
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:NACC1-NACC2 (FusionGDB2 ID:57092) |
Fusion Gene Summary for NACC1-NACC2 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: NACC1-NACC2 | Fusion gene ID: 57092 | Hgene | Tgene | Gene symbol | NACC1 | NACC2 | Gene ID | 112939 | 138151 |
| Gene name | nucleus accumbens associated 1 | NACC family member 2 | |
| Synonyms | BEND8|BTBD14B|BTBD30|NAC-1|NAC1|NECFM | BEND9|BTBD14|BTBD14A|BTBD31|NAC-2|RBB | |
| Cytomap | 19p13.13 | 9q34.3 | |
| Type of gene | protein-coding | protein-coding | |
| Description | nucleus accumbens-associated protein 1BEN domain containing 8BTB/POZ domain-containing protein 14Bnucleus accumbens associated 1, BEN and BTB (POZ) domain containingtranscriptional repressor NAC1 | nucleus accumbens-associated protein 2BEN domain containing 9BTB (POZ) domain containing 14ABTB/POZ domain-containing protein 14ANACC family member 2, BEN and BTB (POZ) domain containingrepressor with BTB domain and BEN domaintranscription repressor | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q96RE7 | Q96BF6 | |
| Ensembl transtripts involved in fusion gene | ENST00000292431, | ENST00000467669, ENST00000277554, ENST00000371753, | |
| Fusion gene scores | * DoF score | 5 X 3 X 5=75 | 4 X 4 X 3=48 |
| # samples | 5 | 4 | |
| ** MAII score | log2(5/75*10)=-0.584962500721156 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(4/48*10)=-0.263034405833794 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: NACC1 [Title/Abstract] AND NACC2 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | NACC1(13248190)-NACC2(138905142), # samples:1 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Tgene | NACC2 | GO:0008285 | negative regulation of cell proliferation | 22926524 |
| Tgene | NACC2 | GO:0034629 | cellular protein-containing complex localization | 22926524 |
| Tgene | NACC2 | GO:0045892 | negative regulation of transcription, DNA-templated | 22926524 |
| Tgene | NACC2 | GO:0051260 | protein homooligomerization | 22926524 |
| Tgene | NACC2 | GO:1900477 | negative regulation of G1/S transition of mitotic cell cycle by negative regulation of transcription from RNA polymerase II promoter | 22926524 |
| Tgene | NACC2 | GO:1902231 | positive regulation of intrinsic apoptotic signaling pathway in response to DNA damage | 22926524 |
| Fusion gene breakpoints across NACC1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across NACC2 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | Non-Cancer | 5381N | NACC1 | chr19 | 13248190 | + | NACC2 | chr9 | 138905142 | - |
Top |
Fusion Gene ORF analysis for NACC1-NACC2 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000292431 | ENST00000467669 | NACC1 | chr19 | 13248190 | + | NACC2 | chr9 | 138905142 | - |
| In-frame | ENST00000292431 | ENST00000277554 | NACC1 | chr19 | 13248190 | + | NACC2 | chr9 | 138905142 | - |
| In-frame | ENST00000292431 | ENST00000371753 | NACC1 | chr19 | 13248190 | + | NACC2 | chr9 | 138905142 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000292431 | NACC1 | chr19 | 13248190 | + | ENST00000371753 | NACC2 | chr9 | 138905142 | - | 6938 | 1352 | 126 | 1958 | 610 |
| ENST00000292431 | NACC1 | chr19 | 13248190 | + | ENST00000277554 | NACC2 | chr9 | 138905142 | - | 2116 | 1352 | 126 | 1958 | 610 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000292431 | ENST00000371753 | NACC1 | chr19 | 13248190 | + | NACC2 | chr9 | 138905142 | - | 0.004079855 | 0.9959202 |
| ENST00000292431 | ENST00000277554 | NACC1 | chr19 | 13248190 | + | NACC2 | chr9 | 138905142 | - | 0.031786 | 0.968214 |
Top |
Fusion Genomic Features for NACC1-NACC2 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
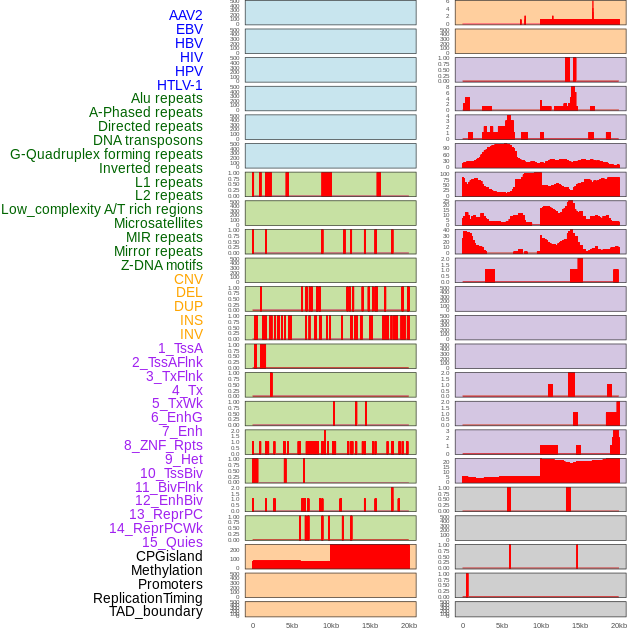 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for NACC1-NACC2 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr19:13248190/chr9:138905142) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| NACC1 | NACC2 |
| FUNCTION: Functions as a transcriptional repressor. Seems to function as a transcriptional corepressor in neuronal cells through recruitment of HDAC3 and HDAC4. Contributes to tumor progression, and tumor cell proliferation and survival. This may be mediated at least in part through repressing transcriptional activity of GADD45GIP1. Required for recruiting the proteasome from the nucleus to the cytoplasm and dendritic spines. {ECO:0000269|PubMed:17130457, ECO:0000269|PubMed:17804717}. | FUNCTION: Functions as a transcriptional repressor through its association with the NuRD complex. Recruits the NuRD complex to the promoter of MDM2, leading to the repression of MDM2 transcription and subsequent stability of p53/TP53. {ECO:0000269|PubMed:22926524}. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | NACC1 | chr19:13248190 | chr9:138905142 | ENST00000292431 | + | 4 | 6 | 194_199 | 408 | 528.0 | Compositional bias | Note=Poly-Gly |
| Hgene | NACC1 | chr19:13248190 | chr9:138905142 | ENST00000292431 | + | 4 | 6 | 30_94 | 408 | 528.0 | Domain | BTB |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | NACC1 | chr19:13248190 | chr9:138905142 | ENST00000292431 | + | 4 | 6 | 374_471 | 408 | 528.0 | Domain | BEN |
| Tgene | NACC2 | chr19:13248190 | chr9:138905142 | ENST00000277554 | 3 | 6 | 30_94 | 385 | 588.0 | Domain | BTB | |
| Tgene | NACC2 | chr19:13248190 | chr9:138905142 | ENST00000277554 | 3 | 6 | 351_448 | 385 | 588.0 | Domain | BEN | |
| Tgene | NACC2 | chr19:13248190 | chr9:138905142 | ENST00000371753 | 2 | 5 | 30_94 | 385 | 588.0 | Domain | BTB | |
| Tgene | NACC2 | chr19:13248190 | chr9:138905142 | ENST00000371753 | 2 | 5 | 351_448 | 385 | 588.0 | Domain | BEN |
Top |
Fusion Gene Sequence for NACC1-NACC2 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >57092_57092_1_NACC1-NACC2_NACC1_chr19_13248190_ENST00000292431_NACC2_chr9_138905142_ENST00000277554_length(transcript)=2116nt_BP=1352nt AGGCCGCGGAGGCGGAGGCCGAGGCCCCGGCGCAGCGGGGCGCGCCCCGGGCCCAGGCCCGGCCCCAGCCGCCGCTGCGGAGCCCGCCGG GACCCCCCGGAGCGCGGCCACGGCGCAGCCGCTGCCATGGCCCAGACACTGCAGATGGAGATCCCGAACTTCGGCAACAGCATCCTGGAG TGCCTCAATGAACAGCGGCTGCAGGGCCTGTACTGTGACGTGTCAGTGGTGGTCAAGGGCCATGCCTTCAAGGCCCACCGGGCCGTGCTT GCTGCCAGCAGCTCCTACTTCCGGGACCTGTTCAACAACAGCCGCAGCGCCGTGGTGGAGCTGCCGGCGGCTGTGCAGCCCCAGTCTTTC CAGCAGATCCTCAGCTTCTGCTACACGGGCCGGCTGAGCATGAACGTGGGCGACCAGTTCCTGCTCATGTACACGGCTGGCTTCCTGCAG ATCCAGGAGATCATGGAGAAGGGCACCGAGTTCTTCCTCAAGGTGAGCTCCCCGAGCTGCGACTCCCAGGGCCTGCATGCGGAGGAGGCC CCATCGTCGGAGCCCCAGAGCCCCGTGGCGCAGACATCGGGCTGGCCAGCCTGTAGCACCCCGCTGCCCCTCGTGTCGCGGGTGAAGACG GAGCAGCAGGAGTCGGACTCCGTGCAGTGCATGCCCGTGGCCAAGCGGCTGTGGGACAGTGGCCAGAAGGAGGCTGGGGGCGGCGGCAAT GGCAGCCGCAAGATGGCCAAGTTCTCCACGCCGGACCTGGCTGCCAACCGGCCTCACCAGCCCCCGCCACCCCAACAGGCTCCGGTGGTG GCAGCAGCCCAGCCCGCCGTGGCTGCGGGAGCAGGGCAGCCAGCCGGTGGGGTGGCAGCAGCAGGGGGTGTGGTGAGTGGGCCCAGCACG TCGGAGCGGACCAGCCCAGGCACCTCAAGCGCCTACACCAGCGACAGCCCTGGCTCCTACCACAATGAGGAGGACGAGGAGGAGGATGGT GGCGAGGAGGGCATGGATGAGCAGTACCGGCAGATCTGCAACATGTACACCATGTACAGCATGATGAACGTCGGCCAGACAGCCGAGAAG GTGGAGGCCCTCCCGGAGCAGGTAGCCCCCGAGTCCCGAAATCGCATCCGGGTTCGGCAAGACCTGGCGTCTCTCCCGGCTGAACTTATC AACCAGATTGGGAACCGCTGCCACCCCAAGCTCTACGACGAGGGCGACCCCTCTGAGAAGCTGGAGCTGGTGACAGGCACCAACGTGTAC ATCACAAGGGCGCAGCTGATGAACTGCCACGTCAGCGCAGGCACGCGGCACAAGGTCCTACTGCGGCGGCTCCTGGCCTCCTTCTTTGAC CGGAACACGCTGGCCAACAGCTGCGGGACTGGCATCCGCTCGTCCACCAGCGACCCCAGCCGGAAGCCGCTGGACAGCCGGGTCCTGAAC GCTGTGAAATTGTACTGTCAGAACTTCGCCCCCAGCTTCAAGGAGAGCGAGATGAACGTGATCGCCGCGGACATGTGCACCAACGCCCGC CGCGTTCGCAAGCGCTGGCTGCCCAAGATCAAGTCCATGCTGCCGGAGGGCGTGGAGATGTACCGCACGGTCATGGGCTCCGCCGCCGCC AGCGTGCCCCTCGACCCCGAGTTCCCGCCTGCCGCGGCACAGGTGTTCGAGCAACGCATCTACGCCGAGCGGCGGGGCGACGCCGCCACC ATCGTGGCTCTGAGAACTGACGCCGTGAATGTTGACCTGAGTGCCGCCGCCAACCCCGCCTTCGACGCCGGCGAGGAGGTGGACGGGGCT GGCTCGGTCATCCAGGAGGTGGCCGCCCCCGAGCCGCTGCCCGCCGATGGCCAGAGCCCCCCACAGCCCTTTGAGCAGGGCGGGGGCGGC CCCAGCAGGCCCCAGACGCCGGCGGCCGCGGCCCGGAGGCCGGAGGGCACCTATGCAGGGACCTTGTAAGCGGAGCTGGGTGGCTGCGCG AGGGACCGAGTACTAGAGCTGCTTGCATGCGTTACTAATACAAACAAATGTGATCAAGCCACTTACCTACTGAACTGCTACTGTTGCCTG >57092_57092_1_NACC1-NACC2_NACC1_chr19_13248190_ENST00000292431_NACC2_chr9_138905142_ENST00000277554_length(amino acids)=610AA_BP=0 MAQTLQMEIPNFGNSILECLNEQRLQGLYCDVSVVVKGHAFKAHRAVLAASSSYFRDLFNNSRSAVVELPAAVQPQSFQQILSFCYTGRL SMNVGDQFLLMYTAGFLQIQEIMEKGTEFFLKVSSPSCDSQGLHAEEAPSSEPQSPVAQTSGWPACSTPLPLVSRVKTEQQESDSVQCMP VAKRLWDSGQKEAGGGGNGSRKMAKFSTPDLAANRPHQPPPPQQAPVVAAAQPAVAAGAGQPAGGVAAAGGVVSGPSTSERTSPGTSSAY TSDSPGSYHNEEDEEEDGGEEGMDEQYRQICNMYTMYSMMNVGQTAEKVEALPEQVAPESRNRIRVRQDLASLPAELINQIGNRCHPKLY DEGDPSEKLELVTGTNVYITRAQLMNCHVSAGTRHKVLLRRLLASFFDRNTLANSCGTGIRSSTSDPSRKPLDSRVLNAVKLYCQNFAPS FKESEMNVIAADMCTNARRVRKRWLPKIKSMLPEGVEMYRTVMGSAAASVPLDPEFPPAAAQVFEQRIYAERRGDAATIVALRTDAVNVD -------------------------------------------------------------- >57092_57092_2_NACC1-NACC2_NACC1_chr19_13248190_ENST00000292431_NACC2_chr9_138905142_ENST00000371753_length(transcript)=6938nt_BP=1352nt AGGCCGCGGAGGCGGAGGCCGAGGCCCCGGCGCAGCGGGGCGCGCCCCGGGCCCAGGCCCGGCCCCAGCCGCCGCTGCGGAGCCCGCCGG GACCCCCCGGAGCGCGGCCACGGCGCAGCCGCTGCCATGGCCCAGACACTGCAGATGGAGATCCCGAACTTCGGCAACAGCATCCTGGAG TGCCTCAATGAACAGCGGCTGCAGGGCCTGTACTGTGACGTGTCAGTGGTGGTCAAGGGCCATGCCTTCAAGGCCCACCGGGCCGTGCTT GCTGCCAGCAGCTCCTACTTCCGGGACCTGTTCAACAACAGCCGCAGCGCCGTGGTGGAGCTGCCGGCGGCTGTGCAGCCCCAGTCTTTC CAGCAGATCCTCAGCTTCTGCTACACGGGCCGGCTGAGCATGAACGTGGGCGACCAGTTCCTGCTCATGTACACGGCTGGCTTCCTGCAG ATCCAGGAGATCATGGAGAAGGGCACCGAGTTCTTCCTCAAGGTGAGCTCCCCGAGCTGCGACTCCCAGGGCCTGCATGCGGAGGAGGCC CCATCGTCGGAGCCCCAGAGCCCCGTGGCGCAGACATCGGGCTGGCCAGCCTGTAGCACCCCGCTGCCCCTCGTGTCGCGGGTGAAGACG GAGCAGCAGGAGTCGGACTCCGTGCAGTGCATGCCCGTGGCCAAGCGGCTGTGGGACAGTGGCCAGAAGGAGGCTGGGGGCGGCGGCAAT GGCAGCCGCAAGATGGCCAAGTTCTCCACGCCGGACCTGGCTGCCAACCGGCCTCACCAGCCCCCGCCACCCCAACAGGCTCCGGTGGTG GCAGCAGCCCAGCCCGCCGTGGCTGCGGGAGCAGGGCAGCCAGCCGGTGGGGTGGCAGCAGCAGGGGGTGTGGTGAGTGGGCCCAGCACG TCGGAGCGGACCAGCCCAGGCACCTCAAGCGCCTACACCAGCGACAGCCCTGGCTCCTACCACAATGAGGAGGACGAGGAGGAGGATGGT GGCGAGGAGGGCATGGATGAGCAGTACCGGCAGATCTGCAACATGTACACCATGTACAGCATGATGAACGTCGGCCAGACAGCCGAGAAG GTGGAGGCCCTCCCGGAGCAGGTAGCCCCCGAGTCCCGAAATCGCATCCGGGTTCGGCAAGACCTGGCGTCTCTCCCGGCTGAACTTATC AACCAGATTGGGAACCGCTGCCACCCCAAGCTCTACGACGAGGGCGACCCCTCTGAGAAGCTGGAGCTGGTGACAGGCACCAACGTGTAC ATCACAAGGGCGCAGCTGATGAACTGCCACGTCAGCGCAGGCACGCGGCACAAGGTCCTACTGCGGCGGCTCCTGGCCTCCTTCTTTGAC CGGAACACGCTGGCCAACAGCTGCGGGACTGGCATCCGCTCGTCCACCAGCGACCCCAGCCGGAAGCCGCTGGACAGCCGGGTCCTGAAC GCTGTGAAATTGTACTGTCAGAACTTCGCCCCCAGCTTCAAGGAGAGCGAGATGAACGTGATCGCCGCGGACATGTGCACCAACGCCCGC CGCGTTCGCAAGCGCTGGCTGCCCAAGATCAAGTCCATGCTGCCGGAGGGCGTGGAGATGTACCGCACGGTCATGGGCTCCGCCGCCGCC AGCGTGCCCCTCGACCCCGAGTTCCCGCCTGCCGCGGCACAGGTGTTCGAGCAACGCATCTACGCCGAGCGGCGGGGCGACGCCGCCACC ATCGTGGCTCTGAGAACTGACGCCGTGAATGTTGACCTGAGTGCCGCCGCCAACCCCGCCTTCGACGCCGGCGAGGAGGTGGACGGGGCT GGCTCGGTCATCCAGGAGGTGGCCGCCCCCGAGCCGCTGCCCGCCGATGGCCAGAGCCCCCCACAGCCCTTTGAGCAGGGCGGGGGCGGC CCCAGCAGGCCCCAGACGCCGGCGGCCGCGGCCCGGAGGCCGGAGGGCACCTATGCAGGGACCTTGTAAGCGGAGCTGGGTGGCTGCGCG AGGGACCGAGTACTAGAGCTGCTTGCATGCGTTACTAATACAAACAAATGTGATCAAGCCACTTACCTACTGAACTGCTACTGTTGCCTG AGAAAAATGTGATTTTTATTCTGCTTGTATTTAAAATTGATGAAGGAAACAAATGCATTCATTATACTGTAAACAATTAGGCCACTGGCA GCCTCCTGCGAGGAAGTTCCCAGGGCTCCCTTTTGATATTCACAAGGTCAGCCTCCAAGTGTAGCTTCCCTCCCCCTTCTTGGGGAGGGT GGGAGGCCGCCAGGCCCCTGGTGCCCAGCCCTGCCCCTTCCTCCCTGCCCTTCCTGCTCCTCCTGCCCGGAAGACGAAGCAGGGGCCGGC GGTGGTCTGTGGCGAGGGGGCTGGGCTGTGCGTCACTGACCCTTCCTTCCTTCCCCATGGAACCTCTCTGGGGCGACGGGGCAGGGCTCA GGCTCCAGGGCCTAACTCCTCGTTTTTCCTTCTTTCGGAGACTCGGGGCCAGGCCCACCGGGCCTTCCACCTGTGTGGGGTGTGTGCACG AGTGTGTGTGTGTGCGTGTGTGTGCAGGGGTGTGGTGAGGGGGCAGTGATGGCTGTGGCCCACCCCTCGGGGTGGAGAAAAGGGTACTTT ACTCTGCCCCCACACCCTGTCCTTGTTCTGCCCGATCCGTCTCGGCTCTGCAGCCCCTCGGTCCCCTGACCCCCAGGGCACCGCTGACCC CGCCTGGCCTCCCACTGTCCCGCCCGGGCCCACTGTGGGACGTGCACAGCTGATGTAGCACACGCTGCCCTCTGCCGCCTCAGCCACTTT GGGATTATGCTTGTCTTGTTTTTTTTAGGTTTTGTTGTAATTTAGATCTATTTCATATATGGTTTGGAAACTTTCAGACTCAATAGAACA AAAACTTTGGGTGGGATGGGTGTCCCTGTCCCCAGCCCACCATGGCTTGGGGTGGGTCATCTGTGGCCGTTAGGGTGCGTCCCCCTGCTC CCCCGCCCAGGGCCAGGGACCACTCGTCTCCCACTGGGGGAAAAAGGGGGTCCCGGGTGGGCGACTAGTACGTGTGAAGCTGAGCTCAGG GCCGGACCTGGGGAGCGGGGGACTCCGCTCGGGCAGGAGGCAGCGGCCAGGGCTGGGCCAGGGCGAGAGTCGGTCCTCCCGGTGCTGGGC TCCCCGTCTGCCTTGAGGGGTGTGCATGGATGGAGGGTGCCTGAGGCTGCAGGCAGGGGATGACCGGGACAGGCCTGGGCTGGGGCAGTT GGAGGTATGGGCACTGGTAGGGGACAGAGGGTTAGGGATCATGTTGGGGGGCCAGGGACAGTGGAGGAAGGGCCCATGGAAGATGGGGCT GTTTGGTTTGAGGCTGGAGTGCTTCCTTTGAAATTTAATTACTGTTTTTTAAGTGGTAGGGCTCACAGACTGTGTGAAGTCCTGTGTGAA GTGCTGGTGTGGCCACCTACCCAGGTGTCCCTCCCTTTTGTTTTGGAGGCCTGTGTCCTTGTCCAGGGGCAGCCCTCCTTCCCAGGTGTG GCCAGAAGAACCCCCCATCCCAAGACTTGAAATGTCTGTTGCTCACCTCTGTCCCTCCAGAACTCGGCTTCCCCATCTTCACTTGCAAAA CAAGTGCAGCCCTGCGCCCATCAGCACCCCCTCCGGTGTGCACACAGGCCAGTGAGCGGTGGCCGACCAGCGCACCCCACTCCCCCAACC TCCACAACCCATCAAGCGGAGGCCGCCTCCGCTAGGGGAGGACCATGTGCTGCACCCTGGCCTGGGGACCTACAGGGTGTGGGTTAGACG CATTCCCACTGGGCGGCTCCTTTCTGCCCCGAAGCCCACCCCTGTGGCGAGGCCCTAGGAGACCTCCCGTGGGGCCGCCTCTACAGACAG CACTCAGCCTCCTGGGCTGCCTCCAGCCAGGCCCAGCACATGCCTGCCCTCCAGAAAAATACGTTGCTTTCCAGAAGGAGGTGGGGGACC ATGGGCAGGCACTGTGGACGCTAACCTCGGCCCCTCCACCCATTCCTCAGGGCCCACGTCCAGGGGGACCAAGACCTGCATTCCTAGGGC TGCAGGTGGCTCAGTGGTGCAGAGGCATCCAGACCTTCTGCTGAACTAAGAACCACCCAGCCTAGAGGGAGCCTTTCTCTGCCTCTTCCT CCCCTGTCTTGGGCACAGGTGGGGTTGGAGCCCCCATGGGGCCCGCTGGGAACCTGGACCAAGCCTTCCTCGGAGATGGGAGGAAGCCGC GGGGTGGAGCAGGGGCAGGTAGGTGAGGTTGAGCTGCACTTGAGTTCCCTCTGGAGTTTCCTTCATCTGCCCCACACCCAAATTTGCACT TTAATTTGACCATCCCTGGGGGCCTGGCTGCTGACAGAAGGGCTCTCTCTGCCCTCCACTCCAAAGTGGGTGCCCCCCCACCCTTGGCCA GGACAGGGAGGGAGCCGCTGGCTGCTGCCGGAGGTGGTGGCTGCACAGAGGACGCCTGACTGCTGTTCAGGCCCGCACAATGTCCCGTGC CCCTTCCTCACTCGTTTGTAATCGCCGTCTGTTTTGTTCTGGGTAAGGAAGGCAAGAGCTATAGATAAAACTTAAATAATAATAATTTAA TGTGAATGGGTTCTGAGCTCTCCCTGCGCCCCGGGCGGGCCAGGCCGAGCATTTTGCACTAATGTGTCCCACGGTGGGCGTGAGTCGGGA GTGTCTGTGGACGTGCGTGGCTGCTGAGCGGACCTGCTGTGTGCTCCCTCCACGTCCTGAATGTACCGTGGGGCGGGGGCGGCGGCCCGG GCTCAGAGGGGCCTTCCAGAGTGCCTTAGCATCCTTTGATCATTTTTCCCAAGGAAACCAATTAAGAAAGCCGGACCCTTCCCTCCTTTG TTTACAAGATGACTAATTCTAGAATCCGGGGTTGTCCTGTCCTGTGAGTGTGACCCTGACTCATCCAGACCCTGTAGAGAGAGACGAGCC ACTCAGTATTTATGAGATGTCTGCACCTTTATCCCTAAGCCTGACTATTAGCAATACGCATATCCTATATAGAATCTATTACAGAGCTAC GTTATCTCCACACCTTTTGAGGAGGACAGAAGGGACTGGACCGTGTTGGAGCTGCCGCCTGGCAGGTGGTGGGCCTGGGATCTAGCCGCC TCTCCTGCCCTGCCTTCCTCTTCCCCAAGGGGATGGGCCCAGGAGGCAGCTGGGTTGCATGGAGAGGTCCAGGAGGGACCGGAGGTGTGA CAGATACTGTGAGCCCGGCGGGCCGCGCCTGGCTGGGTGCCTCGGTACTTGAATTCTGTCTTGTTTTCCGCATTGTGTCTGTCCACCCGA GTTCTCTGTCGTCACTTAACTTTGCATTGGATTTGGTTGTTGTACTTTGCCCCTGAATGTGGACAAAGCTGTGGGCAAGAGGTCAGCAGG ACCCGCCTGGGGGTGCCGGCGTTGGTGACTGCGGGTCGGGGCTCCTAGAACATAGGAGCCGGCTGCCTGGCCTCCTTTCTCCTCCAGGAA GAGTCATTCTTTGGCATTTGTGTTTAGAGCCAGGAGGAAGGCGGAAGGTAGGGAGGGAGGGCTGGTCCCCCTCTGAGGGGGCTCTAGTGC CTGACCCTGACCTGTCCTCATTCGACAGCTGAAACTGTTAAGCGCTGGCCCAGTCCCCCCACCCCACCCAGCCGTGTACTGCCTGGGCTC CCCTCAAAGGGAAATTTTTATGGAAACATCTTGGCAGCAAGTGGAAAAAGATCTATGGCCCATGAACCAACTGAAAACTCCAAGAACCCT CTGTCTGCCTCTGCCAGCAGCGAGTCCTAAGCGCAGAATCCAGAGCTCGTAGCTGTCCTCAGCTGTAACTACTGTTTCAGAATGTTGCTG CTGCATACTTTTGTCATGTCAGCCAGCCAGCTCCGTGGGTGAGAGTGTGCGTGTGCGCGTGTCTGTGTGTGTGTGCGTGTCTGTGTGTGC ACGTCTGTGCGTCTGTGTGTGCGCGTCTGTGCATGTGTGTGTCTGTGCGTGTGTGCGTCTGTGTGTGTGCGTCTGTGTGCGCGTGTGTGT GCGCGTCTGTGTGTATGTGTGCACGCGCGTCTGTGTGCACGTGCGTGTCTCTGCACGCGTGTCTGTGTATGTGTGCACGCGTGTGTCTGT GTGTGTGCACGCGCGTGCACGTCACCACCGGAGCATTTAGGGTTTGGTACAAGATGGTTCTAAAATGGCAAAGGTTTTTCGTGTTTGTTT GTTTTGTTTCTTTGGAAAAAGAAAAGGAAAGGAAAATCATGCAGAATCGCAAGCATTCAGACTGGACGACCGGCTCGTATTCCGATCAGT CGCTTCCATTGTTAGCATCGTACACGATTGTGATTTTTATGTCAAAAGAAGCCAAAACTTGCAATACTATTTTTAGCAGACAAAAAAAAG AACTAAGTATAAAATGTATAAATATTTTTGACTTGAAGATTTGGATGGCACTGGGTGCAAGTAGAGCATCCATCCTTCGGATGGAATGTT TGGAAAAAAGAGACTTTTAAAAAGGAGACGGTTGTTTTAAAGAGTCTGTTTAGGGGTTAAAGTACTGTAACTCACGACTGTTAAAAAATA AATTTTCCTGTGCTGTAAAGGAAGGTTTCACAGTACCACTGAGTTAGATTTCAGCCACAGATGCTTAGCTTTTTTTTTTTGTCTTTTTTT TAAGGAGGAAGCCTTTGTTTTGTTTTCCTGAGCCCTCACTCTGTTTTTGTGCTGTTACTCGGTAGAGTCAAGACTGTTACTTTTTAGCCA TGGCTGACATTGTATCAATAACTAAAACTGAAACATTCAAAAGCGAACAGGGAAACCGAGGGCTTCAAGCGTGCTCAGAGCCGTTTCAGA CAGTGGAAATCCATGACAAACAAAAGGATGTGATCATTAATTGTAAAGCGCTTTGTAAAATTCACATTTACAAAATAATAAAGTCAGTTC >57092_57092_2_NACC1-NACC2_NACC1_chr19_13248190_ENST00000292431_NACC2_chr9_138905142_ENST00000371753_length(amino acids)=610AA_BP=0 MAQTLQMEIPNFGNSILECLNEQRLQGLYCDVSVVVKGHAFKAHRAVLAASSSYFRDLFNNSRSAVVELPAAVQPQSFQQILSFCYTGRL SMNVGDQFLLMYTAGFLQIQEIMEKGTEFFLKVSSPSCDSQGLHAEEAPSSEPQSPVAQTSGWPACSTPLPLVSRVKTEQQESDSVQCMP VAKRLWDSGQKEAGGGGNGSRKMAKFSTPDLAANRPHQPPPPQQAPVVAAAQPAVAAGAGQPAGGVAAAGGVVSGPSTSERTSPGTSSAY TSDSPGSYHNEEDEEEDGGEEGMDEQYRQICNMYTMYSMMNVGQTAEKVEALPEQVAPESRNRIRVRQDLASLPAELINQIGNRCHPKLY DEGDPSEKLELVTGTNVYITRAQLMNCHVSAGTRHKVLLRRLLASFFDRNTLANSCGTGIRSSTSDPSRKPLDSRVLNAVKLYCQNFAPS FKESEMNVIAADMCTNARRVRKRWLPKIKSMLPEGVEMYRTVMGSAAASVPLDPEFPPAAAQVFEQRIYAERRGDAATIVALRTDAVNVD -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for NACC1-NACC2 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for NACC1-NACC2 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for NACC1-NACC2 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies