
|
||||||
|
 | Fusion Gene Summary |
| Fusion Gene ORF analysis |
| Fusion Genomic Features |
| Fusion Protein Features |
| Fusion Gene Sequence |
| Fusion Gene PPI analysis |
| Related Drugs |
| Related Diseases |
Fusion gene:NCOA1-GOLGB1 (FusionGDB2 ID:57684) |
Fusion Gene Summary for NCOA1-GOLGB1 |
 Fusion gene summary Fusion gene summary |
| Fusion gene information | Fusion gene name: NCOA1-GOLGB1 | Fusion gene ID: 57684 | Hgene | Tgene | Gene symbol | NCOA1 | GOLGB1 | Gene ID | 8648 | 2804 |
| Gene name | nuclear receptor coactivator 1 | golgin B1 | |
| Synonyms | F-SRC-1|KAT13A|RIP160|SRC1|bHLHe42|bHLHe74 | GCP|GCP372|GOLIM1 | |
| Cytomap | 2p23.3 | 3q13.33 | |
| Type of gene | protein-coding | protein-coding | |
| Description | nuclear receptor coactivator 1Hin-2 proteinclass E basic helix-loop-helix protein 74renal carcinoma antigen NY-REN-52steroid receptor coactivator-1 | golgin subfamily B member 1372 kDa Golgi complex-associated proteingiantingolgi autoantigen, golgin subfamily b, macrogolgin (with transmembrane signal), 1golgi integral membrane protein 1golgin B1, golgi integral membrane protein | |
| Modification date | 20200313 | 20200313 | |
| UniProtAcc | Q15788 | Q14789 | |
| Ensembl transtripts involved in fusion gene | ENST00000288599, ENST00000348332, ENST00000395856, ENST00000405141, ENST00000406961, ENST00000538539, ENST00000407230, ENST00000469850, | ENST00000472829, ENST00000340645, ENST00000393667, | |
| Fusion gene scores | * DoF score | 16 X 13 X 8=1664 | 12 X 11 X 4=528 |
| # samples | 17 | 13 | |
| ** MAII score | log2(17/1664*10)=-3.29104878200339 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | log2(13/528*10)=-2.02202630633 possibly effective Gene in Pan-Cancer Fusion Genes (peGinPCFGs). DoF>8 and MAII<0 | |
| Context | PubMed: NCOA1 [Title/Abstract] AND GOLGB1 [Title/Abstract] AND fusion [Title/Abstract] | ||
| Most frequent breakpoint | NCOA1(24896332)-GOLGB1(121388202), # samples:4 | ||
| Anticipated loss of major functional domain due to fusion event. | |||
| * DoF score (Degree of Frequency) = # partners X # break points X # cancer types ** MAII score (Major Active Isofusion Index) = log2(# samples/DoF score*10) |
| Gene ontology of each fusion partner gene with evidence of Inferred from Direct Assay (IDA) from Entrez |
| Partner | Gene | GO ID | GO term | PubMed ID |
| Hgene | NCOA1 | GO:0000435 | positive regulation of transcription from RNA polymerase II promoter by galactose | 10207113 |
| Hgene | NCOA1 | GO:0006351 | transcription, DNA-templated | 9223431 |
| Hgene | NCOA1 | GO:0045893 | positive regulation of transcription, DNA-templated | 11891224|15367689 |
| Hgene | NCOA1 | GO:0045944 | positive regulation of transcription by RNA polymerase II | 15919756 |
| Fusion gene breakpoints across NCOA1 (5'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene breakpoints across GOLGB1 (3'-gene) * Click on the image to open the UCSC genome browser with custom track showing this image in a new window. |
 |
| Fusion gene information from two resources (ChiTars 5.0 and ChimerDB 4.0) * All genome coordinats were lifted-over on hg19. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| Source | Disease | Sample | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| ChimerDB4 | BRCA | TCGA-OL-A5RW-01A | NCOA1 | chr2 | 24896332 | - | GOLGB1 | chr3 | 121388202 | - |
| ChimerDB4 | BRCA | TCGA-OL-A5RW-01A | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - |
| ChimerDB4 | BRCA | TCGA-OL-A5RW | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - |
Top |
Fusion Gene ORF analysis for NCOA1-GOLGB1 |
| Open reading frame (ORF) analsis of fusion genes based on Ensembl gene isoform structure. * Click on the break point to see the gene structure around the break point region using the UCSC Genome Browser. |
| ORF | Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand |
| 5CDS-intron | ENST00000288599 | ENST00000472829 | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - |
| 5CDS-intron | ENST00000348332 | ENST00000472829 | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - |
| 5CDS-intron | ENST00000395856 | ENST00000472829 | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - |
| 5CDS-intron | ENST00000405141 | ENST00000472829 | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - |
| 5CDS-intron | ENST00000406961 | ENST00000472829 | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - |
| 5CDS-intron | ENST00000538539 | ENST00000472829 | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - |
| 5UTR-3CDS | ENST00000407230 | ENST00000340645 | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - |
| 5UTR-3CDS | ENST00000407230 | ENST00000393667 | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - |
| 5UTR-intron | ENST00000407230 | ENST00000472829 | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - |
| In-frame | ENST00000288599 | ENST00000340645 | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - |
| In-frame | ENST00000288599 | ENST00000393667 | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - |
| In-frame | ENST00000348332 | ENST00000340645 | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - |
| In-frame | ENST00000348332 | ENST00000393667 | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - |
| In-frame | ENST00000395856 | ENST00000340645 | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - |
| In-frame | ENST00000395856 | ENST00000393667 | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - |
| In-frame | ENST00000405141 | ENST00000340645 | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - |
| In-frame | ENST00000405141 | ENST00000393667 | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - |
| In-frame | ENST00000406961 | ENST00000340645 | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - |
| In-frame | ENST00000406961 | ENST00000393667 | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - |
| In-frame | ENST00000538539 | ENST00000340645 | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - |
| In-frame | ENST00000538539 | ENST00000393667 | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - |
| intron-3CDS | ENST00000469850 | ENST00000340645 | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - |
| intron-3CDS | ENST00000469850 | ENST00000393667 | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - |
| intron-intron | ENST00000469850 | ENST00000472829 | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - |
| ORFfinder result based on the fusion transcript sequence of in-frame fusion genes. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | Seq length (transcript) | BP loci (transcript) | Predicted start (transcript) | Predicted stop (transcript) | Seq length (amino acids) |
| ENST00000406961 | NCOA1 | chr2 | 24896332 | + | ENST00000340645 | GOLGB1 | chr3 | 121388202 | - | 2905 | 1006 | 490 | 1623 | 377 |
| ENST00000406961 | NCOA1 | chr2 | 24896332 | + | ENST00000393667 | GOLGB1 | chr3 | 121388202 | - | 2916 | 1006 | 490 | 1638 | 382 |
| ENST00000405141 | NCOA1 | chr2 | 24896332 | + | ENST00000340645 | GOLGB1 | chr3 | 121388202 | - | 2964 | 1065 | 549 | 1682 | 377 |
| ENST00000405141 | NCOA1 | chr2 | 24896332 | + | ENST00000393667 | GOLGB1 | chr3 | 121388202 | - | 2975 | 1065 | 549 | 1697 | 382 |
| ENST00000538539 | NCOA1 | chr2 | 24896332 | + | ENST00000340645 | GOLGB1 | chr3 | 121388202 | - | 2541 | 642 | 126 | 1259 | 377 |
| ENST00000538539 | NCOA1 | chr2 | 24896332 | + | ENST00000393667 | GOLGB1 | chr3 | 121388202 | - | 2552 | 642 | 126 | 1274 | 382 |
| ENST00000288599 | NCOA1 | chr2 | 24896332 | + | ENST00000340645 | GOLGB1 | chr3 | 121388202 | - | 2511 | 612 | 96 | 1229 | 377 |
| ENST00000288599 | NCOA1 | chr2 | 24896332 | + | ENST00000393667 | GOLGB1 | chr3 | 121388202 | - | 2522 | 612 | 96 | 1244 | 382 |
| ENST00000348332 | NCOA1 | chr2 | 24896332 | + | ENST00000340645 | GOLGB1 | chr3 | 121388202 | - | 2511 | 612 | 96 | 1229 | 377 |
| ENST00000348332 | NCOA1 | chr2 | 24896332 | + | ENST00000393667 | GOLGB1 | chr3 | 121388202 | - | 2522 | 612 | 96 | 1244 | 382 |
| ENST00000395856 | NCOA1 | chr2 | 24896332 | + | ENST00000340645 | GOLGB1 | chr3 | 121388202 | - | 2447 | 548 | 32 | 1165 | 377 |
| ENST00000395856 | NCOA1 | chr2 | 24896332 | + | ENST00000393667 | GOLGB1 | chr3 | 121388202 | - | 2458 | 548 | 32 | 1180 | 382 |
| DeepORF prediction of the coding potential based on the fusion transcript sequence of in-frame fusion genes. DeepORF is a coding potential classifier based on convolutional neural network by comparing the real Ribo-seq data. If the no-coding score < 0.5 and coding score > 0.5, then the in-frame fusion transcript is predicted as being likely translated. |
| Henst | Tenst | Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | No-coding score | Coding score |
| ENST00000406961 | ENST00000340645 | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - | 0.002261237 | 0.9977387 |
| ENST00000406961 | ENST00000393667 | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - | 0.002745235 | 0.9972548 |
| ENST00000405141 | ENST00000340645 | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - | 0.00211572 | 0.9978842 |
| ENST00000405141 | ENST00000393667 | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - | 0.002651316 | 0.99734867 |
| ENST00000538539 | ENST00000340645 | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - | 0.002117651 | 0.9978823 |
| ENST00000538539 | ENST00000393667 | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - | 0.002578416 | 0.9974216 |
| ENST00000288599 | ENST00000340645 | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - | 0.002313182 | 0.99768686 |
| ENST00000288599 | ENST00000393667 | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - | 0.002785504 | 0.9972145 |
| ENST00000348332 | ENST00000340645 | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - | 0.002313182 | 0.99768686 |
| ENST00000348332 | ENST00000393667 | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - | 0.002785504 | 0.9972145 |
| ENST00000395856 | ENST00000340645 | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - | 0.002347433 | 0.9976526 |
| ENST00000395856 | ENST00000393667 | NCOA1 | chr2 | 24896332 | + | GOLGB1 | chr3 | 121388202 | - | 0.002773394 | 0.99722654 |
Top |
Fusion Genomic Features for NCOA1-GOLGB1 |
| FusionAI prediction of the potential fusion gene breakpoint based on the pre-mature RNA sequence context (+/- 5kb of individual partner genes, total 20kb length sequence). FusionAI is a fusion gene breakpoint classifier based on convolutional neural network by comparing the fusion positive and negative sequence context of ~ 20K fusion gene data. From here, we can have the relative potentency of the 20K genomic sequence how individual sequnce will be likely used as the gene fusion breakpoints. |
| Hgene | Hchr | Hbp | Hstrand | Tgene | Tchr | Tbp | Tstrand | 1-p | p (fusion gene breakpoint) |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions. We integrated a total of 44 different types of human genomic feature loci information across five big categories including virus integration sites, repeats, structural variants, chromatin states, and gene expression regulation. More details are in help page. |
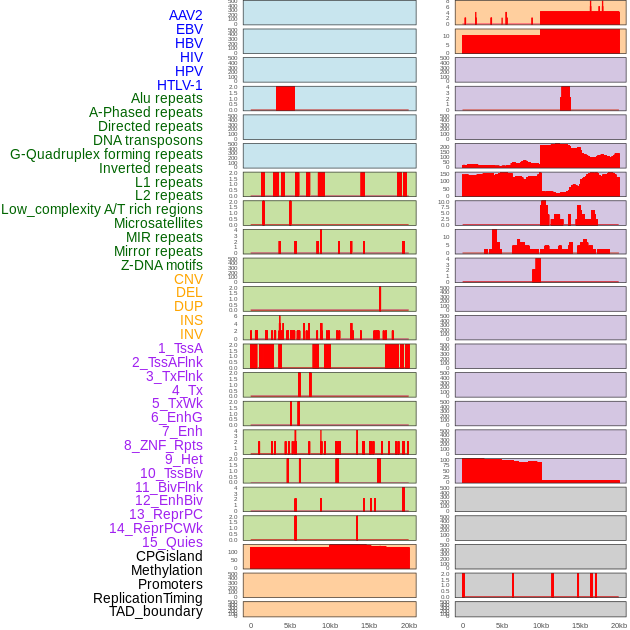 |
| Distribution of 44 human genomic features loci across 20kb length fusion breakpoint regions that are ovelapped with the top 1% feature importance score regions. More details are in help page. |
Top |
Fusion Protein Features for NCOA1-GOLGB1 |
| Four levels of functional features of fusion genes Go to FGviewer search page for the most frequent breakpoint (https://ccsmweb.uth.edu/FGviewer/chr2:24896332/chr3:121388202) - FGviewer provides the online visualization of the retention search of the protein functional features across DNA, RNA, protein, and pathological levels. - How to search 1. Put your fusion gene symbol. 2. Press the tab key until there will be shown the breakpoint information filled. 4. Go down and press 'Search' tab twice. 4. Go down to have the hyperlink of the search result. 5. Click the hyperlink. 6. See the FGviewer result for your fusion gene. |
 |
| Main function of each fusion partner protein. (from UniProt) |
| Hgene | Tgene |
| NCOA1 | GOLGB1 |
| FUNCTION: Nuclear receptor coactivator that directly binds nuclear receptors and stimulates the transcriptional activities in a hormone-dependent fashion. Involved in the coactivation of different nuclear receptors, such as for steroids (PGR, GR and ER), retinoids (RXRs), thyroid hormone (TRs) and prostanoids (PPARs). Also involved in coactivation mediated by STAT3, STAT5A, STAT5B and STAT6 transcription factors. Displays histone acetyltransferase activity toward H3 and H4; the relevance of such activity remains however unclear. Plays a central role in creating multisubunit coactivator complexes that act via remodeling of chromatin, and possibly acts by participating in both chromatin remodeling and recruitment of general transcription factors. Required with NCOA2 to control energy balance between white and brown adipose tissues. Required for mediating steroid hormone response. Isoform 2 has a higher thyroid hormone-dependent transactivation activity than isoform 1 and isoform 3. {ECO:0000269|PubMed:10449719, ECO:0000269|PubMed:12954634, ECO:0000269|PubMed:7481822, ECO:0000269|PubMed:9223281, ECO:0000269|PubMed:9223431, ECO:0000269|PubMed:9296499, ECO:0000269|PubMed:9427757}. | FUNCTION: May participate in forming intercisternal cross-bridges of the Golgi complex. |
| Retention analysis result of each fusion partner protein across 39 protein features of UniProt such as six molecule processing features, 13 region features, four site features, six amino acid modification features, two natural variation features, five experimental info features, and 3 secondary structure features. Here, because of limited space for viewing, we only show the protein feature retention information belong to the 13 regional features. All retention annotation result can be downloaded at * Minus value of BPloci means that the break pointn is located before the CDS. |
| - In-frame and retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000288599 | + | 5 | 22 | 23_80 | 118 | 2199.3333333333335 | Domain | bHLH |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000348332 | + | 5 | 21 | 23_80 | 118 | 1442.0 | Domain | bHLH |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000395856 | + | 5 | 21 | 23_80 | 118 | 1441.0 | Domain | bHLH |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000405141 | + | 8 | 25 | 23_80 | 118 | 2183.6666666666665 | Domain | bHLH |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000406961 | + | 7 | 23 | 23_80 | 118 | 1442.0 | Domain | bHLH |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000538539 | + | 6 | 23 | 23_80 | 118 | 1422.6666666666667 | Domain | bHLH |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000288599 | + | 5 | 22 | 112_116 | 118 | 2199.3333333333335 | Motif | Note=LXXLL motif 2 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000288599 | + | 5 | 22 | 46_50 | 118 | 2199.3333333333335 | Motif | Note=LXXLL motif 1 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000348332 | + | 5 | 21 | 112_116 | 118 | 1442.0 | Motif | Note=LXXLL motif 2 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000348332 | + | 5 | 21 | 46_50 | 118 | 1442.0 | Motif | Note=LXXLL motif 1 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000395856 | + | 5 | 21 | 112_116 | 118 | 1441.0 | Motif | Note=LXXLL motif 2 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000395856 | + | 5 | 21 | 46_50 | 118 | 1441.0 | Motif | Note=LXXLL motif 1 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000405141 | + | 8 | 25 | 112_116 | 118 | 2183.6666666666665 | Motif | Note=LXXLL motif 2 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000405141 | + | 8 | 25 | 46_50 | 118 | 2183.6666666666665 | Motif | Note=LXXLL motif 1 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000406961 | + | 7 | 23 | 112_116 | 118 | 1442.0 | Motif | Note=LXXLL motif 2 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000406961 | + | 7 | 23 | 46_50 | 118 | 1442.0 | Motif | Note=LXXLL motif 1 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000538539 | + | 6 | 23 | 112_116 | 118 | 1422.6666666666667 | Motif | Note=LXXLL motif 2 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000538539 | + | 6 | 23 | 46_50 | 118 | 1422.6666666666667 | Motif | Note=LXXLL motif 1 |
| Tgene | GOLGB1 | chr2:24896332 | chr3:121388202 | ENST00000340645 | 16 | 22 | 3257_3259 | 3054 | 3260.0 | Topological domain | Lumenal | |
| Tgene | GOLGB1 | chr2:24896332 | chr3:121388202 | ENST00000393667 | 16 | 22 | 3257_3259 | 3059 | 3270.0 | Topological domain | Lumenal | |
| Tgene | GOLGB1 | chr2:24896332 | chr3:121388202 | ENST00000340645 | 16 | 22 | 3236_3256 | 3054 | 3260.0 | Transmembrane | Helical | |
| Tgene | GOLGB1 | chr2:24896332 | chr3:121388202 | ENST00000393667 | 16 | 22 | 3236_3256 | 3059 | 3270.0 | Transmembrane | Helical |
| - In-frame and not-retained protein feature among the 13 regional features. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Protein feature | Protein feature note |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000288599 | + | 5 | 22 | 1053_1138 | 118 | 2199.3333333333335 | Compositional bias | Note=Gln-rich |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000288599 | + | 5 | 22 | 389_682 | 118 | 2199.3333333333335 | Compositional bias | Note=Ser-rich |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000348332 | + | 5 | 21 | 1053_1138 | 118 | 1442.0 | Compositional bias | Note=Gln-rich |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000348332 | + | 5 | 21 | 389_682 | 118 | 1442.0 | Compositional bias | Note=Ser-rich |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000395856 | + | 5 | 21 | 1053_1138 | 118 | 1441.0 | Compositional bias | Note=Gln-rich |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000395856 | + | 5 | 21 | 389_682 | 118 | 1441.0 | Compositional bias | Note=Ser-rich |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000405141 | + | 8 | 25 | 1053_1138 | 118 | 2183.6666666666665 | Compositional bias | Note=Gln-rich |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000405141 | + | 8 | 25 | 389_682 | 118 | 2183.6666666666665 | Compositional bias | Note=Ser-rich |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000406961 | + | 7 | 23 | 1053_1138 | 118 | 1442.0 | Compositional bias | Note=Gln-rich |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000406961 | + | 7 | 23 | 389_682 | 118 | 1442.0 | Compositional bias | Note=Ser-rich |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000538539 | + | 6 | 23 | 1053_1138 | 118 | 1422.6666666666667 | Compositional bias | Note=Gln-rich |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000538539 | + | 6 | 23 | 389_682 | 118 | 1422.6666666666667 | Compositional bias | Note=Ser-rich |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000288599 | + | 5 | 22 | 109_180 | 118 | 2199.3333333333335 | Domain | PAS |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000348332 | + | 5 | 21 | 109_180 | 118 | 1442.0 | Domain | PAS |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000395856 | + | 5 | 21 | 109_180 | 118 | 1441.0 | Domain | PAS |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000405141 | + | 8 | 25 | 109_180 | 118 | 2183.6666666666665 | Domain | PAS |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000406961 | + | 7 | 23 | 109_180 | 118 | 1442.0 | Domain | PAS |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000538539 | + | 6 | 23 | 109_180 | 118 | 1422.6666666666667 | Domain | PAS |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000288599 | + | 5 | 22 | 1435_1439 | 118 | 2199.3333333333335 | Motif | Note=LXXLL motif 7 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000288599 | + | 5 | 22 | 633_637 | 118 | 2199.3333333333335 | Motif | Note=LXXLL motif 3 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000288599 | + | 5 | 22 | 690_694 | 118 | 2199.3333333333335 | Motif | Note=LXXLL motif 4 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000288599 | + | 5 | 22 | 749_753 | 118 | 2199.3333333333335 | Motif | Note=LXXLL motif 5 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000288599 | + | 5 | 22 | 913_917 | 118 | 2199.3333333333335 | Motif | Note=LXXLL motif 6 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000348332 | + | 5 | 21 | 1435_1439 | 118 | 1442.0 | Motif | Note=LXXLL motif 7 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000348332 | + | 5 | 21 | 633_637 | 118 | 1442.0 | Motif | Note=LXXLL motif 3 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000348332 | + | 5 | 21 | 690_694 | 118 | 1442.0 | Motif | Note=LXXLL motif 4 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000348332 | + | 5 | 21 | 749_753 | 118 | 1442.0 | Motif | Note=LXXLL motif 5 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000348332 | + | 5 | 21 | 913_917 | 118 | 1442.0 | Motif | Note=LXXLL motif 6 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000395856 | + | 5 | 21 | 1435_1439 | 118 | 1441.0 | Motif | Note=LXXLL motif 7 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000395856 | + | 5 | 21 | 633_637 | 118 | 1441.0 | Motif | Note=LXXLL motif 3 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000395856 | + | 5 | 21 | 690_694 | 118 | 1441.0 | Motif | Note=LXXLL motif 4 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000395856 | + | 5 | 21 | 749_753 | 118 | 1441.0 | Motif | Note=LXXLL motif 5 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000395856 | + | 5 | 21 | 913_917 | 118 | 1441.0 | Motif | Note=LXXLL motif 6 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000405141 | + | 8 | 25 | 1435_1439 | 118 | 2183.6666666666665 | Motif | Note=LXXLL motif 7 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000405141 | + | 8 | 25 | 633_637 | 118 | 2183.6666666666665 | Motif | Note=LXXLL motif 3 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000405141 | + | 8 | 25 | 690_694 | 118 | 2183.6666666666665 | Motif | Note=LXXLL motif 4 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000405141 | + | 8 | 25 | 749_753 | 118 | 2183.6666666666665 | Motif | Note=LXXLL motif 5 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000405141 | + | 8 | 25 | 913_917 | 118 | 2183.6666666666665 | Motif | Note=LXXLL motif 6 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000406961 | + | 7 | 23 | 1435_1439 | 118 | 1442.0 | Motif | Note=LXXLL motif 7 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000406961 | + | 7 | 23 | 633_637 | 118 | 1442.0 | Motif | Note=LXXLL motif 3 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000406961 | + | 7 | 23 | 690_694 | 118 | 1442.0 | Motif | Note=LXXLL motif 4 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000406961 | + | 7 | 23 | 749_753 | 118 | 1442.0 | Motif | Note=LXXLL motif 5 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000406961 | + | 7 | 23 | 913_917 | 118 | 1442.0 | Motif | Note=LXXLL motif 6 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000538539 | + | 6 | 23 | 1435_1439 | 118 | 1422.6666666666667 | Motif | Note=LXXLL motif 7 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000538539 | + | 6 | 23 | 633_637 | 118 | 1422.6666666666667 | Motif | Note=LXXLL motif 3 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000538539 | + | 6 | 23 | 690_694 | 118 | 1422.6666666666667 | Motif | Note=LXXLL motif 4 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000538539 | + | 6 | 23 | 749_753 | 118 | 1422.6666666666667 | Motif | Note=LXXLL motif 5 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000538539 | + | 6 | 23 | 913_917 | 118 | 1422.6666666666667 | Motif | Note=LXXLL motif 6 |
| Tgene | GOLGB1 | chr2:24896332 | chr3:121388202 | ENST00000340645 | 16 | 22 | 1062_1245 | 3054 | 3260.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | GOLGB1 | chr2:24896332 | chr3:121388202 | ENST00000340645 | 16 | 22 | 1301_1779 | 3054 | 3260.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | GOLGB1 | chr2:24896332 | chr3:121388202 | ENST00000340645 | 16 | 22 | 1828_3185 | 3054 | 3260.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | GOLGB1 | chr2:24896332 | chr3:121388202 | ENST00000340645 | 16 | 22 | 48_593 | 3054 | 3260.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | GOLGB1 | chr2:24896332 | chr3:121388202 | ENST00000340645 | 16 | 22 | 677_1028 | 3054 | 3260.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | GOLGB1 | chr2:24896332 | chr3:121388202 | ENST00000393667 | 16 | 22 | 1062_1245 | 3059 | 3270.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | GOLGB1 | chr2:24896332 | chr3:121388202 | ENST00000393667 | 16 | 22 | 1301_1779 | 3059 | 3270.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | GOLGB1 | chr2:24896332 | chr3:121388202 | ENST00000393667 | 16 | 22 | 1828_3185 | 3059 | 3270.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | GOLGB1 | chr2:24896332 | chr3:121388202 | ENST00000393667 | 16 | 22 | 48_593 | 3059 | 3270.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | GOLGB1 | chr2:24896332 | chr3:121388202 | ENST00000393667 | 16 | 22 | 677_1028 | 3059 | 3270.0 | Coiled coil | Ontology_term=ECO:0000255 | |
| Tgene | GOLGB1 | chr2:24896332 | chr3:121388202 | ENST00000340645 | 16 | 22 | 2420_2423 | 3054 | 3260.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | GOLGB1 | chr2:24896332 | chr3:121388202 | ENST00000340645 | 16 | 22 | 2993_2996 | 3054 | 3260.0 | Compositional bias | Note=Poly-Ser | |
| Tgene | GOLGB1 | chr2:24896332 | chr3:121388202 | ENST00000393667 | 16 | 22 | 2420_2423 | 3059 | 3270.0 | Compositional bias | Note=Poly-Glu | |
| Tgene | GOLGB1 | chr2:24896332 | chr3:121388202 | ENST00000393667 | 16 | 22 | 2993_2996 | 3059 | 3270.0 | Compositional bias | Note=Poly-Ser | |
| Tgene | GOLGB1 | chr2:24896332 | chr3:121388202 | ENST00000340645 | 16 | 22 | 1_3235 | 3054 | 3260.0 | Topological domain | Cytoplasmic | |
| Tgene | GOLGB1 | chr2:24896332 | chr3:121388202 | ENST00000393667 | 16 | 22 | 1_3235 | 3059 | 3270.0 | Topological domain | Cytoplasmic |
Top |
Fusion Gene Sequence for NCOA1-GOLGB1 |
| For in-frame fusion transcripts, we provide the fusion transcript sequences and fusion amino acid sequences. To have fusion amino acid sequence, we ran ORFfinder and chose the longest ORF among the all predicted ones. |
| >57684_57684_1_NCOA1-GOLGB1_NCOA1_chr2_24896332_ENST00000288599_GOLGB1_chr3_121388202_ENST00000340645_length(transcript)=2511nt_BP=612nt TTCCAGTTACAGCTATATCAGAGAATGAGTTAATCTCCTCAGAAATCACTAAATACTACTCTGAGGGGCTTAGAAATTAACAGGTTGTTT ATATAATTGGCCTTAAATGAGGTGAGAGTGAAGAGACTAGAGCCATCTCTGGAAAACATCATTATCCCATTCCCCGGGAAGCTACCCTCT GGAACTCAAGATTTGACCATATCTGTTTTGAGGATTCATTATGAACAAAGAAGTCTCCCAGGTGTGAAGTTTTTCAACATGAGTGGCCTC GGGGACAGTTCATCCGACCCTGCTAACCCAGACTCACATAAGAGGAAAGGATCGCCATGTGACACACTGGCATCAAGCACGGAAAAGAGG CGCAGGGAGCAAGAAAATAAATATTTAGAAGAACTAGCTGAGTTACTGTCTGCCAACATTAGTGACATTGACAGCTTGAGTGTAAAACCA GACAAATGCAAGATTTTGAAGAAAACAGTCGATCAGATACAGCTAATGAAGAGAATGGAACAAGAGAAATCAACAACTGATGACGATGTA CAGAAATCAGACATCTCATCAAGTAGTCAAGGAGTGATAGAAAAGGAATCCTTGGGACCTCTTCTTTTGGAGTTCTCTCAGCTACTGGAA GAGAAAAACACCCTTTCCATTCAGCTCTGCGATACCAGTCAGAGTCTTCGTGAGAACCAGCAGCACTATGGTGACCTTTTAAATCACTGT GCAGTCTTGGAGAAGCAGGTTCAAGAGCTGCAGGCGGGGCCACTAAATATAGATGTTGCTCCAGGAGCTCCCCAGGAAAAGAATGGAGTT CACAGAAAGAGTGACCCTGAGGAACTAAGGGAACCGCAGCAAAGCTTTTCTGAAGCTCAGCAGCAGCTATGCAACACCAGACAGGAAGTG AATGAATTAAGGAAGCTGCTGGAAGAAGAACGAGACCAAAGAGTGGCTGCTGAGAATGCTCTCTCTGTGGCCGAGGAGCAGATCAGACGG TTAGAGCACAGTGAATGGGACTCTTCCCGGACTCCTATCATTGGCTCCTGTGGCACTCAGGAGCAGGCACTGTTAATAGATCTTACAAGC AACAGTTGTCGAAGGACCCGGAGTGGCGTTGGATGGAAGCGAGTCCTGCGTTCACTCTGTCATTCACGGACCCGAGTGCCACTTCTAGCA GCCATCTACTTTCTAATGATTCATGTCCTGCTCATTCTGTGTTTTACGGGCCATCTATAGACTTAGTTGTTACTCTTTGGACCACTCCCC TCAAAACTTGGAATTCTCTCACCTCTAACATCAGAACATCAATTCCAGTGGAACAGTCTTCCCATTTACAGGTCTTCTCTCCAACTCTTC ACGGAAAGTGCCTGCAAAAACAGAGGTGGATACGAGGACAGGTTGGAGCTGCAGGGACTGGCGAGTCTGCTTTCTTCTACTGCCCTGAGC CTGAACGCTTCTGCTTAATCTGAGAATCACATTTGGTTTGTTGAGCCTAATATTTGTTGAGATTTTGCAGGACCCTGATCTTTTGTGGTC CTGTAAAAGATACTGAGGAATGTCTTTCAGCCAAGCCAAGAGGATGGTTTCAATAAACCTAATAATCTGAAGTTCAGTATCATTTTGATT GATAACTTTCTTTGCCTTGTTTGCCTGTATTTTCTCCTGTTTCAGGGGGAAGGTGGCTCTGCCATAAACAGAGTTCAGGGAAATGAACAT GTCACCTCATAGGACATCTGATTTAGGTCTCTTGCAGAATAGGGTGGTGAAAGCTGAAGGAACTCCCTAGGGGTTTTAGCTGTTAGATCA CATGGGAGGACAGCATCTTCTTCCCTGCCAATTTCAGATATAATTGGAGGGAGAATTTCAGGTCTTAGACTATAAGGATAGAATCCCTTT GCTTTTGCCCTTGATCACATGTATACTAAGGTATTAAGTGGCCCAAGTCTTTCCTTTCACCAAAGGGCAGGGAGAAGTGTCTATGGACAG CAGGGTTCCAATTCTTGTCATTCCAGGAATATCTGAATATTCCTGGAATGTGGACCCTGAGACAGTGCTCAGGGGCCACTGGGAGCCAAT ATTAGGCATTGACTCTCAGCCAGGAGTCTGACTGGTCTAACACCACACTGCAACTCCTGACCTCTTGAAGTACTAAGCTACTTTGCTGTT AGTGACAGTTATTACAGTTTCTCAGCCCCATTGTCTCTGCCCTCTGTGGCAATGGAAGGAGAATATAGAGAAGACAAAATTAAATATAGA TAGACCTGAGAAGGACAGCCAGGATAGAATTCCATTTGTGCCTATTCCCTGCCTCCCCTCCCCTCCCCCATCCTACCAGTTGGTTATTTT CTCATTGCATACGTGATGTGTTCACTGCCTAGCCTCTCCCTAAAGAAGAGAGAAGACAAGTGGGCTGACTGATCTGCTCTAAATCTACTG >57684_57684_1_NCOA1-GOLGB1_NCOA1_chr2_24896332_ENST00000288599_GOLGB1_chr3_121388202_ENST00000340645_length(amino acids)=377AA_BP=172 MALNEVRVKRLEPSLENIIIPFPGKLPSGTQDLTISVLRIHYEQRSLPGVKFFNMSGLGDSSSDPANPDSHKRKGSPCDTLASSTEKRRR EQENKYLEELAELLSANISDIDSLSVKPDKCKILKKTVDQIQLMKRMEQEKSTTDDDVQKSDISSSSQGVIEKESLGPLLLEFSQLLEEK NTLSIQLCDTSQSLRENQQHYGDLLNHCAVLEKQVQELQAGPLNIDVAPGAPQEKNGVHRKSDPEELREPQQSFSEAQQQLCNTRQEVNE LRKLLEEERDQRVAAENALSVAEEQIRRLEHSEWDSSRTPIIGSCGTQEQALLIDLTSNSCRRTRSGVGWKRVLRSLCHSRTRVPLLAAI -------------------------------------------------------------- >57684_57684_2_NCOA1-GOLGB1_NCOA1_chr2_24896332_ENST00000288599_GOLGB1_chr3_121388202_ENST00000393667_length(transcript)=2522nt_BP=612nt TTCCAGTTACAGCTATATCAGAGAATGAGTTAATCTCCTCAGAAATCACTAAATACTACTCTGAGGGGCTTAGAAATTAACAGGTTGTTT ATATAATTGGCCTTAAATGAGGTGAGAGTGAAGAGACTAGAGCCATCTCTGGAAAACATCATTATCCCATTCCCCGGGAAGCTACCCTCT GGAACTCAAGATTTGACCATATCTGTTTTGAGGATTCATTATGAACAAAGAAGTCTCCCAGGTGTGAAGTTTTTCAACATGAGTGGCCTC GGGGACAGTTCATCCGACCCTGCTAACCCAGACTCACATAAGAGGAAAGGATCGCCATGTGACACACTGGCATCAAGCACGGAAAAGAGG CGCAGGGAGCAAGAAAATAAATATTTAGAAGAACTAGCTGAGTTACTGTCTGCCAACATTAGTGACATTGACAGCTTGAGTGTAAAACCA GACAAATGCAAGATTTTGAAGAAAACAGTCGATCAGATACAGCTAATGAAGAGAATGGAACAAGAGAAATCAACAACTGATGACGATGTA CAGAAATCAGACATCTCATCAAGTAGTCAAGGAGTGATAGAAAAGGAATCCTTGGGACCTCTTCTTTTGGAGTTCTCTCAGCTACTGGAA GAGAAAAACACCCTTTCCATTCAGCTCTGCGATACCAGTCAGAGTCTTCGTGAGAACCAGCAGCACTATGGTGACCTTTTAAATCACTGT GCAGTCTTGGAGAAGCAGGTTCAAGAGCTGCAGGCGGTGAGTAAAGAGAAGGGGCCACTAAATATAGATGTTGCTCCAGGAGCTCCCCAG GAAAAGAATGGAGTTCACAGAAAGAGTGACCCTGAGGAACTAAGGGAACCGCAGCAAAGCTTTTCTGAAGCTCAGCAGCAGCTATGCAAC ACCAGACAGGAAGTGAATGAATTAAGGAAGCTGCTGGAAGAAGAACGAGACCAAAGAGTGGCTGCTGAGAATGCTCTCTCTGTGGCCGAG GAGCAGATCAGACGGTTAGAGCACAGTGAATGGGACTCTTCCCGGACTCCTATCATTGGCTCCTGTGGCACTCAGGAGCAGGCACTGTTA ATAGATCTTACAAGCAACAGTTGTCGAAGGACCCGGAGTGGCGTTGGATGGAAGCGAGTCCTGCGTTCACTCTGTCATTCACGGACCCGA GTGCCACTTCTAGCAGCCATCTACTTTCTAATGATTCATGTCCTGCTCATTCTGTGTTTTACGGGCCATCTATAGACTTAGTTGTTACTC TTTGGACCACTCCCCTCAAAACTTGGAATTCTCTCACCTCTAACATCAGAACATCAATTCCAGTGGAACAGTCTTCCCATTTACAGGTCT TCTCTCCAACTCTTCACGGAAAGTGCCTGCAAAAACAGAGGTGGATACGAGGACAGGTTGGAGCTGCAGGGACTGGCGAGTCTGCTTTCT TCTACTGCCCTGAGCCTGAACGCTTCTGCTTAATCTGAGAATCACATTTGGTTTGTTGAGCCTAATATTTGTTGAGATTTTGCAGGACCC TGATCTTTTGTGGTCCTGTAAAAGATACTGAGGAATGTCTTTCAGCCAAGCCAAGAGGATGGTTTCAATAAACCTAATAATCTGAAGTTC AGTATCATTTTGATTGATAACTTTCTTTGCCTTGTTTGCCTGTATTTTCTCCTGTTTCAGGGGGAAGGTGGCTCTGCCATAAACAGAGTT CAGGGAAATGAACATGTCACCTCATAGGACATCTGATTTAGGTCTCTTGCAGAATAGGGTGGTGAAAGCTGAAGGAACTCCCTAGGGGTT TTAGCTGTTAGATCACATGGGAGGACAGCATCTTCTTCCCTGCCAATTTCAGATATAATTGGAGGGAGAATTTCAGGTCTTAGACTATAA GGATAGAATCCCTTTGCTTTTGCCCTTGATCACATGTATACTAAGGTATTAAGTGGCCCAAGTCTTTCCTTTCACCAAAGGGCAGGGAGA AGTGTCTATGGACAGCAGGGTTCCAATTCTTGTCATTCCAGGAATATCTGAATATTCCTGGAATGTGGACCCTGAGACAGTGCTCAGGGG CCACTGGGAGCCAATATTAGGCATTGACTCTCAGCCAGGAGTCTGACTGGTCTAACACCACACTGCAACTCCTGACCTCTTGAAGTACTA AGCTACTTTGCTGTTAGTGACAGTTATTACAGTTTCTCAGCCCCATTGTCTCTGCCCTCTGTGGCAATGGAAGGAGAATATAGAGAAGAC AAAATTAAATATAGATAGACCTGAGAAGGACAGCCAGGATAGAATTCCATTTGTGCCTATTCCCTGCCTCCCCTCCCCTCCCCCATCCTA CCAGTTGGTTATTTTCTCATTGCATACGTGATGTGTTCACTGCCTAGCCTCTCCCTAAAGAAGAGAGAAGACAAGTGGGCTGACTGATCT GCTCTAAATCTACTGTGGTGATTAAATCTTGGTTACAACATCCTGGGAAGTTTCCTGAACAACTGTAAAATAATAAAATTATTTTCAGAA >57684_57684_2_NCOA1-GOLGB1_NCOA1_chr2_24896332_ENST00000288599_GOLGB1_chr3_121388202_ENST00000393667_length(amino acids)=382AA_BP=172 MALNEVRVKRLEPSLENIIIPFPGKLPSGTQDLTISVLRIHYEQRSLPGVKFFNMSGLGDSSSDPANPDSHKRKGSPCDTLASSTEKRRR EQENKYLEELAELLSANISDIDSLSVKPDKCKILKKTVDQIQLMKRMEQEKSTTDDDVQKSDISSSSQGVIEKESLGPLLLEFSQLLEEK NTLSIQLCDTSQSLRENQQHYGDLLNHCAVLEKQVQELQAVSKEKGPLNIDVAPGAPQEKNGVHRKSDPEELREPQQSFSEAQQQLCNTR QEVNELRKLLEEERDQRVAAENALSVAEEQIRRLEHSEWDSSRTPIIGSCGTQEQALLIDLTSNSCRRTRSGVGWKRVLRSLCHSRTRVP -------------------------------------------------------------- >57684_57684_3_NCOA1-GOLGB1_NCOA1_chr2_24896332_ENST00000348332_GOLGB1_chr3_121388202_ENST00000340645_length(transcript)=2511nt_BP=612nt TTCCAGTTACAGCTATATCAGAGAATGAGTTAATCTCCTCAGAAATCACTAAATACTACTCTGAGGGGCTTAGAAATTAACAGGTTGTTT ATATAATTGGCCTTAAATGAGGTGAGAGTGAAGAGACTAGAGCCATCTCTGGAAAACATCATTATCCCATTCCCCGGGAAGCTACCCTCT GGAACTCAAGATTTGACCATATCTGTTTTGAGGATTCATTATGAACAAAGAAGTCTCCCAGGTGTGAAGTTTTTCAACATGAGTGGCCTC GGGGACAGTTCATCCGACCCTGCTAACCCAGACTCACATAAGAGGAAAGGATCGCCATGTGACACACTGGCATCAAGCACGGAAAAGAGG CGCAGGGAGCAAGAAAATAAATATTTAGAAGAACTAGCTGAGTTACTGTCTGCCAACATTAGTGACATTGACAGCTTGAGTGTAAAACCA GACAAATGCAAGATTTTGAAGAAAACAGTCGATCAGATACAGCTAATGAAGAGAATGGAACAAGAGAAATCAACAACTGATGACGATGTA CAGAAATCAGACATCTCATCAAGTAGTCAAGGAGTGATAGAAAAGGAATCCTTGGGACCTCTTCTTTTGGAGTTCTCTCAGCTACTGGAA GAGAAAAACACCCTTTCCATTCAGCTCTGCGATACCAGTCAGAGTCTTCGTGAGAACCAGCAGCACTATGGTGACCTTTTAAATCACTGT GCAGTCTTGGAGAAGCAGGTTCAAGAGCTGCAGGCGGGGCCACTAAATATAGATGTTGCTCCAGGAGCTCCCCAGGAAAAGAATGGAGTT CACAGAAAGAGTGACCCTGAGGAACTAAGGGAACCGCAGCAAAGCTTTTCTGAAGCTCAGCAGCAGCTATGCAACACCAGACAGGAAGTG AATGAATTAAGGAAGCTGCTGGAAGAAGAACGAGACCAAAGAGTGGCTGCTGAGAATGCTCTCTCTGTGGCCGAGGAGCAGATCAGACGG TTAGAGCACAGTGAATGGGACTCTTCCCGGACTCCTATCATTGGCTCCTGTGGCACTCAGGAGCAGGCACTGTTAATAGATCTTACAAGC AACAGTTGTCGAAGGACCCGGAGTGGCGTTGGATGGAAGCGAGTCCTGCGTTCACTCTGTCATTCACGGACCCGAGTGCCACTTCTAGCA GCCATCTACTTTCTAATGATTCATGTCCTGCTCATTCTGTGTTTTACGGGCCATCTATAGACTTAGTTGTTACTCTTTGGACCACTCCCC TCAAAACTTGGAATTCTCTCACCTCTAACATCAGAACATCAATTCCAGTGGAACAGTCTTCCCATTTACAGGTCTTCTCTCCAACTCTTC ACGGAAAGTGCCTGCAAAAACAGAGGTGGATACGAGGACAGGTTGGAGCTGCAGGGACTGGCGAGTCTGCTTTCTTCTACTGCCCTGAGC CTGAACGCTTCTGCTTAATCTGAGAATCACATTTGGTTTGTTGAGCCTAATATTTGTTGAGATTTTGCAGGACCCTGATCTTTTGTGGTC CTGTAAAAGATACTGAGGAATGTCTTTCAGCCAAGCCAAGAGGATGGTTTCAATAAACCTAATAATCTGAAGTTCAGTATCATTTTGATT GATAACTTTCTTTGCCTTGTTTGCCTGTATTTTCTCCTGTTTCAGGGGGAAGGTGGCTCTGCCATAAACAGAGTTCAGGGAAATGAACAT GTCACCTCATAGGACATCTGATTTAGGTCTCTTGCAGAATAGGGTGGTGAAAGCTGAAGGAACTCCCTAGGGGTTTTAGCTGTTAGATCA CATGGGAGGACAGCATCTTCTTCCCTGCCAATTTCAGATATAATTGGAGGGAGAATTTCAGGTCTTAGACTATAAGGATAGAATCCCTTT GCTTTTGCCCTTGATCACATGTATACTAAGGTATTAAGTGGCCCAAGTCTTTCCTTTCACCAAAGGGCAGGGAGAAGTGTCTATGGACAG CAGGGTTCCAATTCTTGTCATTCCAGGAATATCTGAATATTCCTGGAATGTGGACCCTGAGACAGTGCTCAGGGGCCACTGGGAGCCAAT ATTAGGCATTGACTCTCAGCCAGGAGTCTGACTGGTCTAACACCACACTGCAACTCCTGACCTCTTGAAGTACTAAGCTACTTTGCTGTT AGTGACAGTTATTACAGTTTCTCAGCCCCATTGTCTCTGCCCTCTGTGGCAATGGAAGGAGAATATAGAGAAGACAAAATTAAATATAGA TAGACCTGAGAAGGACAGCCAGGATAGAATTCCATTTGTGCCTATTCCCTGCCTCCCCTCCCCTCCCCCATCCTACCAGTTGGTTATTTT CTCATTGCATACGTGATGTGTTCACTGCCTAGCCTCTCCCTAAAGAAGAGAGAAGACAAGTGGGCTGACTGATCTGCTCTAAATCTACTG >57684_57684_3_NCOA1-GOLGB1_NCOA1_chr2_24896332_ENST00000348332_GOLGB1_chr3_121388202_ENST00000340645_length(amino acids)=377AA_BP=172 MALNEVRVKRLEPSLENIIIPFPGKLPSGTQDLTISVLRIHYEQRSLPGVKFFNMSGLGDSSSDPANPDSHKRKGSPCDTLASSTEKRRR EQENKYLEELAELLSANISDIDSLSVKPDKCKILKKTVDQIQLMKRMEQEKSTTDDDVQKSDISSSSQGVIEKESLGPLLLEFSQLLEEK NTLSIQLCDTSQSLRENQQHYGDLLNHCAVLEKQVQELQAGPLNIDVAPGAPQEKNGVHRKSDPEELREPQQSFSEAQQQLCNTRQEVNE LRKLLEEERDQRVAAENALSVAEEQIRRLEHSEWDSSRTPIIGSCGTQEQALLIDLTSNSCRRTRSGVGWKRVLRSLCHSRTRVPLLAAI -------------------------------------------------------------- >57684_57684_4_NCOA1-GOLGB1_NCOA1_chr2_24896332_ENST00000348332_GOLGB1_chr3_121388202_ENST00000393667_length(transcript)=2522nt_BP=612nt TTCCAGTTACAGCTATATCAGAGAATGAGTTAATCTCCTCAGAAATCACTAAATACTACTCTGAGGGGCTTAGAAATTAACAGGTTGTTT ATATAATTGGCCTTAAATGAGGTGAGAGTGAAGAGACTAGAGCCATCTCTGGAAAACATCATTATCCCATTCCCCGGGAAGCTACCCTCT GGAACTCAAGATTTGACCATATCTGTTTTGAGGATTCATTATGAACAAAGAAGTCTCCCAGGTGTGAAGTTTTTCAACATGAGTGGCCTC GGGGACAGTTCATCCGACCCTGCTAACCCAGACTCACATAAGAGGAAAGGATCGCCATGTGACACACTGGCATCAAGCACGGAAAAGAGG CGCAGGGAGCAAGAAAATAAATATTTAGAAGAACTAGCTGAGTTACTGTCTGCCAACATTAGTGACATTGACAGCTTGAGTGTAAAACCA GACAAATGCAAGATTTTGAAGAAAACAGTCGATCAGATACAGCTAATGAAGAGAATGGAACAAGAGAAATCAACAACTGATGACGATGTA CAGAAATCAGACATCTCATCAAGTAGTCAAGGAGTGATAGAAAAGGAATCCTTGGGACCTCTTCTTTTGGAGTTCTCTCAGCTACTGGAA GAGAAAAACACCCTTTCCATTCAGCTCTGCGATACCAGTCAGAGTCTTCGTGAGAACCAGCAGCACTATGGTGACCTTTTAAATCACTGT GCAGTCTTGGAGAAGCAGGTTCAAGAGCTGCAGGCGGTGAGTAAAGAGAAGGGGCCACTAAATATAGATGTTGCTCCAGGAGCTCCCCAG GAAAAGAATGGAGTTCACAGAAAGAGTGACCCTGAGGAACTAAGGGAACCGCAGCAAAGCTTTTCTGAAGCTCAGCAGCAGCTATGCAAC ACCAGACAGGAAGTGAATGAATTAAGGAAGCTGCTGGAAGAAGAACGAGACCAAAGAGTGGCTGCTGAGAATGCTCTCTCTGTGGCCGAG GAGCAGATCAGACGGTTAGAGCACAGTGAATGGGACTCTTCCCGGACTCCTATCATTGGCTCCTGTGGCACTCAGGAGCAGGCACTGTTA ATAGATCTTACAAGCAACAGTTGTCGAAGGACCCGGAGTGGCGTTGGATGGAAGCGAGTCCTGCGTTCACTCTGTCATTCACGGACCCGA GTGCCACTTCTAGCAGCCATCTACTTTCTAATGATTCATGTCCTGCTCATTCTGTGTTTTACGGGCCATCTATAGACTTAGTTGTTACTC TTTGGACCACTCCCCTCAAAACTTGGAATTCTCTCACCTCTAACATCAGAACATCAATTCCAGTGGAACAGTCTTCCCATTTACAGGTCT TCTCTCCAACTCTTCACGGAAAGTGCCTGCAAAAACAGAGGTGGATACGAGGACAGGTTGGAGCTGCAGGGACTGGCGAGTCTGCTTTCT TCTACTGCCCTGAGCCTGAACGCTTCTGCTTAATCTGAGAATCACATTTGGTTTGTTGAGCCTAATATTTGTTGAGATTTTGCAGGACCC TGATCTTTTGTGGTCCTGTAAAAGATACTGAGGAATGTCTTTCAGCCAAGCCAAGAGGATGGTTTCAATAAACCTAATAATCTGAAGTTC AGTATCATTTTGATTGATAACTTTCTTTGCCTTGTTTGCCTGTATTTTCTCCTGTTTCAGGGGGAAGGTGGCTCTGCCATAAACAGAGTT CAGGGAAATGAACATGTCACCTCATAGGACATCTGATTTAGGTCTCTTGCAGAATAGGGTGGTGAAAGCTGAAGGAACTCCCTAGGGGTT TTAGCTGTTAGATCACATGGGAGGACAGCATCTTCTTCCCTGCCAATTTCAGATATAATTGGAGGGAGAATTTCAGGTCTTAGACTATAA GGATAGAATCCCTTTGCTTTTGCCCTTGATCACATGTATACTAAGGTATTAAGTGGCCCAAGTCTTTCCTTTCACCAAAGGGCAGGGAGA AGTGTCTATGGACAGCAGGGTTCCAATTCTTGTCATTCCAGGAATATCTGAATATTCCTGGAATGTGGACCCTGAGACAGTGCTCAGGGG CCACTGGGAGCCAATATTAGGCATTGACTCTCAGCCAGGAGTCTGACTGGTCTAACACCACACTGCAACTCCTGACCTCTTGAAGTACTA AGCTACTTTGCTGTTAGTGACAGTTATTACAGTTTCTCAGCCCCATTGTCTCTGCCCTCTGTGGCAATGGAAGGAGAATATAGAGAAGAC AAAATTAAATATAGATAGACCTGAGAAGGACAGCCAGGATAGAATTCCATTTGTGCCTATTCCCTGCCTCCCCTCCCCTCCCCCATCCTA CCAGTTGGTTATTTTCTCATTGCATACGTGATGTGTTCACTGCCTAGCCTCTCCCTAAAGAAGAGAGAAGACAAGTGGGCTGACTGATCT GCTCTAAATCTACTGTGGTGATTAAATCTTGGTTACAACATCCTGGGAAGTTTCCTGAACAACTGTAAAATAATAAAATTATTTTCAGAA >57684_57684_4_NCOA1-GOLGB1_NCOA1_chr2_24896332_ENST00000348332_GOLGB1_chr3_121388202_ENST00000393667_length(amino acids)=382AA_BP=172 MALNEVRVKRLEPSLENIIIPFPGKLPSGTQDLTISVLRIHYEQRSLPGVKFFNMSGLGDSSSDPANPDSHKRKGSPCDTLASSTEKRRR EQENKYLEELAELLSANISDIDSLSVKPDKCKILKKTVDQIQLMKRMEQEKSTTDDDVQKSDISSSSQGVIEKESLGPLLLEFSQLLEEK NTLSIQLCDTSQSLRENQQHYGDLLNHCAVLEKQVQELQAVSKEKGPLNIDVAPGAPQEKNGVHRKSDPEELREPQQSFSEAQQQLCNTR QEVNELRKLLEEERDQRVAAENALSVAEEQIRRLEHSEWDSSRTPIIGSCGTQEQALLIDLTSNSCRRTRSGVGWKRVLRSLCHSRTRVP -------------------------------------------------------------- >57684_57684_5_NCOA1-GOLGB1_NCOA1_chr2_24896332_ENST00000395856_GOLGB1_chr3_121388202_ENST00000340645_length(transcript)=2447nt_BP=548nt GGGGCTTAGAAATTAACAGGTTGTTTATATAATTGGCCTTAAATGAGGTGAGAGTGAAGAGACTAGAGCCATCTCTGGAAAACATCATTA TCCCATTCCCCGGGAAGCTACCCTCTGGAACTCAAGATTTGACCATATCTGTTTTGAGGATTCATTATGAACAAAGAAGTCTCCCAGGTG TGAAGTTTTTCAACATGAGTGGCCTCGGGGACAGTTCATCCGACCCTGCTAACCCAGACTCACATAAGAGGAAAGGATCGCCATGTGACA CACTGGCATCAAGCACGGAAAAGAGGCGCAGGGAGCAAGAAAATAAATATTTAGAAGAACTAGCTGAGTTACTGTCTGCCAACATTAGTG ACATTGACAGCTTGAGTGTAAAACCAGACAAATGCAAGATTTTGAAGAAAACAGTCGATCAGATACAGCTAATGAAGAGAATGGAACAAG AGAAATCAACAACTGATGACGATGTACAGAAATCAGACATCTCATCAAGTAGTCAAGGAGTGATAGAAAAGGAATCCTTGGGACCTCTTC TTTTGGAGTTCTCTCAGCTACTGGAAGAGAAAAACACCCTTTCCATTCAGCTCTGCGATACCAGTCAGAGTCTTCGTGAGAACCAGCAGC ACTATGGTGACCTTTTAAATCACTGTGCAGTCTTGGAGAAGCAGGTTCAAGAGCTGCAGGCGGGGCCACTAAATATAGATGTTGCTCCAG GAGCTCCCCAGGAAAAGAATGGAGTTCACAGAAAGAGTGACCCTGAGGAACTAAGGGAACCGCAGCAAAGCTTTTCTGAAGCTCAGCAGC AGCTATGCAACACCAGACAGGAAGTGAATGAATTAAGGAAGCTGCTGGAAGAAGAACGAGACCAAAGAGTGGCTGCTGAGAATGCTCTCT CTGTGGCCGAGGAGCAGATCAGACGGTTAGAGCACAGTGAATGGGACTCTTCCCGGACTCCTATCATTGGCTCCTGTGGCACTCAGGAGC AGGCACTGTTAATAGATCTTACAAGCAACAGTTGTCGAAGGACCCGGAGTGGCGTTGGATGGAAGCGAGTCCTGCGTTCACTCTGTCATT CACGGACCCGAGTGCCACTTCTAGCAGCCATCTACTTTCTAATGATTCATGTCCTGCTCATTCTGTGTTTTACGGGCCATCTATAGACTT AGTTGTTACTCTTTGGACCACTCCCCTCAAAACTTGGAATTCTCTCACCTCTAACATCAGAACATCAATTCCAGTGGAACAGTCTTCCCA TTTACAGGTCTTCTCTCCAACTCTTCACGGAAAGTGCCTGCAAAAACAGAGGTGGATACGAGGACAGGTTGGAGCTGCAGGGACTGGCGA GTCTGCTTTCTTCTACTGCCCTGAGCCTGAACGCTTCTGCTTAATCTGAGAATCACATTTGGTTTGTTGAGCCTAATATTTGTTGAGATT TTGCAGGACCCTGATCTTTTGTGGTCCTGTAAAAGATACTGAGGAATGTCTTTCAGCCAAGCCAAGAGGATGGTTTCAATAAACCTAATA ATCTGAAGTTCAGTATCATTTTGATTGATAACTTTCTTTGCCTTGTTTGCCTGTATTTTCTCCTGTTTCAGGGGGAAGGTGGCTCTGCCA TAAACAGAGTTCAGGGAAATGAACATGTCACCTCATAGGACATCTGATTTAGGTCTCTTGCAGAATAGGGTGGTGAAAGCTGAAGGAACT CCCTAGGGGTTTTAGCTGTTAGATCACATGGGAGGACAGCATCTTCTTCCCTGCCAATTTCAGATATAATTGGAGGGAGAATTTCAGGTC TTAGACTATAAGGATAGAATCCCTTTGCTTTTGCCCTTGATCACATGTATACTAAGGTATTAAGTGGCCCAAGTCTTTCCTTTCACCAAA GGGCAGGGAGAAGTGTCTATGGACAGCAGGGTTCCAATTCTTGTCATTCCAGGAATATCTGAATATTCCTGGAATGTGGACCCTGAGACA GTGCTCAGGGGCCACTGGGAGCCAATATTAGGCATTGACTCTCAGCCAGGAGTCTGACTGGTCTAACACCACACTGCAACTCCTGACCTC TTGAAGTACTAAGCTACTTTGCTGTTAGTGACAGTTATTACAGTTTCTCAGCCCCATTGTCTCTGCCCTCTGTGGCAATGGAAGGAGAAT ATAGAGAAGACAAAATTAAATATAGATAGACCTGAGAAGGACAGCCAGGATAGAATTCCATTTGTGCCTATTCCCTGCCTCCCCTCCCCT CCCCCATCCTACCAGTTGGTTATTTTCTCATTGCATACGTGATGTGTTCACTGCCTAGCCTCTCCCTAAAGAAGAGAGAAGACAAGTGGG CTGACTGATCTGCTCTAAATCTACTGTGGTGATTAAATCTTGGTTACAACATCCTGGGAAGTTTCCTGAACAACTGTAAAATAATAAAAT >57684_57684_5_NCOA1-GOLGB1_NCOA1_chr2_24896332_ENST00000395856_GOLGB1_chr3_121388202_ENST00000340645_length(amino acids)=377AA_BP=172 MALNEVRVKRLEPSLENIIIPFPGKLPSGTQDLTISVLRIHYEQRSLPGVKFFNMSGLGDSSSDPANPDSHKRKGSPCDTLASSTEKRRR EQENKYLEELAELLSANISDIDSLSVKPDKCKILKKTVDQIQLMKRMEQEKSTTDDDVQKSDISSSSQGVIEKESLGPLLLEFSQLLEEK NTLSIQLCDTSQSLRENQQHYGDLLNHCAVLEKQVQELQAGPLNIDVAPGAPQEKNGVHRKSDPEELREPQQSFSEAQQQLCNTRQEVNE LRKLLEEERDQRVAAENALSVAEEQIRRLEHSEWDSSRTPIIGSCGTQEQALLIDLTSNSCRRTRSGVGWKRVLRSLCHSRTRVPLLAAI -------------------------------------------------------------- >57684_57684_6_NCOA1-GOLGB1_NCOA1_chr2_24896332_ENST00000395856_GOLGB1_chr3_121388202_ENST00000393667_length(transcript)=2458nt_BP=548nt GGGGCTTAGAAATTAACAGGTTGTTTATATAATTGGCCTTAAATGAGGTGAGAGTGAAGAGACTAGAGCCATCTCTGGAAAACATCATTA TCCCATTCCCCGGGAAGCTACCCTCTGGAACTCAAGATTTGACCATATCTGTTTTGAGGATTCATTATGAACAAAGAAGTCTCCCAGGTG TGAAGTTTTTCAACATGAGTGGCCTCGGGGACAGTTCATCCGACCCTGCTAACCCAGACTCACATAAGAGGAAAGGATCGCCATGTGACA CACTGGCATCAAGCACGGAAAAGAGGCGCAGGGAGCAAGAAAATAAATATTTAGAAGAACTAGCTGAGTTACTGTCTGCCAACATTAGTG ACATTGACAGCTTGAGTGTAAAACCAGACAAATGCAAGATTTTGAAGAAAACAGTCGATCAGATACAGCTAATGAAGAGAATGGAACAAG AGAAATCAACAACTGATGACGATGTACAGAAATCAGACATCTCATCAAGTAGTCAAGGAGTGATAGAAAAGGAATCCTTGGGACCTCTTC TTTTGGAGTTCTCTCAGCTACTGGAAGAGAAAAACACCCTTTCCATTCAGCTCTGCGATACCAGTCAGAGTCTTCGTGAGAACCAGCAGC ACTATGGTGACCTTTTAAATCACTGTGCAGTCTTGGAGAAGCAGGTTCAAGAGCTGCAGGCGGTGAGTAAAGAGAAGGGGCCACTAAATA TAGATGTTGCTCCAGGAGCTCCCCAGGAAAAGAATGGAGTTCACAGAAAGAGTGACCCTGAGGAACTAAGGGAACCGCAGCAAAGCTTTT CTGAAGCTCAGCAGCAGCTATGCAACACCAGACAGGAAGTGAATGAATTAAGGAAGCTGCTGGAAGAAGAACGAGACCAAAGAGTGGCTG CTGAGAATGCTCTCTCTGTGGCCGAGGAGCAGATCAGACGGTTAGAGCACAGTGAATGGGACTCTTCCCGGACTCCTATCATTGGCTCCT GTGGCACTCAGGAGCAGGCACTGTTAATAGATCTTACAAGCAACAGTTGTCGAAGGACCCGGAGTGGCGTTGGATGGAAGCGAGTCCTGC GTTCACTCTGTCATTCACGGACCCGAGTGCCACTTCTAGCAGCCATCTACTTTCTAATGATTCATGTCCTGCTCATTCTGTGTTTTACGG GCCATCTATAGACTTAGTTGTTACTCTTTGGACCACTCCCCTCAAAACTTGGAATTCTCTCACCTCTAACATCAGAACATCAATTCCAGT GGAACAGTCTTCCCATTTACAGGTCTTCTCTCCAACTCTTCACGGAAAGTGCCTGCAAAAACAGAGGTGGATACGAGGACAGGTTGGAGC TGCAGGGACTGGCGAGTCTGCTTTCTTCTACTGCCCTGAGCCTGAACGCTTCTGCTTAATCTGAGAATCACATTTGGTTTGTTGAGCCTA ATATTTGTTGAGATTTTGCAGGACCCTGATCTTTTGTGGTCCTGTAAAAGATACTGAGGAATGTCTTTCAGCCAAGCCAAGAGGATGGTT TCAATAAACCTAATAATCTGAAGTTCAGTATCATTTTGATTGATAACTTTCTTTGCCTTGTTTGCCTGTATTTTCTCCTGTTTCAGGGGG AAGGTGGCTCTGCCATAAACAGAGTTCAGGGAAATGAACATGTCACCTCATAGGACATCTGATTTAGGTCTCTTGCAGAATAGGGTGGTG AAAGCTGAAGGAACTCCCTAGGGGTTTTAGCTGTTAGATCACATGGGAGGACAGCATCTTCTTCCCTGCCAATTTCAGATATAATTGGAG GGAGAATTTCAGGTCTTAGACTATAAGGATAGAATCCCTTTGCTTTTGCCCTTGATCACATGTATACTAAGGTATTAAGTGGCCCAAGTC TTTCCTTTCACCAAAGGGCAGGGAGAAGTGTCTATGGACAGCAGGGTTCCAATTCTTGTCATTCCAGGAATATCTGAATATTCCTGGAAT GTGGACCCTGAGACAGTGCTCAGGGGCCACTGGGAGCCAATATTAGGCATTGACTCTCAGCCAGGAGTCTGACTGGTCTAACACCACACT GCAACTCCTGACCTCTTGAAGTACTAAGCTACTTTGCTGTTAGTGACAGTTATTACAGTTTCTCAGCCCCATTGTCTCTGCCCTCTGTGG CAATGGAAGGAGAATATAGAGAAGACAAAATTAAATATAGATAGACCTGAGAAGGACAGCCAGGATAGAATTCCATTTGTGCCTATTCCC TGCCTCCCCTCCCCTCCCCCATCCTACCAGTTGGTTATTTTCTCATTGCATACGTGATGTGTTCACTGCCTAGCCTCTCCCTAAAGAAGA GAGAAGACAAGTGGGCTGACTGATCTGCTCTAAATCTACTGTGGTGATTAAATCTTGGTTACAACATCCTGGGAAGTTTCCTGAACAACT >57684_57684_6_NCOA1-GOLGB1_NCOA1_chr2_24896332_ENST00000395856_GOLGB1_chr3_121388202_ENST00000393667_length(amino acids)=382AA_BP=172 MALNEVRVKRLEPSLENIIIPFPGKLPSGTQDLTISVLRIHYEQRSLPGVKFFNMSGLGDSSSDPANPDSHKRKGSPCDTLASSTEKRRR EQENKYLEELAELLSANISDIDSLSVKPDKCKILKKTVDQIQLMKRMEQEKSTTDDDVQKSDISSSSQGVIEKESLGPLLLEFSQLLEEK NTLSIQLCDTSQSLRENQQHYGDLLNHCAVLEKQVQELQAVSKEKGPLNIDVAPGAPQEKNGVHRKSDPEELREPQQSFSEAQQQLCNTR QEVNELRKLLEEERDQRVAAENALSVAEEQIRRLEHSEWDSSRTPIIGSCGTQEQALLIDLTSNSCRRTRSGVGWKRVLRSLCHSRTRVP -------------------------------------------------------------- >57684_57684_7_NCOA1-GOLGB1_NCOA1_chr2_24896332_ENST00000405141_GOLGB1_chr3_121388202_ENST00000340645_length(transcript)=2964nt_BP=1065nt GAATCTCGCCTGCCGGGACCGCGAAATGGGGGCGACCGCGGCGTCCCTCTCCGTCGGCGCAGCCCTCGACGGCGCTTGGGTTTGACCCCG GCGCGCTTGCTCGCCCCTTCTCCCGAGAAGGGGTTTCGGAGGAGCAGAGGTTTAATAGGCAAGAGAAAGAGAAAGGAAAACAGCTCTCTC TCTAATGAGAGAGAGGGGACTTCGGAGAGGAAAAGAGGACAGGAGATACGGCAATCGTGGATAGGAAAGGAGGAAATTACGATAGAAAAG TTGGAGATCCTTTTGCTAACACCCCTTTGGGCAGTTGGATGCTGAGATCTATCCATACTAATGGAAATGTAACTGGAACTGACTCTGATG ATAAAATCAAGGACCATCAAGCAAGATCATGCAGTAGGCAACTTTGCTTCCAAAAGAAGTTACCAACATTTAGAATTTCTACTTATTCTG AGGTTCCAGTTACAGCTATATCAGAGAATGAGTTAATCTCCTCAGAAATCACTAAATACTACTCTGAGGGGCTTAGAAATTAACAGGTTG TTTATATAATTGGCCTTAAATGAGGTGAGAGTGAAGAGACTAGAGCCATCTCTGGAAAACATCATTATCCCATTCCCCGGGAAGCTACCC TCTGGAACTCAAGATTTGACCATATCTGTTTTGAGGATTCATTATGAACAAAGAAGTCTCCCAGGTGTGAAGTTTTTCAACATGAGTGGC CTCGGGGACAGTTCATCCGACCCTGCTAACCCAGACTCACATAAGAGGAAAGGATCGCCATGTGACACACTGGCATCAAGCACGGAAAAG AGGCGCAGGGAGCAAGAAAATAAATATTTAGAAGAACTAGCTGAGTTACTGTCTGCCAACATTAGTGACATTGACAGCTTGAGTGTAAAA CCAGACAAATGCAAGATTTTGAAGAAAACAGTCGATCAGATACAGCTAATGAAGAGAATGGAACAAGAGAAATCAACAACTGATGACGAT GTACAGAAATCAGACATCTCATCAAGTAGTCAAGGAGTGATAGAAAAGGAATCCTTGGGACCTCTTCTTTTGGAGTTCTCTCAGCTACTG GAAGAGAAAAACACCCTTTCCATTCAGCTCTGCGATACCAGTCAGAGTCTTCGTGAGAACCAGCAGCACTATGGTGACCTTTTAAATCAC TGTGCAGTCTTGGAGAAGCAGGTTCAAGAGCTGCAGGCGGGGCCACTAAATATAGATGTTGCTCCAGGAGCTCCCCAGGAAAAGAATGGA GTTCACAGAAAGAGTGACCCTGAGGAACTAAGGGAACCGCAGCAAAGCTTTTCTGAAGCTCAGCAGCAGCTATGCAACACCAGACAGGAA GTGAATGAATTAAGGAAGCTGCTGGAAGAAGAACGAGACCAAAGAGTGGCTGCTGAGAATGCTCTCTCTGTGGCCGAGGAGCAGATCAGA CGGTTAGAGCACAGTGAATGGGACTCTTCCCGGACTCCTATCATTGGCTCCTGTGGCACTCAGGAGCAGGCACTGTTAATAGATCTTACA AGCAACAGTTGTCGAAGGACCCGGAGTGGCGTTGGATGGAAGCGAGTCCTGCGTTCACTCTGTCATTCACGGACCCGAGTGCCACTTCTA GCAGCCATCTACTTTCTAATGATTCATGTCCTGCTCATTCTGTGTTTTACGGGCCATCTATAGACTTAGTTGTTACTCTTTGGACCACTC CCCTCAAAACTTGGAATTCTCTCACCTCTAACATCAGAACATCAATTCCAGTGGAACAGTCTTCCCATTTACAGGTCTTCTCTCCAACTC TTCACGGAAAGTGCCTGCAAAAACAGAGGTGGATACGAGGACAGGTTGGAGCTGCAGGGACTGGCGAGTCTGCTTTCTTCTACTGCCCTG AGCCTGAACGCTTCTGCTTAATCTGAGAATCACATTTGGTTTGTTGAGCCTAATATTTGTTGAGATTTTGCAGGACCCTGATCTTTTGTG GTCCTGTAAAAGATACTGAGGAATGTCTTTCAGCCAAGCCAAGAGGATGGTTTCAATAAACCTAATAATCTGAAGTTCAGTATCATTTTG ATTGATAACTTTCTTTGCCTTGTTTGCCTGTATTTTCTCCTGTTTCAGGGGGAAGGTGGCTCTGCCATAAACAGAGTTCAGGGAAATGAA CATGTCACCTCATAGGACATCTGATTTAGGTCTCTTGCAGAATAGGGTGGTGAAAGCTGAAGGAACTCCCTAGGGGTTTTAGCTGTTAGA TCACATGGGAGGACAGCATCTTCTTCCCTGCCAATTTCAGATATAATTGGAGGGAGAATTTCAGGTCTTAGACTATAAGGATAGAATCCC TTTGCTTTTGCCCTTGATCACATGTATACTAAGGTATTAAGTGGCCCAAGTCTTTCCTTTCACCAAAGGGCAGGGAGAAGTGTCTATGGA CAGCAGGGTTCCAATTCTTGTCATTCCAGGAATATCTGAATATTCCTGGAATGTGGACCCTGAGACAGTGCTCAGGGGCCACTGGGAGCC AATATTAGGCATTGACTCTCAGCCAGGAGTCTGACTGGTCTAACACCACACTGCAACTCCTGACCTCTTGAAGTACTAAGCTACTTTGCT GTTAGTGACAGTTATTACAGTTTCTCAGCCCCATTGTCTCTGCCCTCTGTGGCAATGGAAGGAGAATATAGAGAAGACAAAATTAAATAT AGATAGACCTGAGAAGGACAGCCAGGATAGAATTCCATTTGTGCCTATTCCCTGCCTCCCCTCCCCTCCCCCATCCTACCAGTTGGTTAT TTTCTCATTGCATACGTGATGTGTTCACTGCCTAGCCTCTCCCTAAAGAAGAGAGAAGACAAGTGGGCTGACTGATCTGCTCTAAATCTA >57684_57684_7_NCOA1-GOLGB1_NCOA1_chr2_24896332_ENST00000405141_GOLGB1_chr3_121388202_ENST00000340645_length(amino acids)=377AA_BP=172 MALNEVRVKRLEPSLENIIIPFPGKLPSGTQDLTISVLRIHYEQRSLPGVKFFNMSGLGDSSSDPANPDSHKRKGSPCDTLASSTEKRRR EQENKYLEELAELLSANISDIDSLSVKPDKCKILKKTVDQIQLMKRMEQEKSTTDDDVQKSDISSSSQGVIEKESLGPLLLEFSQLLEEK NTLSIQLCDTSQSLRENQQHYGDLLNHCAVLEKQVQELQAGPLNIDVAPGAPQEKNGVHRKSDPEELREPQQSFSEAQQQLCNTRQEVNE LRKLLEEERDQRVAAENALSVAEEQIRRLEHSEWDSSRTPIIGSCGTQEQALLIDLTSNSCRRTRSGVGWKRVLRSLCHSRTRVPLLAAI -------------------------------------------------------------- >57684_57684_8_NCOA1-GOLGB1_NCOA1_chr2_24896332_ENST00000405141_GOLGB1_chr3_121388202_ENST00000393667_length(transcript)=2975nt_BP=1065nt GAATCTCGCCTGCCGGGACCGCGAAATGGGGGCGACCGCGGCGTCCCTCTCCGTCGGCGCAGCCCTCGACGGCGCTTGGGTTTGACCCCG GCGCGCTTGCTCGCCCCTTCTCCCGAGAAGGGGTTTCGGAGGAGCAGAGGTTTAATAGGCAAGAGAAAGAGAAAGGAAAACAGCTCTCTC TCTAATGAGAGAGAGGGGACTTCGGAGAGGAAAAGAGGACAGGAGATACGGCAATCGTGGATAGGAAAGGAGGAAATTACGATAGAAAAG TTGGAGATCCTTTTGCTAACACCCCTTTGGGCAGTTGGATGCTGAGATCTATCCATACTAATGGAAATGTAACTGGAACTGACTCTGATG ATAAAATCAAGGACCATCAAGCAAGATCATGCAGTAGGCAACTTTGCTTCCAAAAGAAGTTACCAACATTTAGAATTTCTACTTATTCTG AGGTTCCAGTTACAGCTATATCAGAGAATGAGTTAATCTCCTCAGAAATCACTAAATACTACTCTGAGGGGCTTAGAAATTAACAGGTTG TTTATATAATTGGCCTTAAATGAGGTGAGAGTGAAGAGACTAGAGCCATCTCTGGAAAACATCATTATCCCATTCCCCGGGAAGCTACCC TCTGGAACTCAAGATTTGACCATATCTGTTTTGAGGATTCATTATGAACAAAGAAGTCTCCCAGGTGTGAAGTTTTTCAACATGAGTGGC CTCGGGGACAGTTCATCCGACCCTGCTAACCCAGACTCACATAAGAGGAAAGGATCGCCATGTGACACACTGGCATCAAGCACGGAAAAG AGGCGCAGGGAGCAAGAAAATAAATATTTAGAAGAACTAGCTGAGTTACTGTCTGCCAACATTAGTGACATTGACAGCTTGAGTGTAAAA CCAGACAAATGCAAGATTTTGAAGAAAACAGTCGATCAGATACAGCTAATGAAGAGAATGGAACAAGAGAAATCAACAACTGATGACGAT GTACAGAAATCAGACATCTCATCAAGTAGTCAAGGAGTGATAGAAAAGGAATCCTTGGGACCTCTTCTTTTGGAGTTCTCTCAGCTACTG GAAGAGAAAAACACCCTTTCCATTCAGCTCTGCGATACCAGTCAGAGTCTTCGTGAGAACCAGCAGCACTATGGTGACCTTTTAAATCAC TGTGCAGTCTTGGAGAAGCAGGTTCAAGAGCTGCAGGCGGTGAGTAAAGAGAAGGGGCCACTAAATATAGATGTTGCTCCAGGAGCTCCC CAGGAAAAGAATGGAGTTCACAGAAAGAGTGACCCTGAGGAACTAAGGGAACCGCAGCAAAGCTTTTCTGAAGCTCAGCAGCAGCTATGC AACACCAGACAGGAAGTGAATGAATTAAGGAAGCTGCTGGAAGAAGAACGAGACCAAAGAGTGGCTGCTGAGAATGCTCTCTCTGTGGCC GAGGAGCAGATCAGACGGTTAGAGCACAGTGAATGGGACTCTTCCCGGACTCCTATCATTGGCTCCTGTGGCACTCAGGAGCAGGCACTG TTAATAGATCTTACAAGCAACAGTTGTCGAAGGACCCGGAGTGGCGTTGGATGGAAGCGAGTCCTGCGTTCACTCTGTCATTCACGGACC CGAGTGCCACTTCTAGCAGCCATCTACTTTCTAATGATTCATGTCCTGCTCATTCTGTGTTTTACGGGCCATCTATAGACTTAGTTGTTA CTCTTTGGACCACTCCCCTCAAAACTTGGAATTCTCTCACCTCTAACATCAGAACATCAATTCCAGTGGAACAGTCTTCCCATTTACAGG TCTTCTCTCCAACTCTTCACGGAAAGTGCCTGCAAAAACAGAGGTGGATACGAGGACAGGTTGGAGCTGCAGGGACTGGCGAGTCTGCTT TCTTCTACTGCCCTGAGCCTGAACGCTTCTGCTTAATCTGAGAATCACATTTGGTTTGTTGAGCCTAATATTTGTTGAGATTTTGCAGGA CCCTGATCTTTTGTGGTCCTGTAAAAGATACTGAGGAATGTCTTTCAGCCAAGCCAAGAGGATGGTTTCAATAAACCTAATAATCTGAAG TTCAGTATCATTTTGATTGATAACTTTCTTTGCCTTGTTTGCCTGTATTTTCTCCTGTTTCAGGGGGAAGGTGGCTCTGCCATAAACAGA GTTCAGGGAAATGAACATGTCACCTCATAGGACATCTGATTTAGGTCTCTTGCAGAATAGGGTGGTGAAAGCTGAAGGAACTCCCTAGGG GTTTTAGCTGTTAGATCACATGGGAGGACAGCATCTTCTTCCCTGCCAATTTCAGATATAATTGGAGGGAGAATTTCAGGTCTTAGACTA TAAGGATAGAATCCCTTTGCTTTTGCCCTTGATCACATGTATACTAAGGTATTAAGTGGCCCAAGTCTTTCCTTTCACCAAAGGGCAGGG AGAAGTGTCTATGGACAGCAGGGTTCCAATTCTTGTCATTCCAGGAATATCTGAATATTCCTGGAATGTGGACCCTGAGACAGTGCTCAG GGGCCACTGGGAGCCAATATTAGGCATTGACTCTCAGCCAGGAGTCTGACTGGTCTAACACCACACTGCAACTCCTGACCTCTTGAAGTA CTAAGCTACTTTGCTGTTAGTGACAGTTATTACAGTTTCTCAGCCCCATTGTCTCTGCCCTCTGTGGCAATGGAAGGAGAATATAGAGAA GACAAAATTAAATATAGATAGACCTGAGAAGGACAGCCAGGATAGAATTCCATTTGTGCCTATTCCCTGCCTCCCCTCCCCTCCCCCATC CTACCAGTTGGTTATTTTCTCATTGCATACGTGATGTGTTCACTGCCTAGCCTCTCCCTAAAGAAGAGAGAAGACAAGTGGGCTGACTGA TCTGCTCTAAATCTACTGTGGTGATTAAATCTTGGTTACAACATCCTGGGAAGTTTCCTGAACAACTGTAAAATAATAAAATTATTTTCA >57684_57684_8_NCOA1-GOLGB1_NCOA1_chr2_24896332_ENST00000405141_GOLGB1_chr3_121388202_ENST00000393667_length(amino acids)=382AA_BP=172 MALNEVRVKRLEPSLENIIIPFPGKLPSGTQDLTISVLRIHYEQRSLPGVKFFNMSGLGDSSSDPANPDSHKRKGSPCDTLASSTEKRRR EQENKYLEELAELLSANISDIDSLSVKPDKCKILKKTVDQIQLMKRMEQEKSTTDDDVQKSDISSSSQGVIEKESLGPLLLEFSQLLEEK NTLSIQLCDTSQSLRENQQHYGDLLNHCAVLEKQVQELQAVSKEKGPLNIDVAPGAPQEKNGVHRKSDPEELREPQQSFSEAQQQLCNTR QEVNELRKLLEEERDQRVAAENALSVAEEQIRRLEHSEWDSSRTPIIGSCGTQEQALLIDLTSNSCRRTRSGVGWKRVLRSLCHSRTRVP -------------------------------------------------------------- >57684_57684_9_NCOA1-GOLGB1_NCOA1_chr2_24896332_ENST00000406961_GOLGB1_chr3_121388202_ENST00000340645_length(transcript)=2905nt_BP=1006nt GCGGCCGCCTGCCCGGCGTGGGGAGCGGGCGCCCCGGGCCGCCGCCGAGAGGGGGAGCCGGAAGTCGGCGCGGGCGCCCCTCGGCCCCGA CGACGCCGTGACCTTGGCCGGCCCGCTCACCTCTCGGAATCTCGCCTGCCGGGACCGCGAAATGGGGGCGACCGCGGCGTCCCTCTCCGT CGGCGCAGCCCTCGACGGCGCTTGGGTTTGACCCCGGCGCGCTTGCTCGCCCCTTCTCCCGAGAAGGGGTTTCGGAGATCTATCCATACT AATGGAAATGTAACTGGAACTGACTCTGATGATAAAATCAAGGACCATCAAGCAAGATCATGCAGTAGGCAACTTTGCTTCCAAAAGAAG TTACCAACATTTAGAATTTCTACTTATTCTGAGGTTCCAGTTACAGCTATATCAGAGAATGAGTTAATCTCCTCAGAAATCACTAAATAC TACTCTGAGGGGCTTAGAAATTAACAGGTTGTTTATATAATTGGCCTTAAATGAGGTGAGAGTGAAGAGACTAGAGCCATCTCTGGAAAA CATCATTATCCCATTCCCCGGGAAGCTACCCTCTGGAACTCAAGATTTGACCATATCTGTTTTGAGGATTCATTATGAACAAAGAAGTCT CCCAGGTGTGAAGTTTTTCAACATGAGTGGCCTCGGGGACAGTTCATCCGACCCTGCTAACCCAGACTCACATAAGAGGAAAGGATCGCC ATGTGACACACTGGCATCAAGCACGGAAAAGAGGCGCAGGGAGCAAGAAAATAAATATTTAGAAGAACTAGCTGAGTTACTGTCTGCCAA CATTAGTGACATTGACAGCTTGAGTGTAAAACCAGACAAATGCAAGATTTTGAAGAAAACAGTCGATCAGATACAGCTAATGAAGAGAAT GGAACAAGAGAAATCAACAACTGATGACGATGTACAGAAATCAGACATCTCATCAAGTAGTCAAGGAGTGATAGAAAAGGAATCCTTGGG ACCTCTTCTTTTGGAGTTCTCTCAGCTACTGGAAGAGAAAAACACCCTTTCCATTCAGCTCTGCGATACCAGTCAGAGTCTTCGTGAGAA CCAGCAGCACTATGGTGACCTTTTAAATCACTGTGCAGTCTTGGAGAAGCAGGTTCAAGAGCTGCAGGCGGGGCCACTAAATATAGATGT TGCTCCAGGAGCTCCCCAGGAAAAGAATGGAGTTCACAGAAAGAGTGACCCTGAGGAACTAAGGGAACCGCAGCAAAGCTTTTCTGAAGC TCAGCAGCAGCTATGCAACACCAGACAGGAAGTGAATGAATTAAGGAAGCTGCTGGAAGAAGAACGAGACCAAAGAGTGGCTGCTGAGAA TGCTCTCTCTGTGGCCGAGGAGCAGATCAGACGGTTAGAGCACAGTGAATGGGACTCTTCCCGGACTCCTATCATTGGCTCCTGTGGCAC TCAGGAGCAGGCACTGTTAATAGATCTTACAAGCAACAGTTGTCGAAGGACCCGGAGTGGCGTTGGATGGAAGCGAGTCCTGCGTTCACT CTGTCATTCACGGACCCGAGTGCCACTTCTAGCAGCCATCTACTTTCTAATGATTCATGTCCTGCTCATTCTGTGTTTTACGGGCCATCT ATAGACTTAGTTGTTACTCTTTGGACCACTCCCCTCAAAACTTGGAATTCTCTCACCTCTAACATCAGAACATCAATTCCAGTGGAACAG TCTTCCCATTTACAGGTCTTCTCTCCAACTCTTCACGGAAAGTGCCTGCAAAAACAGAGGTGGATACGAGGACAGGTTGGAGCTGCAGGG ACTGGCGAGTCTGCTTTCTTCTACTGCCCTGAGCCTGAACGCTTCTGCTTAATCTGAGAATCACATTTGGTTTGTTGAGCCTAATATTTG TTGAGATTTTGCAGGACCCTGATCTTTTGTGGTCCTGTAAAAGATACTGAGGAATGTCTTTCAGCCAAGCCAAGAGGATGGTTTCAATAA ACCTAATAATCTGAAGTTCAGTATCATTTTGATTGATAACTTTCTTTGCCTTGTTTGCCTGTATTTTCTCCTGTTTCAGGGGGAAGGTGG CTCTGCCATAAACAGAGTTCAGGGAAATGAACATGTCACCTCATAGGACATCTGATTTAGGTCTCTTGCAGAATAGGGTGGTGAAAGCTG AAGGAACTCCCTAGGGGTTTTAGCTGTTAGATCACATGGGAGGACAGCATCTTCTTCCCTGCCAATTTCAGATATAATTGGAGGGAGAAT TTCAGGTCTTAGACTATAAGGATAGAATCCCTTTGCTTTTGCCCTTGATCACATGTATACTAAGGTATTAAGTGGCCCAAGTCTTTCCTT TCACCAAAGGGCAGGGAGAAGTGTCTATGGACAGCAGGGTTCCAATTCTTGTCATTCCAGGAATATCTGAATATTCCTGGAATGTGGACC CTGAGACAGTGCTCAGGGGCCACTGGGAGCCAATATTAGGCATTGACTCTCAGCCAGGAGTCTGACTGGTCTAACACCACACTGCAACTC CTGACCTCTTGAAGTACTAAGCTACTTTGCTGTTAGTGACAGTTATTACAGTTTCTCAGCCCCATTGTCTCTGCCCTCTGTGGCAATGGA AGGAGAATATAGAGAAGACAAAATTAAATATAGATAGACCTGAGAAGGACAGCCAGGATAGAATTCCATTTGTGCCTATTCCCTGCCTCC CCTCCCCTCCCCCATCCTACCAGTTGGTTATTTTCTCATTGCATACGTGATGTGTTCACTGCCTAGCCTCTCCCTAAAGAAGAGAGAAGA CAAGTGGGCTGACTGATCTGCTCTAAATCTACTGTGGTGATTAAATCTTGGTTACAACATCCTGGGAAGTTTCCTGAACAACTGTAAAAT >57684_57684_9_NCOA1-GOLGB1_NCOA1_chr2_24896332_ENST00000406961_GOLGB1_chr3_121388202_ENST00000340645_length(amino acids)=377AA_BP=172 MALNEVRVKRLEPSLENIIIPFPGKLPSGTQDLTISVLRIHYEQRSLPGVKFFNMSGLGDSSSDPANPDSHKRKGSPCDTLASSTEKRRR EQENKYLEELAELLSANISDIDSLSVKPDKCKILKKTVDQIQLMKRMEQEKSTTDDDVQKSDISSSSQGVIEKESLGPLLLEFSQLLEEK NTLSIQLCDTSQSLRENQQHYGDLLNHCAVLEKQVQELQAGPLNIDVAPGAPQEKNGVHRKSDPEELREPQQSFSEAQQQLCNTRQEVNE LRKLLEEERDQRVAAENALSVAEEQIRRLEHSEWDSSRTPIIGSCGTQEQALLIDLTSNSCRRTRSGVGWKRVLRSLCHSRTRVPLLAAI -------------------------------------------------------------- >57684_57684_10_NCOA1-GOLGB1_NCOA1_chr2_24896332_ENST00000406961_GOLGB1_chr3_121388202_ENST00000393667_length(transcript)=2916nt_BP=1006nt GCGGCCGCCTGCCCGGCGTGGGGAGCGGGCGCCCCGGGCCGCCGCCGAGAGGGGGAGCCGGAAGTCGGCGCGGGCGCCCCTCGGCCCCGA CGACGCCGTGACCTTGGCCGGCCCGCTCACCTCTCGGAATCTCGCCTGCCGGGACCGCGAAATGGGGGCGACCGCGGCGTCCCTCTCCGT CGGCGCAGCCCTCGACGGCGCTTGGGTTTGACCCCGGCGCGCTTGCTCGCCCCTTCTCCCGAGAAGGGGTTTCGGAGATCTATCCATACT AATGGAAATGTAACTGGAACTGACTCTGATGATAAAATCAAGGACCATCAAGCAAGATCATGCAGTAGGCAACTTTGCTTCCAAAAGAAG TTACCAACATTTAGAATTTCTACTTATTCTGAGGTTCCAGTTACAGCTATATCAGAGAATGAGTTAATCTCCTCAGAAATCACTAAATAC TACTCTGAGGGGCTTAGAAATTAACAGGTTGTTTATATAATTGGCCTTAAATGAGGTGAGAGTGAAGAGACTAGAGCCATCTCTGGAAAA CATCATTATCCCATTCCCCGGGAAGCTACCCTCTGGAACTCAAGATTTGACCATATCTGTTTTGAGGATTCATTATGAACAAAGAAGTCT CCCAGGTGTGAAGTTTTTCAACATGAGTGGCCTCGGGGACAGTTCATCCGACCCTGCTAACCCAGACTCACATAAGAGGAAAGGATCGCC ATGTGACACACTGGCATCAAGCACGGAAAAGAGGCGCAGGGAGCAAGAAAATAAATATTTAGAAGAACTAGCTGAGTTACTGTCTGCCAA CATTAGTGACATTGACAGCTTGAGTGTAAAACCAGACAAATGCAAGATTTTGAAGAAAACAGTCGATCAGATACAGCTAATGAAGAGAAT GGAACAAGAGAAATCAACAACTGATGACGATGTACAGAAATCAGACATCTCATCAAGTAGTCAAGGAGTGATAGAAAAGGAATCCTTGGG ACCTCTTCTTTTGGAGTTCTCTCAGCTACTGGAAGAGAAAAACACCCTTTCCATTCAGCTCTGCGATACCAGTCAGAGTCTTCGTGAGAA CCAGCAGCACTATGGTGACCTTTTAAATCACTGTGCAGTCTTGGAGAAGCAGGTTCAAGAGCTGCAGGCGGTGAGTAAAGAGAAGGGGCC ACTAAATATAGATGTTGCTCCAGGAGCTCCCCAGGAAAAGAATGGAGTTCACAGAAAGAGTGACCCTGAGGAACTAAGGGAACCGCAGCA AAGCTTTTCTGAAGCTCAGCAGCAGCTATGCAACACCAGACAGGAAGTGAATGAATTAAGGAAGCTGCTGGAAGAAGAACGAGACCAAAG AGTGGCTGCTGAGAATGCTCTCTCTGTGGCCGAGGAGCAGATCAGACGGTTAGAGCACAGTGAATGGGACTCTTCCCGGACTCCTATCAT TGGCTCCTGTGGCACTCAGGAGCAGGCACTGTTAATAGATCTTACAAGCAACAGTTGTCGAAGGACCCGGAGTGGCGTTGGATGGAAGCG AGTCCTGCGTTCACTCTGTCATTCACGGACCCGAGTGCCACTTCTAGCAGCCATCTACTTTCTAATGATTCATGTCCTGCTCATTCTGTG TTTTACGGGCCATCTATAGACTTAGTTGTTACTCTTTGGACCACTCCCCTCAAAACTTGGAATTCTCTCACCTCTAACATCAGAACATCA ATTCCAGTGGAACAGTCTTCCCATTTACAGGTCTTCTCTCCAACTCTTCACGGAAAGTGCCTGCAAAAACAGAGGTGGATACGAGGACAG GTTGGAGCTGCAGGGACTGGCGAGTCTGCTTTCTTCTACTGCCCTGAGCCTGAACGCTTCTGCTTAATCTGAGAATCACATTTGGTTTGT TGAGCCTAATATTTGTTGAGATTTTGCAGGACCCTGATCTTTTGTGGTCCTGTAAAAGATACTGAGGAATGTCTTTCAGCCAAGCCAAGA GGATGGTTTCAATAAACCTAATAATCTGAAGTTCAGTATCATTTTGATTGATAACTTTCTTTGCCTTGTTTGCCTGTATTTTCTCCTGTT TCAGGGGGAAGGTGGCTCTGCCATAAACAGAGTTCAGGGAAATGAACATGTCACCTCATAGGACATCTGATTTAGGTCTCTTGCAGAATA GGGTGGTGAAAGCTGAAGGAACTCCCTAGGGGTTTTAGCTGTTAGATCACATGGGAGGACAGCATCTTCTTCCCTGCCAATTTCAGATAT AATTGGAGGGAGAATTTCAGGTCTTAGACTATAAGGATAGAATCCCTTTGCTTTTGCCCTTGATCACATGTATACTAAGGTATTAAGTGG CCCAAGTCTTTCCTTTCACCAAAGGGCAGGGAGAAGTGTCTATGGACAGCAGGGTTCCAATTCTTGTCATTCCAGGAATATCTGAATATT CCTGGAATGTGGACCCTGAGACAGTGCTCAGGGGCCACTGGGAGCCAATATTAGGCATTGACTCTCAGCCAGGAGTCTGACTGGTCTAAC ACCACACTGCAACTCCTGACCTCTTGAAGTACTAAGCTACTTTGCTGTTAGTGACAGTTATTACAGTTTCTCAGCCCCATTGTCTCTGCC CTCTGTGGCAATGGAAGGAGAATATAGAGAAGACAAAATTAAATATAGATAGACCTGAGAAGGACAGCCAGGATAGAATTCCATTTGTGC CTATTCCCTGCCTCCCCTCCCCTCCCCCATCCTACCAGTTGGTTATTTTCTCATTGCATACGTGATGTGTTCACTGCCTAGCCTCTCCCT AAAGAAGAGAGAAGACAAGTGGGCTGACTGATCTGCTCTAAATCTACTGTGGTGATTAAATCTTGGTTACAACATCCTGGGAAGTTTCCT >57684_57684_10_NCOA1-GOLGB1_NCOA1_chr2_24896332_ENST00000406961_GOLGB1_chr3_121388202_ENST00000393667_length(amino acids)=382AA_BP=172 MALNEVRVKRLEPSLENIIIPFPGKLPSGTQDLTISVLRIHYEQRSLPGVKFFNMSGLGDSSSDPANPDSHKRKGSPCDTLASSTEKRRR EQENKYLEELAELLSANISDIDSLSVKPDKCKILKKTVDQIQLMKRMEQEKSTTDDDVQKSDISSSSQGVIEKESLGPLLLEFSQLLEEK NTLSIQLCDTSQSLRENQQHYGDLLNHCAVLEKQVQELQAVSKEKGPLNIDVAPGAPQEKNGVHRKSDPEELREPQQSFSEAQQQLCNTR QEVNELRKLLEEERDQRVAAENALSVAEEQIRRLEHSEWDSSRTPIIGSCGTQEQALLIDLTSNSCRRTRSGVGWKRVLRSLCHSRTRVP -------------------------------------------------------------- >57684_57684_11_NCOA1-GOLGB1_NCOA1_chr2_24896332_ENST00000538539_GOLGB1_chr3_121388202_ENST00000340645_length(transcript)=2541nt_BP=642nt CAACATTTAGAATTTCTACTTATTCTGAGGTTCCAGTTACAGCTATATCAGAGAATGAGTTAATCTCCTCAGAAATCACTAAATACTACT CTGAGGGGCTTAGAAATTAACAGGTTGTTTATATAATTGGCCTTAAATGAGGTGAGAGTGAAGAGACTAGAGCCATCTCTGGAAAACATC ATTATCCCATTCCCCGGGAAGCTACCCTCTGGAACTCAAGATTTGACCATATCTGTTTTGAGGATTCATTATGAACAAAGAAGTCTCCCA GGTGTGAAGTTTTTCAACATGAGTGGCCTCGGGGACAGTTCATCCGACCCTGCTAACCCAGACTCACATAAGAGGAAAGGATCGCCATGT GACACACTGGCATCAAGCACGGAAAAGAGGCGCAGGGAGCAAGAAAATAAATATTTAGAAGAACTAGCTGAGTTACTGTCTGCCAACATT AGTGACATTGACAGCTTGAGTGTAAAACCAGACAAATGCAAGATTTTGAAGAAAACAGTCGATCAGATACAGCTAATGAAGAGAATGGAA CAAGAGAAATCAACAACTGATGACGATGTACAGAAATCAGACATCTCATCAAGTAGTCAAGGAGTGATAGAAAAGGAATCCTTGGGACCT CTTCTTTTGGAGTTCTCTCAGCTACTGGAAGAGAAAAACACCCTTTCCATTCAGCTCTGCGATACCAGTCAGAGTCTTCGTGAGAACCAG CAGCACTATGGTGACCTTTTAAATCACTGTGCAGTCTTGGAGAAGCAGGTTCAAGAGCTGCAGGCGGGGCCACTAAATATAGATGTTGCT CCAGGAGCTCCCCAGGAAAAGAATGGAGTTCACAGAAAGAGTGACCCTGAGGAACTAAGGGAACCGCAGCAAAGCTTTTCTGAAGCTCAG CAGCAGCTATGCAACACCAGACAGGAAGTGAATGAATTAAGGAAGCTGCTGGAAGAAGAACGAGACCAAAGAGTGGCTGCTGAGAATGCT CTCTCTGTGGCCGAGGAGCAGATCAGACGGTTAGAGCACAGTGAATGGGACTCTTCCCGGACTCCTATCATTGGCTCCTGTGGCACTCAG GAGCAGGCACTGTTAATAGATCTTACAAGCAACAGTTGTCGAAGGACCCGGAGTGGCGTTGGATGGAAGCGAGTCCTGCGTTCACTCTGT CATTCACGGACCCGAGTGCCACTTCTAGCAGCCATCTACTTTCTAATGATTCATGTCCTGCTCATTCTGTGTTTTACGGGCCATCTATAG ACTTAGTTGTTACTCTTTGGACCACTCCCCTCAAAACTTGGAATTCTCTCACCTCTAACATCAGAACATCAATTCCAGTGGAACAGTCTT CCCATTTACAGGTCTTCTCTCCAACTCTTCACGGAAAGTGCCTGCAAAAACAGAGGTGGATACGAGGACAGGTTGGAGCTGCAGGGACTG GCGAGTCTGCTTTCTTCTACTGCCCTGAGCCTGAACGCTTCTGCTTAATCTGAGAATCACATTTGGTTTGTTGAGCCTAATATTTGTTGA GATTTTGCAGGACCCTGATCTTTTGTGGTCCTGTAAAAGATACTGAGGAATGTCTTTCAGCCAAGCCAAGAGGATGGTTTCAATAAACCT AATAATCTGAAGTTCAGTATCATTTTGATTGATAACTTTCTTTGCCTTGTTTGCCTGTATTTTCTCCTGTTTCAGGGGGAAGGTGGCTCT GCCATAAACAGAGTTCAGGGAAATGAACATGTCACCTCATAGGACATCTGATTTAGGTCTCTTGCAGAATAGGGTGGTGAAAGCTGAAGG AACTCCCTAGGGGTTTTAGCTGTTAGATCACATGGGAGGACAGCATCTTCTTCCCTGCCAATTTCAGATATAATTGGAGGGAGAATTTCA GGTCTTAGACTATAAGGATAGAATCCCTTTGCTTTTGCCCTTGATCACATGTATACTAAGGTATTAAGTGGCCCAAGTCTTTCCTTTCAC CAAAGGGCAGGGAGAAGTGTCTATGGACAGCAGGGTTCCAATTCTTGTCATTCCAGGAATATCTGAATATTCCTGGAATGTGGACCCTGA GACAGTGCTCAGGGGCCACTGGGAGCCAATATTAGGCATTGACTCTCAGCCAGGAGTCTGACTGGTCTAACACCACACTGCAACTCCTGA CCTCTTGAAGTACTAAGCTACTTTGCTGTTAGTGACAGTTATTACAGTTTCTCAGCCCCATTGTCTCTGCCCTCTGTGGCAATGGAAGGA GAATATAGAGAAGACAAAATTAAATATAGATAGACCTGAGAAGGACAGCCAGGATAGAATTCCATTTGTGCCTATTCCCTGCCTCCCCTC CCCTCCCCCATCCTACCAGTTGGTTATTTTCTCATTGCATACGTGATGTGTTCACTGCCTAGCCTCTCCCTAAAGAAGAGAGAAGACAAG TGGGCTGACTGATCTGCTCTAAATCTACTGTGGTGATTAAATCTTGGTTACAACATCCTGGGAAGTTTCCTGAACAACTGTAAAATAATA >57684_57684_11_NCOA1-GOLGB1_NCOA1_chr2_24896332_ENST00000538539_GOLGB1_chr3_121388202_ENST00000340645_length(amino acids)=377AA_BP=172 MALNEVRVKRLEPSLENIIIPFPGKLPSGTQDLTISVLRIHYEQRSLPGVKFFNMSGLGDSSSDPANPDSHKRKGSPCDTLASSTEKRRR EQENKYLEELAELLSANISDIDSLSVKPDKCKILKKTVDQIQLMKRMEQEKSTTDDDVQKSDISSSSQGVIEKESLGPLLLEFSQLLEEK NTLSIQLCDTSQSLRENQQHYGDLLNHCAVLEKQVQELQAGPLNIDVAPGAPQEKNGVHRKSDPEELREPQQSFSEAQQQLCNTRQEVNE LRKLLEEERDQRVAAENALSVAEEQIRRLEHSEWDSSRTPIIGSCGTQEQALLIDLTSNSCRRTRSGVGWKRVLRSLCHSRTRVPLLAAI -------------------------------------------------------------- >57684_57684_12_NCOA1-GOLGB1_NCOA1_chr2_24896332_ENST00000538539_GOLGB1_chr3_121388202_ENST00000393667_length(transcript)=2552nt_BP=642nt CAACATTTAGAATTTCTACTTATTCTGAGGTTCCAGTTACAGCTATATCAGAGAATGAGTTAATCTCCTCAGAAATCACTAAATACTACT CTGAGGGGCTTAGAAATTAACAGGTTGTTTATATAATTGGCCTTAAATGAGGTGAGAGTGAAGAGACTAGAGCCATCTCTGGAAAACATC ATTATCCCATTCCCCGGGAAGCTACCCTCTGGAACTCAAGATTTGACCATATCTGTTTTGAGGATTCATTATGAACAAAGAAGTCTCCCA GGTGTGAAGTTTTTCAACATGAGTGGCCTCGGGGACAGTTCATCCGACCCTGCTAACCCAGACTCACATAAGAGGAAAGGATCGCCATGT GACACACTGGCATCAAGCACGGAAAAGAGGCGCAGGGAGCAAGAAAATAAATATTTAGAAGAACTAGCTGAGTTACTGTCTGCCAACATT AGTGACATTGACAGCTTGAGTGTAAAACCAGACAAATGCAAGATTTTGAAGAAAACAGTCGATCAGATACAGCTAATGAAGAGAATGGAA CAAGAGAAATCAACAACTGATGACGATGTACAGAAATCAGACATCTCATCAAGTAGTCAAGGAGTGATAGAAAAGGAATCCTTGGGACCT CTTCTTTTGGAGTTCTCTCAGCTACTGGAAGAGAAAAACACCCTTTCCATTCAGCTCTGCGATACCAGTCAGAGTCTTCGTGAGAACCAG CAGCACTATGGTGACCTTTTAAATCACTGTGCAGTCTTGGAGAAGCAGGTTCAAGAGCTGCAGGCGGTGAGTAAAGAGAAGGGGCCACTA AATATAGATGTTGCTCCAGGAGCTCCCCAGGAAAAGAATGGAGTTCACAGAAAGAGTGACCCTGAGGAACTAAGGGAACCGCAGCAAAGC TTTTCTGAAGCTCAGCAGCAGCTATGCAACACCAGACAGGAAGTGAATGAATTAAGGAAGCTGCTGGAAGAAGAACGAGACCAAAGAGTG GCTGCTGAGAATGCTCTCTCTGTGGCCGAGGAGCAGATCAGACGGTTAGAGCACAGTGAATGGGACTCTTCCCGGACTCCTATCATTGGC TCCTGTGGCACTCAGGAGCAGGCACTGTTAATAGATCTTACAAGCAACAGTTGTCGAAGGACCCGGAGTGGCGTTGGATGGAAGCGAGTC CTGCGTTCACTCTGTCATTCACGGACCCGAGTGCCACTTCTAGCAGCCATCTACTTTCTAATGATTCATGTCCTGCTCATTCTGTGTTTT ACGGGCCATCTATAGACTTAGTTGTTACTCTTTGGACCACTCCCCTCAAAACTTGGAATTCTCTCACCTCTAACATCAGAACATCAATTC CAGTGGAACAGTCTTCCCATTTACAGGTCTTCTCTCCAACTCTTCACGGAAAGTGCCTGCAAAAACAGAGGTGGATACGAGGACAGGTTG GAGCTGCAGGGACTGGCGAGTCTGCTTTCTTCTACTGCCCTGAGCCTGAACGCTTCTGCTTAATCTGAGAATCACATTTGGTTTGTTGAG CCTAATATTTGTTGAGATTTTGCAGGACCCTGATCTTTTGTGGTCCTGTAAAAGATACTGAGGAATGTCTTTCAGCCAAGCCAAGAGGAT GGTTTCAATAAACCTAATAATCTGAAGTTCAGTATCATTTTGATTGATAACTTTCTTTGCCTTGTTTGCCTGTATTTTCTCCTGTTTCAG GGGGAAGGTGGCTCTGCCATAAACAGAGTTCAGGGAAATGAACATGTCACCTCATAGGACATCTGATTTAGGTCTCTTGCAGAATAGGGT GGTGAAAGCTGAAGGAACTCCCTAGGGGTTTTAGCTGTTAGATCACATGGGAGGACAGCATCTTCTTCCCTGCCAATTTCAGATATAATT GGAGGGAGAATTTCAGGTCTTAGACTATAAGGATAGAATCCCTTTGCTTTTGCCCTTGATCACATGTATACTAAGGTATTAAGTGGCCCA AGTCTTTCCTTTCACCAAAGGGCAGGGAGAAGTGTCTATGGACAGCAGGGTTCCAATTCTTGTCATTCCAGGAATATCTGAATATTCCTG GAATGTGGACCCTGAGACAGTGCTCAGGGGCCACTGGGAGCCAATATTAGGCATTGACTCTCAGCCAGGAGTCTGACTGGTCTAACACCA CACTGCAACTCCTGACCTCTTGAAGTACTAAGCTACTTTGCTGTTAGTGACAGTTATTACAGTTTCTCAGCCCCATTGTCTCTGCCCTCT GTGGCAATGGAAGGAGAATATAGAGAAGACAAAATTAAATATAGATAGACCTGAGAAGGACAGCCAGGATAGAATTCCATTTGTGCCTAT TCCCTGCCTCCCCTCCCCTCCCCCATCCTACCAGTTGGTTATTTTCTCATTGCATACGTGATGTGTTCACTGCCTAGCCTCTCCCTAAAG AAGAGAGAAGACAAGTGGGCTGACTGATCTGCTCTAAATCTACTGTGGTGATTAAATCTTGGTTACAACATCCTGGGAAGTTTCCTGAAC >57684_57684_12_NCOA1-GOLGB1_NCOA1_chr2_24896332_ENST00000538539_GOLGB1_chr3_121388202_ENST00000393667_length(amino acids)=382AA_BP=172 MALNEVRVKRLEPSLENIIIPFPGKLPSGTQDLTISVLRIHYEQRSLPGVKFFNMSGLGDSSSDPANPDSHKRKGSPCDTLASSTEKRRR EQENKYLEELAELLSANISDIDSLSVKPDKCKILKKTVDQIQLMKRMEQEKSTTDDDVQKSDISSSSQGVIEKESLGPLLLEFSQLLEEK NTLSIQLCDTSQSLRENQQHYGDLLNHCAVLEKQVQELQAVSKEKGPLNIDVAPGAPQEKNGVHRKSDPEELREPQQSFSEAQQQLCNTR QEVNELRKLLEEERDQRVAAENALSVAEEQIRRLEHSEWDSSRTPIIGSCGTQEQALLIDLTSNSCRRTRSGVGWKRVLRSLCHSRTRVP -------------------------------------------------------------- |
Top |
Fusion Gene PPI Analysis for NCOA1-GOLGB1 |
| Go to ChiPPI (Chimeric Protein-Protein interactions) to see the chimeric PPI interaction in |
| Protein-protein interactors with each fusion partner protein in wild-type (BIOGRID-3.4.160) |
| Hgene | Hgene's interactors | Tgene | Tgene's interactors |
| - Retained PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Still interaction with |
| - Lost PPIs in in-frame fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000288599 | + | 5 | 22 | 781_988 | 118.0 | 2199.3333333333335 | CREBBP |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000348332 | + | 5 | 21 | 781_988 | 118.0 | 1442.0 | CREBBP |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000395856 | + | 5 | 21 | 781_988 | 118.0 | 1441.0 | CREBBP |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000405141 | + | 8 | 25 | 781_988 | 118.0 | 2183.6666666666665 | CREBBP |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000406961 | + | 7 | 23 | 781_988 | 118.0 | 1442.0 | CREBBP |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000538539 | + | 6 | 23 | 781_988 | 118.0 | 1422.6666666666667 | CREBBP |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000288599 | + | 5 | 22 | 361_567 | 118.0 | 2199.3333333333335 | STAT3 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000348332 | + | 5 | 21 | 361_567 | 118.0 | 1442.0 | STAT3 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000395856 | + | 5 | 21 | 361_567 | 118.0 | 1441.0 | STAT3 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000405141 | + | 8 | 25 | 361_567 | 118.0 | 2183.6666666666665 | STAT3 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000406961 | + | 7 | 23 | 361_567 | 118.0 | 1442.0 | STAT3 |
| Hgene | NCOA1 | chr2:24896332 | chr3:121388202 | ENST00000538539 | + | 6 | 23 | 361_567 | 118.0 | 1422.6666666666667 | STAT3 |
| - Retained PPIs, but lost function due to frame-shift fusion. |
| Partner | Gene | Hbp | Tbp | ENST | Strand | BPexon | TotalExon | Protein feature loci | *BPloci | TotalLen | Interaction lost with |
Top |
Related Drugs for NCOA1-GOLGB1 |
| Drugs targeting genes involved in this fusion gene. (DrugBank Version 5.1.8 2021-05-08) |
| Partner | Gene | UniProtAcc | DrugBank ID | Drug name | Drug activity | Drug type | Drug status |
Top |
Related Diseases for NCOA1-GOLGB1 |
| Diseases associated with fusion partners. (DisGeNet 4.0) |
| Partner | Gene | Disease ID | Disease name | # pubmeds | Source |
(UTHealth)
Web File Viewing | Emergency Information |Campus Carry|Site Policies