGGCCGCGCTGGGCCGCGCCGCCTGCCTGCACTCGCCGG GACTGGGCCAGCCACGGGGCTTCGCGCACCCACCGGGCCCCTGCAAGATGACCAACCTGCAGGCCGCGCAGGGCCACGCCAGTTGCCTGT CACCGGCCACCCCGTGCTGCGCCAAGATGCACTGCGAGCCACTGACGGCGGACGAGGCGCACGTGCACCTGCAGGAGGAGGGCGCCTTCG GGCACGACCCCCACCTGCACGGGTGCCTTCAGGGCAGAACTAAGCCGCCCTACTTTAGCCGGCACCCAGCAGAGGAGCCCGAGTACGCCT ACCACATCCCATCCAGCCTGGATGGCAGCCCCCGCAGCTCGCGCACAGACAGCCCCCCCAGCTCTCTGGATGGCCCGGCGGGGACACACA CGCTGGCCTGCTGCACCCAGGGCGACCCCTTCCCCATGGTCACCCAGCCCGAGGGCAGTGATGGGAGCCCTGCCCTCTACAGCTGCCCCA CGCAGCCGGGCAGGGAGGCAGCGCTCGGGCCCGGCCACTTGGAGATGCTGCGGAGGACACAGTCCCTGCCCTTTGGTGGCCCCAGCCAGA ACGGGCTGCCCAAGGGTAAATTGCTAGAAGGCCTGCCGTTTGGCACCGACGGGACCGGCAACATCCGAACGGGACCCTGGAAAAACGAAA CTACTGTGTAGATGGGGGCAGAGGACACGGTGTTCCTGGAGGAGCTTCAGAGCAGAGTGGGGGGCCCATCTGCCACATGAGGTCACTGGG GGTACCGAAGTGACCCCGCCTTTCAGAAGCCGTTCACACCCCTGCCCCTTCCTTGTGATCACACCCCTGCCCCTTCCTTGTGATCACACC CCTGCCCCTTCCTTGTGATCACACCCCTGCCCCTTCCTTGTGAAAGACCTCAGCGGGGAAACGCTCCGGGCCACGCCCACTCCCCTTATC CCAATTCCGCGTGCTGGTCCCGCACACGGTCATCCGGTTTCTGTCCTGTGGTCTCCAGTCCTGGGGCACCCTAGAGGCAGAGCAGGGGAT TCCATCAAAGGACCCACTGAGACCCCAGCATGGCCCTGCCCGAGATGCCCTGCTGCCCACGGAGTCCTGGCTTCCCCTGGTGTGGCCGGG CAGGGCCGAGATCGCAGGAGGGGGCTGCCCTGACCTTTCCCAGTGTTCAATGTGTGTGTCTTGCGTTCTACTCCGGGGGTGGCGGCGGCA GGTCTGTCCCCAGCATTCTCGCTCTGGGCAGAACCCTCGGGACCCTCCGCTGTCGTGTGTCTGAGCCACCCCTGCAGCTTCACAGGGCCC CTGCACACCTCTGCCCACTCAGTGTGCCCTGTCAGCCCTGTCCTTGTCGTAGCCCCAGCCCTGCAGGGCTGAGAGCACCACAGATGCTGG GGGCTGCTCTGGACTTTGGGGATGGCTGTCAGCCTCAGAGGGCCAATGGGGGGCTTTCACGGGCCCAAGGCTTGGGAAAATGCCCAGACA TCCTTTAGTGAAGACTCGACTTCCAAAACCAGCCACCGCTGGGACTGGATTCCACTCCAGTATAGGCACTTAGCAACACGAAGGTTTATT CCAAAAAGAAAAGGGGCTGACAGACGGGAGATTCTCATGGACAAAATCCCTTTCCCTTTTTCTCGTCTCCATGAACATCTGGGTACCAAG CCCTGACTCAAAGGACAGATGTGGATGACAGCAAGACTTCTGTGAAAGCAAGTGGCCCGTCCCTAGGTGGGAGGGAGTCCAGAGGGTCAT GGGTGTGAAACTGTGCACAGCTTTCCCTCCCTCCCTCTTCCTCCTTGTCTGTGACACATGTGCACCCACACACACACACACAAACACATG TGCATATCACACACATGCACACACACAAACACATGTGCATATCACACACGCGCACACACCCAAACACGTGCATATCACACACATGCACAC ACACAAACACGTGCATATCACACACATGCACACAAACGTGCATATCACACACACGCACACACACCCAAACACGTGCATATCACACACACG CACACACACAAACACGTGCATATCACACACAAACACACGTGCACACATACTTAACACACACTTGCACCTGCTGTGCACATGTGCACACAC ACGTAGTAGTGTGTTTTCCAGCCACCCACACACTGGGTTTGCATTGGAGATTGTTTCACCCTGCAAACGTCAACGTCAGCAGACTCGTCG GTGCGCTGTGCTATCCGGTTGGGAGGTCTCACCAGGAGCAGAGCCTCCCTAACGTGCACCTCCGAGAAGAGGGGTGTCGGGGAGTGTTCC CAGCACCTGCTCGGTGGAAGGGCTCTCCGGAGACTGGCACTCAGTATCTGAGTATGAGGAGCCTCACTTCCCGGGGTGTCGGTAAACTTG ACCGTGACTCAGTAACCCACAGCGTGCTCCTCCCAGCAAACCCCGTGTGTCCTTACAGGTCGACCAGACGGGCCGTCGGAGGACCACCAG GTGGCTCTGCCTCTGCCTCACCTTCTCACCTGCTTCCATAGCTGATGTGAACCCGAATCCCCACGCTGTGCTGTGTACGCACTGTAGGTG CAGAACCGTCCACACAAAAATACAGTCTTGGCATTGTTTGTTCTTTGTGAGGCTGGTTAATAGCATCCCCGTGTGTTTTTCTCACCCTCG ATGGGGTAGAGGGGCACCTGAATGTGTGGCCCCCGTCTGTGTCCTGGATCCTGGGGCAGGGCTGCTCTCCCTGGCCCCTGCAGCCCCTCA TGAACTTTCCACCCTCAGTGCCCCCGGCTGAGCAGAGAGGCGTCCCACCATTCAACCAAAGAAAGTCAACATTGAACATTAAACCTCTGT >55664_55664_3_MTG1-GPR123_MTG1_chr10_135216277_ENST00000317502_GPR123_chr10_134940737_ENST00000607359_length(amino acids)=676AA_BP=251 MRLTPRALCSAAQAAWRENFPLCGRDVARWFPGHMAKGLKKMQSSLKLVDCIIEVHDARIPLSGRNPLFQETLGLKPHLLVLNKMDLADL TEQQKIMQHLEGEGLKNVIFTNCVKDENVKQIIPMVTELIGRSHRYHRKENLEYCIMVIGVPNVGKSSLINSLRRQHLRKGKATRVGGEP GITRAVMSKIQVSERPLMFLLDTPGVLAPRIESVETGLKLALCGTVLDHLVGEETMADYLLYTLNKHQRFGFYLVSGGVPFIICGVTAAT NIRNYGTEDEDTACWMAWEPSLGAFYGPAAIITLVTCVYFLGTYVQLRRHPGRRYELRTQPEEQRRLATPEGGRGIRPGTPPAHDAPGAS VLQNEHSFQAQLRAAAFTLFLFTATWAFGALAVSQGHFLDMVFSCLYGAFCVTLGLFVLIHHCAKREDVWQCWWACCPPRKDAHPALDAN GAALGRAACLHSPGLGQPRGFAHPPGPCKMTNLQAAQGHASCLSPATPCCAKMHCEPLTADEAHVHLQEEGAFGHDPHLHGCLQGRTKPP YFSRHPAEEPEYAYHIPSSLDGSPRSSRTDSPPSSLDGPAGTHTLACCTQGDPFPMVTQPEGSDGSPALYSCPTQPGREAALGPGHLEML -------------------------------------------------------------- >55664_55664_4_MTG1-GPR123_MTG1_chr10_135216277_ENST00000477902_GPR123_chr10_134940737_ENST00000392606_length(transcript)=3930nt_BP=731nt GTGGTGCGGCCCCTTGGAGCGCCGGAAGCCCGCAGTGCCGGAGGCCCGCAGCGCCGGAACCTCAGAGGCGGGTCGCAGCGGCGCAGAGGA GGGCTGAAGAAGATGCAGAGCAGCCTGAAGCTGGTGGACTGTATCATCGAGGTCCACGATGCCCGGATCCCACTTTCAGGCCGCAACCCT CTGTTTCAGGAAACCCTTGGGCTTAAGCCTCACTTGCTGGTCCTCAACAAGATGGACTTGGCGGATCTTACAGAGCAGCAGAAAATTATG CAACACTTAGAAGGAGAAGGCCTAAAAAATGTCATTTTTACCAACTGTGTAAAGGATGAAAATGTCAAGCAGATCATCCCGATGGTCACT GAACTGATTGGGAGAAGCCACCGCTACCACCGAAAAGAGAACCTGGAGTACTGTATCATGGTCATTGGGGTCCCCAACGTGGGCAAGTCC TCCCTCATCAACTCCCTCCGGAGGCAGCACCTCAGGAAAGGGAAAGCCACCAGGGTGGGTGGCGAGCCTGGGATCACCAGAGCTGTGATG TCCAAAATTCAGGTCTCTGAGCGGCCCCTGATGTTCCTGTTGGACACTCCTGGCGTGCTGGCTCCTCGGATTGAAAGTGTGGAGACAGGC CTGAAGCTGGCCCTGTGTGGAACGGTGCTGGACCACCTGGTCGGGGAGGAGACCATGGCTGACTACCTGCTGTACACCCTCAACAAACAC CAGCGCTTTGGGTTTTACCTCGTCAGCGGAGGGGTCCCCTTTATCATCTGTGGGGTCACGGCTGCCACGAACATCAGGAATTACGGGACA GAGGACGAGGACACGGCGTACTGCTGGATGGCCTGGGAGCCCAGCCTGGGCGCCTTCTACGGCCCAGCCGCCATCATCACCCTGGTCACC TGTGTGTACTTCCTGGGCACCTACGTGCAGCTGCGGCGCCACCCAGGGCGCAGGTACGAGCTGCGCACACAGCCCGAGGAGCAGCGGCGG CTGGCGACACCCGAGGGCGGCCGTGGGATCCGGCCAGGCACCCCACCCGCACACGATGCCCCCGGCGCCTCCGTGCTGCAGAACGAGCAC TCATTCCAGGCACAGCTGCGCGCCGCCGCCTTCACGCTGTTCCTGTTCACGGCCACGTGGGCCTTCGGGGCGCTGGCGGTGTCACAGGGC CACTTCCTGGACATGGTCTTCAGCTGCCTGTACGGCGCCTTCTGCGTGACCCTGGGACTCTTCGTGCTCATCCACCACTGCGCCAAGCGT GAGGACGTGTGGCAGTGCTGGTGGGCATGCTGCCCGCCCCGCAAGGACGCCCACCCCGCACTTGACGCCAACGGGGCCGCGCTGGGCCGC GCCGCCTGCCTGCACTCGCCGGGACTGGGCCAGCCACGGGGCTTCGCGCACCCACCGGGCCCCTGCAAGATGACCAACCTGCAGGCCGCG CAGGGCCACGCCAGTTGCCTGTCACCGGCCACCCCGTGCTGCGCCAAGATGCACTGCGAGCCACTGACGGCGGACGAGGCGCACGTGCAC CTGCAGGAGGAGGGCGCCTTCGGGCACGACCCCCACCTGCACGGGTGCCTTCAGGGCAGAACTAAGCCGCCCTACTTTAGCCGGCACCCA GCAGAGGAGCCCGAGTACGCCTACCACATCCCATCCAGCCTGGATGGCAGCCCCCGCAGCTCGCGCACAGACAGCCCCCCCAGCTCTCTG GATGGCCCGGCGGGGACACACACGCTGGCCTGCTGCACCCAGGGCGACCCCTTCCCCATGGTCACCCAGCCCGAGGGCAGTGATGGGAGC CCTGCCCTCTACAGCTGCCCCACGCAGCCGGGCAGGGAGGCAGCGCTCGGGCCCGGCCACTTGGAGATGCTGCGGAGGACACAGTCCCTG CCCTTTGGTGGCCCCAGCCAGAACGGGCTGCCCAAGGGTAAATTGCTAGAAGGCCTGCCGTTTGGCACCGACGGGACCGGCAACATCCGA ACGGGACCCTGGAAAAACGAAACTACTGTGTAGATGGGGGCAGAGGACACGGTGTTCCTGGAGGAGCTTCAGAGCAGAGTGGGGGGCCCA TCTGCCACATGAGGTCACTGGGGGTACCGAAGTGACCCCGCCTTTCAGAAGCCGTTCACACCCCTGCCCCTTCCTTGTGATCACACCCCT GCCCCTTCCTTGTGATCACACCCCTGCCCCTTCCTTGTGATCACACCCCTGCCCCTTCCTTGTGAAAGACCTCAGCGGGGAAACGCTCCG GGCCACGCCCACTCCCCTTATCCCAATTCCGCGTGCTGGTCCCGCACACGGTCATCCGGTTTCTGTCCTGTGGTCTCCAGTCCTGGGGCA CCCTAGAGGCAGAGCAGGGGATTCCATCAAAGGACCCACTGAGACCCCAGCATGGCCCTGCCCGAGATGCCCTGCTGCCCACGGAGTCCT GGCTTCCCCTGGTGTGGCCGGGCAGGGCCGAGATCGCAGGAGGGGGCTGCCCTGACCTTTCCCAGTGTTCAATGTGTGTGTCTTGCGTTC TACTCCGGGGGTGGCGGCGGCAGGTCTGTCCCCAGCATTCTCGCTCTGGGCAGAACCCTCGGGACCCTCCGCTGTCGTGTGTCTGAGCCA CCCCTGCAGCTTCACAGGGCCCCTGCACACCTCTGCCCACTCAGTGTGCCCTGTCAGCCCTGTCCTTGTCGTAGCCCCAGCCCTGCAGGG CTGAGAGCACCACAGATGCTGGGGGCTGCTCTGGACTTTGGGGATGGCTGTCAGCCTCAGAGGGCCAATGGGGGGCTTTCACGGGCCCAA GGCTTGGGAAAATGCCCAGACATCCTTTAGTGAAGACTCGACTTCCAAAACCAGCCACCGCTGGGACTGGATTCCACTCCAGTATAGGCA CTTAGCAACACGAAGGTTTATTCCAAAAAGAAAAGGGGCTGACAGACGGGAGATTCTCATGGACAAAATCCCTTTCCCTTTTTCTCGTCT CCATGAACATCTGGGTACCAAGCCCTGACTCAAAGGACAGATGTGGATGACAGCAAGACTTCTGTGAAAGCAAGTGGCCCGTCCCTAGGT GGGAGGGAGTCCAGAGGGTCATGGGTGTGAAACTGTGCACAGCTTTCCCTCCCTCCCTCTTCCTCCTTGTCTGTGACACATGTGCACCCA CACACACACACACAAACACATGTGCATATCACACACATGCACACACACAAACACATGTGCATATCACACACGCGCACACACCCAAACACG TGCATATCACACACATGCACACACACAAACACGTGCATATCACACACATGCACACAAACGTGCATATCACACACACGCACACACACCCAA ACACGTGCATATCACACACACGCACACACACAAACACGTGCATATCACACACAAACACACGTGCACACATACTTAACACACACTTGCACC TGCTGTGCACATGTGCACACACACGTAGTAGTGTGTTTTCCAGCCACCCACACACTGGGTTTGCATTGGAGATTGTTTCACCCTGCAAAC GTCAACGTCAGCAGACTCGTCGGTGCGCTGTGCTATCCGGTTGGGAGGTCTCACCAGGAGCAGAGCCTCCCTAACGTGCACCTCCGAGAA GAGGGGTGTCGGGGAGTGTTCCCAGCACCTGCTCGGTGGAAGGGCTCTCCGGAGACTGGCACTCAGTATCTGAGTATGAGGAGCCTCACT TCCCGGGGTGTCGGTAAACTTGACCGTGACTCAGTAACCCACAGCGTGCTCCTCCCAGCAAACCCCGTGTGTCCTTACAGGTCGACCAGA CGGGCCGTCGGAGGACCACCAGGTGGCTCTGCCTCTGCCTCACCTTCTCACCTGCTTCCATAGCTGATGTGAACCCGAATCCCCACGCTG >55664_55664_4_MTG1-GPR123_MTG1_chr10_135216277_ENST00000477902_GPR123_chr10_134940737_ENST00000392606_length(amino acids)=639AA_BP=213 MKKMQSSLKLVDCIIEVHDARIPLSGRNPLFQETLGLKPHLLVLNKMDLADLTEQQKIMQHLEGEGLKNVIFTNCVKDENVKQIIPMVTE LIGRSHRYHRKENLEYCIMVIGVPNVGKSSLINSLRRQHLRKGKATRVGGEPGITRAVMSKIQVSERPLMFLLDTPGVLAPRIESVETGL KLALCGTVLDHLVGEETMADYLLYTLNKHQRFGFYLVSGGVPFIICGVTAATNIRNYGTEDEDTAYCWMAWEPSLGAFYGPAAIITLVTC VYFLGTYVQLRRHPGRRYELRTQPEEQRRLATPEGGRGIRPGTPPAHDAPGASVLQNEHSFQAQLRAAAFTLFLFTATWAFGALAVSQGH FLDMVFSCLYGAFCVTLGLFVLIHHCAKREDVWQCWWACCPPRKDAHPALDANGAALGRAACLHSPGLGQPRGFAHPPGPCKMTNLQAAQ GHASCLSPATPCCAKMHCEPLTADEAHVHLQEEGAFGHDPHLHGCLQGRTKPPYFSRHPAEEPEYAYHIPSSLDGSPRSSRTDSPPSSLD GPAGTHTLACCTQGDPFPMVTQPEGSDGSPALYSCPTQPGREAALGPGHLEMLRRTQSLPFGGPSQNGLPKGKLLEGLPFGTDGTGNIRT -------------------------------------------------------------- >55664_55664_5_MTG1-GPR123_MTG1_chr10_135216277_ENST00000477902_GPR123_chr10_134940737_ENST00000392607_length(transcript)=4177nt_BP=731nt GTGGTGCGGCCCCTTGGAGCGCCGGAAGCCCGCAGTGCCGGAGGCCCGCAGCGCCGGAACCTCAGAGGCGGGTCGCAGCGGCGCAGAGGA GGGCTGAAGAAGATGCAGAGCAGCCTGAAGCTGGTGGACTGTATCATCGAGGTCCACGATGCCCGGATCCCACTTTCAGGCCGCAACCCT CTGTTTCAGGAAACCCTTGGGCTTAAGCCTCACTTGCTGGTCCTCAACAAGATGGACTTGGCGGATCTTACAGAGCAGCAGAAAATTATG CAACACTTAGAAGGAGAAGGCCTAAAAAATGTCATTTTTACCAACTGTGTAAAGGATGAAAATGTCAAGCAGATCATCCCGATGGTCACT GAACTGATTGGGAGAAGCCACCGCTACCACCGAAAAGAGAACCTGGAGTACTGTATCATGGTCATTGGGGTCCCCAACGTGGGCAAGTCC TCCCTCATCAACTCCCTCCGGAGGCAGCACCTCAGGAAAGGGAAAGCCACCAGGGTGGGTGGCGAGCCTGGGATCACCAGAGCTGTGATG TCCAAAATTCAGGTCTCTGAGCGGCCCCTGATGTTCCTGTTGGACACTCCTGGCGTGCTGGCTCCTCGGATTGAAAGTGTGGAGACAGGC CTGAAGCTGGCCCTGTGTGGAACGGTGCTGGACCACCTGGTCGGGGAGGAGACCATGGCTGACTACCTGCTGTACACCCTCAACAAACAC CAGCGCTTTGGGTTTTACCTCGTCAGCGGAGGGGTCCCCTTTATCATCTGTGGGGTCACGGCTGCCACGAACATCAGGAATTACGGGACA GAGGACGAGGACACGGCGTACTGCTGGATGGCCTGGGAGCCCAGCCTGGGCGCCTTCTACGGCCCAGCCGCCATCATCACCCTGGTCACC TGTGTGTACTTCCTGGGCACCTACGTGCAGCTGCGGCGCCACCCAGGGCGCAGGTACGAGCTGCGCACACAGCCCGAGGAGCAGCGGCGG CTGGCGACACCCGAGGGCGGCCGTGGGATCCGGCCAGGCACCCCACCCGCACACGATGCCCCCGGCGCCTCCGTGCTGCAGAACGAGCAC TCATTCCAGGCACAGCTGCGCGCCGCCGCCTTCACGCTGTTCCTGTTCACGGCCACGTGGGCCTTCGGGGCGCTGGCGGTGTCACAGGGC CACTTCCTGGACATGGTCTTCAGCTGCCTGTACGGCGCCTTCTGCGTGACCCTGGGACTCTTCGTGCTCATCCACCACTGCGCCAAGCGT GAGGACGTGTGGCAGTGCTGGTGGGCATGCTGCCCGCCCCGCAAGGACGCCCACCCCGCACTTGACGCCAACGGGGCCGCGCTGGGCCGC GCCGCCTGCCTGCACTCGCCGGGACTGGGCCAGCCACGGGGCTTCGCGCACCCACCGGGCCCCTGCAAGATGACCAACCTGCAGGCCGCG CAGGGCCACGCCAGTTGCCTGTCACCGGCCACCCCGTGCTGCGCCAAGATGCACTGCGAGCCACTGACGGCGGACGAGGCGCACGTGCAC CTGCAGGAGGAGGGCGCCTTCGGGCACGACCCCCACCTGCACGGGTGCCTTCAGGGCAGAACTAAGCCGCCCTACTTTAGCCGGCACCCA GCAGAGGAGCCCGAGTACGCCTACCACATCCCATCCAGCCTGGATGGCAGCCCCCGCAGCTCGCGCACAGACAGCCCCCCCAGCTCTCTG GATGGCCCGGCGGGGACACACACGCTGGCCTGCTGCACCCAGGGCGACCCCTTCCCCATGGTCACCCAGCCCGAGGGCAGTGATGGGAGC CCTGCCCTCTACAGCTGCCCCACGCAGCCGGGCAGGGAGGCAGCGCTCGGGCCCGGCCACTTGGAGATGCTGCGGAGGACACAGTCCCTG CCCTTTGGTGGCCCCAGCCAGAACGGGCTGCCCAAGGGTAAATTGCTAGAAGGCCTGCCGTTTGGCACCGACGGGACCGGCAACATCCGA ACGGGACCCTGGAAAAACGAAACTACTGTGTAGATGGGGGCAGAGGACACGGTGTTCCTGGAGGAGCTTCAGAGCAGAGTGGGGGGCCCA TCTGCCACATGAGGTCACTGGGGGTACCGAAGTGACCCCGCCTTTCAGAAGCCGTTCACACCCCTGCCCCTTCCTTGTGATCACACCCCT GCCCCTTCCTTGTGATCACACCCCTGCCCCTTCCTTGTGATCACACCCCTGCCCCTTCCTTGTGAAAGACCTCAGCGGGGAAACGCTCCG GGCCACGCCCACTCCCCTTATCCCAATTCCGCGTGCTGGTCCCGCACACGGTCATCCGGTTTCTGTCCTGTGGTCTCCAGTCCTGGGGCA CCCTAGAGGCAGAGCAGGGGATTCCATCAAAGGACCCACTGAGACCCCAGCATGGCCCTGCCCGAGATGCCCTGCTGCCCACGGAGTCCT GGCTTCCCCTGGTGTGGCCGGGCAGGGCCGAGATCGCAGGAGGGGGCTGCCCTGACCTTTCCCAGTGTTCAATGTGTGTGTCTTGCGTTC TACTCCGGGGGTGGCGGCGGCAGGTCTGTCCCCAGCATTCTCGCTCTGGGCAGAACCCTCGGGACCCTCCGCTGTCGTGTGTCTGAGCCA CCCCTGCAGCTTCACAGGGCCCCTGCACACCTCTGCCCACTCAGTGTGCCCTGTCAGCCCTGTCCTTGTCGTAGCCCCAGCCCTGCAGGG CTGAGAGCACCACAGATGCTGGGGGCTGCTCTGGACTTTGGGGATGGCTGTCAGCCTCAGAGGGCCAATGGGGGGCTTTCACGGGCCCAA GGCTTGGGAAAATGCCCAGACATCCTTTAGTGAAGACTCGACTTCCAAAACCAGCCACCGCTGGGACTGGATTCCACTCCAGTATAGGCA CTTAGCAACACGAAGGTTTATTCCAAAAAGAAAAGGGGCTGACAGACGGGAGATTCTCATGGACAAAATCCCTTTCCCTTTTTCTCGTCT CCATGAACATCTGGGTACCAAGCCCTGACTCAAAGGACAGATGTGGATGACAGCAAGACTTCTGTGAAAGCAAGTGGCCCGTCCCTAGGT GGGAGGGAGTCCAGAGGGTCATGGGTGTGAAACTGTGCACAGCTTTCCCTCCCTCCCTCTTCCTCCTTGTCTGTGACACATGTGCACCCA CACACACACACACAAACACATGTGCATATCACACACATGCACACACACAAACACATGTGCATATCACACACGCGCACACACCCAAACACG TGCATATCACACACATGCACACACACAAACACGTGCATATCACACACATGCACACAAACGTGCATATCACACACACGCACACACACCCAA ACACGTGCATATCACACACACGCACACACACAAACACGTGCATATCACACACAAACACACGTGCACACATACTTAACACACACTTGCACC TGCTGTGCACATGTGCACACACACGTAGTAGTGTGTTTTCCAGCCACCCACACACTGGGTTTGCATTGGAGATTGTTTCACCCTGCAAAC GTCAACGTCAGCAGACTCGTCGGTGCGCTGTGCTATCCGGTTGGGAGGTCTCACCAGGAGCAGAGCCTCCCTAACGTGCACCTCCGAGAA GAGGGGTGTCGGGGAGTGTTCCCAGCACCTGCTCGGTGGAAGGGCTCTCCGGAGACTGGCACTCAGTATCTGAGTATGAGGAGCCTCACT TCCCGGGGTGTCGGTAAACTTGACCGTGACTCAGTAACCCACAGCGTGCTCCTCCCAGCAAACCCCGTGTGTCCTTACAGGTCGACCAGA CGGGCCGTCGGAGGACCACCAGGTGGCTCTGCCTCTGCCTCACCTTCTCACCTGCTTCCATAGCTGATGTGAACCCGAATCCCCACGCTG TGCTGTGTACGCACTGTAGGTGCAGAACCGTCCACACAAAAATACAGTCTTGGCATTGTTTGTTCTTTGTGAGGCTGGTTAATAGCATCC CCGTGTGTTTTTCTCACCCTCGATGGGGTAGAGGGGCACCTGAATGTGTGGCCCCCGTCTGTGTCCTGGATCCTGGGGCAGGGCTGCTCT CCCTGGCCCCTGCAGCCCCTCATGAACTTTCCACCCTCAGTGCCCCCGGCTGAGCAGAGAGGCGTCCCACCATTCAACCAAAGAAAGTCA >55664_55664_5_MTG1-GPR123_MTG1_chr10_135216277_ENST00000477902_GPR123_chr10_134940737_ENST00000392607_length(amino acids)=639AA_BP=213 MKKMQSSLKLVDCIIEVHDARIPLSGRNPLFQETLGLKPHLLVLNKMDLADLTEQQKIMQHLEGEGLKNVIFTNCVKDENVKQIIPMVTE LIGRSHRYHRKENLEYCIMVIGVPNVGKSSLINSLRRQHLRKGKATRVGGEPGITRAVMSKIQVSERPLMFLLDTPGVLAPRIESVETGL KLALCGTVLDHLVGEETMADYLLYTLNKHQRFGFYLVSGGVPFIICGVTAATNIRNYGTEDEDTAYCWMAWEPSLGAFYGPAAIITLVTC VYFLGTYVQLRRHPGRRYELRTQPEEQRRLATPEGGRGIRPGTPPAHDAPGASVLQNEHSFQAQLRAAAFTLFLFTATWAFGALAVSQGH FLDMVFSCLYGAFCVTLGLFVLIHHCAKREDVWQCWWACCPPRKDAHPALDANGAALGRAACLHSPGLGQPRGFAHPPGPCKMTNLQAAQ GHASCLSPATPCCAKMHCEPLTADEAHVHLQEEGAFGHDPHLHGCLQGRTKPPYFSRHPAEEPEYAYHIPSSLDGSPRSSRTDSPPSSLD GPAGTHTLACCTQGDPFPMVTQPEGSDGSPALYSCPTQPGREAALGPGHLEMLRRTQSLPFGGPSQNGLPKGKLLEGLPFGTDGTGNIRT -------------------------------------------------------------- >55664_55664_6_MTG1-GPR123_MTG1_chr10_135216277_ENST00000477902_GPR123_chr10_134940737_ENST00000607359_length(transcript)=4174nt_BP=731nt GTGGTGCGGCCCCTTGGAGCGCCGGAAGCCCGCAGTGCCGGAGGCCCGCAGCGCCGGAACCTCAGAGGCGGGTCGCAGCGGCGCAGAGGA GGGCTGAAGAAGATGCAGAGCAGCCTGAAGCTGGTGGACTGTATCATCGAGGTCCACGATGCCCGGATCCCACTTTCAGGCCGCAACCCT CTGTTTCAGGAAACCCTTGGGCTTAAGCCTCACTTGCTGGTCCTCAACAAGATGGACTTGGCGGATCTTACAGAGCAGCAGAAAATTATG CAACACTTAGAAGGAGAAGGCCTAAAAAATGTCATTTTTACCAACTGTGTAAAGGATGAAAATGTCAAGCAGATCATCCCGATGGTCACT GAACTGATTGGGAGAAGCCACCGCTACCACCGAAAAGAGAACCTGGAGTACTGTATCATGGTCATTGGGGTCCCCAACGTGGGCAAGTCC TCCCTCATCAACTCCCTCCGGAGGCAGCACCTCAGGAAAGGGAAAGCCACCAGGGTGGGTGGCGAGCCTGGGATCACCAGAGCTGTGATG TCCAAAATTCAGGTCTCTGAGCGGCCCCTGATGTTCCTGTTGGACACTCCTGGCGTGCTGGCTCCTCGGATTGAAAGTGTGGAGACAGGC CTGAAGCTGGCCCTGTGTGGAACGGTGCTGGACCACCTGGTCGGGGAGGAGACCATGGCTGACTACCTGCTGTACACCCTCAACAAACAC CAGCGCTTTGGGTTTTACCTCGTCAGCGGAGGGGTCCCCTTTATCATCTGTGGGGTCACGGCTGCCACGAACATCAGGAATTACGGGACA GAGGACGAGGACACGGCCTGCTGGATGGCCTGGGAGCCCAGCCTGGGCGCCTTCTACGGCCCAGCCGCCATCATCACCCTGGTCACCTGT GTGTACTTCCTGGGCACCTACGTGCAGCTGCGGCGCCACCCAGGGCGCAGGTACGAGCTGCGCACACAGCCCGAGGAGCAGCGGCGGCTG GCGACACCCGAGGGCGGCCGTGGGATCCGGCCAGGCACCCCACCCGCACACGATGCCCCCGGCGCCTCCGTGCTGCAGAACGAGCACTCA TTCCAGGCACAGCTGCGCGCCGCCGCCTTCACGCTGTTCCTGTTCACGGCCACGTGGGCCTTCGGGGCGCTGGCGGTGTCACAGGGCCAC TTCCTGGACATGGTCTTCAGCTGCCTGTACGGCGCCTTCTGCGTGACCCTGGGACTCTTCGTGCTCATCCACCACTGCGCCAAGCGTGAG GACGTGTGGCAGTGCTGGTGGGCATGCTGCCCGCCCCGCAAGGACGCCCACCCCGCACTTGACGCCAACGGGGCCGCGCTGGGCCGCGCC GCCTGCCTGCACTCGCCGGGACTGGGCCAGCCACGGGGCTTCGCGCACCCACCGGGCCCCTGCAAGATGACCAACCTGCAGGCCGCGCAG GGCCACGCCAGTTGCCTGTCACCGGCCACCCCGTGCTGCGCCAAGATGCACTGCGAGCCACTGACGGCGGACGAGGCGCACGTGCACCTG CAGGAGGAGGGCGCCTTCGGGCACGACCCCCACCTGCACGGGTGCCTTCAGGGCAGAACTAAGCCGCCCTACTTTAGCCGGCACCCAGCA GAGGAGCCCGAGTACGCCTACCACATCCCATCCAGCCTGGATGGCAGCCCCCGCAGCTCGCGCACAGACAGCCCCCCCAGCTCTCTGGAT GGCCCGGCGGGGACACACACGCTGGCCTGCTGCACCCAGGGCGACCCCTTCCCCATGGTCACCCAGCCCGAGGGCAGTGATGGGAGCCCT GCCCTCTACAGCTGCCCCACGCAGCCGGGCAGGGAGGCAGCGCTCGGGCCCGGCCACTTGGAGATGCTGCGGAGGACACAGTCCCTGCCC TTTGGTGGCCCCAGCCAGAACGGGCTGCCCAAGGGTAAATTGCTAGAAGGCCTGCCGTTTGGCACCGACGGGACCGGCAACATCCGAACG GGACCCTGGAAAAACGAAACTACTGTGTAGATGGGGGCAGAGGACACGGTGTTCCTGGAGGAGCTTCAGAGCAGAGTGGGGGGCCCATCT GCCACATGAGGTCACTGGGGGTACCGAAGTGACCCCGCCTTTCAGAAGCCGTTCACACCCCTGCCCCTTCCTTGTGATCACACCCCTGCC CCTTCCTTGTGATCACACCCCTGCCCCTTCCTTGTGATCACACCCCTGCCCCTTCCTTGTGAAAGACCTCAGCGGGGAAACGCTCCGGGC CACGCCCACTCCCCTTATCCCAATTCCGCGTGCTGGTCCCGCACACGGTCATCCGGTTTCTGTCCTGTGGTCTCCAGTCCTGGGGCACCC TAGAGGCAGAGCAGGGGATTCCATCAAAGGACCCACTGAGACCCCAGCATGGCCCTGCCCGAGATGCCCTGCTGCCCACGGAGTCCTGGC TTCCCCTGGTGTGGCCGGGCAGGGCCGAGATCGCAGGAGGGGGCTGCCCTGACCTTTCCCAGTGTTCAATGTGTGTGTCTTGCGTTCTAC TCCGGGGGTGGCGGCGGCAGGTCTGTCCCCAGCATTCTCGCTCTGGGCAGAACCCTCGGGACCCTCCGCTGTCGTGTGTCTGAGCCACCC CTGCAGCTTCACAGGGCCCCTGCACACCTCTGCCCACTCAGTGTGCCCTGTCAGCCCTGTCCTTGTCGTAGCCCCAGCCCTGCAGGGCTG AGAGCACCACAGATGCTGGGGGCTGCTCTGGACTTTGGGGATGGCTGTCAGCCTCAGAGGGCCAATGGGGGGCTTTCACGGGCCCAAGGC TTGGGAAAATGCCCAGACATCCTTTAGTGAAGACTCGACTTCCAAAACCAGCCACCGCTGGGACTGGATTCCACTCCAGTATAGGCACTT AGCAACACGAAGGTTTATTCCAAAAAGAAAAGGGGCTGACAGACGGGAGATTCTCATGGACAAAATCCCTTTCCCTTTTTCTCGTCTCCA TGAACATCTGGGTACCAAGCCCTGACTCAAAGGACAGATGTGGATGACAGCAAGACTTCTGTGAAAGCAAGTGGCCCGTCCCTAGGTGGG AGGGAGTCCAGAGGGTCATGGGTGTGAAACTGTGCACAGCTTTCCCTCCCTCCCTCTTCCTCCTTGTCTGTGACACATGTGCACCCACAC ACACACACACAAACACATGTGCATATCACACACATGCACACACACAAACACATGTGCATATCACACACGCGCACACACCCAAACACGTGC ATATCACACACATGCACACACACAAACACGTGCATATCACACACATGCACACAAACGTGCATATCACACACACGCACACACACCCAAACA CGTGCATATCACACACACGCACACACACAAACACGTGCATATCACACACAAACACACGTGCACACATACTTAACACACACTTGCACCTGC TGTGCACATGTGCACACACACGTAGTAGTGTGTTTTCCAGCCACCCACACACTGGGTTTGCATTGGAGATTGTTTCACCCTGCAAACGTC AACGTCAGCAGACTCGTCGGTGCGCTGTGCTATCCGGTTGGGAGGTCTCACCAGGAGCAGAGCCTCCCTAACGTGCACCTCCGAGAAGAG GGGTGTCGGGGAGTGTTCCCAGCACCTGCTCGGTGGAAGGGCTCTCCGGAGACTGGCACTCAGTATCTGAGTATGAGGAGCCTCACTTCC CGGGGTGTCGGTAAACTTGACCGTGACTCAGTAACCCACAGCGTGCTCCTCCCAGCAAACCCCGTGTGTCCTTACAGGTCGACCAGACGG GCCGTCGGAGGACCACCAGGTGGCTCTGCCTCTGCCTCACCTTCTCACCTGCTTCCATAGCTGATGTGAACCCGAATCCCCACGCTGTGC TGTGTACGCACTGTAGGTGCAGAACCGTCCACACAAAAATACAGTCTTGGCATTGTTTGTTCTTTGTGAGGCTGGTTAATAGCATCCCCG TGTGTTTTTCTCACCCTCGATGGGGTAGAGGGGCACCTGAATGTGTGGCCCCCGTCTGTGTCCTGGATCCTGGGGCAGGGCTGCTCTCCC TGGCCCCTGCAGCCCCTCATGAACTTTCCACCCTCAGTGCCCCCGGCTGAGCAGAGAGGCGTCCCACCATTCAACCAAAGAAAGTCAACA >55664_55664_6_MTG1-GPR123_MTG1_chr10_135216277_ENST00000477902_GPR123_chr10_134940737_ENST00000607359_length(amino acids)=638AA_BP=213 MKKMQSSLKLVDCIIEVHDARIPLSGRNPLFQETLGLKPHLLVLNKMDLADLTEQQKIMQHLEGEGLKNVIFTNCVKDENVKQIIPMVTE LIGRSHRYHRKENLEYCIMVIGVPNVGKSSLINSLRRQHLRKGKATRVGGEPGITRAVMSKIQVSERPLMFLLDTPGVLAPRIESVETGL KLALCGTVLDHLVGEETMADYLLYTLNKHQRFGFYLVSGGVPFIICGVTAATNIRNYGTEDEDTACWMAWEPSLGAFYGPAAIITLVTCV YFLGTYVQLRRHPGRRYELRTQPEEQRRLATPEGGRGIRPGTPPAHDAPGASVLQNEHSFQAQLRAAAFTLFLFTATWAFGALAVSQGHF LDMVFSCLYGAFCVTLGLFVLIHHCAKREDVWQCWWACCPPRKDAHPALDANGAALGRAACLHSPGLGQPRGFAHPPGPCKMTNLQAAQG HASCLSPATPCCAKMHCEPLTADEAHVHLQEEGAFGHDPHLHGCLQGRTKPPYFSRHPAEEPEYAYHIPSSLDGSPRSSRTDSPPSSLDG PAGTHTLACCTQGDPFPMVTQPEGSDGSPALYSCPTQPGREAALGPGHLEMLRRTQSLPFGGPSQNGLPKGKLLEGLPFGTDGTGNIRTG -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for MTG1-GPR123 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for MTG1-GPR123 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for MTG1-GPR123 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies