
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:MYCBP2-CPB2 (FusionGDB2 ID:56200) |
Fusion Gene Summary for MYCBP2-CPB2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: MYCBP2-CPB2 | Fusion gene ID: 56200 | Hgene | Tgene | Gene symbol | MYCBP2 | CPB2 | Gene ID | 23077 | 1361 |
| Gene name | MYC binding protein 2 | carboxypeptidase B2 | |
| Synonyms | Myc-bp2|PAM|PHR1|Phr | CPU|PCPB|TAFI | |
| Cytomap | 13q22.3 | 13q14.13 | |
| Type of gene | protein-coding | protein-coding | |
| Description | E3 ubiquitin-protein ligase MYCBP2HighwireMYC binding protein 2, E3 ubiquitin protein ligasePAM/Highwire/RPM-1 protein 1RING-type E3 ubiquitin transferase MYCBP2myc-binding protein 2pam/highwire/rpm-1 proteinprotein associated with Myc | carboxypeptidase B2carboxypeptidase B-like proteincarboxypeptidase B2 (plasma)carboxypeptidase B2 (plasma, carboxypeptidase U)carboxypeptidase Rthrombin-activable fibrinolysis inhibitorthrombin-activatable fibrinolysis inhibitor | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | O75592 | Q96IY4 | |
| Ensembl transtripts involved in fusion gene | ENST00000360084, ENST00000357337, ENST00000407578, ENST00000544440, ENST00000482517, | ENST00000181383, ENST00000439329, | |
| Fusion gene scores | * DoF score | 14 X 16 X 8=1792 | 2 X 2 X 2=8 |
| # samples | 15 | 2 | |
| ** MAII score | log2(15/1792*10)=-3.57853623156172 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(2/8*10)=1.32192809488736 | |
| Context | PubMed: MYCBP2 [Title/Abstract] AND CPB2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | MYCBP2(77862296)-CPB2(46638876), # samples:3 | ||
| Anticipated loss of major functional domain due to fusion event. | MYCBP2-CPB2 seems lost the major protein functional domain in Hgene partner, which is a essential gene due to the frame-shifted ORF. MYCBP2-CPB2 seems lost the major protein functional domain in Tgene partner, which is a IUPHAR drug target due to the frame-shifted ORF. | ||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | MYCBP2 | GO:0016567 | protein ubiquitination | 29643511 |
| Hgene | MYCBP2 | GO:0031398 | positive regulation of protein ubiquitination | 20534529 |
| Fusion gene breakpoints across MYCBP2 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
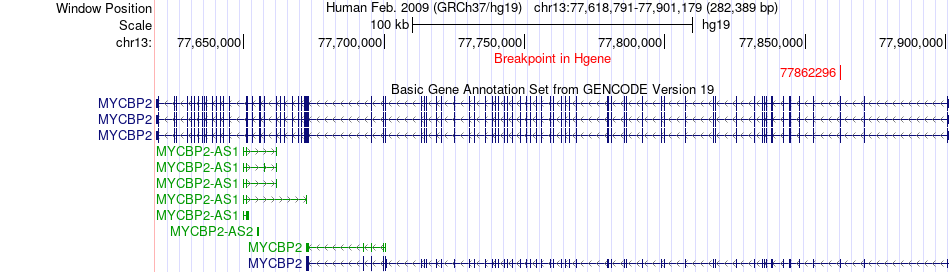 |
| Fusion gene breakpoints across CPB2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
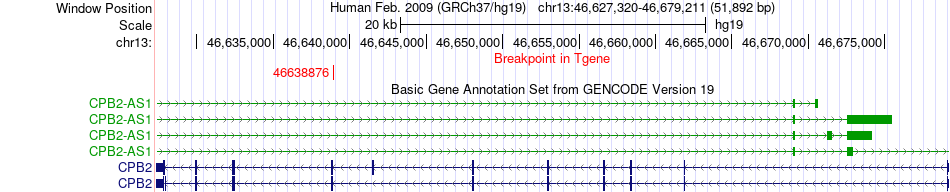 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BLCA | TCGA-UY-A78N-01A | MYCBP2 | chr13 | 77862296 | - | CPB2 | chr13 | 46638876 | - |
Top |
Fusion Gene ORF analysis for MYCBP2-CPB2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5UTR-3CDS | ENST00000360084 | ENST00000181383 | MYCBP2 | chr13 | 77862296 | - | CPB2 | chr13 | 46638876 | - |
| 5UTR-3CDS | ENST00000360084 | ENST00000439329 | MYCBP2 | chr13 | 77862296 | - | CPB2 | chr13 | 46638876 | - |
| Frame-shift | ENST00000357337 | ENST00000181383 | MYCBP2 | chr13 | 77862296 | - | CPB2 | chr13 | 46638876 | - |
| Frame-shift | ENST00000357337 | ENST00000439329 | MYCBP2 | chr13 | 77862296 | - | CPB2 | chr13 | 46638876 | - |
| In-frame | ENST00000407578 | ENST00000181383 | MYCBP2 | chr13 | 77862296 | - | CPB2 | chr13 | 46638876 | - |
| In-frame | ENST00000407578 | ENST00000439329 | MYCBP2 | chr13 | 77862296 | - | CPB2 | chr13 | 46638876 | - |
| In-frame | ENST00000544440 | ENST00000181383 | MYCBP2 | chr13 | 77862296 | - | CPB2 | chr13 | 46638876 | - |
| In-frame | ENST00000544440 | ENST00000439329 | MYCBP2 | chr13 | 77862296 | - | CPB2 | chr13 | 46638876 | - |
| intron-3CDS | ENST00000482517 | ENST00000181383 | MYCBP2 | chr13 | 77862296 | - | CPB2 | chr13 | 46638876 | - |
| intron-3CDS | ENST00000482517 | ENST00000439329 | MYCBP2 | chr13 | 77862296 | - | CPB2 | chr13 | 46638876 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000544440 | MYCBP2 | chr13 | 77862296 | - | ENST00000181383 | CPB2 | chr13 | 46638876 | - | 1496 | 498 | 12 | 1067 | 351 |
| ENST00000544440 | MYCBP2 | chr13 | 77862296 | - | ENST00000439329 | CPB2 | chr13 | 46638876 | - | 1443 | 498 | 12 | 989 | 325 |
| ENST00000407578 | MYCBP2 | chr13 | 77862296 | - | ENST00000181383 | CPB2 | chr13 | 46638876 | - | 1859 | 861 | 183 | 1430 | 415 |
| ENST00000407578 | MYCBP2 | chr13 | 77862296 | - | ENST00000439329 | CPB2 | chr13 | 46638876 | - | 1806 | 861 | 183 | 1352 | 389 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000544440 | ENST00000181383 | MYCBP2 | chr13 | 77862296 | - | CPB2 | chr13 | 46638876 | - | 0.001025955 | 0.9989741 |
| ENST00000544440 | ENST00000439329 | MYCBP2 | chr13 | 77862296 | - | CPB2 | chr13 | 46638876 | - | 0.001211324 | 0.99878865 |
| ENST00000407578 | ENST00000181383 | MYCBP2 | chr13 | 77862296 | - | CPB2 | chr13 | 46638876 | - | 0.001603996 | 0.998396 |
| ENST00000407578 | ENST00000439329 | MYCBP2 | chr13 | 77862296 | - | CPB2 | chr13 | 46638876 | - | 0.001544565 | 0.9984554 |
Top |
Fusion Genomic Features for MYCBP2-CPB2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
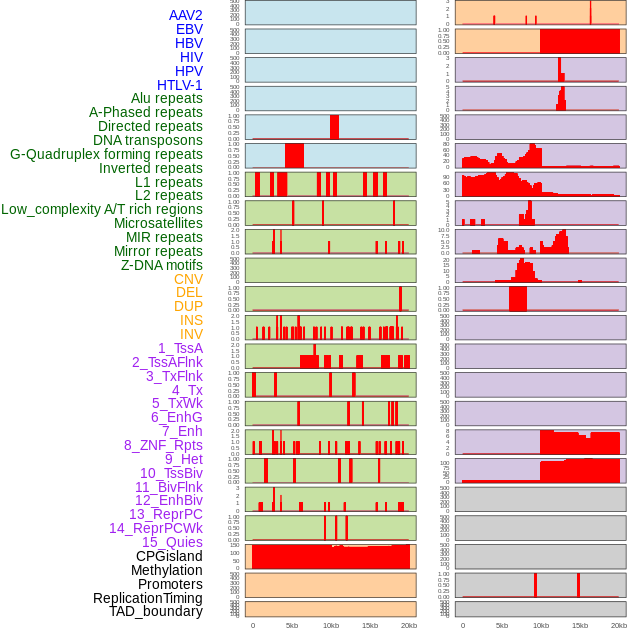 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for MYCBP2-CPB2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr13:77862296/chr13:46638876) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| MYCBP2 | CPB2 |
| FUNCTION: Atypical E3 ubiquitin-protein ligase which specifically mediates ubiquitination of threonine and serine residues on target proteins, instead of ubiquitinating lysine residues (PubMed:29643511). Shows esterification activity towards both threonine and serine, with a preference for threonine, and acts via two essential catalytic cysteine residues that relay ubiquitin to its substrate via thioester intermediates (PubMed:29643511). Interacts with the E2 enzymes UBE2D1, UBE2D3, UBE2E1 and UBE2L3 (PubMed:18308511, PubMed:29643511). Plays a key role in neural development, probably by mediating ubiquitination of threonine residues on target proteins (Probable). Involved in different processes such as regulation of neurite outgrowth, synaptic growth, synaptogenesis and axon degeneration (By similarity). Required for the formation of major central nervous system axon tracts (By similarity). Required for proper axon growth by regulating axon navigation and axon branching: acts by regulating the subcellular location and stability of MAP3K12/DLK (By similarity). Required for proper localization of retinogeniculate projections but not for eye-specific segregation (By similarity). Regulates axon guidance in the olfactory system (By similarity). Involved in Wallerian axon degeneration, an evolutionarily conserved process that drives the loss of damaged axons: acts by promoting destabilization of NMNAT2, probably via ubiquitination of NMNAT2 (By similarity). Catalyzes ubiquitination of threonine and/or serine residues on NMNAT2, consequences of threonine and/or serine ubiquitination are however unknown (PubMed:29643511). Regulates the internalization of TRPV1 in peripheral sensory neurons (By similarity). Mediates ubiquitination and subsequent proteasomal degradation of TSC2/tuberin (PubMed:18308511, PubMed:27278822). Independently of the E3 ubiquitin-protein ligase activity, also acts as a guanosine exchange factor (GEF) for RAN in neurons of dorsal root ganglia (PubMed:26304119). May function as a facilitator or regulator of transcriptional activation by MYC (PubMed:9689053). Acts in concert with HUWE1 to regulate the circadian clock gene expression by promoting the lithium-induced ubiquination and degradation of NR1D1 (PubMed:20534529). {ECO:0000250|UniProtKB:Q7TPH6, ECO:0000269|PubMed:18308511, ECO:0000269|PubMed:20534529, ECO:0000269|PubMed:26304119, ECO:0000269|PubMed:27278822, ECO:0000269|PubMed:29643511, ECO:0000269|PubMed:9689053}. | FUNCTION: Cleaves C-terminal arginine or lysine residues from biologically active peptides such as kinins or anaphylatoxins in the circulation thereby regulating their activities. Down-regulates fibrinolysis by removing C-terminal lysine residues from fibrin that has already been partially degraded by plasmin. {ECO:0000269|PubMed:10574983}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | MYCBP2 | chr13:77862296 | chr13:46638876 | ENST00000357337 | - | 4 | 84 | 103_126 | 160 | 4641.0 | Compositional bias | Lys-rich |
| Hgene | MYCBP2 | chr13:77862296 | chr13:46638876 | ENST00000544440 | - | 3 | 83 | 103_126 | 160 | 4641.0 | Compositional bias | Lys-rich |
| Tgene | CPB2 | chr13:77862296 | chr13:46638876 | ENST00000181383 | 6 | 11 | 256_257 | 234 | 424.0 | Region | Substrate binding | |
| Tgene | CPB2 | chr13:77862296 | chr13:46638876 | ENST00000181383 | 6 | 11 | 311_312 | 234 | 424.0 | Region | Substrate binding |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | MYCBP2 | chr13:77862296 | chr13:46638876 | ENST00000357337 | - | 4 | 84 | 2720_2844 | 160 | 4641.0 | Compositional bias | Ser-rich |
| Hgene | MYCBP2 | chr13:77862296 | chr13:46638876 | ENST00000357337 | - | 4 | 84 | 3194_3215 | 160 | 4641.0 | Compositional bias | Lys-rich |
| Hgene | MYCBP2 | chr13:77862296 | chr13:46638876 | ENST00000357337 | - | 4 | 84 | 3262_3293 | 160 | 4641.0 | Compositional bias | Note=Gly-rich |
| Hgene | MYCBP2 | chr13:77862296 | chr13:46638876 | ENST00000357337 | - | 4 | 84 | 766_814 | 160 | 4641.0 | Compositional bias | Cys-rich |
| Hgene | MYCBP2 | chr13:77862296 | chr13:46638876 | ENST00000544440 | - | 3 | 83 | 2720_2844 | 160 | 4641.0 | Compositional bias | Ser-rich |
| Hgene | MYCBP2 | chr13:77862296 | chr13:46638876 | ENST00000544440 | - | 3 | 83 | 3194_3215 | 160 | 4641.0 | Compositional bias | Lys-rich |
| Hgene | MYCBP2 | chr13:77862296 | chr13:46638876 | ENST00000544440 | - | 3 | 83 | 3262_3293 | 160 | 4641.0 | Compositional bias | Note=Gly-rich |
| Hgene | MYCBP2 | chr13:77862296 | chr13:46638876 | ENST00000544440 | - | 3 | 83 | 766_814 | 160 | 4641.0 | Compositional bias | Cys-rich |
| Hgene | MYCBP2 | chr13:77862296 | chr13:46638876 | ENST00000357337 | - | 4 | 84 | 3719_3897 | 160 | 4641.0 | Domain | DOC |
| Hgene | MYCBP2 | chr13:77862296 | chr13:46638876 | ENST00000544440 | - | 3 | 83 | 3719_3897 | 160 | 4641.0 | Domain | DOC |
| Hgene | MYCBP2 | chr13:77862296 | chr13:46638876 | ENST00000357337 | - | 4 | 84 | 1235_1386 | 160 | 4641.0 | Region | PHR domain 1 |
| Hgene | MYCBP2 | chr13:77862296 | chr13:46638876 | ENST00000357337 | - | 4 | 84 | 1726_1884 | 160 | 4641.0 | Region | PHR domain 2 |
| Hgene | MYCBP2 | chr13:77862296 | chr13:46638876 | ENST00000357337 | - | 4 | 84 | 2022_2550 | 160 | 4641.0 | Region | RAE1 binding |
| Hgene | MYCBP2 | chr13:77862296 | chr13:46638876 | ENST00000357337 | - | 4 | 84 | 4539_4676 | 160 | 4641.0 | Region | Tandem cysteine domain |
| Hgene | MYCBP2 | chr13:77862296 | chr13:46638876 | ENST00000544440 | - | 3 | 83 | 1235_1386 | 160 | 4641.0 | Region | PHR domain 1 |
| Hgene | MYCBP2 | chr13:77862296 | chr13:46638876 | ENST00000544440 | - | 3 | 83 | 1726_1884 | 160 | 4641.0 | Region | PHR domain 2 |
| Hgene | MYCBP2 | chr13:77862296 | chr13:46638876 | ENST00000544440 | - | 3 | 83 | 2022_2550 | 160 | 4641.0 | Region | RAE1 binding |
| Hgene | MYCBP2 | chr13:77862296 | chr13:46638876 | ENST00000544440 | - | 3 | 83 | 4539_4676 | 160 | 4641.0 | Region | Tandem cysteine domain |
| Hgene | MYCBP2 | chr13:77862296 | chr13:46638876 | ENST00000357337 | - | 4 | 84 | 1010_1066 | 160 | 4641.0 | Repeat | RCC1 5 |
| Hgene | MYCBP2 | chr13:77862296 | chr13:46638876 | ENST00000357337 | - | 4 | 84 | 2341_2443 | 160 | 4641.0 | Repeat | Filamin |
| Hgene | MYCBP2 | chr13:77862296 | chr13:46638876 | ENST00000357337 | - | 4 | 84 | 600_655 | 160 | 4641.0 | Repeat | RCC1 1 |
| Hgene | MYCBP2 | chr13:77862296 | chr13:46638876 | ENST00000357337 | - | 4 | 84 | 699_755 | 160 | 4641.0 | Repeat | RCC1 2 |
| Hgene | MYCBP2 | chr13:77862296 | chr13:46638876 | ENST00000357337 | - | 4 | 84 | 907_957 | 160 | 4641.0 | Repeat | RCC1 3 |
| Hgene | MYCBP2 | chr13:77862296 | chr13:46638876 | ENST00000357337 | - | 4 | 84 | 958_1008 | 160 | 4641.0 | Repeat | RCC1 4 |
| Hgene | MYCBP2 | chr13:77862296 | chr13:46638876 | ENST00000544440 | - | 3 | 83 | 1010_1066 | 160 | 4641.0 | Repeat | RCC1 5 |
| Hgene | MYCBP2 | chr13:77862296 | chr13:46638876 | ENST00000544440 | - | 3 | 83 | 2341_2443 | 160 | 4641.0 | Repeat | Filamin |
| Hgene | MYCBP2 | chr13:77862296 | chr13:46638876 | ENST00000544440 | - | 3 | 83 | 600_655 | 160 | 4641.0 | Repeat | RCC1 1 |
| Hgene | MYCBP2 | chr13:77862296 | chr13:46638876 | ENST00000544440 | - | 3 | 83 | 699_755 | 160 | 4641.0 | Repeat | RCC1 2 |
| Hgene | MYCBP2 | chr13:77862296 | chr13:46638876 | ENST00000544440 | - | 3 | 83 | 907_957 | 160 | 4641.0 | Repeat | RCC1 3 |
| Hgene | MYCBP2 | chr13:77862296 | chr13:46638876 | ENST00000544440 | - | 3 | 83 | 958_1008 | 160 | 4641.0 | Repeat | RCC1 4 |
| Hgene | MYCBP2 | chr13:77862296 | chr13:46638876 | ENST00000357337 | - | 4 | 84 | 4428_4479 | 160 | 4641.0 | Zinc finger | RING-type%3B atypical |
| Hgene | MYCBP2 | chr13:77862296 | chr13:46638876 | ENST00000544440 | - | 3 | 83 | 4428_4479 | 160 | 4641.0 | Zinc finger | RING-type%3B atypical |
| Tgene | CPB2 | chr13:77862296 | chr13:46638876 | ENST00000181383 | 6 | 11 | 181_184 | 234 | 424.0 | Region | Substrate binding |
Top |
Fusion Gene Sequence for MYCBP2-CPB2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >56200_56200_1_MYCBP2-CPB2_MYCBP2_chr13_77862296_ENST00000407578_CPB2_chr13_46638876_ENST00000181383_length(transcript)=1859nt_BP=861nt CGGCGGCAGTGGCGGCACCGCCTCCTCCTCACATTCCCGGGGTGGCGGGGTTAGATGAGCGGCCCCAGTAGCGGCGAGGGCGGCGCGGGG GGGAGGAGGAGAAGAAGGAGGAGGAGAAGGAGGTCGCTGTCTTTGTAGTCTCCCTGCTGCGGGAGCCAGAGGCCGCCGCCGGAGCCGTCG TCGTTGGAAAAGGGCTGTGTGTGCGCGCGCGTGTCTGCCCGCCCGGCCCGCGGGGACGAGGCGGCGGCGGCGGCGGCGGCGGCGAGGATG ATGATGTGCGCAGCGACTGCCTCCCCCGCCGCCGCCTCCTCGGGGCTCGGCGGGGACGGATTCTACCCAGCCGCCACCTTCTCTTCCTCC CCGGCGCCGGGGGCGCTGTTCATGCCGGTTCCCGACGGCTCCGTGGCTGCTGCGGGGCTGGGGCTGGGGCTACCCGCCGCGGACTCCCGG GGTCACTACCAGCTGCTGCTGTCAGGCCGGGCCCTGGCCGACCGCTACCGGAGGATTTATACCGCTGCGCTCAATGACAGGGACCAGGGG GGCGGCAGCGCTGGACACCCAGCCTCCAGGAATAAGAAAATTTTAAATAAGAAGAAATTGAAAAGAAAACAGAAGAGCAAATCAAAAGTG AAGACAAGAAGCAAGTCTGAAAACTTAGAGAATACAGTAATCATACCAGATATCAAACTACATAGCAATCCTTCTGCTTTCAATATTTAC TGTAATGTACGCCATTGCGTTCTGGAATGGCAGAAAAAGGAAATATCATTGGCAGCCGCATCTAAGAACTCTGTGCAGAGTGGAGAATCA GATAGTGATGAAGAAGAGGAATCCAAAGAGCCCCCTATCAAGCTTCCAAAGAATCGAATGTGGAGAAAGAACCGTTCTTTCTATGCGAAC AATCATTGCATCGGAACAGACCTGAATAGGAACTTTGCTTCCAAACACTGGTGTGAGGAAGGTGCATCCAGTTCCTCATGCTCGGAAACC TACTGTGGACTTTATCCTGAGTCAGAACCAGAAGTGAAGGCAGTGGCTAGTTTCTTGAGAAGAAATATCAACCAGATTAAAGCATACATC AGCATGCATTCATACTCCCAGCATATAGTGTTTCCATATTCCTATACACGAAGTAAAAGCAAAGACCATGAGGAACTGTCTCTAGTAGCC AGTGAAGCAGTTCGTGCTATTGAGAAAATTAGTAAAAATACCAGGTATACACATGGCCATGGCTCAGAAACCTTATACCTAGCTCCTGGA GGTGGGGACGATTGGATCTATGATTTGGGCATCAAATATTCGTTTACAATTGAACTTCGAGATACGGGCACATACGGATTCTTGCTGCCG GAGCGTTACATCAAACCCACCTGTAGAGAAGCTTTTGCCGCTGTCTCTAAAATAGCTTGGCATGTCATTAGGAATGTTTAATGCCCCTGA TTTTATCATTCTGCTTCCGTATTTTAATTTACTGATTCCAGCAAGACCAAATCATTGTATCAAATTATTTTTAAGTTTTATCCGTAGTTT TGATAAAAGATTTTCCTATTCCTTGGTTCTGTCAGAGAACCTAATAAGTGCTACTTTGCCATTAAGGCAGACTAGGGTTCATGTCTTTTT ACCCTTTAAAAAAAATTGTAAAAGTCTAGTTACCTACTTTTTCTTTGATTTTCGACGTTTGACTAGCCATCTCAAGCAAGTTTCGACGTT TGACTAGCCATCTCAAGCAAGTTTAATCAATGATCATCTCACGCTGATCATTGGATCCTACTCAACAAAAGGAAGGGTGGTCAGAAGTAC >56200_56200_1_MYCBP2-CPB2_MYCBP2_chr13_77862296_ENST00000407578_CPB2_chr13_46638876_ENST00000181383_length(amino acids)=415AA_BP=226 MEKGCVCARVSARPARGDEAAAAAAAARMMMCAATASPAAASSGLGGDGFYPAATFSSSPAPGALFMPVPDGSVAAAGLGLGLPAADSRG HYQLLLSGRALADRYRRIYTAALNDRDQGGGSAGHPASRNKKILNKKKLKRKQKSKSKVKTRSKSENLENTVIIPDIKLHSNPSAFNIYC NVRHCVLEWQKKEISLAAASKNSVQSGESDSDEEEESKEPPIKLPKNRMWRKNRSFYANNHCIGTDLNRNFASKHWCEEGASSSSCSETY CGLYPESEPEVKAVASFLRRNINQIKAYISMHSYSQHIVFPYSYTRSKSKDHEELSLVASEAVRAIEKISKNTRYTHGHGSETLYLAPGG -------------------------------------------------------------- >56200_56200_2_MYCBP2-CPB2_MYCBP2_chr13_77862296_ENST00000407578_CPB2_chr13_46638876_ENST00000439329_length(transcript)=1806nt_BP=861nt CGGCGGCAGTGGCGGCACCGCCTCCTCCTCACATTCCCGGGGTGGCGGGGTTAGATGAGCGGCCCCAGTAGCGGCGAGGGCGGCGCGGGG GGGAGGAGGAGAAGAAGGAGGAGGAGAAGGAGGTCGCTGTCTTTGTAGTCTCCCTGCTGCGGGAGCCAGAGGCCGCCGCCGGAGCCGTCG TCGTTGGAAAAGGGCTGTGTGTGCGCGCGCGTGTCTGCCCGCCCGGCCCGCGGGGACGAGGCGGCGGCGGCGGCGGCGGCGGCGAGGATG ATGATGTGCGCAGCGACTGCCTCCCCCGCCGCCGCCTCCTCGGGGCTCGGCGGGGACGGATTCTACCCAGCCGCCACCTTCTCTTCCTCC CCGGCGCCGGGGGCGCTGTTCATGCCGGTTCCCGACGGCTCCGTGGCTGCTGCGGGGCTGGGGCTGGGGCTACCCGCCGCGGACTCCCGG GGTCACTACCAGCTGCTGCTGTCAGGCCGGGCCCTGGCCGACCGCTACCGGAGGATTTATACCGCTGCGCTCAATGACAGGGACCAGGGG GGCGGCAGCGCTGGACACCCAGCCTCCAGGAATAAGAAAATTTTAAATAAGAAGAAATTGAAAAGAAAACAGAAGAGCAAATCAAAAGTG AAGACAAGAAGCAAGTCTGAAAACTTAGAGAATACAGTAATCATACCAGATATCAAACTACATAGCAATCCTTCTGCTTTCAATATTTAC TGTAATGTACGCCATTGCGTTCTGGAATGGCAGAAAAAGGAAATATCATTGGCAGCCGCATCTAAGAACTCTGTGCAGAGTGGAGAATCA GATAGTGATGAAGAAGAGGAATCCAAAGAGCCCCCTATCAAGCTTCCAAAGAATCGAATGTGGAGAAAGAACCGTTCTTTCTATGCGAAC AATCATTGCATCGGAACAGACCTGAATAGGAACTTTGCTTCCAAACACTGGTGTGAGGAAGGTGCATCCAGTTCCTCATGCTCGGAAACC TACTGTGGACTTTATCCTGAGTCAGAACCAGAAGTGAAGGCAGTGGCTAGTTTCTTGAGAAGAAATATCAACCAGATTAAAGCATACATC AGCATGCATTCATACTCCCAGCATATAGTGTTTCCATATTCCTATACACGAAGTAAAAGCAAAGACCATGAGGAACTGTCTCTAGTAGCC AGTGAAGCAGTTCGTGCTATTGAGAAAATTAGTAAAAATACCAGGTATACACATGGCCATGGCTCAGAAACCTTATACCTAGCTCCTGGA GGTGGGGACGATTGGATCTATGATTTGGGCATCAAATATTCCGTTACATCAAACCCACCTGTAGAGAAGCTTTTGCCGCTGTCTCTAAAA TAGCTTGGCATGTCATTAGGAATGTTTAATGCCCCTGATTTTATCATTCTGCTTCCGTATTTTAATTTACTGATTCCAGCAAGACCAAAT CATTGTATCAAATTATTTTTAAGTTTTATCCGTAGTTTTGATAAAAGATTTTCCTATTCCTTGGTTCTGTCAGAGAACCTAATAAGTGCT ACTTTGCCATTAAGGCAGACTAGGGTTCATGTCTTTTTACCCTTTAAAAAAAATTGTAAAAGTCTAGTTACCTACTTTTTCTTTGATTTT CGACGTTTGACTAGCCATCTCAAGCAAGTTTCGACGTTTGACTAGCCATCTCAAGCAAGTTTAATCAATGATCATCTCACGCTGATCATT GGATCCTACTCAACAAAAGGAAGGGTGGTCAGAAGTACATTAAAGATTTCTGCTCCAAATTTTCAATAAATTTCTGCTTGTGCCTTTAGA >56200_56200_2_MYCBP2-CPB2_MYCBP2_chr13_77862296_ENST00000407578_CPB2_chr13_46638876_ENST00000439329_length(amino acids)=389AA_BP=226 MEKGCVCARVSARPARGDEAAAAAAAARMMMCAATASPAAASSGLGGDGFYPAATFSSSPAPGALFMPVPDGSVAAAGLGLGLPAADSRG HYQLLLSGRALADRYRRIYTAALNDRDQGGGSAGHPASRNKKILNKKKLKRKQKSKSKVKTRSKSENLENTVIIPDIKLHSNPSAFNIYC NVRHCVLEWQKKEISLAAASKNSVQSGESDSDEEEESKEPPIKLPKNRMWRKNRSFYANNHCIGTDLNRNFASKHWCEEGASSSSCSETY CGLYPESEPEVKAVASFLRRNINQIKAYISMHSYSQHIVFPYSYTRSKSKDHEELSLVASEAVRAIEKISKNTRYTHGHGSETLYLAPGG -------------------------------------------------------------- >56200_56200_3_MYCBP2-CPB2_MYCBP2_chr13_77862296_ENST00000544440_CPB2_chr13_46638876_ENST00000181383_length(transcript)=1496nt_BP=498nt GCGCCGGGGGCGCTGTTCATGCCGGTTCCCGACGGCTCCGTGGCTGCTGCGGGGCTGGGGCTGGGGCTACCCGCCGCGGACTCCCGGGGT CACTACCAGCTGCTGCTGTCAGGCCGGGCCCTGGCCGACCGCTACCGGAGGATTTATACCGCTGCGCTCAATGACAGGGACCAGGGGGGC GGCAGCGCTGGACACCCAGCCTCCAGGAATAAGAAAATTTTAAATAAGAAGAAATTGAAAAGAAAACAGAAGAGCAAATCAAAAGTGAAG ACAAGAAGCAAGTCTGAAAACTTAGAGAATACAGTAATCATACCAGATATCAAACTACATAGCAATCCTTCTGCTTTCAATATTTACTGT AATGTACGCCATTGCGTTCTGGAATGGCAGAAAAAGGAAATATCATTGGCAGCCGCATCTAAGAACTCTGTGCAGAGTGGAGAATCAGAT AGTGATGAAGAAGAGGAATCCAAAGAGCCCCCTATCAAGCTTCCAAAGAATCGAATGTGGAGAAAGAACCGTTCTTTCTATGCGAACAAT CATTGCATCGGAACAGACCTGAATAGGAACTTTGCTTCCAAACACTGGTGTGAGGAAGGTGCATCCAGTTCCTCATGCTCGGAAACCTAC TGTGGACTTTATCCTGAGTCAGAACCAGAAGTGAAGGCAGTGGCTAGTTTCTTGAGAAGAAATATCAACCAGATTAAAGCATACATCAGC ATGCATTCATACTCCCAGCATATAGTGTTTCCATATTCCTATACACGAAGTAAAAGCAAAGACCATGAGGAACTGTCTCTAGTAGCCAGT GAAGCAGTTCGTGCTATTGAGAAAATTAGTAAAAATACCAGGTATACACATGGCCATGGCTCAGAAACCTTATACCTAGCTCCTGGAGGT GGGGACGATTGGATCTATGATTTGGGCATCAAATATTCGTTTACAATTGAACTTCGAGATACGGGCACATACGGATTCTTGCTGCCGGAG CGTTACATCAAACCCACCTGTAGAGAAGCTTTTGCCGCTGTCTCTAAAATAGCTTGGCATGTCATTAGGAATGTTTAATGCCCCTGATTT TATCATTCTGCTTCCGTATTTTAATTTACTGATTCCAGCAAGACCAAATCATTGTATCAAATTATTTTTAAGTTTTATCCGTAGTTTTGA TAAAAGATTTTCCTATTCCTTGGTTCTGTCAGAGAACCTAATAAGTGCTACTTTGCCATTAAGGCAGACTAGGGTTCATGTCTTTTTACC CTTTAAAAAAAATTGTAAAAGTCTAGTTACCTACTTTTTCTTTGATTTTCGACGTTTGACTAGCCATCTCAAGCAAGTTTCGACGTTTGA CTAGCCATCTCAAGCAAGTTTAATCAATGATCATCTCACGCTGATCATTGGATCCTACTCAACAAAAGGAAGGGTGGTCAGAAGTACATT >56200_56200_3_MYCBP2-CPB2_MYCBP2_chr13_77862296_ENST00000544440_CPB2_chr13_46638876_ENST00000181383_length(amino acids)=351AA_BP=162 MFMPVPDGSVAAAGLGLGLPAADSRGHYQLLLSGRALADRYRRIYTAALNDRDQGGGSAGHPASRNKKILNKKKLKRKQKSKSKVKTRSK SENLENTVIIPDIKLHSNPSAFNIYCNVRHCVLEWQKKEISLAAASKNSVQSGESDSDEEEESKEPPIKLPKNRMWRKNRSFYANNHCIG TDLNRNFASKHWCEEGASSSSCSETYCGLYPESEPEVKAVASFLRRNINQIKAYISMHSYSQHIVFPYSYTRSKSKDHEELSLVASEAVR -------------------------------------------------------------- >56200_56200_4_MYCBP2-CPB2_MYCBP2_chr13_77862296_ENST00000544440_CPB2_chr13_46638876_ENST00000439329_length(transcript)=1443nt_BP=498nt GCGCCGGGGGCGCTGTTCATGCCGGTTCCCGACGGCTCCGTGGCTGCTGCGGGGCTGGGGCTGGGGCTACCCGCCGCGGACTCCCGGGGT CACTACCAGCTGCTGCTGTCAGGCCGGGCCCTGGCCGACCGCTACCGGAGGATTTATACCGCTGCGCTCAATGACAGGGACCAGGGGGGC GGCAGCGCTGGACACCCAGCCTCCAGGAATAAGAAAATTTTAAATAAGAAGAAATTGAAAAGAAAACAGAAGAGCAAATCAAAAGTGAAG ACAAGAAGCAAGTCTGAAAACTTAGAGAATACAGTAATCATACCAGATATCAAACTACATAGCAATCCTTCTGCTTTCAATATTTACTGT AATGTACGCCATTGCGTTCTGGAATGGCAGAAAAAGGAAATATCATTGGCAGCCGCATCTAAGAACTCTGTGCAGAGTGGAGAATCAGAT AGTGATGAAGAAGAGGAATCCAAAGAGCCCCCTATCAAGCTTCCAAAGAATCGAATGTGGAGAAAGAACCGTTCTTTCTATGCGAACAAT CATTGCATCGGAACAGACCTGAATAGGAACTTTGCTTCCAAACACTGGTGTGAGGAAGGTGCATCCAGTTCCTCATGCTCGGAAACCTAC TGTGGACTTTATCCTGAGTCAGAACCAGAAGTGAAGGCAGTGGCTAGTTTCTTGAGAAGAAATATCAACCAGATTAAAGCATACATCAGC ATGCATTCATACTCCCAGCATATAGTGTTTCCATATTCCTATACACGAAGTAAAAGCAAAGACCATGAGGAACTGTCTCTAGTAGCCAGT GAAGCAGTTCGTGCTATTGAGAAAATTAGTAAAAATACCAGGTATACACATGGCCATGGCTCAGAAACCTTATACCTAGCTCCTGGAGGT GGGGACGATTGGATCTATGATTTGGGCATCAAATATTCCGTTACATCAAACCCACCTGTAGAGAAGCTTTTGCCGCTGTCTCTAAAATAG CTTGGCATGTCATTAGGAATGTTTAATGCCCCTGATTTTATCATTCTGCTTCCGTATTTTAATTTACTGATTCCAGCAAGACCAAATCAT TGTATCAAATTATTTTTAAGTTTTATCCGTAGTTTTGATAAAAGATTTTCCTATTCCTTGGTTCTGTCAGAGAACCTAATAAGTGCTACT TTGCCATTAAGGCAGACTAGGGTTCATGTCTTTTTACCCTTTAAAAAAAATTGTAAAAGTCTAGTTACCTACTTTTTCTTTGATTTTCGA CGTTTGACTAGCCATCTCAAGCAAGTTTCGACGTTTGACTAGCCATCTCAAGCAAGTTTAATCAATGATCATCTCACGCTGATCATTGGA TCCTACTCAACAAAAGGAAGGGTGGTCAGAAGTACATTAAAGATTTCTGCTCCAAATTTTCAATAAATTTCTGCTTGTGCCTTTAGAAAT >56200_56200_4_MYCBP2-CPB2_MYCBP2_chr13_77862296_ENST00000544440_CPB2_chr13_46638876_ENST00000439329_length(amino acids)=325AA_BP=162 MFMPVPDGSVAAAGLGLGLPAADSRGHYQLLLSGRALADRYRRIYTAALNDRDQGGGSAGHPASRNKKILNKKKLKRKQKSKSKVKTRSK SENLENTVIIPDIKLHSNPSAFNIYCNVRHCVLEWQKKEISLAAASKNSVQSGESDSDEEEESKEPPIKLPKNRMWRKNRSFYANNHCIG TDLNRNFASKHWCEEGASSSSCSETYCGLYPESEPEVKAVASFLRRNINQIKAYISMHSYSQHIVFPYSYTRSKSKDHEELSLVASEAVR -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for MYCBP2-CPB2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for MYCBP2-CPB2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for MYCBP2-CPB2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies